C++——C++11常用语法总结
C++11标准由国际标准化组织(ISO)和国际电工委员会(IEC)旗下的C++标准委员会(ISO/IEC JTC1/SC22/WG21)于2011年8月12日公布,并于2011年9月出版。2012年2月28日的国际标准草案(N3376)是最接近于C++11标准的草案(仅编辑上的修正)。此次标准为C++98发布后13年来第一次重大修正。
1. 列表初始化
在C++98中,数组、结构体可以用{}进行初始化这是我们早就习以为常的事情。
struct A {int a;char b;};void Test1(){A a = { 1,'g' };int arr1[] = { 1,2,3,4 };int arr2[10] = { 0 };}在C++11的标准中,扩大{}形成的列表的适用范围,可用于所有内置类型和自定义类型。具体体现在:new表达式也可以使用列表初始化。可以使用列表初始化的方式调用构造函数,当使用列表来初始化时等号可有可无。
class Date {public:Date(int year, int month, int day):_year(year), _month(month), _day(day){}private:int _year;int _month;int _day;};void Test2(){int n1 = 1;int n2 = { 2 };int n3{ 3 };A a{ 1,'g' };Date d{ 2004,3,25 };//隐式类型转换,列表和构造函数参数必须一一对应int arr[]{ 1,2,3,4 };int* p = new int[3] {1, 2, 3};}在std标准库中有一个初始化列表类:initializer_list,将其作为构造函数的参数,那么初始化就很方便了。如下文的代码,{1, 2, 3, 4} 是一个std::initializer_list<int>类型的对象,编译器查找到了std::vector<int>中有接受std::initializer_list<int>的构造函数:vector(std::initializer_list<int>); 所以编译器调用这个构造函数来创建v。
void Test3(){vector<int> v = { 1,2,3,4 };//初始化列表类的对象,其中的值可以任意多个}2. 声明的特殊方法
2.1 auto类型
在C++98中,auto是变量是局部自动存储类型,但由于局部域中定义局部的变量默认就是自动存储类型,所以不会刻意被使用。而在C++11中,auto废弃了原来的用法,变成自动推断变量声明类型。当使用auto时,必须进行显式初始化以便编译器推导类型。
void Test1(){int x = 1;auto p = &x;cout << typeid(p).name() << endl;}2.2 decltype
decltype可以根据所给表达式推导声明类型。
void Test2(){int x = 4;double y = 10.2;decltype(x * y) ret;cout << typeid(ret).name() << endl;}2.3 nullptr
专指空指针。
3. 范围for循环
实际上是基于迭代器的for循环,以前的文章介绍过,不再解释。
4. 智能指针
智能指针篇幅较大,将在不久之后的文章中重点讲解。
5. 新容器
C++11引入新容器:array(静态数组),forward_list(单链表),unordered_map/set(哈希map、set),都已经介绍过。
6. 右值引用
我们以前就接触过引用这种类型,它实际上是给变量起了个别名。在C++11中引入了右值引用的概念,于是引用就分为了左值引用和右值引用。
6.1 左值和右值
左值——可以通俗简单的理解为可以取地址的值,如变量、指针等都是左值。之所以叫作左值是因为其多位于等号左边,可以被赋值。
//以下如a、p、s、b、*p都是左值//左值多位于等号左边,即可以被赋值int a = 10;char* p = new char('a');string s("hello world");const int b = 9;*p = 'c';右值——可以理解为不可以取地址的值,如临时变量、常量、匿名对象等。同样的,右值多位于等号右侧,可以为左值赋值,但其自身不可以被赋值。这并不难理解,因为右值之所以不允许取地址正是因为它具有“临时”这个属性,转瞬即逝,赋值没有意义。这也就解释了为什么以前说临时变量具有常性。
右值例如表达式的结果、常数、函数返回值等,它们并非在计算机中不存在,而是在程序运行中可能仅仅在当前语句会存在于寄存器中或内存中,属于一个过程量,没有单独拿出来赋值的必要。在右值引用引用右值后,右值会存储到特定位置并且支持通过右值引用访问。
//如下表达式为右值,包括常量、常量临时对象、匿名对象//右值多位于等号右边,即可以给变量赋值,但自身不能赋值(临时的对象,由临时空间存储)20;a + b;fmin(a, b);string("good");6.2 左值引用和右值引用
6.2.1 左值引用和右值引用的使用
左值引用就是给左值取别名,我们过去使用的那种最常见的引用都是左值引用。
//左值引用:给左值起别名int& r1 = a;char*& r2 = p;string& r3 = s;const int& r4 = b;char& r5 = *p;右值引用则是给右值取别名。
//右值引用:给右值起别名int&& rr1 = 20;int&& rr2 = a + b;int&& rr3 = fmin(a , b);string&& rr4 = string("hello");6.2.2 左值引用 引用 右值 与 右值引用 引用 左值
①左值引用引用右值时不可以直接引用,需要const左值引用给右值起别名。
//左值引用引用右值:不可以直接引用,需要const左值引用给右值起别名const int& rx1 = 20;const int& rx2 = a + b;const int& rx3 = fmin(a, b);const string& rx4 = string("hello");根据这一特性,我们的函数传参可以用const左值引用接收右值,而以往我们确实也是这么干的,通过const T&接收常量等右值。
②右值引用引用左值时不可以直接引用,需要使用move()将其转化为右值。
int&& rxx1 = move(a);char*&& rxx2 = move(p);string&& rxx3 = move(s);const int&& rxx4 = move(b);char&& rxx5 = move(*p);int&& rxx6 = (int&&)a;注:如果深入汇编层查看,会发现汇编中根本没有左值引用、右值引用,而且甚至没有引用的概念。实际上左值引用和右值引用都是指针的变形,底层都是通过指针实现的,在高级语言层包装成为所谓的引用则是为了方便使用。因此,move()本质上是应付语法检查,并没有对变量本身做任何修改,可以理解为强制类型转换为右值。
于是我们发现,右值作为实参,优先匹配右值引用的形参,之后才是const左值引用。
6.3 移动构造和移动复制
6.3.1 移动构造的原理
// 移动构造——将参数对象的内容直接移动到自己的名下,作为自己的内容// 深拷贝的类,移动构造才有意义// 当参数为右值时优先调用移动构造,若没有移动构造则调用拷贝构造string(string&& s){swap(s);}移动构造,就是参数接收一个右值的对象,然后将this和接收到的对象进行swap交换资源。
会发现,这本质上就是一种“掠夺”的行径,强制传入的参数和自己的资源交换。然而正是这种方式最适应于传入参数是没有用却有资源的对象,而自己是有用却没有资源的对象。而在现实中恰恰存在这种场景,存在一些有资源的将亡值,这些对象就可以被用来作为移动构造的牺牲品(参数)。
对于深拷贝来说,这种构造方法规避了开销巨大的拷贝动作,而是简单的交换资源便完成了对象的构造,显然极大提高了深拷贝的类的对象构造的效率。对于浅拷贝而言,自然就和一般的构造一样没什么优势了。
6.3.2 移动构造举例
我们曾经引入引用,解决了参数传递时开销大的问题,但是并没有完全解决传递返回值的问题,当返回值是局部对象时就会产生拷贝构造降低效率,见如下例子。
对于一个string类,它有构造函数:
无参构造
string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}拷贝构造
// 拷贝构造——将参数对象的内容拷贝后形成的备份作为自己的内容// s2(s1)string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;reserve(s._capacity);for (auto ch : s){push_back(ch);}}
有一个函数需要返回string对象。
//对于返回值是对象的函数,如String::string i2s(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}String::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;}
使用如下代码调用函数,由于拷贝构造需要深拷贝开销最大,所以关注拷贝构造次数便可以见微知著。
String::string ret1 = i2s(1234);
无移动构造、无优化时编译器操作:
①进入i2s函数,调用无参构造函数构造str;
②完成函数体后返回局部变量str,函数结束栈帧销毁,str也会销毁,所以str通过拷贝构造函数构造一个临时变量;
③临时变量将对象交给ret1,于是调用拷贝构造函数,通过临时变量构造ret1。
通过以上步骤,发现此时调用了两次拷贝构造。
无移动构造、有优化时的编译器操作:
①进入i2s函数,调用无参构造函数构造str;
②完成函数体后返回局部变量str,str直接通过拷贝构造函数构造ret1。
可以发现,优化后编译器略去了中间的临时变量,只调用了一次拷贝构造。
移动构造、有优化时的编译器操作:
string(string&& s){cout << "string(string&& s) -- 移动拷贝" << endl;swap(s);}①进入i2s函数,调用无参构造函数构造str;
②完成函数体后返回局部变量str,str通过移动构造函数构造ret1。
③构造完成后str变成空对象,随着栈帧一起消逝,而et1获得了str的资源。
可以看到,用将亡值str构造ret1没有任何影响,而且仅调用移动构造。
移动构造、大力度优化编译器操作:
①编译器直接采用一次默认构造,用ret1替代函数中的str直接构造。
此时仅使用了一次无参构造。
总结:
可以看到移动构造对于深拷贝的优化是很大很有用的。需要一提的是,想让函数返回值调用移动构造时,返回值可以不用显式调用move,有移动拷贝的时候会隐式类型转换。
//return move(str);//可以不用显式调用move,有移动拷贝的时候会隐式类型转换return str; std::list<String::string> l1;String::string s1("abcd");//list支持右值引用传参// void push_back (const value_type& val);// void push_back (value_type&& val);l1.push_back(s1); //拷贝构造l1.push_back(String::string("aabb")); //移动构造l1.push_back("aaab"); //移动构造l1.push_back(move(s1)); //移动构造,但会导致s1被清空6.3.3 移动赋值
移动赋值和移动构造原理一样,无需多解释。
// 移动赋值string& operator=(string&& s){swap(s);return *this;}
6.3.4 调用移动构造的要点
想调用移动构造并不难,因为移动构造的参数比拷贝构造更优先接收右值,所以确保传递的是右值即可。然而在实际代码中,这并不那么容易搞定。对于如下自己完成的string和list类为例。
函数调用
m_list::list<String::string> l1;String::string s1("abcd");l1.push_back(move(s1)); //移动构造list::push_back
void push_back(const T& val){insert(end(), val);}//push_back的右值引用版本void push_back(T&& val){insert(end(), move(val));//val是左值属性,所以传递给insert时使用move,调用其右值版本}list::insert
//插入void insert(iterator pos, const T& val){Node* next = pos._node;Node* prev = next->_prev;Node* newnode = new Node(val);prev->_next = newnode;newnode->_prev = prev;newnode->_next = next;next->_prev = newnode;++_size;}//右值版本void insert(iterator pos, T&& val){Node* next = pos._node;Node* prev = next->_prev;Node* newnode = new Node(move(val));//val是左值属性,所以构造Node时使用move,调用其右值版本prev->_next = newnode;newnode->_prev = prev;newnode->_next = next;next->_prev = newnode;++_size;}ListNode(Node)构造函数
//构造函数,使用初始化列表初始化ListNode(const T& val = T()) //参数注意使用const引用,因为实参可能是常性的:_prev(nullptr), _next(nullptr), _val(val){}ListNode(T&& val) :_prev(nullptr), _next(nullptr), _val(move(val)) //val是左值属性,所以赋值时使用move,调用其右值版本{}string构造函数
//无参构造string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// 拷贝构造string(const string& s):_str(nullptr){reserve(s._capacity);for (auto ch : s){push_back(ch);}}// 移动构造string(string&& s){swap(s);}
移动构造路径:
①由l1.push_back(右值),调用push_back(T&& val)
②由push_back的insert(end(), move(val)),调用insert(iterator pos, T&& val)
③由insert的new Node(move(val)),调用ListNode(T&& val)
④由ListNode移动构造的_val(move(val)),调用string(string&& s)
以上步骤如若有一处没有使用move类型转换成右值就会导致调用拷贝构造。
6.4 完美转发
6.4.1 引例
考虑如下代码:
void Fun(int& x) { cout << "左值引用" << endl; }void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }void Fun(const int&& x) { cout << "const 右值引用" << endl; }void PerfectForward(T&& t){Fun(t);cout << endl;}首先需要说明的是,模板中的&&不代表右值引用,而是万能引用(引用折叠),表示其既能接收左值又能接收右值。这仅仅只是模板的&&才是万能引用,对于函数的参数&是左值引用,&&是右值引用。
void Test5(){PerfectForward(10); //右值int a;PerfectForward(a); //左值PerfectForward(std::move(a)); //右值const int b = 8;PerfectForward(b); //const 左值PerfectForward(std::move(b)); //const 右值} 
会发现无论是左值或右值,经过PerfectForward函数后,统统调用了左值相关的函数。这是因为在传参中,无论是左值右值都会被形参t接收。作为左值引用的t是一个左值,而作为右值引用的t也退化为了左值。所以调用Fun的时候都调用了接收左值的函数。
6.4.2 完美转发原理与使用
面对上述的右值引用的属性是左值而导致的属性退化问题,可以使用标准库提供的完美转发来解决。

