从线性到非线性:简单聊聊神经网络的常见三大激活函数
大家好,我是沛哥儿,我们今天一起来学习下神经网络的三个常用的激活函数。
引言:什么是激活函数
激活函数是神经网络中非常重要的组成部分,它引入了非线性因素,使得神经网络能够学习和表示复杂的函数关系。
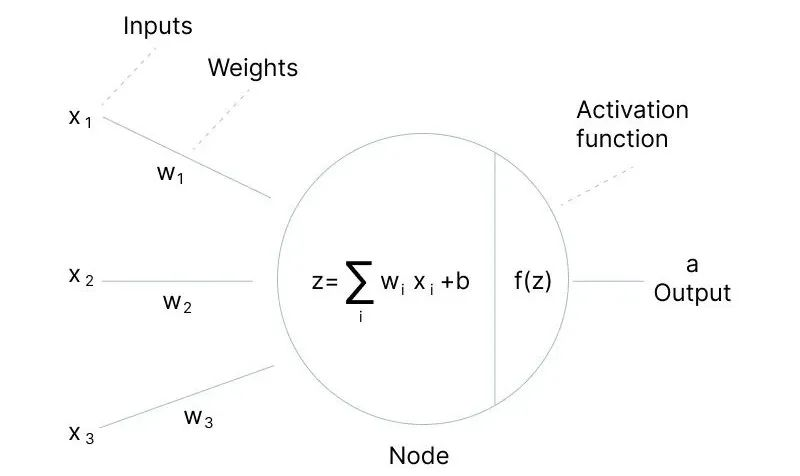
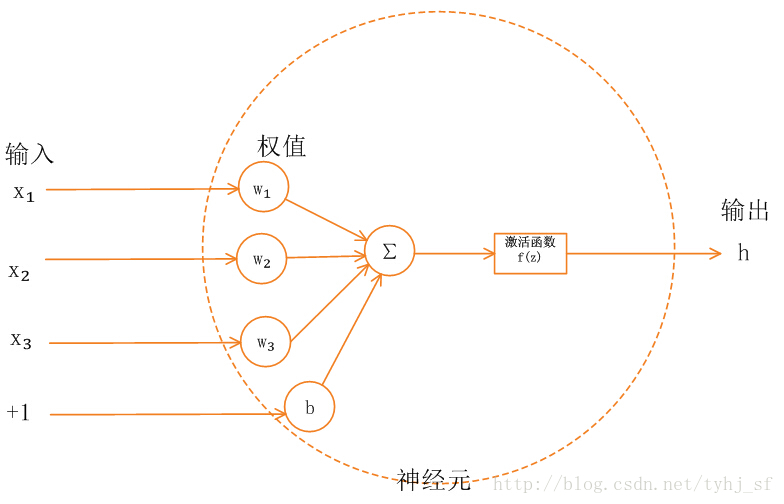
在神经网络中,神经元接收到多个输入信号,将这些输入信号进行加权求和后,再通过一个激活函数进行转换,得到神经元的输出。激活函数决定了神经元是否被激活,即是否将信号传递给下一层神经元。
一、为什么神经网络需要激活函数?
在探讨具体的激活函数之前,我们先来理解一下它在神经网络中扮演的关键角色。
神经网络,从本质上来说,是一种模仿生物神经系统结构和功能的计算模型。它由大量的神经元相互连接组成,这些神经元按照层次结构排列,包括输入层、隐藏层和输出层。
在神经网络里,每个神经元的基础操作是对输入进行线性加权求和,然后输出结果。简单来说,如果输入为 $ x_1, x_2, …, x_n $,对应的权重为 $ w_1, w_2, …, w_n $,偏置为 $ b $,那么神经元的输出 $ z $ 可以表示为 $ z = w_1x_1 + w_2x_2 + … + w_nx_n + b $ 。这是一个线性变换的过程。

