Transformer起源-Attention Is All You Need
这篇笔记主要讲解Attention Is All You Need论文。《Attention Is All You Need》由 Ashish Vaswani 等人撰写,于 2017 年发表在 NIPS(Neural Information Processing Systems)会议上。它提出了一种全新的神经网络架构——Transformer,该架构完全基于注意力机制(Attention Mechanism),摒弃了传统的循环(Recurrent)和卷积(Convolutional)网络结构。Transformer 在机器翻译任务上取得了显著的性能提升,并且训练速度更快,成为自然语言处理(NLP)领域的一个重要里程碑。
Abstract
主流的序列转导模型基于复杂的包括编码器和解码器的递归或卷积神经网络。表现最佳的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构——Transformer,完全基于注意力机制,摒弃了递归和卷积。在两个机器翻译任务上的实验表明,这些模型不仅质量更优,而且更加并行化,训练时间显著减少。我们的模型在WMT 2014英德翻译任务中达到了28.4的BLEU值,比现有的最佳结果,包括集成方法,提高了超过2个BLEU值。在WMT 2014英法翻译任务中,我们的模型经过3.5天的八块GPU训练后,建立了单模型最先进的BLEU分数41.0,这仅占文献中最佳模型训练成本的一小部分。
1&2. Introduction & Background
传统的序列转换模型(如机器翻译、语言建模等)大多基于复杂的循环神经网络(RNN)或卷积神经网络(CNN),这些模型通常包含编码器(Encoder)和解码器(Decoder)。尽管这些模型在性能上取得了很好的结果,但它们存在一些局限性:
-
训练速度慢:RNN 的逐时间步处理方式限制了并行化计算,导致训练时间长。
-
难以捕捉长距离依赖:CNN 虽然可以并行计算,但其感受野有限,难以捕捉长距离依赖关系。
注意力机制(Attention Mechanism)已经被证明可以有效地捕捉序列中任意位置之间的依赖关系,但以往的模型通常将注意力机制与 RNN 或 CNN 结合使用。Transformer 架构则完全基于注意力机制,摒弃了 RNN 和 CNN,从而实现了更高的并行化程度和更快的训练速度。
3. Model Architecture
在这里,编码器将输入的符号表示序列(x1,...,xn)映射到连续表示序列z =(z1,...,zn)。给定z,解码器随后生成一个输出符号序列(y1,...,ym),每次生成一个元素。在每一步中,模型采用自回归[自回归模型 -CSDN博客],利用之前生成的符号作为额外输入来生成下一个符号。Transformer模型遵循这一总体架构,使用堆叠的自注意力层和逐点全连接层,分别用于编码器和解码器,如图1的左半部分和右半部分所示。
Transformer 架构由编码器(Encoder)和解码器(Decoder)组成,两者均基于堆叠的自注意力(Self-Attention)层和前馈神经网络(Feed-Forward Network)。
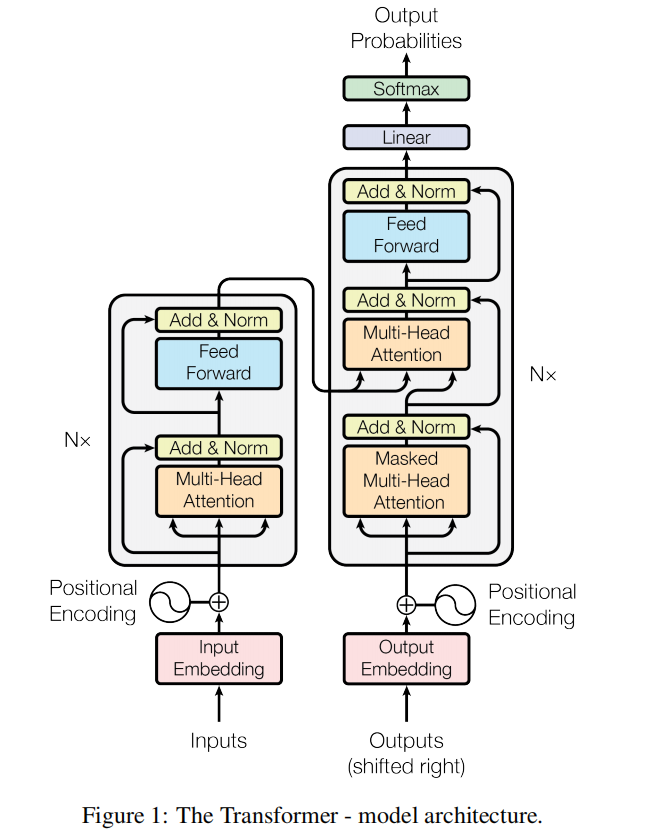
3.1.Encoder and Decoder Stacks
3.1.1.Encoder
编码器由多个相同的层(论文中使用了6层)堆叠而成,每层包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention):允许模型在不同子空间中并行地学习信息。
-
前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换。
我们在每个子层周围使用残差连接,随后进行层归一化。也就是说,每个子层的输出是LayerNorm(x +Sublayer(x)),其中Sublayer(x)是由该子层本身实现的功能。为了便于这些残差连接,模型中的所有子层以及嵌入层都生成维度为dmodel = 512的输出。
扩展介绍-Residual Connection(残差连接) 和 Layer Normalization(层归一化)
1. Residual Connection(残差连接)
残差连接是一种网络结构设计,它允许输入直接传递到网络的更深层次,而不仅仅是通过逐层的非线性变换。这种设计的核心思想是引入一个残差学习的概念,即网络学习输入与输出之间的残差(差异)而不是直接学习输出。
在训练非常深的神经网络时,随着网络层数的增加,梯度消失或梯度爆炸的问题会变得更加严重。这导致网络难以训练,性能下降。残差连接通过允许梯度直接传播,缓解了这一问题。
数学表示。假设 x 是输入,F(x) 是网络层的输出,残差连接可以表示为: y=F(x)+x 其中 y 是残差连接的输出。这种结构允许网络学习输入 x 和输出 y 之间的残差 F(x)=y−x。
2. Layer Normalization(层归一化)
层归一化是一种归一化技术,它对每个样本的特征进行归一化处理,使得每个特征的均值为 0,标准差为 1。与批量归一化(Batch Normalization)不同,层归一化在每个样本上独立进行,而不是在批次上进行。在训练深度神经网络时,内部协变量偏移(Internal Covariate Shift)是一个常见的问题,即每一层的输入分布会随着训练过程而变化。这种变化会影响网络的训练速度和稳定性。层归一化通过归一化输入,使得每一层的输入分布保持一致,从而缓解了这一问题。
数学表示。假设 x 是输入,层归一化的输出 y 可以表示为: y=γ((x−μ)/σ)+β 其中:
-
μ 是输入 x 的均值。
-
σ 是输入 x 的标准差。
-
γ 和 β 是可学习的参数,用于调整归一化后的数据。
3.1.2.Decoder
编码器由多个相同的层(论文中使用了6层)堆叠而成,解码器的结构与编码器类似,但额外包含一个子层:
-
编码器-解码器注意力机制(Encoder-Decoder Attention):允许解码器的每个位置关注编码器的输出。
解码器中的自注意力层需要进行掩码(Masking),以防止当前位置关注到未来的位置,从而保持自回归(Auto-Regressive)特性。
3.2.Attention
注意力函数可以描述为将查询和一组键-值对映射到输出的过程,其中查询、键、值和输出都是向量。输出是值的加权和,每个值的权重由查询与相应键的兼容性函数计算得出。
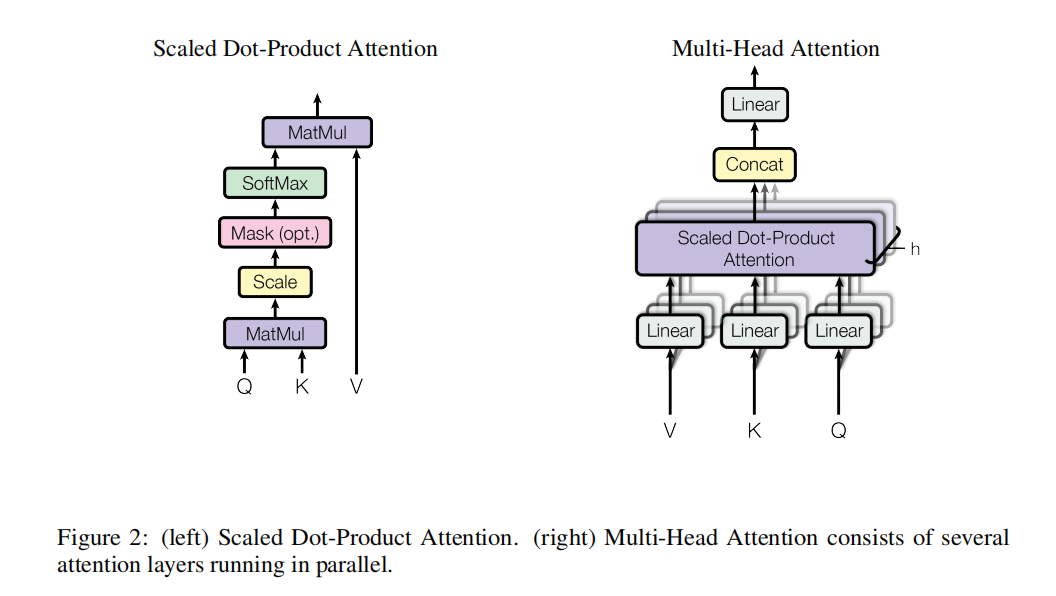
3.2.1.Scaled Dot-Product Attention
我们称这种特殊的注意力机制为“Scaled Dot-Product Attention”(图2)。输入由查询和维度为dk的键以及维度为dv的值组成。
我们计算查询向量与所有键向量的点积,将每个点积结果除以√dk,并应用一个softmax函数来获得值的权重。在实践中,我们同时计算一组查询的注意力函数,将其打包成一个矩阵Q。键和值也打包成矩阵K和V。我们计算输出矩阵如下:
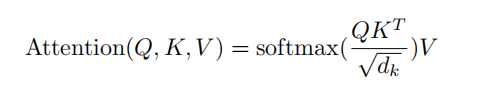
-
Q 是查询(Query)矩阵。
-
K 是键(Key)矩阵。
-
V 是值(Value)矩阵。
-
dk 是键向量的维度,用于缩放点积以避免数值不稳定。
3.2.2. Multi-Head Attention
我们没有采用单一的注意力函数来处理dmodel-dimensional的键、值和查询,而是发现将查询、键和值分别通过不同的学习线性投影线性地投影h次到dk、dk和dv维度是有益的。在这些投影后的查询、键和值上,我们并行执行注意力函数,得到dv维的输出值。这些输出值被连接起来,再次进行投影,最终得到如图2所示的结果。
多头注意力使得模型能够联合关注不同位置的不同表示子空间的信息,而单个注意力头的平均抑制了这一点。为了进一步增强模型的表示能力,Transformer 引入了多头注意力(Multi-Head Attention):

