计算机组成与体系结构:缓存(Cache)
目录
为什么需要 Cache?
🧱 Cache 的分层设计
🔹 Level 1 Cache(L1 Cache)一级缓存
🔹 Level 2 Cache(L2 Cache)二级缓存
🔹 Level 3 Cache(L3 Cache)三级缓存
Cache 的运行机制
🔄 CPU 核心数量与 Cache 的关系
🔎 Cache 相关术语(Cache-related Terms)
🧠 引用的局部性( Locality of Reference)
1️⃣ 时间局部性(Temporal Locality)
2️⃣ 空间局部性(Spatial Locality)
为什么需要 Cache?
想象你在玩一个 100GB 的大型 3D 开放世界游戏,比如《赛博朋克 2077》或《原神》。
这个游戏包含:
-
成千上万张地图贴图;
-
数百个角色模型;
你可能会想:
我们不能把所有代码都放在主存里吗?
从第一性原理看,这个问题非常自然。我们来分析一下背后的限制:
💡 为什么不能把整个游戏都放进主存?
原因一:主存容量有限
-
游戏是按需加载的,因为大部分内容你“当前并不会用到”。
-
比如你现在在城市区域,森林那部分地图用不到,加载了反而浪费空间。
原因二:主存速度不够快
-
CPU 执行速度以纳秒为单位,而主存(通常是 DRAM)访问延迟达几十甚至上百纳秒。
-
如果 CPU 每执行一条指令就等几十纳秒,那执行效率会非常低。
这就引出了我们今天的主角:
Cache(缓存):一种高速小容量的临时存储区域,用于存放“最近正在用”或“即将用到”的数据,让 CPU 不用一直等主存。
🧱 Cache 的分层设计
💡从第一性原理出发:
我们知道,Cache 的设计目标是解决 CPU 和主存(DRAM)之间巨大的速度差。
| 元件 | 速度(延迟) |
|---|---|
| CPU(寄存器) | <1 ns |
| L1 Cache | 1–2 ns |
| L2 Cache | ~5 ns |
| L3 Cache | 10–20 ns |
| 主存 DRAM | 50–100 ns |
你可以看到,主存的访问时间是 L1 Cache 的几十倍。为了缩小这个“速度鸿沟”,我们引入了多级缓存(Multilevel Cache Architecture):
🔹 Level 1 Cache(L1 Cache)一级缓存
-
位置:直接嵌入在 CPU 核心内部,与执行单元关系最紧密。
-
速度:最快,通常只有 1–2 个 CPU 时钟周期的延迟。
-
大小:非常小(一般为 16KB–64KB),分为:
-
L1I(指令缓存,Instruction Cache)
-
L1D(数据缓存,Data Cache)
