26考研 | 王道 | 数据结构 | 第七章 查找
第七章 查找
文章目录
- 第七章 查找
- 7.1 查找概念
- 7.2 顺序查找
- 7.3 折半查找
- 7.4 分块查找
- 7.5 二叉排序树
- 7.6 平衡二叉树
- 平衡二叉树的插入
- 平衡二叉树的删除
- 7.7 红黑树
- 7.7.1 为什么要发明红黑树?
- 7.7.2 红黑树的定义和性质
- 7.7.3 红黑树的插入和删除
- `插入`
- `删除`
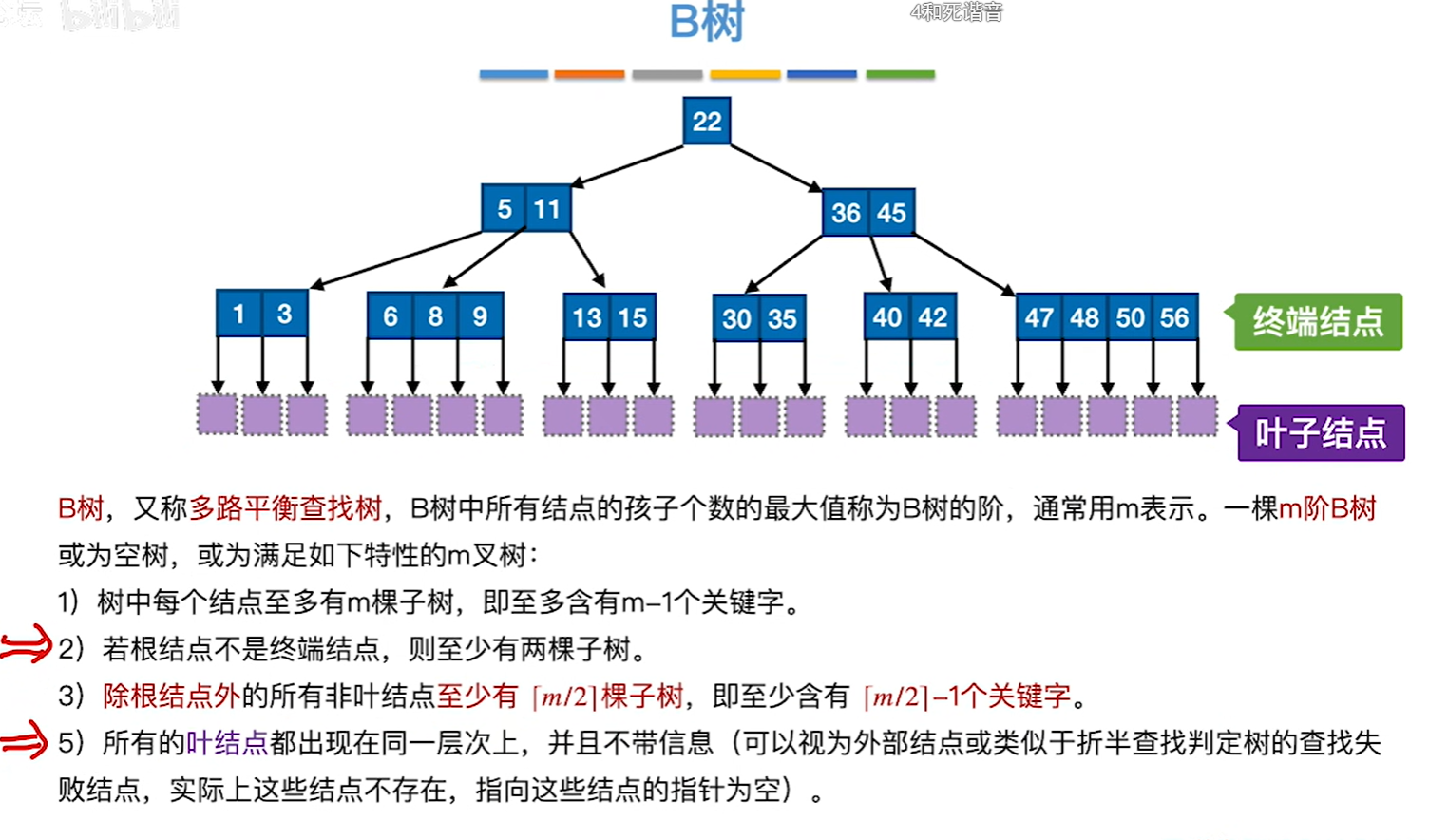
- 7.8 B树和B+树
- 7.8.1 B树
- 7.8.2 B树的基本操作
- 7.8.3 B+树
- 7.8.4 B树和B+树的比较
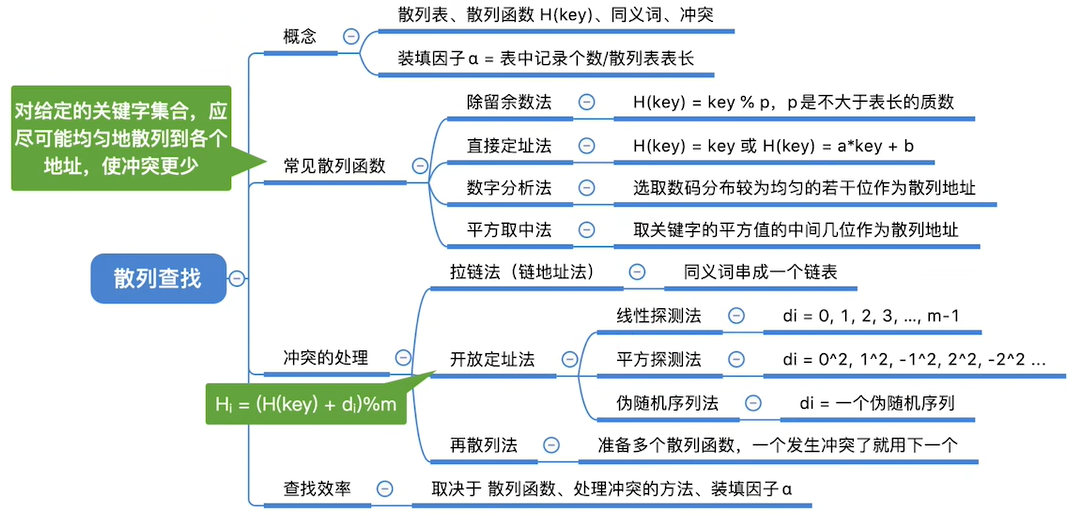
- 7.9 散列查找及其性能分析
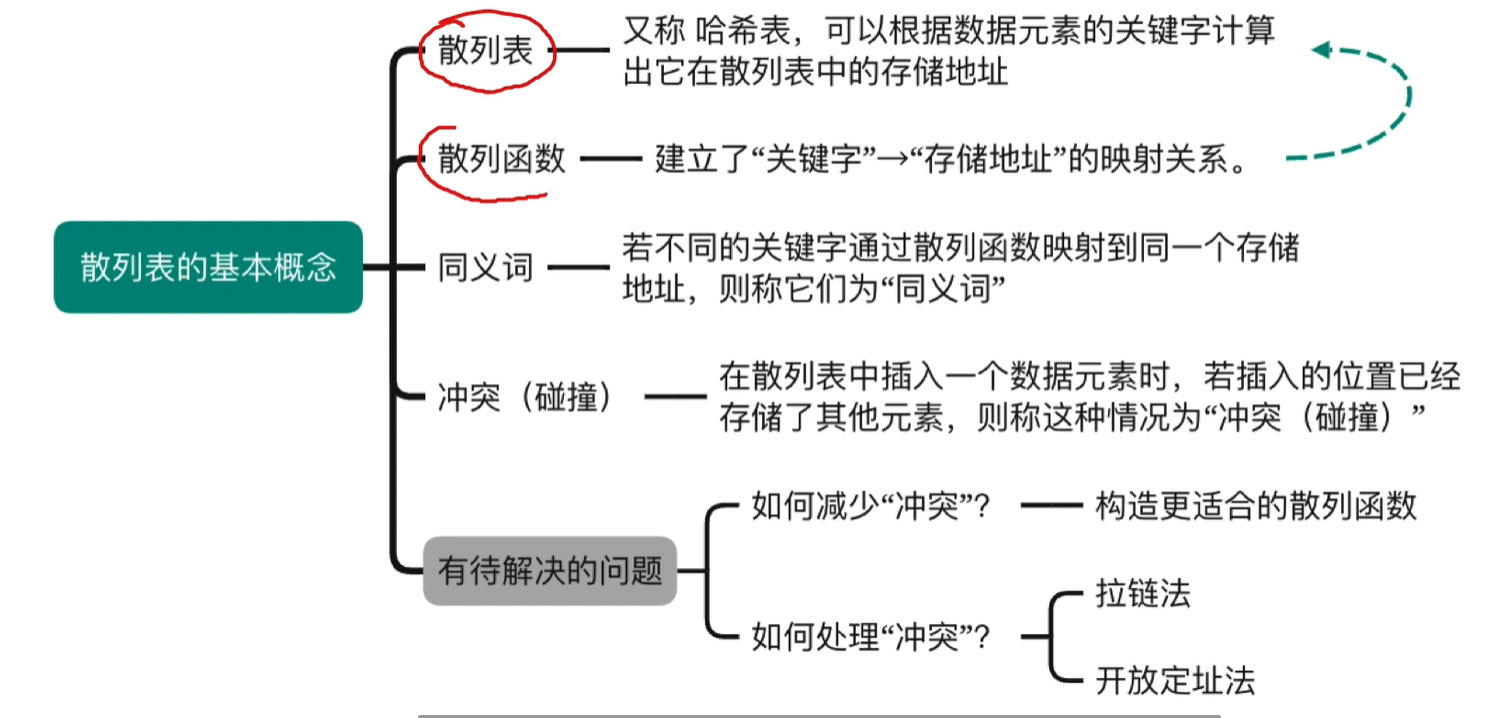
- 7.9.1 散列表的基本概念
- 7.9.2 散列函数的构造方法
- 1.除留余数法
- 2.直接定址法
- 3.数字分析法
- 4.平方取中法
- 7.9.3 处理冲突的方法
- 1.拉链法
- 2.开放地址法
- 7.9.4 散列查找及性能分析
7.1 查找概念
-
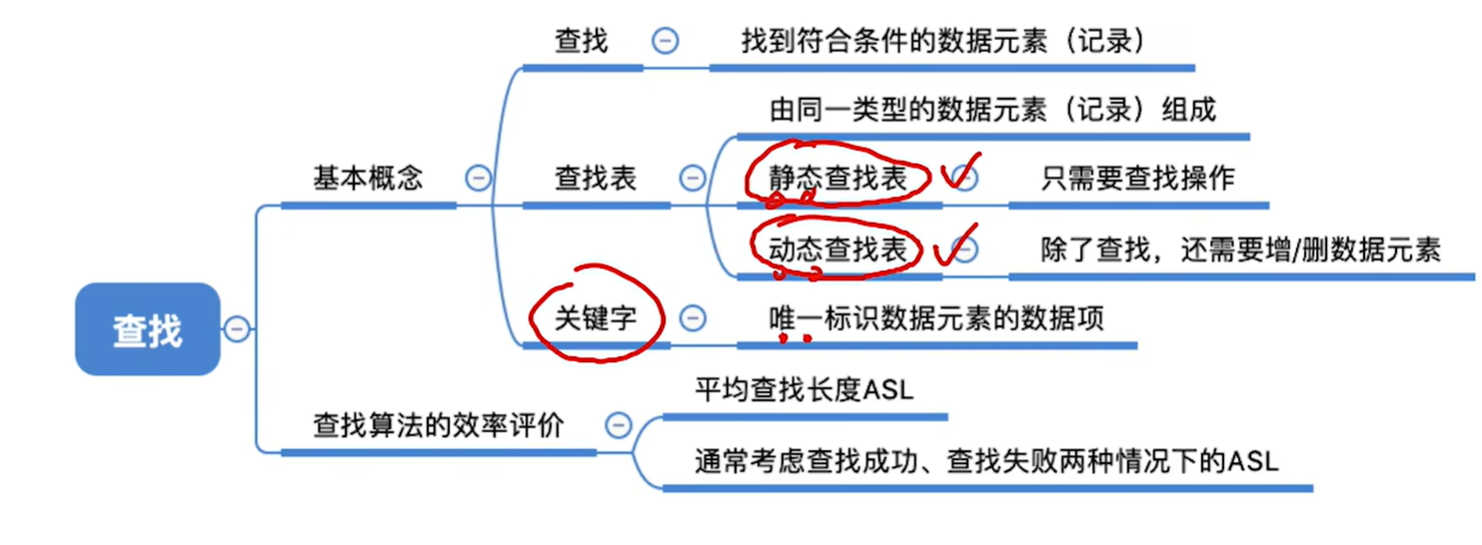
**查找:**在数据集合中寻找满足某种条件的数据元素的过程称为查找。
-
**查找表(查找结构):**用于查找的数据集合称为查找表,它由同一类型的数据元素 (或记录)组成。
-
**关键字:**数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。
-
对查找表的常⻅操作:
- 查找符合条件的数据元素
- 插⼊、删除某个数据元素
- 只需要进行操作1的是静态查找表
- 1和2都需要进行的是动态查找表
-
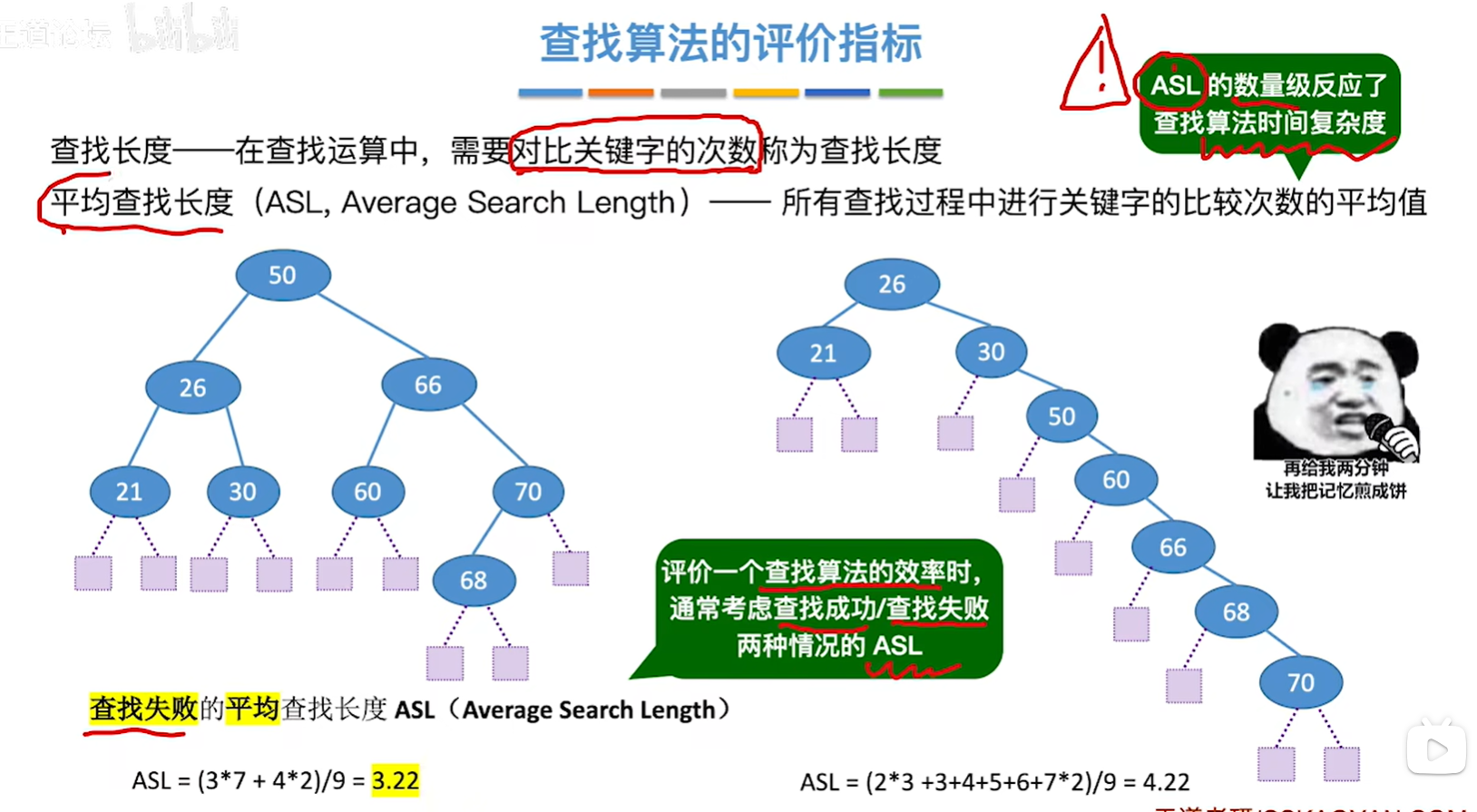
**查找长度:**在查找运算中,需要对比关键字的次数称为查找长度。
-
平均查找长度(ASL,Average Search Length): 所有查找过程中进行关键字的比较次数的平均值。
-
-
ASL的数量级反应了查找算法时间复杂度
7.2 顺序查找
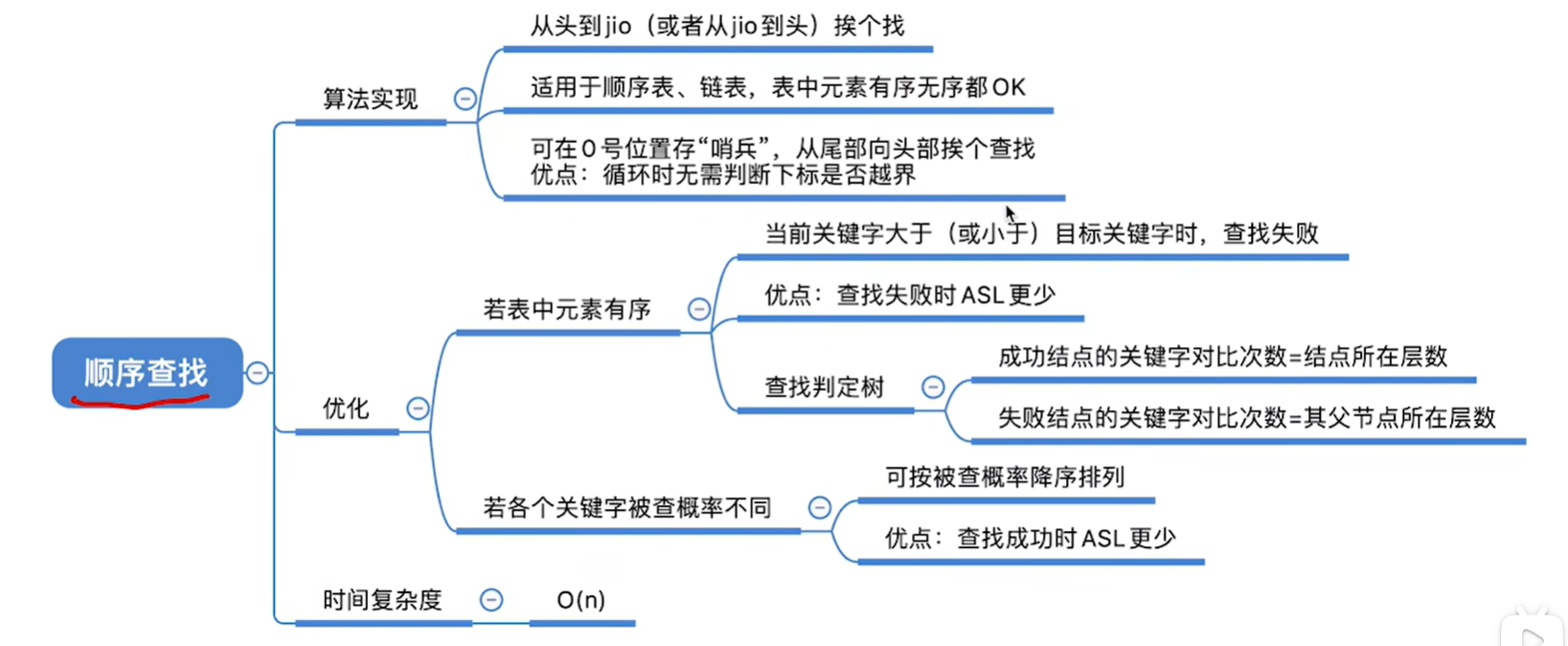
- **顺序查找,**又叫“线性查找”,通常用于线性表算法。
- **思想:**从头到尾遍历
代码实现:
typedef struct{ //查找表的数据结构(顺序表)ElemType *elem; //动态数组基址int TableLen; //表的长度
}SSTable;//顺序查找
int Search_Seq(SSTable ST,ElemType key){int i;for(i=0;i<ST.TableLen && ST.elem[i]!=key;++i);// 查找成功返回数组下标,否则返回-1return i=ST.TableLen? -1 : i;
}
哨兵方式代码实现:
思想:顺序表从下表1开始存储,把key存储在下标为0的地方,从后往前遍历,只要找到key就退出循环。
查找失败的的话那么返回的i值为0,表示查找失败
查找成功则返回对应的下标值
优点是无需判断是否越界,因为遍历到下标为0的时候,它本身肯定和它本身相同,肯定就退出了

typedef struct{ //查找表的数据结构(顺序表)ElemType *elem; //动态数组基址int TableLen; //表的长度
}SSTable;//顺序查找
int Search_Seq(SSTable ST,ElemType key){ST.elem[0]=key;int i;for(i=ST.TableLen;ST.elem[i]!=key;--i)// 查找成功返回数组下标,否则返回0return i;
}
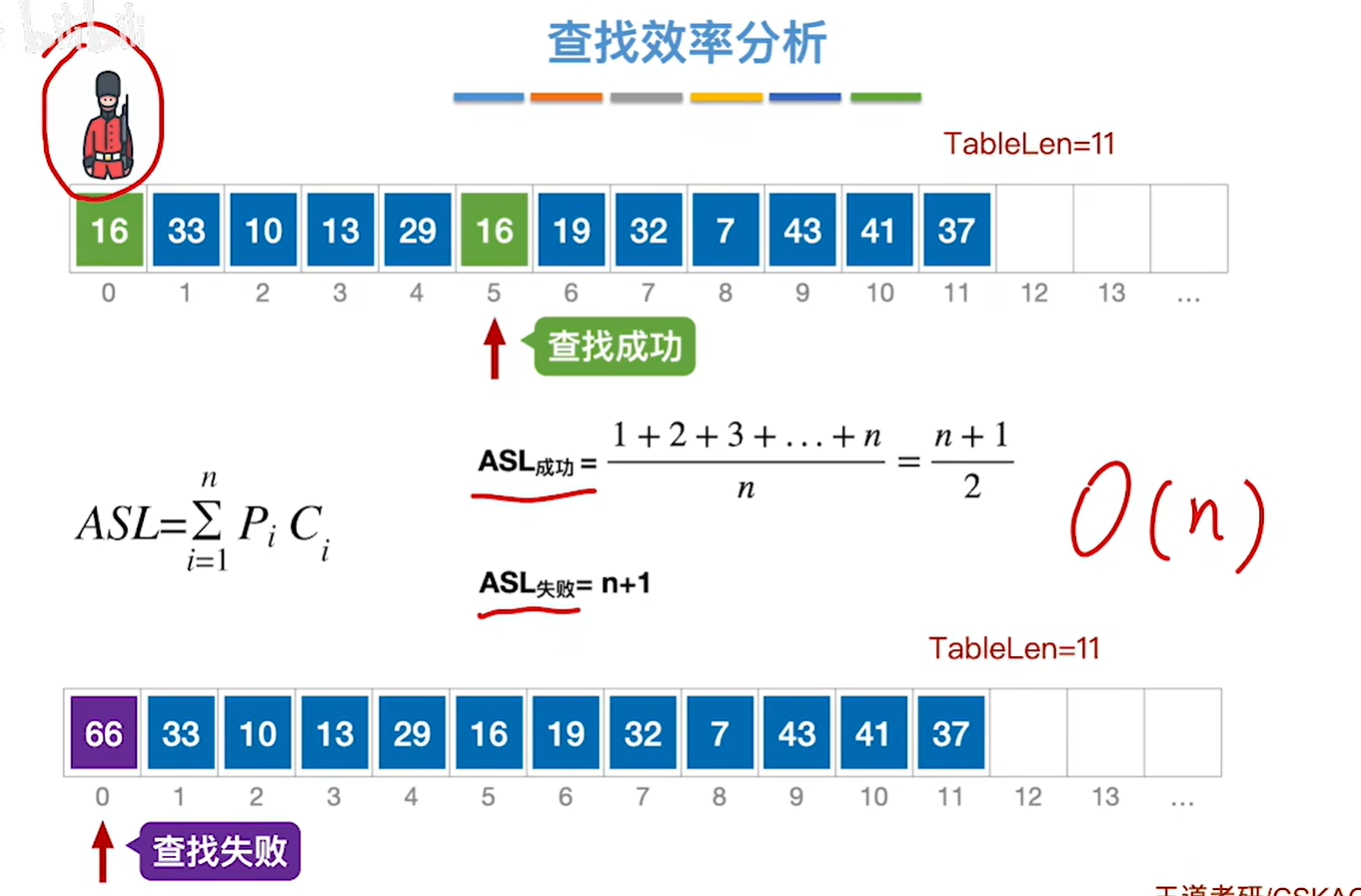
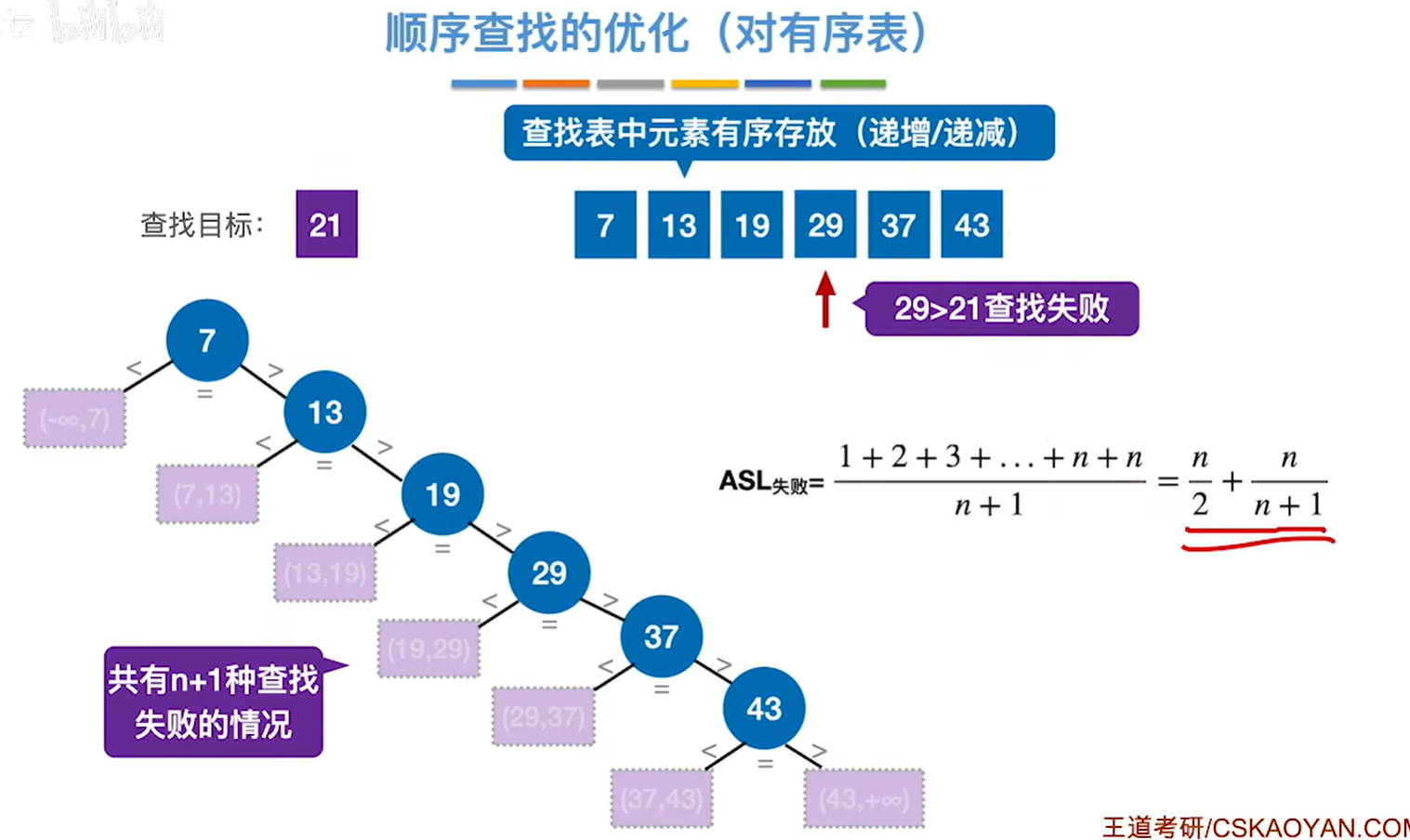
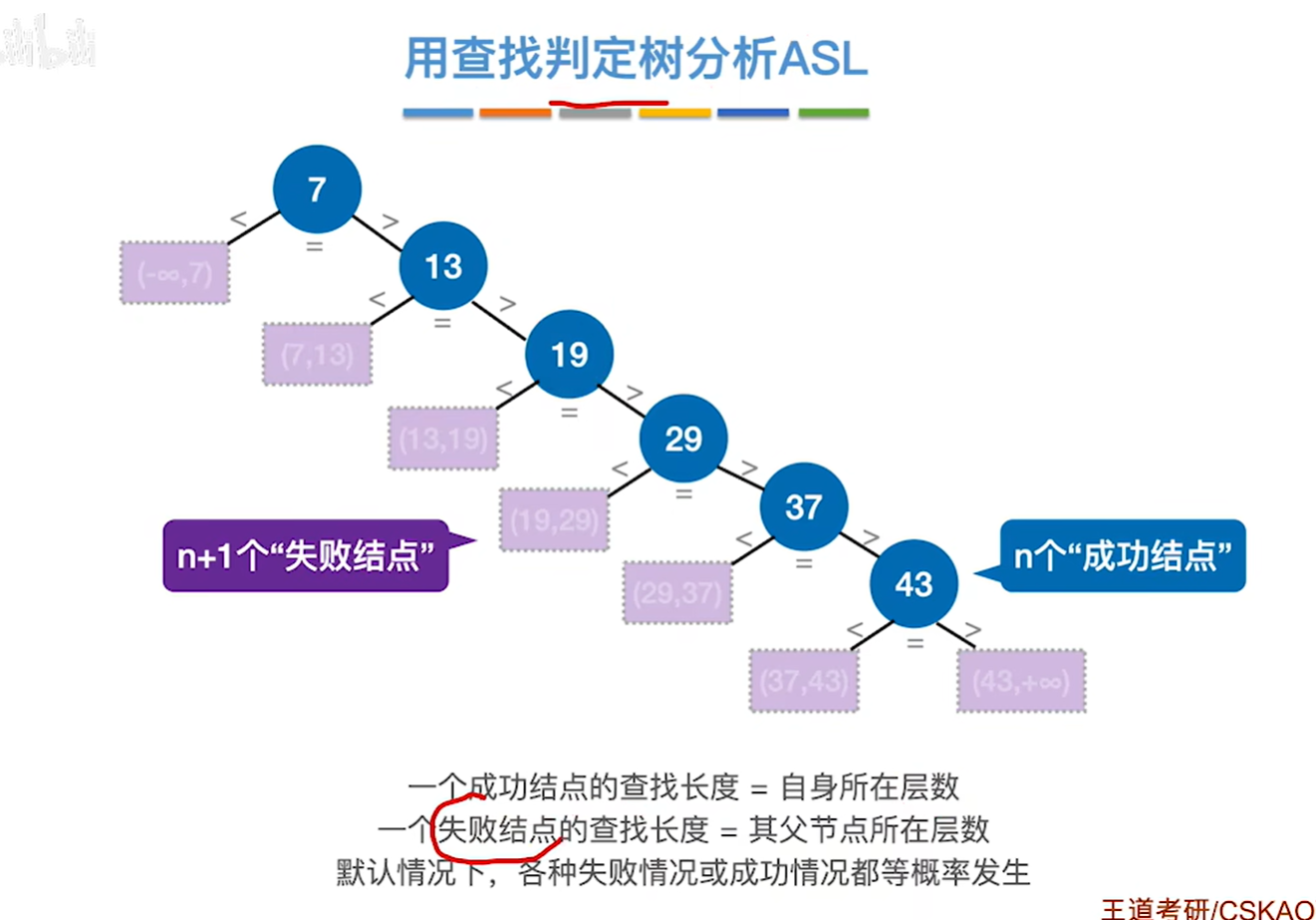
圆形是成功,方格是失败
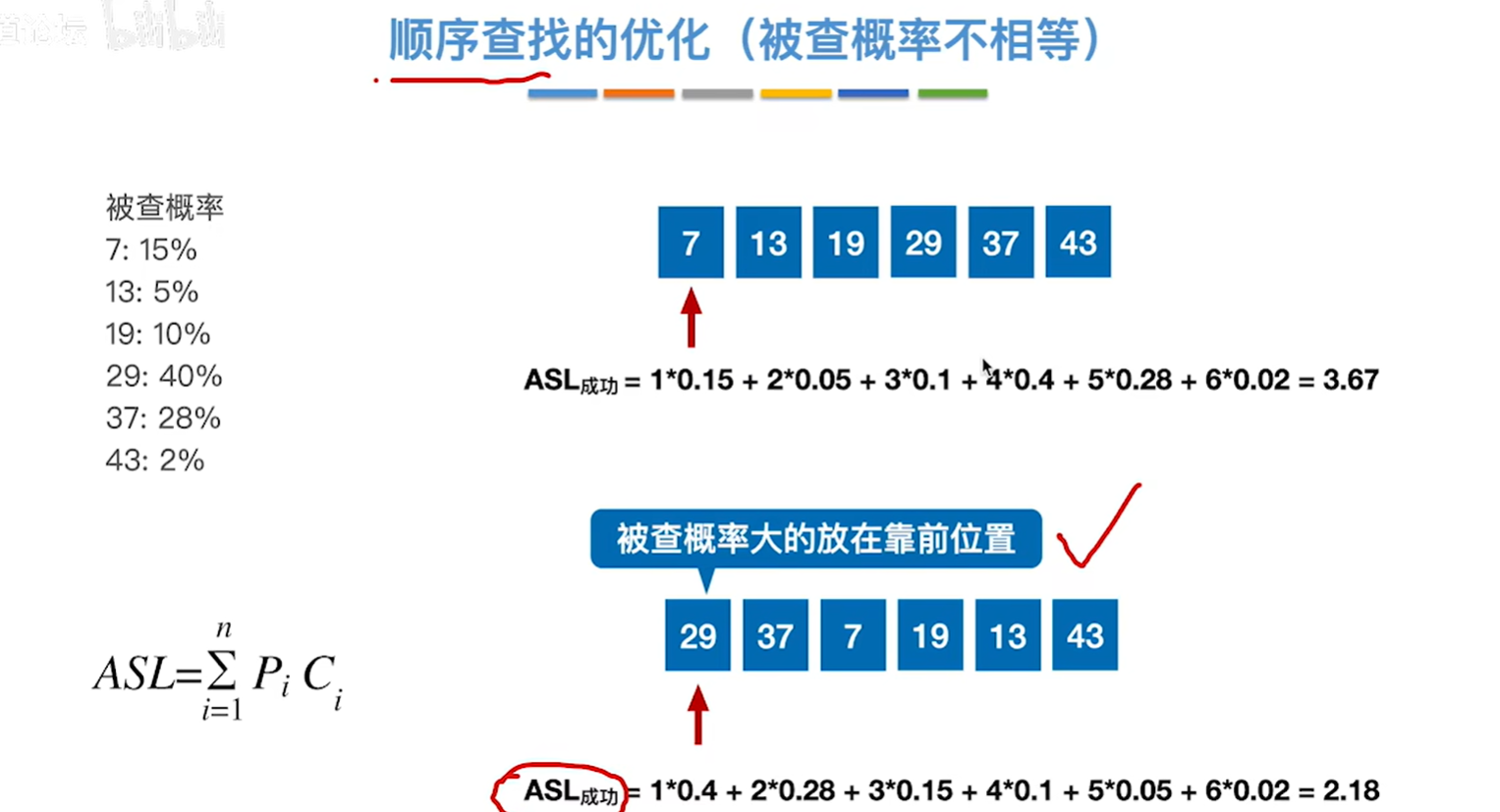
优化要根据具体情况具体分析
7.3 折半查找
如果是左闭右闭区间的话,查找失败循环结束时left=right+1
而如果是左闭右开区间的话,查找失败循环结束时是left=right
除了有序这个条件还必须是顺序存储
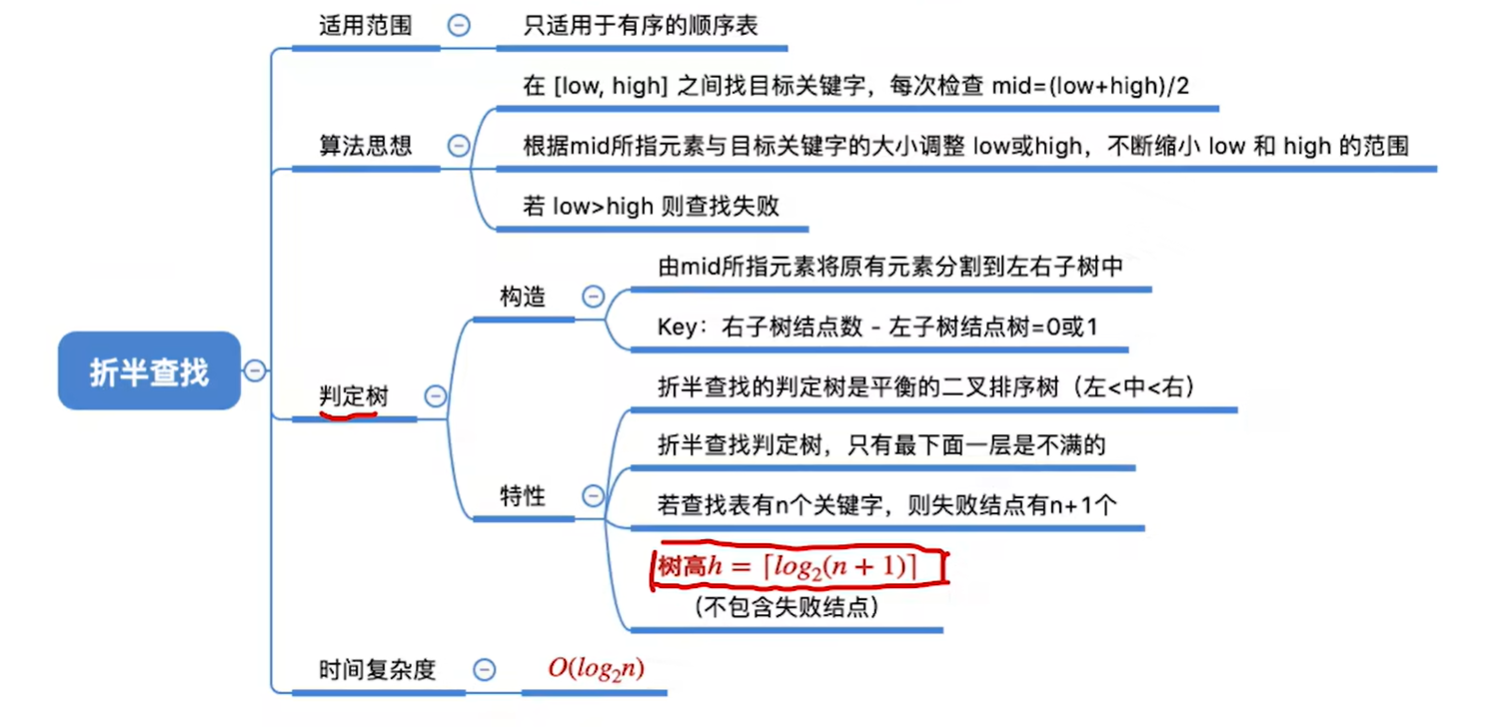
- 折半查找,又称“二分查找”,仅适用于有序的顺序表

折半查找代码实现:
typedef struct{ElemType *elem;int TableLen;
}SSTable;// 折半查找
int Binary_Search(SSTable L,ElemType key){int low=0,high=L.TableLen,mid;while(low<=high){mid=(low+high)/2;if(L.elem[mid]==key)return mid;else if(L.elem[mid]>key)high=mid-1; //从前半部分继续查找elselow=mid+1; //从后半部分继续查找}return -1;
}
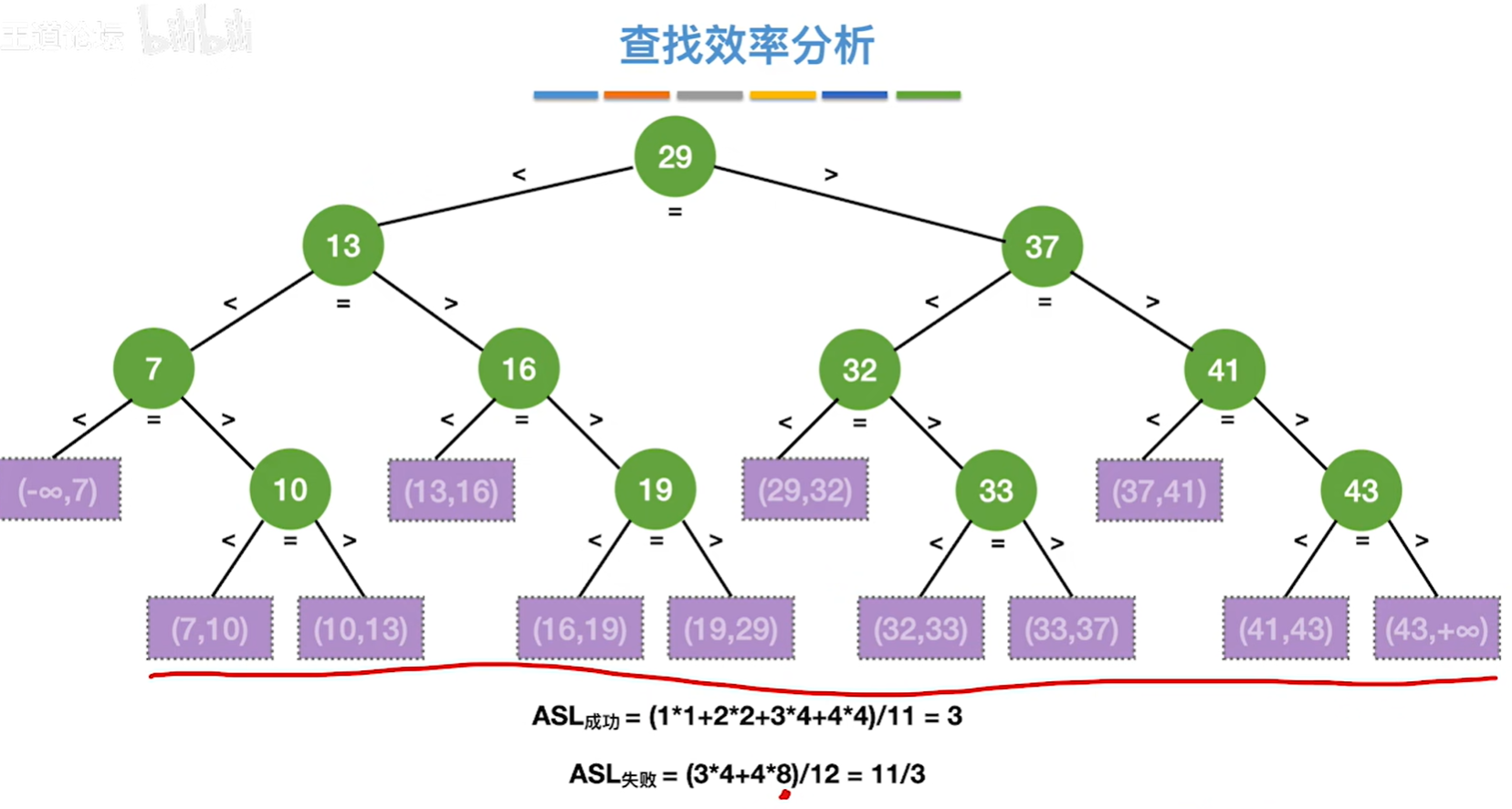

