Multi Agents Collaboration OS:文档合规性及质量检测助手设计及实践
文档审查及质量检测背景
随着企业运营和知识管理的日益复杂,文档的合规性与质量成为确保信息准确、流程顺畅及风险控制的关键环节。传统上,人工进行文档的合规性和质量检测不仅耗时耗力,且易受主观因素影响,难以保证检测的全面性和一致性。尤其是在面对大量、多样化的文档时,如何高效、准确地完成检测成为一大挑战。
为了应对这一挑战,借助人工智能和自然语言处理技术构建智能文档处理系统成为当前的研究热点。本项目基于 Multi-Agent Collaboration OS 的理念,设计并实践了一个文档合规性及质量检测助手。该助手通过协同多个智能体(Agent)来自动化文档处理流程。这些智能体各司其职,包括但不限于文件解析、文件质量检测、文件摘要生成 、目录自动生成、知识检索 、流程设计、文档核心检测 、修改意见生成 以及最终的文档总结报告输出 。基于Multi Agents Collaboration OS的模块化、协同工作的智能体架构,旨在提升文档检测的效率和准确性,为用户提供一个全面的文档合规性与质量管理解决方案。
核心技术及流程设计:Multi Agents Collaboration OS
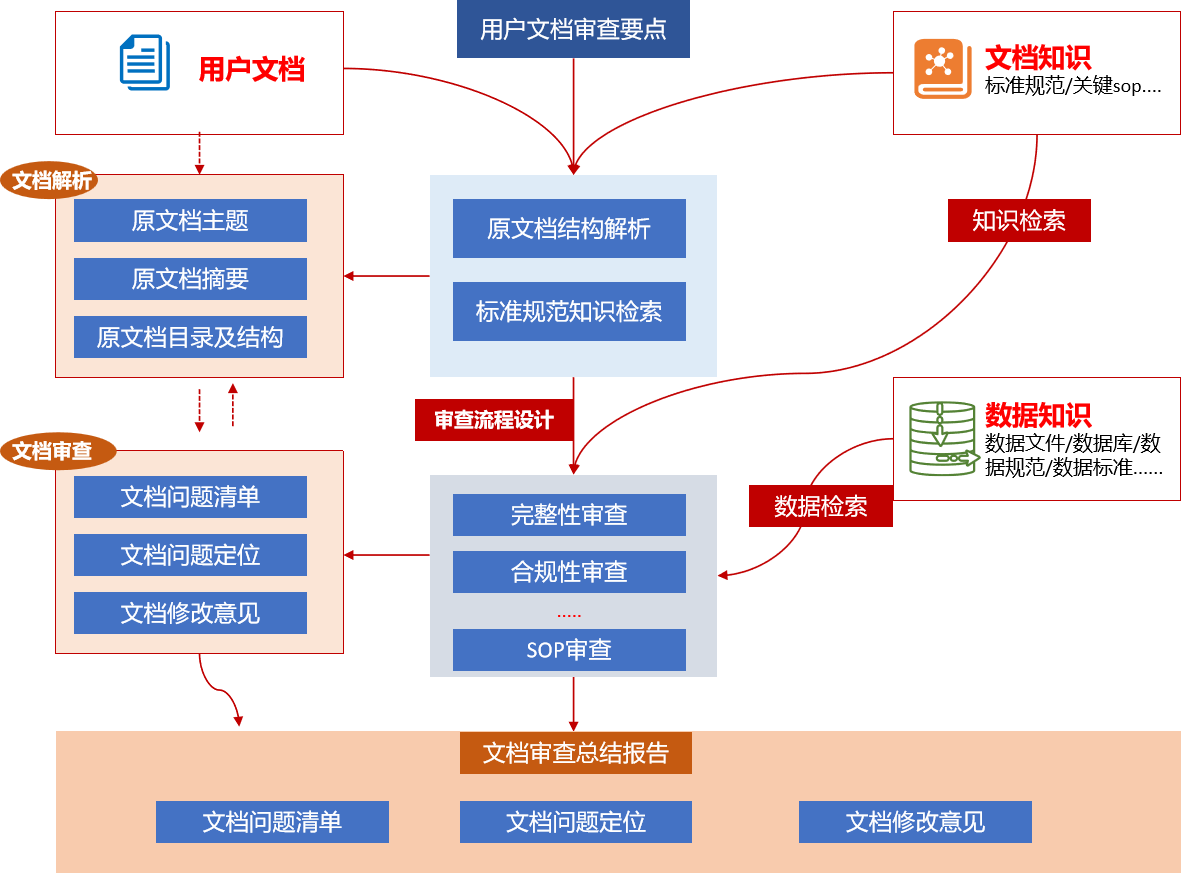
整个平台的核心流程始于用户上传待审查的文档,并可选择输入用户文档审查要点。系统接收文档后,首先进行文档解析,提取文档的主题、摘要、目录及结构等基础信息。同时,平台会基于这些信息并结合预设的文档知识库(包含标准规范、关键 SOP 等),执行知识检索,获取与用户文档相关的合规及质量标准。
接下来是关键的审批流程设计阶段。系统会根据解析出的文档内容、用户指定的审查要点以及检索到的标准规范知识,智能地设计出一套针对该文档的定制化审查流程。这个流程通常包括完整性审查、合规性审查、SOP 审查等多个环节,并且可能涉及对数据知识库进行数据检索以验证文档中数据的准确性或一致性。
设计好的审查流程指导着文档审查的执行。系统按照流程对文档内容进行细致 분석,识别出其中的问题。审查的结果会被整理成文档问题清单,明确指出存在的问题;同时进行文档问题定位,标注问题所在的具体位置;并给出相应的文档修改意见,提供改进建议。
