【橘子大模型】Tools/Function call
一、简介
截止目前,我们对大模型的使用模式仅仅是简单的你问他答。即便是拥有rag,也只是让大模型的回答更加丰富。但是大模型目前为止并没有对外操作的能力,他只是局限于他自己的知识库。
举个例子,到今天4.21为止,你去问任何一个本地部署的大模型,美国对中国加的关税是多少,相信他们都不能给出答案,因为这个事件太新了。相信所有的模型还没有这部分知识。
那我们除了训练rag检索,能不能让大模型主动去外部的网站去搜一下呢,比如维基百科,百度百科等等有实时新闻的网站。
这个概念的意思是,让大模型具有对外操作的能力,而问答只是他的一个子集。既然能对外操作,我们可以让他去读取数据库,或者修改文件。这样也是一个能力。基于这个能力,我们涉及到的几个相关概念分别是tools和fucntion call。本文我们先来看tools。
二、langchain的文档阅读
有人之前问我,如何在langchain中找到对应的概念,这里我来说一下流程。首先进入langchain的文档页面找到概览。
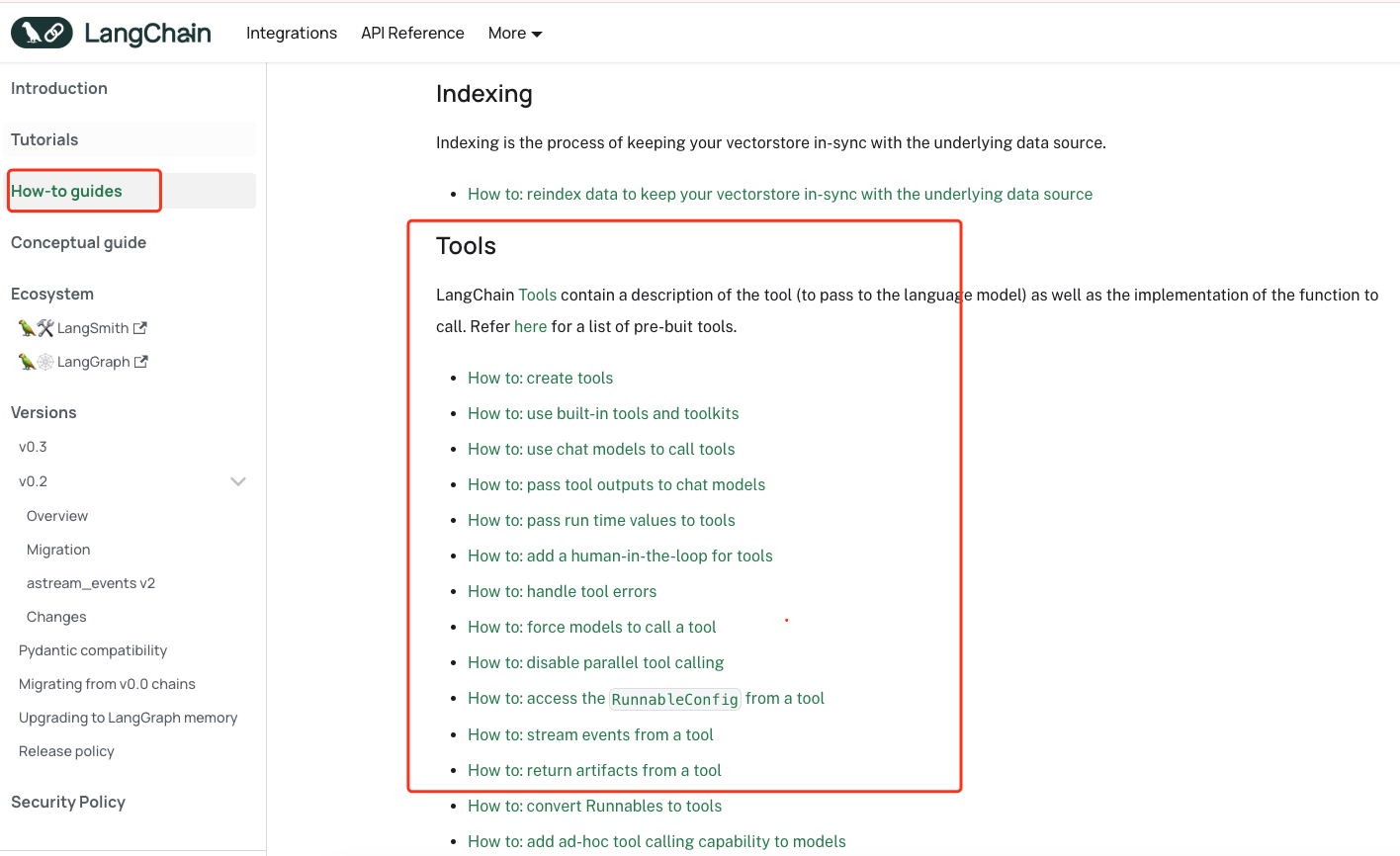
你可以针对性的找到你想要的实现。比如我们这次要找tools。我们可以找到
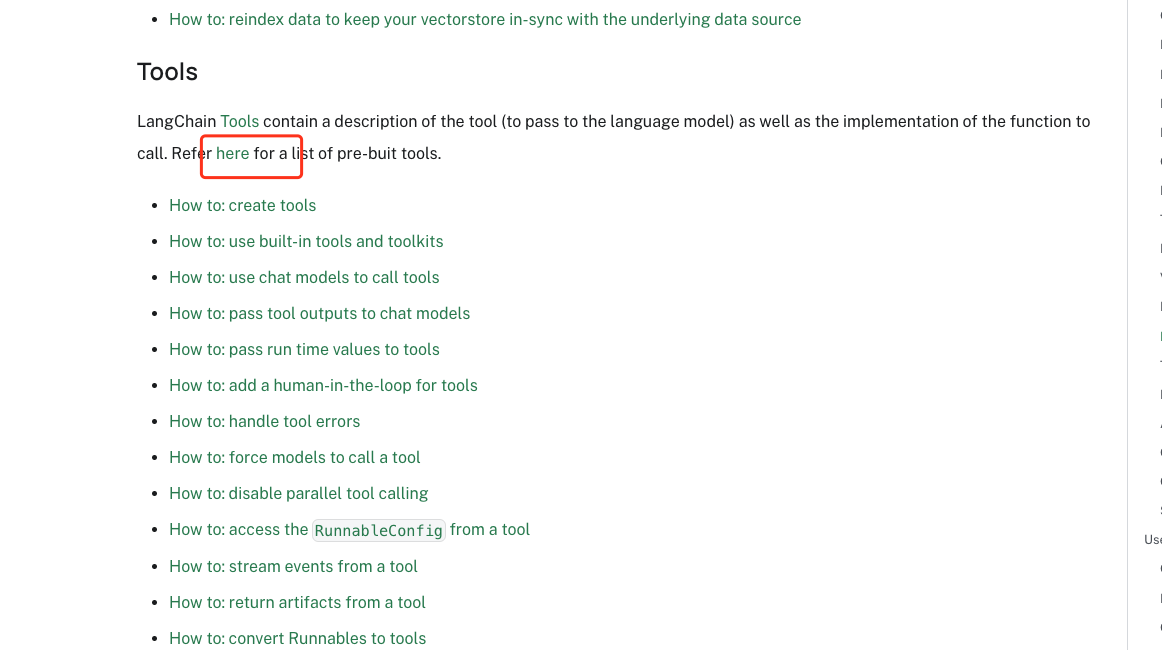
点击进去可以看到,langchain支持多种外部搜索来丰富检索。
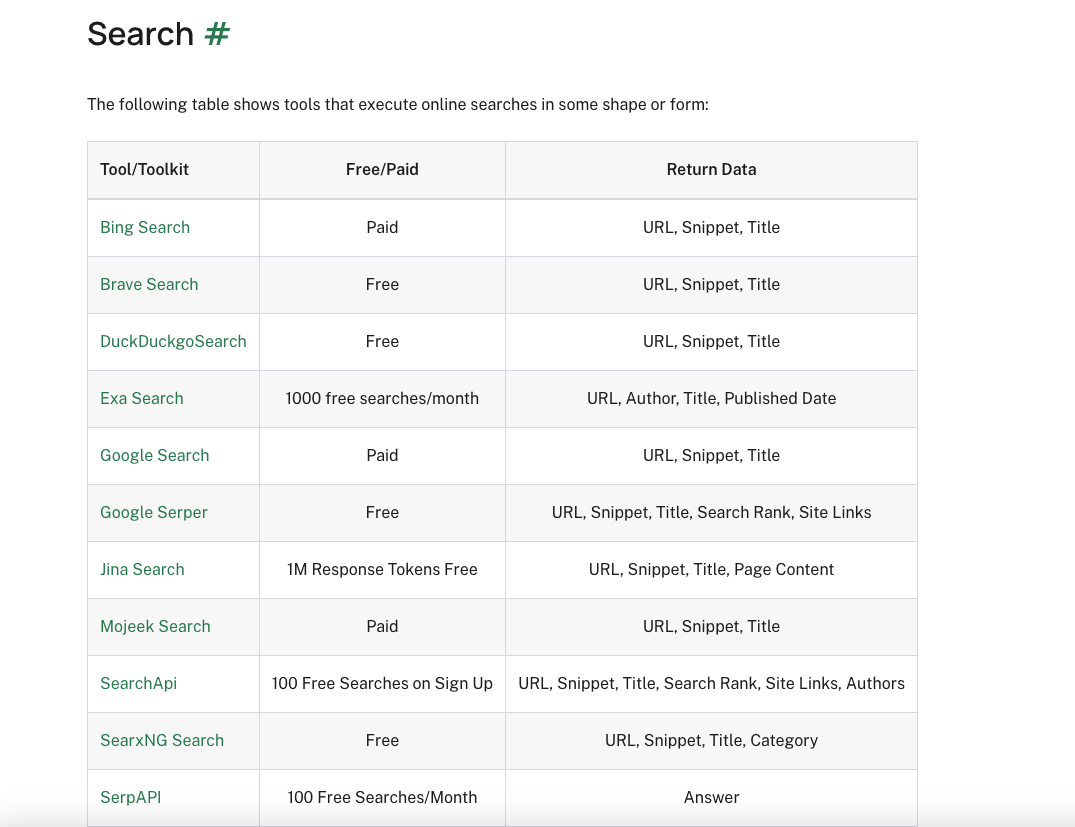
其中当然包括维基百科和谷歌搜索等等你常用的搜索模式。
当然除了搜索他还集成了很多其他的能力。

