AI语音助手自定义角色百度大模型 【全新AI开发套件掌上AI+4w字教程+零基础上手】
1、简介
此项目主要使用ESP32-S3实现一个自定义角色的AI语音聊天助手(比如医生角色),可以通过该项目熟悉ESP32-S3 arduino的开发,百度语音识别,百度语音合成API调用,百度APPBuilder API的调用实现自定义角色的方法,自定义唤醒词的训练,SD卡的读写,触摸屏的使用,Wifi的配置(smartconfig方式)等基本开发方法。本项目的所有软硬件工程开源,并配备了详细的教程文档,和对应的视频教程,对零基础的同学非常适用,希望能够帮助到大家。
1.1具备的功能
- 支持小程序实现Wifi配网
- 语音唤醒词唤醒ESP32-S3
- 自定义唤醒词模型训练
- 百度语音识别语音合成api访问
- 自定义角色agent
- 独立电源供电
- 按键开关机
- 1.28TFT触摸屏唤醒
1.2开源地址
- 项目开源网址:
https://gitee.com/chging/esp32s3-ai-chat
- 视频教程网址:
【厚国兄的个人空间-哔哩哔哩】 https://b23.tv/AsFNSeJ
- 本教程的word文档版本:
我用夸克网盘分享了「ESP32-S3-AI-Chat-V2.docx」,点击链接即可保存。打开「夸克APP」在线查看,支持多种文档格式转换。
链接:https://pan.quark.cn/s/19835014b2d6
2、AI集成套件购买链接

购买链接:https://h5.m.taobao.com/awp/core/detail.htm?ft=t&id=833542085705
3、软件环境
3.1Arduino 软件安装
软件下载
- 下载网站:https://www.arduino.cc/en/software
- 下载操作步骤如下:
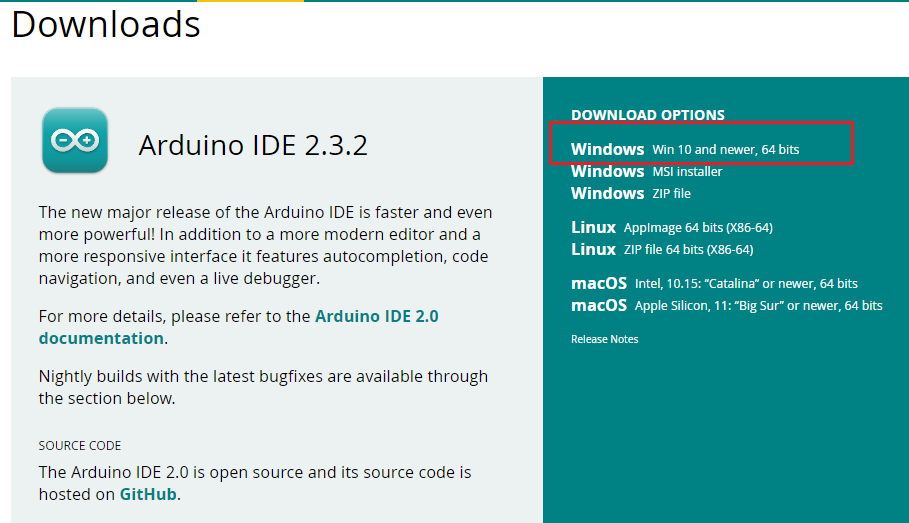
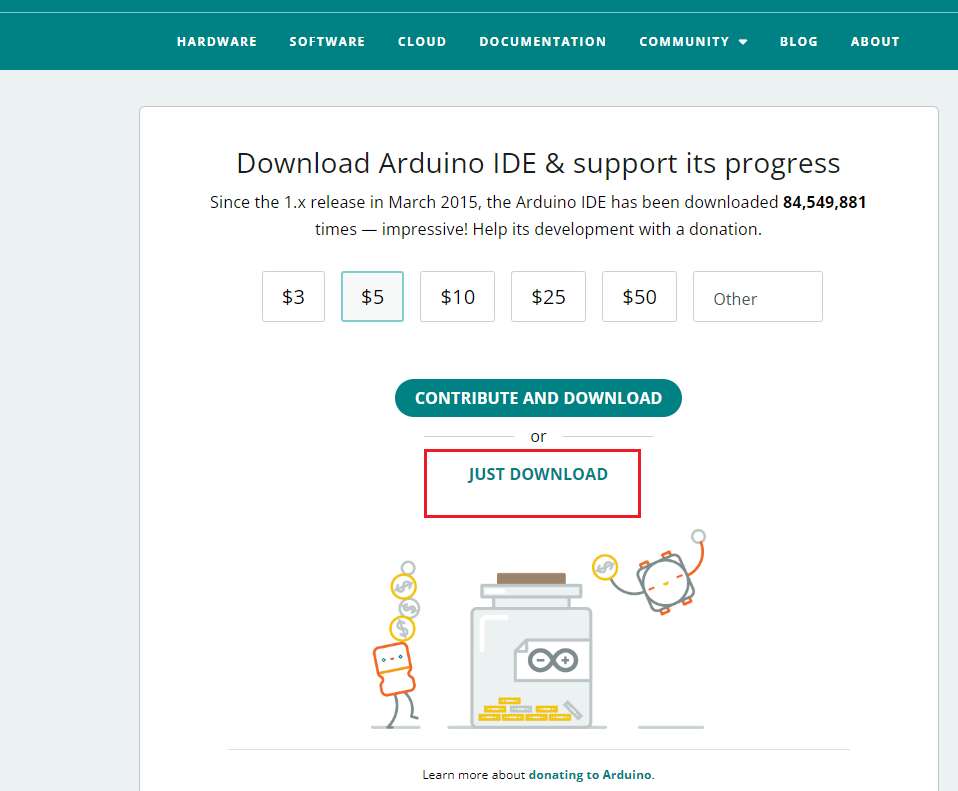
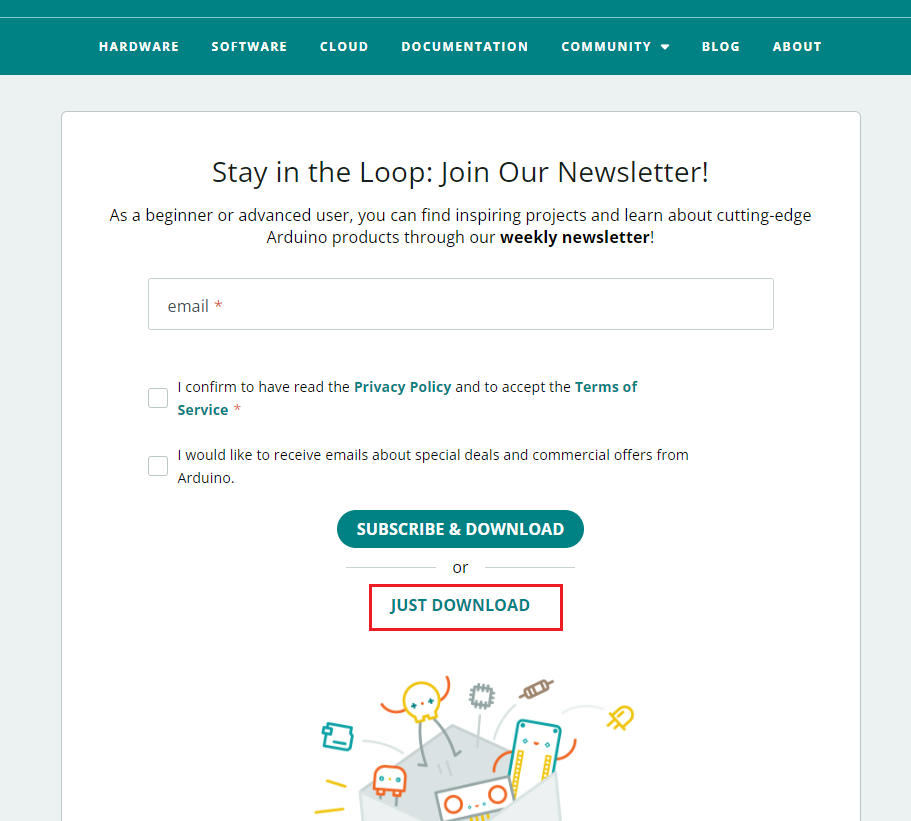
软件安装
双击下载的安装软件包,按照如下图所示步骤进行安装:
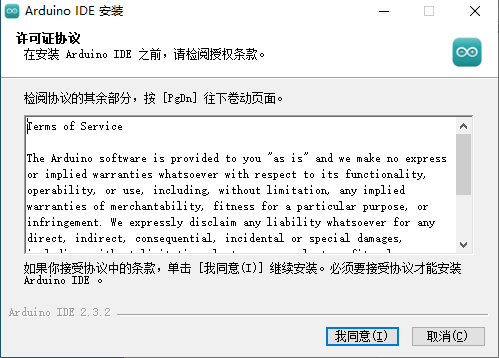
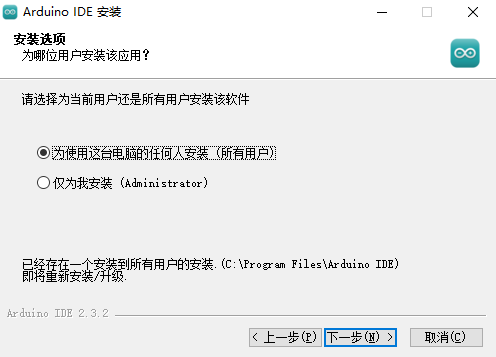
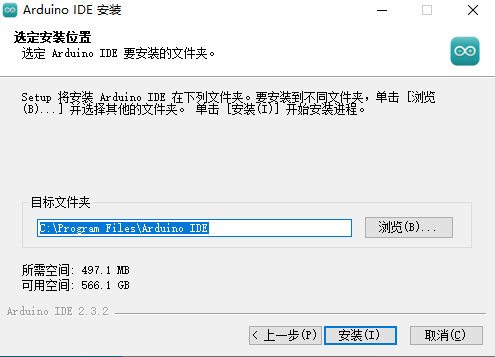
等待一会,安装完成。
arduino字体转换为中文
3.2ESP32芯片包安装
本项目需要安装esp32芯片包,可以先通过在线安装方式进行,如果失败,也可以选择用离线方式进行。
在线安装
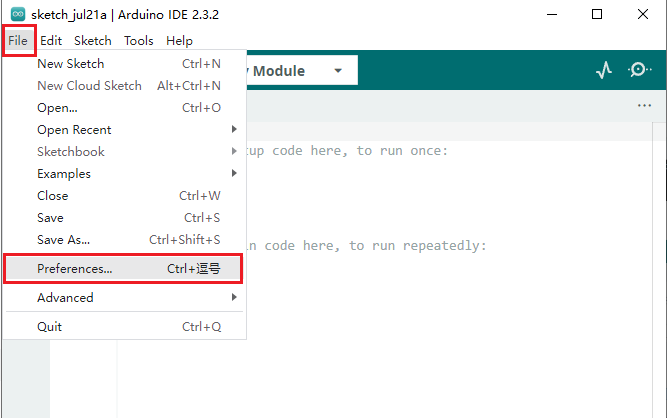
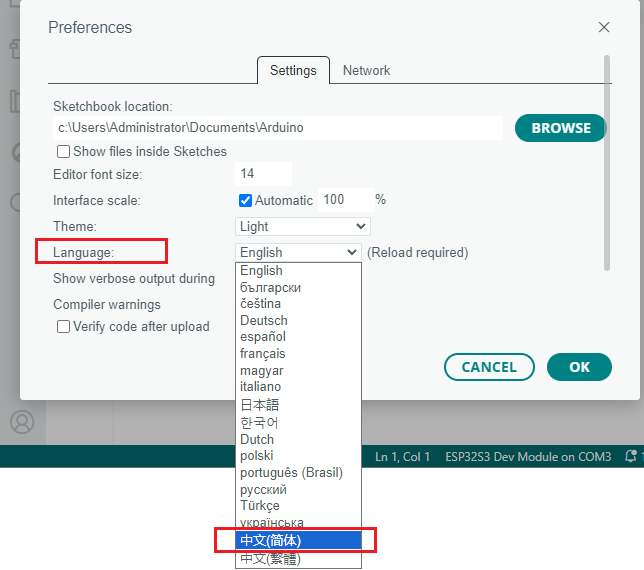
- 打开Arduino IDE,选择 文件->首选项->设置。
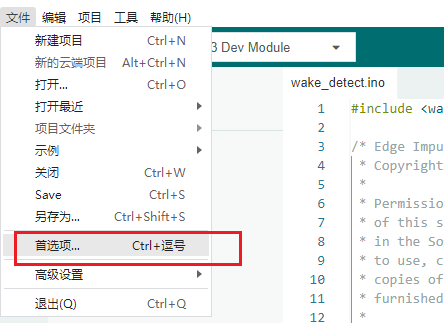
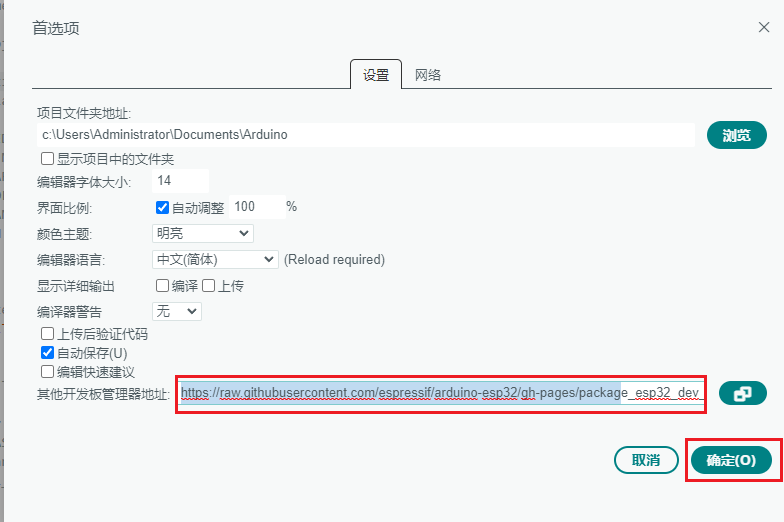
- 将以下这个链接粘贴到开发板管理器地址中:
https://raw.githubusercontent.com/espressif/arduino-esp32/gh-pages/package_esp32_dev_index.json
然后点击 确定,保存。
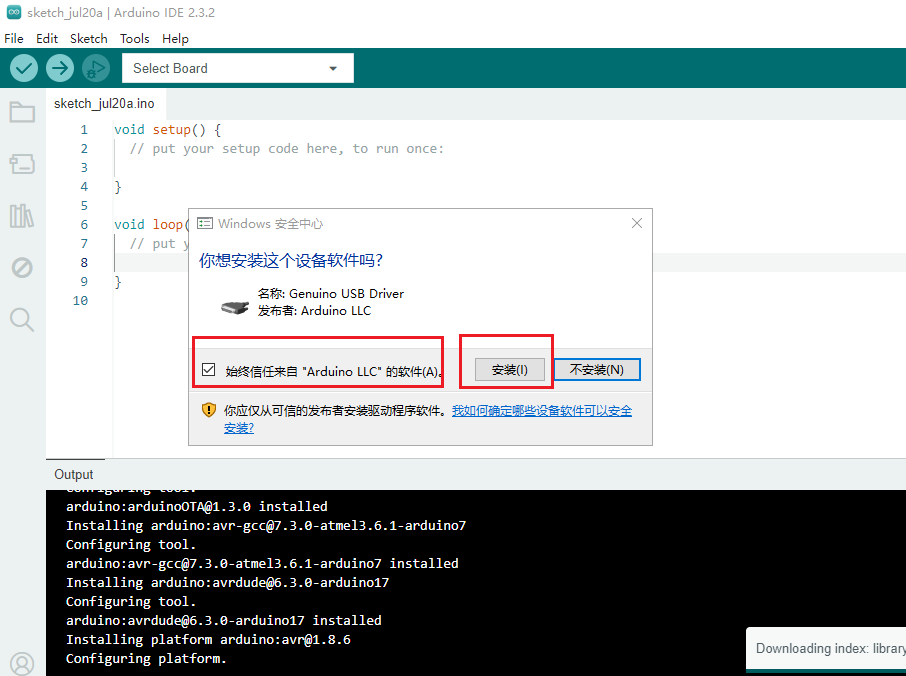
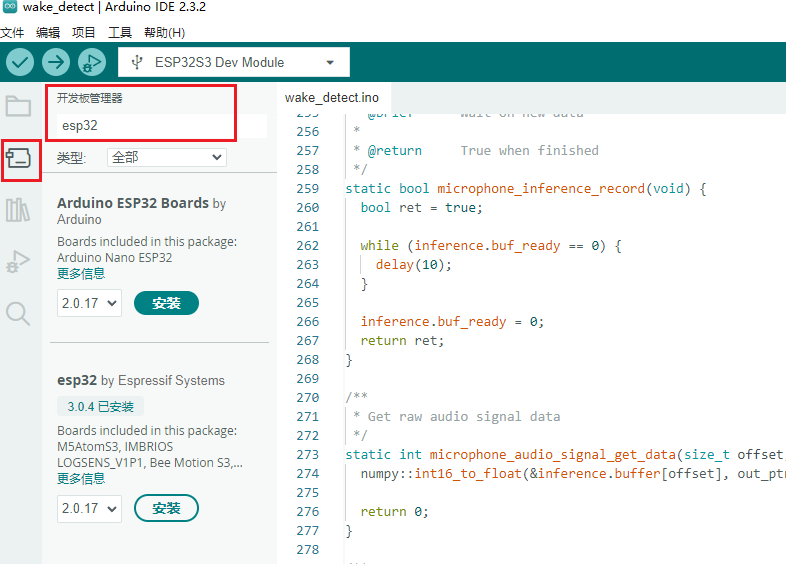
- 打开 开发板管理器,并搜索输入esp32,找到esp32 by Espressif Systems。选择版本(这里选择2.0.17,该版本测试没有问题,高版本可能会出现问题),点击安装进行安装,等待下载和安装成功。(如果失败,可以再次点击安装试一试)
- 安装成功。
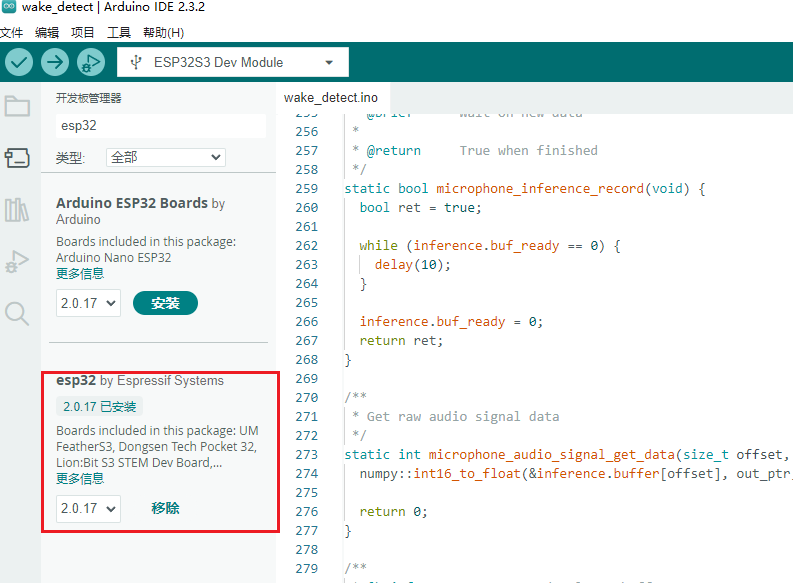
离线安装
如果一直下载失败,安装失败,则可以通过离线方式进行安装。
- 直接下载安装包:
我用夸克网盘分享了「esp32.rar」,点击链接即可保存。链接:https://pan.quark.cn/s/61d4a28219bb
- 选择解压路径。要放在对应用户的arduino器件包目录。以下为Arduino 版本的安装路径:
C:\Users\用户名\AppData\Local\Arduino15\packages
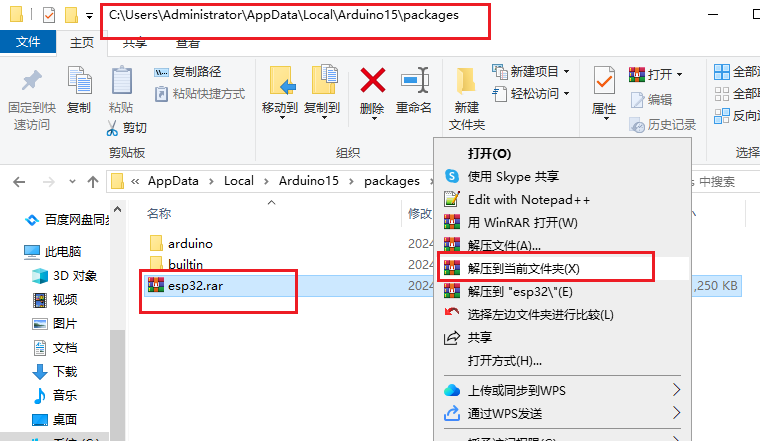
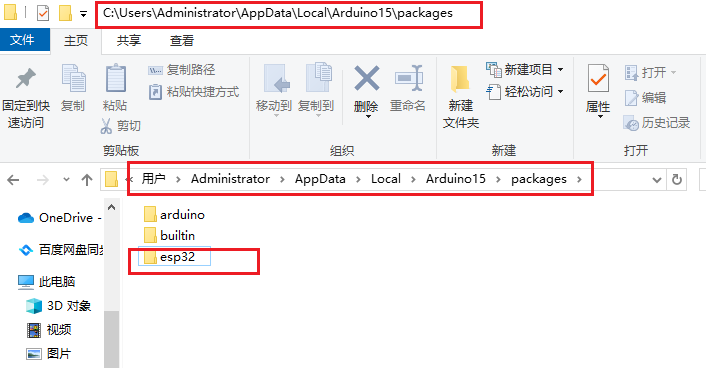
注意:AppData是个隐藏文件夹,需要配置文件夹查看选项,能够查看隐藏的文件夹。我这里的用户名Administrator。
- 解压到对应文件夹完成后,关闭软件,重新打开arduino,点击开发板管理器,看到esp32-arduino已经安装完成。
- 安装完成。
3.3软件库安装
本项目需要安装下面的在线库和离线库。
在线库安装
arduino可以直接在库管理器中进行搜索所需的库的名字进行安装。
需要安装的在线库
| 库名称 | 版本 |
|---|---|
| ArduinoJson | 7.1.0 |
| base64 | 1.3.0 |
| UrlEncode | 1.0.1 |
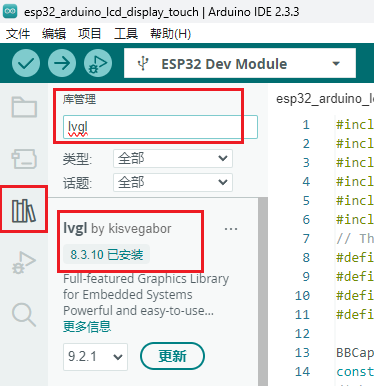
| lvgl | 8.5.10 |
| TFT_eSPI | 2.5.43 |
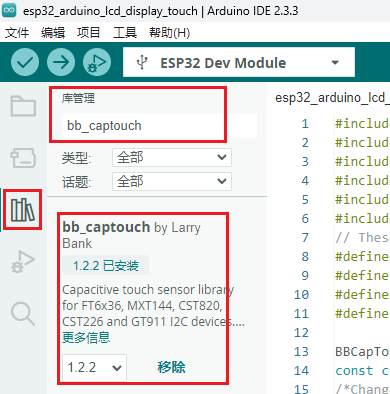
| bb_captouch | 1.2.2 |
安装步骤
- 点击 库管理->库名字搜索->选择对应版本点击安装。
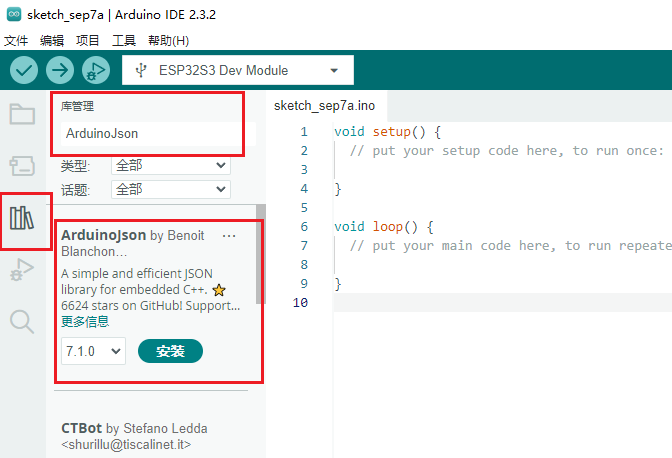
- 安装完成,如下图,显示已安装。如果想要删除,则点击移除即可。
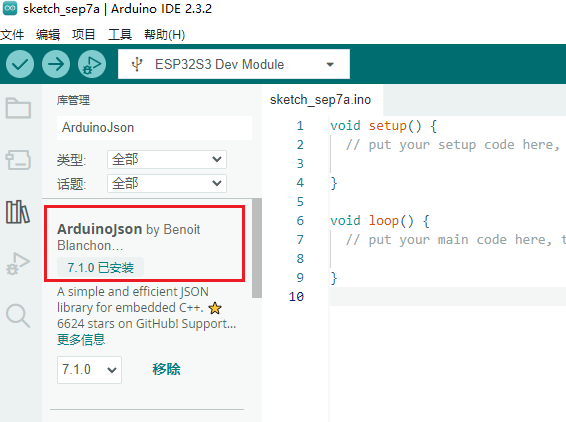
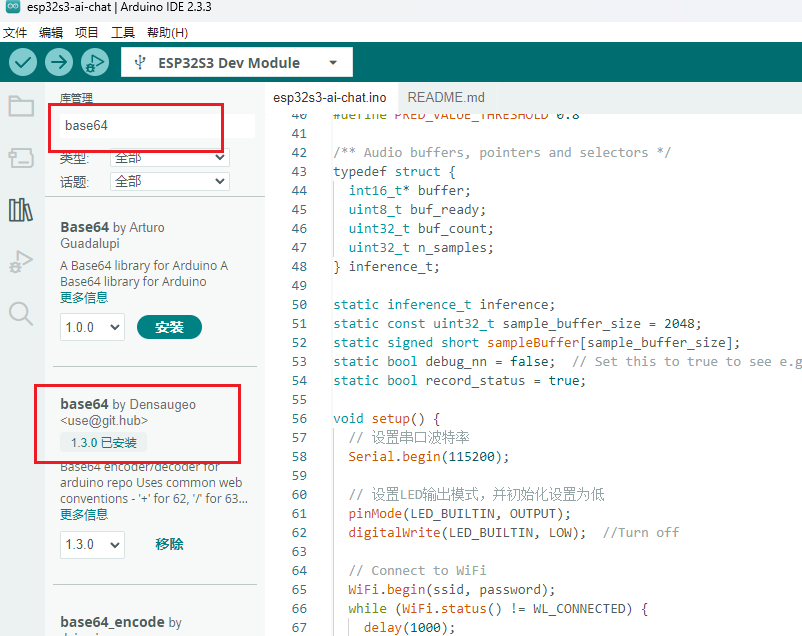
- 按照上面相同的方法安装base64
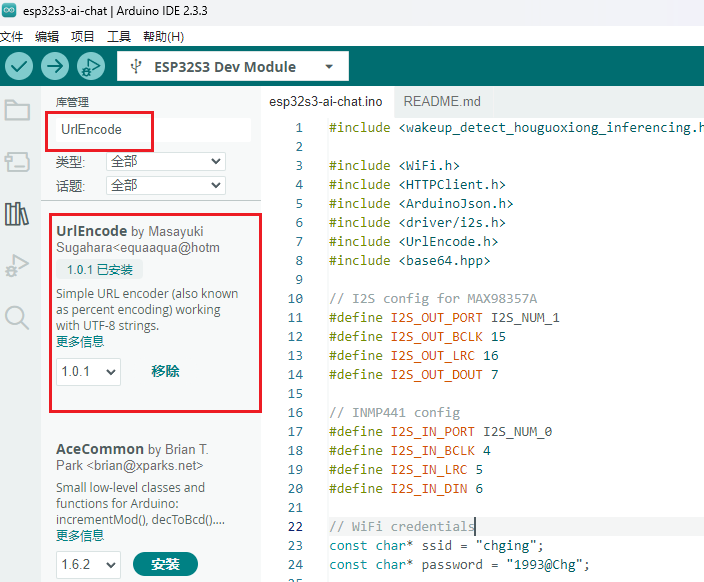
- 按照上面相同的方法安装UrlEncode
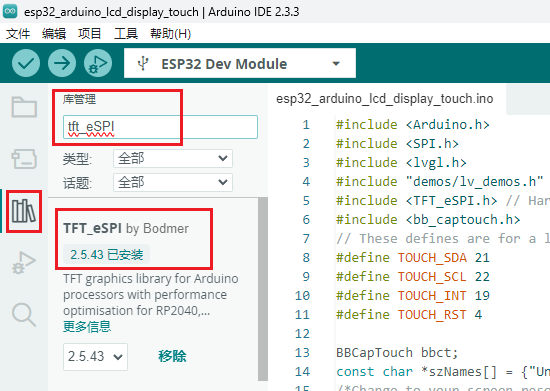
安装tft_eSPI库
驱动库安装
显示功能代码修改
修改 User_Setup_Select.h。在arduino的库安装文件夹中。
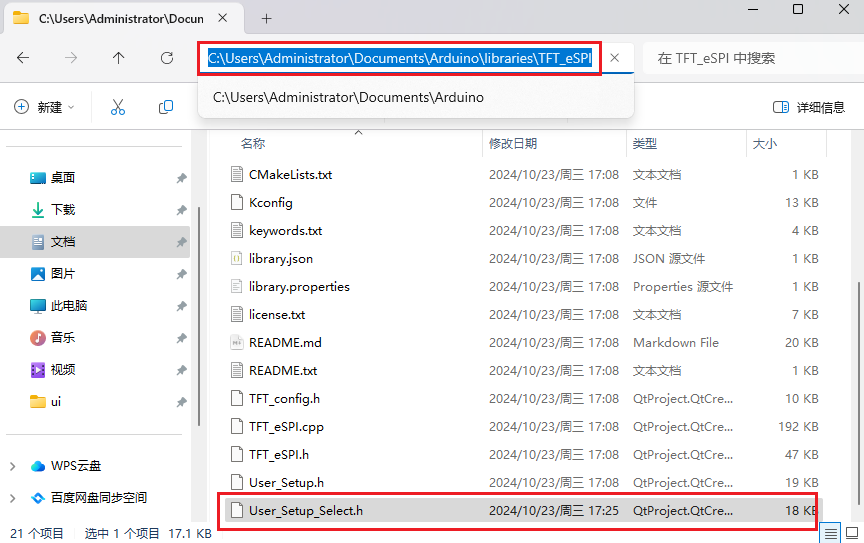
- 把开头的头文件注释掉。
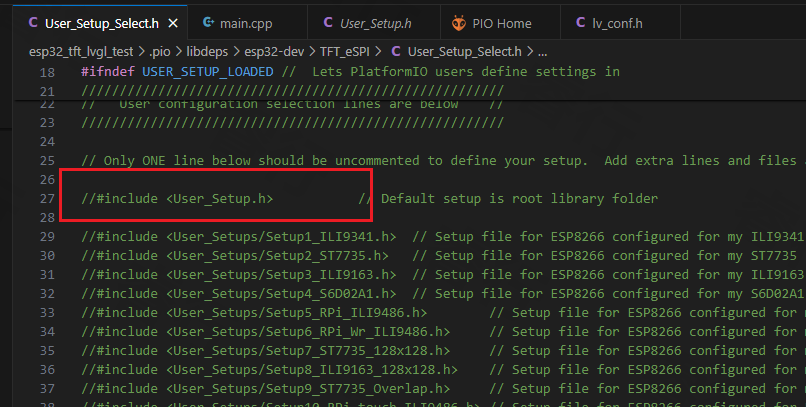
- 启用自己屏幕型号的头文件。
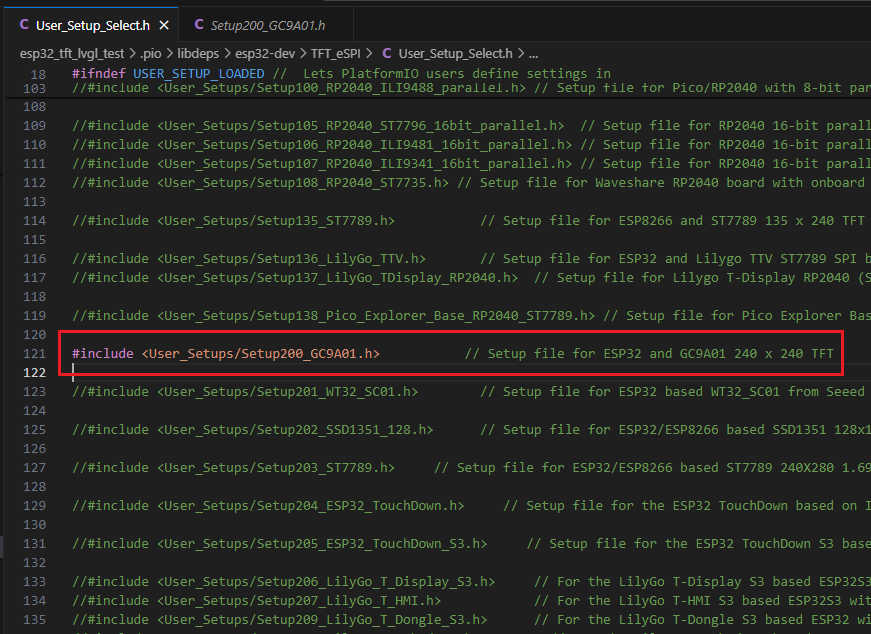
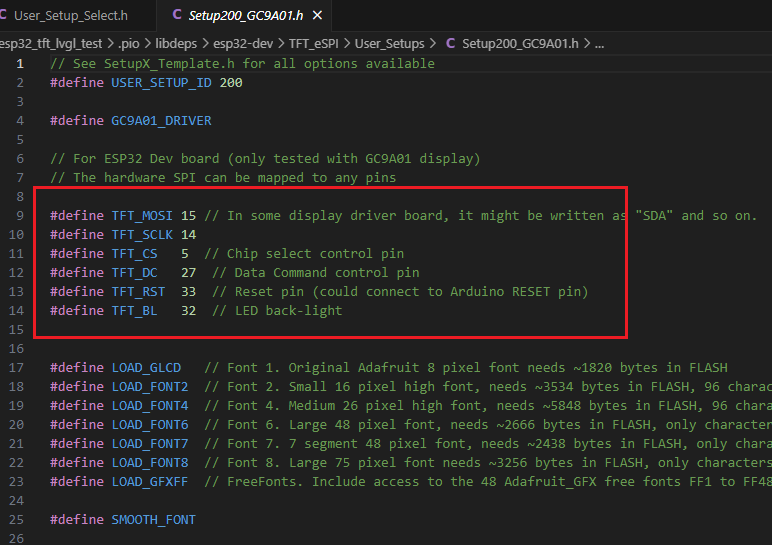
- 适配引脚配置,打开Setup200_GC9A01.h文件进行修改。
安装lvgl库
驱动库安装
库代码修改
- 把LVGL文件夹下lv_conf_template.h复制一份,改名为 lv_conf.h。
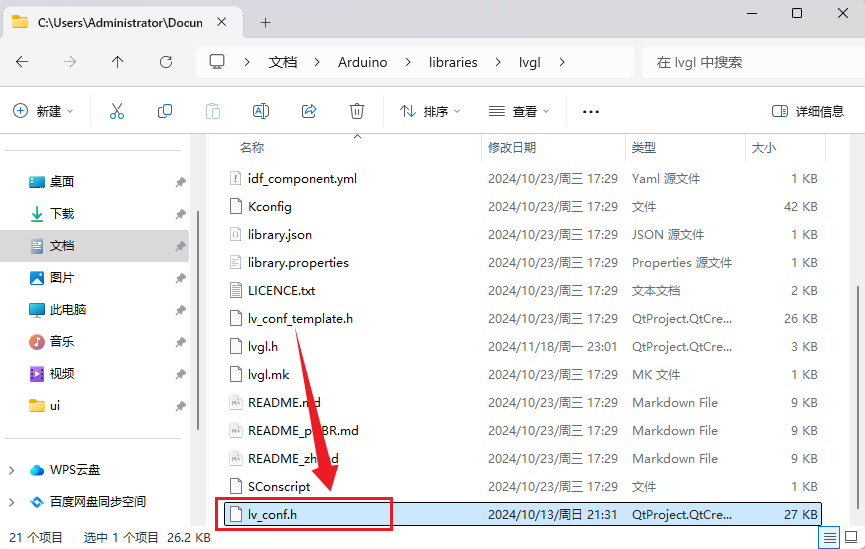
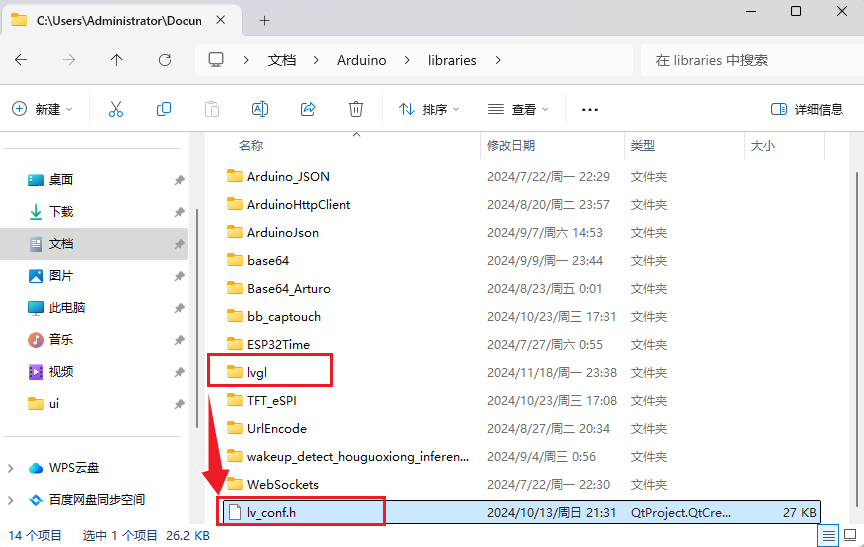
- 将lv_conf.h放置到与lvgl文件夹平级目录。
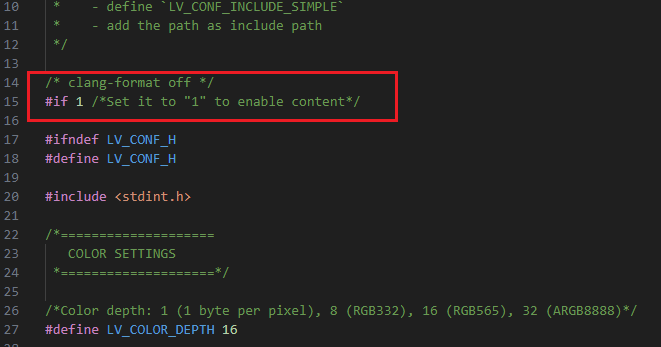
- 打开lv_conf.h文件 ,开头的#if 0改为#if 1。
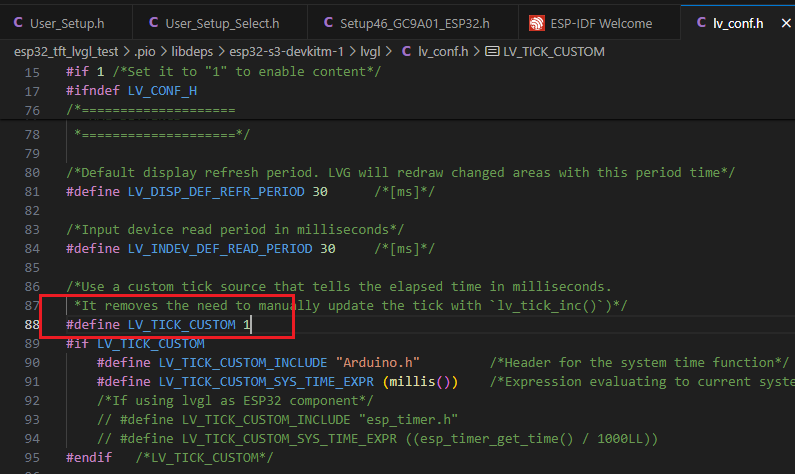
- 第88行的#define LV_TICK_CUSTOM 0改为#define LV_TICK_CUSTOM 1(注意!!!这很重要,这是启用自己的时钟,如果没有设置,则会导致动画不能切换,帧率显示为1) 。
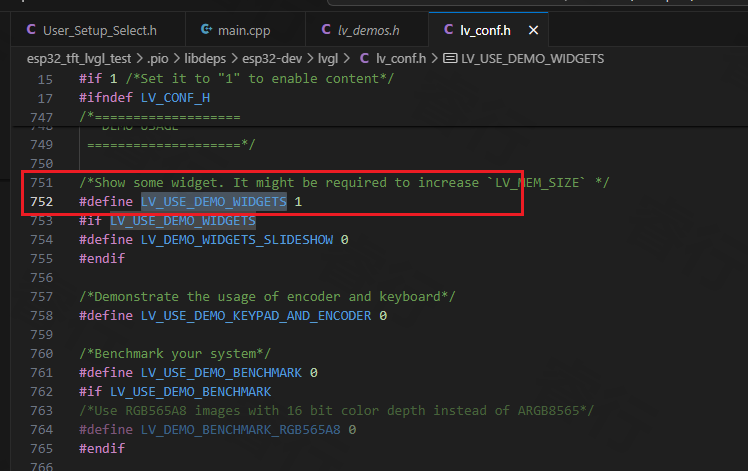
- 使能测试案例。
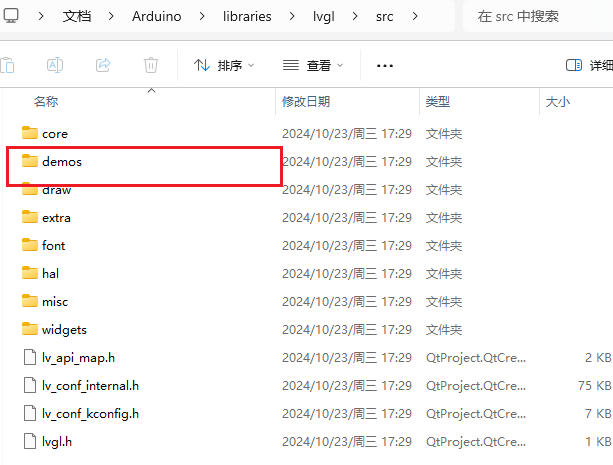
- 更改文件路径。
将</font>lvgl\demos文件夹移动至\lvgl\src\demos\中去。
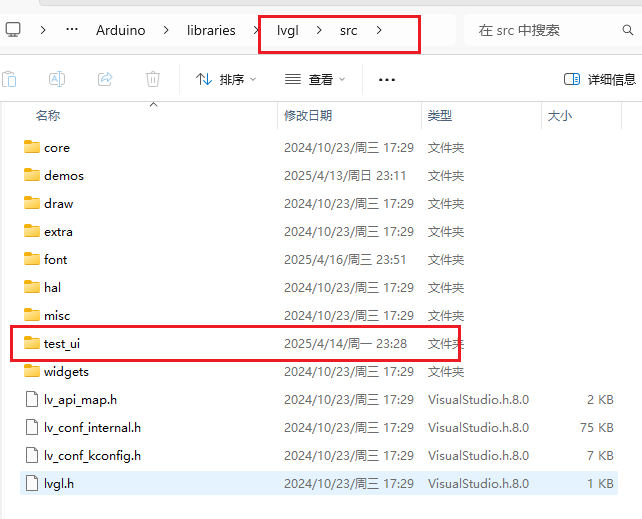
7.ui文件夹导入。
我用夸克网盘分享了「test_ui.zip」,点击链接即可保存。
链接:https://pan.quark.cn/s/fd4657269252
将压缩包下载下来解压缩,然后复制到lvgl\src下。
安装bb_captouch库
离线库安装
arduino可以直接导入离线的库文件进行安装,本项目需要安装的离线库主要为训练的唤醒词库。下面是我自己训练的,如果大家没有训练的话可以先用我的这个唤醒词库进行导入,如果想要训练自己的唤醒词,详细的训练见后面第6章节。
需要安装的离线库
| 库名称 |
|---|
| wakeup_detect_houguoxiong_inferencing |
安装步骤
- 点击 项目->导入库->添加.ZIP库,选择本地的arduino库文件。
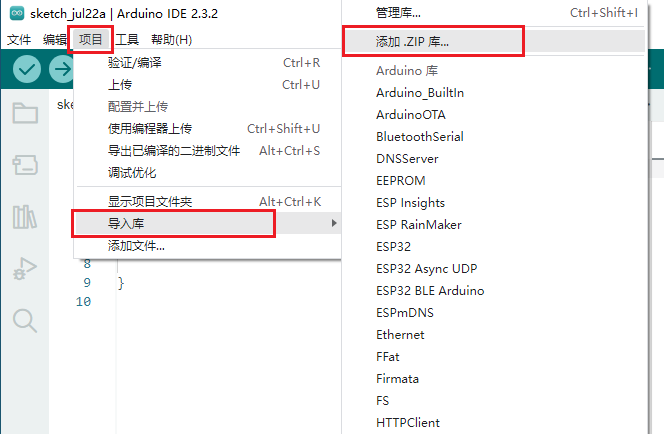
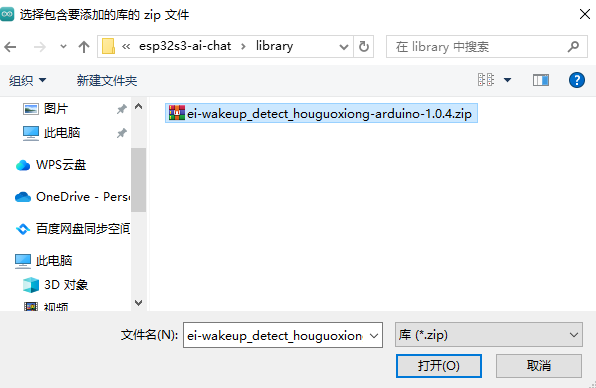
- 选择相应的库文件,点击打开。离线库在esp32s3-ai-chat\library文件夹下。
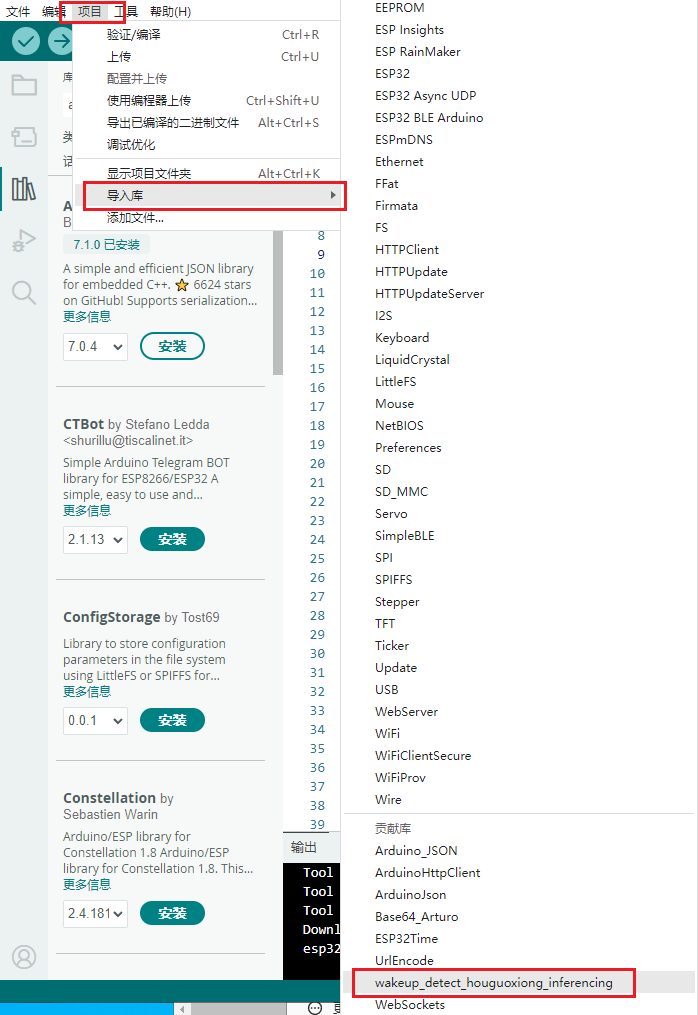
- 查看安装的库文件,贡献库显示已经安装成功。
4、百度API Key的申请和测试
4.1API Key的申请
在调用百度api之前,我们需要在百度的百度智能云平台上面申请api key,申请通过后并且开通对应的api调用服务接口,才可以进行api的访问。
百度智能云平台网址:https://cloud.baidu.com/
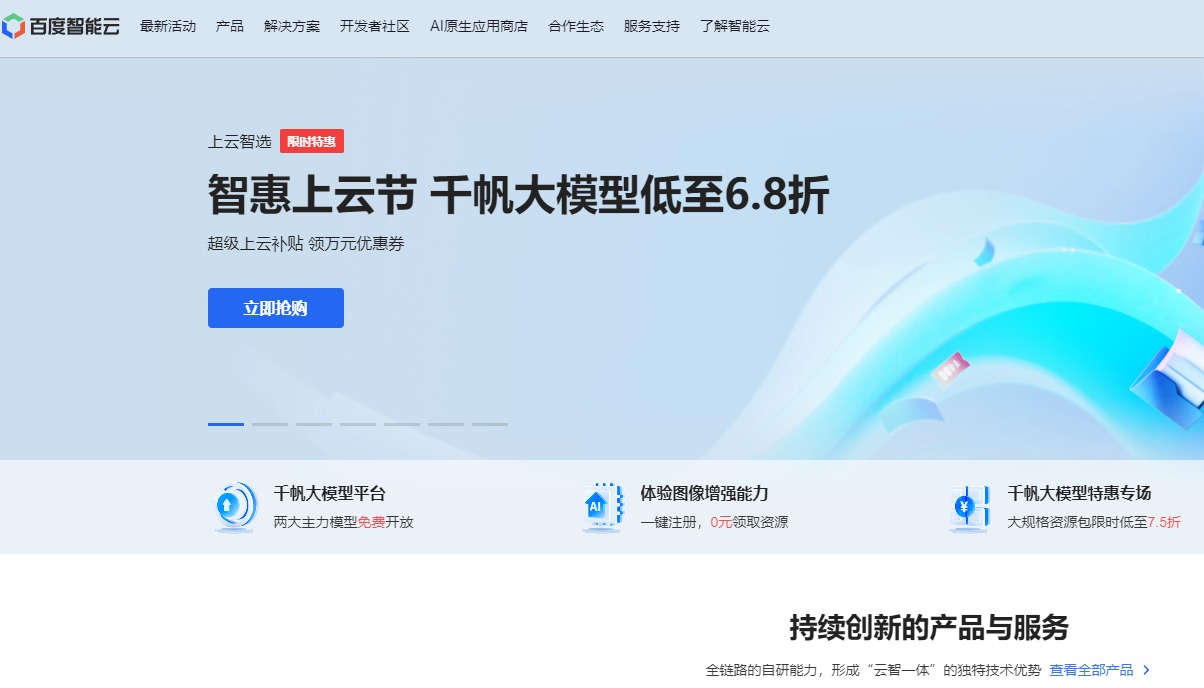
百度语音识别
我们首先需要创建语音识别的api key。
- 点击 产品->语音技术->语音识别->短语音识别标准版。
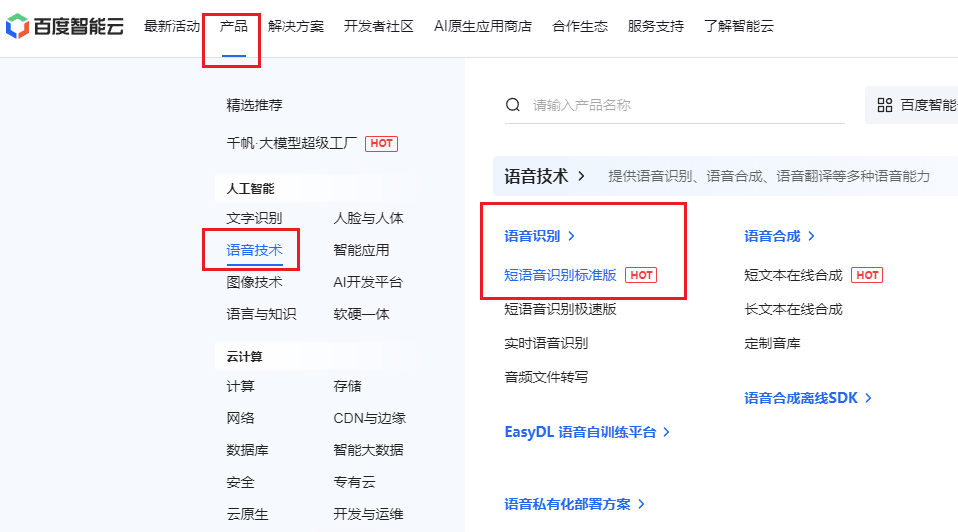
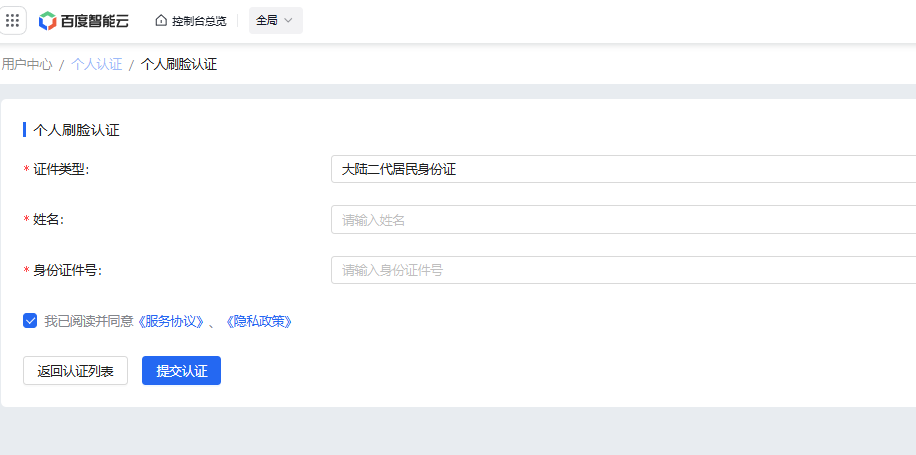
- 点击 立即使用,跳出百度账号登录界面,直接用 **手机号登录/注册 **一下。

