19_大模型微调和训练之-基于LLamaFactory+LoRA微调LLama3
基于LLamaFactory微调_LLama3的LoRA微调
- 1. 基本概念
- 1.1. LoRA微调的基本原理
- 1.2. LoRA与QLoRA
- 1.3. 什么是 GGUF
- 2.LLaMA-Factory介绍
- 3. 实操
- 3.1 实验环境
- 3.2 基座模型
- 3.3 安装 LLaMA-Factory 框架
- 3.3.1 前置条件
- 3.4 数据准备
- 3.5 微调和训练模型
- torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.94 GiB. GPU 问题解决
- 使用chat检查我们训练模型效果
- 3.6 评估
- 3.7 Lora模型合并
- 量化
- 3.8 llama.cpp
- 3.8.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
- 3.8.2 执行转换
- 3.8.3 创建ModelFile
- 3.8.4 创建自定义模型
- 2.5 运行模型:
1. 基本概念
1.1. LoRA微调的基本原理
• LoRA(Low-Rank Adaptation)是一种用于大模型微调的技术, 通过引入低秩矩阵来减少微调时的参数量。在预训练的模型中, LoRA通过添加两个小矩阵B和A来近似原始的大矩阵ΔW,从而减 少需要更新的参数数量。具体来说,LoRA通过将全参微调的增量 参数矩阵ΔW表示为两个参数量更小的矩阵B和A的低秩近似来实 现:
[ W_0 + \Delta W = W_0 + BA ]
• 其中,B和A的秩远小于原始矩阵的秩,从而大大减少了需要更新 的参数数量。
思想:
• 预训练模型中存在一个极小的内在维度,这个内在维度是发挥核 心作用的地方。在继续训练的过程中,权重的更新依然也有如此 特点,即也存在一个内在维度(内在秩)
• 权重更新:W=W+^W
• 因此,可以通过矩阵分解的方式,将原本要更新的大的矩阵变为 两个小的矩阵
• 权重更新:W=W+^W=W+BA
• 具体做法,即在矩阵计算中增加一个旁系分支,旁系分支由两个 低秩矩阵A和B组成
原理
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得 到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并, 合并后的模型与原始模型无异
借图一用
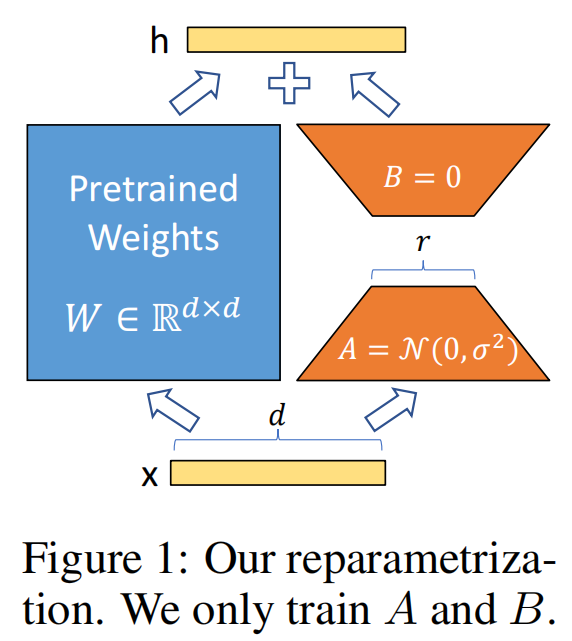
我们训练的 就是有边的AB ,训练完成后把权重(参数)再和 base model 进行整合
1.2. LoRA与QLoRA
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近 似方法降低适应数十亿参数模型(如 GPT-3)到特定任务或领域。
QLoRA:QLoRA 是一种高效的大型语言模型微调方法,它显著降 低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个 固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配 器来实现这一目标。
个人理解 LoRA 是微调的一种调优算法, QLoRA 是大模型进行量化的时候一种算法
大模型量化又是什么概念? 随着模型参数越来越大,占用的资源太大了, 量化就是牺牲精度换性能的做法, 如果不考虑资源成本的话,我考虑不会进行量化,比较大模型看重的是精度
1.3. 什么是 GGUF
GGUF 格式的全名为(GPT-Generated Unified Format),提到 GGUF 就不得不提到它的前身 GGML(GPT-Generated Model Language)。GGML 是专门为了机器学习设计的张量库,最早可 以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并 且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发 中,遇到了灵活性不足、相容性及难以维护的问题。
为什么要转换 GGUF 格式?
在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
- 可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
- 对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGJT 开 始导入,可参考 GitHub)
- 易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
- 模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
- 有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
2.LLaMA-Factory介绍
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、DeepSeek、Yi、Gemma、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、APOLLO、Adam-mini、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
- 广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
- 极速推理:基于 vLLM 或 SGLang 的 OpenAI 风格 API、浏览器界面和命令行接口。
3. 实操
3.1 实验环境
-
机器
RTX 4090(24GB) * 1
16 vCPU Intel® Xeon® Platinum 8352V CPU @ 2.10GHz -
软件环境
llamafactory version: 0.9.1.dev0
Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python version: 3.10.8
PyTorch version: 2.3.0+cu121
Transformers version: 4.46.1
Datasets version: 3.1.0
Accelerate version: 1.0.1
PEFT version: 0.12.0
TRL version: 0.9.6
vLLM version: 0.4.3
auto-gptq: 0.7.1
建议先安装auto-gptq,再安装vLLM
这环境安装是非常的难搞, 版本各种冲突和不适配
直接安装的时候 PyTorch version 还是默认的cpu版本,gpu不起作用需要自己替换版本
总结一句话:版本冲突需要自己单独卸载再重新安装对应的版本
建议先安装auto-gptq,再安装vLLM 当时安装vLLM引擎的时候 安装失败,但是后来的镜像又可以直接安装了
3.2 基座模型
基于中文数据训练过的 LLaMA3 8B 模型:
shenzhi-wang/Llama3-8B-Chinese-Chat
(可选)配置 hf 国内镜像站:
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --
local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1
3.3 安装 LLaMA-Factory 框架
3.3.1 前置条件
安装前一定注意版本问题,这个案子经常出现一些问题
CUDA 安装
CUDA 是由 NVIDIA 创建的一个并行计算平台和编程模型,它让开发者可以使用 NVIDIA 的 GPU 进行高性能的并行计算。
查看是否支持CUDA
uname -m && cat /etc/*release
显示类似下面的字样
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
获取去英伟达官网上查看是否支持也可以: https://developer.nvidia.com/cuda-gpus
检查是否安装gcc
gcc --version
安装CUDA版本 12.2如果你安装的其他的 建议删除
删除
sudo /usr/local/cuda-12.1/bin/cuda-uninstaller
或者
sudo rm -r /usr/local/cuda-12.1/
sudo apt clean && sudo apt autoclean
安装
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sudo sh cuda_12.2.0_535.54.03_linux.run
版本检查
nvcc -V
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
校验是否安装成功
llamafactory-cli version
3.4 数据准备
把数据都放 data 文件夹下
修改 dataset_info.json 增加自己的数据集
存在几分数据增加对于的配置即可
"fintech": {"file_name": "fintech.json","columns": {"prompt": "instruction","query": "input","response": "output","history": "history"}},
训练数据:
fintech.json
identity.json
将训练数据放在 LLaMA-Factory/data/fintech.json
3.5 微调和训练模型
WEB UI
cd LLaMA-Factory
llamafactory-cli webui

