VLA论文精读(十四)PointVLA: Injecting the 3D World into Vision-Language-Action Models
这篇论文瞄准的是2025年在arxiv上发布的一篇VLA领域论文。这篇文章最大的创新点在于将3D点云信息作为补充条件送入模型,而不是DP3一样只用纯3D数据从头训练模型,按照作者的说法这样可以在保留模型原有2D解释能力的同时添加了其3D能力,并且可以有效识别真实物体与2D照片,作者设置的各种任务中都超越了baseline模型。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:PointVLA: Injecting the 3D World into Vision-Language-Action Models
- 原文链接: https://arxiv.org/abs/2503.07511
- 发表时间:2025年03月10日
- 发表平台:arxiv
- 预印版本号:[v1] Mon, 10 Mar 2025 16:32:41 UTC (8,134 KB)
- 作者团队:Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, Yichen Zhu
- 院校机构:
- Shanghai University;
- East China Normal University
- 项目链接: pointvla.github.io
- GitHub仓库: 【暂无】
Abstract
VLA 利用大规模 2D 视觉语言进行预训练,擅长完成机器人任务,但对 RGB 图像的输入依赖限制了真实世界交互中至关重要的空间推理能力。使用 3D 数据重新训练这些模型在计算上过于昂贵,如果丢弃现有2D 数据集则会浪费宝贵的资源。为了弥补这一差距,作者提出了 PointVLA 框架,该框架可以使用点云输入增强预训练的 VLA,而无需重新训练,具体操作是冻结原始动作专家部分并使用轻量级模块化块注入 3D 特征。为了证明集成点云输入能够提升模型性能,作者进行了跳块分析,以精确定位原始动作专家中贡献不强的块,确保仅将 3D 特征注入这些块中,最大限度地减少对预训练表示的干扰。
实验表明 PointVLA 在仿真和真机任务中都优于SOTA 2D 模仿学习方法,例如 OpenVLA、Diffusion Policy 和 DexVLA 。PointVLA 有以下几个关键优势:
- 少样本多任务处理:
PointVLA成功执行了四种不同的任务,每种任务仅使用 20 次演示; - 真实与平面图像的区分:
PointVLA能够区分真实物体与2D照片,并利用 3D 知识来提高安全性和可靠性; - 高度适应性:
PointVLA使机器人能够适应训练数据中未见过的不同桌面高度物体; - 长程任务表现:
PointVLA在长程任务中表现出色,例如从移动的传送带上拾取和包装物体,展示了其在复杂动态环境中泛化的能力;
1. Introduction
机器人基础模型,尤其是VLA 让机器人能够感知、理解物理世界并与之进行交互。利用预训练 VLM作为backbone,处理视觉和语言信息,并嵌入到共享的表示空间中,然后将转换为机器人动作。此过程使机器人能够以有意义的方式与其环境交互。VLA 性能很大程度上取决于其训练数据的规模和质量。例如,Open-VLA 在 4000 小时的开源数据集上进行训练,而像 π0 这样更先进的模型则利用 10000 小时的专用数据。除了这些大规模的基础模型外,许多项目还贡献了现实世界中人类遥操作机器人演示的大规模数据集,例如,AgiBot-World 发布了包含数百万条轨迹的海量数据集,演示了复杂的类人交互。这些预训练的 VLA 模型与开源机器人数据集一起,通过提供丰富多样且高质量的训练数据,显著推动了机器人学习的发展。
尽管取得了上述进展,但大多数基础模型都是基于 2D 视觉输入进行训练的,而人类是在三维空间中感知和与世界互动的。训练数据中缺乏 3D 空间信息,阻碍了机器人深入了解其环境的能力,对于需要精确空间意识、深度感知、物体操控的任务尤为重要。作者完成本文的动力在于,许多研究已经在基础 VLA 和大规模 2D 机器人数据集上投入了大量资金。使用 3D 数据从头开始重新训练这些模型在计算上过于昂贵,丢弃宝贵的 2D 机器人数据是不切实际的。因此,探索能够将 3D 输入集成到现有基础模型中的新型框架至关重要,这是一个在先前文献中尚未被充分探索的研究领域。
本文绍了 PointVLA 一个将点云集成到预训练的VLA中的新框架。3D 数据总量远小于 2D 数据,基于该假设,重点是不破坏已获得的 2D 特征表示。为了解决这个问题,作者提出了一个 3D 模块,将点云信息直接注入动作专家,并保持VL主干的完整性,确保 2D 视觉文本嵌入得以保留并仍然是可靠的信息来源。此外,本文的目标是最大限度地减少对动作专家特征空间的干扰。通过跳块分析,识别出在执行时不太重要的层。这些“不太有用”的特征嵌入更适合追加新的模态。在识别出这些不太重要的块之后,通过加法注入提取的 3D 特征。最终整体模型保持了预训练 VLA 的完整性,同时结合了点云输入的优势。
作者开展了大量实验来验证方法的有效性:在 RoboTwin 仿真平台上,模型优于纯 3D 模仿学习方法,如 3D DP ;还在两个型号的双臂真机上进行了实验:类人形 UR5e 和类似 Aloha 平台的 AglieX 机械臂。实验还凸显了 PointVLA 的几个关键优势:
- Few-shot multi-tasking:
PointVLA可以根据指令执行四类任务,每类任务仅需 20 个演示即可完成训练。在小的数据集上进行多任务训练极具挑战性,而模型方法显著优于baseline; - Real-vs-photo discrimination:真实物体与其照片在二维中可能非常相似,这会导致机器人产生混淆并造成安全隐患,
PointVLA能够有效地区分真实物体及其照片,避免被虚假照片欺骗; - Height adaptability:
PointVLA可根据桌子高度的变化调整机器人的动作(例如,在更高的桌子上抓取同一物品),而传统的 2D VLA 模型通常会在这种情况下失败;
此外,作者还测试了一些具有挑战性的长程任务,例如从移动的传送带上拾取多件物品并将其装入箱中。实验证明了 PointVLA 框架在不同场景下的稳健性能和泛化能力,为将更多模态集成到预训练的 VLA 模型中指明了一个有前景的方向。
2. Related Works
Vision-Language-Action models
最近的研究越来越侧重于开发基于大规模机器人学习数据集训练的通用机器人策略。VLA 已成为训练此类策略的一种有前途的方法。VLA 将VLM(已在海量互联网规模的图像和文本数据集上进行预训练)扩展到机器人控制。这种方法提供了几个关键优势:利用具有数十亿个参数的大规模视觉语言模型主干,可以从庞大的机器人数据集中进行有效学习,复用来自互联网规模数据的预训练权重,增强 VLA 解释不同语言命令和推广到新物体和环境的能力,使其高度适应现实世界的机器人应用。
Robot learning with 3D modalities
在 3D 场景中学习鲁棒的视觉运动策略是机器人学习中的一个重要领域。现有的方法如 3DVLA 已经提出了综合框架,将各种 3D 任务(如泛化、视觉问答 (VQA)、3D 场景理解和机器人控制)集成到统一的VLA中。然而 3DVLA 的一个局限性在于其为仿真平台上完成,使得仿真与现实之间存在显著的差距;其他研究如 3D 扩散策略,已经证明使用外部 3D 输入(例如来自外部摄像头)可以提高模型对不同光照条件和物体属性的泛化能力; iDP3 进一步增强了 3D 视觉编码器,并将其应用于人形机器人,在以自身为中心和外部摄像机视角的各种环境中均实现了稳健的性能。然而,丢弃现有的 2D 机器人数据,或基于 3D 视觉输入完全从零开始训练,计算成本高昂且资源密集。一个更实用的解决方案是开发一种方法,将 3D 视觉输入作为补充知识源集成到预训练的基础模型中,从而在不影响已训练模型性能的情况下获得新模态的优势。
3. Methodology
3.1. Preliminaries: Vision-Language-Action Models
VLA正在推动现实世界机器人学习的重大转变,其强大之处在于一个基于海量互联网数据训练得到的底层的VLM。这种训练能够在共享嵌入空间内有效地对齐图像和文本表示。VLM 充当模型的“大脑”,处理指令和当前视觉输入以理解任务状态。随后,“动作专家”模块将 VLM 的状态信息转化为机器人动作。本文工作以 DexVLA 为基础,DexVLA 是一个具有 20 亿个参数、以 Qwen2-VL VLM 为backbone,以及一个 10 亿个参数的 ScaleDP (一种扩散策略变体)动作专家模块。 DexVLA 的三个训练阶段:
- 100 小时的跨本体训练;
- 本体训练;
- 针对复杂任务的可选特定训练;
这三个阶段均采用二维视觉输入,虽然这些 VLA 模型在各种操作任务中展现出令人印象深刻的能力,但二维视觉输入限制了在需要三维理解的任务表现,例如通过照片进行物体欺骗或在不同桌子高度上进行泛化。下一节旨在说明如何将 3D 世界注入预训练的 VLA,整体框架如Fig.2 所示。
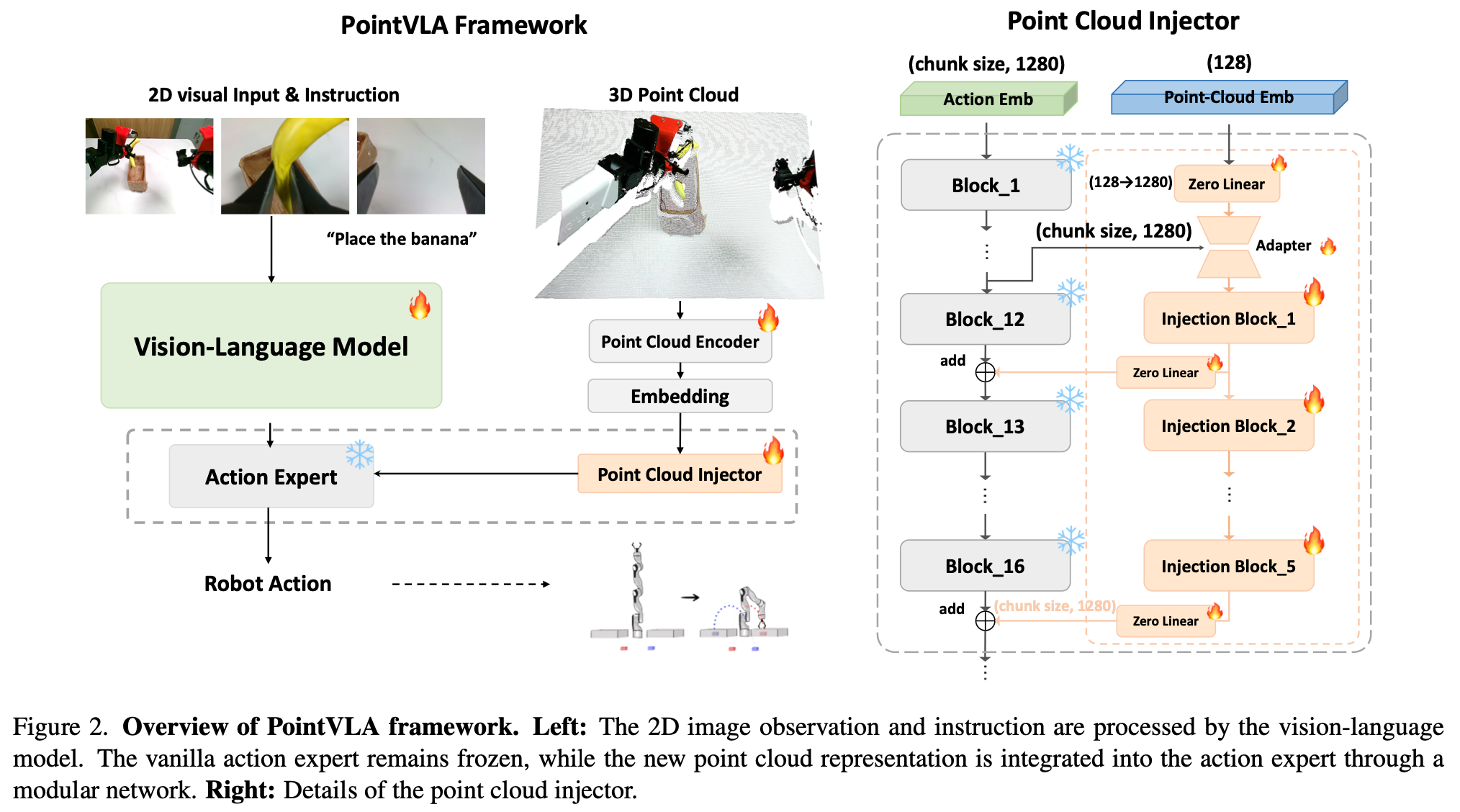
3.2. Injecting Point Cloud into VLA
Motivation
VLA 通常在大规模二维机器人数据集上进行预训练。作者提出的模型其中一个核心点在于:解决现有二维预训练语料库与新的三维数据之间规模上的内在差异。假设三维传感器数据(例如点云、深度图)的体量是二维VL数据集的小几个数量级,这种差异需要一种方法来保留从二维预训练中学习到的丰富视觉表征,同时有效地集成稀疏的三维数据。
一种简单策略是将 3D 视觉输入直接转换为 3D 视觉标记并将它们混合到LLM中,这种方法已被许多 3DVLM 采用,例如 LLaVA-3D。然而,当前的VL在小规模 3D 数据集微调后表现出有限的 3D 理解能力,这种限制会因为下面两个因素而加剧:
- 2D 像素和 3D 几何结构之间的巨大领域差距;
- 与丰富的图像文本和纯文本语料库相比,高质量 3D 文本配对数据集稀少;
为了规避这些问题作者提出了一种范式,将 3D 点云数据视为 补充调节信号 而不是主要输入模态。该策略将 3D 处理与核心 2D 视觉编码器分离,从而在保留预训练 2D 表示完整性的同时,使模型能够利用几何线索。作者的方法能够缓解 2D 知识的灾难性遗忘,并降低在有限的 3D 数据上过拟合的风险。
Model architecture for point cloud injector
点云嵌入器的整体架构如Fig.1 (right)所示(Note:这里可能是作者的一个笔误,因该是 Fig.2 (right) 因为Fig.1并没有介绍模型结构,因此这里放的是我理解的 Fig.2)。对于传入的点云嵌入,首先转换通道维度使其与原始动作专家的通道维度匹配。由于来自点云的动作嵌入可能很大(具体取决于块的大小),作者设计了一个动作嵌入限制来压缩来自动作专家的信息,同时将其与 3D 点云嵌入对齐。对于动作专家中选定的块,首先应用一个 MLP 层作为每个块的适配器,然后执行加法运算将点云嵌入注入模型。
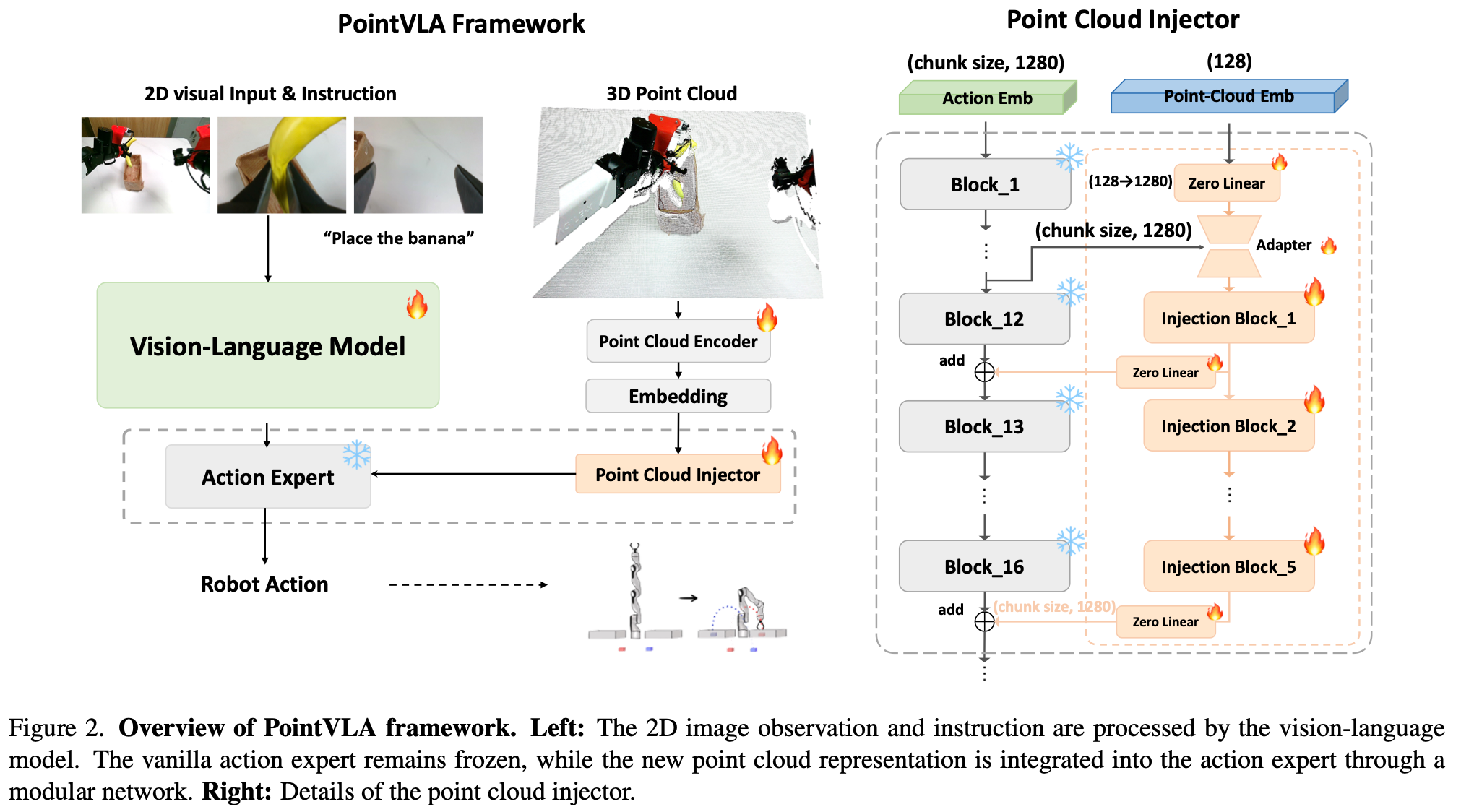
不能将 3D 特征注入每个动作专家块中,原因如下:1.微调每个块计算成本会过高;2.注入会影响对应块的2D性能。鉴于训练目标是最大限度地减少有限的 3D 视觉知识对预训练 2D 动作嵌入的干扰,作者筛选出了可以在推理过程中跳过而不会影响整体性能的块。随后,仅将 3D 特征注入这些不太重要的块中。
Point cloud encoder