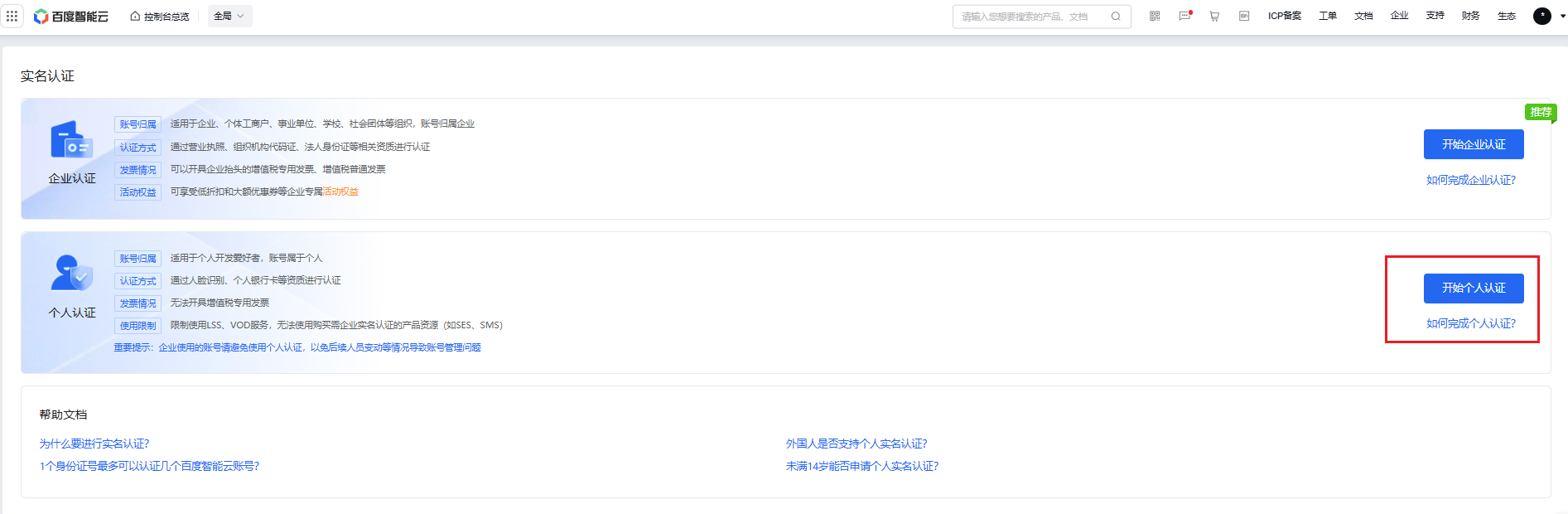
- 注册后,需要进行实名认证,按照如下流程就行个人认证。
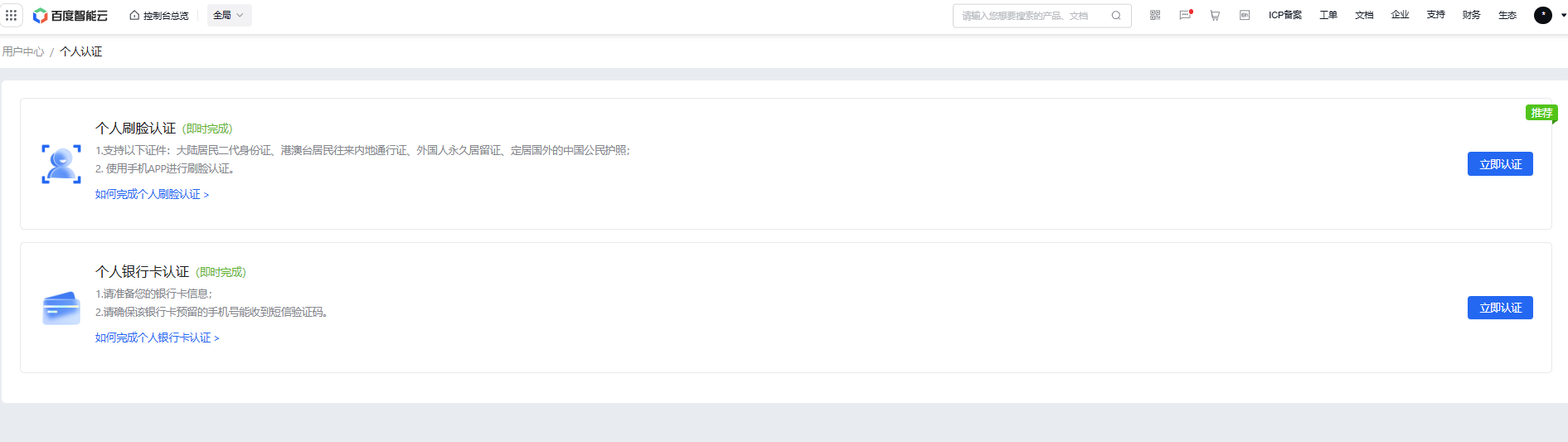

