6.6.图的广度优先遍历(英文缩写BFS)
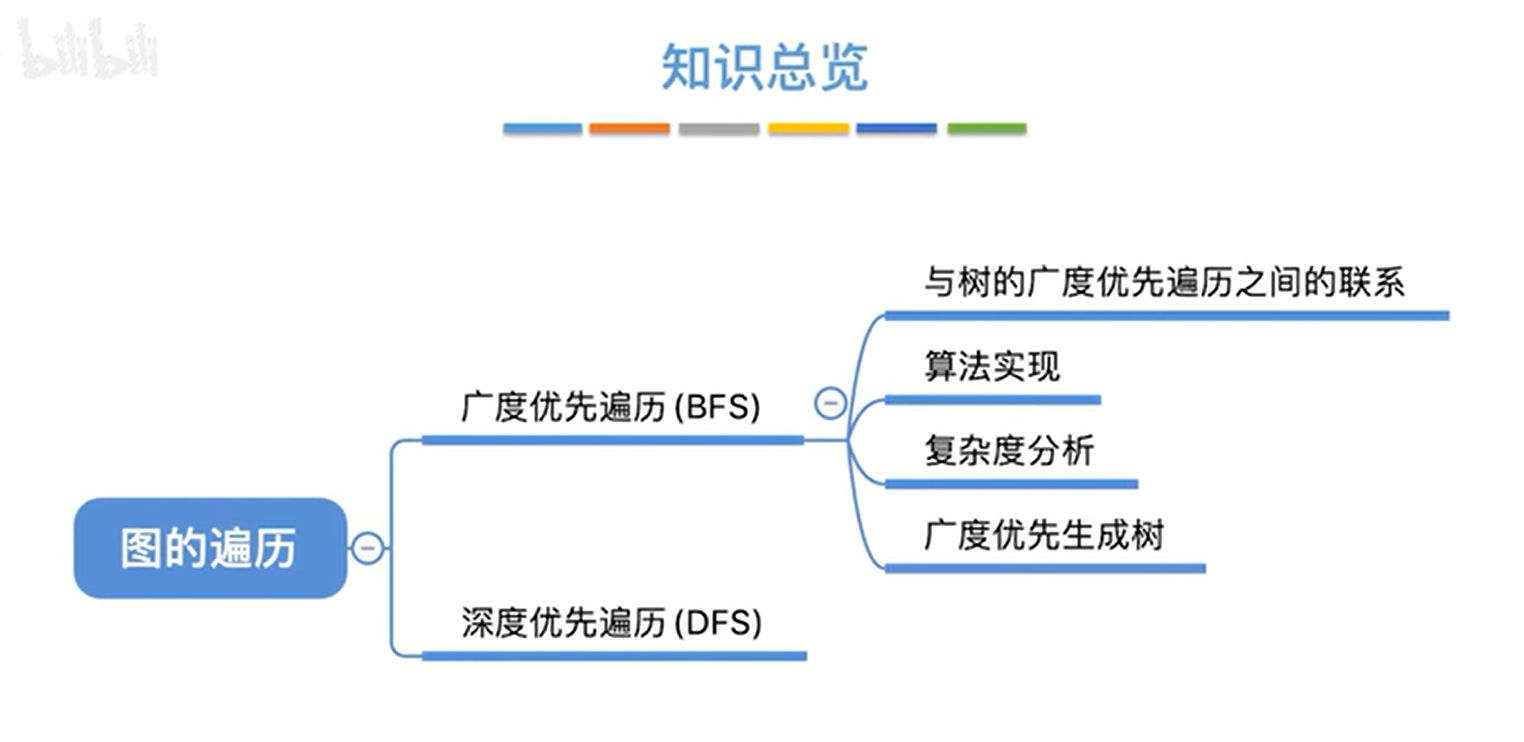
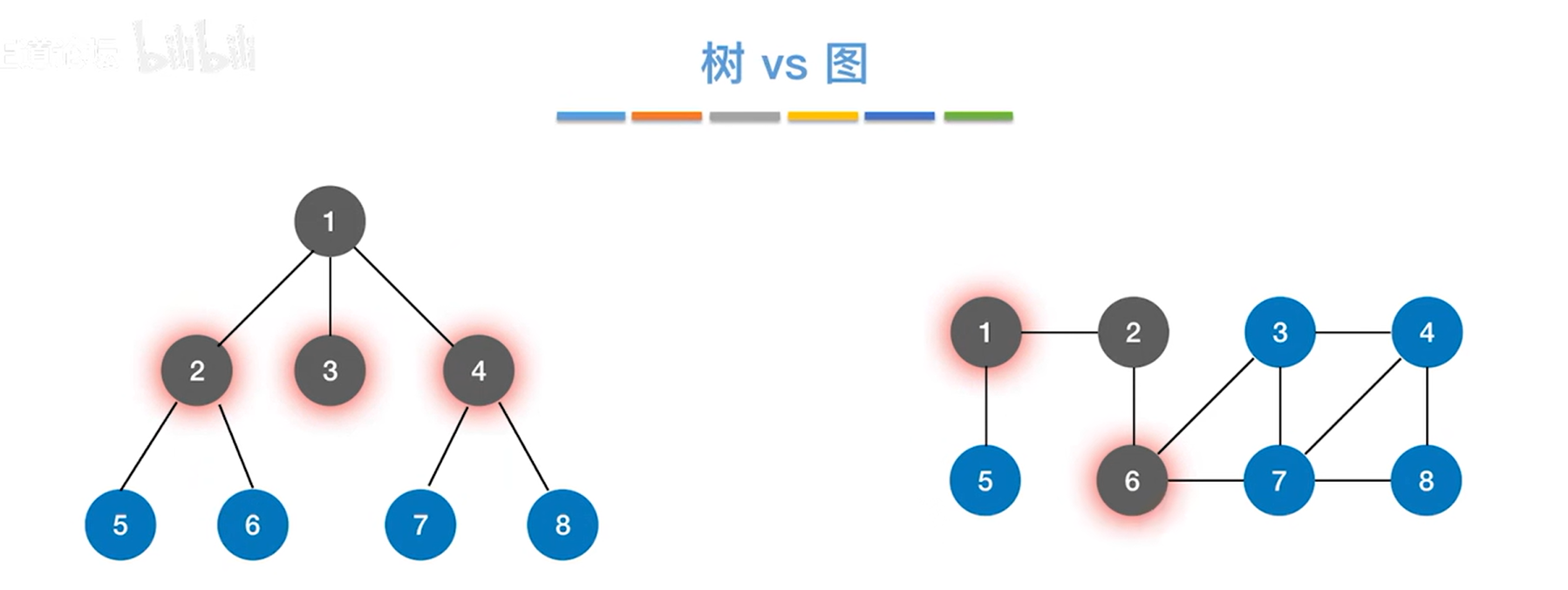
树是一种特殊的图,树的广度优先遍历即层次遍历,所以会从树的角度入手图的广度优先遍历:
-
BFS与DFS的区别在于,BFS使用了队列,DFS使用了栈
一.广度优先遍历:
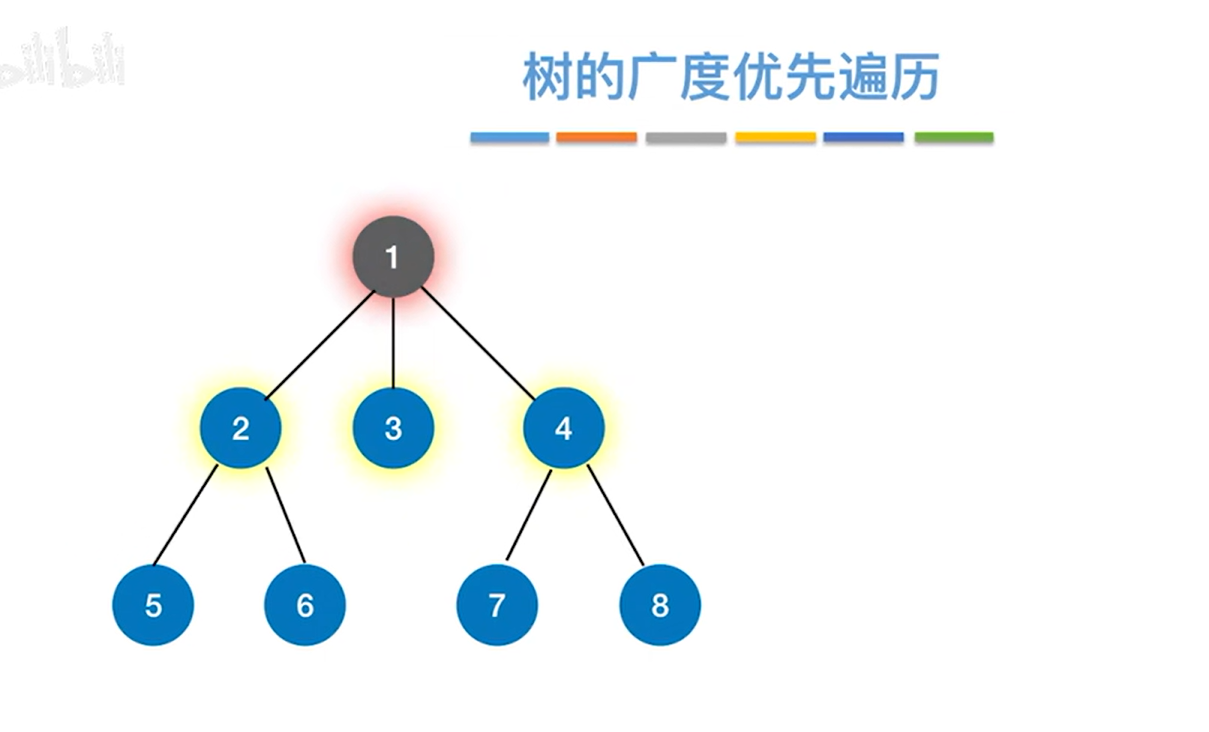
1.树的广度优先遍历:
详情见"5.13.树和森林的遍历"
2.图的广度优先遍历:
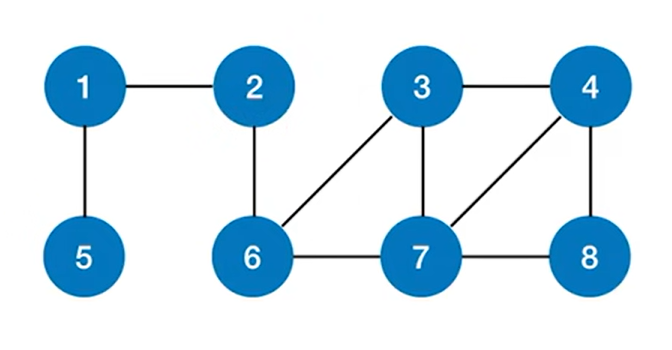
以上述图片为例,从2号结点出发,开始图的广度优先遍历,首先访问2号结点:
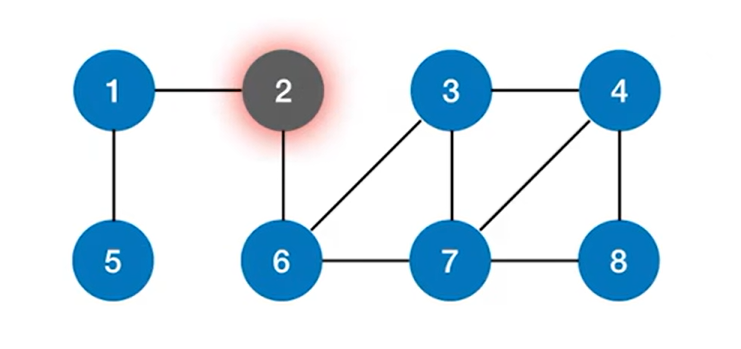
通过2号结点可以找到下一个与之邻近的结点即1号结点和6号结点,并访问1号结点和6号结点:
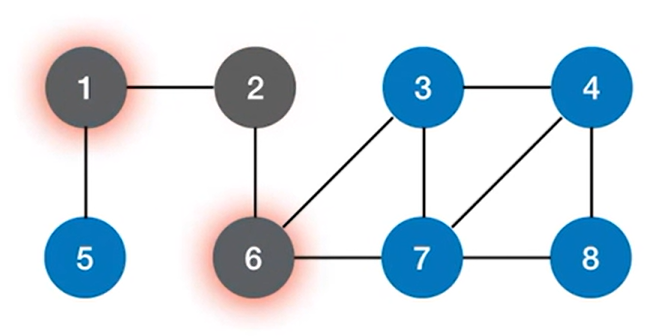
之后分别从1号结点和6号结点出发,再找到与他们邻近的下一个结点并进行访问,通过1号结点找到下一个与之邻近的结点即5号结点并访问5号结点,通过6号结点找到下一个与之邻近的结点即3号结点和7号结点,并访问3号结点和7号结点:
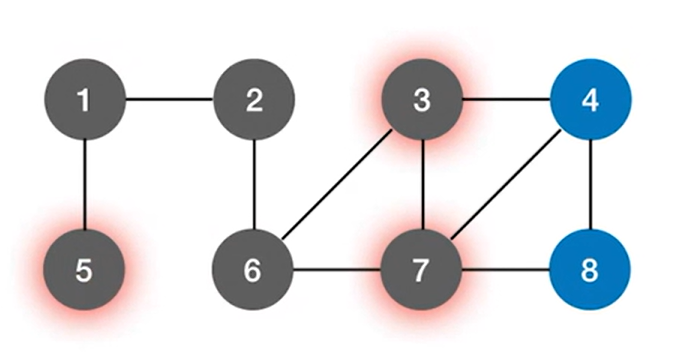
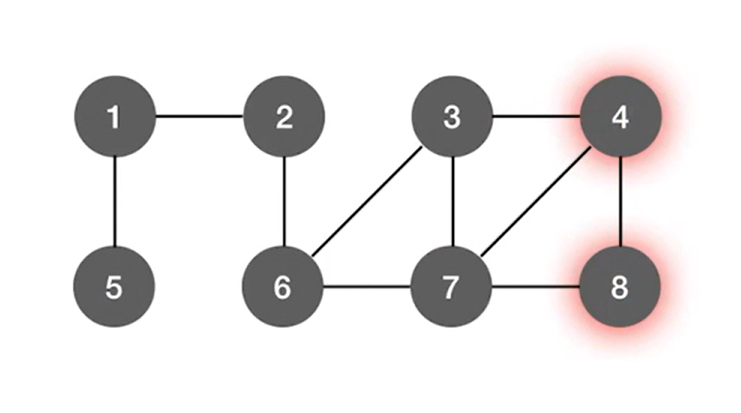
再分别从5号结点、3号结点和7号结点出发,分别找到下一个与之邻近的结点,可知5号结点已经没有与之邻近的下一个结点,通过7号结点可以找到与之邻近的下一个结点即4号结点和8号结点,并访问4号结点和8号结点,3号结点只能找到下一个与之邻近的结点即4号结点并访问4号结点:
二.对比树和图的广度优先遍历:
1.遍历结点:
无论是树,还是图,在进行广度优先遍历时,都需要通过某一个结点找到与之相邻的其他结点,只有实现了这个操作,才可以一层一层往下找到所有的结点:
对于树而言,要找到与某一个结点相邻的其他结点,只需要找该结点的孩子即可;
对于图而言,找相邻的结点只需要通过下述图片的基本操作即可(详情见"图的基本操作"):

