Scenario Dreamer:用于生成驾驶模拟环境的矢量化潜扩散模型
25年3月来自加拿大 Mila AI研究院、蒙特利尔大学、蒙特利尔理工、普林斯顿、加拿大 CIFAR AI Chair 计划和 Torc 机器人公司的论文“Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments”。
Scenario Dreamer,是一个完全数据驱动的自动驾驶汽车规划生成模拟器,它可以生成初始交通场景(包括车道图和智体边框)和闭环智体行为。现有的生成驾驶模拟环境方法将初始交通场景编码为光栅化图像,因此需要参数繁重的网络,这些网络由于光栅化场景中存在许多空像素而执行不必要的计算。此外,采用基于规则智体行为的现有方法缺乏多样性和真实感。Scenario Dreamer 采用一种矢量化潜扩散模型进行初始场景生成,该模型直接对矢量化场景元素进行操作,并使用自回归 Transformer 进行数据驱动的智体行为模拟。Scenario Dreamer 还支持通过扩散修复进行场景外推,从而能够生成无界模拟环境。大量实验表明,Scenario Dreamer 在真实感和效率方面均超越现有的生成式模拟器:与最强大的基线相比,矢量化的场景生成基础模型实现卓越的生成质量,参数数量减少约 2倍,生成延迟降低 6倍,GPU 训练时长减少 10倍。其证明强化学习规划智体在 Scenario Dreamer 环境中比传统的非生成式模拟环境面临更大的挑战(尤其是在长途和对抗性驾驶环境中),证实其实用性。
本文将生成式驾驶模拟任务分解为初始场景生成和行为模拟。
问题设置
初始场景生成。初始场景生成涉及在固定视野 (FOV) 内生成初始 BEV 目标边框状态和底层地图结构。根据 [11] 中的方案,生成一个以自智体为中心并旋转至自智体的 64m×64m 视野。将生成的 64m×64m 区域表示为 F,将自智体前方和后方的 32m×64m 区域分别表示为 F_P 和 F_N。初始场景生成器的任务是从初始场景的分布 p(I_F) 中进行采样,其中初始场景 I_F = {O, M} 包含视场角 (FOVF) 内的一组目标 O 和地图结构 M。
定义 O = {o_i} 为一个包含 N_o 个目标的集合,其中包括交通参与者(例如,自智体、车辆、行人、骑行者)和静态目标(例如,交通锥),其中 o_i 是一个 8 维向量,包含二维位置、速度、航向的余弦和正弦、边框的长度、宽度和目标类别。生成一个类似于 [11] 的地图表示 M,其中 M = {L, A} 包含一个由 N_l 条中心线组成的集合 L = {l_i},其中每个 l_i 是一个 20×2 的中心线位置序列,A ∈ {0, 1} 将相关的中心线连通性定义为四个邻接矩阵的堆栈,分别描述后继、前驱、左邻和右邻连接。初始场景生成器还必须支持从条件分布 p(I_F_P |I_F_N) 进行采样,因为这可以通过将新生成的区域 F_P 和现有区域 F_N 拼接在一起来采样任意长的场景(参见下图恢复能力)。
行为模拟给定初始场景生成器规定的初始场景配置,行为模拟任务包括对场景中动态目标随时间的行为进行建模。具体而言,给定初始物体边框状态集合 S_0 := O 和车道结构 M,行为模型采用多智体驾驶策略 π(A_t|S_t, M) 和前向转移模型 P (S_t+1 |S_t , A_t),其中 A_t 是时间步 t 所有动态目标动作的集合。
矢量化潜扩散模型
