SpringCloud 微服务复习笔记
文章目录
- 微服务概述
- 单体架构
- 微服务架构
- 微服务拆分
- 微服务拆分原则
- 拆分实战
- 第一步:创建一个新工程
- 第二步:创建对应模块
- 第三步:引入依赖
- 第四步:被配置文件拷贝过来
- 第五步:把对应的东西全部拷过来
- 第六步:创建启动类
- 远程调用
- 语法
- 存在的缺陷
- 远程调用优化1:`Nocos`服务注册和发现
- 注册中心原理
- `Nacos` 注册中心组件概述
- 使用第一步: 部署 `Nacos`
- 使用第二步:`Nacos` 服务注册
- 使用第三步:服务发现
- 远程调用优化2:`OpenFeign`
- `OpenFeign` 概述
- `OpenFeign` 快速入门
- `OpenFeign` 连接池优化
- `OpenFeign` 最佳实践
- `hm-api` 模块
- `cart-service` 模块
- `OpenFeign` 日志输出
- 日志配置
- 微服务网关
- 微服务网关概述
- 网关路由
- 快速入门
- 路由属性
- 网关登录校验
- 鉴权思路分析
- 网关过滤器概述
- 自定义过滤器
- 自定义 `GolbalFilter`
- 自定义 `GataWayFilter`
- 登录1:登录校验实现
- `JWT` 工具
- 登录校验过滤器
- 登录2:微服务获取用户信息
- 保存用户信息到请求头
- 拦截器获取用户信息
- 登录3: `OpenFeign` 传递用户信息
- 编写 `OpenFeign` 拦截器保存信息
- 检查购物车微服务有没有加入该配置类
- 登录4:方案总结
- 微服务配置管理
- 配置管理概述
- 配置共享
- 第一步:添加配置到 `Nacos`
- 第二步:拉取共享配置
- 配置热更新
- 概述
- 在 `Nacos` 中添加配置
- 配置热更新
- 动态路由
- 监听 `Naocs` 配置变更
- 核心步骤第一步:创建 `ConfigService`
- 核心步骤第二步:编写监听器
- 更新路由
- 实现动态路由
- 微服务保护
- 远程调用可能产生的问题
- 业务健壮性不足
- 级联失败风险(雪崩问题)
- 服务保护方案
- 请求限流
- 线程隔离
- 服务熔断
- 服务保护技术
- `Sentinel`
- 介绍安装
- 微服务整合
- 请求限流
- 线程隔离
- `FallBack`(降级逻辑)
- 服务熔断
- 分布式事务
- 分布式事务概述
- `Seata`
- `Seata` 概述
- 部署 `Seata TC` 服务
- 微服务集成 `Seata TC TM RM`
- `XA` 模式
- `XA` 模式原理
- `XA` 模式优缺点
- 实现 `XA` 模式
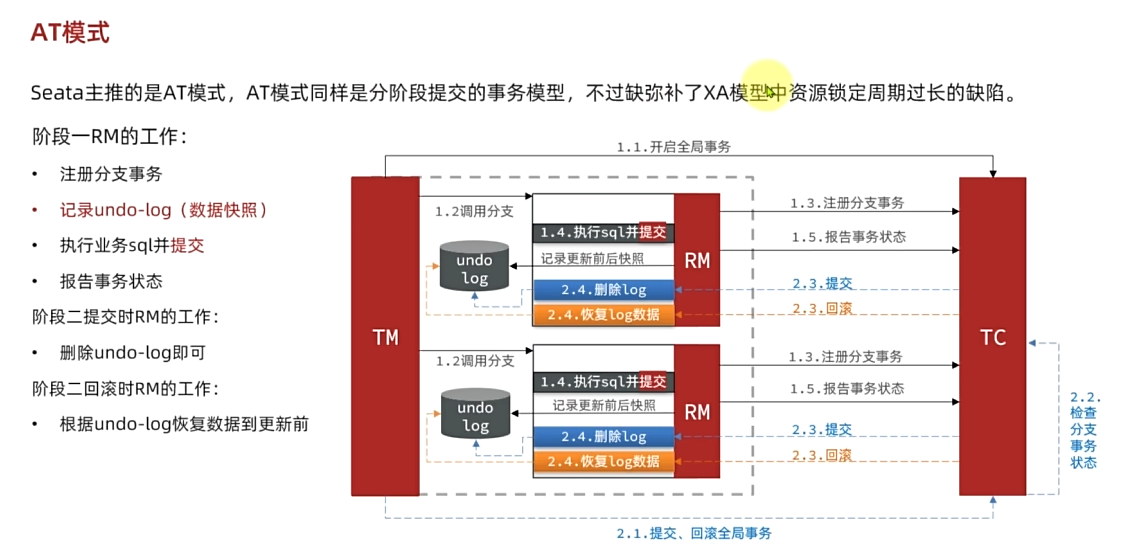
- `AT` 模式
- 流程梳理
- 实现 `AT` 模式
- `AT` 模式和 `XA` 模式的区别
微服务概述
单体架构
单体架构(monolithic structure):顾名思义,整个项目中所有功能模块都在一个工程中开发;项目部署时需要对所有模块一起编译、打包;项目的架构设计、开发模式都非常简单。
当项目规模较小时,这种模式上手快,部署、运维也都很方便,因此早期很多小型项目都采用这种模式。
但随着项目的业务规模越来越大,团队开发人员也不断增加,单体架构就呈现出越来越多的问题:
- 团队协作成本高:试想一下,你们团队数十个人同时协作开发同一个项目,由于所有模块都在一个项目中,不同模块的代码之间物理边界越来越模糊。最终要把功能合并到一个分支,你绝对会陷入到解决冲突的泥潭之中。
- 系统发布效率低:任何模块变更都需要发布整个系统,而系统发布过程中需要多个模块之间制约较多,需要对比各种文件,任何一处出现问题都会导致发布失败,往往一次发布需要数十分钟甚至数小时。
- 系统可用性差:单体架构各个功能模块是作为一个服务部署,相互之间会互相影响,一些热点功能会耗尽系统资源,导致其它服务低可用。
假如 500个线程并发接口,由于该接口存在执行耗时(500毫秒),这就服务端导致每秒能处理的请求数量有限,最终会有越来越多请求积压,直至
Tomcat资源耗尽。这样,其它本来正常的接口(例如/search/list)也都会被拖慢,甚至因超时而无法访问了。
微服务架构
微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。同时要满足下面的一些特点:
- 单一职责:一个微服务负责一部分业务功能,并且其核心数据不依赖于其它模块。
- 团队自治:每个微服务都有自己独立的开发、测试、发布、运维人员,团队人员规模不超过10人(2张披萨能喂饱)
- 服务自治:每个微服务都独立打包部署,访问自己独立的数据库。并且要做好服务隔离,避免对其它服务产生影响
,,例如,黑马商城项目,我们就可以把商品、用户、购物车、交易等模块拆分,交给不同的团队去开发,并独立部署:
缺点
- 团队协作成本高
- 由于服务拆分,每个服务代码量大大减少,参与开发的后台人员在1~3名,协作成本大大降低
- 系统发布效率低
- 每个服务都是独立部署,当有某个服务有代码变更时,只需要打包部署该服务即可
- 系统可用性差
- 每个服务独立部署,并且做好服务隔离,使用自己的服务器资源,不会影响到其它服务。
微服务拆分
微服务拆分原则
- 什么时候拆
初创项目
- 首要任务:验证项目可行性,进行敏捷开发,快速产出生产可用产品并投入市场验证。
- 架构选择:多采用单体架构,因其开发成本低,能快速出结果。若项目不符合市场,损失较小。
- 不选微服务架构的原因:采用复杂微服务架构需投入大量人力和时间成本用于架构设计,若最终产品不符合市场需求,前期工作等于白费。
小型项目
- 架构策略:一般先采用单体架构,待用户规模扩大、业务复杂后逐渐拆分为微服务架构。
- 优势:初期成本较低,能够快速试错。
- 存在问题:后期做服务拆分时,可能会因代码耦合等问题,导致拆分难度较大,呈现前易后难的特点。
大型项目
- 架构策略:在立项之初目的明确,从长远考虑,架构设计直接选择微服务架构。
- 特点:前期投入较多,但后期无需面临拆分服务的烦恼,呈现前难后易的特点。
- 怎么拆
从高内聚、低耦合两个角度落实:
高内聚:
- 每个微服务职责需单一,内部业务关联度与完整度要高。并非一个微服务仅设一个接口,而是以保障微服务内部业务完整性为前提。
- 实现高内聚后,当对某业务进行修改时,只需在当前微服务内操作,可有效降低变更成本。
低耦合:
- 每个微服务功能相对独立,减少对其他微服务的依赖;若存在依赖,所依赖接口需具备稳定性。
- 当微服务间进行业务交互时,例如下单时查询商品数据,订单服务不能直接查询商品数据库,以避免数据耦合。应由商品服务暴露接口,且保证接口外观稳定,如此商品服务内部的任何修改都不会影响订单微服务,降低服务间耦合度。
拆分方式
- 纵向拆分:
- 按照项目功能模块进行拆分。以黑马商城为例,将用户管理、订单管理、购物车管理、商品管理、支付等功能模块,分别拆分为独立服务。
- 这种拆分方式有助于提升服务的内聚性。
- 横向拆分:
- 分析各功能模块间是否存在公共业务部分,若有则将其抽取出来,构建通用服务。如用户登录和下单过程中,都需要发送消息通知、记录风控数据,便可将消息发送和风控数据记录抽取为消息中心服务、风控管理服务。
- 横向拆分能够提高业务复用性,避免重复开发。同时,通用业务接口稳定性强,可防止服务间过度耦合。
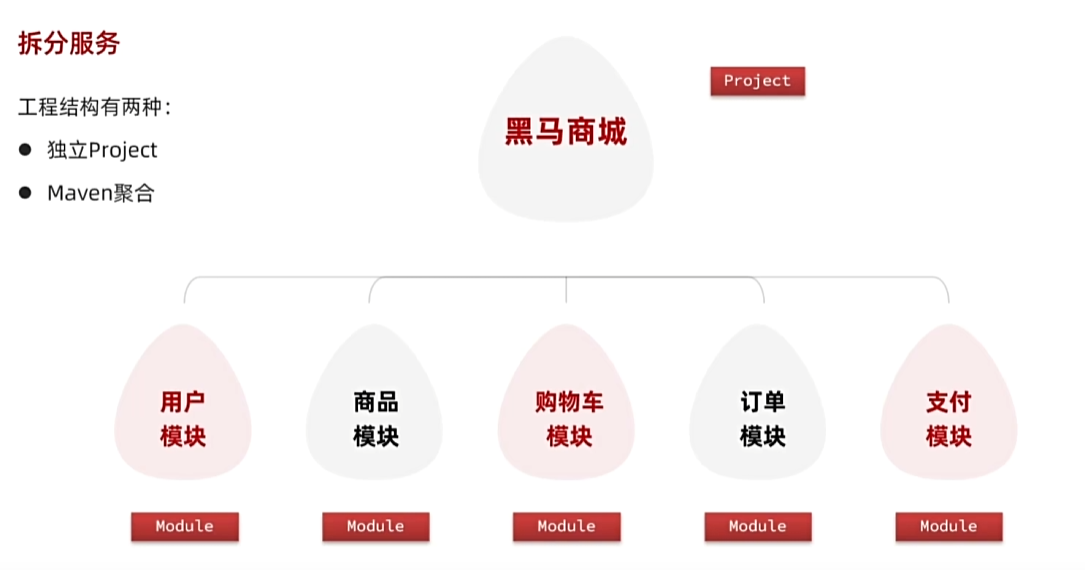
- 拆分服务
完全解耦:全部拆成单独的
Project然后再丢进一个文件夹管理
- 优点:服务之间耦合度低
- 缺点:每个项目都有自己的独立仓库,管理起来比较麻烦
- 适合特别大型项目
Maven聚合:创建一个父工程,然后里面创建单独Module
- 优点:项目代码集中,管理和运维方便
- 缺点:服务之间耦合,编译时间较长
- 中小型企业项目适合
拆分实战
第一步:创建一个新工程
第二步:创建对应模块
第三步:引入依赖
不用的依赖删掉,不确定要不要就删掉
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>hmall</artifactId><groupId>com.heima</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>item-service</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target></properties><dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--数据库--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--mybatis--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId></dependency><!--单元测试--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
第四步:被配置文件拷贝过来
记得检查配置文件做必要修改,
- 每个微服务一个独立端口号
- 微服务名称
- 微服务对应的数据库名称
- 接口文档名称,及扫描包
第五步:把对应的东西全部拷过来
从
Mapper层开始拷贝,只考关于这个模块的东西,关联的其他模块的不要拷贝。比如list模块就拷贝list相关就行。当然相关也可能名字不一样。后面不是一个模块的使用openFeign远程调用
第六步:创建启动类
@MapperScan("com.hmall.cart.mapper")
@SpringBootApplication
public class CartApplication {public static void main(String[] args) {SpringApplication.run(CartApplication.class, args);}@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}远程调用
从物理上隔离了,但是网络没隔离。所以我们调用
Item模块的数据库数据。可以模拟Java发送HTTP请求获取数据
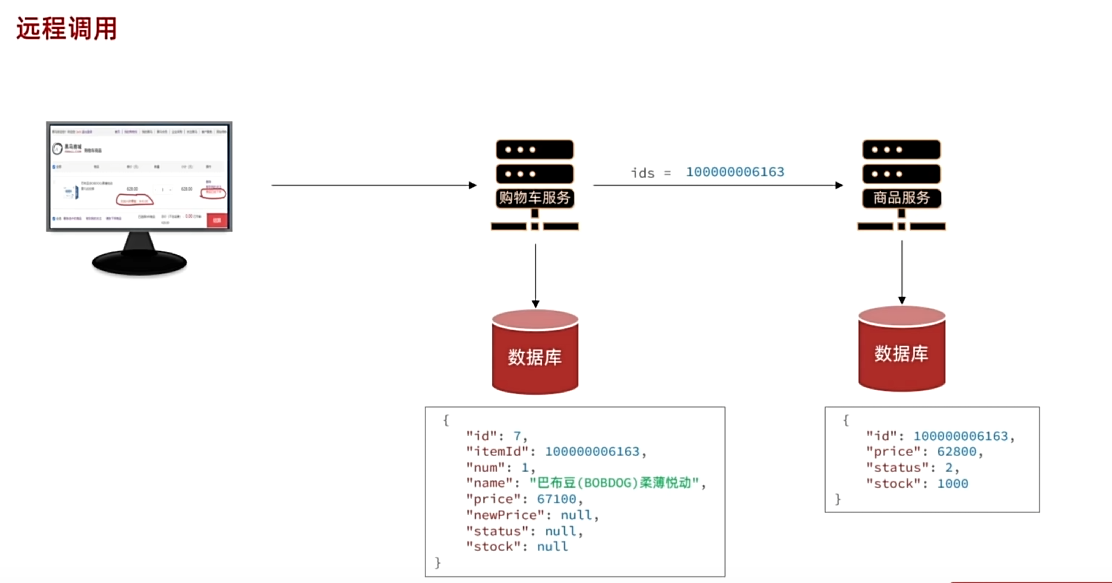
语法
这种方法有缺陷,不建议使用
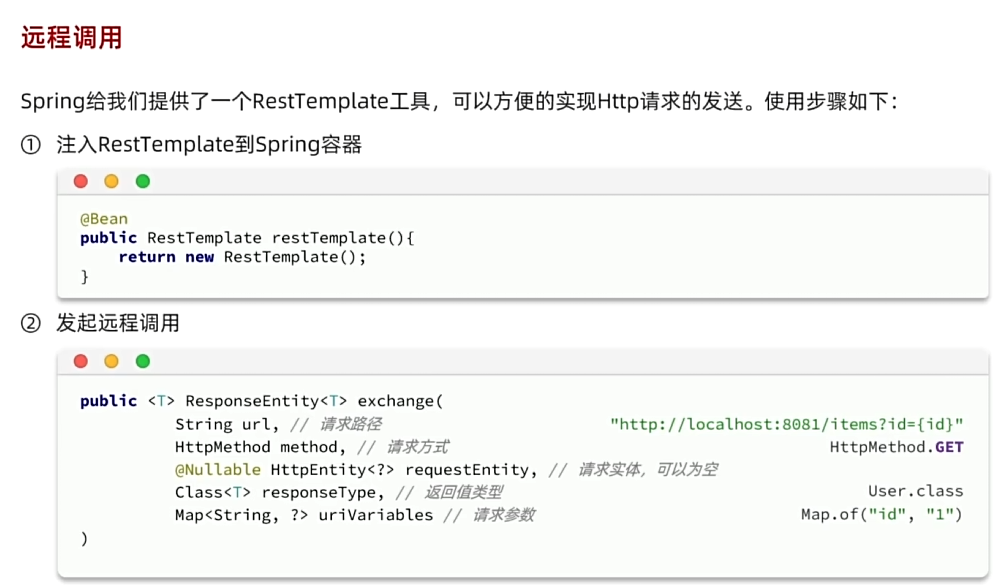
private void handleCartItems(List<CartVO> vos) {// 1.获取商品idSet<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// // 2.查询商品
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);// 2.1.利用RestTemplate发起http请求, 得到http的响应ResponseEntity<List<ItemDTO>> response = restTemplate.exchange("http://localhost:8081/items?ids={ids}",HttpMethod.GET,null,//这里不能直接用泛型, 需要使用ParameterizedTypeReference 因为泛型是 List<ItemDTO>比较深new ParameterizedTypeReference<List<ItemDTO>>() {},//把集合自动用,拼接Map.of("ids", CollUtil.join(itemIds, ",")));// 2.2解析响应if (!response.getStatusCode().is2xxSuccessful()) {//查询失败, 直接结束return;}List<ItemDTO> items = response.getBody();if (CollUtils.isEmpty(items)) {return;}// 3.转为 id 到 item的mapMap<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));// 4.写入vofor (CartVO v : vos) {ItemDTO item = itemMap.get(v.getItemId());if (item == null) {continue;}v.setNewPrice(item.getPrice());v.setStatus(item.getStatus());v.setStock(item.getStock());}}
存在的缺陷
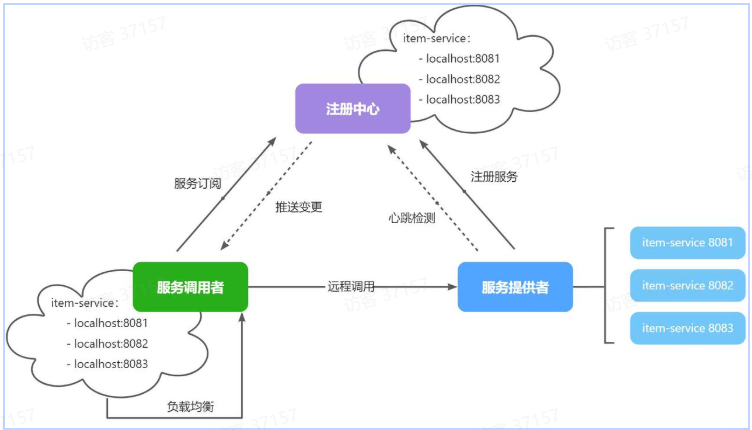
试想一下,假如商品微服务被调用较多,为了应对更高的并发,我们进行了多实例部署,如图:
此时,每个
item-service的实例其IP或端口不同,问题来了:
item-service这么多实例,cart-service如何知道每一个实例的地址?http请求要写url地址,cart-service服务到底该调用哪个实例呢?- 如果在运行过程中,某一个
item-service实例宕机,cart-service依然在调用该怎么办?- 如果并发太高,
item-service临时多部署了N台实例,cart-service如何知道新实例的地址?我们可以使用服务注册解决

远程调用优化1:Nocos服务注册和发现
注册中心原理
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如
item-service- 服务消费者:调用其它微服务提供的接口,比如
cart-service流程如下:
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
Nacos 注册中心组件概述
目前开源的注册中心框架有很多,国内比较常见的有:
Eureka:Netflix公司出品,目前被集成在SpringCloud当中,一般用于Java应用Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java应用Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服务语言以上几种注册中心都遵循
SpringCloud中的API规范,因此在业务开发使用上没有太大差异。由于Nacos是国内产品,中文文档比较丰富,而且同时具备配置管理功能(后面会学习),因此在国内使用较多
使用第一步: 部署 Nacos
- 准备
mysql数据库表
基于
Docker来部署Nacos的注册中心,首先我们要准备MySQL数据库表,用来存储Nacos的数据。由于是Docker部署,所以大家需要将SQL文件导入到你Docker中的MySQL容器中
nacos.sql
Docker拉取Nacos镜像
- 可以下载好
tar包。然后直接load。或者直接pull
- **启动
Nacos**
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
- 启动完成可以登录
Nocas
启动完成后,访问下面地址:http://192.168.150.101:8848/nacos/,注意将
192.168.150.101替换为你自己的虚拟机IP地址。
使用第二步:Nacos 服务注册
- 添加依赖
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 配置
Nacos地址
spring:application:name: item-service # 服务名称cloud:nacos:server-addr: 192.168.150.101:8848 # nacos地址
- 配置
yaml文件
spring:application:name: item-service # 服务名称cloud:nacos:server-addr: 192.168.150.101:8848 # nacos地址
- 启动服务实例
- 访问
nacos控制台可以发现服务注册成功了

使用第三步:服务发现

private void handleCartItems(List<CartVO> vos) {// 1.获取商品idSet<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// // 2.查询商品
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);// 2.1.根据服务的名称获取服务的实例列表List<ServiceInstance> instances = discoveryClient.getInstances("item-service");if (CollUtil.isEmpty(instances)) {return;}// 2.2.手写负载均衡, 从实例列表中挑选一个实例 instance.size 有几个实例就返回几ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));// 2.1.利用RestTemplate发起http请求, 得到http的响应ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(instance.getUri() + "/items?ids={ids}",HttpMethod.GET,null,//这里不能直接用泛型, 需要使用ParameterizedTypeReference 因为泛型是 List<ItemDTO>比较深//如果是 ItemDTO 这样就可以直接 ItemDTO.classnew ParameterizedTypeReference<List<ItemDTO>>() {},//把集合自动用,拼接Map.of("ids", CollUtil.join(itemIds, ",")));// 2.2解析响应if (!response.getStatusCode().is2xxSuccessful()) {//查询失败, 直接结束return;}List<ItemDTO> items = response.getBody();if (CollUtils.isEmpty(items)) {return;}// 3.转为 id 到 item的mapMap<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));// 4.写入vofor (CartVO v : vos) {ItemDTO item = itemMap.get(v.getItemId());if (item == null) {continue;}v.setNewPrice(item.getPrice());v.setStatus(item.getStatus());v.setStock(item.getStock());}}远程调用优化2:OpenFeign
OpenFeign 概述
利用
Nacos实现了服务的治理,利用RestTemplate实现了服务的远程调用。但是远程调用的代码太复杂了:而且这种调用方式,与原本的本地方法调用差异太大,编程时的体验也不统一,一会儿远程调用,一会儿本地调用。
因此,我们必须想办法改变远程调用的开发模式,让远程调用像本地方法调用一样简单。而这就要用到
OpenFeign组件了。其实远程调用的关键点就在于四个:
- 请求方式
- 请求路径
- 请求参数
- 返回值类型
所以,
OpenFeign就利用SpringMVC的相关注解来声明上述4个参数,然后基于动态代理帮我们生成远程调用的代码,而无需我们手动再编写,非常方便。
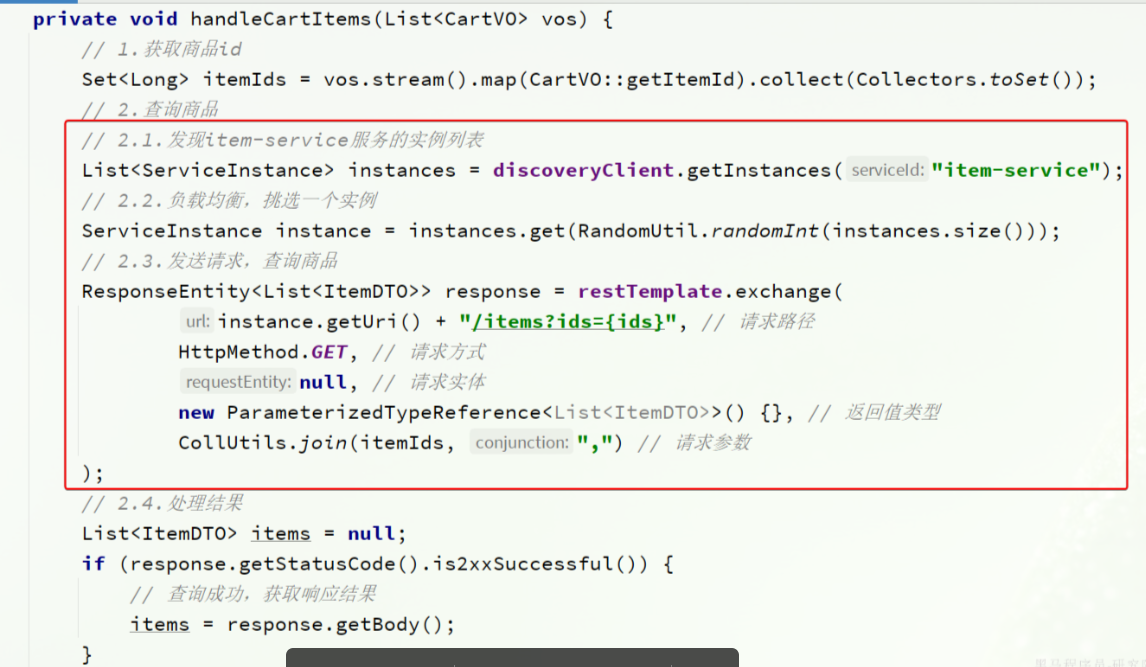
OpenFeign 快速入门