可以直接点击这个url,如果是用audol 可以直接本地访问,vscode可以内网穿透
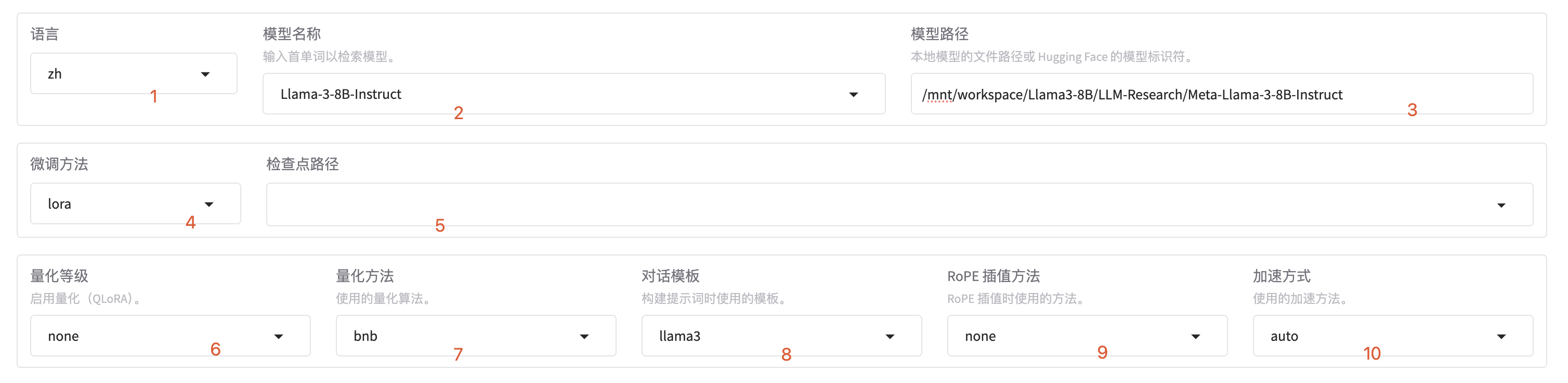
- 语言选择
- 模型名称
- 模型路径,就是我们自己提前下载的模型路径
- 微调微调方式,我们这个地方是选择的lora,除了lora还有 freeze, full
- 检查点: 训练过的参数权重,一般是训练一半中断继续训练使用
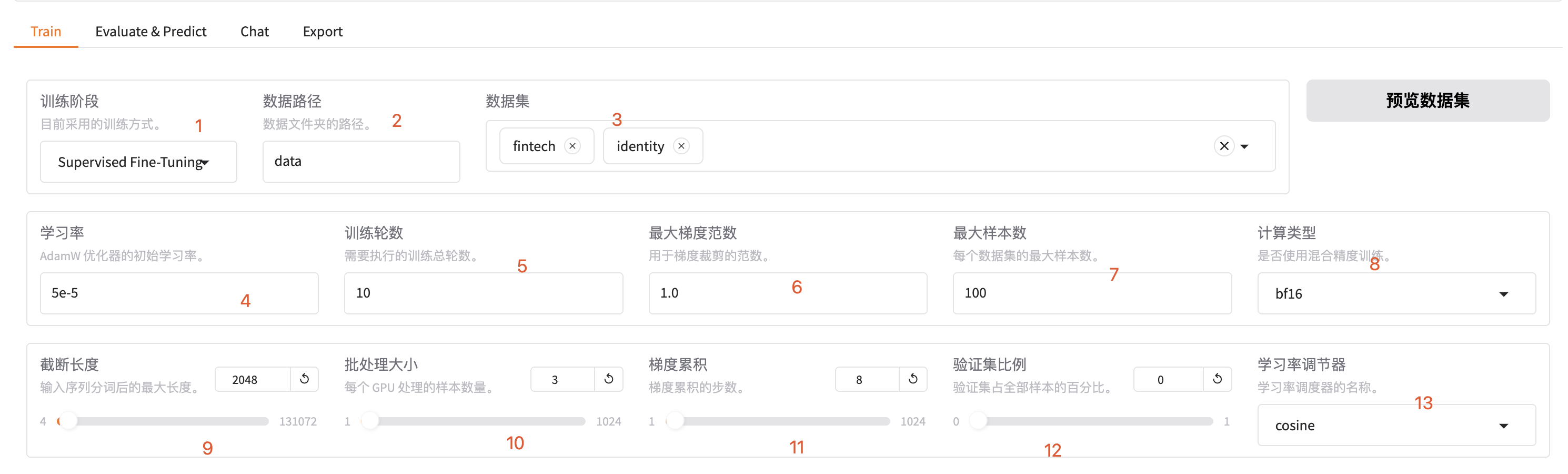
- 训练阶段,可选: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO
- 默认数据存储文件夹
- 选择我们的训练数据
- 根据自己的文档内容填写
- 是否用混合精度
- 0.02 数据集的多大比例作为验证集
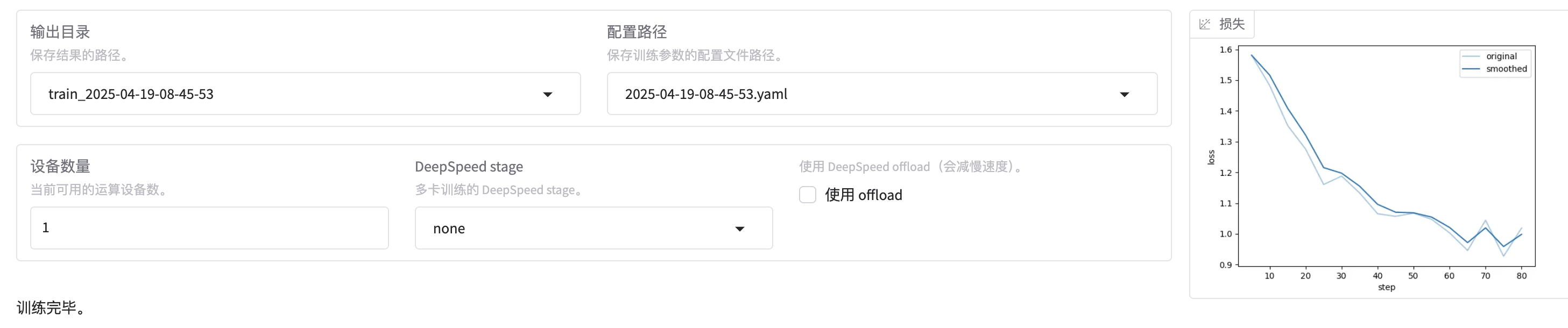
可以从训练图片看到loss在下降
训练参数已保存至:config/2025-04-19-08-45-53.yaml
命令训练:
llamafactory-cli train config/2025-04-19-08-45-53.yaml
cust/train_llama3_lora_sft.yaml 的内容如下: 根据自己的实际情况进行修改
llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /mnt/workspace/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct \--preprocessing_num_workers 16 \--finetuning_type lora \--template llama3 \--flash_attn auto \--dataset_dir data \--dataset fintech,identity \--cutoff_len 2048 \--learning_rate 5e-05 \--num_train_epochs 10.0 \--max_samples 100000 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 0 \--packing False \--report_to none \--output_dir saves/Llama-3-8B-Instruct/lora/train_2025-04-19-08-45-53 \--bf16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0 \--lora_target all
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.94 GiB. GPU 问题解决
降低 GPU 内存占用的方法
- 减小批量大小(Batch Size)
- 批量大小是影响 GPU 内存占用的重要因素之一。减小批量大小可以显著降低每次迭代所需的内存。例如,如果你当前的批量大小是 64,可以尝试将其减小到 32 或更小。在代码中,找到设置批量大小的参数,如
batch_size,将其值修改为较小的数字。 - 示例代码片段(假设使用 PyTorch 的 DataLoader):
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
- 批量大小是影响 GPU 内存占用的重要因素之一。减小批量大小可以显著降低每次迭代所需的内存。例如,如果你当前的批量大小是 64,可以尝试将其减小到 32 或更小。在代码中,找到设置批量大小的参数,如
- 使用梯度累积(Gradient Accumulation)
- 当你减小批量大小后,可能会对模型的训练效果产生一定影响。梯度累积可以在减小批量大小的同时,保持与较大批量大小相似的训练效果。它通过在多个小批量上累积梯度,然后一次性更新模型参数来实现。
- 示例代码片段:
gradient_accumulation_steps = 4 # 梯度累积步数 for batch in train_loader:outputs = model(batch)loss = loss_fn(outputs, batch['labels'])loss = loss / gradient_accumulation_steps # 平均损失loss.backward()if (step + 1) % gradient_accumulation_steps == 0:optimizer.step()optimizer.zero_grad()step += 1
- 优化模型结构
- 如果可能,可以对模型进行简化,例如减少模型层数、隐藏单元数量等。这将直接减少模型的参数数量,从而降低 GPU 内存占用。
- 以一个简单的全连接神经网络为例,如果原始模型有 5 层,每层有 1024 个隐藏单元,可以尝试将层数减少到 3 层,隐藏单元数量减少到 512。
- 示例代码片段(假设使用 PyTorch 定义模型):
class SimplifiedModel(nn.Module):def __init__(self):super(SimplifiedModel, self).__init__()self.fc1 = nn.Linear(input_dim, 512)self.fc2 = nn.Linear(512, 512)self.fc3 = nn.Linear(512, output_dim)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
- 使用混合精度训练(Mixed Precision Training)
- 混合精度训练是一种在训练过程中同时使用单精度(float32)和半精度(float16)浮点数的方法。它可以显著减少 GPU 内存占用,同时还能加快训练速度。
- PyTorch 提供了
torch.cuda.amp模块来支持混合精度训练。使用torch.cuda.amp.autocast上下文管理器可以自动将部分计算转换为半精度。 - 示例代码片段:
scaler = torch.cuda.amp.GradScaler() # 创建梯度缩放器 for batch in train_loader:with torch.cuda.amp.autocast(): # 启用混合精度outputs = model(batch)loss = loss_fn(outputs, batch['labels'])scaler.scale(loss).backward() # 缩放损失并反向传播scaler.step(optimizer) # 更新参数scaler.update() # 更新缩放器
训练日志
***** train metrics *****epoch = 9.9362num_input_tokens_seen = 626288total_flos = 26338054GFtrain_loss = 1.1442train_runtime = 0:13:54.22train_samples_per_second = 2.242train_steps_per_second = 0.132
Figure saved at: saves/Llama-3-8B/lora/train_2025-04-19-15-59-34/training_loss.png
Figure saved at: saves/Llama-3-8B/lora/train_2025-04-19-15-59-34/training_eval_loss.png
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 9.08it/s]
***** eval metrics *****epoch = 9.9362eval_loss = 1.3733eval_runtime = 0:00:00.50eval_samples_per_second = 7.952eval_steps_per_second = 3.976num_input_tokens_seen = 626288
使用chat检查我们训练模型效果
