深入理解无监督学习:探索数据的潜在结构
📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
在机器学习的广阔领域中,学习算法可以大致分为三类:监督学习、无监督学习和强化学习。其中,无监督学习因其在没有标签数据的情况下探索数据的潜在结构而备受关注。在本篇博文中,我们将深入探讨无监督学习的基本概念、常见算法及其在实际应用中的重要性。
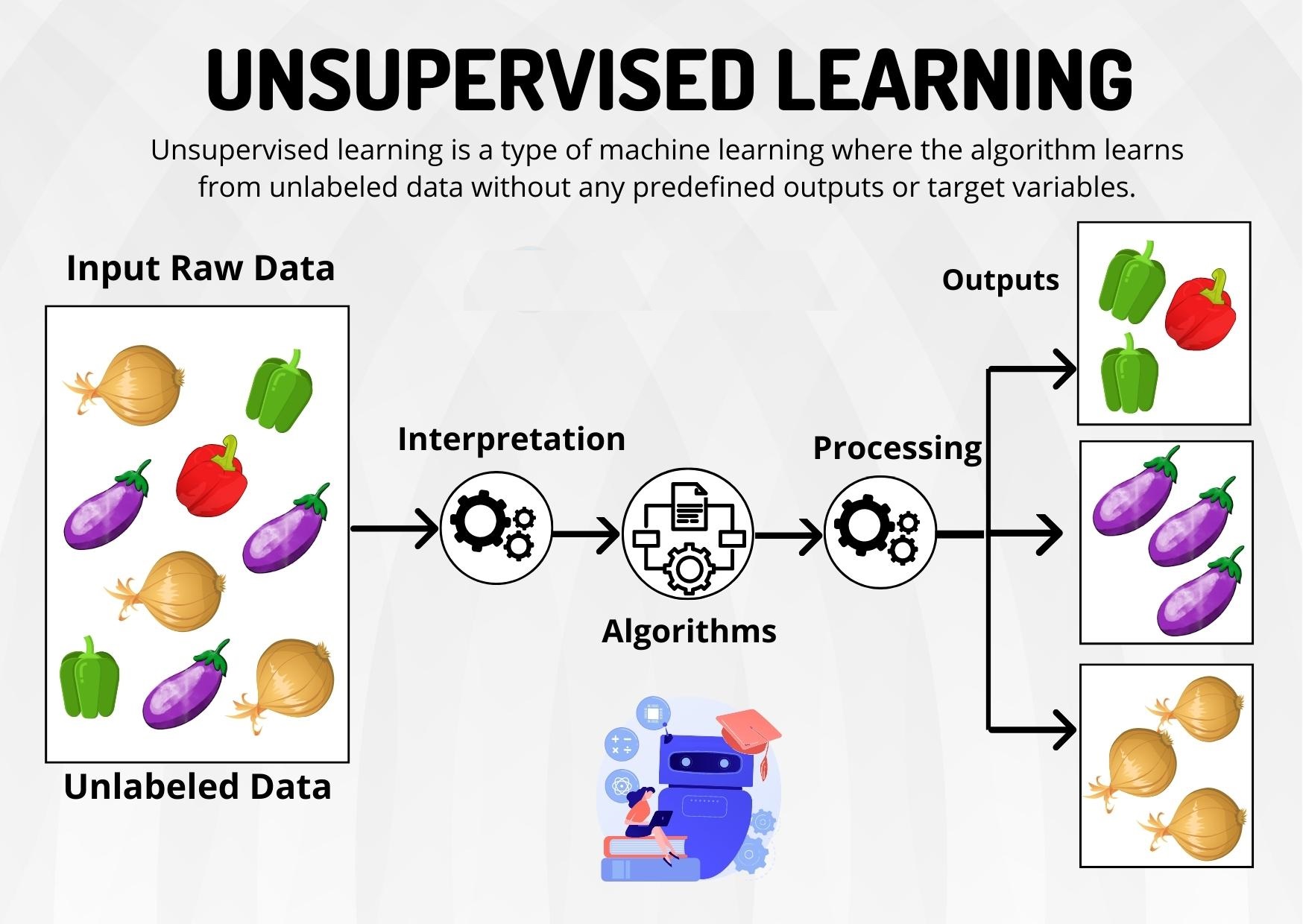
一、什么是无监督学习?
无监督学习是一种机器学习的类型,它使得算法在没有任何标签数据的情况下对输入数据进行分析。与监督学习不同,后者依赖于已标注的数据集来训练模型,目的是通过学习输入与输出之间的映射关系来进行预测。无监督学习则试图从未标注的数据中发掘潜在的模式和结构,旨在识别数据的内在特征。
无监督学习的主要任务有两个:聚类和降维。
1.1 聚类
聚类是一种将数据集划分为多个组(或簇)的方法,使得同一组内的数据点相似度高而不同组之间的数据点相似度低。聚类算法通过分析数据点之间的距离或相似性来确定这些组的边界。常见的聚类算法包括K-Means、层次聚类和DBSCAN等。聚类的应用非常广泛,例如在市场营销中,可以将客户分成不同的群体,以制定更有针对性的营销策略。
1.2 降维
降维则是通过减少数据集中的特征数量来简化数据,同时尽量保留其重要的信息。这种方法在数据可视化和高性能计算中尤为重要。降维可以帮助减少过拟合,提升模型的训练速度。主成分分析(PCA)和t-SNE是两种常用的降维技术。通过降低数据的维度,可以将复杂的高维数据映射到低维空间,便于进行进一步的分析和理解。
1.3 无监督学习的特点
无监督学习的一个显著特点是它不依赖于标签,因此可以处理大规模的、未标注的数据。这使得无监督学习在许多实际应用中具有广阔的前景,例如在图像处理、自然语言处理和生物信息学等领域。通过无监督学习,研究人员和工程师能够从庞大的数据集中提取信息,而无需进行劳动密集的标注工作。
二、无监督学习的应用
无监督学习在各行各业中都有广泛的应用,它能够帮助我们从复杂的数据集中抽取有用的信息。以下是一些具体的应用示例,展示无监督学习的强大能力和灵活性。
2.1 客户细分
在市场营销中,企业可以使用无监督学习对客户进行细分。通过聚类算法,企业能够识别不同类型的客户群体,了解他们的购买行为、偏好和需求。这种分析帮助企业制定更有效的营销策略,从而提升客户满意度和忠诚度。例如,在线零售商可以根据客户的购买历史将顾客分为频繁购买者、偶尔购买者和潜在客户,以便针对性地推出个性化的促销活动。
2.2 图像处理
在图像处理领域,无监督学习可以用于图像分割和特征提取。通过无监督学习,系统能够自动识别图像中的不同区域,并将其分类。例如,在医学影像分析中,无监督学习可以帮助医生分割出肿瘤区域,从而为后续的分析和诊断提供支持。此外,图像处理中的降维技术也可以用于减少图像数据的维度,提升图像处理和存储的效率。
2.3 异常检测
无监督学习在异常检测中的应用也非常重要。在金融领域,银行和金融机构可以利用无监督学习方法检测信用卡欺诈和其他可疑交易。例如,通过分析历史交易数据,模型可以建立正常交易模式的基线并实时监测交易。一旦发现与正常模式显著偏离的交易,系统就会发出警报,从而帮助防止潜在的欺诈行为。
2.4 推荐系统
无监督学习在推荐系统中的应用日益增多,尤其是在内容推荐和商品推荐方面。通过分析用户的行为数据,无监督学习能够识别出潜在的用户兴趣和偏好,从而为用户提供个性化的推荐。例如,流媒体平台可以利用用户观看历史聚类出相似的用户群体,并基于这些群体的共同偏好向用户推荐相关的电影或电视剧。
2.5 文本分析与自然语言处理
