深度学习-全连接神经网络-3
七、过拟合与欠拟合
在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。
1. 概念认知
这里我们简单的回顾下过拟合和欠拟合的基本概念~
1.1 过拟合
过拟合是指模型对训练数据拟合能力很强并表现很好,但在测试数据上表现较差。
过拟合常见原因有:
-
数据量不足:当训练数据较少时,模型可能会过度学习数据中的噪声和细节。
-
模型太复杂:如果模型很复杂,也会过度学习训练数据中的细节和噪声。
-
正则化强度不足:如果正则化强度不足,可能会导致模型过度学习训练数据中的细节和噪声。
举个例子: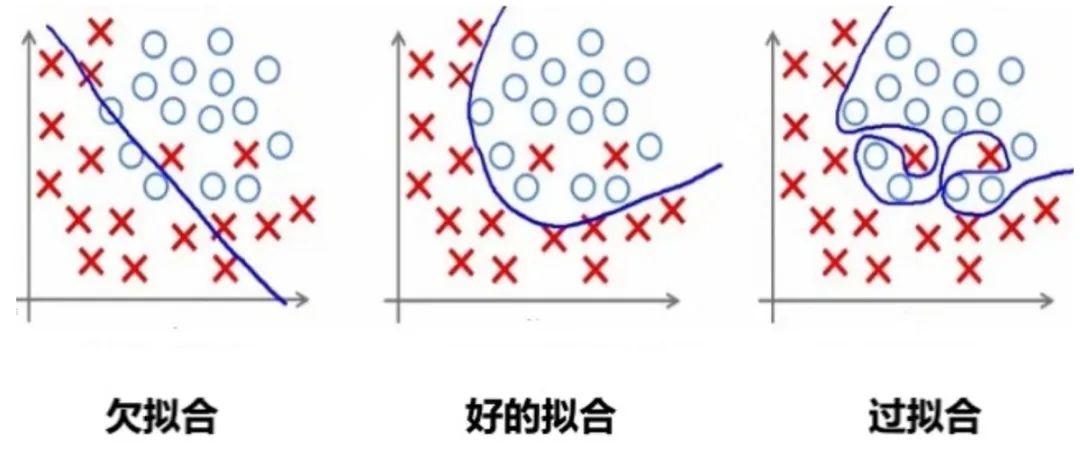
1.2 欠拟合
欠拟合是由于模型学习能力不足,无法充分捕捉数据中的复杂关系。
1.3 如何判断
那如何判断一个错误的结果是过拟合还是欠拟合呢?
过拟合
训练误差低,但验证时误差高。模型在训练数据上表现很好,但在验证数据上表现不佳,说明模型可能过度拟合了训练数据中的噪声或特定模式。
欠拟合
训练误差和测试误差都高。模型在训练数据和测试数据上的表现都不好,说明模型可能太简单,无法捕捉到数据中的复杂模式。
2. 解决欠拟合
欠拟合的解决思路比较直接:
-
增加模型复杂度:引入更多的参数、增加神经网络的层数或节点数量,使模型能够捕捉到数据中的复杂模式。
-
增加特征:通过特征工程添加更多有意义的特征,使模型能够更好地理解数据。
-
减少正则化强度:适当减小 L1、L2 正则化强度,允许模型有更多自由度来拟合数据。
-
训练更长时间:如果是因为训练不足导致的欠拟合,可以增加训练的轮数或时间.
3. 解决过拟合
避免模型参数过大是防止过拟合的关键步骤之一。
模型的复杂度主要由权重w决定,而不是偏置b。偏置只是对模型输出的平移,不会导致模型过度拟合数据。
怎么控制权重w,使w在比较小的范围内?
考虑损失函数,损失函数的目的是使预测值与真实值无限接近,如果在原来的损失函数上添加一个非0的变量
其中是关于权重w的函数,
要使L1变小,就要使L变小的同时,也要使f(w)变小。从而控制权重w在较小的范围内。
3.1 L2正则化
L2 正则化通过在损失函数中添加权重参数的平方和来实现,目标是惩罚过大的参数值。
3.1.1 数学表示
设损失函数为 ,其中
表示权重参数,加入L2正则化后的损失函数表示为:
其中:
-
是原始损失函数(比如均方误差、交叉熵等)。
-
是正则化强度,控制正则化的力度。
-
是模型的第 i 个权重参数。
-
是所有权重参数的平方和,称为 L2 正则化项。
L2 正则化会惩罚权重参数过大的情况,通过参数平方值对损失函数进行约束。
为什么是?
假设没有1/2,则对L2 正则化项\theta_i的梯度为:2\lambda\theta_i,会引入一个额外的系数 2,使梯度计算和更新公式变得复杂。
添加1/2后,对的梯度为:
。
3.1.2 梯度更新
在 L2 正则化下,梯度更新时,不仅要考虑原始损失函数的梯度,还要考虑正则化项的影响。更新规则为:
其中:
-
是学习率。
-
是损失函数关于参数
的梯度。
-
是 L2 正则化项的梯度,对应的是参数值本身的衰减。
很明显,参数越大惩罚力度就越大,从而让参数逐渐趋向于较小值,避免出现过大的参数。
3.1.3 作用
-
防止过拟合:当模型过于复杂、参数较多时,模型会倾向于记住训练数据中的噪声,导致过拟合。L2 正则化通过抑制参数的过大值,使得模型更加平滑,降低模型对训练数据噪声的敏感性。
-
限制模型复杂度:L2 正则化项强制权重参数尽量接近 0,避免模型中某些参数过大,从而限制模型的复杂度。通过引入平方和项,L2 正则化鼓励模型的权重均匀分布,避免单个权重的值过大。
-
提高模型的泛化能力:正则化项的存在使得模型在测试集上的表现更加稳健,避免在训练集上取得极高精度但在测试集上表现不佳。
-
平滑权重分布:L2 正则化不会将权重直接变为 0,而是将权重值缩小。这样模型就更加平滑的拟合数据,同时保留足够的表达能力。
3.1.4 代码实现
代码实现如下:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 设置随机种子以保证可重复性
torch.manual_seed(42)# 生成随机数据
n_samples = 100
n_features = 20
X = torch.randn(n_samples, n_features) # 输入数据
y = torch.randn(n_samples, 1) # 目标值# 定义一个简单的全连接神经网络
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(n_features, 50)self.fc2 = nn.Linear(50, 1)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)# 训练函数
def train_model(use_l2=False, weight_decay=0.01, n_epochs=100):# 初始化模型model = SimpleNet()criterion = nn.MSELoss() # 损失函数(均方误差)# 选择优化器if use_l2:optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=weight_decay) # 使用 L2 正则化else:optimizer = optim.SGD(model.parameters(), lr=0.01) # 不使用 L2 正则化# 记录训练损失train_losses = []# 训练过程for epoch in range(n_epochs):optimizer.zero_grad() # 清空梯度outputs = model(X) # 前向传播loss = criterion(outputs, y) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数train_losses.append(loss.item()) # 记录损失if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{n_epochs}], Loss: {loss.item():.4f}')return train_losses# 训练并比较两种模型
train_losses_no_l2 = train_model(use_l2=False) # 不使用 L2 正则化
train_losses_with_l2 = train_model(use_l2=True, weight_decay=0.01) # 使用 L2 正则化# 绘制训练损失曲线
plt.plot(train_losses_no_l2, label='Without L2 Regularization')
plt.plot(train_losses_with_l2, label='With L2 Regularization')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss: L2 Regularization vs No Regularization')
plt.legend()
plt.show()3.2 L1正则化
L1 正则化通过在损失函数中添加权重参数的绝对值之和来约束模型的复杂度。
3.2.1 数学表示
设模型的原始损失函数为,其中
表示模型权重参数,则加入 L1 正则化后的损失函数表示为:
其中:
-
-
-
是模型第i 个参数的绝对值。
-
是所有权重参数的绝对值之和,这个项即为 L1 正则化项。
3.2.2 梯度更新
在 L1 正则化下,梯度更新时的公式是:
其中:
-
-
-
是参数
