B+树节点与插入操作
B+树节点与插入操作
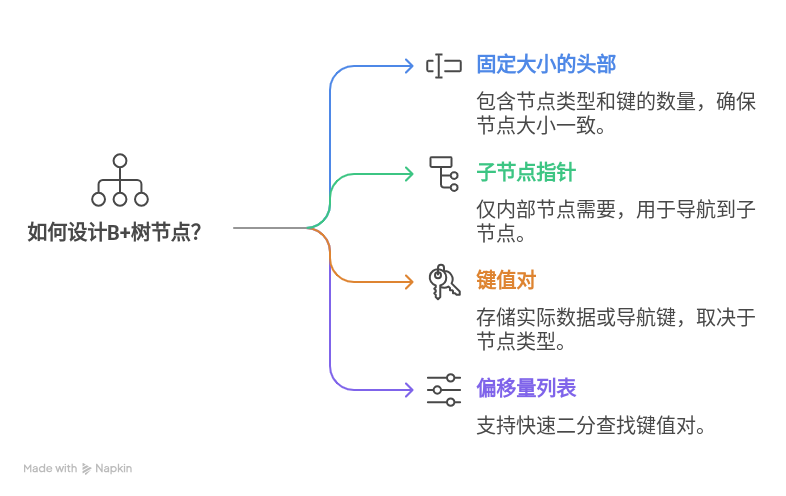
设计B+树节点
在设计B+树的数据结构时,我们首先需要定义节点的格式,这将帮助我们理解如何进行插入、删除以及分裂和合并操作。以下是对B+树节点设计的详细说明。
节点格式概述
所有的B+树节点大小相同,这是为了后续使用自由列表机制。即使当前阶段不处理磁盘数据,一个具体的节点格式仍然是必要的,因为它决定了节点的字节大小以及何时应该分裂一个节点。
节点组成部分
-
固定大小的头部(Header):
- 包含节点类型(叶节点或内部节点)。
- 包含键的数量(nkeys)。
-
子节点指针列表(仅内部节点有):
- 每个内部节点包含指向其子节点的指针列表。
-
KV对列表:
- 包含键值对(key-value pairs),对于叶节点是实际数据,对于内部节点则是用于导航的键。
-
到KV对的偏移量列表:
- 用于支持KV对的二分查找,通过记录每个KV对在节点中的位置来加速查找过程。
节点格式示例:
| type | nkeys | pointers | offsets | key-values | unused |
|---|---|---|---|---|---|
| 2B | 2B | nkeys * 8B | nkeys * 2B | … | … |
每个KV对的格式如下:
| klen | vlen | key | val |
|---|---|---|---|
| 2B | 2B | … | … |
简化与限制
为了专注于学习基础知识,而不是创建一个真实的数据库系统,这里做出了一些简化:
- 叶节点和内部节点使用相同的格式,尽管这会导致一些空间浪费(例如,叶节点不需要指针,内部节点不需要存储值)。
- 内部节点的分支数为𝑛时,包含𝑛个键,每个键都是从相应子树的最小键复制而来。实际上,对于𝑛个分支只需要𝑛−1个键。额外的键主要是为了简化可视化。
- 设置节点大小为4KB,这是典型的操作系统页面大小。然而,键和值可能非常大,超过单个节点的容量。解决这个问题的方法包括外部存储大型KVs或使节点大小可变,但这些不是基础问题的核心部分,因此我们将通过限制KV大小来避免这些问题,确保它们总是能适应于一个节点内。
这种设计使得我们可以集中精力于理解和实现B+树的基本操作,如插入、删除、分裂和合并,同时保持代码的简洁性和易理解性。
const HEADER = 4
const BTREE_PAGE_SIZE = 4096
const BTREE_MAX_KEY_SIZE = 1000
const BTREE_MAX_VAL_SIZE = 3000
func init() {node1max := HEADER + 8 + 2 + 4 + BTREE_MAX_KEY_SIZE + BTREE_MAX_VAL_SIZEassert(node1max <= BTREE_PAGE_SIZE) // maximum KV
}
键大小限制
键大小的限制也确保了内部节点总是能够容纳至少2个键。这对于维持B+树的结构完整性非常重要。
内存中的数据类型
在我们的代码中,一个节点只是一个按这种格式解释的字节块。从内存移动数据到磁盘时,没有序列化步骤会更简单。
type BNode []byte // 可以直接写入磁盘
解耦数据结构与IO
在设计B+树时,无论是内存中的还是磁盘上的数据结构,都需要进行空间的分配和释放。通过使用回调函数,我们可以将这些操作抽象出来,形成数据结构与其他数据库组件之间的边界。
回调机制的设计
以下是Go语言中定义的BTree结构示例,它展示了如何通过回调来管理磁盘页面:
type BTree struct {// 指针(非零页号)root uint64// 管理磁盘页面的回调函数get func(uint64) []byte // 解引用一个指针new func([]byte) uint64 // 分配一个新的页面(写时复制)del func(uint64) // 释放一个页面
}
对于磁盘上的B+树,数据库文件是一个由页号(指针)引用的页面(节点)数组。我们将按照以下方式实现这些回调:
get:从磁盘读取一个页面。new:分配并写入一个新的页面(采用写时复制的方式)。del:释放一个页面。
这种方法允许我们以统一的方式处理内存和磁盘上的数据结构,同时保持代码的清晰和模块化。
为了操作B+树节点的字节格式,我们需要定义一些辅助函数来解析和访问节点中的数据。以下是基于节点格式的详细实现。
节点格式回顾
因为Node的类型就是[]byte,我们可以定义一些辅助函数来解析和访问节点中的数据。
| type | nkeys | pointers | offsets | key-values | unused |
|---|---|---|---|---|---|
| 2B | 2B | nkeys * 8B | nkeys * 2B | … | … |
每个键值对(key-value pair)的格式为:
| klen | vlen | key | val |
|---|---|---|---|
| 2B | 2B | … | … |
辅助函数的实现
我们将为节点定义以下辅助函数:
- 解析头部信息:获取节点类型和键的数量。
- 访问指针列表:用于内部节点的子节点指针。
- 访问偏移量列表:用于快速定位键值对。
- 解析键值对:从偏移量中提取键和值。
解析头部信息
节点头部包含两部分:
type(2字节):节点类型(叶节点或内部节点)。nkeys(2字节):键的数量。
const (BNODE_NODE = 1 // internal nodes without values BNODE_LEAF = 2 // leaf nodes with values
)
func (node BNode) btype() uint16 {return binary.LittleEndian.Uint16(node[0:2])
}
func (node BNode) nkeys() uint16 {return binary.LittleEndian.Uint16(node[2:4])
}func (node BNode) setHeader(btype uint16, nkeys uint16) {binary.LittleEndian.PutUint16(node[0:2], btype)binary.LittleEndian.PutUint16(node[2:4], nkeys)
}
子节点
// pointers
func (node BNode) getPtr(idx uint16) uint64 {//assert(idx < node.nkeys())pos := HEADER + 8*idxreturn binary.LittleEndian.Uint64(node[pos:])
}
func (node BNode) setPtr(idx uint16, val uint64) {
//assert(idx < node.nkeys())pos := HEADER + 8*idxbinary.LittleEndian.PutUint64(node[pos:], val)
}
解析节点中的键值对与偏移量
