DQN在Gym的MountainCar环境的实现
DQN on MountainCar
引言
在本次实验里,我构建了DQN和Dueling DQN,并在Gymnasium库的MountainCar环境中对它们展开测试。我通过调整训练任务的超参数,同时设计不同的奖励函数及其对应参数,致力于获取更优的训练效果。最后,将训练结果进行可视化处理并加以比较。
DQN实现流程
实现方法
- 实现了DQN类。
- 实现了经验回放缓冲区(Buffer)类。
- 编写了训练流程。
- 将所有超参数集中配置在一处。
- 设计了程序运行参数,具体如下:
--train:训练模式。--test:测试模式。--resume:断点续训模式。--checkpoint:指定用于断点续训或测试模式加载的模型。--task_name:确定任务名称,该名称与保存日志的路径相关。--visualize_train:开启Gym环境的可视化功能。--dueling:使用Dueling DQN网络。--stop_threshold:早停阈值。
遇到的难题
难题一
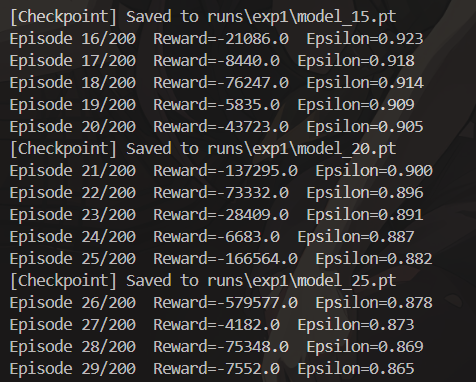
在进行DQN训练时,进程常常在第20多轮(episode)时卡住。起初,我考虑可能是超参数设计的问题,但后来怀疑并非是训练超参数设置不当所致。我了解到Gym环境设定了停止条件,要么是完成任务,要么是达到最大步数。鉴于进程一直卡在第29轮不动,按常理应该早就达到了200步的上限,触发停止条件。然而,我在本地保存的日志文件,其TensorBoard日志文件大小却持续变化,似乎训练仍在进行。由此推测,可能是DQN算法中的经验回放缓冲区部分存在问题,导致缓冲区占用内存过大。
经过更为细致的分析,我发现编写循环终止条件时,仅设置了到达终点这一条件,而未考虑步数达到上限的情况。这就使得每次奖励值都为负几万。因此,应判定每个回合在步数达到上限时也停止。
修改终止条件后,训练能够以正常速度推进。
难题二
由于Gym中封装的MountainCar环境每走一步奖励值为 -1,小车很难学会先向左再向右冲刺的策略。
我先后尝试了多种奖励设计方法:
- 提取状态( s t a t e state state)中的位置信息( p o s i t i o n position position),在该环境中, p o s i t i o n position position 取值范围为 [ − 1.2 , 0.6 ] [-1.2, 0.6] [−1.2,0.6]。若 p o s i t i o n ≥ 0.4 position \geq 0.4 position≥0.4,则 r e w a r d reward reward 加 1,以此奖励小车到达更靠右的位置。
- 为奖励小车尽可能到达更靠右的位置,直接设计一个关于 p o s i t i o n position position 的一次多项式,即 r e w a r d + = α ( p o s i t i o n + 0.5 ) reward += \alpha(position + 0.5) reward+=α(position+0.5),加 0.5 是因为小车初始位置约为 -0.5。
- 奖励小车向右的速度,公式为 r e w a r d + = α ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha(position + 0.5) + \beta velocity reward+=α(position+0.5)+βvelocity。
- 为激励小车更多地探索先向左再向右的路径,设计了一个势能奖励函数,采用二次多项式形式,即 r e w a r d + = α 2 ( p o s i t i o n + 0.5 ) 2 + α 1 ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha_2(position + 0.5)^2 + \alpha_1(position + 0.5) + \beta velocity reward+=α2(position+0.5)2+α1(position+0.5)+βvelocity。
经过逐步设计与尝试,最终发现第四种方案最为完善。经过参数调整后,成功训练小车到达山顶。
Dueling DQN实现流程
使用DQN的改进版本Dueling DQN,只需在DQN网络基础上拆分为两个子网络,并进行优势函数的计算。
遇到的难题
最初,网络结构设定为 2->128->128->128->3,训练结果难以收敛。我推测可能是网络结构过于复杂,导致权重参数极为稀疏。于是,我去掉了两个隐藏层,将网络结构改为 2->128->3,训练效果得到显著提升。

