机器学习 Day12 集成学习简单介绍
1.集成学习概述
1.1. 什么是集成学习
集成学习是一种通过组合多个模型来提高预测性能的机器学习方法。它类似于:
-
超级个体 vs 弱者联盟
-
单个复杂模型(如9次多项式函数)可能能力过强但容易过拟合
-
组合多个简单模型(如一堆1次函数)可以增强能力而不易过拟合
-
集成学习通过生成多个分类器/模型,将它们的预测结果组合起来,通常能获得优于任何单一分类器的预测性能。
1.2. 机器学习的两个核心任务
-
如何优化训练数据 - 主要用于解决欠拟合问题——booting
-
如何提升泛化性能 - 主要用于解决过拟合问题——bagging
1.3. 集成学习的两种主要方法
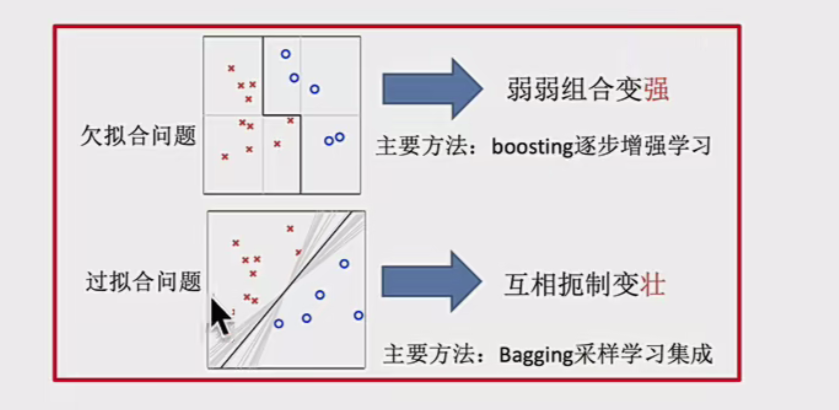
Boosting方法
-
逐步增强学习
-
通过序列化方式构建模型,每个新模型都更关注前序模型处理不好的样本(错误数据增强)
-
典型算法:AdaBoost, Gradient Boosting, XGBoost
Bagging方法
-
采样学习集成
-
通过并行方式构建多个模型,每个模型基于数据的随机子集
-
典型算法:随机森林
集成学习的关键优势是:只要单分类器的表现不太差,集成后的结果通常优于单分类器。这种方法能有效平衡模型的偏差和方差,提高泛化能力
2.Bagging和随机森林
2.1Bagging集成原理
先看一个图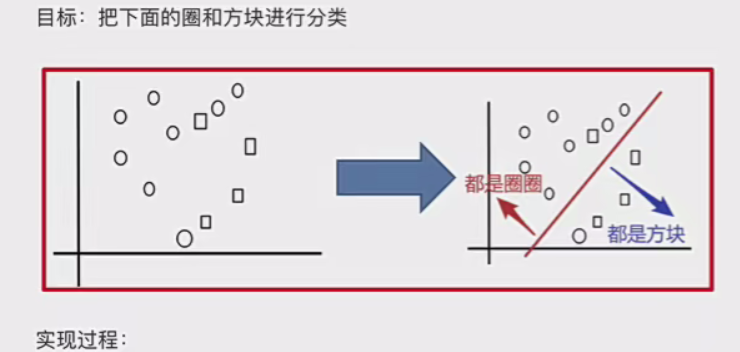
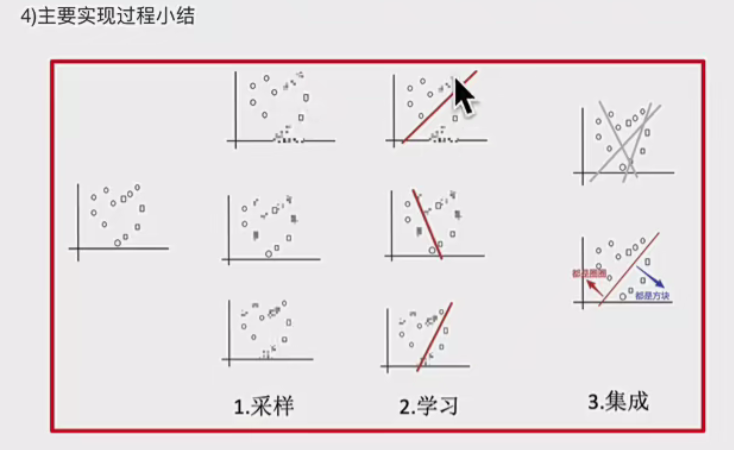
2.1.1. Bagging 基本概念
Bagging(Bootstrap Aggregating,自助聚合)是一种并行式集成学习方法,通过构建多个相互独立的基学习器,并综合它们的预测结果来提高模型的泛化能力。
核心思想:
-
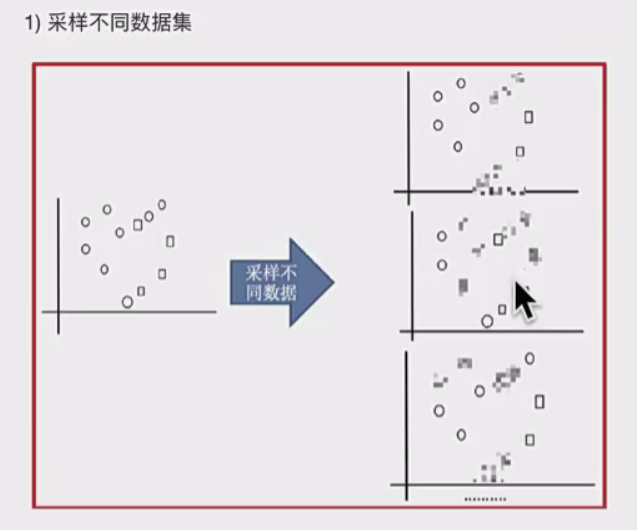
Bootstrap(自助采样):从训练数据中有放回地随机抽取多个子集,每个子集用于训练一个基学习器。
-
Aggregating(聚合):所有基学习器的预测结果通过投票(分类)或平均(回归)进行集成,得到最终预测。
📌 关键特点:
适用于高方差、低偏差的模型(如决策树、神经网络)。
能有效降低方差,减少过拟合风险。(可以理解因为你随机选取数据)
2.1.2. Bagging 算法流程
-
自助采样(Bootstrap Sampling)
-
从原始训练集 DD 中有放回地随机抽取 mm 个样本,构成一个子集 DiDi。
-
重复该过程 TT 次,得到 TT 个不同的训练子集。
-
-
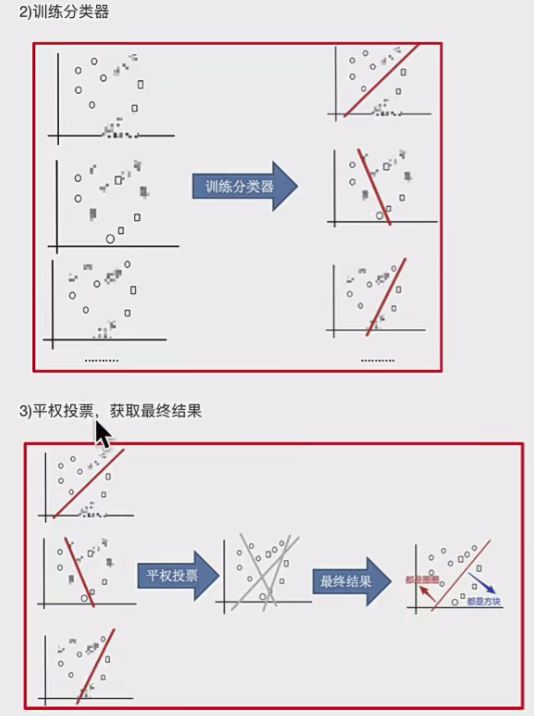
基学习器训练
-
每个子集 DiDi 训练一个基学习器(如决策树)。
-
基学习器之间相互独立(可并行训练)。
-
-
集成预测
-
分类任务:采用投票法(多数表决)
-
回归任务:采用平均法(取均值)
-
2.1.3. Bagging 的典型算法:随机森林(Random Forest)
-
改进点:不仅对样本进行自助采样,还对特征进行随机选择(进一步降低相关性)。
-
优势:
-
比普通 Bagging 更鲁棒,抗过拟合能力更强。
-
能处理高维数据,适用于分类和回归任务。
-
2.1.4. Bagging 的优缺点
✅ 优点
-
有效减少方差,防止过拟合。
-
适用于高噪声数据,鲁棒性强。
-
可并行训练,计算效率高。
❌ 缺点
-
对低偏差、高方差的模型(如线性回归)提升有限。
-
如果基学习器本身偏差较大,Bagging 可能无法显著提升性能。
2.2随机森林
2.2.1. 随机森林的核心概念
随机森林是一种基于 Bagging + 决策树(基学习器是决策树) 的集成学习方法,通过构建多棵决策树并综合它们的预测结果来提高模型的泛化能力。
2.2.2核心特点:
双重随机性:样本随机(自助采样),特征随机(随机选择部分特征)
投票机制:分类任务:众数投票(多数表决),回归任务:均值预测
2.2.3构造过程:
2.2.4关键问题解答
Q1:为什么要随机抽样训练集?
-
如果所有树使用相同的训练数据,会导致所有树高度相似,失去集成的意义。
-
随机抽样 保证每棵树学习到数据的不同方面,提高多样性。
Q2:为什么要有放回地抽样?
-
无放回抽样会导致每棵树的训练数据完全不同,可能引入偏差。
-
有放回抽样 使不同树的数据分布相似但不相同,平衡偏差与方差。
2.3包外估计(之前讲的自助法)

