PCA——主成分分析数学原理及代码
主成分分析
PCA的目的是:对数据进行一个线性变换,在最大程度保留原始信息的前提下去除数据中彼此相关的信息。反映在变量上就是说,对所有的变量进行一个线性变换,使得变换后得到的变量彼此之间不相关,并且是所有可能的线性变换中方差最大的一些变量(我们认为方差体现了信息量的大小)。
总体主成分分析
设 X \mathbf{X} X是一个 n n n维随机向量,其均值向量为 μ = μ 1 , … , μ n \mu=\mu_1,\dots,\mu_n μ=μ1,…,μn、协方差矩阵为 Σ = ( σ i j ) , i , j = 1 , 2 , … , n \Sigma=(\sigma_{ij}),\;i,j=1,2,\dots,n Σ=(σij),i,j=1,2,…,n。对 X \mathbf{X} X进行一个线性变换 T \mathcal{T} T得到一个 n n n维随机向量 Y = ( Y 1 , … , Y n ) \mathbf{Y}=(\mathbf{Y}_1,\dots,\mathbf{Y}_n) Y=(Y1,…,Yn), T \mathcal{T} T的矩阵为:
A = ( α 1 α 2 ⋮ α n ) \begin{equation*} A= \begin{pmatrix} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{pmatrix} \end{equation*} A= α1α2⋮αn
若:
- Cov ( Y ) \operatorname{Cov}(\mathbf{Y}) Cov(Y)是一个对角矩阵,即 Cov ( Y i , Y j ) = 0 , i ≠ j \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=0,\;i\ne j Cov(Yi,Yj)=0,i=j;
- Y 1 \mathbf{Y}_1 Y1是所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差最大的随机变量, Y 2 \mathbf{Y}_2 Y2是与 Y 1 \mathbf{Y}_1 Y1不相关的所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差第二大的随机变量,以此类推。
则分别称 Y 1 , Y 2 , … , Y n \mathbf{Y}_1,\mathbf{Y}_2,\dots,\mathbf{Y}_n Y1,Y2,…,Yn是第一、第二、……、第 n n n主成分。
这一定义是否足够?
若不对 T \mathcal{T} T的矩阵 A A A作出相应的限制,对 X \mathbf{X} X进行线性变换后得到的 Y i , i = 1 , 2 , … , n \mathbf{Y}_i,\;i=1,2,\dots,n Yi,i=1,2,…,n的方差可以任意大。
Var ( Y i ) = Cov ( Y ) ( i , i ) = Cov ( A X ) ( i , i ) = ( A Σ A T ) i , i = α i Σ α i T \begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=\operatorname{Cov}(\mathbf{Y})_{(i,i)}=\operatorname{Cov}(A\mathbf{X})_{(i,i)}=(A\Sigma A^T)_{i,i}=\alpha_i\Sigma\alpha_i^T \end{equation*} Var(Yi)=Cov(Y)(i,i)=Cov(AX)(i,i)=(AΣAT)i,i=αiΣαiT
若 Var ( Y i ) > 0 \operatorname{Var}(\mathbf{Y}_i)>0 Var(Yi)>0,取矩阵 B = k A B=kA B=kA, Z = k A X \mathbf{Z}=kA\mathbf{X} Z=kAX,则:
Var ( Y i ) = ( k α i ) Σ ( k α i ) T = k 2 α i Σ α i \begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=(k\alpha_i)\Sigma(k\alpha_i)^T=k^2\alpha_i\Sigma\alpha_i \end{equation*} Var(Yi)=(kαi)Σ(kαi)T=k2αiΣαi
改变 k k k的值,即可对 Y i , i = 1 , 2 , … , n \mathbf{Y}_i,\;i=1,2,\dots,n Yi,i=1,2,…,n的方差进行任意的放缩。
因此,我们需要对 A A A进行相应的限制,在这里我们人为地选择要求 A A A是一个正交矩阵,也就是让 α i α i T = 1 \alpha_i\alpha_i^T=1 αiαiT=1。
总体主成分完整定义
设 X \mathbf{X} X是一个 n n n维随机向量,其均值向量为 μ = μ 1 , … , μ n \mu=\mu_1,\dots,\mu_n μ=μ1,…,μn、协方差矩阵为 Σ = ( σ i j ) , i , j = 1 , 2 , … , n \Sigma=(\sigma_{ij}),\;i,j=1,2,\dots,n Σ=(σij),i,j=1,2,…,n。对 X \mathbf{X} X进行一个线性变换 T \mathcal{T} T得到一个 n n n维随机向量 Y = ( Y 1 , … , Y n ) \mathbf{Y}=(\mathbf{Y}_1,\dots,\mathbf{Y}_n) Y=(Y1,…,Yn), T \mathcal{T} T的矩阵为:
A = ( α 1 α 2 ⋮ α n ) \begin{equation*} A= \begin{pmatrix} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{pmatrix} \end{equation*} A= α1α2⋮αn
若:
- A A T = I AA^T=I AAT=I;
- Cov ( Y ) \operatorname{Cov}(\mathbf{Y}) Cov(Y)是一个对角矩阵,即 Cov ( Y i , Y j ) = 0 , i ≠ j \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=0,\;i\ne j Cov(Yi,Yj)=0,i=j;
- Y 1 \mathbf{Y}_1 Y1是所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差最大的随机变量, Y 2 \mathbf{Y}_2 Y2是与 Y 1 \mathbf{Y}_1 Y1不相关的所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差第二大的随机变量,以此类推。
则分别称 Y 1 , Y 2 , … , Y n \mathbf{Y}_1,\mathbf{Y}_2,\dots,\mathbf{Y}_n Y1,Y2,…,Yn是第一、第二、……、第 n n n主成分。
主成分求解定理
设 X \mathbf{X} X是一个 n n n维随机向量, Σ \Sigma Σ是其协方差矩阵, Σ \Sigma Σ的特征值\footnote{若特征多项式有重根,则标准正交化特征向量组不唯一,主成分也不唯一。}从大到小记作 λ 1 , … , λ n \lambda_1,\dots,\lambda_n λ1,…,λn, φ 1 , … , φ n \varphi_1,\dots,\varphi_n φ1,…,φn为对应的标准正交化特征向量,则 X \mathbf{X} X的第 i i i个主成分以及其方差为:
Y i = φ i T X , Var ( Y i ) = φ i T Σ φ i = λ i \begin{equation*} \mathbf{Y}_i=\varphi_i^T\mathbf{X},\;\operatorname{Var}(\mathbf{Y}_i)=\varphi_i^T\Sigma\varphi_i=\lambda_i \end{equation*} Yi=φiTX,Var(Yi)=φiTΣφi=λi
考虑到:
Var ( Y i ) = α i Σ α i T , Cov ( Y i , Y j ) = α i Σ α j T \begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=\alpha_i\Sigma\alpha_i^T,\quad \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=\alpha_i\Sigma\alpha_j^T \end{equation*} Var(Yi)=αiΣαiT,Cov(Yi,Yj)=αiΣαjT
求解主成分的过程即为求解:
α i = arg max α i Σ α i T s.t. { ∣ ∣ α i ∣ ∣ = 1 , i = 1 , 2 , … , n α i Σ α j = 0 , j < i \begin{gather*} \alpha_i=\arg\max\alpha_i\Sigma\alpha_i^T \\ \operatorname{s.t.} \begin{cases} ||\alpha_i||=1,\;&i=1,2,\dots,n\\ \alpha_i\Sigma\alpha_j=0,\;&j<i \end{cases} \end{gather*} αi=argmaxαiΣαiTs.t.{∣∣αi∣∣=1,αiΣαj=0,i=1,2,…,nj<i

