基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
原文: Analysis and visualization of accidents severity based on LightGBM-TPE
1. 引言部分
文章开篇强调了道路交通事故作为意外死亡的主要原因,引起了多学科领域的关注。分析事故严重性特征有助于明确不同风险因素与道路事故间的因果关系,从而提升道路安全。但现有研究在将数据可视化应用于交通安全调查方面存在不足。基于此,作者提出了一种结合LightGBM-TPE(Light Gradient Boosting Machine-Tree-structured Parzen Estimator)与数据可视化的分析方法,以2017年英国交通事故数据为研究对象。该方法相较于其他典型机器学习算法,在f1分数、准确率、召回率和精确率等指标上表现更优。通过LightGBM-TPE计算SHAP值,发现经度、纬度、小时和星期几是与事故严重性最密切相关的四个风险因素,可视化分析进一步验证了这一结论。研究旨在探索一种理解与评估道路交通事故特征重要性的创新方式,为改善交通安全提供建议。
2. 数据描述与预处理
2.1 数据描述
本文研究使用了 2017 年英国交通事故数据集,该数据集来源于 Kaggle 平台,包含了丰富的道路事故信息。数据集中的每一行代表一个交通事故,共提供了 34 个信息列来详细描述每个事故的各个方面。在本研究中,作者将交通事故主要分为两类,即致命事故(fatal accidents)和非致命事故(non-fatal accidents),其中非致命事故包括严重事故和轻微事故。这样的分类方式有助于研究者集中分析导致致命事故的关键因素,为改善交通安全策略提供更有针对性的建议。
研究选取了 2017 年英国发生的交通事故数据,其中致命事故有 1642 起被归类为正类案例,而非致命事故则包括 21780 起严重事故和 100308 起轻微事故,均被标记为负类案例。通过对数据集的初步统计分析,作者对数据集中的分类数据进行了描述性统计,如天气状况、道路类型、星期几、道路表面状况以及光照条件等,这些统计信息为后续的数据预处理和分析奠定了基础。
2.2 数据预处理
在将原始数据输入机器学习模型之前,数据预处理是一个关键步骤,它主要包括数据清洗和数据格式化两个部分,同时针对数据集中的类别不平衡问题进行了处理。
数据清洗
原始数据中包含了许多与事故严重性无关的信息。例如,“Did_Police_Officer_Attend_Scene_of_Accident”(是否有警官出席事故现场)这一特征对于研究事故严重性并无直接关联;“InScotland” 这一信息也因与 “Longitude”(经度)和 “Latitude”(纬度)存在冗余而被剔除。通过数据清洗,作者保留了与事故严重性密切相关的 10 个特征,这些特征可以分为以下四个类别:
- 事故位置相关特征:“Longitude”(经度)和 “Latitude”(纬度),用于定位事故发生的地理位置。
- 事故时间相关特征:“Hour”(小时)、“Month”(月份)和 “Day_of_Week”(星期几),用于分析事故发生的时刻及其潜在规律。
- 环境状况相关特征:“Light Condition”(光照条件)和 “Weather Condition”(天气状况),用于考察事故发生时的环境因素。
- 道路状况相关特征:“Speed Limit”(限速)、“Road Type”(道路类型)和 “Road Surface Condition”(道路表面状况),用于评估道路条件对事故的影响。
这些经过筛选的特征将作为模型的输入变量,而事故的严重性(致命或非致命)则作为输出变量。
数据格式化
为了使数据更适合机器学习算法的处理,作者对许多分类变量进行了独热编码(one-hot encoding)。例如,原始数据集中的 “Day_of_Week”(星期几)这一分类变量被转换为具体的每一天(如 Sunday、Friday 等),从而为算法提供更明确的信息。这种转换方式能够使模型更好地理解不同类别的特征值对事故严重性的影响,而无需依赖于变量之间的数值大小关系。
数据平衡
在交通事故数据集中,通常非致命事故的数量会远多于致命事故,这导致数据集存在类别不平衡的问题。为了解决这一问题,作者采用了合成少数过采样技术(SMOTE)。SMOTE 算法通过在少数类样本(即致命事故)周围生成新的合成样本,来平衡数据集中的正负类样本数量。相比于简单的欠采样方法,SMOTE 能够避免因减少多数类样本数量而导致的预测准确性下降问题,从而提高模型在处理不平衡数据时的性能。
