机器人操作中的生成式 AI:综述(下)
25年3月来自香港大学、香港理工、香港科大、浙大和清华大学的论文“Generative Artificial Intelligence in Robotic Manipulation: A Survey”。
本综述全面回顾机器人操作领域生成学习模型的最新进展,并探讨该领域的关键挑战。机器人操作面临着关键瓶颈,包括数据不足和数据采集效率低下、长期和复杂任务规划,以及在不同环境下实现稳健策略学习性能所需的多模态推理能力等重大挑战。为了应对这些挑战,本综述介绍几种生成模型范式,包括生成对抗网络 (GAN)、变分自编码器 (VAE)、扩散模型、概率流模型和自回归模型,并重点介绍它们的优势和局限性。这些模型的应用分为三个层次:基础层,侧重于数据生成和奖励生成;中间层,涵盖语言、代码、视觉和状态生成;以及策略层,强调抓取生成和轨迹生成。本综述对每一层都进行详细探讨,并列举一些推动当前最佳研究成果的重要成果。最后,该调查概述未来的研究方向和挑战,强调需要提高数据利用效率、更好地处理长期任务以及增强在不同机器人场景中的泛化能力。
。。。。。。。。。继续。。。。。。。。。。
策略层
在机器人操作范式中,策略层模块旨在根据高级任务命令和观察结果(包括视觉和本体感受测量)为机器人硬件系统生成可执行动作。通常,最终的动作空间要么是目标末端执行器的位姿,要么是末端执行器的轨迹。
抓取生成
作为机器人操作中策略生成的第一个实例,抓取生成类专注于找到目标末端执行器的位姿,通常表示为机器人空间中的 4 维或 6 维坐标,输入包括 RGB 图像、深度图像或点云、网格,以及最近的隐形状表示,例如神经辐射场 (NeRF) [185]。这些输入提供关于待抓取物体的丰富空间和视觉信息,使模型能够推理物体的几何形状、外观和affordance。
在某些情况下,中间表示(例如图像空间中的抓取矩形)可用于简化问题表述。当输入包含观测和候选姿势时,一些方法会将抓取质量预测为输出,从而使模型能够评估每个候选抓取的成功可能性。
基于学习的抓取合成,在机器人领域得到广泛的研究 [196, 197, 198]。为了解决抓取合成问题,人们提出了各种学习模型。例如,确定性模型将输入观测直接映射到抓取姿势或抓取质量得分。这些模型旨在建立特定观测与确定的输出姿势之间的映射 [13, 199]。虽然确定性模型在许多情况下被证明是有效的,但它在处理多模态抓取姿势分布时可能会遇到困难,因为对于单个物体存在多个不同的抓取解决方案——本质上是映射一个非单射(non-injective)、非全射(non-surjective)的函数。
为了解决这一局限性,生成式模型近年来越来越受欢迎。与确定性方法不同,生成式模型旨在学习抓取姿势的分布。通过将复杂的多模态抓取分布映射到更简单、更易处理的分布,生成式模型可以更好地捕捉抓取任务中固有的不确定性和多样性。这对于形状复杂的物体尤其有益,因为这些物体可能存在多种有效的抓取配置。生成式模型能够表示此类多模态分布,这使得它们非常适合机器人抓取,因为它们能够自然地适应现实世界物体中存在的多变性和模糊性。
抓取生成的生成式模型如表所示:
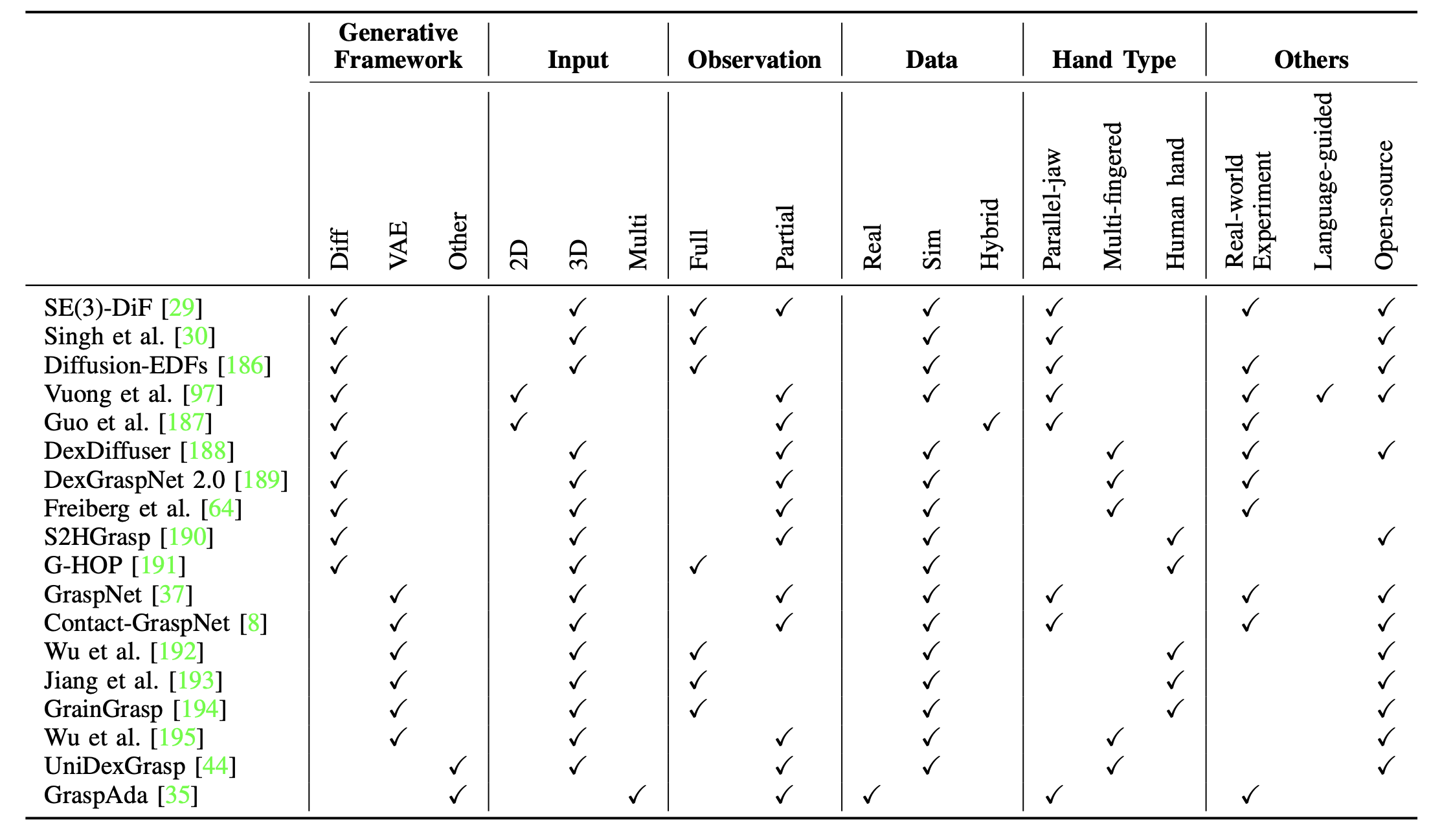
基于 VAE 的方法。变分自编码器 (VAE) 已成为解决机器人抓握生成固有复杂性和多模态特性的强大框架。通过学习紧凑的潜表示并从学习的分布中进行采样,VAE 有助于生成多样化且物理上合理的抓握动作,使其特别适合于需要适应物体多变性和不确定性的任务。Mousavian [37] 提出 VAE 在抓握合成中的一项显著应用,将抓握生成定义为一个采样问题。该模型采用 VAE 直接从部分 3D 点云生成一组多样化的稳定抓握姿势。潜空间可以捕捉抓握动作的多模态分布,从而可以有效地探索可行的解决方案。Sundermeyer [8] 介绍一种在杂乱环境中生成 6 自由度抓握动作的简化但有效的表示。与传统的变分自编码器 (VAE) 不同,该方法通过将抓取配置植根于物体的观测点云,将抓取姿势投射到精简的四自由度空间中。
除了纯粹的机器人抓取之外,Wu [192] 将变分自编码器 (VAE) 的实用性扩展到人体抓取生成,重点关注全身交互。该模型采用条件变分自编码器 (CVAE) 来联合生成静态抓取姿势和详细的接触图。这种集成能够合成逼真且多样的全身抓取动作,既能捕捉灵巧的手指运动,又能捕捉全身动态。Jiang [193] 通过一种 CVAE 架构进一步探索接触一致性在人体抓取生成中的作用。该模型通过引入定制的损失函数来惩罚预测的手部配置和物体接触图之间的错位,从而确保手部-物体接触点之间的相互一致性。
在灵巧抓取的背景下,Zhao[194] 提出的 CVAE 框架可以预测每个手指的单独接触图,并利用这些详细的表示来优化抓取配置。Wu [195] [195] 将基于 VAE 的采样与双层优化相结合,以应对多样性和物理可行性的双重挑战。初始抓握配置从 VAE 中采样,以捕获多模态抓握分布。然后,这些样本为双层优化框架提供种子,该框架强制执行诸如防撞、扳手闭合和摩擦稳定性等约束。总体而言,将 VAE 集成到抓握合成中,突显了其通过嵌入特定于任务的约束并利用潜变量建模,有效捕捉机器人和人类抓握任务的多模态和不确定性特性的能力。
基于扩散的方法。Urain [29] 采用基于能量的扩散模型,以物体形状和噪声姿态作为输入,输出能量作为代价函数。对于抓握姿态生成,它采用自微分来计算得分,并采用逆朗之万动力学对 SE(3) 空间中表示的 6D 姿态进行去噪。Singh [30] 通过采用部件引导的扩散方法扩展 SE(3)-DiF,以实现区域约束的抓取,从而可以在没有条件标记数据集的情况下在复杂物体形状上生成高效、密集的抓取。为了提高数据效率和泛化能力,Ryu [186] 在 SE(3) 上使用一个基于双等变扩散的生成模型,可以用最少的演示从点云观测中生成有效的抓取姿势。此外,Vuong [97] 提出一种语言驱动的抓取检测方法,以图像空间中的抓取矩形为目标。该方法引入开放词汇抓取数据集和一个具有对比训练目标的扩散模型,以改进语言指令的去噪和抓取姿势检测。Guo [187] 提出一个两阶段扩散框架,利用基于分数的扩散网络从自上而下的 RGB 图像生成 4D 抓取姿势及其相应的残差,从而提高机器人任务中拾取操作的精度。
