网络原理 - 应用层, 传输层(UDP 和 TCP) 进阶, 网络层, 数据链路层 [Java EE]
目录
应用层
1. 应用层的作用
2. 自定义应用层协议
3. 应用层的 "通用协议格式"
3.1 xml
3.2 json
3.3 protobuffer (pd)
传输层
1. UDP
1.1 无连接
1.2 不可靠传输
1.3 面向数据报
1.4 全双工
1.5 缓冲区
1.6 UDP 数据报
2. TCP
2.1 有连接
2.2 可靠传输
2.2.1 确认应答
2.2.2 超时重传
2.2.3 连接管理
2.2.4 滑动窗口
2.2.5 流量控制
2.2.6 拥塞控制
2.2.7 延迟应答
2.2.8 捎带应答
2.2.9 面向字节流
2.2.10 TCP 异常情况的处理
2.3 TCP 十个核心特性简要总结
2.4 TCP / UDP 对比
网络层
1. IP 协议
1.1 基本概念
1.2 协议头格式
1.3 IPv4 (IP 地址不够用了怎么办 )
1.4 IPv6 (从根本上解决了 IP 地址不够用的问题)
2. 地址管理
2.1 网段划分
2.2 特殊的 IP 地址
3. 路由选择
数据链路层
1. 认识以太网
1.1 以太网帧格式
1.2 认识 MAC 地址
1.3 认识 MTU
1.4 DNS (域名解析系统)
应用层
1. 应用层的作用
// 满⾜我们⽇常需求的⽹络程序,都是在应⽤层
2. 自定义应用层协议
// 我们可以根据自己具体的需求, 来设定应用层协议
// 自定义的协议格式, 是可以任意的
3. 应用层的 "通用协议格式"
// 为了避免一些过于 "个性化" 的设计, 圈内大佬就搞出来了 "通用的协议格式"
// 参考一些 "通用的协议格式", 可以对我们的协议设计产生重要的指导作用
// "通用协议格式" 有很多种体现形式
3.1 xml
// 以成对的标签, 来表示 "键值对" 信息, 同时标签支持嵌套, 就可以构成一些更复杂的树形结构数据
// <request> (开始标签)
// <useId>...</useId> (内容: 键值对 结构)
// </request> (结束标签)
// 优点: 可以非常清晰的把结构化数据表示出来
// 缺点: 表示数据需要引入大量的标签, 看起来繁琐, 还会占用不少的网络带宽
3.2 json
// 当前最流行的一种数据组织形式
// 本质上也是键值对, 但看起来比 xml 要干净不少
// {
// useId: ... ,
// }
// json 中, 使用 { } 表示 键值对, 使用 [ ] 表示数组, 数组里的每个元素, 可以是字符串, 还可以是其他的 { } 或 [ ]
// json 对于换行并不敏感, 所有内容放在同一行也是合法的
// 一般网络传输的时候, 会对 json 进行压缩 (去掉不必要的换行和空格), 同时将所以数据放到一行中去, 整体占用的带宽就会降低 (影响到可读性)
// 我们格式化 json 时也有很多 json 格式化工具, 可以直接使用
// 优势: 相比于 xml , 表示的数据简洁很多, 可读性非常好, 方便我们观察中间结果, 方便调试问题
// 劣势: 终究需要花费一定的带宽来传输 key 的名字的
3.3 protobuffer (pd)
// 谷歌提出的一套, 二进制的数据序列化方式
// 使用二进制的方式, 约定某几个字节, 表示哪个属性
// 优点: 节省带宽, 最大化效率
// 最大程度的节省空间 (不必传输 key, 是根据位置和长度, 区分每个属性的)
// 缺点: 二进制数据, 无法肉眼直接观察, 不方便调试
// 使用起来比较复杂, 需要专门编写一个 proto 文件, 描述数据的格式 (需要先学习它的语法规则), 再进一步通过人家提供的工具, 把 proto 文件转换成一些代码, 再嵌入到程序中使用
// 相当于是 牺牲了开发效率, 换来了运行效率
传输层
1. UDP
// 基本特点: 无连接 不可靠传输 面向数据报 全双工
// UDP 传输过程类似于寄信
1.1 无连接
// 指导对象端的 IP 和端口号就可以直接进行传输, 不需要建立连接
1.2 不可靠传输
// 没有任何安全机制, 发送端发送数据报之后, 如果因为网络故障该段无法发给对方, UDP 协议层也不会给应用层返回任何的错误信息
1.3 面向数据报
// 应用层交给 UDP 多长的报文, UDP 照原样发送, 既不会拆分,也不会合并
1.4 全双工
// 既可以发送数据, 也可以接收数据, 这两个操作也可以同时进行 (既能读也能写)
1.5 缓冲区
// UDP 只有接收缓冲区, 没有发送缓冲区
1.6 UDP 数据报
// UDP 数据报由: UDP 报头 + 载荷
// UDP 报头由: 源端口 (2 字节) + 目的端口 (2 字节) + UDP 报文长度 (2 字节) + 校验和 (2 字节)
2. TCP
// 基本特点: 有连接 可靠传输 面向字节流 全双工
// TCP 的报头是 "变长" 的, 最大长度是 60 字节
2.1 有连接
// 在进行数据传输之前, 需要先进行连接
2.2 可靠传输
// 靠内核实现的可靠传输 (校验和)
// 可靠传输实现的最重要 (核心) 的机制: 确认应答
// 我们可以通过编号的方式来确保数据传输的可靠性 (对每个字节进行编号)