综上所述,通过数据清洗、数据格式化和数据平衡等预处理步骤,作者有效地提高了数据质量,使其更适合后续的机器学习分析。这些预处理工作为确保模型的准确性和可靠性提供了重要保障,同时也为深入挖掘交通事故数据中的关键特征奠定了坚实基础。
3. 方法论
文章首先介绍了几种典型的机器学习方法,包括逻辑回归、GBDT、XGBoost、LightGBM及本文提出的LightGBM-TPE,并指出将选用预测准确率最高的模型来计算特征重要性,进而进行可视化分析。在LightGBM-TPE中,LightGBM采用基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)等技术,提高了训练速度并减少了内存占用。TPE算法用于优化LightGBM的超参数,通过构建响应面模型并基于原始模型迭代收集额外数据,以找到最佳超参数组合,提升模型性能。研究中通过5折交叉验证确定了最佳超参数,包括树的最大深度(max_depth=10)、叶子数(num_leaves=246)、树的数量(n_estimators=380)和叶子中的最小数据量(min_data_in_leaf=20)。此外,文章还介绍了SHAP(SHapley Additive exPlanation)方法,用于计算每个特征对模型预测的贡献值(SHAP值),并基于此进行可视化分析,展示各特征对事故严重性的影响。
4. 结果与讨论
4.1 性能比较
在这一部分,作者对比了LightGBM-TPE与其他四种主流机器学习模型(LightGBM、逻辑回归、GBDT和XGBoost)的预测性能。对比的指标包括f1分数、准确率、召回率和精确率,而模型性能的验证则通过5折交叉验证完成。具体来说,数据集被随机分为5个连续的子集,每次将一个子集作为验证集,其余四个子集作为训练集,最终结果取五次验证的平均值。
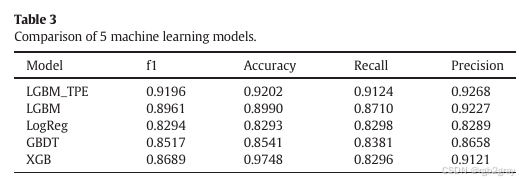
结果表明,LightGBM-TPE在精确率上表现最为优异,达到了0.9268,而在f1分数、准确率和召回率方面同样取得了最优的成绩。相比之下,GBDT在这五种机器学习方法中表现最差。基于这些结果,作者选择了LightGBM-TPE作为预测模型,用于后续的SHAP值计算和特征重要性分析。这一选择与先前研究的结论一致,即模型的预测性能越高,其计算出的特征重要性结果越可信。
4.2 特征重要性与SHAP值
为了更准确地衡量特征的重要性,作者采用了SHAP值的平均绝对值作为指标。SHAP值基于合作博弈论,能够量化每个特征对模型预测的贡献。结果显示,经度、纬度和小时是影响事故严重性的三个最关键特征,其中经度的重要性位居榜首,随后是纬度和小时。
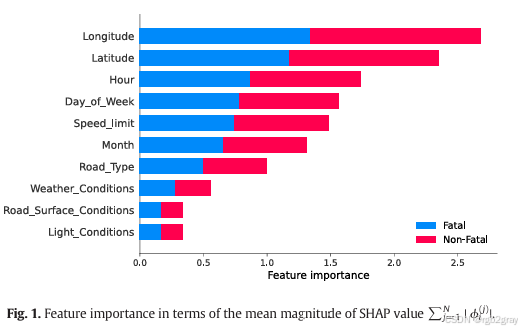
SHAP总结图进一步揭示了每个特征对预测输出的影响范围和分布情况。在总结图中,每个点代表一个事故数据,其在y轴和x轴上的位置分别对应特征值和SHAP值,颜色则表示特征值的大小。对于经度和纬度而言,SHAP值相对接近对称轴,这意味着相似的特征值可能对事故严重性产生截然相反的影响。因此,经度和纬度的组合效应比单一特征更能解释事故的严重性。而其他特征则可以独立分析其影响。此外,空间特征(经度和纬度)在LightGBM-TPE模型中占据最为重要的地位,时间特征(小时、星期几和月份)次之,而环境特征(如天气状况)对致命事故发生的影响则相对较弱。
4.3 可视化分析
基于SHAP值的可视化分析,作者深入探讨了关键特征对事故严重性的具体影响。以下是对主要特征的详细分析:
经度和纬度
- SHAP依赖图显示,随着经度的变化,SHAP值呈现出非线性趋势。特别是在经度介于-4.5到-3.5或0到1.5之间时,大多数事故的SHAP值为负,表明这些区域的致命事故相对较少。
- 图中还揭示了经度和纬度之间的复杂关系。例如,当经度约为-3.9时,纬度越高,SHAP值也越高,对应的致命事故数量也越多。
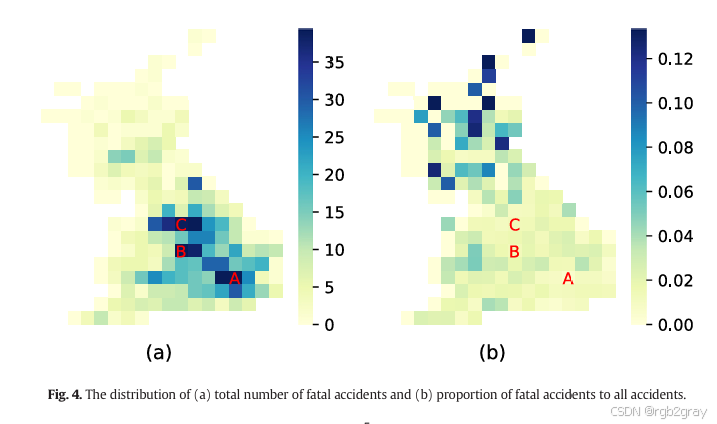
- 进一步分析英国致命事故的地理分布,作者将研究区域划分为18×20的网格,并标出了三个主要城市区域(伦敦、伯明翰以及利物浦、曼彻斯特和谢菲尔德)。结果显示,大城市的致命事故总数显著高于其他地区。然而,高纬度地区的致命事故比例却稳定在最高水平。这表明,尽管大城市的致命事故绝对数量多,但高纬度地区的事故致命比例更高,提示这些地区需要加强交通管理和控制策略。
小时和星期几