但是,单纯的线性变换叠加存在很大的局限性。无论我们堆叠多少层这样的线性变换,其最终的输出仍然只是输入的线性组合。数学上可以证明,多层线性变换的组合等价于一个单层的线性变换 。这就意味着,仅靠线性变换,神经网络无法学习到数据中的复杂非线性模式。
举个简单的例子,异或(XOR)问题是一个典型的线性不可分问题。对于异或运算,输入有两个变量 $ x_1 $ 和 $ x_2 $,输出 $ y $ 满足:当 $ x_1 = 0, x_2 = 0 $ 时, $ y = 0 $;当 $ x_1 = 0, x_2 = 1 $ 时, $ y = 1 $;当 $ x_1 = 1, x_2 = 0 $ 时, $ y = 1 $;当 $ x_1 = 1, x_2 = 1 $ 时, $ y = 0 $ 。我们无法用一条直线将这四种情况正确地分类,也就是说,简单的线性模型无法解决异或问题。
再比如在图像识别任务中,图像中的物体形状、颜色、纹理等特征之间存在着复杂的非线性关系。如果神经网络没有引入非线性因素,就无法准确地提取和学习这些特征,从而难以实现高精度的图像分类、目标检测等任务。
激活函数的出现,就是为了解决这个问题。它的核心作用是为神经网络引入非线性,让多层神经网络能够学习到数据中的复杂模式。通过在神经元的线性加权求和输出之后,再经过一个激活函数的变换,神经网络就具备了强大的非线性表达能力。
根据通用近似定理,一个包含足够多隐藏层神经元的神经网络,加上合适的激活函数,可以逼近任意复杂的连续函数 。这使得神经网络能够处理各种复杂的任务,如语音识别、自然语言处理、图像生成等等。
可以说,激活函数是神经网络的灵魂所在,它赋予了神经网络强大的学习能力和适应性,让神经网络在众多领域取得了巨大的成功。
接下来,我们就详细介绍三种常见且重要的激活函数:Sigmoid 函数、ReLU 函数和 Tanh 函数。
二、Sigmoid 函数:从生物曲线到二分类的经典选择
(一)函数特性与数学表达
Sigmoid 函数在神经网络的发展历程中占据着重要的地位。
它的数学表达式为
$ \sigma(x)=\frac{1}{1 + e^{-x}} $
从这个公式可以看出,Sigmoid 函数的输入 $ x $ 可以是任意实数,而输出则被限定在 $ (0,1) $ 这个区间内。
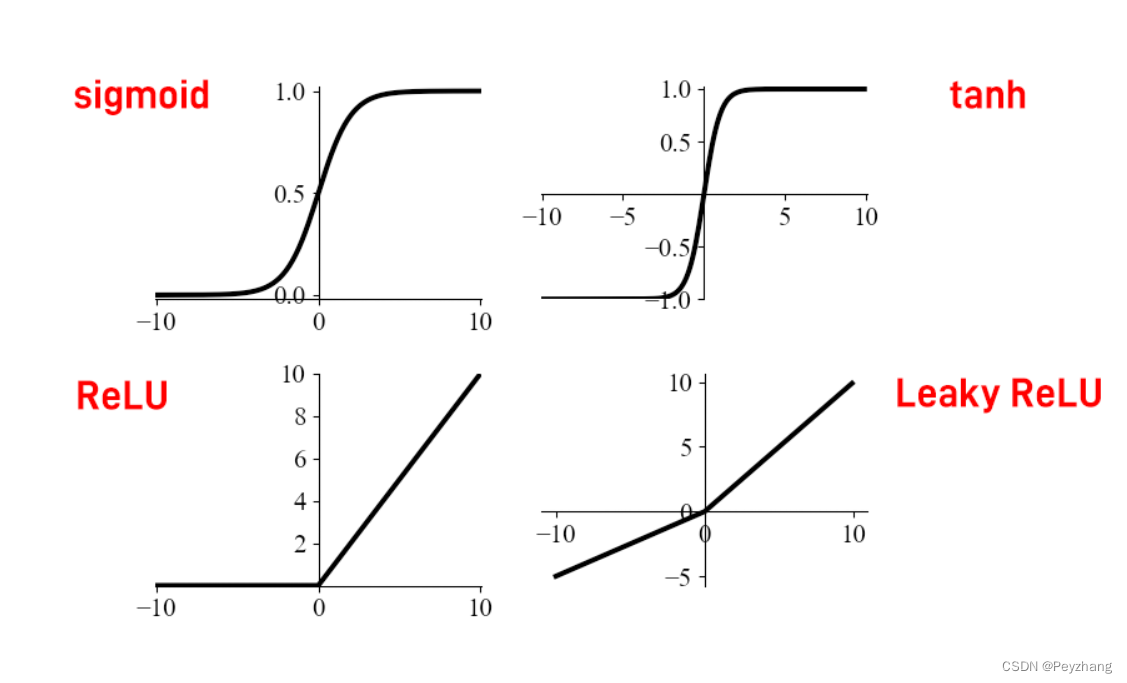
- 当 $ x $ 趋近于正无穷时,$ e^{-x} $ 趋近于 0,那么 $ \sigma(x) $ 就趋近于 1;
- 当 $ x $ 趋近于负无穷时,$ e^{-x} $ 趋近于正无穷,此时 $ \sigma(x) $ 趋近于 0 。
- 当 $ x = 0 $ 时,$ \sigma(0)=\frac{1}{1 + e^{0}} = 0.5 $ 。
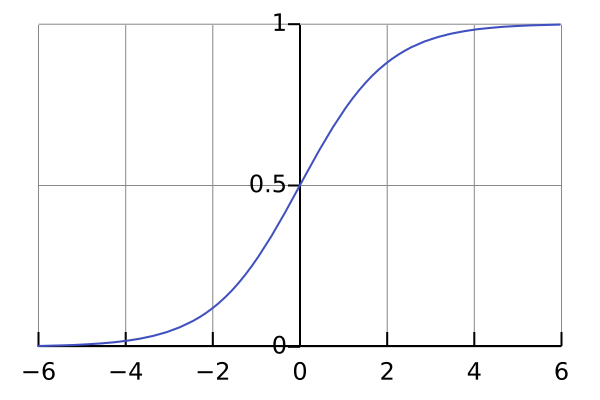
Sigmoid 函数的图像是一条非常独特的 S 型曲线。
- 在 $ x $ 值较小时,函数值接近 0 ,并且随着 $ x $ 的增加,函数值增长缓慢;
- 当 $ x $ 逐渐增大并接近 0 时,函数值开始快速增长;
- 而当 $ x $ 继续增大超过 0 后,函数值增长又逐渐变缓,最终趋近于 1 。
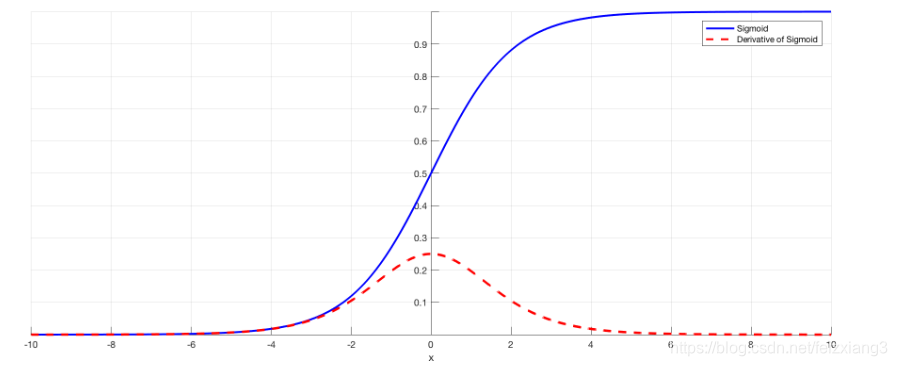
这种 S 型的曲线形状使得 Sigmoid 函数具有很好的平滑性和连续性,在整个实数域上都是可导的。它的导数公式为
$ \sigma’(x)=\sigma(x)(1 - \sigma(x)) $** **
从导数公式可以看出,Sigmoid 函数的导数与它自身的输出值密切相关 。当 $ \sigma(x) $ 接近 0 或 1 时,导数 $ \sigma’(x) $ 接近 0 ;而当 $ \sigma(x)=0.5 $ 时,导数达到最大值 0.25 。
什么是导数:
设函数$ y=f(x)
在点 在点 在点 x_0
的某个邻域内有定义,当自变量 的某个邻域内有定义,当自变量 的某个邻域内有定义,当自变量 x
在 在 在 x_0 处有增量 处有增量 处有增量 Δx
( ( ( x_0+Δx
仍在该邻域内)时,相应地函数有增量 仍在该邻域内)时,相应地函数有增量 仍在该邻域内)时,相应地函数有增量 Δy=f(x0+Δx)−f(x0)
。如果当 。如果当 。如果当 Δx→0 时,比值 时,比值 时,比值 \frac{Δx}{Δy} 的极限存在,那么称函数 的极限存在,那么称函数 的极限存在,那么称函数 y=f(x) 在点 在点 在点 x_0 处可导,这个极限值就称为函数 处可导,这个极限值就称为函数 处可导,这个极限值就称为函数 y=f(x) 在点 在点 在点 x_0 处的导数,记作 处的导数,记作 处的导数,记作 f′(x0) KaTeX parse error: Expected group after '_' at position 3: ,即_̲_ f’(x_0)=\lim\limits_{\Delta x\to0}\frac{\Delta y}{\Delta x}=\lim\limits_{\Delta x\to0}\frac{f(x_0 + \Delta x)-f(x_0)}{\Delta x} $。
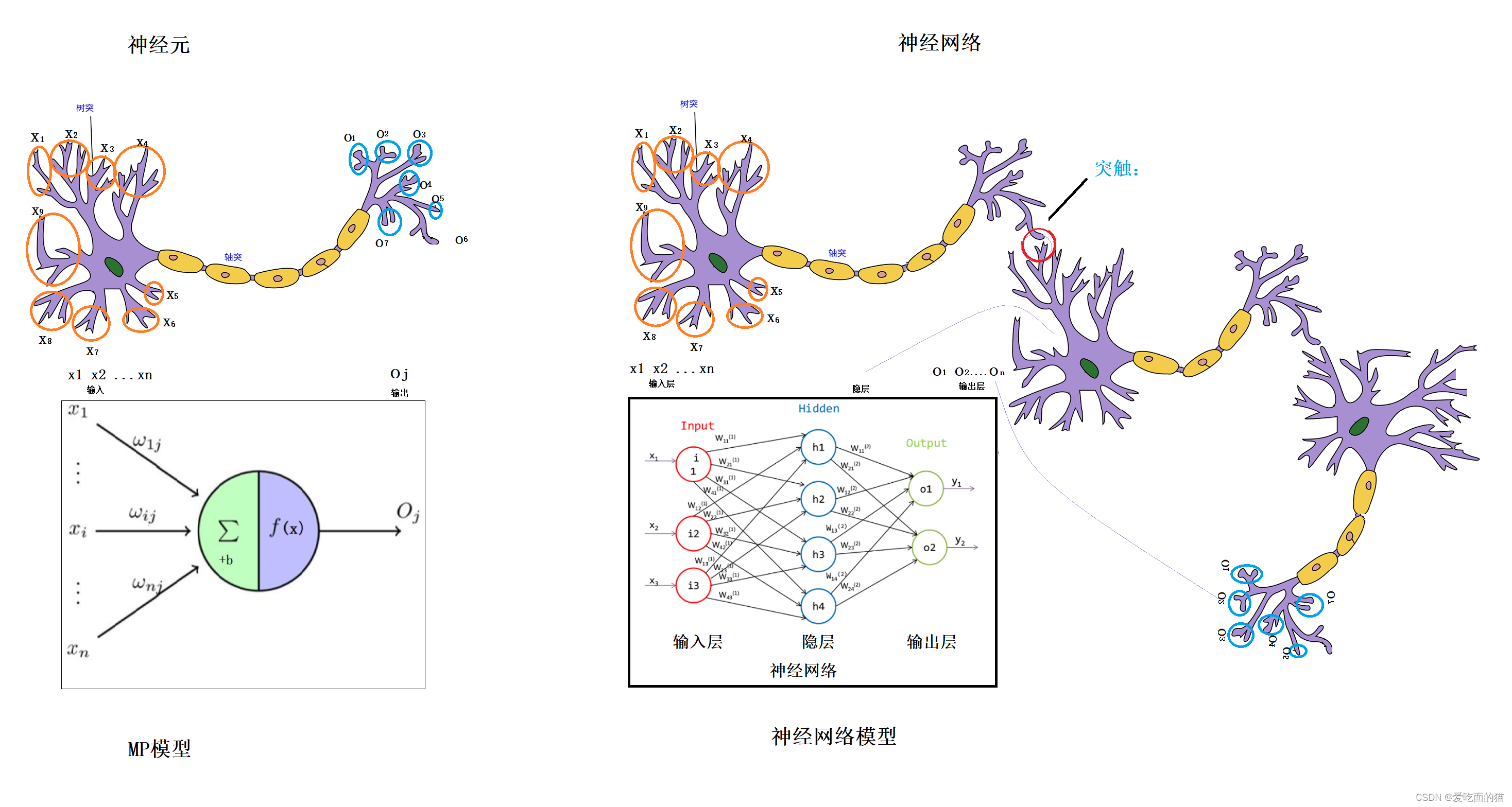
Sigmoid 函数的设计灵感来源于生物学中的神经元激活机制。在生物神经系统中,神经元接收到来自其他神经元的信号,当这些信号的强度积累到一定阈值时,神经元就会被激活并发送信号,否则就处于抑制状态。
Sigmoid 函数就类似于这种神经元的激活过程,输入信号 $ x $ 越大,越趋近于 1(表示激活),输入信号越小,越趋近于 0(表示抑制) 。这种直观的物理意义使得 Sigmoid 函数在早期的神经网络研究中被广泛应用。
(二)核心优势与应用场景
Sigmoid 函数的优点之一是其输出天然适配二分类概率预测。
在逻辑回归模型中,我们通过 Sigmoid 函数将线性回归的输出 $ z = w^Tx + b $ 转换为概率值 $ p = \sigma(z) $ ,其中 $ p $ 表示样本属于正类的概率。
- 当 $ p \gt 0.5 $ 时,我们将样本预测为正类;
- 当 $ p \leq 0.5 $ 时,预测为负类。
在图像二分类任务中,比如判断一张图片是猫还是狗,我们可以使用逻辑回归模型,通过 Sigmoid 函数输出图片是猫的概率,如果概率大于 0.5,则认为图片中的动物是猫,否则是狗。
Sigmoid 函数的梯度计算相对简单,这在基于梯度下降的优化算法中非常重要。
在反向传播过程中,我们需要计算每个神经元的梯度来更新权重,Sigmoid 函数简单的梯度计算公式
$ \sigma’(x)=\sigma(x)(1 - \sigma(x)) $** **
使得梯度计算的效率较高,能够加快模型的训练速度。
但是 Sigmoid 函数也存在明显的缺点,最突出的就是梯度饱和问题。当 $ x $ 的绝对值较大时,也就是 $ x \gt 3 $ 或 $ x \lt -3 $ 时,Sigmoid 函数的梯度接近 0 。
在深层神经网络中,梯度消失会导致靠近输入层的神经元权重更新非常缓慢,甚至几乎不更新,使得模型难以学习到有效的特征。这就好比在一个长长的接力赛中,梯度是传递的 “接力棒”,当梯度消失时,前面的 “选手”(靠近输入层的神经元)就很难接到 “接力棒”,无法有效地进行训练。
Sigmoid 函数的输出非零中心化,其输出值始终大于 0 。这会导致下一层神经元的输入发生偏置偏移,使得梯度下降的收敛速度变慢。当一个神经元的输入全是正数时,其梯度在反向传播过程中也全是正数,这就使得权重更新只能朝着一个方向进行,形成 “Z 字型” 震荡,不利于模型的收敛。
