人工智能-模型评价与优化(过拟合与欠拟合,数据分离与混淆矩阵,模型优化,实战)
欠拟合与过拟合
模型不合适,导致其无法与数据实现有效预测
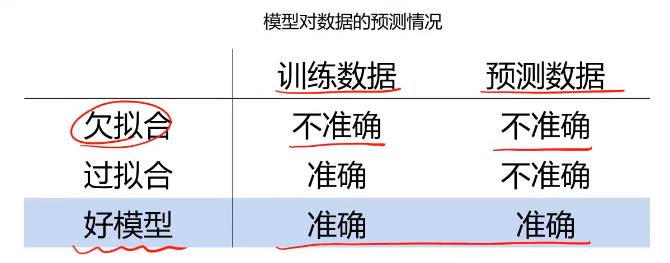
欠拟合可以通过观察训练数据及时发现,通过优化模型结果解决
过拟合的原因:
1、模型结构过于复杂(维度太高)
2、使用了过多属性,模型训练时包含了干扰项信息
过拟合的解决方法:
1、简化模型(使用低阶模型,如线性模型)
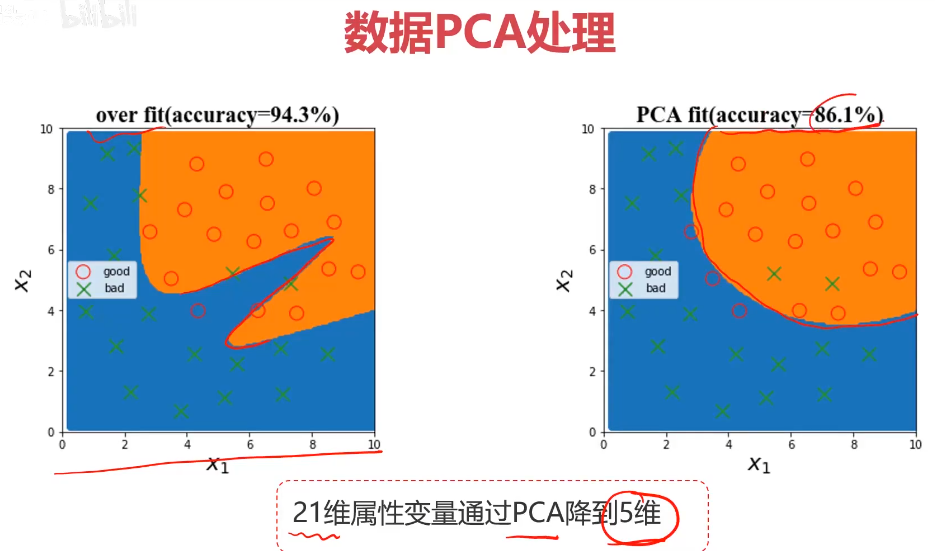
2、数据预处理,保留主成分信息(PCA处理)
3、训练时增加正则化项(regularization)

