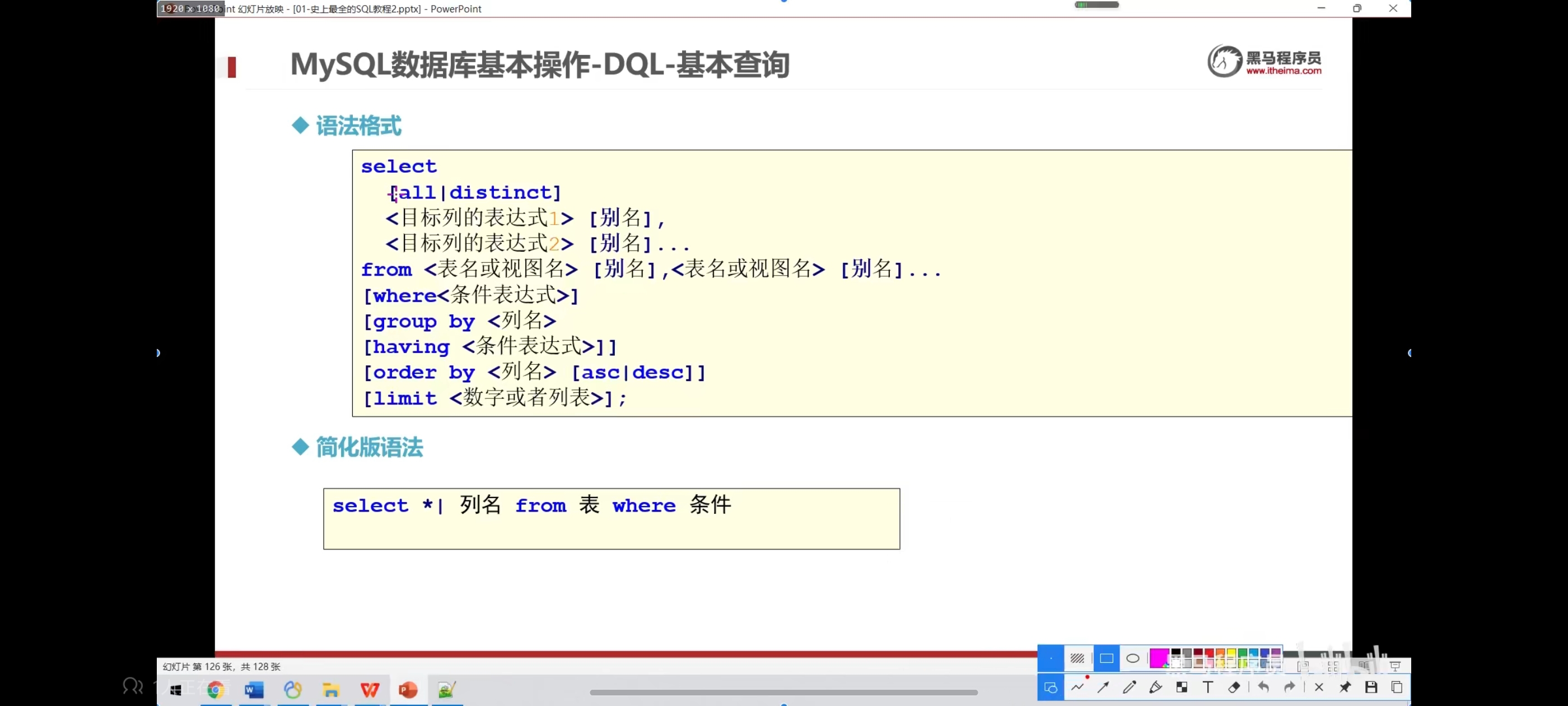
MySQL数据库基本操作-DQL-基本查询
数据库的操作中,查询是最重要的
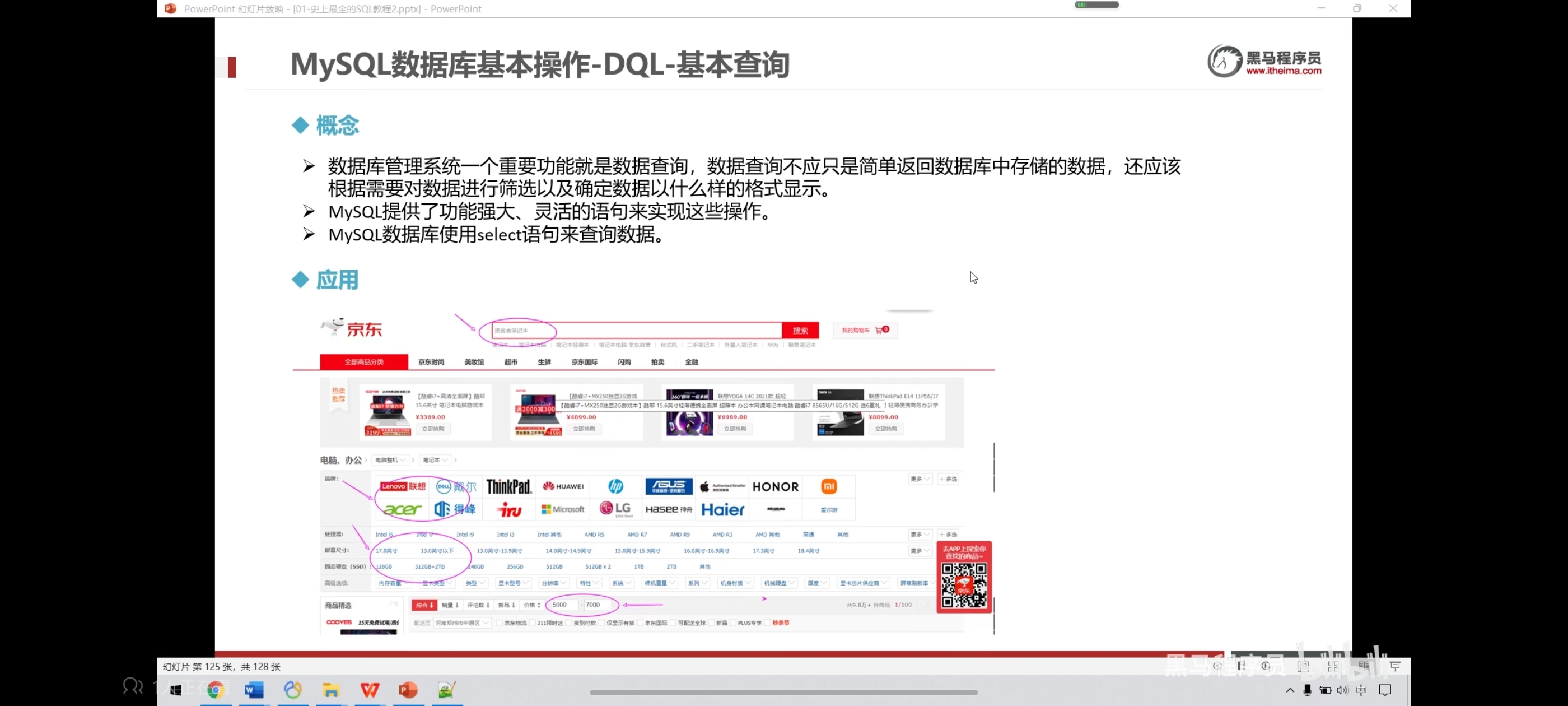
一、基本查询-数据准备
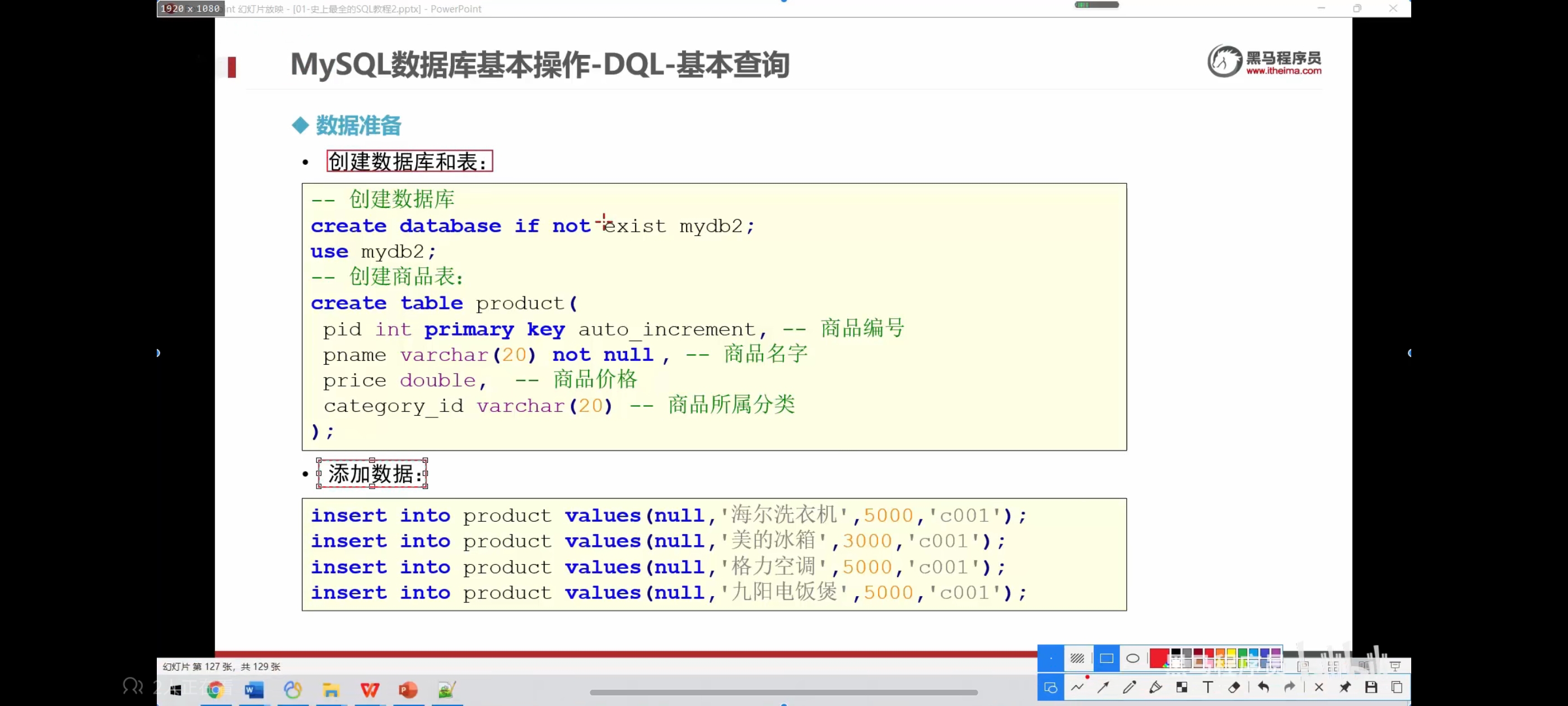
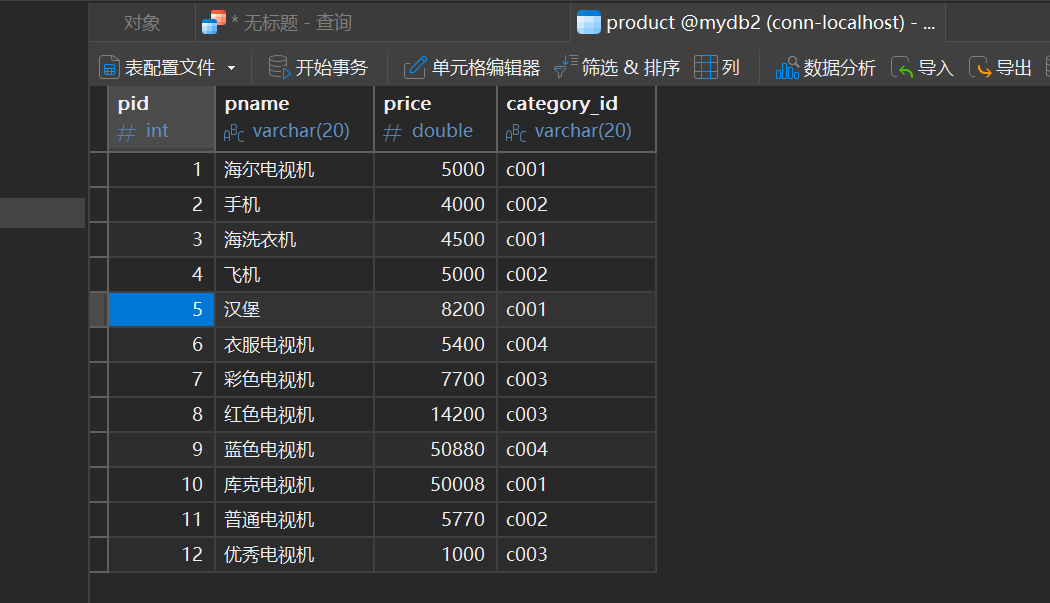
-- 数据准备
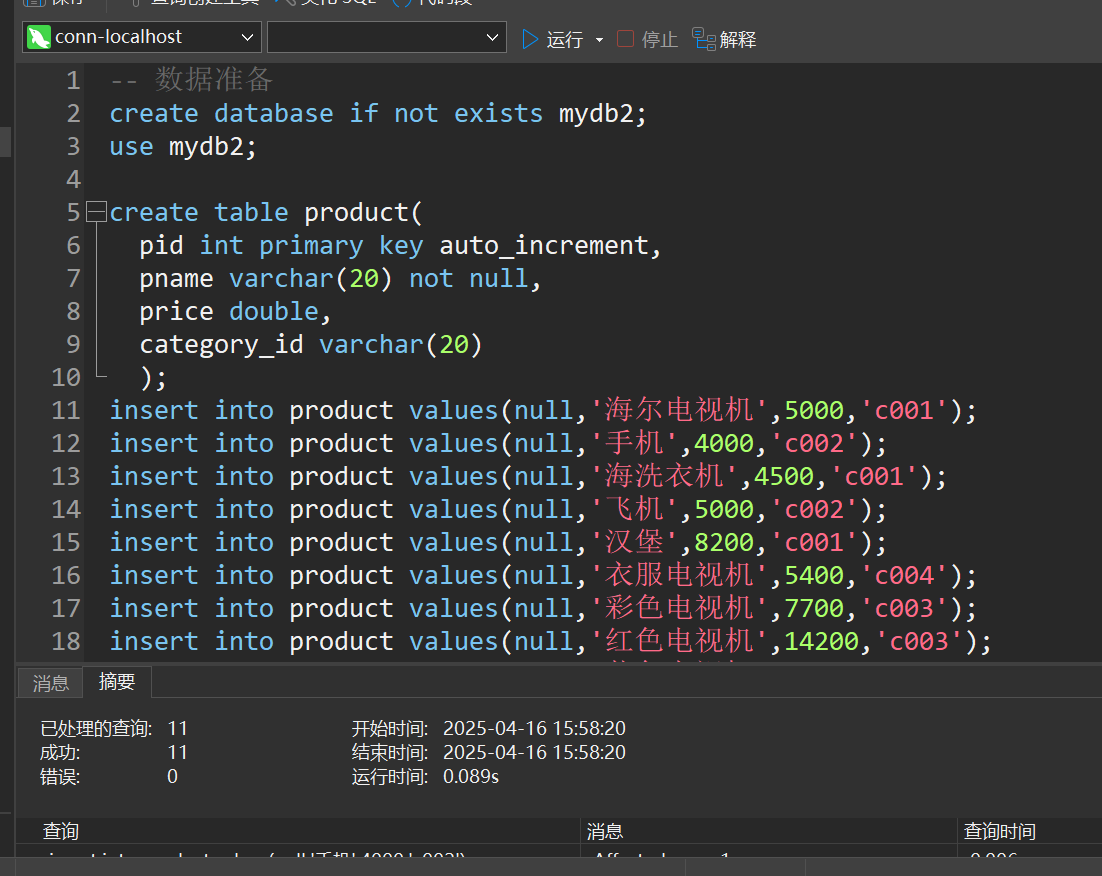
create database if not exists mydb2;
use mydb2;
create table product(
pid int primary key auto_increment,
pname varchar(20) not null,
price double,
category_id varchar(20)
);
insert into product values(null,'海尔电视机',5000,'c001');
insert into product values(null,'手机',4000,'c002');
insert into product values(null,'海洗衣机',4500,'c001');
insert into product values(null,'飞机',5000,'c002');
insert into product values(null,'汉堡',8200,'c001');
insert into product values(null,'衣服电视机',5400,'c004');
insert into product values(null,'彩色电视机',7700,'c003');
insert into product values(null,'红色电视机',14200,'c003');
insert into product values(null,'蓝色电视机',50880,'c004');
insert into product values(null,'库克电视机',50008,'c001');
insert into product values(null,'普通电视机',5770,'c002');
insert into product values(null,'优秀电视机',1000,'c003');
二、简单查询
别名查询给表或者列起一个别名
-- 查询所有的商品
select pid,pname,price,category_id from product;
select * from product;
-- 查询商品名和商品价格
select pname,price from product;
-- 别名查询,使用关键字是as(as可以省略的)
-- 表别名,就是给表起一个别名
select * from product as p;
select * from product p;
-- 多表查询会用
select p.id,u.id from product p,user u;
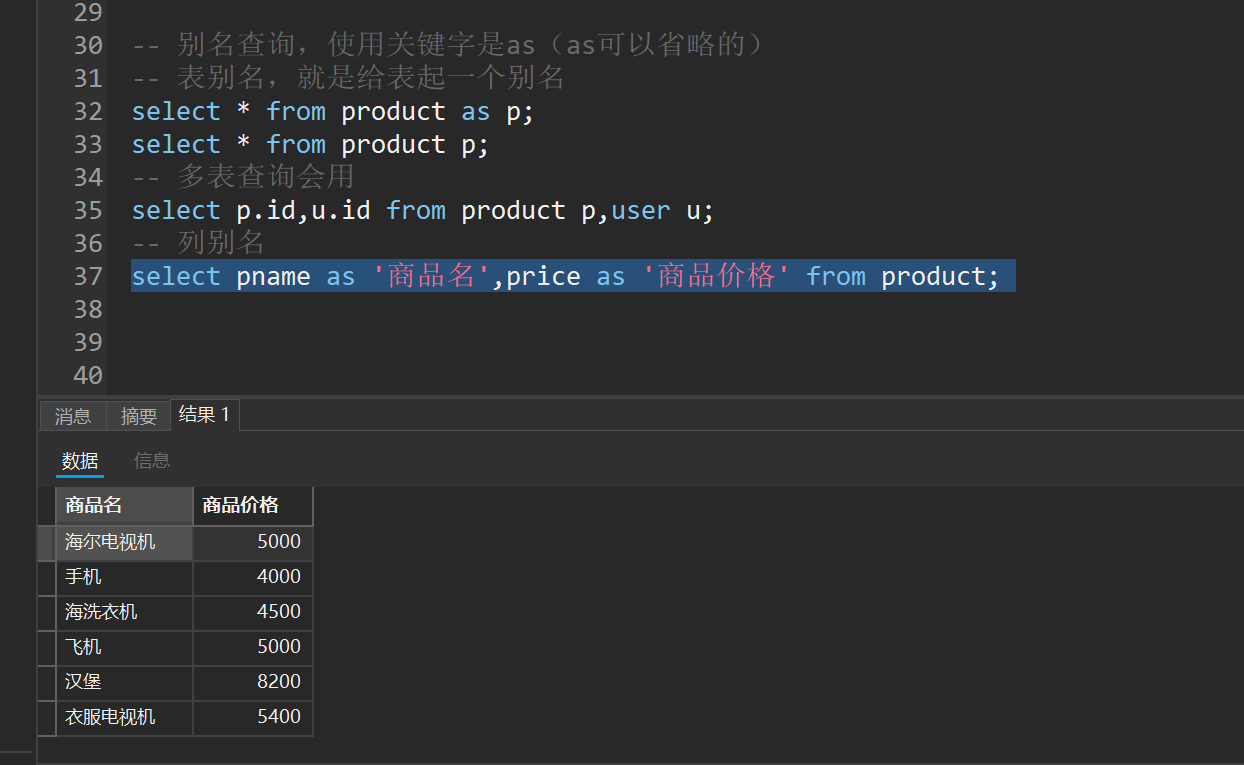
-- 列别名
select pname as '商品名',price as '商品价格' from product;
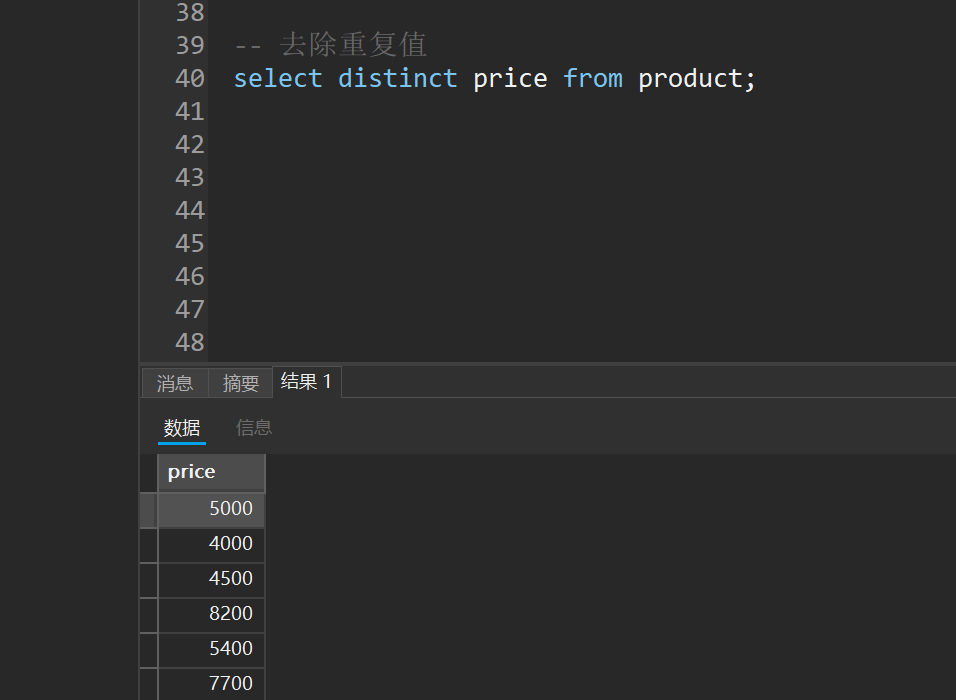
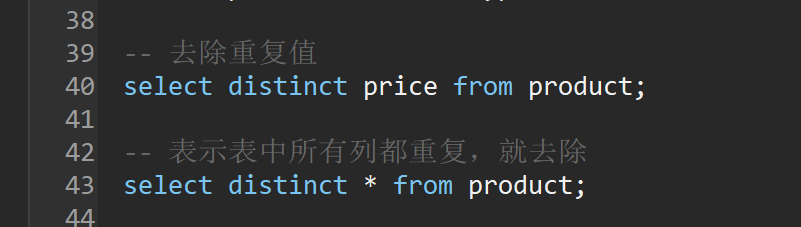
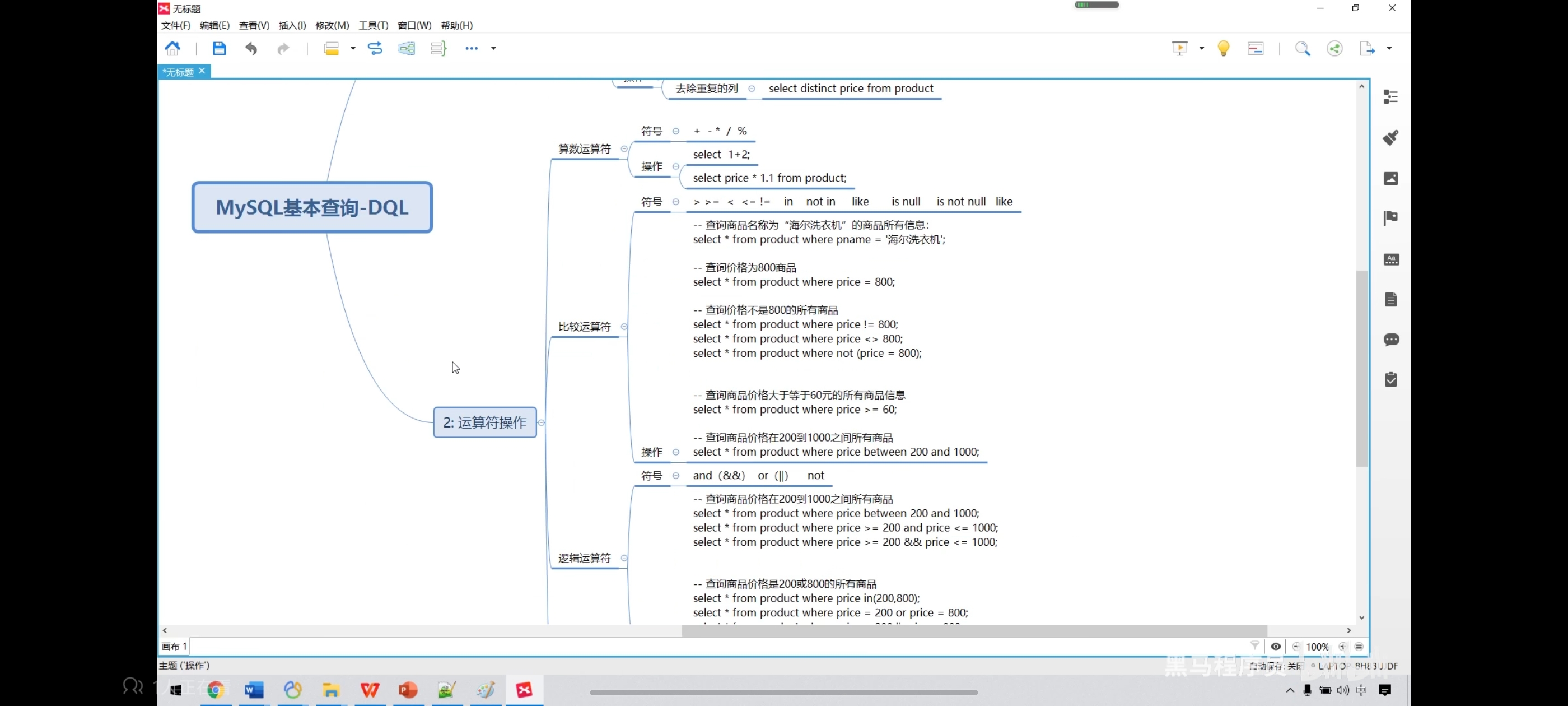
-- 去除重复值
select distinct price from product;
-- 表示表中所有列都重复,就去除
select distinct * from product;
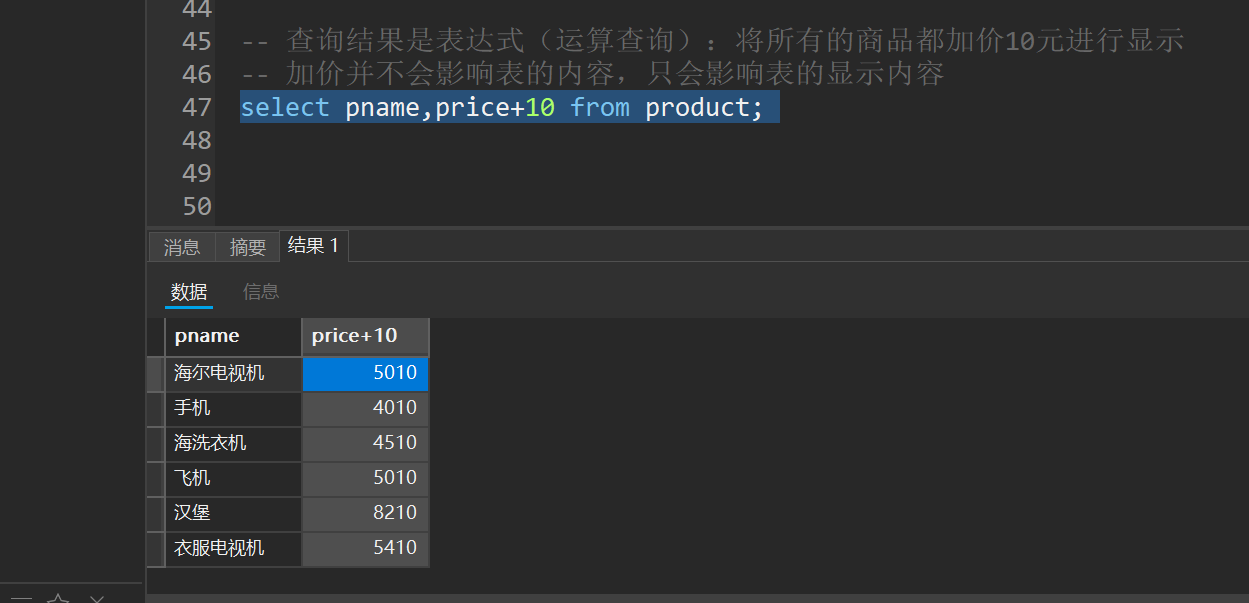
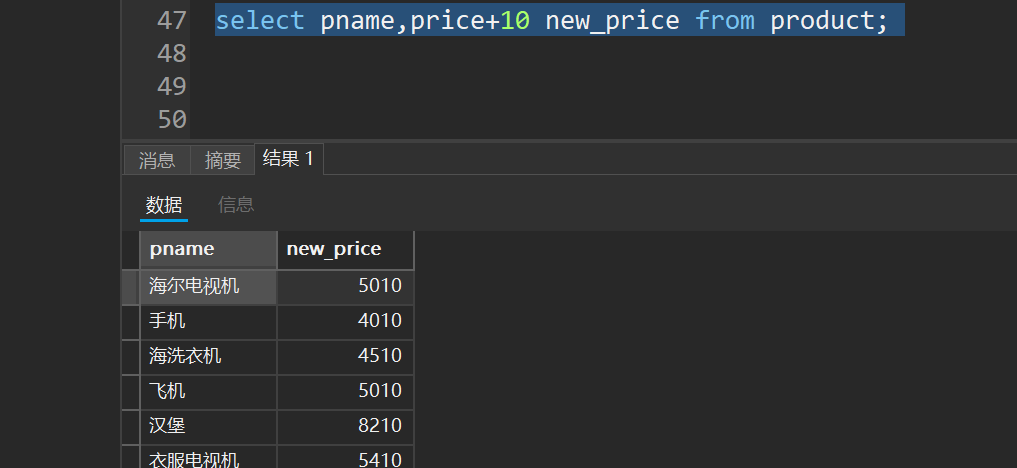
-- 查询结果是表达式(运算查询):将所有的商品都加价10元进行显示
-- 加价并不会影响表的内容,只会影响表的显示内容
select pname,price+10 new_price from product;
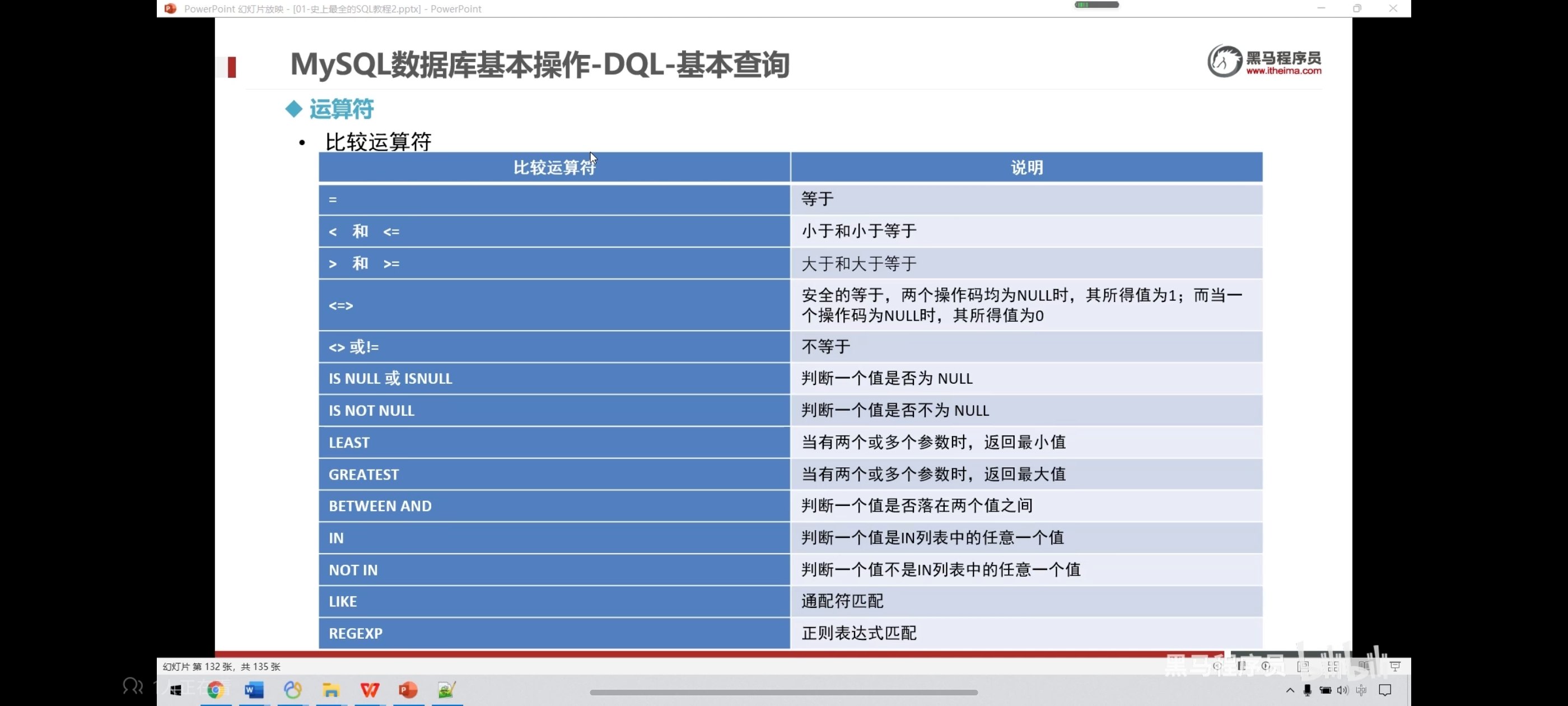
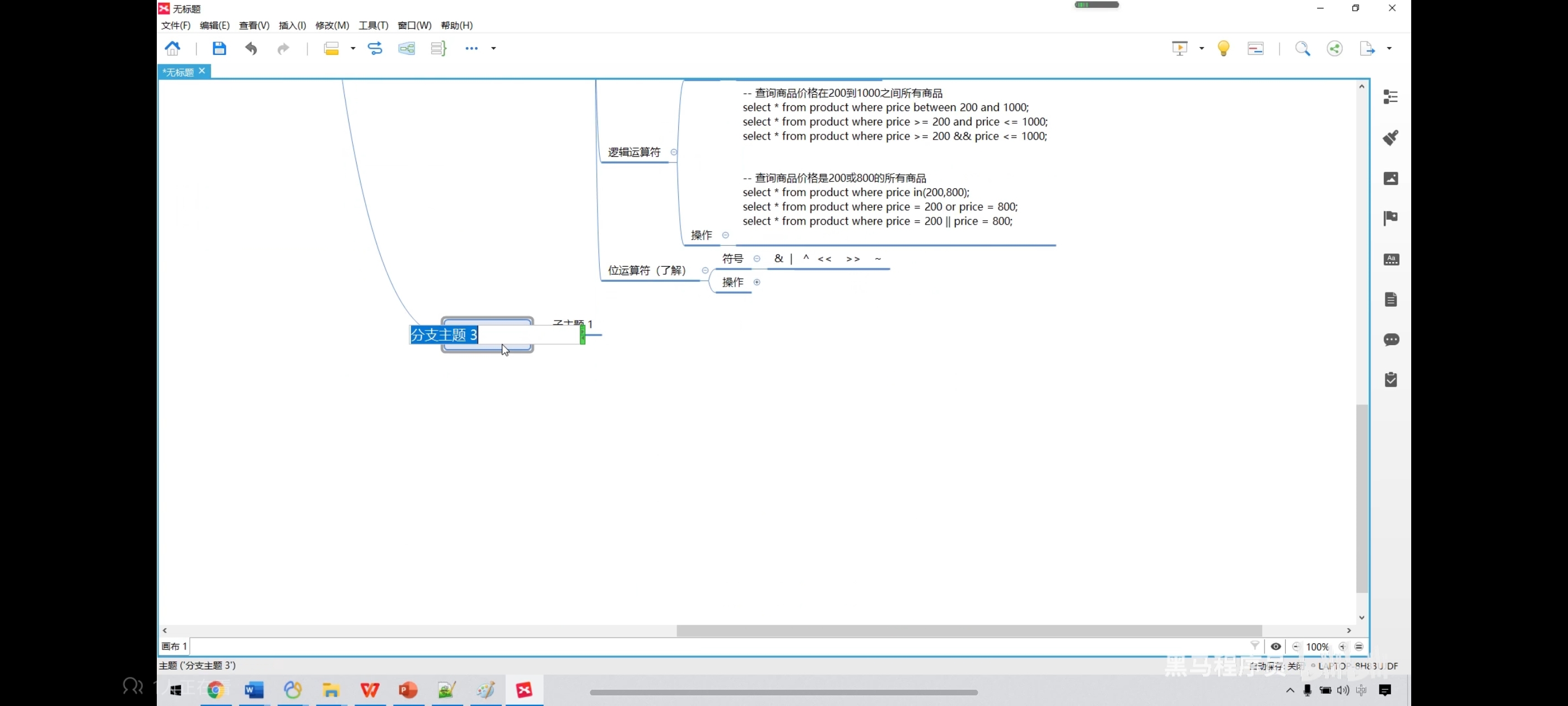
三、运算符
异或:不同为真,相同为假