尽管存在这些缺点,Sigmoid 函数在一些特定场景下仍然有着重要的应用。在早期的神经网络中,它常被用于输出层,尤其是在二分类任务中。在生成对抗网络(GAN)的判别器中,Sigmoid 函数也经常被使用,用于判断输入数据是真实数据还是生成数据的概率。
(三)实践中的注意事项
在使用 Sigmoid 函数时,初始化权重需严格控制。由于 Sigmoid 函数的梯度饱和问题,如果初始化权重过大,会导致大部分神经元处于饱和状态,使得梯度消失,模型无法正常训练。因此,通常会使用一些特定的权重初始化方法,如 Xavier 初始化,来确保权重在合适的范围内,避免落入饱和区。
为了缓解梯度消失问题,在输出层搭配交叉熵损失函数是一个有效的方法。交叉熵损失函数与 Sigmoid 函数结合时,在反向传播过程中能够避免梯度消失的问题,使得模型能够更好地进行训练。在二分类的逻辑回归模型中,我们通常使用交叉熵损失函数 $ L = -[y\log§+(1 - y)\log(1 - p)] $ ,其中 $ y $ 是真实标签,$ p $ 是通过 Sigmoid 函数得到的预测概率,这种组合能够有效地优化模型的性能。
Xavier 初始化
Xavier 初始化是一种在神经网络训练中用于初始化权重参数的方法,目的是让网络在训练初期能更稳定地学习,减少梯度消失或梯度爆炸问题。
- 原理:Xavier 初始化基于这样的想法,即如果每一层输入的方差在经过该层传递到输出时保持不变,那么网络训练过程会更稳定。它通过计算每层神经元的输入和输出数量,按照特定公式来确定权重的初始分布。假设某一层神经网络的输入维度为nin,输出维度为nout ,对于服从均匀分布的权重初始化,权重参数$ W < f o n t s t y l e = " c o l o r : r g b ( 31 , 35 , 41 ) ; b a c k g r o u n d − c o l o r : r g b ( 239 , 240 , 241 ) ; " > 在区间 < / f o n t > <font style="color:rgb(31, 35, 41);background-color:rgb(239, 240, 241);">在区间 </font> <fontstyle="color:rgb(31,35,41);background−color:rgb(239,240,241);">在区间</font> [-\frac{\sqrt{6}}{\sqrt{n_{in}+n_{out}}}, \frac{\sqrt{6}}{\sqrt{n_{in}+n_{out}}}]
KaTeX parse error: Expected group after '_' at position 198: …rtant;"></font>_̲ W < f o n t s t y l e = " c o l o r : r g b ( 31 , 35 , 41 ) ; b a c k g r o u n d − c o l o r : r g b ( 239 , 240 , 241 ) ; " > 的均值设为 < / f o n t > < f o n t s t y l e = " c o l o r : r g b ( 31 , 35 , 41 ) ; b a c k g r o u n d − c o l o r : r g b ( 225 , 234 , 255 ) ! i m p o r t a n t ; " > 0 < / f o n t > < f o n t s t y l e = " c o l o r : r g b ( 31 , 35 , 41 ) ; b a c k g r o u n d − c o l o r : r g b ( 239 , 240 , 241 ) ; " > ,方差设为 < / f o n t > <font style="color:rgb(31, 35, 41);background-color:rgb(239, 240, 241);">的均值设为</font><font style="color:rgb(31, 35, 41);background-color:rgb(225, 234, 255) !important;">0</font><font style="color:rgb(31, 35, 41);background-color:rgb(239, 240, 241);">,方差设为 </font> <fontstyle="color:rgb(31,35,41);background−color:rgb(239,240,241);">的均值设为</font><fontstyle="color:rgb(31,35,41);background−color:rgb(225,234,255)!important;">0</font><fontstyle="color:rgb(31,35,41);background−color:rgb(239,240,241);">,方差设为</font> \frac{2}{n_{in}+n_{out}} $。- 优势:相比随机初始化,Xavier 初始化能让网络在训练初期的梯度分布更合理,使得网络训练更加稳定,加速收敛过程。它能让信号在网络中更顺畅地传播,减少因权重过大或过小导致的训练困难问题。
- 局限:Xavier 初始化的假设是网络层之间的激活函数是线性的,然而在实际应用中,许多激活函数(如 ReLU、Sigmoid 等)是非线性的,这可能导致其效果受到一定影响。对于一些深度非常深、结构复杂的网络,Xavier 初始化可能无法完全避免梯度消失或梯度爆炸问题,仍需结合其他技术(如 Batch Normalization)一起使用 。
三、Tanh 函数:对称输出的隐层优化方案
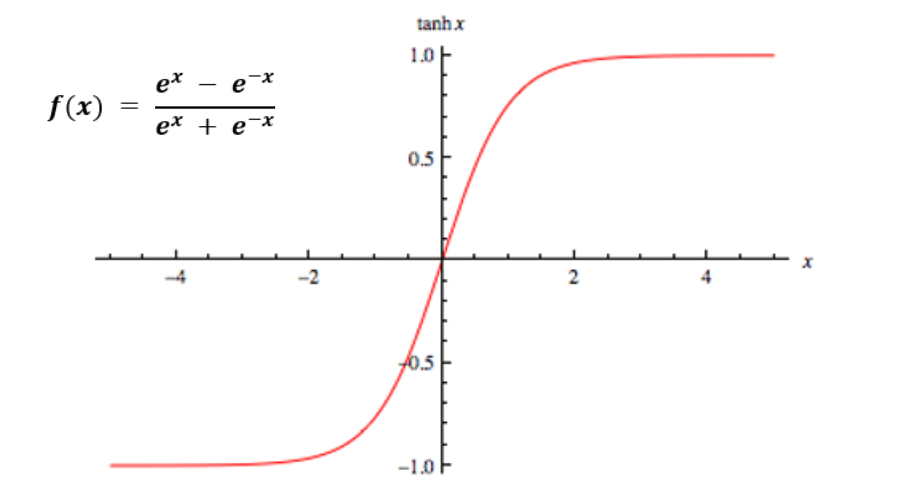
(一)函数特性与数学表达
Tanh 函数即双曲正切函数,在神经网络的发展历程中同样占据着重要的地位,它的数学表达式为 $ \tanh(x)=\frac{e{x}-e{-x}}{e{x}+e{-x}} $
从这个公式我们可以清晰地看到,Tanh 函数通过自然指数函数 $ e^{x} $ 和 $ e^{-x} $ 的组合,将任意实数输入 $ x $ 映射到了 $ (-1,1) $ 这个区间内。
- 当 $ x $ 趋近于正无穷时,$ e^{x} $ 会远远大于 $ e^{-x} $ ,此时分子 $ e{x}-e{-x} $ 趋近于 $ e^{x} $ ,分母 $ e{x}+e{-x} $ 也趋近于 $ e^{x} $ ,那么 $ \tanh(x) $ 就趋近于 1;
- 反之,当 $ x $ 趋近于负无穷时,$ e^{-x} $ 远远大于 $ e^{x} $ ,分子趋近于 $ -e^{-x} $ ,分母趋近于 $ e^{-x} $ ,$ \tanh(x) $ 趋近于 - 1 。
- 而当 $ x = 0 $ 时,$ e^{0}=1 $ ,代入公式可得 $ \tanh(0)=\frac{1 - 1}{1 + 1}=0 $ 。
Tanh 函数的图像呈现出非常独特的 S 型曲线,并且关于原点对称。这意味着对于任意的 $ x $ ,都有 $ \tanh(-x)=-\tanh(x) $ 。在 $ x $ 从负无穷逐渐增大到 0 的过程中,函数值从 - 1 逐渐增大到 0,且增长速度逐渐加快;当 $ x $ 从 0 继续增大到正无穷时,函数值从 0 逐渐增大到 1,增长速度逐渐变慢 。这种对称的 S 型曲线特性使得 Tanh 函数在处理数据时具有很好的对称性和平衡性。
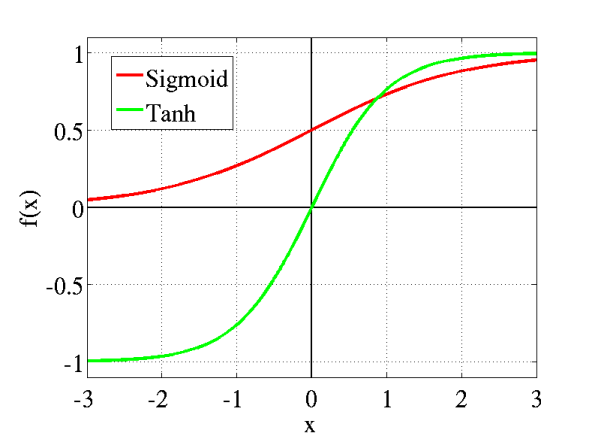
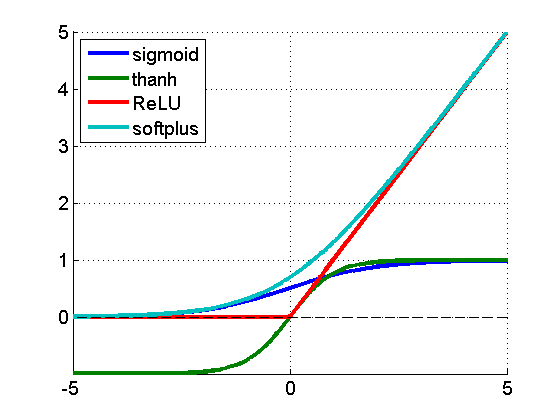
