【Python爬虫基础篇】--2.模块解析
目录
1.urllib库
1.1.request模块
1.1.1、urllib.request.urlopen() 函数
1.1.2.urllib.request.urlretrieve() 函数
1.2. error模块
1.3. parse 模块
2. BeautifulSoup4库
2.1.对象种类
2.2.对象属性
2.2.1.子节点
2.2.2.父节点
2.2.3.兄弟节点
2.2.4.回退和前进
2.3.对象方法
2.3.1.find_all()
2.3.2.find()
2.3.3.CSS选择器查找
2.3.4.修改内容
2.4.输出
2.4.1.格式化输出
2.4.2.压缩输出
2.4.3.文本输出
3.re标准库
大概会用到以下这些模块
| 分类 | 库名 | 主要用途 |
|---|---|---|
| 网络请求 | requests | 同步HTTP请求 |
aiohttp | 异步HTTP请求 | |
| 动态渲染 | selenium | 浏览器自动化 |
playwright | 高性能无头浏览器控制 | |
| 数据解析 | BeautifulSoup4 | HTML/XML解析 |
lxml | XPath/CSS选择器解析 | |
re | 字符串正则匹配(文本清洗/数据提取) | |
| 爬虫框架 | scrapy | 全功能爬虫框架 |
| 反反爬 | fake-useragent | 随机生成请求头 |
1.urllib库
Python3 中将 Python2 中的 urllib 和 urllib2 两个库整合为一个 urllib 库,所以现在一般说的都是 Python3 中的 urllib 库,它是python3内置标准库,不需要额外安装。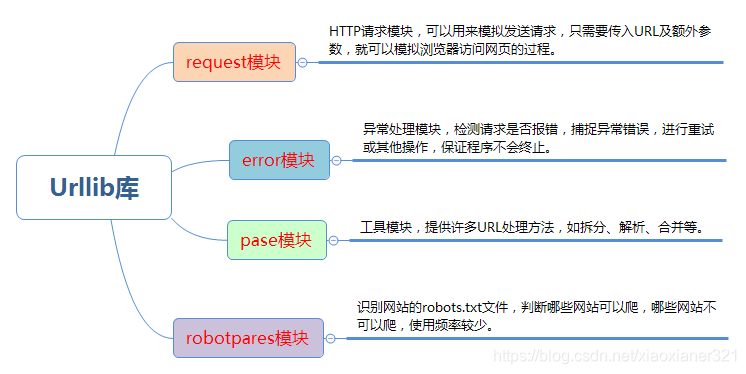
1.1.request模块
request模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理authenticaton(授权验证),redirections(重定向),cookies(浏览器Cookies)以及其它内容。
1.1.1、urllib.request.urlopen() 函数
语法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)参数说明:
url:请求的 url,也可以是request对象
data:请求的 data,如果设置了这个值,那么将变成 post 请求,如果要传递一个字典,则应该用urllib.parse模块的urlencode()函数编码;
timeout:设置网站的访问超时时间句柄对象;
cafile和capath:用于 HTTPS 请求中,设置 CA 证书及其路径;
cadefault:忽略*cadefault*参数;
context:如果指定了*context*,则它必须是一个ssl.SSLContext实例。urlopen() 返回对象HTTPResponse提供的方法和属性:1)read()、readline()、readlines()、fileno()、close():对 HTTPResponse 类型数据进行操作;
2)info():返回 HTTPMessage 对象,表示远程服务器 返回的头信息 ;
3)getcode():返回 HTTP 状态码 geturl():返回请求的 url;
4)getheaders():响应的头部信息;
5)status:返回状态码;
6)reason:返回状态的详细信息.案例一:使用urlopen()函数抓取百度
import urllib.request
url = "http://www.baidu.com/"
res = urllib.request.urlopen(url) # get方式请求
print(res) # 返回HTTPResponse对象<http.client.HTTPResponse object at 0x00000000026D3D00>
# 读取响应体
bys = res.read() # 调用read()方法得到的是bytes对象。
print(bys) # <!DOCTYPE html><!--STATUS OK-->\n\n\n <html><head><meta...
print(bys.decode("utf-8")) # 获取字符串内容,需要指定解码方式,这部分我们放到html文件中就是百度的主页# 获取HTTP协议版本号(10 是 HTTP/1.0, 11 是 HTTP/1.1)
print(res.version) # 11# 获取响应码
print(res.getcode()) # 200
print(res.status) # 200# 获取响应描述字符串
print(res.reason) # OK# 获取实际请求的页面url(防止重定向用)
print(res.geturl()) # http://www.baidu.com/# 获取响应头信息,返回字符串
print(res.info()) # Bdpagetype: 1 Bdqid: 0x803fb2b9000fdebb...
# 获取响应头信息,返回二元元组列表
print(res.getheaders()) # [('Bdpagetype', '1'), ('Bdqid', '0x803fb2b9000fdebb'),...]
print(res.getheaders()[0]) # ('Bdpagetype', '1')
# 获取特定响应头信息
print(res.getheader(name="Content-Type")) # text/html;charset=utf-8案例二:get请求
我们在http://httpbin.org/网站,发送一个get测试请求:
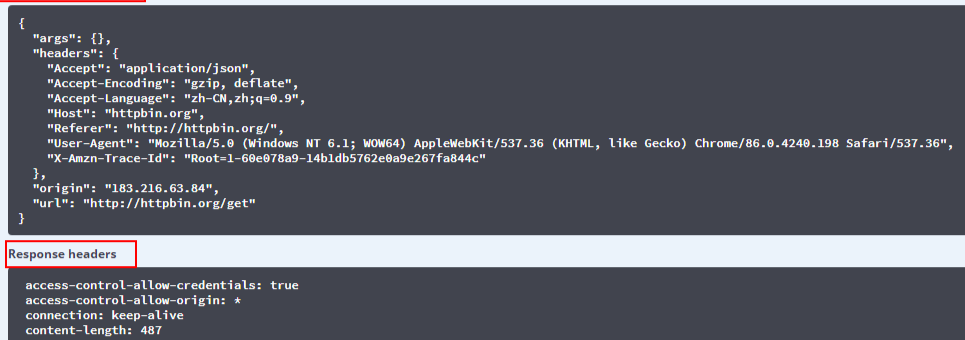
然后我们在使用python模拟浏览器发送一个get请求:
import urllib.request
# 请求的URL
url = "http://httpbin.org/get"
# 模拟浏览器打开网页(get请求)
res = urllib.request.urlopen(url)
print(res.read().decode("utf-8")) 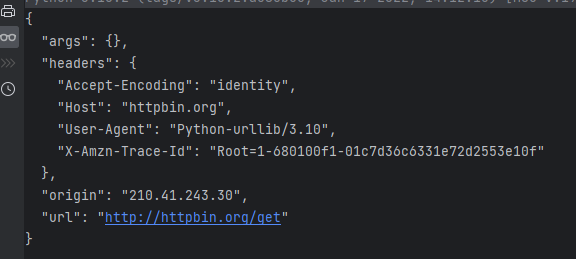
通过上面的案例,不难发现使用urllib发送的请求,比较不同的地方是:"User-Agent",使用urllib发送的会有一个默认的Headers:User-Agent: Python-urllib/3.8。所以遇到一些验证User-Agent的网站时,有可能会直接拒绝爬虫,因此我们需要自定义Headers把自己伪装的像一个浏览器一样。
案例三: 伪装Headers
我去爬取豆瓣网时:
import urllib.requesturl = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))返回错误:反爬虫
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418: HTTP 418 客户端错误响应代码表示服务器拒绝。
自定义Headers:
import urllib.requesturl = "http://douban.com"
# 自定义headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# urlopen(也可以是request对象)
print(urllib.request.urlopen(req).read().decode('utf-8')) # 获取字符串内容,需要指定解码方式1.1.2.urllib.request.urlretrieve() 函数
urlretrieve()函数的作用是直接将远程的网页数据htlm下载到本地
# 语法:
urlretrieve(url, filename=None, reporthook=None, data=None)
# 参数说明
url:传入的网址
filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度
data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header表示服务器的响应头
import urllib.requesturl = "http://www.hao6v.com/"
filename = "C:\\pythonProject\\python爬虫\\gyp.html"def callback(blocknum, blocksize, totalsize):"""@blocknum:目前为此传递的数据块数量@blocksize:每个数据块的大小,单位是byte,字节@totalsize:远程文件的大小"""if totalsize == 0:percent = 0else:percent = blocknum * blocksize / totalsizeif percent > 1.0:percent = 1.0percent = percent * 100print("download : %.2f%%" % (percent))local_filename, headers = urllib.request.urlretrieve(url, filename, callback)
1.2. error模块
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
