YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍
CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。
关于CPA-Enhancer的详细介绍可以看论文:[2403.11220v3] CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations

Input Image│▼
[Conv + BN + ReLU](通用预处理)│├─► 分支1:多尺度卷积提取├─► 分支2:亮度补偿模块├─► 分支3:注意力增强机制(通道注意力+空间注意力)└─► 分支4:上下文结构感知(Transformer 模块等)│▼
[特征融合 + 残差连接]│▼
Enhanced Feature Map → YOLOv8 Backbone
CPA 处理图像的核心机制
1. 多尺度特征提取(Multi-Scale Extraction)
- 使用多个不同尺寸的卷积核(如 1x1, 3x3, 5x5)或金字塔结构提取局部+全局特征;
- 有效增强图像纹理信息和边缘结构;
- 防止小目标被弱特征淹没。
2. 亮度与对比度增强(Light & Contrast Enhancement)
- 模仿传统图像增强方法(如 CLAHE、Gamma 校正等)思想,但使用神经网络完成:
-
- 网络自动学习一套光照补偿策略;
- 增强图像暗部细节;
- 保留高光部分结构。
3. 上下文感知(Context-Aware Attention)
- 利用注意力机制(如 SE、CBAM、Transformer-style Attention)增强重要区域;
- 学习图像中哪些部分应该被重点关注(如前景物体、边缘);
- 抑制背景冗余信息。
4. 结构保留增强(Structure-Aware Enhancement)
- 保持图像结构(如边缘、角点)不被模糊化;
- 可能引入边缘检测或梯度引导模块,增强空间纹理信息;
- 可引入残差连接,减少特征漂移。
2.将CPA-Enhancer融合进YOLOv8
2.1 步骤一:放代码
首先找到如下的目录'ultralytics/nn',然后在这个目录下创建一个'Addmodules'文件夹,然后在这个目录下创建一个Enhancer.py文件,文件名字可以根据你自己的习惯起,然后将CPA-Enhancer的核心代码复制进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numbers
from einops import rearrange
from einops.layers.torch import Rearrange__all__ = ['CPA_arch']class RFAConv(nn.Module): # 基于Group Conv实现的RFAConvdef __init__(self, in_channel, out_channel, kernel_size=3, stride=1):super().__init__()self.kernel_size = kernel_sizeself.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1,groups=in_channel, bias=False))self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2,stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())self.conv = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size),nn.BatchNorm2d(out_channel),nn.ReLU())def forward(self, x):b, c = x.shape[0:2]weight = self.get_weight(x)h, w = weight.shape[2:]weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*kernel**2,h,w -> b c k**2 h wfeature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h,w) # b c*kernel**2,h,w -> b c k**2 h w 获得感受野空间特征weighted_data = feature * weightedconv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size,# b c k**2 h w -> b c h*k w*kn2=self.kernel_size)return self.conv(conv_data)class Downsample(nn.Module):def __init__(self, n_feat):super(Downsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelUnshuffle(2))def forward(self, x):return self.body(x)class Upsample(nn.Module):def __init__(self, n_feat):super(Upsample, self).__init__()self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat * 2, kernel_size=3, stride=1, padding=1, bias=False),nn.PixelShuffle(2))def forward(self, x): # (b,c,h,w)return self.body(x) # (b,c/2,h*2,w*2)class SpatialAttention(nn.Module):def __init__(self):super(SpatialAttention, self).__init__()self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect', bias=True)def forward(self, x): # x:[b,c,h,w]x_avg = torch.mean(x, dim=1, keepdim=True) # (b,1,h,w)x_max, _ = torch.max(x, dim=1, keepdim=True) # (b,1,h,w)x2 = torch.concat([x_avg, x_max], dim=1) # (b,2,h,w)sattn = self.sa(x2) # 7x7conv (b,1,h,w)return sattn * xclass ChannelAttention(nn.Module):def __init__(self, dim, reduction=8):super(ChannelAttention, self).__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.ca = nn.Sequential(nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True), # Relunn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True),)def forward(self, x): # x:[b,c,h,w]x_gap = self.gap(x) # [b,c,1,1]cattn = self.ca(x_gap) # [b,c,1,1]return cattn * xclass Channel_Shuffle(nn.Module):def __init__(self, num_groups):super(Channel_Shuffle, self).__init__()self.num_groups = num_groupsdef forward(self, x):batch_size, chs, h, w = x.shapechs_per_group = chs // self.num_groupsx = torch.reshape(x, (batch_size, self.num_groups, chs_per_group, h, w))# (batch_size, num_groups, chs_per_group, h, w)x = x.transpose(1, 2) # dim_1 and dim_2out = torch.reshape(x, (batch_size, -1, h, w))return outclass TransformerBlock(nn.Module):def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):super(TransformerBlock, self).