与 Sigmoid 函数相比,Tanh 函数可以看作是 Sigmoid 函数的 “中心化” 版本。Sigmoid 函数的输出范围是 $ (0,1) $ ,其输出值始终大于 0 ,而 Tanh 函数的输出范围是 $ (-1,1) $ ,输出均值更接近 0 。这种以 0 为中心的输出特性,使得 Tanh 函数在神经网络的隐藏层中表现出更好的性能,能够让神经元的输出在网络中更有效地传递和处理 。
(二)核心优势与应用场景
Tanh 函数的主要优点之一是解决了 Sigmoid 函数输出非对称的问题。
由于其输出以 0 为中心,当 Tanh 函数作为隐藏层的激活函数时,神经元的输出在网络中传递时,能够使下一层神经元接收到的输入信号在正负两个方向上都有较好的分布,避免了因输入信号始终为正而导致的权重更新偏差。在多层神经网络中,如果前一层神经元使用 Tanh 函数作为激活函数,其输出会在正负值之间波动,这样传递到下一层神经元时,下一层神经元的权重更新会更加合理,有助于模型更快地收敛。
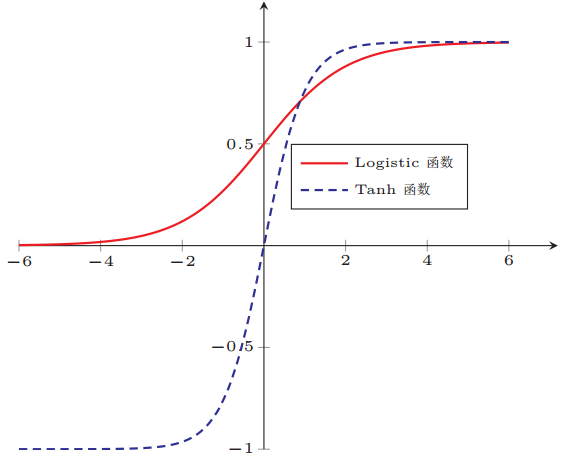
Tanh 函数的收敛速度略快于 Sigmoid 函数。这是因为在相同的输入范围内,Tanh 函数的梯度相对较大。从导数的角度来看,Tanh 函数的导数公式为 $ \tanh’(x)=1-\tanh^{2}(x) $ ,当输入值在 0 附近时,$ \tanh(x) $ 的值也接近 0,此时导数 $ \tanh’(x) $ 接近 1 ,而 Sigmoid 函数在输入为 0 时,导数仅为 0.25 。更大的梯度意味着在反向传播过程中,权重更新的步长可以更大,从而加快模型的训练速度 。
Tanh 函数的梯度饱和区域相对 Sigmoid 函数更为平缓。虽然当 $ x $ 的绝对值较大时(一般认为 $ x\gt2 $ 或 $ x\lt -2 $ 时),Tanh 函数也会出现梯度饱和问题,即梯度趋近于 0 ,但相比 Sigmoid 函数,Tanh 函数在梯度饱和时的变化更为平缓。这使得在训练过程中,即使输入值进入了梯度饱和区域,模型的训练也不会像 Sigmoid 函数那样急剧恶化,仍然能够保持一定的训练效果 。
然而,Tanh 函数也并非完美无缺。它同样没有从根本上解决梯度饱和问题,当输入值过大或过小时,梯度仍然会趋近于 0 ,这在深层神经网络中会导致靠近输入层的神经元权重更新缓慢,影响模型的训练效果。Tanh 函数的计算过程涉及指数运算,这使得它的计算成本相对较高,在大规模数据集和深层网络的训练中,会增加计算资源的消耗和训练时间 。
在实际应用中,Tanh 函数常用于早期神经网络的隐藏层。在循环神经网络(RNN)中,Tanh 函数被广泛应用于隐藏层,因为 RNN 需要处理序列数据,Tanh 函数的对称输出特性能够更好地捕捉序列中的正负信息,帮助模型学习到序列数据之间的复杂依赖关系。在自然语言处理任务中,文本数据通常以序列的形式呈现,Tanh 函数可以对输入的词向量进行有效的变换,提取文本中的关键特征,从而提升模型在情感分析、机器翻译等任务中的性能 。
(三)与 Sigmoid 的关键区别
Tanh 函数与 Sigmoid 函数最直观的区别在于输出范围。**Sigmoid 函数的输出范围是 **$ (0,1) ∗ ∗ ,而 T a n h 函数的输出范围是 ∗ ∗ ** ,而 Tanh 函数的输出范围是 ** ∗∗,而Tanh函数的输出范围是∗∗ (-1,1) $
这个差异看似简单,却对神经网络的性能产生了重要影响。在隐藏层中,Tanh 函数的对称输出使得神经元的输出能够在正负两个方向上传递信息,避免了 Sigmoid 函数输出始终为正所带来的权重更新偏差问题。这就好比在一条信息传递的链条中,Tanh 函数能够让信息更加全面地在各个环节中流动,而 Sigmoid 函数可能会导致信息的传递出现偏向 。
在输出层的选择上,两者也有所不同。对于多分类任务,通常会使用 Softmax 函数作为输出层的激活函数,它能够将输出值转换为各个类别的概率分布 。但对于二分类任务,Sigmoid 函数仍然有其用武之地,因为它的输出可以直接解释为样本属于正类的概率 。而 Tanh 函数由于其输出范围和特性,一般不直接用于二分类任务的输出层 。
从梯度特性来看,虽然两者都存在梯度饱和问题,但 Tanh 函数在大部分定义域上的梯度大于 Sigmoid 函数。这使得 Tanh 函数在训练过程中能够更快地收敛,减少训练时间 。在计算复杂度方面,两者都涉及指数运算,但由于 Tanh 函数的输出范围和特性,在某些情况下,其计算效率可能会略高于 Sigmoid 函数 。
四、ReLU 函数:开启深度学习的非线性革命
(一)函数特性与数学表达
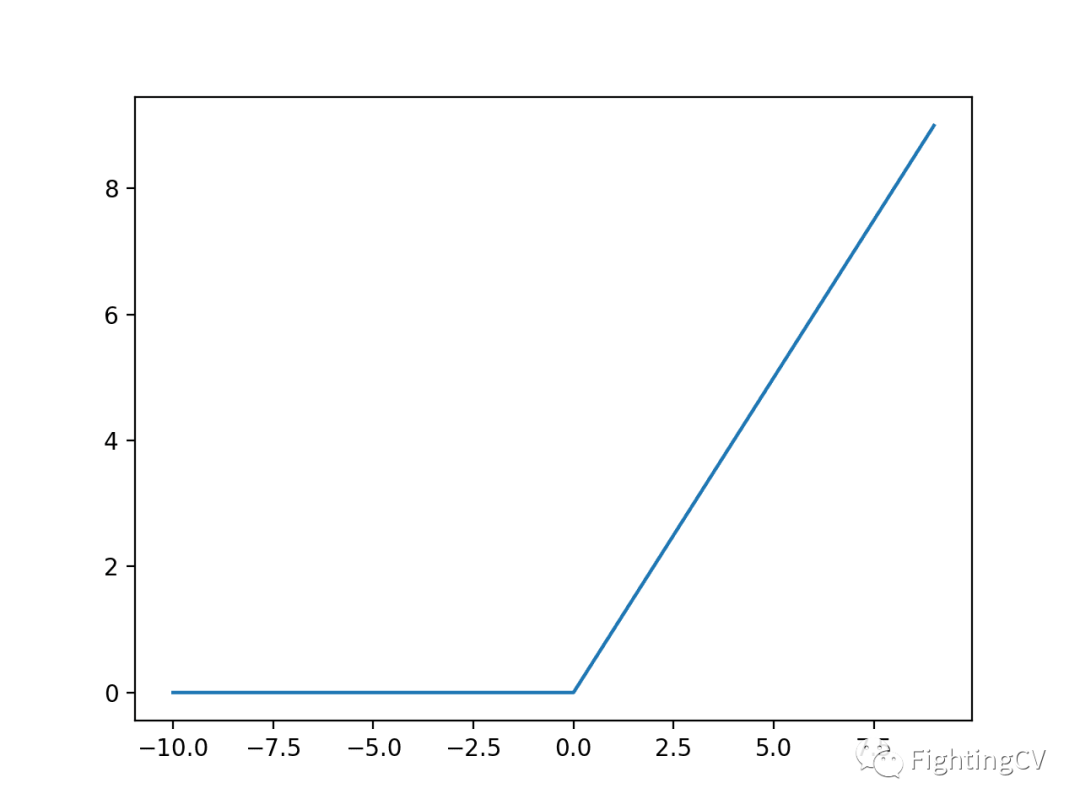
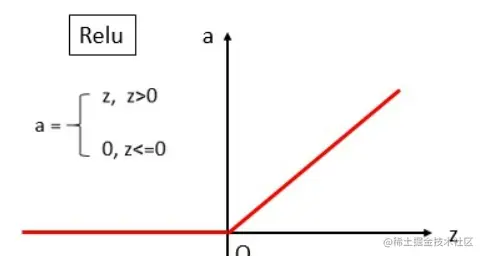
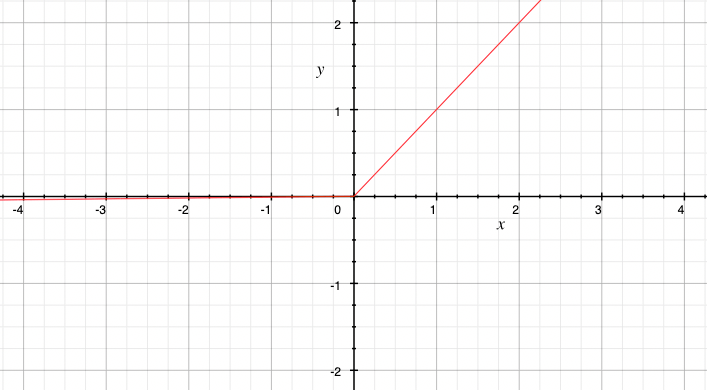
ReLU(修正线性单元)在现代深度学习中占据着举足轻重的地位,它的数学表达式简洁明了:$ f(x)=\max(0,x) $
这个式子的含义是:
- 当输入 $ x $ 大于 0 时,函数直接输出 $ x $ ;
- 当输入 $ x $ 小于等于 0 时,函数输出 0 。
从图像上看,ReLU 函数呈现出一种独特的分段线性曲线。
- 当 $ x \lt 0 $ 时,函数值恒为 0 ,图像与 $ x $ 轴重合;
- 当 $ x \gt 0 $ 时,函数值等于 $ x $ ,图像是一条斜率为 1 的直线。
这种简单而直观的函数形式,使得 ReLU 函数在神经网络中具有高效的计算特性。
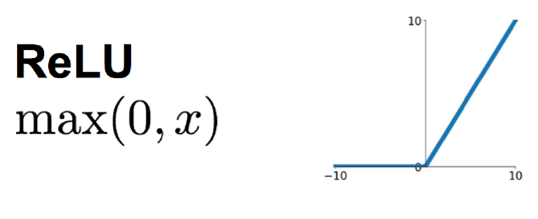
与 Sigmoid 和 Tanh 函数相比,ReLU 函数的计算过程大大简化。Sigmoid 函数涉及指数运算,计算 $ e^{-x} $ 相对复杂;Tanh 函数同样需要进行指数运算来计算 $ \frac{e{x}-e{-x}}{e{x}+e{-x}} $ 。而 ReLU 函数只需要进行一次简单的比较操作,判断输入值是否大于 0 ,这在大规模的神经网络计算中,能够显著减少计算资源的消耗,提高计算效率。
(二)核心优势与应用场景
ReLU 函数最突出的优势之一是它完全避免了梯度饱和问题。在 Sigmoid 和 Tanh 函数中,当输入值较大或较小时,梯度会趋近于 0 ,导致在深层神经网络中出现梯度消失,使得靠近输入层的神经元权重难以更新。而 ReLU 函数在 $ x \gt 0 $ 的区域,梯度始终为 1 。这意味着在反向传播过程中,梯度能够稳定地传递到前面的层,不会因为多层传递而逐渐消失,从而大大加速了模型的收敛速度 。
在计算速度方面,ReLU 函数具有天然的优势。由于其简单的计算逻辑,仅需判断输入的符号,不需要进行复杂的指数运算,这使得它在处理大规模数据时,能够快速完成计算,节省大量的计算时间。在图像识别任务中,一张图片通常包含大量的像素点,经过多层神经网络处理时,如果使用计算复杂的激活函数,会极大地增加计算量和处理时间。而 ReLU 函数的高效计算特性,使得模型能够快速对图像进行特征提取和分类,提高了整个系统的运行效率 。
ReLU 函数还具有天然的稀疏性。在实际应用中,大约 50% 的神经元输出会为 0 ,这是因为当输入为负时,ReLU 函数的输出为 0 。这种稀疏性使得神经网络中的神经元激活呈现出稀疏状态,类似于生物神经元的部分激活特性。稀疏激活有诸多好处,一方面可以减少神经元之间的冗余连接,降低计算量;另一方面,能够减少参数之间的相互依存关系,从而有效缓解过拟合问题,提高模型的泛化能力 。
然而,ReLU 函数也并非完美无缺。它存在一个被称为 “死神经元” 的问题。当神经元的输入持续为负时,该神经元的输出将始终为 0 ,并且在反向传播过程中,其梯度也为 0 ,这就导致该神经元的权重无法得到更新,从而永久性地 “死亡” 。如果在训练过程中,学习率设置过高,可能会导致大量神经元进入这种 “死亡” 状态,严重影响模型的性能。