因为 L1 正则化依赖于参数的绝对值,其梯度更新时不是简单的线性缩小,而是通过符号函数来直接调整参数的方向。这就是为什么 L1 正则化能促使某些参数完全变为 0。
3.2.3 作用
-
稀疏性:L1 正则化的一个显著特性是它会促使许多权重参数变为 零。这是因为 L1 正则化倾向于将权重绝对值缩小到零,使得模型只保留对结果最重要的特征,而将其他不相关的特征权重设为零,从而实现 特征选择 的功能。
-
防止过拟合:通过限制权重的绝对值,L1 正则化减少了模型的复杂度,使其不容易过拟合训练数据。相比于 L2 正则化,L1 正则化更倾向于将某些权重完全移除,而不是减小它们的值。
-
简化模型:由于 L1 正则化会将一些权重变为零,因此模型最终会变得更加简单,仅依赖于少数重要特征。这对于高维度数据特别有用,尤其是在特征数量远多于样本数量的情况下。
-
特征选择:因为 L1 正则化会将部分权重置零,因此它天然具有特征选择的能力,有助于自动筛选出对模型预测最重要的特征。
3.2.4 与L2对比
-
L1 正则化 更适合用于产生稀疏模型,会让部分权重完全为零,适合做特征选择。
-
L2 正则化 更适合平滑模型的参数,避免过大参数,但不会使权重变为零,适合处理高维特征较为密集的场景。
3.2.5 代码实现
代码需要自己实现:
l1_lambda = 0.001
# 计算 L1 正则化项并将其加入到总损失中
l1_norm = sum(p.abs().sum() for p in model.parameters())
loss = loss + l1_lambda * l1_norm3.3 Dropout
Dropout 的工作流程如下:
-
在每次训练迭代中,随机选择一部分神经元(通常以概率 p丢弃,比如 p=0.5)。
-
被选中的神经元在当前迭代中不参与前向传播和反向传播。
-
在测试阶段,所有神经元都参与计算,但需要对权重进行缩放(通常乘以 1−p),以保持输出的期望值一致。
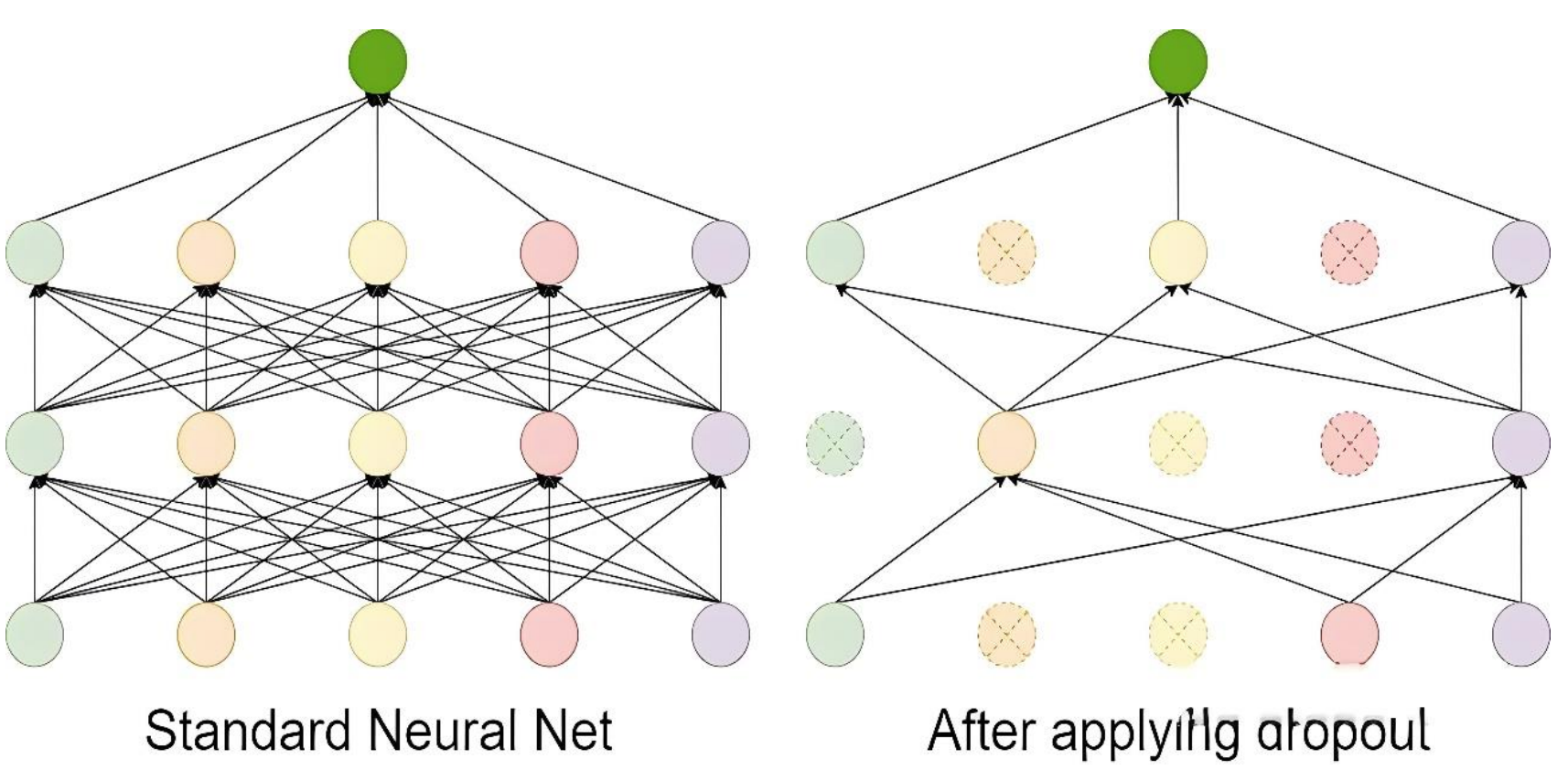
Dropout 是一种在训练过程中随机丢弃部分神经元的技术。它通过减少神经元之间的依赖来防止模型过于复杂,从而避免过拟合。
3.3.1 基本实现
import torch
import torch.nn as nndef dropout():dropout = nn.Dropout(p=0.5)x = torch.randint(0, 10, (5, 6), dtype=torch.float)print(x)# 开始dropoutprint(dropout(x))if __name__ == "__main__":dropout()
Dropout过程:
-
按照指定的概率把部分神经元的值设置为0;
-
为了规避该操作带来的影响,需对非 0 的元素使用缩放因子1/(1-p)进行强化。
假设某个神经元的输出为 x,Dropout 的操作可以表示为:
-
在训练阶段:
-
在测试阶段:
为什么要使用缩放因子1/(1-p)?
在训练阶段,Dropout 会以概率 p随机将某些神经元的输出设置为 0,而以概率 1−p 保留这些神经元。
假设某个神经元的原始输出是 x,那么在训练阶段,它的期望输出值为:
通过这种缩放,训练阶段的期望输出值仍然是 x,与没有 Dropout 时一致。
3.3.2 权重影响
import torch
import torch.nn as nndef test001():torch.manual_seed(0)w = torch.randn(12, 1, requires_grad=True)x = torch.randint(0, 8, (3, 12)).float()output = x @ woutput = output.sum()output.backward()print(w.grad.flatten())def test002():torch.manual_seed(0)dropout = nn.Dropout(0.8)w = torch.randn(12, 1, requires_grad=True)x = torch.randint(0, 8, (3, 12)).float()# 随机抛点x = dropout(x)print(x)output = x @ woutput = output.sum()output.backward()print(w.grad.flatten())if __name__ == "__main__":test001()test002()
输出结果:如果所有的数据的对应特征都为0,则参数梯度为0
tensor([12., 15., 12., 2., 8., 4., 8., 5., 13., 7., 10., 15.])
tensor([[ 0., 5., 25., 0., 0., 0., 0., 0., 15., 0., 15., 0.],[ 0., 0., 0., 0., 0., 15., 0., 0., 0., 0., 0., 0.],[30., 0., 0., 0., 5., 5., 0., 0., 0., 0., 0., 0.]])
tensor([30., 5., 25., 0., 5., 20., 0., 0., 15., 0., 15., 0.])示例:对图片进行随机丢弃
import torch
from torch import nn
from PIL import Image
from torchvision import transforms
import osfrom matplotlib import pyplot as plttorch.manual_seed(42)def load_img(path, resize=(224, 224)):pil_img = Image.open(path).convert('RGB')print("Original image size:", pil_img.size) # 打印原始尺寸transform = transforms.Compose([transforms.Resize(resize),transforms.ToTensor() # 转换为Tensor并自动归一化到[0,1]])return transform(pil_img) # 返回[C,H,W]格式的tensorif __name__ == '__main__':dirpath = os.path.dirname(__file__)path = os.path.join(dirpath, 'img', '100.jpg') # 使用os.path.join更安全# 加载图像 (已经是[0,1]范围的Tensor)trans_img = load_img(path)# 添加batch维度 [1, C, H, W],因为Dropout默认需要4D输入trans_img = trans_img.unsqueeze(0)# 创建Dropout层dropout = nn.Dropout2d(p=0.2)drop_img = dropout(trans_img)# 移除batch维度并转换为[H,W,C]格式供matplotlib显示trans_img = trans_img.squeeze(0).permute(1, 2, 0).numpy()drop_img = drop_img.squeeze(0).permute(1, 2, 0).numpy()# 确保数据在[0,1]范围内drop_img = drop_img.clip(0, 1)# 显示图像fig = plt.figure(figsize=(10, 5))ax1 = fig.add_subplot(1, 2, 1)ax1.imshow(trans_img)ax2 = fig.add_subplot(1, 2, 2)ax2.imshow(drop_img)plt.show()效果:

说明:
nn.Dropout2d(p):Dropout2d 是针对二维数据设计的 Dropout 层,它在训练过程中随机将输入张量的某些通道(二维平面)置为零。
| 参数 | 要求格式 | 示例形状 | 说明 |
|---|---|---|---|
| 输入 | (N, C, H, W) | (16, 64, 32, 32) | 批大小×通道×高×宽 |
| 输出 | (N, C, H, W) | (16, 64, 32, 32) | 与输入同形,部分通道归零 |
3.4 简化模型
-
减少网络层数和参数: 通过减少网络的层数、每层的神经元数量或减少卷积层的滤波器数量,可以降低模型的复杂度,减少过拟合的风险。
-
使用更简单的模型: 对于复杂问题,使用更简单的模型或较小的网络架构可以减少参数数量,从而降低过拟合的可能性。
3.5 数据增强
样本数量不足(即训练数据过少)是导致过拟合(Overfitting)的常见原因之一,可以从以下角度理解:
-
当训练数据过少时,模型容易“记住”有限的样本(包括噪声和无关细节),而非学习通用的规律。
-
简单模型更可能捕捉真实规律,但数据不足时,复杂模型会倾向于拟合训练集中的偶然性模式(噪声)。
-
样本不足时,训练集的分布可能与真实分布偏差较大,导致模型学到错误的规律。
-
小数据集中,个别样本的噪声(如标注错误、异常值)会被放大,模型可能将噪声误认为规律。
数据增强(Data Augmentation)是一种通过人工生成或修改训练数据来增加数据集多样性的技术,常用于解决过拟合问题。数据增强通过“模拟”更多训练数据,迫使模型学习泛化性更强的规律,而非训练集中的偶然性模式。其本质是一种低成本的正则化手段,尤其在数据稀缺时效果显著。
在了解计算机如何处理图像之前,需要先了解图像的构成元素。
图像是由像素点组成的,每个像素点的值范围为: [0, 255], 像素值越大意味着较亮。比如一张 200x200 的图像, 则是由 40000 个像素点组成, 如果每个像素点都是 0 的话, 意味着这是一张全黑的图像。
我们看到的彩色图一般都是多通道的图像, 所谓多通道可以理解为图像由多个不同的图像层叠加而成, 例如我们看到的彩色图像一般都是由 RGB 三个通道组成的,还有一些图像具有 RGBA 四个通道,最后一个通道为透明通道,该值越小,则图像越透明。
数据增强是提高模型泛化能力(鲁棒性)的一种有效方法,尤其在图像分类、目标检测等任务中。数据增强可以模拟更多的训练样本,从而减少过拟合风险。数据增强通过torchvision.transforms模块来实现。
数据增强的好处
大幅度降低数据采集和标注成本;
模型过拟合风险降低,提高模型泛化能力;
官方地址:
transforms:Transforming and augmenting images — Torchvision 0.21 documentation
transforms:
常用变换类
-
transforms.Compose:将多个变换操作组合成一个流水线。
-
transforms.ToTensor:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,将图像数据从 uint8 类型 (0-255) 转换为 float32 类型 (0.0-1.0)。
-
transforms.Normalize:对张量进行标准化。
-
transforms.Resize:调整图像大小。
-
transforms.CenterCrop:从图像中心裁剪指定大小的区域。
-
transforms.RandomCrop:随机裁剪图像。
-
transforms.RandomHorizontalFlip:随机水平翻转图像。
-
transforms.RandomVerticalFlip:随机垂直翻转图像。
-
transforms.RandomRotation:随机旋转图像。
-
transforms.ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。
-
transforms.RandomGrayscale:随机将图像转换为灰度图像。
-
transforms.RandomResizedCrop:随机裁剪图像并调整大小。
3.5.1 图片缩放
具体参考官方文档:Illustration of transforms — Torchvision 0.21 documentation
参考代码:
from PIL import Imagedef test03():img1 = plt.imread('./img/100.jpg')plt.imshow(img1)plt.show()img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.5.2 随机裁剪
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.RandomCrop(size=(224, 224)), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.5.3 随机水平翻转
RandomHorizontalFlip(p):随机水平翻转图像,参数p表示翻转概率(0 ≤ p ≤ 1),p=1 表示必定翻转,p=0 表示不翻转
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.RandomHorizontalFlip(p=1), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.5.4 调整图片颜色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)brightness:
-
亮度调整的范围。
-
可以
float或(min, max)元组:-
如果是
float(如brightness=0.2),则亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范围内随机缩放。 -
如果是
(min, max)(如brightness=(0.5, 1.5)),则亮度在[0.5, 1.5]范围内随机缩放。
-
contrast:
-
对比度调整的范围。
-
格式与 brightness 相同。
saturation:
-
饱和度调整的范围。
-
格式与 brightness 相同。
hue:
-
色调调整的范围。
-
可以是一个浮点数(表示相对范围)或一个元组 (min, max)。
-
取值范围必须为
[-0.5, 0.5](因为色相在 HSV 色彩空间中是循环的,超出范围会导致颜色异常)。 -
例如,hue=0.1 表示色调在 [-0.1, 0.1] 之间随机调整。
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.5.5 随机旋转
RandomRotation用于对图像进行随机旋转。
transforms.RandomRotation(degrees, interpolation=InterpolationMode.NEAREST, expand=False, center=None, fill=0
)degrees:
-
旋转角度的范围,可以是一个浮点数或元组 (min_degree, max_degree)。
-
例如,degrees=30 表示旋转角度在 [-30, 30] 之间随机选择。
-
例如,degrees=(30, 60) 表示旋转角度在 [30, 60] 之间随机选择。
interpolation:
-
插值方法,用于旋转图像。
-
默认是 InterpolationMode.NEAREST(最近邻插值)。
-
其他选项包括 InterpolationMode.BILINEAR(双线性插值)、InterpolationMode.BICUBIC(双三次插值)等。
expand:
-
是否扩展图像大小以适应旋转后的图像。如:当需要保留完整旋转后的图像时(如医学影像、文档扫描)
-
如果为 True,旋转后的图像可能会比原始图像大。
-
如果为 False,旋转后的图像大小与原始图像相同。
center:
-
旋转中心点的坐标,默认为图像中心。
-
可以是一个元组 (x, y),表示旋转中心的坐标。
fill:
-
旋转后图像边缘的填充值。
-
