深度解析算法之前缀和
25.【模版】一维前缀和
题目链接
描述

输入描述

输出描述
输出q行,每行代表一次查询的结果.
示例
输入:
3 2
1 2 4
1 2
2 3
复制
输出:
3
6
这个题的话就是下面的样子,我们第一行输入 3 2的意思即是这个数组是3个元素大小的数组,2是接下来我们是需要输入两行数据下标的
然后第二行我们输入的n个整数表示的就是我们数组中的元素
然后后面的2行就是我们想计算数组中从哪里到哪里的和
这里的话我们是第一个数到第二个数的和,那么我们这里的就是3了
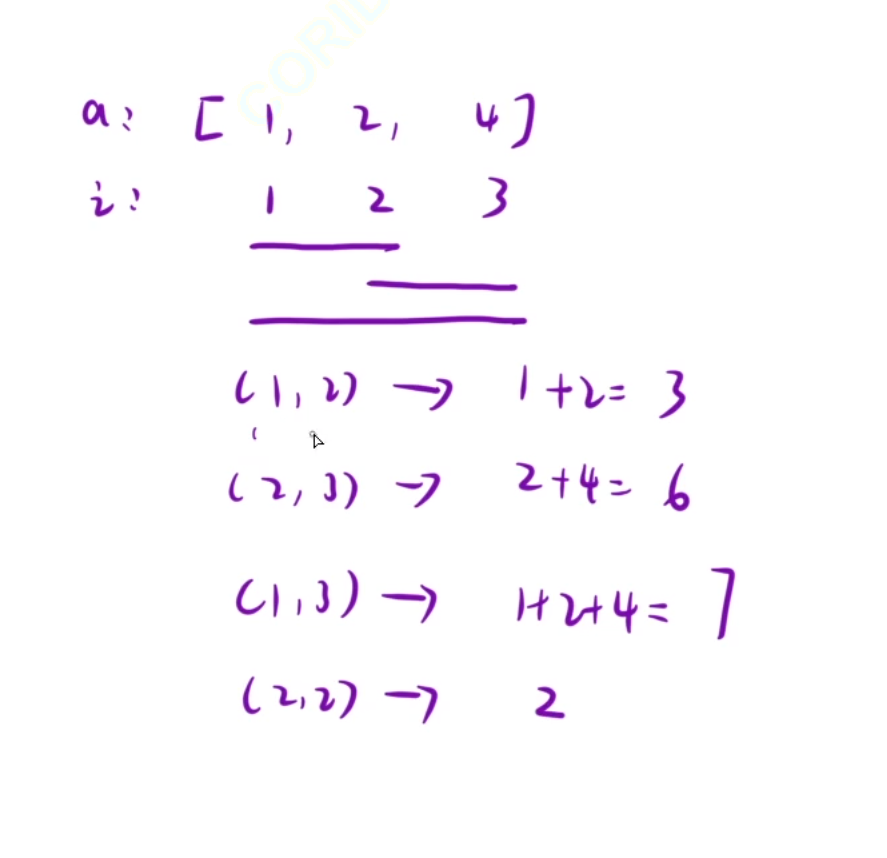
如果我们使用暴力解法解决这个题的话,那么我们的时间复杂度会超的
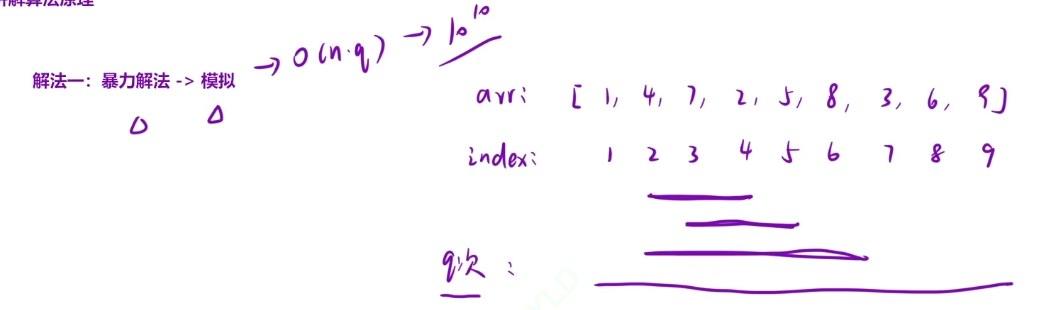
所以我们这里需要使用算法:前缀和,这个算法可以快速得出我们的某一段区间之和的大小的,我们这个算法的时间复杂度只需要O(1)
我们第一步:预处理出来一个前缀和数组dp
dp[i]表示:表示[1,i]区间内所有的元素的和
dp[3]就表示的是这个位置存放的时候我们数组第一个元素到第三个元素的和
dp[3]=dp[2]+arr[3],因为我们现在要求前三个位置的和,我们的dp[2]已经求出来了,那么我们直接加上第三个数就行了
dp[i]=dp[i-1]+arr[i]
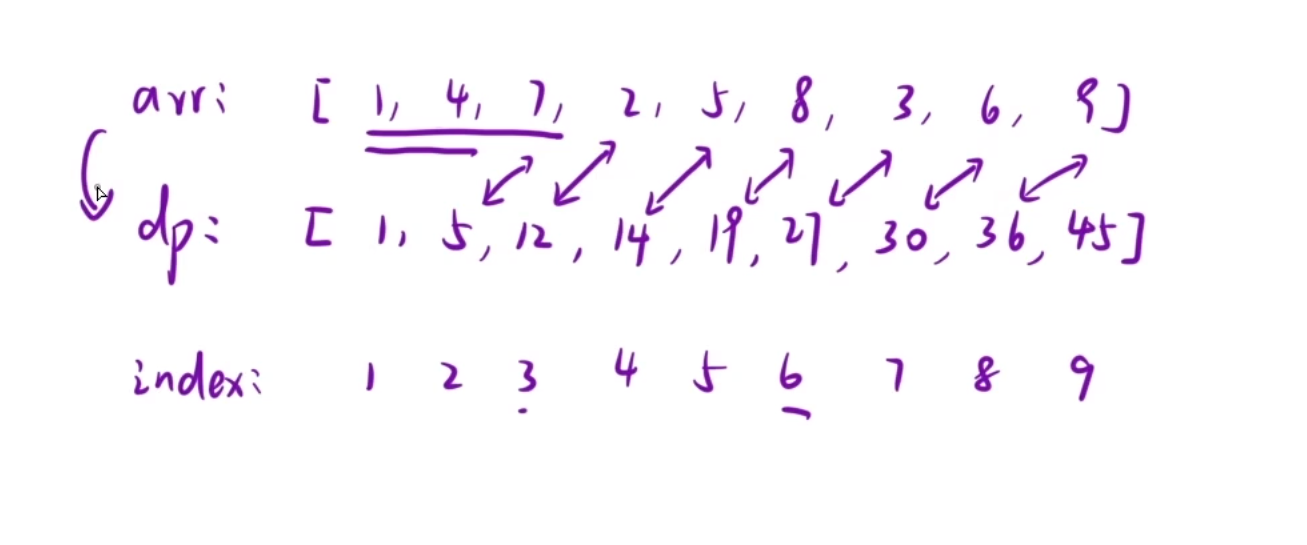
那么现在我们已经处理出来了一个前缀和数组
那么现在我们就需要使用我们前缀和数组了
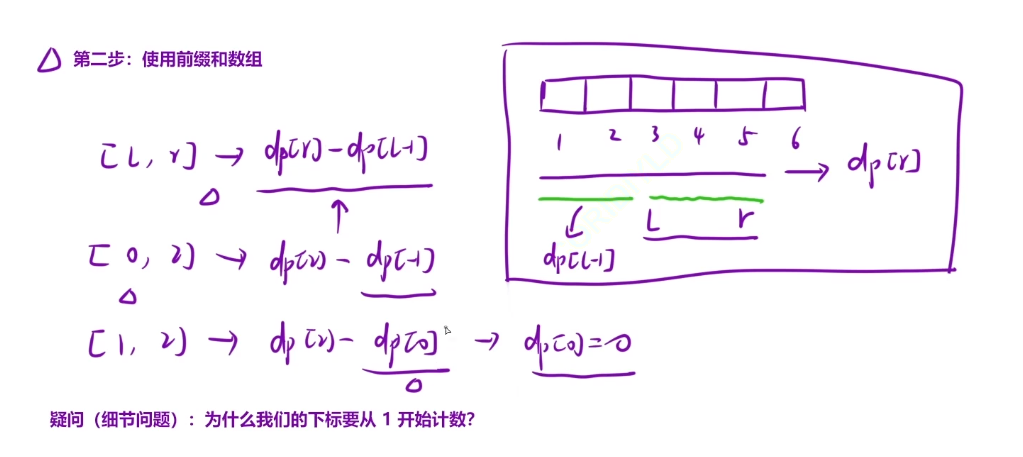
现在如果我们需要算出3到5区间的和,那么我们可以先求出1-5区间的和,然后再算出1-2区间的和,再由前者减去后者,就得到了我们的要的结果了
那么我们现在需要求出[l,r]区间的大小,那么我们可以推理出,这段区间的大小等于 dp[r]-dp[l-1]
疑问:为什么我们的dp下标从1开始计数
假设我们想求出[0,2]区间的大小的话,那么利用dp我们就得到==dp[2]-dp[-1]
==很明显这个越界了
但是如果我们从1开始的话,那么最终结果是不会被干扰的,一切是正常的
之所以这么设置的话就是为了处理边界情况
#include <iostream>#include<vector>using namespace std;int main(){//1.读入数据int n,q;cin>>n>>q;vector<int> arr(n+1);for(int i=1;i<=n;i++) cin >>arr[i];//将我们输入的数据填入进去//2.预处理出来一个前缀和数组vector<long long> dp(n+1);//设置为long long 防止移除的问题for(int i=1;i<=n;i++) dp[i]=dp[i-1]+arr[i];//3.使用前缀合数组int l=0,r=0;while(q--){cin>>l>>r;//读入cout<<dp[r]-dp[l-1]<<endl;//将我们这个区间的和输出}return 0;}
26.【模版】二维前缀和
题目链接
描述
给你一个 n 行 m 列的矩阵 A ,下标从1开始。
接下来有 q 次查询,每次查询输入 4 个参数 x1 , y1 , x2 , y2
请输出以 (x1, y1) 为左上角 , (x2,y2) 为右下角的子矩阵的和,
**输入描述:
第一行包含三个整数n,m,q.
接下来n行,每行m个整数,代表矩阵的元素
接下来q行,每行4个整数x1, y1, x2, y2,分别代表这次查询的参数
1≤n,m≤10001≤n,m≤1000
1≤q≤1051≤q≤105
−109≤a[i][j]≤109−109≤a[i][j]≤109
1≤x1≤x2≤n1≤x1≤x2≤n
1≤y1≤y2≤m1≤y1≤y2≤m
**输出描述:
输出q行,每行表示查询结果。
**示例1
输入:
3 4 3
1 2 3 4
3 2 1 0
1 5 7 8
1 1 2 2
1 1 3 3
1 2 3 4输出:8
25
32
我们输入3 4 3第一个三就是三行,四就是四列,第二个三就是三次询问
我们这里输入的下面三行的数据就是我们想要求和区间的坐标
(1,1)~(2,2)->1+2+3+2=8
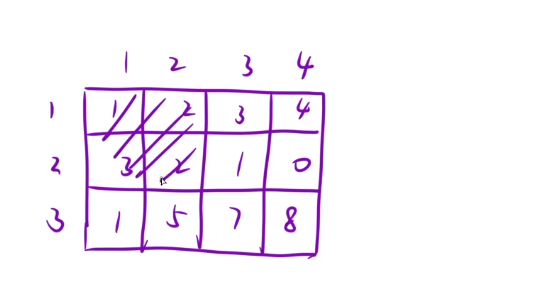
(1,1)~(3,3)->1+2+3+3+2+1+1+2+7= 25
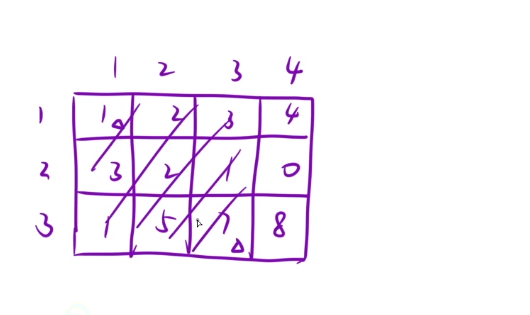
(1,2)~(3,4)->2+3+4+2+1+0+5+7+8=32
我们这里依旧使用前缀和进行问题的解决
1.预处理出来一个前缀和矩阵
重新创建一个矩阵,这个矩阵的规模和之前矩阵的规模一样
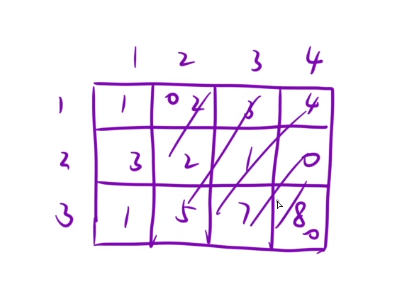
dp [i] [j]表示的是从(1,1)到位置[i,j]位置,这段区间里面所有元素的和
我们得先想一个方法快速求出这个dp的值是多少
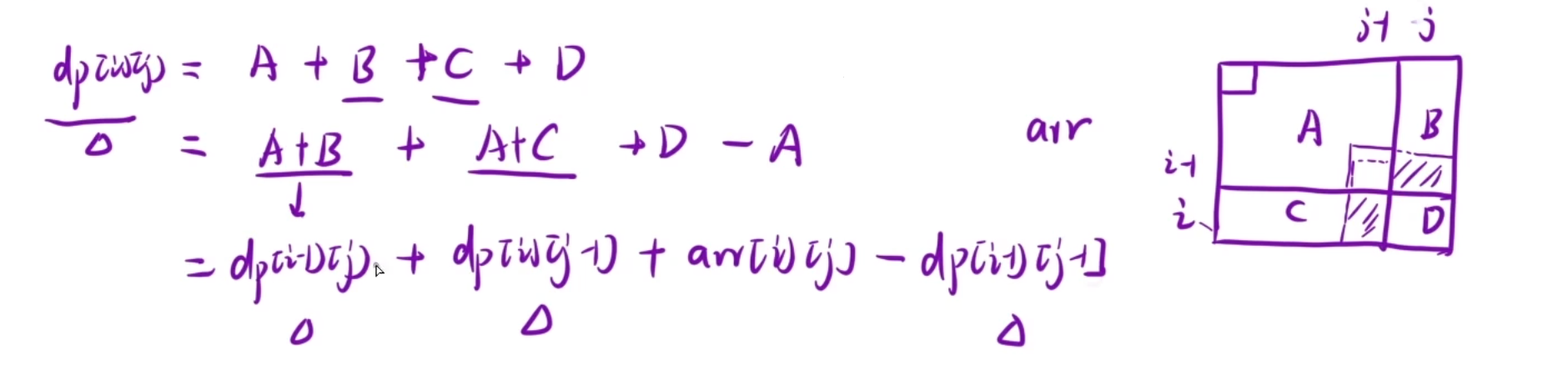
dp [i] [j] =A+B+C+D =A+B +A+C +D -A =dp [i-1] [j] +dp[i] [j-1] +arr[i] [j]-dp [i-1] [j-1]
2.使用前缀和矩阵
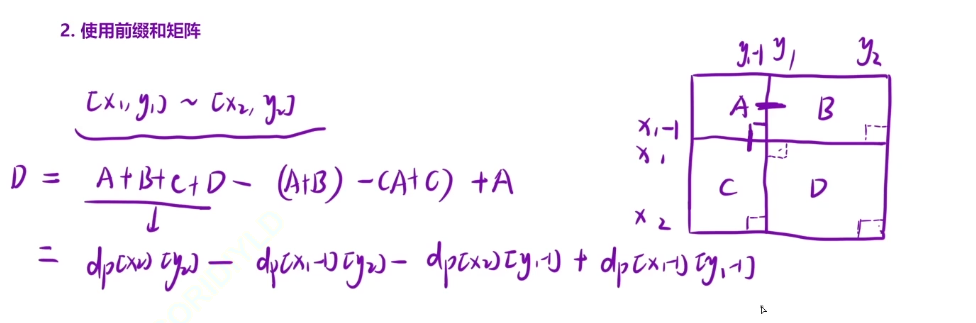
最后的面积等于
dp[x2] [y2]-dp[x1-1] [y2]- dp[x2] [y1-1] +dp[x1-1] [y1-1]