前述研究主要将扩散模型应用于双指抓握任务,而近期研究也广泛探索包括灵巧手在内的多指末端执行器抓握。具体而言,Weng [188] 使用基于去噪扩散概率模型 (DDPM) [38] 的条件扩散模型在部分点云上生成灵巧抓握。他们进一步利用 Mayer [200] 的方法进行质量评估,并采用改进策略来提高成功率。Zhang [189] 也采用 DDPM 在杂乱场景中生成灵巧抓握姿势,其中条件基于从场景中提取的局部特征,目标是一个表示手腕姿势的 12 维向量,结合平移和扁平旋转矩阵。为了将该方法推广到不同的硬件设备,Freiberg [64] 提出一种与抓取器无关的抓取方法,该方法使用等变扩散模型。该方法对包含可抓取物体的场景进行编码,并通过整合抓取器的几何形状来解码抓取姿势,证明了该方法对从平行颌到灵巧手的多种抓取器都具有通用性。
此外,最近的研究也侧重于人手建模,旨在实现更自然、更逼真的抓取行为。其中,Wang [190] 提出一个从单视图场景点云生成人体抓取动作的框架。他们使用一个全局感知(Global Perception)模块来感知部分可见物体的全局形状,并使用基于条件扩散模型的 DiffuGrasp 模块。该模型以手部参数为目标,逐步对其进行去噪以生成稳定的抓取动作。为了避免训练过程中的穿透,该模型采用穿透损失来惩罚手部与物体之间的碰撞,从而确保生成自然可行的抓取动作。Ye [191] 转而开发一种基于去噪扩散的生成模型,该模型可以捕捉交互过程中手和物体的联合三维分布。给定一个类别条件描述,该模型可以合成合理的物体形状以及人手的相对结构和关节活动。
其他生成模型。Xu [44] 利用概率模型从点云数据中生成不同的预抓取姿势,有效地将旋转与平移和关节活动分离。旋转空间由隐式 PDF [201] 表示,这是一个基于 SO(3) 的概率模型,而平移和关节活动的条件分布则使用生成流模型 [202] 建模。Chen [35] 没有直接对数据分布进行建模,而是采用条件生成对抗网络 (cGAN) [203] 来调整来自新域的 RGB-D 数据,使其与训练域保持一致,同时保持抓取特征的一致性。通过确保图像特征符合特定域的抓握特征分布,可以使用预训练的抓握合成模型来生成抓握姿势,包括角度、宽度和质量分数。
轨迹生成
轨迹生成是机器人操作的另一个基础方面,直接影响机器人准确、高效、安全地执行复杂任务的能力。
不同的方法利用各种输入格式来产生一致且稳定的输出。除了使用单步环境观测 [55](其模式类似于抓取姿势的生成)作为下一步动作预测的输入外,历史信息(包括连续观测 [204, 205])也被广泛用于增强动作一致性。此外,多步动作预测是一种常用技术,它通过使模型能够预测一系列未来动作来生成稳定且连贯的轨迹 [204, 205, 206]。
从方法论的角度来看,传统的轨迹规划方法面临着重大的局限性,包括高维配置空间中的高计算需求、对动态环境的适应性有限、对新任务的泛化能力不足,以及在管理长期、多阶段规划方面面临挑战。生成模型能够高效直接地生成轨迹,通过数据驱动学习提高适应性,并增强在不同任务和环境中的泛化能力,从而带来极具前景的范式转变。这些模型还支持集成视觉和语言等多模态输入,同时生成平滑且时间一致的轨迹。尽管取得这些进展,生成模型仍面临着严峻的挑战,包括实时推理约束、对多样化和高质量训练数据的依赖、物理和动态约束的结合、对实际应用中不确定性的鲁棒性,以及对安全性和可解释性的需求。解决这些局限性对于推进生成方法以满足实际场景中机器人操作的严格要求至关重要。
根据生成策略,将这些模型分为三种主要方法:基于采样的生成、基于大型预训练模型的生成和混合模式生成。
基于采样的生成,依赖于概率模型(例如扩散模型或高斯过程)从学习或预定义的分布中采样高质量轨迹,从而有效地处理高维空间和复杂约束(例如避障)。
基于大型预训练模型的生成,利用强大的预训练模型(例如视觉语言转换器或自回归架构)来预测以语言命令或任务描述等高级输入为条件的轨迹,从而展示出在不同任务和环境中的强大泛化能力。
混合模式生成结合多种生成技术,集成潜变量表示、预训练知识和视频动态,以在复杂的多阶段任务中实现效率和适应性。
总之,这些方法解决轨迹生成中的关键挑战,从多模态集成到长期任务规划,从而提高机器人在动态和非结构化环境中的能力。
代表性机器人操纵的轨迹生成工作如图所示:
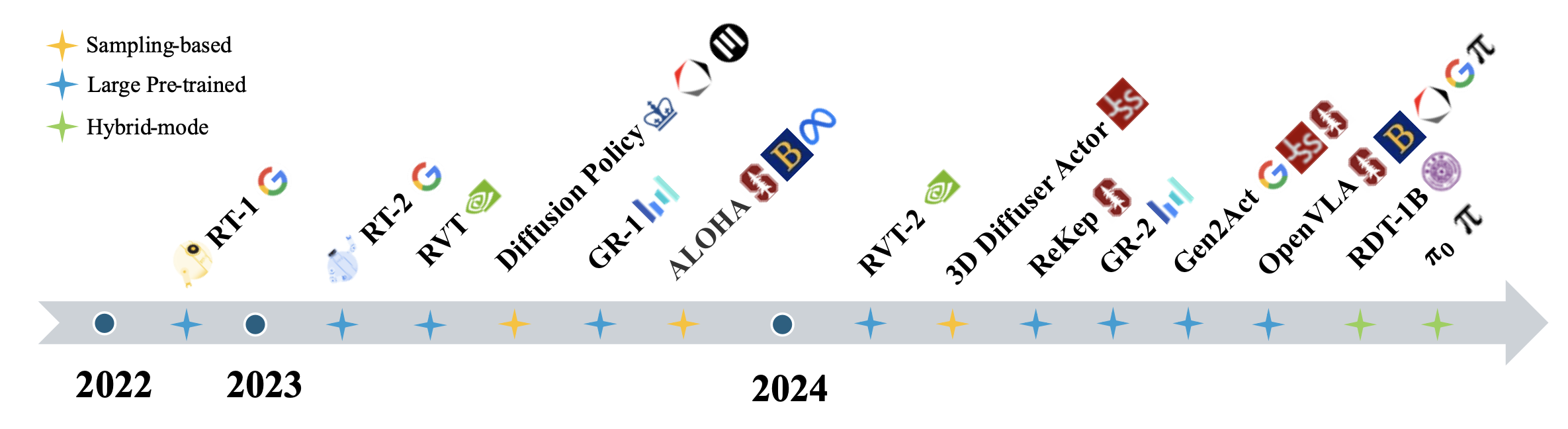
基于采样的生成,是指通过从学习的或预定义的可能动作或状态分布中进行采样,来生成机器人操作轨迹或策略的方法。这些方法通常依赖于概率模型,例如高斯过程、蒙特卡洛方法或扩散模型,来探索可行解的空间并针对特定任务的目标进行优化。基于采样的技术对于处理高维状态和动作空间,以及诸如避障或动态环境等复杂约束条件特别有用。ALOHA [31] 专为需要高精度和协调性的细粒度双手操作任务而设计,采用现成的硬件和定制的 3D 打印组件来增强可访问性。其关键创新是带有 Transformers 的动作分块 (ACT) 算法,该算法利用条件变分自编码器 (CVAE) 框架,使机器人仅需 10 分钟的演示数据即可通过模仿学习来学习和执行精确任务,在插入电池和打开杯子等任务中取得了很高的成功率。RoboAgent [84] 引入 MT-ACT,它通过语义增强和新策略架构增强 7500 条轨迹的小型数据集,在多任务设置中的表现优于基线,并证实其设计选择的有效性。分块因果 transformer (CCT) [207] 将自回归模型扩展到机器人技术,可以有效地预测多个未来动作 token 并提高准确性。相比之下,基于 CCT 的自回归策略 (ARP) 模型在各种任务中都表现出色。
扩散策略 [6] 提出一种新方法,利用条件扩散模型来学习机器人操作的视觉运动策略。该方法将策略定义为一个去噪扩散过程,能够有效地建模多模态动作分布和高维动作序列,从而增强训练过程中的稳定性,并能够很好地适应需要时间一致性的任务。关键创新包括用于连续重规划的滚动时域控制、用于实时观察的视觉条件反射,以及用于管理高频动作变化的时间序列扩散 transformer。实证结果表明,该方法在 15 项任务中的平均性能比最先进的方法提高了 46.9%。 3D 扩散器执行器 [7] 将 3D 场景表征和动作扩散相结合,用于机器人操作策略,利用 token化的 3D 场景表征、语言指令和带噪声的机器人姿态轨迹作为输入,在 RLBench [208] 和 CALVIN [209] 基准上取得新SOTA 成果,尽管它存在一些局限性,例如需要相机标定,而且与非扩散策略相比性能较慢。等变(equi-variant)扩散策略 [210] 利用等变神经模型来提高样本效率和泛化能力,在模拟和实际实验中表现出更高的成功率,尽管它在对称匹配方面存在局限性。EquiBot [211] 将 SIM(3) 等变神经网络与扩散模型相结合,以增强泛化能力和数据效率,在模拟和实际任务中均表现良好。交叉扩散 [212] 通过集成辅助自监督目标来改进基于扩散的视觉运动策略,与基线方法相比表现出持续的改进。一致性策略 [213] 解决扩散模型中推理速度慢的问题,在保持性能的同时实现显著的加速,尽管它在多模态性方面存在缺陷。最后,ALOHA Unleashed [206] 利用基于 Transformer 的架构和扩散策略进行大规模数据收集,以应对具有挑战性的双手操作任务,展示卓越的性能,并为未来的多任务学习模型奠定了基础。