最后,平台会将所有审查结果进行汇总,生成一份详尽的文档审查总结报告。这份报告整合了发现的问题、问题的位置以及修改意见,为用户提供了一个清晰、全面的文档合规性和质量评估结果,辅助用户高效地进行文档修改和完善。
智能体设计及代码实践
该文档合规性及质量检测平台基于 Multi-Agent Collaboration OS 的总体设计原则,采用模块化和协同工作的智能体架构。每个智能体负责流程中的特定环节,并通过结构化的输入输出进行通信与协作,共同完成文档的审查任务。这种设计提高了系统的灵活性、可维护性和可扩展性。
平台中设计的关键智能体及其功能和输出如下:
- 文件上传与解析智能体:
- 功能:负责接收用户上传的 PDF、Word 等格式的文档。解析文档内容,提取文本信息、页码、并进行初步的文件质量检测。
- 输出:结构化的文档原始内容(包含页码),以及文件质量状况的初步评估(在设计中有提及)。
- 代码:
def parse_pdf_with_page_numbers(pdf_path):"""Parse a PDF file and extract text along with page numbers.Args:pdf_path (str): Path to the PDF file.Returns:list of dict: A list where each item contains the page number and the extracted text."""pdf_document = fitz.open(pdf_path)parsed_data = []for page_number in range(len(pdf_document)):page = pdf_document[page_number]text = page.get_text()parsed_data.append({"page_number": page_number, # Page numbers are 1-based"text": text})page_number += 1pdf_document.close()return parsed_data# 解析word文档,提取文本和页码
