【Redis】 Redis中常见的数据类型(二)
文章目录
- 前言
- 一、 List 列表
- 1. List 列表简介
- 2.命令
- 3. 阻塞版本命令
- 4. 内部编码
- 5. 使用场景
- 二、Set 集合
- 1. Set简单介绍
- 2. 普通命令
- 3 . 集合间操作
- 4. 内部编码
- 5. 使用场景
- 三、Zset 有序集合
- 1.Zset 有序集合简介
- 2. 普通命令
- 3. 集合间操作
- 4. 内部编码
- 5. 使用场景
- 结语

前言
在Redis中常见的数据类型(一)中,为大家介绍了redis中的String字符串以及哈希表两种数据结构,接下来本文将延续上文,接着介绍redis中的常见数据类型
一、 List 列表
1. List 列表简介
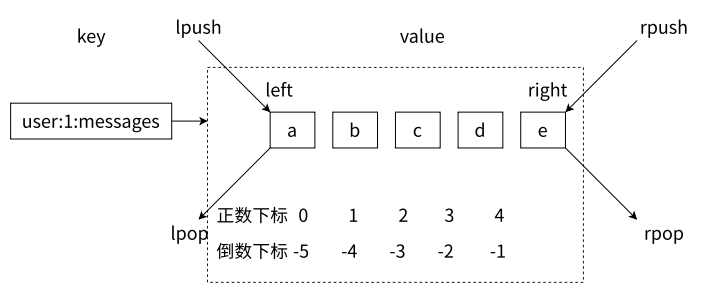
列表类型是用来存储多个有序的字符串,如下图所示,a、b、c、d、e 五个元素从左到右组成 了一个有序的列表,列表中的每个字符串称为元素(element),⼀个列表最多可以存储个元素。在 Redis 中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、 获取指定索引下标的元素等(见下图)。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
列表两端插入和弹出操作:
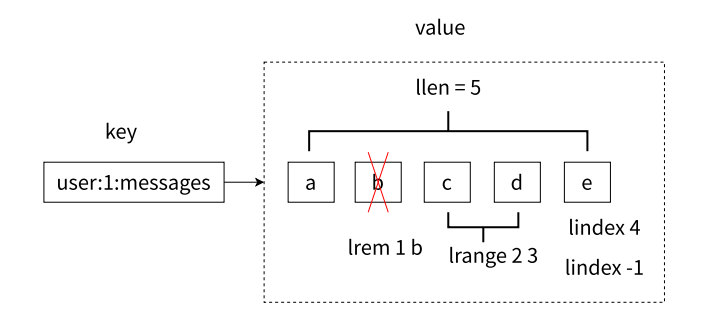
列表的获取、删除等操作
列表类型的特点:
第⼀、列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表, 例如要获取上图的第 5 个元素,可以执行 lindex user:1:messages 4 或者倒数第 1 个元素,lindexuser:1:messages -1 就可以得到元素 e。
第二、区分获取和删除的区别,例如图 2-20 中的 lrem 1 b 是从列表中把从左数遇到的前 1 个 b 元素删除,这个操作会导致列表的长度从 5 变成 4;但是执行 lindex 4 只会获取元素,但列表长度是不会变化 的。
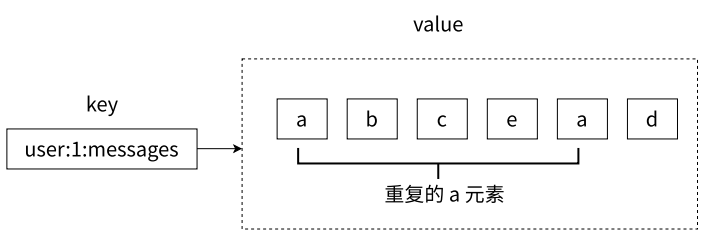
第三、列表中的元素是允许重复的,例如下图中的列表中是包含了两个 a 元素的。
列表中允许有重复元素
2.命令
LPUSH
将⼀个或者多个元素从左侧放入(头插)到 list 中
语法:
LPUSH key element [element ...]
时间复杂度:只插入一个元素为 O(1), 插⼊多个元素为 O(N), N 为插⼊元素个数.
返回值:插入后 list 的长度
示例:
redis> LPUSH mylist "world"
(integer) 1
redis> LPUSH mylist "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "world
LPUSHX
在 key 存在时,将⼀个或者多个元素从左侧放⼊(头插)到 list 中。不存在,直接返回
语法:
LPUSHX key element [element ...]
时间复杂度:只插入⼀个元素为 O(1), 插入多个元素为 O(N), N 为插入元素个数.
返回值:插入后 list 的长度。
示例:
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSHX mylist "Hello"
(integer) 2
redis> LPUSHX myotherlist "Hello"
(integer) 0
redis> LRANGE mylist 0 -1
1) "Hello"
2) "World"
redis> LRANGE myotherlist 0 -1
(empty array)
RPUSH
将⼀个或者多个元素从右侧放入(尾插)到 list 中。
语法:
RPUSH key element [element ...
时间复杂度:只插入⼀个元素为 O(1), 插入多个元素为 O(N), N 为插入元素个数.
返回值:插入后 list 的长度。
示例:
redis> RPUSH mylist "world"
(integer) 1
redis> RPUSH mylist "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "world"
2) "hello"
RPUSHX
在 key 存在时,将⼀个或者多个元素从右侧放⼊(尾插)到 list 中。
语法:
RPUSHX key element [element ...]
时间复杂度:只插入⼀个元素为 O(1), 插入多个元素为 O(N), N 为插入元素个数.
返回值:插入后 list 的长度。
示例:
redis> RPUSH mylist "World"
(integer) 1
redis> RPUSHX mylist "Hello"
(integer) 2
redis> RPUSHX myotherlist "Hello"
(integer) 0
redis> LRANGE mylist 0 -1
1) "World"
2) "Hello"
redis> LRANGE myotherlist 0 -1
(empty array)
LRANGE
获取从 start 到 end 区间的所有元素,左闭右闭。
语法:
LRANGE key start stop
时间复杂度:O(N)
返回值:指定区间的元素。
示例:
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LRANGE mylist 0 0
1) "one"
redis> LRANGE mylist -3 2
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist -100 100
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist 5 10
(empty array)
LPOP
从 list 左侧取出元素(即头删)。
语法:
LPOP key
时间复杂度:O(1)
返回值:取出的元素或者 nil。
示例:
redis> RPUSH mylist "one" "two" "three" "four" "five"
(integer) 5
redis> LPOP mylist
"one"
redis> LPOP mylist
"two"
redis> LPOP mylist
"three"
redis> LRANGE mylist 0 -1
1) "four"
2) "five"
RPOP
从 list 右侧取出元素(即尾删)
语法:
RPOP key
时间复杂度:O(1)
返回值:取出的元素或者 nil。
示例:
redis> RPUSH mylist "one" "two" "three" "four" "five"
(integer) 5
redis> RPOP mylist
"five"
redis> LRANGE mylist 0 -1
1) "one"
2) "two"
3) "three"
4) "four"
LINDEX
获取从左数第 index 位置的元素。
语法:
LINDEX key index
时间复杂度:O(N)
返回值:取出的元素或者 nil。
示例:
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LINDEX mylist 0
"Hello"
redis> LINDEX mylist -1
"World"
redis> LINDEX mylist 3
(nil)
LINSERT
在特定位置插入元素。
语法:
LINSERT key <BEFORE | AFTER> pivot element
时间复杂度:O(N)
返回值:插⼊后的 list 长度。
示例:
redis> RPUSH mylist "Hello"
(integer) 1
redis> RPUSH mylist "World"
(integer) 2
redis> LINSERT mylist BEFORE "World" "There"
(integer) 3
redis> LRANGE mylist 0 -1
1) "Hello"
2) "There"
3) "World
LLEN
获取 list 长度。
语法:
LLEN key
时间复杂度:O(1)
返回值:list 的长度。
示例:
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LLEN mylist
(integer) 2
3. 阻塞版本命令
blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作用基本⼀致,除了:
• 在列表中有元素的情况下,阻塞和非阻塞表现是⼀致的。但如果列表中没有元素,非阻塞版本会理解返回 nil,但阻塞版本会根据 timeout,阻塞⼀段时间,期间 Redis 可以执行其他命令,但要求执行该命令的客户端会表现为阻塞状态。(如下图所示)
• 命令中如果设置了多个键,那么会从左向右进行遍历键,一旦有⼀个键对应的列表中可以弹出元素,命令立即返回。
• 如果多个客户端同时多⼀个键执行pop,则最先执行命令的客户端会得到弹出的元素。
阻塞版本的 blpop 和非阻塞版本 lpop 的区别:
列表不为空时:
lpop user:1:messages 得到 x 元素
blpop user:1:messages 得到 x 元素
两者行为⼀致
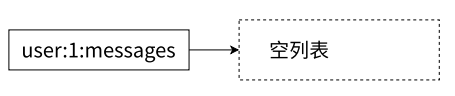
列表不为空时,且 5 秒内没有新元素加入:
lpop user:1:messages 立即得到 nil
blpop user:1:messages 5 执行命令 5 秒后得到 nil
两者行为不一致
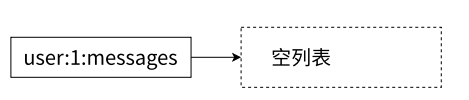
列表不为空时,且 5 秒内有新元素加⼊:
lpop user:1:messages 立即得到 nil
blpop user:1:messages 5 执行命令,直到新元素加入,得到新元素
两者行为不⼀致
BLPOP
LPOP 的阻塞版本。
语法:
BLPOP key [key ...] timeout
时间复杂度:O(1)
返回值:取出的元素或者 nil。
示例:
redis> EXISTS list1 list2
(integer) 0
redis> RPUSH list1 a b c
(integer) 3
redis> BLPOP list1 list2 0
1) "list1"
2) "a"
BRPOP
RPOP 的阻塞版本。
语法:
BRPOP key [key ...] timeout
时间复杂度:O(1)
返回值:取出的元素或者 nil。
示例:
redis> DEL list1 list2
(integer) 0
redis> RPUSH list1 a b c
(integer) 3
redis> BRPOP list1 list2 0
1) "list1"
2) "c"
4. 内部编码
列表类型的内部编码有两种:
• ziplist(压缩列表):当列表的元素个数小于 list-max-ziplist-entries 配置(默认 512 个),同时 列表中每个元素的长度都小于 list-max-ziplist-value 配置(默认 64 字节)时,Redis 会选用ziplist 来作为列表的内部编码实现来减少内存消耗。
• linkedlist(链表):当列表类型无法满足 ziplist 的条件时,Redis 会使用linkedlist 作为列表的内部实现。
1)当元素个数较少且没有大元素时,内部编码为 ziplist:
127.0.0.1:6379> rpush listkey e1 e2 e3
OK
127.0.0.1:6379> object encoding listkey
"ziplist"
2)当元素个数超过 512 时,内部编码为 linkedlist:
127.0.0.1:6379> rpush listkey e1 e2 e3 ... 省略 e512 e513
OK
127.0.0.1:6379> object encoding listkey
"linkedlist"
3)当某个元素的长度超过 64 字节时,内部编码为 linkedlist:
127.0.0.1:6379> rpush listkey "one string is bigger than 64 bytes ... 省略 ..."
OK
127.0.0.1:6379> object encoding listkey
"linkedlist"
5. 使用场景
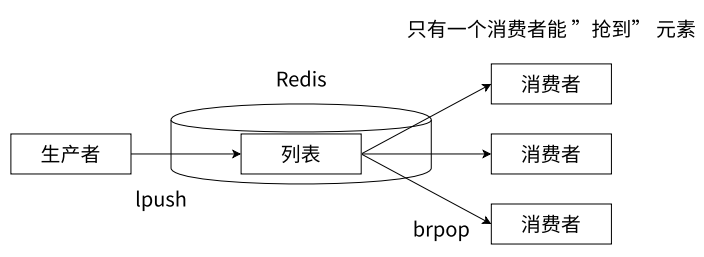
消息队列
如下图所示,Redis 可以使用 lpush + brpop 命令组合实现经典的阻塞式生产者-消费者模型队列, 生产者客户端使用 lpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式地从队列中 “争抢” 队首元素。通过多个客户端来保证消费的负载均衡和高可用性。
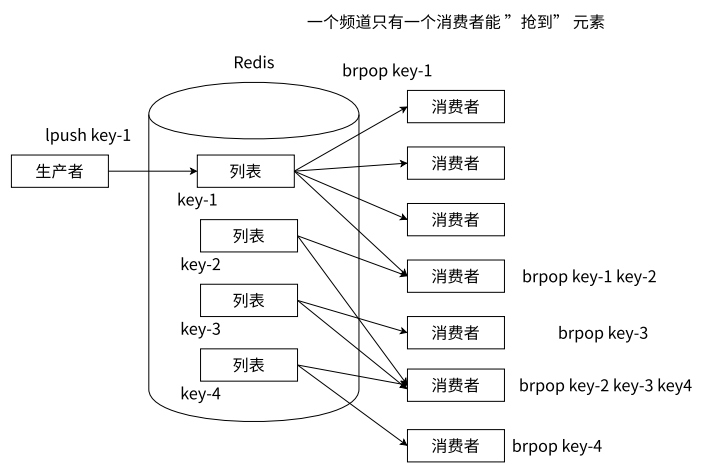
分频道的消息队列
如下图 所示,Redis 同样使用 lpush + brpop 命令,但通过不同的键模拟频道的概念,不同的消费者可以通过 brpop 不同的键值,实现订阅不同频道的理念。
微博 Timeline
每个用户都有属于自己的 Timeline(微博列表),现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
1)每篇微博使用哈希结构存储,例如微博中 3 个属性:title、timestamp、content:
hmset mblog:1 title xx timestamp 1476536196 content xxxxx
...
hmset mblog:n title xx timestamp 1476536196 content xxxxx
2)向用户 Timeline 添加微博,user::mblogs 作为微博的键:
lpush user:1:mblogs mblog:1 mblog:3
...
lpush user:k:mblogs mblog:9
3)分页获取用户的 Timeline,例如获取用户 1 的前 10 篇微博:
keylist = lrange user:1:mblogs 0 9
for key in keylist {hgetall key
}
此方案在实际中可能存在两个问题:
1 . 1 + n 问题。即如果每次分页获取的微博个数较多,需要执行多次 hgetall 操作,此时可以考虑使用pipeline(流⽔线)模式批量提交命令,或者微博不采用哈希类型,而是使用序列化的字符串类 型,使用 mget 获取。
2 . 分裂获取文章时,lrange 在列表两端表现较好,获取列表中间的元素表现较差,此时可以考虑将列表做拆分。
注意:
选择列表类型时,请参考:
同侧存取(lpush + lpop 或者 rpush + rpop)为栈
异侧存取(lpush + rpop 或者 rpush + lpop)为队列
二、Set 集合
1. Set简单介绍
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中 1)元素之间是无序 的 2)元素不允许重复,如下图所示。一个集合中最多可以存储个元素。Redis 除了支持集合内的增删查改操作,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多问题。
集合类型
2. 普通命令
SADD
将一个或者多个元素添加到 set 中。注意,重复的元素无法添加到 set 中。
语法:
SADD key member [member ...]
时间复杂度:O(1)
返回值:本次添加成功的元素个数。
示例:
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SADD myset "World"
(integer) 0
redis> SMEMBERS myset
1) "Hello"
2) "World"
SMEMBERS
获取⼀个 set 中的所有元素,注意,元素间的顺序是无序的。
语法:
SMEMBERS key
时间复杂度:O(N)
返回值:所有元素的列表。
示例:
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SMEMBERS myset
1) "Hello"
2) "World"
SISMEMBER
判断⼀个元素在不在 set 中。
语法:
SISMEMBER key member
时间复杂度:O(1)
返回值:1 表⽰元素在 set 中。0 表⽰元素不在 set 中或者 key 不存在。
示例:
redis> SADD myset "one"
(integer) 1
redis> SISMEMBER myset "one"
(integer) 1
redis> SISMEMBER myset "two"
(integer) 0
SCARD
获取⼀个 set 的基数(cardinality),即 set 中的元素个数。
语法:
SCARD key
时间复杂度:O(1)
返回值:set 内的元素个数。