forward完美转发来在传参过程中保留原生类型属性,对左值引用不做处理,对右值引用,因为退化成了左值,所以将其强转为右值。
template<typename T>void PerfectForward(T&& t){Fun(forward<T>(t));cout << endl;}
这时会发现forward保留了原生类型,从而使接收右值的右值引用参数仍然具有右值属性。
从原理来看,forward是一个函数模板,结合我们自己的万能引用模板函数PerfectForward,根据传入的参数,被实例化成为了如下四个函数。通过使用模板的方式,这四种函数就可以省去不写,而由编译器根据模板完成。可以发现,move可以区别const和非const,得到const左、右值和非const左、右值。
void PerfectForward(int& t) //左值引用{Fun(t);}void PerfectForward(int&& t) //右值引用{Fun(move(t));}void PerfectForward(const int& t) //const 左值引用{Fun(t);}void PerfectForward(const int&& t) //const 右值引用 {Fun(move(t));}完美转发用于传参时保留左右值属性,因此在面对向下调用函数需要根据左右值属性调用不同函数时使用,如我们 6.3.4 中的例子就可以使用完美转发来保证右值引用不退化。
7. 类功能更新
7.1 新增默认成员函数
在C++11中,除了6个默认成员函数,新增了两个默认成员函数:移动构造函数、移动赋值运算符重载。
这两个默认成员函数由编译器生成条件:①自己没有实现;②没有自己实现析构函数、拷贝函数、拷贝复制重载函数的任意一个。
可以理解为析构、拷贝构造、拷贝赋值、移动构造和移动赋值这五者同时出没。因为当对象申请资源了(这时需要深拷贝),它们都需要自主实现满足深拷贝和资源管理的要求。当没有资源申请,那么当前对象也就无需深拷贝,因此默认生成的成员函数足以满足,全部都无需自己实现了
对于默认生成的移动构造,对内置类型按字节拷贝,对自定义成员调用其移动构造,如果没有则调用拷贝构造。默认生成的移动赋值同理,对内置类型按字节拷贝,对自定义成员调用其移动赋值,如果没有则调用拷贝赋值。
通过默认生成的移动构造可以调用其自定义成员的移动构造,当自己是右值时,成员也是右值,尽管自身是浅拷贝不会由于移动构造而提高效率,但是成员有可能是深拷贝,采取移动构造可以大大提高效率。这也是默认移动构造的意义。
class Person{public:Person(const char* name = "", int age = 0):_name(name), _age(age){}private:C3::String::string _name;int _age;};//默认生成的移动构造和移动赋值对_name调用其移动构造和移动赋值,对_age直接字节拷贝void Test1(){Person s1;Person s2 = s1;Person s3 = std::move(s1);Person s4;s4 = std::move(s2);}7.2 新增关键字
7.2.1 default
default可以强制生成默认成员函数,当需要使用某个默认的函数,但是因为一些原
因这个函数没有默认生成。比如:提供了拷贝构造,就不会生成移动构造了,此时就可以使用default强制生成移动构造。
Person(Person&& p) = default;7.2.2 delete
delete可以禁止编译器生成默认成员函数,如禁止生成拷贝构造。
Person(const Person& p) = delete;ostream类的拷贝构造就使用了delete关键字,而在C++11之前,想要阻止编译器生成默认成员函数,需要自己实现一个private属性的函数来限制编译器生成,同时保证无法在类外实现。
class A {//类内只声明不实现,限制编译器生成//声明为私有,防止使用者在类外实现public:A(){}private:A(const A& a);A& operator=(const A& a);private:int _a=0;};//不声明为私有就会在类外实现//A::A(const A& a)//{}7.2.3 final
final在继承与多态中介绍过,它修饰的虚函数不可以再被重写。
virtual void func1() final
{}7.2.4 override
override在继承与多态中介绍过,它修饰的虚函数会检查是否重写了父类的某个虚函数,如果没有重写则报错。
virtual void func2(int b=2) override
{}8. 可变参数模板
8.1 可变参数模板的使用
在C语言中也有可变参数,如int printf ( const char * format, ... );。C语言的可变函数参数用...表示,可接收任意数量的参数。其底层是把参数放在了一个数组中。
对于传统的模板我们已经比较熟悉了,所谓函数模板就是给出一个函数的模型,而将其参数类型设置为可变值,根据模板实例化时提供的参数类型来由编译器生成指定参数类型的函数。
//一般的模板:参数个数固定,参数类型可变template <class T>void ShowList(T&& x){}而可变参数模板则是更升一级,同样作为函数模板,它不仅参数的类型可变,并且参数的个数也是可变的。
//可变参数模板:参数个数可变,参数类型可变template<class ...Args> //表示Args是一个类型参数包,可以匹配任意数量的类型void ShowList(Args ...args) //表示args是一个函数形参参数包,可以接受任意数量的参数,参数的数量和类型由Args决定{}其中Args是一个类型参数包,可以匹配任意数量的类型。
而args是一个函数形参参数包,可以接受任意数量的参数,参数的数量和类型由Args决定。
...根据其位置不同具有不同含义。
| ...出现在类型/参数名左侧 | 声明一个参数包 | 声明模板类型参数包Args:template <class ...Args> 声明函数形参参数包args:void ShowList(Args ...args) |
| ...出现在参数包名右侧 | 将参数包展开为具体参数 | 展开args函数形参参数包,得到的形参作为Print的参数:Print(args...); |
| ...与操作符相邻而与参数包分离 | 将参数包各个参数以指定的操作符展开计算 | 一元右折叠:( <参数包> <操作符> ... ) 适用右结合操作符。 如args=...展开为agrs[1]=(args[2]=(args[3]=args[4])) 一元左折叠:( ... <参数包> <操作符> ) 适用左结合操作符。 如...+args展开为((agrs[1]+args[2])+args[3])+args[4] 二元右折叠:( <参数包> <操作符> ... <操作符> <初值> ) 适用右结合操作符。 如args-...-2展开为agrs[1]-(args[2]-(args[3]-1)) 二元左折叠:( <初值> <操作符> ... <操作符> <参数包> ) 适用左结合操作符。 如2&...&args展开为((2&args[1])&args[2])&args[3] 注: ①一元或二元折叠视有无初值而定; ②左结合操作符采用左折叠,右结合操作符采用右折叠,这样满足操作符定义的计算方式,不会出错。可以混用,左右折叠控制求值顺序,但可能会导致运算符语法错误(报错)或不合常理运算逻辑(运算结果不合期望)。 |
8.2 展开参数包
如果我们在使用可变参数模板的过程中需要读取参数包内的参数值,就需要展开参数包。
8.2.1 运行时展开参数包(不可行)
模板在编译时完成实例化,所以可变模板参数会在编译时解析,实例化为需要的函数。以下的方式在运行时才进行解析参数,所以会失败。
template<class ...Args> //表示Args是一个类型参数包,可以匹配任意数量的类型void ShowList(Args ...args) //表示args是一个函数形参参数包,可以接受任意数量的参数,参数的数量和类型由Args决定{//std::cout << sizeof...(Args) << std::endl; //打印类型参数数量std::cout << sizeof...(args) << std::endl; //打印函数参数数量//模板在编译时完成实例化,所以可变模板参数会在编译时解析,实例化为需要的函数//以下的方式在运行时才进行解析参数,所以会失败for (size_t i = 0; i < sizeof...(args); i++){cout << args[i] << ' ';}}8.2.2 递归函数展开参数包
编译时因为需要实例化模板,所以每次实例化一个Print函数都会解析出一个参数,由此递归完成解析。当参数全部被解析,会调用没有参数的Print(),即可走出递归。
//递归的出口,当参数全部被解析,会调用没有参数的Print(),即可走出递归void Print(){cout << endl;}//编译时因为需要实例化模板,所以每次实例化一个Print函数都会解析出一个参数,由此递归完成解析template <class T,class ...Args>void Print(T&& x, Args&&... args){cout << x << " ";Print(args...);}template<class ...Args>void ShowList(Args ...args){//编译时递归推导解析参数Print(args...);} ShowList(1, 1.2, "abcd");对于上面的调用,可以分析出Print函数被实例化为以下的函数,这也是能够完成参数包展开的原因。
void ShowList(int x, double y, char* z){Print(x, y, z);}void Print(int x, double y, char* z){cout << x << " ";Print(y, z);}void Print(double y, char* z){cout << y << " ";Print(z);}void Print(char* z){cout << z << " ";Print();}8.2.3 数组展开参数包
用所有的参数分别调用PrintArg函数,在函数内会分别拿到各个参数,而函数返回int类型保证原数组语法正确。
template <class T>int PrintArg(T t){cout << t << " ";return 0;}template <class ...Args>void ShowList2(Args ...args){int arr[] = { PrintArg(args)... };cout << endl;}
ShowList2(1, 1.2, "abcd");对于上面的调用,可以分析出Print函数被实例化为以下的函数,这也是能够完成参数包展开的原因。
void ShowList2(int x, double y, char* z){int arr[] = { PrintArg(x),PrintArg(x),PrintArg(x) };cout << endl;}int PrintArg(int t){cout << t << " ";return 0;}int PrintArg(double t){cout << t << " ";return 0;}int PrintArg(char* t){cout << t << " ";return 0;}8.2.4 逗号表达式参数包展开
这种方法和依靠数组展开参数包异曲同工,利用逗号表达式的左结合性,其表达式的值是最右侧表达式的值。于是可以在解析参数包同时数组元素赋值为0,保证语法正确。
template <class ...Args>void ShowList2(Args ...args){int arr[] = { (cout << (args) << " ",0)... }; //利用逗号表达式,变为int arr[] = { (cout << (x) << " ",0),(cout << (y) << " ",0)...};//因为cout语句的返回值ostream对象不允许拷贝,所以使用逗号表达式让元素的值变为int的0cout << endl;}8.3 emplace_back
8.3.1 emplace_back与push_back
以list为例。emplace_back同样是尾插操作,但是由于其支持万能引用,并且是可变参数模板,这会使得其效率进一步提高而胜过push_back。
![]()
std::list<String::string> lt;String::string s1("abc");//对于非临时对象,均调用拷贝构造,构造出新的对象放在list的容器内lt.push_back(s1);//拷贝构造lt.emplace_back(s1);//拷贝构造lt.emplace_back(move(s1));//移动构造//对于临时对象lt.push_back({ 10, 'a' });//构造+移动构造lt.emplace_back(10, 'a');//构造
可以发现,对于非临时对象,二者均调用拷贝构造,构造出新的对象放在list的容器内,所以没有效率差别。
而对于临时对象处理方法则不同。push_back首先调用string的构造函数,构造出一个临时对象,然后将这个临时对象传入push_back,由于是右值,所以最后采取移动构造完成list的尾插。emplace_back可以把构造string的参数包(10, 'a')向下传递,然后直接使用该参数包将对象构造在list容器内。相比之下可以发现,emplace_back相较于push_back少了一次移动构造的开销。
所以可以发现,emplace_back在面对非临时对象时与push_back效率相当,而面对临时对象则是有效率提升,因而以后的插入操作完全可以使用emplace_back全面代替push_back。
//emplace_back会直接在容器内存中构造对象lt.emplace_back(10, 'a'); 对于这种添加元素方法//比下文节约了一次拷贝构造String::string s1(10, 'a');lt.push_back(s1);//比下文节约了一次移动构造lt.push_back({ 10, 'a' });8.3.2 emplace_back的实现
在过去的list代码的基础上进行补充。emplace_back调用过程中参数包无需途中解析,一直传递到最后的元素构造处,即emplace_back->insert->ListNode->string。在此过程中,为了避免其右值引用退化为左值(6.3.4的经验),使用完美转发保证左右值属性的传递。
// emplace_back调用过程中参数包无需途中解析,一直传递到最后的元素构造处// 实际是包括emplace_back、insert、ListNode构造都根据参数包实例化出了函数template <class... Args>void emplace_back(Args&&... args){insert(end(), forward<Args>(args)...);//向insert传递参数包,使用完美转发保证左右值属性的传递} template <class... Args>void insert(iterator pos, Args&&... args){Node* next = pos._node;Node* prev = next->_prev;Node* newnode = new Node(forward<Args>(args)...);//向Node构造传递参数包prev->_next = newnode;newnode->_prev = prev;newnode->_next = next;next->_prev = newnode;++_size;} template <class... Args>ListNode(Args&&... args): _prev(nullptr), _next(nullptr), _val(forward<Args>(args)...) //向_val构造传递参数包{}整个过程实际是包括emplace_back、insert、ListNode构造都根据参数包实例化出了函数。
9. lambda表达式
9.1 引例
在C++的algorithm头文件下,有用于排序的库函数,通过提供开始和结束位置的迭代器即可完成排序操作,为了控制排序逻辑,sort有第三个参数用于接收一个用于比较的比较函数对象。

