服务器部署LLaMAFactory进行LoRA微调
一、什么是LLaMAFactory
LlamaFactory 是一个专为 大型语言模型(LLM)微调 设计的开源工具库,旨在简化大模型(如 LLaMA、GPT、Mistral 等)的定制化训练流程,降低技术门槛和硬件成本。以下是它的核心功能和应用场景:
1. 核心功能
① 高效微调技术
-
参数高效微调(PEFT)
支持 LoRA、QLoRA、Adapter 等方法,仅训练少量参数(如原模型的0.1%),显存需求降低50%-80%。-
示例:在24GB显存的RTX 4090上微调7B模型(默认全参数微调需80GB+显存)。
-
-
量化训练
支持4/8-bit量化(结合bitsandbytes),进一步压缩显存占用。 -
梯度检查点
通过牺牲计算时间换取显存,支持更长上下文训练。
② 多模型与多任务支持
-
兼容主流架构:LLaMA、Baichuan、ChatGLM、Qwen、GPT、Mistral等。
-
多任务适配:支持指令微调(Instruction Tuning)、领域适配(如医疗、法律)、对话模型优化等。
③ 分布式训练优化
-
支持多卡并行(数据并行、模型并行)、DeepSpeed ZeRO 加速,适合大模型训练。
④ 用户友好设计
-
可视化Web UI:无需编码即可配置超参数、启动训练。
-
CLI工具:一行命令启动微调,支持自定义数据集格式。
二、部署LLaMAFactroy
首先,让我们尝试使用github的方式克隆仓库:
git config --global http.sslVerify false && git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
仓库已经成功克隆下来了。现在让我们进入项目目录并查看一下环境要求:
cd LLaMA-Factory && cat requirements.txt
接下来让我们先检查一下 Python 环境:
python3 --version && pip3 --version
现在让我们安装所需的依赖:
pip3 install -r requirements.txt要启动Web UI,可以运行:
cd LLaMA-Factory && python3 src/web_demo.py新建原始数据json文件夹
Factory支持的格式。LLaMA-Factory支持多种格式,对于文本分类任务,我们可以使用alpaca格式。创建一个转换脚本:
import pandas as pd
import json
from pathlib import Pathdef convert_tnews(input_file):df = pd.read_csv(input_file, sep='\t', header=None, names=['id', 'text', 'label'])# 更新后的标签映射label_map = {'100': '民生','101': '文化','102': '娱乐','103': '体育','104': '财经','106': '房产','107': '教育','108': '科技','109': '军事','110': '旅游','112': '国际','113': '证券','114': '农业','115': '政务','116': '电商'}conversations = []for _, row in df.iterrows():label = str(row['label'])if label in label_map:category = label_map[label]else:continueitem = {"instruction": "请判断以下新闻属于哪个类别。","input": row['text'],"output": category}conversations.append(item)return conversationsdef convert_ocemotion(input_file):df = pd.read_csv(input_file, sep='\t', header=None, names=['id', 'text', 'label'])# 更新后的标签映射label_map = {'sadness': '悲伤','happiness': '快乐','disgust': '厌恶','anger': '愤怒','like': '喜欢','surprise': '惊讶','fear': '恐惧'}conversations = []for _, row in df.iterrows():label = str(row['label']).strip()if label in label_map:emotion = label_map[label]else:continueitem = {"instruction": "请判断以下文本表达的情感。","input": row['text'],"output": emotion}conversations.append(item)return conversationsdef convert_ocnli(input_file):df = pd.read_csv(input_file, sep='\t', header=None, names=['id', 'sentence1', 'sentence2', 'label'])label_map = {'0': '蕴含','1': '矛盾','2': '中立'}conversations = []for _, row in df.iterrows():label = str(row['label'])if label in label_map:relation = label_map[label]else:continueitem = {"instruction": "判断两个句子之间的关系。","input": f"句子1:{row['sentence1']}\n句子2:{row['sentence2']}","output": relation}conversations.append(item)return conversationsdef main():# 修改为正确的路径data_dir = Path('/root/LLaMA-Factory/tcdata')output_dir = Path('/root/LLaMA-Factory/data')output_dir.mkdir(parents=True, exist_ok=True)# 转换TNEWS数据print("Converting TNEWS dataset...")tnews_conversations = convert_tnews(data_dir / 'TNEWS_train1128.csv')with open(output_dir / 'tnews_train.json', 'w', encoding='utf-8') as f:json.dump(tnews_conversations, f, ensure_ascii=False, indent=2)print(f"Converted {len(tnews_conversations)} TNEWS examples")# 转换OCEMOTION数据print("\nConverting OCEMOTION dataset...")emotion_conversations = convert_ocemotion(data_dir / 'OCEMOTION_train1128.csv')with open(output_dir / 'emotion_train.json', 'w', encoding='utf-8') as f:json.dump(emotion_conversations, f, ensure_ascii=False, indent=2)print(f"Converted {len(emotion_conversations)} OCEMOTION examples")# 转换OCNLI数据print("\nConverting OCNLI dataset...")ocnli_conversations = convert_ocnli(data_dir / 'OCNLI_train1128.csv')with open(output_dir / 'ocnli_train.json', 'w', encoding='utf-8') as f:json.dump(ocnli_conversations, f, ensure_ascii=False, indent=2)print(f"Converted {len(ocnli_conversations)} OCNLI examples")if __name__ == '__main__':main() dataset_info.json 包含了所有可用的数据集。使用刚刚自定义三个数据采集数据集,需要在 dataset_info.json 文件中添加数据集描述,并通过修改 dataset: 数据集名称 配置来使用数据集。
现在让我们添加我们的三个自定义数据集。修改 dataset_info.json 文件:
"tnews_train": {"file_name": "tnews_train.json","formatting": "alpaca","columns": {"prompt": "instruction","query": "input","response": "output"}},"emotion_train": {"file_name": "emotion_train.json","formatting": "alpaca","columns": {"prompt": "instruction","query": "input","response": "output"}},"ocnli_train": {"file_name": "ocnli_train.json","formatting": "alpaca","columns": {"prompt": "instruction","query": "input","response": "output"}}现在我们已经在 dataset_info.json 中添加了三个新的数据集配置:
tnews_train:新闻分类数据集
emotion_train:情感分类数据集
ocnli_train:自然语言推理数据集
数据已经成功转换并保存到了正确的位置。接下来可以开始使用这些数据进行训练了。以下是后续步骤:
1.下载Qwen基础模型:
- 您可以使用Qwen-7B或Qwen-14B作为基础模型
- 模型可以从Hugging Face下载
pip install -U huggingface_hub
创建一个目录来存放模型:
mkdir -p LLaMA-Factory/models/Qwen-7B-Chat && cd LLaMA-Factory/models/Qwen-7B-Chat 
方法一:使用Git LFS克隆Qwen-7B-Chat模型仓库:
cd LLaMA-Factory/models && GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Qwen/Qwen-7B-Chat方法二:使用ModelScope镜像来下载模型:
pip install modelscope && cd /root/LLaMA-Factory/models && python3 -c "from modelscope import snapshot_download; snapshot_download('qwen/Qwen-7B-Chat', cache_dir='.')" 
接下来我们将使用LLaMA-Factory进行微调。我们将使用Qwen-7B-Chat作为基础模型,使用我们处理好的三个数据集进行训练。
接下来让我们理解一下,lora微调所涉及到的文件
qwen2vl_lora_dpo.yaml qwen2vl_lora_sft.yaml 这两个文件有什么区别?
这两个文件都是LLaMA-Factory的训练配置文件,但它们有几个重要的区别:
训练阶段(stage)不同:
- qwen2vl_lora_sft.yaml: stage: sft (监督微调,Supervised Fine-Tuning)
- qwen2vl_lora_dpo.yaml: stage: dpo (直接偏好优化,Direct Preference Optimization)
学习率(learning_rate)不同:
- sft: learning_rate: 1.0e-4 (较大的学习率)
- dpo: learning_rate: 5.0e-6 (较小的学习率)
特有参数:
- dpo 特有:
pref_beta: 0.1 # DPO的beta参数
pref_loss: sigmoid # 偏好学习的损失函数类型
数据集配置不同:
- sft: dataset: mllm_demo,identity,alpaca_en_demo (普通的指令数据集)
- dpo: dataset: rlhf_v (包含偏好信息的数据集)
主要区别在于它们的用途:
- sft配置用于第一阶段的监督微调,让模型学习基本的指令跟随能力
- dpo配置用于第二阶段的偏好优化,通过人类偏好数据来改进模型输出的质量
这反映了现代大语言模型训练的两个重要阶段:
- SFT(监督微调):让模型学会基本的任务完成能力
- DPO(偏好优化):让模型的输出更符合人类偏好,提高输出质量
如果是第一次训练模型,建议先使用sft配置进行基础训练,然后再考虑使用dpo配置进行优化。
LoRA 是一种 参数高效微调技术(Parameter-Efficient Fine-Tuning, PEFT),专为大型语言模型(如 LLaMA、GPT)设计,旨在显著减少微调所需的计算资源和显存,同时保持模型性能。