示例:
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SCARD myset
(integer) 2
SPOP
从 set 中删除并返回⼀个或者多个元素。注意,由于 set 内的元素是⽆序的,所以取出哪个元素实际是 未定义行为,即可以看作随机的。
语法:
SPOP key [count]
时间复杂度:O(N), n 是 count
返回值:取出的元素。
示例:
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SPOP myset
"one"
redis> SMEMBERS myset
1) "three"
2) "two"
redis> SADD myset "four"
(integer) 1
redis> SADD myset "five"
(integer) 1
redis> SPOP myset 3
1) "three"
2) "four"
3) "two"
redis> SMEMBERS myset
1) "five"
SMOVE
将⼀个元素从源 set 取出并放入目标 set 中。
语法:
SMOVE source destination member
时间复杂度:O(1)
返回值:1 表示移动成功,0 表示失败。
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myotherset "three"
(integer) 1
redis> SMOVE myset myotherset "two"
(integer) 1
redis> SMEMBERS myset
1) "one"
redis> SMEMBERS myotherset
1) "three"
2) "two"
SREM
将指定的元素从 set 中删除。
语法:
SREM key member [member ...]
时间复杂度:O(N), N 是要删除的元素个数.
返回值:本次操作删除的元素个数。
示例:
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SREM myset "one"
(integer) 1
redis> SREM myset "four"
(integer) 0
redis> SMEMBERS myset
1) "three"
2) "two"
3 . 集合间操作
交集(inter)、并集(union)、差集(diff)的概念如下图所示。
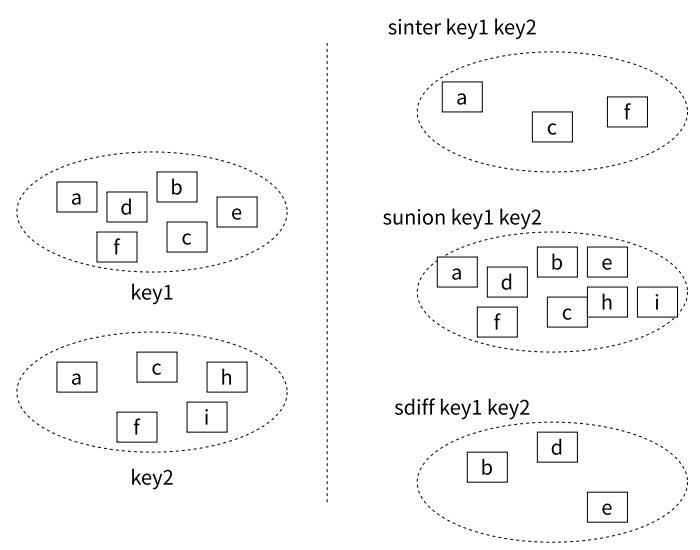
SINTER
获取给定 set 的交集中的元素。
语法:
SINTER key [key ...]
时间复杂度:O(N * M), N 是最⼩的集合元素个数. M 是最大的集合元素个数.
返回值:交集的元素
示例:
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SINTER key1 key2
1) ”c“
SINTERSTORE
获取给定 set 的交集中的元素并保存到目标 set 中。
语法:
SINTERSTORE destination key [key ...]
时间复杂度:O(N * M), N 是最小的集合元素个数. M 是最大的集合元素个数.
返回值:交集的元素个数。
示例:
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SINTERSTORE key key1 key2
(integer) 1
redis> SMEMBERS key
1) "c"
SUNION
获取给定 set 的并集中的元素。
语法:
SUNION key [key ...]
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:并集的元素。
示例:
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SUNION key1 key2
1) "a"
2) "c"
3) "e"
4) "b"
5) "d"
SUNIONSTORE
获取给定 set 的并集中的元素并保存到目标 set 中。
语法:
SUNIONSTORE destination key [key ...]
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:并集的元素个数。
示例:
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SDIFF key1 key2
1) "a"
2) "b"
SDIFFSTORE
获取给定 set 的差集中的元素并保存到目标 set 中
语法:
SDIFFSTORE destination key [key ...]
时间复杂度:O(N), N 给定的所有集合的总的元素个数.
返回值:差集的元素个数。
示例:
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SDIFFSTORE key key1 key2
(integer) 2
redis> SMEMBERS key
1) "a"
2) "b"
4. 内部编码
集合类型的内部编码有两种:
• intset(整数集合):当集合中的元素都是整数并且元素的个数小于 set-max-intset-entries 配置 (默认 512 个)时,Redis 会选用intset 来作为集合的内部实现,从而减少内存的使用。
• hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现
1)当元素个数较少并且都为整数时,内部编码为 intset:
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.0.1:6379> object encoding setkey
"intset”
2)当元素个数超过 512 个,内部编码为 hashtable:
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 513
127.0.0.1:6379> object encoding setkey
"hashtable“
3)当存在元素不是整数时,内部编码为 hashtable:
127.0.0.1:6379> sadd setkey a
(integer) 1
127.0.0.1:6379> object encoding setkey
"hashtable”
5. 使用场景
集合类型比较典型的使⽤场景是标签(tag)。例如 A 用户对娱乐、体育板块比较感兴趣,B 用户对历史、新闻比较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同⼀个标签 的⼈,以及用户的共同喜好的标签,这些数据对于增强用户体验和用户黏度都非常有帮助。 例如⼀个 电子商务网站会对不同标签的用户做不同的产品推荐。
下面的演示通过集合类型来实现标签的若干功能。
1)给用户添加标签
sadd user:1:tags tag1 tag2 tag5
sadd user:2:tags tag2 tag3 tag5
...
sadd user:k:tags tag1 tag2 tag4
2)给标签添加用户
sadd tag1:users user:1 user:3
sadd tag2:users user:1 user:2 user:3
...
sadd tagk:users user:1 user:4 user:9 user:28
3)删除用户下的标签
srem user:1:tags tag1 tag5
...
4)删除标签下的用户
srem tag1:users user:1
srem tag5:users user:1
...
5)计算用户的共同兴趣标签
sinter user:1:tags user:2:tags
三、Zset 有序集合
1.Zset 有序集合简介
有序集合相对于字符串、列表、哈希、集合来说会有⼀些陌生。它保留了集合不能有重复成员的特点,但与集合不同的是,有序集合中的每个元素都有⼀个唯⼀的浮点类型的分数(score)与之关 联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据⽽是⽤这个 分数。如下图所示,该有序集合显示了三国中的武将的武力。
有序集合:
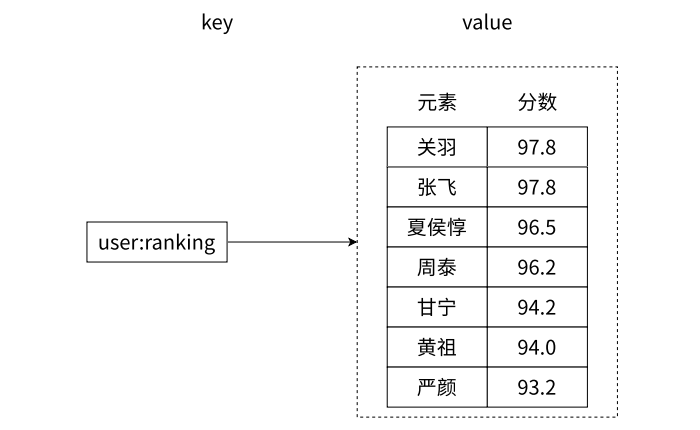
有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能,合理地利用有序集合,可 以帮助我们在实际开发中解决很多问题。
注意:
有序集合中的元素是不能重复的,但分数允许重复。类⽐于⼀次考试之后,每个人⼀定有一个唯一的分数,但分数允许相同
下表描述列表、集合、有序集合三者的异同点
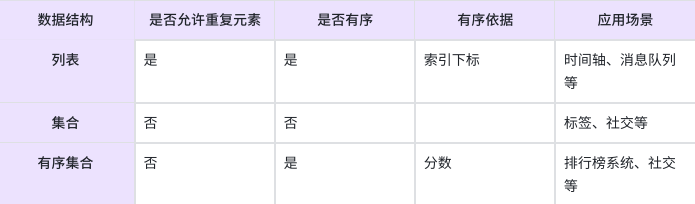
2. 普通命令
ZADD
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负 极限也是合法的。
ZADD 的相关选项:
• XX:仅仅用于更新已经存在的元素,不会添加新元素。
• NX:仅用于添加新元素,不会更新已经存在的元素。
• CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更 新的元素的个数。
• INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数。
语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]
时间复杂度:O(log(N))
返回值:本次添加成功的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 1 "uno"
(integer) 1
redis> ZADD myzset 2 "two" 3 "three"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
redis> ZADD myzset 10 one 20 two 30 three
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "uno"
2) "1"
3) "one"
4) "10"
5) "two"
6) "20"
7) "three"
8) "30"
redis> ZADD myzset CH 100 one 200 two 300 three
(integer) 3
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "uno"
2) "1"
3) "one"
4) "100"
5) "two"
6) "200"
7) "three"
8) "300"
redis> ZADD myzset XX 1 one 2 two 3 three 4 four 5 five
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
redis> ZADD myzset NX 100 one 200 two 300 three 400 four 500 five
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES1) "one"2) "1"3) "uno"4) "1"5) "two"6) "2"7) "three"8) "3"9) "four"
10) "400"
11) "five"
12) "500"
redis> ZADD myzset INCR 10 one
"11"
redis> ZRANGE myzset 0 -1 WITHSCORES1) "uno"2) "1"3) "two"4) "2"5) "three"6) "3"7) "one"8) "11"9) "four"
10) "400"
11) "five"
12) "500"
redis> ZADD myzset -inf "negative infinity" +inf "positive infinity"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES1) "negative infinity"2) "-inf"3) "uno"4) "1"5) "two"6) "2"7) "three"8) "3"9) "one"
10) "11"
11) "four"
12) "400"
13) "five"
14) "500"
15) "positive infinity"
16) "inf"
ZCARD
获取⼀个 zset 的基数(cardinality),即 zset 中的元素个数。
语法:
ZCARD key
时间复杂度:O(1)
返回值:zset 内的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2
ZCOUNT
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:
ZCOUNT key min max
时间复杂度:O(log(N))
返回值:满⾜条件的元素列表个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZCOUNT myzset -inf +inf
(integer) 3
redis> ZCOUNT myzset 1 3
(integer) 3
redis> ZCOUNT myzset (1 3
(integer) 2
redis> ZCOUNT myzset (1 (3
(integer) 1
ZRANGE
返回指定区间里的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
语法:
ZRANGE key start stop [WITHSCORES]
此处的 [start, stop] 为下标构成的区间. 从 0 开始, 支持负数.
时间复杂度:O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset 2 3
1) "three"
redis> ZRANGE myzset -2 -1
1) "two"
2) "three"
ZREVRANGE
返回指定区间里的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
语法:
ZREVRANGE key start stop [WITHSCORES]
时间复杂度:O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
3) "two"
4) "2"
5) "one"
6) "1"
redis> ZREVRANGE myzset 0 -1
1) "three"
2) "two"
3) "one"
redis> ZREVRANGE myzset 2 3
1) "one"
redis> ZREVRANGE myzset -2 -1
1) "two"
2) "one"
ZRANGEBYSCORE
返回分数在 min 和 max 之间的元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:
ZRANGEBYSCORE key min max [WITHSCORES]
时间复杂度:O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
redis> ZRANGEBYSCORE myzset (1 2
1) "two"
redis> ZRANGEBYSCORE myzset (1 (2
(empty array)ZPOPMAX
删除并返回分数最⾼的 count 个元素。
语法:
ZPOPMAX key [count]
时间复杂度:O(log(N) * M)
返回值:分数和元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMAX myzset
1) "three"
2) "3"
BZPOPMAX
ZPOPMAX 的阻塞版本。
语法:
BZPOPMAX key [key ...] timeout
时间复杂度:O(log(N))
返回值:元素列表。
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMAX zset1 zset2 0
1) "zset1"
2) "c"
3) "2"
ZPOPMIN
删除并返回分数最低的 count 个元素。
语法:
ZPOPMIN key [count]
时间复杂度:O(log(N) * M)
返回值:分数和元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMIN myzset
1) "one"
2) "1"
BZPOPMIN
ZPOPMIN 的阻塞版本。
语法:
BZPOPMIN key [key ...] timeout
时间复杂度:O(log(N))
返回值:元素列表
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMIN zset1 zset2 0
1) "zset1"
2) "a"
3) "0"
ZRANK
