使用PyTorch构建神经网络笔记
专有名词
Batch Size
在深度学习中,批大小(Batch Size) 是指每次前向传播和反向传播时使用的样本数量。它是训练神经网络时的一个关键超参数,直接影响训练速度、内存占用和模型性能。
(1) 计算梯度
-
在训练时,模型通过损失函数计算预测值与真实值的误差。
-
梯度(Gradient) 表示损失函数对模型参数的偏导数,用于更新权重。
-
批大小决定了一次计算梯度时使用的样本数量:
-
Batch Size = 1(随机梯度下降,SGD):每次用 1 个样本 计算梯度,更新参数。
-
Batch Size = N(小批量梯度下降,Mini-batch SGD):每次用 N 个样本 的平均梯度更新参数。
-
Batch Size = 全部训练数据(批量梯度下降,Batch GD):每次用 所有数据 计算梯度(计算量大,内存要求高)。
-
(2) 影响训练稳定性
-
较大的 Batch Size:
-
梯度计算更稳定(噪声小)。
-
训练速度更快(GPU 并行计算)。
-
但可能陷入局部最优,泛化能力较差。
-
-
较小的 Batch Size:
-
梯度噪声大,训练不稳定。
-
可能跳出局部最优,泛化能力更好。
-
但训练速度较慢(GPU 利用率低)。
-
构建神经网络
1. 数据准备
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]
X = torch.tensor(x).float() # 转换为浮点型张量
Y = torch.tensor(y).float()# 将数据移动到GPU(如果可用)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X = X.to(device)
Y = Y.to(device)-
数据:
-
x是输入数据,形状为[4, 2](4个样本,每个样本2个特征)。 -
y是目标数据,形状为[4, 1](4个样本,每个样本1个输出值)。
-
-
设备切换:通过
.to(device)将数据移动到 GPU(如果可用)。
2. 神经网络定义
from torch import nnclass MyNeuralNet(nn.Module):def __init__(self):super().__init__()self.input_to_hidden_layer = nn.Linear(2, 8) # 输入层→隐藏层(2→8)self.hidden_layer_activation = nn.ReLU() # 激活函数self.hidden_to_output_layer = nn.Linear(8, 1) # 隐藏层→输出层(8→1)def forward(self, x):x = self.input_to_hidden_layer(x) # 线性变换x = self.hidden_layer_activation(x) # ReLU激活x = self.hidden_to_output_layer(x) # 输出层return x-
y = x @ W.T + b
-
网络结构:
-
输入层→隐藏层:
nn.Linear(2, 8)-
输入特征数:2,输出特征数:8(隐藏层神经元数)。
-
权重矩阵形状:
[8, 2],偏置形状:[8]。
-
-
激活函数:
nn.ReLU()(非线性变换)。 -
隐藏层→输出层:
nn.Linear(8, 1)-
输入特征数:8,输出特征数:1。
-
权重矩阵形状:
[1, 8],偏置形状:[1]。
-
-
3. 打印 nn.Linear 信息
print(nn.Linear(2, 7))
# 输出:Linear(in_features=2, out_features=7, bias=True)-
解释:
-
nn.Linear(2, 7)是一个未初始化的线性层,输入特征数为2,输出特征数为7,默认启用偏置(bias=True)。 -
了解一下,这跟上面的没有关系。
-
4. 创建模型并打印权重
mynet = MyNeuralNet().to(device) # 实例化模型并移动到设备
print(mynet.input_to_hidden_layer.weight)tensor([[ 0.0618, -0.1801],[-0.0899, 0.4533],[-0.0178, -0.2600],[ 0.1930, -0.1421],[-0.7004, 0.5656],[ 0.6977, 0.4310],[-0.4469, -0.0127],[-0.4786, -0.3897]], device='cuda:0', requires_grad=True)-
解释:
-
input_to_hidden_layer.weight是隐藏层的权重矩阵,形状为[8, 2]。 -
每个权重是随机初始化的(PyTorch 默认使用均匀分布初始化)。
-
requires_grad=True表示这些权重会在训练时自动计算梯度。
-
5.打印神经网络所有参数
# 获取神经网络模型的所有可学习参数(权重和偏置)
# mynet.parameters() 返回一个生成器,包含模型中所有需要训练的参数(即定义了 requires_grad=True 的张量)
params = mynet.parameters()# 遍历并打印每一个参数张量
for param in params:print(param) # 打印当前参数张量的值和属性print('-' * 50) # 分隔线,便于观察Parameter containing:
tensor([[ 0.0618, -0.1801],[-0.0899, 0.4533],[-0.0178, -0.2600],[ 0.1930, -0.1421],[-0.7004, 0.5656],[ 0.6977, 0.4310],[-0.4469, -0.0127],[-0.4786, -0.3897]], device='cuda:0', requires_grad=True)
--------------------------------------------------
Parameter containing:
tensor([ 0.1349, 0.5562, 0.6507, -0.2334, -0.0498, 0.1597, 0.0484, -0.5478],device='cuda:0', requires_grad=True)
--------------------------------------------------
Parameter containing:
tensor([[ 0.1448, -0.3510, -0.2759, -0.1556, -0.1209, 0.1024, 0.1095, 0.1628]],device='cuda:0', requires_grad=True)
--------------------------------------------------
Parameter containing:
tensor([-0.3037], device='cuda:0', requires_grad=True)
---------------------------------------------------
参数的顺序与模型定义的顺序一致
-
通常先打印权重矩阵,然后是偏置向量
-
对于你的
MyNeuralNet示例,会依次打印:-
input_to_hidden_layer.weight (形状 [8,2])
-
input_to_hidden_layer.bias (形状 [8])
-
hidden_to_output_layer.weight (形状 [1,8])
-
hidden_to_output_layer.bias (形状 [1])
-
6.画epoch变化
# 定义均方误差(MSE)损失函数
loss_func = nn.MSELoss()# 前向传播:用网络(mynet)计算输入X的预测输出(_Y)
_Y = mynet(X)# 计算预测输出(_Y)和真实标签(Y)之间的损失
loss_value = loss_func(_Y,Y)
print(loss_value)
# 输出显示初始损失值(127.4498),在CUDA设备上,带有梯度函数
# tensor(127.4498, device='cuda:0', grad_fn=<MseLossBackward>)# 导入并初始化随机梯度下降(SGD)优化器
# 参数:网络参数和学习率0.001
from torch.optim import SGD
opt = SGD(mynet.parameters(), lr = 0.001)# 清除之前步骤累积的梯度
opt.zero_grad()# 重新计算损失(这里重复计算mynet(X),效率稍低)
loss_value = loss_func(mynet(X),Y)# 反向传播:计算损失对所有可训练参数的梯度
loss_value.backward()# 用计算出的梯度更新网络参数
opt.step()# 初始化列表用于存储训练过程中的损失值
loss_history = []# 训练循环,50次迭代
for _ in range(50):# 在每一步前清除梯度opt.zero_grad()# 前向传播:计算损失loss_value = loss_func(mynet(X),Y)# 反向传播:计算梯度loss_value.backward()# 更新参数opt.step()# 记录当前损失值(转换为Python标量)loss_history.append(loss_value.item())
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.title('Loss variation over increasing epochs')
plt.xlabel('epochs')
plt.ylabel('loss value')
plt.show()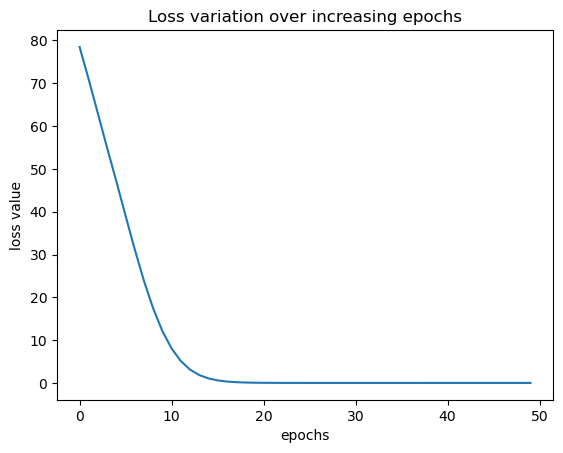
| 操作 | 作用 | 是否必须 |
|---|---|---|
optimizer.zero_grad() | 清除之前计算的梯度,防止梯度累积 | ✅ 必须(除非做梯度累积) |
loss.backward() | 计算当前 batch 的梯度 | ✅ 必须 |
optimizer.step() | 用梯度更新参数 | ✅ 必须 |
7.总体代码
import torch
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]
X = torch.tensor(x).float()
Y = torch.tensor(y).float()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X = X.to(device)
Y = Y.to(device)
from torch import nn
class MyNeuralNet(nn.Module):def __init__(self):super().__init__()self.input_to_hidden_layer = nn.Linear(2,8)self.hidden_layer_activation = nn.ReLU()self.hidden_to_output_layer = nn.Linear(8,1)def forward(self, x):x = self.input_to_hidden_layer(x)x = self.hidden_layer_activation(x)x = self.hidden_to_output_layer(x)return x
print(nn.Linear(2, 7))
# Linear(in_features=2, out_features=7, bias=True)
mynet = MyNeuralNet().to(device)
print(mynet.input_to_hidden_layer.weight)
mynet.parameters()
for param in mynet.parameters():print(param)print('-' * 50)
loss_func = nn.MSELoss()
_Y = mynet(X)
loss_value = loss_func(_Y,Y)
print(loss_value)
# tensor(127.4498, device='cuda:0', grad_fn=<MseLossBackward>)
from torch.optim import SGD
opt = SGD(mynet.parameters(), lr = 0.001)
opt.zero_grad()
loss_value = loss_func(mynet(X),Y)
loss_value.backward()
opt.step()
loss_history = []
for _ in range(50):opt.zero_grad()loss_value = loss_func(mynet(X),Y)loss_value.backward()opt.step()loss_history.append(loss_value.item())