5. 实际应用示例
(1)随机森林的 OOB 误差计算
from sklearn.ensemble import RandomForestClassifier# 启用 OOB 估计
model = RandomForestClassifier(n_estimators=100, oob_score=True)
model.fit(X_train, y_train)# 输出 OOB 准确率
print("OOB Score:", model.oob_score_)(2)特征重要性可视化
import matplotlib.pyplot as plt# 获取特征重要性
importances = model.feature_importances_# 可视化
plt.barh(range(X.shape[1]), importances)
plt.yticks(range(X.shape[1]), X.columns)
plt.show()6. 关键问题
包外数据能完全替代验证集吗?
可以:在随机森林中,OOB 估计已被证明是无偏的。但:对于超参数调优,建议结合交叉验证。
2.4随机森林API和案例
还是和以前一样,先实例化后使用


案例:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.datasets import load_breast_cancer # 示例数据集# 1. 加载数据(这里使用sklearn自带的乳腺癌数据集作为示例)
data = load_breast_cancer()
X = data.data
y = data.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 初始化随机森林分类器(启用OOB估计)
rf = RandomForestClassifier(oob_score=True, random_state=42)# 4. 定义超参数网格
param_grid = {"n_estimators": [120, 200, 300, 500, 800, 1200],"max_depth": [5, 8, 15, 25, 30],"max_features": ["sqrt", "log2"] # 添加特征选择方式
}# 5. 使用GridSearchCV进行超参数调优
gc = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5, # 使用5折交叉验证n_jobs=-1, # 使用所有CPU核心verbose=2 # 显示详细日志
)# 6. 训练模型
gc.fit(X_train, y_train)# 7. 输出最佳参数和模型评估结果
print("\n=== 最佳参数组合 ===")
print(gc.best_params_)print("\n=== 模型评估 ===")
print(f"测试集准确率: {gc.score(X_test, y_test):.4f}")# 8. 获取最佳模型并输出OOB得分
best_rf = gc.best_estimator_
print(f"包外估计(OOB)得分: {best_rf.oob_score_:.4f}")3.通过一个案例,来看一下我们拿到一个数据如何分析:
3.1题目介绍
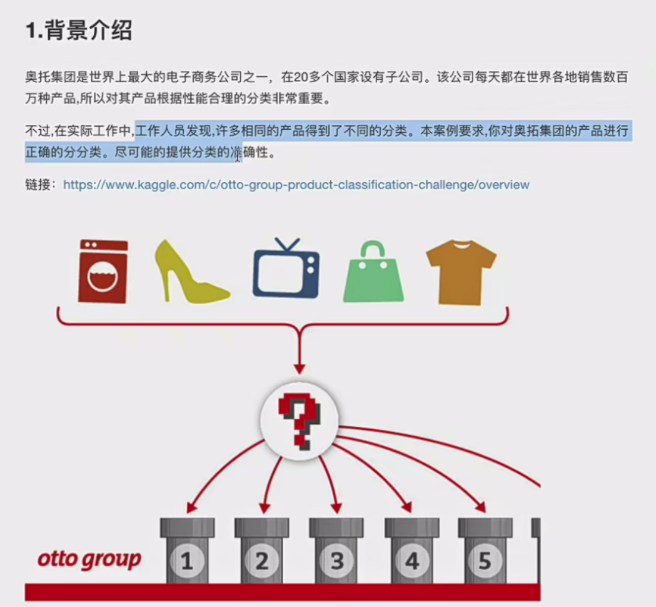
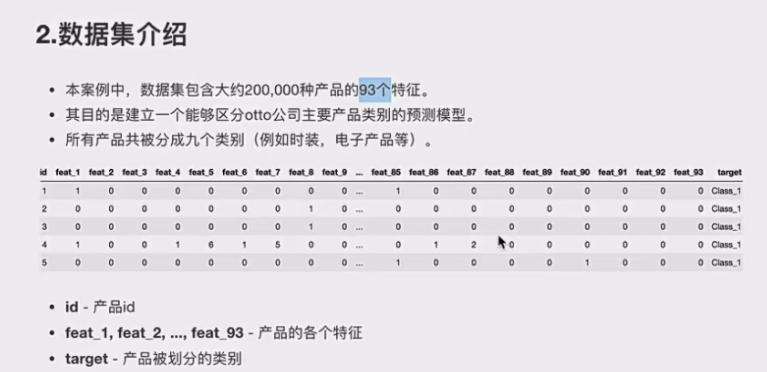
 3.2题目分析:我说一下目前了解到的各个部分
3.2题目分析:我说一下目前了解到的各个部分
3.1获取数据
数据描述,可视化
3.2数据基本处理:选取特征值(部分特征值无用,比如id),对于类别不平衡数据的处理(过采样和欠采样),缺失值和异常值的处理,分割数据,将标签值转化为数字(这个案例里会讲)只有进行数据的可视化才能看到数据是否平衡,有无异常值等,所以可视化很重要。
3.3特征处理:特征预处理(归一化,标准化),特征提取(字典特征提取,文本特征提取,图像特征提取),将类别特征转换为One-hot编码。
3.4模型训练:实际上涉及到参数调优,如果算力够强使用交叉验证和网格搜索即可,不行的话可以一个一个来,我们这个案例就是。
3.5模型评估
3.3代码实现
获取数据,以及数据描述:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.utils import class_weight# 加载数据
data = pd.read_csv('./data/otto/train.csv')# 查看数据形状
print(f"数据集形状: {data.shape}") # (61878, 95)# 查看数据概览
print(data.describe())# 可视化类别分布
plt.figure(figsize=(12, 6))
sns.countplot(x='target', data=data)
plt.title('类别分布情况')
plt.xticks(rotation=45)
plt.show()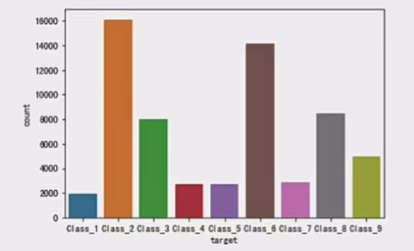
可以看到标签值是一个不平衡数据,所以需要进行处理。
数据预处理
(1)确定特征值和标签值
# 首先需要确定特征值\标签值
y = data["target"]
x = data.drop(["id", "target"], axis=1)(2)类别不平衡问题处理
# 欠采样获取数据
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(x, y)# 图形可视化,查看数据分布
import seaborn as sns