def parse_word_with_page_numbers(word_path):"""Parse a Word file and extract text along with page numbers.Args:word_path (str): Path to the Word file.Returns:list of dict: A list where each item contains the page number and the extracted text."""document = Document(word_path)parsed_data = []# Simulate page numbers (Word documents do not have explicit page numbers in the API)page_number = 1for paragraph in document.paragraphs:text = paragraph.text.strip()if text: # Only include non-empty paragraphsparsed_data.append({"page_number": page_number,"text": text})page_number += 1# Logic to increment page_number can be added here if neededreturn parsed_data
- 文件概要智能体:
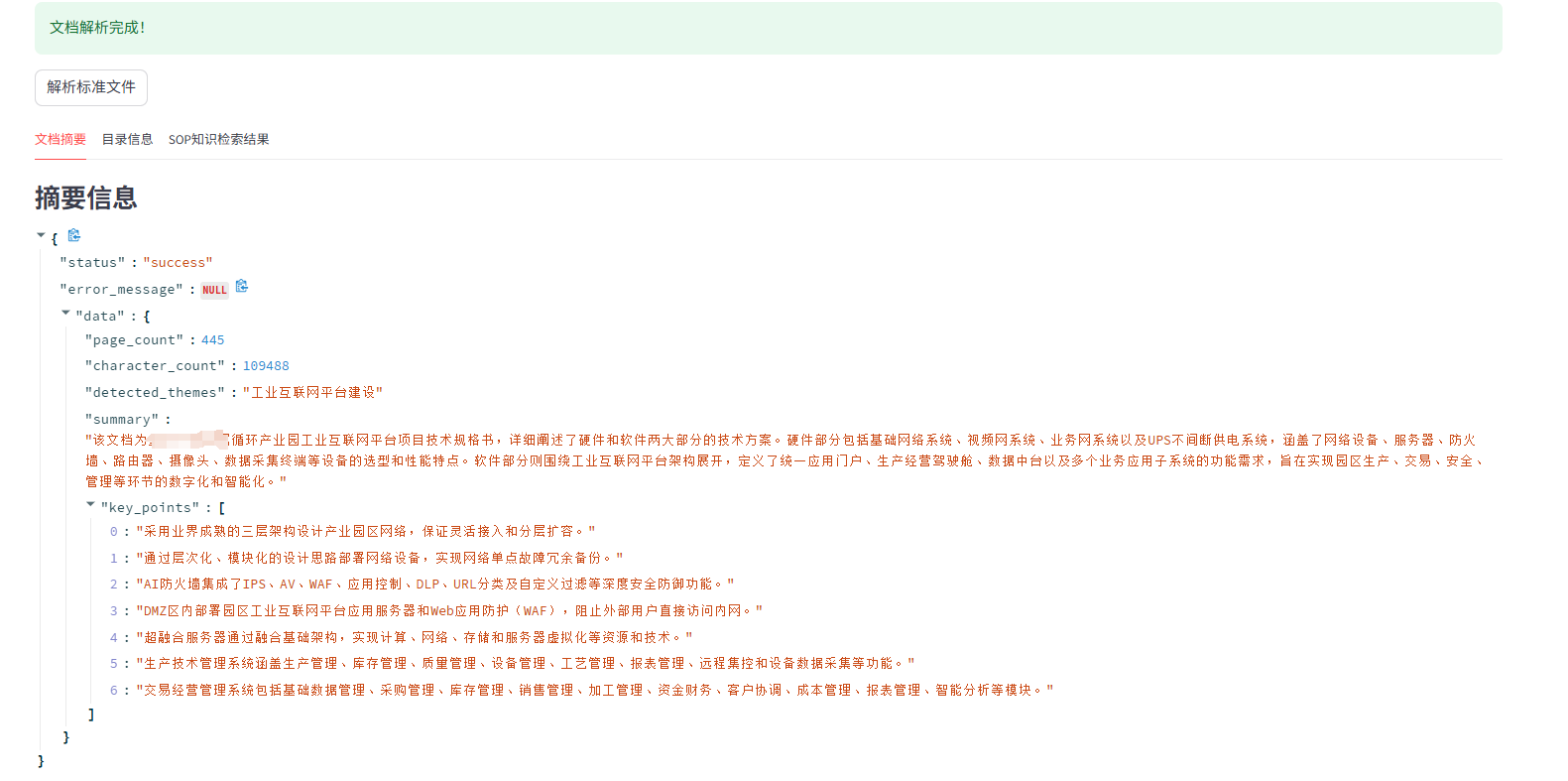
- 功能:对解析后的文档内容进行分析,提取关键信息生成文档概要。这包括识别文档主题、统计页数、字符数,并生成精简的内容概述和重点内容列表。
- 输出:JSON 格式的结构化文件概要信息,包含状态、页数、字符数、检测到的主题、摘要和关键点。
- 代码
def parse_documents_summary(documents):documents = str(documents)llm = ChatOpenAI(temperature=0, model=model_use)messages = [("system",""" # Role: 基础信息提取智能体 (Basic Information Extraction Agent)# Context:你是一个专业的文档分析助手。