与 DP3 和 iDP3 的表现一致,预训练的 3D 视觉编码器会降低性能,通常会阻碍机器人在新环境中成功进行行为学习。因此,作者采用了一种简化的分层卷积架构:上层卷积层提取低级特征、下层卷积块学习高级场景表示、层间最大池化逐步降低点云密度。最后,将每个卷积块的特征嵌入连接成一个统一的嵌入,封装多级 3D 表示知识,保留提取的点云特征嵌入以供后续使用。该架构类似于 iDP3 编码器。作者认为使用更先进的点云编码器可以进一步提高模型性能。但由于这不是本文的重点因此留待以后讨论。
3.3. Which Blocks to Inject Point Cloud? A Skip Block Analysis
如前所述,将点云注入每个动作专家块并不合适,因为会增加计算成本并破坏从 2D 视觉中学习到的原始动作表示,因此需要分析动作专家中哪些块不太重要(即可以在推理过程中跳过而不会影响性能的块)。这种方法在图像生成、视觉模型、LLM中使用的技术一致。此处使用 DexVLA 中衬衫折叠作为分析的案例研究。DexVLA 配备了 10 亿参数动作专家和 32 个扩散 transformer 块,评估时使用平均分数作为指标,该指标时长程任务的标准衡量标准,通过将任务分为多个步骤并根据步骤完成情况评估性能。首先一次跳过一个块,如Fig.3 所示。
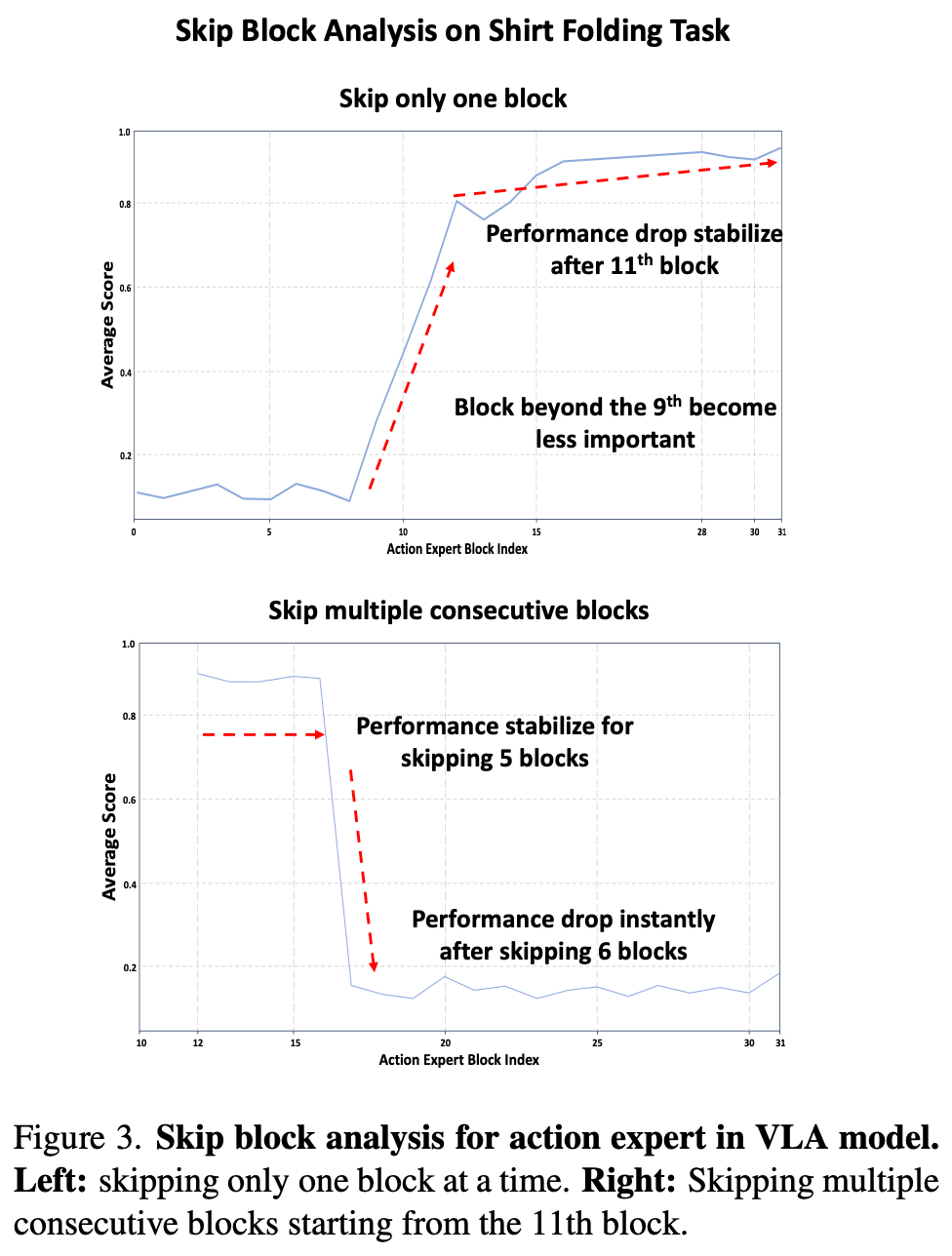
实验表明前 11 个块对于模型至关重要,跳过其中任何一个块都会导致性能显着下降,当跳过这些块后夹持器无法紧密闭合;但从第 11 个块开始直至最后一个块,跳过单个块对整体性能影响不显著,表明从第 11 到第 31 个块对训练后的性能贡献较小。为了进一步研究哪些块适合点云注入,从第 11 个块开始进行多块跳过分析,如Fig.3 (right)所示。发现模型在任务失败前最多可以跳过五个连续的块,表明可以通过特定块将 3D 表示选择性地注入动作专家块进行训练,冻结除了最后几层外原始模型中的所有模块,只训练五个额外的注入块,这些块轻量且推理速度快提升了整体模型的效益。
4. Experiment
本节将通过一系列实验来验证方法的有效性。在第 4.1 节中详细描述了真机工作空间;第 4.2 节和 4.3 节中评估了少样本多任务场景和长程挑战性任务;第 4.4 节和 4.5 节中探索了两种只能通过 3D 视觉输入的独特泛化能力;最后将方法与模拟基准进行了比较。
4.1 Implementation Details
在这项工作中,作者在两个实体中进行了真机实验:
- Bimanual UR5e:两台
UR5e机器人每台配备Robotiq平行爪式夹持器和腕式摄像头。两臂之间安装一台俯拍摄像头,共有三个摄像头视图,以及 14 DoF 的动作空间。数据采集频率为 15Hz,使用RealSense D435i作为腕式摄像头; - Bimanual AgileX:两个 6 DoF
AgileX机械臂,每个机械臂配备一个腕式摄像头和一个底座摄像头,该装置拥有 14 DoF 动作空间以及三个摄像头视图。数据采集频率为 30Hz,使用RealSense D435i作为腕式摄像头;
RealSense L515 摄像头用于采集点云。将 VLM 模型设置为可训练,因为需要学习新的语言指令。在两个实验中都使用了 DexVLA 中第一阶段的预训练权重,并进行了微调。使用与 DexVLA 第二阶段训练相同的训练超参数,以及最后一个 checkpoint 进行评估,避免出现“樱桃采摘”的情况。所有任务的chunk size = 50。
Baseline
baseline 包括扩散策略 DP、3D 扩散策略 DP3、ScaleDP-1B(将扩散策略扩展至 1B 参数的变体)、Octo、OpenVLA 和 DexVLA。由于 PointVLA 建立在 DexVLA 之上,因此 DexVLA 可以看作 PointVLA 的简化版本,无需结合 3D 点云数据。
4.2. Few-Shot Multi-Tasking
Task description
如Fig.5 所示为真机实验设计了四个小样本任务:手机充电、擦拭盘子、放置面包、运输水果。物体被随机放在一个小的范围内,统计每个模型的平均成功率。1)手机充电:机器人拿起一部智能手机并将其放在无线充电器上,手机的大小测试动作精度,并需要需要小心处理易碎性;2)擦拭盘子:机器人同时拿起一块海绵和一个盘子用海绵擦拭盘子,评估双手操作技能;3)放置面包:机器人拿起一块面包并将其放在盘子上,用面包下面一层泡沫测试目标物体高度上的泛化性;4)运输水果:机器人拿起一个随机方向的香蕉并将其放在位于中心的盒子里。
由于此处旨在验证模型的少样本多任务处理能力,每个任务采集了 20 个演示,总共 80 个演示。物体的位置在小空间内随机分配。这些任务评估了模型在不同场景下管理机器人独立运动和协调运动的能力,所有数据均以 30Hz 的频率收集。
Experimental results
实验结果如Table.6 (这里应该还是作者的笔误,对应的内容应为 Fig.6)所示,作者的方法在此场景下的表现优于所有基线方法。扩散策略在大多数情况下会失败,这可能是因为每个任务的样本量太小,导致动作表征空间出现纠,即使增加模型规模 (ScaleDP-1B) 也无法带来显著的提升。
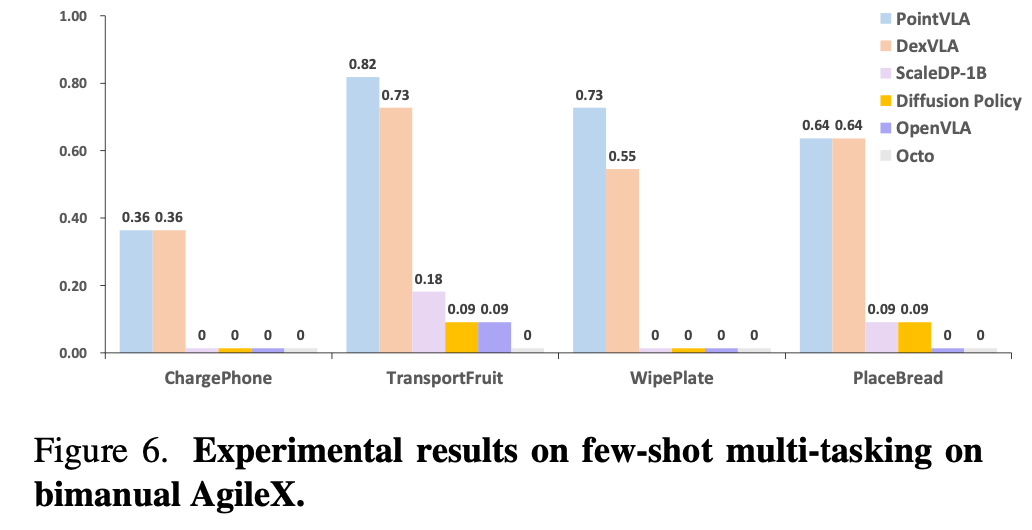
尽管演示样本有限,DexVLA 仍展现出强大的少样本学习能力,性能与 PointVLA 相当甚至略逊一筹;PointVLA 中点云数据的加入使得学习效率更高,凸显了将 3D 信息融入模型的必要性。更重要的是证明了成功地保留从二维预训练 VLA 中学习的能力。
4.3. Long-Horizon Task: Packing on Assembly Line
除了传统的多任务处理之外,作者还进一步对 PointVLA 进行了微调使其能够执行长程的包装任务,如Fig.4 所示。首先,装配线处于运动状态要求机器人快速准确地抓取物体;其次,此场景中的实现方式与预训练数据中的实现方式不同,需要快速适应全新的设置;最后,作为一项长程任务,机器人必须在密封包装箱之前依次拾取并放置两袋洗衣液。这些复杂性使得这项任务的要求极高。

