实操基于MCP驱动的 Agentic RAG:智能调度向量召回或者网络检索
我们展示了一个由 MCP 驱动的 Agentic RAG,它会搜索向量数据库,当然如果有需要他会自行进行网络搜索。
为了构建这个系统,我们将使用以下工具:
- 博查搜索 用于大规模抓取网络数据。
- 作为Faiss向量数据库。
- Cursor 作为 MCP 客户端。
以下是工作流程:
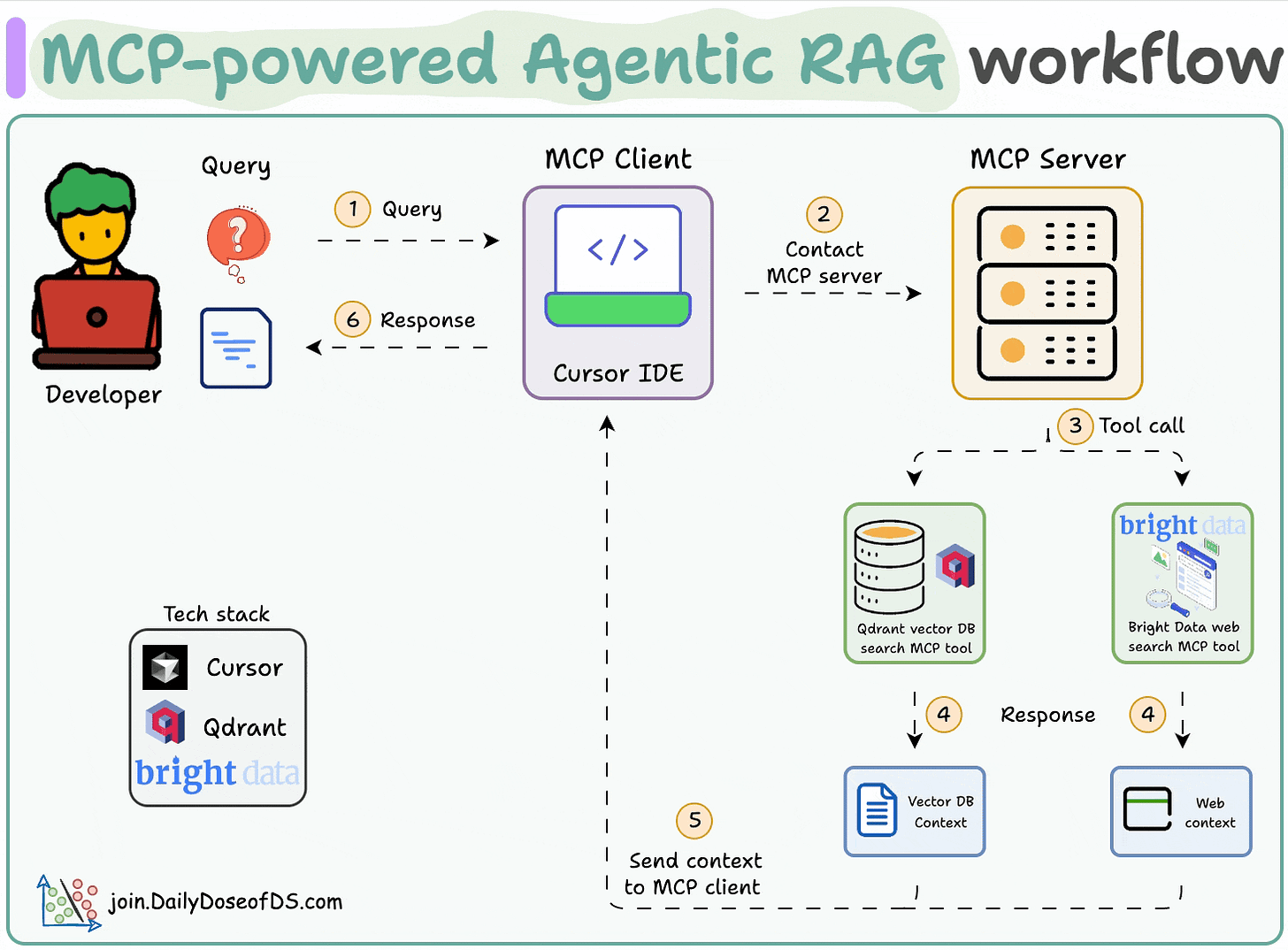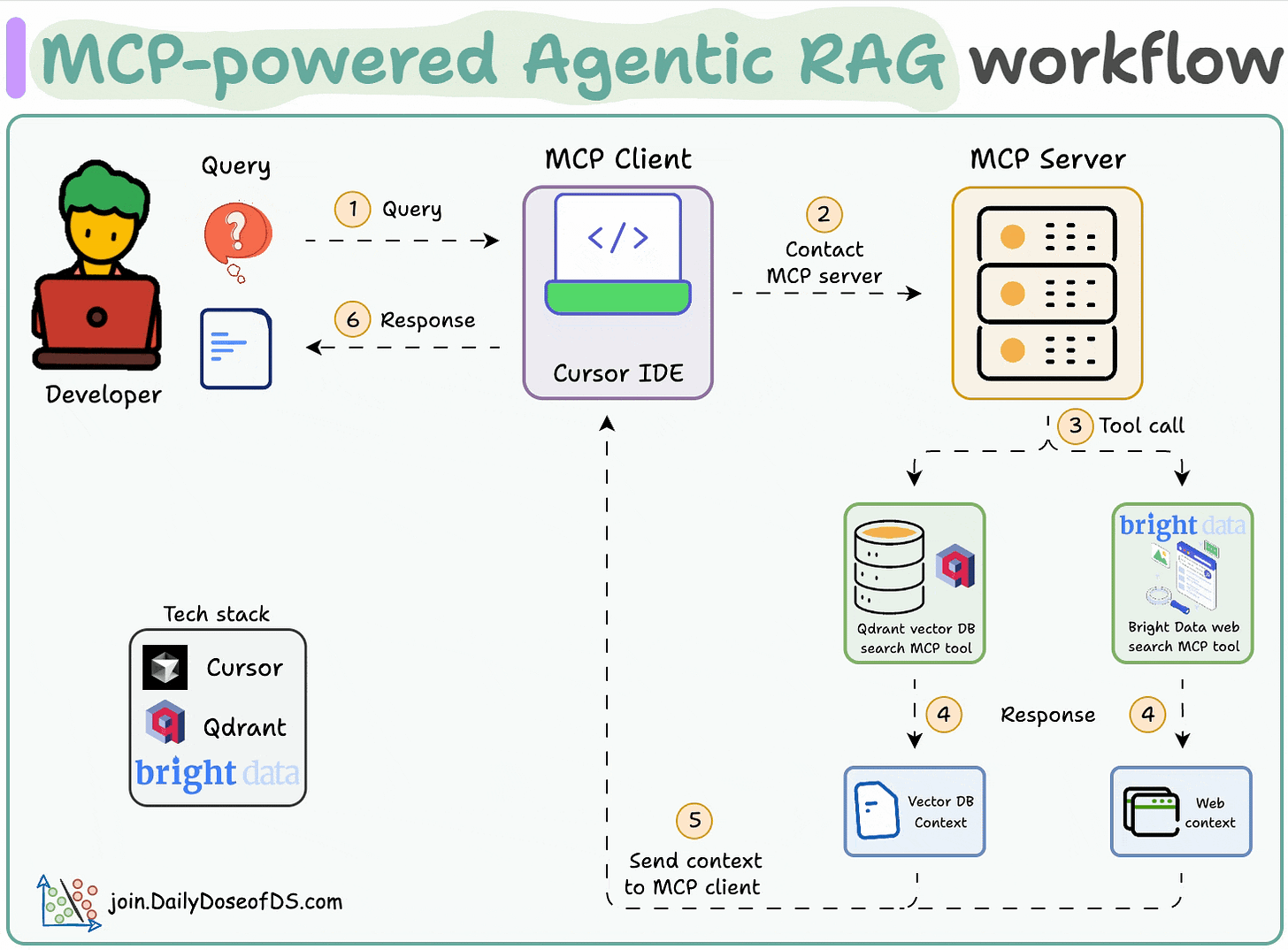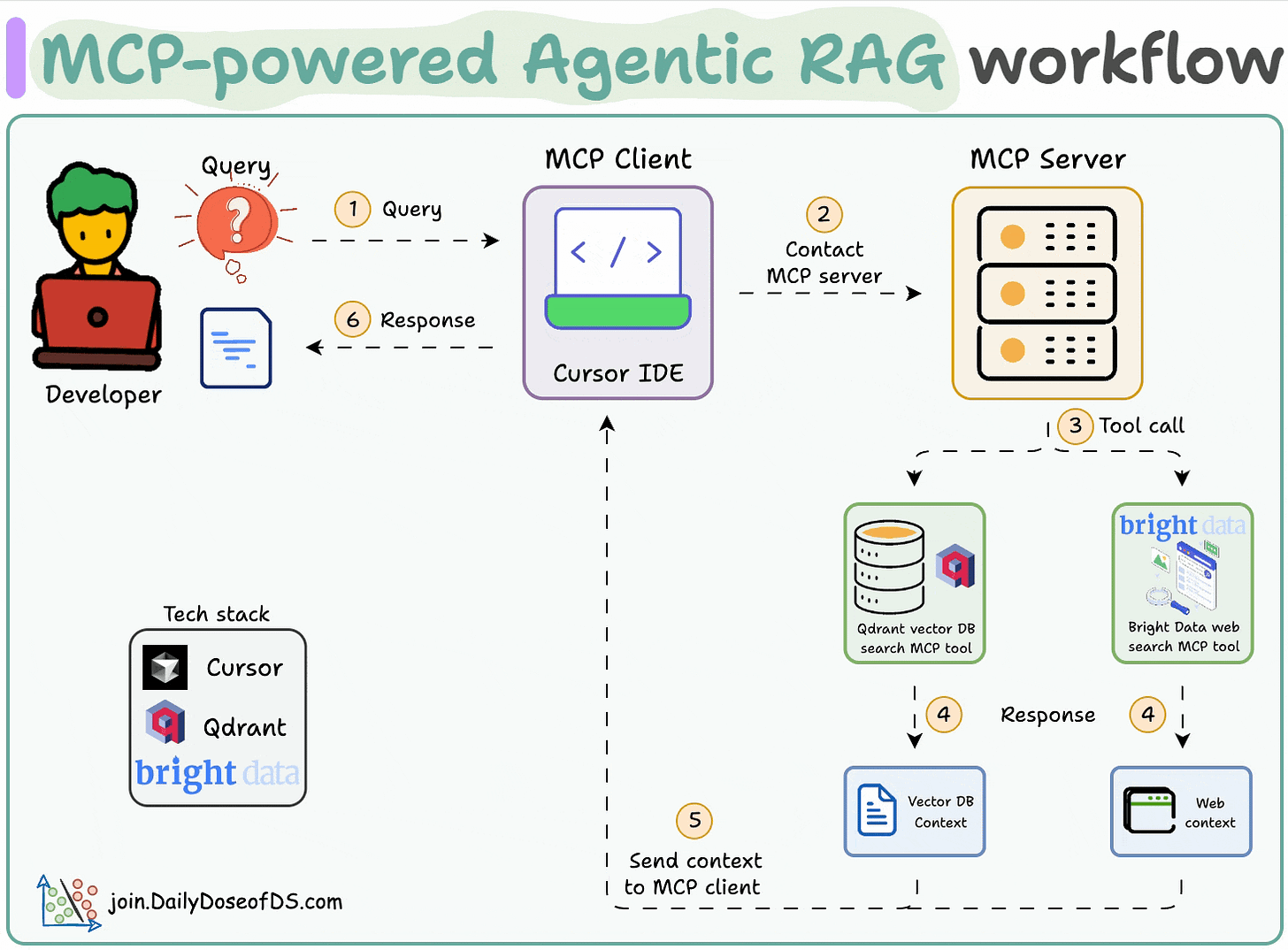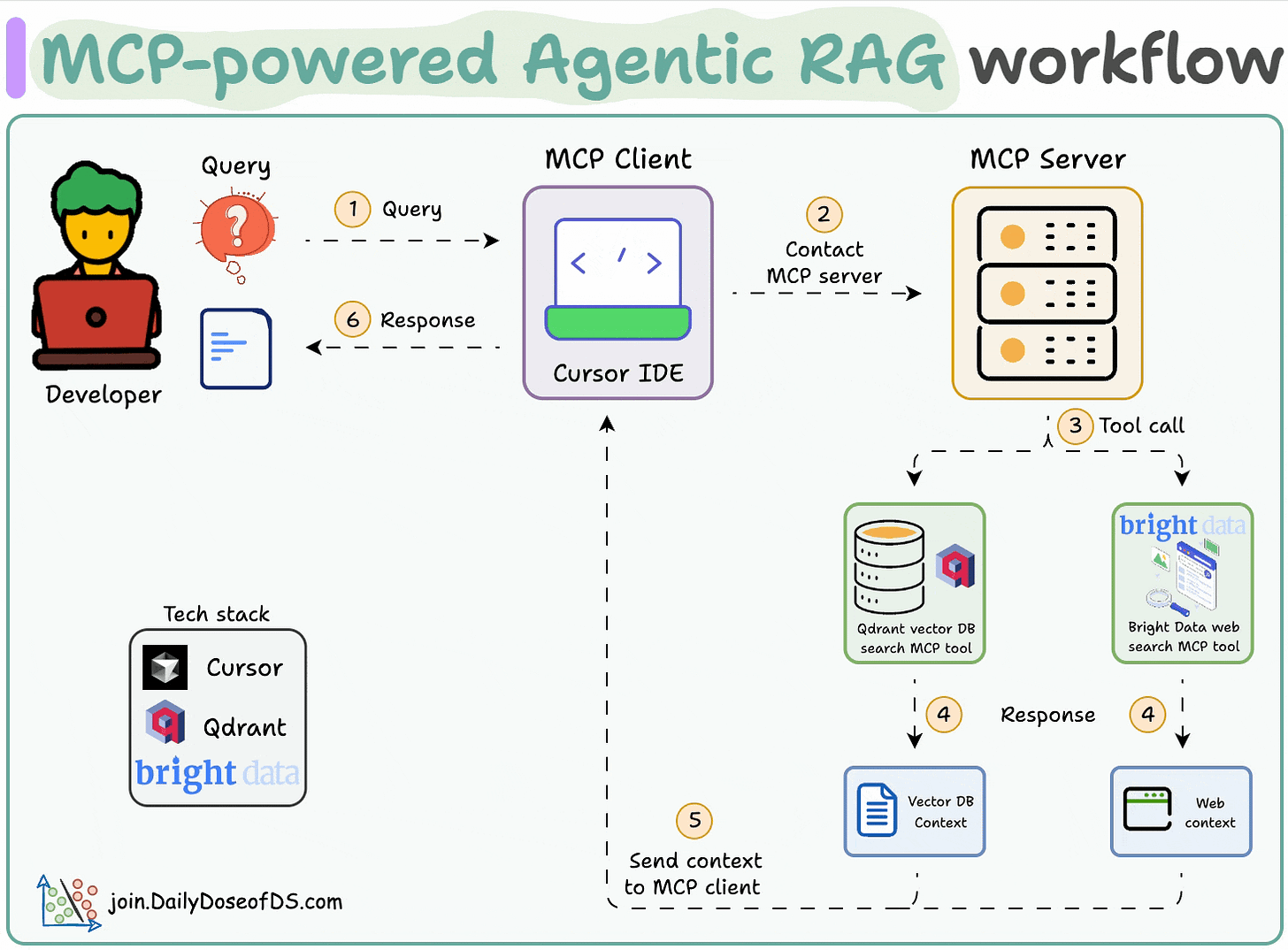
工作流程:
-
- 用户通过 MCP 客户端(Cursor)输入查询。
- 2-3客户端联系 MCP 服务器以选择相关工具。
- 4-6工具输出返回到客户端以生成响应。
环境准备
设置与安装
获取 BrightData API 密钥:
- 访问 Bright Data 并注册一个账户。
- 选择“代理与抓取”并创建一个新的“搜索引擎结果页面 (SERP) API”。
- 选择“原生代理访问”。
- 您将在那里找到您的用户名和密码。
- 将其存储在 .env 文件中。
- 国内最好还是利用国内的搜索引擎比如博查搜索