在文本分析和自然语言处理中,无监督学习也发挥着重要作用。通过对大量文本数据进行聚类和主题建模,机器可以发现文本中的潜在主题和关系。这种能力在文档分类、信息检索和情感分析等领域尤其重要。例如,新闻聚合网站可以使用无监督学习方法将新闻文章自动分类,从而帮助用户快速找到感兴趣的内容。
无监督学习的广泛应用展示了其在处理复杂数据时的强大能力。通过从未标注的数据中提取信息,无监督学习为企业和研究人员提供了重要的决策依据和洞察力。随着数据量的不断增长和无监督学习技术的发展,未来无监督学习将会在更多领域发挥重要作用,推动各行业的创新和发展。
三、常见的无监督学习算法
无监督学习算法种类繁多,适用于不同类型的数据和任务。下面我们将详细介绍几种常见的无监督学习算法,分别包括聚类算法、降维算法和关联规则学习。每种算法的介绍中将包含基本原理、应用场景和相关代码示例,以帮助开发人员理解和实现这些算法。
3.1 聚类算法
3.1.1 K-Means算法
原理: K-Means算法是一种广泛使用的聚类算法,旨在将数据集分成K个簇。算法通过反复迭代来优化每个数据点与其对应质心之间的距离,直到达到收敛条件。每个簇的质心是该簇内所有点的均值。
步骤:
- 随机选择K个初始质心。
- 将每个数据点分配给最近的质心,形成K个簇。
- 更新每个簇的质心,计算每个簇内所有点的均值。
- 重复步骤2和3,直到质心不再改变或达到最大迭代次数。
代码示例(使用Python的scikit-learn库):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans# 生成随机数据
np.random.seed(0)
X = np.random.rand(100, 2)# 使用K-Means进行聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)# 获取聚类结果
labels = kmeans.labels_
centroids = kmeans.cluster_centers_# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, alpha=0.75, marker='X')
plt.title('K-Means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
3.1.2 DBSCAN算法
原理: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法。与K-Means不同,DBSCAN可以识别任意形状的簇,并且能够有效处理噪声数据。它的主要思想是通过密度连接的原则来确定簇。
步骤:
- 选择一个点并找到其ε邻域内的所有点。
- 如果该点的邻域内的点数超过某个最小阈值,便将这些点作为一个簇。
- 对于簇中的每个点,重复步骤1和2,直到无法再扩展簇。
- 对于未被分配到任何簇的点,将其标记为噪声。
代码示例(使用Python的scikit-learn库):
from sklearn.cluster import DBSCAN# 生成随机数据
np.random.seed(0)
X = np.random.rand(100, 2)# 使用DBSCAN进行聚类
dbscan = DBSCAN(eps=0.1, min_samples=5)
labels = dbscan.fit_predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
3.2 降维算法
3.2.1 主成分分析(PCA)
原理: 主成分分析(PCA)是一种线性降维技术,旨在通过线性变换将数据从高维空间映射到低维空间,尽量保留数据的方差。PCA通过计算协方差矩阵的特征值和特征向量来实现降维。