- 时间特征的分析表明,SHAP值在凌晨1:00到3:00以及7:00到8:00期间多为负值,而在凌晨3:00到4:00以及19:00到23:00期间多为正值。这表明夜间(19:00到23:00)是致命事故的高发时段。
- 凌晨3:00是一个显著的转折点,此时SHAP值大幅增加。此外,星期三的凌晨时段记录了最多的致命事故。
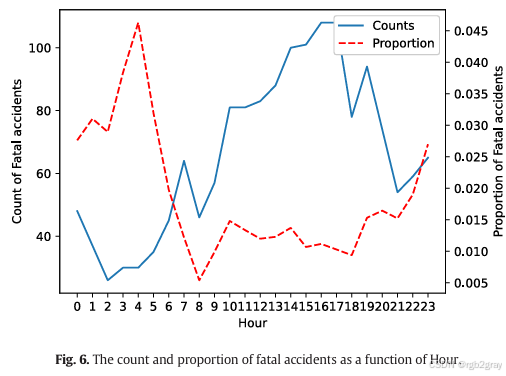
- 通过对小时特征对致命事故数量和比例的影响分析发现,致命事故数量在17:00达到峰值(约118起),而致命事故比例则在凌晨4:00达到最高点(约4.5%)。从19:00到4:00,致命事故比例呈逐步上升趋势。这表明,尽管凌晨时段的事故总数较少,但其致命性却极高。因此,作者建议英国应从夜间到凌晨实施更严格的交通管制政策。
总结
通过性能比较、特征重要性和可视化分析,作者不仅验证了LightGBM-TPE模型在预测交通事故严重性方面的优越性,还揭示了关键风险特征对事故致命性的影响机制。这些发现为城市规划者和交通管理部门提供了有价值的参考,有助于制定更有针对性的交通安全策略,特别是在高风险地理位置和时间段加强监管和控制。研究结果强调了数据可视化在理解复杂交通系统和指导政策制定中的重要作用,同时也为未来的研究方向提供了启发,例如进一步探讨制度激励对交通行为和事故演变的影响。
5. 结论
文章基于2017年英国交通事故数据,提出了一种结合LightGBM-TPE和数据可视化的混合机器学习模型,确定了经度、纬度、小时和星期几是决定事故严重性的最重要因素。研究为城市规划者提供了实际建议,例如在高纬度地区实施更有效的交通控制和管理策略,在夜间到凌晨期间加强交通管制。这项工作有助于理解重要风险因素如何影响事故严重性,并为有效控制致命事故发生提供了新方法。尽管如此,作者也指出,未来研究应深入探讨制度激励存在及其成本对交通事故演变动态的影响。
6. 其他
以下是一份基于文章的Python代码,涵盖了数据预处理、模型训练与评估、特征重要性计算及可视化等部分。在运行代码前,请确保安装了相关依赖库,如pandas、numpy、lightgbm、shap、optuna和scikit-learn等。
数据预处理部分
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from imblearn.over_sampling import SMOTE# 加载数据
data = pd.read_csv('uk_accidents_2017.csv')# 数据清洗:选择相关特征
features = ['Longitude', 'Latitude', 'Hour', 'Month', 'Day_of_Week', 'Light_Condition', 'Weather_Condition', 'Speed_Limit', 'Road_Type', 'Road_Surface_Condition']
target = 'Accident_Severity' # 假设目标变量列为 Accident_Severity,需根据实际数据调整data_selected = data[features + [target]]# 处理缺失值(如果有)
data_selected = data_selected.dropna()# 特征分类
categorical_features = ['Day_of_Week', 'Month', 'Light_Condition', 'Weather_Condition', 'Road_Type', 'Road_Surface_Condition']
numerical_features = ['Longitude', 'Latitude', 'Hour', 'Speed_Limit']# 独热编码
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(data_selected[categorical_features]).toarray()
encoded_features_df = pd.DataFrame(encoded_features, columns=encoder.get_feature_names_out(categorical_features))# 合并数值特征和编码后的分类特征
X = pd.concat([data_selected[numerical_features], encoded_features_df], axis=1)
