基于whisper和ffmpeg语音转文本小程序
目录
一、环境准备
✅ 第一步:安装并准备 Conda 环境
✅ 第二步:创建 Whisper 专用的 Conda 虚拟环境
✅ 第三步:安装 GPU 加速版 PyTorch(适配 RTX 4060)
✅ 第四步:安装 Whisper 和 FFMPEG 依赖
✅ 补充:可以切换到国内镜像(加速)
二、编写代码实现语音转文本功能
✅ 第一步:创建并运行 Whisper 脚本
✅ 第二步:转录完成!🎉
✅ 注意事项:
1. import whisper
2. file_path = r"..."
3. model = whisper.load_model("medium")
4. result = model.transcribe(file_path, verbose=True)
5. print("📄 识别内容:") 和 print(result["text"])
总结底层流程:
三、TXT格式美化
四、例句对照翻译
五、常见报错
✅ 解决方法:给 Python 显式指定 ffmpeg.exe 的路径
六、更高级的功能——使用PyQt添加GUI
一、环境准备
✅ 第一步:安装并准备 Conda 环境
如果你还没装 Conda(Anaconda 或 Miniconda),请先下载安装:
推荐下载 Miniconda(轻量):
👉 Miniconda 官网下载地址
下载 Windows 64-bit 安装版并安装(默认设置即可)。
✅ 第二步:创建 Whisper 专用的 Conda 虚拟环境
打开 Anaconda Prompt 或 CMD 命令行,依次输入以下命令:
# 创建一个新环境,名字叫 whisper_env,使用 Python 3.10
conda create -n whisper_env python=3.10 -y# 进入这个环境
conda activate whisper_env
✅ 第三步:安装 GPU 加速版 PyTorch(适配 RTX 4060)
也可以对照自己的设备安装其他版本或CPU版本。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
这个命令会安装支持 CUDA 11.8 的 PyTorch,完美适配 RTX 4060,自动使用 GPU 加速。
✅ 第四步:安装 Whisper 和 FFMPEG 依赖
pip install git+https://github.com/openai/whisper.git
pip install ffmpeg-python
✅ 补充:可以切换到国内镜像(加速)
如果你还是下载慢或失败,也可以加上清华源:
pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功后你可以验证一下:
python -c "import whisper; print(whisper.__version__)"
确认没有报错即可。
还需要你手动安装 ffmpeg 可执行文件(一次性操作):
Windows 下安装 FFmpeg:
-
访问:https://www.gyan.dev/ffmpeg/builds/
-
下载 “Release full” 版本(Zip 文件)
-
解压到任意文件夹,例如:
C:\ffmpeg -
把
C:\ffmpeg\bin添加到系统环境变量 Path 中:-
搜索“环境变量” → 编辑系统变量 → 找到
Path→ 添加C:\ffmpeg\bin
-
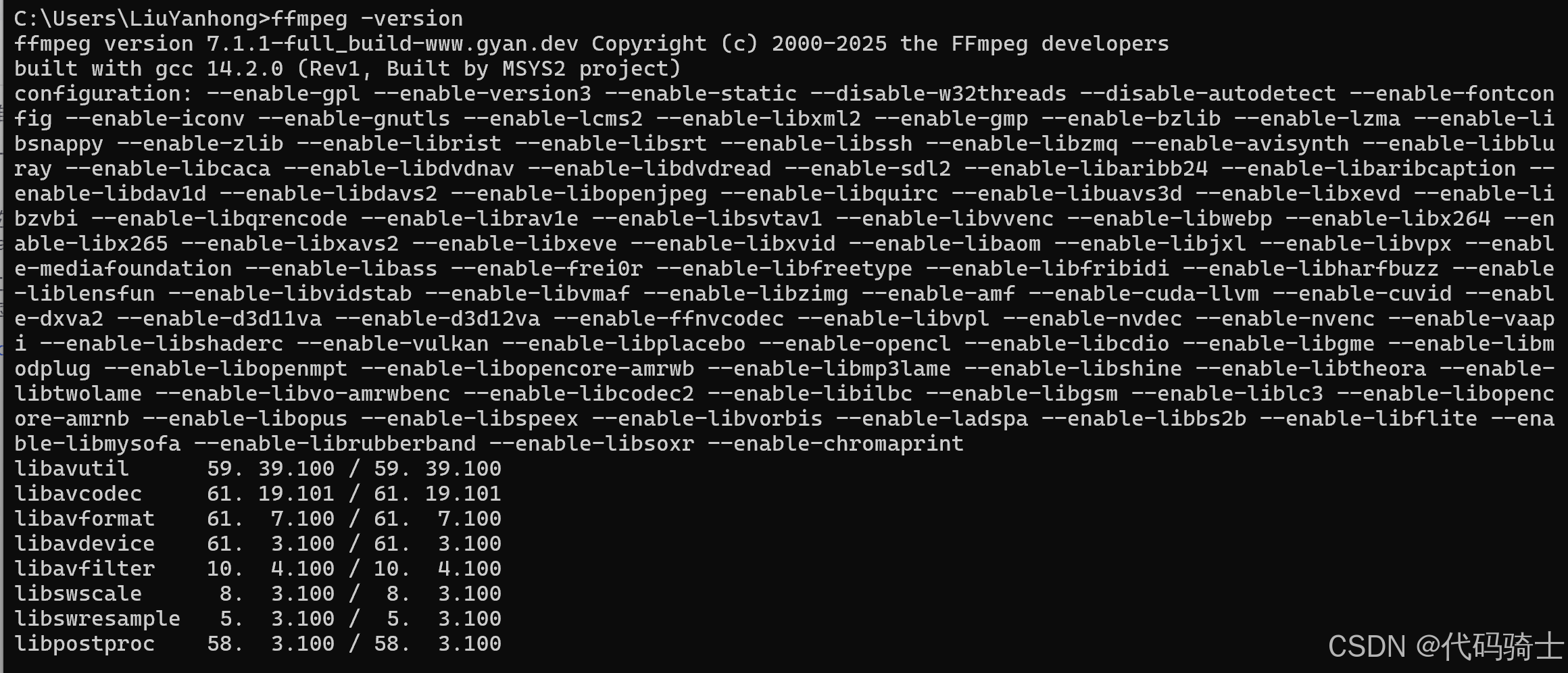
验证成功:打开新的命令行窗口,输入:
ffmpeg -version
二、编写代码实现语音转文本功能
✅ 第一步:创建并运行 Whisper 脚本
-
在当前目录创建
whisper_transcribe_gpu.py,填入以下代码:
import whisper
import osdef transcribe_audio(file_path, model_size="large"):if not os.path.isfile(file_path):print("❌ 找不到文件:", file_path)returnprint(f"🎯 加载 Whisper 模型({model_size})...")model = whisper.load_model(model_size)print(f"🧠 正在识别音频:{file_path}")result = model.transcribe(file_path, fp16=True) # 使用 GPU 加速print("\n📄 识别内容:\n")print(result["text"])output_file = os.path.splitext(file_path)[0] + "_transcription.txt"with open(output_file, "w", encoding="utf-8") as f:f.write(result["text"])print(f"\n✅ 转录已保存至:{output_file}")# 举例用法
if __name__ == "__main__":transcribe_audio("7 Test4.Section1.mp3", model_size="large")
-
将你的 MP3 文件(比如
7 Test4.Section1.mp3)放到这个脚本同目录下。 -
运行脚本:
python whisper_transcribe_gpu.py
✅ 第二步:转录完成!🎉
你将会在终端看到转录内容,并且自动保存为 .txt 文本文件。
✅ 注意事项:
使用ffmpeg转换文件格式:
CMD输入:
ffmpeg -i "D:\xx\Programs\VS_Py_AudiosConvertText\audios\_7Test4_Section1.mp3" -ar 16000 -ac 1 -c:a pcm_s16le "D:\xxx\Programs\VS_Py_AudiosConvertText\audios\_7Test4_Section1.wav"文件路径格式:
“xxx\xxx.mp3”
“xxx\xxx.wav”
“xxx\xxx.m4a”(录音文件)
……
import whisperfile_path = "audios\录音.m4a"
