C++项目 —— 基于多设计模式下的同步异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
C++项目 —— 基于多设计模式下的同步&异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
- 异步线程
- 什么是异步线程?
- C++ 异步线程简单例子
- 代码解释
- 程序输出
- 关键点总结
- 扩展:使用 `std::thread` 实现异步线程
- 分辨同步异步线程
- 1. 看调用是否立即返回
- 同步线程(如排队买奶茶)
- 异步线程(如外卖下单)
- 2. 看是否有专门的工作线程
- 同步
- 异步
- 3. 看资源访问方式
- 同步
- 异步
- 4. 典型场景对比
- 代码示例对比
- 同步日志
- 异步日志
- 双缓冲区异步任务处理器
- 设计思想:异步线程 + 数据池
- 核心思想
- 任务池的设计:双缓冲区阻塞数据池
- 1. 双缓冲区的工作机制
- 2. 减少锁冲突
- 3. 内存管理优化
- 优势分析
- 1. 提高任务处理效率
- 2. 减少锁冲突
- 3. 降低内存分配开销
- 与其他设计方案的对比
- 1. 循环队列
- 2. 单缓冲区
- 3. 双缓冲区的优势
- 总结
- 缓冲区实现
- 总结
- loop.hpp中与线程有关的操作
- 1. 线程的创建与管理
- 2. 线程同步与通信
- 3. 线程入口函数
- 4. 数据生产与消费
- 5. 线程安全的设计
- 总结
- placeholders::_1
- 示例代码
- 说明
- 输出结果
- 具体作用
- 详细解释
- 为什么需要 `std::placeholders::_1`?
- 示例对比
- 不使用 `std::bind` 和占位符:
- 使用 `std::bind` 和占位符:
- 总结
我们上次把同步日志器的编写已经差不多完成了,如果还没有看过同步日志器编写的小伙伴可以点击这里:
https://blog.csdn.net/qq_67693066/article/details/147309275?spm=1011.2415.3001.5331
我们今天主要来编写异步任务处理器,但是在这之前我们得了解一下什么是异步线程:
异步线程
什么是异步线程?
异步线程指的是程序中的一种执行模式,其中某些任务可以在主线程或其他线程中并行运行,而不会阻塞主线程的执行。换句话说,异步线程允许我们在不等待某个操作完成的情况下继续执行其他任务。
在 C++ 中,异步线程可以通过标准库中的 <thread> 或 <future> 来实现。常见的异步编程工具包括:
std::thread:用于创建和管理线程。std::async:用于以异步方式执行任务,并返回结果。std::future和std::promise:用于在线程间传递数据。
C++ 异步线程简单例子
以下是一个使用 std::async 实现异步线程的简单例子:
#include <iostream>
#include <future> // std::async, std::future
#include <chrono> // std::this_thread::sleep_for
#include <thread> // std::this_thread// 模拟一个耗时的任务
int slowTask(int x) {std::cout << "Task started with input: " << x << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟耗时操作int result = x * x;std::cout << "Task completed. Result: " << result << std::endl;return result;
}int main() {// 使用 std::async 启动一个异步任务std::future<int> resultFuture = std::async(std::launch::async, slowTask, 5);// 主线程继续执行其他工作std::cout << "Main thread is doing other work..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟主线程的工作std::cout << "Main thread finished its work." << std::endl;// 获取异步任务的结果(如果任务未完成,会阻塞直到结果可用)int result = resultFuture.get();std::cout << "Final result from async task: " << result << std::endl;return 0;
}
代码解释
-
slowTask函数:- 这是一个模拟的耗时任务,接收一个整数参数
x,经过 2 秒的延迟后返回x * x的结果。
- 这是一个模拟的耗时任务,接收一个整数参数
-
std::async:std::async是一个函数模板,用于启动异步任务。- 参数
std::launch::async表示任务将在一个新线程中异步执行。 - 第二个参数是任务函数(
slowTask),后面的参数是传递给任务函数的参数(这里是5)。
-
主线程的行为:
- 在启动异步任务后,主线程继续执行自己的工作(例如打印消息或进行其他计算)。
- 当主线程需要获取异步任务的结果时,调用
resultFuture.get()。如果异步任务尚未完成,这一步会阻塞,直到结果可用。
-
std::future:std::future是一个模板类,用于存储异步任务的结果。- 调用
get()方法可以获取异步任务的返回值。
程序输出
运行上述代码,输出可能如下(顺序可能会因线程调度而略有不同):
Main thread is doing other work...
Task started with input: 5
Main thread finished its work.
Task completed. Result: 25
Final result from async task: 25
关键点总结
-
异步执行:
std::async允许我们异步地运行任务,而不会阻塞主线程。
-
线程管理:
- 使用
std::future可以方便地获取异步任务的结果。
- 使用
-
非阻塞与阻塞:
- 异步任务启动后,主线程可以继续执行其他任务。
- 调用
future.get()时,如果任务未完成,主线程会被阻塞,直到结果可用。
扩展:使用 std::thread 实现异步线程
如果你不想使用 std::async,也可以直接使用 std::thread 来实现类似的功能:
#include <iostream>
#include <thread>
#include <chrono>// 模拟一个耗时的任务
void slowTask(int x) {std::cout << "Task started with input: " << x << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2));std::cout << "Task completed. Result: " << (x * x) << std::endl;
}int main() {// 创建一个线程执行异步任务std::thread t(slowTask, 5);// 主线程继续执行其他工作std::cout << "Main thread is doing other work..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Main thread finished its work." << std::endl;// 等待线程完成t.join();return 0;
}
在这个版本中,std::thread 直接启动一个线程,主线程通过 t.join() 等待线程完成。

