26考研 | 王道 | 数据结构 | 第八章 排序
第八章 排序
文章目录
- 第八章 排序
- **8.1** 排序的基本概念
- **8.2 插入排序**
- **8.2.1 直接插入排序**
- **8.2.2 折半插入排序**
- **8.2.3 希尔排序**
- 8.3 交换排序
- 8.3.1 冒泡排序
- 8.3.2 快速排序
- 8.4 选择排序
- 8.4.1 简单选择排序
- 8.4.2 堆排序
- 堆的概念:
- 建立大根堆的代码
- 堆排序算法思想
- 堆的插入和删除
- 8.5.1 归并排序
- 8.5.2 基数排序
- 8.5 3 计数排序(考纲没有做个了解吧)
- 8.6 内部排序算法总结
- 8.6.1 内部排序算法比较
- 8.6.2 内部排序算法的应用
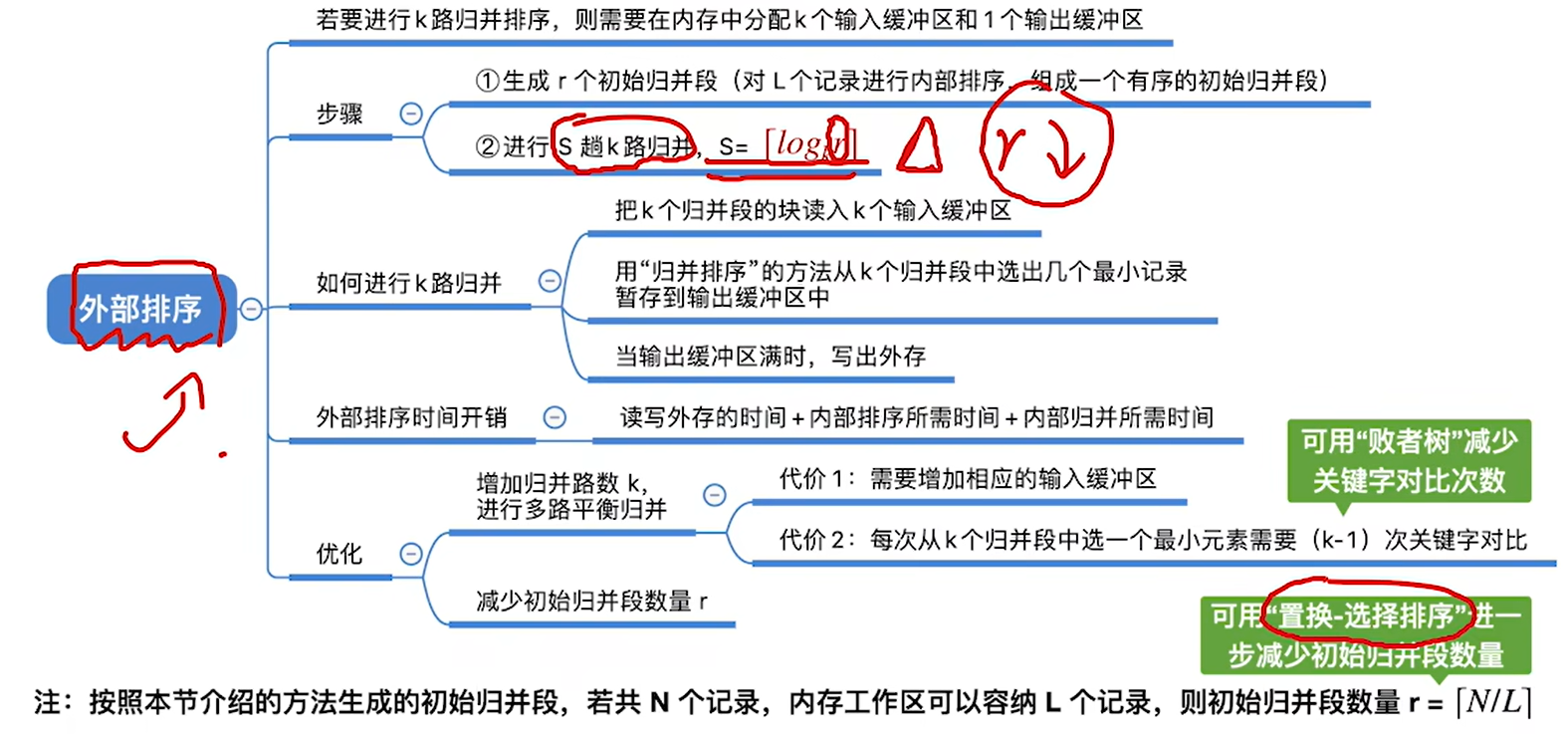
- 8.7 外部排序
- 8.7.1 外部排序的基本概念和方法
- 8.7.2 败者树
- 8.7.3 置换-选择排序(生成初始归并段)
- 8.7.4 最佳归并树
8.1 排序的基本概念
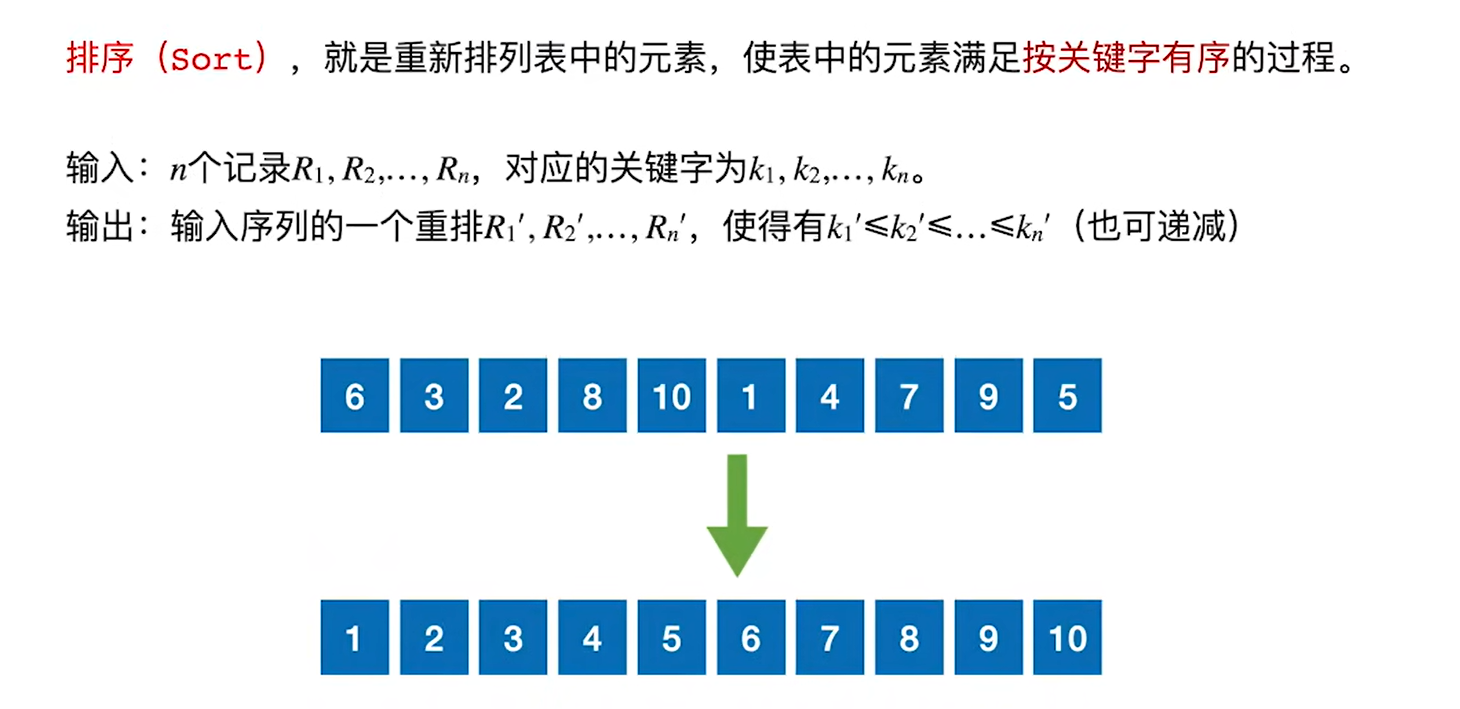
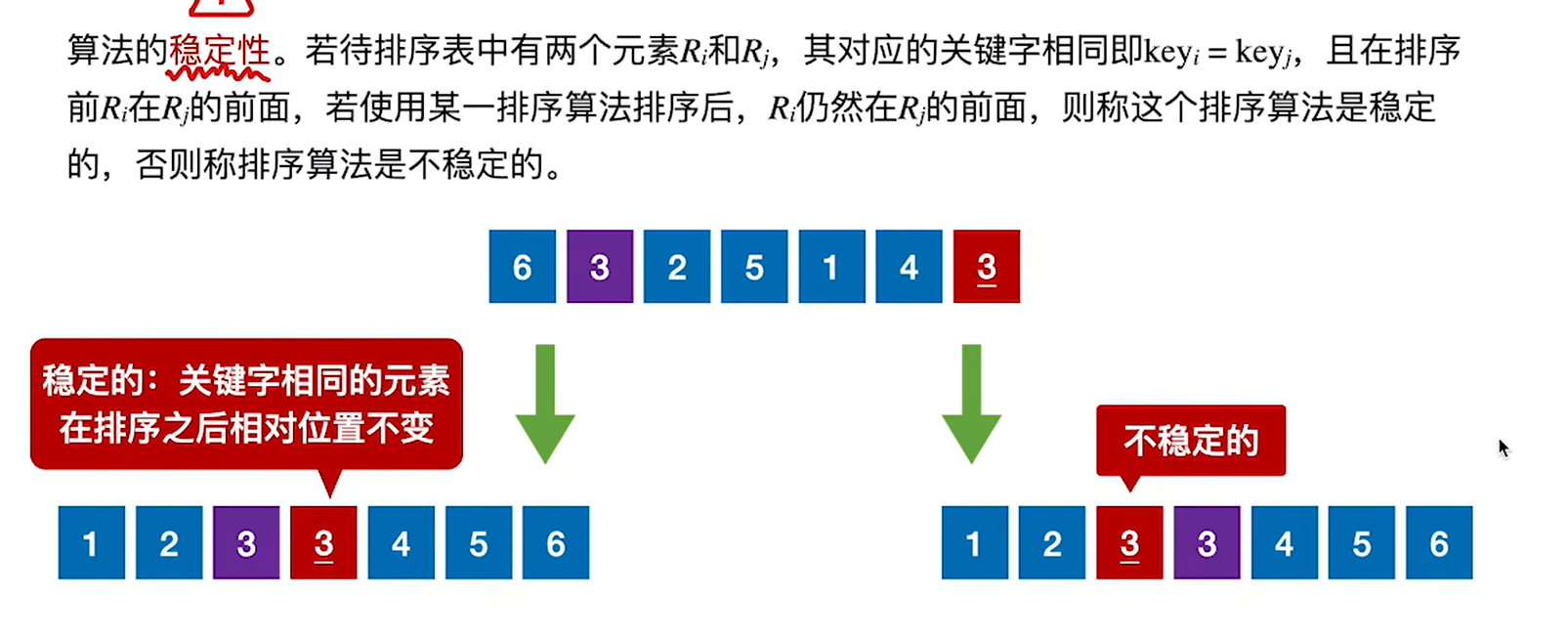
排序算法的评价指标:时间复杂度、空间复杂度、稳定性
8.2 插入排序
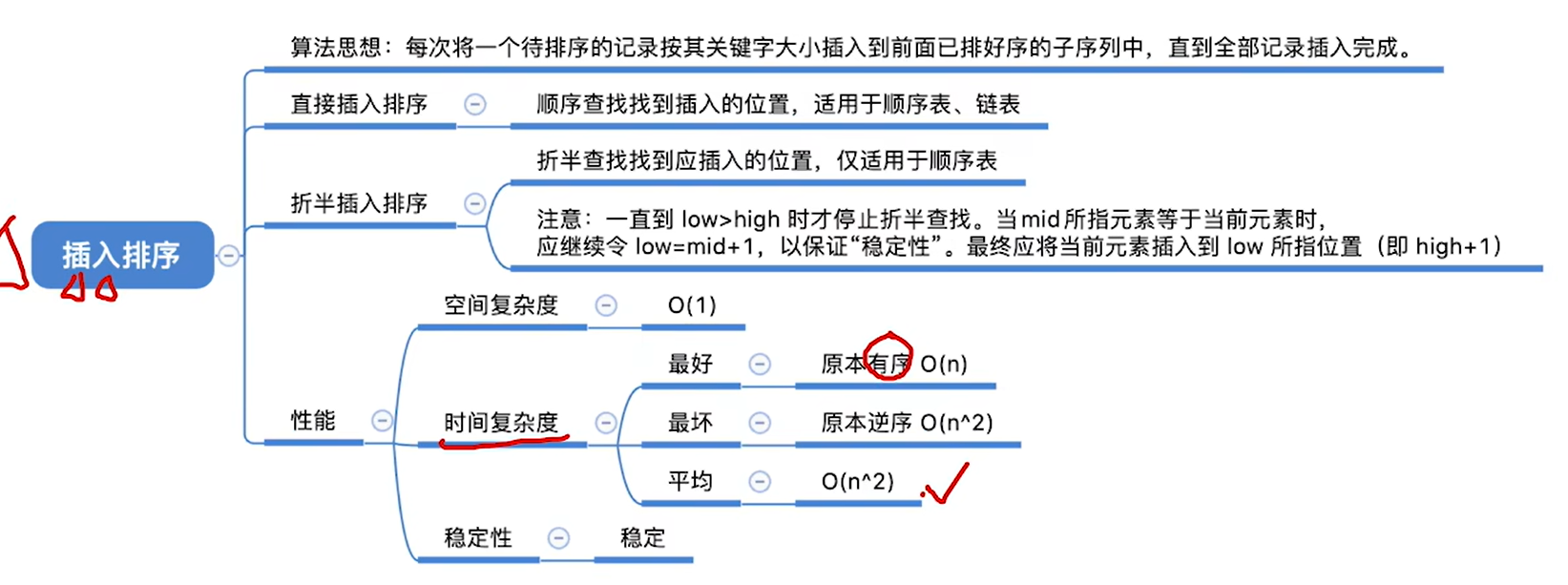
8.2.1 直接插入排序
- 算法思想:每次将一个待排序的记录按其关键字大小,插入到前面已经排好序的子序列中,直到全部记录插入完成。
- 该算法是稳定的
代码实现(不带哨兵):
// 对A[]数组中共n个元素进行插入排序
void InsertSort(int A[],int n){int i,j,temp;for(i=1; i<n; i++){if(A[i]<A[i-1]){ //如果A[i]关键字小于前驱temp=A[i]; for(j=i-1; j>=0 && A[j]>temp; --j)A[j+1]=A[j]; //所有大于temp的元素都向后挪A[j+1]=temp;}}
}
代码实现(带哨兵):
不如没有哨兵的逻辑清晰
// 对A[]数组中共n个元素进行插入排序
void InsertSort(int A[], int n){int i,j;for(i=2; i<=n; i++){if(A[i]<A[i-1]){A[0]=A[i]; //复制为哨兵,A[0]不放元素for(j=i-1; A[0]<A[j]; --j)A[j+1]=A[j];A[j+1]=A[0];}}
}

对链表进行插入排序代码实现:
//对链表L进行插入排序
void InsertSort(LinkList &L){LNode *p=L->next, *pre;LNode *r=p->next;p->next=NULL;p=r;while(p!=NULL){r=p->next;pre=L;while(pre->next!=NULL && pre->next->data<p->data)pre=pre->next;p->next=pre->next;pre->next=p;p=r;}
}
8.2.2 折半插入排序
- 算法思路: 每次将一个待排序的记录按其关键字大小,使用折半查找找到前面子序列中应该插入的位置并插入,直到全部记录插入完成。
- 和直接插入排序就是多了一个折半查找的过程,其他的都一样
- **注意:**一直到low>high 时才停止折半查找。当mid所指元秦等于当前元素时,应继续令low=mid+1,以保证“稳定性”。最终应将当前元素插入到low 所指位置 (即 high+1)
- 最后结束位置是low=hight+1时推出了循环,而low就是元素应该插入的位置,所以要将[low,i-1]的元素全部右移
代码实现:
//对A[]数组中共n个元素进行折半插入排序
void InsertSort(int A[], int n){ int i,j,low,high,mid;for(i=2; i<=n; i++){A[0]=A[i]; //将A[i]暂存到A[0]low=1; high=i-1;while(low<=high){ //折半查找mid=(low+high)/2;if(A[mid]>A[0])high=mid-1;elselow=mid+1;}for(j=i-1; j>high+1; --j)A[j+1]=A[j];A[high+1]=A[0];}
}
- 与直接插入排序相比,比较关键字的次数减少了,但是移动元素的次数没有变。时间复杂度仍为 O(n²)。
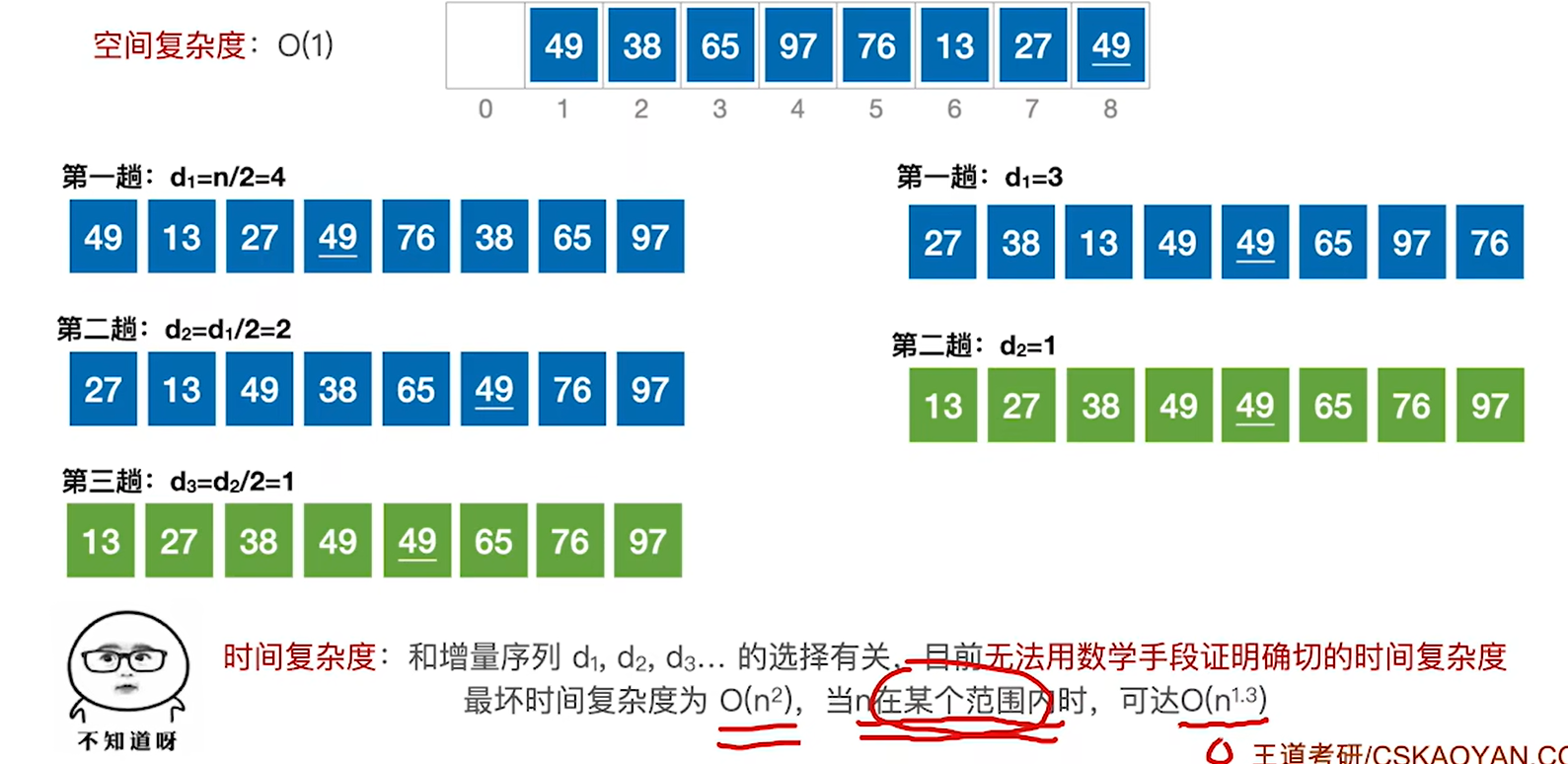
8.2.3 希尔排序
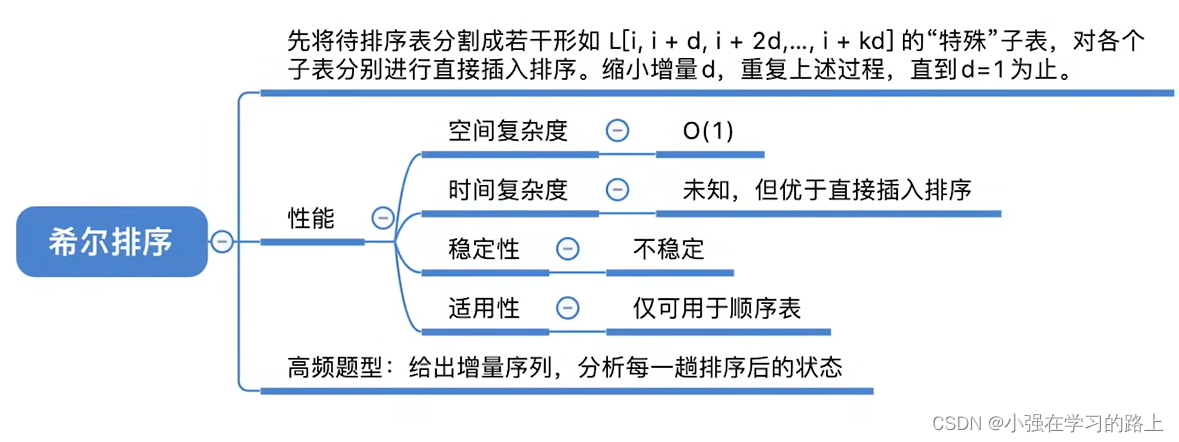
希尔排序:先追求表中元素部分有序,再逐渐逼近全局有序
但是考试中可能会遇到各种各样的增量
具体的例子执行过程:
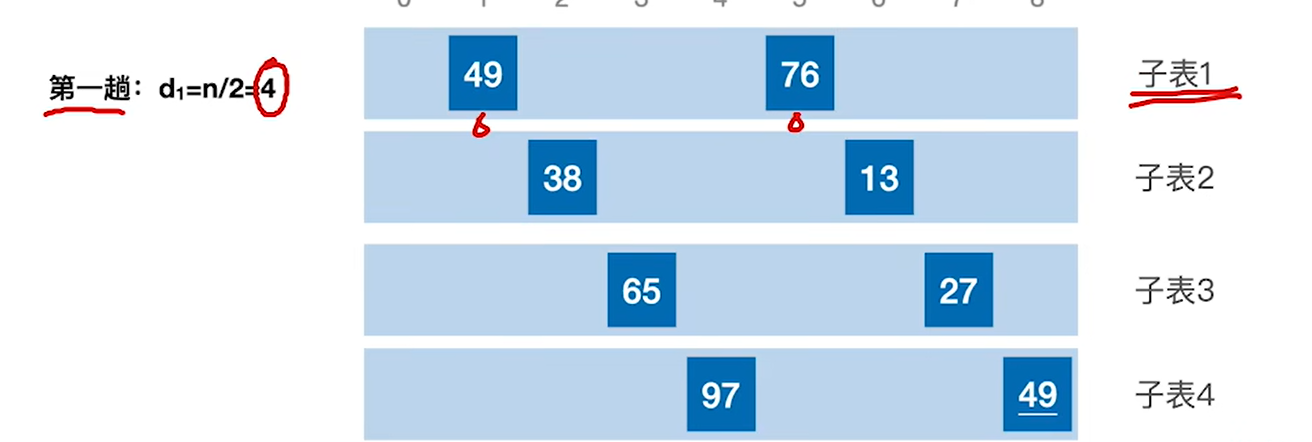
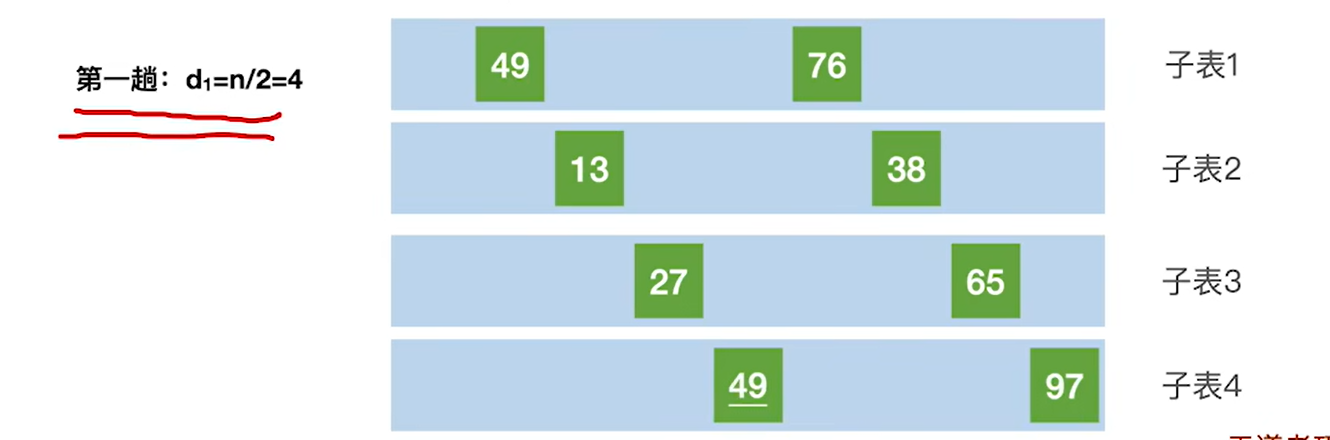



代码实现:
1.代码逻辑一开始会让 i指向第一个子表的第二个元素,方便和第一个元素进行比较,76>49,不需要处理

2.处理第二个子表 最里层的for循环是把子表中大于A[i]的元素往后移动,只是每次都移动的是d的距离,是j+d,而不是j+1,因为处理的是子表而不是整个表

3.第三个第四个子表也是同样的处理,然后第一趟就结束了,就是中间的for循环结束了
4.第二趟的处理,现在d=2,处理第一个子表
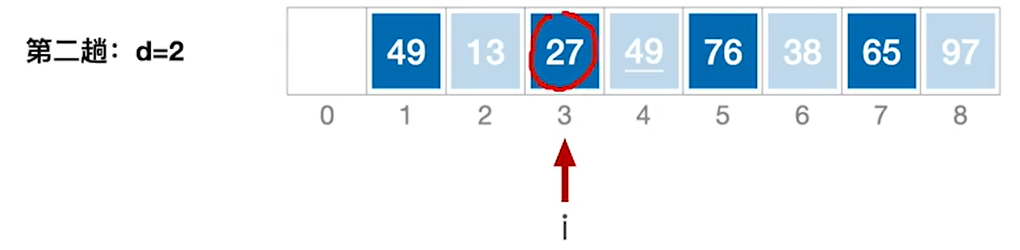
5.处理完27后,本来我们应该去处理76的,但是代码逻辑并不是那样,i++之后是49,是去处理第二个子表的第二个元素49
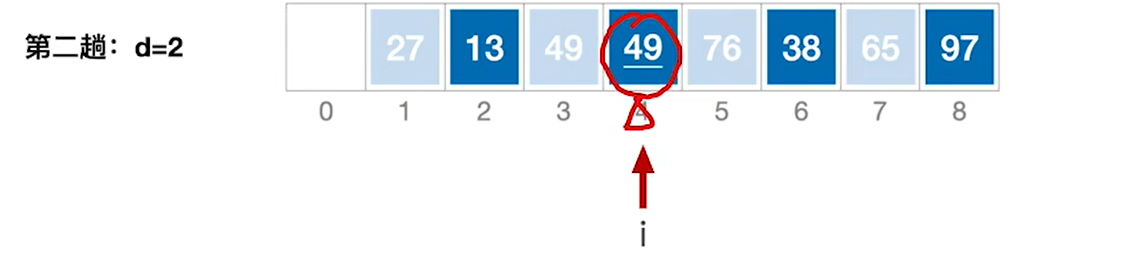
6.处理完49后又切换回了第一个子表的第三个元素76
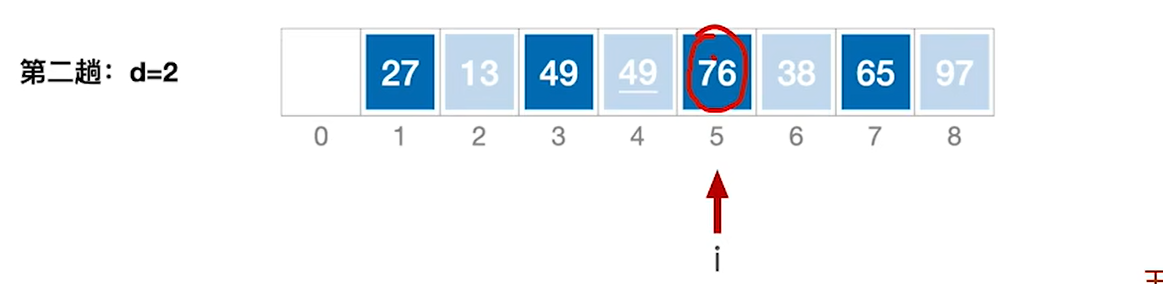
后面的38,65,97也是一样的过程
7.而等到第三趟的时候,d=1,就是直接对整个表进行插入排序了
希尔排序代码实现:
// 对A[]数组共n个元素进行希尔排序
void ShellSort(ElemType A[], int n){int d,i,j;for(d=n/2; d>=1; d=d/2){ //步长d递减for(i=d+1; i<=n; ++i){if(A[i]<A[i-d]){A[0]=A[i]; //A[0]做暂存单元,不是哨兵for(j=i-d; j>0 && A[0]<A[j]; j-=d)A[j+d]=A[j];A[j+d]=A[0];}}}
}
性能分析

不能用于链表是因为希尔排序需要数组的随机访问的特性才可以
8.3 交换排序
8.3.1 冒泡排序
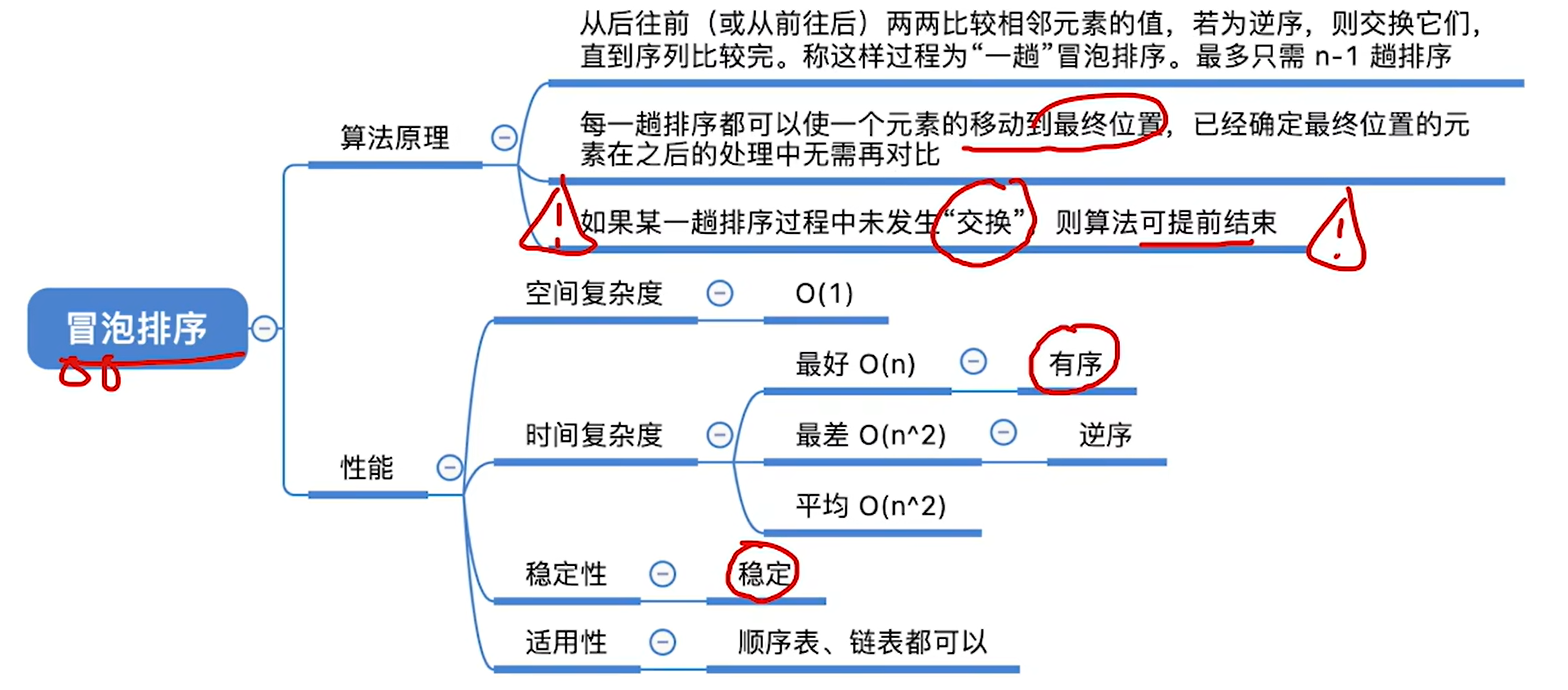
- **算法思路:**从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即 A [ i − 1 ] > A [ i ]) ,则交换它们,直到序列比较完。如此重复最多 n-1 次冒泡就能将所有元素排好序。为保证稳定性,关键字相同的元素不交换。
其实就是每次都是在没有排过序的元素中选一个最小的放到了最前面
冒泡排序代码实现:
// 交换a和b的值
void swap(int &a, int &b){int temp=a;a=b;b=temp;
}// 对A[]数组共n个元素进行冒泡排序
void BubbleSort(int A[], int n){for(int i=0; i<n-1; i++){bool flag = false; //标识本趟冒泡是否发生交换//i所指位置之前的元素都是已经排好序的元素for(int j=n-1; j>i; j--){if(A[j-1]>A[j]){swap(A[j-1],A[j]);flag=true;}}if(flag==false)return; //若本趟遍历没有发生交换,说明已经有序}
}
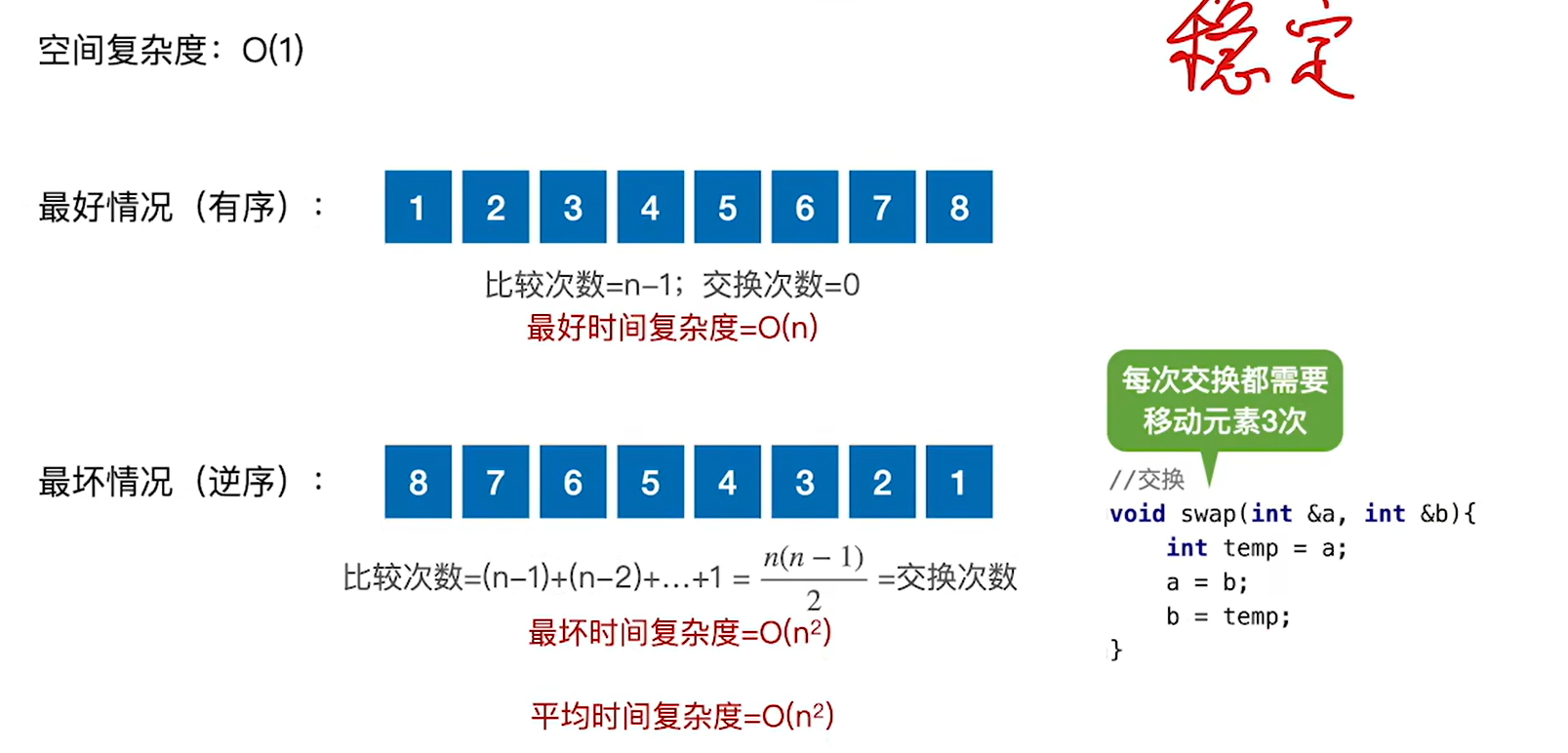
每次只有大于的时候才会交换,所以算法是稳定的
冒泡排序还可以用于链表
8.3.2 快速排序


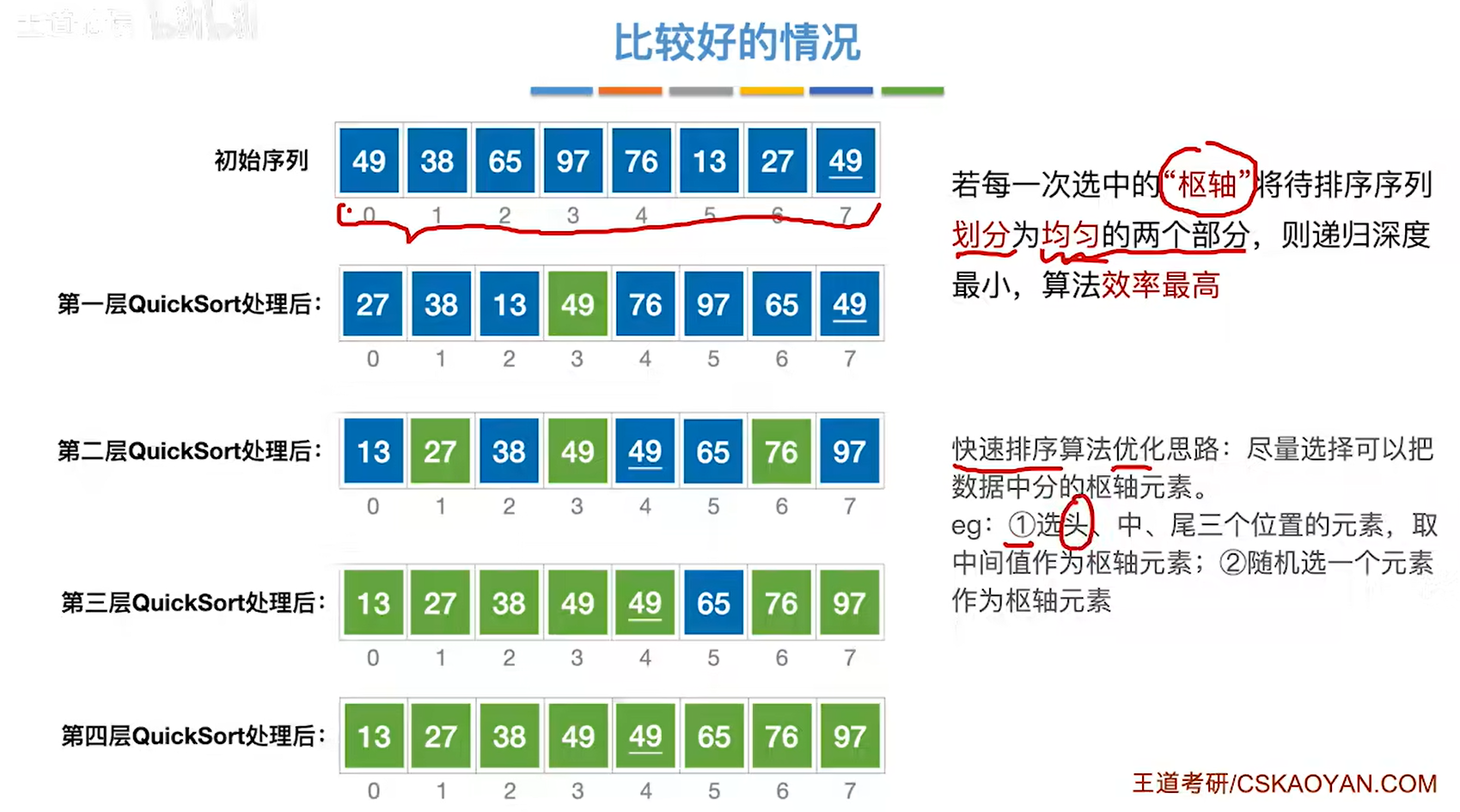
算法执行过程:
1.分别用low和high指向要处理的序列的头和尾的两个位置
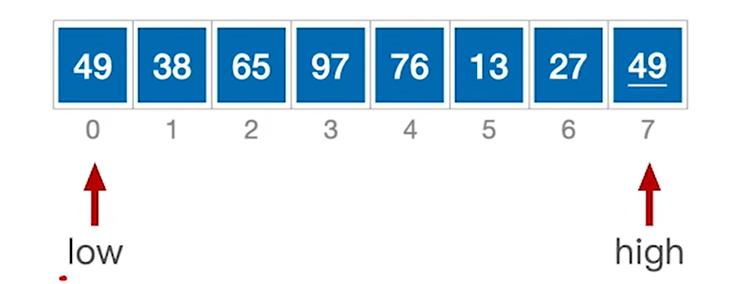
2.选low作为基准元素,然后扫描剩下的所有元素,小于49的都放在low的左边,大于等于49的都放在high的右边
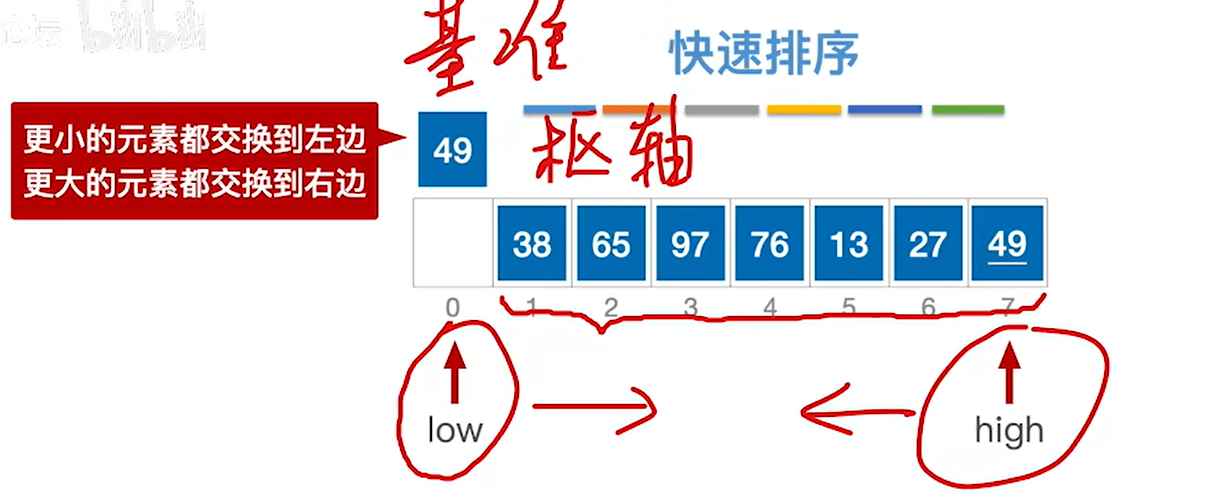
3.一开始low指的地方是空,先让high移动,一开始high是49,大于等于49,所以high–,high–后使得49在high的右侧了就
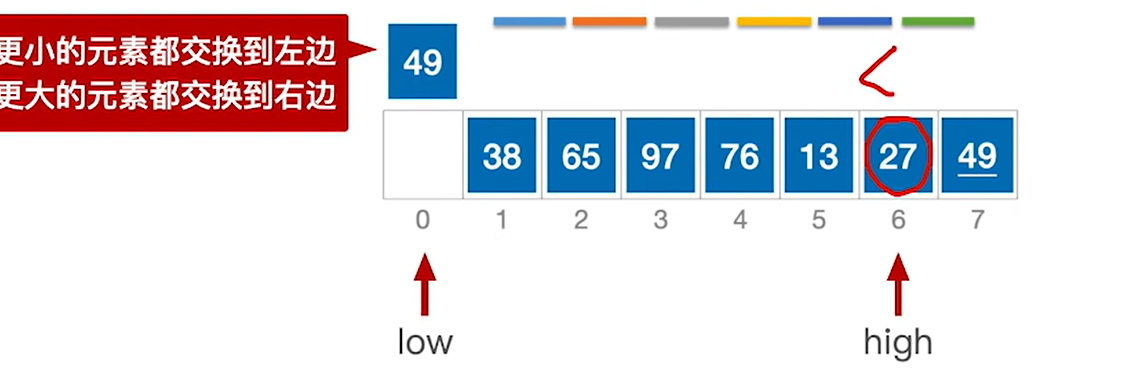
4.high–后,high指向27,27小于49,所以必须放在low的左边,所以就把27移动到low的位置然后让low++
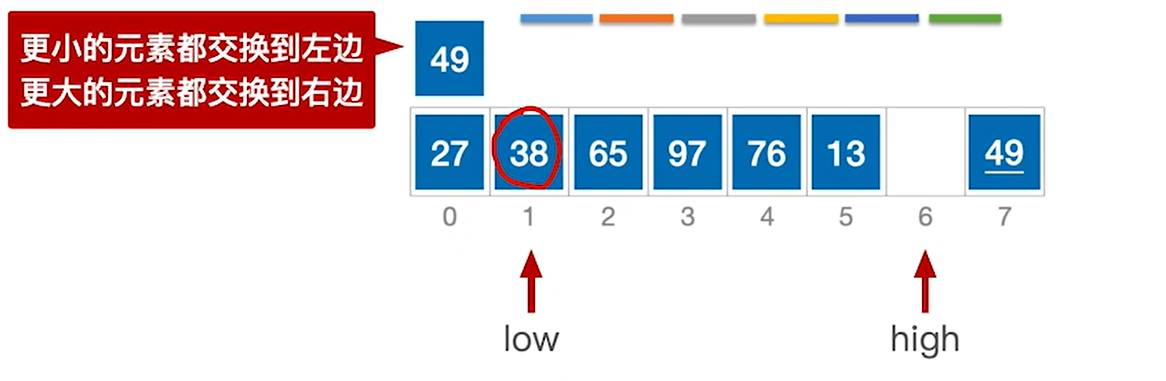
5.low++后指向65,65大于49,把65放到high的位置然后high–
6.重复上述过程直到low==high,那么49就会放在low和high所指的地方,同时49左边都会比49小,49右边都会比49大
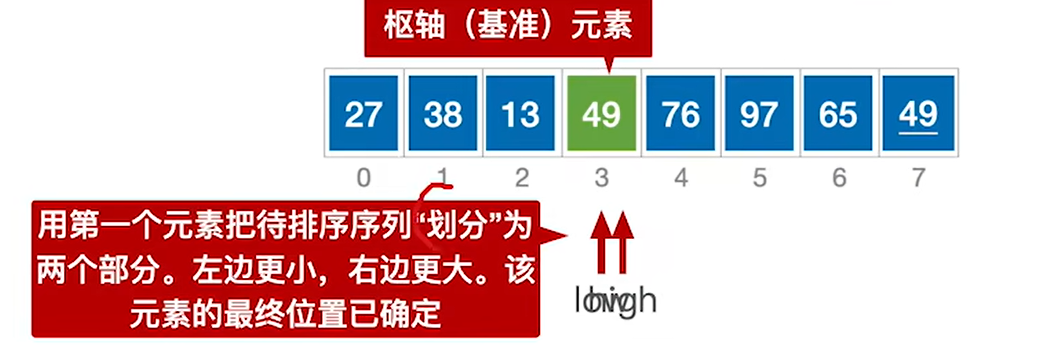
7.通过49把数组划分为左右两个子区间,然后对两个子区间进行同样的过程即可
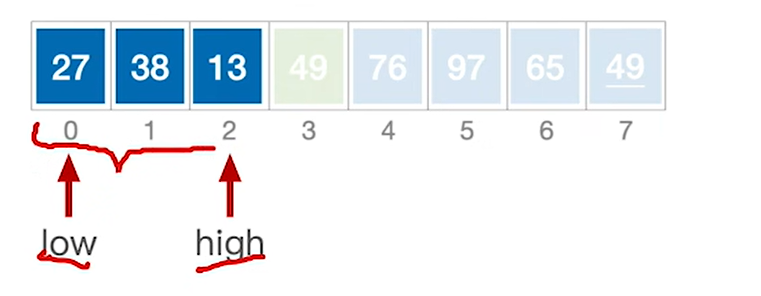
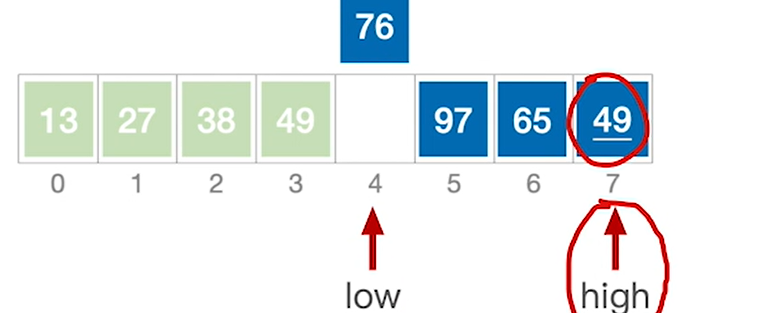
8.得到最终的结果

