NLP系列【自然语言处理的深度学习模型综述】
自然语言处理的深度学习模型
- 摘要
- 传统自然语言处理模型(略 不作重点)
- 神经网络自然语言处理模型
- 经典神经网络
- CNN网络模型
- Word2Vec模型
- RNN模型
- GPT网络模型
- BERT网络模型
- BERT变体模型
- 提升模型性能
- 模型压缩
摘要
在自然语言处理任务方面,依据语料的长度分为词汇、句子和篇章三层面,每一层面又有若干具体任务。
- 在词汇层面,有命名实体识别、中文分词、词性标注、关系抽取等任务;
- 在句子层面,有智能问答、机器翻译、文本匹配和文本纠错等任务;
- 在篇章层面,有文本分类、文本生成、机器阅读、信息过滤与信息推荐等任务。
本文从传统自然语言处理模型和神经网络自然语言处理模型两方面着手,分别介绍相应模型及模型特点、优缺点等相关特性;之后,对目前流行的BERT模型变体从提升模型性能和压缩模型大小两个方面进行介绍,并对每个模型从特点、优缺点及性能方面进行总结归纳;再者,本文阐述目前自然语言处理面临的挑战与解决办法;最后,对本文工作进行总结及展望。
传统自然语言处理模型(略 不作重点)
传统自然语言处理模型,从形式上可以分为基于规则和基于统计两种子类型。

