【NLP 62、实践 ⑮、基于RAG + 智谱语言模型的Dota2英雄故事与技能介绍系统】
羁绊由我而起,痛苦也由我承担
—— 25.4.14
英雄介绍文件:
通过网盘分享的文件:RAG + 智谱语言模型的Dota2英雄故事与技能介绍系统
链接: https://pan.baidu.com/s/1G7Xo5TRvFl2BzUnE0NFaBA?pwd=4d4j 提取码: 4d4j
--来自百度网盘超级会员v3的分享
一、BM25算法实现
1.TF - IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency)算法是信息检索与文本挖掘领域常用的重要算法,用于评估一个词对于一个文档集或语料库中某文档的重要程度。
Ⅰ、核心概念
① 词频(Term Frequency,TF):指某个词在文档中出现的频率。计算方式是该词在文档中出现的次数除以文档中的总词数。比如在文档”苹果、香蕉、苹果、橙子“中,苹果出现了2次,总词数为4,则苹果的词频 TF = 2 / 4 = 0.5,词频越高,说明该词在文档中越重要,但它存在局限性,想一些常见的无实际意义的词(如”的“、”了“等停用词)可能词频很高,但对文档主题的区分度不大
② 逆文档频率(Inverse Document Frequency,IDF):用于衡量一个词的普遍重要性。如果一个词在很多个文档中都出现,它的区分度就低;若只在少数文档中出现,区分度则高。计算方法是文档集的总文档数除以包含这个词的文档数,再取对数。假设文档中有100个文档,其中有20个文档都包含”苹果“这个词,那么”苹果“的逆文档频率 IDF = log(100 / 20) = log(5)。IDF越大,说明该词在文档集中越稀有,对文档的区分能力越强
Ⅱ、计算方法
TF-IDF 值是词频(TF)和逆文档频率(IDF)的乘积,即 TF - IDF = TF × IDF。以”苹果“为例,假设在某文档中某词频 TF = 0.5,计算出的逆文档频率 IDF = log(5),则 TF-IDF = 0.5 × log(5)。通过这种方式,综合考虑了词在文档内的频率和在整个文档集中的稀有程度,能更准确地反应一个词对文档的重要性。
Ⅲ、应用场景
信息检索:在搜索引擎中,计算用户输入的关键词与文档的 TF-IDF 值,将 TF-IDF 值高的文档排在搜索结果前列,提高检索结果的相关性和准确性。例如用户搜索 “人工智能”,搜索引擎会计算各文档中 “人工智能” 的 TF-IDF 值,优先展示该值高的文档。
文本分类:计算训练集中每个词对于不同类别的 TF-IDF 值,选择对区分不同类别贡献大(即 TF-IDF 值高)的词作为特征,用于训练分类模型,提升分类的准确性。比如区分科技类和生活类文档时,“算法” 在科技类文档中的 TF-IDF 值可能较高,可作为区分的重要特征。
关键词提取:在文本中提取 TF-IDF 值较高的词作为关键词,能快速概括文本的核心内容。例如在一篇学术论文中,通过计算 TF-IDF 值,可以找出最能代表论文主题的关键词。
2.算法原理
BM25(Best Matching 25)算法是一种用于信息检索的排序算法,常用于文本检索系统中对文档与查询的相关性进行打分排序。其算法原理主要基于词频、文档长度以及逆文档频率等因素,通过综合计算得出文档与查询的相关性得分。
Ⅰ、核心概念
① 词频(Term Frequency,TF):指的是一个词在文档中出现的次数。在BM25算法中,单纯的词频并不能直接反映其对文档相关性的贡献。因为如果一个词在短文档中出现多次,和在长文档中出现相同次数相比,在短文档中的重要性应该更高。所以,BM25算法使用了一种经过调整的词频计算方式,对长文档的词频进行了折扣处理,以平衡文档长度的影响。例如,对于一个词 t 在文档 d 中的词频 TF(t, d),会通过某种函数进行调整,使得长文档中的高频词不会因为文档长而获得过高的权重
② 逆文档频率(Inverse Document Frequency,IDF):与 TF - IDF算法中的IDF概念类似,它衡量一个词在整个文档集合中的普遍程度。如果一个词在很多文档中都出现。说明它区分不同文档的能力偏弱;反之,如果一个词只在少数文档中出现,它对区分文档的作用就更大。计算 IDF时,通常使用文档集合的大小除以包含该词的文档数量,再取对数。假设文档集合中有N个文档,其中有 n_t 个文档包含词t,那么词t的逆文档频率 IDF(t) = log(N / n_t)
③ 文档长度归一化:由于不同文档的长度差异可能会影响词频的作用,BM25算法对文档长度进行了归一化处理。它通过引入一个参数 k_1(通常在1.2 ~ 2.0之间),对词频进行调整。对于文档 d 中的词 t,调整后的词频计算公式为:![]() ,其中 |d| 是文档 d 的长度,avgdl是文档集合中所有文档的平均长度,b 是一个控制文档长度归一化程度的参数(通常取值在 0 ~ 1之间)。b 越接近于 1,文档长度对词频的影响越大;b 越接近于 0,文档长度对词频的影响越小。
,其中 |d| 是文档 d 的长度,avgdl是文档集合中所有文档的平均长度,b 是一个控制文档长度归一化程度的参数(通常取值在 0 ~ 1之间)。b 越接近于 1,文档长度对词频的影响越大;b 越接近于 0,文档长度对词频的影响越小。
Ⅱ、BM25 计算得分
对于一个查询 Q = {t_1, t_2, …, t_n}和文档 d,BM25 算法计算文档d与查询Q的相关性得分BM25(Q, d)的公式为:![]()
这个公式综合考虑了查询中的每个词与文档的关系,通过对每个词的调整词频和逆文档频率的乘积进行求和,得到文档与查询的相关性得分。得分越高,说明文档与查询的相关性越强。例如,当用户输入一个包含多个关键词的查询时,算法会对每个关键词分别计算其在文档中的得分贡献,然后累加得到文档的总得分,最后根据这些得分对所有文档进行排序,将相关性高的文档排在前面展示给用户。
3.代码实现
Ⅰ、类定义与初始化模块(__init__ 方法)
EPSILON:处理逆文档频率(IDF)计算中特殊情况的常量。在计算 IDF 时,如果某些词的 IDF 值为负(通常是由于这些词在大量文档中出现),会使用 EPSILON 与平均 IDF 的乘积来平滑这些负 IDF 值,避免它们对相关性得分计算产生不合理的影响。
PARAM_K1:超参数,用于调节词频(TF)对相关性得分的影响程度。它控制词频的饱和效应,即当词频增加时,其对得分的贡献不会无限制地增长,而是逐渐趋于饱和。较大的 PARAM_K1 值会使词频对得分的影响更大。
PARAM_B:超参数,用于调整文档长度对相关性得分的影响。它的值在 0 到 1 之间,0 表示不考虑文档长度的影响,1 表示完全考虑文档长度的影响。通过这个参数,可以对长文档和短文档中的词频进行不同程度的归一化处理。
corpus:作为 BM25 类初始化时的输入参数,代表文档集合。字典的键是文档的唯一标识,值是文档的文本内容(已分词成列表形式)。
self.corpus_size:记录文档集合中的文档数量。
self.wordNumsOfAllDoc:表示文档集合中所有文档的总词数。
self.doc_freqs:用于记录每篇文档中各个查询词的词频。字典的键是文档的唯一标识(索引),值是一个字典,其中键是查询词,值是该词在对应文档中出现的频率。
self.idf:存储每个查询词的逆文档频率(IDF)值。字典的键是查询词,值是对应的 IDF 值。
self.doc_len:记录每篇文档的单词数。字典的键是文档的唯一标识(索引),值是该文档的单词数量。
self.docContainedWord:倒排索引,即记录了每个单词在哪些文档中出现。字典的键是查询词,值是一个集合(set),包含了所有包含该词的文档的索引。
self._initialize():根据传入的文档集 corpus 构建倒排索引,并计算每个查询词的逆文档频率(IDF)。
class BM25:EPSILON = 0.25PARAM_K1 = 1.5 # BM25算法中超参数PARAM_B = 0.6 # BM25算法中超参数def __init__(self, corpus: Dict):"""初始化BM25模型:param corpus: 文档集, 文档集合应该是字典形式,key为文档的唯一标识,val对应其文本内容,文本内容需要分词成列表"""self.corpus_size = 0 # 文档数量self.wordNumsOfAllDoc = 0 # 用于计算文档集合中平均每篇文档的词数 -> wordNumsOfAllDoc / corpus_sizeself.doc_freqs = {} # 记录每篇文档中查询词的词频self.idf = {} # 记录查询词的 IDFself.doc_len = {} # 记录每篇文档的单词数self.docContainedWord = {} # 包含单词 word 的文档集合self._initialize(corpus)Ⅱ、倒排索引构建模块(_initialize 方法)
corpus:作为 BM25 类初始化时的输入参数,代表文档集合。字典的键是文档的唯一标识,值是文档的文本内容(已分词成列表形式)。
index:表示当前遍历到的文档在 corpus 中的唯一标识
document:表示当前遍历到的文档的文本内容,且已经被分词成了单词列表。
items(): Python 中字典(dict)类型的一个方法,它的主要作用是返回一个包含字典中所有键值对的可迭代对象(具体来说是一个视图对象,在 Python 3 中),其中每个元素都是一个元组,元组的第一个元素是字典的键,第二个元素是对应的值。
self.corpus_size: BM25 类的实例属性,用于记录文档集合中的文档数量。
self.doc_len:字典(Dict),BM25 类的实例属性,用于记录每篇文档的单词数。字典的键是文档的唯一标识(即 index),值是对应文档的单词数量(len(document))。
self.wordNumsOfAllDoc:BM25 类的实例属性,用于累加所有文档的单词总数。
frequencies:字典(Dict),处理每篇文档时的临时变量,用于记录当前文档中每个单词的出现频率。
self.doc_freqs:BM25 类的实例属性,用于存储每篇文档中各个单词的词频信息。字典的键是文档的唯一标识(index),值是一个字典,其中键是单词,值是该单词在对应文档中的出现频率(即 frequencies 的内容)。
keys():字典对象的方法,它返回一个视图对象,该视图对象包含了字典中的所有键。这个视图对象会动态反映字典的变化,即当字典的键发生变化时,视图对象也会相应更新。
self.docContainedWord:BM25 类的实例属性,用于构建倒排索引。字典的键是单词,值是一个集合(set),集合中包含了所有包含该单词的文档的唯一标识(index)。
set(): Python 的内置函数,用于创建一个新的集合对象。集合是无序且唯一的数据结构,这意味着集合中的元素不会重复,并且没有固定的顺序。你可以传入一个可迭代对象(如列表、元组、字符串等)来初始化集合,若不传入参数,则会创建一个空集合。
| 参数名 | 类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