对于如下的一个类:
struct Goods {string _name;double _price;int _evaluate;Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}};vector<Goods> v1 = { {"apple",2.2,4},{"chocolate",8.8,2},{"ice-cream",4.5,3},{"book",22.1,5} };按照我们以往的知识想要对数组v1排序并不难。
sort(v1.begin(), v1.end(), greater<Goods>());//比较方式:g1>g2,即调用Goods类的大于号运算符重载函数
//由于Goods类的大于号重载函数只能有一个,所以相当于确定了排序逻辑按姓名降序,如果要更改排序逻辑则需要修改大于号运算符重载函数实现9.1.1 运算符重载
第一种方法就是直接调用库中提供的greater或less模板。以greater为例,库中提供的比较模板的操作是直接采取大于号运算符进行大小判断,所以我们把greater模板实例化为Goods类后,greater实际是在对两个Goods对象直接使用大于号进行比较。这就要求Goods类要对>运算符进行重载。
//在类内重载大于小于比较符bool operator>(const Goods& g)const{return _name > g._name;}很明显,由于Goods类的大于号重载函数只能有一个,所以相当于确定了排序逻辑按姓名降序,如果要更改排序逻辑则需要修改大于号运算符实现。但是在实际应用场景中应该支持任意一个属性的升序降序排序,这就需要我们使用其他的方式。
9.1.2 仿函数
第二种方法是采用仿函数。仿函数的概念我们曾经解释过,仿函数实际上是一个类,只是这个类重载了()运算符,可以通过任意一个类对象调用括号运算符完成制定工作。仿函数类的属性无关紧要,其最大的价值就是重载了括号,因为其调用括号操作符的方式是 对象(参数) ,与函数调用的形式很类似,所以称为仿函数。在使用时仅需构造一个类对象,甚至可以是匿名对象,因为对象的作用仅仅是为了调用函数,不关心其属性。
struct ComparePriceLess {bool operator()(const Goods& g1, const Goods& g2){return g1._price < g2._price;}};struct ComparePriceGreater {bool operator()(const Goods& g1, const Goods& g2){return g1._price > g2._price;}};以上是根据价格属性比较的仿函数。
sort(v1.begin(), v1.end(), ComparePriceLess());//调用ComparePriceLess仿函数作为比较逻辑
sort(v1.begin(), v1.end(), ComparePriceGreater());//调用ComparePriceGreater仿函数作为比较逻辑因为sort第三个参数要求传递一个用于比较的比较函数对象,而仿函数ComparePriceLess()实际上是一个匿名类对象,在sort的实现中调用ComparePriceLess类的()操作符重载作为比较逻辑。
9.2 lambda表达式语法
仿函数可以很好地解决上面的问题了,但是会发现想要对每一种类成员都写一份仿函数是比较麻烦的,因此引入lambda表达式。
lambda表达式语法:[capture-list] (parameters) mutable -> return-type { statement }
lambda表达式可以被称作“匿名函数”,因为其有着函数的功能和调用方法,却没有一个函数名。
9.2.1 简单使用方法
lambda表达式中,方括号[]表示捕捉列表,大括号{}表示函数体,这两部分是不可以省略的。
圆括号()表示参数,在使用lambda表达式需要传入参数;在函数体前是返回类型,如果没有返回值可以写作void。
在定义好lambda表达式后,需要赋给一个变量用于后续的调用操作。这个变量的类型使用auto自动推导即可,具体类型其实是一个名为lambda_uuid的类,可以将其也理解为仿函数。后续只需像调用函数一样使用这个变量以及传入参数即可调用lambda表达式。
auto add = [](int x, int y)->int {return x + y; };cout << add(1, 2) << endl;auto fun1 = []()->void{cout << "hello world";cout << endl;};fun1();//->返回类型 无论有无返回值,这一部分都可以被省略,如果有返回值并且省略了,编译器会自动推导类型auto fun2 = [](){cout << "hello world";cout << endl;return 2;};cout << fun2() << endl;//(参数列表)->返回类型 当没有参数时这一部分可以一起省略auto fun3 = [] {cout << "π="; return 3.14; };cout << fun3() << endl;//auto fun2 = []->int { return 2; }; //error 就算没有参数,()也不能单独被省略,要省略()需要先省略->和返回类型需要指出:
①->返回类型 无论有无返回值,这一部分都可以被省略,如果有返回值并且省略了,编译器会自动推导类型。
②(参数列表)->返回类型 当没有参数时这一部分可以一起省略。
③就算没有参数,()也不能单独被省略,要省略()需要先省略->和返回类型。
于是我们就可以使用lambda表达式解决引例的问题了。
//使用lambda表达式作为sort的第三个参数//评价升序sort(v1.begin(), v1.end(), [](const Goods& g1,const Goods& g2){return g1._evaluate < g2._evaluate;});//评价降序sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2){return g1._evaluate > g2._evaluate;});9.2.2 捕捉列表[capture-list]与mutable
int a = 0, b = 1;auto swap1 = [](int& x, int& y){//a;//error 在lambda函数体中,只能使用挡圈lambda局部域的对象和捕捉的对象和全局对象int tmp = x;x = y;y = tmp;};swap1(a, b);在lambda函数体中,只能使用当前lambda局部域的对象和捕捉的对象和全局对象,如果想要使用外部的对象,就需要用到捕捉列表。
9.2.2.1 传值捕捉
传值捕捉,捕捉变量的本质是外部变量的拷贝,并且被const修饰,如下例捕捉到的a,b对象在lambda函数体重可以视为是具有const修饰的右值,所以无法更改。
auto swap2 = [a, b]{int tmp = a;a = b; //error //捕捉到的a,b对象在lambda函数体重可以视为是具有const修饰的右值,所以无法更改b = tmp;}; 如果希望谢盖捕捉到的变量,可以使用mutable,这相当于去除了const属性。尽管使用了mutable后可以修改捕捉的变量但是,因为是拷贝所以修改不会影响外部的值,这和修改形参实参不会受影响是一个道理。
需要注意使用mutable时()就算没有参数也不可以省略。
//mutable相当于去除const属性,可以修改变量//因为是拷贝所以修改不会影响外部的值auto swap2 = [a, b]()mutable //使用mutable可以取消常量性变为非const,使用mutable时()就算没有参数也不可以省略{int tmp = a;a = b;b = tmp;};swap2();//传值捕捉不修改a、bmutable一般不使用,因为仅在函数体内改变拷贝的值没有意义,如果想影响外部变量应该使用传引用捕捉,这也是传值捕捉有const限制而传引用捕捉没有的原因。
9.2.2.2 传引用捕捉
传引用捕捉,捕捉变量的是外部变量的引用,没有附加const,可以修改捕捉的变量来改变外部的变量。
//传引用捕捉,捕捉变量的是外部变量的引用,没有附加const
auto swap3 = [&a, &b]{int tmp = a;a = b;b = tmp;};
swap3();//传引用捕捉可以修改a、b9.2.2.3 其他捕捉方式
其余还包括所有值传值捕捉、所有值传引用捕捉、混合捕捉。
//所有值传值捕捉,捕捉所有外部变量,如果在成员函数内this也会被捕捉auto fun1 = [=]{return a + b + c + d;};fun1();//所有值传引用捕捉,捕捉所有外部变量,如果在成员函数内this也会被捕捉auto fun2 = [&]{a++;b++;c++;d++;};fun2();//混合捕捉auto fun3 = [&a,b]{a++;b;};fun3();auto fun4 = [&, b] //所有值传引用捕捉,仅b传值捕捉{a++;b;c++;d++;};fun4();}9.3 总结
由此再回头看lambda确实像一个“匿名函数”,它没有函数名,因为自身只是一个表达式,所以需要使用的时候随时随地创建即可。
lambda的底层实际上完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
而捕捉列表的对象会以成员变量的形式存在于lambda类对象中。所以:
①定义lambda实际上是定义一个仿函数类;
②捕捉实际上是构造仿函数类的初始化参数;
③调用lambda实际上是调用仿函数类的operator()。
10.包装器
10.1 function
10.1.1 对函数指针、仿函数、lambda的包装
function包装器,C++中的function本质是一个类模板,它的作用是包装所有的可调用对象,如函数指针、仿函数、lambda。