| 状态码 | 分类 | 定义 |
|---|---|---|
| 1xx | 信息响应 | |
| 100 | Continue | 服务器已接收请求头,客户端应继续发送请求体 |
| 101 | Switching Protocols | 协议切换(如HTTP→WebSocket) |
| 2xx | 成功响应 | |
| 200 | OK | 请求成功,响应内容取决于请求方法(GET/POST等) |
| 201 | Created | 资源创建成功(常用于POST/PUT) |
| 204 | No Content | 无返回内容,但响应头可能含元信息 |
| 3xx | 重定向 | |
| 301 | Moved Permanently | 资源永久重定向到新URI |
| 302 | Found | 资源临时重定向(早期规范语义不明确,建议用307/308替代) |
| 304 | Not Modified | 资源未修改(缓存相关) |
| 4xx | 客户端错误 | |
| 400 | Bad Request | 请求语法错误 |
| 403 | Forbidden | 服务器拒绝执行(无权限) |
| 404 | Not Found | 资源不存在 |
| 408 | Request Timeout | 请求超时 |
| 5xx | 服务器错误 | |
| 500 | Internal Server Error | 服务器内部错误(无具体信息) |
| 503 | Service Unavailable | 服务不可用(临时过载或维护) |
| 504 | Gateway Timeout | 网关超时(上游服务器未响应) |
import urllib.request,urllib.errortry:url = "http://www.baidus.com"resp = urllib.request.urlopen(url)print(resp.read().decode('utf-8'))
# except urllib.error.HTTPError as e:
# print("请检查url是否正确")
# URLError是urllib.request异常的超类
except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason) 
1.3. parse 模块
| 功能分类 | 函数 | 核心作用 |
|---|---|---|
| URL解析 | urlparse(url) | 将URL拆分为6组件(协议/域名/路径等),保留参数分隔符;和& |
urlsplit(url) | 类似urlparse但不拆分参数分隔符,返回5组件 | |
urldefrag(url) | 分离URL中的片段标识(如#anchor) | |
| URL构建 | urlunparse(parts) | 将urlparse的6组件重组为完整URL |
urljoin(base, url) | 基于基URL合并相对路径(智能处理./和../) | |
| 查询参数处理 | urlencode(query_dict) | 将字典转为URL查询字符串(自动编码特殊字符) |
parse_qs(query_str) | 将查询字符串解析为字典(值类型为list) | |
parse_qsl(query_str) | 将查询字符串解析为键值对列表(保留原始顺序) |
2. BeautifulSoup4库
学了urllib标准库之后,我们已经能爬到些比较正常的网页源码(html文档)了,但这离结果还差一步——就是如何筛选我们想要的数据,这时候BeautifulSoup库就来了,BeautifulSoup目前最新版本为BeautifulSoup4。
用于解析HTML和XML文档的流行库,它能够从网页中提取数据并生成易于遍历的解析树。
(官网文档:Beautiful Soup 4.12.0 文档 — Beautiful Soup 4.12.0 documentation)
soup = BeautifulSoup("<html>Hello</html>", "html.parser")参数解析:
(1)markup
需要解析的HTML/XML文档内容(字符串或文件对象)。
(2)解析器选择(features 或第二参数)
| 解析器 | 安装方式 | 特点 | 示例 |
|---|---|---|---|
"html.parser" | Python内置 | 速度中等,无依赖 | BeautifulSoup(html, "html.parser") |
"lxml" | pip install lxml | 最快,支持复杂文档 | BeautifulSoup(html, "lxml") |
"html5lib" | pip install html5lib | 容错性最强,速度慢 | BeautifulSoup(html, "html5lib") |
from bs4 import BeautifulSoup # 导入BeautifulSoup4库# 未指定就使用html.parser这个python标准解析器 BeautifulSoup(markup, "html.parser") 未指定会产生警告 GuessedAtParserWarning: No parser was explicitly specified# BeautifulSoup 第一个参数接受:一个文件对象或字符串对象
soup1 = BeautifulSoup(markup=open("C:\\pythonProject\\python爬虫\\gyp.html"), features="html.parser")
soup2 = BeautifulSoup("<html>hello python</html>") # 得到文档的对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup1) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
print(soup2) # <html><head></head><body>hello python</body></html>2.1.对象种类
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。
| 对象类型 | 关键属性/方法 | 功能描述 | 注意事项 |
|---|---|---|---|
| Tag 标签对象 | name(标签名)attributes(属性字典) | 表示HTML/XML文档中的标签节点,可获取标签名和属性(如class、id等) | 通过遍历或搜索文档树获取,支持嵌套操作(如tag.contents ) |
| NavigableString | tag.string | 提取标签对内的纯文本内容(仅限直接包含的字符串) | 若标签内含注释或其他子标签,需用.strings或.get_text()获取完整文本 |
| BeautifulSoup | 文档根对象 | 代表整个解析后的文档,可视为特殊的Tag对象(包含<html>顶层标签) | 初始化时需指定解析器(如lxml),支持全局搜索方法(如.find_all()) |
| Comment 对象 | 继承自NavigableString | 处理HTML注释内容(如<!-- comment -->),输出时自动去掉注释符号 | 需用type(tag.string)==bs4.Comment 判断,避免误将注释当作普通文本处理 |
from bs4 import BeautifulSoup# 导入BeautifulSoup4库
# python 标准解析器 未指定就使用这个 BeautifulSoup(markup, "html.parser")
soup2 = BeautifulSoup("<html>""<p class='boldest'>我是p标签<b>hello python</b></p>""<!--我是标签外部的内容注释-->""<p class='boldest2'><!--我p标签内的注释-->我是独立的p标签</p>""<a><!--我a标签内的注释-->我是链接</a>""<h1><!--这是一个h1标签的注释--></h1>""</html>","html5lib") # 得到文档的对象
# Tag 标签对象
print(type(soup2.p)) # 输出Tag对象<class 'bs4.element.Tag'>
print(soup2.p.name) # 输出Tag标签对象的名称
print(soup2.p.attrs) # 输出第一个p标签的属性信息:{'class': ['boldest']}
soup2.p['class'] = ['boldest', 'boldest1']
print(soup2.p.attrs) # {'class': ['boldest', 'boldest1']}# NavigableString 可以遍历的字符串对象
print(type(soup2.b.string)) # <class 'bs4.element.NavigableString'>
print(soup2.b.string) # hello python
print(soup2.a.string) # None 存在注释或者其他标签内容均无法获取
print(soup2.b.string.replace_with("hello world")) # replace_with()方法可替换标签中的内容