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.title('Loss variation over increasing epochs')
plt.xlabel('epochs')
plt.ylabel('loss value')
plt.show()神经网络数据加载
1. 数据准备
(1) 定义输入 x 和输出 y
x = [[1,2],[3,4],[5,6],[7,8]] # 输入数据(4 个样本,每个样本 2 个特征)
y = [[3],[7],[11],[15]] # 输出数据(4 个样本,每个样本 1 个目标值)-
这是一个简单的线性关系:
y = 2 * x1 + 1 * x2(例如2*1 + 1*2 = 4,但给定的y是3,可能是模拟带噪声的数据)。
(2) 转换为 PyTorch Tensor 并移至 GPU(如果可用)
X = torch.tensor(x).float() # 转换为 float32 Tensor
Y = torch.tensor(y).float() # 同上
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 检查 GPU
X = X.to(device) # 数据移至 GPU/CPU
Y = Y.to(device)2. 构建数据集(Dataset)和数据加载器(DataLoader)
(1) 自定义 MyDataset 类
class MyDataset(Dataset):def __init__(self, x, y):self.x = x.clone().detach() # 避免修改原数据self.y = y.clone().detach()def __len__(self):return len(self.x) # 返回数据集大小def __getitem__(self, idx):return self.x[idx], self.y[idx] # 返回第 idx 个样本-
.clone().detach():创建数据的独立副本,确保对数据集的操作不会影响原始数据。 -
如果省略这一步,直接赋值
self.x = x,外部对x的修改会直接影响数据集。 -
如果
x的形状是[100, 5](100个样本,每个样本5个特征),__len__会返回100。 -
根据索引
idx返回对应的样本和标签。
(2) 创建 DataLoader
ds = MyDataset(X, Y) # 实例化 Dataset
dl = DataLoader(ds, batch_size=2, shuffle=True) # 按 batch_size=2 加载,并打乱数据-
batch_size=2:每次训练用 2 个样本 计算梯度。训练的每个样本梯度之和除以训练样本数。 -
shuffle=True:每个epoch数据顺序随机打乱,防止模型学习到顺序偏差。
3. 定义神经网络模型
class MyNeuralNet(nn.Module):def __init__(self):super().__init__()self.input_to_hidden = nn.Linear(2, 8) # 输入层→隐藏层(2→8)self.activation = nn.ReLU() # 激活函数self.hidden_to_output = nn.Linear(8, 1) # 隐藏层→输出层(8→1)def forward(self, x):x = self.input_to_hidden(x) # 线性变换x = self.activation(x) # ReLU 激活x = self.hidden_to_output(x) # 输出预测return x-
网络结构:
-
输入层:2 个神经元(对应
x的 2 个特征)。 -
隐藏层:8 个神经元(使用
ReLU激活函数)。 -
输出层:1 个神经元(回归任务,无激活函数)。
-
-
前向传播:
-
x → Linear(2,8) → ReLU → Linear(8,1) → 输出。
-
4. 训练流程
(1) 初始化模型、损失函数、优化器
mynet = MyNeuralNet().to(device) # 实例化模型并移至 GPU/CPU
loss_func = nn.MSELoss() # 均方误差损失(回归任务常用)
opt = SGD(mynet.parameters(), lr=0.001) # 随机梯度下降优化器(2) 训练循环
loss_history = [] # 记录损失值
start = time.time()for _ in range(50): # 训练 50 个 epochfor x, y in dl: # 遍历每个 batchopt.zero_grad() # 清除梯度pred = mynet(x) # 前向传播loss = loss_func(pred, y) # 计算损失loss.backward() # 反向传播opt.step() # 更新参数loss_history.append(loss.item()) # 记录损失end = time.time()
print(f"训练时间: {end - start:.4f} 秒") # 输出耗时-
关键步骤:
-
opt.zero_grad():清除上一轮的梯度。 -
pred = mynet(x):前向计算预测值。 -
loss = loss_func(pred, y):计算预测值与真实值的误差。 -
loss.backward():反向传播计算梯度。 -
opt.step():用梯度更新模型参数。
-
5. 输出分析
(1) 训练时间
print(end - start) # 输出: 0.0854 秒-
在 GPU 上训练 50 个 epoch(共 4 个样本,batch_size=2,每个 epoch 2 次迭代),速度非常快。
(1) Epoch(训练轮次)
-
1 Epoch = 完整遍历一次所有训练数据。
-
你的数据
x有 4 个样本,所以 1 个 Epoch 会处理全部 4 个样本。
(2) Batch Size(批大小)
-
Batch Size = 2,表示每次训练用 2 个样本 计算梯度并更新模型。
-
因为总样本数是 4,所以:
-
每个 Epoch 的迭代次数(Steps) = 总样本数 / Batch Size = 4 / 2 = 2 次迭代。
-
(3) 50 Epochs
-
你设置了
for _ in range(50),表示训练 50 轮。 -
因此:
-
总迭代次数 = 50 Epochs × 2 Steps/Epoch = 100 次梯度更新。
-
(2) 损失变化
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.show()模型测试