- 引入依赖
<!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
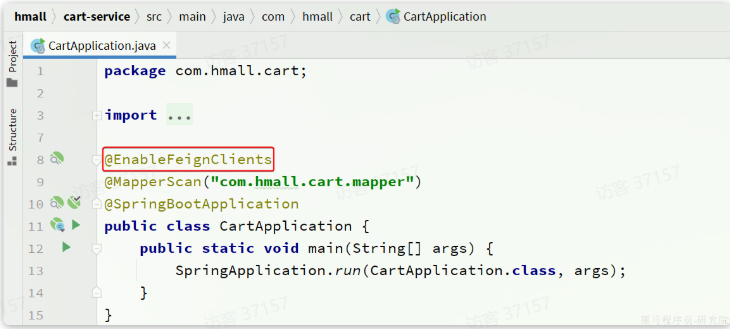
- 再启动类启用
OpenFeign
接下来,我们在
cart-service的CartApplication启动类上添加注解,启动OpenFeign功能
- 编写
OpenFeign客户端
在
cart-service中,定义一个新的接口,编写Feign客户端这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型有了上述信息,
OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。我们只需要直接调用这个方法,即可实现远程调用了。
@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
- 使用
FeignClient,实现远程调用
List<ItemDTO> items = itemClient.queryItemByIds(List.of(1,2,3));
OpenFeign 连接池优化

- 引入依赖
<!--OK http 的依赖 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>
- **
yaml配置文件很中开启连接池 **
feign:okhttp:enabled: true # 开启OKHttp功能
OpenFeign 最佳实践
将来我们要把与下单有关的业务抽取为一个独立微服务:
trade-service,不过我们先来看一下hm-service中原本与下单有关的业务逻辑。也就是说,如果拆分了交易微服务(
trade-service),它也需要远程调用item-service中的根据id批量查询商品功能。这个需求与cart-service中是一样的。因此,我们就需要在
trade-service中再次定义ItemClient接口,这不是重复编码吗? 有什么办法能加避免重复编码呢?
思路分析
- 思路1:抽取到微服务之外的公共
module- 思路2:每个微服务自己抽取一个
module方案1 抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2 抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
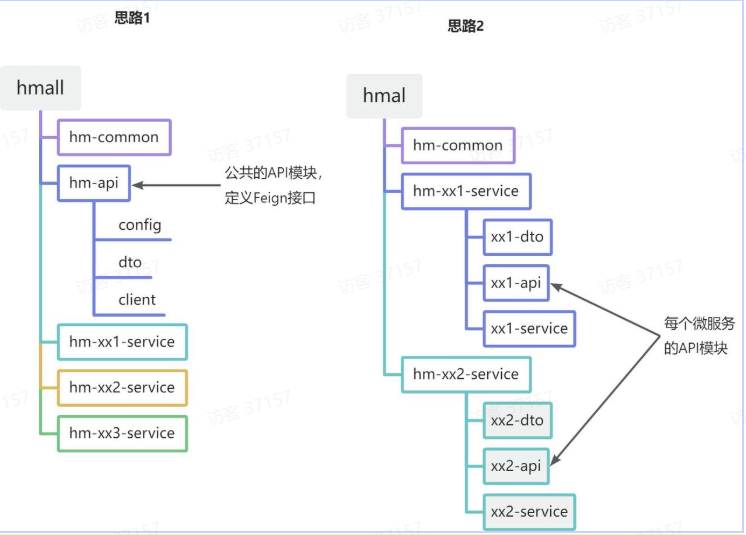
hm-api 模块
用于存放共同模块的。我们远程调用就是从这里拿
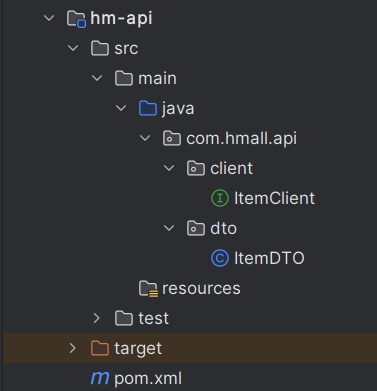
pom
<dependencies><!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency><dependency><groupId>io.swagger</groupId><artifactId>swagger-annotations</artifactId><version>1.6.6</version><scope>compile</scope></dependency></dependencies>
Client
//要调用的nacos服务的名字
@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
ItemDTO
@Data
@ApiModel(description = "商品实体")
public class ItemDTO {@ApiModelProperty("商品id")private Long id;@ApiModelProperty("SKU名称")private String name;@ApiModelProperty("价格(分)")private Integer price;@ApiModelProperty("库存数量")private Integer stock;@ApiModelProperty("商品图片")private String image;@ApiModelProperty("类目名称")private String category;@ApiModelProperty("品牌名称")private String brand;@ApiModelProperty("规格")private String spec;@ApiModelProperty("销量")private Integer sold;@ApiModelProperty("评论数")private Integer commentCount;@ApiModelProperty("是否是推广广告,true/false")private Boolean isAD;@ApiModelProperty("商品状态 1-正常,2-下架,3-删除")private Integer status;
}
cart-service 模块
把那个
OpenFeign抽取出去了
pom文件
引入
hm-api坐标。就能用hm-api的东西了
<dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--数据库--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--mybatis--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--OK http 的依赖 --><dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId></dependency><!--hm-api--><dependency><groupId>com.heima</groupId><artifactId>hm-api</artifactId><version>1.0.0</version></dependency></dependencies>
CartServiceImpl
这里会出现
ItemClient扫描不到的问题。因为,SpringBoot默认只扫描所在包及其子包。
//这里就是从公共模块拿去 ItemClient 的东西。使用 OpenFeign
private final ItemClient itemClient;private void handleCartItems(List<CartVO> vos) {// 1.获取商品idSet<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());// 2.使用 OpenFegin 调用 ItemClient 的接口List<ItemDTO> items = itemClient.queryItemByIds(itemIds);if (CollUtils.isEmpty(items)) {return;}// 3.转为 id 到 item的mapMap<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));// 4.写入vofor (CartVO v : vos) {ItemDTO item = itemMap.get(v.getItemId());if (item == null) {continue;}v.setNewPrice(item.getPrice());v.setStatus(item.getStatus());v.setStock(item.getStock());}}
- 解决扫描不到的问题
第一种方式
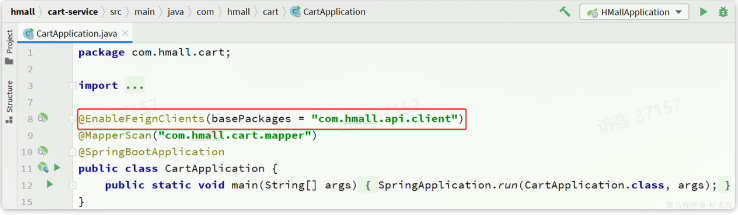
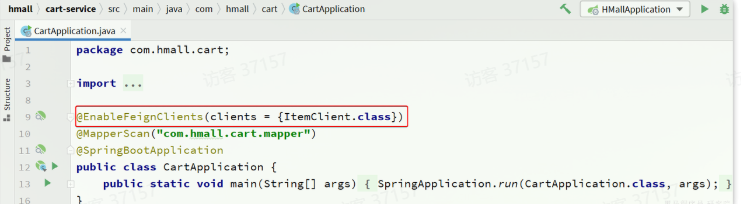
- 在启动类声明涉及到的包名
第二种方式:
- 再启动类声明要用的
FeignClient
OpenFeign 日志输出

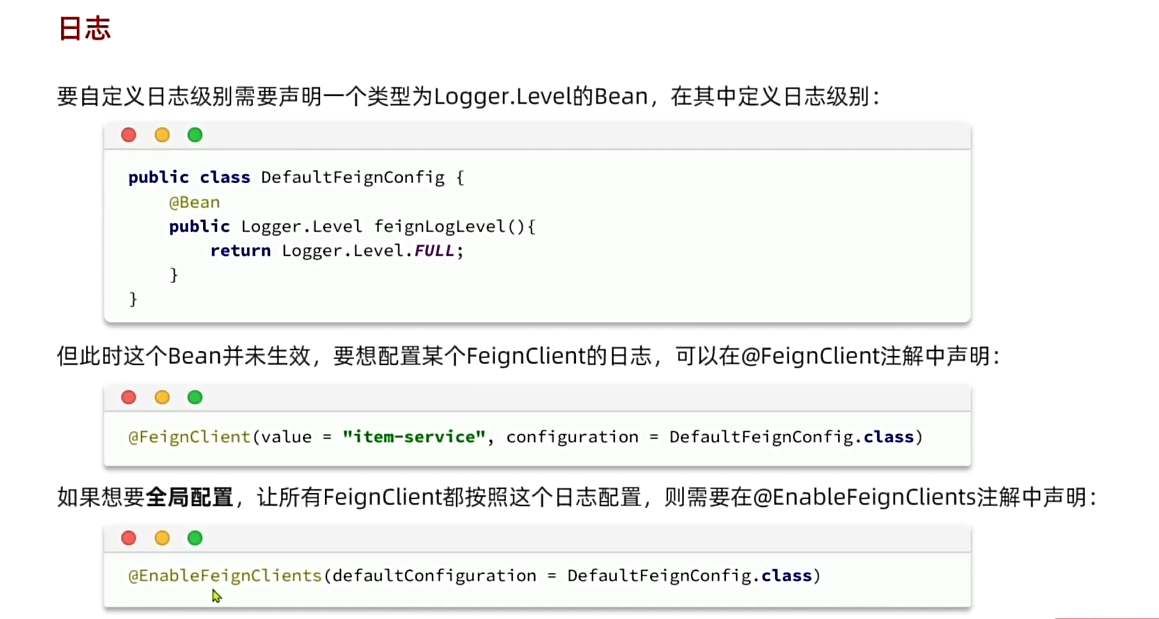
日志配置
Logger.Level这个类不要加@Configuration。我们一般不开日志。只有调试的时候才开。因为会有性能影响
微服务网关
微服务网关概述
不用网关出现的问题
前端调用问题
前端需要记住一堆不同的服务地址(比如订单服务
http://a.com、支付服务http://b.com),就像记多个电话号码一样麻烦。服务地址变化时,前端无法自动感知(比如支付服务换了端口),需要手动通知前端改代码。
用户身份难题
总不能让每个微服务都自己写一套登录验证逻辑吧?就像超市每个收银台都自己雇保安查会员卡,太浪费人力了!
微服务之间互相调用时(比如订单服务调支付服务),不能用
ThreadLocal。用户信息怎么悄无声息地传过去?总不能每次打电话都重新报一遍身份证号。问题解决
- 网关路由,解决前端请求入口的问题。
- 网关鉴权,解决统一登录校验和用户信息获取的问题。
- 统一配置管理,解决微服务的配置文件重复和配置热更新问题。
网关简介
网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。通俗的来讲,
网关就像是以前园区传达室的大爷。
- 外面的人要想进入园区,必须经过大爷的认可,如果你是不怀好意的人,肯定被直接拦截。
- 外面的人要传话或送信,要找大爷。大爷帮你带给目标人。
现在,微服务网关就起到同样的作用。前端请求不能直接访问微服务,而是要请求网关:
- 网关可以做安全控制,也就是登录身份校验,校验通过才放行
- 通过认证后,网关再根据请求判断应该访问哪个微服务,将请求转发过去
在
SpringCloud当中,提供了两种网关实现方案:
Netflix Zuul:早期实现,目前已经淘汰SpringCloudGateway:基于Spring的WebFlux技术,完全支持响应式编程,吞吐能力更强
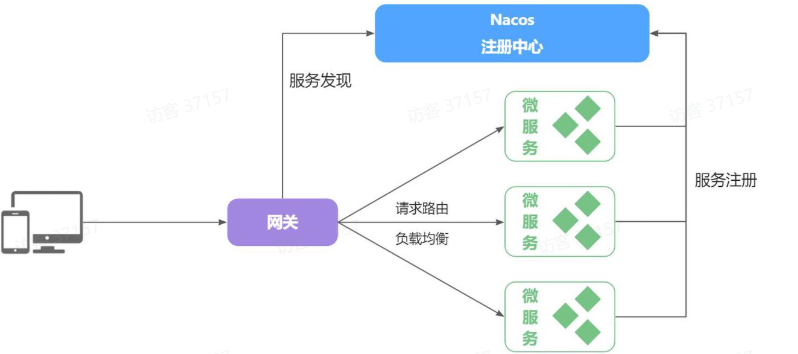
网关路由
快速入门
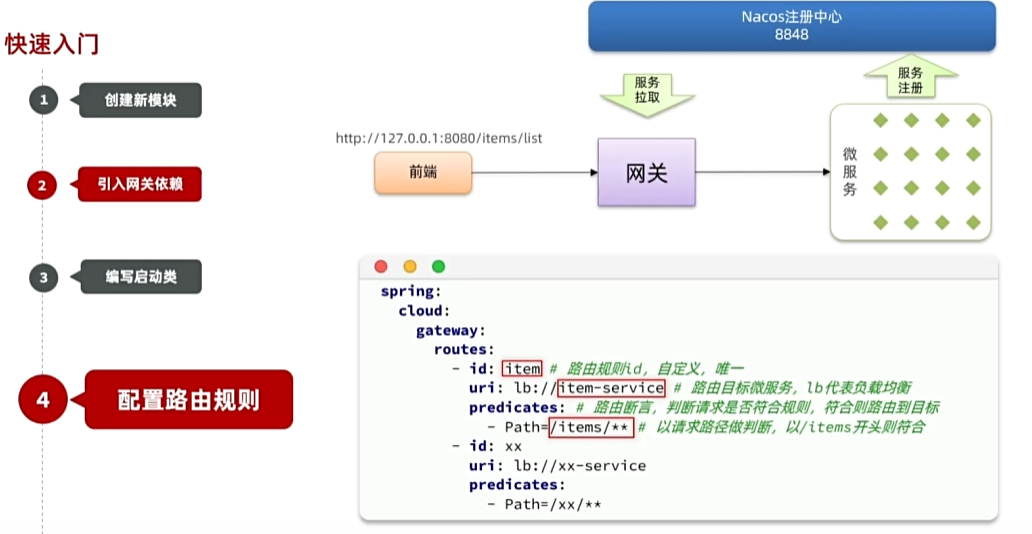
比如图中 访问
http://127.0.0.1:8080/items/list就会从根据匹配规则从注册中心找到item-service微服务的端口然后访问那个端口的items/list接口
- 第一步导入依赖
<!--网关--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--nacos discovery--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--负载均衡--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
- 编写启动类
@SpringBootApplication
public class GetewayApplication {public static void main(String[] args) {org.springframework.boot.SpringApplication.run(GetewayApplication.class, args);}
}
- 配置路由规则
server:port: 8080
spring:application:name: geteway #微服务名称cloud:nacos:server-addr: 192.168.88.130:8848 #nacos地址gateway:routes:- id: item-service #路由规则 id, 自定义 唯一uri: lb://item-service #lb代表负载均衡 item-service 代表路由目标微服务模块的名称 predicates:- Path=/items/**, /search/** #判断请求是否满足这些路径条件。满足就可以访问到目标微服务 —— 也就是 item-service 的端口- id: user-serviceuri: lb://user-service predicates:- Path=/addresses/**, /users/** - 启动测试
输入:
http://192.168.88.130:8080/items/page,访问gateway微服务然后匹配到Path = /items/**转发到item-service微服务模块。相当于访问http://localhost:8083/items/page
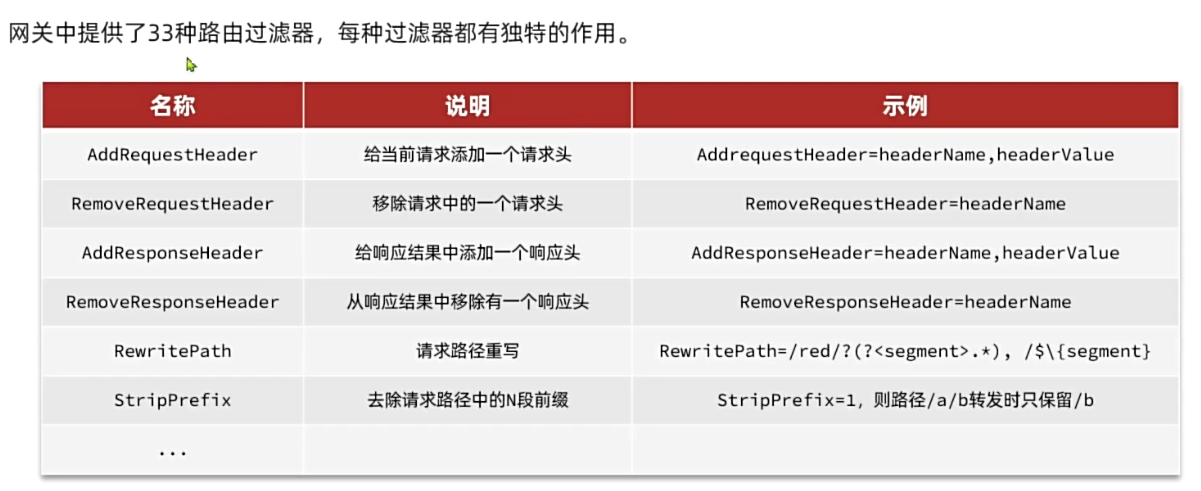
路由属性

- 路由断言

- 过滤器
cloud:nacos:server-addr: 192.168.88.130:8848gateway:routes:- id: item-serviceuri: lb://item-service #lb代表负载均衡predicates:- Path=/items/**, /search/** #前端请求到这些路径就路由到 item-service 商品微服务- id: user-serviceuri: lb://user-service #lb代表负载均衡predicates:- Path=/addresses/**, /users/** #前端请求到这些路径就路由到 item-service 商品微服务#全局配置过滤器 前面是请求头 k 后面是 v#如果要单个配置就在各自的路由上面加就行default-filters: - AddRequestHeader=truth, Default-Bar
网关登录校验
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,不再共享数据。也就意味着每个微服务都需要做登录校验,这显然不可取。
鉴权思路分析
我们的登录是基于
JWT来实现的,校验JWT的算法复杂,而且需要用到秘钥。如果每个微服务都去做登录校验,这就存在着两大问题:
- 每个微服务都需要知道
JWT的秘钥,不安全- 每个微服务重复编写登录校验代码、权限校验代码,麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关。我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就解决了:
- 只需要在网关和用户服务保存秘钥
- 只需要在网关开发登录校验功能
不过,这里存在几个问题:
- 网关路由是配置的,请求转发是
Gateway内部代码,我们如何在转发之前做登录校验?- 网关校验
JWT之后,如何将用户信息传递给微服务?- 微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?