两种方法训练结果对比
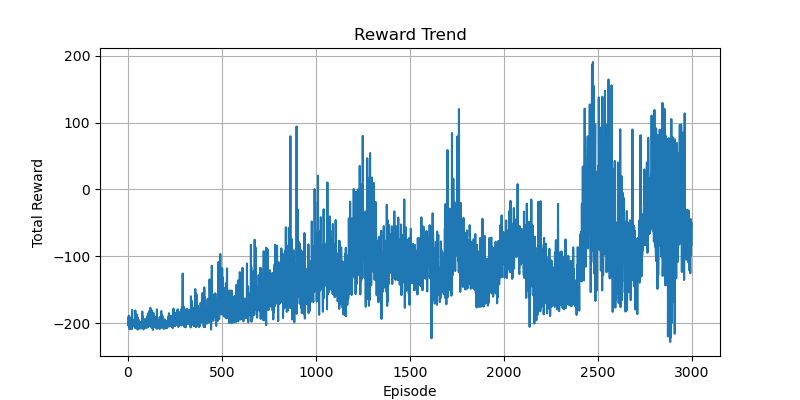
训练曲线比较
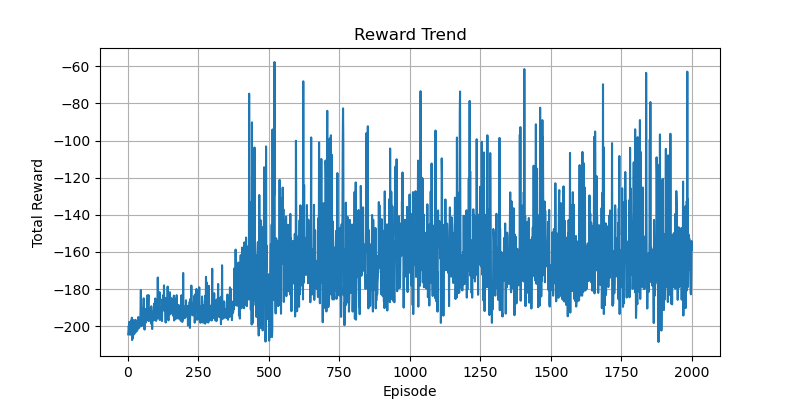
我在代码中添加了保存TensorBoard日志的功能,这样可以通过TensorBoard查看不同训练任务的曲线变化。
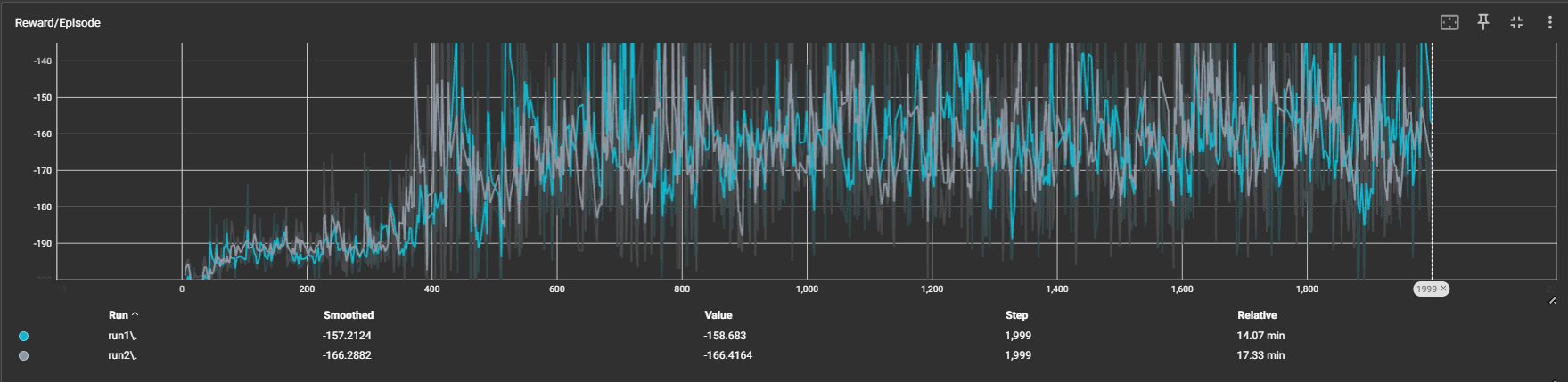
从图中可以看出,在同一套奖励函数和参数设置下,两种方法的训练速度和收敛速度相近。
最终策略比较
通过测试功能,可以观察到两种方法训练出的策略。两种方法都能让小车成功到达山顶,但奖励表现存在些许差异。可以发现,Dueling DQN的训练结果得分更高,策略变化的波动更小。
[检查点] 从 runs/Dueling_exp6/model_final.pt 加载模型:回合数 = 2000,探索率(epsilon) = 0.600
进行 10 个回合的测试...测试 #1:奖励值 = -113.00测试 #2:奖励值 = -113.00测试 #3:奖励值 = -113.00测试 #4:奖励值 = -113.00测试 #5:奖励值 = -113.00测试 #6:奖励值 = -112.00测试 #7:奖励值 = -113.00测试 #8:奖励值 = -113.00测试 #9:奖励值 = -92.00测试 #10:奖励值 = -115.00
10 个回合的平均奖励值:-111.00 ± 6.37[检查点] 从 runs/exp6/model_final.pt 加载模型:回合数 = 2000,探索率(epsilon) = 0.600
进行 10 个回合的测试...测试 #1:奖励值 = -119.00测试 #2:奖励值 = -121.00测试 #3:奖励值 = -186.00测试 #4:奖励值 = -160.00测试 #5:奖励值 = -158.00测试 #6:奖励值 = -115.00测试 #7:奖励值 = -160.00测试 #8:奖励值 = -158.00测试 #9:奖励值 = -89.00测试 #10:奖励值 = -119.00
10 个回合的平均奖励值:-138.50 ± 28.30
最后提供代码:
import os
import time
import argparse
import random
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from collections import deque
import matplotlib.pyplot as plt# ---------- 参数配置区域 ----------
EPISODES = 2000 # 最大训练轮数
BATCH_SIZE = 64 # 批次大小
GAMMA = 0.99 # 折扣因子
LR = 1e-3 # 学习率
EPS_START, EPS_END = 1.0, 0.6 # ε-greedy 起始/最小
EPS_DECAY = 0.995 # ε 衰减
TARGET_UPDATE = 10 # (已废弃,按步数更新)
TARGET_UPDATE_STEPS = 500 # 梯度更新步数间隔更新目标网络
REPLAY_BUFFER_SIZE = 10000 # Replay Buffer 容量
SAVE_INTERVAL = 50 # Checkpoint 保存间隔 (episodes)
RENDER_DELAY = 0.01 # 渲染延迟(秒)
ALPHA = 6 # reward 参数(未用)
ALPHA2 = 2
ALPHA1 = 1
BETA = 1
# ----------------------------device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ---------- 标准 DQN ----------
class DQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()self.net = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))def forward(self, x):return self.net(x)# ---------- Dueling DQN ----------
class DuelingDQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()# 共享特征层self.feature = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU())# Advantage 分支self.advantage = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))# Value 分支self.value = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, 1))def forward(self, x):x = self.feature(x)adv = self.advantage(x) # [B, A]val = self.value(x) # [B, 1]# Q(s,a) = V(s) + (A(s,a) - mean_a A(s,a))q = val + adv - adv.mean(dim=1, keepdim=True)return qclass ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):batch = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = map(np.array, zip(*batch))return state, action, reward, next_state, donedef __len__(self):return len(self.buffer)def save_checkpoint(path, policy_net, target_net, optimizer, episode, epsilon, rewards):os.makedirs(os.path.dirname(path), exist_ok=True)torch.save({'episode': episode,'epsilon': epsilon,'policy_state': policy_net.state_dict(),'target_state': target_net.state_dict(),'optim_state': optimizer.state_dict(),'episode_rewards': rewards,}, path)print(f"[Checkpoint] Saved