#include <iostream>#include<vector>using namespace std;int main(){//1.先读入数据int n=0,m=0,q=0;cin>>n>>m>>q;vector<vector<int>>arr(n+1,vector<int>(m+1));//n+1行,m+1列for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){cin>>arr[i][j];//将我们输入的数据放到数组中去}}//2.预处理前缀和矩阵vector<vector<long long >>dp(n+1,vector<long long>(m+1));//n+1行,m+1列,long long防止溢出for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){dp[i][j]=dp[i-1][j]+dp[i][j-1]+arr[i][j]-dp[i-1][j-1];}}//使用前缀和矩阵int x1=0,y1=0,x2=0,y2=0;while(q--){cin>>x1>>y1>>x2>>y2;cout<<dp[x2][y2]-dp[x1-1][y2]-dp[x2][y1-1]+dp[x1-1][y1-1]<<endl;}return 0;}
27.寻找数组的中心下标
题目链接
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入: nums = [1, 7, 3, 6, 5, 6]
输出: 3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:
输入: nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
示例 3:
输入: nums = [2, 1, -1]
输出: 0
解释:
中心下标是 0 。
左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
利用前缀和解决这个问题
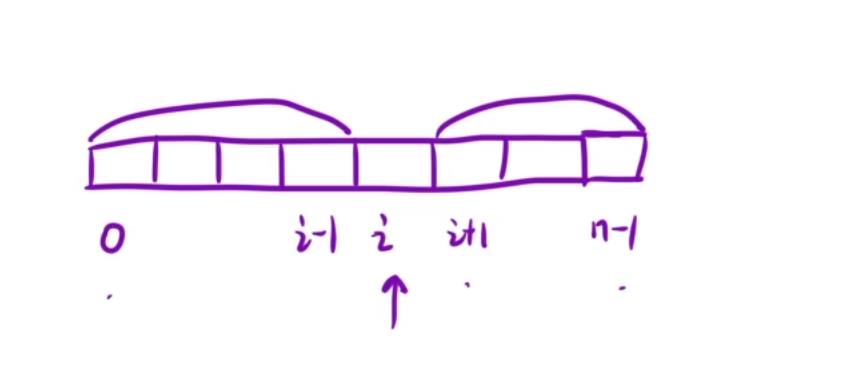
我们利用前缀和的方式将i的前缀和和后缀和都求出来,来进行比较
预处理:
f:前缀和数组:f[i]表示:[0,i-1]区间,所有元素的和
f[i]=f[i-1]+nums[i-1]
g:后缀和数组:g[i]表示[i+1,n-1]区间,所有元素的和
g[i]=g[i+1]+nums[i+1]
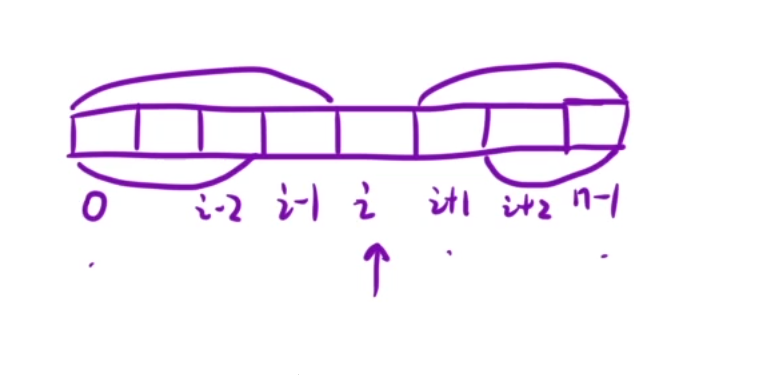
如何使用
我们枚举出0~n-1中所有的下标,然后带进去
细节问题,当我们将f[0]带进去的话是会出现问题的,会出现越界的情况,
g[n-1]这个位置也会出现问题
我们两个边界问题得提前处理下
class Solution {public:int pivotIndex(vector<int>& nums){int n=nums.size();vector<int>f(n),g(n);//一个是前缀和数组,一个是后缀和数组//这里我们已经将f(n)、g(n)初始化为0了,避免边界问题//1.预处理前缀和数组以及后缀和数组for(int i=1;i<n;i++){f[i]=f[i-1]+nums[i-1];}for(int i=n-2;i>=0;i--){g[i]=g[i+1]+nums[i+1];}//2.使用,枚举所有的中心下标for(int i=0;i<n;i++){if(f[i]==g[i]) return i;}//整个循环下来没有返回的话就是说明没有找到return -1;}};
先预处理前缀和数组以及后缀和数组,然后再枚举所有的可能进行判断
28.除自身以外数组的乘积
题目链接
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法, 且在 O(n) 时间复杂度内完成此题。
示例 1:
输入: nums = [1,2,3,4]
输出: [24,12,8,6]
示例 2:
输入: nums = [-1,1,0,-3,3]
输出: [0,0,9,0,0]
我们想计算i位置除自身外的乘积,那么我们分别把前面的i-10位置的和i+1n-1位置的乘积之和计算出来。
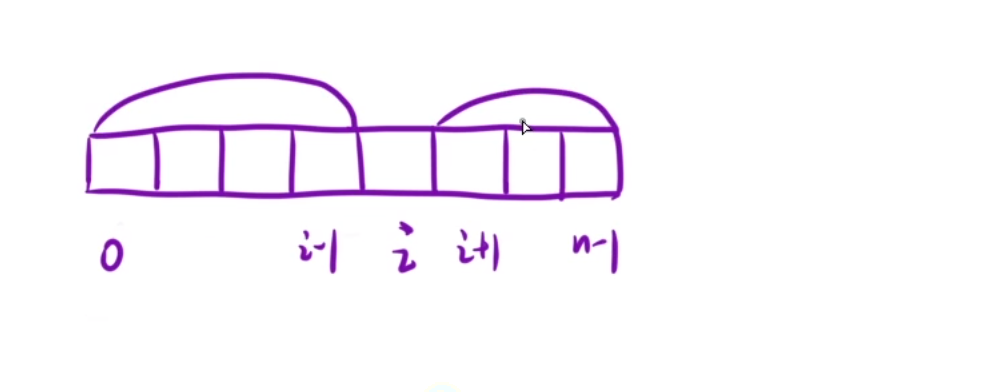
预处理前缀积和后缀积
f:表示前缀积
f[i]表示:[0,i-1]区间内所有元素的乘积
f[i]=f[i-1] * nums[i-1]
g:表示后缀积
g[i]=g[i+1]* nums[i+1]
使用,我们直接return f[i]* g[i]就行了
处理细节问题
f[o]和g[n-1],我们这里需要将这两个设置为1,避免越界问题
class Solution {public:vector<int> productExceptSelf(vector<int>& nums){int n=nums.size();vector<int>f(n),g(n);//1.预处理前缀积数组和后缀积数组f[0]=g[n-1]=1;//细节问题for(int i=1;i<n;i++){f[i]=f[i-1]*nums[i-1];}for(int i=n-2;i>=0;i--){g[i]=g[i+1]*nums[i+1];}//使用前缀积数组和后缀积数组vector<int>ret(n);for(int i=0;i<n;i++){ret[i]=f[i]*g[i];}return ret;}};
29.和为 K 的子数组
题目链接
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
输入: nums = [1,1,1], k = 2
输出: 2
示例 2:
输入: nums = [1,2,3], k = 3
输出: 2
这个题是不能使用双指针滑动窗口做优化的

