Kafka和Spark-Streaming
Kafka和Spark-Streaming
一、Kafka
1、Kafka和Flume的整合
① 需求1:利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台:
在flume/conf下添加.conf文件,
vi flume-kafka.conf 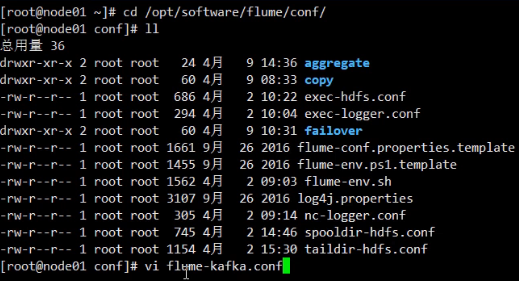
# 定义 Agent 组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# 配置 Source(监控目录)
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/root/flume-kafka/
a1.sources.r1.inputCharset=utf-8
# 配置 Sink(写入 Kafka)
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
#指定写入数据到哪一个topic
a1.sinks.k1.kafka.topic=testTopic
#指定写入数据到哪一个集群
a1.sinks.k1.kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
#指定写入批次
a1.sinks.k1.kafka.flumeBatchSize=20
#指定acks机制
a1.sinks.k1.kafka.producer.acks=1
# 配置 Channel(内存缓冲)
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
# 最大存储 1000 个 Event
a1.channels.c1.transactionCapacity=100
# 每次事务处理 100 个 Event
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
在指定目录之下创建文件夹: 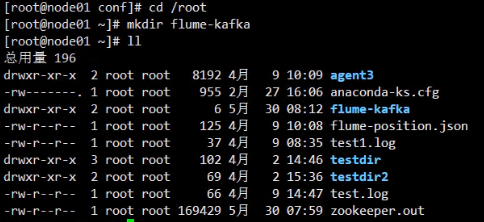
kafka中创建topic:
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic testTopic --partitions 3 --replication-factor 3
启动flume:
flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
启动kafka消费者,验证数据写入成功
kafka-console-consumer.sh --topic testTopic --bootstrap-server node01:9092,node02:9029,node03:9092 --from-beginning
新增测试数据:
echo "hello flume,hello kafka" >> /root/flume-kafka/1.txt
flume:

Kafka消费者: 
② 需求2:Kafka生产者生成的数据利用Flume进行采集,将采集到的数据打印到Flume的控制台上。
vi kafka-flume.conf

# 定义 Agent 组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# 将 Flume Source 设置为 Kafka 消费者,从指定 Kafka 主题拉取数据。
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
#指定zookeeper集群地址
a1.sources.r1.zookeepers=node01:2181,node02:2181,node03:2181
#指定kafka集群地址
a1.sources.r1.kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
#指定生成消息的topic
a1.sources.r1.kafka.topics=testTopic
# 将 Flume 传输的数据内容直接打印到日志中,
a1.sinks.k1.type=logger
# 配置 Channel(内存缓冲)
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transcationCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动Kafka生产者
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic testTopic
启动Flume
flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/kafka-flume.conf -n a1 -Dflume.root.logger=INFO,console
在生产者中写入数据 
Flume中采集到数据