四、运算符操作-算数运算符查询
五、运算符操作-条件查询
<>表示的也是不等于,和!=一样
use mydb1;
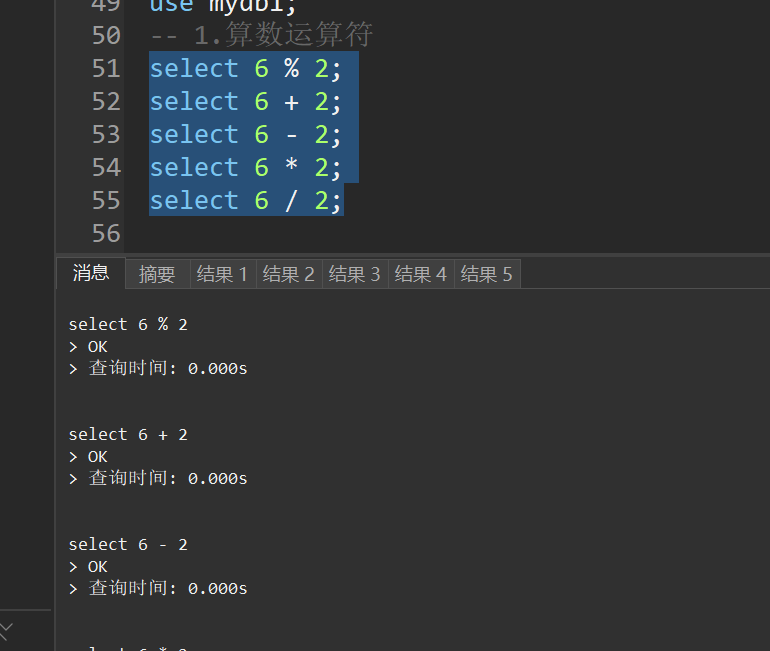
-- 1.算数运算符查询
select 6 % 2;
select 6 + 2;
select 6 - 2;
select 6 * 2;
select 6 / 2;
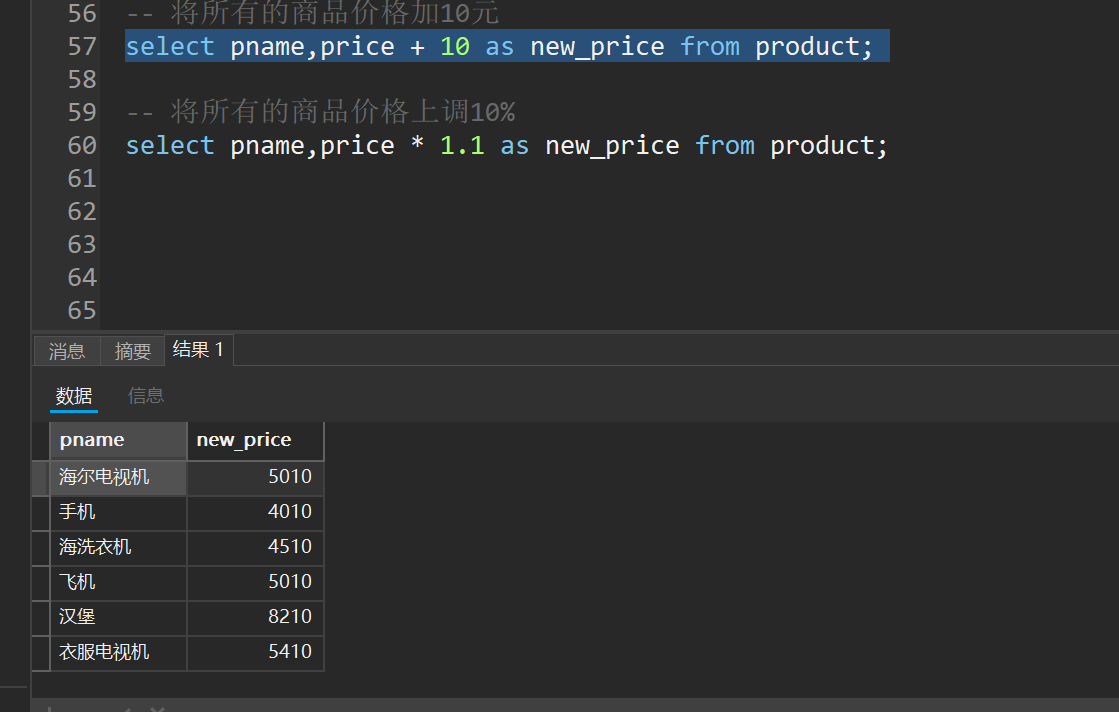
-- 将所有的商品价格加10元
select pname,price + 10 as new_price from product;
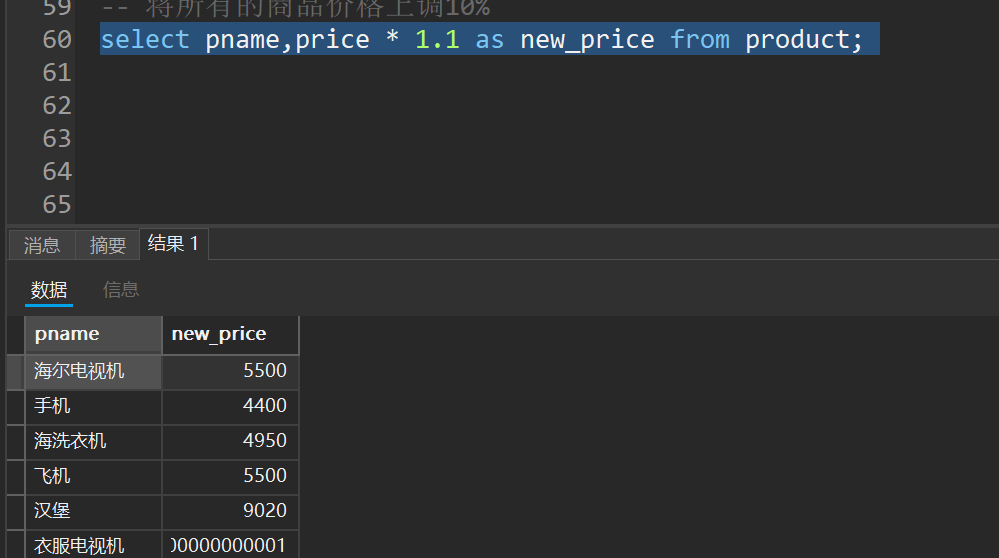
-- 将所有的商品价格上调10%
select pname,price * 1.1 as new_price from product;
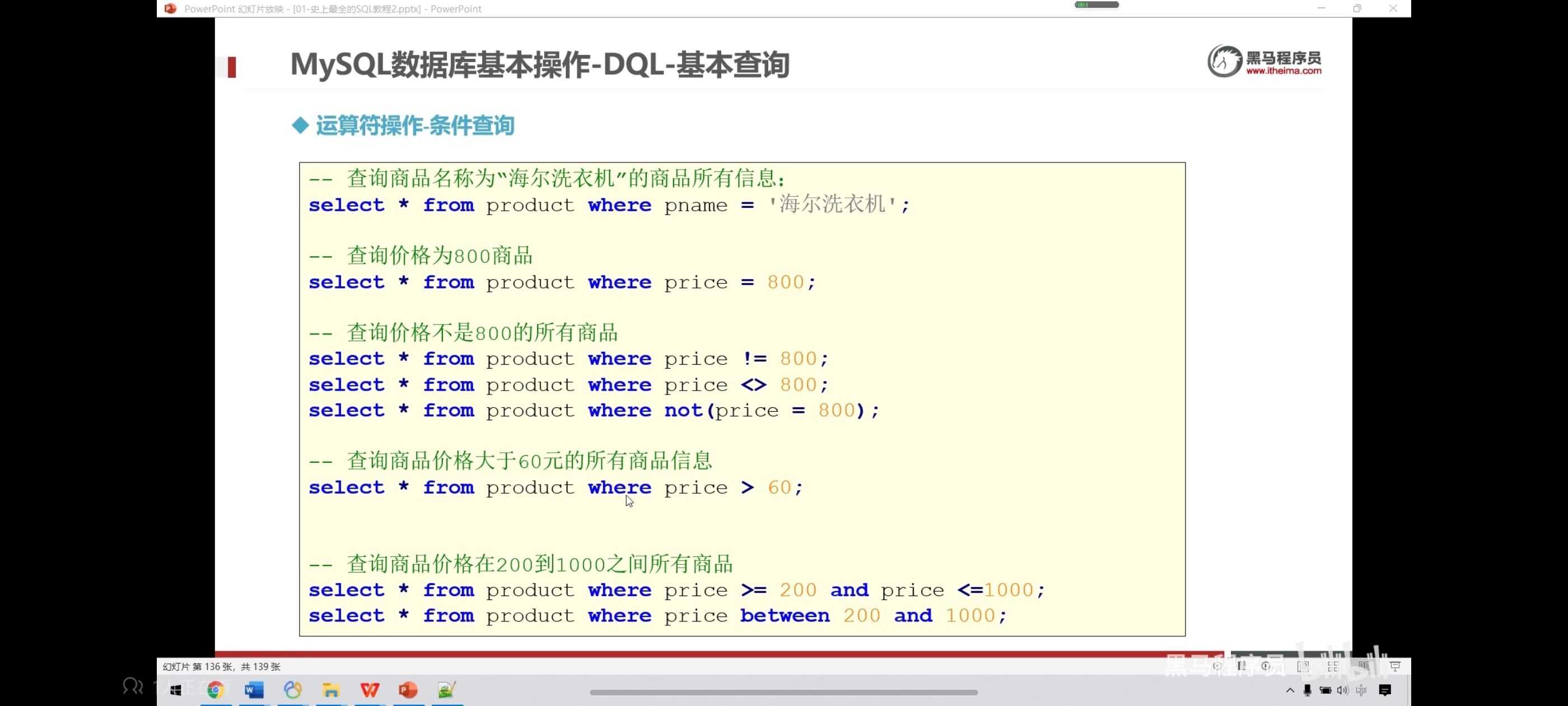
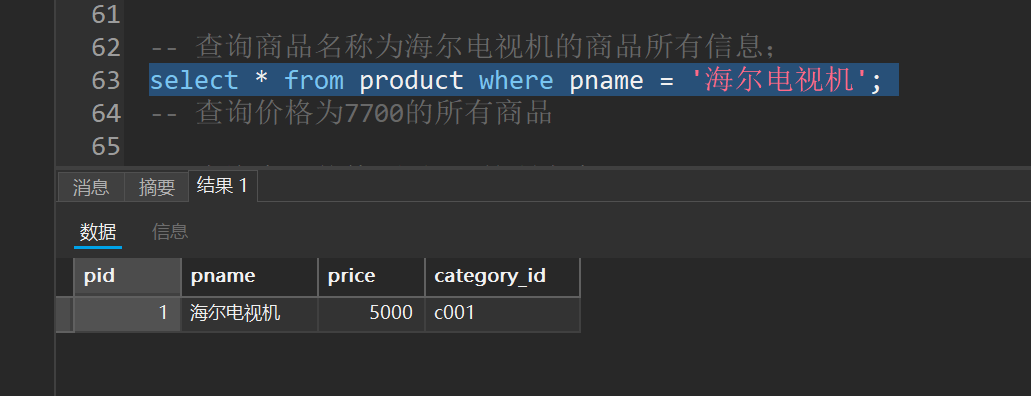
-- 查询商品名称为海尔电视机的商品所有信息;
select * from product where pname = '海尔电视机';
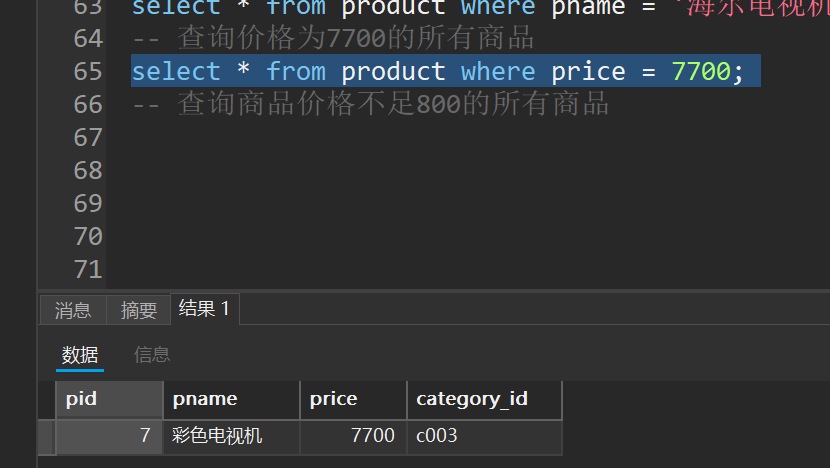
-- 查询价格为7700的所有商品
select * from product where price = 7700;
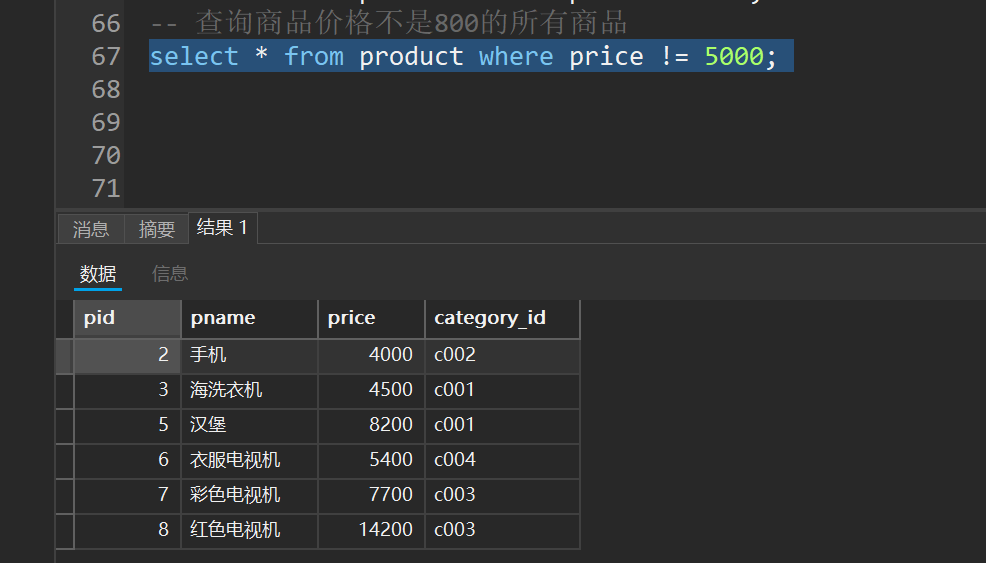
-- 查询商品价格不是800的所有商品
select * from product where price != 5000;
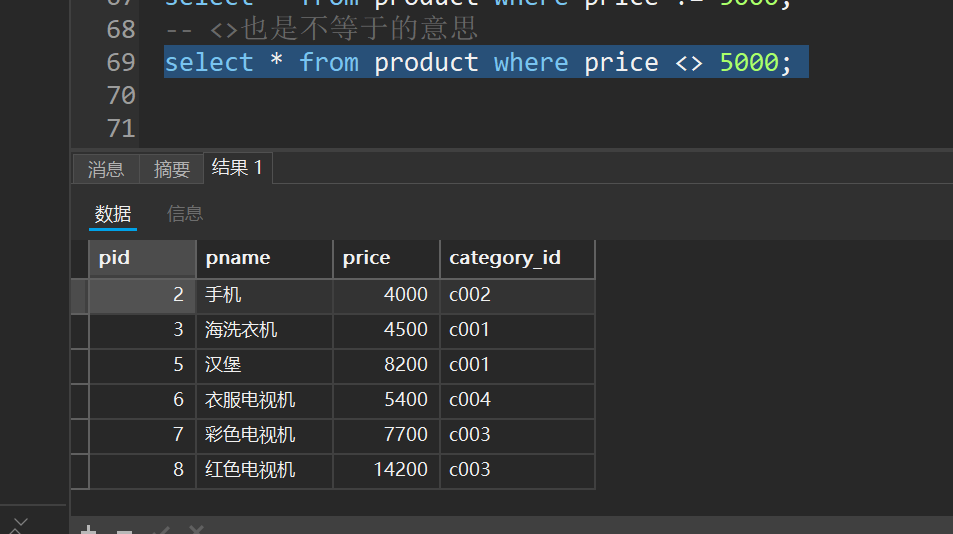
-- <>也是不等于的意思
select * from product where price <> 5000;
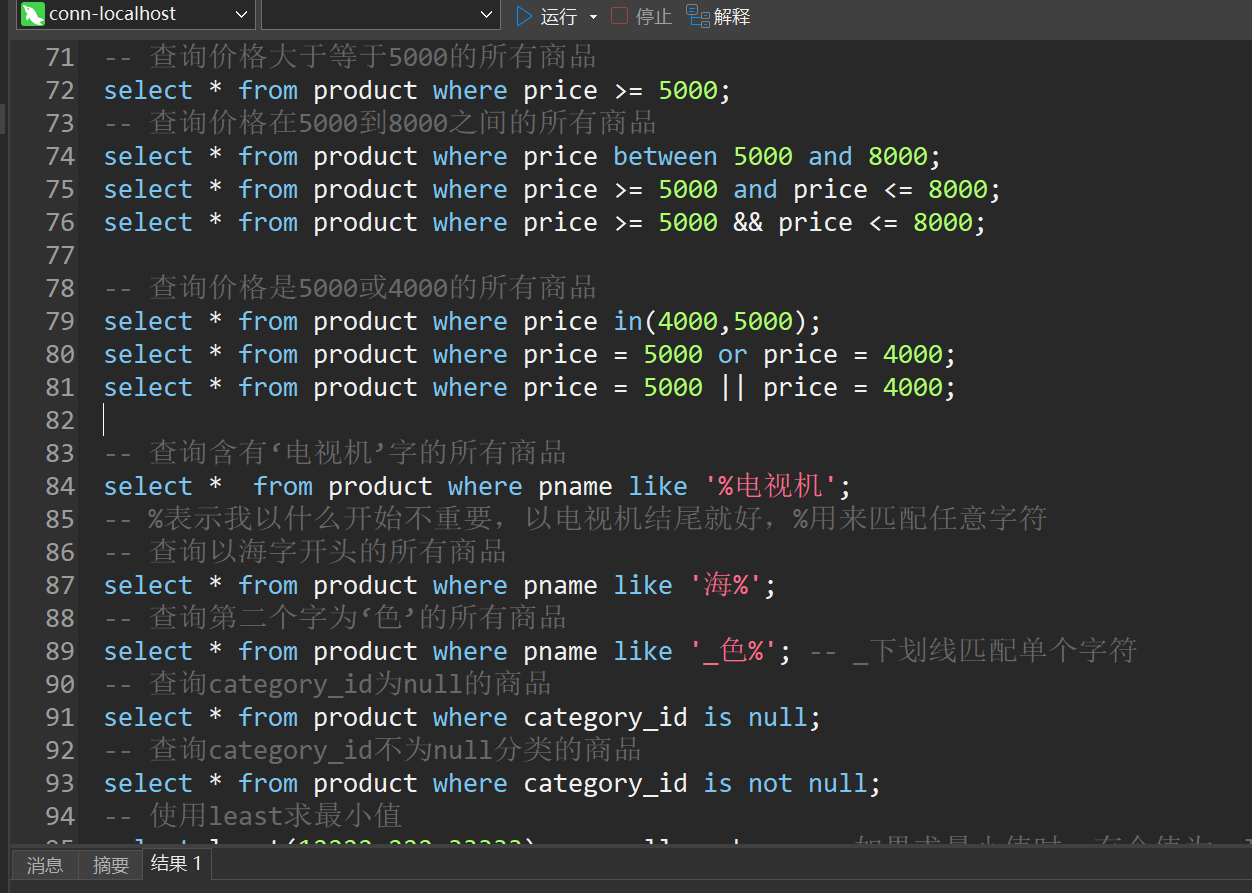
-- 查询价格大于等于5000的所有商品
select * from product where price >= 5000;
-- 查询价格在5000到8000之间的所有商品
select * from product where price between 5000 and 8000;
select * from product where price >= 5000 and price <= 8000;
select * from product where price >= 5000 && price <= 8000;
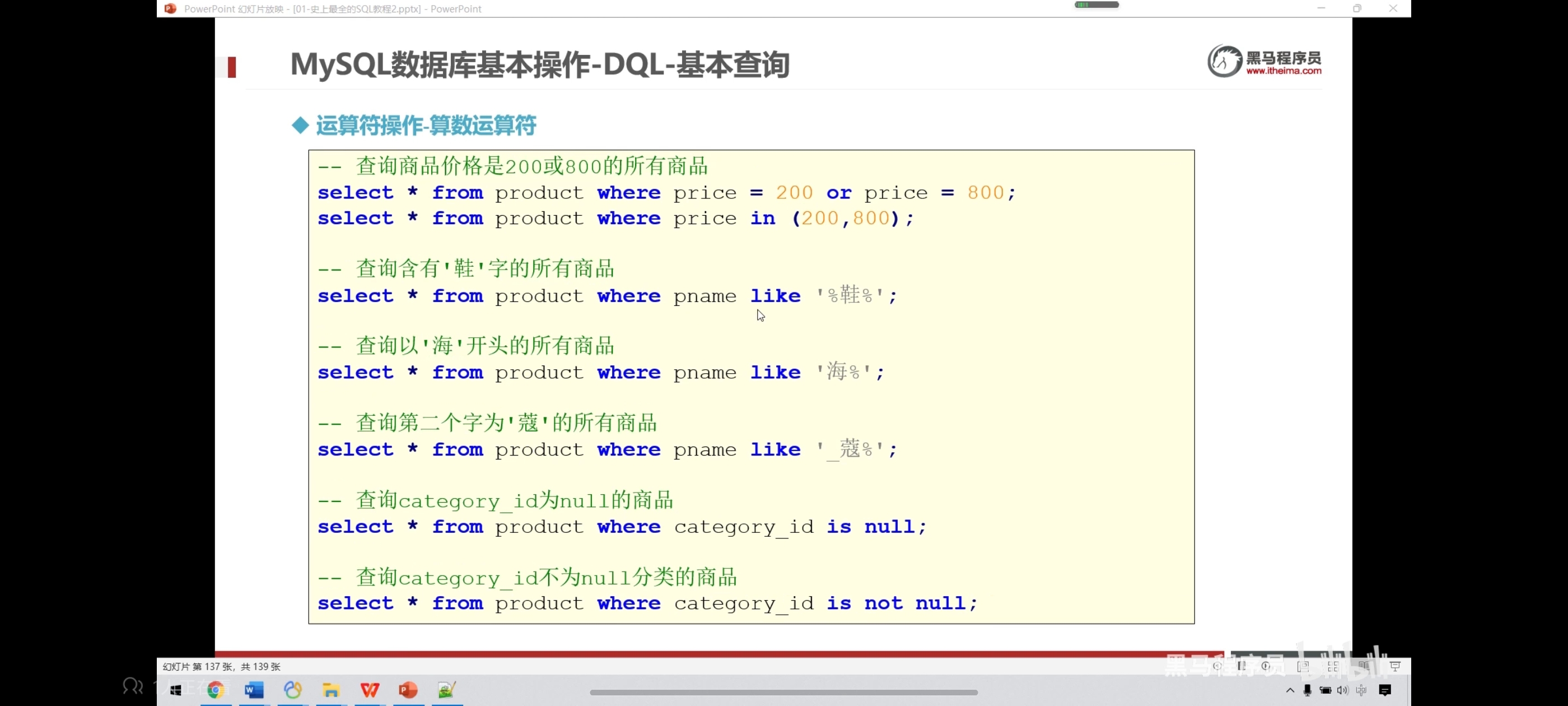
-- 查询价格是5000或4000的所有商品
select * from product where price in(4000,5000);
select * from product where price = 5000 or price = 4000;
select * from product where price = 5000 || price = 4000;
-- 查询含有‘电视机’字的所有商品
select * from product where pname like '%电视机';
-- %表示我以什么开始不重要,以电视机结尾就好,%用来匹配任意字符
-- 查询以海字开头的所有商品
select * from product where pname like '海%';
-- 查询第二个字为‘色’的所有商品
select * from product where pname like '_色%'; -- _下划线匹配单个字符
-- 查询category_id为null的商品
select * from product where category_id is null;
-- 查询category_id不为null分类的商品
select * from product where category_id is not null;