2.搜索结点:
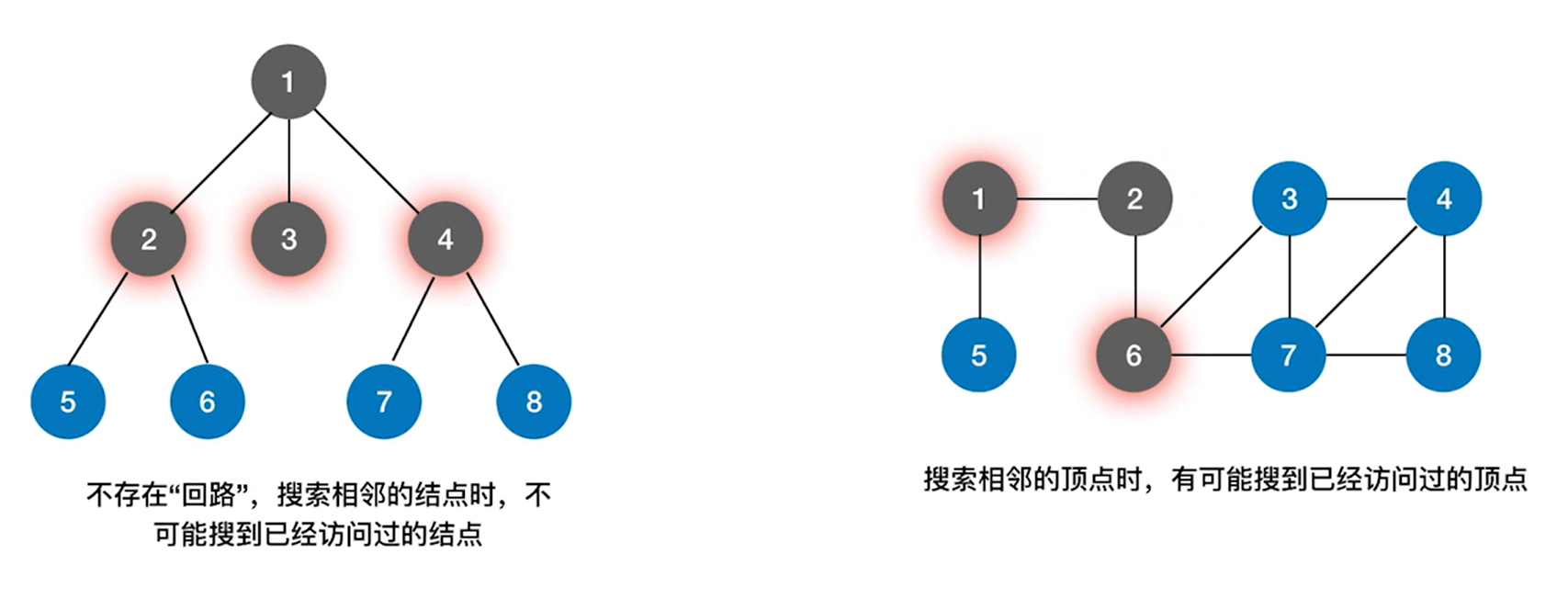
上述图片所示,
对于树而言,由于各个结点之间的路径不存在"回路",因此通过树里的某一个结点搜索其他结点时,搜索到的一定是某个结点的孩子即搜索到的结点一定是之前没有访问过的结点;
对于图而言,由于图中存在环路,而且像上述图片里的无向图,每一条边不存在方向,比如首先访问2号结点,通过2号结点可以搜索到6号结点,通过6号结点,可以找到2、3、7号结点,又或者通过3号结点可以找到4号结点,通过7号结点也可以找到4号结点,此时4号结点就被访问过两次,所以需要对这种情况进行处理->此时只需要对各个结点进行一个标记,标记一个结点是否被访问过,如果访问过,下一次如果搜索到被访问的结点,就跳过这个被访问过的结点即可->这样就可以保证在遍历时每个结点只访问一次。
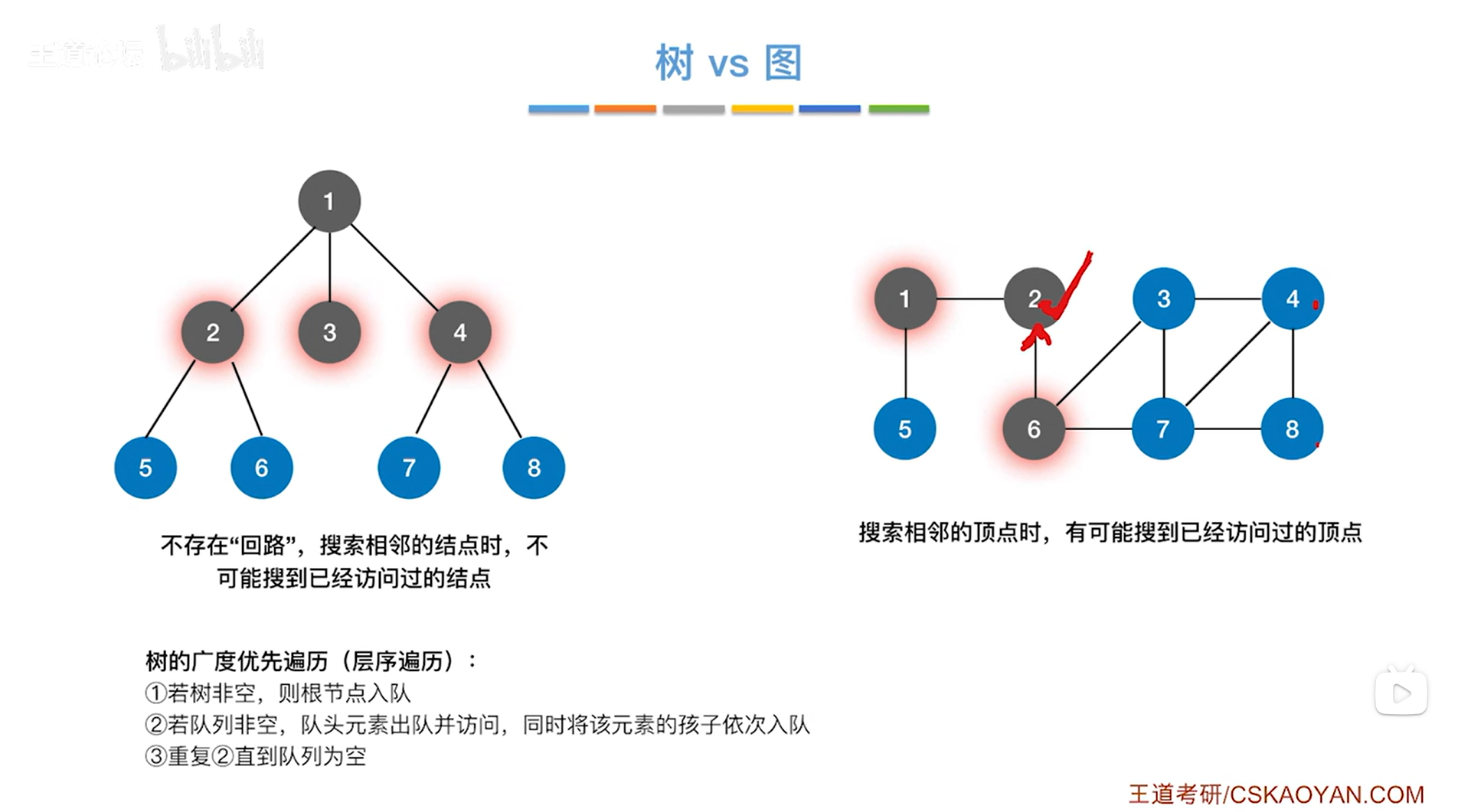
上述图片所示,
实现树的广度优先遍历的时候,需要队列的帮助,因为虽然用肉眼来看,与2号结点同层的3、4号结点一眼就可以找到,但对于计算机而言结点却只能一个一个处理这些结点,暂时还没有处理的结点就需要用一个队列存储起来。
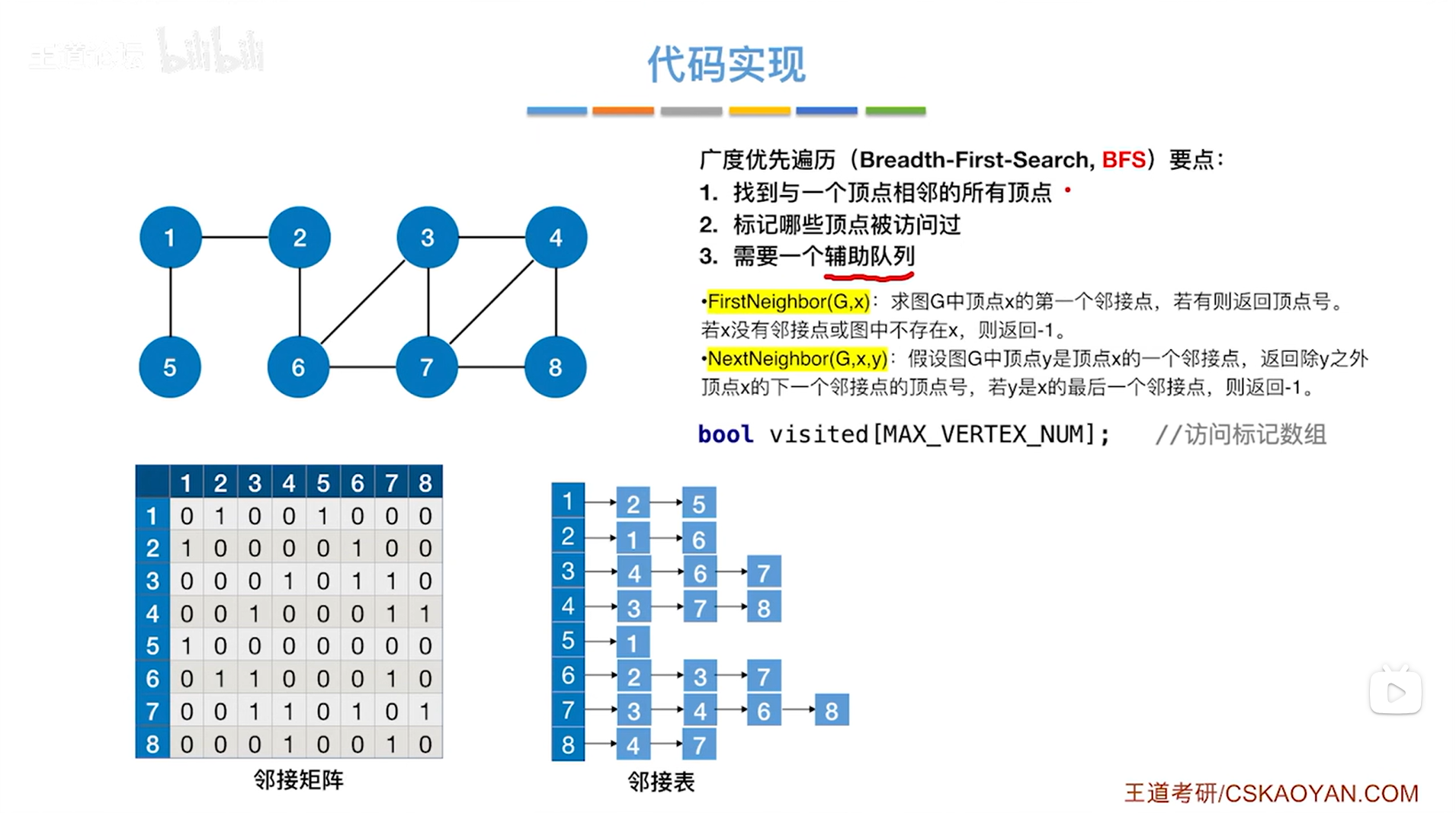
类似的,如上述图片所示,
实现图的广度优先遍历,也可以设置一个队列,此时有3个问题:
1.需要找到与某一个指定顶点相邻的所有顶点,可以利用"图的基本操作"中提到的两个操作(找第一个邻接点,找后一个与之相邻接的顶点);
2.标记哪些顶点被访问过,只需要定义一个布尔类型数组来标记每一个顶点是否被访问过;
3.需要一个辅助队列;
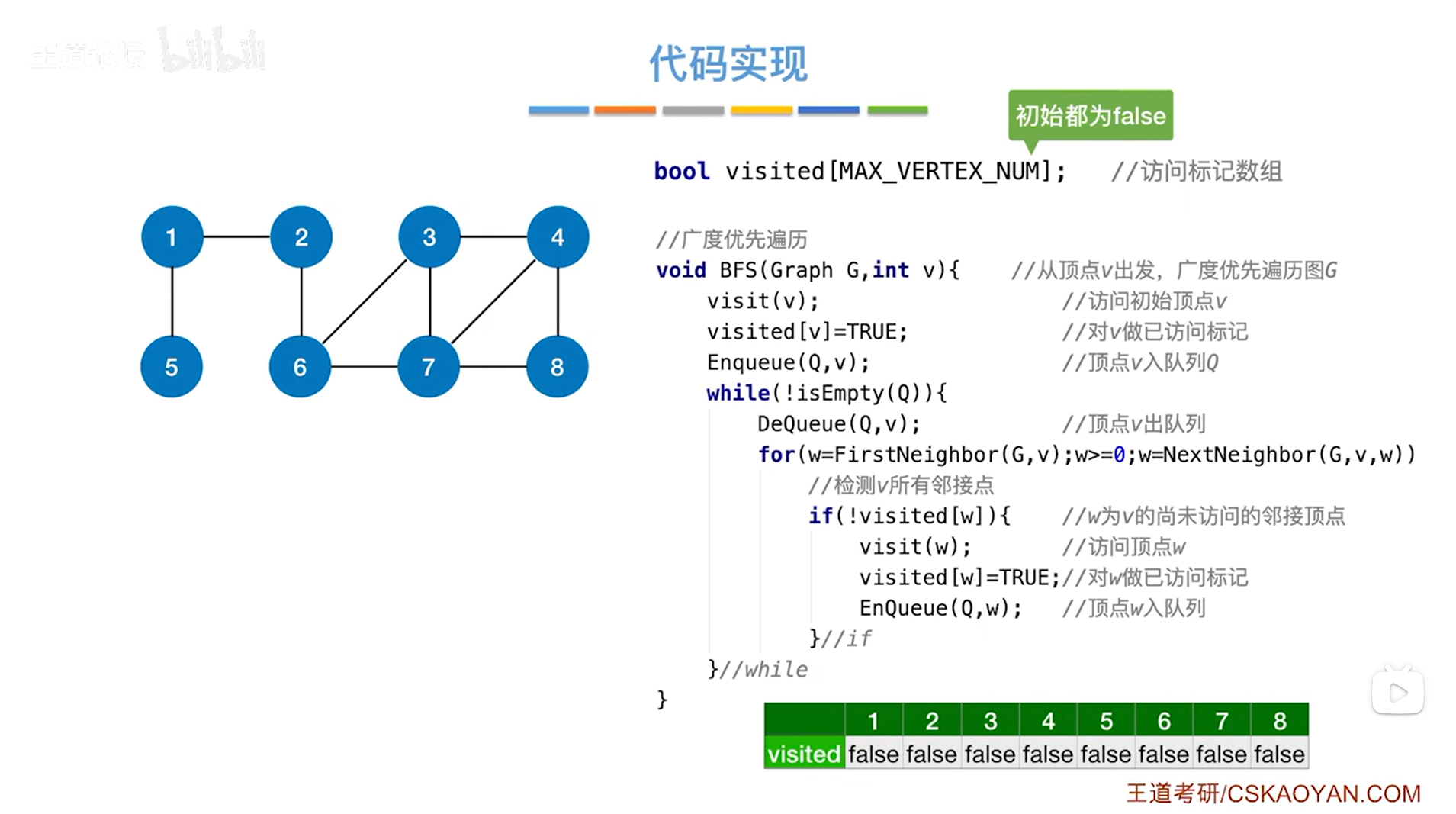
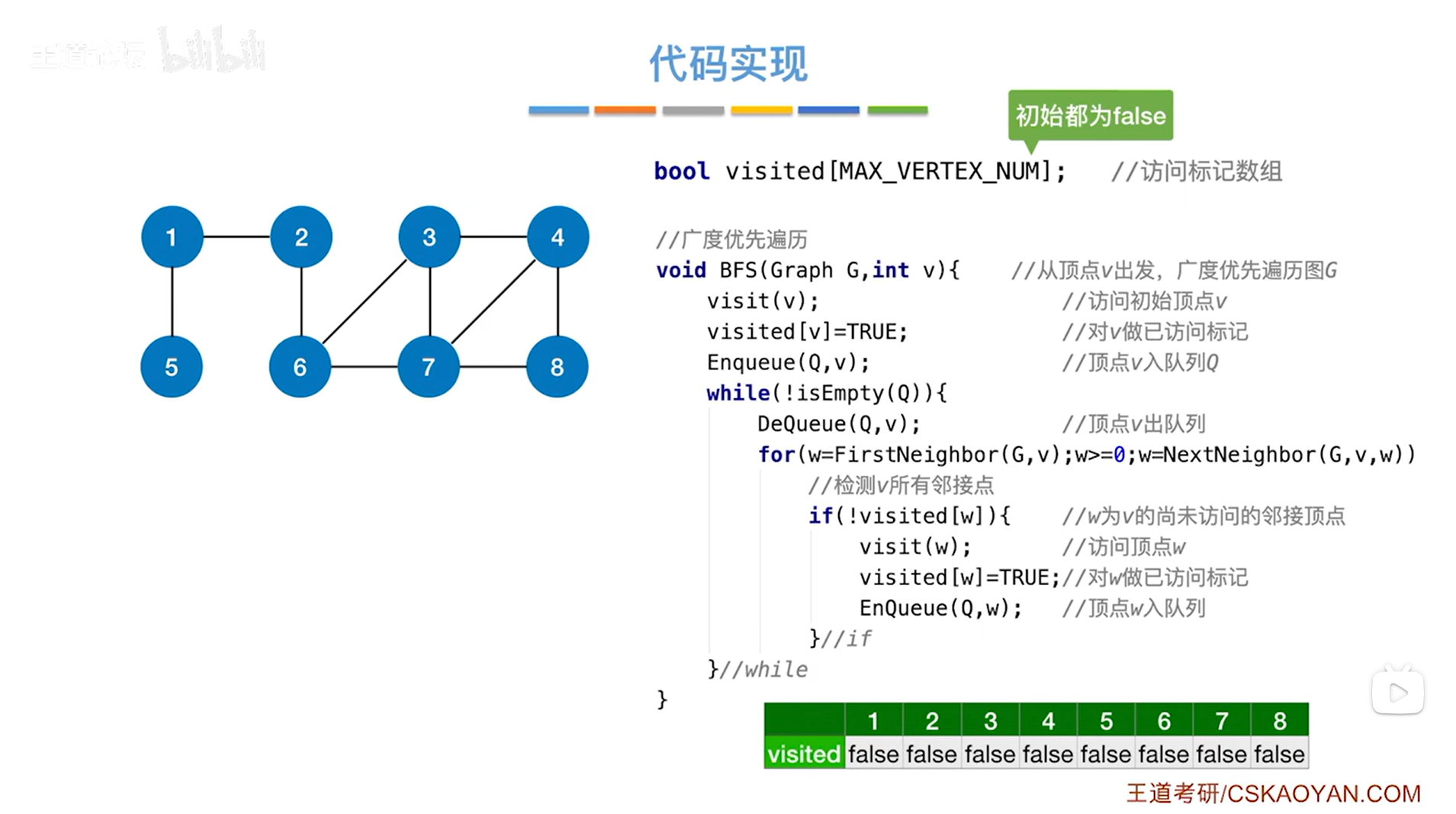
图的广度优先遍历的代码实现如下:
-
visited[MAX_VERTEX_NUM]中的MAX_VERTEX_NUM就是图中顶点最大个数
-
visited数组初始值都设为false,代表一开始所有顶点都没有被访问过,数组的下标都是从0开始,但此时给出的例子中编号是从1开始,所以数组从1索引开始操作,0索引就保持false不动
-
BFS函数的形参v和形参G,表示从第v号顶点出发,遍历图G,Graph是图的类型,在"图的存储结构-邻接矩阵法"中有提到
-
visit函数代表访问顶点,传入v表示访问图G中第v号顶点;visited数组表示第v号顶点是否被访问过,visited[v]=true表示图G中第v号顶点被访问过
-
Enquene函数的作用是把数据添加到队列中,Q是队列,数据类型为SqQueue,详情见"队列的顺序实现",v代表第v号顶点,Enqueue(Q,v)就是把第v号顶点添加到队列Q中
-
while循环的循环条件是判断队列Q是否为空,isEmpty函数的作用用来判断队列Q是否为空,为空的话返回true,不为空的话返回false,如果队列Q不为空,!isEmpty(Q)的结果为true,此时执行while循环
-
while循环中,DeQueue的作用是让队列Q中第v号顶点即队头元素出队,然后队头指针指向下一个元素,接下来要操作出队的第v号顶点->首先要通过第v号顶点找到与第v号顶点相邻的所有顶点,这个操作可以通过while循环里的for循环实现,其中FirstNeighbor(G,v)用来找第v号顶点在G中的第一个邻接点,若存在该邻接点,返回该第一个邻接点的编号,赋值给w,如果w非负,执行for循环,首先判断是否执行if语句,若符合条件!visited[w]为true即第w号顶点没有被访问过,那么就执行if语句,先访问第w号顶点,再把第w号顶点对应的数组的值修改为true,然后第w号顶点进入队列Q,该层for循环结束,再执行NextNeighbor(G,v,w)函数,第w号顶点是第v号顶点的第一个邻接点,找除了第w号顶点外第v号顶点的的下一个邻接点,找到了返回该邻接点的顶点号,赋值给w,判断是否非负,若非负,执行for循环,如不是非负即小于0,跳出for循环->for循环结束后需要判断是否执行下一层while循环,之后以此类推,执行完while循环,图G的广度优先遍历结束
-