BiKC [214] 是一个分层的 IL 框架,具有高级关键姿势预测器和低级轨迹生成器,可应对多阶段双手操作任务的挑战,这些任务需要高效的手臂协调,并面临多模态演示和每步/每阶段可靠性等问题。关键姿势预测器使用启发式算法和双手协调的合并方法来识别关键姿势,并经过训练以预测目标关键姿势。轨迹生成器是一个一致性模型,用于生成以观测值和关键姿势为条件的动作序列。在模拟和真实任务(转移、插入、螺丝刀包装等)上的实验表明,BiKC 在成功率和运行效率方面优于基线(ACT,DP),同时还展示多模态建模和推理速度优势,尽管它具有样本平滑度和关键姿势表示等局限性,可以在未来的研究中改进。
基于大规模预训练模型的生成,是指利用大规模预训练模型(例如 Transformer 或 GPT 风格的架构)来生成机器人操控策略或轨迹的方法。这些模型通常在海量数据集上进行训练,通常包含视觉、语言和传感器数据等多模态输入,从而使它们能够学习丰富的表征并在各种任务中进行泛化。通过针对特定的机器人任务进行微调,这些模型即使在复杂动态的环境中也能生成高质量、情境感知的动作或规划。视觉-语言-动作 (VLA) 模型将动作视为一组语言 token,LLM 可以同时生成动作和语言。RT-2 [54] 引入 VLA 概念,并基于 PaLI-X [215] 和 PaLM-E [216] 开发两个 VLA 模型。VLA 模型利用 LLM 丰富的预训练知识,展现出增强的泛化性能。
RT-1 [217] 和 RT-2 利用基于 Transformer 的架构在各种任务中实现稳健性能,而 RVT [218] 和 RVT-2 [219] 则专注于多视图转换,以提高任务执行效率和在实际应用中的泛化能力。由于 RT-2 并非开源,OpenVLA [55] 被提出作为可公开访问的替代方案。OpenVLA 基于 Prismatic 多模态 LLM [220] 构建,并使用 DINOv2 [221] 和 SigLIP [222] 作为视觉编码器。它使用 LLM 直接输出动作 token。OpenVLA 在大规模 Open-X-Embodiment 数据集 [223] 上进行预训练,与 RT-2 相比表现出更优异的性能。DeL-TaCo [224] 将机器人策略与来自视觉演示和语言指令的任务嵌入相结合,从而提高了泛化能力并减少对演示的需求。 PERACT [176] 是一个用于多任务操作的语言条件行为克隆智体,其表现优于传统方法;PolarNet [225] 将点云表示与语言指令相结合,在现实世界任务中展现出强大的鲁棒性;Im2Flow2Act[226] 使机器人能够利用目标流从多样化数据中学习操作技能;Dreamitate[227] 利用视频扩散模型进行鲁棒的视觉运动策略学习;Gen2Act [228] 将零样本人类视频生成与有限的机器人演示相结合,在泛化方面取得很高的成功率;ReKep [152] 使用关系关键点约束进行任务表示;Surfer [171] 将操作解耦为动作和场景预测。GemBench [229] 的推出为评估视觉语言机器人操作的泛化能力提供基准。 GR-1 [166] 和 GR-2 [167] 探索大规模视频生成预训练,以增强机器人的视觉操作能力,并取得最佳成果。
混合模式生成,是指结合多种生成技术(例如隐变量模型、预训练模型和视频生成模型)的方法,以增强机器人操作算法的鲁棒性和多功能性。通过整合不同方法的优势,这些方法可以解决需要高级规划和低级控制的复杂任务,同时还能处理视觉、语言和传感器数据等多模态输入。GenDP [230] 框架通过使用从多视图 RGBD 观测生成的 3D 语义场来解决基于扩散的策略的泛化局限性,显著提高对未见实例的成功率,并实现类别级泛化。分层扩散策略 (HDP) [231] 将策略分解为层次结构,以实现高效的视觉操作,其表现优于最先进的方法,并证明运动感知的重要性,同时又能应对长期任务中的挑战。一种大语言模型强化学习策略 (LLaRP) [232] 的新方法将大语言模型 (LLM) 调整为可泛化的策略,用于体现视觉任务,利用通过强化学习预先训练的 LLM 来处理文本指令和视觉观察,在 1000 个新任务中实现了 42% 的成功率,并引入了语言重排基准来评估语言条件重排任务。机器人扩散transformer (RDT) [233] 使用扩散模型,通过可扩展的 Transformer 架构来处理多模态动作分布,提出了一个物理上可解释的统一动作空间,用于在异构多机器人数据上进行训练。RDT 在一个大型多机器人数据集上进行了预训练,并在一个自行收集的双手数据集上进行了微调,在真实机器人实验中展现出了强大的零样本泛化能力、有效的指令遵循能力和少样本学习能力。最后,π0 [205] 提出一种用于通用机器人控制的架构,它利用预训练的视觉语言模型 (VLM) 作为其骨干,并将来自海量数据集的语义理解与流匹配方法相结合,以生成连续动作,从而实现高频控制(高达 50 Hz)。π0 基于涵盖不同机器人和任务的多样化数据集进行训练,能够实现零样本任务性能,并可针对折叠衣物和组装物品等复杂任务进行微调。这使其成为迈向多功能通用机器人学习模型的重要一步,该模型可与大型语言模型相媲美,但专注于物理定位、多阶段机器人任务。
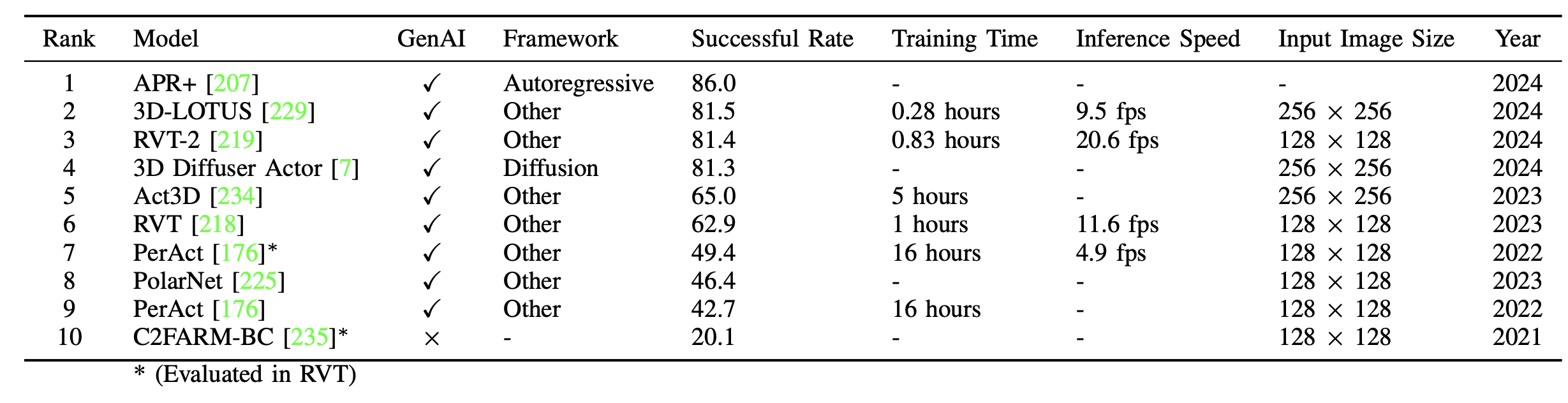
每种生成方法都根据不同机器人任务的操作要求提供独特的优势。大多数研究已在 RLBench 基准上进行广泛的验证,如表所示。潜空间模型能够生成平滑的轨迹,尤其适用于运动连续性和一致性至关重要的任务。基于采样的模型在轨迹精度和控制至关重要的情况下是最佳选择,尤其是在具有可预测障碍物的结构化环境中。混合生成技术实现平衡的权衡,为各种机器人操作任务提供灵活的解决方案。机器人轨迹生成的生成模型体现精度、适应性和效率之间的权衡。