说直白的,就是主线程创建了一个子线程,本来是由主线程完成的,现在由这个子线程完成。
分辨同步异步线程
要判断一个线程模型是同步还是异步,可以从以下几个关键特征进行区分。我用最简单的比喻和代码示例来说明:
1. 看调用是否立即返回
同步线程(如排队买奶茶)
void syncLog(const std::string& msg) {std::ofstream file("log.txt");file << msg; // 必须等待文件写入完成// 调用者在这里阻塞等待
}
- 特征:函数执行完所有操作(包括I/O)后才返回
- 类比:就像在奶茶店排队,必须等到拿到奶茶才能离开
异步线程(如外卖下单)
void asyncLog(const std::string& msg) {_buffer.push(msg); // 只是把消息放入队列// 立即返回,后台线程会处理写入
}
- 特征:函数只把任务放入队列/缓冲区后立即返回
- 类比:像点外卖,下单后就可以做其他事情,外卖员会异步配送
2. 看是否有专门的工作线程
同步
// 没有额外线程,直接在当前线程处理
syncLog("error"); // 直接卡在这里写文件
异步
class AsyncLogger {std::thread _worker; // 关键:有专门的工作线程void workerThread() {while (true) { /* 处理队列中的任务 */ }}
};
3. 看资源访问方式
同步
void writeFile(const std::string& data) {// 直接访问资源(文件/网络)_file.write(data); // 同步I/O
}
异步
void asyncWrite(const std::string& data) {_queue.push(data); // 只是提交任务// 实际由其他线程从_queue取出数据后写文件
}
4. 典型场景对比
| 特征 | 同步 | 异步 |
|---|---|---|
| 调用阻塞 | 是 | 否 |
| 工作线程 | 无(当前线程处理) | 有专门线程 |
| 性能影响 | 受I/O速度限制 | 几乎不影响主线程 |
| 代码复杂度 | 简单 | 需要线程安全控制 |
| 适合场景 | 简单应用、低频操作 | 高性能服务、高频日志 |
代码示例对比
同步日志
// 当前线程直接写文件(阻塞)
void logSync(const std::string& msg) {std::lock_guard<std::mutex> lock(_mutex);_file << msg; // 同步写入,耗时操作!
}
异步日志
// 只是提交任务到队列
void logAsync(const std::string& msg) {std::lock_guard<std::mutex> lock(_mutex);_queue.push(msg); // 内存操作,极快_cond.notify_one(); // 通知工作线程
}// 工作线程
void workerThread() {while (true) {std::string msg = _queue.pop(); // 从队列取任务_file << msg; // 实际耗时操作在这里}
}
只要记住:异步=把任务丢给别人处理,自己不等结果,就能轻松区分了!
双缓冲区异步任务处理器
设计思想:异步线程 + 数据池
核心思想
通过引入异步线程和双缓冲区数据池,将任务的生产和消费分离。生产者负责生成任务并将其放入任务池,而消费者(异步线程)从任务池中取出任务并执行。这种设计的目标是提高任务处理效率,减少锁冲突,并降低内存分配和释放的开销。
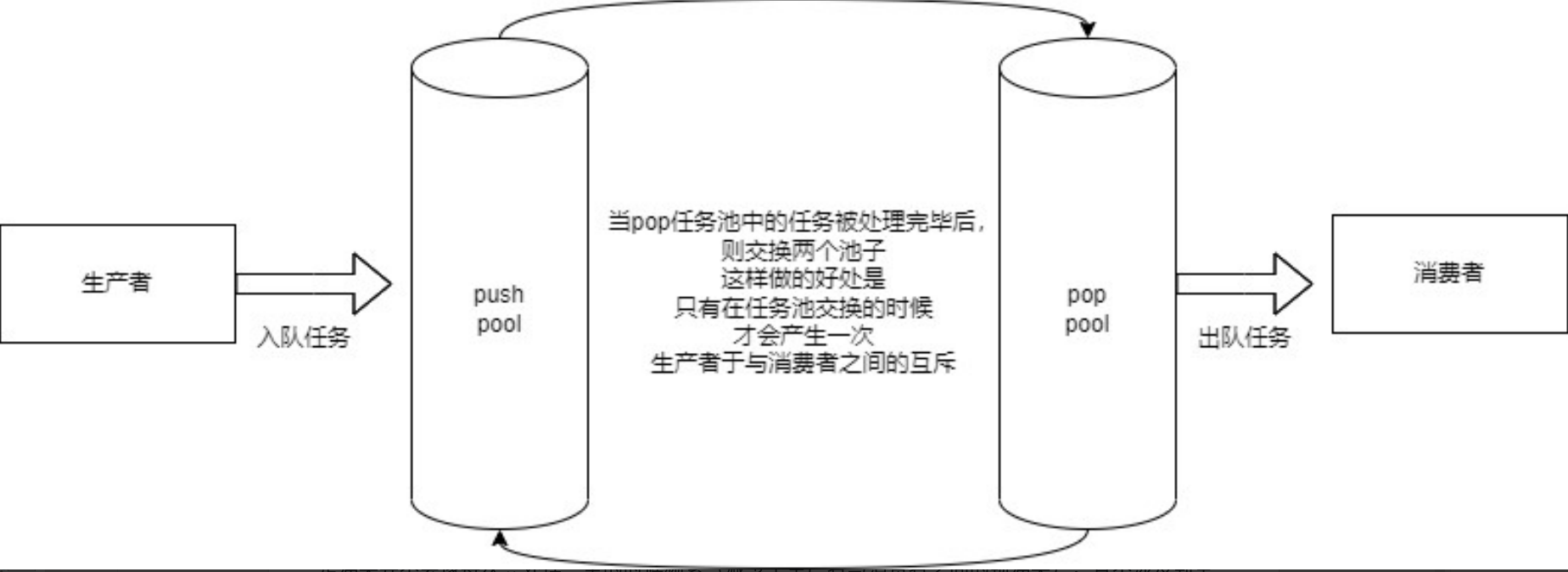
任务池的设计:双缓冲区阻塞数据池
1. 双缓冲区的工作机制
- 两个缓冲区:任务池由两个独立的缓冲区组成,分别称为主缓冲区和备用缓冲区。
- 主缓冲区:用于存放生产者提交的任务。
- 备用缓冲区:在主缓冲区被消费者完全处理后,与主缓冲区交换角色。
- 交换机制:
- 当主缓冲区中的所有任务被消费者处理完毕后,主缓冲区和备用缓冲区的角色互换。
- 这样,消费者可以立即开始处理新的任务,而生产者可以继续向新的主缓冲区添加任务。
2. 减少锁冲突
- 在传统的单缓冲区或循环队列中,每次任务的添加或取出都需要加锁,导致生产者和消费者之间的锁冲突频繁发生。
- 而双缓冲区通过批量处理的方式减少了锁冲突的概率:
- 生产者只需要在向主缓冲区添加任务时加锁,消费者只需要在处理完主缓冲区的所有任务后进行一次锁操作来交换缓冲区。
- 这种方式大大减少了锁的使用频率,降低了线程间的竞争。
3. 内存管理优化
- 双缓冲区的设计避免了频繁申请和释放内存空间。
- 缓冲区的大小通常是固定的,生产者和消费者只需在缓冲区内操作,无需动态分配或释放内存。
- 这不仅提高了性能,还减少了内存碎片化的风险。
优势分析
1. 提高任务处理效率
- 消费者可以一次性处理主缓冲区中的所有任务,而不是逐条处理。这种方式减少了任务调度的开销,提升了整体效率。
2. 减少锁冲突
- 由于锁操作只发生在缓冲区交换时,而非每次任务的添加或取出,锁冲突的概率显著降低。
- 生产者和消费者之间的交互更加高效,尤其在高并发场景下表现尤为明显。
3. 降低内存分配开销
- 固定大小的缓冲区避免了频繁的内存申请和释放操作,减少了系统资源的消耗。
- 同时,固定大小的设计也使得内存管理更加可控,避免了因动态内存分配引发的问题。
与其他设计方案的对比
1. 循环队列
- 循环队列是一种常见的任务池实现方式,但其每次任务的添加或取出都需要加锁,容易引发生产者和消费者之间的锁冲突。
- 此外,循环队列通常需要动态调整大小,这会增加内存管理的复杂性。
2. 单缓冲区
- 单缓冲区的设计简单,但在高并发场景下,锁冲突问题尤为突出。
- 生产者和消费者需要频繁地争夺缓冲区的访问权,导致性能下降。
3. 双缓冲区的优势
- 相比循环队列和单缓冲区,双缓冲区通过批量处理和缓冲区交换机制,减少了锁冲突和内存管理的开销。
- 它在保证高效的同时,提供了一种简单且可靠的解决方案。
总结
双缓冲区阻塞数据池的设计思想旨在通过批量处理和缓冲区交换,减少锁冲突和内存分配的开销,从而提高任务处理效率。它特别适用于高并发场景下的任务池设计,能够有效平衡生产者和消费者之间的关系,提升系统的整体性能。
不过在这之前,我们得要实现一下缓冲区:
缓冲区实现
创建一个头文件,用来专门实现缓冲区:
buffer.hpp
#ifndef __M_BUFFER_H__
#define __M_BUFFER_H__
#include "utils.hpp"
#include <vector>
#include <cassert>namespace logs
{#define DEFAULT_BUFFER_SIZE (1 * 1024 * 1024)#define THRESHOLD_BUFFER_SIZE (8 * 1024 * 1024)#define INCREAMENT_BUFFER_SIZE (1 * 1024 * 1024)class Buffer{public:Buffer(): _buffer(DEFAULT_BUFFER_SIZE), _writer_idx(0), _read_idx(0){}// 1、写入操作void push(const char *data, size_t len){// 1.