iterable | 可迭代对象(如列表、元组、字符串等) | 否 | 无 | 该参数是可选的,用于提供要包含在集合中的初始元素。如果传入了可迭代对象,集合会包含其中的所有唯一元素;若未传入参数,会创建一个空集合。 |
add():集合对象的方法,用于向集合中添加一个新元素。若该元素已存在于集合中,集合不会发生任何变化;若元素不存在,则会将其添加到集合里。
| 参数名 | 类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
element | 任意不可变类型(如数字、字符串、元组等) | 是 | 无 | 要添加到集合中的元素。由于集合的元素必须是可哈希的(不可变),所以不能添加列表、字典等可变对象。 |
def _initialize(self, corpus: Dict):"""根据语料库构建倒排索引"""# nd = {} # word -> number of documents containing the wordfor index, document in corpus.items():self.corpus_size += 1self.doc_len[index] = len(document) # 文档的单词数self.wordNumsOfAllDoc += len(document)frequencies = {} # 一篇文档中单词出现的频率for word in document:if word not in frequencies:frequencies[word] = 0frequencies[word] += 1self.doc_freqs[index] = frequencies# 构建词到文档的倒排索引,将包含单词的和文档和包含关系进行反向映射for word in frequencies.keys():if word not in self.docContainedWord:self.docContainedWord[word] = set()self.docContainedWord[word].add(index)Ⅲ、IDF 计算模块(_initialize 后续逻辑)
IDF计算公式:![]()
idf_sum:用于累加所有单词的逆文档频率(IDF)值。
negative_idfs:列表(List),存储那些计算出的 IDF 值为负的单词。
self.docContainedWord:BM25 类的实例属性,用于构建倒排索引。字典的键是单词,值是一个集合(set),集合中包含了所有包含该单词的文档的唯一标识(index)。
字典.keys():返回字典的键视图
doc_nums_contained_word:表示包含当前单词 word 的文档数量。
idf:存储当前单词 word 的逆文档频率(IDF)值。
math.log():计算自然对数或指定底数的对数
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| x | float | 是 | 无 | 数值(必须>0) |
| base | float | 否 | e | 对数的底数(默认自然对数) |
self.corpus_size:BM25 类的实例属性,用于记录文档集合中的文档数量。
self.idf:字典(Dict),BM25 类的实例属性,用于存储每个单词的 IDF 值。字典的键是单词,值是对应的 IDF 值。
列表.append():向列表末尾添加元素
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| item | 任意类型 | 是 | 无 | 待添加的元素 |
average_idf:表示所有单词的平均 IDF 值。通过将 idf_sum 除以 self.idf 字典的长度(即单词的总数)计算得到。
eps:修正负 IDF 值的参数。
BM25.EPSILON:处理逆文档频率(IDF)计算中特殊情况的常量。
# 计算 idfidf_sum = 0 # collect idf sum to calculate an average idf for epsilon valuenegative_idfs = []for word in self.docContainedWord.keys():doc_nums_contained_word = len(self.docContainedWord[word])# BM25 IDF公式idf = math.log(self.corpus_size - doc_nums_contained_word +0.5) - math.log(doc_nums_contained_word + 0.5)self.idf[word] = idfidf_sum += idfif idf < 0:negative_idfs.append(word)# 修正负IDF值average_idf = float(idf_sum) / len(self.idf)eps = BM25.EPSILON * average_idffor word in negative_idfs:self.idf[word] = epsⅣ、辅助模块(avgdl 属性)
平均文档长度,用于长度归一化计算
avgdl计算公式:![]()
self.wordNumsOfAllDoc:记录整个语料库(文档集合)里所有文档的单词总数。
self.corpus_size:语料库中文档的总数。
@property:Python 的一个内置装饰器,用于将类中的方法转换为属性。
float():将值转换为浮点数
| 数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| value | int/str | 是 | 无 | 待转换的数值或字符串 |
@propertydef avgdl(self):return float(self.wordNumsOfAllDoc) / self.corpus_sizeⅤ、评分方法 get_score
query:列表(List),作为函数的输入参数,query 是一个由查询词组成的列表,这些查询词是用户输入的查询内容经过分词后的结果。
doc_index:表示语料库中某篇文档对应的唯一索引。
k1:从 BM25 类的类属性 PARAM_K1 中获取,是 BM25 算法中的一个超参数。在计算相关性分数的公式中,k1 用于调节词频(TF)对相关性得分的影响程度,控制词频的饱和效应,即词频增加到一定程度后对得分的贡献不再无限制增长。
b:从 BM25 类的类属性 PARAM_B 中获取,是 BM25 算法中的另一个超参数。在计算相关性分数的公式中,b 用于调整文档长度对相关性得分的影响,对不同长度文档中的词频进行归一化处理,以平衡文档长度因素在相关性计算中的作用。
BM25.PARAM_K1:超参数,用于调节词频(TF)对相关性得分的影响程度。它控制词频的饱和效应,即当词频增加时,其对得分的贡献不会无限制地增长,而是逐渐趋于饱和。较大的 PARAM_K1 值会使词频对得分的影响更大。
BM25.PARAM_B:超参数,用于调整文档长度对相关性得分的影响。它的值在 0 到 1 之间,0 表示不考虑文档长度的影响,1 表示完全考虑文档长度的影响。通过这个参数,可以对长文档和短文档中的词频进行不同程度的归一化处理。
score:存储计算得到的查询 query 与文档 doc_index 之间的相关性分数
doc_freqs:记录指定文档 doc_index 中各个单词词频的字典。字典的键是单词,值是该单词在文档 doc_index 中出现的频率。
self.idf:储每个单词逆文档频率(IDF)值的字典。字典的键是单词,值是对应的 IDF 值。
self.doc_len:BM25 类实例的一个属性,是一个字典,存储了每篇文档的单词数。
self.avgdl: BM25 类实例的一个属性,通过计算得到文档集合中平均每篇文档的词数。在公式中用于对文档长度进行归一化处理,以调整词频在不同长度文档中的权重。
def get_score(self, query: List, doc_index):"""计算查询 q 和文档 d 的相关性分数:param query: 查询词列表:param doc_index: 为语料库中某篇文档对应的索引"""k1 = BM25.PARAM_K1b = BM25.PARAM_Bscore = 0doc_freqs = self.doc_freqs[doc_index]for word in query:if word not in doc_freqs:continuescore += self.idf[word] * doc_freqs[word] * (k1 + 1) / (doc_freqs[word] + k1 * (1 - b + b * self.doc_len[doc_index] / self.avgdl))return [doc_index, score]Ⅵ、批量评分方法 get_scores
score计算公式: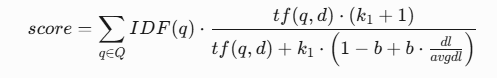
query:列表(List),表示用户输入的查询内容经过分词后的单词列表。这个查询词列表用于计算与语料库中每篇文档的相关性得分
scores:列表(List),用于存储查询 query 与语料库中每篇文档的相关性得分信息。
self.get_score():计算给定查询 query 和文档 doc_index 之间的相关性分数。
self.doc_len:BM25 类实例的一个属性,是一个字典,存储了每篇文档的单词数。
字典.keys(): 返回字典的键视图
def get_scores(self, query):scores = [self.get_score(query, index) for index in self.doc_len.keys()]return scores
Ⅶ、完整代码
import json
import math
import os
import pickle
import sys