-
为什么分为 I/D?
从第一性原理看:
CPU 在执行程序时,“取指”和“取数据”是两条并行路径,如果混在一起会互相干扰。
🔹 Level 2 Cache(L2 Cache)二级缓存
-
位置:仍在 CPU 核心附近,但通常不嵌入执行单元。
-
大小:较大(128KB–1MB),统一存储指令和数据。
-
速度:比 L1 慢,但比主存快,通常延迟在 5–15 个周期之间。
功能:
弥补 L1 空间不足的问题,把 L1 Cache Miss 的数据“接住”。
🔹 Level 3 Cache(L3 Cache)三级缓存
-
位置:多个核心之间共享的缓存,不再是每个核心私有。
-
大小:大(2MB–几十 MB)
-
速度:相对较慢,但比主存快得多。
设计目的:
为多个核心之间的数据共享提供“中转站”。
层级结构图示(逻辑上):
CPU Core/ | \L1I L1D -> L2\______/↓L3 (共享)↓Main Memory
| 层级 | 中文名 | 主要作用 | 特点 | 与 CPU 距离 |
|---|---|---|---|---|
| L1 Cache | 一级缓存 | 执行级加速,紧贴指令和数据 | 最小(16~64KB),最快(1ns) | 嵌在每个 CPU 核内部 |
| L2 Cache | 二级缓存 | 衔接 L1 和 L3,扩大命中率 | 中等大小(256KB~1MB),速度快 | 通常也是每核私有 |
| L3 Cache | 三级缓存 | 跨核心共享、减少主存访问 | 最大(2MB~64MB),最慢但仍比 RAM 快 | 多核之间共享 |
这套结构就像一个数据“梯子”:
-
越靠近 CPU,越快,但越小;
-
越远,越大,但越慢。
🧠 从第一性原理讲:
越靠近 CPU 的缓存必须越小越快,以匹配 CPU 的指令节奏;而越远的缓存可以稍慢,但容量要大些,用于存放更多数据。
Cache 的运行机制
我们以 CPU 执行一条指令为例,看看 Cache 是怎么参与工作的:
步骤一:CPU 需要一个数据(比如变量 x)
CPU 发出一个“内存读取请求”:我要取地址 0x1000 的值。
步骤二:先查 L1 Cache(一级缓存)
-
L1 是最小但最快的缓存(通常在 1ns 内响应)
-
CPU 立即在 L1 中查找这个地址。
如果找到了,就叫 Cache Hit(命中)
直接读取数据,立即返回!
如果没有找到,就叫 Cache Miss(未命中)
进入下一层:查 L2。
步骤三:L1 Miss → 查 L2 Cache(二级缓存)
-
L2 比 L1 稍远、稍大、稍慢(通常 5–15ns)。
-
如果在 L2 找到了 → 把数据送回 L1(便于下次快速访问)。
