【深度学习】#8 循环神经网络
主要参考学习资料:
《动手学深度学习》阿斯顿·张 等 著
【动手学深度学习 PyTorch版】哔哩哔哩@跟李牧学AI
为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习”消除误导性。在学习中将理论与实践紧密结合固然有其好处,但在所学知识的广度面前,先铺垫广泛的理论基础,再根据最终实践的目标筛选出需要得到深化的理论知识可能是更有效的策略。
目录
- 序列模型
- 文本预处理
- 语言模型
- 马尔可夫模型与n元语法
- 自然语言统计
- 学习语言模型
- 循环神经网络
- 有隐状态的循环神经网络
- 困惑度
- 通过时间反向传播
- 循环神经网络的梯度分析
- 1.截断时间步
- 2.随机截断
- 通过时间反向传播的细节
- 梯度裁剪
概述
- 序列模型是处理序列信息的模型。
- 处理文本序列信息的语言模型存在其独有的挑战。
- 循环神经网络通过隐状态存储过去的信息。
- 通过时间反向传播是反向传播在循环神经网络中的特定应用。
- 截断时间步和梯度裁剪可以缓解循环神经网络的梯度消失与爆炸问题。
序列模型
卷积神经网络可以有效地处理空间信息,而循环神经网络(RNN)则可以很好地处理序列信息。循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
音乐、语音、文本和视频都是序列信息,如果它们的序列被重排,就会失去原本的意义。
处理序列数据需要统计工具和新的深度神经网络架构。假设对于一组序列数据,在时间步 t ∈ Z + t\in\mathbb Z^+ t∈Z+时观察到的数据为 x t x_t xt,则预测 x t x_t xt的途径为:
x t ∼ P ( x t ∣ x t − 1 , ⋯ , x 1 ) x_t\sim P(x_t|x_{t-1},\cdots,x_1) xt∼P(xt∣xt−1,⋯,x1)
有效估计 P ( x t ∣ x t − 1 , ⋯ , x 1 ) P(x_t|x_{t-1,\cdots,x_1}) P(xt∣xt−1,⋯,x1)的策略归结为以下两种:
第一种,假设现实情况下观测所有之前的序列是不必要的,只需要满足某个长度为 τ \tau τ的时间跨度,即观测序列 x t − 1 , ⋯ , x t − τ x_{t-1},\cdots,x_{t-\tau} xt−1,⋯,xt−τ,至少在 t > τ t>\tau t>τ时。此时输入的数量固定,可以使用之前的深度网络,这种模型被称为自回归模型。
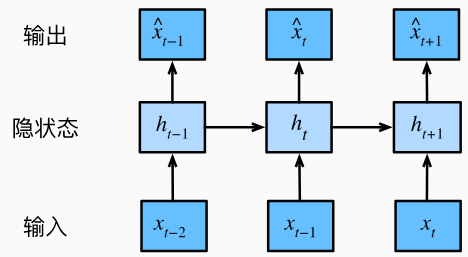
第二种,引入潜变量 h ( t ) h(t) h(t)表示过去的信息,并且同时更新 x ^ t = P ( x t ∣ h t ) \hat x_t=P(x_t|h_t) x^t=P(xt∣ht)和 h t = g ( h t − 1 , x t − 1 ) h_t=g(h_{t-1},x_{t-1}) ht=g(ht−1,xt−1)。由于 h ( t ) h(t) h(t)从未被观测到,这类模型被称为隐变量自回归模型,如下图所示:
文本预处理
文本是最常见的序列数据之一。文本常见的预处理步骤通常包括:
- 将文本作为字符串加载到内存中;
- 将字符串拆分为词元(如单词和字符);
- 建立一个词表,将拆分的词元映射到数字索引;
- 将文本转换为数字索引序列,以便模型操作。
词元是文本的基本单位,可以是单词或字符。但模型需要的输入是数字而不是字符串,因此需要构建一个字典,也称词表,来将字符串类型的词元映射到从0开始的数字索引中。统计一个文本数据集中出现的所有不重复的词元,得到的结果称为语料库。词表根据语料库中每个词元出现的频率为其分配一个数字索引,很少出现的词元则通常被移除以降低复杂度。除此之外,未知词元 ’<unk>’ \texttt{'<unk>'} ’<unk>’用于映射语料库中不存在的词元,填充词元 ’<pad>’ \texttt{'<pad>'} ’<pad>’用于填充长度不足的序列使输入序列具有相同的长度,序列开始词元 ’<bos>’ \texttt{'<bos>'} ’<bos>’和序列结束词元 ’<eos>’ \texttt{'<eos>'} ’<eos>’定义序列的开始与结束。
语言模型
马尔可夫模型与n元语法
在自回归模型中,我们使用 x t − 1 , ⋯ , x t − τ x_{t-1},\cdots,x_{t-\tau} xt−1,⋯,xt−τ而非 x t − 1 , ⋯ , x 1 x_{t-1},\cdots,x_1 xt−1,⋯,x1预测 x t x_t xt。当预测的状态只与其前 n n n个时间步的状态有关,我们称其满足 n n n阶马尔可夫性质,相应的模型被称为 n n n阶马尔可夫模型。阶数越高,对应的依赖关系链就越长。根据马尔可夫性质可以推导出许多应用于序列建模的近似公式:
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2)P(x_3)P(x_4) P(x1,x2,x3,x4)=P(x1)P(x2)P(x3)P(x4)
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 2 ) P ( x 4 ∣ x 3 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_2)P(x_4|x_3) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x2)P(x4∣x3)
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 4 ∣ x 3 , x 2 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)P(x_4|x_3,x_2) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x1,x2)P(x4∣x3,x2)
使用 1 1 1阶、 2 2 2阶、 3 3 3阶马尔可夫性质的概率公式被称为一元语法、二元语法和三元语法模型。
自然语言统计
自然语言的统计结果往往符合一些规律。
首先,词频最高的词很多为虚词(the、and、of等),这些词通常被称为停用词,在做文本分析时可以被过滤掉。但它们本身有一定意义,因此模型仍然使用它们。
还有一个问题是词频衰减的速度相当快,以下是H.G.Wells的小说The Time Machine的词频图:
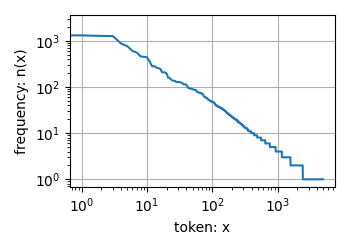
除去前几个单词,剩余的单词与其词频的变化规律大致遵循双对数坐标图上的一条直线。这意味着单词的频率满足齐普夫定律,即第 i i i个最常用单词的频率 n i n_i ni满足
n i ∝ 1 i α n_i\propto\displaystyle\frac1{i^\alpha} ni∝iα1
其等价于
log n i = − α log i + c \log n_i=-\alpha\log i+c logni=−αlogi+c
其中 α \alpha α是描述分布的指数, c c c是常数。这意味着较少的单词拥有极高的词频,而大部分单词的词频与之相比十分地低。
在二元语法(bigram)和三元语法(trigram)的情况下,即两个单词和三个单词构成的序列,它们的分布也在一定程度上遵循齐普夫定律:
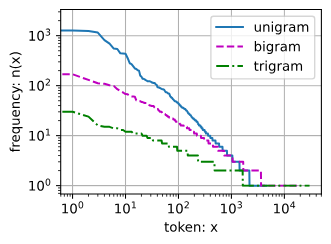
随着 n n n元语法中 n n n的增大, n n n个单词的序列的最高词频的衰减也十分迅速,且越来越多的单词序列只会出现 1 1 1次。
学习语言模型
假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , ⋯ , x T x_1,x_2,\cdots,x_T x1,x2,⋯,xT,于是 x t ( 1 ⩽ t ⩽ T ) x_t(1\leqslant t\leqslant T) xt(1⩽t⩽T)可以被认为是文本序列在时间步 t t t处的观测或标签。在给定这样的文本序列时,语言模型的目标是估计序列的联合概率
P ( x 1 , x 2 , ⋯ , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , ⋯ , x t − 1 ) P(x_1,x_2,\cdots,x_T)=\displaystyle\prod^T_{t=1}P(x_t|x_1,\cdots,x_{t-1}) P(x1,x2,⋯,xT)=t=1∏TP(xt∣x1,⋯,xt−1)
例如,包含 4 4 4个单词的一个文本序列是