model = whisper.load_model("medium")result = model.transcribe(file_path, verbose=True)print("📄 识别内容:")
print(result["text"])output_txt_path = "results\录音.txt"
with open(output_txt_path, "w", encoding="utf-8") as f:f.write(result["text"])
1. import whisper
-
这是导入 OpenAI 的 Whisper 语音识别库的 Python 模块。
-
Whisper 底层是一个基于 Transformer 架构的端到端语音识别模型,支持多种语言的语音转文字。
2. file_path = r"..."
-
指定要识别的音频文件的路径。
-
r""是Python的原始字符串表示法,避免路径中的反斜杠被误解析。
3. model = whisper.load_model("medium")
-
调用 Whisper 的
load_model函数加载一个预训练的模型,这里选用的是"medium"版本。 -
Whisper 提供多种模型大小(tiny, base, small, medium, large),不同模型准确度和运行速度不同。
-
这个加载过程会在后台从本地缓存或网络下载模型权重文件,初始化模型结构。
-
加载后模型就可以接受音频输入,做后续识别。
4. result = model.transcribe(file_path, verbose=True)
-
这里调用了模型的
transcribe方法,传入音频文件路径,执行音频识别任务。 -
transcribe内部做了以下步骤:-
音频预处理:将音频文件解码成统一采样率的波形数据(通常是16kHz单声道)。
-
特征提取:将音频波形转换成声学特征(如梅尔频谱),这是模型输入的格式。
-
模型推理:通过 Transformer 模型进行前向计算,解码出对应的文本序列。
-
解码:模型输出的是概率分布,结合语言模型概率,使用贪心或beam search方法确定最终的文字。
-
可选参数 verbose=True 会在识别过程中打印详细的日志,帮助调试和观察进度。
-
-
返回结果
result是一个字典,至少包含"text"字段,是识别出来的文本内容。
5. print("📄 识别内容:") 和 print(result["text"])
-
这两行是将识别结果文本打印到控制台。
6. 保存识别结果到txt文件:
output_txt_path = r"..."
with open(output_txt_path, "w", encoding="utf-8") as f:f.write(result["text"])
总结底层流程:
-
加载预训练模型(初始化模型参数和结构)
-
读取并预处理音频数据
-
使用模型进行声学特征提取和文本解码
-
输出文字识别结果
-
将结果保存到文件。
三、TXT格式美化
import whisperfile_path = "audios\_7Test4_Section1.wav"
model = whisper.load_model("large")# 进行转录
result = model.transcribe(file_path, verbose=True)# 输出路径
output_txt_path = "results\result_output.txt"# 保存为纯文本格式(无时间戳)
with open(output_txt_path, "w", encoding="utf-8") as f:f.write("Detecting language using up to the first 30 seconds. Use `--language` to specify the language\n")f.write(f"Detected language: {result['language'].capitalize()}\n")f.write(result["text"].strip()) # 写入识别结果的纯文本部分print("✅ 文本文件保存完成(无时间戳)!路径如下:")
print(output_txt_path)
四、例句对照翻译
使用 whisper 提取的英文文本,再用 Google Translate 或 deep-translator 这类工具翻译成中文,然后生成如下格式的中英对照文本:
🛠 安装依赖(只需一次):
pip install deep-translator
✅ 脚本代码:
import whisper
from deep_translator import GoogleTranslator
import os
# 添加 ffmpeg 路径到系统环境变量中(你之前写的)
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"file_path = "audios\_7Test4_Section1.mp3"model = whisper.load_model("small", device='cpu') # 使用 CPU 进行转录,避免内存不足问题# 转录音频
result = model.transcribe(file_path, verbose=True, fp16=False) # 使用 CPU 进行转录,避免内存不足问题# 提取文本,按句子拆分
text = result["text"].strip()
sentences = [s.strip() for s in text.split('.') if s.strip()]
# 补上句号
sentences = [s + '.' for s in sentences]# 翻译
translator = GoogleTranslator(source='en', target='zh-CN')translated_sentences = [translator.translate(s) for s in sentences]# 确保保存目录存在
output_dir = "results"
os.makedirs(output_dir, exist_ok=True)# 生成保存路径