步骤四:L2 Miss → 查 L3 Cache(三级缓存)
-
L3 是多核共享的,容量最大,速度较慢(10–20ns 或更高)。
-
如果找到了 → 同样送回 L2 → 再写进 L1 → 最后给 CPU 用。
步骤五:L3 也 Miss → 去 Main Memory(主存)
-
如果三层都没命中,说明这块数据根本没在 Cache 中。
-
系统需要从主存(DRAM)加载数据(延迟可能高达 100ns)。
这就是最典型的 “缓存访问路径”:
CPU → L1 → L2 → L3 → 主存
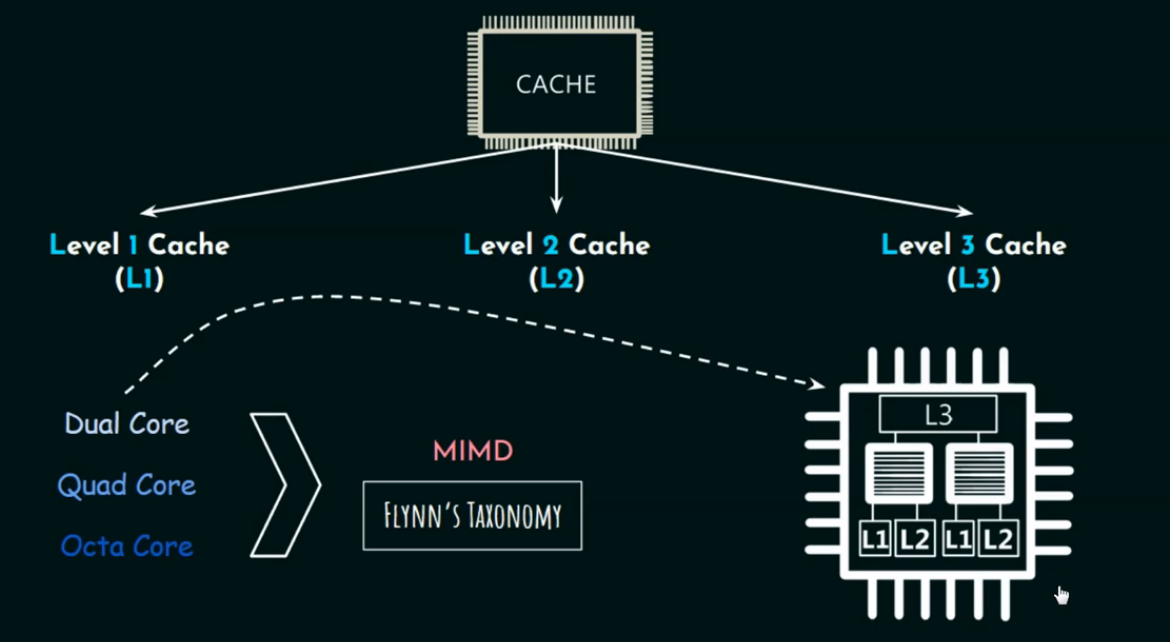
🔄 CPU 核心数量与 Cache 的关系
现代 CPU 通常不是单核,而是 多核结构(Multicore CPU)。
-
Dual-core(双核):2 个处理核心
-
Quad-core(四核):4 个处理核心
-
Octa-core(八核):8 个处理核心
这些术语表示CPU 中的处理核心数量。
那这些核心如何共享和配置 Cache 呢?我们来详细说说:
每个核心都拥有 自己的私有缓存(Private Cache)
| 缓存层级 | 分配方式 | 理由 |
|---|---|---|
| L1 Cache | 每个核心独立拥有 | 距离近、快速访问、不干扰其他核心 |
| L2 Cache | 大多数情况下也是私有 | 帮助每个核心缓存更多数据,防止竞争冲突 |
多个核心 共享 L3 Cache(Shared Cache)
L3 Cache 通常被设计为多核心共享的一层高速缓存。
原因:
-
可以减少重复缓存:比如多个线程访问同一个数据,不需要每个核心都复制一份。
-
提供跨核心通信的中转站。
结构示意(以四核为例):
[Core1]--L1--L2
[Core2]--L1--L2
[Core3]--L1--L2
[Core4]--L1--L2\ | /↘ L3 Cache ↙↓Main Memory
这和 Cache 有什么关系?
每个核心通常有自己独立的 L1、L2 Cache,而多个核心之间会共享 L3 Cache,如下:
[Core1] --> L1/L2 --\
[Core2] --> L1/L2 ---|--> 共享 L3 Cache
[Core3] --> L1/L2 --/
为什么这样设计?
从第一性原理看:
每个核心有自己的“工作空间”,但也要能互相通信,所以共享 L3 是折中的办法。
这一套缓存层级 + 多核架构,最终的目标只有一个:
让 CPU 每时每刻都能有“足够快”的数据可用,最大化它的执行效率。
🔎 Cache 相关术语(Cache-related Terms)