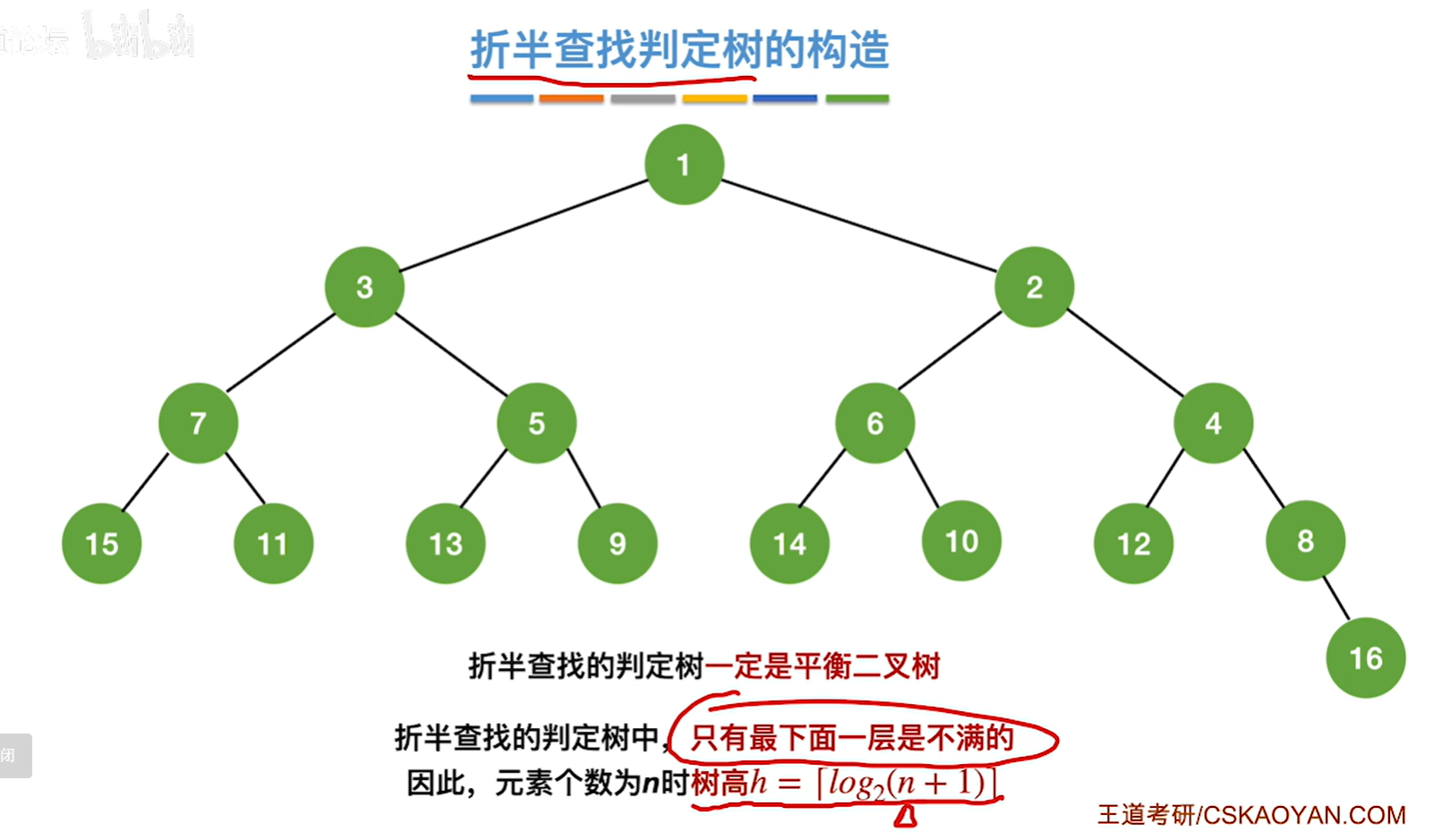
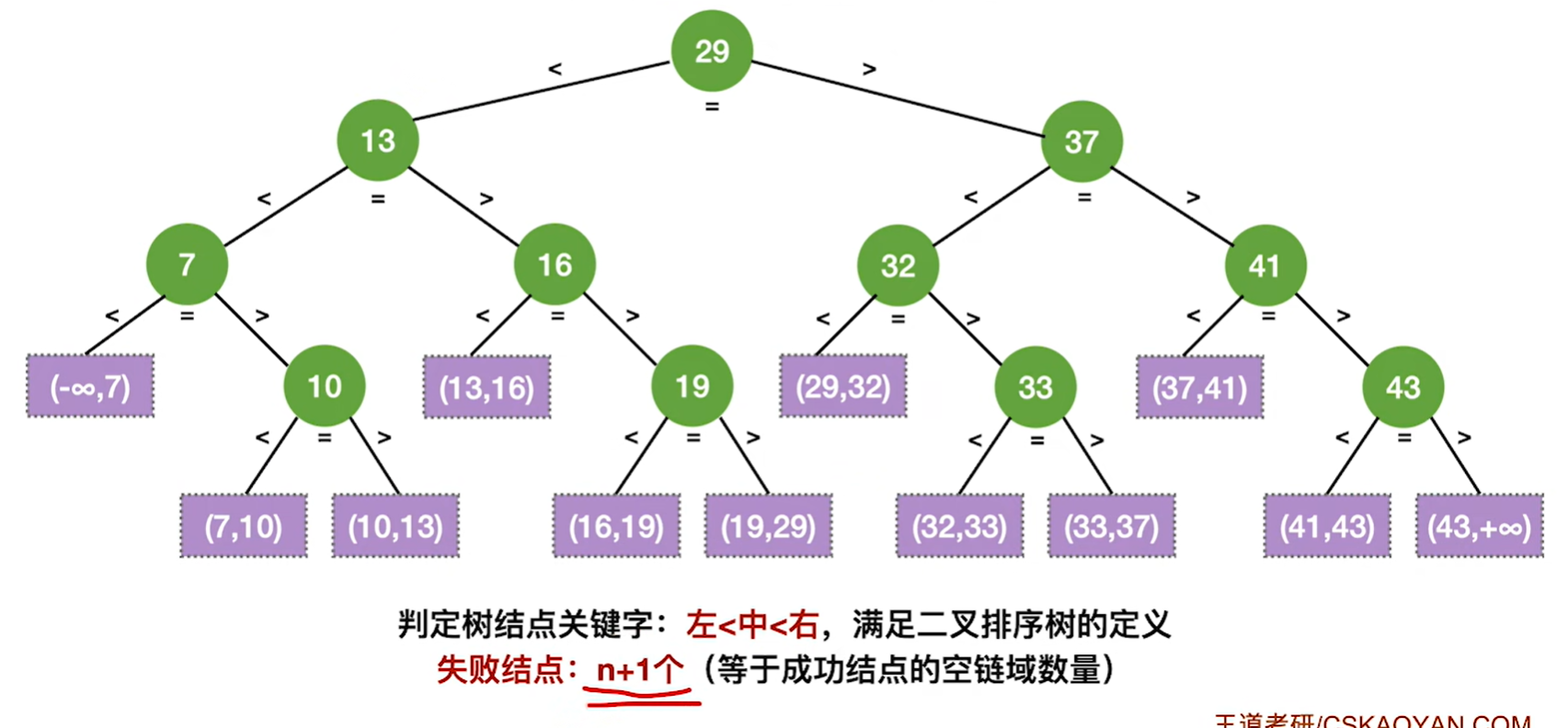
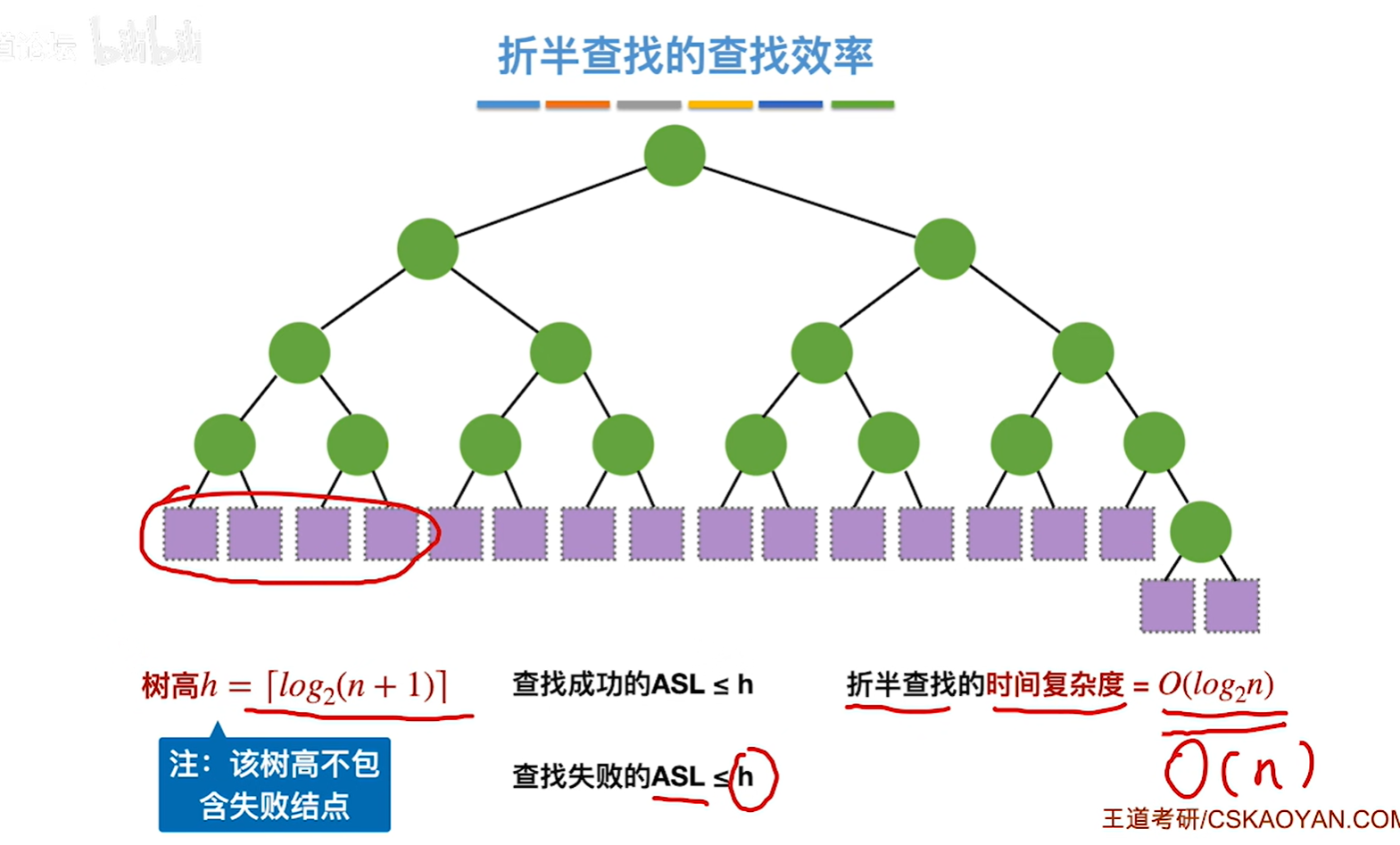
如果mid是向上取整,那就是左子树比右子树多一个或者0个结点了
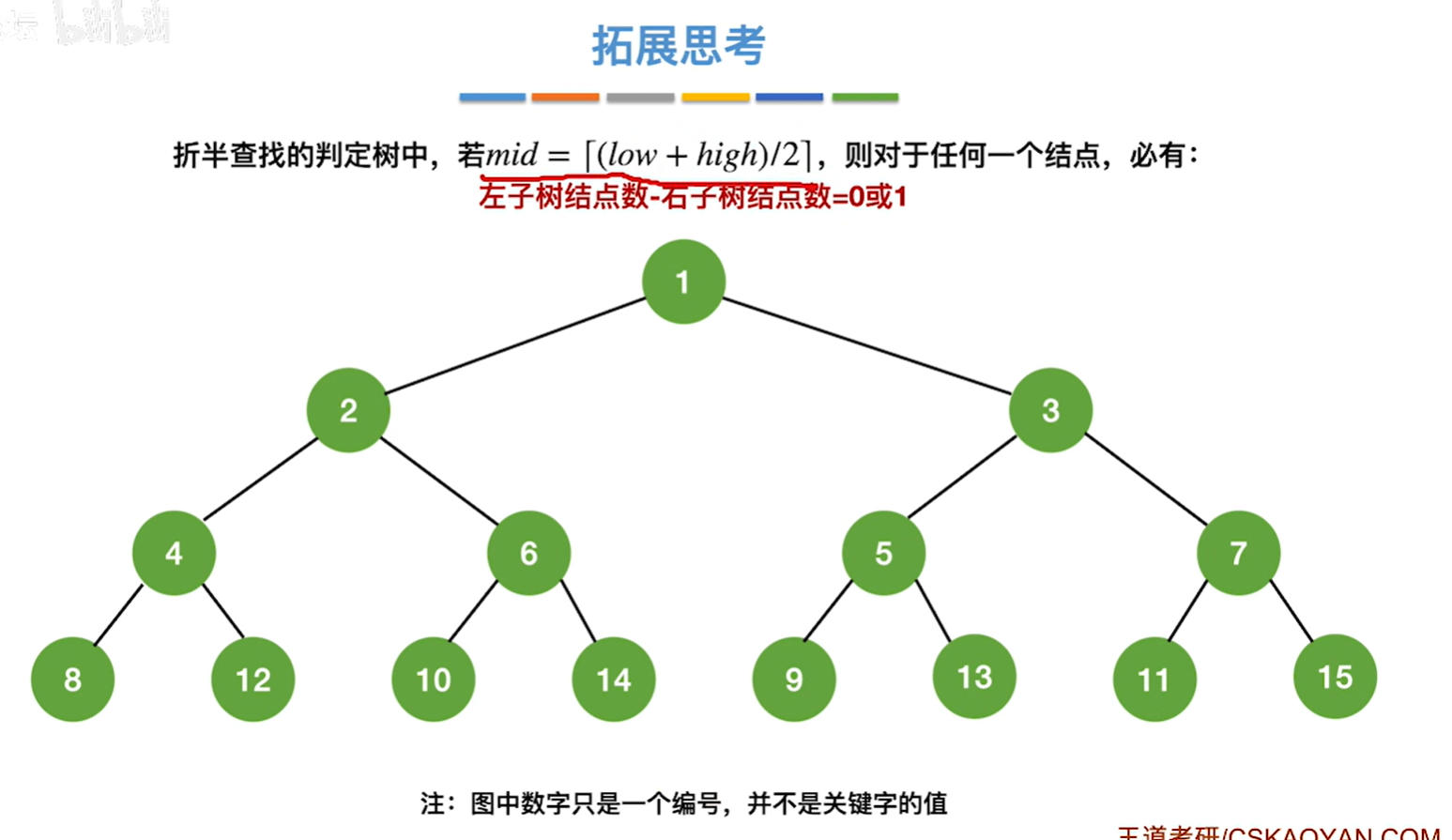
注:折半查找一般都比顺序查找更优秀。但不是一定比顺序查找更优秀。
7.4 分块查找
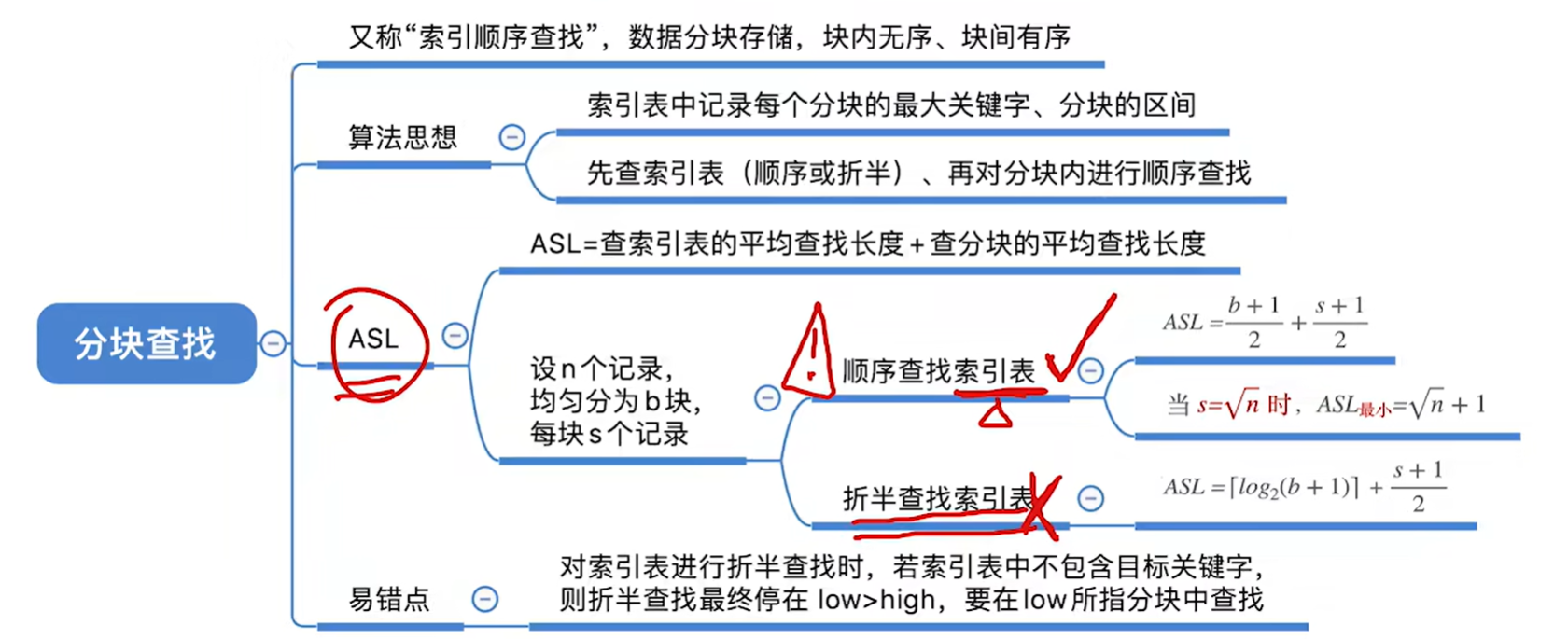
分块查找所针对的情况:块内无序、块间有序。
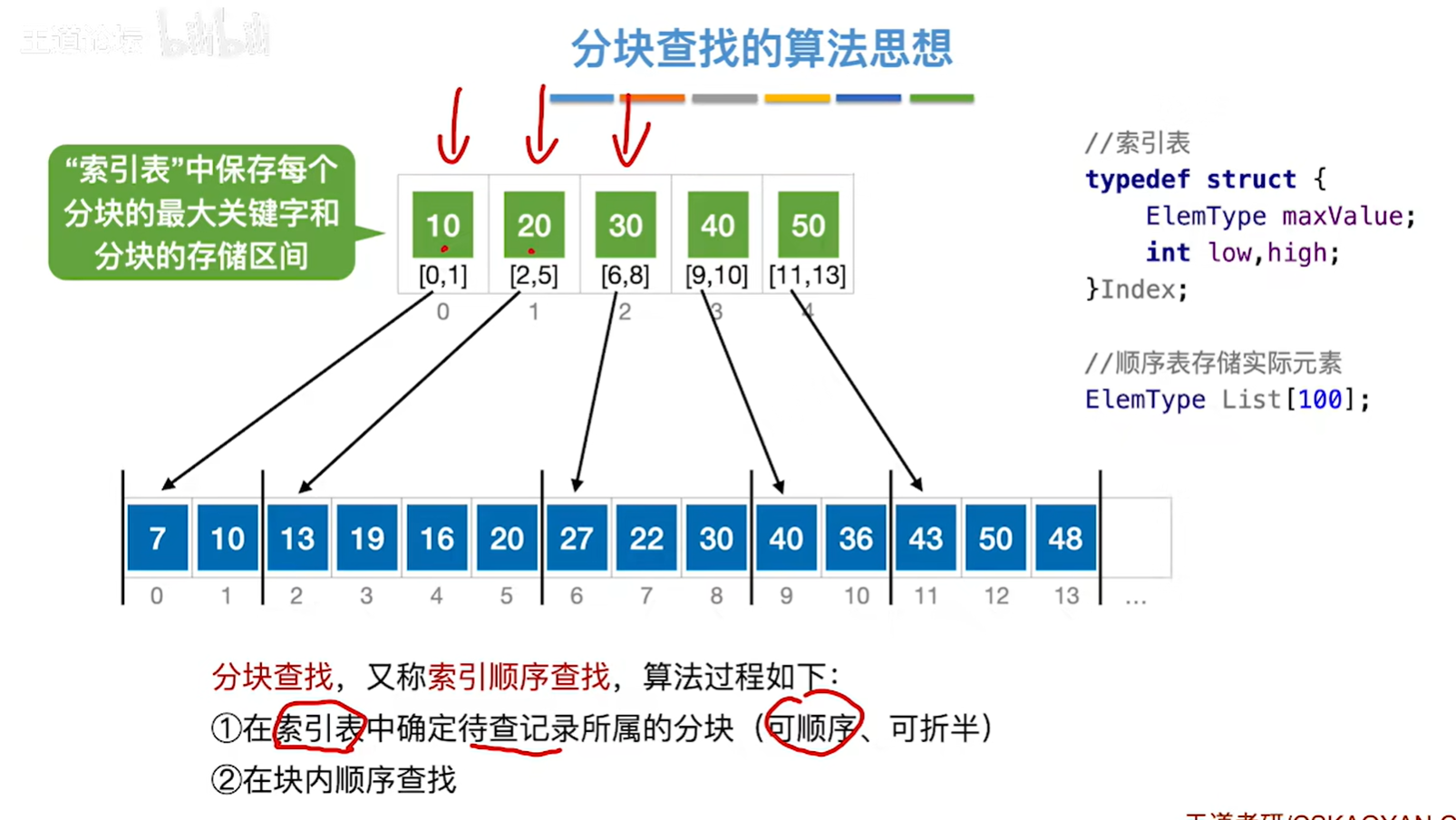
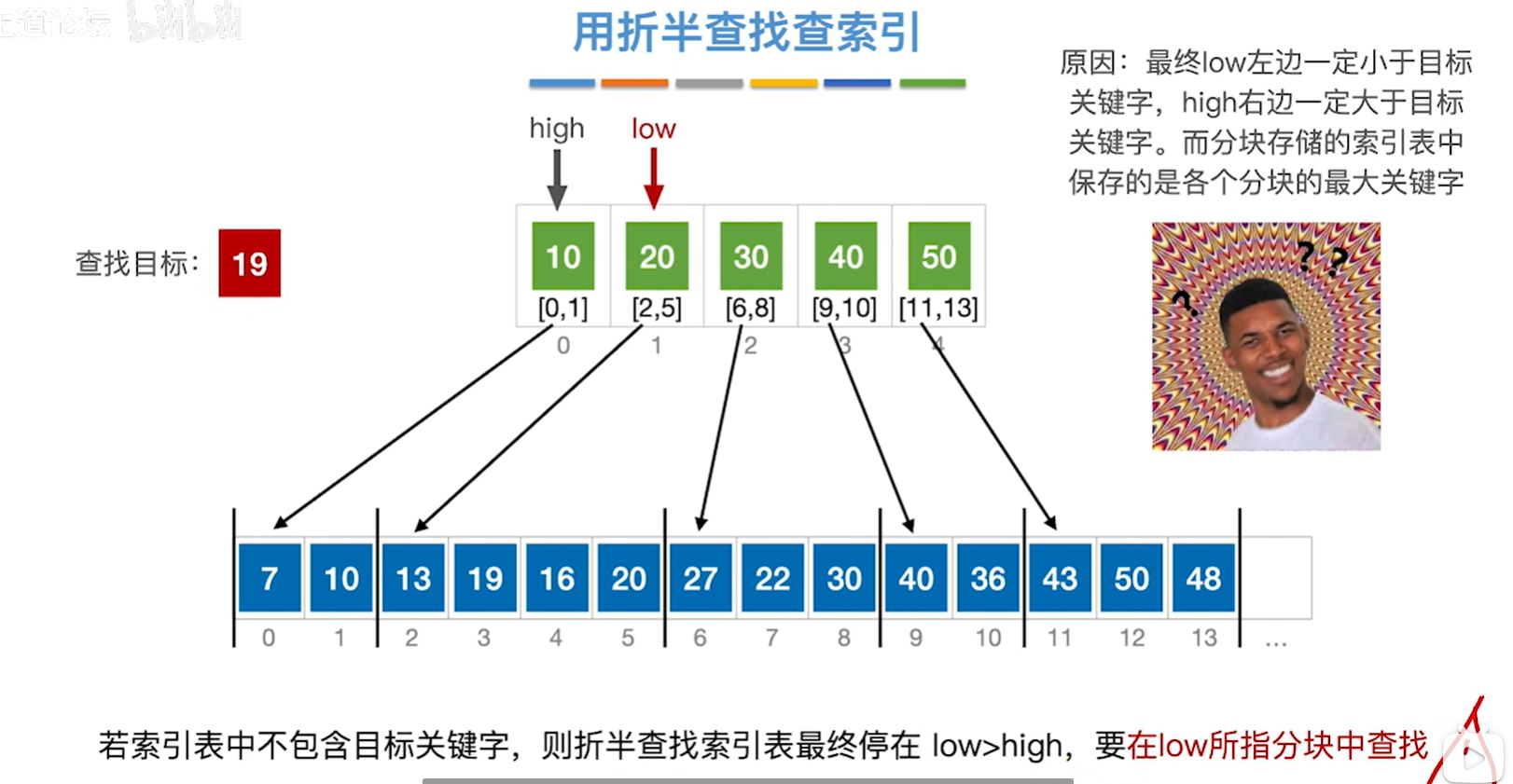
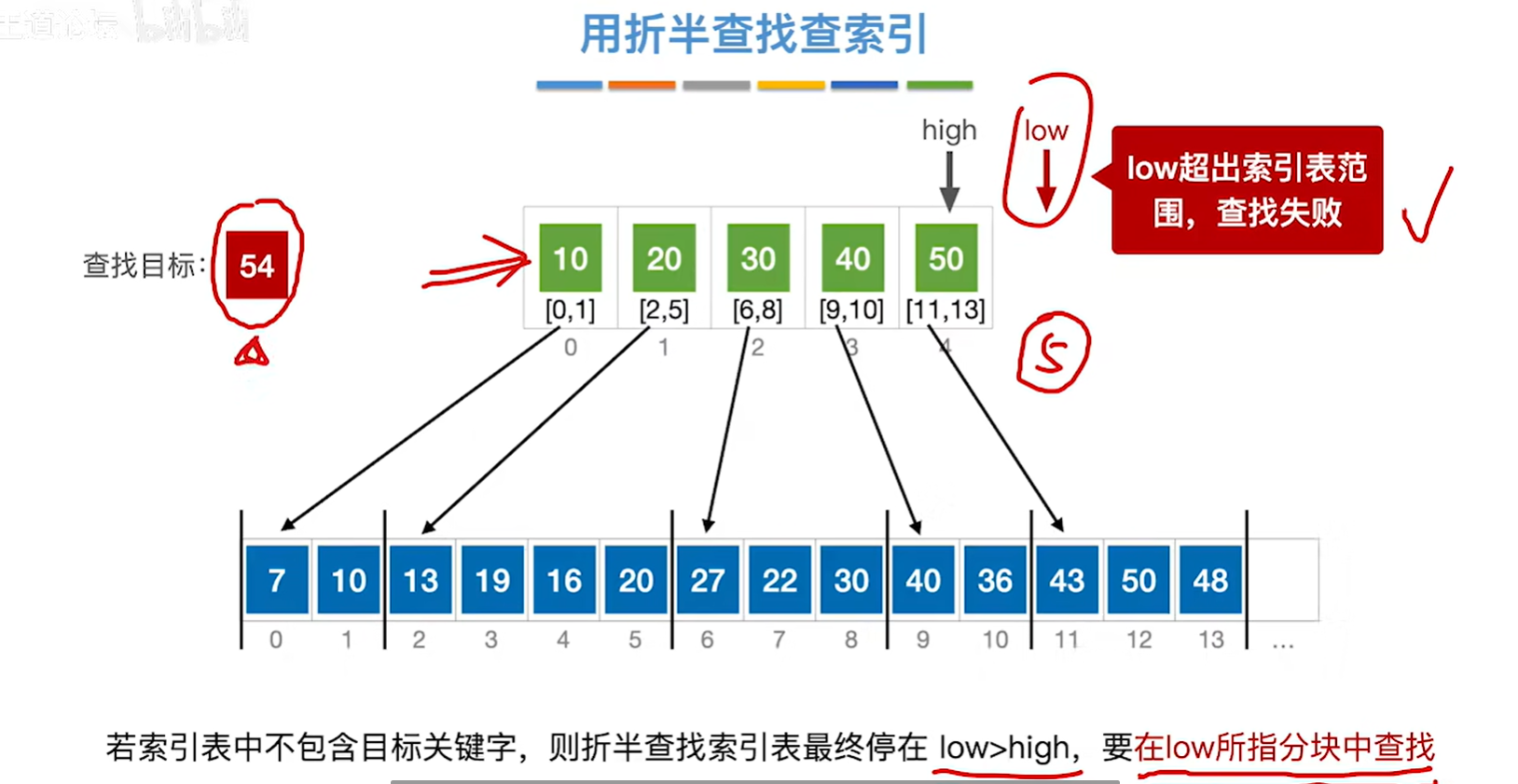
这个太复杂了,会模拟就行,一般不会考,考也就是少量的数据
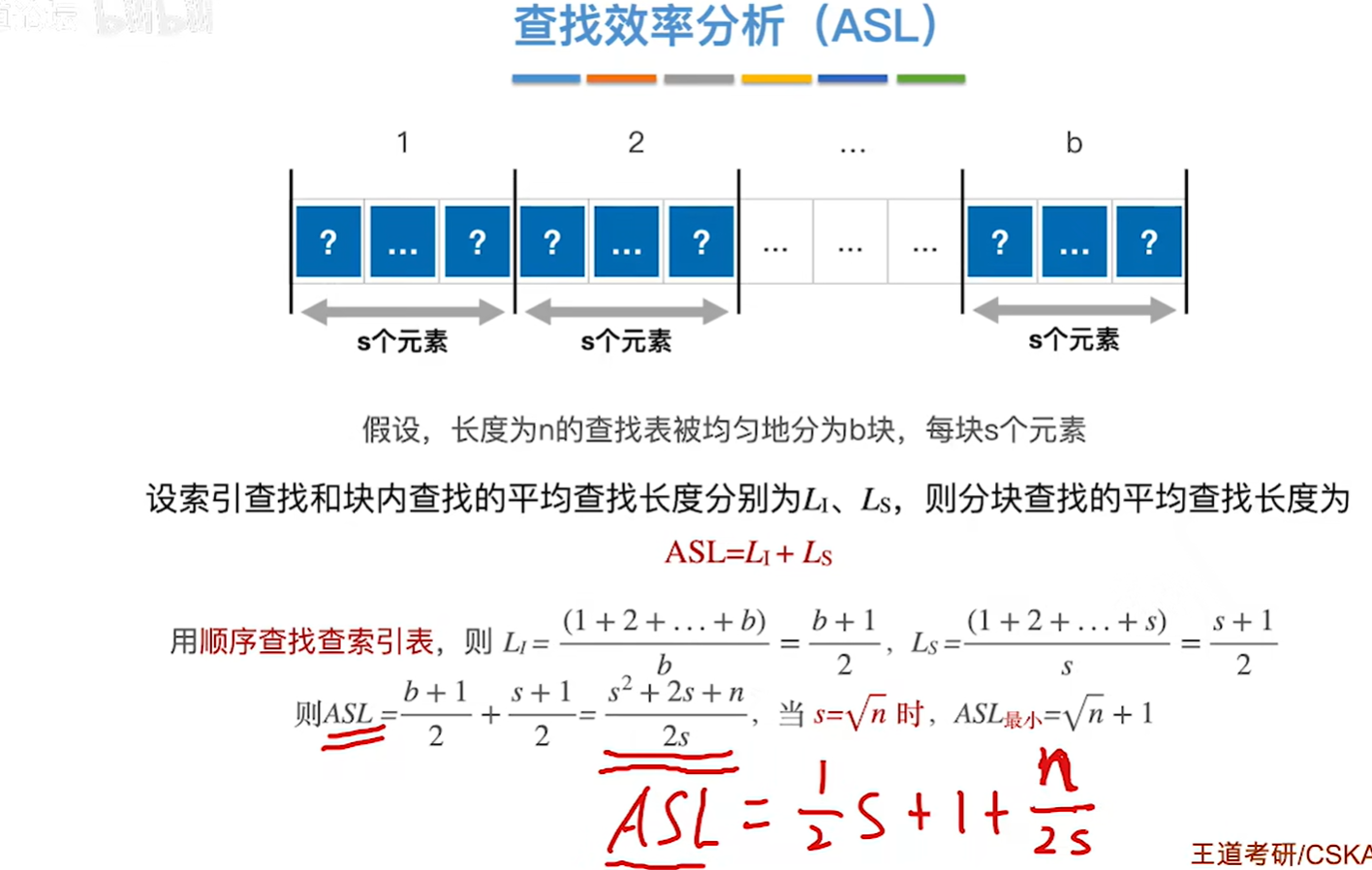
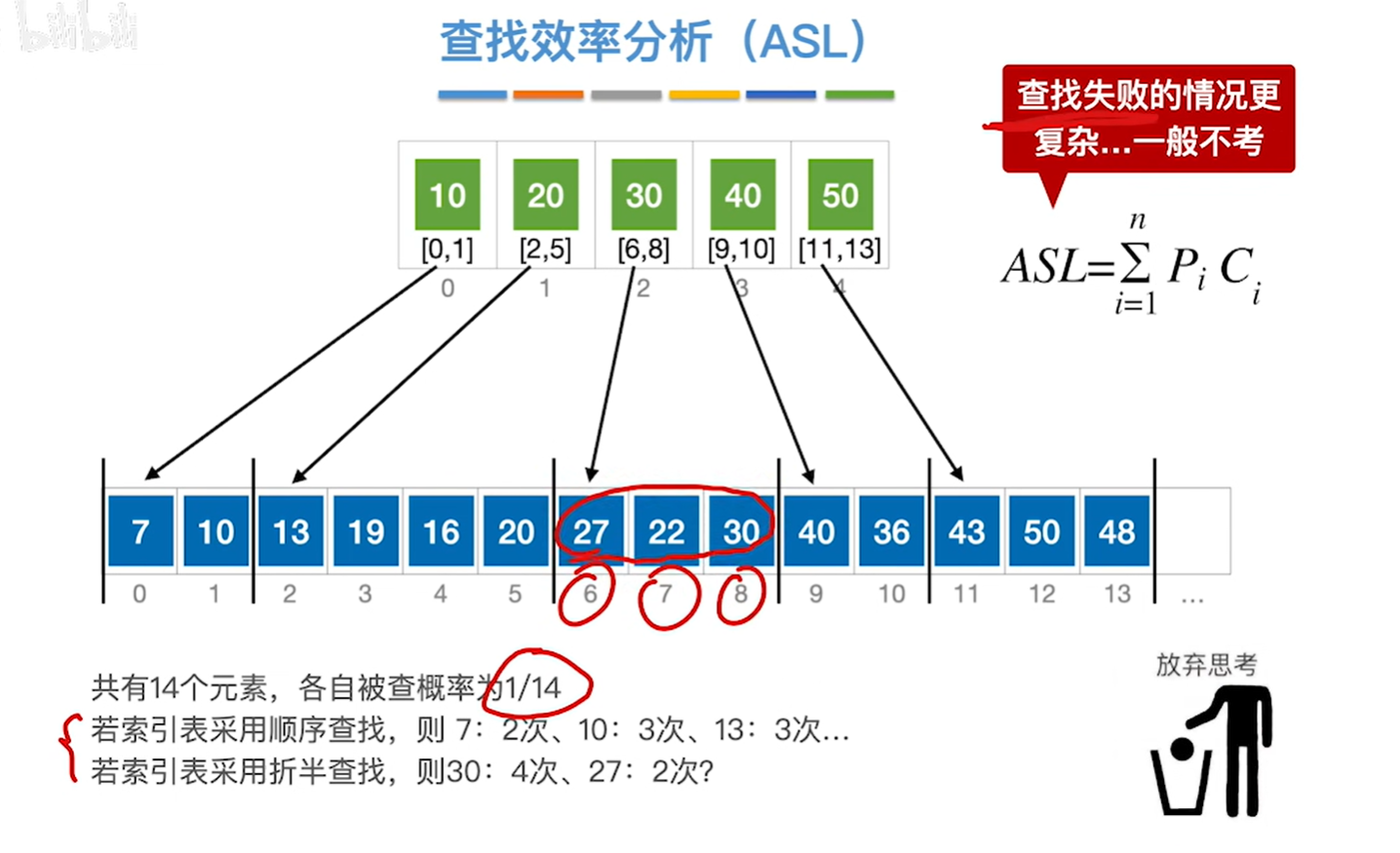
如果每个块中的元素数量都相同 的话就比较有规律,如上图所示(注:n=sb,b=n/s带入ASL算出最后的表达式求极值的得到最小值)
最后的结果是,每个块内如果是根号n个元素,那么一共有根号n个块,那么就会得到最小的ASL
如果n=10000,则ASL最小为根号n+1=100+1=101
也就是平均值需要对比101次关键字就可以查找到我们想要的关键字
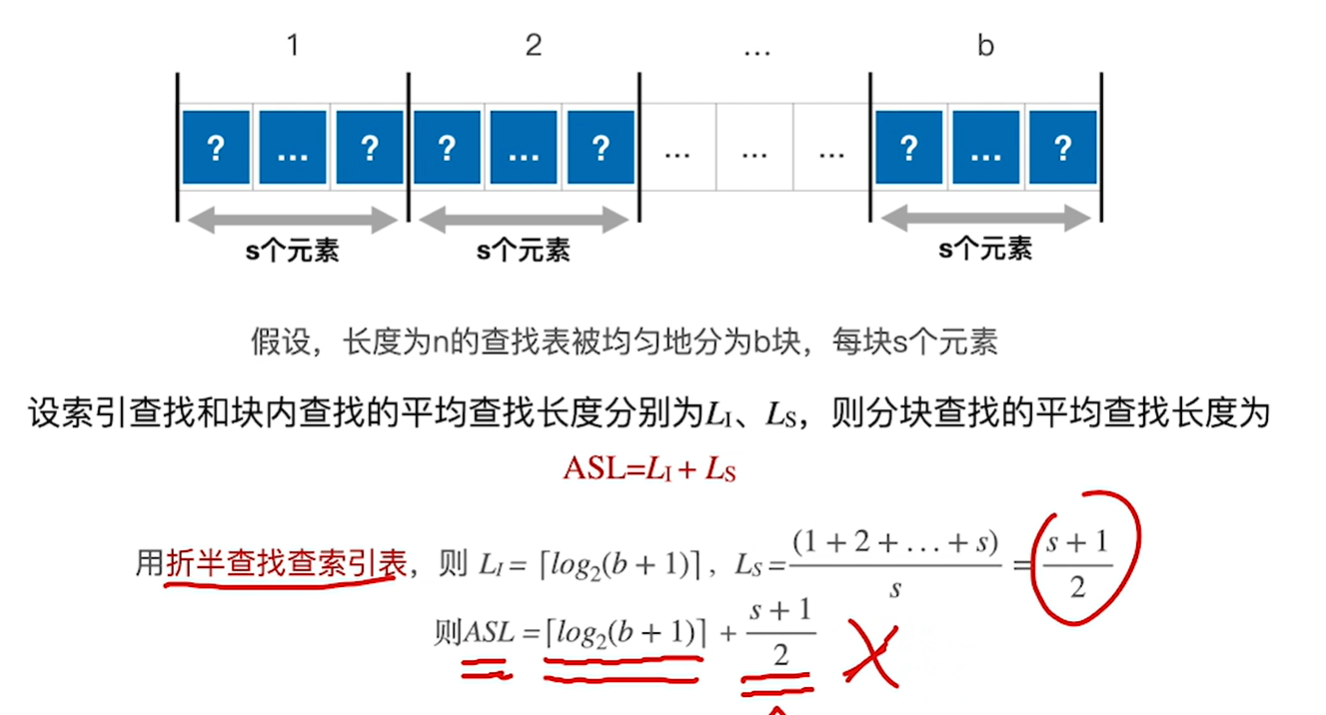
如果使用折半查找查找块的话,asl如上图所示,有个印象就行不是很重要