base_name = os.path.splitext(os.path.basename(file_path))[0]
output_txt_path = os.path.join(output_dir, f"{base_name}_transcription.txt")# 写入中英对照内容
with open(output_txt_path, "w", encoding="utf-8") as f:f.write("Detecting language using up to the first 30 seconds. Use `--language` to specify the language\n")f.write(f"Detected language: {result['language'].capitalize()}\n\n")for en, zh in zip(sentences, translated_sentences):f.write(en + "\n")f.write(zh + "\n\n")print("✅ 中英对照文本文件保存完成!路径如下:")
print(output_txt_path)
五、常见报错
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
这个错误 [WinError 2] 系统找不到指定的文件。 明确是因为 Whisper 在底层调用 ffmpeg 时找不到 ffmpeg 可执行文件。
虽然你可以在命令行中用 ffmpeg 成功转换音频,但是 Python 中的 Whisper 并不会使用你系统 PATH 中的 ffmpeg,它会调用 ffmpeg 命令,要求它能在 Python 环境里被找到。
最常见的一个报错:
✅ 解决方法:给 Python 显式指定 ffmpeg.exe 的路径
你只需要把 ffmpeg.exe 所在的文件夹加入到 Python 脚本的环境变量中。操作如下:
import os
# 添加 ffmpeg 路径到系统环境变量中(你之前写的)
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"
六、更高级的功能——使用PyQt添加GUI
import sys
import os
from PyQt5.QtWidgets import (QApplication, QWidget, QLabel, QPushButton,QVBoxLayout, QFileDialog, QTextEdit, QMessageBox,QComboBox, QCheckBox
)
from PyQt5.QtCore import QThread, pyqtSignal
import whisper
from deep_translator import GoogleTranslator# 添加 ffmpeg 路径
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"# Whisper 模型
model = whisper.load_model("small", device="cpu")# 可选语言映射
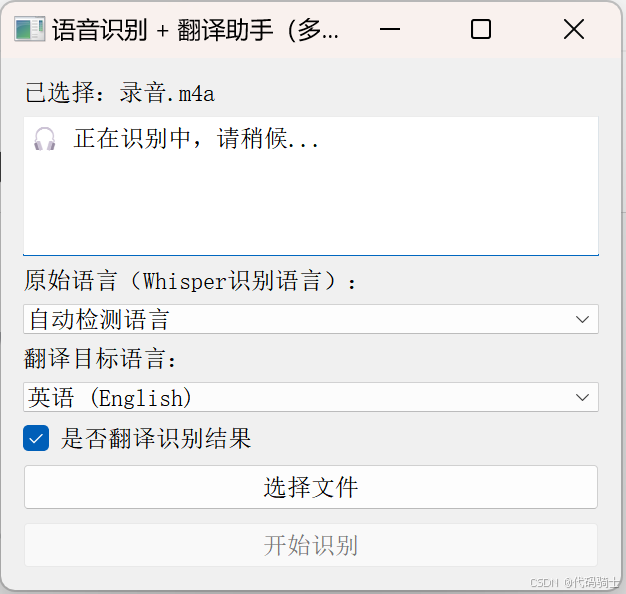
LANGUAGES = {"英语 (English)": "en","中文 (Chinese)": "zh-CN","日语 (Japanese)": "ja","韩语 (Korean)": "ko","法语 (French)": "fr","德语 (German)": "de","西班牙语 (Spanish)": "es","俄语 (Russian)": "ru"
}class TranscriptionWorker(QThread):finished = pyqtSignal(str, str)error = pyqtSignal(str)def __init__(self, file_path, source_lang, target_lang, translate_enabled=True):super().__init__()self.file_path = file_pathself.source_lang = source_langself.target_lang = target_langself.translate_enabled = translate_enableddef run(self):try:result = model.transcribe(self.file_path,language=self.source_lang if self.source_lang != "auto" else None,verbose=False,fp16=False)text = result["text"].strip()sentences = [s.strip() for s in text.split('.') if s.strip()]sentences = [s + '.' for s in sentences]output = f"Detected language: {result['language']}\n\n"if self.translate_enabled:translator = GoogleTranslator(source='auto', target=self.target_lang)translated_sentences = [translator.translate(s) for s in sentences]for en, zh in zip(sentences, translated_sentences):output += f"{en}\n{zh}\n\n"else:output += "\n".join(sentences)# 保存结果output_dir = "results"os.makedirs(output_dir, exist_ok=True)base_name = os.path.splitext(os.path.basename(self.file_path))[0]output_path = os.path.join(output_dir, f"{base_name}_transcription.txt")with open(output_path, "w", encoding="utf-8") as f:f.write(output)self.finished.emit(output, output_path)except Exception as e:self.error.emit(str(e))class TranscriptionApp(QWidget):def __init__(self):super().