ok,我们先使用一下搜索吧。
我们可以在All tools栏目找到Wikipedia的栏目,点击进去查看即可。
三、如何使用tools来进行搜索
我们点击进去查看维基百科的内容如下。
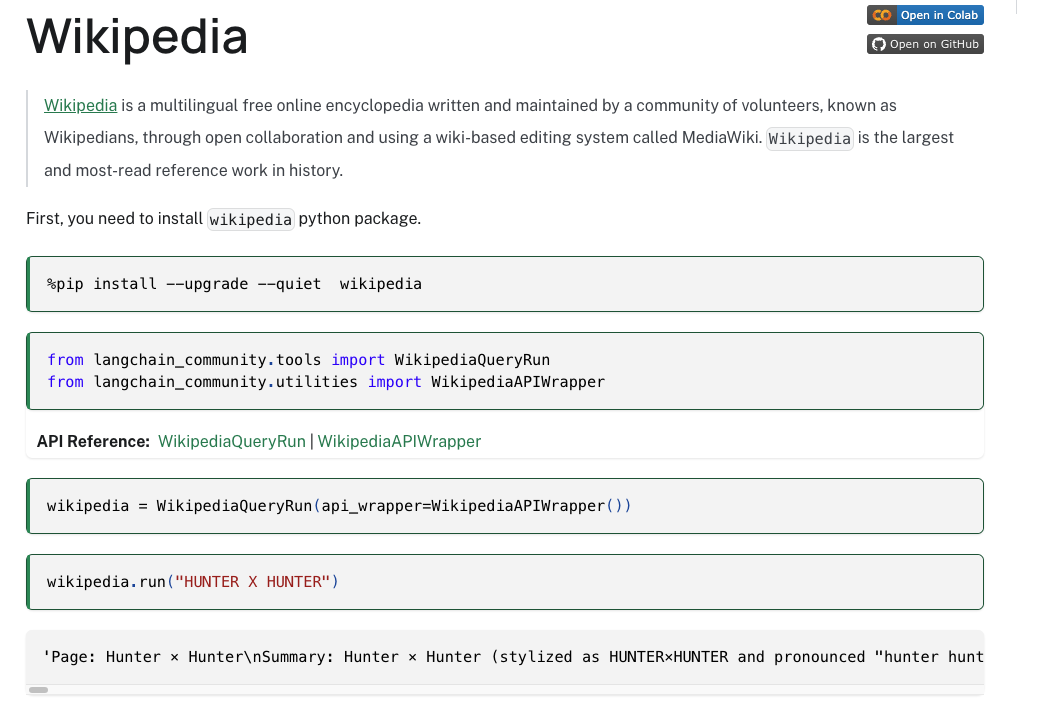
首先第一步就是安装一个组件,wikipedia。
1、安装wikipedia依赖
我们目前位于pycharm的虚拟环境中,打开setting->Project 然后选择项目名称buildchatBot。
进入Python Interpreter这个地方。点击加号,在线搜索这个依赖。安装即可。
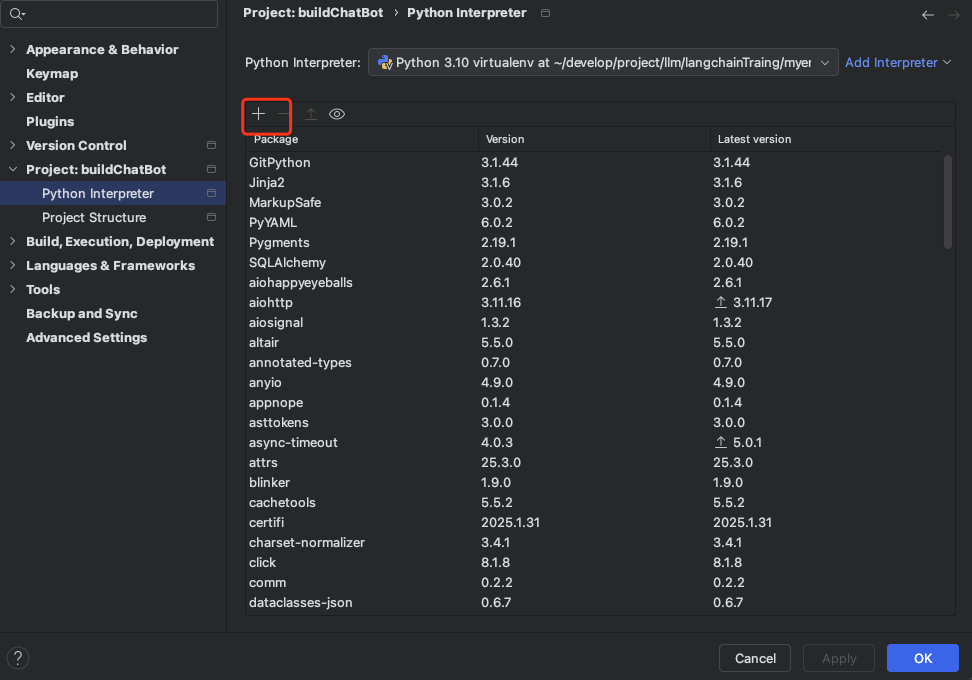
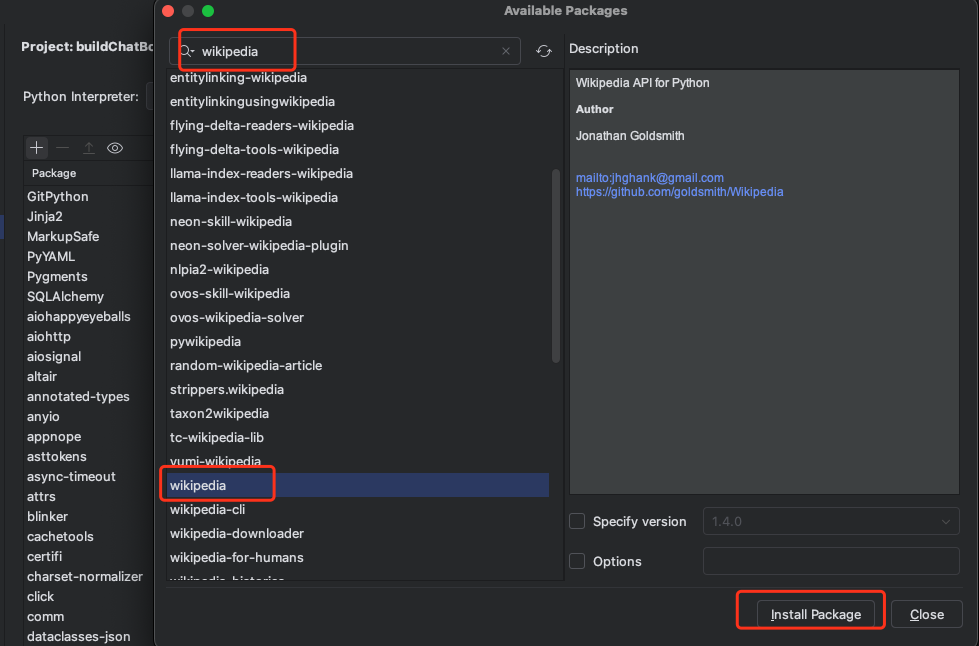
你可以再点进去看看安装列表里面有没有,或者直接使用命令行进入虚拟环境使用命令pip list查看即可。
至于langchain_community之前我们就安装过了,这里就不再安装了,方式和维基百科这个一样。
2、代码编写
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapperwikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())resp = wikipedia.run("Who is kobe")
print(resp)
我们看到输出没毛病。
ok,到这里我们完成了对他内置的一些tools的调用,我们当然可以自己写一些tools来实现功能。
四、自定义tools
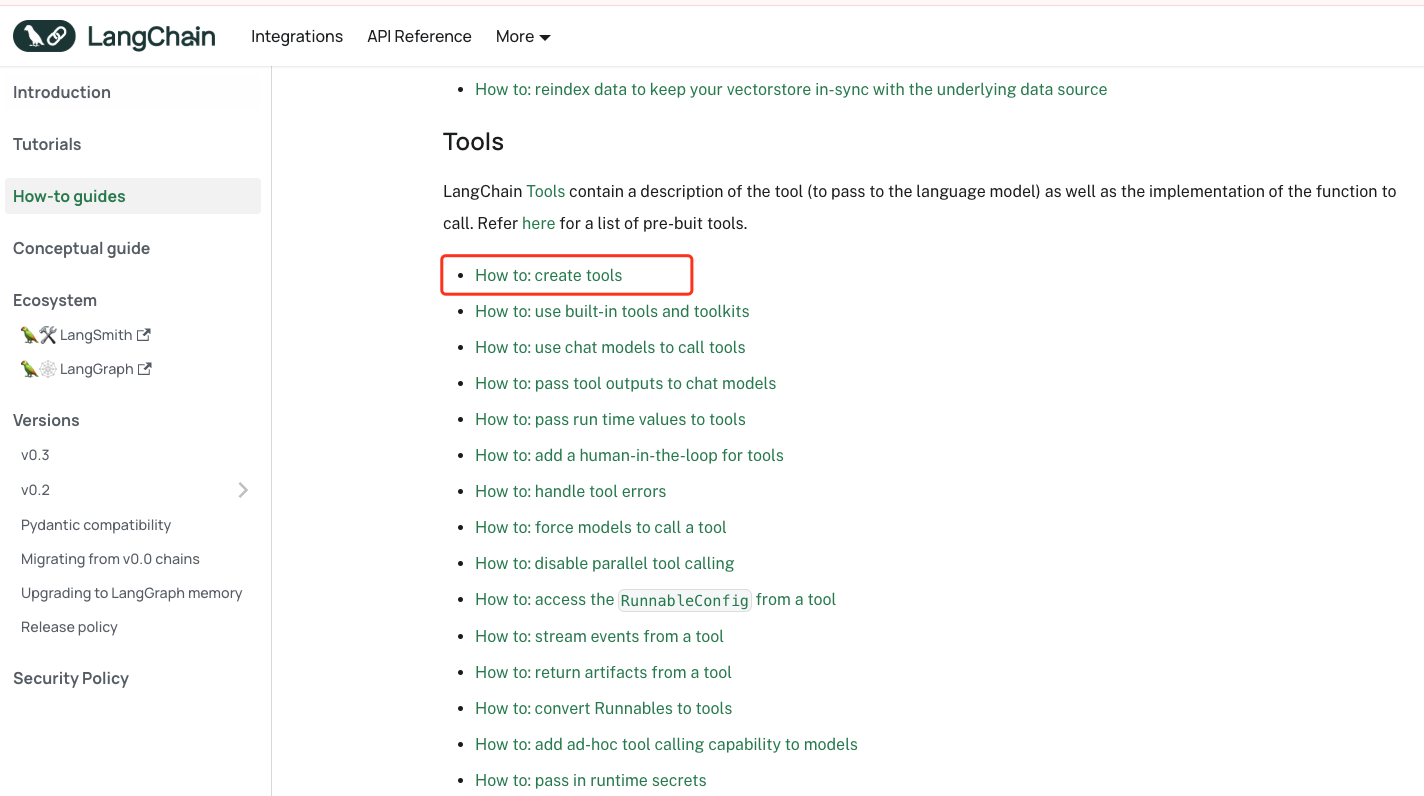
我们可以参考这里来实现。而且我们看到他支持三种方式来创建tools。