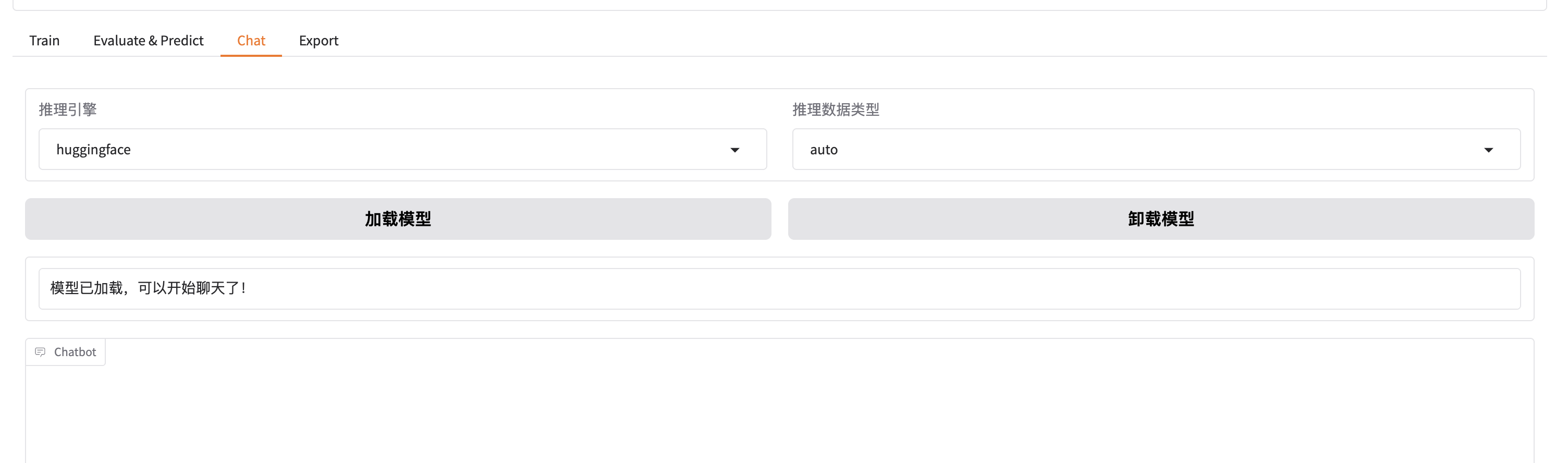
模型修改成我们训练的lora模型进行加载模型,加载完毕就可以直接对话测试我们训练效果
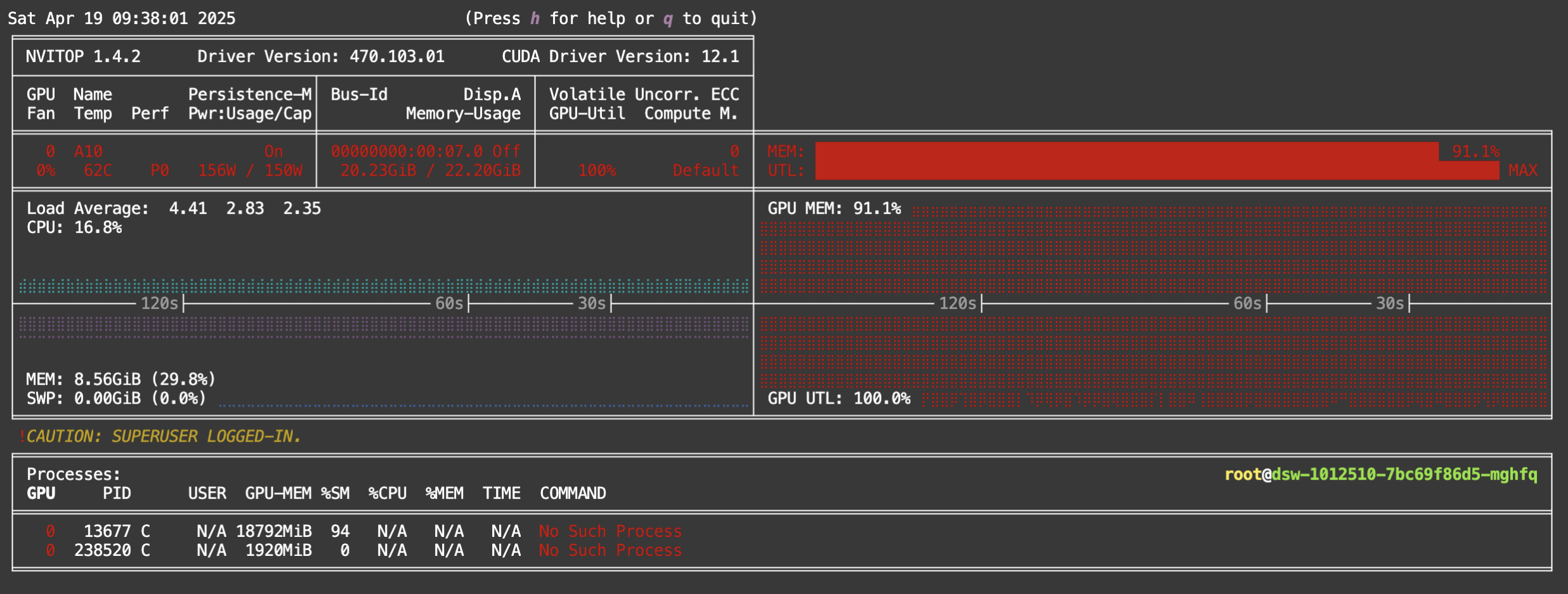
nvitop 检查设备利用率
3.6 评估
LLama Factory模型评估
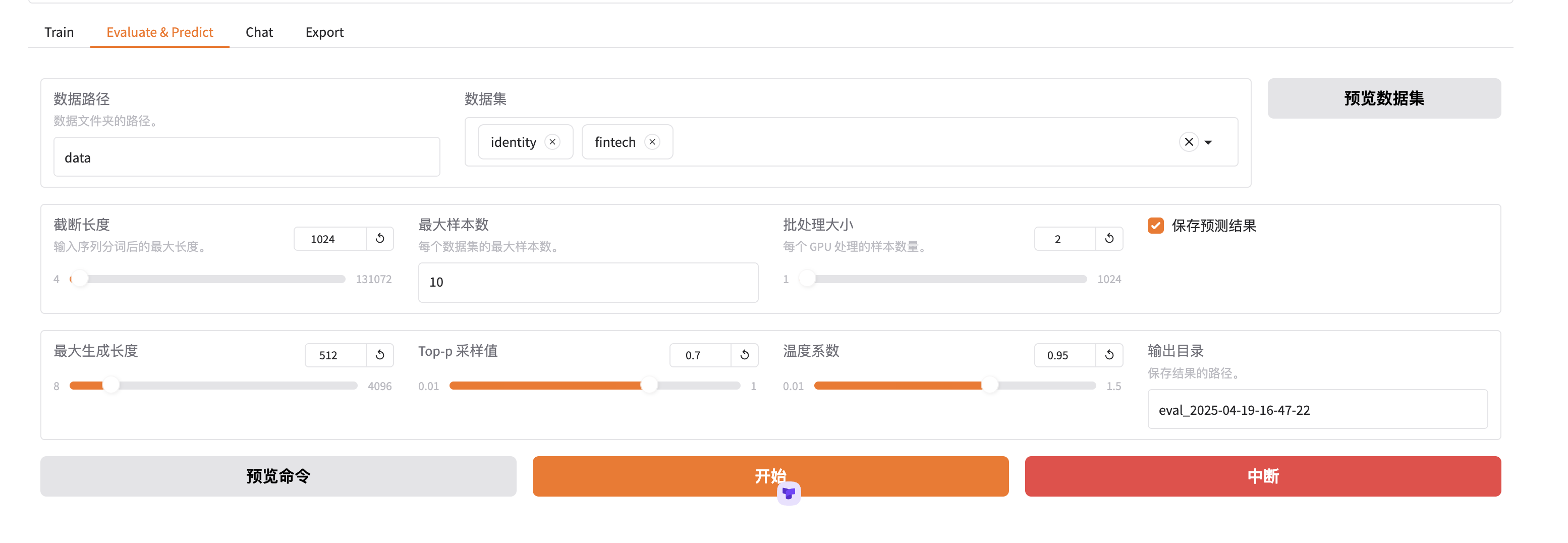
模型评估是我们判断模型训练十分有效的方法。
一般有两种方法:
主观评估: 让相关的领域(如医疗问诊系统)专家,让专家提供一些测试问题,根据模块给出的答案进行判断模型是否有效。
客观评估: 事先准备好评估模型使用的测试数据(该数据不要出现在训练集中),然后让训练好的模型去处理这批测试数据,根据得到的输出和数据集的标签计算得分。根据得分输出评估结果。
{
精度指标"predict_bleu-4": 29.408524999999997, 生成指标 问答和翻译场景,按照4个单词生成的指标"predict_model_preparation_time": 0.0055,"predict_rouge-1": 48.65773,"predict_rouge-2": 28.11527,"predict_rouge-l": 40.571055,性能指标"predict_runtime": 54.332, 总运行时间(秒)"predict_samples_per_second": 0.368, 每秒处理的样本出"predict_steps_per_second": 0.184。没秒处理的步骤数
}
这些指标用于评估模型性能,帮助优化。
这里我用的训练数据进行的评估,实际不应该这么操作,应该用专门的测试集进行评估
客观指标:不应该完全追求更高的分数,如果分数过高,会导致模型创造性更差,简单的理解就是分数越高,和我们样本数据更相近,因此创作力更差
命令
llamafactory-cli train \--stage sft \--model_name_or_path /mnt/workspace/LLaMA-Factory/merge-llama3-8-01 \--preprocessing_num_workers 16 \--finetuning_type lora \--quantization_method bnb \--template default \--flash_attn auto \--dataset_dir data \--eval_dataset identity,fintech \--cutoff_len 1024 \--max_samples 10 \--per_device_eval_batch_size 2 \--predict_with_generate True \--max_new_tokens 512 \--top_p 0.7 \--temperature 0.95 \--output_dir saves/Llama-3-8B/lora/eval_2025-04-19-16-47-22 \--trust_remote_code True \--do_predict True
3.7 Lora模型合并
当我们训练完成我们需要把lora模型和llama3模型进行合并,方便我们后面使用
因为我们训练完成后我们测试的是两个模型,一个base mode 和lora 模型
模型合并只能把适配base mode的lora模型进行合并
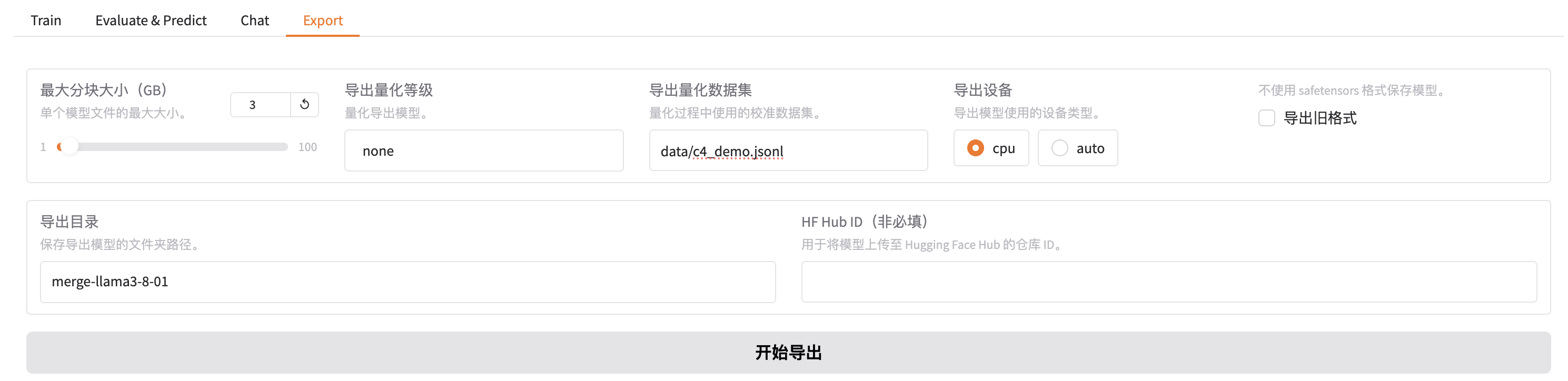
Lora模型合并
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。注意:不要使用量化后的模型或 参数进行合并。
以下是 merge_llama3_lora_sft.yaml 的内容:
#model(基座模型)