初始场景生成器旨在从 p(I_F) 中进行采样。为了实现此目标,其使用扩散模型,基于真实驾驶数据学习一个近似值 p ̃(I_F) ≈ p(I_F),因为扩散模型具有捕捉高度复杂分布的强大能力 [1, 55]。
采用两阶段训练流程:首先,通过低 β 变分自编码器[23]学习 N_o 个目标 {h_iO} 和 N_l 条中心线 {h_iL} 的紧凑潜表示;接下来,训练一个扩散模型,从分布 p(H) := p({h_iO}, {h_i^L}) 中进行采样。该架构如图所示:
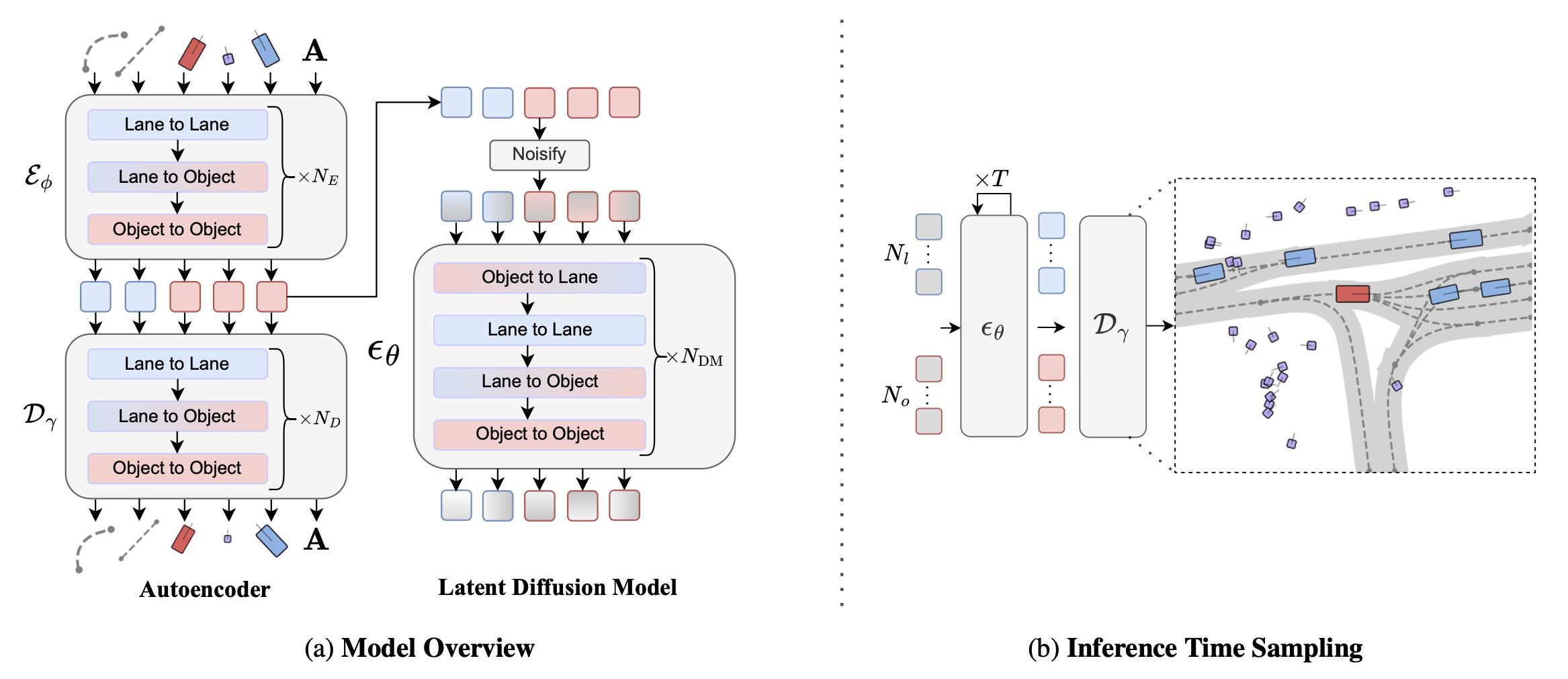
自动编码器
自动编码器由基于 Transformer 的 [69] 编码器 E_φ 和解码器 D_γ 组成,它们直接对矢量化的场景元素进行操作——相比之下,先前的研究 [11] 将驾驶场景编码为光栅化图像。
编码器。编码器 E_φ 首先将 N_o + N_l 个矢量元素嵌入到每个矢量的多层感知器 (MLP) 中,此外,还将车道连接类型 c_ij 的独热表示嵌入到所有中心线段对 i 和 j 的多层感知器 (MLP) 中。然后,E_φ 将一系列 N_E 个分解后的注意模块应用于 N_o + N_l 个嵌入的场景元素,其中每个分解后的注意模块包含一个车道-到-车道、车道-到-物体和物体-到-物体的多头注意层 [20, 42, 49]。车道间注意机制捕捉中心线段之间的空间关系,其中嵌入的车道连接性被额外融合到注意机制的 K 和 V 中。车道间注意机制将地图上下文融入目标嵌入中,而目标间注意机制则捕捉目标之间的空间关系。在 N_E 分解的注意模块之后,编码器将每个目标和车道嵌入分别映射到潜维度 K_o 和 K_l,均值和方差均如在变分自编码器 (VAE) 中一样进行参数化 [36]。重要的是,设计 E_φ,使得车道潜维度不依赖于目标特征(即没有目标间注意机制),从而允许在推理过程中生成基于车道条件的目标。
解码器。解码器 D_γ 从编码器参数化的潜分布 {{h_O}, {h_L}} ∼ E_φ 中进行采样,并通过一系列 ND 分解的注意模块处理嵌入的车道和物体潜信息。在这些模块之后,解码器在 l_2 损失函数的监督下,重建连续的车道和物体向量输入。对于车道连通性预测,将每对车道嵌入连接起来,并通过 MLP 传递,以预测连通性类型的分类分布,并使用交叉熵损失函数进行训练。Scenario Dreamer 自编码器采用标准证据下限 (ELBO) 目标函数和低-β 正则化进行训练。
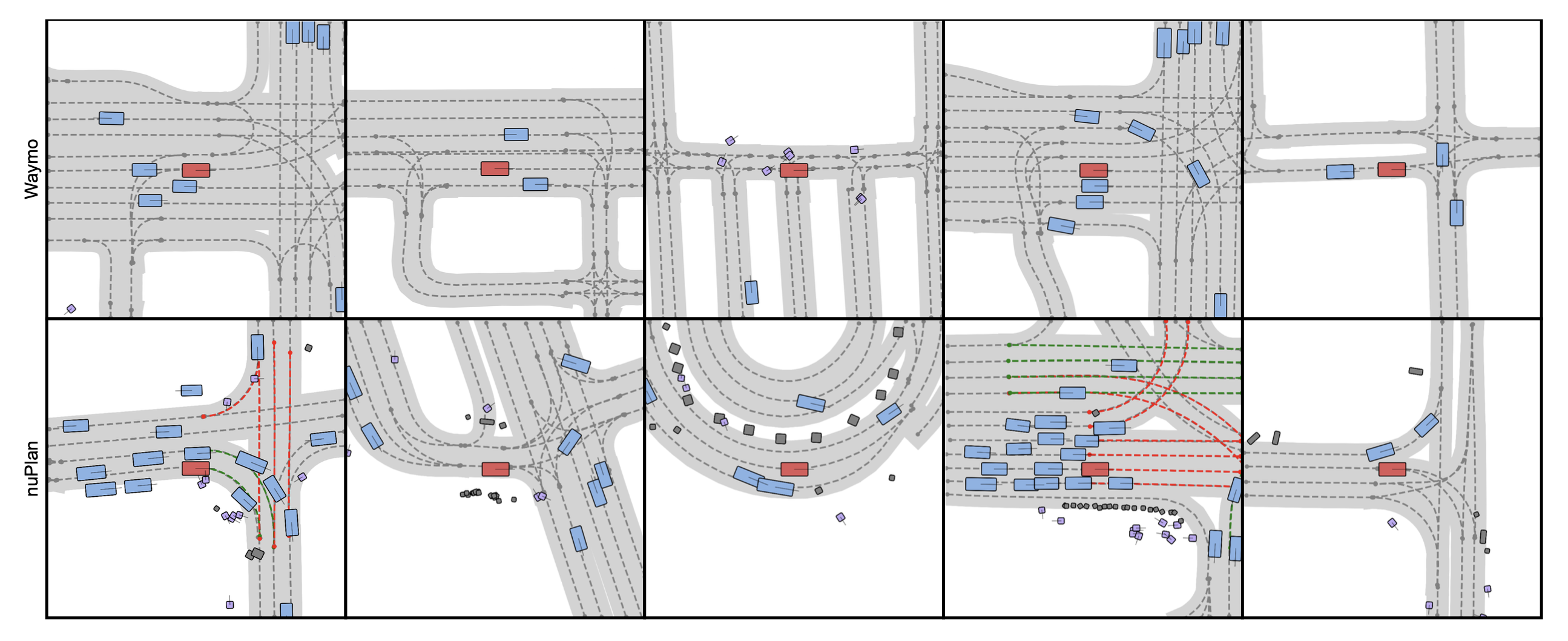
如图所示:Scenario Dreamer 产生的矢量化环境。
潜扩散采样
训练一个潜扩散模型,从自编码器的潜分布 p(H) 中采样,该分布分解为:
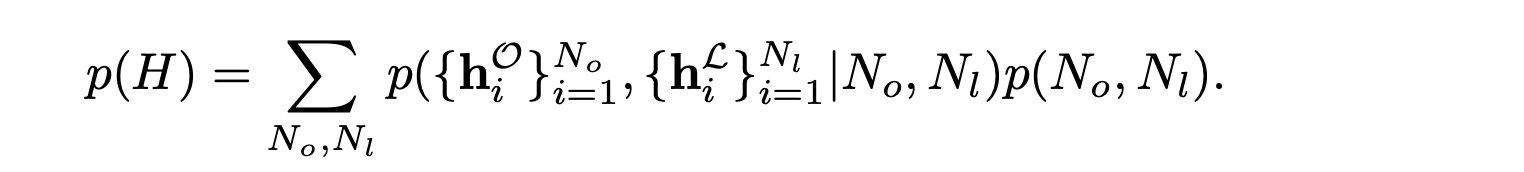
此处,条件分布 p_θ (·|N_o, N_l) 由一个权重为 θ 的扩散模型参数化,该模型对 N_o 个目标潜样本和 N_l 个车道潜样本进行采样。与基于图像的模型不同,p_θ 必须适应可变的潜样本大小,因此设计一个基于 AdaLN-Zero 条件的定制 Transformer 架构 [52]。该架构与自编码器类似,由一系列 NDM 分解式注意模块组成,其中包含连续的目标-到-车道、车道-到-车道、车道-到-目标和目标-到-目标的注意层。这种分解式处理方法允许每一层对特定层的交互进行建模,同时允许目标和车道标记具有不同的隐藏维度。值得注意的是,由于真实车道生成需要高度的空间推理和细节,车道 tokens 需要更大的隐藏维度,而目标 tokens 则能有效地用较小的维度表示,这使得扩散模型整体上更高效。采用标准 DDPM 目标函数来训练 p_θ,其中 p_θ 被参数化为噪声预测网络 ε_θ,该网络学习预测不同噪声水平下带噪声车道和目标潜特征的噪声:
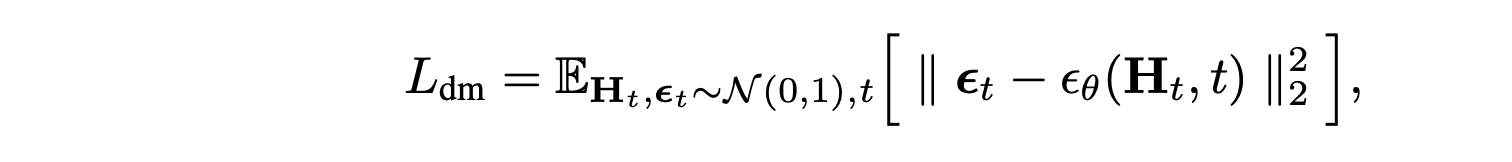
排列模糊性。与具有自然网格结构的图像不同,Scenario Dreamer 中的集合结构化数据对扩散模型提出独特的挑战。具体而言,出现一种称为排列模糊性 [8] 的现象:训练期间噪声充足的向量元素会丢失足够的底层结构,导致模型无法可靠地推断出应该回归的真值信号排列。在基于图像的 Transformer 扩散方法(例如 DiT)中,通过对每个网格块应用位置编码来解决此问题。为了类似地解决模型中的排列模糊性问题,本文在分解注意模块之前对潜 tokens 引入正弦位置编码。
位置编码方案涉及在训练期间定义 token 的排序(每种 token 类型),从而使模型能够更好地推断带噪声 token 的可能相对空间位置,从而推断出模型应该回归的真实信号。为此,其提出一个递归排序程序:token 按最小 x 值排序,如果 x 值的差异小于 ε 米,则依次按最小 y 值、最大 x 值和最大 y 值排序。值得注意的是,初始按 x 值排序有利于图像修复,因为 IFN 中的 tokens 构成一个连续的有序 token 子序列,这些子序列位于 IFP 中的 token 之前。
场景生成
Scenario Dreamer 潜扩散模型在单个训练模型中支持多种场景生成模式:初始场景生成,从 p(I_F) 中采样 64m × 64m 的场景;车道条件目标生成,以已知地图 M 为条件采样物体边框 O;场景修复,从 p(I_F_P |I_F_N) 中采样。
初始场景生成。Scenario Dreamer 首先从训练数据中的联合分布中采样 (N_o, N_l) ∼ p(N_o, N_l),生成新的初始驾驶场景 IF,并对 N_o 和 N_l 设置数据集相关的限制,以确保真实的场景密度。或者,用户可以直接指定 (N_o,N_l),从而控制场景密度。设置 (N_o,N_l) 后,从扩散模型中采样潜向量 {h_i^O}, {h_i^L},经过 T = 100 个扩散步骤,并使用自编码器解码器将潜向量解码为矢量化的场景元素。
车道条件化目标生成 (Lane-conditioned Object Generation) 包括使用 E_φ 对给定映射 M 的矢量化元素进行编码,然后从扩散模型中采样 N_o ∼ p(N_o|N_l) 个目标潜向量,这些潜向量在每个去噪时间步长上对编码后的映射潜向量进行条件化处理,并进行扩散。得到的目标潜向量可以用 D_γ 解码为目标边框配置。
场景修复。遵循 [11],将从 P (I_F_P |I_F_N) 中进行条件采样定义为修复任务。与网格结构图像不同,在网格结构图像中,区域(例如 I_F_P 和 I_F_N)之间的边界是自然定义的(例如,沿 x = 0),而设置中的车道向量可以不受限制地跨越此边界。为了解决这个问题,将数据集预处理为两种场景类型:分区场景(在 x = 0 处人为分割)和非分区场景(其中车道向量可能跨越 x = 0)。训练自动编码器以重建这两种场景类型,而扩散模型通过使用条件标签来区分它们,从而生成这两种场景。为了进一步提高修复质量,在训练期间,扩散模型以分区场景的 I_F_N 编码潜变量为条件,从而明确地训练它进行修复。这显著提升了修复性能,因为模型可以学习利用 I_F_N 中的相关场景上下文,确保车道几何形状在 x = 0 边界上保持空间一致性。