val_x = [[10,11]]
val_x = torch.tensor(val_x).float().to(device)
print(mynet(val_x))
# tensor([[20.0105]], device='cuda:0', grad_fn=<AddmmBackward>)获取中间层的值
假设网络结构如下:
class MyNeuralNet(nn.Module):def __init__(self):super().__init__()self.input_to_hidden_layer = nn.Linear(2, 8) # 输入层→隐藏层self.hidden_layer_activation = nn.ReLU() # 激活函数self.hidden_to_output_layer = nn.Linear(8, 1) # 隐藏层→输出层def forward(self, x):x = self.input_to_hidden_layer(x)x = self.hidden_layer_activation(x)x = self.hidden_to_output_layer(x)return x直接获取隐藏层输出的方式:
print(mynet.hidden_layer_activation(mynet.input_to_hidden_layer(X)))
或者修改隐藏层
class MyNeuralNet(nn.Module):def __init__(self):super().__init__()self.input_to_hidden_layer = nn.Linear(2,8)self.hidden_layer_activation = nn.ReLU()self.hidden_to_output_layer = nn.Linear(8,1)def forward(self, x):hidden1 = self.input_to_hidden_layer(x)hidden2 = self.hidden_layer_activation(hidden1)x = self.hidden_to_output_layer(hidden2)return x, hidden2
print(mynet(X)[1])
1输出隐藏层激活后的值
0输出预测结果
使用Sequential构建神经网络
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]class MyDataset(Dataset):def __init__(self, x, y):self.x = torch.tensor(x).float().to(device)self.y = torch.tensor(y).float().to(device)def __getitem__(self, ix):return self.x[ix], self.y[ix]def __len__(self): return len(self.x)
ds = MyDataset(x, y)
dl = DataLoader(ds, batch_size=2, shuffle=True)
model = nn.Sequential(nn.Linear(2, 8),nn.ReLU(),nn.Linear(8, 1)
).to(device)
from torchsummary import summary
print(summary(model, (2,)))
loss_func = nn.MSELoss()
from torch.optim import SGD
opt = SGD(model.parameters(), lr = 0.001)
import time
loss_history = []
start = time.time()
for _ in range(50):for ix, iy in dl:opt.zero_grad()loss_value = loss_func(model(ix),iy)loss_value.backward()opt.step()loss_history.append(loss_value.item())
end = time.time()
print(end - start)
val = [[8,9],[10,11],[1.5,2.5]]
val = torch.tensor(val).float()
print(model(val.to(device)))
"""
tensor([[16.7774],[20.6186],[ 4.2415]], device='cuda:0', grad_fn=<AddmmBackward>)
"""
pytorch模型保存和加载
1.模型状态
print(model.state_dict())
"""
OrderedDict([('0.weight', tensor([[-0.4732, 0.1934],[ 0.1475, -0.2335],[-0.2586, 0.0823],[-0.2979, -0.5979],[ 0.2605, 0.2293],[ 0.0566, 0.6848],[-0.1116, -0.3301],[ 0.0324, 0.2609]], device='cuda:0')), ('0.bias', tensor([ 0.6835, 0.2860, 0.1953, -0.2162, 0.5106, 0.3625, 0.1360, 0.2495],device='cuda:0')), ('2.weight', tensor([[ 0.0475, 0.0664, -0.0167, -0.1608, -0.2412, -0.3332, -0.1607, -0.1857]],device='cuda:0')), ('2.bias', tensor([0.2595], device='cuda:0'))])
"""
2.模型保存
save_path = 'mymodel.pth'
torch.save(model.state_dict(), save_path)
3.模型加载
model = nn.Sequential(nn.Linear(2, 8),nn.ReLU(),nn.Linear(8, 1)
).to(device)state_dict = torch.load('mymodel.pth')model.load_state_dict(state_dict)
model.to(device)val = [[8,9],[10,11],[1.5,2.5]]
val = torch.tensor(val).float()
model(val.to(device))
相关文章:

使用PyTorch构建神经网络笔记
专有名词 Batch Size 在深度学习中,批大小(Batch Size) 是指每次前向传播和反向传播时使用的样本数量。它是训练神经网络时的一个关键超参数,直接影响训练速度、内存占用和模型性能。 (1) 计算梯度 在训练时,模型通过…...

麒麟系统网络连接问题排查
麒麟系统网络连接有红色叹号,不能上外网 了。 首先执行 ping -c4 8.8.8.8 和 nc -zv 8.8.8.8 53,如果 都能正常通信,说明你的网络可以访问公共 DNS 服务器(如 Google DNS 8.8.8.8),但域名解析仍然失败,可能是 DNS 解析配置问题 或 系统 DNS 缓存/代理干扰。以下是进一步…...

python高级特性01
装饰器 基本语法 在不改变原函数的基础上,新增/修改一些功能 在被装饰函数/类前使用:decorator_name 装饰器接收一个函数返回一个新函数 def decorator_name(func):# 装饰器的操作...def wrapper(*args, **kwargs):# 前置操作...result func()# 后置…...

shared_ptr八股收集 C++
(1)、具体讲一下shared_ptr自动管理内存的原理/引用计数的具体原理/shared_ptr引用计数什么时候会增加,什么时候会减少? 在shared_ptr的内部维护了⼀个计数器,来跟踪有多少个shared_ptr对象指向了某⼀个资源。当计数器…...

【gpt生成-其二】以go语言为例,详细讲解 并发模型:线程/协程/ Actor 实现
Go语言并发模型详解:线程、协程与Actor实现 1. 线程模型 概念 线程是操作系统调度的最小单位,每个线程拥有独立的栈和寄存器上下文,但共享进程的内存空间。线程的创建、切换和同步需要较高的系统开销。 Go中的实现…...

nodejs创建文件
环境要求:nodejs 运行命令: node createComponent.js各文件内容: createComponent.js /** 功能概述:* 1. 通过命令行交互,用户输入组件名称,选择模板类型。* 2. 根据用户输入生成对应的Vue组件、Service…...

三餐四季、灯火阑珊
2025年4月22日,15~28℃,挺好的 待办: 教学技能大赛教案(2025年4月24日,校赛,小组合作,其他成员给力,暂不影响校赛进度,搁置) 教学技能大赛PPT(202…...

HTTP状态码有哪些常见的类型?
HTTP 状态码用于表示服务器对客户端请求的响应状态,常见的 HTTP 状态码可以分为以下几类: 一、1xx:信息提示 状态码以 1 开头,表示请求已接收,客户端应继续其请求。常见的状态码有: • 100 Continue&…...

01-STM32基本知识点和keil5的安装
一、微控制器: 1、微控制器也被称为MCU(国内称为单片机),微控制器集成了处理器、内存、输入/输出接口等多种功能模块,能够独立完成特定的控制任务。它主要用于对设备或系统的控制和监测,MCU通常是一个高度…...