如Table.1所示,PointVLA 在长距离任务中实现了最高平均长度,比强大的基线 DexVLA 高出 0.64 倍,同时优于其他几个基线。下一节将重点介绍 PointVLA 的物体幻觉问题。
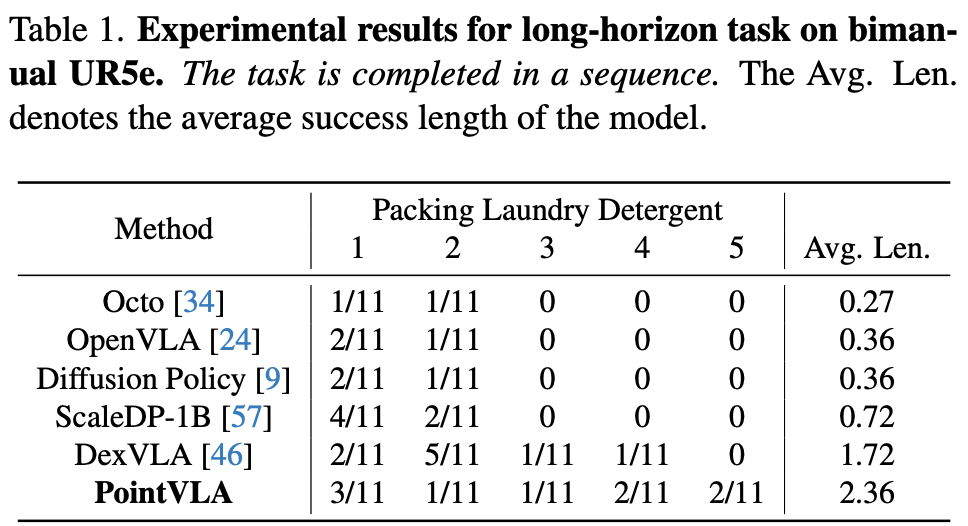
4.4. Real-vs-Photo Discrimination
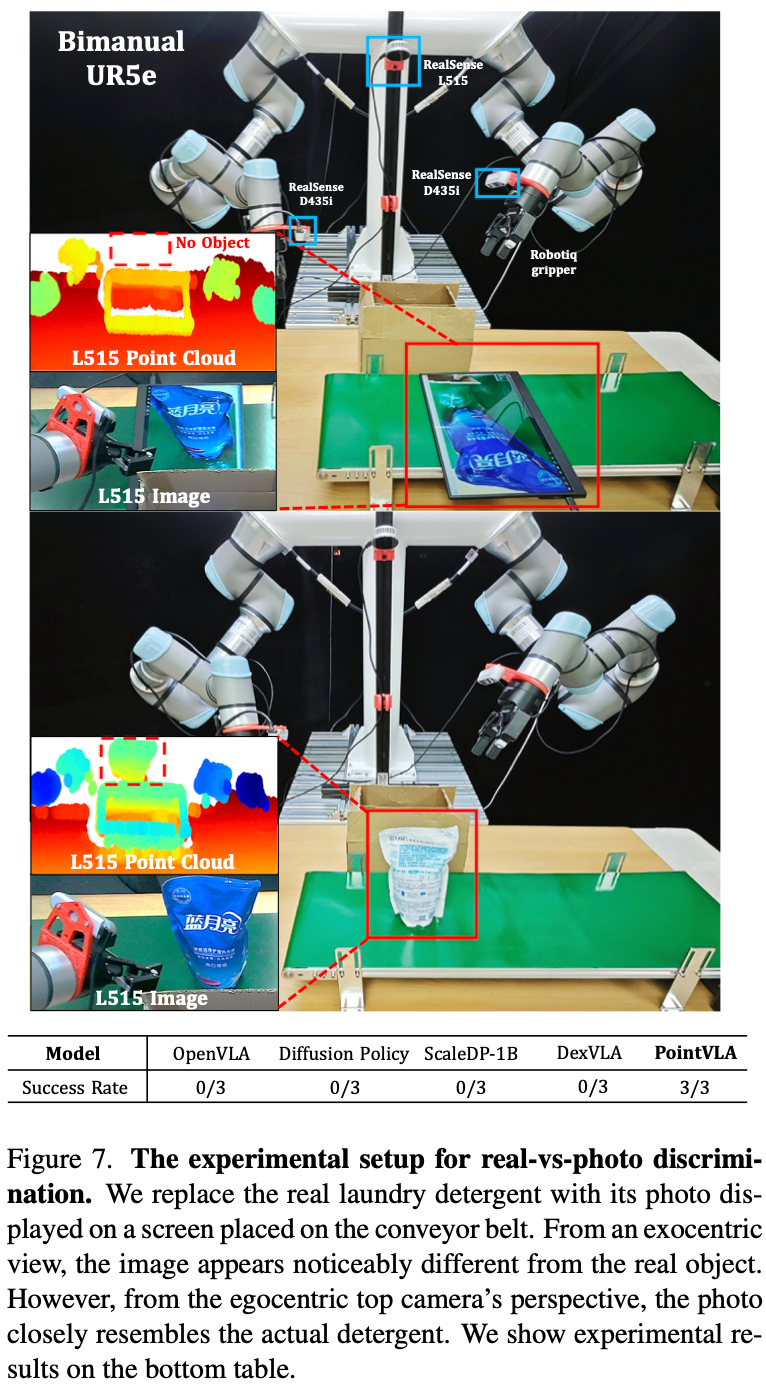
在本节将探索“实物与照片辨别”任务(使用物体的照片替换真实物体),从二维视角来看,屏幕上显示的“假”物体与真实物体几乎完全相同。
使用双臂 UR5e 机器人进行了一项打包任务。实验内容如下:将洗衣液替换为投影在屏幕上的洗衣液照片如Fig.7 所示。从第三人称视角来看,照片与真实物体明显不同。然而,从机器人自身为中心的顶部摄像头视角看,照片与真实的洗衣液非常相似。传统的 2D 的VLA(例如 OpenVLA 和 DexVLA)无法区分照片和实物,会尝试抓取物体,DexVLA 会反复尝试抓取不存在的洗衣液。由于模型认为物体存在但却无法成功抓取,因此陷入了循环。相比之下,PointVLA 成功识别出传送带上不存在物体,利用 3D 空间理解确定物体所在的空间实际上是空的,证明了 3D 感知模型在缓解物体幻觉方面的优势。
4.5. Height Adaptability
这里的高度泛化是指模型适应不同桌面高度的能力,这对于机器人模型来说至关重要,因为大多数演示都是在固定高度的桌面上进行的。然而,当机器人部署到桌面高度与其训练环境明显不同的环境中时,会有怎样的表现需要进行验证。
作者设计了一个如Fig.8所示的实验。在“放置面包”任务中,在面包下面放置了一层泡沫塑料。训练期间这层泡沫厚度为 3 毫米,所有采集的数据都基于这个高度;推理过程中,将泡沫厚度增加到 52 毫米,以评估模型的高度泛化能力。实验结果表明,传统的基于 2D 的 VLA 模型,例如 OpenVLA、DP、ScaleDP-1B 和 DexVLA,在这种情况下都失败了,在检测到面包后,这些模型尝试将机械臂向下推至训练数据中的高度后再进行抓取,无法适应增加的高度。相比之下,PointVLA 成功完成了任务,利用点云数据准确地感知了面包的新高度,相应地调整了抓取器,并成功执行了抓取。该实验表明,结合 3D 信息可以使 VLA 模型处理物体高度的变化。