随着生成模型持续革新机器人操作,一些颇具前景的途径应运而生,旨在应对现有挑战并释放新功能。
首先,通过混合显式-隐式表示学习和以任务为中心的自适应方法,将域通用模型与特定领域约束相结合,例如 Robotic-CLIP [236] 和 ManiGaussian [177],这将使机器人能够在编码特定动作动态的同时继承视觉泛化能力。
其次,建立包含标准化任务、数据集和评估指标的统一基准,对于促进研究间的公平比较和可重复性至关重要。
最后,通过物理增强训练、物理约束生成和带物理反馈的强化学习来增强物理定律意识,将弥合模拟与现实之间的差距,并提高在现实环境中的泛化能力。
通过应对这些挑战,该领域可以实现能够在复杂非结构化环境中运行的鲁棒、自适应且高效的机器人操纵系统。
a) 将领域通用模型应用于域特定数据:将生成式 AI 应用于机器人操作的一个基本挑战,在于将域通用模型应用于域特定约束。虽然视觉-语言模型 (VLM) [95, 99] 在物体识别和分割任务中展现出卓越的零样本泛化能力,但它们的表征缺乏关键的物理交互特征,例如空间关系、力动态等。这种限制源于它们的训练目标集中在静态互联网源数据而非动态物理交互上。
两个关键问题加剧这一挑战。
首先,当针对网络规模视觉理解优化的视觉-语言模型 (VLM) 无法编码与机器人相关的属性时,就会出现语义-物理表征错位。例如,基于 CLIP 的架构 [95] 中的图文对齐难以处理操作视频中的动态动作语义,因此需要时间感知的模型结构和针对特定域的动作序列微调来弥补这一差距。
其次,数据引发的物理偏差源于互联网规模的预训练数据与现实世界物理定律之间的差异。当 VLM 误解材料特性时,这会导致灾难性的操作故障:机器人可能会因为表面反射率的视觉相似性而将软橡胶误认为硬质金属,从而导致不恰当的抓取策略(例如,抓握力过大)。VLBiasBench [237] 的实证证据表明,VLM 在区分“金属与塑料”材料方面的准确率仅为 62%,并且有 78% 的概率会将反射表面误认为金属,同时忽略刚度或柔顺性等机械特性。此类偏差源于 VLM 过度依赖静态网络图像,而缺乏物理交互动力学和符合材料科学原理的多模态注释。
为了克服这些障碍,两个新兴的研究方向展现出特别的前景。一方面,混合显式-隐式表示学习将神经场与基础模型相结合,以动态编码几何精度和任务语义。近期的扩展,如 ManiGaussian,进一步展示Gaussian Splatting 如何正则化三维高斯基元,以便利用视觉基础特征学习动态[177]。另一方面,基于交互感知数据集的以任务为中心的自适应方法也越来越受到关注。Robotic-CLIP [236] 开创这一范式,通过对比学习在 740 万个动作帧上对 CLIP 进行微调,在保留原始语义对齐的同时,显著提高语言驱动机器人任务的性能。它引入一个适配器网络,可以在不改变原始模型权重的情况下,将特定动作的动态有效地映射到 CLIP 嵌入空间,从而实现参数高效的自适应。实验结果表明,Robotic-CLIP 在语言驱动的抓握检测和策略学习等任务中优于其他 CLIP 变体,实现更高的成功率,并实现文本指令与视觉框架之间更佳的对齐。这种方法使机器人能够继承视觉泛化能力,同时通过参数高效的自适应编码特定于动作的动态特性。
b) 碎片化的基准测试阻碍了技术进展和公平比较:具身操控算法缺乏统一的基准测试,这构成重大挑战,阻碍公平的性能比较和跨研究的可重复性。当前存在的问题包括:任务定义多样化[6, 7, 31, 208]、数据集不一致[208, 209, 223]、模拟平台差异化[56, 57, 238]以及评估指标不标准化。为了解决这些问题,未来的工作应侧重于建立标准化的任务、数据集和模拟环境,同时开发涵盖成功率、完成时间、能效和泛化能力的综合评估框架。此外,推广开源代码、可重复性挑战和跨平台兼容性将增强研究社区的透明度和协作。通过统一基准测试,该领域可以加速进展,并使具身操控算法取得更可靠的进展。
c) 有限的物理定律觉察:有限的物理定律觉察是具身操控中的一项重大挑战,尤其是在弥合模拟-到-现实的差距和利用视觉生成模型方面。许多当前的方法依赖于物理定律(例如摩擦、动力学和材料特性)的简化或不完整表示,这导致从模拟-到-现实环境的泛化能力较差。模拟-到-现实的差距是指从模拟 (sim) 过渡到现实世界 (real) 时的性能和行为差异。这种差距可能导致在模拟中运行良好的模型在现实中无法达到预期效果。造成这种差距的因素包括物理模拟的局限性、模拟和现实世界之间的传感器差异、执行器的变化、环境复杂性以及现实世界中未建模的动态特性 [239, 240, 241]。已经提出一些方法来解决这个问题。域随机化是一种在模拟中应用随机化物理参数、光照条件和传感器噪声的常用方法 [242, 243, 244]。模拟-到-现实的迁移学习和域自适应技术也有助于解决模拟-到-现实的差距 [14, 245, 246]。通过师生学习进行的特权蒸馏表明,学习像接触更多信息的教师模型一样行事也能有效地解决模拟-到-现实的差距问题 [247, 248, 249]。虽然视觉生成模型,特别是在机器人操作领域,在制作逼真的图像和视频方面取得重大进展,但它们往往缺乏对支配现实世界交互的底层物理定律的深刻理解 [250, 251, 252, 253]。这些模型主要侧重于根据从大型数据集中学习的模式生成视觉上可信的序列,但它们通常没有接受过有关重力、动量、碰撞动力学或材料特性等概念的明确训练。因此,生成的场景可能并不总是符合物理世界的约束,从而导致不切实际或物理上不可行的视觉提示。这种有限的物理意识会降低机器人操作任务的规划质量。因此,依赖这些模型的机器人可能会难以完成涉及精细物体操作、动态交互或长期规划的任务,因为理解物理动作的后果对于成功至关重要。为了解决这一限制,可以探索几种未来的研究途径,包括 1)结合物理模拟来微调生成模型的物理增强训练,2)将物理约束纳入生成过程的物理约束生成,以及 3)利用显式物理反馈来改进物理定律意识的物理反馈强化学习。
相关文章:
)
机器人操作中的生成式 AI:综述(下)
25年3月来自香港大学、香港理工、香港科大、浙大和清华大学的论文“Generative Artificial Intelligence in Robotic Manipulation: A Survey”。 本综述全面回顾机器人操作领域生成学习模型的最新进展,并探讨该领域的关键挑战。机器人操作面临着关键瓶颈ÿ…...