在B+树的节点中,键值对(KV pairs)是紧密排列存储的。为了高效地访问第n个键值对,我们引入了偏移量列表,以实现O(1)的时间复杂度来定位键值对,并支持节点内的二分查找。
以下是相关代码和解释:
1. 偏移量列表
偏移量列表用于快速定位键值对的位置。每个偏移量表示相对于第一个键值对起点的字节位置(即键值对的结束位置)。通过偏移量列表,我们可以直接跳到指定的键值对,而无需逐一遍历整个节点。
// 计算偏移量列表中第idx个偏移量的位置
func offsetPos(node BNode, idx uint16) uint16 {assert(1 <= idx && idx <= node.nkeys()) // 确保索引有效return HEADER + 8*node.nkeys() + 2*(idx-1)
}// 获取第idx个偏移量
func (node BNode) getOffset(idx uint16) uint16 {if idx == 0 {return 0 // 第一个键值对的起始偏移量为0}return binary.LittleEndian.Uint16(node[offsetPos(node, idx):])
}// 设置第idx个偏移量
func (node BNode) setOffset(idx uint16, offset uint16) {pos := offsetPos(node, idx)binary.LittleEndian.PutUint16(node[pos:], offset)
}
2. 键值对的位置计算
kvPos函数返回第n个键值对相对于整个节点的字节偏移量。它结合了偏移量列表的信息,使得可以直接定位键值对。
// 返回第idx个键值对的位置
func (node BNode) kvPos(idx uint16) uint16 {assert(idx <= node.nkeys()) // 确保索引有效return HEADER + 8*node.nkeys() + 2*node.nkeys() + node.getOffset(idx)
}
3. 获取键和值
通过kvPos函数,我们可以轻松提取键值对中的键和值。
// 获取第idx个键
func (node BNode) getKey(idx uint16) []byte {assert(idx < node.nkeys()) // 确保索引有效pos := node.kvPos(idx)klen := binary.LittleEndian.Uint16(node[pos:]) // 键长度return node[pos+4 : pos+4+uint16(klen)] // 跳过klen和vlen字段
}// 获取第idx个值
func (node BNode) getVal(idx uint16) []byte {assert(idx < node.nkeys()) // 确保索引有效pos := node.kvPos(idx)klen := binary.LittleEndian.Uint16(node[pos:]) // 键长度vlen := binary.LittleEndian.Uint16(node[pos+2:]) // 值长度return node[pos+4+uint16(klen) : pos+4+uint16(klen)+uint16(vlen)]
}
4. 节点大小
nbytes函数通过访问最后一个键值对的结束位置,可以方便地计算节点中已使用的字节数。
// 返回节点的大小(已使用字节数)
func (node BNode) nbytes() uint16 {return node.kvPos(node.nkeys())
}
5. 节点内查找操作
节点内的查找操作是B+树的核心功能之一,既支持范围查询也支持点查询。以下是一个基于线性扫描的实现,未来可以替换为二分查找以提高效率。
// 返回第一个满足 kid[i] <= key 的子节点索引
func nodeLookupLE(node BNode, key []byte) uint16 {nkeys := node.nkeys()found := uint16(0)// 第一个键是从父节点复制来的,因此总是小于等于keyfor i := uint16(1); i < nkeys; i++ {cmp := bytes.Compare(node.getKey(i), key)if cmp <= 0 {found = i // 更新找到的索引}if cmp >= 0 {break // 找到大于等于key的键时停止}}return found
}
这种设计不仅提高了节点操作的效率,还为后续扩展(如二分查找和插入删除操作)奠定了坚实的基础。
更新 B+ 树节点
在 B+ 树中,更新节点的操作涉及插入键值对、复制节点(Copy-on-Write)、以及处理内部节点的链接更新。以下是详细的设计和实现。
1. 插入到叶节点
插入键值对到叶节点的过程包括以下步骤:
- 使用
nodeLookupLE找到插入位置。 - 创建一个新节点,并将旧节点的内容复制到新节点中,同时插入新的键值对。
// 向叶节点插入一个新的键值对
func leafInsert(new BNode, old BNode, idx uint16,key []byte, val []byte,
) {// 设置新节点的头部信息(类型为叶节点,键的数量增加1)new.setHeader(BNODE_LEAF, old.nkeys()+1)// 复制旧节点中 [0, idx) 范围内的键值对到新节点nodeAppendRange(new, old, 0, 0, idx)// 在新节点的 idx 位置插入新的键值对nodeAppendKV(new, idx, 0, key, val)// 复制旧节点中 [idx, nkeys) 范围内的键值对到新节点nodeAppendRange(new, old, idx+1, idx, old.nkeys()-idx)
}
2. 节点复制函数
为了支持高效的节点复制操作,我们定义了两个辅助函数:
nodeAppendKV:将单个键值对插入到指定位置。nodeAppendRange:将多个键值对从旧节点复制到新节点。
2.1 插入单个键值对
// 将一个键值对插入到指定位置
func nodeAppendKV(new BNode, idx uint16, ptr uint64, key []byte, val []byte) {// 设置指针(仅内部节点需要)new.setPtr(idx, ptr)// 获取当前键值对的位置pos := new.kvPos(idx)// 写入键长度binary.LittleEndian.PutUint16(new[pos+0:], uint16(len(key)))// 写入值长度binary.LittleEndian.PutUint16(new[pos+2:], uint16(len(val)))// 写入键copy(new[pos+4:], key)// 写入值copy(new[pos+4+uint16(len(key)):], val)// 更新下一个键的偏移量new.setOffset(idx+1, new.getOffset(idx)+4+uint16(len(key)+len(val)))
}