具体的内容可以去阅读文档,我们这里先使用第一种来实现一下。
1、使用Functions方式实现tools
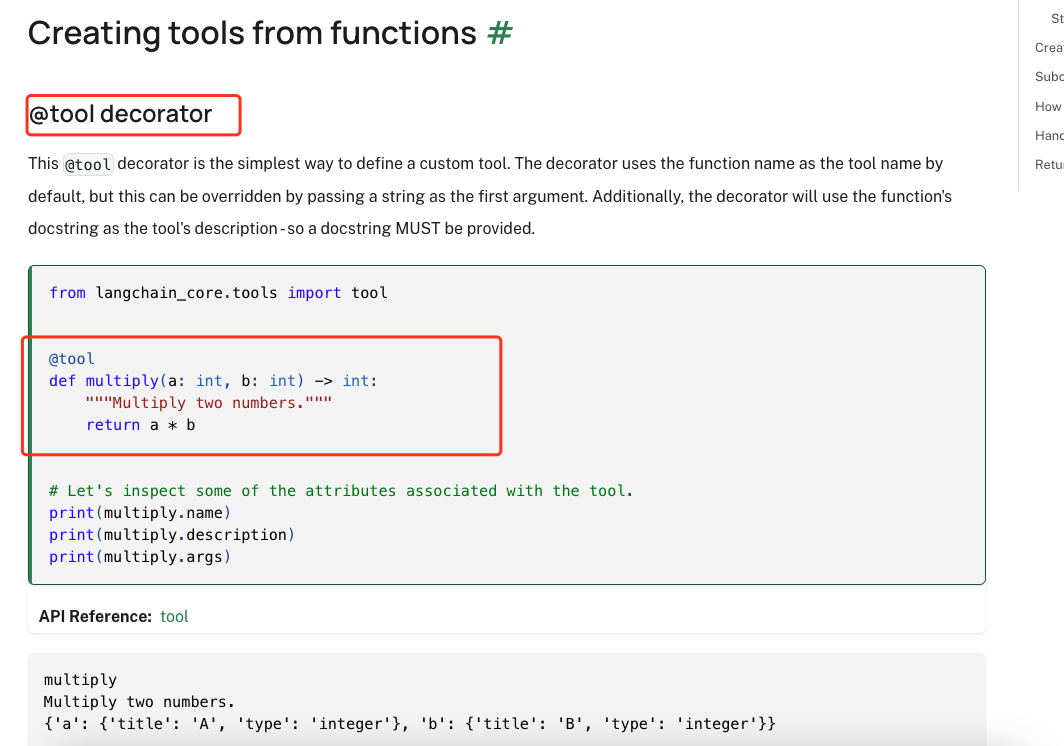
这种方式下,我们导入tool的包,然后使用一个@tool的注解即可把一段函数定义为tools。一旦被定义为tools,他就和我们上面的wikipedia一样了。
# 注意,这里构建出来的wikipedia就是一个tools
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
下面我们来定义一组tools。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import toolwikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())@tool
def add(a: int, b: int) -> int:"""Add two numbers and return a result."""return a - b@tool
def subtract(a: int, b: int) -> int:"""Subtract two numbers and return a result."""return a - b@tool
def multiply(a: int, b: int) -> int:"""Multiply two numbers and return a result."""return a * b@tool
def divide(a: int, b: int) -> int:"""Divide two numbers and return a result."""return int(a / b)# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
print(multiply.invoke({"a": 1, "b": 2}))# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
print(map_of_tools)注意我们自己定义的tool每一个函数内部一定要写上这个函数的功能注释,不然llm不知道它要干啥。
此时我们在map_of_tools中存储着tool的名字和tool本身的映射。
但是到现在为止不管是上面的wikipedia还是我们自己构建的这三个,我们都是直接调用它,没有做到和大模型整合。所以我们接下来要把他们集成到大模型中。而且我们有如此多的tools,大模型如何映射到对应的tool上呢。下面我们就要把tool绑定到大模型上,也就是
2、tool和llm绑定
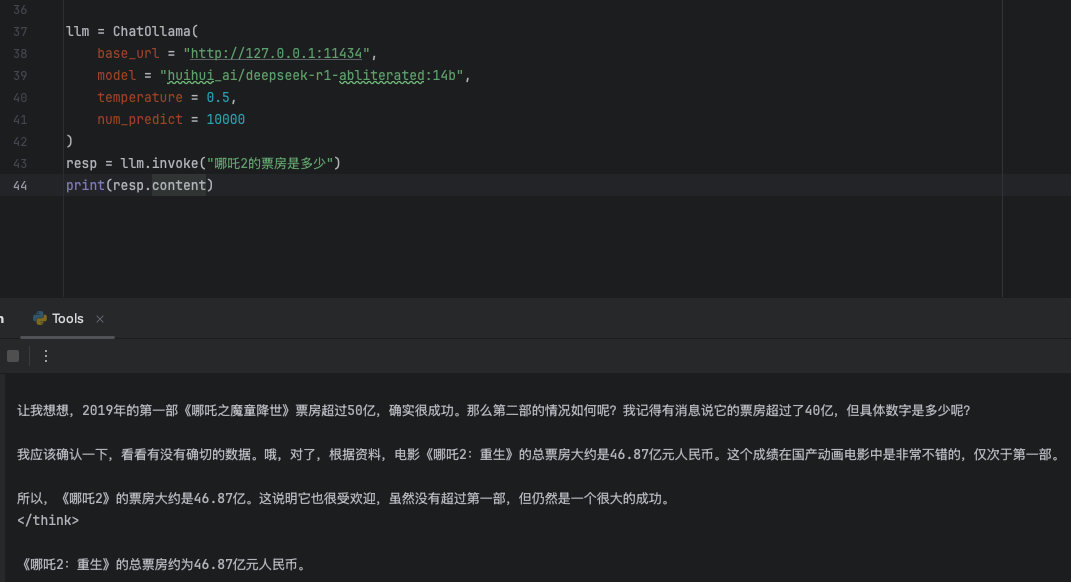
ok,我们在绑定tool之前,先试试没绑定是啥样的。我们直接问deepseek模型,哪吒2的票房是多少,他回答的啥玩意。