这个例子说明了,要具体问题具体分析,删除插入频繁就不用数组而是用链表了
7.5 二叉排序树
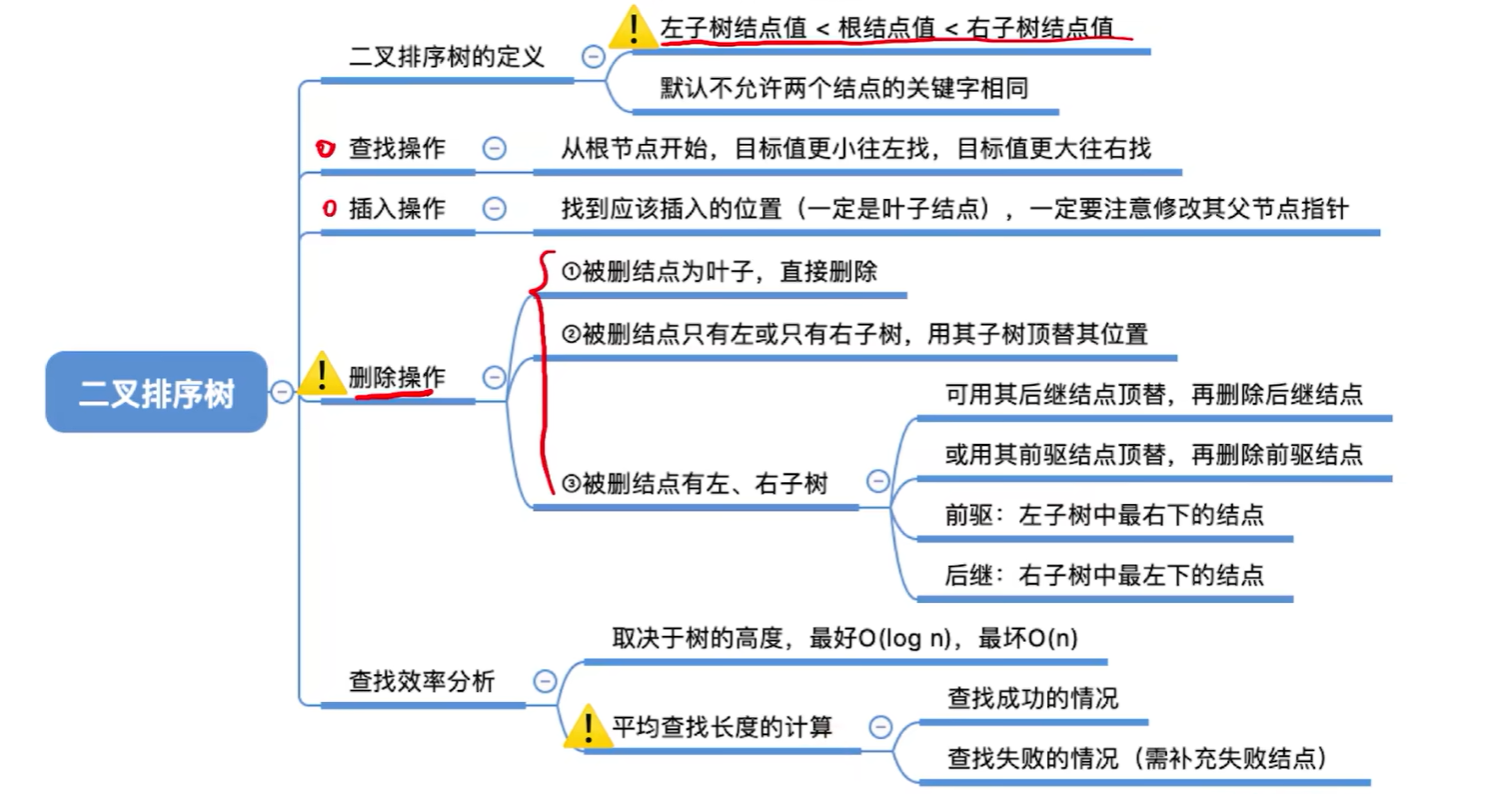
**二又排序树,**又称二叉查找树(BST,Binary Search Tree)棵二叉树或者是空二叉树,或者是具有如下性质的二叉树:
- 左子树上所有结点的关键字均小于根结点的关键字;
- 右子树上所有结点的关键字均大于根结点的关键字;
- 左子树和右子树又各是一棵二叉排序树;
- 左子树结点值< 根结点值< 右子树结点值;
- 进行中序遍历,可以得到一个递增的有序序列。
【二叉排序树的查找】
- 若树非空,目标值与根结点的值比较;
- 若相等,则查找成功;
- 若小于根结点,则在左子树上查找;
- 否则在右子树上查找;
- 查找成功,返回结点指针;查找失败返回NULL 。
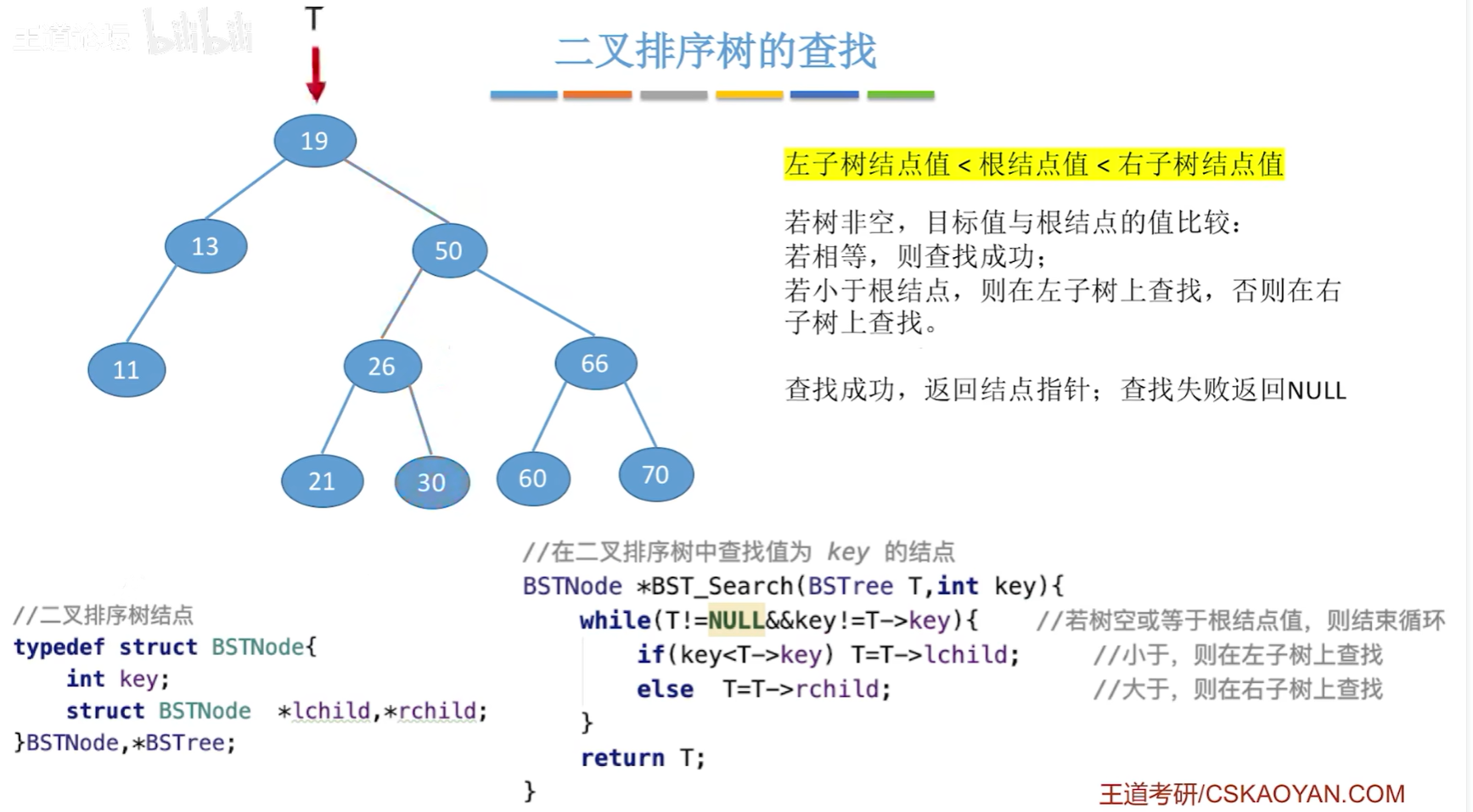
非递归实现最坏空间复杂度为O(1),递归实现最坏空间复杂度为O(h),为树的高度
typedef struct BSTNode{int key;struct BSTNode *lchild, *rchild;
}BSTNode, *BSTree;//在二叉排序树中查找值为key的结点(非递归)
//最坏空间复杂度:O(1)
BSTNode *BST_Search(BSTree T, int key){while(T!=NULL && key!=T->key){ //若树空或等于跟结点值,则结束循环if(key<T->key) //值小于根结点值,在左子树上查找T = T->lchild;else //值大于根结点值,在右子树上查找T = T->rchild;}return T;
}//在二叉排序树中查找值为key的结点(递归)
//最坏空间复杂度:O(h) h为树的高度
BSTNode *BSTSearch(BSTree T, int key){if(T == NULL)return NULL;if(Kry == T->key)return T;else if(key < T->key)return BSTSearch(T->lchild, key);else return BSTSearch(T->rchild, key);
}
【二叉排序树的插入操作】
- 若原二叉排序树为空,则直接插入结点;否则;
- 若关键字k小于根结点值,则插入到左子树;
- 若关键字k大于根结点值,则插入到右子树。
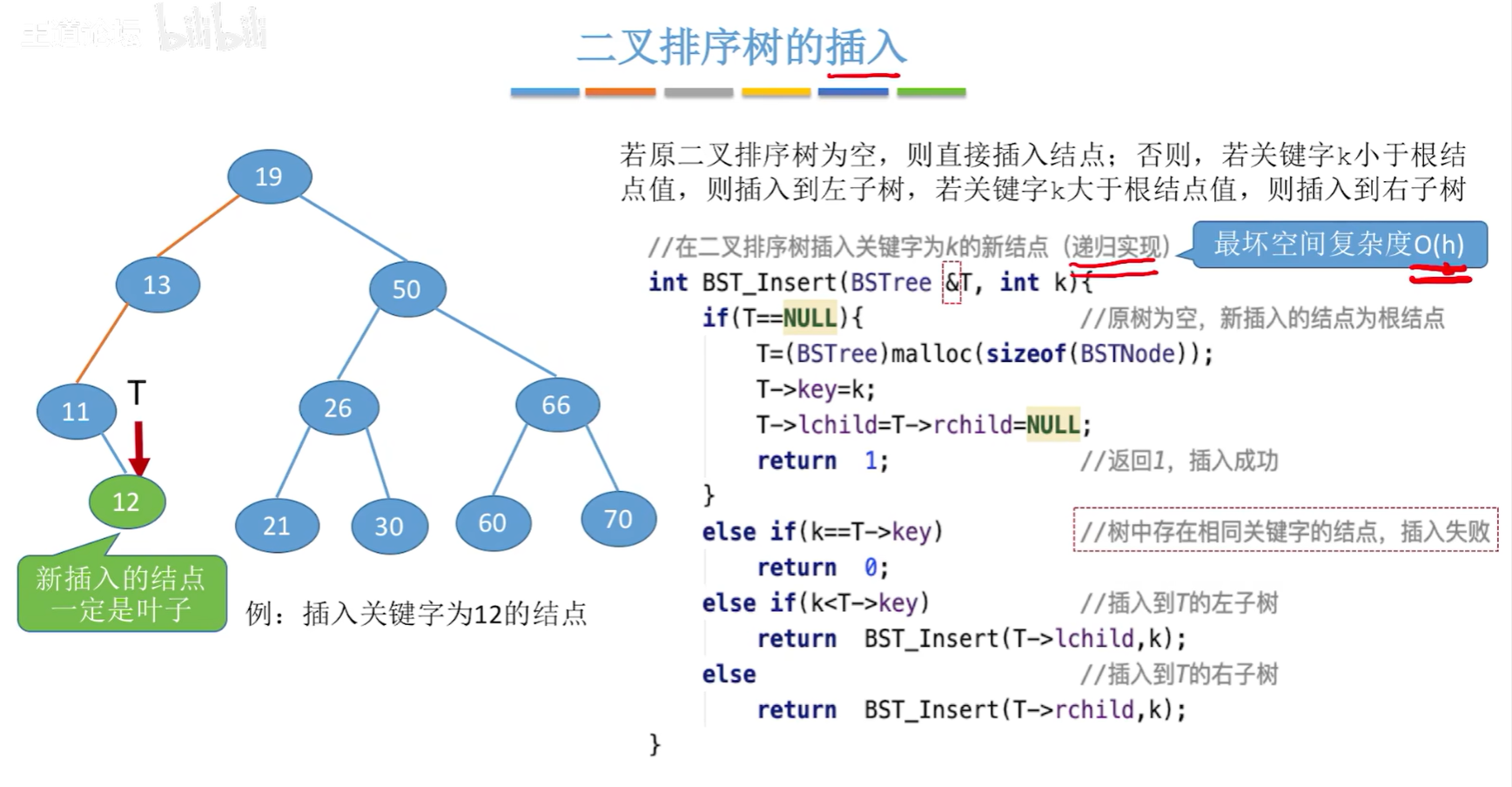
//在二叉排序树中插入关键字为k的新结点(递归)
//最坏空间复杂度:O(h)
int BST_Insert(BSTree &T, int k){if(T==NULL){ //原树为空,新插入的结点为根结点T = (BSTree)malloc(sizeof(BSTNode));T->key = k;T->lchild = T->rchild = NULL;return 1; //插入成功}else if(K == T->key) //树中存在相同关键字的结点,插入失败return 0;else if(k < T->key) return BST_Insert(T->lchild,k);else return BST_Insert(T->rchild,k);
}
【二叉排序树的构造】
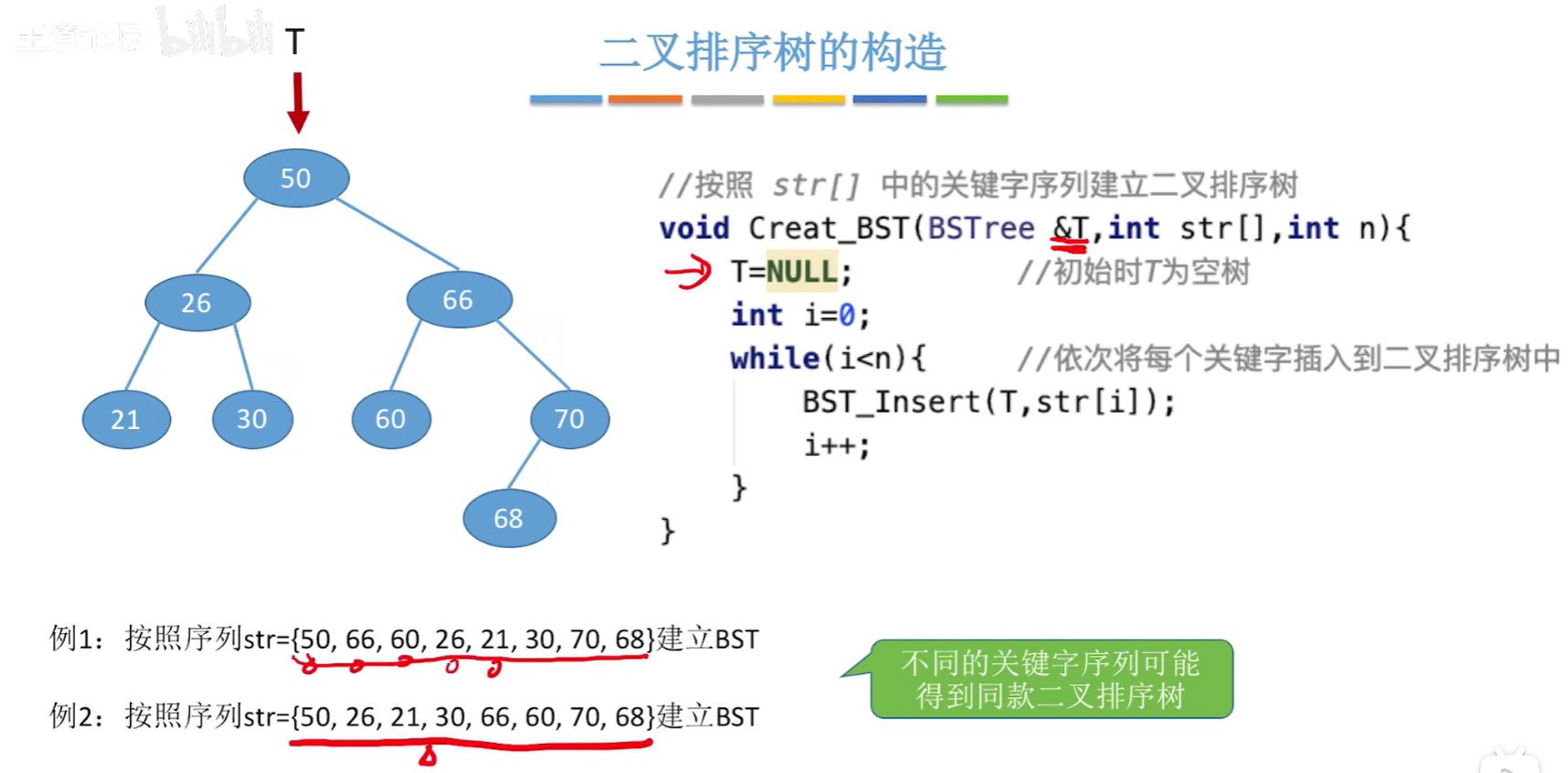
//按照str[]中的关键字序列建立二叉排序树
void Crear_BST(BSTree &T, int str[], int n){T = NULL; //初始时T为空树int i=0;while(i<n){BST_Insert(T,str[i]); //依次将每个关键字插入到二叉排序树中i++;}
}
【二叉排序树的删除】
先搜索找到目标结点:
- 若被删除结点z是叶结点则直接删除,不会破坏二叉排序树的性质;
- 若结点z只有一棵左子树或右子树,则让z的子树成为z父结点的子树,替代z的位置;
- 若结点z有左、右两棵子树,则令z的直接后继 (或直接前驱) 替代z,然后从二叉排序树中删去这个直接后继(或直接前驱),这样就转换成了第一或第二种情况。
- 直接前驱就是中序遍历二叉排序树的要删除结点的前一个结点,即该节点的左子树的最右下的节点
- 直接后继就是中序遍历二叉排序树的要删除结点的后一个结点,即该节点的右子树的最左下的节点
**查找长度:**在查找运算中,需要对比关键字的次数称为查找长度,反映了查找操作时间复杂度
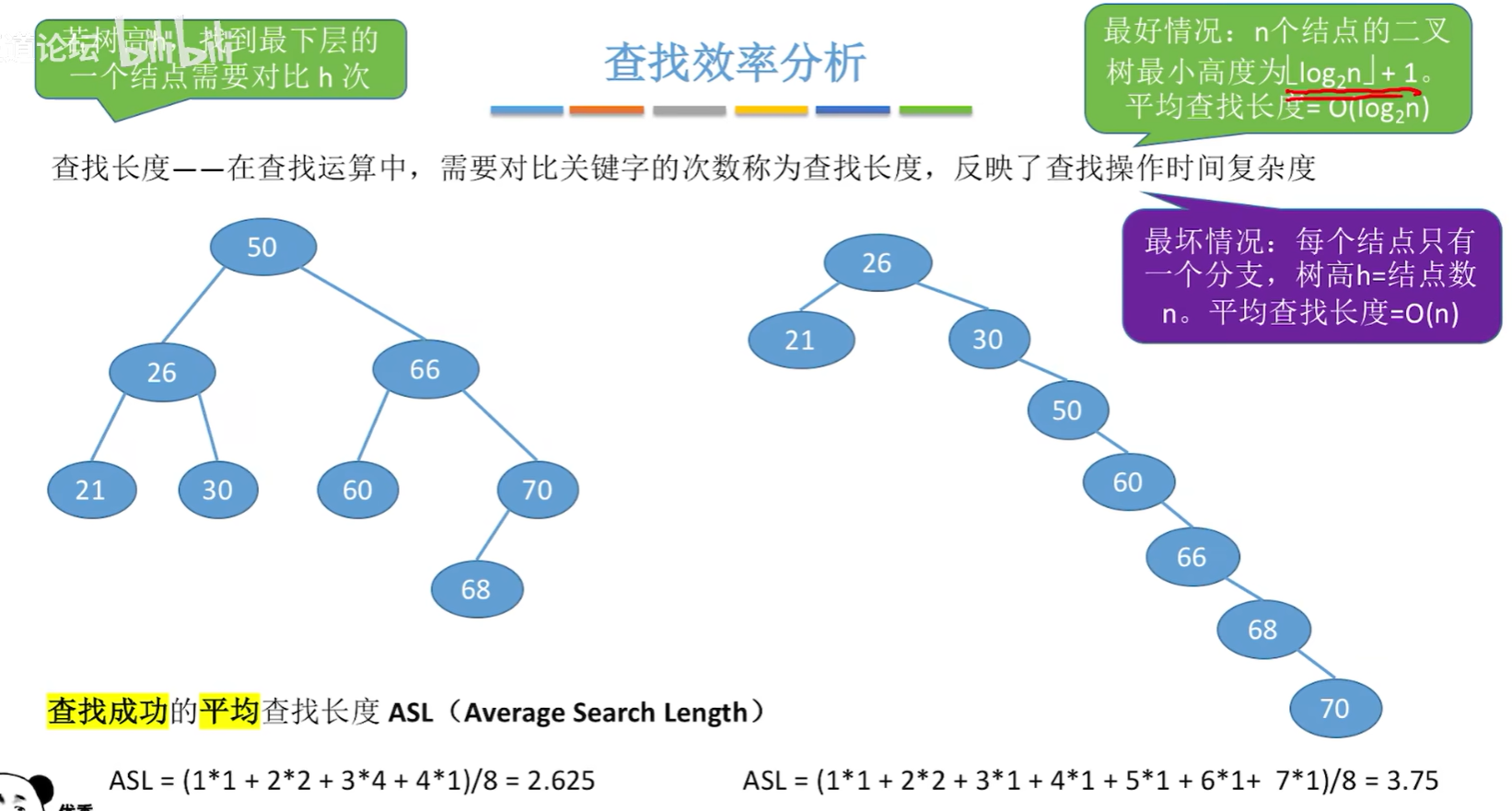
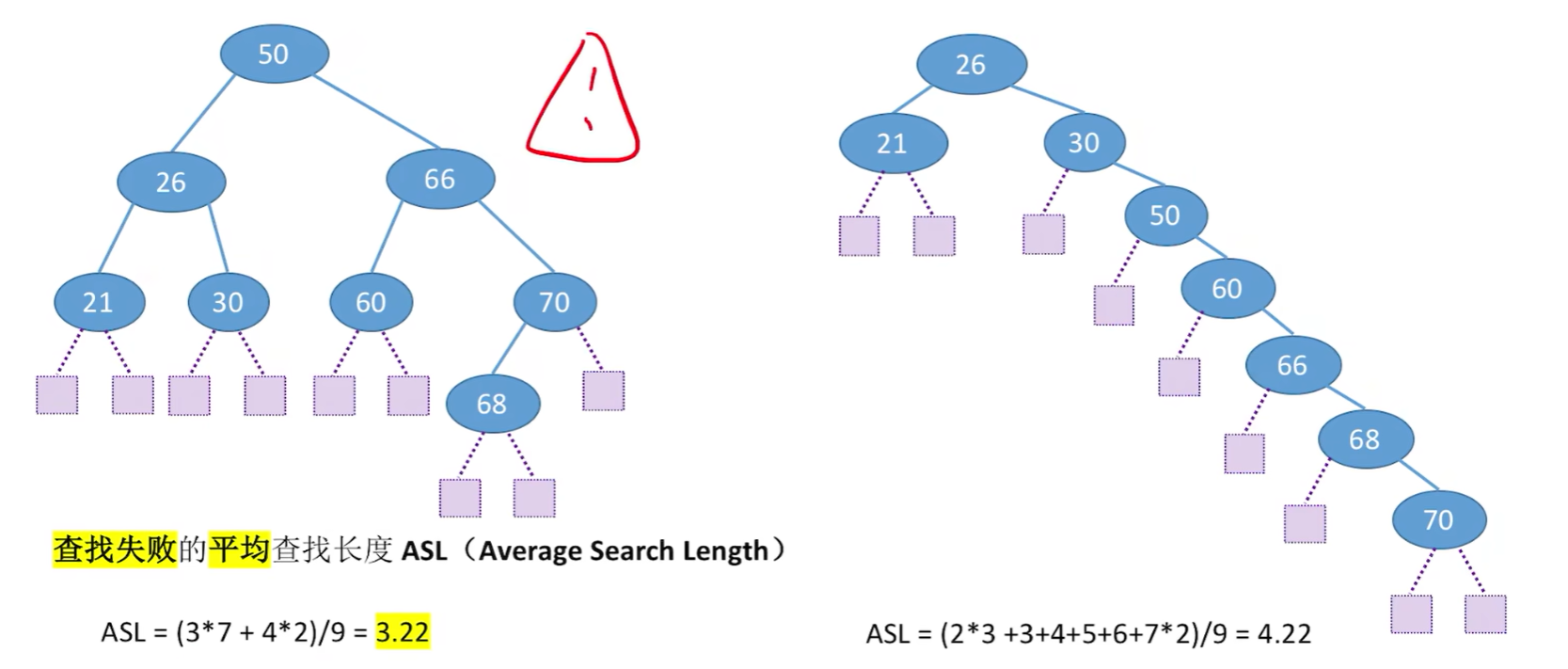
7.6 平衡二叉树
平衡二叉树的插入
**平衡二叉树(Balanced Binary Tree),**简称平衡树(AVL树)–上任一结点的左子树和右子树的高度之差不超过1。
结点的平衡因子 = 左子树高 - 右子树高
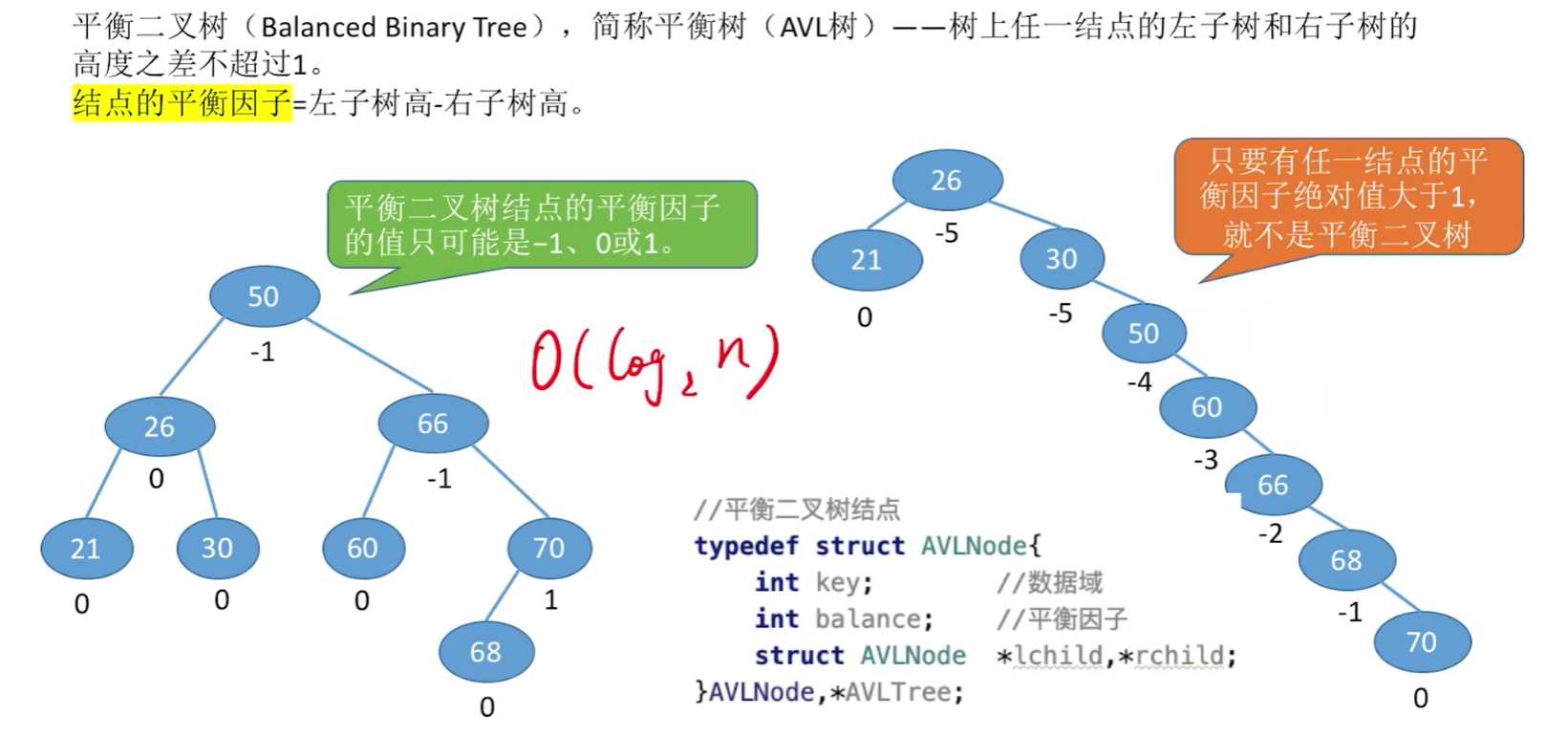
//平衡二叉树结点
typedef struct AVLNode{int key; //数据域int balance; //平衡因子struct AVLNode *lchild; *rchild;
}AVLNode, *AVLTree;
平衡二叉树的插入
- 每次调整的对象都是“最小不平衡子树“
- 在插入操作中,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡。
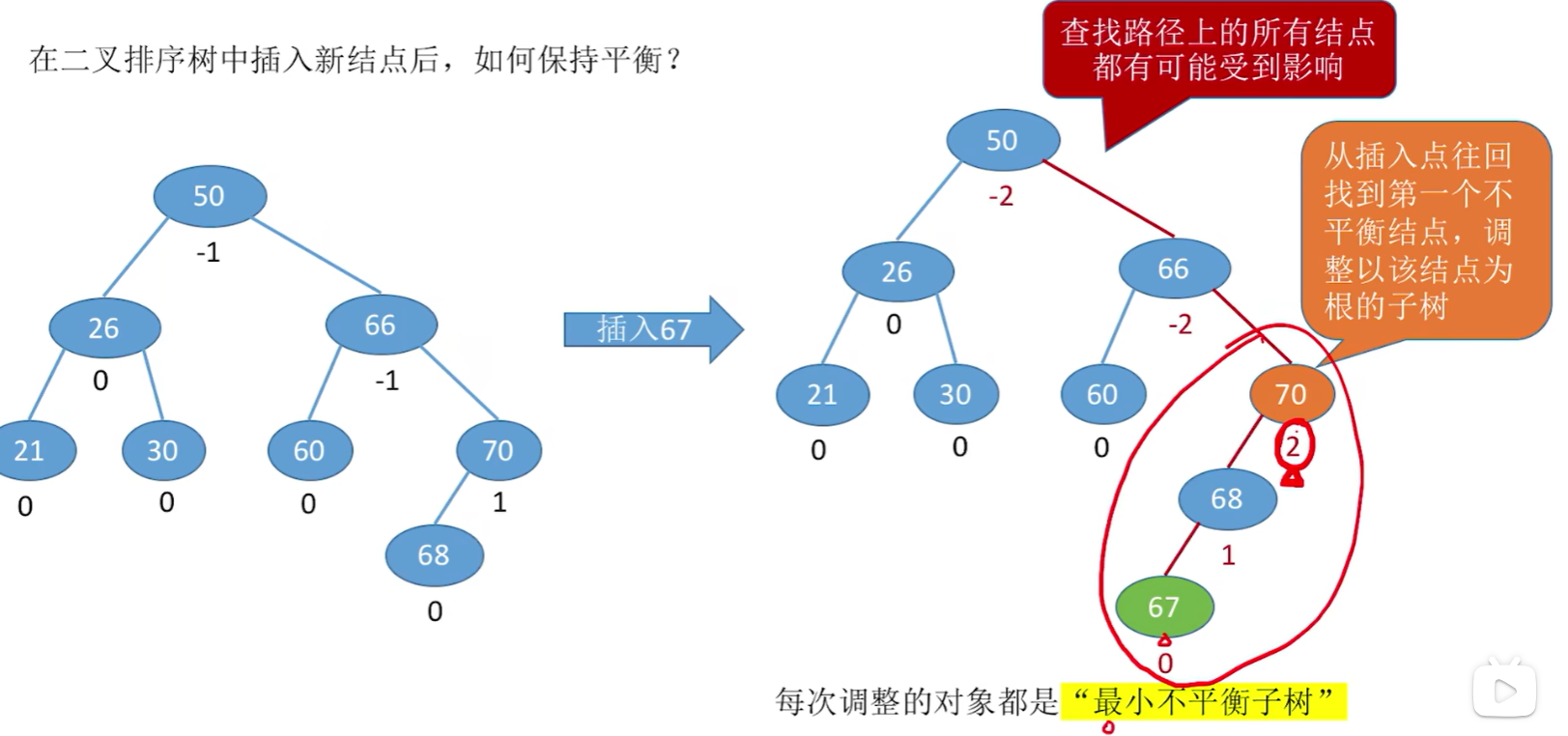
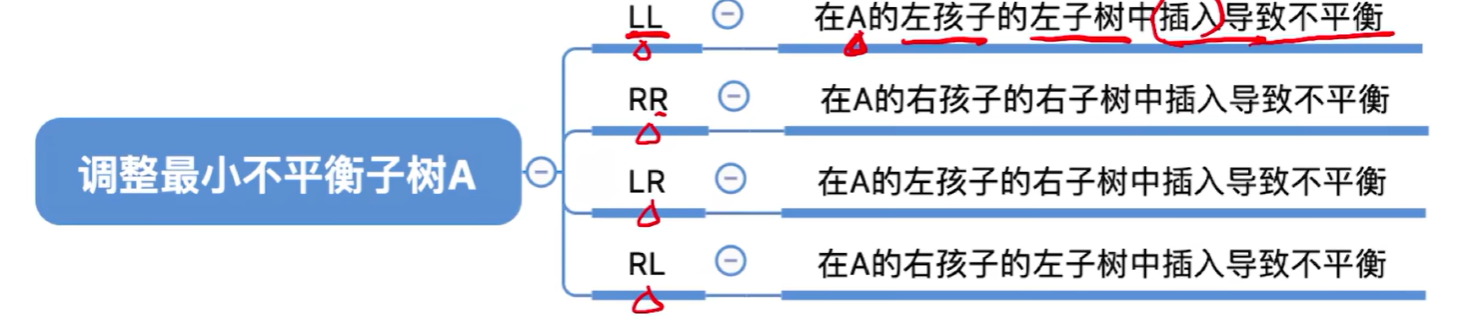
调整最小不平衡子树(LL):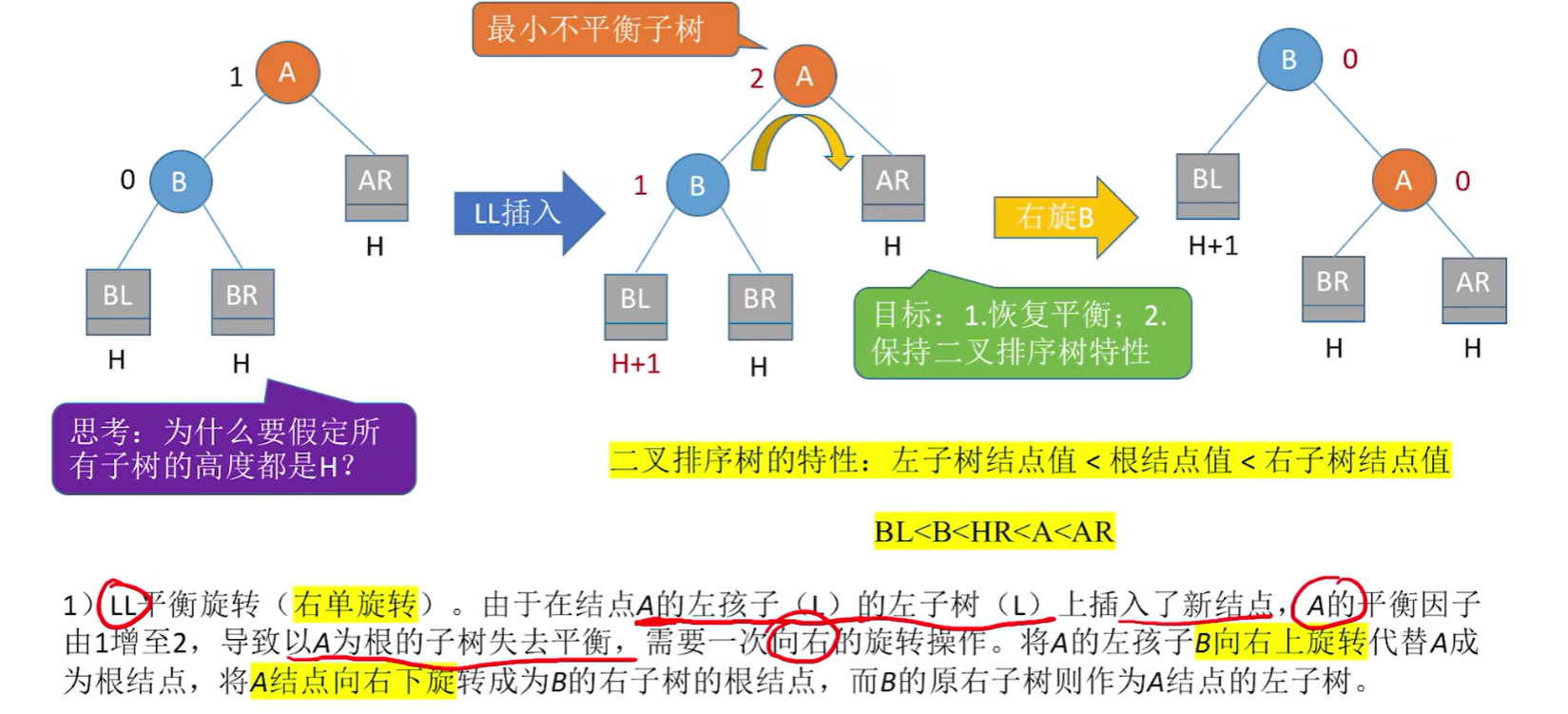
调整最小不平衡子树(RR):
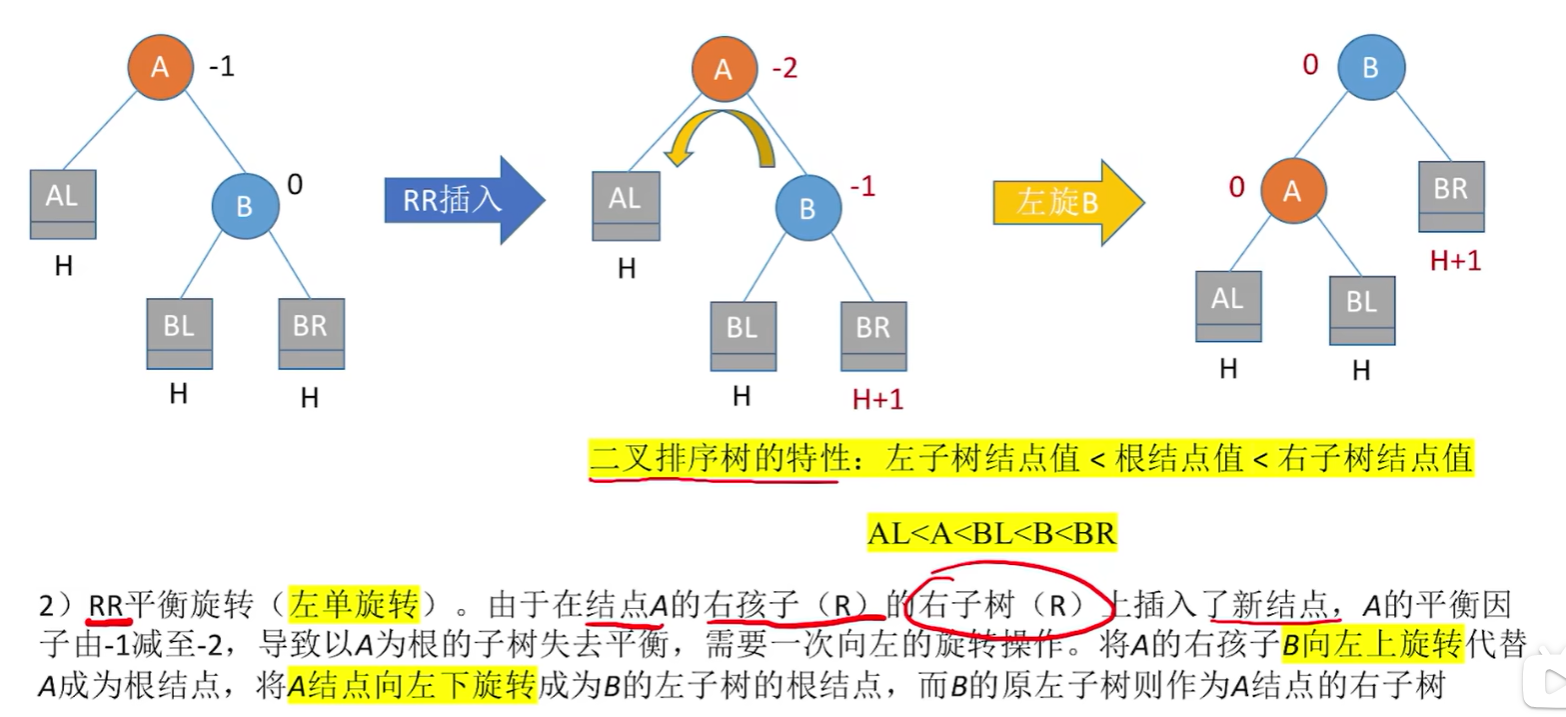
左旋右旋的的代码思路:
其实就还是链表的操作,这个指针指到这边,那个指针指到那边,唯一要注意的就是改完指针之后不要忘记还要连接原来的二叉树,即gf的操作
调整最小不平衡子树(LR):
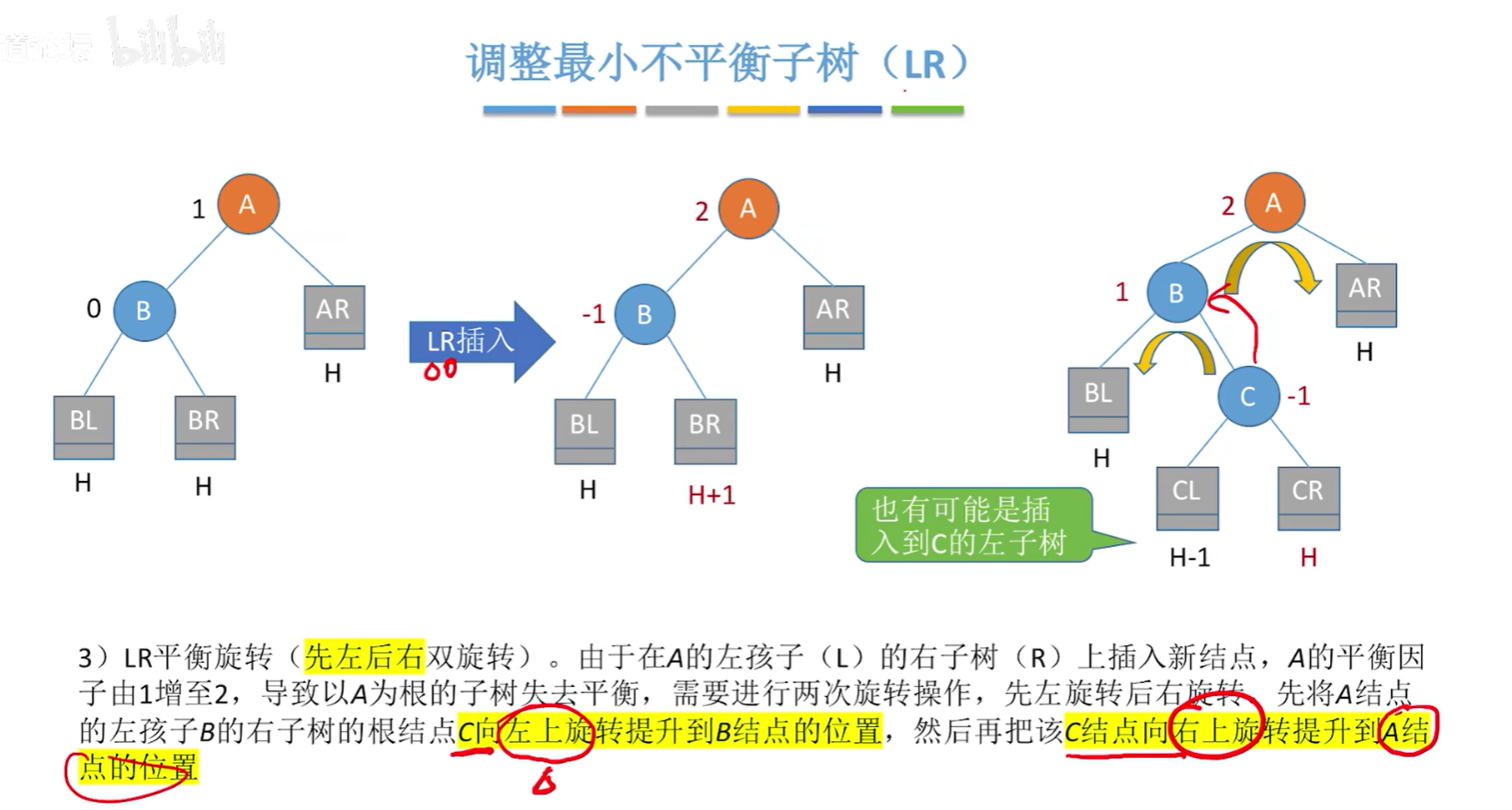
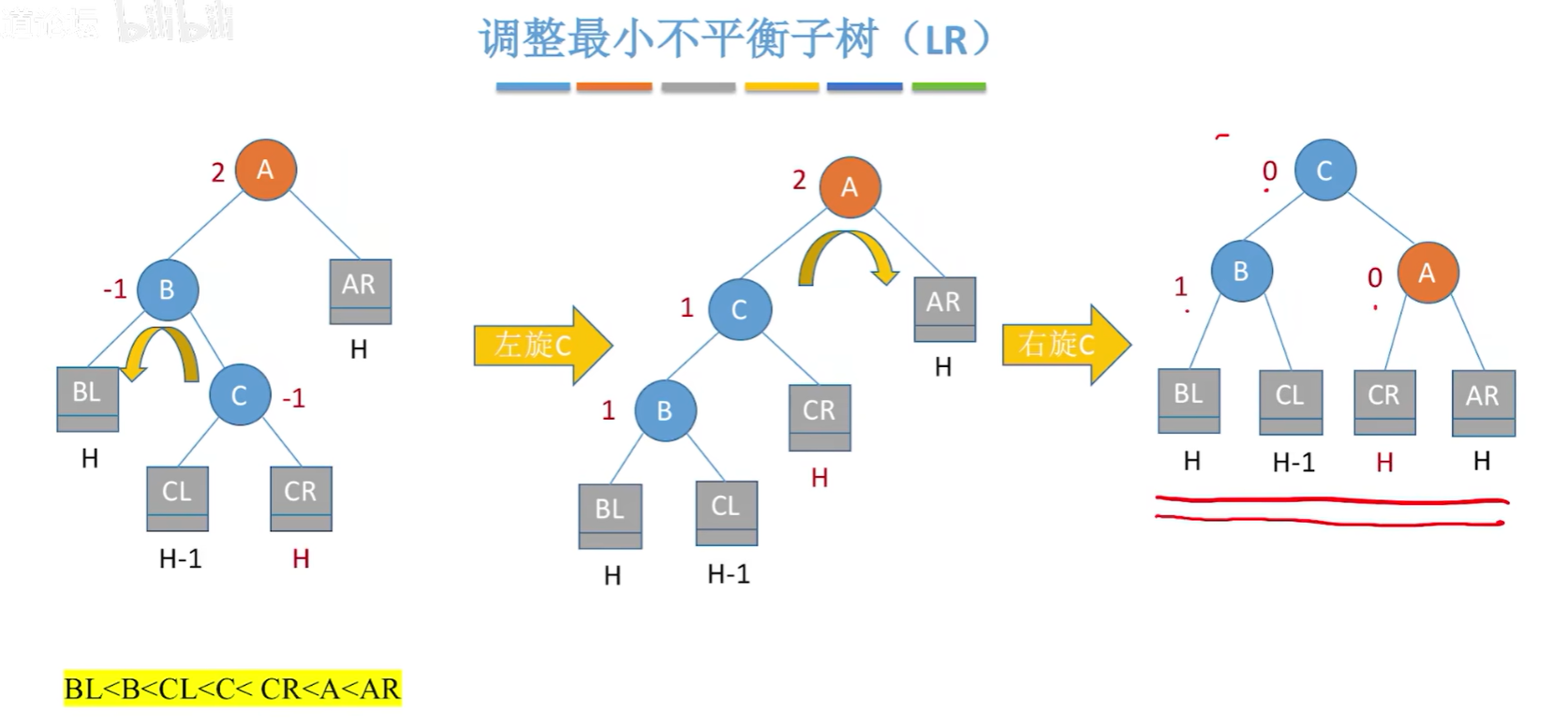
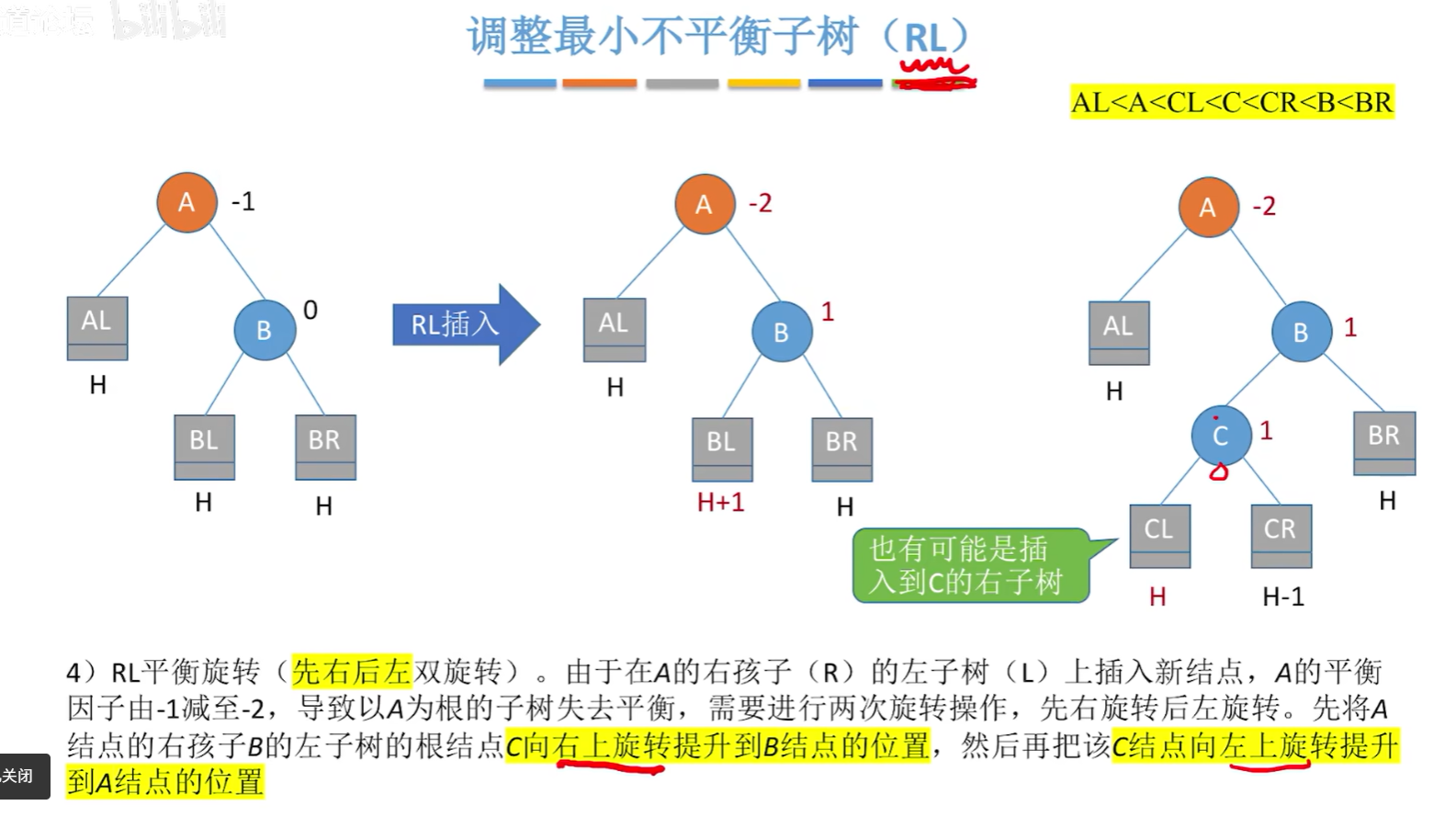
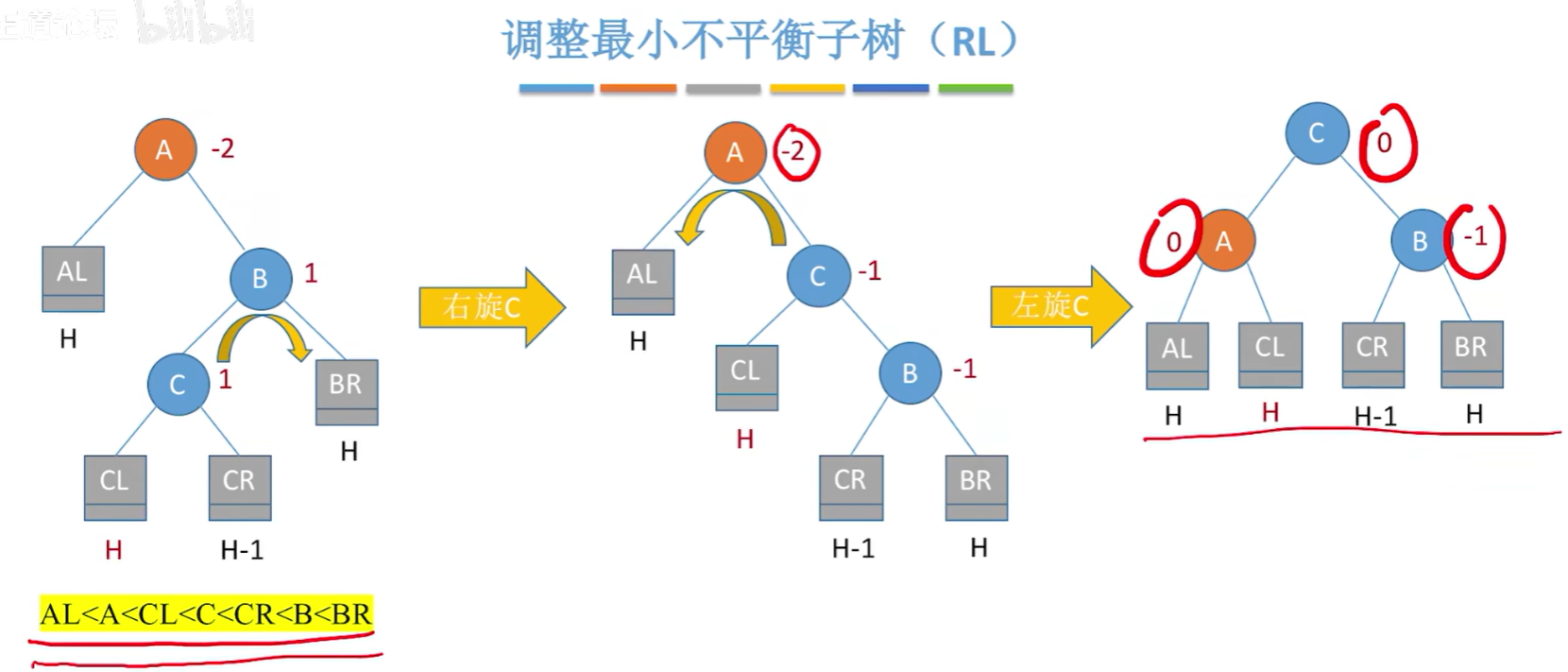
调整最小不平衡子树(RL):
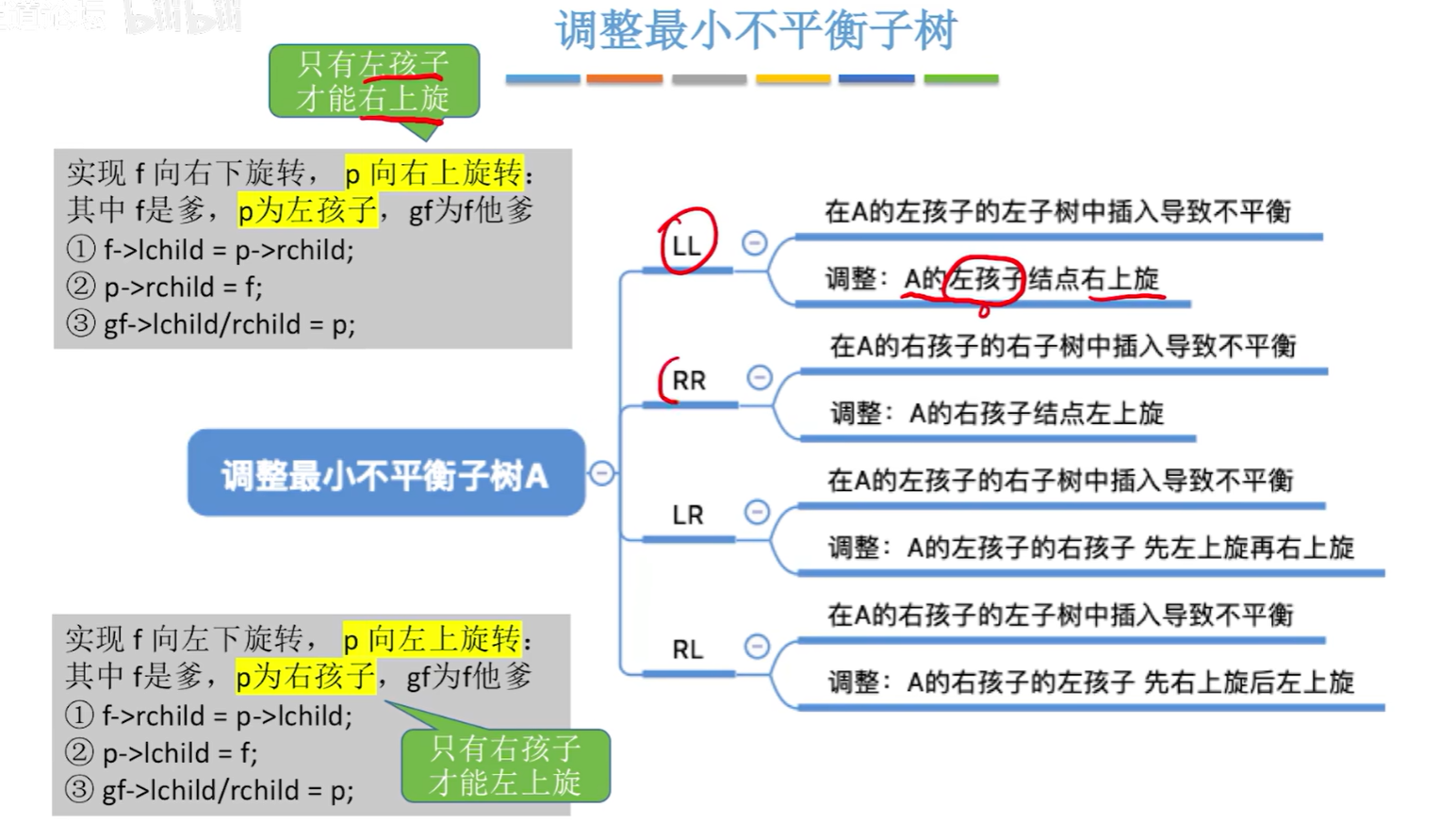

n3=4,n4=7,n5=12,n6=20
4层7个节点
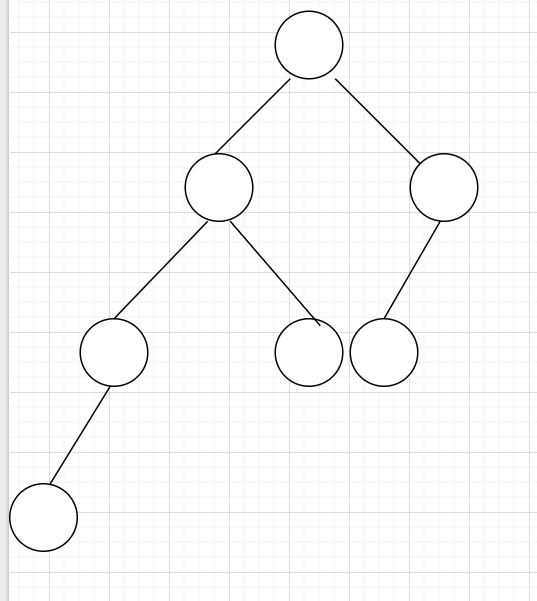
5层12结点
做题所得结论(五颗星):当你用上面的递推公式推出来一个深度为h的最小节点数量nh,深度为h的二叉平衡树只有nh个节点的话,那么所有的非叶子节点的平衡因子都是1或-1,反过来也成立。
平衡二叉树的删除

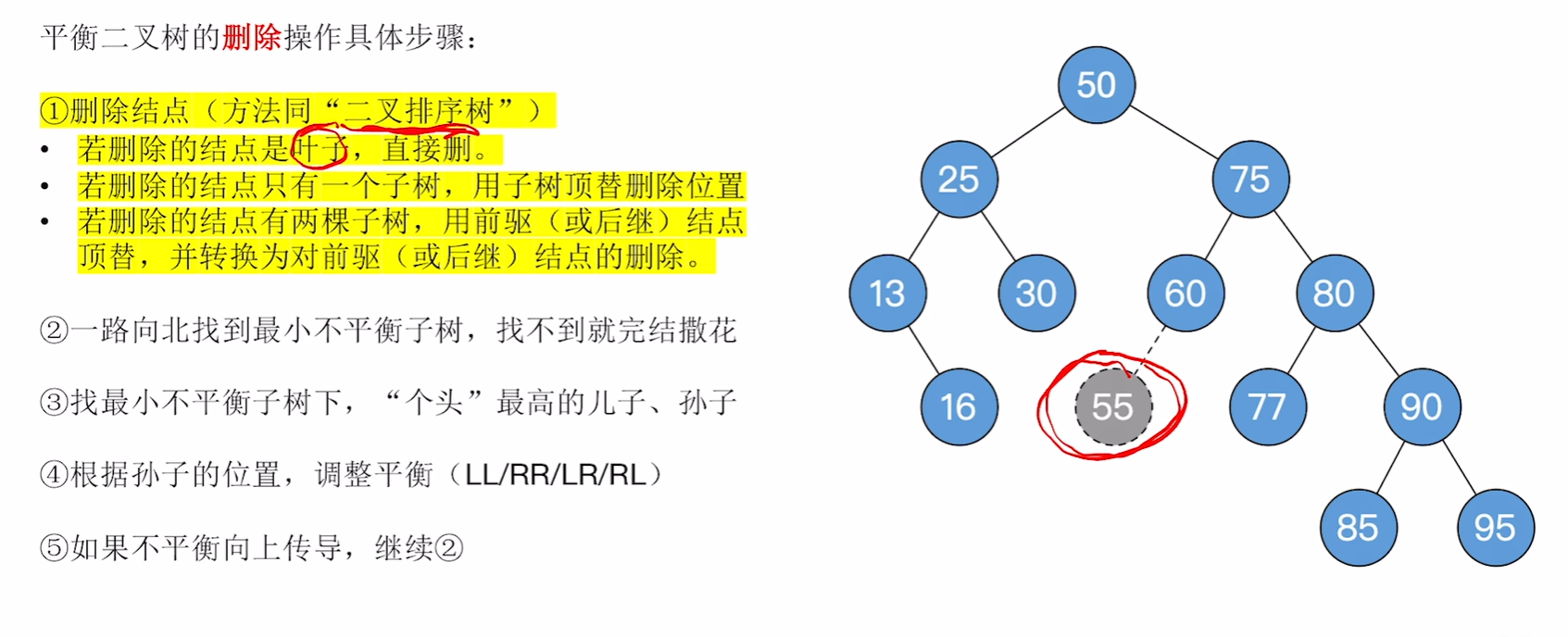
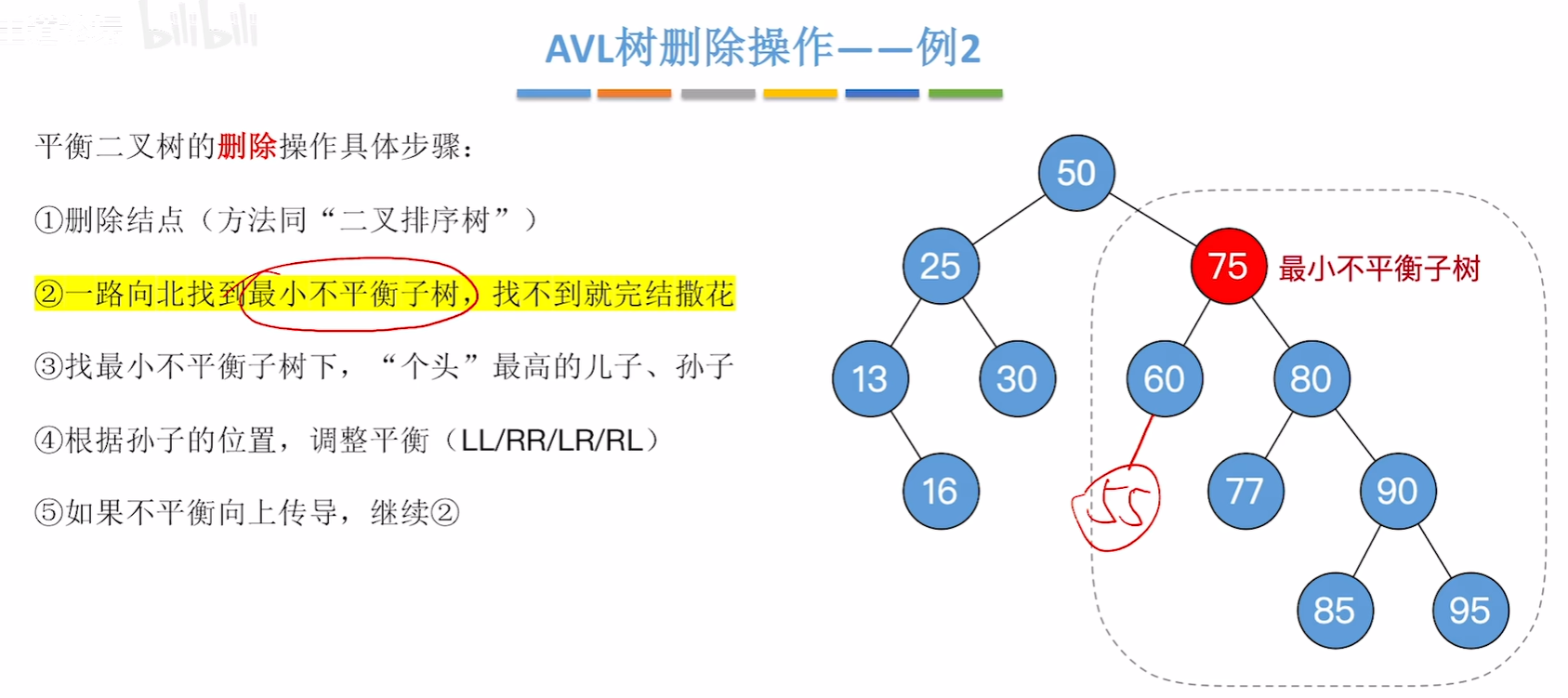
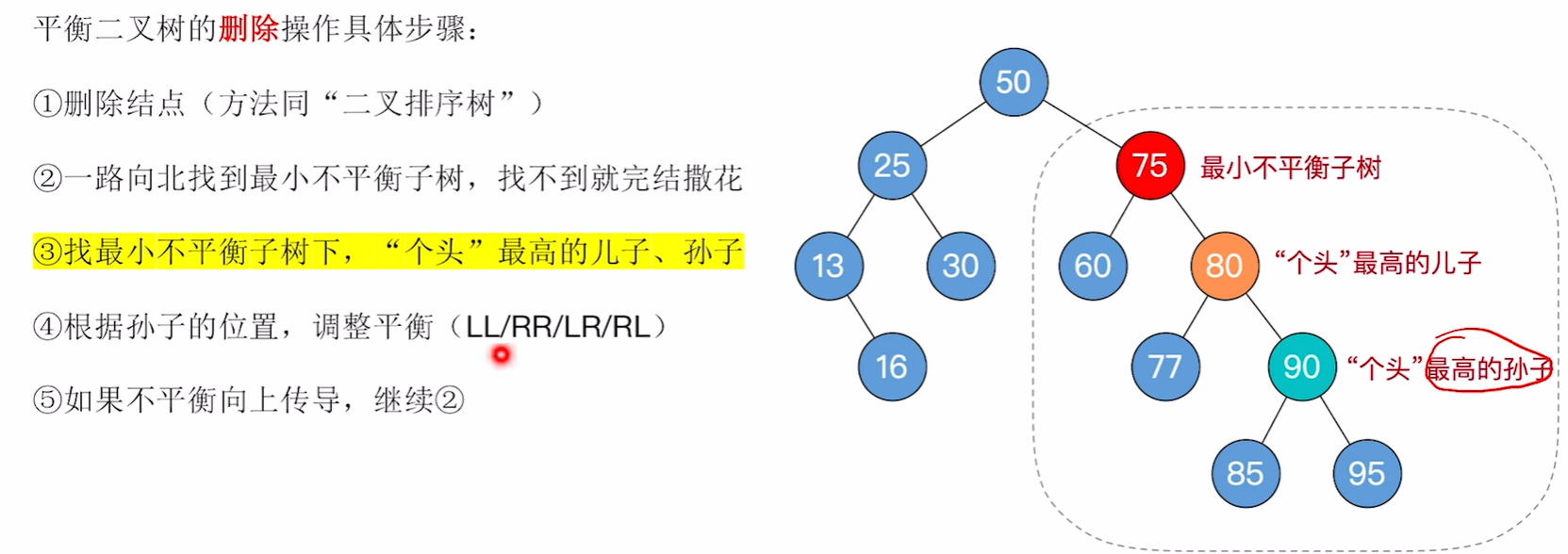
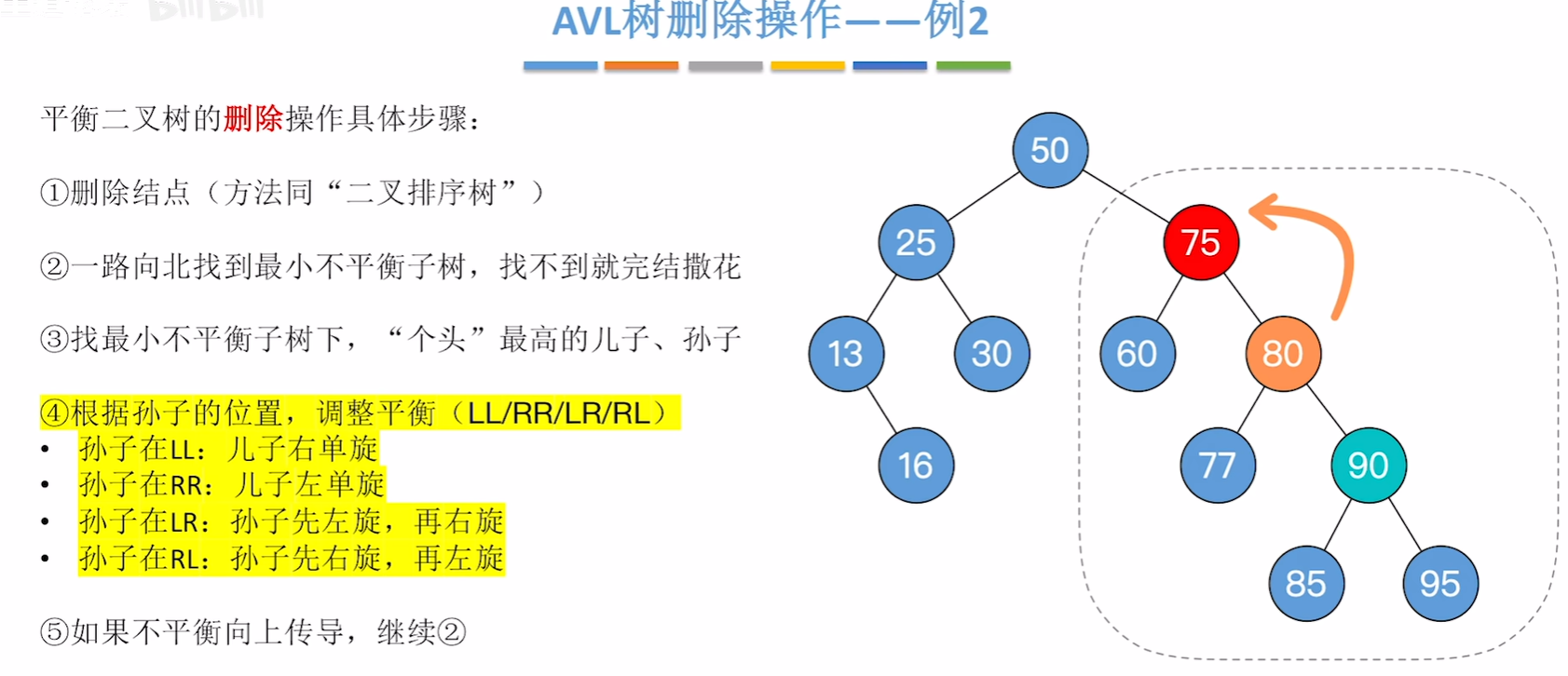
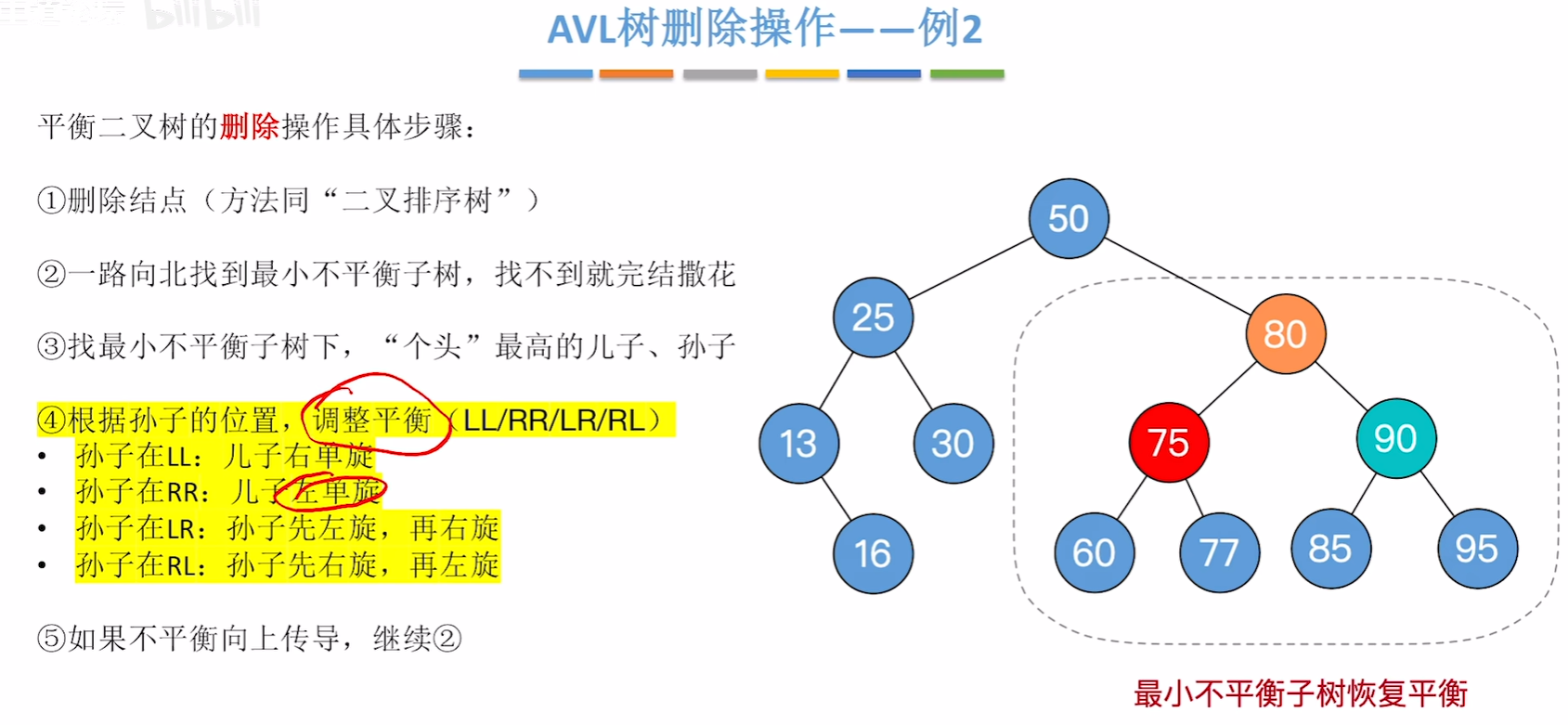
对最小不平衡子树的旋转可能导致树变矮,从而导致上层祖先不平衡(不平衡向上传递)
7.7 红黑树
可能的考法

7.7.1 为什么要发明红黑树?
红黑树是适度平衡的二叉排序树
平衡二叉树是高度平衡的二叉排序树
所以一般相同结点的话,平衡二叉树的性能会更优秀
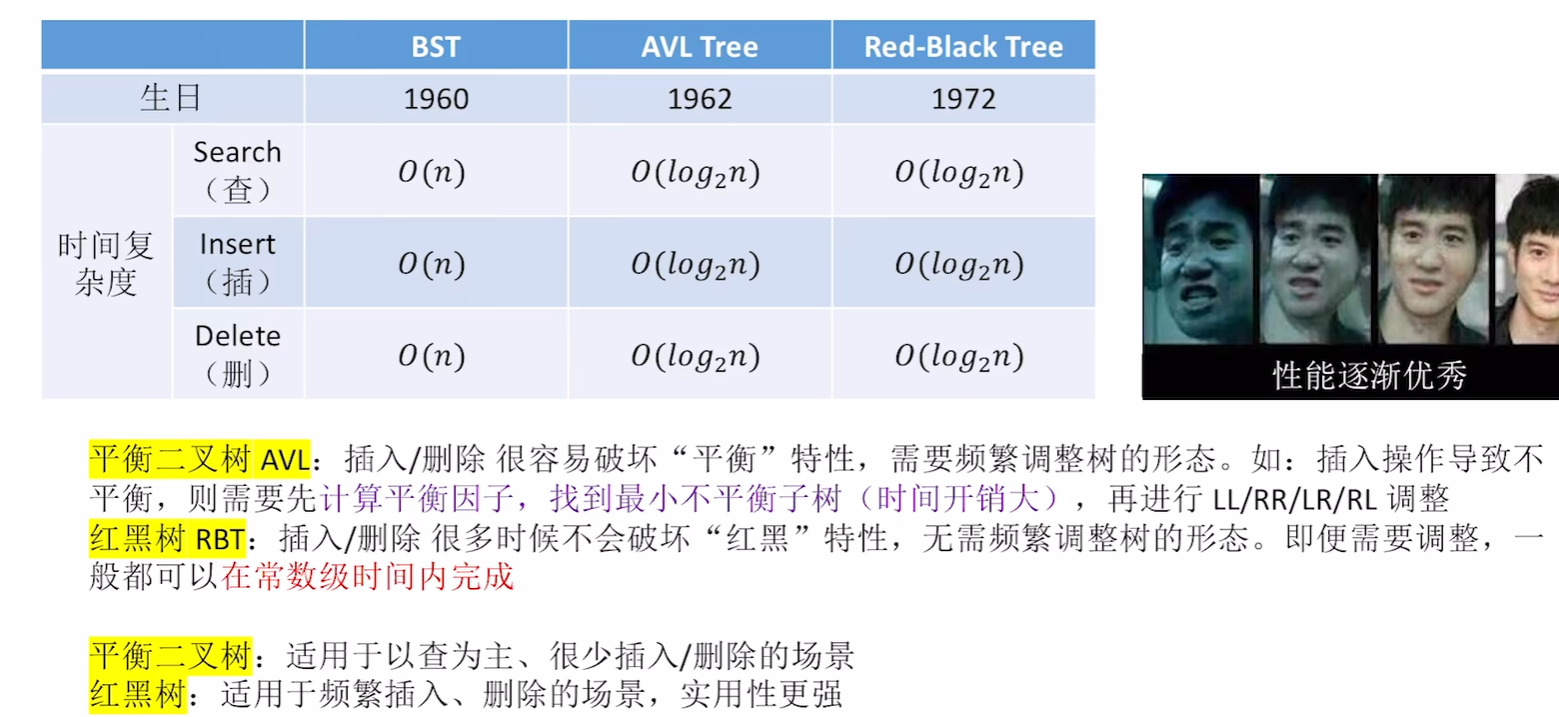
7.7.2 红黑树的定义和性质
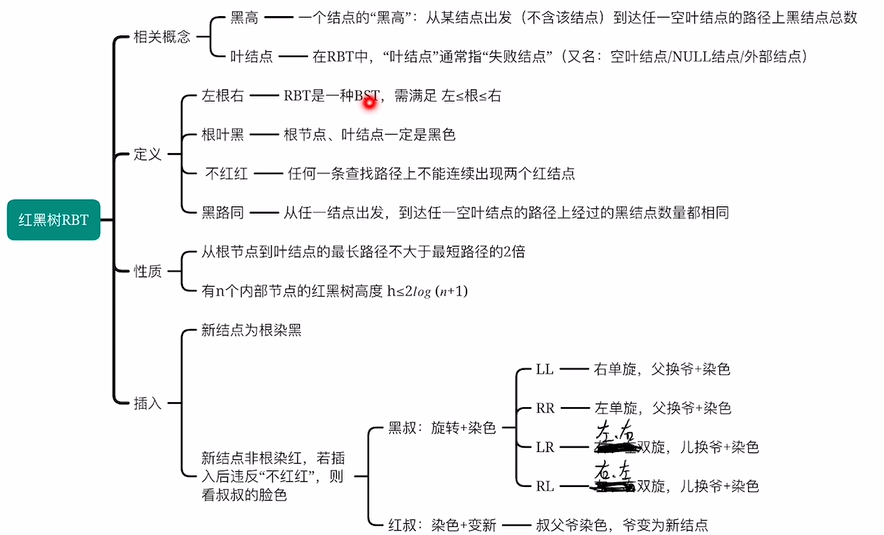
定义:

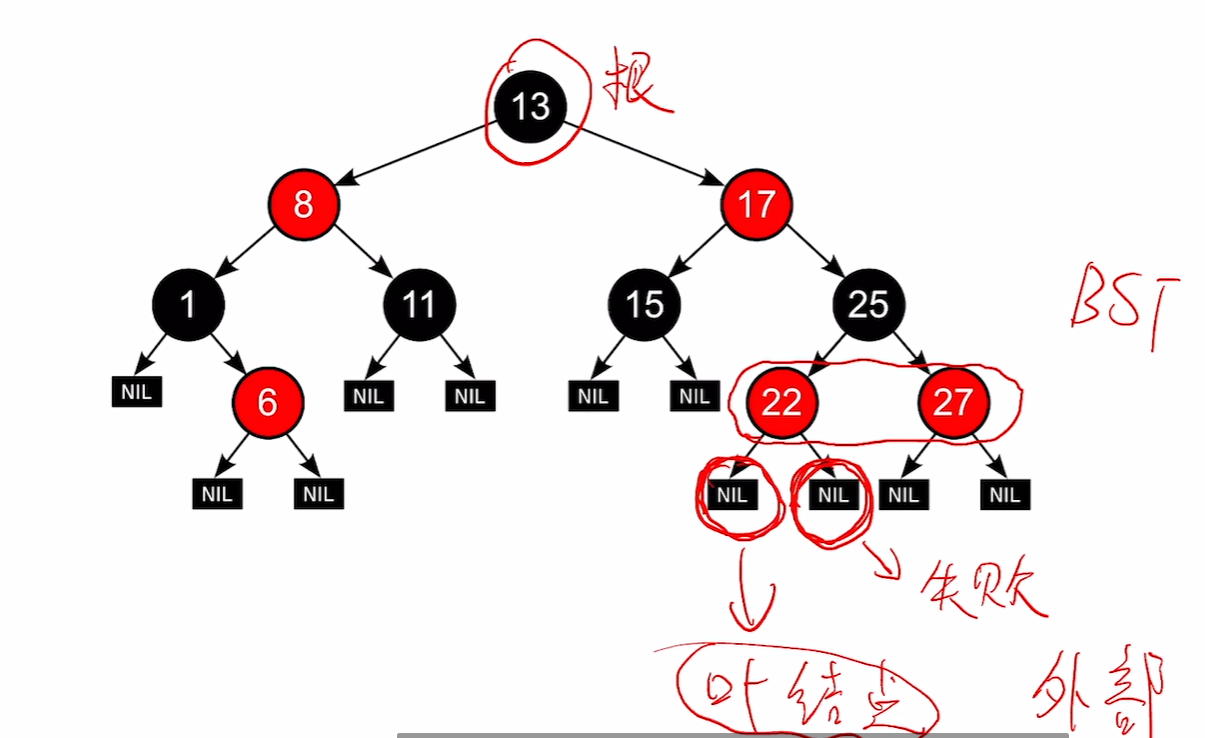
叶节点,失败节点,null节点说的是一个东西。也就是说红黑树里面的叶子节点并不是最下面一层
左根右,根叶黑,不红红,黑路同
是二叉排序树,左子树小于根小于右子树,根节点和叶节点都是黑的,不可以有两个相连红色,从一个节点出发到达叶节点的路径上的黑色节点数量一定相同
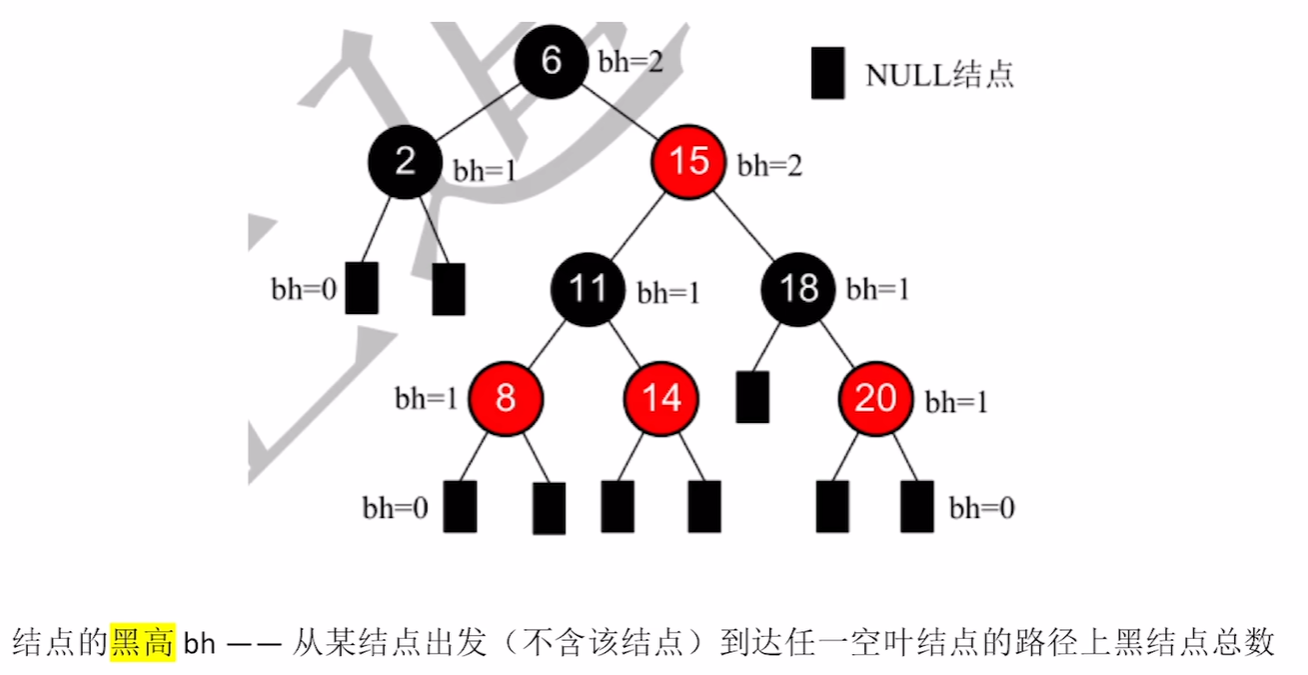
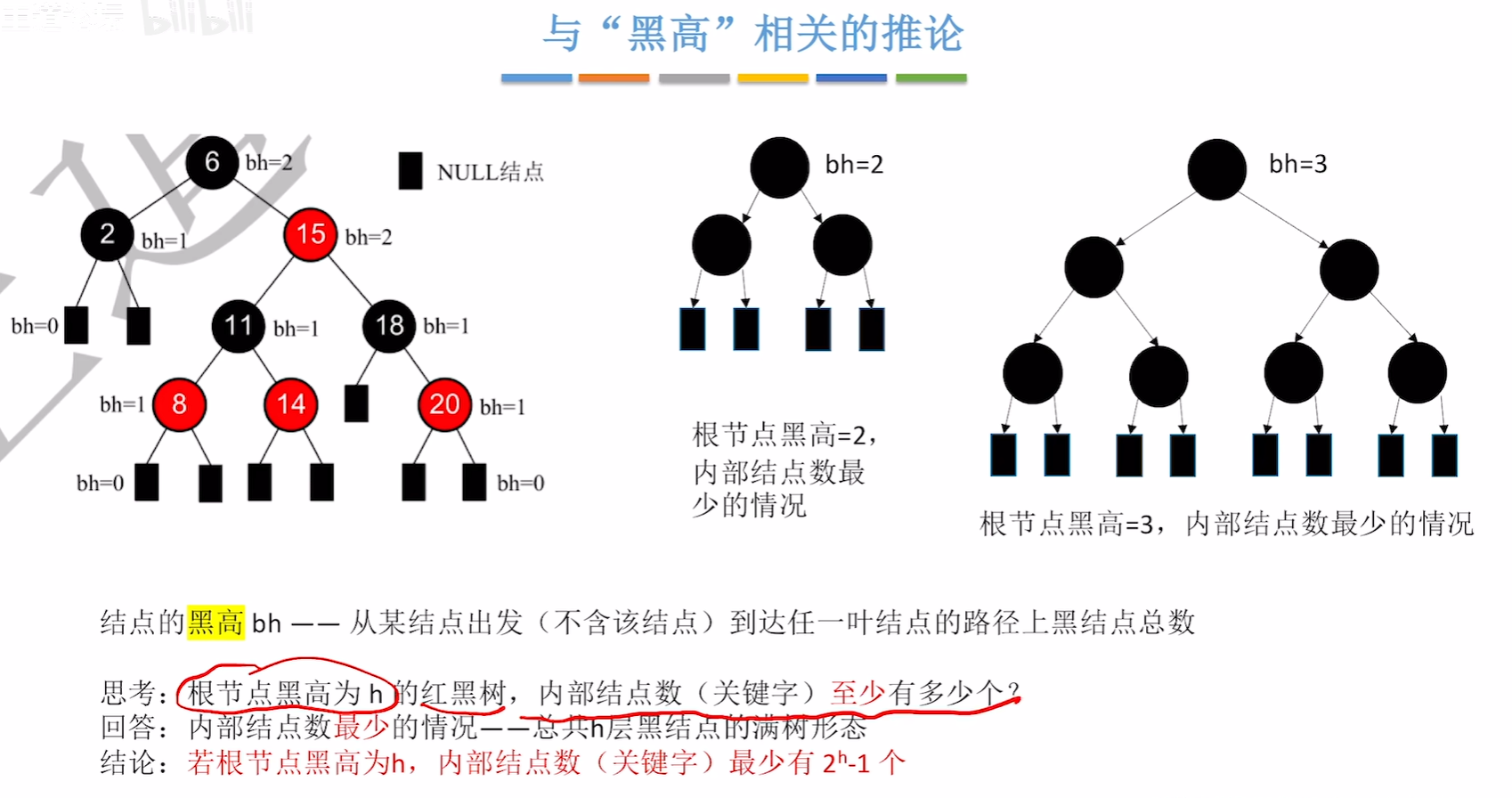
性质:
红色节点数目最大可以是黑节点数目的两倍
若红黑树所有节点都是黑色的,那肯定是一颗满二叉树(因为根节点到叶节点的所有路径上的黑色节点数量必须相同)

查找:
和BST,AVL一样,从根出发,左小右大,若查找到一个空叶节点,则查找失败
7.7.3 红黑树的插入和删除
插入

1.如果插入的新结点不是根,为什么要染成红色呢?因为要保证黑路同,如果染成黑色,那必然导致新增加节点的;路径上的黑色节点数量比其他路径多
2.判断LL还是RR还是其他型都是通过爷节点来判断的而不是父节点
3.图中的染色的意思其实就是取反,只要涉及到x换y的,那么x和y的颜色都要取反,黑的变红的,红的变黑的
4.爷变为新结点是把爷结点看做新结点重新走一遍上述的流程,看爷节点作为新结点有没有破坏红黑树特性,比如:如果爷结点此时是红的,还是根节点,那必然要被染成黑色
5.其实每次插入的如果不是根节点,那么破坏的基本都是不红红这个特性
重点:所以每次插入的如果是非根节点就直接看有没有违背不红红就行,不用管其它特性有没有被违背,因为一定不会被违背
具体的例子
插入20,10,5
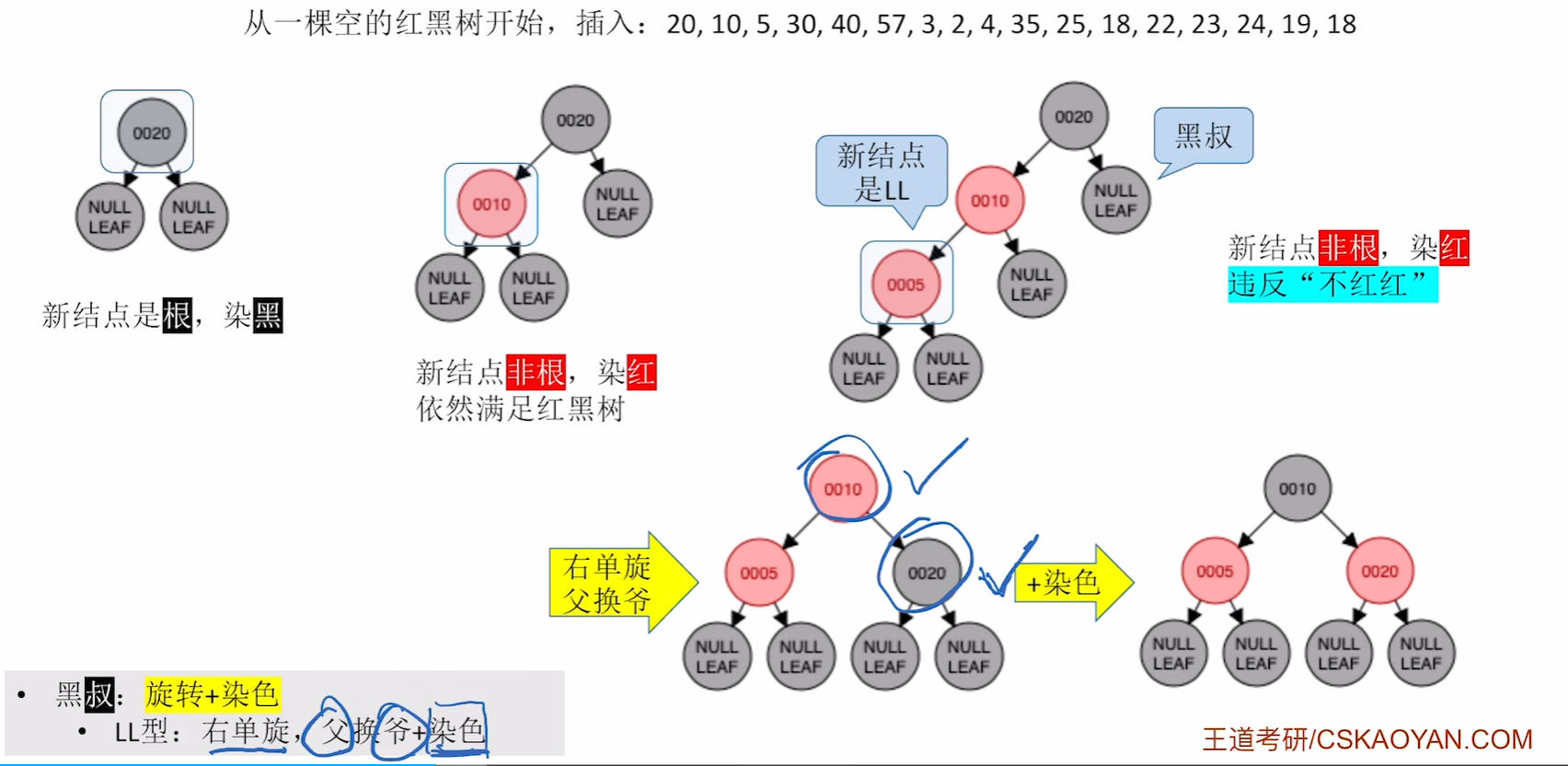
插入30
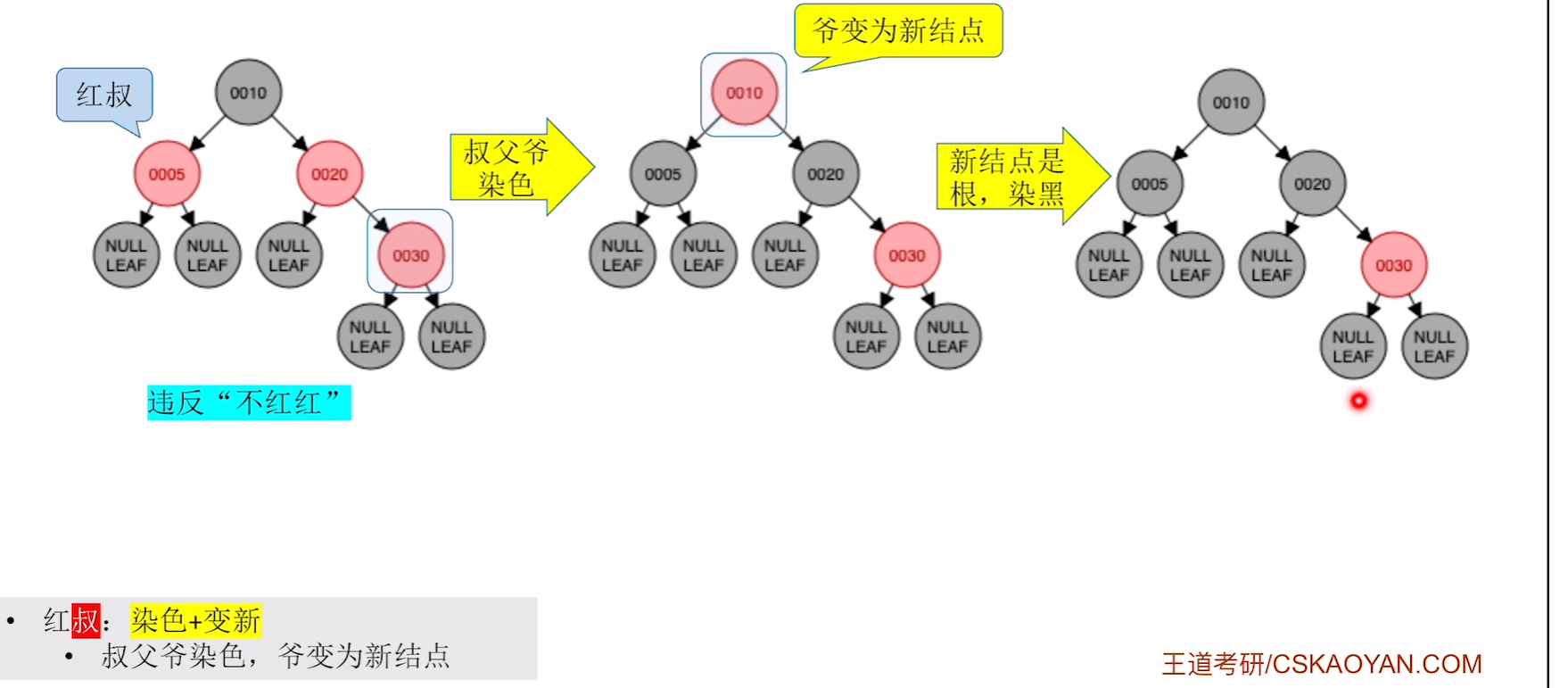
插入40
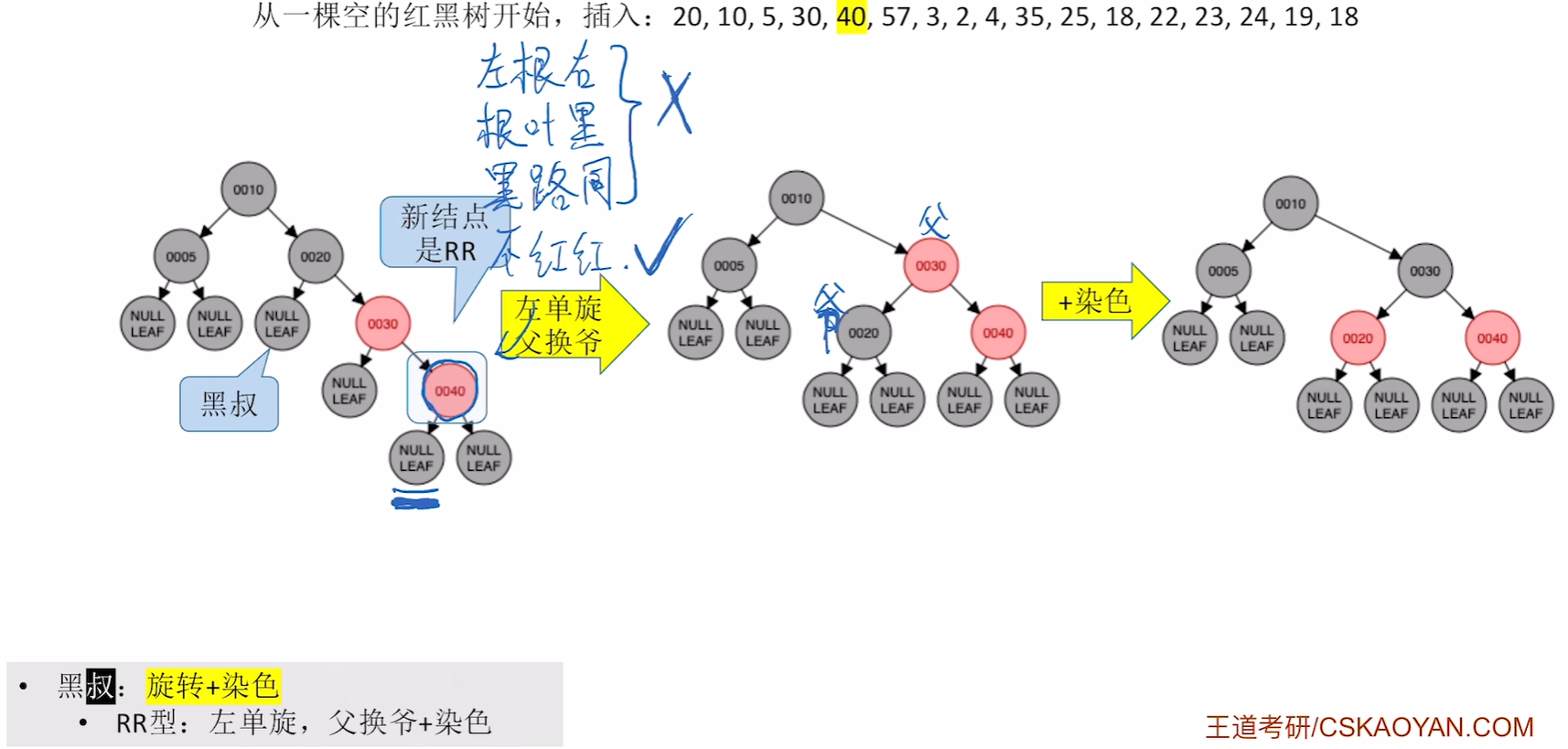
插入57
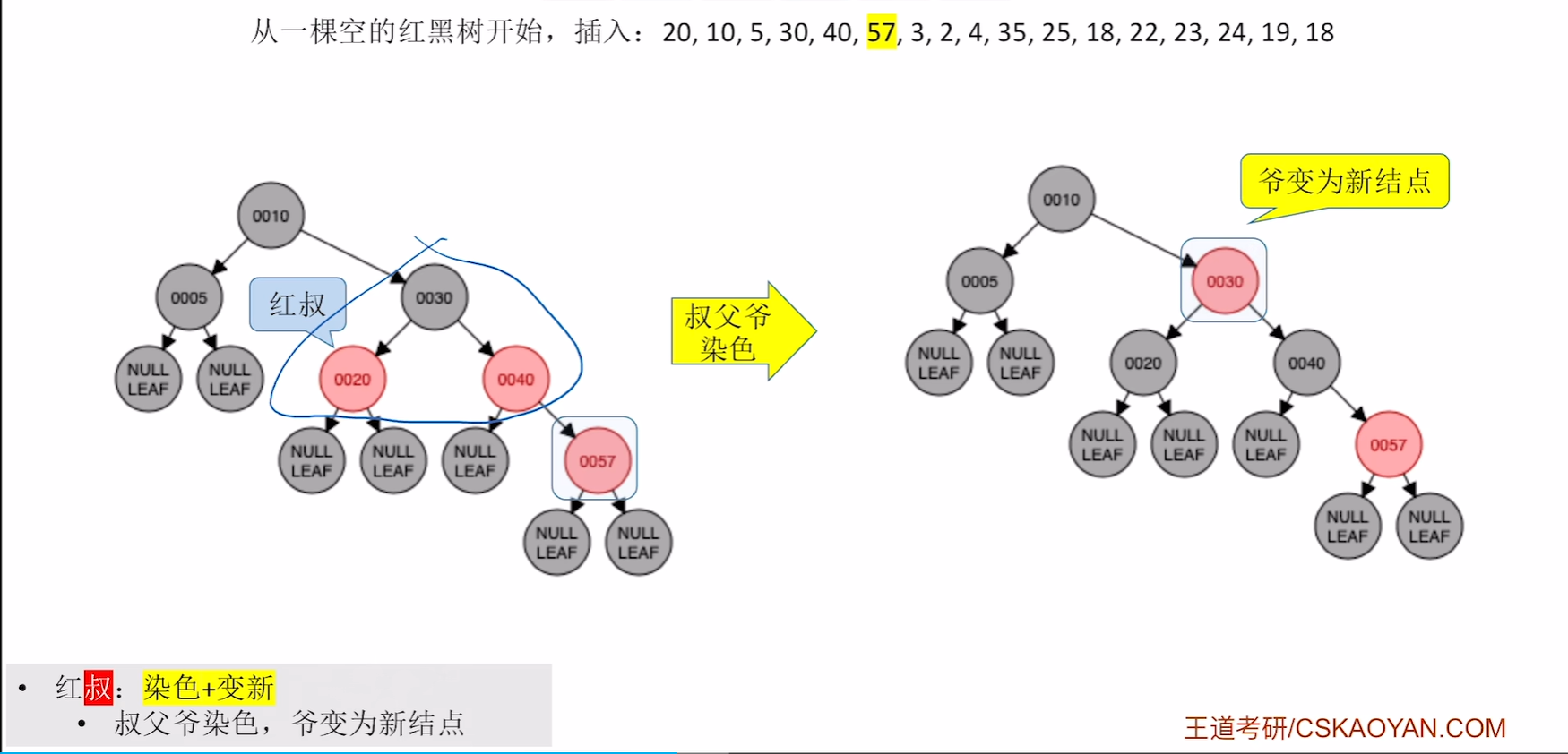
插入3
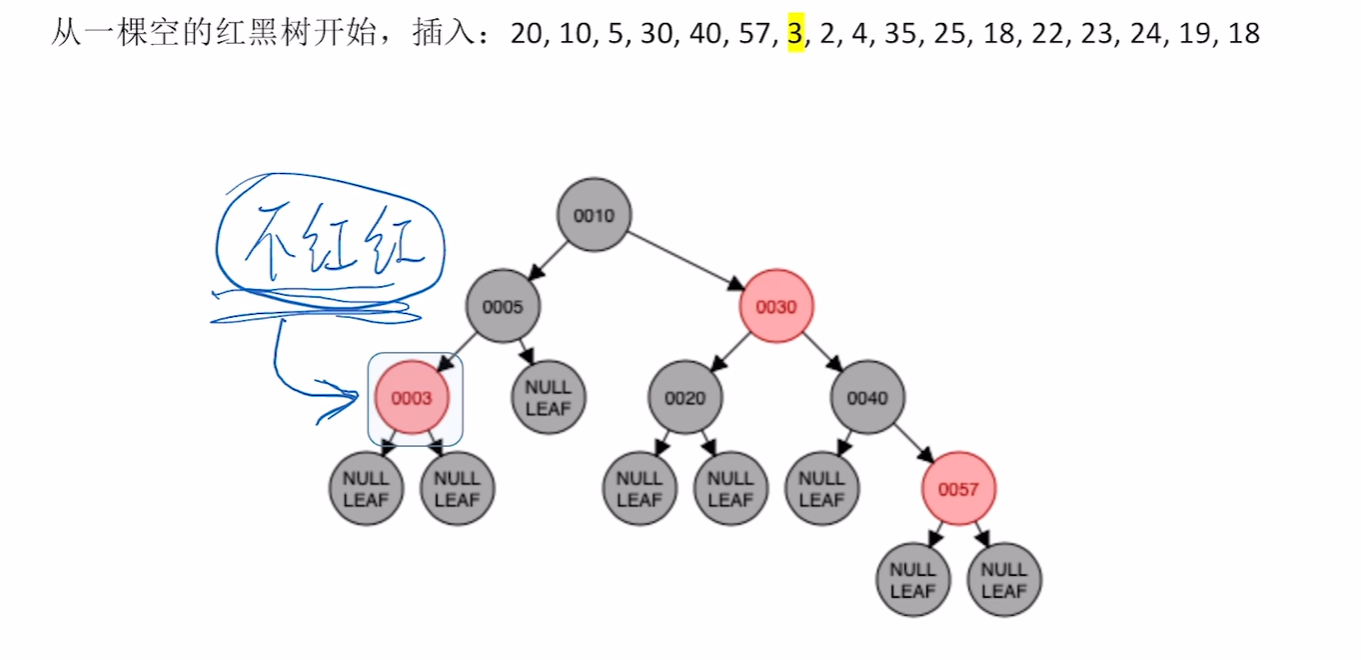
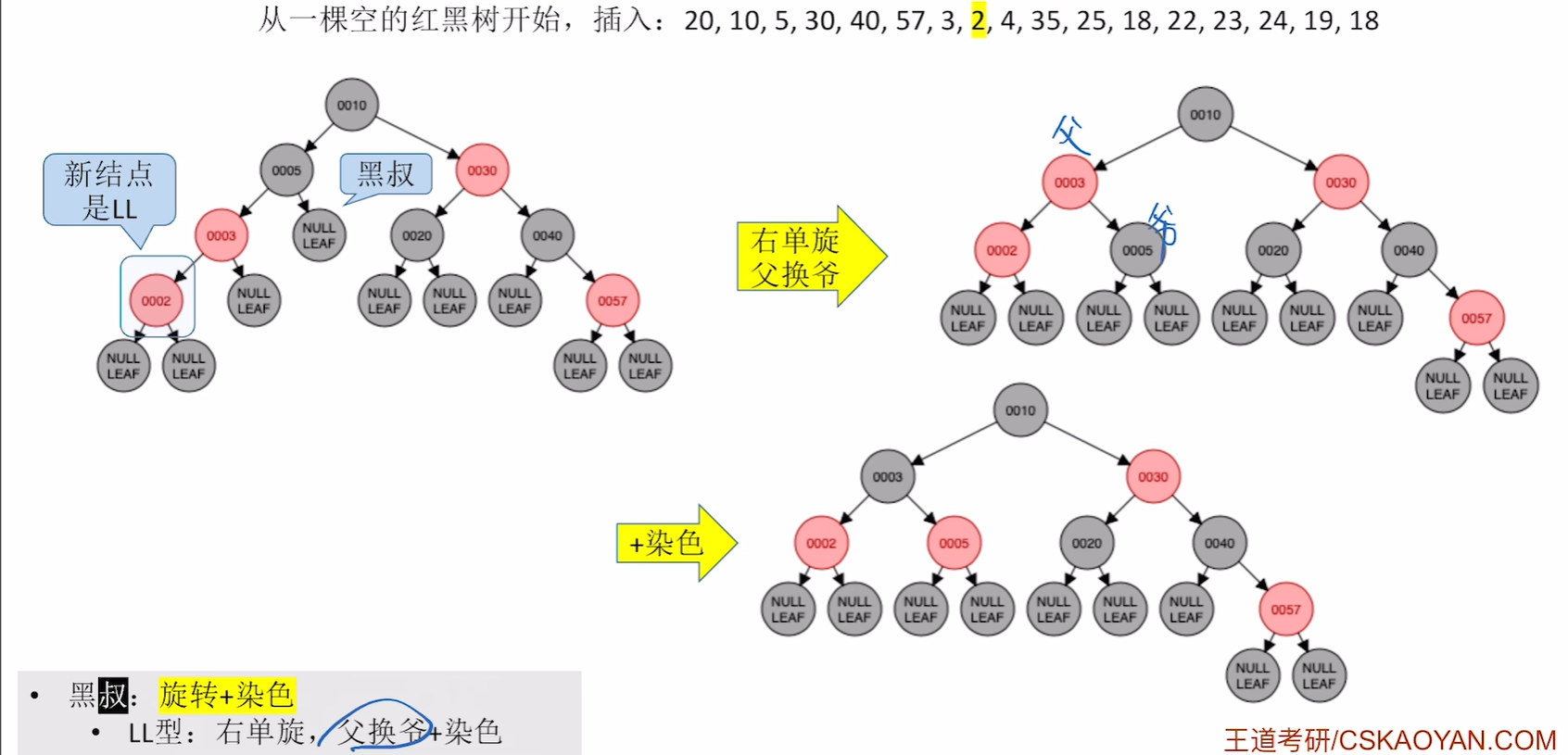
插入2
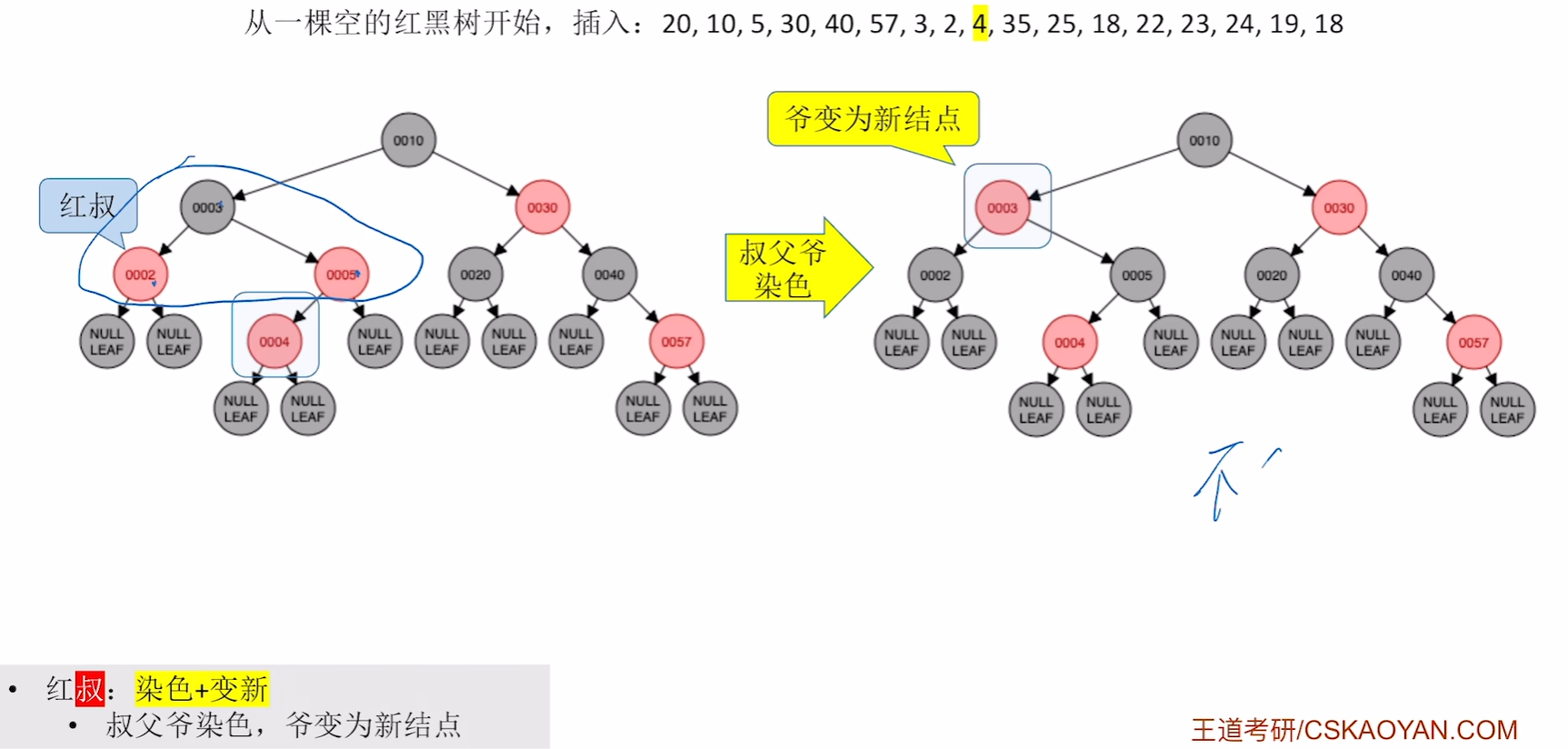
插入4
插入35,25,18都没有违反不红红,直接插入就好
其实当红黑树越来越大的时候插入很多时间都是直接插入的
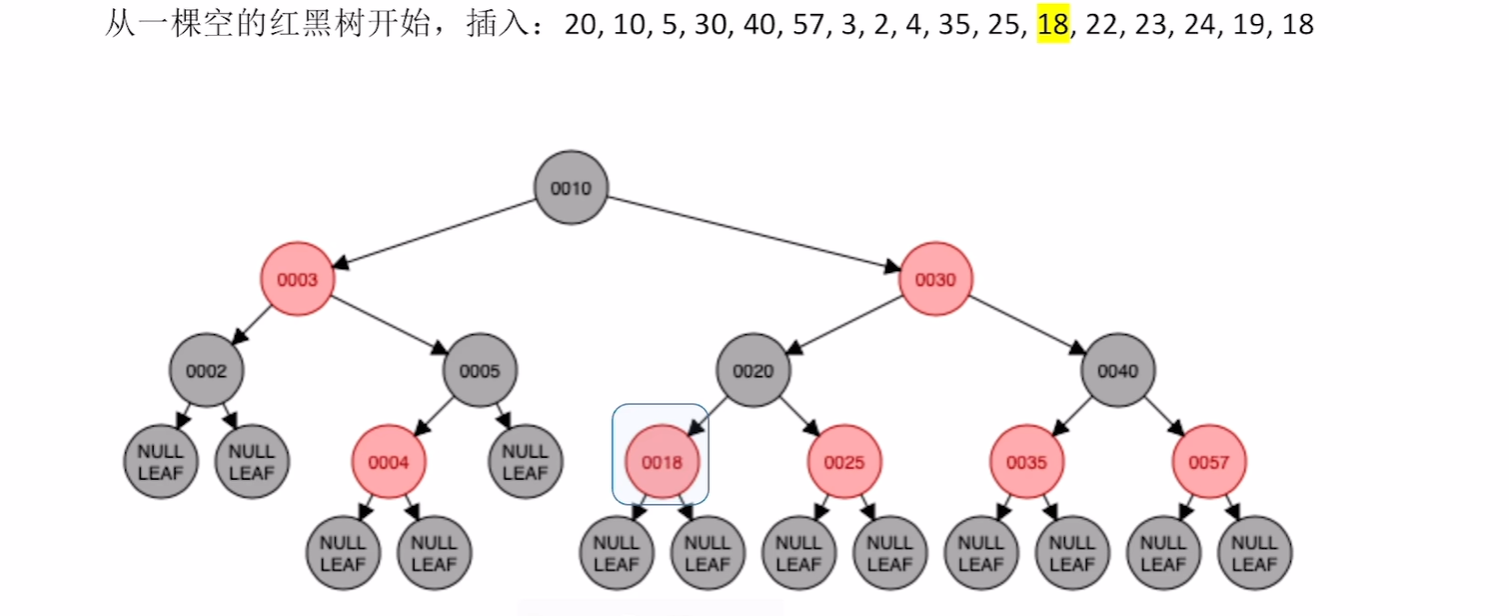
插入22
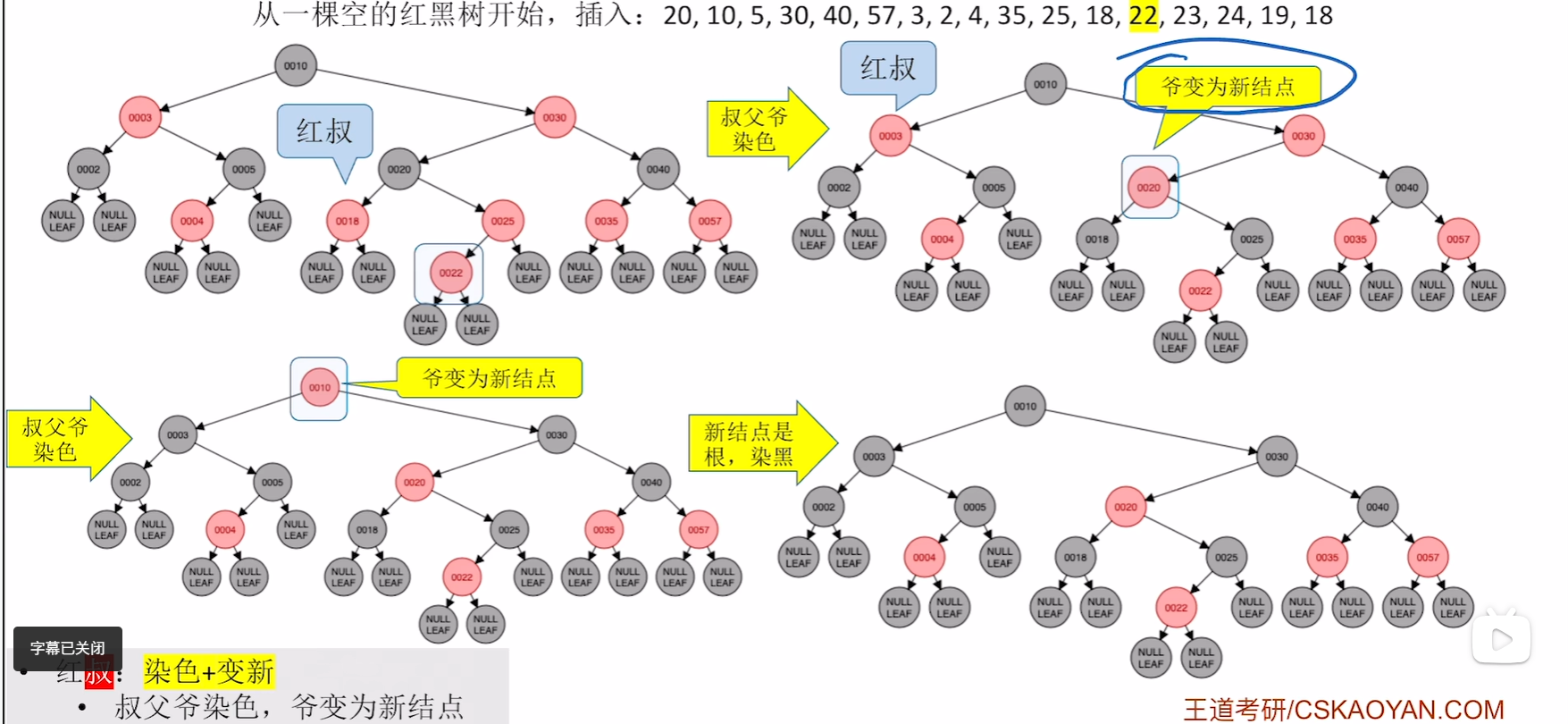
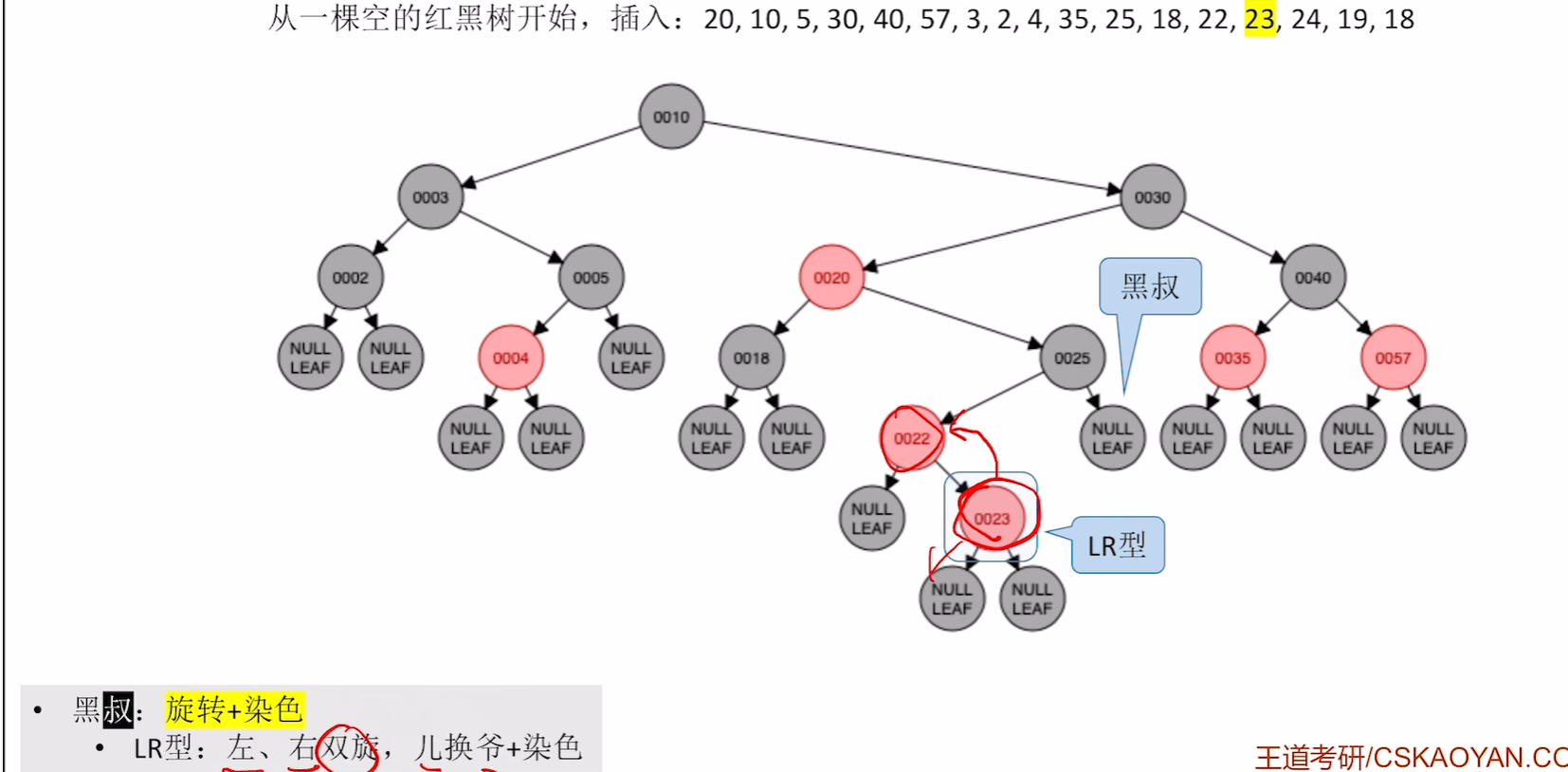
插入23
第一步违反了不红红且叔叔是黑的,判断为LR型
第二步左旋
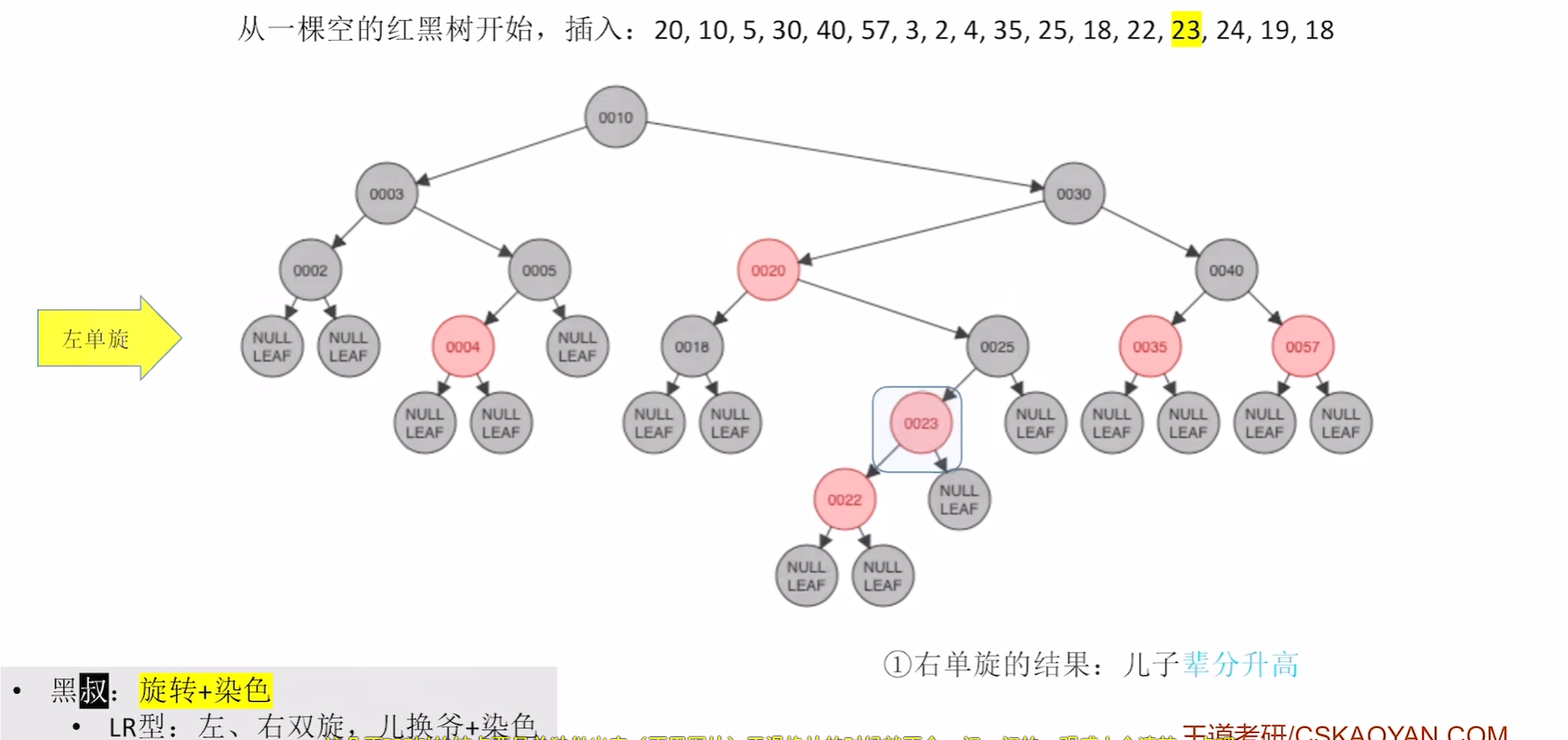
第三步右旋
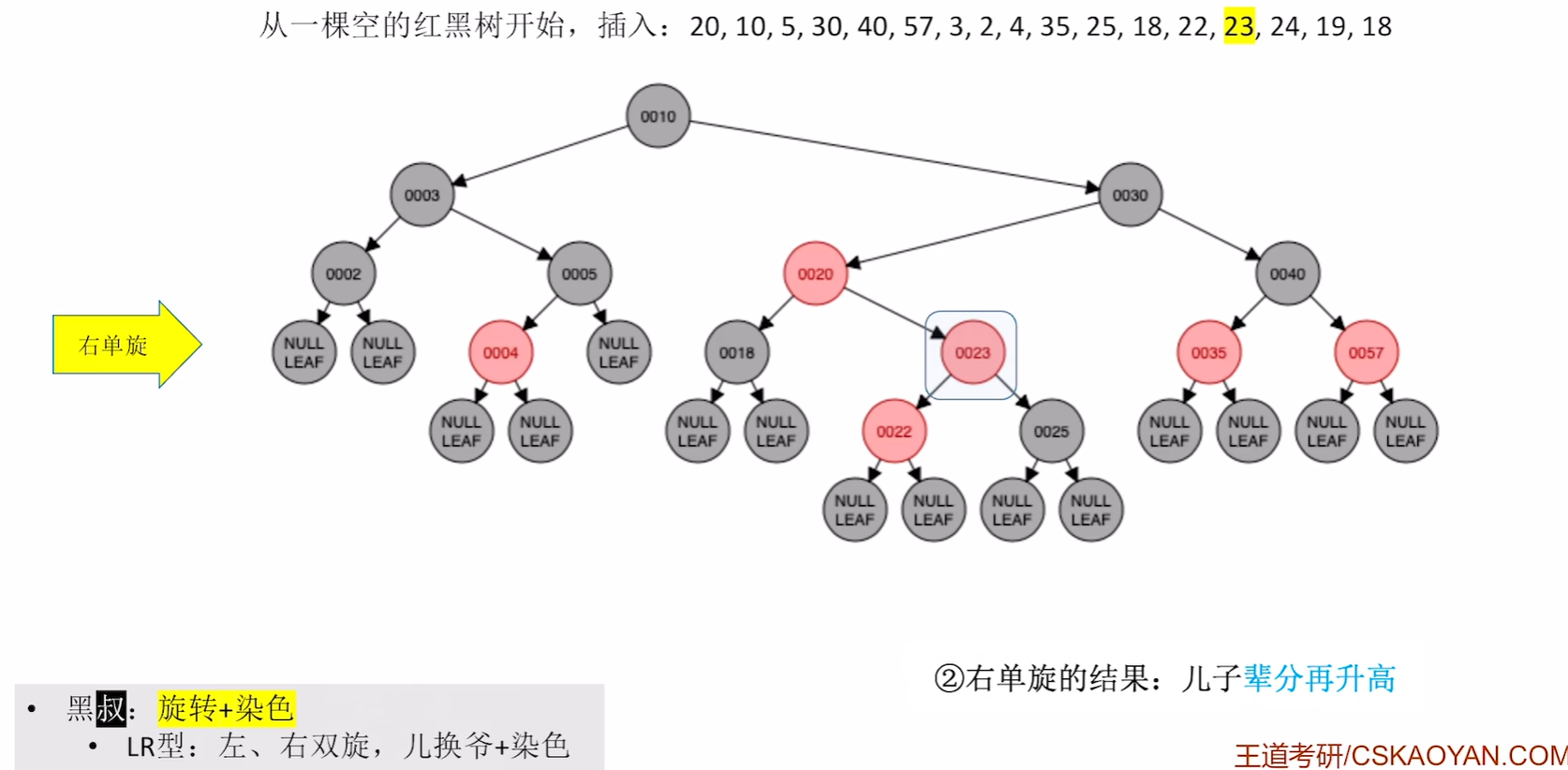
第四步 儿子和爷染色
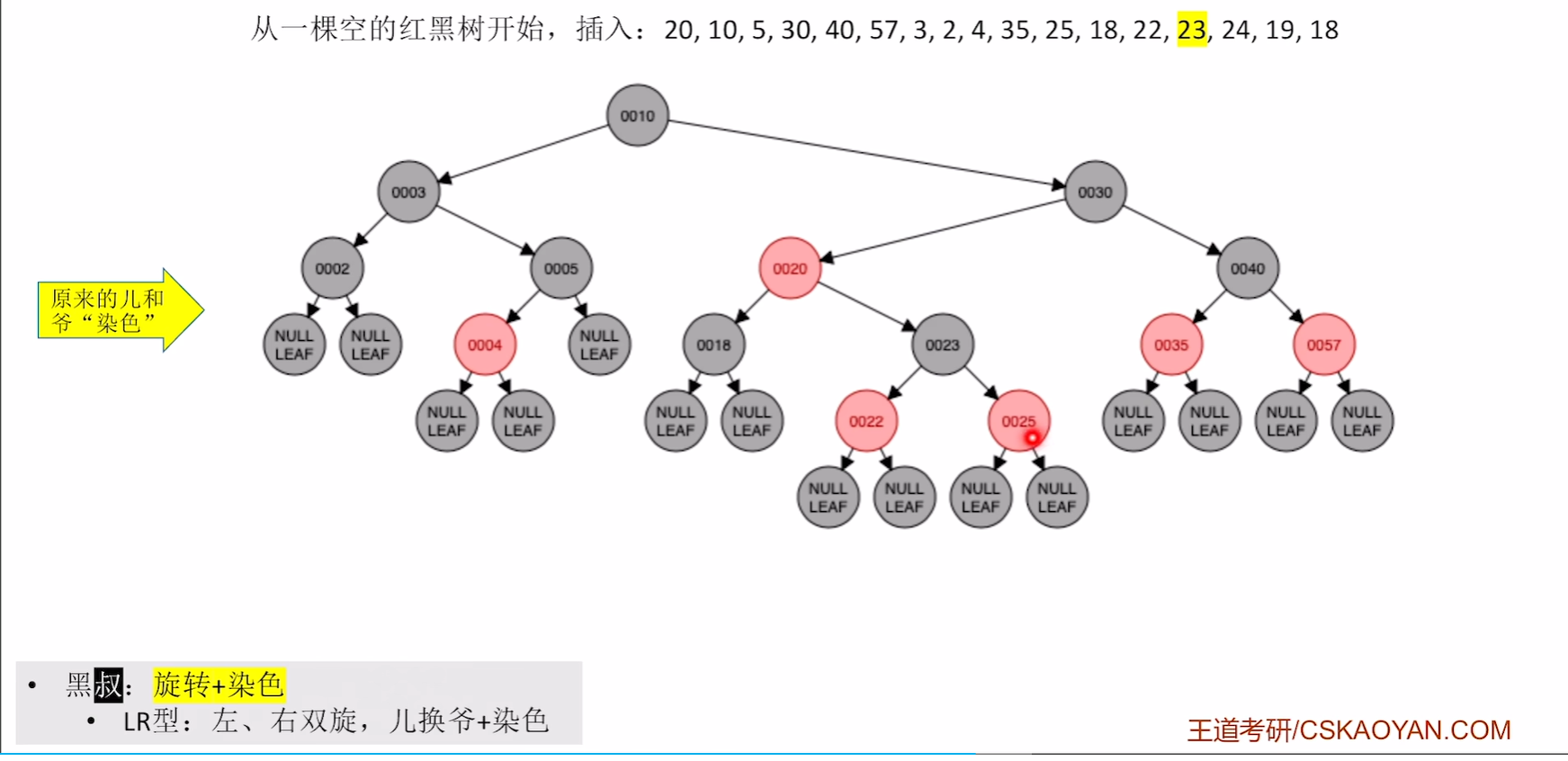
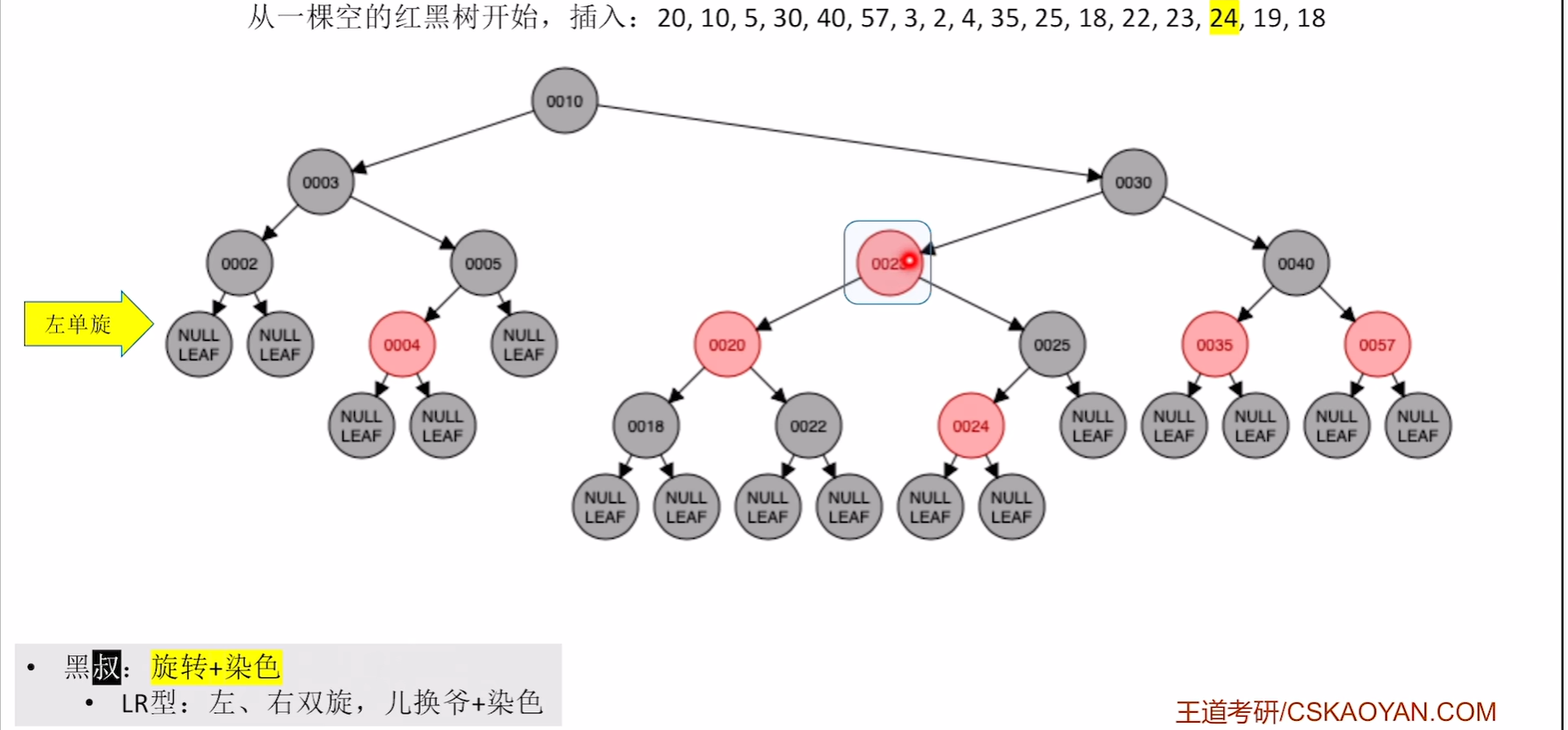
插入24
破坏不红红,且是红叔,则染色,爷变为新结点
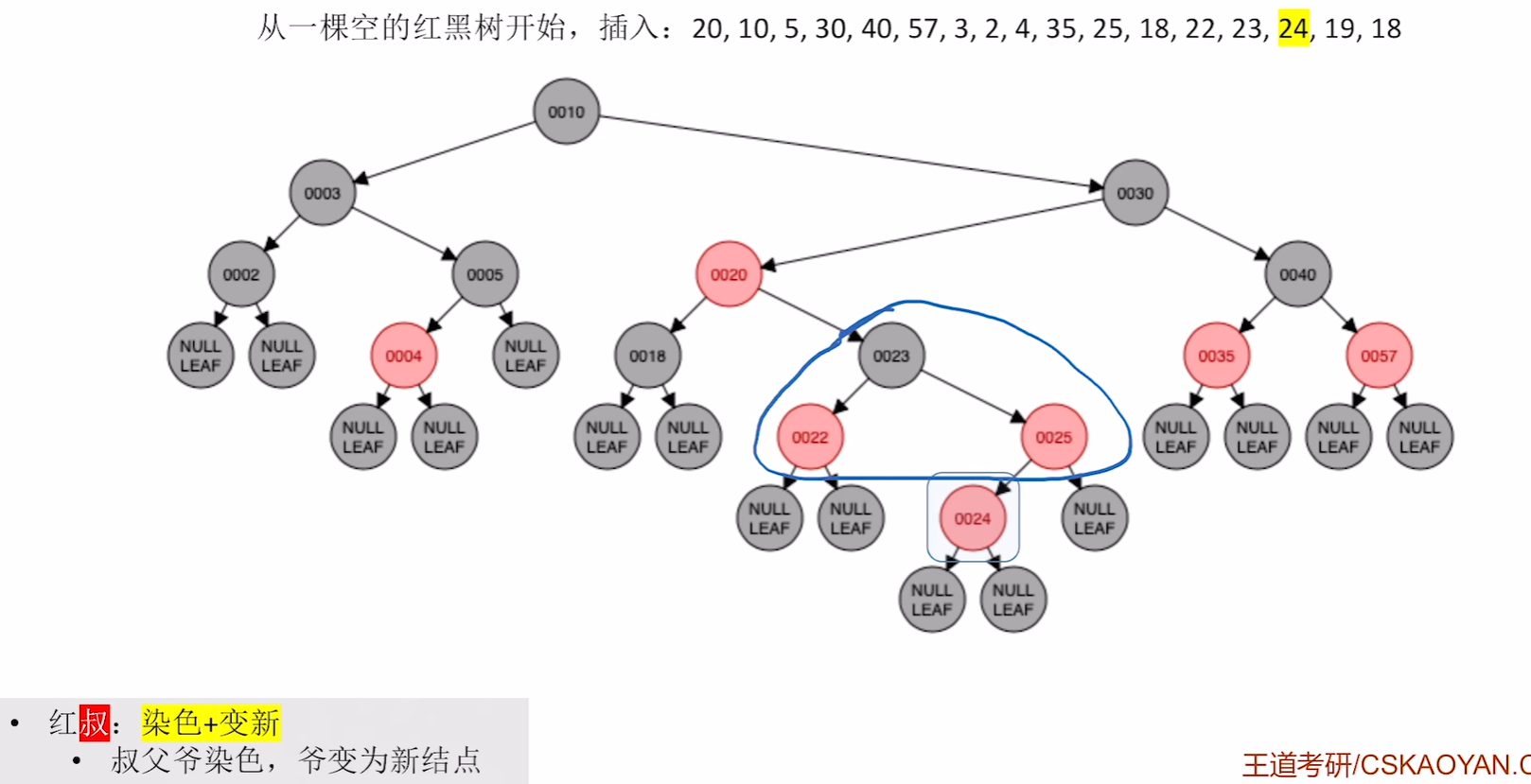
爷变为新结点后发现违反了不红红,则继续进行之前的对应步骤
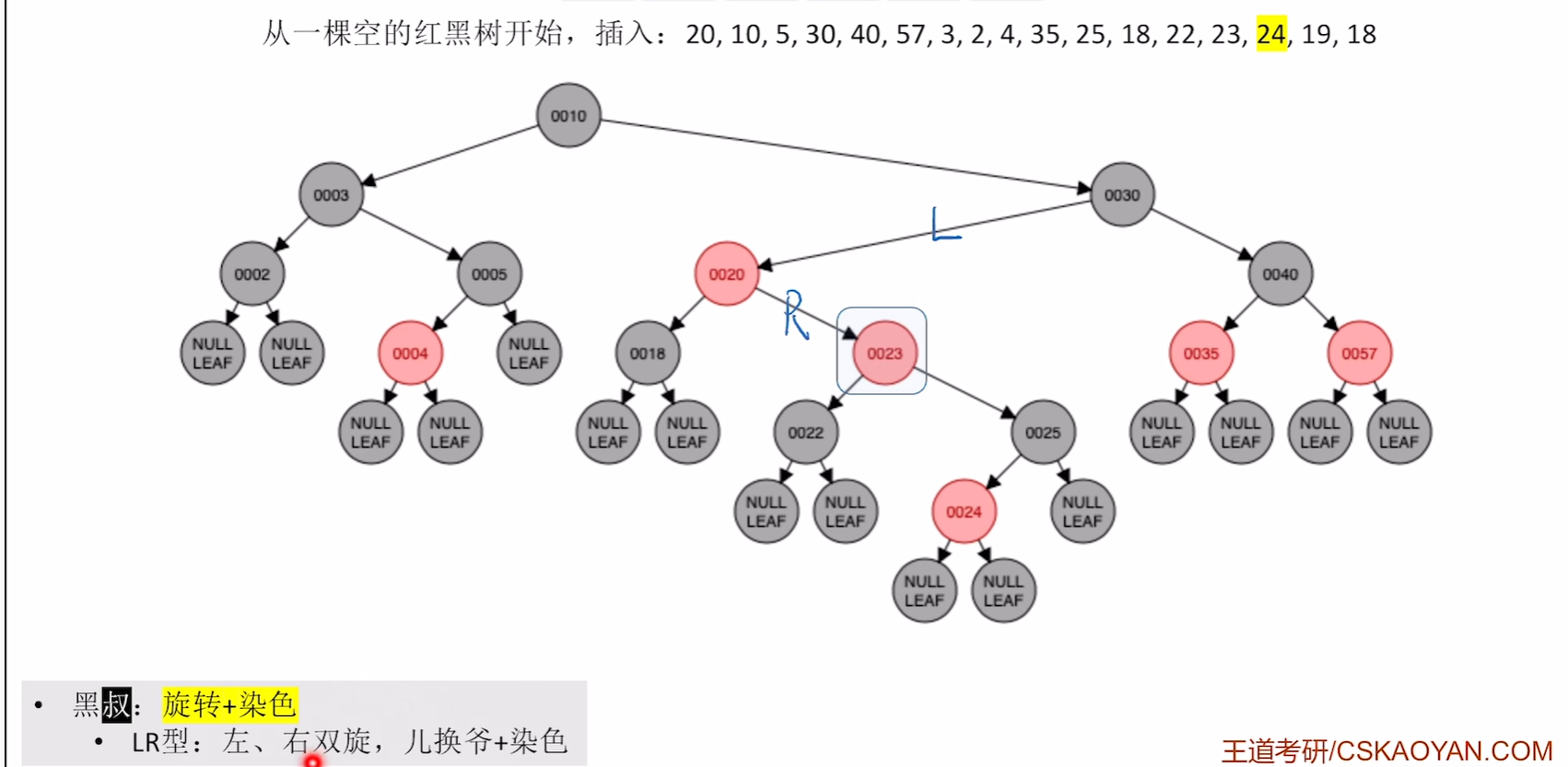
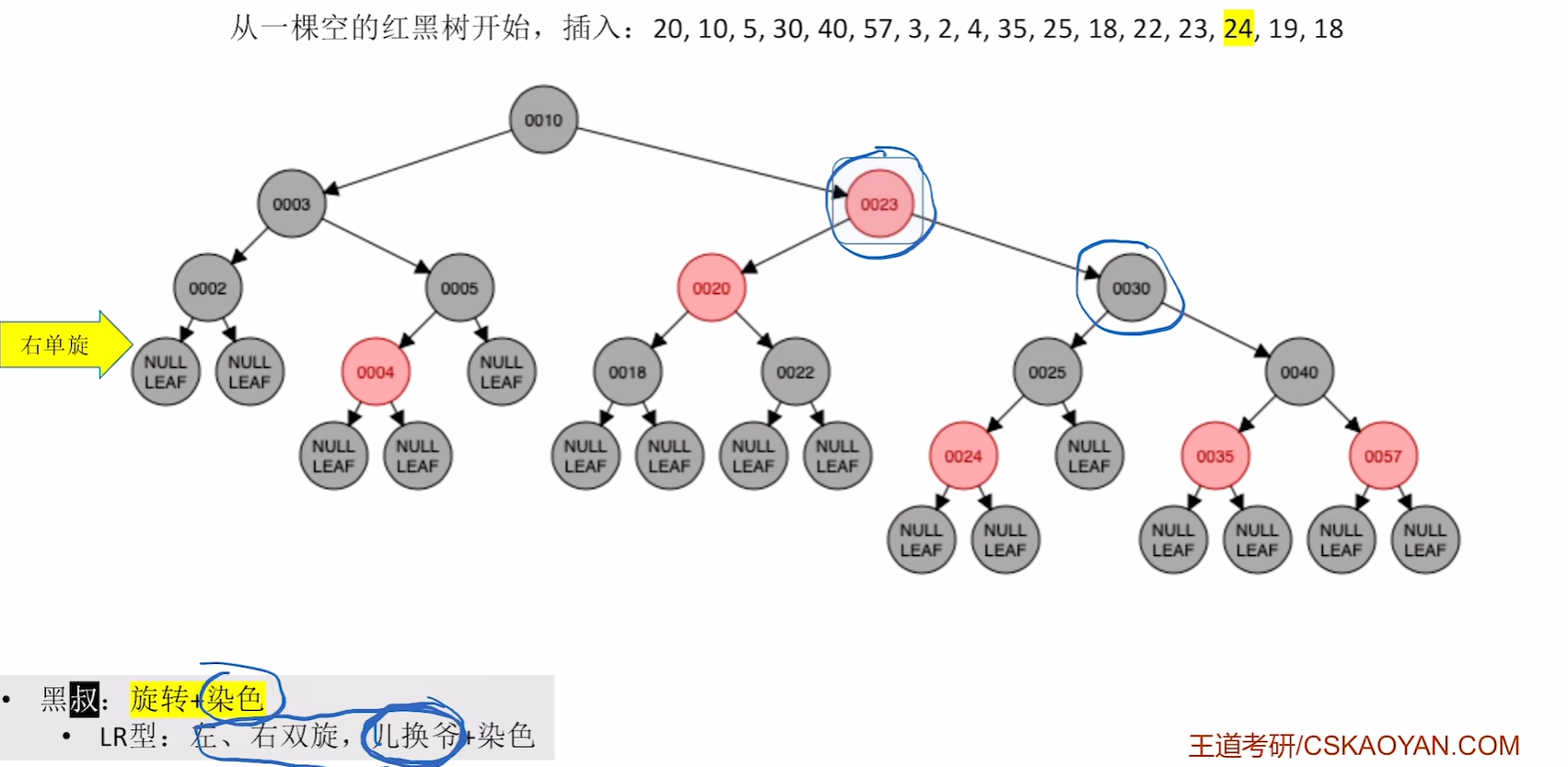
左旋
右旋
染色
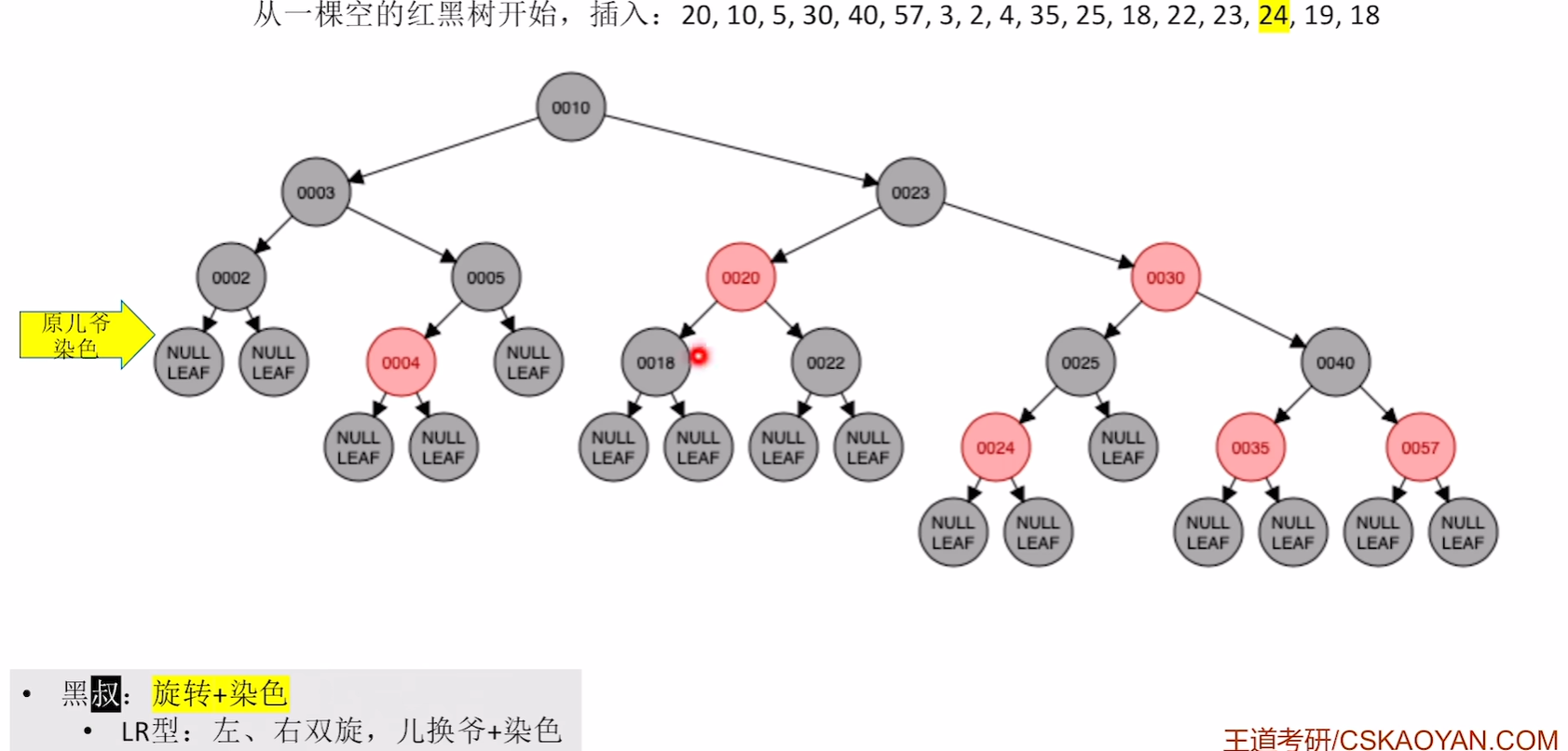
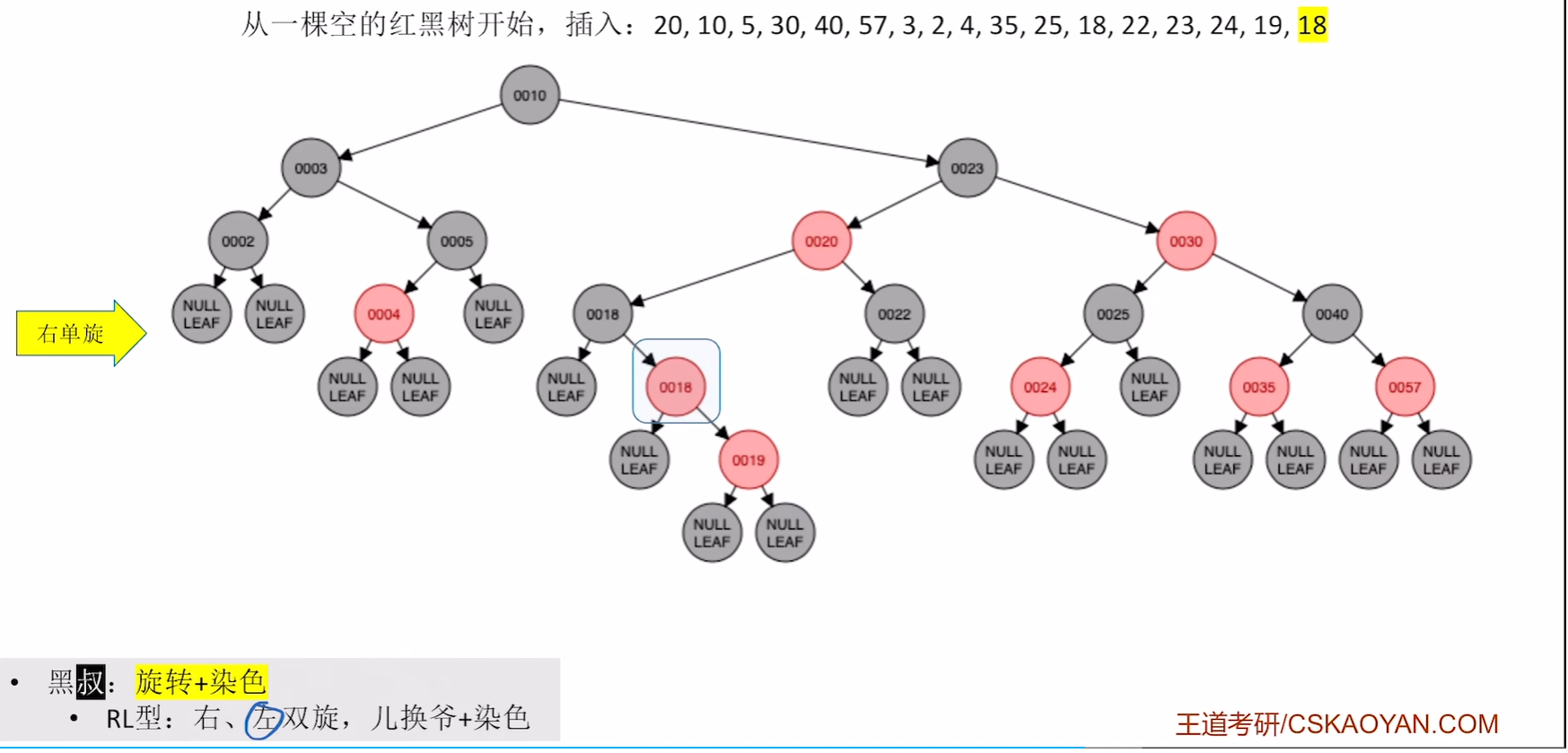
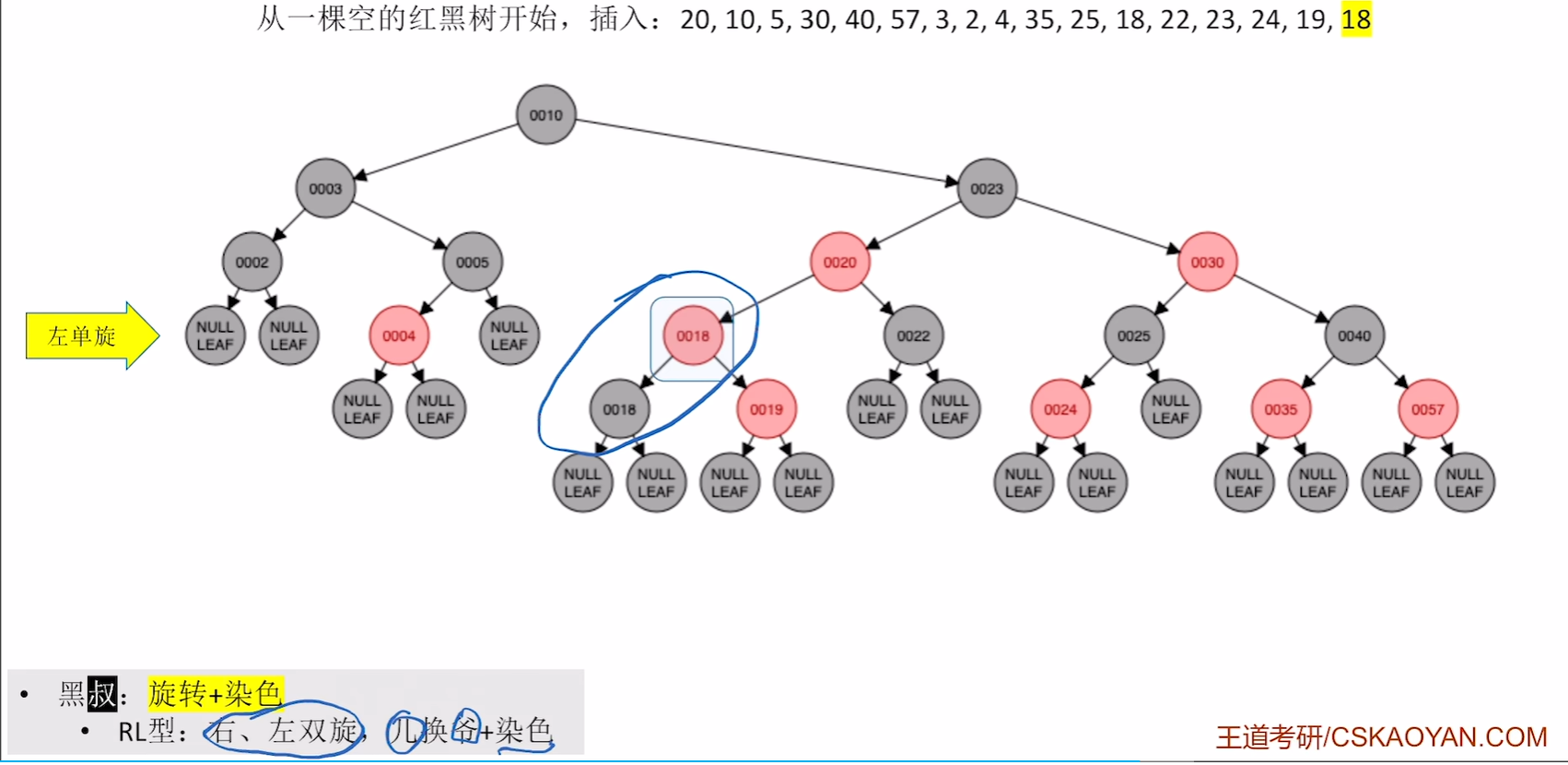
插入19,18
19没有破坏不红红直接插入,而红黑树中已经有18这个关键字了,那么18插入到哪里就看自己的算法 是如何设计的了,可以在18左孩子,也可以去18右孩子
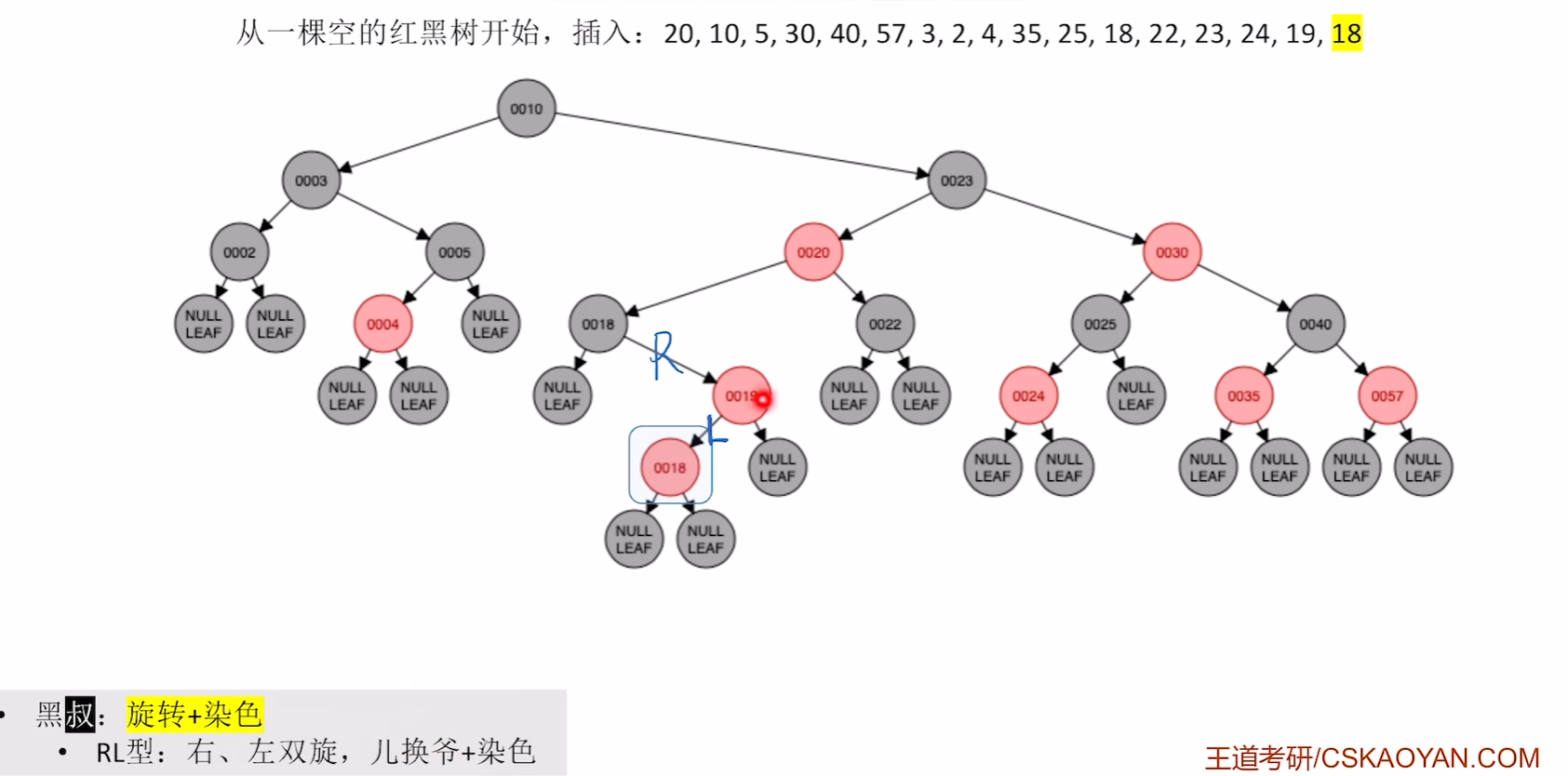
右旋
左旋
染色
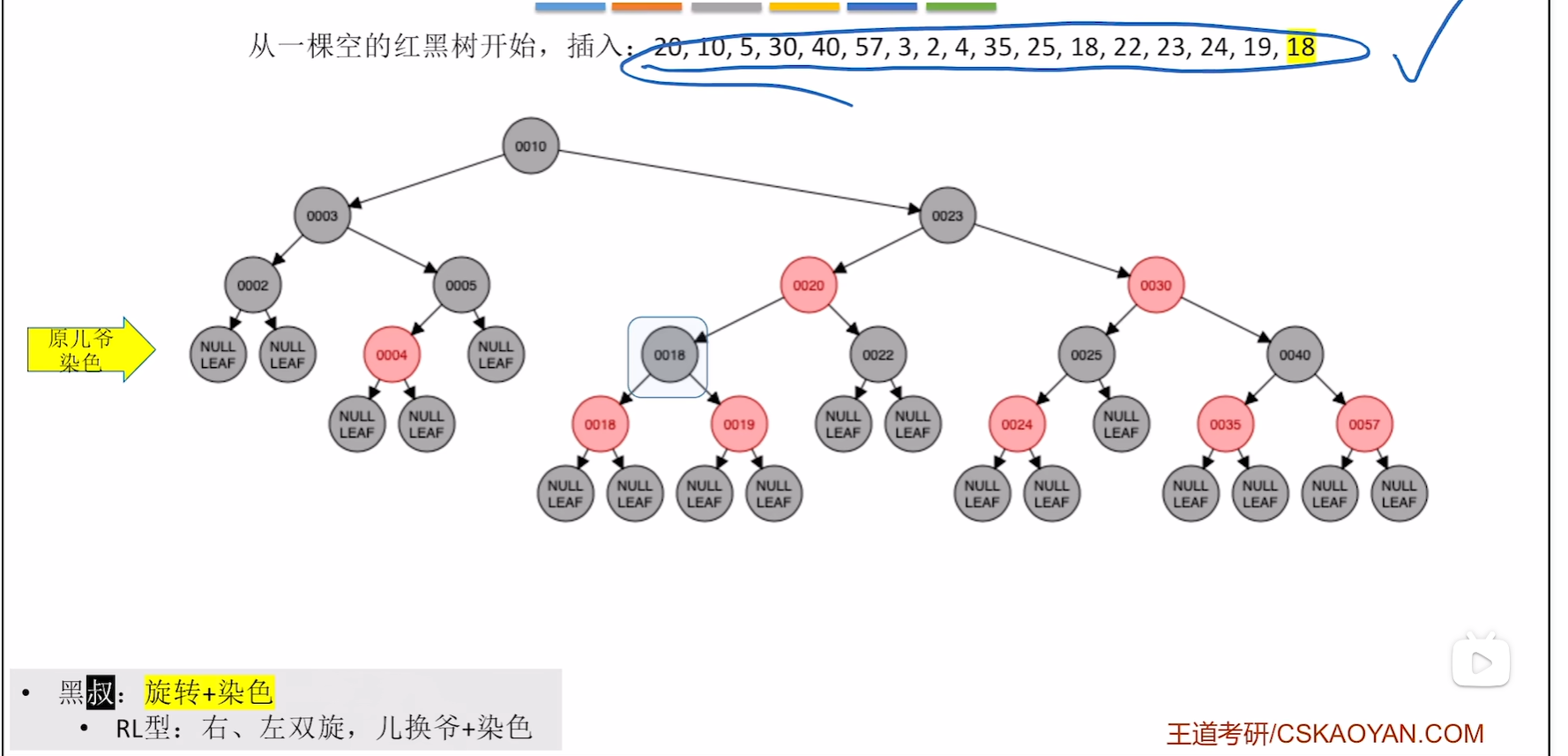
到此为止插入完成
删除