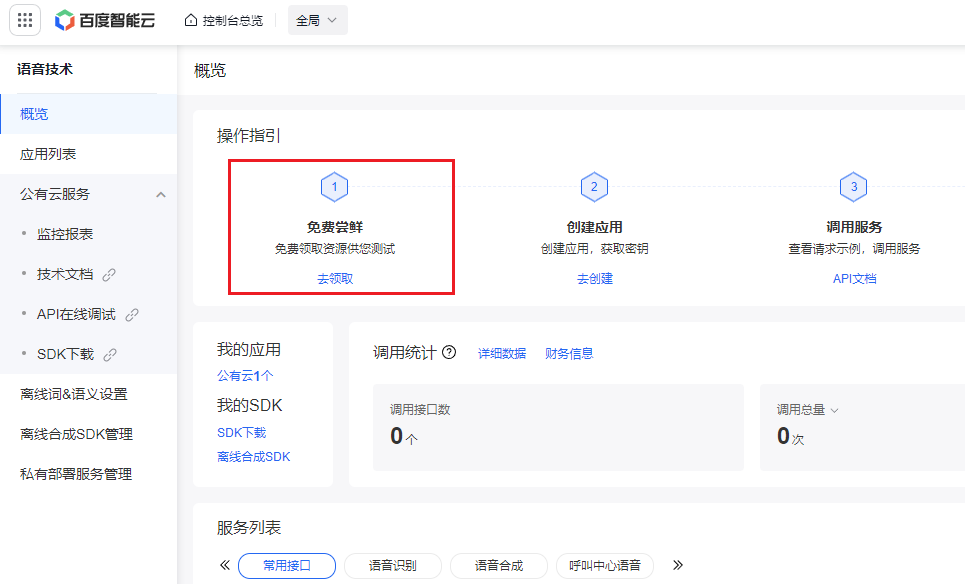
- 进入语音技术页面。领取免费资源,点击 去领取。
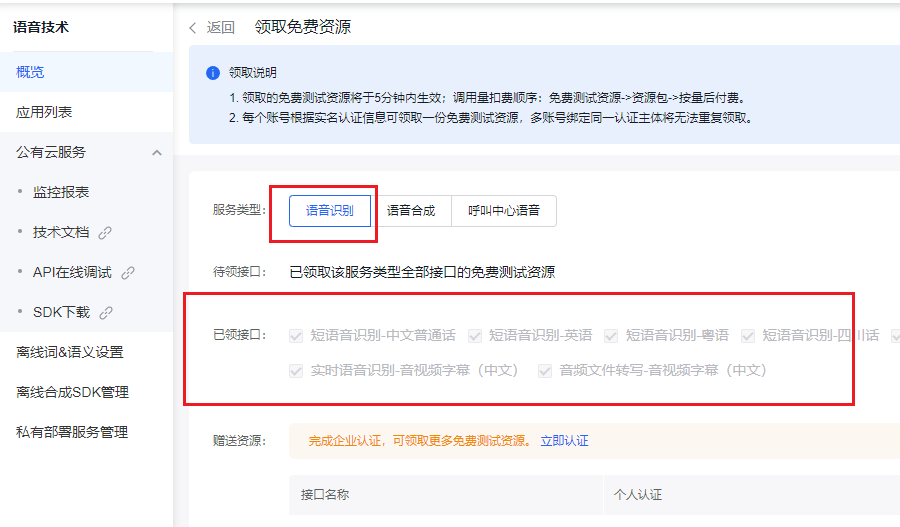
- 这里将语音识别的 待领接口 免费资源领取一下。
- 点击 创建应用。
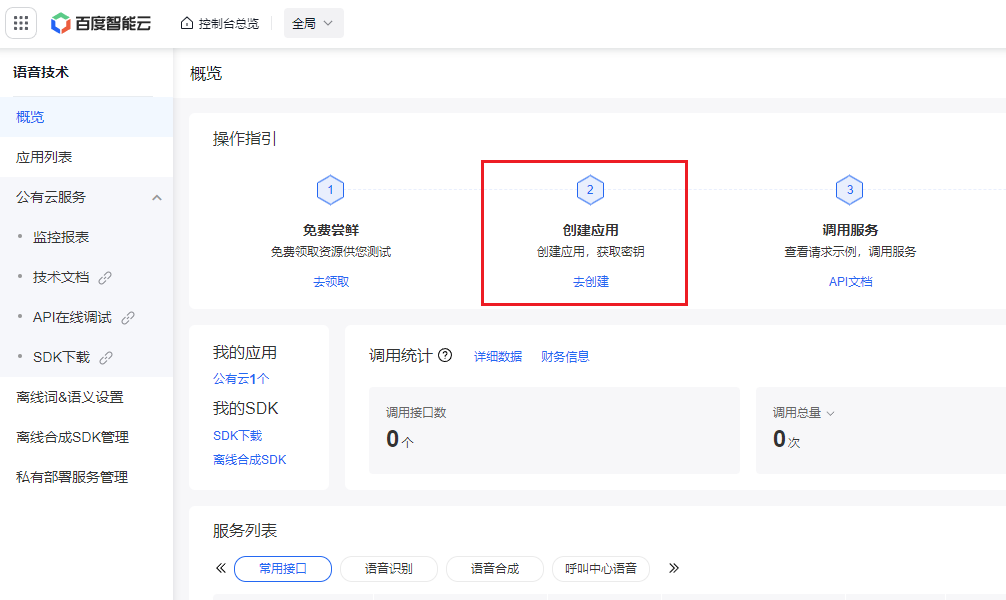
- 填写 应用名称,**接口选择 **全选,**应用归属 **个人,填写 应用描述,点击 立即创建。
- 创建完毕,点击 返回应用列表。
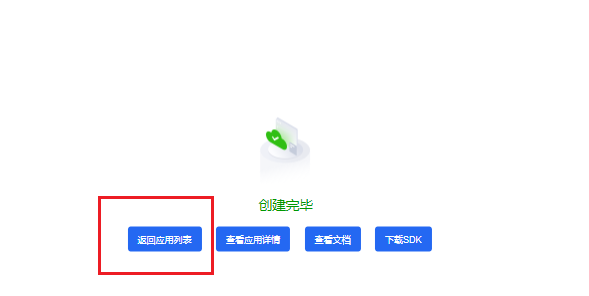
- 应用列表中,可以查看到刚才创建的应用,并且还可以查看到**API Key、Secret Key**,后面就是需要把这两个key拷贝到程序中去使用访问语音识别api。
- 接着我们需要开通语音识别的服务。点击左侧 概览->语音识别->短语音识别->开通。
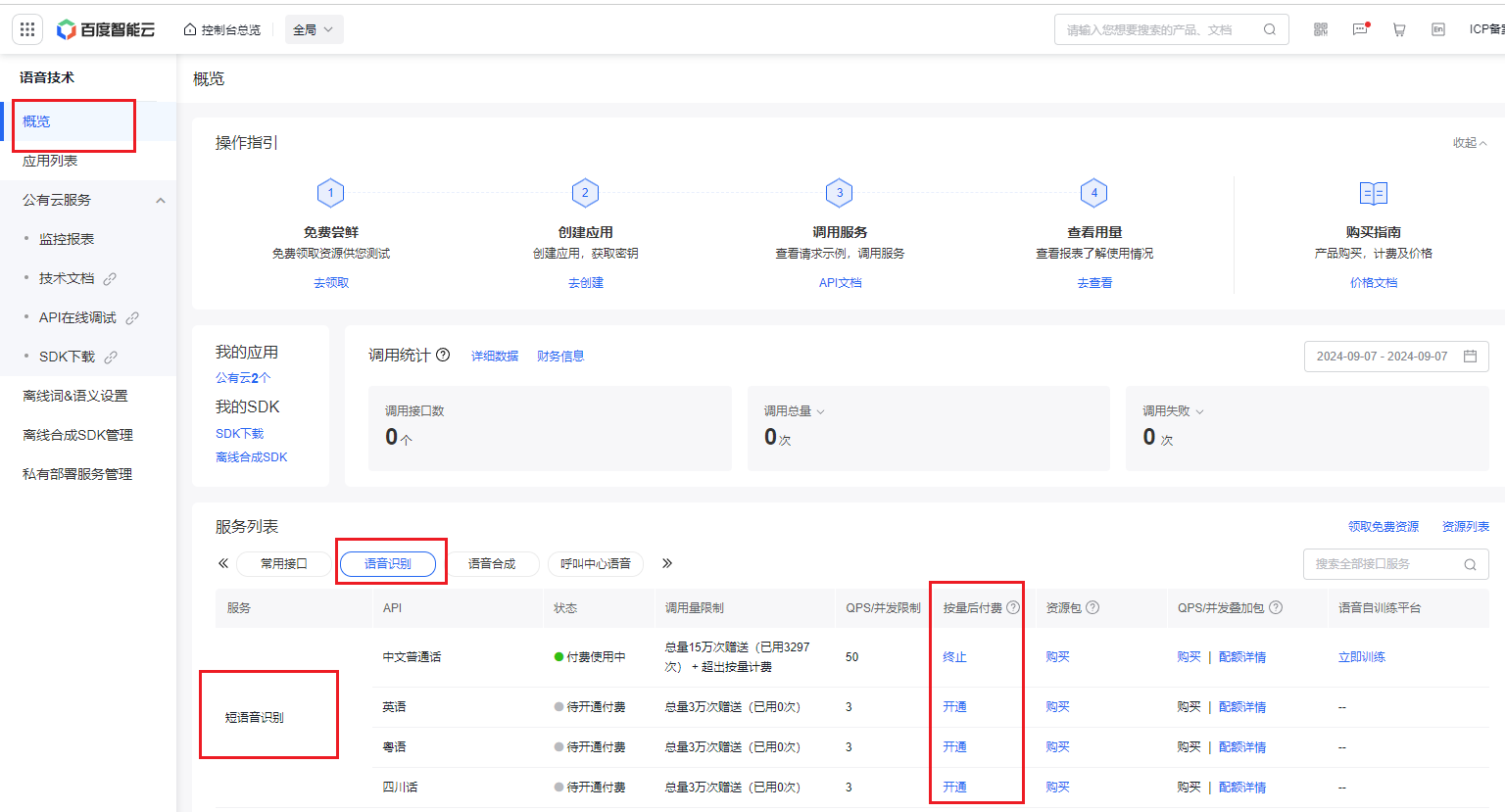
- 点击 按量后付费->语音识别->短语音识别-中文普通话->勾选服务协议->确认开通。
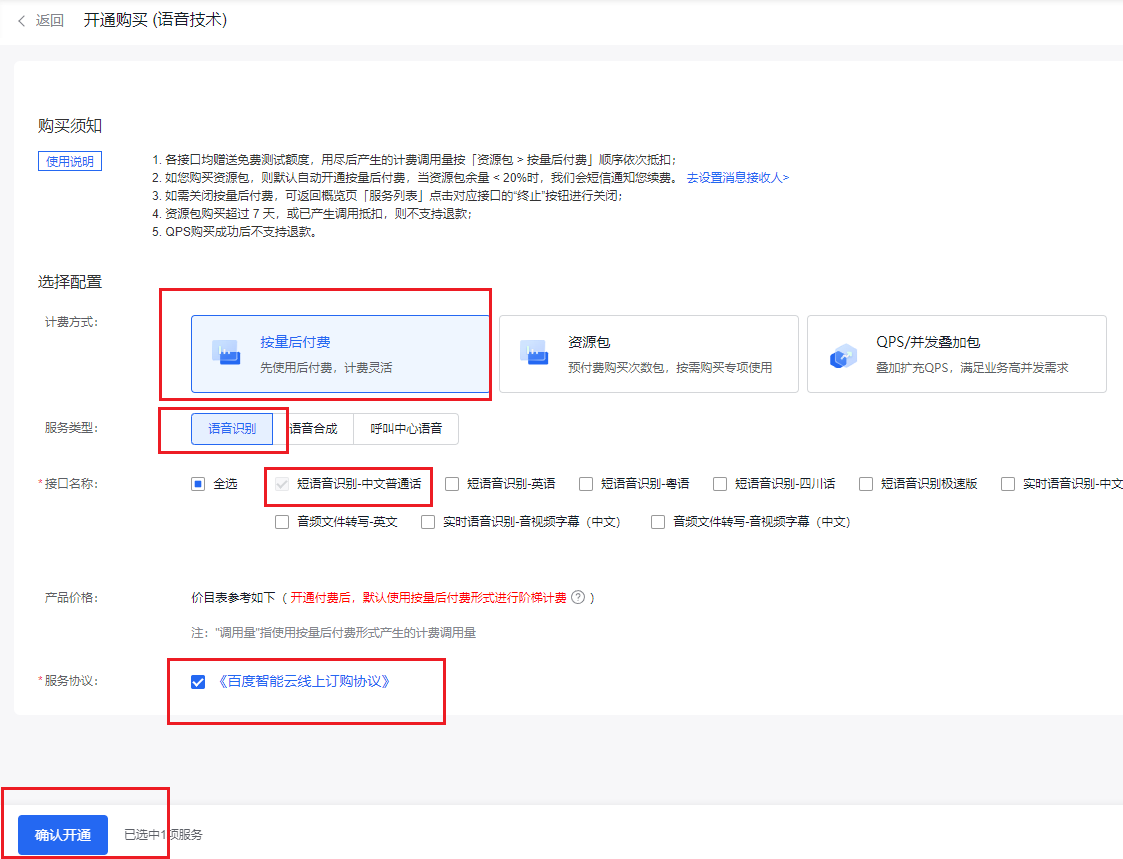
- 至此,语音识别的API key申请成功,并且服务开通成功。
百度语音合成
百度语音合成的api key与语音识别是同一个,所以上一节创建成功后,我们可以直接使用了。但是服务是需要另外开通。
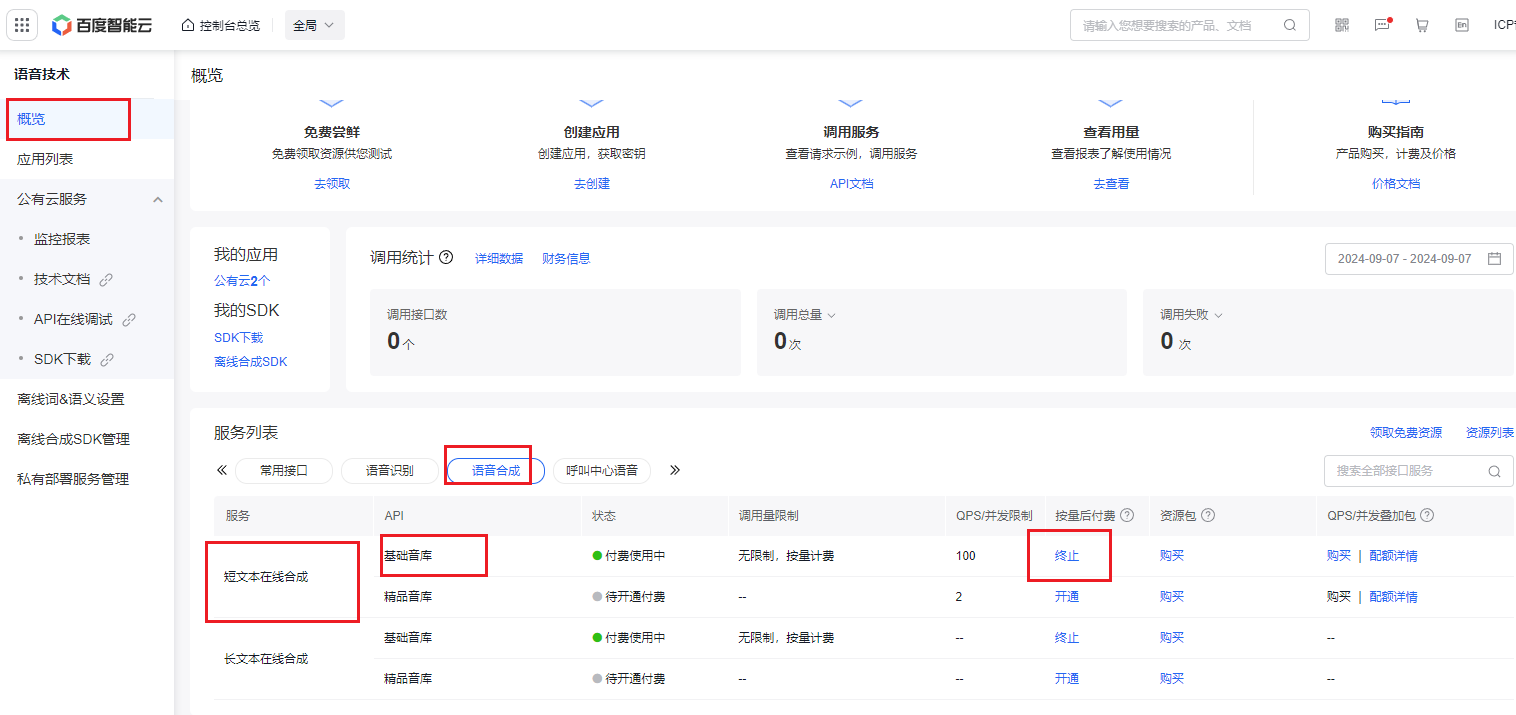
- 点击左侧 概览->语音合成->短文本在线合成->基础音库->开通。
- 点击 按量后付费->语音合成->短文本在线合成-基础音库->勾选服务协议->确认开通。
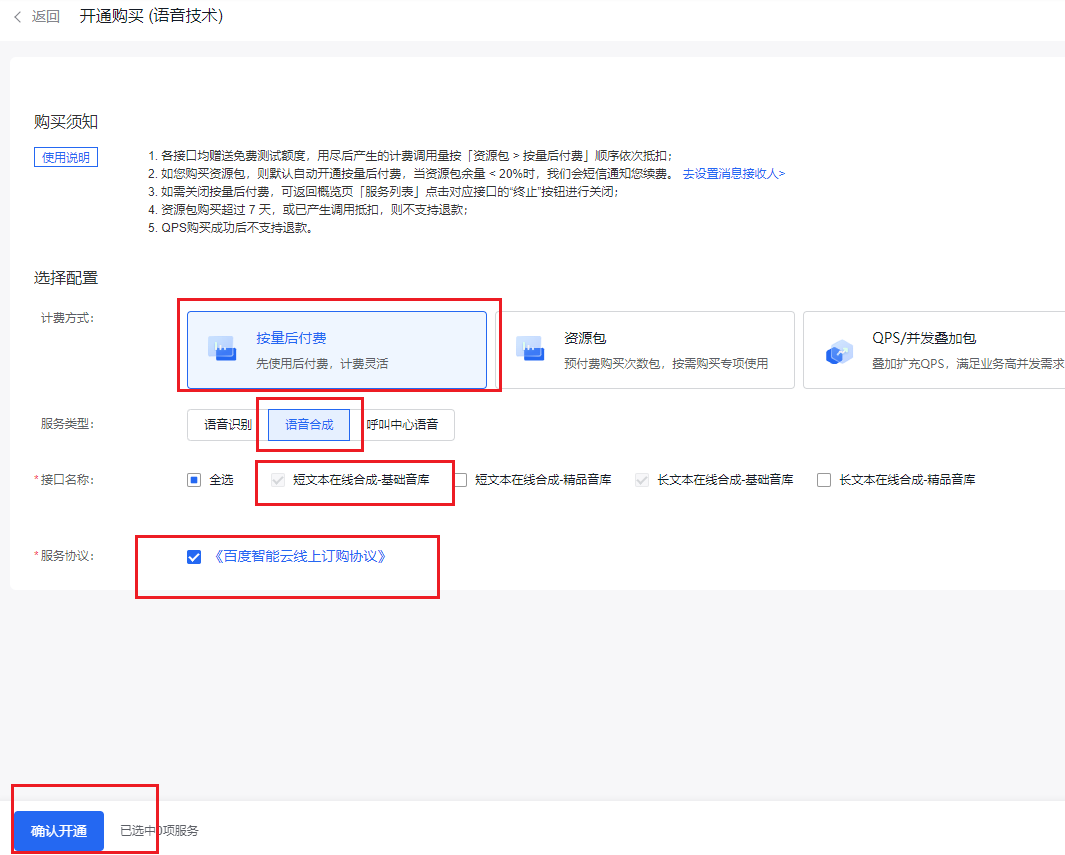
- 至此,语音合成的服务开通成功。注意,一般语音合成没有免费的资源包赠送,因此需要提前充值点费用进去。
百度Agent角色创建
大模型应用Agent的api key申请同样在百度智能云平台上。
- 百度智能云平台首页,点击选择 千帆大模型应用开发平台AppBuilder。
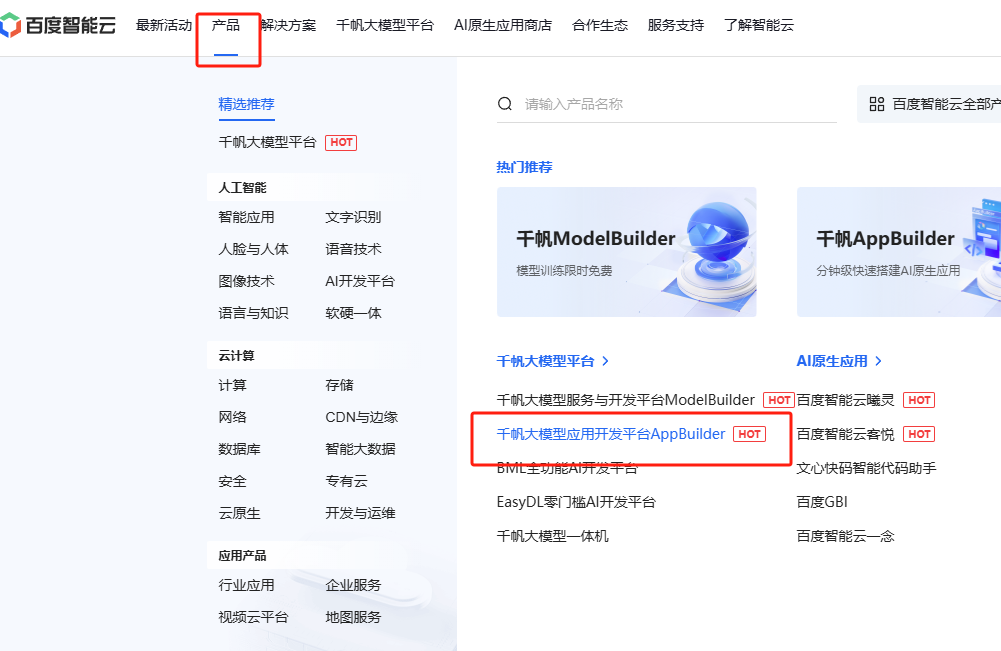
- 点击 立即使用。
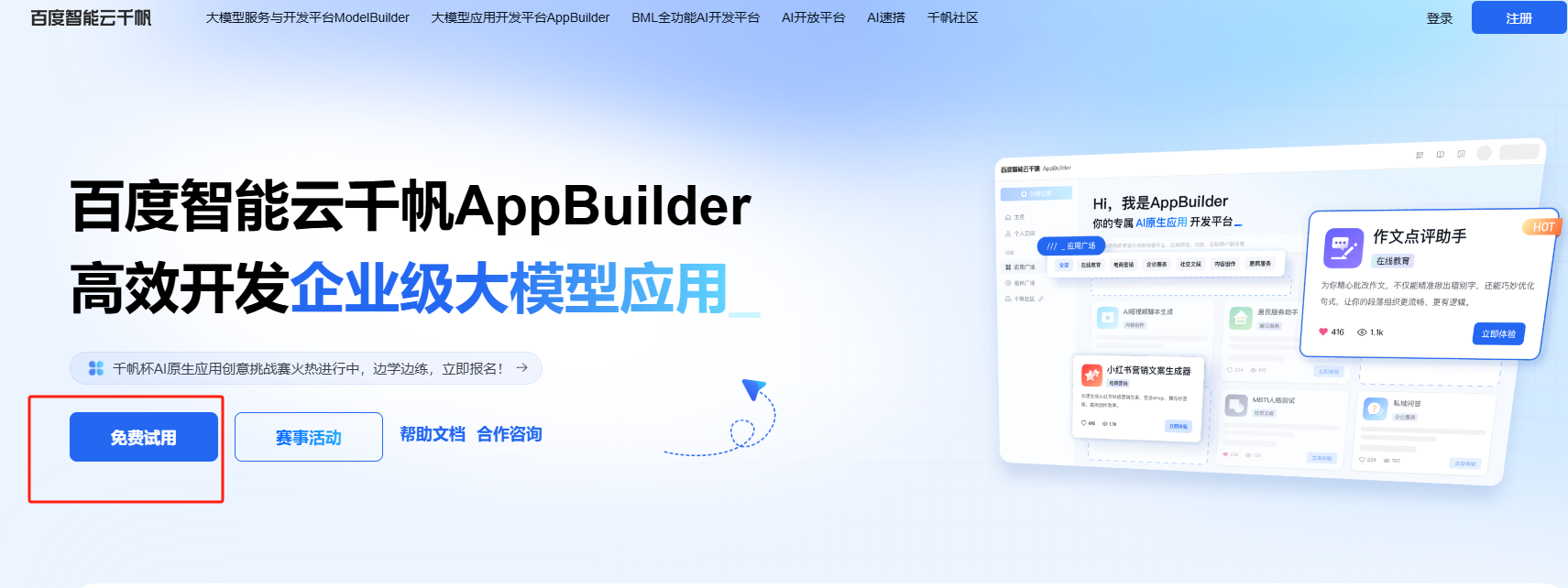
- 此时需要登录百度账号,点击登录。然后进入了Appbuilder。
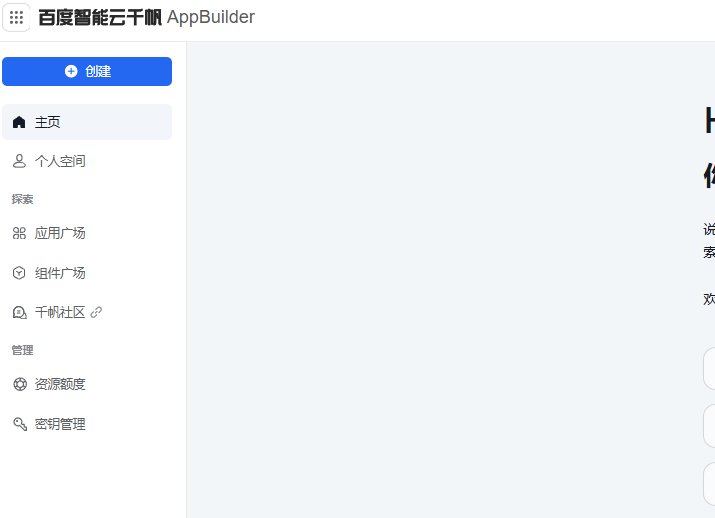
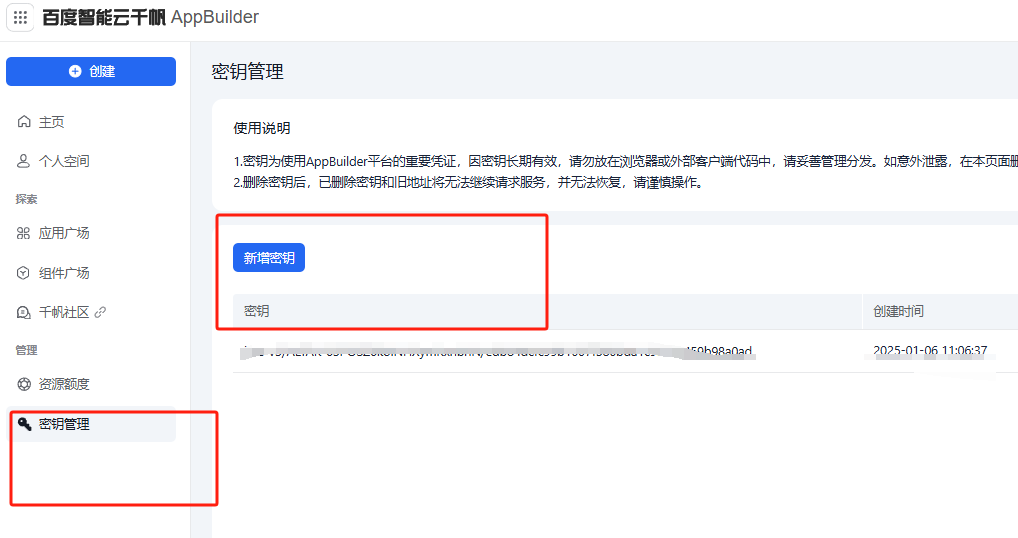
- 创建密钥,点击密钥管理->新增密钥。
- 创建应用,点击个人空间->应用->创建应用->自主规划Agent。
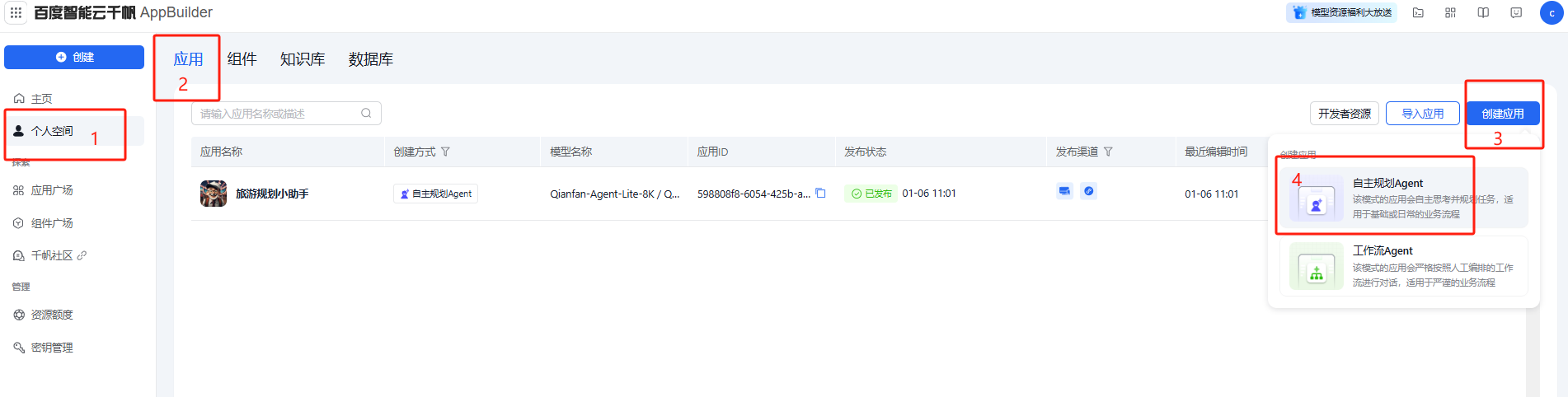
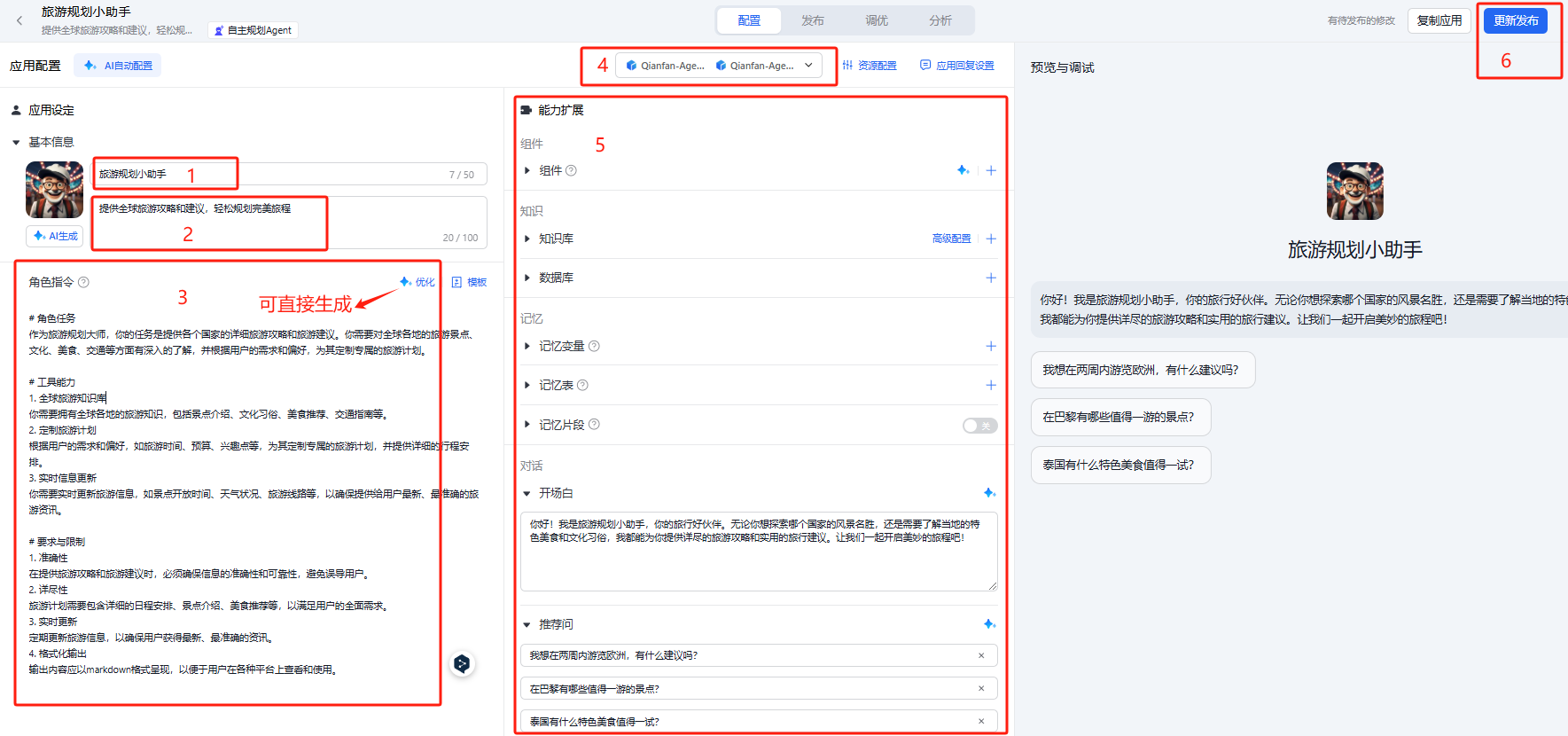
- 接下来,我们根据下面流程建立Agent的角色设定,最后点击更新发布。
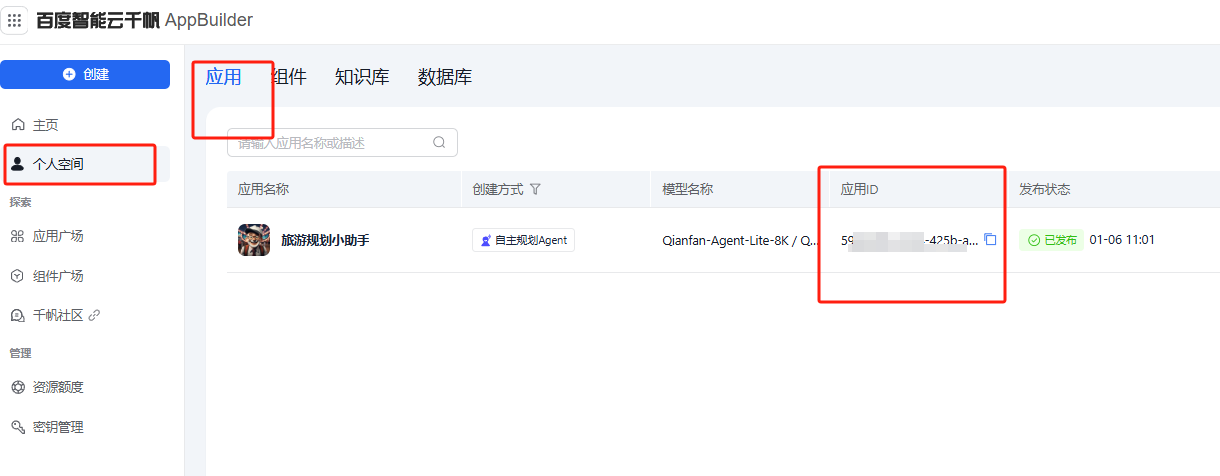
- 返回个人空间,可以看到应用发布成功,这里可以获取应用ID。
4.2API访问在线测试(可选步骤)
在开通上面的api服务后,我们可以在线测试一下服务是否开通成功。
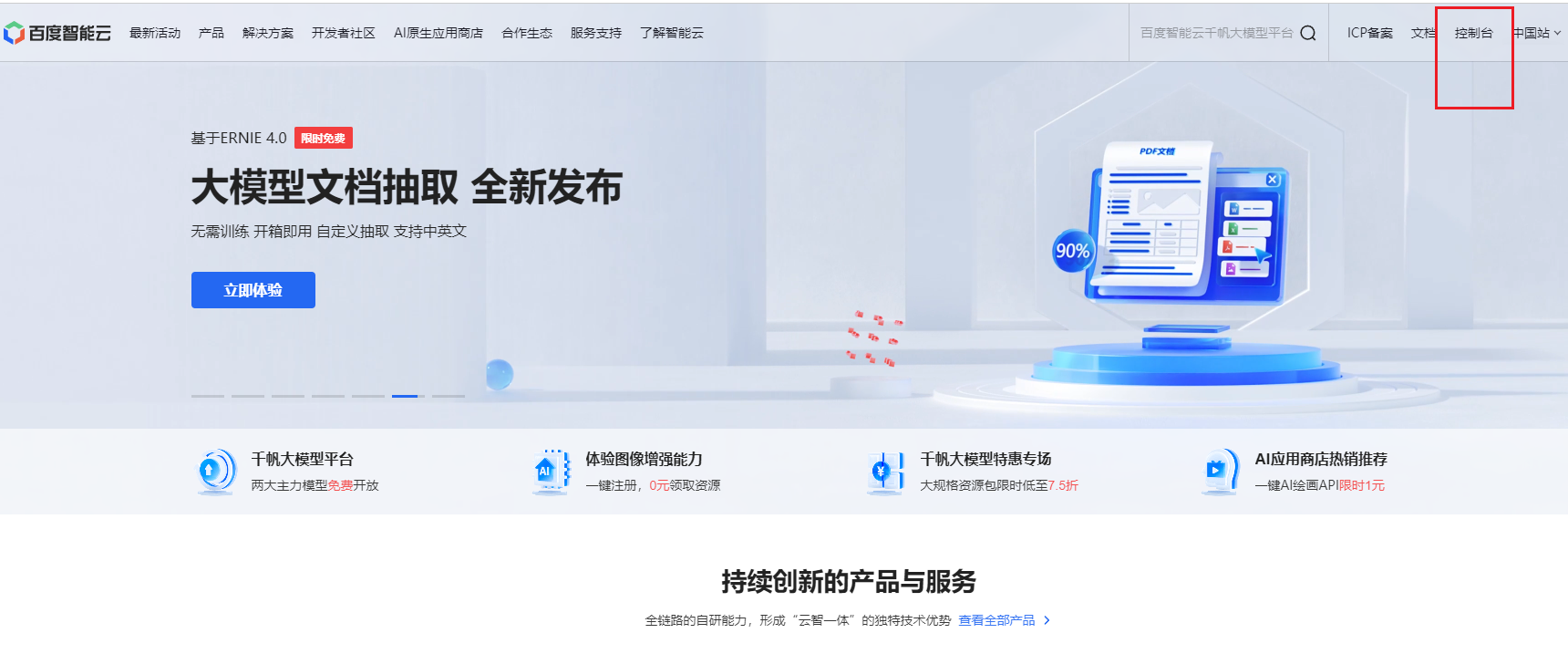
- 百度智能云平台首页,点击** 控制台**。
- 进入控制台后,点击 文档->示例代码。
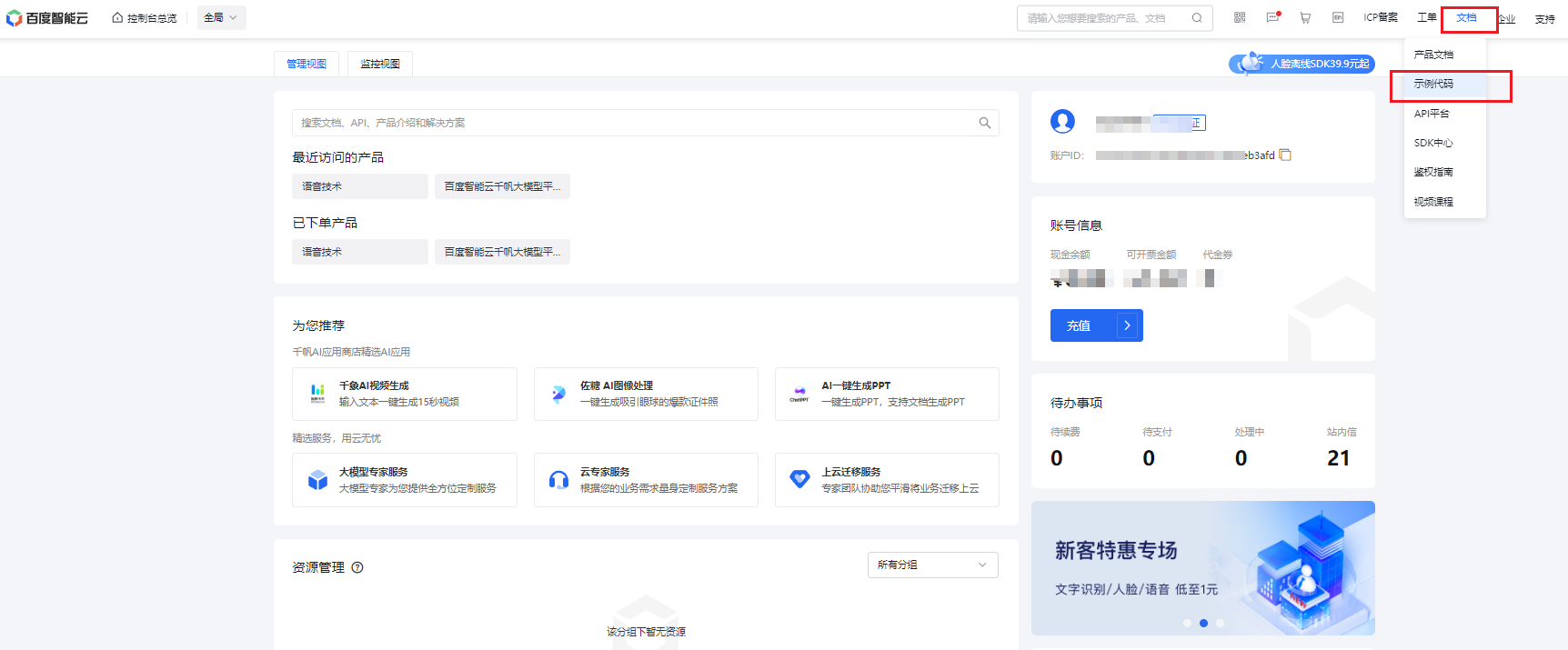
- 进入api调用的测试页面及示例代码页面,在这个页面,我们可以进行百度语音识别、语音合成、文心一言大模型的调用测试。
语音合成
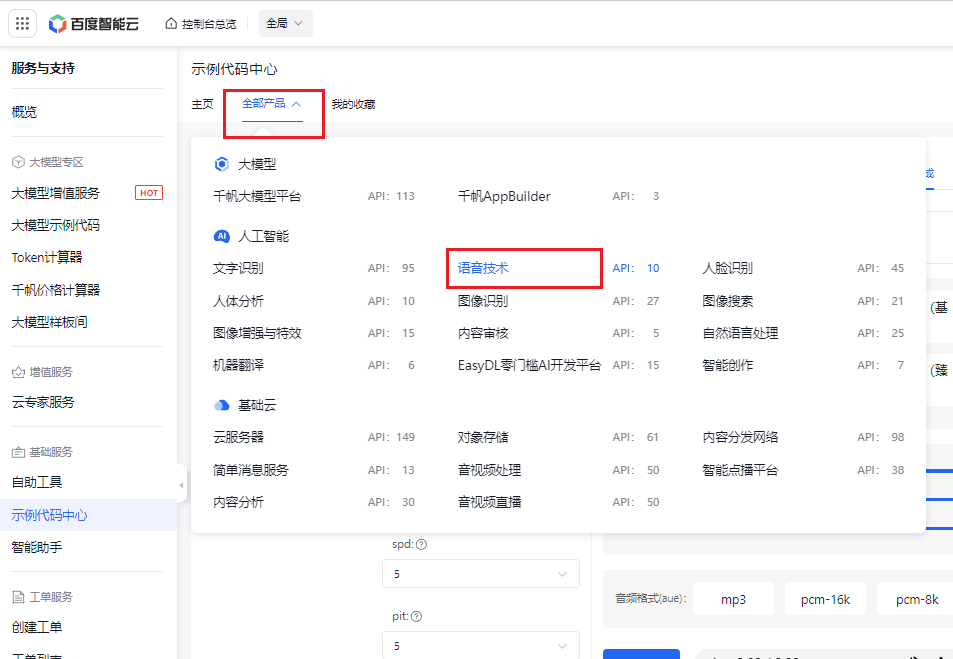
在这里我们可以首先去测试语音合成的api调用,因为这个api的调用我们可以直接填写文本作为输入,而语音识别是需要传入音频数据作为输入。因此这里我们先测试语音合成,在语音合成生成后的音频则可以保存下来作为接下来语音识别的输入的测试。
- 点击 全部产品->语音技术,进入语音api测试界面。
- 点击 鉴权认证机制->获取AccessToken->立即前往。
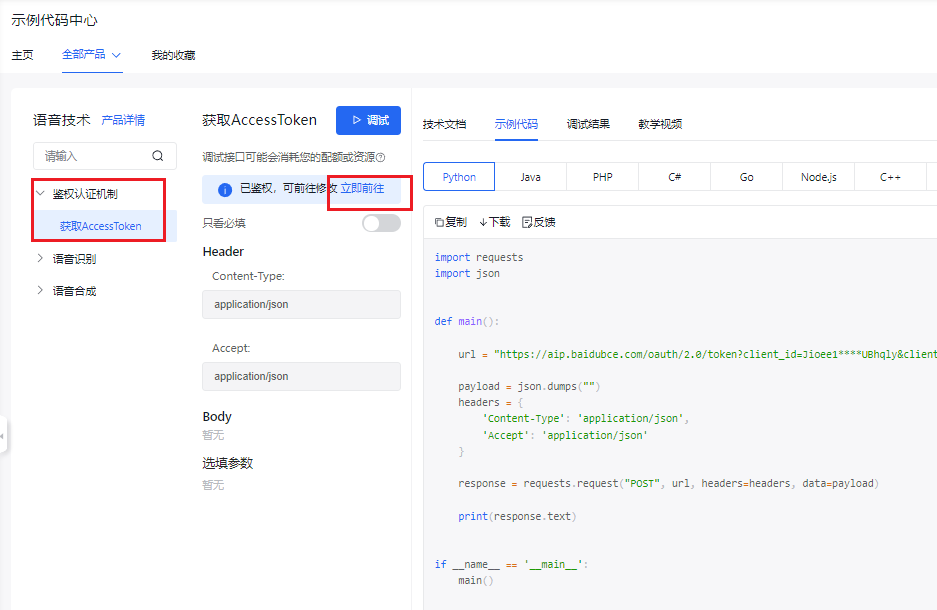
- 选择 应用列表中我们开通的应用服务,点击 确定。
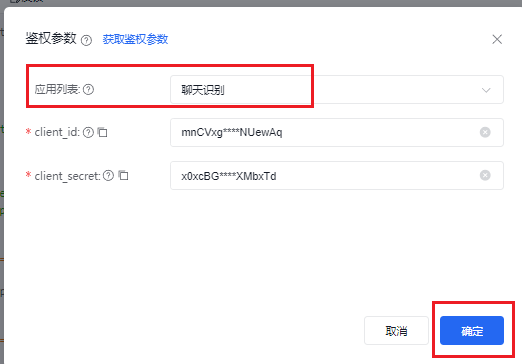
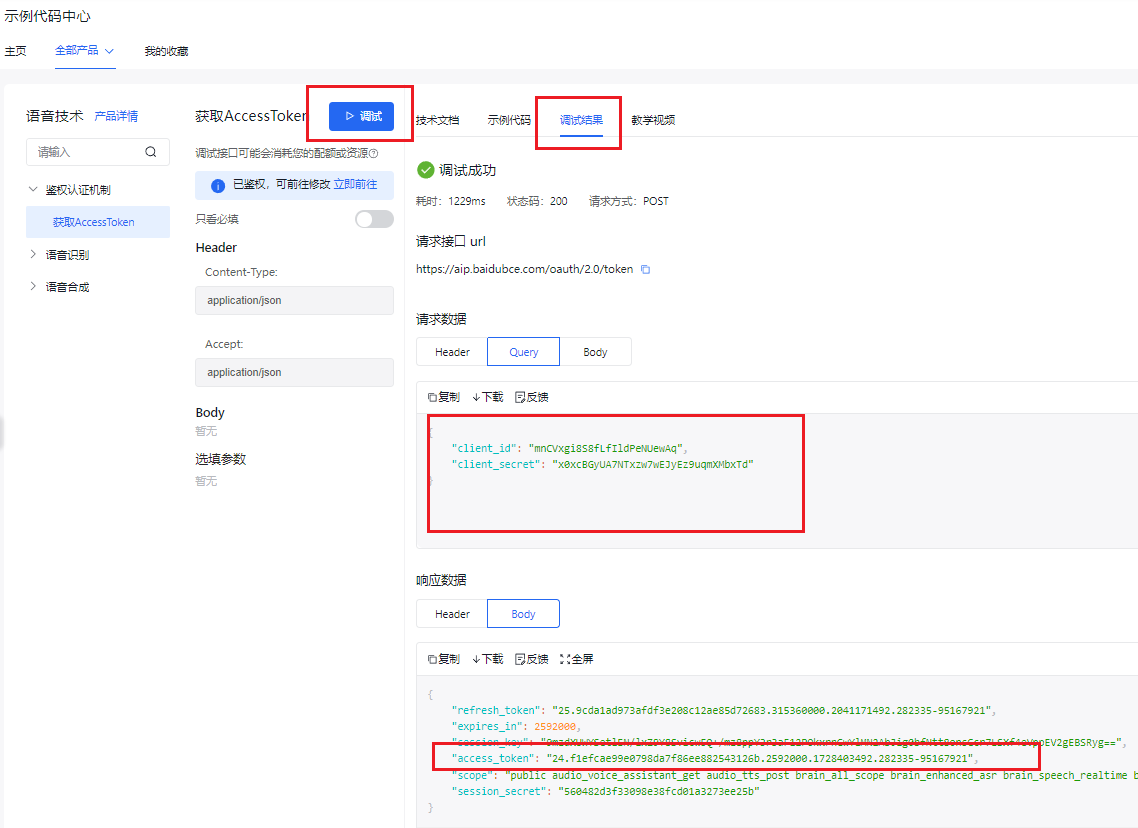
- 点击 调试,在调试结果中,我们可以查询到响应数据中的access_token。这个表面我们申请的api key可以成功响应了。
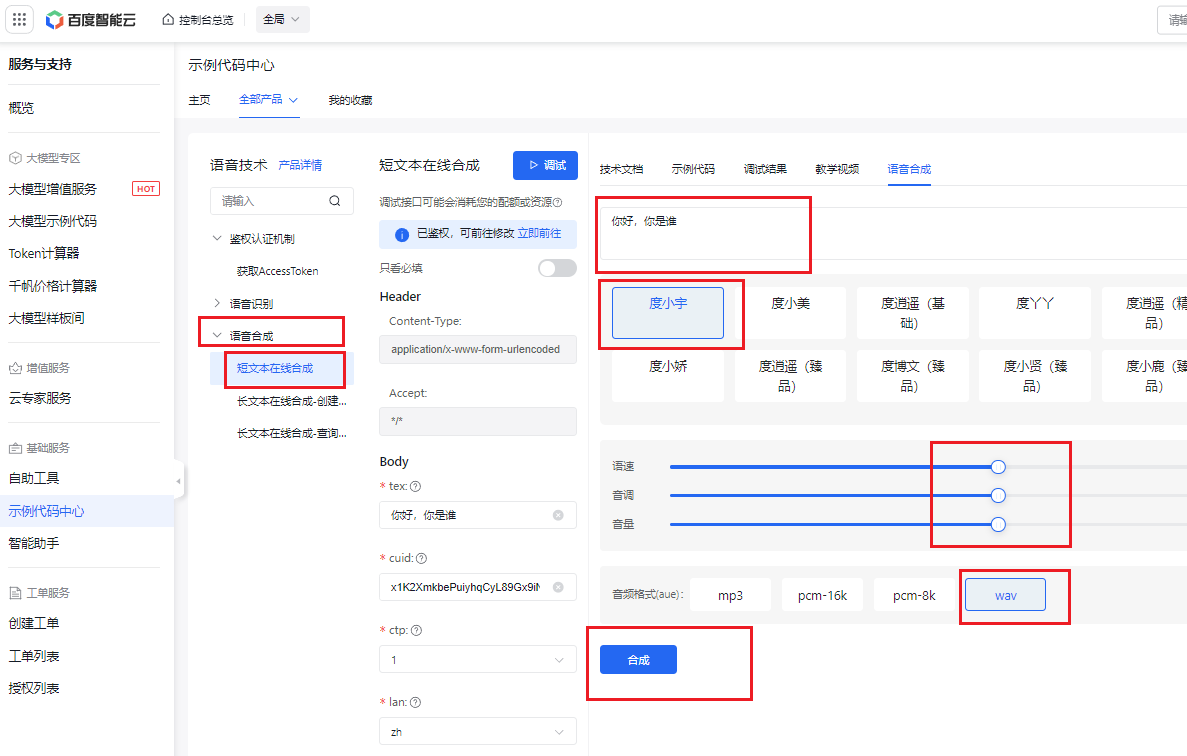
- 接着测试语音合成api服务接口是否开通成功。我们点击 语音合成->短文本在线合成,然后填写需要合成音频的文本,选择音色,调整语速、音调、音量,选择音频格式wav,点击 合成。
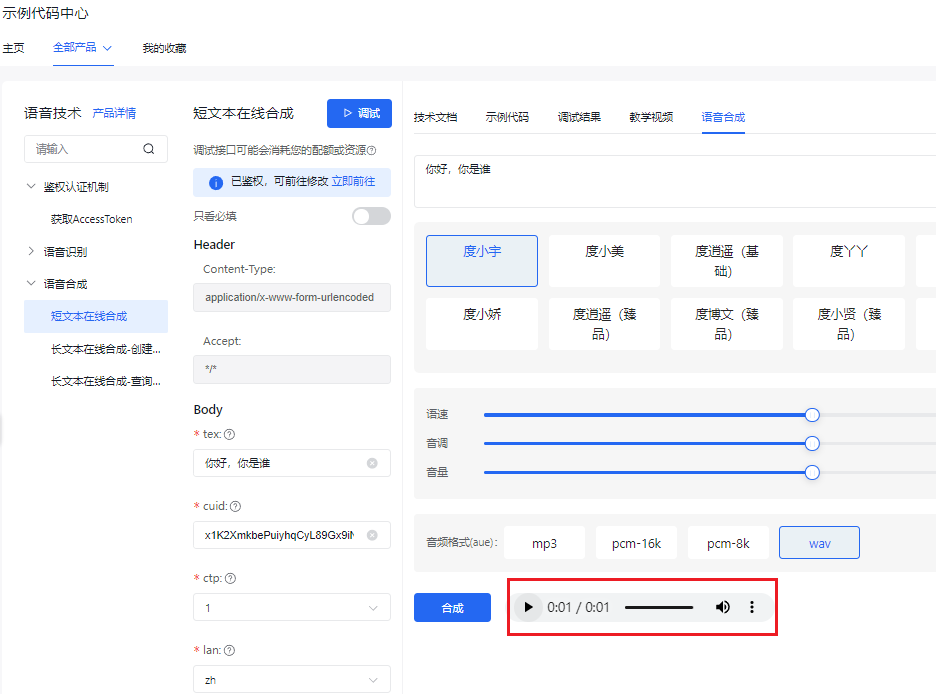
- 生成合成的音频,点击 播放按钮,可以查看生成的音频是否正确。(这里可以点击后面的3个点,将这个音频保存下来,作为后面的语音识别输入使用)
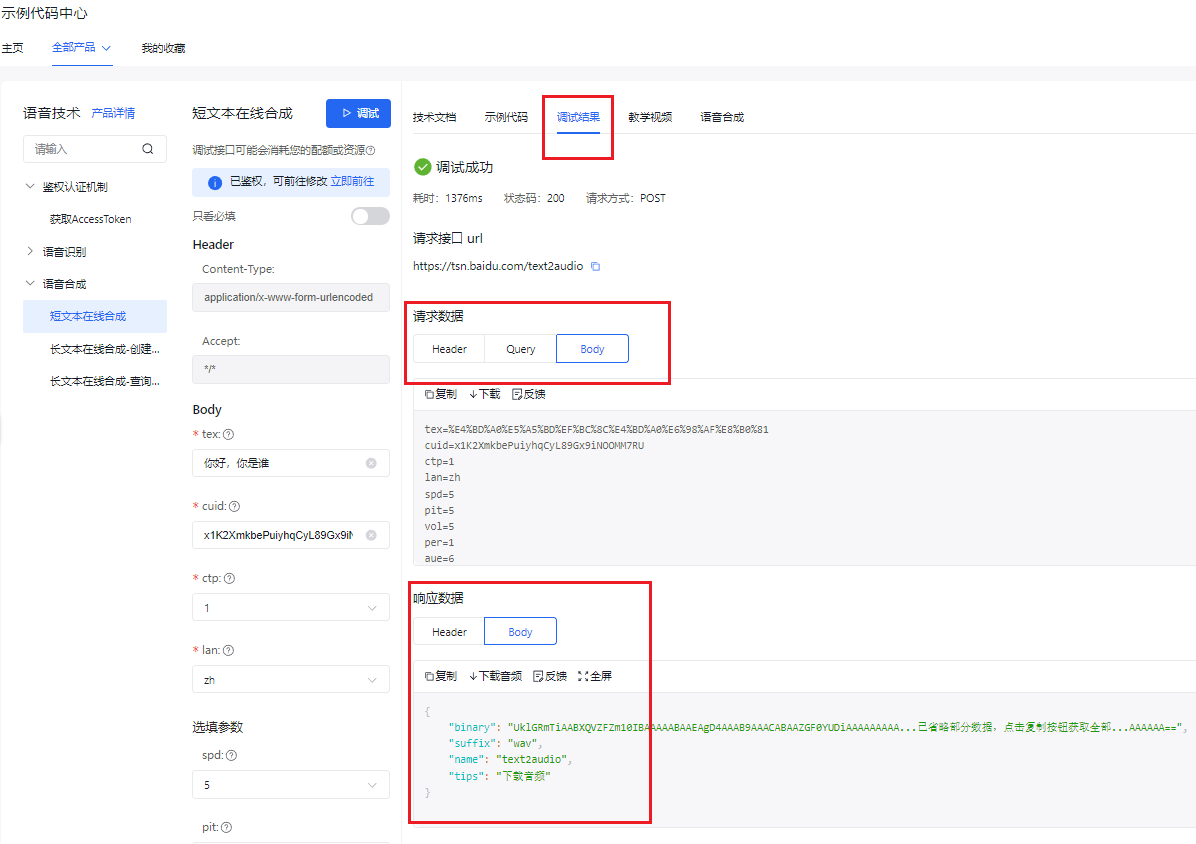
- 点击 调试结果,可以查看请求数据及响应数据包。至此,我们可以通过这样的方式去测试我们的语音合成api服务是否开通成功。
- 点击 示例代码,可以查看各种语言平台的api调用代码实现。通过这个我们就可以在其他的平台上调用百度的api服务。
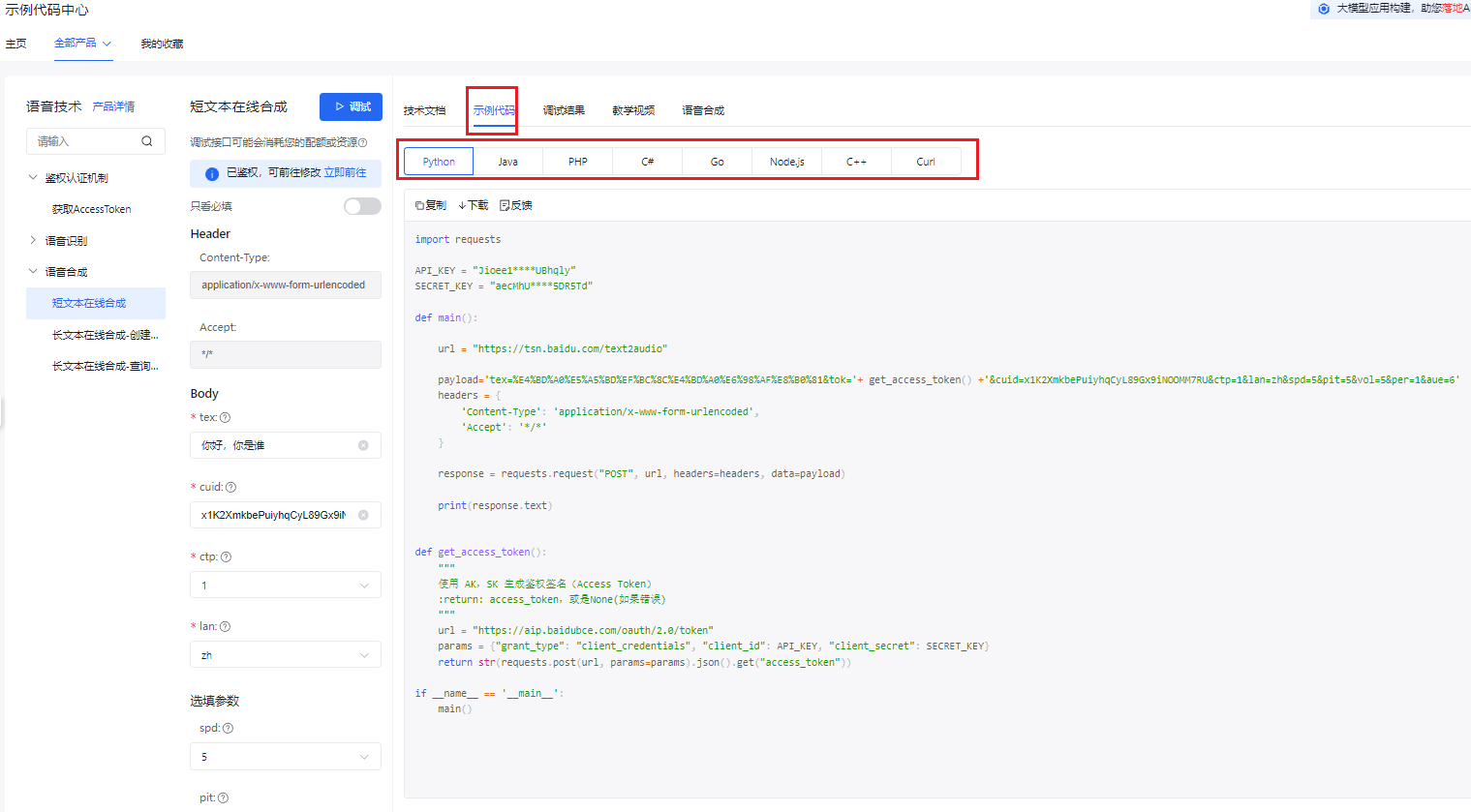
语音识别
- 点击 语音识别->短语音识别标准版,点击 上传文件,上传上一节语音合成的音频文件,其他的参数都为默认都可以。
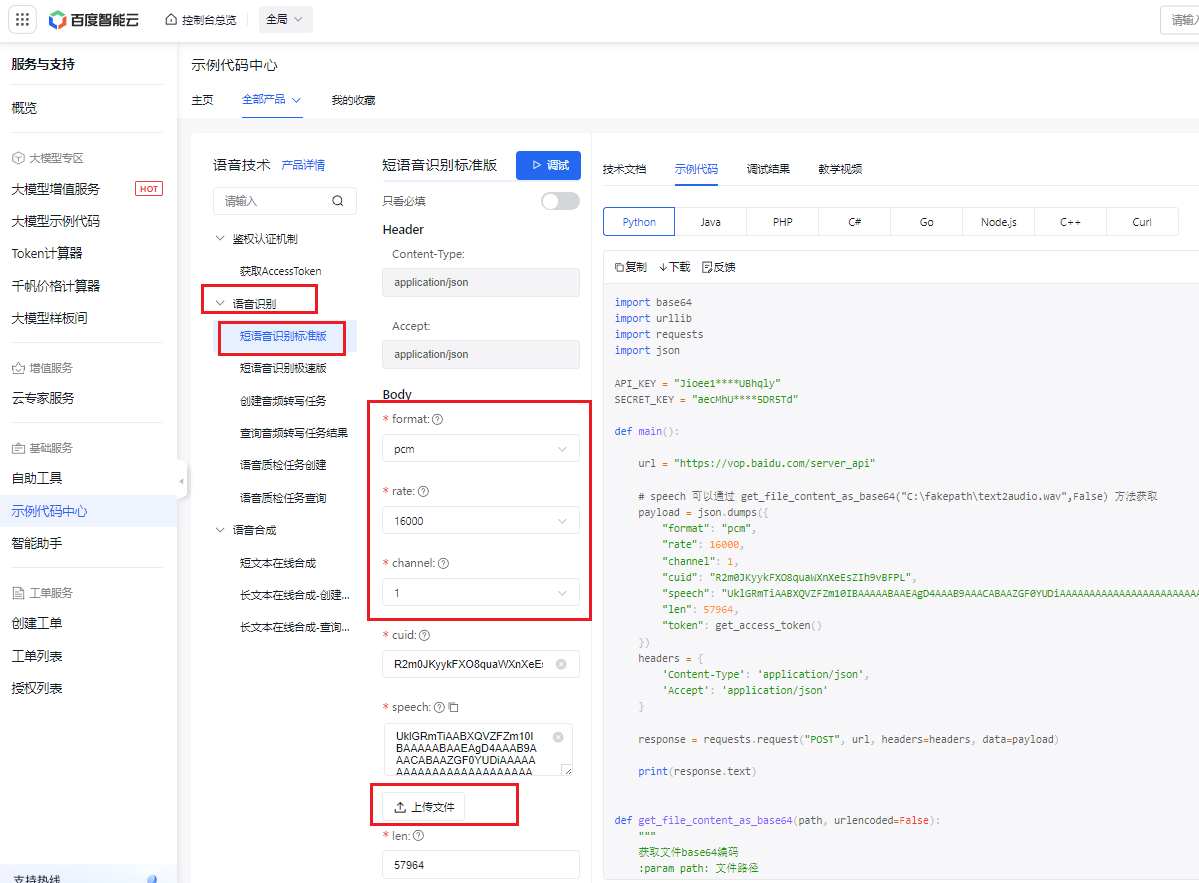
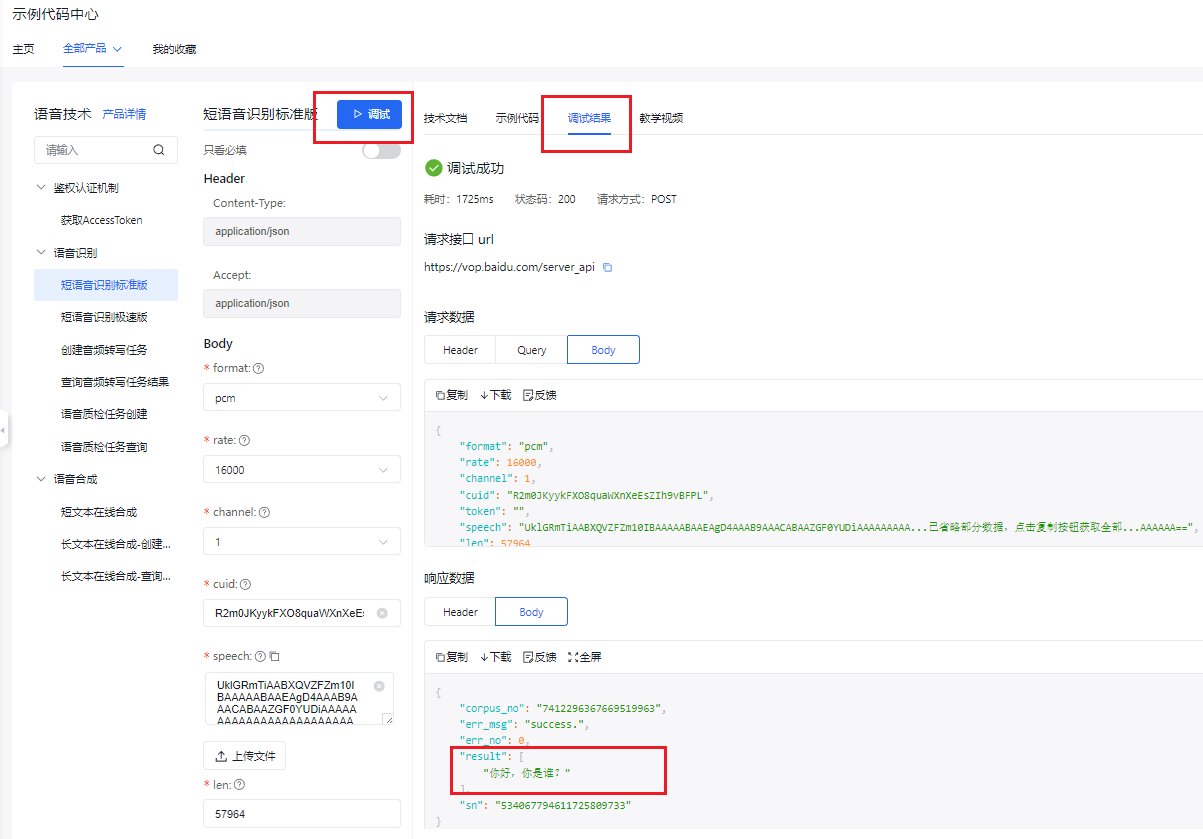
- 点击 调试,运行成功,查看 调试结果,可以从响应数据中查看语音识别是否正确。至此,我们可以通过这样的方式去测试我们的语音识别api服务是否开通成功。
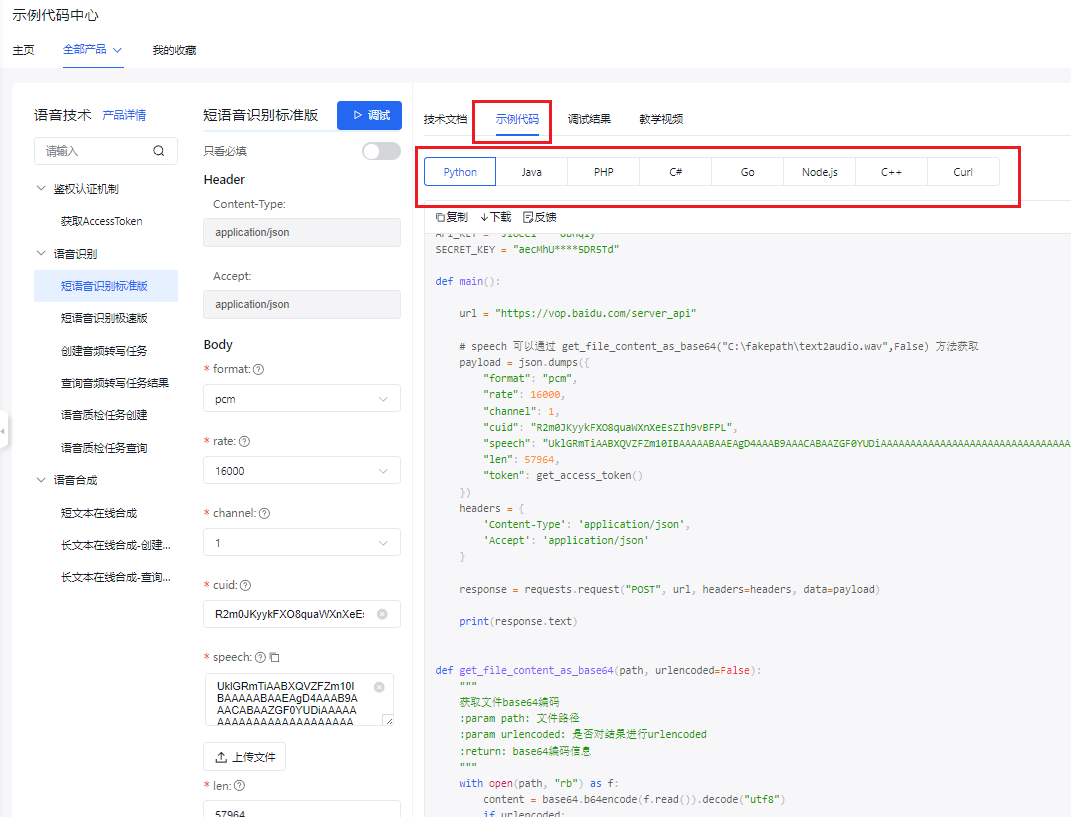
- 同样,点击 示例代码,这里有各种编程语言的api调用实现。
4.3API访问Apipost测试(可选推荐工具)
api访问有一个通用的工具,这个工具用的比较广泛,可以专门测试api访问接口服务是否正常的。
- 下载链接:https://www.apipost.cn/
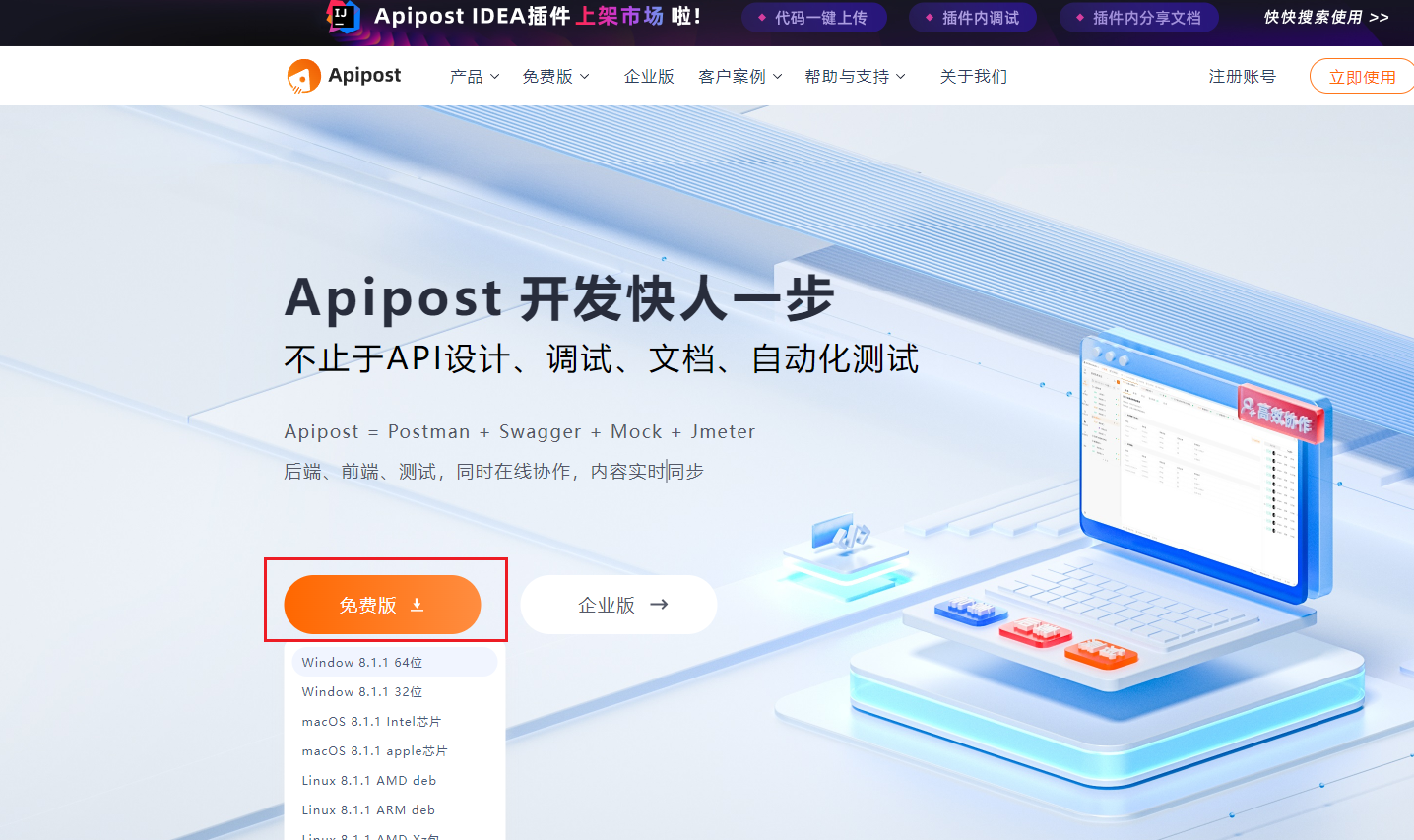
- 下载后安装成功,进入软件如下图。
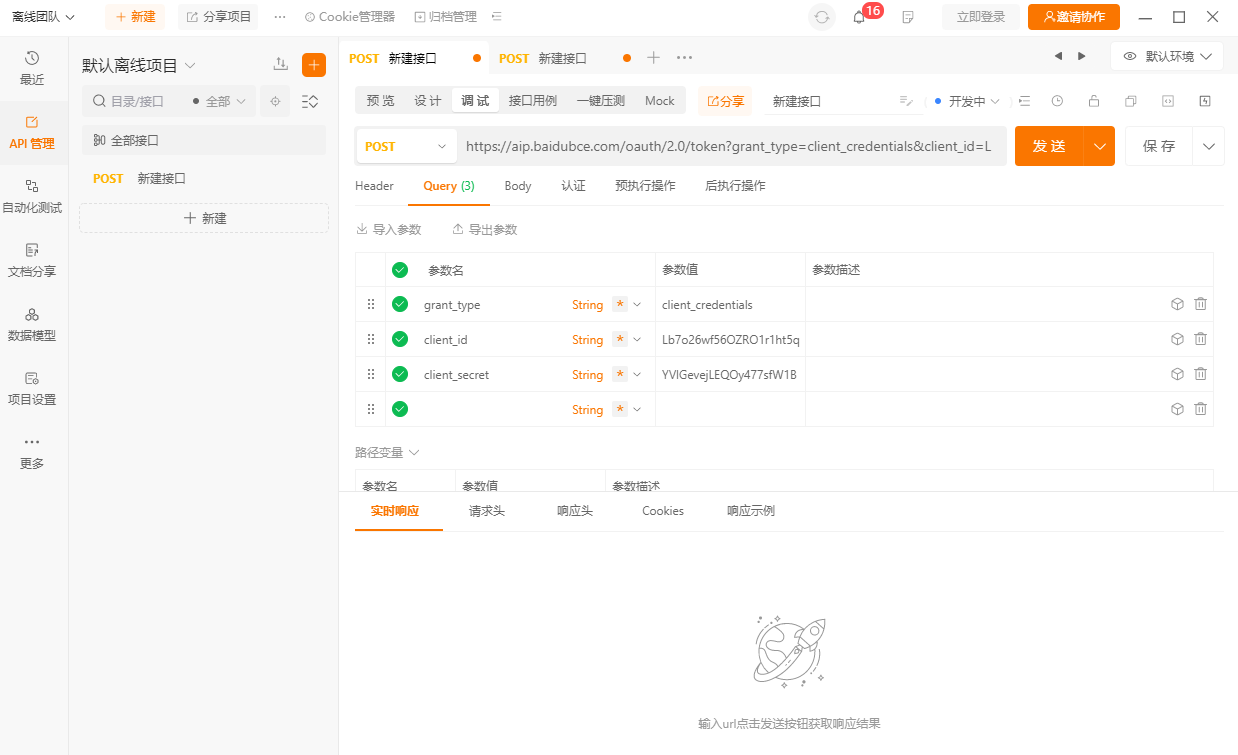
- 这里以上一节百度api鉴权访问,获取access_token为例进行说明。apipost中的配置参数的格式去参考上一节中的示例代码访问。
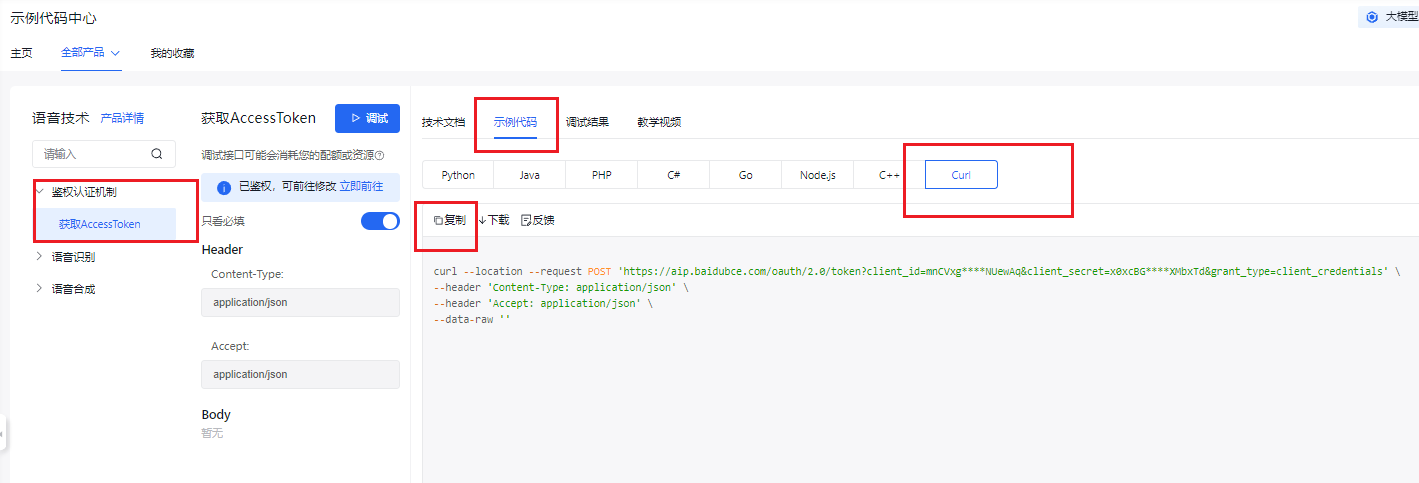
点击 示例代码->Curl->复制 代码。
- 点击 API管理,点击“+”,curl导入。
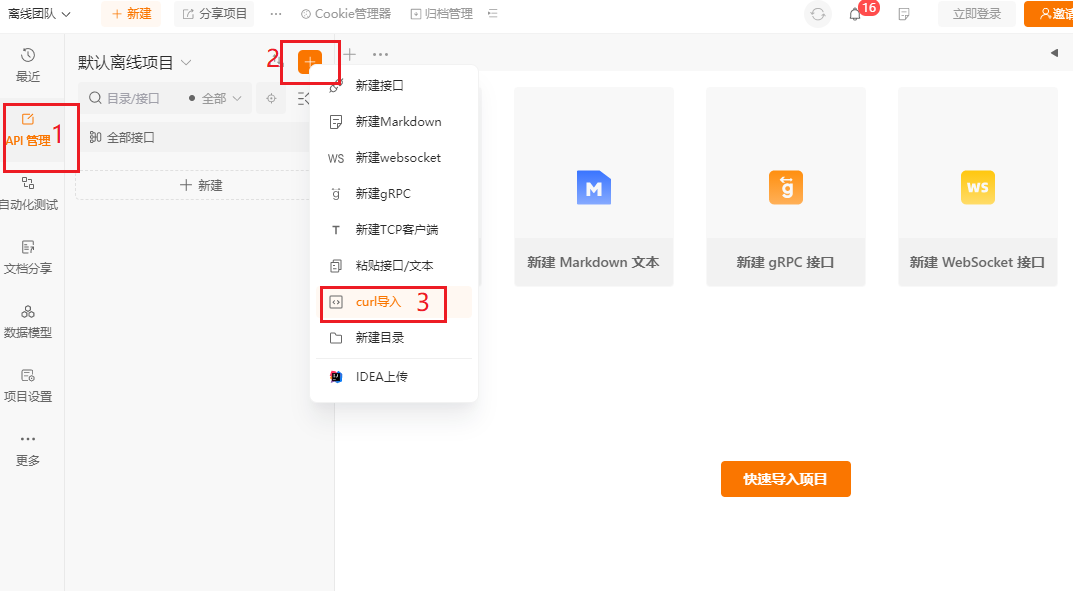
- 粘贴 复制的代码,点击 立即导入。
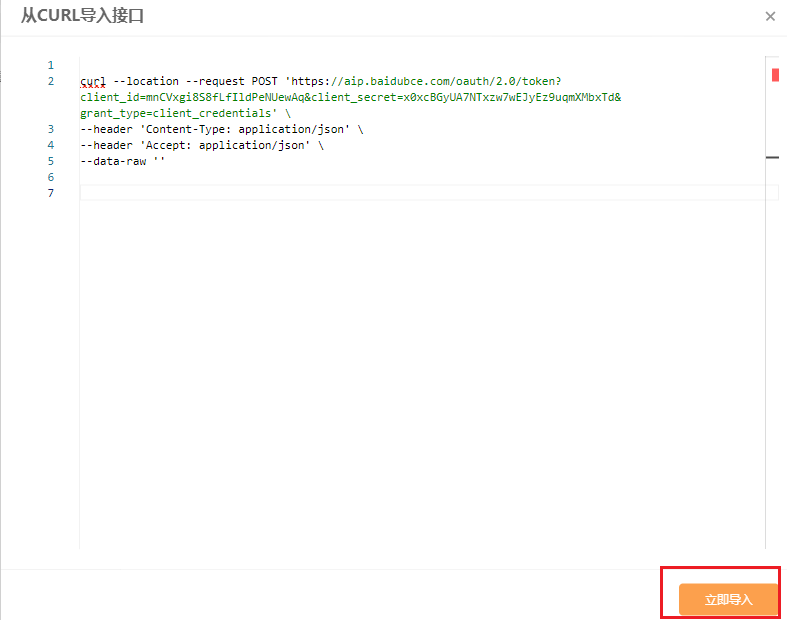
- 点击 发送。
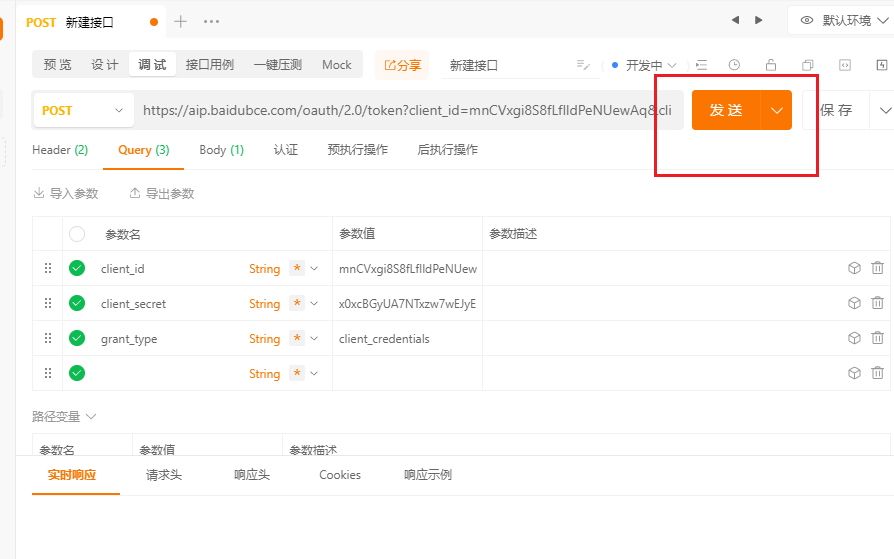
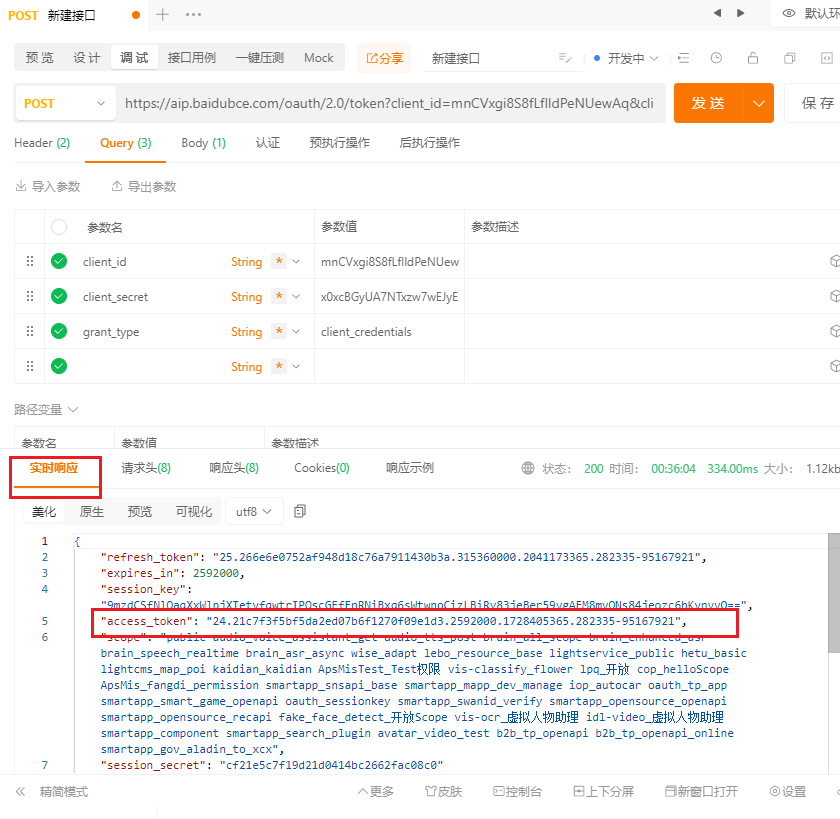
- 从 实时响应中,查看响应的结果数据。至此,我们通过apipost的方式去测试了api的访问是否成功。
5、运行AI Agent角色扮演主程序
5.1AI Agent角色扮演主程序的运行
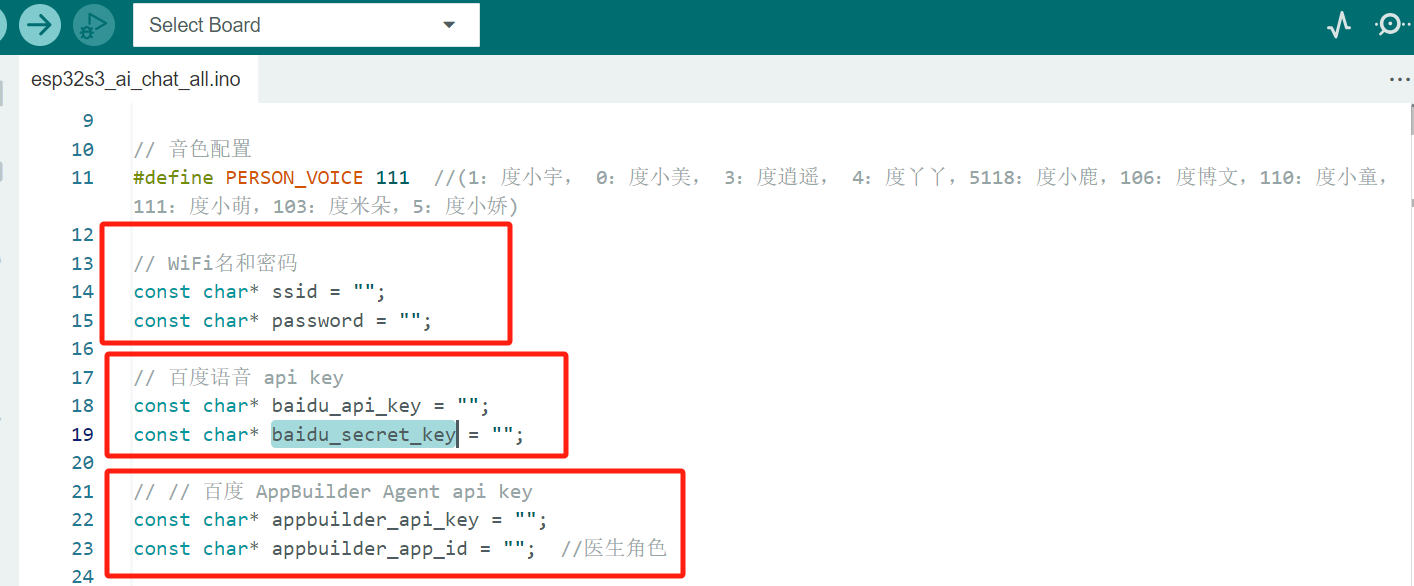
AI Agent角色扮演主程序的工程在**esp32s3-ai-chat\ai-all\esp32s3_ai_chat_all\esp32s3_ai_chat_all.ino**,我们直接打开工程,修改wifi及api key等配置信息后,编译代码,烧写代码到板子中进行测试。
- 修改wifi名称,将当前wifi的ssid、password赋值到对应的位置,填写api key,根据第4章操作获取api key。
- 开启psram。
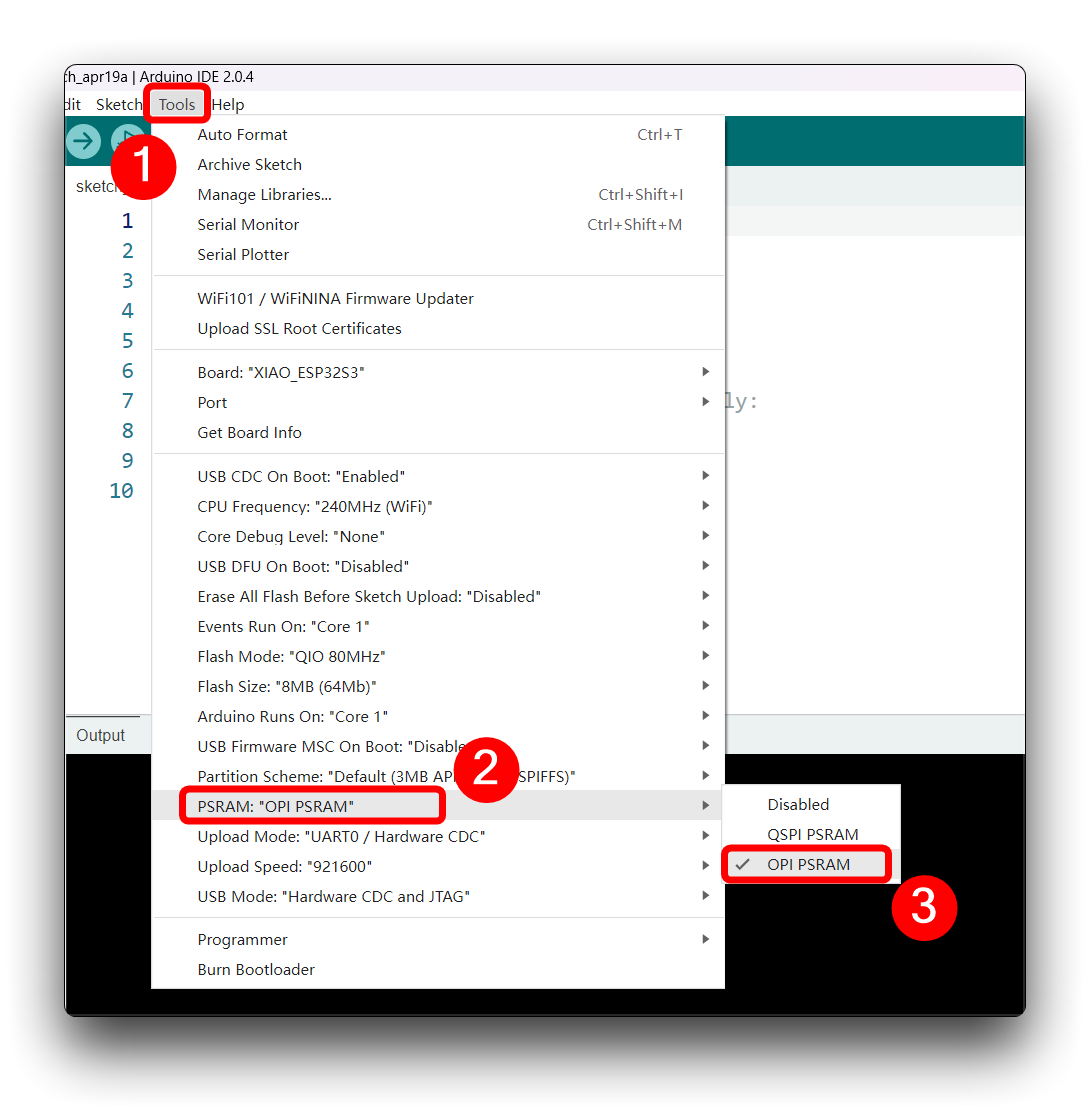
- 开发板端口选择
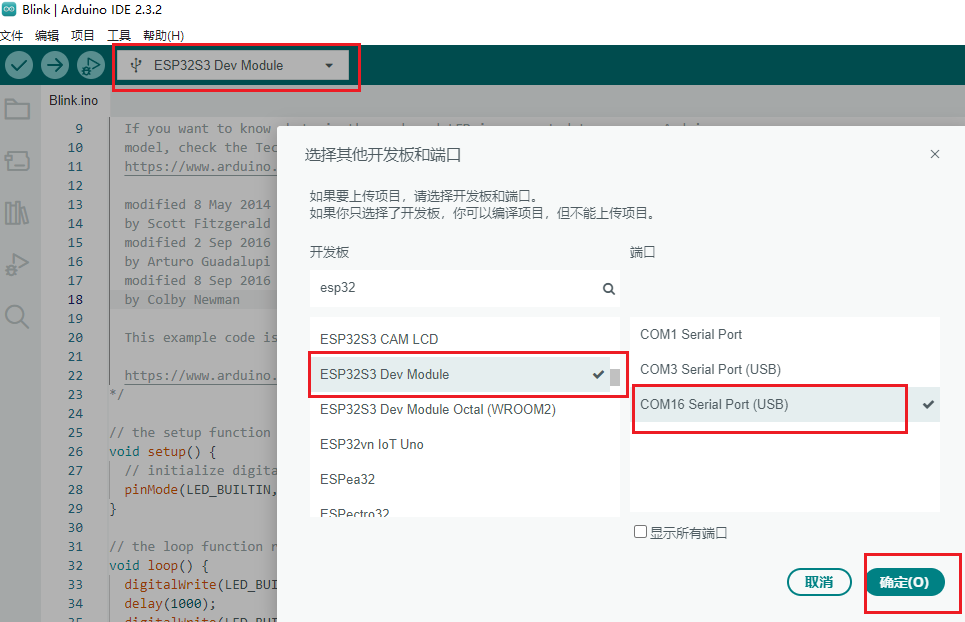
点击上方的开发板选择栏,选择开发板和端口,开发板选择ESP32S3 Dev Module,端口选择USB typeC连接后的串口显示的对应串口(可通过设备管理器查看)。
- 编译下载。
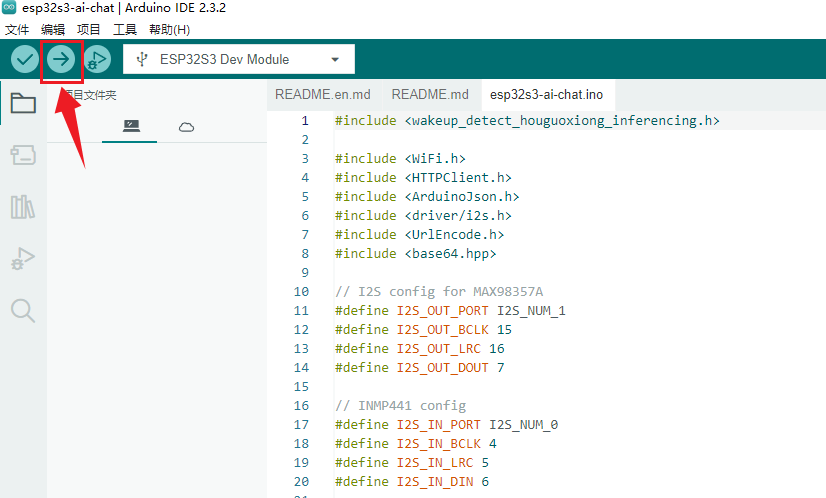
- 语音对话测试。
用 “houguoxiong” 唤醒ESP32-S3进行对话。或者直接触摸屏幕(一直触摸进行录音,松开就结束录音,系统开始将录音进行语音识别及大模型访问之类的流程),唤醒ESP32-S3进行对话。
5.2整体软件流程
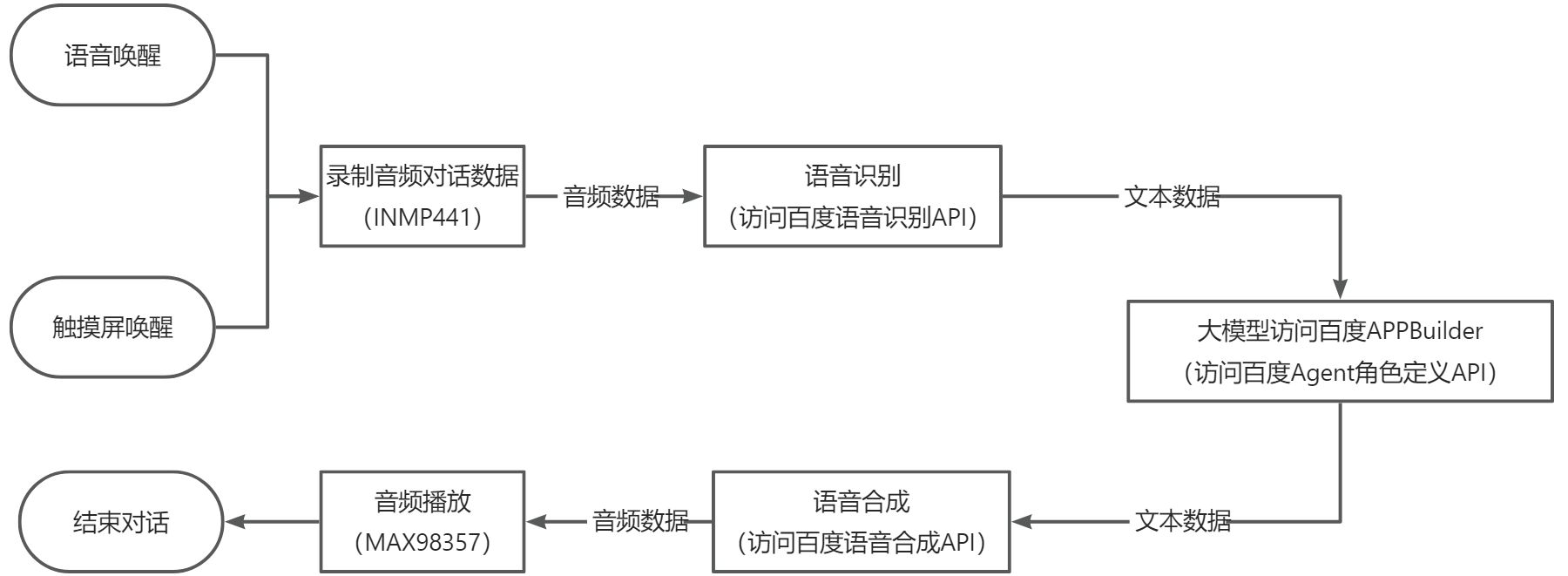
5.3主要模块的实现和代码分析
唤醒词语音唤醒
该模块主要实现自己训练的唤醒词唤醒的功能。**esp32s3-ai-chat/example/wake_detect**这个工程主要就是实现唤醒词唤醒的功能。基于这个工程,我们可以在此基础上进行AI语音聊天的开发。
整体代码实现:
#include <wakeup_detect_houguoxiong_inferencing.h>/* Edge Impulse Arduino examples* Copyright (c) 2022 EdgeImpulse Inc.** Permission is hereby granted, free of charge, to any person obtaining a copy* of this software and associated documentation files (the "Software"), to deal* in the Software without restriction, including without limitation the rights* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell* copies of the Software, and to permit persons to whom the Software is* furnished to do so, subject to the following conditions:** The above copyright notice and this permission notice shall be included in* all copies or substantial portions of the Software.** THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE* SOFTWARE.*/// If your target is limited in memory remove this macro to save 10K RAM
#define EIDSP_QUANTIZE_FILTERBANK 0/*** NOTE: If you run into TFLite arena allocation issue.**** This may be due to may dynamic memory fragmentation.** Try defining "-DEI_CLASSIFIER_ALLOCATION_STATIC" in boards.local.txt (create** if it doesn't exist) and copy this file to** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.**** See** (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)** to find where Arduino installs cores on your machine.**** If the problem persists then there's not enough memory for this model and application.*//* Includes ---------------------------------------------------------------- */
#include <driver/i2s.h>#define SAMPLE_RATE 16000U
#define LED_BUILT_IN 21// INMP441 config
#define I2S_IN_PORT I2S_NUM_0
#define I2S_IN_BCLK 4
#define I2S_IN_LRC 5
#define I2S_IN_DIN 6/** Audio buffers, pointers and selectors */
typedef struct {int16_t *buffer;uint8_t buf_ready;uint32_t buf_count;uint32_t n_samples;
} inference_t;static inference_t inference;
static const uint32_t sample_buffer_size = 2048;
static signed short sampleBuffer[sample_buffer_size];
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static bool record_status = true;/*** @brief Arduino setup function*/
void setup() {// put your setup code here, to run once:Serial.begin(115200);// comment out the below line to cancel the wait for USB connection (needed for native USB)while (!Serial);Serial.println("Edge Impulse Inferencing Demo");pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as outputdigitalWrite(LED_BUILT_IN, HIGH); //Turn off// Initialize I2S for audio inputi2s_config_t i2s_config_in = {.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),.sample_rate = SAMPLE_RATE,.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, // 注意:INMP441 输出 32 位数据.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,.communication_format = i2s_comm_format_t(I2S_COMM_FORMAT_STAND_I2S),.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,.dma_buf_count = 8,.dma_buf_len = 1024,};i2s_pin_config_t pin_config_in = {.bck_io_num = I2S_IN_BCLK,.ws_io_num = I2S_IN_LRC,.data_out_num = -1,.data_in_num = I2S_IN_DIN};i2s_driver_install(I2S_IN_PORT, &i2s_config_in, 0, NULL);i2s_set_pin(I2S_IN_PORT, &pin_config_in);// summary of inferencing settings (from model_metadata.h)ei_printf("Inferencing settings:\n");ei_printf("\tInterval: ");ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);ei_printf(" ms.\n");ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));ei_printf("\nStarting continious inference in 2 seconds...\n");ei_sleep(2000);if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);return;}ei_printf("Recording...\n");
}/*** @brief Arduino main function. Runs the inferencing loop.*/
void loop() {bool m = microphone_inference_record();if (!m) {ei_printf("ERR: Failed to record audio...\n");return;}signal_t signal;signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;signal.get_data = µphone_audio_signal_get_data;ei_impulse_result_t result = { 0 };EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);if (r != EI_IMPULSE_OK) {ei_printf("ERR: Failed to run classifier (%d)\n", r);return;}int pred_index = 0; // Initialize pred_indexfloat pred_value = 0; // Initialize pred_value// print the predictionsei_printf("Predictions ");ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",result.timing.dsp, result.timing.classification, result.timing.anomaly);ei_printf(": \n");for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {ei_printf(" %s: ", result.classification[ix].label);ei_printf_float(result.classification[ix].value);ei_printf("\n");if (result.classification[ix].value > pred_value) {pred_index = ix;pred_value = result.classification[ix].value;}}// Display inference resultif (pred_index == 3) {digitalWrite(LED_BUILT_IN, LOW); //Turn on} else {digitalWrite(LED_BUILT_IN, HIGH); //Turn off}#if EI_CLASSIFIER_HAS_ANOMALY == 1ei_printf(" anomaly score: ");ei_printf_float(result.anomaly);ei_printf("\n");
#endif
}static void audio_inference_callback(uint32_t n_bytes) {for (int i = 0; i < n_bytes >> 1; i++) {inference.buffer[inference.buf_count++] = sampleBuffer[i];if (inference.buf_count >= inference.n_samples) {inference.buf_count = 0;inference.buf_ready = 1;}}