P ( d e e p , l e a r n i n g , i s , f u n ) = P ( d e e p ) P ( l e a r n i n g ∣ d e e p ) P ( i s ∣ d e e p , l e a r n i n g ) P ( f u n ∣ d e e p , l e a r n i n g , i s ) P(\mathrm{deep},\mathrm{learning},\mathrm{is},\mathrm{fun})=P(\mathrm{deep})P(\mathrm{learning}|\mathrm{deep})P(\mathrm{is}|\mathrm{deep},\mathrm{learning})P(\mathrm{fun}|\mathrm{deep},\mathrm{learning},\mathrm{is}) P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is)
为了训练语言模型,我们需要计算单词出现的概率以及给定前面几个单词后出现某个单词的条件概率。训练数据集中单词的概率可以根据给定单词的相对词频计算,例如通过统计单词“deep”在数据集中出现的次数,然后除以整个语料库中的单词数来得到估计值 P ^ ( d e e p ) \hat P(\mathrm{deep}) P^(deep)。这对频繁出现的单词效果不错。
接下来我们尝试估计
P ^ ( l e a r n i n g ∣ d e e p ) = n ( d e e p , l e a r n i n g ) n ( d e e p ) \hat P(\mathrm{learning}|\mathrm{deep})=\displaystyle\frac{n(\mathrm{deep},\mathrm{learning})}{n(\mathrm{deep})} P^(learning∣deep)=n(deep)n(deep,learning)
其中 n ( x ) n(x) n(x)和 n ( x , x ′ ) n(x,x') n(x,x′)分别为单个单词和连续单词对出现的次数。但是根据齐普夫定律可想而知,连续单词对“deep learning”出现的频率低得多,要想找到足够的出现次数来获得准确的估计并不容易。而对于 3 3 3个或更多单词的组合,情况会变得更糟。
一种常见的应对小概率和零概率问题的策略是拉普拉斯平滑,它在所有计数中添加一个小常量 ϵ \epsilon ϵ:
P ^ ( x ) = n ( x ) + ϵ 1 / m n + ϵ 1 \hat P(x)=\displaystyle\frac{n(x)+\epsilon_1/m}{n+\epsilon_1} P^(x)=n+ϵ1n(x)+ϵ1/m
P ^ ( x ′ ∣ x ) = n ( x , x ′ ) + ϵ 2 P ^ ( x ) n ( x ) + ϵ 2 \hat P(x'|x)=\displaystyle\frac{n(x,x')+\epsilon_2\hat P(x)}{n(x)+\epsilon_2} P^(x′∣x)=n(x)+ϵ2n(x,x′)+ϵ2P^(x)
其中 m m m为训练集中不重复单词的数量,不同变量数目的条件概率估计所用的 ϵ \epsilon ϵ都是超参数。但这种方法很容易变得无效,原因如下:
- 我们需要存储所有单词和单词序列的计数。
- 该方法忽视了单词的意思和具有跨度的上下文关系。
- 长单词序列中的大部分是没出现过的,因而无法区分它们。
循环神经网络及其变体,和后续介绍的其他序列模型将克服这些问题。
循环神经网络
对于 n n n元语法模型,想要基于更大的时间跨度作出预测,只有增大 n n n,代价是参数将指数级增长,因为每个不重复的单词都需要存储在所有长度小于 n n n的单词序列之后其出现的条件概率。使用隐变量自回归模型则可以对参数进行压缩:
P ( x t ∣ x t − 1 , ⋯ , x 1 ) ≈ P ( x t ∣ h t − 1 ) P(x_t|x_{t-1},\cdots,x_1)\approx P(x_t|h_{t-1}) P(xt∣xt−1,⋯,x1)≈P(xt∣ht−1)
其中 h t − 1 h_{t-1} ht−1是隐状态,也称为隐藏变量,它会在每个时间步以新的输入 x t x_t xt和前一时刻的隐状态 h t − 1 h_{t-1} ht−1更新自己:
h t = f ( x t , h t − 1 ) h_t=f(x_t,h_{t-1}) ht=f(xt,ht−1)
尽管我们不知道隐状态具体存储了怎样的信息,但就公式来看,它在每个时间步确实是由所有之前的输入共同决定的。缺乏直观的可解释性是深度学习的普遍特点。
有隐状态的循环神经网络
循环神经网络(RNN)是具有隐状态的神经网络。
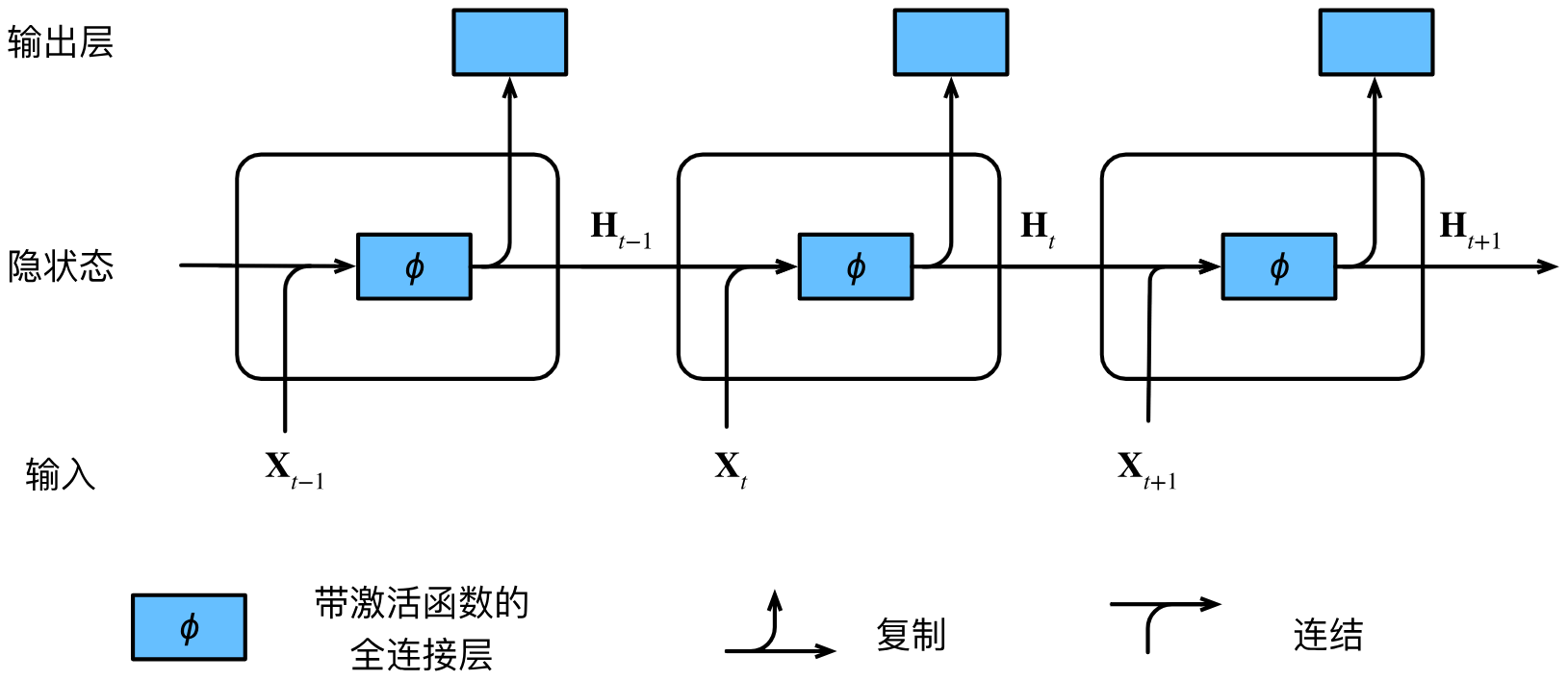
假设有 n n n个序列样本的小批量,在时间步 t t t,小批量输入 X t ∈ R n × d \mathbf X_t\in\mathbb R^{n\times d} Xt∈Rn×d的每一行对应一个序列时间步 t t t处的一个样本。接下来,我们用 H t ∈ R n × h \mathbf H_t\in\mathbb R^{n\times h} Ht∈Rn×h表示时间步 t t t的隐藏变量,并保存了前一个时间步的隐藏变量 H t − 1 \mathbf H_{t-1} Ht−1和利用它更新自身的权重参数 W h h ∈ R h × h \mathbf W_{hh}\in\mathbb R^{h\times h} Whh∈Rh×h。接收到输入时,RNN会先更新隐藏变量:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) \mathbf H_t=\phi(\mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh}+\mathbf b_h) Ht=ϕ(XtWxh+Ht−1Whh+bh)
再根据新的隐藏变量计算输出层的输出:
O t = H t W h q + b q \mathbf O_t=\mathbf H_t\mathbf W_{hq}+\mathbf b_q Ot=HtWhq+bq
可见,隐藏变量类似于多层感知机中隐藏层的输出,但不同的是它在计算时多出了 H t − 1 W h h \mathbf H_{t-1}\mathbf W_{hh} Ht−1Whh一项,不再仅由当前的输入决定。
对于更多的时间步,RNN不会引入新的参数,只会更新已有的参数,以此维持稳定的参数开销。同时,和普通的自回归模型相比,RNN有固定数量的输入,不会因考虑的时间步而改变。
将 X t W x h + H t − 1 W h h \mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh} XtWxh+Ht−1Whh写成分块矩阵乘法可得:
X t W x h + H t − 1 W h h = [ X t , H t − 1 ] [ W x h W h h ] \mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh}=\begin{bmatrix}\mathbf X_t,\mathbf H_{t-1}\end{bmatrix}\begin{bmatrix}\mathbf W_{xh}\\\mathbf W_{hh}\end{bmatrix} XtWxh+Ht−1Whh=[Xt,Ht−1][WxhWhh]
因此该计算相当于将 X t \mathbf X_t Xt和 H t − 1 \boldsymbol H_{t-1} Ht−1按行连接,将 W x h \mathbf W_{xh} Wxh和 W h h \mathbf W_{hh} Whh按列连接再相乘。由此有隐状态的循环神经网络的计算逻辑如下图所示:
困惑度
由于语言模型和分类模型在本质上有共通之处,输出都是离散的,因此可以引入交叉熵衡量其质量。一个更好的语言模型应该在预测中对序列下一个标签词元给出更高的概率,对序列中所有 n n n个词元的交叉熵损失求平均值得到:
1 n ∑ i = 1 n − log P ( x i ∣ x i − 1 , ⋯ , x 1 ) \displaystyle\frac1n\sum^n_{i=1}-\log P(x_i|x_{i-1},\cdots,x_1) n1i=1∑n−logP(xi∣xi−1,⋯,x1)
由于历史原因,自然语言处理领域更常使用困惑度,它是对上式进行指数运算的结果:
P P = exp ( − 1 n ∑ i = 1 n log P ( x i ∣ x i − 1 , ⋯ , x 1 ) ) PP=\exp\left(-\displaystyle\frac1n\sum^n_{i=1}\log P(x_i|x_{i-1},\cdots,x_1)\right) PP=exp(−n1i=1∑nlogP(xi∣xi−1,⋯,x1))
- 在最好的情况下,模型对标签词元的概率估计总是 1 1 1,此时困惑度为 1 1 1。
- 在最坏的情况下,模型对标签词元的概率估计总是 0 0 0,此时困惑度为正无穷。