ReLU 函数在 0 点处不可导,这在使用基于梯度的优化算法时需要特殊处理。虽然在实际应用中,可以通过一些近似方法来解决这个问题,但不可导性仍然给模型的训练带来了一定的复杂性 。
ReLU 函数广泛应用于现代深层神经网络中,成为默认的隐藏层激活函数。在卷积神经网络(CNN)中,ReLU 函数被大量使用,通过卷积层和 ReLU 激活函数的组合,能够有效地提取图像的特征。在著名的 AlexNet、VGGNet、ResNet 等模型中,ReLU 函数都发挥了关键作用,帮助模型在图像分类、目标检测等任务中取得了优异的成绩 。
在 Transformer 架构中,ReLU 函数同样是不可或缺的一部分。Transformer 在自然语言处理领域取得了巨大的成功,如 BERT、GPT 等模型,它们利用 ReLU 函数增强了模型的非线性表达能力,能够更好地处理长序列依赖关系,对文本进行准确的理解和生成 。
(三)改进变种与优化策略
为了缓解 ReLU 函数的 “死神经元” 问题,研究人员提出了多种改进变种。Leaky ReLU 就是其中之一,它的数学表达式为 $ f(x)=\begin{cases}x, & x \gt 0 \ \alpha x, & x \leq 0\end{cases} $ ,其中 $ \alpha $ 是一个很小的正数,通常取值为 0.01 。Leaky ReLU 在输入为负时,不再将输出置为 0 ,而是乘以一个小的系数 $ \alpha $ ,这样即使输入为负,神经元仍然有微弱的激活,避免了神经元 “死亡” 。
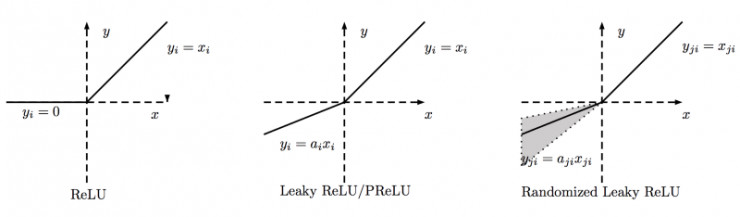
PReLU(参数化 ReLU)则进一步改进了 Leaky ReLU,它将 $ \alpha $ 变成了一个可学习的参数。在训练过程中,模型可以根据数据自动调整 $ \alpha $ 的值,从而更加灵活地适应不同的数据分布,提高模型的性能 。
在实际应用中,为了避免 ReLU 函数的 “死神经元” 问题,除了使用这些改进变种外,还需要合理控制学习率。学习率过大容易导致神经元 “死亡”,而过小则会使模型收敛速度过慢。通常可以采用一些自适应学习率的优化算法,如 Adagrad、Adadelta、Adam 等,这些算法能够根据参数的更新情况自动调整学习率,在一定程度上减少 “死神经元” 问题的发生 。
五、如何选择合适的激活函数?
在实际的深度学习应用中,选择合适的激活函数是一个关键步骤,它直接影响着模型的性能、训练效率以及泛化能力。不同的任务类型和网络结构对激活函数的需求各不相同,下面我们就从任务类型、网络结构以及一些避坑指南等方面来详细探讨如何选择合适的激活函数。
(一)按任务类型选择
二分类输出层:**在二分类任务中,Sigmoid 函数是一个经典的选择。**由于 Sigmoid 函数的输出范围在 (0,1) 之间,它可以自然地表示样本属于正类的概率 。在图像的二分类任务中,判断一张图片是猫还是狗,通过 Sigmoid 函数输出图片是猫的概率,当概率大于 0.5 时,就认为图片中的动物是猫,否则是狗。为了避免梯度消失问题,在输出层搭配交叉熵损失函数是非常必要的。交叉熵损失函数能够有效地衡量预测概率与真实标签之间的差异,在反向传播过程中,它与 Sigmoid 函数结合,可以避免梯度消失,使得模型能够更好地收敛 。
多分类输出层:对于多分类任务,Softmax 函数是最常用的激活函数。Softmax 函数将神经网络的输出转换为各个类别的概率分布,并且这些概率之和为 1 。假设我们有一个图像分类任务,要识别图片中的物体是猫、狗还是兔子,经过神经网络的计算后,再通过 Softmax 函数处理,就可以得到图片分别属于猫、狗、兔子这三个类别的概率,概率最大的类别就是模型的预测结果 。这里需要注意将 Softmax 函数与 Sigmoid 函数区分开来。
**Sigmoid 函数主要用于二分类任务,它输出的是一个概率值,表示样本属于正类的概率 。**而 Softmax 函数用于多分类任务,它将多个输出值转换为各个类别的概率分布,这些概率之间相互关联,总和为 1 。在一个三分类任务中,Sigmoid 函数会对每个类别分别计算一个概率值,这些概率值之间没有必然的联系,总和也不一定为 1 ;而 Softmax 函数会综合考虑所有类别,计算出每个类别相对于其他类别的概率,最终所有类别的概率之和为 1 。
**隐层首选:在隐藏层中,ReLU 函数通常是默认的首选。**ReLU 函数具有计算简单、能够有效避免梯度饱和问题、加速模型收敛等优点,还能使网络产生稀疏激活,减少参数之间的相互依存关系,缓解过拟合问题 。在卷积神经网络(CNN)中,大量的隐藏层使用 ReLU 函数,能够快速地提取图像的特征,提高模型的训练效率和准确性 。但是,如果在训练过程中发现死神经元问题严重,导致模型性能下降,就可以考虑换用 Leaky ReLU 或 Tanh 函数。
Leaky ReLU 通过在输入为负时给予一个小的非零输出,避免了神经元的 “死亡” 。
Tanh 函数则适用于一些浅层网络,它的对称输出特性在处理某些数据时能够表现出较好的性能 。在一些简单的图像分类任务中,如果使用 ReLU 函数出现了较多的死神经元,导致模型对某些特征的学习能力下降,这时可以尝试使用 Leaky ReLU 函数,为负输入提供一定的梯度,使得神经元能够正常更新权重,提升模型的性能 。
(二)按网络结构选择
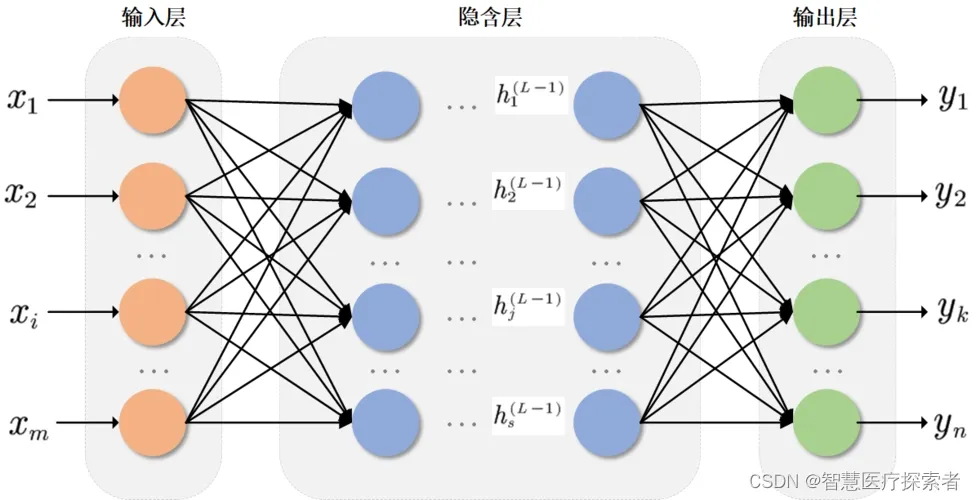
深层网络:当网络层数大于 5 层时,必须使用 ReLU 系激活函数,如 ReLU、Leaky ReLU、PReLU 等。
这是因为在深层网络中,梯度消失问题会变得非常严重,如果使用 Sigmoid 或 Tanh 函数,梯度在反向传播过程中会迅速趋近于 0 ,导致靠近输入层的神经元权重几乎无法更新,使得模型难以训练 。而 ReLU 系激活函数在正区间的梯度为常数,能够有效地避免梯度消失问题,保证梯度在网络中的稳定传播,使得深层网络能够正常训练 。在著名的 ResNet 网络中,通过使用 ReLU 激活函数,成功地训练了高达 152 层的网络,在图像分类任务中取得了优异的成绩 。
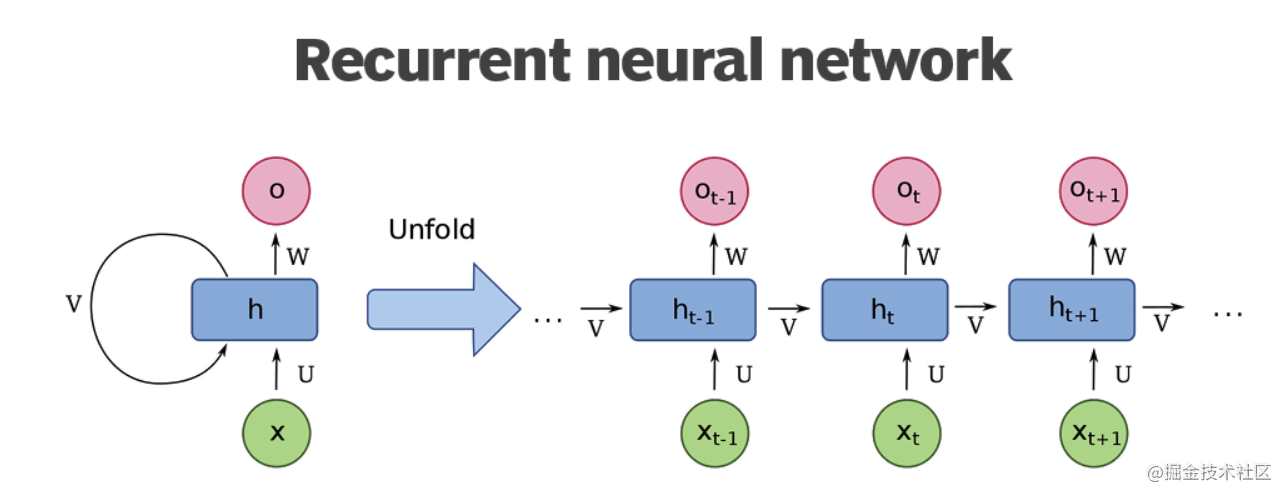
循环网络:在循环网络(RNN/LSTM)中,早期常用 Tanh 函数作为激活函数。
这是因为 Tanh 函数的对称输出特性能够较好地捕捉序列数据中的正负信息,帮助模型学习到序列数据之间的复杂依赖关系 。在自然语言处理任务中,文本数据以序列的形式呈现,Tanh 函数可以对输入的词向量进行有效的变换,提取文本中的关键特征 。然而,随着研究的发展,当前在循环网络中也更倾向于使用 ReLU 的变种,如 Leaky ReLU 等。这些变种在一定程度上解决了 ReLU 函数的死神经元问题,同时保持了 ReLU 函数的优点,使得循环网络在处理长序列数据时能够表现出更好的性能 。在处理长文本的情感分析任务时,使用 Leaky ReLU 作为循环网络的激活函数,可以避免死神经元问题,更好地捕捉文本中的情感信息,提高情感分析的准确率 。
(三)避坑指南
避免在隐层使用 Sigmoid/Tanh:除非有特殊的正则化需求,一般应避免在隐藏层使用 Sigmoid 和 Tanh 函数。这两个函数存在梯度饱和问题,在深层网络中会导致梯度消失,使得模型的训练变得非常困难 。它们的计算复杂度相对较高,涉及指数运算,会增加模型的训练时间和计算资源消耗 。
输出层激活函数与损失函数匹配:输出层的激活函数需要与损失函数进行正确匹配。Sigmoid 函数搭配二元交叉熵损失函数(BCELoss)适用于二分类任务,Softmax 函数搭配交叉熵损失函数适用于多分类任务 。如果不进行正确匹配,可能会导致模型的训练不稳定,无法收敛到较好的结果 。在一个多分类任务中,如果错误地使用 Sigmoid 函数作为输出层激活函数,并且搭配了均方误差损失函数,就会使得模型的训练效果很差,无法准确地进行分类 。