神经网络自然语言处理模型
目前来说,神经网络模型分为经典神经网络模型、CNN网络模型、Word2Vec模型、RNN网络模型、GPT网络模型、BERT网络模型。
经典神经网络
神经网络语言模型(Nerual Network Language Model,NNLM)
NNLM由Bengio于2003年提出,该模型由四层组成,分别为输入层、嵌入层、隐藏层和输出层。NNLM接受的输入是一个长度为N的词序列,输出是下一个词的类别。模型的训练过程为:首先接受词序列的index,然后将index进行嵌入处理后送入网络进行训练,其中以tanh作为激活函数,最后送入带Softmax的输出层中进行概率输出,模型如下图所示。
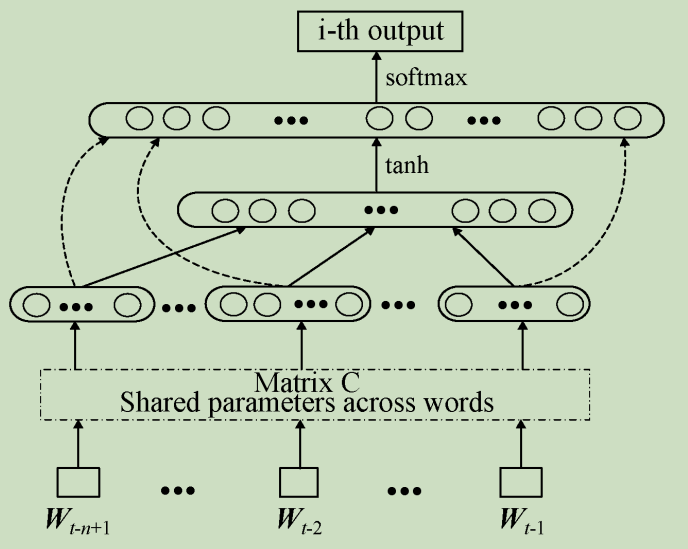
NNLM作为第一个具有重大影响力的神经网络模型,泛化能力强于传统自然语言处理模型。但是由于当时软硬件条件限制,相对于其他传统自然语言处理模型,NNLM具有参数量巨大、训练速度慢、输入序列要求为定长和不能利用完整历史信息等缺点。
多任务学习(Multi-Task Learning,MTL)
多任务学习基于共享表示,是将多个相关性任务放在一起学习的机器学习方法。相对于单任务模型,多任务学习往往可以取得更好的效果,模型如下图所示。
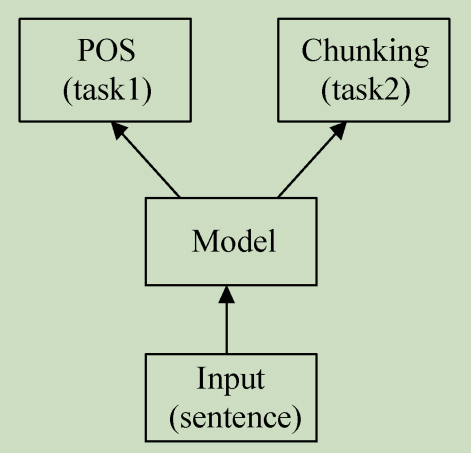
多任务学习涉及多个相关任务并行学习,梯度同时反向传播。多个任务通过底层的共享表示来互相帮助学习,提升泛化效果。从共享形式上来说,多任务学习包括硬共享模型、软共享模式、共享-私有模式、函数共享模式、多级共享模式和辅助任务模式等。
多任务学习具有隐式的数据增强功能(一个任务的语料相对较少时,实现多个事物时语料量就得到了扩充)、更好地表示学习、能在一定程度上防止过拟合等优点。但是,多任务学习基于任务的宽度扩展,在深度学习的通常情况下,在相同代价的条件下,越深的模型比越宽的模型效果好。因此,若要达到较高性能,多任务学习比单任务学习所需要的耗费更高。
小结
经典神经网络由于模型层数较浅,导致整体性能不高,在计算能力和条件不发达的当时,并未引起研究人员太大的关注。但是,经典神经网络模型是深度神经网络模型的基石,随着软硬件的大力发展,越来越多的研究者转向深度神经网络模型。
CNN网络模型
卷积神经网络(Convolutional Neural Network,CNN)是一种建立在经典神经网络基础上的深度神经网络。在结构上,通常由卷积层、池化层、激励函数和全连接层组成。下图为CNN的结构。
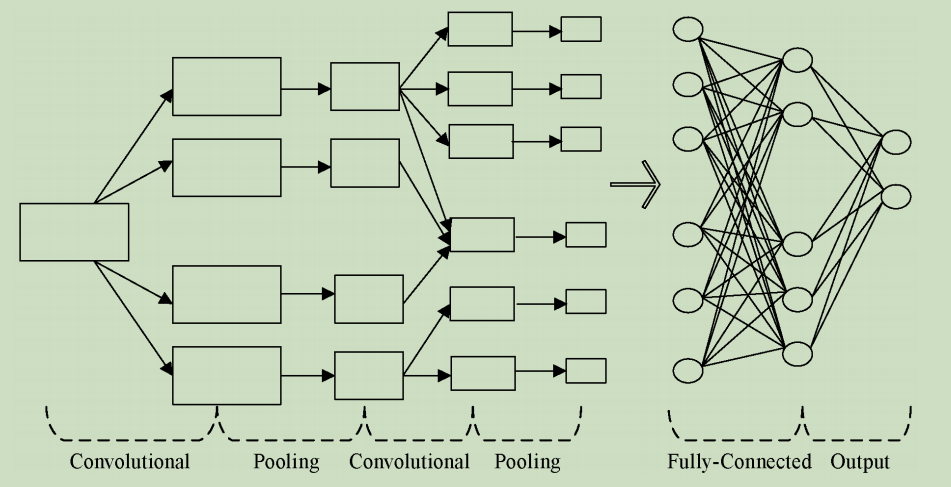
Kim利用CNN模型进行文本分类任务,在该模型中,句子表示采用预训练好的词向量矩阵,这一矩阵作为卷积神经网络的输入层,通过标记好的语料训练出神经网络模型从而达到预测语料类别的效果。该模型在7种语料库上进行训练,弱化了各个文本语料之间的联系,为文本分类的泛化提供有利的前景。但是不同的语料有不同粒度的特征提取尺度,而该方法统一了特征提取尺度,会存在特征丢失现象。
Wang等人对CNN网络进行了一定的改进,主要改进措施为将各层进行密集连接以及多尺度的特征提取。通过密集连接,模型能够从可变的较小n-gram特征灵活生成较大的n-gram特征;通过关注多尺度特征,模型可以从多尺度特征中自适应地选择任务友好且有效地特征进行分类。
CNN的特征提取能力较强,用来提取图像等非序列性特征信息特别有效,但是该网络模型不擅长处理序列问题,若采用感受野叠加的方式进行自然语言处理,系统开销会呈指数级增大。
Word2Vec模型
Word2Vec是Google于2013年开源的词嵌入(Word Embedding)模型。Embedding本质是用低维向量表示文本语料,距离相近的向量对应的语料有相似的含义。Word2Vec主要包含两个模型:连续词袋模型(Continuous Bag of Words,CBOW)和跳字模型(Skip-gram)。
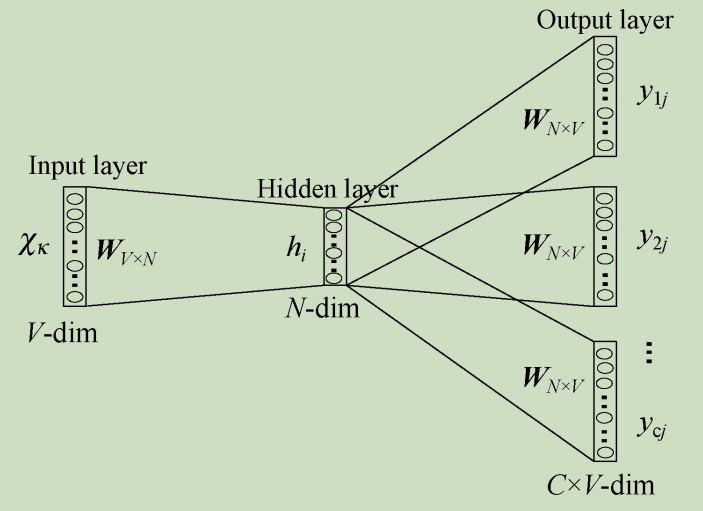
连续词袋模型CBOW根据输入的上下文语料预测当前单词。模型输入为One-hot码;隐藏层为线性单元;输出层维度与输入层维度相同并在最后使用Softmax回归,模型如下图所示。
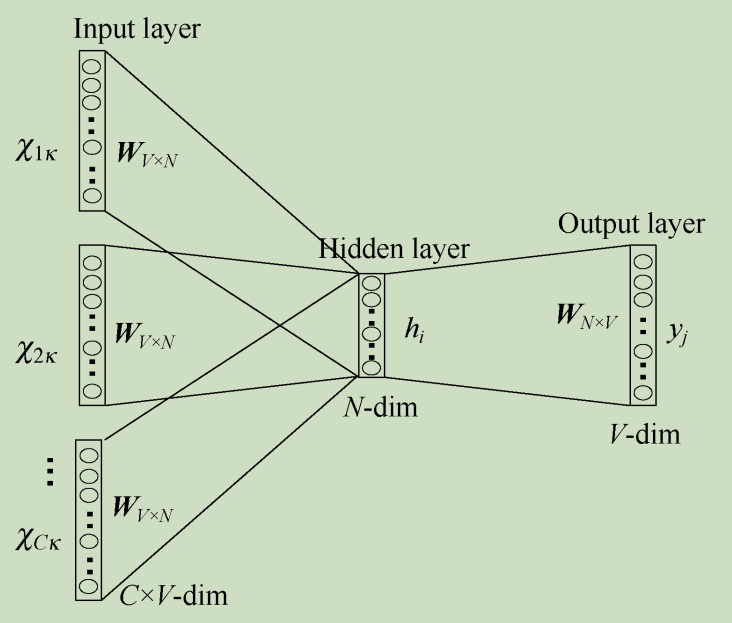
CBOW模型具体处理流程如下:
(1)输入层:上下文单词的独热码(设定语料向量空间维度为 V V V,上下文单词个数为 C C C);
(2)所有独热码分别乘以输入权重矩阵 W W W得到新向量( W W W矩阵大小为 V × N V×N V×N, N N N为超参数);
(3)所得的向量(因为是独热码处理,所以是向量)相加求平均作为隐藏层向量;