sns.countplot(y_resampled)
plt.show() 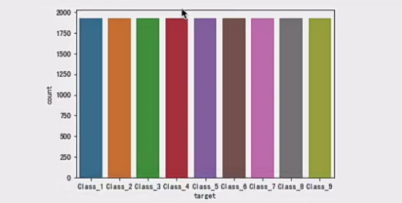
看到处理完毕,并且 类别平衡。
(3)标签值的转化
使用转换器即可
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)
(4)分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2)特征工程 这个数据全是0-1数据,是被脱敏处理过后的数据,无需再进行处理
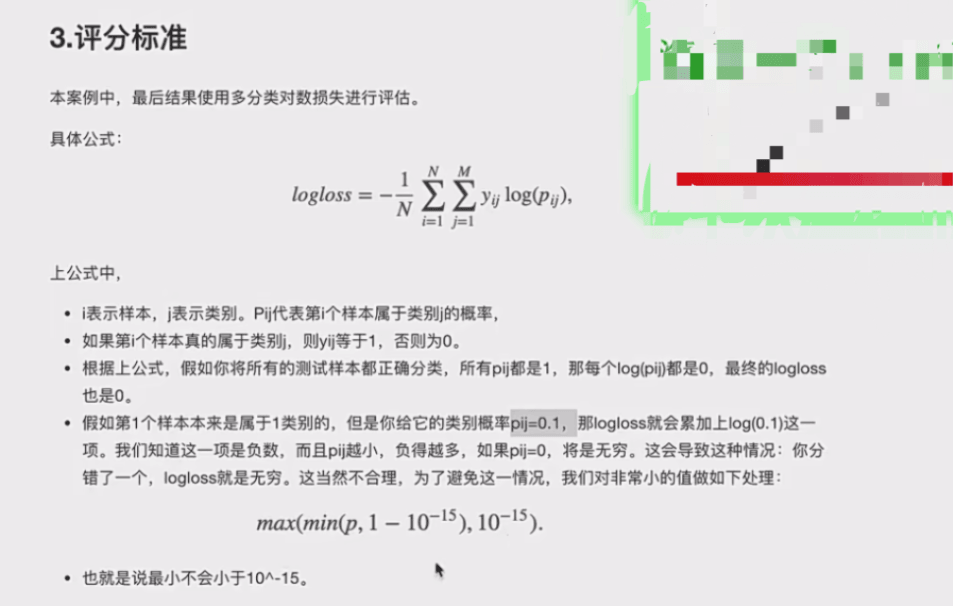
模型训练与评估(这里要使用要求的损失函数)
# 模型训练
rf = RandomForestClassifier(oob_score=True)#使用包外估计
rf.fit(x_train, y_train)# 模型预测
y_pre = rf.predict(x_test)# 计算模型准确率
accuracy = rf.score(x_test, y_test)
print(f"模型在测试集上的准确率: {accuracy}")# 查看袋外分数
oob_score = rf.oob_score_
print(f"模型的包外估计分数: {oob_score}")
按要求评估:
from sklearn.metrics import log_loss
log_loss(y_test, y_pre, eps=1e-15, normalize=True)
#normalize是将损失进行归一化但我们会发现这样会报错,因为 这个评估函数要求输入是一堆矩阵,y_test是一个one-hot编码矩阵,后面的也要求是相应的大小。于是我们更改方式:
from sklearn.preprocessing import OneHotEncoder
one_hot = OneHotEncoder(sparse=False)#不是密集矩阵y_test1 = one_hot.fit_transform(y_test.reshape(-1, 1))
y_pre1 = one_hot.fit_transform(y_pre.reshape(-1, 1))对于
y_test.reshape(-1, 1):y_test原本可能是一维数组,reshape(-1, 1)将其转换为二维列向量形式,因为OneHotEncoder要求输入数据是二维数组。
这样就可以了吗,但是我们可以通过将预测值的那个矩阵替换为概率矩阵,就是每一行代表一个样本,每一列是代表这个样本属于这个类别的概率:这样会降低特别大
# 改变预测值的输出模式,让输出结果为百分比概率
y_pre_proba = rf.predict_proba(x_test)# 再次查看袋外分数
oob_score = rf.oob_score_
print(f"模型的袋外分数: {oob_score}")# 第二次 logloss 模型评估
log_loss_value_2 = log_loss(y_test1, y_pre_proba, eps=1e-15, normalize=True)
print(f"第二次计算的 log_loss 值: {log_loss_value_2}")参数调优 最好使用网格搜索的方法,当算力小的时候可以如下调优
# 确定n_estimators的取值范围
tuned_parameters = range(10, 200, 10)
# 创建添加存放accuracy的一个numpy数组
accuracy_t = np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy数组(就是要求的损失函数数组)
error_t = np.zeros(len(tuned_parameters))
# 调优过程实现
for j, one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=one_parameter,max_depth=10,max_features=10,min_samples_leaf=10,oob_score=True,random_state=0,n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, eps=1e-15, normalize=True)print(error_t)# 优化结果过程可视化
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 4), dpi=100)
axes[0].plot(tuned_parameters, error_t)
axes[1].plot(tuned_parameters, accuracy_t)
axes[0].set_xlabel("n_estimators")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("n_estimators")
axes[1].set_ylabel("accuracy_t")
axes[0].grid(True)
axes[1].grid(True)
plt.show()for j, one_parameter in enumerate(tuned_parameters):相当于给原本的要调优的值加了一个从0开始的索引,方便把每个值存到数组里
注意我们并不是选取数组里最小的作为最优调参,而是通过绘图查看趋势,通常选取趋势平缓的转折点
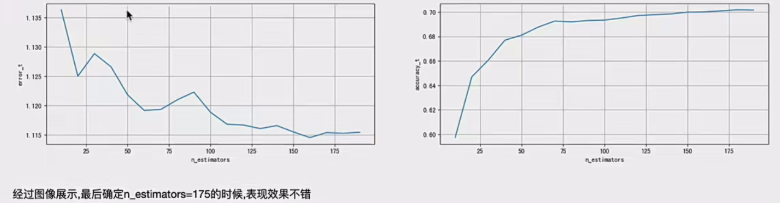
之后我们固定这个参数,继续进行调优,直到全部调优完毕!
相关文章:

机器学习 Day12 集成学习简单介绍
1.集成学习概述 1.1. 什么是集成学习 集成学习是一种通过组合多个模型来提高预测性能的机器学习方法。它类似于: 超级个体 vs 弱者联盟 单个复杂模型(如9次多项式函数)可能能力过强但容易过拟合 组合多个简单模型(如一堆1次函数)可以增强能力而不易过拟合 集成…...
)
基于 Spring Boot 瑞吉外卖系统开发(五)
基于 Spring Boot 瑞吉外卖系统开发(五) 删除分类 分类列表中每条分类信息右侧提供了一个“删除”按钮,当需要将已经存在的分类信息删除时,可以通过单击“删除”按钮实现。 请求路径为/category,携带参数id…...

PyTorch基础笔记
PyTorch张量 多维数组:张量可以是标量(0D)、向量(1D)、矩阵(2D)或更高维的数据(3D)。 数据类型:支持多种数据类型(如 float32, int64, bool 等&a…...

什么是 IDE?集成开发环境的功能与优势
原文:什么是 IDE?集成开发环境的功能与优势 | w3cschool笔记 (注意:此为科普文章,请勿标记为付费文章!且此文章并非我原创,不要标记为付费!) IDE 是什么? …...

基于大数据的房产估价解决方案
基于大数据的房产估价解决方案 一、项目背景与目标 1.1 背景 在房地产市场中,准确的房产估价至关重要。传统的房产估价方法往往依赖于估价师的经验和有限的数据样本,存在主观性强、效率低等问题。随着大数据技术的发展,大量的房产相关数据被积…...

基于深度学习的线性预测:创新应用与挑战
一、引言 1.1 研究背景 深度学习作为人工智能领域的重要分支,近年来在各个领域都取得了显著的进展。在线性预测领域,深度学习也逐渐兴起并展现出强大的潜力。传统的线性预测方法在处理复杂数据和动态变化的情况时往往存在一定的局限性。而深度学习凭借…...

WEMOS LOLIN32
ESP32是結合Wi-Fi和藍牙的32位元系統單晶片(SoC)與外接快閃記憶體的模組。許多廠商生產採用ESP32模組的控制板,最基本的ESP控制板包含ESP32模組、直流電壓轉換器和USB序列通訊介面IC。一款名為WEMOS LOLIN32的ESP32控制板具備3.7V鋰電池插座。…...

VSCode 扩展离线下载方法
学习自该文章,感谢作者! 2025 年 VSCode 插件离线下载攻略:官方渠道一键获取 - 知乎 获取扩展关键信息 方法一:官网获取 打开 VSCode 扩展官方网站 搜索要下载的扩展,以 CodeGeeX 为例,网址为…...