前端如何优雅地对接后端
作为一名前端开发者,与后端对接是我们日常工作中不可避免的一部分。从API设计的理解到错误处理的优雅实现,前端需要的不只是调用接口的代码,更是一种协作的艺术。本文将从Vue 3项目出发,分享如何与后端高效协作,减少联…...

Centos虚拟机远程连接缓慢
文章目录 Centos虚拟机远程连接缓慢1. 问题:SSH远程连接卡顿现象2. 原因:SSH服务端DNS检测机制3. 解决方案:禁用DNS检测与性能调优3.1 核心修复步骤3.2 辅助优化措施 4. 扩展认识:SSH协议的核心机制4.1 SSH工作原理4.2 关键配置文…...

Centos 、Linux 基础运维命令
查看系统IP ifconfig 巡检常用 显示磁盘空间使用情况 df -h 配置主机名查称看主机名称 hostname 修改主机名称 打开修改的配置文件 vim /etc/sysconfig/network 防火墙 查看防火墙状态 service iptables status 临时关闭防火墙:关机重启后防火墙还会开启 …...
)
算力网络有关论文自用笔记(2)
MADRLOM: A Computation offloading mechanism for software-defined cloud-edge computing power network 本质上还是计算卸载,概念套壳 主要工作 一种由软件定义的云边缘计算电力网络体系结构,包括多个用户设备、多个边缘节点和一个云数据中心。用户…...

基于外部中中断机制,实现以下功能: 1.按键1,按下和释放后,点亮LED 2.按键2,按下和释放后,熄灭LED 3.按键3,按下和释放后,使得LED闪烁
题目: 参照外部中断的原理和代码示例,再结合之前已经实现的按键切换LED状态的实验,用外部中断改进其实现。 请自行参考文档《中断》当中,有关按键切换LED状态的内容, 自行连接电路图,基于外部中断机制,实现以下功能&am…...

Go语言和Python 3的协程对比
Go语言和Python 3都支持协程(concurrent coroutines),但它们的实现机制、使用方式、调度方式和性能表现差异很大。下面是对比分析: 一、基本概念对比 特性Go 协程(goroutine)Python3 协程(asyn…...

量子计算在密码学中的应用与挑战:重塑信息安全的未来
在当今数字化时代,信息安全已成为全球关注的焦点。随着量子计算技术的飞速发展,密码学领域正面临着前所未有的机遇与挑战。量子计算的强大计算能力为密码学带来了新的应用场景,同时也对传统密码体系构成了潜在威胁。本文将深入探讨量子计算在…...

java知识点
一、ArrayList 的扩容 1.ArrayList 的扩容机制是将新容量计算为原容量的 15倍,即 oldcapacity(oldcapacity >>1)。这个操作将新容量设置为当前容量的 1.5 倍。 2.在 ArrayList 扩容时,会使用 Arrays.copyof()方法来复制原数组中的元素到新数组中&a…...

工厂模式:工厂方法模式 和 抽象工厂模式
工厂方法模式:优化,工厂类也分子类和父类 流程: 实例: #include <iostream> using namespace std; /*抽象产品类 TV(电视机类)*/ class TV { public: virtual void Show() 0; virtual ~TV();//声明析构函数为虚函数&…...

遨游通讯发布国产化旗舰三防手机AORO AU1:以自主可控重塑工业安全
在全球产业链加速重构的背景下,国产化技术突破已成为工业领域高质量发展的核心驱动力。作为专精特新中小企业,遨游通讯始终以“让世界更安全、更高效、更简单”为使命,深耕“危、急、特”场景智能通信设备的研发。近日,遨游通讯正…...

全波暗室和半波暗室的区别
什么是微波暗室?其作用是什么: 微波暗室又叫吸波室、电波暗室,一般是指由吸波材料和金属屏蔽体组成的特殊房间,该房间可有效防止电磁波的多次反射、隔绝外界电磁波的干扰,提供一个稳定的电磁环境,(高级点的…...

Qt 下载的地址集合
Qt 下载离线安装包 download.qt.io/archive/qt/5.14/5.14.2/ Qt 6 安装下载在线安装包 Index of /qt/official_releases/online_installers/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror...

08_Docker Portainer可视化管理
简介: Portainer 是一个轻量级的、基于 Web 的 Docker 管理用户界面。它允许用户轻松管理 Docker 环境,包括 Docker 主机、容器、镜像、网络等。 多主机管理,Portainer 支持通过 agent 的方式管理多台 Docker 主机。无论是企业级大规模的 D…...