首先判断是否需要扩容ensureEnoughSize(len);std::copy(data, data + len, &_buffer[_writer_idx]);moveWriter(len);}//返回可读数据的起始地址const char* begin(){return &_buffer[_read_idx];}size_t writeAbleSize(){return (_buffer.size() - _writer_idx);}size_t readAbleSize(){return (_writer_idx - _read_idx);}void reset(){_read_idx = 0; // 缓冲区所有空间都是空闲的_writer_idx = 0; // 与_writer_idx相等表示没有数据可读}// 对一个buffer进行一个交换void swap(Buffer &buffer){_buffer.swap(buffer._buffer);// 交换指针std::swap(_read_idx, buffer._read_idx);std::swap(_writer_idx, buffer._writer_idx);}void moveReader(size_t len){assert(len <= readAbleSize());_read_idx += len;}// 判断缓冲区是否为空bool empty(){return (_read_idx == _writer_idx);}private:// 扩容操作void ensureEnoughSize(size_t len){if (len <= writeAbleSize()){return;}size_t new_size = 0;if (_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size() * 2;}else{new_size = _buffer.size() + INCREAMENT_BUFFER_SIZE;}_buffer.resize(new_size);}// 对读写指针进行向后偏移操作void moveWriter(size_t len){assert(len + _writer_idx <= _buffer.size());_writer_idx += len;}std::vector<char> _buffer; // 缓冲区size_t _writer_idx; // 写指针size_t _read_idx; // 读指针};
}#endif
这是一个缓冲区的定义,我们要的是一个双缓冲区,所以我们再建一个头文件:
loop.hpp
#ifndef __M_LOOP_H__
#define __M_LOOP_H__#include "utils.hpp"
#include <condition_variable>
#include <thread>
#include <mutex>
#include <functional>
#include <atomic>
#include "message.hpp"
#include "buffer.hpp"
#include "loop.hpp"// 命名空间
namespace logs
{using Functor = std::function<void(Buffer &)>;class AsyncLooper{public:using ptr = std::shared_ptr<AsyncLooper>;enum class AsyncType{ASYNC_SAFE, // 安全模式,对空间索取有限制ASYNC_UNSAFE // 非安全模式,对空间索取无限制};AsyncLooper(const Functor &cb, AsyncType looper_type = AsyncType::ASYNC_SAFE): _stop(false), _thread(std::thread(&AsyncLooper::threadEntry, this)), _callback(cb), _looper_type(_looper_type){}~AsyncLooper(){stop();}void stop(){_stop = true;_cond_con.notify_all(); // 唤醒所有工作线程_thread.join();}void push(const char *data, size_t len){// 无限扩容或固定大小std::unique_lock<std::mutex> lock(_mutex);// 条件变量空值,如缓冲区空间大小大于数据长度,则可以添加数据if (_looper_type == AsyncType::ASYNC_SAFE)_cond_pro.wait(lock, [&](){ return _pron_buf.writeAbleSize() >= len; });// 如果走下来,可以向缓冲区添加数据_pron_buf.push(data, len);// 唤醒消费者对缓冲区的数据进行处理_cond_con.notify_one();}private:// 线程入口函数void threadEntry(){while (1){// 1.判断生产缓冲区有没有数据,有则交换,无则阻塞std::unique_lock<std::mutex> lock(_mutex);// 若是当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则重新进入休眠_cond_con.wait(lock, [&](){ return _stop || !_pron_buf.empty(); });退出标志被设置,且生产缓冲区无数据if (_stop && _pron_buf.empty()){break;}_con_buf.swap(_pron_buf);// 2.唤醒生产者_cond_pro.notify_all();}// 3.被唤醒后,对消费缓冲区进行数据处理_callback(_con_buf);// 4.初始化消费缓冲区_con_buf.reset();}Functor _callback; // 具体对缓冲区进行处理的回调函数,由异步工作器使用者传入private:AsyncType _looper_type; // 异步日志器类型std::atomic<bool> _stop; // 停止标志位Buffer _pron_buf; // 生产缓冲区Buffer _con_buf; // 消费缓冲区std::mutex _mutex;std::condition_variable _cond_pro; // 生产条件变量std::condition_variable _cond_con; // 消费者条件变量std::thread _thread; // 异步工作器对应的工作线程};
} // namespace logs#endif
这里的_pron_buf 和 _con_buf就是两个缓冲区,当_pron_buf缓冲区充满数据之后,就会和_con_buf进行交换,_pron_buf里面的数据就会到_con_buf里面去,这个时候工作线程就会从_con_buf中拿出数据进行工作。
异步任务处理器的构建是基于以上两个文件的,这个时候回到我们之前定义logger的头文件里面去:
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
#include "utils.hpp"
#include "message.hpp"
#include "utils.hpp"
#include "level.hpp"
#include "sink.hpp"
#include <atomic>
#include <mutex>
#include <iostream>
#include <memory>
#include <ctime>
#include <vector>
#include <cassert>
#include <sstream>
#include <stdarg.h>
#include "loop.hpp"namespace logs