- 在基线上,模型对词表中所有不重复词元的概率估计均匀分布,此时困惑度为不重复词元的数量。
通过时间反向传播
通过时间反向传播(BPTT)是循环神经网络中反向传播技术的一个特定应用。
循环神经网络的梯度分析
我们先从循环神经网络的简化模型开始,将时间步 t t t的隐状态表示为 h t h_t ht,输入表示为 x t x_t xt,输出表示为 o t o_t ot,并使用 w h w_h wh和 w o w_o wo表示隐藏层(拼接后)和输出层的权重。则每个时间步的隐状态和输出可写为:
h t = f ( x t , h t − 1 , w h ) h_t=f(x_t,h_{t-1},w_h) ht=f(xt,ht−1,wh)
o t = g ( h t , w o ) o_t=g(h_t,w_o) ot=g(ht,wo)
对于前向传播,我们有目标函数 L L L评估所有 T T T个时间步内输出 o t o_t ot和对应的标签 y t y_t yt之间的差距:
L ( x 1 , ⋯ , x T , y 1 , ⋯ , y T , w h , w o ) = 1 T ∑ t = 1 T l ( y t , o t ) L(x_1,\cdots,x_T,y_1,\cdots,y_T,w_h,w_o)=\displaystyle\frac1T\sum^T_{t=1}l(y_t,o_t) L(x1,⋯,xT,y1,⋯,yT,wh,wo)=T1t=1∑Tl(yt,ot)
对于反向传播,目标函数 L L L对于参数 w h w_h wh的梯度按照链式法则有:
∂ L ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ o t ∂ g ( h t , w o ) ∂ h t ∂ h t ∂ w h \begin{equation}\begin{split}\displaystyle\frac{\partial L}{\partial w_h}&=\frac1T\sum^T_{t=1}\frac{\partial l(y_t,o_t)}{\partial w_h}\\&=\frac1T\sum^T_{t=1}\frac{\partial l(y_t,o_t)}{\partial o_t}\frac{\partial g(h_t,w_o)}{\partial h_t}\frac{\partial h_t}{\partial w_h}\end{split}\end{equation} ∂wh∂L=T1t=1∑T∂wh∂l(yt,ot)=T1t=1∑T∂ot∂l(yt,ot)∂ht∂g(ht,wo)∂wh∂ht
乘积的第一项和第二项很容易计算,而第三项 ∂ h t ∂ w h \displaystyle\frac{\partial h_t}{\partial w_h} ∂wh∂ht既依赖 h t − 1 h_{t-1} ht−1又依赖 w h w_h wh,而 h t − 1 h_{t-1} ht−1也依赖 w h w_h wh,需要循环计算参数 w h w_h wh对 h t h_t ht的影响:
∂ h t ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∂ f ( x t , h t − 1 , w h ) ∂ h t − 1 ∂ h t − 1 ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∑ i = 1 t − 1 ( ∏ j = i + 1 t ∂ f ( x j , h j − 1 , w h ) ∂ h j − 1 ) ∂ f ( x i , h i − 1 , w h ) ∂ w h \begin{equation}\begin{split}\displaystyle\frac{\partial h_t}{\partial w_h}&=\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\frac{\partial f(x_t,h_{t-1},w_h)}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial w_h}\\&=\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\sum^{t-1}_{i=1}\left(\prod^t_{j=i+1}\frac{\partial f(x_j,h_{j-1},w_h)}{\partial h_{j-1}}\right)\frac{\partial f(x_i,h_{i-1},w_h)}{\partial w_h}\end{split}\end{equation} ∂wh∂ht=∂wh∂f(xt,ht−1,wh)+∂ht−1∂f(xt,ht−1,wh)∂wh∂ht−1=∂wh∂f(xt,ht−1,wh)+i=1∑t−1(j=i+1∏t∂hj−1∂f(xj,hj−1,wh))∂wh∂f(xi,hi−1,wh)
当 t t t很大时,计算链条会变得很长,需要采取办法解决这一问题。
1.截断时间步
截断时间步在 τ \tau τ步后截断上式的求和运算,只将求和终止到 ∂ h t − τ ∂ w h \displaystyle\frac{\partial h_{t-\tau}}{\partial w_h} ∂wh∂ht−τ来近似实际梯度。这使得模型主要侧重于短期影响而非长期影响,变得更简单但也更稳定。
2.随机截断
随机截断通过随机变量序列 ξ t \xi_t ξt实现在随机时间步后截断。 ξ t \xi_t ξt预先确定好一个值 0 ⩽ π t ⩽ 1 0\leqslant\pi_t\leqslant1 0⩽πt⩽1,再根据如下两点分布生成序列:
P ( ξ t = 0 ) = 1 − π t P(\xi_t=0)=1-\pi_t P(ξt=0)=1−πt
P ( ξ t = π t − 1 ) = π t P(\xi_t=\pi_t^{-1})=\pi_t P(ξt=πt−1)=πt
于是我们用如下式子来替换 ∂ h t ∂ w h \displaystyle\frac{\partial h_t}{\partial w_h} ∂wh∂ht的计算:
z t = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ξ t ∂ f ( x t , h t − 1 , w h ) ∂ h t − 1 ∂ h t − 1 ∂ w h z_t=\displaystyle\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\xi_t\frac{\partial f(x_t,h_{t-1},w_h)}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial w_h} zt=∂wh∂f(xt,ht−1,wh)+ξt∂ht−1∂f(xt,ht−1,wh)∂wh∂ht−1
在递归计算的过程中, ξ t \xi_t ξt会随机在某个时间步取到 0 0 0,进而截断后续的计算,同时之前计算的权重会随着递归的次数而增加。最终效果是短序列梯度出现的概率高,而长序列梯度出现的概率低,但长序列得到的权重更高。根据 E [ ξ t ] = 1 \mathbb E[\xi_t]=1 E[ξt]=1和期望的线性性质可以得到 E [ z t ] = ∂ h t ∂ w h \mathbb E[z_t]=\displaystyle\frac{\partial h_t}{\partial w_h} E[zt]=∂wh∂ht,因此该估计是无偏的。
随机截断在实践中可能并不比常规截断好,原因有三:
- 在对过去若干时间步进行反向传播后,观测结果足以捕获实际的依赖关系。
- 随机变量带来的方差抵消了时间步越多梯度越精确的效果。
- 局部性先验的小范围交互模型更匹配数据的本质。
通过时间反向传播的细节
从简化模型扩展到对单个样本的运算,对于时间步 t t t,设单个样本的输入及其对应的标签分别为 x t ∈ R d \boldsymbol x_t\in\mathbb R^d xt∈Rd和 y t y_t yt,计算隐状态 h t ∈ R h \boldsymbol h_t\in\mathbb R^h ht∈Rh和输出 o t ∈ R q o_t\in\mathbb R^q ot∈Rq的公式为:
h t = W h x x t + W h h h t − 1 \boldsymbol h_t=\boldsymbol W_{hx}\boldsymbol x_t+\boldsymbol W_{hh}\boldsymbol h_{t-1} ht=Whxxt+Whhht−1
o t = W q h h t \boldsymbol o_t=\boldsymbol W_{qh}\boldsymbol h_t ot=Wqhht