网关过滤器概述
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是
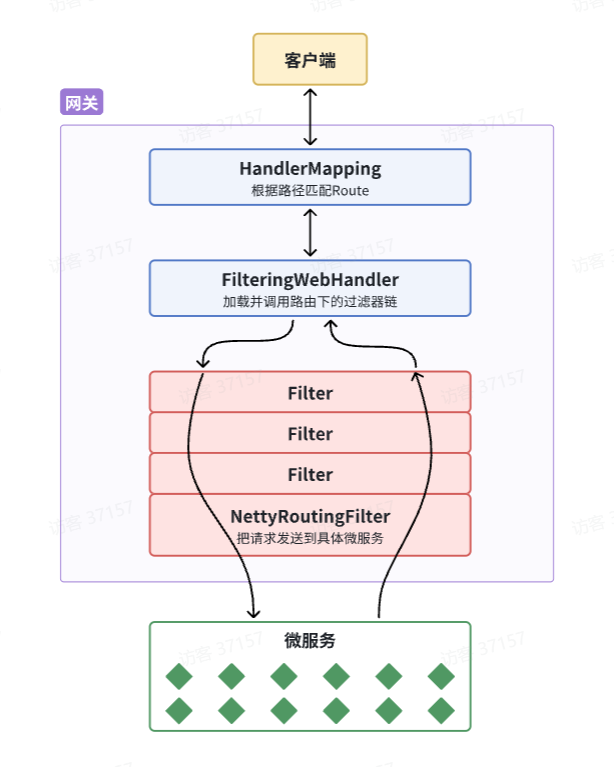
Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。如图所示:
- 客户端请求进入网关后由
HandlerMapping对请求做判断,找到与当前请求匹配的路由规则(Route),然后将请求交给WebHandler去处理。WebHandler则会加载当前路由下需要执行的过滤器链(Filter chain),然后按照顺序逐一执行过滤器(后面称为Filter)。- 图中
Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前和之后被执行。- 只有所有
Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务。- 微服务返回结果后,再倒序执行
Filter的post逻辑。- 最终把响应结果返回。
如图中所示,最终请求转发是有一个名为
NettyRoutingFilter的过滤器来执行的,而且这个过滤器是整个过滤器链中顺序最靠后的一个。如果我们能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器执行顺序定义到NettyRoutingFilter之前**,这就符合我们的需求了!**网关过滤器链中的过滤器有两种:
GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route.GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。
自定义过滤器
两个过滤器签名接口一致

自定义 GolbalFilter
- 第一步:编写类实现
GlobalFilter并打上@Component
exchange得到请求头信息。然后通过chain放行给下一个过滤器
@Component
public class MyGlobalFilter implements GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// TODO 模拟登录校验逻辑//得到 request 中的请求头信息ServerHttpRequest request = exchange.getRequest();HttpHeaders headers = request.getHeaders();System.out.println("headers = " + headers);//放行return chain.filter(exchange);}
}
- 第二步:实现
Ordered接口让优先级最高
NettyRoutingFilter的优先级是int的最大值,也就是最小优先级。我们做登录校验优先级要在它之前。因为它直接给微服务了。我们要在给微服务之前拿到 请求头信息
@Component
public class MyGlobalFilter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// TODO 模拟登录校验逻辑//得到 request 中的请求头信息ServerHttpRequest request = exchange.getRequest();HttpHeaders headers = request.getHeaders();System.out.println("headers = " + headers);//放行return chain.filter(exchange);}//定义优先级。数字越小优先级越高@Overridepublic int getOrder() {return 0;}
}
自定义 GataWayFilter
编写固定后缀为
GatewayFilterFactory的类继承AbstractGatewayFilterFactory实现apply方法,return一个GateWayFilter()过滤器对象固定后缀前面的名称就是:过滤器配置的名称

如果有参数要编写
Config静态类,还有重写shortcutFieldOrder()方法。然后还有用构造函数把config字节码传递给父类,父类帮我们读取yaml文件。泛型也要改成Config类

如果要排序使用这个
@Component
public class PrintAnyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {@Overridepublic GatewayFilter apply(Object config) {//这种方式可以制定优先级return new OrderedGatewayFilter((exchange, chain) -> {System.out.println("打印日志");return chain.filter(exchange);}, 0);}
}
登录1:登录校验实现
JWT 工具
登录校验需要用到
JWT,而且JWT的加密需要秘钥和加密工具。具体作用如下:
AuthProperties:配置登录校验需要拦截的路径,因为不是所有的路径都需要登录才能访问JwtProperties:定义与JWT工具有关的属性,比如秘钥文件位置SecurityConfig:工具的自动装配JwtTool:JWT工具,其中包含了校验和解析token的功能hmall.jks:秘钥文件
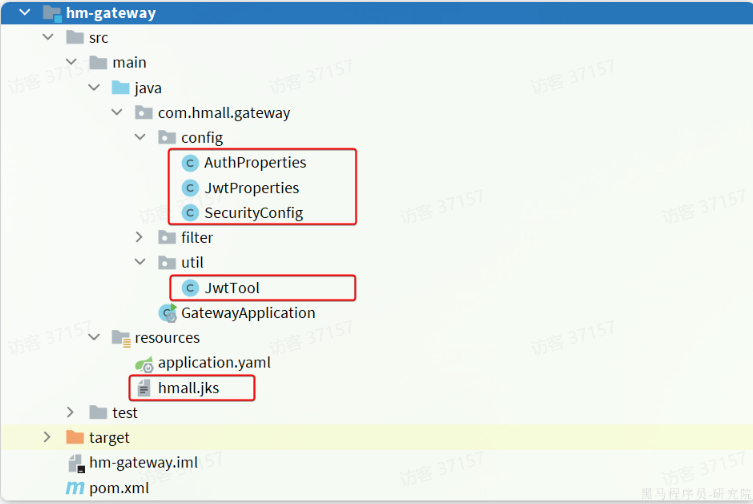
其中AuthProperties和 JwtProperties 所需的属性要在 application.yaml 中配置:
server:port: 8080
spring:application:name: getewaycloud:nacos:server-addr: 192.168.88.130:8848gateway:routes:- id: item-serviceuri: lb://item-service #lb代表负载均衡predicates:- Path=/items/**, /search/** #前端请求到这些路径就路由到 item-service 商品微服务- id: user-serviceuri: lb://user-service #lb代表负载均衡predicates:- Path=/addresses/**, /users/** #前端请求到这些路径就路由到 user-service 商品微服务- id: cart-serviceuri: lb://cart-servicepredicates:- Path=/carts/**default-filters:- AddRequestHeader=truth, Default-Bar- PrintAny
hm:jwt:location: classpath:hmall.jksalias: hmallpassword: hmall123tokenTTL: 30mauth:excludePaths:- /search/**- /users/login- /items/**- /hi
登录校验过滤器
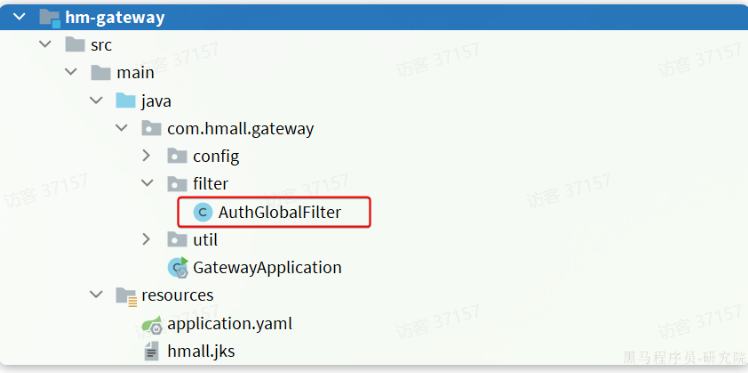
@Component
@RequiredArgsConstructor
public class AuthGlobalFilter implements GlobalFilter, Ordered {private final AuthProperties authProperties;private final JwtTool jwtTool;// 路径匹配器private final AntPathMatcher antPathMatcher = new AntPathMatcher();@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 1. 获取 requestServerHttpRequest request = exchange.getRequest();// 2. 判断是否需要做登录拦截if (isExclude(request.getPath().toString())) {// 放行return chain.filter(exchange);}// 3. 根据请求头 获取 tokenString token = null;List<String> headers = request.getHeaders().get("authorization");if (headers != null && !headers.isEmpty()) {token = headers.get(0);}// 4. 校验并解析 tokenLong userId = null;try {userId = jwtTool.parseToken(token);} catch (UnauthorizedException e) {// 拦截, 设置响应状态码为 401ServerHttpResponse response = exchange.getResponse();//设置响应状态码为未登录response.setStatusCode(HttpStatus.UNAUTHORIZED);//设置在这里终止返回 responese 了return response.setComplete();}// 5. TODO 5.传递用户信息System.out.println("userId = " + userId);// 6. 放行return null;}private boolean isExclude(String path) {for (String excludePath : authProperties.getExcludePaths()) {if (antPathMatcher.match(excludePath, path)) {return true;}}return false;}@Overridepublic int getOrder() {return 0;}}
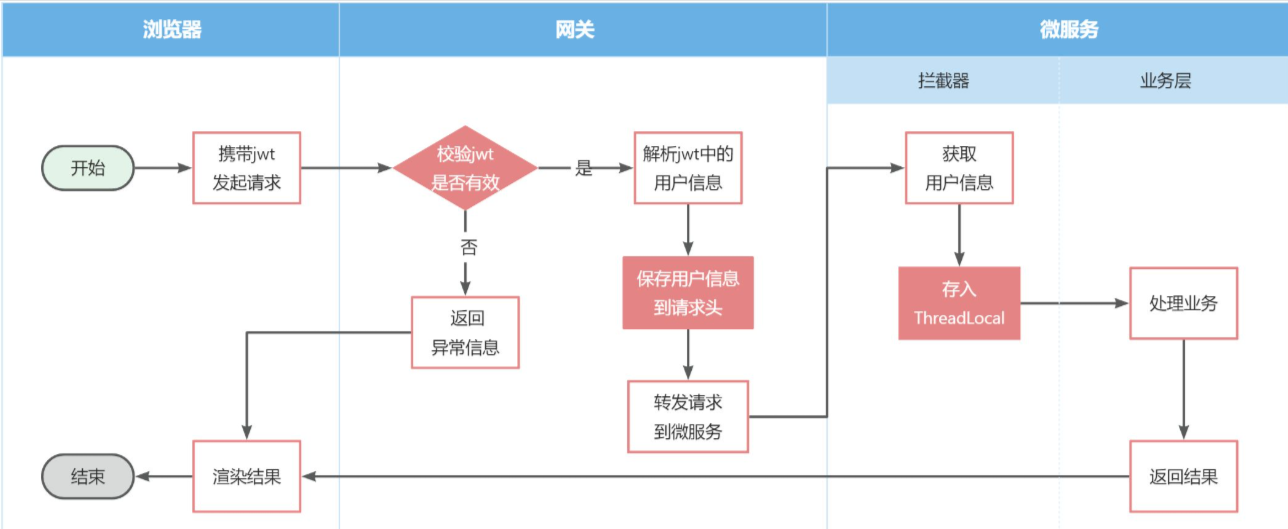
登录2:微服务获取用户信息
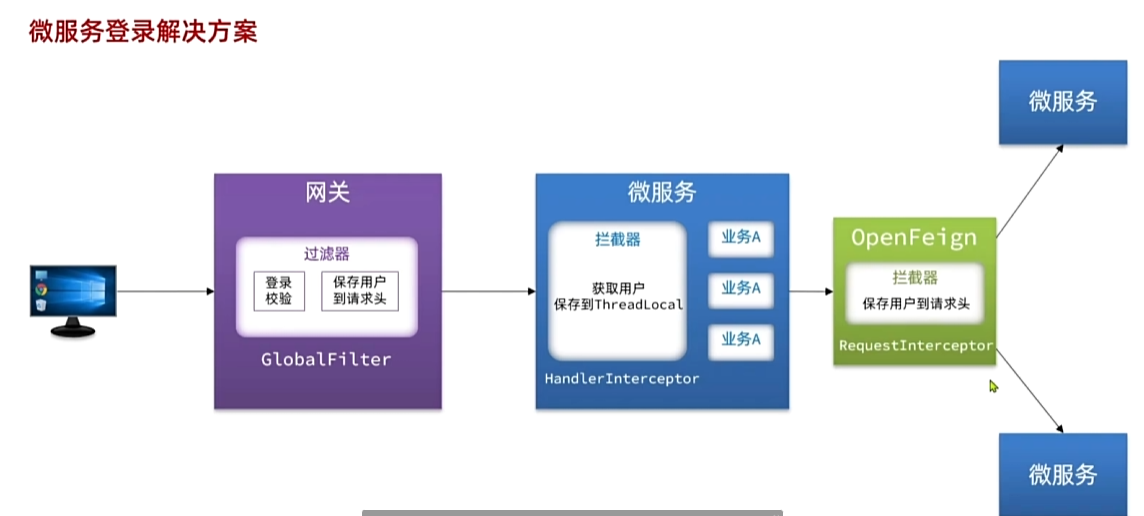
通过网关将请求转发到下游微服务。由于网关发送请求到微服务依然采用的是
Http请求,因此我们可以将用户信息以请求头的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
保存用户信息到请求头
利用
mutate和build定义请求
@Component
@RequiredArgsConstructor
public class AuthGlobalFilter implements GlobalFilter, Ordered {private final AuthProperties authProperties;private final JwtTool jwtTool;// 路径匹配器private final AntPathMatcher antPathMatcher = new AntPathMatcher();@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 1. 获取 requestServerHttpRequest request = exchange.getRequest();// 2. 判断是否需要做登录拦截if (isExclude(request.getPath().toString())) {// 放行return chain.filter(exchange);}// 3. 根据请求头 获取 tokenString token = null;List<String> headers = request.getHeaders().get("authorization");if (headers != null && !headers.isEmpty()) {token = headers.get(0);}// 4. 校验并解析 tokenLong userId = null;try {userId = jwtTool.parseToken(token);} catch (UnauthorizedException e) {// 拦截, 设置响应状态码为 401ServerHttpResponse response = exchange.getResponse();//设置响应状态码为未登录response.setStatusCode(HttpStatus.UNAUTHORIZED);//设置在这里终止返回 responese 了return response.setComplete();}// 5. 传递用户信息String userInfo = userId.toString();/** mutate 复制当前请求响应情况,也就是当前 exchange 可到一个可以修改的版本* 然后.request(builder.header(...) 在请求头添加 userinfo* 最后.build 覆盖之前的 exchange 然后我们把新的传递给下一个过滤器就行*/ServerWebExchange swe = exchange.mutate().request(new Consumer<ServerHttpRequest.Builder>() {@Overridepublic void accept(ServerHttpRequest.Builder builder) {builder.header("userId", userInfo);}}).build();System.out.println("userId = " + userId);// 6. 放行return chain.filter(swe);}private boolean isExclude(String path) {for (String excludePath : authProperties.getExcludePaths()) {if (antPathMatcher.match(excludePath, path)) {return true;}}return false;}@Overridepublic int getOrder() {return 0;}}
拦截器获取用户信息
在访问各个独立微服务的
controller的时候拦截一下。传递个用户信息
hm-common有一个用于保存登录用户的ThreadLocal工具类
public class UserContext {private static final ThreadLocal<Long> tl = new ThreadLocal<>();/*** 保存当前登录用户信息到ThreadLocal* @param userId 用户id*/public static void setUser(Long userId) {tl.set(userId);}/*** 获取当前登录用户信息* @return 用户id*/public static Long getUser() {return tl.get();}/*** 移除当前登录用户信息*/public static void removeUser(){tl.remove();}
}- 编写拦截器
我们只需要编写拦截器,获取用户信息并保存到
UserContext,然后放行即可。由于每个微服务都有获取登录用户的需求,因此拦截器我们直接写在
hm-common中,并写好自动装配。这样微服务只需要引入hm-common就可以直接具备拦截器功能,无需重复编写。
public class UserInfoInterceptor implements HandlerInterceptor {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 1.获取用户信息String userInfo = request.getHeader("user-info");// 2.判断是否获取了用户信息, 如果有, 存入 ThreadLocalif (StrUtil.isNotBlank(userInfo)) {UserContext.setUser(Long.valueOf(userInfo));}return true;// 3.放行}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {//清理用户UserContext.removeUser();}
}- 在
hm-common下编写SpringMVC配置类,配置登录拦截器
要注意这个配置类默认是不会生效的,因为它所在的包是
com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。基于
SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:并且我们的
gateway网关是基于交互式api不是springmvc所以我们要用ConditionalOnClass让它只能在DispatcherServlet也就是springmvc情况下有效
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new UserInfoInterceptor());}
}
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.hmall.common.config.MyBatisConfig,\com.hmall.common.config.JsonConfig,\com.hmall.common.config.MvcConfig
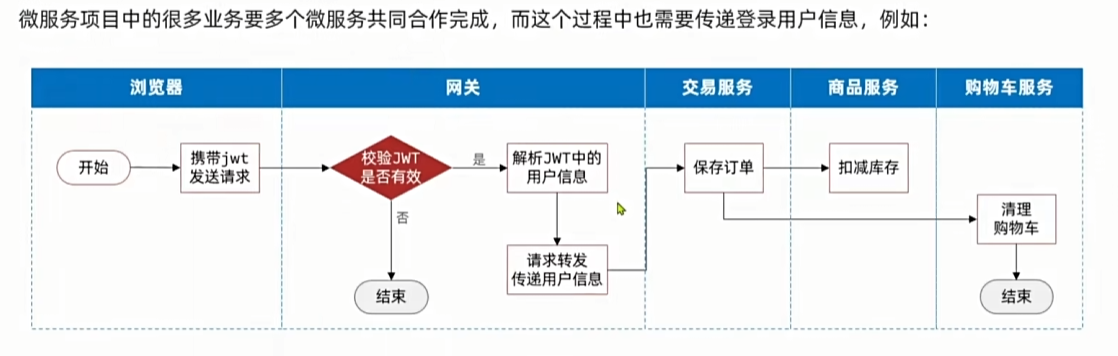
登录3: OpenFeign 传递用户信息
订单微服务服务调用购物车微服务,是利用
OpenFeign不是走的网关所以拿不到ThreadLocal中的共享信息。所以我们必须在OpenFeign发起的请求自动携带登录用户信息。这时候需要用到Feign中的拦截器RequestInterceptor
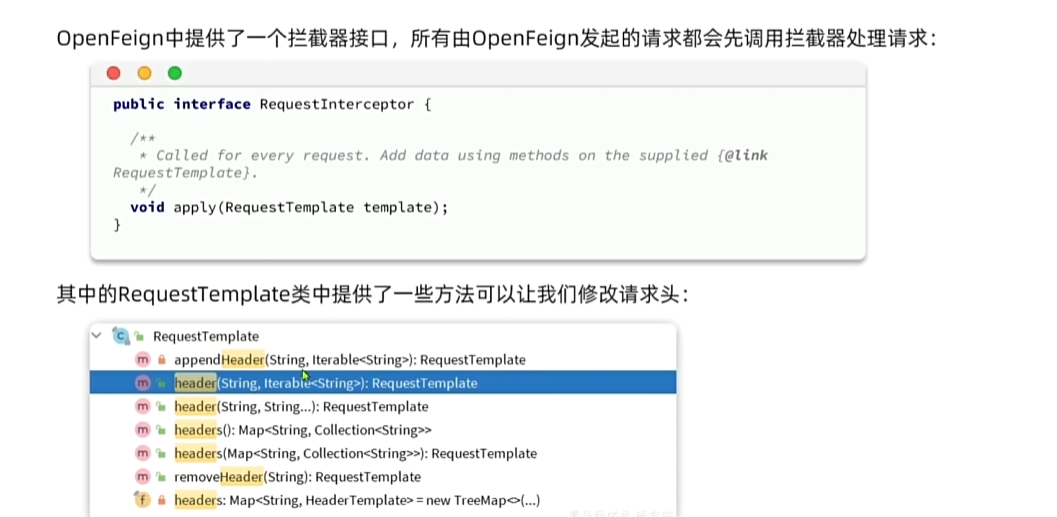
编写 OpenFeign 拦截器保存信息
DefaultFeignConfig
因为可能在多个微服务中使用。所以我们写在
hm-api公共模块中
public class DefaultFeignConfig {@Beanpublic Logger.Level feignLoggerLevel() {return Logger.Level.FULL;}@Beanpublic RequestInterceptor userInfoInterceptor() {return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate template) {Long userId = UserContext.getUser();if (userId != null) {template.header("userId", userId.toString());}}};}
}
检查购物车微服务有没有加入该配置类
TradeApplication
defaultConfiguration = DefaultFeignConfig.class表示模块下所有FeignClient配置该配置类
@EnableFeignClients(basePackages = "com.hmall.api.client", defaultConfiguration = DefaultFeignConfig.class)
@MapperScan("com.hmall.trade.mapper")
@SpringBootApplication
public class TradeApplication {public static void main(String[] args) {SpringApplication.run(TradeApplication.class, args);}}
登录4:方案总结
微服务配置管理
配置管理概述
到目前为止我们已经解决了微服务相关的几个问题:
- 微服务远程调用
- 微服务注册、发现
- 微服务请求路由、负载均衡
- 微服务登录用户信息传递
不过,现在依然还有几个问题需要解决:
- 网关路由在配置文件中写死了,如果变更必须重启微服务
- 某些业务配置在配置文件中写死了,每次修改都要重启服务
- 每个微服务都有很多重复的配置,维护成本高
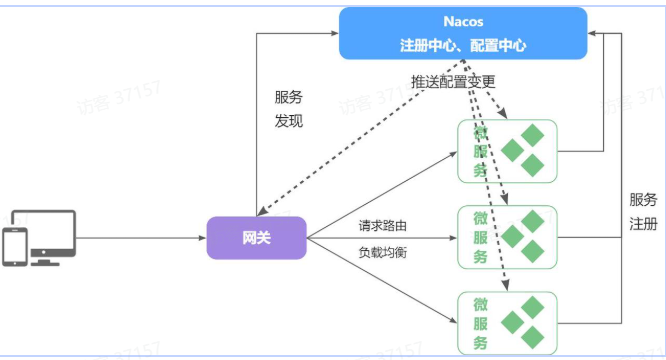
这些问题都可以通过统一的配置管理器服务解决。而
Nacos不仅仅具备注册中心功能,也具备配置管理的功能微服务共享的配置可以统一交给
Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
配置共享
我们可以把微服务共享的配置抽取到
Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
- 在
Nacos中添加共享配置- 微服务拉取配置
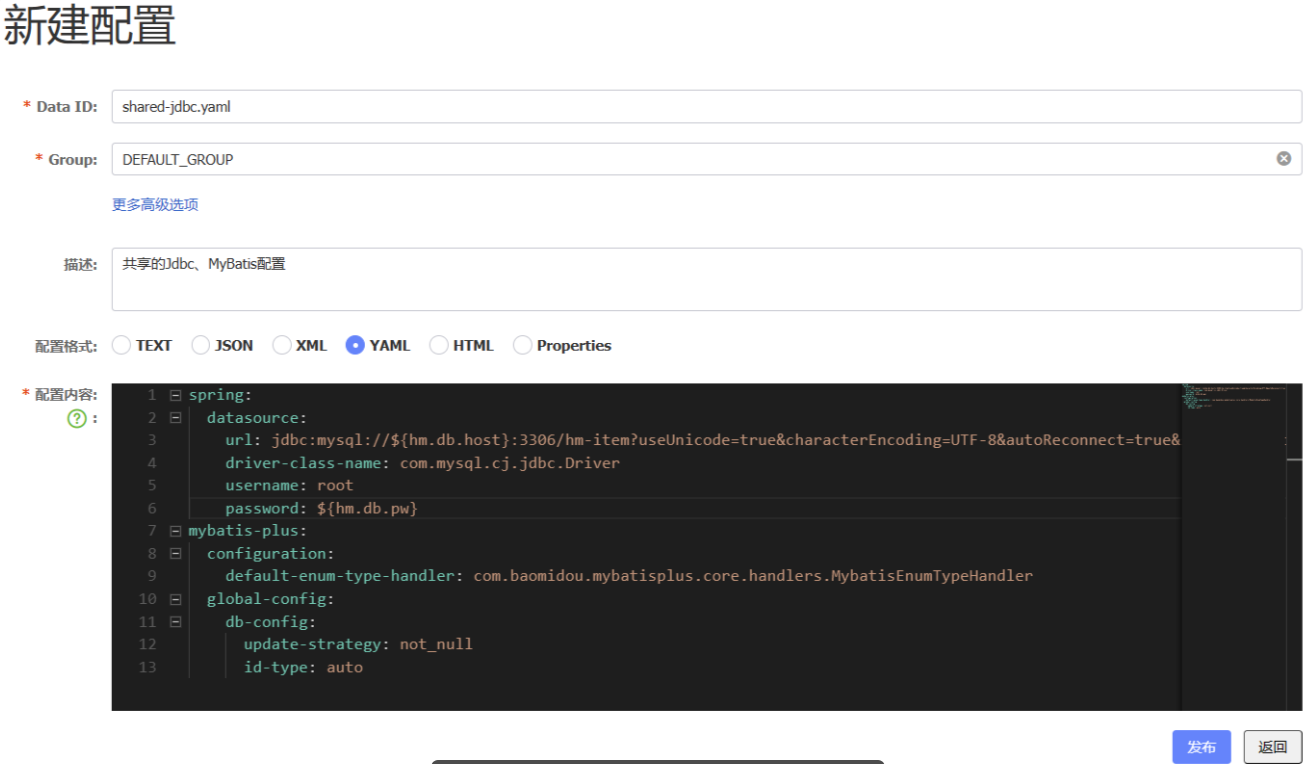
第一步:添加配置到 Nacos
注意如果不是共享的配置可以用
${}动态解决
JDBC相关配置
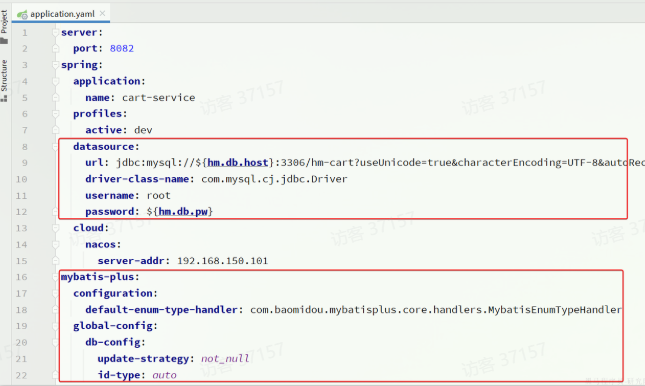
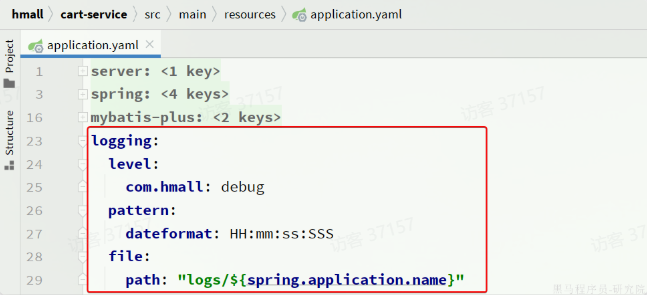
- 日志配置
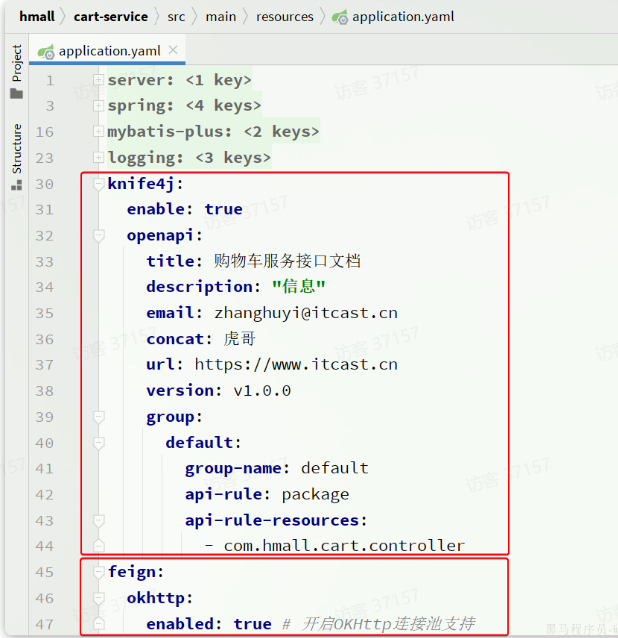
swagger以及OpenFeign配置
第二步:拉取共享配置
在微服务中拉取共享配置时,需将拉取的共享配置与本地
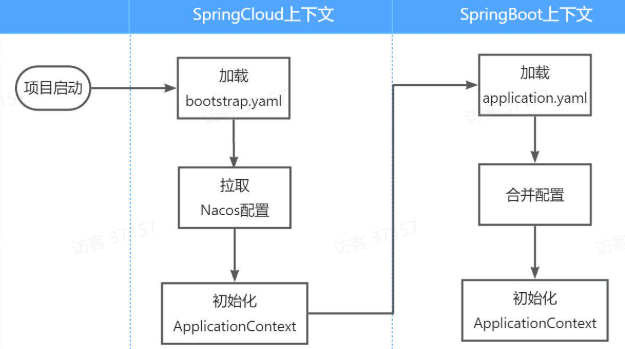
application.yaml配置合并以完成项目上下文初始化。不过,读取 Nacos 配置是在Spring Cloud上下文初始化的引导阶段进行的,此时application.yaml还未被读取,无法从中获取 Nacos 地址。
Spring Cloud会在初始化上下文时先读取bootstrap.yaml(或bootstrap.properties)文件。因此,把Nacos地址配置在bootstrap.yaml里,就能在项目引导阶段读取Nacos中的配置了。
- 引入依赖
<!--nacos配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency>
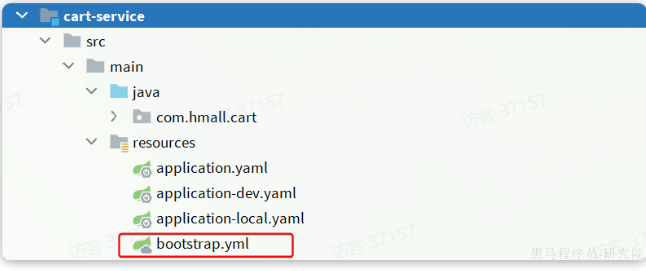
- 新建
bootstrap.yaml文件
spring:application:name: cart-service # 服务名称profiles:active: devcloud:nacos:server-addr: 192.168.150.101 # nacos地址config:file-extension: yaml # 文件后缀名shared-configs: # 共享配置- dataId: shared-jdbc.yaml # 共享mybatis配置- dataId: shared-log.yaml # 共享日志配置- dataId: shared-swagger.yaml # 共享日志配置
- 修改
application.yaml
由于一些配置挪到了
bootstrap.yaml,因此application.yaml需要修改
server:port: 8082
feign:okhttp:enabled: true # 开启OKHttp连接池支持
hm:swagger:title: "购物车服务接口文档"package: com.hmall.cart.controllerdb:database: hm-cart
配置热更新
概述
有很多的业务相关参数,将来可能会根据实际情况临时调整。例如购物车业务,购物车数量有一个上限,默认是10,对应代码如下:
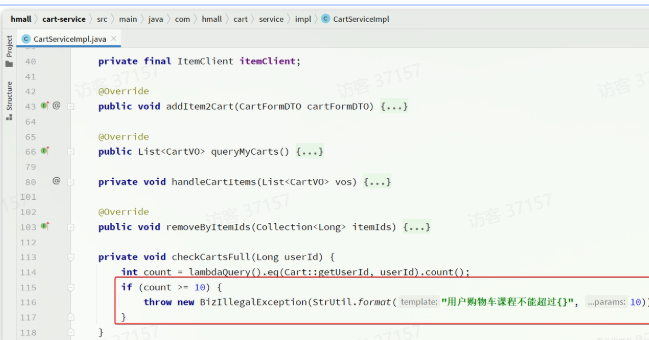
现在这里购物车是写死的固定值,我们应该将其配置在配置文件中,方便后期修改。
但现在的问题是,即便写在配置文件中,修改了配置还是需要重新打包、重启服务才能生效。能不能不用重启,直接生效呢?
这就要用到
Nacos的配置热更新能力了,分为两步:
- 在
Nacos中添加配置- 在微服务读取配置
在 Nacos 中添加配置
文件的
dataId格式:[服务名]-[spring.active.profile].[后缀名]比如cart-service-dev.yaml如果不添加配置环境就是全环境生效

