YOLOv11改进——基于注意力机制和密集小目标增强型EVA模块的设计与实现
随着计算机视觉技术的快速发展,目标检测算法在实时性与检测精度间的平衡成为研究重点。YOLO(You Only Look Once)系列算法以其高效性和准确性,长期占据实时目标检测领域的前沿位置。然而,尽管最新版本在通用场景表现优异,但在处理密集小目标检测(如遥感图像中的车辆、医学影像中的细胞或自动驾驶场景中的行人)时仍面临显著挑战。核心问题在于:(1)密集小目标的局部特征易被背景干扰,导致特征表征模糊;(2)模型对关键区域的注意力不足,难以有效区分高密度目标间的关联性;(3)传统特征金字塔架构难以高效融合多尺度信息以提升小目标细节捕捉能力。为此,本研究以注意力机制与密集小目标增强型EVA(Enhanced Vision Attention)模块为核心,提出YOLOv11的改进方案。在注意力机制方面,改进后模型通过混合空间-通道注意力机制,动态强化目标区域的空间显著性与通道间的重要性权重,解决小目标因面积占比小导致的注意力分配不足问题。进一步,针对密集小目标场景,本文设计了EVA模块,该模块融合了①多尺度密集特征增强路径,通过轻量级卷积与跨层特征交互(CFA)提升小目标边界细节的可辨性;②自适应特征金字塔重组,结合Transformer机制增强长距离依赖关系,缓解密集目标间的遮挡与混淆效应;③动态权重损失函数,针对密集小目标在训练中因采样不足引发的类别不平衡问题,通过自适应调整损失权重以提升模型对小目标的鲁棒性。