to {path}")def load_checkpoint(path, policy_net, target_net, optimizer):data = torch.load(path, map_location=device)policy_net.load_state_dict(data['policy_state'])target_net.load_state_dict(data['target_state'])optimizer.load_state_dict(data['optim_state'])print(f"[Checkpoint] Loaded from {path}: episode={data['episode']}, epsilon={data['epsilon']:.3f}")return data['episode'], data['epsilon'], data['episode_rewards']def train(args):base_dir = os.path.join('runs', args.task_name)env = gym.make("MountainCar-v0", render_mode="human") if args.visualize_train else gym.make("MountainCar-v0")obs_dim = env.observation_space.shape[0]action_dim = env.action_space.n# 根据命令行参数选择网络net_cls = DuelingDQN if args.dueling else DQNpolicy_net = net_cls(obs_dim, action_dim).to(device)target_net = net_cls(obs_dim, action_dim).to(device)target_net.load_state_dict(policy_net.state_dict())target_net.eval()optimizer = optim.Adam(policy_net.parameters(), lr=LR)buffer = ReplayBuffer(REPLAY_BUFFER_SIZE)writer = SummaryWriter(base_dir)episode_rewards = []epsilon = EPS_STARTstart_ep = 0update_steps = 0if args.resume and args.checkpoint and os.path.isfile(args.checkpoint):start_ep, epsilon, episode_rewards = load_checkpoint(args.checkpoint, policy_net, target_net, optimizer)print("Start training...")for episode in range(start_ep, EPISODES):state, _ = env.reset()state = np.array(state, dtype=np.float32)total_r = 0.0done = Falsewhile not done:if args.visualize_train:env.render()time.sleep(RENDER_DELAY)# ε-greedyif random.random() < epsilon:action = env.action_space.sample()else:with torch.no_grad():qv = policy_net(torch.from_numpy(state).unsqueeze(0).to(device))action = qv.argmax(dim=1).item()next_s, r, terminated, truncated, _ = env.step(action)done = terminated or truncatednext_s = np.array(next_s, dtype=np.float32)position, velocity = next_sshaped_r = rshaped_r += (ALPHA2 * (position + 0.5)**2 + ALPHA1 * (position + 0.5)) + BETA * velocity# if (position >= 0.4):# shaped_r += 1buffer.push(state, action, shaped_r, next_s, done)state = next_stotal_r += shaped_r# 学习更新if len(buffer) >= BATCH_SIZE:s, a, r_b, s2, d = buffer.sample(BATCH_SIZE)s_t = torch.from_numpy(s).to(device)a_t = torch.from_numpy(a).long().unsqueeze(1).to(device)r_t = torch.from_numpy(r_b).float().unsqueeze(1).to(device)s2_t = torch.from_numpy(s2).to(device)d_t = torch.from_numpy(d.astype(np.float32)).unsqueeze(1).to(device)q_curr = policy_net(s_t).gather(1, a_t)with torch.no_grad():q_next = target_net(s2_t).max(1)[0].unsqueeze(1)q_target = r_t + GAMMA * q_next * (1 - d_t)loss = nn.functional.mse_loss(q_curr, q_target)optimizer.zero_grad()loss.backward()optimizer.step()writer.add_scalar("Loss/Train", loss.item(), episode)# 按步数更新目标网络update_steps += 1if update_steps % TARGET_UPDATE_STEPS == 0:target_net.load_state_dict(policy_net.state_dict())# 每集结束后的记录epsilon = max(EPS_END, epsilon * EPS_DECAY)episode_rewards.append(total_r)writer.add_scalar("Reward/Episode", total_r, episode)writer.add_scalar("Epsilon", epsilon, episode)print(f"Episode {episode+1}/{EPISODES} Reward={total_r:.2f} Epsilon={epsilon:.3f}")# 早停检查if args.stop_threshold is not None and len(episode_rewards) >= 10:last10_avg = np.mean(episode_rewards[-10:])if last10_avg > args.stop_threshold:print(f"[Early Stop] Last 10 episodes avg reward = {last10_avg:.2f} > threshold {args.stop_threshold}")break# 定期保存if (episode+1) % SAVE_INTERVAL == 0:ckpt = os.path.join(base_dir, f"model_{episode+1}.pt")save_checkpoint(ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)# 保存最后一版模型final_ckpt = os.path.join(base_dir, "model_final.pt")save_checkpoint(final_ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)env.close()writer.close()# 画训练曲线plt.figure(figsize=(8,4))plt.plot(range(1, len(episode_rewards)+1), episode_rewards)plt.xlabel("Episode")plt.ylabel("Total Reward")plt.title("Reward Trend")plt.grid(True)plt.savefig(os.path.join(base_dir, "training_rewards.png"))plt.show()return policy_netdef test(policy_net, episodes=10):env = gym.make("MountainCar-v0", render_mode="human")rewards = []print(f"Testing over {episodes} episodes...")for i in range(episodes):state, _ = env.reset()state = np.array(state, dtype=np.float32)done = Falsetotal_r = 0.0while not done:env.render()with torch.no_grad():action = policy_net(torch.from_numpy(state).unsqueeze(0).to(device)).argmax(1).item()state, r, terminated, truncated, _ = env.step(action)done = terminated or truncatedstate = np.array(state, dtype=np.float32)total_r += rtime.sleep(0.02)rewards.append(total_r)print(f" Test #{i+1}: Reward = {total_r:.2f}")env.close()mean_r = np.mean(rewards)std_r = np.std(rewards)print(f"Average Reward over {episodes} episodes: {mean_r:.2f} ± {std_r:.2f}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="DQN / DuelingDQN MountainCar with Early Stop & Step-wise Target Update")parser.add_argument("--train", action="store_true")parser.add_argument("--test", action="store_true")parser.add_argument("--resume", action="store_true")parser.add_argument("--checkpoint", type=str, default=None)parser.add_argument("--task_name", type=str, default="default")parser.add_argument("--visualize_train",action="store_true")parser.add_argument("--dueling", action="store_true", help="Use Dueling DQN instead of standard DQN")parser.add_argument("--stop_threshold", type=float, default=None,help="Early stop if avg reward over last 10 eps > this")args = parser.parse_args()model = Noneif args.train:model = train(args)if args.test:net_cls = DuelingDQN if args.dueling else DQNif not model:dummy = net_cls(2, 3).to(device)opt = optim.Adam(dummy.parameters(), lr=LR)ckpt = args.checkpoint or os.path.join('runs', args.task_name, "model_final.pt")if os.path.isfile(ckpt):_, _, _ = load_checkpoint(ckpt, dummy, dummy, opt)model = dummyif model:test(model)相关文章:

DQN在Gym的MountainCar环境的实现
DQN on MountainCar 引言 在本次实验里,我构建了DQN和Dueling DQN,并在Gymnasium库的MountainCar环境中对它们展开测试。我通过调整训练任务的超参数,同时设计不同的奖励函数及其对应参数,致力于获取更优的训练效果。最后&#…...

typescript判断是否为空
1 判断数据类型 1.1 基础数据类型 比如number,string,boolean,使用typeof,返回值是string类型: 例如: if("number" typeof(item)) {egret.log("item的类型是number"); } else if(&…...
)
JavaScript forEach介绍(JS forEach、JS for循环)
文章目录 JavaScript forEach 方法全面解析基本概念语法详解参数说明 工作原理与其他循环方法的比较forEach vs for循环forEach vs map 实际应用场景DOM元素批量操作数据处理 性能考量常见陷阱与解决方案无法中断循环异步操作问题 高级技巧链式调用(不使用 forEach …...

C语言之图像文件的属性
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 图像文件属性提取系统设计与实现 目录 设计题目设计内容系统分析总体设计详细设计程序实现…...

Java链表反转方法详解
一、理解链表结构 假设链表节点定义为: class ListNode {int val;ListNode next;ListNode(int x) { val x; } } 二、迭代法反转链表 核心思路 逐步反转每个节点的指针方向,最终使整个链表反向。 步骤拆解 初始化三个指针: prev…...

lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1
一、软件介绍 文末提供程序和源码下载学习 lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1。 二、简介 小型 3B 大型多模态模型(LMMs)由于参数容量有限以及将视觉感知与逻辑推理相结合的固有复杂性…...
)
Java学习笔记(数组,方法)
一,数组 1.数组初始化 1.1动态初始化 格式:数据类型[] 数组名 new 数据类型[数组长度]; int[] arr new int[3]; // 定义长度为3的int数组,元素默认值为0 double[] scores new double[5]; // 长度5,元素默认0.0 String[…...
)
嵌入式---零点漂移(Zero Drift)
一、零点漂移的定义与本质 零点漂移(简称“零漂”)指传感器在输入信号为零(或理论上应输出固定零值)时,输出信号随时间、温度、环境等因素变化而偏离初始零点的现象。 核心特征:无输入时输出非零且缓慢变…...
含万字详细文档)
健身房管理系统设计与实现(springboot+ssm+vue+mysql)含万字详细文档
健身房管理系统设计与实现(springbootssmvuemysql)含万字详细文档 健身房管理系统是一个全面的解决方案,旨在帮助健身房高效管理日常运营。系统主要功能模块包括个人中心、会员管理、员工管理、会员卡管理、会员卡类型管理、教练信息管理、解聘管理、健身项目管理、…...

C语言if
一、题目引入 如果从键盘输入58,则以下程序输出的结果是多少? 二、运行结果 三、题目分析 因为这道题中的多个if是并列结构 所以只要条件满足都会执行 这一题58满足所有的条件 所以可以运行出来 也就是说每个if里面的条件都满足 所以都会打印出来 而下面的这种情况就是 if e…...