2.2 复制多个键值对
// 将多个键值对从旧节点复制到新节点
func nodeAppendRange(new BNode, old BNode,dstNew uint16, srcOld uint16, n uint16,
) {for i := uint16(0); i < n; i++ {srcIdx := srcOld + idstIdx := dstNew + i// 复制键值对key := old.getKey(srcIdx)val := old.getVal(srcIdx)nodeAppendKV(new, dstIdx, old.getPtr(srcIdx), key, val)}
}
3. 更新内部节点
对于内部节点,当子节点被分裂时,可能需要更新多个链接。我们使用 nodeReplaceKidN 函数来替换一个子节点链接为多个链接。
// 替换一个子节点链接为多个链接
func nodeReplaceKidN(tree *BTree, new BNode, old BNode, idx uint16,kids ...BNode,
) {inc := uint16(len(kids)) // 新增的子节点数量// 设置新节点的头部信息(类型为内部节点,键的数量增加 inc-1)new.setHeader(BNODE_NODE, old.nkeys()+inc-1)// 复制旧节点中 [0, idx) 范围内的键值对到新节点nodeAppendRange(new, old, 0, 0, idx)// 插入新的子节点链接for i, node := range kids {// 为每个子节点分配页号,并插入其第一个键作为边界键nodeAppendKV(new, idx+uint16(i), tree.new(node), node.getKey(0), nil)}// 复制旧节点中 [idx+1, nkeys) 范围内的键值对到新节点nodeAppendRange(new, old, idx+inc, idx+1, old.nkeys()-(idx+1))
}
4. 关键点总结
-
Copy-on-Write:
- 每次修改节点时,都会创建一个新节点并复制旧节点的内容。这种设计确保了数据的一致性和持久性。
-
插入逻辑:
- 叶节点的插入通过
leafInsert实现,而内部节点的更新通过nodeReplaceKidN实现。 - 在插入过程中,键值对的顺序必须保持一致,因为偏移量列表依赖于前一个键值对的位置。
- 叶节点的插入通过
-
回调机制:
tree.new回调用于分配新的子节点页号,这使得我们可以灵活地支持内存和磁盘上的存储。
-
扩展性:
- 当前实现基于线性扫描,未来可以通过二分查找优化查找效率。
- 支持多链接更新,方便处理子节点分裂的情况。
示例用法
以下是一个简单的例子,展示如何向叶节点插入键值对:
func ExampleLeafInsert() {// 创建一个旧节点old := make(BNode, 4096)old.setHeader(BNODE_LEAF, 0)// 创建一个新节点new := make(BNode, 4096)// 插入键值对leafInsert(new, old, 0, []byte("key1"), []byte("value1"))// 验证插入结果fmt.Printf("Key: %s, Value: %s\n", new.getKey(0), new.getVal(0))
}
分裂 B+ 树节点
在 B+ 树中,由于每个节点的大小受到页面限制(BTREE_PAGE_SIZE),当一个节点变得过大时,我们需要将其分裂为多个节点。最坏情况下,一个超大的节点可能需要被分裂为 3 个节点。
以下是详细的设计和实现。
1. 分裂逻辑概述
1.1 节点分裂的基本规则
- 如果节点的大小小于等于
BTREE_PAGE_SIZE,则无需分裂。 - 如果节点的大小超过
BTREE_PAGE_SIZE,我们首先尝试将其分裂为两个节点:- 左节点:包含前半部分数据。
- 右节点:包含后半部分数据。
- 如果左节点仍然过大,则需要进一步分裂为三个节点:
- 左左节点:包含左节点的前半部分数据。
- 中间节点:包含左节点的后半部分数据。
- 右节点:保持不变。
1.2 返回值
- 函数返回分裂后的节点数量(1、2 或 3)以及对应的节点数组。
2. 实现细节
2.1 nodeSplit2 函数
该函数将一个超大的节点分裂为两个节点,确保右节点始终适合一个页面。
// 将超大的节点分裂为两个节点
func nodeSplit2(left BNode, right BNode, old BNode) {nkeys := old.nkeys()half := nkeys / 2// 复制前半部分到左节点left.setHeader(old.NodeType(), half)nodeAppendRange(left, old, 0, 0, half)// 复制后半部分到右节点right.setHeader(old.NodeType(), nkeys-half)nodeAppendRange(right, old, 0, half, nkeys-half)
}
2.2 nodeSplit3 函数
该函数处理节点的完整分裂逻辑,返回 1 至 3 个节点。
// 分裂一个过大的节点,结果是 1~3 个节点
func nodeSplit3(old BNode) (uint16, [3]BNode) {if old.nbytes() <= BTREE_PAGE_SIZE {// 如果节点大小符合限制,则无需分裂old = old[:BTREE_PAGE_SIZE]return 1, [3]BNode{old, nil, nil} // 返回单个节点}// 创建临时节点left := BNode(make([]byte, 2*BTREE_PAGE_SIZE)) // 左节点可能需要再次分裂right := BNode(make([]byte, BTREE_PAGE_SIZE))// 第一次分裂:将旧节点分裂为左节点和右节点nodeSplit2(left, right, old)if left.nbytes() <= BTREE_PAGE_SIZE {// 如果左节点大小符合限制,则返回两个节点left = left[:BTREE_PAGE_SIZE]return 2, [3]BNode{left, right, nil}}// 如果左节点仍然过大,则需要第二次分裂leftleft := BNode(make([]byte, BTREE_PAGE_SIZE))middle := BNode(make([]byte, BTREE_PAGE_SIZE))// 第二次分裂:将左节点分裂为左左节点和中间节点nodeSplit2(leftleft, middle, left)// 验证分裂结果assert(leftleft.nbytes() <= BTREE_PAGE_SIZE)// 返回三个节点return 3, [3]BNode{leftleft, middle, right}
}
3. 关键点分析
-
分裂条件:
- 如果节点的大小小于等于
BTREE_PAGE_SIZE,则无需分裂。 - 如果节点的大小超过限制,则需要进行一次或两次分裂。