2、Kafka和SparkStreaming的整合
① 导包。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.2</version>
</dependency>
② 代码实现。
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setNode01("local[*]")
.setAppName(this.getClass.getSimpleName)
val ssc= new StreamingContext(conf,Seconds(2))
// kafka的参数配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "hello_topic_group",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("helloTopic3")
//指定泛型的约定[String, String] key value
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd=>{
rdd.foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
③ 利用Redis维护偏移量。使用Spark消费Kafka中的数据。
val config = ConfigFactory.load()
val conf = new SparkConf()
.setNode01("local[*]")
.setAppName(this.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(3))
val groupId = "hello_topic_group"
val topic = "helloTopic7"
val topicArr = Array(topic)
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
// 是否可以自动提交偏移量 自定义
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 需要设置偏移量的值
val offsets = mutable.HashMap[TopicPartition, Long]()
// 从redis中获取到值
val jedis1 = JedisPoolUtils.getJedis()
val allPO: util.Map[String, String] = jedis1.hgetAll(groupId + "-" + topic)
// 导入转换
import scala.collection.JavaConversions._
for(i<- allPO){
// 主题 和分区 -> offset
offsets += (new TopicPartition(topic,i._1.toInt) -> i._2.toLong)
}
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
Subscribe[String, String](topicArr, kafkaParams, offsets)
)
stream.foreachRDD(rdd => {
// rdd ConsumerRecord[String, String]
val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val result = rdd.map(_.value()).map((_, 1)).reduceByKey(_ + _)
result.foreachPartition(it => {
val jedis = JedisPoolUtils.getJedis()
it.foreach(tp => jedis.hincrBy("streamkfkwc", tp._1, tp._2))
// 等迭代器中的数据,全部完成之后,再关
jedis.close()
})
// 把偏移量的Array 写入到redis中
val jedis = JedisPoolUtils.getJedis()
ranges.foreach(t => {
jedis.hset(groupId + "-" + t.topic, t.partition.toString, t.untilOffset + "")
})
jedis.close()
})
ssc.start()
ssc.awaitTermination()
二、Spark-Streaming核心编程(三)
DStream转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
1、无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。
注意,针对键值对的 DStream 转化操作(比如reduceByKey())要添加
import StreamingContext._才能在 Scala 中使用。 
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。
例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
1.1、Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineDStream :ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
val wordAndCountDStream :DStream[(String,Int)] = lineDStream.transform(rdd => {
val words :RDD[String] = rdd.flatMap(_.split(" "))
val wordAndOne :RDD[(String,Int)] = words.map((_,1))
val value :RDD[(String,Int)] = wordAndOne.reduceByKey(_+_)
value
})
wordAndCountDStream.print()
ssc.start()
ssc.awaitTermination()

1.2、join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("join")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineDStream1 :ReceiverInputDStream[String] = ssc.
socketTextStream("node01",9999)
val lineDStream2 :ReceiverInputDStream[String] = ssc.
socketTextStream("node02",8888)
val wordToOneDStream :DStream[(String,Int)] = lineDStream1
.flatMap(_.split(" ")).map((_,1))
val wordToADstream :DStream[(String,String)] = lineDStream2
.flatMap(_.split(" ")).map((_,"a"))
val joinDStream :DStream[(String,(Int,String))]=wordToOneDStream
.join(wordToADstream)
joinDStream.print()
ssc.start()
ssc.awaitTermination()
相关文章:

Kafka和Spark-Streaming
Kafka和Spark-Streaming 一、Kafka 1、Kafka和Flume的整合 ① 需求1:利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台: 在flume/conf下添加.conf文件, vi flume…...

5.2 AutoGen:支持多Agent对话的开源框架,适合自动化任务
AutoGen作为由Microsoft开发的开源框架,已成为构建多Agent对话系统和自动化任务的领先工具。其核心在于通过自然语言和代码驱动的多Agent对话,支持复杂任务的自治执行或结合人类反馈优化,广泛应用于客服自动化、金融分析、供应链优化和医疗诊…...

探索亚马逊云科技:开启您的云计算之旅
前言 在当今数字化时代,云计算已成为企业和个人不可或缺的技术基础设施。作为全球领先的云服务提供商,亚马逊云科技(Amazon Web Services)为您提供强大、可靠且安全的云计算解决方案。 想要立即体验亚马逊云科技的强大功能&#x…...

2023年第十四届蓝桥杯Scratch02月stema选拔赛真题——算式题
完整题目可点击下方地址查看,支持在线编程,支持源码和素材获取: 算式题_scratch_少儿编程题库学习中心-嗨信奥https://www.hixinao.com/tiku/scratch/show-4267.html?_shareid3 程序演示可点击下方地址查看,支持源码和素材获取&…...