Scenario Dreamer 需要指定新的车道和目标向量的数量,以填充新的 32x64 区域 I_F_P,从而有效地从 p(N_oF_P, N_lF_P | I_lF_N) 中进行采样。虽然可以通过训练统计数据从 p(N_oF_P, N_lF_P | N_oF_Nv, N_l^F_N) 进行近似采样,但 p(N_l^F_P | IF_N) 高度依赖于几何形状。为了解决这个问题,训练一个分类器 f_φ (N_l^F_P | M_F_N) 和 E_φ,以基于上下文 I_F_N 预测 I_F_P 中的车道数量,该分类器仅在分区场景上进行训练。
具体来说,一个可学习的查询向量在 E_φ 的每个分解注意模块中与 I_F_N 中的车道 token 进行交叉关注,输出一个在 N_oF_P 上经过交叉熵损失训练的分类分布。在推理阶段,首先对 N_lF_P∼ f_φ 进行采样,然后对 N_oF_P ∼ p(N_o^F_P |N_o^F_N ,N_l^F_N + N_l^F_P ) 进行采样。采样 (N_o^F_P, N_o^F_P) 后,对 I_F_N 的潜向量进行编码,并生成 N_o^F_P 和 N_l^F_P 个新 tokens,并初始化为高斯噪声。然后应用标准扩散修复 [11],其中 I_F_N 中的带噪 tokens 在每个去噪步骤中被设置为其编码的潜向量。对得到的潜信息进行解码,以生成 I_F_P 中的新场景元素。
行为模拟
从潜扩散模型生成的初始场景 I 开始,扩展 CtRL-Sim [58](一个基于 Transformer 的自回归行为模型),以控制多种智体类型(例如,车辆、行人和骑行者)。为了支持多种智体类型,使用 Philion 提出的 k 盘 方案 [53]。CtRL-Sim 是一个基于回报条件的多智体策略,专为行为模拟而设计。调整 CtRL-Sim 架构,该架构参数化未来回报 G_t 和动作 A_t 的联合分布,分解为 p_θ (A_t, G_t | S_t) = π_θ (A_t | S_t, G_t) p_θ (G_t | S_t)。这种分解的一个关键优势在于其回报条件,这使得学习的回报模型在推理过程中能够呈指数级倾斜[38],从而生成良好或对抗性的驾驶行为。在scenario dreamer 框架中,目标是创建对抗性场景,专门挑战自动驾驶汽车 (AV) 规划器。为此,设计一个奖励函数,用于惩罚与自车的碰撞,并基于 H = 2s 范围内的累积奖励,对折扣回报 G_t = sum (r_t) 进行建模。与对完整回报进行建模相比,这具有更好的可控性。
模拟框架
基于 Scenario Dreamer,描述提出的模拟框架独特属性。首先,Scenario Dreamer 支持在其生成模拟环境中对自动驾驶汽车规划器进行任意长模拟时长的评估。为自动驾驶汽车规划器定义一条要遵循的路线,并使用 CtRL-Sim 模拟其他智体。遵循 Nocturne [70] 和 GPUDrive [34] 中采用的 Waymo 数据集过滤方案,以确保场景对于模拟有效(例如,没有交通信号灯,即没有带注释的交通信号灯状态)。为了确保 Scenario Dreamer 生成的场景对于模拟有效,Scenario Dreamer 在训练期间以二进制指标为条件,该指标指示训练场景是否通过 Nocturne 过滤方案。在推理阶段,利用分类器引导从模拟兼容场景中进行采样。
相关文章:

Scenario Dreamer:用于生成驾驶模拟环境的矢量化潜扩散模型
25年3月来自加拿大 Mila AI研究院、蒙特利尔大学、蒙特利尔理工、普林斯顿、加拿大 CIFAR AI Chair 计划和 Torc 机器人公司的论文“Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments”。 Scenario Dreamer,是一个完…...

# 基于PyTorch的食品图像分类系统:从训练到部署全流程指南
基于PyTorch的食品图像分类系统:从训练到部署全流程指南 本文将详细介绍如何使用PyTorch框架构建一个完整的食品图像分类系统,涵盖数据预处理、模型构建、训练优化以及模型保存与加载的全过程。 1. 系统概述 本系统实现了一个基于卷积神经网络(CNN)的…...
:MCP开发环境搭建详解)
【MCP Node.js SDK 全栈进阶指南】初级篇(1):MCP开发环境搭建详解
引言 Model Context Protocol (MCP) 是一种开放标准,旨在规范模型与应用程序之间的交互方式。本文作为MCP TypeScript-SDK系列的第一篇,将详细介绍如何搭建MCP开发环境,包括Node.js与TypeScript环境配置、SDK安装、开发工具推荐以及项目结构设计,帮助你快速入门MCP应用开发…...

unity脚本-FBX自动化模型面数校验
根据目前模型资源平均面数预算进行脚本制作,自动化校验模型面数是否符合规范。 *注:文件格式为.cs。需要放置在unity资源文件夹Assets>Editor下。 测试效果(拖一个fbx文件进unity时自动检测): 以下为完整代码 us…...