然后我们来操作绑定tool。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllamawikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())@tool
def add(a: int, b: int) -> int:"""Add two numbers and return a result."""return a - b@tool
def subtract(a: int, b: int) -> int:"""Subtract two numbers and return a result."""return a - b@tool
def multiply(a: int, b: int) -> int:"""Multiply two numbers and return a result."""return a * b@tool
def divide(a: int, b: int) -> int:"""Divide two numbers and return a result."""return int(a / b)# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
# print(multiply.invoke({"a": 1, "b": 2}))# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
#print(map_of_tools)llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "huihui_ai/deepseek-r1-abliterated:14b",temperature = 0.5,num_predict = 10000
)# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools = tools)
# 执行问题
resp = llm_bind_tools.invoke("哪吒2的票房是多少")
print(resp.content)
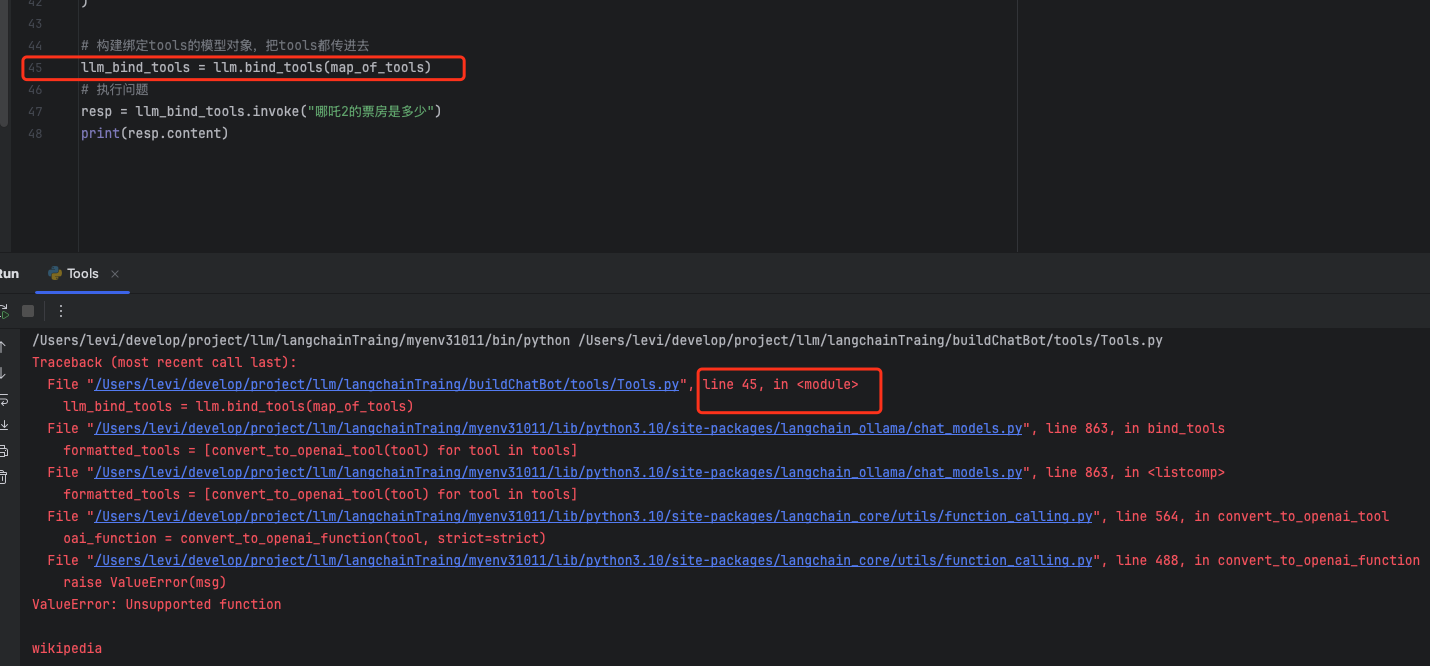
此时我们绑定了tools,然后我们来测试。哦哦,绑定报错。
这是个问题,我们先来看ollama的官方网站。我们看tools栏目。
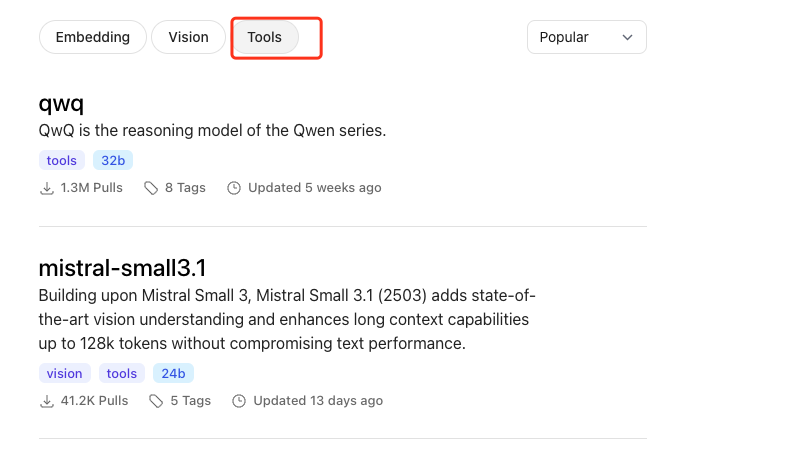
这个列表并没有deepseek,所以他不能绑定tools,不知道他啥时候支持,起码现在不行。我们换一个可以支持的。llama3.2:latest。我们再来测试一下他没绑定之前的回答,我不想改代码了,直接在命令行测试,一样的。
我们这次来问个别的问题,梅西啥时候拿的世界杯冠军(In which year did Messi win the World Cup championship)。