y = data_selected[target]# 处理类别不平衡:使用SMOTE
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X, y)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=42)
模型训练与评估部分
import lightgbm as lgb
from sklearn.metrics import f1_score, accuracy_score, recall_score, precision_score# 转换为LightGBM数据格式
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)# LightGBM默认参数
params = {'objective': 'binary', # 二分类问题'metric': 'binary_logloss','boosting_type': 'gbdt','num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9
}# 使用TPE进行超参数优化
def objective(trial):params_tpe = {'objective': 'binary','metric': 'binary_logloss','boosting_type': 'gbdt','num_leaves': trial.suggest_int('num_leaves', 20, 256),'max_depth': trial.suggest_int('max_depth', 1, 12),'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 20, 300),'n_estimators': trial.suggest_int('n_estimators', 10, 500),'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1),'feature_fraction': trial.suggest_float('feature_fraction', 0.5, 1.0)}model = lgb.train(params_tpe, train_data, valid_sets=[test_data], early_stopping_rounds=50, verbose_eval=False)predictions = model.predict(X_test)preds = [1 if x > 0.5 else 0 for x in predictions]return f1_score(y_test, preds)import optunastudy = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)best_params = study.best_params
print("最佳超参数:", best_params)# 使用最佳超参数训练模型
model = lgb.train(best_params, train_data, valid_sets=[test_data], early_stopping_rounds=50, verbose_eval=False)# 模型评估
predictions = model.predict(X_test)
preds = [1 if x > 0.5 else 0 for x in predictions]print("F1 Score:", f1_score(y_test, preds))
print("Accuracy:", accuracy_score(y_test, preds))
print("Recall:", recall_score(y_test, preds))
print("Precision:", precision_score(y_test, preds))
特征重要性计算与可视化部分
import shap# 计算SHAP值
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)# 特征重要性可视化
shap.summary_plot(shap_values, X_test)# SHAP依赖图(以经度为例)
shap.dependence_plot("Longitude", shap_values[1], X_test)
相关文章:

基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化 原文: Analysis and visualization of accidents severity based on LightGBM-TPE 1. 引言部分 文章开篇强调了道路交通事故作为意外死亡的主要原因,引起了多学科领域的关注。分析事故严重性特…...

音视频小白系统入门课-3
本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅 往期课程笔记传送门: 音视频小白系统入门笔记-0音视频小白系统入门笔记-1音视频小白系统入门笔记-2 视频: 由一组图像组成:像素、分辨率、RGB 8888(24位) 、RGBA(32位)为…...

考研系列-计算机网络-第五章、传输层
一、传输层提供的服务 1.重点知识...

将Ubuntu系统中已有的Python环境迁移到Anaconda的虚拟环境中
需求:关于如何将Ubuntu系统中已有的Python环境迁移到Anaconda的虚拟环境test2里,而且他们提到用requirements.txt 安装一直报错,所以想尝试直接拷贝的方法。 可以尝试通过直接拷贝移植的方式迁移Python环境到Anaconda虚拟环境,但…...

AI 数字短视频数字人源码开发:多维赋能短视频生态革新
在短视频行业深度发展的进程中,AI 数字短视频数字人源码开发凭借其独特的技术优势,从多个维度为行业生态带来了革命性的变化,重塑短视频创作、传播与应用的格局。 数据驱动,实现内容精准化创作 AI 数字短视频数字人源码开发能够深…...

ffmpeg 硬解码相关知识
一:FFMPEG 支持的硬解方式:如下都是了解知识 DXVA2 - windows DXVA2 硬件加速技术解析 一、核心特性与适用场景 技术定义:DXVA2(DirectX Video Acceleration 2)是微软推出的基于 DirectX 的硬件加速标准…...

Ubuntu数据连接访问崩溃问题
目录 一、分析问题 1、崩溃问题本地调试gdb调试: 二、解决问题 1. 停止 MySQL 服务 2. 卸载 MySQL 相关包 3. 删除 MySQL 数据目录 4. 清理依赖和缓存 5.重新安装mysql数据库 6.创建程序需要的数据库 三、验证 1、动态库更新了 2、头文件更新了 3、重新…...

边缘计算全透视:架构、应用与未来图景
边缘计算全透视:架构、应用与未来图景 一、产生背景二、本质三、特点(一)位置靠近数据源(二)分布式架构(三)实时性要求高 四、关键技术(一)硬件技术(二&#…...

迅为iTOP-RK3576开发板/核心板6TOPS超强算力NPU适用于ARM PC、边缘计算、个人移动互联网设备及其他多媒体产品
迅为iTOP-3576开发板采用瑞芯微RK3576高性能、低功耗的应用处理芯片,集成了4个Cortex-A72和4个Cortex-A53核心,以及独立的NEON协处理器。它适用于ARM PC、边缘计算、个人移动互联网设备及其他多媒体产品。 支持INT4/INT8/INT16/FP16/BF16/TF32混合运算&a…...

前沿分享|技术雷达202504月刊精华
本期雷达 ###技术部分 7. GraphRAG 试验 在上次关于 检索增强生成(RAG)的更新中,我们已经介绍了GraphRAG。它最初在微软的文章中被描述为一个两步的流程: (1)对文档进行分块,并使用基于大语言…...

[创业之路-380]:企业法务 - 企业经营中,企业为什么会虚开増值税发票?哪些是虚开増值税发票的行为?示例?风险?
一、动机与风险 1、企业虚开增值税发票的动机 利益驱动 骗抵税款:通过虚开发票虚增进项税额,减少应纳税额,降低税负。公司套取国家的利益。非法套现:虚构交易开具发票,将资金从公司账户转移至个人账户,用…...

嵌入式:ARM公司发展史与核心技术演进
一、发展历程:从Acorn到全球算力基石 1. 起源(1978-1990) 1978年:奥地利物理学家Hermann Hauser与工程师Chris Curry创立剑桥处理器公司(CPU Ltd.),后更名为**艾康电脑(Acor…...

ubuntu的各种工具配置
1.nfs:虚拟机桥接模式下,开发板和虚拟机保持在同一网段下,开发板不要直连电脑 挂载命令:mount -v -t nfs 192.168.110.154:/home/lhj /mnt -o nolock (1) 安装 NFS 服务器 sudo apt update sudo apt install nfs-kernel-server -y…...