于是上述结论成立。
因子载荷的定义
将第 i i i个主成分 Y i \mathbf{Y}_i Yi与变量 X j \mathbf{X}_j Xj的相关系数 ρ ( Y i , X j ) \rho(\mathbf{Y}_i,\mathbf{X}_j) ρ(Yi,Xj)称为因子载荷。可推得:
ρ ( Y i , X j ) = λ i α i j σ j j , i , j = 1 , 2 , … , n \begin{equation*} \rho(\mathbf{Y}_i,\mathbf{X}_j)=\frac{\sqrt{\lambda_i}\alpha_{ij}}{\sqrt{\sigma_{jj}}},\;i,j=1,2,\dots,n \end{equation*} ρ(Yi,Xj)=σjjλiαij,i,j=1,2,…,n
由相关系数的定义:
ρ ( Y i , X j ) = Cov ( Y i , X j ) Var ( Y i ) Var ( X j ) = Cov ( α i X , e j T X ) λ i σ j j = α i Σ e j λ i σ j j = e j T Σ α i λ i σ j j = e j T λ i α i λ i σ j j = λ i α i j σ j j \begin{align} \rho(\mathbf{Y}_i,\mathbf{X}_j) &=\frac{\operatorname{Cov}(\mathbf{Y}_i,\mathbf{X}_j)}{\sqrt{\operatorname{Var}(\mathbf{Y}_i)\operatorname{Var}(\mathbf{X}_j)}}=\frac{\operatorname{Cov}(\alpha_i\mathbf{X},e_j^T\mathbf{X})}{\sqrt{\lambda_i\sigma_{jj}}} \\ &=\frac{\alpha_i\Sigma e_j}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{e_j^T\Sigma\alpha_i}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{e_j^T\lambda_i\alpha_i}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{\sqrt{\lambda_i}\alpha_{ij}}{\sqrt{\sigma_{jj}}} \end{align} ρ(Yi,Xj)=Var(Yi)Var(Xj)Cov(Yi,Xj)=λiσjjCov(αiX,ejTX)=λiσjjαiΣej=λiσjjejTΣαi=λiσjjejTλiαi=σjjλiαij
总体主成分的性质
总体主成分具有如下性质:
- Cov ( Y ) = diag { λ 1 , … , λ n } \operatorname{Cov}(\mathbf{Y})=\operatorname{diag}\{\lambda_1,\dots,\lambda_n\} Cov(Y)=diag{λ1,…,λn};
- Y \mathbf{Y} Y的方差之和等于 X \mathbf{X} X的方差之和,即 ∑ i = 1 n λ i = ∑ i = 1 n σ i i \sum\limits_{i=1}^{n}\lambda_i=\sum\limits_{i=1}^{n}\sigma_{ii} i=1∑nλi=i=1∑nσii;
- 第 i i i个主成分与原变量的因子负荷量满足:
∑ j = 1 n σ j j ρ 2 ( Y i , X j ) = λ i \begin{equation*} \sum_{j=1}^{n}\sigma_{jj}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=\lambda_i \end{equation*} j=1∑nσjjρ2(Yi,Xj)=λi - 原变量的第 j j j个分量与所有主成分的因子负荷量满足:
∑ i = 1 n ρ 2 ( Y i , X j ) = 1 \begin{equation*} \sum_{i=1}^{n}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=1 \end{equation*} i=1∑nρ2(Yi,Xj)=1
证明:- 由PCA求解过程直接可得。
- 显然:
∑ i = 1 n Var ( Y i ) = tr [ Cov ( Y ) ] = tr [ Cov ( A X ) ] = tr ( A Σ A T ) = tr ( Σ A T A ) = tr ( Σ ) = ∑ i = 1 n Var ( X i ) \begin{align*} \sum_{i=1}^{n}\operatorname{Var}(\mathbf{Y}_i) &=\operatorname{tr}[\operatorname{Cov}(\mathbf{Y})]=\operatorname{tr}[\operatorname{Cov}(A\mathbf{X})]=\operatorname{tr}(A\Sigma A^T) \\ &=\operatorname{tr}(\Sigma A^TA)=\operatorname{tr}(\Sigma)=\sum_{i=1}^{n}\operatorname{Var}(\mathbf{X}_i) \end{align*} i=1∑nVar(Yi)=tr[Cov(Y)]=tr[Cov(AX)]=tr(AΣAT)=tr(ΣATA)=tr(Σ)=i=1∑nVar(Xi) - 显然:
∑ j = 1 n σ j j ρ 2 ( Y i , X j ) = ∑ j = 1 n λ i α i j 2 = λ i α i α i T = λ i \begin{equation*} \sum_{j=1}^{n}\sigma_{jj}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=\sum_{j=1}^{n}\lambda_i\alpha_{ij}^2=\lambda_i\alpha_i\alpha_i^T=\lambda_i \end{equation*} j=1∑nσjjρ2(Yi,Xj)=j=1∑nλiαij2=λiαiαiT=λi - 因为 A A A是正交矩阵,所以 A A A可逆,于是 X \mathbf{X} X可以表示为 Y 1 , … , n \mathbf{Y}_1,\dots,\mathbf{n} Y1,…,n的线性组合,所以二者的复相关系数为 1 1 1。由复相关系数性质可直接得出结论。
贡献率定义
称第 i i i个主成分 Y i \mathbf{Y}_i Yi的方差与所有主成分方差之和为 Y i \mathbf{Y}_i Yi的方差贡献率,记为 η i \eta_i ηi,即:
η i = λ i ∑ j = 1 n λ j \begin{equation*} \eta_i=\frac{\lambda_i}{\sum\limits_{j=1}^{n}\lambda_j} \end{equation*} ηi=j=1∑nλjλi
将:
∑ i = 1 k λ i ∑ i = 1 n λ i \begin{equation*} \frac{\sum\limits_{i=1}^{k}\lambda_i}{\sum\limits_{i=1}^{n}\lambda_i} \end{equation*} i=1∑nλii=1∑kλi
称为主成分 Y 1 , … . Y k \mathbf{Y}_1,\dots.\mathbf{Y}_k Y1,….Yk的累计方差贡献率。称主成分 Y 1 , … . Y k \mathbf{Y}_1,\dots.\mathbf{Y}_k Y1,….Yk与变量 X j \mathbf{X}_j Xj之间的复相关系数的平方 R 2 R^2 R2为 Y 1 , … . Y k \mathbf{Y}_1,\dots.\mathbf{Y}_k Y1,….Yk对 X j \mathbf{X}_j Xj的贡献率,其计算公式为:
R 2 = ∑ i = 1 k λ i α i j 2 σ i i \begin{equation*} R^2=\sum_{i=1}^{k}\frac{\lambda_i\alpha_{ij}^2}{\sigma_{ii}} \end{equation*} R2=i=1∑kσiiλiαij2
由前述,我们一般通过选择主成分的个数来实现对数据的降维,即选择主成分的个数使它们的累计方差贡献率达到一定比例(一般为 85 % 85\% 85%)。
样本主成分分析
假设对 n n n维随机变量 X \mathbf{X} X进行 m m m次独立观测,得到 m m m个 n n n维样本 x 1 , … , x m x_1,\dots,x_m x1,…,xm。在样本主成分分析中,我们使用样本来估计 X \mathbf{X} X的协方差矩阵,即:
S = ( s i j ) , s i j = 1 m − 1 ∑ k = 1 m ( x k i − X ^ i ) ( x k j − X ^ j ) , i , j = 1 , 2 , … , n \begin{equation*} S=(s_{ij}),\;s_{ij}=\frac{1}{m-1}\sum_{k=1}^{m}(x_{ki}-\hat{\mathbf{X}}_i)(x_{kj}-\hat{\mathbf{X}}_j),\;i,j=1,2,\dots,n \end{equation*} S=(sij),sij=m−11k=1∑m(xki−X^i)(xkj−X^j),i,j=1,2,…,n
其中:
X ^ i = 1 m ∑ j = 1 m x j i , i = 1 , 2 , … , n \begin{equation*} \hat{\mathbf{X}}_i=\frac{1}{m}\sum_{j=1}^{m}x_{ji},\;i=1,2,\dots,n \end{equation*} X^i=m1j=1∑mxji,i=1,2,…,n
其余步骤与总体主成分分析一致。
注意事项
多重共线性问题
当原始变量出现多重共线性时,PCA的效果会受到影响,这是因为重复的信息在方差占比中重复进行了计算。我们可以通过计算协方差矩阵的最小特征值来判断是否出现多重共线性的情况。若最小特征值趋于 0 0 0,则需要对纳入研究的变量进行考察与筛选。
相关矩阵导出主成分
上面我们都是对协方差矩阵的特征值分解进行计算,但在现实中,我们可能会对数据进行标准化处理来消除量纲带来的影响,注意到标准化后数据的协方差矩阵即为相关矩阵,此时将相关矩阵作对应的特征值分解即可。但需要注意:标准化后各变量方差相等均为 1 1 1,损失了部分信息,所以会使得标准化后的各变量在对主成分构成中的作用趋于相等。因此,取值范围在同量级的数据建议使用协方差矩阵直接求解主成分,若变量之间数量级差异较大,再使用相关矩阵求解主成分。
算法流程