FirstNeighbor(G,v)函数和NextNeighbor(G,v,w)函数就是用来找邻接点的,然后返回邻接点的序号,对于这两个函数如何找邻接点,有什么不同,详情见"图的基本操作"
3.图的广度优先遍历实例:
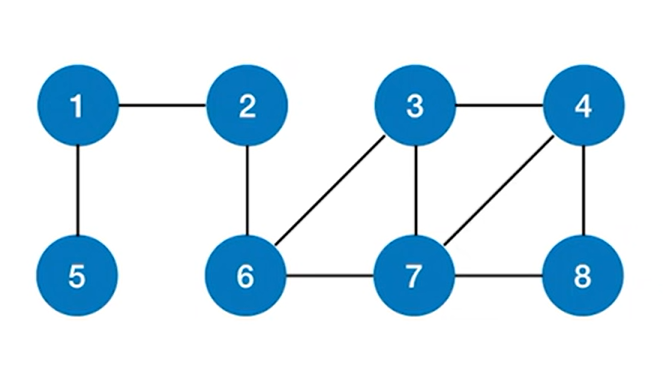
例如使用广度优先遍历,遍历上述图,
下述图片的代码之前有详解:
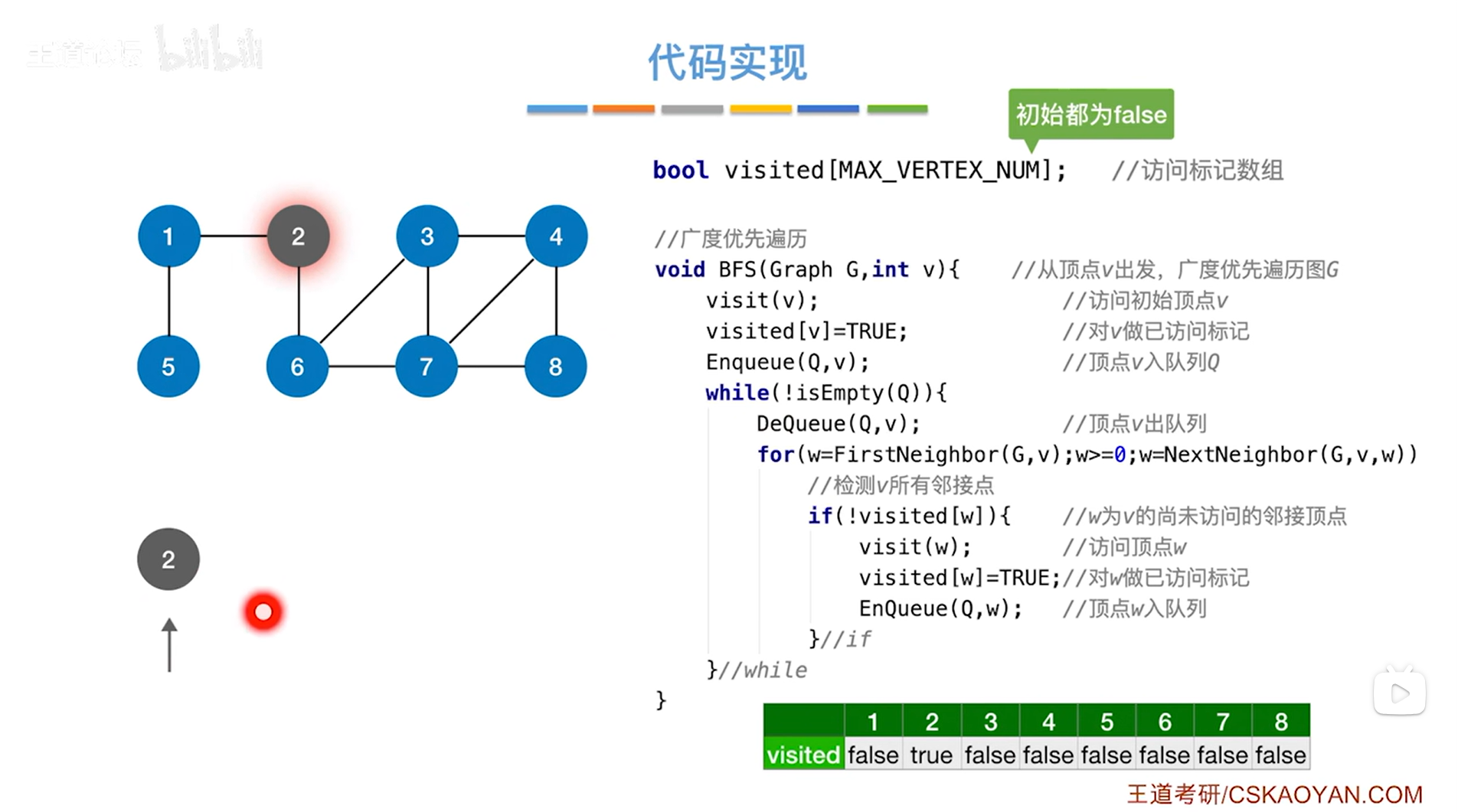
如上述图片所示,假设首先访问2号顶点,修改2号顶点对应的visited数组里的值为true,之后2号顶点入队,此时队头指针指向2号顶点,执行while循环,调用isEmpty函数判断Q队列是否为空(为空的话isEmpty函数返回true,不为空的话isEmpty函数返回false),显然不为空,!isEmpty(Q)的结果为true,执行while循环体->
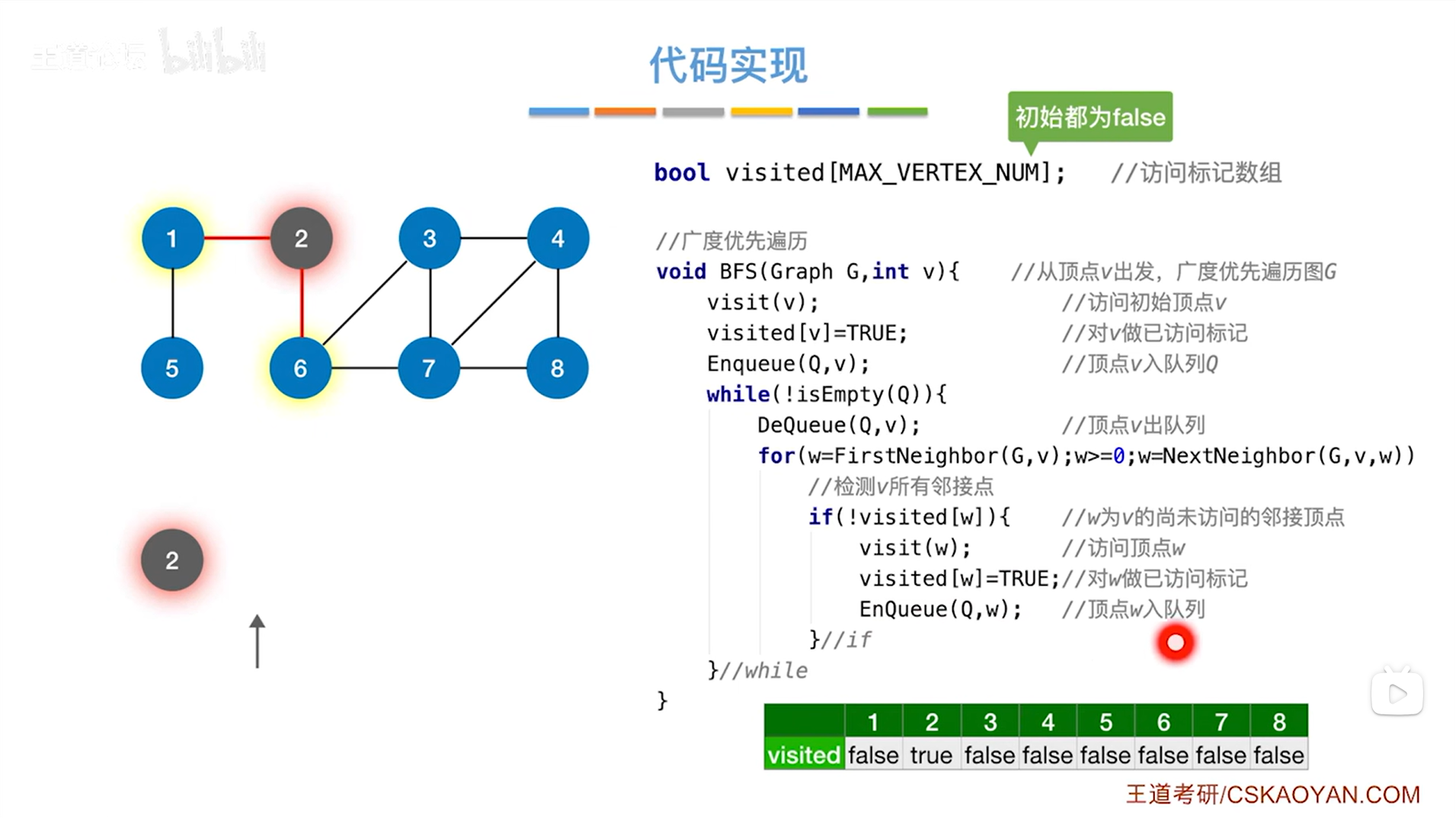
如上述图片所示,调用DeQueue函数让2号顶点即队头顶点出队,开始操作2号顶点,通过for循环找到与2号顶点相邻的所有顶点->
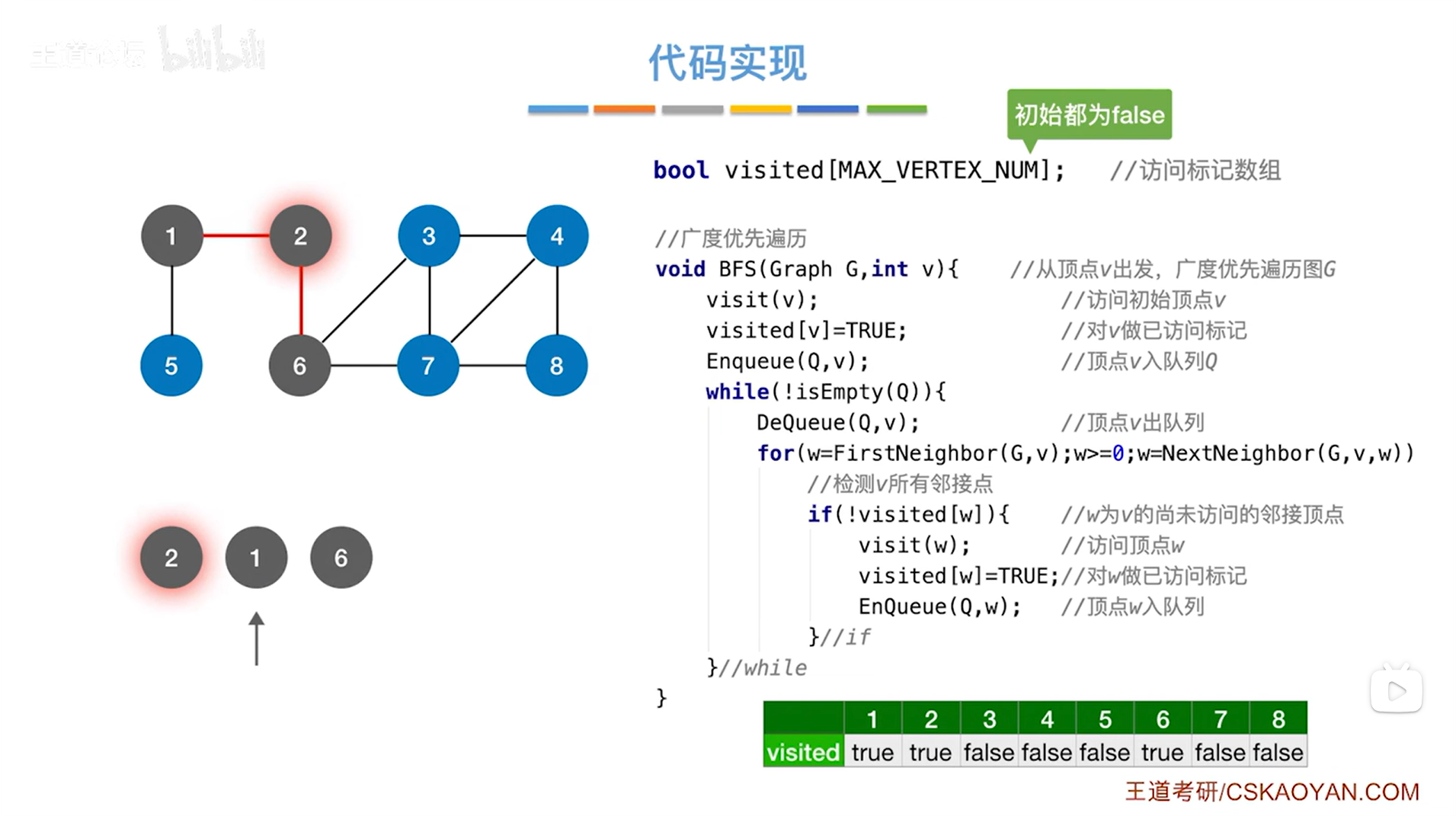
如上述图片所示,最终会找到与2号顶点相邻的1号顶点和6号顶点,1号顶点和6号顶点都没有被访问过,所以会执行if语句,调用其中的visit函数、修改visited数组中的值,而且访问过的顶点即1号顶点和6号顶点还需要放到对应的队列的尾部即执行EnQueue函数->
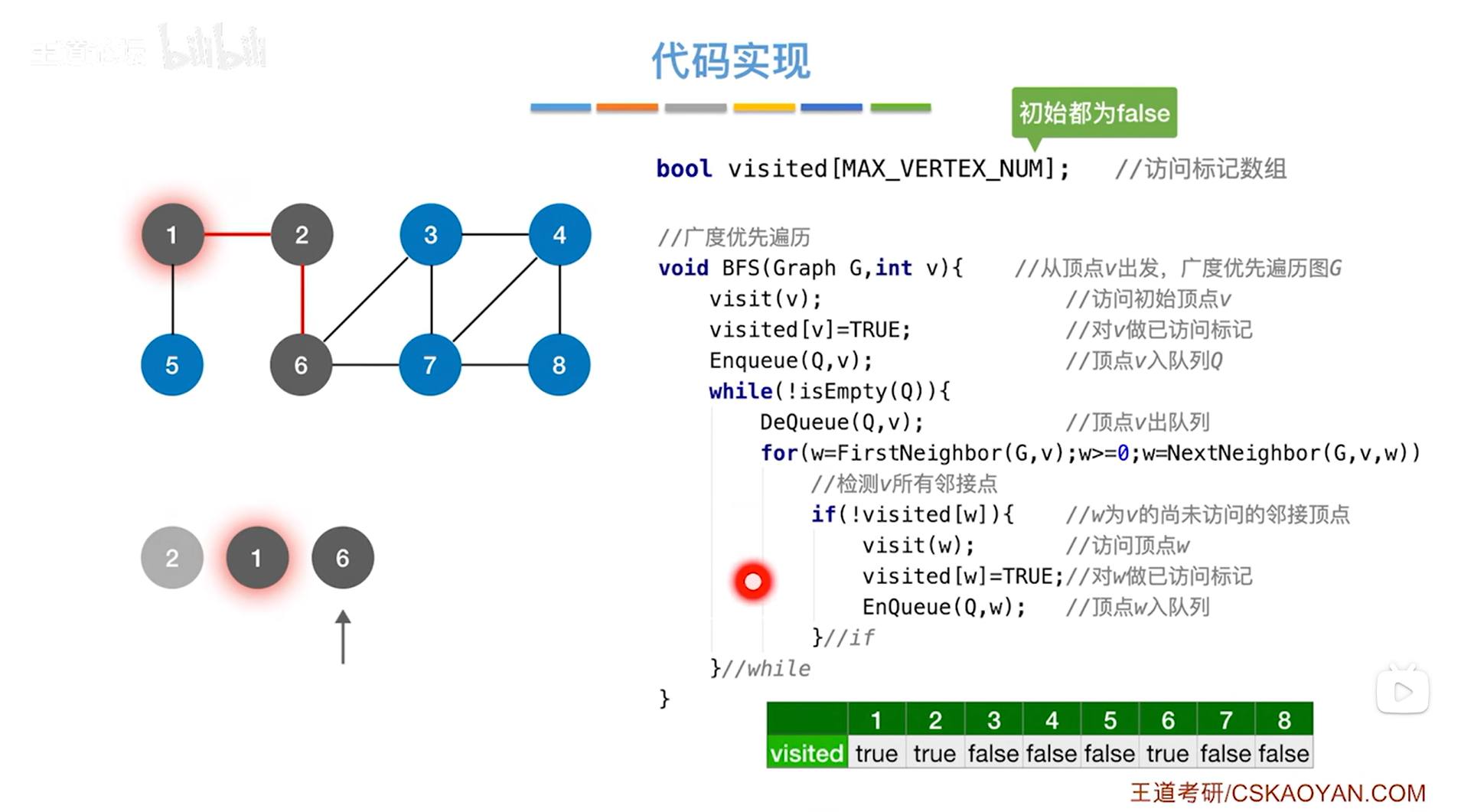
如上述图片所示,for循环结束后,就访问完和2号顶点相邻的所有顶点即处理完2号顶点->
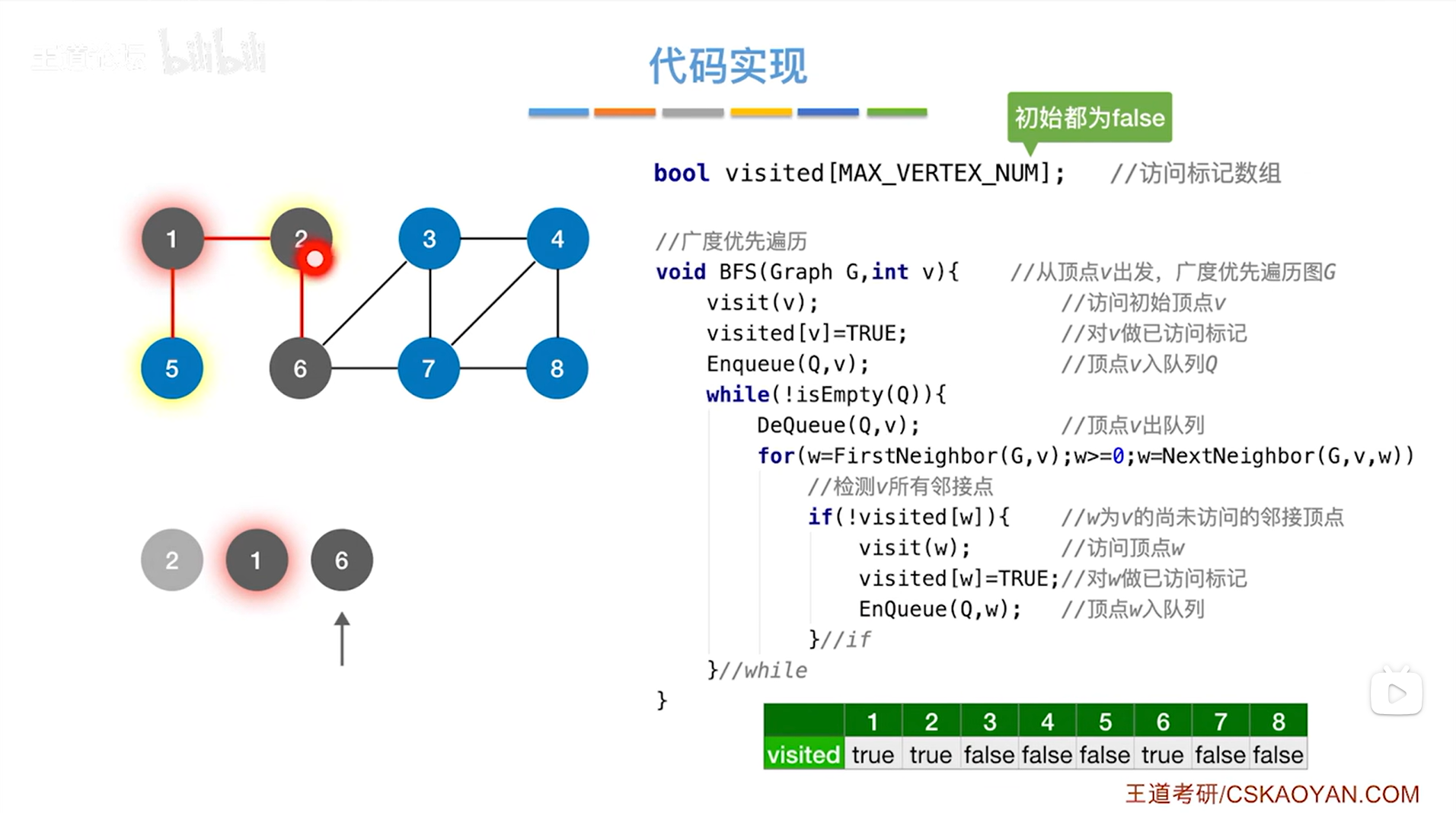
如上述图片所示,会再次判断是否执行while循环,此时2号顶点已出队,队列里只剩1号顶点和6号顶点,而且队头顶点是1号顶点,当前队列不为空,意味着执行while循环,首先调用DeQueue函数把队头指针指向的1号顶点出队,然后执行for循环找与1号顶点相邻的所有顶点,与1号顶点相邻的顶点有2号顶点和5号顶点,由于2号顶点在visited数组中对应的值为true,意味着2号顶点被访问过,所以不满足if语句,因此不会再操作2号顶点,但对于5号顶点,由于5号顶点对应的数组的值为false,符合if语句,因此会访问5号顶点,并且修改5号顶点对应数组的值,并把5号顶点入队尾,至此,1号顶点处理完毕,开始处理下一个顶点即进行下一层while循环->
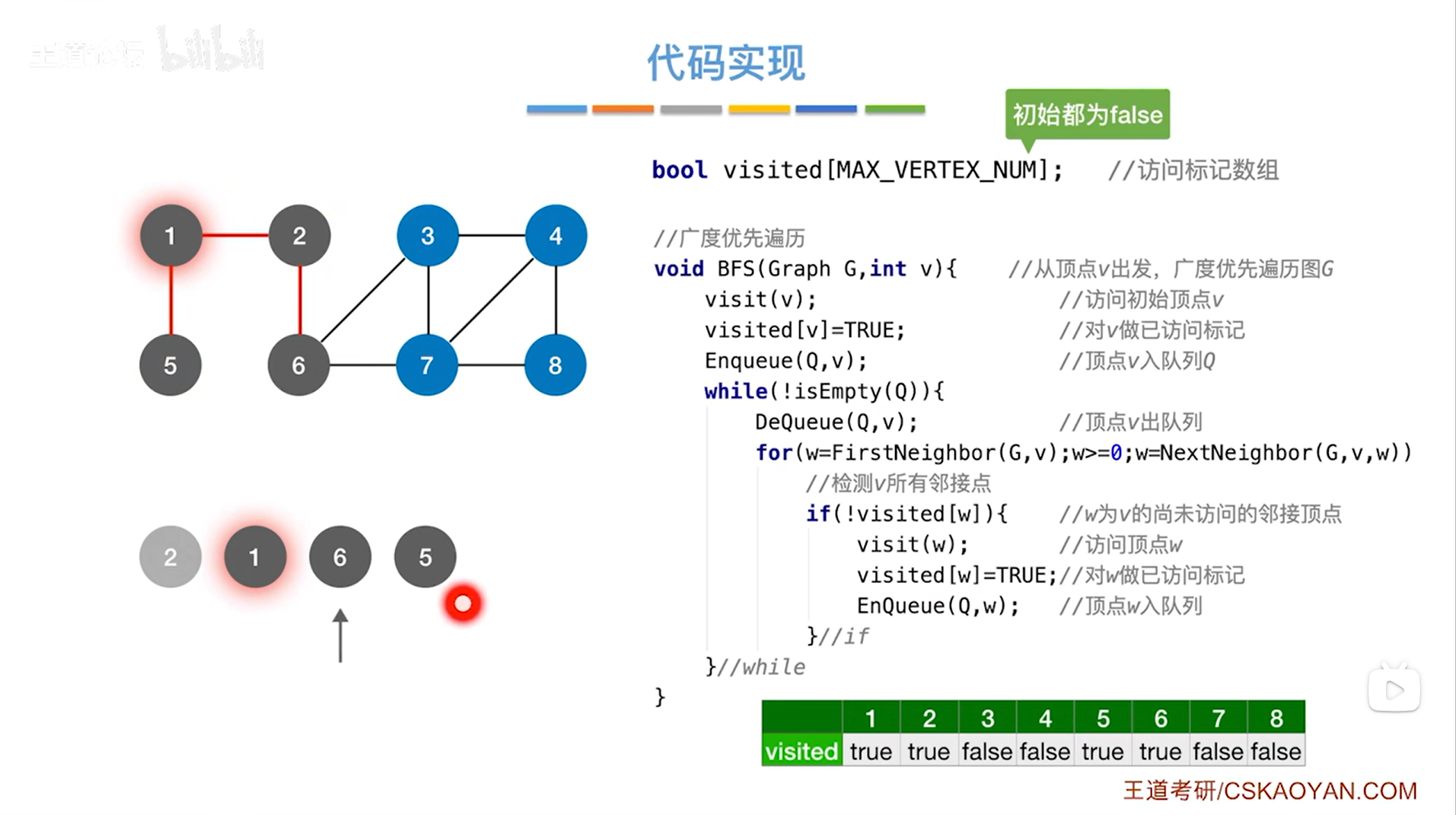
如上述图片所示,当前队列不为空,因此执行while循环->
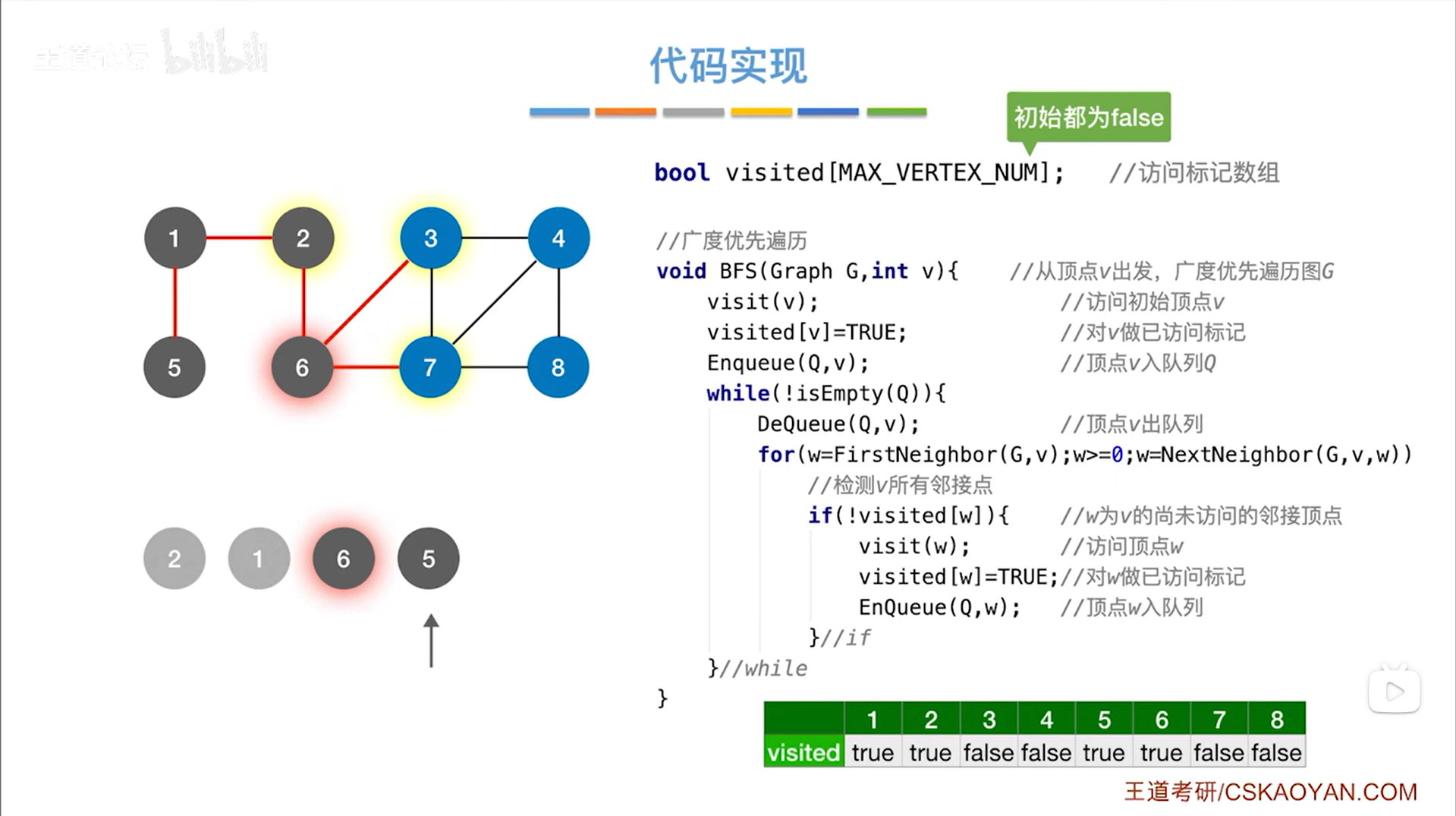
如上述图片所示,队头元素为6号顶点,调用DeQueue函数让6号顶点出队,执行for循环找和6号顶点相邻的所有顶点,和6号顶点相邻的顶点有2、3、7号顶点,2号顶点已经被处理过,所以只会处理3、7号顶点,3、7号顶点会入队,这样就处理完6号顶点->
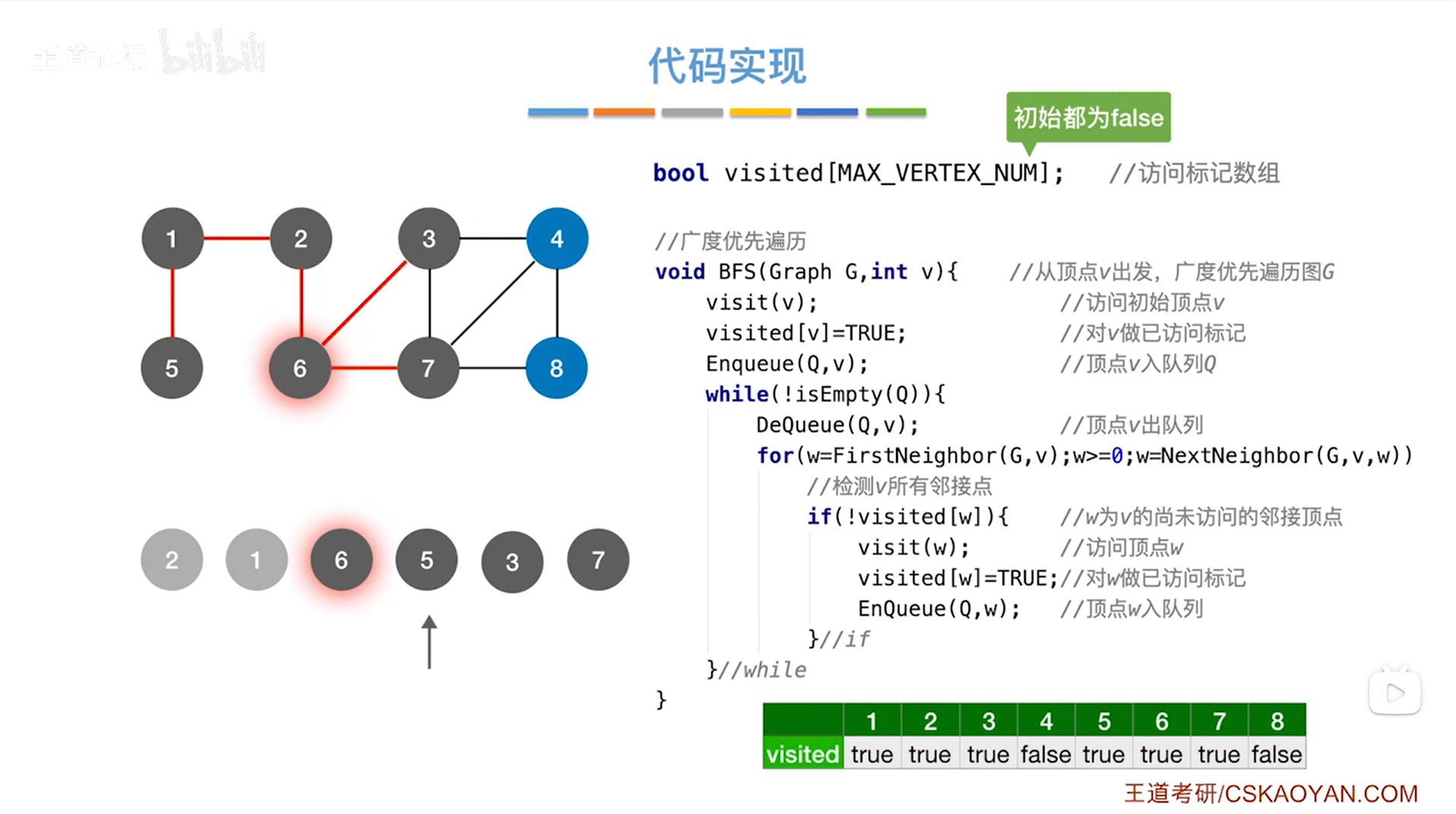
如上述图片所示,同理开始处理5号顶点->
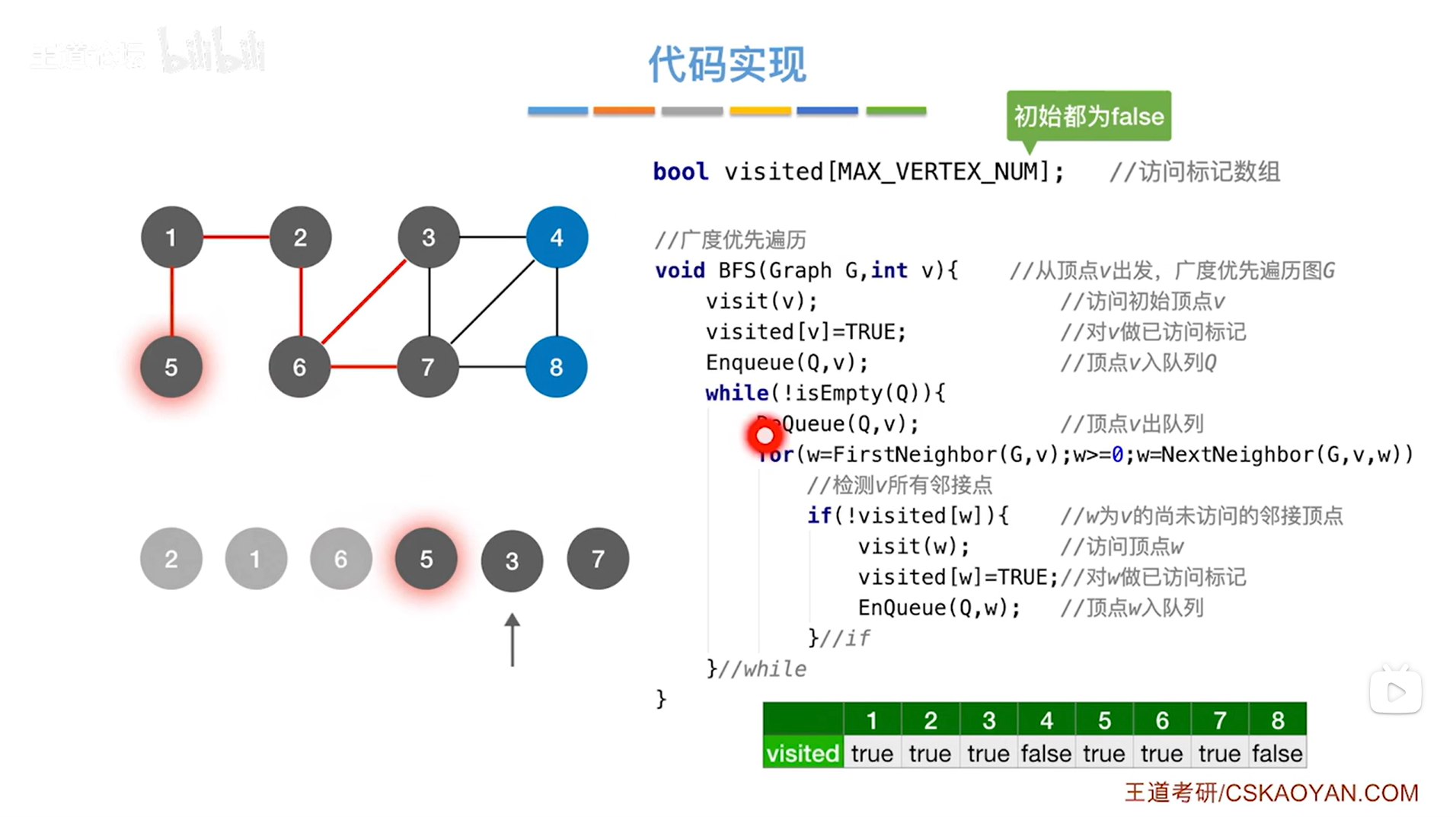
如上述图片所示,5号顶点出队,5号顶点相邻的只有1号顶点,1号顶点已经被处理过,所以不执行if语句,5号顶点处理完毕->
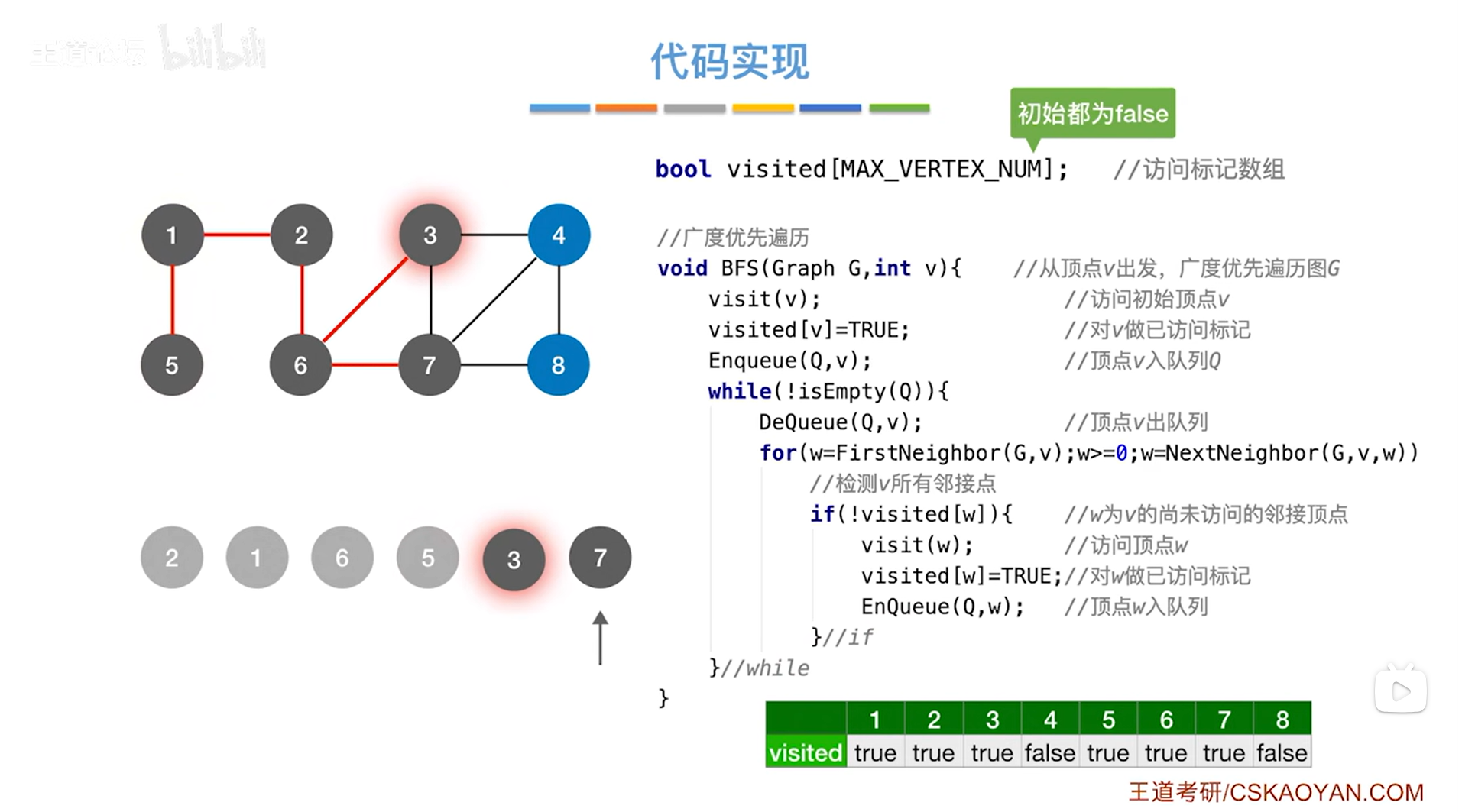
如上述图片所示,同理处理3号顶点,3号顶点出队列,与3号顶点相邻的顶点有4、6、7号顶点,其中只有4号顶点没有被访问过,所以访问4号顶点,修改4号顶点对应的数组的值,把4号顶点放入队尾,3号顶点处理完毕->
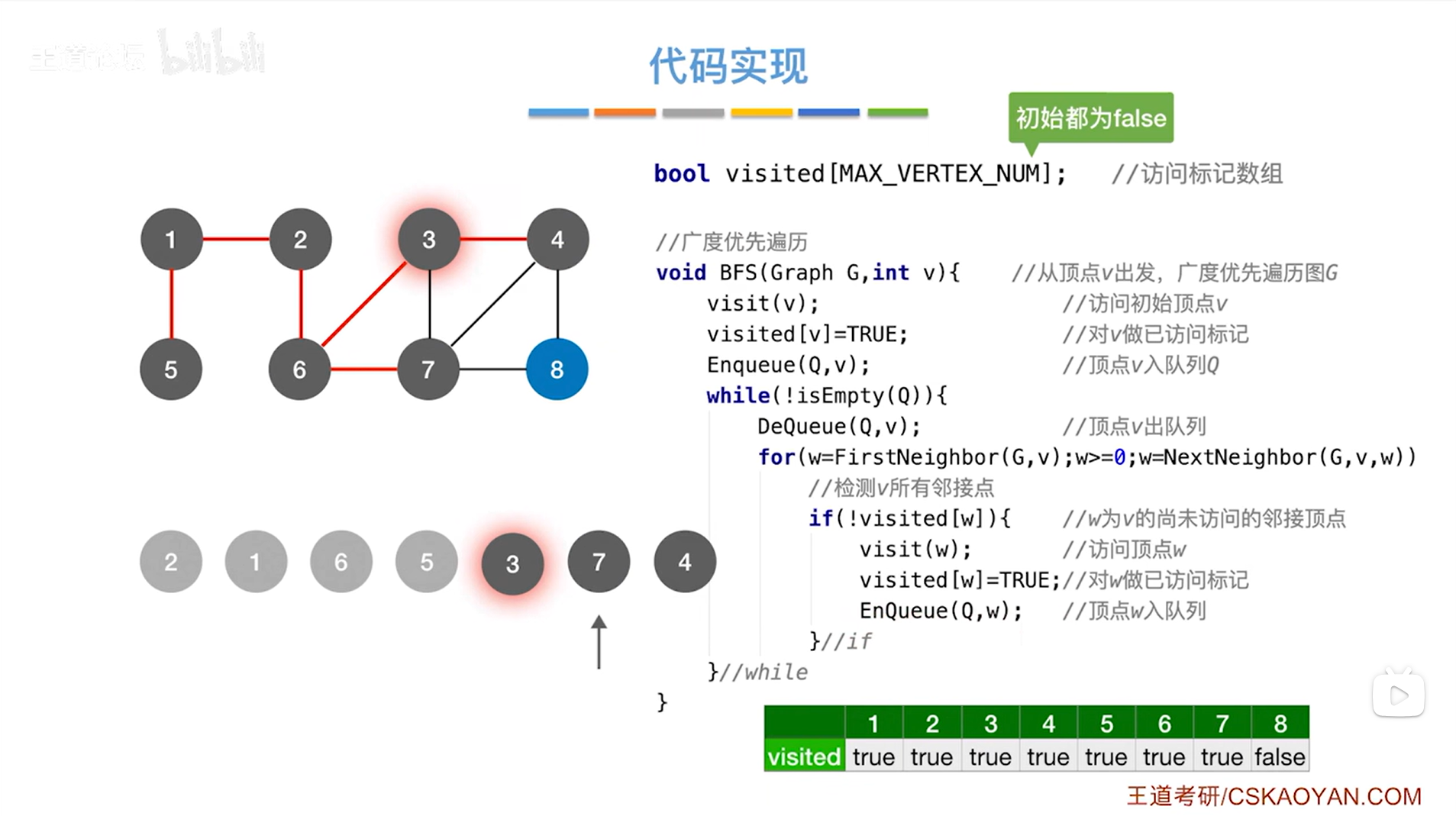
如上述图片所示,同理处理7号顶点->
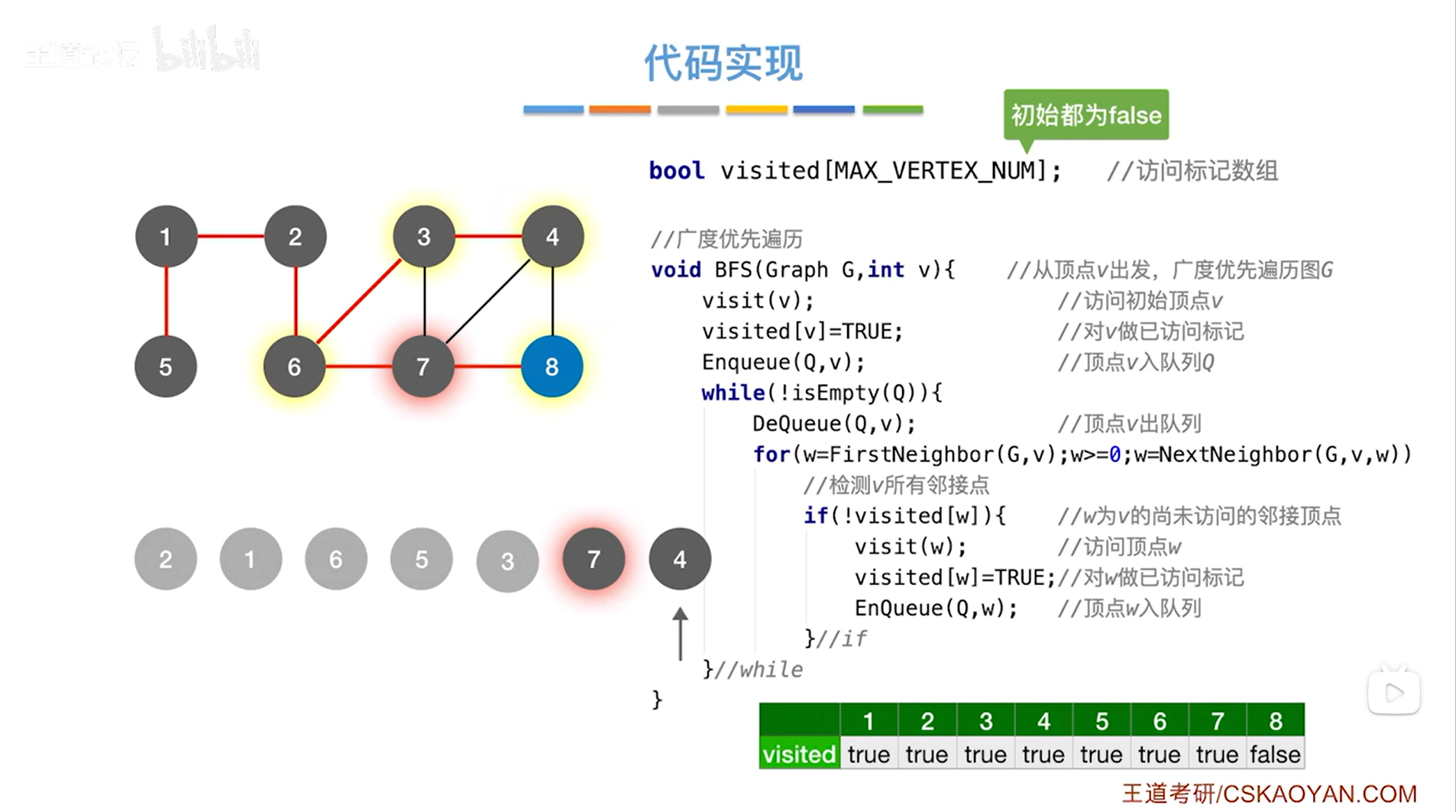
如上述图片所示,7号顶点出队,7号顶点与3、4、6、8号顶点相邻,只有8号顶点没有被访问过->