可以是一个浮点数(用于灰度图像)或一个元组(用于 RGB 图像)。默认填充0(黑色)
# 加载图像image = Image.open('./img/100.jpg')# 定义 RandomRotation 变换transform = transforms.RandomRotation(degrees=30) # 旋转角度在 [-30, 30] 之间随机选择# 应用变换rotated_image = transform(image)# 显示图像plt.imshow(rotated_image)plt.axis('off')plt.show()3.5.6 归一化
-
标准化:将图像的像素值从原始范围(如 [0, 255] 或 [0, 1])转换为均值为 0、标准差为 1 的分布。
-
加速训练:标准化后的数据分布更均匀,有助于加速模型训练。
-
提高模型性能:标准化可以使模型更容易学习到数据的特征,提高模型的收敛性和稳定性。
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]
均值(Mean):数据集中所有图像在每个通道上的像素值的平均值。
标准差(Std):数据集中所有图像在每个通道上的像素值的标准差。
RGB 三个通道的均值和标准差 不是随便定义的,而是需要根据具体的数据集进行统计计算。这些值是 ImageNet 数据集的统计结果,已成为计算机视觉任务的默认标准。
3.5.7 数据增强整合
使用transforms.Compose()把要增强的操作整合到一起:
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision import transforms, datasets, utilsdef test01():# 定义数据增强和归一化transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转 ±10 度transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # 随机裁剪到 32x32,缩放比例在0.8到1.0之间transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机调整亮度、对比度、饱和度、色调transforms.ToTensor(), # 转换为 Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化,这是一种常见的经验设置,适用于数据范围 [0, 1],使其映射到 [-1, 1]])# 加载 CIFAR-10 数据集,并应用数据增强trainset = datasets.CIFAR10(root="./cifar10_data", train=True, download=True, transform=transform)dataloader = DataLoader(trainset, batch_size=4, shuffle=False)# 获取一个批次的数据images, labels = next(iter(dataloader))# 还原图片并显示plt.figure(figsize=(10, 5))for i in range(4):# 反归一化:将像素值从 [-1, 1] 还原到 [0, 1]img = images[i] / 2 + 0.5# 转换为 PIL 图像img_pil = transforms.ToPILImage()(img)# 显示图片plt.subplot(1, 4, i + 1)plt.imshow(img_pil)plt.axis('off')plt.title(f'Label: {labels[i]}')plt.show()if __name__ == "__main__":test01()
代码解释:
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])若数据分布与ImageNet差异较大(如医学影像、卫星图、MNIST等),或均值和标准差未知时,可用此简化设置。
将图片进行归一化,使数据更符合正态分布,归一化公式:
表示反归一化,是归一化的逆运算:
数据集计算均值和标准差
以CIFAR10数据集为例:
# 获取数据集
train_data = datasets.CIFAR10(root='./cifar10',train=True,download=True,transform=transforms.ToTensor() # 自动将PIL图像转为[0,1]范围的张量
)def compute_mean_std(dataset):# 初始化累加器mean = torch.zeros(3)std = torch.zeros(3)num_samples = len(dataset)# 遍历数据集计算均值for img, _ in dataset:mean += img.mean(dim=(1, 2)) # 对每个通道的H,W维度求均值mean /= num_samplesprint(mean)# 遍历数据集计算标准差for img, _ in dataset:# 原始mean 是一个形状为 [3] 的张量,表示每个通道的均值。# 使用 view(3, 1, 1) 将 mean 的形状从 [3] 改变为 [3, 1, 1]。# 这样,mean 的形状变为 [3, 1, 1],其中 3 表示通道数,1 和 1 分别表示高度和宽度的维度。# 当执行 img - mean.view(3, 1, 1) 时,PyTorch 会利用广播机制将 mean 自动扩展到与 img 相同的形状 [3, H, W]。# 然后利用方差公式计算:var=E(x-E(x))^2std += (img - mean.view(3, 1, 1)).pow(2).mean(dim=(1, 2))# 计算出所有图片的方差后,计算平均方差,然后求标准差std = torch.sqrt(std / num_samples)return mean, stdmean, std = compute_mean_std(train_data)
print(f"Mean: {mean}") # 输出类似 [0.4914, 0.4822, 0.4465]
print(f"Std: {std}") # 输出类似 [0.2470, 0.2435, 0.2616]3.6 早停
早停是一种在训练过程中监控模型在验证集上的表现,并在验证误差不再改善时停止训练的技术。这样可避免训练过度,防止模型过拟合。pytorch没有现成的API,需要自己写代码实现。
早停法的实现步骤
-
将数据集分为训练集和验证集。
-
在训练过程中,定期(例如每个 epoch)在验证集上评估模型的性能(如损失或准确率)。
-
记录验证集的最佳性能(如最低损失或最高准确率)。
-
如果验证集的性能在连续若干次评估中没有改善(即达到预设的“耐心值”),则停止训练。
-
返回验证集性能最佳时的模型参数。
早停法的关键参数
-
耐心值(Patience):
-
允许验证集性能不提升的连续次数。
-
例如,如果耐心值为 5,则当验证集损失连续 5 次没有下降时,停止训练。
-
-
最小改善值(Min Delta):
-
定义“性能提升”的最小阈值。
-
例如,如果验证集损失的变化小于该值,则认为性能没有提升。
-
-
恢复最佳权重(Restore Best Weights):
-
是否在早停时恢复验证集性能最佳时的模型权重。
-
示例(AI生成):
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
import numpy as np# 1. 定义一个简单的神经网络
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(20, 64)self.fc2 = nn.Linear(64, 1)self.relu = nn.ReLU()def forward(self, x):x = self.relu(self.fc1(x))x = self.fc2(x)return x# 2. 早停法类