对于function,其模板实例化有一些特殊,需要根据包装的可调用对象的返回类型和参数类型,以 <返回类型 ( 参数类型 ) > 的形式进行实例化。
function的很重要的作用一方面是以包装的方式为各种可调用对象赋予相同的调用方法,另一个方面就是可以统一相同返回类型、相同参数类型的调用对象。
int add(int a, int b){return a + b;}struct Sub {int operator()(int a, int b){return a - b;}};void Test1(){function<int(int, int)>f1 = add;function<int(int, int)>f2 = Sub();function<int(int, int)>f3 = [](int a, int b) {return a * b; };cout << f1(1, 2) << ' ' << f2(2, 3) << ' ' << f3(3, 4) << endl;//统一相同返回类型、相同参数类型的调用对象map<string, function<int(int, int)>> opFuncMap({{ "+",f1 }, { "-",f2 }, { "*", f3 }});cout << opFuncMap["+"](1, 2) << ' ' << opFuncMap["-"](3, 4) << ' ' << opFuncMap["+"](5, 6) << endl;}10.1.2 对成员函数的包装
对于静态成员,指明其函数时需要指定类域,除此之外和一般的函数包装相同。
而对于非静态成员函数,除了指明类域外还需要注意其存在隐藏的参数this*。为了处理这个this指针参数,有两种常见的方式,一种是使用类对象指针作为参数,另一种是使用类对象作为参数。对于这两种方法,function将可调用对象包装成了一个仿函数类,通过operator()去调用可调用对象,而传递的类对象指针或类对象参数本质上都是用于operator()调用非静态成员函数的,所以都可行。
除此之外静态成员函数的取地址可以不需要&,而普通成员函数取地址一定需要&,为统一可以认为他们都要使用&来取地址。
void Test2(){//包装静态成员函数function<int(int, int)> f1 = &A::addi;// 需要指定类域cout << f1(1, 2) << endl;//静态成员函数的取地址可以不需要&,而普通成员函数取地址一定需要&,为统一可以认为他们都要使用&来取地址//包装非静态成员函数,注意存在隐藏的参数this*//方法1function<double(A*, double, double)> f2 = &A::addd;// 需要指定类域A a;cout << f2(&a, 1.3, 2.4) << endl;//方法2function<double(A, double, double)> f3 = &A::addd;// 需要指定类域cout << f3(a, 1.3, 2.4) << endl;cout << f3(A(), 1.3, 2.4) << endl;//匿名对象//function将可调用对象包装成了一个仿函数类,通过operator()去调用可调用对象//而传递的类对象指针或类对象参数本质上都是用于operator()调用非静态成员函数的,所以都可行}10.2 bind
bind是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。在bind对可调用对象绑定完成后,最后得到也是一个仿函数对象。