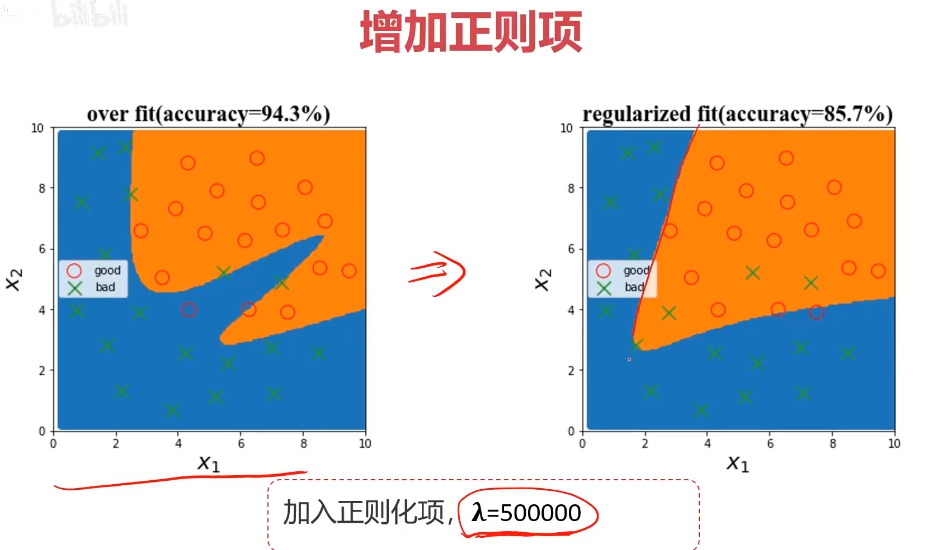
正则项越大,参数的数值就会变小,对应的值,影响就会变小,就更平滑。
数据分离与混淆矩阵
数据分离:
建立模型的意义,不在于对训练数据做出准确预测,而在于对新数据的准确预测
对全数据进行数据分离,部分用于训练,部分用于预测。(训练集,测试集)
混淆矩阵:
局限性:无法真实反映模型针对各个分类的预测准确度
例子:900个1,100个0的数据集。
模型1:850个1,50个0,准确率90%
模型2:全都是1,准确率90%。(空准确率)
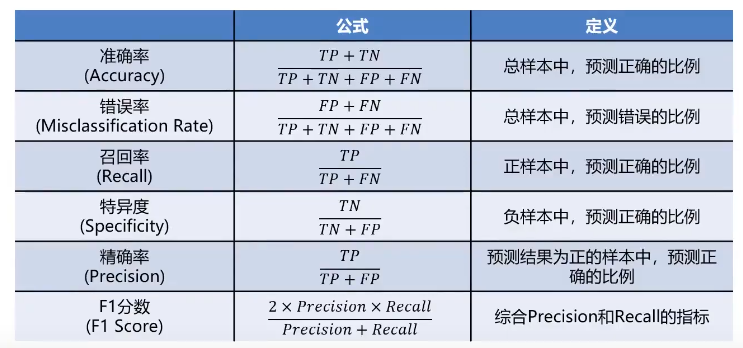
准确率可以方便用于衡量模型的整体预测效果,但无法反应细节信息,具体表现在:
1、没有体现数据预测的实际分布情况
2、没有体现模型错误预测的类型
混淆矩阵
混淆矩阵,又称为误差矩阵,用于衡量分类算法的准确程度
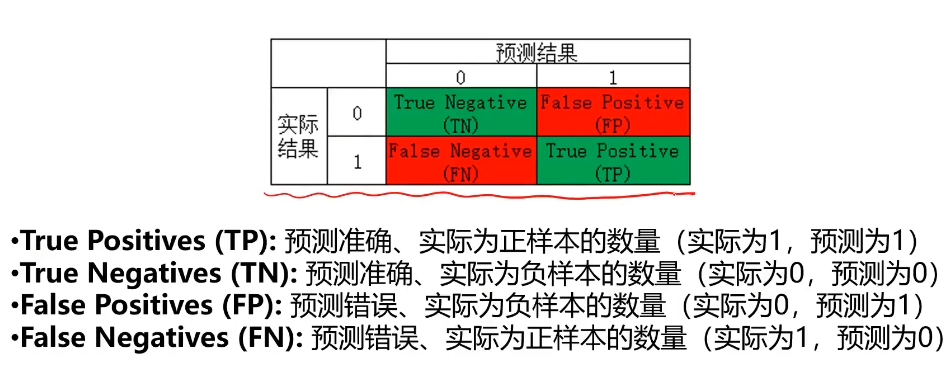
混淆矩阵指标特点:
1、分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息
2、通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型
哪个衡量指标更关键?
1、衡量指标的选择取决于应用场景
2、垃圾邮件检测,需精确率和召回率(希望垃圾邮箱尽可能多被判断出来)
3、异常交易检测,还需要特异度
模型优化
任务:根据检测数据x1,x2及其标签,判断x1=6,x2=4时所属类别
问题1:用什么算法?
如:逻辑回归,KNN,决策树,神经网络
问题2:具体算法的核心结构或参数如何选择?
如:逻辑回归边界函数用什么?线性、多项式?
KNN的核心参数n_neighbors取多少合适?
问题3:模型表现不佳,怎么办?
如:训练数据准确率太低,测试数据准确率下降明显,召回率/特异度/精确率低
数据的重要性:
数据的质量决定模型表现的上限!
Always check:
1、数据属性的一样,是否为无关数据
2、不同属性数据的数量级差异性如何
3、是否有异常数据
4、采集数据的方法是否合理,采集到的数据是否有代表性
5、对于标签结果,要确保标签判定规则的一致性(统一标准)
Always try:
1、删除不必要的属性
2、数据预处理:归一化、标准化
3、确定是否保留或过滤掉异常数据
4、尝试不同的模型,对比模型表现
Benefits:
1、减少过拟合,节约运算时间
2、平衡数据影响,加快训练收敛
3、提高鲁棒性
4、帮助确定更合适的模型
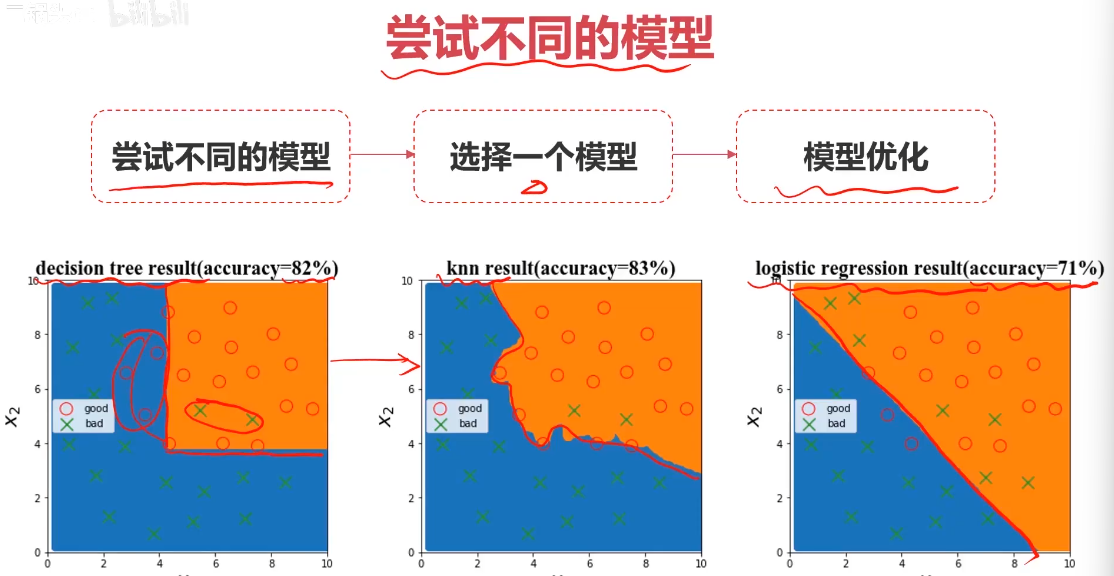
模型优化的目的:
在确定模型后,如何让模型表现更好
三方面:数据,模型核心参数,正则化
尝试以下方法:
1、遍历核心参数组合,评估对应模型表现(比如回归边界函数考虑多项式、KNN尝试不同的n_neighbors值)
2、扩大数据样本
3、增加或减少数据属性
4、对数据进行降维处理
5、对模型进行正则化处理,调整正则项 入 入 入 的数值
模型关键参数选择:
选择使用KNN模型,尝试不同n_neighbors值对结果的影响
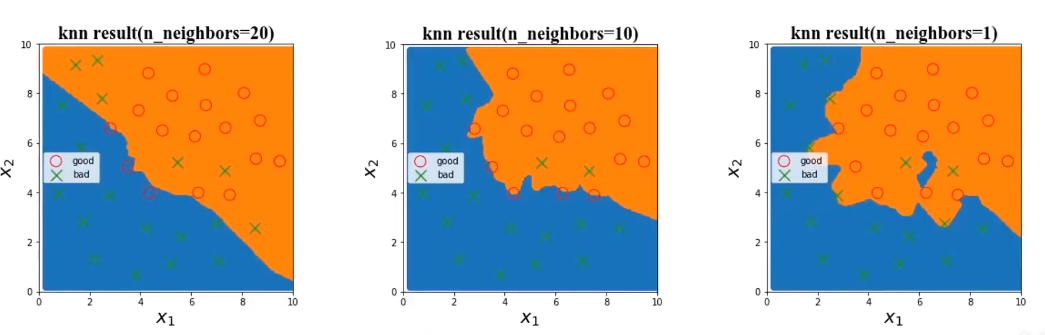
1、KNN模型中,模型复杂度由n_neighbors值决定
2、n_neighbors值越小,模型复杂度越高
训练数据集准确率随着模型复杂而提高
测试数据集准确率在模型过于简单或过于复杂的情况时下降
实战
实战(1):酶活性预测:
生成新数据并用于预测:
X_range = np.linspace(40,90,300).reshape(-1,1)
y_range_predict = lr1.predict(X_range)
linspace 函数的作用:
生成40~90的300个数据
reshape 函数的作用:
-1:表示让 NumPy 自动计算该维度的大小。在这种情况下,-1 表示让 NumPy 自动确定行数,以确保总元素数量保持不变。
1:表示将数组的列数设置为 1。
生成多项式(二次)数据:
from sklearn.preprocessing import
PolynomialFeatures
poly2 = PolynomialFeatures(degree=2)
X_2_train = poly2.fit_transform(X_train)
X_2_test = poly2.transform(X_test)
PolynomialFeatures(degree=2)生成最高项为2的多项式
实战(2):质量好坏预测
数据分离:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=4,test_size=0.4)
test_size=0.4:划分训练集和测试集的比例,训练6,测试4.
生成决策区域数据:
xx, yy = np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05))
x_range = np.c_[xx.ravel(),yy.ravel()]
y_range_predict = knn.predict(x_range)
np.c_ 的作用:
np.c_ 是 NumPy 中的一个工具,用于按列连接数组。
np.c_[xx.ravel(), yy.ravel()] 的结果是一个二维数组,其中每行是一个坐标点 (x,y)。
可视化决策区域:
bad_knn = plt.scatter(x_range[:,0][y_range_predict==0],x_range[:,1][y_range_predict==0])
good_knn = plt.scatter(x_range[:,0][y_range_predict==1],x_range[:,1][y_range_predict==1])
计算混淆矩阵:
from sklearn.metrics import confusion matrix
cm = confusion_matrix(y_test,y_test_predict)
TP = cm[1,1]
TN = cm[0,0]
FP = cm[0,1]
FN = cm[1,0]
计算召回率、特异度、精确率、F1分数:
recall = TP/(TP+FN)
specificity = TN/(TN+FP)
precision = TP/(TP+FP)
f1 = 2 * precision * recall / (precision+recall)
实战(1):酶活性预测
- 基于T-R-train.csv数据,建立线性回归模型,计算其在T-R-test.csv数据上的r2分数,可视化模型预测结果
- 加入多项式特征(2次,5次),建立回归模型
- 计算多项式回归模型对测试数据进行预测的r2分数,判断哪个模型预测更准确
- 可视化多项式回归模型数据预测结果,判断哪个模型预测更准确
#load the data
import pandas as pd
import numpy as np