}static void capture_samples(void *arg) {const int32_t i2s_bytes_to_read = (uint32_t)arg;size_t bytes_read = i2s_bytes_to_read;while (record_status) {/* read data at once from i2s - Modified for XIAO ESP2S3 Sense and I2S.h library */i2s_read(I2S_IN_PORT, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);// esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void *)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);if (bytes_read <= 0) {ei_printf("Error in I2S read : %d", bytes_read);} else {if (bytes_read < i2s_bytes_to_read) {ei_printf("Partial I2S read");}// scale the data (otherwise the sound is too quiet)for (int x = 0; x < i2s_bytes_to_read / 2; x++) {sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;}if (record_status) {audio_inference_callback(i2s_bytes_to_read);} else {break;}}}vTaskDelete(NULL);
}/*** @brief Init inferencing struct and setup/start PDM** @param[in] n_samples The n samples** @return { description_of_the_return_value }*/
static bool microphone_inference_start(uint32_t n_samples) {inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));if (inference.buffer == NULL) {return false;}inference.buf_count = 0;inference.n_samples = n_samples;inference.buf_ready = 0;// if (i2s_init(EI_CLASSIFIER_FREQUENCY)) {// ei_printf("Failed to start I2S!");// }ei_sleep(100);record_status = true;xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void *)sample_buffer_size, 10, NULL);return true;
}/*** @brief Wait on new data** @return True when finished*/
static bool microphone_inference_record(void) {bool ret = true;while (inference.buf_ready == 0) {delay(10);}inference.buf_ready = 0;return ret;
}/*** Get raw audio signal data*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);return 0;
}/*** @brief Stop PDM and release buffers*/
static void microphone_inference_end(void) {free(sampleBuffer);ei_free(inference.buffer);
}#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endif
下面进行各模块代码的介绍:
- 这个是自己训练好的唤醒词模型库的头文件,需要引用到工程中。
#include <wakeup_detect_houguotongxue_inferencing.h>
- 初始化麦克风NMP441的i2s的配置。
// Initialize I2S for audio inputi2s_config_t i2s_config_in = {.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),.sample_rate = SAMPLE_RATE,.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, // 注意:INMP441 输出 32 位数据.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,.communication_format = i2s_comm_format_t(I2S_COMM_FORMAT_STAND_I2S),.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,.dma_buf_count = 8,.dma_buf_len = 1024,};i2s_pin_config_t pin_config_in = {.bck_io_num = I2S_IN_BCLK,.ws_io_num = I2S_IN_LRC,.data_out_num = -1,.data_in_num = I2S_IN_DIN};i2s_driver_install(I2S_IN_PORT, &i2s_config_in, 0, NULL);i2s_set_pin(I2S_IN_PORT, &pin_config_in);
- 这个是唤醒词识别接口的初始化。
// summary of inferencing settings (from model_metadata.h)ei_printf("Inferencing settings:\n");ei_printf("\tInterval: ");ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);ei_printf(" ms.\n");ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));ei_printf("\nStarting continious inference in 2 seconds...\n");ei_sleep(2000);if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);return;}
- 这个初始化的函数主要就是创建了一个freeRTOS的task,task主要为实时采集音频数据。
static bool microphone_inference_start(uint32_t n_samples) {inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));if (inference.buffer == NULL) {return false;}inference.buf_count = 0;inference.n_samples = n_samples;inference.buf_ready = 0;ei_sleep(100);record_status = true;xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void *)sample_buffer_size, 10, NULL);return true;
}
- 实时采集音频数据的task,将采集到的数据存储到一个全局的数据变量sampleBuffer中去。
static void capture_samples(void *arg) {const int32_t i2s_bytes_to_read = (uint32_t)arg;size_t bytes_read = i2s_bytes_to_read;while (record_status) {/* read data at once from i2s - Modified for XIAO ESP2S3 Sense and I2S.h library */i2s_read(I2S_IN_PORT, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);// esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void *)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);if (bytes_read <= 0) {ei_printf("Error in I2S read : %d", bytes_read);} else {if (bytes_read < i2s_bytes_to_read) {ei_printf("Partial I2S read");}// scale the data (otherwise the sound is too quiet)for (int x = 0; x < i2s_bytes_to_read / 2; x++) {sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;}if (record_status) {audio_inference_callback(i2s_bytes_to_read);} else {break;}}}vTaskDelete(NULL);
}
- 将缓存到sampleBuffer变量中的数据复制到inference数据结构体中去,这个结构体用于后面的分类函数的输入参数。到此,音频输入的数据准备的代码实现已经完成。
static void audio_inference_callback(uint32_t n_bytes) {for (int i = 0; i < n_bytes >> 1; i++) {inference.buffer[inference.buf_count++] = sampleBuffer[i];if (inference.buf_count >= inference.n_samples) {inference.buf_count = 0;inference.buf_ready = 1;}}
}
- 接下来看具体的分类。
void loop() {bool m = microphone_inference_record();if (!m) {ei_printf("ERR: Failed to record audio...\n");return;}signal_t signal;signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;signal.get_data = µphone_audio_signal_get_data;ei_impulse_result_t result = { 0 };EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);if (r != EI_IMPULSE_OK) {ei_printf("ERR: Failed to run classifier (%d)\n", r);return;}int pred_index = 0; // Initialize pred_indexfloat pred_value = 0; // Initialize pred_value// print the predictionsei_printf("Predictions ");ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",result.timing.dsp, result.timing.classification, result.timing.anomaly);ei_printf(": \n");for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {ei_printf(" %s: ", result.classification[ix].label);ei_printf_float(result.classification[ix].value);ei_printf("\n");if (result.classification[ix].value > pred_value) {pred_index = ix;pred_value = result.classification[ix].value;}}// Display inference resultif (pred_index == 3) {digitalWrite(LED_BUILT_IN, LOW); //Turn on} else {digitalWrite(LED_BUILT_IN, HIGH); //Turn off}#if EI_CLASSIFIER_HAS_ANOMALY == 1ei_printf(" anomaly score: ");ei_printf_float(result.anomaly);ei_printf("\n");
#endif
}
- 在loop主循环中,主要是对采集到的音频数据进行分类预测。microphone_audio_signal_get_data获取之前存储的音频数据,然后调用run_classifier(&signal, &result, debug_nn),计算出分类的预测值。在模型训练时候,训练有几个标签的数据,这里result就会返回对应几个标签的预测结果。
- result.classification[ix].value预测值越接近1.0的标签,则表示当前识别的是相应的标签。当说出我们训练的唤醒词时,对应的唤醒词预测值也会接近1.0,从而实现唤醒。
- 我们可以进行一个阈值来与result.classification[ix].value进行比较来判断是否唤醒成功,控制这个比较的阈值大小,则可以控制识别的灵敏程度。至此,整个唤醒流程的代码实现结束。
百度API访问的access_token获取
在访问百度的语音识别、语音合成、文心一言大模型时,都需要提供access_token。在ESP32-S3中,我们通过创建http请求,根据access_token的api访问格式构建请求包,通过http发送请求,等待响应的数据,然后从响应的数据中解析出access_token。
整体代码实现如下:
// Get Baidu API access token
String getAccessToken(const char* api_key, const char* secret_key) {String access_token = "";HTTPClient http;// 创建http请求http.begin("https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + String(api_key) + "&client_secret=" + String(secret_key));int httpCode = http.POST("");if (httpCode == HTTP_CODE_OK) {String response = http.getString();DynamicJsonDocument doc(1024);deserializeJson(doc, response);access_token = doc["access_token"].as<String>();Serial.printf("[HTTP] GET access_token: %s\n", access_token);} else {Serial.printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());}http.end();return access_token;
}
在这里,我们需要先在百度智能云网站上申请api_key、secret_key,参考第5章节的操作方式。然后将api_key、secret_key作为输入参数,根据api访问格式,发送http.POST请求,然后从响应数据中解析出access_token。
百度语音识别API访问
在ESP32-S3通过i2s采集INMP441的音频数据后,需要将采集的音频数据流识别为文本模式,因此需要调用语音识别API实现实时的语音识别,这里我们采用了百度的语音识别API访问。
主要代码实现如下:
String baiduSTT_Send(String access_token, uint8_t* audioData, int audioDataSize) {String recognizedText = "";if (access_token == "") {Serial.println("access_token is null");return recognizedText;}// audio数据包许愿哦进行Base64编码,数据量会增大1/3int audio_data_len = audioDataSize * sizeof(char) * 1.4;unsigned char* audioDataBase64 = (unsigned char*)ps_malloc(audio_data_len);if (!audioDataBase64) {Serial.println("Failed to allocate memory for audioDataBase64");return recognizedText;}// json包大小,由于需要将audioData数据进行Base64的编码,数据量会增大1/3int data_json_len = audioDataSize * sizeof(char) * 1.4;char* data_json = (char*)ps_malloc(data_json_len);if (!data_json) {Serial.println("Failed to allocate memory for data_json");return recognizedText;}// Base64 encode audio dataencode_base64(audioData, audioDataSize, audioDataBase64);memset(data_json, '\0', data_json_len);strcat(data_json, "{");strcat(data_json, "\"format\":\"pcm\",");strcat(data_json, "\"rate\":16000,");strcat(data_json, "\"dev_pid\":1537,");strcat(data_json, "\"channel\":1,");strcat(data_json, "\"cuid\":\"57722200\",");strcat(data_json, "\"token\":\"");strcat(data_json, access_token.c_str());strcat(data_json, "\",");sprintf(data_json + strlen(data_json), "\"len\":%d,", audioDataSize);strcat(data_json, "\"speech\":\"");strcat(data_json, (const char*)audioDataBase64);strcat(data_json, "\"");strcat(data_json, "}");// 创建http请求HTTPClient http_client;http_client.begin("http://vop.baidu.com/server_api");http_client.addHeader("Content-Type", "application/json");int httpCode = http_client.POST(data_json);if (httpCode > 0) {if (httpCode == HTTP_CODE_OK) {// 获取返回结果String response = http_client.getString();Serial.println(response);// 从json中解析对应的resultDynamicJsonDocument responseDoc(2048);deserializeJson(responseDoc, response);recognizedText = responseDoc["result"].as<String>();}} else {Serial.printf("[HTTP] POST failed, error: %s\n", http_client.errorToString(httpCode).c_str());}// 释放内存if (audioDataBase64) {free(audioDataBase64);}if (data_json) {free(data_json);}http_client.end();return recognizedText;
