初阶数据结构--排序算法(全解析!!!)
排序
1. 排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些些关键字的大小,递增或递减的排列起来的操作。
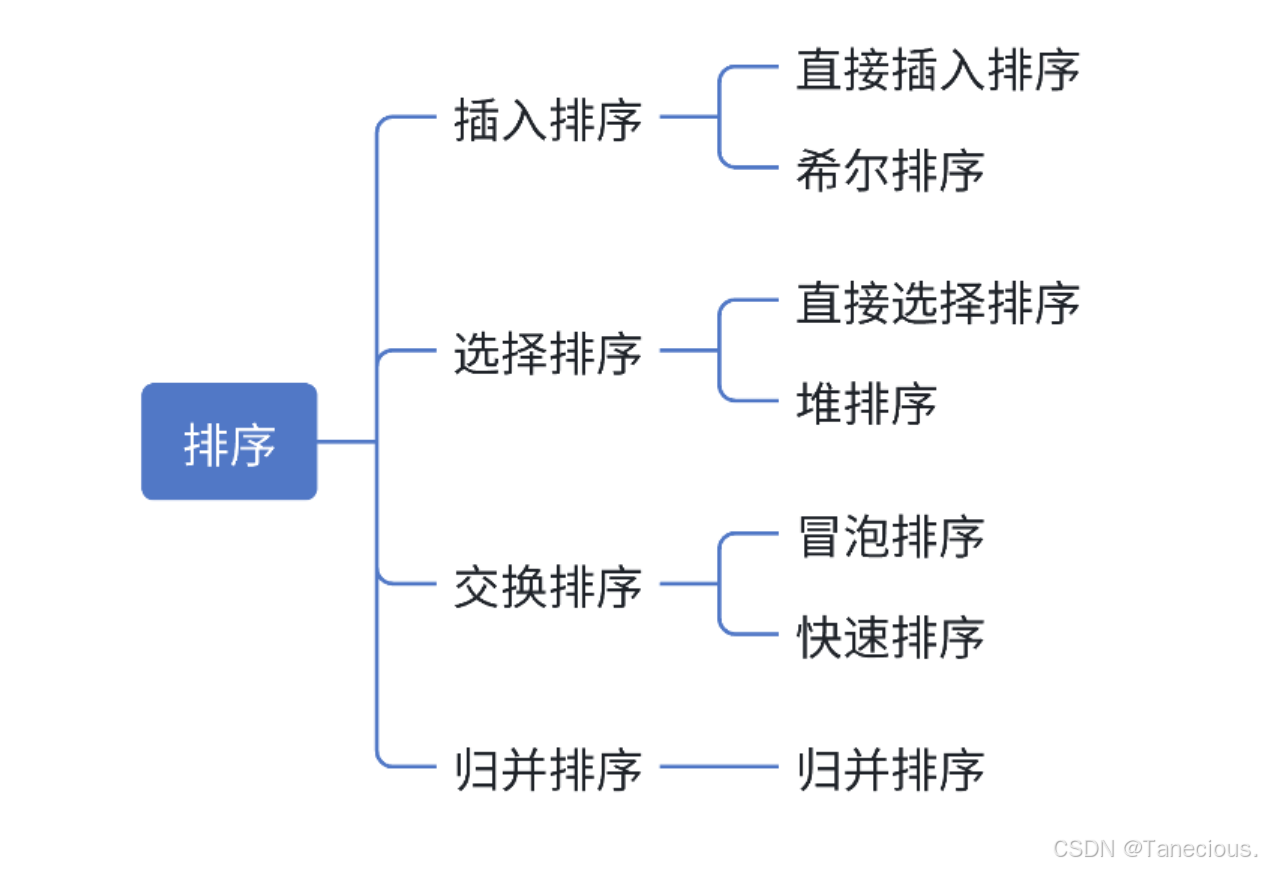
2. 常见的排序算法
3. 实现常见的排序算法
以下排序算法均是以排升序为示例。
3.1 插入排序
基本思想:
排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有记录插入完为止,得到一个新的有序序列。
这种思想类似于玩扑克牌的时候,将牌按一定顺序排好。

