rust编程学习(三):8大容器类型
1简介
rust标准库std::collections也提供了像C++ STL库中的容器,分为4种通用的容器,8种类型,如下表所示。
线性容器类型:
| 名称 | 简介 |
|---|---|
| Vec<T> | 内存空间连续,可变长度的数组,类似于C++中Vector<T>容器 |
| VecDeque<T> | 内存空间连续,可变长度的双端队列,类似于C++中Deque<T>容器 |
| LinkedList<T> | 内存空间不连续,双向链表,类似于C++中的list<T> |
key-value 键-值对存储
| 名称 | 简介 |
|---|---|
| HashMap<K,V> | 基于哈希表的无序键-值对,类似于C++ STL中unordered_map<K,V> |
| BTreeMap<K,V> | 基于B树的有序键-值对,类似于C++ STL中map<K,V>,不过map是基于红黑色的实现的 |
集合
| 名称 | 简介 |
|---|---|
| HashSet<T> | 基于哈希表实现的无序集合,类似于C++ STL中的set<T> |
| BTreeMap<T> | 基于B数的有序集合,类似于C++ STL中的unordered_set<T> |
优先队列
| 名称 | 简介 |
|---|---|
| BinaryHeap<T> | 基于二叉堆的优先队列,类似于C++ STL中的priority_queue<T> |
2. Vec使用方式
Vec是一种动态可变长数组(简称动态数组),即在运行时可增长或者缩短数组的长度。动态数组在内存中开辟了一段连续内存块用于存储元素,且只能存储相同类型的元素。新加入的元素每次都会被添加到动态数组的尾部。动态数组根据添加顺序将数据存储为元素序列。序列中每个元素都分配有唯一的索引,元素的索引从0开始计数。
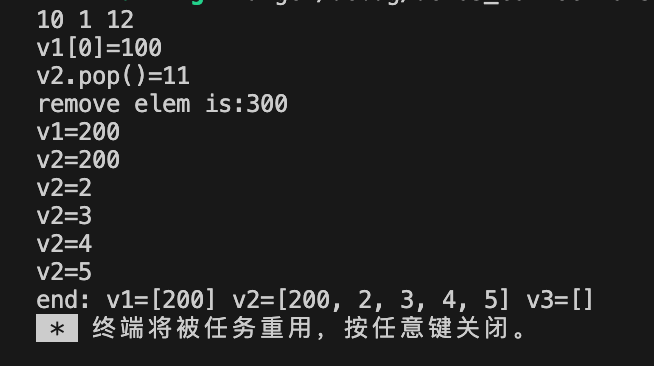
下面例子给出常用的10种使用vec的方式,使用示例如下:
fn main() {//1.使用Vec::new()方式创建let mut v1:Vec<i32> = Vec::new(); // 2.使用vec!宏创建,创建动态数组的同时进行初始化let mut v2:Vec<i32> = vec![1,2,3,4,5];// 3.使用Vec::with_capacity函数创建指定容量的动态数组let mut v3:Vec<i32> = Vec::with_capacity(1024);//4.使用push方法向动态数组中添加元素v1.push(10);v2.push(11);v3.push(12);//5. 使用[]访问动态数组中的元素println!("{} {} {}", v1[0], v2[0], v3[0]);//5.1修改动态数组中的元素v1[0] = 100;v2[0] = 200;v3[0] = 300;//6.使用get方法访问动态数组中的元素//这种方式可以避免下标索引越界,get()返回的是Option枚举,所以使用match进行匹配解构match v1.get(0) {Some(v) => println!("v1[0]={}", v),None => println!("v1[0] is None"),};//7.使用pop()删除最后一个元素,并返回最后一个元素match v2.pop() {Some(val)=>println!("v2.pop()={}", val),None=>println!("v2 is empty"),} //8.使用remove()删除指定索引的元素,并返回被删除的元素let ret = v3.remove(0);println!("remove elem is:{}", ret);//9.使用iter_mut() 迭代器方法遍历并修改动态数组中的元素for i in v1.iter_mut() {*i += 100;println!("v1={}", i);}//10.使用iter() 迭代器方法遍历动态数组中的元素for i in v2.iter() { //这个方法是不能修改元素的println!("v2={}", i);}println!("end: v1={:?} v2={:?} v3={:?}", v1, v2, v3);
}输出内容:
3.VecDeque使用方式
双端队列是一种同时具有栈(先进后出)和队列(先进先出)特征的数据结构,适用于只能在队列两端进行添加或删除元素操作的应用场景。使用VecDeque结构体之前需要显式导入std::collections::VecDeque。
在步骤7中使用remove删除元素,我们这里使用了一种新的语法,if let进行匹配函数返回的枚举类型,它的作用和match类似,但是它只匹配其中某个枚举类型,在某些我们只关注某个枚举类型时候简化语法。使用示例如下:
use std::collections::VecDeque;
fn main() {//1. 使用VecDeque::new创建方式let mut vd1:VecDeque<u32> = VecDeque::new();//2.使用数组进行创建并初始化,10个元素,值为0let mut vd2:VecDeque<u32> = VecDeque::from([0;10]);//3.使用vec!进行初始化let mut vd3:VecDeque<u32> = VecDeque::from(vec![1,2,3,4,5]); //4.使用VecDeque::with_capacity创建指定容量的VecDequelet mut vd4:VecDeque<u32> = VecDeque::with_capacity(1024);//5.添加元素vd1.push_back(101); //从尾部添加元素vd1.push_front(102); //从头部添加元素//6.索引 修改元素vd2[0] = 100;match vd2.get(0){ //get(index)返回Option枚举,需要match解构Some(val) => println!("vd2[0]={}", val),None => println!("vd2[0] is None"),}//7.删除元素match vd3.pop_back(){ //从尾部删除元素 返回Option需要match解构Some(val) => println!("pop_back() elem={}", val),None => println!("vd3 is empty!!!"),}match vd3.pop_front() { //从头部删除元素 返回Option需要match解构Some(val) => println!("pop_front() elem={}", val),None => println!("vd3 is empty!!!"),}if let Some(val) = vd3.remove(2){ //remove(index)删除指定索引的元素println!("remove index 2 elem={}", val);//这里使用的if let语法,remove结果返回Option枚举,//如果枚举是Some(val),就进入if let块,如果枚举是None,就进入else块或不处理//if let语法和match语法的区别,match语法是匹配所有枚举类型,if let语法是匹配某一种枚举类型//if let语法可以用在返回值是枚举的函数中,简化代码编写}println!("vd1={:?} vd2={:?} vd3={:?} vd4={:?}", vd1, vd2, vd3, vd4);}输出内容:

4. LinkedList使用方式
链表(LinkedList) 是一种动态数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针(单链表)或指向前一个和下一个节点的指针(双链表)。
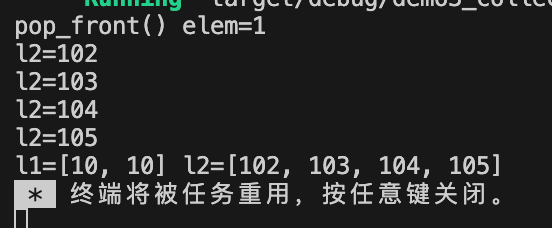
使用示例:
use std::collections::LinkedList;
fn main() {//1.使用LinkedList::new创建方式let mut l1:LinkedList<u32> = LinkedList::new();//2.使用数组进行初始化let mut l2:LinkedList<u32> = LinkedList::from([1,2,3,4,5]);//3. 添加元素l1.push_front(10); //从头部添加元素l1.push_back(10); //从尾部添加元素//4.删除元素match l2.pop_front(){ //从头部删除元素Some(val) => println!("pop_front() elem={}", val),None => println!("l2 is empty!!!"),}//5.遍历 修改元素for i in l2.iter_mut() {*i += 100;println!("l2={}", i);}println!("l1={:?} l2={:?}", l1, l2);
}
输出信息:
5.HashMap使用方式
哈希表(HashMap)是基于哈希算法来存储键-值对的集合,其中所有的键必须是同一类型,所有的值也必须是同一类型,不允许有重复的键,但允许不同的键有相同的值。使用HashMap结构体之前需要显式导入std::collections::HashMap。
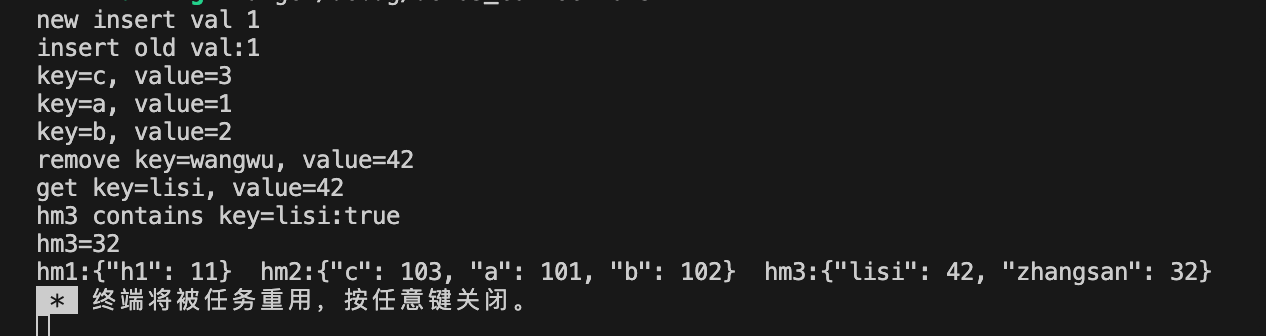
使用示例:
fn main() {//1.使用HashMap::new函数创建空的HashMaplet mut hm1:HashMap<&str, i32> = HashMap::new();//2.使用HashMap::from函数创建HashMap 使用数组进行初始化let mut hm2:HashMap<&str, i32> = HashMap::from([("a", 1), ("b", 2), ("c", 3)]);//3.使用HashMap::with_capacity函数创建指定容量的HashMaplet mut hm3:HashMap<&str, i32> = HashMap::with_capacity(1024);//4.添加元素、修改元素//使用insert方法在HashMap中插入或更新键-值对。//如果键不存在,执行插入操作并返回None。//如果键已存在,执行更新操作,将对应键的值更新并返回旧值。if let None = hm1.insert("h1", 1){ //如果返回None,说明插入成功println!("new insert val 1");}if let Some(old) = hm1.insert("h1", 11){ //如果返回旧值,说明更新成功println!("insert old val:{}", old);}//5.使用entry和or_insert方法检查键是否有对应值,//没有对应值就插入键-值对,已有对应值则不执行任何操作。hm3.entry("zhangsan").or_insert(32);hm3.entry("lisi").or_insert(42);hm3.entry("wangwu").or_insert(42);//6.使用iter()方法遍历HashMapfor (key, value) in hm2.iter_mut() {println!("key={}, value={}", key, value);*value += 100;}//7.使用remove方法删除并返回指定的键-值对,如果不存在就返回Noneif let Some(v) = hm3.remove("wangwu"){println!("remove key=wangwu, value={}", v);}//8.使用get方法获取指定键对应的值,如果不存在就返回Noneif let Some(v) = hm3.get("lisi"){println!("get key=lisi, value={}", v);}//9.使用contains_key方法检查HashMap中是否存在指定的键,返回布尔值println!("hm3 contains key=lisi:{}", hm3.contains_key("lisi"));//10.使用【】进行索引xuanprintln!("hm3={}", hm3["zhangsan"]);println!("hm1:{:?} hm2:{:?} hm3:{:?}", hm1, hm2, hm3);}输出结果:
6.BTreeMap使用方法
-
使用BTreeMap存储的KV键值对,Key存储是有序的,除了像HashMap一样插入、删除、修改外,还支持range遍历,即范围遍历查找。
-
这是因为BTreeMap基于B树实现的,底层数据结构是一个自平衡的b树,确保有效的插入、删除和查找,键按排序顺序存储和访问,支持高效的范围查询和有序迭代。