步骤:
- 标准化数据,使每个特征具有零均值和单位方差。
- 计算协方差矩阵。
- 计算协方差矩阵的特征值和特征向量。
- 选择前K个特征向量,形成新的特征空间。
- 将数据映射到新的特征空间。
代码示例(使用Python的scikit-learn库):
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris# 加载Iris数据集
iris = load_iris()
X = iris.data# 使用PCA进行降维
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)# 可视化降维结果
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=iris.target, cmap='viridis')
plt.title('PCA of Iris Dataset')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
3.2.2 t-SNE
原理: t-SNE(t-distributed Stochastic Neighbor Embedding)是一种用于高维数据可视化的非线性降维技术。t-SNE通过保留数据点之间的相似度关系,使得在低维空间中相似的数据点尽量靠近,而不相似的数据点尽量远离。
步骤:
- 计算高维数据点之间的相似度。
- 在低维空间中,使用随机初始化的点构建分布。
- 通过优化算法调整低维空间中的点,使其分布尽量保留高维空间中的相似度。
代码示例(使用Python的scikit-learn库):
from sklearn.manifold import TSNE# 使用t-SNE进行降维
tsne = TSNE(n_components=2, random_state=0)
X_embedded = tsne.fit_transform(X)# 可视化降维结果
plt.scatter(X_embedded[:, 0], X_embedded[:, 1], c=iris.target, cmap='viridis')
plt.title('t-SNE of Iris Dataset')
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.show()
3.3 关联规则学习
3.3.1 Apriori算法
原理: Apriori算法是一种经典的关联规则学习算法,主要用于挖掘频繁项集和生成关联规则。该算法采用“自下而上”的策略,通过迭代生成候选项集并计算其支持度,识别出频繁项集。
步骤:
- 从数据集中找到所有单个项的支持度。
- 生成频繁项集并计算其支持度。
- 使用频繁项集生成关联规则,并计算其置信度。
代码示例(使用Python的mlxtend库):
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd# 创建交易数据
data = {'Milk': [1, 1, 0, 0, 1],'Bread': [1, 1, 1, 0, 1],'Eggs': [0, 1, 1, 1, 0]}
df = pd.DataFrame(data)# 使用Apriori算法生成频繁项集
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)print("Frequent Itemsets:")
print(frequent_itemsets)
print("\nAssociation Rules:")
print(rules)