__init__()self.norm1 = LayerNorm(dim, LayerNorm_type)self.attn = Attention(dim, num_heads, bias)self.norm2 = LayerNorm(dim, LayerNorm_type)self.ffn = FeedForward(dim, ffn_expansion_factor, bias)def forward(self, x):x = x + self.attn(self.norm1(x))x = x + self.ffn(self.norm2(x))return xdef to_3d(x):return rearrange(x, 'b c h w -> b (h w) c')def to_4d(x, h, w):return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)class BiasFree_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(BiasFree_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):sigma = x.var(-1, keepdim=True, unbiased=False)return x / torch.sqrt(sigma + 1e-5) * self.weightclass WithBias_LayerNorm(nn.Module):def __init__(self, normalized_shape):super(WithBias_LayerNorm, self).__init__()if isinstance(normalized_shape, numbers.Integral):normalized_shape = (normalized_shape,)normalized_shape = torch.Size(normalized_shape)assert len(normalized_shape) == 1self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):device = x.devicemu = x.mean(-1, keepdim=True)sigma = x.var(-1, keepdim=True, unbiased=False)result = (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight.to(device) + self.bias.to(device)return resultclass LayerNorm(nn.Module):def __init__(self, dim, LayerNorm_type):super(LayerNorm, self).__init__()if LayerNorm_type == 'BiasFree':self.body = BiasFree_LayerNorm(dim)else:self.body = WithBias_LayerNorm(dim)def forward(self, x):h, w = x.shape[-2:]return to_4d(self.body(to_3d(x)), h, w)class FeedForward(nn.Module):def __init__(self, dim, ffn_expansion_factor, bias):super(FeedForward, self).__init__()hidden_features = int(dim * ffn_expansion_factor)self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,groups=hidden_features * 2, bias=bias)self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)def forward(self, x):device = x.deviceself.project_in = self.project_in.to(device)self.dwconv = self.dwconv.to(device)self.project_out = self.project_out.to(device)x = self.project_in(x)x1, x2 = self.dwconv(x).chunk(2, dim=1)x = F.gelu(x1) * x2x = self.project_out(x)return xclass Attention(nn.Module):def __init__(self, dim, num_heads, bias):super(Attention, self).__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1, dtype=torch.float32), requires_grad=True)self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3,bias=bias)self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)def forward(self, x):b, c, h, w = x.shapedevice = x.deviceself.qkv = self.qkv.to(device)self.qkv_dwconv = self.qkv_dwconv.to(device)self.project_out = self.project_out.to(device)qkv = self.qkv(x)qkv = self.qkv_dwconv(qkv)q, k, v = qkv.chunk(3, dim=1)q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperature.to(device)attn = attn.softmax(dim=-1)out = (attn @ v)out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)out = self.project_out(out)return outclass resblock(nn.Module):def __init__(self, dim):super(resblock, self).__init__()# self.norm = LayerNorm(dim, LayerNorm_type='BiasFree')self.body = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False),nn.PReLU(),nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=False))def forward(self, x):res = self.body((x))res += xreturn res#########################################################################
# Chain-of-Thought Prompt Generation Module (CGM)
class CotPromptParaGen(nn.Module):def __init__(self,prompt_inch,prompt_size, num_path=3):super(CotPromptParaGen, self).__init__()# (128,32,32)->(64,64,64)->(32,128,128)self.chain_prompts=nn.ModuleList([nn.ConvTranspose2d(in_channels=prompt_inch if idx==0 else prompt_inch//(2**idx),out_channels=prompt_inch//(2**(idx+1)),kernel_size=3, stride=2, padding=1) for idx in range(num_path)])def forward(self,x):prompt_params = []prompt_params.append(x)for pe in self.chain_prompts:x=pe(x)prompt_params.append(x)return prompt_params#########################################################################