3.1.1 直接插入排序
3.1.1.1 代码示例
//直接插入排序(从大到小)n表示数组有效数据个数
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;//从首元素开始记录有序序列的最后一个元素的下标int tmp = arr[end + 1];//待插入的元素//确保end在有序区间范围内,不能越界 while (end >= 0){//比较有序区间数据,tmp数据小if (arr[end] > tmp){//有序空间数据移动,寻找空间插入数据arr[end + 1] = arr[end];//继续向前寻找合适数据end--;}//比较有序区间数据,tmp数据大else{//直接跳出循环,将tmp数据插入到end+1下标处break;}}arr[end + 1] = tmp;//代码执行到此位置有两种情况://1.待插入元素找到应插入位置(break跳出循环到此)。//2.待插入元素比当前有序序列中的所有元素都小(while循环结束后到此)。}
}
时间复杂度: O ( N 2 ) O ( N^2 ) O(N2)(最差情况,数组为降序) 空间复杂度: O ( 1 ) O ( 1 ) O(1)
3.1.1.2 代码详解
-
函数参数:
int* arr:需要排序的数组的数组名(数组的首元素地址)int n:数组中有效元素的个数
-
外层for循环:
for (int i = 0; i < n - 1; i++)- 外层的for循环表示,控制end的下标需要遍历数组中的每个数据,每个数据均需要参与比较。
- 这里的循环边界是tmp不能越界,所以tmp最大值为 n − 2 n-2 n−2,所以 i < n − 1 i<n-1 i<n−1为边界
-
临时变量的创建:
int end:用于表示有序数组中的最后一位数据的下标,从首元素开始。int tmp:将待插入元素拷贝一份。存在有序数组后移覆盖掉待插入元素的情况。
-
内层while循环:
while (end >= 0)- 内层的while循环表示,要保证end在有序数组的范围内,不可以越界。
-
if判断语句
- 如果此时以
end为下标的数组数据 大于待插入数据,则将以end为下标的数组数据先后移(注意:这里是通过end+1的方式实现数据的后移,此时end的位置并没有改变),在将end--,在比较前面较小的有序数据。 - 如果此时以
end为下标的数组数据小于待插入数据,则需要在end后面一个位置插入此数据,并也不需要再与有序数组中的数据比较,故跳出循环。
- 如果此时以
-
插入数据
arr[end + 1] = tmp- 代码执行到此位置有两种情况:
- 待插入元素找到应插入位置(break跳出循环到此)。
- 待插入元素比当前有序序列中的所有元素都小(while循环结束后到此)。
3.1.2 希尔排序
3.1.2.1 思路详解
相关介绍
希尔排序是按其设计者希尔的名字命名的,该算法由希尔1959年公布。他对普通直接插入排序的时间复杂度进行分析,得出了以下结论:
- 直接插入排序的时间复杂度最坏情况下为 O ( N 2 ) O(N^2) O(N2),此时待排序列为逆序,或者说接近逆序。
- 直接插入排序的时间复杂度最好情况下为 O ( N ) O(N) O(N),此时待排序列为升序,或者说接近升序。
是否可以有一种算法,可以规避掉直接插入排序的最坏的逆序情况,这样的话就可以大幅降低直接插入排序的复杂度了。
**规避掉逆序情况的方式:**先将待排序的数据进行预排序,使代排序列就接近有序,再对此序列进行一次直接插入排序,此时因为一定不是逆序序列,所以对于直接插入排序的复杂度就一定小于 O ( N 2 ) O(N^2) O(N2)。
基本思想:
-
希尔排序的核心思想:先用较大间距进行局部排序,逐渐缩小间距提高整体有序性,最终用间距为1的插入排序完成,这样效率比普通插入排序高很多。
-
因为希尔排序又被成为缩小增量排序。
- 先选定一个小于N的整数gap(步长)作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复进行上述操作…
- 当增量的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。
补充
-
问题1:为什么要让gap由小到大?
因为当gap(步长)越大,数据间隔越大,数据移动的越快。前期让gap较大,可以让数据更快移动到自己对应位置附近,减少数据的挪动次数,减少复杂度。
-
问题2:gap的值应该应该如何选取?
一般情况下,取序列的一半作为增量,然后依次减半,并确保最终增量可以减为1。
具体示例:
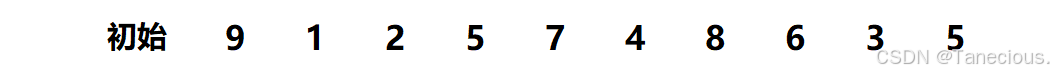
首先对这10个乱序数组作为示例进行排序,用序列长度的一半作为第一次增量,也就是gap = 10/2 = 5,因此此时相隔距离为5的数据被分为一个**(共分了5组,每组有2个元素),然后对这5组在组内进行直接插入排序**,调整数据顺序。
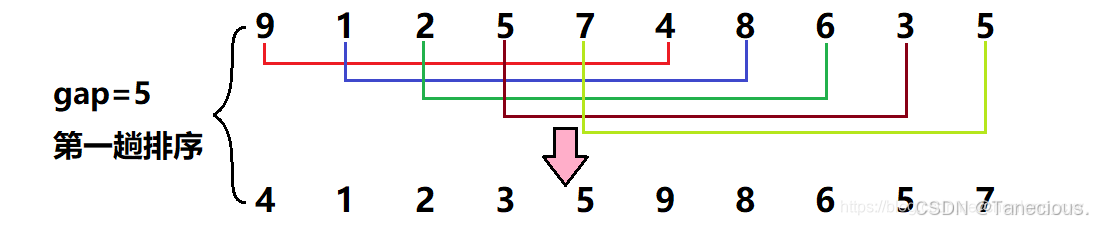
经过第一次调整之后,可以大致看出新的序列大体呈现左边为小数据,右边为大数据的规律。之后继续进行第二次调整,此时gap的值对半gap = 5/2 = 2,此时相隔距离为2的元素被分为一组**(共分了2组,每组有5个元素)**,然后再对这2组数据在组内进行直接插入排序,调整数据顺序。
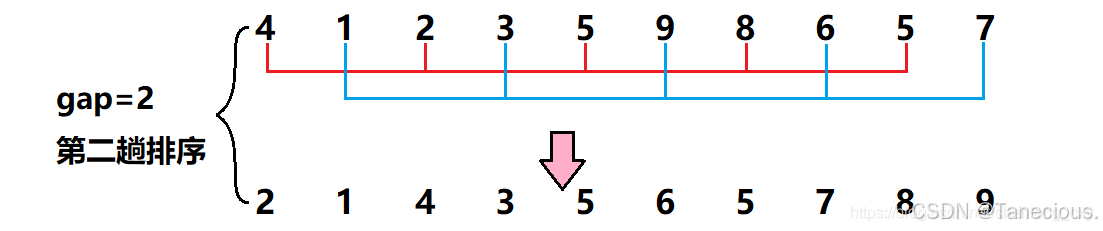
此时再将gap的值对半,gap = 2/2 = 1,此时gap减为1,即整个序列被分为一组,进行一个直接插入排序。
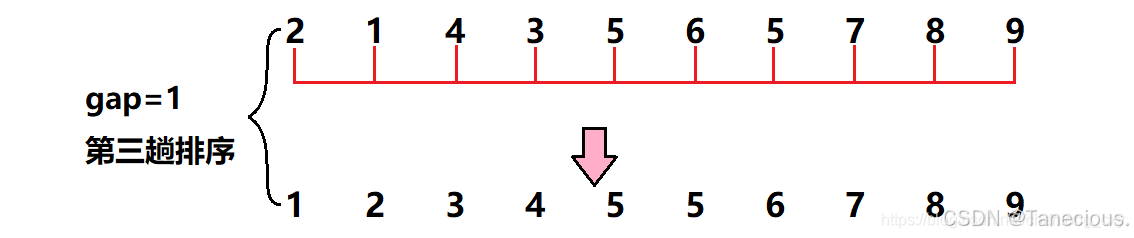
这样就利用希尔排序完成了以上序列的排序方法,其中前两趟为希尔排序的预排序,最后一趟是希尔排序的直接排序。
3.1.2.2 示例代码
//希尔排序
void ShellSort(int* arr, int n)
{//定义步长int gap = n;//6//控制排序次数,调整步长while (gap > 1){gap = gap / 3 + 1;//保证最后一次gap一定为1//遍历被步长分隔的数组内部的数据for (int i = 0; i < n - gap; i++){int end = i;//n-gap-1int tmp = arr[end + gap];//防止end越界while (end >= 0){//进行元素的比较和交换if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else {break;}}arr[end + gap] = tmp;//代码执行到此位置有两种情况://1.待插入元素在组中找到应插入位置(break跳出循环到此)。//2.待插入元素比当前组中的有序序列中的所有元素都小(while循环结束后到此)。 }}
}
平均时间复杂度大约为: O ( N 1.3 ) O(N^{1.3}) O(N1.3) 空间复杂度: O ( 1 ) O ( 1 ) O(1)
3.1.2.2 代码详解
-
函数参数与步长定义
-
int* arr:需要调整的序列所属数组的数组名 -
int n:数组中有效元素的个数 -
int gap = n;:步长的定义,一般初始值即为n,在后续排序会先折半
-
-
外层while循环
- 先由
gap = gap / 3 + 1;语句,对初始化的gap值进行调整,便于后续使用 - 再有外层while循环控制整体排序的次数
- 先由
-
内层for循环
- 在
arr数组中的序列已经被gap切分之后,由for循环遍历各个组中的数据 - 同时定义
end与tmp,含义与直接插入排序中一样 - for循环的截止条件还是需要防止tmp的下标越界,所以为 i < n − g a p i < n - gap i<n−gap
- 在
-
算法核心实现
- 插入算法的核心实现逻辑
- 由外层while循环控制end遍历该组数据中的每个数据
- if判断语句,实现数据比较与交换的功能
3.2 选择排序
基本思想:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
3.2.1 直接选择排序
3.2.1.1 代码示例
//直接选择排序
void SelectSort(int* arr, int n)
{//起始位置元素下标int begin = 0;//结尾位置元素下标int end = n - 1;//开始从数组两头遍历数组while (begin < end){//最大最小值初始状态都定义在首元素处int mini = begin, maxi = begin;//在begin~end未排序区间之间,进行比较for (int i = begin; i <= end; i++){if (arr[i] > arr[maxi]) {//确定未排序区间中的最大数,并将maxi指向他maxi = i;}if (arr[i] < arr[maxi]){//确定未排序区间中的最小数,并将mini指向他mini = i;}}//mini和begin交换,maxi和end交换//避免maxi begin指向同一个位置,造成maxi mini互换两次,相当于没换if (maxi == begin){maxi = mini;}Swap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);//调整无序序列下标++begin;--end;}
}
时间复杂度: O ( N 2 ) O(N^2) O(N2) 空间复杂度: O ( 1 ) O(1) O(1)
3.2.2 堆排序
这里的堆排序在前面堆的数据结构类型有过相关介绍。所以要想学习到堆排序,首先需要了解堆的向下调整算法,因为堆排序的核心就是先利用无序序列建堆,再利用堆的向下调整算法将堆构造成小根堆(以排升序为例),再将堆顶数据不断出堆即可。
3.2.2.1 思路详解
首先,拿到一个无序序列先将此序列依照堆的向下调整算法建堆。
向下调整算法的介绍:
在使用堆的向下调整算法的使用前提:
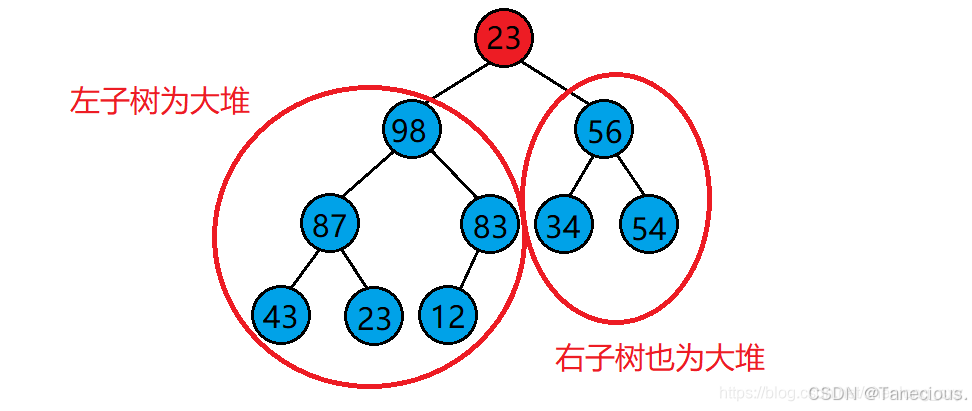
- 若想将其调整为小堆,那么根结点的左右子树必须都为小堆。(排降序用小堆)
- 若想将其调整为大堆,那么根结点的左右子树必须都为大堆。(排升序用大堆)
堆的向下调整算法的基本思想:
- 从根结点处的数据开始操作,选出根结点左右孩子中值较大的那一个。
- 让较大的孩子与其父亲进行比较
- 若孩子结点比父亲结点大,则该孩子结点与父亲结点的位置进行交换,并将原来大孩子的位置作为新的父亲结点(根结点)继续遍历向下调整。
- 若孩子结点比父亲结点小,则不需要处理,整个树已经是大堆了。