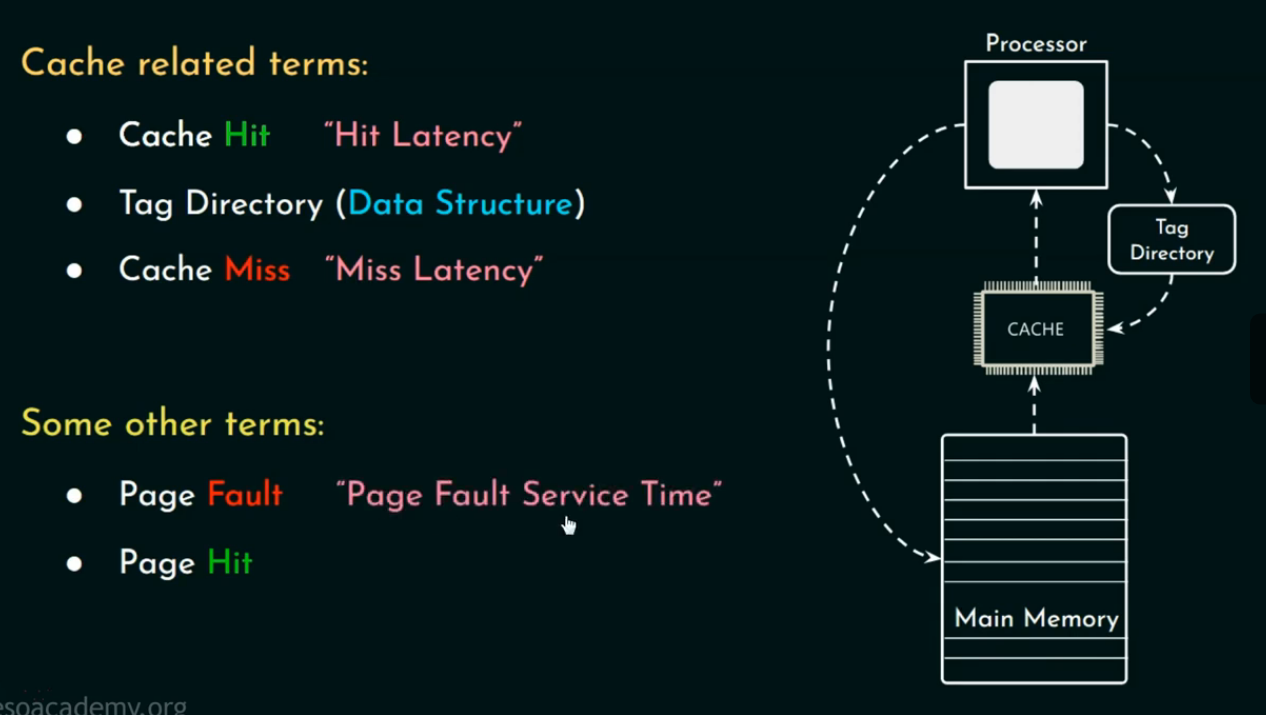
🏷️ 1. Cache Hit(缓存命中)
当 CPU 需要某个数据,而该数据已经在 Cache 中,就称为命中(Hit)。
🏷️ 2. Cache Miss(缓存未命中)
数据不在 Cache 中,CPU 需要从更下层(比如主存)去取。
Miss 会带来延迟,也叫 Miss Penalty(未命中惩罚)。
🏷️ 3. Tag Directory(标记目录)
每条 Cache 数据都会带一个“Tag”,用于记录该数据来自内存的哪个位置。
Cache 查询时会通过比对 Tag 来判断是否命中。
🏷️ 4. 其他术语(补充说明):
🏷️ Page Fault(页错误)
-
当程序要访问的数据既不在 Cache,也不在主存,而是在磁盘(比如换页文件中),就会发生 Page Fault。
-
此时操作系统需要从磁盘中调入数据,成本极高。
🏷️Page Hit(页命中)
-
数据在内存页中已经存在,无需调入磁盘。
📌 注意:Page Fault / Page Hit 是虚拟内存管理里的概念,而不是 Cache 的,但它们也体现了内存的层级思想。
🧠 引用的局部性( Locality of Reference)
为什么 Cache 能提高性能?核心原理是:
程序访问数据时是有“规律”的,而不是随机的。
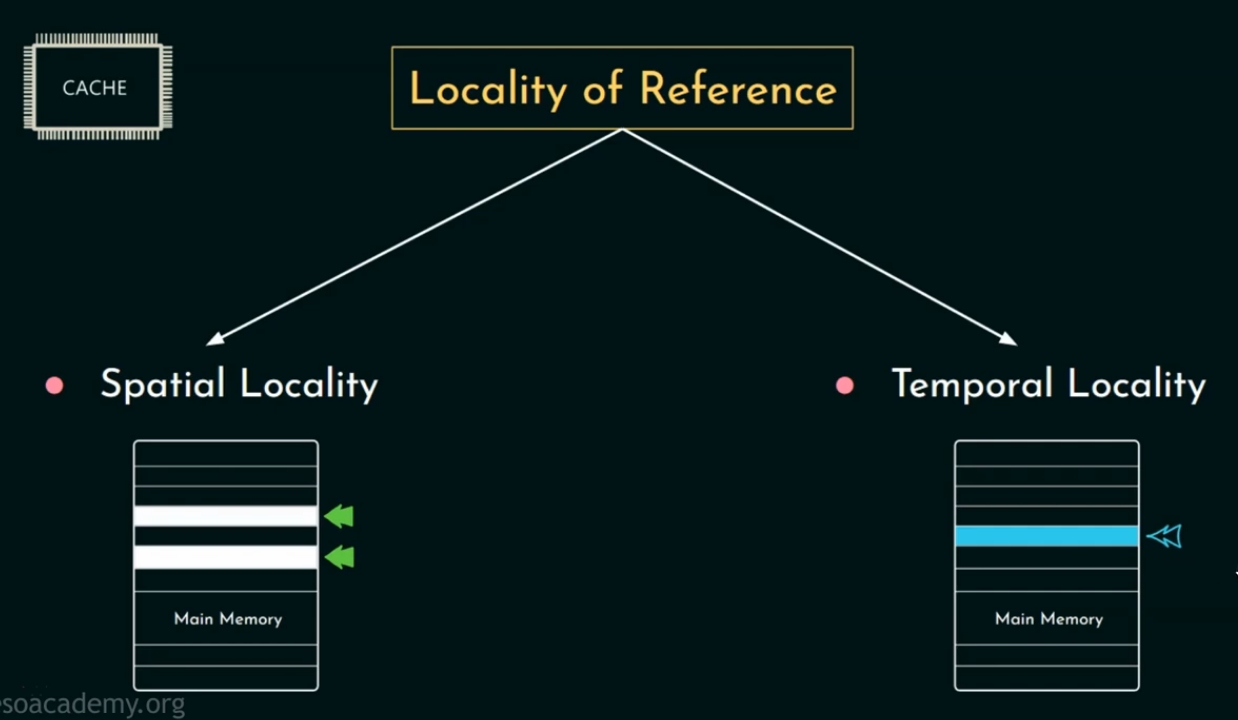
引用的局部性是指程序在访问内存时,有集中访问某些区域”的倾向。
就是说:程序不会随便乱跳着访问内存,它有“偏好”:
要么访问同一块地方(空间局部性),要么短时间反复访问同样的内容(时间局部性)。
引用局部性分两种:
1️⃣ 时间局部性(Temporal Locality)
如果某个数据刚刚被访问过,很快还会再次被访问。
举例:
-
一个变量
x被频繁使用; -
一个循环不断用到数组第0项;
-
函数刚被调用,马上又调用一次。
2️⃣ 空间局部性(Spatial Locality)
如果访问了某个地址,很可能会接着访问它“附近”的地址。
举例:
-
遍历数组时会依次访问相邻的内存单元;
-
连续的结构体或局部变量通常排在栈上连续的空间。
计算机为了加快访问速度,就利用这个“局部性原理”,把近期访问的数据(和它附近的数据)放到更快的缓存(Cache)里。
这样,下次再访问这些内容时就更快了。
相关文章:
)
计算机组成与体系结构:缓存(Cache)
目录 为什么需要 Cache? 🧱 Cache 的分层设计 🔹 Level 1 Cache(L1 Cache)一级缓存 🔹 Level 2 Cache(L2 Cache)二级缓存 🔹 Level 3 Cache(L3 Cache&am…...