from typing import Dict, Listclass BM25:EPSILON = 0.25PARAM_K1 = 1.5 # BM25算法中超参数PARAM_B = 0.6 # BM25算法中超参数def __init__(self, corpus: Dict):"""初始化BM25模型:param corpus: 文档集, 文档集合应该是字典形式,key为文档的唯一标识,val对应其文本内容,文本内容需要分词成列表"""self.corpus_size = 0 # 文档数量self.wordNumsOfAllDoc = 0 # 用于计算文档集合中平均每篇文档的词数 -> wordNumsOfAllDoc / corpus_sizeself.doc_freqs = {} # 记录每篇文档中查询词的词频self.idf = {} # 记录查询词的 IDFself.doc_len = {} # 记录每篇文档的单词数self.docContainedWord = {} # 包含单词 word 的文档集合self._initialize(corpus)def _initialize(self, corpus: Dict):"""根据语料库构建倒排索引"""# nd = {} # word -> number of documents containing the wordfor index, document in corpus.items():self.corpus_size += 1self.doc_len[index] = len(document) # 文档的单词数self.wordNumsOfAllDoc += len(document)frequencies = {} # 一篇文档中单词出现的频率for word in document:if word not in frequencies:frequencies[word] = 0frequencies[word] += 1self.doc_freqs[index] = frequencies# 构建词到文档的倒排索引,将包含单词的和文档和包含关系进行反向映射for word in frequencies.keys():if word not in self.docContainedWord:self.docContainedWord[word] = set()self.docContainedWord[word].add(index)# 计算 idfidf_sum = 0 # collect idf sum to calculate an average idf for epsilon valuenegative_idfs = []for word in self.docContainedWord.keys():doc_nums_contained_word = len(self.docContainedWord[word])idf = math.log(self.corpus_size - doc_nums_contained_word +0.5) - math.log(doc_nums_contained_word + 0.5)self.idf[word] = idfidf_sum += idfif idf < 0:negative_idfs.append(word)average_idf = float(idf_sum) / len(self.idf)eps = BM25.EPSILON * average_idffor word in negative_idfs:self.idf[word] = eps@propertydef avgdl(self):return float(self.wordNumsOfAllDoc) / self.corpus_sizedef get_score(self, query: List, doc_index):"""计算查询 q 和文档 d 的相关性分数:param query: 查询词列表:param doc_index: 为语料库中某篇文档对应的索引"""k1 = BM25.PARAM_K1b = BM25.PARAM_Bscore = 0doc_freqs = self.doc_freqs[doc_index]for word in query:if word not in doc_freqs:continuescore += self.idf[word] * doc_freqs[word] * (k1 + 1) / (doc_freqs[word] + k1 * (1 - b + b * self.doc_len[doc_index] / self.avgdl))return [doc_index, score]def get_scores(self, query):scores = [self.get_score(query, index) for index in self.doc_len.keys()]return scoresⅧ、算法核心变量与公式映射
| 变量 / 公式部分 | 代码实现 | BM25 公式对应部分 |
|---|---|---|
| 文档总数 N | self.corpus_size | IDF 公式中的分母和分子 |
| 包含词 t 的文档数 \(df_t\) | len(self.docContainedWord[word]) | IDF 公式中的 \(df_t\) |
| 词 t 在文档 d 中的词频 \(f(t,d)\) | doc_freqs[doc_id][word] | 词频公式的分子和分母 |
| 文档长度 \(|d|\) | self.doc_len[doc_id] | 词频公式中的文档长度归一化项 |
| 平均文档长度 \(\text{avgdl}\) | self.avgdl | 词频公式中的归一化基准 |
| IDF 平滑参数 \(\epsilon\) | EPSILON * average_idf | 处理负 IDF 的平滑策略 |
Ⅸ、代码亮点与算法改进
倒排索引优化:通过 docContainedWord 快速获取包含某个词的所有文档,避免逐文档扫描,提升 IDF 计算效率。
IDF 平滑处理:对负 IDF 词(高频通用词)赋予正数权重(而非直接设为 0),避免完全忽略其影响,更符合实际场景。
参数可配置:PARAM_K1 和 PARAM_B 作为类变量,方便后续调整超参数,探索不同配置对检索效果的影响。
二、RAG + bm25召回介绍Dota2英雄故事和技能
1.大模型调用
prompt:用户传入的提示词(如 “请分析这篇作文的主题”),指导模型执行任务
client:ZhipuAI客户端实例,用于发起 API 请求,api_key需从智谱 AI 官网申请
model:指定使用智谱 AI 的glm-3-turbo模型(支持对话式交互)。
messages:输入格式为列表,每个元素是包含role(角色,此处为user)和content(内容,即prompt)的字典,符合智谱 AI 对话模型的输入规范。
response:模型返回的原始响应。
response_text:提取第一个生成结果的文本内容。
ZhipuAI():初始化智谱 AI(ZhipuAI)的客户端实例,用于与智谱 AI 的大模型服务进行交互,支持调用模型 API 发送请求并获取响应。
| 参数名 | 类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
api_key | 字符串 | 是 | 无 | 智谱 AI 的 API 密钥,用于身份验证(需从智谱 AI 官网申请,示例中为占位符) |
chat.completions.create():调用智谱 AI 的大模型(如glm-3-turbo)生成响应,支持对话式交互,传入对话历史和提示词,获取模型的文本生成结果。
| 参数名 | 类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
model | 字符串 | 是 | 无 | 指定使用的模型名称(如glm-3-turbo) |
messages | 列表 [字典] | 是 | 无 | 对话历史列表,每个元素包含role(角色)和content(内容) |
temperature | 浮点型 | 否 | 0.7 | 控制生成文本的随机性(值越高越随机,范围:0-1) |
max_tokens | 整数 | 否 | 1000 | 生成文本的最大 tokens 数(控制输出长度) |
top_p | 浮点型 | 否 | 1.0 | 核采样参数,与temperature共同控制随机性 |
def call_large_model(prompt):client = ZhipuAI(api_key="ZhipuAPI") # 填写您自己的APIKeyresponse = client.chat.completions.create(model="glm-4-plus", # 填写需要调用的模型名称messages=[{"role": "user", "content": prompt},],)response_text = response.choices[0].message.contentreturn response_text2.RAG主类 —— 初始化
类实例化入口,指定存储英雄数据的文件夹路径
folder_path:字符串类型,指定包含英雄数据文件的文件夹路径,默认值为 "Heroes"
self.load_hero_data():数据的加载和预处理,为后续的文本检索和问答提供数据支持,构建好用于 BM25 算法的相关数据结构和模型。
def __init__(self, folder_path="Heroes"):self.load_hero_data(folder_path)3.RAG主类 —— 加载本地英雄数据
加载本地英雄数据并构建检索系统
folder_path:字符串类型,指定包含英雄数据文件的文件夹路径。
self.hero_data:字典类型,用于存储每个英雄的名称和对应的故事及技能介绍。
os.listdir():列出目录下的文件和子目录
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| path | str | 是 | 当前目录 | 目标目录路径 |
str.endswith():检查字符串是否以指定后缀结尾
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| suffix | str/tuple | 是 | 无 | 要检查的后缀(支持元组) |
open():打开文件并返回文件对象
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| file | str | 是 | 无 | 文件路径 |
| mode | str | 否 | "r" | 打开模式(如"r"/"w") |
| buffering | int | 否 | -1 | 缓冲策略(默认系统默认) |
file_name:字符串类型,循环变量,代表当前遍历到的文件名。
os.path.join():拼接多个路径组件
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| *paths | str | 是 | 无 | 多个路径组件(可变参数) |
intro:字符串类型,从文件中读取的英雄故事及技能介绍内容。
文件对象.read():读取文件内容
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| size | int | 否 | -1 | 读取的字节数(-1全读) |
hero:字符串类型,从文件名中提取的英雄名称。
str.split():按分隔符分割字符串
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| sep | str | 否 | None | 分隔符(默认所有空字符) |
| maxsplit | int | 否 | -1 | 最大分割次数(-1全分割) |
corpus:字典类型,用于存储每个英雄的分词结果,键为英雄名称,值为分词后的列表。
self.index_to_name::字典类型,用于存储索引和英雄名称的映射关系。