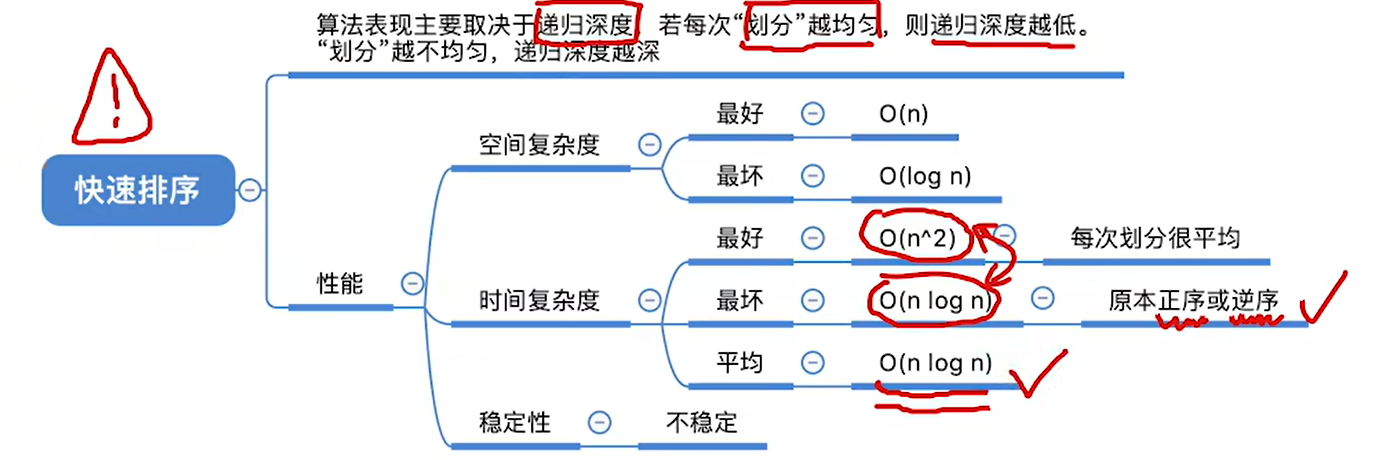
- 快速排序是所有内部排序算法中性能最优的排序算法
- 快速排序是所有内部排序算法中考察频率最高的算法
- 在快速排序算法中每一趟都会将枢轴元素放到其最终位置上(可用来判断进行了几趟快速排序)
- 快速排序可以看作数组中n个元素组织成二叉树,每趟处理的枢轴是二叉树的根节点,递归调用的层数是二叉树的层数
快速排序代码实现:
注:返回值是low和high,作为下一次划分子表的依据

// 用第一个元素将数组A[]划分为两个部分
int Partition(int A[], int low, int high){int pivot = A[low];while(low<high){while(low<high && A[high]>=pivot)--high;A[low] = A[high];while(low<high && A[low]<=pivot) ++low;A[high] = A[low];}A[low] = pivot;return low;
} // 对A[]数组的low到high进行快速排序
void QuickSort(int A[], int low, int high){if(low<high){int pivotpos = Partition(A, low, high); //划分QuickSort(A, low, pivotpos - 1);QuickSort(A, pivotpos + 1, high);}
}
性能分析
稳定性:不稳定
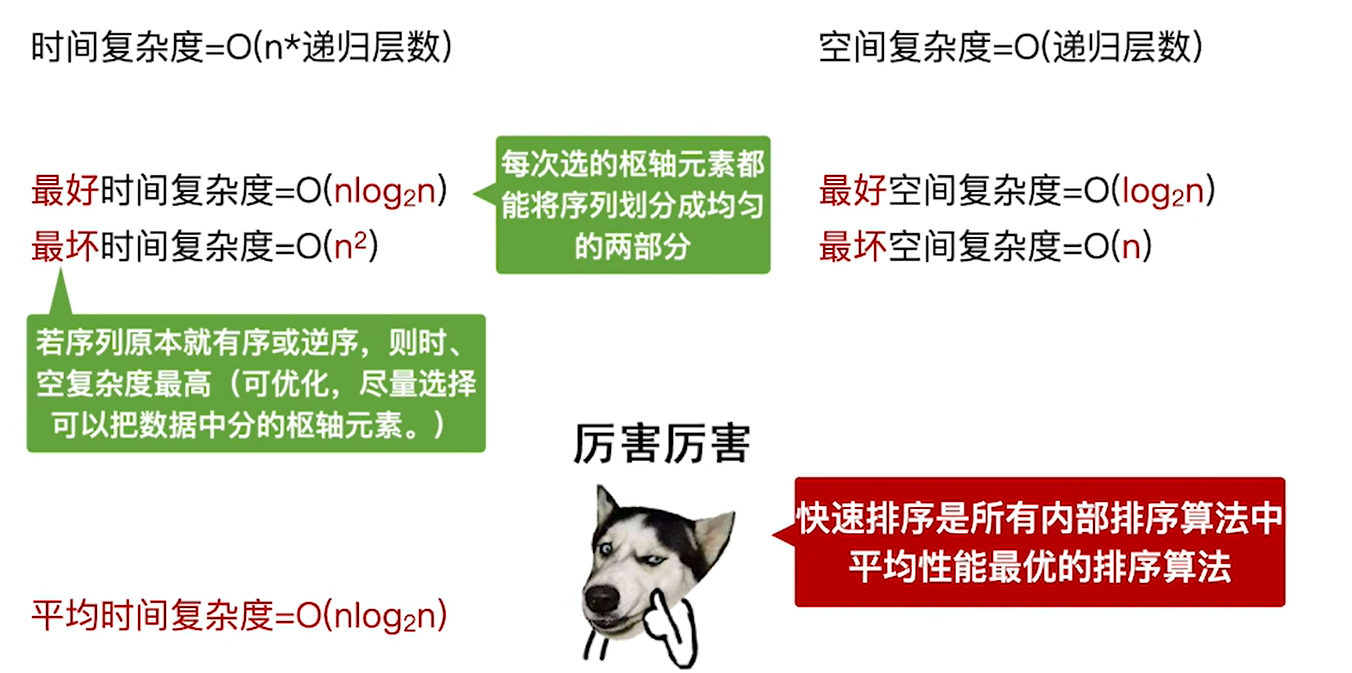
在平常的使用中,平均时间复杂度更加接近最好的时间复杂度而不是最坏,所以才是内部排序中最优的排序算法

空间复杂度=O(递归深度)
递归深度:
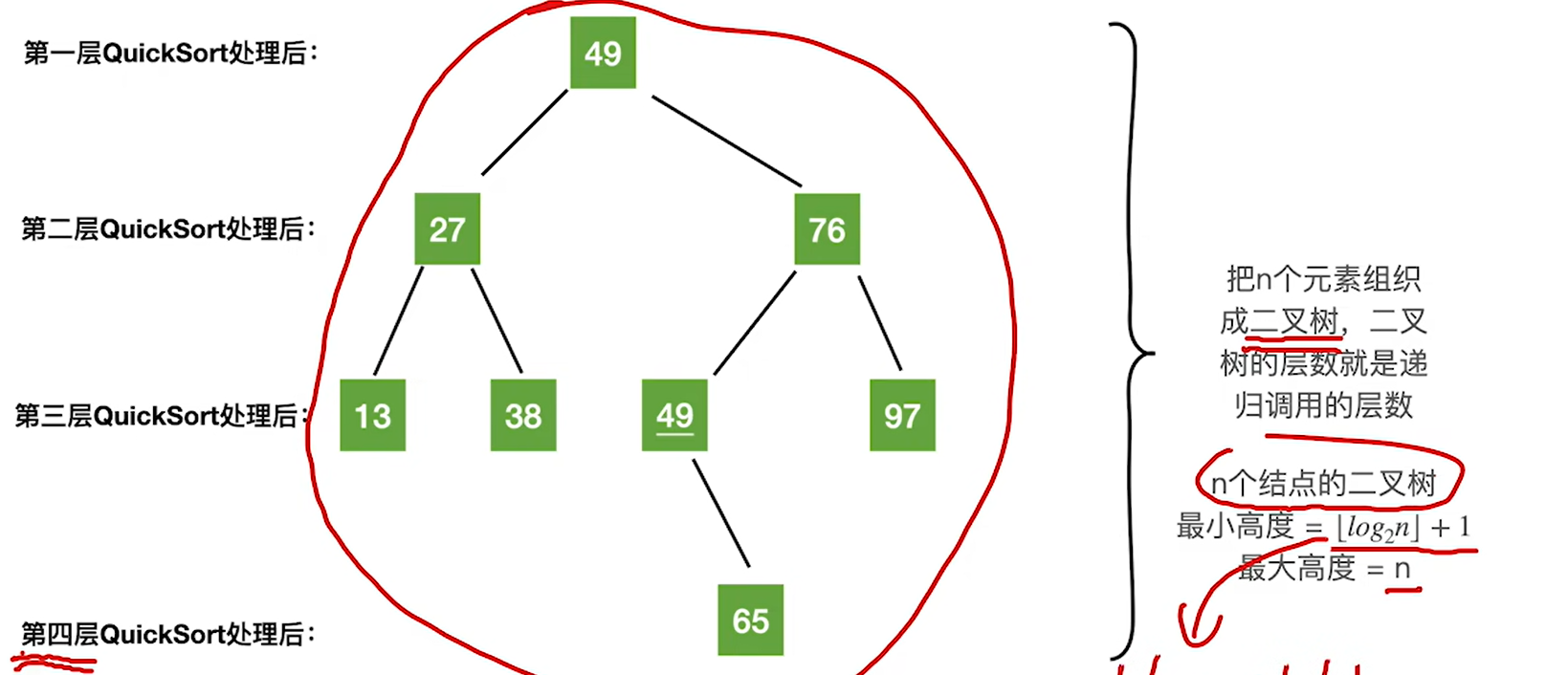

最好时间复杂度就是每次选取的枢轴元素可以把元素分为两个差不多均匀地区间,那这样就可以尽量减小二叉树深度,也就是减少递归深度从而降低时间复杂度
所以优化思路就是途中的,尽量选取可以把数据中分的枢轴元素
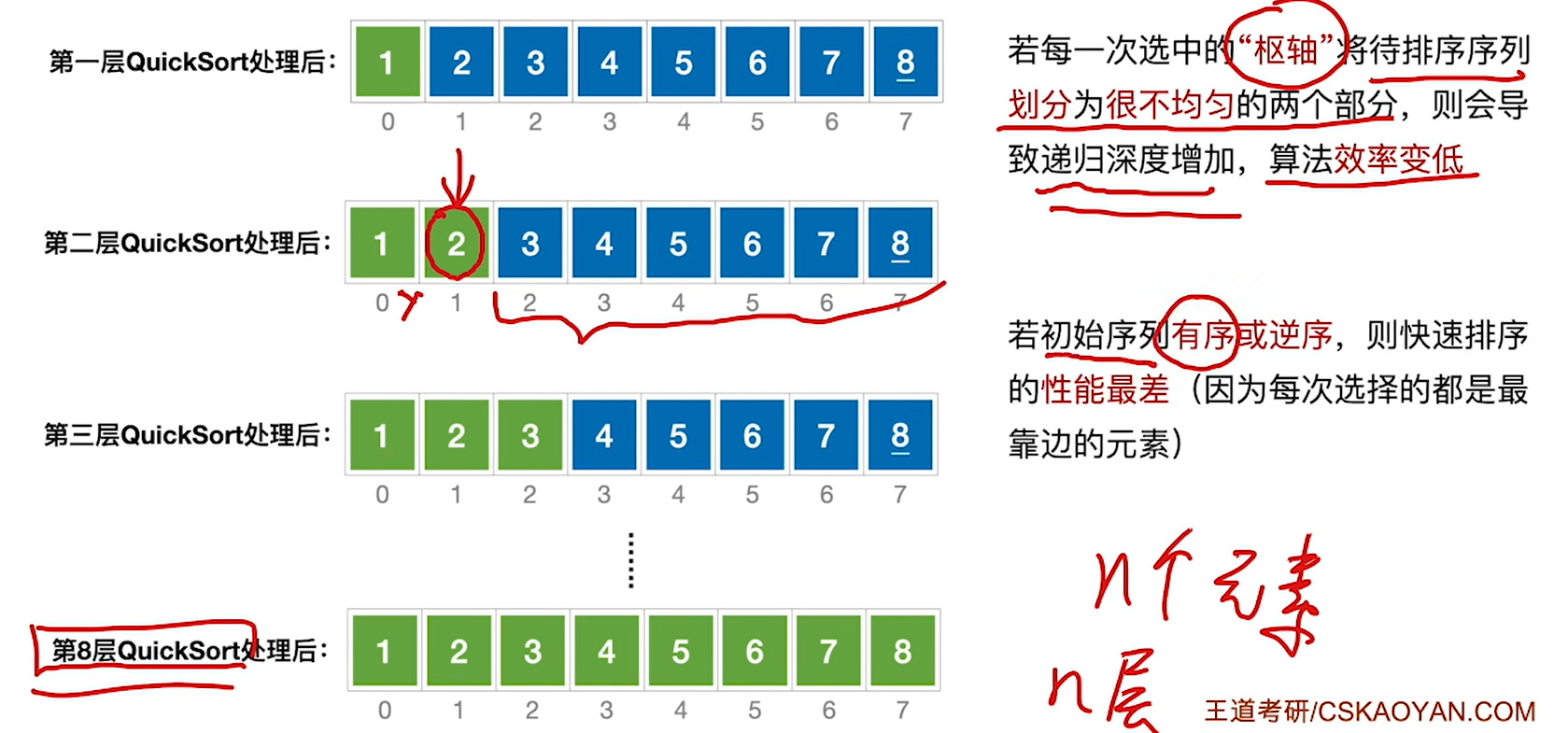
最坏的情况是本来有序的情况,如果原来有序或者逆序的话,每次选择的枢轴都是靠边的元素,划分的区间就是1和n-1,那二叉树就只有左子树或者右子树了,变成链表了,递归深度就高了,自然时间复杂度就高了
8.4 选择排序
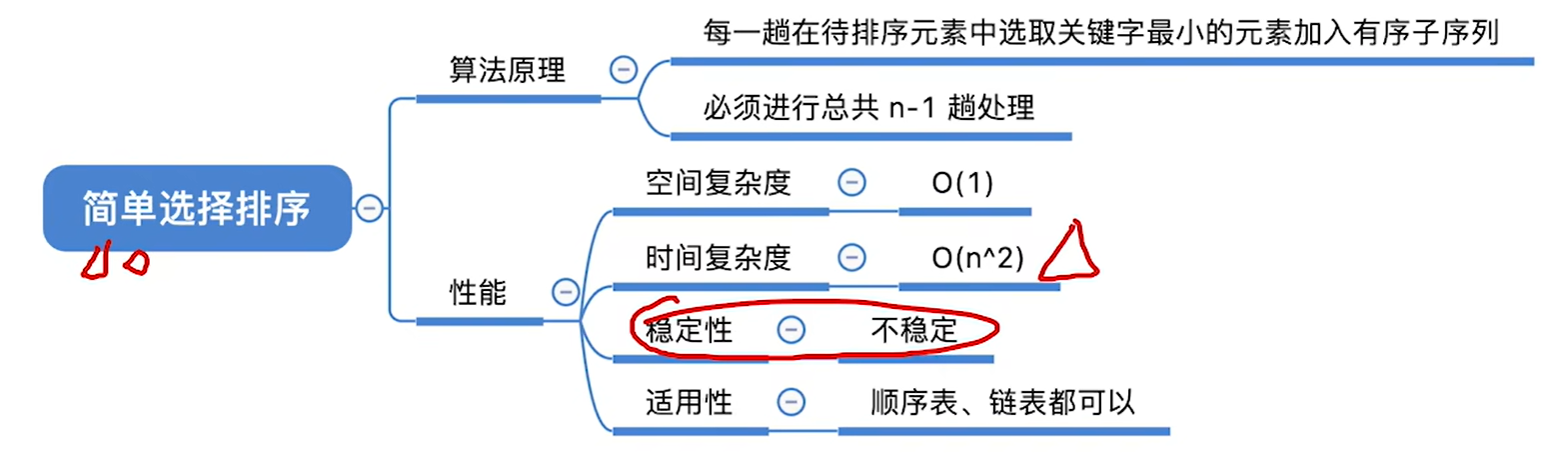
- 选择排序思想: 每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序子序列。
8.4.1 简单选择排序
- **算法思路:**每一趟在待排序元素中选取关键字最小的元素与待排序元素中的第一个元素交换位置
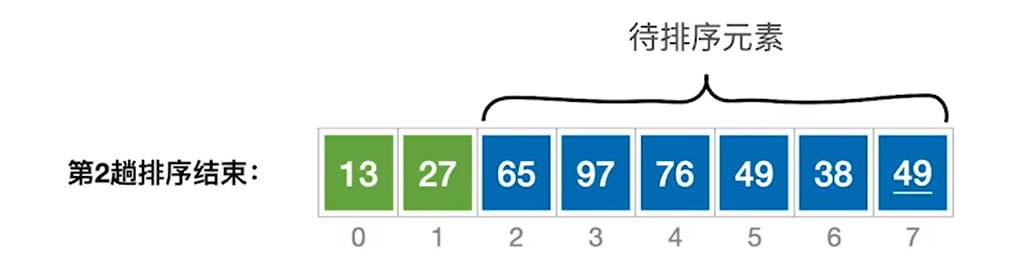
如图所示,在剩下的6个元素中找到最小的49把它和65换位置即可
简单选择排序代码实现:
注:调用一次封装的swap函数一共移动了3次元素
// 交换a和b的值
void swap(int &a, int &b){int temp = a;a = b;b = temp;
}// 对A[]数组共n个元素进行选择排序
void SelectSort(int A[], int n){for(int i=0; i<n-1; i++){ //一共进行n-1趟,i指向待排序序列中第一个元素int min = i;for(int j=i+1; j<n; j++){ //在A[i...n-1]中选择最小的元素if(A[j]<A[min])min = j;}if(min!=i) swap(A[i], A[min]);}
}
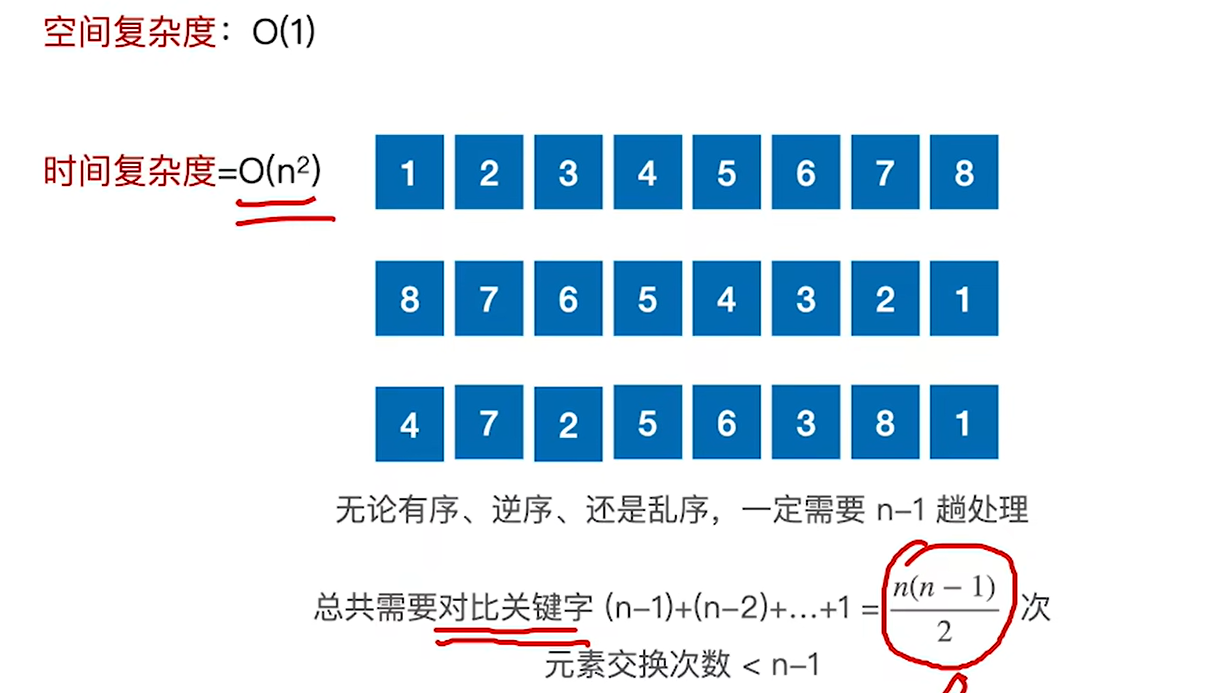
算法效率分析:
简单选择排序不管怎么样都得对比n(n-1)/2这么多次,和序列的初始状态无关
适用于链表和数组
对链表进行简单选择排序:
void selectSort(LinkList &L){LNode *h=L,*p,*q,*r,*s;L=NULL;while(h!=NULL){p=s=h; q=r=NULL;while(p!=NULL){if(p->data>s->data){s=p; r=q;}q=p; p=p->next;}if(s==h)h=h->next;elser->next=s->next;s->next=L; L=s;}
}
8.4.2 堆排序
重点:
1.给定序列调整成大根堆和给定序列和空堆依次按照序列插入的结果是不同的,最终得到的根的形式也不同,因为可能会在插入过程中进行根的调整
2.大根堆中的最小值在[n/2下取整]+1到n之间
小根堆中的最大值也是如此
3.堆是顺序存储的完全二叉树,因此高度小于等于节点数相同的二叉排序树
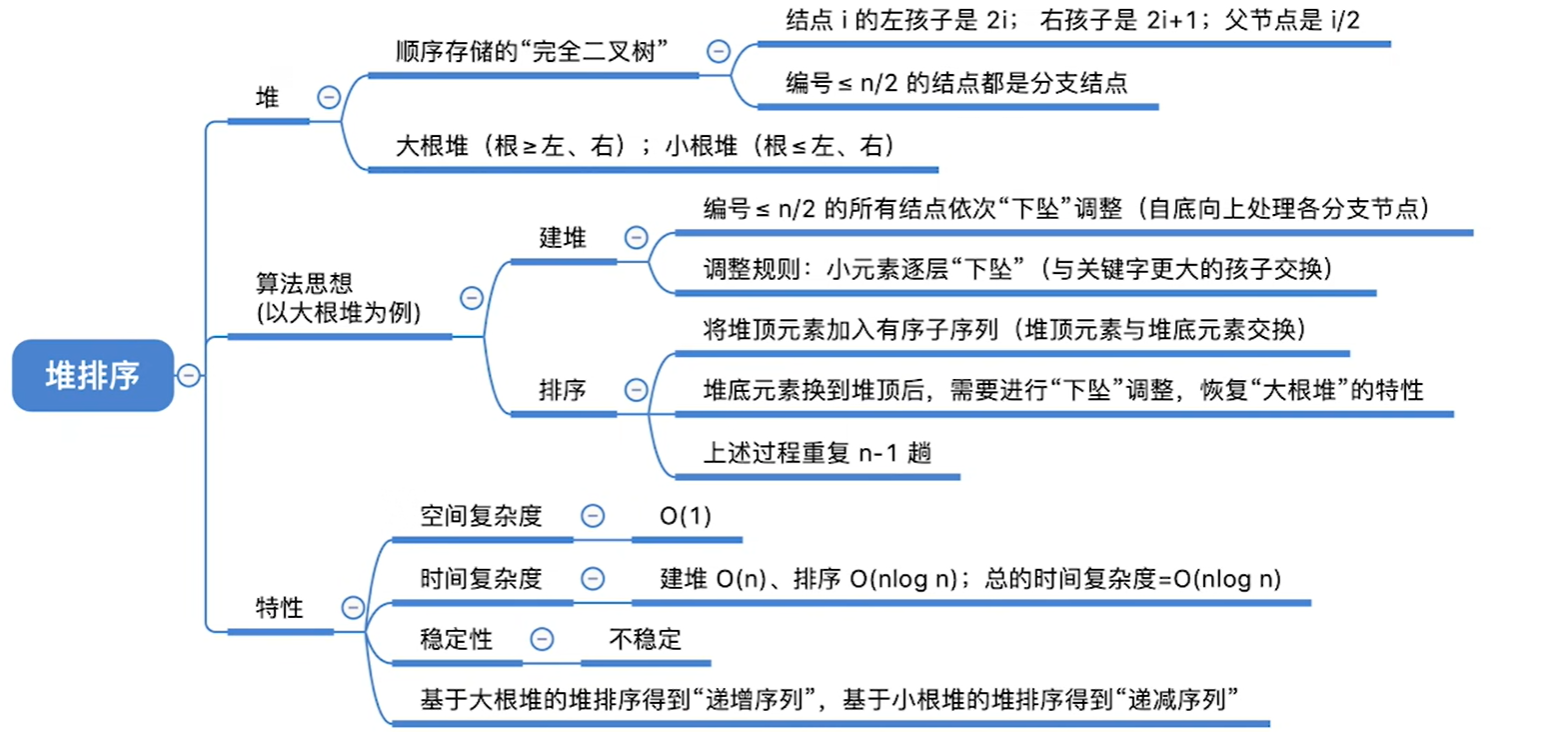
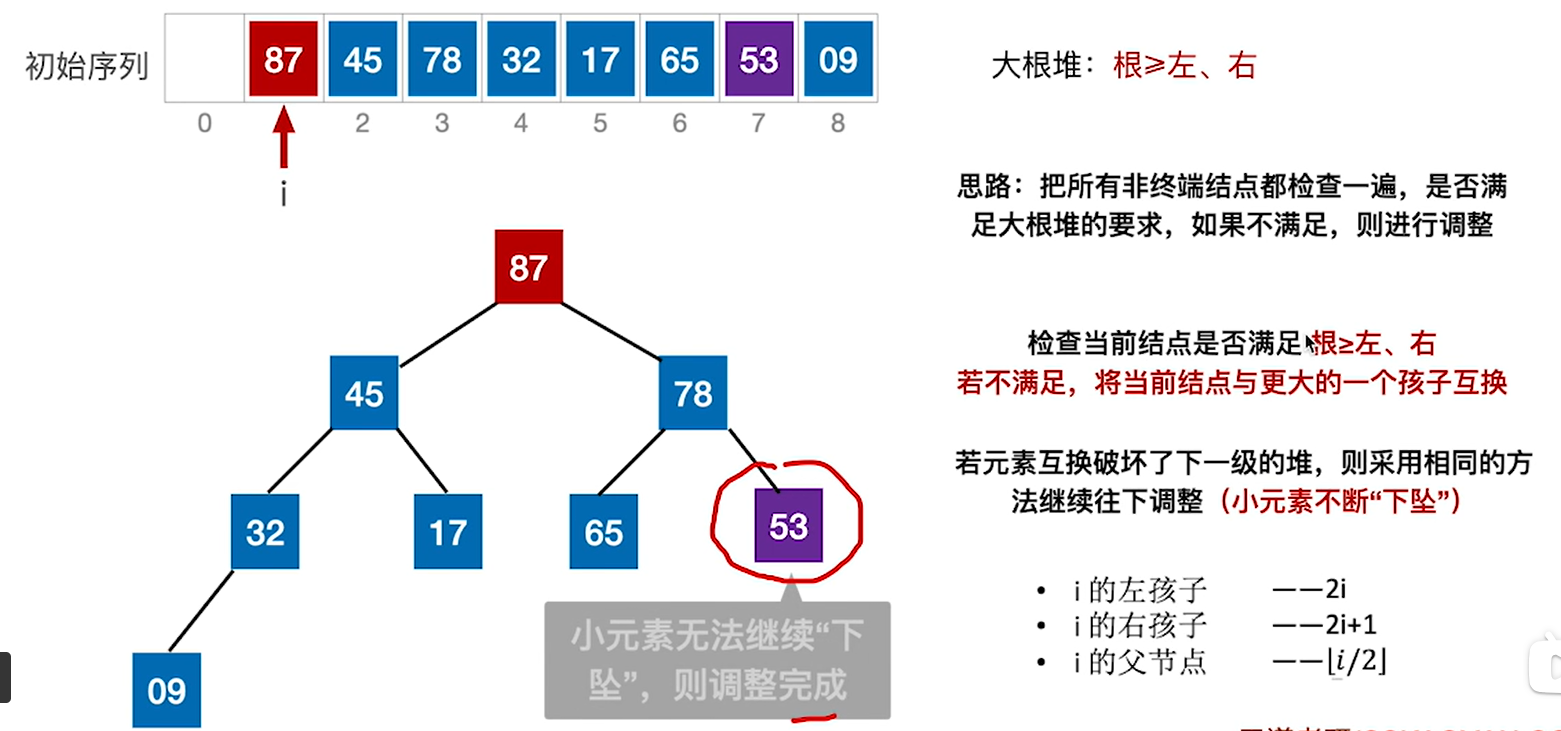
堆的概念:

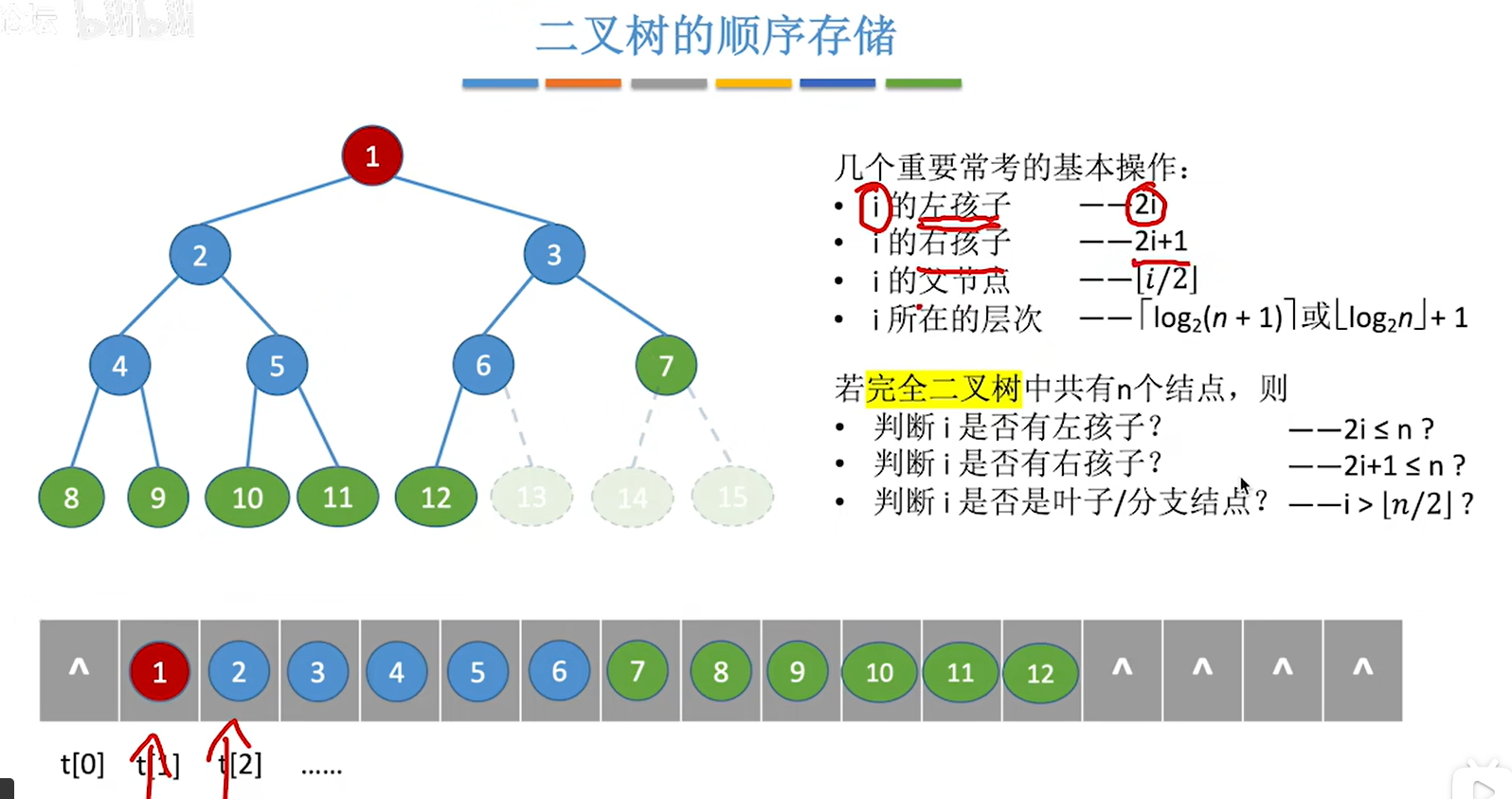
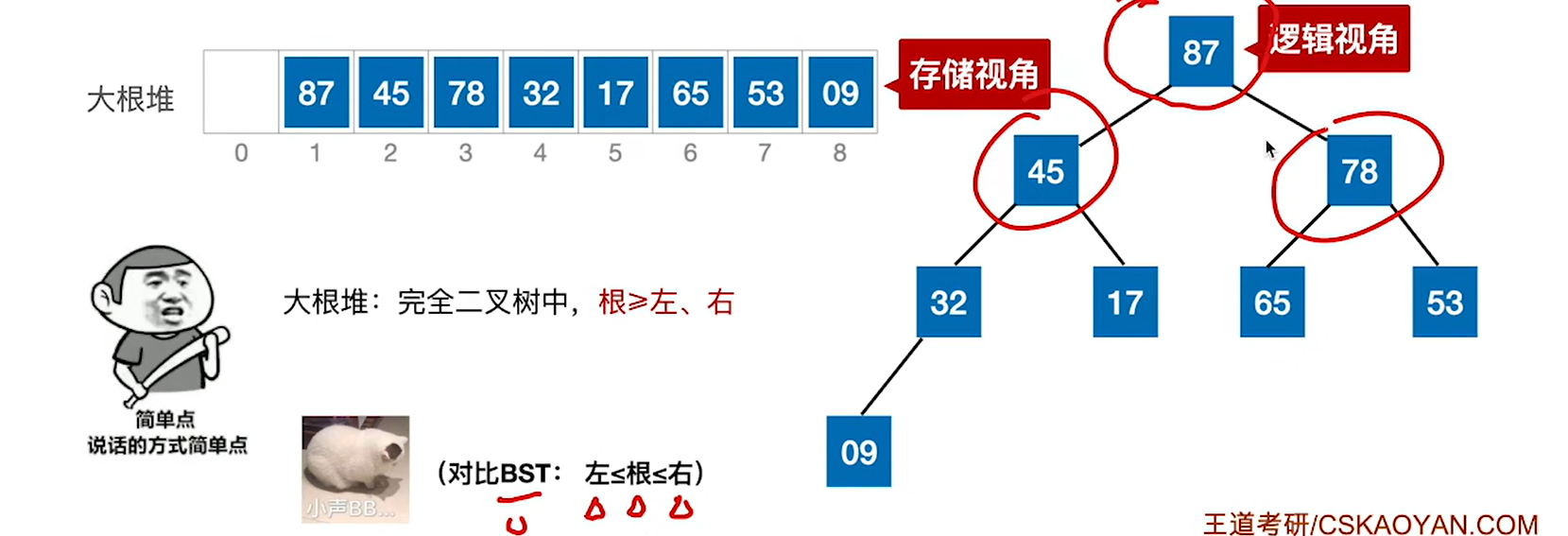
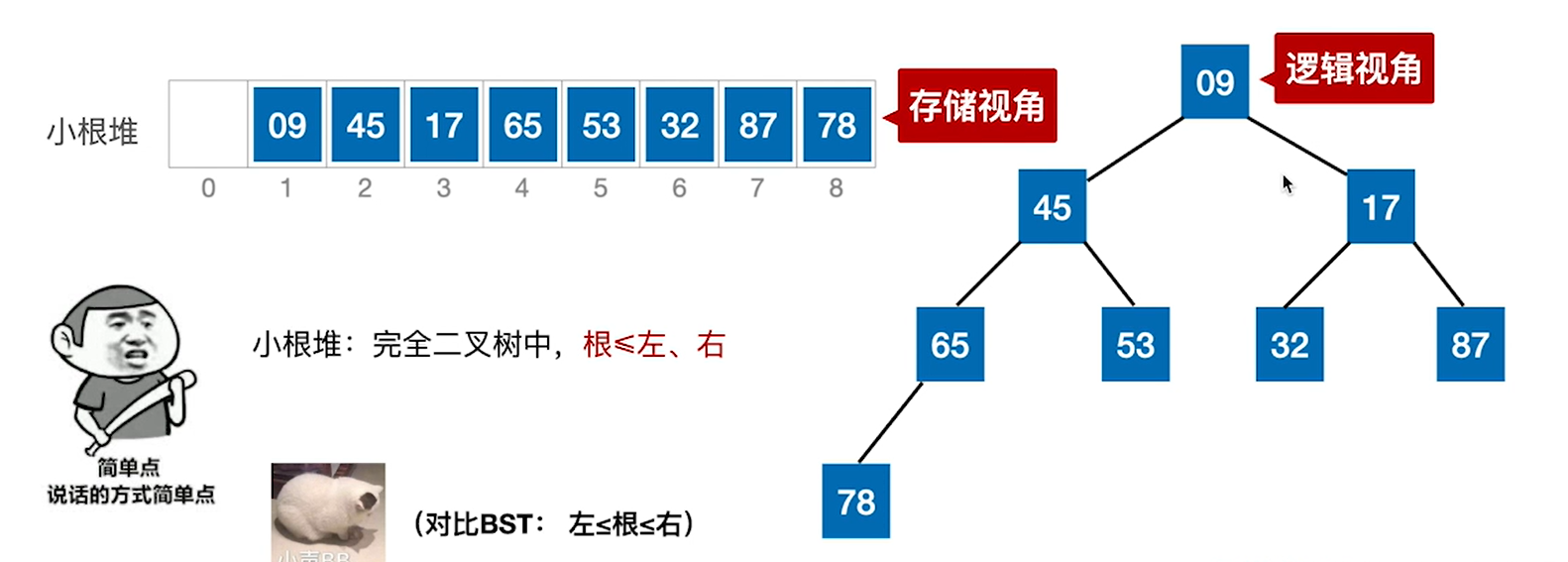
可以看出来,如果我们要进行排序,那么利用大根堆或者小根堆会很方便,因为最大最小值就在数组前面
那么如果把一个序列变成大根堆或者小根堆呢,即如何建立大根堆或者小根堆呢?
1.从n/2下取整的编号倒着往前检查,那么例子中就是9
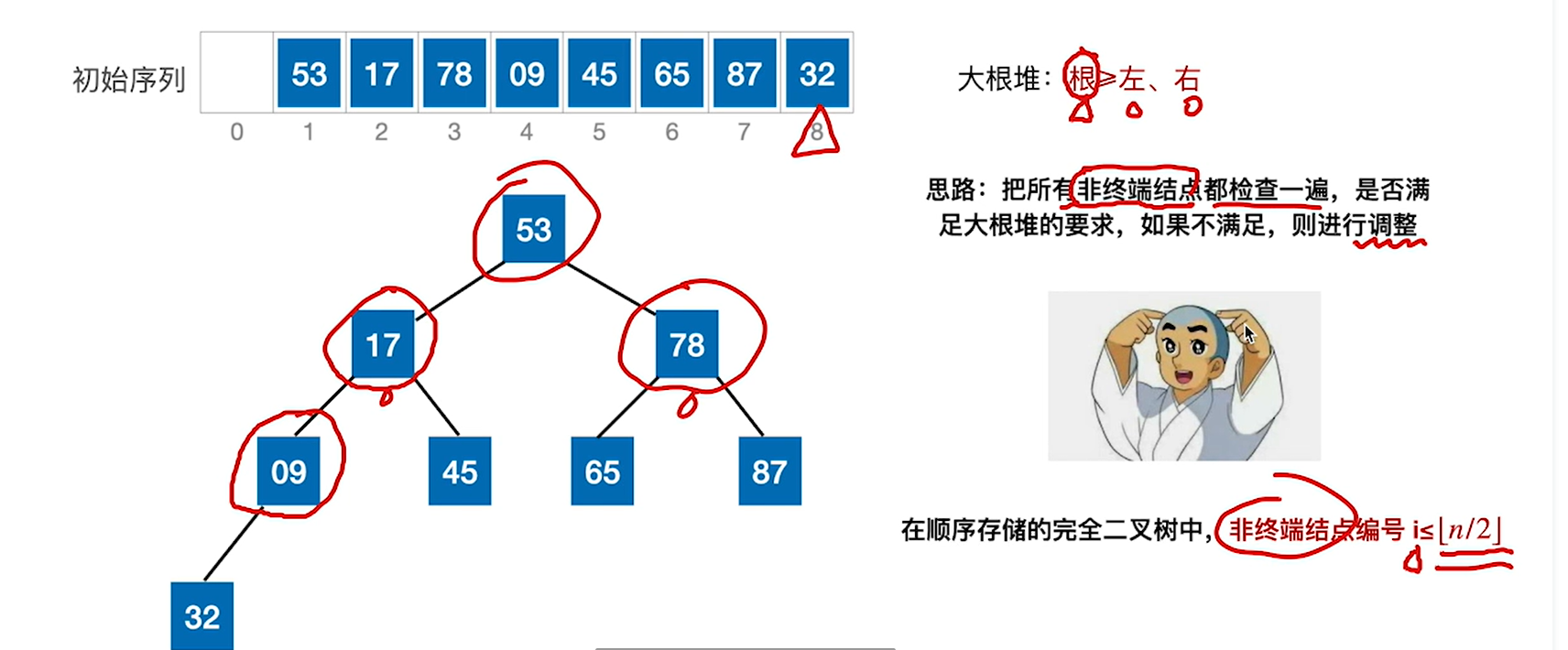
2.看9和它的左右孩子的的大小,如果比9大的话,就把孩子中更大的孩子和9互换就行,孩子是2i和2i+1,32和45
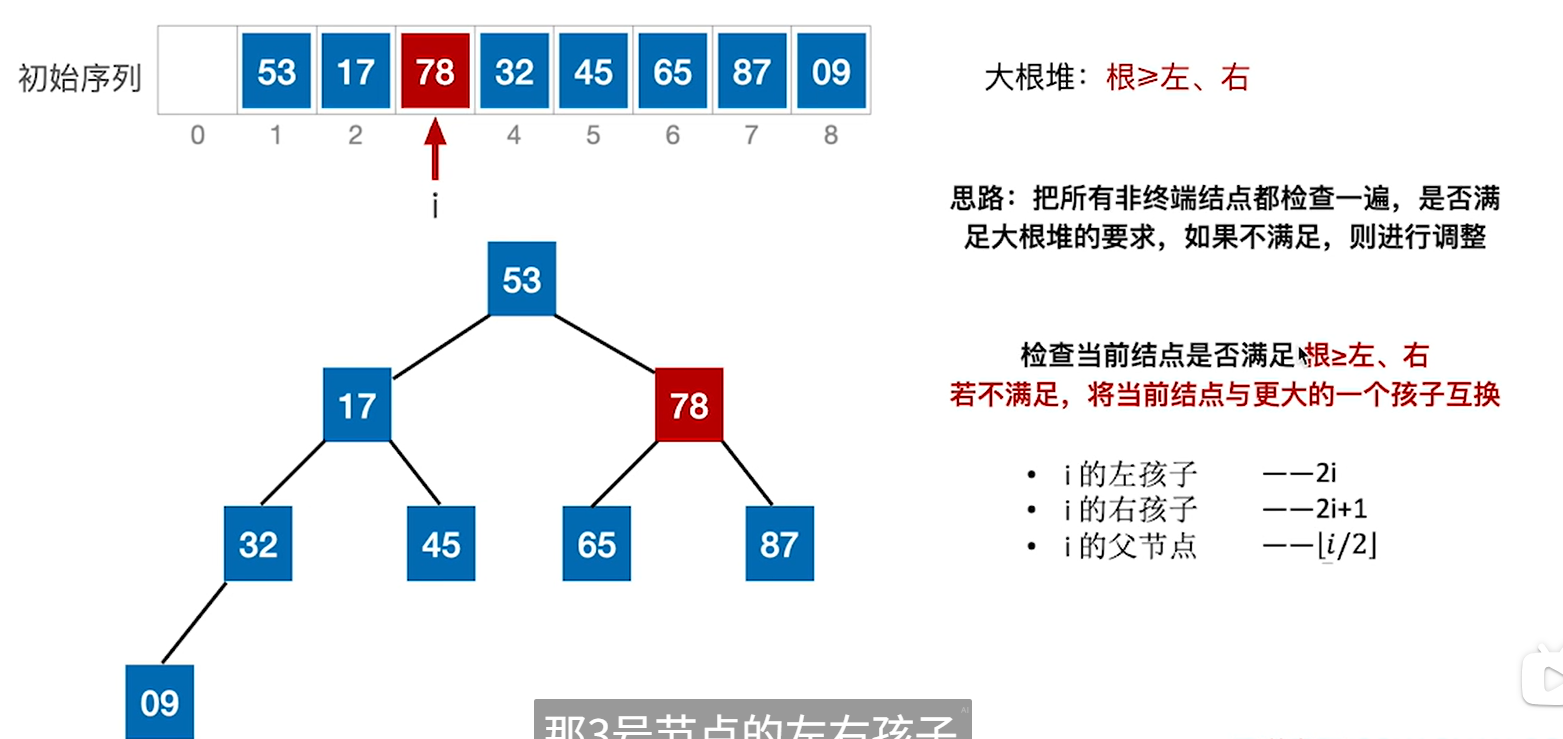
3.处理完9的话就i–,处理78,78的2i和2i+1是65和87
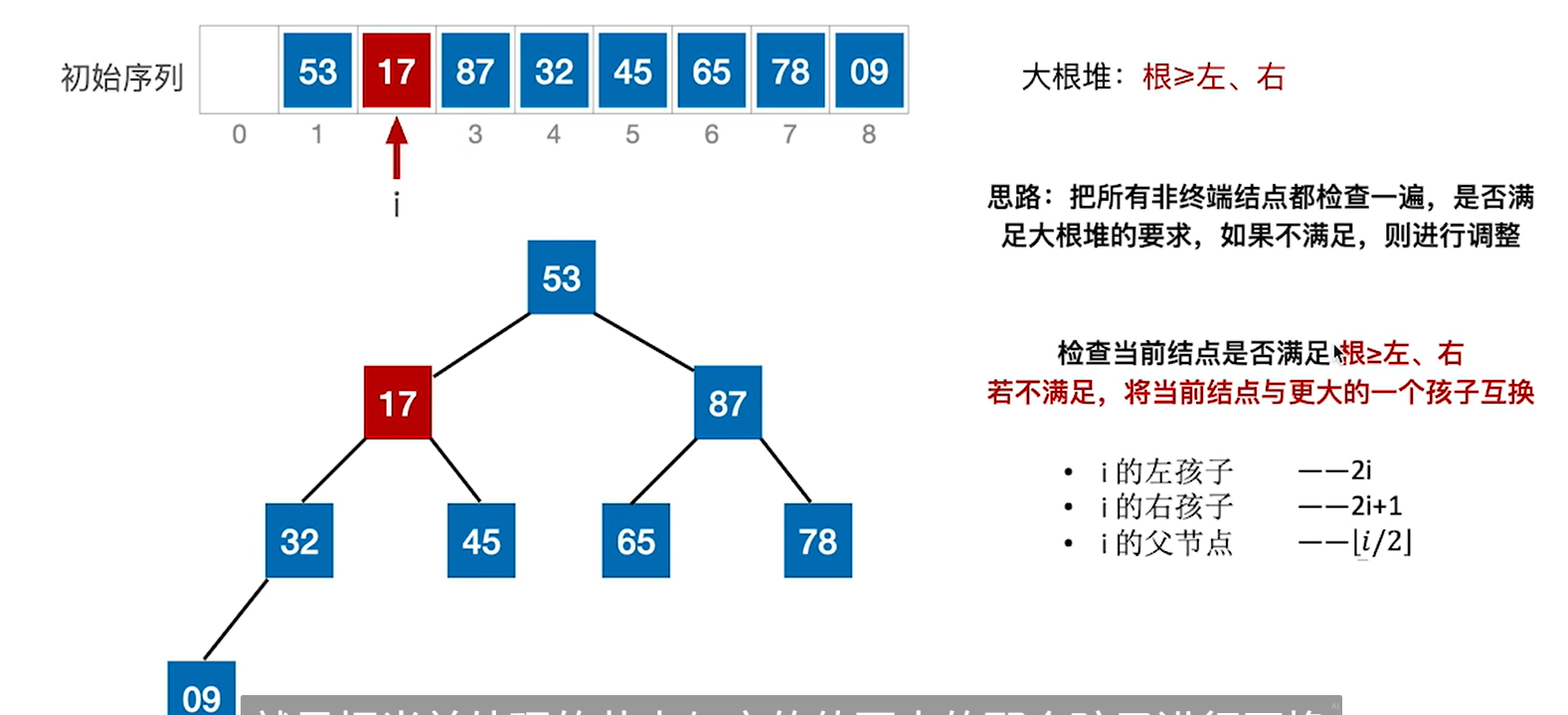
4.重复这个过程,直到根节点,也就是第一个结点
5.根节点的是45和87,于是把87放到根节点
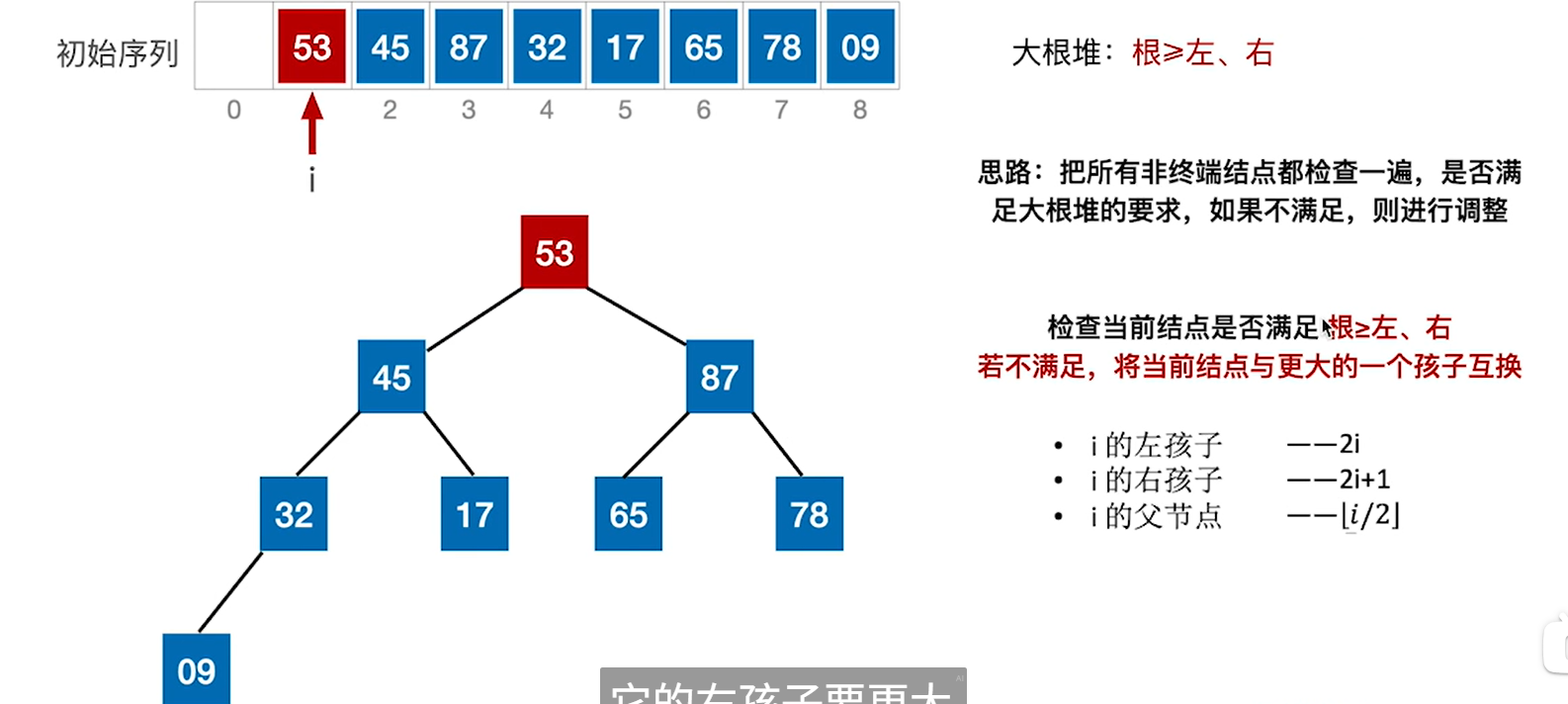
6.发现 53下去之后破坏了下一级的堆,所以要继续换,当小元素无法继续下坠的时候就调整结束了
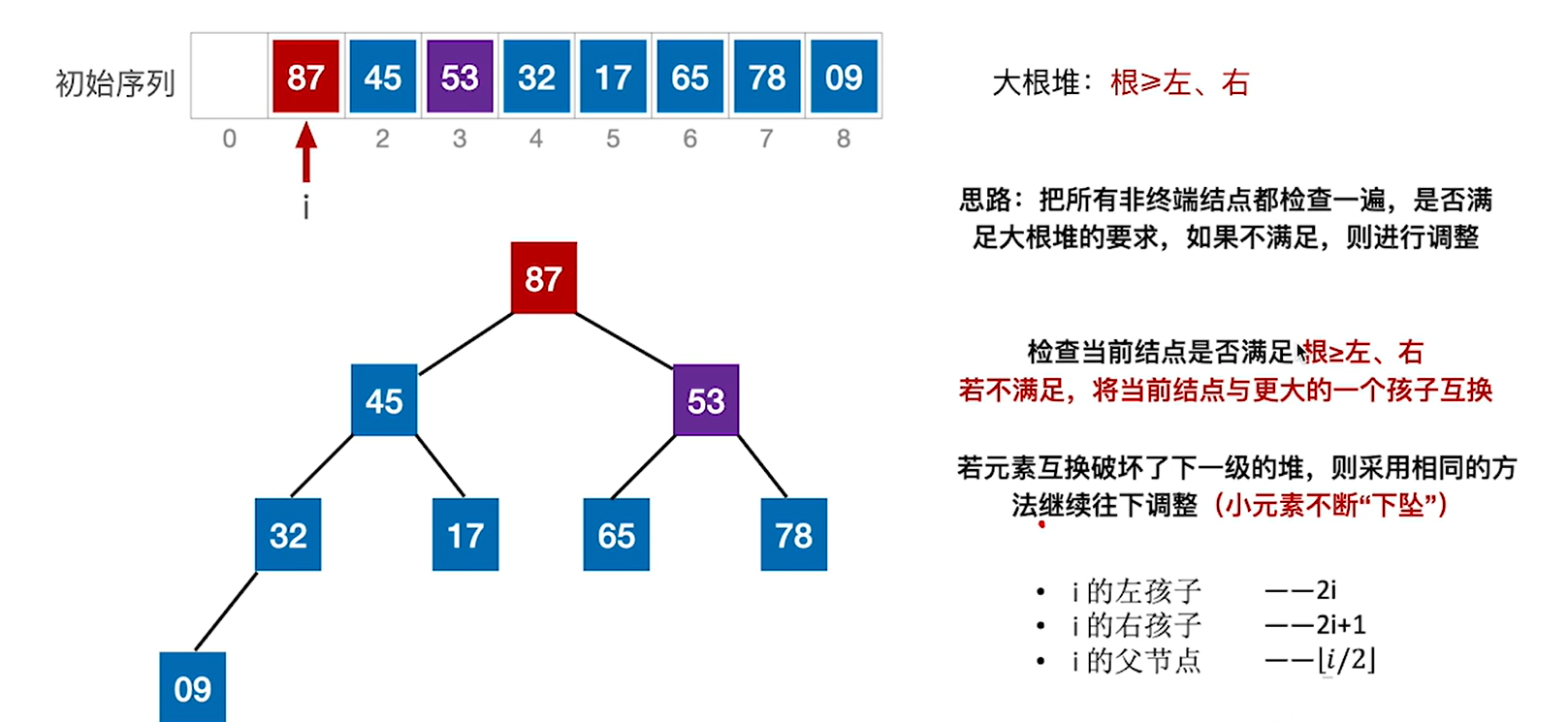
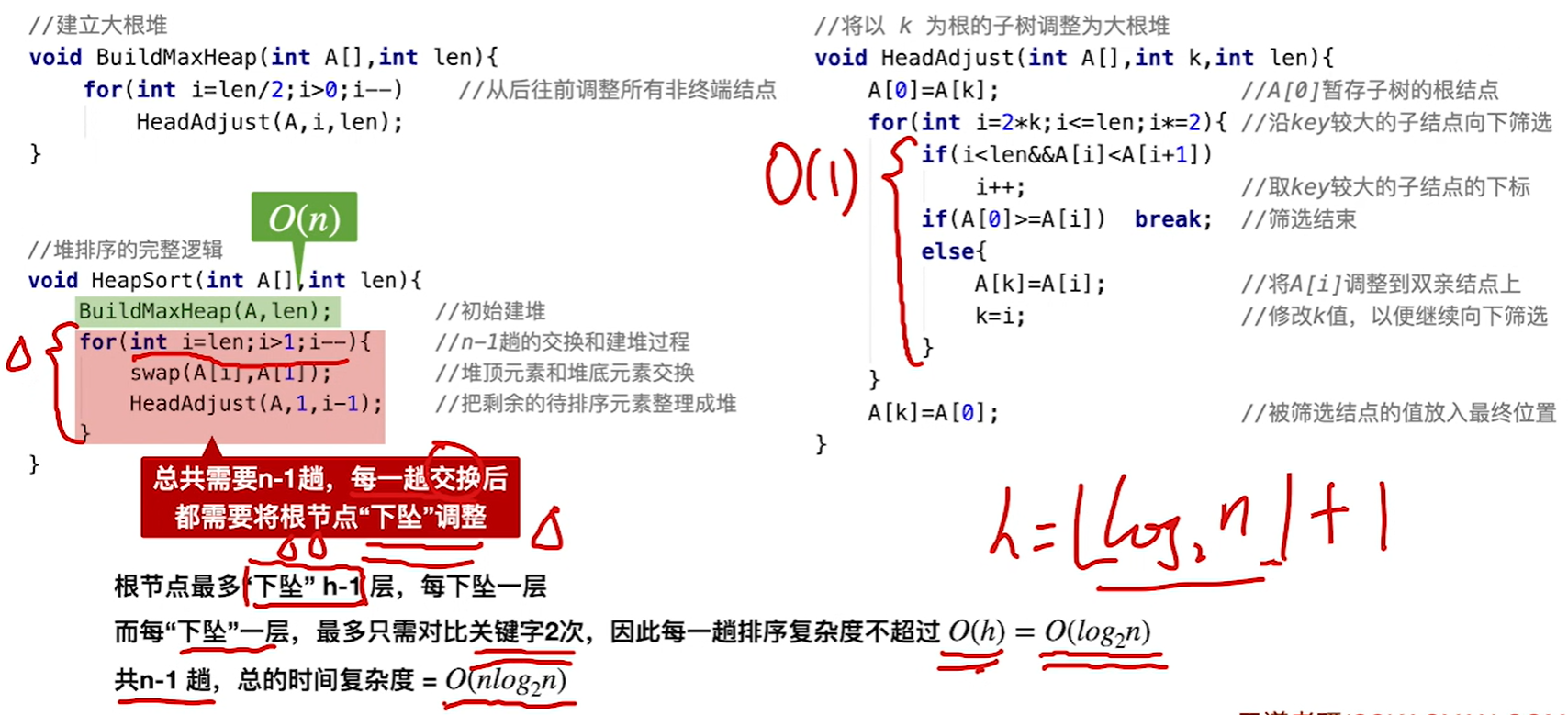
建立大根堆的代码
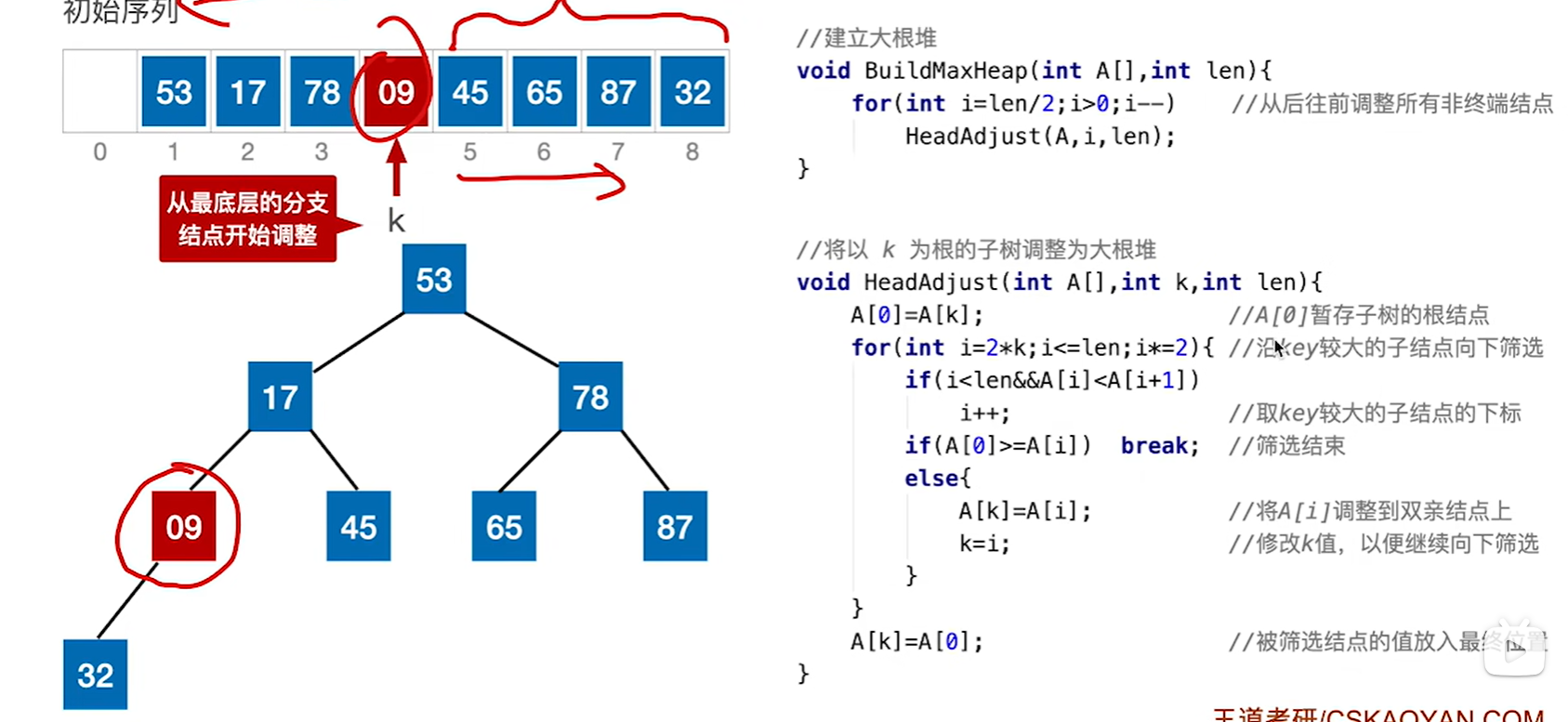
// 对初始序列建立大根堆
void BuildMaxHeap(int A[], int len){for(int i=len/2; i>0; i--) //从后往前调整所有非终端结点HeadAdjust(A, i, len);
}// 将以k为根的子树调整为大根堆
void HeadAdjust(int A[], int k, int len){A[0] = A[k];for(int i=2*k; i<=len; i*=2){ //沿k较大的子结点向下调整//这个if就是在选左右孩子里面较大的孩子,因为一会交换也是把大的孩子放上去而不是把小的孩子放上去,所以如果右孩子更大就选右孩子了if(i<len && A[i]<A[i+1]) i++;if(A[0] >= A[i])break;else{A[k] = A[i]; //将A[i]调整至双亲结点上k=i; //修改k值,以便继续向下筛选}}A[k] = A[0]
}
以处理53这个结点为例子,第一个if,87笔45更大,所以我们选择走87这边
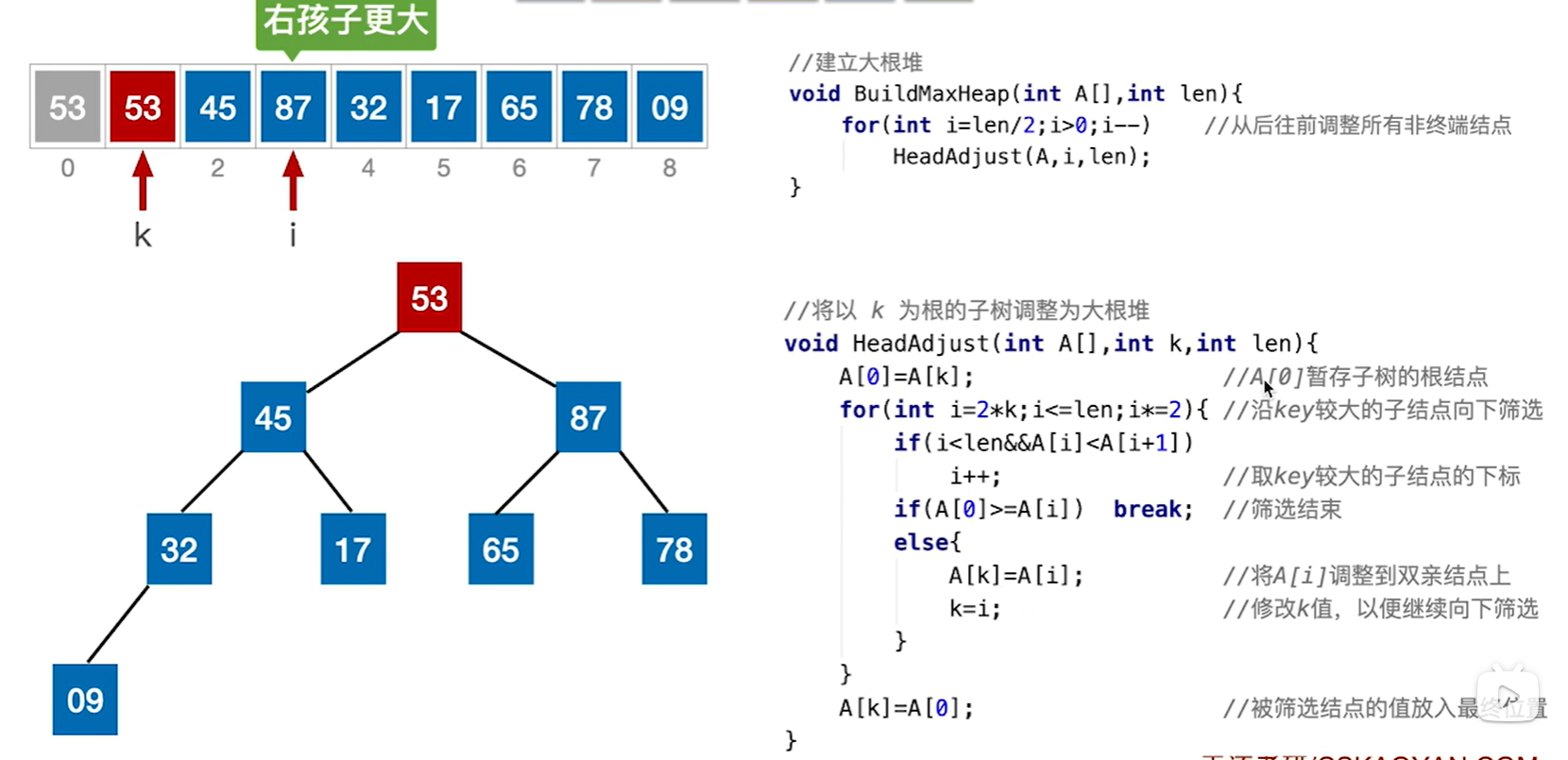
走到第二个if发现53比87小,那么就把87放到53的位置(其实现在87的位置还是87,只是为了方便讲解才画成空的),然后把k赋值为i,这就是继续去找87原来的左右子树,也就是在找53实际上应该在的位置,也就是进入第二层循环
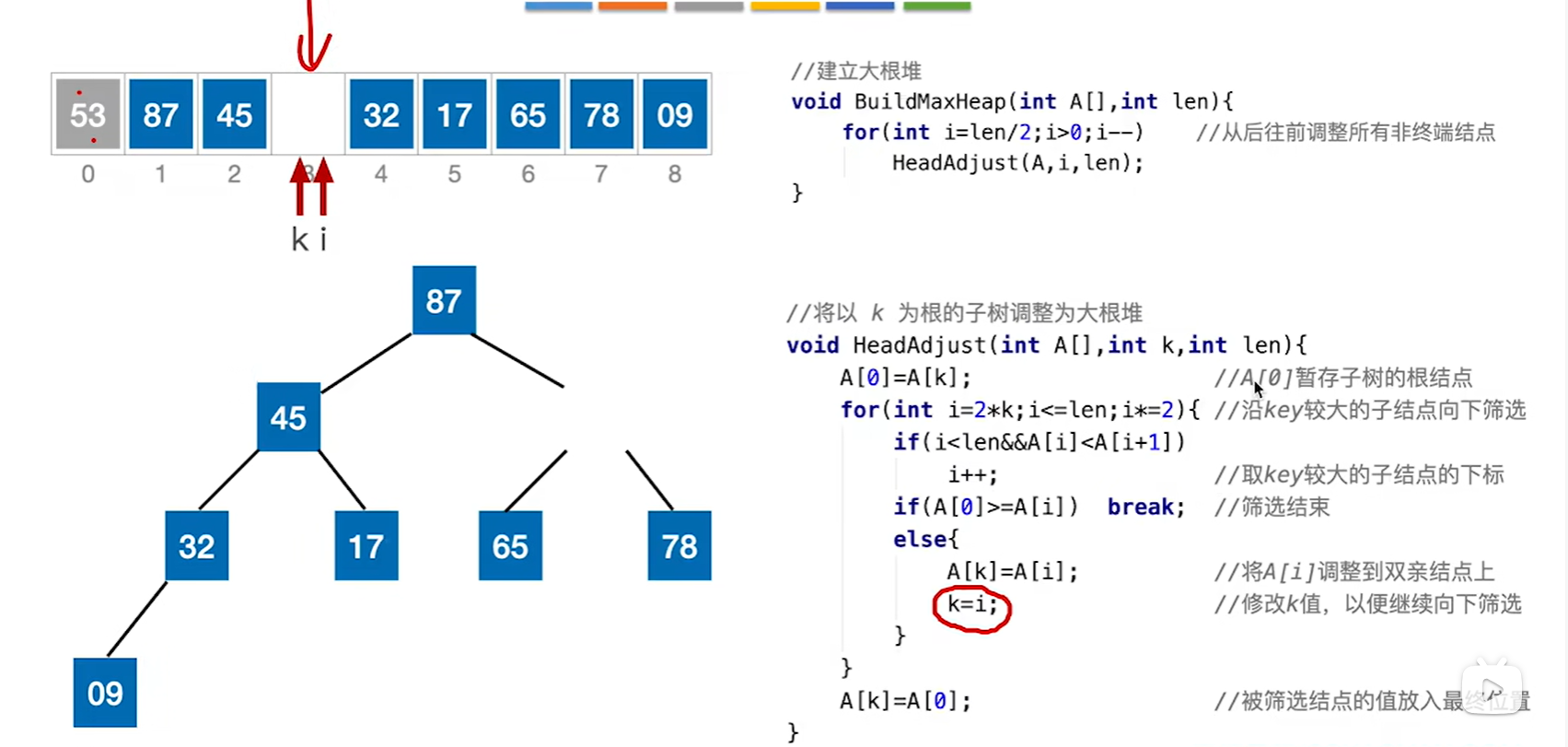
第二轮循环开始,很明显78大于65,我们走78这边,而78也比53大,说明87的位置不是53去的地方,那么还是父子交换,就把78放过来变成图中这样
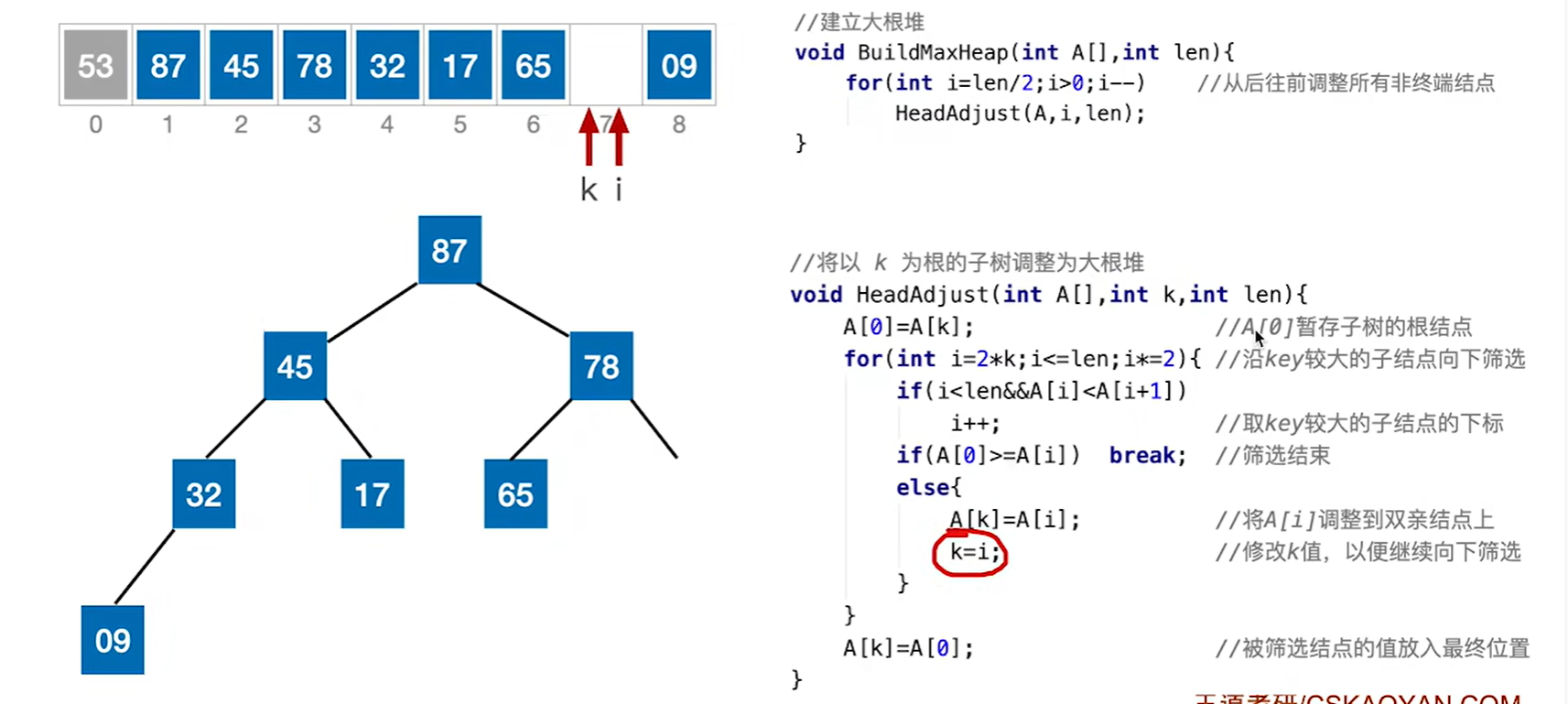
最后i大于len退出了循环,k所在的位置就是i应该在的位置
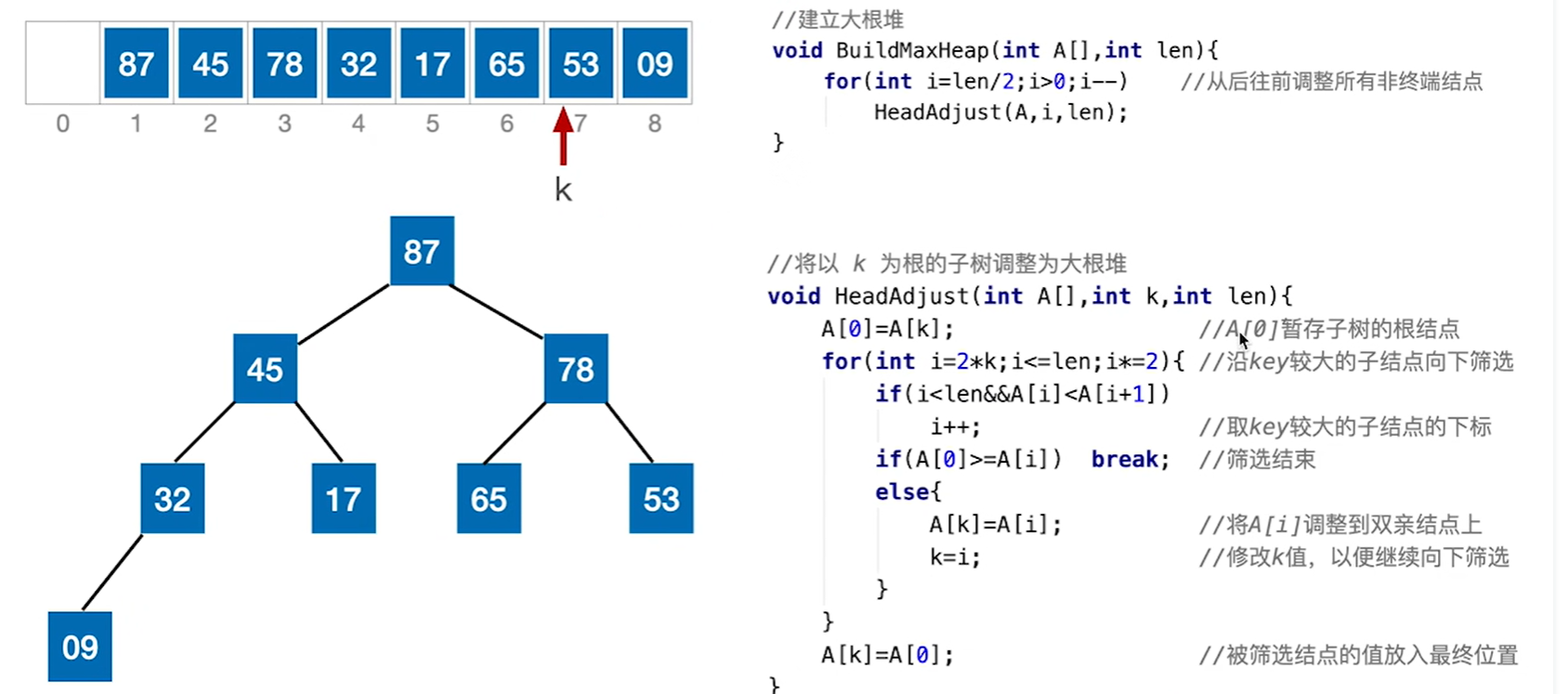
堆排序算法思想
选择排序就是每一趟在待排序元素中选取关键字最大的元素加入有序序列
堆排序就是每一趟将堆顶元素加入有序子序列(与待排序序列中的最后一个元素互换)
因为堆顶元素一定是数组中最大的,而最末尾的位置就是最大元素的位置
具体例子:
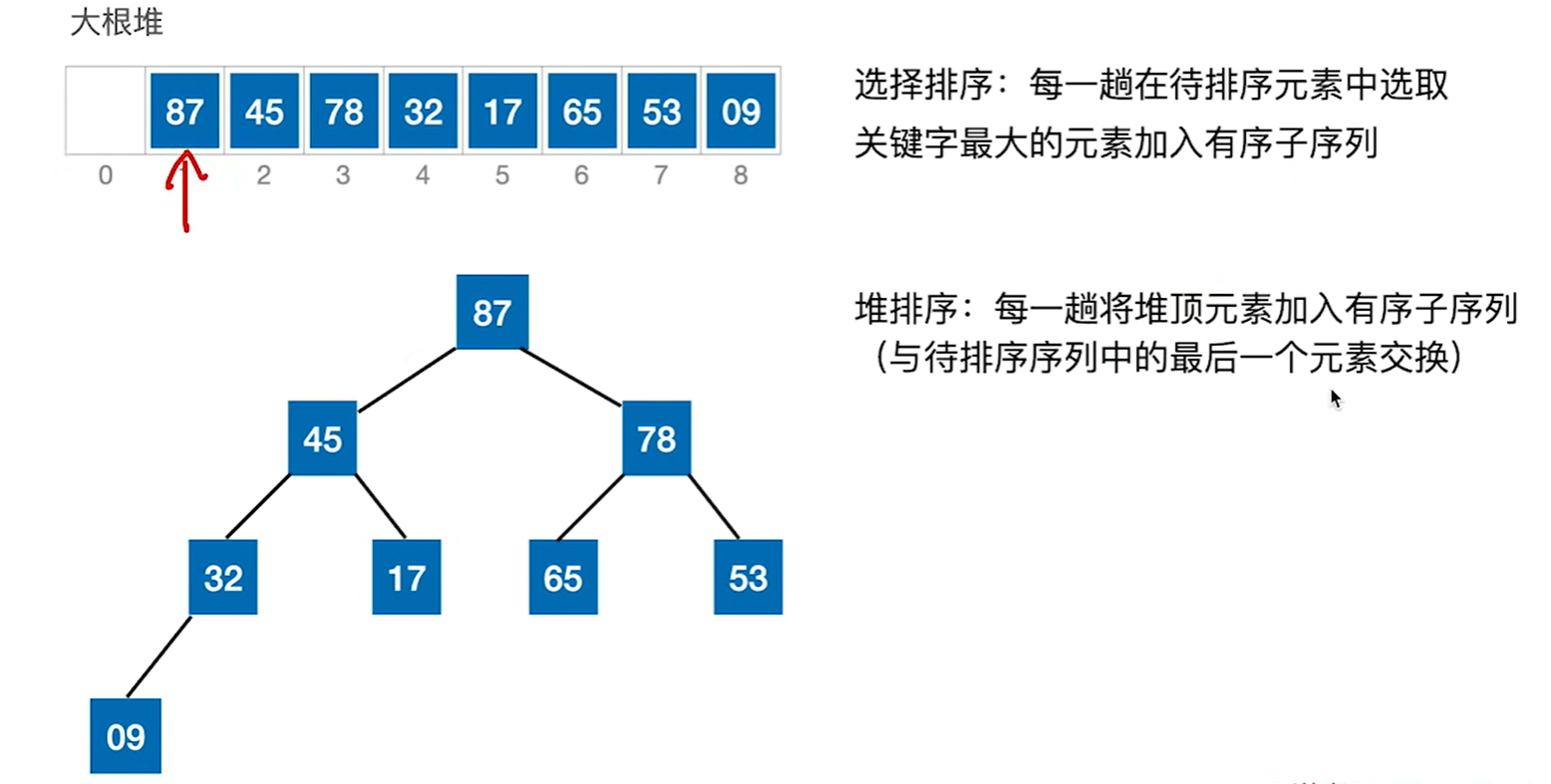
第一步把87移到最后,也就是和最后一个元素9做一个交换,然后就相当于87已经不在堆内,然后把剩下的数看做一个堆,然后重新进行调整,因为交换过后很有可能已经不是大根堆了
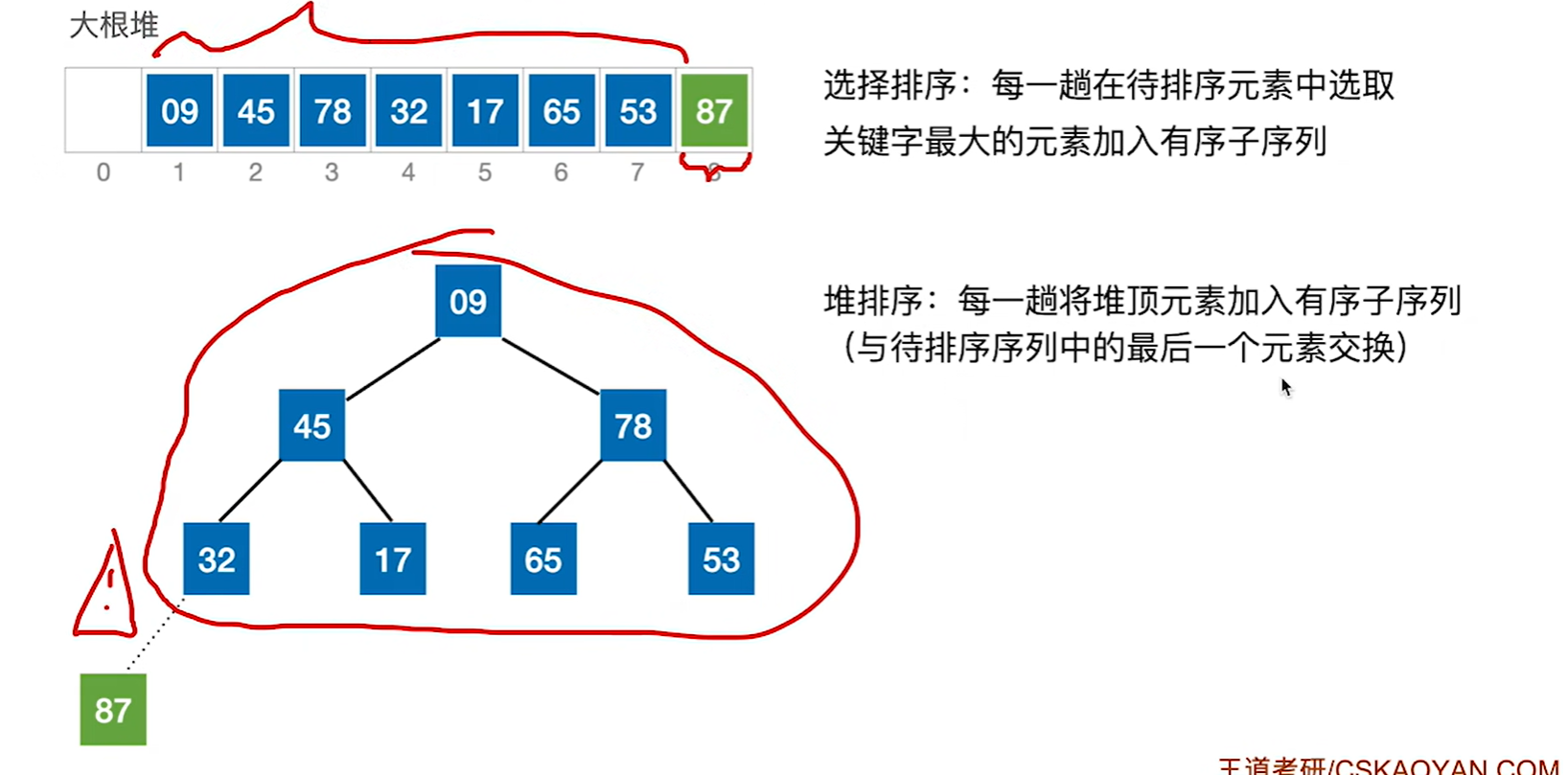
下图就是处理不包括87的大根堆,到此为止,完成了第一趟的处理

接下来把堆顶元素78和待排序序列的最后一个元素53交换,那么78,87就已经是一个已经排好序的序列了
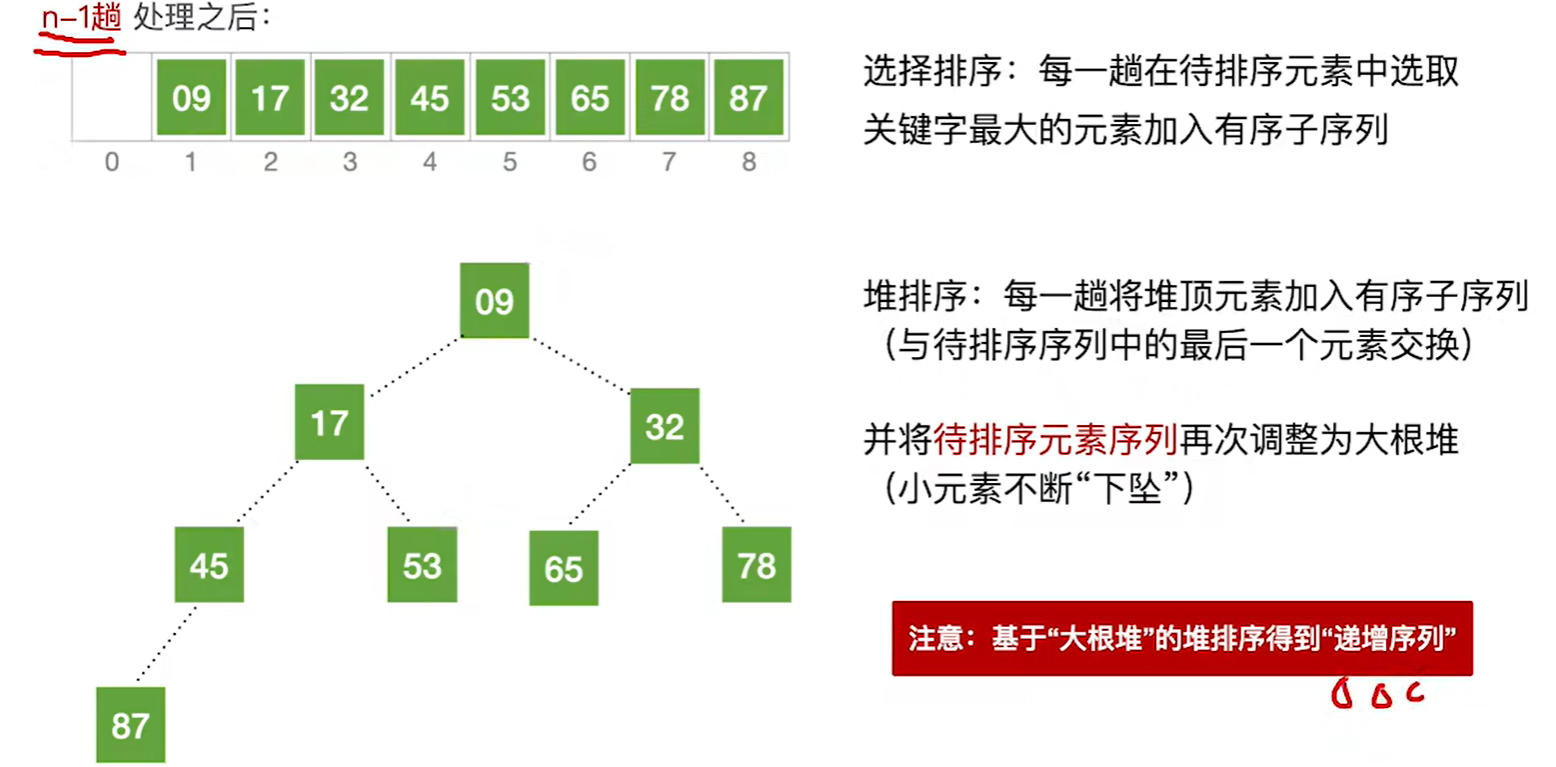
然后在调整除了78,87其他的数组成的大根堆,重复这个过程直到全都排序完成
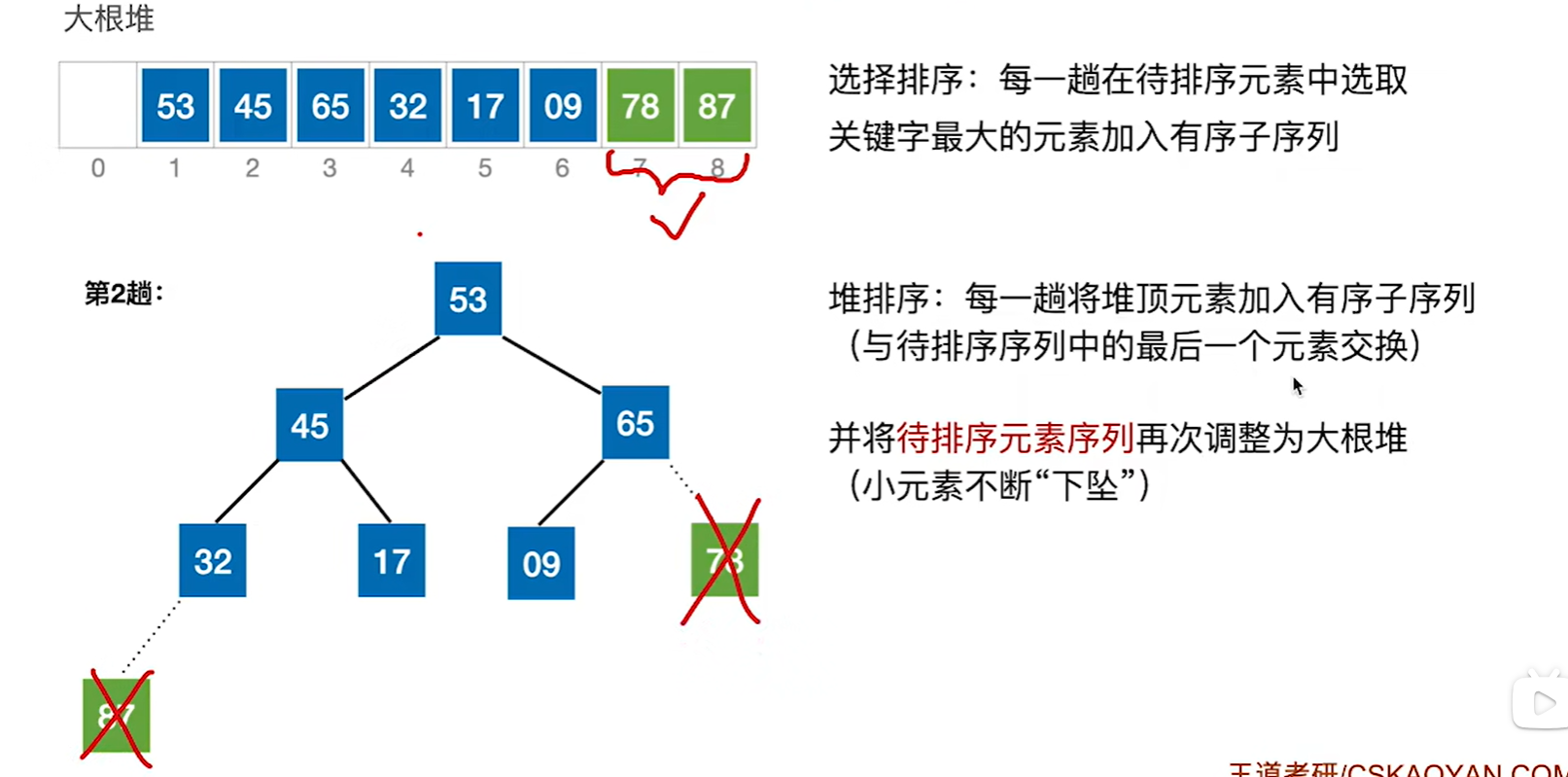
经过n-1趟处理后,就可以得到一个递增的序列了(如果是小根堆,那就是递减序列)
堆排序代码实现:
// 交换a和b的值
void swap(int &a, int &b){int temp = a;a = b;b = temp;
}// 对长为len的数组A[]进行堆排序
void HeapSort(int A[], int len){BuildMaxHeap(A, len); //初始建立大根堆for(int i=len; i>1; i--){ //n-1趟的交换和建堆过程swap(A[i], A[1]);//交换堆顶和待排序序列的最后一个元素交换HeadAdjust(A,1,i-1);//调整不包含已经排过序的数的大根堆}
}
算法性能分析

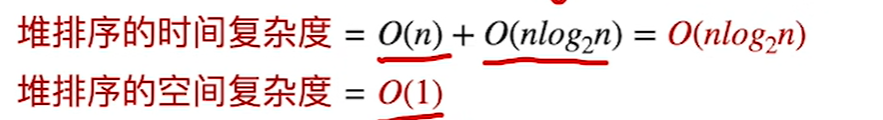
稳定性:不稳定的
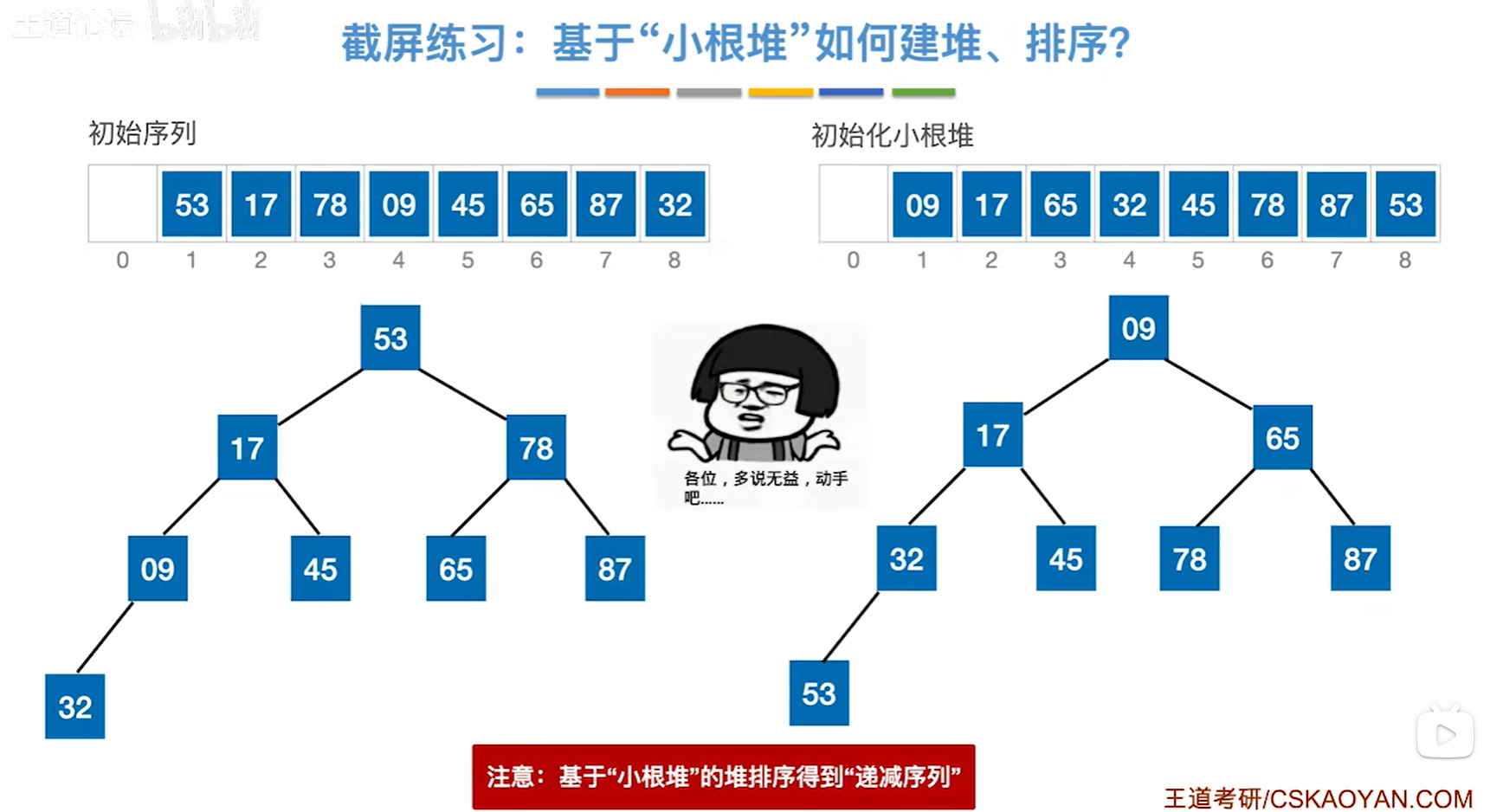
堆的插入和删除
注意下调整时候的关键字对比次数,要考的
插入和删除的复杂度都是log2的n