data_train = pd.read('T-R-train.csv)
#define X_train and y_train
X_train = data_train.loc[:,'T']
y_train = data_train.loc[:,'rate']
#visual the data
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(10,10))
plt.scatter(X_train, y_train)
plt.title('raw data')
plt.xlabel('temperatrue')
plt.ylabel('rate')
plt.show()
X_train = np.array(X_train).reshape(-1,1)
#linear regression model prediction
from sklearn.linear_model import LinearRegression
lr1 = LinearRegression()
lr1.fit(X_train, y_train)
#load the test data
data_test = pd.read_csv('T-R-test.csv')
X_test = data_test.loc[:,'T']
y_test = data_test.loc[:,'rate']
X_test = np.array(X_test).reshape(-1,1)
#make prediction on the training and testing data
y_train_predict = lr1.predict(X_train)
y_test_predict = lr1.predict(X_test)
from sklearn.metrics import r2_score
r2_train = r2_score(y_train, y_train_predict)
r2_test = r2_score(y_test, y_test_predict)
print('training r2:', r2_train)
print('test r2:', r2_test)
#generate new data
X_range = np.linspace(40, 90, 300).reshape(-1,1)
y_range_predict = lr1.predict(X_range)
#visual the data
fig2 = plt.figure(figsize=(10,10))
plt.plot(X_range , y_range_predict )
plt.scatter(X_train, y_train)
plt.title('predoction data')
plt.xlabel('temperatrue')
plt.ylabel('rate')
plt.show()
#多项式模型
#generate new features
from sklearn.preprocessing import PolynomialFeatures
poly2 = PolynomialFeatures(degree=2)
X_2_train = poly2.fit_transform(X_train)
X_2_test = poly2.transform(X_test)
print(X_2_train)
lr2 = LinearRegression()
lr2.fit(X_2_train, y_train)
y_2_train_predict = lr2.predict(X_2_train)
y_2_test_predict = lr2.predict(X_2_test)
r2_2_train = r2_score(y_train, y_2_train_predict)
r2_2_test = r2_score(y_test, y_2_test_predict)
print('training r2_2:', r2_train)
print('test r2_2:', r2_test)
#generate new data
X_2_range = np.linspace(40, 90, 300).reshape(-1,1)
X_2_range = poly2.transform(X_2_range)
y_2_range_predict = lr2 .predict(X_2_range)
#visual the data
fig3 = plt.figure(figsize=(10,10))
plt.plot(X_range , y_2_range_predict )
plt.scatter(X_train, y_train)
plt.scatter(X_test, y_test)
plt.title('polynomial prediction result(2)')
plt.xlabel('temperatrue')
plt.ylabel('rate')
plt.show()
实战(2):质量好坏预测
1、基于data_class_raw.csv数据,根据高斯分布概率密度函数,寻找异常点并剔除
2、基于data_class_processed.csv数据,进行PCA处理,确定重要数据维度及成分
3、完成数据分离,数据分离参数:random_state=4,test_size=0.4
4、建立KNN模型完成分类,n_neighbors取10,计算分类准确率,可视化分类边界
5、计算测试数据集对应的混淆矩阵,计算准确率、召回率、特异度、精确率、F1分数
6、尝试不同的n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('data_class_raw.csv')
#data.head()
#define X and y
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
#visual the data
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])
plt.legend((good, bad),('good', 'bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
#anomay detection
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope(contamination=0.02)
ad_model.fit(X[y==0])
y_predict_bad = ad_model.predict(X[y==0])
print(y_predict_bad)
fig2 = plt.figure(figsize=(5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])
