Python基础语法3
目录
1、函数
1.1、语法格式
1.2、函数返回值
1.3、变量作用域
1.4、执行过程
1.5、链式调用
1.6、嵌套调用
1.7、函数递归
1.8、参数默认值
1.9、关键字参数
2、列表
2.1、创建列表
2.2、下标访问
2.3、切片操作
2.4、遍历列表元素
2.5、新增元素
2.6、查找元素
2.7、删除元素
2.8、连接列表
3、元组
4、字典
4.1、创建字典
4.2、查找key
4.3、新增和修改元素
4.4、删除元素
4.5、遍历字典元素
4.6、合法的key类型
1、函数
编程中的函数和数学中的函数有一定的相似之处。编程中的函数,是一段可以被重复使用的代码片段。例如:
# 1. 求 1 - 100 的和
sum = 0
for i in range(1, 101):sum += i
print(sum)
# 2. 求 300 - 400 的和
sum = 0
for i in range(300, 401):sum += i
print(sum)
# 3. 求 1 - 1000 的和
sum = 0
for i in range(1, 1001):sum += i
print(sum)可以发现,这几组代码基本是相似的,只有一点点差异,可以把重复代码提取出来,做成一个函数
1.1、语法格式
定义函数:
def 函数名(形参列表):函数体return 返回值调用函数:
函数名(实参列表)函数定义并不会执行函数体内容, 必须要调用才会执行。调用几次就会执行几次。函数必须先定义,再使用。Python要求函数定义必须写在前面,函数调用写在后面。例如:
# 定义函数
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += iprint(sum)
# 调用函数
calcSum(1, 100)
calcSum(300, 400)
calcSum(1, 1000)一个函数可以有一个形参, 也可以有多个形参, 也可以没有形参。一个函数的形参有几个, 那么传递实参的时候也得传几个。保证个数要匹配。
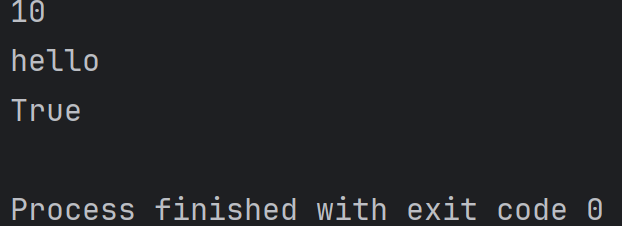
和 C++ / Java 不同,Python 是动态类型的编程语言,函数的形参不必指定参数类型。换句话说, 一个函数可以支持多种不同类型的参数。例如:
def test(a):print(a)
test(10)
test('hello')
test(True)结果为:
1.2、函数返回值
函数的参数可以视为是函数的 "输入", 则函数的返回值, 就可以视为是函数的 "输出" 。
例如:我们可以将之前的加法函数写为
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += ireturn sum
result = calcSum(1, 100)
print(result)这个代码与之前的代码的区别就在于,前者直接在函数内部进行了打印,后者则使用return语句把结果返回给函数调用者,再由调用者负责打印。
我们一般倾向于第二种写法,因为实际开发中我们的一个通常的编程原则是 "逻辑和用户交互分离"。 而第一种写法的函数中,既包含了计算逻辑,又包含了和用户交互(打印到控制台上),这种写法是不太好的,如果后续我们需要的是把计算结果保存到文件中,或者通过网络发送,或者展示到图形化界面里,那么第一种写法的函数,就难以胜任了。而第二种写法则专注于做计算逻辑,不负责和用户交互,那么就很容易把这个逻辑与其他代码搭配,来实现不同的效果。简单来说就是:一个函数只做一件事。
一个函数是可以一次返回多个返回值的,使用,来分割多个返回值。例如:
def getPoint():x = 10y = 20return x, y
a, b = getPoint()
print(a,b)如果只想关注其中的部分返回值,可以使用 _ 来忽略不想要的返回值。例如:
def getPoint():x = 10y = 20return x, y
_, b = getPoint()
print(b)注:Python中的一个函数可以返回多个返回值,这一点和C++与JAVA不同。
1.3、变量作用域
观察以下代码:
def getPoint():x = 10y = 20return x, y
x, y = getPoint()
print(x,y)在这个代码中, 函数内部存在 x, y, 函数外部也有 x, y。但是这两组 x, y 不是相同的变量, 而只是恰好有一样的名字。
在函数 getPoint() 内部定义的 x, y 只是在函数内部生效。一旦出了函数的范围, 这两个变量就不再生效了。例如:像下面这样写就会报错
def getPoint():x = 10y = 20return x, y
getPoint()
print(x, y)在不同的作用域中, 允许存在同名的变量,例如:
x = 20
def test():x = 10print(f'函数内部 x = {x}')
test()
print(f'函数外部 x = {x}')虽然名字相同,实际上是不同的变量。结果为:

注意:在函数内部的变量,也称为 "局部变量" 。不在任何函数内部的变量,也称为 "全局变量"。
全局变量是在整个程序中都有效的,局部变量只是在函数内部有效。
如果函数内部尝试访问的变量在局部不存在,就会尝试去全局作用域中查找。例如:
x = 20
def test():print(f'x = {x}')
test()如果是想在函数内部,修改全局变量的值,需要使用 global 关键字声明。例如:
x = 20
def test():global xx = 10print(f'函数内部 x = {x}')
test()
print(f'函数外部 x = {x}')如果此处没有 global ,则函数内部的 x = 10 就会被视为是创建一个局部变量 x,这样就和全局变量 x 不相关了。
if / while / for 等语句块不会影响到变量作用域。换而言之,在 if / while / for 中定义的变量,在语句外面也可以正常使用。例如:
for i in range(1, 10):print(f'函数内部 i = {i}')
print(f'函数外部 i = {i}')1.4、执行过程
调用函数才会执行函数体代码。不调用则不会执行。函数体执行结束(或者遇到 return 语句)。则回到函数调用位置,继续往下执行。例如:
def test():print("执行函数内部代码")print("执行函数内部代码")print("执行函数内部代码")
print("1111")
test()
print("2222")
test()
print("3333")上面的代码的执行过程还可以使用 PyCharm 自带的调试器来观察:
1、点击行号右侧的空白, 可以在代码中插入断点。
2、右键,Debug,可以按照调试模式执行代码,每次执行到断点,程序都会暂停下来。
3、使用 Step Into (F7) 功能可以逐行执行代码。
1.5、链式调用
把一个函数的返回值,作为另一个函数的参数,这种操作称为链式调用。链式调用中,先执行里面的函数,再执行外面的函数。例如:
# 判定是否是奇数
def isOdd(num):if num % 2 == 0:return Falseelse:return True
print(isOdd(10))1.6、嵌套调用
函数内部还可以调用其他的函数,这个动作称为 "嵌套调用"。一个函数里面可以嵌套调用任意多个函数。例如:
def test():print("执行函数内部代码")print("执行函数内部代码")print("执行函数内部代码")test 函数内部调用了 print 函数,这里就属于嵌套调用。
函数嵌套的过程是非常灵活的,例如:
def a():print("函数 a")
def b():print("函数 b")a()
def c():print("函数 c")b()
def d():print("函数 d")c()
d()如果把代码稍微调整,打印结果则可能发生很大变化,例如:
def a():print("函数 a")
def b():a()print("函数 b")
def c():b()print("函数 c")
def d():c()print("函数 d")
d()函数之间的调用关系,在 Python 中会使用一个特定的数据结构来表示,称为函数调用栈。每次函数调用,都会在调用栈里新增一个元素,称为栈帧。可以通过 PyCharm 调试器看到函数调用栈和栈帧。在调试状态下,PyCharm 左下角一般就会显示出函数调用栈。例如:
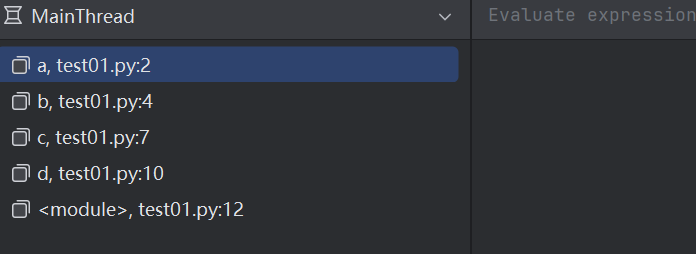
每个函数的局部变量,都包含在自己的栈帧中。调用函数则生成对应的栈帧,函数结束,则对应的栈帧消灭,里面的局部变量也就没了。例如:
def a():num1 = 10print("函数 a")
def b():num2 = 20a()print("函数 b")
def c():num3 = 30b()print("函数 c")
def d():num4 = 40c()print("函数 d")
d()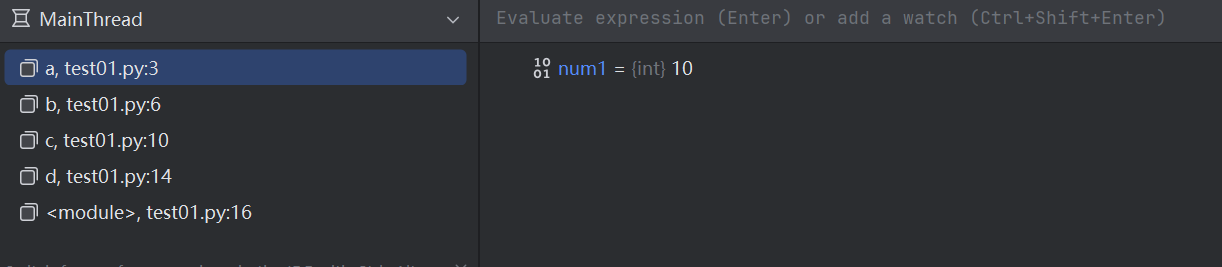
选择不同的栈帧,就可以看到各自栈帧中的局部变量。
1.7、函数递归
递归是嵌套调用中的一种特殊情况,即一个函数嵌套调用自己。例如:递归计算 5!
def factor(n):if n == 1:return 1return n * factor(n - 1)
result = factor(5)
print(result)上述代码中,就属于典型的递归操作。在 factor 函数内部,又调用了 factor 自身。
注意:递归代码务必要保证存在递归结束条件,比如 if n == 1 就是结束条件,当 n 为 1 的时候, 递归就结束了。每次递归的时候,要保证函数的实参是逐渐逼近结束条件的。
如果上述条件不能满足,就会出现 "无限递归" 。这是一种典型的代码错误。例如:
def factor(n):return n * factor(n - 1)
result = factor(5)
print(result)结果为:

如前面所描述, 函数调用时会在函数调用栈中记录每一层函数调用的信息,但是函数调用栈的空间不是无限大的,如果调用层数太多, 就会超出栈的最大范围, 导致出现问题。
递归的优点:递归类似于 "数学归纳法" ,明确初始条件和递推公式,就可以解决一系列的问题,递归代码往往代码量非常少。
递归的缺点:递归代码往往难以理解,很容易超出掌控范围。递归代码容易出现栈溢出的情况。递归代码往往可以转换成等价的循环代码。并且通常来说循环版本的代码执行效率要略高于递归版 本。
1.8、参数默认值
Python 中的函数, 可以给形参指定默认值,带有默认值的参数, 可以在调用的时候不传参。例如:
def add(x, y, debug=False):if debug:print(f'调试信息: x={x}, y={y}')return x + y
print(add(10, 20))
print(add(10, 20, True))此处 debug=False 即为参数默认值。当我们不指定第三个参数的时候,默认debug 的取值即为 False。
带有默认值的参数需要放到没有默认值的参数的后面。如果不这样做就会报错,例如:
def add(x, debug=False, y):if debug:print(f'调试信息: x={x}, y={y}')return x + y
print(add(10, 20))结果为:

如果有多个带有默认参数的形参,也是要放在后面的。
1.9、关键字参数
在调用函数的时候,需要给函数指定实参。一般默认情况下是按照形参的顺序,来依次传递实参的
但是我们也可以通过关键字参数, 来调整这里的传参顺序, 显式指定当前实参传递给哪个形参。
例如:
def test(x, y):print(f'x = {x}')print(f'y = {y}')
test(x=10, y=20)
test(y=100, x=200)形如上述 test(x=10, y=20) 这样的操作,即为关键字参数。
使用关键字参数能非常明显的告诉读代码的人参数要传递给谁。另外这种写法可以无视形参和实参的顺序。
2、列表
编程中, 经常需要使用变量, 来保存或表示数据。如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可。但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据。这个时候, 就需要用到列表。
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时候就设定好的, 不能修改调整。
2.1、创建列表
创建列表主要有两种方式。alist = [ ] 和alist = list() ,其中[ ] 表示一个空的列表。例如:
alist = [ ] #使用列表字面值来创建列表
blist = list() #使用list()函数来创建列表
print(type(alist))
print(type(blist))注:列表的类型为list。
如果需要往里面设置初始值,可以直接写在 [ ] 当中。可以直接使用 print 来打印 list 中的元素内容
alist = [1, 2, 3, 4]
print(alist)列表中存放的元素允许是不同的类型,这一点和 C++ Java 差别较大。例如:
alist = [1, 'hello', True]
print(alist)注:列表内还可以放列表类型的元素。
注:因为 list 本身是 Python 中的内建函数, 不宜再使用 list 作为变量名, 因此命名为alist。
2.2、下标访问
可以通过下标访问操作符 [ ] 来获取到列表中的任意元素。我们把 [ ] 中填写的数字, 称为下标或者索引。例如:
alist = [1, 2, 3, 4]
print(alist[2])注意:下标是从 0 开始计数的, 因此下标为 2 , 则对应着 3 这个元素。
通过下标不光能读取元素内容, 还能修改元素的值,如果下标超出列表的有效范围, 会抛出异常。
alist = [1, 2, 3, 4]
print(alist[100])结果为:
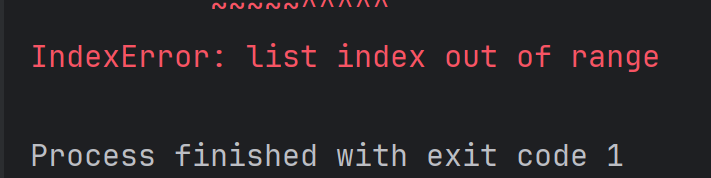
因为下标是从 0 开始的, 因此下标的有效范围是 [0, 列表长度 - 1]。使用 len函数可以获取列表的元素个数。例如:
alist = [1, 2, 3, 4]
print(len(alist))下标可以取负数,表示 "倒数第几个元素"。
alist = [1, 2, 3, 4]
print(alist[3])
print(alist[-1])alist[-1] 相当于alist[len(alist) - 1]。
2.3、切片操作
通过下标操作是一次取出里面第一个元素。通过切片, 则是一次取出一组连续的元素, 相当于得到一个子列表。列表的切片操作是一个比较高效的操作,进行切片时,只是取出原有列表的一部分,并不涉及到数据的拷贝。
1、使用 [ : ] 的方式进行切片操作。例如:
alist = [1, 2, 3, 4]
print(alist[1:3])结果为:
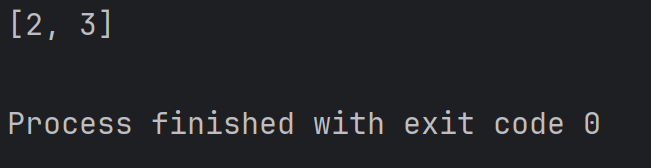
其中,alist[1:3] 中的 1:3 表示的是 [1, 3) 这样的由下标构成的前闭后开区间。也就是从下标为 1 的元素开始(2), 到下标为 3 的元素结束(4), 但是不包含下标为 3 的元素。
2、切片操作中可以省略前后边界。例如:
alist = [1, 2, 3, 4]
print(alist[1:])
print(alist[:-1])
print(alist[:]) 结果为:
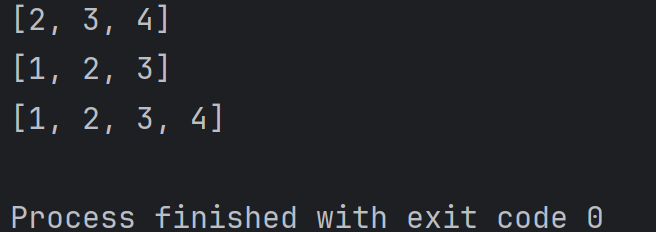
3、切片操作还可以指定 "步长" , 也就是 "每访问一个元素后, 下标自增几步"。例如:
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::1])
print(alist[::2])
print(alist[::3])
print(alist[::5])结果为:
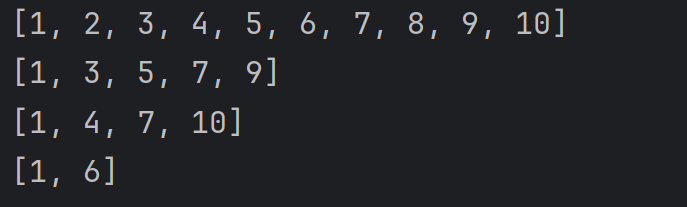
4、切片操作指定的步长还可以是负数, 此时是从后往前进行取元素。表示 "每访问一个元素之后, 下标自减几步"。例如:
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::-1])
print(alist[::-2])
print(alist[::-3])
print(alist[::-5])结果为:

注:如果切片中填写的数字越界了, 不会出现异常,只会尽可能的把满足条件的元素给获取到。例如:
alist = [1, 2, 3, 4]
print(alist[100:200])结果为:
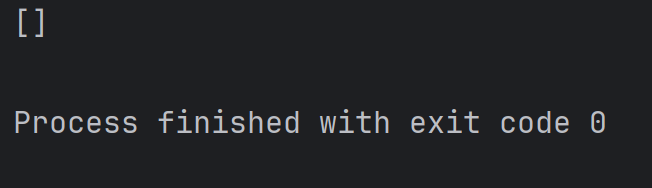
2.4、遍历列表元素
"遍历" 指的是把元素一个一个的取出来。
1、最简单的办法就是使用 for 循环,例如:
alist = [1, 2, 3, 4]
for elem in alist:print(elem)也可以使用 for 按照范围生成下标, 按下标访问,例如:
alist = [1, 2, 3, 4]
for i in range(0, len(alist)):print(alist[i])2、还可以使用 while 循环,手动控制下标的变化,例如:
alist = [1, 2, 3, 4]
i = 0
while i < len(alist):print(alist[i])i += 12.5、新增元素
使用 append 方法, 向列表末尾插入一个元素(尾插)。例如:
alist = [1, 2, 3, 4]
alist.append('hello')
print(alist)使用 insert 方法, 向任意位置插入一个元素,insert 第一个参数表示要插入元素的下标。例如:
alist = [1, 2, 3, 4]
alist.insert(1, 'hello')
print(alist)另外,如果插入的下标越界的话,不会出现异常,而是把要插入的元素进行尾插,例如:
alist = [1, 2, 3, 4]
alist.insert(100, 'hello')
print(alist)注:方法其实就是函数,只不过函数是独立存在的,而方法往往要依附于某个 "对象"。像上述代码 alist.append , append 就是依附于 alist,而不是作为一个独立的函数,相当于是 "针对 alist 这个列表, 进行尾插操作"。type,print,input等都是独立的函数,不用搭配其他的东西就能使用。
2.6、查找元素
使用 in 操作符, 判定元素是否在列表中存在,返回值是布尔类型,例如:
alist = [1, 2, 3, 4]
print(2 in alist)
print(10 in alist)
print(2 not in alist) #逻辑取反,结果为False使用 index 方法, 查找列表中的元素,返回值是一个整数,这个整数也就是查找到的元素的下标,如果元素不存在, 则会抛出异常,例如:
alist = [1, 2, 3, 4]
print(alist.index(2))
print(alist.index(10)) #会发生异常2.7、删除元素
使用 pop 方法删除最末尾元素,例如:
alist = [1, 2, 3, 4]
alist.pop()
print(alist)pop 也能按照下标来删除元素,例如:
alist = [1, 2, 3, 4]
alist.pop(2)
print(alist)使用 remove 方法, 按照元素值删除元素。例如:
alist = [1, 2, 3, 4]
alist.remove(2)
print(alist)2.8、连接列表
使用 + 能够把两个列表拼接在一起。此处的 + 结果会生成一个新的列表,而不会影响到旧列表的内容。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
print(alist + blist)使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面。a.extend(b) , 是把 b 中的内容拼接到 a 的末尾,不会修改 b, 但是会修改 a。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
alist.extend(blist)
print(alist)
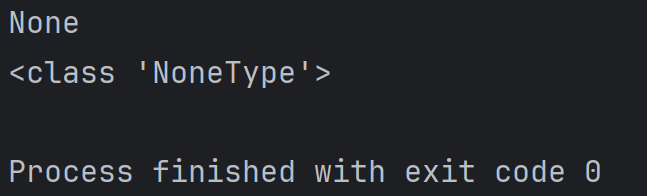
print(blist)注意:None在Python中是一个特殊的变量值,表示啥都没有。拿一个变量接收没有返回值的方法的返回值,这个变量的结果就为None,类型为Nonetype。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
a=alist.extend(blist)
print(a)
print(type(a))结果为:
3、元组
元组的功能和列表相比, 基本是一致的,元组使用 ( ) 来表示。元组的类型为tuple,例如:
atuple = ( )
atuple = tuple()元组不能修改里面的元素, 列表则可以修改里面的元素。
因此,像读操作,比如访问下标,切片,遍历,in,index,+ 等,元组也是一样支持的。但是,像写操作,比如修改元素,新增元素,删除元素,extend 等,元组则不能支持。
另外, 元组在 Python 中很多时候是默认的集合类型。例如, 当一个函数返回多个值的时候。
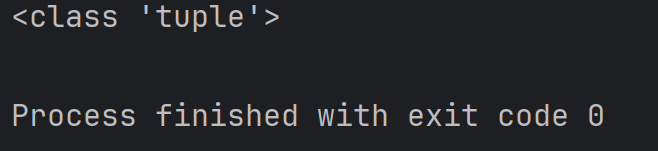
def getPoint():return 10, 20
result = getPoint()
print(type(result))结果为:
此处的 result 的类型,其实就是元组。
问题来了, 既然已经有了列表, 为啥还需要有元组?
元组相比于列表来说, 优势有两方面:
1、比如有一个列表, 现在需要调用一个函数进行一些处理,但是你有不是特别确认这个函数是否会修改你列表的数据,那么这时候传一个元组就安全很多。
2、我们马上要说的字典, 是一个键值对结构,要求字典的键必须是 "可hash对象" (字典本质上也 是一个hash表),而一个可hash对象的前提就是不可变,因此元组可以作为字典的键, 但是列表不行。
4、字典
字典是一种存储键值对的结构。把键(key)和值(value) 进行一个一对一的映射,这就是键值对,然后就可以根据键,快速找到值。
4.1、创建字典
创建一个空的字典,使用 { } 表示字典,字典的类型为dict,例如:
a = { }
b = dict()
print(type(a))
print(type(b))也可以在创建的同时指定初始值,键值对之间使用,分割,键和值之间使用 : 分割。冒号后面推荐加一个空格。例如:
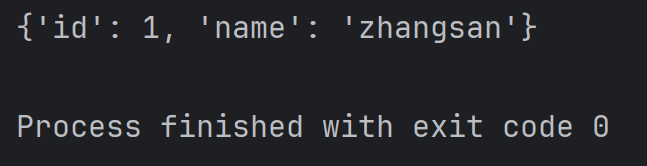
student = { 'id': 1, 'name': 'zhangsan' }
print(student)结果为:
注意:字典的key是不能重复的。
为了代码更规范美观, 在创建字典的时候往往会把多个键值对, 分成多行来书写。例如:
student = {'id': 1,'name': 'zhangsan'
}最后一个键值对,后面可以写,也可以不写,例如:
student = {'id': 1,'name': 'zhangsan',
}4.2、查找key
使用 in 可以判定 key 是否在字典中存在,返回布尔值,但是不能使用in判断value是否在字典中。例如:
student = {'id': 1,'name': 'zhangsan'
}
print('id' in student)
print('score' in student)使用 [ ] 通过类似于取下标的方式,获取到元素的值,只不过此处的 "下标" 是 key。(可能是整数, 也可能是字符串等其他类型)。
student = {'id': 1,'name': 'zhangsan',
}
print(student['id'])
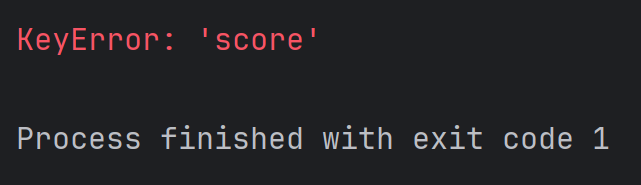
print(student['name'])如果 key 在字典中不存在,则会抛出异常。例如:
student = {'id': 1,'name': 'zhangsan',
}
print(student['score'])结果为:
4.3、新增和修改元素
使用 [ ] 可以根据 key 来新增/修改 value。
如果 key 不存在, 对取下标操作赋值, 即为新增键值对,例如:
student = {'id': 1,'name': 'zhangsan',
}
student['score'] = 90
print(student)如果 key 已经存在, 对取下标操作赋值, 即为修改键值对的值。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student['score'] = 90
print(student)4.4、删除元素
使用 pop 方法根据 key 删除对应的键值对。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student.pop('score')
print(student)4.5、遍历字典元素
直接使用 for 循环能够获取到字典中的所有的 key, 进一步的就可以取出每个值了。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key in student:print(key, student[key])注:在C++和JAVA中,哈希表里面的键值对的存储是无序的,Python中做了特殊处理,能够保证遍历出来的顺序,就是和插入的顺序一致的。Python中的字典不是一个单纯的哈希表。
使用 keys 方法可以获取到字典中的所有的 key,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.keys())结果为:
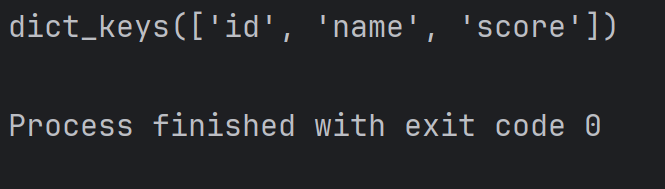
注:此处 dict_keys 是一个特殊的类型,专门用来表示字典的所有 key,这是一个自定义类型,返回的结果看起来像列表,又不完全是,但使用的时候也可以把他当作一个列表来使用。
使用 values 方法可以获取到字典中的所有 value,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.values())结果为:
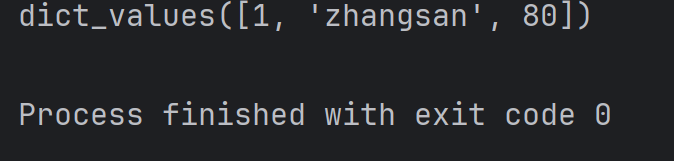
注:此处 dict_values 也是一个特殊的类型, 和 dict_keys 类似。
使用 items 方法可以获取到字典中所有的键值对。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.items())结果为:

注:此处 dict_items 也是一个特殊的类型,首先是一个列表一样的结构,里面每个元素又是一个元组,元组里面包含了键和值。
我们还可以这样遍历字典元素,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key,value in student.items():print(key,value)4.6、合法的key类型
不是所有的类型都可以作为字典的 key。字典本质上是一个 哈希表,哈希表的 key 要求是 "可哈希的",也就是可以计算出一个哈希值。
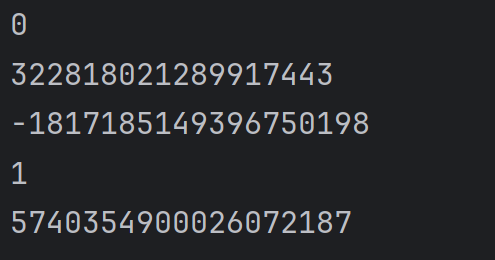
可以使用 hash 函数计算某个对象的哈希值。但凡能够计算出哈希值的类型,都可以作为字典的 key。例如:
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash(()))结果为:
注意:列表无法计算哈希值,字典也无法计算哈希值,例如:
print(hash([1, 2, 3]))结果为:
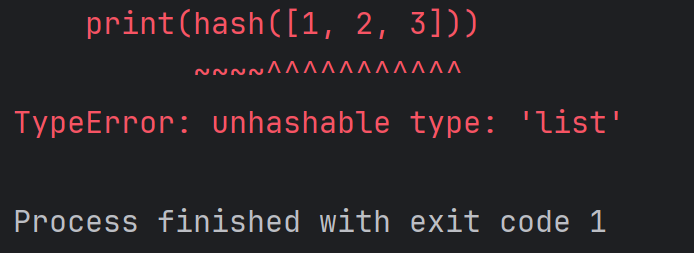
再比如:
print(hash({ 'id': 1 }))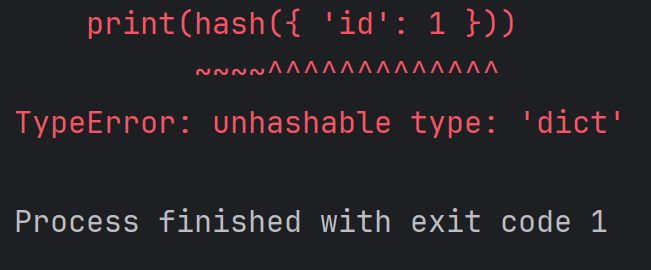
注:不可变的对象,一般就是可哈希的;可变的对象一般就是不可哈希的。
相关文章:

Python基础语法3
目录 1、函数 1.1、语法格式 1.2、函数返回值 1.3、变量作用域 1.4、执行过程 1.5、链式调用 1.6、嵌套调用 1.7、函数递归 1.8、参数默认值 1.9、关键字参数 2、列表 2.1、创建列表 2.2、下标访问 2.3、切片操作 2.4、遍历列表元素 2.5、新增元素 2.6、查找元…...

45、子类需要重写父类的构造函数嘛,子类自己的构造函数呢?
45、子类需要重写父类的构造函数嘛,子类自己的构造函数呢? 一、子类是否需要重写父类的构造函数? 1. 不需要重写的场景 基类有无参构造函数 若父类(基类)显式或隐式定义了无参构造函数,子类无需重写构造函…...

C语言 ——— 分支循环语句
目录 分支循环语句 单分支 多分支 switch 分支语句 牛刀小试 判断一个数是否是奇数 输出 1-100之间 的奇数 计算 n 的阶乘 计算 1! 2! 3! ... n! 在一个有序数组中查找具体的某一个数字 打印 100-200 之间的素数 求两个整数的最大公约数 getchar函数 和 putc…...
实战解析)
解耦旧系统的利器:Java 中的适配器模式(Adapter Pattern)实战解析
在现代软件开发中,我们经常需要与旧系统、第三方库或不一致接口打交道。这时候,如果能优雅地整合这些不兼容组件,又不破坏原有结构,就需要一位“翻译官” —— 适配器模式。本文将通过 Java 实例,详细讲解适配器模式的…...

C++学习之游戏服务器开发十五QT登录器实现
目录 1.界面搭建 2.登录客户端步骤分析 3.拼接登录请求实现 4.发送http请求 5.服务器登录请求处理 6.客户端处理服务器回复数据 7.注册页面启动 8.qt启动游戏程序 1.界面搭建 2.登录客户端步骤分析 3.拼接登录请求实现 CGI 程序处理流程 程序员自己写程序处理各种业务 …...
)
搭建Stable Diffusion图像生成系统实现通过网址访问(Ngrok+Flask实现项目系统公网测试,轻量易部署)
目录 前言 背景与需求 🎯 需求分析 核心功能 网络优化 方案确认 1. 安装 Flask 和 Ngrok 2. 构建 Flask 应用 3. 使用 Ngrok 实现内网穿透 4. 测试图像生成接口 技术栈 实现流程 优化目标 实现细节 1. 迁移到Flask 2. 持久化提示词 3. 图像下载功能 …...

第五章:5.3 ESP32物联网应用:阿里云IoT平台与腾讯云IoT平台的数据上传与远程控制
一、阿里云IoT平台接入 1. 准备工作 注册阿里云账号 访问阿里云官网,注册并完成实名认证。创建产品和设备 进入物联网平台控制台 → 公共实例 → 创建产品(例如产品名称“ESP32_Sensor”,节点…...

【AI News | 20250423】每日AI进展
AI Repos 1、suna Suna是一款完全开源的AI助手,旨在通过自然对话帮助用户轻松完成现实世界的任务。它作为您的数字伙伴,提供研究、数据分析和日常问题解决等功能,并结合强大的能力与直观的界面,理解您的需求并交付成果。Suna的工…...

3.1 Agent定义与分类:自主Agent、协作Agent与混合Agent的特点
随着人工智能技术的快速发展,智能代理(Agent)作为一种能够感知环境、自主决策并采取行动的计算实体,已成为人工智能领域的重要研究对象和应用工具。特别是在大模型(Large Models)的赋能下,Agent…...

stack和queue的学习
stack的介绍 stack的文档介绍 stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,…...

leetcode-位运算
位运算 371. 两整数之和 题目 给你两个整数 a 和 b ,不使用 运算符 和 - ,计算并返回两整数之和。 示例 1: 输入: a 1, b 2 输出: 3 示例 2: 输入: a 2, b 3 输出: 5 提示&am…...

《浔川AI翻译v6.1.0问题已修复公告》
《浔川AI翻译v6.1.0问题已修复公告》 尊敬的浔川AI翻译用户: 感谢您对浔川AI翻译的支持与反馈!我们已针对 **v6.1.0** 版本中用户反馈的多个问题进行了全面修复,并优化了系统稳定性。以下是本次修复的主要内容: 已修复问题 ✅…...

Unity 创建、读取、改写Excel表格数据
1.导入EPPlus.dll、Excel.dll、Mysql.Data.dll、System.Data.dll;(我这里用的是:Unity2017.3.0) 2.代码如下: using System.Data; using System.IO; using UnityEngine; using OfficeOpenXml; using UnityEditor; us…...

【阿里云大模型高级工程师ACP习题集】2.3 优化提示词改善答疑机器人回答质量
练习题: 【单选题】在使用大模型进行意图识别时,通过设计特定提示词引导模型生成符合预期回答的方法,其本质是( )。 A. 修改模型本身参数 B. 依靠构造输入激发模型内部已有知识 C. 对模型进行微调 D. 改变模型的训练数据 【多选题】以下哪些属于提示词框架中的要素( )。…...

富文本编辑器实现
🎨 富文本编辑器实现原理全解析 📝 基本实现路径图 #mermaid-svg-MO1B8a6kAOmD8B6Y {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-MO1B8a6kAOmD8B6Y .error-icon{fill:#552222;}#mermaid-s…...