我们只需要找到i位置前面,就是[0,i-1]位置中间,有多少个前缀和等用户sum[i]-k的
我们利用哈希表记录我们前缀和出现的次数
细节问题
前缀和加入哈希表的时机,在计算i位置之前,哈希表里面只保存[0,i-1]位置的前缀和,当我们计算玩i位置之后的,我们再将这个丢到哈希表里面去
我们 不用真的创建一个真的前缀和数组,我们只需要用一个变量sum来标记前一个位置的前缀和即可
如果整个前缀和等于k呢?那我们按照我们上面的逻辑的话,是不是要到[0,-1]这个区间去找呢?
这个区间很明显是违法了的,不存在
所以我们在创建哈希表的时候,我们需要将hash[0]=1丢到哈希表中
如果整个数组等于k的话,那么我们最后返回的结果就是1
class Solution {public:int subarraySum(vector<int>& nums, int k){unordered_map<int,int>hash;//统计前缀和出现的次数hash[0]=1;int sum=0,ret=0;//sum用来标记我们的前缀和for(auto x:nums){sum+=x;//记录当前位置的前缀和//寻找当前位置之前一共有多少个sum-k//如果我们当前位置前面存在sum-k的话,那么我们就记录我们此时sum-k出现的次数if(hash.count(sum-k))ret+=hash[sum-k];//统计sum-k出现次数并惊醒统计操作hash[sum]++;//将当前的前缀和 sum 出现次数加一,更新哈希表。} return ret;}};//该算法的时间复杂度是 O(n),其中 n 是数组的长度。因为我们只遍历一次数组,且每次查找哈希表中的值和插入新值的操作时间复杂度为 O(1)。//总结:这是一个高效的解决子数组和为 k 问题的算法,利用哈希表记录前缀和的出现次数,可以在 O(n) 时间内得到答案。
利用哈希表记录我们当前位置前面出现sum-k的次数就能判断我们前缀和为k出现的次数
我们这里只遍历了一次数组,就将每个位置前面sum-k出现的次数都记录下来了
30.和可被 K 整除的子数组
题目链接
给定一个整数数组 nums 和一个整数 k ,返回其中元素之和可被 k 整除的非空 子数组 的数目。
子数组 是数组中 连续 的部分。
示例 1:
输入: nums = [4,5,0,-2,-3,1], k = 5
输出: 7
解释:
有 7 个子数组满足其元素之和可被 k = 5 整除:
[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
示例 2:
输入: nums = [5], k = 9
输出: 0
同余定理
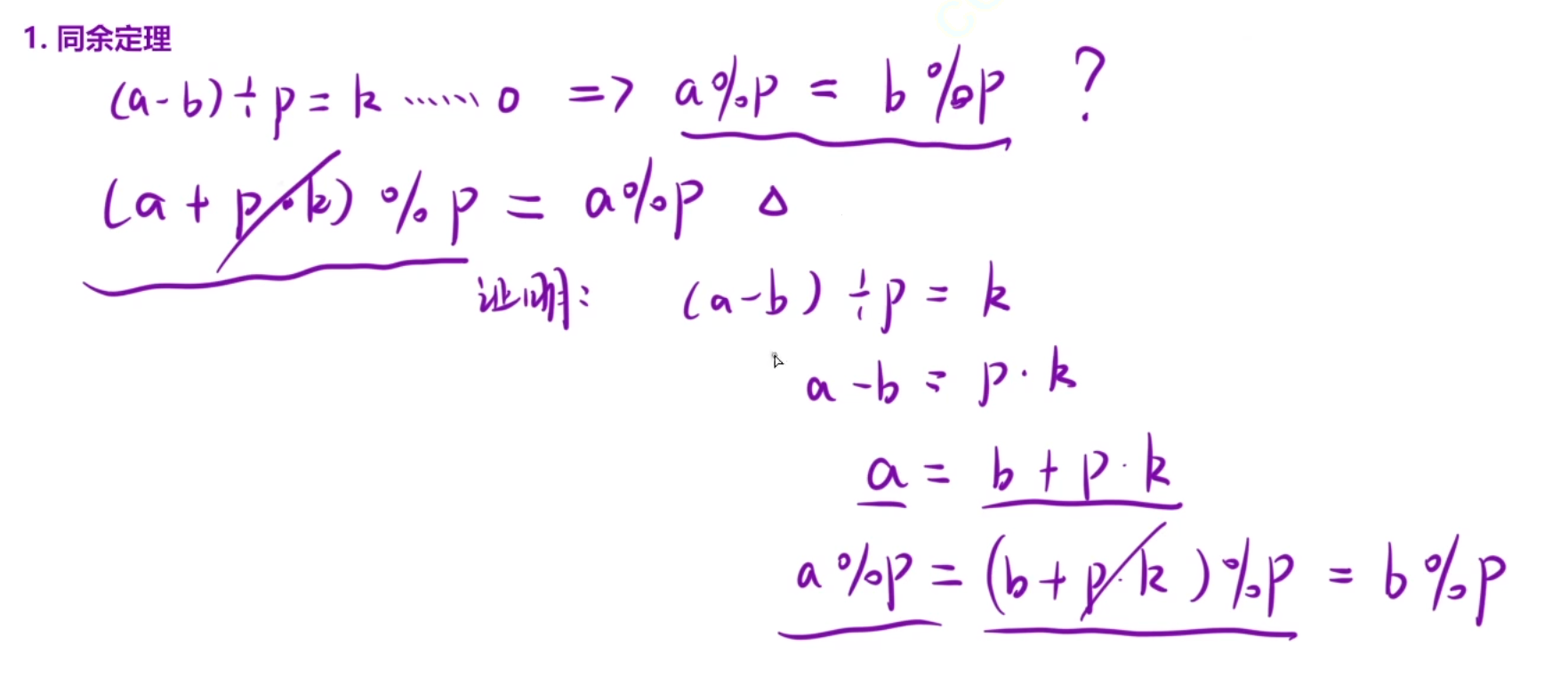
a对p取得余数就等于b对p取的余数,前提是(a-b)除以p=k。。。。0
下面是我们在c++和java中处理负数的情况,
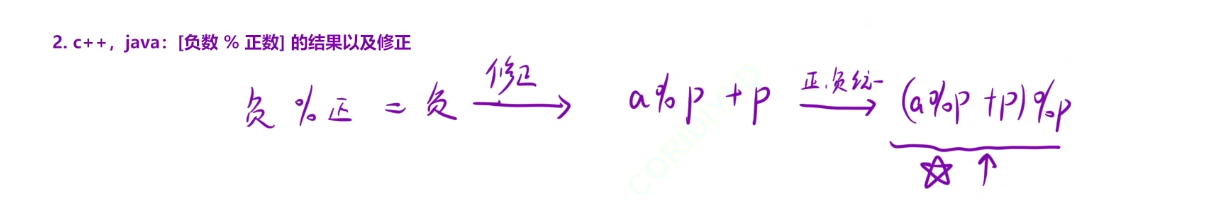
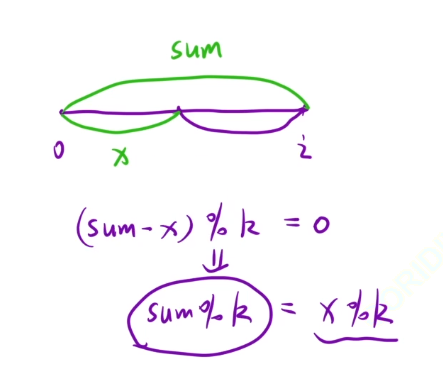
(sum-x)%k=0->sum%k=x%k
就是在[0,i-1]区间内,找到有多少个前缀和的余数等于sum%k
但是这里的话可能是负数,所以我们需要对余数进行修正==(sum%k+k)%k==
所以这个题就是在[0,i-1]区间内,找到有多少个前缀和的余数等于==(sum%k+k)%k==
我们这里不需要存储前缀和,我们存储前缀和的余数就行了
这里我们使用哈希表进行存储
hash<int ,int>左边的int表示的前缀和的余数,右边的int表示的是这个余数出现的次数
class Solution {public:int subarraysDivByK(vector<int>& nums, int k){unordered_map<int,int>hash;hash[0%k]=1;//我们需要将前缀和为0的这个提前进行处理,如果不处理的话后面带入到代码会出错的//这里的0也是余数,0%k=0,余数为0出现的次数,我们这里存的是0这个数的余数int sum=0,ret=0;//使用sum标记当前位置前面的前缀和for(auto x:nums){sum+=x;//算出当前位置的前缀和int r=(sum%k+k)%k;//修正后的余数,对正数、负数都有效的if(hash.count(r)) ret+=hash[r];//统计余数出现的次数hash[r]++;}return ret;}};
-
前缀和:我们计算数组每个位置的前缀和
sum,即sum[i]表示从数组开始到第i个位置的所有元素的和。 -
取余操作:为了找到和为
k的子数组,我们需要通过前缀和的差来判断。具体来说,子数组的和sum[i] - sum[j]能被k整除,即sum[i] % k == sum[j] % k。 -
哈希表:我们使用哈希表(
unordered_map)来存储前缀和对k取余的结果。哈希表的键是余数,值是该余数出现的次数。如果一个余数重复出现,就说明在这两个位置之间存在一个和为k的子数组。 -
处理负数:由于前缀和可能是负数,我们使用
(sum % k + k) % k来确保余数始终为非负数,这样可以正确处理负数的情况。 -
初始条件:我们初始化哈希表
hash[0 % k] = 1,用来处理前缀和从数组开始就能被k整除的情况。 -
sum % k: 这是对sum进行模k运算,得到的结果可能是负数(当sum是负数时)。比如,假设
sum = -3,而k = 5,那么-3 % 5的结果是-3,这是负数。 -
sum % k + k: 这是将得到的负余数加上k,目的是将负数转为正数。继续上面的例子,
-3 + 5 = 2。这时,我们得到了一个正数余数。 -
(sum % k + k) % k: 这一步再对结果进行一次模k运算,确保余数始终在0到k-1之间。虽然前面的加k已经将负数转为正数,但我们还是要确保结果不超过k-1。例如,
(2 % 5) = 2。如果sum % k + k的结果已经在0到k-1范围内,第二次% k操作不会改变结果。
假设sum = -3且k = 5: -
sum % k = -3 % 5 = -3 -
sum % k + k = -3 + 5 = 2 -
(sum % k + k) % k = 2 % 5 = 2
31.连续数组
题目链接
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。
示例 1:
输入: nums = [0,1]
输出: 2
说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。
示例 2:
输入: nums = [0,1,0]
输出: 2
说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。
对于这个数组来说的话,如果我们将上面数组中的0变-1,然后我们在下面数组中进行匹配,1和-1相加,那么结果就是0,那么问题就变成了在数组中找到一个连续的子数组,让这个子数组中的值的和是0就可以了
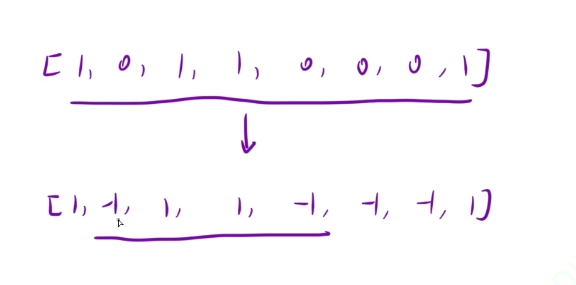