-
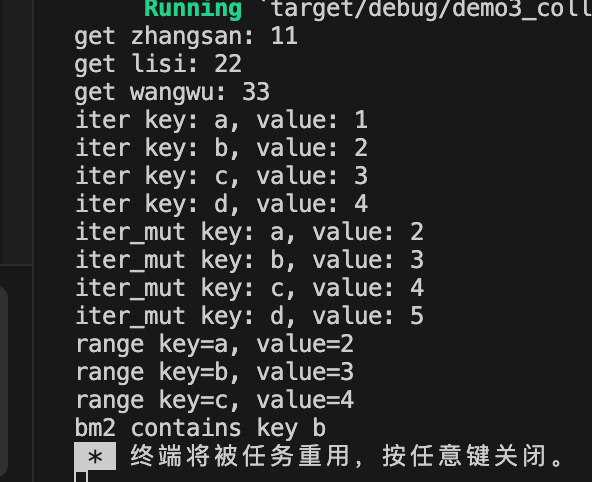
使用示例:
use std::collections::BTreeMap;
fn main() {//1.使用BTreeMap::new函数创建空的BTreeMaplet mut bm1:BTreeMap<&str, i32> = BTreeMap::new();//2.使用BTreeMap::from函数创建BTreeMap 使用数组进行初始化let mut bm2:BTreeMap<&str, i32> = BTreeMap::from([("a", 1), ("d", 4),("b", 2), ("c", 3)]);//3.插入元素bm1.insert("zhangsan", 11);bm1.insert("lisi", 22);bm1.insert("wangwu", 33);//4.获取元素println!("get zhangsan: {}", bm1.get("zhangsan").unwrap());println!("get lisi: {}", bm1.get("lisi").unwrap());println!("get wangwu: {}", bm1["wangwu"]);//5.遍历元素//5.1 迭代器遍历for (key, value) in bm2.iter() {println!("iter key: {}, value: {}", key, value);}//5.2 迭代器可变引用遍历for (key, val) in bm2.iter_mut() {*val += 1;println!("iter_mut key: {}, value: {}", key, val);}//5.3 迭代器范围遍历 遍历key的范围["a" 到 “c”]for (key, value) in bm2.range("a"..="c") {println!("range key={}, value={}", key, value);}//6.删除元素bm2.remove("a");//7.检查键是否存在if bm2.contains_key("b") {println!("bm2 contains key b");}else{println!("bm2 not contains key b");}
}
输出信息:
7.HashSet使用方法
HashSet是基于HashMap实现的,即Key和Value的值都是一样的(实际上在Rust实现没有为Value分配空间),HashSet是一个集合,存放一组同一类型的数据,可以实现并集、交集、差集操作。
使用例子:
use std::collections::HashSet;
fn main() {//1.使用HashSet::new()创建一个空的HashSetlet mut s1:HashSet<i32> = HashSet::new();//2.使用HashSet::from()创建一个HashSet,使用数组进行初始化let mut s2:HashSet<i32> = HashSet::from([1,2,3,4,5]);//3.使用 vec! 宏和 into_iter 创建集合let mut s3:HashSet<i32> = vec![2,3,4,9,8,7,6,5].into_iter().collect();//4.使用HashSet::insert()插入数据s1.insert(4);s1.insert(6);s1.insert(7);//5.使用HashSet::remove()删除数据s2.remove(&5);//&代表 引用//6.使用take()方法获取并删除集合中的第一个元素if let Some(v) = s3.take(&9){println!("take 9:{}", v);}//7.使用HashSet::contains()检查集合中是否包含某个元素if s3.contains(&6) {println!("s3 contains 6");}//8.遍历元素for val in s1.iter() {println!("s1:{}", val);}// let v:Vec<i32> = s1.into_iter().collect();//9.集合操作//9.1 并集let ss1: HashSet<i32> = s1.union(&s2).cloned().collect();println!("s1={:?} s2={:?} s1与s2并集={:?}", s1, s2, ss1);//9.2 交集let ss2:HashSet<i32> = s2.intersection(&s3).cloned().collect();println!("s2={:?} s3={:?} s1与s2交集={:?}", s2, s3, ss2);//9.3 差集let ss3:HashSet<i32> = s3.difference(&s1).cloned().collect();println!("s3={:?} s1={:?} s3与s1差集={:?}", s3, s1, ss3);}输出信息:
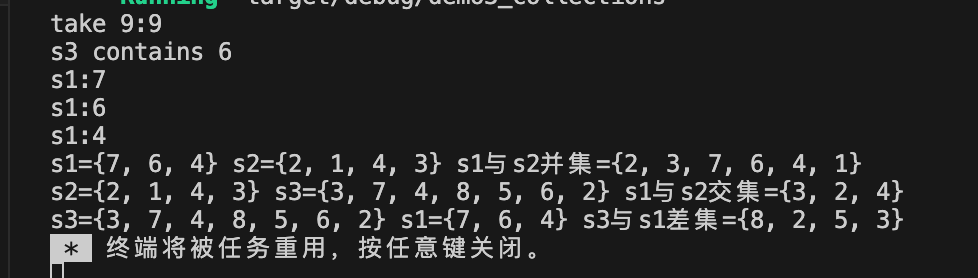