海量粒子特效解决方案:VEG
Unity 官方除了一个 GPU 粒子特效的解决方案:Visual Effect Graph,即 VEG,能支持百万级粒子特效的播放。在性能要求高的使用场景中,这个解决方案就能完美解决原本 Particle System 性能低下的问题。关于 VEG 的基本使用方法参考官…...

Java高频面试之并发编程-06
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:线程上下文切换是什么? 线程上下文切换(Thread Context Switching)是操作系统中 CPU…...

Windows 同步技术-一次性初始化
组件通常设计为在首次调用时执行初始化任务,而不是加载它们时。 一次性初始化函数可确保此初始化仅发生一次,即使多个线程可能尝试初始化也是如此。 Windows Server 2003 和 Windows XP: 应用程序必须使用 互锁函数 或其他同步机制提供自己的…...
Transformer起源-Attention Is All You Need
这篇笔记主要讲解Attention Is All You Need论文。《Attention Is All You Need》由 Ashish Vaswani 等人撰写,于 2017 年发表在 NIPS(Neural Information Processing Systems)会议上。它提出了一种全新的神经网络架构——Transformer&#x…...

被裁20240927 --- 视觉目标跟踪算法
永远都像初次见你那样使我心荡漾 参考文献目前主流的视觉目标跟踪算法一、传统跟踪算法1. 卡尔曼滤波(Kalman Filter)2. 相关滤波(Correlation Filter,如KCF、MOSSE)3. 均值漂移(MeanShift/CamShift&#x…...
)
每日学习Java之一万个为什么(JUC)
文章目录 Git复习synchronized介绍基本概念特点 使用模板1. 同步方法格式特点 2. 同步代码块格式特点 常见面试题1. synchronized的实现原理?2. synchronized与ReentrantLock的区别?3. synchronized的缺点?4. 死锁的四个必要条件?…...

代码分享:python实现svg图片转换为png和gif
import cairosvg import imageio from PIL import Image import io import osdef svg_to_png(svg_path, png_path):try:cairosvg.svg2png(urlsvg_path, write_topng_path)print(f"成功将 {svg_path} 转换为 {png_path}")except Exception as e:print(f"转换为 P…...

前端热门面试题day1
内容回答较粗糙,如有疑问请自行搜索资料 什么是vue中的slot?它有什么作用 Vue中的Slot(插槽)就像给组件预先留的“内容停车位”,让父组件能把自定义内容“塞”到子组件的指定位置。它的主要作用是: 灵活定…...

DCAN,ECAN和MCAN的区别
DCAN、ECAN和MCAN的主要区别在于它们各自的管理范围和功能。 DCAN(动力CAN系统):DCAN主要负责协调电机控制单元(MCU)、电池管理系统(BMS)、直流电压变换器(DC/DC)和…...
)
基于Python爬虫的豆瓣电影信息爬取(可以根据选择电影编号得到需要的电影信息)
# 豆瓣电影信息爬虫(展示效果如下图所示:) 这是一个功能强大的豆瓣电影信息爬虫程序,可以获取豆瓣电影 Top 250 的详细信息。 ## 功能特点 - 自动爬取豆瓣电影 Top 250 的所有电影信息 - 支持分页获取,每页 25 部电影,共 10 页 - 获取每部电影的详细信息,包括: - 标题…...

Linux系统学习----概述与目录结构
linux 是一个开源、免费的操作系统,其稳定性、安全性、处理多并发已经得到业界的认可,目前很多企业级的项目 (c/c/php/python/java/go)都会部署到 Linux/unix 系统上。 一、虚拟机系统操作 1.网络连接的三种方式(桥接模式、nat模式、主机模…...

软考资料分享
分享一些软考资料 16系统分析师-基础知识精讲夸克网盘分享1701系统分析师夸克网盘分享1804系统架构设计师夸克网盘分享19软考系统架构设计师2024年11月夸克网盘分享2006信息系统项目管理师夸克网盘分享21软考高级信息系统项目夸克网盘分享22系统分析师视频教程真题资料夸克网盘…...

什么是 GLTF/GLB? 3D 内容创建的基本数据格式说明,怎么下载GLB/GLTF格式模型
GLTF 概述 GLTF 是一种 3D 模型格式,广泛用于在 Web 上共享和显示 3D 内容。 它经过优化,可在 WebGL 中轻松加载,使用 WebGL 可以快速高效地渲染 3D 模型。 GLTF 是 Khronos Group 开发的开放标准之一,以 JSON 或二进制格式表示…...

湖南大学-操作系统实验四
HUNAN UNIVERSITY 操作系统实验报告 一、实验题目 实验四 中断、异常和陷阱指令是操作系统的基石,现代操作系统就是由中断驱动的。本实验和实验五的目的在于深刻理解中断的原理和机制,掌握CPU访问中断控制器的方法,掌握Arm体系结构的中断机…...

3.第三章:数据治理的战略价值
文章目录 3.1 数据治理与企业战略3.1.1 数据驱动的决策体系3.1.2 数据资产的价值挖掘3.1.3 风险防控与合规管理 3.2 数据治理的业务价值3.2.1 提升客户体验3.2.2 优化运营效率3.2.3 加速产品创新 3.3 数据治理的技术价值3.3.1 提升数据质量3.3.2 优化数据架构3.3.3 增强系统集成…...

[KVM] KVM挂起状态恢复失败与KVM存储池迁移
背景:发现KVM host上的几台虚拟机挂起了(paused),但是并没有执行virsh suspend <vm_hostname>,且使用virsh resume <vm_hostname> 无法恢复。原因是这个几个虚拟机归属的存储池所在的磁盘满了。所以想把虚拟机迁移到磁盘空间富余…...
慧知开源充电桩平台)
图文结合 - 光伏系统产品设计PRD文档 -(慧哥)慧知开源充电桩平台
光伏系统产品设计PRD文档 版本号:1.0 修订日期:2023年10月 作者: 一、文档概述 1.1 背景与目标 行业背景:全球光伏装机量年增长20%,数字化运维需求迫切用户痛点:现有系统存在数据延…...

linux-相关命令
一、Linux 详细介绍 1. 什么是 Linux? Linux 是一个开源的类 Unix 操作系统,其核心是 Linux 内核。它最早由 Linus Torvalds 在 1991 年发布,后来逐渐发展成各种发行版(如 Ubuntu、CentOS、Debian、Arch 等)。 2. L…...