压力容器的优化设计
1 优化设计概述 优化设计是一种寻找确定最优设计方案的技术。所谓“最优设计”,指的是一种方案可以满足所有的设计要求,而且所需的支出(如重量,面积,体积,应力,费用等)最小。也就是…...

在Windows上安装Git
一、安装 Git 下载 Git地址:Git - Downloads (git-scm.com) 1、在页面中找到适用于 Windows 系统的最新版本安装包(通常为.exe 格式文件),点击下载链接。 出于访问Git官网需要科学上网,不会的可以私信我要软件包&…...

python包管理器,conda和uv 的区别
python包管理器,conda和uv 的区别 以下是 conda 和 uv 在 Python 包管理中的深度对比,结合知识库内容进行分析: 1. 核心设计理念 conda 以“环境为中心”,强调跨语言支持(如 Python、R、Julia)和严格的依赖…...

Oracle在ERP市场击败SAP
2024年,甲骨文(Oracle)以87亿美元的ERP收入和6.63%的市场份额,首次超越SAP,成为全球最大的ERP应用软件供应商,结束了SAP自上世纪80年代以来在该领域的长期霸主地位。据APPS RUN THE WORLD的市场调研&#x…...

Kafka 消息积压监控和报警配置的详细步骤
Kafka 消息积压监控和报警配置的详细步骤示例,涵盖常用工具(如 Prometheus Grafana、云服务监控)和自定义脚本方法: 一、监控配置 方法1:使用 Prometheus Grafana kafka-exporter 步骤1:部署 kafka-ex…...

记录一次使用面向对象的C语言封装步进电机驱动
简介 (2025/4/21) 本库对目前仅针对TB6600驱动下的42步进电机的基础功能进行了一定的封装, 也是我初次尝试以面向对象的思想去编写嵌入式代码, 和直流电机的驱动步骤相似在调用stepmotor_attach()函数和stepmotor_init()函数之后仅通过结构体数组stepm然后指定枚举变量中的id即…...

QTextDocument 入门
一、QTextDocument QTextDocument 是 Qt 中用于处理富文本文档的核心类,支持文本格式、图片、表格等复杂内容。 1. QTextDocument 入门 1.1 基本概念 QTextDocument 是 Qt 中用于处理富文本内容的核心类,它提供了: 结构化文本存储(段落、列表、表格等) 文本格式支持(…...

Arthas进阶用法
目录 查看已加载的类反编译代码动态执行代码排查 HTTP 请求问题热更新代码获取 Spring Context 并操作查看 JVM 信息自定义命令Web Console重置与退出 查看已加载的类 sc 命令 :可以查找所有 JVM 已经加载到的类。如果搜索的是接口,还会搜索所有的实现类…...

三生原理与现有密码学的核心区别?
AI辅助创作: 三生原理与现有密码学的核心区别 一、哲学基础与设计逻辑 动态生成 vs 静态分析 三生原理以“阴阳动态平衡”为核心,通过参数化生成(如素数构造中的阴阳元联动公式)模拟系统演化过程,而现有密码…...

定义python中的函数和类
1.函数 在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回 1.1 定义函数 def showshow(sex):if sex1:return manelse:retu…...

明远智睿2351开发板四核1.4G Linux处理器:驱动创新的引擎
在科技日新月异的今天,创新成为了推动社会进步的核心动力。而在这场创新的浪潮中,一款性能卓越、功能全面的处理器无疑是不可或缺的引擎。今天,我们介绍的这款四核1.4G处理器搭配Linux系统的组合,正是这样一款能够驱动未来创新的强…...

【前端】【业务逻辑】【面试】JSONP处理跨域原理与封装
🧠 一、JSONP 是什么? 项目内容📌 全称JSON with Padding📍 用途跨域请求数据的一种方式,绕过同源策略📦 本质通过 <script> 标签加载远程 JS 文件,这个文件执行一个回调函数并传入数据 …...

深入探索RAG:用LlamaIndex为大语言模型扩展知识,实现智能检索增强生成
大型语言模型(LLM),如ChatGPT和Llama,在回答问题方面表现出色,但它们的知识仅限于训练时所获取的信息。它们无法访问私有数据,也无法在训练截止日期之后学习新知识。那么,核心问题就是……我们如…...

移远通信智能模组助力东成“无边界智能割草机器人“闪耀欧美市场
2025年4月21日,移远通信宣布,旗下SC206E-EM智能模组已成功应用于江苏东成电动工具有限公司旗下的DCK TERRAINA无边界智能割草机器人。 这款智能模组高度集成计算、通信、定位等多元能力,以小型化、低功耗、实时性强和低成本等综合优势&#…...

测试-时间规模化定律可以改进世界基础模型吗?
25年3月来自 UT Austin、UW Madison 和 Nvidia 的论文“Can Test-Time Scaling Improve World Foundation Model?”。 世界基础模型(WFM)通过根据当前的观察和输入预测未来状态来模拟物理世界,已成为许多物理智能(PI)…...

VMwaer虚拟机复制粘贴、ROS系统安装
一、VMwaer虚拟机复制粘贴设置:设置完记得重启VMwaer 1.首先确定 虚拟机设置-->选项-->客户机隔离-->勾选 启用拖放 启用复制粘贴 2.如果还是不能粘贴 可能是 没有 VMware Tools 可参考 怎么在linux安装vmware tools-CSDN博客 设置完记得重启VMwaer。…...