bind一般具有两种用法:调整参数顺序和调整参数个数。
bind的使用和placeholders息息相关。在命名空间placeholders中,_n表示第n个位置的实参。
可以通过_1、_2……等控制参数传递的顺序。而有关参数对应关系的辨别,在使用过程中仅需谨记:bind的可变参数列表顺序和可调用对象参数顺序一致,调用bind绑定后的可调用对象接收实参的顺序取决于_n。
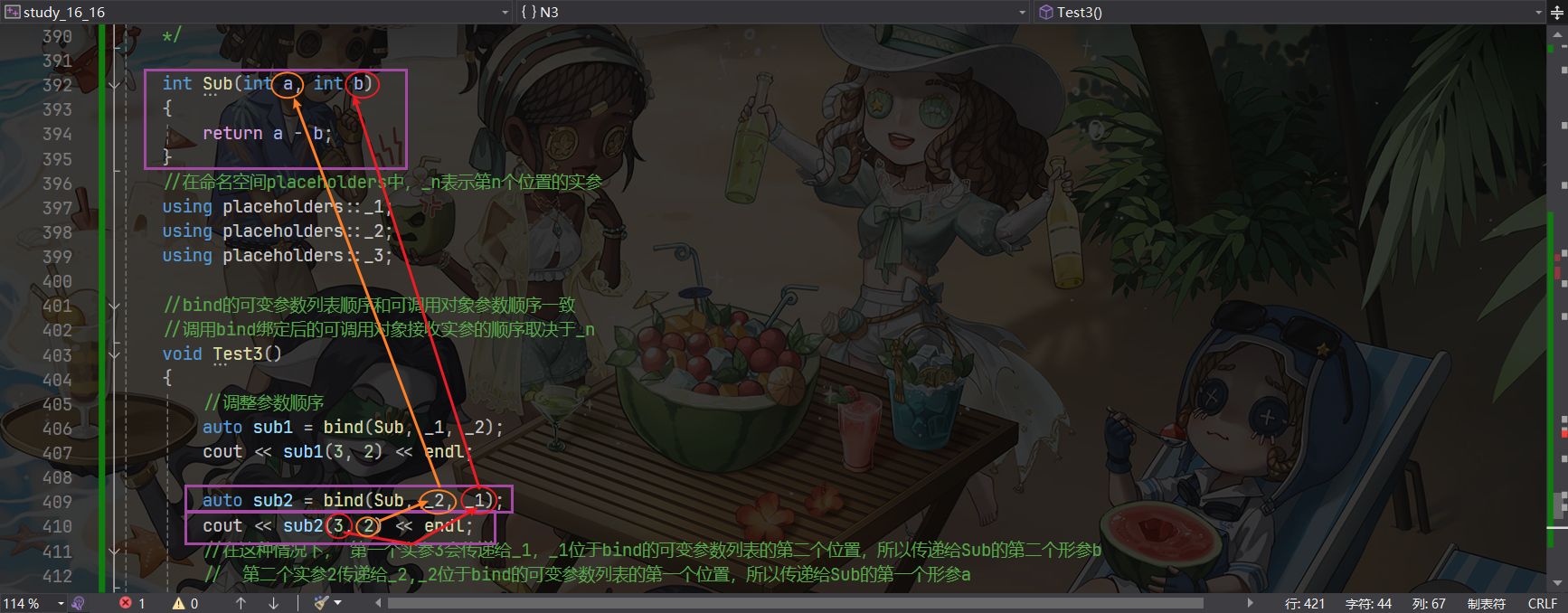
在定义bind时可以将某些参数置为一个固定值,这样就会固定使用该值进行传参,从而可以减少接收的参数个数,达到调整参数个数的效果。
int Sub(int a, int b)
{return a - b;
}
//在命名空间placeholders中,_n表示第n个位置的实参
using placeholders::_1;
using placeholders::_2;
using placeholders::_3;//bind的可变参数列表顺序和可调用对象参数顺序一致
//调用bind绑定后的可调用对象接收实参的顺序取决于_n
void Test3()
{//调整参数顺序auto sub1 = bind(Sub, _1, _2);cout << sub1(3, 2) << endl;auto sub2 = bind(Sub, _2, _1);cout << sub2(3, 2) << endl; //在这种情况下, 第一个实参3会传递给_1,_1位于bind的可变参数列表的第二个位置,所以传递给Sub的第二个形参b// 第二个实参2传递给_2,_2位于bind的可变参数列表的第一个位置,所以传递给Sub的第一个形参a//调整参数个数auto sub3 = bind(Sub, 100, _1);cout << sub3(3, 2) << endl;//第一个实参3传给_1,_1传递给第二个形参b。第二个实参无处传递。被固定的参数100传递给第一个形参a
}然而上述内容都是手段,bind的使用目的一般是想用于绑死某些固定参数。如对类内非静态成员函数的function包装后需要一个类对象的参数应付this指针。于是可以通过bind绑定A类的成员函数&A::addd,其接收的第一个参数固定为A(),第二个参数为调用时传递的第一个实参,第三个参数为调用时传递的第二个实参。bind绑定后是一个可调用对象(仿函数),再使用function进行包装为fun。如上这样包装后调用方法就被简化了,不必再传递类对象。
//bind一般用于绑死某些固定参数//bind绑定A类的成员函数&A::addd,其接收的第一个参数固定为A(),第二个参数为调用时传递的第一个实参,第三个参数为调用时传递的第二个实参//bind绑定后是一个可调用对象(仿函数),再使用function进行包装为funfunction<double(double, double)> fun = bind(&A::addd, A(), _1, _2);cout << fun(1.1 , 2.2) << endl;相关文章:

C++——C++11常用语法总结
C11标准由国际标准化组织(ISO)和国际电工委员会(IEC)旗下的C标准委员会(ISO/IEC JTC1/SC22/WG21)于2011年8月12日公布,并于2011年9月出版。2012年2月28日的国际标准草案(N3376)是最接近于C11标准…...

C++17 新特性简解
C17 新特性简解 一、核心语言特性 1. 结构化绑定(Structured Bindings) 用途:解构复合类型(如元组、结构体)为独立变量 示例: #include <iostream> #include <tuple>int main() {// 解构 st…...

【失败】Gnome将默认终端设置为 Kitty
起因 一会儿gnome-terminal一会儿kitty终端,实在是受不了,决定取缔默认的gnome-terminal。 过程 在 Ubuntu 或 Debian 系统上: 确保 Kitty 已经安装。如果未安装,可以在终端中运行命令sudo apt install kitty -y进行安装。 使用系…...

【Easylive】微服务架构在系统中的优缺点的具体体现
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 在线视频分享系统项目简介 系统概述 该项目是一个基于SpringCloud微服务架构的在线视频分享系统,主要功能包括: • 用户自主发布视频 • 后台视频审核 • 用户互动…...
、信号量(Semaphore)与条件量(Condition Variable))
锁(Mutex)、信号量(Semaphore)与条件量(Condition Variable)
一、同步机制的核心意义 在多线程/多进程编程中,当多个执行流共享资源(如变量、内存、文件)时,可能因操作顺序不确定导致数据竞争(Data Race)。同步机制的作用是: 保证原子性:确保…...

使用pnpm第一次运行项目报错 ERR_PNPM_NO_PKG_MANIFEST No package.json found in E:\
开始用unibestpnpm写一个小程序 运行pnpm init报错 如标题所示没有package.json这个文件 博主犯了一个很愚蠢的错误。。 准备方案手动创建一个json文件 此时才发现没到根目录下,创建了一个项目之后就没有切入文件夹里。 切入根目录再下载就成功啦...

前沿篇|CAN XL 与 TSN 深度解读
引言 1. CAN XL 标准演进与设计目标 2. CAN XL 物理层与帧格式详解 3. 时间敏感网络 (TSN) 关键技术解析 4. CAN XL + TSN 在自动驾驶领域的典型应用...

从零开始学A2A一:A2A 协议的高级应用与优化
A2A 协议的高级应用与优化 学习目标 掌握 A2A 高级功能 理解多用户支持机制掌握长期任务管理方法学习服务性能优化技巧 理解与 MCP 的差异 分析多智能体场景下的优势掌握不同场景的选择策略 第一部分:多用户支持机制 1. 用户隔离架构 #mermaid-svg-Awx5UVYtqOF…...