霍格软件测试-JMeter高级性能测试一期
课程大小:32.2G 课程下载:https://download.csdn.net/download/m0_66047725/90631395 更多资源下载:关注我 当下BAT、TMD等互联网一线企业已几乎不再招募传统测试工程师,而只招测试开发工程师!在软件测试技术栈迭代…...
)
django.db.utils.OperationalError: (1050, “Table ‘你的表名‘ already exists“)
这个错误意味着 Django 尝试执行迁移时,发现数据库中已经有一张叫 你的表名的表了,但这张表不是通过 Django 当前的迁移系统管理的,或者迁移状态和数据库实际状态不一致。 🧠 可能出现这个问题的几种情况: 1.你手动创…...

分布式ID生成方案详解
分布式ID生成方案详解 一、问题背景 分库分表场景下,传统自增ID会导致不同库/表的ID重复,需要分布式ID生成方案解决以下核心需求: •全局唯一性:跨数据库/表的ID不重复 •有序性:利于索引优化和范围查询 •高性能&…...

短视频矩阵系统可视化剪辑功能开发,支持OEM
在短视频营销与内容创作竞争日益激烈的当下,矩阵系统中的可视化剪辑功能成为提升内容产出效率与质量的关键模块。它以直观的操作界面和强大的编辑能力,帮助创作者快速将创意转化为优质视频。本文将结合实际开发经验,从需求分析、技术选型到核…...

使用开源免费雷池WAF防火墙,接入保护你的网站
使用开源免费雷池WAF防火墙,接入保护你的网站 大家好,我是星哥,昨天介绍了《开源免费WEB防火墙,不让黑客越雷池一步!》链接:https://mp.weixin.qq.com/s/9TOXth3128N6PtXhaWI5aw 今天讲一下如何把网站接入…...

Python-Agent调用多个Server-FastAPI版本
Python-Agent调用多个Server-FastAPI版本 Agent调用多个McpServer进行工具调用 1-核心知识点 fastAPI的快速使用agent调用多个server 2-思路整理 1)先把每个子服务搭建起来2)再暴露一个Agent 3-参考网址 VSCode配置Python开发环境:https:/…...

spark-standalone模式
Spark Standalone模式是Spark集群的一种部署方式,即在没有使用其他资源管理器(如YARN或Mesos)的情况下,在Spark自身提供的集群管理器中部署和运行Spark应用程序。 在Spark Standalone模式下,有一个主节点(…...

3、LangChain基础:LangChain Chat Model
Prompt templates: Few shot、Example selector Few shot(少量示例) 创建少量示例的格式化程序 创建一个简单的提示模板,用于在生成时向模型提供示例输入和输出。向LLM提供少量这样的示例被称为少量示例,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型…...

信创时代开发工具选择指南:国产替代背景下的技术生态与实践路径
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
)
Coze高阶玩法 | 使用Coze制作思维认知提升视频,效率提升300%!(附保姆级教程)
目录 一、工作流整体设计 二、制作工作流 2.1 开始节点 2.2 大模型 2.3 文本处理 2.4 代码 2.5 批处理 2.6 选择器 2.7 画板_视频模板 2.8 合成音频 2.9 图片与音频合并视频 2.10 视频合并 2.11 结束节点 三、智能体应用体验 中午吃饭的时候,刷到了一个思维认知…...

数据湖DataLake和传统数据仓库Datawarehouse的主要区别是什么?优缺点是什么?
数据湖和传统数据仓库的主要区别 以下是数据湖和传统数据仓库的主要区别,以表格形式展示: 特性数据湖传统数据仓库数据类型支持结构化、半结构化及非结构化数据主要处理结构化数据架构设计扁平化架构,所有数据存储在一个大的“池”中多层架…...
:插件开发,以一个音频生成(Audio Source)插件为例)
GStreamer 简明教程(十一):插件开发,以一个音频生成(Audio Source)插件为例
系列文章目录 GStreamer 简明教程(一):环境搭建,运行 Basic Tutorial 1 Hello world! GStreamer 简明教程(二):基本概念介绍,Element 和 Pipeline GStreamer 简明教程(三…...

chrome://inspect/#devices 调试 HTTP/1.1 404 Not Found 如何解决
使用chrome是需要翻墙的,可以换个浏览器进行使用 可以使用edge浏览器,下载地址如下 微软官方edge浏览器|Mac版:浏览更智能,工作更高效 下载Edge浏览器 edge://inspect/#devices 点击inspect即可 qq浏览器 1. 下载qq浏览器 2. …...