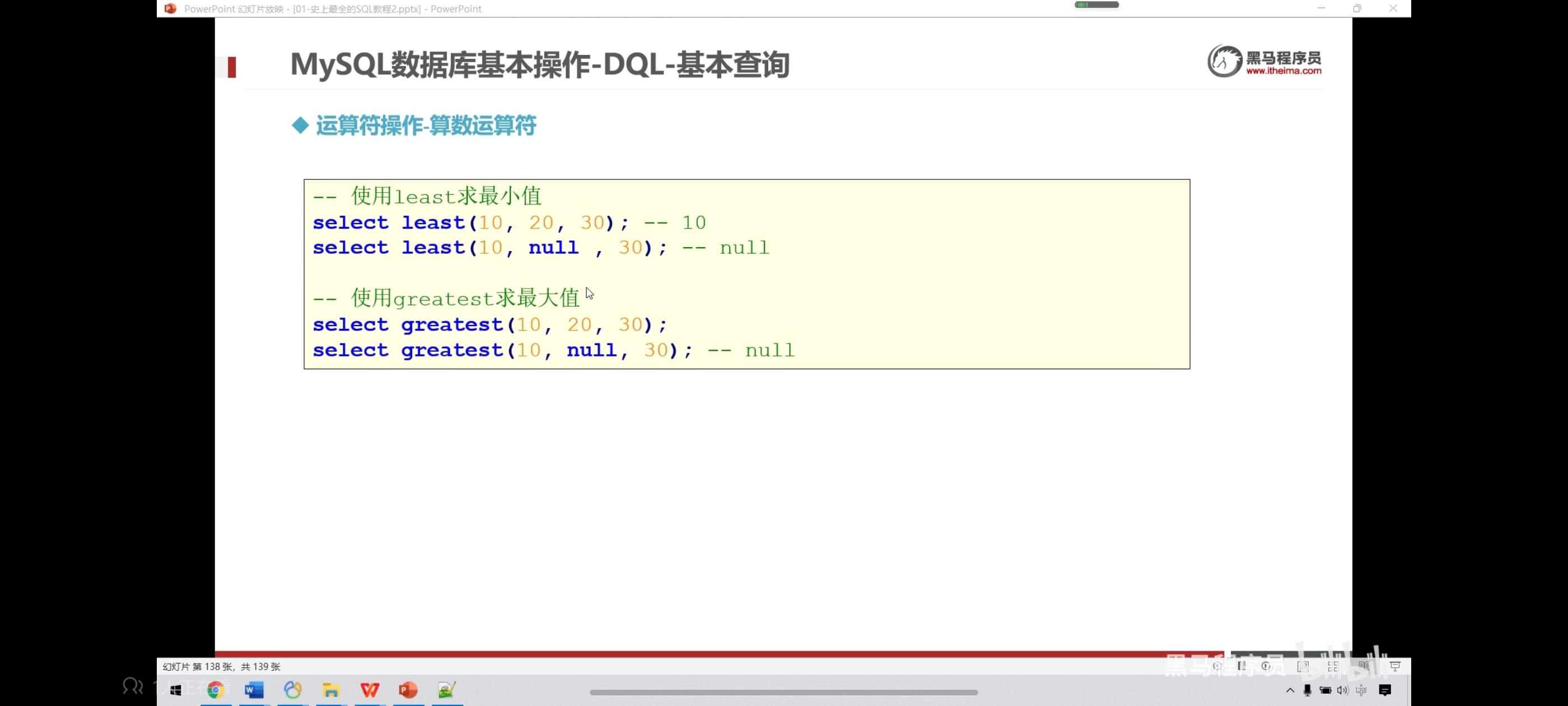
-- 使用least求最小值
select least(12222,222,33333) as small_number; -- 如果求最小值时,有个值为null,则不会进行比较,直接为null
-- 使用greatest求最大值
select greatest(121,232,23232) as big_number; -- 如果求最大值时,有个值为null,则不会进行比较,直接为null
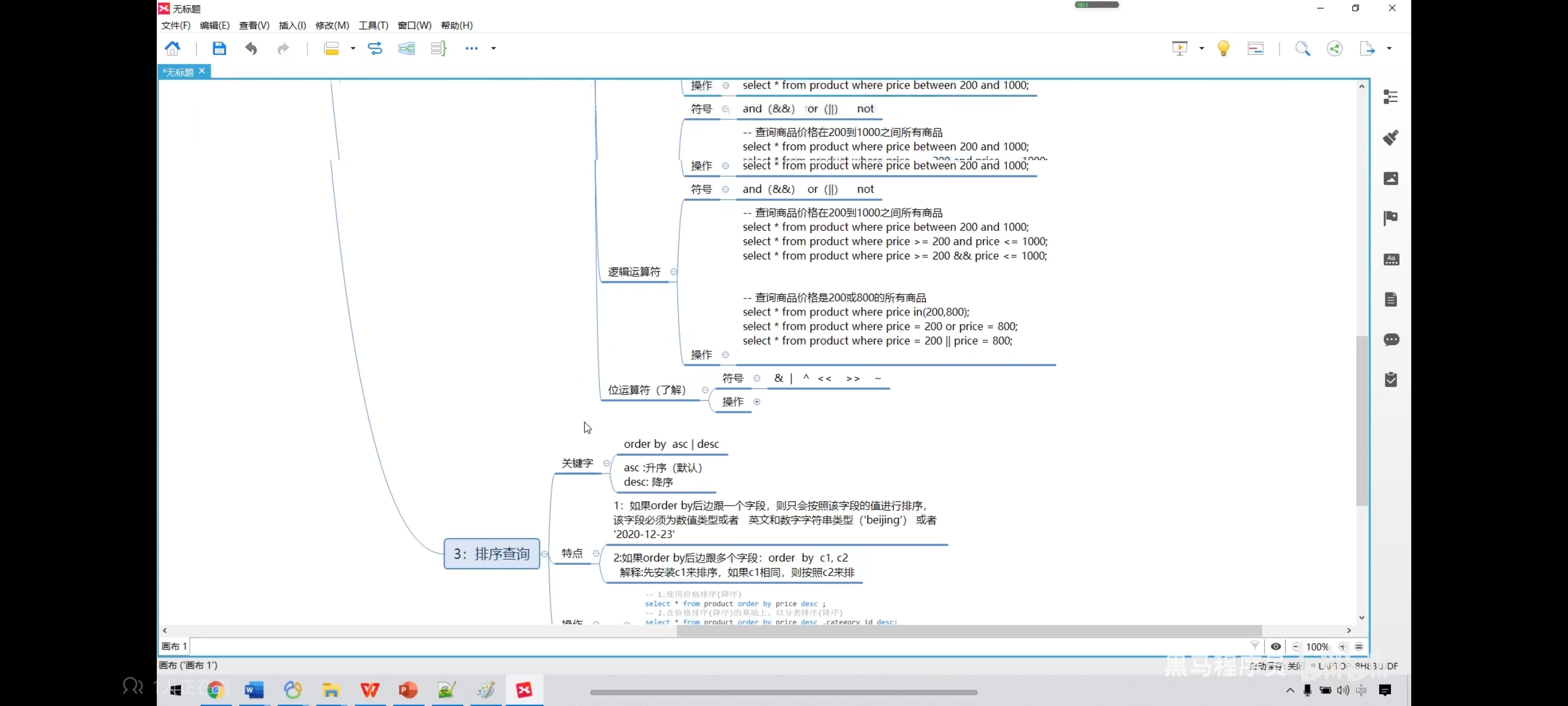
六、运算符操作-位运算操作
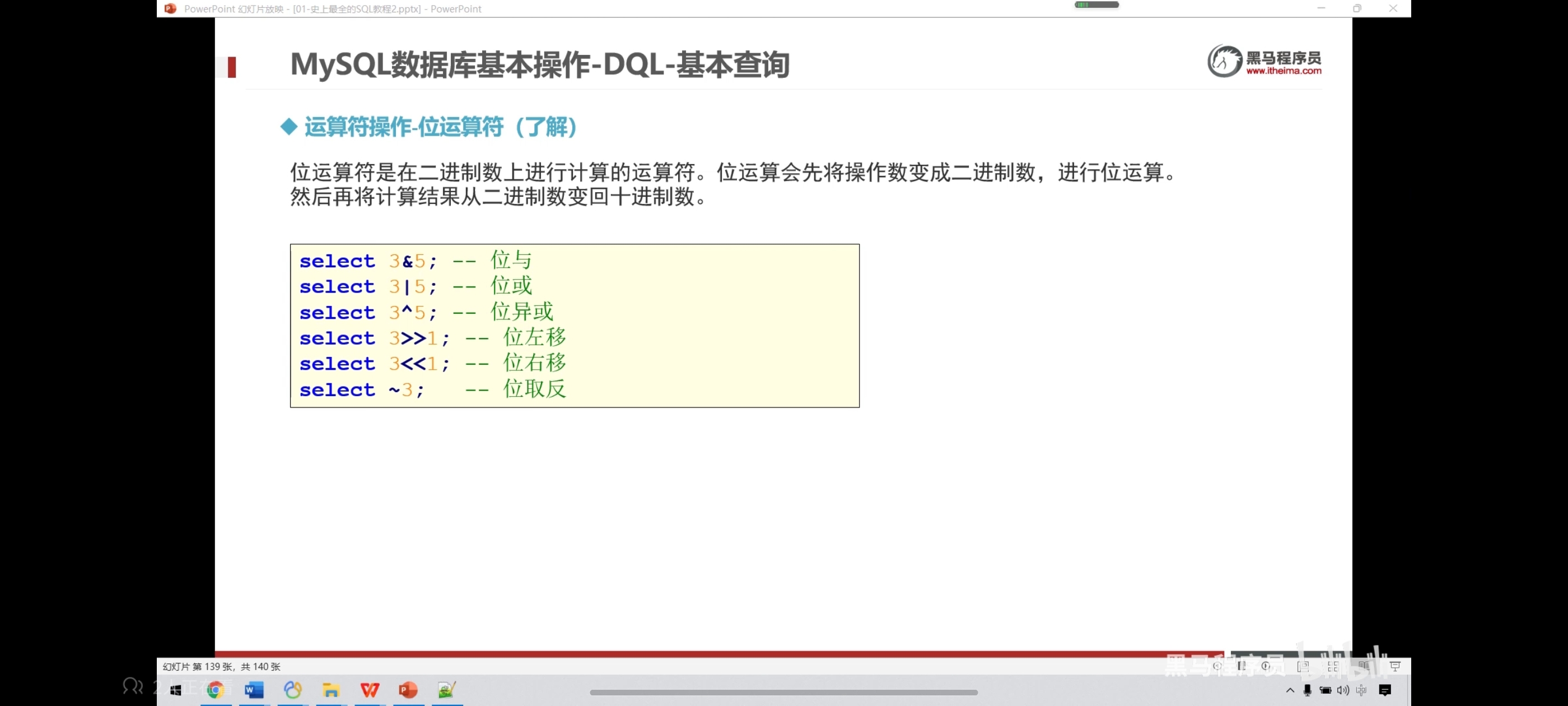
select 3 & 5; -- 位与,两个都为1就为1
select 3|5; -- 位或,有一个有一个为1就为1
select 3^5; -- 相同为0不同为1
select 3>>1; -- 位右移
select 3<<1; -- 位左移
select ~3; -- 位取反,取反就是把0变1,1变0
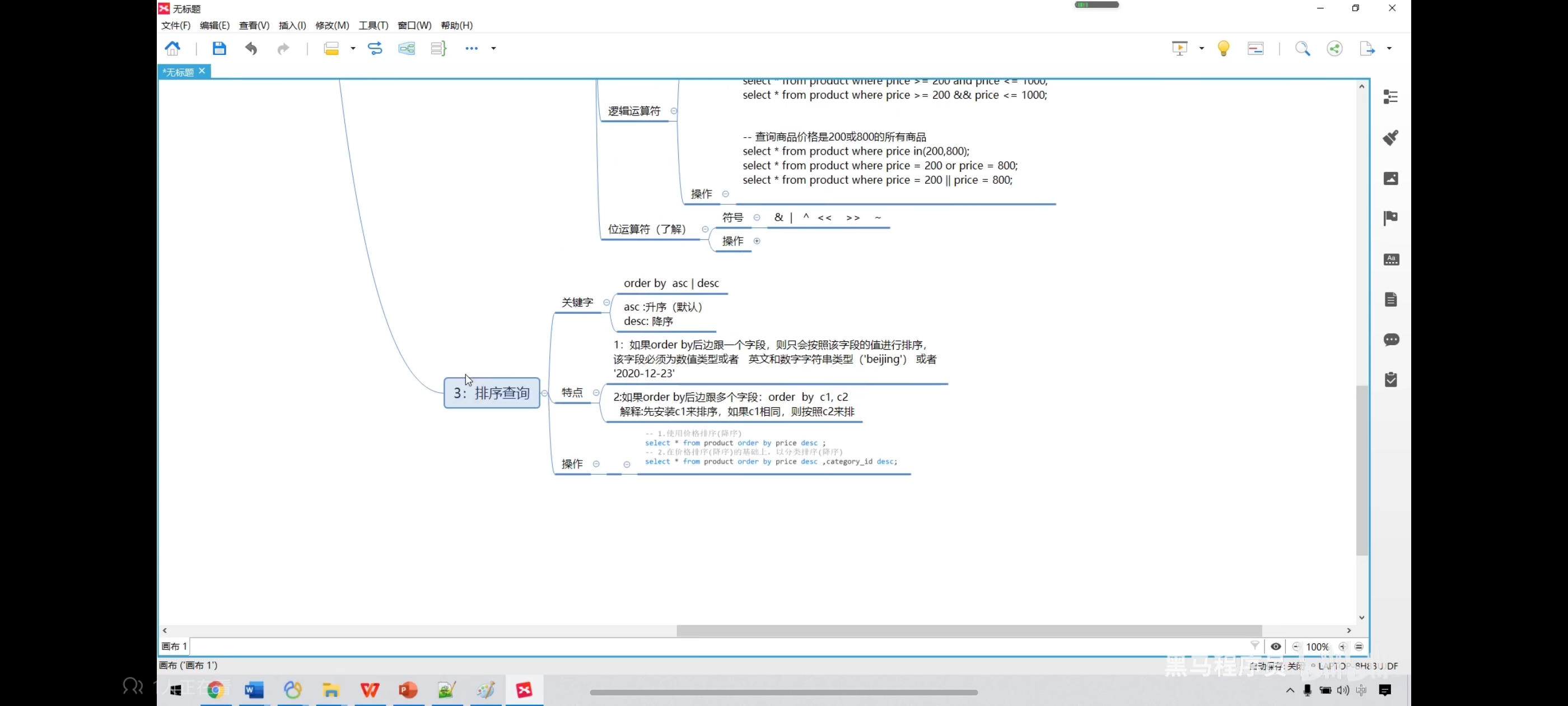
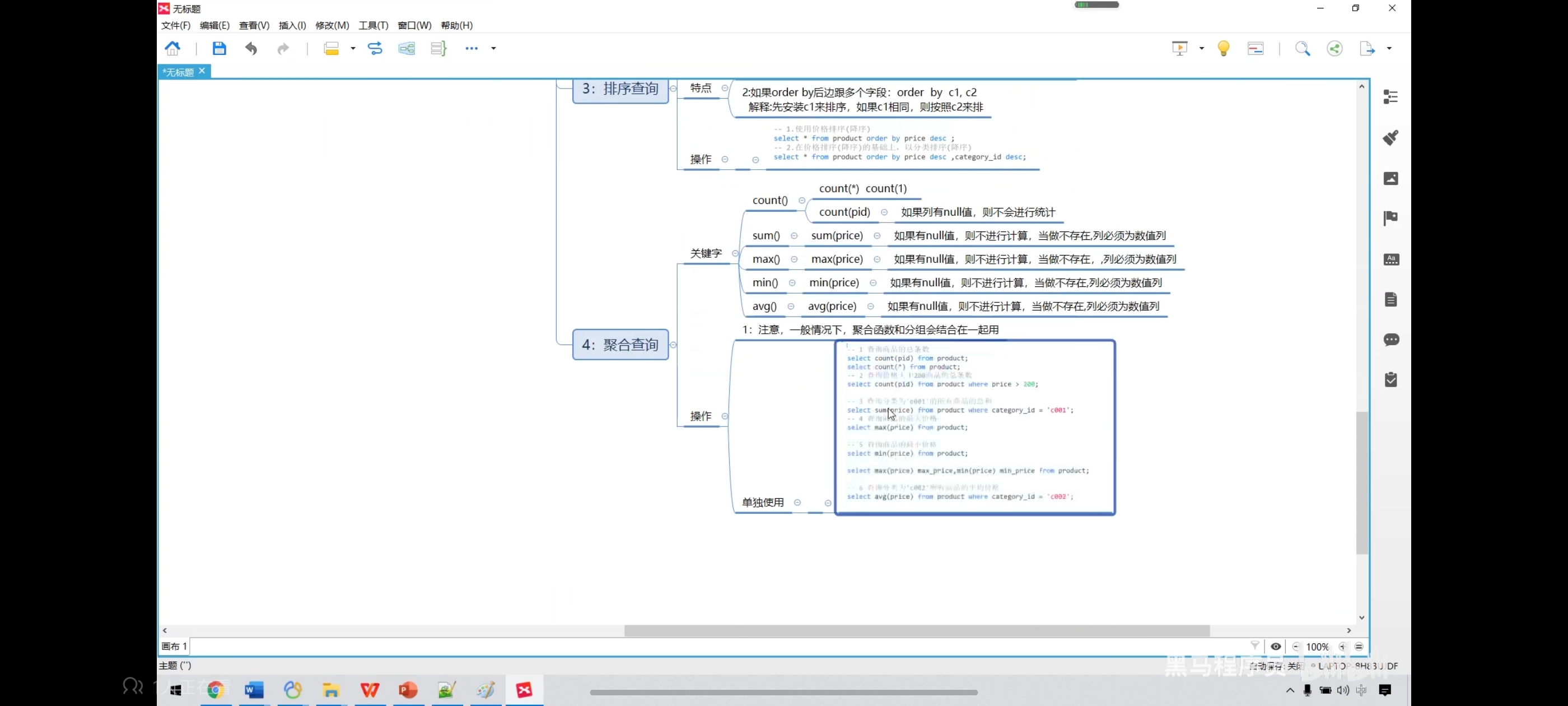
七、排序查询
写去重排序时记得只写一个字段名,如果写好几个就可能会导致无法一一对应。
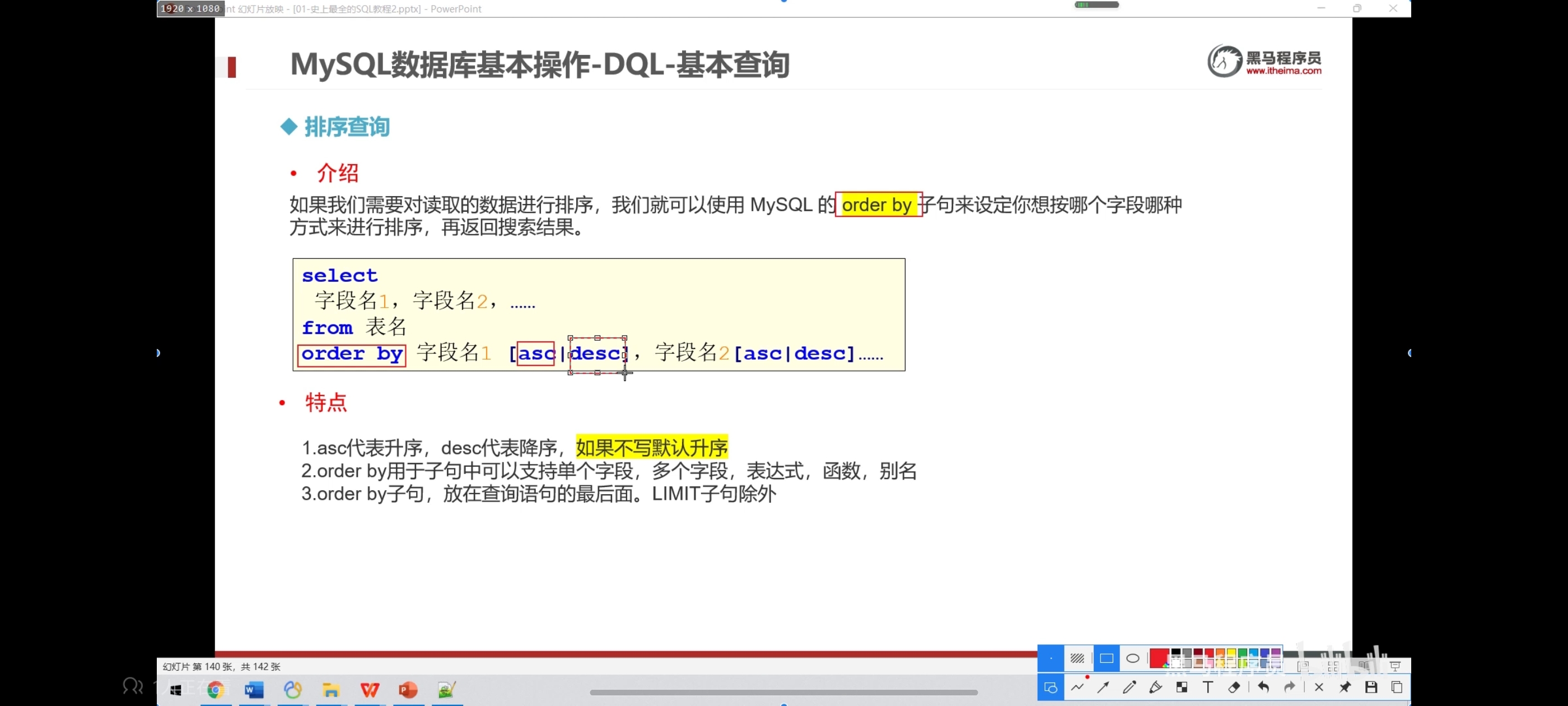
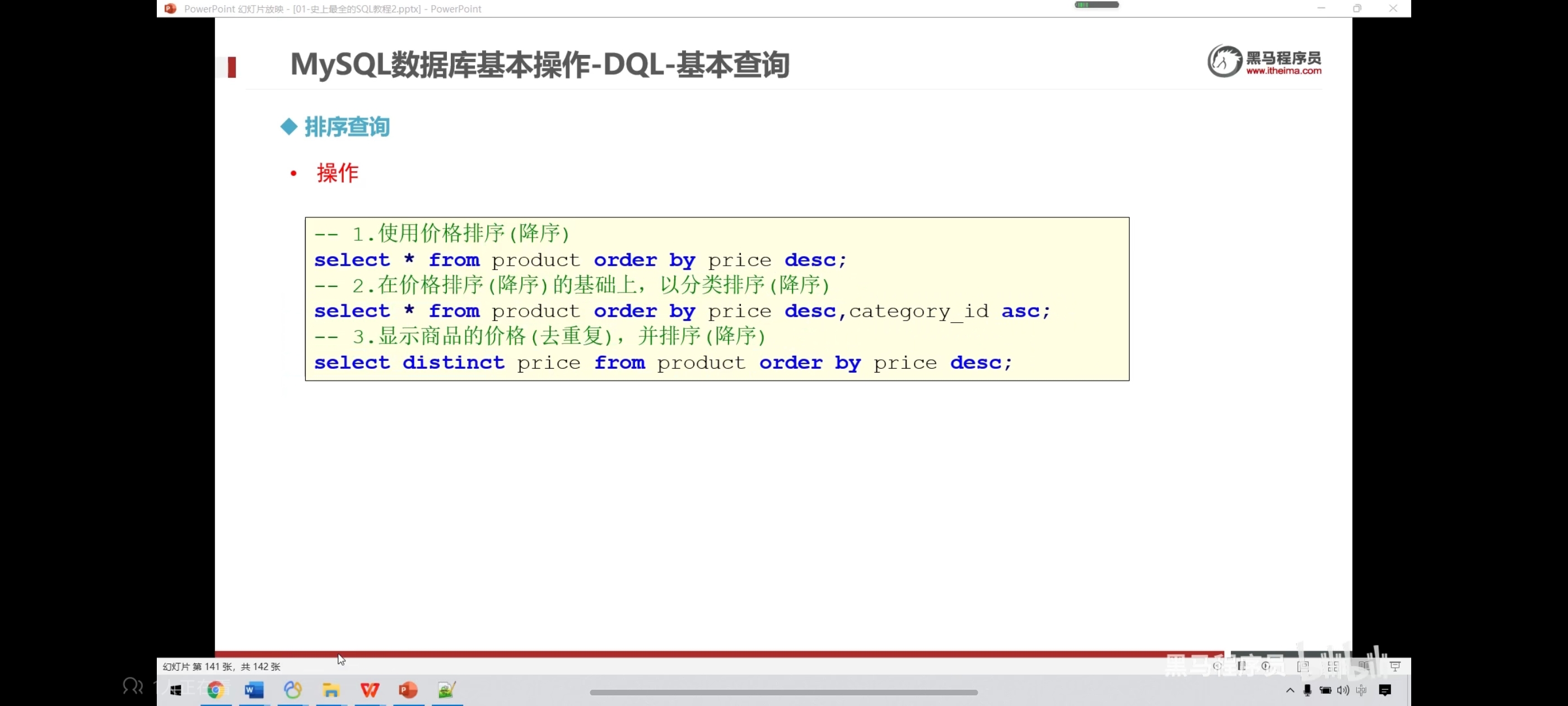
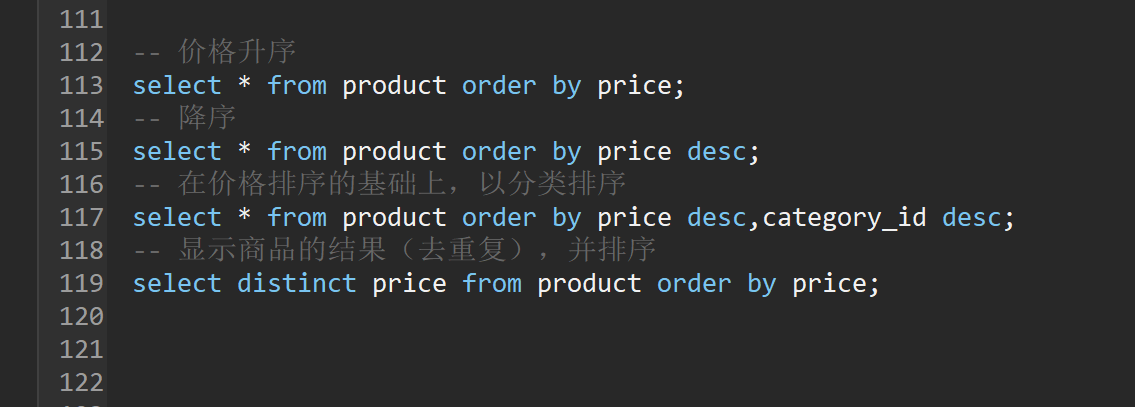
-- 价格升序
select * from product order by price;
-- 降序
select * from product order by price desc;
-- 在价格排序的基础上,以分类排序
select * from product order by price desc,category_id desc;
-- 显示商品的结果(去重复),并排序
select distinct price from product order by price;
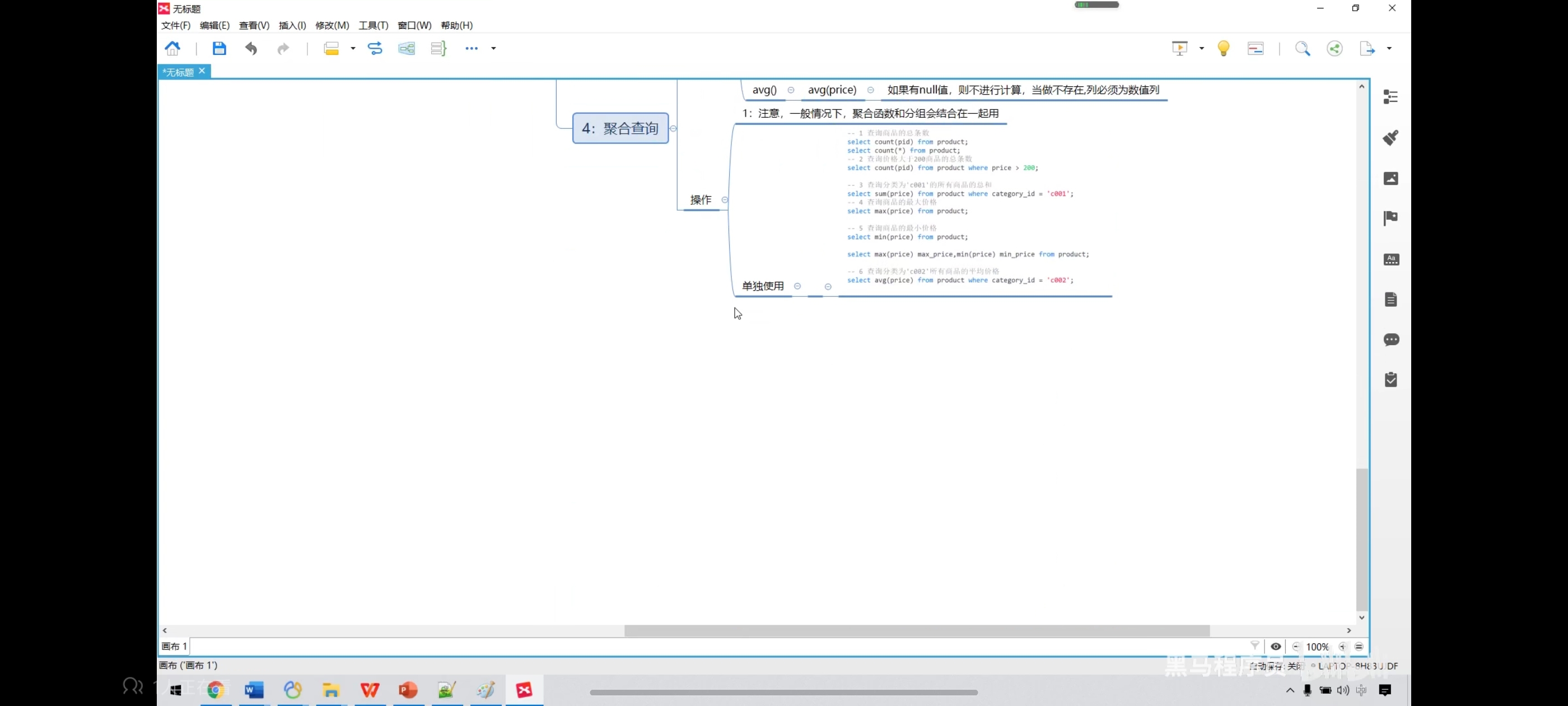
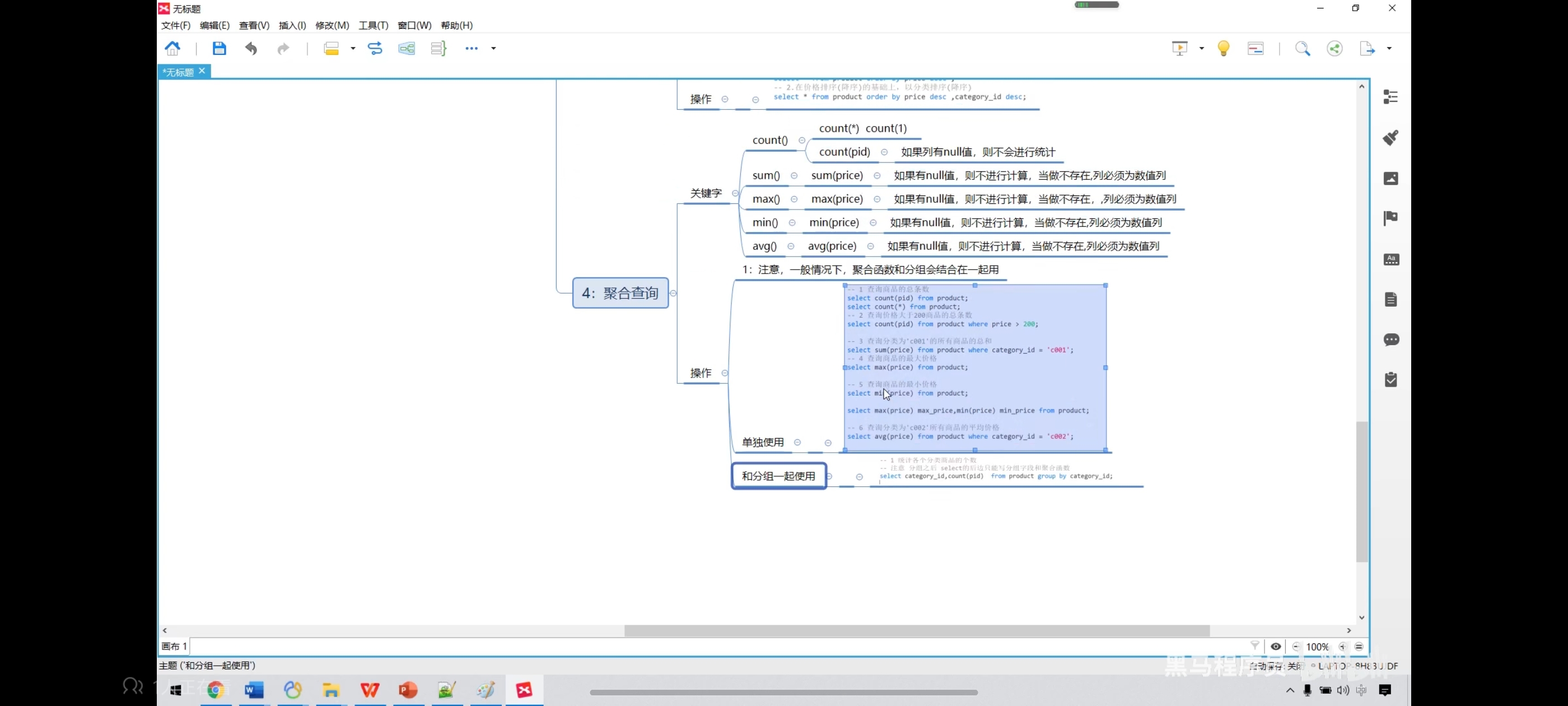
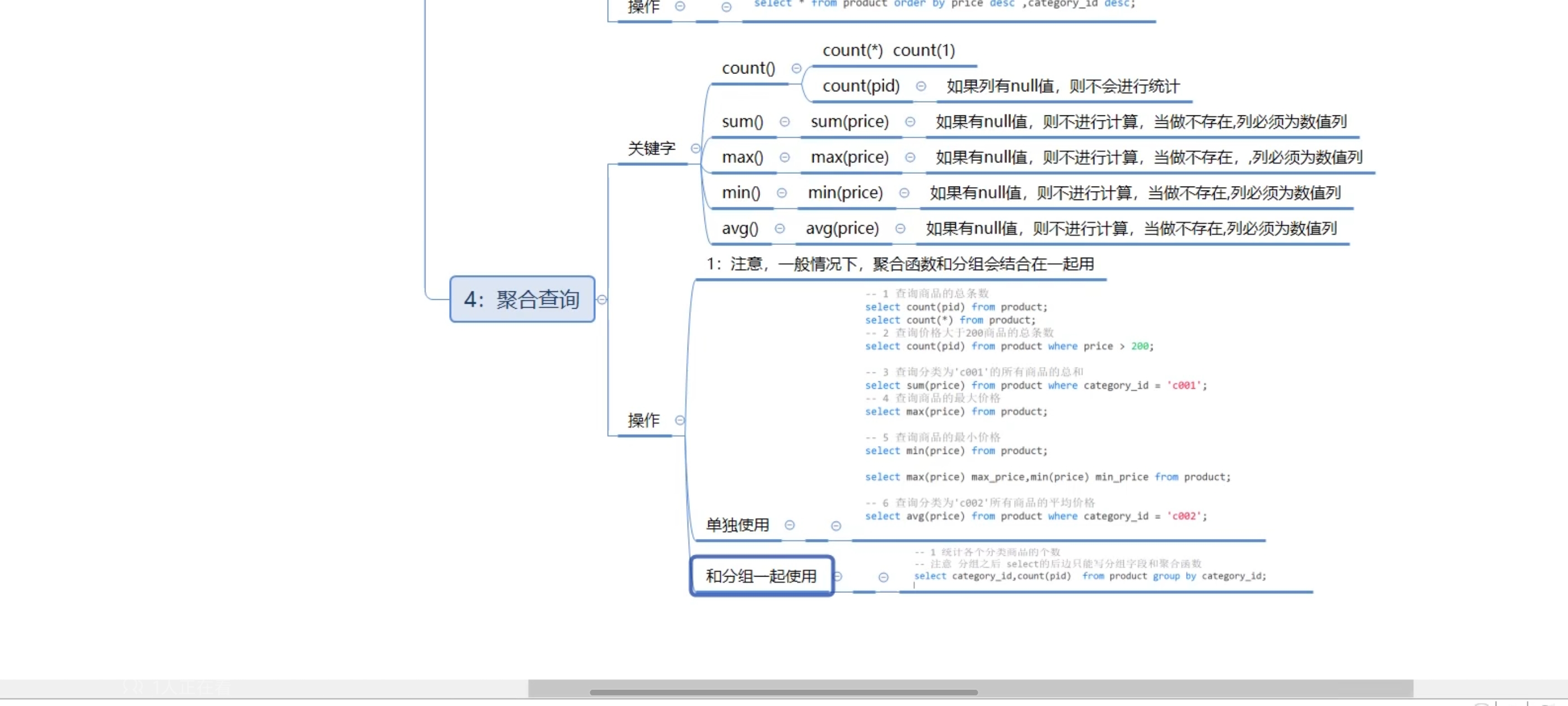
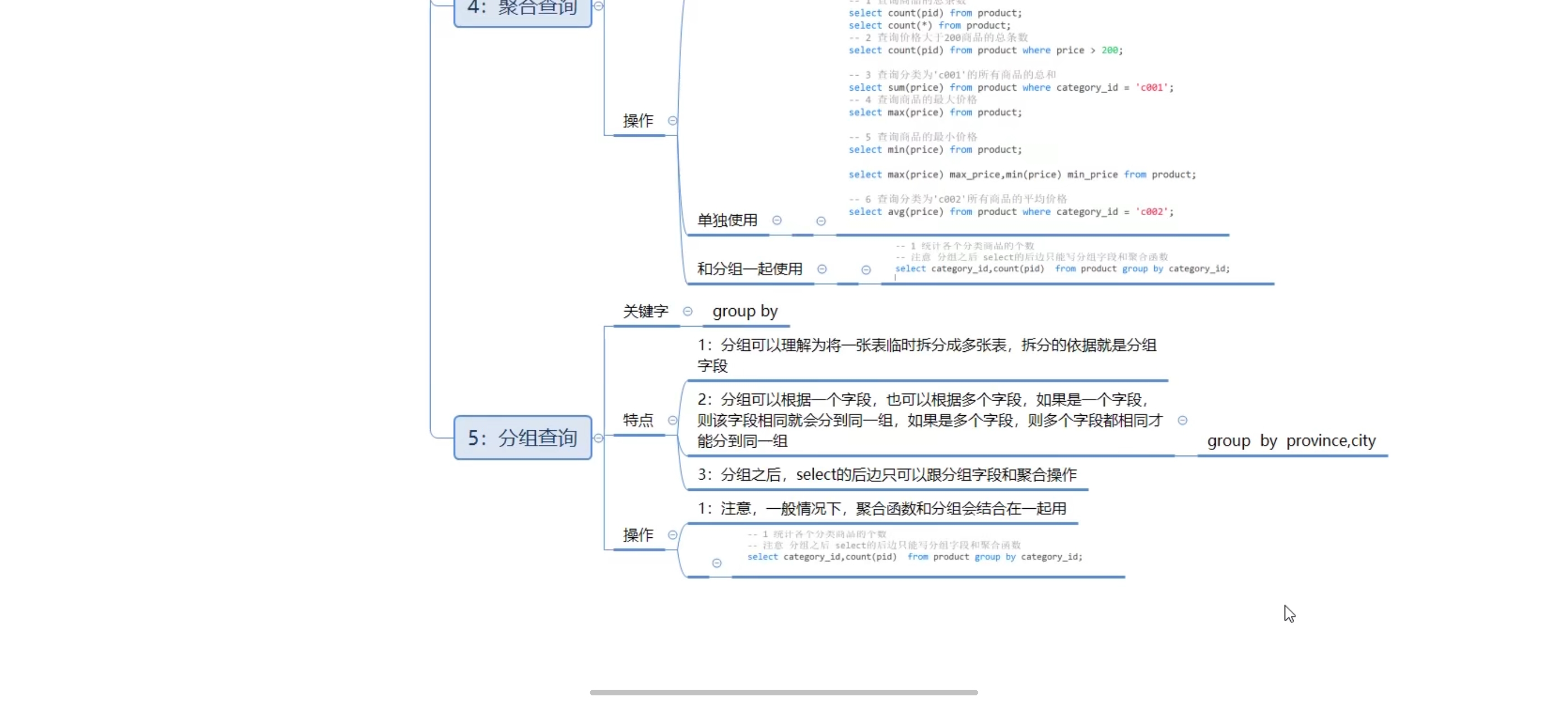
八、聚合查询
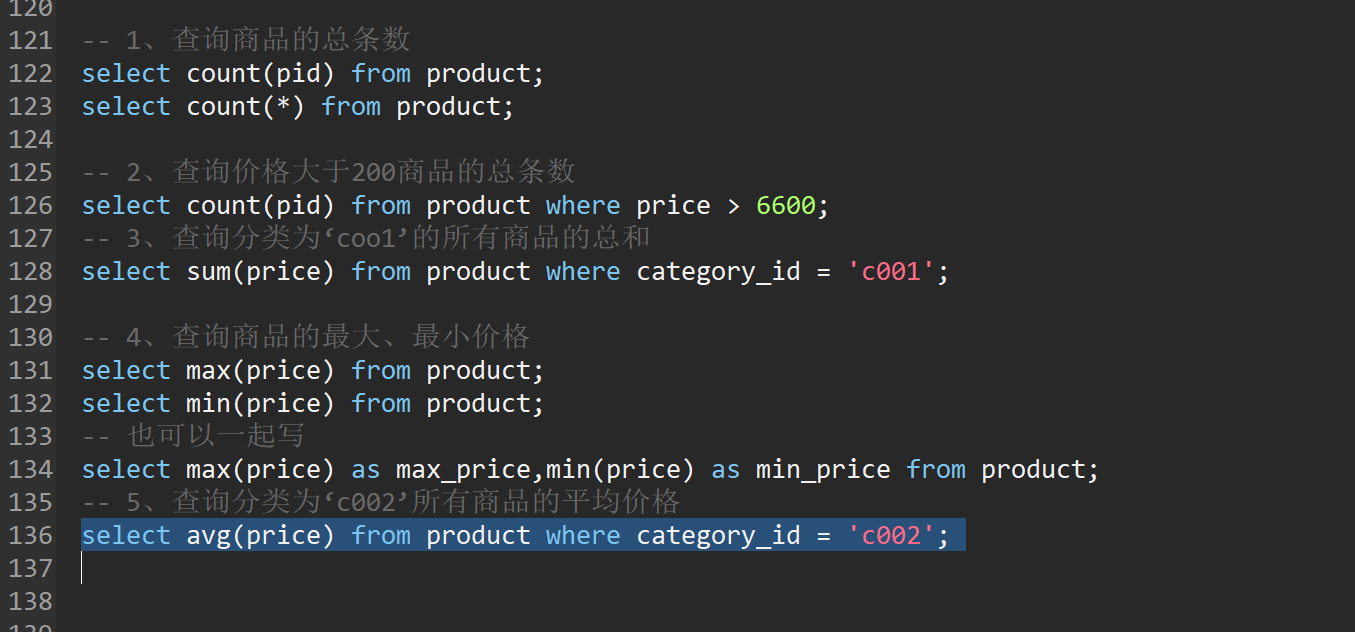
-- 1、查询商品的总条数
select count(pid) from product;
select count(*) from product;
-- 2、查询价格大于200商品的总条数
select count(pid) from product where price > 6600;
-- 3、查询分类为‘coo1’的所有商品的总和
select sum(price) from product where category_id = 'c001';
-- 4、查询商品的最大、最小价格
select max(price) from product;
select min(price) from product;
-- 也可以一起写
select max(price) as max_price,min(price) as min_price from product;
-- 5、查询分类为‘c002’所有商品的平均价格
select avg(price) from product where category_id = 'c002';
九、聚合查询-null值处理
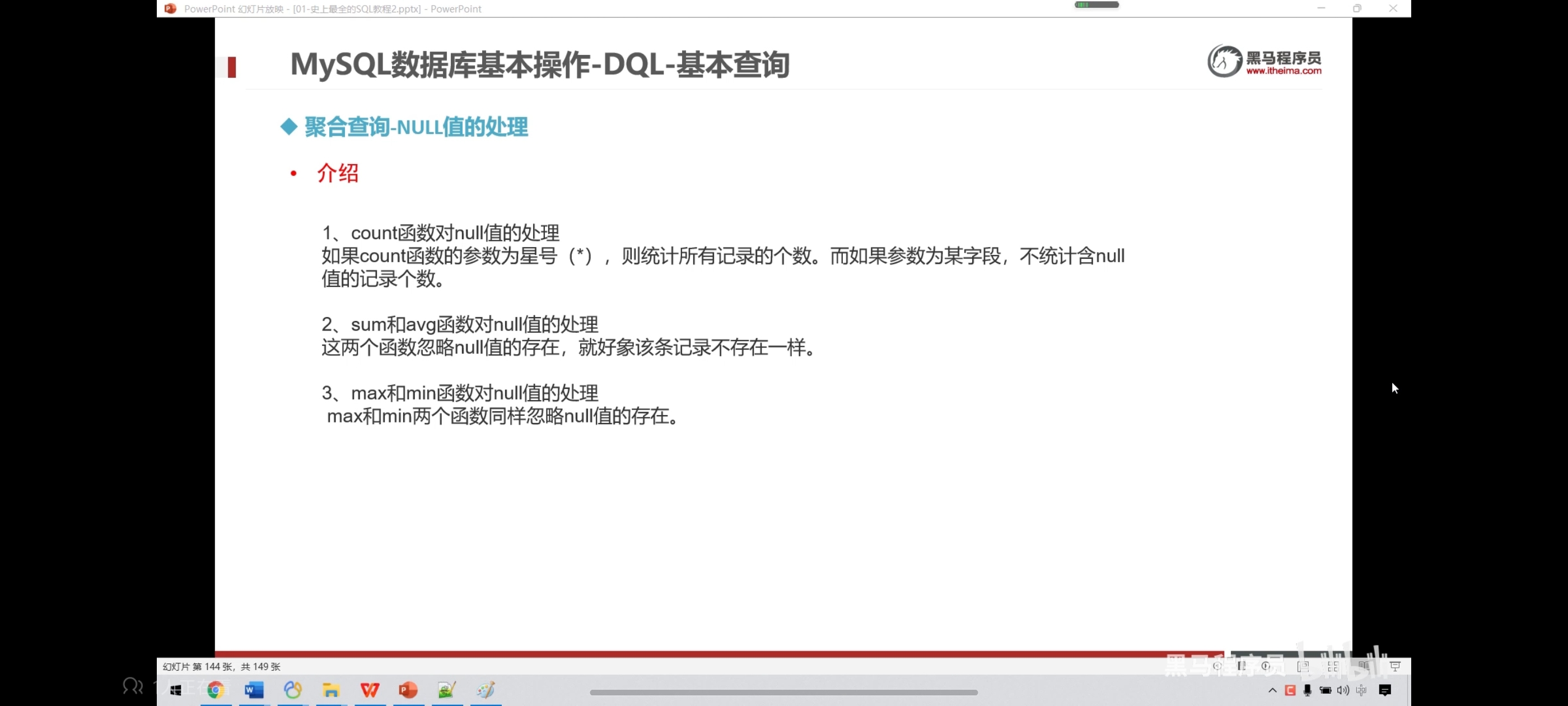
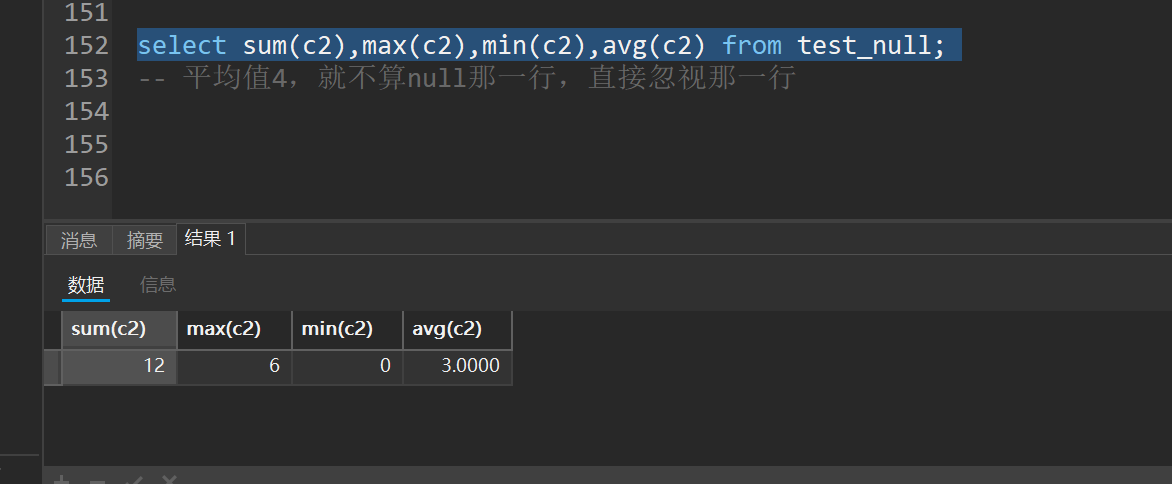
聚合查询里面都忽视null