- 如果节点的大小小于等于
-
分裂策略:
- 每次分裂都将节点分为两部分,确保右节点始终适合一个页面。
- 如果左节点仍然过大,则需要进一步分裂。
-
临时节点:
- 分裂过程中创建的节点是临时分配在内存中的。
- 这些节点只有在调用
nodeReplaceKidN时才会真正分配到磁盘上。
-
边界情况:
- 确保左节点和右节点的大小始终符合限制。
- 使用断言(
assert)验证分裂结果的正确性。
这种分裂机制为构建高效的 B+ 树奠定了基础,同时也为后续优化(如动态调整页面大小)提供了良好的起点。
B+ 树插入操作
在 B+ 树中,插入操作是核心功能之一。我们已经实现了以下三个节点操作:
leafInsert:更新叶节点。nodeReplaceKidN:更新内部节点。nodeSplit3:分裂超大的节点。
现在,我们将这些操作组合起来,实现完整的 B+ 树插入逻辑。插入操作从根节点开始,通过键查找直到到达目标叶节点,然后执行插入操作。
1. 插入逻辑概述
1.1 插入流程
- 从根节点开始递归查找,找到目标叶节点。
- 如果找到的键已存在,则更新其值(
leafUpdate)。 - 如果键不存在,则插入新键值对(
leafInsert)。 - 如果节点过大,则进行分裂(
nodeSplit3)。 - 更新父节点以反映子节点的变化(
nodeReplaceKidN)。
1.2 递归处理
- 内部节点的插入是递归的,每次插入完成后返回更新后的节点。
- 如果返回的节点过大,则需要分裂,并更新父节点的链接。
2. 实现细节
2.1 treeInsert 函数
该函数是 B+ 树插入的核心入口,负责处理递归插入和分裂逻辑。
// 插入一个键值对到节点中,结果可能需要分裂。
// 调用者负责释放输入节点并分配分裂后的结果节点。
func treeInsert(tree *BTree, node BNode, key []byte, val []byte) BNode {// 创建一个新的临时节点,允许其大小超过一页new := BNode{data: make([]byte, 2*BTREE_PAGE_SIZE)}// 查找插入位置idx := nodeLookupLE(node, key)// 根据节点类型执行不同的操作switch node.btype() {case BNODE_LEAF:// 叶节点if bytes.Equal(key, node.getKey(idx)) {// 键已存在,更新其值leafUpdate(new, node, idx, key, val)} else {// 插入新键值对leafInsert(new, node, idx+1, key, val)}case BNODE_NODE:// 内部节点nodeInsert(tree, new, node, idx, key, val)default:panic("bad node!")}return new
}
2.2 leafUpdate 函数
leafUpdate 类似于 leafInsert,但它用于更新已存在的键值对,而不是插入重复的键。
// 更新叶节点中的现有键值对
func leafUpdate(new BNode, old BNode, idx uint16,key []byte, val []byte,
) {// 设置新节点的头部信息new.setHeader(BNODE_LEAF, old.nkeys())// 复制旧节点的内容到新节点nodeAppendRange(new, old, 0, 0, old.nkeys())// 更新指定位置的键值对pos := new.kvPos(idx)binary.LittleEndian.PutUint16(new[pos+2:], uint16(len(val))) // 更新值长度copy(new[pos+4+uint16(len(key)):], val) // 更新值内容
}
2.3 nodeInsert 函数
对于内部节点,插入操作是递归的。插入完成后,需要检查子节点是否过大,并进行分裂。
// 向内部节点插入键值对
func nodeInsert(tree *BTree, new BNode, node BNode, idx uint16,key []byte, val []byte,
) {// 获取子节点的指针kptr := node.getPtr(idx)// 递归插入到子节点knode := treeInsert(tree, tree.get(kptr), key, val)// 分裂子节点nsplit, split := nodeSplit3(knode)// 释放旧的子节点tree.del(kptr)// 更新父节点的链接nodeReplaceKidN(tree, new, node, idx, split[:nsplit]...)
}
3. 关键点分析
-
递归与分裂:
- 插入操作是递归的,从根节点开始,直到找到目标叶节点。
- 每次插入完成后,如果节点过大,则需要分裂,并更新父节点的链接。
-
内存管理:
- 插入过程中创建的临时节点需要由调用者负责释放。
- 使用回调函数(如
tree.new和tree.del)管理页面的分配和释放。
-
分裂策略:
- 使用
nodeSplit3处理节点分裂,确保分裂后的节点始终符合页面大小限制。 - 分裂后的节点数量可能是 1、2 或 3。
- 使用
-
边界情况:
- 如果键已存在,则直接更新其值。
- 如果插入导致根节点分裂,则需要创建新的根节点。
4. 示例用法
以下是一个简单的例子,展示如何向 B+ 树中插入键值对:
func ExampleTreeInsert() {// 初始化 B+ 树tree := &BTree{root: 1, // 假设根节点页号为 1get: func(pageNum uint64) []byte {// 模拟从磁盘读取节点return loadFromDisk(pageNum)},new: func(data []byte) uint64 {// 模拟分配新页面return allocatePage(data)},del: func(pageNum uint64) {// 模拟释放页面deallocatePage(pageNum)},}// 插入键值对key := []byte("example_key")value := []byte("example_value")// 获取根节点rootNode := tree.get(tree.root)// 执行插入操作updatedRoot := treeInsert(tree, rootNode, key, value)// 更新根节点tree.root = tree.new(updatedRoot)
}
5. 总结
通过上述设计和实现,我们能够高效地完成 B+ 树的插入操作。关键点包括:
- 递归插入:从根节点开始,递归查找目标叶节点。
- 分裂机制:使用
nodeSplit3确保节点大小始终符合限制。 - 内存管理:通过回调函数管理页面的分配和释放。
- 灵活性:支持动态调整树的结构,适应不同大小的数据。
这种插入机制为构建高效的 B+ 树奠定了基础,同时也为后续优化(如批量插入、并发控制)提供了良好的起点。
代码仓库地址:database-go
相关文章:

B+树节点与插入操作
B树节点与插入操作 设计B树节点 在设计B树的数据结构时,我们首先需要定义节点的格式,这将帮助我们理解如何进行插入、删除以及分裂和合并操作。以下是对B树节点设计的详细说明。 节点格式概述 所有的B树节点大小相同,这是为了后续使用自由…...

rollup使用讲解
rollup 总结 什么是 rollup? rollup 是一个 JavaScript 模块打包器,在功能上要完成的事和 webpack 性质一样,就是将小块代码编译成大块复杂的代码,例如 library 或应用程序。在平时开发应用程序时,我们基本上选择用 webpack,相比之下,rollup.js 更多是用于 library 打…...

高边开关和低边开关的区别
高边驱动和低边驱动的区别 在高边驱动和低边驱动中,开关的位置直接影响电路在负载短路时的安全性和电流路径。以下是关键原理的分步解释: 1. 高低边驱动的结构对比 高边驱动(High-Side Drive) 电路结构: 电源正极 →…...
PG psql --single-transaction 参数功能
文章目录 PG psql --single-transaction 参数功能 PG psql --single-transaction 参数功能 test.sql 文件 create table test1(id int); CREATE OR REPLACE FUNCTION func_test() RETURNS INTEGER AS $BODY$ BEGINxxxreturn 0; END; $BODY$ LANGUAGE plpgsql VOLATILE CALLE…...