论文地址:https://arxiv.org/pdf/2210.02093
代码地址:https://github.com/QY1994-0919/CFPNet
1. 整体架构
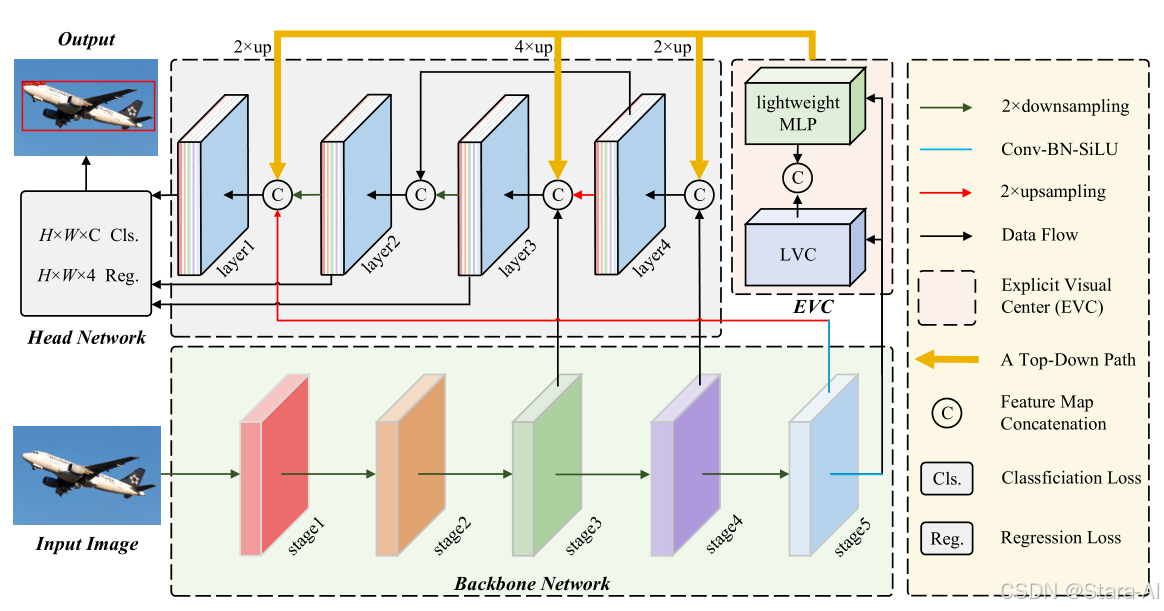
EVAblock是YOLO11中专门为密集和小目标设计的一种新型模块,其核心思想是通过高效的多尺度特征融合和局部-全局注意力机制,提升模型对复杂场景的适应能力。
1.1 多尺度特征融合
EVAblock通过金字塔结构提取多尺度特征,并利用深度可分离卷积(Depthwise Separable Convolution)降低计算成本。具体步骤如下:
- 特征分组 :将输入特征图分为多个子特征图,分别对应不同的感受野。
- 多分支处理 :每个子特征图通过独立的卷积路径进行处理,捕获不同尺度的目标信息。
- 特征融合 :将各分支的输出特征图通过加权求和的方式融合,形成统一的多尺度特征表示。
1.2 局部-全局注意力机制
为了进一步增强特征表达能力,EVAblock引入了局部-全局注意力机制(Local-Global Attention Mechanism, LGAM)。该机制包含两个部分:
- 局部注意力 :通过滑动窗口操作,捕获局部区域内的上下文信息。局部注意力模块能够有效保留目标的细节特征,特别适合小目标检测。
- 全局注意力 :通过全局池化操作,生成整个特征图的全局描述符。全局注意力模块能够建模目标之间的长程依赖关系,适合处理密集目标。
LGAM通过自适应权重分配策略,动态平衡局部和全局注意力的作用,从而在精度和效率之间取得良好的折衷。
2. 将EVC添加到YOLO11
2.1 EVC代码
步骤一:将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/block.py中
class Encoding(nn.Module):def __init__(self, in_channels, num_codes):super(Encoding, self).__init__()# init codewords and smoothing factorself.in_channels, self.num_codes = in_channels, num_codesnum_codes = 64std = 1. / ((num_codes * in_channels) ** 0.5)# [num_codes, channels]self.codewords = nn.Parameter(torch.empty(num_codes, in_channels, dtype=torch.float).uniform_(-std, std), requires_grad=True)# [num_codes]self.scale = nn.Parameter(torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0), requires_grad=True)@staticmethoddef scaled_l2(x, codewords, scale):num_codes, in_channels = codewords.size()b = x.size(0)expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))# ---处理codebook (num_code, c1)reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))# 把scale从1, num_code变成 batch, c2, N, num_codesreshaped_scale = scale.view((1, 1, num_codes)) # N, num_codes# ---计算rik = z1 - d # b, N, num_codesscaled_l2_norm = reshaped_scale * (expanded_x - reshaped_codewords).pow(2).sum(dim=3)return scaled_l2_norm@staticmethoddef aggregate(assignment_weights, x, codewords):num_codes, in_channels = codewords.size()# ---处理codebookreshaped_codewords = codewords.view((1, 1, num_codes, in_channels))b = x.size(0)# ---处理特征向量x b, c1, Nexpanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))# 变换rei b, N, num_codes,-assignment_weights = assignment_weights.unsqueeze(3) # b, N, num_codes,# ---开始计算eik,必须在Rei计算完之后encoded_feat = (assignment_weights * (expanded_x - reshaped_codewords)).sum(1)return encoded_featdef forward(self, x):assert x.dim() == 4 and x.size(1) == self.in_channelsb, in_channels, w, h = x.size()# [batch_size, height x width, channels]x = x.view(b, self.in_channels, -1).transpose(1, 2).contiguous()# assignment_weights: [batch_size, channels, num_codes]assignment_weights = torch.softmax(self.scaled_l2(x, self.codewords, self.scale), dim=2)# aggregateencoded_feat = self.aggregate(assignment_weights, x, self.codewords)return encoded_featclass Mlp(nn.Module):"""Implementation of MLP with 1*1 convolutions. Input: tensor with shape [B, C, H, W]"""def __init__(self, in_features, hidden_features=None,out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Conv2d):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# 1*1 3*3 1*1
class ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.SiLU, groups=1,norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):super(ConvBlock, self).__init__()self.in_channels = in_channelsexpansion = 4c = out_channels // expansionself.conv1 = Conv(in_channels, c, act=nn.SiLU())self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.SiLU())self.conv3 = Conv(c, out_channels, 1, act=False)self.act3 = act_layer(inplace=True)if res_conv:self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)self.residual_bn = norm_layer(out_channels)self.res_conv = res_convdef zero_init_last_bn(self):nn.init.zeros_(self.bn3.weight)def forward(self, x, return_x_2=True):residual = xx = self.conv1(x)x2 = self.conv2(x) # if x_t_r is None else self.conv2(x + x_t_r)x = self.conv3(x2)if self.res_conv:residual = self.residual_conv(residual)residual = self.residual_bn(residual)x += residualx = self.act3(x)if return_x_2:return x, x2else:return xclass Mean(nn.Module):def __init__(self, dim, keep_dim=False):super(Mean, self).__init__()self.dim = dimself.keep_dim = keep_dimdef forward(self, input):return input.mean(self.dim, self.keep_dim)class LVCBlock(nn.Module):def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):super(LVCBlock, self).__init__()self.out_channels = out_channelsself.num_codes = num_codesnum_codes = 64self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)self.LVC = nn.Sequential(Conv(in_channels, in_channels, 1, act=nn.SiLU()),Encoding(in_channels=in_channels, num_codes=num_codes),nn.BatchNorm1d(num_codes),nn.SiLU(inplace=True),Mean(dim=1))self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())def forward(self, x):x = self.conv_1(x, return_x_2=False)en = self.LVC(x)gam = self.fc(en)b, in_channels, _, _ = x.size()y = gam.view(b, in_channels, 1, 1)x = F.relu_(x + x * y)return xclass GroupNorm(nn.GroupNorm):"""Group Normalization with 1 group.Input: tensor in shape [B, C, H, W]"""def __init__(self, num_channels, **kwargs):super().__init__(1, num_channels, **kwargs)class DWConv_LMLP(nn.Module):"""Depthwise Conv + Conv"""def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):super().__init__()self.dconv = Conv(in_channels,in_channels,k=ksize,s=stride,g=in_channels,)self.pconv = Conv(in_channels, out_channels, k=1, s=1, g=1)def forward(self, x):x = self.dconv(x)return self.pconv(x)# LightMLPBlock
class LightMLPBlock(nn.Module):def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",mlp_ratio=4., drop=0., act_layer=nn.GELU,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm): # act_layer=nn.GELU,super().__init__()self.dw = DWConv_LMLP(in_channels, out_channels, ksize=1, stride=1, act="silu")self.linear = nn.Linear(out_channels, out_channels) # learnable position embeddingself.out_channels = out_channelsself.norm1 = norm_layer(in_channels)self.norm2 = norm_layer(in_channels)mlp_hidden_dim = int(in_channels * mlp_ratio)self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.use_layer_scale = use_layer_scaleif use_layer_scale:self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones(out_channels), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones(out_channels), requires_grad=True)def forward(self, x):if self.use_layer_scale:x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))else:x = x + self.drop_path(self.dw(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x# EVCBlock