如上述图片所示,所以访问8号顶点,修改8号顶点对应的数组的值,把8号顶点放入队尾,7号顶点处理完毕->
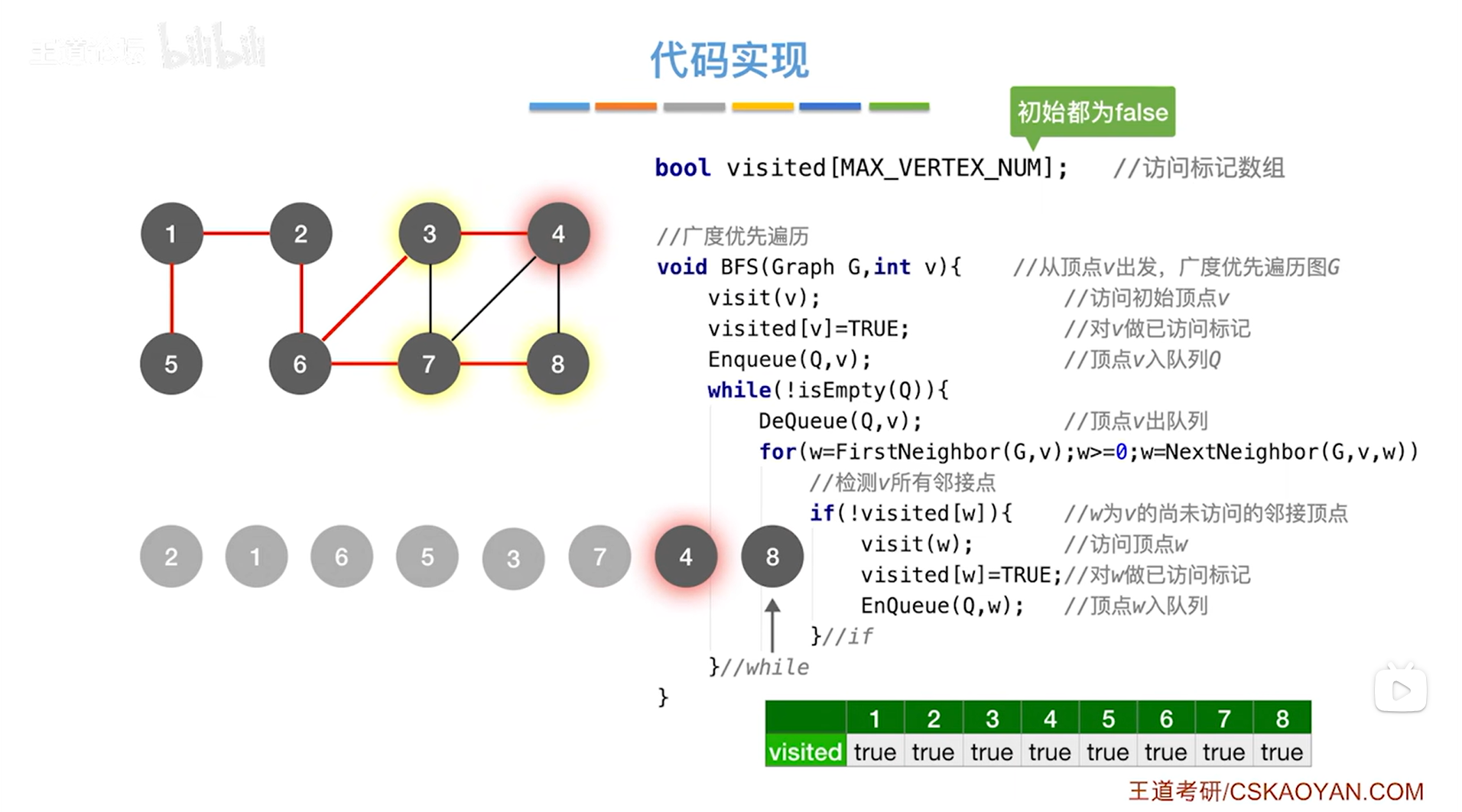
如上述图片所示,以此类推,接下来会依次操作队列里的4号顶点和8号顶点,由于和他们相邻的所有的顶点都已经处理完毕,所以4、8号顶点的for循环是不会执行的->
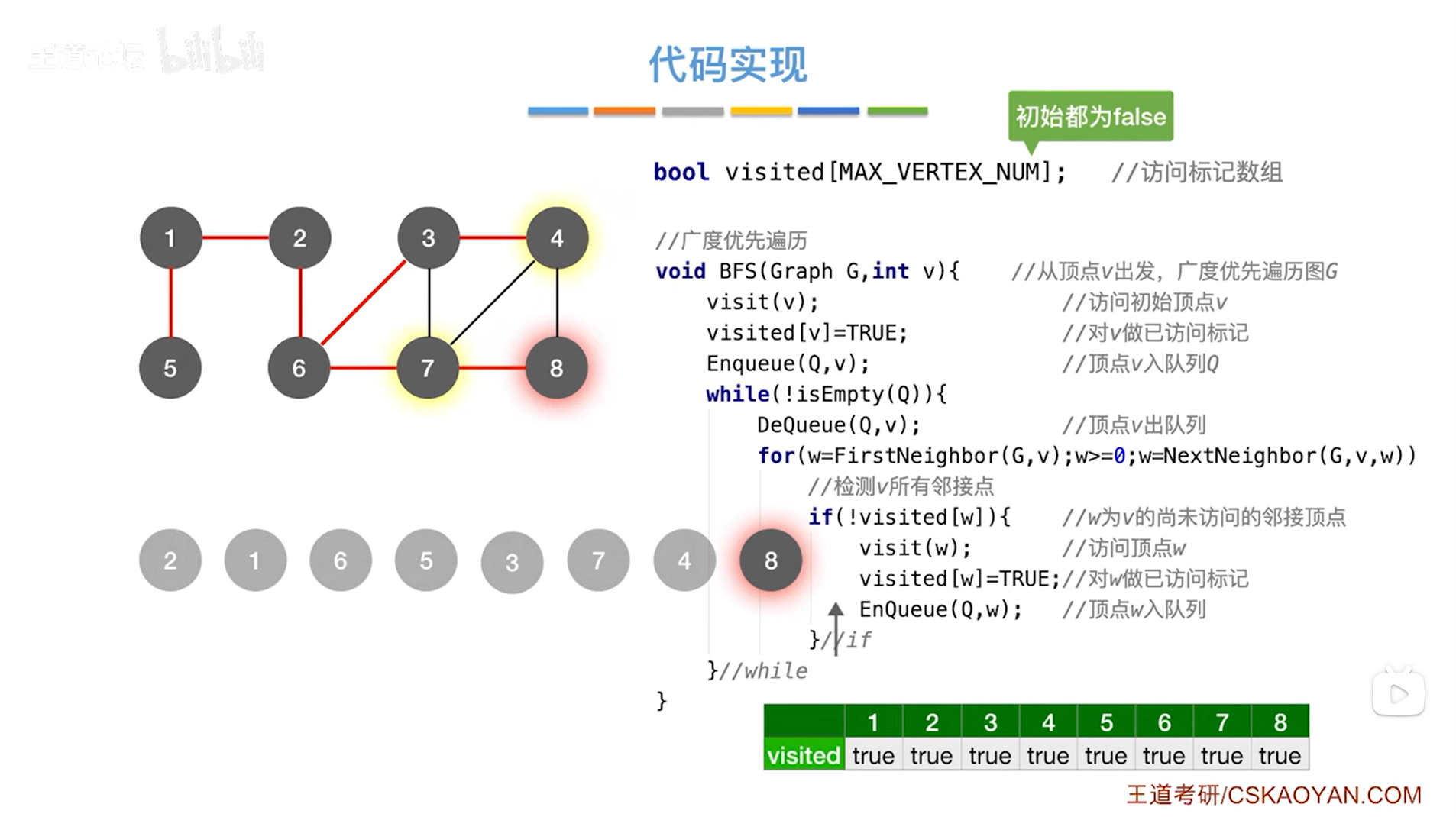
完成了该图的广度优先遍历,最终得出的遍历序列如下图所示:
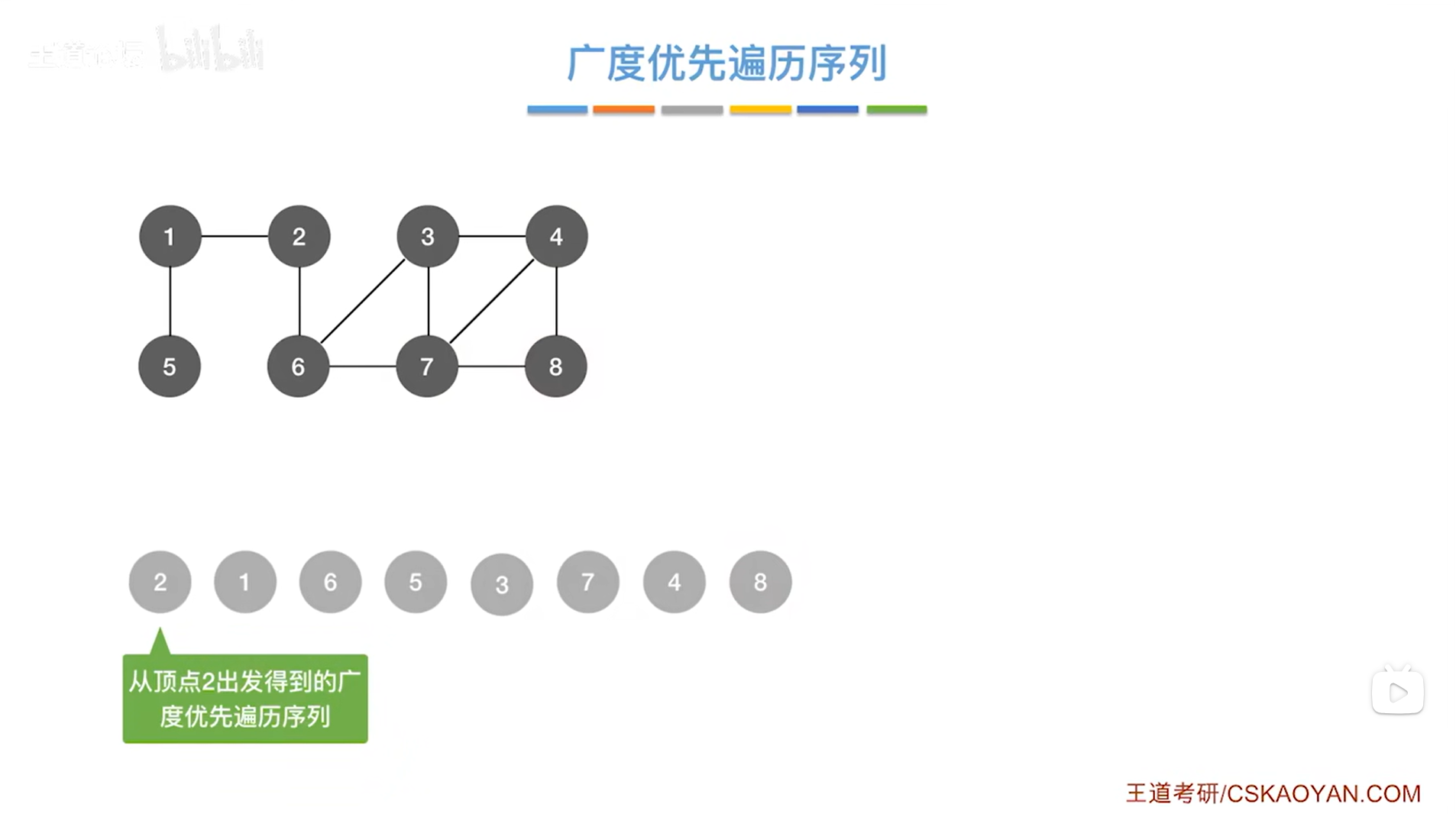
4.图的广度优先遍历的遍历序列具有可变性:
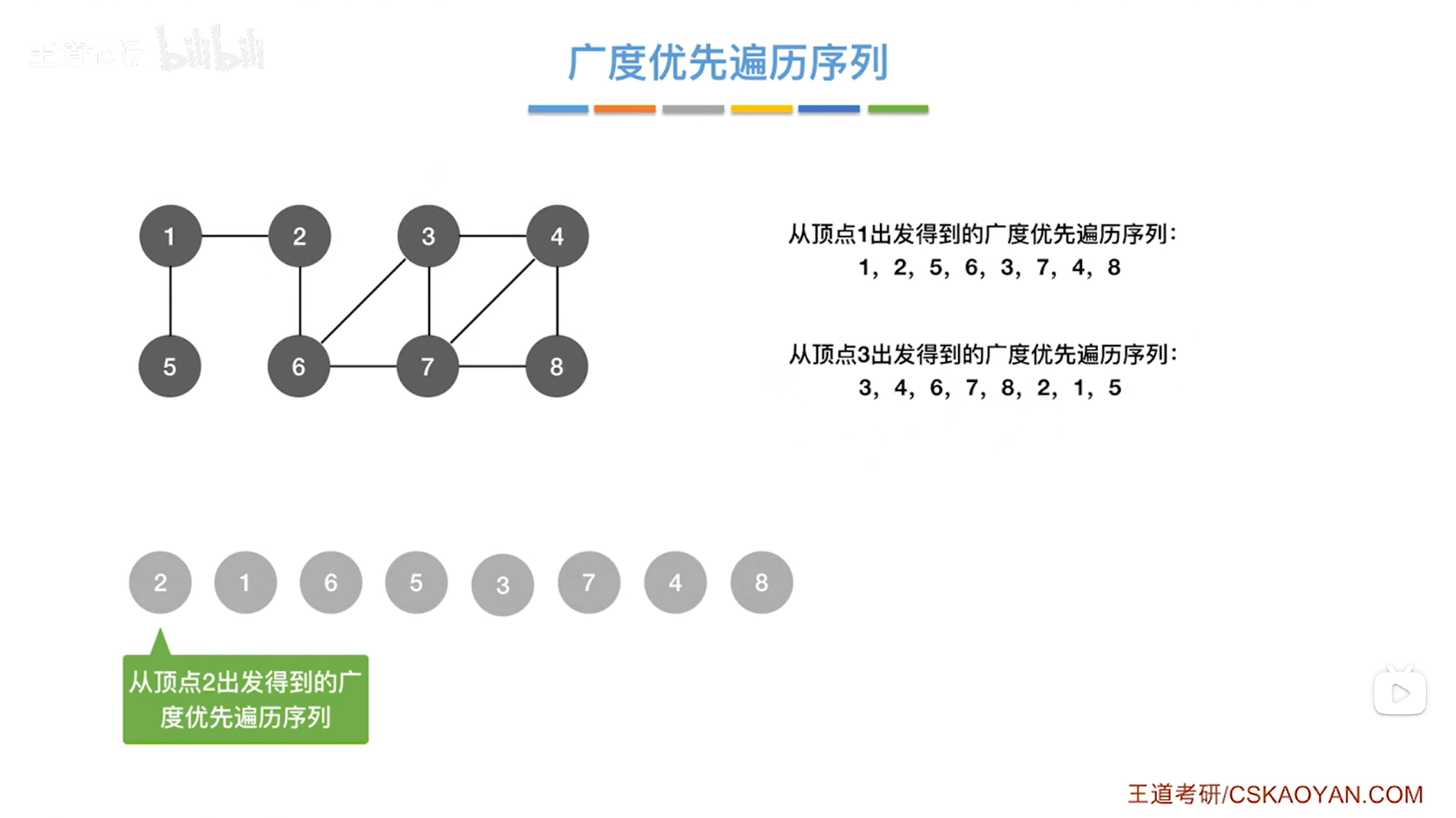
如上述图片所示,从不同顶点出发遍历同一张图,得到的遍历序列是不同的。
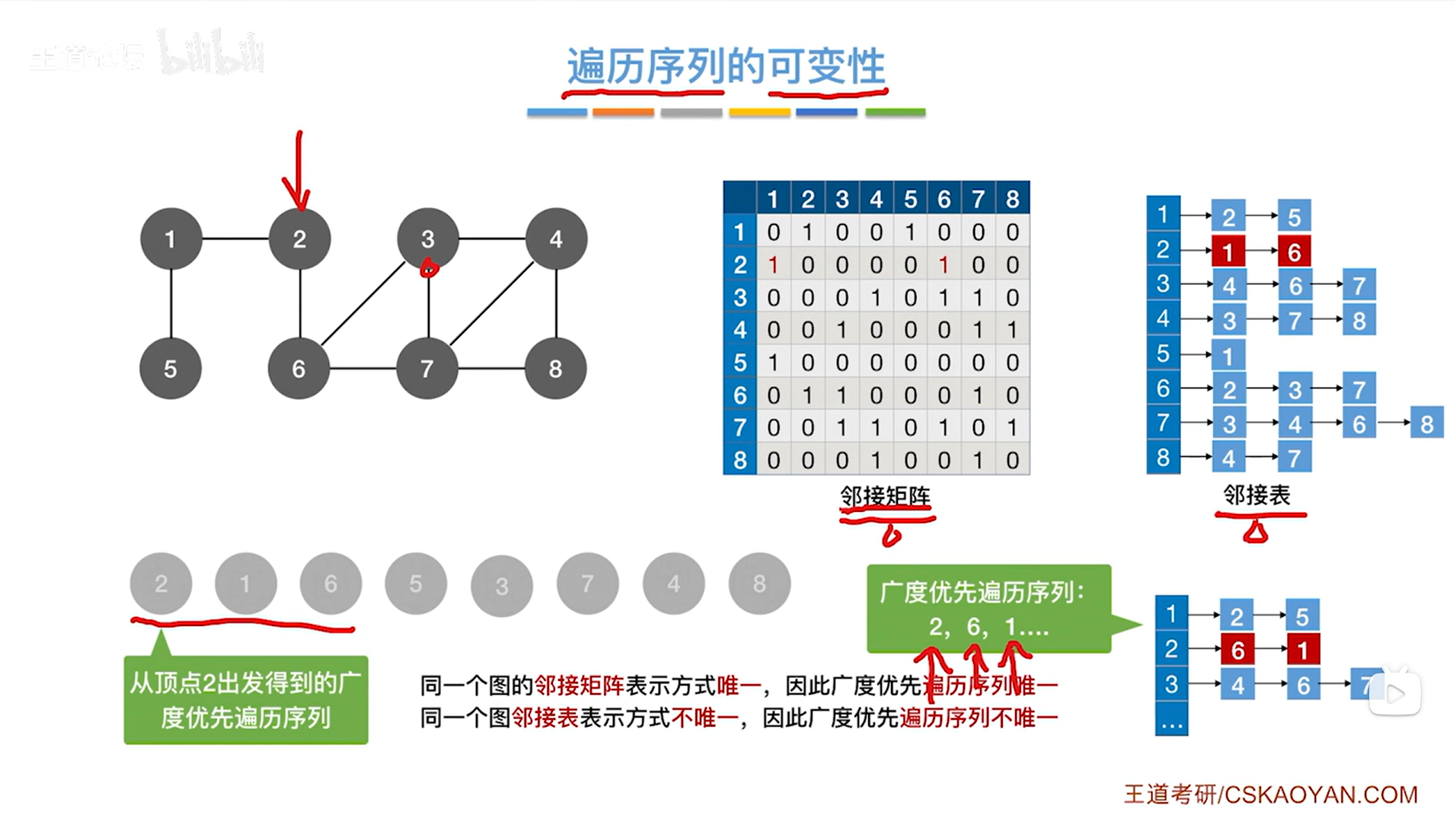
对于上述图片中,从顶点3开始广度优先遍历图,与顶点3相邻的分别是4、6、7号顶点,其中顶点序号是按照递增的顺序来的->
事实上,对于广度优先遍历算法,如果图的存储结构不一样,从一个顶点出发,那么找到与之相邻的顶点的顺序也可能不一样:
-
如果图使用邻接矩阵存储,图的邻接矩阵的表示方式是唯一的,所以如果图使用邻接矩阵来存储,要找到和3号顶点相邻的其他顶点的话,找到的顶点的序号就固定依次是4、6、7号->顺序固定
-
如果图是用邻接表存储,那么最终查找邻接点的顶点号结果就可能不一样,如上图,从2号顶点出发,和2号顶点相邻的两个顶点的顺序可以是先找到1号顶点,再找到6号顶点,也可以是先找到6号顶点,再找到1号顶点,因为邻接表中顶点对应的链表的存储结构没有先后之分->顺序不固定
所以在图的广度优先遍历中,如果图采用邻接表存储的话,那么最终的遍历序列就是不唯一的;如果图采用邻接矩阵存储的话,由于邻接矩阵的表示方式唯一,那么最终的遍历序列也是唯一的。
5.图的广度优先遍历算法存在的问题以及解决方案:
如上述图片所示,其中的图任意两个顶点都是连通的,所以是连通图,从任何一个顶点出发,都能遍历完所有顶点,但存在一些问题->
以下述图片为例,该图中相较于上述图片里的图,增加了3个顶点即第9、10、11号顶点,这3个顶点与其他顶点不连通,此时存在两个顶点之间不连通,此图为非连通图,从某一个顶点出发,是无法遍历完所有顶点的:
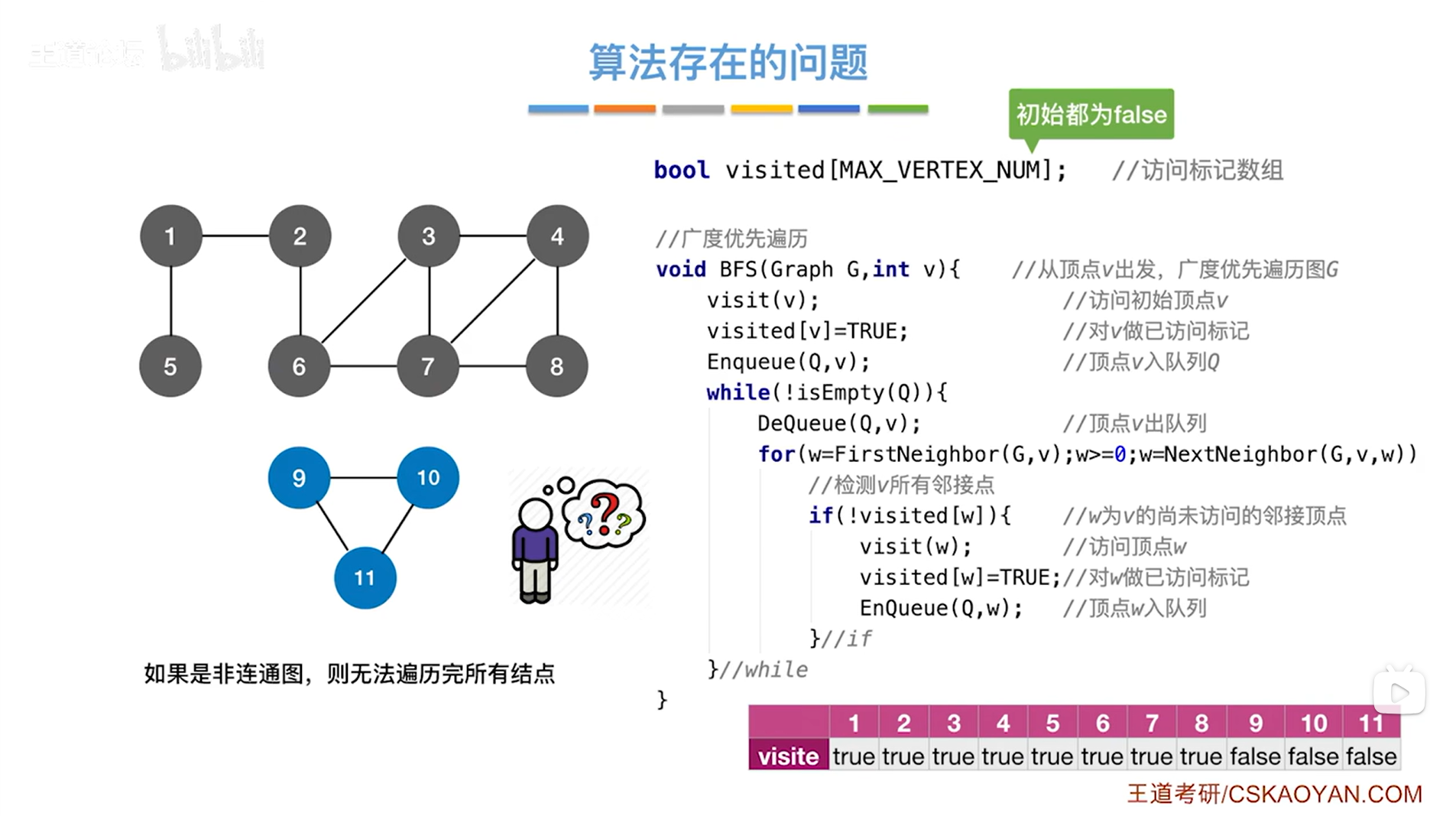
从2号顶点出发遍历上述图片的图,通过上述图片里的代码是无法访问到第9、10、11号顶点的,那这个该怎么处理呢?
在visited数组中,这个数组记录了所有顶点是否已经被访问,那我们在第一次调用BFS函数之后,其实可以检查一下在visited数组当中能不能找到值为false的顶点,如果能找到,那就从该顶点出发,再调用一次BFS函数即可,此时就可以把没访问的顶点访问完,所以改进方案如下:
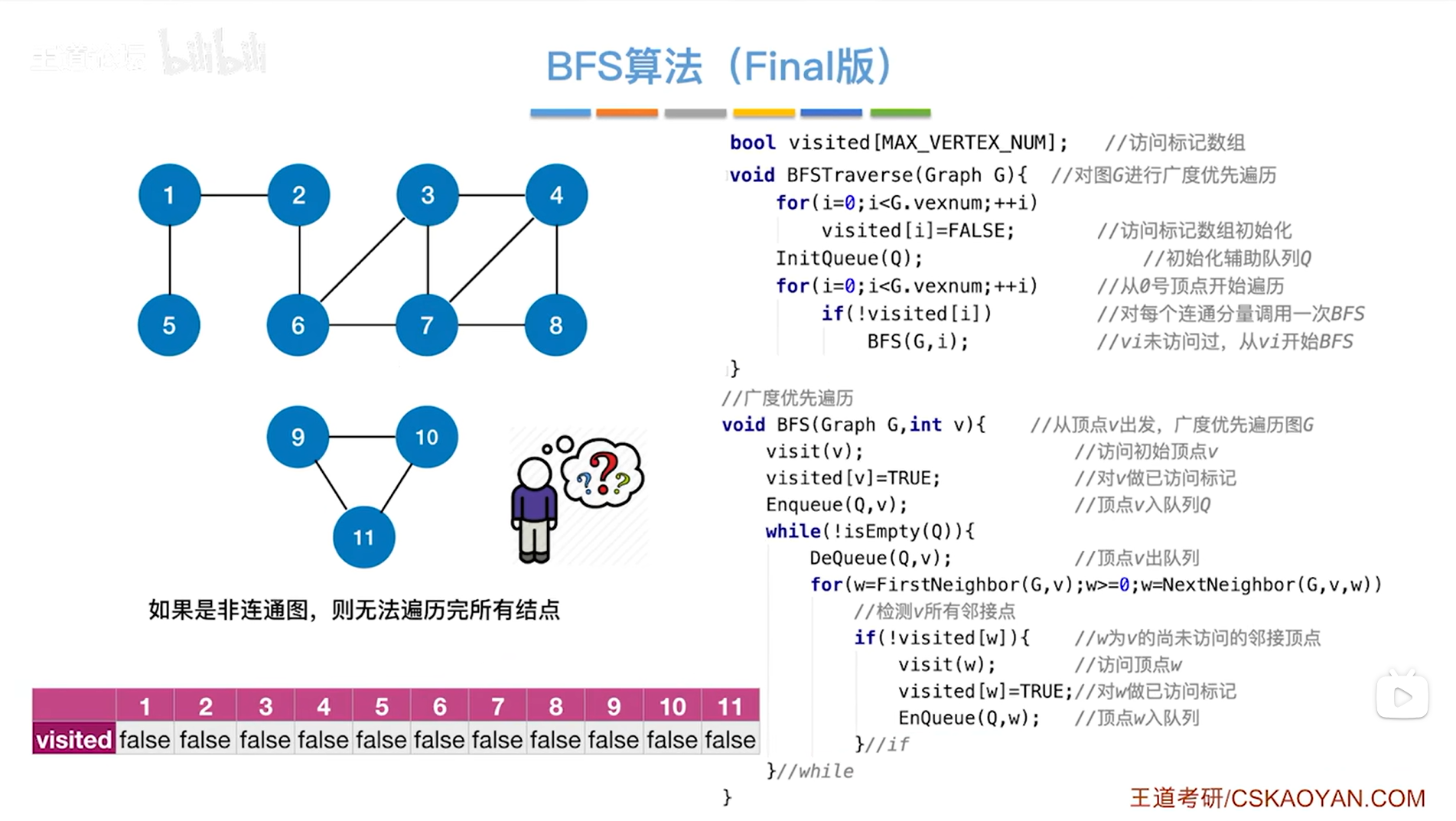
对于上述图片里的代码,增加了一个BFSTraverse函数,该函数的解读如下:
-
BFSTraverse函数的形参Graph G是图
-
vexnum是图G的顶点个数,G.vexnum代表图G中的顶点个数
-
第一个for循环中visited[i]=false就是初始化visited数组,都赋值为false,代表图G中的顶点都没有被访问过
-
InitQueue(Q)函数用来初始化辅助队列Q,Q是队列,详情见"队列的顺序实现"
-
第二个for循环用来扫描visited数组中是否有值为false的数据,如果有,那么就会执行if语句再次调用BFS函数,从当前visited数组中值为false对应的顶点开始遍历
以上述图片为例,执行到BFSTraverse函数的第二个for循环时,第一个值为false的顶点为1号顶点(注:这里是从1号顶点开始,但BFSTraverse函数里的两个for循环都是从0开始,这个不用管,只需要知道他们都是从第一个开始即可),此时从1号顶点出发,调用BFS函数进行图的广度优先遍历,最终可以把1、2、3、4、5、6、7、8号顶点都访问完,因为这些顶点是连通的:
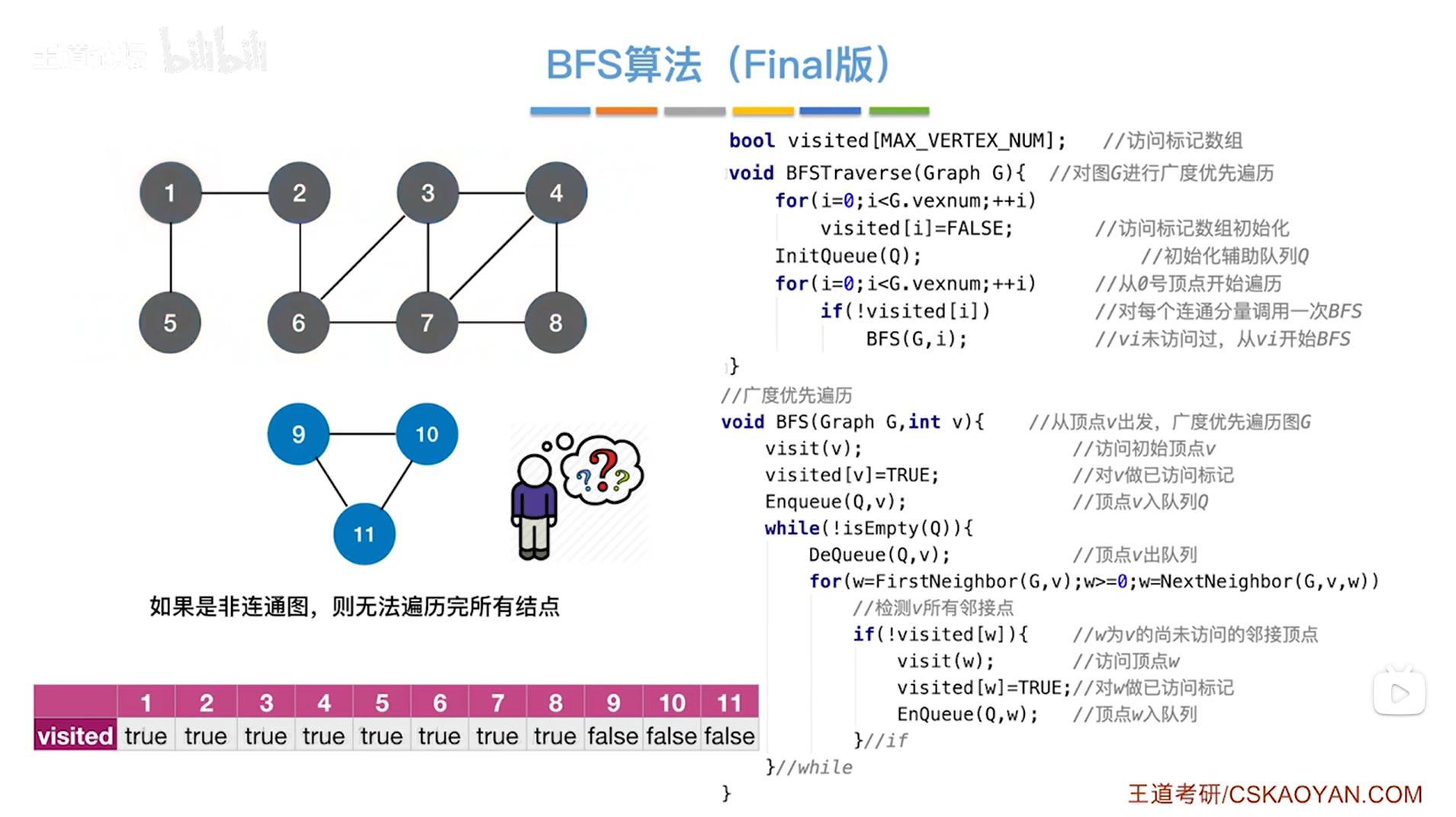
访问完1、2、3、4、5、6、7、8号顶点后,BFS函数第一次调用结束,此时1、2、3、4、5、6、7、8号顶点对应的visited数组里的值都变为true,第一次调用完BFS函数之后,for循环会继续往后找,判断是否需要再次调用BFS函数,此时的第9号顶点对应的visited的值为false,所以再次调用BFS函数,从9号顶点出发,最终通过9号顶点可以把剩下的9、10、11号顶点全部访问完,最终图全部遍历完毕,for循环结束,BFSTraverse函数结束:
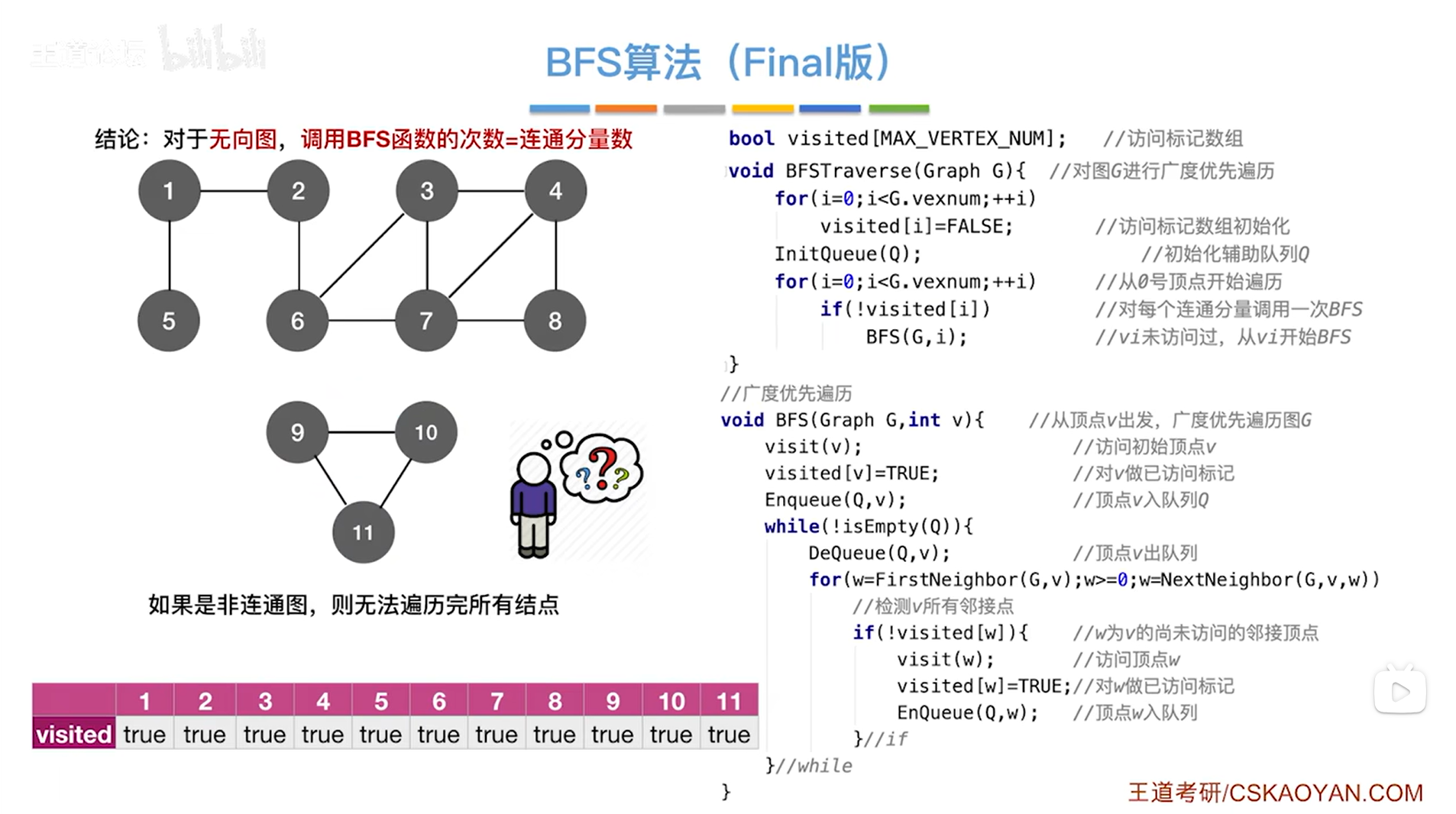
所以加上BFSTraverse函数里的第二个for循环之后,就可以遍历完非连通图里的所有顶点,总共调用了两次BFS函数。
结论:对于无向图,调用BFS函数的次数=连通分量数(连通分量数就是极大连通子图的个数,上述图片中,图的极大的连通子图分别由1、2、3、4、5、6、7、8号顶点组成和9、10、11号顶点组成,也就是有两个极大连通子图,所以连通分量数为2->找极大连通子图可以先把图的连通子图列出来,再找极大的)
三.图的广度优先遍历算法的效率:时间复杂度和空间复杂度
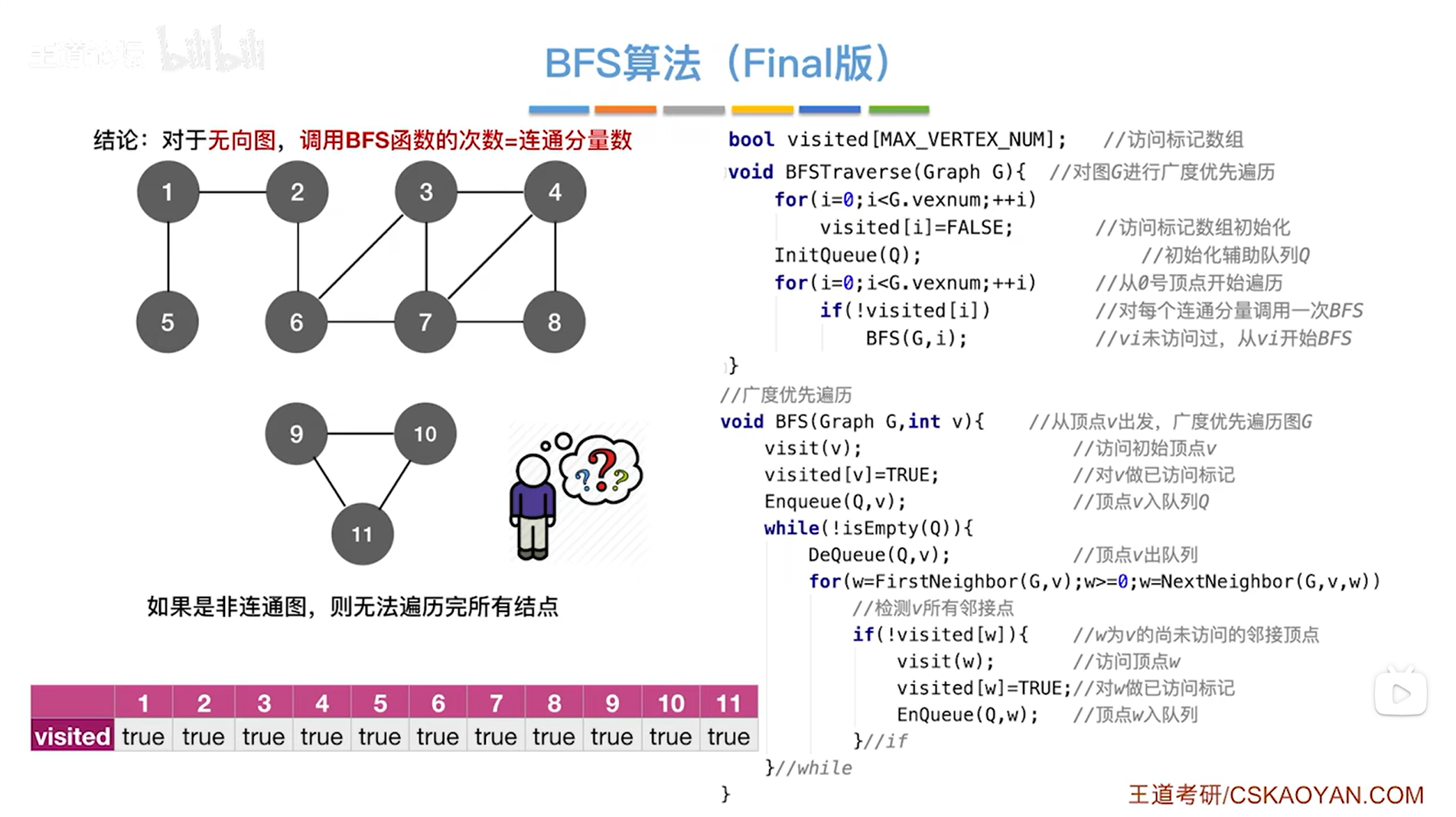
1.空间复杂度:
主要来自于定义的辅助队列InitQueue(Q),因为队列里存顶点。
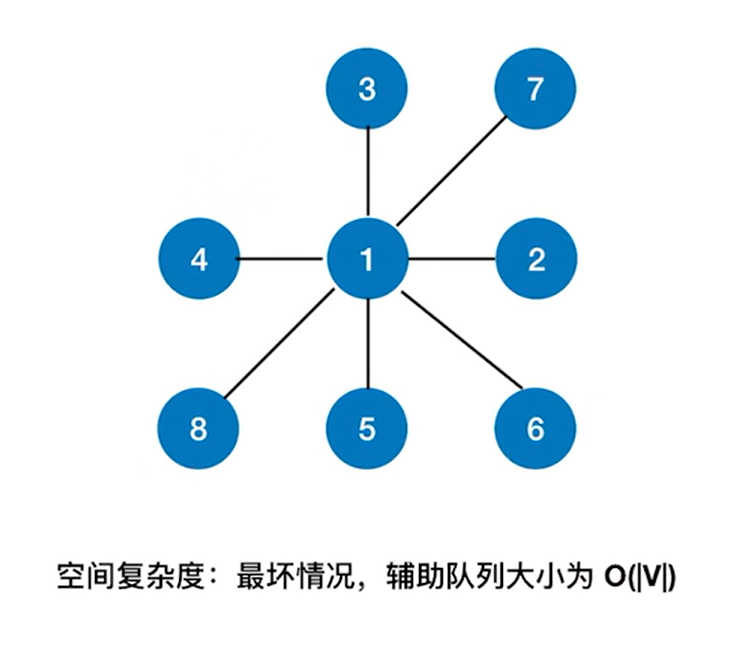
最坏的情况取决于辅助队列最大会有多少->
以上述图片为例,从1号顶点出发遍历图,显然除了1号顶点外所有顶点都和1号顶点邻接,所以在访问1号顶点时,同时要把和1号顶点相邻的所有顶点都放入辅助队列中,假设图中有V个顶点,那么辅助队列的最坏的情况就是需要O( |V-1| )个数量级,等价于O( |V| )。
2.时间复杂度:
在遍历图时,需要调用BFS函数里的visit函数遍历每一个顶点,同时在BFS函数里的for循环里还需要探索每一条边即找邻接点,所以可以简化的认为该算法的时间开销主要就是访问各个顶点和探索每一条边。
a.使用邻接矩阵存储图时:
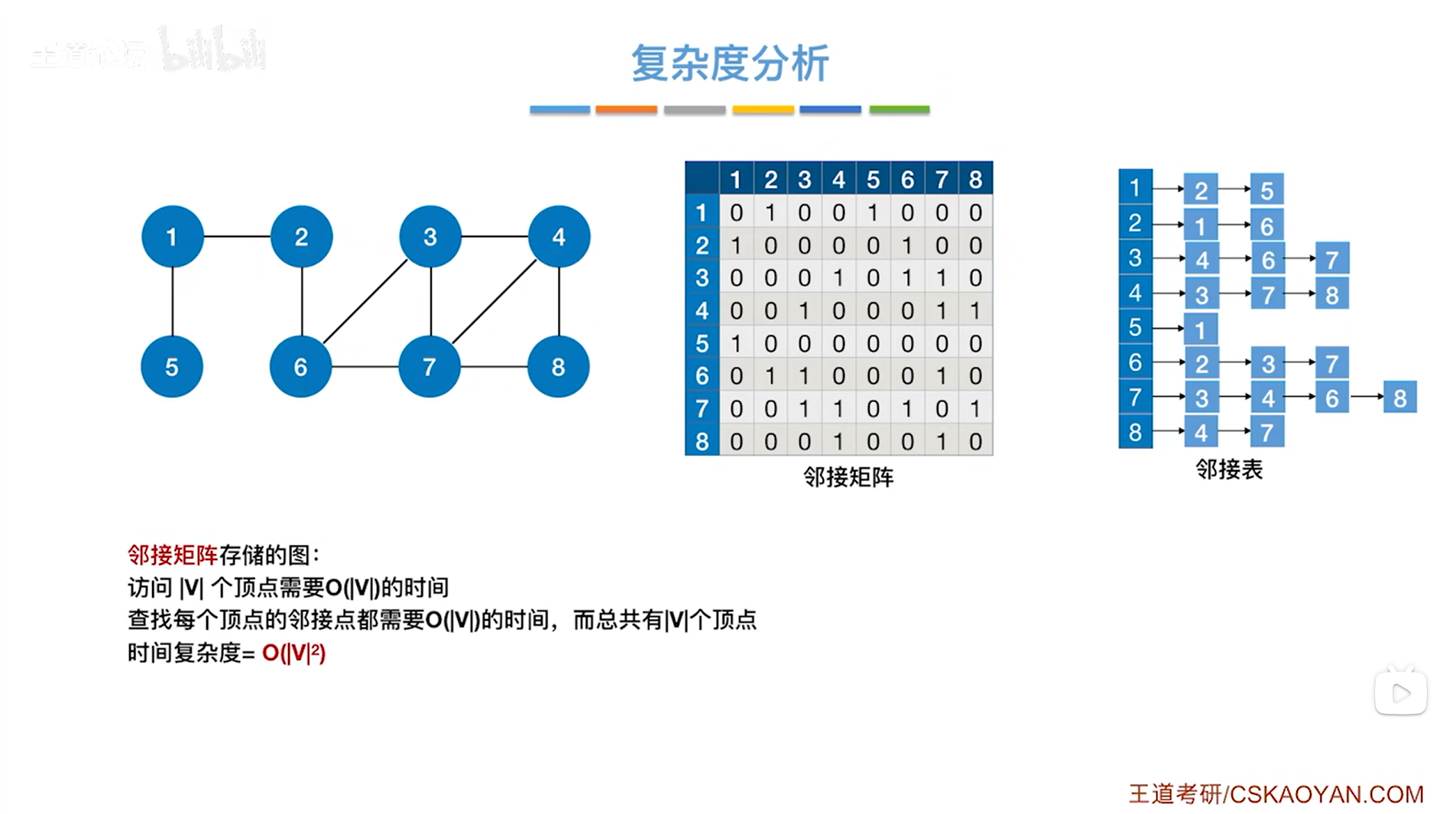
假设图中有V个顶点,那么访问|V|个顶点就需要O( |V| )的时间(因为要用到循环),
当访问某个顶点时,还需要探索与该顶点相邻接的所有顶点,对于邻接矩阵,要找到和某一个顶点相邻接的所有顶点,只能把该顶点对应的一整行(或一整列,因为此时是无向图,无向图的邻接矩阵具有对称性)都遍历一遍,一整行总共有|V|个元素,
所以在找某一个顶点的邻接点时需要O( |V| )的时间,此时总共有|V|个顶点,因此找图中所有顶点的邻接点总共需要的时间复杂度为O( |V| * |V| ),
又因为要访问某个顶点,需要O( |V| )的时间,所以图使用邻接矩阵存储时,进行广度优先遍历的时间复杂度为O( |V| * |V| )+O( |V| ) ,等价于O( |V| * |V| ),其中V是图的顶点总数。
b.使用邻接表存储图时:

假设图中有V个顶点,那么访问|V|个顶点就需要O( |V| )的时间(因为要用到循环),
当访问某个顶点时,还需要探索与该顶点相邻接的所有顶点,对于邻接表,找到和某一个顶点邻接的所有顶点,只需要遍历该顶点对应的链表即可,因此邻接了多少个顶点即共有多少条边,就需要多少时间,
对于无向图来说,假设图中有E条边,在无向图的邻接表中,由于一条边有两个顶点,所以边顶点的个数是2|E|,所以要访问无向图的邻接表中某个顶点的所有邻接点(这个过程也是找和某个顶点邻接的所有边,是等价的,其中可能关于图中的所有边),总共需要的时间消耗为O( 2|E| ),等价于O( |E| ),
因此,当图使用邻接表存储时进行广度优先遍历,由于需要O( |V| )的时间复杂度进行顶点的访问,需要O( |E| )的时间复杂度进行对各个边进行访问即查找邻接点,因此图使用邻接表存储时,进行广度优先遍历的时间复杂度为O( |V| + |E| ),其中V是图的顶点总数,E是图的边总数。
注意:这里可以发现,在分析上述算法的时间复杂度时并没有像以前那样分析最深层的循环次数,为什么没有这么做呢?
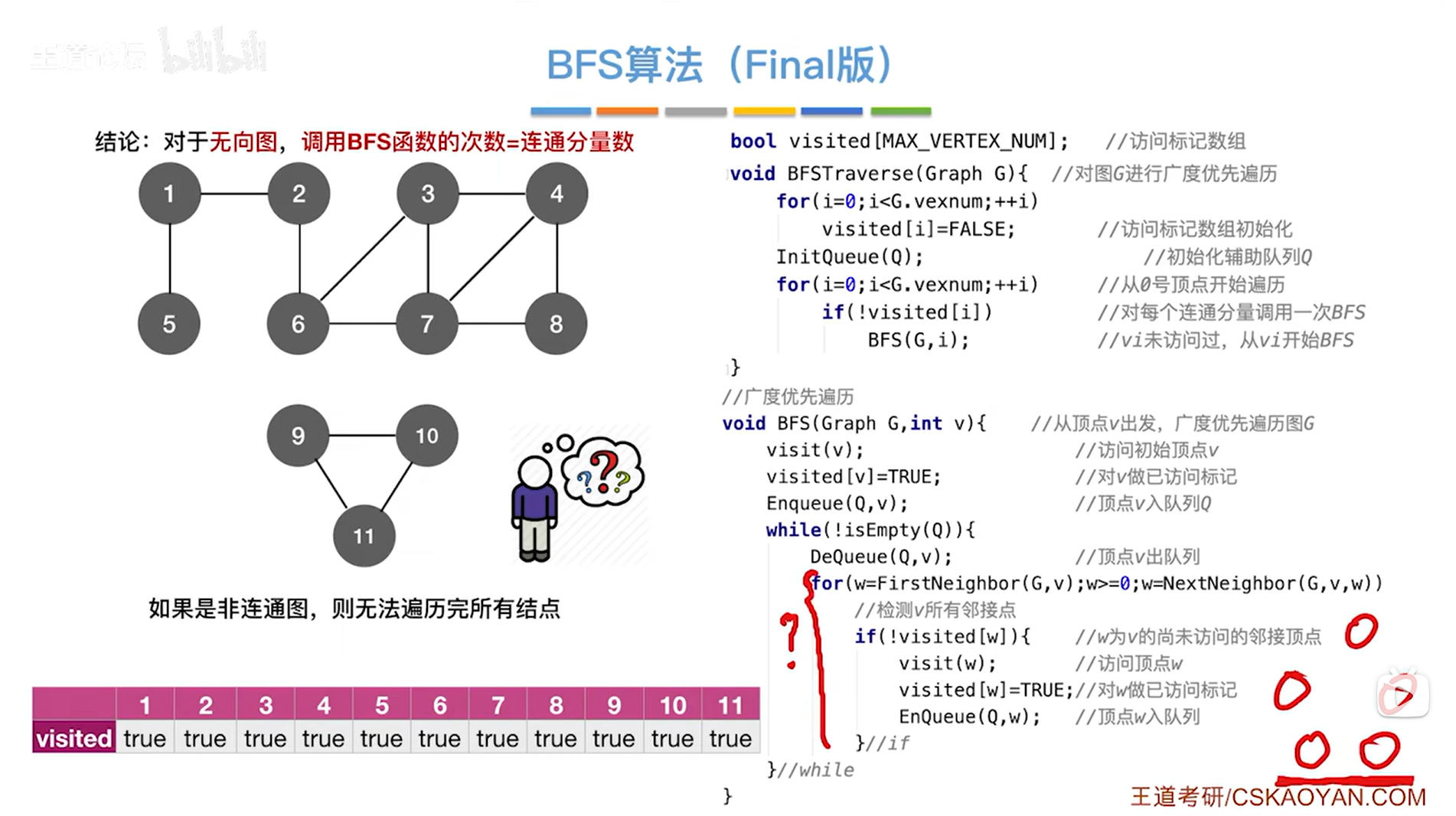
举个例子,如果一个图的所有顶点之间都没有边相连,并且这个图是使用邻接表存储的话,
显然BFS函数里的for循环的循环次数就应该是0次(因为该for循环是找邻接点等价于找顶点连接的边,此时图中没有边),
在图的广度优先遍历中该图的每一个顶点都需要被访问,意味着每一次都需要调用BFS函数里的visit函数进行访问对应的顶点,假设图中有V个顶点,那么访问所有的顶点需要O( |V| )的时间复杂度,
但如果像以前那样只考虑最深层的循环次数是会出现问题的,因为此时最深层的BFS函数里的for循环一次也不执行(分析该for循环会导致时间复杂度为0,和实际的需要O( |V| )的时间复杂度不符),这个和算法的实现方式有关,
所以以后遇到分析图的广度优先遍历算法或者图的深度优先遍历算法的时间复杂度时,建议不要钻到代码里,就把问题简化->
记住图的广度优先遍历算法和图的深度优先遍历算法的时间开销都主要来自访问顶点和找各条边即找邻接点,所以只需要拆开来分析,访问各个顶点需要多长时间,访问各条边即找邻接点需要多长时间,结合具体的存储结构进行分析即可。
四.广度优先生成树:
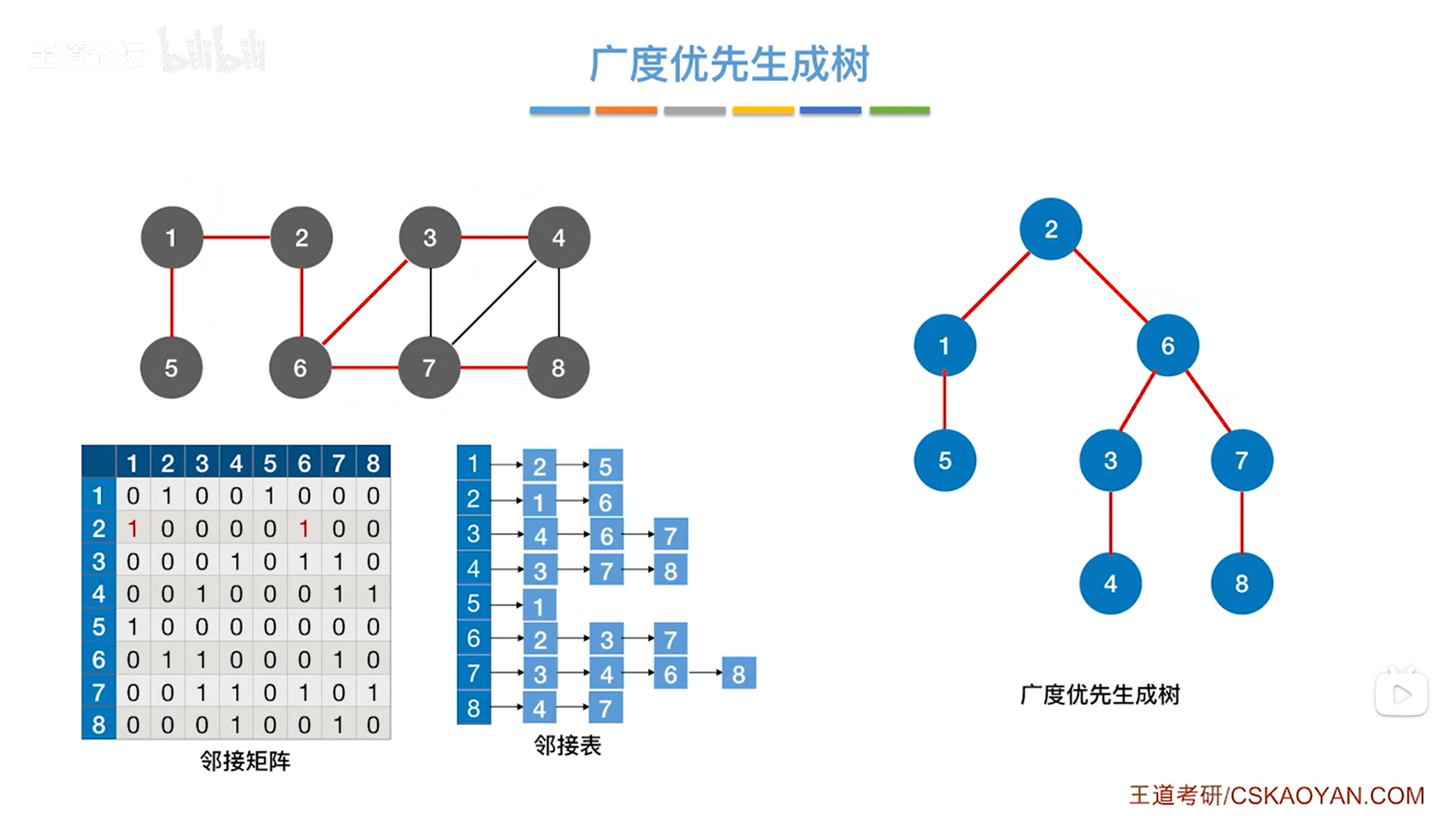
1.实例:
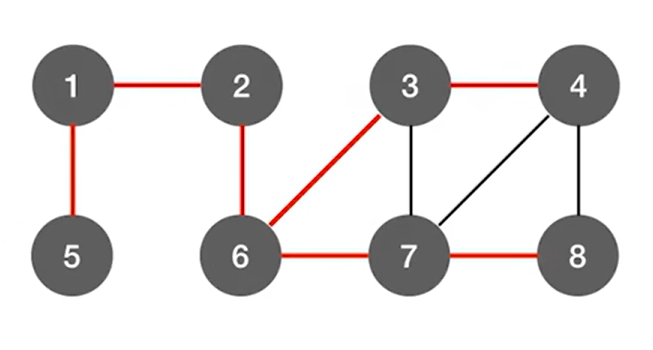
上述图片中标红的边意味着当某一个顶点第一次被访问的时候是从哪一条边过去的,
比如第一次访问4号顶点时,是从3号顶点过去的,而不是从7、8号顶点过去,
用这样的方式,如果图中有n个顶点,那么总共标红了n-1条边(上述图片中有8个顶点,此时标红了7条边),
如果只把红色的边留下,结果如下:
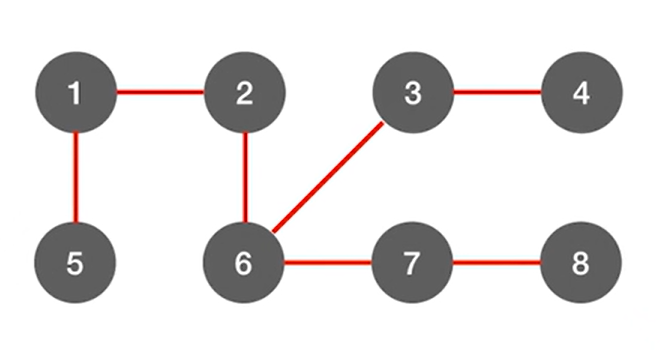
此时就变成了树,因为其中就不存在回路了,上述图片的树就是最终得出的广度优先生成树,
这个树是根据图的广度优先遍历的过程得来的。
再回顾一遍:
如下图,首先访问的是2号顶点:
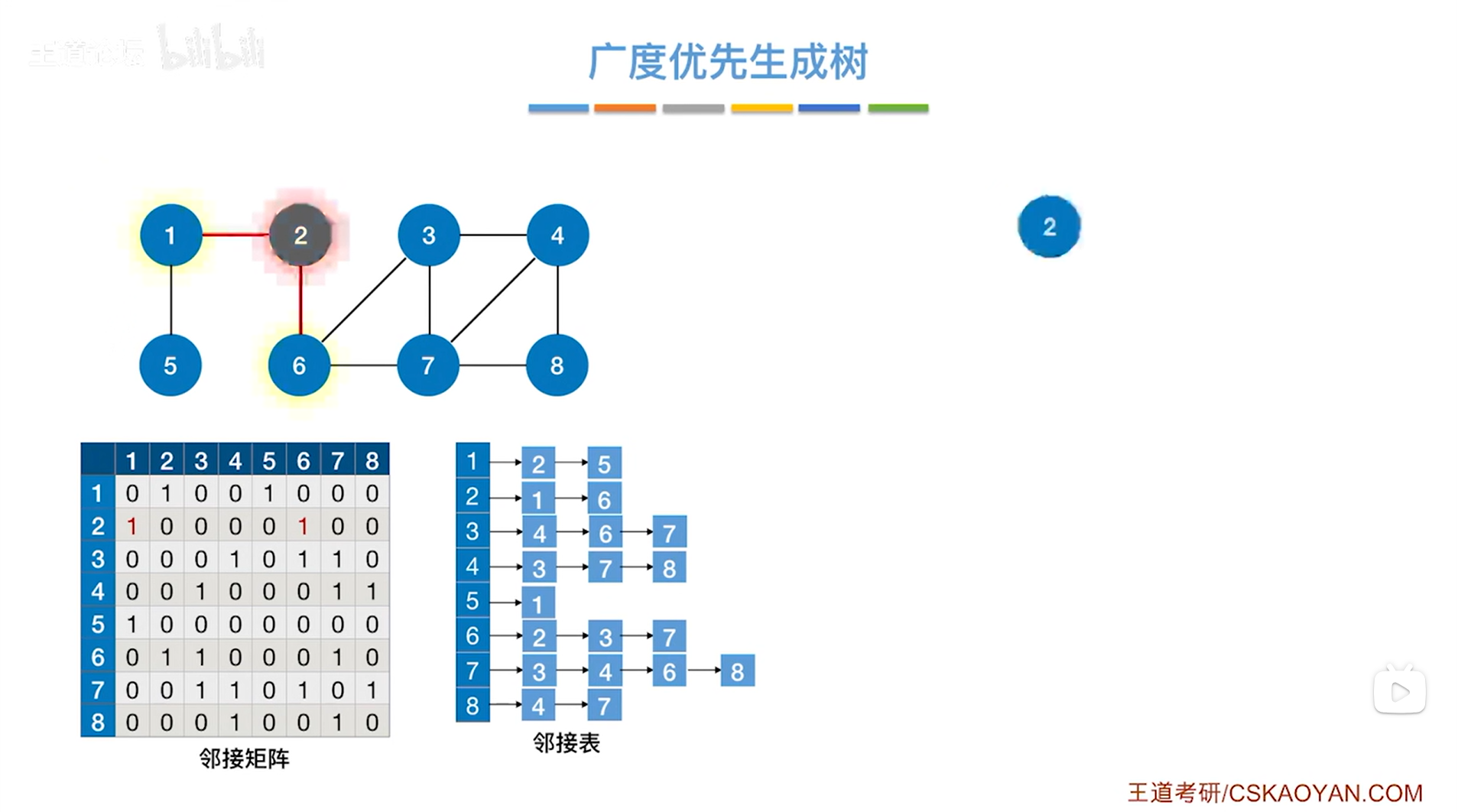
如下图,和2号顶点相邻的顶点是1、6号顶点即通过2号顶点可以找到1、6号顶点,其中1号顶点先入队列,6号顶点后入队列:
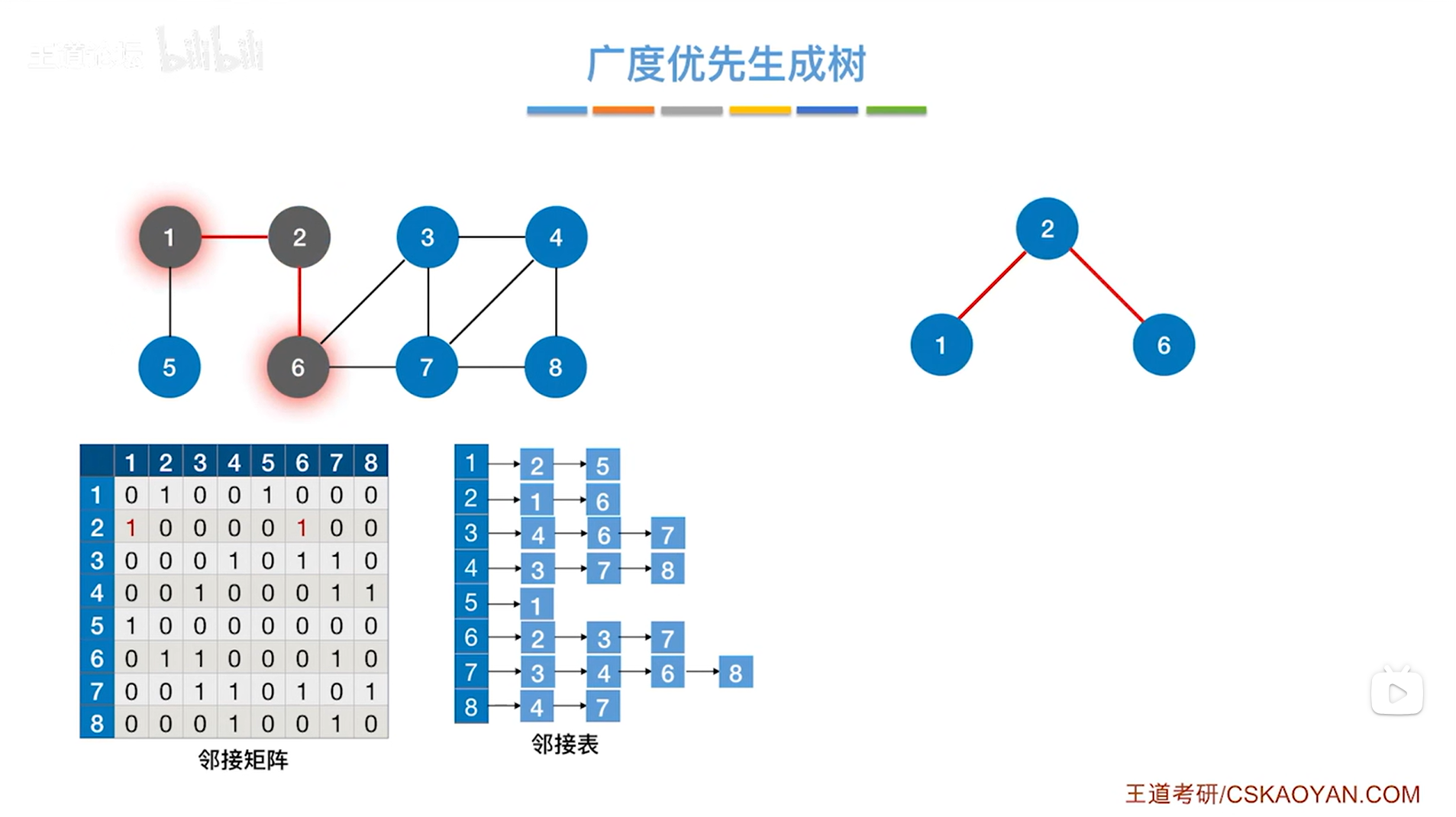
如下图,通过1号顶点可以找到5号顶点,通过6号顶点可以找到3、7号顶点,通过邻接矩阵或邻接表中可以看出,通过顶点6往后找,找到没有访问的顶点中(2号顶点已经访问过了),应该先找到3号顶点,再找到7号顶点,所以3号顶点应该先入队,7号顶点后入队:
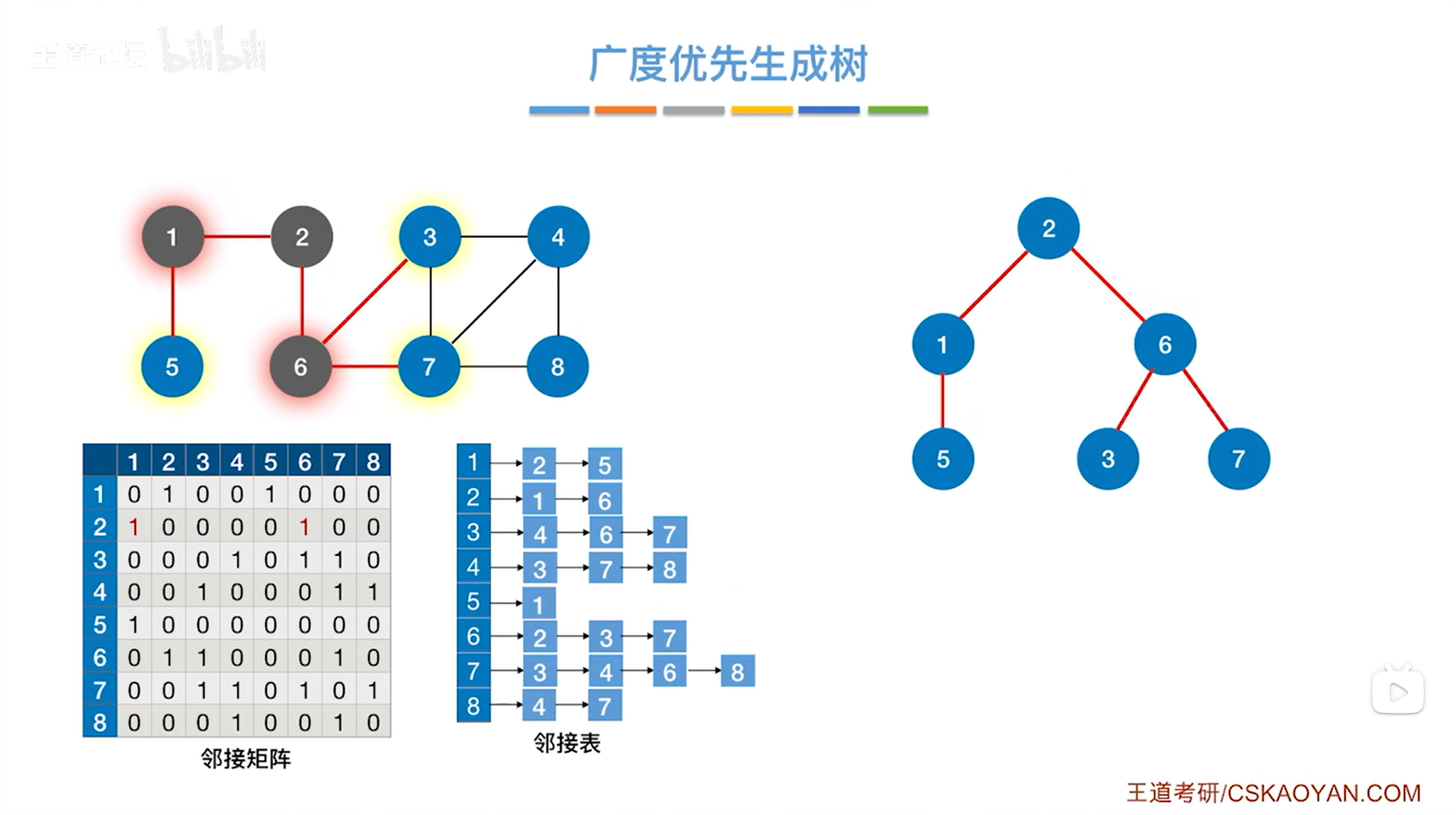
如下图,接下来通过3号顶点可以找到4号顶点,通过7号顶点可以找到8号顶点:
最终得到了广度优先生成树。
2.变式:
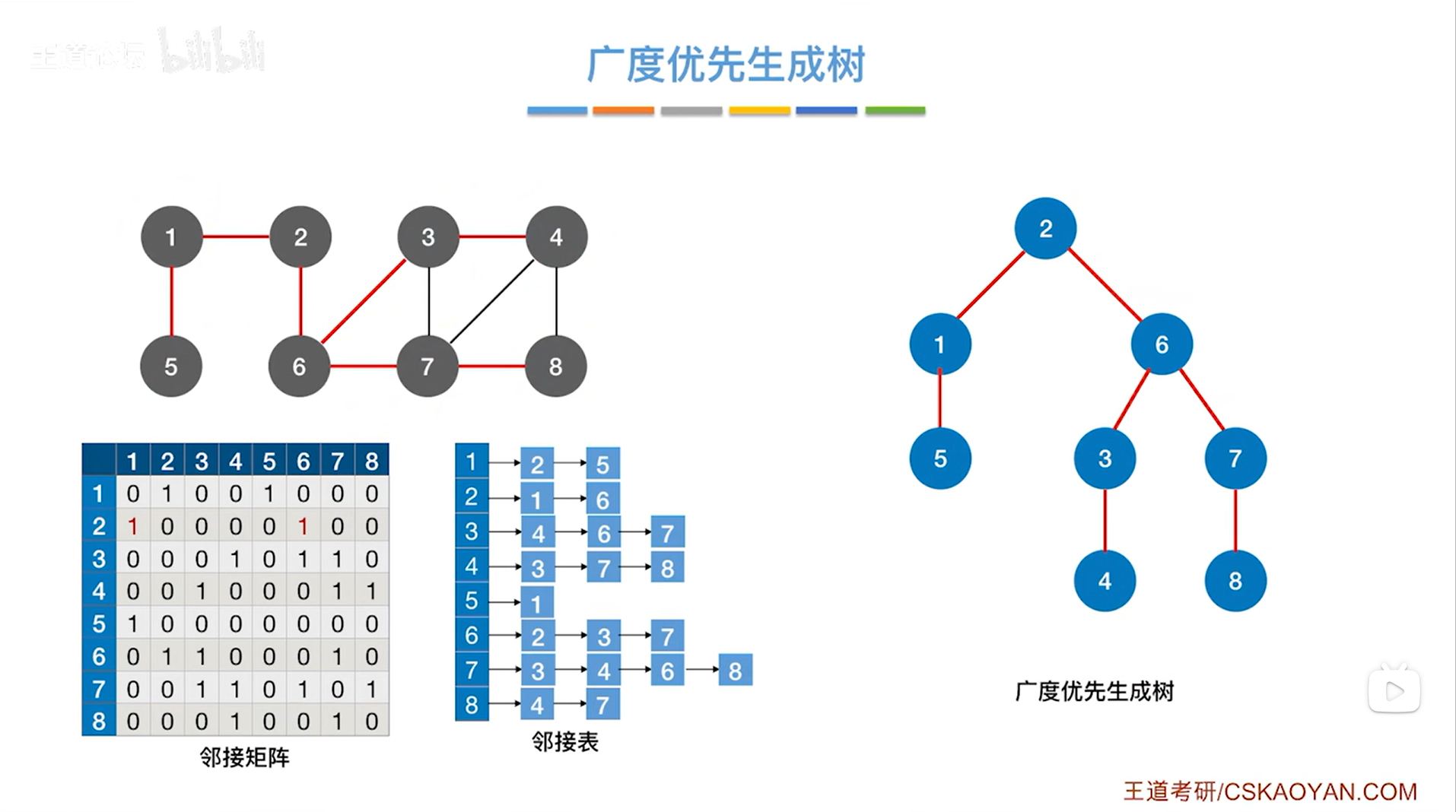
如上述图片的邻接表里,把顶点6对应的链表中3号和7号进行互换,结果如下:
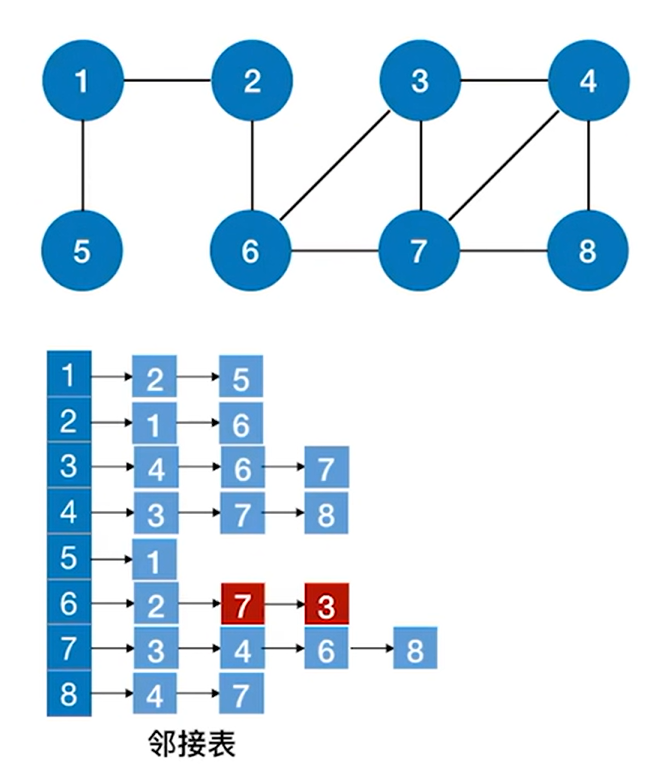