BRIGHDATA_USERNAME="..."
BRIGHDATA_PASSWORD="..."
安装依赖项:
确保您已安装 Python 3.11 或更高版本。
pip install mcp qdrant-client
运行项目
首先,按如下方式启动一个 Qdrant Docker 容器(确保您已下载 Docker):
docker run -p 6333:6333 -p 6334:6334 \-v $(pwd)/qdrant_storage:/qdrant/storage:z \qdrant/qdrant
接下来,运行代码在向量数据库中创建一个集合。
配置MCP服务
最后,按如下方式设置您的本地 MCP 服务器:
- 转到 Cursor 设置。
- 选择 MCP。
- 添加新的全局 MCP 服务器。
在 JSON 文件中添加以下内容:
{"mcpServers": {"mcp-rag-app": {"command": "python","args": ["/absolute/path/to/server.py"],"host": "127.0.0.1","port": 8080,"timeout": 30000}}
}
完成!您现在可以与向量数据库进行交互,并在需要时使用网络搜索作为后备方案。
本文将提供的完整的源代码工大家参考练习。
让我们开始实现吧!
1.启动一个 MCP 服务器
首先,我们定义一个带有主机 URL 和端口的 MCP 服务器。

2.向量数据库 MCP 工具
通过 MCP 服务器暴露的工具有两个要求:
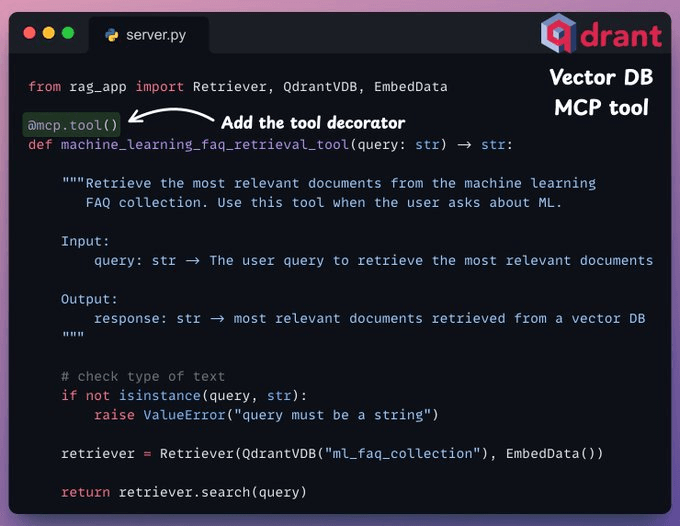
- 必须使用“tool”装饰器进行装饰。
- 必须有清晰的文档字符串。
在下面的代码中,我们有一个用于查询向量数据库的 MCP 工具。它存储了与机器学习相关的常见问题解答。
3.网络搜索 MCP 工具
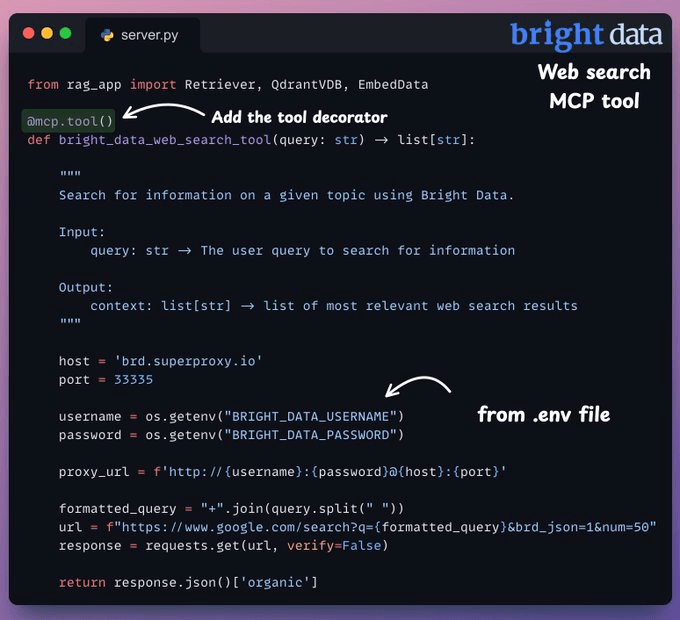
如果查询与机器学习无关,我们需要一个回退机制。
因此,我们使用 Bright Data 的 SERP API 进行网络搜索,以从多个来源抓取数据,获取相关上下文。
4.将 MCP 服务器与 Cursor 集成
在我们的设置中,Cursor 是一个使用 MCP 服务器暴露的工具的 MCP 客户端。
要集成 MCP 服务器,请转到设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下内容👇
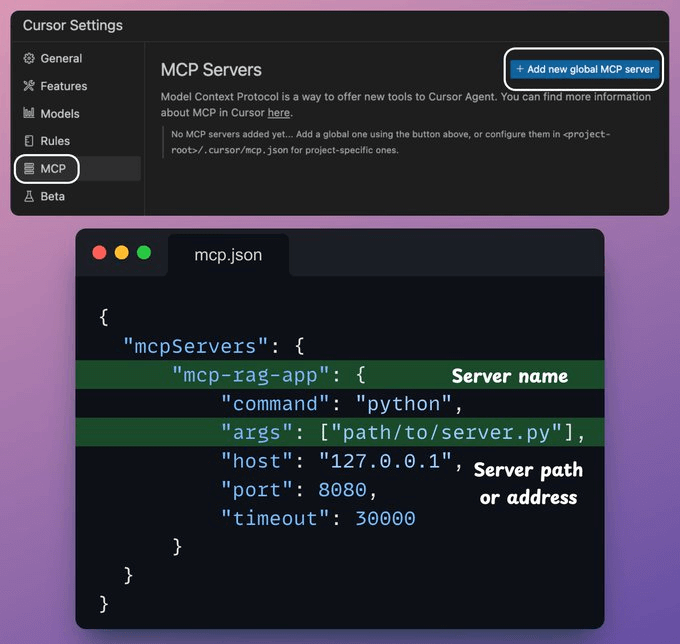
搞定啦!你的本地 MCP 服务器已经启动并且与 Cursor 连接成功🚀!
它有两个 MCP 工具:

- Bright Data 网络搜索工具,用于大规模抓取数据。
- 向量数据库搜索工具,用于查询相关文档。
接下来,我们与 MCP 服务器进行交互。
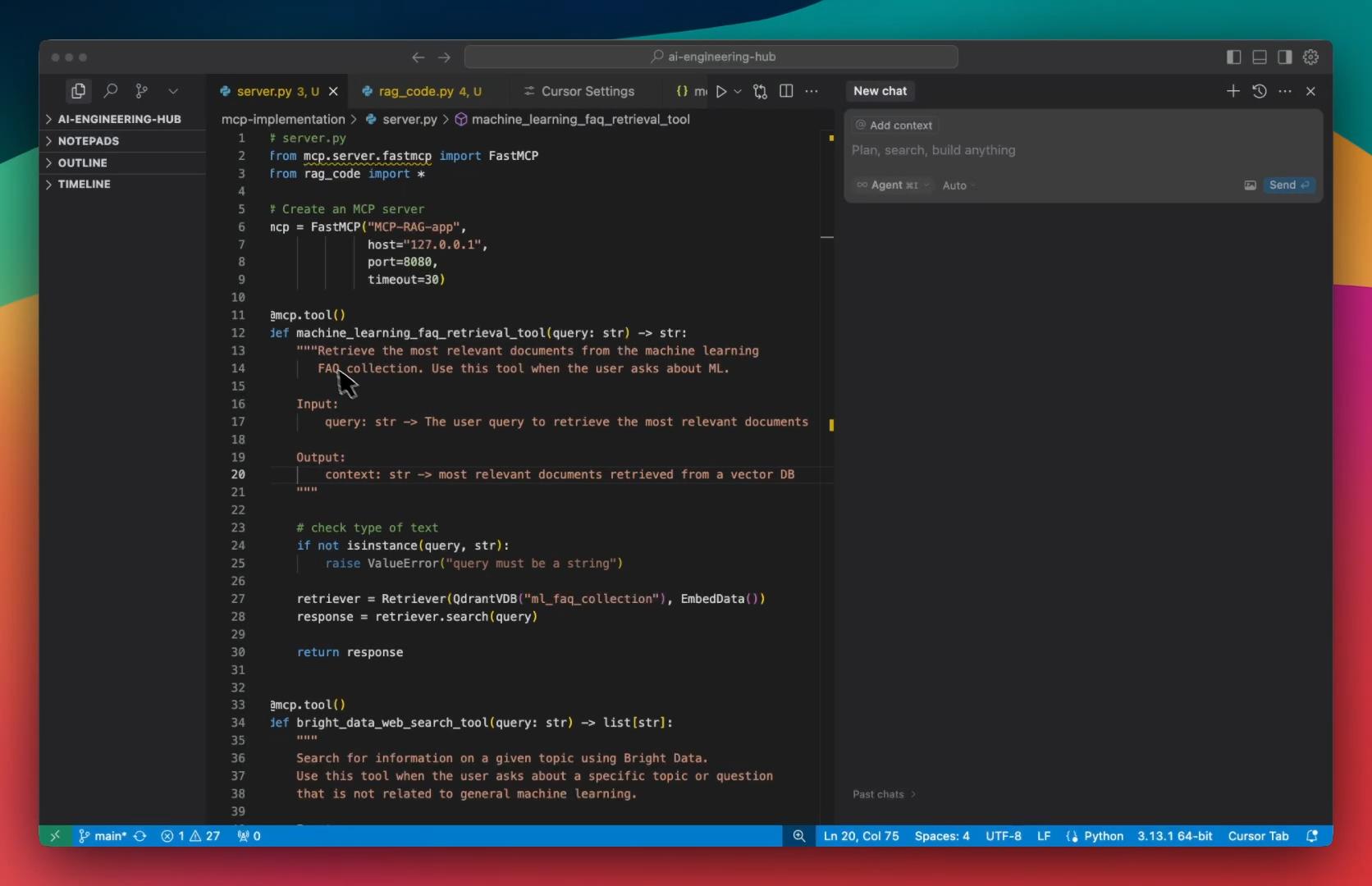
- 当我们提出与机器学习相关的查询时,它会调用向量数据库工具。这是一个标准RAG召回。
- 但是当我们提出一个通用查询时,它会调用 博查搜索 网络搜索工具,从多个来源收集网络数据。
当代理使用工具时,它们会遇到诸如 IP 封锁、机器人流量、验证码破解等问题。这些问题会阻碍代理的执行。
为了解决这个问题,我们在这个演示中使用了 博查搜索。
它可以让您:
- 在不被封锁的情况下为代理大规模抓取数据。
- 使用高级浏览器工具模拟用户行为。
- 使用实时和历史网络数据构建代理应用程序。
详细代码
server.py
# server.py
from mcp.server.fastmcp import FastMCP
from rag_code import *# Create an MCP server
mcp = FastMCP("MCP-RAG-app",host="127.0.0.1",port=8080,timeout=30)@mcp.tool()
def machine_learning_faq_retrieval_tool(query: str) -> str:"""Retrieve the most relevant documents from the machine learningFAQ collection. Use this tool when the user asks about ML.Input:query: str -> The user query to retrieve the most relevant documentsOutput:context: str -> most relevant documents retrieved from a vector DB"""# check type of textif not isinstance(query, str):raise ValueError("query must be a string")retriever = Retriever(QdrantVDB("ml_faq_collection"), EmbedData())response = retriever.search(query)return response@mcp.tool()
def bright_data_web_search_tool(query: str) -> list[str]:"""Search for information on a given topic using Bright Data.Use this tool when the user asks about a specific topic or question that is not related to general machine learning.Input:query: str -> The user query to search for informationOutput:context: list[str] -> list of most relevant web search results"""# check type of textif not isinstance(query, str):raise ValueError("query must be a string")import osimport requestsimport jsonfrom dotenv import load_dotenv# Load environment variablesload_dotenv()# 博查搜索 API 配置url = "https://api.bochaai.com/v1/web-search"api_key = os.getenv("BOCHAAI_API_KEY")if not api_key:raise ValueError("请在 .env 文件中设置 BOCHAAI_API_KEY")payload = json.dumps({"query": query,"summary": True,"count": 10,"page": 1})headers = {'Authorization': f'Bearer {api_key}','Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)# Return organic search resultsreturn response.json()['organic']if __name__ == "__main__":print("Starting MCP server at http://127.0.0.1:8080 on port 8080")mcp.run()
rag.py
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from tqdm import tqdm
from fasiimcp import FasiClient, FasiConfigfaq_text = """Question 1: What is the first step before building a machine learning model?
Answer 1: Understand the problem, define the objective, and identify the right metrics for evaluation.Question 2: How important is data cleaning in ML?
Answer 2: Extremely important. Clean data improves model performance and reduces the chance of misleading results.Question 3: Should I normalize or standardize my data?