8.BTreeSet使用方法
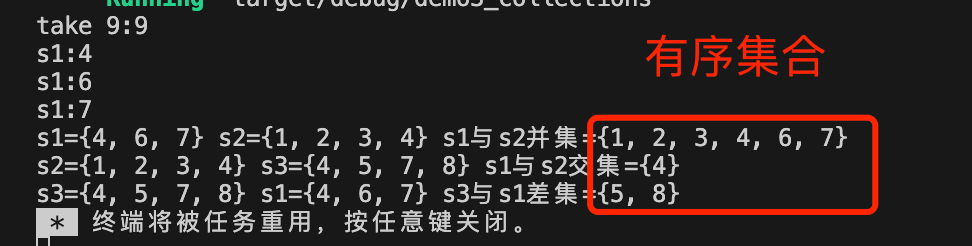
BTreeSet是基于BTreeMap实现的,即Key和Value的值都是一样的(实际上在Rust实现没有为Value分配空间),BTreeSet是一个集合,存放一组同一类型的数据,可以实现并集、交集、差集操作。与HashSet不同的是BTreeSet是有序集合,大家可以观察示例输出的信息验证。
使用示例:
use std::collections::BTreeSet;
fn main() {//1.使用BTreeSet::new()创建一个空的BTreeSetlet mut s1:BTreeSet<i32> = BTreeSet::new();//2.使用BTreeSet::from()创建一个BTreeSet,使用数组进行初始化let mut s2:BTreeSet<i32> = BTreeSet::from([1,2,3,4,5]);//3.使用 vec! 宏和 into_iter 创建集合let mut s3:BTreeSet<i32> = vec![8,5,4,9,8,7].into_iter().collect();//4.使用BTreeSet::insert()插入数据s1.insert(4);s1.insert(6);s1.insert(7);//5.使用BTreeSet::remove()删除数据s2.remove(&5);//&代表 引用//6.使用take()方法获取并删除集合中的第一个元素if let Some(v) = s3.take(&9){println!("take 9:{}", v);}//7.使用HashSet::contains()检查集合中是否包含某个元素if s3.contains(&6) {println!("s3 contains 6");}//8.遍历元素for val in s1.iter() {println!("s1:{}", val);}// let v:Vec<i32> = s1.into_iter().collect();//9.集合操作//9.1 并集let ss1: BTreeSet<i32> = s1.union(&s2).cloned().collect();println!("s1={:?} s2={:?} s1与s2并集={:?}", s1, s2, ss1);//9.2 交集let ss2:BTreeSet<i32> = s2.intersection(&s3).cloned().collect();println!("s2={:?} s3={:?} s1与s2交集={:?}", s2, s3, ss2);//9.3 差集let ss3:BTreeSet<i32> = s3.difference(&s1).cloned().collect();println!("s3={:?} s1={:?} s3与s1差集={:?}", s3, s1, ss3);}输出信息:
9.BinaryHeap使用方法
BinaryHeap 是 Rust 标准库中的一个数据结构,它实现了二叉堆(Binary Heap),默认是一个最大堆(Max-Heap)。二叉堆是一种特殊的完全二叉树,其中每个父节点的值都大于或等于其子节点的值(最大堆),或者每个父节点的值都小于或等于其子节点的值(最小堆)。
使用示例:
use std::collections::BinaryHeap;
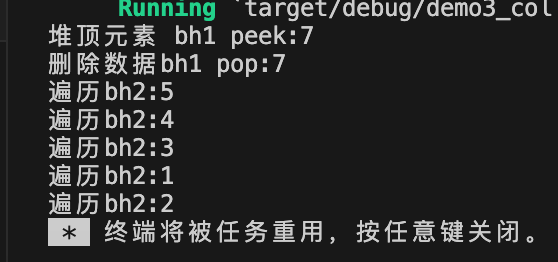
fn main() {//1.使用BinaryHeap::new()创建一个空的BinaryHeaplet mut bh1:BinaryHeap<i32, > = BinaryHeap::new();//2.使用BinaryHeap::from()创建,使用数组进行初始化let mut bh2:BinaryHeap<i32> = BinaryHeap::from([1,2,3,4,5]);//3.使用BinaryHeap::push()插入数据bh1.push(4);bh1.push(7);bh1.push(6);bh1.push(3);//4.使用BinaryHeap::peek()获取堆顶元素,但不删除if let Some(v) = bh1.peek() {println!("堆顶元素 bh1 peek:{}", v);}//5.使用BinaryHeap::pop()删除数据if let Some(v) = bh1.pop() {println!("删除数据bh1 pop:{}", v);}//6.遍历元素for val in bh2.iter() {println!("遍历bh2:{}", val);}
}
输出信息:
10.小结
本篇以示例的方式展示Rust中容器数据结构的使用方式,便于快速的了解基本容器的使用方式。
我是小C,欢迎大家一起学习交流~~~
相关文章:
:8大容器类型)
rust编程学习(三):8大容器类型
1简介 rust标准库std::collections也提供了像C STL库中的容器,分为4种通用的容器,8种类型,如下表所示。 线性容器类型: 名称简介Vec<T>内存空间连续,可变长度的数组,类似于C中Vector<T>容器…...