如下图,从2号顶点出发开始访问:
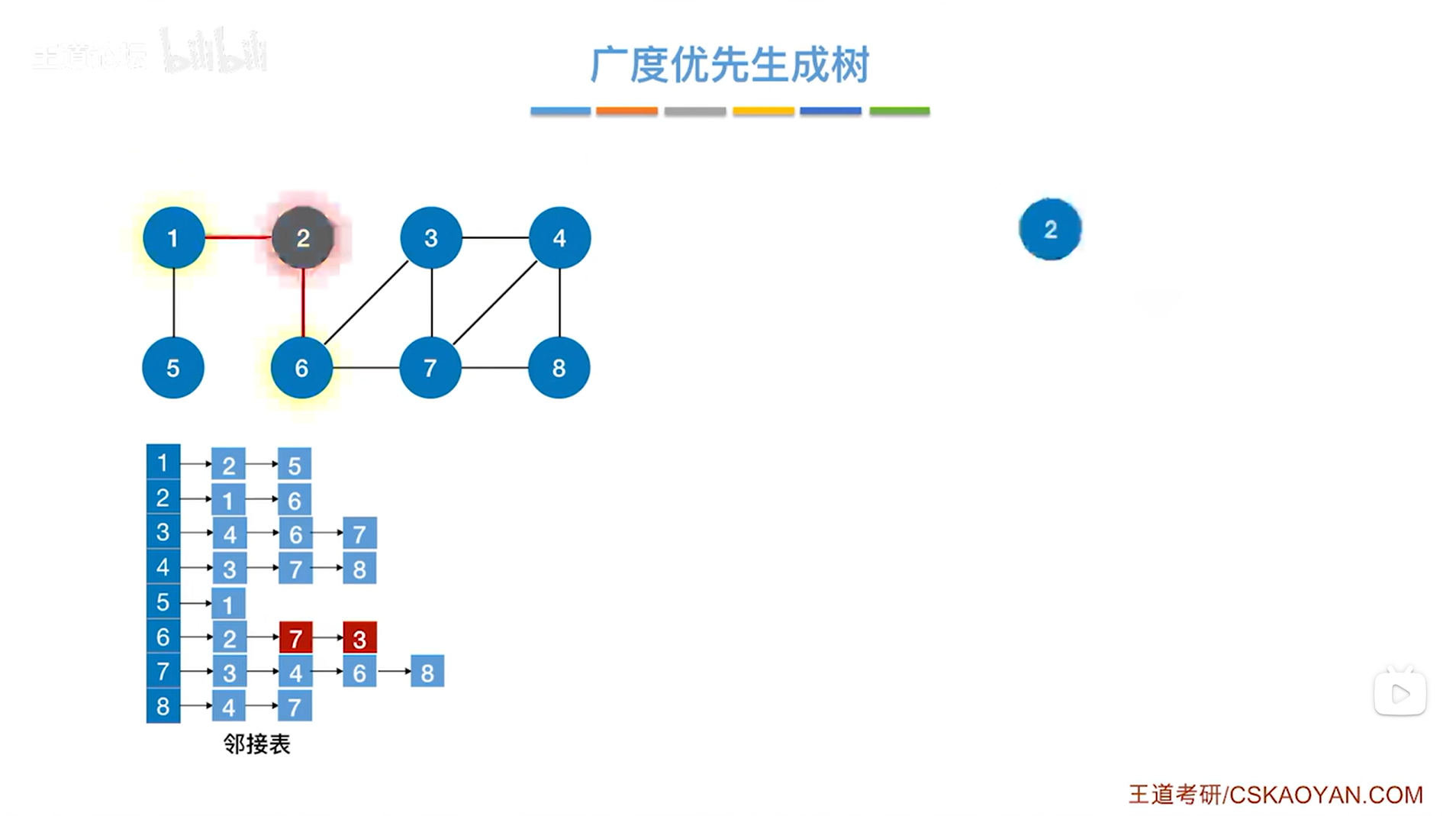
如下图,根据2号顶点会找到1、6号顶点,1号顶点比6号顶点先入队:
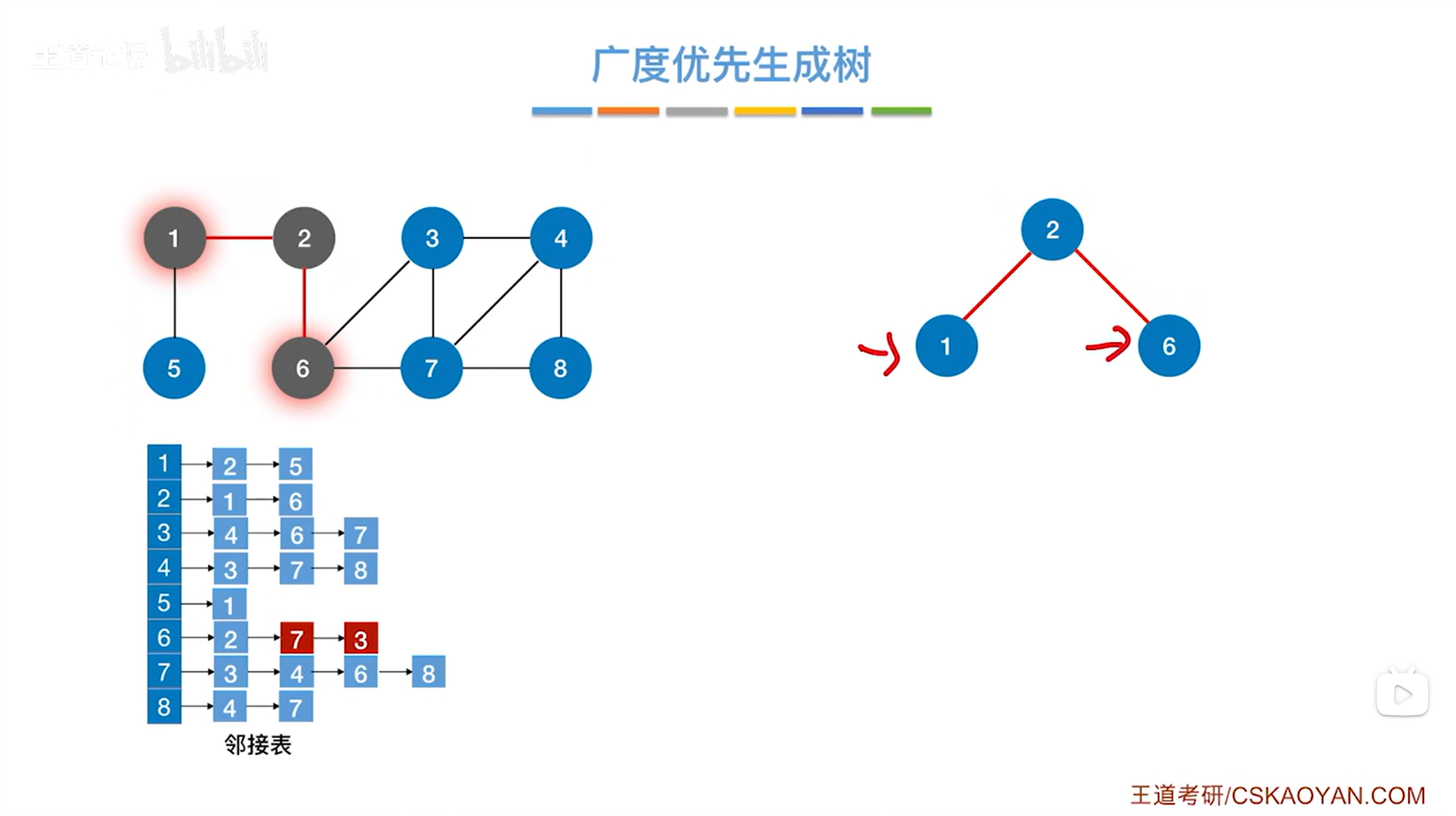
如下图,通过1号顶点可以找到5号顶点,通过6号顶点可以找到7、3号顶点,在当前这个邻接表中找与6号顶点相邻的且没有被访问过的顶点应该是先找到7号顶点,再找到3号顶点,所以7号顶点比3号顶点先入队列->接下来首先要找的是和7号顶点相邻的且没有被访问过的顶点:
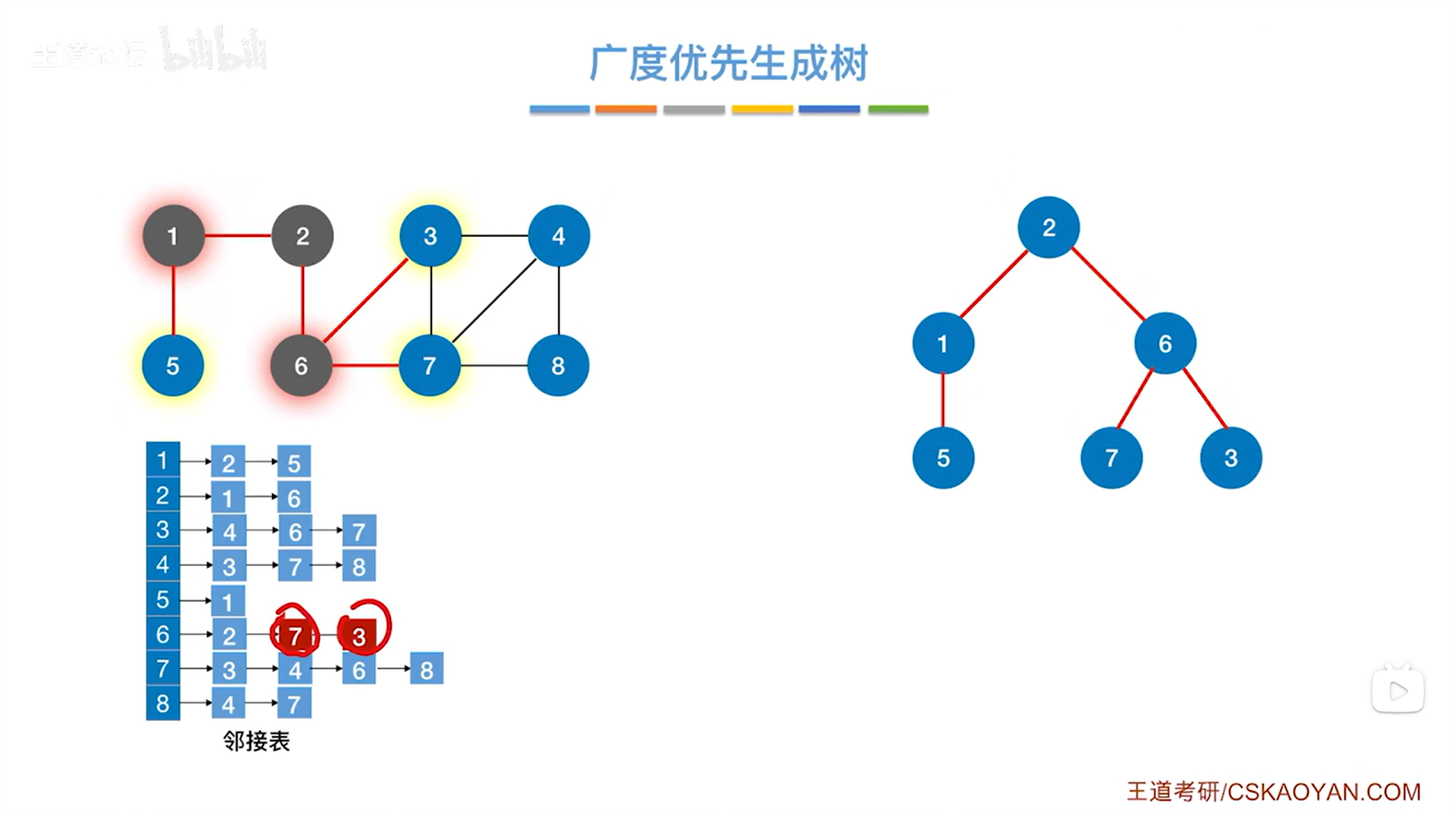
如下图,与7号顶点相邻的且没有被访问过的顶点是4、8号顶点,所以通过7号顶点可以找到4、8号顶点:
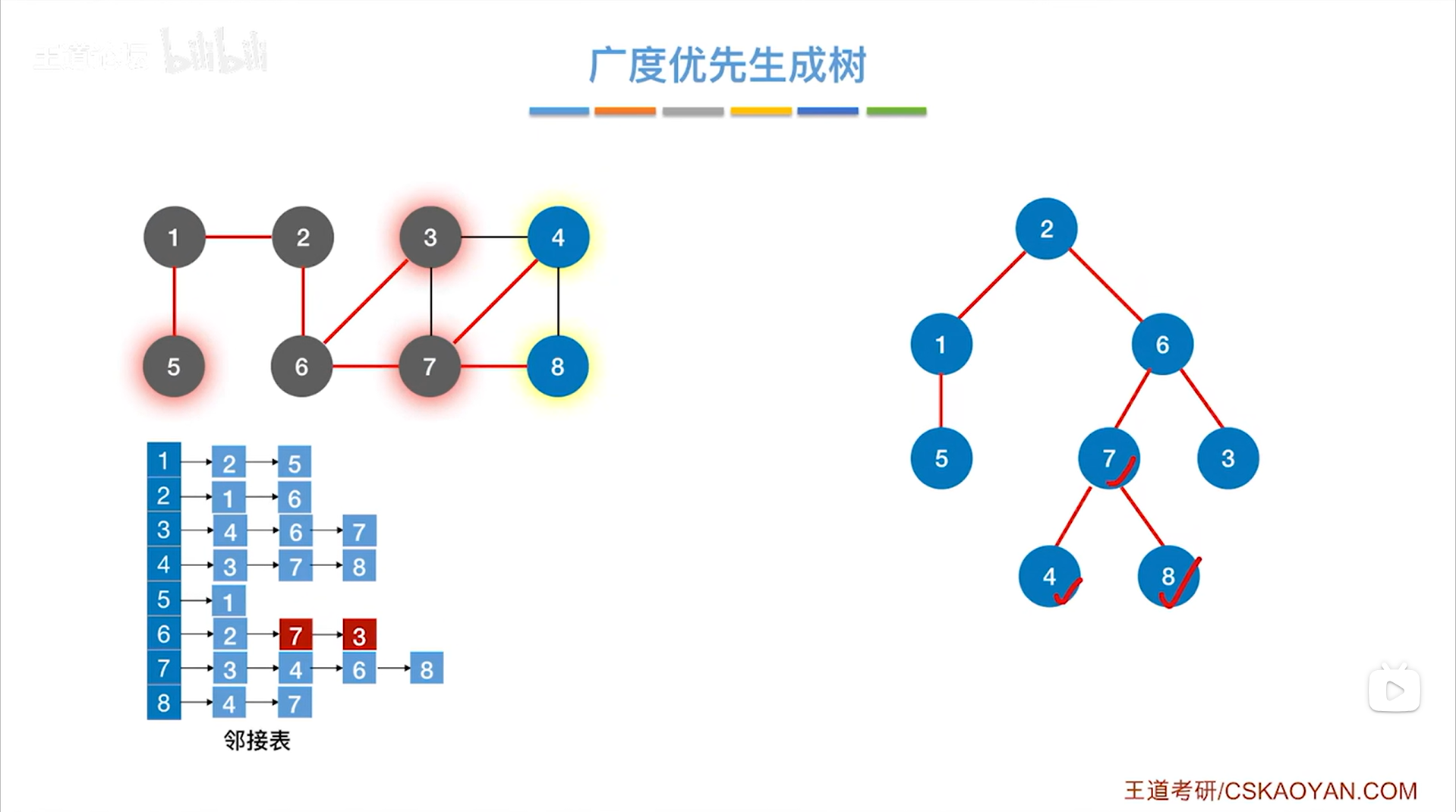
最终得到了该图的广度优先生成树。
3.分析实例与变式:
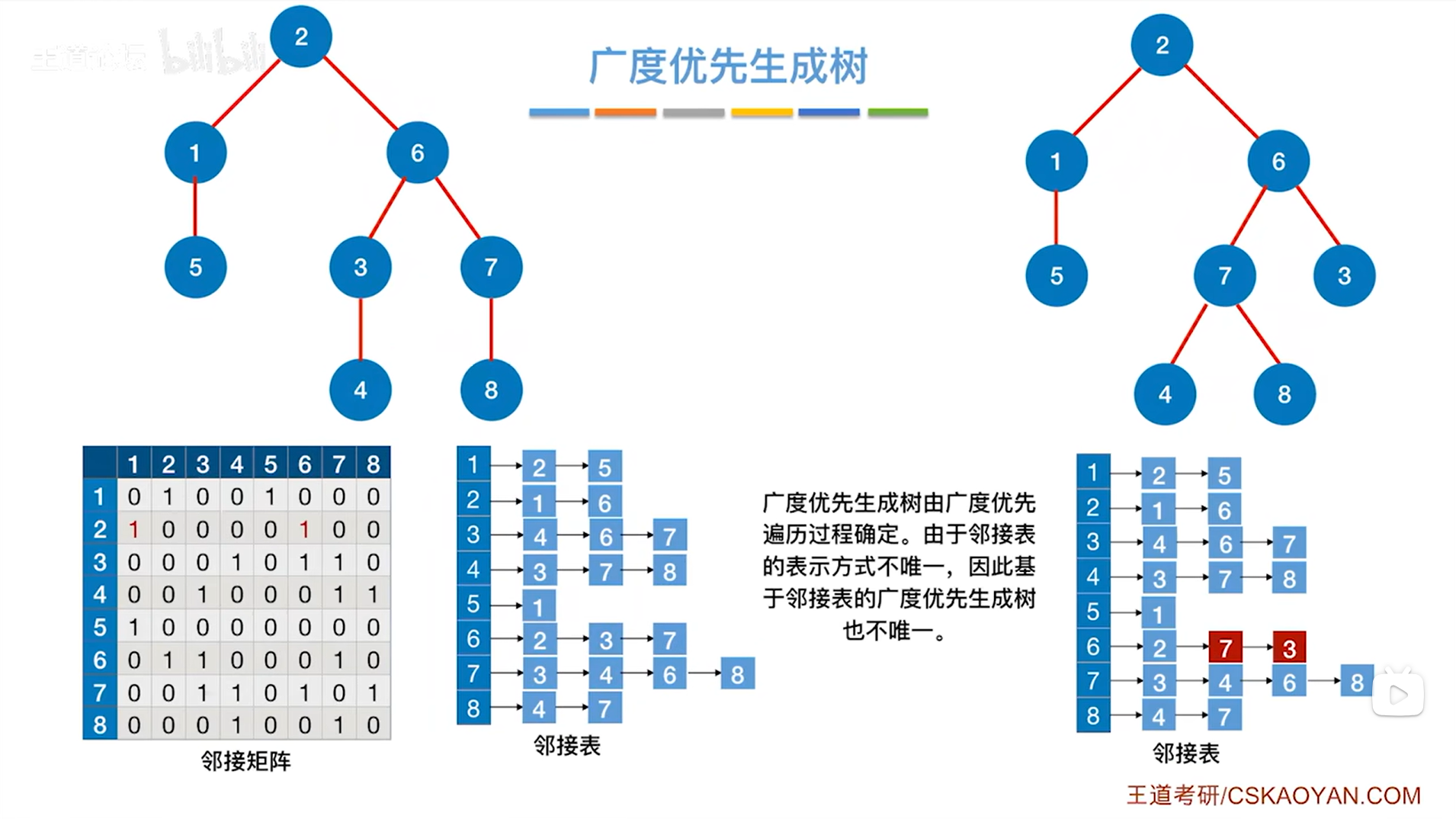
实例中得出的广度优先生成树和变式中得出的广度优先生成树是有区别的,原因在于:
用邻接表存储一个图时表示方式不唯一,因此得到的遍历序列也不唯一,从而得到的广度优先生成树也不唯一;
用邻接矩阵存储一个图时表示方式唯一,因此得到的遍历序列也唯一,从而得到的广度优先生成树也是唯一的。
五.广度优先生成森林:
实例:
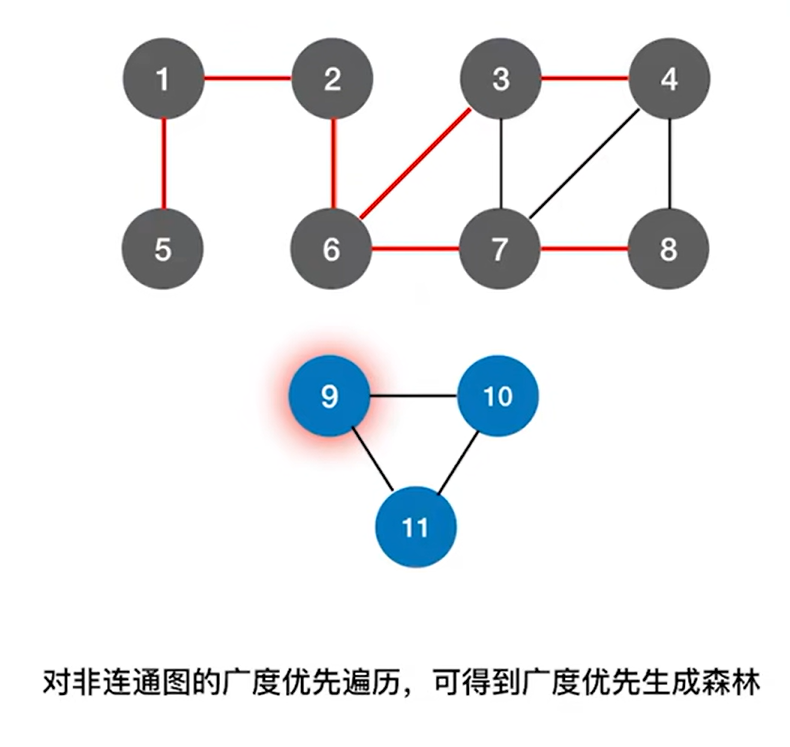
如上图所示,该图是一个非连通图,其中有两个连通分量(连通分量就是极大连通子图的个数,上述图片中,图的极大的连通子图分别由1、2、3、4、5、6、7、8号顶点组成和9、10、11号顶点组成,也就是有两个极大连通子图,所以连通分量为2->找极大连通子图可以先把图的连通子图列出来,再找极大的),由这两个连通分量即由1、2、3、4、5、6、7、8号顶点组成的图和由9、10、11号顶点组成的图就可以得出广度优先生成森林,
由1、2、3、4、5、6、7、8号顶点组成的图可以得出一个广度优先生成树,
由9、10、11号顶点组成的图也可以得出一个广度优先生成树,
这两个广度优先生成树就可以组成广度优先生成森林。
六.练习:
之前的例子是以无向图为例,现在用有向图:
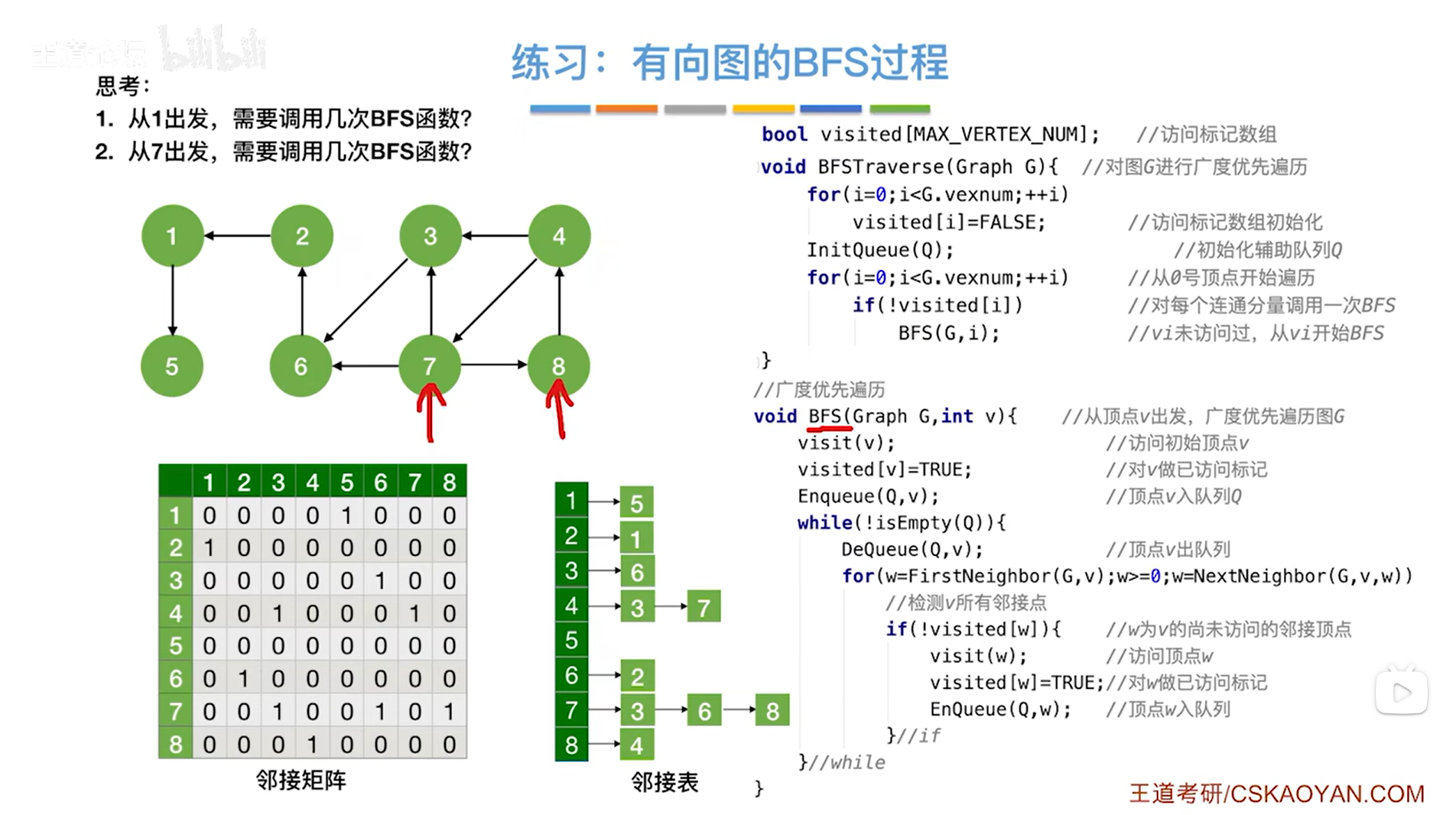
从不同的顶点出发进行广度优先遍历上述图,能不能一次遍历完所有顶点?
如果从1号顶点出发,显然从1号顶点出发只能找到5号顶点,因此就需要调用不止一次BFS函数才能遍历完整张图。
如果从7号顶点或者8号顶点出发,来调用BFS函数的话,由于从7号顶点出发或者从8号顶点出发可以找到任何一个顶点,因此从这两个顶点出发,调用一次BFS函数就可以遍历完整张图,
从7号顶点出发,遍历完整张图的其中一个方案:7号顶点->8号顶点->4号顶点->3号顶点->6号顶点->2号顶点->1号顶点->5号顶点,
从8号顶点出发,遍历完整张图的其中一个方案:8号顶点->4号顶点->7号顶点->3号顶点->6号顶点->2号顶点->1号顶点->5号顶点。
七.总结:
-
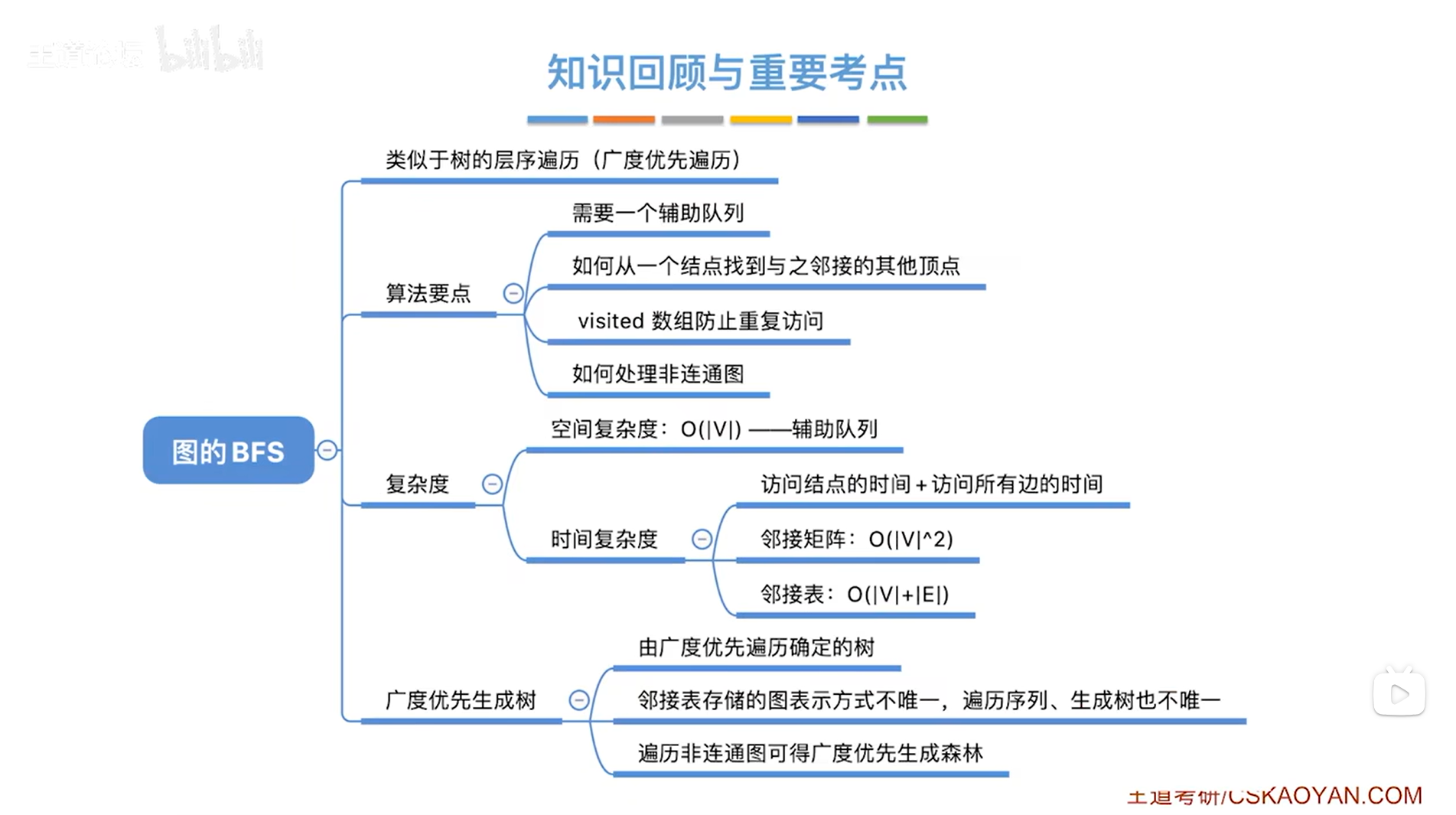
图的广度优先遍历类似于树的层序遍历(广度优先遍历),因为树是特殊的图(没有回路的图就是树)
相关文章:
)
6.6.图的广度优先遍历(英文缩写BFS)
树是一种特殊的图,树的广度优先遍历即层次遍历,所以会从树的角度入手图的广度优先遍历: BFS与DFS的区别在于,BFS使用了队列,DFS使用了栈 一.广度优先遍历: 1.树的广度优先遍历: 详情见"…...
)
练习(杨辉三角、字符串旋转)
一、 以下程序执行的结果: int main() {//0~255unsigned char a 200;//00000000000000000000000011001000//11001000 - a 截断unsigned char b 100;//00000000000000000000000001100100//01100100 - b unsigned char c 0;c a b;//11001000 - a//0110010…...