//堆的向下调整算法(以建大堆为例) //end表示数组中最后一个有效数据的下表,也就是size-1 //该函数第一个参数表示要操作的数组,后两个表示数组有效数据的下标0~end(size - 1) AdjustDown(HPDataType* arr, int parent, int end) {int child = parent * 2 + 1;//当子节点移动到末尾结束循环while (child <= end){ //补充:小堆找左右孩子最小的;大堆找左右孩子最大的//找左右孩子最大的,准备与父节点交换位置//注意越界问题,数组下标不可以大于最后一位数据的下标if (child + 1 >= end && arr[child] < arr[child + 1]){//右孩子更大,改变child的值child++;}//交换位置if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);//坐标变换继续调整数据parent = child;child = parent * 2 + 1;}//换到中间位置已经形成堆结构else{break;}} }
问题1:上面的基本思想是建立在左右子树均为大堆或者小堆的基础上,那么如何将一个任意树调整成堆呢(建堆过程)?
只需要从倒数第一个非叶子结点开始执行堆的向下调整算法,从后往前按下标,依次为根结点去向下调整即可。
//建堆(向下调整算法建(调整)堆)
//(size-1-1)/2指的是最后一个非叶子结点的数组下标,i--不断开始遍历每个节点进行调整
for(int i = (size-1-1)/2; i >= 0; i--)
{AdjustDown(arr, i, size - 1);
}
**问题2:**那么堆建好后,如何进行堆排序呢?
- 将堆顶数据与堆的最后一个数据交换,然后对根结点位置进行一次堆的向下调整,但是调整时被交换到最后的那个最大的数不参与向下调整。
- 完成步骤1后,这棵树除最后一个数之外,其余数又成一个大堆,然后又将堆顶数据与堆的最后一个数据交换,这样一来,第二大的数就被放到了倒数第二个位置上,然后该数又不参与堆的向下调整……反复执行下去,直到堆中只有一个数据时便结束。此时该序列就是一个升序。
//堆排序(大堆 --- 升序)
//因为如果需要实现堆排序,这需要先创建堆结构存放n个数据,空间复杂度为O(n)
//现在需要让堆排序空间复杂度为O(1),可以直接将对传来的数组进行操作
void HeapSort(int* arr, int size)
{//建堆(向下调整算法建(调整)堆)//(size-1-1)/2指的是最后一个非叶子结点的数组下标,i--不断开始遍历每个节点进行调整for(int i = (size-1-1)/2; i >= 0; i--){AdjustDown(arr, i, size - 1);}//排升序 --- 大堆// 循环将堆顶数据跟最后位置(会发生变化,每交换一次位置-1)的数据交换int end = size - 1;//最后一个数据的下标//走到堆底则停止调整while (end > 0){Swap(&arr[0], &arr[end]);//交换,此时堆顶元素为一开始数组中的最后一个数据//向下调整堆(从0调整到end)AdjustDown(arr, 0, end);//数组中最后一个已经是最小,故排出排序范围end--;}//排升序 --- 大堆 //排降序和升序逻辑一致,只需要更改AdjustDown和AdjustUp中的大小于号即可
}
时间复杂度: O ( N l o g N ) O(NlogN) O(NlogN) 空间复杂度: O ( 1 ) O(1) O(1)
补充:
- 因为堆的底层结构是数组,然后无论是堆的向下调整算法还是堆排序,都是直接对乱序数组进行直接操作,所以所谓的建堆,其实不是把数组中的数据一个个插入堆中,而是将已经存在在堆中但是是乱序的数据,重新调整排列,使其满足大/小堆的结构。
3.3 交换排序
基本思想:
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置。
交换排序的特点是:将键值较大的向序列的尾部移动,键值较小的记录向序列的前部移动。
3.3.1 冒泡排序
3.3.1.1 示例代码
//冒泡排序
//时间复杂度:0(N^2)
void BubbleSort(int* arr, int n)
{//外层循环控制整个排序过程的遍历次数,确保每次排序(从乱序到有序算一次)数组中的每个数据都可以被遍历for (int i = 0; i < n; i++){int exchange = 0;//记录该趟冒泡排序是否进行过交换//内层循环负责在当前轮次中进行相邻元素的比较和交换for (int j = 0; j < n - i - 1; j++){//升序if (arr[j] < arr[j + 1]){exchange = 1;Swap(&arr[j], &arr[j + 1]);}}if (exchange == 0)//该趟冒泡排序没有进行过交换,已有序{break;}}
}时间复杂度: O ( N 2 ) O(N^2) O(N2) 空间复杂度: O ( 1 ) O(1) O(1)
3.3.1.2 思路详解
利用两层for循环实现遍历次数的控制和每次遍历的大小比较、元素交换,从而实现冒泡排序。
- 外层for循环:控制遍历次数,一次调整好一个数据故遍历n次。
- 内存for循环:在此次遍历的乱序数组中,每两个数据都比较,将大的放后面,直到将乱序序列中的最大值挑选出并放到最后一个数据位置。完成一个完整的内部循环,回到外层循环,
i++继续开始新的遍历。
3.3.2 快速排序(递归版)
快速排序是Hoare与1962年提出的一种二叉树结构的交换排序方法。
基本思想:
任取待排序元素序列的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后左右子序列重复该过程,直到所有元素都排序在对应位置上为止。
如何按照基准值将待排序列分为两子序列,常见方法:
- Hoare版本
- 挖坑法
- lomuto前后指针法
以下不同版本的仅仅是利用不同的方式得到基准值下标并实现将基准值到达目标位置的子函数
_QuickSort的编写方式的不同。
如上解释,因为快速排序核心思想就是利用递归的方法遍历整个乱序序列,所以其主函数框架在下面进行展示;至于子函数的三种实现方式,在下面会进行一一介绍。
QuickSort函数的实现
-
函数功能:
- 完成整个乱序序列的排序。
-
函数示例:
void QuickSort(int* arr, int left, int right) {//保证下标有效if (left >= right){return;}//[left,right]--->找基准值keyiint keyi = _QuickSort(arr, left, right);//左子序列:[left,keyi-1]QuickSort(arr, left, keyi - 1);//右子序列:[keyi+1,right]QuickSort(arr, keyi + 1, right); }时间复杂度: O ( N l o g N ) O(NlogN) O(NlogN) 空间复杂度: O ( N l o g N ) O(NlogN) O(NlogN)
-
逻辑补充:
- 首先保证函数参数的
left,right有意义。 - 用函数
_QuickSort,找到第一趟排序基准值,记录下来,根据基准值的位置,将序列分成两个子序列。 - 循环递归调用
QuickSort,遍历左右子序列,直到序列有序。
- 首先保证函数参数的
3.3.2.1 Hoare版本
代码思路:
-
_QuickSort函数的实现-
函数功能:
- 用于实现单趟排序,也就是调用一次此函数即
keyi可到达自己的目标位置。
- 用于实现单趟排序,也就是调用一次此函数即
-
函数参数:
- int arr*:待排序的数组
- int left, int right:数组中的待排区间的左右下标标记,后续
left从左向右走,right从右向左走
-
函数逻辑:
- 选取待排区间的最左侧,作为基准值(
keyi),即int keyi = left; left右移一位,基准值不需要遍历。即++left;- 开始遍历
while (left <= right),因为一开始选择最左边的数据作为keyi,则需要right先走;若选择最右边的数据作为keyi,则需要left先走 - 在走的过程中,若
right遇到小于keyi的数,则停下,left开始走,直到left遇到一个大于keyi的数时,停止,将right和left下标所指向的数据交换;然后right再次开始走,如此进行下去,直到left和right最终相遇,此时将相遇点的内容与keyi交换即可。 - 同时此时交换后的基准值的位置,就是此数据在数组中应该所处的位置。
- 选取待排区间的最左侧,作为基准值(
-
函数示例:
//QuickSort子函数,进行单趟的排序 int _QuickSort(int* arr, int left, int right) {//定义基准点int keyi = left;++left;while (left <= right){//right先走,找小于基准值的数while (left <= right && arr[right] > arr[keyi]){right--;}//left后走,找大于基准值的数while (left <= right && arr[left] < arr[keyi]){left++;}//right leftif (left <= right){Swap(&arr[left++], &arr[right--]);}}//right keyi交换Swap(&arr[keyi], &arr[right]);return right; } -
逻辑详解:
-
while (left <= right):包含=是因为left和right相遇的位置的值可能比基准值要大,如果此时跳出循环交换基准值和right指向的值,此时基准值的左子树中就存在一个大于基准值的值。 -
while (left <= right && arr[right] > arr[keyi]):-
这里介绍了right停下的两种原因:①检查到小于基准值的值;②遍历到left左边。只要不是这两种情况,right应该要不断左移。
-
循环前面的限制原因同补充1,第二个限制条件不加
=,是为了解决在二分时,效率过低的问题。**eg:**待排序序列中全是同一个元素,这里若加上等号,right就会一直
--直到与left重合,但是此时交换基准值,才会移动一格子。无法实现有效的数据分割。即遇到
-
-
while (left <= right && arr[left] < arr[keyi]):-
这里介绍了left停下的两种原因:①检查到大于基准值的值;②遍历到right右边。只要不是这两种情况,left应该要不断右移。
-
循环前面的限制原因同补充1,第二个限制条件不加
=,是为了解决在二分时,效率过低的问题。
-
-
if (left <= right):经过上面两层循环,此时left和right都已经停下,这里的停下有两种情况:-
left和right没有相遇,正常的交换调整数据,然后继续移位遍历
-
left和right相遇,先原地交换一下,然后在遍历,使得
left > right,这样一方面可以跳出while循环,表示已经完成一趟排序,还可以将right重新指向一个小于基准值的值,要不然如果相遇值大于大于或者等于基准值就跳出while循环就会造成基准值的左子树中就存在一个大于基准值的值。
-
-
Swap(&arr[keyi], &arr[right]):将基准值keyi移到正确位置,此交换语句仅交换两个数组中的数据,此时的keyi仍是左边第一个数据的下标,right此时才是基准值数据的数组下标。 -