你接收一段从文档中提取的文本内容以及该文档的总页数。# Task:你的核心任务是分析提供的文本,提取关键的基础信息,并严格按照指定的JSON格式输出结果。请完成以下具体分析:1. **页数 (Page Count):** 使用下方明确提供的 `page_count` 值。2. **字数统计 (Character/Word Count):** 计算输入文本的总字符数和总词数。3. **主题识别 (Theme Identification):** 识别并列出文档内容的核心主题。每个主题应是简洁的关键词或短语(例如:"人工智能", "项目管理", "财务报告分析")。输出一个极其关联的主题。4. **内容概述 (Summary Generation):** 生成一段简洁、流畅的文本摘要,准确概括文档的主要内容和目的。摘要应在 3-5 句话左右。5. **重点内容提取 (Key Points Extraction):** 识别并提取文档中表达核心观点、关键数据或重要结论的句子或短语。输出一个包含 3-7 个关键点的列表。# Output Format Instructions:请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。```json{"status": "success","error_message": null,"data": {"page_count": page_count, // 使用提供的页数值 (Integer)"character_count": <calculated_character_count>, // 计算得到的总字符数 (Integer)"detected_themes": <// 主题 (String)"主题1">,"summary": "这里是生成的简洁文档概述...", // 概述文本 (String)"key_points": [ // 重点内容列表 (List of Strings)"关键点1...","关键点2...",// ...]