RFID使用指南
## 什么是RFID? RFID(Radio Frequency Identification)即射频识别技术,是一种通过无线电波进行非接触式数据交换的技术。 ## RFID系统的主要组成部分 1. **RFID标签(Tag)** - 包含芯片和天线 - 分为有源标…...

初识Redis · 哨兵机制
目录 前言: 引入哨兵 模拟哨兵机制 配置docker环境 基于docker环境搭建哨兵环境 对比三种配置文件 编排主从节点和sentinel 主从节点 sentinel 模拟哨兵 前言: 在前文我们介绍了Redis的主从复制有一个最大的缺点就是,主节点挂了之…...
代理模式)
JAVA设计模式——(七)代理模式
JAVA设计模式——(七)代理模式 介绍理解实现抽象主题角色具体主题角色代理类测试 应用 介绍 代理模式和装饰模式还是挺像的。装饰模式是抽象类对装饰对象的实现,在继承装饰对象。代理模式则是直接对代理对象的实现。 理解 代理模式可以看成…...

Redis 原子操作
文章目录 前言✅ 一、什么是「原子操作」?🔍 二、怎么判断一个操作是否原子?🧪 三、项目中的原子 vs 非原子案例(秒杀系统)✅ 原子性(OK)❌ 非原子性(高风险)…...

待办事项日历组件实现
待办事项日历组件实现 今天积累一个简易的待办事项日历组件的实现方法。 需求: 修改样式,变成符合项目要求的日历样式日历上展示待办事项提示(有未完成待办:展示黄点,有已完成待办:展示绿点)…...

Flask 请求数据获取方法详解
一、工作原理 在 Flask 中,所有客户端请求的数据都通过全局的 request 对象访问。该对象是 请求上下文 的一部分,仅在请求处理期间存在。Flask 在收到请求时自动创建 request 对象,并根据请求类型(如 GET、POST)和内容…...

PicoVR眼镜在XR融合现实显示模式下无法显示粒子问题
PicoVR眼镜开启XR融合现实显示模式下,Unity3D粒子效果无法显示问题,其原因是XR融合显示模式下,Unity3D应用显示层在最终合成到眼镜显示器时,驱动层先渲染摄像机画面,再以Alpha透明方式渲染应用层画面,问题就…...

vue-lottie的使用和配置
一、vue-lottie 简介 vue-lottie 是一个 Vue 组件,用于在 Vue 项目中集成 Airbnb 的 Lottie 动画库。它通过 JSON 文件渲染 After Effects 动画,适用于复杂矢量动画的高效展示。 二、安装与基础使用 1. 安装 npm install vue-lottielatest # 或 yarn…...

PyTorch 实现食物图像分类实战:从数据处理到模型训练
一、简介 在计算机视觉领域,图像分类是一项基础且重要的任务,广泛应用于智能安防、医疗诊断、电商推荐等场景。本文将以食物图像分类为例,基于 PyTorch 框架,详细介绍从数据准备、模型构建到训练测试的全流程,帮助读者…...

传统中台的重生——云原生如何重塑政务系统后端架构
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:传统后端架构的“痛”与“变” 在过去十年中,无数企业和机构纷纷构建中台系统,尤其是政务、金融、交通、教育等领域。这些中台系统一般基于 Java EE 单体架构,集中部署于虚拟机上,靠人…...

jQuery AJAX、Axios与Fetch
jQuery AJAX、Axios与Fetch对比 #mermaid-svg-FRNqb7d4i2fmbavm {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-FRNqb7d4i2fmbavm .error-icon{fill:#552222;}#mermaid-svg-FRNqb7d4i2fmbavm .error-text{fill:#552…...