WO 其中每个“头”(Head)计算一个独立的注意力函数,然后将结果拼接起来。在这项工作中,我们使用了h = 8个并行注意力层,或称为头。对于每个头,我们使用dk = dv = dmodel/h = 64。由于每个头的维度降低,总计算成本与全维单头注意力相似。
--->不太理解,再说一遍。
多头注意力(Multi-Head Attention) 通过将输入数据分成多个不同的“头”(heads),分别计算自注意力,然后将结果拼接起来,从而能够捕捉不同子空间中的信息。在传统的单头注意力机制中,模型通过计算查询(Query)、键(Key)和值(Value)之间的关系来捕捉输入序列中的依赖关系。然而,单头注意力机制存在以下局限性:
-
表示能力有限:单头注意力只能在一个固定的子空间中捕捉信息,难以同时捕捉多种不同类型的依赖关系。
-
难以并行化:单头注意力机制在处理长序列时效率较低,因为每个位置的计算依赖于其他所有位置。
为了解决这些问题,Transformer 引入了多头注意力机制。通过将输入数据分成多个不同的“头”,每个头可以独立地学习输入序列中的不同特征和依赖关系,从而显著增强了模型的表示能力和并行化效率。
多头注意力机制的核心思想是将输入数据分成多个不同的子空间(heads),在每个子空间中独立地计算自注意力,然后将所有子空间的结果拼接起来,最后通过一个线性变换进行整合。
假设输入数据为:

在多头注意力中,输入数据 Q,K,V 首先通过线性变换被映射到多个不同的子空间中。具体来说,对于每个头 i:
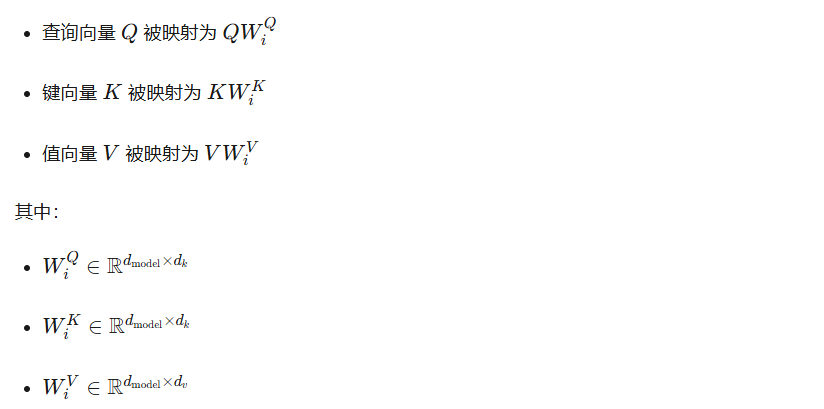
这些权重矩阵是可学习的参数,用于将输入数据映射到不同的子空间中。

将所有头的输出拼接起来,然后通过一个线性变换进行整合:

3.3. Position-wise Feed-Forward Networks(逐位置前馈神经网络)
除了注意力子层之外,我们的编码器和解码器中的每一层都包含一个全连接前馈网络,该网络分别且相同地应用于每个位置。它由两个线性变换组成,中间有一个ReLU激活函数。
![]()
虽然线性变换在不同位置上是相同的,但它们在每一层使用不同的参数。另一种描述方式是两个卷积核大小为1的卷积。输入和输出的维度为dmodel = 512,内层的维度为df=2048。
--->不太理解,看下面。
Position-wise Feed-Forward Networks(逐位置前馈神经网络)在编码器(Encoder)和解码器(Decoder)的每个层中都存在。其主要作用是对每个位置的表示进行非线性变换,从而增强模型的表达能力。
在 Transformer 架构中,自注意力机制(Self-Attention)负责捕捉序列中不同位置之间的依赖关系,但它本身是一个线性变换。为了引入非线性,逐位置前馈神经网络被设计为对每个位置的表示进行进一步的处理。这种非线性变换有助于模型捕捉更复杂的特征和模式。
逐位置前馈神经网络由两个线性变换组成,中间夹着一个非线性激活函数(通常使用 ReLU)。具体来说,对于每个位置 i 的输入 xi,前馈神经网络的输出 yi 可以表示为:
![]()