model_name_or_path: /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct
#lora(自己训练的lora模型部分)
adapter_name_or_path: /root/autodl-tmp/LLaMA-Factory/saves/Llama-3-8B-Instruct/lora/train_2024-11-22-17-18-42
template: llama3
finetuning_type: lora#export
export_dir: /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-merged
export_size: 4
export_device: cuda
export_legacy_format: false
修改好配置文件 运行下面命令进行合并
llamafactory-cli export cust/merge_llama3_lora_sft.yaml
使用合并后的模型进行预测时,您不再需要加载 LoRA Adapter。
量化
模型量化是一种将模型参数从高精度(32 位浮点数,FP32)转换为低精度(如 16 位浮点数,FP16 或 8 位整数,INT8)的过程,用于加速推理过程和减少模型大小。
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。注意:不要使用量化后的模型或 quantization_bit 参数进行合并。
这是一个牺牲精度换取性能的过程
3.8 llama.cpp
llama cpp 也可以完成大模型的部署,但是我们这里不用他的部署,不介绍了
将hf模型转换为GGUF
3.8.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt
3.8.2 执行转换
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype f16 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf.gguf# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype q8_0 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf_q8_0.gguf
这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。q4_0:这是最初的量化方案,使用4位精度。q4_1和q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较慢。q6_k和q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。fp16和f32:不量化,保留原始精度。
安装ollama 不在详细介绍
安装
curl -fsSL https://ollama.com/install.sh | sh
启动 ollama
ollam start
ollama serve
ollam run LLamas 具体的大模型名称
3.8.3 创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下
#GGUF文件路径
FROM /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-gguf8.gguf
3.8.4 创建自定义模型
使用ollama create命令创建自定义模型
ollama create llama-3-8B-Instruct --file ./ModeFile
llama-3-8B-Instruct 这个名字是自己创建的
2.5 运行模型:
ollama run llama-3-8B-Instruct
我们就可以直接进行对话了和原来的一样的,不再赘述。
相关文章:

19_大模型微调和训练之-基于LLamaFactory+LoRA微调LLama3
基于LLamaFactory微调_LLama3的LoRA微调 1. 基本概念1.1. LoRA微调的基本原理1.2. LoRA与QLoRA1.3. 什么是 GGUF 2.LLaMA-Factory介绍3. 实操3.1 实验环境3.2 基座模型3.3 安装 LLaMA-Factory 框架3.3.1 前置条件 3.4 数据准备3.5 微调和训练模型torch.cuda.OutOfMemoryError: …...

【Maven基础】
Maven:一个项目管理工具 前言 传统项目管理存在的问题: 依赖管理混乱 需要自己去网上搜 jar 包,找对版本很痛苦(还容易找错)某个库依赖另一个库(传递依赖),你得自己挨个找齐不小心…...

衡石 ChatBI 用户手册-使用指南
产品概述 衡石 ChatBI 是一款融合了 AI 技术的智能数据分析工具,旨在为企业业务人员提供直观、高效的数据交互体验。通过自然语言处理技术,用户可以直接与数据进行对话,快速获取所需信息,从而为业务决策提供有力支持。此外&…...

DeepSeek+Cursor+Devbox+Sealos项目实战
黑马程序员DeepSeekCursorDevboxSealos带你零代码搞定实战项目开发部署视频教程,基于AI完成项目的设计、开发、测试、联调、部署全流程 原视频地址视频选的项目非常基础,基本就是过了个web开发流程,但我在实际跟着操作时,ai依然会…...

Unreal 如何实现一个Vehicle汽车沿着一条指定Spline路径自动驾驶
文章目录 前言准备工作驾驶原理驾驶轨迹自动驾驶油门控制科普:什么是PID?转向控制科普:点乘和叉乘最终蓝图最后前言 Unreal Engine 的 Chaos Vehicle System(原PhysX Vehicle)是一套基于物理模拟的车辆驾驶系统,支持高度可定制的车辆行为,适用于赛车、模拟驾驶等游戏类…...

开源脚本分享:用matlab处理ltspice生成的.raw双脉冲数据
Author :PNJIE DATE: 2025/04/21 V0.0 前言 该项目旨在使用Matlab处理LTspice的.raw文件,包括动态计算和绘图,部分脚本基于LTspice2Matlab项目: PeterFeicht/ltspice2matlab: LTspice2Matlab - 将LTspice数据导入MATLAB github地址&#x…...

聊透多线程编程-线程互斥与同步-13. C# Mutex类实现线程互斥
目录 一、什么是临界区? 二、Mutex类简介 三、Mutex的基本用法 解释: 四、Mutex的工作原理 五、使用示例1-保护共享资源 解释: 六、使用示例2-跨进程同步 示例场景 1. 进程A - 主进程 2. 进程B - 第二个进程 输出结果 ProcessA …...

Halcon应用:相机标定之应用
提示:若没有查找的算子,可以评论区留言,会尽快更新 Halcon应用:相机标定之应用 前言一、Halcon应用?二、应用实战1、如何应用标定(快速)2、代码讲解(重要)2.1 、我们还是…...
【计算机视觉】CV实战项目- CMU目标检测与跟踪系统 Object Detection Tracking for Surveillance Video
CMU 目标检测与跟踪系统(Object Detection & Tracking for Surveillance Video) 1. 项目概述2. 技术亮点(1)目标检测模型(2)多目标跟踪(MOT)(3)重识别&am…...
` style import is forbidden.)
报错 | 配置 postcss 出现 报错:A `require()` style import is forbidden.
背景:安装 postcss,配置时,出现报错:A require() style import is forbidden. 翻译:禁止导入require()样式 解决:前头添加 /* eslint-env node */ ,也飘红,…...

[Qt]双击事件导致的问题
有如下代码 #include "mymodel.h" #include <QDebug>myModel::myModel(QObject *parent) : QAbstractTableModel(parent) {status << Qt::Unchecked << Qt::Unchecked << Qt::Unchecked; }int myModel::rowCount(const QModelIndex &pa…...

[SpringBoot]配置文件
通过案例可以不难发现,springboot实际上就是spring的一种辅助工具,帮我们更快地使用spring开发。尤其是配置这块,注解springboot解决了很多繁琐重复的配置操作。 但在实际开发需求,当然不可能只用springboot已经配置好的配置信息。…...