前端中阻止事件冒泡的几种方法
在 JavaScript 前端开发中,阻止事件冒泡是处理 DOM 事件时的常见需求。以下是几种阻止事件冒泡的方法: 1. 使用 event.stopPropagation() 这是最常用的阻止事件冒泡的方法。 element.addEventListener(click, function(event) {event.stopPropagation…...
)
ShenNiusModularity项目源码学习(20:ShenNius.Admin.Mvc项目分析-5)
ShenNiusModularity项目的系统管理模块主要用于配置系统的用户、角色、权限、基础数据等信息,上篇文章中学习的日志列表页面相对独立,而后面几个页面之间存在依赖关系,如角色页面依赖菜单页面定义菜单列表以便配置角色的权限,用户…...

前端js需要连接后端c#的wss服务
背景 前端js需要连接后端wss服务 前端:js 后端:c# - 控制台搭建wss服务器 步骤1 wss需要ssl认证,所以需要个证书,随便找一台linux的服务器(windows的话,自己安装下openssl即可),…...

MAGI-1自回归式大规模视频生成
1. 关于 MAGI-1 提出 MAGI-1——一种世界模型(world model),通过自回归方式预测一系列视频块(chunk,固定长度的连续帧片段)来生成视频。 模型被训练为在时间维度上单调递增噪声的条件下对每个块进行去噪&a…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容一):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 TCP网络模型OSI参考模型TCP/IP五层模型 TCP状态TIME_WAIT 连接过程TCP三次握手TCP四次挥手 TCP优化TCP三次握手优化TCP四次挥手优化TCP数据传输优化 TCP TCP是面向连接的、可靠的、基于字节流的传输层通信协议: 面向连接:一定是一对一才能连接…...