插入:就一开始先把13放在最末尾,然后调整堆,让这个堆满足小根堆的要求,其实本质就是让新插入的元素不断的上升找到属于自己的位置。如果一插入进去就满足小根堆的要求,那就不需要调整
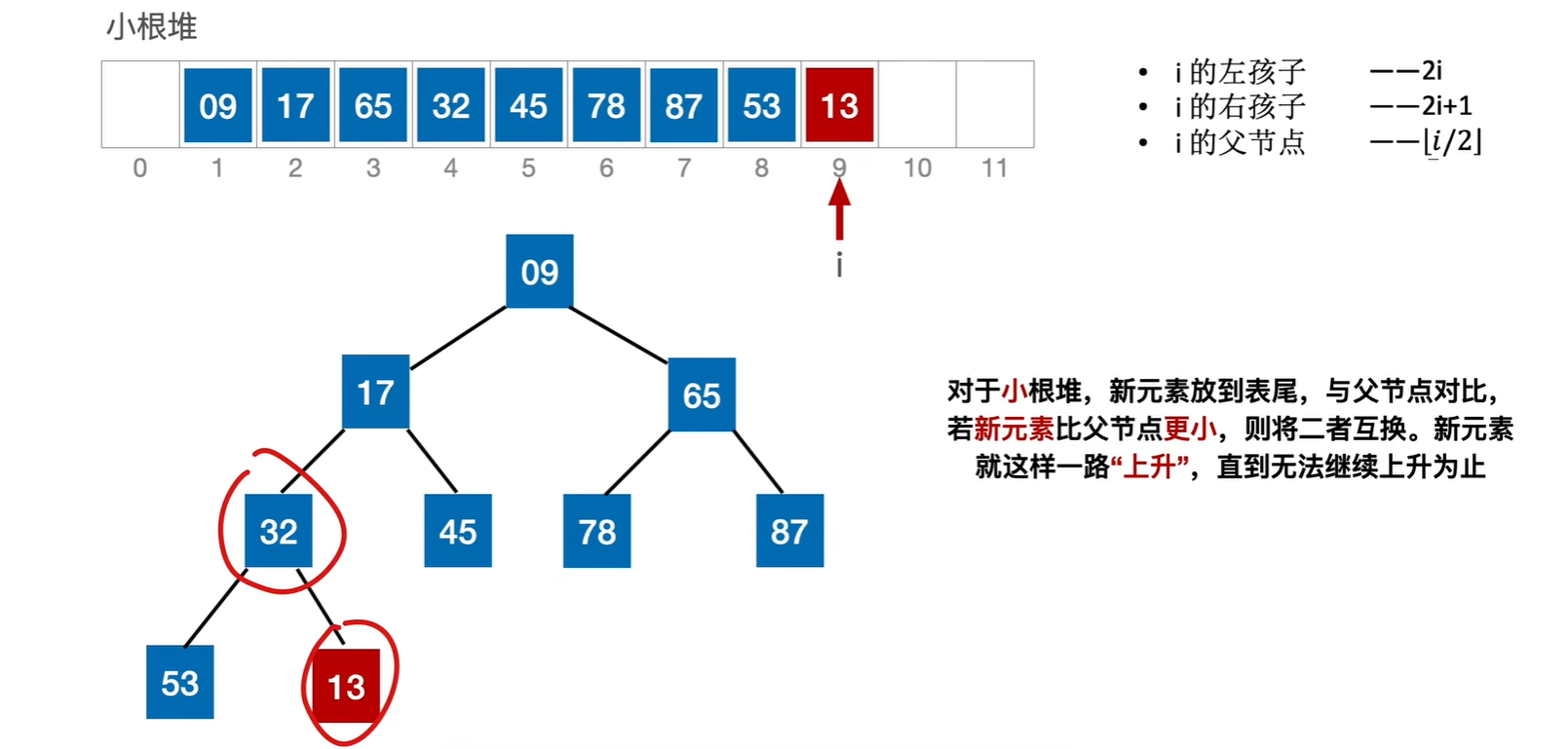
一共进行了3次关键字对比
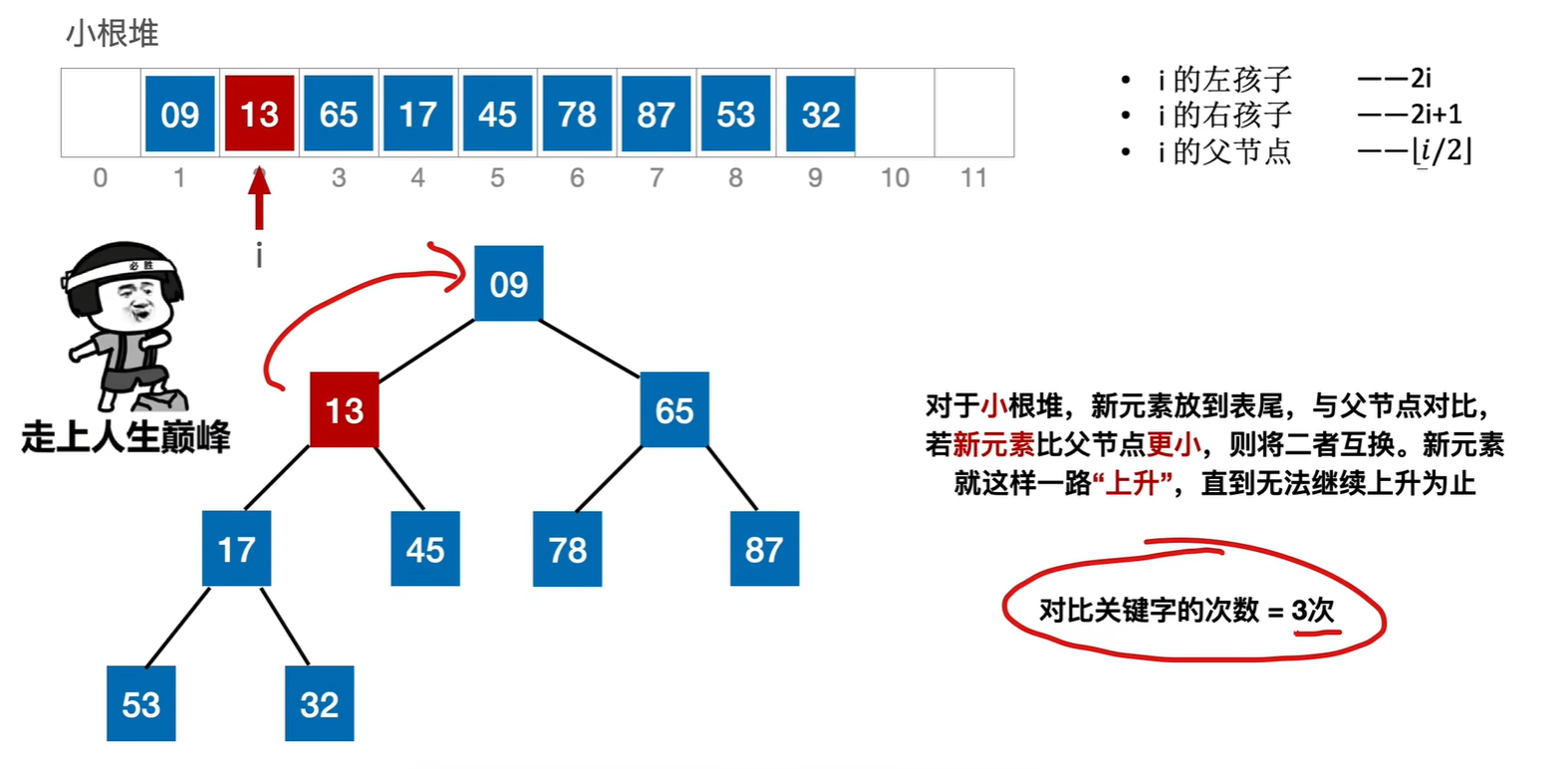
删除
直接删除该元素,然后用末尾元素代替他,然后调整这个元素,让它到自己应该取得位置即可。也有可能末尾元素放到这里刚刚好,那就不用调整,但是关键字对比次数并不是0,因为一定是和子树对比之后才知道需不需要调整
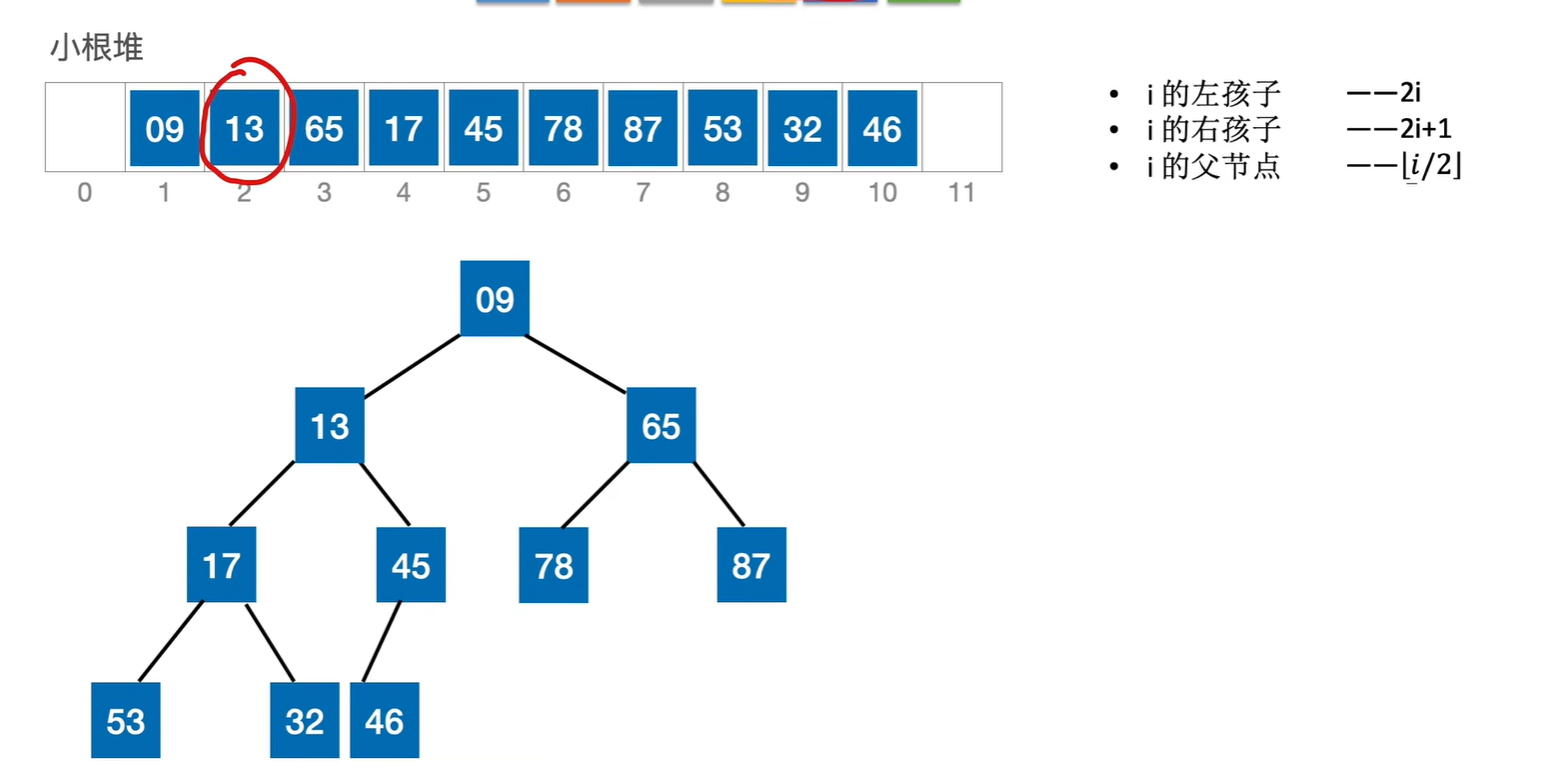
比如要把13删掉,那就用末尾元素46代替他,然后调整这个元素46,让它到自己应该取得位置即可
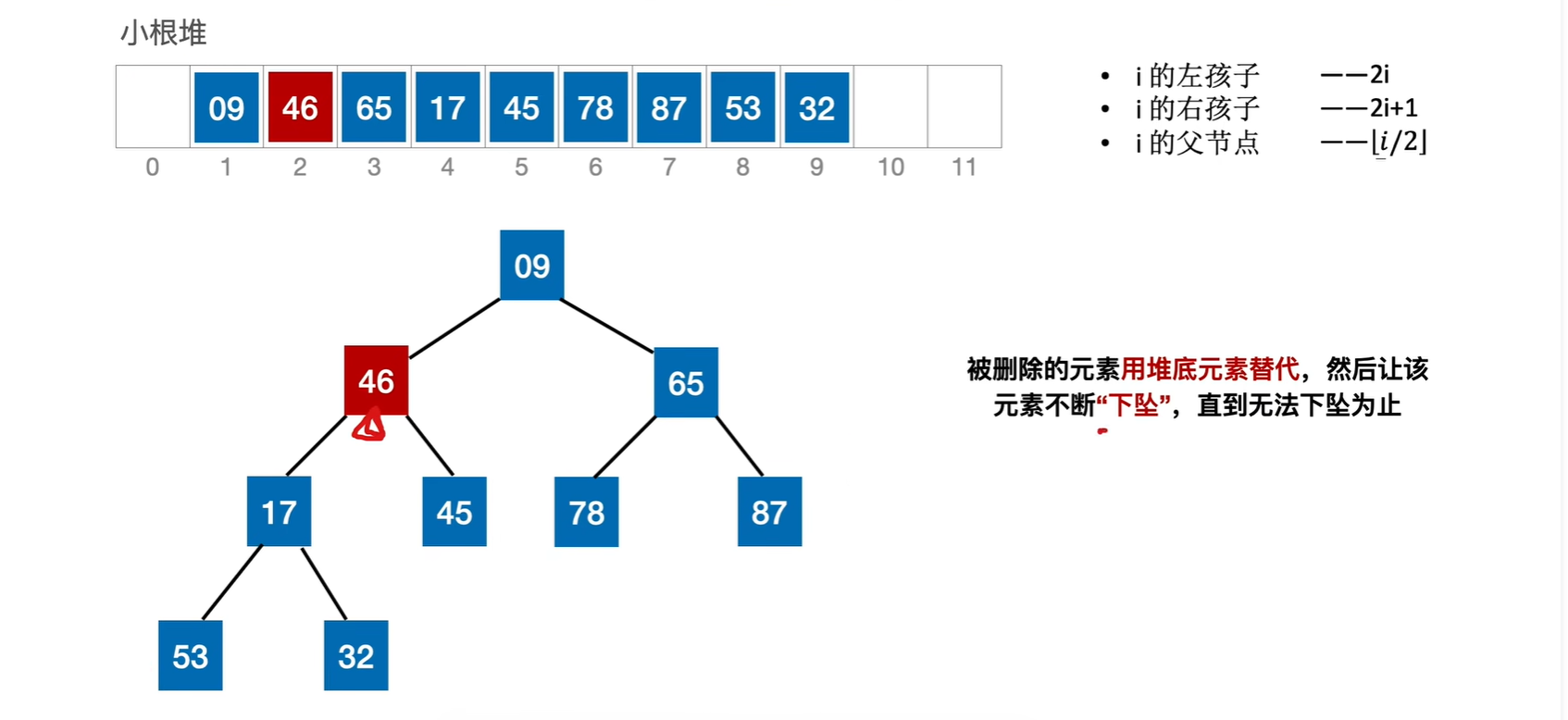
一共对比了4次关键字
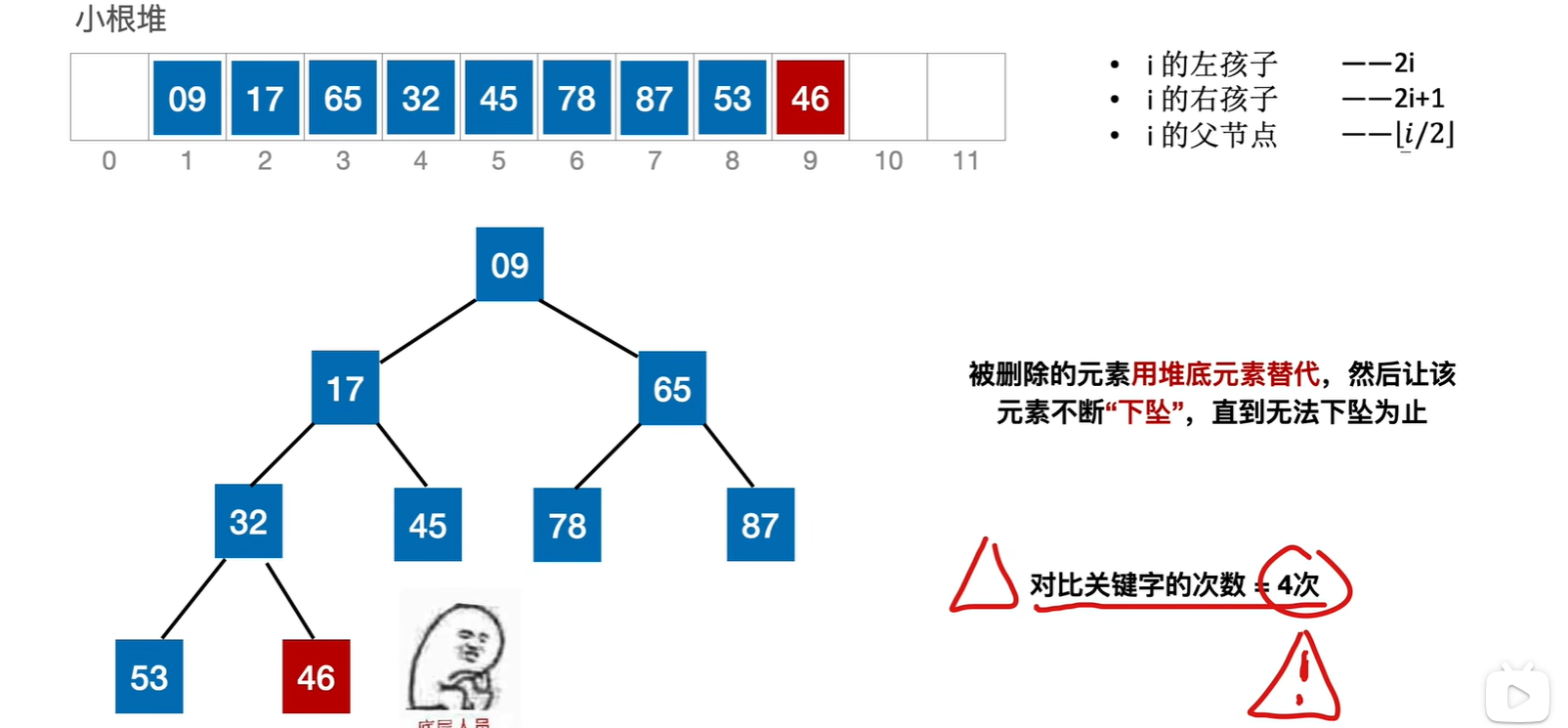
比如删除65,然后46放到这里,一共有两次关键字对比,第一次是78和87对比,选一个更小的,第二次是46和78比,所以有两次关键字对比
8.5.1 归并排序
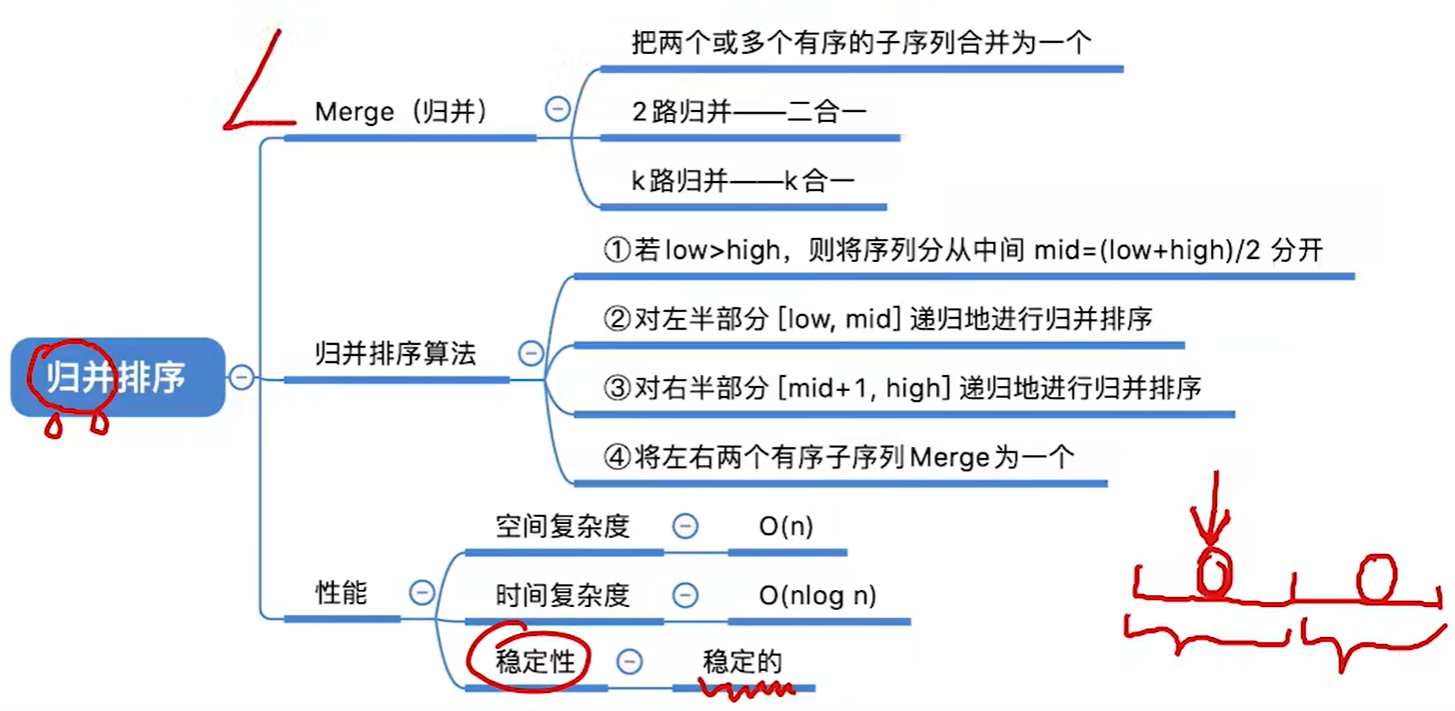
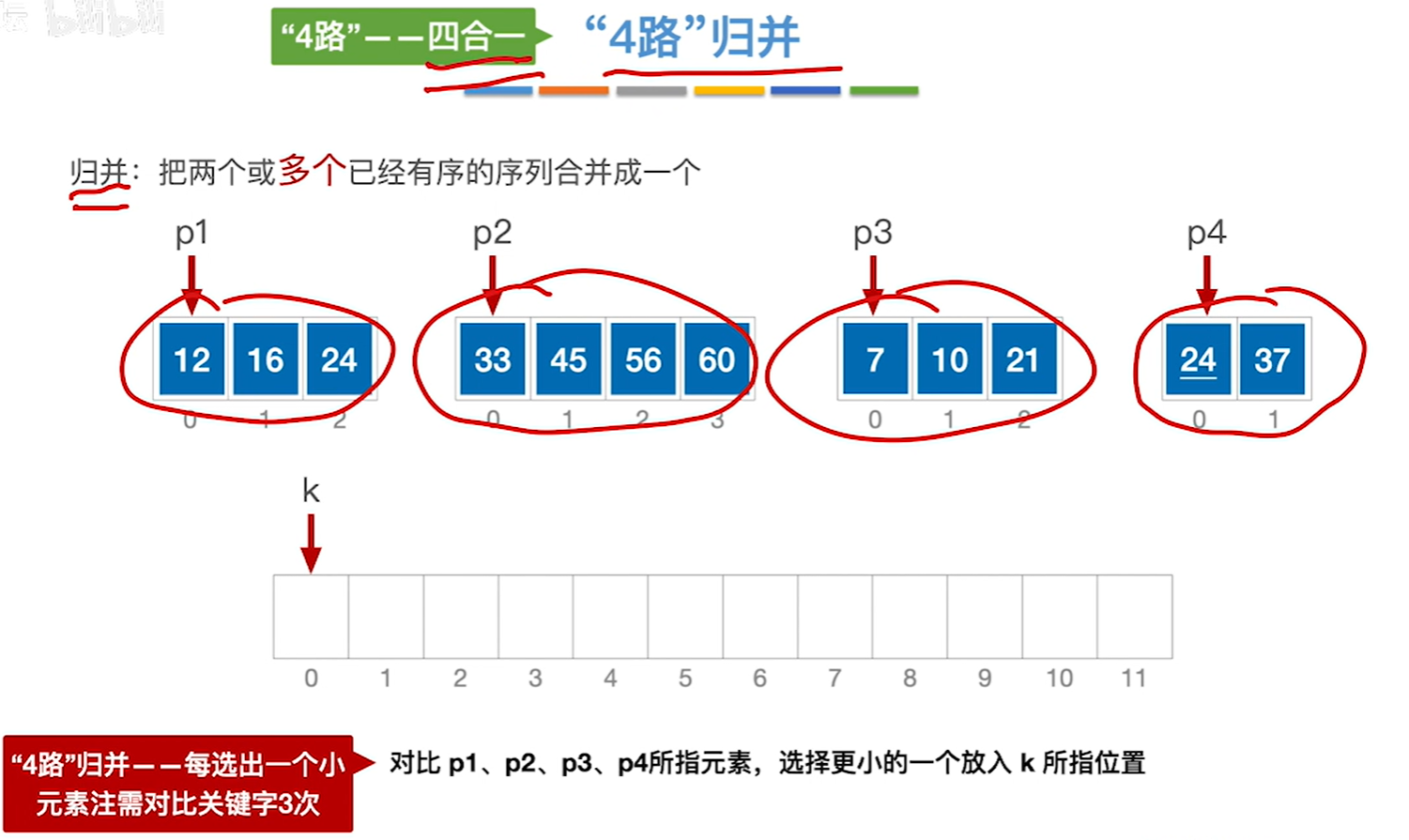
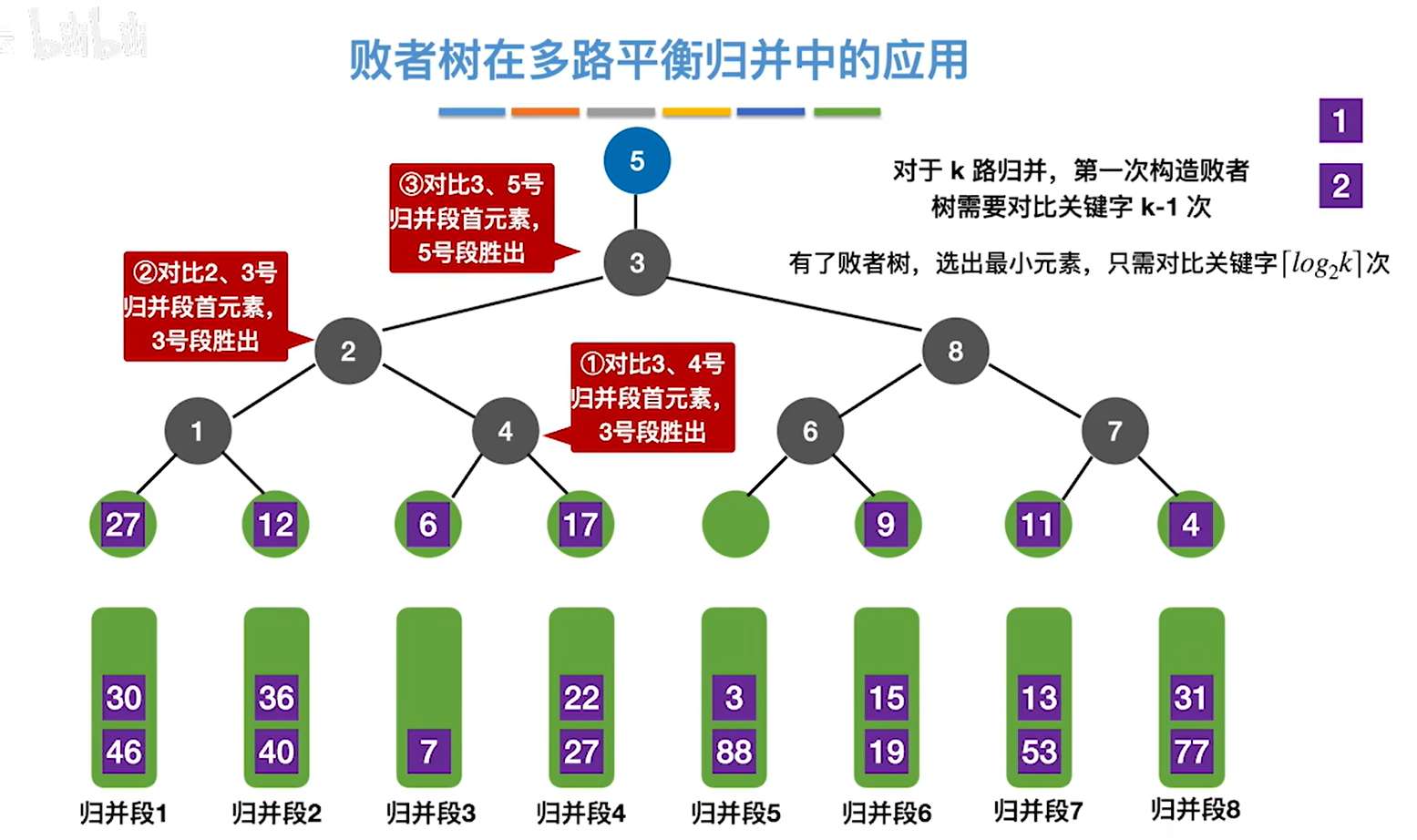
归并(Merge):把两个或多个已经有序的序列合并成一个新的有序表。k路归并每选出一个元素,需对比关键字k-1次。
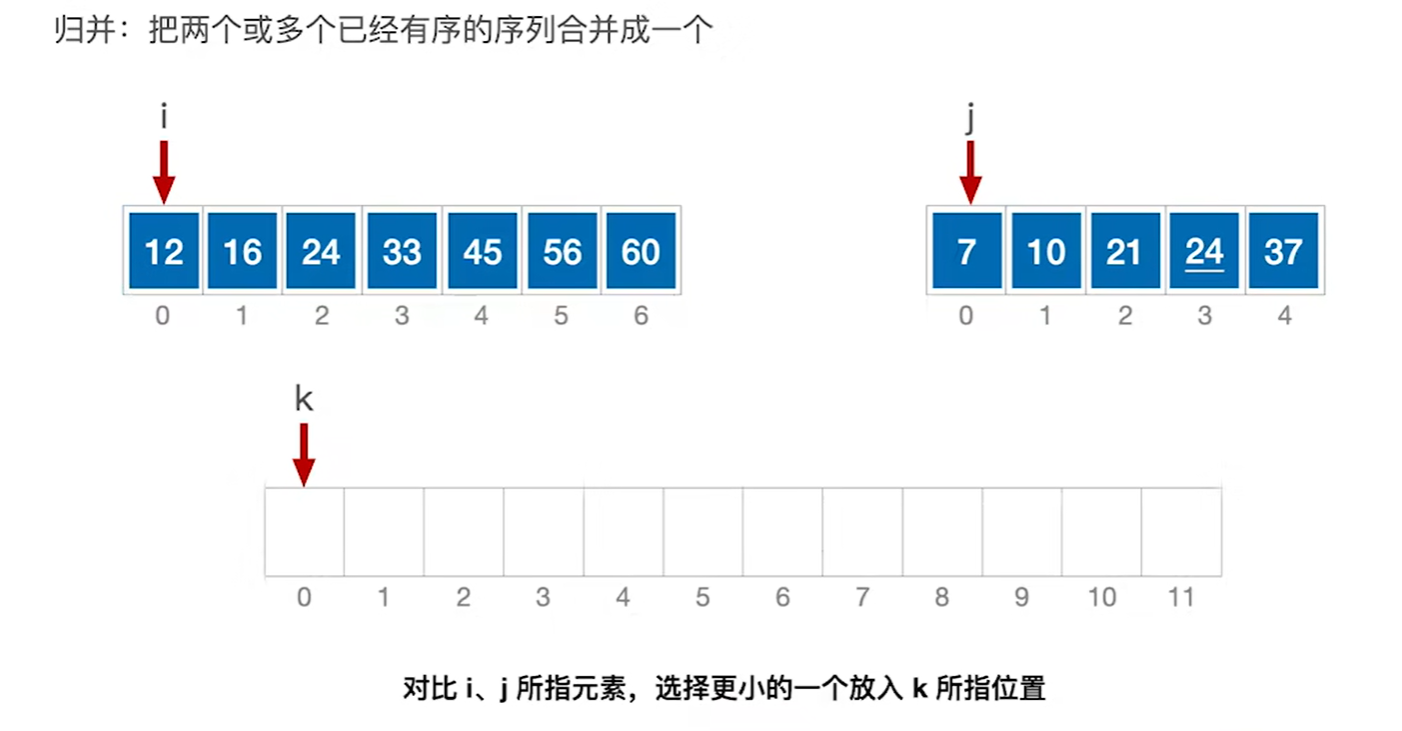
两个有序数组就是二路归并,四个有序数组就是四路归并
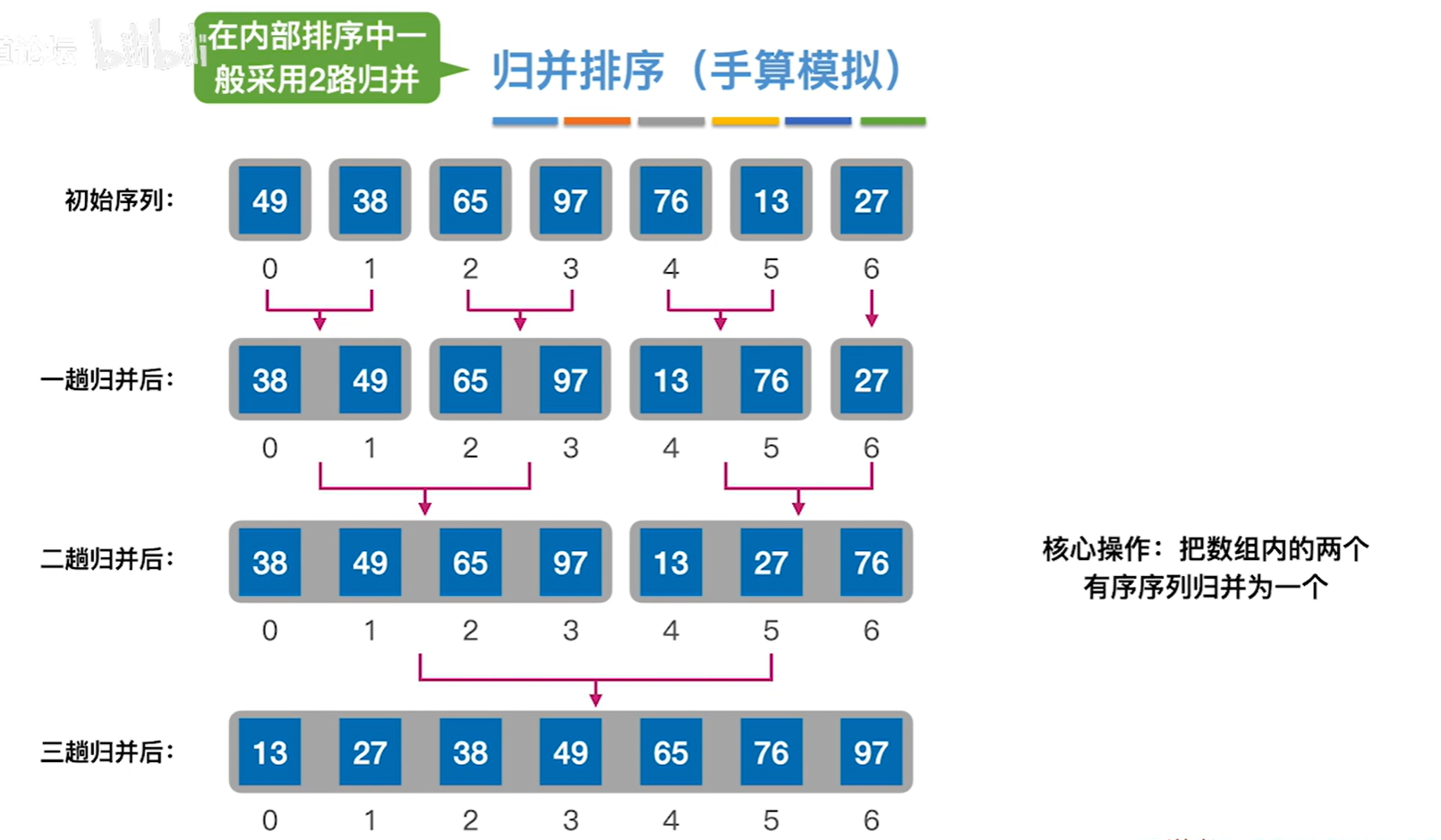
**算法思想:**先将数组进行拆分,每次拆成两份,然后继续拆分直到一组有两个元素为止,然后再进行两两整合排序,重复两两整合排序直至数组元素排序完成
代码实现:
// 辅助数组B
int *B=(int *)malloc(n*sizeof(int));
// A[low,...,mid],A[mid+1,...,high]各自有序,将这两个部分归并
void Merge(int A[], int low, int mid, int high){int i,j,k;for(k=low; k<=high; k++)B[k]=A[k];for(i=low, j=mid+1, k=i; i<=mid && j<= high; k++){if(B[i]<=B[j])A[k]=B[i++];elseA[k]=B[j++];}while(i<=mid)A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
}// 递归操作
void MergeSort(int A[], int low, int high){if(low<high){int mid = (low+high)/2;MergeSort(A, low, mid);MergeSort(A, mid+1, high);Merge(A,low,mid,high); //归并}
}
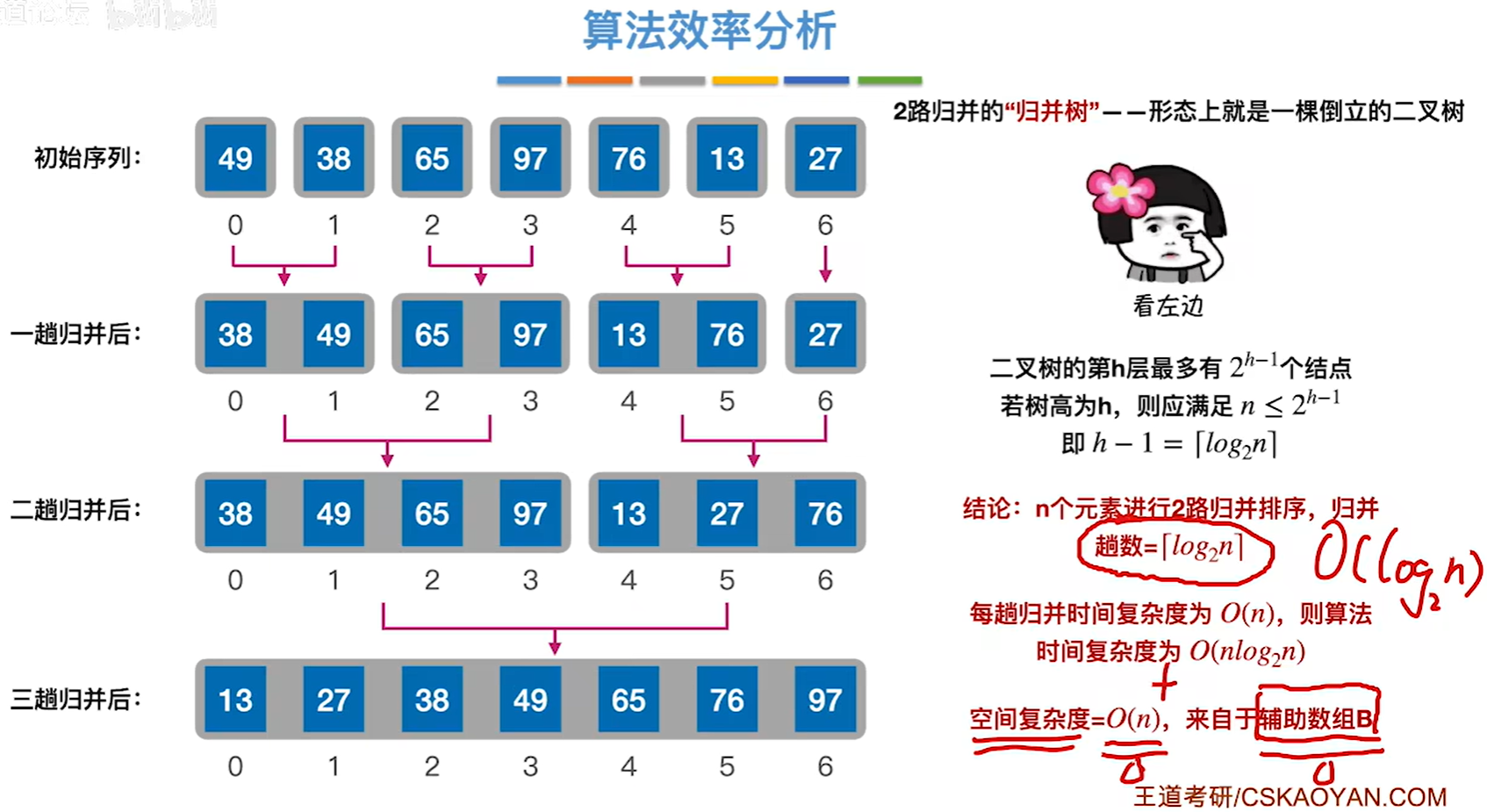
算法效率分析
趟数等于树高h-1
稳定性:稳定(我们在代码实现中,如果是两个元素相同的情况,会把第一个序列的元素放在前面,这样保证了稳定性)
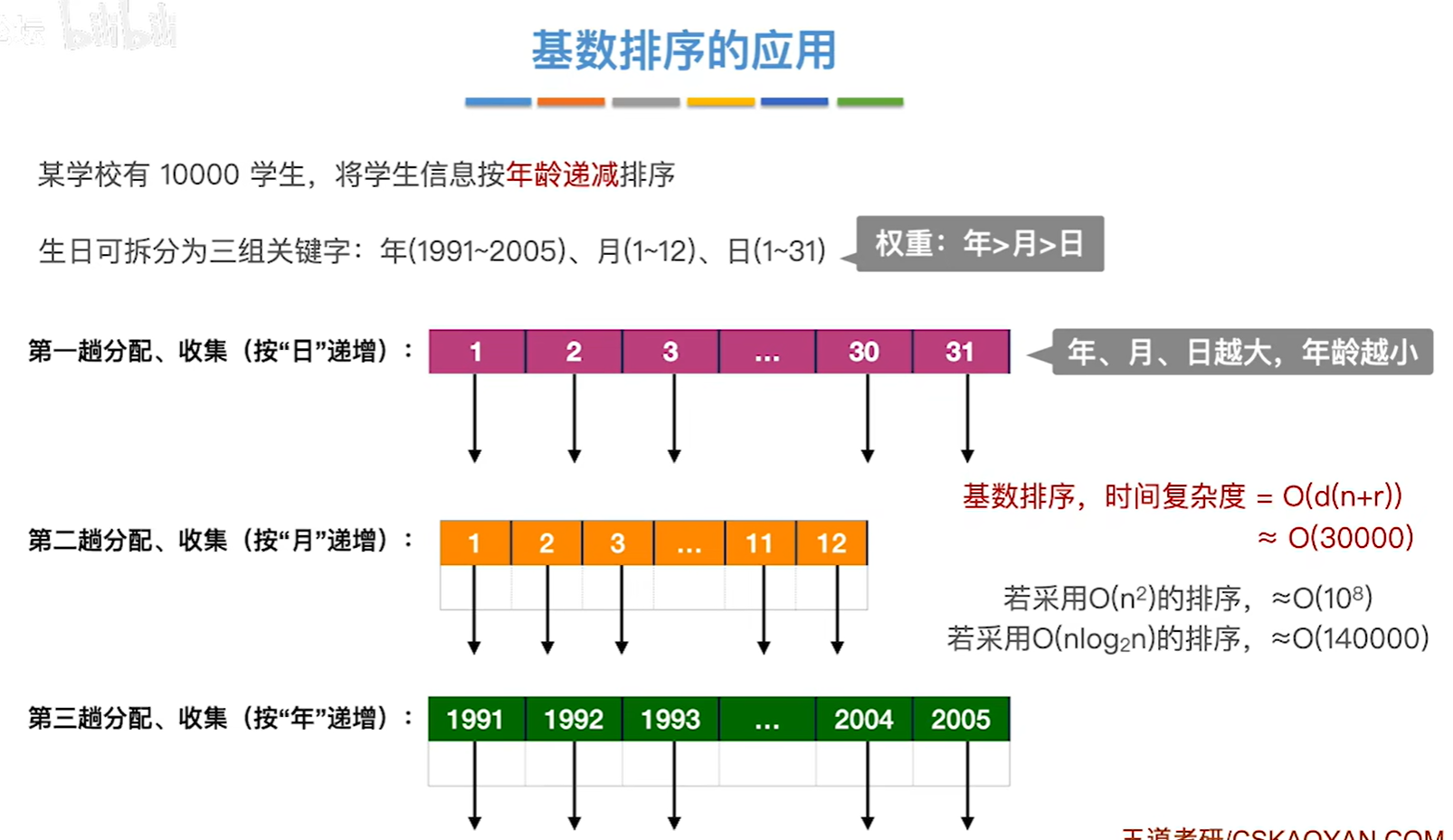
8.5.2 基数排序
考试中一般都是链式存储进行考察的
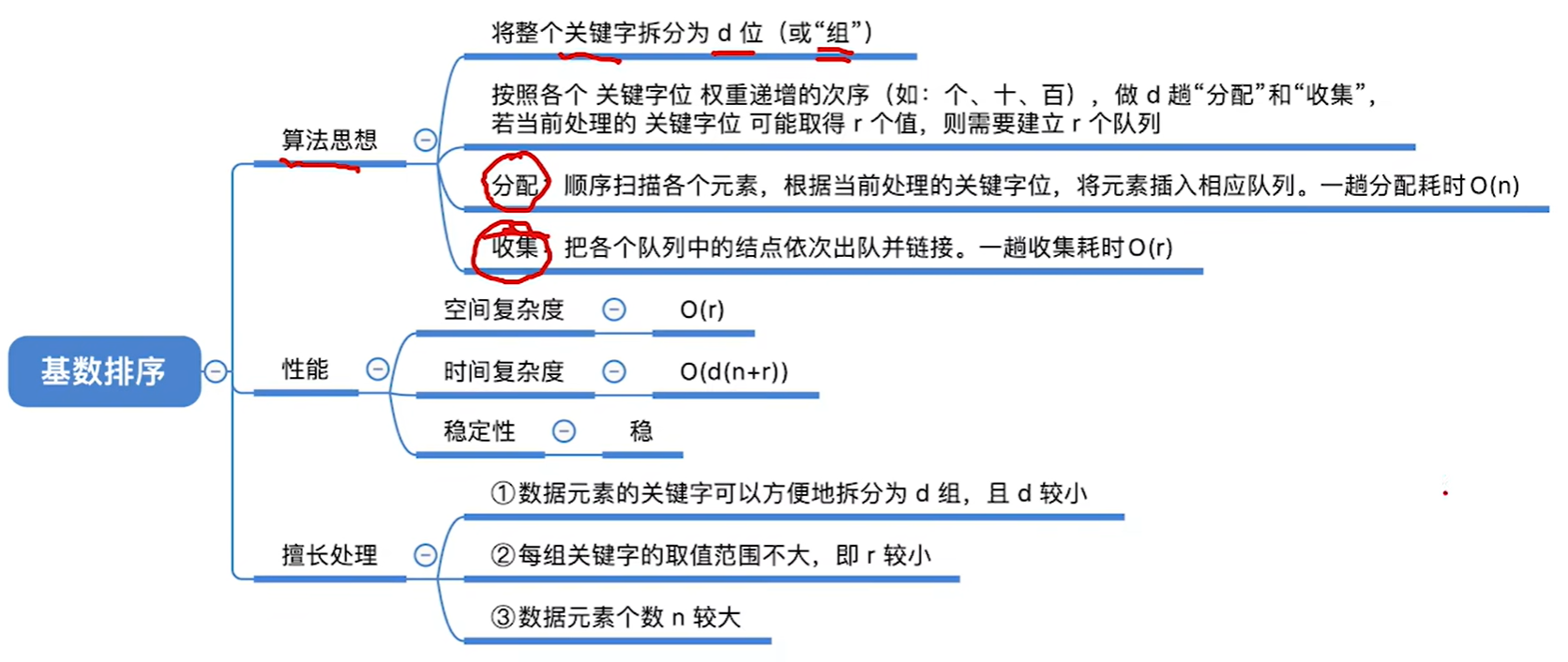
r称为基数,其实就是你的关键字位的取值的情况数量,比如下面的例子中,就可以取0-9,一共10种情况,那么r就等于10
d就是需要几趟,也就是需要几次分配,就是关键字可以拆分为几个部分,显然下图需要分成个位十位百位,那么就是3次分配,那么d就等于3