【VS Code】打开远程服务器Docker项目或文件夹
1、配置SSH连接 在VS Code中,按CtrlShiftP打开命令面板。 输入并选择Remote-SSH: Connect to Host...。 输入远程服务器的SSH地址(例如userhostname或userip_address)。 如果这是您第一次连接到该主机,VS Code可能会要求您配置…...

docker 常见命令
指定服务名查看日志 docker-compose logs -f doc-cleaning docker inspect id 启动所有服务 在docker-compose目录下 docker-compose up -d docker-compose down会删除容器和网络 docker compose stop redis rabbitmq docker compose stop可以快速停止服务,方…...

C#抽象类和虚方法的作用是什么?
抽象类 (abstract class): 不能直接实例化,只能被继承。 用来定义一套基础框架和规范,强制子类必须实现某些方法(抽象方法)。 可用来封装一些共通的逻辑,减少代码重复。 虚方法 (virtual): …...

redis数据类型-基数统计HyperLogLog
redis数据类型-基数统计HyperLogLog 文档 redis单机安装redis常用的五种数据类型redis数据类型-位图bitmap 说明 官网操作命令指南页面:https://redis.io/docs/latest/commands/?nameget&groupstringHyperLogLog介绍页面:https://redis.io/docs…...

音视频学习 - MP3格式
环境 JDK 13 IDEA Build #IC-243.26053.27, built on March 16, 2025 Demo MP3Parser MP3 MP3全称为MPEG Audio Layer 3,它是一种高效的计算机音频编码方案,它以较大的压缩比将音频文件转换成较小的扩展名为.mp3的文件,基本保持源文件的音…...

Oracle--PL/SQL编程
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 PL/SQL(Procedural Language/SQL)是Oracle数据库中的一种过程化编程语言,构建于SQL之上,允许编写包含S…...
)
【愚公系列】《Python网络爬虫从入门到精通》063-项目实战电商数据侦探(主窗体的数据展示)
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...
开发全解析:构建去中心化应用的流程)
DAPP(去中心化应用程序)开发全解析:构建去中心化应用的流程
去中心化应用(DApp)凭借其透明性、抗审查性和用户数据主权,正重塑金融、游戏、社交等领域。本文基于2025年最新开发实践,系统梳理DApp从需求规划到部署运维的全流程,并融入经济模型设计、安全加固等核心要点࿰…...

Spark与Hadoop之间有什么样的对比和联系
一、什么是Spark Spark 是一个快速、通用且可扩展的大数据处理框架,最初由加州大学伯克利分校的AMPLab于2009年开发,并于2010年开源。它在2013年成为Apache软件基金会的顶级项目,是大数据领域的重要工具之一。 Spark 的优势在于其速度和灵活…...

spark和Hadoop之间的对比和联系
Spark 诞生主要是为了解决 Hadoop MapReduce 在迭代计算以及交互式数据处理时面临的性能瓶颈问题。 一,spark的框架 Hadoop MR 框架 从数据源获取数据,经过分析计算后,将结果输出到指定位置,核心是一次计算,不适合迭…...

LeetCode 第 262 题全解析:从 SQL 到 Swift 的数据分析实战
文章目录 摘要描述题解答案(SQL)Swift 题解代码分析代码示例(可运行 Demo)示例测试及结果时间复杂度分析空间复杂度分析总结未来展望 摘要 在实际业务中,打车平台要监控行程的取消率,及时识别服务质量的问…...