- 添加配置到
Nacos
文件名称由三部分组成:
服务名:我们是购物车服务,所以是cart-servicespring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置后缀名:例如yaml
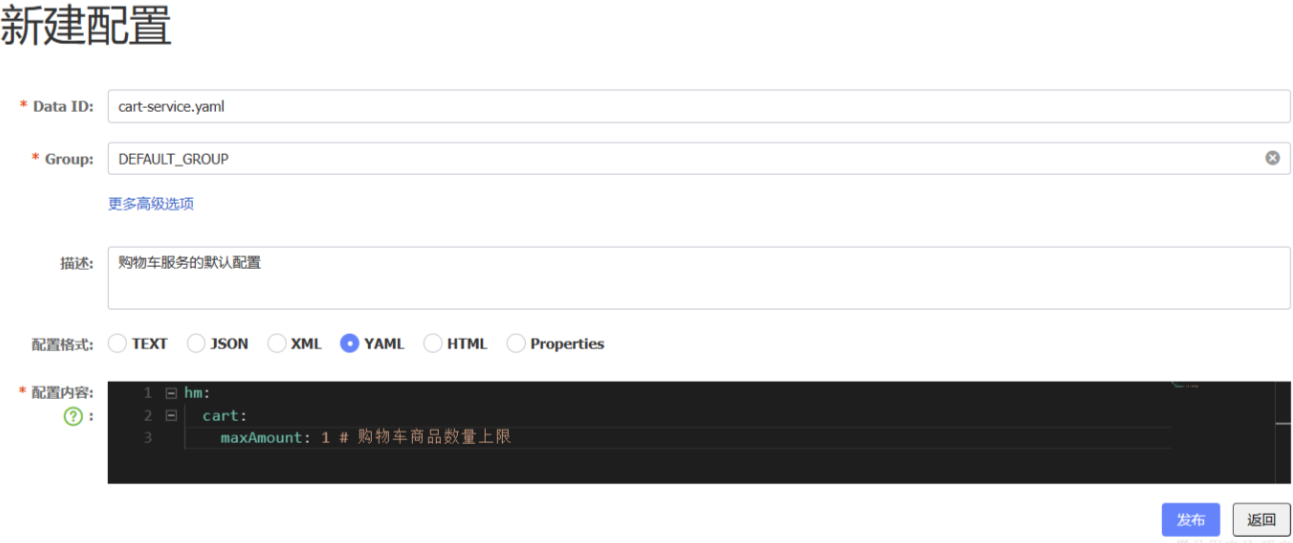
hm:cart:maxAmount: 1 # 购物车商品数量上限
- 提交配置,在控制台看到新添加的配置
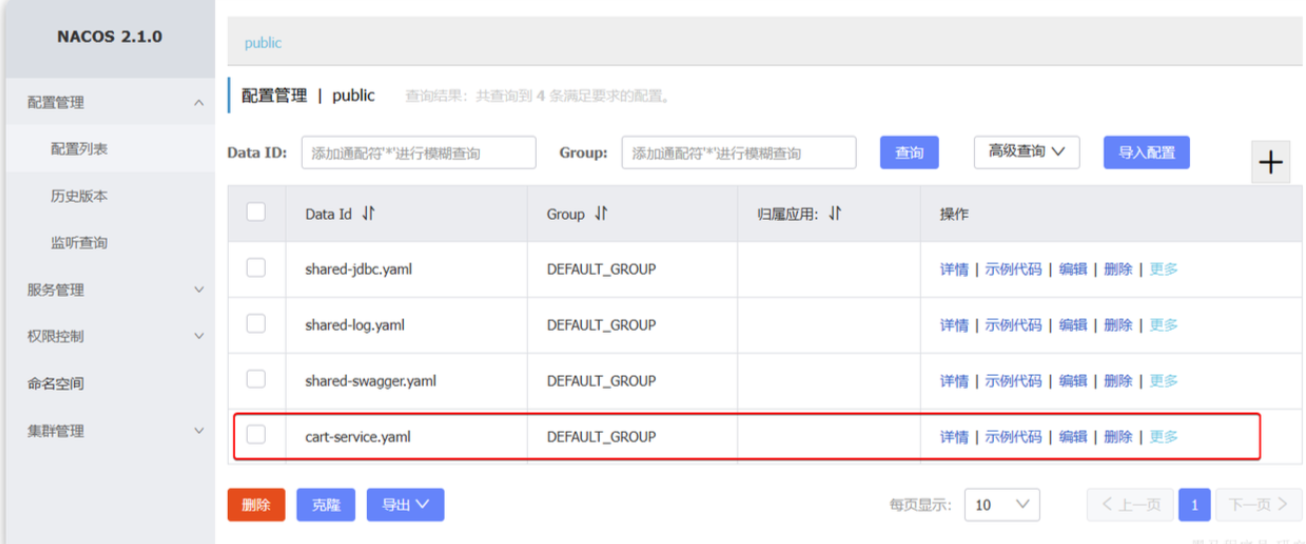
配置热更新
- 创建属性读取类
我们在微服务中读取配置,实现配置热更新。
在
cart-service中新建一个属性读取类:
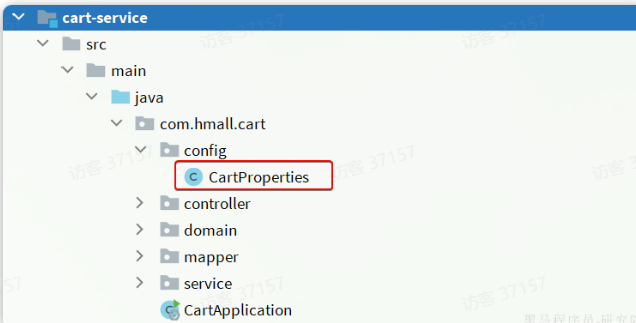
@Data
@Component
@ConfigurationProperties(prefix = "hm.cart")
public class CartProperties {private Integer maxAmount;
}
- 在业务中使用该属性加载类
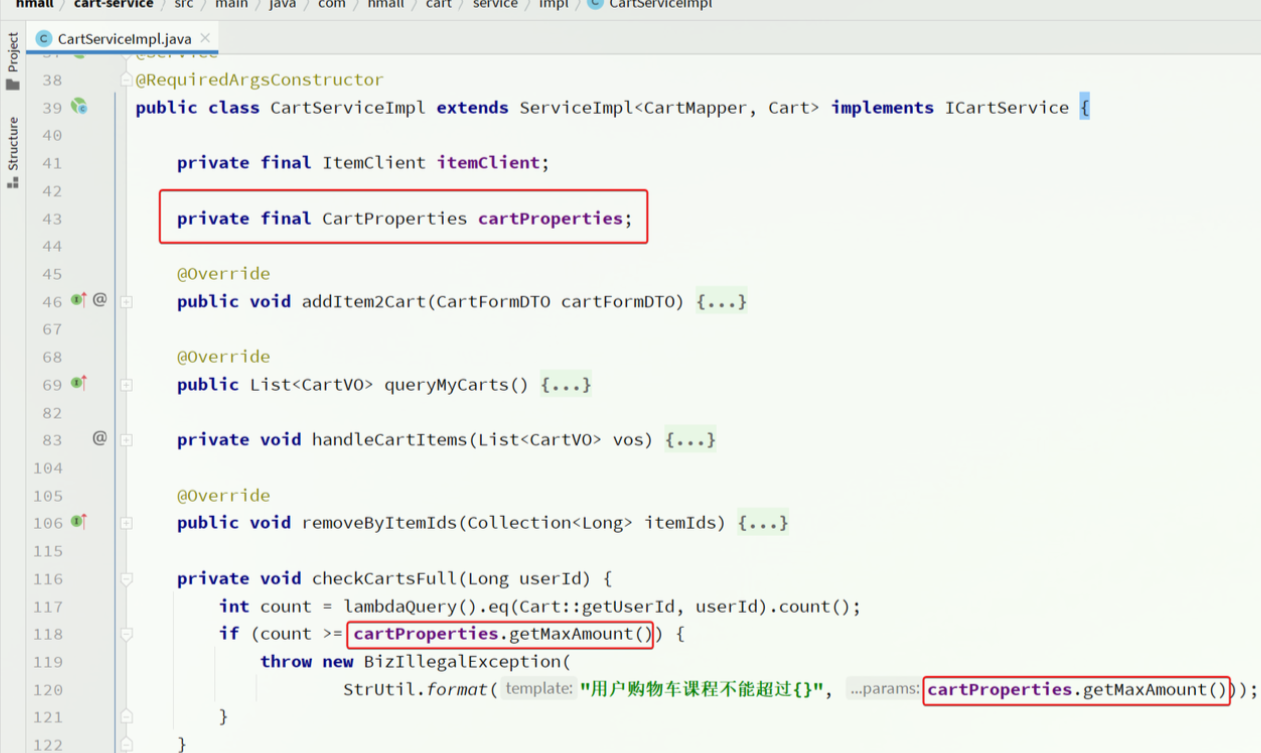
动态路由
网关的路由配置全部是在项目启动时由
org.springframework.cloud.gateway.route.CompositeRouteDefinitionLocator在项目启动的时候加载,并且一经加载就会缓存到内存中的路由表内(一个Map),不会改变。也不会监听路由变更,所以,我们无法利用配置热更新来实现路由更新。因此,我们必须监听
Nacos的配置变更,然后手动把最新的路由更新到路由表中。这里有两个难点:
- 如何监听
Nacos配置变更?- 如何把路由信息更新到路由表?
监听 Naocs 配置变更
手动监听 Nacos 配置变更的 Java SDK
如果希望
Nacos推送配置变更,可以使用Nacos动态监听配置接口来实现
public void addListener(String dataId, String group, Listener listener)
| 参数名 | 参数类型 | 描述 |
|---|---|---|
| dataId | string | 配置 ID,保证全局唯一性,只允许英文字符和 4 种特殊字符(“.”、“:”、“-”、“_”)。不超过 256 字节。 |
| group | string | 配置分组,一般是默认的DEFAULT_GROUP。 |
| listener | Listener | 监听器,配置变更进入监听器的回调函数。 |
String serverAddr = "{serverAddr}";
String dataId = "{dataId}";
String group = "{group}";
// 1.创建ConfigService,连接Nacos
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
ConfigService configService = NacosFactory.createConfigService(properties);
// 2.读取配置
String content = configService.getConfig(dataId, group, 5000);
// 3.添加配置监听器
configService.addListener(dataId, group, new Listener() {@Overridepublic void receiveConfigInfo(String configInfo) {// 配置变更的通知处理System.out.println("recieve1:" + configInfo);}@Overridepublic Executor getExecutor() {return null;}
});
这里核心的步骤有2步:
- 创建
ConfigService,目的是连接到Nacos - 添加配置监听器,编写配置变更的通知处理逻辑
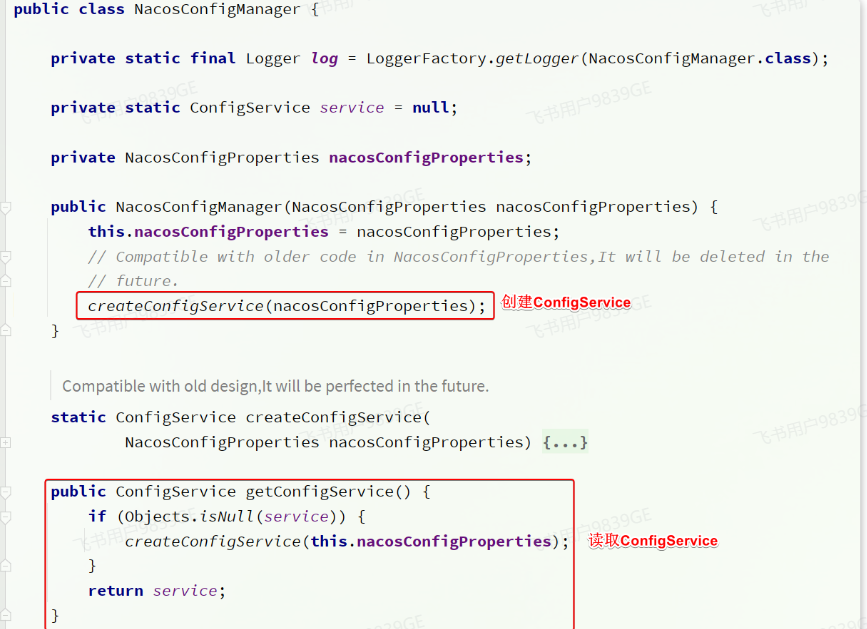
核心步骤第一步:创建 ConfigService
- 由于我们采用了
spring-cloud-starter-alibaba-nacos-config自动装配,因此ConfigService已经在com.alibaba.cloud.nacos.NacosConfigAutoConfiguration中自动创建好了:
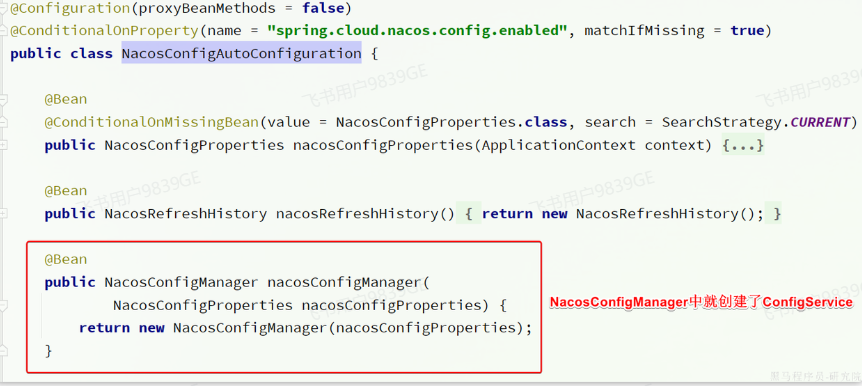
NacosConfigManager中是负责管理Nacos的ConfigService的,具体代码如下:- 因此,只要我们拿到
NacosConfigManager就等于拿到了ConfigService,第一步就实现了。
- 因此,只要我们拿到
核心步骤第二步:编写监听器
虽然官方提供的
SDK是ConfigService中的addListener,不过项目第一次启动时不仅仅需要添加监听器,也需要读取配置,因此建议使用的API是这个:既可以配置监听器,并且会根据
dataId和group读取配置并返回。我们就可以在项目启动时先更新一次路由,后续随着配置变更通知到监听器,完成路由更新。
String getConfigAndSignListener(String dataId, // 配置文件idString group, // 配置组,走默认long timeoutMs, // 读取配置的超时时间Listener listener // 监听器
) throws NacosException;
更新路由
更新路由要用到
org.springframework.cloud.gateway.route.RouteDefinitionWriter这个接口:这里更新的路由,也就是
RouteDefinition,之前我们见过,包含下列常见字段:
id:路由idpredicates:路由匹配规则filters:路由过滤器uri:路由目的地
package org.springframework.cloud.gateway.route;import reactor.core.publisher.Mono;/*** @author Spencer Gibb*/
public interface RouteDefinitionWriter {/*** 更新路由到路由表,如果路由id重复,则会覆盖旧的路由*/Mono<Void> save(Mono<RouteDefinition> route);/*** 根据路由id删除某个路由*/Mono<Void> delete(Mono<String> routeId);}- 将来我们保存到
Nacos的配置也要符合这个对象结构,将来我们以JSON来保存,格式如下:
{"id": "item","predicates": [{"name": "Path","args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}}],"filters": [],"uri": "lb://item-service"
}
以上JSON配置就等同于:
spring:cloud:gateway:routes:- id: itemuri: lb://item-servicepredicates:- Path=/items/**,/search/**
实现动态路由
- 在网关
gateway引入依赖
<!--统一配置管理-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--加载bootstrap-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
- 然后在网关
gateway的resources目录创建bootstrap.yaml文件
spring:application:name: gatewaycloud:nacos:server-addr: 192.168.150.101config:file-extension: yamlshared-configs:- dataId: shared-log.yaml # 共享日志配置
- 修改
gateway的resources目录下的application.yml,把之前的路由移除,最终内容如下:
server:port: 8080 # 端口
hm:jwt:location: classpath:hmall.jks # 秘钥地址alias: hmall # 秘钥别名password: hmall123 # 秘钥文件密码tokenTTL: 30m # 登录有效期auth:excludePaths: # 无需登录校验的路径- /search/**- /users/login- /items/**
- 然后,在
gateway中定义配置监听器
@Slf4j
@Component
@RequiredArgsConstructor
public class DynamicRouteLoader {private final RouteDefinitionWriter writer;private final NacosConfigManager nacosConfigManager;// 路由配置文件的id和分组private final String dataId = "gateway-routes.json";private final String group = "DEFAULT_GROUP";// 保存更新过的路由idprivate final Set<String> routeIds = new HashSet<>();@PostConstructpublic void initRouteConfigListener() throws NacosException {// 1.注册监听器并首次拉取配置String configInfo = nacosConfigManager.getConfigService().getConfigAndSignListener(dataId, group, 5000, new Listener() {@Overridepublic Executor getExecutor() {return null;}@Overridepublic void receiveConfigInfo(String configInfo) {updateConfigInfo(configInfo);}});// 2.首次启动时,更新一次配置updateConfigInfo(configInfo);}private void updateConfigInfo(String configInfo) {log.debug("监听到路由配置变更,{}", configInfo);// 1.反序列化List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);// 2.更新前先清空旧路由// 2.1.清除旧路由for (String routeId : routeIds) {writer.delete(Mono.just(routeId)).subscribe();}routeIds.clear();// 2.2.判断是否有新的路由要更新if (CollUtils.isEmpty(routeDefinitions)) {// 无新路由配置,直接结束return;}// 3.更新路由routeDefinitions.forEach(routeDefinition -> {// 3.1.更新路由writer.save(Mono.just(routeDefinition)).subscribe();// 3.2.记录路由id,方便将来删除routeIds.add(routeDefinition.getId());});}
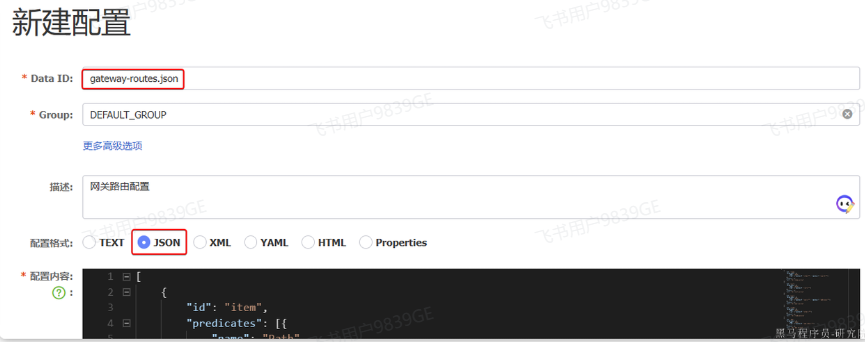
}- 我们直接在
Nacos控制台添加路由,路由文件名为gateway-routes.json,类型为jsondataId要和java路由配置文件中写的dataid一样
[{"id": "item","predicates": [{"name": "Path","args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}}],"filters": [],"uri": "lb://item-service"},{"id": "cart","predicates": [{"name": "Path","args": {"_genkey_0":"/carts/**"}}],"filters": [],"uri": "lb://cart-service"},{"id": "user","predicates": [{"name": "Path","args": {"_genkey_0":"/users/**", "_genkey_1":"/addresses/**"}}],"filters": [],"uri": "lb://user-service"},{"id": "trade","predicates": [{"name": "Path","args": {"_genkey_0":"/orders/**"}}],"filters": [],"uri": "lb://trade-service"},{"id": "pay","predicates": [{"name": "Path","args": {"_genkey_0":"/pay-orders/**"}}],"filters": [],"uri": "lb://pay-service"}
]
微服务保护
远程调用可能产生的问题
业务健壮性不足
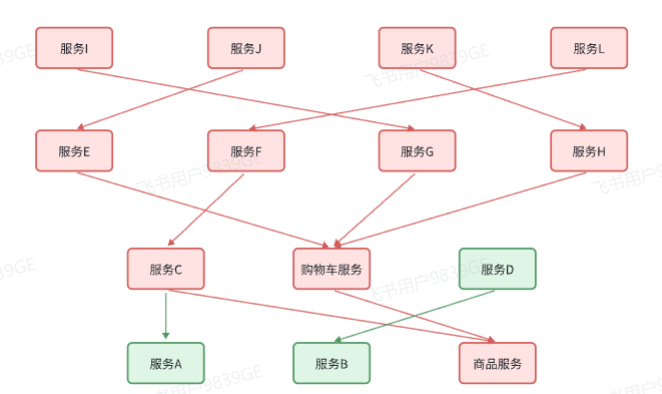
以查询购物车列表业务为例,购物车服务需查询最新商品信息,并与购物车数据对比,为用户提供提醒。然而,当商品服务出现故障时,购物车服务调用商品服务查询商品信息也会失败,进而导致购物车查询失败。从用户体验的角度出发,即便商品查询失败,购物车列表也应正常展示,只不过无法包含最新的商品信息。
级联失败风险(雪崩问题)
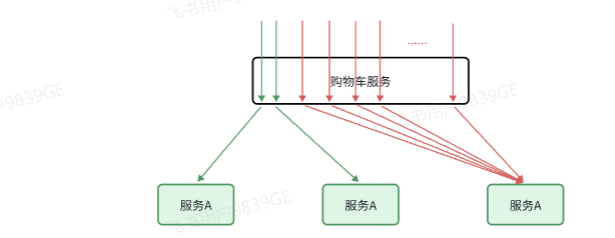
同样以购物车查询业务来说,当商品服务业务并发量过高时,会占用大量 Tomcat 连接,致使商品服务所有接口的响应时间大幅增加,出现高延迟,甚至长时间阻塞,最终导致查询失败。由于购物车服务查询依赖商品服务的结果,在等待商品服务响应的过程中,购物车查询业务的响应时间同样变长,严重时会出现阻塞,导致无法访问。若此时购物车查询请求持续增多,购物车服务的 Tomcat 连接被大量占用,会造成购物车服务所有接口的响应时间全面增加,服务性能急剧下降,甚至不可用 。依次类推,整个微服务群中与购物车服务、商品服务等有调用关系的服务可能都会出现问题,最终导致整个集群不可用。
服务保护方案
请求限流
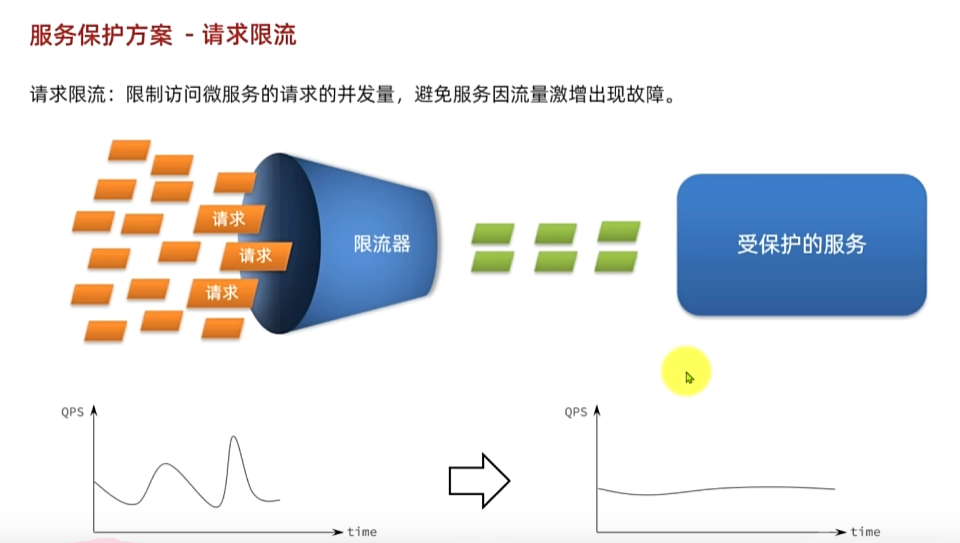
服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发不是一直很高,而是突发的。因此请求限流,就是限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。
请求限流往往会有一个限流器,数量高低起伏的并发请求曲线,经过限流器就变的非常平稳。这就像是水电站的大坝,起到蓄水的作用,可以通过开关控制水流出的大小,让下游水流始终维持在一个平稳的量。
线程隔离
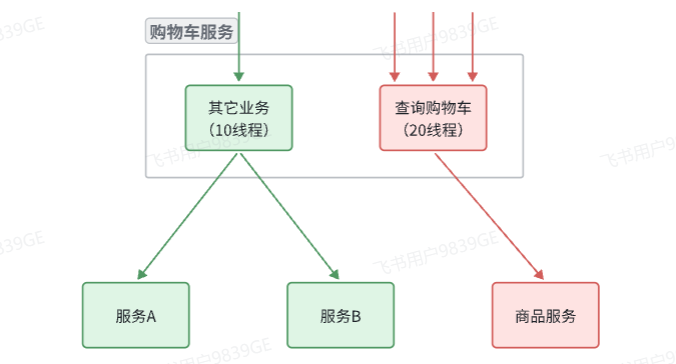
当业务接口响应时间长且并发量高时,很可能耗尽服务器线程资源,影响服务内其他接口。线程隔离能有效降低这种影响。
线程隔离借鉴了轮船的舱壁模式。轮船船舱由隔板分隔成多个相互独立的密闭舱,触礁进水时,仅受损密闭舱会进水,其他舱室因相互隔离不受影响,从而避免整船沉没。
在服务架构中,为防止某个接口故障或负载过高拖垮整个服务,可对每个接口的可用资源进行限制,实现 “隔离”。例如,将查询购物车业务的可用线程数上限设定为 20。如此一来,即便该业务因调用商品服务出现故障,也不会耗尽服务器线程资源,进而不会对其他接口造成影响。
服务熔断
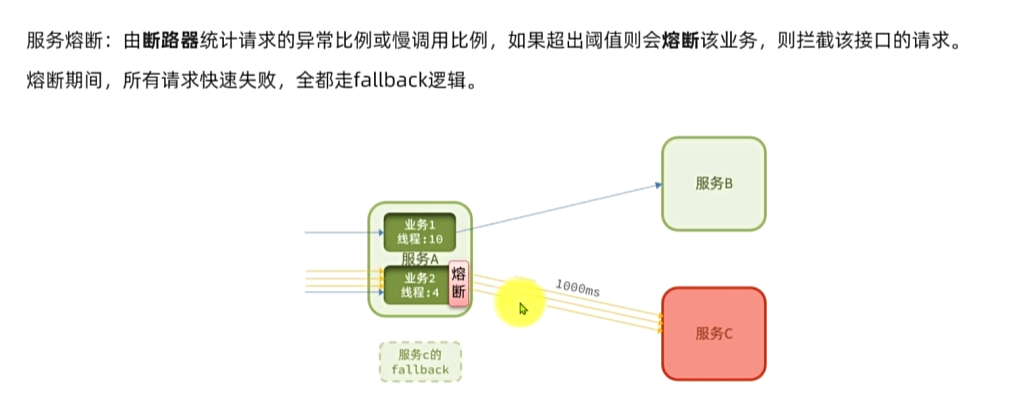
尽管线程隔离能防止雪崩,但故障的商品服务仍会拖慢购物车服务的接口响应速度,导致购物车查询功能因商品查询失败而不可用。
为此,需采取两项应对措施:
- 编写服务降级逻辑:针对服务调用失败的情况,依据业务场景抛出异常,或返回友好提示、默认数据。
- 开展异常统计与熔断:统计服务提供方的异常比例,当比例过高,表明该接口会波及其他服务,此时应拒绝调用,直接执行降级逻辑 。
服务保护技术
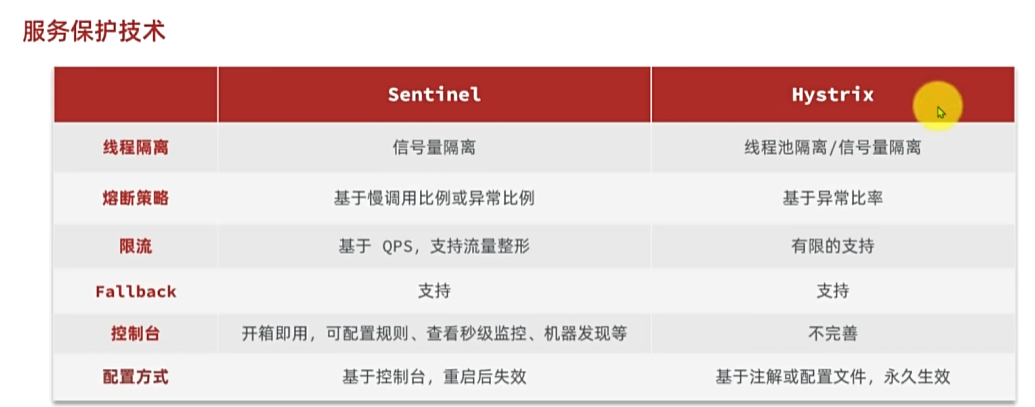
Sentinel
介绍安装
Sentinel是阿里巴巴开源的一款服务保护框架,目前已经加入
SpringCloudAlibaba中。官方网站:https://sentinelguard.io/zh-cn/Sentinel 的使用可以分为两个部分:
- 核心库(Jar包):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
- 控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
- 第一步:下载
jar包
https://github.com/alibaba/Sentinel/releases
- 第二步运行
将
jar包放在任意非中文、不包含特殊字符的目录下,重命名为sentinel-dashboard.jar