三、 详细讲解 qwen2vl_lora_sft.yaml 这个配置文件的主要部分:
### model(模型配置)
model_name_or_path: Qwen/Qwen2.5-VL-7B-Instruct # 基础模型路径
image_max_pixels: 262144 # 图像最大像素数
video_max_pixels: 16384 # 视频最大像素数
trust_remote_code: true # 信任远程代码### method(训练方法配置)
stage: sft # 训练阶段:监督微调
do_train: true # 是否进行训练
finetuning_type: lora # 使用LoRA微调方法
lora_rank: 8 # LoRA秩,越大效果越好但参数量也越大
lora_target: all # 应用LoRA的层,all表示所有层### dataset(数据集配置)
dataset: mllm_demo,identity,alpaca_en_demo # 使用的数据集,可以多个
template: qwen2_vl # 使用的模板
cutoff_len: 2048 # 最大序列长度
max_samples: 1000 # 最大样本数
preprocessing_num_workers: 16 # 数据预处理的工作进程数### output(输出配置)
output_dir: saves/qwen2_vl-7b/lora/sft # 输出目录
logging_steps: 10 # 每10步记录一次日志
save_steps: 500 # 每500步保存一次模型
plot_loss: true # 绘制损失曲线
overwrite_output_dir: true # 覆盖已存在的输出目录
save_only_model: false # 保存完整检查点
report_to: none # 不使用额外的日志记录工具### train(训练配置)
per_device_train_batch_size: 1 # 每个设备的批次大小
gradient_accumulation_steps: 8 # 梯度累积步数
learning_rate: 1.0e-4 # 学习率
num_train_epochs: 3.0 # 训练轮数
lr_scheduler_type: cosine # 学习率调度器类型
warmup_ratio: 0.1 # 预热比例
bf16: true # 是否使用bf16精度要快速开始训练,需要主要关注以下几个部分:
模型配置:
- 修改 model_name_or_path 为我们自己的的模型路径
- 例如:model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
数据集配置:
- 修改 dataset 为要使用的数据集
- 例如:dataset: tnews_train,emotion_train,ocnli_train
输出配置:
- 修改 output_dir 为想保存模型的路径
- 例如:output_dir: /root/LLaMA-Factory/outputs/qwen-7b-chat-chinese
训练配置:
- 根据您的GPU显存调整 per_device_train_batch_size 和 gradient_accumulation_steps
查看系统的 GPU 显存信息。在 Linux 系统中,我们可以使用 nvidia-smi 命令来查看:
使用 df -h 查看文件系统的使用情况:nvidia-smidf -h
- 如果显存不足,可以:
- 降低 per_device_train_batch_size
- 增加 gradient_accumulation_steps
- 减小 cutoff_len
接下来创建一个适合您当前训练任务的配置文件chinese_sft.yaml:
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
trust_remote_code: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 32
lora_dropout: 0.1
lora_target: all### dataset
dataset: tnews_train,emotion_train,ocnli_train
template: qwen
cutoff_len: 2048
max_samples: 100000
preprocessing_num_workers: 8
dataloader_num_workers: 4### output
output_dir: /root/LLaMA-Factory/outputs/qwen-7b-chat-chinese
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
save_only_model: false
do_eval: true### train
per_device_train_batch_size: 4
gradient_accumulation_steps: 4
learning_rate: 5.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000### eval
val_size: 0.01
per_device_eval_batch_size: 4
eval_steps: 100需要先安装 LLaMA-Factory 包,使用 CLI 命令来启动训练:
cd /root/LLaMA-Factory && pip install -e .cd /root/LLaMA-Factory && llamafactory-cli train examples/train_lora/chinese_sft.yaml四、 配置文件中哪些设置和显存有关?
在训练配置文件中,以下参数会直接影响显存使用量:
批量大小相关:
- per_device_train_batch_size: 每个 GPU 的训练批量大小,越大显存占用越多
- gradient_accumulation_steps: 梯度累积步数,可以用来变相减小批量大小
- per_device_eval_batch_size: 评估时的批量大小
精度相关:
- bf16: 是否使用 BF16 精度
- fp16: 是否使用 FP16 精度
- 这两个参数会影响模型权重和计算的精度,从而影响显存使用
模型相关:
- lora_rank: LoRA 的秩,越大参数量越多,显存占用越大
- max_samples: 最大样本数,影响数据加载时的显存占用
- cutoff_len: 序列最大长度,越长显存占用越大
优化器相关:
- max_grad_norm: 梯度裁剪阈值
- optim: 优化器类型,不同优化器显存占用不同
要减少显存使用,可以:
- 减小 per_device_train_batch_size(比如从 64 改为 16 或 8)
- 增加 gradient_accumulation_steps(比如从 1 改为 4 或 8)
- 减小 lora_rank(比如从 8 改为 4)
- 减小 cutoff_len(如果可以的话)
- 减小 max_samples(如果可以的话)
五、训练过程中如遇到显存不够可做以下调整:
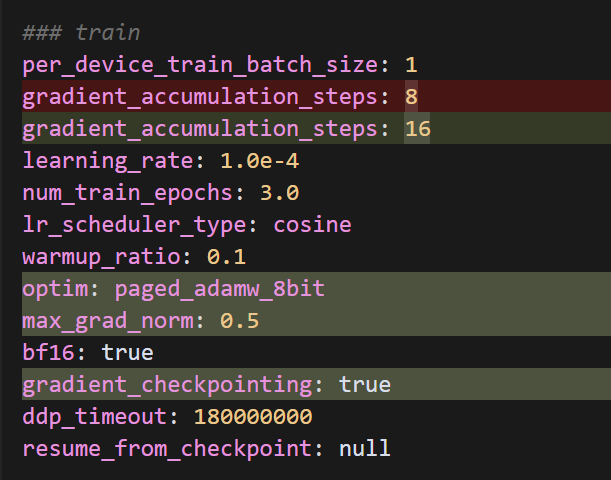
主要更改:
- 增加了 gradient_checkpointing: true 以减少显存使用
- 使用 8-bit 优化器:optim: paged_adamw_8bit
- 增加梯度累积步数:从 8 改为 16
- 添加梯度裁剪:max_grad_norm: 0.5
- 添加 LoRA dropout:lora_dropout: 0.1
即使使用了这些优化方法,显存仍然不够。让我们尝试设置 PYTORCH_CUDA_ALLOC_CONF 环境变量,并进一步优化配置:
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
image_max_pixels: 262144
video_max_pixels: 16384
trust_remote_code: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 4
lora_alpha: 32
lora_target: q_proj,v_proj
lora_dropout: 0.1### dataset
dataset: ocnli_train,emotion_train,tnews_train
template: alpaca
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4### output
output_dir: saves/qwen-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
report_to: none### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 32
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
optim: paged_adamw_8bit
max_grad_norm: 0.5
bf16: true
fp16: false
gradient_checkpointing: true
deepspeed: ds_config.json
ddp_timeout: 180000000
resume_from_checkpoint: null### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500创建 DeepSpeed 配置文件:

{"train_batch_size": 32,"gradient_accumulation_steps": 32,"gradient_clipping": 0.5,"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},"allgather_partitions": true,"allgather_bucket_size": 5e8,"contiguous_gradients": true},"bf16": {"enabled": true},"optimizer": {"type": "AdamW","params": {"lr": 1e-4,"betas": [0.9, 0.999],"eps": 1e-8,"weight_decay": 0.01}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": 0,"warmup_max_lr": 1e-4,"warmup_num_steps": 100,"total_num_steps": 3000}}
}主要优化包括:
减小 LoRA 参数:
- rank 从 8 降到 4
- 只对 q_proj 和 v_proj 进行微调
- 添加 lora_alpha 参数
减小序列长度:
- cutoff_len 从 2048 降到 1024
增加梯度累积:
- gradient_accumulation_steps 从 16 增加到 32
添加 DeepSpeed 支持:
- 使用 ZeRO-2 优化
- 优化器状态卸载到 CPU
- 使用 BF16 混合精度训练
安装Deepspeed
pip install 'deepspeed>=0.9.3'我来解释一下为什么要添加 DeepSpeed 配置以及它的主要功能:
DeepSpeed 是由微软开发的深度学习优化库,它提供了多项重要功能来提升大规模模型训练的效率:
内存优化
- ZeRO (Zero Redundancy Optimizer) 技术:我们在配置中使用了 "stage": 2,这能够将优化器状态和梯度分片到不同设备上
- 优化器状态卸载:通过 "offload_optimizer": {"device": "cpu"} 将优化器状态卸载到 CPU 内存,减少 GPU 内存占用
- 梯度累积:设置 "gradient_accumulation_steps": 32 来实现更大的批次大小,同时保持较低的显存使用
训练加速
- 混合精度训练:启用 "bf16": {"enabled": true} 来使用 BF16 混合精度,在保持训练稳定性的同时提升速度
- 优化的通信:通过 "allgather_bucket_size" 等参数优化设备间的数据传输
训练稳定性
- 梯度裁剪:使用 "gradient_clipping": 0.5 防止梯度爆炸
- 优化器配置:使用 AdamW 优化器,并配置了合适的学习率调度策略
在我们的场景中添加 DeepSpeed 的主要原因是:
解决显存不足问题:
- 之前遇到了 torch.cuda.OutOfMemoryError 错误
- DeepSpeed 的 ZeRO 优化和 CPU 卸载功能可以显著减少 GPU 显存使用
提升训练效率:
- 允许使用更大的批次大小(通过梯度累积)
- 混合精度训练提升计算速度
- 优化的内存管理减少了 OOM(显存不足)的风险
保证训练稳定性:
- 通过精心配置的优化器参数和学习率调度
- 梯度裁剪防止训练不稳定
这些优化对于训练大型语言模型特别重要,因为像 Qwen-7B 这样的模型本身就需要大量计算资源。通过 DeepSpeed,我们可以在有限的硬件资源下更高效地进行模型训练。
使用 DeepSpeed 时需要通过 torchrun 来启动分布式训练。让我们按照错误提示设置 FORCE_TORCHRUN=1 环境变量并重新运行训练命令:
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True && cd /root/LLaMA-Factory && llamafactory-cli train examples/train_lora/chinese_sft.yaml 如仍然遇到了显存不足的问题:
我们可以:
- 减小模型加载时的内存使用
- 启用 8 位量化加载模型
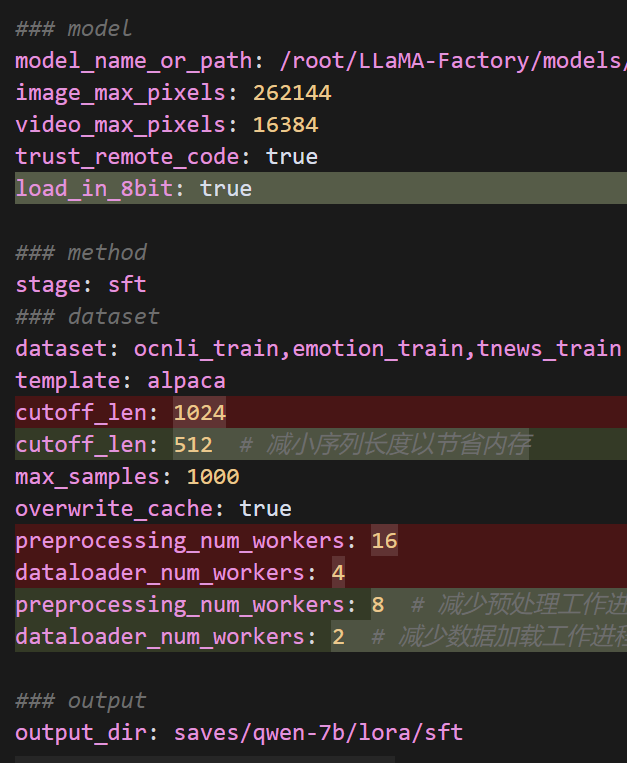
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
image_max_pixels: 262144
video_max_pixels: 16384
trust_remote_code: true
load_in_8bit: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 4
lora_alpha: 32
lora_target: c_attn,c_proj
lora_dropout: 0.1### dataset
dataset: ocnli_train,emotion_train,tnews_train # video: mllm_video_demo
template: alpaca
cutoff_len: 512 # 减小序列长度以节省内存
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 8 # 减少预处理工作进程数
dataloader_num_workers: 2 # 减少数据加载工作进程数### output
output_dir: saves/qwen-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 32
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
optim: paged_adamw_8bit
max_grad_norm: 0.5
bf16: true
fp16: false
gradient_checkpointing: true
deepspeed: ds_config.json
ddp_timeout: 180000000
resume_from_checkpoint: null### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
修改 DeepSpeed 配置以进一步优化内存使用:
{"train_batch_size": 32,"gradient_accumulation_steps": 32,"gradient_clipping": 0.5,"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"reduce_bucket_size": 5e7,"stage3_prefetch_bucket_size": 5e7,"stage3_param_persistence_threshold": 5e5},"bf16": {"enabled": true},"optimizer": {"type": "AdamW","params": {"lr": 1e-4,"betas": [0.9, 0.999],"eps": 1e-8,"weight_decay": 0.01}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": 0,"warmup_max_lr": 1e-4,"warmup_num_steps": 100,"total_num_steps": 3000}}
}我们尝试另一种方式来解决内存问题。我们可以:
- 禁用 DeepSpeed(因为它可能与 8 位量化加载不完全兼容)
- 使用 bitsandbytes 的 8 位量化
- 进一步减小批次大小和序列长度
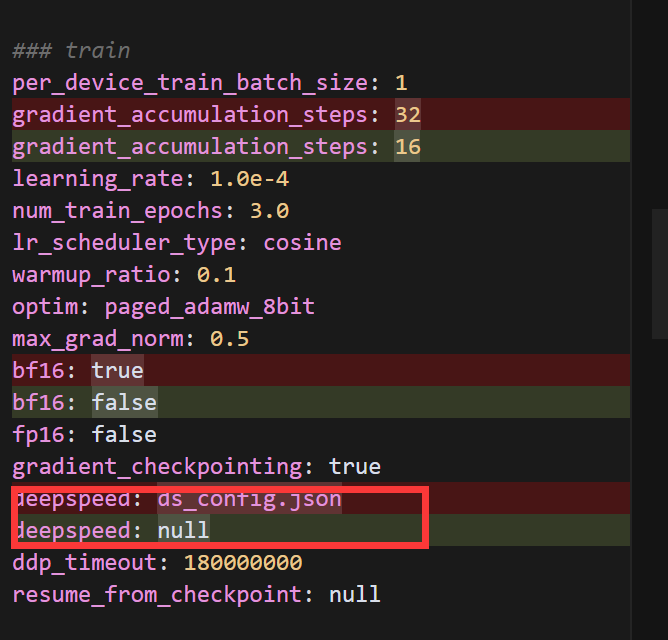
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
image_max_pixels: 262144
video_max_pixels: 16384
trust_remote_code: true
load_in_8bit: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 4
lora_alpha: 32
lora_target: c_attn,c_proj
lora_dropout: 0.1### dataset
dataset: ocnli_train,emotion_train,tnews_train # video: mllm_video_demo
template: alpaca
cutoff_len: 256
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 4
dataloader_num_workers: 1### output
output_dir: saves/qwen-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 16
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
optim: paged_adamw_8bit
max_grad_norm: 0.5
bf16: false
fp16: false
gradient_checkpointing: true
deepspeed: null
ddp_timeout: 180000000
resume_from_checkpoint: null### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
看来 load_in_bits 参数也不是有效的配置参数。让我们尝试另一种方式来减少内存使用。我们可以:
- 完全移除量化相关的参数
- 进一步减小模型参数和批次大小
- 启用 torch.compile 来优化内存使用
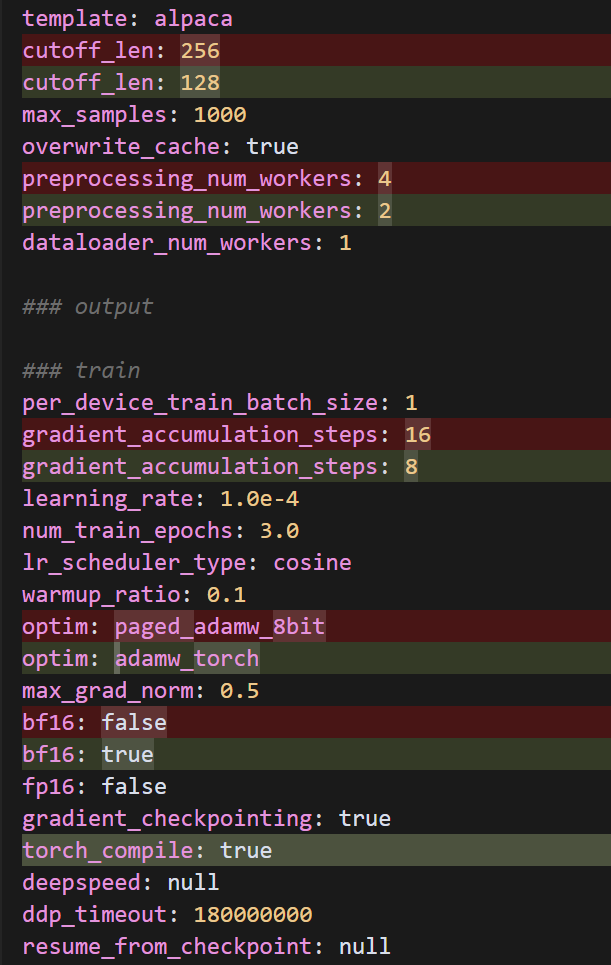
export FORCE_TORCHRUN=1 && export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True && cd /root/LLaMA-Factory && llamafactory-cli train examples/train_lora/chinese_sft.yaml六、训练加速