“融合Python与机器学习的多光谱遥感技术:数据处理、智能分类及跨领域应用”
随着遥感技术的快速发展,多光谱数据凭借其多波段信息获取能力,成为地质、农业及环境监测等领域的重要工具。相较于高光谱数据,Landsat、哨兵-2号等免费中分辨率卫星数据具有长时间序列、广覆盖的优势,而无人机平台的兴起进一步补充…...

JavaScript的JSON处理Map的弊端
直接使用 Map 会遇到的问题及解决方案 直接使用 Map 会导致数据丢失,因为 JSON.stringify 无法序列化 Map。以下是详细分析及解决方法: 问题复现 // 示例代码 const myMap new Map(); myMap.set(user1, { name: Alice }); myMap.set(user2, { name: B…...
)
python的深拷贝浅拷贝(copy /deepcopy )
先说结论: 浅拷贝: 浅拷贝对在第一层的操作都是新建,不改变原对象。 浅拷贝对于原拷贝对象中的嵌套的可变对象是引用,对原拷贝对象中的嵌套的不可变对象是新建。 对新建的对象操作不会影响原被拷贝对象。 对引用对象操作会影…...

新能源汽车充电桩:多元化运营模式助力低碳出行
摘 要:以新能源汽车民用充电桩为研究对象,在分析充电桩建设运营的政府推动模式、电网企业推动模式、汽车厂商推动模式等三种模式利弊的基础上,结合我国的实际情况,提出我国现阶段应实行汽车厂商与电网企业联盟建设充电桩的模式。建立一个考虑…...

Python 设计模式:享元模式
1. 什么是享元模式? 享元模式是一种结构型设计模式,旨在通过共享对象来减少内存使用和提高性能。它特别适用于需要大量相似对象的场景,通过共享相同的对象来避免重复创建,从而节省内存和提高效率。 享元模式的核心思想是将对象的…...

文献×汽车 | 基于 ANSYS 的多级抛物线板簧系统分析
板簧系统是用于减弱或吸收动态系统中发生的应力、应变、偏转和变形等破坏性因素的机械结构。板簧系统可能对外力产生不同的响应,具体取决于其几何结构和材料特性。板簧系统的计算机辅助分析对于高精度确定系统的变形特性和结构特性至关重要。 在这项工作中ÿ…...

Element UI、Element Plus 里的表单验证的required必填的属性不能动态响应?
一 问题背景 想要实现: 新增/修改对话框中(同一个),修改时“备注”字段非必填,新增时"备注"字段必填 结果发现直接写不生效-初始化一次性 edit: [{ required: true, message: "请输入备注", trigger: "blur" }…...

【架构】ANSI/IEEE 1471-2000标准深度解析:软件密集型系统架构描述推荐实践
引言 在软件工程领域,架构设计是确保系统成功的关键因素之一。随着软件系统日益复杂化,如何有效描述和沟通系统架构成为了一个亟待解决的问题。ANSI/IEEE 1471-2000(正式名称为"推荐软件密集型系统架构描述实践")应运而…...

深度学习中的“重参数化”总结
深度学习中的重参数化(Reparameterization)是一种数学技巧,主要用于解决模型训练过程中随机性操作(如采样)导致的梯度不可导问题。其核心思想是将随机变量的生成过程分解为确定性和随机性两部分,使得反向传…...

为TA开发人员介绍具有最新改进的Kinibi-610a
安全之安全(security)博客目录导读 目录 一、引言 二、密码学改进 三、可信应用(TA)的多线程支持 四、C 标准库支持 五、简化的支持与集成 六、参考资料 一、引言 Trustonic 推出的 Kinibi-610a 进行了多项底层优化,以实现更深度的系统集成,并更好地适应不断演进的…...

通信与推理的协同冲突与架构解耦路径
在大规模无人机集群中,AI决策系统依赖实时通信完成状态共享与策略传播,但通信带宽、延迟、信息一致性等问题正在成为系统性能的瓶颈。尤其是在山区、城市低空或信号遮蔽等通信不稳定区域,AI推理系统往往面临状态更新延迟,难以及时…...

《AI大模型应知应会100篇》第32篇:大模型与医疗健康:辅助诊断的可能性与风险
第32篇:大模型与医疗健康:辅助诊断的可能性与风险 摘要 当AI开始读懂CT影像中的细微阴影,当算法能从百万份病历中发现诊断规律,医疗健康领域正经历着一场静默的革命。本文通过技术解构与案例分析,揭示大模型如何重塑临…...
忌(阶)秘(技)术(巧)【第七式】程序的编译)
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第七式】程序的编译
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第七式】程序的编译 【心法】 【第零章】c语言概述 【第一章】分支与循环语句 【第二章】函数 【第三章】数组 【第四章】操作符 【第五章】指针 【第六章】结构体 【第七章】const与c语言中一些错误代码 【禁忌秘术】 【第一式】…...