index:整数类型,用于生成索引。
items():返回字典的键值对视图(dict_items对象)。
jieba.lcut():中文分词,将字符串切分为词语列表
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| text | str | 是 | 无 | 待分词的原始字符串 |
| cut_all | bool | 否 | False | 是否使用全模式分词 |
| hmm | bool | 否 | True | 是否启用HMM新词发现 |
BM25():创建BM25类的实例
def load_hero_data(self, folder_path):self.hero_data = {}for file_name in os.listdir(folder_path):if file_name.endswith(".txt"):with open(os.path.join(folder_path, file_name), "r", encoding="utf-8") as file:intro = file.read()hero = file_name.split(".")[0]self.hero_data[hero] = introcorpus = {}self.index_to_name = {}index = 0for hero, intro in self.hero_data.items():corpus[hero] = jieba.lcut(intro)self.index_to_name[index] = heroindex += 1self.bm25_model = BM25(corpus)return4. RAG主类 —— 基于BM25算法的检索召回
实现基于BM25的检索,返回最相关英雄的介绍文本
user_query:字符串类型,用户提出的问题。
scores:列表类型,存储了每个英雄与用户查询的相关性得分。
get_scores():接收一个查询 query,遍历文档集中的所有文档(通过文档索引),调用 get_score 方法计算每个文档与查询的相关性得分,将所有文档的索引和得分存储在一个列表中并返回。
jieba.lcut():中文分词,将字符串切分为词语列表
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| text | str | 是 | 无 | 待分词的原始字符串 |
| cut_all | bool | 否 | False | 是否使用全模式分词 |
| hmm | bool | 否 | True | 是否启用HMM新词发现 |
sorted():对可迭代对象排序,返回新列表
| 参数名 | 类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
| iterable | 可迭代对象 | 是 | 无 | 待排序的数据 |
| key | function | 否 | None | 自定义排序规则函数 |
| reverse | bool | 否 | False | 是否降序排序 |
sorted_scores:列表类型,将 scores 按得分从高到低排序后的结果。
hero:字符串类型,相关性得分最高的英雄名称。
text:字符串类型,相关性得分最高的英雄的故事及技能介绍内容。
def retrive(self, user_query):scores = self.bm25_model.get_scores(jieba.lcut(user_query))sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)hero = sorted_scores[0][0]text = self.hero_data[hero]return text5. RAG主类 —— 查询方法
整合检索与生成的全流程
user_query:字符串类型,用户提出的问题。
retrive_text:字符串类型,通过 retrive 方法检索到的与用户问题最相关的英雄故事及技能介绍内容。
self.retrive():接收用户的查询 user_query,使用 BM25 模型计算每个英雄与用户查询的相关性得分,对得分进行排序,找到得分最高的英雄,然后从 self.hero_data 中获取该英雄的故事和技能介绍文本并返回。
prompt:字符串类型,包含了检索到的英雄故事及技能介绍和用户问题的提示信息,用于发送给大模型。
response_text:字符串类型,大模型根据提示信息给出的回复内容。
call_large_model():调用智谱 AI 的 glm-4-plus 大模型,向模型发送用户的提示信息 prompt,并获取模型返回的回复内容。
def query(self, user_query): print("user_query:", user_query)print("=======================")retrive_text = self.retrive(user_query)print("retrive_text:", retrive_text)print("=======================")prompt = f"请根据以下从数据库中获得的英雄故事和技能介绍,回答用户问题:\n\n英雄故事及技能介绍:\n{retrive_text}\n\n用户问题:{user_query}"response_text = call_large_model(prompt)print("模型回答:", response_text)print("=======================")6.效果对比
演示RAG与纯大模型的效果对比
rag:SimpleRAG 类的实例,用于进行基于 RAG 的问答。
SimpleRAG():类的构造函数,用于初始化 SimpleRAG 类的实例。
user_query:字符串类型,用户提出的问题。
rag.query():接收用户的查询 user_query,首先调用 retrive 方法获取与用户查询相关的英雄介绍文本 retrive_text,然后构建一个提示信息 prompt,将英雄介绍和用户问题结合起来,调用 call_large_model 函数向大模型发送请求,获取模型的回答 response_text 并打印出来。
call_large_model():调用智谱 AI 的 glm-4-plus 大模型,向模型发送用户的提示信息 prompt,并获取模型返回的回复内容。
if __name__ == "__main__":rag = SimpleRAG()user_query = "高射火炮是谁的技能"rag.query(user_query)print("----------------")print("No RAG (直接请求大模型回答):")print(call_large_model(user_query))7.完整代码
import json
import os
import jieba
import numpy as np
from zhipuai import ZhipuAI
from bm25 import BM25'''
基于RAG来介绍Dota2英雄故事和技能
用bm25做召回
同样以智谱的api:glm-4-plus作为我们的大模型
'''#智谱的api作为我们的大模型def call_large_model(prompt):client = ZhipuAI(api_key="ZhipuAPI") # 填写您自己的APIKeyresponse = client.chat.completions.create(model="glm-4-plus", # 填写需要调用的模型名称messages=[{"role": "user", "content": prompt},],)response_text = response.choices[0].message.contentreturn response_textclass SimpleRAG:def __init__(self, folder_path="Heroes"):self.load_hero_data(folder_path)def load_hero_data(self, folder_path):self.hero_data = {}for file_name in os.listdir(folder_path):if file_name.endswith(".txt"):with open(os.path.join(folder_path, file_name), "r", encoding="utf-8") as file:intro = file.read()hero = file_name.split(".")[0]self.hero_data[hero] = introcorpus = {}self.index_to_name = {}index = 0for hero, intro in self.hero_data.items():corpus[hero] = jieba.lcut(intro)self.index_to_name[index] = heroindex += 1self.bm25_model = BM25(corpus)returndef retrive(self, user_query):scores = self.bm25_model.get_scores(jieba.lcut(user_query))sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)hero = sorted_scores[0][0]text = self.hero_data[hero]return textdef query(self, user_query): print("user_query:", user_query)print("=======================")retrive_text = self.retrive(user_query)print("retrive_text:", retrive_text)print("=======================")prompt = f"请根据以下从数据库中获得的英雄故事和技能介绍,回答用户问题:\n\n英雄故事及技能介绍:\n{retrive_text}\n\n用户问题:{user_query}"response_text = call_large_model(prompt)print("模型回答:", response_text)print("=======================")if __name__ == "__main__":rag = SimpleRAG()user_query = "高射火炮是谁的技能"rag.query(user_query)print("----------------")print("No RAG (直接请求大模型回答):")print(call_large_model(user_query))
相关文章:

【NLP 62、实践 ⑮、基于RAG + 智谱语言模型的Dota2英雄故事与技能介绍系统】
羁绊由我而起,痛苦也由我承担 —— 25.4.14 英雄介绍文件: 通过网盘分享的文件:RAG 智谱语言模型的Dota2英雄故事与技能介绍系统 链接: https://pan.baidu.com/s/1G7Xo5TRvFl2BzUnE0NFaBA?pwd4d4j 提取码: 4d4j --来自百度网盘超级会员v3的…...

Keil MDK 编译问题:function “HAL_IncTick“ declared implicitly
问题与处理策略 问题描述 ..\..\User\stm32f1xx_it.c(141): warning: #223-D: function "HAL_IncTick" declared implicitlyHAL_IncTick(); ..\..\User\stm32f1xx_it.c: 1 warning, 0 errors问题原因 在 stm32f1xx_it.c 文件中调用了 HAL_IncTick(),但…...

OpenCV基础01-图像文件的读取与保存
介绍: OpenCV是 Open Souce C omputer V sion Library的简称。要使用OpenCV需要安装OpenCV包,使用前需要导入OpenCV模块 安装 命令 pip install opencv-python 导入 模块 import cv2 1. 图像的读取 import cv2 img cv2.imread(path, flag)这里的flag 是可选参数&…...