前端框架开发编译阶段与运行时的核心内容详解Tree Shaking核心实现原理详解
前端框架开发编译阶段与运行时的核心内容详解 一、开发编译阶段 开发编译阶段是前端框架将源代码转换为浏览器可执行代码的核心过程,涉及代码转换、优化和资源整合。 模块打包与依赖管理 • 依赖图构建:工具(如Webpack、Vile)通过静态分析生成模块依赖关系图,支持按需加载…...

idea2024.1双击快捷方式打不开
idea2024.1突然双击快捷方式打不开,使用管理员运行也打不开 在安装的idea路径下的bin目录下双击打开idea.bat文件,要是打不开使用txt格式打开,打开后在最后一行加上pause,之后保存。 看看报错信息是不是有一个initializedExcept…...
(ArkTs))
鸿蒙NEXT开发LRUCache缓存工具类(单例模式)(ArkTs)
import { util } from kit.ArkTS;/*** LRUCache缓存工具类(单例模式)* author 鸿蒙布道师* since 2025/04/21*/ export class LRUCacheUtil {private static instance: LRUCacheUtil;private lruCache: util.LRUCache<string, any>;/*** 私有构造函…...
解决方案:Keycloak)
开源身份和访问管理(IAM)解决方案:Keycloak
一、Keycloak介绍 1、什么是 Keycloak? Keycloak 是一个开源的身份和访问管理(Identity and Access Management - IAM)解决方案。它旨在为现代应用程序和服务提供安全保障,简化身份验证和授权过程。Keycloak 提供了集中式的用户…...

Latex科研入门教程
Introduction 这篇文章适合有markdown基础的人看,不会的人可以先去学一下markdown. 仅适用于科研入门. 本文使用的latex环境为overleaf Latex概况 文件格式 以.tex为结尾的文件可能有多个.tex文件最终只编译一个文件,相当于一个文件控制其他子文件. Latex 代码分为三种&…...

CSS 中实现 div 居中有以下几种常用方法
在 CSS 中实现 div 居中有以下几种常用方法,具体取决于需要 水平居中、垂直居中 还是 两者兼具。以下是详细解决方案: 目录 一、水平居中(Horizontal Centering) 1. 行内块元素(Inline-Blo…...

win11修改文件后缀名
一、问题描述 win11系统中,直接添加.py后缀后仍然是txt文本文件 二、处理方式: 点击上方三个小点点击“选项”按钮 点击“查看”取消“隐藏已知文件类型的扩展名”选项点击“应用” 此时,“.txt”文件后缀显示出来了。将txt删去,…...

【数据结构和算法】3. 排序算法
本文根据 数据结构和算法入门 视频记录 文章目录 1. 排序算法2. 插入排序 Insertion Sort2.1 概念2.2 具体步骤2.3 Java 实现2.4 复杂度分析 3. 快排 QuickSort3.1 概念3.2 具体步骤3.3 Java实现3.4 复杂度分析 4. 归并排序 MergeSort4.1 概念4.2 递归具体步骤4.3 Java实现4.4…...

k8s之 kube-prometheus监控
Kubernetes 中的 kube-prometheus 是一个基于 Prometheus Operator 的完整监控解决方案,它集成了 Prometheus、Alertmanager、Grafana 以及一系列预定义的监控规则和仪表盘,专为 Kubernetes 集群设计。 一、核心组件介绍 Prometheus Operator …...
区别)
Docker Compose 和 Kubernetes(k8s)区别
前言:Docker Compose 和 Kubernetes(k8s)是容器化技术中两个常用的工具,但它们的定位、功能和适用场景有显著区别。以下是两者的核心对比: 1. 定位与目标 特性 Docker Compose Kubernet…...
)
【SpringBoot】HttpServletRequest获取使用及失效问题(包含@Async异步执行方案)
目录 1. 在 Controller 方法中作为参数注入 2.使用 RequestContextHolder (1)失效问题 (2)解决方案一: (3)解决方案二: 3、使用AutoWrite自动注入HttpServletRequest 跨线程调…...

【Easylive】为什么需要手动转换 feign.Response 到 HttpServletResponse
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 为什么需要手动转换 feign.Response 到 HttpServletResponse? feign.Response 是 Feign 客户端调用远程服务后返回的原始 HTTP 响应对象,而 HttpServletResponse 是…...

C语言交换函数:为什么必须用指针传递参数?
写一个简单交换两个变量值的函数,我们要理解C语言中参数传递的机制. C语言中的函数参数默认是按值传递,也就是说,如果我写一个函数,如 void swap(int a,int b) {int tmp a;a b;b tmp; }然后在函数内部交换a,b的值,这不会影响到函数外部的变量,因为传递的是值的副本. 就像…...

C#+Visual Studio 2022为AutoCAD 2022开发插件并显示在Ribbon选项卡
1.插件功能开发 (1)建立C#类库项目,添加必要引用,都是autocad二次开发相关的,要注意对引用的库修改其“复制文件”属性为false (2)项目调试使用“属性”打开“启用外部程序”,指定为机器上autocad2022的a…...

全景VR是什么?全景VR有什么热门用途?
全景VR的概念与技术特点 全景VR,即虚拟现实全景,是新型的视觉展示技术。通过拍摄和构建三维模拟环境,使浏览者能够通过网络获得三维立体的空间感觉,仿佛身临其境。全景VR技术的核心在于360全景图像的捕捉和展示,它允许…...

美创科技20周年庆典顺利举行
2025年4月19日 美创科技成立20周年 “稳健前行二十载,创新共赢新未来” 美创科技周年庆典在杭州总部顺利举行 美创科技20周年庆典精彩视频回顾 (点击查看美创科技20周年庆典精彩视频回顾) CEO致辞 20周年再出发,开启新增长周期…...

学习笔记二十二—— 并发五大常见陷阱
⚠️ 并发五大常见陷阱 目录 数据竞争 (Data Race)死锁 (Deadlock)竞态条件 & 饿死现象 (Race Condition & Starvation)悬挂指针 (Dangling Pointer)重复释放 (Double Free)开发自查清单 1. 数据竞争 (Data Race) 专业定义 两个及以上线程在缺乏同步的情况下同时访问同…...
:深度剖析数据指标,驱动创业决策)
精益数据分析(10/126):深度剖析数据指标,驱动创业决策
精益数据分析(10/126):深度剖析数据指标,驱动创业决策 在创业的旅程中,数据指标是我们把握方向的关键工具。今天,我想和大家一起深入学习《精益数据分析》中关于数据指标的知识,共同探索如何利…...