Answer 3: Yes, especially for models sensitive to feature scales like SVMs, KNN, and neural networks.Question 4: When should I use feature engineering?
Answer 4: Always consider it. Well-crafted features often yield better results than complex models.Question 5: How to handle missing values?
Answer 5: Use imputation techniques like mean/median imputation, or model-based imputation depending on the context.Question 6: Should I balance my dataset for classification tasks?
Answer 6: Yes, especially if the classes are imbalanced. Techniques include resampling, SMOTE, and class-weighting.Question 7: How do I select features for my model?
Answer 7: Use domain knowledge, correlation analysis, or techniques like Recursive Feature Elimination or SHAP values.Question 8: Is it good to use all features available?
Answer 8: Not always. Irrelevant or redundant features can reduce performance and increase overfitting.Question 9: How do I avoid overfitting?
Answer 9: Use techniques like cross-validation, regularization, pruning (for trees), and dropout (for neural nets).Question 10: Why is cross-validation important?
Answer 10: It provides a more reliable estimate of model performance by reducing bias from a single train-test split.Question 11: What’s a good train-test split ratio?
Answer 11: Common ratios are 80/20 or 70/30, but use cross-validation for more robust evaluation.Question 12: Should I tune hyperparameters?
Answer 12: Yes. Use grid search, random search, or Bayesian optimization to improve model performance.Question 13: What’s the difference between training and validation sets?
Answer 13: Training set trains the model, validation set tunes hyperparameters, and test set evaluates final performance.Question 14: How do I know if my model is underfitting?
Answer 14: It performs poorly on both training and test sets, indicating it hasn’t learned patterns well.Question 15: What are signs of overfitting?
Answer 15: High accuracy on training data but poor generalization to test or validation data.Question 16: Is ensemble modeling useful?
Answer 16: Yes. Ensembles like Random Forests or Gradient Boosting often outperform individual models.Question 17: When should I use deep learning?
Answer 17: Use it when you have large datasets, complex patterns, or tasks like image and text processing.Question 18: What is data leakage and how to avoid it?
Answer 18: Data leakage is using future or target-related information during training. Avoid by carefully splitting and preprocessing.Question 19: How do I measure model performance?
Answer 19: Choose appropriate metrics: accuracy, precision, recall, F1, ROC-AUC for classification; RMSE, MAE for regression.Question 20: Why is model interpretability important?