// TCP 报头 中的 ACK 若为 0, 表示 这是一个普通报文, 此时只有 32 位序号是有效的, ACK 若为 1, 表示这是一个应答报文, 这个报文的 序号 和 确认序号, 都是有效的 (确认报文的序号和正常报文的序号之间没有关联关系, 各自论各自的)
2.2.1 确认应答
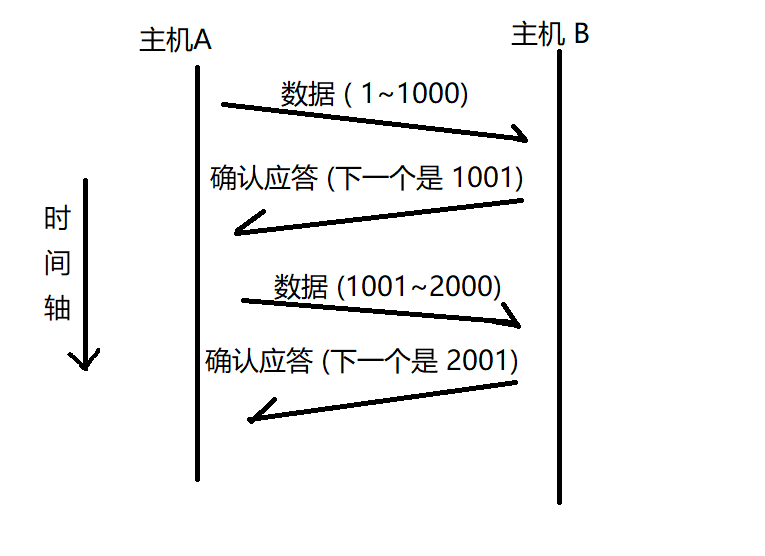
// 每一个 ACK 都带有对应的确认序列号, 意思是告诉发送者, 我已经收到了哪些数据, 下一次你从哪里发
2.2.2 超时重传
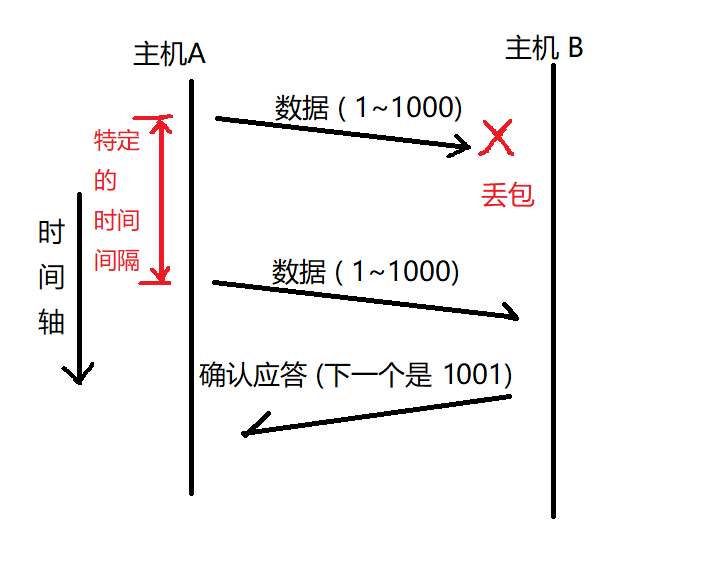
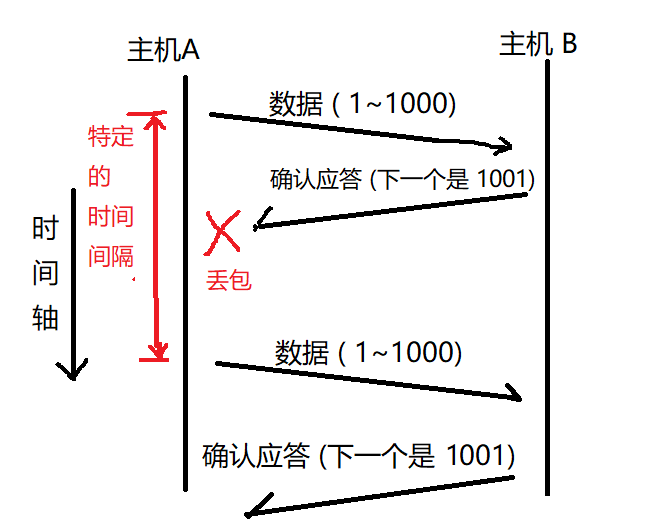
// 主机 A 发送数据给 B 之后, 可能因为网络拥堵等一些原因导致数据无法到达 B
// 如果主机 A 在一个特定时间间隔内没有收到 B 发来的确认应答, 就会进行重发; 但是, 主机 A 未收到 B 发来的确认应答, 可能是因为 ACK 丢失了, 因此主机 B 会收到很多重复数据, 那么 TCP 协议 需要能够识别出哪些包是重复的包, 并且把重复的丢弃掉
// 这时我们可以利用前面提到的序列号, 达到去重的效果
// 接收方, 也会在接收缓冲区中, 对收到的数据进行排序, 也能处理后发先至的问题
2.2.3 连接管理
// 正常情况下, TCP 要建立连接: 需要三次握手, 断开连接: 需要四次挥手
2.2.3.1 建立连接: 三次握手
// 三次握手 (其实是四次交互,但中间两次进行了合并), 这样可以减少封装和分用的次数, 得到更高的传输效率
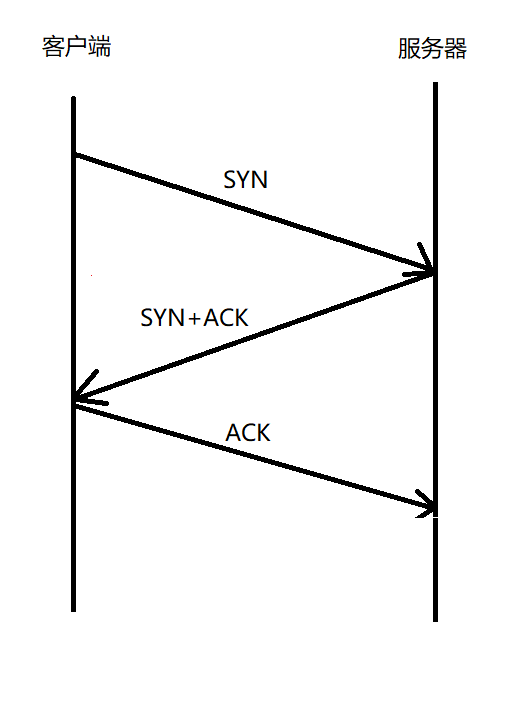
// 三次握手, 第一次 SYN 一定是客户端发起的 (客户端是主动的一方)
// 三次握手的意义: 1) 是一种保证可靠性的机制 (投石问路); 2) 是协商必要的参数, 使客户端和服务器使用相同的参数进行消息传输
// TCP 三次握手, 就是要验证网络通信是否通畅, 以及验证每个主机的发送能力和接收能力是否正常
// 三次握手, 还能起到 "消息协商" 的效果,使通信双⽅共同确认⼀些通信中的必备参数数值
2.2.3.2 断开连接: 四次挥手
// 连接: 通信双方, 各自在内存中保存了对端的相关信息
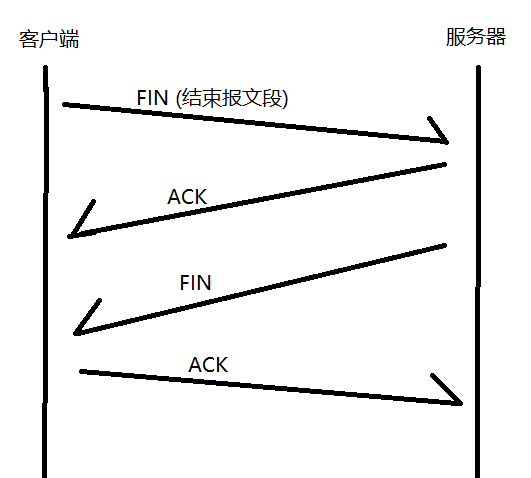
// 经过上述四个步骤之后, 连接就彻底不再使用了, 双方就可以把各自保存对端消息的空间释放了
// 四次挥手中间这两步不一定能合并, 有时候可以, 有时候不行
// FIN 的触发, 是应用程序代码来控制的, 调用 socket.close() 或者进程结束, 就会触发 FIN, 相比之下, ACK 则是由内核控制的, 收到 FIN 就会立马返回 ACK , 所以关键还是要看代码是怎么编写的
// 为了确保最后一次客户端向服务器发送的 ACK 服务器确认收到了, 而没有出现中途丢包导致超时重传, 客户端需要在发送完成 ACK 之后, 等待一定时间后再释放连接, 但是也不用一直等下去, 只要超过应该等待的时间 [MSL] (网络上任意两点之间传输数据所需最大时间的两倍), 服务器还没有重传 FIN, 大概率就是服务器成功接收到了 ACK, 这时候就可以自行释放连接了, 若发生了网络传输问题导致服务器没有成接收到 ACK, 则客户端重传一次即可
// TCP 是如何实现可靠传输的: 1) 确认应答 (起决定性作用) 2) 超时重传 3) 连接管理 (三次握手, 四次挥手)
2.2.4 滑动窗口
// 用来提高传输效率 (更准确的说, 是让 TCP 在可靠传输的前提下, 效率不要太拉胯)
// 使用滑动窗口, 不能使 TCP 变得比 UDP 快, 但是可以缩小差距
// 使用滑动窗口, 一次性发出一组数据, 发这一组数据的过程中, 不需要等待 ACK 就直接往前发, 此时就相当于使用 "一份等待时间" 等四个 ACK
// 把一次发多少数据, 不用等 ACK 这样的大小, 称为窗口
2.2.5 流量控制
// TCP⽀持根据接收端的处理能⼒,来决定发送端的发送速度.这个机制就叫做流量控制 (Flow Control)
// 接收端将自己可以接受的缓冲区大小放入 TCP 首部中的 "窗口大小" 字段, 通过 ACK 端通知发送端
// 窗口大小字段越大, 说明网络的吞吐量越高
// 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端
// 发送端接受到这个窗口之后, 就会减慢自己的发送速度
// 如果接收端缓冲区满了, 就会将窗口置为 0, 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端
2.2.6 拥塞控制
// 总的传输效率, 是一个 木桶效应, 取决于最短板