# Content-driven Prompt Block (CPB)
class ContentDrivenPromptBlock(nn.Module):def __init__(self, dim, prompt_dim, reduction=8, num_splits=4):super(ContentDrivenPromptBlock, self).__init__()self.dim = dimself.num_splits = num_splitsself.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect', groups=dim, bias=True)self.sigmoid = nn.Sigmoid()self.conv3x3 = nn.Conv2d(prompt_dim, prompt_dim, kernel_size=3, stride=1, padding=1, bias=False)self.conv1x1 = nn.Conv2d(dim, prompt_dim, kernel_size=1, stride=1, bias=False)self.sa = SpatialAttention()self.ca = ChannelAttention(dim, reduction)self.myshuffle = Channel_Shuffle(2)self.out_conv1 = nn.Conv2d(prompt_dim + dim, dim, kernel_size=1, stride=1, bias=False)self.transformer_block = [TransformerBlock(dim=dim // num_splits, num_heads=1, ffn_expansion_factor=2.66, bias=False,LayerNorm_type='WithBias') for _ in range(num_splits)]def forward(self, x, prompt_param):# latent: (b,dim*8,h/8,w/8) prompt_param3: (1, 256, 16, 16)x_ = xB, C, H, W = x.shapecattn = self.ca(x) # channel-wise attnsattn = self.sa(x) # spatial-wise attnpattn1 = sattn + cattnpattn1 = pattn1.unsqueeze(dim=2) # [b,c,1,h,w]x = x.unsqueeze(dim=2) # [b,c,1,h,w]x2 = torch.cat([x, pattn1], dim=2) # [b,c,2,h,w]x2 = Rearrange('b c t h w -> b (c t) h w')(x2) # [b,c*2,h,w]x2 = self.myshuffle(x2) # [c1,c1_att,c2,c2_att,...]pattn2 = self.pa2(x2)pattn2 = self.conv1x1(pattn2) # [b,prompt_dim,h,w]prompt_weight = self.sigmoid(pattn2) # Sigmodprompt_param = F.interpolate(prompt_param, (H, W), mode="bilinear")# (b,prompt_dim,prompt_size,prompt_size) -> (b,prompt_dim,h,w)prompt = prompt_weight * prompt_paramprompt = self.conv3x3(prompt) # (b,prompt_dim,h,w)inter_x = torch.cat([x_, prompt], dim=1) # (b,prompt_dim+dim,h,w)inter_x = self.out_conv1(inter_x) # (b,dim,h,w) dim=64splits = torch.split(inter_x, self.dim // self.num_splits, dim=1)transformered_splits = []for i, split in enumerate(splits):transformered_split = self.transformer_block[i](split)transformered_splits.append(transformered_split)result = torch.cat(transformered_splits, dim=1)return result#########################################################################
# CPA_Enhancer
class CPA_arch(nn.Module):def __init__(self, c_in=3, c_out=3, dim=4, prompt_inch=128, prompt_size=32):super(CPA_arch, self).__init__()self.conv0 = RFAConv(c_in, dim)self.conv1 = RFAConv(dim, dim)self.conv2 = RFAConv(dim * 2, dim * 2)self.conv3 = RFAConv(dim * 4, dim * 4)self.conv4 = RFAConv(dim * 8, dim * 8)self.conv5 = RFAConv(dim * 8, dim * 4)self.conv6 = RFAConv(dim * 4, dim * 2)self.conv7 = RFAConv(dim * 2, c_out)self.down1 = Downsample(dim)self.down2 = Downsample(dim * 2)self.down3 = Downsample(dim * 4)self.prompt_param_ini = nn.Parameter(torch.rand(1, prompt_inch, prompt_size, prompt_size)) # (b,c,h,w)self.myPromptParamGen = CotPromptParaGen(prompt_inch=prompt_inch,prompt_size=prompt_size)self.prompt1 = ContentDrivenPromptBlock(dim=dim * 2 ** 1, prompt_dim=prompt_inch // 4, reduction=8) # !!!!self.prompt2 = ContentDrivenPromptBlock(dim=dim * 2 ** 2, prompt_dim=prompt_inch // 2, reduction=8)self.prompt3 = ContentDrivenPromptBlock(dim=dim * 2 ** 3, prompt_dim=prompt_inch , reduction=8)self.up3 = Upsample(dim * 8)self.up2 = Upsample(dim * 4)self.up1 = Upsample(dim * 2)def forward(self, x): # (b,c_in,h,w)prompt_params = self.myPromptParamGen(self.prompt_param_ini)prompt_param1 = prompt_params[2] # [1, 64, 64, 64]prompt_param2 = prompt_params[1] # [1, 128, 32, 32]prompt_param3 = prompt_params[0] # [1, 256, 16, 16]x0 = self.conv0(x) # (b,dim,h,w)x1 = self.conv1(x0) # (b,dim,h,w)x1_down = self.down1(x1) # (b,dim,h/2,w/2)x2 = self.conv2(x1_down) # (b,dim,h/2,w/2)x2_down = self.down2(x2)x3 = self.conv3(x2_down)x3_down = self.down3(x3)x4 = self.conv4(x3_down)device = x4.deviceself.prompt1 = self.prompt1.to(device)self.prompt2 = self.prompt2.to(device)self.prompt3 = self.prompt3.to(device)x4_prompt = self.prompt3(x4, prompt_param3)x3_up = self.up3(x4_prompt)x5 = self.conv5(torch.cat([x3_up, x3], 1))x5_prompt = self.prompt2(x5, prompt_param2)x2_up = self.up2(x5_prompt)x2_cat = torch.cat([x2_up, x2], 1)x6 = self.conv6(x2_cat)x6_prompt = self.prompt1(x6, prompt_param1)x1_up = self.up1(x6_prompt)x7 = self.conv7(torch.cat([x1_up, x1], 1))return x7if __name__ == "__main__":# Generating Sample imageimage_size = (1, 3, 640, 640)image = torch.rand(*image_size)out = CPA_arch(3, 3, 4)out = out(image)print(out.size())2.2 步骤二:告诉 YOLOv8 有新东西
在Addmodules下创建一个新的py文件名字为'__init__.py',然后在其内部添加如下代码