- 然后在所在目录控制台输入启动命令
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
- 然后 访问http://localhost:8090页面,就可以看到sentinel的控制台了
- 账号密码默认都是
sentinel
- 账号密码默认都是

其他启动配置项
https://github.com/alibaba/Sentinel/wiki/%E5%90%AF%E5%8A%A8%E9%85%8D%E7%BD%AE%E9%A1%B9
微服务整合
注意配完要访问一下相关业务才会监控
我们在
cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下
- 引入
sentinel依赖
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 配置控制台
spring:cloud: sentinel:transport:dashboard: localhost:8090
- 访问
cart-service的任意端点
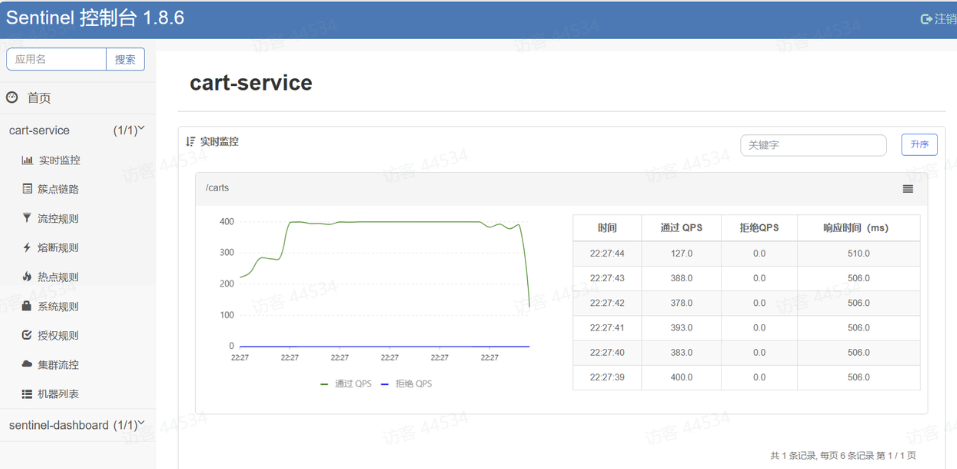
重启
cart-service,然后访问查询购物车接口,sentinel的客户端就会将服务访问的信息提交到sentinel-dashboard控制台。并展示出统计信息:
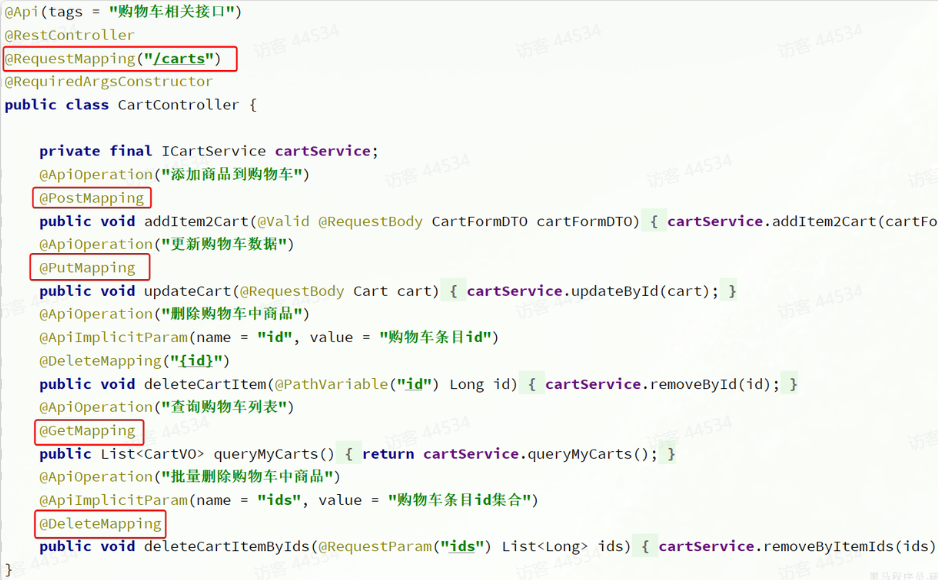
- 点击簇点链路菜单,会看到下面的页面
所谓簇点链路,就是单机调用链路,是一次请求进入服务后经过的每一个被
Sentinel监控的资源。默认情况下,Sentinel会监控SpringMVC的每一个Endpoint(接口)。因此,我们看到
/carts这个接口路径就是其中一个簇点,我们可以对其进行限流、熔断、隔离等保护措施。不过,需要注意的是,我们的
SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径:
默认情况下Sentinel会把路径作为簇点资源的名称,无法区分路径相同但请求方式不同的接口,查询、删除、修改等都被识别为一个簇点资源,这显然是不合适的。
所以我们可以选择打开
Sentinel的请求方式前缀,把请求方式 + 请求路径作为簇点资源名:首先,在
cart-service的application.yml中添加下面的配置:spring:cloud:sentinel:transport:dashboard: localhost:8090http-method-specify: true # 开启请求方式前缀
请求限流
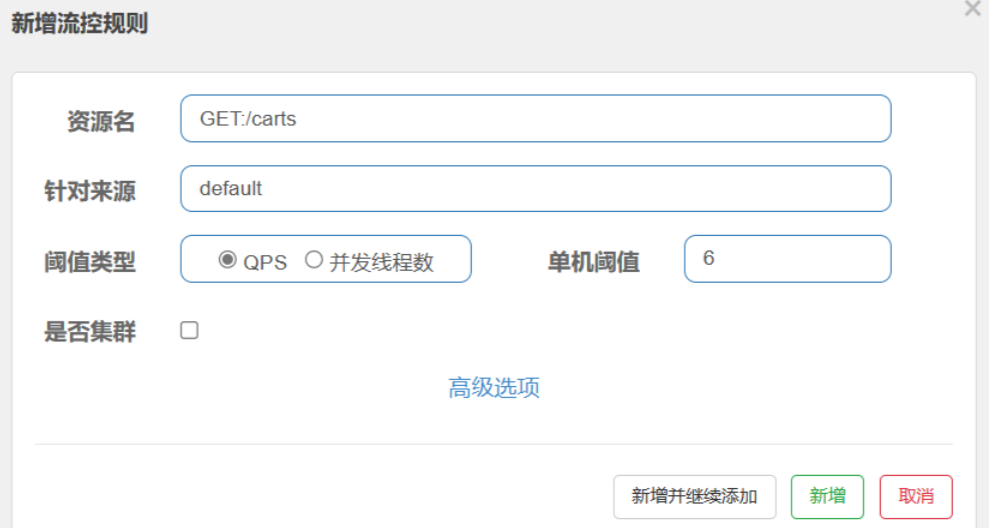
- 在簇点链路后面点击流控按钮,即可对其做限流配置
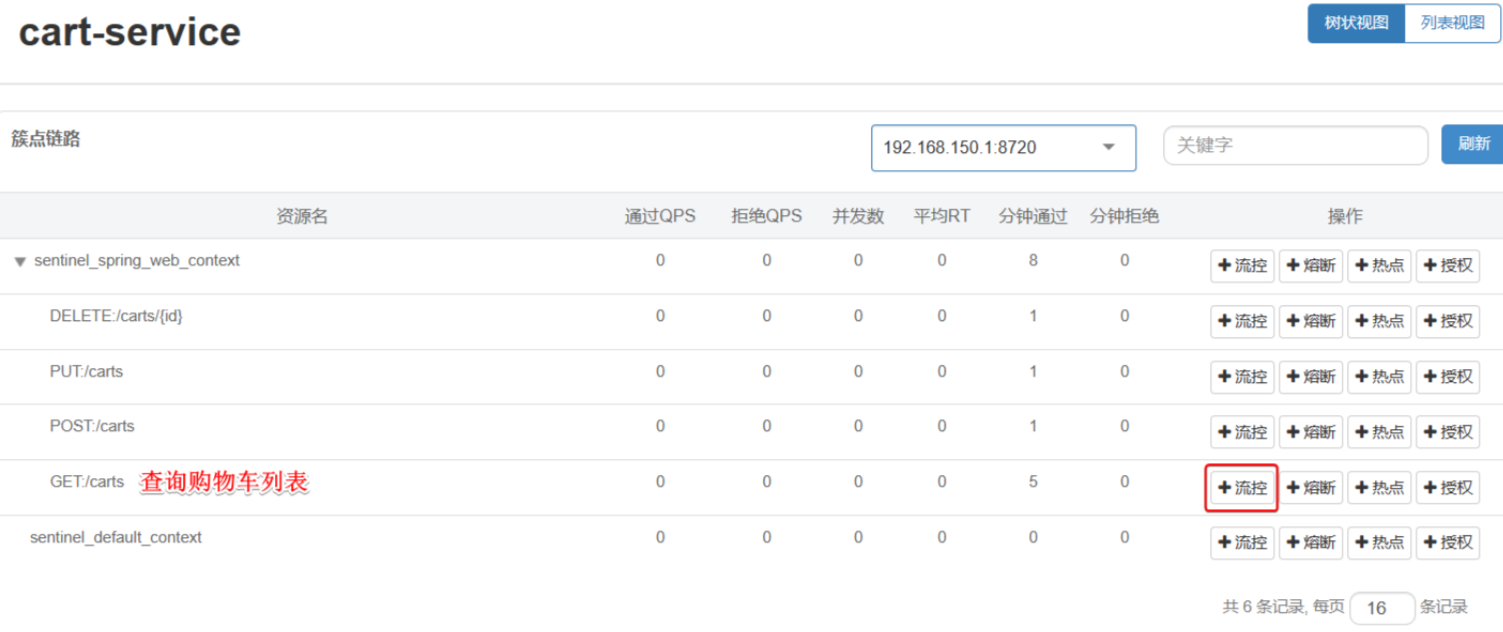
- 在弹出的菜单中这样填写:
这样就把查询购物车列表这个簇点资源的流量限制在了每秒
6个,也就是最大QPS为6.
- 利用
Jemeter做限流测试,我们每秒发出10个请求
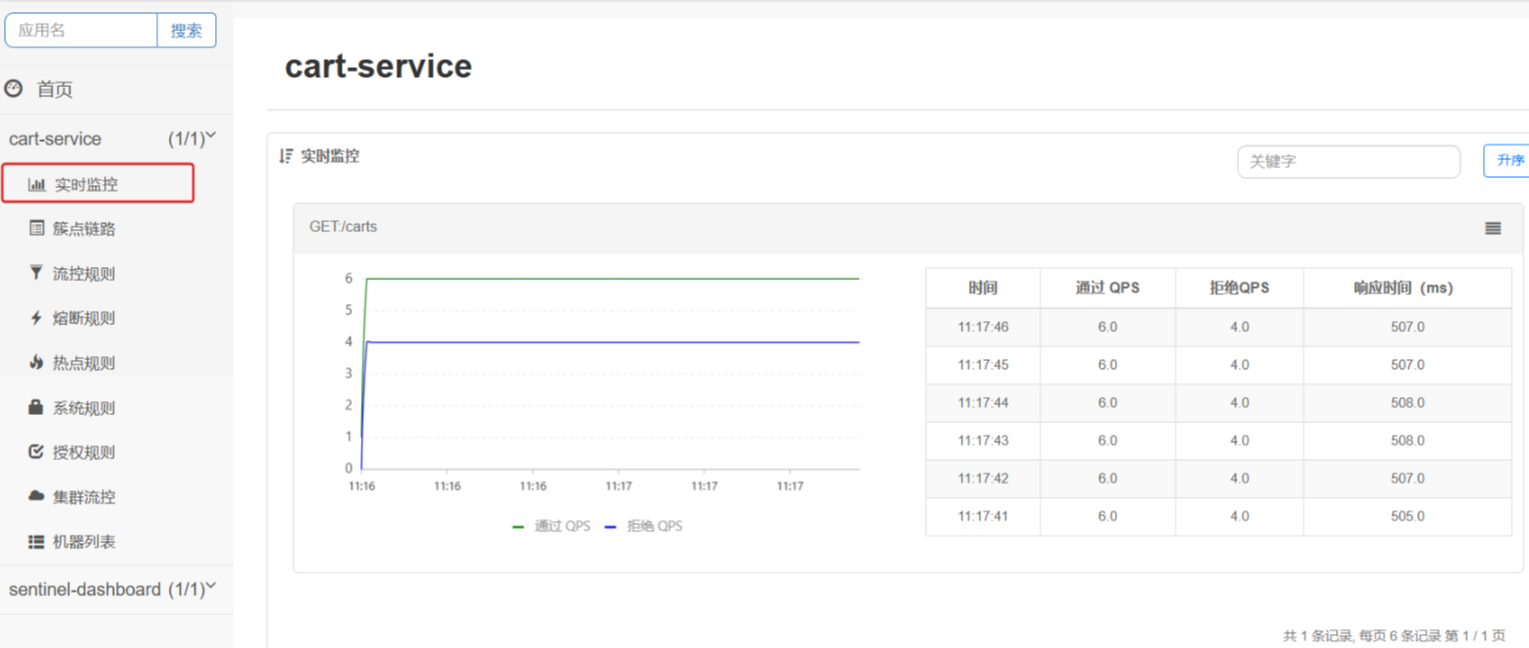
- 可以看出
GET:/carts这个接口的通过QPS稳定在6附近,而拒绝的QPS在4附近,符合我们的预期。
线程隔离
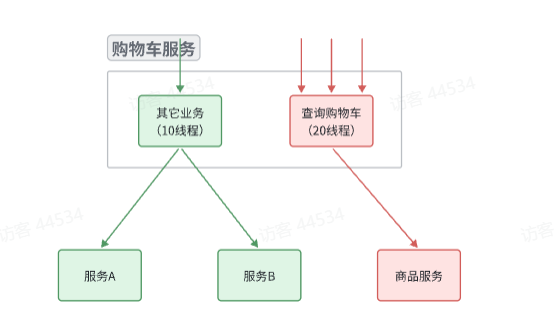
限流可以降低服务器压力,尽量减少因并发流量引起的服务故障的概率,但并不能完全避免服务故障。一旦某个服务出现故障,我们必须隔离对这个服务的调用,避免发生雪崩。
比如,查询购物车的时候需要查询商品,为了避免因商品服务出现故障导致购物车服务级联失败,我们可以把购物车业务中查询商品的部分隔离起来,限制可用的线程资源这样,即便商品服务出现故障,最多导致查询购物车业务故障,并且可用的线程资源也被限定在一定范围,不会导致整个购物车服务崩溃。所以,我们要对查询商品的
FeignClient接口做线程隔离。这里保护的是查询购物车服务的线程
OpenFeign整合Sentinel
feign:sentinel:enabled: true # 开启feign对sentinel的支持
- 默认情况下
SpringBoot项目的tomcat最大线程数是200,允许的最大连接是8492,单机测试很难打满。
server:port: 8082tomcat:threads:max: 50 # 允许的最大线程数accept-count: 50 # 最大排队等待数量max-connections: 100 # 允许的最大连接
- 然后重启
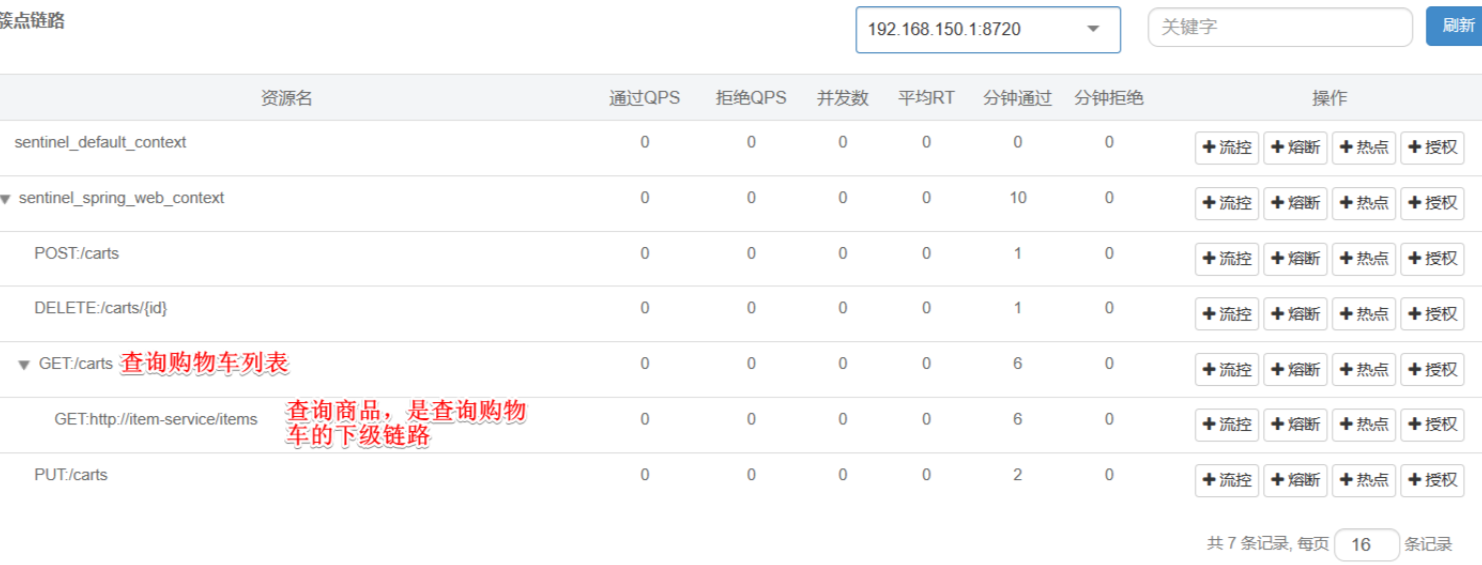
cart-service服务,可以看到查询商品的FeignClient自动变成了一个簇点资源
- 配置线程隔离
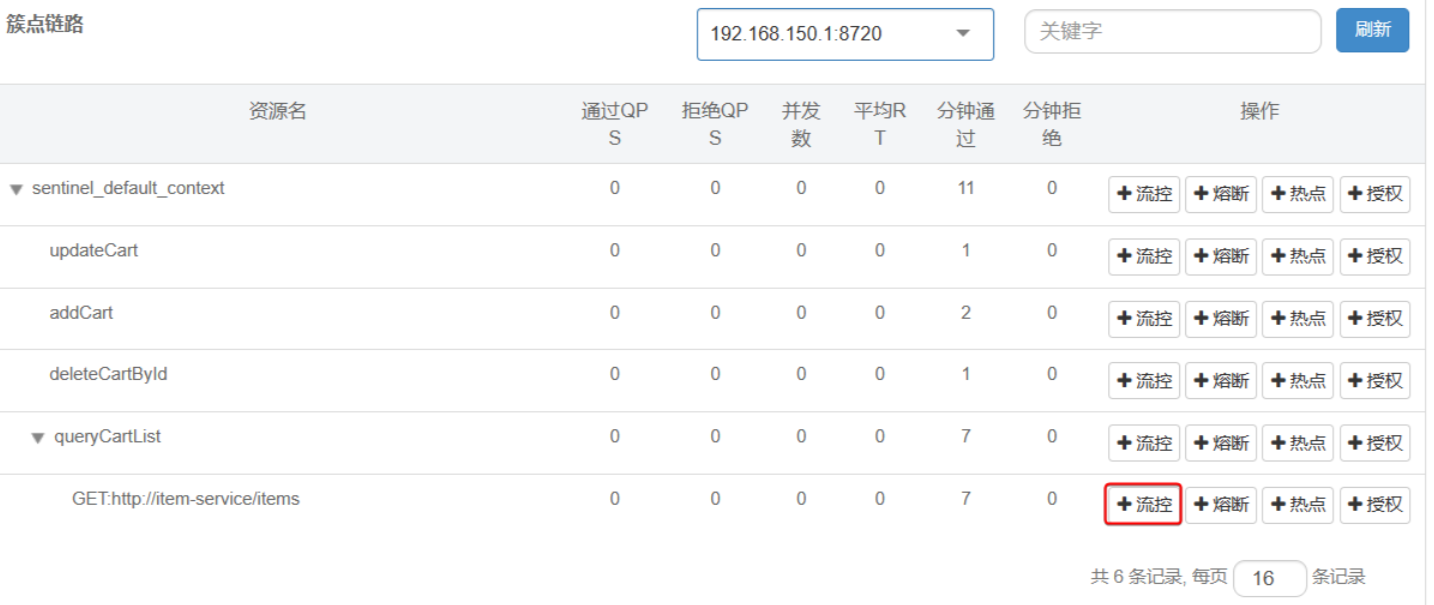
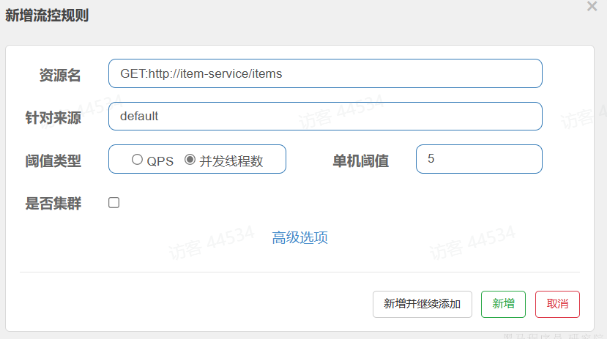
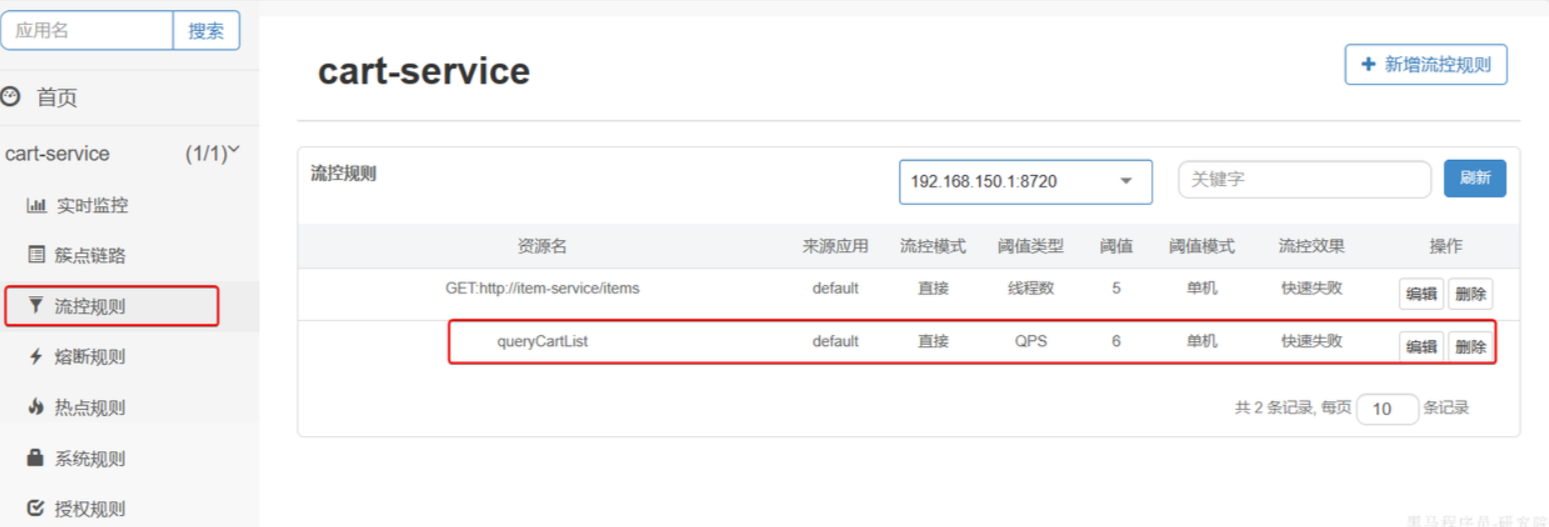
注意,这里勾选的是并发线程数限制,也就是说这个查询功能最多使用
5个线程,而不是5 QPS。如果查询商品的接口每秒处理2个请求,则5个线程的实际QPS在10左右,而超出的请求自然会被拒绝。
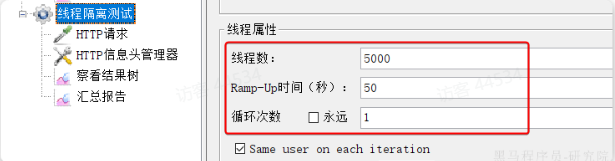
- 利用
Jemeter测试,每秒发送100个请求
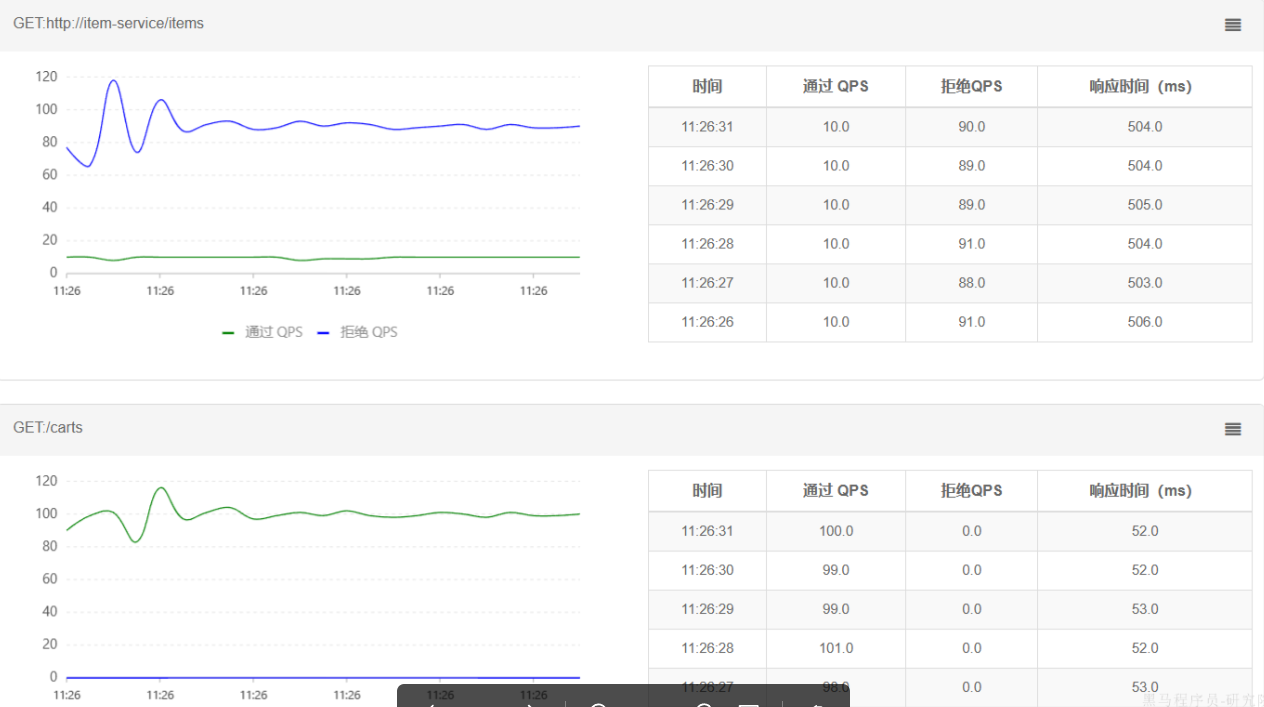
- 查看测试结果
进入查询购物车的请求每秒大概在100,而在查询商品时却只剩下每秒10左右,符合我们的预期。
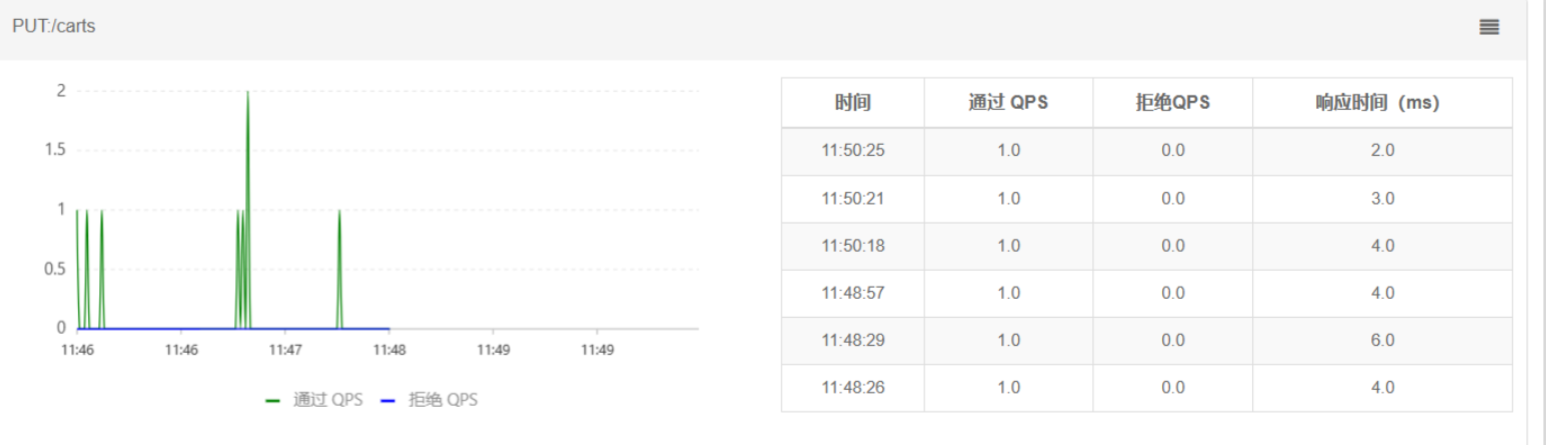
- 查看其他接口影响
此时如果我们通过页面访问购物车的其它接口,例如添加购物车、修改购物车商品数量,发现不受影响。响应时间非常短,这就证明线程隔离起到了作用,尽管查询购物车这个接口并发很高,但是它能使用的线程资源被限制了,因此不会影响到其它接口。
FallBack(降级逻辑)
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给
FeignClient编写失败后的降级逻辑有两种方式:
- 方式一:
FallbackClass,无法对远程调用的异常做处理- 方式二:
FallbackFactory,可以对远程调用的异常做处理,我们一般选择这种方式。
- 在
hm-api模块中给ItemClient商品服务定义降级处理类,实现FallbackFactory
package com.hmall.api.client.fallback;import com.hmall.api.client.ItemClient;
import com.hmall.api.dto.ItemDTO;
import com.hmall.api.dto.OrderDetailDTO;