其中权重参数为 W h t ∈ R h × d \mathbf W_{ht}\in\mathbb R^{h\times d} Wht∈Rh×d、 W h h ∈ R h × h \mathbf W_{hh}\in\mathbb R^{h\times h} Whh∈Rh×h和 W q h ∈ R q × h \mathbf W_{qh}\in\mathbb R^{q\times h} Wqh∈Rq×h。
用 l ( o t , y t ) l(\mathbf o_t,y_t) l(ot,yt)表示时间步 t t t处的损失函数,则目标函数的总体损失为:
L = 1 T ∑ t = 1 T l ( o t , y t ) L=\displaystyle\frac1T\sum^T_{t=1}l(\mathbf o_t,y_t) L=T1t=1∑Tl(ot,yt)
接下来沿箭头所指反方向遍历循环神经网络的计算图:
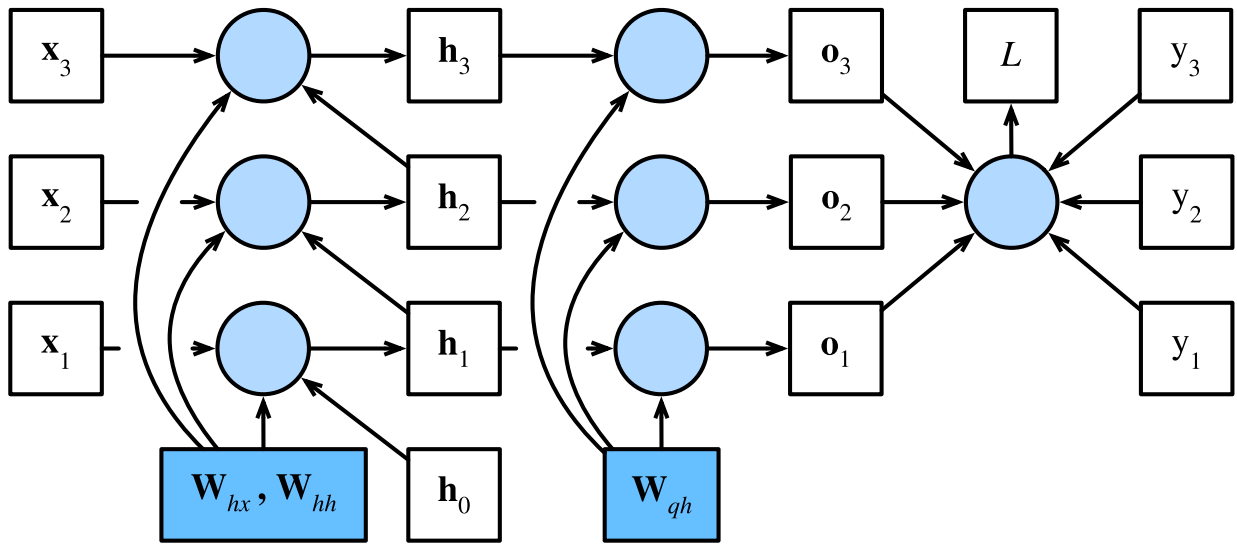
首先,在任意时间步 t t t,目标函数关于模型输出的微分计算为:
∂ L ∂ o t = ∂ l ( o t , y t ) T ⋅ ∂ o t ∈ R q \displaystyle\frac{\partial L}{\partial\boldsymbol o_t}=\frac{\partial l(\boldsymbol o_t,y_t)}{T\cdot\partial\boldsymbol o_t}\in\mathbb R^q ∂ot∂L=T⋅∂ot∂l(ot,yt)∈Rq
目标函数对 W q h \mathbf W_{qh} Wqh的梯度依赖于 o t \boldsymbol o_t ot,根据链式法则有(prod表示链式法则中的乘法运算):
∂ L ∂ W q h = ∑ t = 1 T prod ( ∂ L ∂ o t , ∂ o t ∂ W q h ) = ∑ t = 1 T ∂ L ∂ o t h t ⊤ ∈ R q × h \displaystyle\frac{\partial L}{\partial\mathbf{W}_{qh}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_t},\frac{\partial\mathbf{o}_t}{\partial\mathbf{W}_{qh}}\right)=\sum_{t=1}^T\frac{\partial L}{\partial\mathbf{o}_t}\mathbf{h}_t^\top\in\mathbb R^{q\times h} ∂Wqh∂L=t=1∑Tprod(∂ot∂L,∂Wqh∂ot)=t=1∑T∂ot∂Lht⊤∈Rq×h
在最终时间步 T T T,目标函数对 h T \mathbf h_T hT的梯度仅依赖于 o T \mathbf o_T oT:
∂ L ∂ h T = prod ( ∂ L ∂ o T , ∂ o T ∂ h T ) = W q h ⊤ ∂ L ∂ o T ∈ R h \displaystyle\frac{\partial L}{\partial\mathbf{h}_T}=\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_T},\frac{\partial\mathbf{o}_T}{\partial\mathbf{h}_T}\right)=\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_T}\in\mathbb R^h ∂hT∂L=prod(∂oT∂L,∂hT∂oT)=Wqh⊤∂oT∂L∈Rh
但目标函数对其余时间步下 h t \mathbf h_t ht的梯度依赖于 o t \mathbf o_t ot和 h t + 1 \mathbf h_{t+1} ht+1,此时需要进行递归运算:
∂ L ∂ h t = prod ( ∂ L ∂ h t + 1 , ∂ h t + 1 ∂ h t ) + prod ( ∂ L ∂ o t , ∂ o t ∂ h t ) = W h h ⊤ ∂ L ∂ h t + 1 + W q h ⊤ ∂ L ∂ o t \displaystyle\frac{\partial L}{\partial\mathbf{h}_t}=\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_{t+1}},\frac{\partial\mathbf{h}_{t+1}}{\partial\mathbf{h}_t}\right)+\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_t},\frac{\partial\mathbf{o}_t}{\partial\mathbf{h}_t} \right) = \mathbf{W}_{hh}^\top\frac{\partial L}{\partial\mathbf{h}_{t+1}}+\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_t} ∂ht∂L=prod(∂ht+1∂L,∂ht∂ht+1)+prod(∂ot∂L,∂ht∂ot)=Whh⊤∂ht+1∂L+Wqh⊤∂ot∂L
将该递归式展开可得:
∂ L ∂ h t = ∑ i = t T ( W h h ⊤ ) T − i W q h ⊤ ∂ L ∂ o T + t − i \displaystyle\frac{\partial L}{\partial\mathbf{h}_t}=\sum_{i=t}^T{\left(\mathbf{W}_{hh}^\top\right)}^{T-i}\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_{T+t-i}} ∂ht∂L=i=t∑T(Whh⊤)T−iWqh⊤∂oT+t−i∂L
上式出现了 W h h ⊤ \mathbf W_{hh}^\top Whh⊤的幂运算,当指数非常大时,幂中小于 1 1 1的特征值会消失,大于 1 1 1的特征值会发散,表现形式为梯度消失和梯度爆炸。一种解决方法是截断时间步,下一章将介绍缓解这一问题的更复杂的序列模型。
最后,目标函数对隐藏层模型参数 W x h \mathbf W_{xh} Wxh和 W h h \mathbf W_{hh} Whh的梯度依赖于所有的 h t \mathbf h_t ht,根据链式法则有:
∂ L ∂ W h x = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h x ) ∑ t = 1 T ∂ L ∂ h t x t ⊤ \displaystyle\frac{\partial L}{\partial\mathbf{W}_{hx}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_t},\frac{\partial\mathbf{h}_t}{\partial\mathbf{W}_{hx}}\right)\sum_{t=1}^T \frac{\partial L}{\partial\mathbf{h}_t}\mathbf{x}_t^\top ∂Whx∂L=t=1∑Tprod(∂ht∂L,∂Whx∂ht)t=1∑T∂ht∂Lxt⊤
∂ L ∂ W h h = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h h ) = ∑ t = 1 T ∂ L ∂ h t h t − 1 ⊤ \displaystyle\frac{\partial L}{\partial \mathbf{W}_{hh}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_t}, \frac{\partial\mathbf{h}_t}{\partial \mathbf{W}_{hh}}\right)= \sum_{t=1}^T \frac{\partial L}{\partial \mathbf{h}_t} \mathbf{h}_{t-1}^\top ∂Whh∂L=t=1∑Tprod(∂ht∂L,∂Whh∂ht)=t=1∑T∂ht∂Lht−1⊤
梯度裁剪
除了专门针对BPTT的截断时间步,还有一种更普适的修复梯度爆炸的方法,称为梯度裁剪。
最基本的梯度裁剪在反向传播的过程中对梯度进行限制,在梯度的范数超过某个阈值时,将其按比例缩小,其公式为:
g ← min ( 1 , θ ∣ ∣ g ∣ ∣ ) g \boldsymbol g\leftarrow\min\left(\displaystyle1,\frac\theta{||\boldsymbol g||}\right)\boldsymbol g g←min(1,∣∣g∣∣θ)g
通过这样做,梯度范数将永远不会超过 θ \theta θ。
相关文章:

【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...
)
三角形神经网络(TNN)
三角形神经网络(TNN)是一种新兴的神经网络架构,不过目前它并非像 CNN、RNN 等传统网络那样被广泛研究和应用,以下为你解释其原理并结合例子说明: 原理 基本结构 三角形神经网络的核心思想是构建一种类似三角形的层次…...
)
【JavaEE】-- MyBatis操作数据库(1)
文章目录 1. 什么是MyBatis2 MyBatis入门2.1 准备工作2.1.1 创建工程 2.2 配置数据库连接字符串2.3 写持久层代码2.4 单元测试 3. MyBatis的基础操作3.1 打印日志3.2 参数传递3.3 增(insert)3.3.1 返回主键 3.4 删(delete)3.5 改&…...

人工智能大模型备案与服务登记:监管体系的双轨逻辑与实操指南
一、核心差异:监管框架的分层设计 适用范围的本质分野 大模型备案:针对直接向公众提供生成式服务的自研或微调模型(如 ChatGPT 类产品),要求模型具备舆论属性或社会动员能力。典型场景包括智能客服、内容创作平台等。大…...

衡石ChatBI:依托开放架构构建技术驱动的差异化数据服务
在当今数字化浪潮中,企业对数据价值的挖掘和利用需求日益增长。BI(商业智能)工具作为企业获取数据洞察的关键手段,其技术架构的创新与发展至关重要。衡石科技的Chat BI凭借其独特的开放架构,在BI领域脱颖而出ÿ…...