return right:函数的返回值是基准值所在下标。
-
-
3.3.2.2 挖坑版
代码思路:
-
_QuickSort函数的实现-
函数示例:
//挖坑法 int _QuickSort2(int* arr, int left, int right) {// 挖坑+记录基准值int hole = left;int key = arr[hole];//开始遍历while (left < right){//right向左,找小while (left < right && arr[right] > key){--right;}arr[hole] = arr[right];hole = right;//left向右,找大while (left < right && arr[left] < key){++left;}arr[hole] = arr[left];hole = left;}//left和right相遇arr[hole] = key;//将基准值填入坑位return hole;//返回此时基准值下标 } -
逻辑详解:
int hole = left; int key = arr[hole];:首先在left位置挖坑并将坑中的数值记录下来,作为标准值。这里就像将left位置的土(数据),挖出装进key的车上(基准值)。while (left < right):开始循环遍历序列,直到left和right相遇。while (left < right && arr[right] > key):right循环遍历,跳出循环有两个情况:arr[right] <= key,检测到小于等于基准值的数据,此时right停下,此时将arr[right]中的土(数据),挖出填到arr[hole]的坑中,在将此时下标right标记为新的坑。left = right,此时left和right相遇,停止遍历,将相遇位置的土(数据),填到坑的位置上去,再将相遇位置标记为新的坑。
while (left < right && arr[left] < key):left循环遍历语句,和上述逻辑一致,不做过多赘述。arr[hole] = key; return hole;:left和right相遇时的调整语句,将原先存在装进key的车上的标准值的土,填入相遇位置的坑中。这个位置就是标准值的目标位置,最后将目标位置的返回回去。
-
3.3.2.3 lomuto前后指针法
基本步骤:
- 将序列最左边数据作为基准值
key - 创建两个指针,prev指向序列开头,cur指针指向prev+1
- 若cur指向的内容小于key,则prev先移动一位并且不等于cur,然后交换prev和cur指针指向的内容,然后cur指针++;若cur指向的内容大于key,则cur指针直接++后移
- 如此进行下去,直到cur指针越界,此时将key和prev指针指向的内容交换即可
函数示例:
//lomuto前后指针法
int _QuickSort3(int* arr, int left, int right)
{//前后指针和基准值的初始化int prev = left, cur = left + 1;int key = left;//开始遍历序列while (cur <= right){//cur的内容小于基准值并且prev+1不等于cur交换数据if (arr[cur] < arr[key] && ++prev != cur){Swap(&arr[cur], &arr[prev]);}//继续后移遍历cur++;}//将基准值移到目标位置Swap(&arr[key], &arr[prev]);return prev;
}
3.3.3 快速排序(非递归版)
因为快速排序是根据二叉树结构的基础上进行排序,所以就涉及了函数的递归思想,但是因为涉及函数递归就需要函数栈帧的创建,每创建一个函数栈帧就相当于将一个数据移动到目标位置。但是如果序列中数据极大,没有那么大的空间创建足够的函数栈帧,可能就会出现栈溢出的情况。
所以下面会介绍快速排序的非递归版本的相关内容。而非递归版本的快速排序需要借助数据结构:栈
因为上面已经将Hoare版本、挖坑法和前后指针法的单趟排序单独封装起来。此时只需要更改QuickSort函数的内部递归逻辑改为非递归逻辑,再在QuickSort函数内部调用单趟排序的函数即可。
基本步骤:
- 先将待排序列的第一个元素的下标和最后一个元素的下标入栈。
- 当栈不为空时,读取栈中的信息(一次读取两个:一个是
begin,另一个是end),然后调用某一版本的单趟排序,排完后获得了基准值的下标,然后判断基准值的左序列和右序列是否还需要排序,若还需要排序**(左右序列区间有意义),就将相应序列的begin和end入栈;若不需排序了(左右序列区间无意义或者左右区间相同)**,就不需要将该序列的信息入栈。 - 反复执行步骤2,直到栈为空为止。
示例代码:
//非递归版本快排
//--借助数据结构--栈
void QuickSortNonR(int* arr, int left, int right)
{ST st;STInit(&st);StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){//取栈顶元素---取两次int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);//[begin,end]---找基准值keyi = _QuickSort(arr, begin, end);//根据基准值划分左右区间//左区间:[begin,keyi-1]//右区间:[keyi+1,end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}}STDestroy(&st);
}
代码详解:
由递归版本代码改为为非递归主要是对于左右序列的区间如何获取的方式不同。
-
ST st;STInit(&st);STDestroy(&st);非递归版本需要借用数据结构–栈,创建栈、初始化栈、销毁栈为固定操作。
-
StackPush(&st, right);StackPush(&st, left);将乱序区间的左右序列下标入栈。
-
while (!StackEmpty(&st)){}利用循环检测栈里面有没有有效区间的方式,代替函数的递归。
-
//取栈顶元素---取两次int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);取两次栈顶数据,作为单趟排序函数的左右区间参数。
-
//[begin,end]---找基准值keyi = _QuickSort(arr, begin, end);参考上文三中单趟排序的子函数,任选一种单趟排序找基准值。
-
//根据基准值划分左右区间//左区间:[begin,keyi-1]//右区间:[keyi+1,end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}找到基准之后重新划分左右区间。但是在插入栈之前需要保证两个条件:
- 左右区间为有效区间,起点位置不能大于终点位置。
- 区间中数据必须大于一个,起点位置不能和终点位置相同。
3.3.4 快排的深入优化
3.3.4.1 三数取中选key
在快速排序中的每趟排序中,都是key占整个序列的位置,是影响快速排序效率最大的因素,将key越接近中间位置,则越可以增强快速快速排序的效率。因为这里引入了一个三数取中的思想解决这个问题。
基本思想:
所谓三数取中,就是取头,中,尾三个元素,比较大小,选择排在中间的数据作为基准值key。这执行快速排序,这就确保了所选取的数不会是序列中的最大或是最小值,这种算法可以一定程度提升快速排序的效率。
- 首先将此功能封装为一个函数
GetMidIndex将待排数组和数组的最左边数据下标和最后边数组下标传入函数。 - 再通过左右位置下标确定中间位置下标,之后利用
if-else,对三个数据进行比较,最后将大小处于中间的数据作为key返回。
// 快速排序--优化1---三数取中选key
int GetMidIndex(int* a, int left, int right)
{//获取中间位置下标int mid = (left + right) / 2;//开始比较if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[right] < a[left]){return left;}else{return right;}}else{if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}
}
算法总结:
-
在调用这个函数之后,就可以将中间值的下标返回给快速排序,之后再将此数据与起始的最左侧数据进行交换位置,之后进行正常的快速排序就可以了。此时的key就是
GetMidIndex函数的返回值了// 快速排序--递归法 void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}int mid = GetMidIndex1(a, begin, end);Swap(&a[begin], &a[mid]); // 再交换中间值位置与最左边位置int keyi = QuickSort(a, begin, end);// [beign,keyi-1] keyi [keyi+1,end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end); }
3.3.4.2 随机数选取key
在选取key的时候已经有了上一个三数取中的思路,但是三数取中的思路可能有点死板,所取得值只能是固定位置,于是现在就有了基于三数取中的算法进行优化,即随机数算key法。
基本思想:
随机数选key的和基本思想和三数取中一致,只是mid的值并不是由(left + right)/2得来的,而是由随机数生成而来,即 mid = left + (rand() % (right - left))。
示例代码:
// 快速排序--优化2---随机数选key
int GetMidIndex2(int* a, int left, int right)
{//随机数获取中间值下标int mid = left + (rand() % (right - left));if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[right] < a[left]){return left;}else{return right;}}else{if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}
}
3.3.4.3 三路划分
在递归版的快速排序中,当待排序列中含有多个相同元素的时候,单纯的使用普通的快速排序的优势就不是那么明显了。这时候使用三路划分就可以很好的解决这个问题。
图片理解:
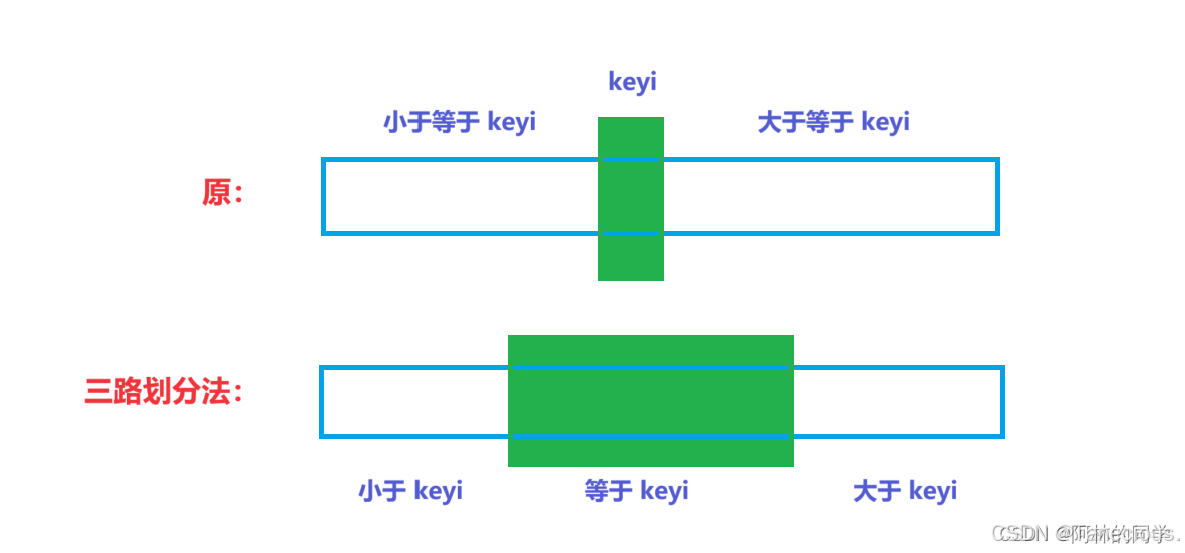
基本思想:
当面对有大量和key(基准值)相同的值的时候,三路划分的核心思想有点类似于hoare的左右指针和lomuto的前后指针的结合。核心思想是把数组分为三段比key小的值,跟key相等的值,比key大的值,所以叫做三路划分算法。结合下图具体阐述实现思想:

- key默认取left位置的值。
- left指向区间最左边,right指向区间最后面,cur指向left + 1的位置。
- 开始遍历比较,调整序列
- 情况①:cur遇到比key小的值后跟left位置交换,换到左边,然后left++,cur++
- 情况②:cur遇到比key大的值后跟right位置交换,换到右边,然后right–
- 情况③:cur遇到跟key相等的值之后,cur++
- 直到cur > right结束
示例代码:
// 快速排序--递归法---三路划分法
//begin:待排序列最左侧数据下标
//end:待排序列最右侧数据下标
void QuickSort(int* a, int begin, int end)
{//保证序列有意义if (begin >= end){return;}//初始化int left = begin;int right = end;int key = a[left];int cur = left + 1;//开始遍历比较while (cur <= right){//情况1:大的放到右边,由于交换过来的cur不确定,故cur不移动,进行下一轮检测if (a[cur] > key){Swap(&a[cur], &a[right]);--right;}//情况2:小的放左边,此时的交换值是确定的,交换后left和cur均后移else if (a[cur] < key){Swap(&a[left], &a[cur]);++left;++cur;}//情况3:与key相等的值推到中间,cur继续后移遍历else{++cur;}}// 此时的区间:[begin,left-1][left,right][righ+1,end]//递归左右乱序序列QuickSort(a, begin, left - 1);QuickSort(a, right + 1, end);
}
算法总结:
三路划分的算法思想在解决序列中包含多个重复数据的时候效率很好,其他场景就比较一般。但是三路划分思路还是很有价值的,有些快排思想变形体,要用划分去选数,他能保证和key相等的数都排到中间去,三路划分的价值就可以提现出来了。
3.3.4.3 introsort的快速排序
快排是会受到数据样本的分布和形态的影响的,所以经常有的时候遇到一些特殊数据的数组,如大量重复数据的数组,因为快排需要选key,每次key都选到重复数据就会导致key将序列分割的很偏,就会出现效率退化的问题。
无论是hoare、lomuto还是三路划分他们的思想在特殊场景下效率会退化,比如在选key的时候大多数都选择了接近最小或者最大值,导致划分不均衡,效率退化。
因为以上情况的出现,所以introsort诞生了,introsort是由David Musser在1997年设计的排序算法,C++sgi STLsort中就是用的 introspectivesort (内省排序) 思想实现的。内省排序可以认为不受数据分布的影响,无论什么原因划分不均匀,导致递归深度太深,他就是转换堆排了,堆排不受数据分布影响。
基本思路:
- 如果快排递归深度太深**(sgi stl 中使用的是深度为2倍元素数量的对数值)**,也就是
depth大于 2 ∗ l o g n 2*logn 2∗logn ,则说明在这种数据序列下,选key出现了问题,性能在快速退化,就不再进行快排分割递归了,改为堆排序。
示例代码:
/*** Note: The returned array must be malloced, assume caller calls free().*///堆排序的实现
//交换函数
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}//堆的向下调整算法
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 选出左右孩⼦中⼤的那⼀个 if (child + 1 < n && a[child + 1] > a[child]){++child;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}//实现堆排序
void HeapSort(int* a, int n)
{// 建堆 -- 向下调整建堆 for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[end], &a[0]);AdjustDown(a, end, 0);--end;}
}//直接插入算法
void InsertSort(int* a, int n)
{for (int i = 1; i < n; i++){int end = i-1;int tmp = a[i];// 将tmp插⼊到[0,end]区间中,保持有序 while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];--end;}else{break;}}a[end + 1] = tmp;}
}//Introsort排序
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{//保证序列有效if (left >= right)return;// 数组长度⼩于16的⼩数组,换为插⼊排序,简单递归次数 if(right - left + 1 < 16){InsertSort(a+left, right-left+1);return; }// 当深度超过2*logN时改用堆排序 if(depth > defaultDepth){HeapSort(a+left, right-left+1);return;}depth++;//常规情况使用lomuto快速排序//下标初始化int begin = left;int end = right;// 随机选key int randi = left + (rand() % (right-left + 1));Swap(&a[left], &a[randi]);//参量初始化int prev = left;int cur = prev + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;//遍历左右乱序序列// [begin, keyi-1] keyi [keyi+1, end]IntroSort(a, begin, keyi - 1, depth, defaultDepth);IntroSort(a, keyi+1, end, depth, defaultDepth);
}//快速排序入口函数
void QuickSort(int* a, int left, int right)
{//初始化参数int depth = 0; //参数int logn = 0; //数组大小 N 的对数(基数为2)int N = right-left+1;//数组大小//求数组长度N的是2的多少次方,求将数组放入二叉树的层数for(int i = 1; i < N; i *= 2){logn++;}// introspective sort -- ⾃省排序 IntroSort(a, left, right, depth, logn*2);
}//对整数数组 nums 进行排序,并返回排序后的数组
int* sortArray(int* nums, int numsSize, int* returnSize)
{//随机数取keysrand(time(0));QuickSort(nums, 0, numsSize-1);*returnSize = numsSize;return nums;
}
算法总结:
- 本质上就是根据数据的实时情况,选择不同的排序算法,增强程序的效率和适应性。
3.4 归并排序
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。归并排序核心步骤:
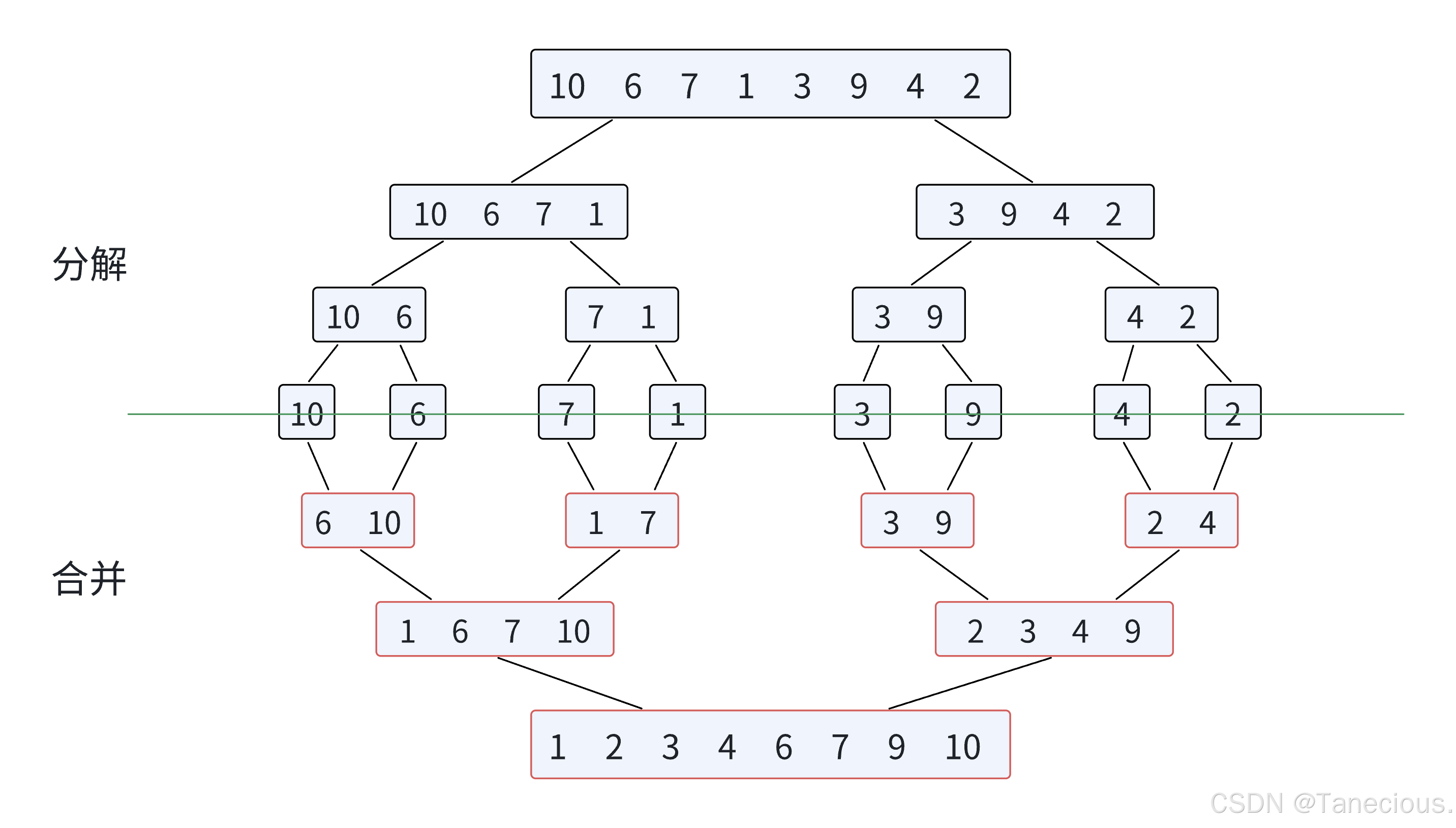
3.4.1 思路详解
基本思想的核心总结:将已有序的子序列合并,从而得到完全有序的序列,即先让每个子序列有序,再使子序列段间有序。
-
分解:
先将乱序序列通过 m i d = ( r i g h t + l e f t ) / 2 mid = (right + left)/2 mid=(right+left)/2 获取中间位置的下标,将序列从中间
mid开始分为两个序列,再不断递归循环,直到将数据分为一个个零散的数据(此时这个数据可以看做一个left等于right的序列) -
合并:
每次合并都是两个有序序列进行合并。
对于要合并的两个序列用
begin1和end1、begin2和end2分别来表示这两个序列的首位数据。之后再利用两个序列的begin下标不断遍历序列按顺序循环取出较小的数据,放入临时数组tmp中,最后利用end作为截止循环的条件,最后将完整的有序数组tmp赋给arr。
3.4.2 示例代码
//归并排序
//子函数
void _MergeSort(int* arr,int left,int right,int* tmp)
{//非有效区间if (left >= right){return;}//找中间下标int mid = (left + right) / 2;//递归分割序列//左序列:[left,mid] 右序列:[mid+1,right]_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid + 1, right, tmp);//合并序列//左序列:[left,mid] 右序列:[mid+1,right]int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;//用于指示tmp数组数据下标int index = left;//合并两个有序序列while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else {tmp[index++] = arr[begin2++];}}//要么begin1越界 要么begin2越界while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}//把tmp中的数据拷贝回arr中for (int i = left; i < right; i++){arr[i] = tmp[i];}
}//主函数
void MergeSort(int* arr, int n)
{//动态创建一个临时数组,用于排序int* tmp = (int*)malloc(sizeof(int) * n);//执行子函数_MergeSort(arr, 0, n - 1, tmp);free(tmp);
}
时间复杂度: O ( N l o g N ) O(NlogN) O(NlogN) 空间复杂度: O ( N ) O(N) O(N)
3.4.4 知识补充:文件排序
以上介绍了很多种排序算法,但是基本都是基于内排序,均是基于内存中的进行的,但是在排序中面对数量极多的序列,上述的排序算法都是无法实现的,但是归并排序是可以实习的。
下面先简单介绍一下内排序、外排序:
- **内排序:**数据量相对少一些,可以放到内存中进行排序。
- **外排序:**数据量较大,内存中放不下,数据只能放到磁盘文件中,需要排序。
基本思路:
假设现在有10亿个整数(4GB)存放在文件A中,需要我们进行排序,而内存一次只能提供512MB空间,归并排序解决该问题的基本思路如下:
合并思路1:
- 每次从文件A中读取八分之一,即512MB到内存中进行排序(内排序),并将排序结果写入到一个文件中,然后再读取八分之一,重复这个过程。那么最终会生成8个各自有序的小文件(A1~A8)。
- 对生成的8个小文件进行11合并,最终8个文件被合成为4个,然后再11合并,就变成2个文件了,最后再进行一次11合并,就变成1个有序文件了。
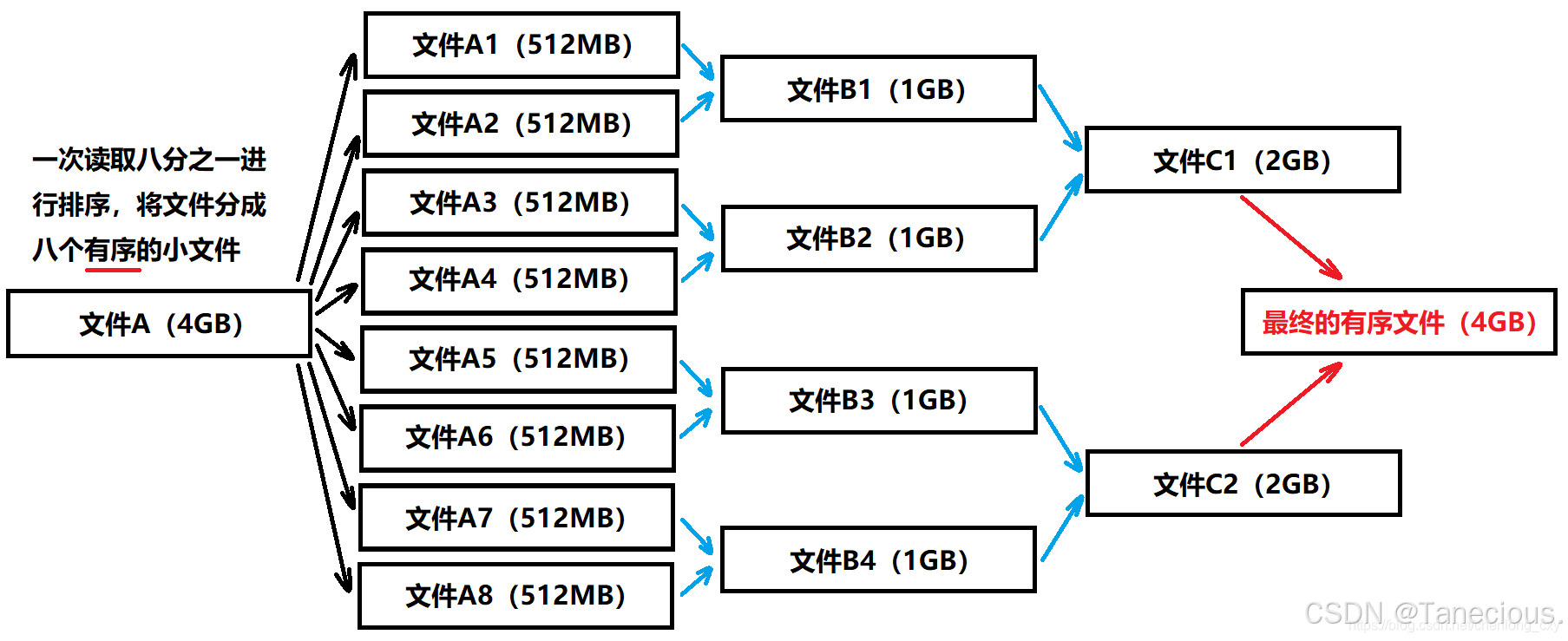
合并思路2:
- 每次从文件A中读取八分之一,即512MB到内存中进行排序(内排序),并将排序结果写入到一个文件中,然后再读取八分之一,重复这个过程。那么最终会生成8个各自有序的小文件(A1~A8)。
- 对生成的8小文件,按顺序第一次先归并排序前两个小文件,形成一个新的文件,再将新的文件和第三个小文件进行归并排序,不断合并,最后变成一个有序文件。
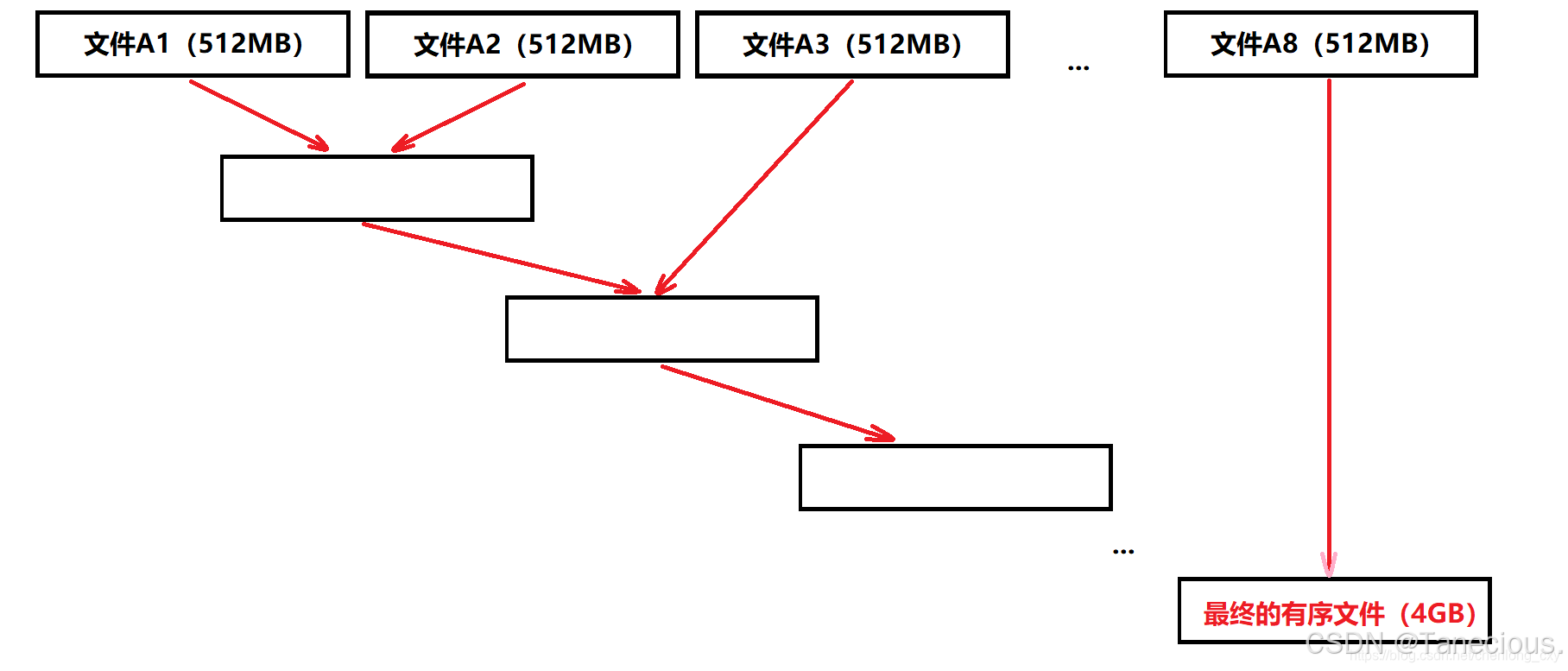
示例代码:
下面的示例代码,是按照合并思路2编写:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<time.h>
#include<stdlib.h>// 创建N个随机数,写到文件中
void CreateNDate()
{// 创造一千万个数据int n = 10000000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}//将生成的一千万个数据写进“data.txt”for (int i = 0; i < n; ++i){int x = rand() + i;fprintf(fin, "%d\n", x);}fclose(fin);
}//作为qsort()函数的比较回调函数,用于控制qsort是排升序还是降序
int compare(const void* a, const void* b)
{return (*(int*)a - *(int*)b);
}//函数功能:从一个输入文件读取整数数据,将它们排序后写入另一个文件
//函数参数:FILE* fout:输入文件指针(从这里读取数据)
// const char* file1:输出文件名(排序后的数据将写入此文件)
// 函数返回值:返回实际读到的数据个数,没有数据了,返回0