import com.hmall.common.exception.BizIllegalException;
import com.hmall.common.utils.CollUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.openfeign.FallbackFactory;import java.util.Collection;
import java.util.List;@Slf4j
public class ItemClientFallback implements FallbackFactory<ItemClient> {@Overridepublic ItemClient create(Throwable cause) {return new ItemClient() {@Overridepublic List<ItemDTO> queryItemByIds(Collection<Long> ids) {log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause);// 查询购物车允许失败,查询失败,返回空集合return CollUtils.emptyList();}@Overridepublic void deductStock(List<OrderDetailDTO> items) {// 库存扣减业务需要触发事务回滚,查询失败,抛出异常throw new BizIllegalException(cause);}};}
}
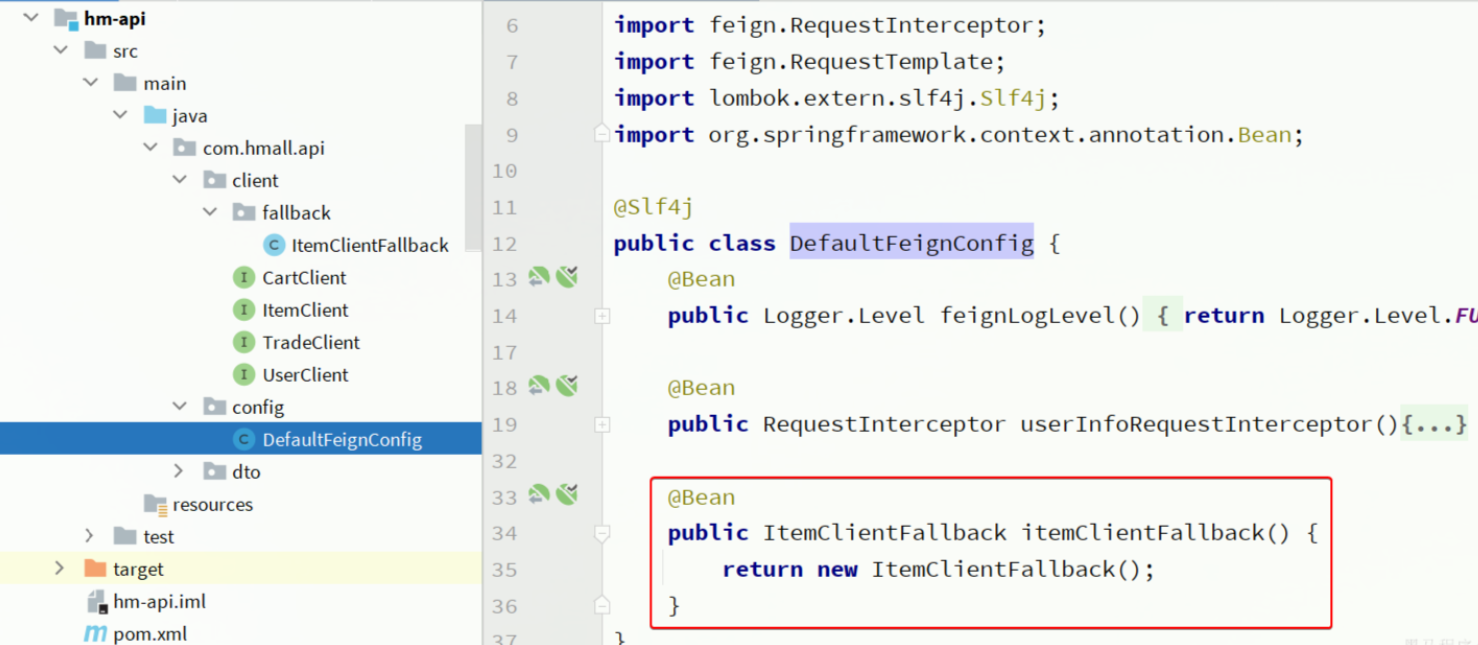
- 在
hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean
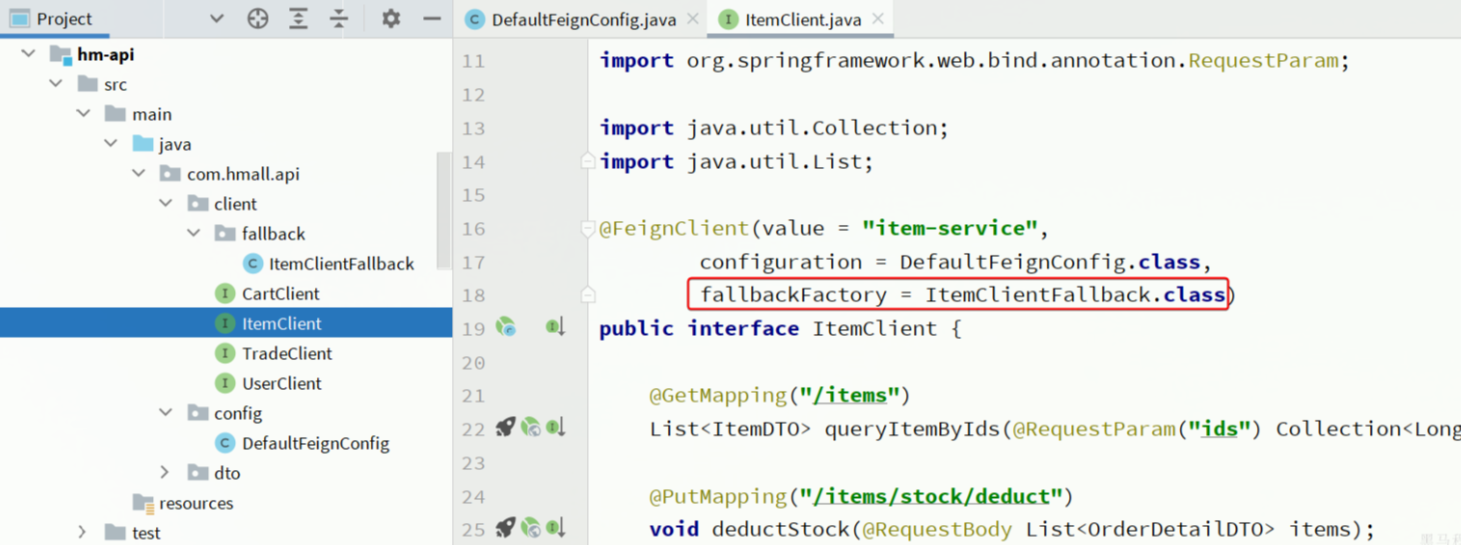
- 在
hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory
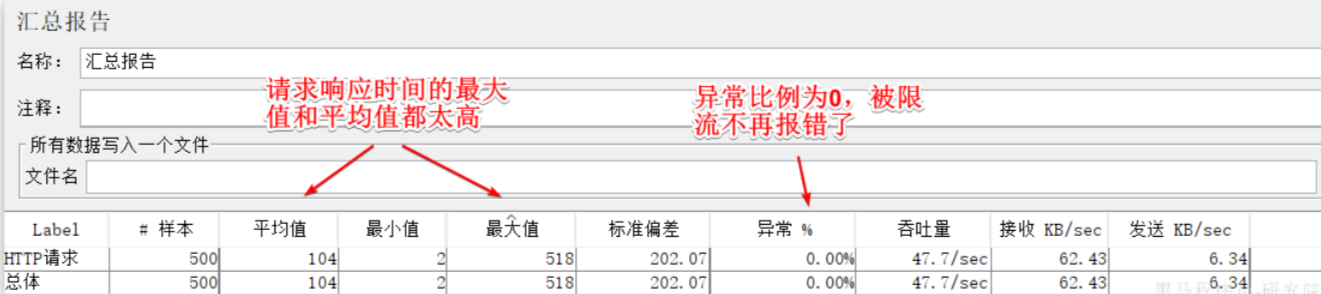
- 重启后,再次测试,发现被限流的请求不再报错,走了降级逻辑
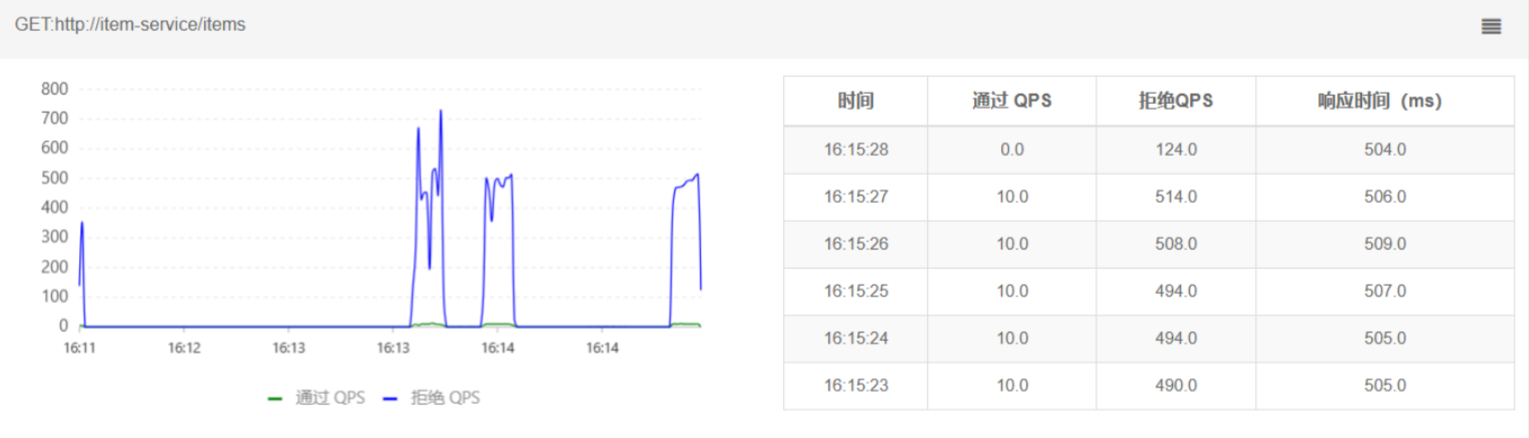
- 但是未被限流的请求延时依然很高
服务熔断
查询商品的RT较高(模拟的500ms),从而导致查询购物车的RT也变的很长。这样不仅拖慢了购物车服务,消耗了购物车服务的更多资源,而且用户体验也很差。
对于商品服务这种不太健康的接口,我们应该停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。当商品服务接口恢复正常后,再允许调用。这其实就是断路器的工作模式了。
Sentinel中的断路器不仅可以统计某个接口的慢请求比例,还可以统计异常请求比例。当这些比例超出阈值时,就会熔断该接口,即拦截访问该接口的一切请求,降级处理;当该接口恢复正常时,再放行对于该接口的请求。
断路器的工作状态切换有一个状态机来控制:
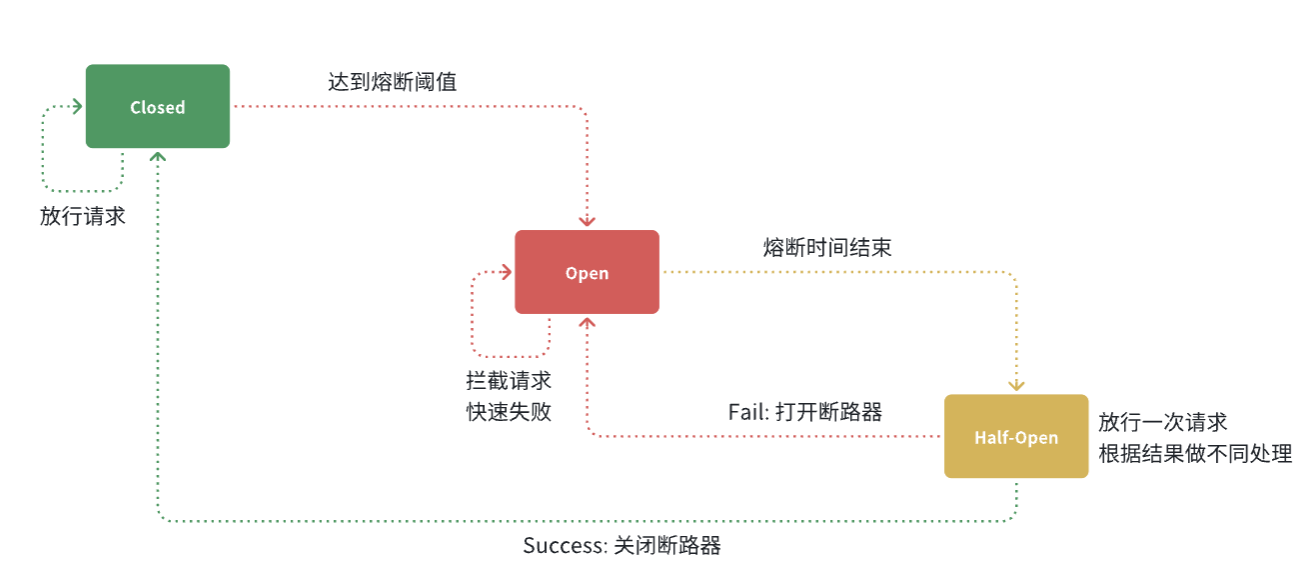
状态机包括三个状态:
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到
closed状态- 请求失败:则切换到
open状态
- 我们可以在控制台通过点击簇点后的熔断按钮来配置熔断策略:
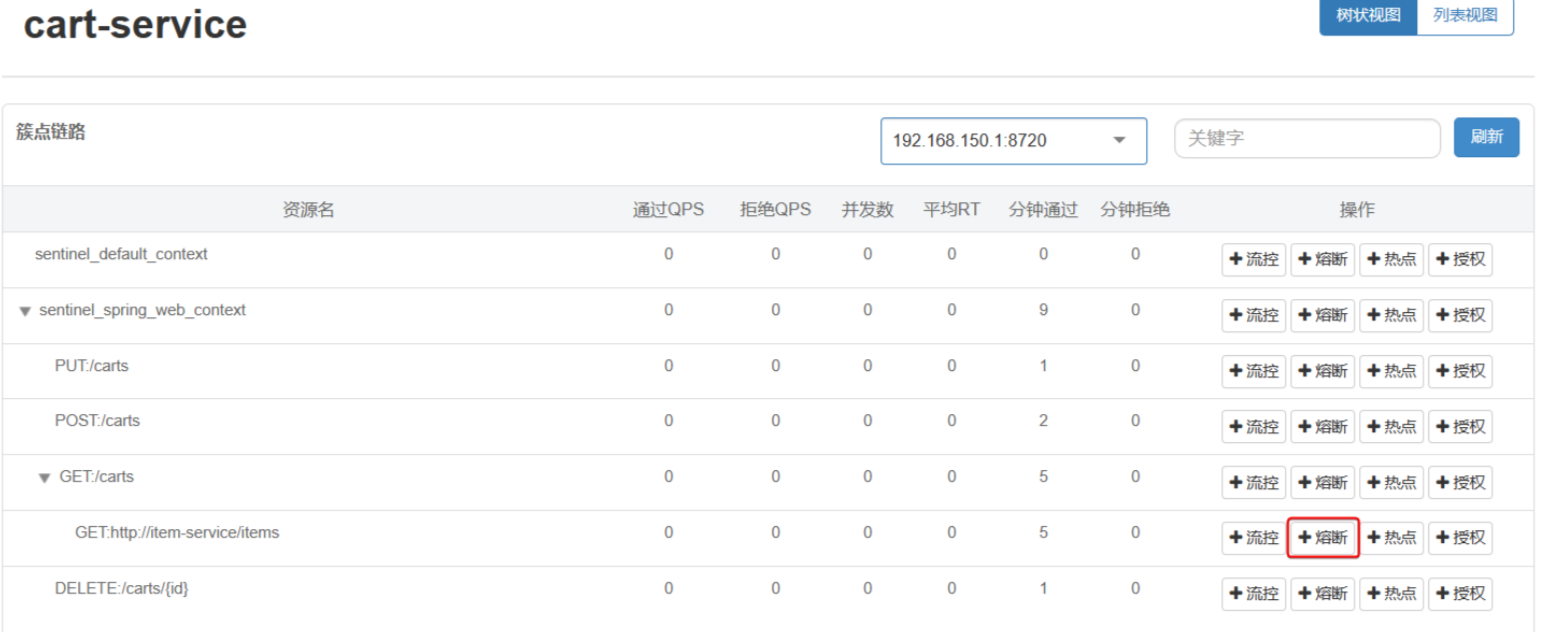
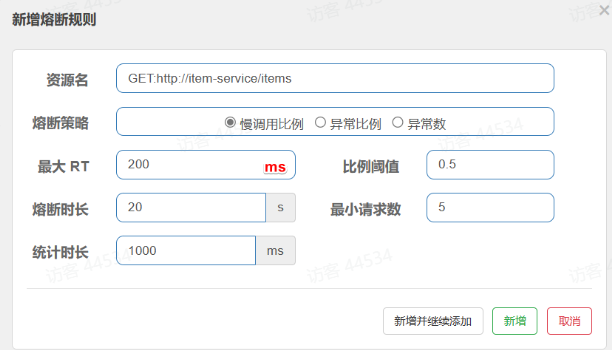
- 在弹出的表格中这样填写:
这种是按照慢调用比例来做熔断,上述配置的含义是:
RT超过200毫秒的请求调用就是慢调用- 统计最近
1000ms内的最少5次请求,如果慢调用比例不低于0.5,则触发熔断- 熔断持续时长
20s
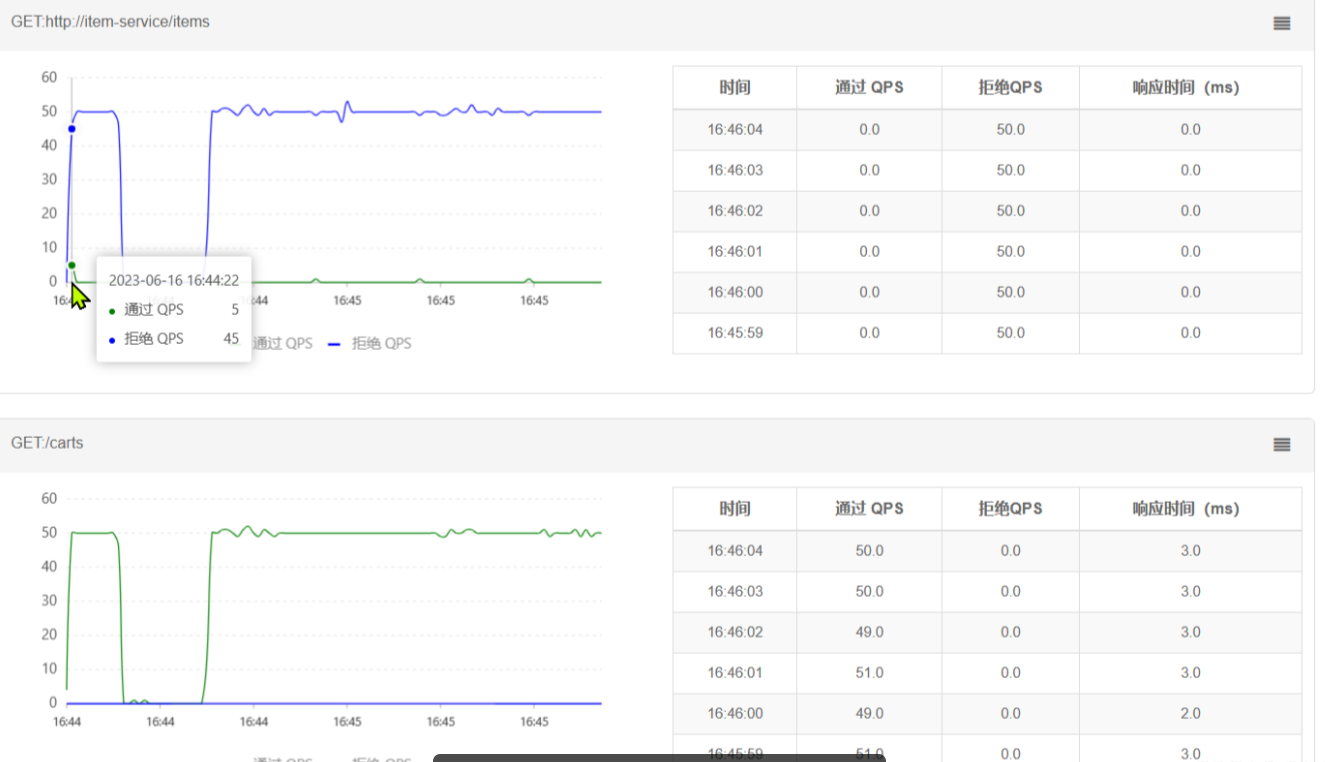
- 配置完成后,再次利用
Jemeter测试,
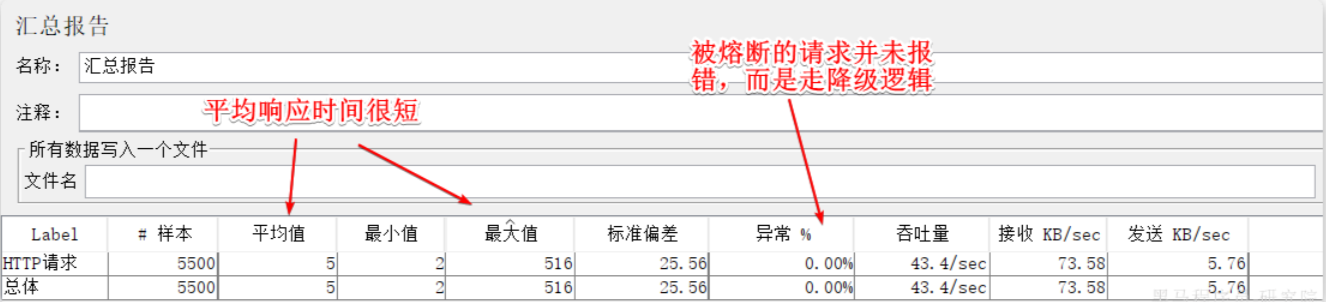
在一开始一段时间是允许访问的,后来触发熔断后,查询商品服务的接口通过QPS直接为0,所有请求都被熔断了。而查询购物车的本身并没有受到影响。
此时整个购物车查询服务的平均RT影响不大:
分布式事务
分布式事务概述
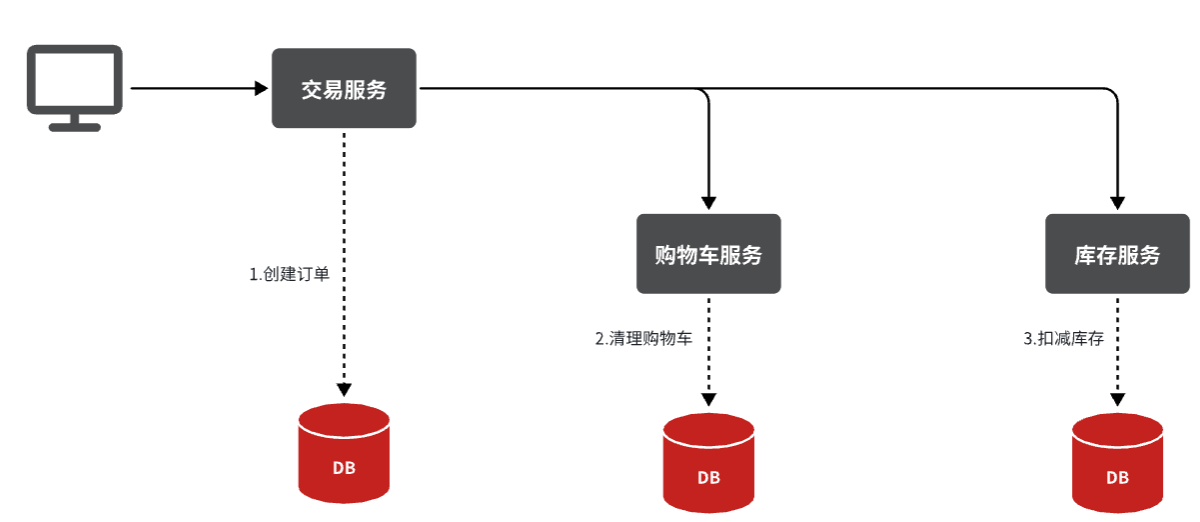
由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
- 交易服务:下单事务
- 购物车服务:清理购物车事务
- 库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。但是事务不能跨服务
事务并未遵循
ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。这就是分布式事务问题,出现以下情况之一就可能产生分布式事务问题:
- 业务跨多个服务实现
- 业务跨多个数据源实现
Seata
Seata 概述
解决分布式事务的方案众多,且实现过程复杂,因此通常借助开源框架。在众多开源分布式事务框架里,阿里巴巴于 2019 年开源的
Seata功能最为完善,应用也最为广泛。其官网为:https://seata.apache.org/zh-cn/docs/overview/what-is-seata/ 。分布式事务产生的关键原因,是参与事务的多个分支事务彼此无感知,不清楚对方执行状态。所以,解决分布式事务的思路很简单:设置一个统一的事务协调者,它与多个分支事务通信,检测各分支事务的执行状态,确保全局事务下所有分支事务要么同时成功,要么同时失败。多数分布式事务框架都基于此理论实现,
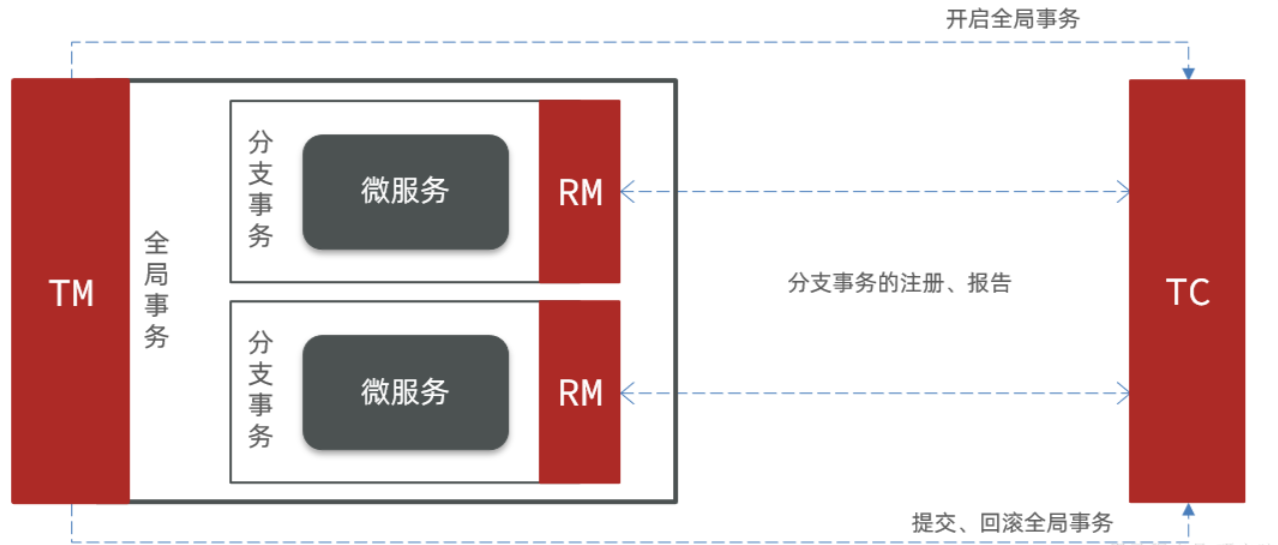
Seata也不例外。在
Seata的事务管理中,有三个重要角色:
- TC (Transaction Coordinator) - 事务协调者:负责维护全局和分支事务状态,协调全局事务的提交或回滚。
- TM (Transaction Manager) - 事务管理器:用于定义全局事务范围,开启、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务,与 TC 交互,进行分支事务的注册、状态报告,并驱动其提交或回滚。
TM 和 RM 可视为
Seata的客户端部分,将其引入参与事务的微服务依赖即可。后续,TM 和 RM 会协助微服务,实现本地分支事务与TC的交互,完成事务提交或回滚。而 TC 服务作为事务协调中心,是一个需单独部署的独立微服务。
部署 Seata TC 服务
- 准备数据库
seata-tc.sql
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。、