// TCP 中, 拥塞控制是这样展开的: 1) 慢启动: 刚开始进行通信的时候, 会使用一个非常小的窗口, 先试试水; 2) 指数增长: 在传输通常的过程中, 拥塞窗口就会指数增长 (*2) (指数增长的速度是极快的, 必须加以限制,否则会出现非常大的值) 3) 线性增长: 指数增长到拥塞窗口达到一个阈值之后, 就会从指数增长转换成 线性增长(+n) (线性增长也会使得发送速度越来越快, 当快到一定程度, 接近网络传输的极限, 就可能会出现丢包了) 4) 拥塞窗口回归一个小窗口: 当窗口大小增长过程中, 如果传输出现丢包, 就认为事当前网络出现拥堵了, 此时就会把窗口大小调整成最初的小窗口, 继续回到之前 指数增长 + 线性增长 的过程, 另外此处也会根据当前出现丢包的窗口大小, 调整阈值 (指数增长 -> 线性增长), 新的阈值是: 出现丢包的窗口大小/2
// 拥塞窗口, 就是在这个过程中不断发生变化, 不断重新调整的过程
// 这样的调整就可以非常好的适应多变的网络环境
// 当然, 也是有不少的性能损失
// 实际发送方的窗口 = min (拥塞窗口, 流量控制窗口)
// 拥塞控制和流量控制, 共同限制了滑动窗口机制, 可以使滑动窗口能够在可靠性的前提下, 提高传输速率
2.2.7 延迟应答
// 是一种提高传输效率的机制, 还是围绕滑动窗口琢磨的, 在条件允许的基础山, 尽可能的提高窗口大小
// 在返回 ACK 的时候, 拖延一点时间, 利用这个拖延时间, 就可以给应用程序藤出来更多的消费数据的时间, 这样接收缓冲区的剩余空间就更大了
2.2.8 捎带应答
// 在延迟应答基础上, 引入的一个进一步提高效率的方式
// 延迟应答: 让 ACK 传输的时机更慢
// 捎带应答: 基于延迟应答, 让数据进行合并
// 四次挥手有时也可以是三次的主要原因就是延迟应答和捎带应答的功劳, 可以将两个数据包合成一个, 效率会有明显的提升
2.2.9 面向字节流
// 粘包问题: 这里 "粘" 的是 "应用层数据包"
// 在 TCP 协议头中, 没有如同 UDP 一样的 "报文长度" 这样的字段, 但是有一个序号字段
// 站在传输层的角度, TCP 是一个一个报文过来的, 按照序号排好序放在缓冲区中
// 站在应用层的角度, 看到的只是一串连续的字节数据
// 那么应用程序看到了这么一连串的字节数据, 就不知道从哪个部分开始到哪个部分是一个完整的应用层数据包
// 解决粘包问题的核心就是明确来那个包之间的边界
// 粘包问题不仅仅是 TCP 才有的, 只要是面向字节流的机制 (文件) 也有同样的问题, 解决方案也都是一样的, 要么使用分隔符, 要么在数据前固定几个字节来表示数据长度
2.2.10 TCP 异常情况的处理
// 网络本身存在一些变数, 导致 TCP 连续不能继续正常工作了
// 进程崩溃: 进程没了, 相当于调用了 socket.close(), 崩溃的这一方就会发出 FIN, 进一步的触发 四次挥手, 此时连接就正常释放了, 这种情况下 TCP 的处理和进程正常退出没啥区别
// 主机关机 (正常步骤关机): 关机前会先去强制终止所有的进程, 和之前的崩溃处理是一样的
// 主机掉电 (拔电源, 不留反应空间): 此时就没有任何可以操作的空间了, 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行 reset . 即使没有写入操作, TCP 自己也内置了一个保活定时器 (心跳包), 会定期询问对方是否还在, 如果对方不在, 也会把连接释放
// 网线断开: 相当于主机掉电的升级版本
2.3 TCP 十个核心特性简要总结
// 确认应答 -> 可靠性
// 超时重传 -> 可靠性
// 连接管理 -> 可靠性
// 滑动窗口 -> 效率
// 流量控制 -> 可靠性
// 拥塞控制 -> 可靠性
// 延时应答 -> 效率
// 捎带应答 -> 效率
// 面向字节流 => 粘包问题 -> 编程注意事项
// 异常情况处理 => 心跳包 -> 异常情况
2.4 TCP / UDP 对比
// TCP 优势在于可靠性: 适用于绝大部分场景, 应用于文件传输, 重要状态更新等场景
// UDP 优势在于效率: 适合于机房内部的主机之间通信, 用于对高速传输和实时性要求较高的通信领域
2.4.1 用 UDP 实现可靠传输
// 本质还是要到 TCP 上去, 使用 TCP 中的一些保证可靠性的方法实现可靠性传输
网络层
1. IP 协议
1.1 基本概念
// 主机: 配有 IP 地址, 但是不进行路由控制的设备
// 路由器: 既配有 IP 地址, 又能进行路由控制
// 节点: 主机和路由器的统称
1.2 协议头格式
// 4 位版本号, 用来表示 IP 协议的版本, 现有的 IP 协议只有 IPv4 和 IPv6
// 4位首部长度, 设定和 TCP 一样, IP 报头可变长的, IP 报头又是带有选项的, 此处单位也是 4 字节
// 8 位服务类型 (其中真正只有 4 位才有效果), 类似于 模式/形态 切换
// 16 位总长度: IP 报头 + 载荷 的长度
// 16 位标识, 3 位标志位, 13位片偏移, 描述了整个 IP 数据报拆包组包的过程
// 8 位生存时间 (TTL), 单位是 次, 初始情况下, TTL 会有个数值, 每次经过一个路由器转发, TTL 就会 -1, 减到 0 了就会被丢弃; 正常来说 TTL 足以支持数据报到达网络的任一位置, 如果确实出现 0 了, 基本可以认为目标 IP 不可达
// 16 位首部校验和: 校验数据是否正确的机制, 只需要校验首部即可