结语:激活函数的 “进化” 与未来方向
回顾激活函数的发展历程,从早期的 Sigmoid 和 Tanh 函数,到如今 ReLU 及其变种在深度学习领域的广泛应用,我们见证了激活函数不断演进以适应神经网络发展的需求。每一种激活函数的出现都伴随着对前一种函数局限性的突破,Sigmoid 函数为神经网络引入了非线性,但因其梯度消失和输出非零中心的问题,在深层网络中表现不佳;Tanh 函数虽解决了输出对称问题且收敛速度略快,但仍未摆脱梯度饱和的困扰;ReLU 函数的诞生则开启了深度学习的新纪元,其简单高效、有效避免梯度饱和等特性,使其成为现代神经网络的首选。
图片来源网络
相关文章:

从线性到非线性:简单聊聊神经网络的常见三大激活函数
大家好,我是沛哥儿,我们今天一起来学习下神经网络的三个常用的激活函数。 引言:什么是激活函数 激活函数是神经网络中非常重要的组成部分,它引入了非线性因素,使得神经网络能够学习和表示复杂的函数关系。 在神经网络…...

重生之--js原生甘特图实现
需求: 一个树形结构,根据子节点的时间范围显示显示进度 ,不同的时间范围对应不同的颜色 数据类型大概是这个样子的 甘特图 dom部分 首先要计算所有节点的 最大时间和最小时间 然后再计算每个甘特图的宽度 再计算他的偏移量 再计算颜色...