C++ 多态
1.多态的概念 多态(polymorphism)通俗来说就是多种形态。多态分为编译时多态(静态多态)和运行时多态(动态多态),这里我们重点是运行时多态,编译时多态主要就是我们前面的函数重载和…...

【matlab|python】矢量棍棒图应用场景和代码
【matlab|python】矢量棍棒图应用场景和代码 矢量棍棒图的介绍和作用 矢量棍棒图(stick plot)是一种用于可视化 方向性时间序列数据 的图形工具。它常用于大气科学和海洋科学中,以直观地展示 风场、海流 或 其他矢量变量 随时间的变化情况。 …...

Matlab 五相电机仿真
1、内容简介 Matlab 208-五相电机仿真 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

计算机视觉cv2入门之视频处理
在我们进行计算机视觉任务时,经常会对视频中的图像进行操作,这里我来给大家分享一下,如何cv2中视频文件的操作方法。这里我们主要介绍cv2.VideoCapture函数的基本使用方法。 cv2.VideoCapture函数...

力扣每日一题781题解-算法:贪心,数学公式 - 数据结构:哈希
https://leetcode.cn/problems/rabbits-in-forest/description/?envTypedaily-question&envId2025-04-20 781.推测兔子数 算法:贪心,数学公式 数据结构:哈希 用哈希存每个兔子报告的同色数量,作为key,同个key…...

MAC-QueryWrapper中用的exists,是不是用join效果更好
在使用MyBatis-Plus的QueryWrapper中的exists方法时,是否改为使用join效果会更好,以及如何 修改。这涉及到SQL优化和MyBatis-Plus的用法。 首先,需要理解exists和join在SQL中的区别。exists用于检查子查询是否返回结果,而join则是将 两个表连接起来,根据某些条件合并行…...

使用 Visual Studio 2022 中的 .http 文件
转自微软技术文档: https://learn.microsoft.com/zh-cn/aspnet/core/test/http-files?viewaspnetcore-9.0 Visual Studio 2022.http 文件编辑器提供了一种便捷的方式来测试 ASP.NET Core项目,尤其是 API 应用。 编辑器提供一个 UI,用于&am…...

相得益彰 — 基于 GraphRAG 事理图谱驱动的实时金融行情新闻资讯洞察
*本文为亚马逊云科技博客文章,仅用于技术分享,不构成投资建议或金融决策支持。文中涉及的公司名称仅用于技术示例,不代表亚马逊云科技观点或与这些公司的商业合作关系。 背景介绍 在当今这个信息爆炸的时代,金融市场每天都在产生…...

为什么this与super不能出现在同一构造器的原因
在 Java 中,this() 和 super() 不能同时出现在同一个构造器中,因为它们都必须作为构造器的第一条语句,而一个构造器的第一条语句只能有一个。以下是详细解释和示例: ⚠️ 核心规则 只能二选一: 每个构造器的第一条语句…...

Linux:网络基础
hello,各位小伙伴,本篇文章跟大家一起学习《Linux:网络基础》,感谢大家对我上一篇的支持,如有什么问题,还请多多指教 ! 如果本篇文章对你有帮助,还请各位点点赞!…...
)
C++入门篇(下)
目录 1、引用 1.1 引用概念 1.2 引用特性 1.3 常引用 1.4 使用场景 1.4.1 引用做参数 1.4.2 引用做返回值 1.5 引用和指针的区别 2、内联函数 2.1 概念 2.2 特性 3、auto关键字 4、基于范围的for循环 5、指针空值nullptr 5.1 C98 中的指针空值处理 5.2 C11 …...

QCustomPlot中自定义QCPAbstractPlottable绘图元素
QCPAbstractPlottable 是 QCustomPlot 中所有可绘制图形(如曲线、柱状图等)的基类。要创建自定义的绘图元素,通常需要继承这个类并实现其纯虚函数。 基本步骤 继承 QCPAbstractPlottable 实现必要的纯虚函数 添加自定义属性和方法 注册到 QCustomPlot 系统 完…...

【Bluedroid】蓝牙 HID 设备信息加载与注册机制及配置缓存系统源码解析
本篇解析Android蓝牙子系统加载配对HID设备的核心流程,通过btif_storage_load_bonded_hid_info实现从NVRAM读取设备属性、验证绑定状态、构造描述符并注册到BTA_HH模块。重点剖析基于ConfigCache的三层存储架构(全局配置/持久设备/临时设备)&…...

【计算机视觉】CV实战项目 - PCC-Net 人群计数
PCC-Net 人群计数项目 项目特点项目运行方式与步骤1. 环境准备2. 数据准备3. 模型训练4. 实验结果 常见问题及解决方法 PCC-Net(Perspective Crowd Counting via Spatial Convolutional Network)是一个用于人群计数的深度学习项目,旨在通过空…...
Towards Transferable Targeted 3D Adversarial Attack in the Physical World--阅读笔记
目录 简介: 背景: 挑战: 目的: 技术细节: 贡献: 1. NeRF的核心作用:3D重建与参数化表示 2. 对抗优化的创新:NeRF参数空间的双优化 2.1 传统方法的局限…...

opencv图像库编程
一、下载安装 opencv 1.1 下载安装包 1.2 解压缩 unzip opencv-3.4.11.zip 解压缩以后主目录文件夹如下: 1.3 进入到解压后的文件夹中 cd opencv-3.4.11 二、使用 cmake安装opencv 2.1 进入 root 用户,并更新一下 sudo su sudo apt-get update …...