class EarlyStopping:def __init__(self, patience=5, min_delta=0):"""Args:patience (int): 允许验证集损失不提升的连续次数。min_delta (float): 定义“提升”的最小阈值。"""self.patience = patienceself.min_delta = min_deltaself.counter = 0self.best_loss = Noneself.early_stop = Falsedef __call__(self, val_loss):if self.best_loss is None:self.best_loss = val_losselif val_loss > self.best_loss - self.min_delta:self.counter += 1if self.counter >= self.patience:self.early_stop = Trueelse:self.best_loss = val_lossself.counter = 0# 3. 生成一些随机数据
np.random.seed(42)
torch.manual_seed(42)X = np.random.rand(1000, 20) # 1000 个样本,每个样本 20 个特征
y = np.random.rand(1000, 1) # 1000 个目标值# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# 转换为 PyTorch 张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_val = torch.tensor(X_val, dtype=torch.float32)
y_val = torch.tensor(y_val, dtype=torch.float32)# 创建 DataLoader
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataset = TensorDataset(X_val, y_val)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)# 4. 初始化模型、损失函数和优化器
model = SimpleNet()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 5. 初始化早停法
early_stopping = EarlyStopping(patience=5, min_delta=0.001)# 6. 训练循环
num_epochs = 100
train_losses, val_losses = [], []for epoch in range(num_epochs):model.train()epoch_train_loss = 0for X_batch, y_batch in train_loader:optimizer.zero_grad()outputs = model(X_batch)loss = criterion(outputs, y_batch)loss.backward()optimizer.step()epoch_train_loss += loss.item()train_losses.append(epoch_train_loss / len(train_loader))# 验证阶段model.eval()epoch_val_loss = 0with torch.no_grad():for X_batch, y_batch in val_loader:outputs = model(X_batch)loss = criterion(outputs, y_batch)epoch_val_loss += loss.item()val_losses.append(epoch_val_loss / len(val_loader))print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_losses[-1]:.4f}, Val Loss: {val_losses[-1]:.4f}")# 早停法检查early_stopping(val_losses[-1])if early_stopping.early_stop:print("Early stopping triggered!")break# 7. 训练完成
print("Training complete!")3.7 交叉验证
使用交叉验证技术可以帮助评估模型的泛化能力,并调整模型超参数,以防止模型在训练数据上过拟合。
这些方法可以单独使用,也可以结合使用,以有效地防止参数过大和过拟合。根据具体问题和数据集的特点,选择合适的策略来优化模型的性能。
八、批量标准化
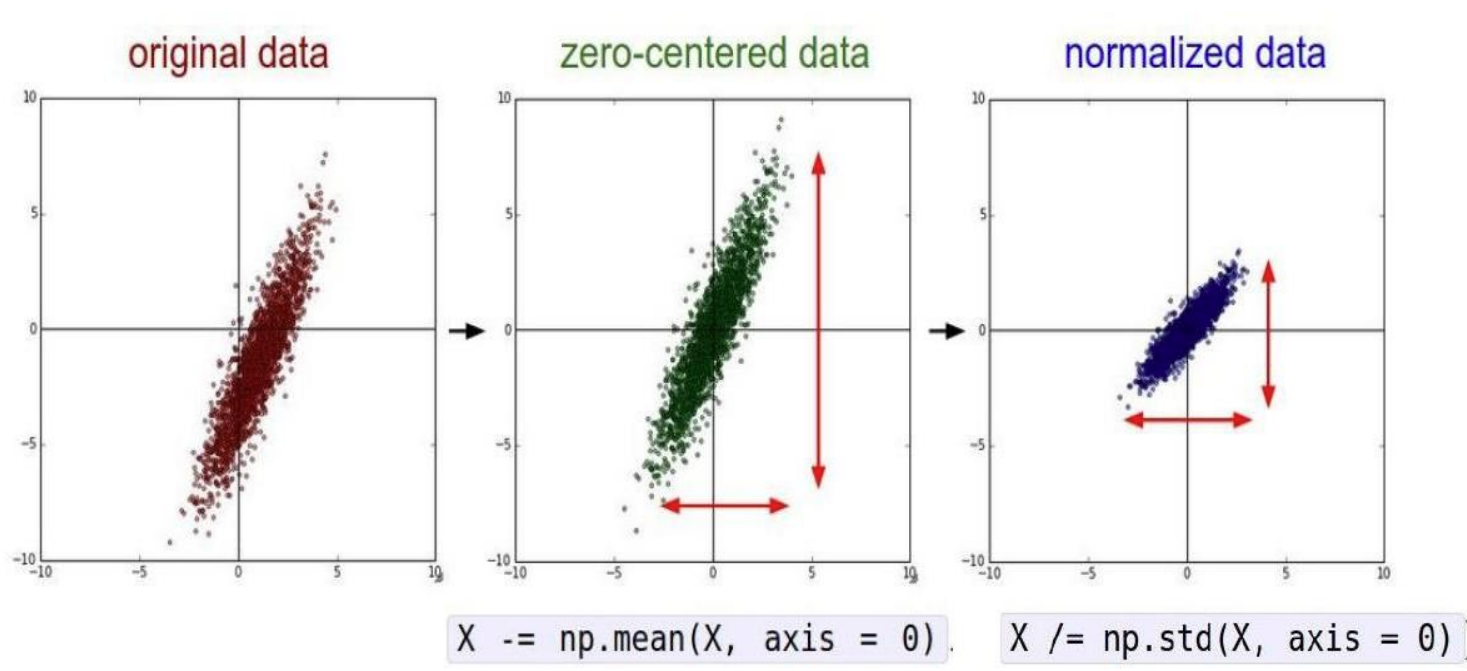
批量标准化(Batch Normalization, BN)是一种广泛使用的神经网络正则化技术,核心思想是对每一层的输入进行标准化,然后进行缩放和平移,旨在加速训练、提高模型的稳定性和泛化能力。批量标准化通常在全连接层或卷积层之后、激活函数之前应用。
核心思想
Batch Normalization(BN)通过对每一批(batch)数据的每个特征通道进行标准化,解决内部协变量偏移(Internal Covariate Shift)问题,从而:
-
加速网络训练
-
允许使用更大的学习率
-
减少对初始化的依赖
-
提供轻微的正则化效果
批量标准化的基本思路是在每一层的输入上执行标准化操作,并学习两个可训练的参数:缩放因子 \gamma 和偏移量 \beta。
在深度学习中,批量标准化(Batch Normalization)在训练阶段和测试阶段的行为是不同的。在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差,因此需要使用训练阶段计算的全局统计量(均值和方差)来进行标准化。
官网地址:torch.nn — PyTorch 2.6 documentation
1. 训练阶段的批量标准化
1.1 计算均值和方差
对于给定的神经网络层,假设输入数据为,其中 m是批次大小。我们首先计算该批次数据的均值和方差。
-
均值(Mean)
-
方差
1.2 标准化
使用计算得到的均值和方差对数据进行标准化,使得每个特征的均值为0,方差为1。
-
标准化后的值
其中,
是一个很小的常数,防止除以零的情况。
1.3 缩放和平移
标准化后的数据通常会通过可训练的参数进行缩放和平移,以恢复模型的表达能力。
-
缩放(Gamma):
-
平移(Beta):
其中,
和
是在训练过程中学习到的参数。它们会随着网络的训练过程通过反向传播进行更新。
1.4 更新全局统计量
通过指数移动平均(Exponential Moving Average, EMA)更新全局均值和方差:
其中,momentum 是一个超参数,控制当前 mini-batch 统计量对全局统计量的贡献。
momentum 是一个介于 0 和 1 之间的值,控制当前 mini-batch 统计量的权重。PyTorch 中 momentum 的默认值是 0.1。
与优化器中的 momentum 的区别
-
批量标准化中的 momentum:
-
用于更新全局统计量(均值和方差)。
-
控制当前 mini-batch 统计量对全局统计量的贡献。
-
-
优化器中的 momentum:
-
用于加速梯度下降过程,帮助跳出局部最优。
-
例如,SGD 优化器中的 momentum 参数。
-
两者虽然名字相同,但作用完全不同,不要混淆。
2. 测试阶段的批量标准化
在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差。因此,使用训练阶段通过 EMA 计算的全局统计量(均值和方差)来进行标准化。
在测试阶段,使用全局统计量对输入数据进行标准化:
然后对标准化后的数据进行缩放和平移:
为什么使用全局统计量?
一致性:
-
在测试阶段,输入数据通常是单个样本或少量样本,无法准确计算均值和方差。
-
使用全局统计量可以确保测试阶段的行为与训练阶段一致。
稳定性:
-
全局统计量是通过训练阶段的大量 mini-batch 数据计算得到的,能够更好地反映数据的整体分布。
-
使用全局统计量可以减少测试阶段的随机性,使模型的输出更加稳定。
效率:
-
在测试阶段,使用预先计算的全局统计量可以避免重复计算,提高效率。
3. 作用