计算机视觉与深度学习 | RNN原理,公式,代码,应用
RNN(循环神经网络)详解 一、原理 RNN(Recurrent Neural Network)是一种处理序列数据的神经网络,其核心思想是通过循环连接(隐藏状态)捕捉序列中的时序信息。每个时间步的隐藏状态 ( h_t ) 不仅依赖当前输入 ( x_t ),还依赖前一时间步的隐藏状态 ( h_{t-1} ),从而实现…...

对于网络资源二级缓存的简单学习
缓存学习 前言认识缓存磁盘储存内存储存磁盘内存组合优化 具体实现WebCacheMD5签名 WebDownloadOperationWebDownloaderWebCombineOperation 总结 前言 在最近的写的仿抖音app中,遇到了当往下滑动视频后,当上方的视频进入复用池后,会自动清空…...

【计量地理学】实验六 地理属性空间插值
一、实验目的 本次实验的主要目的在于熟练掌握空间克里格法插值的理论基础,包括其核心概念和步骤,能够通过数据可视化和统计分析方法识别数据中的异常值,并且掌握数据正态性的检验方法,理解正态分布对克里格法的重要性࿰…...

26考研 | 王道 | 数据结构 | 第六章 图
第六章 图 文章目录 第六章 图6.1. 图的基本概念6.2. 图的存储6.2.1. 邻接矩阵6.2.2. 邻接表6.2.3. 十字链表、临接多重表6.2.4. 图的基本操作 6.3. 图的遍历6.3.1. 广度优先遍历6.3.2. 深度优先遍历6.3.3 图的遍历与连通性 6.4. 图的应用6.4.1. 最小生成树6.4.2. 无权图的单源…...

window.addEventListener 和 document.addEventListener
window.addEventListener 和 document.addEventListener 是 JavaScript 中绑定事件的两个常用方法,核心区别在于 绑定的对象不同,导致事件的作用范围、触发时机和适用场景不同。下面用最直白的语言和案例对比说明: 一、核心区别:…...

51单片机的原理图和PCB绘制
51单片机最小系统原理图 加了两个led灯和按键检测电路。 PCB中原件摆放位置 成品 资源链接:https://download.csdn.net/download/qq_61556106/90656365...
 :Android 协程全解析,从作用域到异常处理的全面指南)
kotlin知识体系(五) :Android 协程全解析,从作用域到异常处理的全面指南
1. 什么是协程 协程(Coroutine)是轻量级的线程,支持挂起和恢复,从而避免阻塞线程。 2. 协程的优势 协程通过结构化并发和简洁的语法,显著提升了异步编程的效率与代码质量。 2.1 资源占用低(一个线程可运行多个协程)…...

数据通信学习笔记之OSPF其他内容3
对发送的 LSA 进行过滤 当两台路由器之间存在多条链路时,可以在某些链路上通过对发送的 LSA 进行过滤,减少不必要的重传,节省带宽资源。 通过对 OSPF 接口出方向的 LSA 进行过滤可以不向邻居发送无用的 LSA,从而减少邻居 LSDB 的…...
)
Kubernetes相关的名词解释API Server组件(9)
什么是API Server? API Server(kube-apiserver) 是 Kubernetes 的核心组件之一,负责管理整个集群的通信和操作入口。 API Server 的作用在整个 Kubernetes 集群的正常运作中至关重要,可以说它是整个系统的神经中枢。…...

[密码学实战]密码服务平台部署架构详解与学习路线
密码服务平台部署架构详解与学习路线 引言 在数字化转型的浪潮中,数据安全已成为企业生存的“生命线”。国密算法(SM2/SM3/SM4)作为我国自主研发的密码标准,正在政务、金融、医疗等领域加速落地。然而,构建一套高可用、高性能、合规的密码服务平台,仍需攻克架构设计、性…...

如何成为Prompt工程师:学习路径、核心技能与职业发展
一、什么是Prompt工程师? Prompt工程师是专注于通过设计、优化和调试大语言模型(LLM)的输入提示词(Prompt),以精准引导模型输出符合业务需求结果的技术人才。其核心能力在于将模糊的业务需求转化为结构化、…...
cv2.Canny)
OpenCV 边缘检测(Edge Detection)cv2.Canny
OpenCV 边缘检测(Edge Detection)cv2.Canny flyfish import cv2video_path input_video.mp4 cap cv2.VideoCapture(video_path)while True:ret, frame cap.read()if not ret:break # 视频结束# 转灰度frame_gray cv2.cvtColor(frame, cv2.COLOR_B…...

【C++】win 10 / win 11:Dev-C++ 下载与安装
目录 一、Dev-C 下载 (1)sourceforge 官网下载 (2)腾讯官网下载 二、Dev-C 安装 三、Dev-C 配置 (1)配置 C11 (2)配置产生调试信息 (3)个性化配置…...

2025年MathorCup竞赛助攻资料免费分享
对于本界竞赛B题其中问题需要设计软件框架,对于该问题回答,个人认为可以在设计框架下简单的进行软件展示,下面是初步展示的结果,仅供参考 【问题四:老城区平移置换决策软件设计】规划局希望这个案例能起到示范作用&am…...