}
下面对上面代码重点地方进行分析说明:
- 这里json包的buffer创建需要为输入数据的1.4倍左右,因为需要进行base64的编码作为输入。这里分配的内存比较大,因此需要从psram中分配。
// audio数据包许愿哦进行Base64编码,数据量会增大1/3int audio_data_len = audioDataSize * sizeof(char) * 1.4;unsigned char* audioDataBase64 = (unsigned char*)ps_malloc(audio_data_len);if (!audioDataBase64) {Serial.println("Failed to allocate memory for audioDataBase64");return recognizedText;}// json包大小,由于需要将audioData数据进行Base64的编码,数据量会增大1/3int data_json_len = audioDataSize * sizeof(char) * 1.4;char* data_json = (char*)ps_malloc(data_json_len);if (!data_json) {Serial.println("Failed to allocate memory for data_json");return recognizedText;}
- 这里根据api调用文档的格式进行打包,需要注意的是len为原始的数据大小,不是base64编码后的数据大小。
// Base64 encode audio dataencode_base64(audioData, audioDataSize, audioDataBase64);memset(data_json, '\0', data_json_len);strcat(data_json, "{");strcat(data_json, "\"format\":\"pcm\",");strcat(data_json, "\"rate\":16000,");strcat(data_json, "\"dev_pid\":1537,");strcat(data_json, "\"channel\":1,");strcat(data_json, "\"cuid\":\"57722200\",");strcat(data_json, "\"token\":\"");strcat(data_json, access_token.c_str());strcat(data_json, "\",");sprintf(data_json + strlen(data_json), "\"len\":%d,", audioDataSize);strcat(data_json, "\"speech\":\"");strcat(data_json, (const char*)audioDataBase64);strcat(data_json, "\"");strcat(data_json, "}");
- 这里,响应数据的json文档要足够大,够响应的返回数据的大小。
// 从json中解析对应的result
DynamicJsonDocument responseDoc(2048);
deserializeJson(responseDoc, response);
recognizedText = responseDoc["result"].as<String>();
百度Agent 角色定义API访问
语音识别会以文本的格式返回识别的结果,然后我们可以用这个作为百度大模型Agent的api的输入。大模型api的调用代码实现如下:
// Get Baidu API conversation id
String getConversation_id(const char* api_key, const char* app_id) {String conversation_id = "";// 创建http请求HTTPClient http;http.begin("https://qianfan.baidubce.com/v2/app/conversation");http.addHeader("Content-Type", "application/json");http.addHeader("X-Appbuilder-Authorization", "Bearer " + String(api_key));// 创建一个 JSON 文档DynamicJsonDocument requestJson(1024);requestJson["app_id"] = app_id;// 将 JSON 数据序列化为字符串String requestBody;serializeJson(requestJson, requestBody);// 发送http访问请求int httpCode = http.POST(requestBody);if (httpCode == HTTP_CODE_OK) {String response = http.getString();DynamicJsonDocument doc(1024);deserializeJson(doc, response);conversation_id = doc["conversation_id"].as<String>();ei_printf("[HTTP] GET conversation_id: %s\n", conversation_id.c_str());} else {ei_printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());}http.end();return conversation_id;
}
百度语音合成API访问
从百度文心一言api返回的文本数据,我们需要通过扬声器播放出来,因此需要将文本数据转化为音频数据输出。这里我们通过调用百度语音合成api接口,实现文本转音频的功能。主要代码实现如下:
void baiduTTS_Send(String access_token, String text) {if (access_token == "") {Serial.println("access_token is null");return;}if (text.length() == 0) {Serial.println("text is null");return;}const int per = 1;const int spd = 5;const int pit = 5;const int vol = 10;const int aue = 6;// 进行 URL 编码String encodedText = urlEncode(urlEncode(text));// URL http请求数据封装String url = "https://tsn.baidu.com/text2audio";const char* header[] = { "Content-Type", "Content-Length" };url += "?tok=" + access_token;url += "&tex=" + encodedText;url += "&per=" + String(per);url += "&spd=" + String(spd);url += "&pit=" + String(pit);url += "&vol=" + String(vol);url += "&aue=" + String(aue);url += "&cuid=esp32s3";url += "&lan=zh";url += "&ctp=1";// http请求创建HTTPClient http;http.begin(url);http.collectHeaders(header, 2);// http请求int httpResponseCode = http.GET();if (httpResponseCode > 0) {if (httpResponseCode == HTTP_CODE_OK) {String contentType = http.header("Content-Type");Serial.println(contentType);if (contentType.startsWith("audio")) {Serial.println("合成成功");// 获取返回的音频数据流Stream* stream = http.getStreamPtr();uint8_t buffer[512];size_t bytesRead = 0;// 设置timeout为200ms 避免最后出现杂音stream->setTimeout(200);while (http.connected() && (bytesRead = stream->readBytes(buffer, sizeof(buffer))) > 0) {// 音频输出playAudio(buffer, bytesRead);delay(1);}// 清空I2S DMA缓冲区clearAudio();} else if (contentType.equals("application/json")) {Serial.println("合成出现错误");} else {Serial.println("未知的Content-Type");}} else {Serial.println("Failed to receive audio file");}} else {Serial.print("Error code: ");Serial.println(httpResponseCode);}http.end();
}// Play audio data using MAX98357A
void playAudio(uint8_t* audioData, size_t audioDataSize) {if (audioDataSize > 0) {// 发送size_t bytes_written = 0;i2s_write(I2S_OUT_PORT, (int16_t*)audioData, audioDataSize, &bytes_written, portMAX_DELAY);}
}void clearAudio(void) {// 清空I2S DMA缓冲区i2s_zero_dma_buffer(I2S_OUT_PORT);Serial.print("clearAudio");
}
下面对上面代码重点地方进行分析说明:
- 这里是进行两次的url编码,参考的官网api调用文档说明的推荐方式。
// 进行 URL 编码String encodedText = urlEncode(urlEncode(text));
- http的请求包封装,根据api调用格式进行参数设置
// URL http请求数据封装String url = "https://tsn.baidu.com/text2audio";const char* header[] = { "Content-Type", "Content-Length" };url += "?tok=" + access_token;url += "&tex=" + encodedText;url += "&per=" + String(per);url += "&spd=" + String(spd);url += "&pit=" + String(pit);url += "&vol=" + String(vol);url += "&aue=" + String(aue);url += "&cuid=esp32s3";url += "&lan=zh";url += "&ctp=1";// http请求创建HTTPClient http;http.begin(url);http.collectHeaders(header, 2);
- 这里是对http api请求的最大超时时间的设置,系统库默认为1s,但是在喇叭播报的最后会出现颤音现象,因此需要在这里将超时时间减小。
// 设置timeout为200ms 避免最后出现杂音
stream->setTimeout(200);
- 这里是获取http音频流数据,在while中需要加入delay的处理,不然这里会占用系统,其他的task运行不了,比如音频录制、唤醒任务都不能运行,导致在音频输出时唤醒不了,因此这里我们做一个释放cpu的处理。
while (http.connected() && (bytesRead = stream->readBytes(buffer, sizeof(buffer))) > 0) {// 音频输出playAudio(buffer, bytesRead);delay(1);
}
- 这个是清除i2s dma的缓冲区数据,消除杂音的作用。
void clearAudio(void) {// 清空I2S DMA缓冲区i2s_zero_dma_buffer(I2S_OUT_PORT);Serial.print("clearAudio");
}
6、训练自己的唤醒词(进阶)
6.1音频录制
硬件准备
需要准备以下硬件:
- AI集成套件
- microSD卡(不大于32GB)
- microSD读卡器
microSD卡格式化
- 将microSD卡装进读卡器中,并连接至电脑,将microSD卡**格式化为FAT32格式**。如下图:
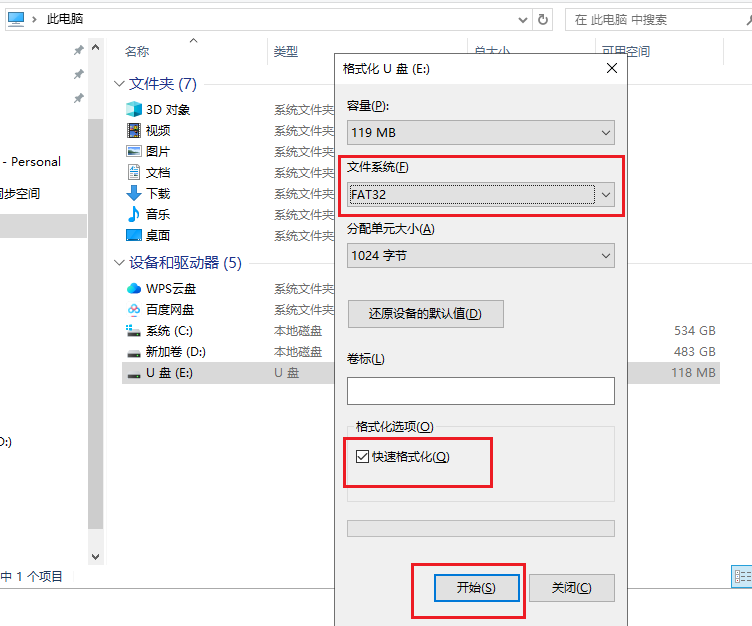
- 格式化完成后,将microSD卡装到AI集成套件的卡槽中去。
开始录制音频数据
我们通过烧写录制音频软件到ESP32-S3中进行录制音频数据,录制的音频数据会保存到microSD卡中,然后我们可以通过电脑去读取出来。
烧写录制音频软件到ESP32-S3
音频录制软件工程在**esp32s3-ai-chat/example/capture_audio_data** 下。打开工程文件,在工程编译前,我们使用到了psram,因此需要**打开psram启动开关**,如下图所示,设置好后编译并且烧录到ESP32-S3中去。
串口发送标签进行录制音频
- 程序运行之后,正常运行的串口日志如下图。
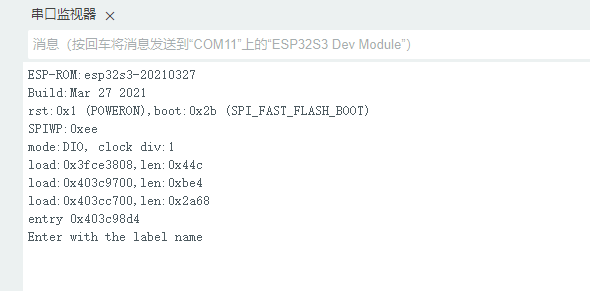
- 程序运行正常后,我们就可以开始打开串口助手工具,发送相应的控制指令进行音频录制。发送“hgx”标签。
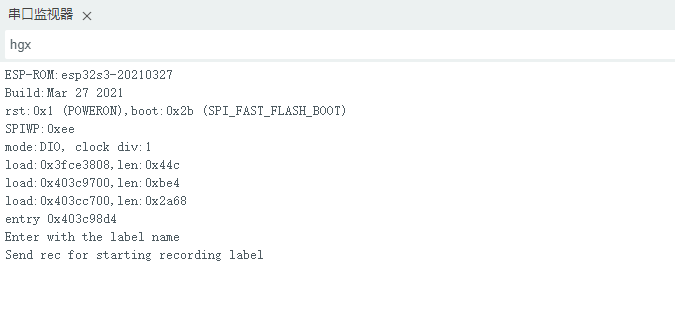
- 发送“rec”录制指令,开始录制一次。
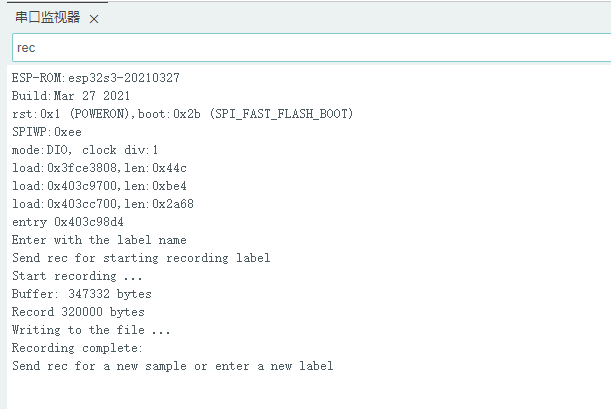
- 发送**标签(例如:hgx)后,程序将等待另一个命令rec,每次发送命令rec**时,程序就会开始记录新的样本(持续录制10秒钟后自动结束),文件将保存为hgx.1.wav、hgx.2.wav、hgx.3.wav等。
- 直到发送一个新标签(例如:noise),在这种情况下,程序开始记录一个新标签样本,当你同样为每个新标签样本发送命令rec时,它将开始录音并被保存为noise.1.wav、noise.2.wav、noise.3.wav等。
- 最终,我们将得到保存在SD卡上的所有录制的标签样本文件,可以在电脑上通过读卡器读取到SD卡上的所有音频数据。如下图所示:
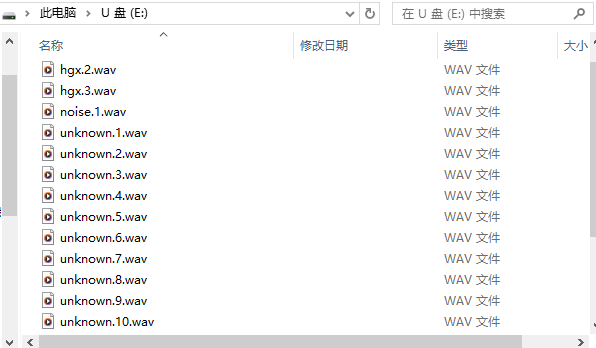
各标签样本的音频录制方法
至少录制**3个标签的样本数据,唤醒词标签样本、噪音标签样本、未知标签样本,每个标签样本数据各自最少录制10组**,数据越多,训练后的模型识别能力越好。
- 唤醒词标签样本:在录制的10秒钟内,对着麦克风不断重复的说出唤醒词,可以每次说出的语速、音调不同等,样本越丰富,识别的泛化能力越强。
- 噪音标签样本:直接录制环境声音,可以不对着麦克风讲话。
- 未知标签样本:在录制的10秒钟内,可以对着麦克风说一些其他的非唤醒词的话。
6.2训练录制的音频数据
Edge Impulse上创建工程
登录Edge Impulse,https://edgeimpulse.com/,注册账号,并创建工程。
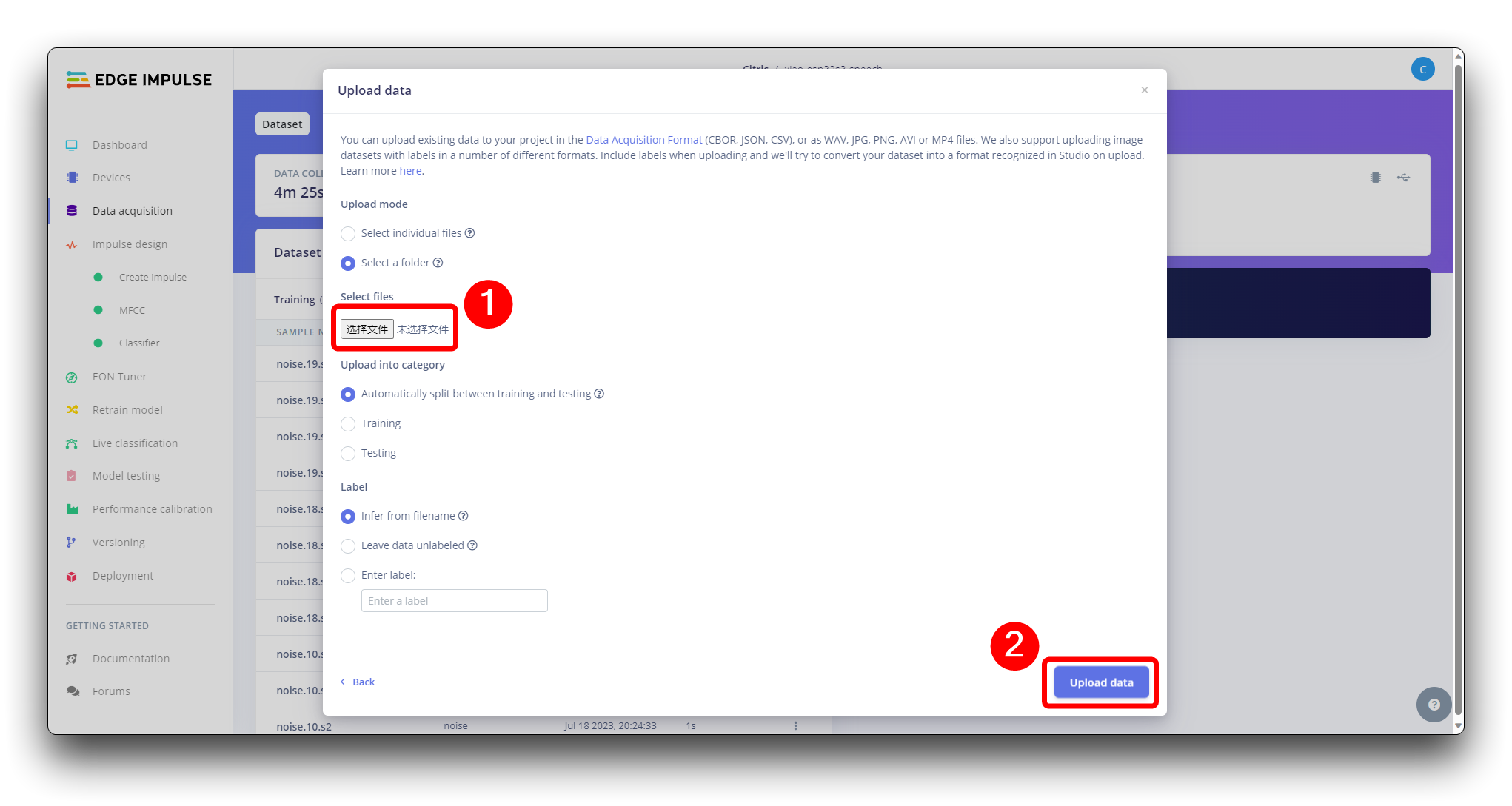
上传录制的音频数据
创建项目后,在Data Acquisition部分选择Upload Existing Data工具。选择要上传的文件。
数据上传完成后,系统会自动将它们分为Training、Test集(按照80% 20%的比例)。
分割数据集
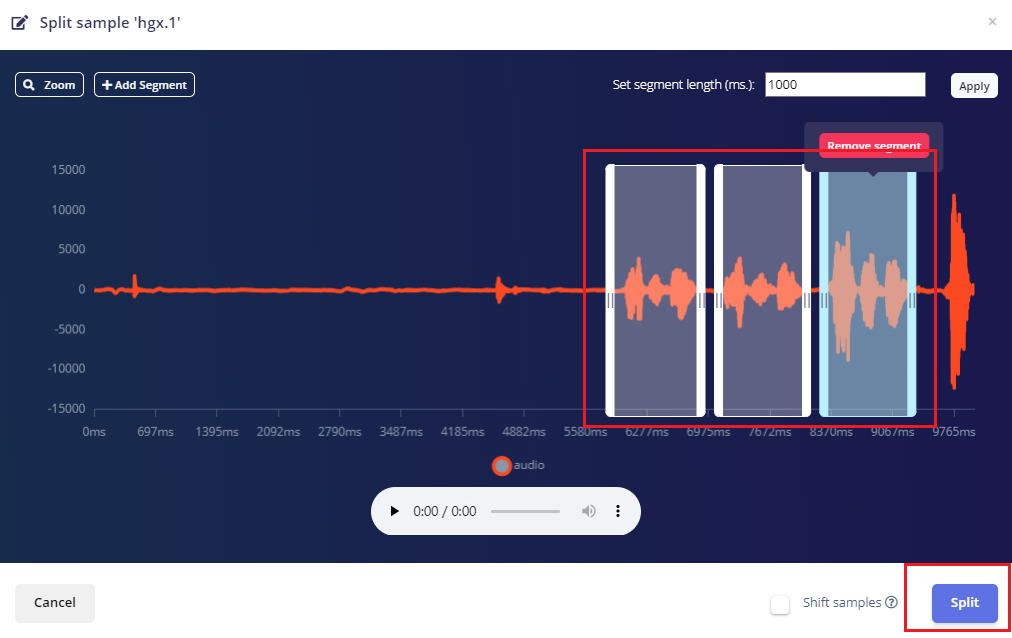
系统进行训练的数据集要求所有数据长度都是1秒,但上一节中上传的记录样本长度为10秒,必须将其拆分为1秒的样本才能兼容,因此需要对每个样本数据进行分割的操作。如下图所示:
- 点击样本名称后的三个点,并选择Split sample。
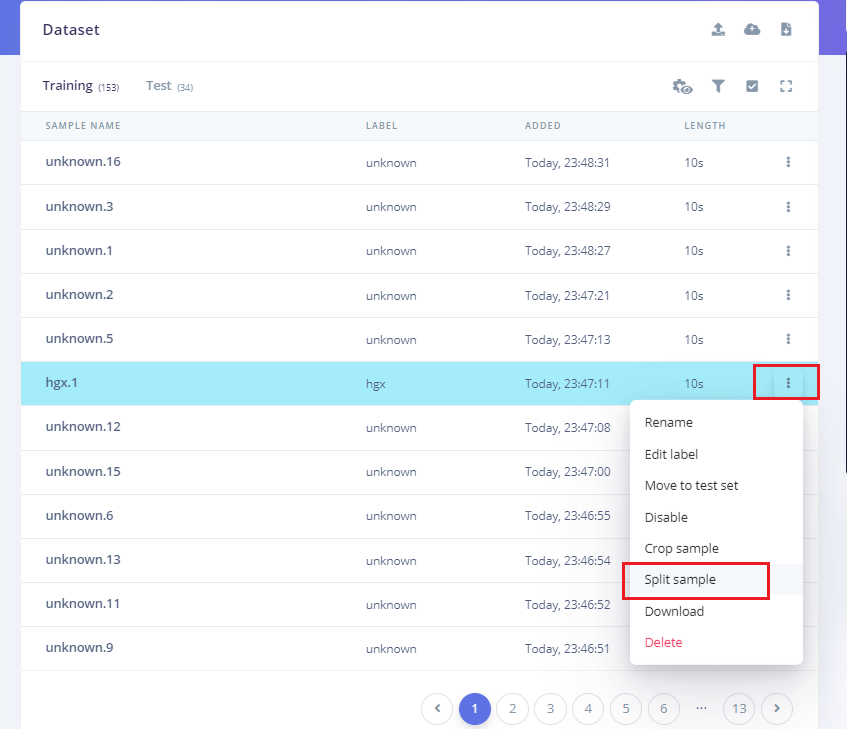
- 一旦进入该工具,将数据拆分为1秒的样本数据记录。每个矩形框就是拆分提取的一个子模块,如有必要,可以调整矩形的位置,让其完全覆盖住我们的唤醒词音频区,或者也可以做一些添加或删除片段的操作。
- 裁剪后的音频数据如下:
- 所有样本数据都应重复此操作,直到所有样本数据**(Training、Test)**都为1s长度的音频数据。
创造脉冲信号(预处理/模型定义)
创建脉冲信号,进行数据预处理和模型的选择,如下图所示:
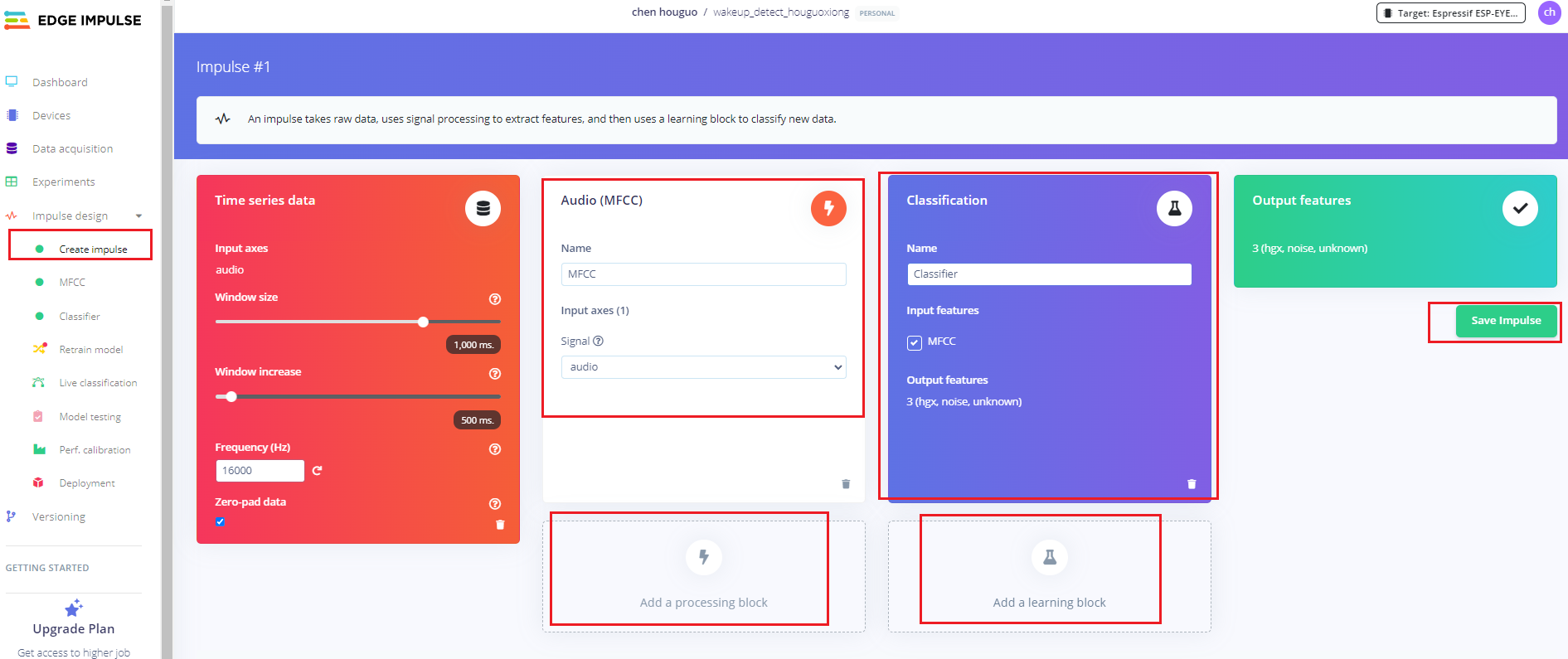
操作步骤如下:
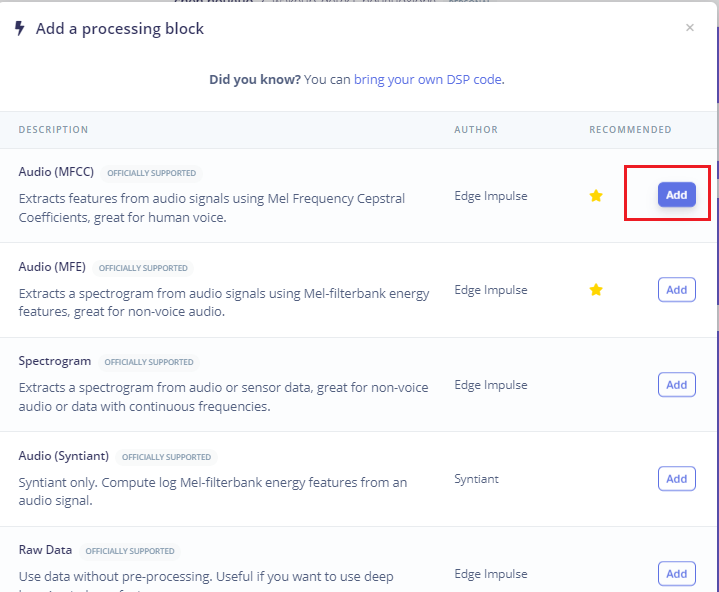
- 点击左侧Create impulse,然后点击Add a processing block添加Audio(MFCC),使用MFCC,它使用梅尔频率倒谱系数从音频信号中提取特征,这对人类声音非常有用。
- 然后点击Add a learning block添加Classification模块,它通过使用卷积神经网络进行图像分类从头开始构建我们的模型。
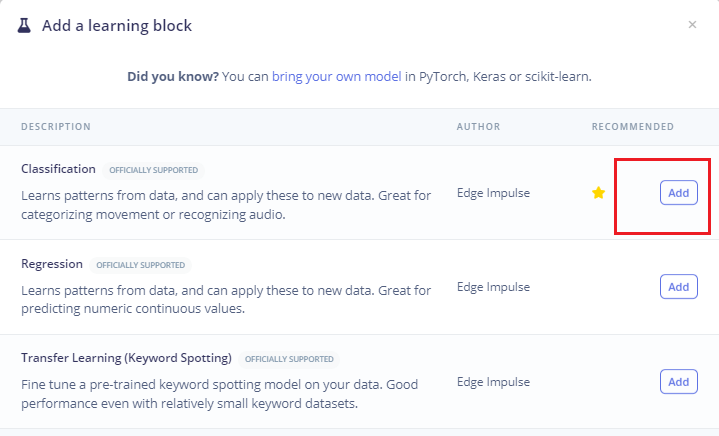
- 最后点击save impulse,保存配置。
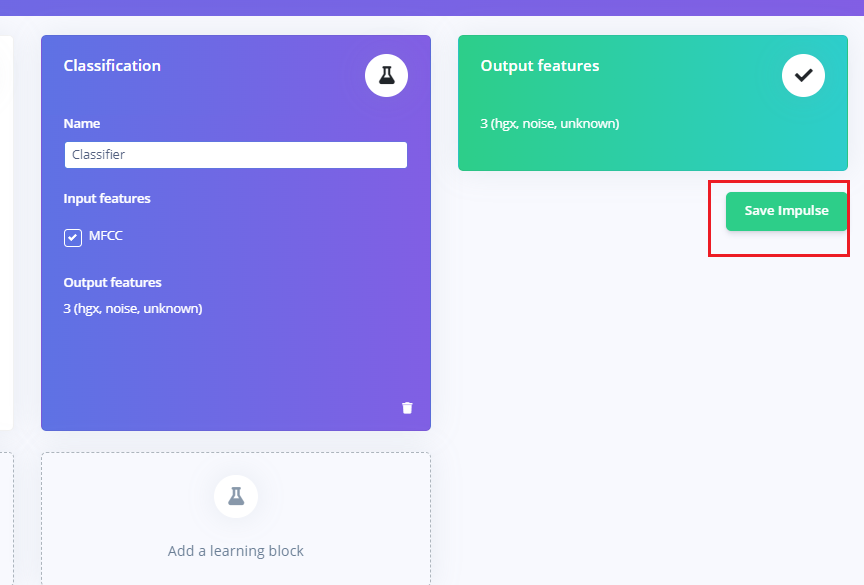
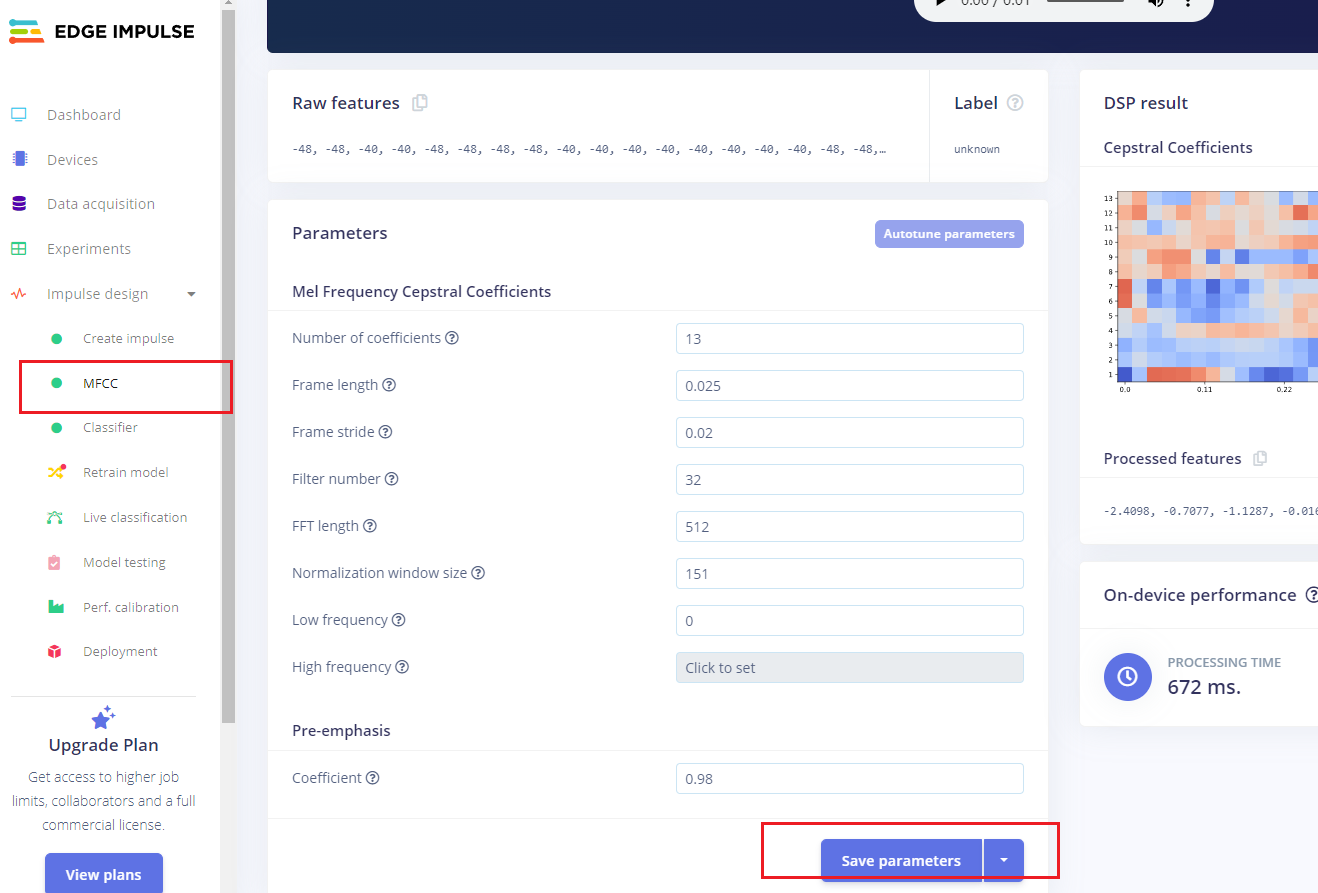
预处理(MFCC)
下一步是创建下一阶段要训练的图像。
- 点击MFCC,我们可以保留默认参数值,直接点击Save parameters。
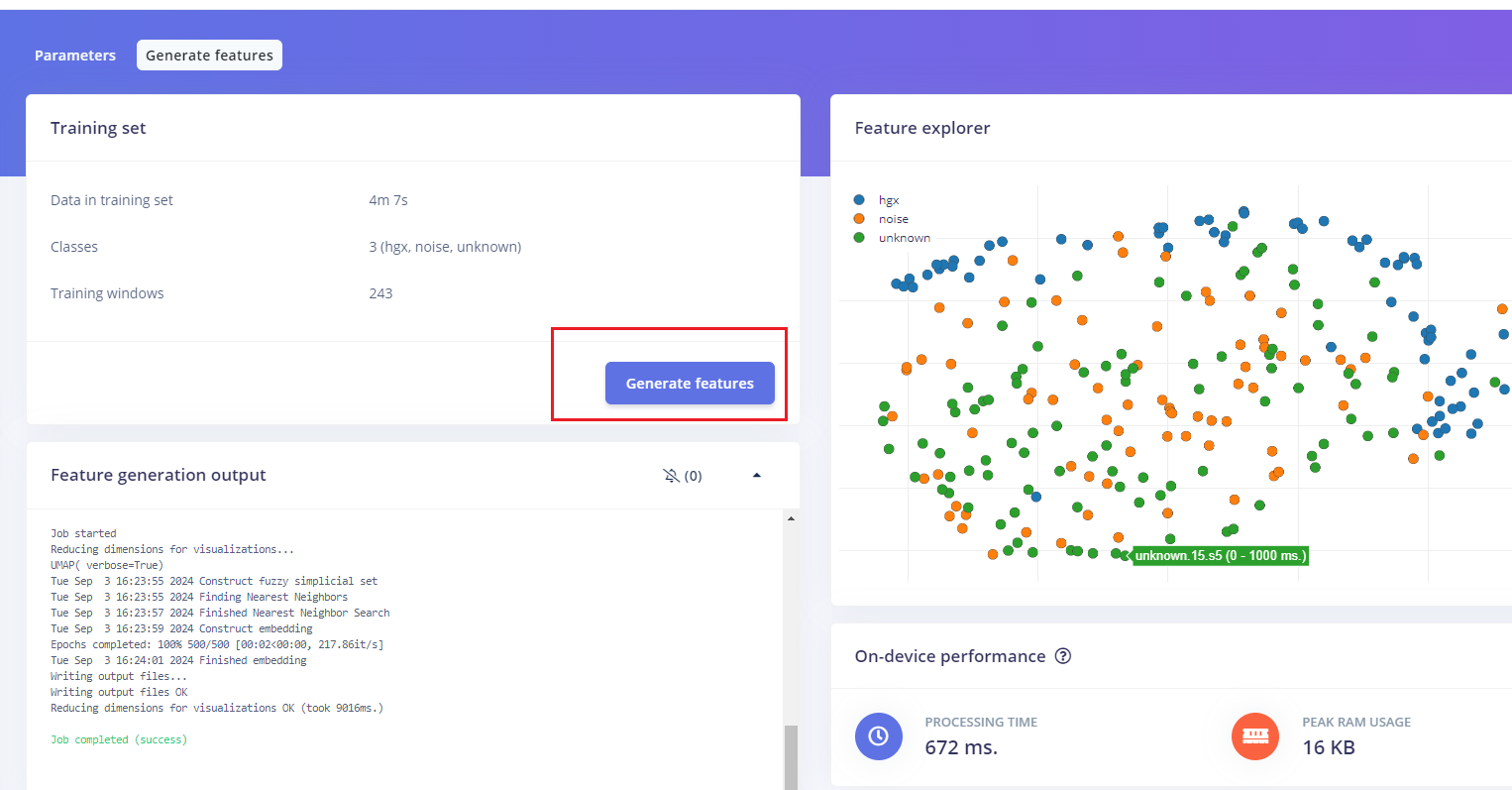
- 点击Generate features,生成3个标签数据的特征。
模型设计与训练(Classifier)
接着,我们需要对模型的结构进行设计和开始训练,步骤如下:
- 点击左侧 Classifier,整个模型的结构设计已经配置好,然后点击 save&train,开始训练模型。
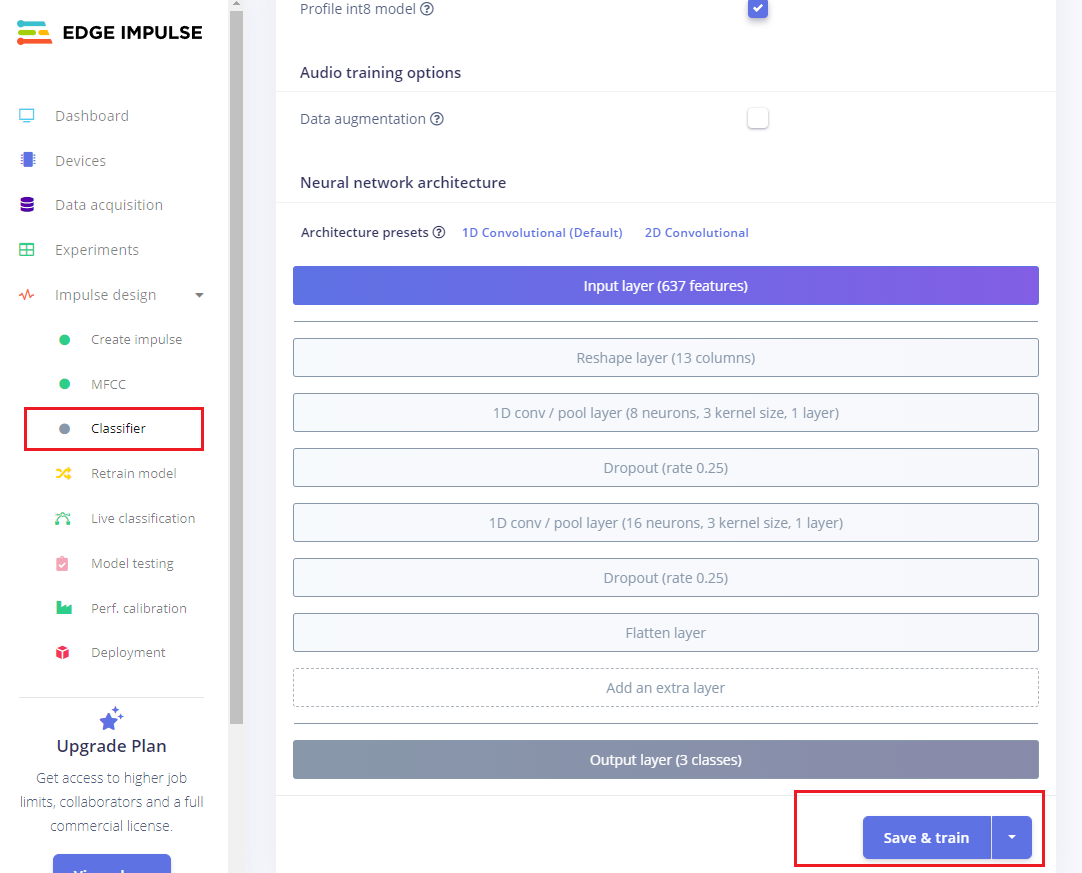
- 训练完成后,会出现如上图所示的分类结果。
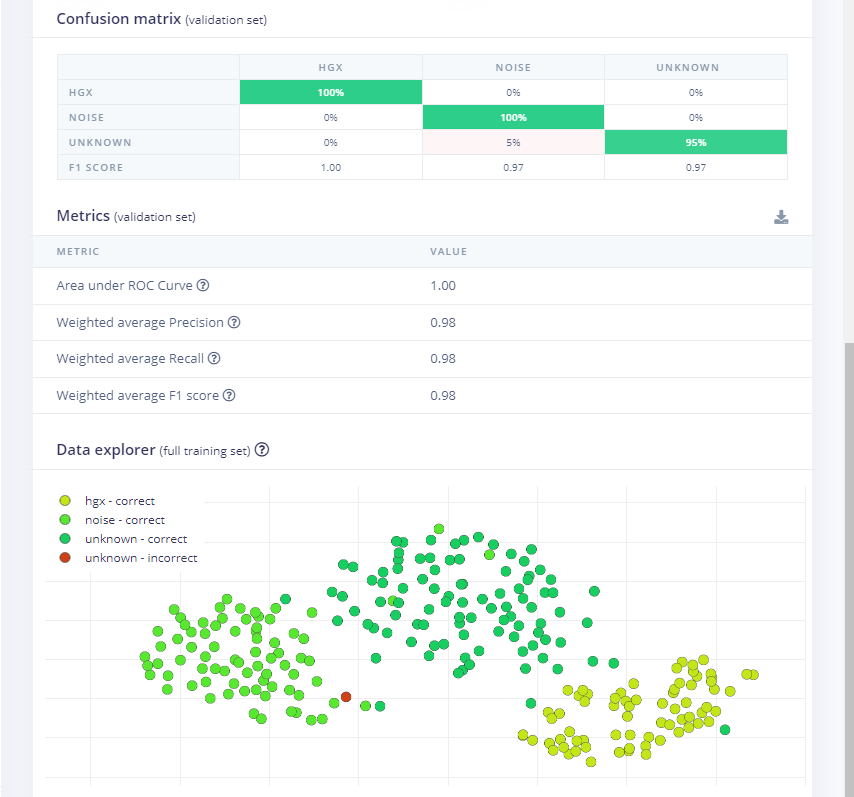
模型测试
在模型训练好后,我们可以用测试集数据测试一下训练好的模型的准确率。
- 点击左侧的Model testing,然后点击Classify all,开始分类所有的测试集数据。
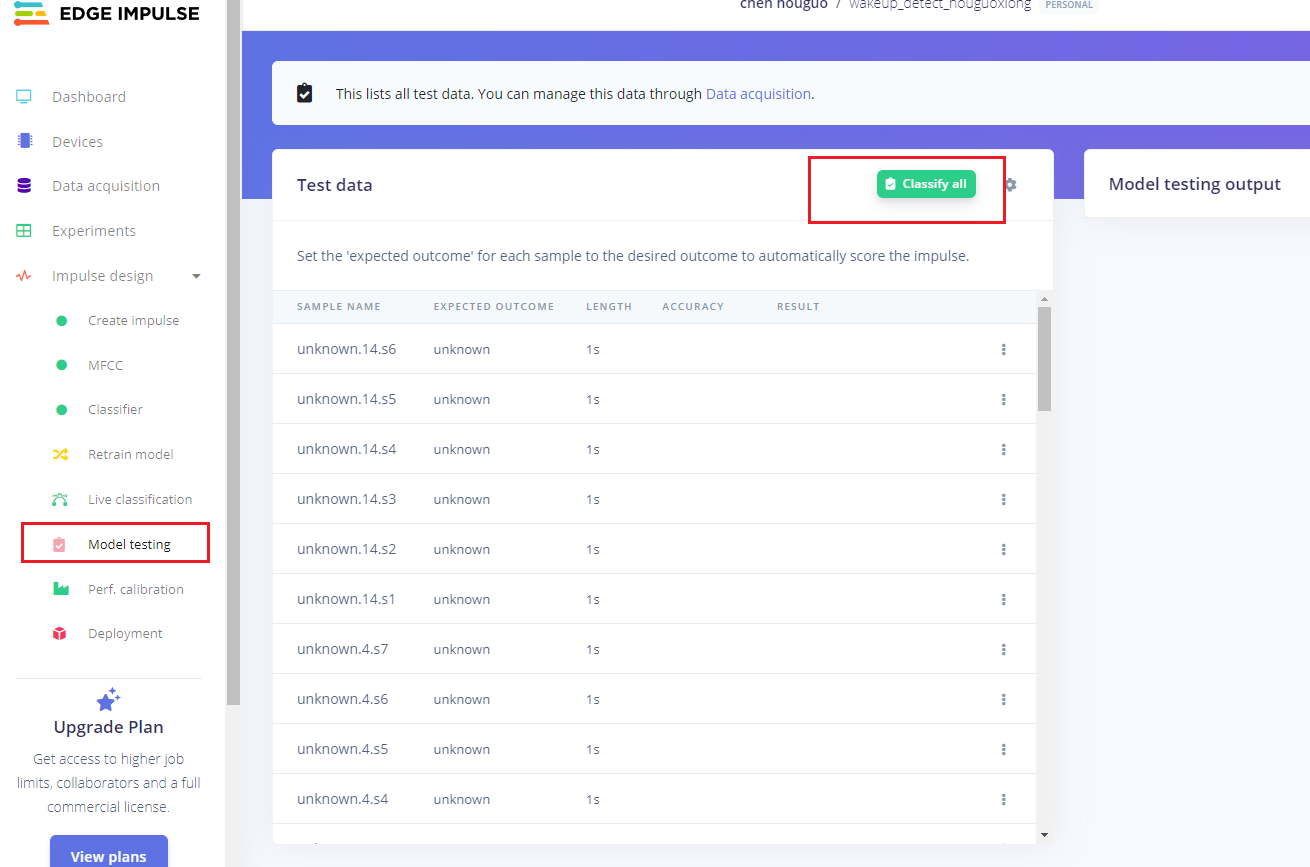
- 等待一会,所有的测试集数据分类结果将会计算出来,如上图。根据这个结果可以基本判断我们训练的唤醒词模型的识别准确率是否满足要求。
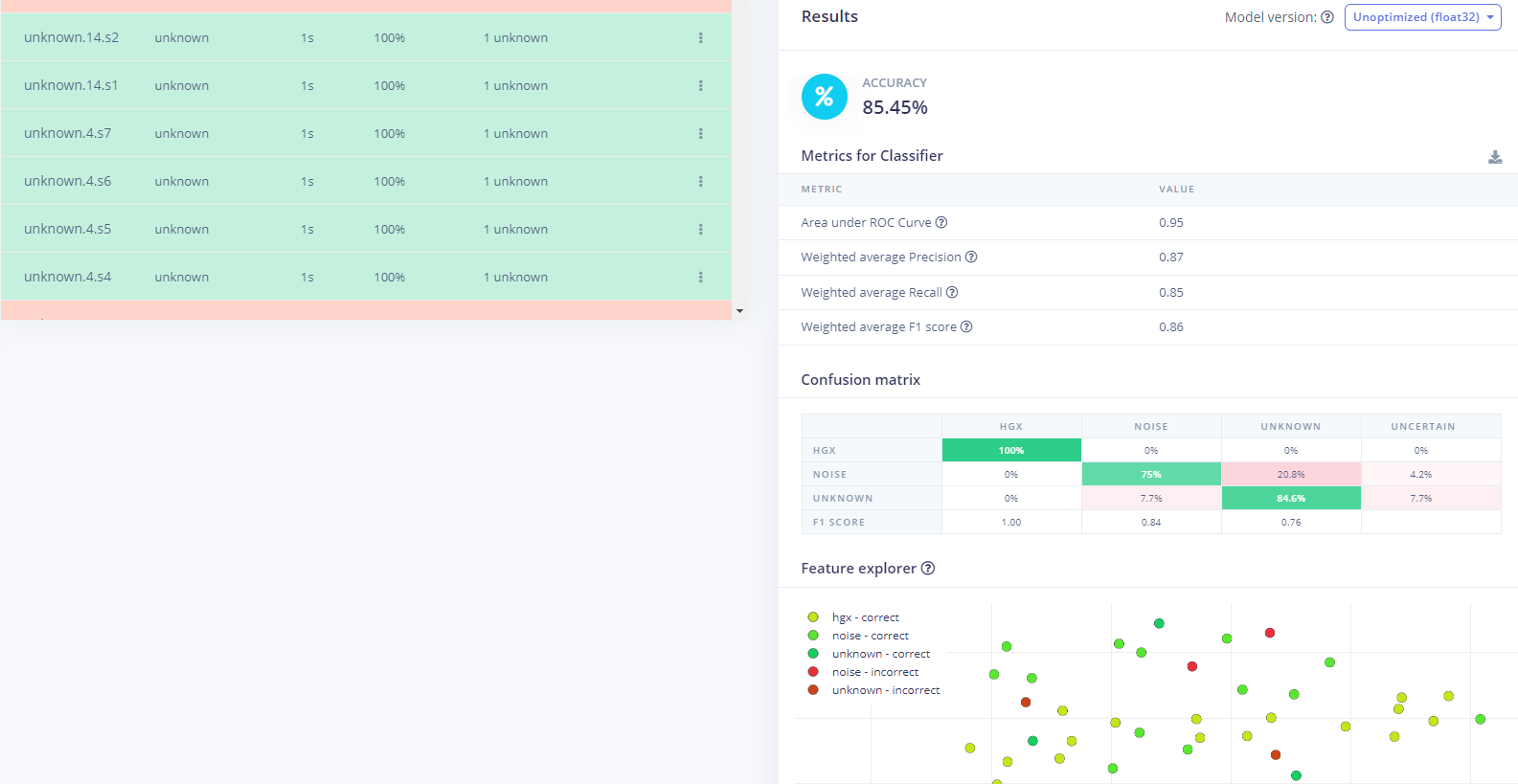
6.3部署模型到ESP32-S3
生成模型库文件
模型训练完成后,我们需要生成在arduino esp32平台上运行的库文件。
- 在生成库文件之前,我们先设置一下我们的硬件平台,点击右侧的 Target,选择Target device为ESP-EYE,然后点击 Save。

