【智驾中的大模型 -3】VLA 在自动驾驶中的应用
1.前言
在上一篇文章中,我们深入探讨了 VLM 模型在自动驾驶中的应用。VLA(Very Large Architecture,大型架构)和 VLM(Very Large Model,非常大模型)在 AI 领域皆指向超大规模的神经网络模型,然而,它们的侧重点存在显著差异。VLA 端到端特指融合视觉、语言和动作这三种能力的端到端自动驾驶架构。细致来讲,它是一种前沿的多模态机器学习模型,致力于达成从感知输入径直映射到机器人或汽车控制动作的完备闭环。
今天,我们就来全面介绍一下 VLA 模型在自动驾驶中的具体应用。
2.VLA 与 VLM 的区别
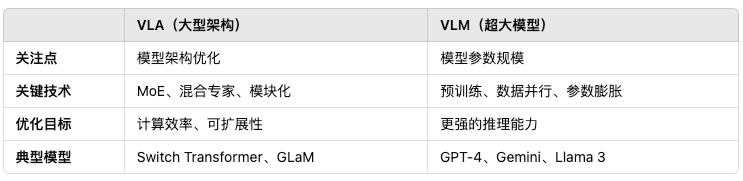
VLA 强调的是 模型的架构设计,指的是超大规模的深度学习模型架构,通常涉及以下特征:
- 创新的网络结构:如 Mixture of Experts(MoE)、稀疏激活 Transformer、多模态融合等架构优化技术。
- 模块化设计:VLA 可能采用多个子模型(如 MoE)或层次化结构,以提高效率和可扩展性。
- 分布式训练优化:大规模架构需要高效的并行计算和内存优化,如流水线并行、张量并行等。
示例:
- Google 的 Switch Transformer(采用 MoE 架构,部分专家激活,提高计算效率)
- DeepMind 的 GLaM(Gated MoE 架构,可扩展计算)
VLM 更关注 模型参数规模,通常指参数量达到百亿、千亿甚至万亿级别的 AI 模型。这类模型的特点包括:
- 大规模参数:模型参数量极大,如 GPT-4(数万亿参数)或 Gemini-1.5(多万亿参数)。
- 大数据训练:VLM 需要使用全球范围的大规模文本、图像、音频等数据进行训练。
- 高计算需求:训练 VLM 需要超大计算集群(TPU/GPU),且推理时也需要高算力支持。
示例:
- GPT-4( OpenAI)
- Gemini 1.5( Google DeepMind)
- Llama 3( Meta)
核心区别总结:
3.VLA 的核心技术
VLA(Very Large Architecture,大型架构)的核心技术主要围绕高效扩展、计算优化和智能推理,以支持超大规模 AI 模型(如 GPT-4、Gemini、Claude)在训练和推理时的高效计算。
3.1 Mixture of Experts(MoE,混合专家)
Mixture of Experts(MoE,混合专家)是一种神经网络架构**,通过多个**专家网络(Experts)协作完成任务,并由一个门控网络(Gating Network)决定激活哪些专家,从而提高计算效率和泛化能力。MoE 的关键特性是稀疏激活(Sparse Activation)——每次推理或训练时,只使用部分专家,而不是整个模型,从而减少计算开销。
MoE 由三部分组成:
- 输入层(Input Layer):接受输入数据,如文本、图像、语音等。
- 专家网络(Experts):多个子网络,每个专家专注于不同的数据特征。
- 门控网络(Gating Network):用于选择最适合当前输入的专家,并分配计算权重。
对于输入 x,MoE 的输出可以表示为:
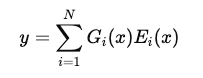
3.1.1 门控策略(Gating Strategies)
门控网络用于选择合适的专家,常见方法包括:
- Softmax 门控:对所有专家计算得分,并通过 softmax 归一化。
- Top-k 门控:仅选择得分最高的 kkk 个专家进行计算(常见于 Switch Transformer)。
- Gated MoE(门控 MoE):使用可训练的门控层,如 GLaM 采用的 gated attention。
3.1.2 稀疏计算(Sparse Computation)
MoE 通过稀疏激活减少计算量,关键方法有:
- Top-k 选择:仅激活部分专家(如 2-4 个),避免所有专家计算,提高效率。
- 负载均衡(Load Balancing):确保不同专家被均匀使用,避免计算不均衡。
3.1.3 训练优化
MoE 由于稀疏性,训练时存在负载不均衡问题,优化策略包括:
- Auxiliary Loss:额外损失项,确保专家负载均衡。
- Routing Regularization:避免部分专家被过度使用,提高泛化能力。