(4)隐藏层向量乘以输出权重矩阵 W ′ W^\prime W′( N × V N×V N×V矩阵);
(5)激活函数处理得到V-dim概率分布(因为是独热码,因而每一维都代表着一个单词);
(6)概率最大的index所指示的单词为预测出的目标词(Target word);
(7)将目标词与真实值的独热码值作比较,误差越小越好(从而根据误差更新权重矩阵)。经过若干轮迭代训练后,即可得到模型。
Skip-gram模型的输入是特定单词的词向量,输出是特定单词对应的上下文单词。模型结构如下图所示,具体训练过程与CBOW模型类似。
无论是CBOW模型还是Skip-gram模型,研究人员更愿意使用模型训练过程中的副产品 W W W权重矩阵。输入层的每个单词向量与矩阵 W W W相乘得到的向量即为想要的词向量(预训练词向量只是其中的副产物)。后续任务用训练模型所学习的参数(例如隐层的权重矩阵)处理新任务,而非用已训练好的模型。
为了提高学习效率,Ma等人采用Word2Vec处理大量文本语料。首先对大量文本采用Word2Vec计算单词之间的相似度;然后采用k-means算法对相似单词进行分组以降低特征维度;最后再采用LinearSVC(Linear Support Vector Classifier)与LIBLINEAR算法评估分类性能。Siencnik将Word2Vec用于命名实体识别(从非结构化文本中识别出特定类别的实体,并将其分类到预定义的类别中)中并得出了增加未标记语料量不会提高分类器性能的结论。
由于Word2Vec考虑上下文关系,与传统Embedding相比,嵌入的维度相对更少、速度更快、通用性更强,从而效果更好,可以应用在多种自然语言处理任务中。然而,由于单词与向量是一对一的关系,无法解决一词多义问题。同时,Word2Vec是一种静态的方法,相对于RNN等模型,无法针对特定任务做动态优化,并且它的相关上下文不能太长。
RNN模型
循环神经网络(Recurrent Neural Network,RNN)是由Hopfield网络启发变种而来,Hopfield网络是1982年由Hopfield提出的网络结构,此类网络内部有反馈连接,能够处理信号中的时间依赖性。RNN用来处理序列建模问题,即给定一个长度为 T T T的输入序列 X = x 0 , x 1 , . . . , x t , . . . x T X={x_0,x_1,...,x_t,...x_T} X=x0,x1,...,xt,...xT,这里 x t x_t xt表示的是序列在 t t t时刻的输入特征向量,得到每个时刻的隐含特征 H = h 0 , h 1 , . . . , h t , . . . h T H={h_0,h_1,...,h_t,...h_T} H=h0,h1,...,ht,...hT,这些隐含特征用于后续网络层的特征输入。下图分别为RNN的总体模型及其展开式。
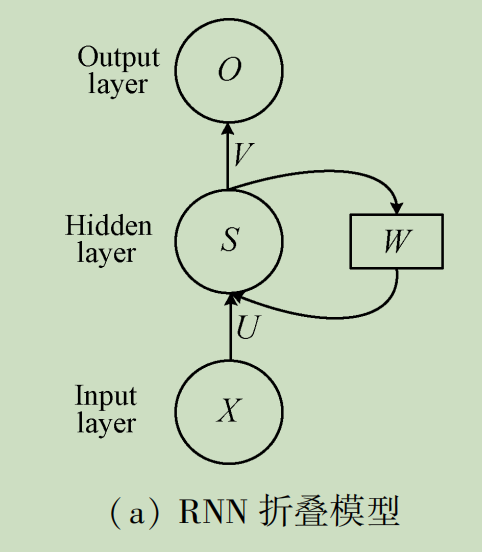
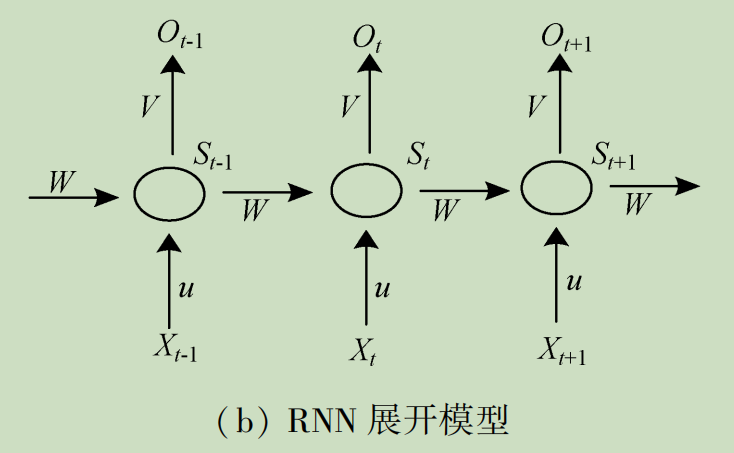
相较于CNN,RNN可以更好地处理时序相关问题,因此较适用于自然语言处理任务,但是该模型处理长时间问题时存在梯度弥散和梯度爆炸问题,这在一定程度上限制了RNN发展,为了解决这一问题,研究者们对RNN进行优化,提出了多种改进版本的RNN。
长短时记忆网络(Long Short-Term Memory,LSTM)在RNN基础上进行改进,主要解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,相较于RNN,LSTM能够在更长的序列中有更好的表现。LSTM模型如下图所示。
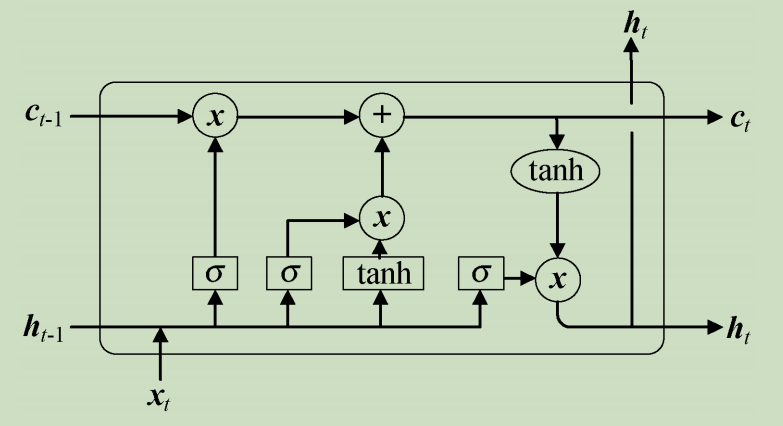
具体而言,LSTM单元由输入门、遗忘门和输出门控制,通过若干LSTM单元依次连接即可构造一个序列神经网络,用于Seq2Seq形式的预测或序列数据的分类。
相对于RNN而言,LSTM在一定程度上解决了梯度弥散和梯度爆炸问题,但是对于一些量级较长的序列,LSTM仍存在一定的性能缺失,同时,该网络模型结构相对复杂且不能并行运行。
**门控循环单元(Gate Recurrent Unit,GRU)**是循环神经网络RNN的另外一种变体。GRU与LSTM一样,也是为了解决长期记忆和反向传播中的梯度消失等问题而提出来。GRU模型如下图所示。
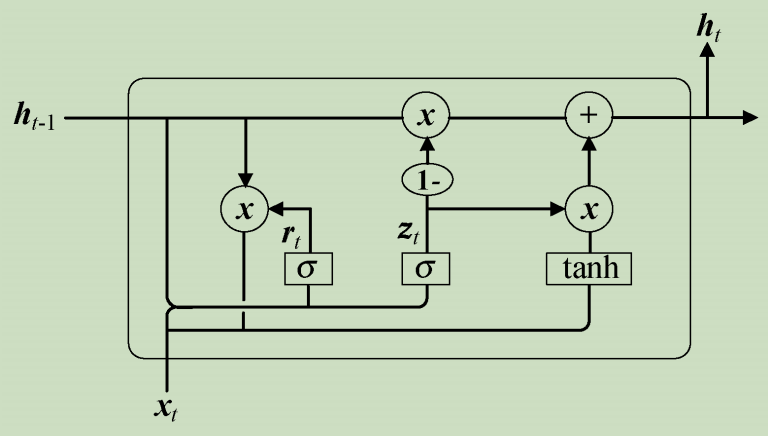
GRU由更新门(Update Gate,控制前面记忆信息能够继续保留到当前时刻的数据量)与重置门(Reset Gate,控制要遗忘多少过去的信息)组成。
Cho等人使用了GRU作为RNN的基本单元,由于GRU相对于LSTM简单方便且性能相差不大,所以在一定程度上代替了LSTM。该方法不容易出现过拟合且该模型较早地将seq2seq应用在机器翻译领域,从而取得了不错的成绩。