如上图所示训练时间过长,我对配置文件做了以下优化,以显著提高训练速度:
数据处理优化:
- 减少了 cutoff_len 从 2048 到 1024,减少处理的序列长度
- 减少了 max_samples 从 100000 到 50000,减少总训练样本数
- 增加了数据处理的并行workers数量
训练参数优化:
- 移除了梯度累积(gradient_accumulation_steps 从 4 改为 1)
- 减少训练轮数(num_train_epochs 从 3.0 改为 1.0)
- 指定了具体的 LoRA 目标层(lora_target),而不是训练所有层
- 启用了 FP16 混合精度训练
- 使用更高效的 adamw_torch 优化器
评估优化:
- 增加了评估的批量大小
- 减少评估频率(eval_steps 从 100 改为 200)
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
trust_remote_code: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 32
lora_dropout: 0.1
lora_target: c_attn,c_proj,w1,w2### dataset
dataset: tnews_train,emotion_train,ocnli_train
template: qwen
cutoff_len: 1024
max_samples: 50000
preprocessing_num_workers: 16
dataloader_num_workers: 8### output
output_dir: /root/LLaMA-Factory/outputs/qwen-7b-chat-chinese
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
save_only_model: false
do_eval: true### train
per_device_train_batch_size: 32
gradient_accumulation_steps: 1
learning_rate: 5.0e-5
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
max_grad_norm: 0.3
optim: adamw_torch### eval
val_size: 0.01
per_device_eval_batch_size: 32
eval_steps: 200⭐小知识:
fp16: true 设置和 bf16: true设置:
- BF16(Brain Float 16)通常在现代GPU上性能更好
- 对于大语言模型训练,BF16通常是更好的选择,因为它有更大的动态范围