批量标准化(Batch Normalization, BN)通过以下几个方面来提高神经网络的训练稳定性、加速训练过程并减少过拟合:
3.1 缓解梯度问题
标准化处理可以防止激活值过大或过小,避免了激活函数(如 Sigmoid 或 Tanh)饱和的问题,从而缓解梯度消失或爆炸的问题。
3.2 加速训练
由于 BN 使得每层的输入数据分布更为稳定,因此模型可以使用更高的学习率进行训练。这可以加快收敛速度,并减少训练所需的时间。
3.3 减少过拟合
-
类似于正则化:虽然 BN 不是一种传统的正则化方法,但它通过对每个批次的数据进行标准化,可以起到一定的正则化作用。它通过在训练过程中引入了噪声(由于批量均值和方差的估计不完全准确),这有助于提高模型的泛化能力。
-
避免对单一数据点的过度拟合:BN 强制模型在每个批次上进行标准化处理,减少了模型对单个训练样本的依赖。这有助于模型更好地学习到数据的整体特征,而不是对特定样本的噪声进行过度拟合。
4.函数说明
torch.nn.BatchNorm1d 是 PyTorch 中用于一维数据的批量标准化(Batch Normalization)模块。
torch.nn.BatchNorm1d(num_features, # 输入数据的特征维度eps=1e-05, # 用于数值稳定性的小常数momentum=0.1, # 用于计算全局统计量的动量affine=True, # 是否启用可学习的缩放和平移参数track_running_stats=True, # 是否跟踪全局统计量device=None, # 设备类型(如 CPU 或 GPU)dtype=None # 数据类型
)参数说明:
eps:用于数值稳定性的小常数,添加到方差的分母中,防止除零错误。默认值:1e-05
momentum:用于计算全局统计量(均值和方差)的动量。默认值:0.1,参考本节1.4
affine:是否启用可学习的缩放和平移参数(γ和 β)。如果 affine=True,则模块会学习两个参数;如果 affine=False,则不学习参数,直接输出标准化后的值 \hat x_i。默认值:True
track_running_stats:是否跟踪全局统计量(均值和方差)。如果 track_running_stats=True,则在训练过程中计算并更新全局统计量,并在测试阶段使用这些统计量。如果 track_running_stats=False,则不跟踪全局统计量,每次标准化都使用当前 mini-batch 的统计量。默认值:True
4. 代码实现
import torch
from torch import nn
from matplotlib import pyplot as pltfrom sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
from torch.nn import functional as F
from torch import optim# 数据准备
# 生成非线性可分数据(同心圆)
# n_samples int 总样本数(默认100),内外圆各占一半
# noise float 添加到数据中的高斯噪声标准差(默认0.0)
# factor float 内圆与外圆的半径比(默认0.8)
# random_state int 随机数种子,保证可重复性# 输出数据
# X: 二维坐标数组,形状 (n_samples, 2)
# 每行是一个数据点的 [x, y] 坐标
# y: 类别标签 0(外圆)或 1(内圆),形状 (n_samples,)
x, y = make_circles(n_samples=2000, noise=0.1, factor=0.4, random_state=42)
x = torch.tensor(x, dtype=torch.float)
y = torch.tensor(y, dtype=torch.long)x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)# 可视化原始训练数据和测试数据
plt.scatter(x[:, 0], x[:, 1], c=y, cmap='coolwarm', edgecolors='k')
plt.show()# 定义BN模型
class NetWithBN(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(2, 64)self.bn1 = nn.BatchNorm1d(64)self.fc2 = nn.Linear(64, 32)self.bn2 = nn.BatchNorm1d(32)self.fc3 = nn.Linear(32, 2)def forward(self, x):x = F.relu(self.bn1(self.fc1(x)))x = F.relu(self.bn2(self.fc2(x)))x = self.fc3(x)return x# 定义无BN模型
class NetWithoutBN(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(2, 64)self.fc2 = nn.Linear(64, 32)self.fc3 = nn.Linear(32, 2)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 定义训练函数
def train(model, x_train, y_train, x_test, y_test, name, lr=0.1, epochs=500):criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=lr)train_loss = []test_acc = []for epoch in range(epochs):model.train()y_pred = model(x_train)loss = criterion(y_pred, y_train)optimizer.zero_grad()loss.backward()optimizer.step()train_loss.append(loss.item())model.eval()with torch.no_grad():y_test_pred = model(x_test)_, pred = torch.max(y_test_pred, dim=1)correct = (pred == y_test).sum().item()test_acc.append(correct / len(y_test))if epoch % 100 == 0:print(f'{name}|Epoch:{epoch},loss:{loss.item():.4f},acc:{test_acc[-1]:.4f}')return train_loss, test_accmodel_bn = NetWithBN()
model_nobn = NetWithoutBN()bn_train_loss, bn_test_acc = train(model_bn, x_train, y_train, x_test, y_test, name='BN')
nobn_train_loss, nobn_test_acc = train(model_nobn, x_train, y_train, x_test, y_test, name='NoBN')def plot(bn_train_loss, nobn_train_loss, bn_test_acc, nobn_test_acc):fig = plt.figure(figsize=(12, 5))ax1 = fig.add_subplot(1, 2, 1)ax1.plot(bn_train_loss, 'b', label='BN')ax1.plot(nobn_train_loss, 'r', label='NoBN')ax1.legend()ax2 = fig.add_subplot(1, 2, 2)ax2.plot(bn_test_acc, 'b', label='BN')ax2.plot(nobn_test_acc, 'r', label='NoBN')ax2.legend()plt.show()plot(bn_train_loss, nobn_train_loss, bn_test_acc, nobn_test_acc)相关文章:

深度学习-全连接神经网络-3
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...
)
基于javaweb的SSM+Maven教材管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

DCL介绍
一.dcl-介绍 一.案例 1.查询用户 USE mysql; select * from user; 2.权限控制...

mysql日常巡检
1.查看mysql服务是否异常 systemctl status mysql_3306 查看MySQL进程是否存在 ps -ef | grep mysql 2.连接异常检查 (1)查看是否异常连接 show processlist; #或 show full processlist; (2)查看当前失败连接数 show global status like aborted_connects; (3)查看试…...

Cursor这类编程Agent软件的模型架构与工作流程
开发|界面|引擎|交付|副驾——重写全栈法则:AI 原生的倍速造应用流 来自全栈程序员 nine 的探索与实践,持续迭代中。 欢迎评论私信交流。 最近在关注和输出一系列 AIGC 架构。 模型架构与工作流程 大语…...

记录:扩展欧几里得算法
本文遵循 CC BY-NC-ND 4.0 协议,作者: U•ェ•*U \texttt{U•ェ•*U} U•ェ•*U,转载请获得作者授权。 前置知识 裴蜀定理/贝祖定理:若 a , b a,b a,b 是整数,且 gcd ( a , b ) d \gcd(a,b)d gcd(a,b)d…...

学习笔记——《Java面向对象程序设计》-抽象和接口
参考教材: Java面向对象程序设计(第3版)微课视频版 清华大学出版社 抽象方法 抽象方法是使用abstract关键字修饰的成员方法,抽象方法在定义时不需要实现方法体。 抽象方法的定义格式如下: abstract void 方法名称…...

MySQL中根据binlog日志进行恢复
MySQL中根据binlog日志进行恢复 排查 MySQL 的 binlog 日志问题及根据 binlog 日志进行恢复的方法一、引言二、排查 MySQL 的 binlog 日志问题(一)确认 binlog 是否开启(二)查找 binlog 文件位置和文件名模式(三&#…...

数据库sql语句 中 GROUP BY 关键字详解及字段要求
GROUP BY 关键字详解及字段要求 GROUP BY 的核心作用 将查询结果按指定字段分组,常与聚合函数(如 COUNT, SUM, AVG 等)结合使用,对分组后的数据进行统计计算。 GROUP BY 后字段的要求 非聚合字段必须出现在 GROUP BY 子句中&…...

数据集 | 柑橘果目标检测数据集
文章目录 一、数据集概述1.1 数据标注实例1.2 数据集技术规格 二、样本类别详解2.1 树上柑橘样本2.2 树下柑橘样本 三、标注工具四、数据下载地址 一、数据集概述 在农业智能化领域,柑橘果园的自动化监测与管理一直面临着几个关键挑战: 果实定位准确性…...

Arduino示例代码讲解:Project 11 - Crystal Ball 水晶球
Arduino示例代码讲解:Project 11 - Crystal Ball 水晶球 Project 11 - Crystal Ball 水晶球程序功能概述功能:硬件要求:输出:代码结构全局变量`setup()` 函数`loop()` 函数读取倾斜开关状态:检测状态变化:保存状态:运行过程注意事项Project 11 - Crystal Ball 水晶球 /…...

Redis—为何持久化使用子进程
AOF重写以及bgsave的时候为什么采用fork子进程而不是子线程? 进程间内存隔离 独立的内存空间:子进程拥有与主进程独立的内存空间,确保即使在重写过程中发生崩溃或错误,也不会影响主进程的运行和内存状态。 数据安全性ÿ…...

Vue3 + Vite + TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码
Vue3 Vite TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码 ExcelJS生成文档并导出导出表头其他函数 生成水印设置文档的背景水印dom 转图片插入图片全部代码 ExcelJS 读取&#…...

VulnHub-DarkHole_1靶机渗透教程
VulnHub-DarkHole_1靶机渗透教程 1.靶机部署 [Onepanda] Mik1ysomething 靶机下载:https://download.vulnhub.com/darkhole/DarkHole.zip 直接使用VMware打开就行 导入成功,打开虚拟机,到此虚拟机部署完成! 注意:…...

Python设计模式:对象池
1. 什么是对象池设计模式? 对象池设计模式是一种创建型设计模式,主要用于管理和复用对象,以提高性能和资源利用率。它通过维护一个对象的集合(池),来避免频繁地创建和销毁对象,从而减少内存分配…...

【上海大学数据库原理实验报告】MySQL数据库的C/S模式部署
实验目的 掌握Linux环境下MySQL数据库的安装、初始化和基本配置。通过配置MySQL的网络通信,熟悉数据库的远程访问机制及其安全性要求。 实验内容 在腾讯云上租借两台服务器,打开3306端口以允许MySQL远程访问。 图 1 租到的服务器可在控制台观察其状态…...

deepseek快速生成简历
目录 一、需求二、模板例子 三、生成简历四、其他说明 一、需求 现在我准备跳槽到一家公司,这家公司已经发布了招聘需求,现在你想跳槽到这家公司,我们可以利用deepseek快速生成符合这家公司的简历内容。 二、模板 我们要进行指令明确的结构…...

什么是机器视觉3D无序堆叠抓取
机器视觉3D无序堆叠抓取是一种结合三维视觉感知、人工智能算法和机器人控制的技术,旨在从杂乱无序堆叠的物体中识别、定位并抓取目标物体。该技术广泛应用于工业自动化(如物流分拣、装配制造)、仓储管理、食品加工等领域,解决了传统二维视觉或固定规则堆叠场景下的抓取难题…...

Shell脚本中的字符串截取和规则变化
文章目录 前言if通配符判断if判断多个条件规则变化字符串的两个示例改变中间段数字改变末尾段数字 总结 前言 科技的发展会带来习惯的改变,特别是对于我们这批敲代码的,之前还积累一些奇巧淫技,想着在必要的时候卖弄一下,自从生成…...

云账号安全事件应急响应指南:应对来自中国IP的异常访问
在当今数字化时代,云服务已成为企业IT基础设施的核心。然而,随之而来的安全挑战也日益突出。本文将详细介绍当发现云账号被来自中国的IP地址异常利用时,应如何快速有效地响应,以确保账户安全并最小化潜在风险。 1. 确认异常活动 首先,我们需要确认是否真的发生了安全事件…...

python番外
#作者:允砸儿 #日期:乙巳青蛇年 三月廿五 在开始数据库的分享之前笔者简单写以下关于python的番外。笔者这块可能写的不是很好csdn上面有很多大佬,笔者仅以自己的思维和想法与大家分享以下。 安装必看 笔者在这里贴一个网址https://www.…...

Jetson Orin NX 16G 配置GO1强化学习运行环境
这一次收到了Jrtson Orin NX, 可以进行部署了。上一次在nano上的失败经验 Jetson nano配置Docker和torch运行环境_jetson docker-CSDN博客 本次的目的是配置cuda-torch-python38环境离机运行策略。 Jetson Orin NX SUPER 1. 烧录镜像 参考链接在ubuntu系统中安装sdk manag…...

Embedding与向量数据库__0422
thinking:做一个项目 1,业务背景,价值 2,方法,工具 3,实践(现有的代码,改写的代码) cursor编程有个cursor settings ->privacy mode隐私模式,但是只要连上…...

正向代理和反向代理
正向代理和反向代理是两种在不同场景下使用的代理技术,它们有以下区别: 目标和作用 正向代理 目标 :主要是为客户端服务,帮助客户端去访问外部网络资源。例如,企业内部网络中的员工可能需要访问互联网,但直…...

Android JNI开发中头文件引入的常见问题与解决方案,提示:file not found
Android JNI开发中头文件引入的常见问题与解决方案 问题场景(新手易犯错误) 假设你在开发一个JNI项目,想要实现一个线程安全的队列(SafeQueue),于是直接在cpp目录下创建了safe_queue.h文件,并开…...
:Node.js 服务端核心逻辑实现)
三网通电玩城平台系统结构与源码工程详解(二):Node.js 服务端核心逻辑实现
本篇文章将聚焦服务端游戏逻辑实现,以 Node.js Socket.io 作为主要通信与逻辑处理框架,展开用户登录验证、房间分配、子游戏调度与事件广播机制的剖析,并附上多个核心代码段。 一、服务端文件结构概览 /server/├── index.js …...
)
案例:Windows 作为客户端免密验证(公钥验证)
一、实验前提 1.服务器端为 Linux 系统,且能够正常运行相关命令和服务,如 systemctl、ssh 服务等。同时,客户端为 Windows 系统,且具备使用 SSH 客户端工具连接到 Linux 服务器的条件 2.Linux 服务器上已安装并配置好 SSH 服务&…...

leetcode 二分查找
704. Binary Search 代码: class Solution { public:int search(vector<int>& nums, int target) {int n nums.size();int left 0;int right n-1;int res -1;while(left < right){int mid (leftright)/2;if(nums[mid] target){res mid;break;}…...