Bansal等提出了一种深层递归神经网络GRU,将文本序列编码为潜在向量的方法,结合多任务学习,一定程度地解决数据稀疏问题,该论文结果表明推荐准确性明显上升的同时对冷启动问题也能得到一定程度的解决。
GRU与LSTM在大多数情况下性能大体相同,但是GRU相对于LSTM少一个门控单元,从数学的角度讲,就少了相应的矩阵乘法,在训练语料较大的情况下,GRU能节省一定训练时间。但是在语料较大的情况下,LSTM性能略微优于GRU且该模型仍不能并行处理语料。
**简单循环单元(Simple Recurrent Unit,SRU)**为了解决RNN训练速度较慢(包括LSTM和GRU)和网络结构的可解释性不足问题,Lei等人提出了一种简单的循环神经网络SRU,旨在提供简单快速并更具解释性的循环神经网络。SRU模型如下图所示。
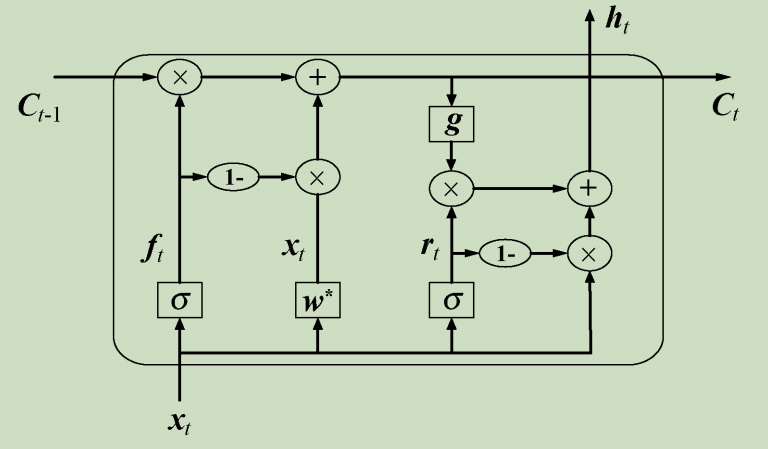
与LSTM和GRU相似,通过若干叠加即可进行神经网络学习。张文等人采用SRU代替GRU,通过堆叠网络层数加深编码器和解码器的结构,从而提高了神经网络机器翻译模型的性能。他们在德语—英语和维语—汉语翻译任务上进行实验,结果表明,在神经网络机器翻译模型中使用SRU单元,可以有效地解决梯度消失带来的模型难以训练的问题,同时,通过加深模型能够显著地提升系统的翻译性能且保证训练速度基本不变,但是,所需要的系统开销会增大。
Peters等人提出ELMo模型(Embeddings from Language Models),该模型的本质思想是先用模型学习一个单词的嵌入表示(可以用Word2Vec或Glove等得到,原文中使用的是字符级别的残差CNN得到Token Embedding),此时无法区分多义词。在实际使用单词嵌入的时候,单词已经具备特定的上下文,这时可以根据上下文单词的语义调整单词的嵌入表示,这样经过调整后的单词嵌入更能表达上下文信息,自然就解决了多义词的问题。经过如上处理,ELMo在一定程度上解决了一词多义的问题,但是它仍存在一定不足:首先,在特征提取器方面,ELMo使用的是LSTM而非Transformer(在已有的研究中表明,Transformer的特征提取能力远强于LSTM);其次,ELMo采用的双向拼接融合特征方式比一体式融合方式要弱一些。
相对于LSTM和GRU,SRU去掉了前后时刻的依赖,从而可以将各个时刻之间的计算并行,进而获得更高的加速比。除此之外,基于以上结构的各种变体层出不穷。其中用得较多的有双向RNN(Bidirectional RNN,BRNN)、深度RNN(Deep RNN,DRNN)、深度双向RNN(Deep Bidirectional RNN,DBRNN)等(这里的RNN是泛指,即RNN及各种改进模型)。虽然RNN能在一定程度上为自然语言处理注入新的活力,但是相对于Transformer机制来说,存在明显不足,在现阶段,Transformer及变体机制在自然语言处理应用中占主流地位。
GPT网络模型
**GPT模型(Generative Pre-Training)**用多层多个单向Transformer完成预训练任务,模型将12层Transform叠加,训练过程较简单,将句子的 n n n个词向量嵌入加上位置编码后输入到Transformer中, n n n个输出分别预测该位置的下一个词。下图为GPT的单向Transformer结构和GPT的模型结构。
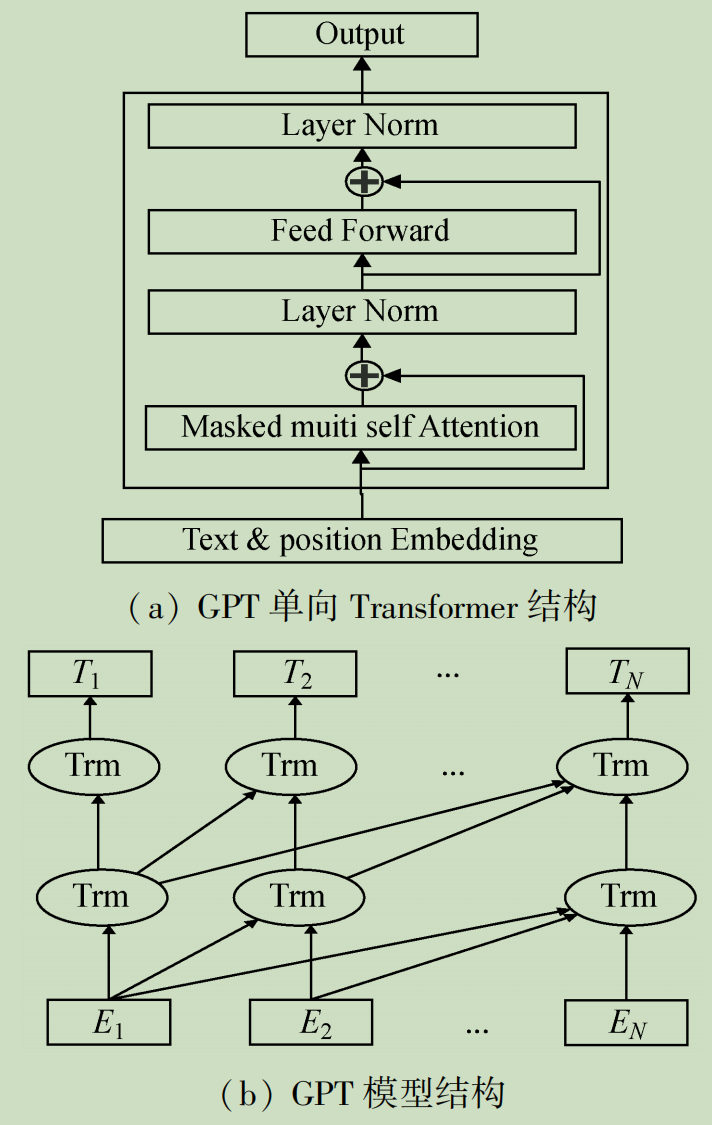
具体而言,GPT分无监督Pre-Training和有监督Fine-tuning两个训练阶段,第一阶段预训练后有一个下游拟合阶段。该模型与ELMo流程类似,主要不同在于:首先,使用Transformer而非RNN作为特征抽取器,Transformer作为特征提取器,能有效提取语料特征;其次,GPT采用的是单向语言模型作为目标任务。但是,该模型采用的单向语言模型,丢失较多信息。为此,基于GPT的改进措施是研究者们关注的一个热点。
1.预训练任务通常是在大规模无标注数据集上通过自监督学习方式来学习与任务无关的通用知识,而微调任务则是在小规模标注数据集上通过监督学习方式来学习任务特定的知识。
2.提示学习(prompt learning)的核心思想在于利用LM在大量无标记数据上学习到的通用知识,通过特定任务的提示,帮助模型有效地表示和理解任务数据,从而将LM学习到的通用知识迁移到具体的下游任务中。这一过程减少模型对新任务数据的依赖,提高了LM在新任务上的泛化能力和适应性。