{class BaseLogger{public:using ptr = std::shared_ptr<BaseLogger>;BaseLogger(const std::string &logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks): _logger_name(logger_name), _limt_level(limt_level), _formetter(formetter), _sinks(sinks.begin(), sinks.end()){}const std::string &get_logger_name(){return _logger_name;}/*完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串---然后进行输出*/void debug(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::DEBUG < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::DEBUG, file, line, res);free(res);}void info(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::INFO < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::INFO, file, line, res);free(res);}void warn(const std::string &file, size_t line, const std::string fmt, ...){// 如果限制输出的日志等级比debug高,则直接返回if (Loglevel::value::WARN < _limt_level){return;}// 声明参数列表变量va_list ap;va_start(ap, fmt); // 初始化fmt是最后一个固定的参数char *res; // 声明缓冲区int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放参数列表变量serialize(Loglevel::value::WARN, file, line, res);free(res);}void error(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::ERROR < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::ERROR, file, line, res);free(res);}void fatal(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::FATAL < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::FATAL, file, line, res);free(res);}protected:void serialize(Loglevel::value level, const std::string &file_name,size_t line, char *str){// 1.构造msg对象logs::logMsg msg(level, file_name, line, _logger_name, str);// 2.利用Formetter进行消息格式化std::stringstream ss;_formetter->format(ss, msg);// 3.落地方向的输出log(ss.str().c_str(), ss.str().size());}/*抽象接口完成实际的落地输出---不同的日志器会有不同的落地方式*/virtual void log(const char *data, size_t len) = 0;protected:std::mutex _mutex; // 锁std::string _logger_name; // 日志器名称std::atomic<Loglevel::value> _limt_level; // 日志等级Formetter::ptr _formetter; // 格式化消息指针std::vector<BaseSink::ptr> _sinks; // 落地方向};class SyncLogger : public BaseLogger{public:SyncLogger(const std::string &logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks): BaseLogger(logger_name, limt_level, formetter, sinks) {}protected:void log(const char *data, size_t len){// 1.上锁std::unique_lock<std::mutex> _lock(std::mutex);if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(data, len);}}};enum class loggerType{LOGGER_SYNC,LOGGER_ASYNC};class AsyncLogger : public BaseLogger{public:AsyncLogger(const std::string &logger_name, Loglevel::value level,Formetter::ptr &formatter,std::vector<BaseSink::ptr> &sinks,logs::AsyncLooper::AsyncType looper_type): BaseLogger(logger_name, level, formatter, sinks), _looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type)){}void log(const char *data, size_t len){_looper->push(data,len);}void realLog(Buffer& buffer){if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(buffer.begin(), buffer.readAbleSize());}}private:AsyncLooper::ptr _looper;};
}#endif
我们可以来测试一下:
#include "utils.hpp"
#include "level.hpp"
#include "message.hpp"
#include "fometter.hpp"
#include "sink.hpp"
#include "logger.hpp"int main()
{logs::Formetter formatter("abc[%d{%H:%M:%S}][%c]%T%m%n");logs::Formetter::ptr fmt_ptr = std::make_shared<logs::Formetter>(formatter);auto st1 = logs::SinkFactory::create<logs::StdoutSink>();std::vector<logs::BaseSink::ptr> sinks = {st1};std::string logger_name = "asynclogger";logs::BaseLogger::ptr logger(new logs::AsyncLogger(logger_name, logs::Loglevel::value::DEBUG, fmt_ptr, sinks,logs::AsyncLooper::AsyncType::ASYNC_SAFE));logger->debug("main.cc", 53, "%s","格式化功能测试....");// 5. 确保异步日志线程有足够时间处理std::this_thread::sleep_for(std::chrono::milliseconds(100)); }