__init__()self.setWindowTitle("语音识别 + 翻译助手(多线程+语言选择)")self.setGeometry(300, 300, 620, 500)self.layout = QVBoxLayout()self.label = QLabel("请选择音频/视频文件:")self.layout.addWidget(self.label)self.result_box = QTextEdit()self.result_box.setReadOnly(True)self.layout.addWidget(self.result_box)# 源语言选择self.source_lang_box = QComboBox()self.source_lang_box.addItem("自动检测语言", "auto")for name, code in LANGUAGES.items():self.source_lang_box.addItem(name, code)self.layout.addWidget(QLabel("原始语言(Whisper识别语言):"))self.layout.addWidget(self.source_lang_box)# 目标语言选择self.target_lang_box = QComboBox()for name, code in LANGUAGES.items():self.target_lang_box.addItem(name, code)self.target_lang_box.setCurrentText("中文 (Chinese)")self.layout.addWidget(QLabel("翻译目标语言:"))self.layout.addWidget(self.target_lang_box)# 是否翻译的复选框self.translate_checkbox = QCheckBox("是否翻译识别结果")self.translate_checkbox.setChecked(True)self.layout.addWidget(self.translate_checkbox)self.select_button = QPushButton("选择文件")self.select_button.clicked.connect(self.select_audio)self.layout.addWidget(self.select_button)self.transcribe_button = QPushButton("开始识别")self.transcribe_button.clicked.connect(self.transcribe_and_translate)self.layout.addWidget(self.transcribe_button)self.setLayout(self.layout)self.audio_path = Noneself.worker = Nonedef select_audio(self):path, _ = QFileDialog.getOpenFileName(self, "选择音频/视频文件", "", "音频/视频文件 (*.mp3 *.wav *.m4a *.flac *.mp4)")if path:self.audio_path = pathself.label.setText(f"已选择:{os.path.basename(path)}")self.result_box.setPlainText("")def transcribe_and_translate(self):if not self.audio_path:QMessageBox.warning(self, "警告", "请先选择一个文件!")returnsource_lang = self.source_lang_box.currentData()target_lang = self.target_lang_box.currentData()translate_enabled = self.translate_checkbox.isChecked()self.result_box.setPlainText("🎧 正在识别中,请稍候...")self.transcribe_button.setEnabled(False)self.worker = TranscriptionWorker(self.audio_path, source_lang, target_lang, translate_enabled)self.worker.finished.connect(self.on_result)self.worker.error.connect(self.on_error)self.worker.start()def on_result(self, result_text, save_path):self.result_box.setPlainText(result_text)self.transcribe_button.setEnabled(True)QMessageBox.information(self, "完成", f"✅ 操作完成,已保存到:\n{save_path}")def on_error(self, error_msg):self.result_box.setPlainText("")self.transcribe_button.setEnabled(True)QMessageBox.critical(self, "错误", f"❌ 错误:\n{error_msg}")if __name__ == "__main__":app = QApplication(sys.argv)window = TranscriptionApp()window.show()sys.exit(app.exec_())
相关文章:

基于whisper和ffmpeg语音转文本小程序
目录 一、环境准备 ✅ 第一步:安装并准备 Conda 环境 ✅ 第二步:创建 Whisper 专用的 Conda 虚拟环境 ✅ 第三步:安装 GPU 加速版 PyTorch(适配 RTX 4060) ✅ 第四步:安装 Whisper 和 FFMPEG 依赖 ✅…...

使用ffmpeg 将图片合成为视频,填充模糊背景,并添加两段音乐
1.输入3张图片,每张播放一次,播放两秒,视频分辨率设置为1920:1080,每张图片前0.3秒淡入,后0.3秒淡出,图片宽高比不变,用白色填充空白区域 ffmpeg -loop 1 -t 2 -i "img1.jpg" \-loop 1 -t 2 -i "img2.jpg" \-loop 1 -t 2 -i "img3.jpg" \-filte…...

Python协程详解:从基础到实战
协程是Python中实现并发编程的重要方式之一,它比线程更轻量级,能够高效处理I/O密集型任务。本文将全面介绍协程的概念、原理、实现方式以及与线程、进程的对比,包含完整的效率对比代码和详细说明,帮助Python开发者深入理解并掌握协…...

服务器部署LLaMAFactory进行LoRA微调
一、什么是LLaMAFactory LlamaFactory 是一个专为 大型语言模型(LLM)微调 设计的开源工具库,旨在简化大模型(如 LLaMA、GPT、Mistral 等)的定制化训练流程,降低技术门槛和硬件成本。以下是它的核心功能和应…...

ASP.NET MVC 入门指南
以下是一份 MVC(Model - View - Controller)培训教程,以ASP.NET MVC 为例进行讲解,适合有一定编程基础的学习者快速上手。 1. MVC 概述 1.1 什么是 MVC MVC 是一种软件设计模式,它将应用程序分为三个主要部分&#…...

mapbox高阶,高程影像、行政区边界阴影效果实现
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️line线图层样式1.4 ☘️symbol符号图层…...

如何下载适用于语音识别功能增强的Google Chrome浏览器
谷歌浏览器一直是互联网用户的首选工具之一,尤其是它强大的扩展功能,使得用户可以根据需求定制浏览器。对于需要使用语音识别功能的用户来说,谷歌浏览器提供了优秀的支持,通过简单的设置和插件,可以显著提升语音识别的…...

运维打铁:Centos 7 安装 redis_exporter 1.3.5
文章目录 一、CentOS 7 安装 redis_exporter 1.3.51. 安装2. 配置自启动,并连接 Redis,修改端口3. 配置 Prometheus 采集 redis_exporter 数据4. 配置 Grafana 查看数据5. Redis 集群配置 二、常见问题及解决办法1. 下载二进制包失败2. 解压部署时权限问…...

3台CentOS虚拟机部署 StarRocks 1 FE+ 3 BE集群
背景:公司最近业务数据量上去了,需要做一个漏斗分析功能,实时性要求较高,mysql已经已经不在适用,做了个大数据技术栈选型调研后,决定使用StarRocks StarRocks官网:StarRocks | A High-Performa…...

Oracle 11g RAC ASM磁盘组剔盘、加盘实施过程
环境:AIX6.1 Oracle RAC 11.2.0.3 前期准备: 1.查看DG磁盘组空间情况: –查看DG磁盘组空间情况: ASMCMD> lsdg State Type Rebal Sector Block AU Total_MB Free_MB Req_mir_free_MB Usable_file_MB Of…...