AOSP Android14 Launcher3——RecentsView最近任务数据加载
最近任务是Launcher中的一个重要的功能,显示用户最近使用的应用,并可以快速切换到其中的应用;用户可以通过底部上滑停顿进入最近任务,也可以在第三方应用底部上滑进最近任务。 这两种场景之前的博客也介绍过,本文就不…...

分析型数据库与事务型数据库?核心差异与选型指南
在当今数据驱动的业务环境中,选择合适的数据库架构已成为企业技术决策的关键。然而,面对事务型数据库和分析型数据库的选择,许多技术团队往往陷入困境:日常运行良好的系统在数据量激增时性能骤降,简单的查询在复杂分析…...

Linux-信号
信号是由用户,系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常。 进程分为前台进程和后台进程,对于前台进程我们可以输入特殊的终端字符来给它发送信号,比如输入Ctrlc,发送一个中断信号 系…...

Oracle数据库学习之路-目录
Oracle数据库学习之路 一、安装 (一)数据库安装步骤详解 (二)开发工具安装与配置 二、基础语法篇 (一)基础 SQL 语法详解 (二)SQL 语法练习与案例分析 三、高级语法篇 &…...

用selenium4 webdriver + java 搭建并完成第一个自动化测试脚本
自动化测试任务: 百度搜索自己的姓名。点击第一个链接(或者第二个),在新的页面上,添加断言,验证你的名字是否存在。 实验资料百度网盘下载路径: 链接: https://pan.baidu.com/s/1nVlHX_ivres…...

晨控CK-FR12与欧姆龙NX系列PLC配置EtherNet/IP通讯连接操作手册
晨控CK-FR12系列作为晨控智能工业级别RFID读写器,支持大部分工业协议如RS232、RS485、以太网。支持工业协议Modbus RTU、Modbus TCP、Profinet、EtherNet/lP、EtherCat以及自由协议TCP/IP等。 本期主题:围绕CK-FR12产品的EtherNet/IP通讯协议与欧姆龙PLC进行通讯配置…...

武装Burp Suite工具:RouteVulScan插件_被动扫描发现漏洞.
武装Burp Suite工具:RouteVulScan插件_被动扫描. RouteVulScan 是一款使用Java语言编写,基于Burp Suite API的插件,用于递归地检测潜在的脆弱路径。 该插件通过被动扫描的方式,对路径的各个层级进行深度分析。利用预设的正则表达…...

Selenium+Java 环境搭建
windows电脑环境搭建Chrome浏览器 1.下载 Google Chrome 网络浏览器 (一定要下载官方的!!!) 注:最好下载在浏览器默认的路径 便于查找,而且占内存不是很大 2.查看chrome浏览器的版本 3.下载…...

网易云IP属地可以查看城市吗?深度解析与使用指南
在互联网时代,用户的隐私和数据安全越来越受到关注。许多社交平台和应用都会显示用户的IP属地,以增加透明度和真实性。网易云音乐作为国内领先的音乐平台,也引入了IP属地显示功能。那么,网易云IP属地能否精确到城市?这…...