class EVCBlock(nn.Module):def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):super().__init__()expansion = 2ch = out_channels * expansion# Stem stage: get the feature maps by conv block (copied form resnet.py) 进入conformer框架之前的处理self.conv1 = Conv(in_channels, in_channels, k=3, act=nn.SiLU())self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 1 / 4 [56, 56]# LVCself.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64) # c1值暂时未定# LightMLPBlockself.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=3, stride=1, act="silu", act_layer=nn.GELU,mlp_ratio=4., drop=0.,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm)self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)def forward(self, x):x1 = self.maxpool((self.conv1(x)))# LVCBlockx_lvc = self.lvc(x1)# LightMLPBlockx_lmlp = self.l_MLP(x1)# concatx = torch.cat((x_lvc, x_lmlp), dim=1)x = self.cnv1(x)return x
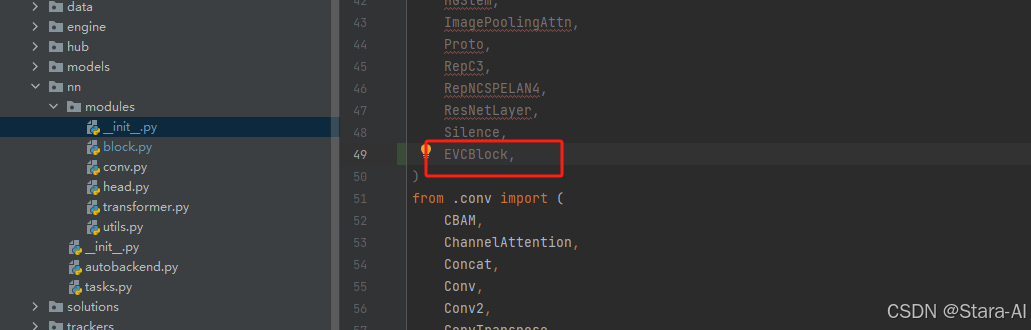
2.2 修改init.py文件
步骤二:修改modules文件夹下的__init__.py文件,先导入函数
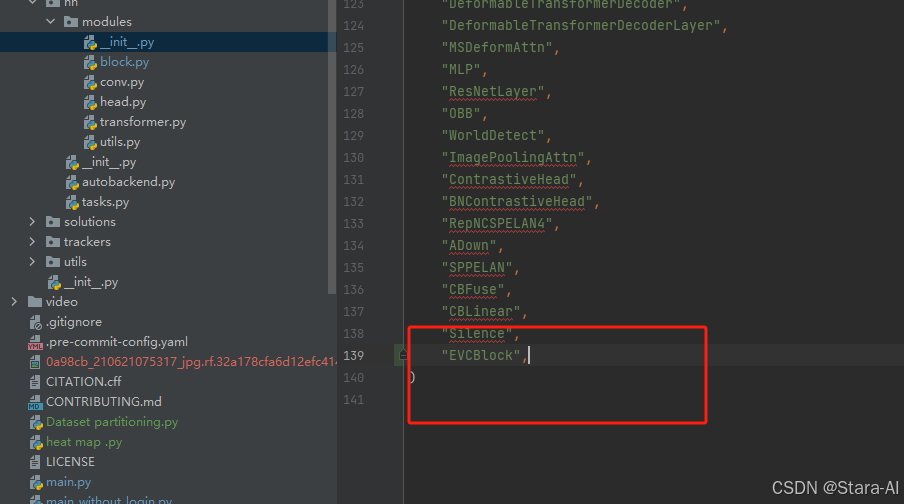
然后在下面的__all__中声明函数
2.3 添加yaml文件
步骤三:在/ultralytics/ultralytics/cfg/models/11下面新建文件yolo11_EVC.yaml文件。粘贴下面内容
- 目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [ -1, 1, EVCBlock, [ 1024 ] ]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
- 语义分割
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [ -1, 1, EVCBlock, [ 1024 ] ]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
- 旋转目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [ -1, 1, EVCBlock, [ 1024 ] ]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[17, 20, 23], 1, OBB, [nc, 1]] # Detect(P3, P4, P5)
本文只是对yolo11基础上添加模块,如果要对yolo11n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple
# YOLO11n
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channel:1024# YOLO11s
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channel:1024# YOLO11m
depth_multiple: 0.50 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512# YOLO11l
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512 # YOLO11x
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.50 # layer channel multiple
max_channel:512
2.4 在task.py中进行注册
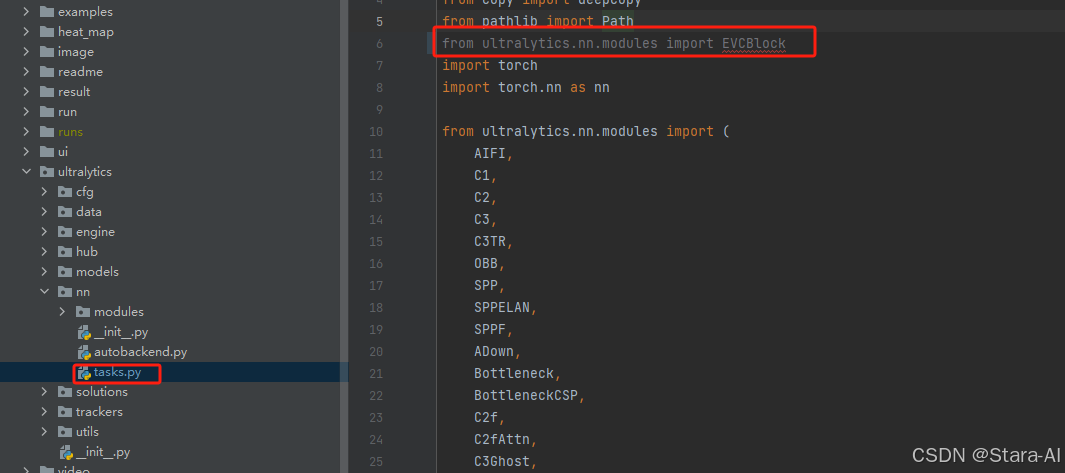
步骤四:在task.py的parse_model函数中进行注册
先在task.py导入函数:
然后在task.py文件下找到parse_model这个函数,添加 EVCBlock
2.5 执行train.py训练
步骤五:新建train.py,将model的参数路径设置为yolo11_EVC.yaml的路径即可
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':# model.load('yolo11n.pt') # 加载预训练权重,改进或者做对比实验时候不建议打开,因为用预训练模型整体精度没有很明显的提升model = YOLO(model=r'ultralytics/cfg/11/yolo11_EVC.yaml')model.train(data=r'/root/lanyun-tmp/yolov8-crops-app/dataset/data.yaml',imgsz=640,epochs=300,batch=32,workers=16,device='0',optimizer='SGD',close_mosaic=10,resume=False,project='run/train1',name='exp',single_cls=False,cache=False,)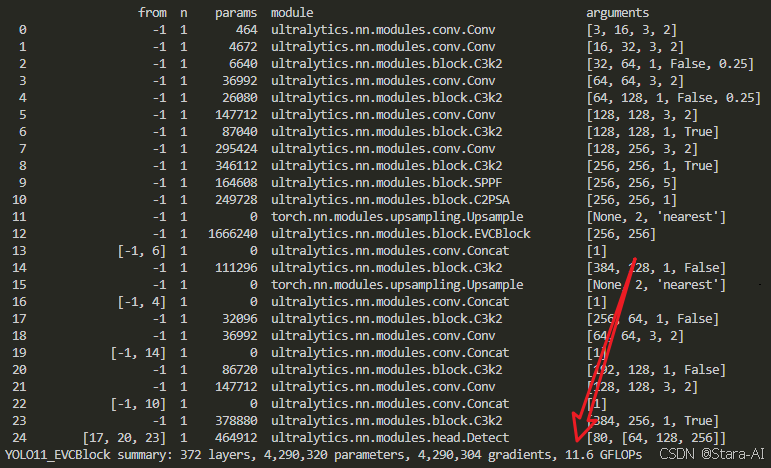
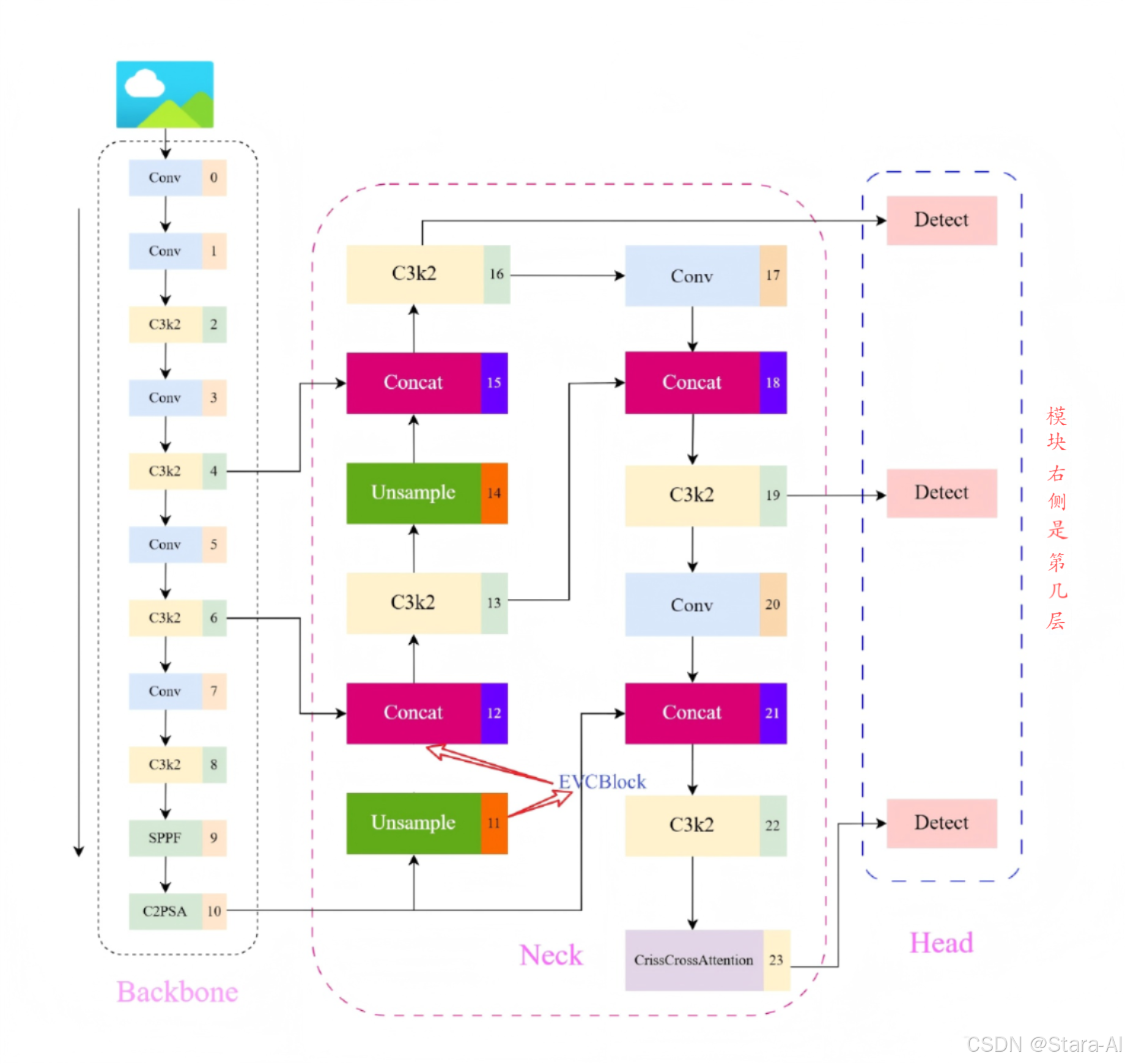
3. 网络结构图
未来的研究方向包括:
- 进一步优化注意力机制的计算复杂度。
- 探索更高效的多尺度特征融合策略。
- 将YOLO11应用于更多实际场景,如自动驾驶、无人机监控等
相关文章:

YOLOv11改进——基于注意力机制和密集小目标增强型EVA模块的设计与实现
随着计算机视觉技术的快速发展,目标检测算法在实时性与检测精度间的平衡成为研究重点。YOLO(You Only Look Once)系列算法以其高效性和准确性,长期占据实时目标检测领域的前沿位置。然而,尽管最新版本在通用场景表现优…...

n8n 中文系列教程_04.半开放节点深度解析:Code与HTTP Request高阶用法指南
在低代码开发领域,n8n凭借其独特的半开放架构打破了传统自动化工具的边界。本文深度剖析两大核心节点——Code与HTTP Request,从底层原理到企业级实战,揭秘如何通过代码自由扩展与API无缝集成,突破平台限制。无论是对接国产生态&a…...

Linux学习——了解和熟悉Linux系统的远程终端登录
Linux学习——了解和熟悉Linux系统的远程终端登录 一.配置Ubuntu系统的网络和用户 1、设置虚拟机网络为桥接模式 打开VMWare,选择编辑虚拟机设置,在网络适配器设置中,选择“桥接模式”,保存设置并启动Ubuntu。 2、配置Ubuntu的…...

PFLM: Privacy-preserving federated learning with membership proof证明阅读
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目…...

十倍开发效率 - IDEA插件之 Maven Helper
0X00 先看效果 第一个选项表示存在冲突的依赖,可以看到图片中 mysql 的连接依赖发生了冲突,在低版本的上面直接右键选择 Exclude,冲突的依赖就被解决掉了。 0X01 安装 在 Plugins 中直接搜索 Maven Helper,选择第一个进行安装&am…...

线程安全总结
1.线程安全 1.1什么是线程安全 线程安全问题指的是当多个线程同时访问和操作共享资源(如变量、数据结构等)时,由于缺乏有效的同步控制,导致程序出现不可预期的错误或数据不一致的现象。其核心在于并发操作破坏了程序的正确性。 …...