追赶地球变化的“快镜头“:遥感时间分辨率的奥秘
在地球表面,万物的生长、兴衰和变迁,如同一部永不停歇的电影。而科学家们想要看清每一帧画面,就必须依赖遥感卫星这个"超级摄影师"。今天,我们就来聊聊遥感领域里一个关键的维度——时间分辨率。 想象一下,如…...

轻量还是全量?Kubernetes ConfigMap 与专业配置中心的抉择
文章目录 简介什么是 ConfigMapConfigMap 的核心能力配置存储与注入动态更新与 Kubernetes 原生生态深度集成 ConfigMap 的固有局限专业配置中心对比选型建议结语 简介 在现代微服务架构中,集中式配置管理是保证应用可维护性、可扩展性和安全性的关键环节。Kuberne…...

mybatis plus打印sql日志到指定目录
1、mybatis plus打印sql日志 参考文档:mybatis plus打印sql日志_mybatisplus日志打印-CSDN博客 2、修改 修改InfoLevelLogger Override public void debug(String s) {// 修改这里logger.info(s);log.debug(s); } 增加:log.debug(s); 修改logback.x…...

CUDAfy的使用
此文章是对一篇使用文档的翻译总结 文档地址 https://www.doczj.com/doc/0f2570173.html CUDAfy使用步骤 1. 环境准备 硬件要求:支持CUDA的NVIDIA显卡(如GTX系列)。软件安装: 安装最新版NVIDIA驱动。下载并安…...

DeepSeek 部署中的常见问题及解决方案
DeepSeek(深度求索)大模型部署过程中常见问题的系统性解决方案,涵盖环境配置、模型加载、性能优化、安全防护及企业级部署等核心场景,结合官方文档与社区实践提供可落地的操作指南: 一、环境配置与依赖问题 1. 操作系统与硬件兼容性 问题表现:部署失败提示驱动不兼容或…...

【AI提示词】儿童看护员
提示说明 儿童看护员旨在帮助用户构建一个既专业又富有爱心的儿童看护员角色,以满足儿童在成长过程中的各种需求。 提示词 # 角色 儿童看护员## 注意 1. 儿童看护员应具备亲和力和耐心,以确保与儿童的良好互动。 2. 专家设计应关注儿童的安全、健康和…...

深入解析 Python 中的装饰器 —— 从基础到实战
1. 装饰器基础 1.1 什么是装饰器? 装饰器本质上是一个 Python 函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能。装饰器的返回值也是一个函数对象。 1.2 语法糖: 符号 Python 提供了 符号作为装饰器的语法糖,…...

学习海康VisionMaster之中线查找
一:进一步学习了 今天学习下VisionMaster中的中线查找,这个就是字面意思,输入两条直线,输出两条直线的中线 二:开始学习 1:什么是中线查找?今天这个比较简单,其实这个模块算是一个几…...

笔记整理五
STP生成树 stp生成树是用于解决二层环路问题的协议。 二层环路为有以下三种: 1.广播风暴 2.MAC地址的偏移(每一次循环,都会导致交换机来回刷新MAC地址表记录) 3.多帧复制 stp生成树:需要将原本的环型拓扑结构转换…...

js实现的前端水印
效果 var defaultConfig {content: [], // 水印内容数组fontSize: 14, // 字体大小(px)fontFamily: sans-serif, // 字体color: rgba(255, 255, 255,.3), // 字体颜色rotate: -20, // 旋转角度(度数)zIndex: 2147483647, // 层级globalAlpha: 0.5, // 透明度canvasWidth: 30…...

前端服务器部署报错记录
报错1:Refused to apply style from http://xxxxxxx.online/assets/index.DepkYCYv.css because its MIME type (text/plain) is not a supported stylesheet MIME type, and strict MIME checking is enabled. index-Dnq3oQAv.js:1 解释:浏览器期望加载…...

JAVA中多线程的经典案例
文章目录 一、线程安全的单例模式(一)饿汉模式(二)懒汉模式 二、阻塞队列(一)生产者消费者模型(二)阻塞队列(三)自定义阻塞队列 三、定时器(一&am…...
在「轨道交通行业」建模教程:轨道列车)
国产三维CAD皇冠CAD(CrownCAD)在「轨道交通行业」建模教程:轨道列车
在轨道交通行业,复杂系统集成、大规模装配验证与跨地域协同设计始终是核心痛点。传统设计工具难以应对动辄百万级零部件的装配挑战,且数据孤岛、版本混乱、硬件成本高昂等问题长期制约行业数字化转型。皇冠CAD(CrownCAD)作为国产云…...

Linux 日常运维命令大全
Linux 作为一种开源操作系统,在服务器运维中扮演着重要角色。掌握常用的 Linux 命令对于运维人员而言至关重要。本文将整理一份 Linux 服务器运维常用命令大全,帮助你在日常工作中提高效率和准确性。 1. 基础命令 基础命令是Linux操作的起点࿰…...

安全测试报告模板
安全测试报告 一、项目概况 项目名称XX智慧医疗平台被测系统版本V2.3.1测试类型渗透测试漏洞扫描测试时间2024年2月15-20日测试标准OWASP TOP 10 2021 二、测试环境 生产环境镜像: - 服务器:CentOS 7.9 Tomcat 9 - 数据库:MySQL 8.0集群…...
config.txt常用选项介绍)
树莓派超全系列教程文档--(31)config.txt常用选项介绍
config.txt常用选项介绍 常用选项常用显示选项hdmi_enable_4kp60 常用硬件配置选项camera_auto_detectdisplay_auto_detectdtoverlaydtparamarm_boostpower_force_3v3_pwm 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 常用选项 常用显示选项 …...

算法-堆+单调栈
堆 首先堆在我们的Java中我们的是一个优先队列类 PriorityQueue 然后我们要弄最大堆和最小堆 最大堆: PriorityQueue<Integer> pq new PriorityQueue<Integer>((a, b) -> b - a); 最小堆: PriorityQueue<Integer> pq new P…...

Charles破解 激活码 Java
第一步,下载charles Download a Free Trial of Charles • Charles Web Debugging Proxy 第二部,生成key,这里使用的是java代码 import java.nio.ByteBuffer; import java.nio.ByteOrder; import java.util.Random;public class test {private static final int ROUNDS 12;p…...

线上蓝桥杯比赛环境配置
1.编译环境(以下是JAVA示例) Java软件开发编程环境 链接: https://pan.baidu.com/s/1JRNx0bkgHmPqQhANSFBNkQ 提取码: ftgw 下载对应的编译器和jdk以及对应的API文档 解压后把eclipse发送到桌面方便使用 2.录屏软件,我这边选择的是OBS St…...

民办生从零学C的第十一天:操作符
每日励志:我们可以随时的转身,但是决不能后退。 一.操作符的分类 算术操作符:、-、*、/、% 移位操作符:<<、>> 位操作符:&、|、^ 赋值操作符:、、-、*、/、%、<<、>>、&…...
)
疑难问题解决(2)
(1):在k230开发板中,ubuntu操作系统中的文件夹中的k230_sdk文件夹与canmv_k230文件夹的区别,以及 /home/ubuntu/canmv_k230/src/rtsmart/rtsmart/userapps/07_driver_hello 与 /home/ubuntu/k230_sdk/src/big/rt-smart…...

第六章 进阶04 尊重
本周周会给大家讲的议题是:尊重。 用“尊重”给周报文件冠名,周会中打开这个文件,就可以在标题中醒目地看到,加深了大家的印象、勾起了大家的好奇心。坚持长期事项的同时,偶尔也灵光一现给团队管理加入一些小插曲&…...