返回指定元素的排名,升序。
语法:
ZRANK key member
时间复杂度:O(log(N))
返回值:排名。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)
ZREVRANK
返回指定元素的排名,降序。
语法:
ZREVRANK key member
时间复杂度:O(log(N))
返回值:排名。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANK myzset "one"
(integer) 2
redis> ZREVRANK myzset "four"
(nil)
ZSCORE
返回指定元素的分数。
语法:
`ZSCORE key member`
时间复杂度:O(1)
返回值:分数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"
ZREM
删除指定的元素。
语法:
ZREM key member [member ...]
时间复杂度:O(M*log(N))
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3“
ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop
时间复杂度:O(log(N)+M)
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYRANK myzset 0 1
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3”
ZREMRANGEBYSCORE
按照分数删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYSCORE key min max
时间复杂度:O(log(N)+M)
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYSCORE myzset -inf (2
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "three"
4) "3"
ZINCRBY
为指定的元素的关联分数添加指定的分数值。
语法:
ZINCRBY key increment member
时间复杂度:O(log(N))
返回值:增加后元素的分数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZINCRBY myzset 2 "one"
"3"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "one"
4) "3"
3. 集合间操作
有序集合的交集操作
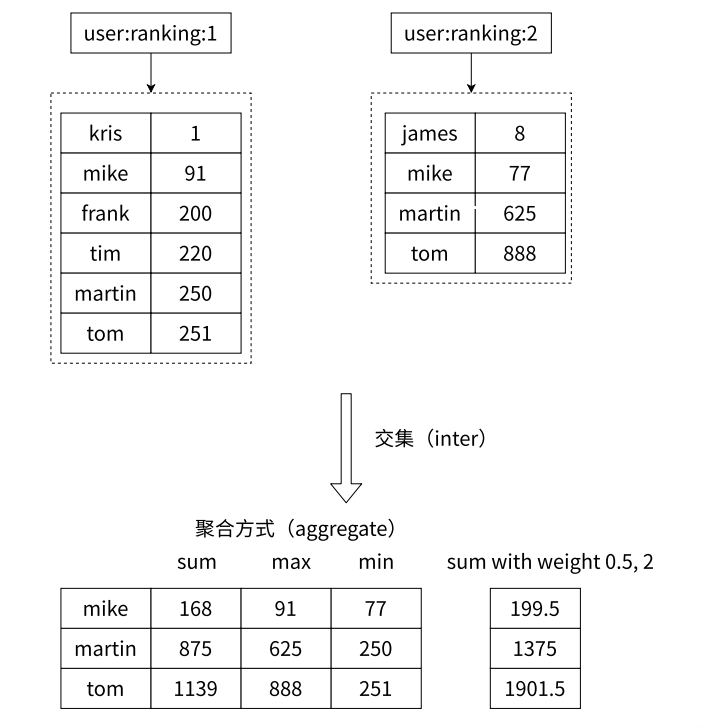
ZINTERSTORE
求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元 素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight[weight ...]] [AGGREGATE <SUM | MIN | MAX>]
时间复杂度:O(NK)+O(Mlog(M)) N 是输⼊的有序集合中, 最⼩的有序集合的元素个数; K 是输⼊了 ⼏个有序集合; M 是最终结果的有序集合的元素个数.
返回值:目标集合中的元素个数
示例:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZINTERSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 2
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "two"
4) "10"
有序集合的并集操作
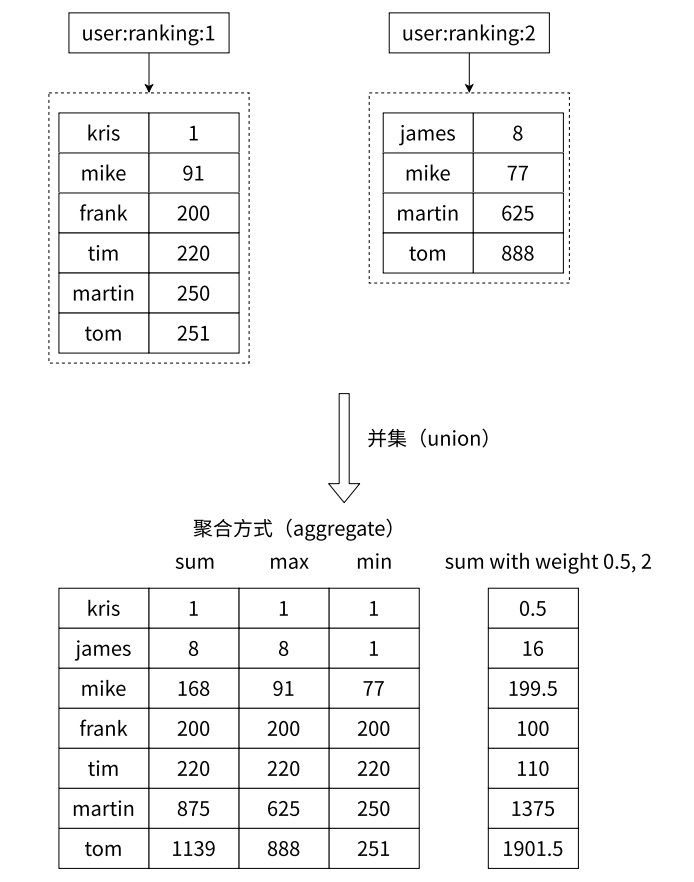
ZUNIONSTORE
求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight[weight ...]] [AGGREGATE <SUM | MIN | MAX>]
时间复杂度:O(N)+O(M*log(M)) N 是输⼊的有序集合总的元素个数; M 是最终结果的有序集合的元素 个数. 返回值:⽬标集合中的元素个数
示例:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZUNIONSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 3
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "three"
4) "9"
5) "two"
6) "10"
4. 内部编码
有序集合类型的内部编码有两种:
• ziplist(压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个),
同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用ziplist 来作 为有序集合的内部实现,ziplist 可以有效减少内存的使用。
• skiplist(跳表):当 ziplist 条件不满足时,有序集合会使⽤ skiplist 作为内部实现,因为此时ziplist 的操作效率会下降
1)当元素个数较少且每个元素较小时,内部编码为 ziplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist“
2)当元素个数超过 128 个,内部编码 skiplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3 ... 省略 ... 82 e129
(integer) 129
127.0.0.1:6379> object encoding zsetkey
"skiplist"
3)当某个元素⼤于 64 字节时,内部编码 skiplist:
127.0.0.1:6379> zadd zsetkey 50 "one string bigger than 64 bytes ... 省略 ..."
(integer) 1
127.0.0.1:6379> object encoding zsetkey
"skiplist"
5. 使用场景
有序集合比较典型的使用场景就是排行榜系统。例如常见的网站上的热榜信息,榜单的维度可能 是方面的:按照时间、按照阅读量、按照点赞量。本例中我们使用点赞数这个维度,维护每天的热榜:
1)添加用户赞数
例如用户 james 发布了⼀篇文章,并获得 3 个赞,可以使用有序集合的 zadd 和 zincrby 功能:
zadd user:ranking:2022-03-15 3 james
之后如果再获得赞,可以使用 zincrby:
zincrby user:ranking:2022-03-15 1 james
2)取消用户赞数
由于各种原因(例如用户注销、用户作弊等)需要将⽤⼾删除,此时需要将用户从榜单中删除掉,可以使用 zrem。例如删除成员 tom:
zrem user:ranking: tom
3)展示获取赞数最多的 10 个用户
此功能使用 zrevrange 命令实现:
zrevrangebyrank user:ranking 0 9
4)展示用户信息以及用户分数次功能将用户名作为键后缀,将⽤⼾信息保存在哈希类型中,至于用户的分数和排名可以使用zscore和 zrank 来实现
hgetall user:info:tom
zscore user:ranking: mike
zrank user:ranking: mike
结语
本文主要介绍了Redis中剩下的常见数据类型:List列表、set无序集合、Zset有序集合。分别介绍了他们的命令以及相关操作与内部编码和相关应用场景。
以上就是本文全部内容,感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!
最后,大家再见!祝好!我们下期见!
相关文章:
)
【Redis】 Redis中常见的数据类型(二)
文章目录 前言一、 List 列表1. List 列表简介2.命令3. 阻塞版本命令4. 内部编码5. 使用场景 二、Set 集合1. Set简单介绍2. 普通命令3 . 集合间操作4. 内部编码5. 使用场景 三、Zset 有序集合1.Zset 有序集合简介2. 普通命令3. 集合间操作4. 内部编码5. 使用场景 结语 前言 在…...