在 Transformer 架构中,逐位置前馈神经网络的参数(即 W1,W2,b1,b2)在所有位置上是共享的。这意味着每个位置的输入 xi 都通过相同的网络结构进行变换。这种参数共享机制减少了模型的参数数量,同时使得模型能够更高效地处理不同位置的输入。
逐位置前馈神经网络的内部结构可以分为两部分:
1.第一层线性变换:
![]()
这一层将输入 X 映射到一个隐藏层,通常隐藏层的维度 dff 比模型维度 dmodel 更大(例如,dff=2048)。
2.非线性激活函数:
![]()
ReLU 激活函数引入了非线性,使得模型能够捕捉更复杂的特征。
3.第二层线性变换:
![]()
这一层将隐藏层的输出映射回模型维度 dmodel。
3.4. Embeddings and Softmax
类似于其他序列转导模型,我们使用学习到的嵌入将输入标记和输出标记转换为维度为dmodel的向量。我们还使用常规的学习线性变换和softmax函数将解码器输出转换为预测的下一个标记概率。在我们的模型中,两个嵌入层和预softmax线性变换之间共享相同的权重矩阵,类似于[24]。在嵌入层中,我们将这些权重乘以√dmodel。
3.5. Positional Encoding
由于我们的模型不包含循环和卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于标记在序列中相对或绝对位置的信息。为此,我们添加了“位置编码”在输入嵌入中编码器和解码器堆栈的底部。位置编码与嵌入具有相同的维度dmodel,因此两者可以相加。有许多位置编码的选择,包括学习的和固定的[8]。
在本工作中,我们使用不同频率的正弦和余弦函数:
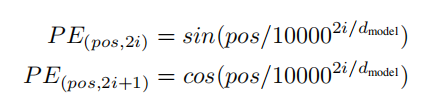
其中pos是位置,i是维度。也就是说,每个位置编码的维度对应一个正弦波。波长从2π到10000·2π形成几何级数。我们选择这个函数是因为假设它能让模型轻松学习通过相对位置进行关注,因为对于任何固定的偏移k,P Epos+k可以表示为P Epos的线性函数。
下面的部分并没有看的很仔细,有些只有翻译。
4. Why Self-Attention
在本节中,我们将自注意力层与常用的循环和卷积层进行比较,这些层通常用于将一个可变长度的符号表示序列(x1,...,xn)映射到另一个等长的序列(z1,...,zn),其中xi,zi∈R d,例如典型序列转导编码器或解码器中的隐藏层。为了说明我们使用自注意力的原因,我们考虑了三个理想特性。
一是每层的总计算复杂度。二是可以并行化的计算量,以所需最少顺序操作的数量来衡量。三是网络中长程依赖之间的路径长度。学习长程依赖是许多序列转换任务中的关键挑战。影响学习此类依赖能力的一个重要因素是信号在网络中前后传播所需路径的长度。输入和输出序列中任意位置组合之间的这些路径越短,学习长程依赖就越容易[11]。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
1.总计算复杂度(Total Computational Complexity)
-
自注意力层:自注意力层的计算复杂度为 O(n2⋅d),其中 n 是序列长度,d 是表示的维度。这是因为自注意力机制需要计算每个位置与其他所有位置之间的关系。
-
循环层:循环层(如 RNN、LSTM、GRU)的计算复杂度为 O(n⋅d2),因为每个时间步的计算依赖于前一个时间步的状态。
-
卷积层:卷积层的计算复杂度为 O(k⋅n⋅d2),其中 k 是卷积核的大小。即使使用高效的分离卷积(Separable Convolutions),复杂度仍然较高。
在大多数自然语言处理任务中,序列长度 n 通常小于表示维度 d,因此自注意力层在计算复杂度上具有优势。
2.并行化能力(Parallelization)
-
自注意力层:自注意力层可以并行计算所有位置之间的关系,因为每个位置的计算不依赖于其他位置的计算结果。这使得自注意力层在训练时能够充分利用现代硬件(如 GPU)的并行计算能力。
-
循环层:循环层的计算是逐时间步进行的,每个时间步的计算依赖于前一个时间步的结果,因此无法并行化。这在处理长序列时会导致训练速度显著下降。
-
卷积层:卷积层虽然可以并行计算,但其感受野有限,需要多层卷积才能捕捉长距离依赖关系,这增加了计算复杂度。
3.长距离依赖关系(Long-Range Dependencies)
-
自注意力层:自注意力层通过计算每个位置与其他所有位置之间的关系,能够直接捕捉长距离依赖关系。这种机制使得模型能够更有效地学习输入序列中任意两个位置之间的依赖关系。
-
循环层:循环层在处理长序列时,由于梯度消失或梯度爆炸的问题,难以捕捉长距离依赖关系。虽然有一些技巧(如残差连接、门控机制)可以缓解这一问题,但仍然存在限制。
-
卷积层:卷积层的感受野有限,需要多层卷积才能捕捉长距离依赖关系。这不仅增加了计算复杂度,还可能导致信息丢失。
5. Training
5.1. Training Data and Batching
我们在标准的WMT 2014英德语数据集上进行了训练,该数据集包含约450万句对。句子使用字节对编码[3]进行编码,该编码共享约37000个源目标词汇。对于英法语,我们使用了显著更大的WMT 2014英法语数据集,包含3600万句,并将词元拆分为32000个词块词汇[31]。句子对根据近似序列长度批量处理。每个训练批次包含一组句子对,其中大约有25000个源词元和25000个目标词元。
5.2. Hardware and Schedule
我们在一台配备8个NVIDIA P100 GPU的机器上训练了模型。对于使用本文所述超参数的基本模型,每个训练步骤大约需要0.4秒。我们总共训练了100,000个步骤或12小时。对于我们的大型模型(见表3底部),每步时间是1.0秒。大型模型训练了300,000个步骤(3.5天)。
5.3. Optimizer
我们使用了Adam优化器[17],β1 = 0.9、β2 = 0.98和![]() 。我们在训练过程中根据公式调整学习率:
。我们在训练过程中根据公式调整学习率:
![]()
这相当于在前warmup_steps个训练步骤中线性增加学习率,之后按步数的平方根倒数比例降低学习率。我们使用了warmup_steps = 4000。
5.4. Regularization
我们在训练过程中使用了三种类型的正则化
残差丢弃。我们在每个子层的输出上应用丢弃,然后再将其加入到子层输入并进行归一化。此外,我们还对编码器和解码器堆栈中的嵌入和位置编码的总和应用丢弃。对于基础模型,我们使用Pdrop = 0.1的丢弃率。
标签平滑。训练过程中,我们采用了![]() 的标签平滑。这会损害困惑度,因为模型学会了更加不确定,但提高了准确率和BLEU分数
的标签平滑。这会损害困惑度,因为模型学会了更加不确定,但提高了准确率和BLEU分数
6. result
7.conclusion
在这项工作中,我们介绍了Transformer,这是首个完全基于注意力机制的序列转换模型,用多头自注意力取代了编码器-解码器架构中最常用的循环层。
对于翻译任务,Transformer的训练速度显著快于基于循环或卷积层的架构。在WMT 2014英德和WMT 2014英法翻译任务中,我们取得了新的突破。在前者任务中,我们的最佳模型甚至超越了所有先前报道的集成方法。
我们对基于注意力机制的模型未来充满期待,并计划将其应用于其他任务。我们打算将Transformer扩展到涉及文本以外的输入和输出模态的问题,并研究局部、受限注意力机制,以高效处理图像、音频和视频等大型输入和输出。
减少生成过程的顺序性也是我们的另一个研究目标。用于训练和评估模型的代码可在https://github.com/ tensorflow/tensor2tensor获取。
相关文章:
Transformer起源-Attention Is All You Need
这篇笔记主要讲解Attention Is All You Need论文。《Attention Is All You Need》由 Ashish Vaswani 等人撰写,于 2017 年发表在 NIPS(Neural Information Processing Systems)会议上。它提出了一种全新的神经网络架构——Transformer&#x…...