- 点击左侧的 Deployment部署,依次按照上图的选项配置,点击 Build,开始生成库文件。
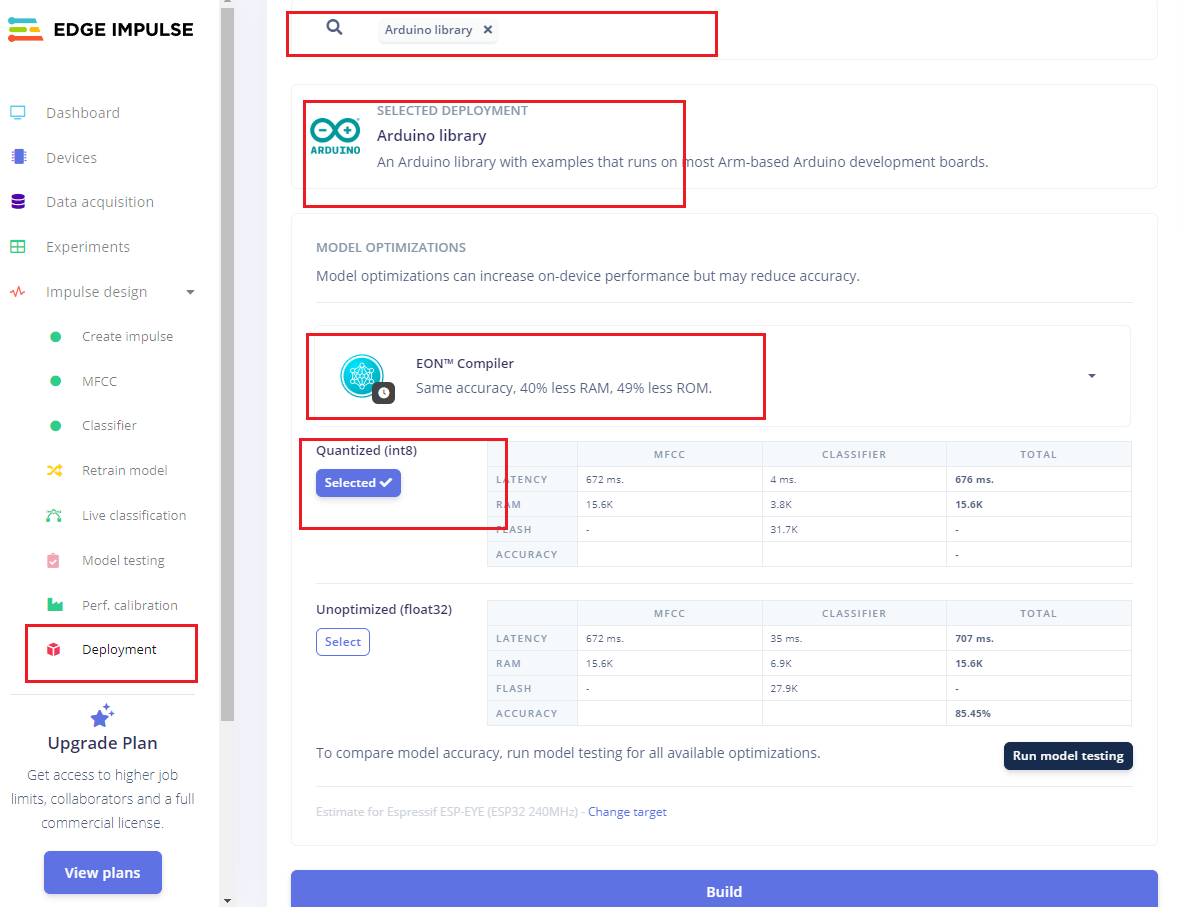
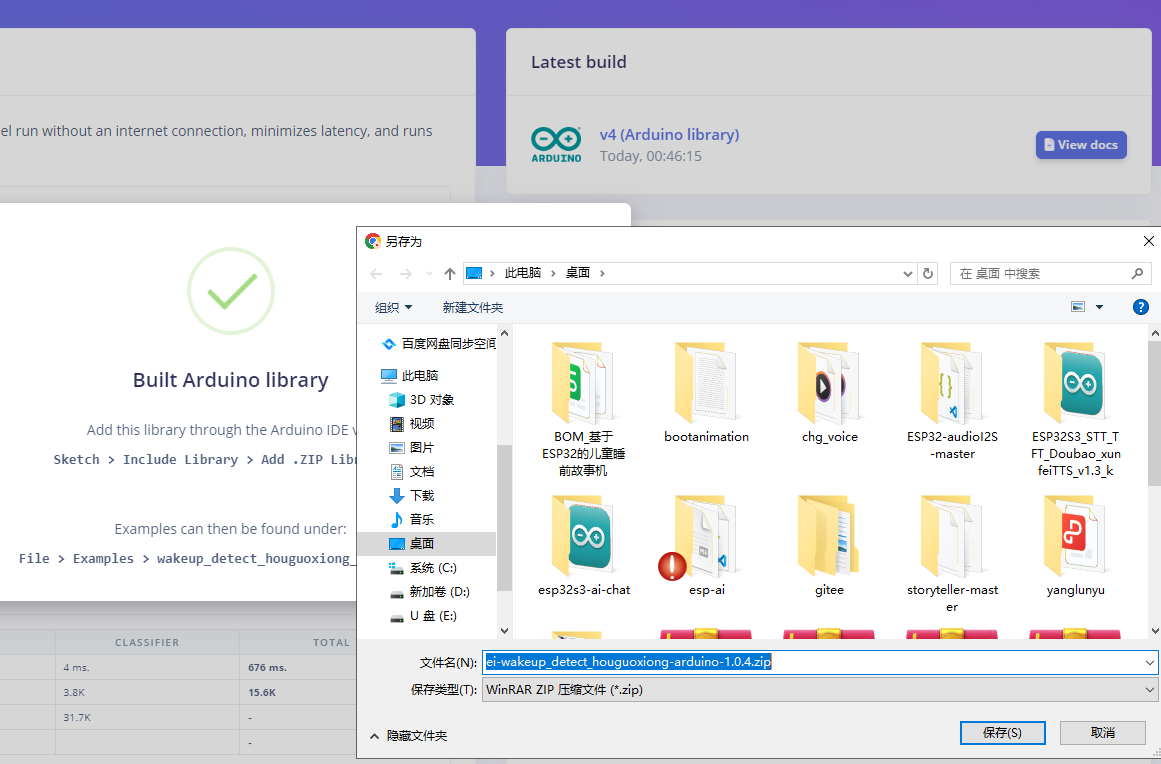
- 生成完成后,我们将库文件.zip保存到我们的工程目录下。
ESP32-S3唤醒词测试
训练好唤醒词库文件后,我们需要在ESP32-S3上测试一下唤醒词功能。打开工程目录下的
**esp32s3-ai-chat/example/wake_detect**工程,进行唤醒功能测试。
- 选择项目,导入库,添加.ZIP库文件,选择我们训练好的唤醒词库文件。
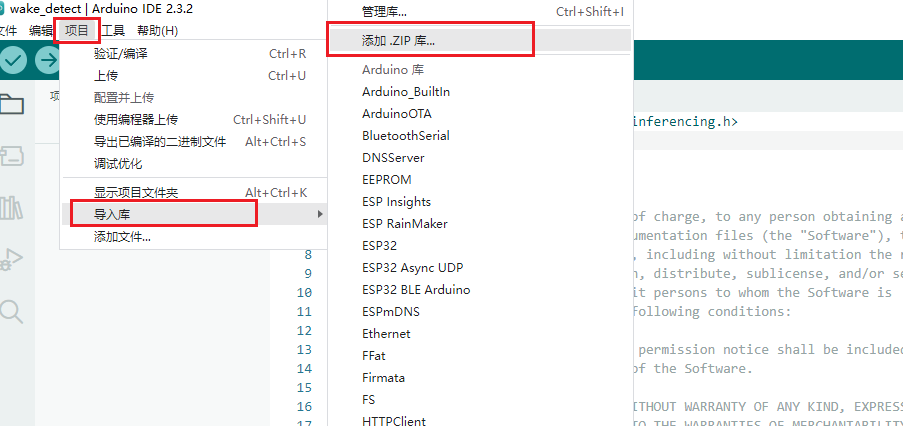
- 导入成功后,我们需要引用该库文件,因此再次点击项目,导入库,点击选择刚才导入的库文件。
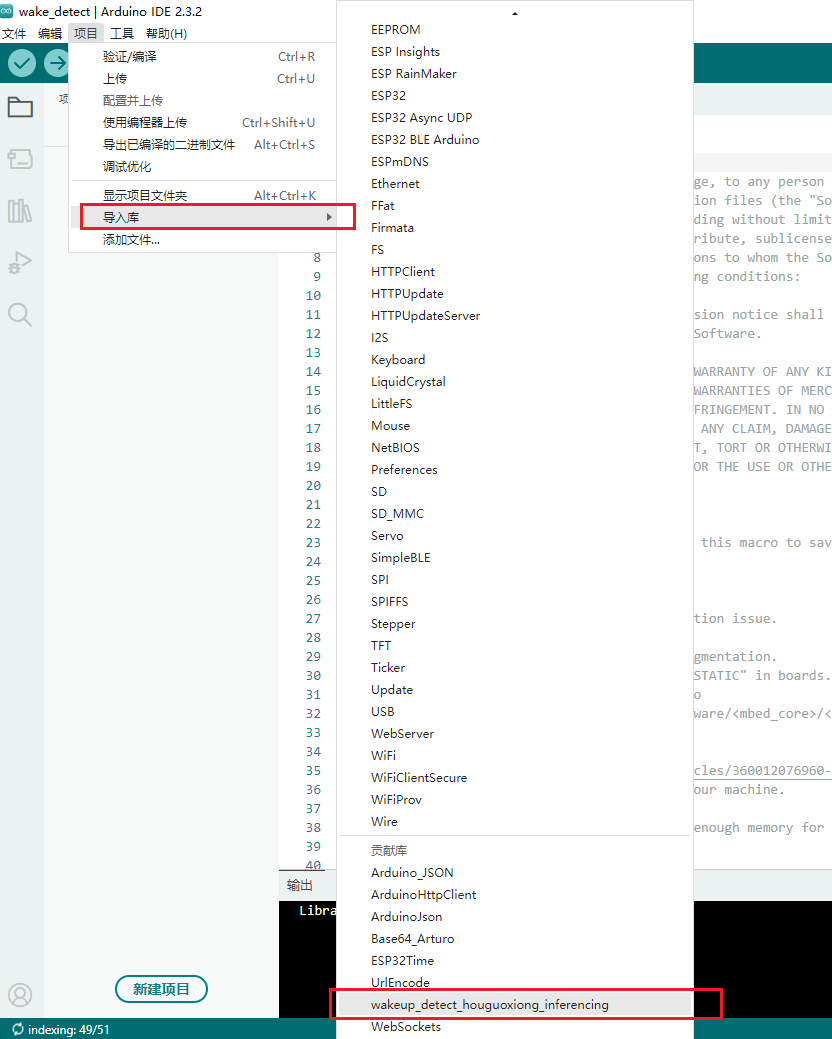
- 导入后,头文件会被引用进去,这样我们自己训练的唤醒词模型就引用成功了。
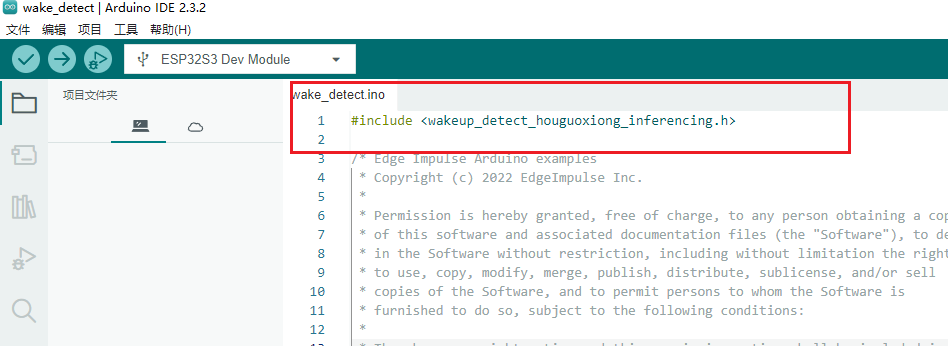
- 编译工程,烧录程序到ESP32-S3开发板中,程序运行后会实时的进行唤醒词监控,并且给出之前训练的3个标签的分类预测值,标签的预测值越接近1.0,则表示当前识别的可信结果为这个标签。
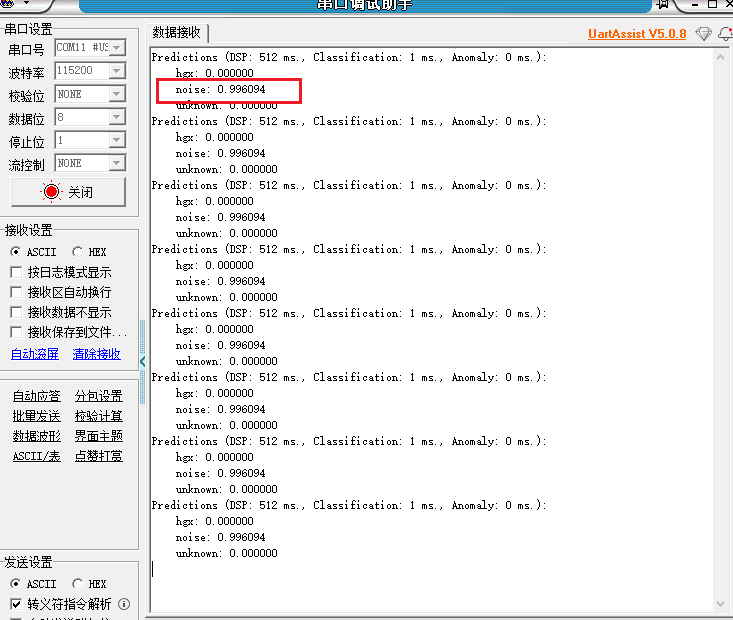
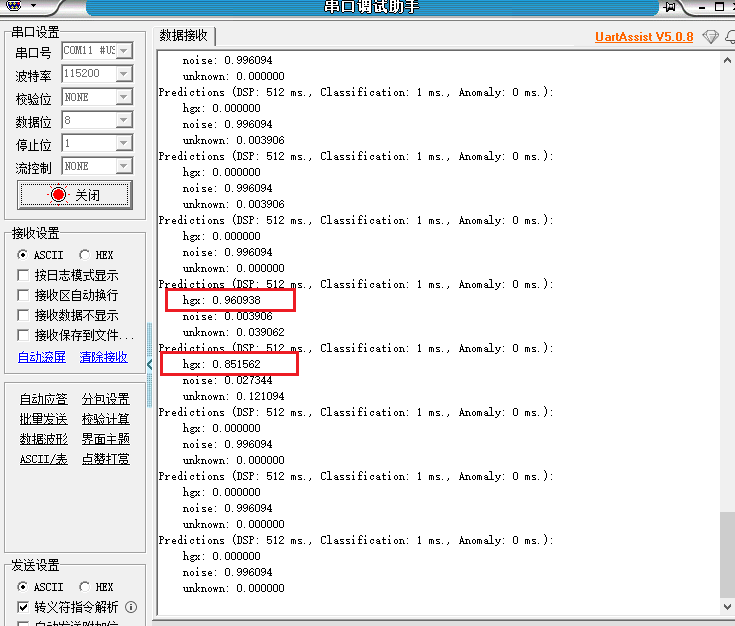
- 当我说出“houguoxiong”时,“hgx”这个标签的预测值直接快接近1.0了,证明我们的唤醒成功。
唤醒词模型的替换
当在arduino工程中需要替换新训练的唤醒词模型时,我们可以删除掉之前导入的模型库文件,然后删掉工程中之前引用的头文件,最后重新按照之前7.3.2章节导入模型库并引用的方式操作一遍即可。
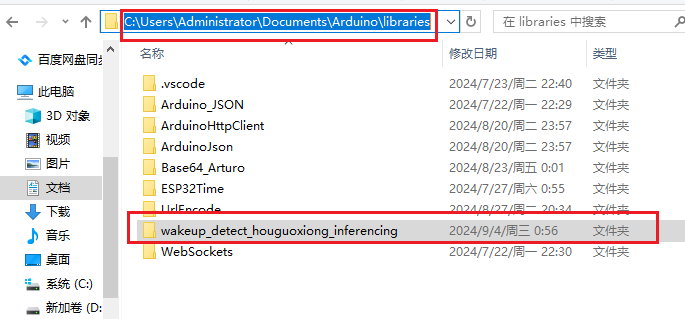
删除库文件在该目录下直接删除导入的库文件夹,然后关闭arduino软件,重新打开arduino工程就可以。
相关文章:

AI语音助手自定义角色百度大模型 【全新AI开发套件掌上AI+4w字教程+零基础上手】
1、简介 此项目主要使用ESP32-S3实现一个自定义角色的AI语音聊天助手(比如医生角色),可以通过该项目熟悉ESP32-S3 arduino的开发,百度语音识别,百度语音合成API调用,百度APPBuilder API的调用实现自定义角…...

【Java面试笔记:基础】13.谈谈接口和抽象类有什么区别?
在 Java 中,接口(Interface) 和 抽象类(Abstract Class) 都是实现多态和代码抽象的机制,但它们在设计目的、语法特性及使用场景上有显著差异。 1. 接口和抽象类的区别 接口(Interface) 定义:接口是对行为的抽象,是抽象方法的集合,用于定义 API 规范。 特点: 不能…...
)
内存管理(Linux程序设计)
内存管理 目录 内存管理 一.简单的内存分配 代码功能概述 代码流程图 变量声明 动态内存分配 内存分配错误检查 向内存写入字符串 设置退出状态并退出程序 二.请求全部的物理内存 代码功能概述 变量声明 三..可用内存 四.滥用内存 1.代码功能(预期 …...

Prompt 结构化提示工程
Prompt 结构化提示工程 目前ai开发工具都大同小异,随着deepseek的流行,ai工具的能力都差不太多,功能基本都覆盖到了。而prompt能力反而是需要更加关注的(说白了就是能不能把需求清晰的输出成文档)。因此大家可能需要加…...