int ReadNDataSortToFile(FILE* fout, int n, const char* file1)
{int x = 0;//用于在内存中存放文件中的数据int* a = (int*)malloc(sizeof(int) * n);if (a == NULL){perror("malloc error");return 0;}// 想读取n个数据,如果遇到文件结束(最后读取的个数不满n个),应该读到j个int j = 0;for (int i = 0; i < n; i++){//将文件数据读取到内存,并在内存申请的空间中进行排序if (fscanf(fout, "%d", &x) == EOF)break;a[j++] = x;}if (j == 0){free(a);return 0;}// 对内存中的数据进行排序,利用C语言内置qsort函数qsort(a, j, sizeof(int), compare);FILE* fin = fopen(file1, "w");if (fin == NULL){free(a);perror("fopen error");return 0;}// 写回file1文件for (int i = 0; i < j; i++){fprintf(fin, "%d\n", a[i]);}free(a);fclose(fin);return j;
}//对文件进行排序归并,将file1和file2归并到mfile中
void MergeFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (fout1 == NULL){perror("fopen error");return;}FILE* fout2 = fopen(file2, "r");if (fout2 == NULL){perror("fopen error");return;}FILE* mfin = fopen(mfile, "w");if (mfin == NULL){perror("fopen error");return;}// 归并逻辑int x1 = 0;int x2 = 0;//从两个文件中不断读取数据int ret1 = fscanf(fout1, "%d", &x1);int ret2 = fscanf(fout2, "%d", &x2);//当两个文件中有一个文件遇到文件末尾则跳出循环while (ret1 != EOF && ret2 != EOF){if (x1 < x2){fprintf(mfin, "%d\n", x1);ret1 = fscanf(fout1, "%d", &x1);}else{fprintf(mfin, "%d\n", x2);ret2 = fscanf(fout2, "%d", &x2);}}//文件2遇到文件末尾while (ret1 != EOF){fprintf(mfin, "%d\n", x1);ret1 = fscanf(fout1, "%d", &x1);}//文件1遇到文件末尾while (ret2 != EOF){fprintf(mfin, "%d\n", x2);ret2 = fscanf(fout2, "%d", &x2);}fclose(fout1);fclose(fout2);fclose(mfin);
}int main()
{//创造待排数据CreateNDate();//设置const char* file1 = "file1.txt";const char* file2 = "file2.txt";const char* mfile = "mfile.txt";//"data.txt"用于存储创造了一千万个数据FILE* fout = fopen("data.txt", "r");if (fout == NULL){perror("fopen error");return;}//从data.txt中分别读取一百万个数据放进file1和file2中int m = 1000000;ReadNDataSortToFile(fout, m, file1);ReadNDataSortToFile(fout, m, file2);//开始循环归并文件while (1){//将file1和file2归并到mfile中MergeFile(file1, file2, mfile);// 删除file1和file2remove(file1);remove(file2);// 重命名mfile为file1,将mfile当做新的file1继续循环rename(mfile, file1);// 当再去读取数据,一个都读不到,说明已经没有数据了,说明已经归并完成,归并结果在file1int n = 0;//此语句的功能1:从原始数据文件data.txt中读取新的数据块创建新的file2,继续与新的file1归并//此语句的功能2:用来检测是否已经到data.txt的数据末尾,看是否需要结束循环if ((n = ReadNDataSortToFile(fout, m, file2)) == 0)break;//调试语句,可以此处打断点观察最后一次不满n个数据时的排序结果/*if (n < 100){int x = 0;}*/}return 0;
}
3.5 非比较排序
3.5.1 计数排序
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
3.5.1.1 图片理解
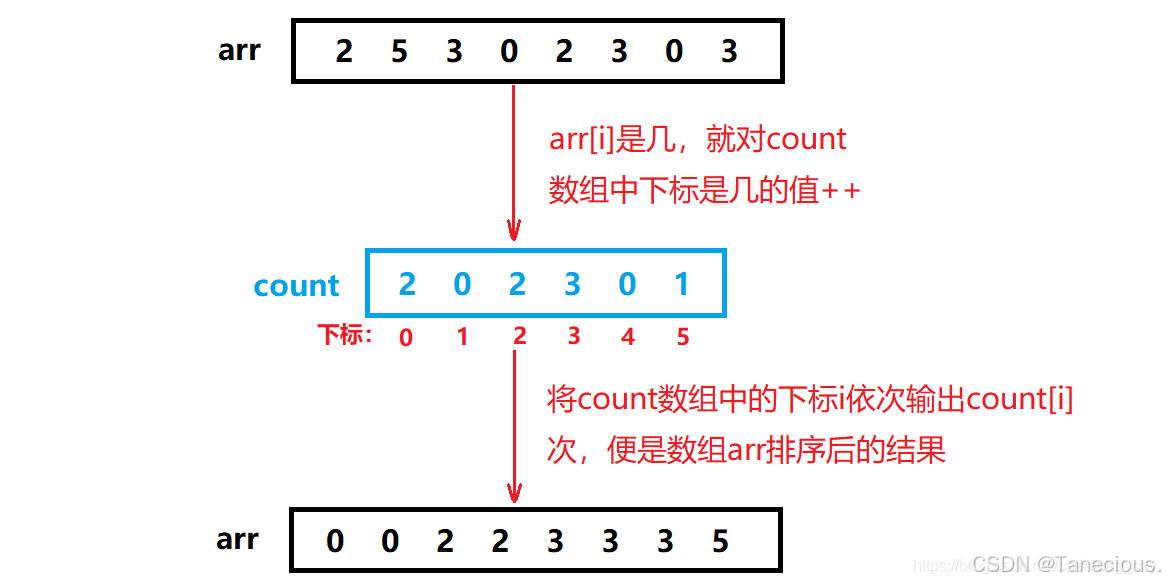
上图这种映射关系是绝对映射,即arr数组中的元素是几就在count数组中下标为几的位置++,但这样会造成空间浪费。例如,要将数组:1020,1021,1018,进行排序,难道需要开辟1022个整型空间吗?
所以在计数排序中,一般使用相对映射。即**数组中的最小值就相对于count数组中的0下标,数组中的最大值就相对于count数组中的最后一个下标。**这样,对于数组:1020,1021,1018,就只需要开辟用于储存4个整型的空间大小了,此时count数组中下标为i的位置记录的实际上是1018+i这个数出现的次数。
综上所述:
- 绝对映射:count数组中下标为i的位置记录的是arr数组中数字i出现的次数。
- 相对映射:count数组中下标为i的位置记录的是arr数组中数字min+i出现的次数。
3.5.1.2 代码示例
//计数排序
void CountSort(int* arr, int n)
{//根据最大值最小值确定数组大小(相对映射)int max = arr[0], min = arr[0];//打擂台,遍历数组确定最大值与最小值for (int i = 1; i < n; i++){if (arr[i] > max){max = arr[i];}if (arr[i] < min){min = arr[i];}}//确定数组大小,并申请对应空间int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail!");exit(1);}//初始化range数组中所有的数据为0memset(count, 0, range * sizeof(int));//统计数组中每个数据出现的次数for (int i = 0; i < n; i++){count[arr[i] - min]++;}//取count中的数据,往arr中放int index = 0;for (int i = 0; i < range; i++){while (count[i]--){arr[index++] = i + min;}}
}
时间复杂度: O ( N + r a n g e ) O(N+range) O(N+range) 空间复杂度: O ( r a n g e ) O(range) O(range)
3.6 测试代码:排序性性能的对比
为了更加直观地显示各个排序的性能和排序速度,下面的代码通过生成十万个随机数,并利用上述排序算法对这个十万个随机数的乱序序列进行排序,并记录下时间,打印在屏幕上。
// 测试排序的性能对⽐
void TestOP()
{ //生成十万个随机数srand(time(0)); const int N = 100000; //开辟承载十万个随机数的数组int* a1 = (int*)malloc(sizeof(int)*N); int* a2 = (int*)malloc(sizeof(int)*N); int* a3 = (int*)malloc(sizeof(int)*N); int* a4 = (int*)malloc(sizeof(int)*N); int* a5 = (int*)malloc(sizeof(int)*N); int* a6 = (int*)malloc(sizeof(int)*N); int* a7 = (int*)malloc(sizeof(int)*N); //将七个数组都变为同样的内容,方便比较for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; a3[i] = a1[i]; a4[i] = a1[i]; a5[i] = a1[i]; a6[i] = a1[i];a7[i] = a1[i]; } //直接插入排序int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); //希尔排序int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); //直接选择排序int begin3 = clock(); SelectSort(a3, N); int end3 = clock(); //堆排序int begin4 = clock(); HeapSort(a4, N); int end4 = clock(); //快速排序int begin5 = clock(); QuickSort(a5, 0, N-1); int end5 = clock(); //归并排序int begin6 = clock(); MergeSort(a6, N); int end6 = clock(); //冒泡排序int begin7 = clock(); BubbleSort(a7, N); int end7 = clock();//显示各个排序算法的时间printf("InsertSort:%d\n", end1 - begin1); printf("ShellSort:%d\n", end2 - begin2); printf("SelectSort:%d\n", end3 - begin3); printf("HeapSort:%d\n", end4 - begin4); printf("QuickSort:%d\n", end5 - begin5); printf("MergeSort:%d\n", end6 - begin6); printf("BubbleSort:%d\n", end7 - begin7); //释放申请的空间free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); free(a7);
}
4. 排序算法复杂度及稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O ( n 2 ) O(n²) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n²) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 直接选择排序 | O ( n 2 ) O(n²) O(n2) | O ( n 2 ) O(n²) O(n2) | O ( n 2 ) O(n²) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 直接插入排序 | O ( n 2 ) O(n²) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n²) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 希尔排序 | O ( n l o g n ) ∼ O ( n 2 ) O(n log n) \sim O(n²) O(nlogn)∼O(n2) | O ( n l o g n ) ∼ O ( n 2 ) O(n log n) \sim O(n²) O(nlogn)∼O(n2) | O ( n 2 ) O(n²) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 堆排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( 1 ) O(1) O(1) | 不稳定 |
| 归并排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n ) O(n) O(n) | 稳定 |
| 快速排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n 2 ) O(n²) O(n2) | O ( l o g n ) ∼ O ( n ) O(log n) \sim O(n) O(logn)∼O(n) | 不稳定 |
本文中有多个插图取自前辈2021dragon和爱写代码的捣蛋鬼
感谢前辈的知识分享,能让我们这些后来者可以站在巨人的肩膀上不断向前!!感谢阅读!!
相关文章:
)
初阶数据结构--排序算法(全解析!!!)
排序 1. 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些些关键字的大小,递增或递减的排列起来的操作。 2. 常见的排序算法 3. 实现常见的排序算法 以下排序算法均是以排升序为示例。 3.1 插入排序 基本思想:…...

SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...

加油站小程序实战教程14会员充值页面搭建
目录 1 原型2 搭建充值金额选择功能3 搭建金额输入4 搭建支付方式5 充值按钮最终的效果 上一篇我们介绍了充值规则的后台功能,有了基础的规则,在会员充值页面就可以显示具体的充值规则。本篇我们介绍一下会员充值的开发过程。 1 原型 充值页面我们是分为…...

内卷的中国智驾,合资品牌如何弯道超车?
作者 |德新 编辑 |王博 上海车展前夕,一汽丰田举办重磅车型bZ5的技术发布会,脱口秀演员庞博透露了这款车型的一大重要特性,其搭载来自Momenta的智能辅助驾驶系统行驶里程已经超过20亿公里。 携手中国科技公司提高车型智能化的属性ÿ…...

【go】go run-gcflags常用参数归纳,go逃逸分析执行语句,go返回局部变量指针是安全的
go官方参考文档: https://pkg.go.dev/cmd/compile 基本语法 go run 命令用来编译并运行Go程序,-gcflags 后面可以跟一系列的编译选项,多个选项之间用空格分隔。基本语法如下: go run -gcflags "<flags>" main.…...
)
数据库11(触发器)
触发器有三种类型,包括删除触发器,更新触发器,添加触发器 触发器的作用是:当某个表发生某个操作时,自动触发触发器,进行触发器规定的操作 触发器语句 create trigger tname --创建触发器 on aa --创建在表…...

十大物联网平台-物联网十大品牌
物联网十大品牌及平台解析 物联网(IoT)作为当下极具影响力的技术,正逐步渗透至社会各领域,为人们生活与社会发展带来诸多便利与变革。如今,众多企业投身于物联网行业,致力于推动其发展。以下是对物联网相关…...

心智模式VS系统思考
很多人常说,“改变自己,从改变思维开始。”但事实上,打破一个人的心智模式,远比想象中要困难得多。我们的思维方式、行为习惯,甚至是对世界的认知,往往是多年积累下来的产物。那些曾经的经历、长期的学习与…...

QT 打包安装程序【windeployqt.exe】报错c000007d原因:Conda巨坑
一、命令行执行命令 E:\Project\GNCGC\Bin\Win32\Vc22\RS422地检>E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe CGC170.exe二、安装了Conda的朋友,巨坑 无语,E:\SoftWare\Qt\5.14.2\msvc2017\bin\windeployqt.exe 优先把Conda环境关联的Qt动…...

Vue3祖先后代组件数据双向同步实现方法
在 Vue3 中实现祖先后代组件的双向数据同步,可以通过组合式 API 的 provide/inject 配合响应式数据实现。以下是两种常见实现方案: 方案一:共享响应式对象 方法 html <!-- 祖先组件 --> <script setup> import { ref, provide…...

OpenBayes 一周速览|EasyControl 高效控制 DiT 架构,助力吉卜力风图像一键生成;TripoSG 单图秒变高保真 3D 模型
公共资源速递 10 个教程: * 一键部署 R1-OneVision * UNO:通用定制化图像生成 * TripoSG:单图秒变高保真 3D * 使用 VASP 进行机器学习力场训练 * InfiniteYou 高保真图像生成 Demo * VenusFactory 蛋白质工程设计平台 * Qwen2.5-0mni…...

服务器-conda下载速度慢-国内源
文章目录 前言一、解决问题:使用国内conda镜像下载(差)二、解决问题:使用pip下载(优)总结 前言 conda频道中有无效频道导致下载失败 一、解决问题:使用国内conda镜像下载(差) 步骤 1ÿ…...

python的pip download命令-2
当然可以,下面我详细解释一下 pip download 的作用、用法和技术原理。 🧠 一句话总结: pip download 是 pip 提供的一个命令,用来下载 Python 包及其依赖项的安装文件,但不会安装。 🔍 和 pip install 的区别: 命令作用是否安装是否联网典型用途pip install安装指定包…...

【Java设计模式及实践学习-第4章节-结构型模式】
第4章节-结构型模式 笔记记录 1. 适配器模式2. 代理模式3. 装饰器模式4. 桥接模式5. 组合模式6. 外观模式7. 享元模式8. 总结 1. 适配器模式 2. 代理模式 3. 装饰器模式 4. 桥接模式 5. 组合模式 6. 外观模式 7. 享元模式 Java语言中的String字符串就使用了享元模式&…...

python:mido 提取 midi文件中某一音轨的音乐数据
pip install mido 使用 mido库可以方便地处理 MIDI 文件,提取其中音轨的音乐数据。 1.下面的程序会读取指定的 MIDI 文件,并提取指定编号音轨的音乐数据,主要包括音符事件等信息。 编写 mido_extract.py 如下 # -*- coding: utf-8 -*- &…...

将输入帧上下文打包到下一个帧的预测模型中用于视频生成
Paper Title: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation 论文发布于2025年4月17日 Abstract部分 在这篇论文中,FramePack是一种新提出的网络结构,旨在解决视频生成中的两个主要问题:遗忘和漂移。 具体来说,遗忘指的是在生成视…...