Go 剥离 HTML 标签的三把「瑞士军刀」——从正则到 Bluemonday
1 为什么要「剥皮」? 安全:去掉潜在的 <script onload…> 等恶意标签,防止存储型 XSS。可读性:日志、消息队列、搜索索引里往往只需要纯文本。一致性:不同富文本编辑器生成的 HTML 五花八门,统一成「…...

【Java面试笔记:基础】6.动态代理是基于什么原理?
1. 反射机制 定义:反射是 Java 语言提供的一种基础功能,允许程序在运行时自省(introspect),直接操作类或对象。功能: 获取类定义、属性和方法。调用方法或构造对象。运行时修改类定义。 应用场景ÿ…...

docker容器中uv的使用
文章目录 TL;DRuv简介uv管理项目依赖step 1step 2WindowsLinux/Mac step 3依赖包恢复 在Docker容器中使用uv TL;DR 本文记录uv在docker容器中使用注意点, uv简介 uv是用rust编写的一个python包管理器,特点是速度快,且功能强大,目标是替代p…...

分部积分选取u、v的核心是什么?
分部积分选取u、v的核心是什么?是反对幂指三吗? 不全是,其实核心是:v要比u更容易积分,也就是更容易求得原函数,来看一道例题:...

Android Studio调试中的坑二
下载新的Android studio Meerkat后,打开发现始终无法更新对应的SDK,连Android 15的SDK也无法在SDK Manger中显示出来,但是Meerkat必须要使用新版本SDK。 Android studio下载地址 命令行工具 | Android Studio | Android Developers 解决…...
)
【Redis】缓存三剑客问题实践(上)
本篇对缓存三剑客问题进行介绍和解决方案说明,下篇将进行实践,有需要的同学可以跳转下篇查看实践篇:(待发布) 缓存三剑客是什么? 缓存三剑客指的是在分布式系统下使用缓存技术最常见的三类典型问题。它们分…...
)
2025年4月22日(平滑)
在学术和工程语境中,表达“平滑”需根据具体含义选择术语。以下是专业场景下的精准翻译及用法解析: 1. 数学/信号处理中的「平滑」(消除噪声) Smooth (verb/noun/adjective) “Apply a Gaussian filter to smooth the noisy signa…...

给vue-admin-template菜单栏 sidebar-item 添加消息提示
<el-badge :value"200" :max"99" class"item"><el-button size"small">评论</el-button> </el-badge> <!-- 在 SidebarItem.vue 中 --> <template><div v-if"!item.hidden" class&q…...
(十二)——stack和queue)
C++(初阶)(十二)——stack和queue
十二,stack和queue 十二,stack和queueStackQueuepriority_queue 简单使用模拟实现deque Stack 函数说明stack()构造空栈empty()判断栈是否为空size()返回栈的有效元素个数top()返会栈顶元素的引用push()将所给元素val压入栈中pop()将栈的尾部元素弹出 …...

数据采集:AI 发展的基石与驱动力
人工智能(AI)无疑是最具变革性的技术力量之一,正以惊人的速度重塑着各行各业的格局。从智能语音助手到自动驾驶汽车,从精准的医疗诊断到个性化的推荐系统,AI 的广泛应用已深刻融入人们的日常生活与工作的各个层面。而在…...

Kubernetes Docker 部署达梦8数据库
Kubernetes & Docker 部署达梦8数据库 一、达梦镜像获取 目前达梦官方暂未在公共镜像仓库提供Docker镜像,需通过达梦官网联系获取官方镜像包。 二、Kubernetes部署方案 部署配置文件示例 apiVersion: apps/v1 kind: Deployment metadata:labels:app: dm8na…...

宏碁笔记本电脑怎样开启/关闭触摸板
使用快捷键:大多数宏碁笔记本可以使用 “FnF7” 或 “FnF8” 组合键来开启或关闭触摸板,部分型号可能是 “FnF2”“FnF9” 等。如果不确定,可以查看键盘上的功能键图标,一般有触摸板图案的按键就是触摸板的快捷键。通过设备管理器…...
)
计算机组成与体系结构:缓存(Cache)
目录 为什么需要 Cache? 🧱 Cache 的分层设计 🔹 Level 1 Cache(L1 Cache)一级缓存 🔹 Level 2 Cache(L2 Cache)二级缓存 🔹 Level 3 Cache(L3 Cache&am…...