例子:
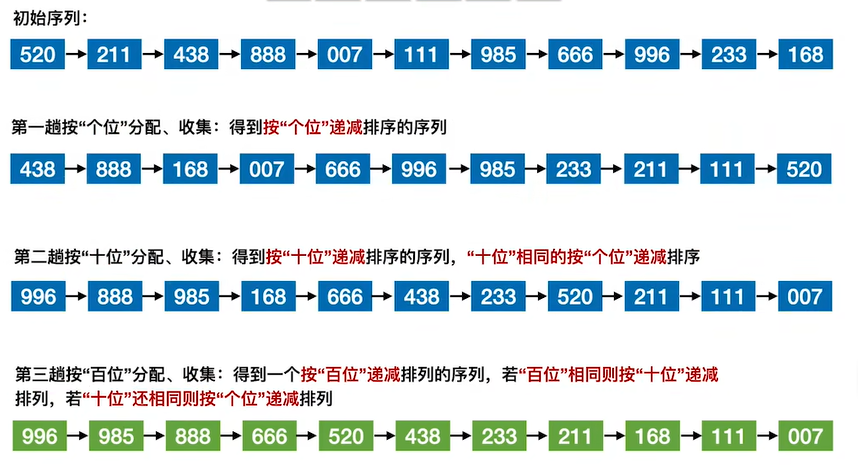
算法效率分析
稳定性:稳定
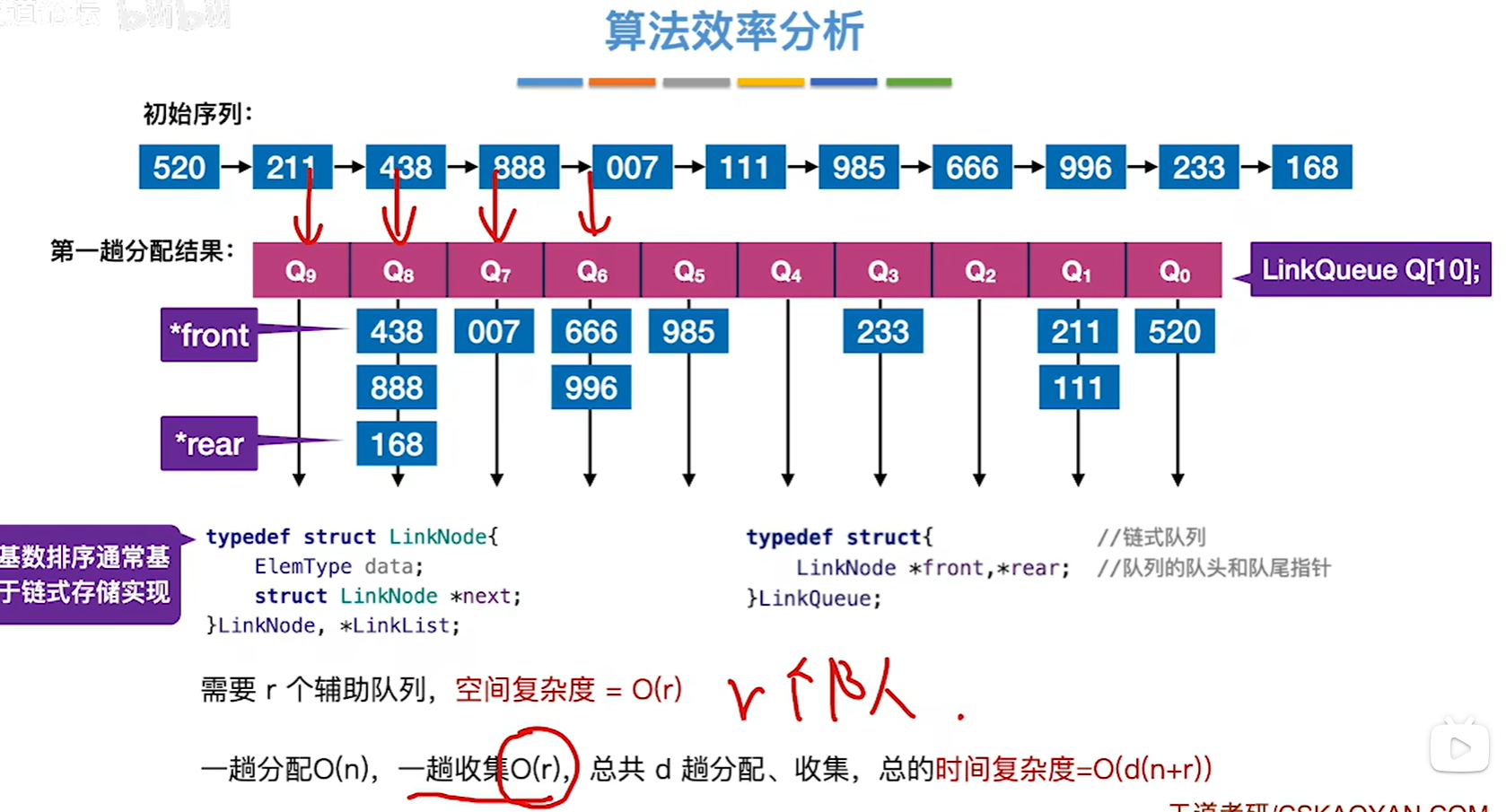
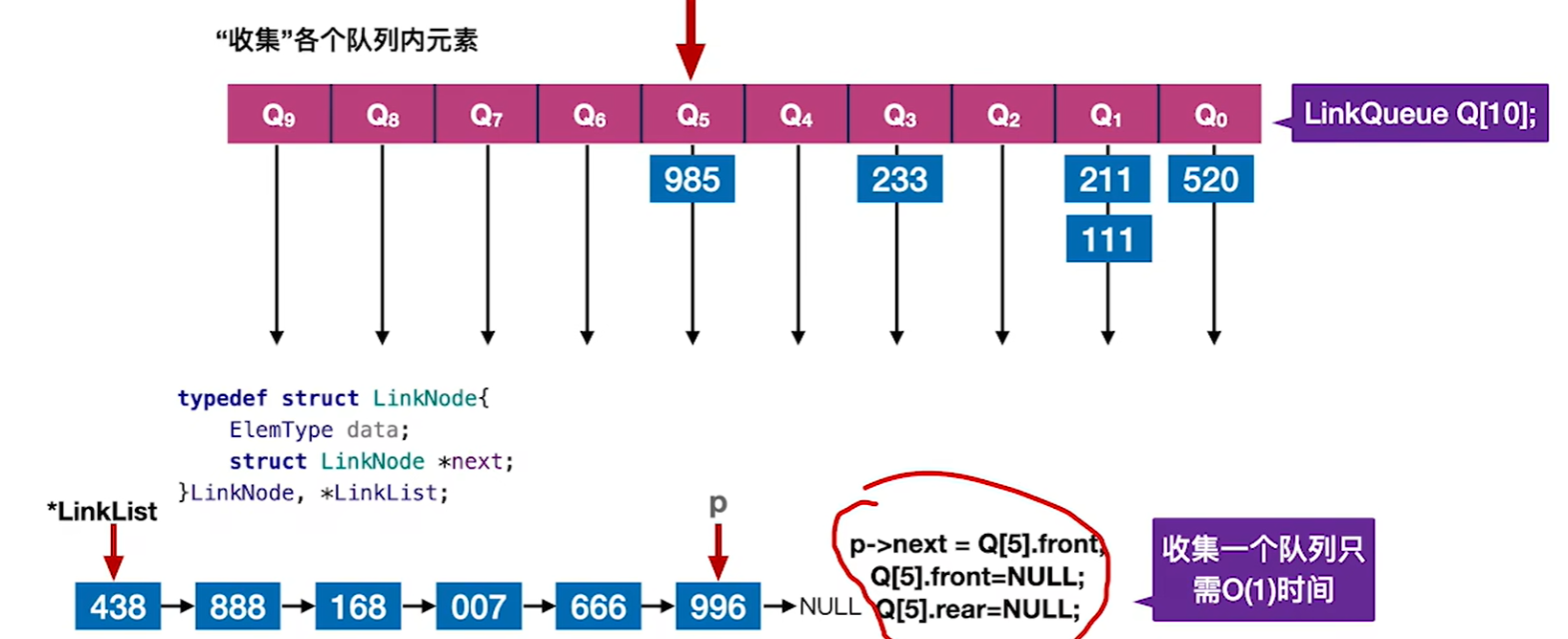
一趟收集为什么是O®?
因为我们已经有了队头的指针,而队内是有序的,把队头的指针直接接到链表里面去就是了,那么一共是r个队列,所以是O®
基数排序擅长处理的问题:
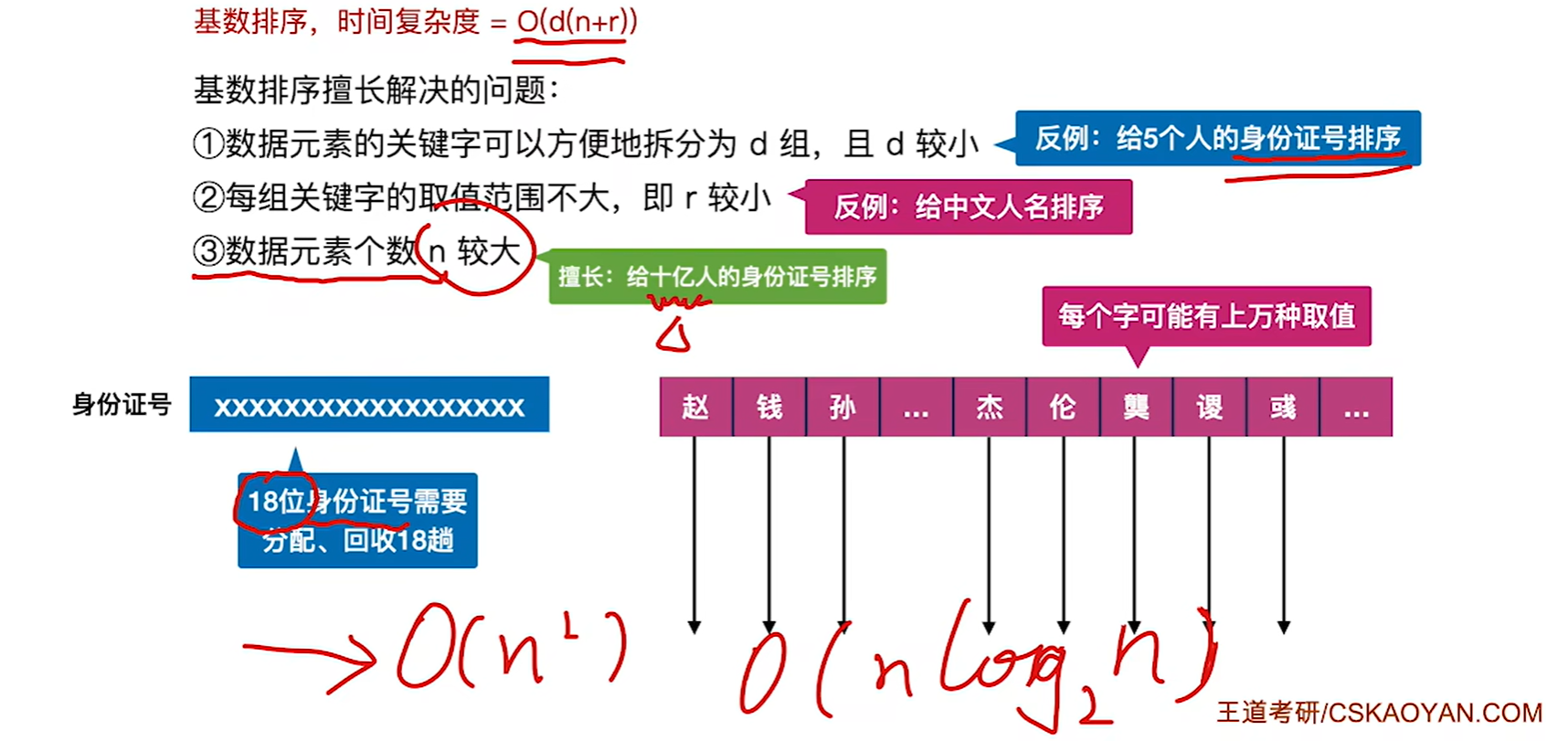
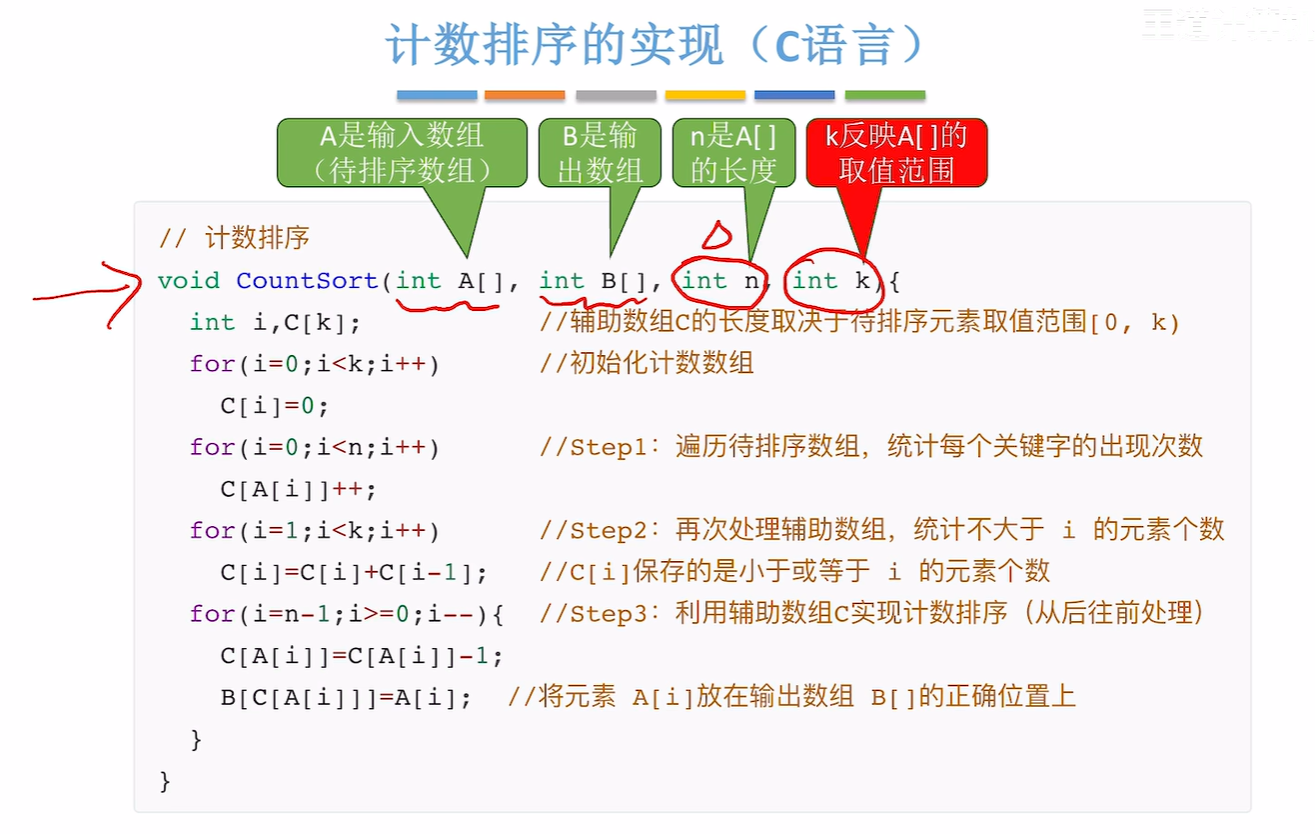
8.5 3 计数排序(考纲没有做个了解吧)
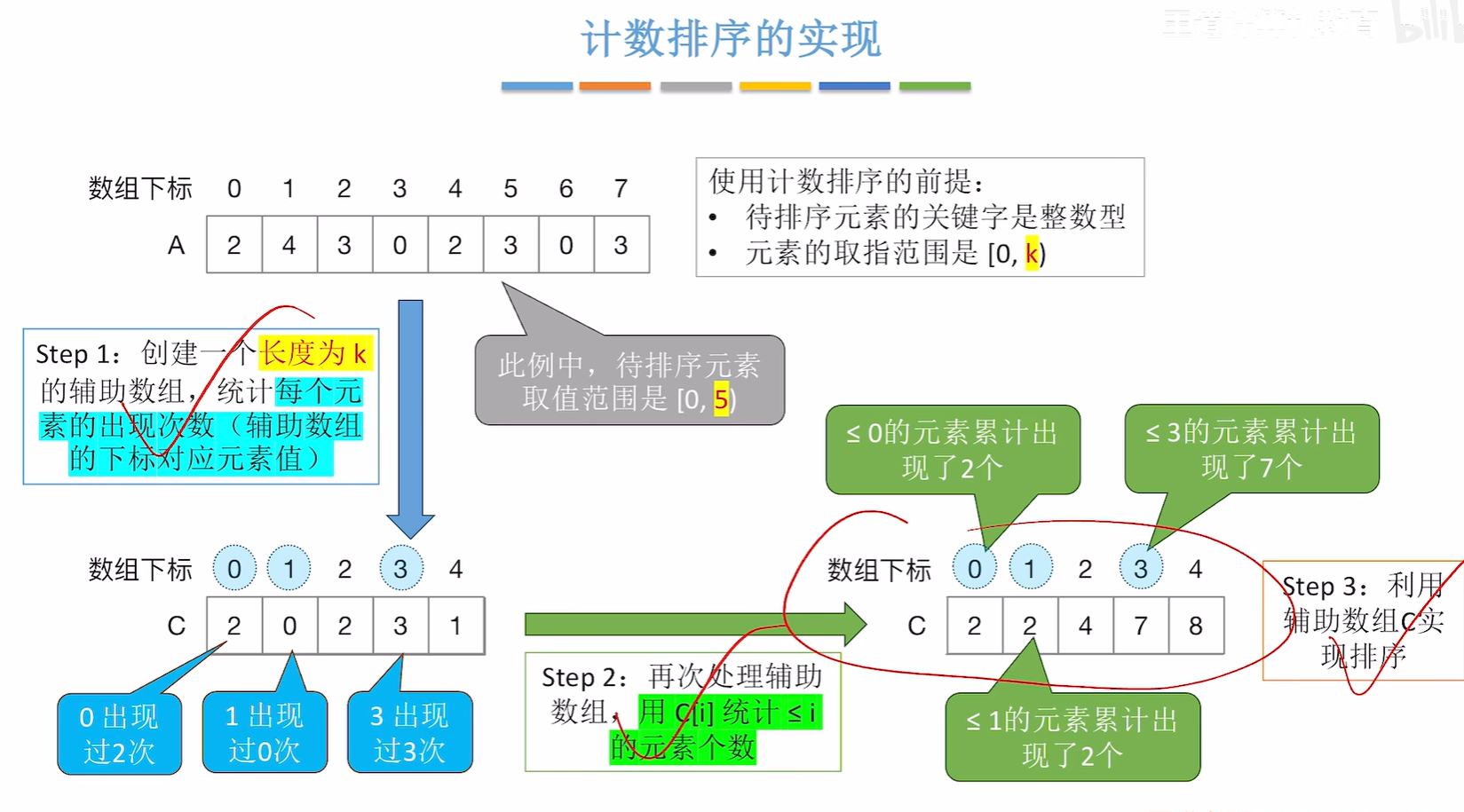
第二步其实就是求一下辅助函数的前缀和
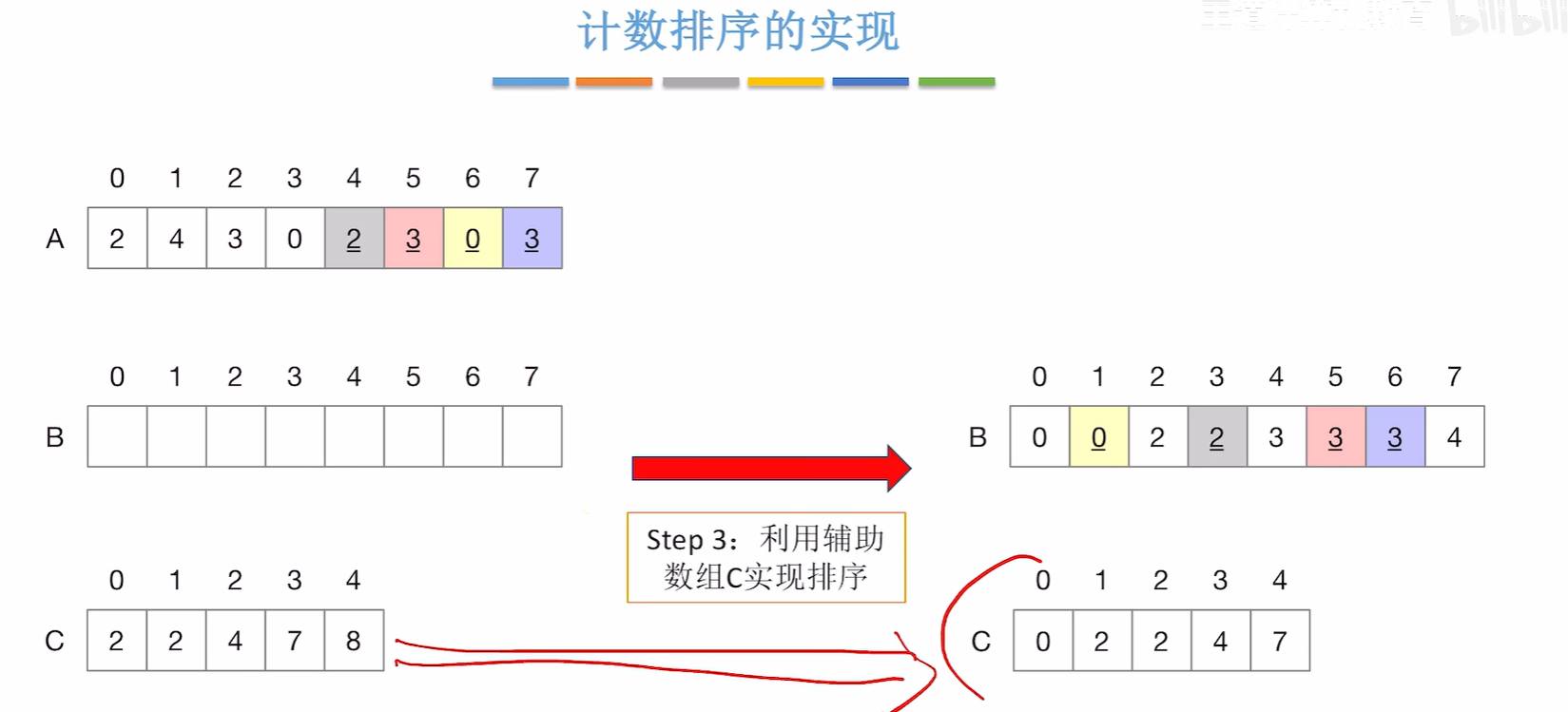
第三步是倒数遍历a数组然后把对应的数字填写到b数组去
倒着遍历A数组是为了保持算法的稳定性
复习的时候可以看一下代码,看不懂的话就去看视频吧(大概在10:00处-14:00)
C[A[i]]=C[A[i]]-1相当于C[A[i]]--然后C[A[i]]就是A[i]这个数在B数组中存放的位置所以才有下面的B[C[A[i]]]=A[i]
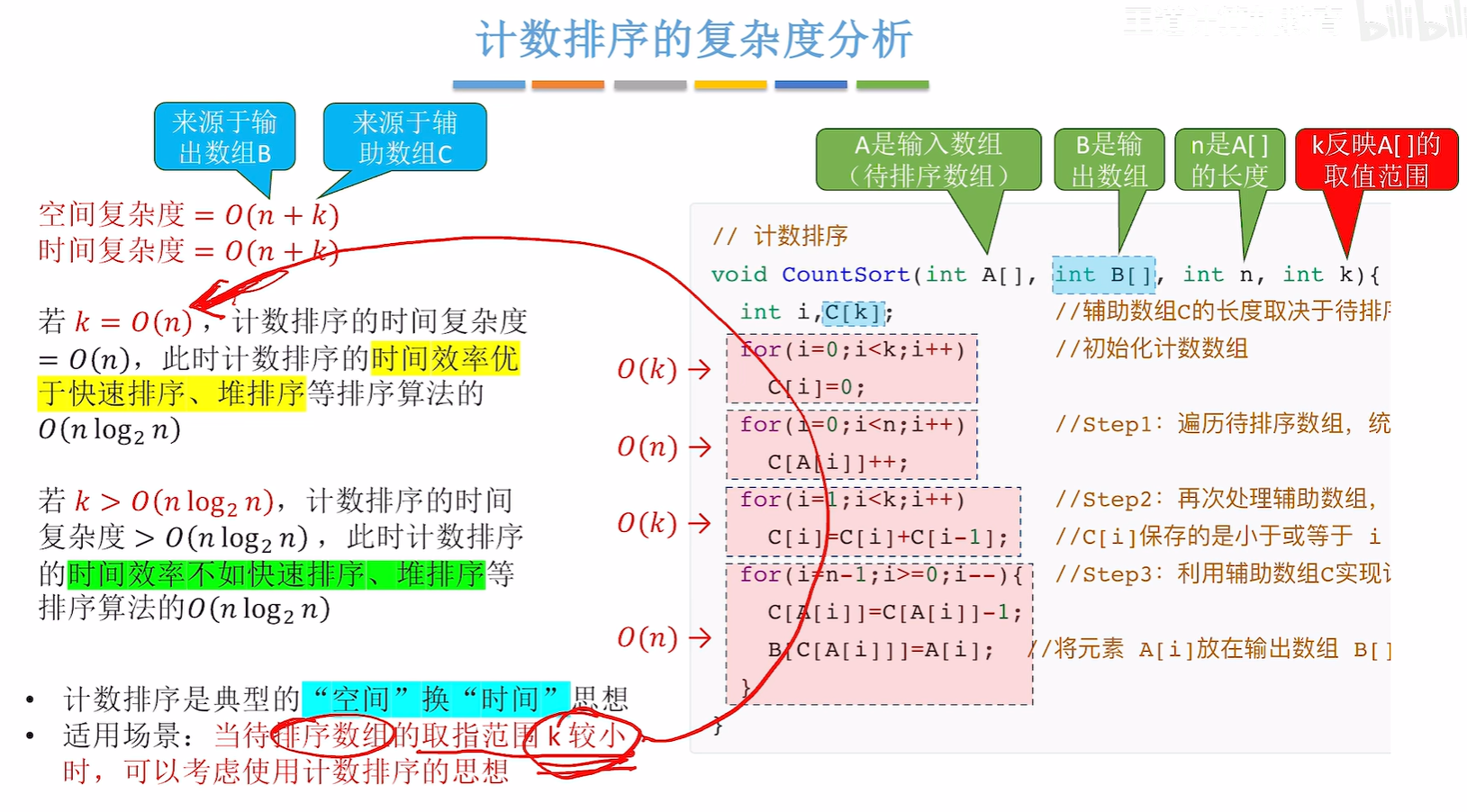
8.6 内部排序算法总结
1.元素如果基本有序的话,效率最高的是直接插入排序
2.快排比较好的情况是每次选择的元素可以把区间均匀地划分开
3.冒泡,快排,选择排序,堆排序一趟结束后,至少有一个元素在它的最终位置上。而插入排序则不一定,也就是一趟下来可能所有元素都不在最后的位置上面
4.快排在要排序数组基本有序情况下不利于发挥其长处
5.就平均性能而言,内部算法中最好的是快排
6.排序趟数和有元素要发生交换的躺数不同
排序躺数还要多一轮没有任何元素发生交换的一趟
7.快排每一趟可以确定一个元素,所以如果一个序列经历了两趟快排,那至少有两个元素的最终位置是确定的
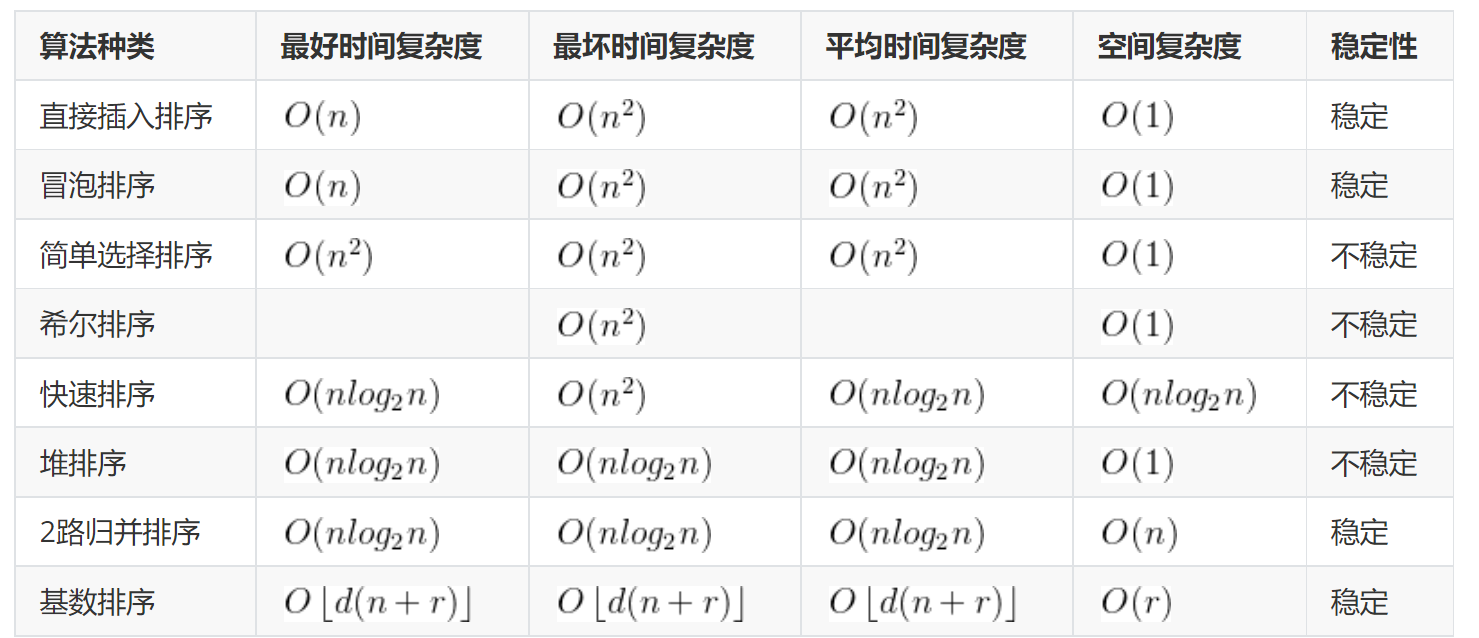
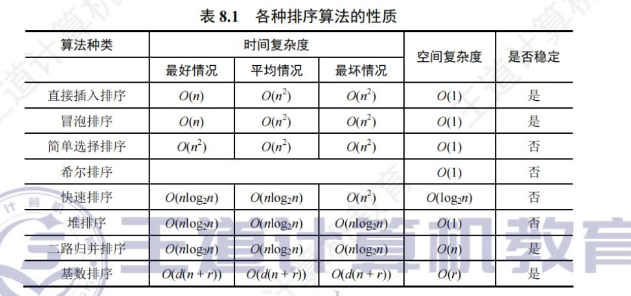
8.6.1 内部排序算法比较


8.6.2 内部排序算法的应用
选取排序方法需要考虑的因素:
- 待排序的元素数目n。
- 元素本身信息量的大小。
- 关键字的结构及其分布情况。
- 稳定性的要求。
- 语言工具的条件,存储结构及辅助空间的大小等。
排序算法的选择:


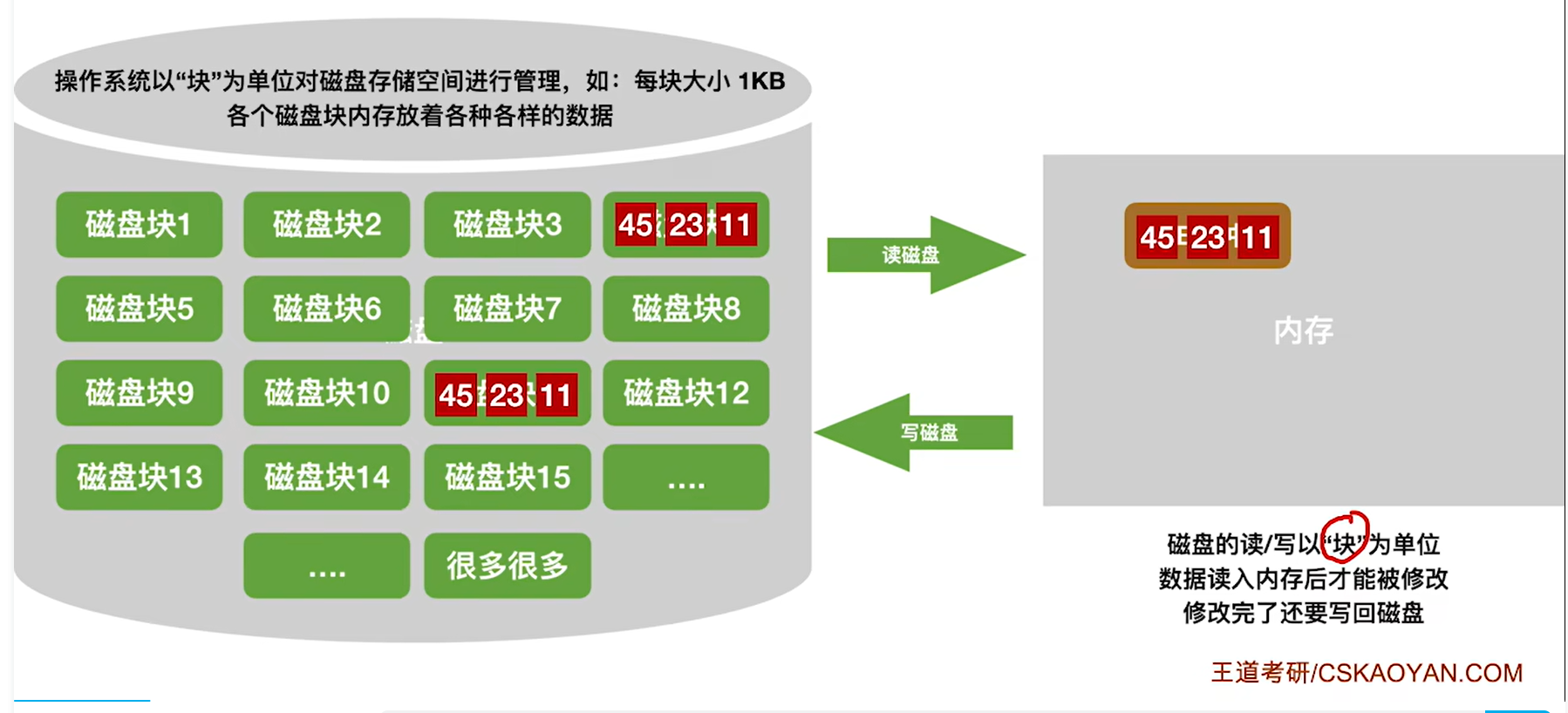
8.7 外部排序
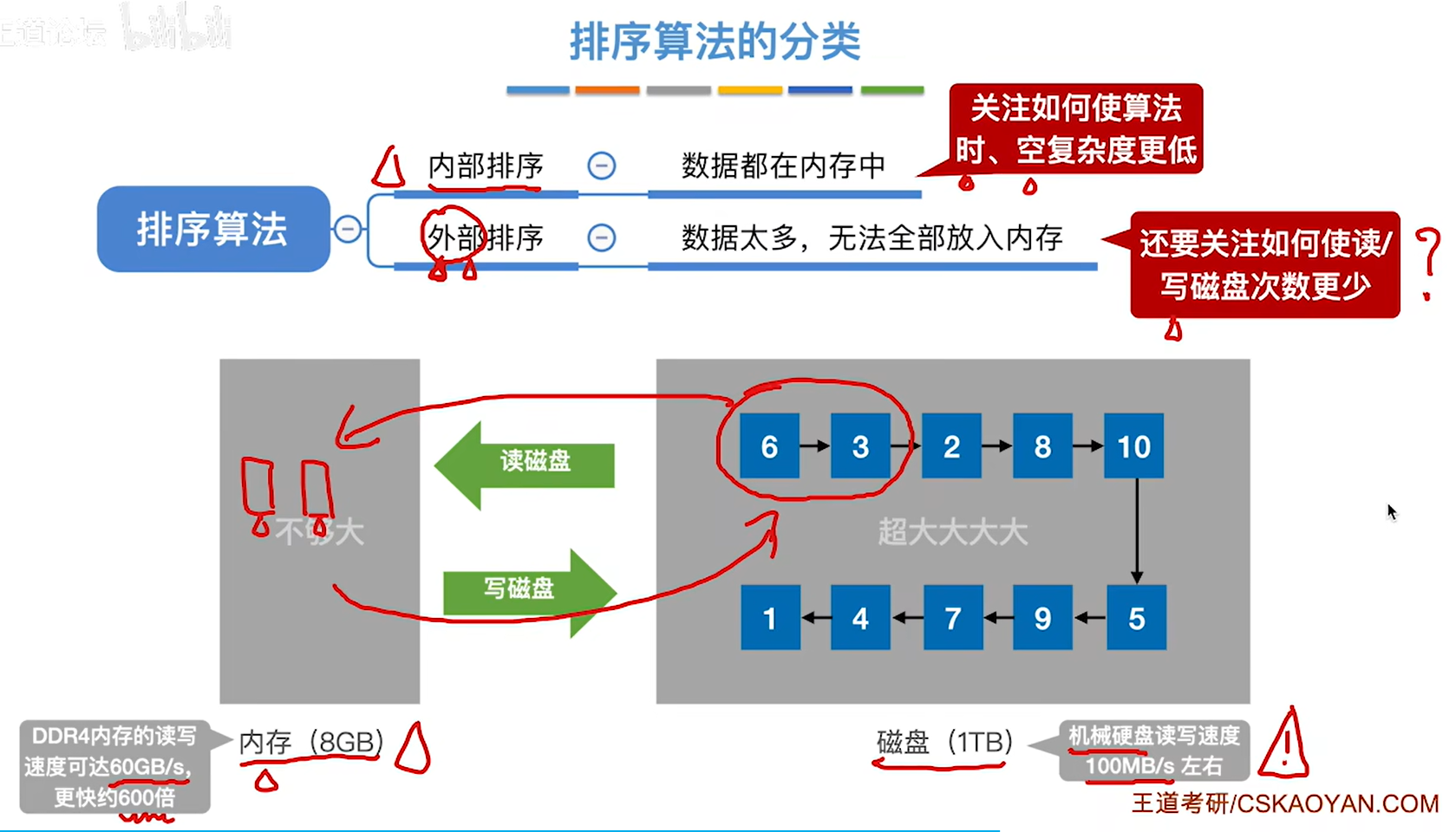
外存和内存之间的数据交换
8.7.1 外部排序的基本概念和方法
外部排序:对大文件进行排序时,因为文件中的记录很多、信息量庞大,无法将整个文件复制进内存中进行排序。因此需要将待排序的记录存储在外存上,排序时再把数据一部分一部分地调入内存进行排序,在排序过程中需要多次进行内存和外存之间的交换。
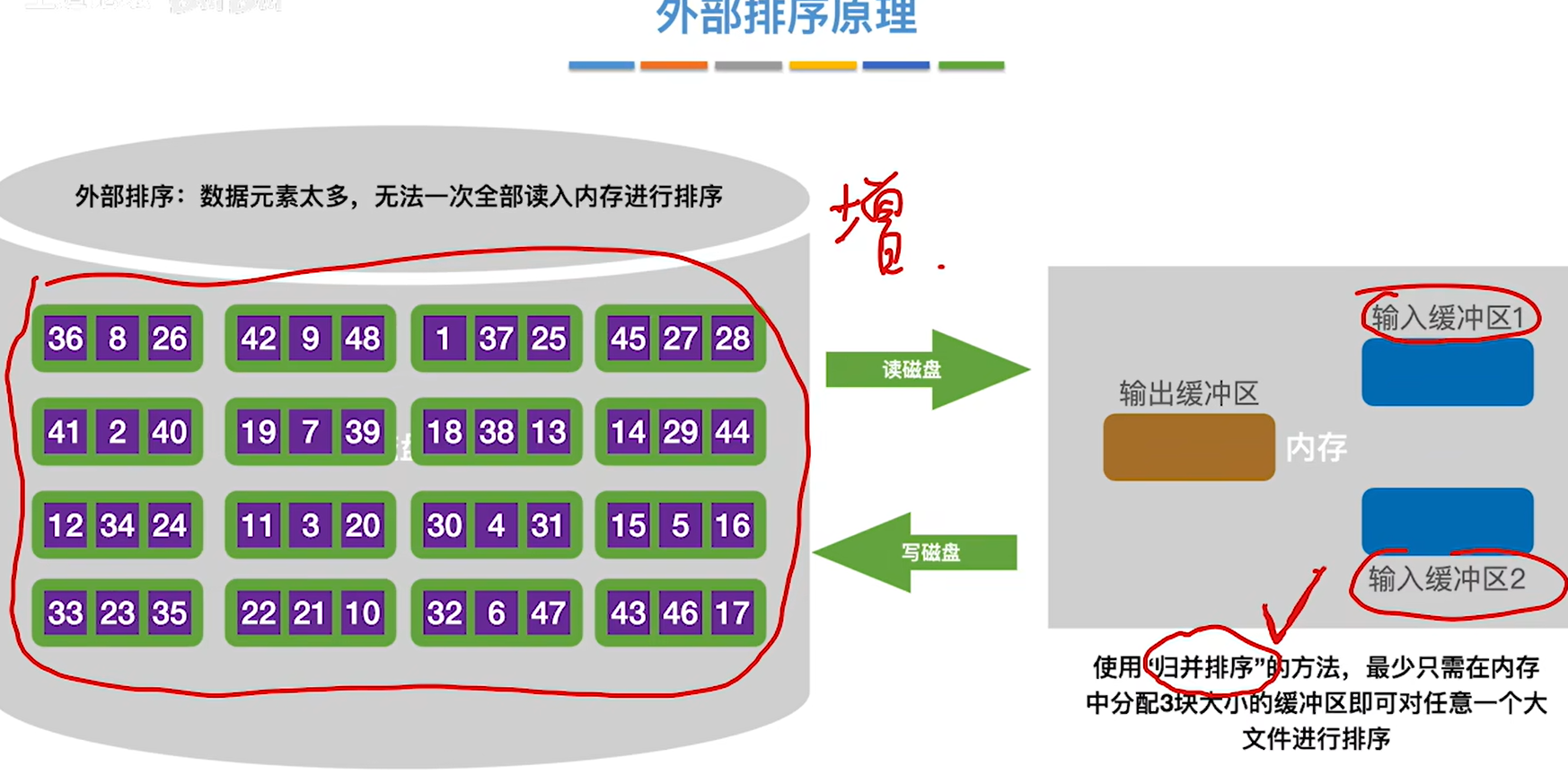
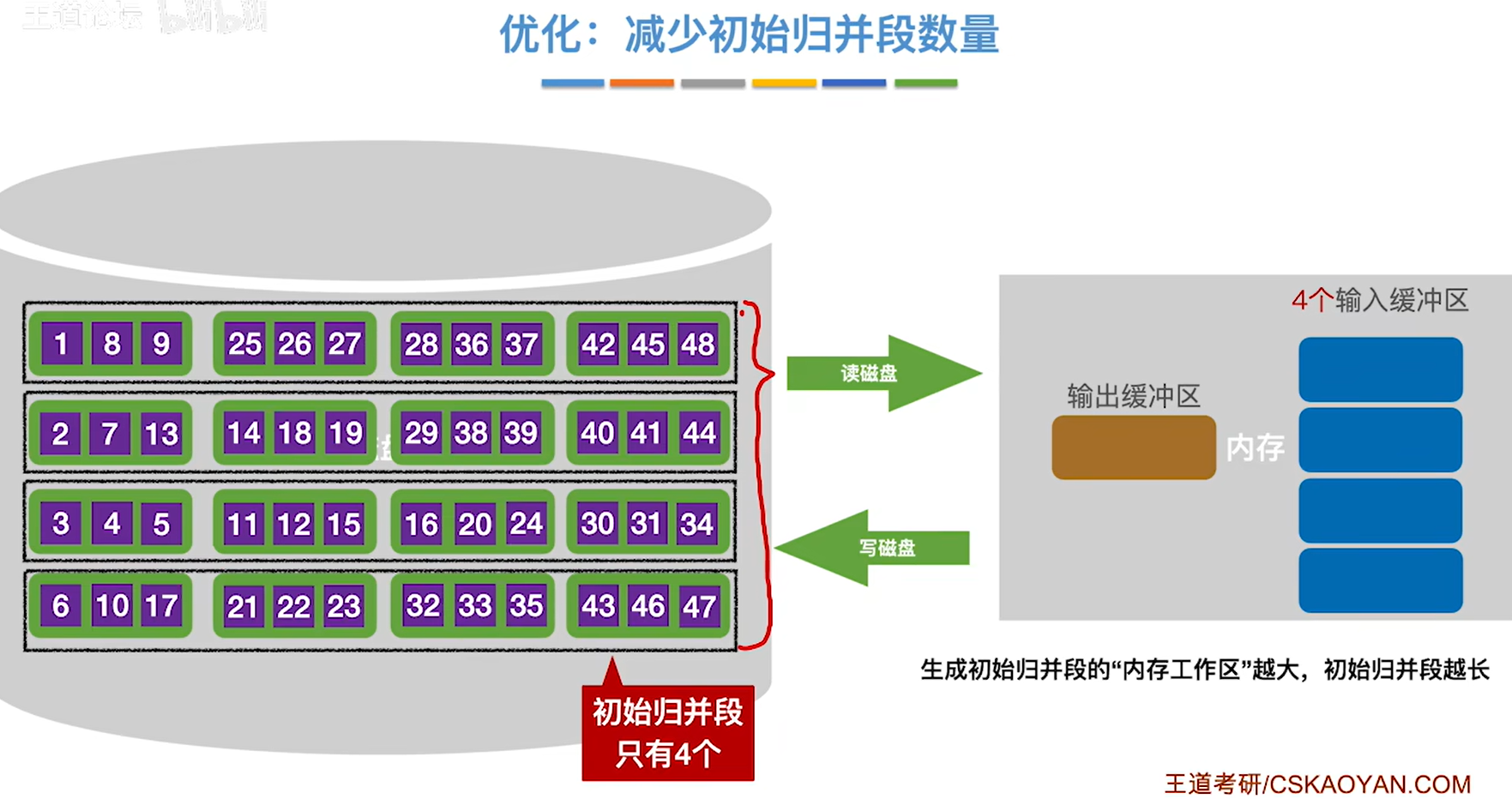
1.将数据块读入内存的输入缓冲区
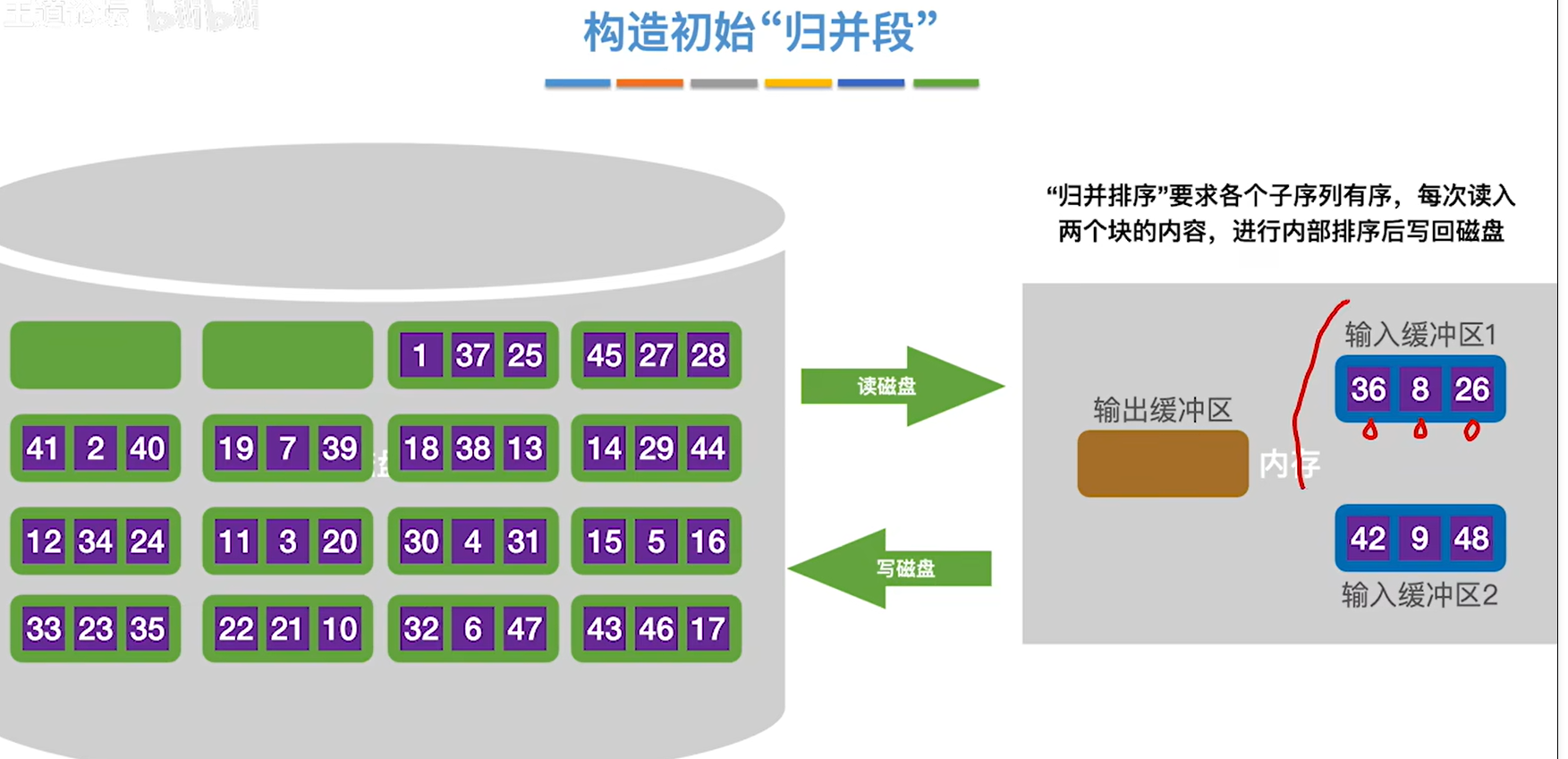
2.对数据块内的数据进行内部排序,然后将排好序的数据块放入输出缓冲区
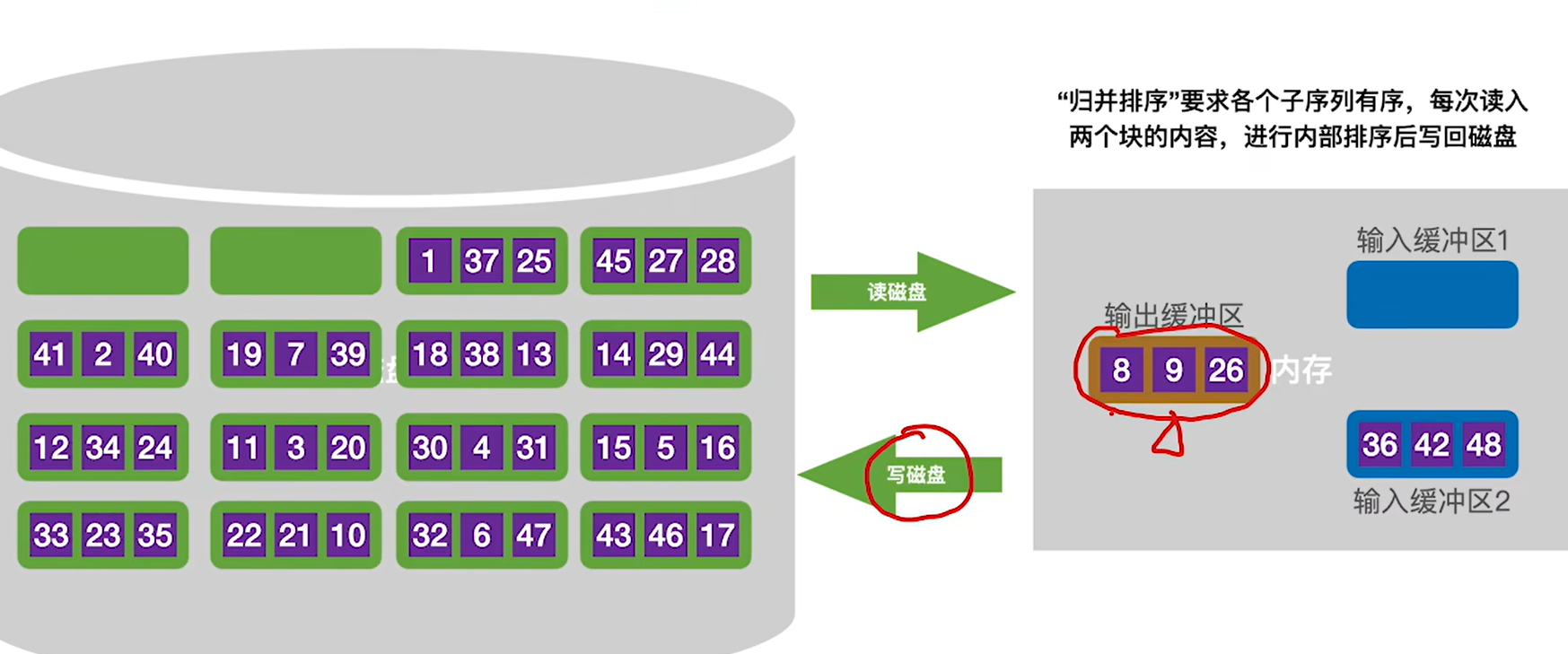
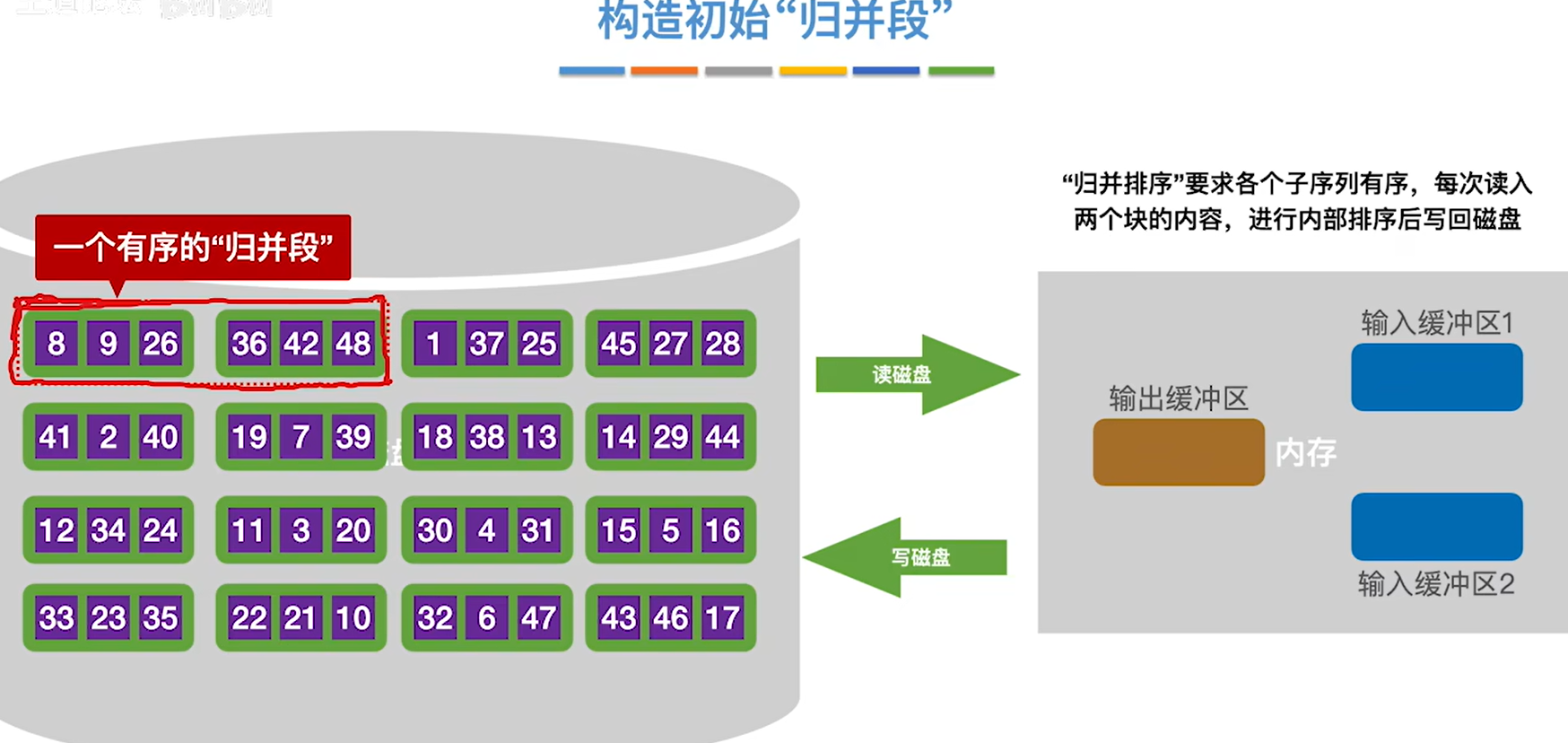
- 写回磁盘,得到了一个有序的归并段
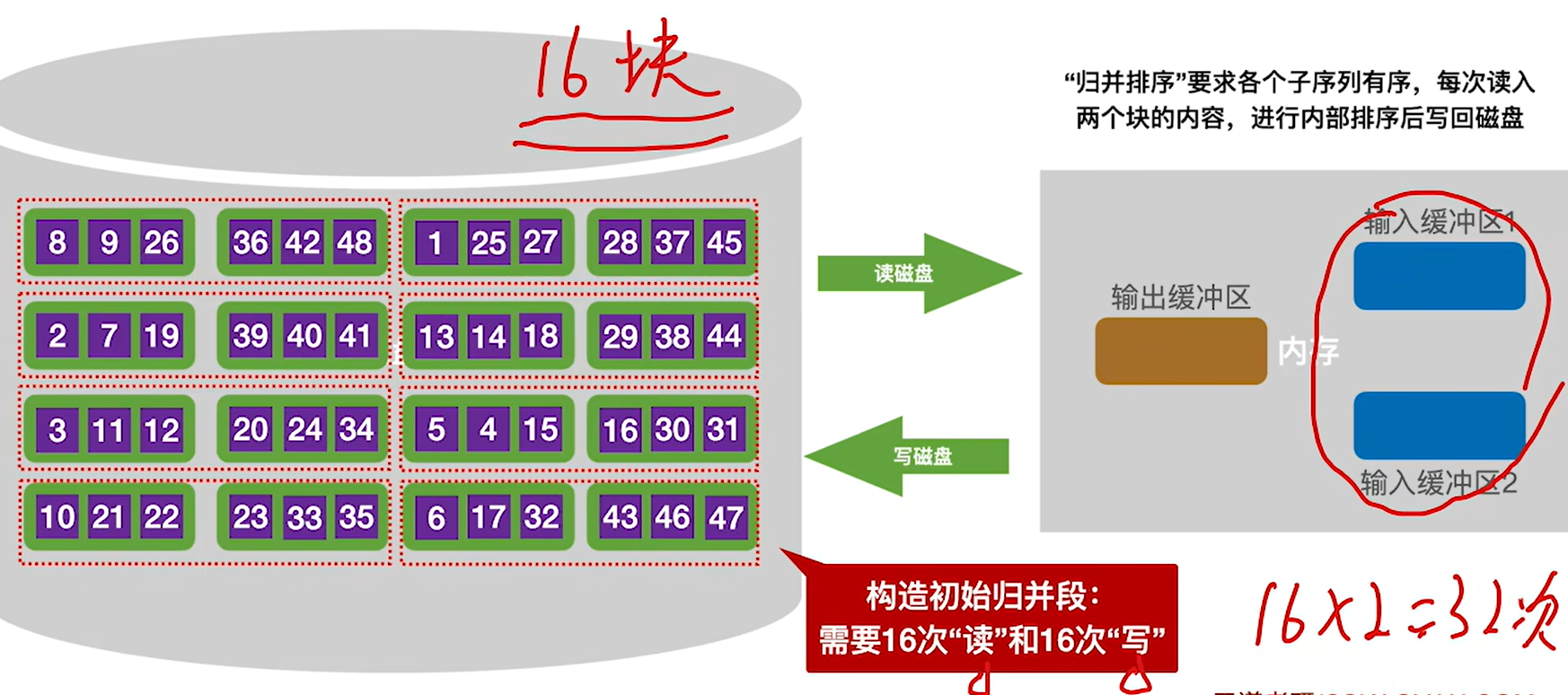
4.重复上述步骤,直到所有的数据块排完序,一共进行了16次读和16次写,一共32次读写磁盘操作
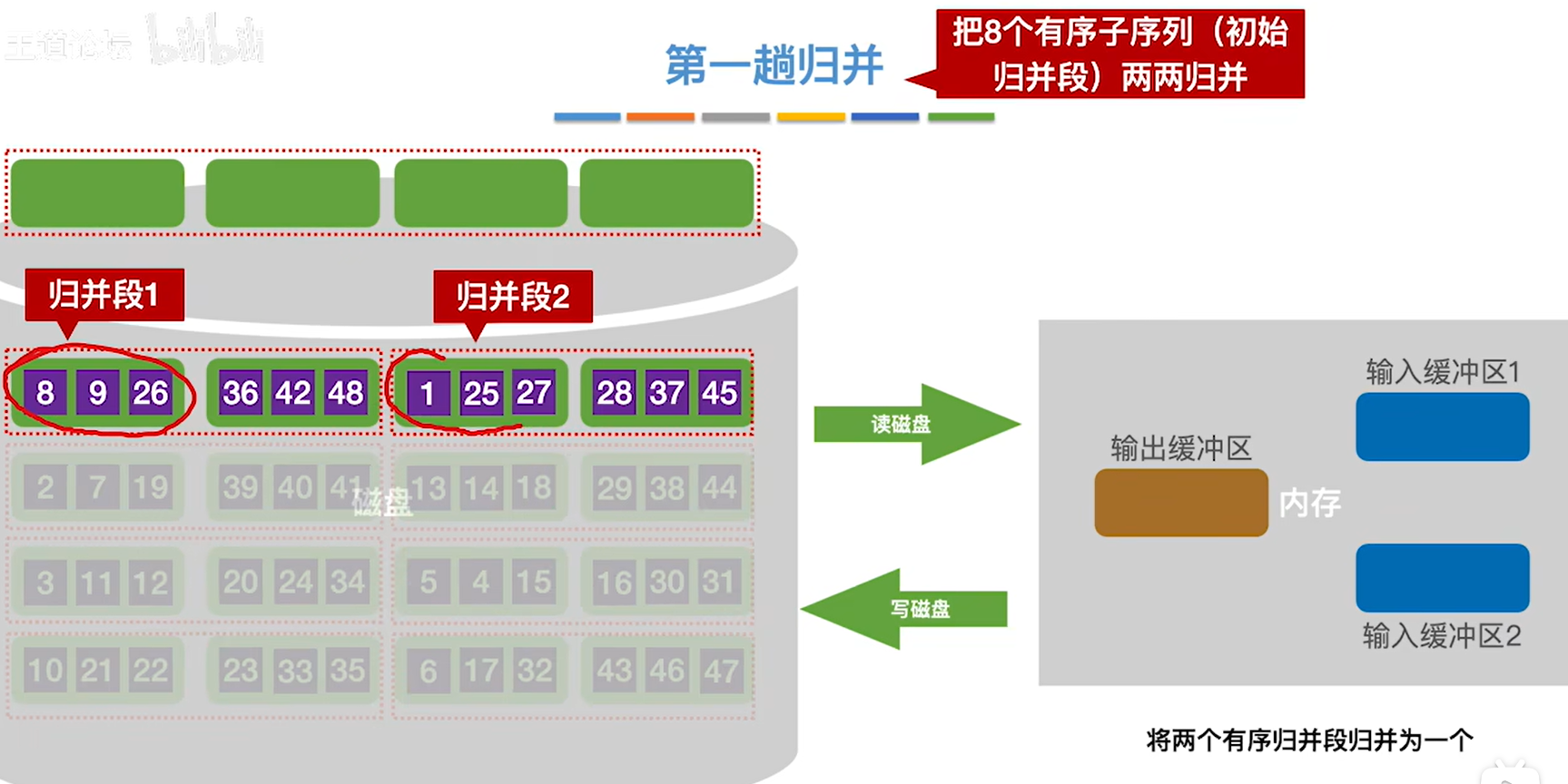
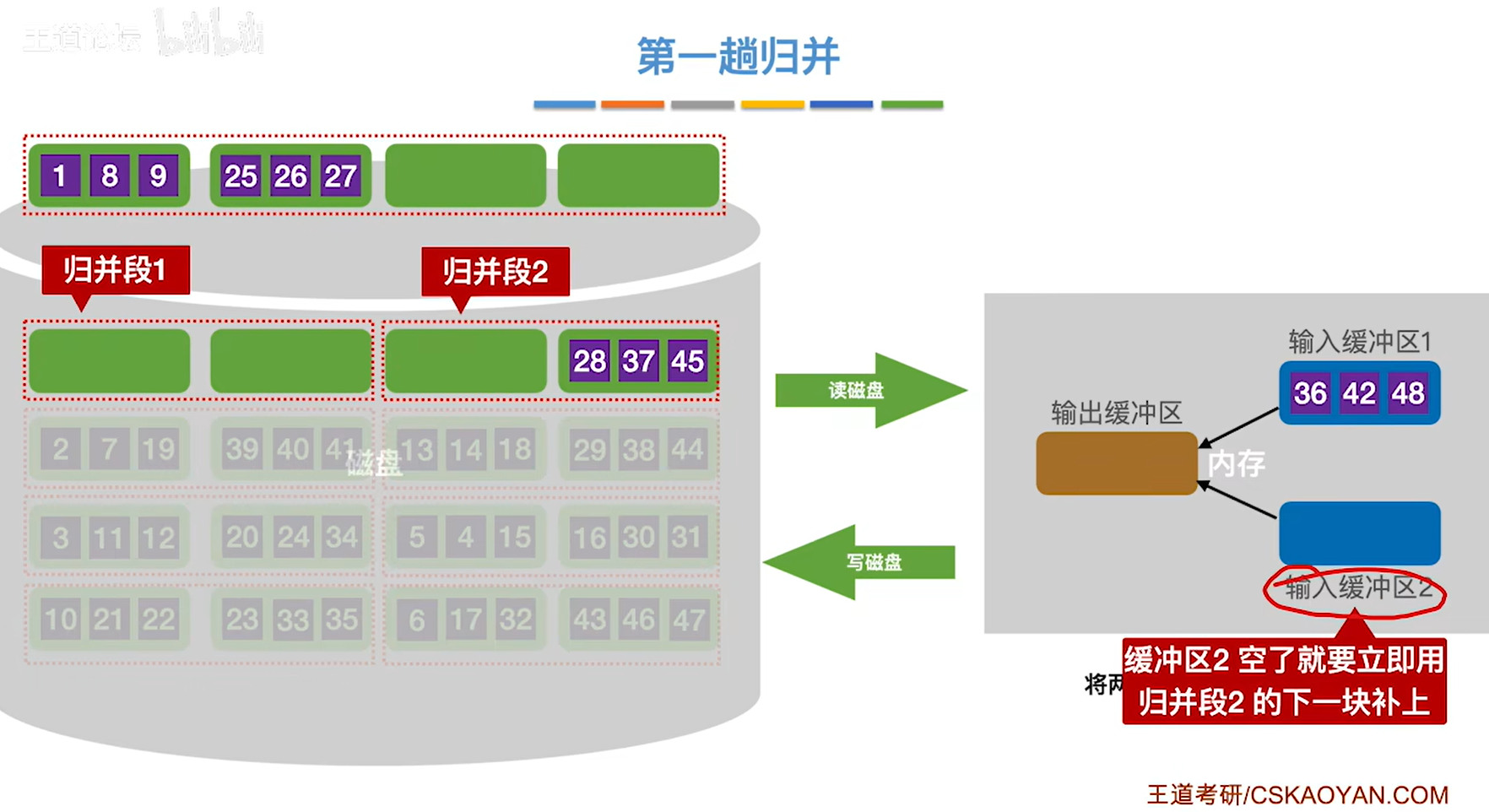
5.挑选两个归并段中小的那个数据块放到两个输入缓冲区
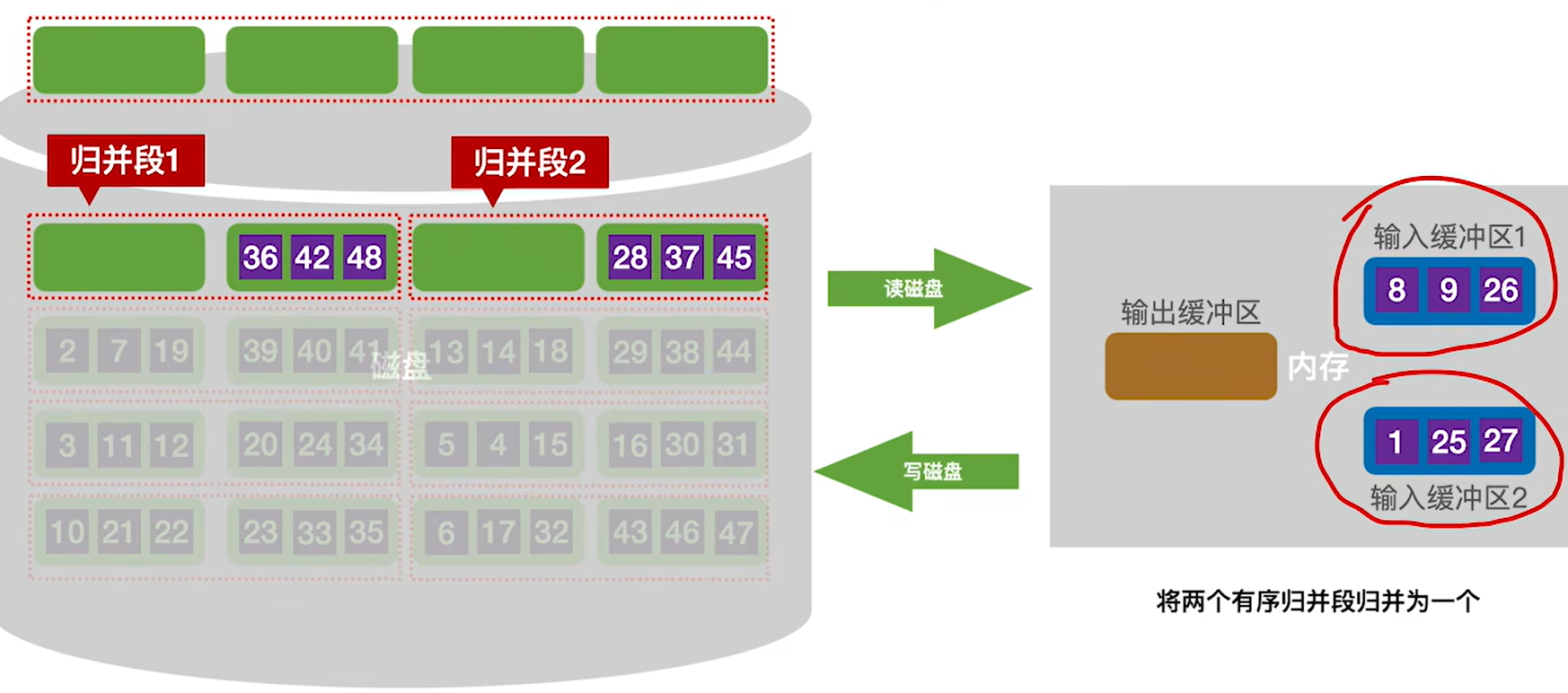
6.然后和归并排序一样,挑选两个输入缓冲区里面小的放入输出缓冲区
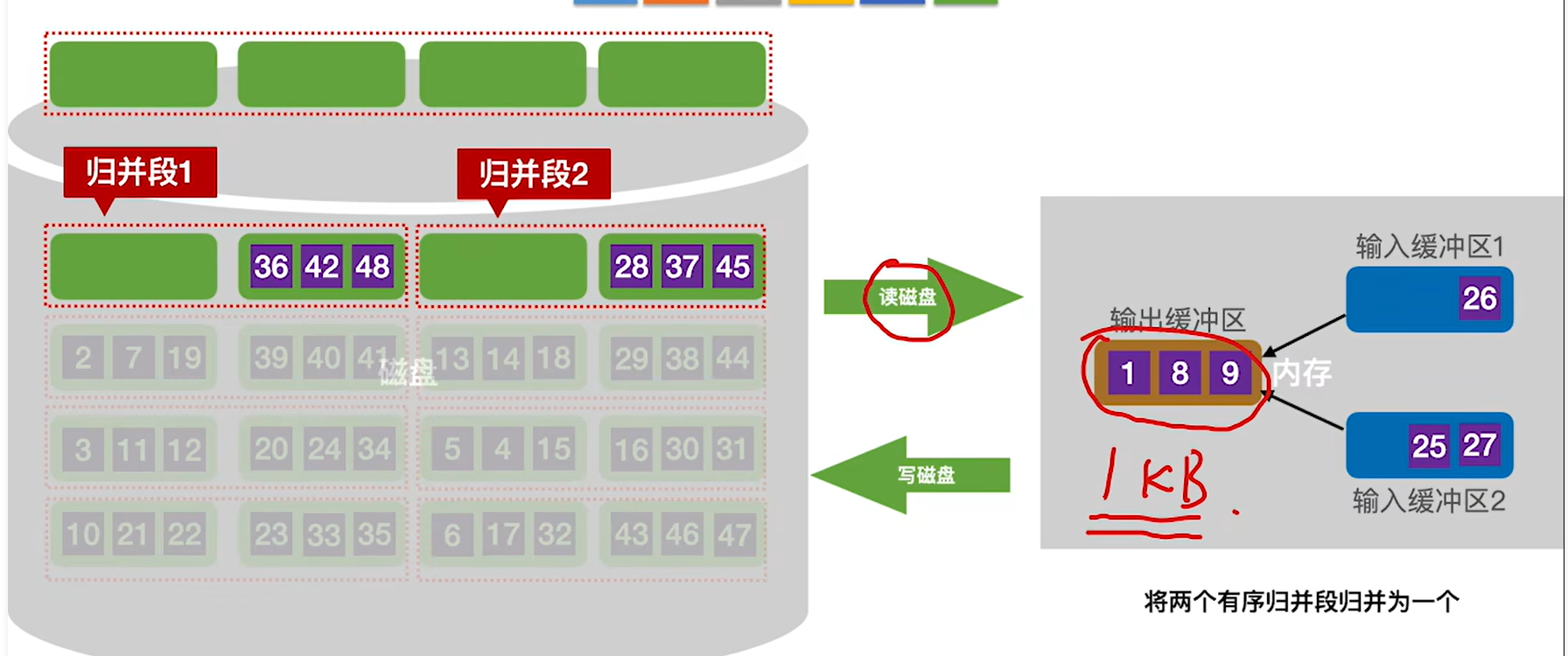
7.输出缓冲区满了就写回磁盘
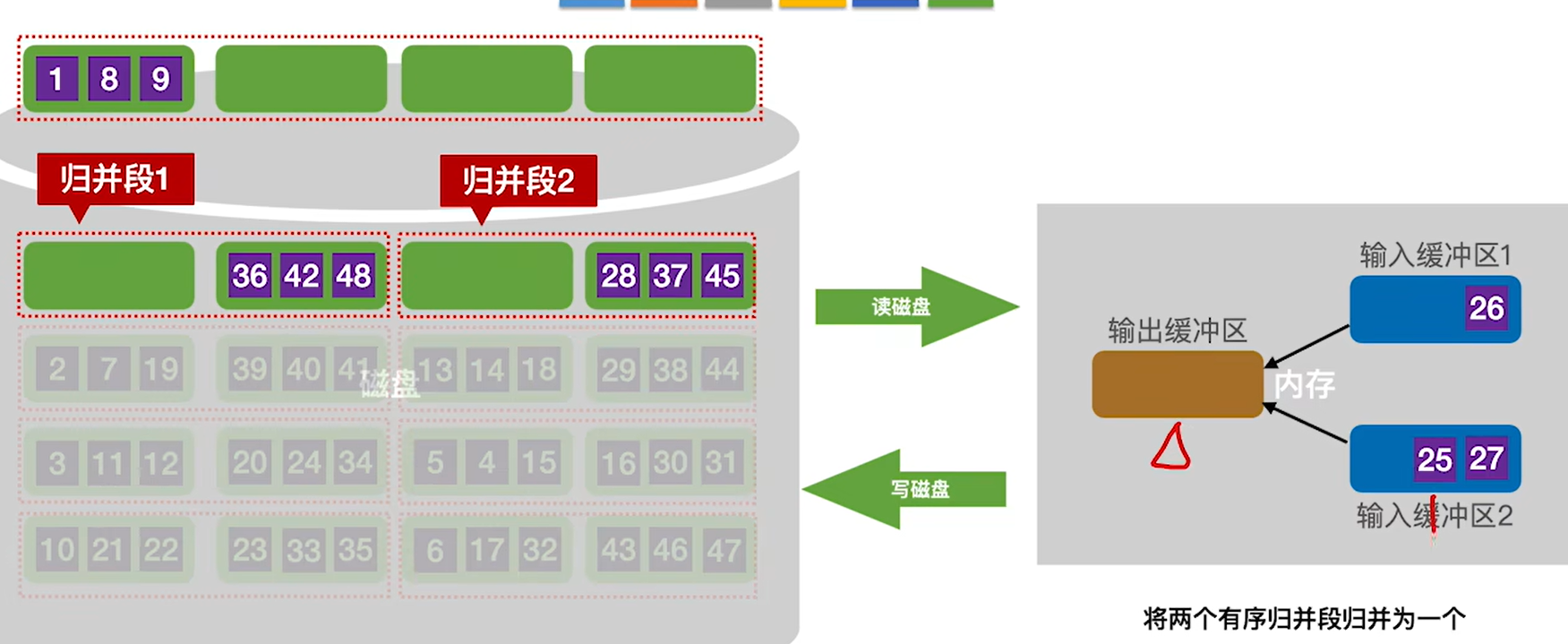
8.继续给输出缓冲区输入25,26,此时缓冲区1空了,立刻用归并段1的给补上,这样才能保证接下来输入给输出缓冲区的数据是最小的
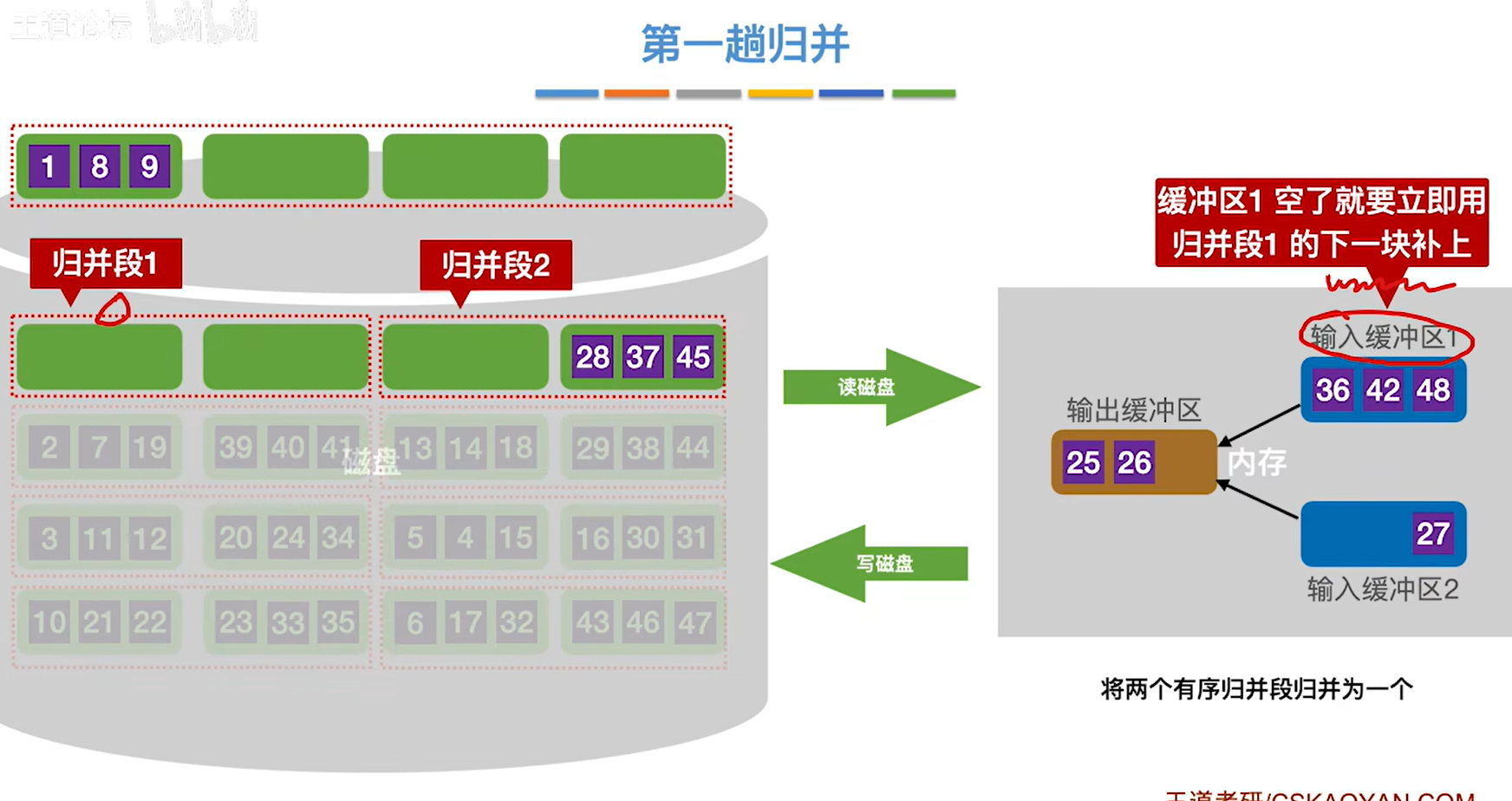
8.满了就写回磁盘,空了就补上
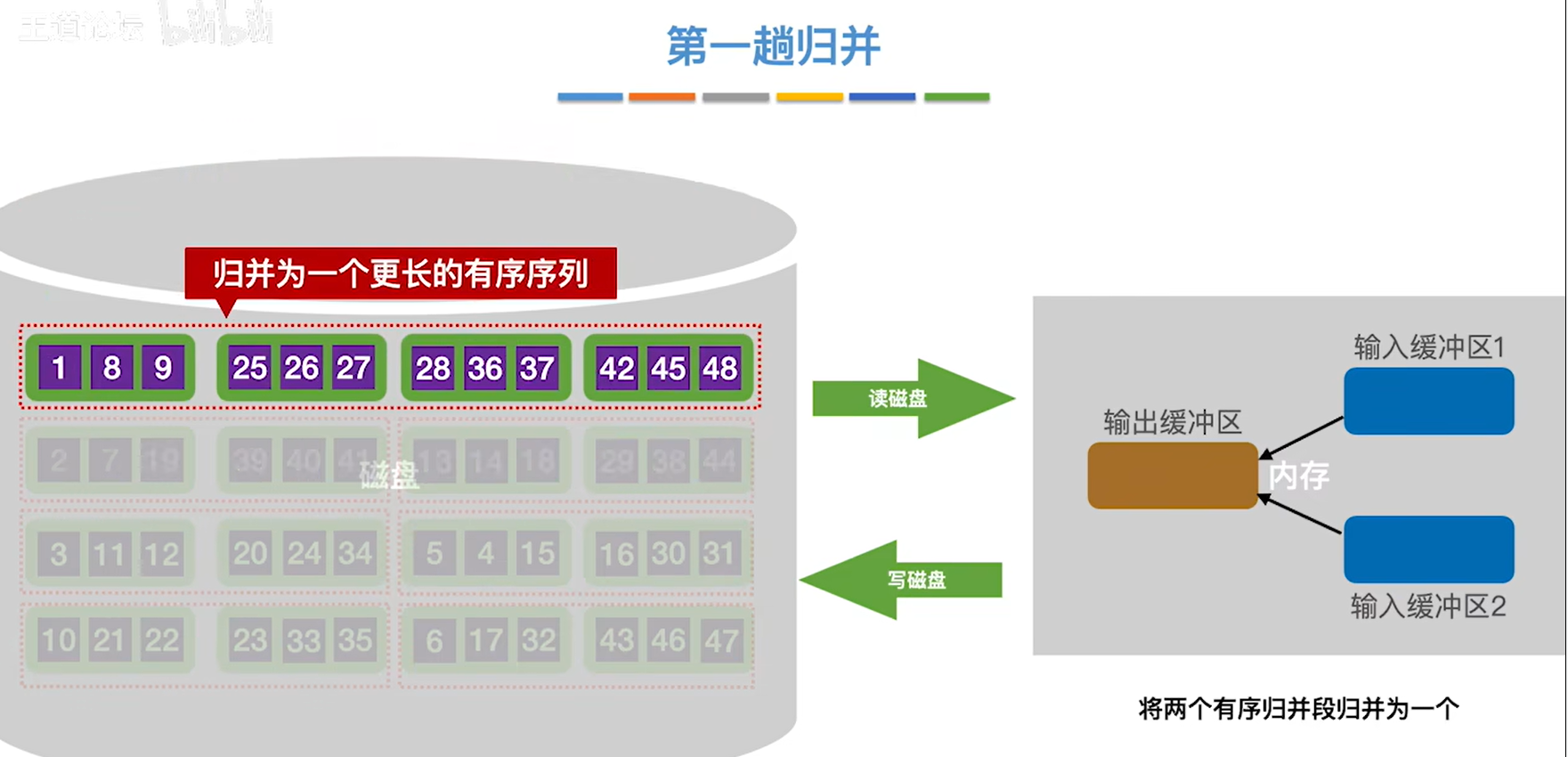
9.到此为止组成一个更大的有序序列
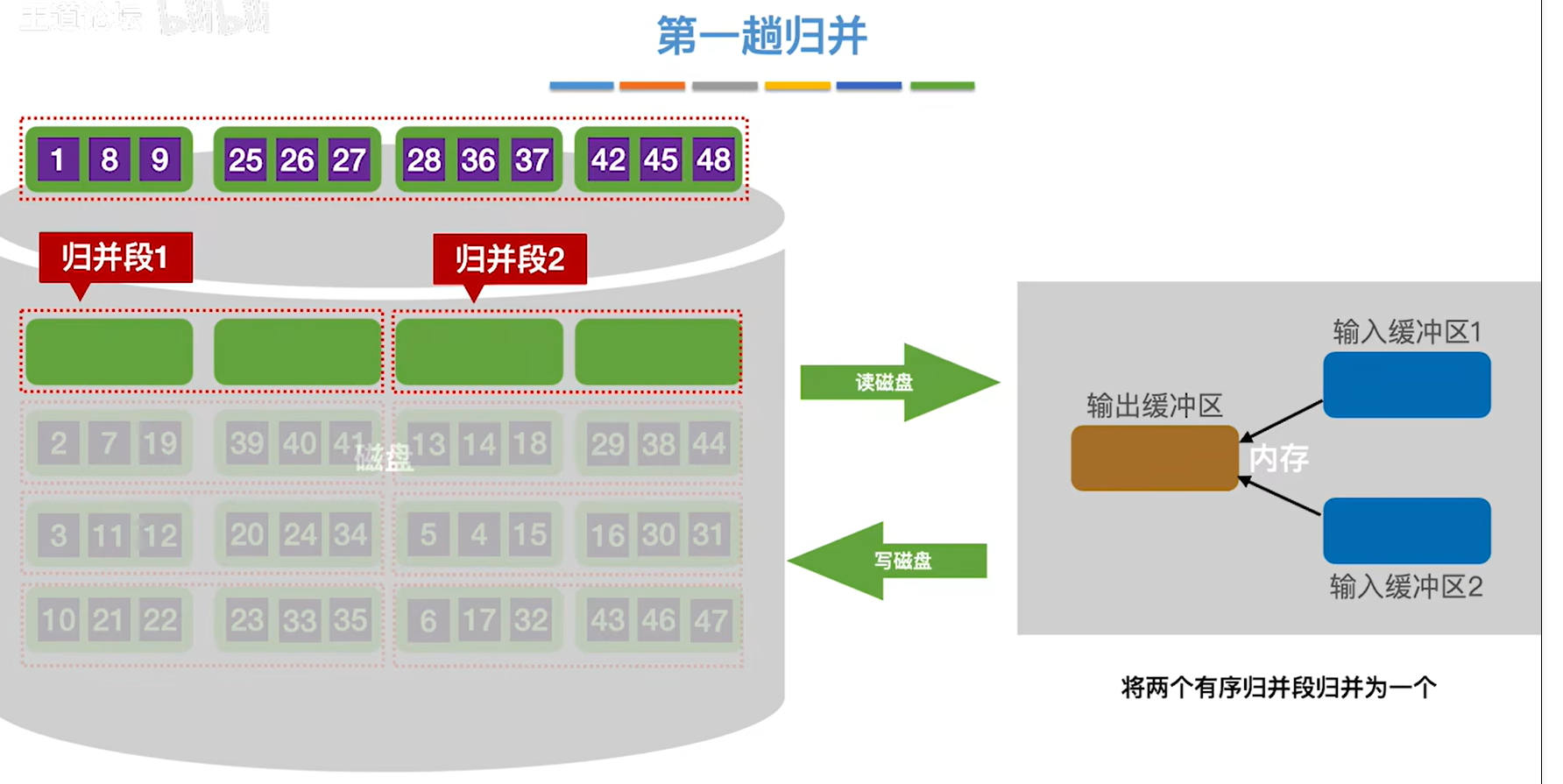
10.对其他的数据块做相同的处理
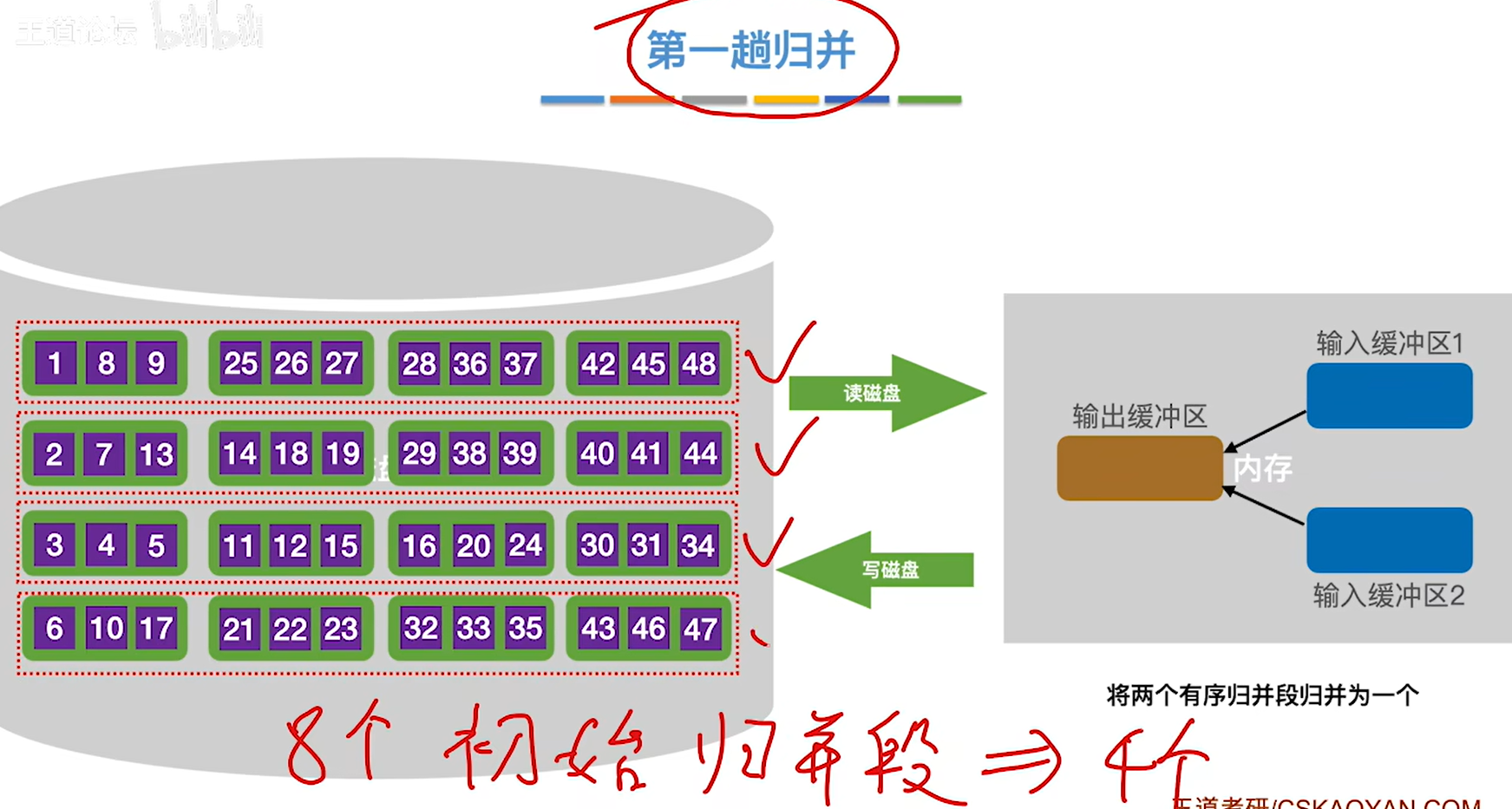
11.进行第二趟归并
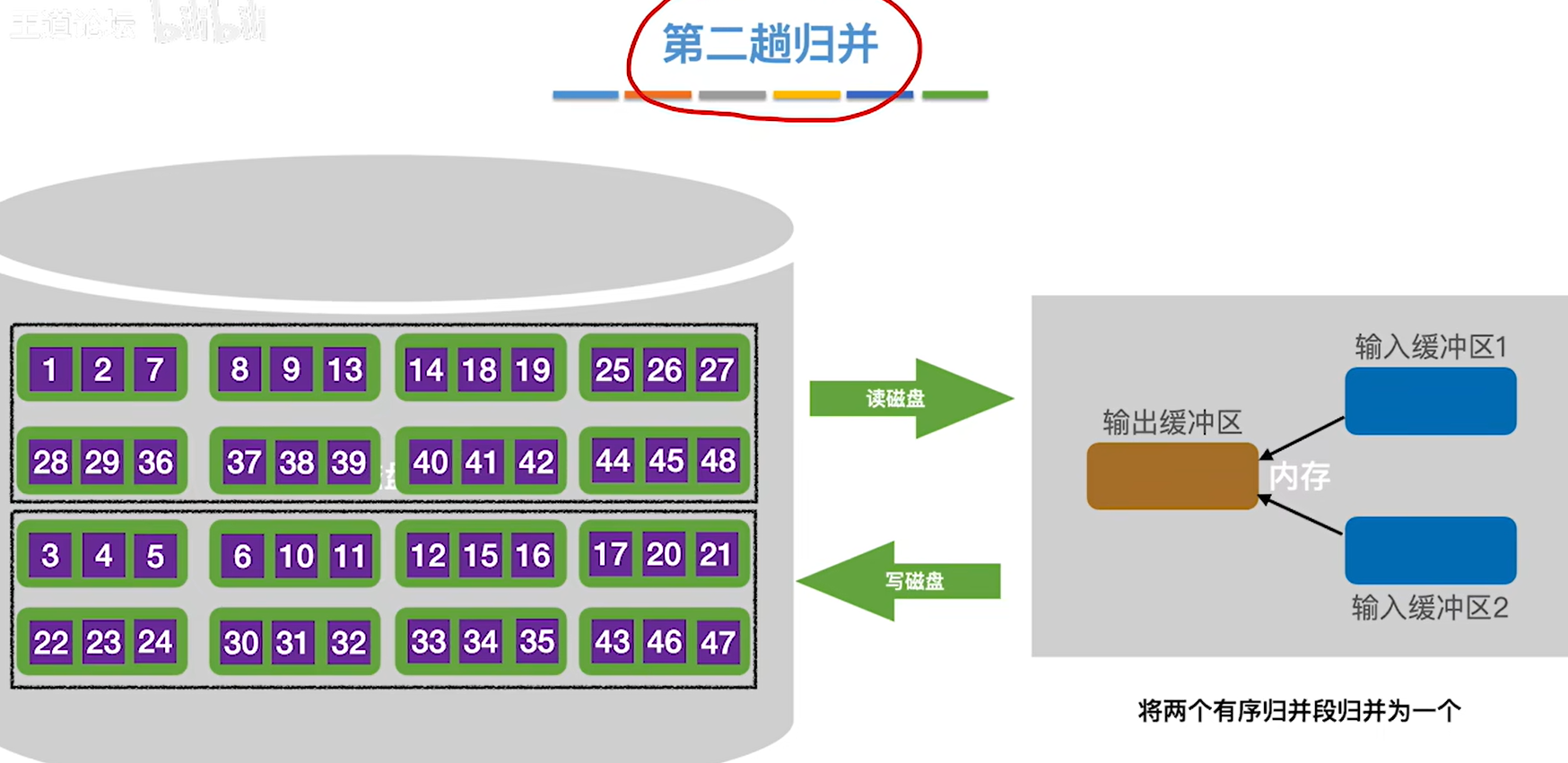
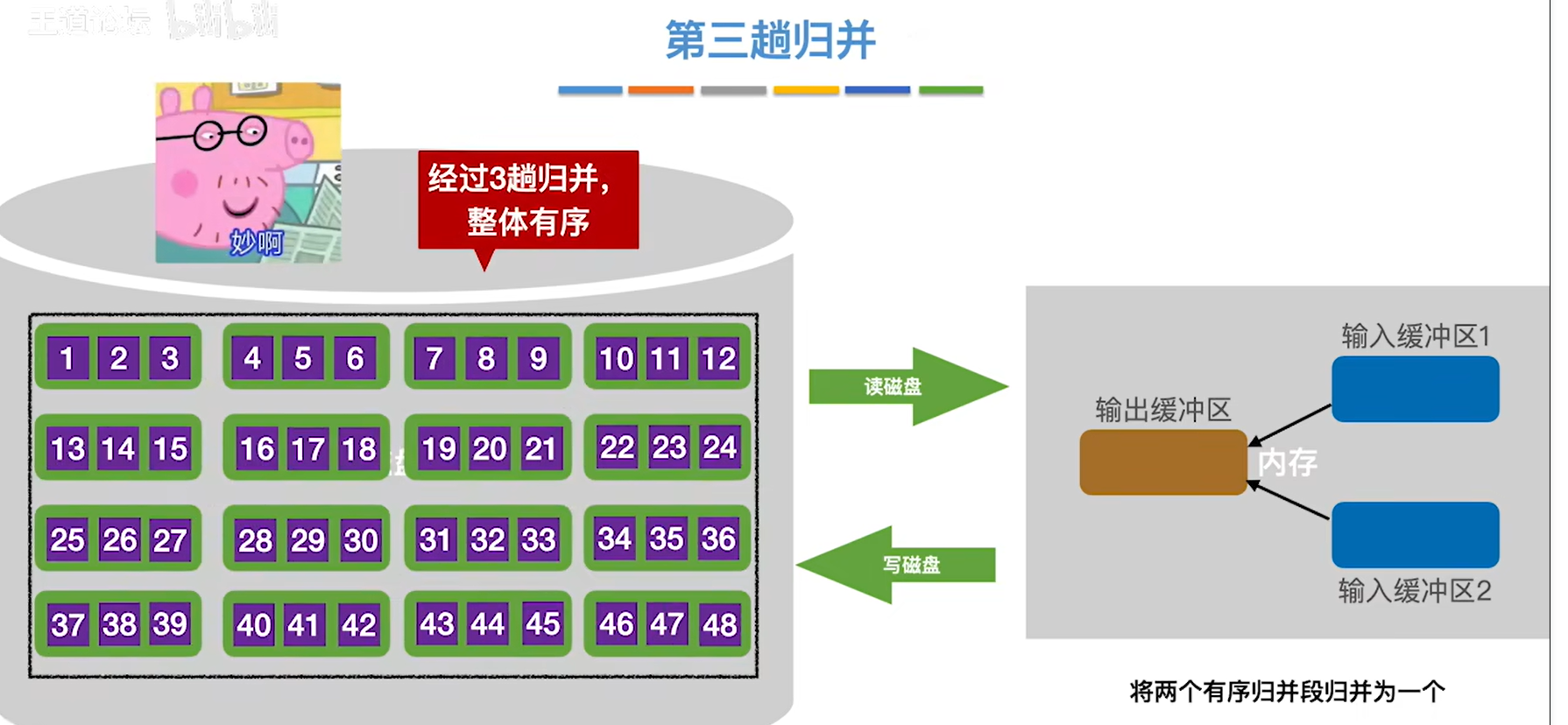
12.第三次归并,结束后整个文件就有序了
时间开销分析
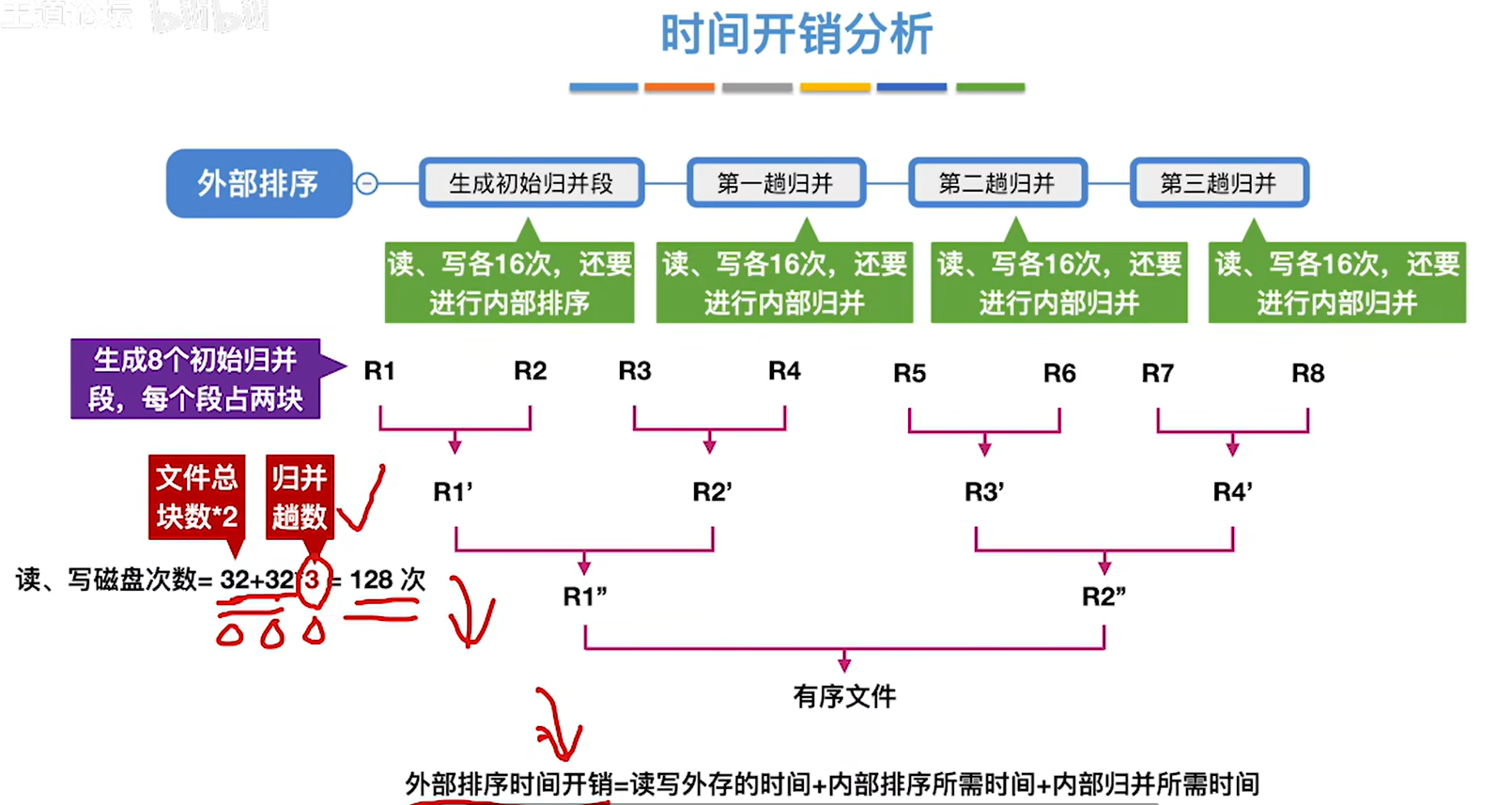
外部排序时间开销 = 读写外存的时间 + 内部排序所需时间+内部归并所需时间,其中读写外存时间占大头、
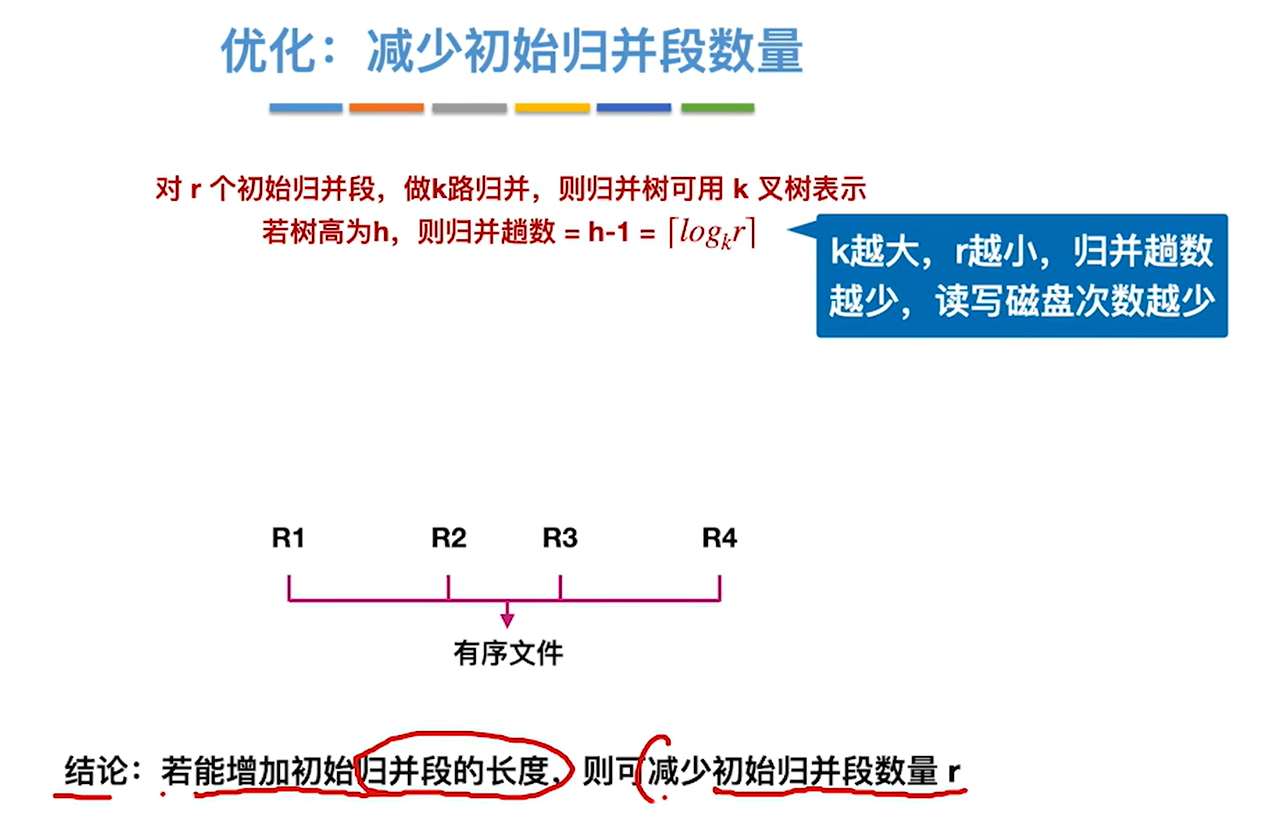
优化方向:优化读写磁盘的次数,尽量减少。这个取决于文件总块数和归并的趟数,文件总块数基本是不可改变的,所以我们主要优化的是归并的趟数
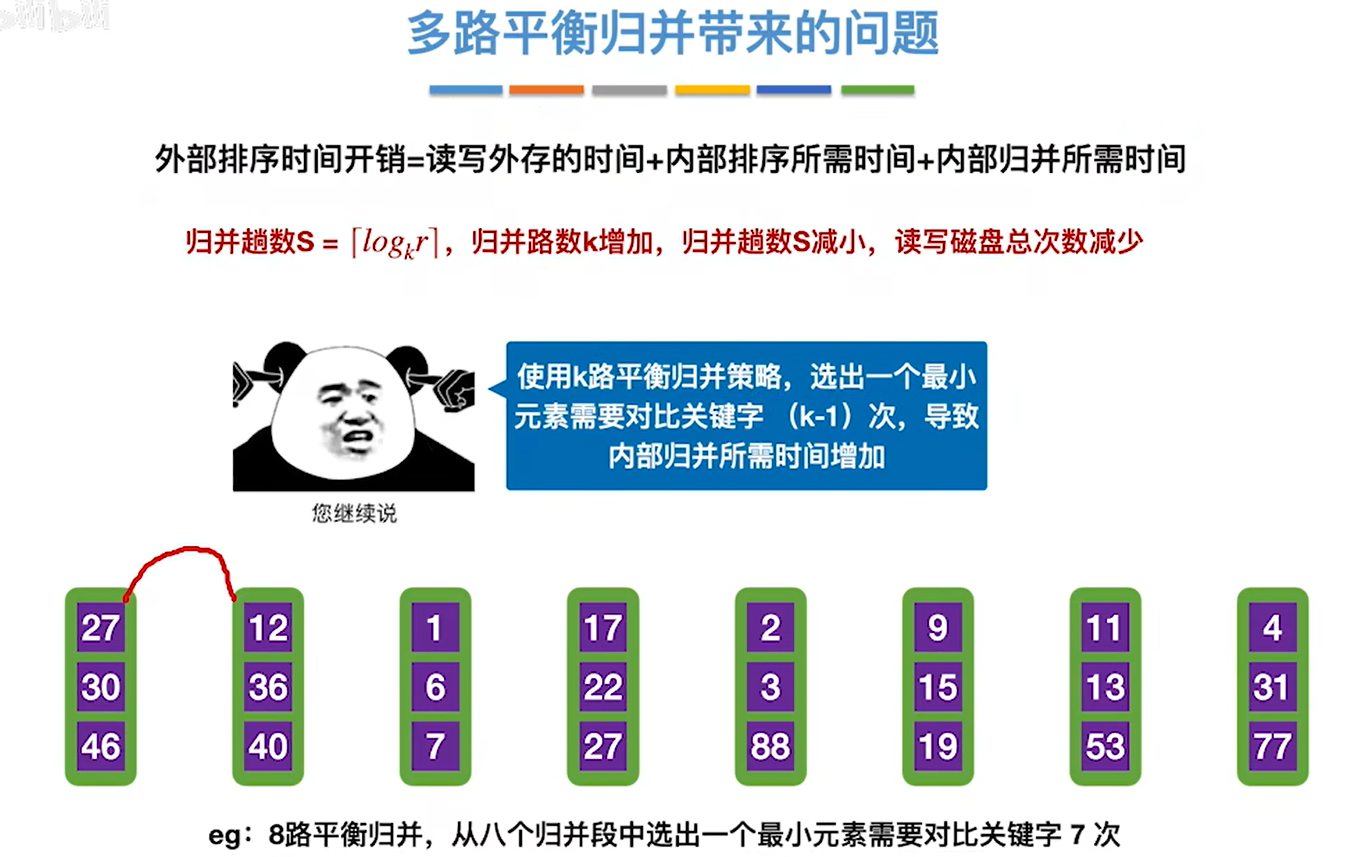
优化1:多路归并
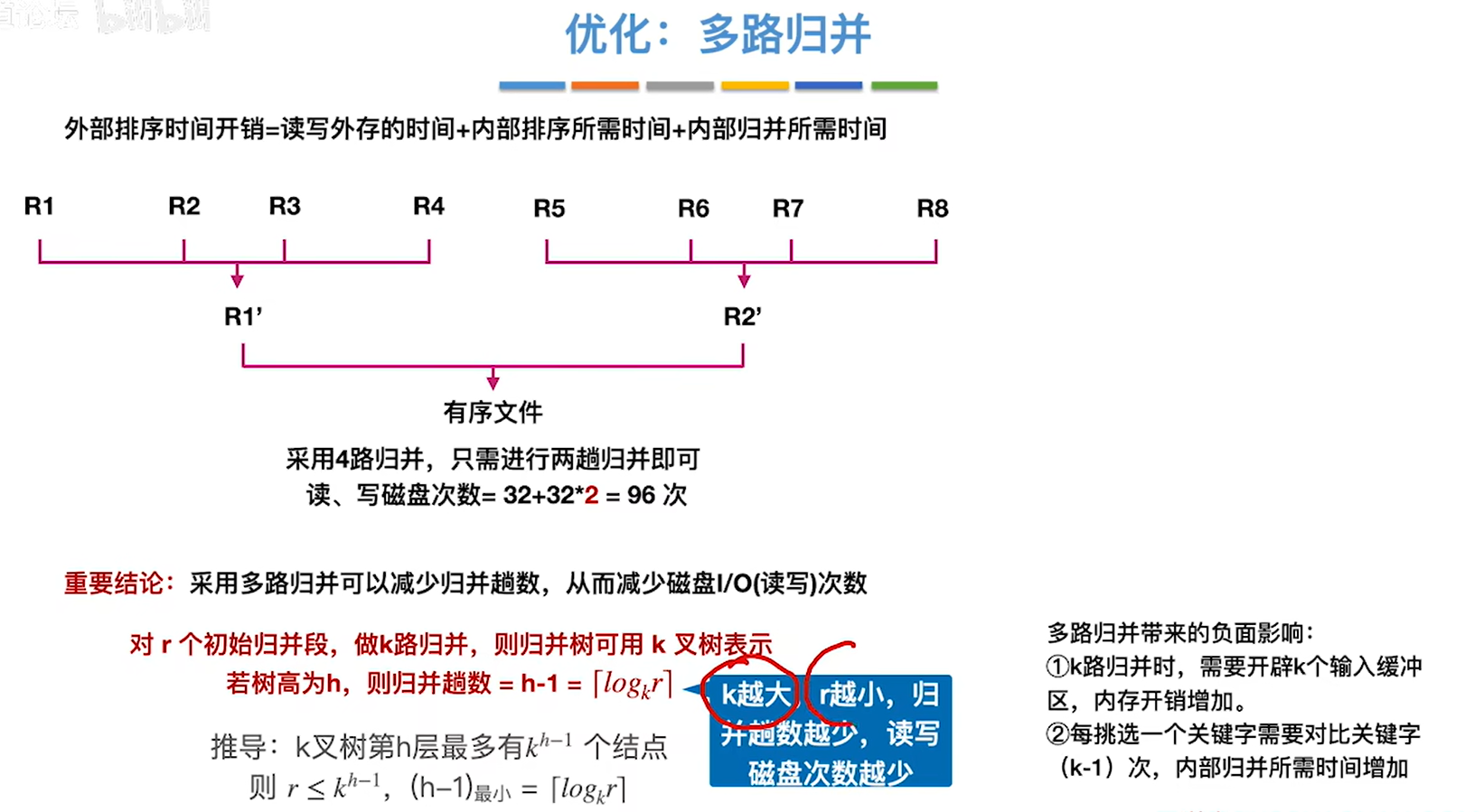
多路归并的路数k并不是越大越好,会带来负面影响
优化2:减少归并段数量
生成的初始归并段越少,那我们需要读写磁盘的次数也就越少
要想生成的初始归并段越少,那生成初识归并段的内存工作区就得大,这样才能生成更长的初始归并段
归并段越长,而文件大小是一定的,所以归并段数量肯定越少
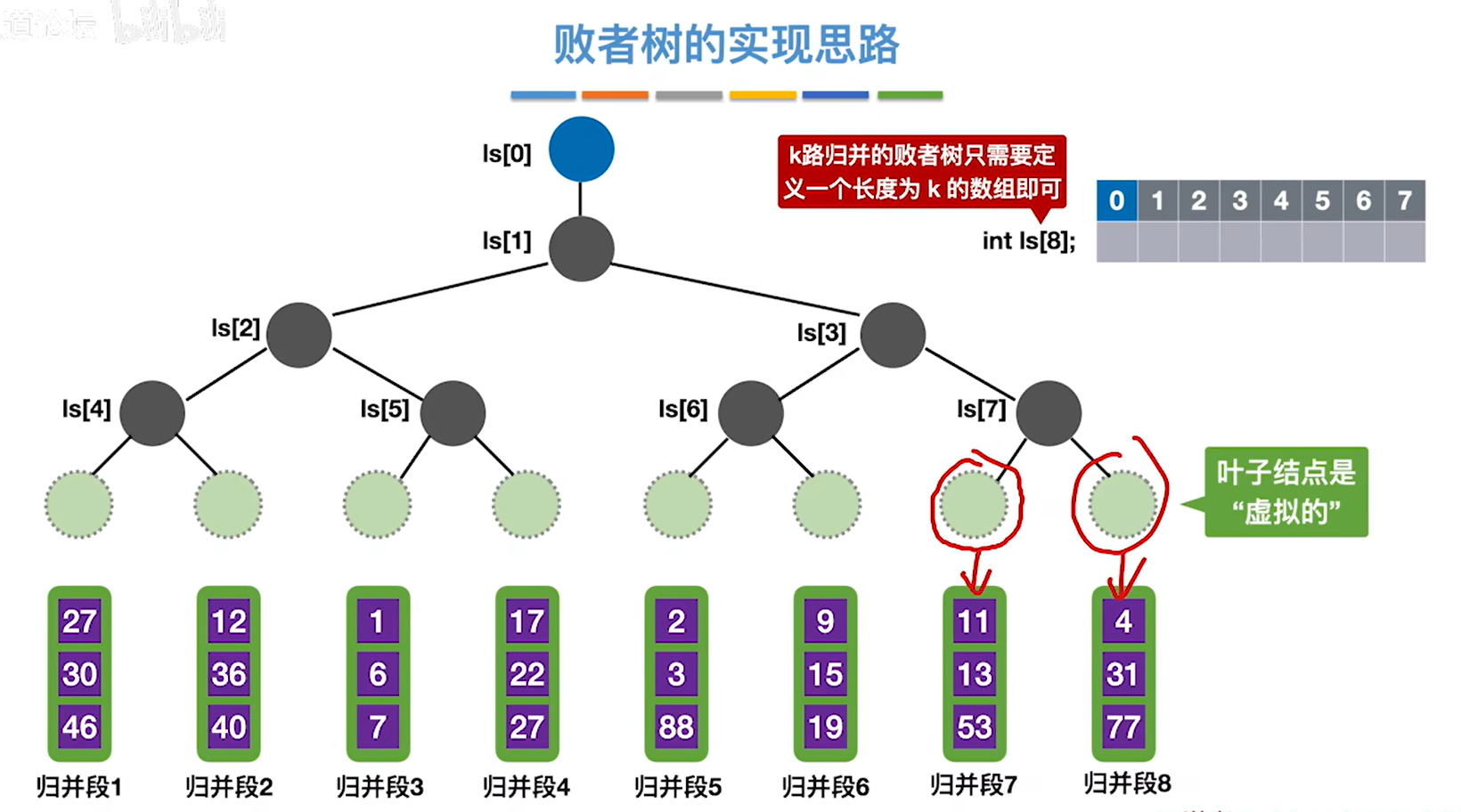
8.7.2 败者树
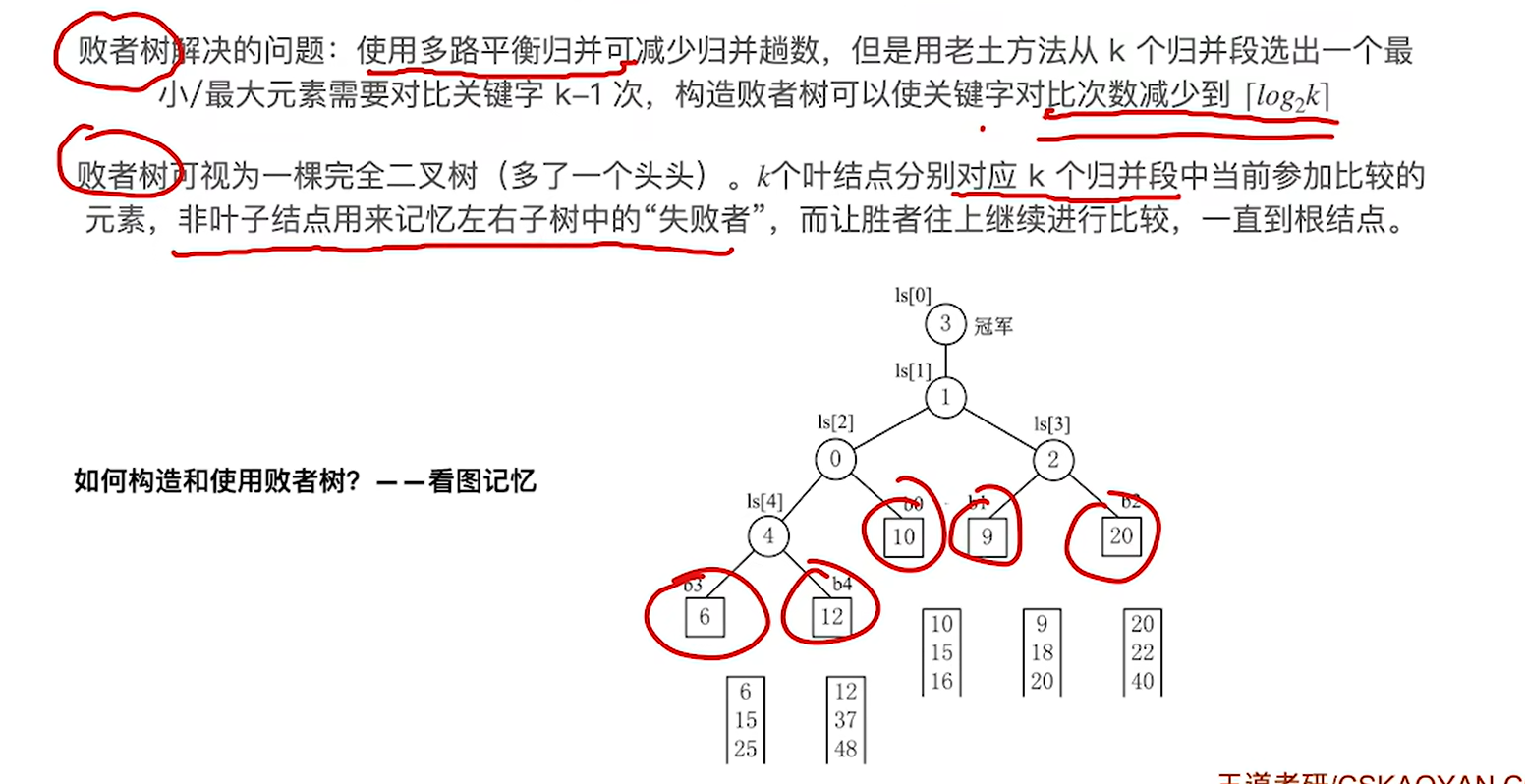
路数更大那么每趟关键字对比的次数会增加导致内部排序的时间增加,而败者树可以优化这个问题
也就是可以让我们从k个关键字中选出最小关键字的时间变短
1.叶子结点分别对应归并段,两个结点比大小,小的可以继续往上走
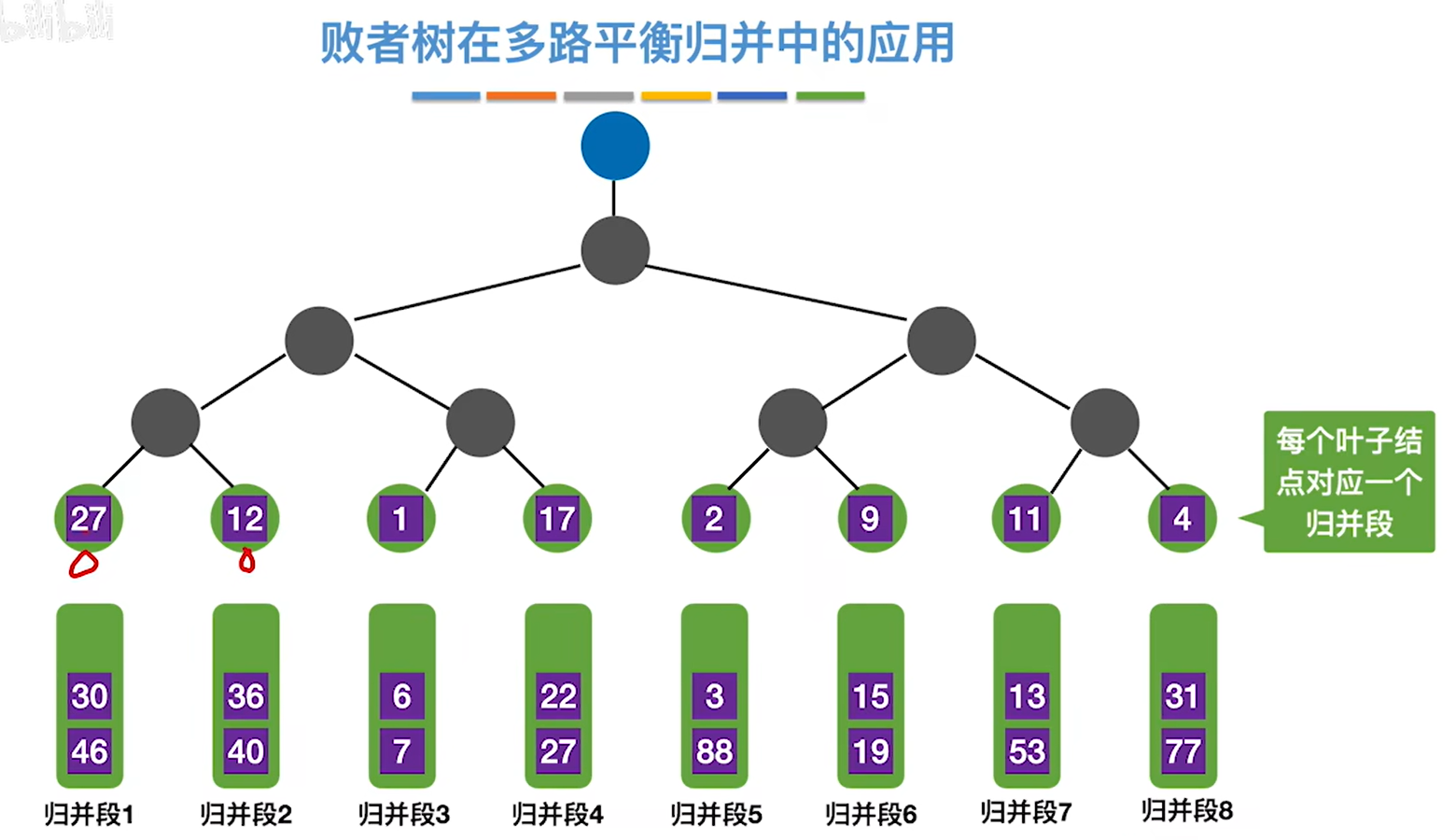
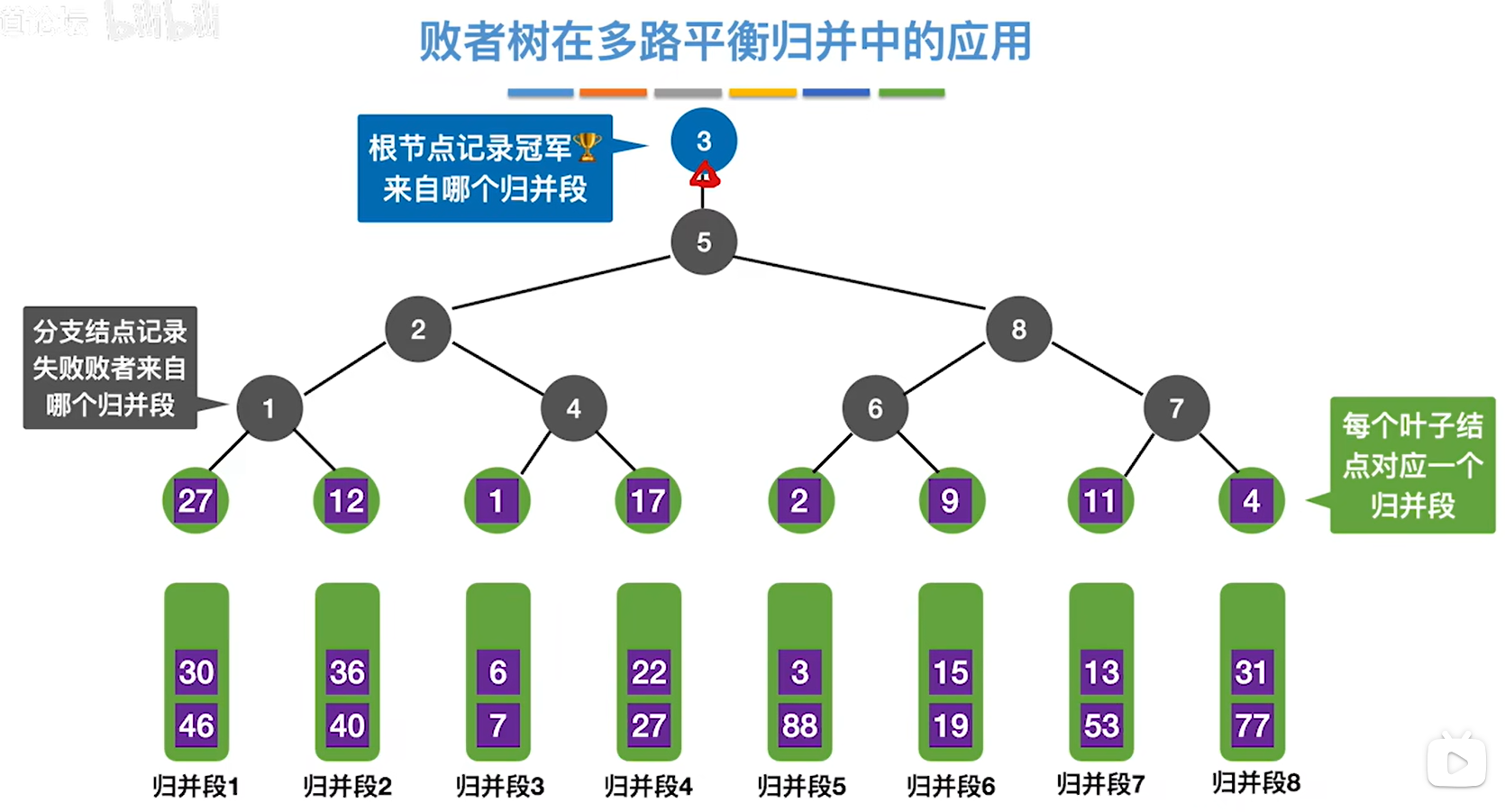
2.但是非叶结点记录的是获胜的节点来自哪个归并段,而不是具体的节点值,这个结果说明了,归并段3的元素最小,那就把第三个叶子节点的1输出出去
这是我们第一次构建败者树,需要k-1次也就是7次关键字对比
3.接下来把1输出后,把归并段3的下一个元素6放在1原来的位置,然后再次进行关键字对比,这时我们发现只需要对比3次就知道下一个输出的元素该是谁了,对比次数就和除了最上面的蓝色节点的树的高度是一样的,其实就是log以二为底k上取整。然后重复这个过程就是了
代码实现思路
节点其实就和完全二叉树对应(不包含蓝色的,也就is[0]),叶子节点是虚拟的,是脑补的,每个叶子节点就是i和i+1的归并段的大小比较,小的那个是第几个归并段,is[i]就是几
8.7.3 置换-选择排序(生成初始归并段)
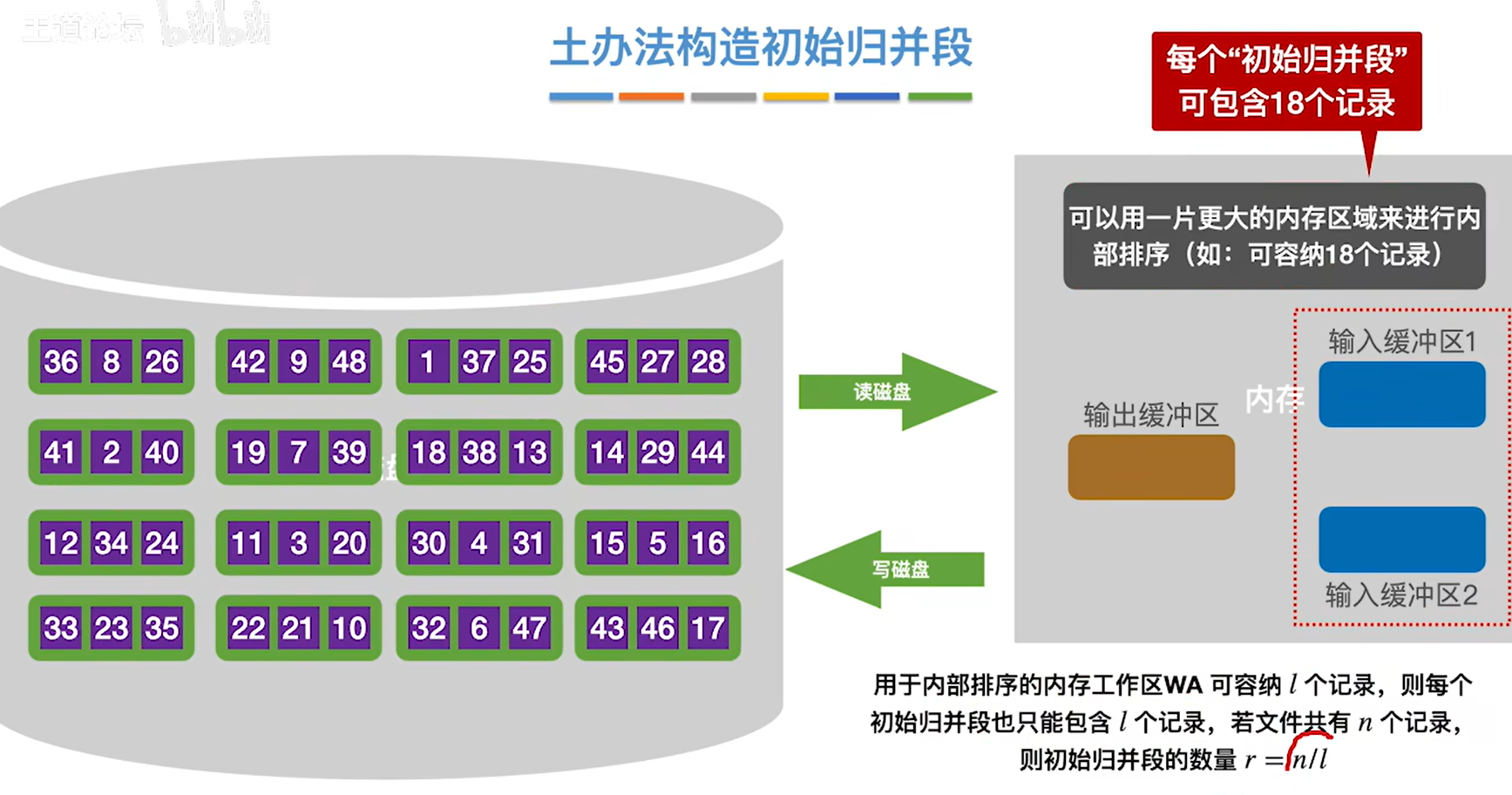
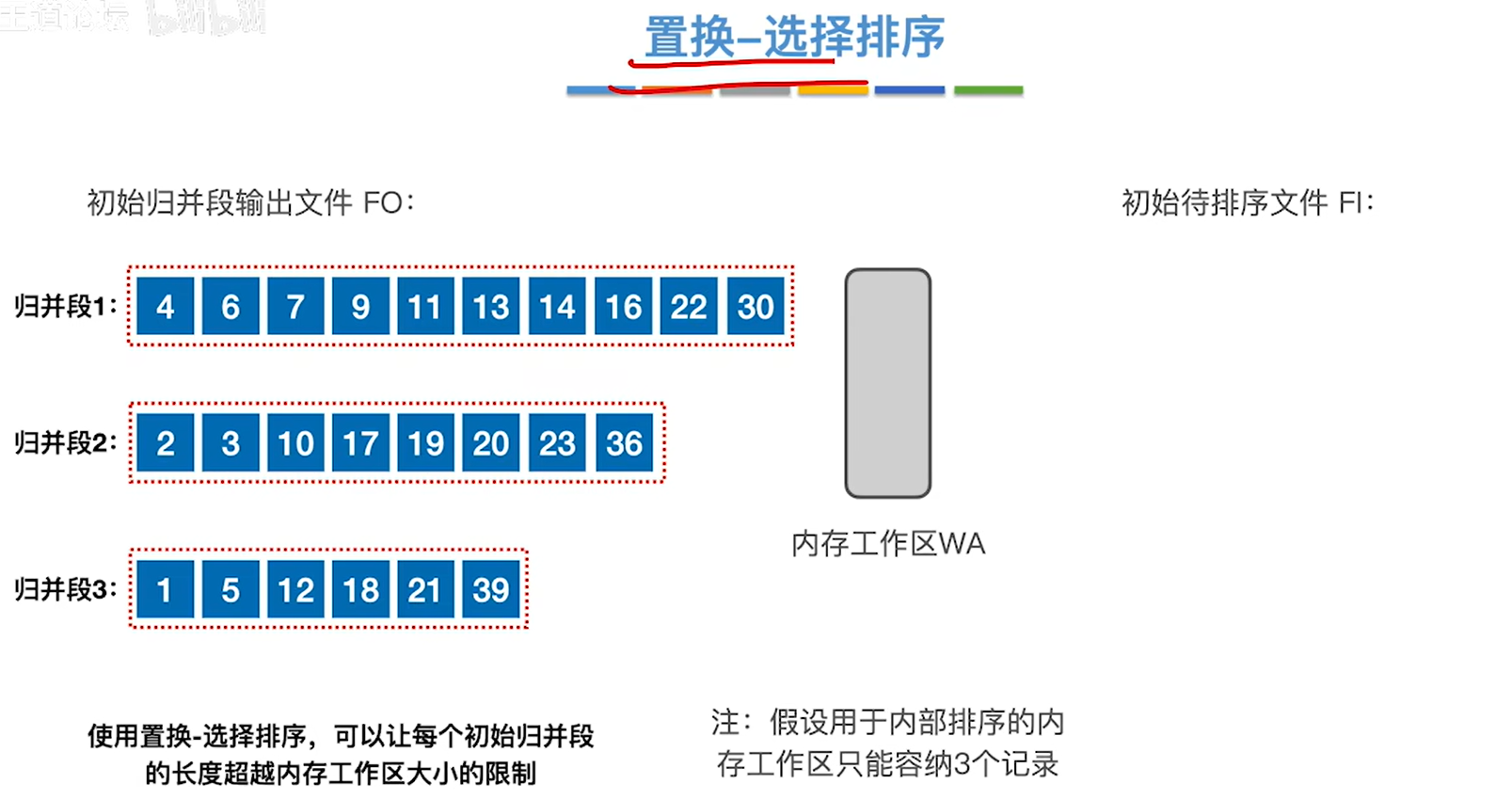
置换-选择排序:产生更长的初始归并段,从而减少初始归并段数量。
之前外部排序的办法构造的初始归并段长度由内存工作区的大小决定的
而如何构造更大的初始归并段,是由置换选择排序来解决的