plt.scatter(X.loc[:,'x1'][y==0][y_predict_bad ==-1], X.loc[:,'x2'][y==0][y_predict_bad==-1],marker='x',s=150)
plt.legend((good, bad),('good', 'bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
#load the data
data = pd.read_csv('data_class_processed.csv')
data.head()
#define X and y
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
#pca
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
X_norm = StandardScaler().fit_transform(X)
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X_norm)
var_ratio = pca.explained_variance_ratio_
print(var_ratio)
fig4 = plt.figure(figsize=(5,5))
plt.bar([1,2],var_ratio)
plt.show()
#train and test split: random_state=4, test_size=0.4
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4,test_size=0.4)
print(X_train.shape,X_test.shape,X.shape)
#knn model
from sklearn.neighbors import KNeighborsClassifier
knn_10 = KNeighborsClassifier(n_neighbors=10)
knn_10.fit(X_train,y_train)
y_train_predict = knn_10.predict(X_train)
y_test_predict = knn_10.predict(X_test)
#calculate the accuracy
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train, y_train_predict)
accuracy_test = accuracy_score(y_test, y_test_predict)
print("training accuracy:", accuracy_train)
print("testing accuracy:", accuracy_test)
#visualize the knn result and baundary
xx, yy = np.meshgrid(np.arrange(0,10,0.05),np.arrange(0,10,0.05))
x_range = np.c_[xx.ravel(),yy.ravel()]
#print(x_range.shape)
y_range_predict = knn_10.predict(x_range)
fig4 = plt.figure(figsize=(10,10))
knn_bad = plt.scatter(x_range.loc[:,0][y_range_predict ==0], x_range.loc[:,1][y_range_predict ==0])
knn_good = plt.scatter(x_range.loc[:,0][y_range_predict ==1], x_range.loc[:,1][y_range_predict ==1])
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])
plt.legend((good, bad),('good', 'bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_test_predict)
#print(cm)
TP = cm[1,1]
TN = cm[0,0]
FP = cm[0,1]
FN = cm[1,0]
#print(TP,TN,FP,FN)
accuracy = (TP+TN)/(TP+TN+FP+FN)
recall = TP/(TP+FN)
specificity = TN/(TN+FP)
precision = TP/(TP+FP)
f1 = 2*precision*recall/(precision+recall)
#try different k and calculate the accuracy for each
n = [i for i in range(1,21)]
accuracy_train = []
accuracy_test = []
for i in n:knn = KNeighborsClassifier(n_neighbors=i)knn.fit(X_train,y_train)y_train_predict = knn.predict(X_train)y_test_predict = knn.predict(X_test)accuracy_train_i = accuracy_score(y_train,y_train_predict)accuracy_test_i = accuracy_score(y_test,y_test_predict)accuracy_train.append(accuracy_train_i)accuracy_test.appedn(accuracy_test_i)
print(accuracy_train,accuracy_test)
#visual
fig5 = plt.figure(figsize=(12,5))
plt.subplot(121)
plt.plot(n, accuracy_train,marker='0')
plt.title('training accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.tlabel('accuracy')
plt.subplot(122)
plt.plot(n, accuracy_test,marker='0')
plt.title('testing accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.tlabel('accuracy')
plt.show()
相关文章:
)
人工智能-模型评价与优化(过拟合与欠拟合,数据分离与混淆矩阵,模型优化,实战)
欠拟合与过拟合 模型不合适,导致其无法与数据实现有效预测 欠拟合可以通过观察训练数据及时发现,通过优化模型结果解决 过拟合的原因: 1、模型结构过于复杂(维度太高) 2、使用了过多属性,模型训练时包含了…...