Hive中Map和Reduce阶段的分工
在Hive查询执行过程中,Map和Reduce阶段有明确的分工,但实际情况要复杂一些。 基本分工原则 Map阶段: 主要职责是读取输入数据并进行初步处理输出键值对形式的数据Reduce阶段: 接收Map阶段输出的键值对对相同键的值进行聚合/计算输出最终结果实际执行中的复…...

前端笔记-Vue router
学习目标 Vue Router路由管理1、路由配置2、嵌套路由3、路由守卫与权限控制 一、路由配置(给网站做地图) npm i vue-router 作用:告诉浏览器什么地址该显示什么页面 核心代码: // 创建路由并暴露出去// 第一步&#x…...

MySQL的日志--Redo Log【学习笔记】
MySQL的日志--Redo Log 知识来源: 《MySQL是怎样运行的》--- 小孩子4919 MySQL的事务四大特性之一就是持久性(Durability)。但是底层是如何实现的呢?这就需要我们的Redo Log(重做日志)闪亮登场了。它记录着…...
》)
《系统分析师-第三阶段—总结(五)》
背景 采用三遍读书法进行阅读,此阶段是第三遍。 过程 第9章 总结 在这个过程中,对导图的规范越来越清楚,开始结构化,找关系,找联系。...

【LangChain4j】AI 第二弹:项目中接入 LangChain4j
普通接入方式 参考文档: Get Started https://docs.langchain4j.dev/get-started 1.添加依赖 <!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 --> <dependency><groupId>dev.langchain4j</grou…...

测试基础笔记第十天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、查询语句1.基本查询2.条件查询3.模糊查询4.范围查询5.判断空 二、其他复杂查询1.排序2.聚合函数3.分组4.分页查询 一、查询语句 1.基本查询 – 需求1: 准备商…...

代理模式:控制对象访问的中间层设计
代理模式:控制对象访问的中间层设计 一、模式核心:通过代理对象控制对目标对象的访问 在软件开发中,有时需要为对象添加一个 “代理” 来控制对它的访问,例如: 远程代理:访问远程对象时(如 R…...
)
Python类和对象二(十一)
构造函数: 重写: 通过类名访问类里面的方法的做法,称为调用未绑定的父类方法,他有时候会产生钻石继承问题: 发现A重复初始化了两次,类c同事继承类B1和B2,类B1和B2又是继承类A的,当c…...

大模型在代码安全检测中的应用
大模型在代码安全检测领域的应用近年来取得显著进展,尤其在代码审查(Code Review, CR)场景中展现出高效性与准确性。以下是其核心优势、技术路径、挑战及实践案例的总结: 一、技术优势与核心能力 语义理解与上下文分析 大模型通过…...

Python实现图片浏览器
Python实现图片浏览器 支持浏览多种常见图片格式:JPG, JPEG, PNG, GIF, BMP, TIFF, WEBP 通过"打开文件夹"按钮选择任何包含图片的文件夹 灵活的排序选项: 按时间排序(新→旧或旧→新) 按文件名排序(A→…...

网页设计规范:从布局到交互的全方位指南
网页设计规范看似繁杂,但其实都是为了给用户提供更好的体验。只有遵循这些规范,才能设计出既美观又实用的网页,让用户在浏览网页时感到舒适、愉悦。 一、用户体验至上 用户体验(UX)是网页设计的核心原则之一。设计师…...

哪些心电图表现无缘事业编体检呢?
根据《公务员录用体检通用标准》心血管系统条款及事业单位体检实施细则,心电图不合格主要涉及以下类型及处置方案: 一、心律失常类 早搏:包括房性早搏、室性早搏和交界性早搏。如果每分钟早搏次数较多(如超过5次)&…...

Java基础系列-HashMap源码解析1-BST树
文章目录 序二叉搜索树(BST)引入查找5插入9极端情况删除删除叶节点 10删除节点只有左子树或只有右子树删除节点既有左子树又有右子树为什么这么代替? 序 提到HashMap,就不得不提红黑树(HashMap1.8之后)&am…...

生物计算安全攻防战:从DNA存储破译到碳基芯片防御体系重构
随着碳基生物芯片突破冯诺依曼架构限制,DNA数据存储密度达到1EB/克量级,合成生物学与信息技术的融合正引发新一轮安全革命。本文深入解析碳基芯片逆向工程路径,揭示酶驱动DNA数据解码的技术突破,预警合成生物回路潜在的数据泄露风…...

【金仓数据库征文】从Oracle到KingbaseES的语法兼容与迁移
随着“信创”战略的深入推进,国产数据库逐渐成为IT系统的重要组成部分。KingbaseES(金仓数据库)凭借其良好的Oracle兼容性和日益完善的生态,成为金融、政务等核心行业国产化替代的重要选项。本文将从语法兼容性分析出发࿰…...

MATLAB 下载安装教程
## 一、下载MATLAB 1. 访问 MathWorks 官方网站:https://www.mathworks.com/ 2. 点击右上角的"登录"按钮 - 如果没有账号,需要先注册一个 MathWorks 账号 - 学生可以使用教育邮箱注册,获得教育版授权 3. 登录后,点击&…...

Android kotlin通知功能完整实现指南:从基础到高级功能
本文将详细介绍如何在Android应用中实现通知功能,包括基础通知、动作按钮和内联回复等高级特性。 一、基础通知实现 1. 基本通知发送方法 fun sendBasicNotification(context: Context, title: String, message: String) {// 1. 创建通知渠道(Android 8.0必需)va…...