主成分分析的应用
主成分分类
可以实现对变量之间的分类。将变量进行主成分分析,得到第一主成分与第二主成分,然后画出各变量与两个主成分载荷的二维平面图,即将各变量画在以两个主成分为轴的平面上,变量的两个坐标是主成分在变量上的载荷。可以认为相似变量会聚在平面图中聚在一起。
主成分回归
若数据存在高度的多重共线性,对数据进行主成分筛选,然后用主成分去进行回归。
R语言代码
> # 以鸢尾花数据集作为示例
> data <- iris[1:4]
> # 变量间量纲差异不大,使用协方差矩阵进行分析
> Sigma <- cov(data)
> # 计算特征值,因为是示例就不做处理了
> eigen(Sigma)$values
[1] 4.22824171 0.24267075 0.07820950 0.02383509
> # center和scale.控制是否对原始数据进行标准化
> # 注意scale.,后面有一个点,不是scale
> x <- prcomp(data, center=FALSE, scale.=FALSE)
> # 呈现结果
> summary(x)
Importance of components:PC1 PC2 PC3 PC4
Standard deviation 7.8613 1.45504 0.28353 0.15441
Proportion of Variance 0.9653 0.03307 0.00126 0.00037
Cumulative Proportion 0.9653 0.99837 0.99963 1.00000
> # 输出因子载荷矩阵,显示出的矩阵其实就是A^T
> # 可以自己尝试证明一下,利用协方差的性质以及Y之间的线性无关性
> x$rotationPC1 PC2 PC3 PC4
Sepal.Length -0.7511082 0.2841749 0.50215472 0.3208143
Sepal.Width -0.3800862 0.5467445 -0.67524332 -0.3172561
Petal.Length -0.5130089 -0.7086646 -0.05916621 -0.4807451
Petal.Width -0.1679075 -0.3436708 -0.53701625 0.7518717
> # 如果输入x,则输出训练样本经过主成分分析后的结果,即Y值
> # 如果输入一组新的数据newdata,则输出newdata经过主成分分析后的结果
> # 这里因为数据太多就用head函数控制只显示前10行
> head(predict(x), 10)PC1 PC2 PC3 PC4[1,] -5.912747 2.302033 0.007401536 0.003087706[2,] -5.572482 1.971826 0.244592251 0.097552888[3,] -5.446977 2.095206 0.015029262 0.018013331[4,] -5.436459 1.870382 0.020504880 -0.078491501[5,] -5.875645 2.328290 -0.110338269 -0.060719326[6,] -6.477598 2.324650 -0.237202487 -0.021419633[7,] -5.515975 2.070904 -0.229853120 -0.050406649[8,] -5.850929 2.148075 0.018793774 -0.045342619[9,] -5.158920 1.775064 0.061039220 -0.031128633
[10,] -5.645001 1.990001 0.224852923 -0.057434390
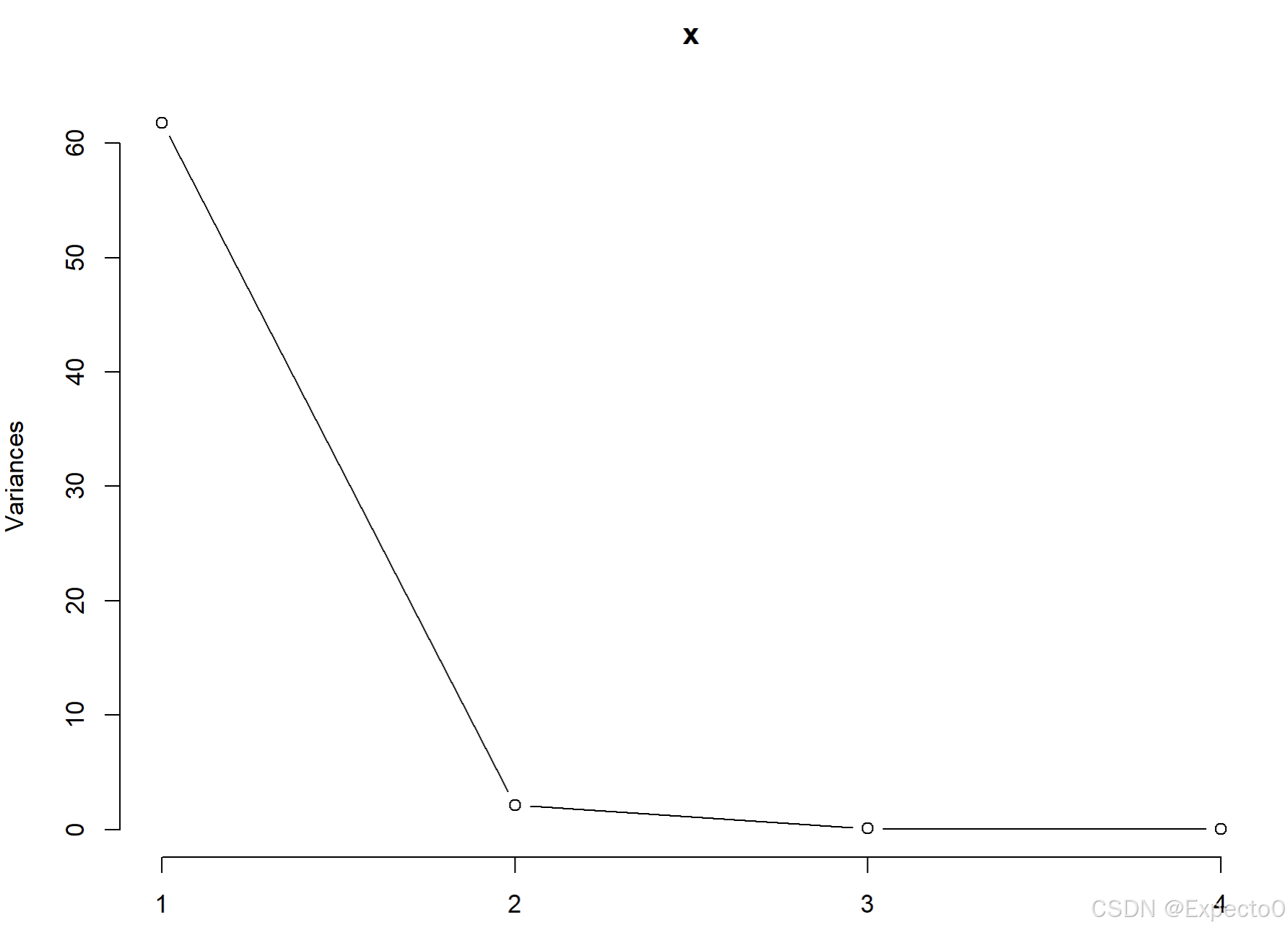
> # 画碎石图,即样本主成分与方差贡献率之间的曲线图或条形图
> screeplot(x, type = "barplot")
> screeplot(x, type = "lines")