- 数据并行 + 模型并行结合:适配大规模训练框架,如 Tensor Parallelism。
3.1.4 MoE 的优势:
- 计算高效:仅激活部分专家,减少计算需求,相比全参数模型更节省算力。
- 可扩展性强:可以轻松增加专家数量,而不会显著增加计算开销。
- 泛化能力好:不同专家学习不同特征,提高模型适应性。
- 更强性能:MoE 在多个任务上超越传统 Transformer,如 NLP、CV 等领域。
- 示例:
- Switch Transformer(Google):激活少量专家,提高计算效率
- GLaM(Gated MoE)(DeepMind):智能选择专家,提高推理质量
3.2 分布式并行计算(Distributed Parallelism)
分布式并行计算是指在多个计算设备(如 GPU、TPU 或 CPU 集群)上并行执行 AI 模型的训练或推理,以加速计算并支持超大规模模型。
在深度学习中,大规模模型(如 GPT-4、Gemini-1.5、Llama 3)参数量可达数千亿或万亿级,单台计算设备的显存(VRAM)和计算能力无法承载,因此需要分布式并行计算来高效利用计算资源。
分布式计算可以分为数据并行(Data Parallelism, DP)、模型并行(Model Parallelism, MP)和流水线并行(PipelineParallelism, PP)等,此外还有一些混合方法,如 ZeRO 优化。
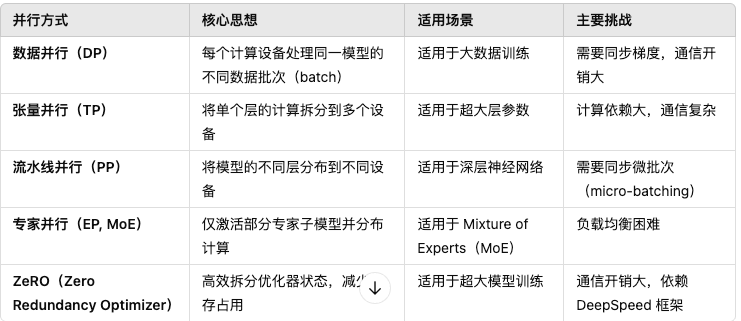
3.2.1 数据并行(Data Parallelism, DP)
核心思想:每个计算设备(GPU/TPU)持有完整的模型副本,但处理不同的数据子集,然后聚合梯度更新参数。
工作流程:
- 每个设备接收不同的数据批次(batch)。
- 计算损失(loss)并计算梯度(gradients)。
- 通过全局梯度同步(AllReduce),计算所有设备的平均梯度。
- 更新模型参数,并同步到所有设备。
优点: 易于实现,框架(如 PyTorch DDP, TensorFlow MirroredStrategy)提供支持。 适用于大数据集训练,不需要拆分模型结构。
缺点: 通信开销大:每次梯度同步需要大量 GPU 间通信,影响扩展性。 显存压力大:每个设备都存完整模型,不能训练超大模型。
优化方法:
- 梯度压缩(Gradient Compression):减少梯度传输的数据量。
- FSDP(Fully Sharded Data Parallel):优化 DP,使其占用更少的显存。
3.2.2 张量并行(Tensor Parallelism, TP)
核心思想:将单个神经网络层的计算拆分到多个设备上,每个设备只计算部分矩阵运算,并进行通信交换数据。
适用于:超大层参数的模型(如 GPT-4、BERT-Large)。
优点: 减少显存占用**,可以训练更大模型。 **减少计算负载,分摊矩阵计算到多个 GPU。
缺点: 通信开销大,多个 GPU 需要频繁交换数据。 适用于特定层结构,不如 DP 泛用性强。
优化方法:
- Megatron-LM:优化 TP 并减少 GPU 之间的通信成本。
- NVIDIA NCCL:用于高效 GPU 间数据交换。
3.2.3 流水线并行(Pipeline Parallelism, PP)
核心思想:将模型的不同层放到不同的设备上,每个设备计算一部分前向和反向传播,形成流水线执行。
适用于:超深层神经网络(如 1000 层 Transformer)。
工作流程:
- 第一个 GPU 计算前几层,并将中间结果传递给下一个 GPU。
- 依次向下传递,直到最后一层计算完毕。
- 反向传播按照相反顺序执行,计算梯度更新。
优点: 减少显存占用**,适用于深层网络。 **更好的计算利用率,减少空闲 GPU 资源。
缺点: 微批次(Micro-batch)问题:必须拆分数据为多个微批次,否则流水线无法充分利用计算资源。 同步问题:不同 GPU 计算速度不同,可能导致计算空转(bubble)。
优化方法:
- GPipe(Google):优化流水线执行,提高吞吐量。
- 1F1B(1 Forward, 1 Backward)策略:减少流水线空转,提高计算效率。
3.2.4 专家并行(Expert Parallelism, MoE)**
核心思想:使用 Mixture of Experts (MoE),让不同 GPU 计算不同的专家网络,只激活部分专家,减少计算负担。
适用于:超大规模 MoE 模型(如 Switch Transformer, GLaM)。