总结
loop.hpp中与线程有关的操作
在这段代码中,与线程相关的操作和函数主要包括以下几个方面:
1. 线程的创建与管理
-
线程的创建:
- 在
AsyncLooper构造函数中,通过std::thread创建一个新的线程_thread,并将其绑定到成员函数threadEntry。
这个线程是异步工作器的核心,负责处理缓冲区中的数据。_thread(std::thread(&AsyncLooper::threadEntry, this))
- 在
-
线程的销毁:
- 在析构函数
~AsyncLooper()中调用stop()函数,确保线程安全退出。~AsyncLooper() {stop(); }
- 在析构函数
-
线程的停止:
stop()函数用于优雅地停止线程:- 设置
_stop标志位为true,通知线程准备退出。 - 调用
_cond_con.notify_all()唤醒所有等待的线程。 - 使用
_thread.join()等待线程执行完毕后回收资源。void stop() {_stop = true;_cond_con.notify_all(); // 唤醒所有工作线程_thread.join(); }
- 设置
2. 线程同步与通信
为了确保线程之间的安全协作,使用了互斥锁(std::mutex)和条件变量(std::condition_variable)。
-
互斥锁 (
std::mutex):_mutex用于保护共享资源(如生产缓冲区_pron_buf和消费缓冲区_con_buf),防止多个线程同时访问导致数据竞争。- 在
push()和threadEntry()中使用std::unique_lock<std::mutex>对_mutex加锁。
-
条件变量 (
std::condition_variable):-
生产者条件变量
_cond_pro:- 用于控制生产者的阻塞和唤醒。
- 在
push()中,当缓冲区空间不足时,生产者会调用_cond_pro.wait()阻塞,直到消费者释放空间。_cond_pro.wait(lock, [&]() { return _pron_buf.writeAbleSize() >= len; }); - 消费者在处理完数据后,调用
_cond_pro.notify_all()唤醒所有等待的生产者。_cond_pro.notify_all();
-
消费者条件变量
_cond_con:- 用于控制消费者的阻塞和唤醒。
- 在
threadEntry()中,当生产缓冲区为空时,消费者会调用_cond_con.wait()阻塞,直到有新数据可用。_cond_con.wait(lock, [&]() { return _stop || !_pron_buf.empty(); }); - 生产者在向缓冲区添加数据后,调用
_cond_con.notify_one()唤醒一个消费者。_cond_con.notify_one();
-
3. 线程入口函数
threadEntry():- 这是线程的主要执行逻辑,负责从生产缓冲区
_pron_buf中读取数据并处理。 - 主要流程:
- 判断生产缓冲区是否有数据。如果有,则交换生产缓冲区和消费缓冲区;如果没有,则阻塞等待。
- 如果退出标志
_stop被设置且生产缓冲区为空,则线程退出。 - 调用回调函数
_callback(_con_buf)处理消费缓冲区中的数据。 - 初始化消费缓冲区
_con_buf,以便下一次使用。
void threadEntry() {while (1){std::unique_lock<std::mutex> lock(_mutex);_cond_con.wait(lock, [&]() { return _stop || !_pron_buf.empty(); });if (_stop && _pron_buf.empty()){break;}_con_buf.swap(_pron_buf);_cond_pro.notify_all();}_callback(_con_buf);_con_buf.reset(); }
- 这是线程的主要执行逻辑,负责从生产缓冲区
4. 数据生产与消费
-
生产数据:
push(const char *data, size_t len)是生产者接口,用于向生产缓冲区_pron_buf添加数据。- 在安全模式下(
ASYNC_SAFE),如果缓冲区空间不足,生产者会阻塞等待。if (_looper_type == AsyncType::ASYNC_SAFE)_cond_pro.wait(lock, [&]() { return _pron_buf.writeAbleSize() >= len; });
-
消费数据:
- 消费者线程通过
threadEntry()不断从生产缓冲区中获取数据,并调用用户提供的回调函数_callback进行处理。
- 消费者线程通过
5. 线程安全的设计
-
原子变量
_stop:- 使用
std::atomic<bool>类型的_stop标志位,确保多线程环境下的安全读写。std::atomic<bool> _stop;
- 使用
-
双重检查机制:
- 在
threadEntry()中,使用_stop && _pron_buf.empty()来判断是否需要退出线程,避免误退出或死锁。
- 在
总结
这段代码通过多线程技术实现了生产者-消费者模型,核心线程相关的操作包括:
- 线程的创建、管理和销毁。
- 使用互斥锁和条件变量实现线程同步与通信。
- 提供生产者接口
push()和消费者逻辑threadEntry()。 - 通过原子变量和双重检查机制确保线程安全。
这种设计适用于异步日志记录等场景,能够高效地处理大量并发数据。
placeholders::_1
下面是一个简单的例子来展示 std::bind 和 std::placeholders::_1 的使用方法。这个例子定义了一个类 Calculator,其中包含一个成员函数 add,该函数接受两个参数:一个整数和另一个整数引用。我们将通过 std::bind 将这个成员函数绑定到一个对象实例,并使用占位符 _1 来预留第二个参数的位置。
示例代码
#include <iostream>
#include <functional> // 包含 std::bind 和 std::placeholdersclass Calculator {
public:// 成员函数 add 接受一个整数 n 和一个整数引用 mvoid add(int n, int& m) {m += n;std::cout << "After adding " << n << ", m = " << m << std::endl;}
};int main() {Calculator calc; // 创建 Calculator 类的实例int value = 10;// 使用 std::bind 绑定成员函数 add 到 calc 实例,并预留第二个参数的位置auto boundFunc = std::bind(&Calculator::add, &calc, 5, std::placeholders::_1);// 调用绑定后的函数对象,传递 value 变量作为第二个参数boundFunc(value);return 0;
}
说明
-
Calculator::add:- 这个成员函数接收两个参数:一个整数
n和一个整数引用m。它将n加到m上,并输出结果。
- 这个成员函数接收两个参数:一个整数
-
std::bind:- 我们使用
std::bind函数将Calculator::add成员函数绑定到calc对象实例上,并固定第一个参数为5(即每次调用都会加上5),同时使用std::placeholders::_1占位符表示第二个参数将在实际调用时传入。
- 我们使用
-
boundFunc:boundFunc是一个可调用对象,当调用它并传入一个整数引用时,实际上会调用calc.add(5, /*传入的值*/)。
-
boundFunc(value);:- 在这里,我们调用了
boundFunc并传入了value变量作为第二个参数。这将导致Calculator::add函数被调用,执行value += 5操作,并打印出更新后的value值。
- 在这里,我们调用了
输出结果
当你运行上述代码时,程序将输出:
After adding 5, m = 15
这表明原始的 value 变量从 10 变为了 15,因为 5 被加到了 value 上。通过这种方式,我们可以看到如何使用 std::bind 和 std::placeholders::_1 来创建一个绑定特定参数的函数对象,并在调用时动态地提供剩余的参数。
放到代码中:
具体作用
在这段代码中:
_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type))
std::bind用于将成员函数AsyncLogger::realLog绑定到一个可调用对象。this表示当前对象(即AsyncLogger的实例),作为成员函数的第一个隐式参数。std::placeholders::_1是一个占位符,表示这个绑定的函数对象在调用时需要接收一个参数,并将该参数传递给AsyncLogger::realLog的第一个显式参数。
换句话说,std::placeholders::_1 在这里的作用是预留一个位置,使得 AsyncLooper 的回调函数可以在运行时动态地传入一个参数(比如 Buffer & 类型的数据)。
详细解释
假设 AsyncLogger::realLog 的定义如下:
void AsyncLogger::realLog(Buffer &buffer);
通过 std::bind 和 std::placeholders::_1,我们创建了一个函数对象,其行为等价于:
void callback(Buffer &buffer) {this->realLog(buffer);
}
这个函数对象会被传递给 AsyncLooper 的构造函数,作为 _callback 回调函数。当 AsyncLooper 调用 _callback 时,它会将一个 Buffer 对象作为参数传递给 realLog。
为什么需要 std::placeholders::_1?
-
适配函数签名:
AsyncLooper的构造函数期望一个std::function<void(Buffer &)>类型的回调函数。AsyncLogger::realLog是一个成员函数,需要绑定到某个对象(this)才能调用。- 使用
std::placeholders::_1可以确保绑定后的函数对象能够接受一个参数,并将其正确传递给realLog。
-
灵活性:
- 占位符允许我们灵活地控制参数的传递顺序和数量。例如,如果有多个参数,可以使用
_1,_2,_3等分别表示不同的参数位置。
- 占位符允许我们灵活地控制参数的传递顺序和数量。例如,如果有多个参数,可以使用
示例对比
不使用 std::bind 和占位符:
如果直接传递成员函数指针,编译器会报错,因为成员函数需要绑定到一个对象:
_looper(std::make_shared<AsyncLooper>(&AsyncLogger::realLog, looper_type));
// 错误:无法直接传递成员函数指针
使用 std::bind 和占位符:
通过 std::bind,我们可以将成员函数绑定到当前对象,并预留参数位置:
_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type));
// 正确:绑定后的函数对象符合 std::function<void(Buffer &)> 的要求
总结
std::placeholders::_1 的作用是为绑定的函数对象预留一个参数位置,使得 AsyncLogger::realLog 可以在运行时接受一个参数(如 Buffer &)。这种机制让 std::bind 更加灵活,能够适配不同函数签名的需求。
相关文章:
(双缓冲区异步任务处理器(AsyncLooper)设计))
C++项目 —— 基于多设计模式下的同步异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计)
C项目 —— 基于多设计模式下的同步&异步日志系统(4)(双缓冲区异步任务处理器(AsyncLooper)设计) 异步线程什么是异步线程?C 异步线程简单例子代码解释程序输出关键点总结扩展:使…...