IP数据报
IP数据报组成 IP数据报(IP Datagram)是网络中传输数据的基本单位。 IP数据报头部 版本(Version) 4bit 告诉我们使用的是哪种IP协议。IPv4版本是“4”,IPv6版本是“6”。 头部长度(IHL,Intern…...

视频联网平台与AI识别技术在电力行业的创新应用
一、电力行业智能化转型的迫切需求 在能源革命与数字化转型的双重推动下,电力行业正面临着前所未有的智能化升级需求。随着特高压电网的大规模建设和新能源占比的不断提高,传统的电力运维管理模式已经难以满足现代电网安全、高效运行的要求。据统计&…...

Apache Parquet 文件组织结构
简要概述 Apache Parquet 是一个开源、列式存储文件格式,最初由 Twitter 与 Cloudera 联合开发,旨在提供高效的压缩与编码方案以支持大规模复杂数据的快速分析与处理。Parquet 文件采用分离式元数据设计 —— 在数据写入完成后,再追加文件级…...

深度学习方向急出成果,是先广泛调研还是边做实验边优化?
目录 有限资源下本科生快速发表深度学习顶会论文的实战策略 1.短周期内可出成果的研究路径 2.论文阅读与复现的优先顺序 3.无一对一指导时的调研与实验组织 4.成功案例:本科生顶会论文经验 5.快速上手的研究子方向推荐 大家好这里是AIWritePaper官方账号&…...
实例)
Python 深度学习实战 第11章 自然语言处理(NLP)实例
Python 深度学习实战 第11章 自然语言处理(NLP)实例 内容概要 第11章深入探讨了自然语言处理(NLP)的深度学习应用,涵盖了从文本预处理到序列到序列学习的多种技术。本章通过IMDB电影评论情感分类和英西翻译任务,详细介绍了如何使…...

9、Hooks:现代魔法咒语集——React 19 核心Hooks
一、魔法咒语的本质革新 "类组件如同古老的魔杖挥舞仪式,而Hooks是新时代的无杖施法!"霍格沃茨魔法研究院的魔杖动力学教授惊叹道。React Hooks通过函数式能量场重构了魔法运作模式,让组件能量流转如尼可勒梅的炼金术。 ——以《国…...

FutureTask底层实现
一、FutureTask的基本使用 平时一些业务需要做并行处理,正常如果你没有返回结果的需求,直接上Runnable。 很多时候咱们是需要开启一个新的线程执行任务后,给我一个返回结果。此时咱们需要使用Callable。 在使用Callable的时候,…...

深入浅出:LDAP 协议全面解析
在网络安全和系统管理的世界中,LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是一个不可忽视的核心技术。它广泛应用于身份管理、认证授权以及目录服务,尤其在企业级环境中占据重要地位。本文将从基…...
)
学习笔记—C++—string(练习题)
练习题 仅仅反转字母 917. 仅仅反转字母 - 力扣(LeetCode) 题目 给你一个字符串 s ,根据下述规则反转字符串: 所有非英文字母保留在原有位置。所有英文字母(小写或大写)位置反转。 返回反转后的 s 。…...

论文阅读:2024 arxiv DeepInception: Hypnotize Large Language Model to Be Jailbreaker
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 DeepInception: Hypnotize Large Language Model to Be Jailbreaker DeepInception:催眠大型语言模型,助你成为越狱者 https://arxiv.org/pdf/2311.0…...