Answer 20: It builds trust, helps debug, and ensures compliance—especially important in high-stakes domains like healthcare.
"""new_faq_text = [i.replace("\n", " ") for i in faq_text.split("\n\n")]
def batch_iterate(lst, batch_size):for i in range(0, len(lst), batch_size):yield lst[i : i + batch_size]class EmbedData:def __init__(self, embed_model_name="nomic-ai/nomic-embed-text-v1.5",batch_size=32):self.embed_model_name = embed_model_nameself.embed_model = self._load_embed_model()self.batch_size = batch_sizeself.embeddings = []def _load_embed_model(self):embed_model = HuggingFaceEmbedding(model_name=self.embed_model_name,trust_remote_code=True,cache_folder='./hf_cache')return embed_modeldef generate_embedding(self, context):return self.embed_model.get_text_embedding_batch(context)def embed(self, contexts):self.contexts = contextsfor batch_context in tqdm(batch_iterate(contexts, self.batch_size),total=len(contexts)//self.batch_size,desc="Embedding data in batches"):batch_embeddings = self.generate_embedding(batch_context)self.embeddings.extend(batch_embeddings)class FasiiVDB:def __init__(self, collection_name, vector_dim=768, batch_size=512):self.collection_name = collection_nameself.batch_size = batch_sizeself.vector_dim = vector_dimself.config = FasiConfig(url="http://localhost:6333")self.client = FasiClient(self.config)def create_collection(self):if not self.client.collection_exists(self.collection_name):self.client.create_collection(self.collection_name, self.vector_dim)def ingest_data(self, embeddata):for batch_context, batch_embeddings in tqdm(zip(batch_iterate(embeddata.contexts, self.batch_size), batch_iterate(embeddata.embeddings, self.batch_size)), total=len(embeddata.contexts)//self.batch_size, desc="Ingesting in batches"):self.client.upload_vectors(self.collection_name, batch_embeddings, [{"context": context} for context in batch_context])class Retriever:def __init__(self, vector_db, embeddata):self.vector_db = vector_dbself.embeddata = embeddatadef search(self, query):query_embedding = self.embeddata.embed_model.get_query_embedding(query)# select the top 3 resultsresult = self.vector_db.client.search(collection_name=self.vector_db.collection_name,query_vector=query_embedding,limit=3)combined_prompt = [item["payload"]["context"] for item in result]final_output = "\n\n---\n\n".join(combined_prompt)return final_output
应该还想了解
各种构建RAG 系统的技术
在纸上,实现一个 RAG 系统似乎很简单——连接一个向量数据库,处理文档,嵌入数据,嵌入查询,查询向量数据库,然后提示 LLM。
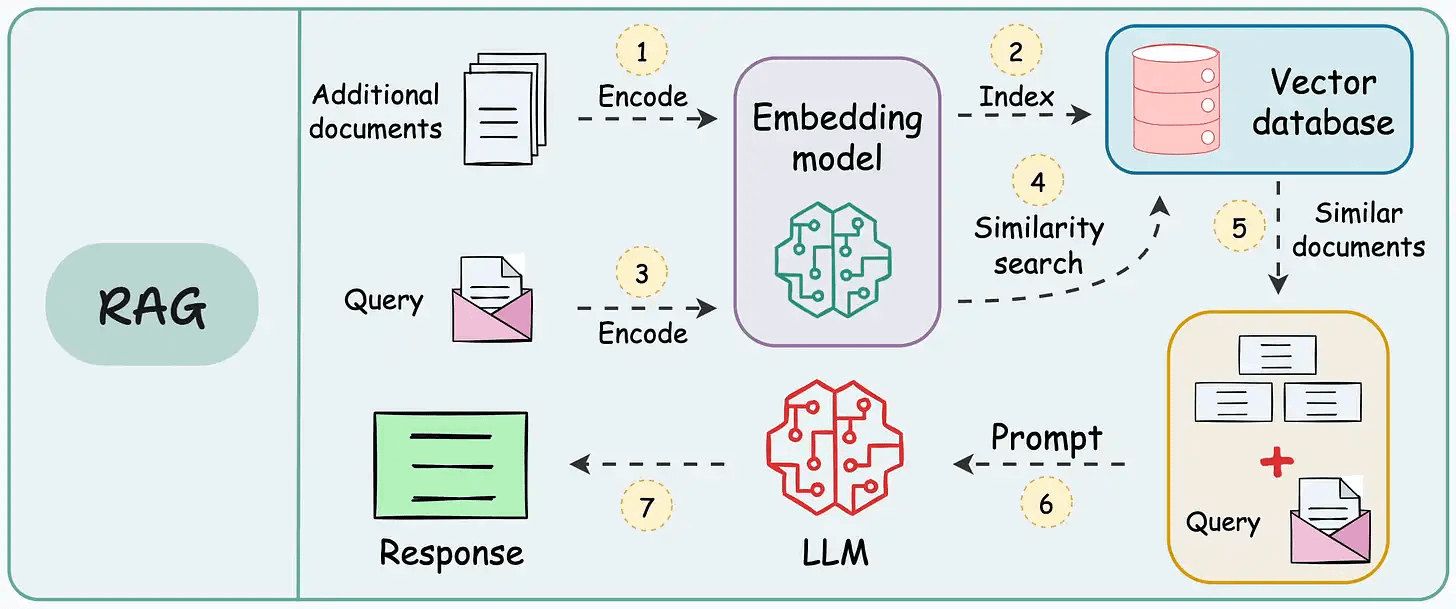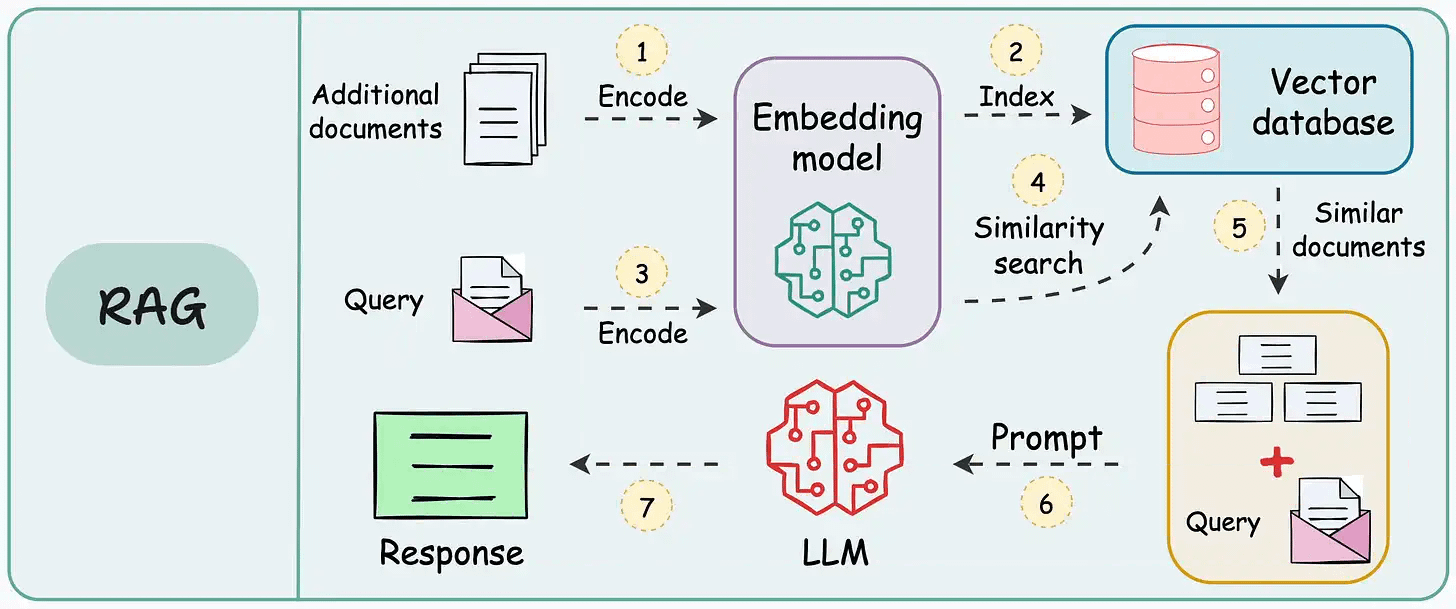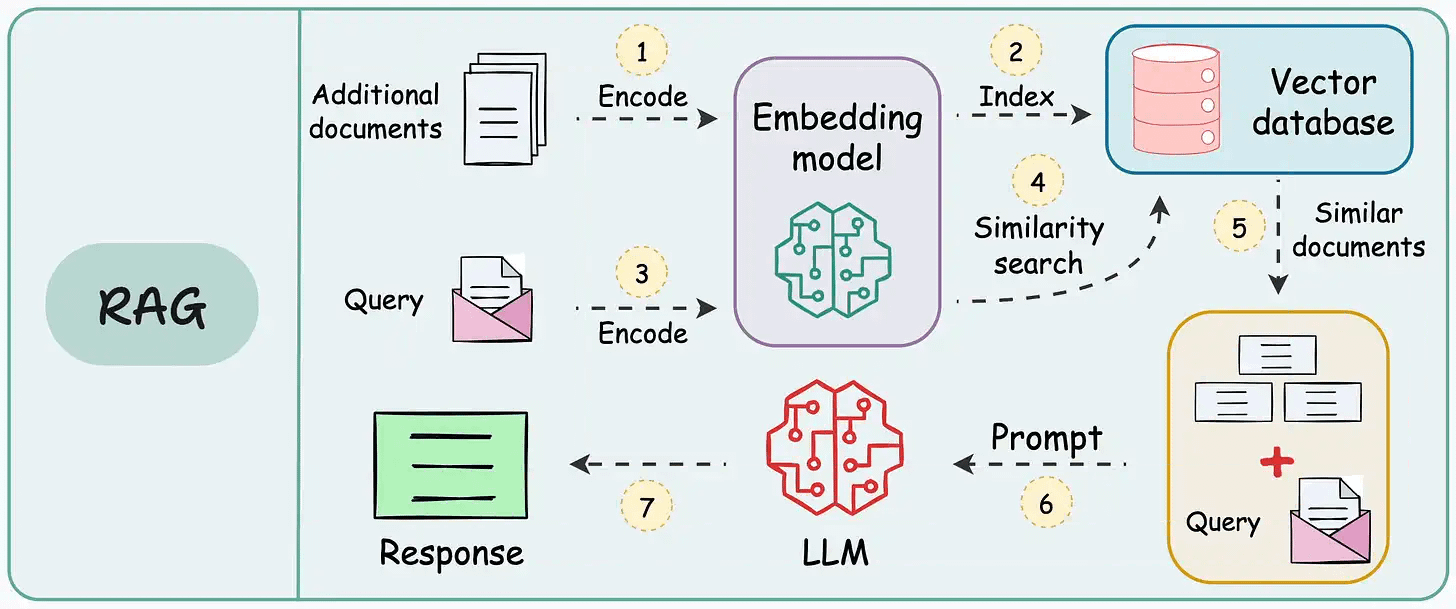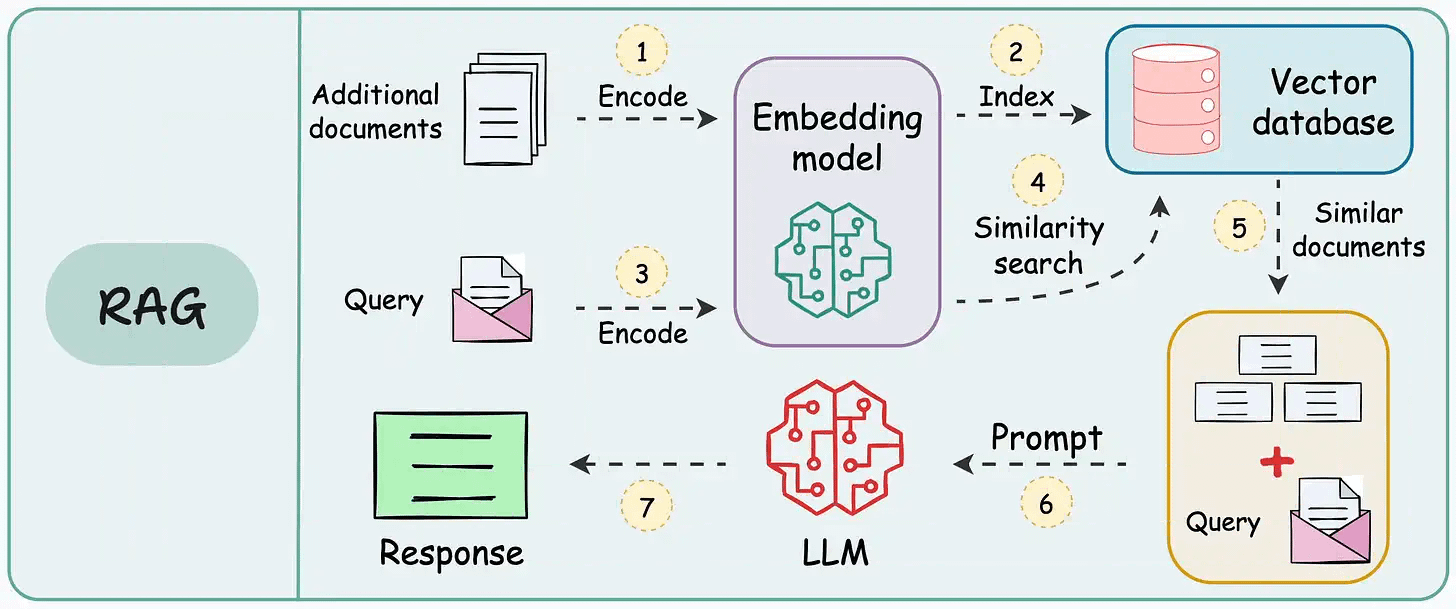
但在实践中,将原型转化为高性能应用程序是一个完全不同的挑战。
我之前发布了一个两个专栏,涵盖了 各种实用技术来构建现实世界的 RAG 系统:
- 阅读第一部分 →基于python从零实现各类RAG
- 阅读第二部分 →LlamaIndex实战
相关文章:

实操基于MCP驱动的 Agentic RAG:智能调度向量召回或者网络检索
我们展示了一个由 MCP 驱动的 Agentic RAG,它会搜索向量数据库,当然如果有需要他会自行进行网络搜索。 为了构建这个系统,我们将使用以下工具: 博查搜索 用于大规模抓取网络数据。作为Faiss向量数据库。Cursor 作为 MCP 客户端。…...

位运算---总结
位运算 基础 1. & 运算符 : 有 0 就是 0 2. | 运算符 : 有 1 就是 1 3. ^ 运算符 : 相同为0 相异为1 and 无进位相加位运算的优选级 不用在意优先级,能加括号就加括号给一个数 n ,确定它的二进制位中第 x 位是 0 还是 1? 规定: 题中所说的第x位指:int 在32位机器下4个…...

从0开始搭建一套工具函数库,发布npm,支持commonjs模块es模块和script引入使用
文章目录 文章目标技术选型工程搭建1. 初始化项目2. 安装开发依赖3. 项目结构4. 配置文件tsconfig.json.eslintrc.jseslint.config.prettierrc.jsrollup.config.cjs创建 .gitignore文件 设置 Git 钩子创建示例工具函数8. 版本管理和发布9 工具函数测试方案1. 安装测试依赖2. 配…...

精通 Spring Cache + Redis:避坑指南与最佳实践
Spring Cache 以其优雅的注解方式,极大地简化了 Java 应用中缓存逻辑的实现。结合高性能的内存数据库 Redis,我们可以轻松构建出响应迅速、扩展性强的应用程序。然而,在享受便捷的同时,一些常见的“坑”和被忽视的最佳实践可能会悄…...

DSP28335入门学习——第一节:工程项目创建
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.20 DSP28335开发板学习——第一节:工程项目创建 前言开发板说明引用解答…...
)
Docker Registry(镜像仓库)
官方架构 Docker 使用客户端 - 服务器 (C/S) 架构模式,使用远程 API 来管理和创建 Docker 容器。Docker 容器通过 Docker 镜像来创建。 Docker 仓库(Registry):Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hu…...

通过Dify快速搭建本地AI智能体开发平台
1. 安装Docker Desktop 访问 Docker官网 点击Download Docker Desktop,直接按照官方要求来就可以。 # 这串命令就像魔法咒语,在黑色窗口(命令提示符)里输入就能检查安装是否成功 docker --version2.安装dify 3.运行 Ollama 大…...
计算机视觉与深度学习 | Transformer原理,公式,代码,应用
Transformer 详解 Transformer 是 Google 在 2017 年提出的基于自注意力机制的深度学习模型,彻底改变了序列建模的范式,解决了 RNN 和 LSTM 在长距离依赖和并行计算上的局限性。以下是其原理、公式、代码和应用的详细解析。 一、原理 核心架构 Transformer 由 编码器(Encod…...

skywalking agent 关联docker镜像
Apache SkyWalking 提供了多种方式来部署和使用 SkyWalking Agent,包括在 Docker 容器中运行的应用。虽然 SkyWalking Agent 本身不是一个独立的 Docker 镜像,但你可以通过几种方式将 SkyWalking Agent 集成到你的 Docker 应用中。 方式一:手…...

【中间件】nginx将请求负载均衡转发给网关,网关再将请求转发给对应服务
一、场景 前端将请求发送给nginx,nginx将请求再转发给网关,网关再将请求转发至对应服务。由于网关会部署在多台服务器上,因此nginx需要负载均衡给网关发请求。nginx所有配置均参照官方文档nginx开发文档,可参考负载均衡板块内容 二…...
:什么是 Milvus)
Milvus(1):什么是 Milvus
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅…...

第十六节:高频开放题-React与Vue设计哲学差异
响应式原理(Proxy vs 虚拟DOM) 组合式API vs Hooks React 与 Vue 设计哲学差异深度解析 一、响应式原理的底层实现差异 1. Vue 的响应式模型(Proxy/数据劫持) Vue 的响应式系统通过 数据劫持 实现自动依赖追踪: • …...

【Hot100】 240. 搜索二维矩阵 II
目录 引言搜索二维矩阵 II我的解题贪心求解解题思路详解搜索策略(以从右上角开始为例)为什么这种方法有效? 完整代码实现复杂度分析示例演示 🙋♂️ 作者:海码007📜 专栏:算法专栏Ὂ…...

每日面试实录·携程·社招·JAVA
📍面试公司:携程 👜面试岗位:后端开发工程师(社招) 🕐面试时长:约 50 分钟 🔄面试轮次:第 1 轮技术面 ✨面试整体节奏: 这场携程的社招 Java 一面…...

Oracle--用户管理
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 用户管理在 Oracle 数据库中至关重要。一个服务器通常只运行一个 Oracle 实例,而一个 Oracle 用户代表一个用户群,他们通过该用…...

20.3 使用技巧5
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 20.3.8 CellContentClick事件 当增加新按钮列或者超链接列后,按钮或者超链接,会发现,按钮或者超链…...
)
Kubernetes相关的名词解释Metrics Server组件(7)
什么是Metrics Server? Metrics Server 是 Kubernetes 集群中的一个关键组件,主要用于资源监控和自动扩缩容。 kubernetes 从1.8版本开始不再集成cadvisor,也废弃了heapster,使用metrics server来提供metrics。那么...... 什么…...

17.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--SonarQube部署与配置
在将孢子记账系统从单体架构转向微服务架构的过程中,代码质量的管理变得尤为重要。随着项目规模的扩大和团队协作的深入,我们需要一个强大的工具来帮助我们持续监控和改进代码质量。我们首选SonarQube,它能够帮助我们识别代码中的潜在问题、技…...

计算机是如何看待数据的?
一、计算机如何“看待”数据? 物理层本质: 计算机的所有数据最终以二进制(0和1)在电路中表示(高电平1,低电平0)。 无论你用何种进制描述数据(如十六进制 0xA1 或十进制 161…...

25.4.20学习总结
如何使用listView组件来做聊天界面 1. 什么是CellFactory? 在JavaFX中,控件(比如ListView、TableView等)用Cell来显示每一条数据。 Cell:代表这个单元格(即每个列表项)中显示的内容和样式。 …...

SpringBoot3集成ES8.15实现余额监控
1. gradle依赖新增 implementation org.springframework.boot:spring-boot-starter-data-elasticsearch implementation co.elastic.clients:elasticsearch-java:8.15.02. application.yml配置 spring:elasticsearch:uris: http://localhost:9200username: elasticpassword: …...

STM32基础教程——串口收发
目录 前言 字长设置 编辑 停止位 起始位侦测 波特率 1. UART波特率的基本原理 2. 为什么需要先除以分频因子(USARTDIV)? (1)PCLK频率太高 (2)分频因子的作用 3. 为什么还需要再除以…...

Matlab 步进电机传递函数模糊pid
1、内容简介 Matlab 210-步进电机传递函数模糊pid 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

unordered_map、unordered_set详解
深入理解C中的 unordered_map 和 unordered_set 在C标准库中,unordered_map 和 unordered_set 是两个基于哈希表(Hash Table)实现的高效容器。它们以O(1)的平均时间复杂度实现快速查找、插入和删除操作,特别适合需要高频…...

详解trl中的GRPOTrainer和GRPOConfig
引言 在大型语言模型(LLM)的强化学习微调领域, Group Relative Policy Optimization (GRPO) 算法因其高效性和资源友好性受到广泛关注。Hugging Face的 TRL (Transformer Reinforcement Learning) 库通过GRPOTrainer和GRPOConfig提供了该算法的开箱即用实现。本文将深入解析…...

【C++】多态 - 从虚函数到动态绑定的核心原理
📌 个人主页: 孙同学_ 🔧 文章专栏:C 💡 关注我,分享经验,助你少走弯路 文章目录 1. 多态的概念2. 多态的定义及实现2.1 多态的构成条件2.1.1实现多态还有两个必须重要条件:2.1.2 虚…...