// 32 位源地址, 32 位目的地址: IP 协议中最为重要的部分, 说明了 数据报 从哪来, 到哪去
1.3 IPv4 (IP 地址不够用了怎么办 )
// IPv4, 是 4 个字节, 32 位表示 IP 地址
// 动态分配 IP (DHCP) : 这杯需要上网了才分配 IP, 不需要就先不分配, 这种方法只能缓解, 但不能根治
// NAT 机制 (网络地址转换): 把 IP 地址分为内网 IP (不同的局域网内的设备, 内网 IP 可以重复, 同一个局域网内的设备, 内网 IP 不能重复) 和外网 IP (不能重复), 它也只是提高了 IP 地址的 "利用率", 并没有从根本上解决 IP 不够用的问题, 缺点也很明显: 1) 效率不高; 2) 非常繁琐; 3) 不方便直接访问局域网内的设备; 但是它有一个很大的优点: NAT 是一个 "纯软件实现" 的方案
1.4 IPv6 (从根本上解决了 IP 地址不够用的问题)
// IPv6, 是 16 个字节, 128 位, 表示 IP 地址
2. 地址管理
2.1 网段划分
// IP 地址分为两个部分, 网络号和主机号 (192.168.22.25)
// 网络号: 标识网段, 保证相互连接的两个网段具有不同的标识
// 主机号: 标识主机, 同一网段内, 主机之间具有相同的网络号, 但是必须有不同的主机号
// 子网掩码是现代用来划分网络号的方案 (255.255.255.0)
// 过去是用 A B C D E 将 IP地址划分为五类
2.2 特殊的 IP 地址
// 将 IP 地址中的主机地址全部设为 0, 就成为了网络号, 代表这个局域网
// 将 IP 地址中的主机地址全部设为 1 , 就成为了广播地址, 用于给同一个链路中相互连接的所有主机发送数据包; 此处广播, 在传输层只能使用 UDP, 而不能使用 TCP (TCP 无法针对广播地址进行三次握手, 建立连接的操作)
// 127.* 的 IP 地址用于本机环回 (loop back) 测试, 通常是 127.0.0.1
// 本机环回主要用于本机到本机的网络通信 (系统内部为了性能, 不会走网络的方式传输), 对于开发网络通信的程序 (即网络编程) 而言, 常见的开发方式都是本机到本机的网络通信
3. 路由选择
// 路由选择的过程, 是一跳一跳 (Hop by Hop) "问路" 的过程, 这里给出的路径, 不一定是最优解, 只能说是 "较优解"
数据链路层
// 代表协议: 以太网
1. 认识以太网
1.1 以太网帧格式
// 以太网帧格式: 目的地址 (6个字节) + 源地址 (6个字节) + 类型 (2个字节) + 数据 + CRC (4个字节)
// 源地址和目的地址是指: 物理地址 (MAC 地址), 长度是 48 位, 是在网卡出厂时固化的
// 帧协议类型字段有 3 种值, 分别对应 IP, ARP, RARP
// 一个以太网数据帧, body 部分, 最大长度 1500, 受限于硬件
// 帧末尾是 CRC 校验码
1.2 认识 MAC 地址
// MAC 地址用来失败数据链路层中相连的节点
// 长度为 48 位, 即 6个字节, 一般用 16 进制数字加上冒号的形式来表示 (例如:08:00:27:03:fb:19)
// 在网卡出厂时就确定了, 不能修改. MAC 地址通常是唯一的
1.3 认识 MTU
// MTU 相当于发快递时对包裹尺寸的限制, 这个限制是不同的数据链路对应的物理层, 产生的限制
// 以太网帧中的数据长度规定最小 46 字节, 最大 1500 字节, ARP 数据包的长度不够 46 字节, 要在后面补填充位
// 最大值 1500 称为以太网的最大传输单元 (MTU), 不同的网络类型有不同的 MTU;
// 如果一个数据包从以太网路由到拨号链路上, 数据包长度大于拨号链路的 MTU 了, 则需要对数据包进行分片 (fragmentation)
// 不同的数据链路层标准的 MTU 是不同的
1.4 DNS (域名解析系统)
// 上网要访问服务器, 知道服务器的 IP 地址, IP 地址是一串数字, 虽然这个数字使用点分十进制已经清晰不少了, 但是任然不方便人们记忆和传播, 我们可以通过单词 (域名) 来代替 IP 地址
// 域名往往是分级的, 例如: www.sougou.com 中 com (一级域名); sougou (二级域名); www (三级域名)
// DNS 服务器如何能够承载高并发量 (开源, 节流): 1) 在每个电脑上, 在进行域名解析的时候, 都会有缓存, 访问很多次, 只有第一次真的访问 DNS, 后面几次不一定访问; 2) 全世界会搭建出很多的 "DNS 镜像服务器", 从最初的 DNS 服务器这里同步数据
相关文章:
 进阶, 网络层, 数据链路层 [Java EE])
网络原理 - 应用层, 传输层(UDP 和 TCP) 进阶, 网络层, 数据链路层 [Java EE]
目录 应用层 1. 应用层的作用 2. 自定义应用层协议 3. 应用层的 "通用协议格式" 3.1 xml 3.2 json 3.3 protobuffer (pd) 传输层 1. UDP 1.1 无连接 1.2 不可靠传输 1.3 面向数据报 1.4 全双工 1.5 缓冲区 1.6 UDP 数据报 2. TCP 2.1 有连接 …...