电力作业安全工器具全解析:分类、配置与检查要点
在电力行业,每一次作业都面临潜在危险,安全工器具是保障作业人员生命安全的关键。今天,金能电力带大家深入了解电力作业中常见的安全工器具,以及它们的检查与使用要点。 电力作业中安全工器具种类繁多。绝缘安全工器具因直接关联带…...

PowerBI-使用参数动态修改数据源路径
PowerBI-使用参数动态修改数据源路径 在PowerQuery中可以使用参数,通过参数我们可以将多个文件路径相同的字符串进行替换。 以一个案例分享下过程: 第一步,导入一个含有多个sheet表的EXCEL工作薄,点击转换数据,如图…...

Temperature
模型中Temperature参数的详细解释 Temperature 是生成模型(如GPT、LLaMA等)中用于控制输出多样性和随机性的关键超参数。它通过调整模型预测概率分布的平滑程度,直接影响生成文本的创造性与稳定性。 模型中Temperature参数的详细解…...

C++ 日志系统实战第二步:不定参数函数解析
全是通俗易懂的讲解,如果你本节之前的知识都掌握清楚,那就速速来看我的项目笔记吧~ 相关技术知识补充 不定参宏函数 在 C 语言中,不定参宏函数是一种强大的工具,它允许宏接受可变数量的参数,类似于不定参函数&#…...

【高并发】 MySQL锁优化策略
在数据库高并发场景中,行锁、表锁和高并发处理是密切相关的概念,它们共同影响着系统的并发性能和数据一致性。以下是三者的详细解释及高并发处理的策略: 1. 行锁(Row-Level Locking) 行锁是数据库中最小的锁粒度&…...

C语言——填充矩阵
C语言——填充矩阵 一、问题描述二、格式要求1.输入形式2.输出形式3.样例 三、实验代码 一、问题描述 编程实现自动填充nn矩阵元素数值,填充规则为:从第一行最后一列矩阵元素开始按逆时针方向螺旋式填充数值1,2,…,nn…...
)
CSS3 基础(背景-文本效果)
二、背景效果 属性功能示例值说明background设置背景颜色或渐变background: linear-gradient(45deg, #4CAF50, #FF5722);设置背景颜色、图片或渐变效果。background-size调整背景图片大小background-size: cover;设置背景图片的显示大小,如 cover 或 contain。back…...

点云配准算法之NDT算法原理详解
一、算法概述 NDT(Normal Distributions Transform)最初用于2D激光雷达地图构建(Biber & Straer, 2003),后扩展为3D点云配准。它将点云数据空间划分为网格单元(Voxel),在每个体…...

springboot在eclipse里面运行 run as 是Java Application还是 Maven
在 Eclipse 里运行 Spring Boot 项目时,既可以选择以“Java Application”方式运行,也可以通过 Maven 命令来运行,下面为你详细介绍这两种方式及适用场景。 以“Java Application”方式运行 操作步骤 在项目中找到带有 SpringBootApplicat…...