- 准备配置文件
把整个文件夹拷贝到
linux虚拟机
seata

Docker部署
前置条件就是
docker中要有mysql和sentinel注意:
mysql和sentinel和seata要在同一个网络中如果
seata镜像pull不下来就手动load可以用
docker logs -f seata查看是否正常部署seataseata-1.5.2.tar
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.88.130 \ #这里换自己的虚拟机ip
-v ./seata:/seata-server/resources \
--privileged=true \
--ulimit nofile=65536:65536 \
--network heima \ #这里换自己的自定义网络
-d \
seataio/seata-server:1.5.2
- 检查
nacos的服务管理中的服务列表有没有seata-server

- 输入
http://192.168.88.130:7099登录Seata- 默认账号密码都是
admin
- 默认账号密码都是
微服务集成 Seata TC TM RM
- 引入依赖
为了方便各个微服务集成
seata,我们需要把seata配置共享到nacos,因此trade-service等模块不仅仅要引入seata依赖,还要引入nacos依赖
<!--统一配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
- 在
springboot中改造各个模块配置
首先在
nacos上添加一个共享的seata配置,命名为shared-seata.yaml然后配置进
bootstrap.yml中

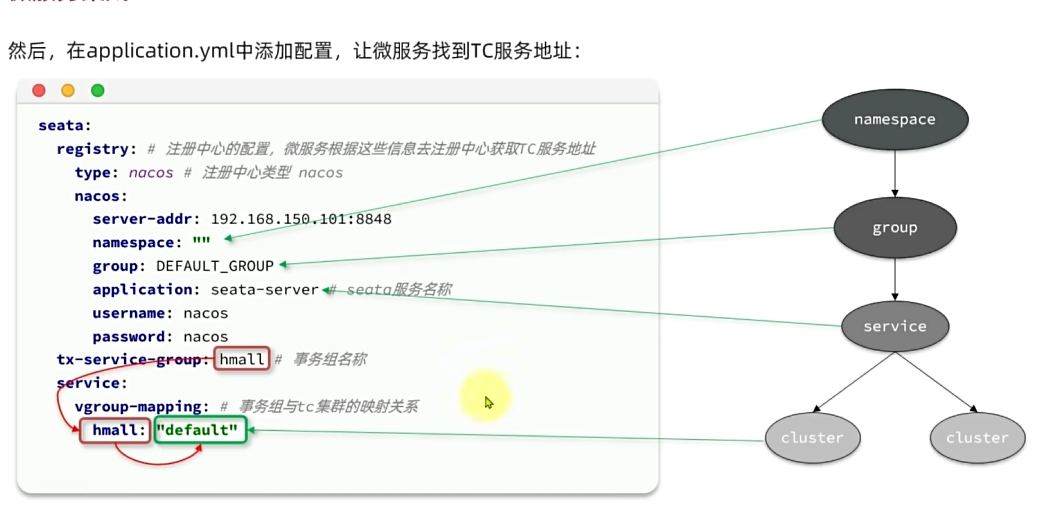
seata:registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址type: nacos # 注册中心类型 nacosnacos:server-addr: 192.168.88.130:8848 # 改成自己的nacos地址namespace: "" # namespace,默认为空group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUPapplication: seata-server # seata服务名称username: nacospassword: nacostx-service-group: hmall # 事务组名称service:vgroup-mapping: # 事务组与tc集群的映射关系hmall: "default"
spring:application:name: cart-service # 微服务名称profiles:active: devcloud:nacos:server-addr: 192.168.88.130:8848config:file-extension: yamlshared-configs:- data-id: shared-jdbc.yaml- data-id: shared-log.yaml- data-id: shared-swagger.yaml- data-id: shared-seata.yaml
- 添加数据库表
AT模式记录日志用
**
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。 seata-at.sql **