L1-7 矩阵列平移
题目 给定一个 nn 的整数矩阵。对任一给定的正整数 k<n,我们将矩阵的偶数列的元素整体向下依次平移 1、……、k、1、……、k、…… 个位置,平移空出的位置用整数 x 补。你需要计算出结果矩阵的每一行元素的和。 输入格式: 输入第一行给出…...
基本概念)
webgl入门实例-11模型矩阵 (Model Matrix)基本概念
WebGL 模型矩阵 (Model Matrix) 在WebGL和3D图形编程中,模型矩阵(Model Matrix)是将物体从局部坐标系(模型空间)转换到世界坐标系的关键变换矩阵。 什么是模型矩阵? 模型矩阵是一个4x4的矩阵,用于表示物体在世界空间中的位置、旋转和缩放。…...
)
【漫话机器学习系列】209.均值的标准误差(Standard Error of the Mean)
均值的标准误差(Standard Error of the Mean)详解 在统计学中,我们经常会遇到“均值的标准误差”这个概念,英文称为 Standard Error of the Mean(简称 SEM)。它是对样本均值作为总体均值估计的可靠程度的一…...

Multi Agents Collaboration OS:文档合规性及质量检测助手设计及实践
文档审查及质量检测背景 随着企业运营和知识管理的日益复杂,文档的合规性与质量成为确保信息准确、流程顺畅及风险控制的关键环节。传统上,人工进行文档的合规性和质量检测不仅耗时耗力,且易受主观因素影响,难以保证检测的全面性…...