OC底层原理【一】 alloc init new
OC底层原理【一】 alloc init && new 文章目录 OC底层原理【一】 alloc init && new前言allocslowpath(checkNil && !cls)) 和 fastpath(!cls->ISA()->hasCustomAWZ())!cls->ISA()->hasCustomAWZ()) obj->initInstanceIsa();将类与isa关…...

集合框架拓展--stream流的使用
Stream(JDK8新特性) 什么是Stream? 也叫stream流,是JDK8开始新增的一套API(java.util.stream.*),可以用于操作集合或数组中的数据 优势:Stream流大量地结合了Lambda的语法风格来编程ÿ…...

Beszel 轻量级服务器监控平台的详细安装步骤
什么是 Beszel Beszel 是一个轻量级的服务器监控平台,包含 Docker 统计信息、历史数据和警报功能。 它拥有友好的 Web 界面、简单的配置,并且开箱即用。它支持自动备份、多用户、OAuth 身份验证和 API 访问 https://beszel.dev/zh/guide/what-is-besz…...

Spring 微服务解决了单体架构的哪些痛点?
1. 部署困难 (Deployment Difficulty & Risk) 单体痛点: 整体部署: 对单体应用的任何微小修改(哪怕只是一行代码),都需要重新构建、测试和部署整个庞大的应用程序。部署频率低: 由于部署过程复杂且风险高,发布周期通常很长&a…...

Kotlin delay方法解析
本文记录了kotlin协程(Android)中delay方法的字节码实现,并解析了delay方法如何实现挂起操作。 一、delay方法介绍 1.1、delay方法使用举例 class TestDelay {suspend fun testDelay() {Log.d("TestDelay", "before delay")delay(1000)Log.d…...
)
C# 类型、存储和变量(用户定义类型)
本章内容 C#程序是一组类型声明 类型是一种模板 实例化类型 数据成员和函数成员 预定义类型 用户定义类型 栈和堆 值类型和引用类型 变量 静态类型和dynamic关键字 可空类型 用户定义类型 除了C#提供的16种预定义类型,还可以创建自己的用户定义类型。有6种类型可以…...

C语言之高校学生信息快速查询系统的实现
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 C语言之高校学生信息快速查询系统的实现 目录 任务陈述与分析 问题陈述问题分析 数据结构设…...

Windows串口通信
Windows串口通信相比较Android串口通信,在开发上面相对方便一些。原理都是一样,需要仔细阅读厂商设备的串口通信协议。结合串口调试助手进行测试,测试通过后,编写代码实现。 比如近期就接触到了一款天平,其最大测量值为100g,测量精度0.001g。 拿到手之后我就先阅读串口通…...
模型)
从零开始用Pytorch实现LLaMA 4的混合专家(MoE)模型
近期发布的LLaMA 4模型引入了混合专家(Mixture of Experts, MoE)架构,旨在提升模型效率和性能。尽管社区对LLaMA 4的实际表现存在一些讨论,但MoE作为一种重要的模型设计范式,继Mistral等模型之后再次受到关注。 所以我…...
)
python3GUI--仿网课答题播放器 By:PyQt5(分享)
文章目录 一.前言二.相关知识1.PyQt52.QMediaPlayer3.QThread4.Sqlite3 二.展示1.主界面2.课程播放&问答3.字幕调整4.播放列表折叠5.添加课程 三.心得与分享1.数据本地化2.自定义组件3.系统流程图与代码量4.免责声明 四&#…...
之循环语句)
Python基础总结(八)之循环语句
文章目录 一、for循环1.1 for循环格式1.2 for ...else1.3 for...break1.4 for...continue 二、while循环2.1 while循环格式2.2 while...break2.3 while...continue2.4 while ...else 循环语句就如其名,就是重复的执行一段代码,直到满足退出条件时&#x…...

21. git apply
基本概述 git apply 的作用是:应用补丁文件 基本用法 1.命令格式 git apply [选项] <补丁文件>2.应用补丁 git apply patchfile.patch将补丁应用到工作目录,但不会自动添加到暂存区(需手动 git add) 常用选项 1.检查…...

第一章:MySQL视图基础
1. 视图是什么? 定义:视图(View)是一种虚拟表,其内容基于一个或多个真实表(基表)的查询结果。视图不实际存储数据,而是通过查询动态生成数据。核心特点:…...

深入理解基线检查:网络安全的基石
深入理解基线检查:网络安全的基石 一、引言 在信息技术飞速发展的今天,网络安全已成为企业和组织正常运营的关键保障。从日常办公系统到关键业务应用,任何环节的安全漏洞都可能导致严重的后果,如数据泄露、系统瘫痪等。基线检查作…...

33-公交车司机管理系统
技术: 基于 B/S 架构 SpringBootMySQLvueelementui 环境: Idea mysql maven jdk1.8 node 用户端功能 1.首页:展示车辆信息及车辆位置和线路信息 2.模块:车辆信息及车辆位置和线路信息 3.公告、论坛 4.在线留言 5.个人中心:修改个人信息 司机端功能…...

【AI实践】使用DeepSeek+CherryStudio绘制Mermaid格式图表
目录 工具准备创建DeepSeek API Key安装CherryStudioMermaid在线编辑器 绘制图表编写提示词在CherryStudio中调用DeepSeek复制源码到Mermaid编辑器中进行微调 图表示例流程图思维导图甘特图 工具准备 创建DeepSeek API Key 打开DeepSeek开放平台, 注册并充值成功后…...

TCP报文段解析:从抽象到具象的趣味学习框架
TCP报文段解析:从抽象到具象的趣味学习框架 一、What:TCP报文段长什么样? 核心结构(类比快递包裹): 复制 下载 | 源端口(16位)| 目的端口(16位)| |-----…...

B+树节点与插入操作
B树节点与插入操作 设计B树节点 在设计B树的数据结构时,我们首先需要定义节点的格式,这将帮助我们理解如何进行插入、删除以及分裂和合并操作。以下是对B树节点设计的详细说明。 节点格式概述 所有的B树节点大小相同,这是为了后续使用自由…...

rollup使用讲解
rollup 总结 什么是 rollup? rollup 是一个 JavaScript 模块打包器,在功能上要完成的事和 webpack 性质一样,就是将小块代码编译成大块复杂的代码,例如 library 或应用程序。在平时开发应用程序时,我们基本上选择用 webpack,相比之下,rollup.js 更多是用于 library 打…...