[创业之路-377]:企业法务 - 有限责任公司与股份有限公司的优缺点对比
有限责任公司(简称“有限公司”)与股份有限公司(简称“股份公司”)是我国《公司法》规定的两种主要公司形式,二者在设立条件、治理结构、股东权利义务等方面存在显著差异。以下从核心特征、设立条件、治理结构、股东权…...

PowerBi中REMOVEFILTERS怎么使用?
在 Power BI 的 DAX 中,REMOVEFILTERS() 是一个非常重要的函数,常用于取消某个字段或表的筛选上下文(Filter Context),从而让你的计算不受切片器(Slicer)、筛选器或视觉对象的限制。 ✅ 一、REM…...

stat判断路径
int stat(const char *pathname, struct stat *buf); pathname:用于指定一个需要查看属性的文件路径。 buf:struct stat 类型指针,用于指向一个 struct stat 结构体变量。调用 stat 函数的时候需要传入一个 struct stat 变量的指针࿰…...

智能指针之设计模式4
前面的文章介绍了使用工厂模式来封装智能指针对象的创建过程,下面介绍一下工厂类 enable_shared_from_this的实现方案。 4、模板方法模式 在前面的文章分析过,enable_shared_from_this<T>类是一个工厂基类,提供的工厂方法是shared_f…...

Linux信号的产生
Linux系列 文章目录 Linux系列一、信号的产生1.1 异常1.2 alarm()系统调用 二 、信号的默认行为 一、信号的产生 上篇文章我们已经介绍了信号的三种产生方式,这部分是对上篇文章的补充 1.1 异常 在编写程序时,我们的程序经常会出现如:除零…...

FPGA设计 时空变换
1、时空变换基本概念 1.1、时空概念简介 时钟速度决定完成任务需要的时间,规模的大小决定完成任务所需要的空间(资源),因此速度和规模就是FPGA中时间和空间的体现。 如果要提高FPGA的时钟,每个clk内组合逻辑所能做的事…...

客户端本地搭建
connect函数 主要用于客户端套接字向服务器发起连接请求。 头文件 #include <sys/socket.h> #include <arpa/inet.h> 函数原型 int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);参数解释 sockfd:客户端文件描述符。 addr…...

广东食品销售初级考试主要考什么
广东省食品销售初级考试主要考察从业人员对食品安全法律法规、行业规范及基础操作技能的掌握程度,内容涵盖以下几个方面: 1. 食品安全法律法规 考试重点包括《食品安全法》《广东省食品安全条例》等核心法规,要求考生熟悉食品经营许可、从业…...
实战指南:从认知重构、技术落地到内容突围的三维战略)
[盈达科技】GEO(生成式引擎优化)实战指南:从认知重构、技术落地到内容突围的三维战略
GEO(生成式引擎优化)实战指南:从认知重构、技术落地到内容突围的三维战略 引言:AI搜索重构规则,GEO成为企业新护城河 在生成式AI主导的搜索时代,传统SEO的“关键词游戏”已失效。Google数据显示࿰…...

Linux ACL访问控制权限解析:超越传统权限的精细化管理
Linux ACL权限管理示意图 标准输出:Linux文件权限结构(支持ACL) ├── 传统权限 │ ├── 所有者(user): rwx │ ├── 所属组(group): r-x │ └── 其他用户(other): r-- │ └── ACL扩展权限├── 用户条目│ ├── user…...

全面介绍AVFilter 的添加和使用
author: hjjdebug date: 2025年 04月 22日 星期二 13:48:19 CST description: 全面介绍AVFilter 的添加和使用 文章目录 1.两个重要的编码思想1. 写代码不再是我们调用别人,而是别人调用我们!2. 面向对象的编程方法. 2. AVFilter 开发流程2.1 编写AVFilter 文件2.1.…...

复刻低成本机械臂 SO-ARM100 3D 打印篇
视频讲解: 复刻低成本机械臂 SO-ARM100 3D 打印篇 清理了下许久不用的3D打印机,挤出机也裂了,更换了喷嘴和挤出机夹具,终于恢复了正常工作的状态,接下来还是要用起来,不然吃灰生锈了,于是乎想起…...