同样回答的是垃圾。显然他还没有获得这个知识,我们来绑定tools,里面有维基百科的检索,我们看看效果。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllamawikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())@tool
def add(a: int, b: int) -> int:"""Add two numbers and return a result."""return a - b@tool
def subtract(a: int, b: int) -> int:"""Subtract two numbers and return a result."""return a - b@tool
def multiply(a: int, b: int) -> int:"""Multiply two numbers and return a result."""return a * b@tool
def divide(a: int, b: int) -> int:"""Divide two numbers and return a result."""return int(a / b)# 此时每一个@tool函数就成为了一个tool,我们就可以像上面的wikipedia一样直接invoke或者run。
# print(multiply.invoke({"a": 1, "b": 2}))# 构建一个map,py的语法糖好用
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
#print(map_of_tools)llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "llama3.2:latest",temperature = 0.5,num_predict = 10000
)# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools=tools)
# 执行问题
resp = llm_bind_tools.invoke("In which year did Messi win the World Cup championship")
print(resp)
返回的结果如下:
content='' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T08:29:13.856523Z', 'done': True, 'done_reason': 'stop', 'total_duration': 442154000, 'load_duration': 30653750, 'prompt_eval_count': 420, 'prompt_eval_duration': 117939792, 'eval_count': 24, 'eval_duration': 293092167, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-6fd2933c-35e6-48e0-a137-86ab28396f3e-0' tool_calls=[{'name': 'wikipedia', 'args': {'query': 'Lionel Messi World Cup championship year'}, 'id': '5df5fbc5-a739-4633-aa78-c8fdfb0919ca', 'type': 'tool_call'}] usage_metadata={'input_tokens': 420, 'output_tokens': 24, 'total_tokens': 444}我们其实可以看到在tool_calls这里,他去维基百科的tool中去查看了Lionel Messi World Cup championship year这个问题。但是显然他没把答案拿回来。ok,我们先不管这个,我们换个问题,问一下1+1等于几,看看他能不能正确映射到我们的自定义tool中。
我们只需要修改问题:
resp = llm_bind_tools.invoke("1+1 = ?")
输出结果为:
content='' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T08:35:18.014085Z', 'done': True, 'done_reason': 'stop', 'total_duration': 745998916, 'load_duration': 31028541, 'prompt_eval_count': 416, 'prompt_eval_duration': 459532959, 'eval_count': 22, 'eval_duration': 255003166, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-b5eb0d8e-6c2d-4034-8cfe-fdf655805d84-0' tool_calls=[{'name': 'add', 'args': {'a': '1', 'b': '1'}, 'id': '97ec7e63-c9bb-4161-9b03-a7d0d3601224', 'type': 'tool_call'}] usage_metadata={'input_tokens': 416, 'output_tokens': 22, 'total_tokens': 438}tool_calls显示他去调用了add,显然是我们自己定义的tool,ok,这个没问题。我们再来看为啥没结果返回的问题。
3、llm执行tool
我们来看一下我们现在所处的结构。
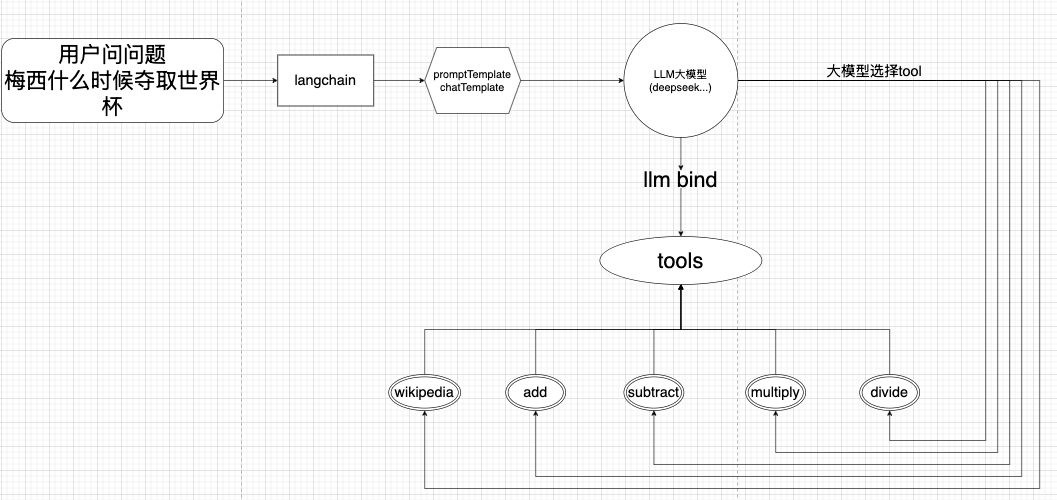
截止现在,我们的大模型绑定tool,以及大模型选择tool都做到了。但是有一点,大模型并没有去执行tool,这也导致我们没有拿到结果。
我们来梳理一下大模型现在要干啥。
1、用户的问题+prompttemplate。
2、大模型自己的数据,可能加一点问题重写等等
3、tool执行的内容
这三个逻辑都是我们需要实现的。或者整合到一起形成一个prompt来交给大模型。
所以我们就基于这个来实现这些功能。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessagellm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "llama3.2:latest",temperature = 0.5,num_predict = 10000
)wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())@tool
def add(a: int, b: int) -> int:"""Add two numbers and return a result."""return a - b@tool
def subtract(a: int, b: int) -> int:"""Subtract two numbers and return a result."""return a - b@tool
def multiply(a: int, b: int) -> int:"""Multiply two numbers and return a result."""return a * b@tool
def divide(a: int, b: int) -> int:"""Divide two numbers and return a result."""return int(a / b)tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}# 初始问题
query = "In which year did Messi win the World Cup championship?"
message = [HumanMessage(query)]# 构建绑定tools的模型对象,把tools都传进去
llm_bind_tools = llm.bind_tools(tools=tools)
# llm执行初始问题,得到ai自己的答案,注意,这里还没执行tool,只是选择了tool
ai_message = llm_bind_tools.invoke(message)# 初始问题也就是人的问题,然后把ai的答案拼起来,此时得到了两个信息
message.append(ai_message)# 遍历ai的执行结果,取出他选择的tool
for tool_call in ai_message.tool_calls:# 统一小写tool_name = tool_call['name'].lower()# 从map映射取出对应的toolexecute_tool = map_of_tools[tool_name]# 执行tool,并且把tool_call传入,其实这个tool_call是个map结构,正是参数print(tool_call)tool_invoke = execute_tool.invoke(tool_call)message.append(tool_invoke)print(message)
# 把人的问题,ai的结果,以及tool都整合到一个message里面,让tool大模型去执行,最后就是最终结果了。
final_output = llm_bind_tools.invoke(message)
print(final_output)
输出如下:
content='Lionel Messi has not yet won a World Cup championship with Argentina. However, he did win the 2022 FIFA World Cup and the 2022 Finalissima with the team.' additional_kwargs={} response_metadata={'model': 'llama3.2:latest', 'created_at': '2025-04-21T10:29:05.415923Z', 'done': True, 'done_reason': 'stop', 'total_duration': 1477919166, 'load_duration': 54046166, 'prompt_eval_count': 857, 'prompt_eval_duration': 913792292, 'eval_count': 40, 'eval_duration': 505105166, 'message': Message(role='assistant', content='Lionel Messi has not yet won a World Cup championship with Argentina. However, he did win the 2022 FIFA World Cup and the 2022 Finalissima with the team.', images=None, tool_calls=None)} id='run-543c9699-2c87-463e-bc1f-2057b46a2f75-0' usage_metadata={'input_tokens': 857, 'output_tokens': 40, 'total_tokens': 897}有一说一,很傻逼,梅西没和阿根廷获得过世界杯冠军,但是他们获得了2022年的fifa世界杯冠军。真的麻了,可能还是模型太小了。
4、文档手册解析
这里很容易有个疑问,就是tool_invoke = execute_tool.invoke(tool_call)这一句为啥传入了tool_call。
可以参考文档
于是问题来了,在langchain的tools文档是这样的。