- 在
Docker中利用日志查看是否开启

- 标记事务范围,初始化全局事务
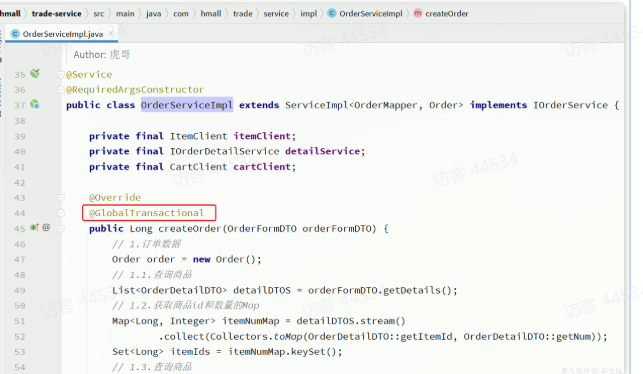
我们找到
trade-service模块下的com.hmall.trade.service.impl.OrderServiceImpl类中的createOrder方法,也就是下单业务方法。将模块中的
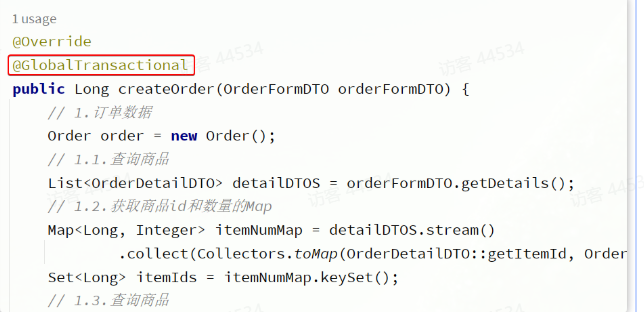
@Transactional注解改为Seata提供的@GlobalTransactional
@GlobalTransactional注解就是在标记事务的起点,将来TM就会基于这个方法判断全局事务范围,初始化全局事务。
.
默认采用AT模式
.
然后我们在全局事务中涉及到的模块的方法标记@Transcation。这里createOrder中涉及到了item的deductStock和cart中的removeByItemIds
- 无需添加:若方法仅含单个 SQL 操作(如
UPDATE),依赖 Seata 的 AT 模式自动管理即可。- 必须添加:若方法包含多个需原子化的操作(如先查询后更新、插入日志等),应添加
@Transactional确保本地事务一致性。
,我们重启
trade-service、item-service、cart-service三个服务。再次测试,发现分布式事务的问题解决了!
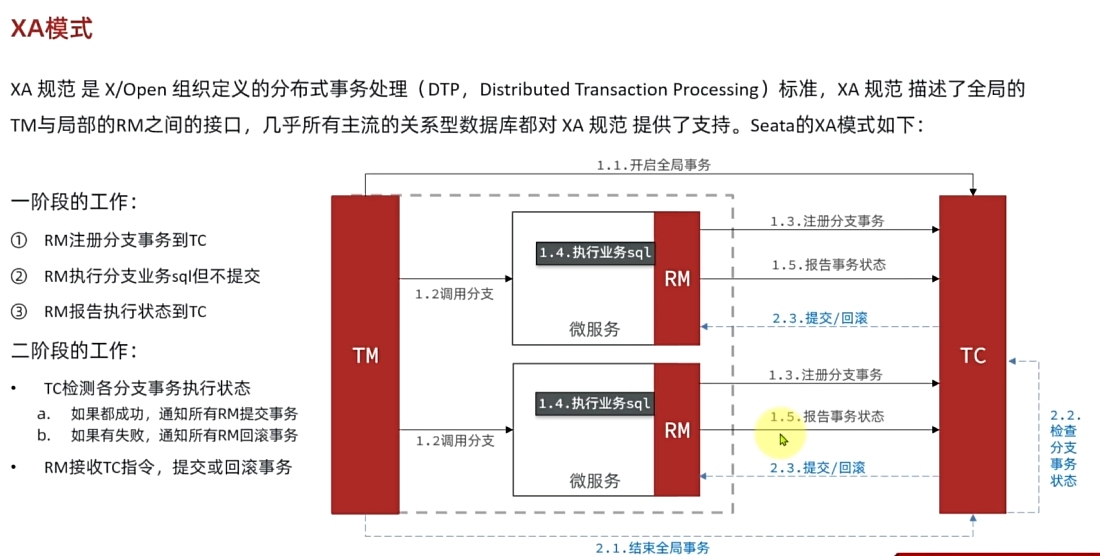
XA 模式
XA 模式原理
XA 模式优缺点
优点
- 事务的强一致性,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
缺点
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现 XA 模式
- 设置
seata为XA模式
我们要在配置文件中指定要采用的分布式事务模式。我们可以在
Nacos中的共享shared-seata.yaml配置文件中设置:
seata:data-source-proxy-mode: XA
- 利用
@GlobalTransactional标记分布式事务的入口方法
AT 模式
流程梳理
我们用一个真实的业务来梳理下
AT模式的原理。比如,现在有一个数据库表,记录用户余额:
id money 1 100 其中一个分支业务要执行的SQL为:
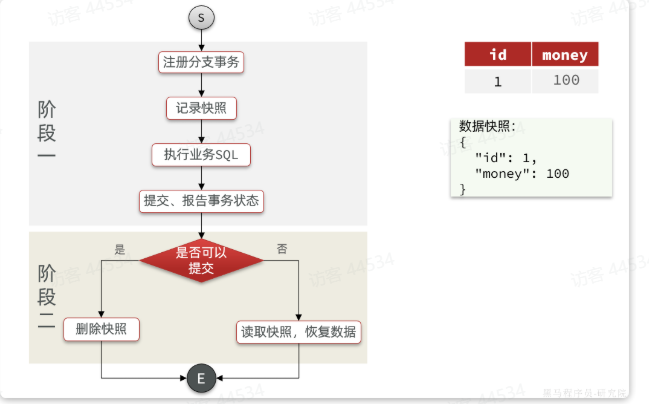
update tb_account set money = money - 10 where id = 1AT模式下,当前分支事务执行流程如下:
一阶段:
TM发起并注册全局事务到TCTM调用分支事务- 分支事务准备执行业务SQL
RM拦截业务SQL,根据where条件查询原始数据,形成快照。{"id": 1, "money": 100 }
RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
RM报告本地事务状态给TC二阶段:
TM通知TC事务结束
TC检查分支事务状态
如果都成功,则立即删除快照
如果有分支事务失败,需要回滚。读取快照数据({“id”: 1, “money”: 100}),将快照恢复到数据库。此时数据库再次恢复为 100
实现 AT 模式
-
添加
seata-at.sql在涉及到的微服务模块中用于回滚 -
配置
data-source-proxy-mode:为AT当然不配也行。默认是AT
seata-at.sql
AT 模式和 XA 模式的区别
XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。XA模式强一致;AT模式最终一致(就是会出现很短暂的数据不一致状态)可见,AT模式使用起来更加简单,无业务侵入,性能更好。因此企业90%的分布式事务都可以用AT模式来解决。
相关文章:

SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...

加油站小程序实战教程14会员充值页面搭建
目录 1 原型2 搭建充值金额选择功能3 搭建金额输入4 搭建支付方式5 充值按钮最终的效果 上一篇我们介绍了充值规则的后台功能,有了基础的规则,在会员充值页面就可以显示具体的充值规则。本篇我们介绍一下会员充值的开发过程。 1 原型 充值页面我们是分为…...

内卷的中国智驾,合资品牌如何弯道超车?
作者 |德新 编辑 |王博 上海车展前夕,一汽丰田举办重磅车型bZ5的技术发布会,脱口秀演员庞博透露了这款车型的一大重要特性,其搭载来自Momenta的智能辅助驾驶系统行驶里程已经超过20亿公里。 携手中国科技公司提高车型智能化的属性ÿ…...

【go】go run-gcflags常用参数归纳,go逃逸分析执行语句,go返回局部变量指针是安全的
go官方参考文档: https://pkg.go.dev/cmd/compile 基本语法 go run 命令用来编译并运行Go程序,-gcflags 后面可以跟一系列的编译选项,多个选项之间用空格分隔。基本语法如下: go run -gcflags "<flags>" main.…...
)
数据库11(触发器)
触发器有三种类型,包括删除触发器,更新触发器,添加触发器 触发器的作用是:当某个表发生某个操作时,自动触发触发器,进行触发器规定的操作 触发器语句 create trigger tname --创建触发器 on aa --创建在表…...

十大物联网平台-物联网十大品牌
物联网十大品牌及平台解析 物联网(IoT)作为当下极具影响力的技术,正逐步渗透至社会各领域,为人们生活与社会发展带来诸多便利与变革。如今,众多企业投身于物联网行业,致力于推动其发展。以下是对物联网相关…...

心智模式VS系统思考
很多人常说,“改变自己,从改变思维开始。”但事实上,打破一个人的心智模式,远比想象中要困难得多。我们的思维方式、行为习惯,甚至是对世界的认知,往往是多年积累下来的产物。那些曾经的经历、长期的学习与…...

QT 打包安装程序【windeployqt.exe】报错c000007d原因:Conda巨坑
一、命令行执行命令 E:\Project\GNCGC\Bin\Win32\Vc22\RS422地检>E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe CGC170.exe二、安装了Conda的朋友,巨坑 无语,E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe 优先把Conda环境关联的Qt动…...

Vue3祖先后代组件数据双向同步实现方法
在 Vue3 中实现祖先后代组件的双向数据同步,可以通过组合式 API 的 provide/inject 配合响应式数据实现。以下是两种常见实现方案: 方案一:共享响应式对象 方法 html <!-- 祖先组件 --> <script setup> import { ref, provide…...

OpenBayes 一周速览|EasyControl 高效控制 DiT 架构,助力吉卜力风图像一键生成;TripoSG 单图秒变高保真 3D 模型
公共资源速递 10 个教程: * 一键部署 R1-OneVision * UNO:通用定制化图像生成 * TripoSG:单图秒变高保真 3D * 使用 VASP 进行机器学习力场训练 * InfiniteYou 高保真图像生成 Demo * VenusFactory 蛋白质工程设计平台 * Qwen2.5-0mni…...

服务器-conda下载速度慢-国内源
文章目录 前言一、解决问题:使用国内conda镜像下载(差)二、解决问题:使用pip下载(优)总结 前言 conda频道中有无效频道导致下载失败 一、解决问题:使用国内conda镜像下载(差) 步骤 1ÿ…...

python的pip download命令-2
当然可以,下面我详细解释一下 pip download 的作用、用法和技术原理。 🧠 一句话总结: pip download 是 pip 提供的一个命令,用来下载 Python 包及其依赖项的安装文件,但不会安装。 🔍 和 pip install 的区别: 命令作用是否安装是否联网典型用途pip install安装指定包…...

【Java设计模式及实践学习-第4章节-结构型模式】
第4章节-结构型模式 笔记记录 1. 适配器模式2. 代理模式3. 装饰器模式4. 桥接模式5. 组合模式6. 外观模式7. 享元模式8. 总结 1. 适配器模式 2. 代理模式 3. 装饰器模式 4. 桥接模式 5. 组合模式 6. 外观模式 7. 享元模式 Java语言中的String字符串就使用了享元模式&…...

python:mido 提取 midi文件中某一音轨的音乐数据
pip install mido 使用 mido库可以方便地处理 MIDI 文件,提取其中音轨的音乐数据。 1.下面的程序会读取指定的 MIDI 文件,并提取指定编号音轨的音乐数据,主要包括音符事件等信息。 编写 mido_extract.py 如下 # -*- coding: utf-8 -*- &…...

将输入帧上下文打包到下一个帧的预测模型中用于视频生成
Paper Title: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation 论文发布于2025年4月17日 Abstract部分 在这篇论文中,FramePack是一种新提出的网络结构,旨在解决视频生成中的两个主要问题:遗忘和漂移。 具体来说,遗忘指的是在生成视…...

第六章:Multi-Backend Configuration
Chapter 6: Multi-Backend Configuration 从交响乐团到变形金刚:如何让代理适应不同环境? 在上一章任务工作流编排,我们学会了如何像指挥家一样协调任务。但就像变形金刚能切换不同形态应对环境变化一样,你的AI代理也需要能灵活切…...

tomcat远程Debug
tomcat远程Debug -- /bin目录下 catalina.bat文件下加一行 SET CATALINA_OPTS-server -Xdebug -Xnoagent -Djava.compilerNONE -Xrunjdwp:transportdt_socket,servery,suspendn,address8088idea端配置如下...
)
Vue3:component(组件:uniapp版本)
目录 一、基本概述二、基本使用三、插槽 一、基本概述 在项目的开发过程中,页面上井场会出现一些通用的内容,例如头部的导航栏,如果我们每一个页面都去写一遍,那实在是太繁琐了,所以,我们使用组件来解决这…...
:8大容器类型)
rust编程学习(三):8大容器类型
1简介 rust标准库std::collections也提供了像C STL库中的容器,分为4种通用的容器,8种类型,如下表所示。 线性容器类型: 名称简介Vec<T>内存空间连续,可变长度的数组,类似于C中Vector<T>容器…...

前端中阻止事件冒泡的几种方法
在 JavaScript 前端开发中,阻止事件冒泡是处理 DOM 事件时的常见需求。以下是几种阻止事件冒泡的方法: 1. 使用 event.stopPropagation() 这是最常用的阻止事件冒泡的方法。 element.addEventListener(click, function(event) {event.stopPropagation…...
)
ShenNiusModularity项目源码学习(20:ShenNius.Admin.Mvc项目分析-5)
ShenNiusModularity项目的系统管理模块主要用于配置系统的用户、角色、权限、基础数据等信息,上篇文章中学习的日志列表页面相对独立,而后面几个页面之间存在依赖关系,如角色页面依赖菜单页面定义菜单列表以便配置角色的权限,用户…...

前端js需要连接后端c#的wss服务
背景 前端js需要连接后端wss服务 前端:js 后端:c# - 控制台搭建wss服务器 步骤1 wss需要ssl认证,所以需要个证书,随便找一台linux的服务器(windows的话,自己安装下openssl即可),…...

MAGI-1自回归式大规模视频生成
1. 关于 MAGI-1 提出 MAGI-1——一种世界模型(world model),通过自回归方式预测一系列视频块(chunk,固定长度的连续帧片段)来生成视频。 模型被训练为在时间维度上单调递增噪声的条件下对每个块进行去噪&a…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容一):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 TCP网络模型OSI参考模型TCP/IP五层模型 TCP状态TIME_WAIT 连接过程TCP三次握手TCP四次挥手 TCP优化TCP三次握手优化TCP四次挥手优化TCP数据传输优化 TCP TCP是面向连接的、可靠的、基于字节流的传输层通信协议: 面向连接:一定是一对一才能连接…...

基于deepseek的模型微调
使用 DeepSeek 模型(如 DeepSeek-VL、DeepSeek-Coder、DeepSeek-LLM)进行微调,可以分为几个关键步骤,下面以 DeepSeek-LLM 为例说明,适用于 Q&A、RAG、聊天机器人等方向的应用。 一、准备工作 1. 环境依赖 建议使用 transformers + accelerate 或 LoRA 等轻量微调方…...
)
node.js 实战——(path模块 知识点学习)
path 模块 提供了操作路径的功能 说明path. resolve拼接规范的绝对路径path. sep获取操作系统的路径分隔符path. parse解析路径并返回对象path. basename获取路径的基础名称path. dirname获取路径的目录名path. extname获得路径的扩展名 resolve 拼接规范的绝对路径 const…...

【k8s】docker、k8s、虚拟机的区别以及使用场景
一、Docker (一)概念 Docker 是一个开源的应用容器引擎,允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可实现虚拟化。 (二)隔离性 Docker 的隔离…...
)
校园外卖服务系统的设计与实现(代码+数据库+LW)
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,外卖信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...

Windows上使用Python 3.10结合Appium-实现APP自动化
一、准备工作 所需条件: Windows 10/11 操作系统 Python 3.10.x(建议3.10.9) Java JDK 8 或以上(建议JDK 8u301) Node.js 14.x 或以上(建议14.21.3) Appium Server 1.22.x 或以上(建…...

【计算机视觉】CV项目实战- SiamMask 单阶段分割跟踪器
SiamMask 单阶段分割跟踪器 一、项目概述与技术原理1.1 核心技术创新1.2 性能优势 二、实战环境搭建2.1 系统要求与依赖安装2.2 项目编译与配置 三、模型推理实战3.1 快速体验Demo3.2 常见运行时错误处理 四、模型训练指南4.1 数据准备流程4.2 训练执行与监控 五、高级应用与优…...

计算机视觉基础
1. 数字图像的基本概念 像素(Pixel):图像的最小构成单元,每个像素存储亮度或颜色信息。 灰度图像:每个像素是 0(黑)~255(白) 的标量值(8位无符号整数&#x…...

系统编程_进程间通信机制_消息队列与共享内存
消息队列概述 消息有类型:每条消息都有一个类型,就像每封信都有一个标签,方便分类和查找。消息有格式:消息的内容有固定的格式,就像每封信都有固定的信纸格式。随机查询:你可以按类型读取消息,…...

一种免费的离线ocr-汉字识别率100%
一般我们手机中常用的ocr库有,Tesseract,paddle ocr,EasyOCR, ocrLite等等,这些ocr库中百度的paddle ocr效果最好,但是再好的效果也会偶尔识别错几个汉字。当我们在做自动化脚本过程中,如果识别…...
)
Maven 工程中的pom.xml 文件(图文)
基本信息 单工程项目【pom.xml文件】中最基本的信息。 依赖引入 可以在Maven 中央仓库查找所需依赖:【直达:https://mvnrepository.com/】。 在【dependencies】标签中添加所需依赖。 <dependency><groupId>com.baomidou</groupId&g…...

图像预处理-模板匹配
就是用模板图在目标图像中不断的滑动比较,通过某种比较方法来判断是否匹配成功,找到模板图所在的位置。 - 不会有边缘填充。 - 类似于卷积,滑动比较,挨个比较象素。 - 返回结果res大小是:目标图大小-模板图大小1(H-…...

操作系统学习笔记
2.4 死锁 在学习本节时,请读者思考以下问题: 1)为什么会产生死锁?产生死锁有什么条件? 2)有什么办法可以解决死锁问题? 学完本节,读者应了解死锁的由来、产…...

5.4.云原生与服务网格
目录 1. Kubernetes与微服务集成 1.1 容器化部署规范 • 多环境配置管理(ConfigMap与Nacos联动) • 健康检查探针配置(Liveness/Readiness定制策略) 1.2 弹性服务治理 • HPA自动扩缩容规则设计 • Sentinel指标驱动弹性伸缩 2…...

[特殊字符][特殊字符]Linux驱动开发入门 | 并发与互斥机制详解
文章目录 👨💻Linux驱动开发入门 | 并发与互斥机制详解📌为什么驱动中需要并发和互斥控制?💡常见的并发控制机制🔐自旋锁和信号量通俗理解🌀自旋锁(Spinlock)——“厕所…...

时序数据库IoTDB自研的Timer模型介绍
一、引言 时序数据库在支持时序特性写入、存储、查询等功能的基础上,正逐步向深度分析领域迈进。自动化异常监测与智能化趋势预测已成为时序数据管理的核心需求。为了满足这些需求,时序数据库IoTDB团队积极探索,成功自研推出了面向时间序列的…...
)
RabbitMQ 详解(核心概念)
本文是博主在梳理 RabbitMQ 知识的过程中,将所遇到和可能会遇到的基础知识记录下来,用作梳理 RabbitMQ 的整体架构和功能的线索文章,通过查找对应的知识能够快速的了解对应的知识而解决相应的问题。 文章目录 一、RabbitMQ 是什么?…...

【数据结构和算法】6. 哈希表
本文根据 数据结构和算法入门 视频记录 文章目录 1. 哈希表的概念1.1 哈希表的实现方式1.2 哈希函数(Hash Function)1.3 哈希表支持的操作 2. Java实现 在前几章的学习中,我们已经了解了数组和链表的基本特性,不管是数组还是链表…...

RHCE第三次作业 搭建dns的正向解析服务器
server为服务器 client为客户端 设置主配置文件 在server下: [rootServer ~]#vim /etc/named.conf #进入到配置页面,并修改 设置区域文件 [rootServer ~]# vim /etc/named.rfc1912.zones 设置域名解析文件 [rootServer named]# cd /var/named…...
问题?)
【每天一个知识点】如何解决大模型幻觉(hallucination)问题?
解决大模型幻觉(hallucination)问题,需要从模型架构、训练方式、推理机制和后处理策略多方面协同优化。 🧠 1. 引入 RAG 框架(Retrieval-Augmented Generation) 思路: 模型生成前先检索知识库中…...

Python深拷贝与浅拷贝:避开对象复制的陷阱
目录 一、为什么需要区分深浅拷贝? 二、内存中的对象真相 三、浅拷贝的真相 四、深拷贝的奥秘 五、自定义对象的拷贝 六、性能对比实验 七、常见陷阱与解决方案 八、最佳实践指南 九、现代Python的拷贝优化 结语 一、为什么需要区分深浅拷贝? …...

批量处理多个 Word 文档:插入和修改页眉页脚,添加页码的方法
Word 页眉页脚的设置在日常工作中非常常见,尤其是需要统一格式的文档,如毕业论文、公司内部资料等。在这些文档中,页眉页脚通常包含时间、公司标志、文档标题、文件名或作者姓名等信息。有时,我们不仅需要简单的文字页眉页脚&…...
的Prompt Engineering:从入门到精通)
大语言模型(LLM)的Prompt Engineering:从入门到精通
大语言模型(LLM)的Prompt Engineering:从入门到精通 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 引言:Prompt Engineering——解锁AI生产力的金钥匙 当ChatGPT在2023年引爆…...

poi生成横向文档以及复杂表头
代码: //创建页面并且创建横向A4XWPFDocument doc new XWPFDocument();CTDocument1 document doc.getDocument();CTBody body document.getBody();if (!body.isSetSectPr()) {body.addNewSectPr();}CTSectPr section body.getSectPr();if (!section.isSetPgSz()) {section.…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容二):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 常见问题TCP和UDPISNUDPTCP数据可靠性TCP协议如何提高传输效率TCP如何处理拥塞 SocketTCP源码tcp_v4_connect()sys_accept()tcp_accept()三次握手客户端发送SYN段服务端发送SYN和ACK处理客户端回复确认ACK段服务端收到ACK段 常见问题 TCP和UDP TCP和UDP的区别&#…...

流程架构是什么?为什么要构建流程架构,以及如何构建流程结构?
本文从:流程架构是什么?为什么要构建流程架构?如何构建流程结构三个方面来介绍。 一、首先,我们来了解流程架构是什么? 流程架构是人体的骨架,是大楼的砌筑,是课本的目录,是流程管理…...

Visium HD多样本拼片拆分
Visium HD实验的时候一个捕获区域内可以包含多个样本拼片(例如多个组织切片或不同样本的排列)是常见的实验设计,多样本拼片能够提升实验效率,单张玻片处理多个样本,降低试剂和测序成本,后续分析的时候只需要…...