【Linux学习笔记】Linux的环境变量和命令行参数
【Linux学习笔记】Linux的环境变量和命令行参数 🔥个人主页:大白的编程日记 🔥专栏:Linux学习笔记 文章目录 【Linux学习笔记】Linux的环境变量和命令行参数前言一.环境变量1.1基本概念1.2常见环境变量1.3和环境变量相关的命令1…...

排序算法-快速排序
描述: 基准值选择:选取数组的最后一个元素 arr[high] 作为基准值 p。初始化索引:i 初始化为 low - 1,其作用是指向比基准值小的最后一个元素的索引。遍历数组:借助 for 循环从 low 到 high - 1 遍历数组。若当前元素 …...

软考高级系统架构设计师-第16章 数学与经济管理
【本章学习建议】 根据考试大纲,本章主要考查系统架构设计师单选题,预计考2分左右。主要是运筹学的计算问题,范围广、难度大,超纲题较多,不用深究。 16.1 线性规划 线性规划是研究在有限的资源条件下,如果…...

爱在冰川-慢就是快
【游资大佬の搞钱心法🔥|小白逆袭必看冰川语录真实案例‼️】 💡刚扒完爱在冰川的万字访谈 发现游资搞钱真的靠"反人性思维" 总结6条狠人法则真实案例 建议收藏反复背诵👇 1️⃣【周期为王】💫 "行情…...

Mac-VScode-C++环境配置
mac上自带了clang所以不是必须下载Homebrew 下面是配置文件(注释记得删一下) package.json {"name": "git-base","displayName": "%displayName%","description": "%description%",&quo…...
)
【JAVA EE初阶】多线程(1)
这样的代码,虽然也能打印hello thread,但是没有创建新的线程,而是直接在main方法所在的主线程中执行了run的逻辑 start方法,是调用系统api,真正在操作系统内部创建一个线程。这个新的线程会以run作为入口方法ÿ…...

PHP伪协议读取文件
借鉴php伪协议实现命令执行,任意文件读取_ctf php文件读取-CSDN博客 总结 在ctf中常用的有data:// , php://input , php://filter ,file:// php://input ,data://用来执行命令 1.php://input 的用法 http://127.0.0.1/include.php?filephp://input [P…...

动态调整映射关系的一致性哈希负载均衡算法详解
一、核心原理与设计要点 双重映射结构 一致性哈希负载均衡通过 哈希环 和 槽动态分配 实现双重映射关系: • 哈希环构建:将节点(物理或虚拟)和数据键(Key)通过哈希函数(如MD5、CRC32)…...
和依赖注入(DI))
控制反转(IOC)和依赖注入(DI)
Target Retention Documented 元注解 Component 将类交给IOC容器管理,成为IOC容器中的bean Autowired 注入运行时所需要依赖的对象 因为Mabatis DAO层注解Reponsitory 基本不用了,现在Mapper层Mapper注解,这里的Mapper层相当于原来的DAO层…...

【每日八股】复习 MySQL Day1:事务
文章目录 复习 MySQL Day1:事务MySQL 事务的四大特性?并发事务会出现什么问题?MySQL 事务的隔离级别?不同事务隔离级别下会发生什么问题?MVCC 的实现原理?核心数据结构版本链构建示例可见性判断算法MVCC 可…...

【数据结构和算法】1. 数据结构和算法简介、二分搜索
本文根据 数据结构和算法入门 视频记录 文章目录 1. 数据结构和算法简介1.1 什么是数据结构?什么是算法?1.2 数据结构和算法之间的关系1.3 “数据结构和算法”有那么重要吗? 2. 二分搜索(Binary Search)2.1 算法概念2…...
算了和周日一块写了 4月20日日记)
4月19日记(补)算了和周日一块写了 4月20日日记
周六啊 昨天晚上又玩的太嗨了。睡觉的时候有点晚了,眼睛疼就没写日记。现在补上 实际上现在是20号晚上八点半了。理论上来说应该写今天的日记。 周六上午打比赛啦,和研究生,输了,我是替补没上场。没关系再练一练明天就可以变强…...