高边开关和低边开关的区别
高边驱动和低边驱动的区别 在高边驱动和低边驱动中,开关的位置直接影响电路在负载短路时的安全性和电流路径。以下是关键原理的分步解释: 1. 高低边驱动的结构对比 高边驱动(High-Side Drive) 电路结构: 电源正极 →…...
PG psql --single-transaction 参数功能
文章目录 PG psql --single-transaction 参数功能 PG psql --single-transaction 参数功能 test.sql 文件 create table test1(id int); CREATE OR REPLACE FUNCTION func_test() RETURNS INTEGER AS $BODY$ BEGINxxxreturn 0; END; $BODY$ LANGUAGE plpgsql VOLATILE CALLE…...

C++ 多态
1.多态的概念 多态(polymorphism)通俗来说就是多种形态。多态分为编译时多态(静态多态)和运行时多态(动态多态),这里我们重点是运行时多态,编译时多态主要就是我们前面的函数重载和…...

【matlab|python】矢量棍棒图应用场景和代码
【matlab|python】矢量棍棒图应用场景和代码 矢量棍棒图的介绍和作用 矢量棍棒图(stick plot)是一种用于可视化 方向性时间序列数据 的图形工具。它常用于大气科学和海洋科学中,以直观地展示 风场、海流 或 其他矢量变量 随时间的变化情况。 …...

Matlab 五相电机仿真
1、内容简介 Matlab 208-五相电机仿真 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

计算机视觉cv2入门之视频处理
在我们进行计算机视觉任务时,经常会对视频中的图像进行操作,这里我来给大家分享一下,如何cv2中视频文件的操作方法。这里我们主要介绍cv2.VideoCapture函数的基本使用方法。 cv2.VideoCapture函数...

力扣每日一题781题解-算法:贪心,数学公式 - 数据结构:哈希
https://leetcode.cn/problems/rabbits-in-forest/description/?envTypedaily-question&envId2025-04-20 781.推测兔子数 算法:贪心,数学公式 数据结构:哈希 用哈希存每个兔子报告的同色数量,作为key,同个key…...

MAC-QueryWrapper中用的exists,是不是用join效果更好
在使用MyBatis-Plus的QueryWrapper中的exists方法时,是否改为使用join效果会更好,以及如何 修改。这涉及到SQL优化和MyBatis-Plus的用法。 首先,需要理解exists和join在SQL中的区别。exists用于检查子查询是否返回结果,而join则是将 两个表连接起来,根据某些条件合并行…...

使用 Visual Studio 2022 中的 .http 文件
转自微软技术文档: https://learn.microsoft.com/zh-cn/aspnet/core/test/http-files?viewaspnetcore-9.0 Visual Studio 2022.http 文件编辑器提供了一种便捷的方式来测试 ASP.NET Core项目,尤其是 API 应用。 编辑器提供一个 UI,用于&am…...

相得益彰 — 基于 GraphRAG 事理图谱驱动的实时金融行情新闻资讯洞察
*本文为亚马逊云科技博客文章,仅用于技术分享,不构成投资建议或金融决策支持。文中涉及的公司名称仅用于技术示例,不代表亚马逊云科技观点或与这些公司的商业合作关系。 背景介绍 在当今这个信息爆炸的时代,金融市场每天都在产生…...

为什么this与super不能出现在同一构造器的原因
在 Java 中,this() 和 super() 不能同时出现在同一个构造器中,因为它们都必须作为构造器的第一条语句,而一个构造器的第一条语句只能有一个。以下是详细解释和示例: ⚠️ 核心规则 只能二选一: 每个构造器的第一条语句…...

Linux:网络基础
hello,各位小伙伴,本篇文章跟大家一起学习《Linux:网络基础》,感谢大家对我上一篇的支持,如有什么问题,还请多多指教 ! 如果本篇文章对你有帮助,还请各位点点赞!…...
)
C++入门篇(下)
目录 1、引用 1.1 引用概念 1.2 引用特性 1.3 常引用 1.4 使用场景 1.4.1 引用做参数 1.4.2 引用做返回值 1.5 引用和指针的区别 2、内联函数 2.1 概念 2.2 特性 3、auto关键字 4、基于范围的for循环 5、指针空值nullptr 5.1 C98 中的指针空值处理 5.2 C11 …...

QCustomPlot中自定义QCPAbstractPlottable绘图元素
QCPAbstractPlottable 是 QCustomPlot 中所有可绘制图形(如曲线、柱状图等)的基类。要创建自定义的绘图元素,通常需要继承这个类并实现其纯虚函数。 基本步骤 继承 QCPAbstractPlottable 实现必要的纯虚函数 添加自定义属性和方法 注册到 QCustomPlot 系统 完…...

【Bluedroid】蓝牙 HID 设备信息加载与注册机制及配置缓存系统源码解析
本篇解析Android蓝牙子系统加载配对HID设备的核心流程,通过btif_storage_load_bonded_hid_info实现从NVRAM读取设备属性、验证绑定状态、构造描述符并注册到BTA_HH模块。重点剖析基于ConfigCache的三层存储架构(全局配置/持久设备/临时设备)&…...

【计算机视觉】CV实战项目 - PCC-Net 人群计数
PCC-Net 人群计数项目 项目特点项目运行方式与步骤1. 环境准备2. 数据准备3. 模型训练4. 实验结果 常见问题及解决方法 PCC-Net(Perspective Crowd Counting via Spatial Convolutional Network)是一个用于人群计数的深度学习项目,旨在通过空…...
Towards Transferable Targeted 3D Adversarial Attack in the Physical World--阅读笔记
目录 简介: 背景: 挑战: 目的: 技术细节: 贡献: 1. NeRF的核心作用:3D重建与参数化表示 2. 对抗优化的创新:NeRF参数空间的双优化 2.1 传统方法的局限…...

opencv图像库编程
一、下载安装 opencv 1.1 下载安装包 1.2 解压缩 unzip opencv-3.4.11.zip 解压缩以后主目录文件夹如下: 1.3 进入到解压后的文件夹中 cd opencv-3.4.11 二、使用 cmake安装opencv 2.1 进入 root 用户,并更新一下 sudo su sudo apt-get update …...