网站高可用架构设计基础——高可用策略和架构原则
一、正面保障与减少损失 要想让系统能够稳定可用,首先要考虑如何避免问题的发生。比如说可以通过 UPS(不间断电源)来避免服务器断电,可以通过事先增加机器来解决硬件资源不足的问题。 然后,如果问题真的发生了&#…...

从入门到精通【MySQL】视图与用户权限管理
文章目录 📕1. 视图✏️1.1 视图的基本概念✏️1.2 试图的基本操作🔖1.2.1 创建视图🔖1.2.2 使用视图🔖1.2.3 修改数据🔖1.2.4 删除视图 ✏️1.3 视图的优点 📕2. 用户与权限管理✏️2.1 用户🔖…...

使用QML Tumbler 实现时间日期选择器
目录 引言相关阅读项目结构示例实现与代码解析示例一:时间选择器(TimePicker)示例二:日期时间选择器(DateTimePicker) 主窗口整合运行效果总结下载链接 引言 在现代应用程序开发中,时间与日期选…...

[golang] 介绍 | 特点 | 应用场景
“编程不仅仅是写代码,更是一种思考方式。” 参考资料 《Unix编程环境》- Brian W. Kernighan, Rob Pike《程序设计实践》- Brian W. Kernighan, Rob PikeGo语言官方网站:https://golang.orgRob Pike的个人博客:http://herpolhode.com/rob/ …...

Python 爬虫实战 | 企名科技
文章目录 一、企名科技1、目标网站2、网站特点3、确定解密位置4、扣js代码 一、企名科技 1、目标网站 网址:https://wx.qmpsee.com/articleDetail?idfeef62bfdac45a94b9cd89aed5c235be目标数据:获取消费行业研究下面的13篇文章数据 2、网站特点 服…...

c加加学习之day06->STL标准库->day01
1.介绍:C 标准模板库(Standard Template Library,简称 STL)是一组泛型编程的模板类和函数,旨在提供常用的数据结构、算法和函数对象。STL 是 C 标准库的一部分,极大地提高了编程效率和代码的可重用性。STL …...
:读写锁)
并发设计模式实战系列(6):读写锁
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第六章读写锁模式,废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 读写锁三维模型 2. 关键实现原理 二、生活化类比&am…...
)
【网络原理】从零开始深入理解TCP的各项特性和机制.(一)
本篇博客给大家带来的是网络原理的相关知识.其中传输层这一部分非常重要,面试中只要是涉及到网络这一部分知识,几乎是必定会考传输层TCP的. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给…...

基于Pytorch的深度学习-第二章
2.1 CIFAR-10数据集简介 CIFAR-10数据集包含10个类别:plane、car、bird、cat、deer、dog、frog、horse、ship、truck,每个类别有6000张图片。其中训练集图片有50000张,测试集有10000张图片。训练集和测试集的生成方法是,分别从每…...
)
gitlab-ce容器镜像源(国内)
下载命令 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/gitlab/gitlab-ce:17.10.4-ce.0 更多参考: https://docker.aityp.com/image/docker.io/gitlab/gitlab-ce:17.10.4-ce.0...

TinyVue v3.22.0 正式发布:深色模式上线!集成 UnoCSS 图标库!TypeScript 类型支持全面升级!
我们非常高兴地宣布,2025年4月7日,TinyVue发布了v3.22.0🎉。 本次 3.22.0 版本主要有以下重大变更: 支持深色模式增加基于 UnoCSS 的图标库更丰富的 TypeScript 类型声明支持 XSS 配置 详细的 Release Notes 请参考:…...

Browser-Use WebUI:让AI自动使用浏览器帮你查询信息执行任务
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

使用PyTorch如何配置一个简单的GTP
目录 一、什么是GPT 1. Transformer Block 的核心结构 2. 关键组件解析 (1) 掩码多头自注意力(Masked Multi-Head Self-Attention) (2) 前馈神经网络(FFN) (3) 层归一化(LayerNorm&…...

【FAQ】针对于消费级NVIDIA GPU的说明
概述 本文概述 HP Anyware 在配备消费级 NVIDIA GPU 的物理工作站上的关键组件、安装说明和重要注意事项。 注意:本文档适用于 NVIDIA 消费级 GPU。NVIDIA Quadro 和 Tesla GPU 也支持 HP Anyware 在公有云、虚拟化或物理工作站环境中运行。请参阅PCoIP Graphi…...