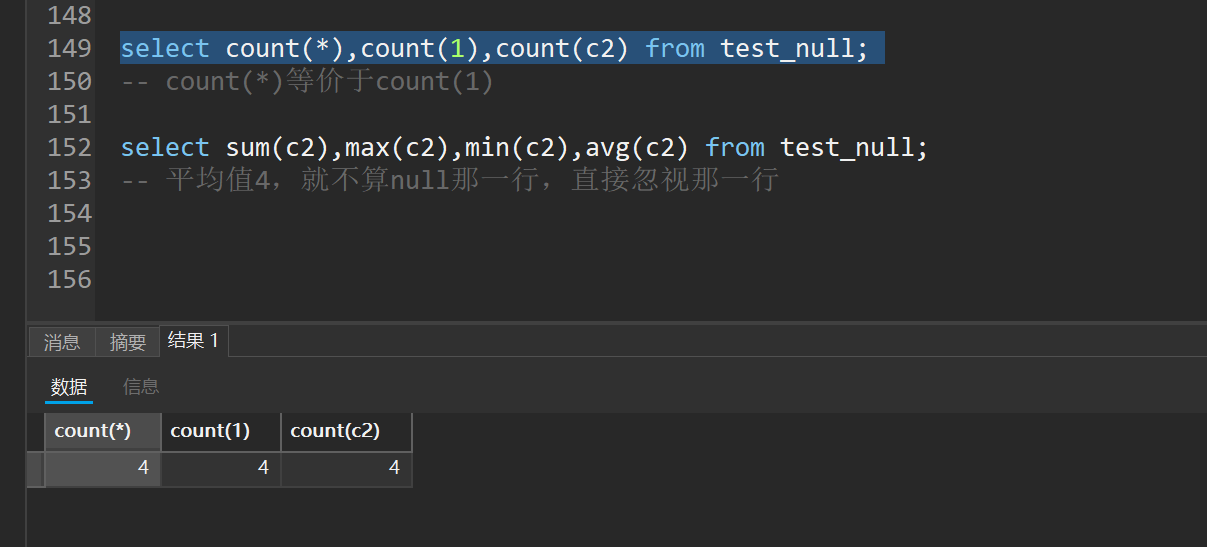
count(*) 和 count(1)等价
如果想处理null,可以把他初始化为0,这样就不影响聚合查询了
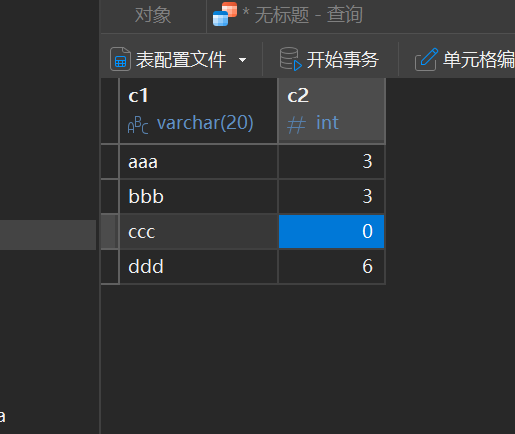
use mydb2;
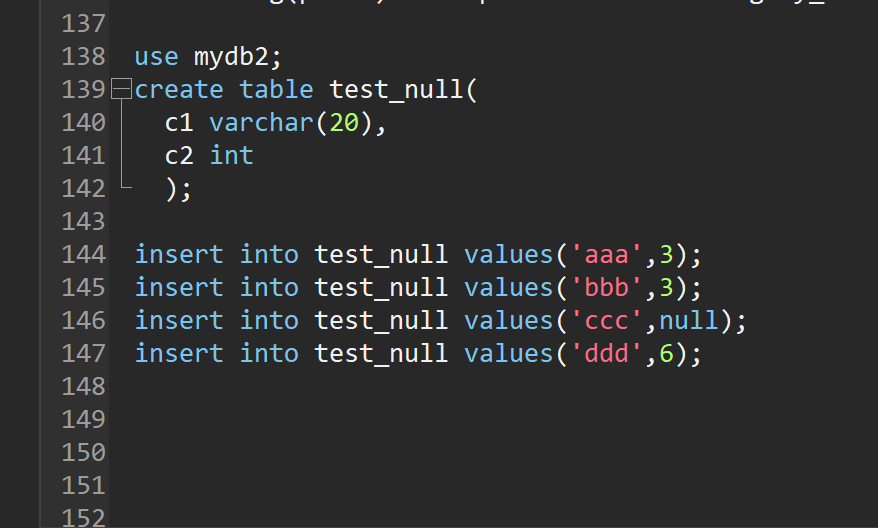
create table test_null(
c1 varchar(20),
c2 int
);
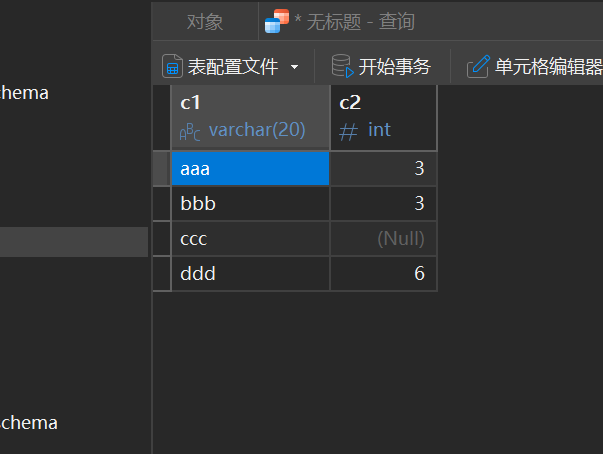
insert into test_null values('aaa',3);
insert into test_null values('bbb',3);
insert into test_null values('ccc',null);
insert into test_null values('ddd',6);
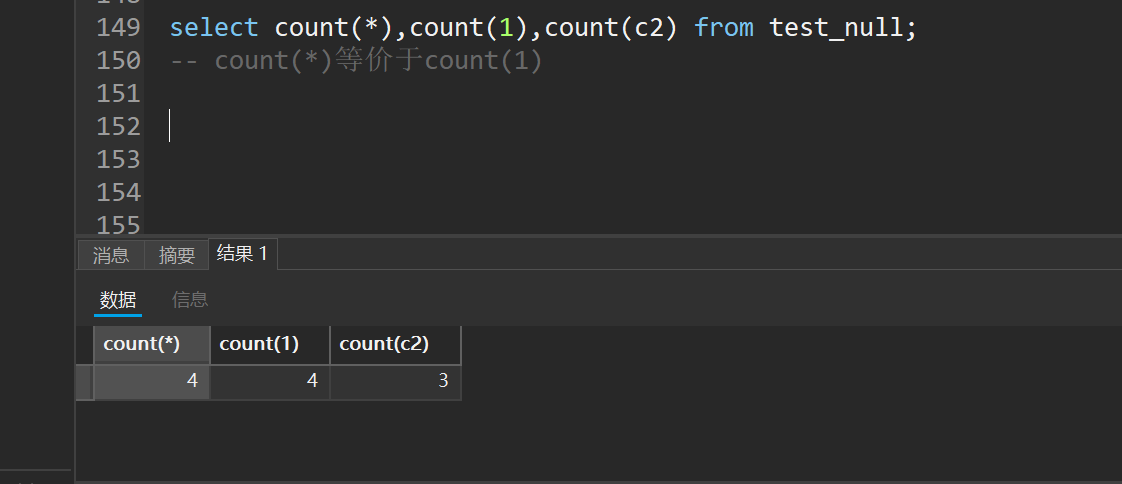
select count(*),count(1),count(c2) from test_null;
-- count(*)等价于count(1)
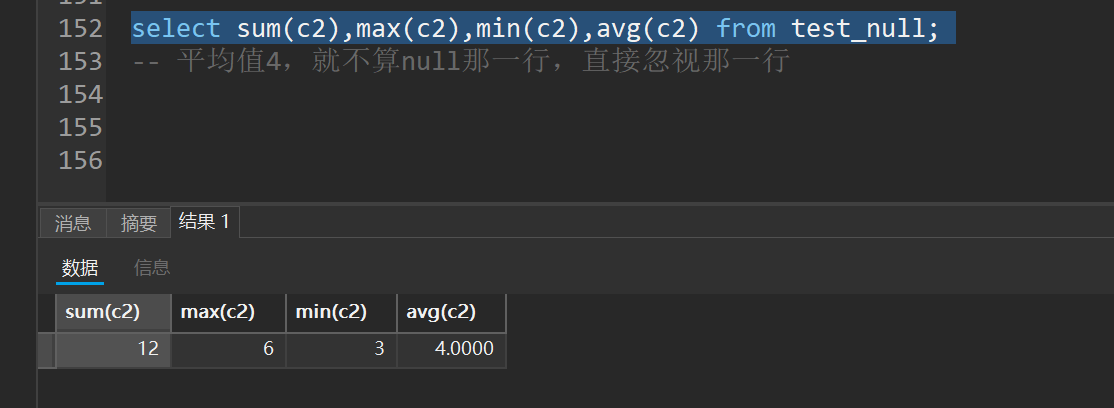
select sum(c2),max(c2),min(c2),avg(c2) from test_null;
-- 平均值4,就不算null那一行,直接忽视那一行
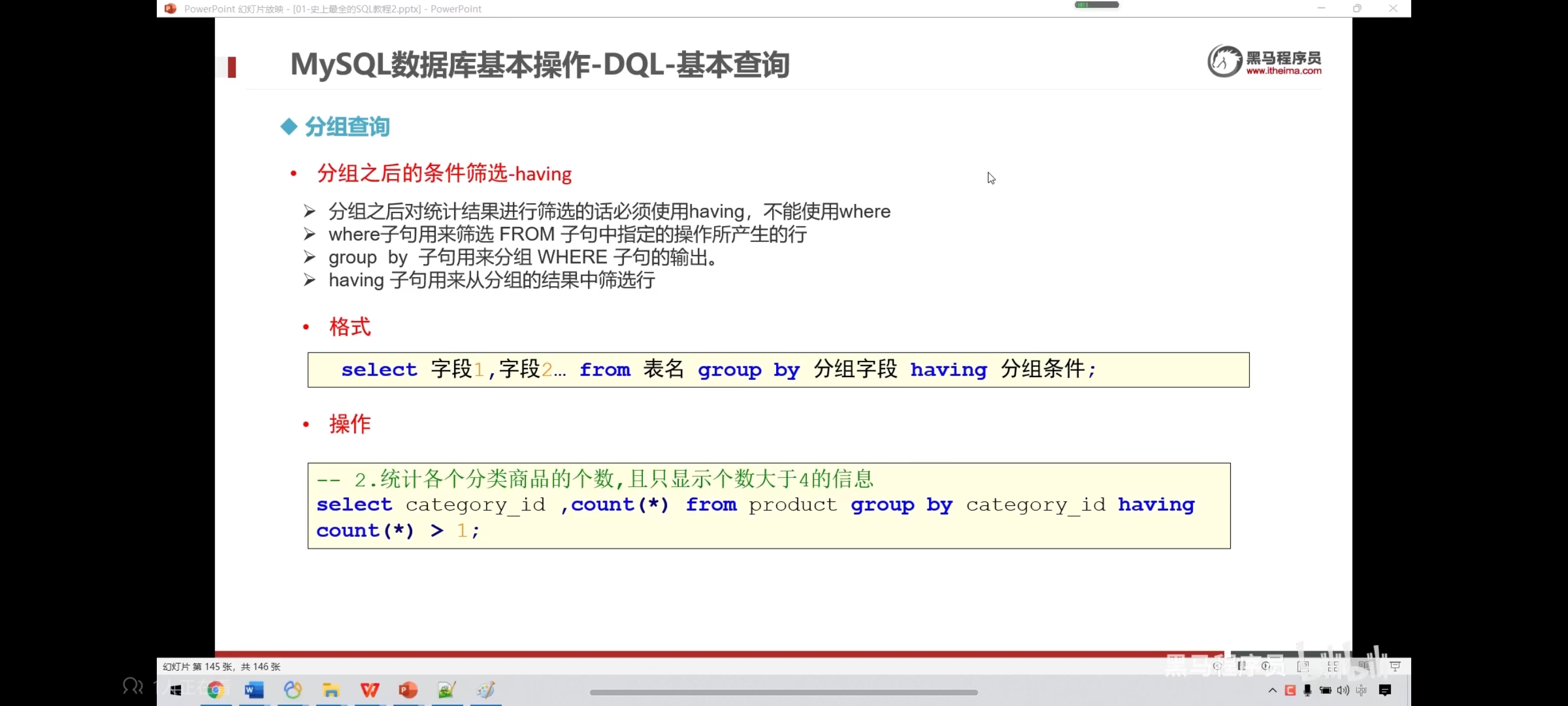
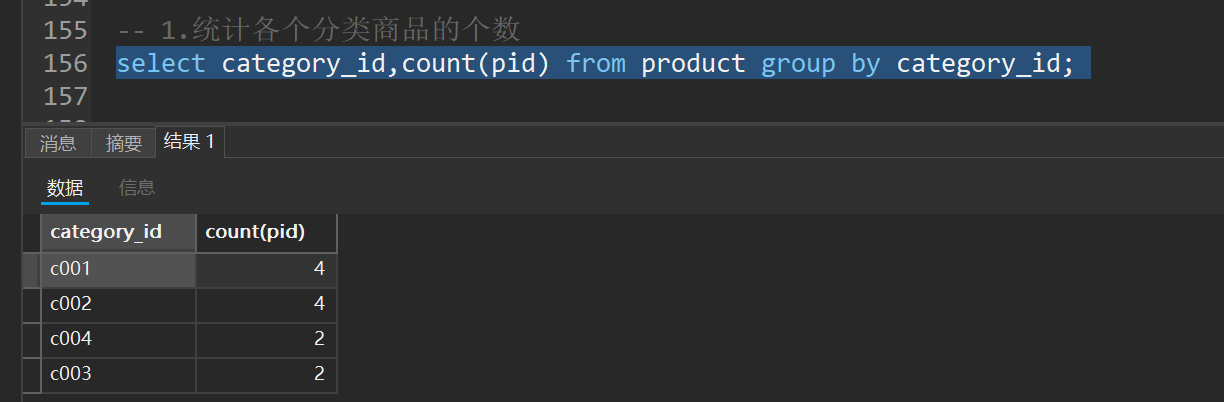
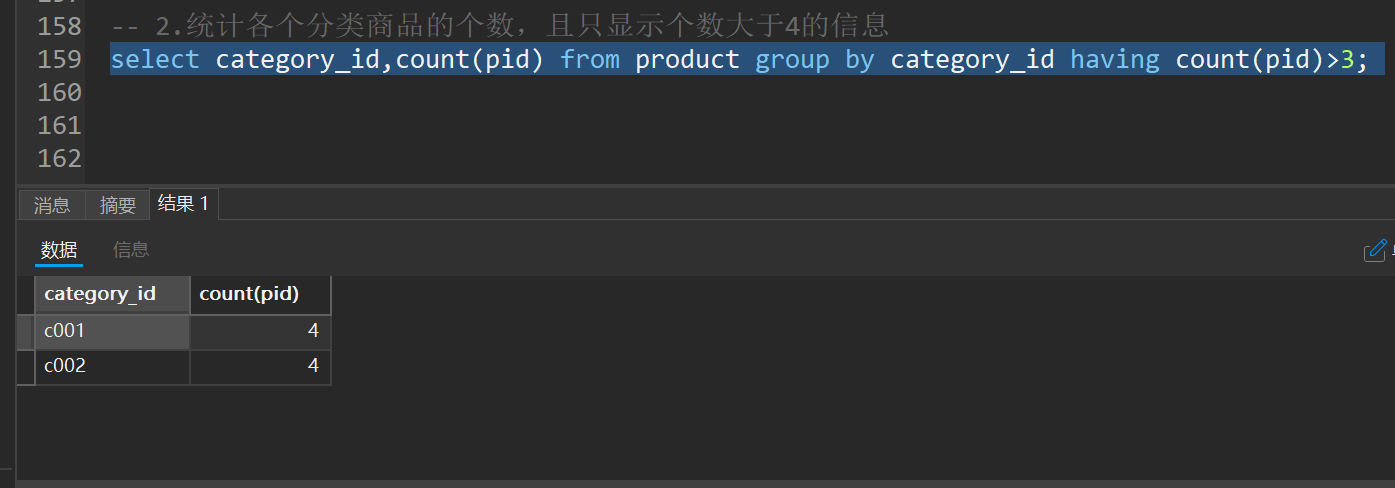
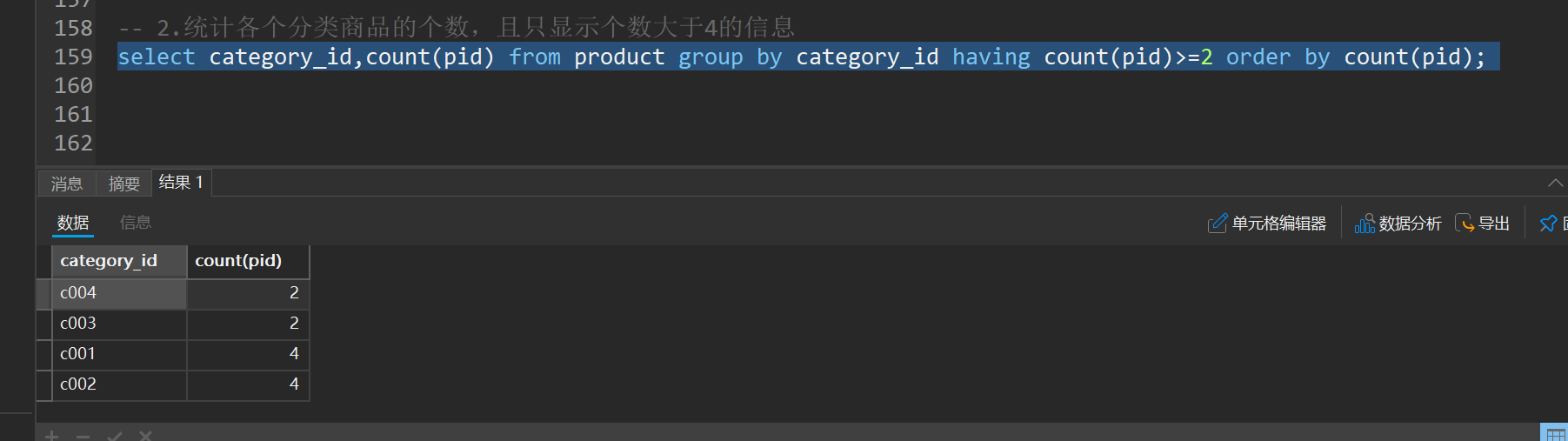
十、分组查询-group by
语法:select 字段1,字段2... from 表名 group by 分组字段 having 分租条件;
注意:分组之后select的后边只能写分组字段和聚合函数
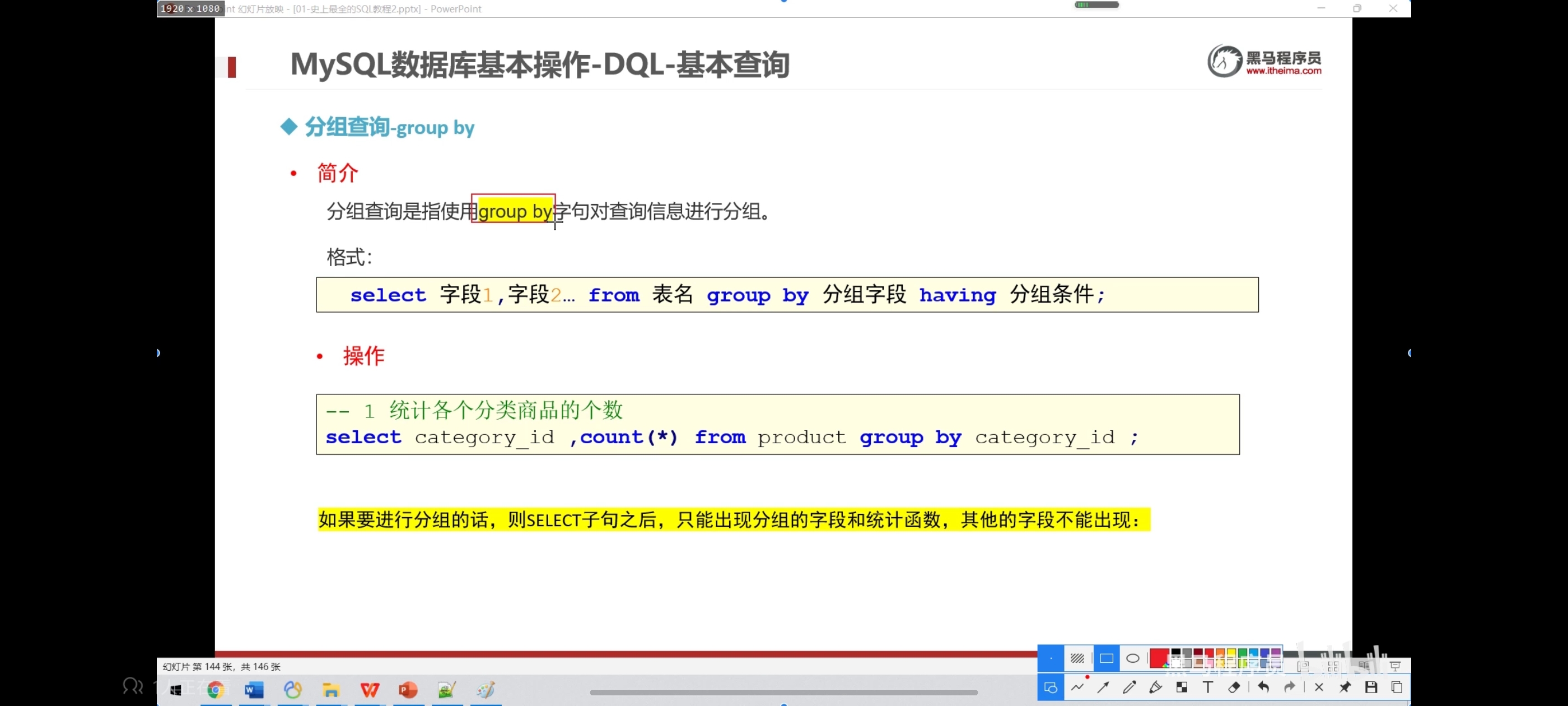
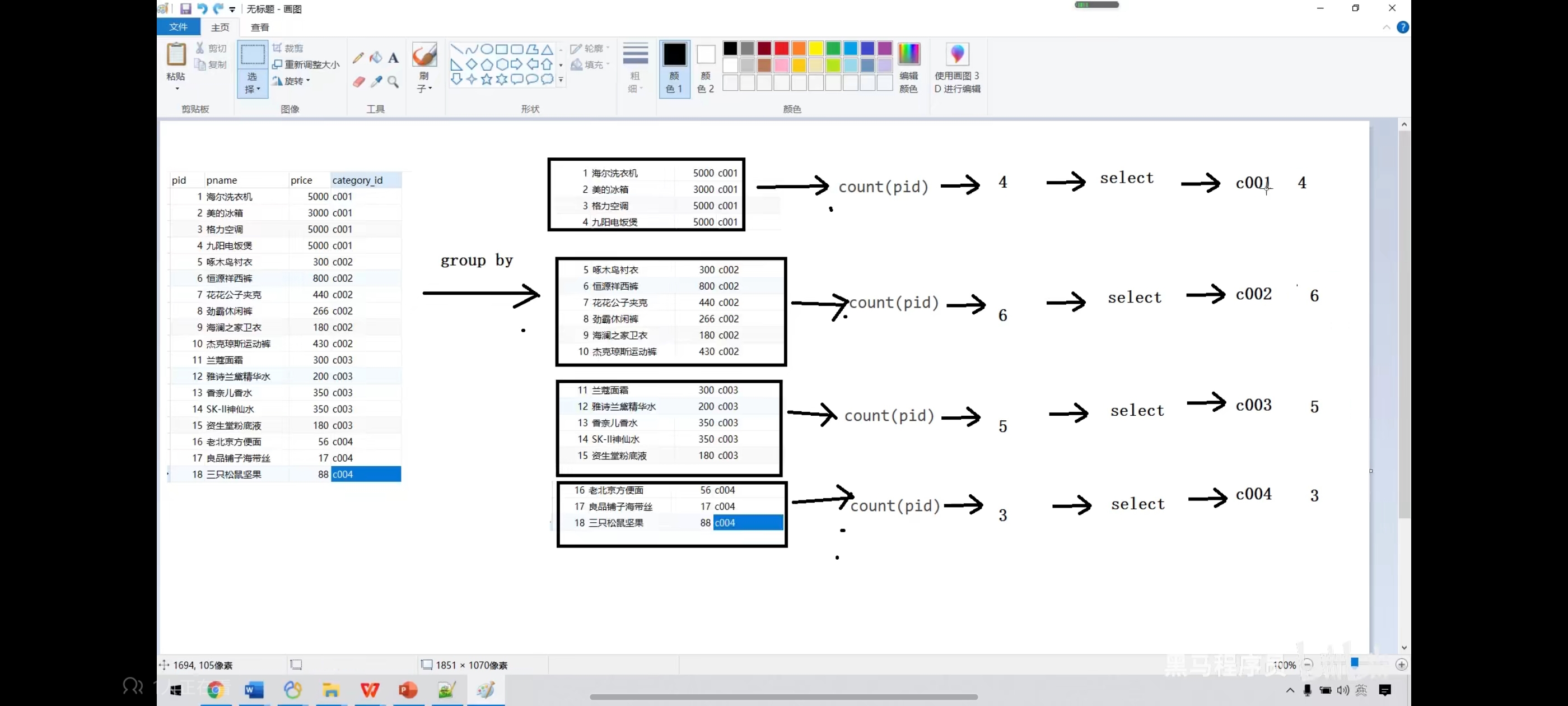
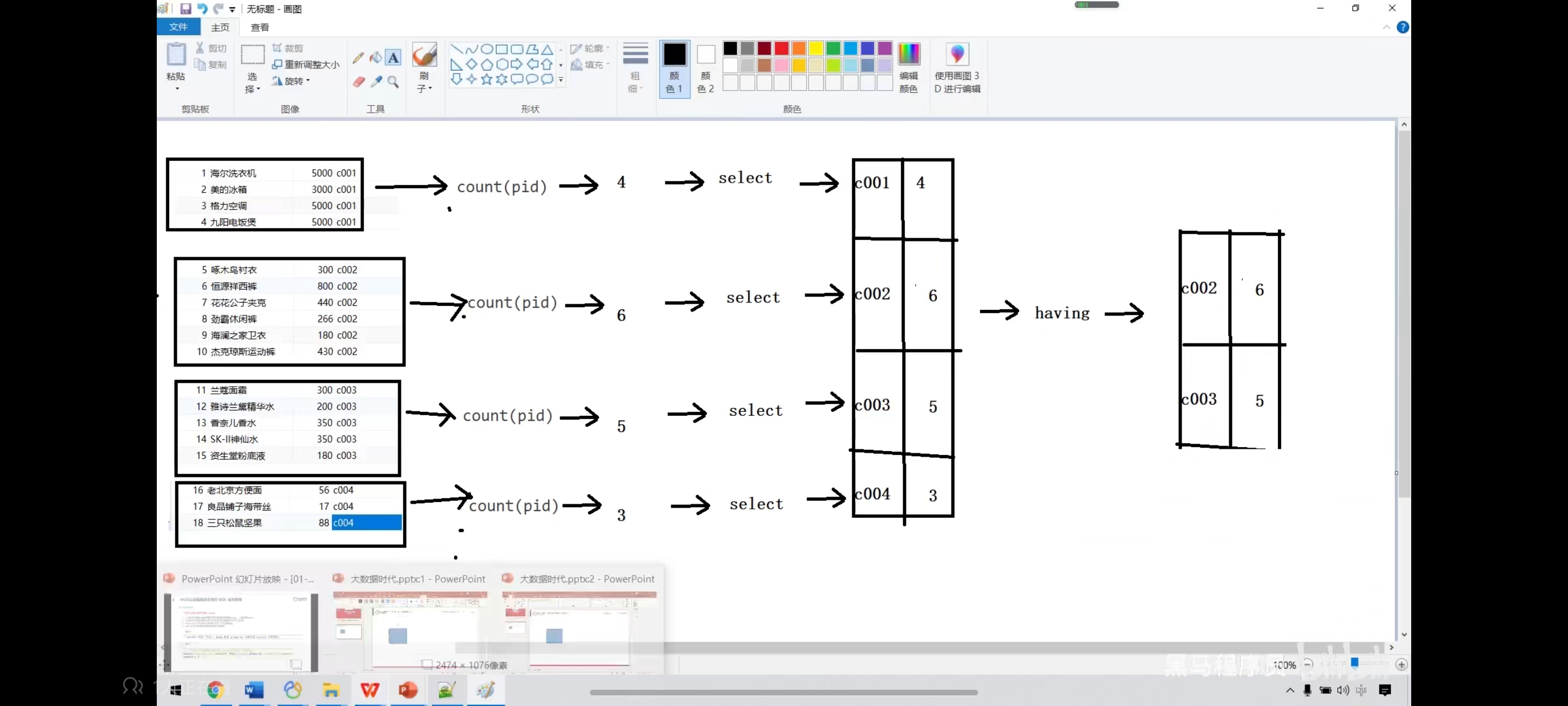
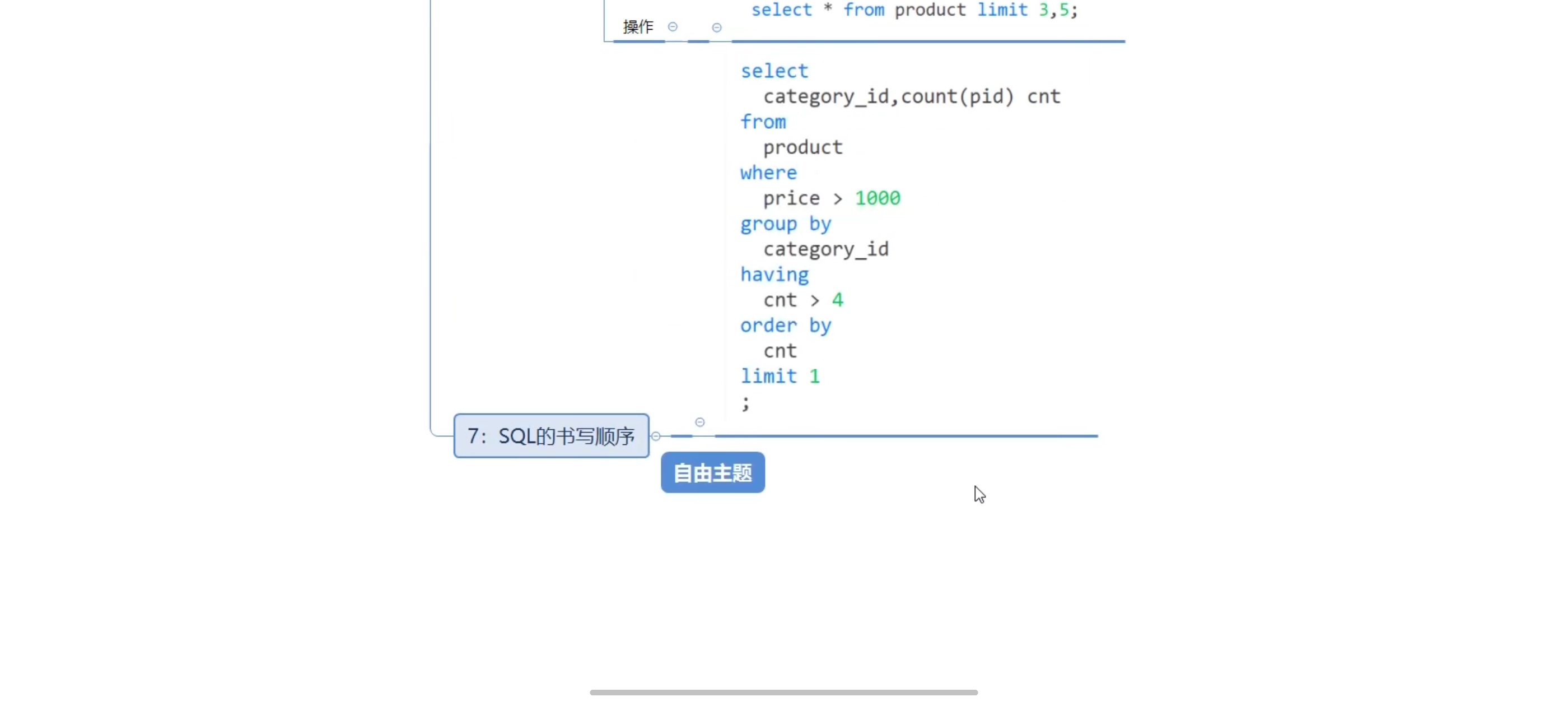
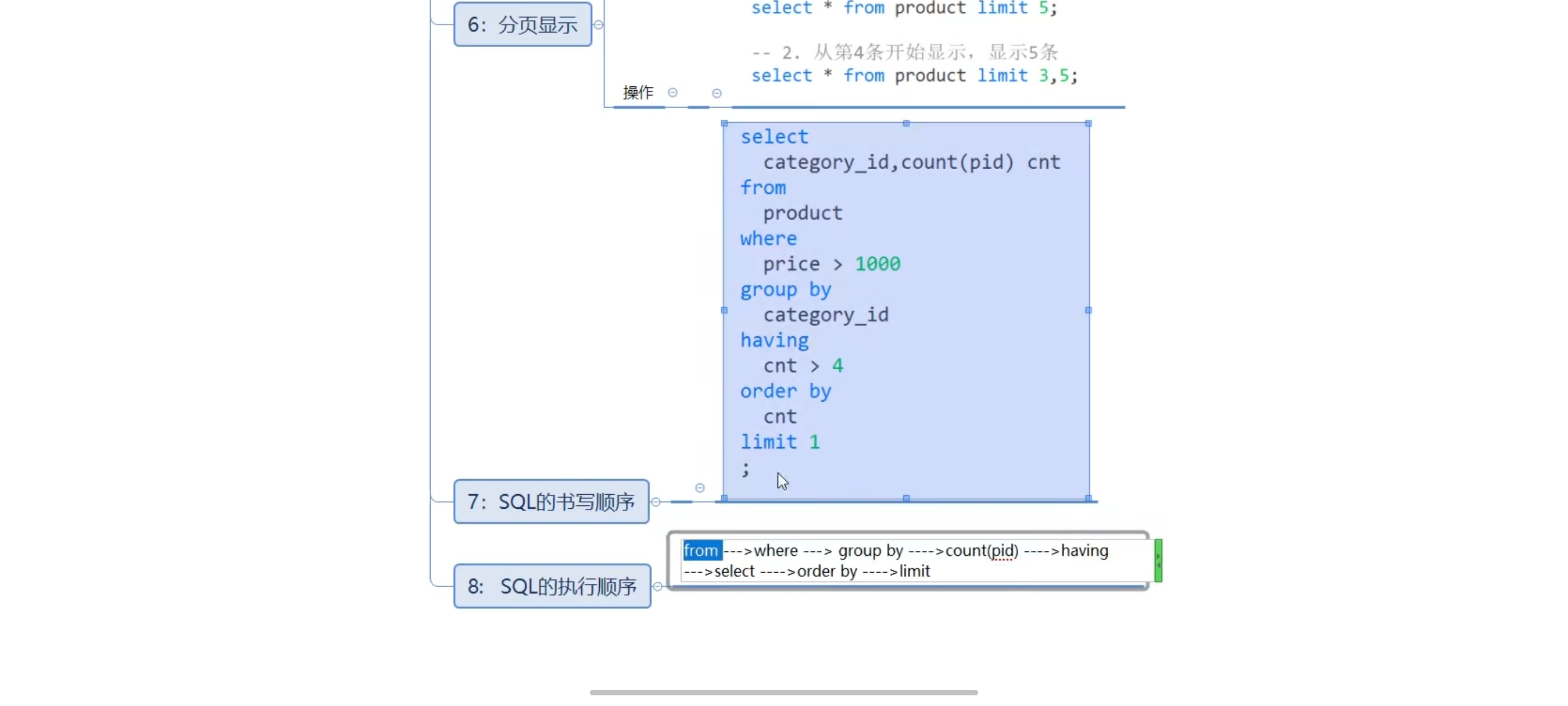
sql执行顺序:from group by count(pid) select having order by
书写顺序:from where group by having
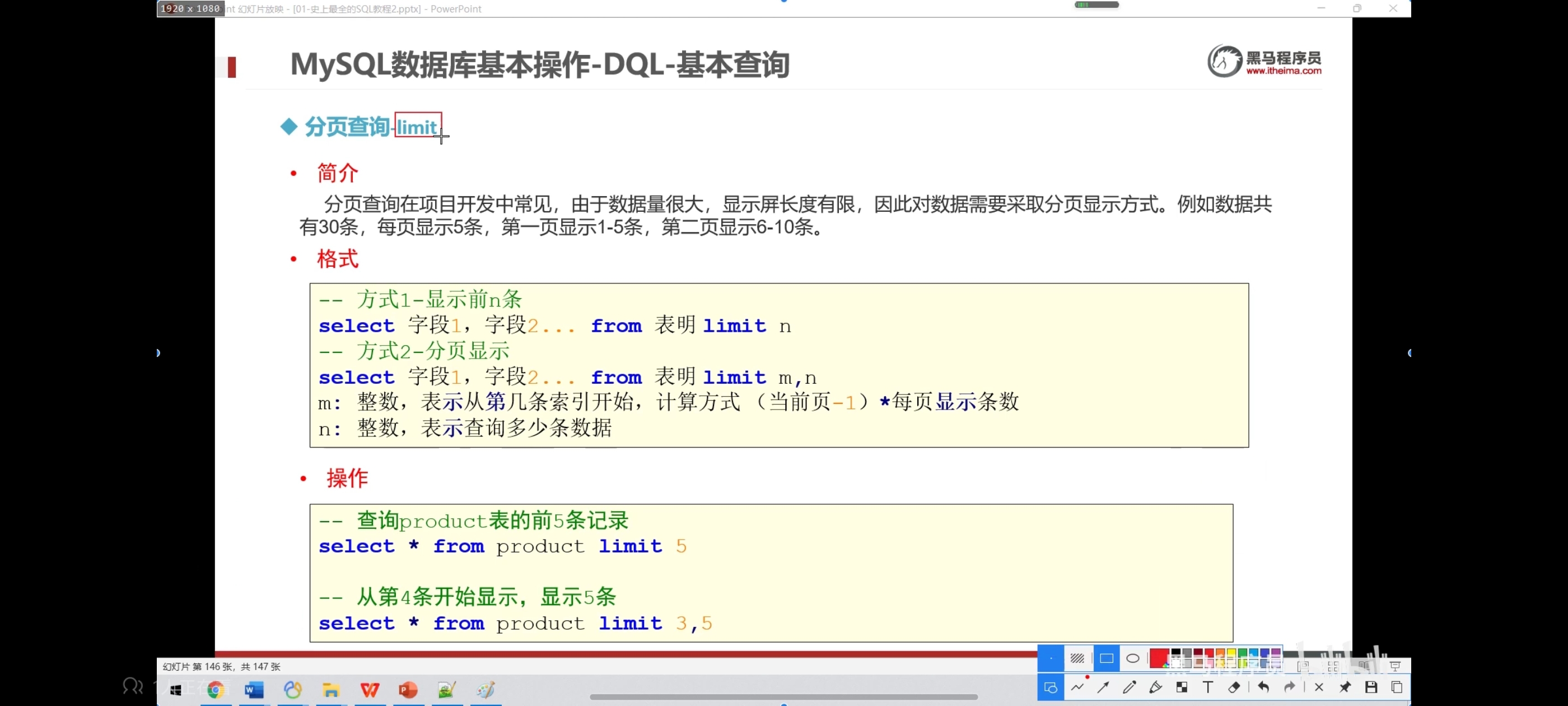
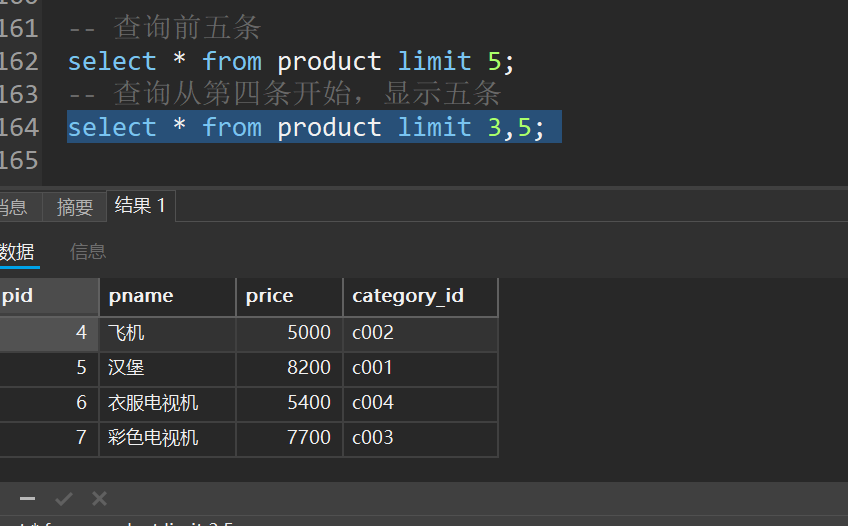
十一、分页查询-limit