Python爬虫从入门到实战详细版教程
Python爬虫从入门到实战详细版教程 文章目录 Python爬虫从入门到实战详细版教程书籍大纲与内容概览第一部分:爬虫基础与核心技术1. 第1章:[爬虫概述](https://blog.csdn.net/qq_37360300/article/details/147431708?spm=1001.2014.3001.5501)2. 第2章:HTTP协议与Requests库…...

Java多线程编程初阶指南
目录 一.线程基础概念 线程是什么? 线程与进程对比 为啥要有线程 二.线程实现方式 继承Thread类 实现Runnable接口 常规实现方式 匿名内部类写法 Lambda表达式写法(Java8) 对比总结 三.Thread 类及常见方法 核心功能 核心构造方…...

Qt信号槽连接的三种方法对比
信号槽连接方法对比 1. 直接连接2. 集中管理3.函数指针初始化列表后期需要disconnect 对比 1. 直接连接 connect(codeWindow, &CodeEditorWindow::SetBaseLineSignal, monitoringWindow, &MonitoringWindow::SetBaseLineSlot),connect(&ButtonTree::Instance(), &a…...

健康生活新指南
在 “朋克养生” 与 “躺平焦虑” 并存的时代,真正的健康生活无需刻意 “内卷”。这几个简单又实用的养生妙招,能让你在忙碌日常中悄悄升级健康状态,轻松拥抱活力人生。 一、饮食:吃对食物,给身体 “加 Buff” 别…...