修改后我们可以看到时间明显缩短
我们继续进行重大优化来显著提升训练速度:
大幅减少训练数据和计算量:
- 将 cutoff_len 从 1024 减少到 512(减少一半的序列长度)
- 将 max_samples 从 50000 减少到 20000(减少训练样本数)
- 将 lora_target 改为只训练关键的注意力层 q_proj,v_proj
提高批处理效率:
- 增加 per_device_train_batch_size 到 64
- 添加 group_by_length: true 来对相似长度的序列进行批处理,提高效率
- 关闭评估 do_eval: false(在训练阶段评估会显著降低速度)
减少存储和日志开销:
- 增加 save_steps 到 500(减少保存检查点的频率)
- 设置 save_only_model: true(只保存模型,不保存优化器状态)
优化学习过程:
- 增加学习率到 1.0e-4 以加快收敛
- 减少预热比例到 0.05
- 保持 bf16 以获得良好的训练效率
### model
model_name_or_path: /root/LLaMA-Factory/models/qwen/Qwen-7B-Chat
trust_remote_code: true### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 32
lora_dropout: 0.1
lora_target: c_attn,c_proj### dataset
dataset: tnews_train,emotion_train,ocnli_train
template: qwen
cutoff_len: 512
max_samples: 20000
preprocessing_num_workers: 16
dataloader_num_workers: 8### output
output_dir: /root/LLaMA-Factory/outputs/qwen-7b-chat-chinese
logging_steps: 5
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
do_eval: false### train
per_device_train_batch_size: 64
gradient_accumulation_steps: 1
learning_rate: 1.0e-4
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.05
bf16: true
ddp_timeout: 180000000
max_grad_norm: 0.3
optim: adamw_torch
group_by_length: true### eval
val_size: 0.01
per_device_eval_batch_size: 64
eval_steps: 500⭐小知识
对于 lora_target 参数,可以填写的内容取决于具体使用的模型架构。我来为您详细解释不同模型的可用选项:
LLaMA/LLaMA2 模型:
- q_proj,k_proj,v_proj,o_proj: 注意力模块的四个投影层
- gate_proj,up_proj,down_proj: MLP 模块的三个投影层
- 常用组合: q_proj,v_proj 或 q_proj,k_proj,v_proj,o_proj
Qwen/ChatGLM 模型:
- c_attn: 注意力的输入投影层(合并了 q,k,v 投影)
- c_proj: 注意力的输出投影层
- 常用组合: c_attn,c_proj
Baichuan 模型:
- W_pack: 注意力的输入投影层
- o_proj: 注意力的输出投影层
- gate_proj,up_proj,down_proj: MLP 部分
- 常用组合: W_pack,o_proj
InternLM 模型:
- q_proj,k_proj,v_proj,o_proj: 注意力模块
- w1,w2,w3: MLP 模块
- 常用组合: q_proj,v_proj 或 q_proj,k_proj,v_proj,o_proj
选择建议:
- 一般来说,训练注意力模块就足够了,不需要全部模块都使用 LoRA
- 模块越多,可训练参数越多,训练越慢,显存占用越大
- 建议从最基础的注意力相关层开始尝试,如果效果不够好再逐步增加其他层
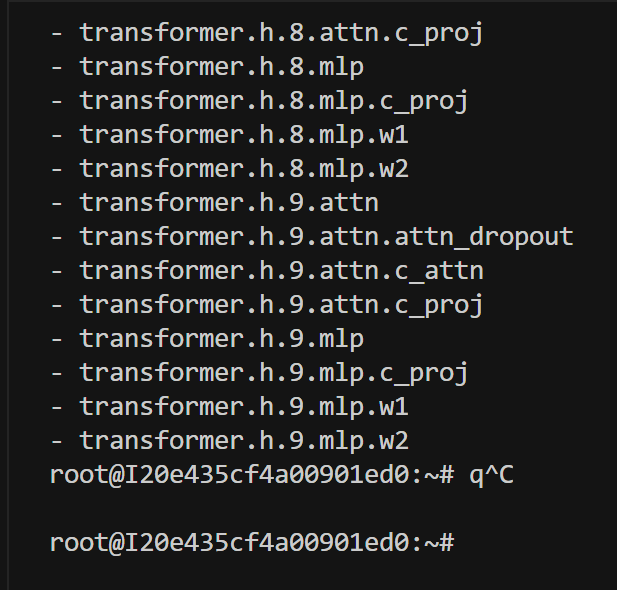
如果想查看具体模型有哪些层,可以使用以下脚本:
from transformers import AutoModelForCausalLM, AutoTokenizer import torchdef print_named_modules(model_path):print(f"Loading model from {model_path}")model = AutoModelForCausalLM.from_pretrained(model_path,trust_remote_code=True,torch_dtype=torch.float16,device_map="auto")# 获取模型的第一个transformer块作为示例print("\nExample transformer block structure:")if hasattr(model, 'transformer'):block = model.transformer.h[0] # 获取第一个transformer块print("\nTransformer block components:")for name, _ in block.named_modules():print(f"Layer: {name}")# 打印所有可能的attention相关层print("\nPotential attention-related layers:")attention_layers = []for name, module in model.named_modules():if any(x in name.lower() for x in ['attn', 'attention', 'proj', 'mlp']):attention_layers.append(name)for layer in sorted(attention_layers):print(f"- {layer}")if __name__ == "__main__":model_path = "/root/LLaMA-Factory/models/qwen/Qwen-7B-Chat"print_named_modules(model_path)现在让我们运行修改后的脚本:
python check_model_structure.py
根据输出结果,我来详细说明 Qwen 模型中可用的 lora_target 参数选项:
对于 Qwen 模型,主要的可训练层包括:
注意力层相关:
- c_attn: 注意力的输入投影层(包含 Q、K、V 的组合投影)
- c_proj: 注意力的输出投影层
MLP 层相关:
- w1: MLP 的第一个投影层
- w2: MLP 的第二个投影层
- c_proj: MLP 的输出投影层
常见的 lora_target 组合方式:
只训练注意力层(推荐)lora_target: c_attn,c_proj只训练 MLP 层 lora_target: w1,w2,c_proj
同时训练注意力层和 MLP 层(参数量较大)lora_target: c_attn,c_proj,w1,w2,c_proj
相关文章:

服务器部署LLaMAFactory进行LoRA微调
一、什么是LLaMAFactory LlamaFactory 是一个专为 大型语言模型(LLM)微调 设计的开源工具库,旨在简化大模型(如 LLaMA、GPT、Mistral 等)的定制化训练流程,降低技术门槛和硬件成本。以下是它的核心功能和应…...

ASP.NET MVC 入门指南
以下是一份 MVC(Model - View - Controller)培训教程,以ASP.NET MVC 为例进行讲解,适合有一定编程基础的学习者快速上手。 1. MVC 概述 1.1 什么是 MVC MVC 是一种软件设计模式,它将应用程序分为三个主要部分&#…...

mapbox高阶,高程影像、行政区边界阴影效果实现
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️line线图层样式1.4 ☘️symbol符号图层…...

如何下载适用于语音识别功能增强的Google Chrome浏览器
谷歌浏览器一直是互联网用户的首选工具之一,尤其是它强大的扩展功能,使得用户可以根据需求定制浏览器。对于需要使用语音识别功能的用户来说,谷歌浏览器提供了优秀的支持,通过简单的设置和插件,可以显著提升语音识别的…...

运维打铁:Centos 7 安装 redis_exporter 1.3.5
文章目录 一、CentOS 7 安装 redis_exporter 1.3.51. 安装2. 配置自启动,并连接 Redis,修改端口3. 配置 Prometheus 采集 redis_exporter 数据4. 配置 Grafana 查看数据5. Redis 集群配置 二、常见问题及解决办法1. 下载二进制包失败2. 解压部署时权限问…...

3台CentOS虚拟机部署 StarRocks 1 FE+ 3 BE集群
背景:公司最近业务数据量上去了,需要做一个漏斗分析功能,实时性要求较高,mysql已经已经不在适用,做了个大数据技术栈选型调研后,决定使用StarRocks StarRocks官网:StarRocks | A High-Performa…...

Oracle 11g RAC ASM磁盘组剔盘、加盘实施过程
环境:AIX6.1 Oracle RAC 11.2.0.3 前期准备: 1.查看DG磁盘组空间情况: –查看DG磁盘组空间情况: ASMCMD> lsdg State Type Rebal Sector Block AU Total_MB Free_MB Req_mir_free_MB Usable_file_MB Of…...

网站高可用架构设计基础——高可用策略和架构原则
一、正面保障与减少损失 要想让系统能够稳定可用,首先要考虑如何避免问题的发生。比如说可以通过 UPS(不间断电源)来避免服务器断电,可以通过事先增加机器来解决硬件资源不足的问题。 然后,如果问题真的发生了&#…...

从入门到精通【MySQL】视图与用户权限管理
文章目录 📕1. 视图✏️1.1 视图的基本概念✏️1.2 试图的基本操作🔖1.2.1 创建视图🔖1.2.2 使用视图🔖1.2.3 修改数据🔖1.2.4 删除视图 ✏️1.3 视图的优点 📕2. 用户与权限管理✏️2.1 用户🔖…...

使用QML Tumbler 实现时间日期选择器
目录 引言相关阅读项目结构示例实现与代码解析示例一:时间选择器(TimePicker)示例二:日期时间选择器(DateTimePicker) 主窗口整合运行效果总结下载链接 引言 在现代应用程序开发中,时间与日期选…...

[golang] 介绍 | 特点 | 应用场景
“编程不仅仅是写代码,更是一种思考方式。” 参考资料 《Unix编程环境》- Brian W. Kernighan, Rob Pike《程序设计实践》- Brian W. Kernighan, Rob PikeGo语言官方网站:https://golang.orgRob Pike的个人博客:http://herpolhode.com/rob/ …...