创建工具,也就是我们构建内置的或者自己的。
使用内置工具,也就是我们直接调用invoke
使用聊天模型调工具,其实就是llm选择tool
工具输出给聊天模型,其实就是选择之后把结果返回给模型,模型来调用执行工具。
后面的可以进一步学习。
五、总结
我们到此就让大模型联网检索了,其实还能进一步调用tool来完成更多的能力。至于很类似的function call功能,我理解就是大模型对外调用的能力,其实就是利用模型的tool功能去实现的一种操作。
相关文章:

【橘子大模型】Tools/Function call
一、简介 截止目前,我们对大模型的使用模式仅仅是简单的你问他答。即便是拥有rag,也只是让大模型的回答更加丰富。但是大模型目前为止并没有对外操作的能力,他只是局限于他自己的知识库。 举个例子,到今天4.21为止,你…...

解决Mac 安装 PyICU 依赖失败
失败日志: 解决办法 1、使用 homebrew 安装相关依赖 brew install icu4c 安装完成后,设置环境变量 echo export PATH"/opt/homebrew/opt/icu4c77/bin:$PATH" >> ~/.zshrcecho export PATH"/opt/homebrew/opt/icu4c77/sbin:$PATH…...

Kafka 生产者的幂等性与事务特性详解
在分布式消息系统中,消息的可靠性传输是一个核心问题。Kafka 通过幂等性(Idempotence)和事务(Transaction)两个重要特性来保证消息传输的可靠性。幂等性确保在生产者重试发送消息的情况下,不会在 Broker 端…...

ubuntu--汉字、中文输入
两种输入框架的安装 ibus 链接 (这种方式安装的中文输入法不是很智能,不好用)。 Fcitx 链接这种输入法要好用些。 简体中文检查 fcitx下载和配置 注意:第一次打开fcitx-config-qt或者fcitx configuration可能没有“简体中文”,需要把勾…...

LabVIEW 开发中数据滤波方式的选择
在 LabVIEW 数据处理开发中,滤波是去除噪声、提取有效信号的关键环节。不同的信号特性和应用场景需要匹配特定的滤波方法。本文结合典型工程案例,详细解析常用滤波方式的技术特点、适用场景及选型策略,为开发者提供系统性参考。 一、常用…...
 -part8)
【图像轮廓特征查找】图像处理(OpenCV) -part8
17 图像轮廓特征查找 图像轮廓特征查找其实就是他的外接轮廓。 应用: 图像分割 形状分析 物体检测与识别 根据轮廓点进行,所以要先找到轮廓。 先灰度化、二值化。目标物体白色,非目标物体黑色,选择合适的儿值化方式。 有了轮…...

丝杆升降机蜗轮蜗杆加工工艺深度解析:从选材到制造的全流程技术要点
在机械传动领域,丝杆升降机凭借其高精度、大负载等优势,广泛应用于自动化设备、精密仪器等众多场景。而蜗轮蜗杆作为丝杆升降机的核心传动部件,其加工工艺的优劣直接决定了设备的传动效率、使用寿命及稳定性。本文将深入剖析丝杆升降机蜗轮蜗…...
)
git远程分支重命名(纯代码操作)
目录 步骤 1:重命名本地分支 步骤 2:推送新分支到远程 简单讲讲: 2.1.-u 和 --set-upstream 的区别 2.2. 为什么需要设置上游(upstream)? 示例对比: 2.3. 如何验证是否设置成功ÿ…...