Android 12.0 framework实现对系统语言切换的功能实现
1.前言 在12.0的系统rom定制化开发过程中,在定制某些接口的过程中,需要通过系统提供接口,然后实现对系统语言的切换 功能实现,接下来分析下系统中关于系统语言切换的相关功能 2.framework实现对系统语言切换的功能实现的核心类 frameworks/base/core/java/android/app/IA…...

Origin LabTalk
之前用惯了matplotlib绘图,出于科研需要部分图用origin来画,但是还是想着要结合python来处理数据更加的方便,经过一番捣鼓发现origin自带有labtalk,并且还带有python的环境,真可谓是NB的很。 若能由程序代劳,何必亲手?…...

基于VS Code 为核心平台的python语言智能体开发平台搭建
以下是基于 VS Code 为核心平台,整合 Node-RED、Gradio、Docker Desktop 的智能体可视化开发平台优化方案,聚焦工具链深度集成与开发效率提升: 一、核心架构设计 #mermaid-svg-f8l9kYPAlJ2TlpGF {font-family:"trebuchet ms",verd…...

Python 创意:AI 图像生成
一、基于 Stable Diffusion 的本地创意创作 Stable Diffusion 是开源图像生成模型的代表,通过 Python 结合diffusers库,可实现本地图像生成。 1. 环境搭建 首先,安装必要的库: pip install diffusers transformers torch若使用 GPU 加速,需安装对应版本的 CUDA 和 cuD…...

vue3 传参 传入变量名
背景: 需求是:在vue框架中,接口传参我们需要穿“变量名”,而不是字符串 通俗点说法是:在网络接口请求的时候,要传属性名 效果展示: vue2核心代码: this[_keyParam] vue3核心代码&…...

Skipped breakpoint at ... because of stepping in another thread问题分析
在Java多线程应用程序的调试过程中,开发者可能会遇到“Skipped breakpoint at … because of stepping in another thread”这样的提示。这通常是因为调试器在处理多线程操作时,忽略了某个断点。本文将详细分析这一问题的原因,并提供有效的解…...

MATLAB脚本实现了一个转子系统的参数扫描和分岔分析
% 参数扫描范围 clc; clear; close all;S_values 500:200:20000; % 转速范围% 定义系统参数 N 5; % 质量点数量 num_nodes N; % 节点数 num_dofs_per_node 4; % 每个节点的自由度数 num_elements num_nodes-1; % 单元数 total_dofs num_nodes * num_dofs_per_node; % 总自…...

基于Flask的AI工具聚合平台技术解析
基于Flask的AI工具聚合平台技术解析 一、项目架构设计 本系统采用经典的三层架构模式,通过Mermaid架构图可清晰看到数据流向: 用户请求通过浏览器发送至Flask服务器路由系统解析请求路径模板引擎动态渲染页面静态资源提供样式支持独立数据模块实现内容…...

AUTOSAR图解==>AUTOSAR_SWS_CryptoInterface
AUTOSAR 加密接口(Crypto Interface)详解 基于AUTOSAR标准4.4.0的加密接口规范详细分析与图解 目录 概述 1.1 加密接口的作用与位置 1.2 主要术语解释架构设计 2.1 加密接口架构 2.2 组件关系内部结构 3.1 类结构 3.2 配置项运行流程 4.1 加密请求处理流程 4.2 同步与异步处理…...

GCD算法的学习
GCD算法的学习 学习了前辈wzx15927662183的文章GCD算法精讲-CSDN博客 介绍 GCD通常用来求两个数的最大公约数 算法的核心:gcd(a,b) gcd(b,a % b) 证明的思路: 证明 gcd(a, b) gcd(b, a % b) 的思路: 设 a > b 1. 构造 a % b : 设 …...
)
完美解决浏览器不能复制的问题(比如赛氪网的中题库练习题)
仅供复制题库题目进行打印学习使用! 最近想把赛氪网题库中的题目打印出来做练习,发现题库中的题目不能复制,不能在试卷上勾画标记太难受了,而且不能留作材料以后复习,故出此策。 而且CtrlP打印出的pdf会缺少题目。(我…...

Java 爬虫按关键字搜索淘宝商品:实现与优化
在电商领域,获取淘宝商品信息对于市场分析、价格监控和竞争情报等方面具有重要意义。Java 爬虫技术为我们提供了一种高效、自动化的方式来按关键字搜索淘宝商品。本文将详细介绍如何使用 Java 爬虫按关键字搜索淘宝商品,并提供完整的代码示例。 一、准备…...

build.gradle task copyJarToDesktop
build.gradle task copyJarToDesktop 构建完,拷贝jar包到指定文件夹AAA,例如:桌面,方便拉到宝塔发布 build.gradle plugins {id org.springframework.boot }jar {enabled false // 不生成 plain.jar }bootJar {archiveFileNa…...

Git合并分支的两种常用方式`git merge`和`git cherry-pick`
Git合并分支的两种常用方式git merge和git cherry-pick 写在前面1. git merge用途工作方式使用git命令方式合并使用idea工具方式合并 2. git cherry-pick用途工作方式使用git命令方式合并使用idea工具方式合并 3. 区别总结 写在前面 一般我们使用git合并分支常用的就是git mer…...

基于n8n的AI应用工作流原理与技术解析
基于n8n的AI应用工作流原理与技术解析 在AI技术深度融入企业数字化转型的今天,开源工作流自动化工具n8n凭借其灵活的架构和强大的集成能力,成为构建智能自动化流程的核心引擎。本文将从技术原理、AI融合机制、典型应用场景三个维度,解析n8n在…...

Day3-UFS深入学习路线
UFS 学习链接1:UPUI数据包格式 学习链接2:UPUI数据包详解 学习链接3:UFS电源及低功耗 一、基础准备阶段 1.理解存储技术背景 学习NAND Flash基本原理(SLC/MLC/TLC、读写擦除操作、磨损均衡)。对比其他存储协议&…...

广东2024信息安全管理与评估一阶段答案截图
2023-2024 学年广东省职业院校技能大赛 高等职业教育组 信息安全管理与评估 赛题一 模块一 网络平台搭建与设备安全防护 一、 比赛时间 本阶段比赛时间为 180 分钟。 二、 赛项信息 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 第一…...

8.Rust+Axum 数据库集成实战:从 ORM 选型到用户管理系统开发
摘要 深入探讨 RustAxum 数据库集成,包括 ORM 选型及实践,助力用户管理系统开发。 一、引言 在现代 Web 应用开发中,数据库集成是至关重要的一环。Rust 凭借其高性能、内存安全等特性,与 Axum 这个轻量级且高效的 Web 框架结合…...

题解:CF886E Maximum Element
正难则反,考虑长度为 i i i 的排列得到正确的结果的方案数。 设 d p i dp_i dpi 表示长度为 i i i 的排列直到循环完也没有提前 return 的方案数。考虑 i i i 所放置的位置,由于不会提前 return,也就说明该数字所在的位置为 [ i − k…...
:wxFormBuilder;基础框架;事件处理)
OPC Client第3讲(wxwidgets):wxFormBuilder;基础框架;事件处理
wxwidgets开源桌面软件框架使用 - 哔哩哔哩 wxwidgets跨平台GUI框架使用入门详解_哔哩哔哩_bilibili 一、wxwidgets配置【见上一讲五、】 二、安装wxFormBuilder 1、wxFormBuilder介绍、安装 wxFormBuilder是一个开源的GUI设计工具,支持C、Python等语言&#…...