把一个 PyTorch 的图像张量转换成 NumPy 格式,并按照正确的维度顺序显示出来
示例代码: plt.imshow(np.transpose(tensor_denorm.numpy(), (1, 2, 0)))它的作用是:把一个 PyTorch 的图像张量转换成 NumPy 格式,并按照正确的维度顺序显示出来。 🚀 一步步解释: ✅ tensor_denorm 这是一个形状为…...

windows上的RagFlow+ollama知识库本地部署
一、 docker的安装与部署 1. 下载Docker Desktop 访问Docker官网并下载适用于Windows的Docker Desktop安装程序。 RagFlow对docker的要求: Docker ≥ 24.0.0 & Docker Compose ≥ v2.26. docker 下载地址: https://www.docker.com/ Get Docker | D…...

【docker】 pull FROM build
镜像拉取失败 token问题 DeadlineExceeded: failed to fetch anonymous token Get "https://auth.docker.io/token?...": dial tcp 157.240.20.8:443: i/o timeout1. 检查网络连通性 如果 curl 命令卡住或超时,说明网络到 Docker Hub 存在问题。 ping regt-1.doc…...

【数据分析实战】使用 Matplotlib 绘制玫瑰图
🌹 1、简述 玫瑰图,又称极坐标柱状图(Polar Bar Chart),是一种特殊的条形图,适用于展示方向型数据,例如: 风向频率图(Wind Rose)每月、每日不同类别统计圆形时间序列展示(如12个月销售量分布)在本篇博客中,我们将使用 matplotlib 画出玫瑰图,包括基本玫瑰图、多…...