2.3 步骤三:让 YOLOv8 认识新工具
在task.py进行导入
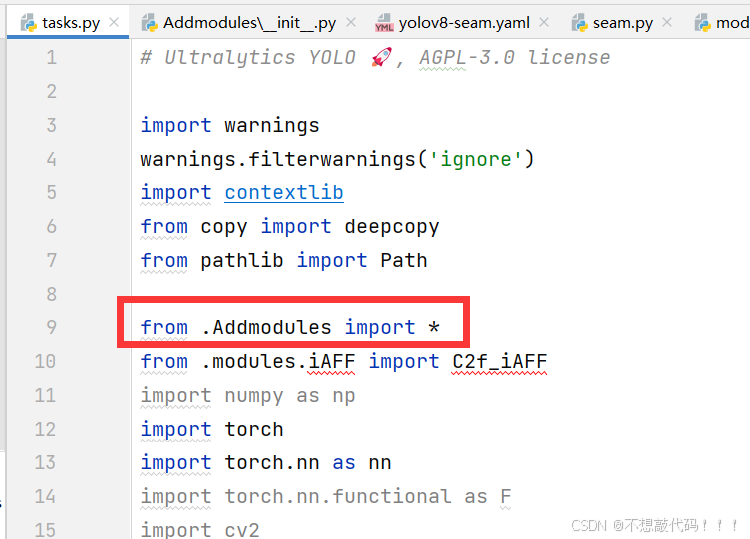
到此注册成功
2.4 步骤四:改 YOLOv8 的“说明书”
复制后面的yaml文件直接运行即可
yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, CPA_arch, []] # 0-P1/2- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 8-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 10# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 7], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 5], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)相关文章:

YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍 CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。 关于CPA-E…...
)
编译 C++ 报错“找不到 g++ 编译器”的终极解决方案(含 Windows/Linux/macOS)
前言 在使用终端编译 C 程序时,报错: 或类似提示,意味着你的系统尚未正确安装或配置 g 编译器。本篇将从零手把手教你在 Windows / Linux / macOS 下安装并配置 g,适用于新手或 C 入门阶段的你。 什么是 g? g 是 GN…...

Spring 过滤器详解:从基础到实战应用
Spring 过滤器详解:从基础到实战应用 引言 在 Spring 框架中,过滤器(Filter)是处理 HTTP 请求和响应的重要组件。它们为开发者提供了一种在请求到达控制器之前或响应返回客户端之前进行操作的机制。本文将深入探讨 Spring 中常见…...

达梦并行收集统计信息
达梦收集统计信息速度如何? 答:1分钟1G 大库收集起来可能比较慢,想并行收集需要一些条件 3个参数先了解一下 我把max_parallel_degree改为16 相关说明可以看一下 对一个3G的表收集 收集方法 DBMS_STATS.GATHER_TABLE_STATS( TEST,T1,…...

AOSP CachedAppOptimizer 冻结方案
背景 Android 一直面临一个核心难题:如何优化进程对有限系统资源(如 CPU、电量)的使用,同时保证用户体验。 当进程进入后台后,它们虽不再贡献用户体验,却仍可能消耗资源。传统的杀后台方案虽然节省资源&a…...

JVM-类加载机制
类加载 前言:为什么需要了解类加载?什么是类加载?生命周期概览类加载过程详解3.1 加载 (Loading)3.2 连接 (Linking)3.2.1 验证 (Verification)3.2.2 准备 (Preparation)3.2.3 解析 (Resolution) 3.3 初始化 (Initialization)3.3.1 <clini…...

【小白福音】SFTP限制权限登录
下面以在 Linux 环境(例如 Ubuntu 或 CentOS)上配置 SFTP chroot 为例,给出详细的步骤说明。即使你不熟悉服务器运维,也可以按照以下步骤进行配置,保证指定的 SFTP 用户只能访问预设目录,而无法触碰其他文件。 目录 一、配置SFTP权限1. 创建专用 SFTP 用户和用户组2. 搭建…...

海量数据笔试题--Top K 高频词汇统计
问题描述: 假设你有一个非常大的文本文件(例如,100GB),文件内容是按行存储的单词(或其他字符串,如 URL、搜索查询词等),单词之间可能由空格或换行符分隔。由于文件巨大&…...

Postman设置环境变量与Token
设置环境变量 设置某个Collection下的变量...

项目中数据结构为什么用数组,不用List
总结 1,从内存和性能角度,数组占用更小的内存(),访问性能更高() 分配效率:数组在内存中是连续分配的一块固定空间 访问速度:直接操作内存,数组的读写操作是…...
)
Linux常见指令介绍下(入门级)
1. head head就和他的名字一样,是显示一个文件头部的内容(会自动排序),默认是打印前10行。 语法:head [参数] [文件] 选项: -n [x] 显示前x行。 2. tail tail 命令从指定点开始将文件写到标准输出.使用t…...

从Kafka读取数据
用Spark-Streaming从Kafka读取数据 在大数据处理领域,Spark-Streaming和Kafka都是明星技术。今天咱们就来聊聊怎么用Spark-Streaming从Kafka读取数据并做处理,就算你是小白,也保证能看懂!先讲讲从Kafka获取数据的两种方式。早期有…...
)
硬件工程师面试常见问题(7)
第三十一问:RTC电路,电池寿命估算 上图可知,该电路有两个供电一个是电池供电,一个是其他供电,已知电池大小为120mAh,该电路在电池供电下吃3uA的电流,计算 120*(10^3)/ 3…...

二分小专题
P1102 A-B 数对 P1102 A-B 数对 暴力枚举还是很好做的,直接上双层循环OK 二分思路:查找边界情况,找出最大下标和最小下标,两者相减1即为答案所求 废话不多说,上代码 //暴力O(n^3) 72pts // #include<bits/stdc.h> // usin…...