冒泡排序详解
void bubbleSort(std::vector& arr) { int n arr.size(); for (int i 0; i < n-1 ; i) { // 需要 n-1 轮 原理是 3个元素 两轮比交即可 10个元素9轮比较即可 bool swapped false; // 用于优化,检测是否发生交换 for (int j 0; j < n - i -1 ; j) { //…...

小刚说C语言刷题——1039 求三个数的最大数
1.题目描述 已知有三个不等的数,将其中的最大数找出来。 输入 输入只有一行,包括3个整数。之间用一个空格分开。 输出 输出只有一行(这意味着末尾有一个回车符号),包括1个整数。 样例 输入 1 5 8 输出 8 2.…...

【日志体系】ELK Stack与云原生日志服务
IaaS日志体系:ELK Stack与云原生日志服务 一、技术演进的双重脉络二、架构设计的范式差异三、关键技术突破解析四、前沿发展与行业实践 当某国际电商平台在"黑色星期五"遭遇每秒百万级日志洪峰时,其运维团队通过混合日志架构实现全链路追踪&am…...

spark和hadoop区别联系
区别 设计理念 Hadoop:主要解决大规模数据的存储和处理问题,其核心是 Hadoop 分布式文件系统(HDFS)和 MapReduce 计算模型。HDFS 用于存储大规模数据,MapReduce 用于处理数据,它将数据处理过程分为 Map 和…...

240422 leetcode exercises
240422 leetcode exercises jarringslee 文章目录 240422 leetcode exercises[237. 删除链表中的节点](https://leetcode.cn/problems/delete-node-in-a-linked-list/)🔁节点覆盖法 [392. 判断子序列](https://leetcode.cn/problems/is-subsequence/)🔁…...

【上位机——MFC】菜单类与工具栏
菜单类 CMenu,封装了关于菜单的各种操作成员函数,另外还封装了一个非常重要的成员变量m_hMenu(菜单句柄) 菜单使用 添加菜单资源加载菜单 工具栏相关类 CToolBarCtrl-》父类是CWnd,封装了关于工具栏控件的各种操作。 CToolBar-》父类是CC…...

Spark-SQL连接Hive总结及实验
一、核心模式与配置要点 1. 内嵌Hive 无需额外配置,直接使用,但生产环境中几乎不使用。 2. 外部Hive(spark-shell连接) 配置文件:将hive-site.xml(修改数据库连接为node01)、core-site.xml、…...

20.3 使用技巧9
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 20.3.13 DataGridView使用日期选择控件 有时为了输入方便或者固定日期格式,可以考虑点击DataGridView中某个单元格时出现…...
)
逻辑回归(Logistic Regression)
逻辑回归(Logistic Regression) 原理 通过 Sigmoid函数( σ ( z ) 1 1 e − z σ(z) \frac{1}{1e^{-z}} σ(z)1e−z1)将线性回归输出 z w T x b z w^Tx b zwTxb 映射到 [0,1] 区间输出值表示样本属于正类的概率&#…...

weblogic12 部署war包 项目运行报错
问题表现 weblogic12 部署war包项目成功,运行启动成功。但是在使用此项目的时候,点击任何功能都会报错,部分报错如下: at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.…...

重新定义户外防护!基于DeepSeek的智能展开伞棚系统技术深度解析
从“手动操作”到“感知决策”,AI重构城市空间弹性 全球极端天气事件频发,传统伞棚依赖人工展开/收纳,存在响应滞后(暴雨突袭时展开需3-5分钟)、抗风能力弱(8级风损毁率超60%)、空间利用率低等痛…...

Android15沉浸式界面顶部有问题
Android15沉浸式界面顶部有问题 往往开发人员的手机没这么高级,客户或者老板的手机是Android15的。 我明明就设了状态栏透明,我的手机也没问题。但Android15是有问题的。 先看下有问题的界面: 解决方案: 处理1: if (…...

git比较不同分支的不同提交文件差异
背景:只想比较某2个分支的某2次提交的差异,不需要带上父提交。 以commitA为基准,用commitB去比较差异 直接上代码: #!/bin/bashcommitAd347dad9f25fb17db89eadcec7ea0f1bacbf7d29 commitBa6cc0c1a863b5c56d5f48bff396e4cd6966e…...

ADB -> pull指令推送电脑文件到手机上
ADB Push命令 在Android开发中,ADB的push命令用于将文件从电脑传输到Android设备上,是开发和测试过程中的重要工具 基本语法 adb push <本地文件路径> <设备目标路径><本地文件路径>:必需参数,指定要推送的本…...

compat-openssl10和libnsl下载安装
在麒麟系统(如银河麒麟)中,compat-openssl10 和 libnsl 是一些软件(如 MySQL、Oracle 等)的依赖包,用于提供兼容性支持。以下是它们的下载方法: 1. 下载 compat-openssl10 compat-openssl10 是…...

射频功率放大器的核心工作机制与组件设计
以下是关于射频功率放大器工作原理的详细说明: 射频功率放大器(RF PA)是无线通信系统的核心组件,其功能基于能量转换与信号放大技术。它通过精确的能量控制与信号处理,将低功率射频信号转化为高功率输出,支…...

制作一款打飞机游戏12:初稿原型
当前进展 任务回顾:在之前,我们做了大量的规划和原型设计。我们创建了关卡,添加了侧向滚动和BOSS模式背景重复,还制作了一个紧凑的瓦片集。原型完成:我们完成了五个原型,基本实现了飞机飞行、滚动…...

C语言高频面试题——指针数组和数组指针
指针数组和数组指针是 C/C 中容易混淆的两个概念,以下是详细对比: 1. 指针数组(Array of Pointers) 定义:一个数组,其元素是 指针类型。语法:type* arr[元素个数]; 例如:int* ptr_a…...

爱普生TG-5006CG成为提升5G RedCap时钟同步精度的理想选择
在 5G 通信技术持续演进的进程中,5G RedCap(Reduced Capability,即降低能力)是5G技术中针对物联网场景优化的一种轻量化标准。它通过降低终端带宽、简化天线配置和调制方式等手段,大幅降低了终端设备的成本和功耗,同时继承了5G NR…...

用Mac M4构建多架构Docker镜像指南
使用Mac M4构建多架构Docker镜像指南 解决问题:WARNING: The requested image‘s platform (linux/amd64) does not match the detected host platform 📌 重点:为什么需要双栈架构镜像? 双栈架构镜像(同时支持ARM64和…...