IF=24.5 靶向MMP9治疗协同提高抗PD1疗效
Targeted MMP9 therapy synergistically improves anti-PD1 efficacy CTNNB1GOF(The gain of function (GOF) CTNNB1 mutations,功能获得型CTNNB1突变)在肝细胞癌(HCC)中,已被证明与免疫排斥相关࿰…...

基于SpringBoot的中华诗词文化分享平台-项目分享
基于SpringBoot的中华诗词文化分享平台-项目分享 项目介绍项目摘要管理员功能图会员功能图系统功能图项目预览会员主页面诗词页面发布问题回复评论 最后 项目介绍 使用者:管理员、会员 开发技术:MySQLJavaSpringBootVue 项目摘要 本文旨在设计与实现一…...
详细操作)
SQLiteDatabase 增删改查(CRUD)详细操作
文章目录 1. 初始化数据库2. 插入数据 (Create)方法一:使用 ContentValues insert()方法二:直接执行SQL 3. 查询数据 (Read)方法一:使用 query() 方法方法二:使用 rawQuery() 执行原始SQL 4. 更新数据 (Update)方法一:…...

从 0 到 1 打通 AI 工作流:Dify+Zapier 实现工具自动化调用实战
一、引言:当 AI 遇到工具孤岛 在企业数字化转型的浪潮中,AI 工具的应用早已从单一的对话交互进阶到复杂的业务流程自动化。但开发者常常面临这样的困境:本地开发的 MCP 工具(如 ERP 数据清洗脚本、CRM 工单系统 API)如…...

第四届商师校赛 web 1
RceMe ezGame 伪装 Ping Are you from SQNU? Look for the homepage Through 根据题目慢慢试 File_download Post上传得到下载文件 反编译一下 /* * Decompiled with CFR 0.152. * * Could not load the following classes: * javax.servlet.http.HttpServlet */ …...

SSH 互信被破坏能导致 RAC 异常关闭吗
一、 SSH 互信和 RAC 的关系 1、SSH 互信对 RAC 的作用 Oracle 11g R2 在安装 Grid Infrastructure 的时候,能够通过安装程序配置节 点间的 SSH 用户等效性,之所以要在安装之前配置 SSH 用户等效性,是为了能 够在安装前使用 C…...
)
工程投标k值分析系统(需求和功能说明)
1 需求总括 2 企业管理模块: 新增、删除、修改企业/部门 <...

Qt-托盘的实现
文章目录 托盘的功能QSystemTrayIcon 类QSystemTrayIcon类的常用函数代码实现 托盘的功能 GUI 程序,如果想要实现当最小化时,程序从任务栏消失,在系统托盘显示一个图标,表示此程序,并能在托盘内通过双击或者菜单使程序…...

【人脸识别】百度人脸识别H5方案对接
经调研,百度的人脸识别使用场景比较广泛且准确率较高,项目上有用到,这里做一下记录,整体对接没有难度,按照文档操作就行。 一、准备工作 1、需要注册百度云开放平台(企业资质)注册指南 2、创…...

用Qt和deepseek创建自己的问答系统
如果你不想花钱调用deepseek,试试下面的方法。 1: 访问 OpenRouter: https://openrouter.ai 2: 搜索 DeepSeek-R1 (free) 要使用这个免费模型,你需要: (1)注册 OpenRouter 账户并获取 API 密钥 访问 …...

飞搭系列 | 组件增加标记,提升用户体验
前言 Preface 飞搭低代码平台(FeiDa,以下简称“飞搭”),为企业提供在线化、灵活的业务应用构建工具,支持高低代码融合,助力企业低门槛、高效率和低成本地快速应对市场变化,加速复杂业务场景落地…...

布隆过滤器的应用
布隆过滤器虽然看起来是一个“算法结构”,但在实际 Web 应用场景中用途非常广泛,尤其在 提升性能、节省资源、防御攻击 等方面非常有用。 缓存穿透保护(常见于 Redis) 📌 问题: 用户频繁请求一些数据库中…...
)
云原生--基础篇-4--CNCF-1-云原生计算基金会(云原生生态发展和目标)
1、CNCF定义与背景 云原生计算基金会(Cloud Native Computing Foundation,CNCF)是由Linux基金会于2015年12月发起成立的非营利组织,旨在推动云原生技术的标准化、开源生态建设和行业协作。其核心目标是通过开源项目和社区协作&am…...
VTK C++开发示例 --- 转换文件格式)
(16)VTK C++开发示例 --- 转换文件格式
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 此示例演示如何读取文件,然后将其写入不同类型的文件。 在此示例中,我们读取一个 vtp 文件并…...