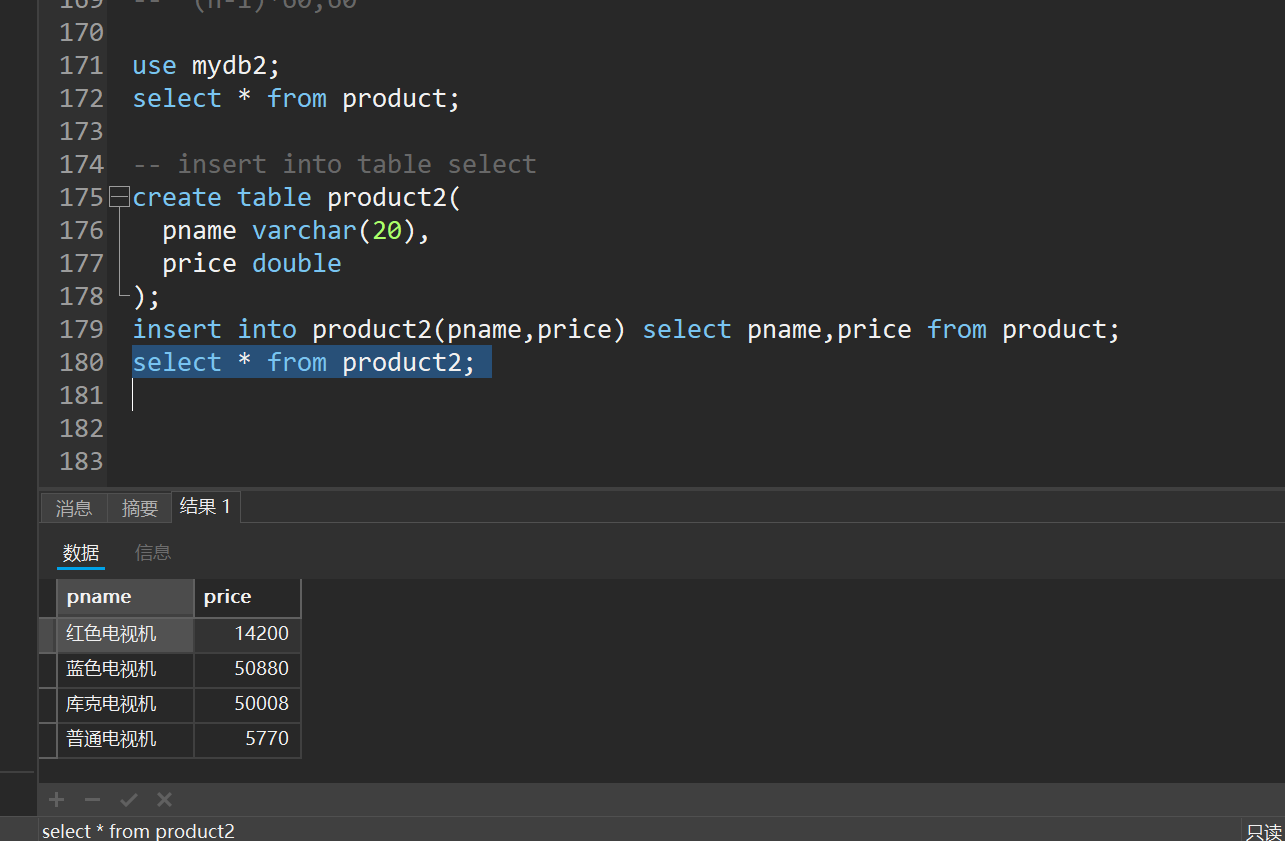
十二、insert_into_select语句
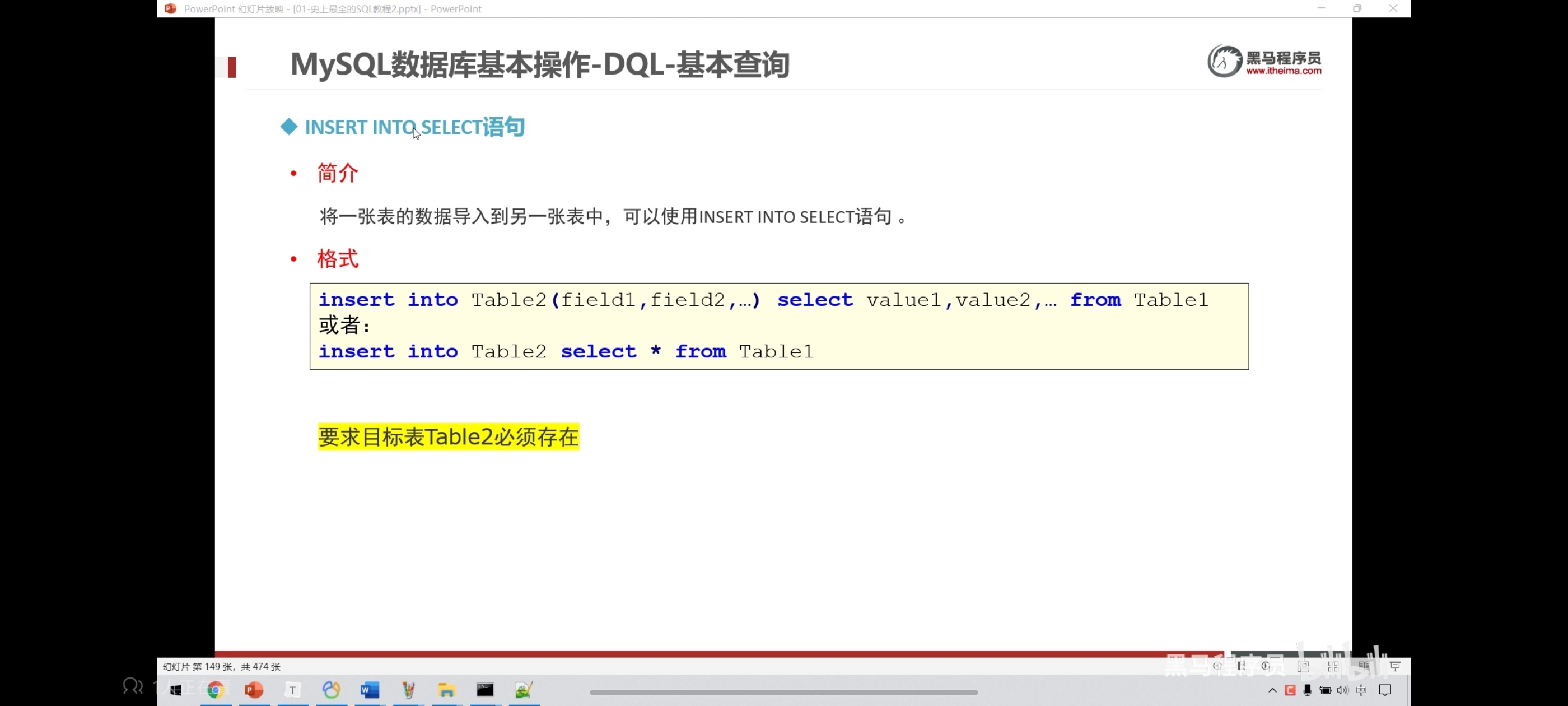
目标表必须存在
十三、总结
思维导图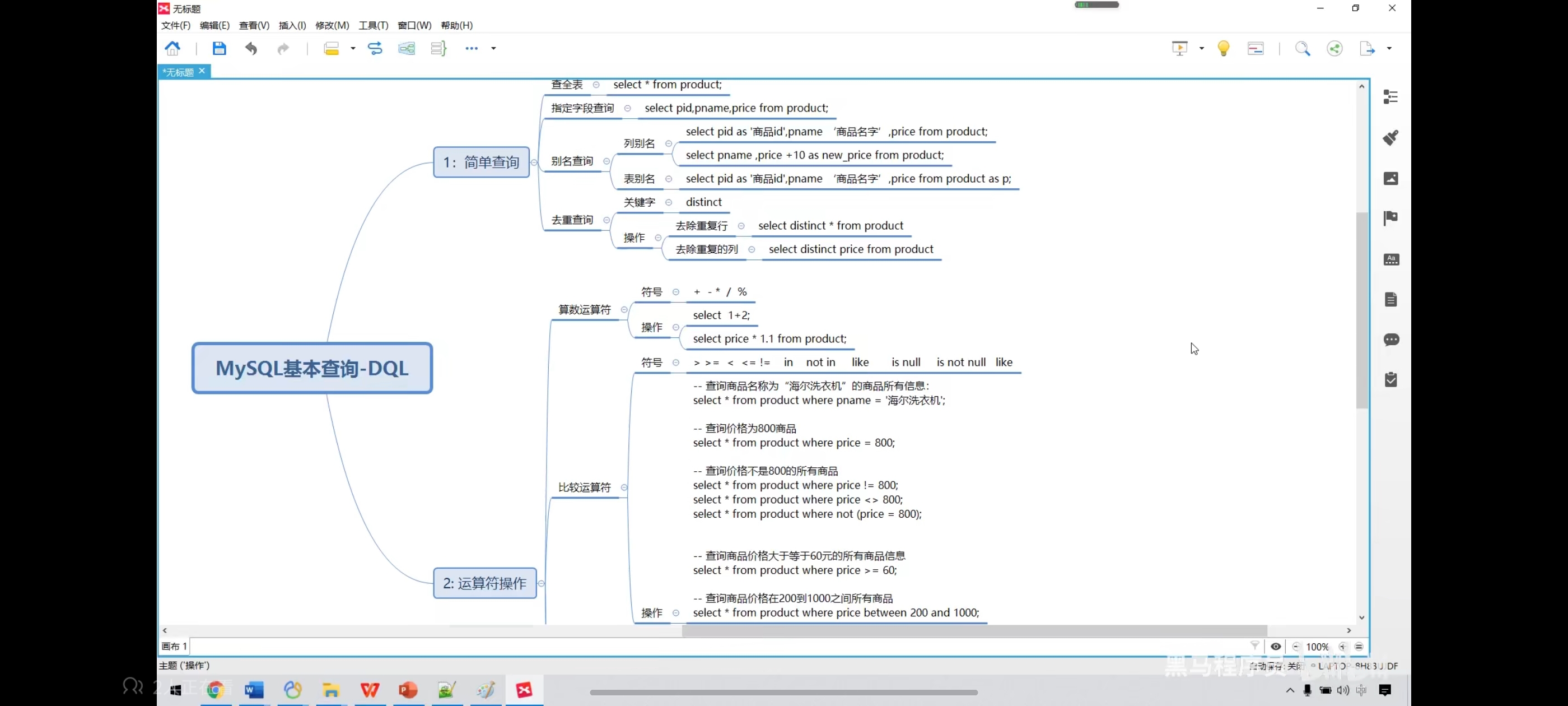