print(soup2.b.string) # hello world# BeautifulSoup 对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup2) # <html><head></head><body><p class="boldest">我是p标签<b>hello python</b></p><!--我是标签外部的内容注释--><p><!--我p标签内的注释-->我是独立的p标签</p></body></html>
print(soup2.name) # [document]# Comment 注释及特殊字符串(是一个特殊类型的 NavigableString 对象)
print(type(soup2.h1.string)) # <class 'bs4.element.Comment'>
print(soup2.h1.string) # 这是一个h1标签的注释 (利用 .string 来输出它的内容,注释符被去除了,不是我们想要的)
print(soup2.h1.prettify()) # 会以特殊格式输出:<h1> <!--这是一个h1标签的注释--> </h1>2.2.对象属性
可以简单理解爬取到的内容是树状图:
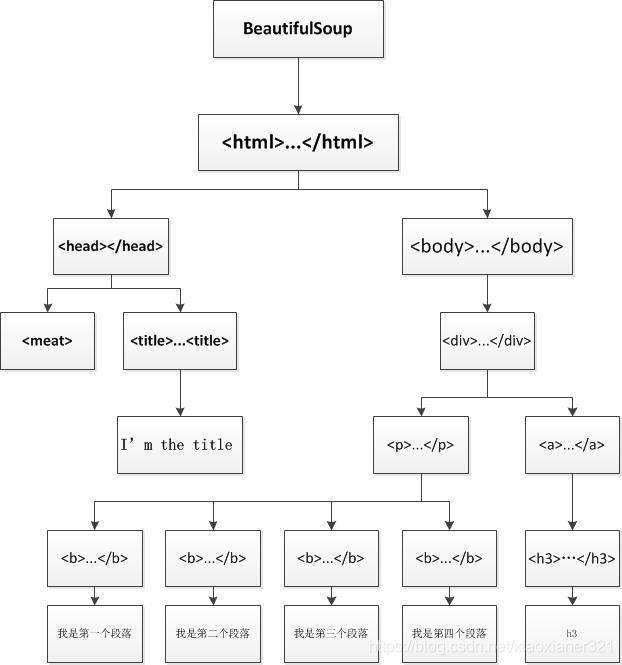
2.2.1.子节点
BeautifulSoup 对象常用属性总结
| 属性/方法 | 描述 | 使用场景与注意事项 |
|---|---|---|
| .tag | 获取标签名(如tag.name 返回'div') | 适用于快速识别标签类型,但需注意某些标签(如<br/>)可能无闭合标签。 |
| .contents | 返回标签的直接子节点列表(包括文本和标签节点) | 需注意列表可能包含换行符等空白文本节点,可通过过滤NavigableString类型处理。 |
| .children | 生成器形式返回直接子节点(性能优于.contents) | 适合遍历大量子节点时节省内存,但不可索引(需转为列表)。 |
| .descendants | 递归生成所有子孙节点(深度优先遍历) | 可用于爬取嵌套结构的完整内容(如表格内的所有文本),但需处理混合节点类型(注释、字符串等)。 |
| .string | 提取标签内唯一字符串子节点(无嵌套标签) | 若标签含多个子节点(如<p>Text<b>bold</b></p>),返回None,需改用.get_text()或.strings。 |
| .strings | 生成器形式返回标签内所有字符串(保留空白) | 需手动去除换行符和缩进(如' '.join(tag.strings).strip() )。 |
| .stripped_strings | 生成器形式返回标签内字符串(自动去除空白) | 适用于清洗文本(如新闻正文提取),但可能合并相邻空格(需根据需求调整)。 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一个段落...</b>我是第一段我是第二段<b>我是另一个段落</b>我是第一段</p><a>我是一个链接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
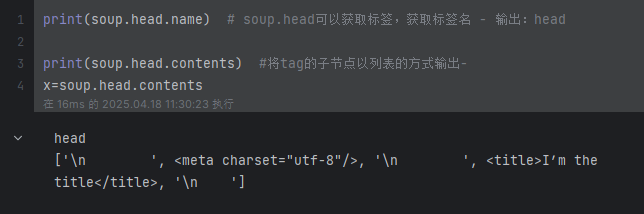
print(soup.head.name) # soup.head可以获取标签,获取标签名 - 输出:head
print(soup.head.contents) # 将tag的子节点以列表的方式输出--输出:['\n ', <meta charset="utf-8"/>, '\n ', <title>I’m the title</title>, '\n ']
print(soup.head.contents[1]) # <meta charset="utf-8"/>
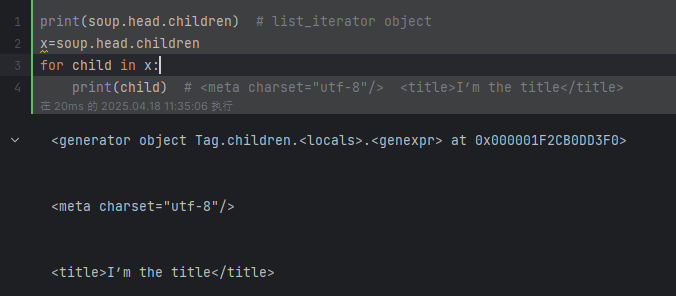
print(soup.head.children) # list_iterator object
for child in soup.head.children:print(child) # <meta charset="utf-8"/> <title>I’m the title</title>
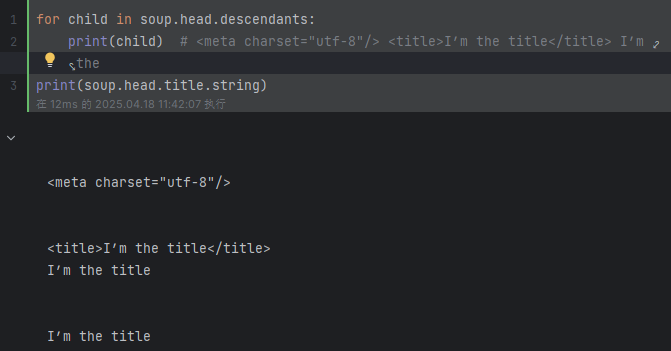
# 标签中的内容其实也是一个节点 使用contents和children无法直接获取间接节点中的内容,但是.descendants 属性可以
for child in soup.head.descendants:print(child) # <meta charset="utf-8"/> <title>I’m the title</title> I’m the title
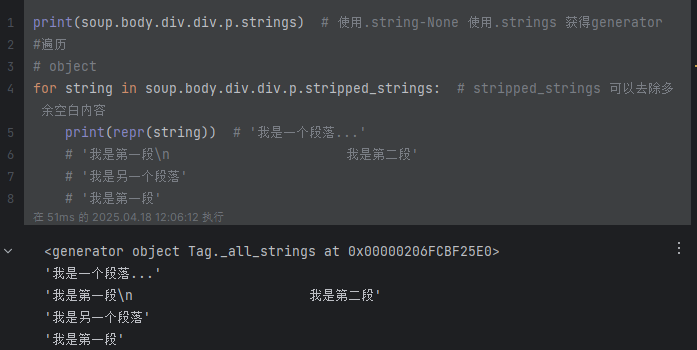
print(soup.head.title.string) # 输出:I’m the title 注:title中有其他节点或者注释都无法获取print(soup.body.div.div.p.strings) # 使用.string-None 使用.strings 获得generator object
for string in soup.body.div.div.p.stripped_strings: # stripped_strings 可以去除多余空白内容print(repr(string)) # '我是一个段落...'# '我是第一段\n 我是第二段'# '我是另一个段落'# '我是第一段'tag+contents:
children:
深度优先遍历:descendants
获取标签字符:string
2.2.2.父节点
| 属性 | 描述 |
| .parent | 获取某个元素的父节点 |
| .parents | 可以递归得到元素的所有父辈节点 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一个段落...</b>我是第一段我是第二段<b>我是另一个段落</b>我是第一段</p><a>我是一个链接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象title = soup.head.title
print(title.parent) # 输出父节点
# <head>
# <meta charset="utf-8"/>
# <title>I’m the title</title>
# </head>
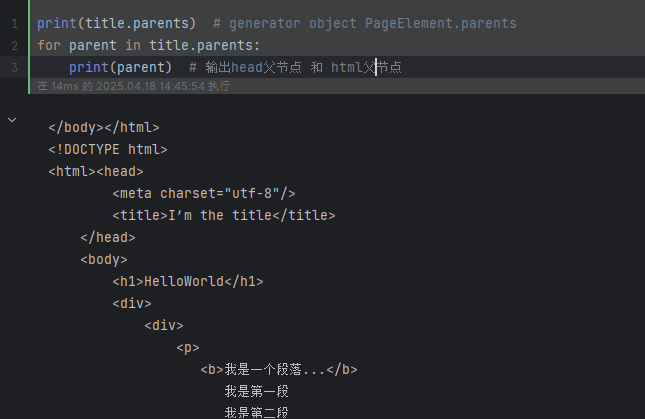
print(title.parents) # generator object PageElement.parents
for parent in title.parents:print(parent) # 输出head父节点 和 html父节点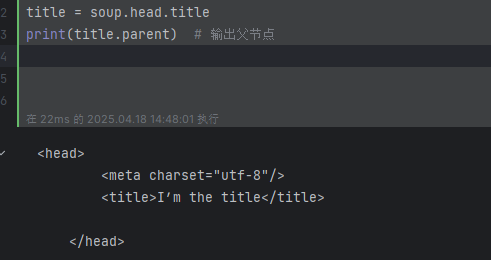
2.2.3.兄弟节点
| 属性 | 描述 |
| .next_sibling | 查询兄弟节点,表示下一个兄弟节点 |
| .previous_sibling | 查询兄弟节点,表示上一个兄弟节点 |
| .next_siblings | 对当前节点的兄弟节点迭代输出(下) |
| .previous_siblings | 对当前节点的兄弟节点迭代输出(上) |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a>我是一个链接</a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_sibling) # <b id="“b2”">我是第二个段落</b>
print(p.next_sibling.previous_sibling) # <b id="“b1”">我是第一个段落</b>
print(p.next_siblings) # generator object PageElement.next_siblings
for nsl in p.next_siblings:print(nsl) # <b id="“b2”">我是第二个段落</b># <b id="“b3”">我是第三个段落</b># <b id="“b4”">我是第四个段落</b>2.2.4.回退和前进
| 属性 | 描述 |
| .next_element | 解析下一个元素对象 |
| .previous_element | 解析上一个元素对象 |
| .next_elements | 迭代解析元素对象 |
| .previous_elements | 迭代解析元素对象 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a>我是一个链接<h3>h3</h3></a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_element) # 我是第一个段落
print(p.next_element.next_element) # <b id="“b2”">我是第二个段落</b>
print(p.next_element.next_element.next_element) # 我是第二个段落
for element in soup.body.div.a.next_element: # 对:我是一个链接 字符串的遍历print(element)2.3.对象方法
这里的搜索文档,其实就是按照某种条件去搜索过滤文档,过滤的规则,往往会使用搜索的API,或者我们也可以自定义正则/过滤器,去搜索文档
2.3.1.find_all()