星拍相机APP:时尚与科技的完美融合,打造你的专属美
在数字时代,手机相机不仅是记录生活的工具,更是表达个性和创意的平台。今天,我们要介绍的 星拍相机APP,就是这样一款匠心制作的手机相机应用。它融合了时尚与科技,提供了多样化的魔法美颜功能,让每一次拍摄…...
脑力航迹)
puzzle(0531)脑力航迹
目录 脑力航迹 规则 解法 简单模式 中等模式 困难模式 专家模式 脑力航迹 规则 2条航迹会产生一个相对航迹: 根据相对航迹和其中一个航迹推导另外一个航迹。 解法 没有任何需要推理的地方,就是纯粹的2个矢量相加。 简单模式 中等模式 困难模…...

【英语语法】词法---形容词
目录 形容词1. 形容词的核心功能2. 形容词的位置(1) 前置定语(最常见)(2) 后置定语(特殊情况)(3) 表语位置(系动词后) 3. 形容词的比较级与最高级(1) 规则变化(2) 不规则变化(3) 用法对比 4. 多个形容词修饰…...

理解 React 的 useEffect
文章目录 React 的 useEffect一、什么是副作用(Side Effects)?二、useEffect 的基本用法三、依赖数组的三种情况1. 无依赖数组(每次渲染后都执行, 不推荐)2. 空依赖数组(仅在挂载时执行一次)3. …...

2.1 基于委托的异步编程方法
基于委托的异步编程模型是 .NET 早期版本中实现异步操作的一种方式,主要通过 BeginInvoke 和 EndInvoke 方法来实现。这种基于委托的异步模式已被 Task 和 async/await 模式取代,但在维护旧代码时仍可能遇到这种模式。 委托的方法中:Invoke用于同步调用; 而BeginInvoke与E…...

对于在线教育或知识付费类网站视频处理方案
一、视频格式: 1. 推荐格式:HLS(HTTP Live Streaming) 优势: 自适应码率:根据用户网络状况自动切换清晰度,避免卡顿。广泛兼容性:iOS/macOS 原生支持,Android…...
)
Gen - CDPT举例说明:动态上下文前缀(输入先和标签结合,输出结果会更贴近标签内容)
Gen - CDPT举例说明:动态上下文前缀(输入先和标签结合,输出结果会更贴近标签内容) 目录 Gen - CDPT举例说明:动态上下文前缀(输入先和标签结合,输出结果会更贴近标签内容)输入文本示例Gen - CDPT模型处理过程示例什么是:提示次优动态前缀提示方法生成与这条评论上下文…...

UCSC CTF 2025|MISC
1、USB flag{ebdfea9b-3469-41c7-9070-d7833ecc6102} 2、three part1是图片隐水印 part1:8f02d3e7 part2是2进制变换 -ce89-4d6b-830e- Part3先从pass.pcapng得到密码字典 解压缩密码:thinkbell 3个部分合并得到flag{8f02d3e7-ce89-4d6b-830e-5d0cb5…...
)
FTP客户端实现(文件传输)
文章目录 🧱 一、FTP 基础架构回顾🚀 二、FTP 客户端的核心结构🔗 三、连接与登录过程📌 1. ftp_create()📌 2. ftp_connect()📌 3. ftp_login() 📁 四、上传文件实现(ftp_upload_fi…...

状态管理最佳实践:Bloc架构实践
状态管理最佳实践:Bloc架构实践 引言 Bloc (Business Logic Component) 是Flutter中一种强大的状态管理解决方案,它基于响应式编程思想,通过分离业务逻辑和UI表现层来实现清晰的代码架构。本文将深入探讨Bloc的核心概念、实现原理和最佳实践…...

嵌入式人工智能应用-第三章 opencv操作 5 二值化、图像缩放
嵌入式人工智能应用 嵌入式人工智能应用-第三章 opencv操作 5 二值化 嵌入式人工智能应用1 二值化1.1 概念介绍1.2 函数介绍1.2 基本应用1.3 参考案例 2 图像缩放2.1 基本概念2.2 函数介绍2.3 基本参考代码2.4 pyrUp 和 pyrDown 函数2.5 函数介绍2.6 参考代码2.7 总结 1 二值化…...

[OS_7] 访问操作系统对象 | offset | FHS | Handle
实验代码可以看去年暑假的这篇文章:【Linux】进程间通信:详解 VSCode使用 | 匿名管道 我们已经知道,进程从 execve 后的初始状态开始,可以通过 mmap 改变自己的地址空间,通过 fork 创建新的进程,再通过 exe…...
)
【Vulkan 入门系列】创建帧缓冲、命令池、命令缓存,和获取图片(六)
这一节主要介绍创建帧缓冲(Framebuffer),创建命令池,创建命令缓存,和从文件加载 PNG 图像数据,解码为 RGBA 格式,并将像素数据暂存到 Vulkan 的 暂存缓冲区中。 一、创建帧缓冲 createFramebu…...
)
Linux 进程控制(自用)
非阻塞调用waitpid 这样父进程就不会阻塞,此时循环使用我们可以让父进程执行其他任务而不是阻塞等待 进程程序替换 进程PCB加载到内存中的代码和数据 替换就是完全替换当前进程的代码段、数据段、堆和栈,保存当前的PCB 代码指的是二进制代码不是源码&a…...