征程 6 VIO 通路断流分析
自动驾驶场景中,常见的是多路感知通路,在不考虑应用获取释放帧异常操作的前提下,一般出现帧获取异常的情况,主要原因是通路中某段断流的情况,如何去准确的定位,对大部分客户来说,依赖我司的支持…...

JavaScript 性能优化
JavaScript 性能优化是提高 Web 应用性能的关键步骤,特别是在处理大量数据、复杂计算或频繁的 DOM 操作时。以下是一些常见的 JavaScript 性能优化技巧和策略: 文章目录 @[TOC]一、代码层面优化1. **减少全局变量**2. **避免使用 `with` 语句**3. **使用局部变量**4. **减少 …...

机器学习中的“三态模型“:过拟合、欠拟合和刚刚好
文章目录 说明1. 模型表现的"三国演义"2. 可视化理解:从曲线看状态3. 诊断模型:你的模型"病"了吗?4. 学习曲线:模型的"体检报告"5. 治疗"模型病"的药方 6. 偏差-方差分解:理解…...
的CFD仿真中,AI和机器学习的应用)
在FVM(有限体积法)的CFD仿真中,AI和机器学习的应用
在FVM(有限体积法)的CFD仿真中,AI和机器学习(ML)可以通过以下方式显著提高收敛速度与计算效率,具体分为六个方向: 1. 加速非线性迭代收敛 替代传统松弛方法: 使用ML模型(…...

【21天学习打卡挑战赛】如何学习WEB安全:逼自己在短时间掌握WEB安全核心内容
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

网络安全知识点3
1.AES密钥长度可以为128,192,256位,但分组长度为128位 2.DES加密算法的密钥长度为56位,三重DES的密钥长度为112位 3.主动攻击:拒绝服务攻击,分布式拒绝服务DDOS,信息篡改,资源使用,欺骗,伪装,重放,会话拦截 被动攻击:窃听,流量分析,破解弱加密的数据流 4.IPSec可对数据进行…...
)
力扣每日打卡16 781. 森林中的兔子(中等)
力扣 781. 森林中的兔子 中等 前言一、题目内容二、解题方法1. 哈希函数(来自评论区大佬的解题方法)2.官方题解2.1 方法一:贪心 前言 这是刷算法题的第十六天,用到的语言是JS 题目:力扣 781. 森林中的兔子 (中等) 一、…...

STM32基础教程——HEX数据包接收
前言 串口,是一种应用范围十分广泛的通信接口,串口的成本较低,容易使用,通信线路简单,可以实现两个设备之间的通信。单片机的串口可以实现单片机与单片机,单片机与电脑,单片机与其他设备的通信…...

【JavaWeb后端开发02】SpringBootWeb + Https协议
课程内容: SpringBootWeb 入门 Http协议 SpringBootWeb案例 分层解耦 文章目录 1. SpringBootWeb入门1.1 概述1.2 入门程序1.2.1 需求1.2.2 开发步骤1.2.3 常见问题 1.3 入门解析 2. HTTP协议2.1 HTTP概述2.1.1 介绍2.1.2 特点 2.2 HTTP请求协议2.2.1 介绍2.2.2…...
)
基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(三)
上一篇 介绍了数据接入处理的整体方案设计。本篇介绍基于SmartETL框架的流程实现。 5. 流程开发 5.1.简单采集流程 从指定时间(yy年 mm月)开始,持续采集arXiv论文。基于月份和顺序号,构造论文ID,进而下载论文PDF文件…...

深入理解Linux中的线程控制:多线程编程的实战技巧
个人主页:chian-ocean 文章专栏-Linux 前言: POSIX线程(Pthreads) 是一种在 POSIX 标准下定义的线程库,它为多线程编程提供了统一的接口,主要用于 UNIX 和类 UNIX 系统(如 Linux、MacOS 和 BS…...

从内核到用户态:Linux信号内核结构、保存与处理全链路剖析
Linux系列 文章目录 Linux系列前言一、信号的保存1.1 信号保存概念引入1.2 信号的阻塞与保存1.2.1 信号其他相关常见概念1.2.2 信号在内核中的表示 二、信号相关接口2.1 signal_t 结构体类型2.2 信号集操作函数 三、信号的处理3.1 进程地址空间信号的检测与处理 总结 前言 Lin…...

【AI图像创作变现】02工具推荐与差异化对比
引言 市面上的AI绘图工具层出不穷,但每款工具都有自己的“性格”:有的美学惊艳但无法微调,有的自由度极高却需要动手配置,还有的完全零门槛适合小白直接上手。本节将用统一格式拆解五类主流工具,帮助你根据风格、控制…...

Spring Boot 集成Poi-tl实现动态Word文档生成
Spring Boot 集成Poi-tl实现动态Word文档生成 「gen-pic-word.zip」 链接: https://pan.quark.cn/s/74396770a5c2 前言 在项目开发过程中,遇到了一个需求:将用户输入的数据填充到给定格式的 Word 文档中。简单来说,就是要根据预…...