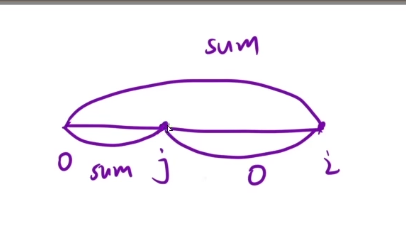
解法:前缀和+哈希表
哈希表中存什么
hash<int,int>,第一个int是前缀和,第二个int存的是下标
什么时候存入哈希表?
使用完之后丢进哈希表
如果有重复的<sum,i>,如何存呢?
只保存前面的那一对<sum,i>
默认的前缀和为0的情况,如何存呢?
我们在之前的话是会进行处理的hash[0]=1
但是这里的话我们存的是下标
我们的处理就是hash[0]=-1
长度怎么算呢?
数组的总长度为sum,我们想找一个子区域和为0,那么这个子区域的前面的前缀和的大小就是sum
长度为i-j
class Solution {public:int findMaxLength(vector<int>& nums){unordered_map<int,int>hash;//我们hash表之中存的是前缀和和下标hash[0]=-1;//此时的下标为-1,默认有一个前缀和为0的情况int sum=0,ret=0;//sum来标记当前位置前面的前缀和for(int i=0;i<nums.size();i++){sum+=nums[i]==0?-1:1;//计算当前位置的前缀和,如果此时我们当前位置的值是0的话,那么我们加的就是-1,否则的话就是1if(hash.count(sum)) ret=max(ret,i-hash[sum]);//找到我们前缀和为sum的位置并且进行更新,只要出现了sum的话,那么我们就进行更新的操作//如果 `sum` 出现过,这意味着从上次出现 `sum` 的位置到当前的位置 `i` 之间,数组的 `0` 和 `1` 数量相等。//这里就是不存在的情况//如果以前不存在sum的话,那么现在的i就是第一个sum的起始下标else hash[sum]=i;}return ret;}};
hash[0] = -1;
这行代码初始化了哈希表,假设在索引 -1 处有一个前缀和为 0。这是为了处理一些特殊情况,比如如果从数组的开头到某个位置的前缀和已经为零,我们可以计算出该段子数组的长度。
sum+=nums[i]== 0?-1:1;
如果我们当前的位置i的数字的大小是0的话,那么我们让这个位置的数变成-1
就是给总和加上了-1
这个就和我们转换的题目对应上了
将数组中原本的0变成-1
如果当前位置的数不是0的话,那么我们就让总和加上1
i - hash[sum]
i是当前的位置,hash[sum]是第一次出现前缀和sum的地方
假设数组是 [0, 1, 0, 1, 0],我们已经将 0 转换为 -1,得到数组 [-1, 1, -1, 1, -1]。
- 遍历过程:
i = 0,sum = -1,hash[-1]没有出现过,存入hash[-1] = 0。i = 1,sum = 0,hash[0]没有出现过,存入hash[0] = 1。i = 2,sum = -1,hash[-1]已经出现,hash[-1] = 0,所以子数组的长度是i - hash[-1] = 2 - 0 = 2,这是一个有效的子数组,包含相同数量的0和1。i = 3,sum = 0,hash[0]已经出现,hash[0] = 1,所以子数组的长度是i - hash[0] = 3 - 1 = 2。i = 4,sum = -1,hash[-1]已经出现,hash[-1] = 0,所以子数组的长度是i - hash[-1] = 4 - 0 = 4,更新ret = 4。
在这里,i - hash[sum]是计算子数组的长度,而不是i - hash[sum] + 1,是因为哈希表中保存的是索引位置,而我们要计算的是子数组的元素个数,而索引是从 0 开始的。
31.矩阵区域和
题目链接
给你一个 m x n 的矩阵 mat 和一个整数 k ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和:
i - k <= r <= i + k,j - k <= c <= j + k且(r, c)在矩阵内。
示例 1:
输入: mat = [[1,2,3],[4,5,6],[7,8,9]], k = 1
输出:[[12,21,16],[27,45,33],[24,39,28]]
示例 2:
输入: mat = [[1,2,3],[4,5,6],[7,8,9]], k = 2
输出:[[45,45,45],[45,45,45],[45,45,45]]
题目要求返回和原始矩阵相同规模的矩阵
在k=1的情况下,以mat数组为基础,我们的answer[0] [0]的大小j就是以mat[ 0] [0]为中心扩展一个格子的区域的总和,如果超出边界,那么超出边界的部分不算,那么我们这里的answer[0] [0]=12
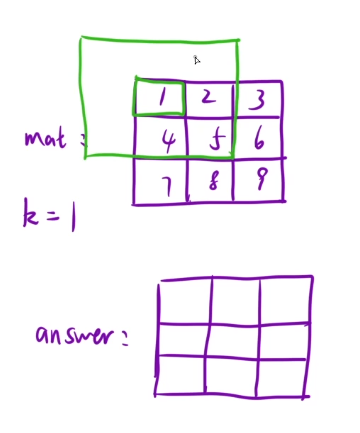
这个题起始就是快速求出某个区域的和,就是在求二维数组前缀和的基础上进行改变
对于右下角区域的和
dp[i] [j] =dp[i-1] [j]+dp[i] [j-1]-dp[i-1] [j-1] +mat[i] [j]
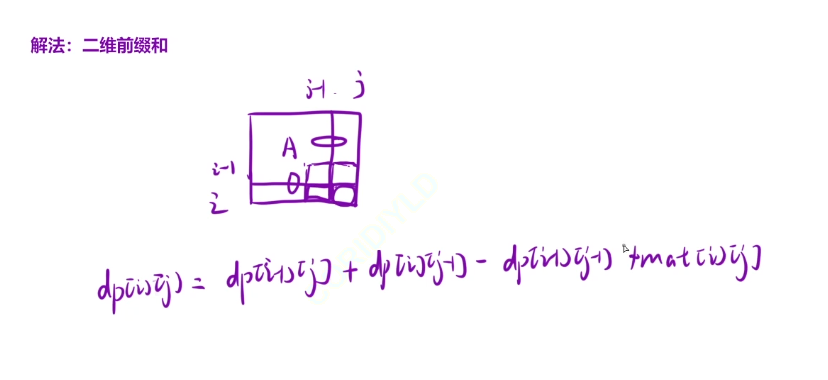
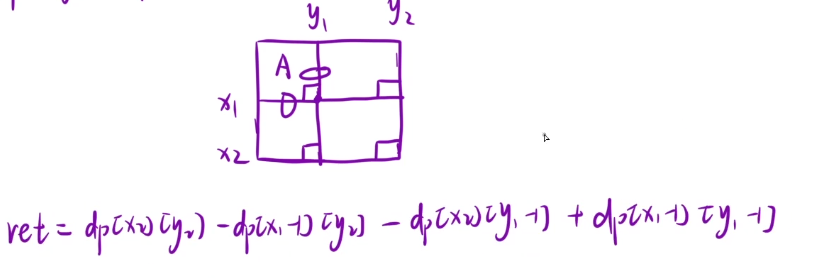
我们在求ans[i] [j]的时候,需要向四周扩展k个单位。如果中间点的坐标是[i] [j]的话,那么左上角的坐标就是[i-k] [j-k] 右下角的坐标是[i+k] [j+k]
如果我们的[i-k]<0的话,那么我们就需要回归到(0,0)这个位置的,因为我们是不能进行越界的
所以我们对左上角的坐标定义为:x1=max(0,i-k),如果i-k小于0的话,那么x1=0,这种就可以处理边界情况,对0处理max就行了
同理我们右下角的一样是可以同样的处理方式
m和n是这个矩阵的长度和宽度
右下角的话可能大于(m-1,n-1),如果x2的坐标大于(m-1,n-1)的话,那么我们直接让x2定义为(m-1,n-1)
那么我们现在求出来中心点右上角和右下角的坐标,那么我们直接带入上面的ret的公式就可以求出我们最终的结果了