这些无监督学习算法为数据分析提供了强大的工具。无论是聚类、降维还是关联规则学习,开发人员都可以根据具体需求选择合适的算法,并通过实际代码示例快速上手。随着数据科学和机器学习的不断发展,深入理解和掌握这些算法将成为开发人员提升技能和优化数据分析能力的重要一环。
四、无监督学习的挑战与未来
无监督学习作为一种重要的机器学习方法,虽然在许多领域中展现出了巨大的潜力和应用价值,但其在实际应用中仍然面临诸多挑战和限制。以下是一些主要的挑战以及未来发展方向的探讨。
4.1 挑战
4.1.1 缺乏标注数据的评估标准
无监督学习的一个主要挑战是缺乏明确的评估标准。在监督学习中,我们可以使用标签来评估模型的准确性和性能。然而,在无监督学习中,由于没有标签,往往难以判断模型的效果和输出的质量。例如,聚类结果的评估通常依赖于轮廓系数、Davies-Bouldin指数等指标,这些指标在不同场景下可能会产生偏差。
4.1.2 模型选择与参数调整
无监督学习中的模型选择和参数调整往往依赖于先验知识和经验。不同的数据集和任务可能需要不同的算法和参数设置,例如,K-Means聚类中的K值选择、DBSCAN中的ε和min_samples参数。这些超参数的选择可能会显著影响算法的输出结果,而缺乏有效的调整策略可能导致模型性能下降。
4.1.3 处理高维数据的挑战
高维数据(即特征数量大于样本数量的数据)是无监督学习中的常见问题。高维数据会导致“维度诅咒”,使得数据点之间的距离变得难以衡量,进而影响聚类效果和降维质量。在高维空间中,数据的稀疏性增加,传统的无监督学习算法可能无法有效捕捉数据的内在结构。
4.1.4 噪声和异常值的影响
无监督学习算法对噪声和异常值的敏感性是一个重要的挑战。在许多实际场景中,数据集可能包含噪声或异常值,这些数据点可能会干扰模型的学习过程并导致错误的结果。例如,在聚类中,噪声点可能被错误地归类到某个簇中,从而影响整体的聚类结果。
4.2 未来发展方向
随着深度学习技术的不断进步和数据规模的快速增长,无监督学习的未来发展潜力巨大。以下是几个可能的发展方向:
4.2.1 深度学习与无监督学习的结合
深度学习在特征提取和表示学习方面表现出色,结合深度学习的方法可以显著提升无监督学习的能力。例如,自编码器、生成对抗网络(GANs)等深度学习模型在无监督学习任务中应用广泛,可以帮助自动提取数据的深层特征。
4.2.2 迁移学习与无监督学习的结合
迁移学习是一种通过借用在源领域上获得的知识来改善目标领域的学习过程的方法。将迁移学习与无监督学习结合起来,可以在没有标注数据的情况下提升模型的适应能力和泛化能力。这种方法在处理新领域的数据时将变得尤为重要。
4.2.3 强化学习与无监督学习的交叉
强化学习近年来取得了显著进展,未来也可能与无监督学习产生交叉。通过设计新的学习框架,使得无监督学习能够借助强化学习中的反馈机制,可以提升模型在复杂环境中的学习能力。
4.2.4 解释性与可解释性的研究
无监督学习的黑箱特性使得模型的可解释性成为一个重要的研究课题。未来的研究将更关注于提升无监督学习模型的可解释性,以便用户能够理解模型的输出和决策过程。这不仅有助于提高用户的信任,还能在多个领域(如医疗和金融)中推动无监督学习的应用。
五、结语
无监督学习作为机器学习的重要分支,凭借其在没有标签的数据中发现潜在模式和结构的能力,已在多个领域取得了显著成果。从客户细分到异常检测,从图像处理到文本分析,无监督学习展现了其强大的应用价值。
然而,无监督学习仍面临许多挑战,包括评估标准的缺乏、模型选择的复杂性、处理高维数据的困难,以及对噪声和异常值的敏感性。面对这些挑战,结合深度学习、迁移学习以及其他新兴技术的发展,无监督学习的未来充满了机遇。随着数据科学的不断进步,无监督学习将在数据分析和人工智能领域中发挥越来越重要的作用。
相关文章:

深入理解无监督学习:探索数据的潜在结构
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

Java实例化对象都有几种方式
在 Java 中,实例化对象的方式有多种,具体取决于场景需求和设计模式。以下是 7 种核心对象实例化方式及其原理、适用场景与代码示例: 1. new 关键字(直接构造) 原理:通过调用类的构造函数直接创建…...

数据结构:顺序表的实现
顺序表是用一段物理地址连续的存储单元依次储存数据的线性结构,一般情况下采用数组储存,在数组上完成数据的增删减改。 这里我们定义一个MyArrayList类,用来实现顺序表的功能: public class MyArrayList{int[] array;int usedsi…...
)
# 06_Elastic Stack 从入门到实践(六)
06_Elastic Stack 从入门到实践(六) 一、课程介绍 1、课程介绍 2、Nginx日志分析系统 3、Filebeat入门学习 4、Metricbeat入门学习 5、Kibana入门学习 6、Logstash入门学习 7、综合练习 二、Nginx 日志分析系统需求分析 1、业务需求 Nginx是一款非常优秀的web服务…...

[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析
拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关于学习,你可能也需要一个“豆包爱学”这样的AI伙伴,它将为你提供全方位的学习帮助…...

重装系统后的自用包
装驱动 sudo apt update sudo apt upgrade sudo apt install nvidia-driver-535搜狗输入法: https://shurufa.sogou.com/linux/guideClash verge: ubuntu20 下载1.7.7版本的 https://github.com/clash-verge-rev/clash-verge-rev/releases/tag/v1.7.7…...

4.22tx视频后台开发一面
总时长大概在一个小时,主要提问C、操作系统、计网以及数据库等方面,最后两个算法编程题。 一上来先介绍项目 Linux下的mybash命令处理器和内存池 mybash可以再总结归纳一下,一上来有点紧张没有条理 内存池是用边界标识法写的,…...

如何Ubuntu 22.04.5 LTS 64 位 操作系统部署运行SLAM3! 详细流程
以下是在本地部署运行 ORB-SLAM3 的详细步骤,基于官方 README.md 和最佳实践整理,适用于 Ubuntu 16.04/18.04/20.04/22.04 系统: 一、系统要求与依赖项安装 1. 基础系统要求 操作系统:Ubuntu 16.04/18.04/20.04/22.04ÿ…...

Ubuntu 上安装 Conda
在 Ubuntu 上安装 Conda(Anaconda 或 Miniconda)的完整步骤如下: --- **方法1:安装 Miniconda(推荐)** Miniconda 是 Anaconda 的精简版,只包含基本组件。 **1. 下载安装脚本** bash # 下载最…...

初级云计算运维工程师学习二
全面解析云计算服务模式:公有云、私有云、混合云及IaaS/PaaS/SaaS/DaaS 云计算部署模式:三种主要形式 1. 公有云(Public Cloud) 定义:云端资源开放给社会公众使用,由第三方云服务提供商通过互联网交付。 …...

物联网蓬勃发展是助力楼宇自控技术迈向成熟的关键
在当今数字化时代,物联网(IoT)正以前所未有的速度蓬勃发展,其影响力已广泛渗透到各个领域,楼宇自控技术便是其中之一。从本质上讲,楼宇自控旨在实现对建筑物内各类机电设备的智能化管理与控制,为…...

数字孪生技术:企业数字化转型的助推器
在当今环境下,企业面临的挑战不断增加。从可持续发展目标的要求到员工数字技能的提升,转型的呼声越来越高。然而,即使是经验丰富的领导者,也很难在这种前所未有的商业环境下实现转型。企业如何在满足可持续发展目标的同时保持盈利…...