【产品经理从0到1】用户研究和需求分析
用户角色 定义 用户角色 user personal,从用户群体中抽象出来的典型用户,一般 会包含: 1、个人基本信息; 2、家庭、工作、生活环境描述; 3、与产品使用相关的具体情境,用户目标或产品使用行为描述等。 特…...
)
神经网络 “疑难杂症” 破解指南:梯度消失与爆炸全攻略(六)
引言 在神经网络的发展历程中,梯度消失和梯度爆炸如同两座难以翻越的大山,阻碍着深层神经网络发挥其强大的潜力。尤其是在处理复杂任务时,这两个问题可能导致模型训练陷入困境,无法达到预期的效果。本文将深入探讨梯度消失和梯度…...

深入理解无监督学习:探索数据的潜在结构
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

Java实例化对象都有几种方式
在 Java 中,实例化对象的方式有多种,具体取决于场景需求和设计模式。以下是 7 种核心对象实例化方式及其原理、适用场景与代码示例: 1. new 关键字(直接构造) 原理:通过调用类的构造函数直接创建…...

数据结构:顺序表的实现
顺序表是用一段物理地址连续的存储单元依次储存数据的线性结构,一般情况下采用数组储存,在数组上完成数据的增删减改。 这里我们定义一个MyArrayList类,用来实现顺序表的功能: public class MyArrayList{int[] array;int usedsi…...
)
# 06_Elastic Stack 从入门到实践(六)
06_Elastic Stack 从入门到实践(六) 一、课程介绍 1、课程介绍 2、Nginx日志分析系统 3、Filebeat入门学习 4、Metricbeat入门学习 5、Kibana入门学习 6、Logstash入门学习 7、综合练习 二、Nginx 日志分析系统需求分析 1、业务需求 Nginx是一款非常优秀的web服务…...

[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析
拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关于学习,你可能也需要一个“豆包爱学”这样的AI伙伴,它将为你提供全方位的学习帮助…...

重装系统后的自用包
装驱动 sudo apt update sudo apt upgrade sudo apt install nvidia-driver-535搜狗输入法: https://shurufa.sogou.com/linux/guideClash verge: ubuntu20 下载1.7.7版本的 https://github.com/clash-verge-rev/clash-verge-rev/releases/tag/v1.7.7…...

4.22tx视频后台开发一面
总时长大概在一个小时,主要提问C、操作系统、计网以及数据库等方面,最后两个算法编程题。 一上来先介绍项目 Linux下的mybash命令处理器和内存池 mybash可以再总结归纳一下,一上来有点紧张没有条理 内存池是用边界标识法写的,…...

如何Ubuntu 22.04.5 LTS 64 位 操作系统部署运行SLAM3! 详细流程
以下是在本地部署运行 ORB-SLAM3 的详细步骤,基于官方 README.md 和最佳实践整理,适用于 Ubuntu 16.04/18.04/20.04/22.04 系统: 一、系统要求与依赖项安装 1. 基础系统要求 操作系统:Ubuntu 16.04/18.04/20.04/22.04ÿ…...

Ubuntu 上安装 Conda
在 Ubuntu 上安装 Conda(Anaconda 或 Miniconda)的完整步骤如下: --- **方法1:安装 Miniconda(推荐)** Miniconda 是 Anaconda 的精简版,只包含基本组件。 **1. 下载安装脚本** bash # 下载最…...

初级云计算运维工程师学习二
全面解析云计算服务模式:公有云、私有云、混合云及IaaS/PaaS/SaaS/DaaS 云计算部署模式:三种主要形式 1. 公有云(Public Cloud) 定义:云端资源开放给社会公众使用,由第三方云服务提供商通过互联网交付。 …...

物联网蓬勃发展是助力楼宇自控技术迈向成熟的关键
在当今数字化时代,物联网(IoT)正以前所未有的速度蓬勃发展,其影响力已广泛渗透到各个领域,楼宇自控技术便是其中之一。从本质上讲,楼宇自控旨在实现对建筑物内各类机电设备的智能化管理与控制,为…...

数字孪生技术:企业数字化转型的助推器
在当今环境下,企业面临的挑战不断增加。从可持续发展目标的要求到员工数字技能的提升,转型的呼声越来越高。然而,即使是经验丰富的领导者,也很难在这种前所未有的商业环境下实现转型。企业如何在满足可持续发展目标的同时保持盈利…...