基于微信小程序的走失儿童帮助系统-项目分享
基于微信小程序的走失儿童帮助系统-项目分享 项目介绍项目摘要管理员功能图用户功能图系统功能图项目预览首页走失儿童个人中心走失儿童管理 最后 项目介绍 使用者:管理员、用户 开发技术:MySQLJavaSpringBootVue 项目摘要 本系统采用微信小程序进行开…...

C++23 中 static_assert 和 if constexpr 的窄化布尔转换
文章目录 背景与动机C23 的改进限制与例外总结 C23 引入了一项重要的语言特性变更,即在 static_assert 和 if constexpr 中允许窄化按语境转换为 bool。这一特性由 Andrzej Krzemieński 提出的 P1401R5 论文推动,旨在使编译器的行为与标准保持一致&a…...

服务网格在DevOps中的落地:如何让微服务更智能、更稳定?
服务网格在DevOps中的落地:如何让微服务更智能、更稳定? 近年来,DevOps在企业IT架构中变得至关重要,而微服务架构的广泛应用更是加速了这一趋势。然而,随着微服务数量不断增长,我们发现自己掉入了一个运维“泥潭”: 服务之间的流量调控变得复杂可观测性不足,出现问题时…...

el-table表格既出现横向滚动条,又出现纵向滚动条?
横向滚动条 自然出现? 当表格所有列的宽度总和超过表格容器宽度时,el-table会默认出现横向滚动条。 比如,给每个<el-table-column>设置固定宽度,且他们相加超过了<el-table>宽度 就会触发 强制出现? 设…...

STL常用算法——C++
1.概述 2.常用遍历算法 1.简介 2.for_each 方式一:传入普通函数(printf1) #include<stdio.h> using namespace std; #include<string> #include<vector> #include<functional> #include<algorithm> #include…...

基于国产 FPGA+ 龙芯2K1000处理器+翼辉国产操作系统继电保护装置测试装备解决方案
0 引言 近年来,我国自主可控芯片在国家政策和政 府的支持下发展迅速,并在电力、军工、机械、 通信、电子、医疗等领域掀起了国产化替代之 风,但在芯片自主可控和国产化替代方面还有明 显的不足之处。 2022年我国集成电路进口量多 达 5 3…...

1.3 本书结构概览:从理论基础到实践案例的系统阐述
本书采用由浅入深、理论联系实践的结构设计,旨在为读者提供一个关于大模型与智能代理(Agent)技术的全面认知框架与实施路径。全书共分为十章,系统性地覆盖了从技术基础到企业落地的完整知识链条,现概述如下: 首先,第一…...

【FPGA开发】Vivado开发中的LUTRAM占用LUT资源吗
LUTRAM在Vivado资源报告中的解释 LUTRAM的本质与实现原理: LUTRAM不是一种独立的物理资源,而是LUT(Look-Up Table)的一种特殊使用方式。在Xilinx FPGA架构中,部分LUT单元可以被配置为小型分布式RAM(也称为…...

【动手学强化学习】番外8-IPPO应用框架学习与复现
文章目录 一、待解决问题1.1 问题描述1.2 解决方法 二、方法详述2.1 必要说明(1)MAPPO 与 IPPO 算法的区别在于什么地方?(2)IPPO 算法应用框架主要参考来源 2.2 应用步骤2.2.1 搭建基础环境2.2.2 IPPO 算法实例复现&am…...
)
C++ 的 输入输出流(I/O Streams)
什么是输入输出流 C 的输入输出操作是通过 流(stream) 机制实现的。 流——就是数据的流动通道,比如: 输入流:从设备(如键盘、文件)读取数据 → 程序 输出流:程序将数据写入设备&…...

Java 安全:如何防止 SQL 注入与 XSS 攻击?
Java 安全:如何防止 SQL 注入与 XSS 攻击? 在 Java 开发领域,安全问题至关重要,而 SQL 注入和 XSS 攻击是两种常见的安全威胁。本文将深入探讨如何有效防止这两种攻击,通过详细代码实例为您呈现解决方案。 一、SQL 注…...

leetcode day36 01背包问题 494
494 目标和 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums [2, 1] ,可以在 2 之前添加 ,在 1 之前添加 - &…...

31Calico网络插件的简单使用
环境准备: 1、删除Flannel 2、集群所有node节点拉取所需镜像(具体版本可以依据calico.yaml文件中): docker pull calico/cni:v3.25.0 docker pull calico/node:v3.25.0 docker pull calico/kube-controllers:v3.25.0一、安装Cali…...