XSS学习1之http回顾
1. HTTP的基本结构与工作流程 HTTP是一个请求-响应协议,基于客户端与服务器之间的交互。每次用户通过浏览器请求某个资源时,HTTP协议都会完成一系列的步骤。 HTTP请求: HTTP请求由以下几个部分构成: 请求行: 请求方…...
)
小迪抓包技术算法加密(6-9天)
抓包技术 https://blog.csdn.net/2301_81015455/article/details/147014382 算法加密入门(了解) 在实际测试中安全性高一些得采用得都是AES等高安全加密,遇到这种,放弃你啥都不知道测个毛啊,所以直接run!!! 大部分解密时碰撞式…...

Tkinter与ttk模块对比:构建现代 Python GUI 的进化之路
在 Python GUI 开发中,标准库 tkinter 及其子模块 ttk(Themed Tkinter)常被同时使用。本文通过功能对比和实际案例,简单介绍这两个模块的核心差异。 1. 区别 Tkinter:Python 标准 GUI 工具包(1994年集成&…...

【数据结构入门训练DAY-18】信息学奥赛一本通T1331-后缀表达式的值
文章目录 前言一、题目二、解题思路总结 前言 本次训练内容: 栈的复习。栈模拟四则运算计算问题的练习。训练解题思维。 一、题目 从键盘读入一个后缀表达式(字符串),只含有0-9组成的运算数及加()、减…...
时序预测 | Transformer-LSTM-SVM时间序列预测(Matlab完整源码和数据,适合基础小白研究)
时序预测 | Transformer-LSTM-SVM时间序列预测(Matlab完整源码和数据,适合基础小白研究) 目录 时序预测 | Transformer-LSTM-SVM时间序列预测(Matlab完整源码和数据,适合基础小白研究)效果一览基本介绍代码…...

【HarmonyOS 5】makeObserved接口详解
【HarmonyOS 5】makeObserved接口详解 一、makeObserved接口是什么? makeObserved 接口(API version 12 起可用)用于将非观察数据转为可观察数据,适用于三方包类、Sendable 装饰的类、JSON.parse 返回的对象、collections.Array…...

色谱图QCPColorMap
一、QCPColorMap 概述 QCPColorMap 是 QCustomPlot 中用于绘制二维颜色图的类,可以将矩阵数据可视化为颜色图(热力图),支持自定义色标和插值方式。 二、主要属性 属性类型描述dataQCPColorMapData存储颜色图数据的对象interpol…...
)
【数据结构_12】二叉树(4)
一、二叉树的层序遍历 思路:可以按照先序的方式来遍历这个树,递归的时候,给递归方法,加上辅助的参数,level表示当前层数,递归过程中,根据level的值,决定当前整个节点要放到哪个list中…...

HCIA-Datacom高阶:vlan、vlanif、单臂路由、静态路由、ospf综合实验
本实验拓扑图如下:实验包含 AR1、AR2、AR3 路由器,LSW1(三层交换机)、LSW2、LSW3 交换机,以及 PC1-4 和 Server1。AR1 与 LSW2 通过单臂路由连接,AR2 与 AR3、LSW1 构成 OSPF 网络,AR1 与 AR2 间…...

HTTP 1.0 和 2.0 的区别
HTTP 1.0 和 2.0 的核心区别体现在性能优化、协议设计和功能扩展上,以下是具体对比: 一、核心区别对比 特性HTTP 1.0HTTP 2.0连接方式非持久连接(默认每次请求新建 TCP 连接)持久连接(默认保持连接,可复用…...

如何一键批量删除多个 Word 文档中的页眉和页脚
在工作中,许多 Word 文档的页眉页脚中包含公司名称、Logo、电话等信息,用于对外宣传。但有时我们需要批量删除这些页眉页脚信息,尤其当信息有误时,手动逐个删除会增加工作量,导致效率低下。本文将介绍一种便捷的方法&a…...

关于编译树莓派内核系统的总结
1.首先获取官方的内核系统源码: 然后在源码根目录执行命令: 🌟ARCHarm64 CROSS_COMPILEaarch64-linux-gnu- KERNELkernel8 make bcm2712_defconfig (注意这里的是树莓派5的64位的) 🌟ARCHarm CROSS_COM…...