FreeSWITCH 简单图形化界面41 - 批量SIP视频呼叫测试
FreeSWITCH 简单图形化界面41 - 批量视频测试 0、界面预览00、安装测试工具1、注册分机2、设置接听选项2.1 上传媒体文件2.2 设置接听设置 3、呼叫测试 0、界面预览 http://myfs.f3322.net:8020/ 用户名:admin,密码:admin FreeSWITCH界面安…...
)
通过爬虫方式实现头条号发布视频(2025年4月)
1、将真实的cookie贴到代码目录中toutiaohao_cookie.txt文件里,修改python代码里的user_agent和video_path, cover_path等变量的值,最后运行python脚本即可; 2、运行之前根据import提示安装一些常见依赖,比如requests等; 3、2025年4月份最新版; 代码如下: import js…...

《AI大模型应知应会100篇》第28篇:大模型在文本创作中的应用技巧
第28篇:大模型在文本创作中的应用技巧 🧠 摘要 在内容为王的时代,AI大模型正在重塑文本创作的每一个环节。从创意构思到风格润色,从论文报告到小说脚本,AI不仅是创作者的助手,更是灵感的激发器。本文将带你…...

字节跳动发布UI-TARS-1.5,入门AI就来近屿智能
近日,字节跳动在 Hugging Face 平台正式开源了其最新多模态代理模型——UI-TARS-1.5。作为 UI-TARS 系列的革新之作,该模型以视觉语言模型为基础,突破性实现跨平台 GUI 自动化交互,为自动化与智能交互领域注入了强劲动能。无论是开…...

大数据学习栈记——MapReduce技术
本文介绍hadoop中的MapReduce技术的应用,使用java API。操作系统:Ubuntu24.04。 MapReduce概述 MapReduce概念 MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序…...

GO语言入门:常用数学函数2
14.6 大型数值 math/big 包中公开了一些实用 API,用于表示大型整数值和浮点数值。当基础类型无法容纳要使用的数值时,应改用 big 包中提供的新类型。例如 Int、Float 等。 14.6.1 大型整数值之间的运算 若希望让下面两个整数值完成加、减法运算&#…...

Django 使用教程
Django 使用教程 Django 是一个高级的 Python Web 框架,采用了 MTV(Model-Template-View)设计模式,旨在帮助开发者快速构建高效、可维护的 Web 应用。它有着非常丰富的功能,包括 ORM、用户认证、表单处理、管理后台等…...

deepseek + kimi制作PPT
目录 一、kimi简介二、deepseek生成内容三、生成PPT四、编辑PPT 一、kimi简介 kimi是一款只能ppt生成器,擅长将文本内容生成PPT。 在这里,DeepSeek 负责内容生成与逻辑梳理,Kimi 优化表达与提供设计建议。 二、deepseek生…...

C++学习:六个月从基础到就业——内存管理:RAII原则
C学习:六个月从基础到就业——内存管理:RAII原则 本文是我C学习之旅系列的第十九篇技术文章,也是第二阶段"C进阶特性"的第四篇,主要介绍C中的RAII原则及其在资源管理中的应用。查看完整系列目录了解更多内容。 引言 在…...

量子计算与经典计算融合:开启计算新时代
一、引言 随着科技的飞速发展,计算技术正迎来一场前所未有的变革。量子计算作为前沿技术,以其强大的并行计算能力和对复杂问题的高效处理能力,吸引了全球科技界的关注。然而,量子计算并非要完全取代经典计算,而是与经典…...
)
RV1126网络环境TFTPNFS搭建(二)
二、RV1126 开发板TFTP环境搭建 2.1、Ubuntu下安装和配置 xinetd 执行以下指令,安装 xinetd sudo apt-get install xinetd 执行以下指令创建一个 xinetd.conf 文件 sudo vi /etc/xinetd.conf 修改 xinetd.conf 文件内容如下: # Simple configurat…...

计算机视觉7——齐次坐标与相机内外参
一、透视投影 透视投影(Perspective Projection)是计算机视觉和图形学中描述三维物体在二维平面成像的基础模型,其核心思想是模拟人类视觉系统的成像原理——中心投影。具体而言,三维空间中的点通过一个固定的投影中心࿰…...
)
学习笔记—C++—string(一)
目录 string 为什么学习string的类 string类的常用接口 string类对象的常见构造 string类对象的访问及遍历操作 operator[] 迭代器 范围for auto 迭代器(二) string类对象的容量操作 size,length,max_size,capacity,clear基本用法 reserve 提…...

Linux命令-Shell编程
Shell是一个命令行解释器,它接收应用程序/用户命令,然后调用操作系统内核。 写一个hello.sh脚本: 1.mkdir scripts 2.cd scripts 3.touch hello.sh 4.vim hello.sh #!/bin/bash echo "hello,world" 5.bash hello.sh(…...

基于Django的AI客服租车分析系统
基于Django的AI客服租车分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】AI智能客服与用户交互指导手册 【技术栈】 ①:系统环境:Python 3.8,Django 4.2框架 ②:开发环境&a…...
)
计算机组成与体系结构:计算机结构的分类(classifications of computer architecture)
目录 Von Neumann Architecture(冯诺依曼结构) Harvard Architecture(哈佛结构) Modified Harvard Architecture(改进哈佛结构) 三种结构对比总结表 💡 从“内存访问结构”角度分类&#x…...