主成分分析在R语言中还有另一个函数叫做princomp,但官方更推荐使用prcomp。主要是因为求解算法问题,prcomp使用svd分解进行求解,后面我会对这里进行一些补充。
Python代码
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names# 对数据进行标准化(可选)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 初始化 PCA,保留所有主成分
pca = PCA(n_components=4)
X_pca = pca.fit_transform(X_scaled)print("各主成分解释的方差比例:")
print(pca.explained_variance_ratio_)
print("累计解释方差:", np.cumsum(pca.explained_variance_ratio_))# 每个主成分上的特征权重(特征向量)
loadings = pd.DataFrame(pca.components_.T,columns=[f'PC{i+1}' for i in range(pca.n_components_)],index=feature_names)print(loadings)参考文献
- 薛毅,统计建模与R软件
- 何晓群,多元统计分析——基于R语言
- 李航,统计学方法
- Richard A.Johnson,Applied Multivariate Statistical Analysis
后续会补充的内容
- 具体数值求解算法
- R语言两个函数的具体差异
- 为什么特征值接近于0就意味着多重共线性
- R2的性质,即为什么R2等于所有自变量与因变量相关系数平方的加和
相关文章:

PCA——主成分分析数学原理及代码
主成分分析 PCA的目的是:对数据进行一个线性变换,在最大程度保留原始信息的前提下去除数据中彼此相关的信息。反映在变量上就是说,对所有的变量进行一个线性变换,使得变换后得到的变量彼此之间不相关,并且是所有可能的…...

[Windows] Adobe Camera Raw 17.2 win/Mac版本
[Windows] Adobe Camera Raw 链接:https://pan.xunlei.com/s/VOOIAXoyaZcKAkf_NdP-qw_6A1?pwdpd5k# Adobe Camera Raw,支持Photoshop,lightroom等Adobe系列软件,对相片无损格式进行编辑调色。 支持PS LR 2022 2023 2024 2025版…...

基于计算机视觉的行为检测:从原理到工业实践
一、行为检测的定义与核心价值 行为检测(Action Recognition)是计算机视觉领域的关键任务,旨在通过分析视频序列理解人类动作的时空特征。其核心价值体现在时序建模和多尺度分析能力上——系统需要捕捉动作的起始、发展和结束全过程,同时适应不同持续时间(0.1秒至数分钟)…...

基于 OpenCV 的图像与视频处理
基于 OpenCV 的图像处理 一、实验背景 OpenCV 是一个开源的计算机视觉库,广泛应用于图像处理、视频分析、目标检测等领域。通过学习 OpenCV,可以快速实现图像和视频的处理功能,为复杂的应用开发 奠定基础。本实验旨在通过实际代码示例&…...