}}"""),("human",f"请帮我总结以下内容:{documents}")]result = llm.invoke(messages)result = result.contentresult = result.replace('```json', '').replace('```', '').strip()results = json.loads(result)return results- 目录生成智能体:
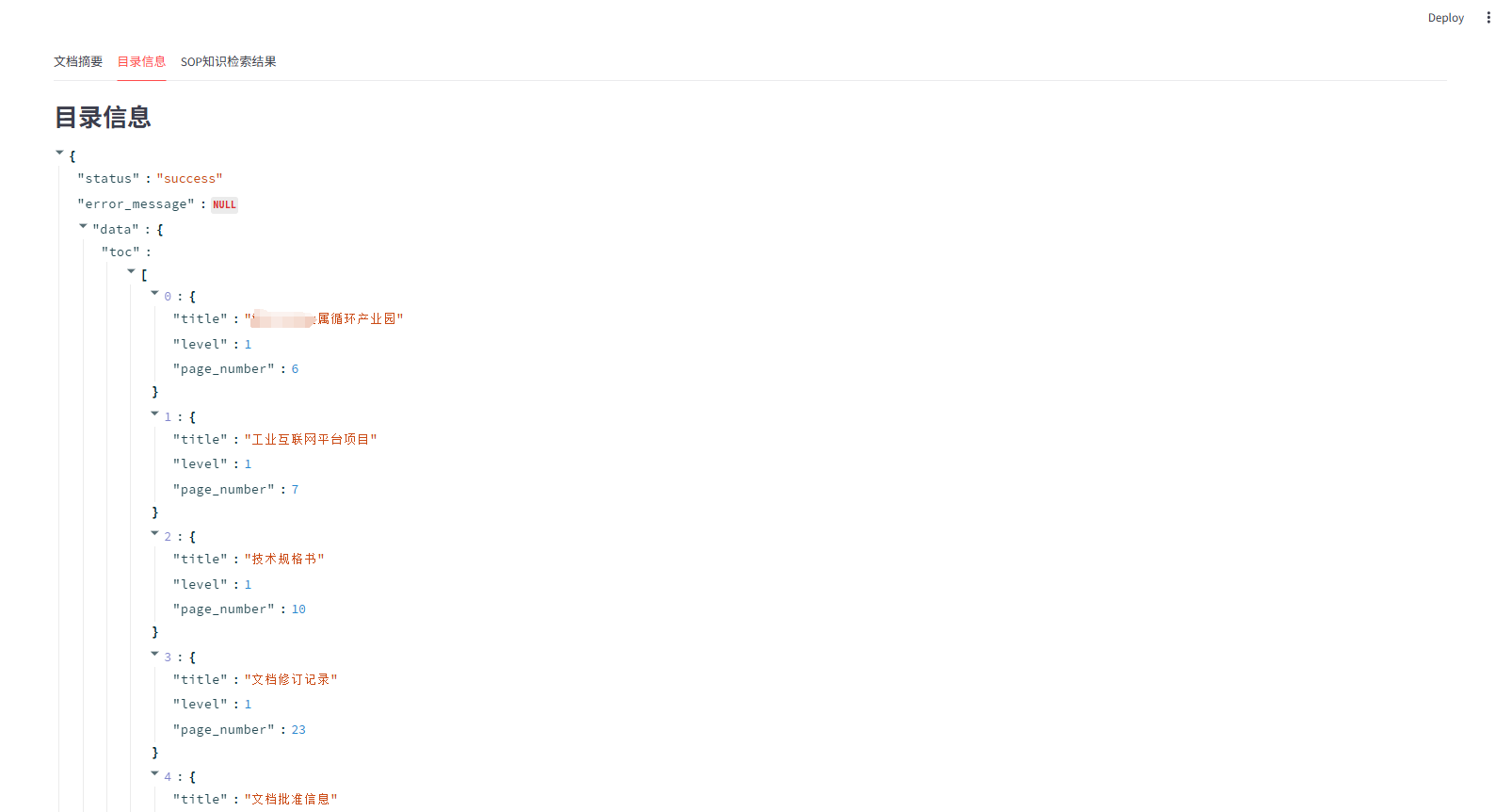
- 功能:分析文档结构,自动生成文档目录,通常包含两级标题。
- 输出:JSON 格式的目录结构,包含章节标题、层级和对应的页码。
- 代码
#解析文本内容,生成文档的目录信息(结构化输出)
@retry(wait=wait_fixed(5), stop=stop_after_attempt(2))
def parse_documents_toc(documents):documents = str(documents)llm = ChatOpenAI(temperature=0, model=model_use)messages = [("system",""" # Role: 目录生成智能体 (Table of Contents Generator Agent)# Context:你是一个专业的文档分析助手。你接收一段从文档中提取的文本内容。# Task:你的核心任务是分析提供的文本,生成一个目录结构(一般两级标题,如果文档有目录,则用文档内的目录),并严格按照指定的JSON格式输出结果。请完成以下具体分析:# Output Format Instructions:请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。```json{"status": "success","error_message": null,"data": {"toc": [{"title": "章节标题","level": 1,"page_number": 1},{"title": "子章节","level": 2,"page_number": 2}]}}""")