面试常用基础算法
目录 快速排序归并排序堆排序 n n n皇后问题最大和子数组爬楼梯中心扩展法求最长回文子序列分割回文串动态规划求最长回文子序列最长回文子串单调栈双指针算法修改 分割回文串滑动窗口栈 快速排序 #include <iostream> #include <algorithm>using namespace std;…...

微服务与 SOA:架构异同全解析与应用指南
微服务和 SOA(面向服务的架构)是两种不同的软件架构风格,它们在很多方面存在相似之处,但也有一些区别。以下是对它们的详细介绍: 一、概念 1.微服务 微服务架构将一个大型应用程序拆分成多个小型、独立的服务&#…...
 - C++ 代码版)
Dijkstra 算法入门笔记 (适用于算法竞赛初学者) - C++ 代码版
目录 算法是做什么的?核心思想:贪就完事了!算法前提:不能有负权边!需要哪些工具?(数据结构)算法具体步骤关键操作:松弛 (Relaxation)两种实现方式 (C 代码) 朴素版 Dijkstra (O(V^2))堆优化版 …...

脑影像分析软件推荐| GraphVar介绍
目录 1.软件界面 2.工具包功能简介 3.软件安装注意事项 1.软件界面 2.工具包功能简介 GraphVar是一个用户友好的 MATLAB 工具箱,用于对功能性大脑连接进行全面的图形分析。这里我们介绍了该工具箱的全面扩展,使用户能够无缝探索跨功能连接测量的可轻…...

如何优雅地实现全局唯一?深入理解单例模式
如何优雅地实现全局唯一?深入理解单例模式 一、什么是单例模式? 单例模式是一种创建型设计模式,旨在确保一个类只有一个实例,并为该实例提供全局访问点,从而避免全局变量的命名污染,并支持延迟初始化Wiki…...

【Flutter】使用LiveKit和Flutter构建实时视频聊天应用
引言 在当今快速发展的数字世界中,实时视频通信已成为许多应用程序的核心功能。无论是远程工作、在线教育还是社交网络,高质量的实时视频功能都至关重要。LiveKit作为一个开源的WebRTC解决方案,提供了构建可扩展实时音视频应用所需的一切工具…...

Android Jetpack Compose 状态管理解析:remember vs mutableStateOf,有啥不一样?为啥要一起用?
🌱《Jetpack Compose 状态管理解析:remember vs mutableStateOf,有啥不一样?为啥要一起用?》 在 Jetpack Compose 的世界里,UI 是响应式的。这意味着当状态发生变化时,UI 会自动重组࿰…...
:界面组件的总基类 QWidget 的源码阅读(下,c++ 代码部分))
QT6 源(37):界面组件的总基类 QWidget 的源码阅读(下,c++ 代码部分)
(1) QT 在 c 的基础上增加了自己的编译器,以支持元对象系统和 UI 界面设计,有 MOC 、 UIC 等 QT 自己的编译器。本节的源代码里,为了减少篇幅,易于阅读,去除了上篇中的属性部分, 上篇…...

进程与线程:01 CPU管理的直观想法
多进程图像与操作系统核心 好从今天开始,我们就要开始学习操作系统,最核心的图像是多进程图像。前面我们讲过,多进程图像对操作系统来说非常重要,它是操作系统的核心图像。明白了它以后,对于理解操作系统的一大部分内…...

19. git reflog
基本概述 git reflog 的作用是:查看本地仓库的引用日志(reference log),例如分支、HEAD等。它可以帮助你找回误删的提交、恢复被覆盖的分支,或回溯操作历史。 基本用法 1.查看完整的reflog git reflog这会显示所有…...

C语言 —— 铭纹织构未诞之镜 - 预处理详解
目录 1. 什么是预处理(预编译) 编辑 2. 预定义符号 3. #define 定义常量 4. #define定义宏 5. 带副作用的宏参数 6. 宏替换的规则 7. 宏和函数的对比 8. #和## 8.1 #运算符 8.2 ## 运算符 9. #undef 10. 条件编译 1. 什么是预处理…...

Linux 文件系统目录结构详解
Linux 文件系统目录结构详解 Linux 文件系统遵循 Filesystem Hierarchy Standard (FHS) 标准,定义了各个目录的用途和文件存放规则。无论是开发者、运维工程师还是普通用户,理解这些目录的作用都至关重要。本文将全面解析 Linux 的目录结构,…...
)
2025-4-19 情绪周期视角复盘(mini)
我本以为市场进化规律下产生龙头战法的末法时代导致情绪周期逐步混乱或者说混沌期漫长。所谓的市场进化无非也是量化的发展和各类资金逐步量化化的充分博弈下的结果。通过逐步向上思考发现,不仅仅我们的市场是处于一个存量的时代背景,重要的是我们的思维…...

-实用类-
1. API是什么 2.什么是枚举 !有点类似封装! 2.包装类 注意: 1.Boolean类构造方法参数为String类型时,若该字符串内容为true(不考虑大小写),则该Boolean对象表示true,否则表示false 2.当包装类构造方法参…...

Unity3D仿星露谷物语开发36之锄地动画2
1、目标 当角色锄地之后,地面会显示开垦后的样貌。 2、思路 上一篇中,虽然角色dig了hoe,同时grid属性也改变了,但是没有任何可视化的反馈。我们现在将添加新的功能,动态地将"dug ground"瓷砖添加到"…...
案例分析及答案详解)
【备考高项】模拟预测题(一)案例分析及答案详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 试题一【问题 1】(10分)【问题 2】(5分)【问题 3】(4分)【问题 4】(6分)试题二【问题 1】(12分)【问题 2】(3分)【问题 3】(6分)【问题 4】(4分)试题三【问题 1】(4分)【问题 2】(10分)【问题 3】…...

7、sentinel
控制台访问地址:http://localhost:8080/ 依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>配置文件 spring:cloud:sentinel:transpo…...

状态管理最佳实践:Provider使用技巧与源码分析
状态管理最佳实践:Provider使用技巧与源码分析 前言 Provider是Flutter官方推荐的状态管理解决方案,它简单易用且功能强大。本文将从实战角度深入讲解Provider的使用技巧和源码实现原理,帮助你更好地在项目中应用Provider进行状态管理。 基…...