B树的异常恢复
B-Tree & Crash Recovery B树作为平衡的n叉树 高度平衡树 许多实用的二叉树(如AVL树或红黑树)被称为高度平衡树,这意味着树的高度(从根节点到叶子节点)被限制为Ο(log 𝑁),因此查找操作的…...

Centos9 离线安装 MYSQL8
centos 9 离线安装 mysql 8 参考教程 1. 官网下载mysql 下载地址 2. 将文件传输到Centos中解压 软件全部安装到了/opt中 在opt中新建mysql目录,解压到mysql目录中 tar -xvf mysql压缩文件 mysql[rootcentoshost mysql]# ls mysql-community-client-8.4.5-1.e…...

【RabbitMQ | 第2篇】RabbitMQ 控制台实现消息路由 + 数据隔离
文章目录 同步调用和异步调用MQRabbitMQ1. RabbitMQ控制台实现交换机路由到队列1.1 创建队列1.2 将消息发送给交换机,是否会到达队列 2. RabbitMQ控制台实现数据隔离2.1 添加一个用户2.2 创建新的虚拟主机 同步调用和异步调用 同步调用是指完成一个功能,…...
)
算法—选择排序—js(场景:简单实现,不关心稳定性)
选择排序原理:(简单但低效) 每次从未排序部分选择最小元素,放到已排序部分的末尾。 特点: 时间复杂度:O(n) 空间复杂度:O(1) 不稳定排序 // 选择排序 function selectionSort(arr) {for (let …...

龙舟中国行走进湖南娄底 2025湖南省龙舟联赛娄底站盛大举行
鼓声震天破碧波,百舸争流显豪情。2025年4月20日星期日,"龙舟中国行2025"首站——龙舟中国行走进湖南娄底2025湖南省龙舟联赛娄底双峰站在双峰县湄水河育才桥至风雨桥水域火热开赛。12支劲旅劈波斩浪,在青山绿水间上演传统与现代交织…...

重构之去除多余的if-else
一、提前返回(Guard Clauses) 适用场景:当 else 块仅用于处理异常或边界条件时。 优化前:if (isValid) {doSomething(); } else {return; }优化后:if (!isValid) return; // 提前处理异常,主流程保持简洁…...

【Vim】vim的简单使用
文章目录 1. vi的模式2. 按键使用说明2.1 一般命令模式光标移动替换和查找删除/复制/粘贴 2.2 编辑模式插入/替换 2.3 命令行模式保存/退出环境修改 3. vim的缓存4. vim可视区块5. vim多文件编辑6. vim多窗口功能7. vim关键词补全 1. vi的模式 一般命令模式:以vi打…...

【消息队列RocketMQ】一、RocketMQ入门核心概念与架构解析
在当今互联网技术飞速发展的时代,分布式系统的架构设计愈发复杂。消息队列作为分布式系统中重要的组件,在解耦应用、异步处理、削峰填谷等方面发挥着关键作用。RocketMQ 作为一款高性能、高可靠的分布式消息中间件,被广泛应用于各类互联网场景…...

hadoop分布式部署
1. 上传jdk和hadoop安装包到服务器 2. 解压压缩包 tar xf jdk1.8.0_112.tgz -C /usr/local/ tar xf hadoop-3.3.6.tar.gz -C /usr/local/3. 关闭防火墙 systemctl stop firewalld systemctl disable firewalld4. 修改配置文件 core-site.xml、hadoop-env.sh、yarn-env.sh、…...
)
C++面试题集合(附答案)
C全家桶 C基础 1. C和C有什么区别? 2. C语言的结构体和C的有什么区别? 3. C 语言的关键字 static 和 C 的关键字 static 有什么区别? 4. C 和 Java有什么核心区别? 5. C中,a和&a有什么区别? 6. …...
)
23种设计模式-结构型模式之装饰器模式(Java版本)
Java 装饰器模式(Decorator Pattern)详解 🎁 什么是装饰器模式? 装饰器模式是一种结构型设计模式,允许向一个对象动态添加新的功能,而不改变其结构。 🧱 你可以想象成在原有功能上“包裹”一…...

UE5的BumpOffset节点
BumpOffset 节点的基本概念 本质上,BumpOffset 节点通过扭曲或偏移纹理坐标来创造深度错觉。它基于视角方向和高度信息动态地调整纹理采样位置,使平面表面看起来具有凹凸感。这是一种称为视差映射(Parallax Mapping)的技术的实现。 当你从不同角度观察…...

从跌倒到领跑:北京亦庄机器人马拉松如何改写人机协作未来?
目录 一、当铁骨遇见马拉松精神 二、半马背后的硬核突破 三、赛事背后的科技博弈 四、当机器人走出实验室 跌倒者的荣光 清晨7:30的南海子公园,发令枪响瞬间——20台形态各异的机器人以千奇百怪的姿态冲出起跑线,有的像蹒跚学步的孩童,有的如专业运动员般矫健,更有机器…...

Internet Protocol
一、IP 1. 基本概念 IP定义:IP 是为计算机网络相互连接进行通信而设计的协议,它规定了网络设备如何标识和寻址,以及数据如何在网络中传输和路由。IP作用:主要负责在不同的网络之间转发数据包,使数据能够从源主机准确…...

Android学习之实战登录注册能力
我们可以从本地 Token 存储、时效管理、服务端通知联动、定时器优化四个维度深入展开 一、本地 Token 存储设计(基于 SharedPreferences) 1. 存储结构优化(包含时效性字段) // 定义存储类(封装SharedPreferences操作…...