《AI大模型应知应会100篇》第31篇:大模型重塑教育:从智能助教到学习革命的实践探索
第31篇:大模型重塑教育:从智能助教到学习革命的实践探索 摘要 当北京大学的AI助教在凌晨三点解答学生微积分难题,当Khan Academy的AI导师为每个学生定制专属学习路径,我们正见证教育史上最具颠覆性的技术变革。本文通过真实教育…...

安装Github软件详细流程,win10系统从配置git到安装软件详解,以及github软件整合包制作方法(
win10系统部署安装开源ai必备 一、安装git应用程序(用来下来github软件) 官网下载git的exe可执行文件,Git - Downloads 或者这里下夸克网盘分享 运行git应用程序,一路’Next’到底即可。 配置安装路径 此时如果直接运行git命…...

重构・协同・共生:传统代理渠道数字化融合全链路解决方案
当 90 后经销商开始用直播卖家电,当药品流向数据在区块链上实时流转,传统代理渠道正在经历一场「数字觉醒」。面对流量碎片化、运营低效化的行业痛点,如何让扎根线下数十年的渠道网络,在数字化平台上焕发新生?蚓链提炼…...

智驱未来:AI大模型重构数据治理新范式
第一章 数据治理的进化之路 1.1 传统数据治理的困境 在制造业巨头西门子的案例中,其全球200个工厂每天产生1.2PB工业数据,传统人工清洗需要300名工程师耗时72小时完成,错误率高达15%。数据孤岛问题导致供应链决策延迟平均达48小时。 1.2 A…...

信息收集之hack用的网络空间搜索引擎
目录 1. Shodan 2. Censys 3. ZoomEye 4. BinaryEdge 5. Onyphe 6. LeakIX 7. GreyNoise 8. PulseDive 9. Spyse 10. Intrigue 11. FOFA (Finger Of Find Anything) 12. 🔍 钟馗之眼 (ZoomEye) 总结 对于黑客、网络安全专家和白帽子工程师来说…...

青少年编程与数学 02-018 C++数据结构与算法 01课题、算法
青少年编程与数学 02-018 C数据结构与算法 01课题、算法 一、算法的定义二、算法的设计方法1. 分治法2. 动态规划法3. 贪心算法4. 回溯法5. 迭代法6. 递归法7. 枚举法8. 分支定界法 三、算法的描述方法1. **自然语言描述**2. **流程图描述**3. **伪代码描述**4. **程序设计语言…...

LangChain、LlamaIndex 和 ChatGPT 的详细对比分析及总结表格
以下是 LangChain、LlamaIndex 和 ChatGPT 的详细对比分析及总结表格: 1. 核心功能对比 工具核心功能LangChain框架,用于构建端到端的 LLM 应用程序,支持 prompt 工程、模型调用、数据集成、工具链开发。LlamaIndex文档处理工具,…...

基于单片机的BMS热管理功能设计
标题:基于单片机的BMS热管理功能设计 内容:1.摘要 摘要:在电动汽车和储能系统中,电池管理系统(BMS)的热管理功能至关重要,它直接影响电池的性能、寿命和安全性。本文的目的是设计一种基于单片机的BMS热管理功能。采用…...

数字虹膜:无网时代的视觉密语 | 讨论
引言:当网络成为枷锁 在断网即失联的当下,我们是否过度依赖脆弱的网络线缆?当两台孤立设备急需交换数据,传统方案或受限于物理介质,或暴露于无线信号被劫持的风险。有没有可能绕过所有中间节点,让数据像光线…...
)
Kubernetes相关的名词解释Container(16)
什么是Container? 在 Kubernetes 中,Container(容器) 是一个核心概念,你可以将镜像(Image)类比为程序的“源代码”,而容器是这段“代码”运行时的进程。例如,一个 nginx…...
上架云应用!)
腾讯云×数语科技:Datablau DDM (AI智能版)上架云应用!
在数据爆炸式增长的时代,传统的数据建模方式已难以满足企业对敏捷性、智能化、自动化的需求。数语科技联合腾讯云推出的 Datablau DDM 数据建模平台(AI智能版),基于AI语义建模技术,深度融合腾讯混元大模型能力…...
)
可穿戴设备待机功耗需降至μA级但需保持实时响应(2万字长文深度解析)
可穿戴设备的功耗与响应需求之矛盾 在过去十年中,可穿戴设备以惊人的速度融入我们的日常生活,成为现代科技与个人健康管理的重要交汇点。从智能手表到健身手环,从医疗监测设备到增强现实眼镜,这些设备不仅仅是科技产品的延伸&…...

【身份证扫描件识别表格】如何识别大量身份证扫描件将内容导出保存到Excel表格,一次性处理多张身份证图片导出Excel表格,基于WPF和腾讯云的实现方案
基于WPF和腾讯云的身份证扫描件批量处理方案 适用场景 本方案适用于需要批量处理大量身份证扫描件的场景,例如: 企业人事部门批量录入新员工身份信息银行或金融机构办理批量开户业务教育机构收集学生身份信息政府部门进行人口信息统计酒店、医院等需要实名登记的场所这些场景…...

数字化补贴:企业转型的 “政策东风” 如何借力?
在数字经济浪潮席卷全球的当下,数字化转型已从企业的 “选修课” 变为 “生存必修课”。面对技术迭代加速与市场竞争加剧的双重压力,如何低成本、高效率完成转型?各级政府推出的数字化补贴政策,正成为企业借势突围的关键抓手。 政…...

动态LOD策略细节层级控制:根据视角距离动态简化远距量子态渲染
动态LOD策略在量子计算可视化中的优化实现 1. 细节层级控制:动态简化远距量子态渲染 在量子计算的可视化中,量子态通常表现为高维数据(如布洛赫球面或多量子比特纠缠态)。动态LOD(Level of Detail)策略通过以下方式优化渲染性能: 距离驱动的几何简化: 远距离渲染:当…...

IP精准检测“ipinfo”
目录 核心功能与特点 使用方法 应用场景 数据隐私与限制 扩展工具与服务 核心功能与特点 IP地址查询 支持输入任意IP地址查询详细信息,包括基础IP、主机名、网络归属等,且无需注册即可使用基础功能。 地理位置识别 提供国家、城市、邮政编码、经纬…...
)
【Linux】调试工具gdb的认识和使用指令介绍(图文详解)
目录 1、debug和release的知识 2、gdb的使用和常用指令介绍: (1)、windows下调试的功能: (2)、进入和退出: (3)、调试过程中的相关指令: 3、调试究竟是在…...

C++ STL:从零开始模拟实现 list 容器
文章目录 引言1. 疑难点解析1.1 迭代器类为什么设置三个模版参数? 2. 完整源码3. 完整测试代码 引言 C 标准模板库(STL)中的 list 是一个双向链表容器,它提供了高效的插入和删除操作。本文将带领你一步步实现一个简化版的 list 容器,帮助你深…...

Spark_SQL
Spark-SQL连接Hive 内嵌的 HIVE 外部的 HIVE 运行 Spark beeline(了解) Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。 运行Spark-SQL CLI Spark SQL CLI 可以很方便的在本地运行 Hive 元数…...

20242817李臻《Linux⾼级编程实践》第8周
20242817李臻《Linux⾼级编程实践》第8周 一、AI对学习内容的总结 计算机网络概述 1. 计算机网络概述 计算机网络的定义:通过通信线路将地理位置不同的多台计算机连接起来,实现资源共享和信息传递。网络的组成: 硬件:计算机、…...