下标的映射关系
我们dp表是从(1,1)开始的
如果我们在填dp表的时候我们下标是要-1的
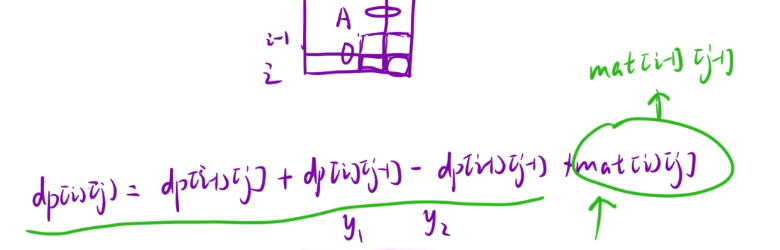
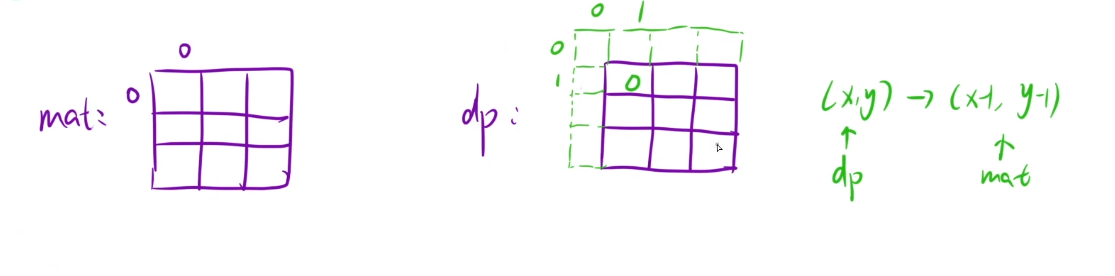
最后我们需要在ans表中使用dp表的时候,我们的坐标是要+1的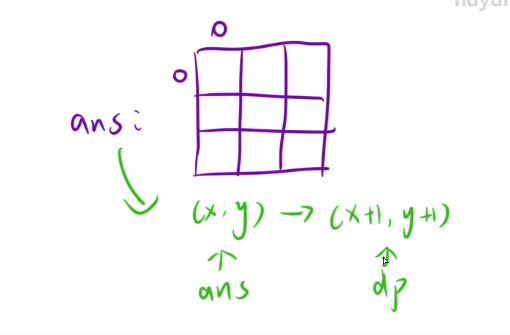
我们在求ans[i] [j]的时候直接在这里的下标处进行+1的操作,因为在ret那里加的话很麻烦的