十四、练习
练习1:
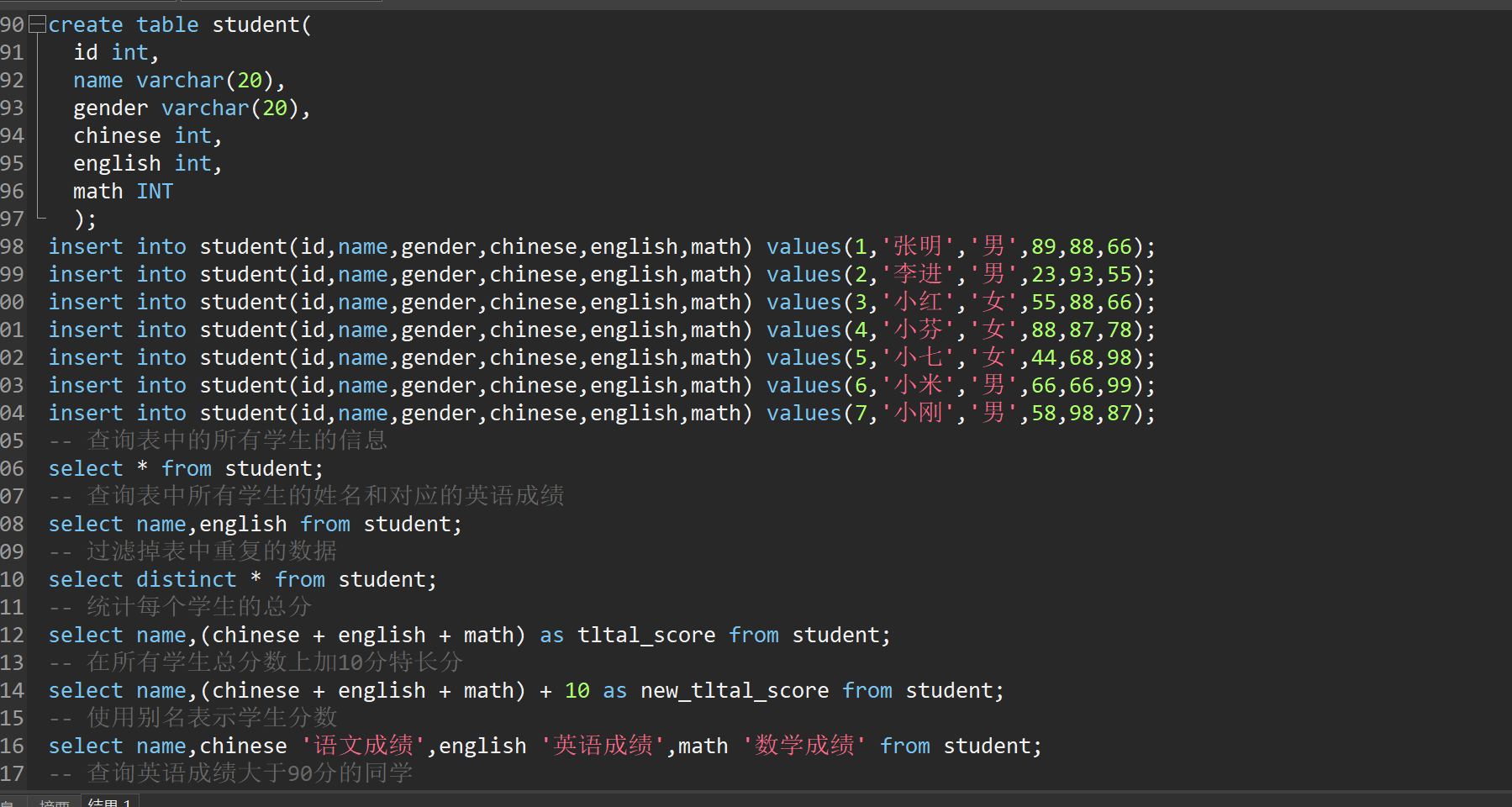
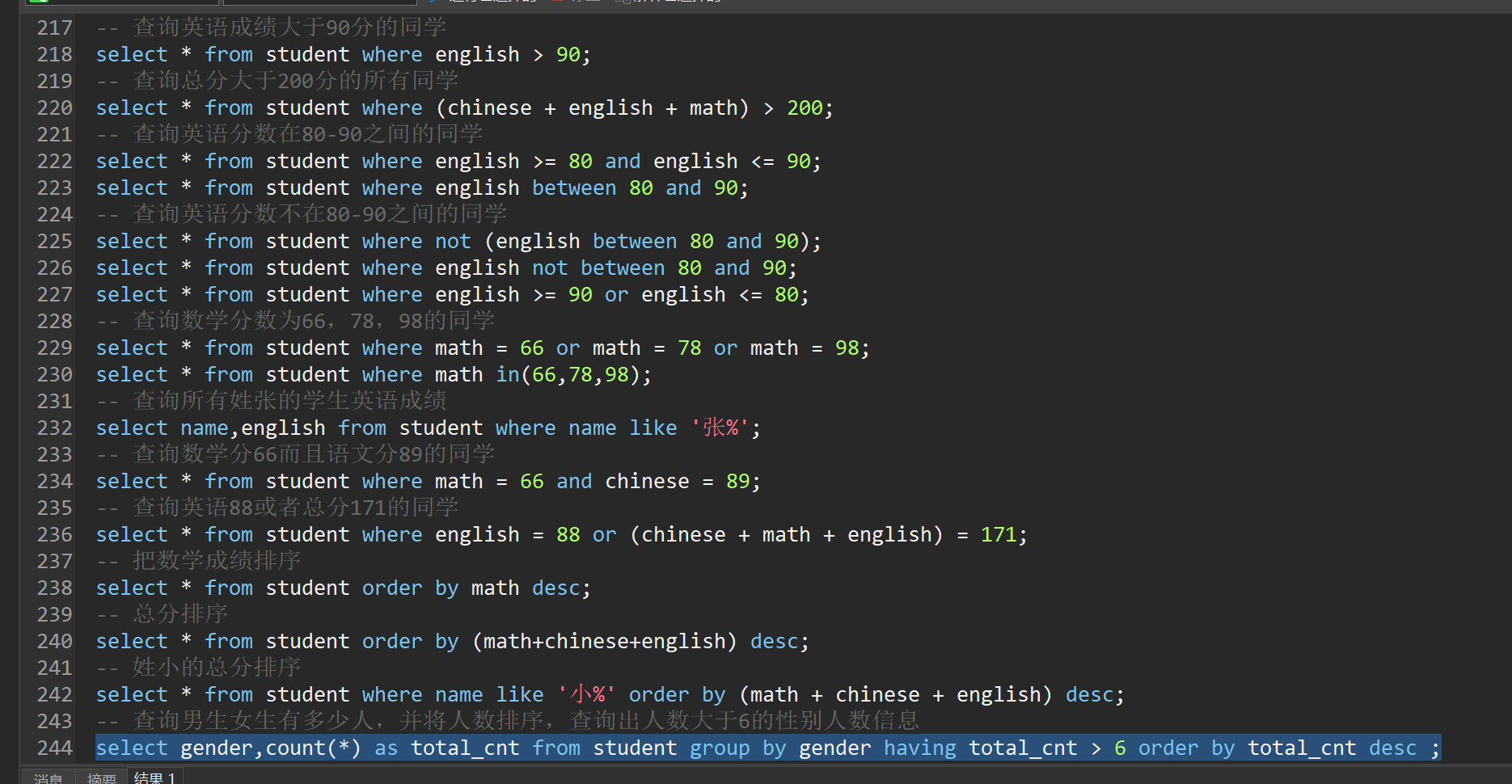
use mydb2;
create table student(
id int,
name varchar(20),
gender varchar(20),
chinese int,
english int,
math INT
);
insert into student(id,name,gender,chinese,english,math) values(1,'张明','男',89,88,66);
insert into student(id,name,gender,chinese,english,math) values(2,'李进','男',23,93,55);
insert into student(id,name,gender,chinese,english,math) values(3,'小红','女',55,88,66);
insert into student(id,name,gender,chinese,english,math) values(4,'小芬','女',88,87,78);
insert into student(id,name,gender,chinese,english,math) values(5,'小七','女',44,68,98);
insert into student(id,name,gender,chinese,english,math) values(6,'小米','男',66,66,99);
insert into student(id,name,gender,chinese,english,math) values(7,'小刚','男',58,98,87);
-- 查询表中的所有学生的信息
select * from student;
-- 查询表中所有学生的姓名和对应的英语成绩
select name,english from student;
-- 过滤掉表中重复的数据
select distinct * from student;
-- 统计每个学生的总分
select name,(chinese + english + math) as tltal_score from student;
-- 在所有学生总分数上加10分特长分
select name,(chinese + english + math) + 10 as new_tltal_score from student;
-- 使用别名表示学生分数
select name,chinese '语文成绩',english '英语成绩',math '数学成绩' from student;
-- 查询英语成绩大于90分的同学
select * from student where english > 90;
-- 查询总分大于200分的所有同学
select * from student where (chinese + english + math) > 200;
-- 查询英语分数在80-90之间的同学
select * from student where english >= 80 and english <= 90;
select * from student where english between 80 and 90;
-- 查询英语分数不在80-90之间的同学
select * from student where not (english between 80 and 90);
select * from student where english not between 80 and 90;
select * from student where english >= 90 or english <= 80;
-- 查询数学分数为66,78,98的同学
select * from student where math = 66 or math = 78 or math = 98;
select * from student where math in(66,78,98);
-- 查询所有姓张的学生英语成绩
select name,english from student where name like '张%';
-- 查询数学分66而且语文分89的同学
select * from student where math = 66 and chinese = 89;
-- 查询英语88或者总分171的同学
select * from student where english = 88 or (chinese + math + english) = 171;
-- 把数学成绩排序
select * from student order by math desc;
-- 总分排序
select * from student order by (math+chinese+english) desc;
-- 姓小的总分排序
select * from student where name like '小%' order by (math + chinese + english) desc;
-- 查询男生女生有多少人,并将人数排序,查询出人数大于6的性别人数信息
select gender,count(*) as total_cnt from student group by gender having total_cnt > 6 order by total_cnt desc ;
练习2:
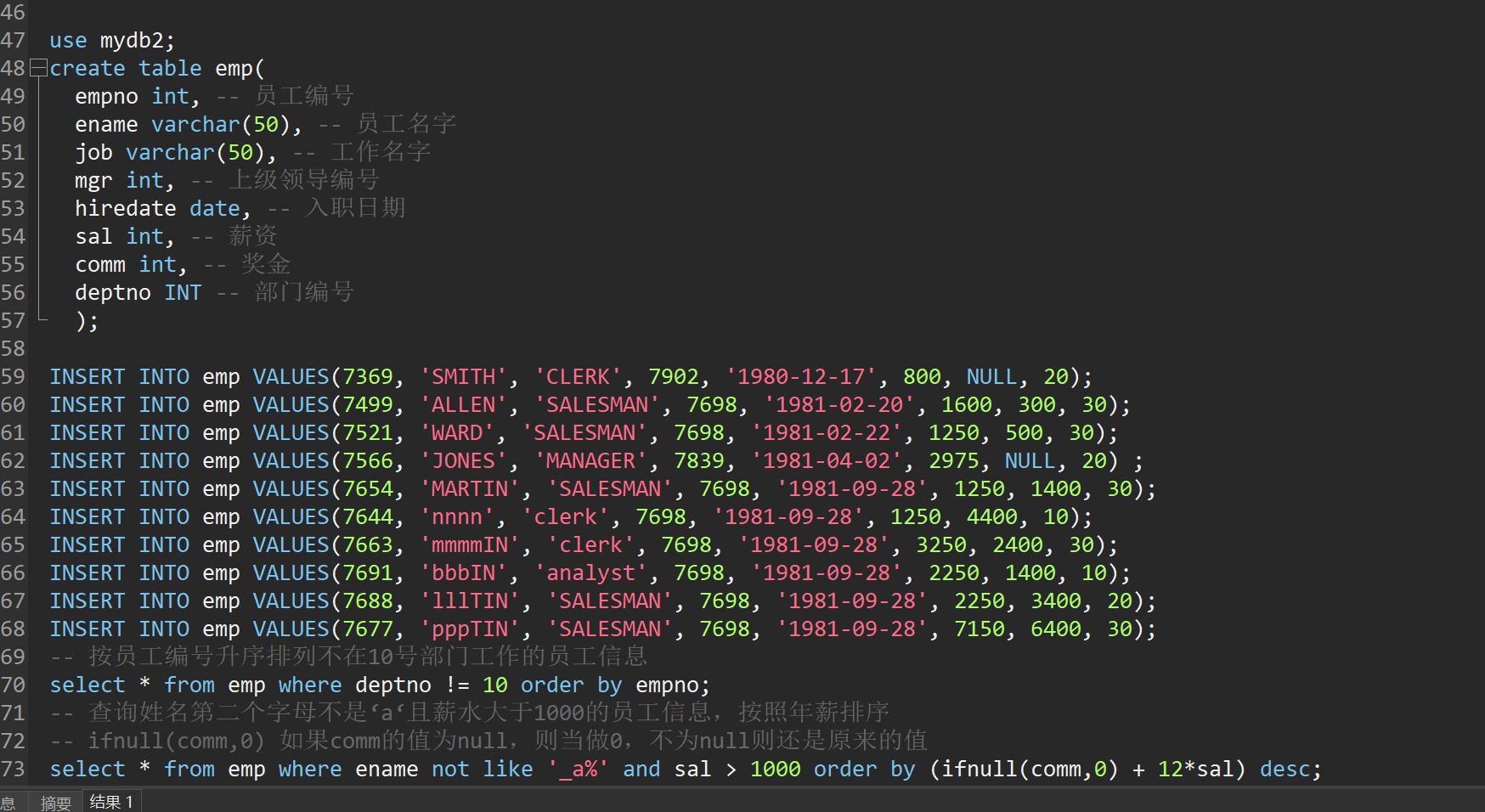
use mydb2;
create table emp(
empno int, -- 员工编号
ename varchar(50), -- 员工名字
job varchar(50), -- 工作名字
mgr int, -- 上级领导编号
hiredate date, -- 入职日期
sal int, -- 薪资
comm int, -- 奖金
deptno INT -- 部门编号
);
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 20);
INSERT INTO emp VALUES(7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
INSERT INTO emp VALUES(7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
INSERT INTO emp VALUES(7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 20) ;
INSERT INTO emp VALUES(7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
INSERT INTO emp VALUES(7644, 'nnnn', 'clerk', 7698, '1981-09-28', 1250, 4400, 10);
INSERT INTO emp VALUES(7663, 'mmmmIN', 'clerk', 7698, '1981-09-28', 3250, 2400, 30);
INSERT INTO emp VALUES(7691, 'bbbIN', 'analyst', 7698, '1981-09-28', 2250, 1400, 10);
INSERT INTO emp VALUES(7688, 'lllTIN', 'SALESMAN', 7698, '1981-09-28', 2250, 3400, 20);
INSERT INTO emp VALUES(7677, 'pppTIN', 'SALESMAN', 7698, '1981-09-28', 7150, 6400, 30);
-- 按员工编号升序排列不在10号部门工作的员工信息
select * from emp where deptno != 10 order by empno;
-- 查询姓名第二个字母不是‘a‘且薪水大于1000的员工信息,按照年薪排序
-- ifnull(comm,0) 如果comm的值为null,则当做0,不为null则还是原来的值
select * from emp where ename not like '_a%' and sal > 1000 order by (ifnull(comm,0) + 12*sal) desc;
select * from emp where ename not like '_a%' and sal > 1000 order by sal desc;
-- 每个部门的平均薪水
select deptno,avg(sal) from emp group by deptno;
select deptno,avg(sal) as avg_sal from emp group by deptno order by avg_sal desc;
-- 各个部门的最高薪水
select deptno,max(sal) from emp group by deptno;
-- 每个部门每个岗位的最高薪水
select deptno,job,max(sal) from emp group by deptno,job order by deptno;
-- 平均薪水大于2000的部门
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
-- 部门平均薪水大于1500的部门编号,按部门平均薪水降序排列
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 1500 order by avg_sal desc;
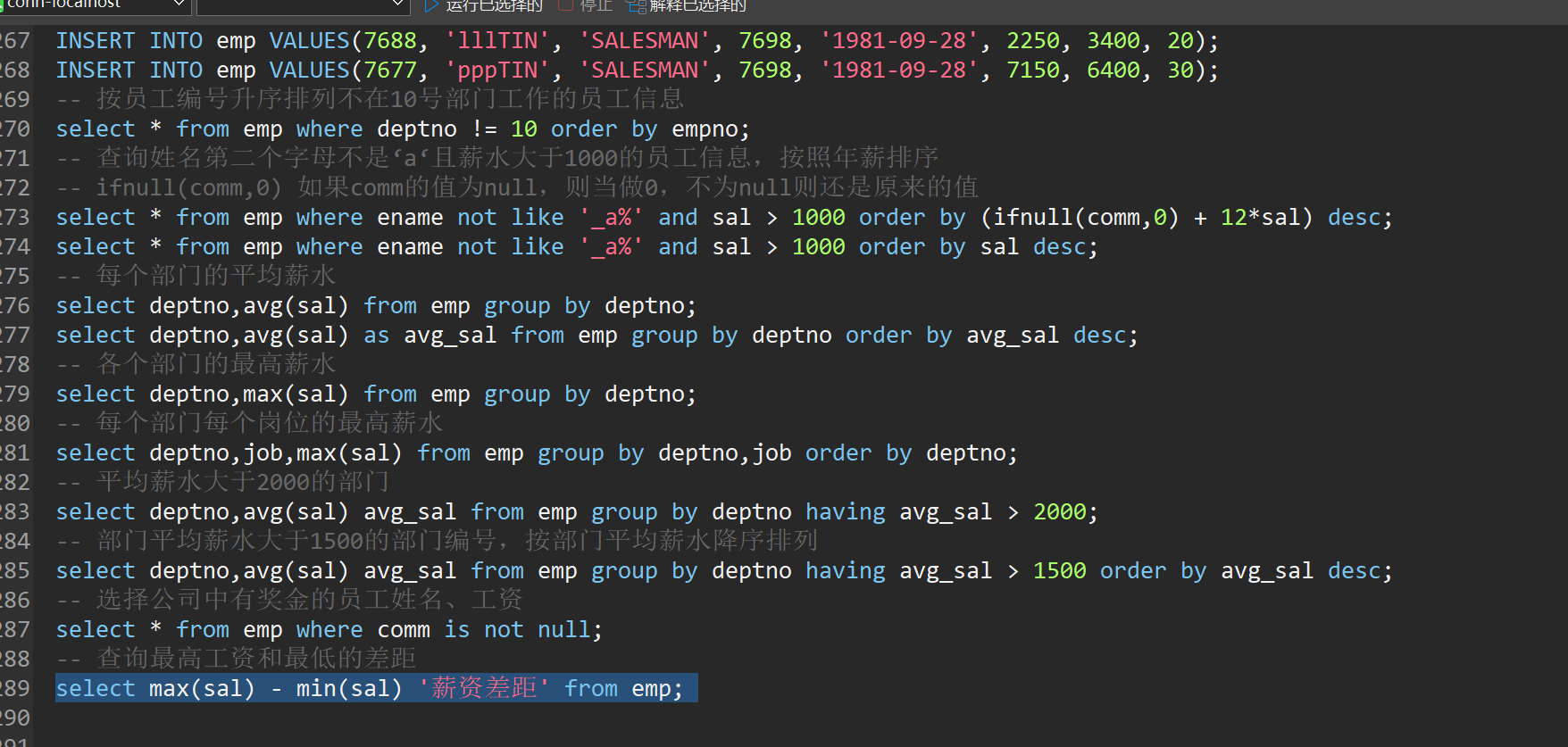
-- 选择公司中有奖金的员工姓名、工资
select * from emp where comm is not null;
-- 查询最高工资和最低的差距
select max(sal) - min(sal) '薪资差距' from emp;
十五、正则表达式匹配查询
正则表达式就是一个字符串,然后定义了一个规则,可以用这个规则去匹配其他字符串