4.6. Experimental Results on Simulation Benchmarks
在 RoboTwin 上评估了模型,该平台是一种 14 DoF 的双臂仿真平台,涵盖了各种各样的任务。将方法与扩散策略和 3D 扩散策略 DP3 进行了比较。扩散策略是视觉运动策略学习的成熟基线,而 DP3 将其扩展到 3D 领域。原始 DP3 仅使用点云数据作为输入。为了公平起见,还将 RGB 图像合并到 DP3 中。对两个版本的 DP3 与原始扩散策略进行了比较。在所有实验中,使用 320×180 的标准图像分辨率作为摄像头输入,包括 L515 和顶部摄像头。
测试分别使用包含 20 和 50 个样本的数据集进行。每次实验使用三个随机种子(0、1、2)进行策略训练,不进行 Cherry Picking。然后,对每个策略进行 100 次测试,得出三个成功率。计算这些成功率的平均值和标准差,以获得如下所示的实验结果。
实验结果如Table.2所示,在所有任务和各种设置中,PointVLA 均实现了最高的平均成功率,无论其训练样本为 20 还是 50 个。表明即使在数据资源有限的情况下,方法仍然有效,并且在拥有丰富的训练数据时仍能保持良好的性能。
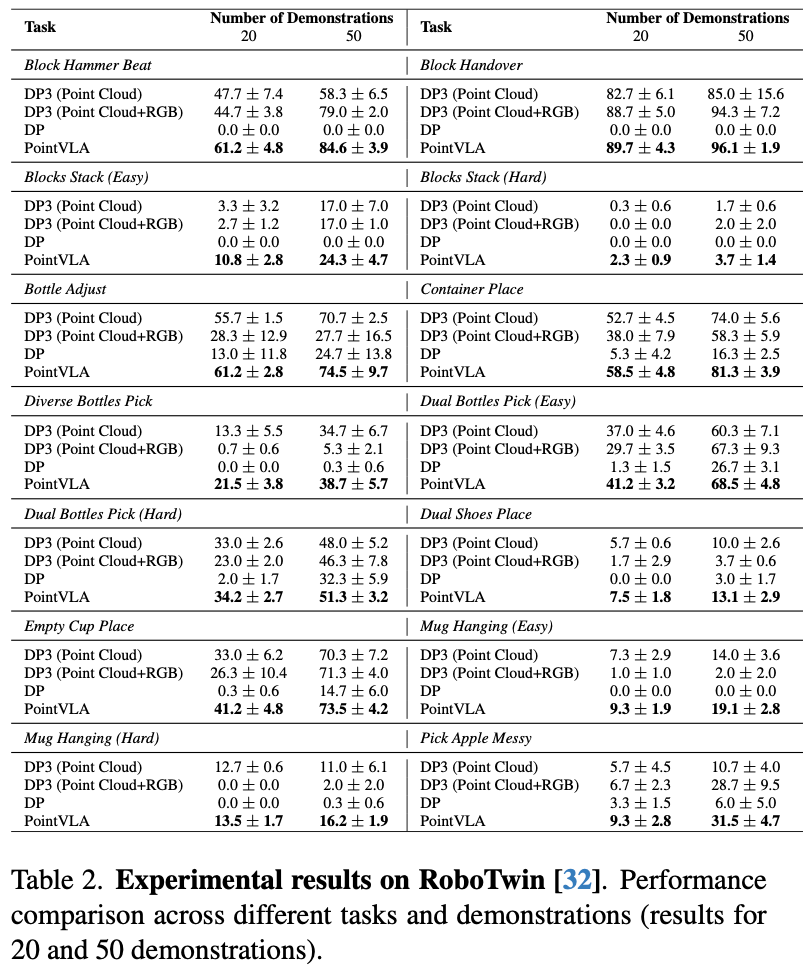
此外,对于像 DP3 这样的纯 3D 模型,直接引入 RGB 输入会对性能产生负面影响。相比之下,作者的方法强调了有条件地将 3D 点云数据集成到模型中的必要性,与仅依赖 2D 视觉输入的模型相比,这显著提高了性能。
5. Conclusion
虽然VLA通过大规模 2D 预训练在机器人学习方面表现出色,但它们对 RGB 输入的依赖限制了 3D 空间推理。而使用 3D 数据进行重新训练成本高昂,丢弃 2D 数据集又会降低泛化能力。为了解决这个问题,作者推出了 PointVLA 一个使用 3D 点云作为增强信息输入的预训练 VLA 的框架,保留了原始模型的 2D 表示能力。通过集成模块化 3D 特征注入器并利用跳过块分析,方法可以有效地整合空间信息,无需从零开始训练。在仿真和现实环境中的实验证明了 PointVLA 的有效性,实现了少样本多任务学习(4 个任务,每个任务仅需 20 次演示),并且在动态物品包装等长期任务中表现出色。在双臂真机(UR5e 和 AgileX )上进行的实际测试进一步验证了其实用性和安全性。作者的工作凸显了在无需进行从零训练的情况下,使用新模式增强预训练机器人模型的可行性。未来的工作包括将 3D 感知预训练扩展到更大的数据集。
相关文章:
PointVLA: Injecting the 3D World into Vision-Language-Action Models)
VLA论文精读(十四)PointVLA: Injecting the 3D World into Vision-Language-Action Models
这篇论文瞄准的是2025年在arxiv上发布的一篇VLA领域论文。这篇文章最大的创新点在于将3D点云信息作为补充条件送入模型,而不是DP3一样只用纯3D数据从头训练模型,按照作者的说法这样可以在保留模型原有2D解释能力的同时添加了其3D能力,并且可以…...

BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
背景 对于现有的BEVDet方法,它对于速度的预测误差要高于基于点云的方法,对于像速度这种与时间有关的属性,仅靠单帧数据很难预测好。因此本文提出了BEVDet4D,旨在获取时间维度上的丰富信息。它是在BEVDet的基础上进行拓展,保留了之前帧的BEV特征,并将其进行空间对齐后与当…...

Java学习路线--自用--带链接
1.Java基础 黑马:黑马程序员Java零基础视频教程_下部 2.MySQL 尚硅谷:MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板 3.Redis 黑马:黑马程序员Redis入门到实战教程,深度透…...
)
【锂电池容量特征提取】NASA数据集锂电池容量特征提取(Matlab完整源码)
目录 效果一览程序获取程序内容代码分享研究内容基于NASA数据集的锂电池容量特征提取方法研究摘要关键词 1. 引言1.1 研究背景1.2 研究意义1.3 研究目的 2. 文献综述2.1 锂电池容量特征提取相关理论基础2.2 国内外研究现状 3. NASA数据集介绍3.1 数据集来源与构成3.2 数据采集方…...

vue2使用markdown-it解析markdown文本
1.安装markdown-it npm instal markdown-it 2. 页面中引用 import MarkdownIt from markdown-it ...const mdRender MarkdownIt(); ...data {return {md: new MarkdownIt(),} } 3. html <p v-html"md.render(conetnt)" ></p>...