ESM 内功心法:化解 require 中的夺命一击!
前言 传闻在JavaScript与TypeScript武林中,曾有两大绝世心法:CommonJS与ESM。两派高手比肩而立,各自称霸一方,江湖一度风平浪静。 岂料,时局突变。ESM逐步修成阳春白雪之姿,登堂入室,成为主流正统。CommonJS则渐入下风,功力不济,逐渐退出主舞台。 话说某日,一位前…...

安全调度系统:安全管理的智能中枢
安全调度系统作为安全管理体系的核心枢纽,正在深刻改变着传统安全管理的模式和效能。这个集成了先进信息技术的智能化平台,通过实时监控、智能分析和快速响应三大核心功能,构建起全方位、多层次的安全防护网络,成为各类场所安全管…...

Python爬虫从入门到实战详细版教程Char01:爬虫基础与核心技术
1.1 什么是网络爬虫? 1.1.1 定义与分类 网络爬虫:互联网世界的“信息捕手” 网络爬虫(Web Crawler),又称网络蜘蛛或网络机器人,是一种通过预设规则自动访问网页、提取数据的程序系统。从技术视角看,其核心任务是通过模拟浏览器行为向目标服务器发起请求,解析网页内容…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

Python线程全面详解:从基础概念到高级应用
一、线程基础概念 1.1 进程与线程的关系 进程是操作系统资源分配的基本单位,它是程序的一次执行过程。当我们将程序加载到内存中运行时,系统会为它分配CPU、内存、文件句柄等资源,这时就形成了一个进程。 线程是CPU调度的基本单位…...

学习模拟电路
学习模拟电路需要掌握以下几个关键领域的知识和技能,涵盖基础理论、器件特性、电路设计、分析工具以及实践应用: 1. 基础理论与概念 电路基本定律:欧姆定律、基尔霍夫电压定律(KVL)和电流定律(KCL…...

解码思维链:AI思维链如何重塑人类与机器的对话逻辑
第一章:思维链的诞生与进化 1.1 从"猜谜游戏"到"推理革命" 传统AI模型如同蒙眼解题的考生:当被问及"玛丽有12块饼干,吃掉4块后剩下多少",它们擅长预测答案,却无法展示"12-48&quo…...
)
css3新特性第六章(2D变换)
css3新特性第五章(2D变换) CSS3 转换可以对元素进行移动、缩放、转动、拉长或拉伸。 2D位移2D缩放2D旋转2D扭曲多重变换变换原点 一、2D位移 2D 位移可以改变元素的位置,具体使用方式如下: 先给元素添加 转换属性 transform 编写 transform 的具体值&…...

L2-2、示范教学与角色扮演:激发模型“模仿力“与“人格“
一、Few-shot 教学的核心原理与优势 在与大语言模型交互时,Few-shot(少样本)教学是一种强大的提示技术。其核心原理是通过提供少量示例,引导模型理解我们期望的输出格式和内容风格。 Few-shot 教学的主要优势包括: …...

MAC系统下完全卸载Android Studio
删除以下文件 /Applications/Android Studio.app /Users/用户名/Library/Application Support/Google/AndroidStudio2024.2 /Users/用户名/Library/Google/AndroidStudio /Users/用户名/Library/Preferences/com.google.android.studio.plist /Users/用户名/Library/Cache…...

rgw的d3n功能配置
背景 最近在看缓存相关,文件系统可以通过fscache加速,加速的效果就是读取的时候能够缓存,原理是在网关的地方加入一个高速缓存盘,这样在后续读取的时候,能够直接从缓存盘读取,这样能够减少与集群的交互&am…...

this._uid:Vue 内部为每个组件实例分配的唯一 ID
Vue 提供了一些方法可以帮助你区分组件实例,例如通过 this._uid(Vue 内部为每个组件实例分配的唯一 ID)或自定义标识符。 以下是具体的实现步骤和代码示例: console.log("当前组件实例ID:", this._uid, "时间戳:&…...
)
使用Python设置excel单元格的字体(font值)
一、前言 通过使用Python的openpyxl库,来操作excel单元格,设置单元格的字体,也就是font值。 把学习的过程分享给大家。大佬勿喷! 二、程序展示 1、新建excel import openpyxl from openpyxl.styles import Font wb openpyxl.…...