基于deepseek的模型微调
使用 DeepSeek 模型(如 DeepSeek-VL、DeepSeek-Coder、DeepSeek-LLM)进行微调,可以分为几个关键步骤,下面以 DeepSeek-LLM 为例说明,适用于 Q&A、RAG、聊天机器人等方向的应用。 一、准备工作 1. 环境依赖 建议使用 transformers + accelerate 或 LoRA 等轻量微调方…...
)
node.js 实战——(path模块 知识点学习)
path 模块 提供了操作路径的功能 说明path. resolve拼接规范的绝对路径path. sep获取操作系统的路径分隔符path. parse解析路径并返回对象path. basename获取路径的基础名称path. dirname获取路径的目录名path. extname获得路径的扩展名 resolve 拼接规范的绝对路径 const…...

【k8s】docker、k8s、虚拟机的区别以及使用场景
一、Docker (一)概念 Docker 是一个开源的应用容器引擎,允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可实现虚拟化。 (二)隔离性 Docker 的隔离…...
)
校园外卖服务系统的设计与实现(代码+数据库+LW)
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,外卖信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...

Windows上使用Python 3.10结合Appium-实现APP自动化
一、准备工作 所需条件: Windows 10/11 操作系统 Python 3.10.x(建议3.10.9) Java JDK 8 或以上(建议JDK 8u301) Node.js 14.x 或以上(建议14.21.3) Appium Server 1.22.x 或以上(建…...

【计算机视觉】CV项目实战- SiamMask 单阶段分割跟踪器
SiamMask 单阶段分割跟踪器 一、项目概述与技术原理1.1 核心技术创新1.2 性能优势 二、实战环境搭建2.1 系统要求与依赖安装2.2 项目编译与配置 三、模型推理实战3.1 快速体验Demo3.2 常见运行时错误处理 四、模型训练指南4.1 数据准备流程4.2 训练执行与监控 五、高级应用与优…...

计算机视觉基础
1. 数字图像的基本概念 像素(Pixel):图像的最小构成单元,每个像素存储亮度或颜色信息。 灰度图像:每个像素是 0(黑)~255(白) 的标量值(8位无符号整数&#x…...

系统编程_进程间通信机制_消息队列与共享内存
消息队列概述 消息有类型:每条消息都有一个类型,就像每封信都有一个标签,方便分类和查找。消息有格式:消息的内容有固定的格式,就像每封信都有固定的信纸格式。随机查询:你可以按类型读取消息,…...

一种免费的离线ocr-汉字识别率100%
一般我们手机中常用的ocr库有,Tesseract,paddle ocr,EasyOCR, ocrLite等等,这些ocr库中百度的paddle ocr效果最好,但是再好的效果也会偶尔识别错几个汉字。当我们在做自动化脚本过程中,如果识别…...
)
Maven 工程中的pom.xml 文件(图文)
基本信息 单工程项目【pom.xml文件】中最基本的信息。 依赖引入 可以在Maven 中央仓库查找所需依赖:【直达:https://mvnrepository.com/】。 在【dependencies】标签中添加所需依赖。 <dependency><groupId>com.baomidou</groupId&g…...

图像预处理-模板匹配
就是用模板图在目标图像中不断的滑动比较,通过某种比较方法来判断是否匹配成功,找到模板图所在的位置。 - 不会有边缘填充。 - 类似于卷积,滑动比较,挨个比较象素。 - 返回结果res大小是:目标图大小-模板图大小1(H-…...

操作系统学习笔记
2.4 死锁 在学习本节时,请读者思考以下问题: 1)为什么会产生死锁?产生死锁有什么条件? 2)有什么办法可以解决死锁问题? 学完本节,读者应了解死锁的由来、产…...

5.4.云原生与服务网格
目录 1. Kubernetes与微服务集成 1.1 容器化部署规范 • 多环境配置管理(ConfigMap与Nacos联动) • 健康检查探针配置(Liveness/Readiness定制策略) 1.2 弹性服务治理 • HPA自动扩缩容规则设计 • Sentinel指标驱动弹性伸缩 2…...

[特殊字符][特殊字符]Linux驱动开发入门 | 并发与互斥机制详解
文章目录 👨💻Linux驱动开发入门 | 并发与互斥机制详解📌为什么驱动中需要并发和互斥控制?💡常见的并发控制机制🔐自旋锁和信号量通俗理解🌀自旋锁(Spinlock)——“厕所…...

时序数据库IoTDB自研的Timer模型介绍
一、引言 时序数据库在支持时序特性写入、存储、查询等功能的基础上,正逐步向深度分析领域迈进。自动化异常监测与智能化趋势预测已成为时序数据管理的核心需求。为了满足这些需求,时序数据库IoTDB团队积极探索,成功自研推出了面向时间序列的…...
)
RabbitMQ 详解(核心概念)
本文是博主在梳理 RabbitMQ 知识的过程中,将所遇到和可能会遇到的基础知识记录下来,用作梳理 RabbitMQ 的整体架构和功能的线索文章,通过查找对应的知识能够快速的了解对应的知识而解决相应的问题。 文章目录 一、RabbitMQ 是什么?…...