23,24届考察概率不大,25不好说,还是看看吧
7.8 B树和B+树
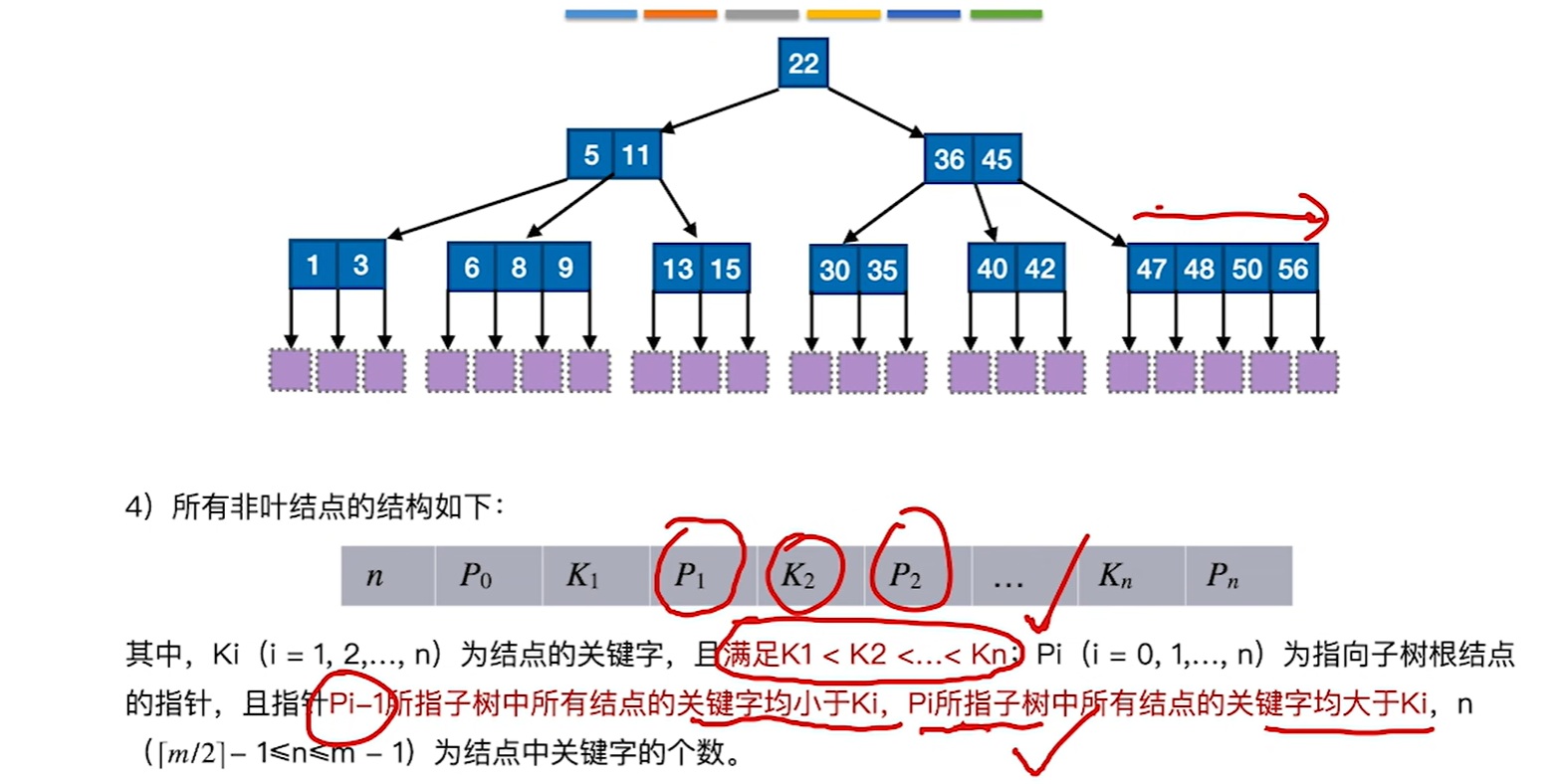
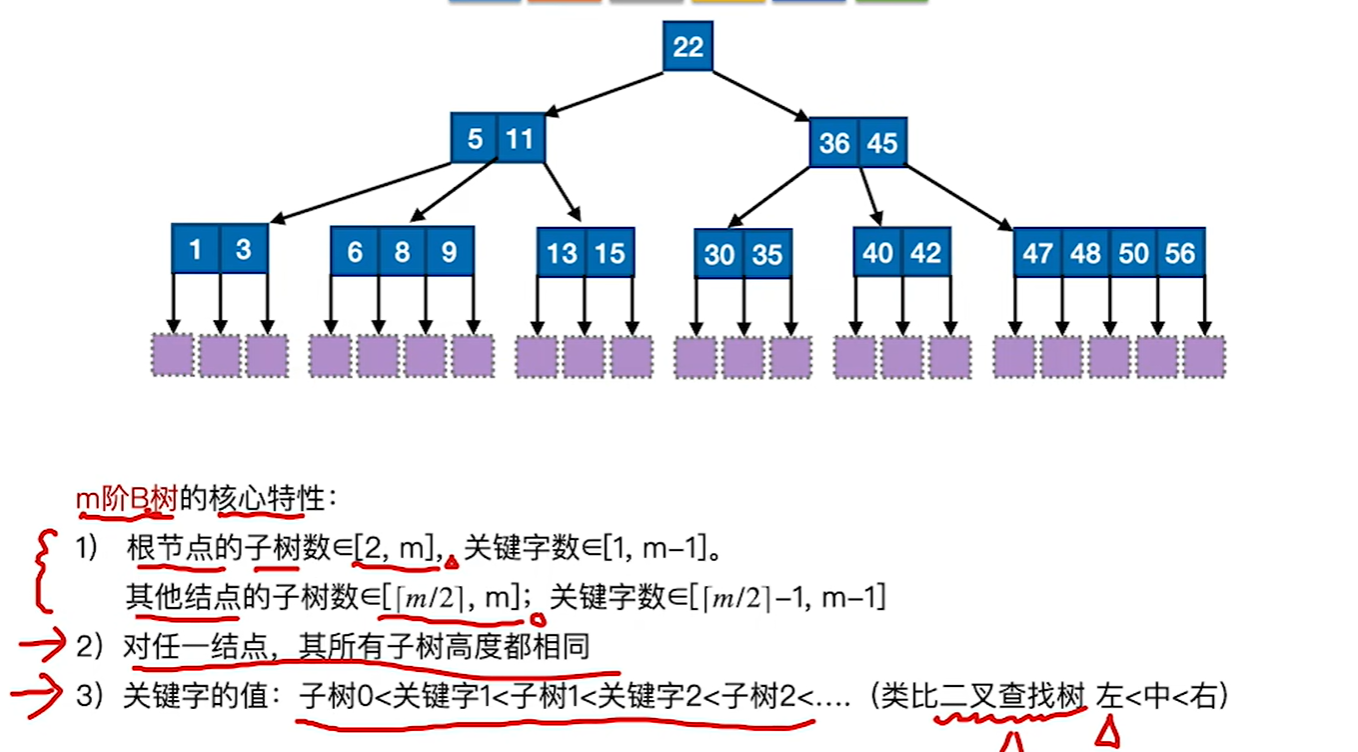
7.8.1 B树
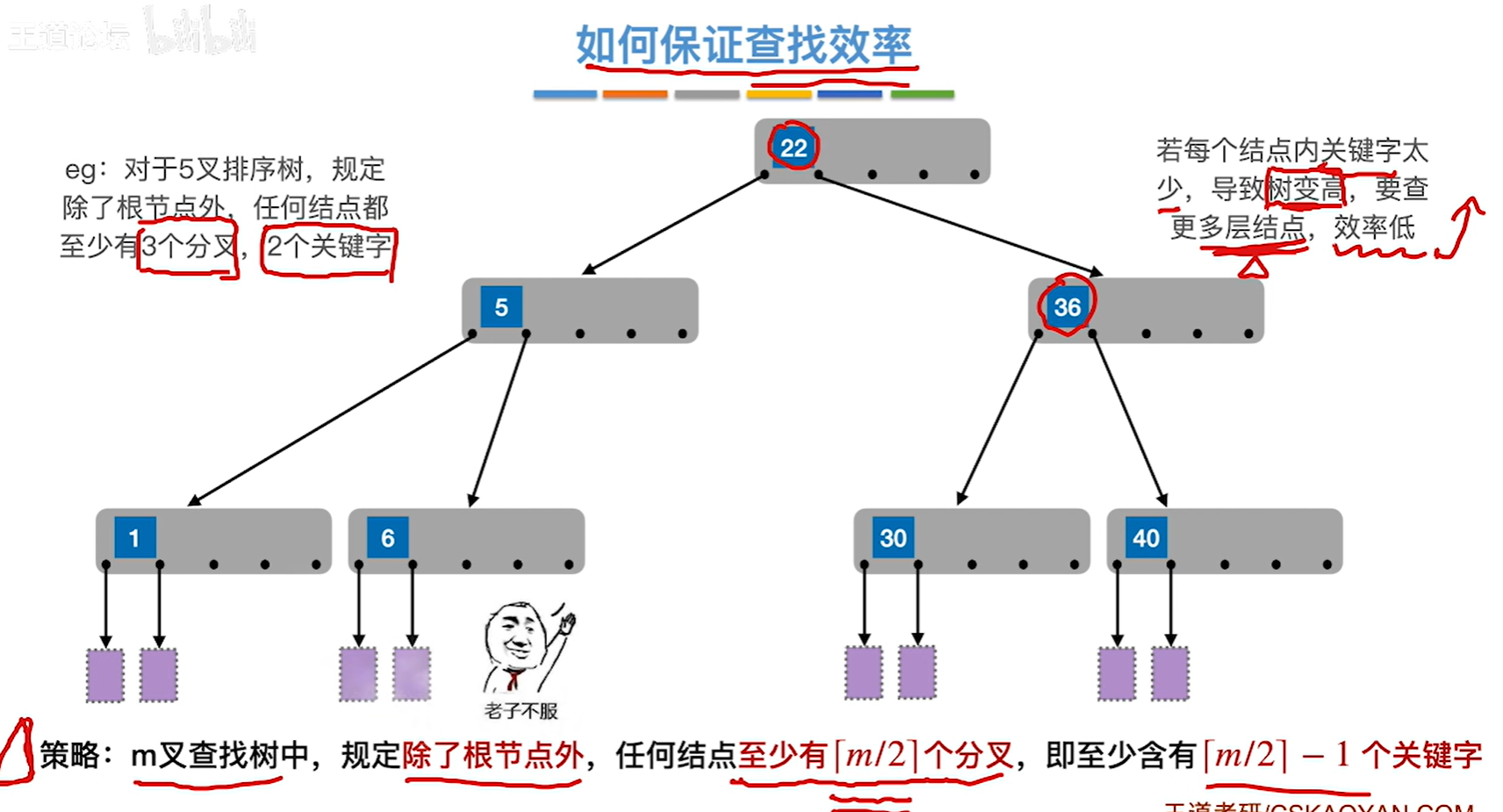
如果每个节点的的关键字太少,比如变成1个的话,那就退化为二叉查找树了,所以才要保证节点的最少分叉和最少关键字的数量
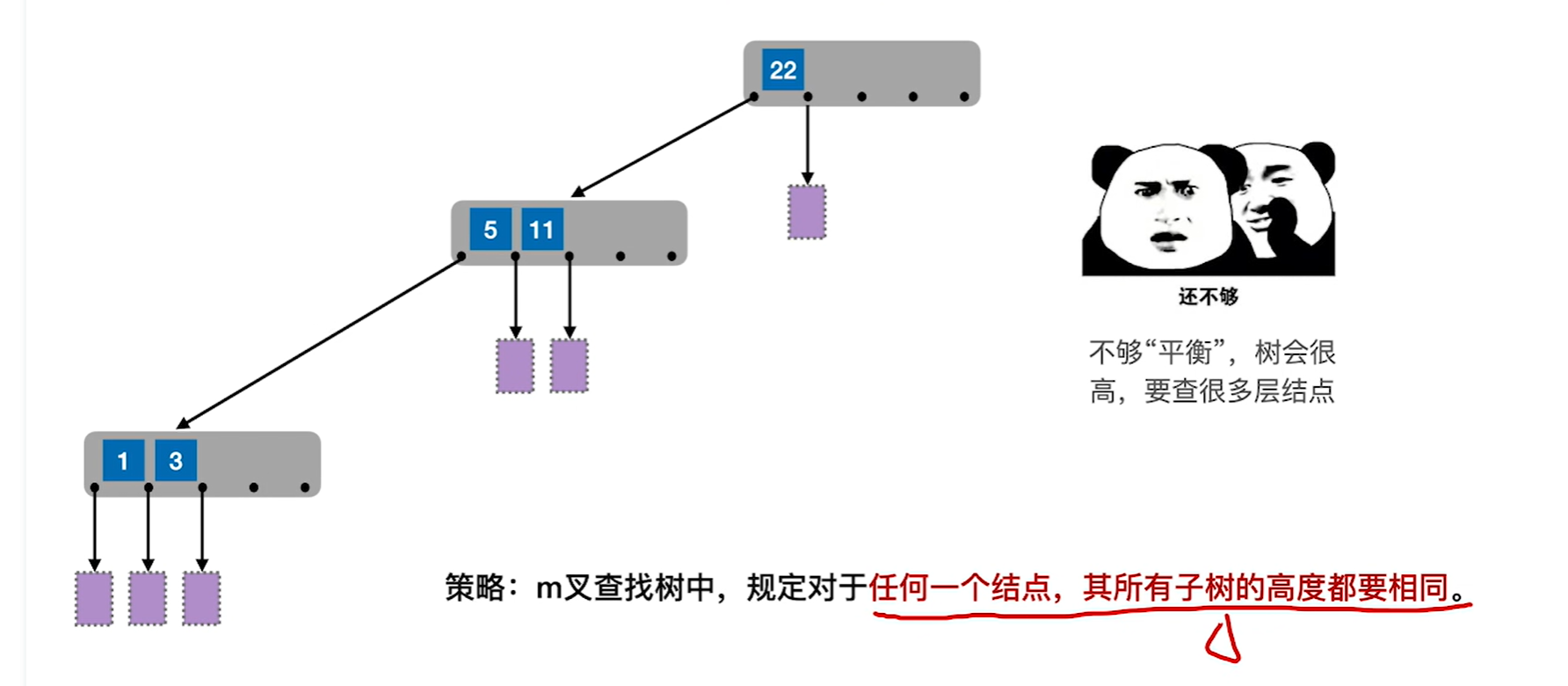
如果可以保证每个节点关键字不少,并且所有子树高度都相同,那这个其实就是一个b树
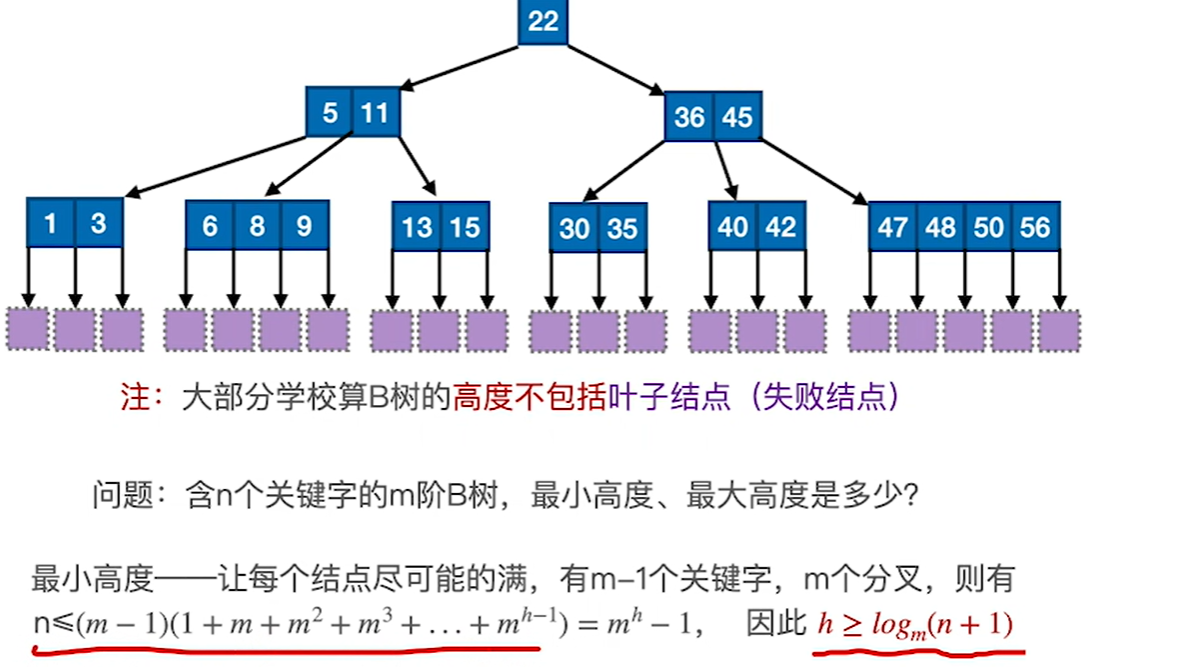
每个节点最多m-1个关键字,第一层1个节点第二层最多m个节点…最多就是1+…m的h-1次方个节点,就是上面这个公式
求最大高度的方法1:
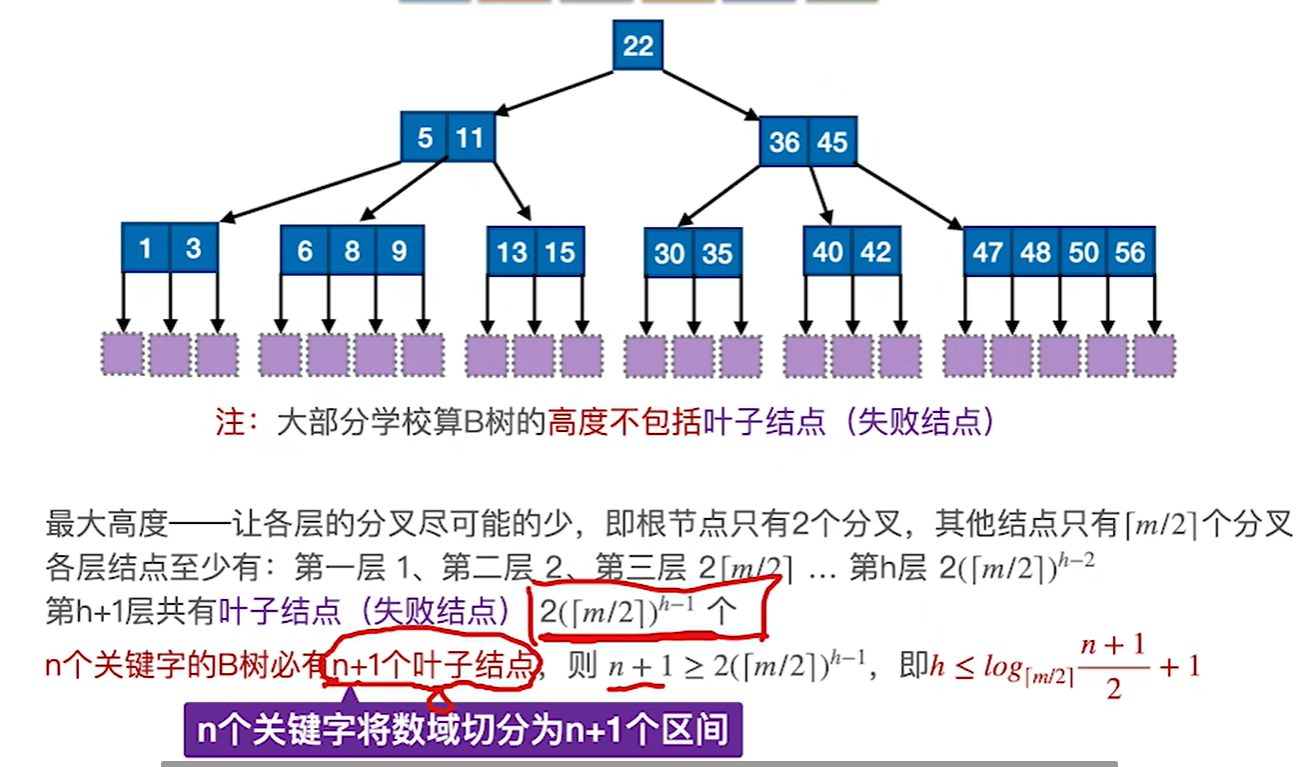
b树的叶子节点代表失败节点,有n个关键字就肯定有n+1个失败的区间,那么就是n+1个叶子
求最大高度的方法2
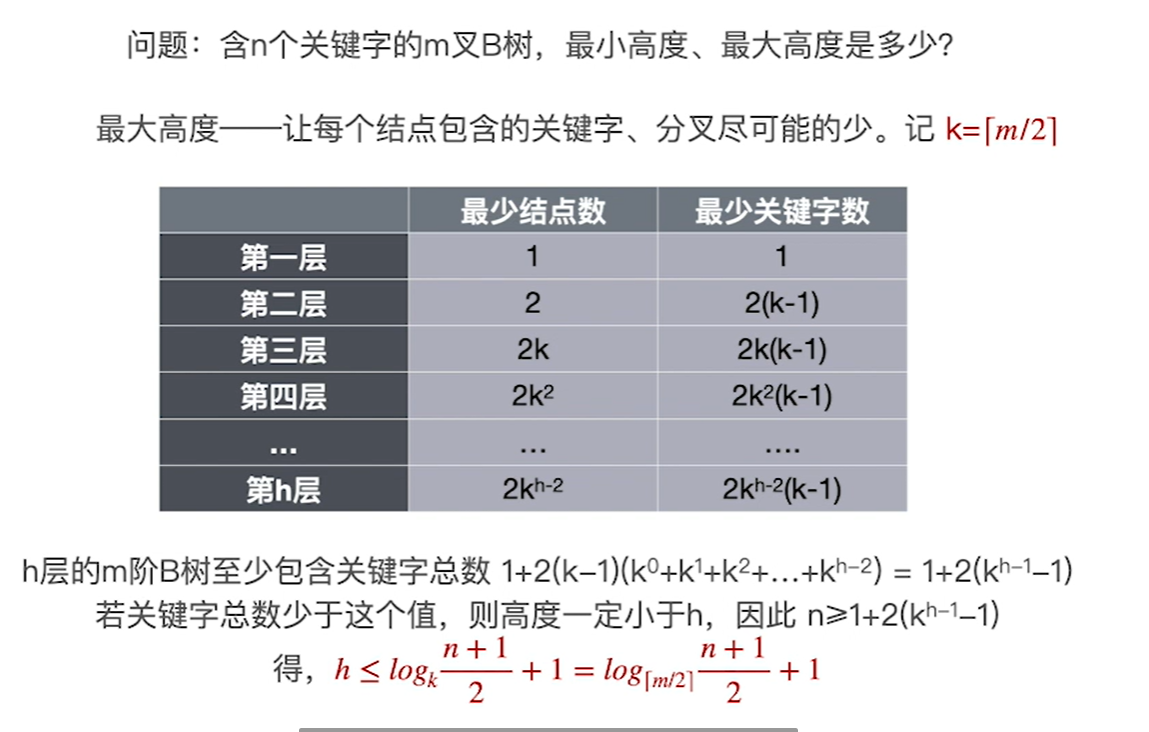
k是一个节点内最少的分叉数量,减去1就是最少的关键字的数量
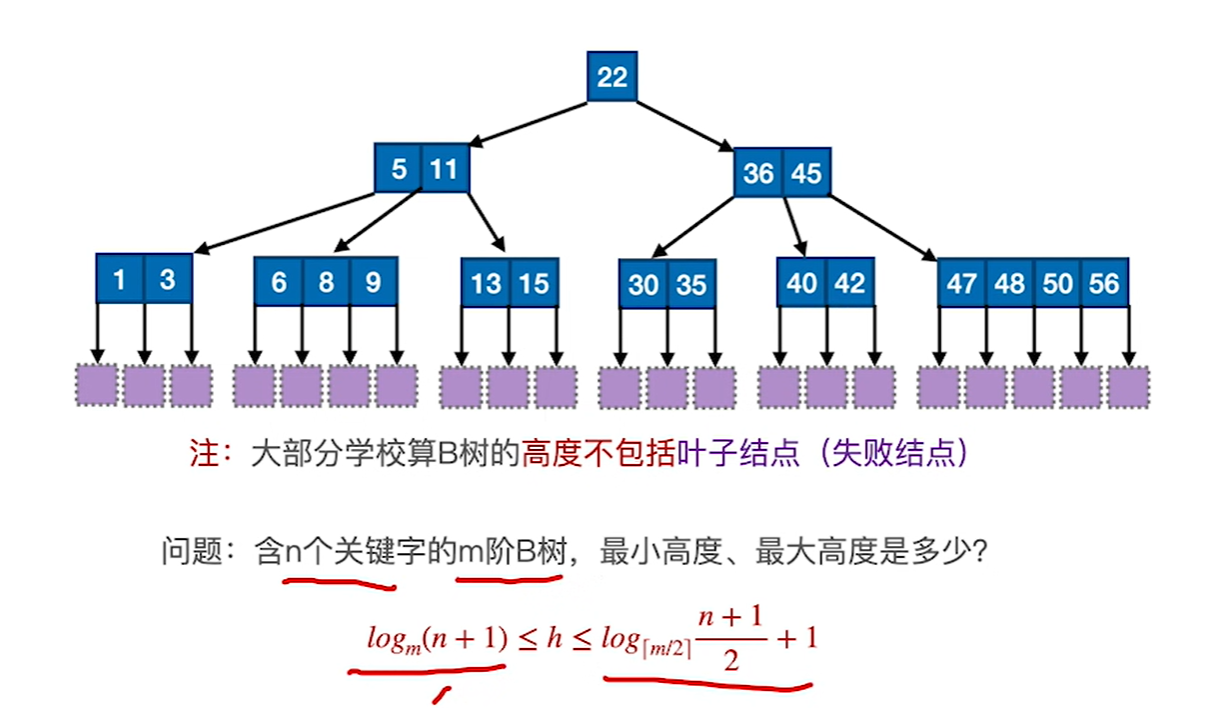
7.8.2 B树的基本操作
B树的查找:
- B树的查找操作与二叉查找树类似。
- B树的查找包含两个基本操作:① 在B树中找结点;② 在结点中找关键字。B树常存储在磁盘上,因此前一个查找操作在磁盘上进行,后一个查找操作在内存中进行。在B树中查找到某个结点后,先在有序表中进行查找,若找到则查找成功,否则按照对应指针信息到所指的子树中去查找。查找到叶子结点(对应指针为空指针),则说明树中没有对应的关键字,查找失败。
B树的插入:

具体的例子:
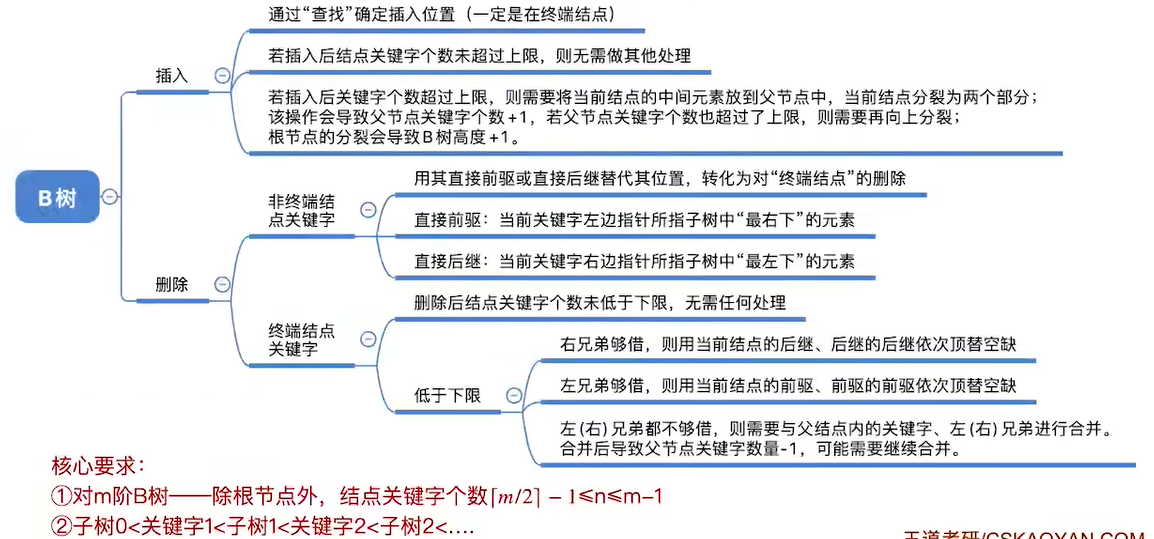
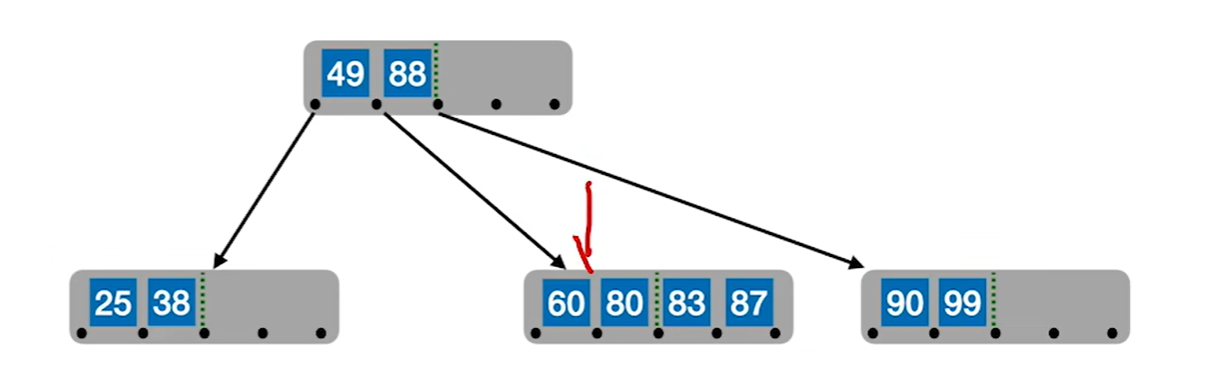
1.在一个节点已经满了的情况下再插入一个关键字
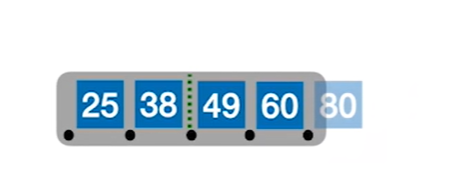
2.把中间的关键字提出来作为左右的父节点
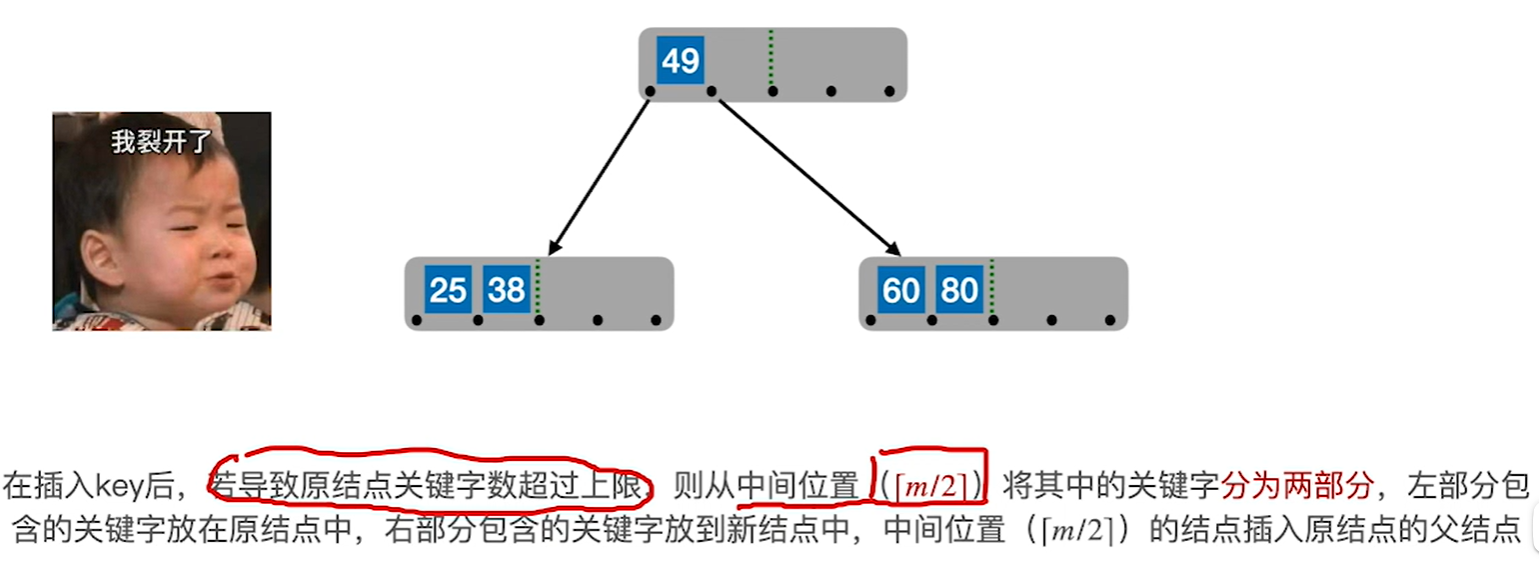
3.继续插入新的关键字,而新的关键字一定是插入到最底层的终端节点,用查找来确定插入的位置
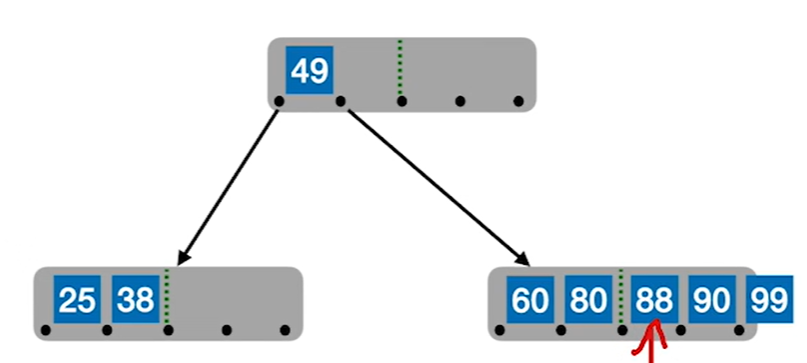
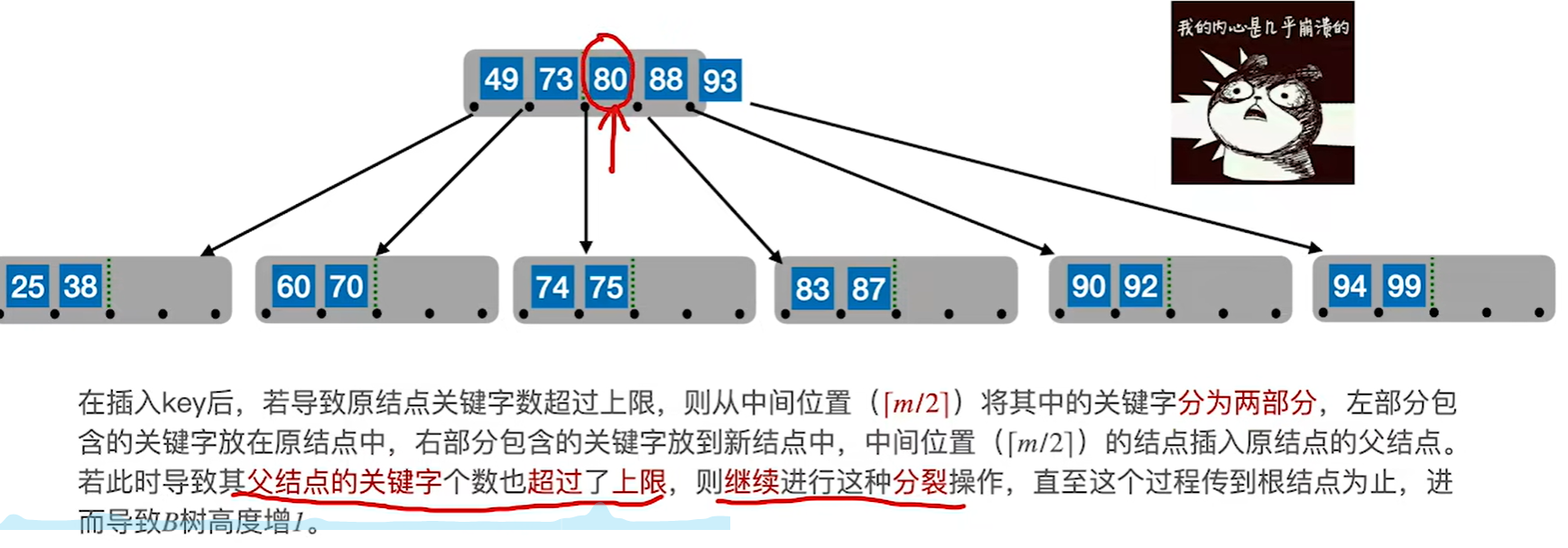
4.当插满之后继续分裂,分裂时需要把结点的中间的关键字提到父节点中,注意保持父节点有序性
5.重复上述过程,直到父节点也满了
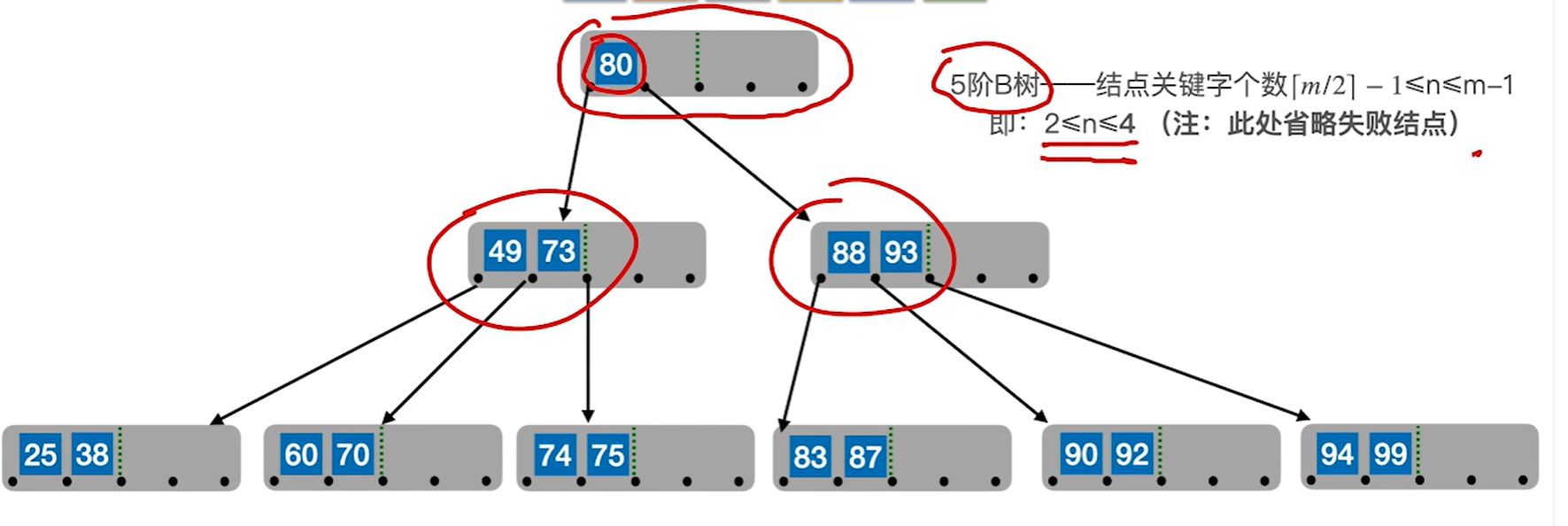
6.分裂父节点,把中间节点作为新的父节点
B树的删除:
删除操作一定会导致叶节点的变化。如果删除的是叶节点,那么必然导致叶节点变化。如果不是叶节点的话,则要先将被删除的节点和它的前驱或者后继交换,最终转换为删除叶节点,还是导致叶节点发生了变化
也可以更简单的说,n个关键字有n+1个叶子,而n-1个关键字只有n个叶子,那么肯定会有叶子被删除的
综述:
具体的例子
情况1:如果删除的关键字在终端节点并且删除关键字之后,该节点还满足最低的关键字数量要求的话,那就直接删除该关键字就行
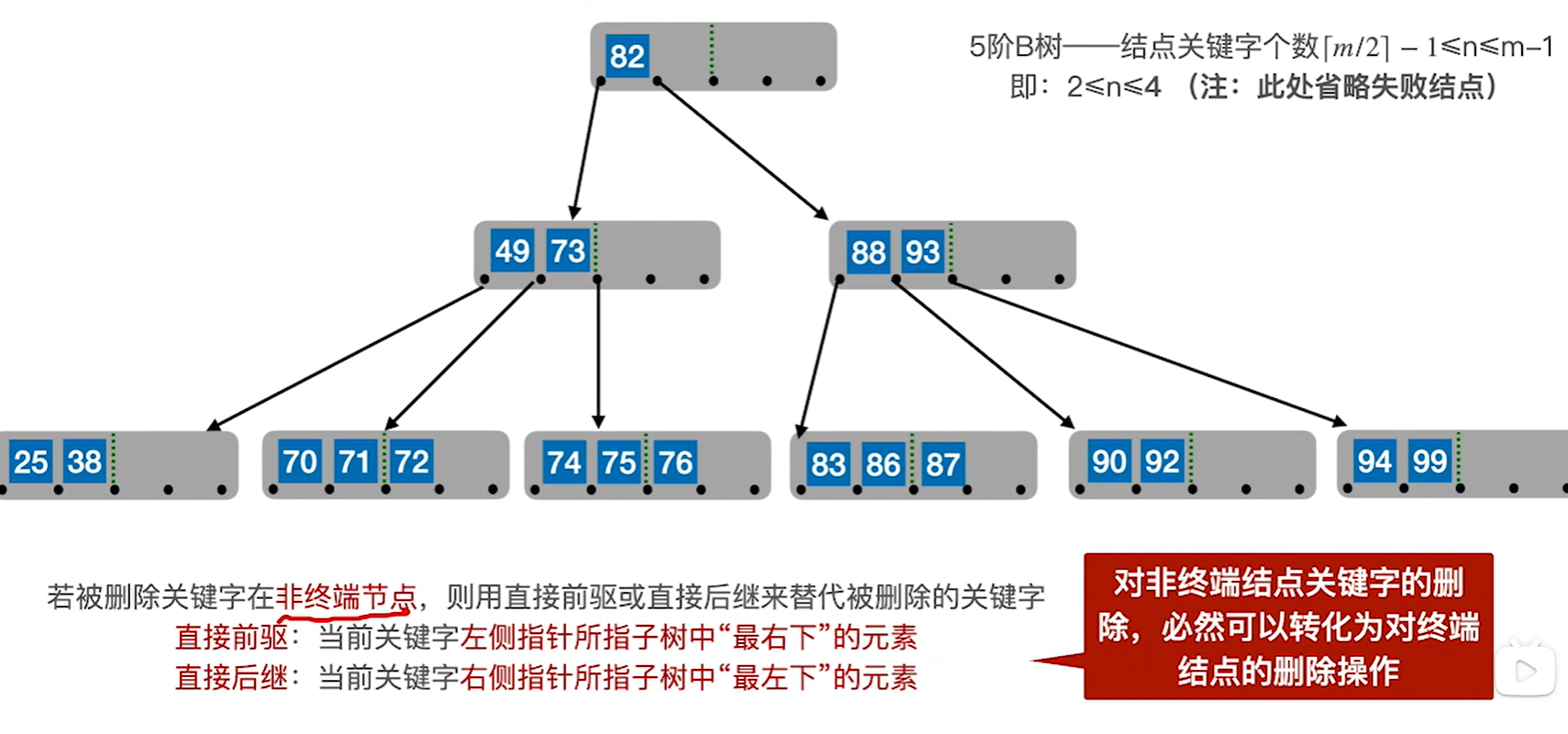
情况2:如果删除的额关键字在非终端节点的话,则使用当前关键字的直接前驱或者直接后继进行替代
比如要删除80,就可以用77和82来代替他,注意要看把77或者82移走之后原来的节点还够不够最低的标准
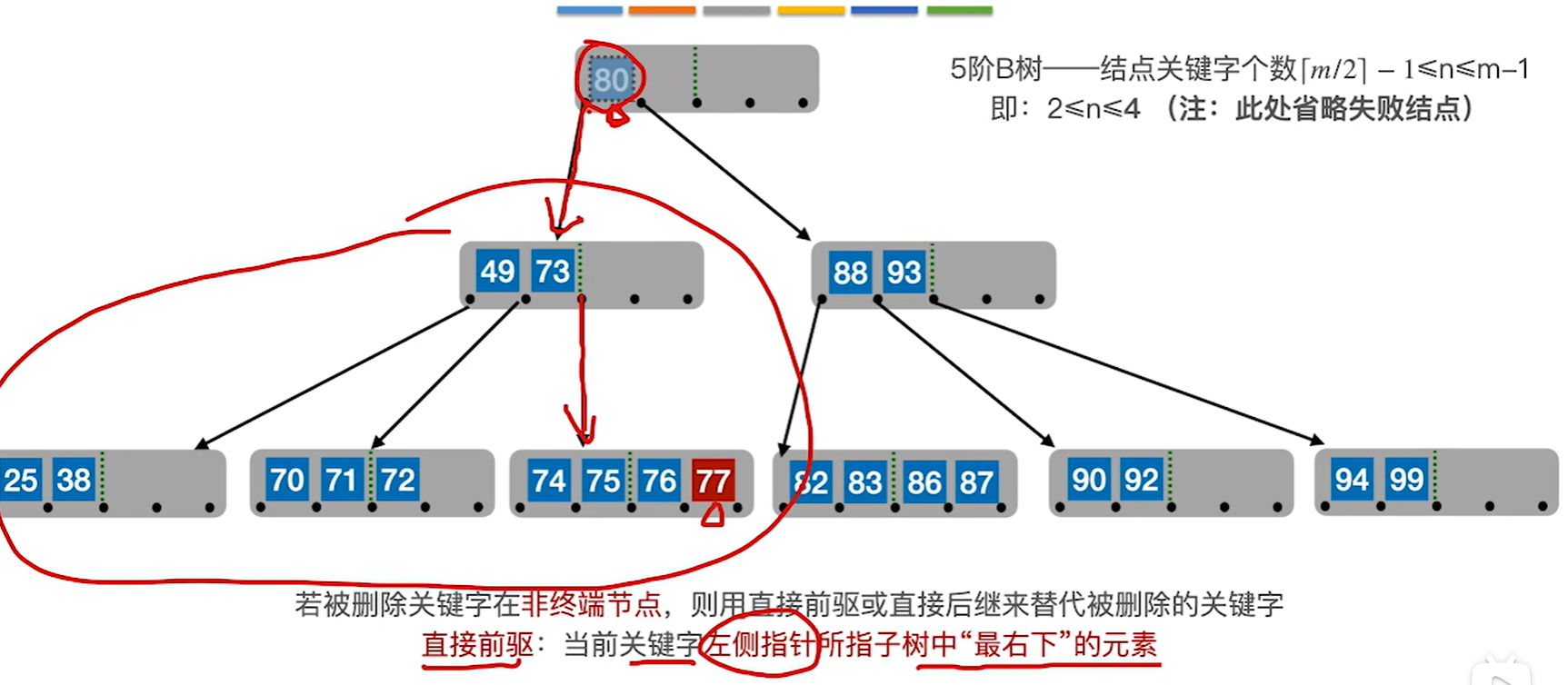
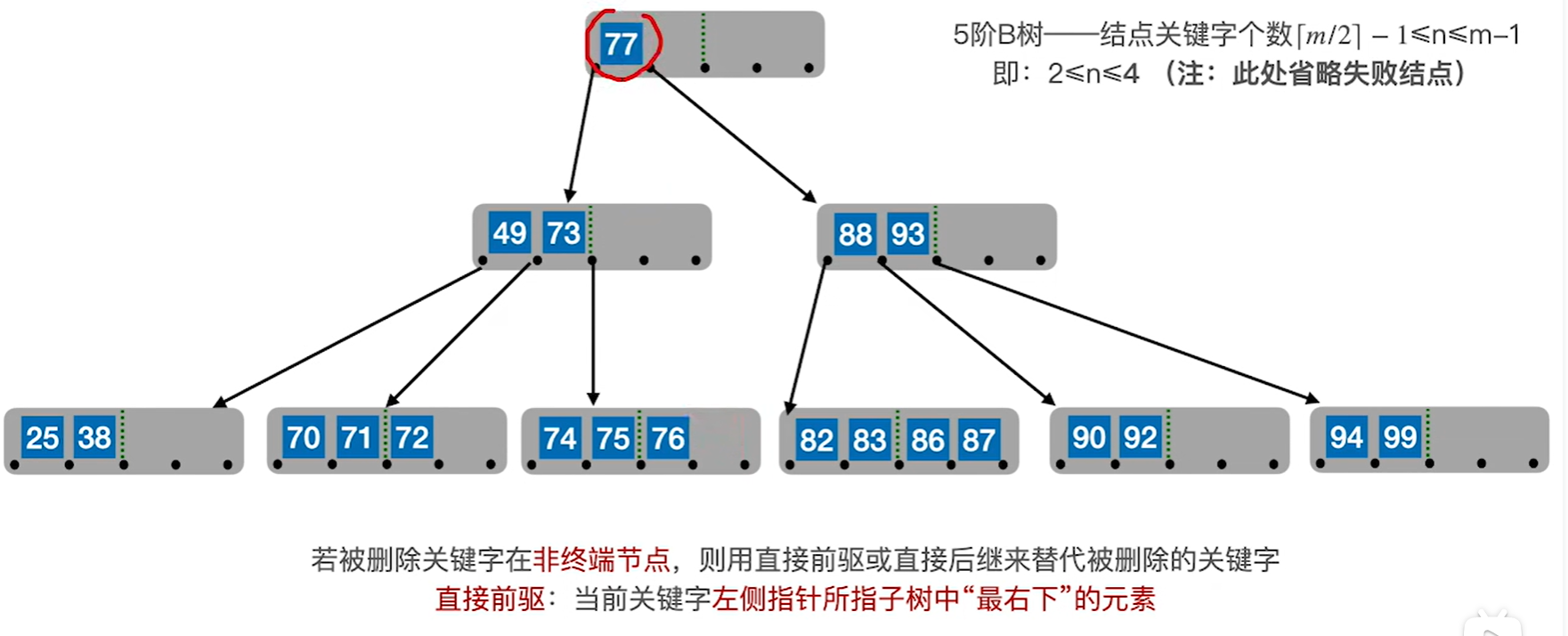
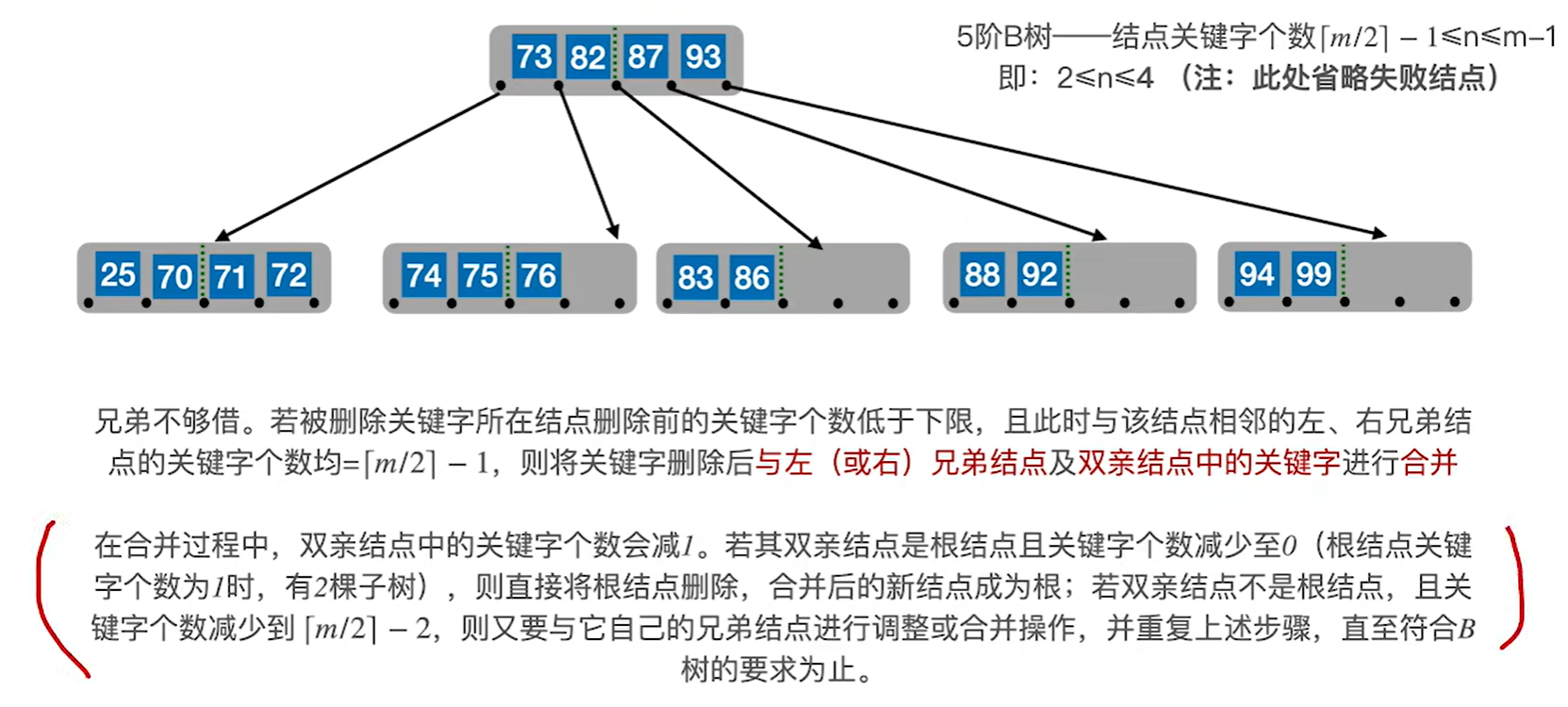
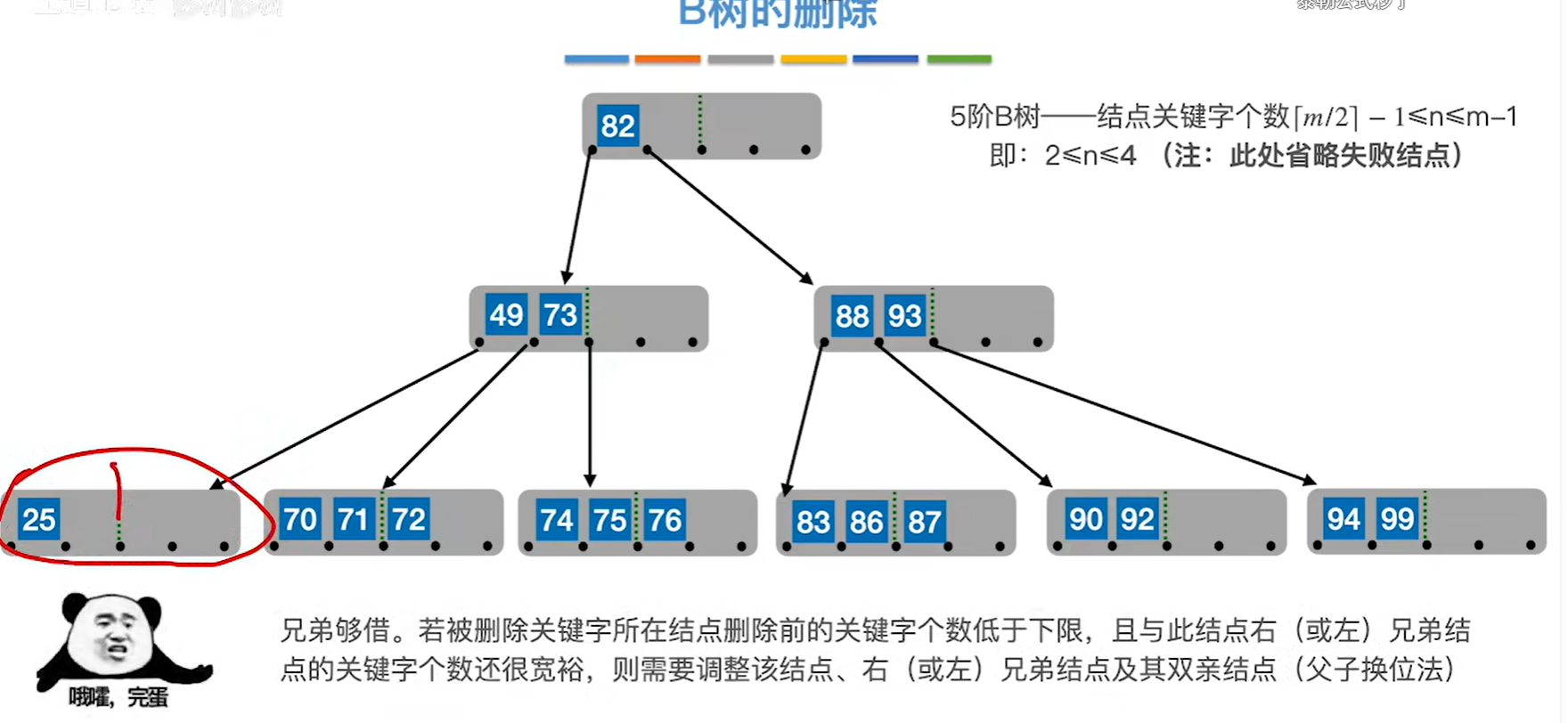
 情况3:假如删除一个非终端节点的关键字以后,该节点不满足b树要求的话。但是兄弟结点借给该节点之后,自己的节点数量还可以满足b树要求
情况3:假如删除一个非终端节点的关键字以后,该节点不满足b树要求的话。但是兄弟结点借给该节点之后,自己的节点数量还可以满足b树要求
比如下图删除38,先把49拉下来,再把70给填到父节点
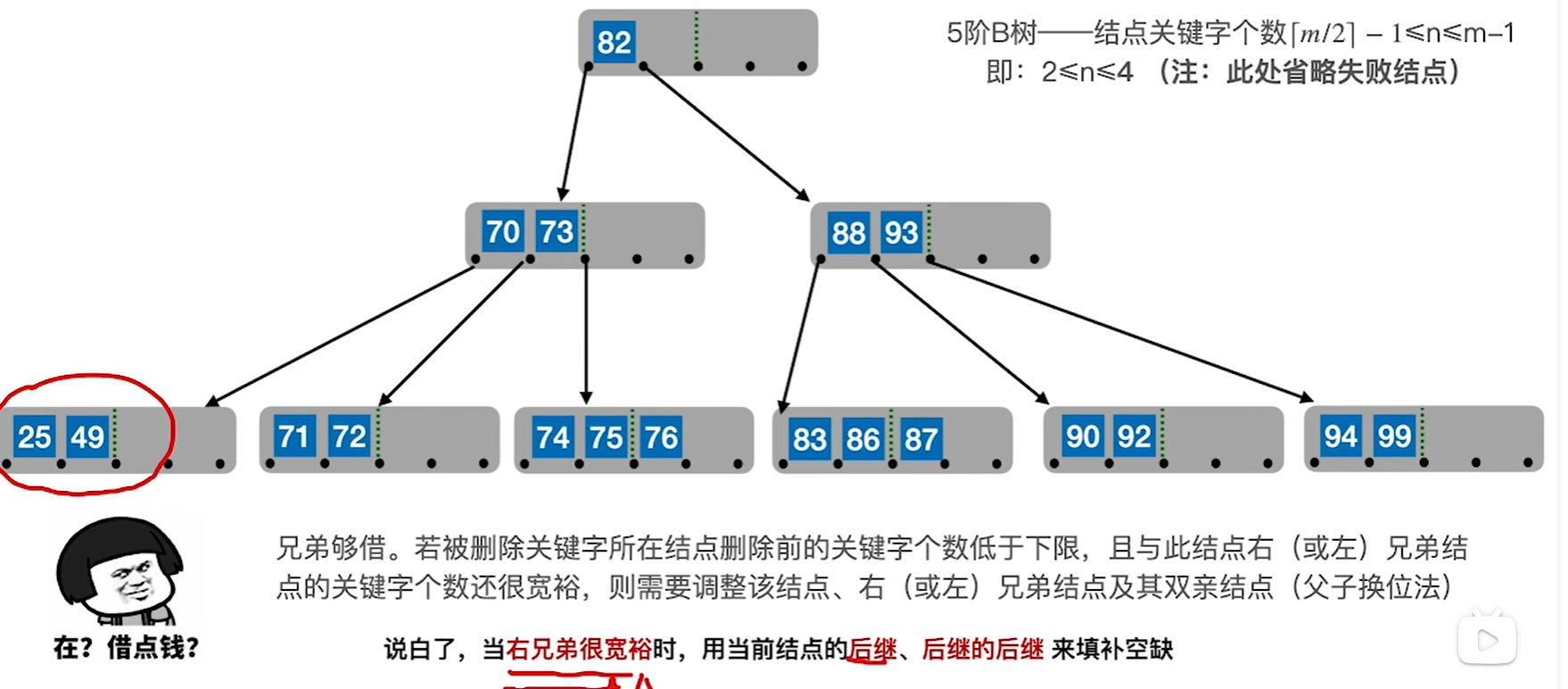
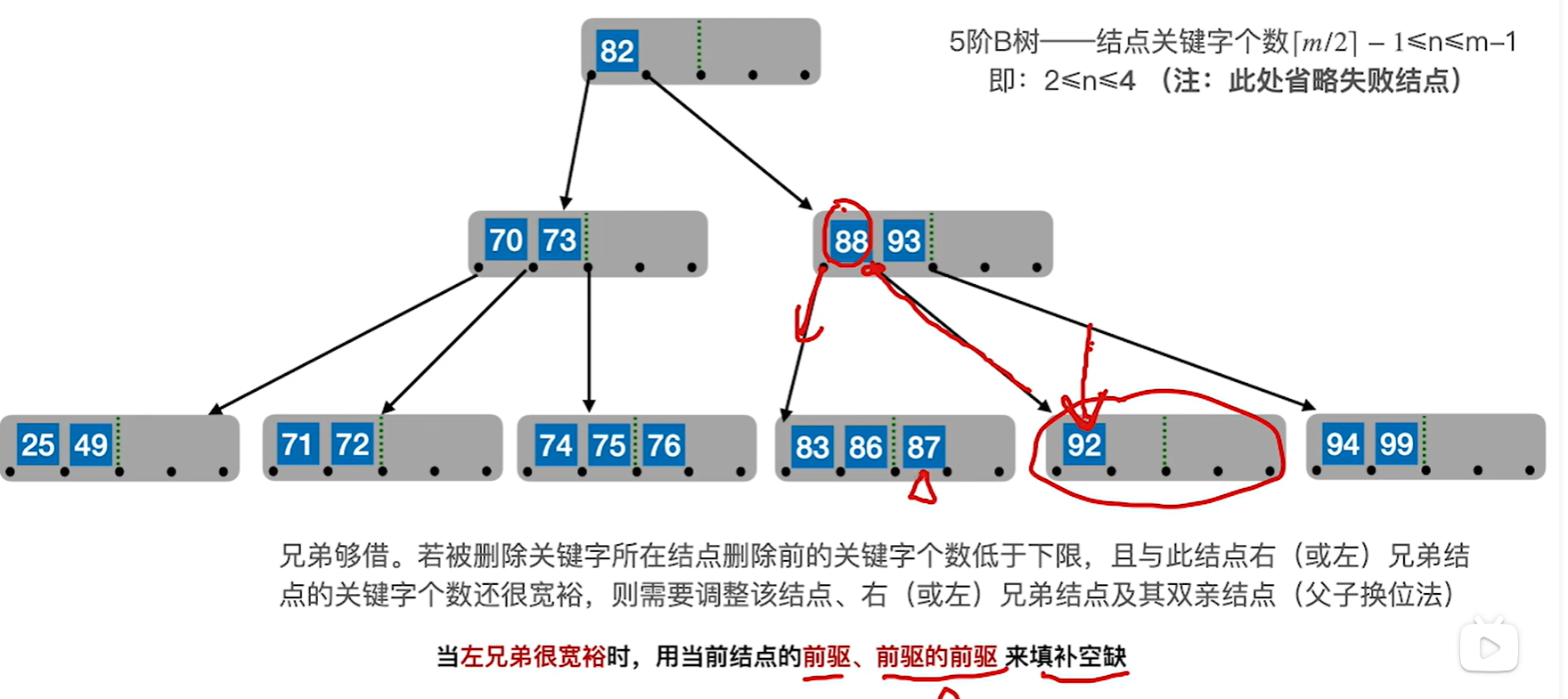
左兄弟同理,只是变成找前驱而已
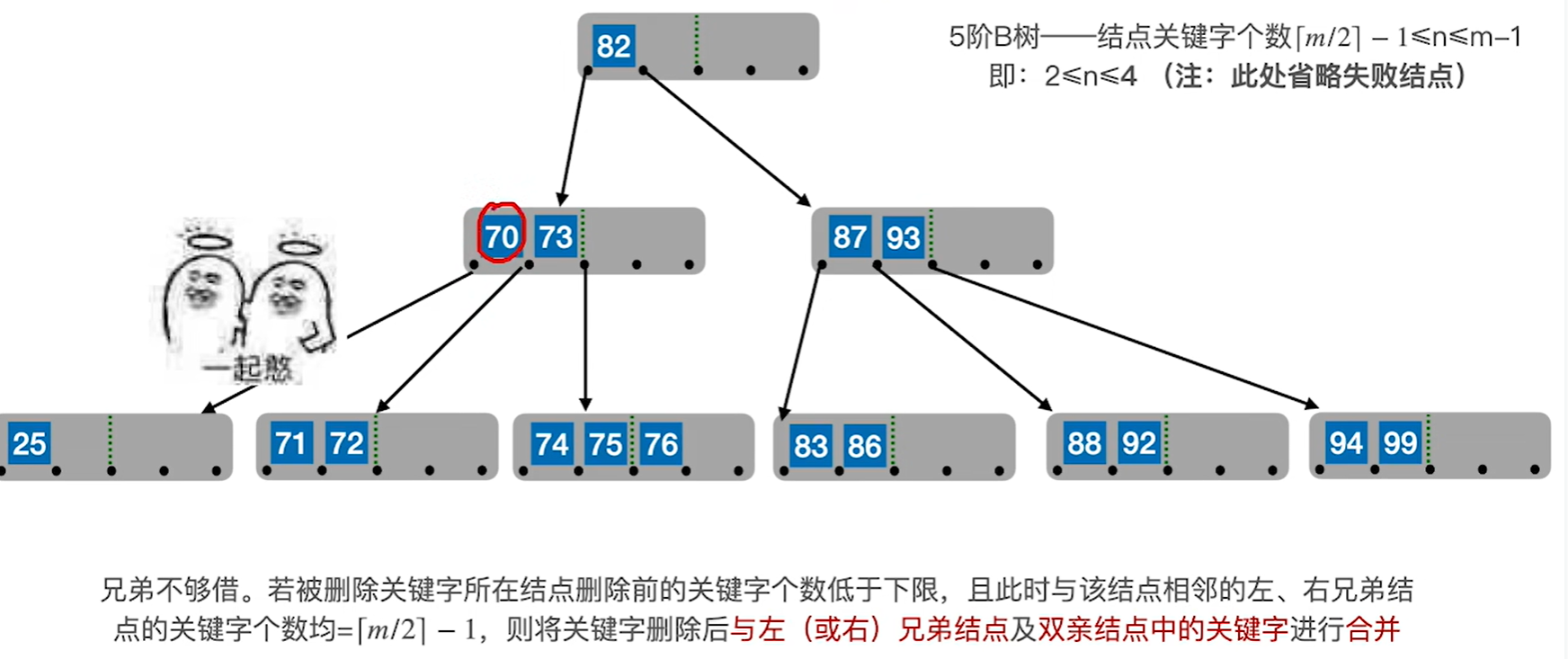
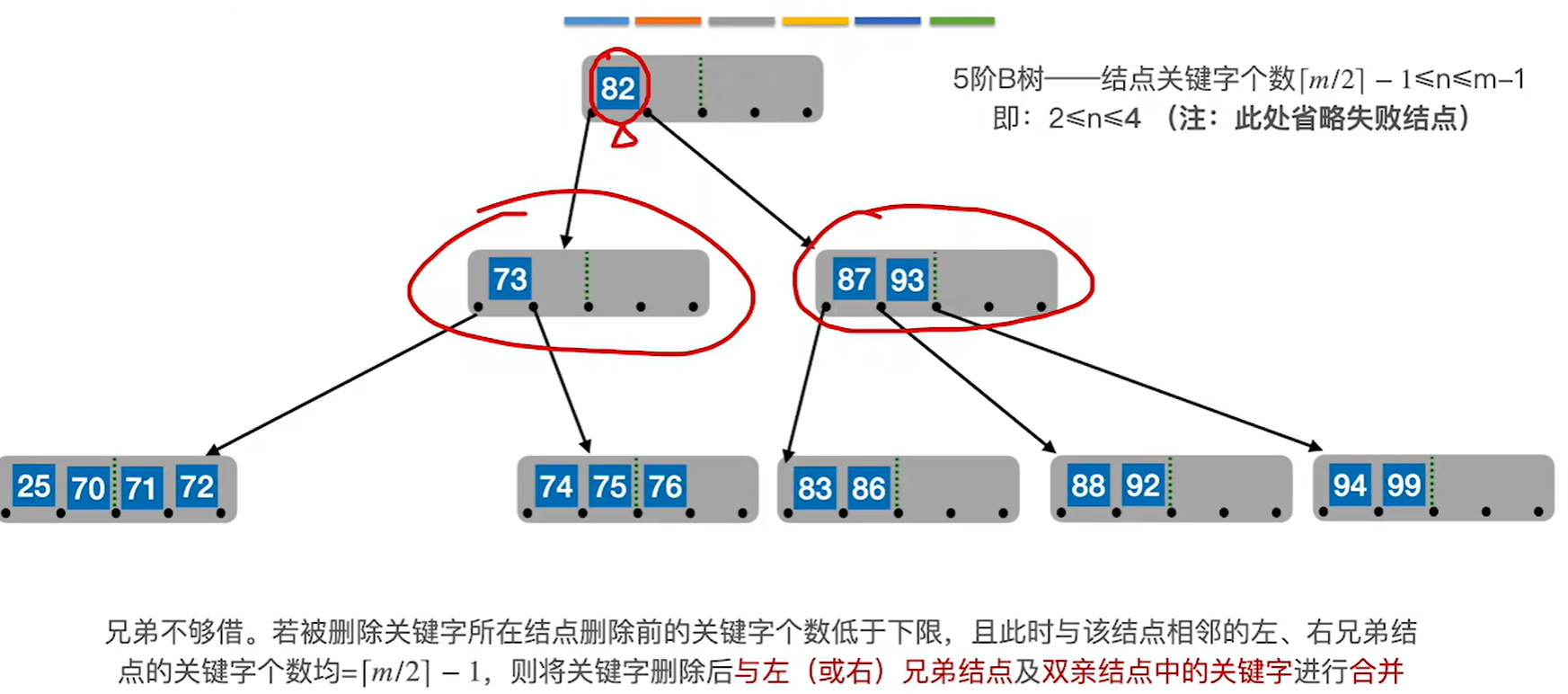
情况4:删除49.即兄弟结点不够借
先把父节点的关键字拉下来一起和左右兄弟合并
再看父节点是否满足b树要求,如果不满足再去分析是情况三还是情况4,这个例子是情况4
也就是说还得再进行一次合并
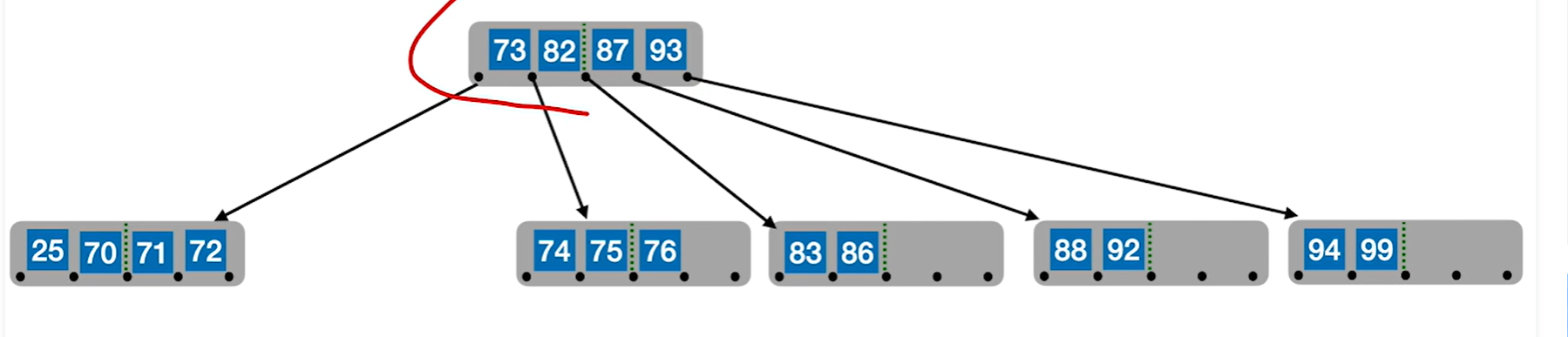
7.8.3 B+树
定义:
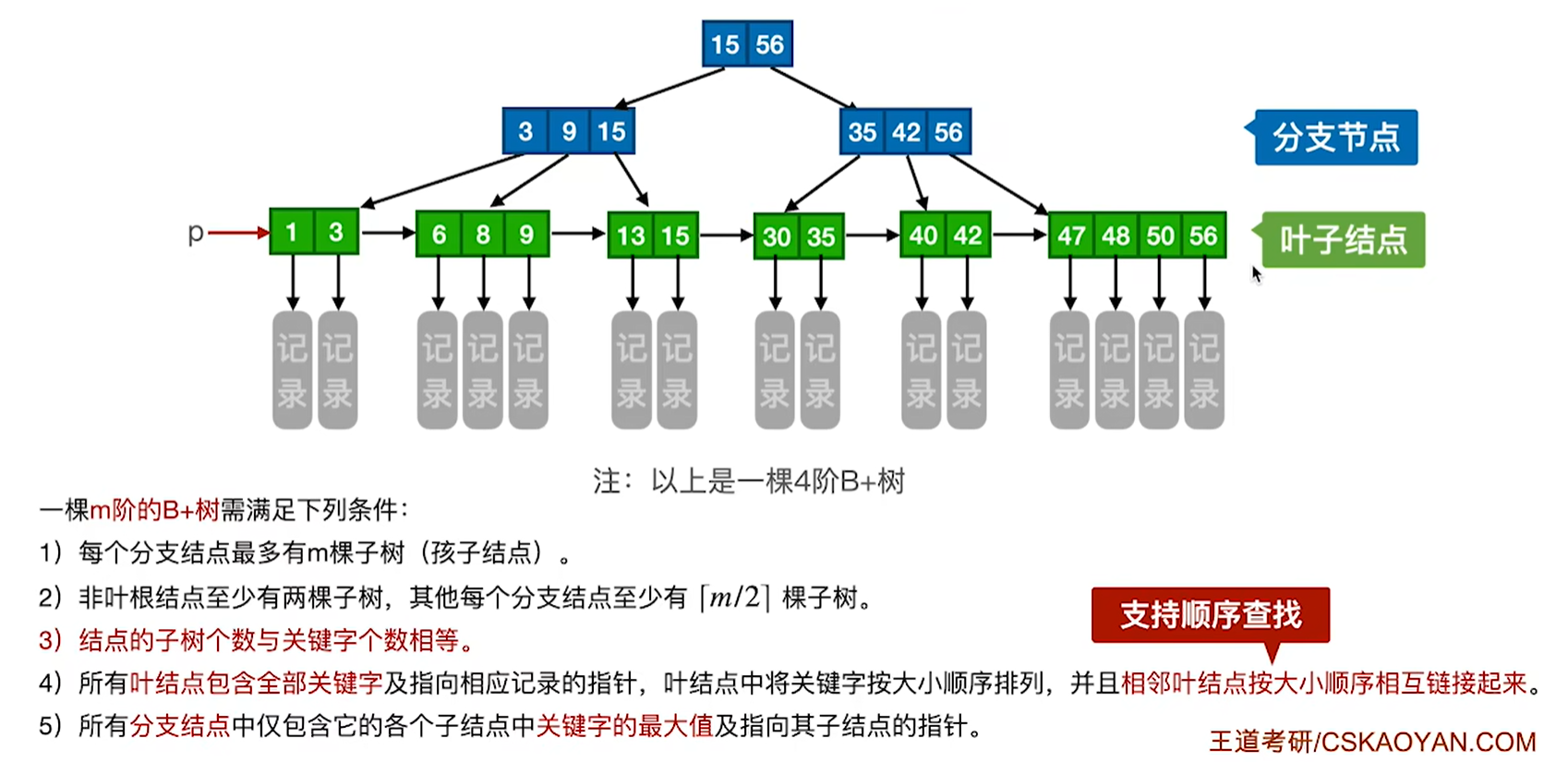
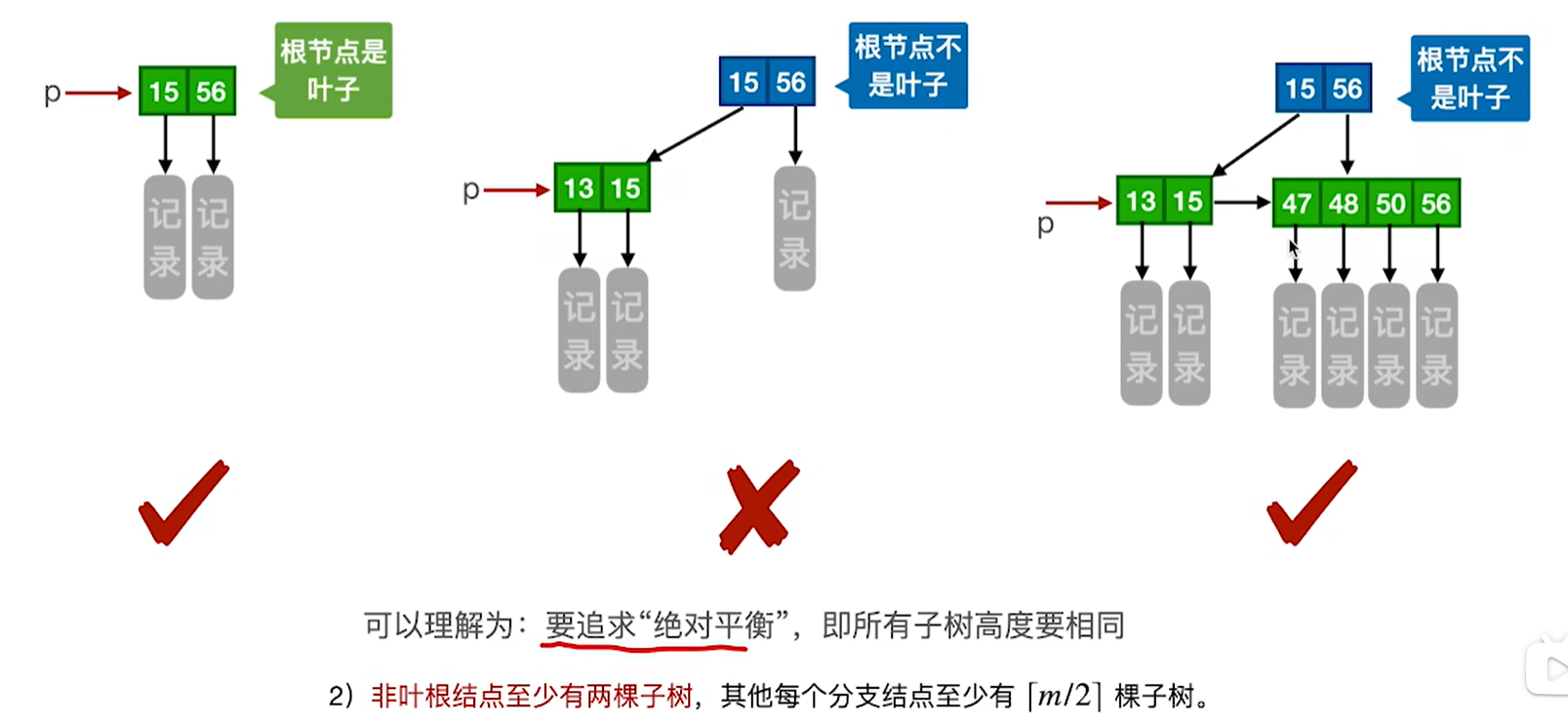
这里说的非叶根节点的意思是,当根节点不是叶子节点的时候,那么当前的根节点最少要有两颗子树
查找
查找方式1:从上到下依次查找,和二叉排序树类似
在分支节点中找到的并不是最后结果,一定得下降到叶子结点才能找到对应的记录或者信息
而在叶子结点中找到才是真的找到,如果分支节点中没有该关键字,但是却可以确定是哪个叶子结点的话,那还要遍历该叶子节点的值才可以确定有没有找得到
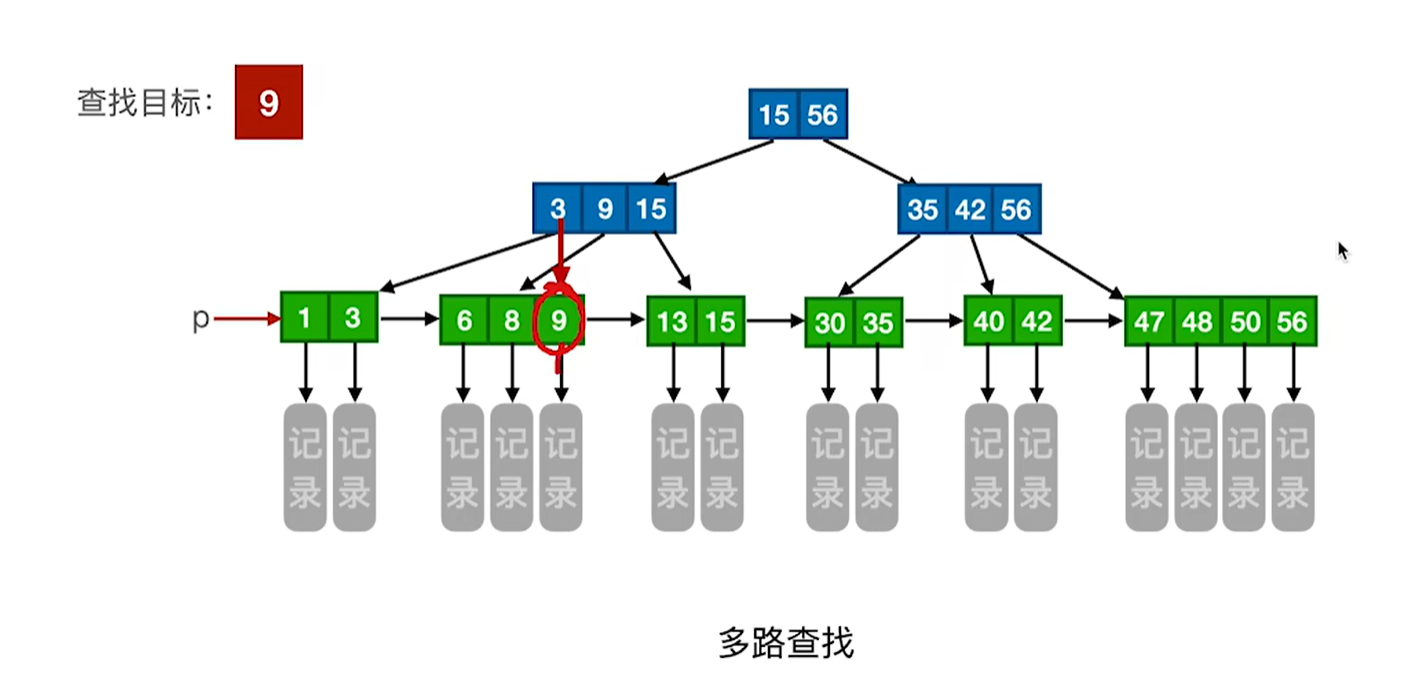
也就是说在B+树中,无论查找成功与否,最终一定都要走到最下面一层结点
而b树却可以停在任何一层
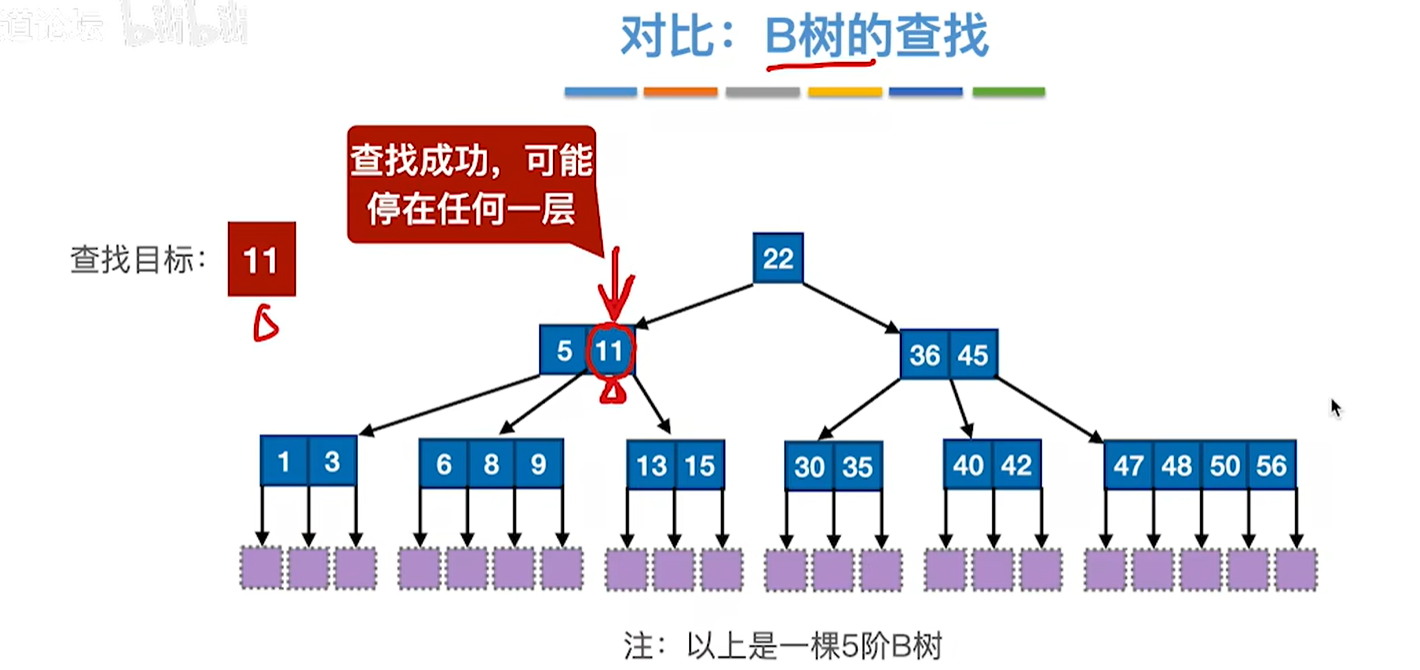
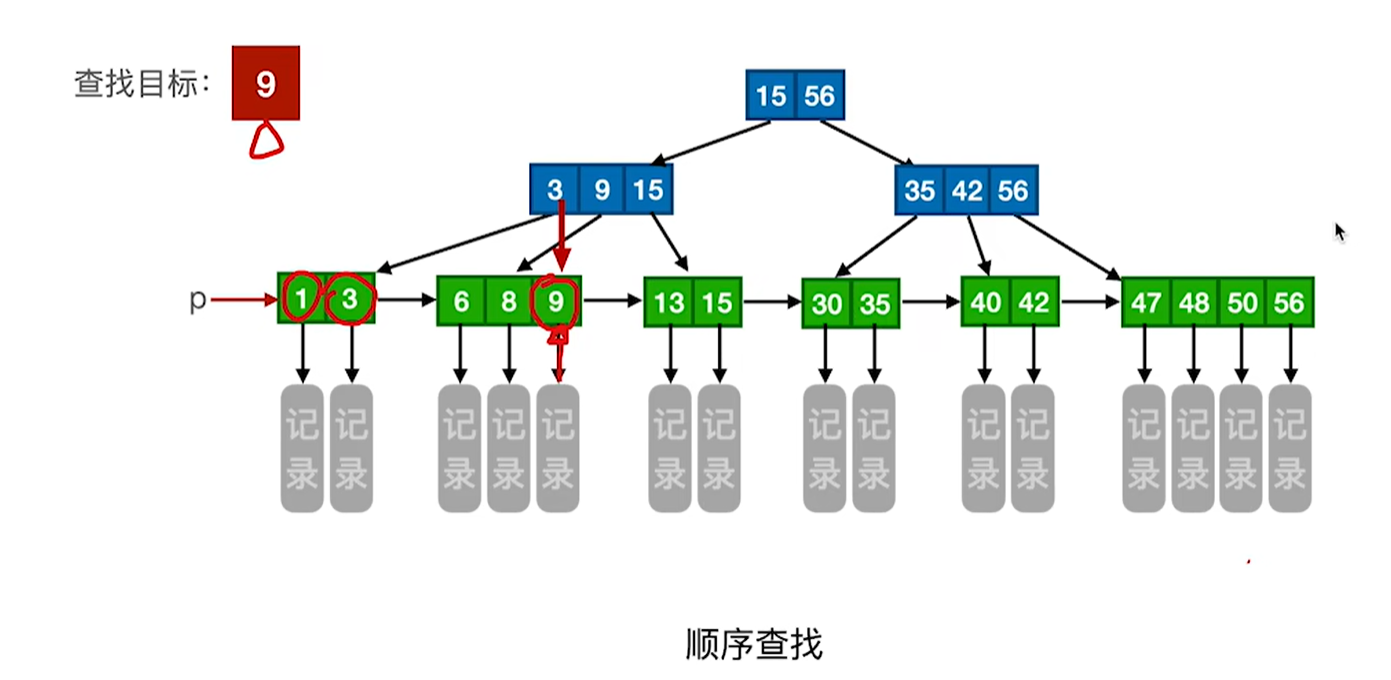
查找方式2:顺序查找 利用p指针遍历叶子节点就好
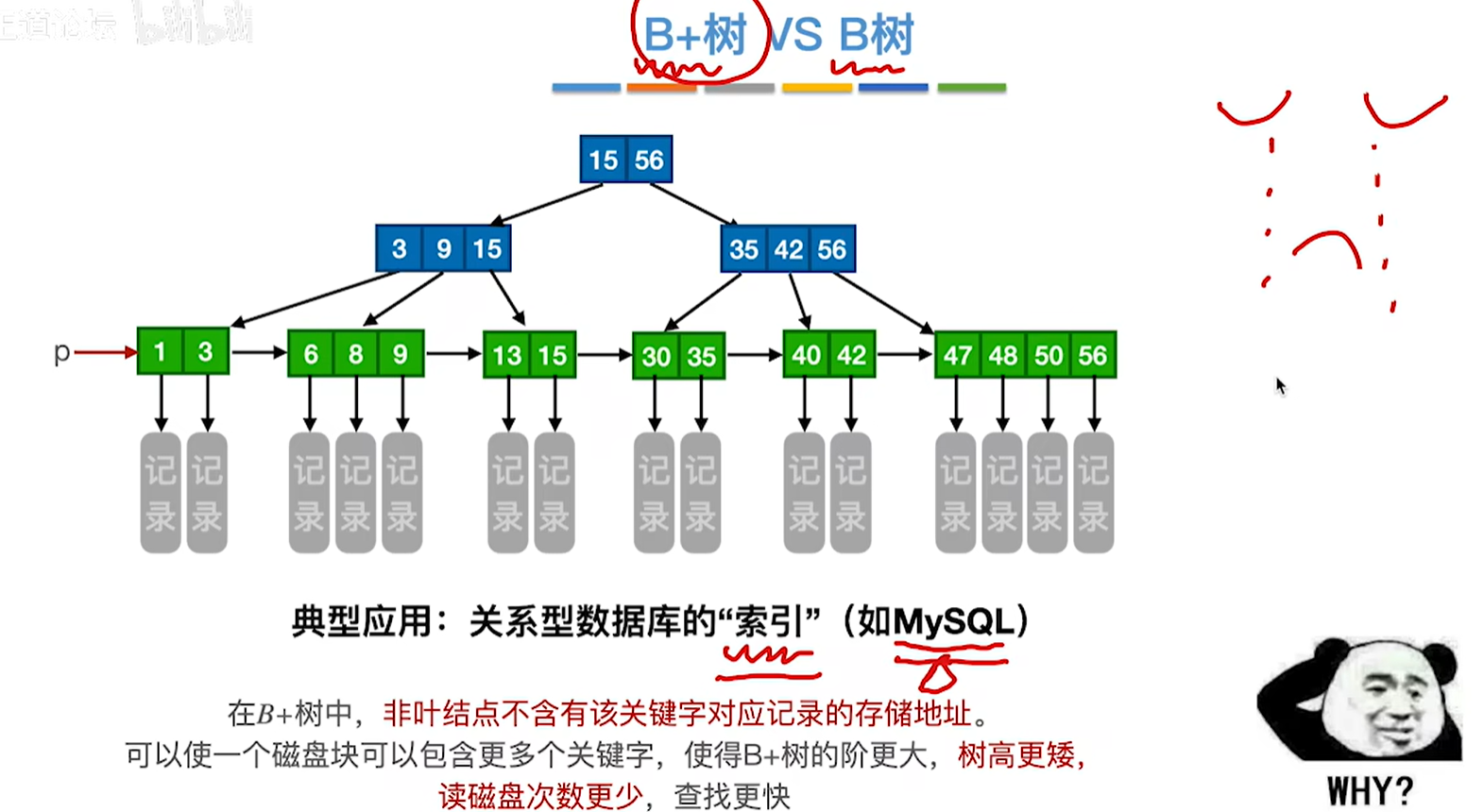
7.8.4 B树和B+树的比较
1.关键字对应子树数量
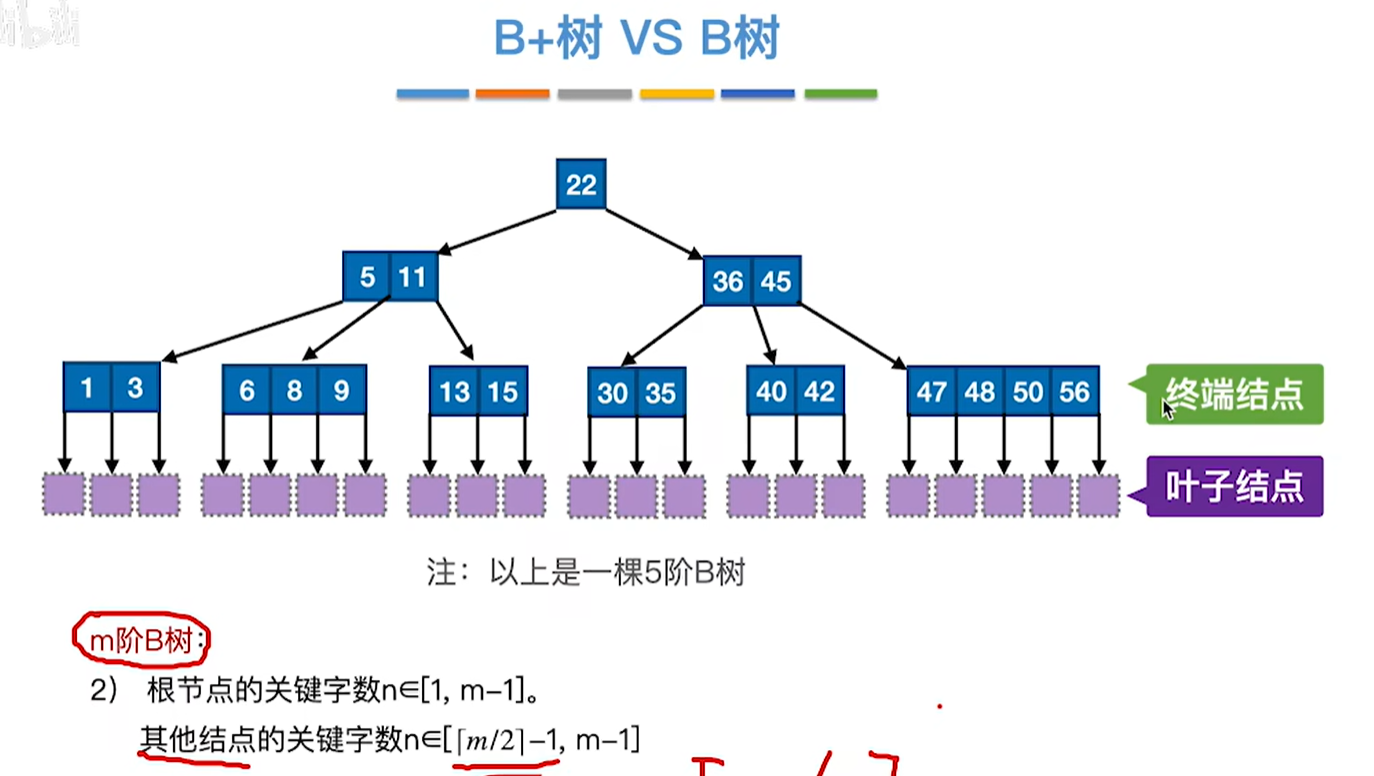
m阶B树:结点中的n个关键字对应n+1棵子树
m阶B+树:结点中的n个关键字对应n棵子树。
2.结点关键字数量
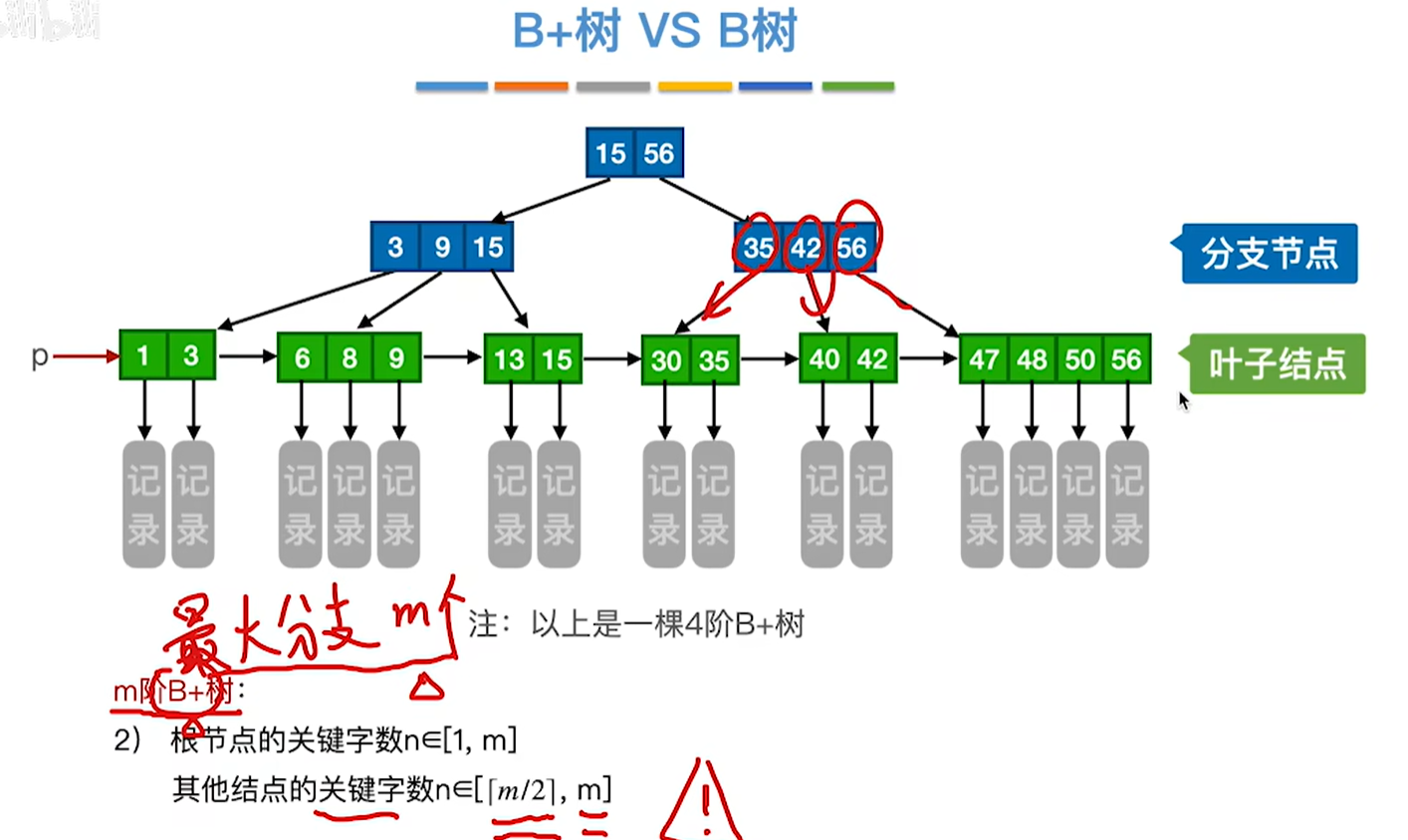
3.关键字是否重复
m阶B树:在B树中,各结点中包含的关键字是不重复的
m阶B+树:在B+树中,叶结点包含全部关键字非叶结点中出现过的关键字也会出现在叶结点中。
4.关键字是否存储对应记录的地址
m阶B树:B树的结点中都包含了关键字对应的记录的存储地址
m阶B+树:在B+树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址
5.查找方式
b树只支持随机查找,不支持顺序查找
而b+树两个都可以
6.b树和B+树都可以用于文件索引结构,但是b+树更合适,因为它的磁盘读写代价更低