pnpm monoreop 打包时 node_modules 内部包 typescript 不能推导出类型报错
报错信息如下: ../../packages/antdv/components/pro-table/src/form-render.vue:405:1 - error TS2742: The inferred type of default cannot be named without a reference to .pnpm/scroll-into-view-if-needed2.2.31/node_modules/scroll-into-view-if-needed…...

告别默认配置!Xray自定义POC开发指南
文章涉及操作均为测试环境,未授权时切勿对真实业务系统进行测试! 下载与解压 官网地址: Xray GitHub Releases 根据系统选择对应版本: Windows:xray_windows_amd64.exe.zipLinux:xray_linux_amd64.zipmacOS:xray_darwin_amd64.zip解压后得到可执行文件(如 xray_linux_…...

websheet之 自定义函数
在线代码 {.is-success} 一、自定义函数约定 必须遵守本控件的自定函数约定才可以正常使用。 {.is-warning} 约定如下: 自定义类名称与函数名称一致。(强制)该类方法名称与函数名称一致,该方法是函数的入口。(强制&am…...

Jenkins Pipeline 构建 CI/CD 流程
文章目录 jenkins 安装jenkins 配置jenkins 快速上手在 jenkins 中创建一个新的 Pipeline 作业配置Pipeline运行 Pipeline 作业 Pipeline概述Declarative PipelineScripted Pipeline jenkins 安装 安装环境: Linux CentOS 10:Linux CentOS9安装配置Jav…...

电脑技巧:路由器内部元器件介绍
目录 1. 处理器(CPU) 2. 内存(RAM) 3. 固态存储(Flash Memory) 4. 网络接口卡(NIC) 5. 电源模块 6. 散热系统 7. 无线天线 结语 路由器是我们日常上网的重要设备,今天我们就来深入了解路由器内部的各个元器件,了解它们是如何协同工作,一起来看看吧。 1. 处理器(CPU…...

ArrayUtils:数组操作的“变形金刚“——让你的数组七十二变
各位数组操控师们好!今天给大家带来的是Apache Commons Lang3中的ArrayUtils工具类。这个工具就像数组界的"孙悟空",能让你的数组随心所欲地变大、变小、变长、变短,再也不用对着原生数组的"死板"叹气了! 一…...

电脑温度怎么看 查看CPU温度的方法
监测电脑温度对于保持硬件健康非常重要,特别是在进行高强度运算、游戏或超频等操作时。过高的温度可能导致硬件性能下降,甚至损坏。本篇文章将介绍查看电脑温度的4种方法。 一、使用Windows内置工具查看CPU温度 Windows系统本身并不直接提供查看CPU温度…...

【合新通信】---浸没式液冷光模块化学兼容性测试方法
一、测试目的与核心挑战 测试目标 验证冷媒(氟化液、矿物油等)与光模块材料的化学稳定性,确保长期浸没环境下无腐蚀、溶胀或性能衰减。关键风险点:密封材料(如硅胶、环氧树脂)的溶解或老化;金…...

shell 循环
shell 循环while语句,shell循环until语句在上一篇shell流程控制 1.shell循环until语句 until 条件 #当后面的条件表达式为假的时候的才循环,为真的时候就停止了 do 循环体 done [root@linux-server script]# cat until.sh (1) #!/bin/bash x=1 until [ $x -ge 10 ] 大于…...

【产品经理】常见的交互说明撰写方法
在产品原型设计中,交互说明是确保开发团队准确理解设计意图的关键文档。以下是常见的交互说明撰写方法及其应用场景,帮助您系统化地传达交互逻辑: 文字描述法 方法:用自然语言详细描述操作流程、反馈及规则。 适用场景ÿ…...

使用kubeadmin 部署k8s集群
成功搭建一个 Kubernetes 1.28.2 集群,包含以下组件和状态: 集群拓扑 1 个 Master 节点 IP:10.1.1.100 角色:control-plane 2 个 Worker 节点 Node2:10.1.1.101 Node3:10.1.1.102 核心组件状态 所有节点通过 kubectl get nodes 显示为 Ready。 核心 Pod(如 etc…...

二项式分布html实验
二项式分布html实验 本文将带你一步步搭建一个纯前端的二项分布 Monte-Carlo 模拟器。 只要一个 HTML 文件,打开就能运行: 动态输入试验次数 n、成功概率 p 与重复次数 m点击按钮立刻得到「模拟频数 vs 理论频数」柱状图随着 m 增大,两组柱状…...

[基础] Windows PCIe设备驱动框架与开发实践深度解析
Windows PCIe设备驱动框架与开发实践深度解析 1. PCIe设备驱动技术背景 PCI Express(Peripheral Component Interrupt Express)作为现代计算机系统的核心互连标准,其驱动程序开发涉及复杂的内核模式编程。Windows系统通过模块化的驱动架构支…...
)
面向智能家居安全的异常行为识别与应急联动关键技术研究与系统实现(源码+论文+部署讲解等)
需要资料,请文末系 一、平台介绍 3D家庭实景 - 动热力图 多模态看板 跌倒行为分析 二、论文内容 在这里插入图片描述](https://i-blog.csdnimg.cn/direct/2dfe7f45d3ce42399e0df9535870d26d.png) bash 摘要 Abstract第一章 绪论 1.1 研究背景与动机 o1.1.1…...

根据JSON动态生成表单表格
根据JSON动态生成表单表格 一. 子组件 DynamicFormTable.vue1,根据JSON数据动态生成表单表格,支持表单验证JS部分1.1,props数据1.2,表单数据和数据监听1.3,自动验证1.4,表单验证1.5,获取表单数据1.6,事件处理1.7,暴露方法给父组件2,HTML部分二,父组件1, 模拟数据2,…...

spring OncePerRequestFilter 作用
概要 OncePerRequestFilter 是 Spring Web 提供的一个抽象滤器基类,用于保证在一次 HTTP 请求的整个分派过程中,该滤器仅执行一次,无论该请求经历了多少次内部转发(forward)、包含(include)或错…...
二次开发或训练经验的关键点和概述)
关于开源大模型(如 LLaMA、InternLM、Baichuan、DeepSeek、Qwen 等)二次开发或训练经验的关键点和概述
以下是适合初学者理解的关于开源大模型(如 LLaMA、InternLM、Baichuan、DeepSeek、Qwen 等)二次开发或训练经验的关键点和概述,: 关键点: 研究表明,二次开发通常涉及微调模型以适应特定任务,需…...

promethus基础
1.下载prometheus并解压 主要配置prometheus.yml文件 在scrape_configs配置项下添加配置(hadoop202是主机名): scrape_configs: job_name: ‘prometheus’ static_configs: targets: [‘hadoop202:9090’] 添加 PushGateway 监控配置 job_name: ‘pushgateway’…...

26考研 | 王道 | 数据结构 | 第八章 排序
第八章 排序 文章目录 第八章 排序**8.1** 排序的基本概念**8.2 插入排序****8.2.1 直接插入排序****8.2.2 折半插入排序****8.2.3 希尔排序** 8.3 交换排序8.3.1 冒泡排序8.3.2 快速排序 8.4 选择排序8.4.1 简单选择排序8.4.2 堆排序堆的概念:建立大根堆的代码堆排…...

SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。 企业环境中A…...

kubesphere 单节点启动 etcd 报错
kubekey安装 ./kk create cluster -f config-sample.yaml --with-local-storage 时报错 etcd health check failed: Failed to exec command: sudo -E /bin/bash -c "export ETCDCTL_API2;export ETCDCTL_CERT_FILE/etc/ssl/etcd/ssl/admin-node1.pem;export ETCDCTL_KEY_…...

femap许可常见问题及解决方案
在使用Femap进行电磁仿真分析时,许可证管理是一个关键环节。然而,许多用户在许可证使用过程中可能会遇到各种问题。本文旨在解答关于Femap许可的常见疑问,并提供相应的解决方案,帮助您更顺畅地使用Femap许可证。 一、常见问题 许…...

游戏引擎学习第244天: 完成异步纹理下载
启动并运行游戏,注意到我们的纹理没有被下载 我们将继续完成游戏的开发。昨天,我们已经实现了多线程的纹理下载,但并没有时间调试它,因此纹理下载功能目前并没有正常工作。我们只是写了相关的代码,但由于大部分时间都…...

【安全扫描器原理】TCP/IP协议编程
【安全扫描器原理】TCP/IP协议编程 1.概述2.Windows Socket结构3.Windows socket转换类函数4.Windows Socket通信类函数 1.概述 TCP/IP协议是目前网络中使用最广泛的协议,Socket称为“套接口”,最早出现在Berkeley Unix中,最初只支持TCP/I…...
)
Cuda-GDB Frame Unwind 管理(未完.)
在计算机编程中,Frame Unwind(栈展开) 是指函数调用栈的逆向操作,即在函数返回或异常发生时,系统逐层释放栈帧(Stack Frame)、恢复调用上下文的过程。以下是详细解释及其在 GPU编程(…...

如何在IDEA中高效使用Test注解进行单元测试?
在软件开发过程中,单元测试是保证代码质量的重要手段之一。而IntelliJ IDEA作为一款强大的Java开发工具,提供了丰富的功能来支持JUnit测试,尤其是通过Test注解可以快速编写和运行单元测试。那么,如何在IDEA中高效使用Test注解进行…...

什么是访客鉴权?全面解析核心原理与CC防护应用实践
一、访客鉴权是什么? 访客鉴权(Visitor Authentication and Authorization)是系统对访问者进行身份验证和权限控制的过程,确保只有合法用户能够访问特定资源或执行特定操作。其核心目标是确认身份、控制权限、保障数据安全&#…...

DeepSeek大模型应用学习通知
随着人工智能在各领域深度融合发展,DeepSeek大模型迅速火爆全网,清华大学以最快的速度发布了DeepSeek从入门到精通使用技巧,能够更好的助力于企业和个人参与到AI研究和应用中,对于AI行业创新有重要意义,被誉为国运级的…...
时间序列预测模型比较分析:SARIMAX、RNN、LSTM、Prophet 及 Transformer
时间序列预测根据过去的模式预测未来事件。我们的目标是找出最佳预测方法,因为不同的技术在特定条件下表现出色。本文章将探讨各种方法在不同数据集上的表现,为你在任何情况下选择和微调正确的预测方法提供真知灼见。 我们将探讨五种主要方法࿱…...

快速了解redis,个人笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note (基于mac展示,别的可以参考)接下来将直接…...

Dify依赖管理poetry切换为uv
Dify升级 1.3.0 后api的依赖管理从poetry切换为了 uv管理,但是官网暂时还没有更新。 升级 tag:Dify 1.3.0版本 在此记录一下 uv 依赖管理操作 使用方法 [重要事项] 在 v1.3.0 版本中,poetry 已被[ uv ](https://docs.astral.sh/uv/) 替代…...

VGA 接口静电防护方案
VGA(Video Graphics Array)即视频图形阵列,具有分辨率高、显示速 率快、颜色丰富等优点,亦称为 D-Sub 接口,在彩色显示器领域得到了广 泛的应用, 如笔记本、投影仪、LCD 液晶显示屏 等。VGA 接口主要用于连接 计算机与显示设备。当…...

MySQL 详解之用户、权限与审计:保障数据安全的基石
在数据库系统中,数据是核心资产,对其的访问必须受到严格控制。谁能连接到数据库?他们能看到哪些数据?能执行哪些操作(读、写、修改结构)?系统中的所有操作是否被记录以便追溯?这正是用户管理、权限系统和审计机制需要解决的问题。 在 MySQL 中: 用户 (Users): 负责认…...

力扣面试150题--环形链表和两数相加
Day 32 题目描述 思路 采取快慢指针 /*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public class Solution {public boolean hasCycle(ListNod…...

HMI与组态,自动化的“灵珠”和“魔丸”
在现代工业自动化领域,组态(Configuration)和人机界面(HMI,Human-Machine Interface)是两个核心概念,它们在智能化控制系统中发挥着至关重要的作用。尽管这两者看似简单,但它们的功能…...
)
AbMole| CU-CPT-8m(CAS号125079-83-6;目录号M9746)
CU-CPT-8m是一种特异性的TLR8(toll-like receptor 8)拮抗剂,其IC50值为67 nM,Kd值为220 nM。 生物活性 CU-CPT-8m是一种特异性的TLR8(toll-like receptor 8)拮抗剂,其IC50值为67 nM,…...

【网络入侵检测】基于源码分析Suricata的PCAP模式
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 本文聚焦于 Suricata 7.0.10 版本源码,深入剖析其 PCAP 模式的实现原理。通过系统性拆解初始化阶段的配置流程、PCAP 数据包接收线程的创建与运行机制,以及数据…...

【滑动窗口+哈希表/数组记录】Leetcode 438. 找到字符串中所有字母异位词
题目要求 给定两个字符串 s 和 p,找到 s 中所有 p 的异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次。 示例 1 输入:s…...

uniapp自定义封装tabbar
uniapp自定义封装tabbar 开发原因: 有很多时候 小程序并没有其类目 需要通过配置发布审核, ps:需要去掉项目pages.json tabbar配置,不然重进会显示默认,跳转页面不能uni.switchTab。 组件tabbar <template><viewclass&…...

uni-app云开发总结
uni-app云开发总结 云开发无非就三个概念:云数据库、云函数、云存储 uni-app中新增了一个概念叫做云对象,它其实就是云函数的加强版,它是导出的一个对象,对象中可以包含多个操作数据库的函数,接下来咱们就详细对uni-…...

uniapp-商城-37-shop 购物车 选好了 进行订单确认3 支付栏
支付栏 就是前面用的 car-Layout 在shop也用来这个组件 只是在那里用来的是购物车。 1、 样式 我们开始进入这个页面是点击的shop的购物篮 到这里就变成了支付栏 其实他们是同一个组件 只是做了样式区分 2、具体看看样式和代码 2.1 消失了购物车和改变了按钮名字 如何…...

搜索二叉树-key的搜索模型
二叉搜索树(Binary Search Tree, BST)是一种重要的数据结构,它有两种基本模型:Key模型和Key/Value模型。 一、Key模型 1.基本概念 Key模型是二叉搜索树中最简单的形式,每个节点只存储一个键值(key),没有额外的数据值(value)。这…...

Qt ModbusSlave多线程实践总结
最近项目中用到了ModbusSlave,也就是Modbus从设备的功能,之前用的基本都是master设备,所以读取数据啥的用单线程就行了,用 void WaitHelper::WaitImplByEventloop(int msec) {QEventLoop loop;QTimer::singleShot(msec, &loop…...

Leetcode刷题记录18——接雨水
题源:https://leetcode.cn/problems/trapping-rain-water/description/?envTypestudy-plan-v2&envIdtop-100-liked 题目描述: 思路一: 🌟 本题核心思想:木桶效应 每个位置的“桶”:假设每个柱子的位…...

IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤
以下是在 IntelliJ IDEA 中配置 Spring MVC 环境的详细步骤: 步骤 1:创建 Maven Web 项目 新建项目 File -> New -> Project → 选择 Maven → 勾选 Create from archetype → 选择 maven-archetype-webapp。输入 GroupId(如 com.examp…...
)
全球玻璃纸市场深度洞察:环保浪潮下的材料革命与产业重构(2025-2031)
一、行业全景:从传统包装到绿色经济的战略支点 玻璃纸(Cellulose Film),即再生纤维素薄膜,以木浆、棉浆等天然纤维素为原料,通过碱化、黄化、成型等工艺制成,兼具透明性、柔韧性及100%生物降解性…...

提示js方法未定义,但是确实<textarea>标签未闭合。
1、问题现象。 Uncaught ReferenceError: showOtherDismantleFn is not defined 但是这个方法,在代码中明明存在。 #if($!{isNewEnergy})#if($!{batteryName} 宁德时代)<button class"btn btn-info btn-xs" onclick"showNingDismantleFn()&quo…...

spring中的@bean注解详解
在Spring框架中,Bean注解是用于显式声明一个Bean的核心方式之一,尤其在基于Java的配置中。Spring框架中的Bean注解实现原理涉及多个核心机制,包括配置类解析、Bean定义注册、动态代理及依赖注入等 一、Bean注解的作用 Bean用于标注在方法上&…...