class Solution {public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k){int m=mat.size(),n=mat[0].size();//先将行和列求出来//预处理一个前缀和矩阵vector<vector<int>>dp(m+1,vector<int>(n+1));//m+1行,n+1列for(int i=1;i<=m;i++){for(int j=1;j<=n;j++){dp[i][j]=dp[i-1][j]+dp[i][j-1]-dp[i-1][j-1]+mat[i-1][j-1];//这里的mat下标是修改过的,因为我们的dp数组从(1,1)位置开始的,我们这里的mat的下标-1是为了处理下标的映射关系的}}//那么到这里的话我们前缀和的数组就搞定了,下面就是使用前缀和的数组了vector<vector<int>>ret(m,vector<int>(n));//最终的结果是和原始的矩阵同等的规模的//我们需要将这个矩阵填上for(int i=0;i<m;i++){for(int j=0;j<n;j++){//我们需要求出当前的(i,j)坐标左上角和右下角的坐标来进行求和//这个是左上角的坐标int x1=max(0,i-k)+1,y1=max(0,j-k)+1;//这里的+1是为了在dp表中找位置的,正好可以在dp表中找到对应的位置int x2=min(m-1,i+k)+1,y2=min(n-1,j+k)+1;//现在我们将当前的(i,j)坐标左上角和右下角的位置都找到了,那么我们直接返回结果了ret[i][j]=dp[x2][y2]-dp[x1-1][y2]-dp[x2][y1-1]+dp[x1-1][y1-1];}}return ret;}};
相关文章:

深度解析算法之前缀和
25.【模版】一维前缀和 题目链接 描述 输入描述 输出描述 输出q行,每行代表一次查询的结果. 示例 输入: 3 2 1 2 4 1 2 2 3 复制 输出: 3 6 这个题的话就是下面的样子,我们第一行输入 3 2的意思即是这个数组是3个元素大小的数组&…...