计算机视觉cv入门之答题卡自动批阅
前边我们已经讲解了使用cv2进行图像预处理与边缘检测等方面的知识,这里我们以答题卡自动批阅这一案例来实操一下。 大致思路 答题卡自动批阅的大致流程可以分为这五步:图像预处理-寻找考试信息区域与涂卡区域-考生信息区域OCR识别-涂卡区域填涂答案判断…...
)
10.QT-显示类控件|LCD Number|ProgressBar|Calendar Widget(C++)
LCD Number QLCDNumer 是⼀个专⻔⽤来显⽰数字的控件.类似于"⽼式计算器"的效果 属性说明intValueQLCDNumber 显⽰的数字值(int).valueQLCDNumber 显⽰的数字值(double).和intValue是联动的.例如给value设为1.5,intValue的值就是2.另外,设置value和intValue的⽅法名…...

深入探索 Unix 与 Linux:历史、内核及发行版
引言 在当今的计算世界中,Unix 和 Linux 操作系统的影响力无处不在。从驱动互联网的服务器到我们口袋里的智能手机,再到无数嵌入式设备,它们的身影随处可见 1。这两个操作系统家族共享着丰富的历史和相似的设计哲学,但又各自走过…...

HCIP第三次作业
一、实验要求 1,R5为ISP,其上只能配置IP地址;R4作为企业边界路由器, 出口公网地址需要通过PPP协议获取,并进行chap认证 2整个0SPF环境IP基于172.16.0.0/16划分; 3所有设备均可访问R5的环回; 4减少LSA的更新量,加快收敛…...
git,cgdb操作指南)
Linux 入门:基础开发工具(下)git,cgdb操作指南
目录 一.进度条 一).补充:回车与换行 二).行缓冲区 三).进度条代码 二.版本控制器Git 一).Git 安装与配置 二).创建仓库 三).开始操作 1.简单流程 2.配置公钥 1).身份…...

【上位机——MFC】消息映射机制
消息映射机制 Window消息分类消息映射机制的使用代码示例 MFC框架利用消息映射机制把消息、命令与它们的处理函数映射起来。具体实现方法是在每个能接收和处理消息的类中,定义一个消息和消息函数指针对照表,即消息映射表。 在不重写WindowProc虚函数的大…...

提交bug单时,应该说明哪些信息?
在提交 Bug 单时,为了让开发人员能够快速定位和解决问题,需要详细说明以下几方面信息: Bug 的基本信息 标题:简洁明了地概括 Bug 的主要问题,例如 “登录页面输入错误密码后提示信息不准确”。Bug 类型:明确…...

max31865典型电路
PT100读取有很多种方案,常用的惠斯通电桥,和专用IC max31865 。 电阻温度检测器(RTD)是一种阻值随温度变化的电阻。铂是最常见、精度最高的测温金属丝材料。铂RTD称为PT-RTD,镍、铜和其它金属亦可用来制造RTD。RTD具有较宽的测温范围&#x…...

【网工第6版】第4章 无线通信网
目录 ■ 移动通信与4G 5G技术 ▲ 移动通信发展 ▲ 移动通信制式 ▲ 移动通信技术标准 ▲ 4G标准 ▲ 4G关键技术 ◎ OFDMA ◎ 4G关键技术-MIMO ◎ 4G关键技术-SDR ◎ 4G关键技术-VolP ▲ 5G应用场景 ▲ 5G两种组网模式 ▲ 5G关键技术 ■ CDMA计算 ■ WLAN通信技术…...
)
辅助函数构造题目(缓慢更新,遇到更道)
题1...

图论基础:图存+记忆化搜索
图的储存 储存图有很多种方式,在此介绍两种:邻接数组,邻接表 第一种虽然简单,但访问的时间和空间花销过大,因此第二种最为常见。 让我们分别看看它们是什么 在介绍之前,我们先解释一下此处说的“图”是什…...

使用docker任意系统编译opengauss
使用docker任意系统编译opengauss 本人使用开发机器为ubuntu系统,不在官方推荐的编译系统内。但是不想为了开发opengauss重装系统。所以采用docker进行编译。 代码拉取 本人是在/home/yuyang/Documents/opengauss目录下进行操作。 先获取源代码:git clone https:/…...

JavaScript 一维数组转二维数组
题目描述: <script>const num [1,2,3,4]const out (function(num,m,n){if(num.length ! m*n){return []}const newarr []for(let i 0;i<m;i){newarr.push(num.slice(i*n,(i1)*n))}return newarr})(num,2,2)console.log(out)</script>不使用Stri…...
常见的泛型数据结构类(3)SortedDictionary<TKey, TValue>与SortedList<TKey, TValue>)
C#进阶学习(八)常见的泛型数据结构类(3)SortedDictionary<TKey, TValue>与SortedList<TKey, TValue>
目录 关于默认的排序可以看这篇文章的第二点中关于排序的部分: 一、SortedDictionary 1. 核心特性 2. 常用方法和属性 二、SortedList 1. 核心特性 2. 常用方法和属性 三、关于TryGetValue(TKey key, out TValue value) 方法的详细说明 (一&…...
)
运维侠职场日记9:用DeepSeek三天通关详解自动化操作pdf批量提取PDF文字将PDF转Word文档(附上脚本代码)
一. 痛点 运维侠小白想将pdf文档转换成word文档,但是,wps等等这些软件的转换功能都是要付费,开通会员,这该怎么办?听说python也有这个功能于是迫不及待想学… 学会基础,学习的乐趣一点点积累 基础学习成本低,掌握所需的技能要求也少,学会一两行代码,看着输出,心理慢…...