Vue Teleport 及其在 SSR 中的潜在问题
Vue 3 的 Teleport 特性为开发者提供了更灵活的 DOM 结构控制能力,但在服务端渲染(SSR)场景中,它可能引发一些需要注意的问题。本文将深入探讨 Teleport 的核心机制及其在 SSR 中的使用陷阱。 一、Teleport 核心机制解析 1. 基本…...

Fastapi 日志处理
uvicorn 日志处理总结: 一、日志的结构 日志结构如下: {"version": 1,"disable_existing_loggers": false,"formatters": {},"handlers": {},"loggers": {} }loggers 用于定义日志处理最顶层的标识…...

FME实现矢量建筑面shp拉伸并贴纹理
文章目录 效果2、数据准备3、整理流程图4、操作步骤4.1 打开软件4.2 添加shp数据4.3 添加Extruder转换器4.4 添加AppearanceSetter转换器4.5 添加png纹理数据4.6 添加输出节点4.7 添加Logger节点4.8 执行5、执行结果效果 2、数据准备 (1)建筑面shp (2)纹理 test.png 其中s…...

仿腾讯会议项目实现——设置配置文件
目录 1、初始化配置 2、实现初始化配置的函数 3、修改配置文件内的ip地址 1、初始化配置 Ckernel.h 2、实现初始化配置的函数 3、修改配置文件内的ip地址 首先修改IP 运行出现设置的IP, 找到运行的配置文件,修改成自己当前的ip 将函数运行条件改成非…...

1187. 【动态规划】竞赛总分
题目描述 学生在我们USACO的竞赛中的得分越多我们越高兴。我们试着设计我们的竞赛以便人们能尽可能的多得分。 现在要进行一次竞赛,总时间T固定,有若干类型可选择的题目,每种类型题目可选入的数量不限,每种类型题目有一个si(解答…...

从零开始学Python游戏编程31-类3
2.6 run()方法 run()方法的作用是在while循环中调用以上方法,运行游戏。代码如图11所示。 图11 run()方法代码 其中,第43行控制while循环的是实例属性running,在图7所示的__init__()方法中定义;第44-46行代码分别调用了processI…...
Transformer 架构 - 解码器 (Transformer Architecture - Decoder)
一、解码器整体结构:多层堆叠设计 Transformer解码器由N个相同结构的解码器层堆叠而成(通常N=6),每层包含三个核心子模块(图1) 1 5 12 : 带掩码的多头自注意力层(Masked Multi-Head Self-Attention)编码器-解码器注意力层(Encoder-Deco…...

解锁健康生活:养生新主张
在生活节奏日益加快的当下,健康养生不再是中老年人的专属话题,越来越多的人开始意识到,它是维持生命活力、抵御疾病的重要保障。 中医养生讲究 “药食同源”,在饮食上,我们可以根据季节变化调整食谱。春天气候多变&…...

__call__ 方法
__call__ 是 Python 中的一个魔法方法,也称为类方法。 它的作用是将类的实例变成可调用对象,类似于像函数一样被调用。 __call__ 使用举例 class MyClass:def __call__(self, x, y):return x yobj MyClass() print(obj(1, 2)) 对比其他类/对象的使用…...

济南通过首个备案生活服务大模型,打造行业新标杆
近日,一则振奋人心的消息在人工智能领域传开:济南本土企业丽阳神州智能科技有限公司自主研发的 “丽阳雨露” 大模型成功通过国家网信办的备案。这一成果不仅是济南企业在科技创新道路上的重大突破,更标志着我国在生活服务领域的人工智能应用…...

UE5有些场景的导航生成失败解决方法
如果导航丢失,就在项目设置下将: 即可解决问题: 看了半个小时的导航生成代码发现,NavDataSet这个数组为空,导致异步构建导航失败。 解决 NavDataSet 空 无法生成如下: 当 NavDataSet 为空的化 如果 bAut…...
生成随机数并显示波形)
STM32使用rand()生成随机数并显示波形
一、随机数生成 1、加入头文件:#include "stdlib.h" 2、定义一个用作生成随机数种子的变量并加入到滴答定时器中不断自增:uint32_t run_times 0; 3、设置种子:srand(run_times);//每次生成随机数前调用一次为佳 4、生成一个随…...

继承的了解与学习
目录 1. 继承的概念及定义 1.1 继承的概念 1.2继承的名称 1.3继承方式 1.4继承类模板 2.基类和派生类之间的转化 3.继承中的作用域 4.派生类的默认成员函数 5.继承与友元 6.继承与静态函数 7.多继承与其菱形继承问题 8.虚继承 9.继承和组合 1. 继承的概念及定义 …...

如何精通C++编程?
如果从学生时代算起的话,我学习和使用C已经差不多快十年了,仍然不敢说自己已经掌握了C的全部特性,但或许能够给出一些有用的建议吧。 我学习C全靠自学,花费了不少的功夫,在这里分享一些学习心得,希望对大家…...
)
【科研绘图系列】R语言绘制多个气泡图组合图(bubble plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图函数画图系统信息介绍 【科研绘图系列】R语言绘制多个气泡图组合图(bubble plot) 加载R包 library(dplyr) library(tidyr) library(ggp…...

利用大模型实现地理领域文档中英文自动化翻译
一、 背景描述 在跨国性企业日常经营过程中,经常会遇到专业性较强的文档翻译的需求,例如法律文书、商务合同、技术文档等;以往遇到此类场景,企业内部往往需要指派专人投入数小时甚至数天来整理和翻译,效率低下&#x…...
)
Oracle 19c部署之手工建库(四)
#Oracle #19c #手工建库 手工创建Oracle数据库(也称为手工建库)是指在已经安装了Oracle数据库软件的基础上,通过手动执行一系列命令和步骤来创建一个新的数据库实例。这种方法与使用Database Configuration Assistant (DBCA)等工具自动创建数…...

Leetcode 2158. 每天绘制新区域的数量【Plus题】
1.题目基本信息 1.1.题目描述 有一幅细长的画,可以用数轴来表示。 给你一个长度为 n 、下标从 0 开始的二维整数数组 paint ,其中 paint[i] [starti, endi] 表示在第 i 天你需要绘制 starti 和 endi 之间的区域。 多次绘制同一区域会导致不均匀&…...

使用最新threejs复刻经典贪吃蛇游戏的3D版,附完整源码
基类Entity 建立基类Entity,实现投影能力、动画入场效果(从小变大的弹性动画)、计算自己在地图格位置的方法。 // 导入gsap动画库(用于创建补间动画) import gsap from gsap// 定义Entity基类 export default class …...
为欧洲用户带来更丰富的结果)
Google优化搜索体验:全新动态摘要功能(Beta)为欧洲用户带来更丰富的结果
Google持续推动搜索体验的创新,最新推出的动态摘要(Dynamic Snippets)功能(Beta版)为欧洲经济区(EEA)的用户和企业带来了全新的交互方式。2025年4月,Google更新了动态摘要的文档&…...

[苍穹外卖 | 项目日记] 第三天
前言 实现了新增菜品接口实现了菜品分页查询接口实现了删除菜品接口实现了根据id查询菜品接口实现了修改菜品接口 今日收获: 今日的这几个接口其实和之前写的对员工的操作是一样的,都是一整套Curd操作,所以今天在技术层面上并没有…...

【Python爬虫基础篇】--2.模块解析
目录 1.urllib库 1.1.request模块 1.1.1、urllib.request.urlopen() 函数 1.1.2.urllib.request.urlretrieve() 函数 1.2. error模块 1.3. parse 模块 2. BeautifulSoup4库 2.1.对象种类 2.2.对象属性 2.2.1.子节点 2.2.2.父节点 2.2.3.兄弟节点 2.2.4.回退和前进 …...

LabVIEW技巧——获取文件版本信息
获取可执行文件(exe)版本信息的几种方法 方法1. LabVIEW自带函数 labview自带了获取文件版本号的VI,但是没有开放到程序框图的函数选板中,在该目录下可以找到:...\LabVIEW 20xx\vi.lib\Platform\fileVersionInfo.llb…...
)
【软件工程】用飞书画各种图(流程图,架构图···)
笔者在做服务外包大赛的时候被文档内容的编写反复折磨,网上的工程图绘画工具要么是展示效果不佳,要么要收大几百的VIP费,最后发现飞书竟然可以直接绘画并插入示意图。 一、为什么选择飞书文档画流程图? 完全免费,无广…...

RFID图书管理系统如何重构数字化仓储管理新生态
引言 在图书馆与出版行业数字化转型进程中,RFID图书管理系统正打破传统人工管理的效率瓶颈,通过与数字化仓储管理系统的深度融合,实现从图书采购、入库到借阅的全链路智能化。本文结合RFID固定资产管理软件的应用逻辑,解析这一技…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...

操作系统-PV
🧠 背景:为什么会有 PV? 类比:内存(生产者) 和 CPU(消费者) 内存 / IO / 磁盘 / 网络下载 → 不断“生产数据” 例如:读取文件、下载视频、从数据库加载信息 CPU → 负…...
)
工厂方法模式详解及c++代码实现(以自动驾驶感知模块中的应用为例)
模式定义 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,通过定义抽象工厂接口将对象创建过程延迟到子类实现,实现对象创建与使用的解耦。该模式特别适合需要动态扩展产品类型的场景。 自动驾驶感知场景分析 自动驾…...

Jsp技术入门指南【五】详细讲解jsp结构页面
Jsp技术入门指南【五】详细讲解jsp结构页面 前言一、JSP页面的结构二、JSP页面的部件1. 指令(核心控制部件)2. 动作(页面交互部件,了解即可)3. 脚本(Java逻辑嵌入部件) 三、JSP指令详解1.1 JSP指…...

游戏APP如何抵御DDoS攻击与黑客勒索?实战防护全攻略
一、游戏行业安全挑战与攻击危害 游戏APP因高实时性、高并发及虚拟资产交易特性,成为DDoS攻击和勒索的重灾区,典型威胁包括: DDoS攻击瘫痪服务: UDP Flood:针对游戏服务器端口(如UDP 7777)发起…...

Mac 选择下载安装工具 x86 还是 arm64 ?
要确定你的 Mac 电脑应该选择下载安装工具的 x86 还是 arm64 版本,关键是判断你的 Mac 使用的是 Intel 处理器(x86 架构)还是 Apple Silicon(如 M1、M2 等,arm64 架构)。具体方法如下: 方法 1&…...

string函数的应用
字符串查找 find 方法 实例 string s "Hello World,C is awesome!";//查找子串 size_t pos1 s.find("World"); //pos16 size_t pos2 s.find("Python"); //pos2string::npos//查找字符 size_tpos3s.find(c); //pos313//从指定位置开始查找 size…...

使用Trae CN分析项目架构
架构分析后的截图 A区是打开的项目、B区是源码区、C区是AI给出当前项目的架构分析结果。 如何用 Trae CN 快速学习 STM32 嵌入式项目架构 在嵌入式开发领域,快速理解现有项目的架构是一项关键技能。Trae CN 作为一款强大的分析工具,能帮助开发者高效剖…...
暴力娱乐篇33)
每日一题(小白)暴力娱乐篇33
由题意可知我们今天要解决的问题是在1~2025中去找合适的数字,这里要找出一些特殊的数字,这些数字要满足以下条件,是三的倍数,是8的倍数,是38的倍数,老板就给要多给一个红包,我们循环然后相应条件…...

MyBatis框架
前言: MyBatis框架相比JDBC来说大大提升了我们写代码的效率,但是对初学者来说框架还是有点难以理解,所以本篇博客会十分详细的讲解MyBatis框架 目录 一.MyBatis概述 1.什么是映射? 2.什么是XML? 二.MyBatis框架搭建 1.创建一张表和表对…...

基于SpringBoot的新闻小程序开发与设计
概述 在信息爆炸的时代,高效获取新闻资讯成为现代人的刚需。幽络源平台今日分享一款基于SpringBoot框架开发的微信小程序新闻资讯系统,该系统采用前后端分离架构,实现了新闻分类管理、个性化推荐、用户收藏等功能,为新闻传播提供…...

IE之路专题12.BGP专题
BGP协议有哪些特点 BGP时边界网关协议(EGP),是一种用在自治系统之间传递路由信息的路由协议; 提供了丰富的路由属性以及强大的路由过滤和路由策略,实现灵活选路和路由控制; 策略方式更改属性或根据更新信息中属性实现过滤和策略 BGP是工作在传输层TCP之上的,使用TCP的端口号…...
)
文件包含(详解)
文件包含漏洞是一种常见的Web安全漏洞,其核心在于应用程序未对用户控制的文件路径或文件名进行严格过滤,导致攻击者能够包含并执行任意文件(包括本地或远程恶意文件)。 1. 文件包含原理 动态文件包含机制 开发者使用动态包含函数…...

智慧养老照护实训室:推动养老服务数字化转型实践
在人口老龄化加速与数字化浪潮席卷的当下,传统养老服务模式在效率、精准度及个性化服务上的局限日益明显。智慧养老成为行业转型的必然方向,但专业人才短缺与技术应用落地困难制约着发展。智慧养老照护实训室通过整合虚拟仿真等前沿技术,构建…...

NOIP2015提高组.信息传递
目录 题目算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量思路 T a r j a n Tarjan Tarjan算法求解代码 题目 517. 信息传递 算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量 思路 使用强连通分量算法求环上点…...

Wireshark 搜索组合速查表
文章目录 Wirshark使用记录基本语法规则搜索条件符号速查表捕获过滤器组合指令速查表筛选过滤器组合命令速查表Wireshark Frame 协议字段解析 Wirshark使用记录 官网地址:https://www.wireshark.org/ 基本语法规则 字段描述示例说明type用于指定数据包的类型&…...

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

我的gittee仓库
日常代码: 日常代码提交https://gitee.com/xinxin-pingping/daily-code 有需要的宝子们可自行读取。...

RT-Thread开发文档合集
瑞萨VisionBoard开发实践指南 RT-Thread 文档中心 RT-Thread-【RA8D1-Vision Board】 RA8D1 Vision Board上的USB实践RT-Thread问答社区 - RT-Thread 【开发板】环境篇:05烧录工具介绍_哔哩哔哩_bilibili 【RA8D1-Vision Board】基于OpenMV 实现图像分类_哔哩哔哩_…...