被裁20240927 --- 视觉目标跟踪算法
永远都像初次见你那样使我心荡漾 参考文献目前主流的视觉目标跟踪算法一、传统跟踪算法1. 卡尔曼滤波(Kalman Filter)2. 相关滤波(Correlation Filter,如KCF、MOSSE)3. 均值漂移(MeanShift/CamShift&#x…...
)
每日学习Java之一万个为什么(JUC)
文章目录 Git复习synchronized介绍基本概念特点 使用模板1. 同步方法格式特点 2. 同步代码块格式特点 常见面试题1. synchronized的实现原理?2. synchronized与ReentrantLock的区别?3. synchronized的缺点?4. 死锁的四个必要条件?…...

代码分享:python实现svg图片转换为png和gif
import cairosvg import imageio from PIL import Image import io import osdef svg_to_png(svg_path, png_path):try:cairosvg.svg2png(urlsvg_path, write_topng_path)print(f"成功将 {svg_path} 转换为 {png_path}")except Exception as e:print(f"转换为 P…...

前端热门面试题day1
内容回答较粗糙,如有疑问请自行搜索资料 什么是vue中的slot?它有什么作用 Vue中的Slot(插槽)就像给组件预先留的“内容停车位”,让父组件能把自定义内容“塞”到子组件的指定位置。它的主要作用是: 灵活定…...