find_all( name , attrs , recursive , string , **kwargs ) | 参数/属性 | 类型 | 作用 | 示例 |
|---|---|---|---|
name | 字符串/正则/列表/函数 | 指定标签名称(如 'div') | soup.find_all('p') 查找所有 <p> 标签 |
attrs | 字典 | 通过属性筛选(如 class、id) | soup.find_all(attrs={'class': 'header'}) 匹配 class="header" 的标签 |
recursive | 布尔值(默认 True) | 是否递归搜索子标签。False 时仅搜索直接子节点 | soup.find_all('div', recursive=False) 仅查顶层 <div> |
string | 字符串/正则/函数 | 直接搜索标签内的文本内容(非标签本身) | soup.find_all(string='Hello') 查找文本为 "Hello" 的节点 |
**kwargs | 关键字参数 | 简化属性筛选语法(等效于 attrs) | soup.find_all(class_='header') 匹配 class="header" |
| 返回值 | ResultSet(类列表) | 返回所有匹配的标签或文本节点的集合,若无结果则返回空列表 [] | results = soup.find_all('a') 获取所有 <a> 标签 |
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a href="www.temp.com">我是一个链接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
# 语法:find_all( name , attrs , recursive , string , **kwargs )
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.findAll('b')) # 返回包含b标签的列表 [<b id="“b1”">我是第一个段落</b>, <b id="“b2”">我是第二个段落</b>, <b id="“b3”">我是第三个段落</b>, <b id="“b4”">我是第四个段落</b>]
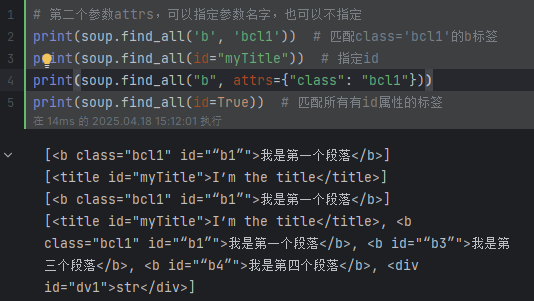
print(soup.findAll(['a', 'h3'])) # 按列表匹配多个 [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>, <h3>h3</h3>]# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.findAll('b', 'bcl1')) # 匹配class='bcl1'的b标签[<b class="bcl1" id="“b1”">我是第一个段落</b>]
print(soup.findAll(id="myTitle")) # 指定id [<title id="myTitle">I’m the title</title>]
print(soup.find_all("b", attrs={"class": "bcl1"})) # [<b class="bcl1" id="“b1”">我是第一个段落</b>]
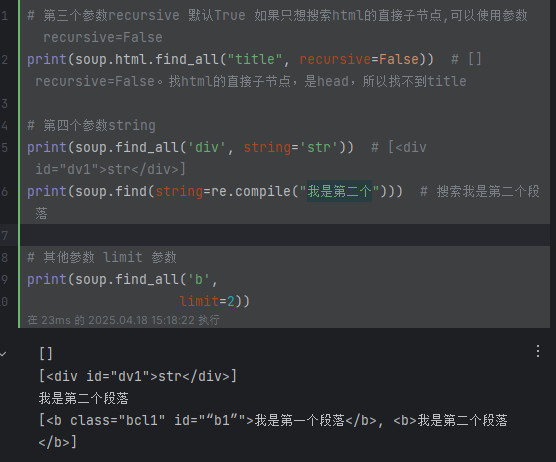
print(soup.findAll(id=True)) # 匹配所有有id属性的标签# 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find_all("title", recursive=False)) # [] recursive=False。找html的直接子节点,是head,所以找不到title# 第四个参数string
print(soup.findAll('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 搜索我是第二个段落# 其他参数 limit 参数
print(soup.findAll('b', limit=2)) # 当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果,[<b class="bcl1" id="“b1”">我是第一个段落</b>, <b>我是第二个段落</b>]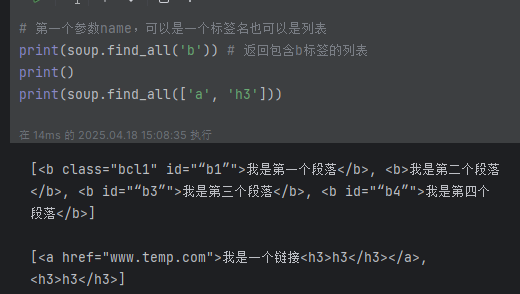
2.3.2.find()
find()与find_all() 的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(即找到了就不再找,只返第一个匹配的),find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None。
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.find('b')) # 返回<b class="bcl1" id="“b1”">我是第一个段落</b>,只要找到一个即返回# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.find('b', 'bcl1')) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id="myTitle")) # <title id="myTitle">I’m the title</title>
print(soup.find("b", attrs={"class": "bcl1"})) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id=True)) # 匹配到第一个<title id="myTitle">I’m the title</title># 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find("title", recursive=False)) # None recursive=False。找html的直接子节点,是head,所以找不到title# 第四个参数string
print(soup.find('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 我是第二个段落find汇总
| 方法分类 | 方法名 | 功能描述 |
|---|---|---|
| 父节点搜索 | find_parents() | 搜索当前节点所有符合条件的父辈节点(包括直接父节点和更上层祖先) |
find_parent() | 搜索当前节点第一个符合条件的直接父节点 | |
| 后续兄弟节点搜索 | find_next_siblings() | 返回当前节点后所有符合条件的兄弟节点(同层级) |
find_next_sibling() | 返回当前节点后第一个符合条件的兄弟节点 | |
| 前序兄弟节点搜索 | find_previous_siblings() | 返回当前节点前所有符合条件的兄弟节点(同层级) |
find_previous_sibling() | 返回当前节点前第一个符合条件的兄弟节点 | |
| 后续所有节点搜索 | find_all_next() | 返回文档中当前节点之后所有符合条件的节点(不限于兄弟节点,跨层级) |
find_next() | 返回文档中当前节点之后第一个符合条件的节点 | |
| 前序所有节点搜索 | find_all_previous() | 返回文档中当前节点之前所有符合条件的节点(不限于兄弟节点,跨层级) |
find_previous() | 返回文档中当前节点之前第一个符合条件的节点 |
2.3.3.CSS选择器查找
soup.select() 方法概述
- 作用:通过 CSS 选择器语法快速定位 HTML/XML 文档中的标签或节点。
- 返回值:返回一个
ResultSet(类似列表的对象),包含所有匹配的节点。若无匹配则返回空列表[]。 - 优势:语法简洁,支持复杂层级选择(比
find_all更灵活)。
参数解析
select('selector')
- 唯一参数:字符串类型的 CSS 选择器表达式。
- 支持的选择器类型:
选择器类型 示例 说明 标签选择器 'div'选择所有 <div>标签类选择器 '.header'选择 class="header"的标签ID 选择器 '#main'选择 id="main"的标签层级选择器 'div > p'选择 <div>直接子级的<p>属性选择器 '[href]'或'[data-id="1"]'按属性名或属性值筛选 组合选择器 'div.header, p#intro'多条件组合选择(逗号分隔)
- 支持的选择器类型:
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a href="www.temp.com">我是一个链接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
print(soup.select("html head title")) # [<title id="myTitle">I’m the title</title>]