Cline 之Plan和Act模式
Cline 提供了 "Plan & Act"双模式开发框架。适用在不同的场景。 一、核心模式理念 通过结构化开发流程提升AI编程效率,采用"先规划后执行"的核心理念。 该框架旨在帮助开发者构建更易维护、准确性更高的代码,同时显著缩短开发…...

【Java面试笔记:基础】7.int和Integer有什么区别?
在Java中,int和Integer虽然都用于表示整数值,但它们在本质、用法和特性上有显著差异。 1. int 和 Integer 的区别 int: 原始数据类型:int 是 Java 的 8 个原始数据类型之一,用于表示整数。性能优势:直接存…...

嘻游后台系统与机器人模块结构详解:功能逻辑 + 定制改造实战
作为“嘻游电玩三端组件”系列的最后一篇,本篇将全面剖析平台自带的后台控制系统与机器人行为逻辑模块,包括:用户管理、房间配置、日志系统、机器人规则编排与行为策略扩展等。通过技术视角展示其整体框架与可拓展性,帮助开发者更…...

Linux 网络编程:select、poll 与 epoll 深度解析 —— 从基础到高并发实战
一、IO 多路复用:解决并发 IO 的核心技术 在网络编程中,当需要同时处理大量客户端连接时,传统阻塞式 IO 会导致程序卡在单个操作上,造成资源浪费。IO 多路复用技术允许单线程监听多个文件描述符(FD)&#…...

在统信UOS1060上安装Fail2Ban并通过邮件发送通知
在统信UOS1060上安装Fail2Ban并通过邮件发送通知 Fail2Ban 是一个开源的防止暴力攻击的软件,可以有效保护您的服务器免受频繁的登录失败攻击。本文将指导您如何在统信UOS 1060上安装Fail2Ban,并在IP被封禁后通过邮件发送通知。 步骤 1:查看…...
)
PyTorch 分布式 DistributedDataParallel (DDP)
在之前的讨论(或者如果你直接跳到这里)中,我们了解了 torch.nn.DataParallel (DP) 作为 PyTorch 多 GPU 训练的入门选项。它简单易用,但其固有的主 GPU 瓶颈、GIL 限制和低效的通信模式,往往让它在实际应用中难以充分发…...
:基于数据洞察优化产品与运营)
精益数据分析(14/126):基于数据洞察优化产品与运营
精益数据分析(14/126):基于数据洞察优化产品与运营 在创业和数据分析的道路上,我们都在不断摸索前行。我一直希望能和大家共同学习、共同进步,所以今天继续为大家解读《精益数据分析》。这次我们将深入探讨HighScore …...

flutter 插件收集
2025年 1月10号Flutter插件手机 声音转文字 speech_to_text | Flutter package 文字转声音 flutter_tts | Flutter package 堆栈信息 stack_trace | Dart package 跳转到app设置里面 app_settings | Flutter package 轻松的动画 animations | Flutter package 日志打印 t…...

WPF特性分析
文章目录 WPF特性全面分析与性能优化指南引言WPF核心特性1. 声明式UI与XAML2. 硬件加速渲染3. 数据绑定与MVVM4. 样式与模板5. 动画系统 WPF与其他框架比较WPF vs. WinFormsWPF vs. UWPWPF vs. MAUI WPF性能优化最佳实践1. 内存管理优化2. UI虚拟化3. 使用冻结对象4. 减少视觉树…...

3.1goweb框架gin下
Gin 框架有内置的模板引擎,它允许你将数据和 HTML 模板结合,动态生成网页内容。 模板引擎基础使用 单模板文件示例 以下是一个简单的使用单个 HTML 模板文件的示例,展示了如何在 Gin 中渲染模板: package mainimport ("g…...

【全解析】深入理解 JavaScript JSON 数据解析
一、JSON 概述 1. 概念 JSON 全称为 JavaScript Object Notation,是一种轻量级的数据交换格式。它是 JavaScript 中用于描述对象数据的语法的扩展。不过并不限于与 JavaScript 一起使用。它采用完全独立于语言的文本格式,这些特性使 JSON 成为理想的数…...

影刀RPA怎么和AI结合,制作自动采集小红书爆款文章+自动用AI改写标题、内容+用AI文生图生成发文图片+自动在小红书上发布文章
环境: 影刀5.26.24 Win10专业版 doubao deepseek r1 wps 问题描述: 影刀RPA怎么和AI结合,制作自动采集小红书爆款文章+自动用AI改写标题、内容+用AI文生图生成发文图片+自动在小红书上发布文章,最后上传到飞书备份 解决方案: 1.主要流程如下: 全局变量设置(关键…...

懒人一键搭建符号执行环境V5K3
0.背景 在写完上一篇文章后发现,其实V5k3的组合也可以使用。Verilator v5.x 系列版本完全支持本项目的编译与仿真。 不同于 v3 版本,Verilator v5 引入了更严格的访问控制机制:要从 Verilator 生成的 C 仿真模型中访问内部信号或变量&#x…...
核心操作与最佳实践:深入解析与面试指南)
Java队列(Queue)核心操作与最佳实践:深入解析与面试指南
文章目录 概述一、Java队列核心实现类对比1. LinkedList2. ArrayDeque3. PriorityQueue 二、核心操作API与时间复杂度三、经典使用场景与最佳实践场景1:BFS层序遍历(树/图)场景2:滑动窗口最大值(单调队列) …...
)
Android 中实现图片翻转动画(卡片翻转效果)
1、简述 通过 ObjectAnimator 和 AnimatorSet 可以实现图片的翻转动画,并在翻转过程中切换图片,同时避免图片被镜像。 ObjectAnimator 是 Android 动画框架中的一个类,用于对对象的属性进行动画效果处理。它通过改变对象的属性值来实现动画效果,非常适合实现复杂的动画,如…...

智能电网第1期 | 工业交换机在变电站自动化系统中的作用
随着智能电网建设的加速推进,变电站自动化系统对通信网络的实时性、可靠性和安全性提出了更高要求。在变电站智能化改造过程中,传统网络架构面临诸多挑战: 多协议兼容难题:继电保护、测控装置等设备通信协议多样,难以统…...

01.浏览器自动化webdriver源码分析之启动函数
日后,网络爬虫也好,数据采集也好,自动化必然是主流。因此,笔者未雨绸缪,在此研究各类自动化源码,希望能够赶上时代,做出一套实用的自动化框架。 这里先研究传统的webdriver中转来进行浏览器自动…...

day35图像处理OpenCV
文章目录 一、图像预处理17 直方图均衡化17.1绘制直方图17.2直方图均衡化1. 自适应直方图均衡化2. 对比度受限的自适应直方图均衡化3. 示例 19 模板匹配 一、图像预处理 17 直方图均衡化 直方图:反映图像像素分布的统计图,横坐标就是图像像素的取值&…...
:解锁数据分析关键方法,驱动业务增长)
精益数据分析(15/126):解锁数据分析关键方法,驱动业务增长
精益数据分析(15/126):解锁数据分析关键方法,驱动业务增长 在创业与数据分析的征程中,我们都在努力探寻成功的密码。今天,我依旧带着和大家共同进步的初衷,深入解读《精益数据分析》的相关内容…...