DCAN,ECAN和MCAN的区别
DCAN、ECAN和MCAN的主要区别在于它们各自的管理范围和功能。 DCAN(动力CAN系统):DCAN主要负责协调电机控制单元(MCU)、电池管理系统(BMS)、直流电压变换器(DC/DC)和…...
)
基于Python爬虫的豆瓣电影信息爬取(可以根据选择电影编号得到需要的电影信息)
# 豆瓣电影信息爬虫(展示效果如下图所示:) 这是一个功能强大的豆瓣电影信息爬虫程序,可以获取豆瓣电影 Top 250 的详细信息。 ## 功能特点 - 自动爬取豆瓣电影 Top 250 的所有电影信息 - 支持分页获取,每页 25 部电影,共 10 页 - 获取每部电影的详细信息,包括: - 标题…...

Linux系统学习----概述与目录结构
linux 是一个开源、免费的操作系统,其稳定性、安全性、处理多并发已经得到业界的认可,目前很多企业级的项目 (c/c/php/python/java/go)都会部署到 Linux/unix 系统上。 一、虚拟机系统操作 1.网络连接的三种方式(桥接模式、nat模式、主机模…...

软考资料分享
分享一些软考资料 16系统分析师-基础知识精讲夸克网盘分享1701系统分析师夸克网盘分享1804系统架构设计师夸克网盘分享19软考系统架构设计师2024年11月夸克网盘分享2006信息系统项目管理师夸克网盘分享21软考高级信息系统项目夸克网盘分享22系统分析师视频教程真题资料夸克网盘…...

什么是 GLTF/GLB? 3D 内容创建的基本数据格式说明,怎么下载GLB/GLTF格式模型
GLTF 概述 GLTF 是一种 3D 模型格式,广泛用于在 Web 上共享和显示 3D 内容。 它经过优化,可在 WebGL 中轻松加载,使用 WebGL 可以快速高效地渲染 3D 模型。 GLTF 是 Khronos Group 开发的开放标准之一,以 JSON 或二进制格式表示…...

湖南大学-操作系统实验四
HUNAN UNIVERSITY 操作系统实验报告 一、实验题目 实验四 中断、异常和陷阱指令是操作系统的基石,现代操作系统就是由中断驱动的。本实验和实验五的目的在于深刻理解中断的原理和机制,掌握CPU访问中断控制器的方法,掌握Arm体系结构的中断机…...

3.第三章:数据治理的战略价值
文章目录 3.1 数据治理与企业战略3.1.1 数据驱动的决策体系3.1.2 数据资产的价值挖掘3.1.3 风险防控与合规管理 3.2 数据治理的业务价值3.2.1 提升客户体验3.2.2 优化运营效率3.2.3 加速产品创新 3.3 数据治理的技术价值3.3.1 提升数据质量3.3.2 优化数据架构3.3.3 增强系统集成…...

[KVM] KVM挂起状态恢复失败与KVM存储池迁移
背景:发现KVM host上的几台虚拟机挂起了(paused),但是并没有执行virsh suspend <vm_hostname>,且使用virsh resume <vm_hostname> 无法恢复。原因是这个几个虚拟机归属的存储池所在的磁盘满了。所以想把虚拟机迁移到磁盘空间富余…...
慧知开源充电桩平台)
图文结合 - 光伏系统产品设计PRD文档 -(慧哥)慧知开源充电桩平台
光伏系统产品设计PRD文档 版本号:1.0 修订日期:2023年10月 作者: 一、文档概述 1.1 背景与目标 行业背景:全球光伏装机量年增长20%,数字化运维需求迫切用户痛点:现有系统存在数据延…...

linux-相关命令
一、Linux 详细介绍 1. 什么是 Linux? Linux 是一个开源的类 Unix 操作系统,其核心是 Linux 内核。它最早由 Linus Torvalds 在 1991 年发布,后来逐渐发展成各种发行版(如 Ubuntu、CentOS、Debian、Arch 等)。 2. L…...

Hive中Map和Reduce阶段的分工
在Hive查询执行过程中,Map和Reduce阶段有明确的分工,但实际情况要复杂一些。 基本分工原则 Map阶段: 主要职责是读取输入数据并进行初步处理输出键值对形式的数据Reduce阶段: 接收Map阶段输出的键值对对相同键的值进行聚合/计算输出最终结果实际执行中的复…...

前端笔记-Vue router
学习目标 Vue Router路由管理1、路由配置2、嵌套路由3、路由守卫与权限控制 一、路由配置(给网站做地图) npm i vue-router 作用:告诉浏览器什么地址该显示什么页面 核心代码: // 创建路由并暴露出去// 第一步&#x…...

MySQL的日志--Redo Log【学习笔记】
MySQL的日志--Redo Log 知识来源: 《MySQL是怎样运行的》--- 小孩子4919 MySQL的事务四大特性之一就是持久性(Durability)。但是底层是如何实现的呢?这就需要我们的Redo Log(重做日志)闪亮登场了。它记录着…...
》)
《系统分析师-第三阶段—总结(五)》
背景 采用三遍读书法进行阅读,此阶段是第三遍。 过程 第9章 总结 在这个过程中,对导图的规范越来越清楚,开始结构化,找关系,找联系。...

【LangChain4j】AI 第二弹:项目中接入 LangChain4j
普通接入方式 参考文档: Get Started https://docs.langchain4j.dev/get-started 1.添加依赖 <!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 --> <dependency><groupId>dev.langchain4j</grou…...