第十四届蓝桥杯省B.砍树
第十四届蓝桥杯省B.砍树 题目 题目解析及思路 考虑一对无序数对的点 x和 y,如果我们砍掉某条边可以让这两个点不连通,那么这条边一定是从 x到 y 路径上的一点,我们可以让从 x到 y 路径的边权值都加1。这个操作我们可以使用树上差分。 对于 …...

windows安装Mysql
一、删除已安装的MySQL服务 1、查找以前是否装有mysql sc query mysql 无结果,说明未安装过mysql或者已经卸载mysql服务,接下来直接安装mysql即可,否则需要删除之前安装的mysql 2、删除mysql 以管理员模式打开命令运行行,运行下…...

Axure大屏可视化模板:多领域数据决策的新引擎
在数据驱动决策的时代,Axure大屏可视化模板凭借交互性与可定制性,成为农业、园区管理、智慧城市、企业及医疗领域的创新工具,助力高效数据展示与智能决策。 核心应用场景 1. 农业精细化:实时监控土壤湿度、作物生长曲线&#x…...

【产品经理从0到1】原型及Axure介绍
原型分类 原型的三种分类: 草图原型:⼿绘稿,制作⽅便,修改不⽅便;低保真原型:简单交互,⽆设计图; 最好的原型是⿊⽩灰的;⾼保真原型:复杂交互,有…...
【激光雷达3D(7)】CenterPoint两阶段细化仅使用BEV特征;PV-RCNN两阶段细化使用体素特征;M3DETRTransformer统一多表征特征
文章目录 1. CenterPoint的两阶段细化模块仅使用鸟瞰视角(BEV)特征2 PV-RCNN 两阶段3 M3DETR(假设为类似DETR的3D检测器) 1. CenterPoint的两阶段细化模块仅使用鸟瞰视角(BEV)特征 CenterPoint的两阶段细化…...
)
C# 音频分离(MP3伴奏)
编程语言:C# 库:NAudio NAudio 是一个开源的 .NET 音频处理库,它为开发者提供了丰富的功能,能在 Windows 平台上方便地进行音频的录制、播放、处理等操作。以下是关于 NAudio 库的详细介绍: 主要特性 多格式支持&am…...
:异步编程与主线程优化)
JavaScript性能优化实战(4):异步编程与主线程优化
JavaScript单线程模型与事件循环深入理解 JavaScript作为一种单线程语言,其执行模型与传统多线程编程语言有着根本性的差异。这种单线程特性既是JavaScript的局限,也是其简洁性的来源。深入理解JavaScript的单线程模型和事件循环机制,对于编写高性能的异步代码至关重要。 …...