Postman设置了Cookies但是请求不携带Cookie
1 问题说明 使用Postman工具往往要向本地服务器发送请求携带Cookie便于测试接口,但是在Send下面的Cookies选项中设置域名127.0.0.1,并添加Cookie,发现发送的请求怎么都不会携带Cookie: 通过Fiddler抓包发现并没有Cookie࿱…...

微服务Nacos组件的介绍、安装、使用
微服务Nacos组件的介绍、安装、使用 在微服务架构日渐普及的今天,服务注册与配置管理成了系统架构中的关键环节。阿里巴巴开源的 Nacos(Naming and Configuration Service)正是解决这一问题的利器。本文将为你全面介绍 Nacos 的概念、安装方…...

深度剖析塔能科技精准节能方案:技术创新与实践价值
在能源管理领域不断追求高效与可持续发展的进程中,塔能科技的精准节能方案逐渐成为行业内备受瞩目的焦点。 精准节能:核心技术与实现路径 塔能科技的精准节能理念建立在对能源消耗的精细监测与深度分析基础之上。以其节能管理平台为例,该平台…...

AI PPT创作原理解析:让你的演示文稿更智能
在当今信息爆炸的时代,演示文稿已成为我们工作和学习中不可或缺的一部分。然而,制作一份高质量的PPT往往需要投入大量的时间和精力。随着人工智能技术的迅猛发展,AI PPT创作工具应运而生,极大地简化了PPT的制作过程。本文将深入解…...

ollama本地搭建大模型
dajdaj人工智能,现在流行的大模型有很多,像流行的:gpt-3.5-turbo、通义千问2.5,Llama3; 本地安装大模型有什么好处 大模型都是开源的,安装在自己的电脑上也是免费使用的;可以结合自己的私有文…...
试用 31 -- AI做软件程序测试 2)
AIGC(生成式AI)试用 31 -- AI做软件程序测试 2
接上文 AIGC(生成式AI)试用 30 -- AI做软件程序测试 1 整合测试项提问并输出测试用例思考并调整提问方式,为完整的输年程序测试提问准备 - 再次对需求提问 --> 实际是之前的提问记录找不到了,不过有新发现;不妨后…...

【深度学习与大模型基础】第13章-什么是机器学习
1. 什么是机器学习? 想象你在教一个小朋友认猫: 传统编程:你写一本《猫的100条特征手册》(比如有胡须、尖耳朵),让计算机对照检查。 机器学习:你直接给计算机看1000张猫和狗的图片,…...

大数据利器Kafka
大数据利器Kafka:从入门到实战的全面指南 在大数据的世界里,Kafka就像是一个高效的“数据快递员”,负责在不同的系统之间快速、可靠地传递数据。今天,咱们就一起来深入了解一下这个强大的工具。Kafka是由LinkedIn开发的分布式发布…...

工具指南:免费将 PDF 转换为 Word 的 10 个工具
可移植文档格式或 PDF 是大多数企业使用的流行文件格式,主要用于共享项目材料并确保整个团队协同工作。它还有助于避免处理大量文档和丢失关键数据。使用顶级 PDF 转换器还可以更轻松地高效地进行日常活动。企业可以依靠专业的文档扫描服务对其他格式的文档进行 PDF…...

Elasticsearch复习笔记
文章目录 ES 基础为什么用 Elasticsearch初识和安装概述安装 elasticsearch安装 Kibana 倒排索引正向索引倒排索引正向和倒排 基础概念文档和字段索引和映射MySQL 和 elasticsearch IK 分词器安装 IK 分词器使用 IK 分词器拓展词典 ES 索引库操作Mapping 映射属性ES 索引库的 C…...

STM32 SysTick定时器
一、SysTick系统定时器概述 1.1 什么是SysTick定时器 SysTick(System Tick Timer)是ARM Cortex-M系列处理器内核集成的24位系统定时器,作为ARM架构的标准外设,它被深度整合在NVIC(嵌套向量中断控制器)中。…...

Modbus TCP协议介绍、原理解析与应用示例
深入了解Modbus TCP协议:介绍、原理解析与应用示例 在工业自动化领域,设备之间的通信与数据交换至关重要。Modbus协议作为一种经典的通信协议,因其简单、开放和易于实现的特点,被广泛应用于各种工业设备之间的数据传输。而Modbus…...

Elasticsearch 报错 Limit of total fields [1000] has been exceeded
一、错误代码: spring boot 链接es 插入审计日志数据报错: Caused by: org.elasticsearch.ElasticsearchException: Elasticsearch exception [typeillegal_argument_exception, reasonLimit of total fields [1000] has been exceeded while adding ne…...

maven中pom.xml setting.xml关系
1 在Spring Boot项目中,pom.xml和settings.xml文件都可以配置Maven仓库地址,但它们的作用和优先级有所不同。 ● settings.xml: ○ 配置本地仓库:使用 <localRepository> 元素指定本地仓库的路径。 ○ 配…...

PubLayNet:文档布局分析领域的大规模数据集
PubLayNet:文档布局分析领域的大规模数据集 1. 数据集概述 PubLayNet(Public Layout Network)是由IBM AUR NLP团队开发的大规模文档图像数据集,旨在推动文档理解与布局分析领域的研究。该数据集通过自动标注技术,对科…...

JAVA----方法
好久没发博客了~~~~~重生之我开始补知识 1.What is 方法(method) 方法是程序中最小的执行单元。 简单来说,就是将一些重复代码打包,要用的时候我们进行调用就好! e.g. public static void main(String…...

mybatis xml中特殊字符处理
1,CDATA区: 它的全称为character data,以"<![CDATA[ "开始,以" ]]>" 结束,在两者之间嵌入不想被解析程序解析的原始数据,解析器不对CDATA区中的内容进行解析,而是将这些数据原封…...

vue3+dhtmlx 甘特图真是案例
使用vue3 ts dhtmlx 实现项目任务甘特图展示 支持拖拽,选择人员,优先级,开发状态,进度 效果图 完整代码 安装命令:npm i dhtmlx-gantt <template><div style"height: 100%; background-color: white…...

Chrome/Edge浏览器使用多屏完美解决方案,http部署使用https部署的功能
多屏使用场景:例如1屏显示录入操作界面,2屏显示SOP。或者每个屏上显示不同的看板内容等 废话不少说,直接上代码:将下面的代码复制到txt记事本里,保存为html格式即可本地观看效果 <!DOCTYPE html> <html>…...

Linux中进程的属性:状态
一、通用OS进程中的各种状态与相关概念 1.1通用进程中的状态 CPU执行进程代码,不是把进程执行完才开始执行下一个,而是给每个进程预分配一个“时间片”, CPU基于时间片进行轮转调度(每个CPU分别进行) 其中发涉及到的…...

软件架构师常用的软件工具有哪些
软件架构师的工作离不开多种工具的支撑,主要包括 建模与设计工具、文档与协作平台、代码质量与静态分析工具、性能与监控工具、DevOps 工具链、架构可视化与管理平台 等。其中,建模与设计工具 是架构师最核心的武器,能够帮助其从业务抽象到技…...

rl中,GRPO损失函数详解。
文章目录 **一、GRPO损失函数的设计背景****二、代码逐行解析****三、关键组件详解****1. 对数概率与KL散度计算****2. 优势值与策略梯度****3. 掩码与平均损失****四、训练动态与调参建议**在TRL(Transformer Reinforcement Learning)库中,GRPO(Group Relative Policy Opt…...

奇安信春招面试题
奇安信面试真题,以下是5道具有代表性的经典技术面试题及其解析,覆盖网络安全、渗透测试、安全架构设计等核心领域。 《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.…...

MineWorld,微软研究院开源的实时交互式世界模型
MineWorld是什么 MineWorld是微软研究院开发并开源的一个基于《我的世界》(Minecraft)的实时互动世界模型。该模型采用了视觉-动作自回归Transformer架构,将游戏场景和玩家动作转化为离散的token ID,并通过下一个token的预测进行…...

Nginx RTMP配置存储位置
window: 支持本地磁盘和远程网络位置 配置文件如下 worker_processes 1;events {worker_connections 1024; }#RTMP服务 rtmp {server { listen 1935; #监听端口chunk_size 4096; #数据传输块大小application my_live { # 创建rtmp应用hlslive on; # 当路径匹…...
)
JVM理解(通俗易懂)
虽然网上有很多关于JVM的教程,但是都天花乱坠,很多都是一上来就JVM内存模型、JVM双亲委派等等,(可能我比较菜看不懂)。于是我自己决定写一篇能看懂的文章~如果有看不懂我就自己百度,大家有什么疑问也可以评论区交流~ 欢迎指点我的Error~ JVM概念 JVM大家都知道,就Ja…...

python三维矩阵的维度
matrix_3x3x3 np.array([[[ 8.35, 16.72, 17.46],[16.72, 33.49, 34.97],[17.46, 34.97, 36.51]],[[16.72, 33.49, 34.97],[33.49, 67.09, 70.05],[34.97, 70.05, 73.13]],[[17.46, 34.97, 36.51],[34.97, 70.05, 73.13],[36.51, 73.13, 76.35]] ]) 例如这样的三维矩阵&#…...

HarmonyOS 是 Android 套壳嘛?
文章目录 HarmonyOS 是 Android 套壳吗?技术视角的深度解析一、核心结论二、技术对比:从底层到应用层1. 内核与基础架构2. 应用开发与运行机制3. 生态与应用场景 三、常见误解的澄清误解 1:“HarmonyOS 使用 Android 应用,所以是套…...

【Java面试笔记:基础】10.如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全?
1. 保证集合线程安全的方式 传统同步容器:如 Hashtable 和 Vector,通过在方法上加 synchronized 关键字实现线程安全,但性能较低。同步包装器:通过 Collections.synchronizedMap 等方法将普通集合包装成线程安全的集合,但仍然使用粗粒度的锁,性能不佳。List<String>…...

【Amazing晶焱科技高速 CAN Bus 传输与 TVS/ESD/EOS 保护,将是车用电子的生死关键无标题】
台北国际车用电子展是亚洲地区重量级的车用电子科技盛会,聚焦于 ADAS、电动车动力系统、智慧座舱、人机界面、车联网等领域。各大车厂与 Tier 1 供应链无不摩拳擦掌,推出最新技术与创新解决方案。 而今年,“智慧座舱” 无疑将成为全场焦点&am…...

电控---DMP库
一、DMP库的本质与核心定位 DMP库是为Invensense(现TDK)系列传感器(如MPU6050、MPU9250等)内置的数字运动处理器(DMP)硬件模块提供的软件接口层。其核心目标是: 抽象硬件操作:将复…...

YOLO数据处理
YOLO(You Only Look Once)的数据处理流程是为了解决目标检测领域的核心挑战,核心目标是为模型训练和推理提供高效、规范化的数据输入。其设计方法系统性地解决了以下关键问题,并对应发展了成熟的技术方案: 一、解决的问…...

Linux实现网络计数器
1.TcpServer.hpp文件 类TcpServer的私有成员变量有端口号,指向类Socket对象的指针,布尔值表示是否运行,以及回调函数,ioservice_t是表示参数为指向Socket对象的指针和InetAddr对象的函数,TcpServer类的构造函数接收端…...

数据分析:用Excel做周报
目录 1.初始模板 编辑 2.填充数据 2.1 日期以及表头 2.2 数据验证 2.3 计算数据填充 2.3.1 灵活计算 2.3.2 单独计算 2.3.3 总计 2.4 数据格式 2.5 周累计 2.6 周环比 2.7 业务进度 3 美化 1.初始模板 2.填充数据 2.1 日期以及表头 结果指标有以下这些&#…...
)
初阶数据结构--排序算法(全解析!!!)
排序 1. 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些些关键字的大小,递增或递减的排列起来的操作。 2. 常见的排序算法 3. 实现常见的排序算法 以下排序算法均是以排升序为示例。 3.1 插入排序 基本思想:…...

SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...

加油站小程序实战教程14会员充值页面搭建
目录 1 原型2 搭建充值金额选择功能3 搭建金额输入4 搭建支付方式5 充值按钮最终的效果 上一篇我们介绍了充值规则的后台功能,有了基础的规则,在会员充值页面就可以显示具体的充值规则。本篇我们介绍一下会员充值的开发过程。 1 原型 充值页面我们是分为…...

内卷的中国智驾,合资品牌如何弯道超车?
作者 |德新 编辑 |王博 上海车展前夕,一汽丰田举办重磅车型bZ5的技术发布会,脱口秀演员庞博透露了这款车型的一大重要特性,其搭载来自Momenta的智能辅助驾驶系统行驶里程已经超过20亿公里。 携手中国科技公司提高车型智能化的属性ÿ…...

【go】go run-gcflags常用参数归纳,go逃逸分析执行语句,go返回局部变量指针是安全的
go官方参考文档: https://pkg.go.dev/cmd/compile 基本语法 go run 命令用来编译并运行Go程序,-gcflags 后面可以跟一系列的编译选项,多个选项之间用空格分隔。基本语法如下: go run -gcflags "<flags>" main.…...
)
数据库11(触发器)
触发器有三种类型,包括删除触发器,更新触发器,添加触发器 触发器的作用是:当某个表发生某个操作时,自动触发触发器,进行触发器规定的操作 触发器语句 create trigger tname --创建触发器 on aa --创建在表…...

十大物联网平台-物联网十大品牌
物联网十大品牌及平台解析 物联网(IoT)作为当下极具影响力的技术,正逐步渗透至社会各领域,为人们生活与社会发展带来诸多便利与变革。如今,众多企业投身于物联网行业,致力于推动其发展。以下是对物联网相关…...

心智模式VS系统思考
很多人常说,“改变自己,从改变思维开始。”但事实上,打破一个人的心智模式,远比想象中要困难得多。我们的思维方式、行为习惯,甚至是对世界的认知,往往是多年积累下来的产物。那些曾经的经历、长期的学习与…...

QT 打包安装程序【windeployqt.exe】报错c000007d原因:Conda巨坑
一、命令行执行命令 E:\Project\GNCGC\Bin\Win32\Vc22\RS422地检>E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe CGC170.exe二、安装了Conda的朋友,巨坑 无语,E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe 优先把Conda环境关联的Qt动…...

Vue3祖先后代组件数据双向同步实现方法
在 Vue3 中实现祖先后代组件的双向数据同步,可以通过组合式 API 的 provide/inject 配合响应式数据实现。以下是两种常见实现方案: 方案一:共享响应式对象 方法 html <!-- 祖先组件 --> <script setup> import { ref, provide…...

OpenBayes 一周速览|EasyControl 高效控制 DiT 架构,助力吉卜力风图像一键生成;TripoSG 单图秒变高保真 3D 模型
公共资源速递 10 个教程: * 一键部署 R1-OneVision * UNO:通用定制化图像生成 * TripoSG:单图秒变高保真 3D * 使用 VASP 进行机器学习力场训练 * InfiniteYou 高保真图像生成 Demo * VenusFactory 蛋白质工程设计平台 * Qwen2.5-0mni…...

服务器-conda下载速度慢-国内源
文章目录 前言一、解决问题:使用国内conda镜像下载(差)二、解决问题:使用pip下载(优)总结 前言 conda频道中有无效频道导致下载失败 一、解决问题:使用国内conda镜像下载(差) 步骤 1ÿ…...