百级Function架构集成DeepSeek实践:Go语言超大规模AI工具系统设计
一、百级Function系统的核心挑战 1.1 代码结构问题 代码膨胀现象:单个文件超过2000行代码路由逻辑复杂:巨型switch-case结构维护困难依赖管理失控:跨Function依赖难以追踪 // 传统实现方式的问题示例 switch functionName { case "fu…...

全同态加密医疗数据分析集python实现
目录 摘要一、前言二、全同态加密与医疗数据分析概述2.1 全同态加密(FHE)简介2.2 医疗数据分析需求三、数据生成与预处理四、系统架构与流程4.1 系统架构图五、核心数学公式六、异步任务调度与(可选)GPU 加速七、PyQt6 GUI 设计八、完整代码实现九、自查测试与总结十、展望…...

字节头条golang二面
docker和云服务的区别 首先明确Docker的核心功能是容器化,它通过容器技术将应用程序及其依赖项打包在一起,确保应用在不同环境中能够一致地运行。而云服务则是由第三方提供商通过互联网提供的计算资源,例如计算能力、存储、数据库等。云服务…...

关于进程状态
目录 进程的各种状态 运行状态 阻塞状态 挂起状态 linux中的进程状态、 进程状态查看 S状态(浅睡眠) t 状态(追踪状态) T状态(暂停状态) 编辑 kill命令手册 D状态(深度睡眠&#…...