《Java工程师面试核心突破》专栏简介
《Java工程师面试核心突破》专栏简介 🔥 大厂Offer收割机 | 源码级技术纵深 | 90%高频考点覆盖 专栏定位 「拒绝八股文,直击技术本质」 本专栏专为Java中高级工程师量身定制,通过6大核心模块、30个硬核专题,系统性拆解大厂面试…...

Spark-SQL与Hive
Spark-SQL与Hive的那些事儿:从连接到数据处理 在大数据处理领域,Spark-SQL和Hive都是非常重要的工具。今天咱们就来聊聊它们之间的关系,以及怎么用Spark-SQL去连接Hive进行数据处理。先说说Hive,它是Hadoop上的SQL引擎࿰…...

Keil5没有stm32的芯片库
下载完重启就行了,我这里就不演示了,stm已经下载,随便选的一个芯片库演示一下...

Kafka 在小流量和大流量场景下的顺序消费问题
一、低流量系统 特点 消息量较少,吞吐量要求低。系统资源(如 CPU、内存、网络)相对充足。对延迟容忍度较高。 保证顺序消费的方案 单分区 单消费者 将消息发送到单个分区(例如固定 Partition 0),由单个…...
)
Spark-SQL(四)
本节课学习了spark连接hive数据,在 spark-shell 中,可以看到连接成功 将依赖放进pom.xml中 运行代码 创建文件夹 spark-warehouse 为了使在 node01:50070 中查看到数据库,需要添加如下代码,就可以看到新创建的数据库 spark-sql_1…...

海外服务器安装Ubuntu 22.04图形界面并配置VNC远程访问指南
在云计算和远程工作日益普及的今天,如何高效地管理和使用海外服务器成为了一个热门话题。本文将详细介绍如何在海外的Ubuntu 22.04服务器上安装图形界面,并配置VNC服务来实现远程访问。无论您是开发者、系统管理员,还是只是想要更便捷地管理您的海外服务器,这篇指南都能为您…...

kafka 分区分散在不同服务器上的原理
目录 原理方面在 1- 5,如果对原理理解,可以直接到图例部分,看结果 1. 分区分配机制 2. 副本分配机制 3. 手动控制分区的分布 4.分区(Partition)如何分布在不同的 Broker 上? 5. 主分区(Le…...

JavaScript 中的单例模式
单例模式在 JavaScript 中是一种确保类只有一个实例,并提供全局访问点的方式。由于 JavaScript 的语言特性(如对象字面量、模块系统等),实现单例有多种方式。 常见实现方式 1. 对象字面量(最简单的单例) …...

19_大模型微调和训练之-基于LLamaFactory+LoRA微调LLama3
基于LLamaFactory微调_LLama3的LoRA微调 1. 基本概念1.1. LoRA微调的基本原理1.2. LoRA与QLoRA1.3. 什么是 GGUF 2.LLaMA-Factory介绍3. 实操3.1 实验环境3.2 基座模型3.3 安装 LLaMA-Factory 框架3.3.1 前置条件 3.4 数据准备3.5 微调和训练模型torch.cuda.OutOfMemoryError: …...

【Maven基础】
Maven:一个项目管理工具 前言 传统项目管理存在的问题: 依赖管理混乱 需要自己去网上搜 jar 包,找对版本很痛苦(还容易找错)某个库依赖另一个库(传递依赖),你得自己挨个找齐不小心…...

衡石 ChatBI 用户手册-使用指南
产品概述 衡石 ChatBI 是一款融合了 AI 技术的智能数据分析工具,旨在为企业业务人员提供直观、高效的数据交互体验。通过自然语言处理技术,用户可以直接与数据进行对话,快速获取所需信息,从而为业务决策提供有力支持。此外&…...

DeepSeek+Cursor+Devbox+Sealos项目实战
黑马程序员DeepSeekCursorDevboxSealos带你零代码搞定实战项目开发部署视频教程,基于AI完成项目的设计、开发、测试、联调、部署全流程 原视频地址视频选的项目非常基础,基本就是过了个web开发流程,但我在实际跟着操作时,ai依然会…...

Unreal 如何实现一个Vehicle汽车沿着一条指定Spline路径自动驾驶
文章目录 前言准备工作驾驶原理驾驶轨迹自动驾驶油门控制科普:什么是PID?转向控制科普:点乘和叉乘最终蓝图最后前言 Unreal Engine 的 Chaos Vehicle System(原PhysX Vehicle)是一套基于物理模拟的车辆驾驶系统,支持高度可定制的车辆行为,适用于赛车、模拟驾驶等游戏类…...

开源脚本分享:用matlab处理ltspice生成的.raw双脉冲数据
Author :PNJIE DATE: 2025/04/21 V0.0 前言 该项目旨在使用Matlab处理LTspice的.raw文件,包括动态计算和绘图,部分脚本基于LTspice2Matlab项目: PeterFeicht/ltspice2matlab: LTspice2Matlab - 将LTspice数据导入MATLAB github地址&#x…...

聊透多线程编程-线程互斥与同步-13. C# Mutex类实现线程互斥
目录 一、什么是临界区? 二、Mutex类简介 三、Mutex的基本用法 解释: 四、Mutex的工作原理 五、使用示例1-保护共享资源 解释: 六、使用示例2-跨进程同步 示例场景 1. 进程A - 主进程 2. 进程B - 第二个进程 输出结果 ProcessA …...

Halcon应用:相机标定之应用
提示:若没有查找的算子,可以评论区留言,会尽快更新 Halcon应用:相机标定之应用 前言一、Halcon应用?二、应用实战1、如何应用标定(快速)2、代码讲解(重要)2.1 、我们还是…...
【计算机视觉】CV实战项目- CMU目标检测与跟踪系统 Object Detection Tracking for Surveillance Video
CMU 目标检测与跟踪系统(Object Detection & Tracking for Surveillance Video) 1. 项目概述2. 技术亮点(1)目标检测模型(2)多目标跟踪(MOT)(3)重识别&am…...
` style import is forbidden.)
报错 | 配置 postcss 出现 报错:A `require()` style import is forbidden.
背景:安装 postcss,配置时,出现报错:A require() style import is forbidden. 翻译:禁止导入require()样式 解决:前头添加 /* eslint-env node */ ,也飘红,…...

[Qt]双击事件导致的问题
有如下代码 #include "mymodel.h" #include <QDebug>myModel::myModel(QObject *parent) : QAbstractTableModel(parent) {status << Qt::Unchecked << Qt::Unchecked << Qt::Unchecked; }int myModel::rowCount(const QModelIndex &pa…...

[SpringBoot]配置文件
通过案例可以不难发现,springboot实际上就是spring的一种辅助工具,帮我们更快地使用spring开发。尤其是配置这块,注解springboot解决了很多繁琐重复的配置操作。 但在实际开发需求,当然不可能只用springboot已经配置好的配置信息。…...

前端框架开发编译阶段与运行时的核心内容详解Tree Shaking核心实现原理详解
前端框架开发编译阶段与运行时的核心内容详解 一、开发编译阶段 开发编译阶段是前端框架将源代码转换为浏览器可执行代码的核心过程,涉及代码转换、优化和资源整合。 模块打包与依赖管理 • 依赖图构建:工具(如Webpack、Vile)通过静态分析生成模块依赖关系图,支持按需加载…...

idea2024.1双击快捷方式打不开
idea2024.1突然双击快捷方式打不开,使用管理员运行也打不开 在安装的idea路径下的bin目录下双击打开idea.bat文件,要是打不开使用txt格式打开,打开后在最后一行加上pause,之后保存。 看看报错信息是不是有一个initializedExcept…...