INFINI Console 系统集群状态异常修复方案
背景介绍 运行 INFINI Console 1.29.0 和 1.29.1 版本 的用户在 新初始化 平台后可能会遇到一个特定问题。如果后台的系统 Easysearch/Elasticsearch 集群(存储 Console 元数据的集群,通常名为 .infini_cluster 或类似名称)包含超过一个节点…...
)
Spring Boot自动装配原理(源码详细剖析!)
什么是Spring Boot的自动装配? 自动装配是Spring Boot的核心功能,它能够根据应用程序的依赖和配置自动配置Spring。这意味着我们只需要添加大量的依赖,Spring Boot就能自动完成配置,减少了人工配置的工作量。 自动装配的核心注…...

大数据驱动的高效能量管理:智能优化与实践探索
大数据驱动的高效能量管理:智能优化与实践探索 在全球能源需求不断增长的背景下,如何提高能源利用效率成为各行业关注的焦点。传统的能源管理方式往往依赖固定规则和人工监测,难以适应复杂多变的应用场景。而大数据技术的兴起,为能量管理提供了新的解决方案——通过数据驱…...

《银行数字化风控-业务于实战》读后知识总结
引言 在金融科技高速发展的今天,银行的风控体系正经历从“人工经验驱动”向“数据智能驱动”的深刻变革。《银行数字化风控-业务于实战》一书以实战为导向,系统性地剖析了数字化风控的核心逻辑、技术实现路径及业务落地方法论。作为深耕风控领域多年的从…...

初级达梦dba的技能水准
在x86环境(windows、linux)安装单机软件,安装客户端创建过至少20套数据库,优化参数并更新过正式许可会用逻辑导出导入以及dmrman备份了解manager工具的使用配置sqllog日志,并能解释输出内容能够分析因磁盘空间不足、内…...
)
C++初阶-类和对象(中)
目录 1.类的默认成员函数 2.构造函数(难度较高) 编辑 编辑 编辑 3.析构函数 4.拷贝构造函数 5.赋值运算符重载 5.1运算符重载 5.2赋值运算符重载 6.取地址运算符重载 6.1const成员函数 6.2取地址运算符重载 7.总结 1.类的默认成员函数…...

Linux网络UDP与TCP
基础知识 传输层 负责数据能够从发送端传输接收端。 端口号(Port)标识了一个主机上进行通信的不同的应用程序; 在 TCP/IP 协议中, 用 “源 IP”, “源端口号”, “目的 IP”, “目的端口号”, “协议号” 这样一个五元组来标识一个通信(可以通过 netstat -n 查看); 端口号范…...

23、.NET和C#有什么区别?
1、定义与范畴 .NET 定义 .NET 是一个由微软开发的开发平台(Platform),它提供了一套完整的工具、库和运行时环境,用于构建各种类型的应用程序。 范畴 包括 .NET Framework、.NET Core(现称为 .NET 5 及以上版本&a…...

Qt6离线安装过程
Qt6离线安装过程 说明解决方案联网笔记本安装qt6拷贝到离线电脑修改qtenv2.bat文件 说明 现在qt6已经不能通过离线的方式下载安装包安装了,只能通过登陆的方式在线安装,但是,又有离线安装运行的需求,那么怎么办呢?请跟…...

如何在 Go 中创建和部署 AWS Lambda 函数
AWS Lambda 是一个无服务器计算平台,您可以使用自己喜欢的编程语言编写代码,无需担心设置虚拟机。 您只需为 Lambda 函数的调用次数和运行时间(毫秒)付费。 我们大多数人都了解 JavaScript 和 Python,但它们的内存效率…...
` 方法详解:数据校验的最后防线)
【后端】【Django】Django 模型中的 `clean()` 方法详解:数据校验的最后防线
Django 模型中的 clean() 方法详解:数据校验的最后防线 在 Django 的模型系统中,我们经常使用字段级别的校验器(validators)来约束某个字段的取值范围。但当校验逻辑涉及多个字段之间的关系时,字段级别校验就无能为力…...
)
内存管理详解(曼波脑图超详细版!)
(✪ω✪)曼波来解答三连问啦!准备好内存知识大礼包了吗?(≧∇≦)ノ ━━━━━━━━━━━━━ ฅ^•ω•^ฅ ━━━━━━━━━━━ 一、内存分配详解 (๑>ᴗ<๑) (1) 栈内存 → 像便签纸📝 void calculate() {int a …...

【2025最新redis数据结构之Hypeloglog介绍】关于Hypeloglog
HyperLogLog (HLL) 算法深度解析 一、HLL 基本概念 HyperLogLog 是一种用于基数统计(distinct counting)的概率算法,能够在极小内存占用下(通常只需几KB)估算巨大数据集的基数(不重复元素数量)…...

软考复习——知识点软件开发
开发模型 瀑布模型 各个活动规定为线性顺序连接的若干阶段的模型。是一种理想的现象开发模型,缺乏灵活性,无法理解软件需求不明确或不准确的问题。适用于需求明确的项目。 演化模型 从初始的原型逐步演化成最终软件产品,特别适用于对软件…...

关于AI:记忆、身份和锁死
作者:John Battelle 当生成式AI迎来投资热潮、产品发布和炒作高峰时,我们大多数人在奔向“下一个大事件”的过程中,忽略了一个深层次的缺陷。我们现在主流的AI产品和服务(比如OpenAI、Google和Microsoft的产品)都是通过…...

2024新版仿蓝奏云网盘源码,已修复已知BUG,样式风格美化,可正常运营生产
说起网盘源码,网络上出现的也很多,不过可真正正能够用于运营的少之又少。今天将的蓝奏云网盘源码,其实网络上也有,不过是残缺版,bug很多。我今天分享的仿蓝奏云模板是经过长时间测试修复后的源码,源码实测可…...

OJ - 设计循环队列
622. 设计循环队列 - 力扣(LeetCode) 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则,并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。 循环队列的一个好处是我们可…...

实战指南:封装Faster-Whisper为FastAPI接口并实现高并发处理-附整合包
实战指南:封装Faster-Whisper为FastAPI接口并实现高并发处理-附整合包 「faster-whisper」 链接:https://pan.quark.cn/s/d4ddffb1b196 标题下面提供一个完整的示例,说明如何使用 FastAPI 封装 faster-whisper 接口,对外提供 RES…...

011数论——算法备赛
素数筛 给定n, 求2~n内的所有素数 埃氏筛 利用素数的定义, 输出素数2,然后筛掉2的倍数,得 {2,3,5,7,9,11,13,…}输出素数3,然后筛掉3的倍数,得 {2,3,5,7,11,13,…} 继续上述步骤࿰…...