print(soup.select("body a")) # [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>]
print(soup.select("#dv1")) # [<div id="dv1">str</div>]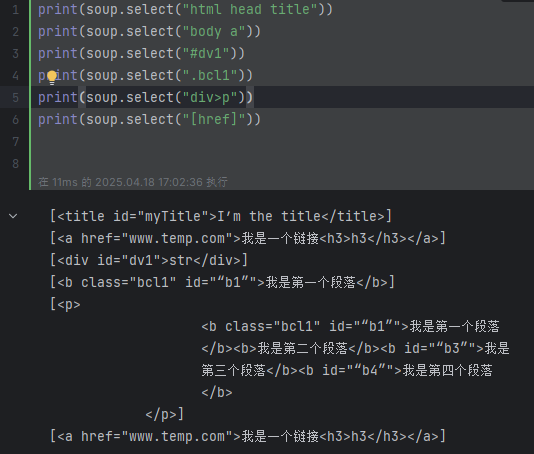
2.3.4.修改内容
修改tag的名称、属性、内容
from bs4 import BeautifulSoupsoup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.name = "blockquote"
print(tag) # <blockquote class="boldest">Extremely bold</blockquote>tag['class'] = 'veryBold'
tag['id'] = 1
tag.string = "replace"tag.append(" append")#添加内容del tag['id'] # 删除属性添加非标签内容:
from bs4 import BeautifulSoup, NavigableString, Commentsoup = BeautifulSoup('<div><b class="boldest">Extremely bold</b></div>', "html5lib")
tag = soup.div
new_string = NavigableString('NavigableString')
tag.append(new_string)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString</div>new_comment = soup.new_string("Nice to see you.", Comment)
tag.append(new_comment)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--></div># 添加标签,推荐使用工厂方法new_tag
new_tag = soup.new_tag("a", href="http://www.example.com")
tag.append(new_tag)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--><a href="http://www.example.com"></a></div>把元素插入到指定的位置:
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup,"html5lib")
tag = soup.a
tag.insert(1, "but did not endorse ") # 和append的区别就是.contents属性获取不一致
print(tag) # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a>
print(tag.contents) # ['I linked to ', 'but did not endorse ', <i>example.com</i>]将当前tag移除文档树,并作为方法结果返回:
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
print(a_tag)#<a href="http://example.com/">I linked to <i>example.com</i></a>
i_tag = soup.i.extract()print(a_tag) # <a href="http://example.com/">I linked to </a>
print(i_tag) # <i>example.com</i> 我们移除的内容| 方法 | 功能描述 | 示例代码 | 输出结果 | 关键区别 |
|---|---|---|---|---|
decompose() | 完全移除并销毁节点,不可恢复 | soup.i.decompose()print(a_tag) | <a href="...">I linked to </a> | 永久性删除,内存中不再存在 |
replace_with() | 用新节点/文本替换原节点,保留文档结构 | new_tag = soup.new_tag("b")new_tag.string = "example.net"soup.a.i.replace_with(new_tag) | <a href="...">I linked to <b>example.net</b></a> | 可灵活替换为任意节点类型(标签/文本/注释等) |
unwrap() | 移除当前标签,但保留其内容(解包操作) | a_tag.i.unwrap()print(a_tag) | <a href="...">I linked to example.com</a> | 仅去除标签外壳,内容提升到父层级 |
wrap() | 用新标签包裹指定内容(反向操作) | soup2.p.string.wrap(soup2.new_tag("b"))print(soup2.p) | <p><b>I wish I was bold.</b></p> | 常用于添加格式化标签(如加粗/高亮) |
2.4.输出
2.4.1.格式化输出
prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(soup.prettify()) #<html># <head># </head># <body># <a href="http://example.com/"># I linked to# <i># example.com# </i># </a># </body># </html>2.4.2.压缩输出
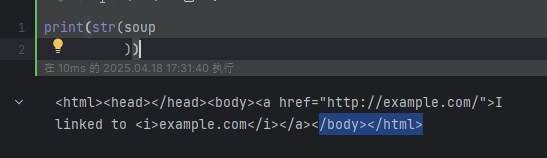
果只想得到结果字符串,不重视格式,那么可以对一个 BeautifulSoup 对象或 Tag 对象使用Python的str() 方法。
2.4.3.文本输出
如果只想得到tag中包含的文本内容,那么可以调用 get_text() 方法。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i>点我</a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup)
print(str(soup))
print(soup.get_text())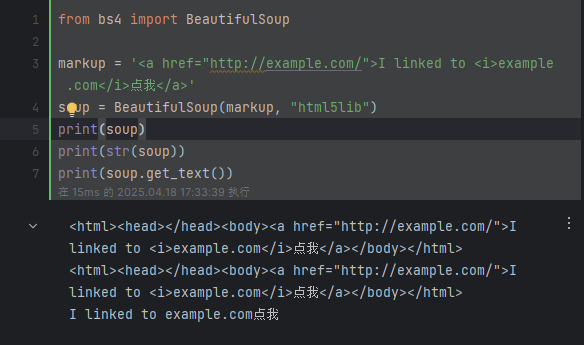
3.re标准库
BeautifulSoup库,重html文档中筛选我们想要的数据,但这些数据可能还有很多更细致的内容,比如,我们取到的是不是我们想要的链接、是不是我们需要提取的邮箱数据等等,为了更细致精确的提取数据,那么正则来了。
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在其他语言中,我们也经常会接触到正则表达式。
| 方法/概念 | 代码示例 | 关键说明 |
|---|---|---|
| re.compile() | pat = re.compile('\d{2}') | 预编译正则模式,匹配连续2位数字 |
| search() | pat.search("12abc") | 在任意位置搜索首次匹配,成功返回Match对象 |
| match() | pat.match('1224abc') | 仅从字符串起始位置匹配,成功返回Match对象 |
| findall() | re.findall(r'apple',s)re.findall(r'apple',s,re.I) | 默认区分大小写,re.I标志忽略大小写 |
| sub()替换 | re.sub('a','A','abcdacdl') | 将所有小写a替换为大写A |
import re# 创建正则对象
pat = re.compile('\d{2}') #出现2次数字的
# search 在任意位置对给定的正则表达式模式搜索第一次出现的匹配情况
s = pat.search("12abc")
print(s.group()) # 12# match 从字符串起始部分对模式进行匹配
m = pat.match('1224abc')
print(m.group()) # 12# search 和 match 的区别 匹配的位置不也一样
s1 = re.search('foo', 'bfoo').group()
print(s1) # foo
try:m1 = re.match('foo','bfoo').group() # AttributeError
except:print('匹配失败') # 匹配失败# 原生字符串(\B 不是以py字母结尾的)
allList = ["py!", "py.", "python"]
for li in allList:# re.match(正则表达式,要匹配的字符串)if re.match(r'py\B', li):print(li) # python# findall()
s = "apple Apple APPLE"
print(re.findall(r'apple', s)) # ['apple']
print(re.findall(r'apple', s, re.I)) # ['apple', 'Apple', 'APPLE']# sub()查找并替换
print(re.sub('a', 'A', 'abcdacdl')) # AbcdAcdl
相关文章:

【Python爬虫基础篇】--2.模块解析
目录 1.urllib库 1.1.request模块 1.1.1、urllib.request.urlopen() 函数 1.1.2.urllib.request.urlretrieve() 函数 1.2. error模块 1.3. parse 模块 2. BeautifulSoup4库 2.1.对象种类 2.2.对象属性 2.2.1.子节点 2.2.2.父节点 2.2.3.兄弟节点 2.2.4.回退和前进 …...

LabVIEW技巧——获取文件版本信息
获取可执行文件(exe)版本信息的几种方法 方法1. LabVIEW自带函数 labview自带了获取文件版本号的VI,但是没有开放到程序框图的函数选板中,在该目录下可以找到:...\LabVIEW 20xx\vi.lib\Platform\fileVersionInfo.llb…...
)
【软件工程】用飞书画各种图(流程图,架构图···)
笔者在做服务外包大赛的时候被文档内容的编写反复折磨,网上的工程图绘画工具要么是展示效果不佳,要么要收大几百的VIP费,最后发现飞书竟然可以直接绘画并插入示意图。 一、为什么选择飞书文档画流程图? 完全免费,无广…...

RFID图书管理系统如何重构数字化仓储管理新生态
引言 在图书馆与出版行业数字化转型进程中,RFID图书管理系统正打破传统人工管理的效率瓶颈,通过与数字化仓储管理系统的深度融合,实现从图书采购、入库到借阅的全链路智能化。本文结合RFID固定资产管理软件的应用逻辑,解析这一技…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...