混合精度训练中的算力浪费分析:FP16/FP8/BF16的隐藏成本
在大模型训练场景中,混合精度训练已成为降低显存占用的标准方案。然而,通过NVIDIA Nsight Compute深度剖析发现,精度转换的隐藏成本可能使理论算力利用率下降40%以上。本文基于真实硬件测试数据,揭示不同精度格式的计算陷阱。…...

6.8 Python定时任务实战:APScheduler+Cron实现每日/每周自动化调度
Python定时任务实战:APScheduler+Cron实现每日/每周自动化调度 实现每日和每周定时任务 关键词:定时任务调度、Python 原生调度器、Cron 脚本、异常重试机制、任务队列管理 1. 定时任务架构设计 采用 分层调度架构 实现灵活的任务管理: #mermaid-svg-PnZcDOgOklVieQ8X {f…...

[Android] 豆包爱学v4.5.0小学到研究生 题目Ai解析
[Android] 豆包爱学 链接:https://pan.xunlei.com/s/VOODT6IclGPsC7leCzDFz521A1?pwdjxd8# 拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关…...

swift-12-Error处理、关联类型、assert、泛型_
一、错误类型 开发过程常见的错误 语法错误(编译报错) 逻辑错误 运行时错误(可能会导致闪退,一般也叫做异常) 2.1 通过结构体 第一步 struct MyError : Errort { var msg: String } 第二步 func divide(_ …...
20250409 - 20250419)
每日定投40刀BTC(14)20250409 - 20250419
定投 坚持 《磨剑篇》浮生多坎壈,志业久盘桓。松柏凌霜易,骅骝涉险难。砺锋临刃缺,淬火取金残。但使精魂在,重开万象端。...
)
【刷题Day20】TCP和UDP(浅)
TCP 和 UDP 有什么区别? TCP提供了可靠、面向连接的传输,适用于需要数据完整性和顺序的场景。 UDP提供了更轻量、面向报文的传输,适用于实时性要求高的场景。 特性TCPUDP连接方式面向连接无连接可靠性提供可靠性,保证数据按顺序…...

大数据建模与评估
文章目录 实战案例:电商用户分群与价值预测核心工具与库总结一、常见数据挖掘模型原理及应用(一)决策树模型(二)随机森林模型(三)支持向量机(SVM)模型(四)K - Means聚类模型(五)K - Nearest Neighbors(KNN)模型二、运用Python机器学习知识实现数据建模与评估(一…...

Python语法系列博客 · 第6期[特殊字符] 文件读写与文本处理基础
上一期小练习解答(第5期回顾) ✅ 练习1:字符串反转模块 string_tools.py # string_tools.py def reverse_string(s):return s[::-1]调用: import string_tools print(string_tools.reverse_string("Hello")) # 输出…...

Pandas取代Excel?
有人在知乎上提问:为什么大公司不用pandas取代excel? 而且列出了几个理由:Pandas功能比Excel强大,运行速度更快,Excel除了简单和可视化界面外,没有其他更多的优势。 有个可怕的现实是,对比Exce…...

《解锁图像“高清密码”:超分辨率重建之路》
在图像的世界里,高分辨率意味着更多细节、更清晰的画面,就像用高清望远镜眺望远方,一切都纤毫毕现。可现实中,我们常被低分辨率图像困扰,模糊的监控画面、老旧照片里难以辨认的面容……不过别担心,图像超分…...

杨校老师课堂之C++入门练习题梳理
采用C完成下列题目,要求每题目的时间限制:1秒 内存限制:128M 1. 交换个位与十位的数字 时间限制:1秒 内存限制:128M 题目描述 试编写一个程序,输入一个两位数,交换十位与个位上的数字并输出。 …...

基于springboot的老年医疗保健系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

数据分析与挖掘
一 Python 基本语法 变量与数据类型 : Python 中变量无需声明,直接赋值即可。 常见的数据类型有数值型(整型 int、浮点型 float、复数型 complex)、字符串型(str,用单引号、双引号或三引号括起来ÿ…...

RoBoflow数据集的介绍
https://public.roboflow.com/object-detection(该数据集的网址) 可以看到一些基本情况 如果我们想要下载,直接点击 点击图像可以看到一些基本情况 可以点击红色箭头所指,右边是可供选择的一些yolo模型的格式 如果你想下载…...

大模型Rag - 两大检索技术
一、稀疏检索:关键词匹配的经典代表 稀疏检索是一种基于关键词统计的传统检索方法。其基本思想是:通过词频和文档频率来衡量一个文档与查询的相关性。 核心原理 文档和查询都被表示为稀疏向量(如词袋模型),只有在词…...

【T型三电平仿真】SVPWM调制
目录 仿真模型分析 克拉克变换 大扇区判断编辑 小区域判断 计算基本电压矢量作用时间 确定基本电压矢量的作用顺序 作用时间和矢量作用顺序对应 七段式化生成阶梯图 矢量状态分布 本人学习过程中提出的问题和解释 SVPWM调制实现了什么功能 SVPWM的算法步骤是什么…...

树莓派5-开发应用笔记
0.树莓派系统目录 /home:用户目录。 除了root用户外,其他所有的使用者的数据都存放在这个目录下,在树莓派的系统中,/home目录中有一个pi的子目录,这个就是pi用户的默认目录。 /bin: 主要放置系统的必备执行文件目录。 …...

[Java实战经验]异常处理最佳实践
一些好的异常处理实践。 目录 异常设计自定义异常为异常设计错误代码(状态码)设计粒度全局异常处理异常日志信息保留 异常处理时机资源管理try-with-resources异常中的事务 异常设计 自定义异常 自定义异常设计,如业务异常定义BusinessExce…...

AOSP的Doze模式-LightIdle初识
前言 从Android 6.0开始,谷歌引入了Doze模式(打盹模式)的省电技术延长电池使用时间。根据第三方测试显示,两台同样的Nexus 5,开启的Doze的一台待机能达到533小时,而未开启Doze的一台待机只能达到200小时。Doze省电效果十分明显。…...

QML动画--ParticleSystem
ParticleSystem 是 QML 中用于创建和管理粒子系统的组件,可以制作各种粒子效果如火焰、烟雾、爆炸等。 基本用法 qml import QtQuick.Particles 2.15ParticleSystem {id: particleSystemImageParticle {source: "particle.png"color: "red"a…...

Win 11 重装 Ubuntu 双系统方法
有时候 Ubuntu 环境崩溃了,或者版本过低,需要卸载重装。本文介绍重装的方法,默认已经有一个双系统。 1. 删除原先 Ubuntu 分区 首先打开 Win 的磁盘管理,找到 Ubuntu 的分区,右键删除分区(注意不要错删 wi…...

单例模式:懒汉式的两种优化写法
单例模式:全局唯一实例 懒汉式:获取时才初始化 ①静态局部变量实现(Meyer’s Singleton)【推荐】 /* 类内创建自身实例的可行性分析:在C中,类可以通过静态成员函数创建自身实例。这种机制的核心在于&…...

详细解释浏览器是如何渲染页面的?
渲染流程概述 渲染的目标:将HTML文本转化为可以看到的像素点 当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务࿰…...

高速系统设计简介
1.1 PCB 设计技术回顾 1981 年 8 月 12 日,IBM 正式发布了历史上第一台个人电脑,自此之后,个人电脑融入了人们生活和工作的各个角落,人类从此进入了个人电脑时代。个人电脑的出现,不仅促进了电子产品在消费领域的发展…...

不规则曲面上两点距离求取
背景 在CT中求皮肤上两点间的弧长。由于人体表面并不是规则的曲面,不可能用圆的弧长求取方法来计算出两点间的弧长。 而在不规则的曲面上求两点的距离,都可以用类似测地线距离求取的方式来求取(积分),而转化为搜索路…...