Redis 基础和高级用法入门
redis 是什么? Redis是一个远程内存数据库,它不仅性能强劲,而且还具有复制特性以及为解决问题而生的独一无二的数据模型。Redis提供了5种不同类型的数据结构,各式各样的问题都可以很自然地映射到这些数据结构上:…...

使用vue2开发一个在线旅游预订平台-前端静态网站项目练习
hello,大家好,今天给大家再分享一个前端vue2练习项目-在线旅游预订平台。我们在学习编程的时候,除了学习编程的基础知识,为了让我们快速的掌握一门编程技术,肯定离不开各种项目的练习,今天分享的这个前端练习项目&…...

Ext Direct 功能与使用详解
Ext Direct 是 Ext JS 框架中的一个功能模块,旨在简化前端 JavaScript 应用与后端服务器之间的通信。其核心思想是通过远程过程调用(RPC)协议,将服务器端的方法透明地映射为前端可直接调用的 JavaScript 函数,从而减少手动编写 Ajax 请求和处理响应的代码量。 一、Ext Dir…...

Android移动应用开发入门示例:Activity跳转界面
介绍如何使用LinearLayout布局实现基本的UI设计,并实现两个Activity之间的跳转,适合刚接触Android Studio的新手学习。我们将使用Java语言开发,布局采用XML文件。以下为完整源码与运行说明: 案例前的准备工作: 1.1XM…...

【hadoop】HBase分布式数据库安装部署
一、HBase集群的安装与配置 步骤: 1、使用XFTP将HBase安装包hbase-1.2.0-bin.tar.gz发送到master机器的主目录。 2、解压安装包: tar -zxvf ~/hbase-1.2.0-bin.tar.gz 3、修改文件夹的名字,将其改为hbase,或者创建软连接也可…...

理解npm的工作原理:优化你的项目依赖管理流程
目录 什么是npm npm核心功能 npm 常用指令及其作用 执行npm i 发生了什么? 1. 解析命令与参数 2. 检查依赖文件 3. 依赖版本解析与树构建 4. 缓存检查与包下载 5. 解压包到 node_modules 6. 更新 package-lock.json 7. 处理特殊依赖类型 8. 执行生命周期脚本 9. …...

【Python笔记 04】输入函数、转义字符
一、Input 输入函数 prompt是提示,会在控制台显示,用作提示函数。 name input("请输入您的姓名:") print (name)提示你输入任意信息: 输入input test后回车,他输出input test 二、常用的转义字符 只讲…...

MySQL数据库基本操作-DQL-基本查询
数据库的操作中,查询是最重要的 一、基本查询-数据准备 -- 数据准备 create database if not exists mydb2; use mydb2; create table product( pid int primary key auto_increment, pname varchar(20) not null, price double, category_id varchar(20) …...

13、性能优化:魔法的流畅之道——React 19 memo/lazy
一、记忆封印术(React.memo) 1. 咒语本质 "memo是时间转换器的记忆晶石,冻结无意义的能量波动!" 通过浅层比较(shallowCompare)或自定义预言契约,阻止组件在props未变时重新渲染。 …...

低代码平台开发手机USB-HID调试助手
项目介绍 USB-HID调试助手是一种专门用于调试和测试USB-HID设备的软件工具。USB-HID设备是一类通过USB接口与计算机通信的设备,常见的HID设备包括键盘、鼠标、游戏控制器、以及一些专用的工业控制设备等。 主要功能包括: 数据监控:实时监控和…...

Langchain_Agent+数据库
本处使用Agent数据库,可以直接执行SQL语句。可以多次循环查询问题 前文通过chain去联系数据库并进行操作; 通过链的不断内嵌组合,生成SQL在执行SQL再返回。 初始化 import os from operator import itemgetterimport bs4 from langchain.ch…...

Code Splitting 分包策略
以下是关于分包策略(Code Splitting)的深度技术解析,涵盖原理、策略、工具实现及优化技巧: 一、分包核心价值与底层原理 1. 核心价值矩阵 维度未分包场景合理分包后首屏速度需加载全部资源仅加载关键资源缓存效率任意修改导致全量缓存失效按模块变更频率分层缓存并行加载单…...

AI 开发入门之 RAG 技术
目录 一、从一个简单的问题开始二、语言模型“闭卷考试”的困境三、RAG 是什么—LLM 的现实世界“外挂”四、RAG 的七步流程第一步:加载数据(Load)第二步:切分文本(Chunking)第三步:向量化&…...

day36图像处理OpenCV
文章目录 一、图像预处理18 模板匹配18.1模板匹配18.2 匹配方法18.2.1 平方差匹配18.2.2 归一化平方差匹配18.2.3 相关匹配18.2.4 归一化相关匹配18.2.5 相关系数匹配18.2.6 归一化相关系数匹配 18.3 绘制轮廓18.4案例 一、图像预处理 18 模板匹配 18.1模板匹配 模板匹配就是…...
)
系统与网络安全------弹性交换网络(3)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 STP协议 环路的危害 单点故障 PC之间的互通链路仅仅存在1个 任何一条链路出现问题,PC之间都会无法通信 解决办法 提高网络可靠性 增加冗余/备份链路 增加备份链路后交换网络上产生二层环路 …...

FPGA上实现YOLOv5的一般过程
在FPGA上实现YOLOv5 YOLO算法现在被工业界广泛的应用,虽说现在有很多的NPU供我们使用,但是我们为了自己去实现一个NPU所以在本文中去实现了一个可以在FPGA上运行的YOLOv5。 YOLOv5的开源代码链接为 https://github.com/ultralytics/yolov5 为了在FPGA中…...

verilog和system verilog常用数据类型以及常量汇总
int和unsigned 在 Verilog-2001 中,没有 int 和 unsigned 这样的数据类型。这些关键字是 SystemVerilog 的特性,而不是 Verilog-2001 的一部分。 Verilog-2001 的数据类型 在 Verilog-2001 中,支持的数据类型主要包括以下几种: …...

wordpress学习笔记
P1 P2 P3...

Rust 学习笔记:编程语言的相关概念
Rust 学习笔记:编程语言的相关概念 Rust 学习笔记:编程语言的相关概念动态类型 vs 静态类型动态类型 (Dynamically Typed)静态类型 (Statically Typed)对比示例 强类型 vs 弱类型强类型 (Strongly Typed)弱类型 (Weakly Typed)对比示例 编译型语言 vs 解…...

react nativeWebView跨页面通信
场景 react native项目里,有一些移动端的应用喜欢使用h5来开发,会出现需要跨tab和跨页面通信的场景,可以使用pubsub-js来实现通信。 实现思路 在react native 层实现pubsub的公共API,提供订阅消息、发布消息、取消订阅接口&…...
HTML核心技巧:从零掌握class与id选择器,精准定位网页元素)
Python爬虫(3)HTML核心技巧:从零掌握class与id选择器,精准定位网页元素
目录 一、背景与意义二、class与id的基础概念与语法规则2.1 什么是class与id?2.2 核心区别总结 三、应用场景与实战案例3.1 场景1:CSS样式管理3.2 场景2:JavaScript交互3.3 场景3:SEO优化与语义化 四、常见误区与最…...
模型详解)
BGE(BAAI General Embedding)模型详解
BGE(BAAI General Embedding)模型详解 BGE(BAAI General Embedding)是北京智源人工智能研究院(BAAI)推出的通用文本嵌入模型系列,旨在为各种自然语言处理任务提供高质量的向量表示。 一、BGE模…...