操作系统是如何运行的?
硬件中断 在我们使用键盘的时候,操作系统要怎么知道键盘上有数据了呢?硬件中断! 硬件中断过程如图所示: 按照图中所示,外设直接与CPU进行交互,但是之前对于冯诺依曼体系架构的学习可知,外设要…...

【智驾中的大模型 -3】VLA 在自动驾驶中的应用
1.前言 在上一篇文章中,我们深入探讨了 VLM 模型在自动驾驶中的应用。VLA(Very Large Architecture,大型架构)和 VLM(Very Large Model,非常大模型)在 AI 领域皆指向超大规模的神经网络模型&am…...

Go语言中的sync.Map与并发安全数据结构完全指南
1. 引言 在Go语言的世界里,并发不是一个附加功能,而是语言的核心设计理念。那句广为人知的"Do not communicate by sharing memory; instead, share memory by communicating"(不要通过共享内存来通信,而应该通过通信来…...

ADVB协议
ADVB:航空数字视频总线 ADVB协议是基于FC光纤通道协议和FC-AV光纤音频视频协议标准来制定 的一种新型的数字视频接口和协议。 FC协议,FC-AV协议,FC-ADVB协议。 协议层次结构,协议拓扑结构。 ADVB总线协议container容器是作为基本传输单元…...

Vue3中provide和inject数据修改规则
在 Vue3 中,通过 inject 接收到的数据是否可以直接修改,取决于 provide 提供的值的类型和响应式处理方式: 1. 若提供的是普通值(非响应式数据) javascript 复制 // 父组件 provide(staticValue, 123); 子组件修改行…...

VuePress 使用教程:从入门到精通
VuePress 使用教程:从入门到精通 VuePress 是一个以 Vue 驱动的静态网站生成器,它为技术文档和技术博客的编写提供了优雅而高效的解决方案。无论你是个人开发者、团队负责人还是开源项目维护者,VuePress 都能帮助你轻松地创建和管理你的文档…...

Linux操作系统简介:从开源内核到技术生态
一、Linux的起源与核心架构 1. 历史背景与发展 1991年,芬兰赫尔辛基大学学生林纳斯托瓦兹(Linus Torvalds)开发了首个Linux内核。这一开源项目与GNU工具链结合,形成完整的GNU/Linux操作系统。截至2023年,Linux内核贡…...

iOS 应用性能测试工具对比:Xcode Instruments、克魔助手与性能狗
iOS 应用性能测试工具对比:Xcode Instruments、克魔助手与性能狗 在移动应用开发领域,性能优化是确保用户体验流畅、留存率高的关键因素。对于 iOS 开发者而言,选择合适的性能测试工具能够帮助快速定位和解决应用中的性能瓶颈。本文将深入分…...

CentOS 10 /root 目录重新挂载到新分区槽
1 观察 ##观察目录/root 所占的磁盘空间大小 rootbogon:~# du -smh /root/ 1.6G /root/ rootbogon:~# du -smh /* |grep root du: 无法访问 /proc/19146/task/19146/fd/3: 没有那个文件或目录 du: 无法访问 /proc/19146/task/19146/fdinfo/3: 没有那个文件或目录 du: 无法访问…...

【读书笔记·VLSI电路设计方法解密】问题64:什么是芯片的功耗分析
低功耗设计是一种针对VLSI芯片功耗持续攀升问题的设计策略。随着工艺尺寸微缩,单颗芯片可集成更多元件,导致功耗相应增长。更严峻的是,现代芯片工作频率较二十年前大幅提升,而功耗与频率呈正比关系。因此,芯片功耗突破…...

python爬虫复习
requests模块 爬虫的分类 通用爬虫:将一整张页面进行数据采集聚焦爬虫:可以将页面中局部或指定的数据进行采集 聚焦爬虫是需要建立在通用的基础上来实现 功能爬虫:基于selenium实现的浏览器自动化的操作分布式爬虫:使用分布式机群…...

深入解析主流数据库体系架构:从关系型到云原生
数据库是现代信息系统的核心组件,其体系架构设计直接影响性能、扩展性和可靠性。本文将从传统关系型数据库到新兴云原生数据库,系统解析主流数据库的架构特点及适用场景。 目录 一、关系型数据库(RDBMS)架构 典型代表&…...
)
2026《数据结构》考研复习笔记四(第一章)
绪论 前言时间复杂度分析 前言 由于先前笔者花费约一周时间将王道《数据结构》知识点大致过了一遍,圈画下来疑难知识点,有了大致的知识框架,现在的任务就是将知识点逐个理解透彻,并将leetcode刷题与课后刷题相结合。因此此后的过…...