热门算法面试题第19天|Leetcode39. 组合总和40.组合总和II131.分割回文串
39. 组合总和 力扣题目链接(opens new window) 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 说明: 所有数字(包括 ta…...

IDEA连接达梦数据库
1. 参考在IDEA中连接达梦数据库:详细配置指南_idea连接达梦数据库-CSDN博客 . jdbc:dm://127.0.0.1:5236?schemaSALES...

React Router V7使用详解
1,安装 React Router是React生态系统中最流行的路由解决方案,它允许开发者在单页应用的不同页面之间进行切换,而不需要重新加载整个页面,React Router与React框架深度集成,使得开发者在单页面应用中进行页面切换时变得轻而易举。 作为官方推荐的路由解决方案,React Rou…...
详解)
国际数据加密算法(IDEA)详解
以下是修正后的准确版本,已解决原文中的术语、符号及技术细节问题: 国际数据加密算法(IDEA) IDEA是一种分组加密算法,由Xuejia Lai(来学嘉)和James Massey于1990年设计。IDEA使用128位密钥对64位明文分组进行加密,经过8轮迭代运算后生成64位密文分组。其安全性基于…...

2025年4月19日-米哈游春招笔试题-第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 魔法网格变换术 问题描述 在魔法学院,卢小姐正在研究一种特殊的魔法网格变换术。这种魔法作用于一个 n n n...

基于STM32串口通信
基于STM32串口通信 一、串口简介 串口,也称为串行接口或串行通信接口(通常指COM接口),是一种采用串行通信方式的扩展接口。它实现了数据一位一位地顺序传送,具有通信线路简单、成本低但传送速度慢的特点。 只要一对传…...

即梦AI与可灵AI视频生成功能对比分分析
一、核心功能与特点对比 维度可灵AI(快手旗下)即梦AI(字节跳动旗下)视频生成能力✅ 支持最长3分钟视频生成(通过续写功能)✅ 1080p分辨率、30fps帧率✅ 物理模拟(流体运动、重力效果࿰…...

【任务调度】Quartz入门
Quartz 入门 代码仓库地址: GitHub:chenmeng-test-demos/demo8-task at master cmty256/chenmeng-test-demosGitee:demo8-task chenmeng/chenmeng-test-demos - 码云 - 开源中国 基本介绍 Quartz 是一个开源的作业调度框架,它完…...
)
【网络编程】从零开始彻底了解网络编程(二)
本篇博客给大家带来的是网络编程的知识点,. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快乐顺便进步 1. …...

常见浏览器 WebDriver 驱动下载
以下是常见浏览器 WebDriver 驱动的下载地址及注意事项,综合多个可靠来源整理而成: 一、Chrome 浏览器(ChromeDriver) 官方下载地址 http://chromedriver.storage.googleapis.com/index.html • • 版本匹配:需与 Chro…...

【每日八股】复习计算机网络 Day3:TCP 协议的其他相关问题
文章目录 昨日内容复习TCP 的四次挥手?TCP 为什么要四次挥手?在客户端处于 FIN_WAIT_2 状态时,如果此时收到了乱序的来自服务端的 FIN 报文,客户端会如何处理?何时进入 TIME_WAIT 状态?TCP 四次挥手丢了怎么…...
预测及治疗方案制定中的应用研究)
大模型在胆管结石(无胆管炎或胆囊炎)预测及治疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 国内外研究现状 二、胆管结石相关理论基础 2.1 胆管结石概述 2.2 临床表现与诊断方法 2.3 传统治疗方法 三、大模型技术原理与应用优势 3.1 大模型基本原理 3.2 在医疗领域的应用潜力 3.3 用于胆管结石预测的可…...

LeetCode第159题_至多包含两个不同字符的最长子串
LeetCode 第159题:至多包含两个不同字符的最长子串 题目描述 给定一个字符串 s,找出 至多 包含两个不同字符的最长子串 t,并返回该子串的长度。 难度 中等 题目链接 点击在LeetCode中查看题目 示例 示例 1: 输入: s &qu…...

PG CTE 递归 SQL 翻译为 达梦版本
文章目录 PG SQLDM SQL总结 PG SQL with recursive result as (select res_id,phy_res_code,res_name from tbl_res where parent_res_id (select res_id from tbl_res where phy_res_code org96000#20211203155858) and res_type_id 1 union all select t1.res_id, t1.p…...

JavaScript 位掩码常量教程
JavaScript 位掩码常量教程 位掩码(Bitmask)是一种高效使用内存的技术,在JavaScript中可以用来存储和操作多个布尔值标志。下面我将为您介绍位掩码的基本概念、应用场景以及实践示例。 什么是位掩码常量? 位掩码利用二进制位&a…...