Explain详解与索引最佳实践
Explain工具介绍 使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL 注意…...
)
【Qt6 QML Book 基础】07:布局项 —— 锚定布局与动态交互(附完整可运行代码)
引言 在 QML 界面开发中,** 锚定布局(Anchors)** 是实现响应式设计的核心机制。通过声明式的锚定规则,开发者无需手动计算坐标,即可让元素与父容器或其他元素保持动态位置关联。本文结合官方示例,详细解析…...
(纯命令))
rocky9.4部署k8s群集v1.28.2版本(containerd)(纯命令)
文章目录 前言三个节点的主机名 所有节点操作主机名和ip解析关闭交换分区,关闭防火墙,关闭selinux更换阿里云yum源时间同步修改内核参数修改系统最大打开文件数开启bridge网桥过滤,加载br_netfilter模块,加载配置文件安装ipset及i…...
)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使) 简介 Crawl4AI 的介绍 一、Crawl4AI 的核心功能 二、Crawl4AI vs Firecrawl Crawl4AI 的本地部署 一、前期准备 二、部署步骤 1、检查系统的网络环境 2、下载 Crawl4AI 源…...

onlyoffice8.3.3发布了-豆豆容器市场同步更新ARM64版本
8.3.3 修复内容 文档编辑器 • 修复从右到左(RTL)段落的计算问题 (DocumentServer#2590) • 修复从右到左段落中"项目符号/编号/多级列表"样式缩略图的显示问题 • 修复从右到左段落中编号列表(项目符号)的显示问题 (…...

rabbitmq安装项目集成
使用Docker来安装 1.1.下载镜像 docker pull rabbitmq:3-management 1.2.安装MQ docker run \-e RABBITMQ_DEFAULT_USER=root \-e RABBITMQ_DEFAULT_PASS=123123 \--name mq \--hostname mq1 \-p 15672:15672 \-p 5672:5672 \-d \rabbitmq:3-management 15672:RabbitMQ提供…...

济南国网数字化培训班学习笔记-第二组-3节-电网工程建设项目部门
电网工程建设项目部 组成 监理项目部 履行监理合同,监理单位派驻:负责合同管理,审查,见证,旁站,巡视,验收,控制进度,安全,质量,协调各方 造价…...
安装及配置 --- app笔记)
JDK(java)安装及配置 --- app笔记
JDK官方下载地址:Java Downloads | Oracle 安装好后,配置 “环境变量”: 新建JAVA_HOME变量,值为 jdk 安装 根目录(C:\Program Files\Java\jdk-24) 在path变量最后面,添加 %JAVA_HOME% 新建 CLA…...

【前端】【面试】在前端开发中,如何优化 CSS 以提升页面渲染性能?
题目:在前端开发中,如何优化 CSS 以提升页面渲染性能? 关键词总结 关键词说明选择器优化避免通配符、减少层级深度、防止后代选择器过度嵌套样式规则优化合并重复规则、慎用高成本属性加载与渲染优化关键 CSS 优先加载、合理使用媒体查询文…...

python的mtcnn检测图片中的人脸并标框
python的mtcnn检测图片中的人脸并标框,标记鼻尖位置 import cv2 from mtcnn import MTCNN# 初始化 MTCNN 检测器 # stages:指定检测阶段 # 指定运行设备为CPU detector MTCNN(stages"face_and_landmarks_detection", device"CPU:0"…...

矩阵系统源码搭建账号分组功能开发全流程解析,支持OEM
在短视频矩阵运营场景下,企业和创作者往往管理着数十甚至上百个不同平台的账号,传统的统一管理模式效率低下,难以满足精细化运营需求。矩阵系统的账号分组功能通过对账号进行分类整合,实现差异化管理与精准化操作。本文将从功能需…...

跟着deepseek学golang--认识golang
文章目录 一、Golang核心优势1. 极简部署方式生产案例:依赖管理:容器实践: 2. 静态类型系统类型安全示例:性能优势:代码重构: 3. 语言级并发支持GMP调度模型实例&…...

如何创建极狐GitLab 议题?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 创建议题 (BASIC ALL) 创建议题时,系统会提示您输入议题的字段。 如果您知道要分配给议题的值,则可…...