测试基础笔记第十天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、查询语句1.基本查询2.条件查询3.模糊查询4.范围查询5.判断空 二、其他复杂查询1.排序2.聚合函数3.分组4.分页查询 一、查询语句 1.基本查询 – 需求1: 准备商…...

代理模式:控制对象访问的中间层设计
代理模式:控制对象访问的中间层设计 一、模式核心:通过代理对象控制对目标对象的访问 在软件开发中,有时需要为对象添加一个 “代理” 来控制对它的访问,例如: 远程代理:访问远程对象时(如 R…...
)
Python类和对象二(十一)
构造函数: 重写: 通过类名访问类里面的方法的做法,称为调用未绑定的父类方法,他有时候会产生钻石继承问题: 发现A重复初始化了两次,类c同事继承类B1和B2,类B1和B2又是继承类A的,当c…...

大模型在代码安全检测中的应用
大模型在代码安全检测领域的应用近年来取得显著进展,尤其在代码审查(Code Review, CR)场景中展现出高效性与准确性。以下是其核心优势、技术路径、挑战及实践案例的总结: 一、技术优势与核心能力 语义理解与上下文分析 大模型通过…...

Python实现图片浏览器
Python实现图片浏览器 支持浏览多种常见图片格式:JPG, JPEG, PNG, GIF, BMP, TIFF, WEBP 通过"打开文件夹"按钮选择任何包含图片的文件夹 灵活的排序选项: 按时间排序(新→旧或旧→新) 按文件名排序(A→…...

网页设计规范:从布局到交互的全方位指南
网页设计规范看似繁杂,但其实都是为了给用户提供更好的体验。只有遵循这些规范,才能设计出既美观又实用的网页,让用户在浏览网页时感到舒适、愉悦。 一、用户体验至上 用户体验(UX)是网页设计的核心原则之一。设计师…...

哪些心电图表现无缘事业编体检呢?
根据《公务员录用体检通用标准》心血管系统条款及事业单位体检实施细则,心电图不合格主要涉及以下类型及处置方案: 一、心律失常类 早搏:包括房性早搏、室性早搏和交界性早搏。如果每分钟早搏次数较多(如超过5次)&…...

Java基础系列-HashMap源码解析1-BST树
文章目录 序二叉搜索树(BST)引入查找5插入9极端情况删除删除叶节点 10删除节点只有左子树或只有右子树删除节点既有左子树又有右子树为什么这么代替? 序 提到HashMap,就不得不提红黑树(HashMap1.8之后)&am…...

生物计算安全攻防战:从DNA存储破译到碳基芯片防御体系重构
随着碳基生物芯片突破冯诺依曼架构限制,DNA数据存储密度达到1EB/克量级,合成生物学与信息技术的融合正引发新一轮安全革命。本文深入解析碳基芯片逆向工程路径,揭示酶驱动DNA数据解码的技术突破,预警合成生物回路潜在的数据泄露风…...

【金仓数据库征文】从Oracle到KingbaseES的语法兼容与迁移
随着“信创”战略的深入推进,国产数据库逐渐成为IT系统的重要组成部分。KingbaseES(金仓数据库)凭借其良好的Oracle兼容性和日益完善的生态,成为金融、政务等核心行业国产化替代的重要选项。本文将从语法兼容性分析出发࿰…...

MATLAB 下载安装教程
## 一、下载MATLAB 1. 访问 MathWorks 官方网站:https://www.mathworks.com/ 2. 点击右上角的"登录"按钮 - 如果没有账号,需要先注册一个 MathWorks 账号 - 学生可以使用教育邮箱注册,获得教育版授权 3. 登录后,点击&…...

Android kotlin通知功能完整实现指南:从基础到高级功能
本文将详细介绍如何在Android应用中实现通知功能,包括基础通知、动作按钮和内联回复等高级特性。 一、基础通知实现 1. 基本通知发送方法 fun sendBasicNotification(context: Context, title: String, message: String) {// 1. 创建通知渠道(Android 8.0必需)va…...

Javase 基础入门 —— 04 继承
本系列为笔者学习Javase的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaAI智能辅助编程全套视频教程,java零基础入门到大牛一套通关》,章节分布参考视频教程,为同样学习Javase系列课程的同学们提供参考。 01 什么是继…...

2.4/Q2,Charls最新文章解读
文章题目:The impact of hearing ability on depression among retired middle-aged and elderly individuals in China: the chain mediating role of self-rated health and life satisfaction DOI:10.1186/s41043-025-00791-9 中文标题:中…...

对流对象的理解
在c里,“流”可以理解为数据传输与操作的“介质”。 从输入输出角度来看,有输入流(比如cin)和输出流(cout)。对于输入流,数据通过它从外部设备(例如键盘)“流入”程序内…...