用usb网卡 虚拟机无法开到全双工的解决办法
今天突发奇想 给unraid宿主机插了两个一摸一样的usb网卡 2.5g的 直通给不同的虚拟机 这里unraid需要安装"USB Manager" 请给unraid自备环境 直通的时候 第一次还没生效 看不到网卡 我又在unraid的管理界面 顶部可以看到多出来一个 "usb"页面 打开可…...

webpack 中 chunks详解
webpack 中 chunks详解 在 Webpack 项目中,webpack.config.js 是核心配置文件,而非 webpack.json。chunks 的概念与 Webpack 的代码分割(Code Splitting)功能密切相关,通过 optimization.splitChunks 配置项可以实现对…...

Java @Serial 注解深度解析
Java Serial 注解深度解析 1. 注解本质 Serial 是 Java 14 引入的编译时校验注解,用于标记序列化相关成员,帮助开发者避免常见的序列化错误。 2. 核心作用 (1) 主要用途 标记序列化相关的特殊方法/字段 提供编译时检查 替代传统的命名约定验证 (…...

齐次坐标变换+Unity矩阵变换
矩阵变换 变换(transform):指的是我们把一些数据,如点,方向向量甚至是颜色,通过某种方式(矩阵运算),进行转换的过程。 变换类型 线性变换:保留矢量加和标量乘的计算 f(x)…...

Python语法系列博客 · 第9期[特殊字符] 函数参数进阶:*args、**kwargs 与参数解包技巧
上一期小练习解答(第8期回顾) ✅ 练习1:整数转字符串列表 nums [1, 2, 3, 4, 5] str_list list(map(str, nums))✅ 练习2:筛选回文字符串 words ["madam", "hello", "noon", "python&qu…...

Python语法系列博客 · 第4期[特殊字符] 函数的定义与使用:构建可复用的模块
上一期小练习解答(第3期回顾) ✅ 练习1:创建一个列表,添加5个名字,并用循环打印 names ["Alice", "Bob", "Charlie", "David", "Eva"] for name in names:print…...

6547网:2025年3月 Python编程等级考试一级真题试卷
2025年3月青少年软件编程Python等级考试(一级)真题试卷 题目总数:37 总分数:100 选择题 第 1 题 单选题 下列哪个软件不能运行Python程序?( ) A.JupyterNotebook B.Pycharm C.原版…...

微前端框架Module Federation
以下是 Module Federation 的核心知识点,并结合微前端架构的设计思想,帮助我们构建完整的知识体系: 一、Module Federation 基础概念 1. 什么是 Module Federation? 定义:Webpack 5 引入的一项革命性功能,允许在运行时动态加载其他独立构建的应用模块(微前端),实现跨…...

AUTOSAR图解==>AUTOSAR_SWS_IntrusionDetectionSystemManager
AUTOSAR 入侵检测系统管理器 (IdsM) 详解 AUTOSAR安全框架的核心组件 1. 概述 AUTOSAR 入侵检测系统管理器(Intrusion Detection System Manager, IdsM)是AUTOSAR标准中安全防护框架的关键组成部分,专门负责处理车载安全事件。IdsM模块提供了…...

Alan AI - 面向Web的生成式AI SDK
本文翻译整理自:https://github.com/alan-ai/alan-sdk-web 文章目录 一、关于 Alan AI相关链接资源关键功能特性Alan AI StudioAlan AI SDKAlan AI Cloud 二、为什么选择Alan AI?三、快速开始四、下载安装五、示例应用六、其他平台SDK七、获取帮助 一、关…...
 型文法 识别二元组文法分析)
递归下降 ll(1) 型文法 识别二元组文法分析
#include <stdio.h> #include <string.h>FILE* fp; FILE* fa2;char* str new char[1200]; // 循环读取文件,分200字节读取char* peek;// 表格 typedef struct table {char* sign;char* kind;char* message; } signtable;signtable* list; // 数…...
 in qt:serialport解决方法)
Qt unknown module(s) in qt:serialport解决方法
在Ubuntu和CentOS系统中,若使用Qt时遇到Unknown module(s) in QT: serialport错误,通常是由于未正确安装Qt的串口模块(QSerialPort)或项目配置不当导致。以下是针对两种系统的解决方案: 一、安装Qt串口模块 1. Ubuntu/Debian系列 安装开发包: 执行以下命令安装Qt5串口模…...

金融数学专题6 证券问题与资本利得税
一、固定利息证券 特点:利息固定,且可以在证券名字中体现。 发行价格:公司公开发行证券的价格。 固定利率证券通常在其名称中包括应付利率,例如,8% Treasury Stock 2021 或 5% Treasury Gilt 2018。每位持有人应得的年利息是通…...

XGBoost
XGBoost 假设一共有 m m m个基模型,分别为 f 1 ( x ) , f 2 ( x ) , … , f m ( x ) f_1(x),f_2(x),\dots,f_m(x) f1(x),f2(x),…,fm(x), n n n个样本, x 1 , x 2 , … , x n x_1,x_2,\dots,x_n x1,x2,…,xn,则XGBoo…...

Kubernetes 多主多从集群部署完整文档
好久不见呀!今天给大家整点干货尝尝(其实是自己的总结),主打的就是全程无尿点。 Kubernetes 多主多从集群部署完整文档 1. 机器列表 PS: master,lb,nfs机器均为CentOS 7,其他为Ubuntu 22.04 L…...

使用Spring Validation实现参数校验
引入Spring Validation 起步依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId> </dependency>参数校验失败异常处理 所有的http请求异常都会被拦截处理 exception…...

用思维导图解锁计算机科学导论的知识宝库
引言 在计算机科学的浩瀚海洋中,“计算机科学导论” 如同开启宝藏的钥匙,是众多学习者踏入这片领域的第一步。今天,我将借助思维导图这一强大工具,带大家梳理计算机科学导论的关键知识点,同时也希望能为大家在学习的道…...

软件架构分层策略对比及Go项目实践
一、水平分层 vs 功能划分 vs 组件划分 维度水平分层功能划分组件划分核心思想按垂直层次划分职责(如表示层、业务层、数据层)按业务功能模块划分(如用户管理、订单服务、支付模块)按技术或业务能力划分独立组件(如数…...

Python学习之Seaborn
Python学习之Seaborn 如果说Matplotlib试图让简单的事情变得容易,让困难的事情成为可能,那么Seaborn试图让一组定义明确的复杂的事情变得简单. Seaborn是在Matplotlib的基础上开发的高级可视化库, 它更专注于数据可视化的美学设计和统计图形的绘制. Matplotlib需要大量的代码创…...

【树莓派Pico FreeRTOS】-中断服务与二值信号量
中断服务与二值信号量 RP2040 由 Raspberry Pi 设计,具有双核 Arm Cortex-M0+ 处理器和 264KB 内部 RAM,并支持高达 16MB 的片外闪存。 广泛的灵活 I/O 选项包括 I2C、SPI 和独特的可编程 I/O (PIO)。 FreeRTOS 由 Real Time Engineers Ltd. 独家拥有、开发和维护。FreeRTO…...

QT采用cmake编译时文件解析
CMakeLists.txt # 设置版本要求 cmake_minimum_required(VERSION 3.16) # 设置项目名 project(QtWidgetsApplication3 LANGUAGES CXX)#设置C版本 set(CMAKE_CXX_STANDARD 20) set(CMAKE_CXX_STANDARD_REQUIRED ON)find_package(QT NAMES Qt6 Qt5 REQUIRED COMPONENTS Core) fi…...

代码随想录背包问题完结
322. 零钱兑换 视频讲解:动态规划之完全背包,装满背包最少的物品件数是多少?| LeetCode:322.零钱兑换_哔哩哔哩_bilibili 代码随想录 该题在递推公式部分和474.一和零一样,求装多少个 不同在于 该题是完全背包&a…...

Java 内存优化:如何避免内存泄漏?
Java 内存优化:如何避免内存泄漏? 在 Java 开发中,内存管理是一个至关重要的主题。尽管 Java 拥有自动垃圾回收机制,但这并不意味着开发人员可以忽视内存管理。内存泄漏是一个常见的问题,如果不加以控制,可…...

数量关系 多级数列1
机械划分 真看不出来 无明显关系 后减前作差 分数数列 无规律 作乘 作积 太复杂啦 太复杂啦...