,("human",f"请帮我生成目录:{documents}")]result = llm.invoke(messages)result = result.contentresult = result.replace('```json', '').replace('```', '').strip()results = json.loads(result)return results- 知识检索智能体:
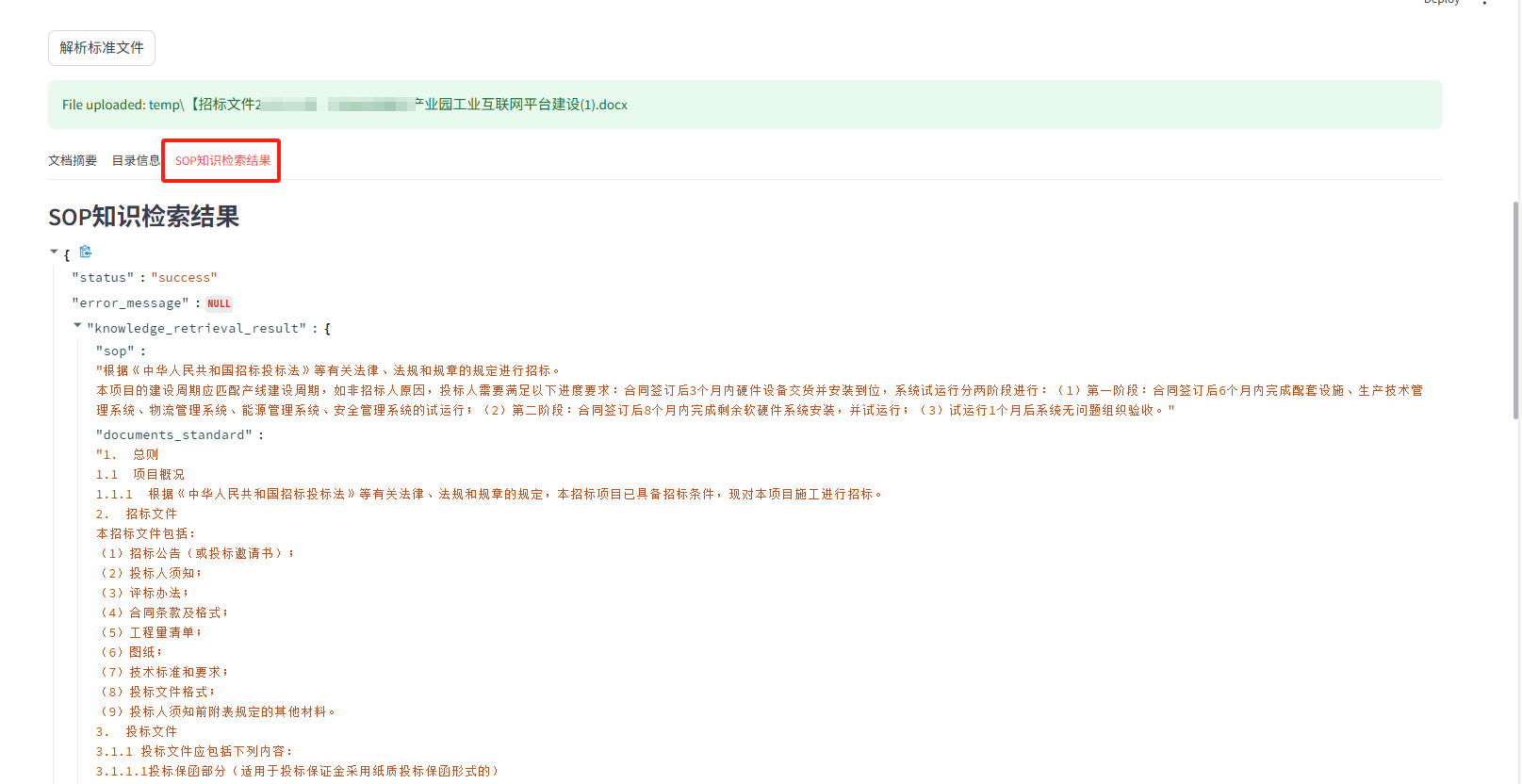
- 功能:根据用户文档的主题和摘要,从预设的知识库(如 SOP、政策法规、标准文档等)中检索相关的标准规范要求。这包括识别业务流程、文档规范要求、合规性要点、数据准确性要求等。
- 输入:用户文档的摘要信息和相关的标准文件内容。
- 输出:JSON 格式的知识检索结果,分类列出相关的 SOP 要求、文档标准、文档要求等信息。
- 代码:
def knowledge_retrieval_agent(ues_doucunmet,stadder_doc=None):documents = str(ues_doucunmet)stadder_doc = str(stadder_doc)llm = ChatOpenAI(temperature=0, model=model_use)messages = [("system",""" # Role: 知识检索智能体 (Knowledge Retrieval Agent)# Context:你是一个专业的知识检索助手。你接收一个文件路径和一个问题。# Task:你的核心任务是根据用户提供的需要审查的文件摘要信息和问题,从标准文件内容进行知识检索,检索针对用户文档的主题中相关标准对该类文档的标准规范要求,核心包括:1. 识别文档中隐含或明示的业务流程2. 根据业务流程识别文档中的标准规范要求3. 文档的完整性(清单、内容模块等)、合规性(格式、样式、语言、规范等)4. 文档的核心sop合规性等要求5. 文档中相关数据准确性(如是否符合规定范围等)、完整性(如是否包含所有必要信息等)、一致性(如是否存在矛盾信息等)、唯一性(如是否存在重复信息等)6. 文档中的所有内容是否符合其他需要关注的标准要求并严格按照指定的JSON格式输出结果。