项目预期管理:超越甘特图,实现客户价值交付
引言 在项目管理实践中,许多项目经理习惯于将注意力集中在甘特图的进度条上,关注任务是否按时完成、里程碑是否达成。然而,这种以计划管理为中心的方法往往忽略了项目管理的核心目标:满足客户预期,交付真正的价值。项…...
)
FISCO 2.0 安装部署WeBASE与区块链浏览器(环境搭建)
FISCO BCOS 2.0 安装部署WeBASE与区块链浏览器-对应的官网地址: WeBASE平台:https://webasedoc.readthedocs.io/zh-cn/latest/docs/WeBASE/install.html 区块链浏览器:https://fisco-bcos-documentation.readthedocs.io/zh-cn/latest/docs/br…...

xss学习3之服务端session
一、服务端的Session 1. cookie和session 1)cookie和session对比 cookie: 保存在客户端,包含所有key-value信息,浏览器访问多个网站时会积累大量cookie,占用存储空间,并在每次请求时携带所有cookie,增加…...
)
23种设计模式-结构型模式之适配器模式(Java版本)
Java 适配器模式(Adapter Pattern)详解 🔌 什么是适配器模式? 适配器模式用于将一个类的接口转换成客户端所期望的另一种接口,让原本接口不兼容的类可以协同工作。 📦 就像插头转换器,让不同…...

【2025计算机网络-面试常问】http和https区别是什么,http的内容有哪些,https用的是对称加密还是非对称加密,流程是怎么样的
HTTP与HTTPS全面对比及HTTPS加密流程详解 一、HTTP与HTTPS核心区别 特性HTTPHTTPS协议基础明文传输HTTP SSL/TLS加密层默认端口80443加密方式无加密混合加密(非对称对称)证书要求不需要需要CA颁发的数字证书安全性易被窃听、篡改、冒充防窃听、防篡改…...

使用安全继电器的急停电路设计
使用安全继电器的急停电路设计 一,急停回路的设计1,如何将急停接到线路当中?2,急停开关 如何接到安全继电器中 一,急停回路的设计 急停是每一个设备必不可少的部分,因为关乎安全,所以说所以说他…...

SpringCloud概述和环境搭建
SpringCloud概述和环境搭建 一.微服务的引入1.单体架构2.集群和分布式架构3.集群和分布式4.微服务架构4.微服务的优缺点 二.微服务解决方案-SpringCloud1.Spring Cloud简介2.Spring Cloud版本3.Spring Cloud实现方案4.Spring Cloud Alibaba 三.环境搭建1.安装JDK172.Ubantu上下…...

System.out 详解
System.out 详解 System.out 是 Java 提供的标准输出流(PrintStream 类型),默认关联控制台(Console),用于向终端打印文本信息。它是 Java 中最常用的输出方式之一,尤其在调试和命令行程序开发中。 1. 核心知识点 (1)System.out 的本质 类型:PrintStream(字节流,但…...
:ln)
每天学一个 Linux 命令(28):ln
可访问网站查看,视觉品味拉满: http://www.616vip.cn/28/index.html ln 是 Linux 中用于创建文件或目录链接的命令,主要生成硬链接(Hard Link)和符号链接(Symbolic Link,软链接)。链接常用于文件共享、快捷访问或版本管理。 命令格式 ln [选项] 源文件 目标链接链…...
)
【微知】服务器如何获取服务器的SN序列号信息?(dmidecode -t 1)
文章目录 背景命令dmidecode -t的数字代表的字段 背景 各种场景都需要获取服务器的SN(Serial Number),比如问题定位,文件命名,该部分信息在dmi中是标准信息,不同服务器,不同os都能用相同方式获…...
)
4.20刷题记录(单调栈)
第一部分:简单介绍 单调栈我的理解是在栈中存储数字出现的位置,然后通过遍历比较当前栈顶元素与当前元素的大小关系,从而确定逻辑相关顺序。 第二部分:真题讲解 (1)739. 每日温度 - 力扣(Lee…...

Opencv图像处理:模板匹配对象
文章目录 一、模板匹配1、什么是模板匹配?2、原理 二、单模板匹配(代码实现)1、预处理2、 开始模板匹配并绘制匹配位置的外接矩形 三、多模板匹配(代码实现)1、读取图片和模板2、模板匹配3、设置阈值1)阈值…...

Web3.0热门领域NFT项目实战课程
课程大小:3.8G 课程下载:https://download.csdn.net/download/m0_66047725/90616383 更多资源下载:关注我 深度掌握Solidity合约开发,助力成为抢手的Web3.0开发工程师 深入Web3.0技术的人才,一将难求。本课程由We…...

DAY 50 leetcode 1047--栈和队列.删除字符串中的所有相邻重复项
题号1047 给出由小写字母组成的字符串 s,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 s 上反复执行重复项删除操作,直到无法继续删除。 在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。 import java.util.Ar…...

单例模式与消费者生产者模型,以及线程池的基本认识与模拟实现
前言 今天我们就来讲讲什么是单例模式与线程池的相关知识,这两个内容也是我们多线程中比较重要的内容。其次单例模式也是我们常见设计模式。 单例模式 那么什么是单例模式呢?上面说到的设计模式又是什么? 其实单例模式就是设计模式的一种。…...

微信小程序通过mqtt控制esp32
目录 1.注册巴法云 2.设备连接mqtt 3.微信小程序 备注 本文esp32用的是MicroPython固件,MQTT服务用的是巴法云。 本文参考巴法云官方教程:https://bemfa.blog.csdn.net/article/details/115282152 1.注册巴法云 注册登陆并新建一个topicÿ…...

QML、Qt Quick 、Qt Quick Controls 2
一、概念 基本关系 QML 是声明式语言,用于描述用户界面。声明式语法(类似JSON+JavaScript),定义UI结构和行为。 Qt Quick 是 QML 的标准库,提供基本类型和功能。提供QML语言运行时的基础能力,相当于QML的"标准模板库(STL)"。 Quick Controls 2 是基于 Qt Quic…...

基于maven-jar-plugin打造一款自动识别主类的maven打包插件
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

利用 HEMT 和 PHEMT 改善无线通信电路中的增益、速度和噪声
本文要点 高电子迁移率晶体管 (High electron mobility transistors ,HEMTs) 和应变式异质接面高迁移率晶体管(pseudomorphic high electron mobility transistors ,PHEMTs) 因其独特的、可提高性能的特点而…...

探秘C#用户定义类型:突破预定义的边界
在C#的编程世界里,除了系统提供的16种预定义类型,开发者还拥有强大的自主能力——创建自己的用户定义类型。这大大拓展了编程的灵活性和可扩展性,让开发者能根据具体需求定制数据结构和功能。 六种用户定义类型 类类型(class&am…...

idea中导入从GitHub上克隆下来的springboot项目解决找不到主类的问题
第一步:删除目录下的.idea和target,然后用idea打开 第二步:如果有需要,idea更换jdk版本 原文链接:https://blog.csdn.net/m0_74036731/article/details/146779040 解决方法(idea中解决)&#…...

北理工宫某的瓜ppt下载地址
关于“北理工宫某瓜”PPT下载地址相关技术探讨 摘要:本文围绕“北理工宫某瓜”事件中PPT下载地址相关情况展开分析,探讨了网络资源传播的技术机制、涉及的网络安全问题以及围绕此类资源分享应遵循的规范和注意事项,旨在从技术角度对这类网络…...

[论文阅读]Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Making Retrieval-Augmented Language Models Robust to Irrelevant Context [2310.01558v2] Making Retrieval-Augmented Language Models Robust to Irrelevant Context 检索增强语言模型(RALMs),它包含一个检索机制,以减少将…...

论文阅读:2023 arxiv A Survey of Reinforcement Learning from Human Feedback
A Survey of Reinforcement Learning from Human Feedback https://arxiv.org/pdf/2312.14925 https://www.doubao.com/chat/3506943124865538 速览 这篇论文是关于“从人类反馈中进行强化学习(RLHF)”的综述,核心是讲如何让AI通过人类反…...