Mysql insert一条数据的详细过程
以下是MySQL在接收到INSERT语句后存储数据的详细过程解析,结合存储引擎(以InnoDB为例)和物理存储机制分步说明。 一、SQL解析与事务启动 1.语法解析 MySQL首先解析INSERT语句,验证字段是否存在、数据类型是否匹配、约束…...
)
流水灯右移程序(STC89C52单片机)
#include <reg52.h> sbit ADDR0 P1^0; sbit ADDR1 P1^1; sbit ADDR2 P1^2; sbit ADDR3 P1^3; sbit ENLED P1^4; void main() { unsigned int i 0; //定义循环变量i,用于软件延时 unsigned char cnt 0; //定义计数变量cnt,用…...

AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B专属管家大模型
环境: AI-Sphere-Butler WSL2 英伟达4070ti 12G Win10 Ubuntu22.04 Qwen2.-1.5B/3B Llama factory llama.cpp 问题描述: AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B管家大模型 解决方案: 一、准备数据集我这…...
)
智能体团队 (Agent Team)
概述 智能体团队是一种多智能体协作模式,它将多个智能体组织成一个团队,共同解决复杂任务。与智能体监督模式不同,智能体团队中的成员通常具有平等的地位,通过相互交流和协作来达成目标。这种模式特别适合需要多种观点或多领域专…...

AI日报 - 2025年04月19日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | OpenAI与Google模型在复杂推理上展现潜力,但距AGI仍有距离;因果AI被视为关键路径。 模型如o3解决复杂迷宫,o4-mini通过棋盘测试,但专家预测AGI仍需30年。 ▎…...
)
【实战中提升自己】内网安全部署之dot1x部署 本地与集成AD域的主流方式(附带MAC认证)
1 dot1x部署【用户名密码认证,也可以解决私接无线AP等功能】 说明:如果一个网络需要通过用户名认证才能访问内网,而认证失败只能访问外网与服务器,可以部署dot1x功能。它能实现的效果是,当内部用户输入正常的…...
)
算法—合并排序—js(场景:大数据且需稳定性)
合并排序基本思想(稳定且高效) 将数组递归拆分为最小单元,合并两个有序数组。 特点: 时间复杂度:O(n log n) 空间复杂度:O(n) 稳定排序 // 合并排序-分解 function mergeSort(arr) {if (arr.length < …...

绝对路径与相对路径
绝对路径和相对路径是在计算机系统中用于定位文件或目录的两种方式,以下是具体介绍: 绝对路径 • 定义:是从文件系统的根目录开始到目标文件或目录的完整路径,它包含了从根目录到目标位置的所有目录和子目录信息,具有…...

RabbitMQ,添加用户时,出现Erlang cookie不一致,导致添加用户失败的问题解决
1. 问题现象 RabbitMQ 添加用户,出现以下报错 ./rabbitmgctl add user admin admin666*2. 问题原因和解决方法 安装的 RabbitMQ 里的 Erlang cookie,和 Erlang 环境的 cookie 不一致导致的 解决方法:将 Erlang 环境的 cookie ,…...

阿拉丁神灯-第16届蓝桥第4次STEMA测评Scratch真题第2题
[导读]:超平老师的《Scratch蓝桥杯真题解析100讲》已经全部完成,后续会不定期解读蓝桥真题,这是Scratch蓝桥真题解析第219讲。 第16届蓝桥第4次STEMA测评已于2025年1月12日落下帷幕,编程题一共有5题(初级组只有前4道编…...

常用的验证验证 onnxruntime-gpu安装的命令
#工作记录 我们经常会遇到明明安装了onnxruntime-gpu或onnxruntime后,无法正常使用的情况。 一、强制重新安装 onnxruntime-gpu 及其依赖 # 强制重新安装 onnxruntime-gpu 及其依赖 pip install --force-reinstall --no-cache-dir onnxruntime-gpu1.18.0 --extra…...

docker配置skywalking 监控springcloud应用
在使用 Docker 配置 SkyWalking 监控 Spring Cloud 应用时,主要分为以下几个步骤: 1. 准备工作 确保你的开发环境已经安装了 Docker 和 Docker Compose。准备好 Spring Cloud 应用代码,并确保它支持 SkyWalking 的探针(Agent&…...

HBase安装与基本操作指南
## 1. 安装准备 首先确保您的系统已经安装了以下组件: - Java JDK 8或更高版本 - Hadoop(HBase可以运行在独立模式下,但建议配合Hadoop使用) ## 2. 下载与安装HBase ```bash # 下载HBase(以2.4.12版本为例) wget https://downloads.apache.org/hbase/2.4.12/hbase-2…...

【Linux】Rhcsa复习5
一、Linux文件系统权限 1、文件的一般权限 文件权限针对三类对象进行定义: owner 属主,缩写u group 属组, 缩写g other 其他,缩写o 每个文件针对每类访问者定义了三种主要权限: r:read 读 w&…...

C++11特性补充
目录 lambda表达式 定义 捕捉的方式 可变模板参数 递归函数方式展开参数包 数组展开参数包 移动构造和移动赋值 包装器 绑定bind 智能指针 RAII auto_ptr unique_ptr shared_ptr 循环引用 weak_ptr 补充 总结 特殊类的设计 不能被拷贝的类 只能在堆上创建…...