GPT-2网络模型依然沿用GPT单向Transformer的模式,在GPT模型上做了相应改进。首先,不再针对不同层分别进行微调,而是不定义这个模型做什么,模型根据下游任务自动识别出需要什么任务;其次,增加语料和网络的复杂度;再者,将每层的正则化(Layer Normalization)放到每个Sub-block之前,并在最后一个Self-attention之后再增加一个层正则化操作。相较于GPT模型,GPT-2提取信息能力更强,尤其是在文本生成方面性能优越。但是,该模型的缺点与GPT一样,采用单向的语言模型会丢失部分关键信息。
GPT-3网络模型是目前在通用知识领域性能最好的模型,核心聚焦于更通用的NLP模型,主要解决对领域内标签数据的过分依赖和对领域数据分布的过拟合问题。依旧沿用了单向语言模型训练方式,但是模型的大小增加到1750亿的参数量以及用45TB的语料进行相关训练。在通用NLP领域中,GPT-3的性能是目前最高的模型之一。但是,其在一些经济政治类问题上表现得不太理想。该模型由于参数量过于巨大,目前大部分学者只能遥望一二,离真正进入实用阶段还有一定距离。
Gao等受GPT-3模型的启发,使用较小的模型并采用少量语料来微调语言模型的权重,该方法相对于普通微调,性能最多可以提升30%。
GPT类模型尤其擅长于文本生成类任务且在通用类任务上也取得了不错的效果。 但是,GPT系列模型越来越大,不便于模型投入实际生产生活,同时,由于预训练语料参差不齐,在一些涉及道德、法律、伦理常识方面存在歧视问题。
BERT网络模型
**BERT网络模型(Bidirectional Encoder Representation from Transformers)**采用与GPT完全相同的两阶段模型,首先是模型预训练,即用大量的无标签语料对模型进行初步训练,得到一个半成品模型;其次是使用Fine-Tuning模式(迁移学习)解决下游任务。与GPT最主要的不同在于预训练阶段采用了类似ELMo的双向语言模型和Mask技术,下图为BERT模型。
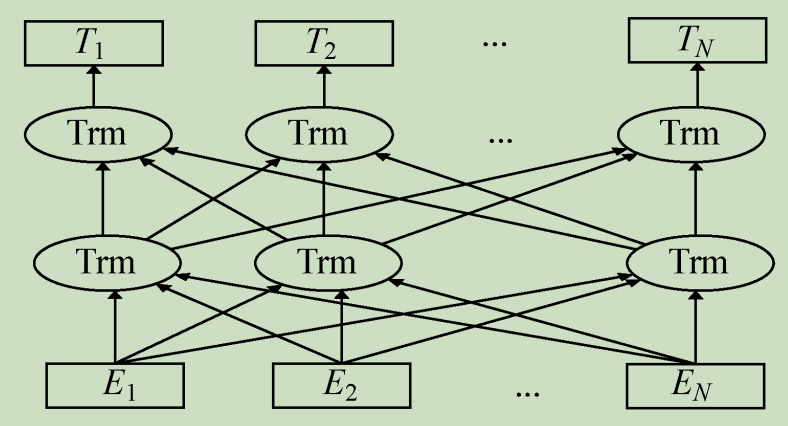
Su等人提出了通用的视觉-语言预训练模型VL-BERT(Visual-Linguistic BERT),该模型采用Transformer作为主干网络,同时将其扩展为包含视觉与语言输入的多模态形式。该模型适合于绝大多数视觉-语言后续任务。
BERT采用双向Transformer技术,能较准确地训练词向量。但是,BERT采用的NSP机制(Next Sentence Prediction)会导致结果出现主题预测,采用随机Mask部分单词而不是连续的词组,这些都会导致BERT的效果出现折扣;同时,BERT相对于其他模型来说,参数量较大,难以部署在性能受限的边缘设备上。
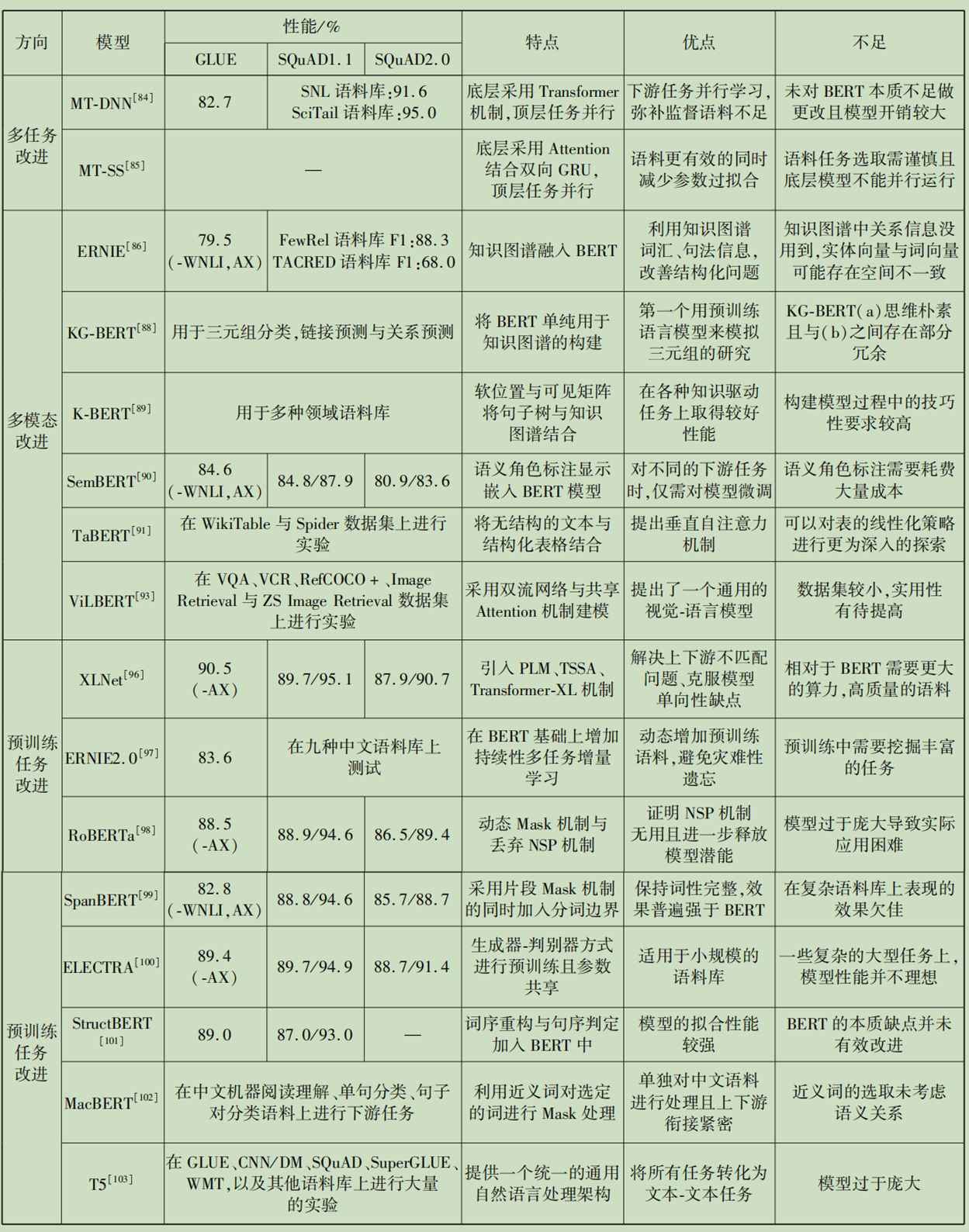
BERT变体模型
基于BERT以上缺点,出现了对BERT改进的两大方向:
(1)尽可能提升BERT的性能;
(2)保持模型性能不受大的影响前提下,缩小BERT模型的规模。
提升模型性能
大体上可以分为多任务改进、多模态改进和预训练改进这三种方式。
- 对于多任务改进,当监督语料过少时,BERT下游任务性能提升有限且性能稳定性较差。
- 多模态改进是将BERT与其他模态进行结合用以提升模型性能。
- 预训练任务改进主要针对BERT上游任务阶段进行改进,使其更好地与下游任务衔接,该方向是近年BERT性能提升的一个主流方向。预训练任务改进从本质上改变了模型的结构从而获得更高的性能;但是,由于BERT模型骨架参数量庞大,从头训练需要强大的硬件支持,这在一般的机构是很难实现的。
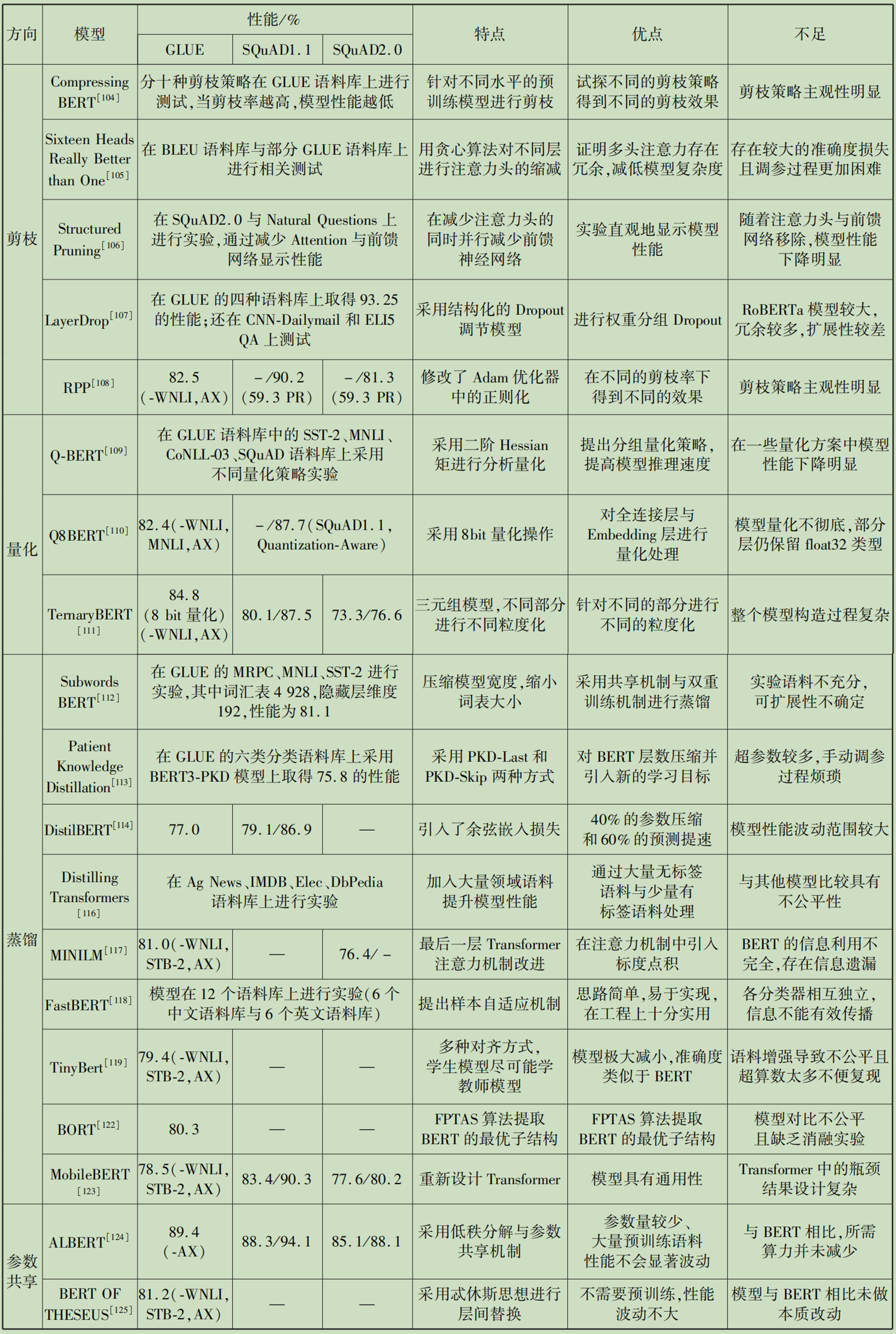
模型压缩
由于BERT模型存在参数量巨大,难以部署在手机、日常家用电脑等计算资源受限设备上。部分学者在追求性能损失不大的基础上降低模型的复杂度。在该方向上,目前有模型剪枝、模型量化、知识蒸馏、参数共享与低秩分解等方法。
- 模型剪枝是从模型中删除不太重要的一部分权重从而产生稀疏的矩阵,进而达到模型轻量化的结果。
- 量化是通过减少每个参数所需要的比特数来压缩原始模型,可以显著降低内存。量化可以减少模型尺寸、储存空间、内存消耗、加快推理速度等优点。但是,模型量化增加了操作复杂度,在量化时需要做一些特殊的处理,否则精度损失更严重;同时,模型量化会损失一定的精度,虽然在微调后可以减少精度损失,但推理精度确实下降。
- 知识蒸馏的核心是将复杂网络迁移进简单网络中,这之中重要的部分是将其中的“精华”蒸馏出来,再用其指导精简的网络进行训练,从而实现模型压缩。蒸馏是模型压缩中最为流行的一个方向,它可以使学生模型获得教师模型的知识从而提升学生模型的效果。但是良好的知识蒸馏模型需要较强的背景知识与经验判断且蒸馏的不确定性较高。
- 参数共享与低秩分解是通过共享部分参数或降低参数的秩从而达到减小模型的目的。
相关文章:

NLP系列【自然语言处理的深度学习模型综述】
自然语言处理的深度学习模型 摘要传统自然语言处理模型(略 不作重点)神经网络自然语言处理模型经典神经网络CNN网络模型Word2Vec模型RNN模型GPT网络模型BERT网络模型 BERT变体模型提升模型性能模型压缩 摘要 在自然语言处理任务方面,依据语料…...

【差分隐私】basic primitive的含义
在差分隐私领域,“basic primitive”一词具有特定的技术含义,需从单词本义及学科背景两个层面解析: 一、单词本义解析 “Primitive”在计算机科学中通常指代基础构建单元或核心组件,例如编程语言中的基本数据类型(如整…...

数字浪潮下的算力担当:GPU 服务器的多元应用、核心价值
在当今数据洪流和信息爆炸的时代,算力已成为衡量国家、行业乃至企业发展水平的关键指标。而算力服务器,特别是 GPU 服务器,作为算力的核心载体,正以其卓越性能深刻改变着世界的运行逻辑与模式。从数据处理到云计算,从人…...

【Echarts】使用echarts绘制多个不同类型的中国地图
一、需求 在同一页面上绘制多个不同类型的中国地图,如果是在同一页面上绘制多个同一种类型的地图可以直接引用一个china.js文件,设置两个独立的div分别用于放置两个地图,并实例化配置相关参数即可,但是如果在同一个页面上绘制多个…...

WEB漏洞-XSS跨站原理分类
本文主要内容 原理 XSS漏洞产生原理? XSS漏洞危害影响? 分类 反射型、存储型、DOM型 手法 XSS平台使用 XSS工具使用 XSS结合其他漏洞 靶场搭建 pikachu 靶场搭建(完整版)-CSDN博客https://blog.csdn.net…...

PR第二课--混剪
1.音乐打点 1.1 手动打点 按钮(如图),或者,快捷键M(如果在已有打点处,再次按M键会进入对标记点的设置界面,如下下图) 1.2 插件打点 一段音乐中,有明显的鼓点时,可以使用打点插件,快捷打点;如果鼓点不明显的话,最好还是手动打点,用插件打点会打出大量的标记点,…...

Kafka和flume整合
需求1:利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台: 在flume/conf下添加.conf文件, vi flume-kafka.conf # 定义 Agent 组件 a1.sourcesr1 a1.sinksk1 a1.c…...