【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...
)
三角形神经网络(TNN)
三角形神经网络(TNN)是一种新兴的神经网络架构,不过目前它并非像 CNN、RNN 等传统网络那样被广泛研究和应用,以下为你解释其原理并结合例子说明: 原理 基本结构 三角形神经网络的核心思想是构建一种类似三角形的层次…...
)
【JavaEE】-- MyBatis操作数据库(1)
文章目录 1. 什么是MyBatis2 MyBatis入门2.1 准备工作2.1.1 创建工程 2.2 配置数据库连接字符串2.3 写持久层代码2.4 单元测试 3. MyBatis的基础操作3.1 打印日志3.2 参数传递3.3 增(insert)3.3.1 返回主键 3.4 删(delete)3.5 改&…...

人工智能大模型备案与服务登记:监管体系的双轨逻辑与实操指南
一、核心差异:监管框架的分层设计 适用范围的本质分野 大模型备案:针对直接向公众提供生成式服务的自研或微调模型(如 ChatGPT 类产品),要求模型具备舆论属性或社会动员能力。典型场景包括智能客服、内容创作平台等。大…...

衡石ChatBI:依托开放架构构建技术驱动的差异化数据服务
在当今数字化浪潮中,企业对数据价值的挖掘和利用需求日益增长。BI(商业智能)工具作为企业获取数据洞察的关键手段,其技术架构的创新与发展至关重要。衡石科技的Chat BI凭借其独特的开放架构,在BI领域脱颖而出ÿ…...

AOSP Android14 Launcher3——RecentsView最近任务数据加载
最近任务是Launcher中的一个重要的功能,显示用户最近使用的应用,并可以快速切换到其中的应用;用户可以通过底部上滑停顿进入最近任务,也可以在第三方应用底部上滑进最近任务。 这两种场景之前的博客也介绍过,本文就不…...

分析型数据库与事务型数据库?核心差异与选型指南
在当今数据驱动的业务环境中,选择合适的数据库架构已成为企业技术决策的关键。然而,面对事务型数据库和分析型数据库的选择,许多技术团队往往陷入困境:日常运行良好的系统在数据量激增时性能骤降,简单的查询在复杂分析…...

Linux-信号
信号是由用户,系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常。 进程分为前台进程和后台进程,对于前台进程我们可以输入特殊的终端字符来给它发送信号,比如输入Ctrlc,发送一个中断信号 系…...

Oracle数据库学习之路-目录
Oracle数据库学习之路 一、安装 (一)数据库安装步骤详解 (二)开发工具安装与配置 二、基础语法篇 (一)基础 SQL 语法详解 (二)SQL 语法练习与案例分析 三、高级语法篇 &…...

用selenium4 webdriver + java 搭建并完成第一个自动化测试脚本
自动化测试任务: 百度搜索自己的姓名。点击第一个链接(或者第二个),在新的页面上,添加断言,验证你的名字是否存在。 实验资料百度网盘下载路径: 链接: https://pan.baidu.com/s/1nVlHX_ivres…...

晨控CK-FR12与欧姆龙NX系列PLC配置EtherNet/IP通讯连接操作手册
晨控CK-FR12系列作为晨控智能工业级别RFID读写器,支持大部分工业协议如RS232、RS485、以太网。支持工业协议Modbus RTU、Modbus TCP、Profinet、EtherNet/lP、EtherCat以及自由协议TCP/IP等。 本期主题:围绕CK-FR12产品的EtherNet/IP通讯协议与欧姆龙PLC进行通讯配置…...

武装Burp Suite工具:RouteVulScan插件_被动扫描发现漏洞.
武装Burp Suite工具:RouteVulScan插件_被动扫描. RouteVulScan 是一款使用Java语言编写,基于Burp Suite API的插件,用于递归地检测潜在的脆弱路径。 该插件通过被动扫描的方式,对路径的各个层级进行深度分析。利用预设的正则表达…...

Selenium+Java 环境搭建
windows电脑环境搭建Chrome浏览器 1.下载 Google Chrome 网络浏览器 (一定要下载官方的!!!) 注:最好下载在浏览器默认的路径 便于查找,而且占内存不是很大 2.查看chrome浏览器的版本 3.下载…...

网易云IP属地可以查看城市吗?深度解析与使用指南
在互联网时代,用户的隐私和数据安全越来越受到关注。许多社交平台和应用都会显示用户的IP属地,以增加透明度和真实性。网易云音乐作为国内领先的音乐平台,也引入了IP属地显示功能。那么,网易云IP属地能否精确到城市?这…...