缓存 --- Redis性能瓶颈和大Key问题
缓存 --- Redis性能瓶颈和大Key问题 内存瓶颈网络瓶颈CPU 瓶颈持久化瓶颈大key问题优化方案 Redis 是一个高性能的内存数据库,但在实际使用中,可能会在内存、网络、CPU、持久化、大键值对等方面遇到性能瓶颈。下面从这些方面详细分析 Redis 的性能瓶颈&a…...
)
css3新特性第三章(文本属性)
一、文本属性 文本阴影文本换行文本溢出文本修饰文本描边 1.1 文本阴影 在 CSS3 中,我们可以使用 text-shadow 属性给文本添加阴影。 语法: text-shadow: h-shadow v-shadow blur color; 值描述h-shadow必需写,水平阴影的位置。允许负值。…...

Redis 缓存—处理高并发问题
Redis的布隆过滤器、单线程架构、双写一致性、比较穿透、击穿及雪崩、缓存更新方案及分布式锁。 1 布隆过滤器 是一种高效的概率型数据结构,用于判断元素是否存在。主要用于防止缓存穿透,通过拦截不存在的数据查询,避免击穿数据库。 原理&…...

嵌入式芯片中的 SRAM 内容细讲
什么是 RAM? RAM 指的是“随机存取”,意思是存储单元都可以在相同的时间内被读写,和“顺序访问”(如磁带)相对。 RAM 不等于 DRAM,而是一类统称,包括 SRAM 和 DRAM 两种主要类型。 静态随机存…...

实操基于MCP驱动的 Agentic RAG:智能调度向量召回或者网络检索
我们展示了一个由 MCP 驱动的 Agentic RAG,它会搜索向量数据库,当然如果有需要他会自行进行网络搜索。 为了构建这个系统,我们将使用以下工具: 博查搜索 用于大规模抓取网络数据。作为Faiss向量数据库。Cursor 作为 MCP 客户端。…...

位运算---总结
位运算 基础 1. & 运算符 : 有 0 就是 0 2. | 运算符 : 有 1 就是 1 3. ^ 运算符 : 相同为0 相异为1 and 无进位相加位运算的优选级 不用在意优先级,能加括号就加括号给一个数 n ,确定它的二进制位中第 x 位是 0 还是 1? 规定: 题中所说的第x位指:int 在32位机器下4个…...

从0开始搭建一套工具函数库,发布npm,支持commonjs模块es模块和script引入使用
文章目录 文章目标技术选型工程搭建1. 初始化项目2. 安装开发依赖3. 项目结构4. 配置文件tsconfig.json.eslintrc.jseslint.config.prettierrc.jsrollup.config.cjs创建 .gitignore文件 设置 Git 钩子创建示例工具函数8. 版本管理和发布9 工具函数测试方案1. 安装测试依赖2. 配…...

精通 Spring Cache + Redis:避坑指南与最佳实践
Spring Cache 以其优雅的注解方式,极大地简化了 Java 应用中缓存逻辑的实现。结合高性能的内存数据库 Redis,我们可以轻松构建出响应迅速、扩展性强的应用程序。然而,在享受便捷的同时,一些常见的“坑”和被忽视的最佳实践可能会悄…...

DSP28335入门学习——第一节:工程项目创建
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.20 DSP28335开发板学习——第一节:工程项目创建 前言开发板说明引用解答…...
)
Docker Registry(镜像仓库)
官方架构 Docker 使用客户端 - 服务器 (C/S) 架构模式,使用远程 API 来管理和创建 Docker 容器。Docker 容器通过 Docker 镜像来创建。 Docker 仓库(Registry):Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hu…...

通过Dify快速搭建本地AI智能体开发平台
1. 安装Docker Desktop 访问 Docker官网 点击Download Docker Desktop,直接按照官方要求来就可以。 # 这串命令就像魔法咒语,在黑色窗口(命令提示符)里输入就能检查安装是否成功 docker --version2.安装dify 3.运行 Ollama 大…...
计算机视觉与深度学习 | Transformer原理,公式,代码,应用
Transformer 详解 Transformer 是 Google 在 2017 年提出的基于自注意力机制的深度学习模型,彻底改变了序列建模的范式,解决了 RNN 和 LSTM 在长距离依赖和并行计算上的局限性。以下是其原理、公式、代码和应用的详细解析。 一、原理 核心架构 Transformer 由 编码器(Encod…...

skywalking agent 关联docker镜像
Apache SkyWalking 提供了多种方式来部署和使用 SkyWalking Agent,包括在 Docker 容器中运行的应用。虽然 SkyWalking Agent 本身不是一个独立的 Docker 镜像,但你可以通过几种方式将 SkyWalking Agent 集成到你的 Docker 应用中。 方式一:手…...

【中间件】nginx将请求负载均衡转发给网关,网关再将请求转发给对应服务
一、场景 前端将请求发送给nginx,nginx将请求再转发给网关,网关再将请求转发至对应服务。由于网关会部署在多台服务器上,因此nginx需要负载均衡给网关发请求。nginx所有配置均参照官方文档nginx开发文档,可参考负载均衡板块内容 二…...
:什么是 Milvus)
Milvus(1):什么是 Milvus
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅…...

第十六节:高频开放题-React与Vue设计哲学差异
响应式原理(Proxy vs 虚拟DOM) 组合式API vs Hooks React 与 Vue 设计哲学差异深度解析 一、响应式原理的底层实现差异 1. Vue 的响应式模型(Proxy/数据劫持) Vue 的响应式系统通过 数据劫持 实现自动依赖追踪: • …...

【Hot100】 240. 搜索二维矩阵 II
目录 引言搜索二维矩阵 II我的解题贪心求解解题思路详解搜索策略(以从右上角开始为例)为什么这种方法有效? 完整代码实现复杂度分析示例演示 🙋♂️ 作者:海码007📜 专栏:算法专栏Ὂ…...