优点: 计算高效,只计算部分专家,减少计算冗余。 适用于 MoE 结构,扩展性强。
缺点: 负载均衡难,部分专家可能被过度使用,影响训练效率。 需要高效的专家分配策略(如 Softmax 门控)。
3.2.5 ZeRO( Zero Redundancy Optimizer)
ZeRO 是 DeepSpeed 提出的优化方法,减少显存占用,使得超大规模模型训练变得可能。
ZeRO 主要包含 3 个阶段:
ZeRO-1:分片优化器状态(Optimizer State Sharding)
ZeRO-2:分片优化器状态 + 梯度(Gradient Sharding)
ZeRO-3:分片优化器状态 + 梯度 + 参数(Parameter Sharding)
优点: 显存占用更低,可以训练 10 倍以上参数 的模型。 适用于超大模型,如 GPT-4、Gemini-1.5。
缺点: 通信开销高,需要高效 GPU 间互联(如 InfiniBand)。
3.3 自监督学习 & 高效训练优化
自监督学习(SSL)是一种无监督学习****方法,模型通过自身生成的伪标签进行训练,无需人工标注数据。SSL 已成为 NLP、CV 以及多模态 AI 领域的核心技术,如 GPT-4、BERT、SimCLR、DINO 等模型都采用了自监督学习进行预训练。
- 自监督学习(Self-Supervised Learning,SSL):VLA 依赖大规模无标注数据进行自监督预训练,比如 BERT、GPT 使用的 Masked Language Model (MLM) 和 Causal Language Model (CLM)。
- 混合精度训练(Mixed Precision Training):采用 FP16/BF16 训练,减少内存占用,提高训练速度。
3.4 多模态融合(Multimodal Fusion)
VLA 关注如何高效处理和融合不同模态(文本、图像、音频、视频等):
- 视觉-语言模型(VLM):结合 Transformer 和 CNN,支持图片+文本输入,如 CLIP、Gemini。
- 跨模态对齐:使用对比学习(Contrastive Learning)对齐不同模态,如 OpenAI 的 CLIP 通过文本-图像对比学习增强理解能力。
- 端到端多模态训练:同时训练不同模态,减少单独训练的开销,提高一致性。
3.5 强化学习与检索增强(RLHF & RAG)
- 强化学习人类反馈(RLHF):如 ChatGPT 采用 RLHF 调优,提高模型输出的对齐性和安全性。
- 检索增强生成(RAG, Retrieval-Augmented Generation):结合外部数据库(如 Wikipedia、私有知识库)进行增强,使模型具有实时信息访问能力。
4.VLA 的主要结构
VLA(Vision-Language-Action)是一类多模态模型,旨在结合视觉(Vision)、语言(Language)和动作(Action)来进行复杂的任务决策,如机器人控制、交互式 AI 以及智能体决策。
VLA 通过融合视觉感知(图像、视频)、语言理解(自然语言指令)和动作规划(强化学习或控制策略)来实现端到端的智能决策。
VLA 通常由以下四个关键模块组成:
- 视觉编码器(Vision Encoder)
- 语言编码器(Language Encoder)
- 跨模态融合(Multi-Modal Fusion)
- 动作生成(Action Decoder / Policy Module)
4.1 视觉编码器
作用:从图像或视频中提取高层次视觉特征,输入格式可以是 RGB 图像、深度图、点云(Point Cloud)等。
常用架构:
- CNN(ResNet, ConvNeXt):用于低级别视觉特征提取。
- Vision Transformer(ViT, Swin Transformer, BEiT):用于全局视觉理解。
- CLIP Vision Encoder:结合大规模文本-图像数据训练,适用于开放世界感知。
4.2 语言编码器
作用:从自然语言输入(如指令、任务描述)中提取文本表征,通常使用 Transformer 结构。
常用架构:
- BERT / RoBERTa:适用于结构化文本理解。
- T5 / GPT 系列:用于文本生成任务。
- CLIP Text Encoder:跨模态对齐的语言编码器。
4.3 跨模态融合
作用:将视觉和语言特征进行融合,以便模型理解多模态信息。
融合方式:

4.4 动作生成
作用:根据融合的多模态信息生成动作,可以是离散动作(分类)或连续动作(回归)。
常见方法:

4.5 典型 VLA 结构示例
以 SayCan(Google DeepMind) 为例,其结构如下:
- 视觉感知:使用 CLIP 提取环境视觉特征。
- 语言理解:使用 PaLM(大语言模型)解析用户指令。
- 跨模态融合:基于 CLIP 计算任务和环境的匹配度。
- 动作决策:结合强化学习选择最佳机器人行动。
4.6 未来优化方向
- 更高效的视觉-语言对齐(如 Video-Text Pretraining)
- 强化多模态记忆(Memory-Augmented Models)
- 自监督学习提升 VLA 训练效率
- 为例,其结构如下:
- 视觉感知:使用 CLIP 提取环境视觉特征。
- 语言理解:使用 PaLM(大语言模型)解析用户指令。
- 跨模态融合:基于 CLIP 计算任务和环境的匹配度。
- 动作决策:结合强化学习选择最佳机器人行动。
4.6 未来优化方向
- 更高效的视觉-语言对齐(如 Video-Text Pretraining)
- 强化多模态记忆(Memory-Augmented Models)
- 自监督学习提升 VLA 训练效率
- 结合 MoE(Mixture of Experts)提升泛化能力
相关文章:

【智驾中的大模型 -3】VLA 在自动驾驶中的应用
1.前言 在上一篇文章中,我们深入探讨了 VLM 模型在自动驾驶中的应用。VLA(Very Large Architecture,大型架构)和 VLM(Very Large Model,非常大模型)在 AI 领域皆指向超大规模的神经网络模型&am…...

Go语言中的sync.Map与并发安全数据结构完全指南
1. 引言 在Go语言的世界里,并发不是一个附加功能,而是语言的核心设计理念。那句广为人知的"Do not communicate by sharing memory; instead, share memory by communicating"(不要通过共享内存来通信,而应该通过通信来…...

ADVB协议
ADVB:航空数字视频总线 ADVB协议是基于FC光纤通道协议和FC-AV光纤音频视频协议标准来制定 的一种新型的数字视频接口和协议。 FC协议,FC-AV协议,FC-ADVB协议。 协议层次结构,协议拓扑结构。 ADVB总线协议container容器是作为基本传输单元…...

Vue3中provide和inject数据修改规则
在 Vue3 中,通过 inject 接收到的数据是否可以直接修改,取决于 provide 提供的值的类型和响应式处理方式: 1. 若提供的是普通值(非响应式数据) javascript 复制 // 父组件 provide(staticValue, 123); 子组件修改行…...

VuePress 使用教程:从入门到精通
VuePress 使用教程:从入门到精通 VuePress 是一个以 Vue 驱动的静态网站生成器,它为技术文档和技术博客的编写提供了优雅而高效的解决方案。无论你是个人开发者、团队负责人还是开源项目维护者,VuePress 都能帮助你轻松地创建和管理你的文档…...

Linux操作系统简介:从开源内核到技术生态
一、Linux的起源与核心架构 1. 历史背景与发展 1991年,芬兰赫尔辛基大学学生林纳斯托瓦兹(Linus Torvalds)开发了首个Linux内核。这一开源项目与GNU工具链结合,形成完整的GNU/Linux操作系统。截至2023年,Linux内核贡…...

iOS 应用性能测试工具对比:Xcode Instruments、克魔助手与性能狗
iOS 应用性能测试工具对比:Xcode Instruments、克魔助手与性能狗 在移动应用开发领域,性能优化是确保用户体验流畅、留存率高的关键因素。对于 iOS 开发者而言,选择合适的性能测试工具能够帮助快速定位和解决应用中的性能瓶颈。本文将深入分…...

CentOS 10 /root 目录重新挂载到新分区槽
1 观察 ##观察目录/root 所占的磁盘空间大小 rootbogon:~# du -smh /root/ 1.6G /root/ rootbogon:~# du -smh /* |grep root du: 无法访问 /proc/19146/task/19146/fd/3: 没有那个文件或目录 du: 无法访问 /proc/19146/task/19146/fdinfo/3: 没有那个文件或目录 du: 无法访问…...

【读书笔记·VLSI电路设计方法解密】问题64:什么是芯片的功耗分析
低功耗设计是一种针对VLSI芯片功耗持续攀升问题的设计策略。随着工艺尺寸微缩,单颗芯片可集成更多元件,导致功耗相应增长。更严峻的是,现代芯片工作频率较二十年前大幅提升,而功耗与频率呈正比关系。因此,芯片功耗突破…...

python爬虫复习
requests模块 爬虫的分类 通用爬虫:将一整张页面进行数据采集聚焦爬虫:可以将页面中局部或指定的数据进行采集 聚焦爬虫是需要建立在通用的基础上来实现 功能爬虫:基于selenium实现的浏览器自动化的操作分布式爬虫:使用分布式机群…...

深入解析主流数据库体系架构:从关系型到云原生
数据库是现代信息系统的核心组件,其体系架构设计直接影响性能、扩展性和可靠性。本文将从传统关系型数据库到新兴云原生数据库,系统解析主流数据库的架构特点及适用场景。 目录 一、关系型数据库(RDBMS)架构 典型代表&…...
)
2026《数据结构》考研复习笔记四(第一章)
绪论 前言时间复杂度分析 前言 由于先前笔者花费约一周时间将王道《数据结构》知识点大致过了一遍,圈画下来疑难知识点,有了大致的知识框架,现在的任务就是将知识点逐个理解透彻,并将leetcode刷题与课后刷题相结合。因此此后的过…...

Mysql insert一条数据的详细过程
以下是MySQL在接收到INSERT语句后存储数据的详细过程解析,结合存储引擎(以InnoDB为例)和物理存储机制分步说明。 一、SQL解析与事务启动 1.语法解析 MySQL首先解析INSERT语句,验证字段是否存在、数据类型是否匹配、约束…...
)
流水灯右移程序(STC89C52单片机)
#include <reg52.h> sbit ADDR0 P1^0; sbit ADDR1 P1^1; sbit ADDR2 P1^2; sbit ADDR3 P1^3; sbit ENLED P1^4; void main() { unsigned int i 0; //定义循环变量i,用于软件延时 unsigned char cnt 0; //定义计数变量cnt,用…...

AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B专属管家大模型
环境: AI-Sphere-Butler WSL2 英伟达4070ti 12G Win10 Ubuntu22.04 Qwen2.-1.5B/3B Llama factory llama.cpp 问题描述: AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B管家大模型 解决方案: 一、准备数据集我这…...
)
智能体团队 (Agent Team)
概述 智能体团队是一种多智能体协作模式,它将多个智能体组织成一个团队,共同解决复杂任务。与智能体监督模式不同,智能体团队中的成员通常具有平等的地位,通过相互交流和协作来达成目标。这种模式特别适合需要多种观点或多领域专…...

AI日报 - 2025年04月19日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | OpenAI与Google模型在复杂推理上展现潜力,但距AGI仍有距离;因果AI被视为关键路径。 模型如o3解决复杂迷宫,o4-mini通过棋盘测试,但专家预测AGI仍需30年。 ▎…...
)
【实战中提升自己】内网安全部署之dot1x部署 本地与集成AD域的主流方式(附带MAC认证)
1 dot1x部署【用户名密码认证,也可以解决私接无线AP等功能】 说明:如果一个网络需要通过用户名认证才能访问内网,而认证失败只能访问外网与服务器,可以部署dot1x功能。它能实现的效果是,当内部用户输入正常的…...
)
算法—合并排序—js(场景:大数据且需稳定性)
合并排序基本思想(稳定且高效) 将数组递归拆分为最小单元,合并两个有序数组。 特点: 时间复杂度:O(n log n) 空间复杂度:O(n) 稳定排序 // 合并排序-分解 function mergeSort(arr) {if (arr.length < …...

绝对路径与相对路径
绝对路径和相对路径是在计算机系统中用于定位文件或目录的两种方式,以下是具体介绍: 绝对路径 • 定义:是从文件系统的根目录开始到目标文件或目录的完整路径,它包含了从根目录到目标位置的所有目录和子目录信息,具有…...

RabbitMQ,添加用户时,出现Erlang cookie不一致,导致添加用户失败的问题解决
1. 问题现象 RabbitMQ 添加用户,出现以下报错 ./rabbitmgctl add user admin admin666*2. 问题原因和解决方法 安装的 RabbitMQ 里的 Erlang cookie,和 Erlang 环境的 cookie 不一致导致的 解决方法:将 Erlang 环境的 cookie ,…...

阿拉丁神灯-第16届蓝桥第4次STEMA测评Scratch真题第2题
[导读]:超平老师的《Scratch蓝桥杯真题解析100讲》已经全部完成,后续会不定期解读蓝桥真题,这是Scratch蓝桥真题解析第219讲。 第16届蓝桥第4次STEMA测评已于2025年1月12日落下帷幕,编程题一共有5题(初级组只有前4道编…...

常用的验证验证 onnxruntime-gpu安装的命令
#工作记录 我们经常会遇到明明安装了onnxruntime-gpu或onnxruntime后,无法正常使用的情况。 一、强制重新安装 onnxruntime-gpu 及其依赖 # 强制重新安装 onnxruntime-gpu 及其依赖 pip install --force-reinstall --no-cache-dir onnxruntime-gpu1.18.0 --extra…...

docker配置skywalking 监控springcloud应用
在使用 Docker 配置 SkyWalking 监控 Spring Cloud 应用时,主要分为以下几个步骤: 1. 准备工作 确保你的开发环境已经安装了 Docker 和 Docker Compose。准备好 Spring Cloud 应用代码,并确保它支持 SkyWalking 的探针(Agent&…...

HBase安装与基本操作指南
## 1. 安装准备 首先确保您的系统已经安装了以下组件: - Java JDK 8或更高版本 - Hadoop(HBase可以运行在独立模式下,但建议配合Hadoop使用) ## 2. 下载与安装HBase ```bash # 下载HBase(以2.4.12版本为例) wget https://downloads.apache.org/hbase/2.4.12/hbase-2…...