【Linux网络】应用层自定义协议与序列化及Socket模拟封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

Rust项目GPG签名配置指南
Rust项目GPG签名配置指南 一、环境准备 # 安装Gpg4win(Windows) winget install -e --id GnuPG.Gpg4win二、密钥生成与配置 # 生成RSA4096密钥 gpg --full-generate-key # 类型选RSA and RSA,长度4096,邮箱填z3266420686202216…...

6.第六章:数据分类的技术体系
文章目录 6.1 数据分类的技术架构6.1.1 数据分类的整体流程6.1.2 数据分类的技术组件6.1.2.1 数据采集与预处理6.1.2.2 特征工程与选择6.1.2.3 分类模型构建6.1.2.4 模型评估与优化6.1.2.5 分类结果应用与反馈 6.2 数据分类的核心技术与算法6.2.1 传统机器学习算法6.2.2 深度学…...

Nginx 反向代理,啥是“反向代理“啊,为啥叫“反向“代理?而不叫“正向”代理?它能干哈?
Nginx 反向代理的理解与配置 User 我打包了我的前端vue项目,上传到服务器,在宝塔面板安装了nginx服务,配置了文件 nginx.txt .运行了项目。 我想清楚,什么是nginx反向代理?是nginx作为一个中介?中间件来集…...
)
下篇:深入剖析 BLE GATT / GAP / SMP 与应用层(约5000字)
引言 在 BLE 协议栈的最上层,GAP 定义设备角色与连接管理,GATT 构建服务与特征,SMP 负责安全保障,应用层则承载具体业务逻辑与 Profile。掌握这一层,可实现安全可靠的设备发现、配对、服务交互和定制化业务。本文将详解 GAP、GATT、SMP 三大模块,并通过示例、PlantUML 时…...

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...

无人设备遥控之调度自动化技术篇
无人设备遥控器的调度自动化技术是现代科技发展的重要成果,它通过集成先进的通信、控制、传感器及人工智能技术,实现了对无人设备的高效、精准调度与自动化管理。 一、核心技术 无线通信技术 调度自动化依赖于高速、稳定的无线通信网络(如5…...
)
STM32F407 HAL库使用 DMA_Normal 模式实现 UART 循环发送(无需中断)
在 STM32 开发中,很多人喜欢使用 DMA 来加速串口发送数据。然而,默认的 DMA 往往配合中断或使用循环模式(DMA_CIRCULAR)使用。但在某些特定需求下,我们希望: 使用 DMA_NORMAL 模式,确保 DMA 每次…...

汽车自动驾驶介绍
0 Preface/Foreword 1 介绍 1.1 FSD FSD: Full Self-Driving,完全自动驾驶 (Tesla) 1.2 自动驾驶级别 L0 - L2:辅助驾驶L3:有条件自动驾驶L4/5 :高度/完全自动驾驶...

Uniapp-小程序从入门到精通
沉淀UNIAPP项目精华模版 ******************************************************************************************************************************************* 1、数据库的导入SQL **************************************************************************…...
:从X86/ARM/MIPS处理器架构到虚拟内存、分段分页、Linux内存管理,再揭秘进程线程限制与优化秘籍,助你成为OS高手!)
深度剖析操作系统核心(第一节):从X86/ARM/MIPS处理器架构到虚拟内存、分段分页、Linux内存管理,再揭秘进程线程限制与优化秘籍,助你成为OS高手!
文章目录 OS处理器X86ARMMIPSPowerPC 内存管理虚拟内存内存分段内存分页段页式内存管理Linux 内存管理 OS 处理器 常见处理器有X86、ARM、MIPS、PowerPC四种。 X86 X86架构是芯片巨头Intel设计制造的一种微处理器体系结构的统称。如果这样说你不理解,那么当我说…...

基于 EFISH-SBC-RK3588 的无人机通信云端数据处理模块方案
一、硬件架构设计 核心计算单元(EFISH-SBC-RK3588) 异构计算能力:搭载 8 核 ARM 架构(4Cortex-A762.4GHz 4Cortex-A551.8GHz),集成 6 TOPS NPU 与 Mali-G610 GPU,支持多任务并行处理…...
)
Unity 内置Standard Shader UNITY_BRDF_PBS函数分析 (二)
四、BRDF1_Unity_PBS // 主物理基BRDF实现 // 基于Disney工作并以Torrance-Sparrow微面模型为基础 // 公式: // BRDF kD / π kS * (D * V * F) / 4 // I BRDF * (N L) // // * NDF(法线分布函数)可根据 UNITY_BRDF_GGX 选择&#…...

GitHub万星项目维护者分享:开源协作的避坑指南
GitHub万星项目维护者分享:开源协作的避坑指南 ——开发者张三与237个文件改动PR的五年战争 序幕:深夜的炸弹 2019年夏天,张三维护的开源项目TerminalX刚突破8000星,一个标题猩红的PR突然弹出:“彻底重构࿰…...

Linux基础篇、第四章_01软件安装rpm_yum_源码安装_二进制安装
Linux基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! ————laowang 基础命令:rpm、yum、源码安装、二进制安装 一、rpm本地安装: (无需网络安装,无法解决软件依赖) rpm -ivh …...

焊接机排错
焊接机 一、前定位后焊接 两个机台,①极柱定位,相机定位所有极柱点和mark点;②焊接机,相机定位mark点原理:极柱定位在成功定位到所有极柱点和mark点后,可以建立mark点和极柱点的关系。焊接机定位到mark点…...

4.2 Prompt工程与任务建模:高效提示词设计与任务拆解方法
提示词工程(Prompt Engineering)和任务建模(Task Modeling)已成为构建高效智能代理(Agent)系统的核心技术。提示词工程通过精心设计的自然语言提示词(Prompts),引导大型语…...

oracle 锁的添加方式和死锁的解决
DML锁添加方式 DML 锁可由一个用户进程以显式的方式加锁,也可通过某些 SQL 语句隐含方式实现。 DML 锁有三种加锁方式:共享锁方式、独占锁方式、共享更新。 共享锁,独占锁用于 TM 锁,共享锁用于 TX 锁。 1)共享方式的表级锁 共享方…...