【VS Code】打开远程服务器Docker项目或文件夹
1、配置SSH连接 在VS Code中,按CtrlShiftP打开命令面板。 输入并选择Remote-SSH: Connect to Host...。 输入远程服务器的SSH地址(例如userhostname或userip_address)。 如果这是您第一次连接到该主机,VS Code可能会要求您配置…...

docker 常见命令
指定服务名查看日志 docker-compose logs -f doc-cleaning docker inspect id 启动所有服务 在docker-compose目录下 docker-compose up -d docker-compose down会删除容器和网络 docker compose stop redis rabbitmq docker compose stop可以快速停止服务,方…...

C#抽象类和虚方法的作用是什么?
抽象类 (abstract class): 不能直接实例化,只能被继承。 用来定义一套基础框架和规范,强制子类必须实现某些方法(抽象方法)。 可用来封装一些共通的逻辑,减少代码重复。 虚方法 (virtual): …...

redis数据类型-基数统计HyperLogLog
redis数据类型-基数统计HyperLogLog 文档 redis单机安装redis常用的五种数据类型redis数据类型-位图bitmap 说明 官网操作命令指南页面:https://redis.io/docs/latest/commands/?nameget&groupstringHyperLogLog介绍页面:https://redis.io/docs…...

音视频学习 - MP3格式
环境 JDK 13 IDEA Build #IC-243.26053.27, built on March 16, 2025 Demo MP3Parser MP3 MP3全称为MPEG Audio Layer 3,它是一种高效的计算机音频编码方案,它以较大的压缩比将音频文件转换成较小的扩展名为.mp3的文件,基本保持源文件的音…...

Oracle--PL/SQL编程
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 PL/SQL(Procedural Language/SQL)是Oracle数据库中的一种过程化编程语言,构建于SQL之上,允许编写包含S…...
)
【愚公系列】《Python网络爬虫从入门到精通》063-项目实战电商数据侦探(主窗体的数据展示)
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...
开发全解析:构建去中心化应用的流程)
DAPP(去中心化应用程序)开发全解析:构建去中心化应用的流程
去中心化应用(DApp)凭借其透明性、抗审查性和用户数据主权,正重塑金融、游戏、社交等领域。本文基于2025年最新开发实践,系统梳理DApp从需求规划到部署运维的全流程,并融入经济模型设计、安全加固等核心要点࿰…...

Spark与Hadoop之间有什么样的对比和联系
一、什么是Spark Spark 是一个快速、通用且可扩展的大数据处理框架,最初由加州大学伯克利分校的AMPLab于2009年开发,并于2010年开源。它在2013年成为Apache软件基金会的顶级项目,是大数据领域的重要工具之一。 Spark 的优势在于其速度和灵活…...

spark和Hadoop之间的对比和联系
Spark 诞生主要是为了解决 Hadoop MapReduce 在迭代计算以及交互式数据处理时面临的性能瓶颈问题。 一,spark的框架 Hadoop MR 框架 从数据源获取数据,经过分析计算后,将结果输出到指定位置,核心是一次计算,不适合迭…...

LeetCode 第 262 题全解析:从 SQL 到 Swift 的数据分析实战
文章目录 摘要描述题解答案(SQL)Swift 题解代码分析代码示例(可运行 Demo)示例测试及结果时间复杂度分析空间复杂度分析总结未来展望 摘要 在实际业务中,打车平台要监控行程的取消率,及时识别服务质量的问…...

“融合Python与机器学习的多光谱遥感技术:数据处理、智能分类及跨领域应用”
随着遥感技术的快速发展,多光谱数据凭借其多波段信息获取能力,成为地质、农业及环境监测等领域的重要工具。相较于高光谱数据,Landsat、哨兵-2号等免费中分辨率卫星数据具有长时间序列、广覆盖的优势,而无人机平台的兴起进一步补充…...