【Linux】Rhcsa复习5
一、Linux文件系统权限 1、文件的一般权限 文件权限针对三类对象进行定义: owner 属主,缩写u group 属组, 缩写g other 其他,缩写o 每个文件针对每类访问者定义了三种主要权限: r:read 读 w&…...

C++11特性补充
目录 lambda表达式 定义 捕捉的方式 可变模板参数 递归函数方式展开参数包 数组展开参数包 移动构造和移动赋值 包装器 绑定bind 智能指针 RAII auto_ptr unique_ptr shared_ptr 循环引用 weak_ptr 补充 总结 特殊类的设计 不能被拷贝的类 只能在堆上创建…...

缓存 --- Redis性能瓶颈和大Key问题
缓存 --- Redis性能瓶颈和大Key问题 内存瓶颈网络瓶颈CPU 瓶颈持久化瓶颈大key问题优化方案 Redis 是一个高性能的内存数据库,但在实际使用中,可能会在内存、网络、CPU、持久化、大键值对等方面遇到性能瓶颈。下面从这些方面详细分析 Redis 的性能瓶颈&a…...
)
css3新特性第三章(文本属性)
一、文本属性 文本阴影文本换行文本溢出文本修饰文本描边 1.1 文本阴影 在 CSS3 中,我们可以使用 text-shadow 属性给文本添加阴影。 语法: text-shadow: h-shadow v-shadow blur color; 值描述h-shadow必需写,水平阴影的位置。允许负值。…...

Redis 缓存—处理高并发问题
Redis的布隆过滤器、单线程架构、双写一致性、比较穿透、击穿及雪崩、缓存更新方案及分布式锁。 1 布隆过滤器 是一种高效的概率型数据结构,用于判断元素是否存在。主要用于防止缓存穿透,通过拦截不存在的数据查询,避免击穿数据库。 原理&…...

嵌入式芯片中的 SRAM 内容细讲
什么是 RAM? RAM 指的是“随机存取”,意思是存储单元都可以在相同的时间内被读写,和“顺序访问”(如磁带)相对。 RAM 不等于 DRAM,而是一类统称,包括 SRAM 和 DRAM 两种主要类型。 静态随机存…...

实操基于MCP驱动的 Agentic RAG:智能调度向量召回或者网络检索
我们展示了一个由 MCP 驱动的 Agentic RAG,它会搜索向量数据库,当然如果有需要他会自行进行网络搜索。 为了构建这个系统,我们将使用以下工具: 博查搜索 用于大规模抓取网络数据。作为Faiss向量数据库。Cursor 作为 MCP 客户端。…...

位运算---总结
位运算 基础 1. & 运算符 : 有 0 就是 0 2. | 运算符 : 有 1 就是 1 3. ^ 运算符 : 相同为0 相异为1 and 无进位相加位运算的优选级 不用在意优先级,能加括号就加括号给一个数 n ,确定它的二进制位中第 x 位是 0 还是 1? 规定: 题中所说的第x位指:int 在32位机器下4个…...

从0开始搭建一套工具函数库,发布npm,支持commonjs模块es模块和script引入使用
文章目录 文章目标技术选型工程搭建1. 初始化项目2. 安装开发依赖3. 项目结构4. 配置文件tsconfig.json.eslintrc.jseslint.config.prettierrc.jsrollup.config.cjs创建 .gitignore文件 设置 Git 钩子创建示例工具函数8. 版本管理和发布9 工具函数测试方案1. 安装测试依赖2. 配…...

精通 Spring Cache + Redis:避坑指南与最佳实践
Spring Cache 以其优雅的注解方式,极大地简化了 Java 应用中缓存逻辑的实现。结合高性能的内存数据库 Redis,我们可以轻松构建出响应迅速、扩展性强的应用程序。然而,在享受便捷的同时,一些常见的“坑”和被忽视的最佳实践可能会悄…...

DSP28335入门学习——第一节:工程项目创建
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.20 DSP28335开发板学习——第一节:工程项目创建 前言开发板说明引用解答…...
)
Docker Registry(镜像仓库)
官方架构 Docker 使用客户端 - 服务器 (C/S) 架构模式,使用远程 API 来管理和创建 Docker 容器。Docker 容器通过 Docker 镜像来创建。 Docker 仓库(Registry):Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hu…...