制造工厂如何借助电子看板实现高效生产管控
在当今高度竞争的制造业环境中,许多企业正面临着严峻的管理和生产挑战。首先,管理流程落后,大量工作仍依赖"人治"方式,高层管理者理论知识薄弱且不愿听取专业意见。其次,生产过程控制能力不足,导…...

QLExpress 深度解析:构建动态规则引擎的利器
QLExpress 深度解析:构建动态规则引擎的利器 在现代业务系统中,“规则变更快、逻辑复杂、发布要求高”已成为常态。传统硬编码已无法满足这种需求。本文以阿里巴巴开源的轻量级表达式引擎 QLExpress 为例,从实际应用、核心结构到落地建议,系统解析其强大能力和设计哲学。 …...

Java Thread类深度解析:构造方法与核心方法全攻略
一、Thread类的作用与线程模型 Thread类是Java多线程编程的核心,每个线程都与一个唯一的Thread对象关联。JVM通过Thread对象管理线程的整个生命周期。理解以下核心概念至关重要: 任务定义:通过run()方法描述线程要执行的任务 线程创建&…...

nodejs导入文件模块和导入文件夹
在 Node.js 中,导入文件模块和导入文件夹的方式略有不同,但都很常见。下面是详细说明: ✅ 一、导入文件模块 1. CommonJS(.js)方式: // 假设有个模块文件叫 utils.js const utils require(./utils); // …...

信息系统项目管理工程师备考计算类真题讲解八
一、风险管理 示例1:EMV 解析:EMV(Expected Monetary Value)预期货币价值。一种定量风险分析技术。通过考虑各种风险事件的概率及其可能带来的货币影响,来计算项目的预期价值。 可以用下面的较长进行表示: 水路的EMV:7000*3/4(7…...

UML 活动图深度解析:以在线购物系统为例
目录 一、UML 活动图的基本构成要素 二、题目原型 三、在线购物系统用户购物活动图详细剖析 (一)概述 (二)节点分析 三、注意事项 四、活动图绘画 五、UML 活动图在软件开发中的关键价值 六、总结 在软件开发与系统设计领…...

Redis--预备知识以及String类型
目录 一、预备知识 1.1 基本全局命令 1.1.1 KEYS 1.1.2 EXISTS 1.1.3 DEL 1.1.4 EXPIRE 1.1.5 TTL 1.1.6 TYPE 1.2 数据结构以及内部编码 1.3 单线程架构 二、String字符串 2.1 常见命令 2.1.1 SET 2.1.2 GET 2.1.3 MGET 2.1.4 MSET 2.1.5 SETNX 2.2 计数命令 2.2.1 INCR 2.2.2…...

电子削铅笔刀顺序图详解:从UML设计到PlantUML实现
题目:为电子削铅笔刀建立一个顺序图和一个通信图。图中的对象包括操作者、铅笔、插入点(也就是铅笔插入铅笔刀的位置)、马达和其他元素。包括哪些交互消息?有那些激活?如何在图中表示出自身调用。 一、顺序图概述 顺序图(Sequence Diagram)…...

负环-P3385-P2136
通过选择标签,洛谷刷一个类型的题目还是很方便的 模版题P3385 P3385 【模板】负环 - 洛谷 Tint(input())def bellman(n,edges,sta):INFfloat(inf)d[INF]*(n1)d[sta]0for i in range(n-1):for u,v,w in edges:ncostd[u]wif ncost<d[v]:d[v]ncostfor u,v,w in e…...

《数据结构之美--栈和队列》
一:引言: 上次我们学习了双向链表的实现,这次我们来学习两个新的数据结构,因为比较简单,就放在一块学习。 二:栈的实现 1. 栈的结构与性质 只凭文字来描述的话不够生动,下面我们就以图画的形…...

如何彻底卸载Android Studio?
要彻底卸载 Android Studio,需要分别在不同操作系统上进行不同的操作,以下为你详细介绍: Windows 系统 卸载主程序 通过 “开始” 菜单,打开 “设置”,选择 “应用”。在应用列表中找到 “Android Studio”ÿ…...