操作系统-PV
🧠 背景:为什么会有 PV? 类比:内存(生产者) 和 CPU(消费者) 内存 / IO / 磁盘 / 网络下载 → 不断“生产数据” 例如:读取文件、下载视频、从数据库加载信息 CPU → 负…...
)
工厂方法模式详解及c++代码实现(以自动驾驶感知模块中的应用为例)
模式定义 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,通过定义抽象工厂接口将对象创建过程延迟到子类实现,实现对象创建与使用的解耦。该模式特别适合需要动态扩展产品类型的场景。 自动驾驶感知场景分析 自动驾…...

Jsp技术入门指南【五】详细讲解jsp结构页面
Jsp技术入门指南【五】详细讲解jsp结构页面 前言一、JSP页面的结构二、JSP页面的部件1. 指令(核心控制部件)2. 动作(页面交互部件,了解即可)3. 脚本(Java逻辑嵌入部件) 三、JSP指令详解1.1 JSP指…...

游戏APP如何抵御DDoS攻击与黑客勒索?实战防护全攻略
一、游戏行业安全挑战与攻击危害 游戏APP因高实时性、高并发及虚拟资产交易特性,成为DDoS攻击和勒索的重灾区,典型威胁包括: DDoS攻击瘫痪服务: UDP Flood:针对游戏服务器端口(如UDP 7777)发起…...

Mac 选择下载安装工具 x86 还是 arm64 ?
要确定你的 Mac 电脑应该选择下载安装工具的 x86 还是 arm64 版本,关键是判断你的 Mac 使用的是 Intel 处理器(x86 架构)还是 Apple Silicon(如 M1、M2 等,arm64 架构)。具体方法如下: 方法 1&…...

string函数的应用
字符串查找 find 方法 实例 string s "Hello World,C is awesome!";//查找子串 size_t pos1 s.find("World"); //pos16 size_t pos2 s.find("Python"); //pos2string::npos//查找字符 size_tpos3s.find(c); //pos313//从指定位置开始查找 size…...

使用Trae CN分析项目架构
架构分析后的截图 A区是打开的项目、B区是源码区、C区是AI给出当前项目的架构分析结果。 如何用 Trae CN 快速学习 STM32 嵌入式项目架构 在嵌入式开发领域,快速理解现有项目的架构是一项关键技能。Trae CN 作为一款强大的分析工具,能帮助开发者高效剖…...
暴力娱乐篇33)
每日一题(小白)暴力娱乐篇33
由题意可知我们今天要解决的问题是在1~2025中去找合适的数字,这里要找出一些特殊的数字,这些数字要满足以下条件,是三的倍数,是8的倍数,是38的倍数,老板就给要多给一个红包,我们循环然后相应条件…...

MyBatis框架
前言: MyBatis框架相比JDBC来说大大提升了我们写代码的效率,但是对初学者来说框架还是有点难以理解,所以本篇博客会十分详细的讲解MyBatis框架 目录 一.MyBatis概述 1.什么是映射? 2.什么是XML? 二.MyBatis框架搭建 1.创建一张表和表对…...

基于SpringBoot的新闻小程序开发与设计
概述 在信息爆炸的时代,高效获取新闻资讯成为现代人的刚需。幽络源平台今日分享一款基于SpringBoot框架开发的微信小程序新闻资讯系统,该系统采用前后端分离架构,实现了新闻分类管理、个性化推荐、用户收藏等功能,为新闻传播提供…...

IE之路专题12.BGP专题
BGP协议有哪些特点 BGP时边界网关协议(EGP),是一种用在自治系统之间传递路由信息的路由协议; 提供了丰富的路由属性以及强大的路由过滤和路由策略,实现灵活选路和路由控制; 策略方式更改属性或根据更新信息中属性实现过滤和策略 BGP是工作在传输层TCP之上的,使用TCP的端口号…...
)
文件包含(详解)
文件包含漏洞是一种常见的Web安全漏洞,其核心在于应用程序未对用户控制的文件路径或文件名进行严格过滤,导致攻击者能够包含并执行任意文件(包括本地或远程恶意文件)。 1. 文件包含原理 动态文件包含机制 开发者使用动态包含函数…...

智慧养老照护实训室:推动养老服务数字化转型实践
在人口老龄化加速与数字化浪潮席卷的当下,传统养老服务模式在效率、精准度及个性化服务上的局限日益明显。智慧养老成为行业转型的必然方向,但专业人才短缺与技术应用落地困难制约着发展。智慧养老照护实训室通过整合虚拟仿真等前沿技术,构建…...

NOIP2015提高组.信息传递
目录 题目算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量思路 T a r j a n Tarjan Tarjan算法求解代码 题目 517. 信息传递 算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量 思路 使用强连通分量算法求环上点…...

Wireshark 搜索组合速查表
文章目录 Wirshark使用记录基本语法规则搜索条件符号速查表捕获过滤器组合指令速查表筛选过滤器组合命令速查表Wireshark Frame 协议字段解析 Wirshark使用记录 官网地址:https://www.wireshark.org/ 基本语法规则 字段描述示例说明type用于指定数据包的类型&…...

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

我的gittee仓库
日常代码: 日常代码提交https://gitee.com/xinxin-pingping/daily-code 有需要的宝子们可自行读取。...

RT-Thread开发文档合集
瑞萨VisionBoard开发实践指南 RT-Thread 文档中心 RT-Thread-【RA8D1-Vision Board】 RA8D1 Vision Board上的USB实践RT-Thread问答社区 - RT-Thread 【开发板】环境篇:05烧录工具介绍_哔哩哔哩_bilibili 【RA8D1-Vision Board】基于OpenMV 实现图像分类_哔哩哔哩_…...

SPWM-H桥逆变器工作原理
SPWM-H桥逆变器(Sinusoidal Pulse Width Modulation H-Bridge Inverter)是一种基于正弦脉宽调制(SPWM)技术的电力电子装置,用于将直流(DC)转换为交流(AC)。它广泛应用于光…...
)
【数据结构_10】二叉树(2)
一、根据树的遍历结果还原树 紧接着(1),我们继续来讨论:如果给了树的遍历结果,我们能否把这个树给还原出来呢? 如果只给一种遍历结果,那么我们无法对树进行还原。 只有给了我们先序中序&…...
---(jdk安装和环境变量配置))
day1-小白学习JAVA(mac版)---(jdk安装和环境变量配置)
JDK安装和环境变量配置 我的电脑系统一、下载JDK1、oracle官网下载适合的JDK安装包,选择Mac OS对应的版本。 二、安装三、配置环境变量1、终端输入/usr/libexec/java_home -V查询所在的路径,复制备用2、输入ls -a3、检查文件目录中是否有.bash_profile文…...

Muduo网络库实现 [十六] - HttpServer模块
设计思路 本模块就是设计一个HttpServer模块,提供便携的搭建http协议的服务器的方法。那么这个模块需要如何设计呢? 这还需要从Http请求说起。 首先从http请求的请求行开始分析,请求行里面有个方法。分为静态资源请求和功能性请求的。 静态…...

工业触摸显示器助力智慧工业实验室发展
工业触摸显示器作为智慧工业实验室的核心人机交互设备,凭借其卓越的性能和灵活性,为实验室的智能化、自动化发展提供了强有力的支持。以下从多个方面阐述工业触摸显示器如何助力智慧工业实验室的发展: 一、提升操作便捷性与效率 直观操作&a…...

k8s介绍与实践
第一节 理论 基础介绍,部署实践,操作实践,点击这里学习 第二节 dashboard操作 查看安装的dashboard服务信息 kubectl get pod,svc -n kubernetes-dashboard 网页登录地址:https://server_ip:30976/#/login 创建token kube…...