AIGC赋能插画创作:技术解析与代码实战详解
文章目录 一、技术架构深度解析二、代码实战:构建AIGC插画生成器1. 环境配置与依赖安装2. 模型加载与文本提示词构建3. 图像生成与参数调优4. 风格迁移与多模型融合 三、进阶技巧:参数调优与效果增强四、应用场景代码示例1. 游戏角色设计2. 广告海报生成…...
)
平衡二叉树(leetcode刷题)
题目描述: 给定一个二叉树,判断它是否是 平衡二叉树 (平衡二叉树 是指该树所有节点的左右子树的高度相差不超过 1。) 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:true示例 2࿱…...

【数据结构 · 初阶】- 带环链表
目录 一.基本结构 二.判断一个单链表带不带环 三.2个问题 1.为什么 slow 走 1 步,fast 走 2 步,他们会相遇,会不会错过?请证明。 2.为什么 slow 走 1 步,fast 走 X 步 ( X > 3 ),他们会相遇&#x…...

ClickHouse简介
OLAP与ClickHouse的定位 OLAP的核心概念 OLTP:服务于高并发、低延迟的短事务操作(如银行转账、订单支付),强调数据的增删改查(CRUD)和事务一致性(ACID)。 OLAP:专注于大…...

强制重装及验证onnxruntime-gpu是否正确工作
#工作记录 我们经常会遇到明明安装了onnxruntime-gpu或onnxruntime后,无法正常使用的情况。 一、强制重新安装 onnxruntime-gpu 及其依赖 # 强制重新安装 onnxruntime-gpu 及其依赖 pip install --force-reinstall --no-cache-dir onnxruntime-gpu1.18.0 --extra…...
附带全代码)
分布自定义shell脚本(详写)附带全代码
涉及知识全排列 常见指令 小知识点 操作系统 什么是进程 进程控制 步骤 1:项目准备 在开始编写代码之前,你需要创建一个新的项目文件夹,并在其中创建一个 .cpp 文件,例如 my_shell.cpp。同时,确保你已经安装了 C…...

windows拷贝文件脚本
1、新建脚本文件xxx.bat,名字任意,后缀未.bat即可,将以下内容拷贝进去,修改src和des为自己文件的目录即可。 echo off :: 设置字符集为UTF-8,命令窗口能正确显示中文字符。 chcp 65001 rem 读取当前目录并进入当前目…...

Arduino编译和烧录STM32——基于J-link SWD模式
一、安装Stm32 Arduino支持 在arduino中添加stm32的开发板地址:https://github.com/stm32duino/BoardManagerFiles/raw/main/package_stmicroelectronics_index.json 安装stm32开发板支持 二、安装STM32CubeProgrammer 从stm32网站中安装:https://ww…...

Java表达式2.0
1 .数据类型转换 自动类型转换的规则 自动类型转换遵循一定的规则,这些规则确保了转换的合理性和安全性。以下是自动类型转换的主要规则: 容量小的类型自动转换为容量大的类型 Java中,数据类型的容量从小到大依次为:byte → shor…...

【概率论,算法】排列的峰值期望
Surtr1 的珂学难题 题目链接:https://ac.nowcoder.com/acm/contest/107965/E 给定一个长度为 n n n 的排列 p p p,排列中任一位置如果满足以下条件,则称该位置为 峰值: 位置 1:若存在元素,满足 p [ 1 ] > p […...

清理C盘组合拳:最高释放空间80GB+
分享一套系统化的C盘清理方案,涵盖从基础清理到深度优化的8个关键步骤,结合安全性与效率,可快速释放5-50GB空间: 一、精准定位空间占用源(必备工具) 空间可视化分析 使用 TreeSize Free 或 WizTree 扫描C…...

容器中的对象切片问题
C 容器(如 std::vector、std::list 等) 通常存储对象的副本,而非指向对象的指针。因此,当与继承结合使用时,可能导致 切片(Object Slicing) 问题,即仅存储基类部分,丢失派…...

SpringBoot编写单元测试
pom.xml引入单元测试的坐标 <!--单元测试坐标--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>编写单元测试类 测试类…...

二、在springboot 中使用 AIService
在上一篇文章中,我们介绍了如何使用langchain4j实现简单的问答功能,本篇文章我们将介绍如何在springboot中使用AIService。 1.实现原理 先看下AiService注解所在的依赖langchain4j-spring-boot-starter中包含什么内容: 1.1 event.AiServi…...

拼多多面经,暑期实习Java一面
项目中的设计模式 mysql连接过程,索引,分库分表场景,路由策略 redis使用场景,分片集群怎么搭建与路由,数据一致性 分布式锁怎么用的,具体使用参数 线程池怎么用的,过程 sql having 分布式事务 如…...