【数据结构和算法】6. 哈希表
本文根据 数据结构和算法入门 视频记录 文章目录 1. 哈希表的概念1.1 哈希表的实现方式1.2 哈希函数(Hash Function)1.3 哈希表支持的操作 2. Java实现 在前几章的学习中,我们已经了解了数组和链表的基本特性,不管是数组还是链表…...

RHCE第三次作业 搭建dns的正向解析服务器
server为服务器 client为客户端 设置主配置文件 在server下: [rootServer ~]#vim /etc/named.conf #进入到配置页面,并修改 设置区域文件 [rootServer ~]# vim /etc/named.rfc1912.zones 设置域名解析文件 [rootServer named]# cd /var/named…...
问题?)
【每天一个知识点】如何解决大模型幻觉(hallucination)问题?
解决大模型幻觉(hallucination)问题,需要从模型架构、训练方式、推理机制和后处理策略多方面协同优化。 🧠 1. 引入 RAG 框架(Retrieval-Augmented Generation) 思路: 模型生成前先检索知识库中…...

Python深拷贝与浅拷贝:避开对象复制的陷阱
目录 一、为什么需要区分深浅拷贝? 二、内存中的对象真相 三、浅拷贝的真相 四、深拷贝的奥秘 五、自定义对象的拷贝 六、性能对比实验 七、常见陷阱与解决方案 八、最佳实践指南 九、现代Python的拷贝优化 结语 一、为什么需要区分深浅拷贝? …...

批量处理多个 Word 文档:插入和修改页眉页脚,添加页码的方法
Word 页眉页脚的设置在日常工作中非常常见,尤其是需要统一格式的文档,如毕业论文、公司内部资料等。在这些文档中,页眉页脚通常包含时间、公司标志、文档标题、文件名或作者姓名等信息。有时,我们不仅需要简单的文字页眉页脚&…...
的Prompt Engineering:从入门到精通)
大语言模型(LLM)的Prompt Engineering:从入门到精通
大语言模型(LLM)的Prompt Engineering:从入门到精通 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 引言:Prompt Engineering——解锁AI生产力的金钥匙 当ChatGPT在2023年引爆…...

poi生成横向文档以及复杂表头
代码: //创建页面并且创建横向A4XWPFDocument doc new XWPFDocument();CTDocument1 document doc.getDocument();CTBody body document.getBody();if (!body.isSetSectPr()) {body.addNewSectPr();}CTSectPr section body.getSectPr();if (!section.isSetPgSz()) {section.…...
:从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南)
深入剖析TCP协议(内容二):从OSI与TCP/IP网络模型到三次握手、四次挥手、状态管理、性能优化及Linux内核源码实现的全面技术指南
文章目录 常见问题TCP和UDPISNUDPTCP数据可靠性TCP协议如何提高传输效率TCP如何处理拥塞 SocketTCP源码tcp_v4_connect()sys_accept()tcp_accept()三次握手客户端发送SYN段服务端发送SYN和ACK处理客户端回复确认ACK段服务端收到ACK段 常见问题 TCP和UDP TCP和UDP的区别&#…...

流程架构是什么?为什么要构建流程架构,以及如何构建流程结构?
本文从:流程架构是什么?为什么要构建流程架构?如何构建流程结构三个方面来介绍。 一、首先,我们来了解流程架构是什么? 流程架构是人体的骨架,是大楼的砌筑,是课本的目录,是流程管理…...

Visium HD多样本拼片拆分
Visium HD实验的时候一个捕获区域内可以包含多个样本拼片(例如多个组织切片或不同样本的排列)是常见的实验设计,多样本拼片能够提升实验效率,单张玻片处理多个样本,降低试剂和测序成本,后续分析的时候只需要…...

3DMAX零售商店生成插件RetailStore自定义贴图库方法详解
3DMAX零售商店生成插件——RetailStore,是一款兼具简洁性与复杂性的工具,专为通过样条线快速创建零售商店而设计。用户只需绘制一条街道廓线,轻点鼠标,即可生成一排随机的零售商店。该插件会在每个样条线段上自动生成一个店铺&…...

从性能到安全:大型网站系统架构演化的 13 个核心维度
大型网站系统架构的演化是一个复杂的过程,涉及到多个维度的技术内容,从关键维度进行详细分析: 1.性能维度 缓存技术:包括浏览器缓存、CDN(内容分发网络)缓存、服务器端缓存(如 Memcached、Red…...

昆仑万维开源SkyReels-V2,近屿智能紧跟AI技术趋势
昆仑万维 SkyReels 团队正式发布并开源全球首个采用扩散强迫框架的无限时长电影生成模型 SkyReels-V2,其通过融合多模态大语言模型、多阶段预训练、强化学习与扩散强迫框架实现协同优化,推动视频生成技术进入新阶段。该模型聚焦解决现有技术在提示词遵循…...
:创建 Collections)
Milvus(4):创建 Collections
1 创建 Collections 可以通过定义 Schema、索引参数、度量类型以及创建时是否加载来创建一个 Collection。 1.1 集合概述 Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。要实现这样的结构化数据管理,…...