ATEngin开发记录_5_C++日志打印引发的崩溃?一次虚函数调用引发的内存错误排查记录
该系列只做记录 不做教程 所以文章简洁直接 会列出碰到的问题和解决方案 只适合C萌新 在使用 C 进行事件系统开发时,我遇到了一次由于调用虚函数 GetName() 输出日志而引发的崩溃问题。通过逐步排查、使用防御性编程和类型检查,最终定位到了隐藏的生命…...

Yocto项目实战教程 · 第4章:4.2小节-菜谱
🔍 B站相应的视频教程: 📌 Yocto项目实战教程-第4章-4.2小节-菜谱 记得三连,标为原始粉丝。 在 Yocto 项目中,**菜谱(Recipe)**承载了包的配置信息、源码获取方式、编译与安装步骤,是…...

7.Rust+Axum:打造高效 RESTful API 的最佳实践
摘要 深入探讨 RustAxum 开发 RESTful API 的关键要点,涵盖资源路由设计、HATEOAS 实现、参数处理及 DTO 序列化与 JSON 处理案例。 一、引言 在现代 Web 开发中,RESTful API 是构建分布式系统的重要组成部分。Rust 作为一种高性能、安全的系统编程语…...

CAN总线嵌入式开发实战:从入门到精通
CAN总线嵌入式开发实战:从入门到精通 一、CAN总线基础概念 CAN(Controller Area Network)是一种广泛应用于汽车电子和工业控制领域的串行通信协议,由Bosch公司于1986年开发。它具有以下核心特点: 多主架构:所有节点地位平等&am…...
)
从头学 | 目标函数、梯度下降相关知识笔记(一)
很多基本的概念最近忘的有点多,简单回顾一些 文章目录 1 目标函数、梯度下降1.1 回归模型中的目标函数1.1.1 回归任务目标函数(1) 均方误差(MSE)(2) Huber损失 1.1.2 分类任务目标函数(1) 交叉熵损失(Cross-Entropy)(2…...

欣佰特携数十款机器人相关前沿产品,亮相第二届人形机器人和具身智能行业盛会
2025年4月15日至16日,备受关注的第二届中国人形机器人与具身智能产业大会已在北京成功举行。作为国内前沿科技及产品服务领域的重要参与者,欣佰特科技携众多前沿产品精彩亮相,全方位展示了其在人形机器人与具身智能领域的创新产品。 在本次大…...

QT常见显示类控件及其属性
Label QLabel可用用来显示文本和图片 核心属性如下 文本格式---textFormat 例: 在ui界面创建3个label,分别用不同的显示格式 在构造函数进行文本格式和文内容设置 此时运行后三种显示格式无区别 可以给富文本加标签 如<B>表示加粗 如果将<…...

基于领域知识的A型主动脉夹层综合分割及面向临床的评估|文献速递-深度学习医疗AI最新文献
Title 题目 Domain knowledge based comprehensive segmentation of Type-A aortic dissection with clinically-oriented evaluation 基于领域知识的A型主动脉夹层综合分割及面向临床的评估 01 文献速递介绍 A型主动脉夹层(TAAD)是一种医疗急症&a…...

守护进程编程、GDB调试以及外网连接树莓派
目录 一、什么是守护进程以及如何创建守护进程1. 什么是守护进程?2. 如何创建守护进程? 二、什么是GDB调试以及如何用GDB命令调试C程序1. 什么是GDB?2. 如何用GDB命令调试C程序? 三、外网访问树莓派 一、什么是守护进程以及如何创…...

HTML理论题
1.什么是HTML? 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。 2.DOCTYPE 的作用是什么?标准与兼容模式(混杂模式)各有什么区别? DOCTYPE 的作用是告知浏览器的解析器用什么文档标准解析这个文档。 标准模式:用于…...

Cables为链上社区树立标杆:专注于实用性、用户主权与全球流动性
在 Web3 世界,“社区”这个词已逐渐沦为炒作、虚高数据与短暂参与的代名词。Cables 正在颠覆这一现状,以真实贡献与长期可持续发展为核心,走出了一条独特的路径。 最近,Cables 推出了其核心长期战略之一——积分计划(…...

Clickhouse 配置参考
Clickhouse 配置参考 适用版本 21.3.9.84 config.xml 配置 <?xml version"1.0"?> <!--NOTE: User and query level settings are set up in "users.xml" file. --> <yandex><access_control_path>/data/clickhouse/clickhous…...

thinkphp实现图像验证码
示例 服务类 app\common\lib\captcha <?php namespace app\common\lib\captcha;use think\facade\Cache; use think\facade\Config; use Exception;class Captcha {private $im null; // 验证码图片实例private $color null; // 验证码字体颜色// 默认配置protected $co…...

【Pandas】pandas DataFrame where
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

redis利用备忘录
fofa: icon_hash"864611937" 防护: redis的安全设置:设置完毕,需要重加载配置文件启动redis 1.绑定内网ip地址进行访问 2. requirepass设置redis密码 3.保护模式开启protected-mode开启(默认开启) 4.最好把…...

【dify实战】chatflow结合deepseek实现基于自然语言的数据库问答、Echarts可视化展示、Excel报表下载
dify结合deepseek实现基于自然语言的数据库问答、Echarts可视化展示、Excel报表下载 观看视频,您将学会 在dify下如何快速的构建一个chatflow,来完成数据分析工作;如何在AI的回复中展示可视化的图表;如何在AI 的回复中加入Excel报…...

医疗行业如何构建合成数据平台?——技术、合规与实践全景
目录 医疗行业如何构建合成数据平台?——技术、合规与实践全景 一、为什么医疗领域尤需合成数据? 二、平台功能全景图 ✅ 模块划分: 三、典型合成数据生成方式 1. 结构化病例合成 2. 医学图像生成 3. 多轮医生-患者问答合成 四、数据…...

6.8.最小生成树
一.复习: 1.生成树: 对于一个连通的无向图,假设图中有n个顶点,如果能找到一个符合以下要求的子图: 子图中包含图中所有的顶点,同时各个顶点保持连通, 而且子图的边的数量只有n-1条࿰…...

MATLAB 控制系统设计与仿真 - 37
范数鲁棒控制器的设计 鲁棒控制器的设计 根据双端子状态方程对象模型结构,控制器设计的目标是找到一个控制器K(s),它能保证闭环系统的范数限制在一个给定的小整数下,即 这时控制器的状态方程为: 其中X与Y分别为下面两个代数Riccati方程的解…...

社交媒体时代的隐私忧虑:聚焦Facebook
在数字化时代,社交媒体平台已成为人们日常生活的重要组成部分。Facebook作为全球最大的社交媒体之一,拥有数十亿用户,其对个人隐私的影响和忧虑也日益凸显。本文将探讨社交媒体时代下,尤其是Facebook平台上的隐私问题。 数据收集…...

9.Rust+Axum 测试驱动开发与性能优化全攻略
摘要 本文深入讲解 RustAxum 测试驱动开发及性能优化,涵盖多种测试工具与优化技术。 一、引言 在当今的软件开发领域,测试驱动开发(TDD)和性能优化是保障软件质量和性能的关键环节。Rust 作为一种安全、高效的系统编程语言&…...