离线-DataX
基本介绍 DataX 是阿里云 DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台,它是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源…...

深度学习-全连接神经网络-3
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...
)
基于javaweb的SSM+Maven教材管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

DCL介绍
一.dcl-介绍 一.案例 1.查询用户 USE mysql; select * from user; 2.权限控制...

mysql日常巡检
1.查看mysql服务是否异常 systemctl status mysql_3306 查看MySQL进程是否存在 ps -ef | grep mysql 2.连接异常检查 (1)查看是否异常连接 show processlist; #或 show full processlist; (2)查看当前失败连接数 show global status like aborted_connects; (3)查看试…...

Cursor这类编程Agent软件的模型架构与工作流程
开发|界面|引擎|交付|副驾——重写全栈法则:AI 原生的倍速造应用流 来自全栈程序员 nine 的探索与实践,持续迭代中。 欢迎评论私信交流。 最近在关注和输出一系列 AIGC 架构。 模型架构与工作流程 大语…...

记录:扩展欧几里得算法
本文遵循 CC BY-NC-ND 4.0 协议,作者: U•ェ•*U \texttt{U•ェ•*U} U•ェ•*U,转载请获得作者授权。 前置知识 裴蜀定理/贝祖定理:若 a , b a,b a,b 是整数,且 gcd ( a , b ) d \gcd(a,b)d gcd(a,b)d…...

学习笔记——《Java面向对象程序设计》-抽象和接口
参考教材: Java面向对象程序设计(第3版)微课视频版 清华大学出版社 抽象方法 抽象方法是使用abstract关键字修饰的成员方法,抽象方法在定义时不需要实现方法体。 抽象方法的定义格式如下: abstract void 方法名称…...

MySQL中根据binlog日志进行恢复
MySQL中根据binlog日志进行恢复 排查 MySQL 的 binlog 日志问题及根据 binlog 日志进行恢复的方法一、引言二、排查 MySQL 的 binlog 日志问题(一)确认 binlog 是否开启(二)查找 binlog 文件位置和文件名模式(三&#…...

数据库sql语句 中 GROUP BY 关键字详解及字段要求
GROUP BY 关键字详解及字段要求 GROUP BY 的核心作用 将查询结果按指定字段分组,常与聚合函数(如 COUNT, SUM, AVG 等)结合使用,对分组后的数据进行统计计算。 GROUP BY 后字段的要求 非聚合字段必须出现在 GROUP BY 子句中&…...

数据集 | 柑橘果目标检测数据集
文章目录 一、数据集概述1.1 数据标注实例1.2 数据集技术规格 二、样本类别详解2.1 树上柑橘样本2.2 树下柑橘样本 三、标注工具四、数据下载地址 一、数据集概述 在农业智能化领域,柑橘果园的自动化监测与管理一直面临着几个关键挑战: 果实定位准确性…...

Arduino示例代码讲解:Project 11 - Crystal Ball 水晶球
Arduino示例代码讲解:Project 11 - Crystal Ball 水晶球 Project 11 - Crystal Ball 水晶球程序功能概述功能:硬件要求:输出:代码结构全局变量`setup()` 函数`loop()` 函数读取倾斜开关状态:检测状态变化:保存状态:运行过程注意事项Project 11 - Crystal Ball 水晶球 /…...

Redis—为何持久化使用子进程
AOF重写以及bgsave的时候为什么采用fork子进程而不是子线程? 进程间内存隔离 独立的内存空间:子进程拥有与主进程独立的内存空间,确保即使在重写过程中发生崩溃或错误,也不会影响主进程的运行和内存状态。 数据安全性ÿ…...

Vue3 + Vite + TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码
Vue3 Vite TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码 ExcelJS生成文档并导出导出表头其他函数 生成水印设置文档的背景水印dom 转图片插入图片全部代码 ExcelJS 读取&#…...

VulnHub-DarkHole_1靶机渗透教程
VulnHub-DarkHole_1靶机渗透教程 1.靶机部署 [Onepanda] Mik1ysomething 靶机下载:https://download.vulnhub.com/darkhole/DarkHole.zip 直接使用VMware打开就行 导入成功,打开虚拟机,到此虚拟机部署完成! 注意:…...

Python设计模式:对象池
1. 什么是对象池设计模式? 对象池设计模式是一种创建型设计模式,主要用于管理和复用对象,以提高性能和资源利用率。它通过维护一个对象的集合(池),来避免频繁地创建和销毁对象,从而减少内存分配…...