Control Center安卓版:自定义控制中心,提升手机操作体验
在使用智能手机的过程中,许多用户希望能够更加便捷地访问常用功能和工具,提升操作效率。今天,我们要介绍的 Control Center安卓版,就是这样一款功能强大的手机控制软件。它不仅提供了简便的操作方法,还允许用户自定义操…...
)
Web3.0的认知补充(去中心化)
涉及开发技术: Vue Web3.js Solidity 基本认知 Web3.0含义: 新一代互联网思想:去中心化及用户为中心的互联网 数据:可读可写可授权 核心技术:区块链、NFT 应用:互联网上应用 NFT &…...

在Vue3中,如何在父组件中使用v-model与子组件进行双向绑定?
在 Vue 3 里,借助 v-model 可以轻松实现父组件与子组件的双向绑定。以下为你详细介绍实现步骤与示例代码。 实现原理 v-model 在 Vue 3 里是一种语法糖,它本质上是 :modelValue 和 update:modelValue 的组合。父组件借助 :modelValue 向子组件传递数据…...

沁恒MounRiver Studio无法printf浮点数
最近在使用沁恒MounRiver Studio进行CH32V307进行开发,但是遇到了已经成功获得浮点数,但是无法printf输出浮点数 如下图所示: 经过查找资料后,发现沁恒MounRiver Studio如果要printf输出浮点数需要打开Use float with nano print…...
)
初识Redis · 主从复制(下)
目录 前言: 数据同步 全量复制 部分复制 实时复制 前言: 前文我们已经介绍过了主从复制的基本概念,即分布式系统中存在多个Redis节点,一个是充当为主节点,其他的为从节点,并且从节点也是可以成为主节…...

BDO分厂开展地沟“大清肠”工作
BDO分厂装置区内的地沟主要回收生产过程中产生的污水、日常雨水,日积月累地沟内堆积了一层淤泥和杂物。厚厚的淤泥气味不仅影响员工健康,而且造成排水系统不畅通,存在安全隐患。分厂借助此次待产停车的有利时机对沉积已久的淤泥进行一次彻底“…...

程序和进程的详细对比
💡 一、程序(Program) ✅ 定义: 程序是一组指令的集合,通常是一个 可执行文件(如 .exe、.out),它是静态的、保存在磁盘上的一段代码,还没有被执行。 ✅ 特点ÿ…...

Flink介绍——实时计算核心论文之Flink论文
引入 通过前面的文章,我们梳理了大数据流计算的核心发展脉络: S4论文详解S4论文总结Storm论文详解Storm论文总结Kafka论文详解Kafka论文总结MillWheel论文详解MillWheel论文总结Dataflow论文详解Dataflow论文总结 而我们专栏的主角Flink正是站在前人的…...

【C++指南】位运算知识详解
. 💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《C指南》 期待您的关注 文章目录 引言一、位运算符概述1. 按位与(&)2. 按位或(|&#…...
之 数据交换格式)
网络开发基础(游戏)之 数据交换格式
数据交换格式是不同系统、应用程序或组件之间传输和共享数据时使用的标准化数据表示方式。在网络通信中,数据交换格式的选择直接影响系统的性能、可维护性和扩展性。以下是常用的数据交换格式的介绍和选择建议。 Protobuf (Protocol Buffers)协议缓冲区 是 Googl…...

怎么配置一个kubectl客户端访问多个k8s集群
怎么配置一个kubectl客户端访问多个k8s集群 为什么有的客户端用token也访问不了k8s集群,因为有的是把~/.kube/config文件,改为了~/.kube/.config文件,文件设置成隐藏文件了。 按照kubectl的寻找配置的逻辑,kubectl找不到要访问集群…...

【MongoDB】卸载、安装低版本
卸载 MongoDB 的步骤因操作系统而异,以下是 Windows、macOS 和 Linux 的详细卸载方法: 1. Windows 卸载 MongoDB 方法 1:通过控制面板卸载 打开控制面板 Win R → 输入 appwiz.cpl → 回车 找到 MongoDB 在程序列表里找到 MongoDB Server …...

WGAN+U-Net架构实现图像修复
简介 简介:该论文提出了一种基于Wasserstein生成对抗网络(WGAN)的图像修复方法,使用U-Net生成器,通过对抗损失与内容损失联合训练,有效解决了传统方法对破损区域形状大小受限、修复痕迹明显的问题。在CelebA和LFW数据集上的实验表明,该方法修复效果优于现有技术,尤其对…...

vscode vue文件单行注释失效解决办法
打开设置,搜索 files.associations,添加项 *.vue html 点击确定即可...
——K均值聚类)
机器学习(7)——K均值聚类
文章目录 1. K均值(K-means)聚类是什么算法?2. 核心思想2. 数学目标3. 算法步骤3.1. 选择K个初始质心:3.2.迭代优化3.3. 重复步骤2和步骤3: 4. 关键参数5. 优缺点6. 改进变种7. K值选择方法8. Python示例9. 应用场景10…...

LainChain技术解析:基于RAG架构的下一代语言模型增强框架
摘要 随着大语言模型(LLM)在自然语言处理领域的突破性进展,如何突破其知识时效性限制、提升事实准确性成为关键挑战。LainChain通过整合检索增强生成(RAG)技术,构建起动态知识接入框架,为LLM提供实时外部知识支持。本文从技术原理、架构设计、应用场景三个维度,深入解…...
)
Java 使用 RabbitMQ 消息处理(快速上手指南)
目录 一、前言二、RabbitMQ 简介三、开发环境搭建3.1 安装 RabbitMQ在 Ubuntu 上安装在 Windows 上安装使用 Docker 安装3.2 添加 Maven 依赖四、RabbitMQ 的核心概念BrokerVirtual hostConnectionChannelExchangeQueueProducerConsumer五、RabbitMQ 基本操作5.1 发送消息(生产…...

Java 2025 技术全景与实战指南:从新特性到架构革新
作为一名Java开发者,2025年的技术浪潮将带给我们前所未有的机遇与挑战。本文将带你深入探索Java生态的最新发展,从语言特性到架构革新,助你在技术洪流中把握先机! 🌟 Java 2025 新特性全景 1. 模式匹配的全面进化 (J…...