JETBRAINS USER AGREEMENT【2025.4.16】更新用户许可协议
JETBRAIN旗下的各产品更新用户许可协议: 大致跟漂亮国出口管制政策有关,以下是详细内容: JETBRAINS USER AGREEMENT Version 2.0, effective as of April 16, 2025 THIS IS A LEGAL AGREEMENT. BY CLICKING ON THE "I AGREE" (OR…...
)
【数字图像处理】立体视觉基础(1)
成像 成像过程:三维空间坐标到二维图像坐标的变换 相机矩阵:建立三维到二维的投影关系 相机的使用步骤(模型-视图变换): (1)视图变换 (2)模型变换 (3&…...

通过AI工具或模型创建PPT的不同方式详解,结合 Assistants API、DALL·E 3 等工具的功能对比及表格总结
以下是通过AI工具或模型创建PPT的不同方式详解,结合 Assistants API、DALLE 3 等工具的功能对比及表格总结: 1. 主要实现方式详解 1.1 基于文本生成PPT 工具示例:Microsoft PowerPoint Copilot、Google Workspace(AI-powered D…...

weibo_har鸿蒙微博分享,单例二次封装,鸿蒙微博,微博登录
weibo_har鸿蒙微博分享,单例二次封装,鸿蒙微博 HarmonyOS 5.0.3 Beta2 SDK,原样包含OpenHarmony SDK Ohos_sdk_public 5.0.3.131 (API Version 15 Beta2) 🏆简介 zyl/weibo_har是微博封装使用,支持原生core使用 &a…...

C++ Lambda表达式复习
C Lambda表达式 (C Lambda Expressions: Beginner to Advanced) Lambda表达式是C11引入的一种轻量级匿名函数语法,支持闭包捕获,可以简化代码逻辑,特别是在函数式编程、回调函数和STL算法场景中尤为常用。本文将从基础语法到高级应用&#x…...
(ArkTs))
鸿蒙NEXT开发权限工具类(申请授权相关)(ArkTs)
import abilityAccessCtrl, { Permissions } from ohos.abilityAccessCtrl; import { bundleManager, common, PermissionRequestResult } from kit.AbilityKit; import { BusinessError } from ohos.base; import { ToastUtil } from ./ToastUtil;/*** 权限工具类(…...

1000 QPS 下 MySQL 性能瓶颈解决方案
当 MySQL 在 1000 QPS 时出现性能瓶颈,需从索引优化、查询逻辑调整、服务器配置调优、架构扩展等多维度综合解决,具体策略如下: 一、索引优化 补充缺失索引 通过慢查询日志定位高频低效 SQL,使用 EXPLAIN 分…...
—— 下篇(内含聚合查询、group by和having子句、联合查询、插入查询结果))
【MySQL】MySQL 表的增删改查(CRUD)—— 下篇(内含聚合查询、group by和having子句、联合查询、插入查询结果)
目录 1. 插入查询结果 2 聚合查询 (行与行之间运算) count 计算查询结果的行数 sum 求和 avg 求平均值 max 最大值 min 最小值 【小结】 3. group by 子句 分组 where 条件 having 条件 4. 联合查询(多表查询) 内连接…...
)
简化K8S部署流程:通过Apisix实现蓝绿发布策略详解(上)
本次主题主要目的是为大家讲解蓝绿发布,但是发现文档和内容太长了,对此将文档拆分成了两部分,视频拆分成了好几部分,这样大家刷起来没疲劳感。 第一部分《apisix argorollout 实现蓝绿发布I-使用apisix发布应用》,主要…...

FLV 与 MP4 格式深度剖析:结构、原理
1 FLV格式分析 1.1 定义 FLV(Flash Video)是Adobe公司推出的⼀种流媒体格式,由于其封装后的⾳视频⽂件体积⼩、封装简单等特点,⾮常适合于互联⽹上使⽤。⽬前主流的视频⽹站基本都⽀持FLV。采⽤FLV格式封装的⽂件后缀为.flv FLV封装格式是由⼀个**⽂件…...

k8s的yaml文件里的volume跟volumeMount的区别
volume 是 Pod 级别的资源,用于定义存储卷。它是一个独立于容器的存储资源,可以被一个或多个容器共享使用。volume 的定义位于 Pod 的 spec.volumes 部分。 特点 独立性:volume 是 Pod 的一部分,而不是容器的一部分。它独立于容…...

Git常用操作命令
配置 Git git config --global user.name "Your Name": 设置用户名。git config --global user.email "your_emailexample.com": 设置用户邮箱。 初始化和克隆仓库 git init: 初始化一个新的 Git 仓库。git clone [URL]: 克隆一个远程仓库到本地。 git cl…...

09.传输层协议 ——— TCP协议
文章目录 TCP协议 谈谈可靠性TCP协议格式 序号与确认序号窗口大小六个标志位 确认应答机制(ACK)超时重传机制连接管理机制 三次握手四次挥手 流量控制滑动窗口拥塞控制延迟应答捎带应答面向字节流粘包问题TCP异常情况TCP小结基于TCP的应用层协议 TCP协…...

NineData 与飞书深度集成,企业级数据管理审批流程全面自动化
NineData 正式推出与飞书审批系统的深度集成功能,企业用户在 NineData 平台发起的审批工单,将自动推送至审批人的飞书中,审批人可以直接在飞书进行审批并通过/拒绝。该功能实现跨系统协作,带来巨大的审批效率提升,为各…...

WebRTC服务器Coturn服务器中的通信协议
1、概述 作为WebRTC服务器,coturn通信协议主要是STUN和TURN协议 STUN&TURN协议头部都是20个字节,用 Message Type来区分不同的协议 |------2------|------2------|------------4------------|------------------------12-------------------------|-----------…...

4.19除自身以外数组的乘积
我自己的思路,想用双指针, 一个从左边left开始乘,一个从右边right开始乘,如果left,或者right遇到了目标索引i(也就是我们要跨过去的当前元素),那么直接让对应的指针加一,当前元素不参与累积的计算ÿ…...

Anaconda3使用conda进行包管理
一、基础包管理操作 安装包 使用 conda install <包名> 安装指定包,支持多包批量安装和版本指定: conda install numpy # 安装单个包 conda install numpy scipy pandas # 批量安装多个包 conda install numpy1.21 # 指定版本 conda instal…...