Linux 内核网络协议栈中 inet_stream_ops 与 tcp_prot 的深度解析
在 Linux 内核网络协议栈中,TCP 协议的实现依赖于多个关键结构体的协作。其中,inet_stream_ops 和 tcp_prot 是两个核心结构体,它们分别属于不同的层次,共同完成从用户态系统调用到底层协议处理的完整链路。本文将从功能定位、协作关系、代码示例及设计哲学等方面,深入分析…...

flume整合kafka
需求一: 启动flume 启动kafka消费者,验证数据写入成功 新增测试数据 需求二: 启动Kafka生产者 启动Flume 在生产者中写入数据...

EasyRTC音视频实时通话嵌入式SDK,打造社交娱乐低延迟实时互动的新体验
一、方案背景 在数字化时代,社交娱乐已经成为人们生活中不可或缺的一部分。随着移动互联网和智能设备的普及,用户对实时互动的需求越来越高。EasyRTC作为一款基于WebRTC技术的实时音视频通信解决方案,凭借其低延迟、高稳定性和跨平台兼容性&…...

制作一款打飞机游戏21:自定义工具
关于如何在Pico 8中创建我们自己的编辑器。 外部编辑器的需求 首先,我想谈谈为什么我们需要外部编辑器。外部编辑器通常用于编辑游戏中的数据。例如,一个游戏卡或程序通常包含一些代码,但也会包含数据,比如静态信息,…...

面向高性能运动控制的MCU:架构创新、算法优化与应用分析
摘要:现代工业自动化、汽车电子以及商业航天等领域对运动控制MCU的性能要求不断提升。本文以国科安芯的MCU芯片AS32A601为例,从架构创新、算法优化到实际应用案例,全方位展示其在高性能运动控制领域的优势与潜力。该MCU以32位RISC-V指令集为基…...

LWIP中两种重要的数据结构pbuf和pcb详细介绍
LWIP(Lightweight IP)是为嵌入式系统设计的轻量级TCP/IP协议栈。pbuf(Packet Buffer)和PCB(Protocol Control Block)是LwIP中两个核心数据结构,分别负责数据包管理和协议状态维护。 1. pbuf&…...

embedding_model模型通没有自带有归一化层该怎么处理?
embedding_model 是什么: 嵌入式模型(Embedding)是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域的机器学习模型,它可以将高维度的数据转化为低维度的嵌入空间࿰…...

【蓝桥杯选拔赛真题104】Scratch回文数 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch回文数 一、题目要求 1、准备工作 2、功能实现 二、案例分析 1、角色分析 2、背景分析 3、前期准备 三、解题思路 四、程序编写 五、考点分析 六、推荐资料 1、scratch资料 2、python资料 3、C++资料 scratch回文数 第十五届青少年蓝桥杯scratch编…...

1.2-1.3考研408计算机组成原理第一章 计算机系统概述
计算机组成原理第一章 计算机系统概述 一、计算机的层次结构 1.1 计算机系统组成 计算机系统由硬件系统和软件系统两大部分构成: 硬件系统:包括运算器、控制器、存储器、输入设备和输出设备五大核心部件(冯诺依曼体系结构)。软…...

【QQmusic自定义控件实现音乐播放器核心交互逻辑】第三章
🌹 作者: 云小逸 🤟 个人主页: 云小逸的主页 🤟 motto: 要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前,其次就是现在&…...

基于图扑 HT 实现的智慧展馆数字孪生应用
在当今数字化时代,智慧展览馆作为传统展览场所的创新升级形态,借助前沿科技与现代化管理理念,实现了全方位的数字化、智能化转型。图扑软件凭借其自主研发的 HT 技术在智慧展馆领域取得了卓越成果,为城市基础设施数字化应用带来了…...

从线性到非线性:简单聊聊神经网络的常见三大激活函数
大家好,我是沛哥儿,我们今天一起来学习下神经网络的三个常用的激活函数。 引言:什么是激活函数 激活函数是神经网络中非常重要的组成部分,它引入了非线性因素,使得神经网络能够学习和表示复杂的函数关系。 在神经网络…...

重生之--js原生甘特图实现
需求: 一个树形结构,根据子节点的时间范围显示显示进度 ,不同的时间范围对应不同的颜色 数据类型大概是这个样子的 甘特图 dom部分 首先要计算所有节点的 最大时间和最小时间 然后再计算每个甘特图的宽度 再计算他的偏移量 再计算颜色...

pnpm monoreop 打包时 node_modules 内部包 typescript 不能推导出类型报错
报错信息如下: ../../packages/antdv/components/pro-table/src/form-render.vue:405:1 - error TS2742: The inferred type of default cannot be named without a reference to .pnpm/scroll-into-view-if-needed2.2.31/node_modules/scroll-into-view-if-needed…...

告别默认配置!Xray自定义POC开发指南
文章涉及操作均为测试环境,未授权时切勿对真实业务系统进行测试! 下载与解压 官网地址: Xray GitHub Releases 根据系统选择对应版本: Windows:xray_windows_amd64.exe.zipLinux:xray_linux_amd64.zipmacOS:xray_darwin_amd64.zip解压后得到可执行文件(如 xray_linux_…...

websheet之 自定义函数
在线代码 {.is-success} 一、自定义函数约定 必须遵守本控件的自定函数约定才可以正常使用。 {.is-warning} 约定如下: 自定义类名称与函数名称一致。(强制)该类方法名称与函数名称一致,该方法是函数的入口。(强制&am…...

Jenkins Pipeline 构建 CI/CD 流程
文章目录 jenkins 安装jenkins 配置jenkins 快速上手在 jenkins 中创建一个新的 Pipeline 作业配置Pipeline运行 Pipeline 作业 Pipeline概述Declarative PipelineScripted Pipeline jenkins 安装 安装环境: Linux CentOS 10:Linux CentOS9安装配置Jav…...

电脑技巧:路由器内部元器件介绍
目录 1. 处理器(CPU) 2. 内存(RAM) 3. 固态存储(Flash Memory) 4. 网络接口卡(NIC) 5. 电源模块 6. 散热系统 7. 无线天线 结语 路由器是我们日常上网的重要设备,今天我们就来深入了解路由器内部的各个元器件,了解它们是如何协同工作,一起来看看吧。 1. 处理器(CPU…...

ArrayUtils:数组操作的“变形金刚“——让你的数组七十二变
各位数组操控师们好!今天给大家带来的是Apache Commons Lang3中的ArrayUtils工具类。这个工具就像数组界的"孙悟空",能让你的数组随心所欲地变大、变小、变长、变短,再也不用对着原生数组的"死板"叹气了! 一…...

电脑温度怎么看 查看CPU温度的方法
监测电脑温度对于保持硬件健康非常重要,特别是在进行高强度运算、游戏或超频等操作时。过高的温度可能导致硬件性能下降,甚至损坏。本篇文章将介绍查看电脑温度的4种方法。 一、使用Windows内置工具查看CPU温度 Windows系统本身并不直接提供查看CPU温度…...

【合新通信】---浸没式液冷光模块化学兼容性测试方法
一、测试目的与核心挑战 测试目标 验证冷媒(氟化液、矿物油等)与光模块材料的化学稳定性,确保长期浸没环境下无腐蚀、溶胀或性能衰减。关键风险点:密封材料(如硅胶、环氧树脂)的溶解或老化;金…...

shell 循环
shell 循环while语句,shell循环until语句在上一篇shell流程控制 1.shell循环until语句 until 条件 #当后面的条件表达式为假的时候的才循环,为真的时候就停止了 do 循环体 done [root@linux-server script]# cat until.sh (1) #!/bin/bash x=1 until [ $x -ge 10 ] 大于…...