02_java的运行机制以及JDKJREJVM基本介绍
1、运行机制 2、JDK&JRE&JVM JDK 基本介绍 (1) JDK 的全称(Java Development Kit Java开发工具包) JDK JRE java的开发工具 [ java, javac, javadoc, javap等 ] (2)JDK是提供给Java开发人员使用的,其…...

go 的 net 包
目录 一、net包的基本功能 1.1 IP地址处理 1.2 网络协议支持 1.3 连接管理 二、net包的主要功能模块 2.1 IP地址处理 2.2 TCP协议 2.3 UDP协议 2.4 Listener和Conn接口 三、高级功能 3.1 超时设置 3.2 KeepAlive控制 3.3 获取连接信息 四、实际应用场景 4.1 Web服…...
)
ShenNiusModularity项目源码学习(21:ShenNius.Admin.Mvc项目分析-6)
菜单列表页面用于新建、维护及删除系统所有模块所需的菜单信息,包括菜单名称、菜单中的按钮、菜单关联的后台服务地址及请求方式等。菜单列表页面的后台控制器类MenuController位于ShenNius.Admin.Mvc项目的Areas\Sys\Controllers内,页面文件位于同项目的…...

基于单片机的游泳馆智能管理系统
标题:基于单片机的游泳馆智能管理系统 内容:1.摘要 随着人们生活水平的提高,游泳馆的规模和客流量不断增大,传统的管理方式已难以满足高效、便捷的管理需求。本研究的目的是设计并实现一种基于单片机的游泳馆智能管理系统。方法上,采用单片机…...

开发了一个b站视频音频提取器
B站资源提取器-说明书 一、功能说明 本程序可自动解密并提取B站客户端缓存的视频资源,支持以下功能: - 自动识别视频缓存目录 - 将加密的.m4s音频文件转换为标准MP3格式 - 将加密的.m4s视频文件转换为标准MP4格式(合并音视频流)…...

vue2项目,为什么开发环境打包出来的js文件名是1.js 2.js,而生产环境打包出来的是chunk-3adddd.djncjdhcbhdc.js
Vue2项目开发环境与生产环境JS文件名差异的核心原理及配置逻辑如下: 一、文件名差异的底层机制 1、Webpack默认命名策略 开发环境默认禁用哈希,采用[id].js命名规则(如1.js),生产环境启用[chunkhash]生成chunk-xxx…...

SQL进阶知识:六、动态SQL
今天介绍下关于动态SQL的详细介绍,并结合MySQL数据库提供实际例子。 动态SQL是指在运行时动态构建和执行SQL语句的技术。这种技术在处理复杂的查询逻辑、参数化查询或在某些情况下需要根据用户输入动态调整查询时非常有用。MySQL支持动态SQL,主要通过PRE…...

Spring Boot常用注解详解:实例与核心概念
Spring Boot常用注解详解:实例与核心概念 前言 Spring Boot作为Java领域最受欢迎的快速开发框架,其核心特性之一是通过注解(Annotation)简化配置,提高开发效率。注解驱动开发模式让开发者告别繁琐的XML配置ÿ…...

java 富文本转pdf
前言: 本文的目的是将传入的富文本内容(html标签,图片)并且分页导出为pdf。 所用的核心依赖为iText7。 因为itextpdf-core的核心包在maven中央仓库中,阿里云华为云等拉不下来,中央仓库在外网,并且此包在中央仓库中未…...

17.第二阶段x64游戏实战-人工遍历二叉树结构
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:16.第二阶段x64游戏实战-分析二叉树结构 上一个内容里把二叉树的结构写了写&am…...

C#基于Sunnyui框架和MVC模式实现用户登录管理
C#基于Sunnyui框架和MVC模式实现用户登录管理 1 Controller1.1 UserManagementController.cs(控制器入口) 2 Model2.1 UserRepository.cs(用户管理模型)2.2 User.cs(用户结构体)2.3 SQLiteHelper.cs&#x…...
编写单元测试)
Spring Boot实战(三十六)编写单元测试
目录 一、什么是单元测试?二、Spring Boot 中的单元测试依赖三、举例 Spring Boot 中不同层次的单元测试3.1 Service层3.2 Controller 层3.3 Repository层 四、Spring Boot 中 Mock、Spy 对象的使用4.1 使用Mock对象的背景4.2 什么是Mock对象,有哪些好处…...

声音分离人声和配乐-从头设计数字生命第4课——仙盟创梦IDE
音频分离在数字人中具有多方面的重要作用,主要体现在以下几个方面: 提高语音合成质量:通过音频分离,可以将原始音频中的语音部分与其他背景噪音或干扰声音分离开来。这样在进行语音合成时,能够获得更纯净的语音信号&am…...

http协议、全站https
一、http协议 1、为何要学http协议? 用户用浏览器访问网页,默认走的都是http协议,所以要深入研究web层,必须掌握http协议 2、什么是http协议 1、全称Hyper Text Transfer Protocol(超文本传输协议) ### 一个请求得到一个响应包 普通…...