【Hive入门】Hive数据导出完全指南:从HDFS到本地文件系统的专业实践
目录 引言 1 Hive数据导出概述 1.1 数据导出的核心概念 1.2 典型导出场景 2 Hive到HDFS导出详解 2.1 INSERT OVERWRITE DIRECTORY方法 2.2 多目录导出技术 2.3 动态分区导出 3 HDFS到本地文件系统转移 3.1 hadoop fs命令操作 3.2 分布式拷贝工具DistCp 4 直接导出到…...
)
stack __ queue(栈和队列)
1. stack的介绍和使用 栈和队列里面都叫容器适配器 存储数据就要交给别的容器 通过封装别的容器,可以进行相应的操作,来达到目的 适配的本质就是复用 这就没有迭代器了,不支持随便遍历 2. queue的介绍和使用 下面用一些题来深入理解 栈…...

UML 类图基础和类关系辨析
UML 类图 目录 1 概述 2 类图MerMaid基本表示法 3 类关系详解 3.1 实现和继承 3.1.1 实现(Realization)3.1.2 继承/泛化(Inheritance/Generalization) 3.2 聚合和组合 3.2.1 组合(Composition)3.2.2 聚…...

STM32F103C8T6信息
STM32F103C8T6 完整参数列表 一、核心参数 内核架构 ARM Cortex-M3 32位RISC处理器 最大主频:72 MHz(基于APB总线时钟) 运算性能:1.25 DMIPS/MHz(Dhrystone 2.1基准) 总线与存储 总线宽度ÿ…...

unity 读取csv
1.读取代码 string filePath Application.streamingAssetsPath "\\data.csv"; public List<MovieData> movieData new List<MovieData>(); private void ReadCSV(string filePath) { List<List<string>> data new List<…...

那些年踩过的坑之Arrays.asList
一、前言 熟悉开发的兄弟都知道,在写新增和删除功能的时候,大多数时候会写成批量的,原因也很简单,批量既支持单个也支持多个对象的操作,事情也是发生在这个批量方法的调用上,下面我简单说一下这个事情。 二…...

ASP.NET Core 自动识别 appsettings.json的机制解析
ASP.NET Core 自动识别 appsettings.json 的机制解析 在 ASP.NET Core 中,IConfiguration 能自动识别 appsettings.json 并直接读取值的机制,是通过框架的 “约定优于配置” 设计和 依赖注入系统 共同实现的。以下是详细原理: 默认配置源的自…...

深入解析Mlivus Cloud核心架构:rootcoord组件的最佳实践与调优指南
作为大禹智库的向量数据库高级研究员,同时也是《向量数据库指南》的作者,我在过去30年的向量数据库和AI应用实战中见证了这项技术的演进与革新。今天,我将以专业视角为您深入剖析Mlivus Cloud的核心组件之一——rootcoord,这个组件在系统架构中扮演着至关重要的角色。如果您…...

ApplicationEventPublisher用法-笔记
1.ApplicationEventPublisher简介 org.springframework.context.ApplicationEventPublisher 是 Spring 框架中用于发布自定义事件的核心接口。它允许你在 Spring 应用上下文中触发事件,并由其他组件(监听器)进行响应。 ApplicationEventPub…...

数字孪生:从概念到实践,重构未来产业的“虚拟镜像”
一、开篇:为什么数字孪生是下一个技术风口? 现象级案例引入: “特斯拉用数字孪生技术将电池故障预测准确率提升40%;西门子通过虚拟工厂模型缩短30%产品研发周期;波音777X飞机设计全程零实物原型……” 数据支撑&#…...