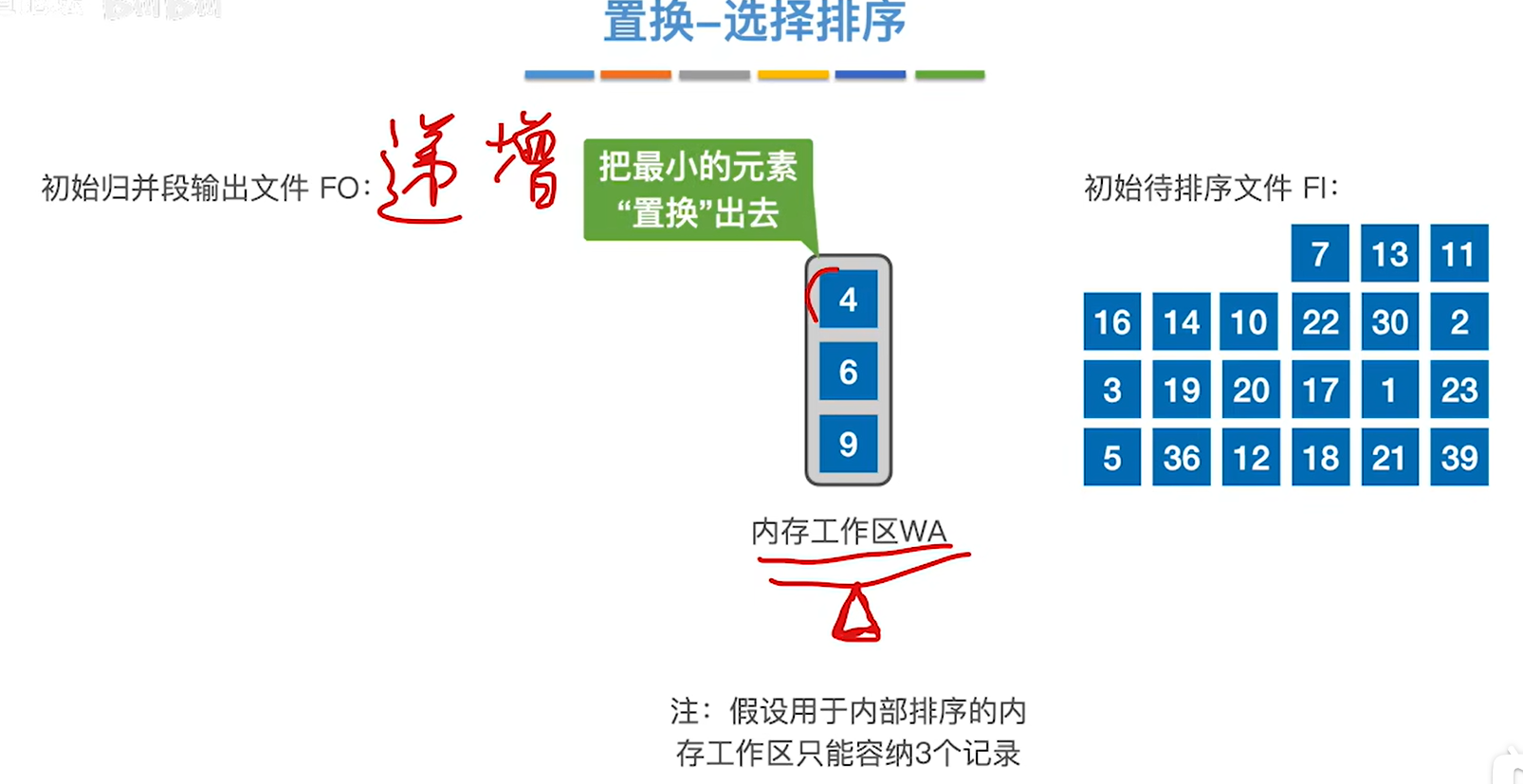
例子:
1.先把开头三个元素放到内存工作区,先后把最小的元素4放到输出文件FO,其实是都放到输出缓冲区,等到输出缓冲区满了一次性写出去。然后把下一个元素7给放进来,然后输出最小的6.重复这样的过程
2.然后到10的时候发现,归并段末尾的元素是13,但是10小于13,所以10就被标红,不被放到归并段1
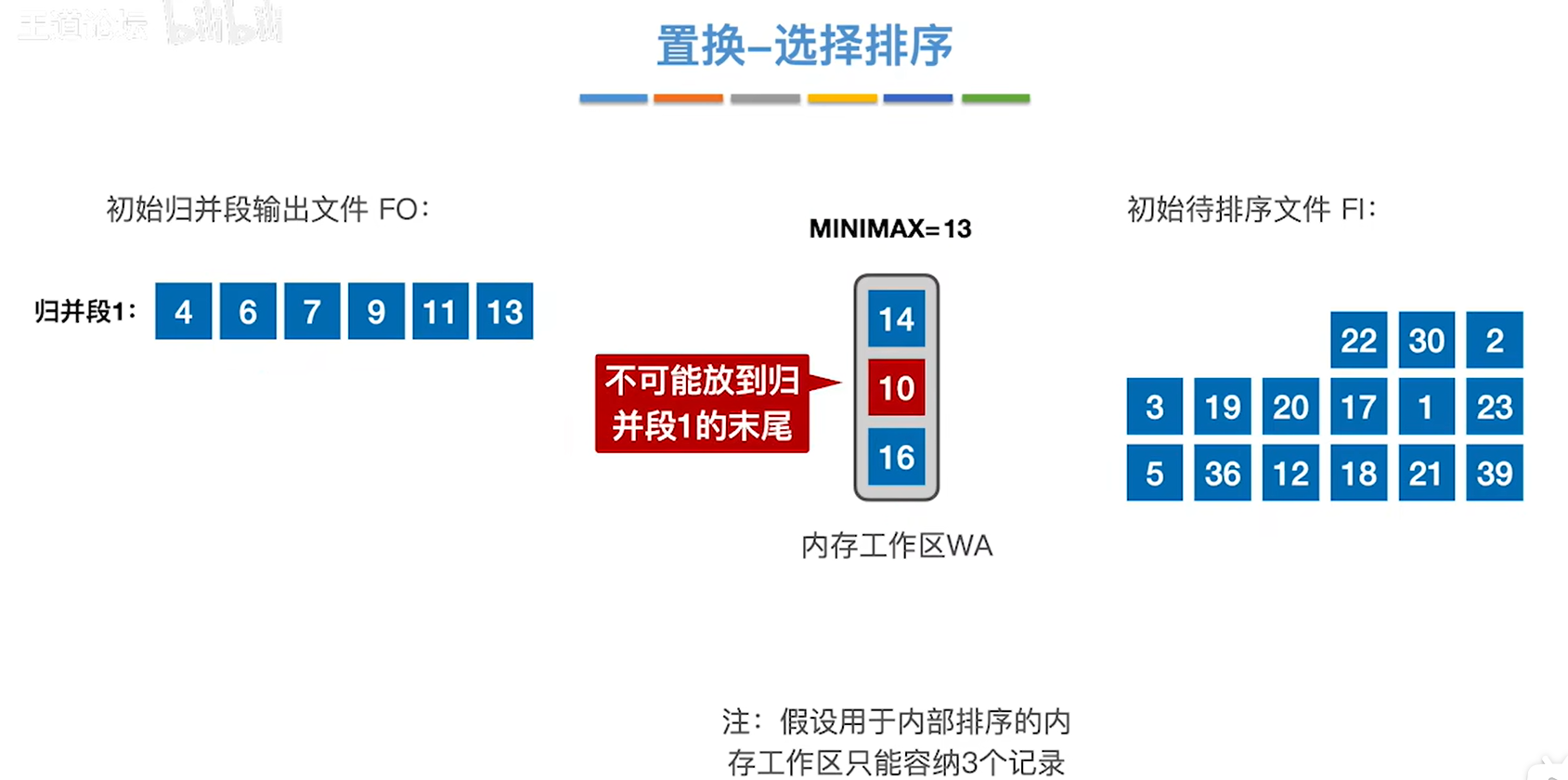
3.当内存工作区的元素都不可以加入归并段的时候,那么这个归并段就在这个地方停止,开始构建下一个归并段
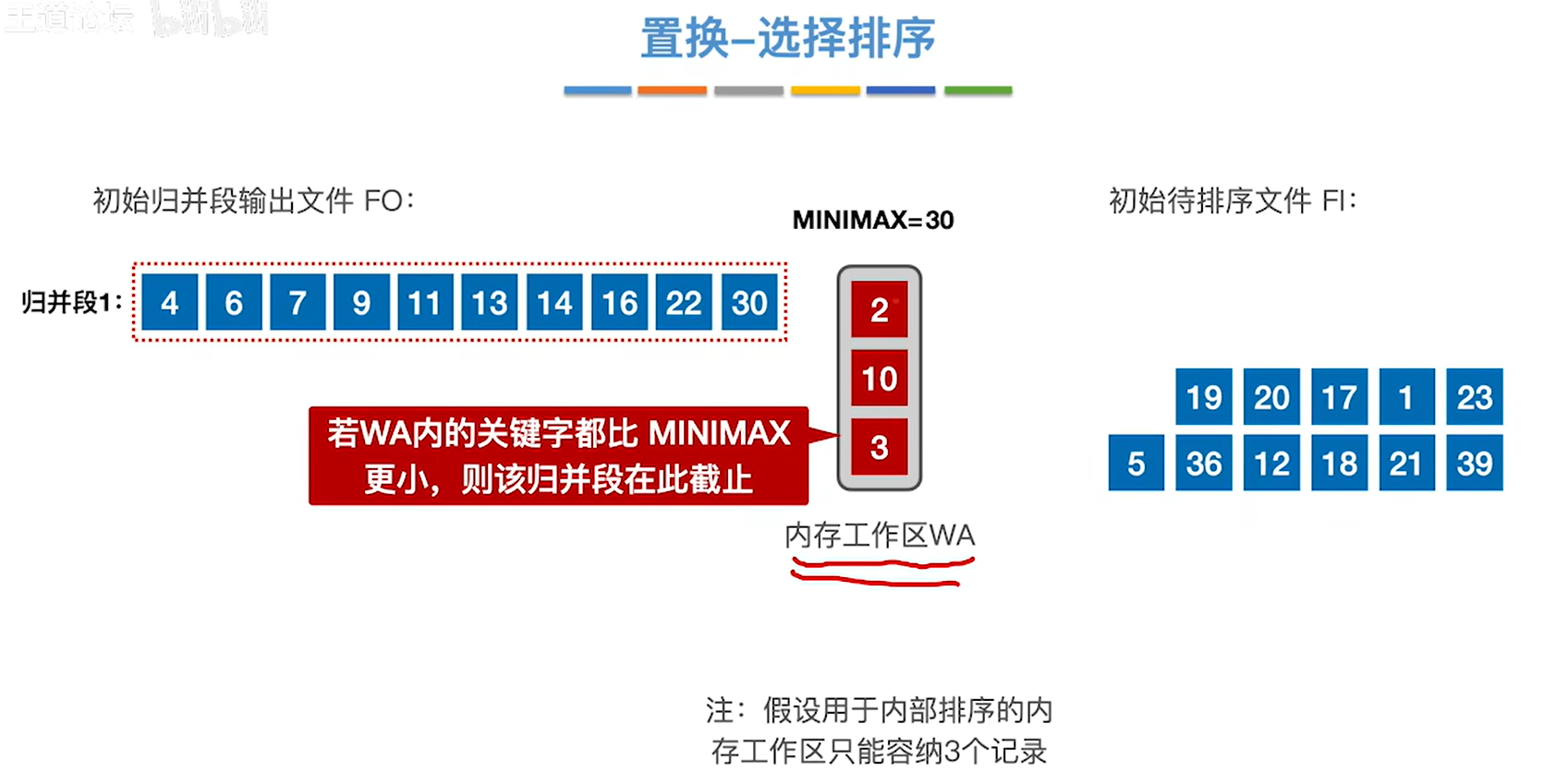
4.重复一样的步骤直到待排序文件的元素都加入内存工作区之后,就把内容工作区的元素按照大小放到最后一个归并段
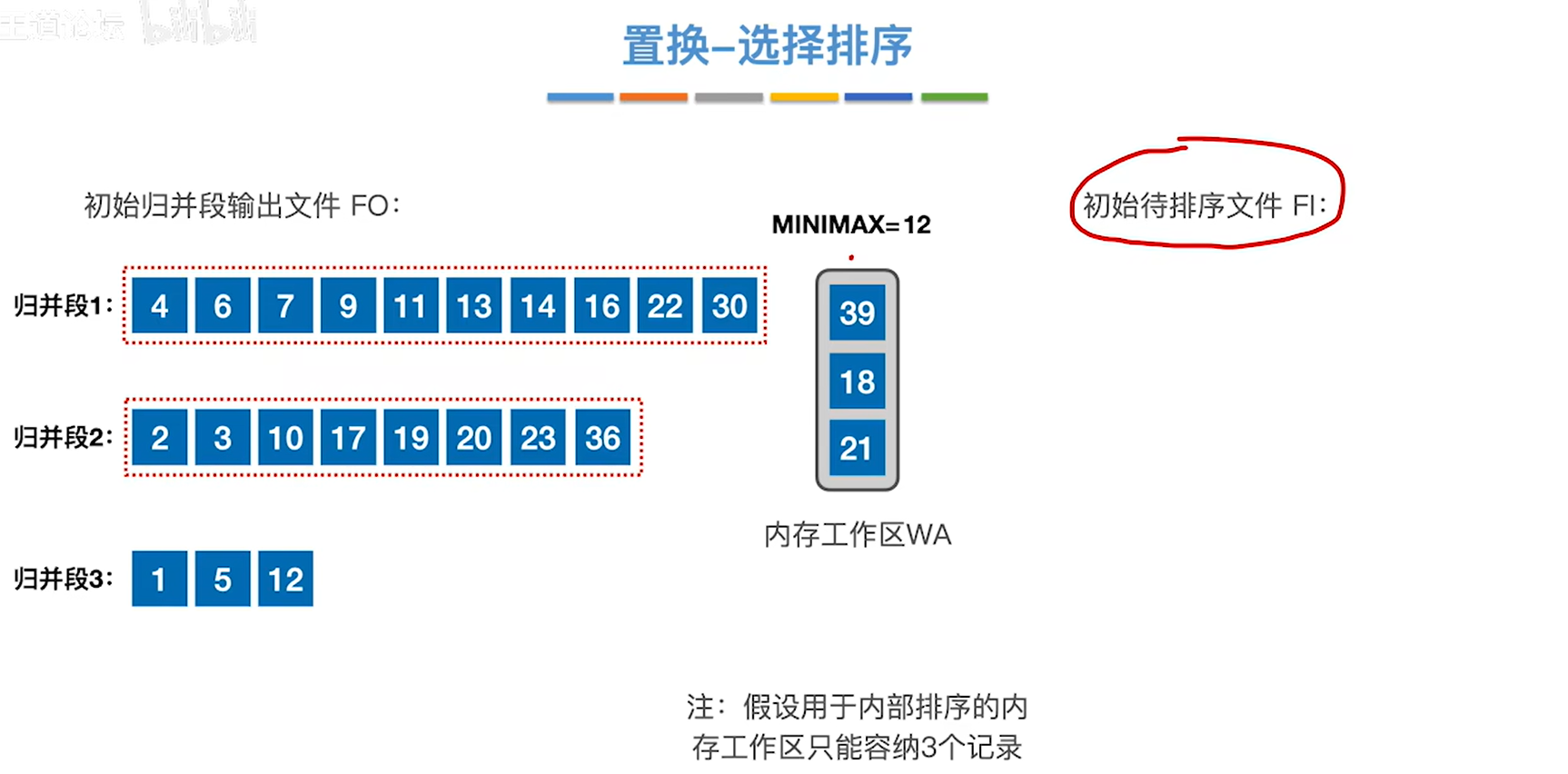
5.通过这种方法就让初始归并段长度可以超过内存工作区大小的限制了
8.7.4 最佳归并树
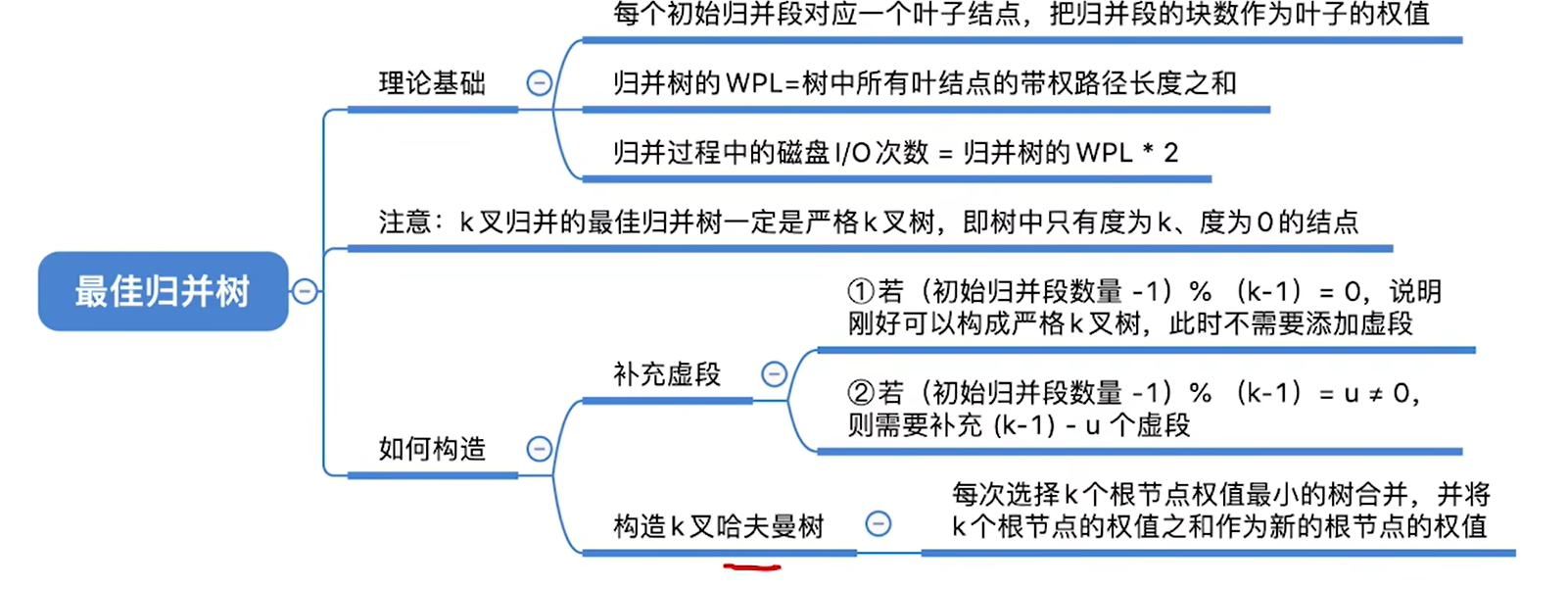
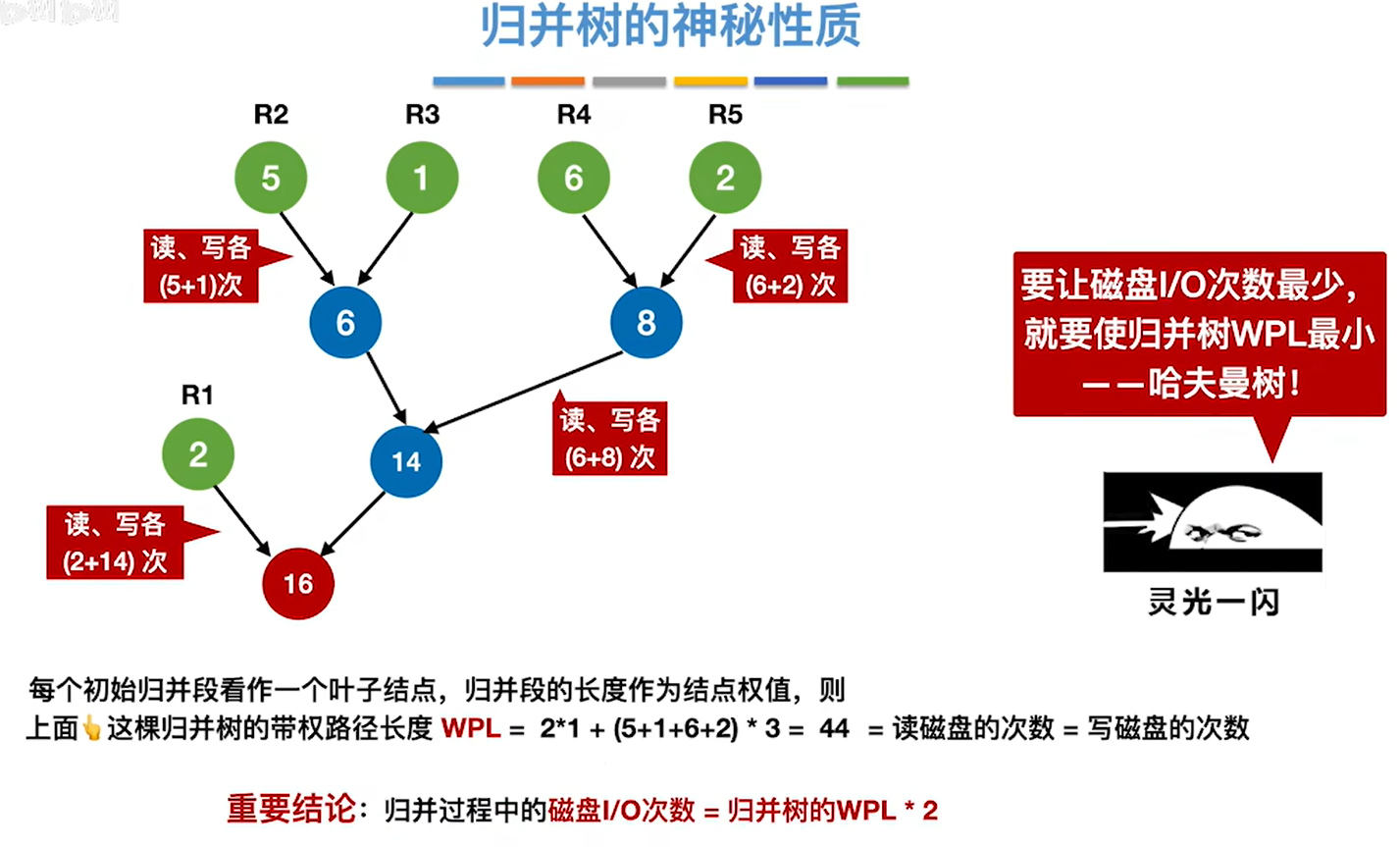
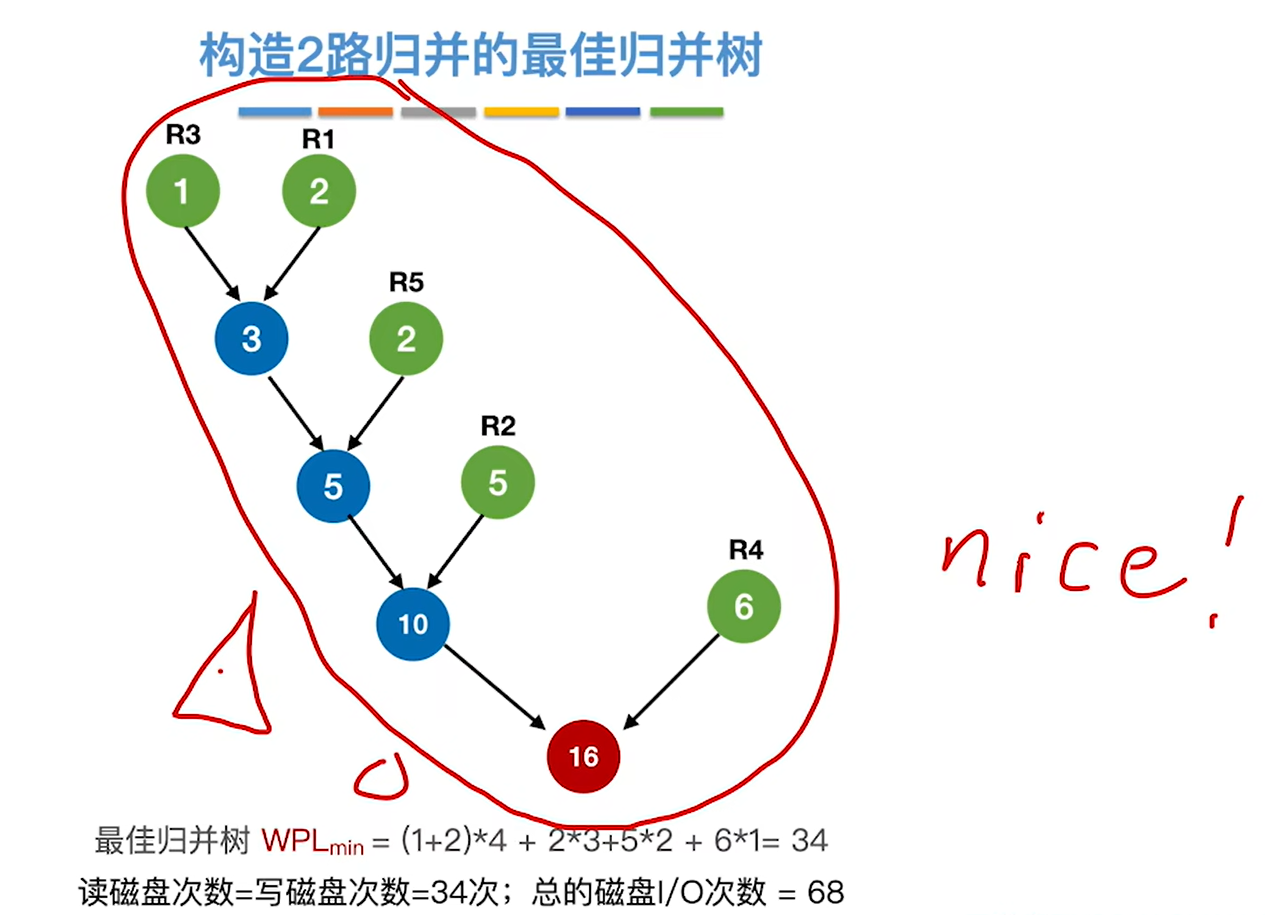
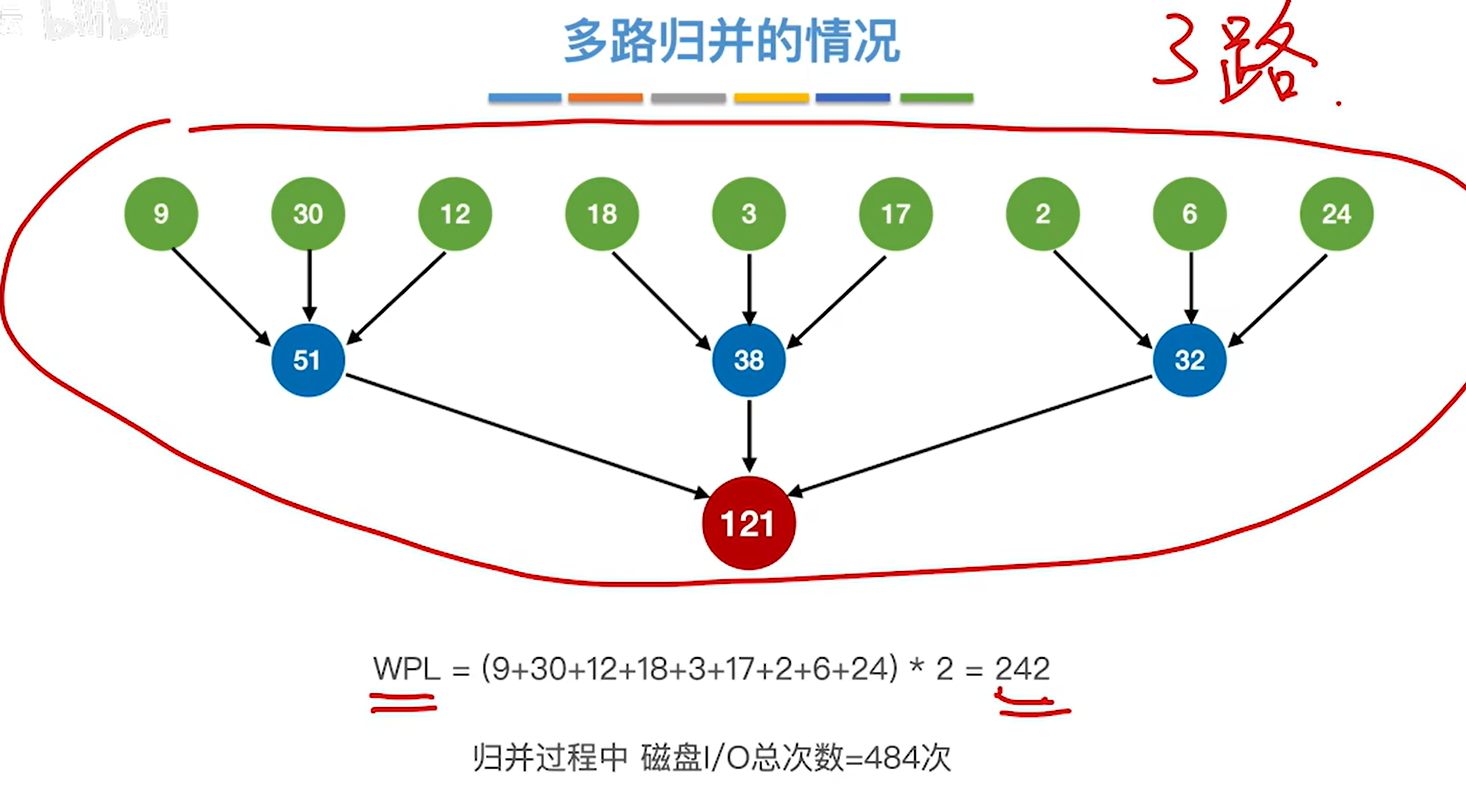
多路的最佳归并树和二路的并没有什么区别,二路的是选两个最小的,多路的就是选多个最小的组成新节点
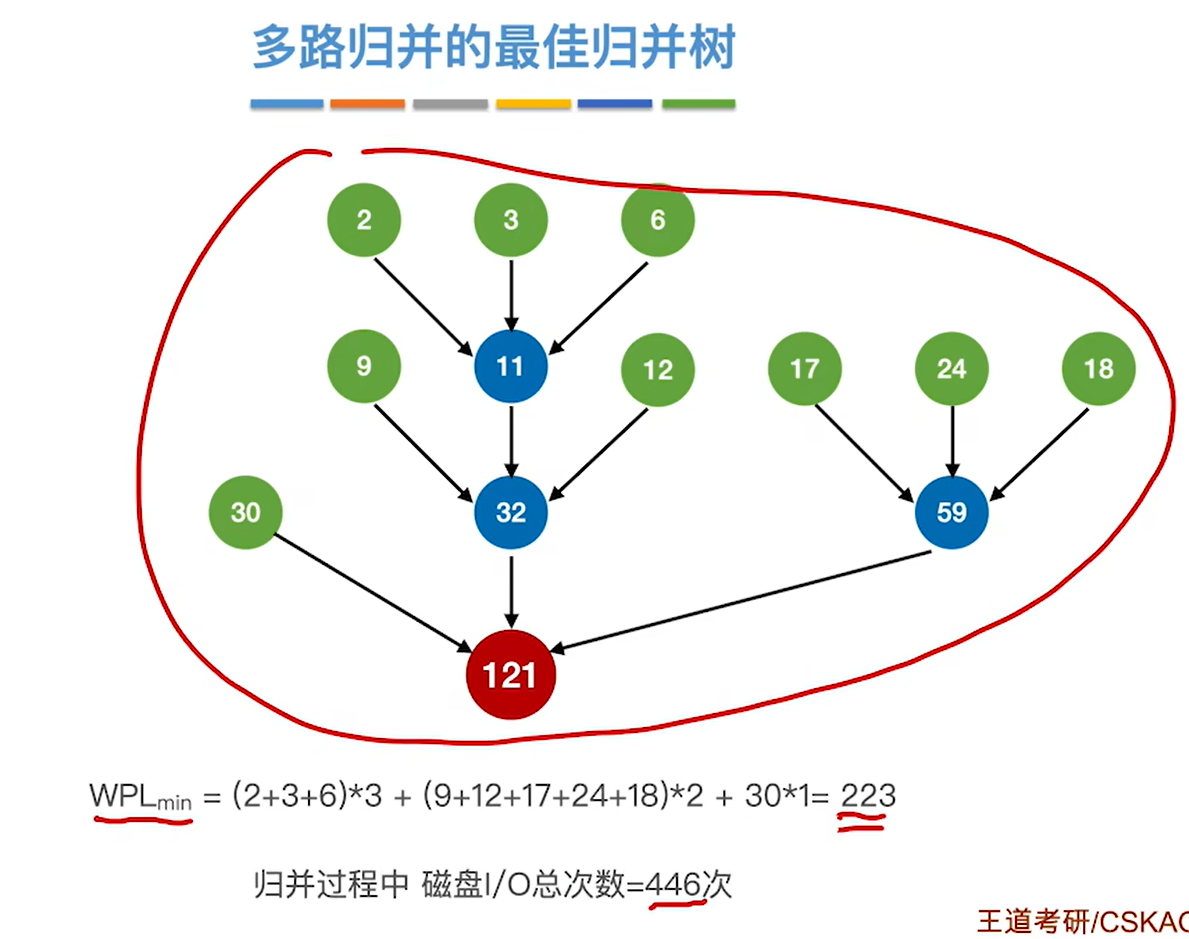
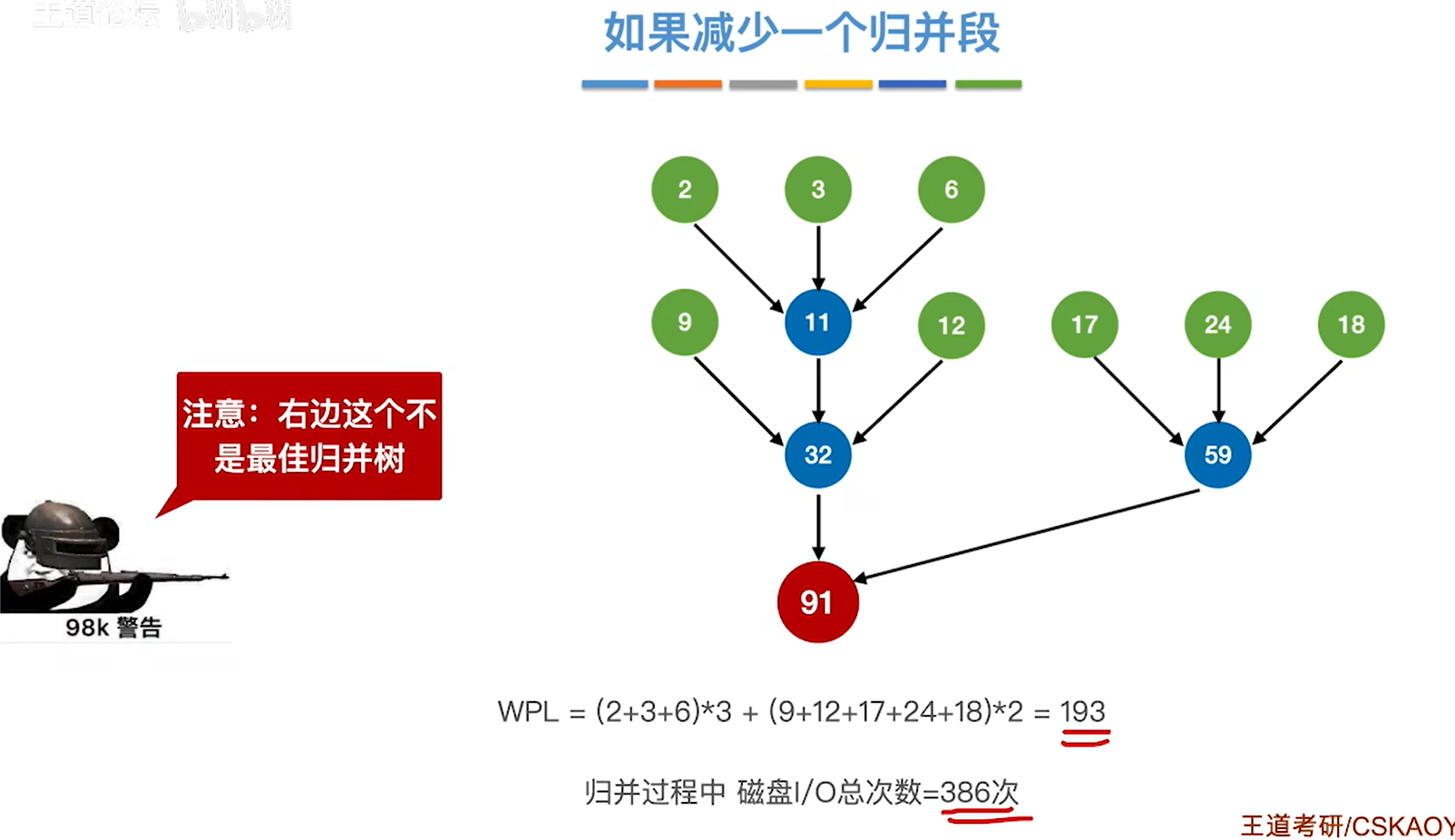
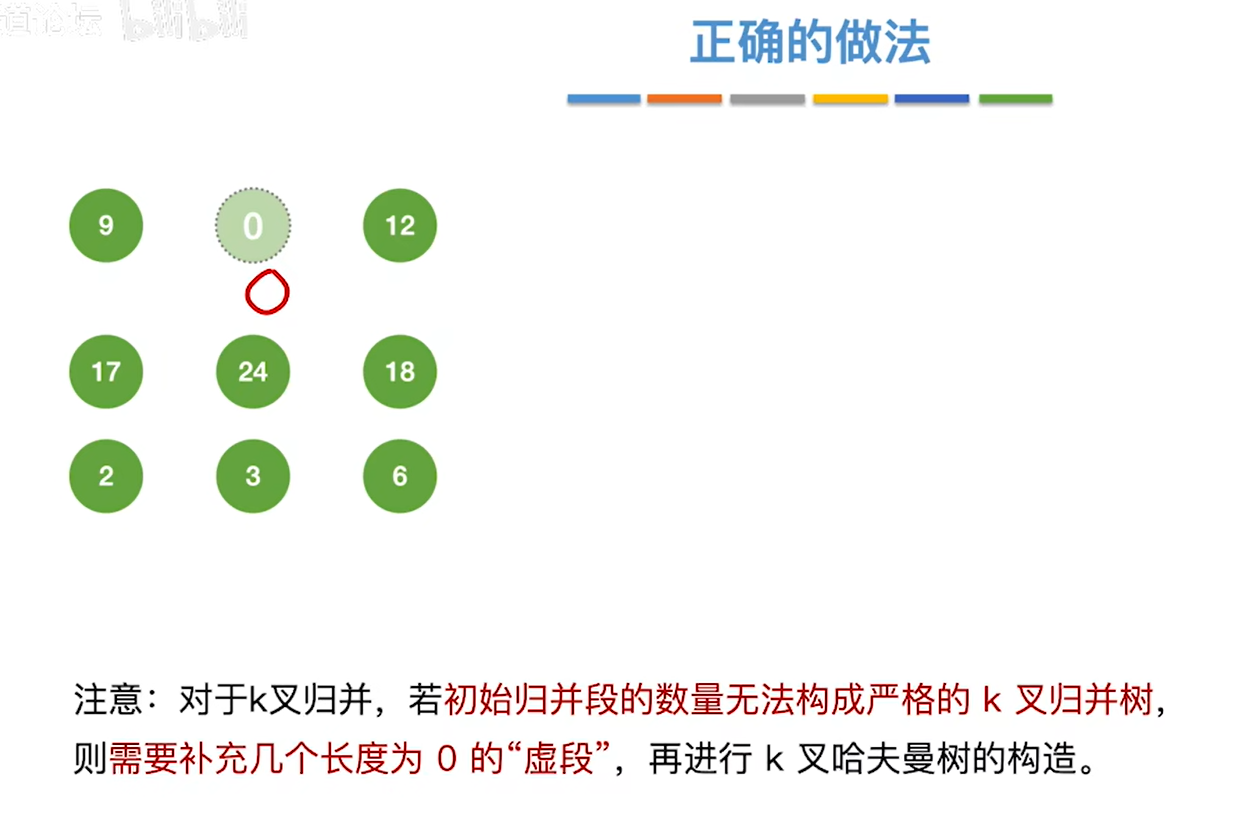
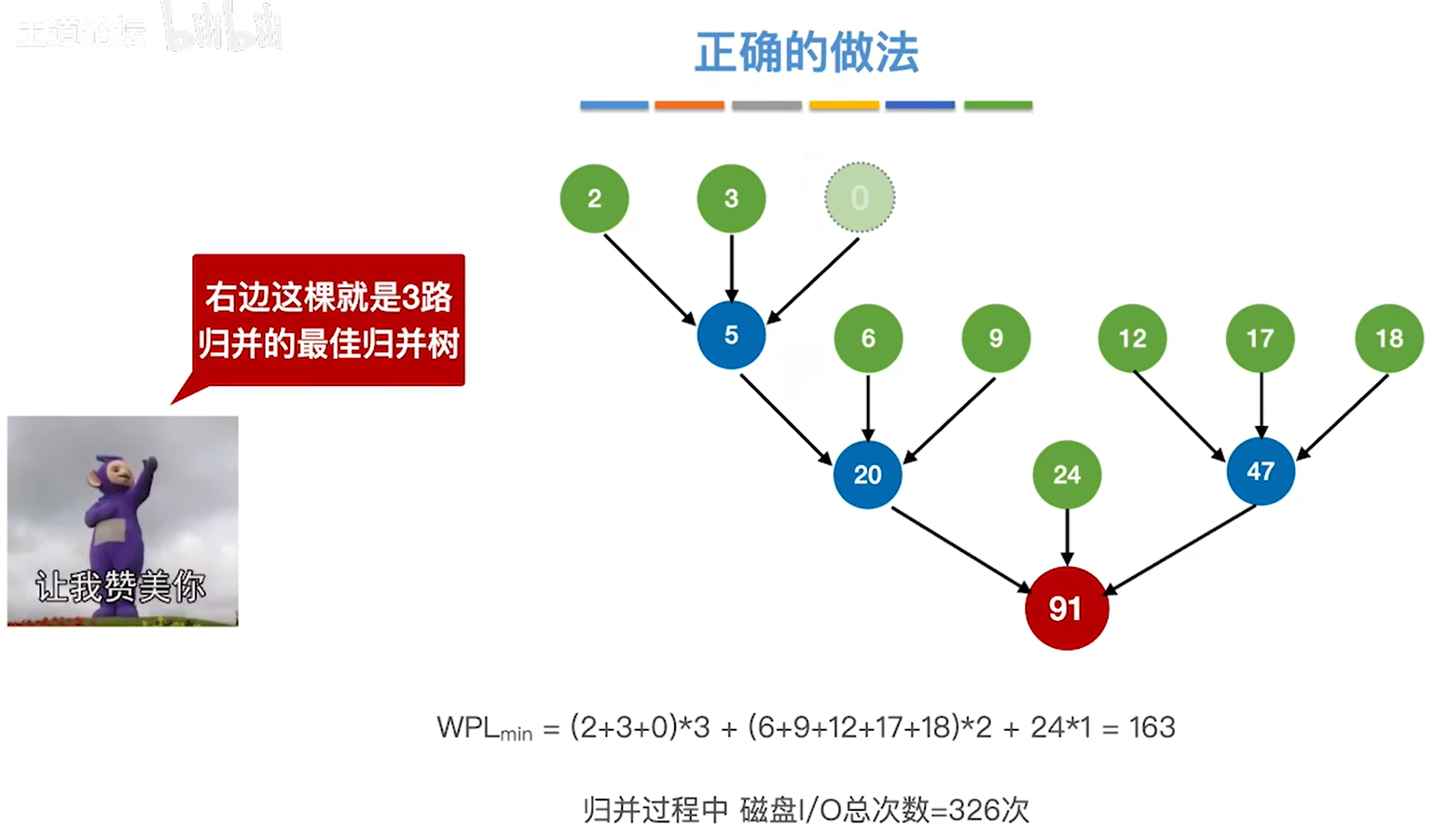
如果把30给删掉,那只剩下8个节点了