7.9 散列查找及其性能分析
7.9.1 散列表的基本概念

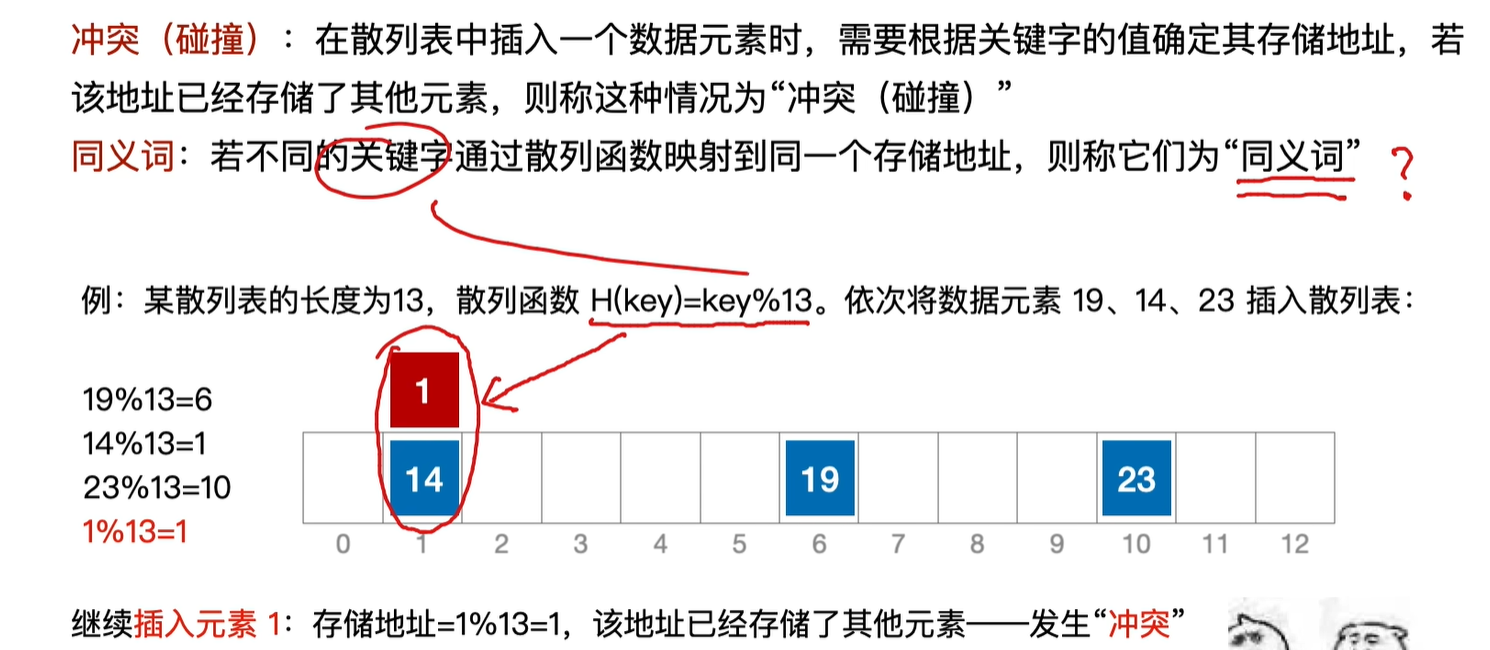
如何减少冲突?
构造更合适的散列函数
7.9.2 散列函数的构造方法


1.除留余数法


2.直接定址法
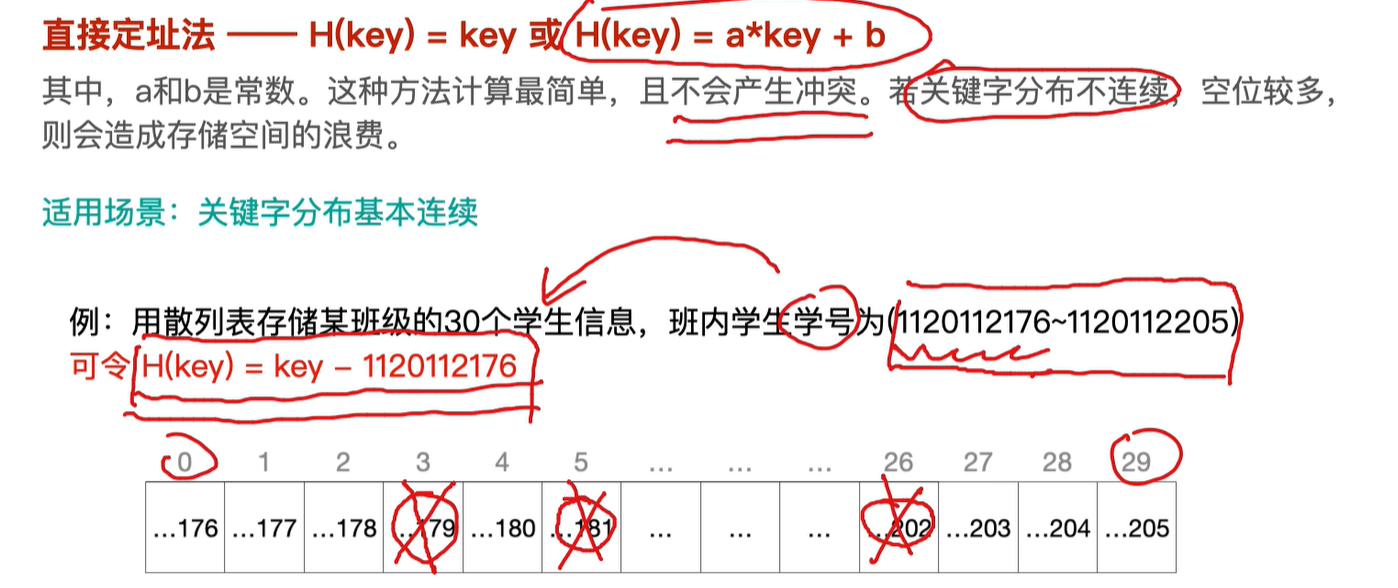
3.数字分析法

4.平方取中法
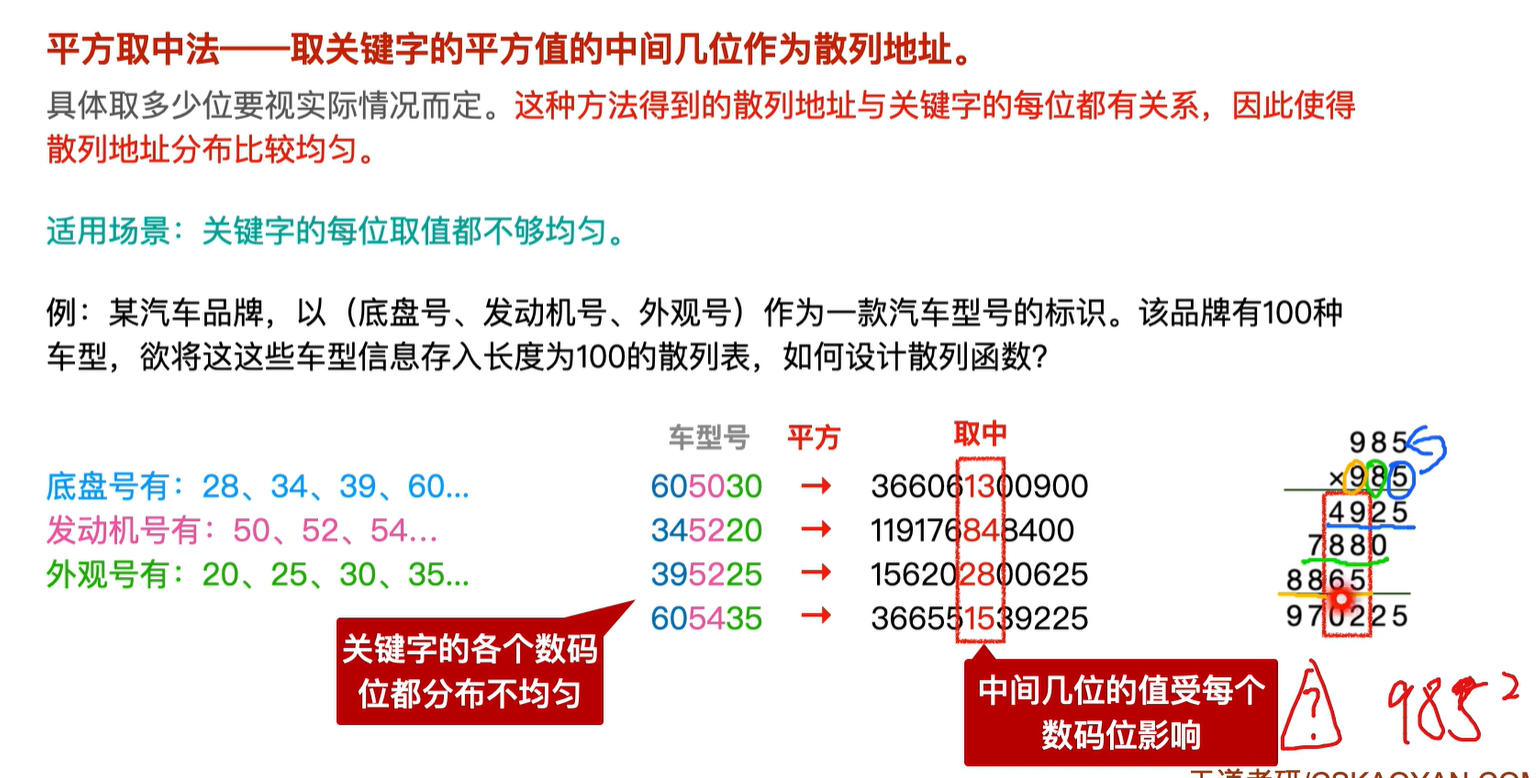
7.9.3 处理冲突的方法
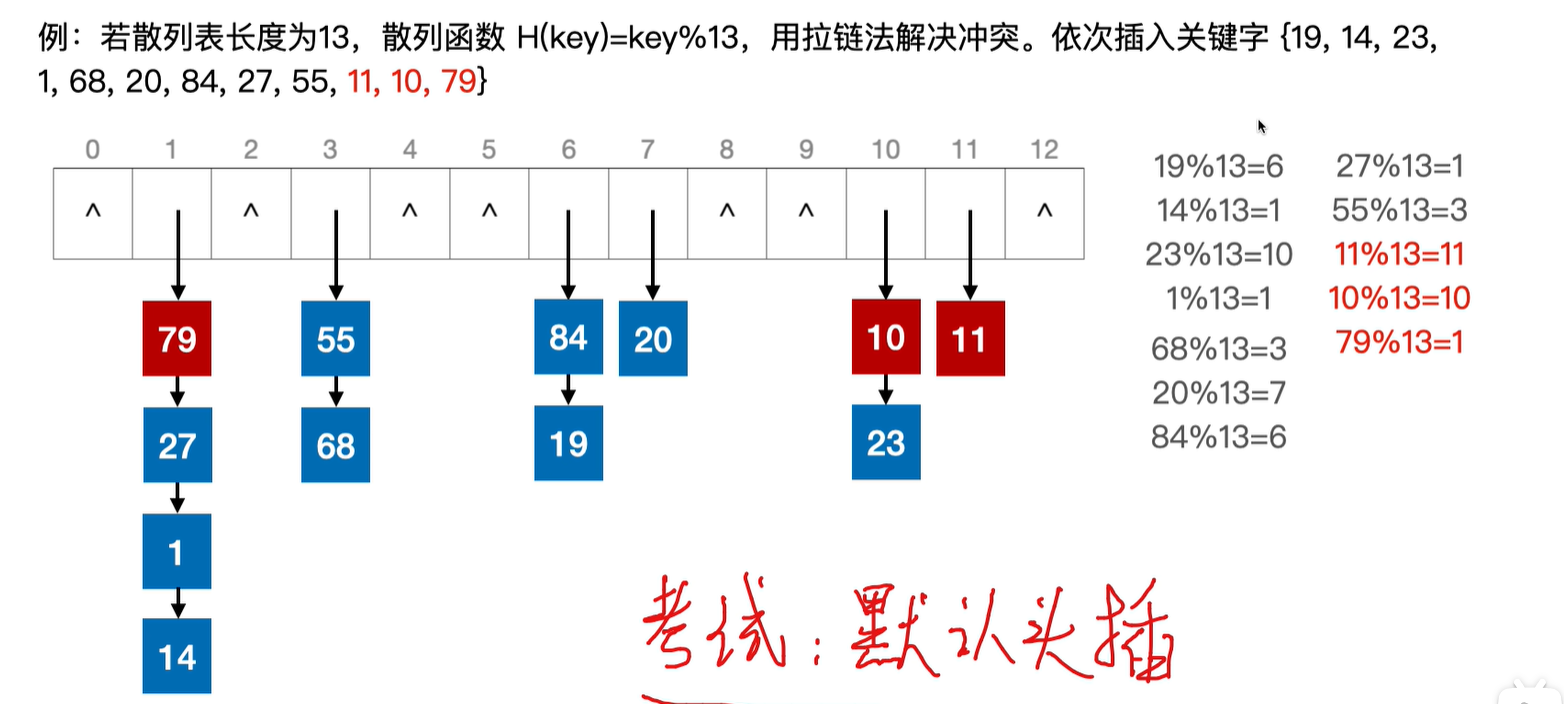
1.拉链法
插入操作:题目如果没有说明的话,那么默认使用头插法

查找操作:
1.根据散列函数找到对应链表
2.遍历链表找到关键字
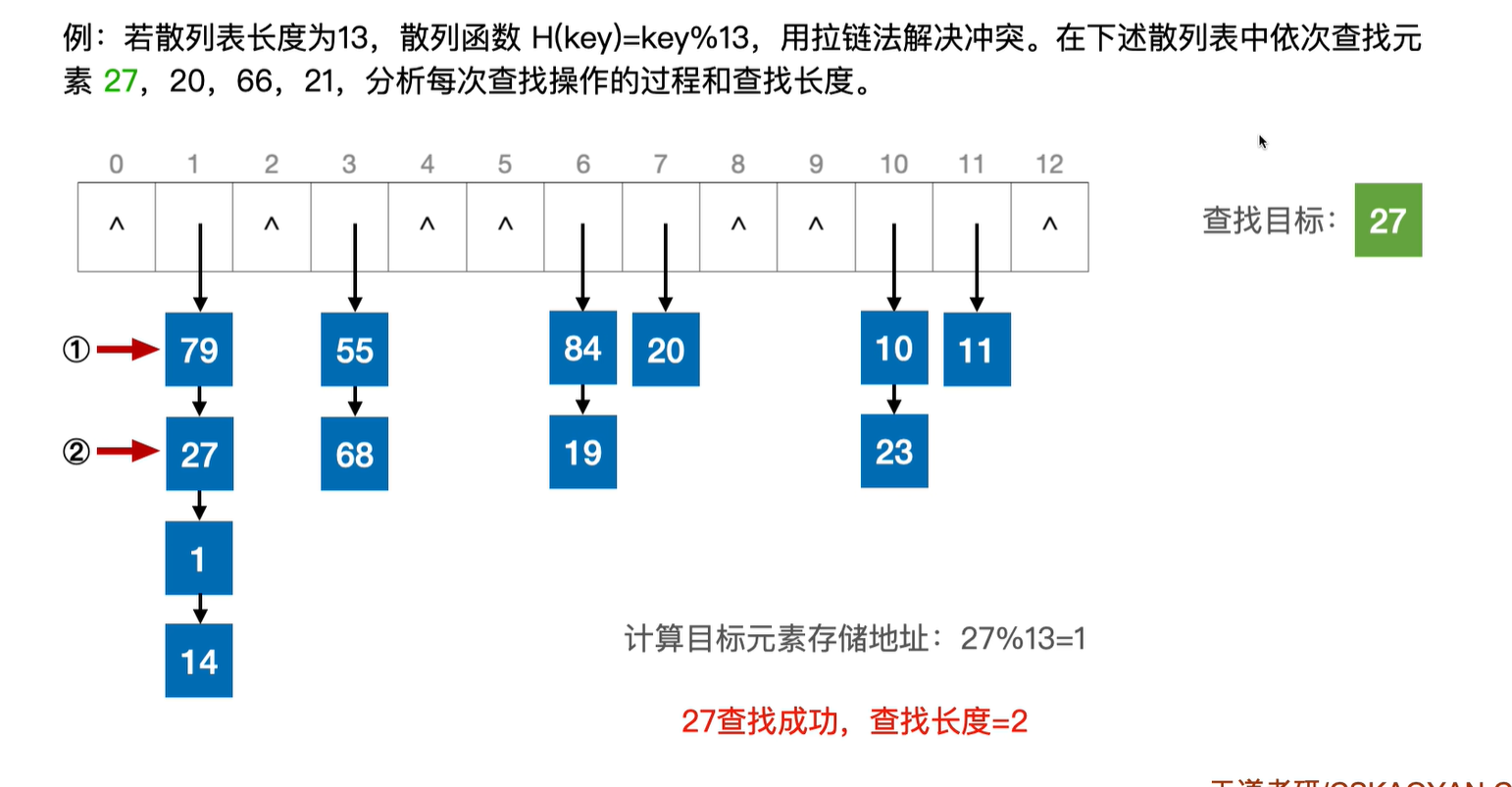
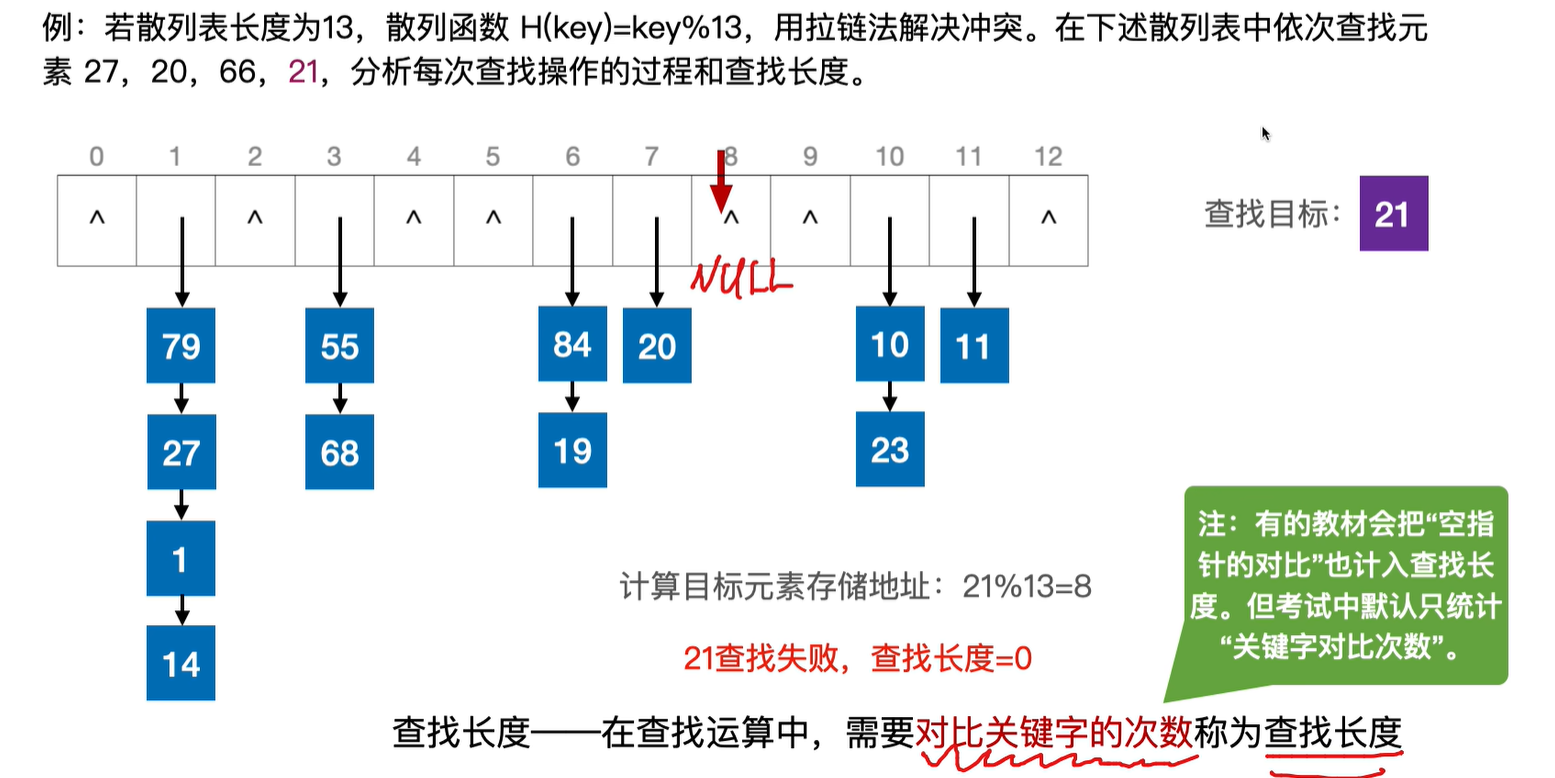
删除操作:
先查找,找到关键字,把它删除,没找到就是删除失败
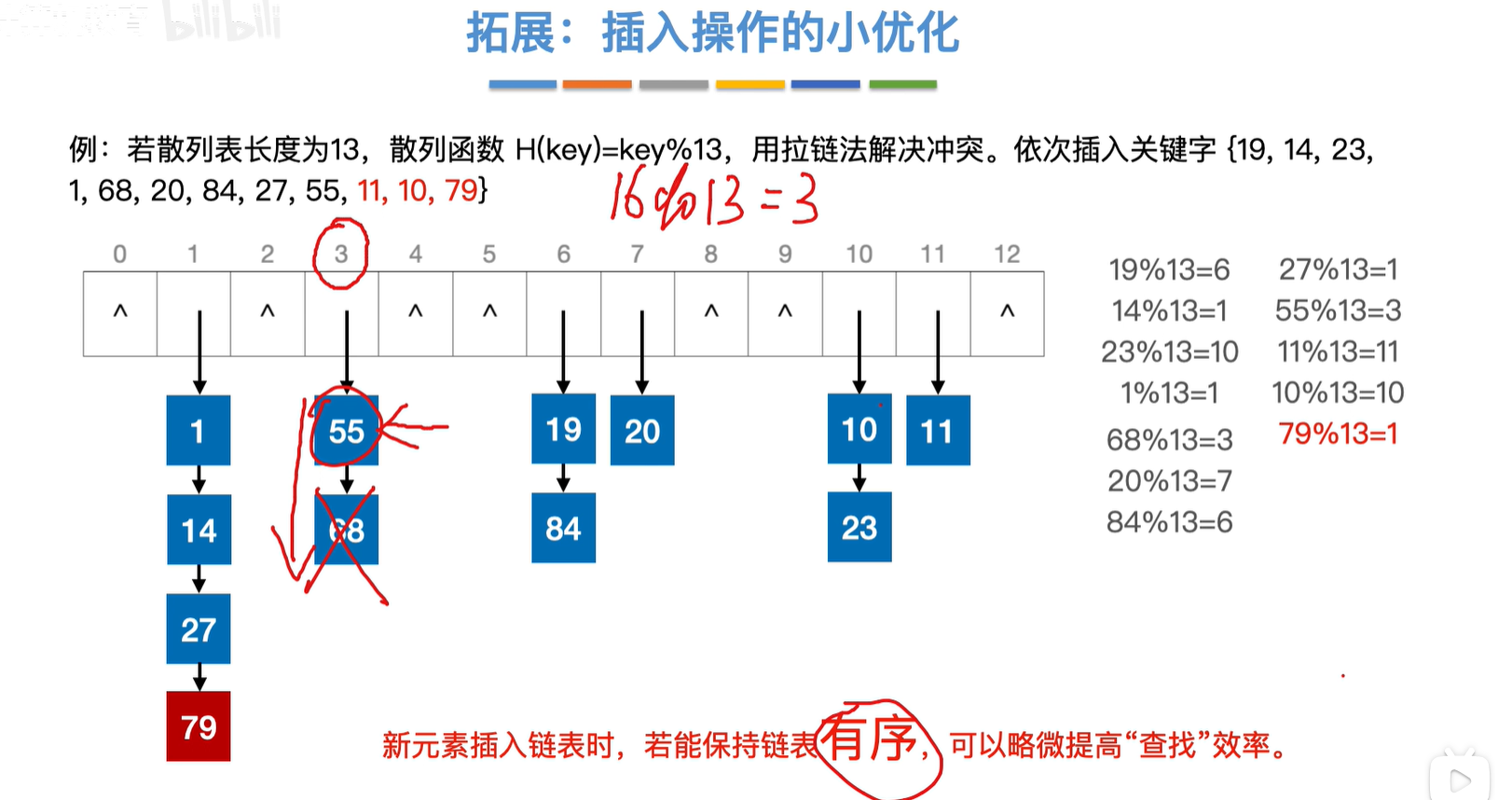
2.开放地址法
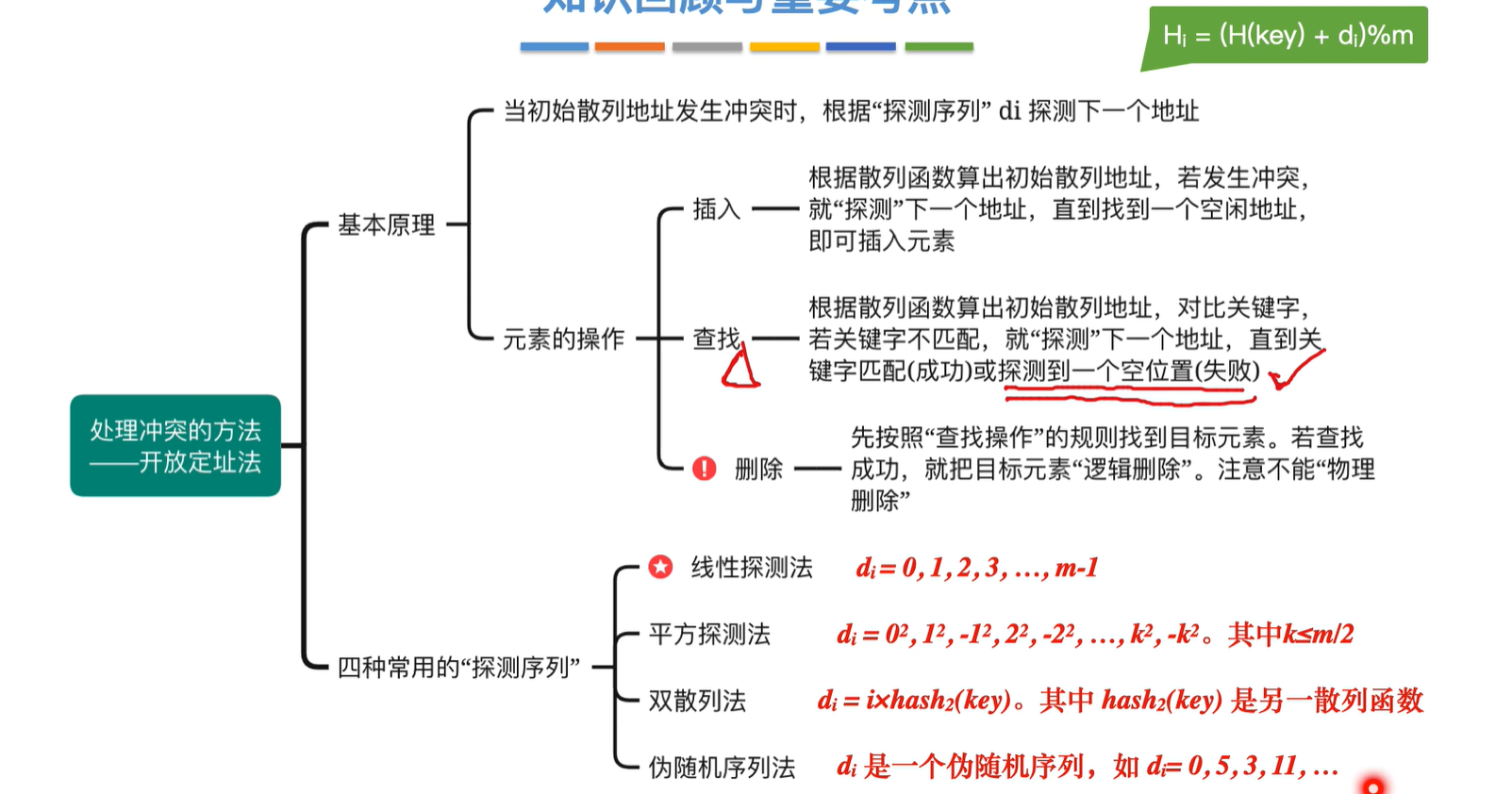

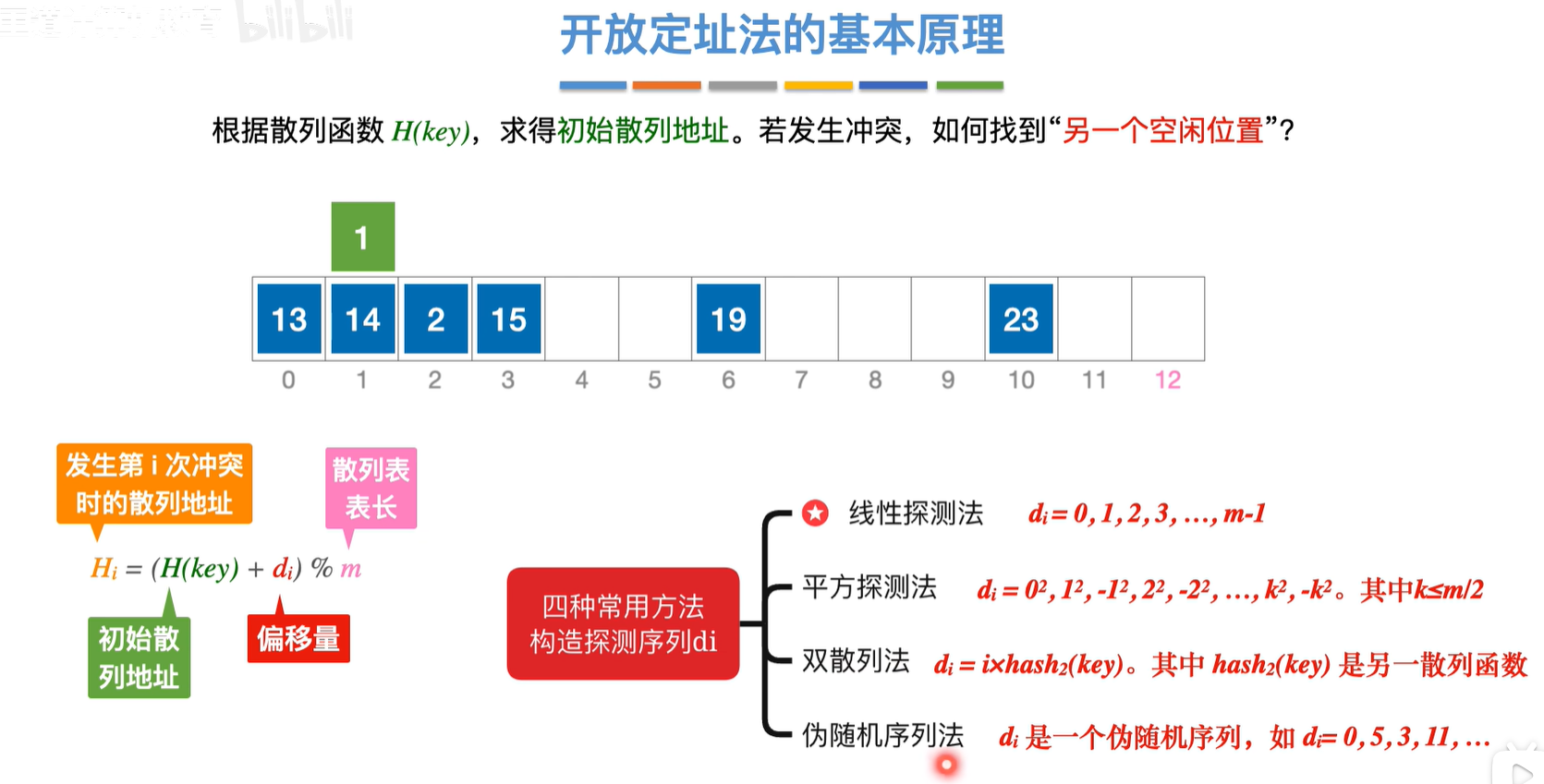
每个探测序列的第一个d0都是0,是因为第0次发生冲突的散列地址就是它本身,其实就是第一次往一个位置插入的时候的理解吧算是
插入和查找操作
插入就按照对应的规则插入
查找也按照对应的规则查找,如果找到空,那么就是没找到答案