ESM 内功心法:化解 require 中的夺命一击!
前言 传闻在JavaScript与TypeScript武林中,曾有两大绝世心法:CommonJS与ESM。两派高手比肩而立,各自称霸一方,江湖一度风平浪静。 岂料,时局突变。ESM逐步修成阳春白雪之姿,登堂入室,成为主流正统。CommonJS则渐入下风,功力不济,逐渐退出主舞台。 话说某日,一位前…...

安全调度系统:安全管理的智能中枢
安全调度系统作为安全管理体系的核心枢纽,正在深刻改变着传统安全管理的模式和效能。这个集成了先进信息技术的智能化平台,通过实时监控、智能分析和快速响应三大核心功能,构建起全方位、多层次的安全防护网络,成为各类场所安全管…...

Python爬虫从入门到实战详细版教程Char01:爬虫基础与核心技术
1.1 什么是网络爬虫? 1.1.1 定义与分类 网络爬虫:互联网世界的“信息捕手” 网络爬虫(Web Crawler),又称网络蜘蛛或网络机器人,是一种通过预设规则自动访问网页、提取数据的程序系统。从技术视角看,其核心任务是通过模拟浏览器行为向目标服务器发起请求,解析网页内容…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

Python线程全面详解:从基础概念到高级应用
一、线程基础概念 1.1 进程与线程的关系 进程是操作系统资源分配的基本单位,它是程序的一次执行过程。当我们将程序加载到内存中运行时,系统会为它分配CPU、内存、文件句柄等资源,这时就形成了一个进程。 线程是CPU调度的基本单位…...

学习模拟电路
学习模拟电路需要掌握以下几个关键领域的知识和技能,涵盖基础理论、器件特性、电路设计、分析工具以及实践应用: 1. 基础理论与概念 电路基本定律:欧姆定律、基尔霍夫电压定律(KVL)和电流定律(KCL…...

解码思维链:AI思维链如何重塑人类与机器的对话逻辑
第一章:思维链的诞生与进化 1.1 从"猜谜游戏"到"推理革命" 传统AI模型如同蒙眼解题的考生:当被问及"玛丽有12块饼干,吃掉4块后剩下多少",它们擅长预测答案,却无法展示"12-48&quo…...
)
css3新特性第六章(2D变换)
css3新特性第五章(2D变换) CSS3 转换可以对元素进行移动、缩放、转动、拉长或拉伸。 2D位移2D缩放2D旋转2D扭曲多重变换变换原点 一、2D位移 2D 位移可以改变元素的位置,具体使用方式如下: 先给元素添加 转换属性 transform 编写 transform 的具体值&…...

L2-2、示范教学与角色扮演:激发模型“模仿力“与“人格“
一、Few-shot 教学的核心原理与优势 在与大语言模型交互时,Few-shot(少样本)教学是一种强大的提示技术。其核心原理是通过提供少量示例,引导模型理解我们期望的输出格式和内容风格。 Few-shot 教学的主要优势包括: …...

MAC系统下完全卸载Android Studio
删除以下文件 /Applications/Android Studio.app /Users/用户名/Library/Application Support/Google/AndroidStudio2024.2 /Users/用户名/Library/Google/AndroidStudio /Users/用户名/Library/Preferences/com.google.android.studio.plist /Users/用户名/Library/Cache…...

rgw的d3n功能配置
背景 最近在看缓存相关,文件系统可以通过fscache加速,加速的效果就是读取的时候能够缓存,原理是在网关的地方加入一个高速缓存盘,这样在后续读取的时候,能够直接从缓存盘读取,这样能够减少与集群的交互&am…...

this._uid:Vue 内部为每个组件实例分配的唯一 ID
Vue 提供了一些方法可以帮助你区分组件实例,例如通过 this._uid(Vue 内部为每个组件实例分配的唯一 ID)或自定义标识符。 以下是具体的实现步骤和代码示例: console.log("当前组件实例ID:", this._uid, "时间戳:&…...
)
使用Python设置excel单元格的字体(font值)
一、前言 通过使用Python的openpyxl库,来操作excel单元格,设置单元格的字体,也就是font值。 把学习的过程分享给大家。大佬勿喷! 二、程序展示 1、新建excel import openpyxl from openpyxl.styles import Font wb openpyxl.…...

【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...