【产品经理】常见的交互说明撰写方法
在产品原型设计中,交互说明是确保开发团队准确理解设计意图的关键文档。以下是常见的交互说明撰写方法及其应用场景,帮助您系统化地传达交互逻辑: 文字描述法 方法:用自然语言详细描述操作流程、反馈及规则。 适用场景ÿ…...

使用kubeadmin 部署k8s集群
成功搭建一个 Kubernetes 1.28.2 集群,包含以下组件和状态: 集群拓扑 1 个 Master 节点 IP:10.1.1.100 角色:control-plane 2 个 Worker 节点 Node2:10.1.1.101 Node3:10.1.1.102 核心组件状态 所有节点通过 kubectl get nodes 显示为 Ready。 核心 Pod(如 etc…...

二项式分布html实验
二项式分布html实验 本文将带你一步步搭建一个纯前端的二项分布 Monte-Carlo 模拟器。 只要一个 HTML 文件,打开就能运行: 动态输入试验次数 n、成功概率 p 与重复次数 m点击按钮立刻得到「模拟频数 vs 理论频数」柱状图随着 m 增大,两组柱状…...

[基础] Windows PCIe设备驱动框架与开发实践深度解析
Windows PCIe设备驱动框架与开发实践深度解析 1. PCIe设备驱动技术背景 PCI Express(Peripheral Component Interrupt Express)作为现代计算机系统的核心互连标准,其驱动程序开发涉及复杂的内核模式编程。Windows系统通过模块化的驱动架构支…...
)
面向智能家居安全的异常行为识别与应急联动关键技术研究与系统实现(源码+论文+部署讲解等)
需要资料,请文末系 一、平台介绍 3D家庭实景 - 动热力图 多模态看板 跌倒行为分析 二、论文内容 在这里插入图片描述](https://i-blog.csdnimg.cn/direct/2dfe7f45d3ce42399e0df9535870d26d.png) bash 摘要 Abstract第一章 绪论 1.1 研究背景与动机 o1.1.1…...

根据JSON动态生成表单表格
根据JSON动态生成表单表格 一. 子组件 DynamicFormTable.vue1,根据JSON数据动态生成表单表格,支持表单验证JS部分1.1,props数据1.2,表单数据和数据监听1.3,自动验证1.4,表单验证1.5,获取表单数据1.6,事件处理1.7,暴露方法给父组件2,HTML部分二,父组件1, 模拟数据2,…...

spring OncePerRequestFilter 作用
概要 OncePerRequestFilter 是 Spring Web 提供的一个抽象滤器基类,用于保证在一次 HTTP 请求的整个分派过程中,该滤器仅执行一次,无论该请求经历了多少次内部转发(forward)、包含(include)或错…...
二次开发或训练经验的关键点和概述)
关于开源大模型(如 LLaMA、InternLM、Baichuan、DeepSeek、Qwen 等)二次开发或训练经验的关键点和概述
以下是适合初学者理解的关于开源大模型(如 LLaMA、InternLM、Baichuan、DeepSeek、Qwen 等)二次开发或训练经验的关键点和概述,: 关键点: 研究表明,二次开发通常涉及微调模型以适应特定任务,需…...

promethus基础
1.下载prometheus并解压 主要配置prometheus.yml文件 在scrape_configs配置项下添加配置(hadoop202是主机名): scrape_configs: job_name: ‘prometheus’ static_configs: targets: [‘hadoop202:9090’] 添加 PushGateway 监控配置 job_name: ‘pushgateway’…...

26考研 | 王道 | 数据结构 | 第八章 排序
第八章 排序 文章目录 第八章 排序**8.1** 排序的基本概念**8.2 插入排序****8.2.1 直接插入排序****8.2.2 折半插入排序****8.2.3 希尔排序** 8.3 交换排序8.3.1 冒泡排序8.3.2 快速排序 8.4 选择排序8.4.1 简单选择排序8.4.2 堆排序堆的概念:建立大根堆的代码堆排…...

SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。 企业环境中A…...

kubesphere 单节点启动 etcd 报错
kubekey安装 ./kk create cluster -f config-sample.yaml --with-local-storage 时报错 etcd health check failed: Failed to exec command: sudo -E /bin/bash -c "export ETCDCTL_API2;export ETCDCTL_CERT_FILE/etc/ssl/etcd/ssl/admin-node1.pem;export ETCDCTL_KEY_…...

femap许可常见问题及解决方案
在使用Femap进行电磁仿真分析时,许可证管理是一个关键环节。然而,许多用户在许可证使用过程中可能会遇到各种问题。本文旨在解答关于Femap许可的常见疑问,并提供相应的解决方案,帮助您更顺畅地使用Femap许可证。 一、常见问题 许…...

游戏引擎学习第244天: 完成异步纹理下载
启动并运行游戏,注意到我们的纹理没有被下载 我们将继续完成游戏的开发。昨天,我们已经实现了多线程的纹理下载,但并没有时间调试它,因此纹理下载功能目前并没有正常工作。我们只是写了相关的代码,但由于大部分时间都…...

【安全扫描器原理】TCP/IP协议编程
【安全扫描器原理】TCP/IP协议编程 1.概述2.Windows Socket结构3.Windows socket转换类函数4.Windows Socket通信类函数 1.概述 TCP/IP协议是目前网络中使用最广泛的协议,Socket称为“套接口”,最早出现在Berkeley Unix中,最初只支持TCP/I…...
)
Cuda-GDB Frame Unwind 管理(未完.)
在计算机编程中,Frame Unwind(栈展开) 是指函数调用栈的逆向操作,即在函数返回或异常发生时,系统逐层释放栈帧(Stack Frame)、恢复调用上下文的过程。以下是详细解释及其在 GPU编程(…...

如何在IDEA中高效使用Test注解进行单元测试?
在软件开发过程中,单元测试是保证代码质量的重要手段之一。而IntelliJ IDEA作为一款强大的Java开发工具,提供了丰富的功能来支持JUnit测试,尤其是通过Test注解可以快速编写和运行单元测试。那么,如何在IDEA中高效使用Test注解进行…...

什么是访客鉴权?全面解析核心原理与CC防护应用实践
一、访客鉴权是什么? 访客鉴权(Visitor Authentication and Authorization)是系统对访问者进行身份验证和权限控制的过程,确保只有合法用户能够访问特定资源或执行特定操作。其核心目标是确认身份、控制权限、保障数据安全&#…...

DeepSeek大模型应用学习通知
随着人工智能在各领域深度融合发展,DeepSeek大模型迅速火爆全网,清华大学以最快的速度发布了DeepSeek从入门到精通使用技巧,能够更好的助力于企业和个人参与到AI研究和应用中,对于AI行业创新有重要意义,被誉为国运级的…...
时间序列预测模型比较分析:SARIMAX、RNN、LSTM、Prophet 及 Transformer
时间序列预测根据过去的模式预测未来事件。我们的目标是找出最佳预测方法,因为不同的技术在特定条件下表现出色。本文章将探讨各种方法在不同数据集上的表现,为你在任何情况下选择和微调正确的预测方法提供真知灼见。 我们将探讨五种主要方法࿱…...

快速了解redis,个人笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note (基于mac展示,别的可以参考)接下来将直接…...