云服务器怎么选择防御最合适
用户问的是怎么选择云服务器的防御最合适。这个问题看起来是关于云安全方面的,尤其是如何配置防御措施来保护云服务器免受攻击。首先,我需要理解用户的需求可能是什么。他们可能是一个企业或者个人用户,正在考虑上云,但担心安全问…...

ubuntu20.04安装安装x11vnc服务基于gdm3或lightdm这两种主流的显示管理器。
前言:在服务端安装vnc服务,可以方便的远程操作服务器,而不用非要插上显示器才行。所以在服务器上安装vnc是很重要的。在ubuntu20中,默认的显示管理器已经变为gdm3,它可以带来与 GNOME 无缝衔接的体验,强调功…...

汽车动力转向器落锤冲击试验台
汽车动力转向器落锤冲击试验台依据标准:QC/T29096-1992《汽车转向器总成台架试验方法》;以工控机为控制核心,采用步进电机举升机构,高精度的光电编码器为位置反馈元件。能够自动完成落锤的起吊、精确的定位、释放、冲击过程的测量…...

Mybatis延迟加载、懒加载、二级缓存
DAY22.2 Java核心基础 Mybatis 延迟加载、懒加载 提高程序运行效率的技术 延迟加载,也叫惰性加载或者懒加载 延迟加载如何提升程序的运行效率? 持久层操作有一个原则:Java 程序和数据库交互频率越低越好 Java 程序每次和数据库进行交互…...

Linux网络编程 多进程UDP聊天室:共享内存与多进程间通信实战解析
知识点1【项目功能介绍】 今天我们写一个 UDP ,多进程与不同进程间通信的综合练习 我这里说一下 这个项目的功能: 1、群发(有设备个数的限制):发送数据,其他所有客户端都要受到数据 2、其他客户端 都 可…...

网络结构及安全科普
文章目录 终端联网网络硬件基础网络协议示例:用户访问网页 OSI七层模型网络攻击(Hack)网络攻击的主要类别(一)按攻击目标分类(二)按攻击技术分类 网络安全防御 典型攻击案例相关名词介绍网络连接…...

CAD文件如何导入BigemapPro
问题描述 在使用 BigemapPro 加载 CAD 文件的过程中,会出现两种不同的情况:部分文件能够被软件自动识别投影并顺利加载;而另一部分文件则无法自动识别投影,需要手动干预才能准确加载到影像上。下面为您详细介绍这两种情况的具体操…...

Spring-AOP分析
Spring分析-AOP 1.案例引入 在上一篇文章中,【Spring–IOC】【https://www.cnblogs.com/jackjavacpp/p/18829545】,我们了解到了IOC容器的创建过程,在文末也提到了AOP相关,但是没有作细致分析,这篇文章就结合示例&am…...

opencv 对图片的操作
对图片的操作 1.图片镜像旋转(cv2.flip())2 图像的矫正 1.图片镜像旋转(cv2.flip()) 图像的旋转是围绕一个特定点进行的,而图像的镜像旋转则是围绕坐标轴进行的。图像的镜像旋转分为水平翻转、垂直翻转、水平垂直翻转…...

Python第一周作业
Python第一周作业 文章目录 Python第一周作业 如何在命令行中创建一个名为venv的虚拟环境?请写出具体命令编写一段代码,判断变量x是否为偶数,如果是则返回"Even",否则返回"Odd"编写代码,使用分支结…...

jinjia2将后端传至前端的字典变量转换为JS变量
后端 country_dict {AE: .amazon.ae, AU: .amazon.com.au} 前端 const country_list JSON.parse({{ country_list | tojson | safe }});...

[渗透测试]渗透测试靶场docker搭建 — —全集
[渗透测试]渗透测试靶场docker搭建 — —全集 对于初学者来说,仅仅了解漏洞原理是不够的,还需要进行实操。对于公网上的服务我们肯定不能轻易验证某些漏洞,否则可能触犯法律。这是就需要用到靶场。 本文主要给大家介绍几种常见漏洞对应的靶场…...

二分查找、分块查找、冒泡排序、选择排序、插入排序、快速排序
二分查找/折半查找 前提条件:数组中的数据必须是有序的 核心逻辑:每次排除一半的查找范围 优点:提高查找效率 代码 public static int binarySearch(int[] arr, int num) {int start 0;int end arr.length - 1;while (start < end) {…...

【AI】SpringAI 第三弹:接入通用大模型平台
1.添加依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency> 2.设置 yml 配置文件 在 application.yml 中添加 DeepSeek 的配置信息: spr…...

C++常用函数合集
万能头文件:#include<bits/stdc.h> 1. 输入输出流(I/O)函数 1.1cin 用于从标准输入流读取数据。 1.2cout 用于向标准输出流写入数据。 // 输入输出流(I/O)函数 #include <iostream> using namespace…...

22. git show
基本概述 git show 的作用是:显示各种 Git 对象(如提交、标签、树对象、文件对象等)的详细信息 基本用法 1.基本语法 git show [选项] [对象]2.查看提交的详细信息 git show <commit-hash> # 示例 git show a1b2c3d # 显示某…...

使用blob文件流
1.后端 GetMapping(value "/static/**")public void view(HttpServletRequest request, HttpServletResponse response) {// ISO-8859-1 > UTF-8 进行编码转换String imgPath extractPathFromPattern(request);if(oConvertUtils.isEmpty(imgPath) || imgPath&q…...

操作指南:在vue-fastapi-admin上增加新的功能模块
近期在github上看到一个很不错的web框架,https://github.com/mizhexiaoxiao/vue-fastapi-admin。该项目基于 FastAPI Vue3 Naive UI 的现代化前后端分离开发平台,融合了 RBAC 权限管理、动态路由和 JWT 鉴权,可以助力中小型应用快速搭建&am…...
的生成技术及理论基础的详细说明及表格总结)
文字、语音、图片、视频四个模态两两之间(共16种转换方向)的生成技术及理论基础的详细说明及表格总结
以下是文字、语音、图片、视频四个模态两两之间(共16种转换方向)的生成技术及理论基础的详细说明及表格总结: 1. 技术与理论基础详解 (1) 文字与其他模态的转换 文字→文字 技术:GPT、BERT、LLaMA等语言模型。理论:T…...

FramePack:让视频生成更高效、更实用
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。 1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其…...

【大语言模型DeepSeek+ChatGPT+python】最新AI-Python机器学习与深度学习技术在植被参数反演中的核心技术应用
在全球气候变化与生态环境监测的重要需求下,植被参数遥感反演作为定量评估植被生理状态、结构特征及生态功能的核心技术,正面临数据复杂度提升、模型精度要求高、多源异构数据融合等挑战。人工智能(AI)技术的快速发展,…...

RSS 2025|苏黎世提出「LLM-MPC混合架构」增强自动驾驶,推理速度提升10.5倍!
论文题目:Enhancing Autonomous Driving Systems with On-Board Deployed Large Language Models 论文作者:Nicolas Baumann,Cheng Hu,Paviththiren Sivasothilingam,Haotong Qin,Lei Xie,Miche…...