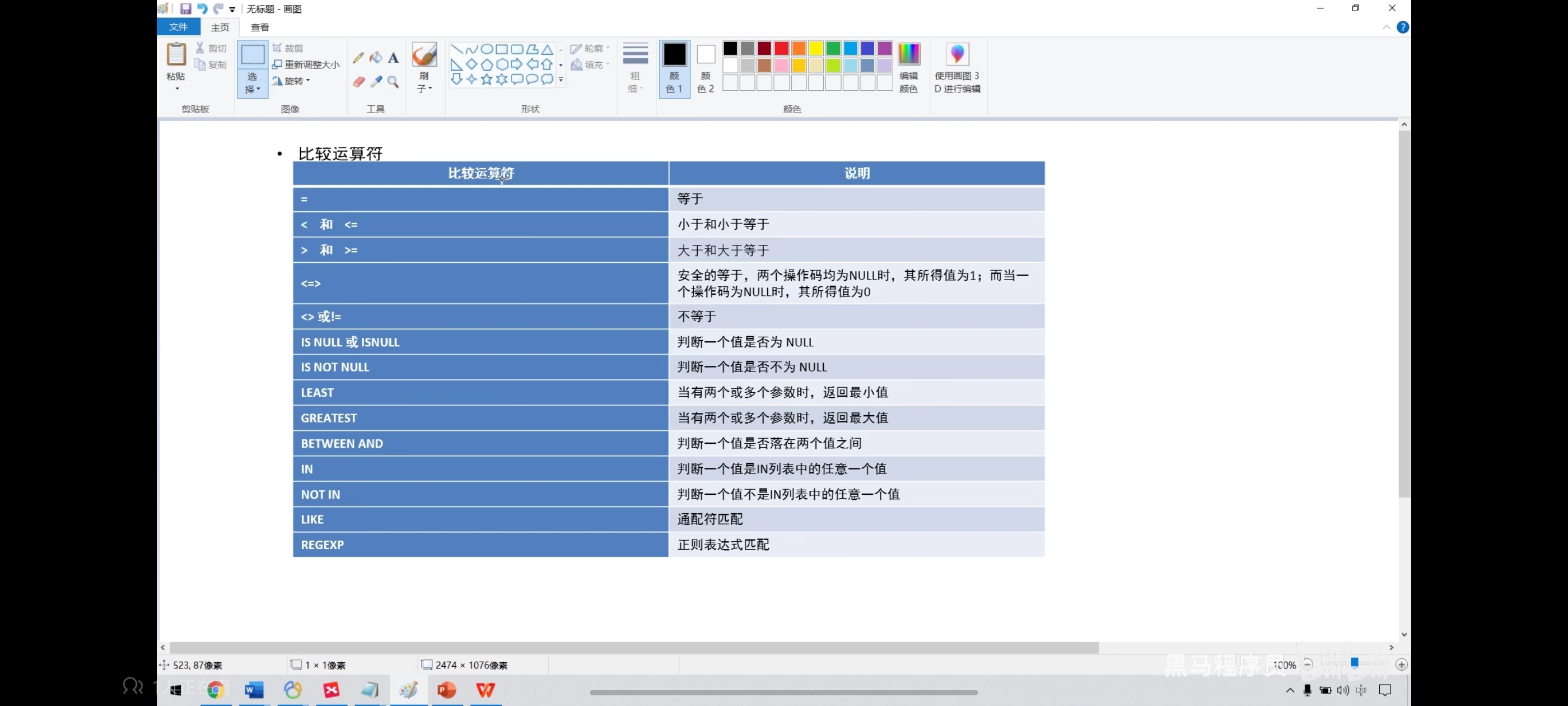
use mydb2;
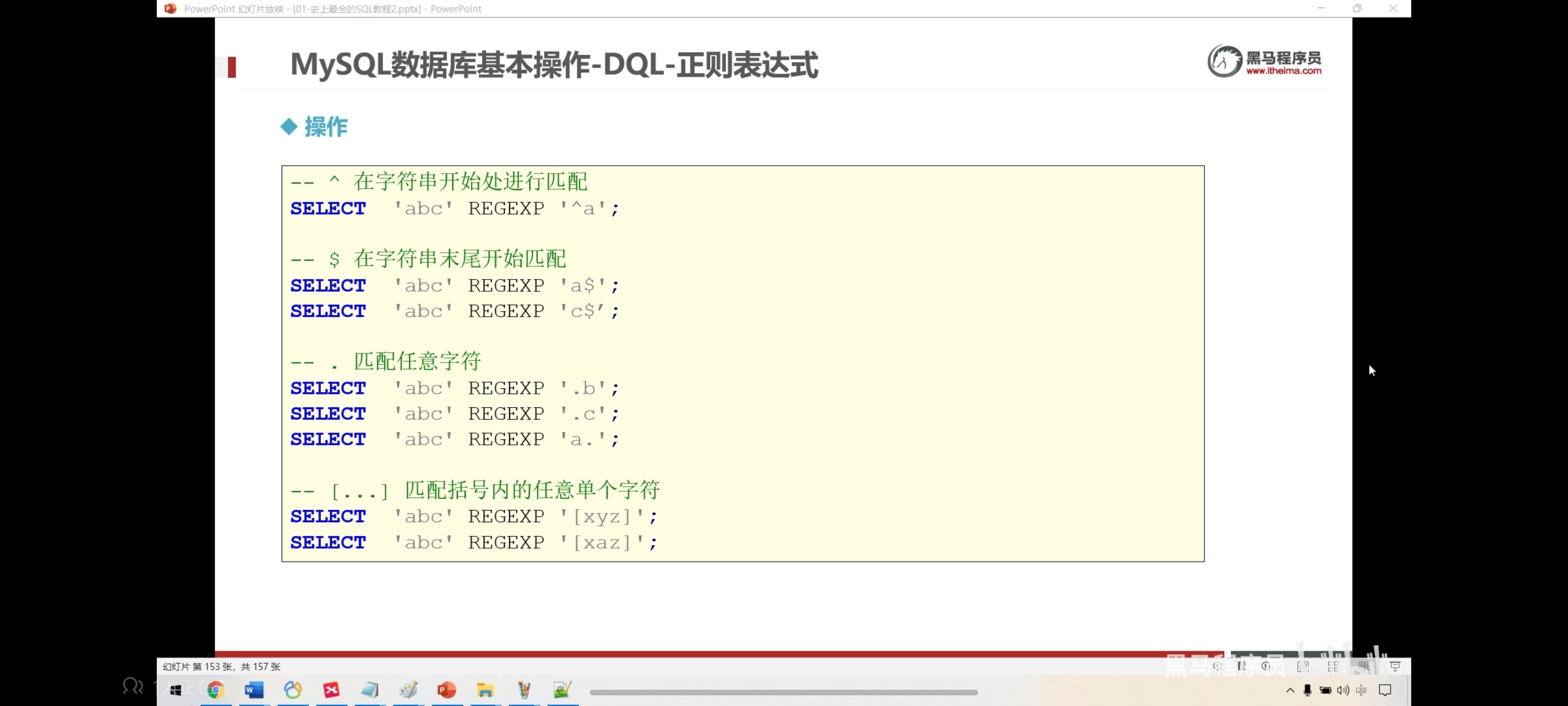
-- 判断是不是a开头
select 'abc' regexp '^a';
select * from product where pname regexp '^海';
select 'abc' regexp 'a$';
select 'abc' regexp 'c$';
select * from product where pname regexp '机$';
select 'abc' regexp '.b';
-- . 可以匹配除了换行符之外的任意字符
select 'abc' regexp '.c';
select 'abc' regexp 'a.';
-- 正则表达式的任意字符是否在前边的字符串中出现
select 'abc' regexp '[xyz]';
select 'abc' regexp '[xaz]';
-- 注意^符号只有在[]里面才是取反的意思,在别的地方都是表示开始处匹配
select 'a' regexp '[^abc]'; -- 0
select 'x' regexp '[^abc]';
select 'abc' regexp '[^a]'; -- 1
select 'stab' regexp '.ta*b';
select 'stb' regexp '.ta*b';
select '' regexp 'a*';
select 'stab' regexp '.ta+b';
select 'stb' regexp '.ta+b';
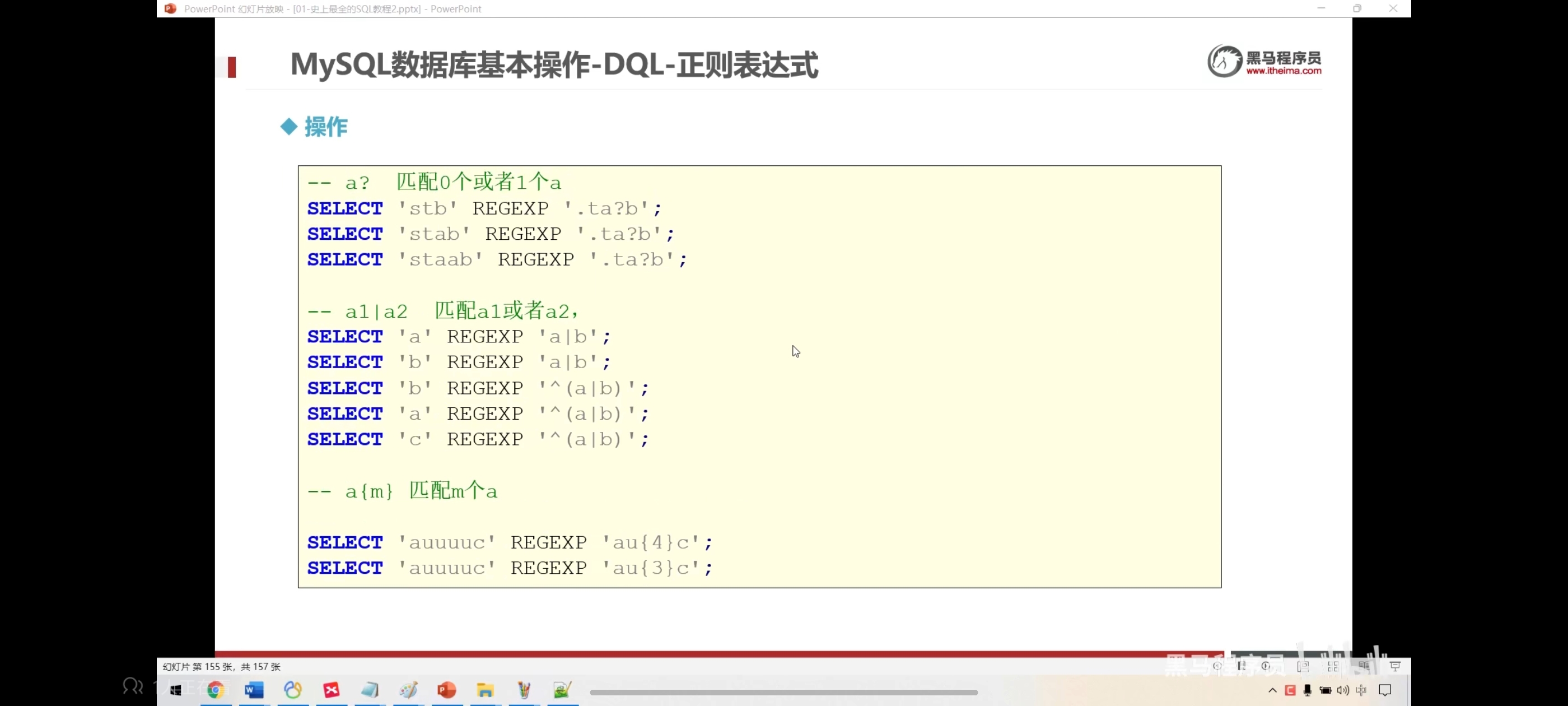
select 'stb' regexp '.ta?b';
select 'stab' regexp '.ta?b';
select 'staab' regexp '.ta?b';
select 'a' regexp 'a|b';
select 'b' regexp 'a|b';
select 'b' regexp '^(a|b)';-- ^以什么开头
select 'a' regexp '^(a|b)';
select 'c' regexp '^(a|b)';
select 'auuuuc' regexp 'au{4}c';
select 'auuuuc' regexp 'au{3}c';
select 'auuuuc' regexp 'au{3,}c';
select 'auuuuc' regexp 'au{4,}c';
select 'auuuuc' regexp 'au{5,}c';
select 'auuuuc' regexp 'au{3,5}c';
select 'auuuuc' regexp 'au{3,4}c';
select 'auuuuc' regexp 'au{5,22}c';
-- ()就是看成一个整体
select 'xababy' regexp 'x(abab)y';
select 'xababy' regexp 'x(ab)*y';
select 'xababy' regexp 'x(ab){1,2}y';
select 'xababy' regexp 'x(ab){3}y';
相关文章:

MySQL数据库基本操作-DQL-基本查询
数据库的操作中,查询是最重要的 一、基本查询-数据准备 -- 数据准备 create database if not exists mydb2; use mydb2; create table product( pid int primary key auto_increment, pname varchar(20) not null, price double, category_id varchar(20) …...

13、性能优化:魔法的流畅之道——React 19 memo/lazy
一、记忆封印术(React.memo) 1. 咒语本质 "memo是时间转换器的记忆晶石,冻结无意义的能量波动!" 通过浅层比较(shallowCompare)或自定义预言契约,阻止组件在props未变时重新渲染。 …...

低代码平台开发手机USB-HID调试助手
项目介绍 USB-HID调试助手是一种专门用于调试和测试USB-HID设备的软件工具。USB-HID设备是一类通过USB接口与计算机通信的设备,常见的HID设备包括键盘、鼠标、游戏控制器、以及一些专用的工业控制设备等。 主要功能包括: 数据监控:实时监控和…...

Langchain_Agent+数据库
本处使用Agent数据库,可以直接执行SQL语句。可以多次循环查询问题 前文通过chain去联系数据库并进行操作; 通过链的不断内嵌组合,生成SQL在执行SQL再返回。 初始化 import os from operator import itemgetterimport bs4 from langchain.ch…...

Code Splitting 分包策略
以下是关于分包策略(Code Splitting)的深度技术解析,涵盖原理、策略、工具实现及优化技巧: 一、分包核心价值与底层原理 1. 核心价值矩阵 维度未分包场景合理分包后首屏速度需加载全部资源仅加载关键资源缓存效率任意修改导致全量缓存失效按模块变更频率分层缓存并行加载单…...

AI 开发入门之 RAG 技术
目录 一、从一个简单的问题开始二、语言模型“闭卷考试”的困境三、RAG 是什么—LLM 的现实世界“外挂”四、RAG 的七步流程第一步:加载数据(Load)第二步:切分文本(Chunking)第三步:向量化&…...

day36图像处理OpenCV
文章目录 一、图像预处理18 模板匹配18.1模板匹配18.2 匹配方法18.2.1 平方差匹配18.2.2 归一化平方差匹配18.2.3 相关匹配18.2.4 归一化相关匹配18.2.5 相关系数匹配18.2.6 归一化相关系数匹配 18.3 绘制轮廓18.4案例 一、图像预处理 18 模板匹配 18.1模板匹配 模板匹配就是…...
)
系统与网络安全------弹性交换网络(3)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 STP协议 环路的危害 单点故障 PC之间的互通链路仅仅存在1个 任何一条链路出现问题,PC之间都会无法通信 解决办法 提高网络可靠性 增加冗余/备份链路 增加备份链路后交换网络上产生二层环路 …...

FPGA上实现YOLOv5的一般过程
在FPGA上实现YOLOv5 YOLO算法现在被工业界广泛的应用,虽说现在有很多的NPU供我们使用,但是我们为了自己去实现一个NPU所以在本文中去实现了一个可以在FPGA上运行的YOLOv5。 YOLOv5的开源代码链接为 https://github.com/ultralytics/yolov5 为了在FPGA中…...

verilog和system verilog常用数据类型以及常量汇总
int和unsigned 在 Verilog-2001 中,没有 int 和 unsigned 这样的数据类型。这些关键字是 SystemVerilog 的特性,而不是 Verilog-2001 的一部分。 Verilog-2001 的数据类型 在 Verilog-2001 中,支持的数据类型主要包括以下几种: …...

wordpress学习笔记
P1 P2 P3...

Rust 学习笔记:编程语言的相关概念
Rust 学习笔记:编程语言的相关概念 Rust 学习笔记:编程语言的相关概念动态类型 vs 静态类型动态类型 (Dynamically Typed)静态类型 (Statically Typed)对比示例 强类型 vs 弱类型强类型 (Strongly Typed)弱类型 (Weakly Typed)对比示例 编译型语言 vs 解…...

react nativeWebView跨页面通信
场景 react native项目里,有一些移动端的应用喜欢使用h5来开发,会出现需要跨tab和跨页面通信的场景,可以使用pubsub-js来实现通信。 实现思路 在react native 层实现pubsub的公共API,提供订阅消息、发布消息、取消订阅接口&…...
HTML核心技巧:从零掌握class与id选择器,精准定位网页元素)
Python爬虫(3)HTML核心技巧:从零掌握class与id选择器,精准定位网页元素
目录 一、背景与意义二、class与id的基础概念与语法规则2.1 什么是class与id?2.2 核心区别总结 三、应用场景与实战案例3.1 场景1:CSS样式管理3.2 场景2:JavaScript交互3.3 场景3:SEO优化与语义化 四、常见误区与最…...
模型详解)
BGE(BAAI General Embedding)模型详解
BGE(BAAI General Embedding)模型详解 BGE(BAAI General Embedding)是北京智源人工智能研究院(BAAI)推出的通用文本嵌入模型系列,旨在为各种自然语言处理任务提供高质量的向量表示。 一、BGE模…...

【Linux网络】应用层自定义协议与序列化及Socket模拟封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

Rust项目GPG签名配置指南
Rust项目GPG签名配置指南 一、环境准备 # 安装Gpg4win(Windows) winget install -e --id GnuPG.Gpg4win二、密钥生成与配置 # 生成RSA4096密钥 gpg --full-generate-key # 类型选RSA and RSA,长度4096,邮箱填z3266420686202216…...

6.第六章:数据分类的技术体系
文章目录 6.1 数据分类的技术架构6.1.1 数据分类的整体流程6.1.2 数据分类的技术组件6.1.2.1 数据采集与预处理6.1.2.2 特征工程与选择6.1.2.3 分类模型构建6.1.2.4 模型评估与优化6.1.2.5 分类结果应用与反馈 6.2 数据分类的核心技术与算法6.2.1 传统机器学习算法6.2.2 深度学…...

Nginx 反向代理,啥是“反向代理“啊,为啥叫“反向“代理?而不叫“正向”代理?它能干哈?
Nginx 反向代理的理解与配置 User 我打包了我的前端vue项目,上传到服务器,在宝塔面板安装了nginx服务,配置了文件 nginx.txt .运行了项目。 我想清楚,什么是nginx反向代理?是nginx作为一个中介?中间件来集…...
)
下篇:深入剖析 BLE GATT / GAP / SMP 与应用层(约5000字)
引言 在 BLE 协议栈的最上层,GAP 定义设备角色与连接管理,GATT 构建服务与特征,SMP 负责安全保障,应用层则承载具体业务逻辑与 Profile。掌握这一层,可实现安全可靠的设备发现、配对、服务交互和定制化业务。本文将详解 GAP、GATT、SMP 三大模块,并通过示例、PlantUML 时…...

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...

无人设备遥控之调度自动化技术篇
无人设备遥控器的调度自动化技术是现代科技发展的重要成果,它通过集成先进的通信、控制、传感器及人工智能技术,实现了对无人设备的高效、精准调度与自动化管理。 一、核心技术 无线通信技术 调度自动化依赖于高速、稳定的无线通信网络(如5…...
)
STM32F407 HAL库使用 DMA_Normal 模式实现 UART 循环发送(无需中断)
在 STM32 开发中,很多人喜欢使用 DMA 来加速串口发送数据。然而,默认的 DMA 往往配合中断或使用循环模式(DMA_CIRCULAR)使用。但在某些特定需求下,我们希望: 使用 DMA_NORMAL 模式,确保 DMA 每次…...

汽车自动驾驶介绍
0 Preface/Foreword 1 介绍 1.1 FSD FSD: Full Self-Driving,完全自动驾驶 (Tesla) 1.2 自动驾驶级别 L0 - L2:辅助驾驶L3:有条件自动驾驶L4/5 :高度/完全自动驾驶...

Uniapp-小程序从入门到精通
沉淀UNIAPP项目精华模版 ******************************************************************************************************************************************* 1、数据库的导入SQL **************************************************************************…...
:从X86/ARM/MIPS处理器架构到虚拟内存、分段分页、Linux内存管理,再揭秘进程线程限制与优化秘籍,助你成为OS高手!)
深度剖析操作系统核心(第一节):从X86/ARM/MIPS处理器架构到虚拟内存、分段分页、Linux内存管理,再揭秘进程线程限制与优化秘籍,助你成为OS高手!
文章目录 OS处理器X86ARMMIPSPowerPC 内存管理虚拟内存内存分段内存分页段页式内存管理Linux 内存管理 OS 处理器 常见处理器有X86、ARM、MIPS、PowerPC四种。 X86 X86架构是芯片巨头Intel设计制造的一种微处理器体系结构的统称。如果这样说你不理解,那么当我说…...

基于 EFISH-SBC-RK3588 的无人机通信云端数据处理模块方案
一、硬件架构设计 核心计算单元(EFISH-SBC-RK3588) 异构计算能力:搭载 8 核 ARM 架构(4Cortex-A762.4GHz 4Cortex-A551.8GHz),集成 6 TOPS NPU 与 Mali-G610 GPU,支持多任务并行处理…...
)
Unity 内置Standard Shader UNITY_BRDF_PBS函数分析 (二)
四、BRDF1_Unity_PBS // 主物理基BRDF实现 // 基于Disney工作并以Torrance-Sparrow微面模型为基础 // 公式: // BRDF kD / π kS * (D * V * F) / 4 // I BRDF * (N L) // // * NDF(法线分布函数)可根据 UNITY_BRDF_GGX 选择&#…...

GitHub万星项目维护者分享:开源协作的避坑指南
GitHub万星项目维护者分享:开源协作的避坑指南 ——开发者张三与237个文件改动PR的五年战争 序幕:深夜的炸弹 2019年夏天,张三维护的开源项目TerminalX刚突破8000星,一个标题猩红的PR突然弹出:“彻底重构࿰…...

Linux基础篇、第四章_01软件安装rpm_yum_源码安装_二进制安装
Linux基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! ————laowang 基础命令:rpm、yum、源码安装、二进制安装 一、rpm本地安装: (无需网络安装,无法解决软件依赖) rpm -ivh …...

焊接机排错
焊接机 一、前定位后焊接 两个机台,①极柱定位,相机定位所有极柱点和mark点;②焊接机,相机定位mark点原理:极柱定位在成功定位到所有极柱点和mark点后,可以建立mark点和极柱点的关系。焊接机定位到mark点…...

4.2 Prompt工程与任务建模:高效提示词设计与任务拆解方法
提示词工程(Prompt Engineering)和任务建模(Task Modeling)已成为构建高效智能代理(Agent)系统的核心技术。提示词工程通过精心设计的自然语言提示词(Prompts),引导大型语…...

oracle 锁的添加方式和死锁的解决
DML锁添加方式 DML 锁可由一个用户进程以显式的方式加锁,也可通过某些 SQL 语句隐含方式实现。 DML 锁有三种加锁方式:共享锁方式、独占锁方式、共享更新。 共享锁,独占锁用于 TM 锁,共享锁用于 TX 锁。 1)共享方式的表级锁 共享方…...

Nginx 二进制部署与 Docker 部署深度对比
一、核心概念解析 1. 二进制部署 通过包管理器(如 apt/yum)或源码编译安装 Nginx,直接运行在宿主机上。其特点包括: 直接性:与操作系统深度绑定,直接使用系统库和内核功能 。定制化:支持通过…...

以太网的mac帧格式
一.以太网的mac帧 帧的要求 1.长度 2.物理层...

每日算法-250424
每日算法打卡 (24/04/25) - LeetCode 2971 & 1647 记录一下今天解决的两道 LeetCode 题目 2971. 找到最大周长的多边形 题目 思路 贪心 一个基本的多边形构成条件是:最长边必须小于其他所有边的长度之和。 为了找到周长最大的多边形,我们应该尽可能…...

在本地部署n8n:完整指南
n8n是一个强大的工作流自动化工具,可以帮助你连接不同的应用程序和服务,无需编写复杂的代码。本指南将带你完成在本地计算机上部署n8n的完整过程。 什么是n8n? n8n(发音为"n-eight-n")是一个开源的工作流自…...

棋盘格角点检测顺序问题
文章目录 前言一、OpenCV函数测试二、原因分析三、libcbdetect修改总结 前言 棋盘格角点检测在相机拼接、机械臂手眼标定中等应用很广泛,通常也要求尽量各种角度摆放从而保证标定精度。然后就自然想到了这个问题:如果棋盘格任意角度摆放怎么能对应上角点…...

C++之类和对象:定义,实例化,this指针,封装
C语言是面向过程的,C是面向对象的,利用对象交互,接口完成事情。 类的定义: 我们在C语言中可以用struct创建自定义结构体,在C中可以在结构体中定义函数了,这种就被称为类。 #include<iostream> usi…...

Ubuntu系统下交叉编译iperf3
一、参考资料 Linux下iperf3移植到arm下测试100M网口-CSDN博客 Iperf3移植到ARM Linux及使用教程-CSDN博客 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编…...

游戏引擎学习第243天:异步纹理下载
仓库 https://gitee.com/mrxiao_com/2d_game_6 https://gitee.com/mrxiao_com/2d_game_5 回顾并为今天设定阶段 目前的开发工作主要回到了图形渲染相关的部分。我们之前写了自己的软件渲染器,这个渲染器性能意外地好,甚至可以以相对不错的帧率运行过场…...

27、Session有什么重⼤BUG?微软提出了什么⽅法加以解决?
Session的重大BUG 1、进程回收导致Session丢失 原理: IIS的进程回收机制会在系统繁忙、达到特定内存阈值等情况下,自动回收工作进程(w3wp.exe)。由于Session数据默认存储在进程内存中,进程回收时这些数据会被清除。 …...

机器学习在网络安全中的应用:守护数字世界的防线
一、引言 随着信息技术的飞速发展,网络安全问题日益凸显,成为全球关注的焦点。传统的网络安全防护手段,如防火墙、入侵检测系统(IDS)和防病毒软件,虽然在一定程度上能够抵御攻击,但在面对复杂多…...

从数据到智慧:解密机器学习的自主学习密码
在数字洪流奔涌的时代,每一次点击、每一行代码、每一条传感器数据都在生成海量信息。传统编程如同精心设计的齿轮组,需要工程师逐行编写规则;而机器学习则打破这一范式,赋予机器从数据中自主提炼规律、总结模式的超能力。这种能力…...
)
Trae或者VsCode无法识别相对路径(不自动切换工作目录)
在VsCode中或者Trae中,只要是在vscode的基础上修改得到的编辑器,都默认没有勾选自动选择当前文件路径为工作路径,因此需要手动修改工作路径或者设置,否则无法识别相对路径,PyCharm中就不会出现这种问题。 解决方法&…...

解决VSCode每次SSH连接服务器时,都需要下载vscode-server
如下图所示,本地下载或者在服务器终端上运行wget指令获得vscode服务器包 注意,解压完成后,需要修改文件名为你本地vscode的commit ID...

架构-系统工程与信息系统基础
一、系统工程核心知识 1. 系统工程定义 本质:一种组织管理技术,从整体出发分析系统要素(组成、结构、信息流、控制机制),追求“整体最优”,借助计算机实现规划、设计、管理、控制的优化。目标:…...

矩阵运算和线性代数操作开源库
用于矩阵运算和线性代数操作常用的开源库推荐,涵盖不同编程语言和硬件平台: C/C 库 Eigen 特点:高性能的模板库,支持矩阵/向量运算、线性求解、特征值计算等,无需依赖外部BLAS/LAPACK。 官网:https://eig…...
算法 —— 无监督或自监督学习)
无标注文本的行业划分(行业分类)算法 —— 无监督或自监督学习
对于无标注文本的行业划分(行业分类),属于典型的无监督或自监督学习任务。以下是几种常见的算法方法及实现思路,适用于缺乏标注数据的场景: 一、基于关键词匹配的规则方法 核心思想:通过预定义的行业关键…...
)
电子病历高质量语料库构建方法与架构项目(计划篇)
电子病历(EMR)作为医疗信息化的重要产物,包含了丰富的医疗信息和临床知识,是辅助临床决策、药物挖掘和医学研究的重要资源。然而,电子病历数据具有非结构化、噪声大、专业性强等特点,如何构建高质量电子病历语料库成为医疗自然语言处理领域的核心挑战。本全计划将从项目背景…...