乐聚机器人与地瓜机器人达成战略合作,联合发布Aelos Embodied具身智能
要闻 4月19日,在CCF人形机器人与人工智能技术巡回研讨会(武汉站)上,乐聚机器人与地瓜机器人达成战略合作,双方将基于RDK X5、RDK S100以及更高性能的国产大算力平台,就夸父(KUAVO)、…...
)
[MERN 项目实战] MERN Multi-Vendor 电商平台开发笔记(v2.0 从 bug 到结构优化的工程记录)
[MERN 项目实战] MERN Multi-Vendor 电商平台开发笔记(v2.0 从 bug 到结构优化的工程记录) 其实之前没想着这么快就能把 2.0 的笔记写出来的,之前的预期是,下一个阶段会一直维持到将 MERN 项目写完,毕竟后期很多东西都…...

KS卡片铃铛知多少,春花秋月何时了
废话不多说,直接上干活 卡片随意跳转技术 可以私信卡片,也可以群发卡片,丝毫不影响使用 铃铛跳转实例 需要一定要找我哦:qmfy01...

SQL 语法
好的,下面是对 SQL 语法的简洁总结,涵盖了常见的 SQL 操作和基本语法结构。 创建一个表 (CREATE TABLE) 首先,我们需要创建一个表 users,如果还没有的话: CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100)…...

《ATPL地面培训教材13:飞行原理》——第1章:概述与定义
翻译:刘远贺;辅助工具:Cluade 3.7 第1章:概述与定义 目录 概述一般定义术语表符号列表希腊符号其他自我评估问题答案 概述 飞机的基本要求如下: 机翼产生升力; 机身容纳载荷; 尾部表面增加…...

https nginx 负载均衡配置
我的系统是OpenEuler。 安装nginx yum install -y nginx 启动&开机启动 systemctl start nginx systemctl enable nginx 自定义conf配置文件 cat <<EOF >> /etc/nginx/conf.d/load_balancer.conf upstream backend {ip_hash; # 防止验证码验证失败server…...

初始https附带c/c++源码使用curl库调用
使用C与CURL开发HTTPS客户端的深度指南 目录 准备工作基础HTTPS请求实现核心功能扩展进阶配置与优化安全注意事项调试与问题排查跨平台适配要点 一、准备工作 1.1 cURL库简介 cURL(Client URL Request Library)是一个支持多种网络协议的开源库&…...

NI Multisim官网下载: 电路设计自动化EDA仿真软件
NI Multisim是一款由美国国家仪器公司(National Instruments,简称 NI)推出的电路设计与仿真软件,广泛应用于工程教育、电子电路开发和科研领域。它结合了图形化的电路绘图界面与强大的 SPICE 仿真引擎,让用户可以在虚拟…...

通过阿里云Milvus与通义千问VL大模型,快速实现多模态搜索
本文主要演示了如何使用阿里云向量检索服务Milvus版与通义千问VL大模型,提取图片特征,并使用多模态Embedding模型,快速实现多模态搜索。 基于灵积(Dashscope)模型服务上的通义千问 API以及Embedding API来接入图片、文…...

React 与 Vue:两大前端框架的深度对比
在前端开发领域,React 和 Vue 无疑是当下最受欢迎的两大框架。它们各自拥有独特的优势和特点,吸引了大量开发者。无论是初学者还是经验丰富的工程师,选择 React 还是 Vue 都是一个常见的问题。本文将从多个角度对 React 和 Vue 进行对比&…...

OpenFeign和Gateway
OpenFeign和Gateway 一.OpenFeign介绍二.快速上手1.引入依赖2.开启openfeign的功能3.编写客户端4.修改远程调用代码5.测试 三.OpenFeign参数传递1.传递单个参数2.多个参数、传递对象和传递JSON字符串3.最佳方式写代码继承的方式抽取的方式 四.部署OpenFeign五.统一服务入口-Gat…...

openwrt作旁路由时的几个常见问题 openwrt作为旁路由配置zerotier 图文讲解
1 先看openwrt时间,一定要保证时间和浏览器和服务器是一致的,不然无法更新 2 openwrt设置旁路由前先测试下,路由器能否ping通主路由,是否能够连接外网,好多旁路由设置完了,发现还不能远程好多就是旁路由本…...