【数据可视化-19】智能手机用户行为可视化分析
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

基于一致性哈希算法原理和分布式系统容错机制
一、传统取模算法的局限性分析 当使用User ID取模路由时,Pod挂断会导致以下问题: 数据雪崩效应:节点失效后所有请求需要重新计算取模值,导致缓存穿透和服务震荡服务不可用窗口:节点失效期间,原本路由到该节…...
)
[SpringBoot-1] 概述和快速入门(使用vscode)
1 SpringBoot 概念 SpringBoot提供了一种快速使用Spring的方式,基于约定优于配置的思想,可以让开发人员不必在配置与逻辑业务之间进行思维的切换,全身心的投入到逻辑业务的代码编写中,从而大大提高了开发的效率,一定程…...

学习笔记二十——Rust trait
🧩 Rust Trait 彻底搞懂版 👀 目标读者:对 Rust 完全陌生,但想真正明白 “Trait、Trait Bound、孤岛法则” 在做什么、怎么用、为什么这样设计。 🛠 方法: 先给“心里模型”——用生活类比把抽象概念掰开揉…...

llama factory
微调大模型可以像这样轻松… https://github.com/user-attachments/assets/e6ce34b0-52d5-4f3e-a830-592106c4c272 选择你的打开方式: 入门教程:https://zhuanlan.zhihu.com/p/695287607框架文档:https://llamafactory.readthedocs.io/zh-…...

机器学习 Day12 集成学习简单介绍
1.集成学习概述 1.1. 什么是集成学习 集成学习是一种通过组合多个模型来提高预测性能的机器学习方法。它类似于: 超级个体 vs 弱者联盟 单个复杂模型(如9次多项式函数)可能能力过强但容易过拟合 组合多个简单模型(如一堆1次函数)可以增强能力而不易过拟合 集成…...
)
基于 Spring Boot 瑞吉外卖系统开发(五)
基于 Spring Boot 瑞吉外卖系统开发(五) 删除分类 分类列表中每条分类信息右侧提供了一个“删除”按钮,当需要将已经存在的分类信息删除时,可以通过单击“删除”按钮实现。 请求路径为/category,携带参数id…...

PyTorch基础笔记
PyTorch张量 多维数组:张量可以是标量(0D)、向量(1D)、矩阵(2D)或更高维的数据(3D)。 数据类型:支持多种数据类型(如 float32, int64, bool 等&a…...

什么是 IDE?集成开发环境的功能与优势
原文:什么是 IDE?集成开发环境的功能与优势 | w3cschool笔记 (注意:此为科普文章,请勿标记为付费文章!且此文章并非我原创,不要标记为付费!) IDE 是什么? …...

基于大数据的房产估价解决方案
基于大数据的房产估价解决方案 一、项目背景与目标 1.1 背景 在房地产市场中,准确的房产估价至关重要。传统的房产估价方法往往依赖于估价师的经验和有限的数据样本,存在主观性强、效率低等问题。随着大数据技术的发展,大量的房产相关数据被积…...

基于深度学习的线性预测:创新应用与挑战
一、引言 1.1 研究背景 深度学习作为人工智能领域的重要分支,近年来在各个领域都取得了显著的进展。在线性预测领域,深度学习也逐渐兴起并展现出强大的潜力。传统的线性预测方法在处理复杂数据和动态变化的情况时往往存在一定的局限性。而深度学习凭借…...

WEMOS LOLIN32
ESP32是結合Wi-Fi和藍牙的32位元系統單晶片(SoC)與外接快閃記憶體的模組。許多廠商生產採用ESP32模組的控制板,最基本的ESP控制板包含ESP32模組、直流電壓轉換器和USB序列通訊介面IC。一款名為WEMOS LOLIN32的ESP32控制板具備3.7V鋰電池插座。…...

VSCode 扩展离线下载方法
学习自该文章,感谢作者! 2025 年 VSCode 插件离线下载攻略:官方渠道一键获取 - 知乎 获取扩展关键信息 方法一:官网获取 打开 VSCode 扩展官方网站 搜索要下载的扩展,以 CodeGeeX 为例,网址为…...

计算机视觉与深度学习 | RNN原理,公式,代码,应用
RNN(循环神经网络)详解 一、原理 RNN(Recurrent Neural Network)是一种处理序列数据的神经网络,其核心思想是通过循环连接(隐藏状态)捕捉序列中的时序信息。每个时间步的隐藏状态 ( h_t ) 不仅依赖当前输入 ( x_t ),还依赖前一时间步的隐藏状态 ( h_{t-1} ),从而实现…...

对于网络资源二级缓存的简单学习
缓存学习 前言认识缓存磁盘储存内存储存磁盘内存组合优化 具体实现WebCacheMD5签名 WebDownloadOperationWebDownloaderWebCombineOperation 总结 前言 在最近的写的仿抖音app中,遇到了当往下滑动视频后,当上方的视频进入复用池后,会自动清空…...

【计量地理学】实验六 地理属性空间插值
一、实验目的 本次实验的主要目的在于熟练掌握空间克里格法插值的理论基础,包括其核心概念和步骤,能够通过数据可视化和统计分析方法识别数据中的异常值,并且掌握数据正态性的检验方法,理解正态分布对克里格法的重要性࿰…...