Oracle expdp的 EXCLUDE 参数详解
Oracle expdp的 EXCLUDE 参数详解 EXCLUDE 是 Oracle Data Pump Export (expdp) 工具中的一个关键参数,用于指定在导出过程中要排除的对象或对象类型。 一、基本语法 expdp username/password DUMPFILEexport.dmp DIRECTORYdpump_dir EXCLUDEobject_type[:name_c…...

Git创建空分支并推送到远程仓库
new-empty-branch是新分支的名称 完全空提交(Git 2.23)【推荐】 git switch --orphan new-empty-branch git config user.email "youexample.com" git config user.name "Your Name" git commit --allow-empty -m "初始空提交…...
)
TDS电导率传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 tds.h文件 tds.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 TDS电导率传感器介绍 : TDS(Total Dissolved Solid),中文名总溶解固…...

初识Redis · C++客户端list和hash
目录 前言: list lpush lrange rpush rpush llen rpop lpop blpop hash hset hget hmget hkeys hvals hexists hdel 前言: 在上一篇文章我们介绍了string的基本使用,并且发现几乎唯一的难点就是使用迭代器方面,并且我们…...

SpringBoot和微服务学习记录Day3
Hystrix 熔断器 在分布式架构中,很多服务因为网络或自身原因不可避免发生故障,如果某个服务出现问题往往会导致一系列的服务都发生故障,导致整个微服务架构瘫痪,称为服务雪崩,Hystrix就是为了解决这个问题的 服务熔…...
)
12个领域近120个典型案例:2024年“数据要素X”大赛典型案例集(附下载)
2024年10月25日,2024年“数据要素”大赛全国总决赛颁奖仪式在北京举行。这次大赛是首届“数据要素x”大赛,全国共有近2万支队伍踊跃参赛,10万参赛者用数据编织梦想,最终角逐出12个赛道120个典型案例。 根据国家数据局等相关公开资…...

如何在腾讯云Ubuntu服务器上部署Node.js项目
最近弄了一个Node.js项目,包含前端用户前台,管理后台和服务端API服务三个项目,本地搭建好了,于是在腾讯云上新建了个Ubuntu 24.04服务器,想要将本地的Node.js项目部署上去,包括环境配置和数据库搭建。 本文…...

【NLP 67、知识图谱】
你像即将到来的夏季一样鲜明, 以至于我这样寡淡的生命, 竟山崩般为你着迷 —— 25.4.18 一、信息 VS 知识 二、知识图谱 1.起源 于2012年5月17日被Google正式提出,初衷是为了提高搜索引擎的能力,增强用户的搜索质量以及搜索体验 …...

Java写数据结构:栈
1.概念: 一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈:栈的插…...

跨境电商行业新周期下的渠道突围策略
2024年初,跨境电商圈动荡不断,多家卖家平台股价大跌,引发行业舆论热议。而作为东南亚主战场的Shopee,仅仅几个月时间跌幅已达23%。在这一波冲击中,大多数卖家都在"止血",但有棵树却逆势而上&…...

Docker如何更换镜像源提高拉取速度
在国内,由于网络政策和限制,直接访问DockerHub速度很慢,尤其是在拉取大型镜像时。为了解决这个问题,常用的方法就是更换镜像源。本文将详细介绍如何更换Docker镜像源,并提供当前可用的镜像源。 换源方法 方法1&#x…...

平方根倒数快速算法
一、平方根倒数算法的由来 在制作3D游戏的时候,曲面是由许多平面构成的,要求出光线在物体表面反射后的效果,就需要知道平面的单位法向量,法向量的长度的平方R很容易求出,单位法向量 坐标值 / R的平方根。电脑每次都要…...

详解.vscode 下的json .vscode文件夹下各个文件的作用
1.背景 看一些开源项目的时候,总是看到vscode先有不同的json文件,再次做一下总结方便之后查看 settings.json肯定不用多说了 vscode 编辑器分为 全局用户配置 和 当前工作区配置 那么.vscode文件夹下的settings.json文件夹肯定就是当前工作区配置了 在此文件对单个的项目进行配…...

【消息队列RocketMQ】二、RocketMQ 消息发送与消费:原理与实践
一、RocketMQ 消息发送原理与模式 1.1 消息发送原理 RocketMQ 消息发送的核心流程围绕 Producer、NameServer 和 Broker 展开。Producer 启动时,会向 NameServer 请求获取 Topic 的路由信息,这些信息包括 Topic 对应的 Broker 列表以及 Broker 上的…...

WPF的发展历程
文章目录 WPF的发展历程引言起源与背景(2001-2006)从Avalon到WPF设计目标与创新理念 WPF核心技术特点与架构基础架构与渲染模型关键技术特点MVVM架构模式 WPF在现代Windows开发中的地位与前景当前市场定位与其他微软UI技术的关系未来发展前景 社区贡献与…...

新书速览|OpenCV计算机视觉开发实践:基于Qt C++
《OpenCV计算机视觉开发实践:基于Qt C》 本书内容 OpenCV是计算机视觉领域的开发者必须掌握的技术。《OpenCV计算机视觉开发实践:基于Qt C》基于 OpenCV 4.10与Qt C进行编写,全面系统地介绍OpenCV的使用及实战案例,并配套提供全书示例源码、PPT课件与作…...

本地搭建一个简易版本的 Web3 服务
一、环境搭建与工具准备 (一)安装 Node.js 和 npm Node.js 是一个基于 JavaScript 的运行时环境,npm 是其默认的包管理器。在 Web3 开发中,Node.js 和 npm 是必不可少的工具。 访问 Node.js 官网 并下载最新的 LTS 版本。 安装…...

电脑安装CentOS系统
前言 电脑是Windows10系统,安装CentOS之前要将硬盘格式化,这个操作会将Windows10系统以及电脑上所有资料抹除,操作前务必谨慎复查是否有重要资料需要备份。 准备工作 准备两个U盘,一台电脑。提前把镜像下载好。镜像在百度网盘里…...

【Linux专栏】zip 多个文件不带路径
Linux && Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 今天发现 Linux 解压缩的文件中,不光包含需要的文件,还保留了目录层级,不是想要的结果。因此,本文关于…...

邀请函 | 「软件定义汽车 同星定义软件」 TOSUN用户日2025·杭州站
参会邀请函 尊敬的客户及合作伙伴: 新能源汽车智能化浪潮席卷全球,杭州作为中国技术创新高地,正引领行业变革。为助力工程师伙伴应对行业挑战,解决工程难题,同星智能将于2025年5月9日(周五)在…...

start_response详解
start_response 是Python的WSGI(Web Server Gateway Interface)中的一个重要概念,它是一个可调用对象(通常是一个函数),在WSGI应用程序里发挥着关键作用,下面为你详细介绍。 作用 在WSGI规范里…...

记一次 .NET某旅行社酒店管理系统 卡死分析
一:背景 1. 讲故事 年初有位朋友找到我,说他们的管理系统不响应了,让我帮忙看下到底咋回事? 手上也有dump,那就来分析吧。 二:为什么没有响应 1. 线程池队列有积压吗? 朋友的系统是一个web系统&#…...

[预备知识]1. 线性代数基础
线性代数基础 线性代数是深度学习的重要基础,本章节将介绍深度学习中常用的线性代数概念和操作。 1. 标量、向量、矩阵与张量 1.1 标量(Scalar) 标量是单个数值,用 x ∈ R x \in \mathbb{R} x∈R 表示。在深度学习中常用于表…...