Python 爬虫实战 | 企名科技
文章目录 一、企名科技1、目标网站2、网站特点3、确定解密位置4、扣js代码 一、企名科技 1、目标网站 网址:https://wx.qmpsee.com/articleDetail?idfeef62bfdac45a94b9cd89aed5c235be目标数据:获取消费行业研究下面的13篇文章数据 2、网站特点 服…...

c加加学习之day06->STL标准库->day01
1.介绍:C 标准模板库(Standard Template Library,简称 STL)是一组泛型编程的模板类和函数,旨在提供常用的数据结构、算法和函数对象。STL 是 C 标准库的一部分,极大地提高了编程效率和代码的可重用性。STL …...
:读写锁)
并发设计模式实战系列(6):读写锁
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第六章读写锁模式,废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 读写锁三维模型 2. 关键实现原理 二、生活化类比&am…...
)
【网络原理】从零开始深入理解TCP的各项特性和机制.(一)
本篇博客给大家带来的是网络原理的相关知识.其中传输层这一部分非常重要,面试中只要是涉及到网络这一部分知识,几乎是必定会考传输层TCP的. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给…...

基于Pytorch的深度学习-第二章
2.1 CIFAR-10数据集简介 CIFAR-10数据集包含10个类别:plane、car、bird、cat、deer、dog、frog、horse、ship、truck,每个类别有6000张图片。其中训练集图片有50000张,测试集有10000张图片。训练集和测试集的生成方法是,分别从每…...
)
gitlab-ce容器镜像源(国内)
下载命令 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/gitlab/gitlab-ce:17.10.4-ce.0 更多参考: https://docker.aityp.com/image/docker.io/gitlab/gitlab-ce:17.10.4-ce.0...

TinyVue v3.22.0 正式发布:深色模式上线!集成 UnoCSS 图标库!TypeScript 类型支持全面升级!
我们非常高兴地宣布,2025年4月7日,TinyVue发布了v3.22.0🎉。 本次 3.22.0 版本主要有以下重大变更: 支持深色模式增加基于 UnoCSS 的图标库更丰富的 TypeScript 类型声明支持 XSS 配置 详细的 Release Notes 请参考:…...

Browser-Use WebUI:让AI自动使用浏览器帮你查询信息执行任务
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

使用PyTorch如何配置一个简单的GTP
目录 一、什么是GPT 1. Transformer Block 的核心结构 2. 关键组件解析 (1) 掩码多头自注意力(Masked Multi-Head Self-Attention) (2) 前馈神经网络(FFN) (3) 层归一化(LayerNorm&…...

【FAQ】针对于消费级NVIDIA GPU的说明
概述 本文概述 HP Anyware 在配备消费级 NVIDIA GPU 的物理工作站上的关键组件、安装说明和重要注意事项。 注意:本文档适用于 NVIDIA 消费级 GPU。NVIDIA Quadro 和 Tesla GPU 也支持 HP Anyware 在公有云、虚拟化或物理工作站环境中运行。请参阅PCoIP Graphi…...

02_java的运行机制以及JDKJREJVM基本介绍
1、运行机制 2、JDK&JRE&JVM JDK 基本介绍 (1) JDK 的全称(Java Development Kit Java开发工具包) JDK JRE java的开发工具 [ java, javac, javadoc, javap等 ] (2)JDK是提供给Java开发人员使用的,其…...

go 的 net 包
目录 一、net包的基本功能 1.1 IP地址处理 1.2 网络协议支持 1.3 连接管理 二、net包的主要功能模块 2.1 IP地址处理 2.2 TCP协议 2.3 UDP协议 2.4 Listener和Conn接口 三、高级功能 3.1 超时设置 3.2 KeepAlive控制 3.3 获取连接信息 四、实际应用场景 4.1 Web服…...
)
ShenNiusModularity项目源码学习(21:ShenNius.Admin.Mvc项目分析-6)
菜单列表页面用于新建、维护及删除系统所有模块所需的菜单信息,包括菜单名称、菜单中的按钮、菜单关联的后台服务地址及请求方式等。菜单列表页面的后台控制器类MenuController位于ShenNius.Admin.Mvc项目的Areas\Sys\Controllers内,页面文件位于同项目的…...

基于单片机的游泳馆智能管理系统
标题:基于单片机的游泳馆智能管理系统 内容:1.摘要 随着人们生活水平的提高,游泳馆的规模和客流量不断增大,传统的管理方式已难以满足高效、便捷的管理需求。本研究的目的是设计并实现一种基于单片机的游泳馆智能管理系统。方法上,采用单片机…...

开发了一个b站视频音频提取器
B站资源提取器-说明书 一、功能说明 本程序可自动解密并提取B站客户端缓存的视频资源,支持以下功能: - 自动识别视频缓存目录 - 将加密的.m4s音频文件转换为标准MP3格式 - 将加密的.m4s视频文件转换为标准MP4格式(合并音视频流)…...

vue2项目,为什么开发环境打包出来的js文件名是1.js 2.js,而生产环境打包出来的是chunk-3adddd.djncjdhcbhdc.js
Vue2项目开发环境与生产环境JS文件名差异的核心原理及配置逻辑如下: 一、文件名差异的底层机制 1、Webpack默认命名策略 开发环境默认禁用哈希,采用[id].js命名规则(如1.js),生产环境启用[chunkhash]生成chunk-xxx…...

SQL进阶知识:六、动态SQL
今天介绍下关于动态SQL的详细介绍,并结合MySQL数据库提供实际例子。 动态SQL是指在运行时动态构建和执行SQL语句的技术。这种技术在处理复杂的查询逻辑、参数化查询或在某些情况下需要根据用户输入动态调整查询时非常有用。MySQL支持动态SQL,主要通过PRE…...

Spring Boot常用注解详解:实例与核心概念
Spring Boot常用注解详解:实例与核心概念 前言 Spring Boot作为Java领域最受欢迎的快速开发框架,其核心特性之一是通过注解(Annotation)简化配置,提高开发效率。注解驱动开发模式让开发者告别繁琐的XML配置ÿ…...

java 富文本转pdf
前言: 本文的目的是将传入的富文本内容(html标签,图片)并且分页导出为pdf。 所用的核心依赖为iText7。 因为itextpdf-core的核心包在maven中央仓库中,阿里云华为云等拉不下来,中央仓库在外网,并且此包在中央仓库中未…...

17.第二阶段x64游戏实战-人工遍历二叉树结构
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:16.第二阶段x64游戏实战-分析二叉树结构 上一个内容里把二叉树的结构写了写&am…...

C#基于Sunnyui框架和MVC模式实现用户登录管理
C#基于Sunnyui框架和MVC模式实现用户登录管理 1 Controller1.1 UserManagementController.cs(控制器入口) 2 Model2.1 UserRepository.cs(用户管理模型)2.2 User.cs(用户结构体)2.3 SQLiteHelper.cs&#x…...
编写单元测试)
Spring Boot实战(三十六)编写单元测试
目录 一、什么是单元测试?二、Spring Boot 中的单元测试依赖三、举例 Spring Boot 中不同层次的单元测试3.1 Service层3.2 Controller 层3.3 Repository层 四、Spring Boot 中 Mock、Spy 对象的使用4.1 使用Mock对象的背景4.2 什么是Mock对象,有哪些好处…...