继续按照老方法构造最佳归并树,构造出来的就不对了,因为最后并不会是三个数一起归并,而只有两个树,得到的就不是最佳归并树了

相关文章:

26考研 | 王道 | 数据结构 | 第八章 排序
第八章 排序 文章目录 第八章 排序**8.1** 排序的基本概念**8.2 插入排序****8.2.1 直接插入排序****8.2.2 折半插入排序****8.2.3 希尔排序** 8.3 交换排序8.3.1 冒泡排序8.3.2 快速排序 8.4 选择排序8.4.1 简单选择排序8.4.2 堆排序堆的概念:建立大根堆的代码堆排…...

SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。 企业环境中A…...

kubesphere 单节点启动 etcd 报错
kubekey安装 ./kk create cluster -f config-sample.yaml --with-local-storage 时报错 etcd health check failed: Failed to exec command: sudo -E /bin/bash -c "export ETCDCTL_API2;export ETCDCTL_CERT_FILE/etc/ssl/etcd/ssl/admin-node1.pem;export ETCDCTL_KEY_…...

femap许可常见问题及解决方案
在使用Femap进行电磁仿真分析时,许可证管理是一个关键环节。然而,许多用户在许可证使用过程中可能会遇到各种问题。本文旨在解答关于Femap许可的常见疑问,并提供相应的解决方案,帮助您更顺畅地使用Femap许可证。 一、常见问题 许…...

游戏引擎学习第244天: 完成异步纹理下载
启动并运行游戏,注意到我们的纹理没有被下载 我们将继续完成游戏的开发。昨天,我们已经实现了多线程的纹理下载,但并没有时间调试它,因此纹理下载功能目前并没有正常工作。我们只是写了相关的代码,但由于大部分时间都…...

【安全扫描器原理】TCP/IP协议编程
【安全扫描器原理】TCP/IP协议编程 1.概述2.Windows Socket结构3.Windows socket转换类函数4.Windows Socket通信类函数 1.概述 TCP/IP协议是目前网络中使用最广泛的协议,Socket称为“套接口”,最早出现在Berkeley Unix中,最初只支持TCP/I…...
)
Cuda-GDB Frame Unwind 管理(未完.)
在计算机编程中,Frame Unwind(栈展开) 是指函数调用栈的逆向操作,即在函数返回或异常发生时,系统逐层释放栈帧(Stack Frame)、恢复调用上下文的过程。以下是详细解释及其在 GPU编程(…...

如何在IDEA中高效使用Test注解进行单元测试?
在软件开发过程中,单元测试是保证代码质量的重要手段之一。而IntelliJ IDEA作为一款强大的Java开发工具,提供了丰富的功能来支持JUnit测试,尤其是通过Test注解可以快速编写和运行单元测试。那么,如何在IDEA中高效使用Test注解进行…...

什么是访客鉴权?全面解析核心原理与CC防护应用实践
一、访客鉴权是什么? 访客鉴权(Visitor Authentication and Authorization)是系统对访问者进行身份验证和权限控制的过程,确保只有合法用户能够访问特定资源或执行特定操作。其核心目标是确认身份、控制权限、保障数据安全&#…...

DeepSeek大模型应用学习通知
随着人工智能在各领域深度融合发展,DeepSeek大模型迅速火爆全网,清华大学以最快的速度发布了DeepSeek从入门到精通使用技巧,能够更好的助力于企业和个人参与到AI研究和应用中,对于AI行业创新有重要意义,被誉为国运级的…...
时间序列预测模型比较分析:SARIMAX、RNN、LSTM、Prophet 及 Transformer
时间序列预测根据过去的模式预测未来事件。我们的目标是找出最佳预测方法,因为不同的技术在特定条件下表现出色。本文章将探讨各种方法在不同数据集上的表现,为你在任何情况下选择和微调正确的预测方法提供真知灼见。 我们将探讨五种主要方法࿱…...

快速了解redis,个人笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note (基于mac展示,别的可以参考)接下来将直接…...

Dify依赖管理poetry切换为uv
Dify升级 1.3.0 后api的依赖管理从poetry切换为了 uv管理,但是官网暂时还没有更新。 升级 tag:Dify 1.3.0版本 在此记录一下 uv 依赖管理操作 使用方法 [重要事项] 在 v1.3.0 版本中,poetry 已被[ uv ](https://docs.astral.sh/uv/) 替代…...

VGA 接口静电防护方案
VGA(Video Graphics Array)即视频图形阵列,具有分辨率高、显示速 率快、颜色丰富等优点,亦称为 D-Sub 接口,在彩色显示器领域得到了广 泛的应用, 如笔记本、投影仪、LCD 液晶显示屏 等。VGA 接口主要用于连接 计算机与显示设备。当…...

MySQL 详解之用户、权限与审计:保障数据安全的基石
在数据库系统中,数据是核心资产,对其的访问必须受到严格控制。谁能连接到数据库?他们能看到哪些数据?能执行哪些操作(读、写、修改结构)?系统中的所有操作是否被记录以便追溯?这正是用户管理、权限系统和审计机制需要解决的问题。 在 MySQL 中: 用户 (Users): 负责认…...

力扣面试150题--环形链表和两数相加
Day 32 题目描述 思路 采取快慢指针 /*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public class Solution {public boolean hasCycle(ListNod…...

HMI与组态,自动化的“灵珠”和“魔丸”
在现代工业自动化领域,组态(Configuration)和人机界面(HMI,Human-Machine Interface)是两个核心概念,它们在智能化控制系统中发挥着至关重要的作用。尽管这两者看似简单,但它们的功能…...
)
AbMole| CU-CPT-8m(CAS号125079-83-6;目录号M9746)
CU-CPT-8m是一种特异性的TLR8(toll-like receptor 8)拮抗剂,其IC50值为67 nM,Kd值为220 nM。 生物活性 CU-CPT-8m是一种特异性的TLR8(toll-like receptor 8)拮抗剂,其IC50值为67 nM,…...

【网络入侵检测】基于源码分析Suricata的PCAP模式
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 本文聚焦于 Suricata 7.0.10 版本源码,深入剖析其 PCAP 模式的实现原理。通过系统性拆解初始化阶段的配置流程、PCAP 数据包接收线程的创建与运行机制,以及数据…...

【滑动窗口+哈希表/数组记录】Leetcode 438. 找到字符串中所有字母异位词
题目要求 给定两个字符串 s 和 p,找到 s 中所有 p 的异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次。 示例 1 输入:s…...

uniapp自定义封装tabbar
uniapp自定义封装tabbar 开发原因: 有很多时候 小程序并没有其类目 需要通过配置发布审核, ps:需要去掉项目pages.json tabbar配置,不然重进会显示默认,跳转页面不能uni.switchTab。 组件tabbar <template><viewclass&…...

uni-app云开发总结
uni-app云开发总结 云开发无非就三个概念:云数据库、云函数、云存储 uni-app中新增了一个概念叫做云对象,它其实就是云函数的加强版,它是导出的一个对象,对象中可以包含多个操作数据库的函数,接下来咱们就详细对uni-…...

uniapp-商城-37-shop 购物车 选好了 进行订单确认3 支付栏
支付栏 就是前面用的 car-Layout 在shop也用来这个组件 只是在那里用来的是购物车。 1、 样式 我们开始进入这个页面是点击的shop的购物篮 到这里就变成了支付栏 其实他们是同一个组件 只是做了样式区分 2、具体看看样式和代码 2.1 消失了购物车和改变了按钮名字 如何…...

搜索二叉树-key的搜索模型
二叉搜索树(Binary Search Tree, BST)是一种重要的数据结构,它有两种基本模型:Key模型和Key/Value模型。 一、Key模型 1.基本概念 Key模型是二叉搜索树中最简单的形式,每个节点只存储一个键值(key),没有额外的数据值(value)。这…...

Qt ModbusSlave多线程实践总结
最近项目中用到了ModbusSlave,也就是Modbus从设备的功能,之前用的基本都是master设备,所以读取数据啥的用单线程就行了,用 void WaitHelper::WaitImplByEventloop(int msec) {QEventLoop loop;QTimer::singleShot(msec, &loop…...

Leetcode刷题记录18——接雨水
题源:https://leetcode.cn/problems/trapping-rain-water/description/?envTypestudy-plan-v2&envIdtop-100-liked 题目描述: 思路一: 🌟 本题核心思想:木桶效应 每个位置的“桶”:假设每个柱子的位…...

IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤
以下是在 IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤: 步骤 1:创建 Maven Web 项目 新建项目 File -> New -> Project → 选择 Maven → 勾选 Create from archetype → 选择 maven-archetype-webapp。输入 GroupId(如 com.examp…...
)
全球玻璃纸市场深度洞察:环保浪潮下的材料革命与产业重构(2025-2031)
一、行业全景:从传统包装到绿色经济的战略支点 玻璃纸(Cellulose Film),即再生纤维素薄膜,以木浆、棉浆等天然纤维素为原料,通过碱化、黄化、成型等工艺制成,兼具透明性、柔韧性及100%生物降解性…...

提示js方法未定义,但是确实<textarea>标签未闭合。
1、问题现象。 Uncaught ReferenceError: showOtherDismantleFn is not defined 但是这个方法,在代码中明明存在。 #if($!{isNewEnergy})#if($!{batteryName} 宁德时代)<button class"btn btn-info btn-xs" onclick"showNingDismantleFn()&quo…...

spring中的@bean注解详解
在Spring框架中,Bean注解是用于显式声明一个Bean的核心方式之一,尤其在基于Java的配置中。Spring框架中的Bean注解实现原理涉及多个核心机制,包括配置类解析、Bean定义注册、动态代理及依赖注入等 一、Bean注解的作用 Bean用于标注在方法上&…...

计算机网络中的DHCP是什么呀? 详情解答
目录 DHCP 是什么? DHCP 的工作原理 主要功能 DHCP 与网络安全的关系 1. 正面作用 2. 潜在安全风险 DHCP 的已知漏洞 1. 协议设计缺陷 2. 软件实现漏洞 3. 配置错误导致的漏洞 4. 已知漏洞总结 举例说明 DHCP 与网络安全 如何提升 DHCP 安全性 总结 D…...

uniapp-商城-38-shop 购物车 选好了 进行订单确认4 配送方式1
配送方式在订单确认页面最上方,可以进行选中配送还是自提,这里先看看配送。 代码样式: 可以看出来是通过组件来实现的。组件名字是:delivery-layout 1、建立组件文件夹和页面,delivery-layout这里就只有配送 2、具体…...
的详细解读)
粒子群优化算法(Particle Swarm Optimization, PSO)的详细解读
最近研究基于进化算法的神经网络架构搜索,仔细阅读了TEVC2023年发表的一篇NAS搜索的文章,觉得收益颇多,对比NSGA-2,这里给出PSO的详细解释。【本人目前研究的是多目标进化算法,欢迎交流、留言】 文章题目是࿱…...

大模型在直肠癌预测及治疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 研究方法与创新点 二、大模型技术概述 2.1 大模型的基本原理 2.2 常见大模型类型及特点 2.3 在医疗领域的应用进展 三、直肠癌预测相关数据收集与处理 3.1 数据来源 3.2 数据清洗与预处理 3.3 特征工程 四、大…...

【C++】继承----下篇
文章目录 前言一、实现一个不能继承的类二、友元与继承三、继承与静态成员四、多继承以及菱形继承问题1.继承模型:2.菱形继承的问题3.虚拟继承解决数据冗余和二义性的原理4.虚拟继承的原理 五、继承的总结和反思1.继承和组合 总结 前言 各位好呀!今天呢我们接着讲继…...
成功安装)
windows安装jax和jaxlib的教程(cuda)成功安装
本文你将解决3个问题:1、jaxlib没有安装的问题;2、python3.9以上(不可忽略)、cuda12.1(可忽略)以上配置要求不满足的问题;3、numpy版本太高的问题。 1、问题描述 当你直接pip install jax或者c…...

软考【网络工程师】2023年5月上午题答案解析
1、固态硬盘的存储介质是()。 A 光盘 B 闪存 C 软盘 D 磁盘 答案是 B。 固态硬盘(Solid State Drive),简称 SSD,是用固态电子存储芯片阵列制成的硬盘,其存储介质是闪存(Flash Memory)。闪存具有非易失性,即在断电后仍能保留存储的数据,且读写速度快、抗震性强、能…...
)
支付场景下,乐观锁的实现(简洁版)
1、问题描述 看到一个同事建的数据库表,好奇打开看看。 create table db_paycenter.t_pay_order_divide (id bigint auto_increment comment 主键id|20250402|XXXprimary key,user_id bigint not null comment user…...

AI视频技术赋能幼儿园安全——教师离岗报警系统的智慧守护
教师离岗报警系统如一位无形的守护者,实时监测教室动态,一旦发现教师离岗超30秒,立即通知园方,确保幼儿不被忽视。这套开源系统以高效检测和即时报警为核心,助力园所优化管理,增强家长信心,开启…...

SCI论文结构笔记
摘要五要素(Abstract): 背景和研究问题研究目的研究方法研究结果结论和意义 引言(Introduction): 研究背景研究问题研究现状现有的研究的问题与不足本研究的研究目标文章结构 研究综述(Literature review): 选题的理由现存文献中可借鉴的…...

《修仙家族模拟器2》:游戏背景故事介绍!
《修仙家族模拟器2》构建了一个以修仙文明为根基的宗族传承世界,玩家将扮演家族初代掌舵者,在动态演变的修仙江湖中完成从凡俗世家到仙道巨擘的蜕变。以下为具体背景设定解析: 一、世界观架构:仙凡交织的修真宇宙 空间维度 游戏…...

Linux部署ragflow,从安装docker开始~
安装docker https://download.docker.com/linux/static/stable/x86_64/docker-28.0.1.tgz #首先创建一个文件夹,存放我们需要的各类文件,并切换到该目录 mkdir /project && cd /project #此时我们的工作目录已经切换到刚刚创建的文件夹下了,接…...

苹果iosApp提交审核常见问题--内购订阅篇
常见问题1- 准则2.1.1 Guideline 2.1 - Information Needed The app binary includes the PassKit framework for implementing Apple Pay, but we were unable to verify any integration of Apple Pay within the app. Next Steps If the app integrates the functionali…...

从代码学习深度学习 - 微调 PyTorch 版
文章目录 前言一、迁移学习与微调概念二、微调步骤解析三、实战案例:热狗识别3.1 数据集准备3.2 图像增强处理3.3 加载预训练模型3.4 模型重构3.5 差异化学习率训练3.6 对比实验分析总结前言 深度学习模型训练通常需要大量数据,但在实际应用中,我们往往难以获得足够的标记数…...

Registry镜像仓库的安装与使用
任务目标 (1)了解目前主流的镜像仓库 (2)掌握registry私有镜像仓库的部署与使用 任务实施 基础信息 Docker私有仓库个宿主机配置信息 主机名 IP地址 节点角色 registry 192.168.110.80 私有仓库 node1 192.168.110.9…...
)
java多线程(6.0)
目录 编辑 阻塞队列 阻塞队列概念 生产者消费者模型 阻塞队列的作用 阻塞队列的使用 阻塞队列的实现 阻塞队列 阻塞队列概念 阻塞队列是一种特殊的队列,同样遵循“先进先出”的原则,支持入队操作和出队操作和一些基础方法。在此基础上&#…...

tkinter的文件对话框:filedialog
诸神缄默不语-个人技术博文与视频目录 文章目录 一、前言二、tkinter.filedialog模块详解2.1 模块导入方式2.2 通用参数说明 三、五大核心函数实战3.1 选择单个文件 - askopenfilename()3.2 多文件选择 - askopenfilenames()3.3 保存文件对话框 - asksaveasfilename()3.4 选择目…...

HOW - 如何模拟实现 gpt 展示答案的交互效果
文章目录 产品设计维度核心目标实现方式主要靠一些技巧1. 用 emoji 做语义锚点2. 每个段落只传达一件事3. 有节奏地对话式切换4. 使用 Markdown 风格来排版5. 用“你”而不是“用户”说话 如果想实现类似体验(比如写文档、教程、产品介绍) 前端开发维度想…...

达梦数据库压力测试报错超出全局hash join空间,适当增加HJ_BUF_GLOBAL_SIZE解决
1.名词解释:达梦数据库中的HJ_BUF_GLOBAL_SIZE是所有哈希连接操作可用的最大哈希缓冲区大小,单位为兆字节(MB) 2.达梦压测报错: 3.找到达梦数据库安装文件 4.压力测试脚本 import http.client import multiprocessi…...

第11章 面向分类任务的表示模型微调
第1章 对大型语言模型的介绍第2章 分词和嵌入第3章 解析大型语言模型的内部机制第4章 文本分类第5章 文本聚类与主题建模第6章 提示工程第7章 高级文本生成技术与工具第8章 语义搜索与检索增强生成第9章 多模态大语言模型第10章 构建文本嵌入模型第12章 微调生成模…...