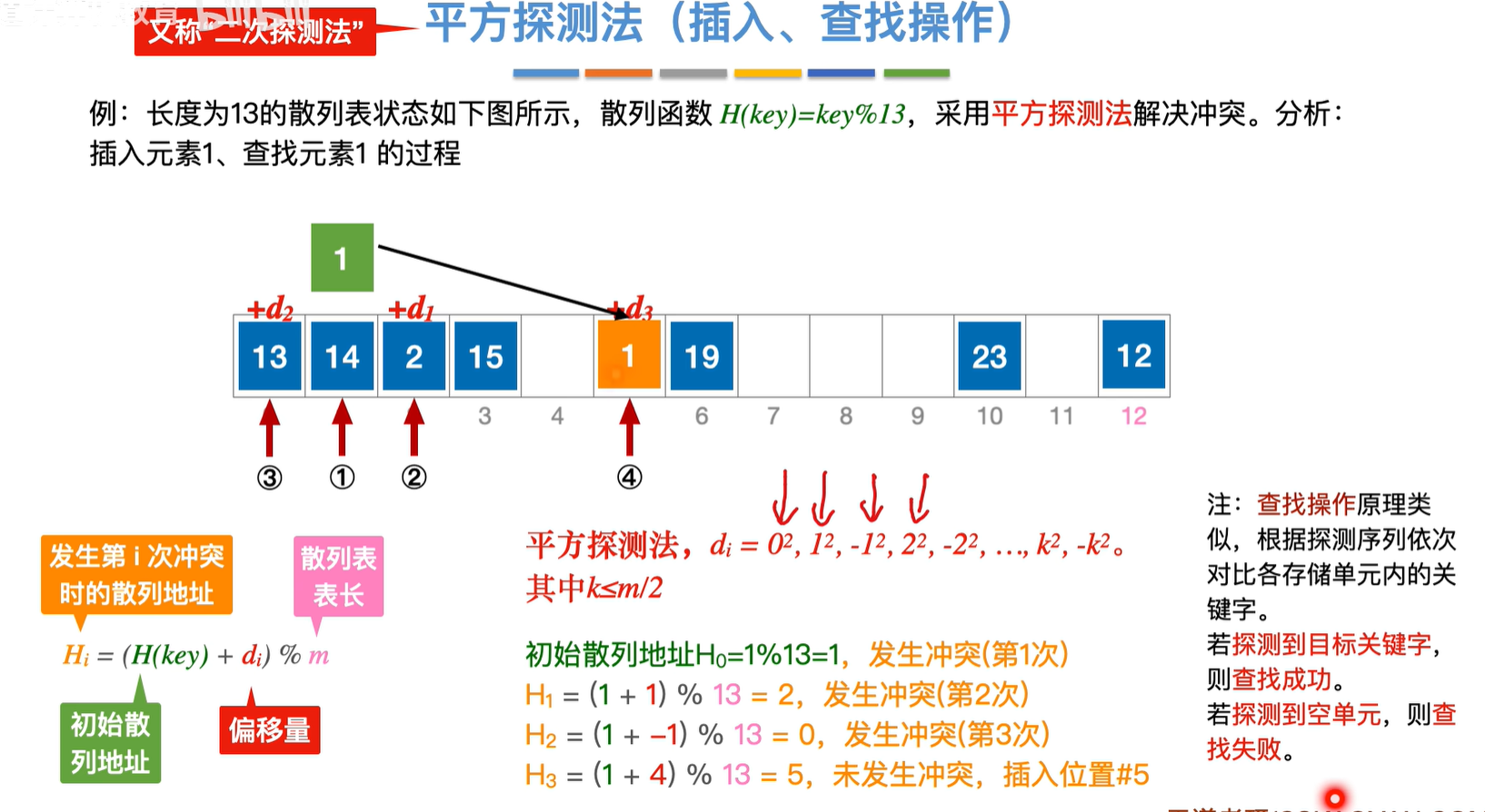
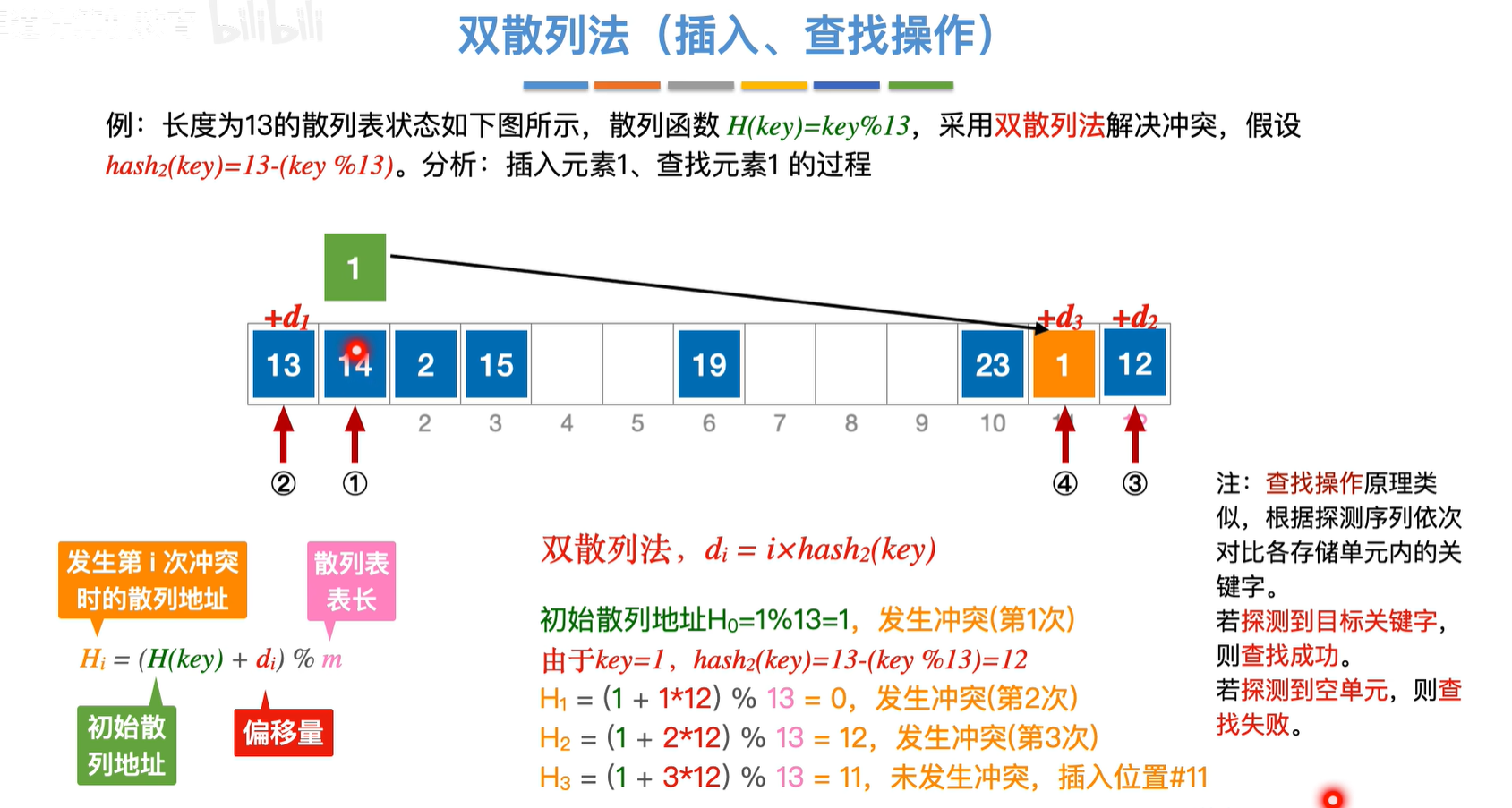

伪随机序列是人为设置的
删除操作


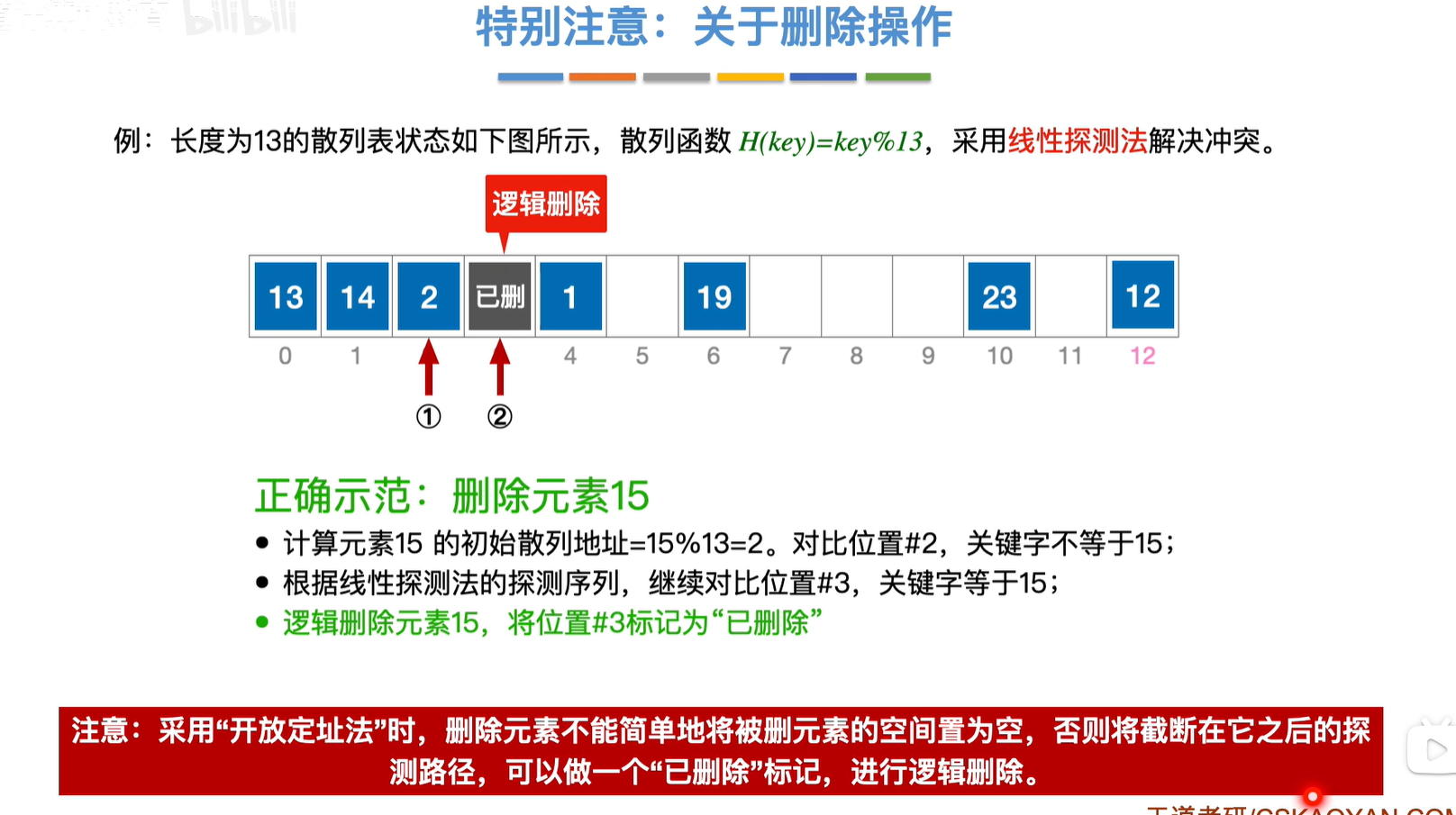


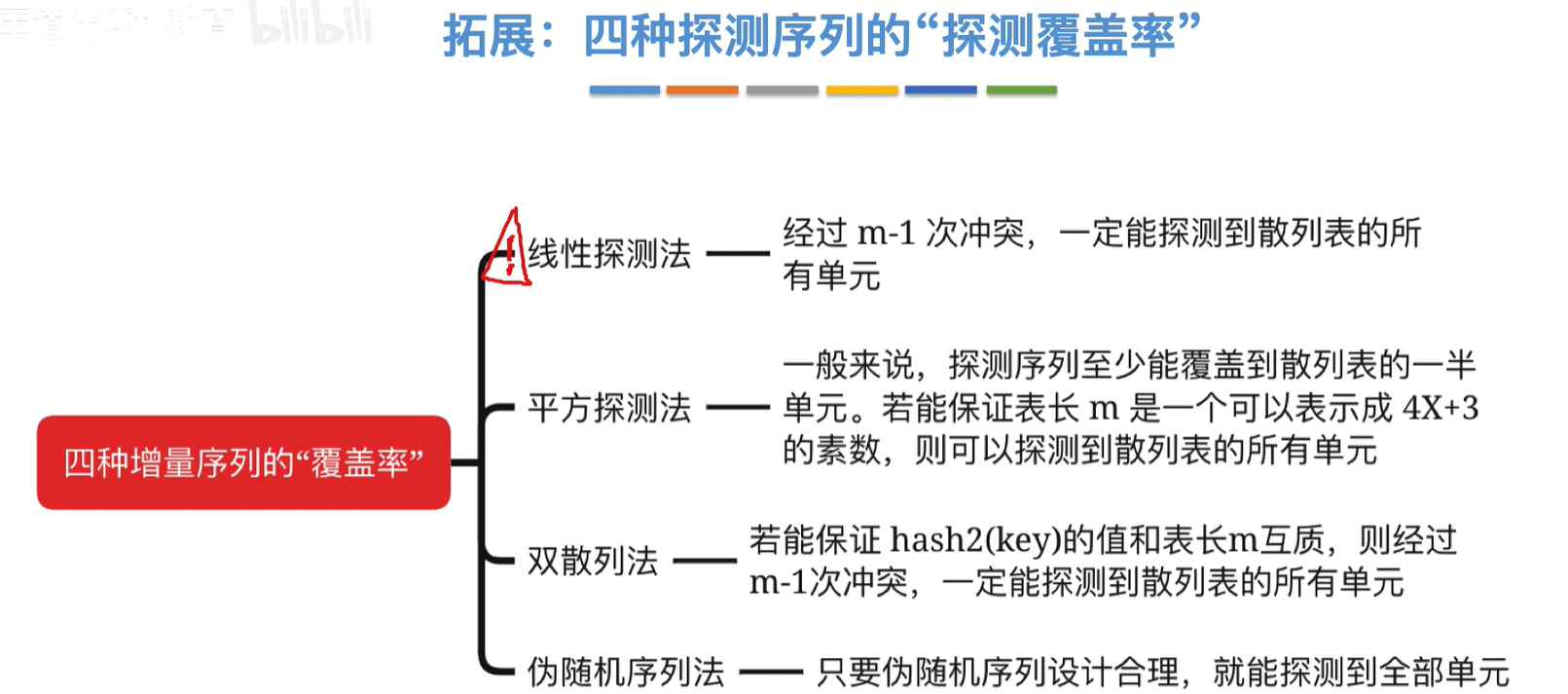
探测覆盖率:了解就好,不考
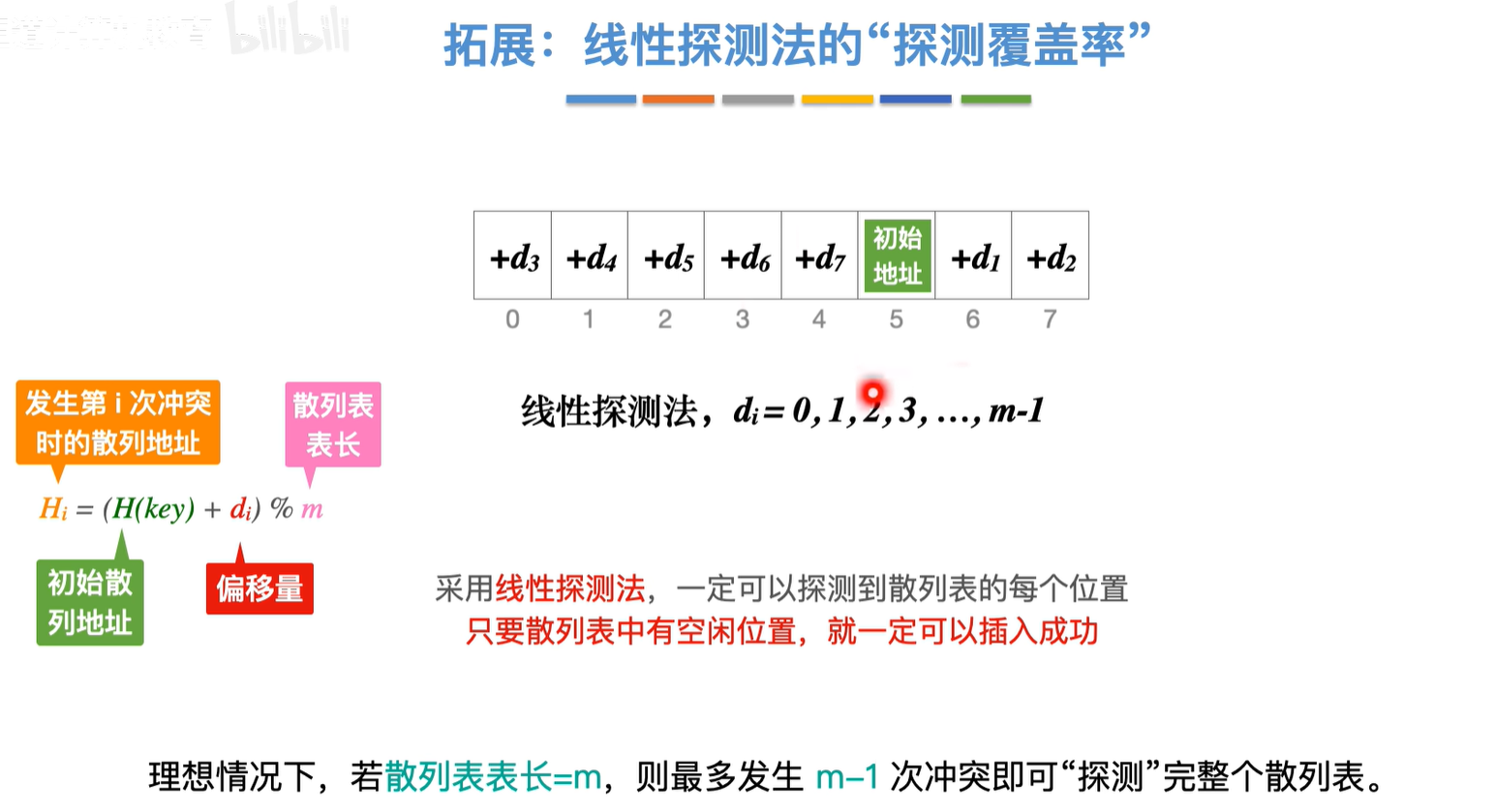
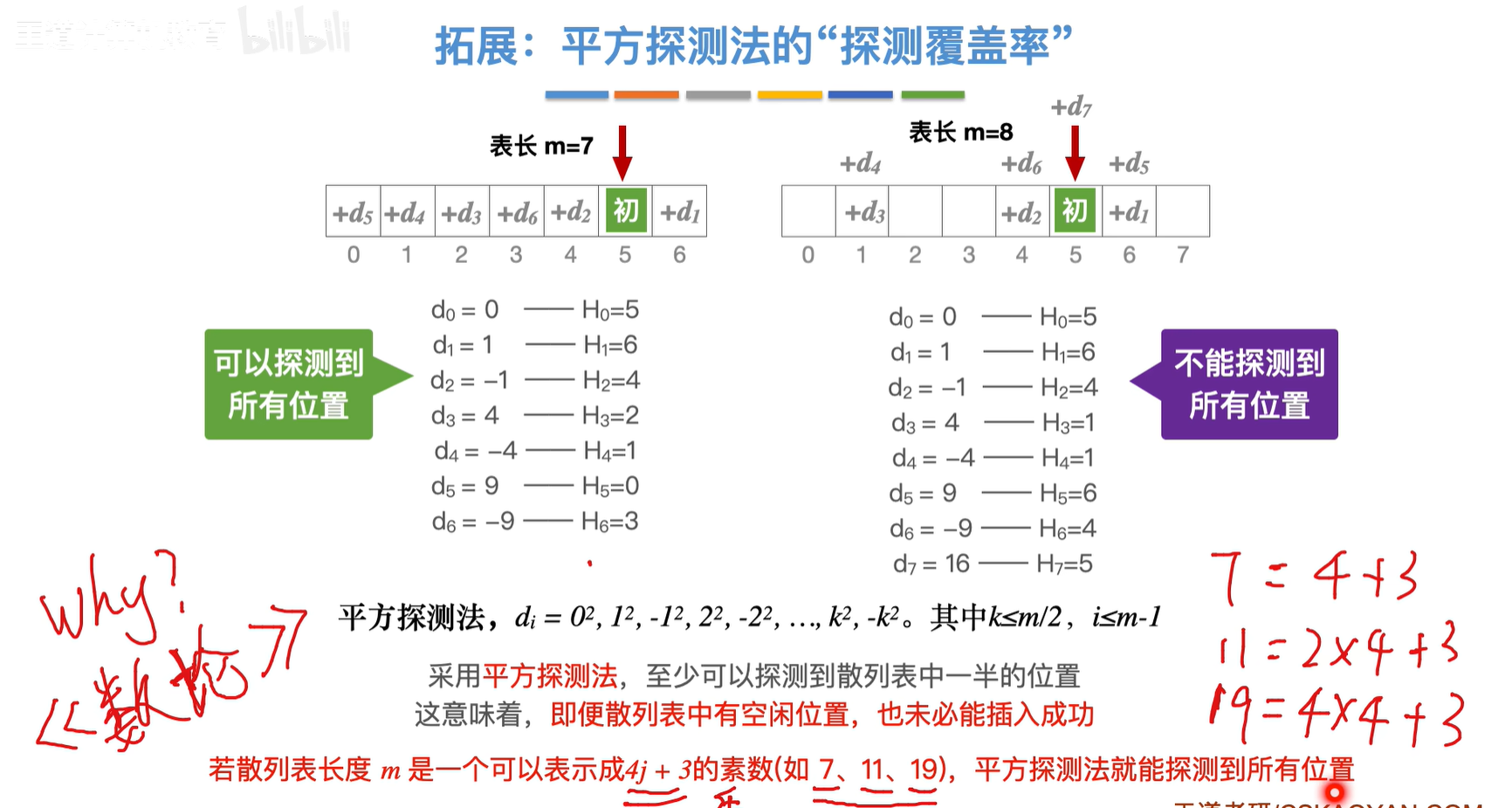
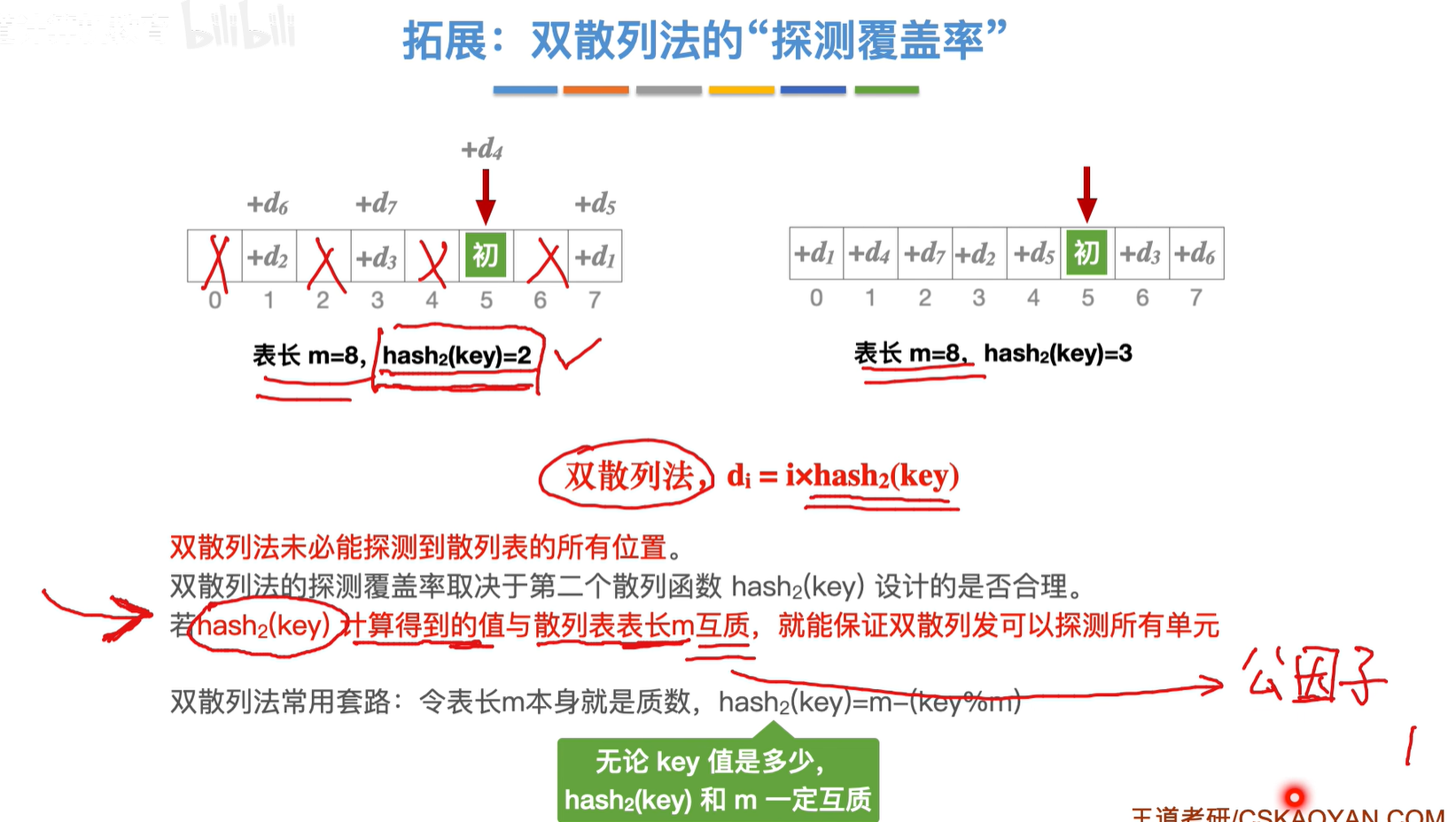
说明:m为质数,表长m和小于它本身的数一定是互质的
7.9.4 散列查找及性能分析
装填因子,散列函数,冲突解决策略略都会影响ASL
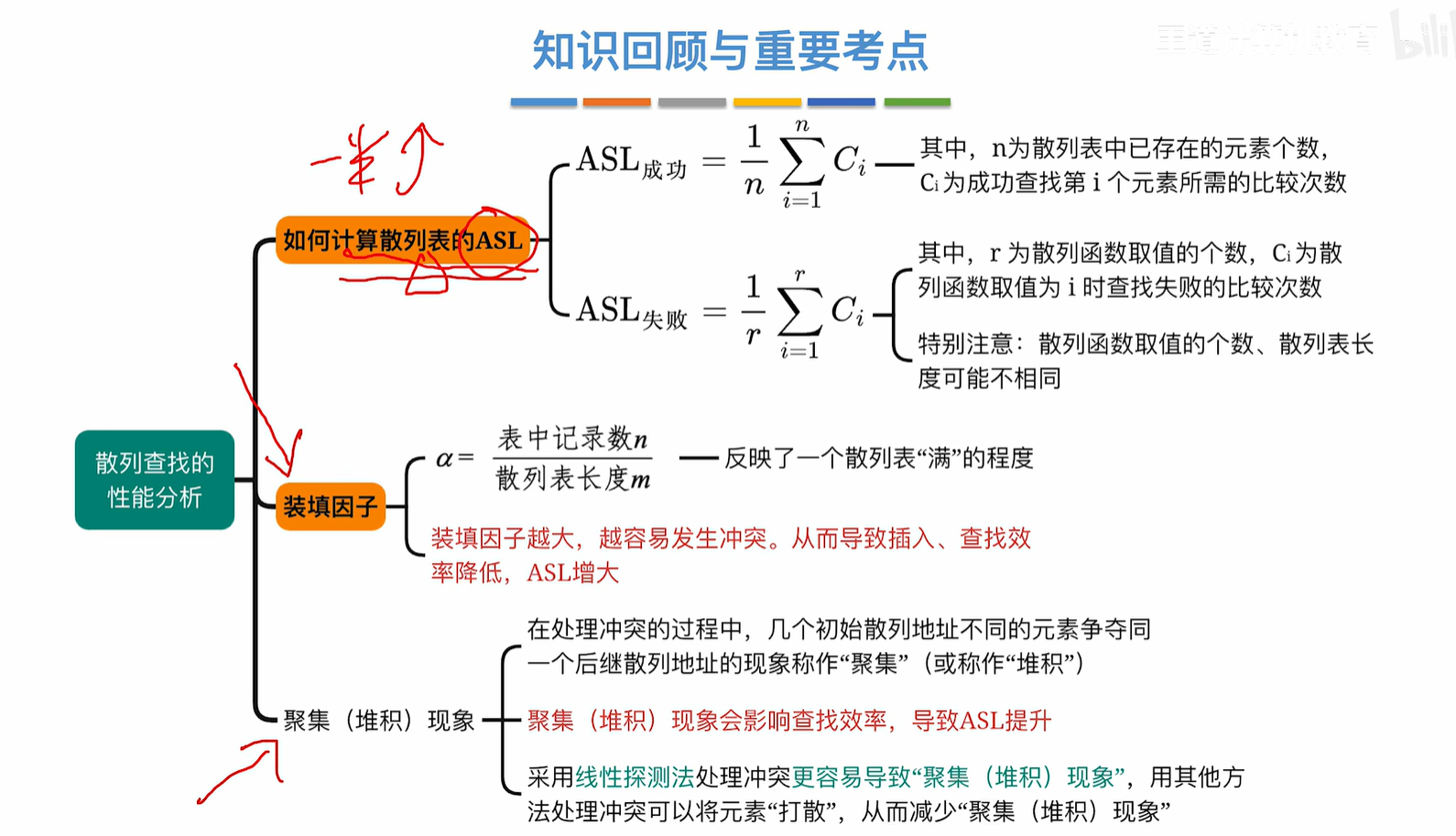
以线性探测为例


查找失败的13,12,11,10怎么来的?因为第一个元素查找失败那就得看后面所有元素等不等于当前要找的元素,因为后面元素都有可能是因为冲突而被线性探测法弄到后面去的
还有经典的错误是,表长虽然为16,但是散列函数取值只有13
1是因为h(key)=0是空,查找一次就知道查找失败了
而第二个是13而不是12的原因是,要知道h(key)=1查找失败除了需要对比1-12以外,还要去看第13个位置,看了第13个位置发现是空的,这样才不会继续对比,那么就是13次而不是只对比1-12就可以了的
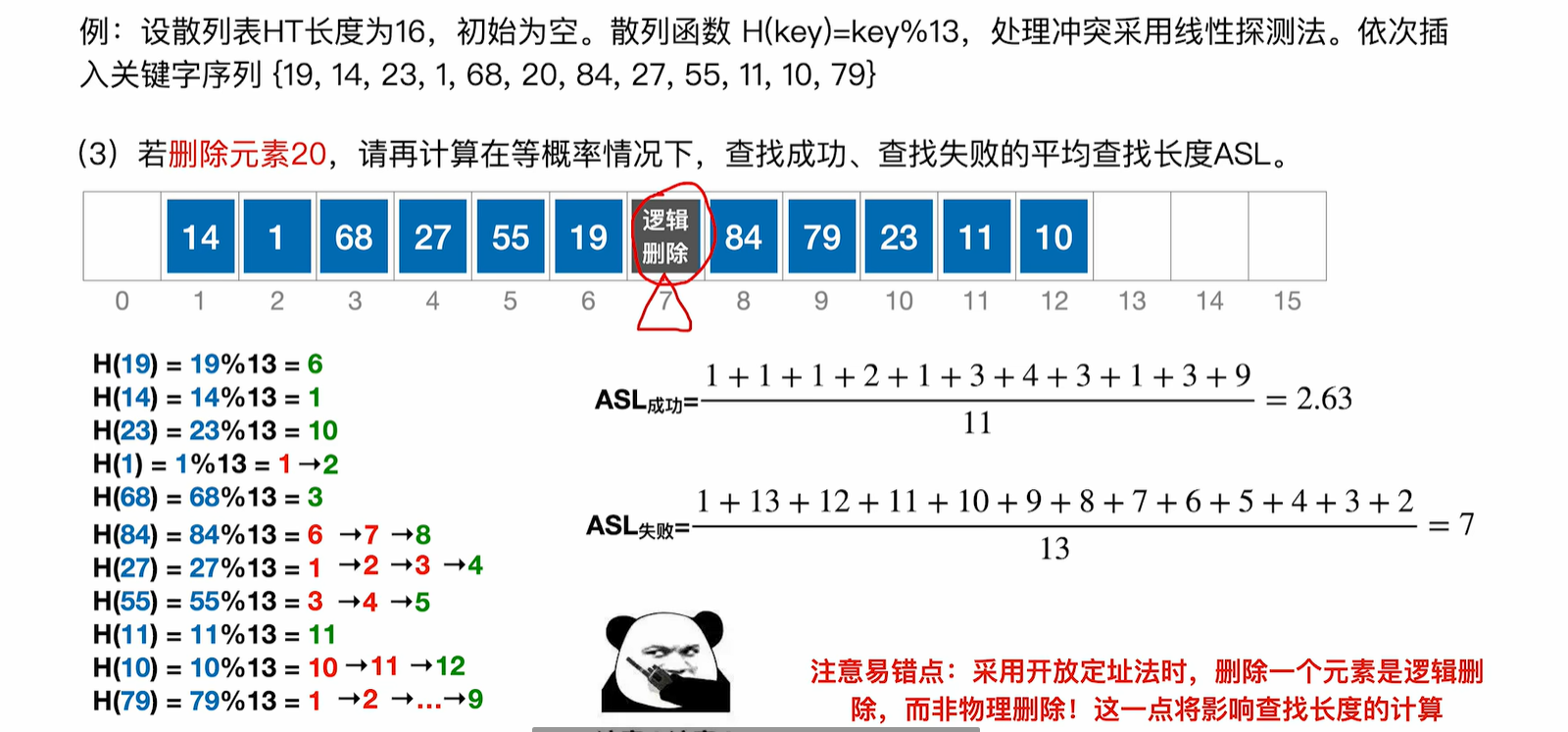
注意是逻辑删除而不是真的删除,计算查找次数的时候不要以为到了7就停了,如果线性探测的时候还往后走了,那么现在也要继续往后查找

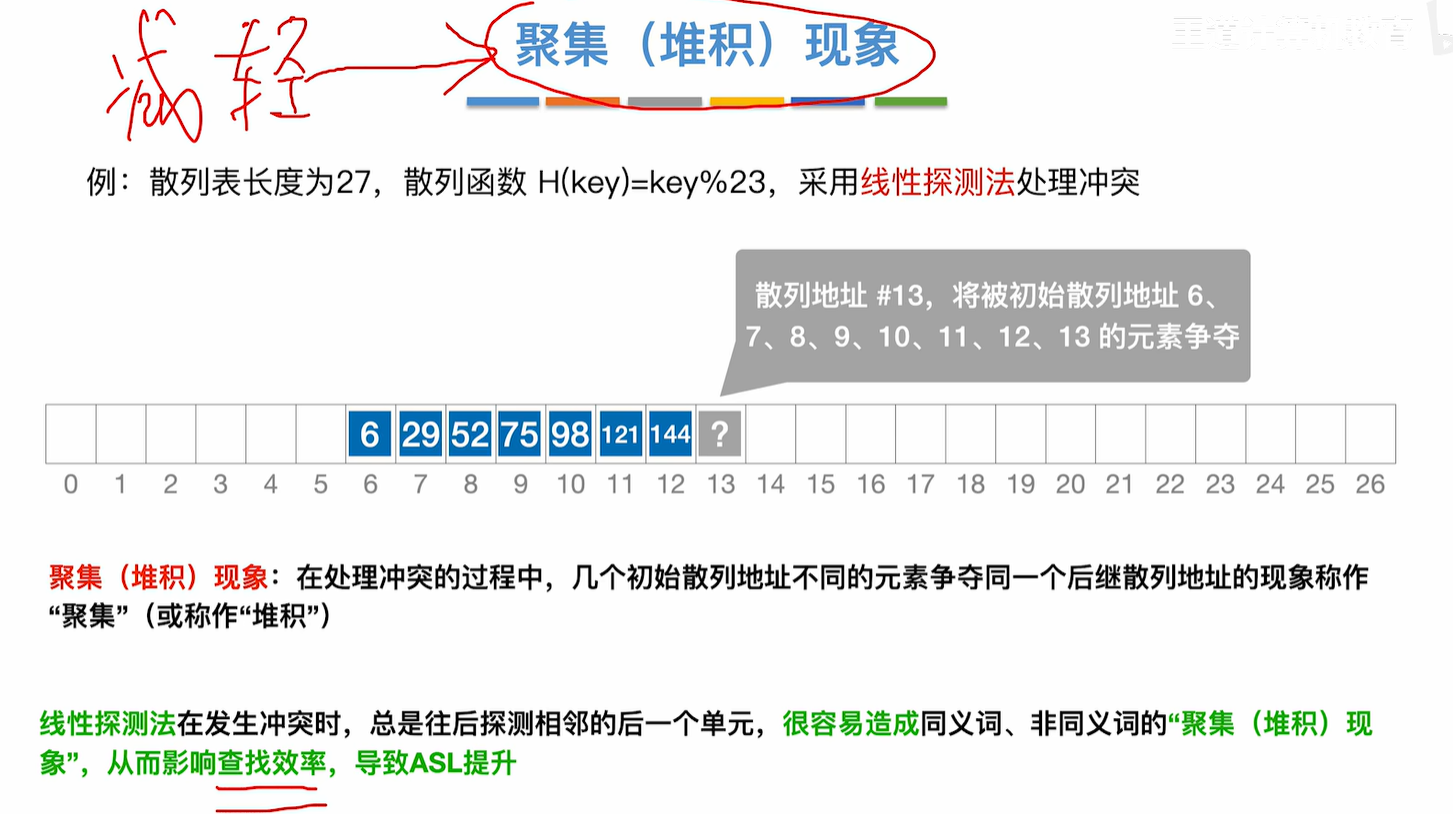
如何减轻聚集现象呢?
使用平方探测法或者 设计合理的双散列法 或者 设计合理的伪随机序列法都可以减轻

ASL成功=(1+1/(1-装填因子))/2
相关文章:

26考研 | 王道 | 数据结构 | 第七章 查找
第七章 查找 文章目录 第七章 查找7.1 查找概念7.2 顺序查找7.3 折半查找7.4 分块查找7.5 二叉排序树7.6 平衡二叉树平衡二叉树的插入平衡二叉树的删除 7.7 红黑树7.7.1 为什么要发明红黑树?7.7.2 红黑树的定义和性质7.7.3 红黑树的插入和删除插入删除 7.8 B树和B树…...

Docker 部署 Redis:快速搭建高效缓存服务
Docker 部署 Redis:快速搭建高效缓存服务 引言 Redis 是一个高性能的键值数据库,广泛应用于缓存、消息队列、实时分析等领域。而 Docker 作为容器化技术的代表,能够帮助我们快速部署和管理应用程序。结合两者,我们可以轻松实现 …...

【缓存与数据库结合最终方案】伪从技术
实现伪从技术:基于Binlog的Following表变更监听与缓存更新 技术方案概述 要实现一个专门消费者服务作为Following表的伪从,订阅binlog并在数据变更时更新缓存,可以采用以下技术方案: 主要组件 MySQL Binlog监听:使…...

如何规避矩阵运营中的限流风险及解决方案
在自媒体矩阵化运营中,系统性规避平台限流机制需建立在精准理解算法逻辑的基础上。根据行业实践数据统计,当前矩阵账号触发限流的核心诱因主要集中在两大维度: 首先需要明确的是设备与网络层面的合规性配置。当单台移动设备频繁切换多账号登…...

TensorFlow Keras“安全模式”真的安全吗?绕过 safe_mode 缓解措施,实现任意代码执行
机器学习框架通常依赖序列化和反序列化机制来存储和加载模型,然而模型中不恰当的代码隔离和可执行组件可能会导致严重的安全风险。 TensorFlow 中的 Keras v3 ML 模型结构 对于基于 TensorFlow 的 Keras 模型,存在一个严重的反序列化漏洞,编号为CVE-2024-3660。攻击者可利…...

PostgreSQL-日志管理介绍
概述 1、日志管理器: 日志模块包括事务提交日志CLOG和数据日志XLOG。其中CLOG是系统为整个事务管理流程所建立的日志,主要用于记录事务的状态,同时通过SUBTRANS日志记录事务的嵌套关系。XLOG日志是数据库日志的主体,记录数据库中…...

【Java 数据结构】泛型
目录 一. 什么是泛型 二. 引出泛型 三. 泛型语法 四. 泛型的使用 五. 泛型是如何编译的 5.1 擦除机制 六. 泛型的继承 6.1 泛型类继承非泛型类 6.2 泛型类继承泛型类 6.2.1 父类的同名传递 6.2 2 父类的异名传递 6.2.3 父类固定类型传递 6.2.4 子类添加参数 七. 泛…...

鲲鹏麒麟搭建Docker仓库
Docker Registry简介 Docker Registry是一个开源的镜像仓库工具,用于存储和分发Docker镜像。它是Docker生态系统中的核心组件之一,提供了镜像的推送(push)、拉取(pull)和管理功能。 主要特性: 1、开源免费:Apache 2.0许可证 2、轻…...
)
Java快速上手之实验4(接口回调)
1.编写接口程序RunTest.java,通过接口回调实现多态性。解释【代码4】和【代码6】的执行结果为何不同? interface Runable{ void run(); } class Cat implements Runable{ public void run(){ System.out.println("猫急上树.."…...

【前端】【业务场景】【面试】在前端开发中,如何实现实时数据更新,比如实时显示服务器推送的消息,并且保证在不同网络环境下的稳定性和性能?
问题:在前端开发中,如何实现实时数据更新,比如实时显示服务器推送的消息,并且保证在不同网络环境下的稳定性和性能? 一、实现实时数据更新的方法 WebSocket: 原理:WebSocket 是一种在单个 TCP …...

redis相关问题整理
Redis 支持多种数据类型: 字符串 示例:存储用户信息 // 假设我们使用 redis-plus-plus 客户端库 auto redis Redis("tcp://127.0.0.1:6379"); redis.set("user:1000", "{name: John Doe, email: john.doeexample.com}"…...

某城乡老旧房屋试点自动化监测服务项目
1. 项目简介 我国是房屋建设增长量最高的国家或地区,但上个世纪末建造的房屋多为砖混结构,使用寿命短且缺乏维护。这些房屋在使用过程中受到地质活动、自然环境和人为改造的影响,其结构强度逐年下降,部分房屋甚至出现墙体裂缝、倾…...

企业为何要求禁用缺省口令?安全风险及应对措施分析
在当今数字化时代,企业网络安全面临着前所未有的挑战。缺省口令的使用是网络安全中的一个重要隐患,许多企业在制定网络安全红线时,明确要求禁用缺省口令。本文将探讨这一要求的原因及其对企业安全的重要性。 引言:一个真实的入侵场…...

在 MySQL 中,索引前缀长度为什么选择为 191
在 MySQL 中,索引前缀长度选择为 191 的常见原因主要与 字符集编码 和 索引长度限制 相关,具体解释如下: 1. 字符集编码的影响 utf8mb4 字符集: MySQL 的 utf8mb4 字符集每个字符最多占用 4 个字节(相比 utf8 的 3 字…...

【Python语言基础】24、并发编程
文章目录 1. 多线程(threading模块)1.1 多线程的实现(threading 模块)1.2 多线程的优缺点1.3 线程同步与锁 2. 多进程(multiprocessing模块)2.1 多进程实现(multiprocessing模块)2.2 多进程的优缺点2.3 进程…...

MySQL-自定义函数
自定义函数 函数的作用 mysql数据库中已经提供了内置的函数,比如:sum,avg,concat等等,方便我们日常的使用,当需要时mysql支持定义自定义的函数,方便与我们对于需用复用的功能进行封装。 基本…...

实时操作系统在服务型机器人中的关键作用
一、服务型机器人的发展现状与需求 近年来,服务型机器人市场呈现出蓬勃发展的态势。据国际机器人联合会(IFR)2024 年度报告显示,全球人形机器人市场规模预计在 2025 年达到 38.7 亿美元,年复合增长率达 19.2%。服务型机…...

智能电网第5期 | 老旧电力设备智能化改造:协议转换与边缘计算
随着电力行业数字化转型加速,大量在役老旧设备面临智能化升级需求。在配电自动化改造过程中,企业面临三大核心挑战: 协议兼容难题:传统设备采用Modbus等老旧协议,无法接入智能电网系统 数据处理瓶颈:设备本…...

【UML建模】starUML工具
一.概述 StarUML是一款UML工具,允许用户创建和管理UML(统一建模语言)模型,广泛应用于软件工程领域。它的主要功能包括创建各种UML图:如用例图、类图、序列图等,支持代码生成与反向工程,以及提供…...

【技术笔记】Cadence实现Orcad与Allegro软件交互式布局设置
【技术笔记】Cadence实现Orcad与Allegro软件交互式布局设置 更多内容见专栏:【硬件设计遇到了不少问题】、【Cadence从原理图到PCB设计】 在做硬件pcb设计的时候,原理图选中一个元器件,希望可以再PCB中可以直接选中。 为了达到原理图和PCB两两…...

第十七届山东省职业院校技能大赛 中职组网络建设与运维赛项
第十七届山东省职业院校技能大赛 中职组网络建设与运维赛项 赛题 B 卷 第十七届山东省职业院校技能大赛中职组网络建设与运维赛项 1 赛题说明 一、竞赛项目简介 “网络建设与运维”竞赛共分为以下三个模块: 网络理论测试; 网络建设与调试…...

深入详解人工智能数学基础——概率论中的KL散度在变分自编码器中的应用
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

Docker配置DNS方法详解及快速下载image方法
根据错误信息,Docker 在拉取镜像时遇到网络连接超时(Client.Timeout exceeded),通常与 代理配置错误、DNS 解析失败、镜像源访问受限 或 网络防火墙限制 有关。以下是详细解决方案: 1. 检查并修复代理配置 如果你使用了 HTTP 代理: 确认代理地址是否有效(替换 speed.ip…...

Rundeck 介绍及安装:自动化调度与执行工具
Rundeck介绍 概述:Rundeck 是什么? Rundeck 是一款开源的自动化调度和任务执行工具,专为运维场景设计,帮助工程师通过统一的平台管理和执行跨系统、跨节点的任务。它由 PagerDuty 维护(2016 年收购)&#…...

济南国网数字化培训班学习笔记-第二组-6-输电线路现场教学
输电线路现场教学 杆塔组装 角钢塔 角钢-连扳-螺栓 螺栓(M): 脚钉-螺栓(螺栓头-无扣长-螺纹-螺帽)-垫片-螺帽/防盗帽/防松帽M20*45 表示直径20mm,长度45mm螺栓级别由一个类似浮点数表示,如…...

数据结构——二叉树,堆
目录 1.树 1.1树的概念 1.2树的结构 2.二叉树 2.1二叉树的概念 2.2特殊的二叉树 2.3二叉树的性质 2.4二叉树的存储结构 2.4.1顺序结构 2.4.2链式结构 3.堆 3.1堆的概念 3.2堆的分类 3.3堆的实现 3.3.1初始化 3.3.2堆的构建 3.3.3堆的销毁 3.3.4堆的插入 3.3.5…...

PostgreSQL 分区表——范围分区SQL实践
PostgreSQL 分区表——范围分区SQL实践 1、环境准备1-1、新增原始表1-2、执行脚本新增2400w行1-3、创建pg分区表-分区键为创建时间1-4、创建24年所有分区1-5、设置默认分区(兜底用)1-6、迁移数据1-7、创建分区表索引 2、SQL增删改查测试2-1、查询速度对比…...

第八节:进阶特性高频题-Pinia与Vuex对比
优势:无嵌套模块、Composition API友好、TypeScript原生支持 核心概念:state、getters、actions(移除mutation) 深度对比 Pinia 与 Vuex:新一代状态管理方案的核心差异 一、核心架构设计对比 维度VuexPinia设计目标集…...

路由交换网络专题 | 第七章 | BGP练习 | 次优路径 | Route-Policy | BGP认证
基本部分配置讲解: 配置BGP相关部分: // BGP区域配置: 用作环回口创建BGP对等体// “ipv4-family unicast”是指进入BGP的IPv4单播地址族视图。 // 配置完后仅仅只在IPV4地址簇下建立对等体。* [AR3]bgp 100 [AR3-bgp]peer 1.1.1.1 as-number 100 [AR…...

序论文42 | patch+MLP用于长序列预测
论文标题:Unlocking the Power of Patch: Patch-Based MLP for Long-Term Time Series Forecasting 论文链接:https://arxiv.org/abs/2405.13575v3 代码链接:https://github.com/TangPeiwang/PatchMLP (后台回复“交流”加入讨…...

【mongodb】系统保留的数据库名
目录 1. admin2. config3. local4. test(非严格保留,但常作为默认测试数据库)5. 注意事项6. 其他相关说明 1. admin 1.用途:用于存储数据库的权限和用户管理相关数据。2.特点:该数据库是 MongoDB 的超级用户数据库&am…...

js 的call 和apply方法用处
主要用于ECMAScript与宿主环境(文档对象(DOM)、浏览器对象(BOM))的交互中; 例子:function changeStyle(attr, value){ this.style[attr] value; } …...

济南国网数字化培训班学习笔记-第二组-2节-输电线路施工及质量
输电线路施工及质量 质量管控基本规定 基本规定 项目分类 土石方(测量挖坑)、基础、杆塔、架线、接地、线路防护 检验项目分类原则: 1.主控项目:影响工程性能、强度、安全性和可靠性,且不易修复和处理 2.一般项…...
从 daz3d 导入到 UE5。在 UE5 中,我发现使用某个表情并与闭眼混合后,上眼睑出现了问题)
“Daz to Unreal”将 G8 角色(包括表情)从 daz3d 导入到 UE5。在 UE5 中,我发现使用某个表情并与闭眼混合后,上眼睑出现了问题
1) Bake & Export Corrective Morphs from Daz before you go into UE5 1) 在进入 UE5 之前,从 Daz 烘焙并导出修正型变形 In Daz Studio 在 Daz Studio 中 Load your G8 head, dial in the exact mix (e.g. Smile 1.0 Eyes Closed 1.0). 加载你的 G8 头部&am…...

Linux系统之----进程优先级、调度与切换
在开启本篇文章的学习之前,我们先要熟悉如下两个事 1.概念 进程优先级指的是进程能得到某种资源的先后顺序,要理解好它与权限的关系,优先级是 能,拥有资源的先后顺序,权限是 能还是不能的问题 2.为什么要有优先级…...

Web3钱包开发功能部署设计
Web3钱包开发功能部署设计全景指南(2025技术架构与实战) ——从核心模块到多链生态的完整解决方案 一、核心功能模块设计 1.1 资产管理体系 Web3钱包的核心功能围绕资产存储、交易验证、多链兼容展开: • 密钥管理:…...

【含文档+PPT+源码】基于SpringBoot的开放实验管理平台设计与实现
项目介绍 本课程演示的是一款基于SpringBoot的开放实验管理平台设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统…...

小刚说C语言刷题——1317正多边形每个内角的度数?
1.题目描述 根据多边形内角和定理,正多边形内角和等于:( n-2 ) 180∘ ( n 大于等于 3且 n 为整数) 请根据正多边形的边数,计算该正多边形每个内角的度数。(结果保留1位小数&#x…...

Spring—AOP
AOP是在不惊动原有的代码的基础上对功能进行增强操作 连接点:JoinPoint,可以被AOP控制的方法 通知:Advice,增强的逻辑,共性功能 切入点:PointCut,匹配连接点的条件,表明连接点中哪…...

算法训练营第二天| 209.长度最小的子数组、59.螺旋矩阵II、区间和
209.长度最小的子数组 题目 思路与解法 **第一想法:**无 carl的讲解: 滑动窗口 class Solution:def minSubArrayLen(self, target: int, nums: List[int]) -> int:ij0lens len(nums)sum 0res lens 1while j < lens:# for m in range(i, j1)…...

【C++ 真题】P3456 [POI2007] GRZ-Ridges and Valleys
[POI2007] GRZ-Ridges and Valleys 题面翻译 题目描述 译自 POI 2007 Stage 2. Day 0「Ridges and Valleys」 给定一个 n n n \times n nn 的网格状地图,每个方格 ( i , j ) (i,j) (i,j) 有一个高度 w i j w_{ij} wij。如果两个方格有公共顶点,…...

Vue3 中 computed的详细用法
Vue 3 中 computed 是一个非常重要的响应式 API,它是基于其依赖项的值来计算得出的值,当依赖项发生变化时,计算属性会自动更新 基本用法 在选项式 API 中,computed 通常作为一个选项直接在组件的选项对象中定义。例如 <temp…...

位带和位带别名区
位带区域和位带别名区域 位带区域(Bit-banding)是一种技术, 允许开发者直接访问和修改内存中的单个位。 这种技术在某些微控制器(如ARM Cortex-M系列)中特别有用,因为它可以简化对寄存器位的访问和修改。 …...

DRF凭什么更高效?Django原生API与DRF框架开发对比解析
一、原生 Django 开发 API 的局限性 虽然 Django 可以通过 JsonResponse 和视图函数手动构建 API,但存在以下问题: 手动序列化与反序列化 需要手动将模型实例转换为 JSON,处理复杂数据类型(如嵌套关系)时代码冗长且易…...

Agent智能体应用详解:从理论到实践的技术探索
一、Agent智能体是什么? 1. 核心定义 Agent智能体是能够感知环境、自主决策并执行动作以实现目标的软件实体。其核心特征包括: 自主性:无需外部指令持续运行。 反应性:实时响应环境变化。 目标导向:基于预设或学习…...

Windows下使用 VS Code + g++ 开发 Qt GUI 项目的完整指南
🚀 使用 VS Code g 开发 Qt GUI 项目的完整指南(Windows MSYS2) 本指南帮助你在 Windows 下使用 VS Code g CMake Qt6 快速搭建 Qt GUI 项目,适合熟悉 Visual Studio 的开发者向跨平台 VS Code 工具链迁移。 🛠️…...

arm64适配系列文章-第三章-arm64环境上mariadb的部署
ARM64适配系列文章 第一章 arm64环境上kubesphere和k8s的部署 第二章 arm64环境上nfs-subdir-external-provisioner的部署 第三章 arm64环境上mariadb的部署 第四章 arm64环境上nacos的部署 第五章 arm64环境上redis的部署 第六章 arm64环境上rabbitmq-management的部署 第七章…...

YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍 CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。 关于CPA-E…...
)
编译 C++ 报错“找不到 g++ 编译器”的终极解决方案(含 Windows/Linux/macOS)
前言 在使用终端编译 C 程序时,报错: 或类似提示,意味着你的系统尚未正确安装或配置 g 编译器。本篇将从零手把手教你在 Windows / Linux / macOS 下安装并配置 g,适用于新手或 C 入门阶段的你。 什么是 g? g 是 GN…...

Spring 过滤器详解:从基础到实战应用
Spring 过滤器详解:从基础到实战应用 引言 在 Spring 框架中,过滤器(Filter)是处理 HTTP 请求和响应的重要组件。它们为开发者提供了一种在请求到达控制器之前或响应返回客户端之前进行操作的机制。本文将深入探讨 Spring 中常见…...