Linux守护进程
一、相关概念 QQ邮箱关于三种协议的解释:SMTP/IMAP服务 1.SMTP协议 SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)是一种用于发送电子邮件的互联网标准。它在TCP/IP协议族中,通常使用25端口进行通…...

Python多进程并发编程:深入理解Lock与Semaphore的实战应用与避坑指南
引言 在多进程并发编程中,资源竞争问题如同“隐形炸弹”,稍有不慎就会导致数据不一致或程序崩溃。无论是银行转账的余额错误,还是火车票超卖,其根源都在于共享资源的无序访问。如何安全高效地管理这些资源?Python中的锁…...

mysql的5.7版本与8.0版本的差异与兼容性
MySQL 5.7 和 8.0 是两个重要的版本,它们在性能、功能、安全性等方面都有显著的改进,同时也存在一些兼容性问题。以下是具体的改进点和兼容性问题: 一、MySQL 8.0 的改进点 性能提升 优化器改进:MySQL 8.0 对查询优化器进行了重大…...

【Rust 精进之路之第4篇-数据基石·上】标量类型:整数、浮点数、布尔与字符的精妙之处
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025-04-20 引言:构成万物的“原子”——标量类型 在上一篇文章【变量观】中,我们深入探讨了 Rust 如何通过 let、mut、const、static 和 Shadowing 来管理变量绑定,并理解了其背后对安全性…...

LangChain4j模型参数配置全解析:释放大语言模型的真正潜力
LangChain4j模型参数配置全解析:释放大语言模型的真正潜力 前言 在大语言模型应用开发中,参数配置是连接算法理论与工程实践的关键桥梁。合理的参数设置能让模型输出更精准、响应更高效,而错误的配置可能导致成本激增或业务逻辑失效。本文将…...

【深度学习入门_NLP自然语言处理】序章
本部分开始深度学习第二大部分NLP章节学习,找了好多资料,终于明确NLP的学习目标了,介于工作之余学习综合考量,还是决定以视频学习为主后期自主实践为主吧。 分享一个总图,其实在定位的时候很迷茫,单各章节…...
——4.1基本算术运算的实现)
计算机组成原理笔记(十六)——4.1基本算术运算的实现
计算机中最基本的算术运算是加法运算,加、减、乘、除运算最终都可以归结为加法运算。 4.1.1加法器 一、加法器的基本单元 加法器的核心单元是 全加器(Full Adder, FA),而所有加法器都由 半加器(Half Adder, HA&…...

AI日报 - 2025年04月21日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | O3模型性能引热议,Rich Sutton提出「体验时代」新范式,自递归AI构建仍存挑战。 新模型如O3展示高IQ,但AGI定义与实现路径讨论加剧,强调自主生成数据与体验学习。 ▎&…...

基于Python的推荐算法的电影推荐系统的设计
标题:基于Python的推荐算法的电影推荐系统的设计与实现 内容:1.摘要 本文围绕基于Python的推荐算法的电影推荐系统展开研究。背景在于随着电影数量的急剧增加,用户在海量电影中找到符合自身喜好的影片变得困难。目的是设计并实现一个高效准确的电影推荐系统&#x…...

【perf】perf工具的使用生成火焰图
文章目录 1. What is perf?2. perf使用2.1 perf的子工具集2.2 常用指令perf list指令格式参数perf中事件分类使用示例 perf stat指令格式参数 perf top指令格式参数交互式界面操作使用示例 perf record指令格式参数使用示例 perf report指令格式参数交互式界面操作使用示例 pe…...

Sentinel源码—6.熔断降级和数据统计的实现一
大纲 1.DegradeSlot实现熔断降级的原理与源码 2.Sentinel数据指标统计的滑动窗口算法 1.DegradeSlot实现熔断降级的原理与源码 (1)熔断降级规则DegradeRule的配置Demo (2)注册熔断降级监听器和加载熔断降级规则 (3)DegradeSlot根据熔断降级规则对请求进行验证 (1)熔断降级…...

C语言自增自减题目
一、题目引入 二、运行结果 三、题目分析 这一题中 i的初始值是2 所以执行case2中的命令i-- 表达式的值此时是2 i--完了之后i最后的值是1 由于是switch没有break 就会往下贯穿 直到遇到break为止 case3里面 i 表达式的值是2 i完了之后i的值也是2 综上所述 i的值最终的值是…...

paddleocr出现: [WinError 127] 找不到指定的程序解决办法
paddleocr是一个由百度开发开源的OCR(光学字符识别)工具库。它支持多种语言的文本识别,包括中文、英文、日文等,并具备高效的文本检测和识别能力。paddleocr基于PaddlePaddle深度学习框架开发,提供了丰富的预处理、模型…...

c++STL——list的使用和模拟实现
文章目录 list的使用和模拟实现使用部分list的结构声名默认成员函数initializer_list容量和访问操作修改操作其他接口list的迭代器迭代器的种类 list的模拟实现明确基本结构预处理函数迭代器部分(重点)思路进一步考虑最终代码operator->的重载总结 begin和end访问接口修改操…...