声音分离人声和配乐-从头设计数字生命第4课——仙盟创梦IDE
音频分离在数字人中具有多方面的重要作用,主要体现在以下几个方面: 提高语音合成质量:通过音频分离,可以将原始音频中的语音部分与其他背景噪音或干扰声音分离开来。这样在进行语音合成时,能够获得更纯净的语音信号&am…...

http协议、全站https
一、http协议 1、为何要学http协议? 用户用浏览器访问网页,默认走的都是http协议,所以要深入研究web层,必须掌握http协议 2、什么是http协议 1、全称Hyper Text Transfer Protocol(超文本传输协议) ### 一个请求得到一个响应包 普通…...

Mediamtx与FFmpeg远程与本地推拉流使用
1.本地推拉流 启服 推流 ffmpeg -re -stream_loop -1 -i ./DJI_0463.MP4 -s 1280x720 -an -c:v h264 -b:v 2000k -maxrate 2500k -minrate 1500k -bufsize 3000k -rtsp_transport tcp -f rtsp rtsp://127.0.0.1:8554/stream 拉流 ffplay -rtsp_transport tcp rtsp://43.136.…...
)
css3新特性第七章(3D变换)
css新特性第七章(3D变换) 一、3d空间和景深 元素进行 3D 变换的首要操作:父元素必须开启 3D 空间! 使用 transform-style 开启 3D 空间,可选值如下: flat : 让子元素位于此元素的二维平面内( 2D 空间&…...

redis经典问题
1.缓存雪崩 指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 解决方案: 1)Redis 高可用,主从哨兵,Redis cluster,避免全盘崩…...

数据仓库是什么?数据仓库架构有哪些?
目录 数据仓库是什么?数据仓库架构有哪些? 一、数据仓库是什么? 二、数据仓库的架构分层 1. 获取层 2. 数据层 3. 应用层 4. 访问层 三、数据仓库的价值体现 1.决策支持 2.业务优化 3.提升竞争力 四、数据仓库的未来发展趋势 总…...

Nginx 通过 Let‘s Encrypt 实现 HTTPS 访问全流程指南
一、Let’s Encrypt 与 Certbot 简介 Let’s Encrypt 是由非营利组织 ISRG 运营的免费证书颁发机构(CA),旨在推动 HTTPS 的普及。其核心工具 Certbot 能自动化完成证书申请、部署与续期,大幅降低 HTTPS 的配置复杂度。通过 Certb…...

网络知识:路由器静态路由与动态路由介绍
目录 一、静态路由 1.1 什么是静态路由? 1.2 静态路由的好处 1.3 静态路由的局限 1.4 静态路由应用场景 微型办公室网络 性能要求高业务流量 安全性要求高的环境 二、动态路由 2.1 什么是动态路由? 2.2 动态路由的好处 2.3 动态路由的局限 2.4 动态路由的应用场…...

LLaMA3微调全流程:从LoRA到QLoRA,7B参数模型推理速度提升4倍的代码实战
LLaMA3微调全流程:从LoRA到QLoRA,7B参数模型推理速度提升4倍的代码实战 发现了一个巨牛的人工智能学习网站,分享一下给大家!https://www.captainbed.cn/ccc 前言 在大模型时代,LLaMA系列作为开源社区的明星模型&#…...

日内组合策略思路
一、策略概述 本策略是一种针对日内交易设计的策略,其核心在于通过识别市场趋势和突破信号,结合动态止损和止盈机制,实现日内交易的盈利。策略以金字塔式的加仓方式控制风险,并通过灵活的平仓策略锁定收益。 二、交易逻辑思路 市场…...

从空气污染监测到嵌入式仿真教学:基于STM32与MQ135的实践探索
一、嵌入式系统在环境监测中的技术演进 随着全球城市化进程加速,世界卫生组织(WHO)数据显示,92%的人口长期暴露于超标PM2.5环境中。在此背景下,基于STM32微控制器的智能监测系统因其高性价比(单节点成本低…...

【数据结构】Map与Set结构详解
数据结构系列五:Map与Set(一) 一、接口的实现 1.方法上 2.成员上 二、Map的内外双接口结构 1.实现 1.1外部Map接口的实现 1.1.1临摹整体 1.1.2外部类实现整体 1.2内部Entry接口的实现 1.2.1临摹内部 1.2.2内部类实现内部 2.关系 3.意义 3.1逻辑内聚 …...
安装rbenv、ruby2.6.5和rails5.2.6)
银河麒麟(内核CentOS8)安装rbenv、ruby2.6.5和rails5.2.6
一、安装 rbenv 和 ruby-build 1.安装 rbenv git clone https://github.com/rbenv/rbenv.git ~/.rbenv 2. 添加 rbenv 到 PATH echo export PATH"$HOME/.rbenv/bin:$PATH" >> ~/.bashrc echo eval "$(rbenv init -)" >> ~/.bashrc source ~…...

豆包桌面版 1.47.4 可做浏览器,免安装绿色版
自己动手升级更新办法: 下载新版本后安装,把 C:\Users\用户名\AppData\Local\Doubao\Application 文件夹的文件,拷贝替换 DoubaoPortable\App\Doubao 文件夹的文件,就升级成功了。 再把安装的豆包彻底卸载就可以。 桌面版比网页版…...

Linux 命令行与 vi/vim 编辑器完全指南
一、Linux 命令行基础 (一)命令与命令行简介 命令:Linux 系统内置的操作指令,以字符化形式使用,用于指示系统执行特定任务。 命令行(终端):提供字符化的操作界面,用户通…...

海量聊天消息处理:ShardingJDBC分库分表、ClickHouse冷热数据分离、ES复合查询方案、Flink实时计算与SpringCloud集成
海量聊天消息处理:ShardingJDBC分库分表、ClickHouse冷热数据分离、ES复合查询方案、Flink实时计算与SpringCloud集成 一、背景介绍 每天有2000万条聊天消息,一年下来几千万亿海量数据。为应对这种规模的数据存储和处理需求,本文将从以下几…...

金融系统上云之路:云原生后端架构在金融行业的演化与实践
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:为什么金融行业也要“云原生”? 金融行业素来以“安全第一、稳定优先”著称,面对每日亿级交易请求、秒级风控响应、PB级数据处理,系统稳定性和性能要求极高。长期以来,大型金融机构往…...