Cline 之Plan和Act模式
Cline 提供了 "Plan & Act"双模式开发框架。适用在不同的场景。 一、核心模式理念 通过结构化开发流程提升AI编程效率,采用"先规划后执行"的核心理念。 该框架旨在帮助开发者构建更易维护、准确性更高的代码,同时显著缩短开发…...

【Java面试笔记:基础】7.int和Integer有什么区别?
在Java中,int和Integer虽然都用于表示整数值,但它们在本质、用法和特性上有显著差异。 1. int 和 Integer 的区别 int: 原始数据类型:int 是 Java 的 8 个原始数据类型之一,用于表示整数。性能优势:直接存…...

嘻游后台系统与机器人模块结构详解:功能逻辑 + 定制改造实战
作为“嘻游电玩三端组件”系列的最后一篇,本篇将全面剖析平台自带的后台控制系统与机器人行为逻辑模块,包括:用户管理、房间配置、日志系统、机器人规则编排与行为策略扩展等。通过技术视角展示其整体框架与可拓展性,帮助开发者更…...

Linux 网络编程:select、poll 与 epoll 深度解析 —— 从基础到高并发实战
一、IO 多路复用:解决并发 IO 的核心技术 在网络编程中,当需要同时处理大量客户端连接时,传统阻塞式 IO 会导致程序卡在单个操作上,造成资源浪费。IO 多路复用技术允许单线程监听多个文件描述符(FD)&#…...

在统信UOS1060上安装Fail2Ban并通过邮件发送通知
在统信UOS1060上安装Fail2Ban并通过邮件发送通知 Fail2Ban 是一个开源的防止暴力攻击的软件,可以有效保护您的服务器免受频繁的登录失败攻击。本文将指导您如何在统信UOS 1060上安装Fail2Ban,并在IP被封禁后通过邮件发送通知。 步骤 1:查看…...
)
PyTorch 分布式 DistributedDataParallel (DDP)
在之前的讨论(或者如果你直接跳到这里)中,我们了解了 torch.nn.DataParallel (DP) 作为 PyTorch 多 GPU 训练的入门选项。它简单易用,但其固有的主 GPU 瓶颈、GIL 限制和低效的通信模式,往往让它在实际应用中难以充分发…...
:基于数据洞察优化产品与运营)
精益数据分析(14/126):基于数据洞察优化产品与运营
精益数据分析(14/126):基于数据洞察优化产品与运营 在创业和数据分析的道路上,我们都在不断摸索前行。我一直希望能和大家共同学习、共同进步,所以今天继续为大家解读《精益数据分析》。这次我们将深入探讨HighScore …...

flutter 插件收集
2025年 1月10号Flutter插件手机 声音转文字 speech_to_text | Flutter package 文字转声音 flutter_tts | Flutter package 堆栈信息 stack_trace | Dart package 跳转到app设置里面 app_settings | Flutter package 轻松的动画 animations | Flutter package 日志打印 t…...

WPF特性分析
文章目录 WPF特性全面分析与性能优化指南引言WPF核心特性1. 声明式UI与XAML2. 硬件加速渲染3. 数据绑定与MVVM4. 样式与模板5. 动画系统 WPF与其他框架比较WPF vs. WinFormsWPF vs. UWPWPF vs. MAUI WPF性能优化最佳实践1. 内存管理优化2. UI虚拟化3. 使用冻结对象4. 减少视觉树…...

3.1goweb框架gin下
Gin 框架有内置的模板引擎,它允许你将数据和 HTML 模板结合,动态生成网页内容。 模板引擎基础使用 单模板文件示例 以下是一个简单的使用单个 HTML 模板文件的示例,展示了如何在 Gin 中渲染模板: package mainimport ("g…...

【全解析】深入理解 JavaScript JSON 数据解析
一、JSON 概述 1. 概念 JSON 全称为 JavaScript Object Notation,是一种轻量级的数据交换格式。它是 JavaScript 中用于描述对象数据的语法的扩展。不过并不限于与 JavaScript 一起使用。它采用完全独立于语言的文本格式,这些特性使 JSON 成为理想的数…...