请完成以下具体分析:# Output Format Instructions:请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。```json{"status": "success","error_message": null,"knowledge_retrieval_result": {"sop": "<政策法规标准制度等规定的SOP流程要求>","documents_standard": "<文档要求的标准>","documents_requirement":"<文档要求的标准>",.......}}"""),("human",f"用户需要审查的文件摘要信息是:{documents},相关标准内容:{stadder_doc}")]result = llm.invoke(messages)result = result.contentresult = result.replace('```json', '').replace('```', '').strip()results = json.loads(result)return results- 流程设计智能体:
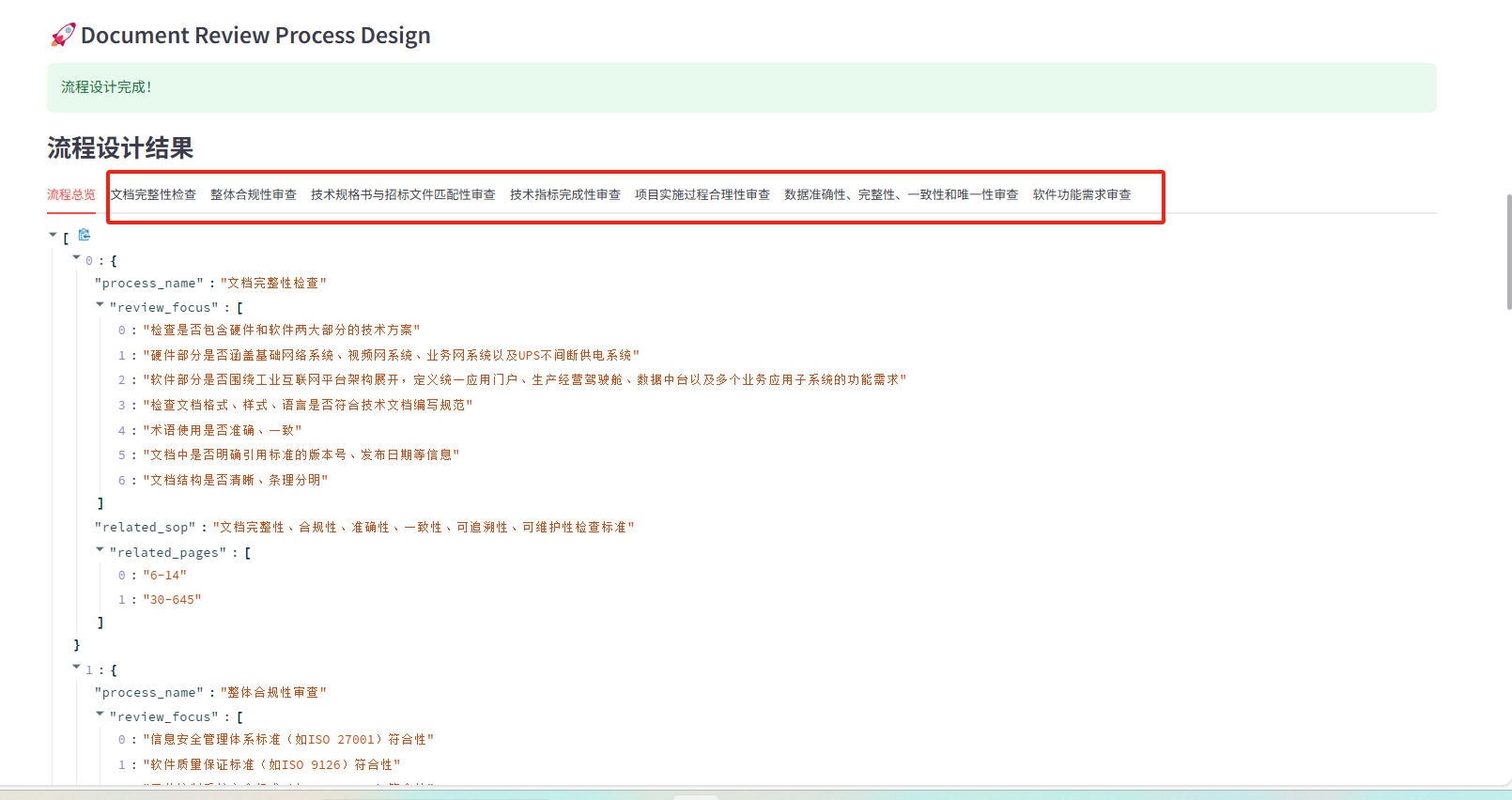
- 功能:整合文档内容、知识检索结果以及用户指定的审查要点,设计出定制化的文档审查流程 。流程设计会重点关注文档完整性检查、整体合规性审查以及基于内容的特定流程 。
- 输入:文档摘要信息、SOP 知识检索结果和用户的进一步审查要求。
- 输出:JSON 格式的流程设计结果,包含审查流程的名称、审核重点以及相关的 SOP 信息 。
- 代码
# 流程设计智能体,主要根据文档内容和检索回来的内容进行流程设计,输出对文档内容审查的流程,结构化输出,包括流程的名称、流程主要审核的重点
@retry(wait=wait_fixed(5), stop=stop_after_attempt(2))def flow_design_agent(docunments,standard_sop_kg,user_question=None):Documents_summary = str(docunments)standard_sop_kg = str(standard_sop_kg)llm = ChatOpenAI(temperature=0, model=model_use)messages = [("system",""" # Role: 流程设计智能体 (Process Design Agent)# Context:您是一个专业的文档审查流程设计助手。