【hadoop】HBase shell 操作
1.创建course表 hbase(main):002:0> create course,cf 2.查看HBase所有表 hbase(main):003:0> list 3.查看course表结构 hbase(main):004:0> describe course 4.向course表插入数据 hbase(main):005:0> put course,001,cf:cname,hbase hbase(main):006:0> …...

rabbitmq死信队列处理
创建私信队列并绑定 # 死信交换机配置 以直连交换机为列 my:exchangeNormalName: exchange.normal.a #正常交换机queueNormalName: queue.normal.a #正常队列exchangeDlxName: exchange.dlx.a #死信交换机queueDlxName: queue.dlx.a #死信队列…...

基于事件驱动的云原生后端架构设计:从理念到落地
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:微服务之后,事件驱动正在成为新范式 随着业务复杂度的提升,传统同步式微服务调用模式逐渐暴露出瓶颈:服务间耦合度高、并发能力有限、出错链路复杂。而在互联网业务、金融交易、物联网等场景中…...

CentOS 7 磁盘阵列搭建与管理全攻略
CentOS 7 磁盘阵列搭建与管理全攻略 在数据存储需求日益增长的今天,磁盘阵列(RAID)凭借其卓越的性能、数据安全性和可靠性,成为企业级服务器和数据中心的核心存储解决方案。CentOS 7 作为一款稳定且功能强大的 Linux 操作系统&am…...

区块链技术:深入共识算法、智能合约与DApps的架构奥秘
引言:区块链的颠覆性潜力 在数字化浪潮席卷全球的今天,区块链技术以其独特的去中心化特性、不可篡改的数据记录和透明的交易机制,正在重塑我们对信任、价值交换和组织形式的理解。从比特币的诞生到以太坊的智能合约革命,再到如今…...

深度学习物理信息神经网络PINN+大模型辅助编程
1. 物理信息神经网络(PINN)的兴起 近年来,物理信息神经网络(Physics-Informed Neural Networks, PINN)成为计算科学与人工智能交叉领域的前沿方向。传统数值方法(如有限差分法、有限单元法)在高…...

vue element使用el-table时,切换tab,table表格列项发生错位问题
展示问题 问题描述:使用el-table的fixed"right"属性后,如果切换tab时,回出现最后一列错误的问题 官网提供解决方法:doLayout 需要注意的事项:我这里是通过组件使用的table组件,涉及多层组件封装…...
深入了解AVFoundation-采集:拍照功能的实现)
(八)深入了解AVFoundation-采集:拍照功能的实现
引言 在上一篇文章中,我们初步完成了使用 AVFoundation 采集视频数据的流程,掌握了 AVCaptureSession 的搭建与视频流的预览显示。 本篇将继续深入 AVFoundation,聚焦于静态图片采集的实现。通过 AVCapturePhotoOutput,我们可以…...
)
C++区别于C语言的提升用法(万字总结)
1.namespace产生原因 在C语言中,变量,函数,以至于类都是大量存在的,因此会产生大量的名称存在于全局作用域中,可能产生很多冲突,至此c的祖师爷为避免命名冲突和名字的污染,造出来了关键字names…...

创新项目实训开发日志4
一、开发简介 核心工作内容:logo实现、注册实现、登录实现、上传gitee 工作时间:第十周 二、logo实现 1.设计logo 2.添加logo const logoUrl new URL(/assets/images/logo.png, import.meta.url).href <div class"aside-first">…...

ospf综合作业
需求 需求分析 区域划分: 网络划分为 area 0、area 1、area 2、area 3、area 4 多个区域。其中 area 0 作为骨干区域,其他为非骨干区域。这种划分符合 OSPF(开放式最短路径优先)协议中区域设计原则,不同区域通过 ABR…...

旋转磁体产生的场-对导航姿态的影响
pitch、yaw、roll是描述物体在空间中旋转的术语,通常用于计算机图形学或航空航天领域中。这些术语描述了物体绕不同轴旋转的方式: Pitch(俯仰):绕横轴旋转,使物体向前或向后倾斜。俯仰角度通常用来描述物体…...

Hive 数据同步到 Doris 最佳实践方案:从场景适配到性能调优全解析
在大数据领域,Hive 作为成熟的数据仓库解决方案,常用于海量数据存储与离线处理,而 Doris 凭借其强大的 OLAP 能力,在实时分析、即席查询等场景表现卓越。当企业需要将 Hive 数据仓库中的数据与 Doris 的分析能力结合时,…...

netty中的Channel与Java NIO中的Channel核心对比
Netty的Channel和Java NIO的Channel虽然都用于网络通信,但设计理念、功能扩展及适用场景存在显著差异。以下从核心特性、设计模式及性能优化等维度展开对比: 1. 抽象层次与功能范围 Java NIO Channel 基础IO模型:仅支持非阻塞IO(NIO),如SocketChannel、ServerSocketChann…...

基于whisper和ffmpeg语音转文本小程序
目录 一、环境准备 ✅ 第一步:安装并准备 Conda 环境 ✅ 第二步:创建 Whisper 专用的 Conda 虚拟环境 ✅ 第三步:安装 GPU 加速版 PyTorch(适配 RTX 4060) ✅ 第四步:安装 Whisper 和 FFMPEG 依赖 ✅…...

使用ffmpeg 将图片合成为视频,填充模糊背景,并添加两段音乐
1.输入3张图片,每张播放一次,播放两秒,视频分辨率设置为1920:1080,每张图片前0.3秒淡入,后0.3秒淡出,图片宽高比不变,用白色填充空白区域 ffmpeg -loop 1 -t 2 -i "img1.jpg" \-loop 1 -t 2 -i "img2.jpg" \-loop 1 -t 2 -i "img3.jpg" \-filte…...

Python协程详解:从基础到实战
协程是Python中实现并发编程的重要方式之一,它比线程更轻量级,能够高效处理I/O密集型任务。本文将全面介绍协程的概念、原理、实现方式以及与线程、进程的对比,包含完整的效率对比代码和详细说明,帮助Python开发者深入理解并掌握协…...

服务器部署LLaMAFactory进行LoRA微调
一、什么是LLaMAFactory LlamaFactory 是一个专为 大型语言模型(LLM)微调 设计的开源工具库,旨在简化大模型(如 LLaMA、GPT、Mistral 等)的定制化训练流程,降低技术门槛和硬件成本。以下是它的核心功能和应…...

ASP.NET MVC 入门指南
以下是一份 MVC(Model - View - Controller)培训教程,以ASP.NET MVC 为例进行讲解,适合有一定编程基础的学习者快速上手。 1. MVC 概述 1.1 什么是 MVC MVC 是一种软件设计模式,它将应用程序分为三个主要部分&#…...

mapbox高阶,高程影像、行政区边界阴影效果实现
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️line线图层样式1.4 ☘️symbol符号图层…...