26考研 | 王道 | 数据结构 | 第六章 图
第六章 图 文章目录 第六章 图6.1. 图的基本概念6.2. 图的存储6.2.1. 邻接矩阵6.2.2. 邻接表6.2.3. 十字链表、临接多重表6.2.4. 图的基本操作 6.3. 图的遍历6.3.1. 广度优先遍历6.3.2. 深度优先遍历6.3.3 图的遍历与连通性 6.4. 图的应用6.4.1. 最小生成树6.4.2. 无权图的单源…...

window.addEventListener 和 document.addEventListener
window.addEventListener 和 document.addEventListener 是 JavaScript 中绑定事件的两个常用方法,核心区别在于 绑定的对象不同,导致事件的作用范围、触发时机和适用场景不同。下面用最直白的语言和案例对比说明: 一、核心区别:…...

51单片机的原理图和PCB绘制
51单片机最小系统原理图 加了两个led灯和按键检测电路。 PCB中原件摆放位置 成品 资源链接:https://download.csdn.net/download/qq_61556106/90656365...
 :Android 协程全解析,从作用域到异常处理的全面指南)
kotlin知识体系(五) :Android 协程全解析,从作用域到异常处理的全面指南
1. 什么是协程 协程(Coroutine)是轻量级的线程,支持挂起和恢复,从而避免阻塞线程。 2. 协程的优势 协程通过结构化并发和简洁的语法,显著提升了异步编程的效率与代码质量。 2.1 资源占用低(一个线程可运行多个协程)…...

数据通信学习笔记之OSPF其他内容3
对发送的 LSA 进行过滤 当两台路由器之间存在多条链路时,可以在某些链路上通过对发送的 LSA 进行过滤,减少不必要的重传,节省带宽资源。 通过对 OSPF 接口出方向的 LSA 进行过滤可以不向邻居发送无用的 LSA,从而减少邻居 LSDB 的…...
)
Kubernetes相关的名词解释API Server组件(9)
什么是API Server? API Server(kube-apiserver) 是 Kubernetes 的核心组件之一,负责管理整个集群的通信和操作入口。 API Server 的作用在整个 Kubernetes 集群的正常运作中至关重要,可以说它是整个系统的神经中枢。…...

[密码学实战]密码服务平台部署架构详解与学习路线
密码服务平台部署架构详解与学习路线 引言 在数字化转型的浪潮中,数据安全已成为企业生存的“生命线”。国密算法(SM2/SM3/SM4)作为我国自主研发的密码标准,正在政务、金融、医疗等领域加速落地。然而,构建一套高可用、高性能、合规的密码服务平台,仍需攻克架构设计、性…...

如何成为Prompt工程师:学习路径、核心技能与职业发展
一、什么是Prompt工程师? Prompt工程师是专注于通过设计、优化和调试大语言模型(LLM)的输入提示词(Prompt),以精准引导模型输出符合业务需求结果的技术人才。其核心能力在于将模糊的业务需求转化为结构化、…...
cv2.Canny)
OpenCV 边缘检测(Edge Detection)cv2.Canny
OpenCV 边缘检测(Edge Detection)cv2.Canny flyfish import cv2video_path input_video.mp4 cap cv2.VideoCapture(video_path)while True:ret, frame cap.read()if not ret:break # 视频结束# 转灰度frame_gray cv2.cvtColor(frame, cv2.COLOR_B…...

【C++】win 10 / win 11:Dev-C++ 下载与安装
目录 一、Dev-C 下载 (1)sourceforge 官网下载 (2)腾讯官网下载 二、Dev-C 安装 三、Dev-C 配置 (1)配置 C11 (2)配置产生调试信息 (3)个性化配置…...

2025年MathorCup竞赛助攻资料免费分享
对于本界竞赛B题其中问题需要设计软件框架,对于该问题回答,个人认为可以在设计框架下简单的进行软件展示,下面是初步展示的结果,仅供参考 【问题四:老城区平移置换决策软件设计】规划局希望这个案例能起到示范作用&am…...

征程 6 VIO 通路断流分析
自动驾驶场景中,常见的是多路感知通路,在不考虑应用获取释放帧异常操作的前提下,一般出现帧获取异常的情况,主要原因是通路中某段断流的情况,如何去准确的定位,对大部分客户来说,依赖我司的支持…...

JavaScript 性能优化
JavaScript 性能优化是提高 Web 应用性能的关键步骤,特别是在处理大量数据、复杂计算或频繁的 DOM 操作时。以下是一些常见的 JavaScript 性能优化技巧和策略: 文章目录 @[TOC]一、代码层面优化1. **减少全局变量**2. **避免使用 `with` 语句**3. **使用局部变量**4. **减少 …...

机器学习中的“三态模型“:过拟合、欠拟合和刚刚好
文章目录 说明1. 模型表现的"三国演义"2. 可视化理解:从曲线看状态3. 诊断模型:你的模型"病"了吗?4. 学习曲线:模型的"体检报告"5. 治疗"模型病"的药方 6. 偏差-方差分解:理解…...
的CFD仿真中,AI和机器学习的应用)
在FVM(有限体积法)的CFD仿真中,AI和机器学习的应用
在FVM(有限体积法)的CFD仿真中,AI和机器学习(ML)可以通过以下方式显著提高收敛速度与计算效率,具体分为六个方向: 1. 加速非线性迭代收敛 替代传统松弛方法: 使用ML模型(…...