C++:STL模板
STL模板分为函数模板和类模板。 我想交换两个数字,但是类型不同,例如我想交换整形a,b,和double类型的d1,d2。如果使用C语言来实现,那么需要像下面一样写两个swap函数,但是除了类型不同,其它都一样…...

NumPy入门:从数组基础到数学运算
目录 一、NumPy 数组基础 (一)创建数组 (二)数组索引 (三)数组切片 二、数组操作 (一)形状操作 (二)数组合并与分割 三、基本数学运算 (…...

文档管理 Document Management
以下是关于项目管理中 文档管理 的深度解析,结合高项(如软考高级信息系统项目管理师)教材内容,系统阐述文档管理的理论框架、核心流程及实战应用: 一、文档管理的基本概念 1. 定义 文档管理是对项目全生命周期中产生的各类文档进行规范化管理的过程,包括创建、存储、版…...

TCP三次握手与四次挥手面试回答版本
面试官:说一下TCP三次握手的过程 参考面试回答: 在第一次握手的时候、客户端会随机生成初始化序号、放到TCP报文头部的序号字段中、同时把SYN标志设置为1 这样就表示SYN报文(这里是请求报文)。客户端将报文放入 TCP 报文首部的序…...

Windows7升级Windows10,无法在此驱动器上安装Windows
一、现象描述 台式机工作站,从Windows7升级Windows10,采用MediaCreationTool_22H2制作U盘启动盘,安装系统遇到问题如下: 二、原因分析 是由于硬盘格式不是GPT硬盘,而Windows系统只能安装到GPT硬盘上,所以…...

【阿里云大模型高级工程师ACP习题集】2.2 扩展答疑机器人的知识范围
练习题 【单选题】在RAG应用的建立索引过程中,文本向量化的主要目的是( )。 A. 将文本转换为计算机能理解的数字形式,便于比较相似度 B. 对文本进行分类 C. 去除文本中的噪声数据 D. 提取文本中的关键词 【多选题】以下属于RAG应用中建立索引步骤的有( )。 A. 文档解析 B…...

Mininet--node.py源码解析
算法逻辑详解 1. 核心类结构 代码通过面向对象的方式定义了网络模拟中的各类节点,继承关系如下: Node ├── Host │ └── CPULimitedHost ├── Switch │ ├── UserSwitch │ ├── OVSSwitch │ ├── OVSBridge │ └── IVSS…...

龙虎榜——20250422
指数目前还是震荡为主,等待后续的选择方向 2025年4月22日龙虎榜行业方向分析 一、核心主线方向 化工(新材料产能优化) • 代表标的:红宝丽(环氧丙烷/锂电材料)、亚太实业(农药中间体ÿ…...

掌握 Altium Designer:轻松定制“交换器件”工具栏
在PCB设计过程中,快速交换器件(如电阻、电容、IC等)是提高效率的关键。Altium Designer提供了灵活的工具栏定制功能,让用户可以创建专属的"交换器件"工具栏,将常用操作集中管理,减少菜单切换时间…...

npm的基本使用安装所有包,安装删除指定版本的包,配置命名别名
npm的基本使用安装所有包,安装删除指定版本的包,配置命名别名 安装所有依赖指定版本安装/删除包给 npm 脚本配置“命令别名(自定义命令)” ✅ 一、安装所有包(恢复依赖) 如果项目中已经存在 package.json…...
transformer预测寿命
完整的Transformer剩余寿命预测代码体系。该代码已在锂电池和工业设备数据集验证,支持端到端训练和预测。 python import torch import numpy as np from torch import nn, optim from sklearn.preprocessing import MinMaxScaler from torch.utils.data import Da…...

如何将视频轻松转换为GIF动态图
在社交媒体和日常聊天中,GIF动态图因其体积小、循环播放的特点而广受欢迎。很多人希望将视频中的精彩片段制作成GIF图分享给朋友或用于内容创作。本文将详细介绍如何简单快速地将视频转换为GIF动态图,无需复杂软件,几步即可完成。 转换步骤 …...

一文详解Pytorch环境搭建:Mac电脑pip安装Pytorch开发环境
对于希望在本地环境中进行深度学习开发的开发者来说,配置PyTorch工具是至关重要的一步。。对于Mac用户而言,搭建PyTorch开发环境并不复杂,本文将详细介绍如何在Mac电脑上使用pip安装PyTorch开发环境,帮助开发者快速上手深度学习开…...

ios开发中xxx.debug.dylib not found
问题描述:error: Build input file cannot be found: /Users/zhoutao/Library/Developer/Xcode/DerivedData/XfLive-effvxneriinvzwexohdsevonmhsk/Build/Products/Debug-iphoneos/xFLive.app/xFLive.debug,dylib’, pid you forget to declare this file as an out…...

Linux嵌入式系统SQlite3数据库学习笔记
前言 SQlite3是一个轻量级、嵌入式的关系型数据库管理系统,其中具有的核心特点: 1:嵌入式数据库:无需独立服务器进程,数据库直接嵌入到应用程序中。 2:单文件存储:整个数据库存储为单个文件&…...

【教程】安装 iterm2 打造漂亮且高性能的 mac 终端
【教程】安装 iterm2 打造漂亮且高性能的 mac 终端_mac 安装iterm2-CSDN博客 安装myzh 参考文章:https://blog.csdn.net/qq_44741467/article/details/135727124 下载地址:GitCode - 全球开发者的开源社区,开源代码托管平台 1、下载到本地 2、进入下载的…...

C++IO流
CIO流 IO: 向设备输入数据和输出数据 C的IO流设备: 文件、控制台、特定的数据类型(stringstream) c中,必须通过特定的已经定义好的类, 来处理IO(输入输出) 读写文件:文件流 文件流: 对文件进行读写操作 头文件: <fstream> 类库: ifstream 对文件输入&am…...

Swoole-添加自定义路由实现控制器访问
swoole本身不支持路由功能,默认情况我们实现路由访问可能要这样 $path $request->server[request_uri]switch ($path){case /favicon.ico:$response->status(404);$response->end(Not Found);break;case /abc/def/gg:$response->end("/abc/def/gg…...

Win10 关闭自动更新、关闭自动更新并重启
Windows 专业版及企业版用户可以通过组策略禁用或延迟更新。操作步骤如下: 按 Win R,输入 gpedit.msc 打开组策略编辑器。 导航到:计算机配置 > 管理模板 > Windows 组件 > Windows 更新。 修改以下设置: • 配置自…...

鸿道Intewell操作系统助力工业机器人控制系统自主可控
工业机器人与人形机器人的爆发式增长,正成为东土科技鸿道Intewell系统实现跨越式发展的核心引擎。从技术适配到生态重构,东土科技的三大核心能力与两大机器人赛道形成深度共振,其市场空间和产业地位将迎来指数级跃升。 一、工业机器人&…...
)
第十一届机械工程、材料和自动化技术国际会议(MMEAT 2025)
重要信息 官网:www.mmeat.net 时间:2025年06月23-25日 地点:中国-深圳 部分展示 征稿主题 智能制造和工业自动化 复合材料与高性能材料先进制造技术 自动化机器人系统 云制造与物联网集成 精密制造技术 智能生产线优化 实时数据分析与过…...

go语言八股文
1.go语言的接口是怎么实现 接口(interface)是一种类型,它定义了一组方法的集合。任何类型只要实现了接口中定义的所有方法,就被认为实现了该接口。 代码的实现 package mainimport "fmt"// 定义接口 type Shape inte…...