Mediamtx与FFmpeg远程与本地推拉流使用
1.本地推拉流 启服 推流 ffmpeg -re -stream_loop -1 -i ./DJI_0463.MP4 -s 1280x720 -an -c:v h264 -b:v 2000k -maxrate 2500k -minrate 1500k -bufsize 3000k -rtsp_transport tcp -f rtsp rtsp://127.0.0.1:8554/stream 拉流 ffplay -rtsp_transport tcp rtsp://43.136.…...
)
css3新特性第七章(3D变换)
css新特性第七章(3D变换) 一、3d空间和景深 元素进行 3D 变换的首要操作:父元素必须开启 3D 空间! 使用 transform-style 开启 3D 空间,可选值如下: flat : 让子元素位于此元素的二维平面内( 2D 空间&…...

redis经典问题
1.缓存雪崩 指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 解决方案: 1)Redis 高可用,主从哨兵,Redis cluster,避免全盘崩…...

数据仓库是什么?数据仓库架构有哪些?
目录 数据仓库是什么?数据仓库架构有哪些? 一、数据仓库是什么? 二、数据仓库的架构分层 1. 获取层 2. 数据层 3. 应用层 4. 访问层 三、数据仓库的价值体现 1.决策支持 2.业务优化 3.提升竞争力 四、数据仓库的未来发展趋势 总…...

Nginx 通过 Let‘s Encrypt 实现 HTTPS 访问全流程指南
一、Let’s Encrypt 与 Certbot 简介 Let’s Encrypt 是由非营利组织 ISRG 运营的免费证书颁发机构(CA),旨在推动 HTTPS 的普及。其核心工具 Certbot 能自动化完成证书申请、部署与续期,大幅降低 HTTPS 的配置复杂度。通过 Certb…...

网络知识:路由器静态路由与动态路由介绍
目录 一、静态路由 1.1 什么是静态路由? 1.2 静态路由的好处 1.3 静态路由的局限 1.4 静态路由应用场景 微型办公室网络 性能要求高业务流量 安全性要求高的环境 二、动态路由 2.1 什么是动态路由? 2.2 动态路由的好处 2.3 动态路由的局限 2.4 动态路由的应用场…...

LLaMA3微调全流程:从LoRA到QLoRA,7B参数模型推理速度提升4倍的代码实战
LLaMA3微调全流程:从LoRA到QLoRA,7B参数模型推理速度提升4倍的代码实战 发现了一个巨牛的人工智能学习网站,分享一下给大家!https://www.captainbed.cn/ccc 前言 在大模型时代,LLaMA系列作为开源社区的明星模型&#…...

日内组合策略思路
一、策略概述 本策略是一种针对日内交易设计的策略,其核心在于通过识别市场趋势和突破信号,结合动态止损和止盈机制,实现日内交易的盈利。策略以金字塔式的加仓方式控制风险,并通过灵活的平仓策略锁定收益。 二、交易逻辑思路 市场…...

从空气污染监测到嵌入式仿真教学:基于STM32与MQ135的实践探索
一、嵌入式系统在环境监测中的技术演进 随着全球城市化进程加速,世界卫生组织(WHO)数据显示,92%的人口长期暴露于超标PM2.5环境中。在此背景下,基于STM32微控制器的智能监测系统因其高性价比(单节点成本低…...

【数据结构】Map与Set结构详解
数据结构系列五:Map与Set(一) 一、接口的实现 1.方法上 2.成员上 二、Map的内外双接口结构 1.实现 1.1外部Map接口的实现 1.1.1临摹整体 1.1.2外部类实现整体 1.2内部Entry接口的实现 1.2.1临摹内部 1.2.2内部类实现内部 2.关系 3.意义 3.1逻辑内聚 …...
安装rbenv、ruby2.6.5和rails5.2.6)
银河麒麟(内核CentOS8)安装rbenv、ruby2.6.5和rails5.2.6
一、安装 rbenv 和 ruby-build 1.安装 rbenv git clone https://github.com/rbenv/rbenv.git ~/.rbenv 2. 添加 rbenv 到 PATH echo export PATH"$HOME/.rbenv/bin:$PATH" >> ~/.bashrc echo eval "$(rbenv init -)" >> ~/.bashrc source ~…...

豆包桌面版 1.47.4 可做浏览器,免安装绿色版
自己动手升级更新办法: 下载新版本后安装,把 C:\Users\用户名\AppData\Local\Doubao\Application 文件夹的文件,拷贝替换 DoubaoPortable\App\Doubao 文件夹的文件,就升级成功了。 再把安装的豆包彻底卸载就可以。 桌面版比网页版…...