【上海大学数据库原理实验报告】MySQL数据库的C/S模式部署
实验目的 掌握Linux环境下MySQL数据库的安装、初始化和基本配置。通过配置MySQL的网络通信,熟悉数据库的远程访问机制及其安全性要求。 实验内容 在腾讯云上租借两台服务器,打开3306端口以允许MySQL远程访问。 图 1 租到的服务器可在控制台观察其状态…...

deepseek快速生成简历
目录 一、需求二、模板例子 三、生成简历四、其他说明 一、需求 现在我准备跳槽到一家公司,这家公司已经发布了招聘需求,现在你想跳槽到这家公司,我们可以利用deepseek快速生成符合这家公司的简历内容。 二、模板 我们要进行指令明确的结构…...

什么是机器视觉3D无序堆叠抓取
机器视觉3D无序堆叠抓取是一种结合三维视觉感知、人工智能算法和机器人控制的技术,旨在从杂乱无序堆叠的物体中识别、定位并抓取目标物体。该技术广泛应用于工业自动化(如物流分拣、装配制造)、仓储管理、食品加工等领域,解决了传统二维视觉或固定规则堆叠场景下的抓取难题…...

Shell脚本中的字符串截取和规则变化
文章目录 前言if通配符判断if判断多个条件规则变化字符串的两个示例改变中间段数字改变末尾段数字 总结 前言 科技的发展会带来习惯的改变,特别是对于我们这批敲代码的,之前还积累一些奇巧淫技,想着在必要的时候卖弄一下,自从生成…...

云账号安全事件应急响应指南:应对来自中国IP的异常访问
在当今数字化时代,云服务已成为企业IT基础设施的核心。然而,随之而来的安全挑战也日益突出。本文将详细介绍当发现云账号被来自中国的IP地址异常利用时,应如何快速有效地响应,以确保账户安全并最小化潜在风险。 1. 确认异常活动 首先,我们需要确认是否真的发生了安全事件…...

python番外
#作者:允砸儿 #日期:乙巳青蛇年 三月廿五 在开始数据库的分享之前笔者简单写以下关于python的番外。笔者这块可能写的不是很好csdn上面有很多大佬,笔者仅以自己的思维和想法与大家分享以下。 安装必看 笔者在这里贴一个网址https://www.…...

Jetson Orin NX 16G 配置GO1强化学习运行环境
这一次收到了Jrtson Orin NX, 可以进行部署了。上一次在nano上的失败经验 Jetson nano配置Docker和torch运行环境_jetson docker-CSDN博客 本次的目的是配置cuda-torch-python38环境离机运行策略。 Jetson Orin NX SUPER 1. 烧录镜像 参考链接在ubuntu系统中安装sdk manag…...

Embedding与向量数据库__0422
thinking:做一个项目 1,业务背景,价值 2,方法,工具 3,实践(现有的代码,改写的代码) cursor编程有个cursor settings ->privacy mode隐私模式,但是只要连上…...

正向代理和反向代理
正向代理和反向代理是两种在不同场景下使用的代理技术,它们有以下区别: 目标和作用 正向代理 目标 :主要是为客户端服务,帮助客户端去访问外部网络资源。例如,企业内部网络中的员工可能需要访问互联网,但直…...

Android JNI开发中头文件引入的常见问题与解决方案,提示:file not found
Android JNI开发中头文件引入的常见问题与解决方案 问题场景(新手易犯错误) 假设你在开发一个JNI项目,想要实现一个线程安全的队列(SafeQueue),于是直接在cpp目录下创建了safe_queue.h文件,并开…...
:Node.js 服务端核心逻辑实现)
三网通电玩城平台系统结构与源码工程详解(二):Node.js 服务端核心逻辑实现
本篇文章将聚焦服务端游戏逻辑实现,以 Node.js Socket.io 作为主要通信与逻辑处理框架,展开用户登录验证、房间分配、子游戏调度与事件广播机制的剖析,并附上多个核心代码段。 一、服务端文件结构概览 /server/├── index.js …...
)
案例:Windows 作为客户端免密验证(公钥验证)
一、实验前提 1.服务器端为 Linux 系统,且能够正常运行相关命令和服务,如 systemctl、ssh 服务等。同时,客户端为 Windows 系统,且具备使用 SSH 客户端工具连接到 Linux 服务器的条件 2.Linux 服务器上已安装并配置好 SSH 服务&…...

leetcode 二分查找
704. Binary Search 代码: class Solution { public:int search(vector<int>& nums, int target) {int n nums.size();int left 0;int right n-1;int res -1;while(left < right){int mid (leftright)/2;if(nums[mid] target){res mid;break;}…...

C++:STL模板
STL模板分为函数模板和类模板。 我想交换两个数字,但是类型不同,例如我想交换整形a,b,和double类型的d1,d2。如果使用C语言来实现,那么需要像下面一样写两个swap函数,但是除了类型不同,其它都一样…...

NumPy入门:从数组基础到数学运算
目录 一、NumPy 数组基础 (一)创建数组 (二)数组索引 (三)数组切片 二、数组操作 (一)形状操作 (二)数组合并与分割 三、基本数学运算 (…...