JavaScript的JSON处理Map的弊端
直接使用 Map 会遇到的问题及解决方案 直接使用 Map 会导致数据丢失,因为 JSON.stringify 无法序列化 Map。以下是详细分析及解决方法: 问题复现 // 示例代码 const myMap new Map(); myMap.set(user1, { name: Alice }); myMap.set(user2, { name: B…...
)
python的深拷贝浅拷贝(copy /deepcopy )
先说结论: 浅拷贝: 浅拷贝对在第一层的操作都是新建,不改变原对象。 浅拷贝对于原拷贝对象中的嵌套的可变对象是引用,对原拷贝对象中的嵌套的不可变对象是新建。 对新建的对象操作不会影响原被拷贝对象。 对引用对象操作会影…...

新能源汽车充电桩:多元化运营模式助力低碳出行
摘 要:以新能源汽车民用充电桩为研究对象,在分析充电桩建设运营的政府推动模式、电网企业推动模式、汽车厂商推动模式等三种模式利弊的基础上,结合我国的实际情况,提出我国现阶段应实行汽车厂商与电网企业联盟建设充电桩的模式。建立一个考虑…...

Python 设计模式:享元模式
1. 什么是享元模式? 享元模式是一种结构型设计模式,旨在通过共享对象来减少内存使用和提高性能。它特别适用于需要大量相似对象的场景,通过共享相同的对象来避免重复创建,从而节省内存和提高效率。 享元模式的核心思想是将对象的…...

文献×汽车 | 基于 ANSYS 的多级抛物线板簧系统分析
板簧系统是用于减弱或吸收动态系统中发生的应力、应变、偏转和变形等破坏性因素的机械结构。板簧系统可能对外力产生不同的响应,具体取决于其几何结构和材料特性。板簧系统的计算机辅助分析对于高精度确定系统的变形特性和结构特性至关重要。 在这项工作中ÿ…...

Element UI、Element Plus 里的表单验证的required必填的属性不能动态响应?
一 问题背景 想要实现: 新增/修改对话框中(同一个),修改时“备注”字段非必填,新增时"备注"字段必填 结果发现直接写不生效-初始化一次性 edit: [{ required: true, message: "请输入备注", trigger: "blur" }…...

【架构】ANSI/IEEE 1471-2000标准深度解析:软件密集型系统架构描述推荐实践
引言 在软件工程领域,架构设计是确保系统成功的关键因素之一。随着软件系统日益复杂化,如何有效描述和沟通系统架构成为了一个亟待解决的问题。ANSI/IEEE 1471-2000(正式名称为"推荐软件密集型系统架构描述实践")应运而…...

深度学习中的“重参数化”总结
深度学习中的重参数化(Reparameterization)是一种数学技巧,主要用于解决模型训练过程中随机性操作(如采样)导致的梯度不可导问题。其核心思想是将随机变量的生成过程分解为确定性和随机性两部分,使得反向传…...

为TA开发人员介绍具有最新改进的Kinibi-610a
安全之安全(security)博客目录导读 目录 一、引言 二、密码学改进 三、可信应用(TA)的多线程支持 四、C 标准库支持 五、简化的支持与集成 六、参考资料 一、引言 Trustonic 推出的 Kinibi-610a 进行了多项底层优化,以实现更深度的系统集成,并更好地适应不断演进的…...

通信与推理的协同冲突与架构解耦路径
在大规模无人机集群中,AI决策系统依赖实时通信完成状态共享与策略传播,但通信带宽、延迟、信息一致性等问题正在成为系统性能的瓶颈。尤其是在山区、城市低空或信号遮蔽等通信不稳定区域,AI推理系统往往面临状态更新延迟,难以及时…...

《AI大模型应知应会100篇》第32篇:大模型与医疗健康:辅助诊断的可能性与风险
第32篇:大模型与医疗健康:辅助诊断的可能性与风险 摘要 当AI开始读懂CT影像中的细微阴影,当算法能从百万份病历中发现诊断规律,医疗健康领域正经历着一场静默的革命。本文通过技术解构与案例分析,揭示大模型如何重塑临…...
忌(阶)秘(技)术(巧)【第七式】程序的编译)
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第七式】程序的编译
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第七式】程序的编译 【心法】 【第零章】c语言概述 【第一章】分支与循环语句 【第二章】函数 【第三章】数组 【第四章】操作符 【第五章】指针 【第六章】结构体 【第七章】const与c语言中一些错误代码 【禁忌秘术】 【第一式】…...