Python笔记:VS2013编译Python-3.5.10
注:本文是编译老版本,有点麻烦,测试了编译新版,基本上是傻瓜是操作即可 1. python官网下载源码 https://www.python.org/ftp/python/3.5.10/Python-3.5.10.tgz 2. 编译前查看目录中相关文档 源码目录结构 看README文档 经过查…...
设计)
STM32八股【6】-----CortexM3的双堆栈(MSP、PSP)设计
STM32的线程模式(Thread Mode)和内核模式(Handler Mode)以及其对应的权级和堆栈指针 线程模式: 正常代码执行时的模式(如 main 函数、FreeRTOS任务) 可以是特权级(使用MSPÿ…...

MySQL触法器
1. 什么是触发器及其特点 MySQL数据库中触发器是一个特殊的存储过程,不同的是执行存储过程要使用 CALL 语句来调用,而触发器的执行不需要使用 CALL 语句来调用,也不需要手工启动,只要一个预定义的事件发生就会被 MySQL自动调用。…...

金仓数据库征文-政务领域国产化数据库更替:金仓 KingbaseES 应用实践
目录 一.金仓数据库介绍 二.政务领域数据库替换的时代需求 三.金仓数据库 KingbaseES 在政务领域的替换优势 1.强大的兼容性与迁移能力 2.高安全性与稳定性保障 3.良好的国产化适配性 四.金仓数据库 KingbaseES 在政务领域的典型应用实践 1.电子政务办公系…...

微服务架构在云原生后端的深度融合与实践路径
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:后端架构的演变,走向云原生与微服务融合 过去十余年,后端架构经历了从单体应用(Monolithic)、垂直切分(Modularization)、到微服务(Microservices)的演进,每一次变化都是为了解决…...

北斗导航 | 北斗卫星导航单点定位与深度学习结合提升精度
以下是北斗卫星导航单点定位(SPP)与深度学习结合提升精度的关键方法总结,综合了误差建模、信号识别、动态环境适应等技术方向: 一、非直射信号(NLOS)抑制与权重修正 1. 双自注意力网络(Dual Self-Attention Network) 原理:通过同时建模卫星信号的空间环境特征(如天空…...
桌面时钟工具软件下载安装教程)
AlarmClock4.8.4(官方版)桌面时钟工具软件下载安装教程
1.软件名称:AlarmClock 2.软件版本:4.8.4 3.软件大小:187 MB 4.安装环境:win7/win10/win11(64位) 5.下载地址: https://www.kdocs.cn/l/cdZMwizD2ZL1?RL1MvMTM%3D 提示:先转存后下载,防止资…...
:把握创业阶段与第一关键指标)
精益数据分析(23/126):把握创业阶段与第一关键指标
精益数据分析(23/126):把握创业阶段与第一关键指标 在创业和数据分析的学习过程中,每一次深入探索都可能为我们打开新的大门。今天,我依旧带着和大家共同进步的想法,来解读《精益数据分析》中的重要内容—…...

【华为HCIP | 华为数通工程师】821—多选解析—第十六页
多选814、关于OSPF AS-External-LSA说法正确的是: A、Net mask被设置全0 B、Link State ID被设置为目的网段地址 C、Advertising Router被设置为ASBR的Router ID D、使用Link State ID和Advertising Router可以唯一标识一条AS-External-LSA 解析:Net mask代表的是掩码…...

Linux:进程间通信->匿名管道实现内存池
1. 进程间通信 (1) 概念 进程间通信(IPC) 就是不同进程间交换数据的方法,进程间是独立的所以不能访问彼此的内存,需要某种机制来通信(管道、消息队列,共享内存等) (2) 目的 数据传输:一个进程需要他的数据发送给另一个进程 资源…...

Linux服务器离线安装ollama及大模型
Linux服务器离线安装ollama及大模型 核心思路:使用一台可以联网的电脑将需要的ollama安装包和大模型下载到本地,之后传输到Linux服务器上安装并配置 环境说明 联网机:macOS M1Pro Linux服务器:x86_64 安装ollama版本:…...

C++ 类及函数原型详解
一、引言 在C 编程中,类(Class)是面向对象编程的核心概念之一,它是一种用户自定义的数据类型,封装了数据和操作数据的函数(成员函数)。函数原型则为函数的声明提供了必要的信息,让编…...