第六章:Multi-Backend Configuration
Chapter 6: Multi-Backend Configuration 从交响乐团到变形金刚:如何让代理适应不同环境? 在上一章任务工作流编排,我们学会了如何像指挥家一样协调任务。但就像变形金刚能切换不同形态应对环境变化一样,你的AI代理也需要能灵活切…...

tomcat远程Debug
tomcat远程Debug -- /bin目录下 catalina.bat文件下加一行 SET CATALINA_OPTS-server -Xdebug -Xnoagent -Djava.compilerNONE -Xrunjdwp:transportdt_socket,servery,suspendn,address8088idea端配置如下...
)
Vue3:component(组件:uniapp版本)
目录 一、基本概述二、基本使用三、插槽 一、基本概述 在项目的开发过程中,页面上井场会出现一些通用的内容,例如头部的导航栏,如果我们每一个页面都去写一遍,那实在是太繁琐了,所以,我们使用组件来解决这…...
:8大容器类型)
rust编程学习(三):8大容器类型
1简介 rust标准库std::collections也提供了像C STL库中的容器,分为4种通用的容器,8种类型,如下表所示。 线性容器类型: 名称简介Vec<T>内存空间连续,可变长度的数组,类似于C中Vector<T>容器…...

前端中阻止事件冒泡的几种方法
在 JavaScript 前端开发中,阻止事件冒泡是处理 DOM 事件时的常见需求。以下是几种阻止事件冒泡的方法: 1. 使用 event.stopPropagation() 这是最常用的阻止事件冒泡的方法。 element.addEventListener(click, function(event) {event.stopPropagation…...
)
ShenNiusModularity项目源码学习(20:ShenNius.Admin.Mvc项目分析-5)
ShenNiusModularity项目的系统管理模块主要用于配置系统的用户、角色、权限、基础数据等信息,上篇文章中学习的日志列表页面相对独立,而后面几个页面之间存在依赖关系,如角色页面依赖菜单页面定义菜单列表以便配置角色的权限,用户…...

前端js需要连接后端c#的wss服务
背景 前端js需要连接后端wss服务 前端:js 后端:c# - 控制台搭建wss服务器 步骤1 wss需要ssl认证,所以需要个证书,随便找一台linux的服务器(windows的话,自己安装下openssl即可),…...

MAGI-1自回归式大规模视频生成
1. 关于 MAGI-1 提出 MAGI-1——一种世界模型(world model),通过自回归方式预测一系列视频块(chunk,固定长度的连续帧片段)来生成视频。 模型被训练为在时间维度上单调递增噪声的条件下对每个块进行去噪&a…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容一):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 TCP网络模型OSI参考模型TCP/IP五层模型 TCP状态TIME_WAIT 连接过程TCP三次握手TCP四次挥手 TCP优化TCP三次握手优化TCP四次挥手优化TCP数据传输优化 TCP TCP是面向连接的、可靠的、基于字节流的传输层通信协议: 面向连接:一定是一对一才能连接…...

基于deepseek的模型微调
使用 DeepSeek 模型(如 DeepSeek-VL、DeepSeek-Coder、DeepSeek-LLM)进行微调,可以分为几个关键步骤,下面以 DeepSeek-LLM 为例说明,适用于 Q&A、RAG、聊天机器人等方向的应用。 一、准备工作 1. 环境依赖 建议使用 transformers + accelerate 或 LoRA 等轻量微调方…...
)
node.js 实战——(path模块 知识点学习)
path 模块 提供了操作路径的功能 说明path. resolve拼接规范的绝对路径path. sep获取操作系统的路径分隔符path. parse解析路径并返回对象path. basename获取路径的基础名称path. dirname获取路径的目录名path. extname获得路径的扩展名 resolve 拼接规范的绝对路径 const…...

【k8s】docker、k8s、虚拟机的区别以及使用场景
一、Docker (一)概念 Docker 是一个开源的应用容器引擎,允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可实现虚拟化。 (二)隔离性 Docker 的隔离…...
)
校园外卖服务系统的设计与实现(代码+数据库+LW)
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,外卖信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...

Windows上使用Python 3.10结合Appium-实现APP自动化
一、准备工作 所需条件: Windows 10/11 操作系统 Python 3.10.x(建议3.10.9) Java JDK 8 或以上(建议JDK 8u301) Node.js 14.x 或以上(建议14.21.3) Appium Server 1.22.x 或以上(建…...

【计算机视觉】CV项目实战- SiamMask 单阶段分割跟踪器
SiamMask 单阶段分割跟踪器 一、项目概述与技术原理1.1 核心技术创新1.2 性能优势 二、实战环境搭建2.1 系统要求与依赖安装2.2 项目编译与配置 三、模型推理实战3.1 快速体验Demo3.2 常见运行时错误处理 四、模型训练指南4.1 数据准备流程4.2 训练执行与监控 五、高级应用与优…...

计算机视觉基础
1. 数字图像的基本概念 像素(Pixel):图像的最小构成单元,每个像素存储亮度或颜色信息。 灰度图像:每个像素是 0(黑)~255(白) 的标量值(8位无符号整数&#x…...

系统编程_进程间通信机制_消息队列与共享内存
消息队列概述 消息有类型:每条消息都有一个类型,就像每封信都有一个标签,方便分类和查找。消息有格式:消息的内容有固定的格式,就像每封信都有固定的信纸格式。随机查询:你可以按类型读取消息,…...

一种免费的离线ocr-汉字识别率100%
一般我们手机中常用的ocr库有,Tesseract,paddle ocr,EasyOCR, ocrLite等等,这些ocr库中百度的paddle ocr效果最好,但是再好的效果也会偶尔识别错几个汉字。当我们在做自动化脚本过程中,如果识别…...
)
Maven 工程中的pom.xml 文件(图文)
基本信息 单工程项目【pom.xml文件】中最基本的信息。 依赖引入 可以在Maven 中央仓库查找所需依赖:【直达:https://mvnrepository.com/】。 在【dependencies】标签中添加所需依赖。 <dependency><groupId>com.baomidou</groupId&g…...

图像预处理-模板匹配
就是用模板图在目标图像中不断的滑动比较,通过某种比较方法来判断是否匹配成功,找到模板图所在的位置。 - 不会有边缘填充。 - 类似于卷积,滑动比较,挨个比较象素。 - 返回结果res大小是:目标图大小-模板图大小1(H-…...

操作系统学习笔记
2.4 死锁 在学习本节时,请读者思考以下问题: 1)为什么会产生死锁?产生死锁有什么条件? 2)有什么办法可以解决死锁问题? 学完本节,读者应了解死锁的由来、产…...

5.4.云原生与服务网格
目录 1. Kubernetes与微服务集成 1.1 容器化部署规范 • 多环境配置管理(ConfigMap与Nacos联动) • 健康检查探针配置(Liveness/Readiness定制策略) 1.2 弹性服务治理 • HPA自动扩缩容规则设计 • Sentinel指标驱动弹性伸缩 2…...

[特殊字符][特殊字符]Linux驱动开发入门 | 并发与互斥机制详解
文章目录 👨💻Linux驱动开发入门 | 并发与互斥机制详解📌为什么驱动中需要并发和互斥控制?💡常见的并发控制机制🔐自旋锁和信号量通俗理解🌀自旋锁(Spinlock)——“厕所…...

时序数据库IoTDB自研的Timer模型介绍
一、引言 时序数据库在支持时序特性写入、存储、查询等功能的基础上,正逐步向深度分析领域迈进。自动化异常监测与智能化趋势预测已成为时序数据管理的核心需求。为了满足这些需求,时序数据库IoTDB团队积极探索,成功自研推出了面向时间序列的…...
)
RabbitMQ 详解(核心概念)
本文是博主在梳理 RabbitMQ 知识的过程中,将所遇到和可能会遇到的基础知识记录下来,用作梳理 RabbitMQ 的整体架构和功能的线索文章,通过查找对应的知识能够快速的了解对应的知识而解决相应的问题。 文章目录 一、RabbitMQ 是什么?…...

【数据结构和算法】6. 哈希表
本文根据 数据结构和算法入门 视频记录 文章目录 1. 哈希表的概念1.1 哈希表的实现方式1.2 哈希函数(Hash Function)1.3 哈希表支持的操作 2. Java实现 在前几章的学习中,我们已经了解了数组和链表的基本特性,不管是数组还是链表…...

RHCE第三次作业 搭建dns的正向解析服务器
server为服务器 client为客户端 设置主配置文件 在server下: [rootServer ~]#vim /etc/named.conf #进入到配置页面,并修改 设置区域文件 [rootServer ~]# vim /etc/named.rfc1912.zones 设置域名解析文件 [rootServer named]# cd /var/named…...
问题?)
【每天一个知识点】如何解决大模型幻觉(hallucination)问题?
解决大模型幻觉(hallucination)问题,需要从模型架构、训练方式、推理机制和后处理策略多方面协同优化。 🧠 1. 引入 RAG 框架(Retrieval-Augmented Generation) 思路: 模型生成前先检索知识库中…...

Python深拷贝与浅拷贝:避开对象复制的陷阱
目录 一、为什么需要区分深浅拷贝? 二、内存中的对象真相 三、浅拷贝的真相 四、深拷贝的奥秘 五、自定义对象的拷贝 六、性能对比实验 七、常见陷阱与解决方案 八、最佳实践指南 九、现代Python的拷贝优化 结语 一、为什么需要区分深浅拷贝? …...

批量处理多个 Word 文档:插入和修改页眉页脚,添加页码的方法
Word 页眉页脚的设置在日常工作中非常常见,尤其是需要统一格式的文档,如毕业论文、公司内部资料等。在这些文档中,页眉页脚通常包含时间、公司标志、文档标题、文件名或作者姓名等信息。有时,我们不仅需要简单的文字页眉页脚&…...
的Prompt Engineering:从入门到精通)
大语言模型(LLM)的Prompt Engineering:从入门到精通
大语言模型(LLM)的Prompt Engineering:从入门到精通 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 引言:Prompt Engineering——解锁AI生产力的金钥匙 当ChatGPT在2023年引爆…...

poi生成横向文档以及复杂表头
代码: //创建页面并且创建横向A4XWPFDocument doc new XWPFDocument();CTDocument1 document doc.getDocument();CTBody body document.getBody();if (!body.isSetSectPr()) {body.addNewSectPr();}CTSectPr section body.getSectPr();if (!section.isSetPgSz()) {section.…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容二):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 常见问题TCP和UDPISNUDPTCP数据可靠性TCP协议如何提高传输效率TCP如何处理拥塞 SocketTCP源码tcp_v4_connect()sys_accept()tcp_accept()三次握手客户端发送SYN段服务端发送SYN和ACK处理客户端回复确认ACK段服务端收到ACK段 常见问题 TCP和UDP TCP和UDP的区别&#…...

流程架构是什么?为什么要构建流程架构,以及如何构建流程结构?
本文从:流程架构是什么?为什么要构建流程架构?如何构建流程结构三个方面来介绍。 一、首先,我们来了解流程架构是什么? 流程架构是人体的骨架,是大楼的砌筑,是课本的目录,是流程管理…...