数据预处理:前缀和算法详解
数据预处理:前缀和算法详解 文章目录 数据预处理:前缀和算法详解1.算法原理2.算法作用3.C代码实现4.实战题目 1.算法原理 基本概念 前缀和(Prefix Sum)是一种常用的数据预处理技术,它可以快速求解区间和问题…...

盈达科技:登顶GEO优化全球制高点,以AICC定义AI时代内容智能优化新标杆
一、技术制高点——全球独创AICC系统架构,构建AI内容优化新范式 作为全球首个实现AI内容全链路优化的技术供应商,盈达科技凭借AICC智能协同中心(自适应内容改造、智能数据投喂、认知权重博弈、风险动态响应四大引擎)&#…...

【Linux】详细介绍进程的概念
目录 一、初识进程概念 真正的进程概念如下: 二、Linux中PCB的操作系统学科叫法:task_struct 1、简单认识task_ struct内容分类 2、问题:操作系统怎么知道当前程序执行到哪一行代码了? 三、linux关于进程的常用指令ÿ…...

mybatis框架补充
一,#{} 和${}区别 1.传数值 #{} 占位符,是经过预编译的,编译好SQL语句再取值,#方式能够防止sql注入 eg:#{}:delete from admin where id #{id} 结果: dalete from admin where id &#x…...

Alertmanager的安装和详细使用步骤总结
一、安装步骤 1. 二进制安装 下载与解压 从GitHub下载最新版本(如v0.23.0):wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz tar -xzf alertmanager-0.23.0.linux-amd6…...

C++学习:六个月从基础到就业——C++学习之旅:STL迭代器系统
C学习:六个月从基础到就业——C学习之旅:STL迭代器系统 本文是我C学习之旅系列的第二十四篇技术文章,也是第二阶段"C进阶特性"的第二篇,主要介绍C STL迭代器系统。查看完整系列目录了解更多内容。 引言 在上一篇文章中…...

缓存与数据库一致性方案
一、缓存更新策略概述 在现代分布式系统中,缓存作为数据库的前置层,能显著提升系统性能。然而,缓存与数据库之间的数据一致性是一个经典难题。以下是三种常见的缓存更新策略及其优缺点分析。 二、方案对比分析 方案一:直接更新…...

国内ip地址怎么改?详细教程
在中国,更改IP地址需要遵守规则,并确保所有操作合规。在特定情况下,可能需要修改IP地址以满足不同需求或解决特定问题。以下是一些常见且合法的IP地址变更方法及注意事项: 一、理解IP地址 IP地址是设备在网络中的唯一标识&#x…...

通过Quartus II实现Nios II编程
目录 一、认识Nios II二、使用Quartus II 18.0Lite搭建Nios II硬件部分三、软件部分四、运行项目 一、认识Nios II Nios II软核处理器简介 Nios II是Altera公司推出的一款32位RISC嵌入式处理器,专门设计用于在FPGA上运行。作为软核处理器,Nios II可以通…...

拥抱基因体检,迎接精准健康管理新时代
2025年4月20日,由早筛网、细胞科技网联合中国食品药品企业质量安全促进会细胞医药分会、中国抗衰老促进会健康管理工作委员会、中国抗癌协会肿瘤分子医学专业委员会、广东省保健协会,伯温生物冠名支持的《基因体检赋能精准健康管理新时代》圆满召开。 伯…...

QT容器类控件及其属性
Group Box 使用QGroupBox实现一个带有标题的分组框,可以把其它的控件放到里面作为一组 例: 核心属性 属性 说明 title 分组框的标题 alignment 分组框内部内容的对齐方式 flat 是否”扁平模式” checkable 是否可选中 设为true,则…...
)
云原生--CNCF-3-核心工具介绍(容器和编排、服务网格和通信、监控和日志、运行时和资源管理,安全和存储、CI/CD等)
1、核心工具分类介绍 (1)、容器编排与管理 1、Docker 它是一款轻量级的容器化技术,可把应用及其依赖打包成独立的容器。借助Docker,开发者能够确保应用在不同环境中保持一致的运行状态。比如在开发环境中创建的容器,…...

网络基础知识
文章目录 一、网络架构1. 网络架构图2. 各层级功能3. 机房网络常见问题及解决方案 二、交换技术1. 交换技术基础2. 交换技术分类3. 广播域相关概念4. ARP 协议5. 三层交换机6. VLAN(虚拟局域网) 三、路由技术1. 路由器端口类型及功能2. 路由器功能3. 路由…...

第3课:运算符与流程控制——JS的“决策者”
一切美好都值得你全力以赴。即使过程艰难,但只要坚持,必有回响。加油! 欢迎来到「JavaScript 魔法学院」第 3 课!今天我们将化身代码世界的“指挥官”,用运算符计算数据,用流程控制做出决策!文…...