Function calling LLMs 的 MCP:AI开发的双剑合璧
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创AI未来! 🚀 在 MCPs 成为主流(或者像现在这样火得一塌糊涂)之前,大多数 AI …...

数字系统与编码
1. 数字系统(Number Systems) 1.1 常见数字系统 系统基数符号集示例应用场景二进制20, 11010计算机底层电路、数据存储八进制80-717Unix文件权限(如chmod 755)十进制100-942日常计算十六进制160-9, A-F0x1F内存地址、颜色编码&a…...

Pytorch实战
1、安装 安装 conda, Python工具大全,方便管理多个 Python 环境,必须选择跟自己环境配套的版本。 https://www.anaconda.com 网速慢的,可以参考国内源,也可以去这里看看: torch PyPI Index of /anaconda/miniconda…...

如何高效利用呼叫中心系统和AI语音机器人
要更好地使用呼叫中心系统和语音机器人,需要结合两者的优势,实现自动化、智能化、高效率的客户服务与业务运营。以下是优化策略和具体实践方法: 一、呼叫中心系统优化 1. 智能路由与IVR优化 智能ACD(自动呼叫分配) …...

LeetCode[232]用栈实现队列
思路: 一道很简单的题,就是栈是先进后出,队列是先进先出,用两个栈底相互对着,这样一个队列就产生了,右栈为空的情况,左栈栈底就是队首元素,所以我们需要将左栈全部压入右栈ÿ…...

using用法整理
using 的极简新手教程,用最直白的语言和代码解释: 美图美图 一、核心作用:给类型起别名 目的:让复杂类型名变短、变好记。 例子: // 原名:std::vector<std::string> // 起个别名就叫 StringList…...

《猎豹夕阳》
年少时很喜欢的一篇文章,曾和挚友一遍又一遍的记诵,今天又偶然遇到他,转载如下: 我第一次见到它,是在风雪的夜里。我不会抱怨这种天气,因为我是个优秀的登山探险者,我必须在这种天气下工作。我…...

【AI训练环境搭建】在Windows11上搭建WSL2+Ubuntu22.04+Tensorflow+GPU机器学习训练环境
一、安装Ubuntu 拿到该文件Ubuntu-22.04.tar 通过wsl导入该虚拟机镜像,然后查看wsl虚拟机列表。 wsl --import Ubuntu-22.04-tensorflow D:\wsl-data\Ubuntu-22.04-tensorflow D:\wsl-data\temp\Ubuntu-22.04.tarwsl -l 进入虚拟机 wsl -d Ubuntu-22.04-tensorfl…...

如何轻松实现用户充值系统的API自动化测试
在现代软件开发中,API(应用程序编程接口)作为连接不同系统和模块的关键组件,其重要性日益凸显。随着软件应用的互联性不断增强,API的数量和复杂度也在不断增加。传统的API测试方法面临着诸多挑战: 1.手动测…...
)
Python 一等函数( 高阶函数)
高阶函数 接受函数为参数,或者把函数作为结果返回的函数是高阶函数(higherorder function)。map 函数就是一例,如示例 5-2 所示。此外,内置函 数 sorted 也是:可选的 key 参数用于提供一个函数,…...

用于手部康复设备的TinyML语音分类嵌入式人工智能模块
论文标题 英文标题:TinyML Speech Classification Embedded AI Module for Hand Rehabilitation Device 中文标题:用于手部康复设备的 TinyML 语音分类嵌入式人工智能模块 作者信息 Arkorn Numsomran:Triam Udom Suksa Pattanakarn Suvarna…...

【HarmonyOS 5】VisionKit人脸活体检测详解
【HarmonyOS 5】VisionKit人脸活体检测详解 一、VisionKit人脸活体检测是什么? VisionKit是HamronyOS提供的场景化视觉服务工具包。 华为将常见的解决方案,通常需要三方应用使用SDK进行集成。华为以Kit的形式集成在HarmoyOS系统中,方便三方…...

Linux操作系统--进程的创建和终止
目录 1.进程创建 1.1fork()函数初识 1.2写时拷贝 1. 提升系统效率 2. 隔离错误影响 3. 支持并行计算 2.进程终止: 2.1进程退出场景: 2.2进程常见退出方法: 2.3_exit()系统调用接口 2.4exit函数 2.5return退出 1.进程创建 1.1for…...