【失败总结】Win10系统安装docker
1.启用或关闭windows功能中,将Hyper-V功能勾选全部启用,容器勾选。设置好后要重启电脑。 2.管网下载下载安装Docker Docker官网:https://www.docker.com/ 3.可以自定义Docker安装路径 新建安装目录:d:\MySoftware\Docker并将D…...
详解:如何打通链上与现实世界的关键桥梁?)
区块链预言机(Oracle)详解:如何打通链上与现实世界的关键桥梁?
文章目录 一、什么是区块链预言机?1.1 区块链的封闭性问题1.2 预言机的定义与作用举个例子: 1.3 为什么预言机是 Web3 的关键基础设施? 二、预言机的基本分类与工作模式2.1 输入型与输出型预言机(1)输入型预言机&#…...

Halcon应用:相机标定
提示:若没有查找的算子,可以评论区留言,会尽快更新 Halcon应用:相机标定 前言一、Halcon应用?二、应用实战1、图像理解1.1、开始标定 前言 本篇博文主要用于记录学习Halcon中算子的应用场景,及其使用代码和…...

【中间件】redis使用
一、redis介绍 redis是一种NoSQL类型的数据库,其数据存储在内存中,因此其数据查询效率很高,很快。常被用作数据缓存,分布式锁 等。SpringBoot集成了Redis,可查看开发文档Redis开发文档。Redis有自己的可视化工具Redis …...

【OSG学习笔记】Day 4: 相机与视口——控制观察视角
相机与视口 相机和视口的关系如下图: ```paintext +----------------------+ | 相机 (Camera) | +----------------------+ | - FOV | | - 投影模式 | | - 裁剪平面 | | - 视点矩阵 | +----------------------+|V +--…...

Vue.js 简介
Vue.js 简介 Vue.js 是一款非常流行的 渐进式 JavaScript 框架,用于构建用户界面,特别是在开发 单页应用(SPA) 时表现出色。Vue 由 尤雨溪(Evan You)在 2014 年创建,它的核心库专注于 视图层&a…...

快速下载Node.js
Node.js 是基于 Chrome V8 引擎的开源 JavaScript 运行时,允许开发者使用 JavaScript 构建服务器端应用、命令行工具和分布式系统。它以事件驱动、非阻塞 I/O 模型著称,适合开发高性能、可扩展的网络应用。 下载与安装配置 下载 LTS 版本:访问…...

使用 PCL 和 Qt 实现点云可视化与交互
下面我将介绍如何结合点云库(PCL)和Qt框架(特别是QML)来实现点云的可视化与交互功能,包括高亮选择等效果。 1. 基本架构设计 首先需要建立一个结合PCL和Qt的基本架构: // PCLQtViewer.h #pragma once#include <QObject> #include <pcl/point…...
 - 什么是MCP)
SpringAI系列 - MCP篇(一) - 什么是MCP
目录 一、引言二、MCP核心架构三、MCP传输层(stdio / sse)四、MCP能力协商机制(Capability Negotiation)五、MCP Client相关能力(Roots / Sampling)六、MCP Server相关能力(Prompts / Resources / Tools)一、引言 之前我们在接入大模型时,不同的大模型通常都有自己的…...
在 C# 中的应用与实现)
深入理解组合实体模式(Composite Entity Pattern)在 C# 中的应用与实现
在面向对象的设计中,如何管理复杂的对象以及其内部的多个子实体一直是一个挑战。为了应对这种复杂性,**组合实体模式(Composite Entity Pattern)**应运而生。这种设计模式允许将一个复杂对象表示为多个子对象的组合,提…...

大数据开发知识1:数据仓库
文章目录 数据仓库基本常识离线数仓和实时数仓的区别数仓分层数据引入层(ODS,Operational Data Store )数据公共层(CDM,Common Dimensions Model )数据应用层(ADS,Application Data …...
:从Airbnb案例看精益创业与数据驱动增长)
精益数据分析(8/126):从Airbnb案例看精益创业与数据驱动增长
精益数据分析(8/126):从Airbnb案例看精益创业与数据驱动增长 大家好!一直以来,我都坚信在创业和技术的领域里,持续学习与分享是不断进步的关键。今天,咱们继续深入学习《精益数据分析》&#x…...

深入浅出 C++ 核心基础:从语法特性到入门体系构建
一、C 的前世今生:从 C 语言到现代编程的进化之路 1. 起源与标准化历程(1979 年至今) 诞生背景(1979-1983):Bjarne Stroustrup 在贝尔实验室因 C 语言在复杂系统开发中的不足,于 1983 年在 C …...
差错控制、奇偶校验、CRC、海明码)
【25软考网工】第二章(8)差错控制、奇偶校验、CRC、海明码
目录 一、差错控制、奇偶校验 1、差错控制 1)检错和纠错 2)检错与纠错的比较: 2、奇偶校验 1)例题1 2)例题2(网工2018年11月第2题) 2)例题3(网工2022年5月案例分析试题二/问题3) 知识小结 二、差错控制——CR…...