安装 vmtools
第2章 安装 vmtools 1.安装 vmtools 的准备工作 1)现在查看是否安装了 gcc 查看是否安装gcc 打开终端 输入 gcc - v 安装 gcc 链接:https://blog.csdn.net/qq_45316173/article/details/122018354?ops_request_misc&request_id&biz_id10…...
)
HCIP(综合实验2)
1.实验拓补图 2.实验要求 1.根据提供材料划分VLAN以及IP地址,PC1/PC2属于生产一部员工划分VLAN10,PC3属于生产二部划分VLAN20 2.HJ-1HJ-2交换机需要配置链路聚合以保证业务数据访问的高带宽需求 3.VLAN的放通遵循最小VLAN透传原则 4.配置MSTP生成树解决二层环路问题…...

机器学习第一篇 线性回归
数据集:公开的World Happiness Report | Kaggle中的happiness dataset2017. 目标:基于GDP值预测幸福指数。(单特征预测) 代码: 文件一:prepare_for_traning.py """用于科学计算的一个库…...

Spark-Streaming简介及核心编程
一、核心概念: 1.Spark-Streaming 是流式数据处理框架,基于 **DStream(离散化流)** 抽象,将实时数据划分为多个时间区间的 RDD 序列。 DStream 本质是RDD 序列,每个时间区间数据对应一个 RDD。 2.特点&a…...

优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论
优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论 目录 优化提示词方面可以使用的数学方法理论:信息熵,概率论 ,最优化理论信息论信息熵明确问题主题提供具体细节限定回答方向规范语言表达概率论最优化理论信息论 原理:信息论中的熵可以衡量信息的不确定性。…...

Sqlserver安全篇之_Sqlcmd命令使用windows域账号认证sqlserver遇到问题如何处理的案例
sqlcmd https://learn.microsoft.com/zh-cn/sql/tools/sqlcmd/sqlcmd-connect-database-engine?viewsql-server-ver16 sqlcmd -S指定的数据库连接字符串必须有对应的有效的SPN信息,否则会报错SSPI Provider: Server not found in Kerberos database. 正常连接 1、…...
)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块) 一、本节目标 了解并掌握 Requests 模块的特点与用法学会通过 PythonRequests 访问华为云 ModelArts 在线推理服务熟悉 JSON 模块在 Python 中的数据序列化与反序列化掌握 Python 文件 I/O 的基…...

Graph Database Self-Managed Neo4j 知识图谱存储实践1:安装和基础知识学习
Neo4j 是一个原生图数据库,这意味着它在存储层实现了真正的图模型。它不是在其他技术之上使用“图抽象”,而是以您在白板上绘制想法的相同方式在Neo4j中存储数据。 自2007年以来,Neo4j已经发展成为一个丰富的工具、应用程序和库的生态系统。…...

【Python进阶】VSCode Python开发完全指南:从环境配置到高效调试
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:配置虚拟环境案例2:智能代码补全案例3:调试配置 运行结果…...

vscode:Live Server Preview插件
这个插件不用另外打开浏览器;它是直接在Vscode里面预览html的,并且是自动实时更新的,不用不停地CtrlS保存查看 使用方法:F1 -> 弹出一个窗口输入live,选择即可。 运行结果如下:...

关于在Springboot中设置时间格式问题
目录 1-设置全局时间格式1.Date类型的时间2.JDK8时间3.使Date类和JDK8时间类统统格式化时间 2-关于DateTimeFormat注解 1-设置全局时间格式 1.Date类型的时间 对于老项目来说,springboot中许多类使用的是Date类型的时间,没有用到LocalDateTime等JDK8时…...

双周报Vol.70: 运算符重载语义变化、String API 改动、IDE Markdown 格式支持优化...多项更新升级!
2025-04-21 语言更新 async 函数的调用处语法改为和 error 相同的 f!(..),原语法 f!!(..) 将触发警告 运算符重载的语义从基于方法迁移到了基于 trait,以后重载运算符需要通过给 moonbitlang/core/builtin 中对应的 trait 添加 impl 的形式。各个运算符…...

AI 技术发展:从起源到未来的深度剖析
一、AI 的起源与早期发展 人工智能(AI)作为计算机科学的重要分支,其诞生可以追溯到 20 世纪中叶。1943 年,艾伦・图灵提出图灵机的概念,为计算机科学和 AI 理论奠定了基础。1950 年,图灵又提出著名的图灵…...

【前端】【业务逻辑】 数据大屏自适应方案汇总
前端数据大屏自适应设计方案全解析 在前端数据大屏的开发中,自适应设计是关键环节,它能确保大屏在不同设备和屏幕尺寸上都能呈现出良好的视觉效果和交互体验。除了常见的 transform: scale、rem/vw、Flex/Grid 等方案外,还有其他有效的方法可…...
第六章 IO流体系)
Java基础复习(JavaSE进阶)第六章 IO流体系
6-1 File类 01 122、File、IO流概述 02 123、File类:对象的创建 03 124、File类:判断、判断信息相关的方法 04 125、File类:创建、删除文件的方法 05 126、File类:遍历文件夹的方法 6-2 前置知识 01 127、前置知识:方…...

kvm下的ceph主机启动io请求统计
背景 假如一个主机存储在ceph里面,我们想统计下一次启动过程中的io读取的情况,那么可以通过下面的方法来统计 启动时间也可以通过在宿主机里面去查看,通过日志这边要方便一点,无需登录到虚拟机内部 日志开启 [global] fsid 406…...

go-Casbin使用
本次测试代码是基于单租户的RBAC鉴权 依赖 github.com/casbin/casbin/v2 github.com/casbin/gorm-adapter/v2文件存储规则文件 model.pml [request_definition] r sub, obj, act[policy_definition] p sub, obj, act[role_definition] g _, _ # 用户,角色[polic…...