通过Dify快速搭建本地AI智能体开发平台
1. 安装Docker Desktop 访问 Docker官网 点击Download Docker Desktop,直接按照官方要求来就可以。 # 这串命令就像魔法咒语,在黑色窗口(命令提示符)里输入就能检查安装是否成功 docker --version2.安装dify 3.运行 Ollama 大…...
计算机视觉与深度学习 | Transformer原理,公式,代码,应用
Transformer 详解 Transformer 是 Google 在 2017 年提出的基于自注意力机制的深度学习模型,彻底改变了序列建模的范式,解决了 RNN 和 LSTM 在长距离依赖和并行计算上的局限性。以下是其原理、公式、代码和应用的详细解析。 一、原理 核心架构 Transformer 由 编码器(Encod…...

skywalking agent 关联docker镜像
Apache SkyWalking 提供了多种方式来部署和使用 SkyWalking Agent,包括在 Docker 容器中运行的应用。虽然 SkyWalking Agent 本身不是一个独立的 Docker 镜像,但你可以通过几种方式将 SkyWalking Agent 集成到你的 Docker 应用中。 方式一:手…...

【中间件】nginx将请求负载均衡转发给网关,网关再将请求转发给对应服务
一、场景 前端将请求发送给nginx,nginx将请求再转发给网关,网关再将请求转发至对应服务。由于网关会部署在多台服务器上,因此nginx需要负载均衡给网关发请求。nginx所有配置均参照官方文档nginx开发文档,可参考负载均衡板块内容 二…...
:什么是 Milvus)
Milvus(1):什么是 Milvus
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅…...

第十六节:高频开放题-React与Vue设计哲学差异
响应式原理(Proxy vs 虚拟DOM) 组合式API vs Hooks React 与 Vue 设计哲学差异深度解析 一、响应式原理的底层实现差异 1. Vue 的响应式模型(Proxy/数据劫持) Vue 的响应式系统通过 数据劫持 实现自动依赖追踪: • …...

【Hot100】 240. 搜索二维矩阵 II
目录 引言搜索二维矩阵 II我的解题贪心求解解题思路详解搜索策略(以从右上角开始为例)为什么这种方法有效? 完整代码实现复杂度分析示例演示 🙋♂️ 作者:海码007📜 专栏:算法专栏Ὂ…...

每日面试实录·携程·社招·JAVA
📍面试公司:携程 👜面试岗位:后端开发工程师(社招) 🕐面试时长:约 50 分钟 🔄面试轮次:第 1 轮技术面 ✨面试整体节奏: 这场携程的社招 Java 一面…...

Oracle--用户管理
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 用户管理在 Oracle 数据库中至关重要。一个服务器通常只运行一个 Oracle 实例,而一个 Oracle 用户代表一个用户群,他们通过该用…...

20.3 使用技巧5
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 20.3.8 CellContentClick事件 当增加新按钮列或者超链接列后,按钮或者超链接,会发现,按钮或者超链…...
)
Kubernetes相关的名词解释Metrics Server组件(7)
什么是Metrics Server? Metrics Server 是 Kubernetes 集群中的一个关键组件,主要用于资源监控和自动扩缩容。 kubernetes 从1.8版本开始不再集成cadvisor,也废弃了heapster,使用metrics server来提供metrics。那么...... 什么…...

17.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--SonarQube部署与配置
在将孢子记账系统从单体架构转向微服务架构的过程中,代码质量的管理变得尤为重要。随着项目规模的扩大和团队协作的深入,我们需要一个强大的工具来帮助我们持续监控和改进代码质量。我们首选SonarQube,它能够帮助我们识别代码中的潜在问题、技…...

计算机是如何看待数据的?
一、计算机如何“看待”数据? 物理层本质: 计算机的所有数据最终以二进制(0和1)在电路中表示(高电平1,低电平0)。 无论你用何种进制描述数据(如十六进制 0xA1 或十进制 161…...