RBAC权限-笔记
1. RBAC模型简介 1.1. RBAC三要素 RBAC权限模型(Role-Based Access Control:基于角色的访问控制)有3个基础组成部分,分别是:用户、角色和权限。它们之间的关系如下图所示: 用户(User)…...

stm32之GPIO函数详解和上机实验
目录 1.LED和蜂鸣器1.1 LED1.2 蜂鸣器 2.实验2.1 库函数:RCC和GPIO2.1.1 RCC函数1. RCC_AHBPeriphClockCmd2. RCC_APB2PeriphClockCmd3. RCC_APB1PeriphClockCmd 2.1.2 GPIO函数1. GPIO_DeInit2. GPIO_AFIODeInit3. GPIO_Init4. GPIO_StructInit5. GPIO_ReadInputDa…...

MsQuick编译和使用
MsQuick编译和使用 编译克隆代码使用cmakevs2022编译 使用示例 编译 克隆代码 git clone --recurse-submodules https://github.com/microsoft/msquic.git使用cmakevs2022编译 然后直接configure之后Generate然后打开vs工程编译即可生成动态库 使用示例 #include <s…...

01 ubuntu中wps桌面快捷键无法使用
文章目录 1. 问题描述:2. 解决方法:3. 结果展示4. 参考 1. 问题描述: 2. 解决方法: 添加权限 chmod 755 ./wps-office-prometheus.desktop 右键选择允许运行 3. 结果展示 修改前 修改后 4. 参考 参考1...

云原生后端架构:重塑后端开发的新范式
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:后端开发的新时代正在到来 传统的后端开发常常面临如下挑战:部署流程复杂、环境不一致、系统难以扩展、监控能力薄弱、上线流程缓慢。在企业数字化转型、业务快速迭代的大背景下,这些问题暴露得…...

Linux命令-tcpdump
tcpdump 是一个功能强大的网络数据包捕获和分析工具。以下是 tcpdump 命令的完整参数列表及说明: 参数 -a 将网络地址和广播地址转换为名字 tcpdump -a -i eth0-A 以 ASCII 格式打印所有分组,最小化链路层头部信息 tcpdump -A-b 在数据链路层上选择协议…...

分糖果——牛客
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 幼儿园准备了nnn包糖果,每包糖果里有111、222或333颗美味的糖果。现在需要将这些这些糖果平分给两个表现优异的小朋友以作奖励,为了公平公正,需要…...

L0、L2和L∞范数这三种范数的区别
目录 一、解释 1. L0范数:数一数你有多少件行李 2. L2范数:别把行李塞得太满 3. L∞范数:别带任何超重的东西 一句话总结 二、作用 1. L0范数的作用:做减法,只留最重要的…...

[实战]zynq7000设备树自动导出GPIO
目录 zynq7000设备树自动导出GPIO添加设备树节点验证实验 结论 zynq7000设备树自动导出GPIO 今天无聊,掏出我82年产的microzed玩一玩。玩啥好呢,要不点个灯吧。于是,三下五除二,通过linux sys接口以及echo,很快就点亮…...

java六人打分
import java.util.Scanner;public class HelloWorld {public static void main(String[] args) {//打分平均分System.out.println("请输入六个评分");Scanner sc new Scanner(System.in);double[] score new double[6];for(int i0;i<score.length;i){System.ou…...

量子计算浪潮下的安全应对之法
量子计算凭借其强大的计算能力,被传言能够在极短时间内秒级破解传统计算机需耗时漫长岁月(以万年算)才能解开的密码,成为了近年来人们讨论的热点。这看似高深的科技名词在网络安全中又扮演着何种角色?我们应从当前人们…...

Windows Server 2022 常见问题解答
一、安装与部署 1.1 系统要求 硬件配置:最低需要 1.4 GHz 64 位处理器、512 MB 内存、32 GB 硬盘空间。但在实际生产环境中,为确保系统流畅运行,建议使用 2.0 GHz 以上处理器、8 GB 以上内存和 100 GB 以上硬盘。软件兼容性:与大多数基于 Windows 的企业级应用兼容,但在安…...

项目组合管理PPM
项目组合管理(Project Portfolio Management, PPM)详述 一、定义与核心目标 定义 项目组合管理是通过系统化的方法,对组织的所有项目和项目集进行识别、选择、优先级排序、资源配置和动态监控,以确保其与战略目标一致,并最大化投资回报(ROI)的管理过程。 核心目标 战略…...

自建开源远程协助服务RustDesk —— 筑梦之路
开源项目 # 服务端https://github.com/rustdesk/rustdesk-server.git# 客户端https://github.com/rustdesk/rustdesk.git 搭建服务端 需要使用的端口、协议 hbbs - RustDesk ID 注册服务器 hbbr - RustDesk 中继服务器默认情况下,hbbs 监听 21115(tcp) , 21…...

【android bluetooth 协议分析 11】【AVDTP详解 2】【avdtp 初始化阶段主要回调关系梳理】
在车机中 a2dp 通常情况下作为 sink. 本篇来帮助各位 朋友梳理一下,这部分的初始化流程。 我们着重梳理 native 层的逻辑, framework - java 侧一般比较容易看明白, 暂时不做梳理。 如果需要笨叔梳理的可以在博客评论。 出专门的章节来梳理。…...