基于YOLOv11的106种手语识别分析系统
基于YOLOv11的手语识别分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】多平台适配优化,支持Windows、macOS和Linux系统,确保中文字体正常渲染 【四】识别的类别数量:106种,具体类…...

CentOS创建swap内存
服务器版本为CentOS7 一、检查现有 swap 空间 sudo swapon --show如果系统中没有 swap 空间或者现有的 swap 空间不足,可以继续后续步骤来创建 swap 空间。 二、创建 swap 文件(推荐 2GB 作为示例) sudo dd if/dev/zero of/swapfile bs1M …...

OpenHarmony OS 5.0与Android 13显示框架对比
1. 架构概述 1.1 OpenHarmony OS 5.0架构 OpenHarmony OS 5.0采用分层架构设计,图形显示系统从底层到顶层包括: 应用层:ArkUI应用和第三方应用框架层:ArkUI框架、窗口管理API系统服务层:图形合成服务、窗口管理服务…...
函数)
详解Node.js中的setImmediate()函数
setImmediate() 是 Node.js 提供的一个定时器函数,用于在 事件循环的 “Check” 阶段 执行回调函数。它与 setTimeout() 相似,但两者有着显著的区别,主要体现在回调函数的执行时机上。 什么是事件循环(Event Loop) 在…...

使用C#写的HTTPS简易服务器
由于监控网络之用,需要写一个https服务器。 由于用到https,因此还需一个域名证书,可以免费申请,也可以用一个现有的。 接下来还需在Windows上安装证书,注册证书。 安装证书 找到证书,点击,一路…...

C# 事件知识文档
C# 事件知识文档 概述 在 C# 中,事件(Event) 是一种特殊的机制,它基于委托实现,用于支持发布-订阅模式。事件允许对象在发生特定操作时通知其他对象,而无需直接引用这些对象。这种机制非常适合于实现诸如用户界面交互、状态变化通知等场景。 核心概念 发布者(Publishe…...

C++进阶--二叉搜索树
文章目录 C进阶--二叉搜索树概念算法复杂度模拟实现结构定义插入查找删除剩余的次要接口中序遍历: 构造,析构,拷贝构造,赋值重载 结语 很高兴和大家见面,给生活加点impetus!!开启今天的编程之路…...

互联网大厂Java面试:从基础到进阶的技术点探讨
场景:赵大宝的面试旅程 在互联网大厂的面试现场,严肃的面试官李老师正在准备对求职者赵大宝进行一场Java技术栈的深度考核。赵大宝是一位以幽默著称的程序员,面试官希望通过这次面试能全面了解他的技术能力。 第一轮提问 李老师࿱…...
:MCP动态服务器高级应用)
【MCP Node.js SDK 全栈进阶指南】中级篇(1):MCP动态服务器高级应用
前言 在初级篇中,我们已经掌握了MCP TypeScript-SDK的基础知识,包括开发环境搭建、基础服务器开发、资源开发、工具开发、提示模板开发以及传输层配置等核心内容。随着我们对MCP的理解不断深入,是时候进入更高级的应用场景了。 MCP的一个强大特性是其动态性,能够在运行时…...

LM35 温度传感器介绍
【本文基于Arduino项目】 1. LM35 温度传感器简介 LM35 是一款 精密模拟温度传感器,由德州仪器(TI)推出,具有线性输出、无需校准、低功耗等特点,广泛应用于环境监测、工业控制等领域。 主要特性 参数规格测量范围-…...

【网络应用程序设计】实验一:本地机上的聊天室
个人博客:https://alive0103.github.io/ 代码在GitHub:https://github.com/Alive0103/XDU-CS-lab 能点个Star就更好了,欢迎来逛逛哇~❣ 主播写的刚够满足基本功能,多有不足,仅供参考,还请提PR指正ÿ…...

Cursor 设置规则
文章目录 1、一个可以参考的网站-各种语言都有2、正向设置规则通过 符号还可以引用子规则 3、逆向设置规则 1、一个可以参考的网站-各种语言都有 https://cursor.directory/rules 2、正向设置规则 注意,最开始规则设置已经作废(下图下面的红框&#…...
)
人工智能-模型评价与优化(过拟合与欠拟合,数据分离与混淆矩阵,模型优化,实战)
欠拟合与过拟合 模型不合适,导致其无法与数据实现有效预测 欠拟合可以通过观察训练数据及时发现,通过优化模型结果解决 过拟合的原因: 1、模型结构过于复杂(维度太高) 2、使用了过多属性,模型训练时包含了…...