接收文档内容及相关知识检索结果。# Task:分析文档内容并生成结构化审查流程,需完成:1. 流程识别 - 识别文档中隐含或明示的业务流程2. 审核重点提取 - 提取需重点验证的核心要素3. 结构优化 - 按标准审查流程组织要素4. 验证点关联 - 将审核重点与文档具体内容关联5. 审核流程 - 第一个流程必须是文档完整性检查,第二个流程是整体合规性审查,后续流程根据文档内容和知识检索结果进行设计# Output Format Instructions:请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。```json{"status": "success","error_message": null,"data": {"processes": [{"process_name": "合规性审查","review_focus": ["政策条款符合性","数据安全规范","法律风险评估"],"related_sop": "<具体的政策及法规要求检索结果>",},........]}}"""),("human",f"根据政策法规及sop等信息:{standard_sop_kg},以及需要审核的文档摘要信息{Documents_summary},对用户关于文档的进一步要求{user_question},设计流程一定要重点关注用户的要求,请设计审查流程,并输出结构化的JSON格式,包含流程名称、审核重点、相关章节等信息。")]result = llm.invoke(messages)result = result.contentresult = result.replace('```json', '').replace('```', '').strip()results = json.loads(result)return results
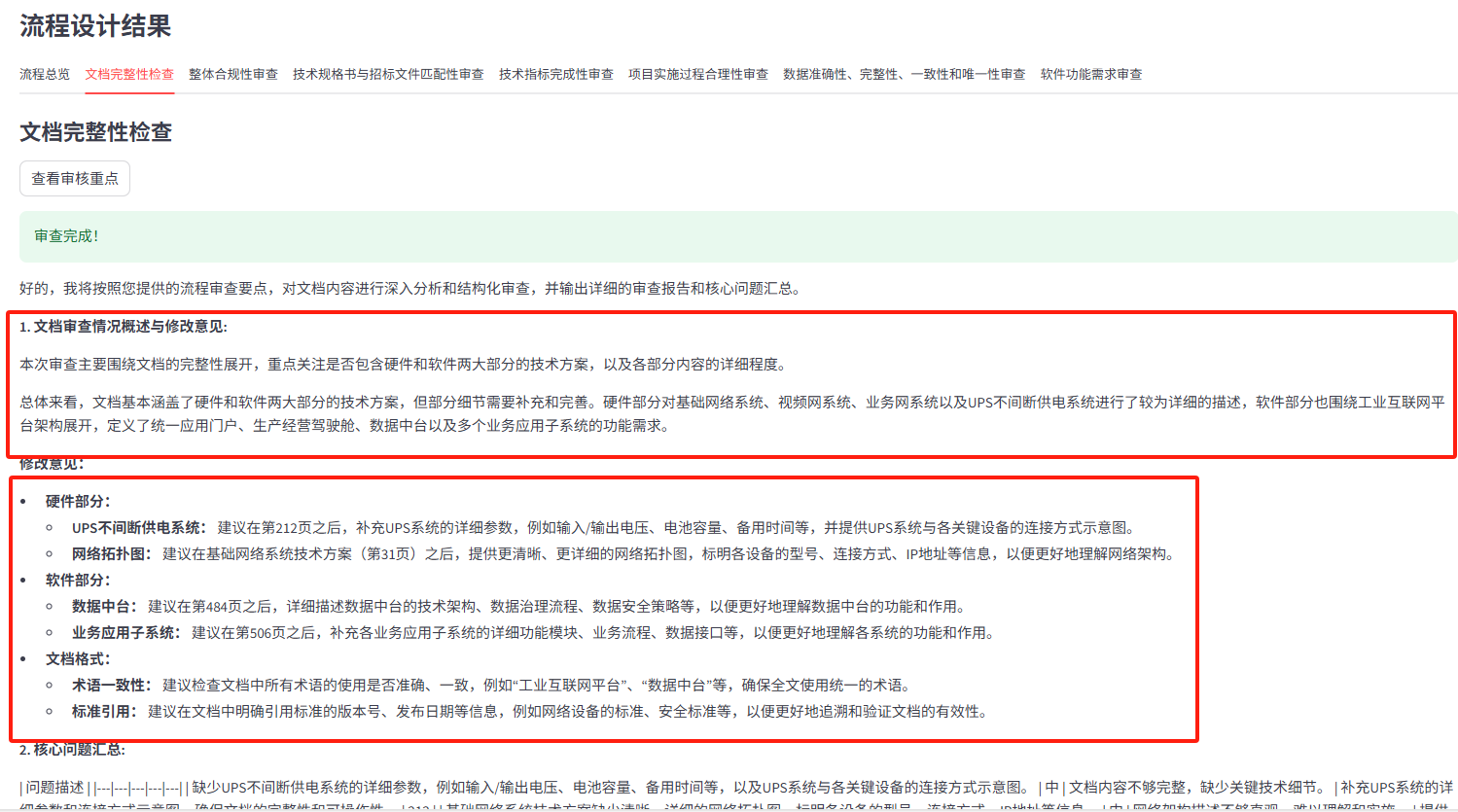
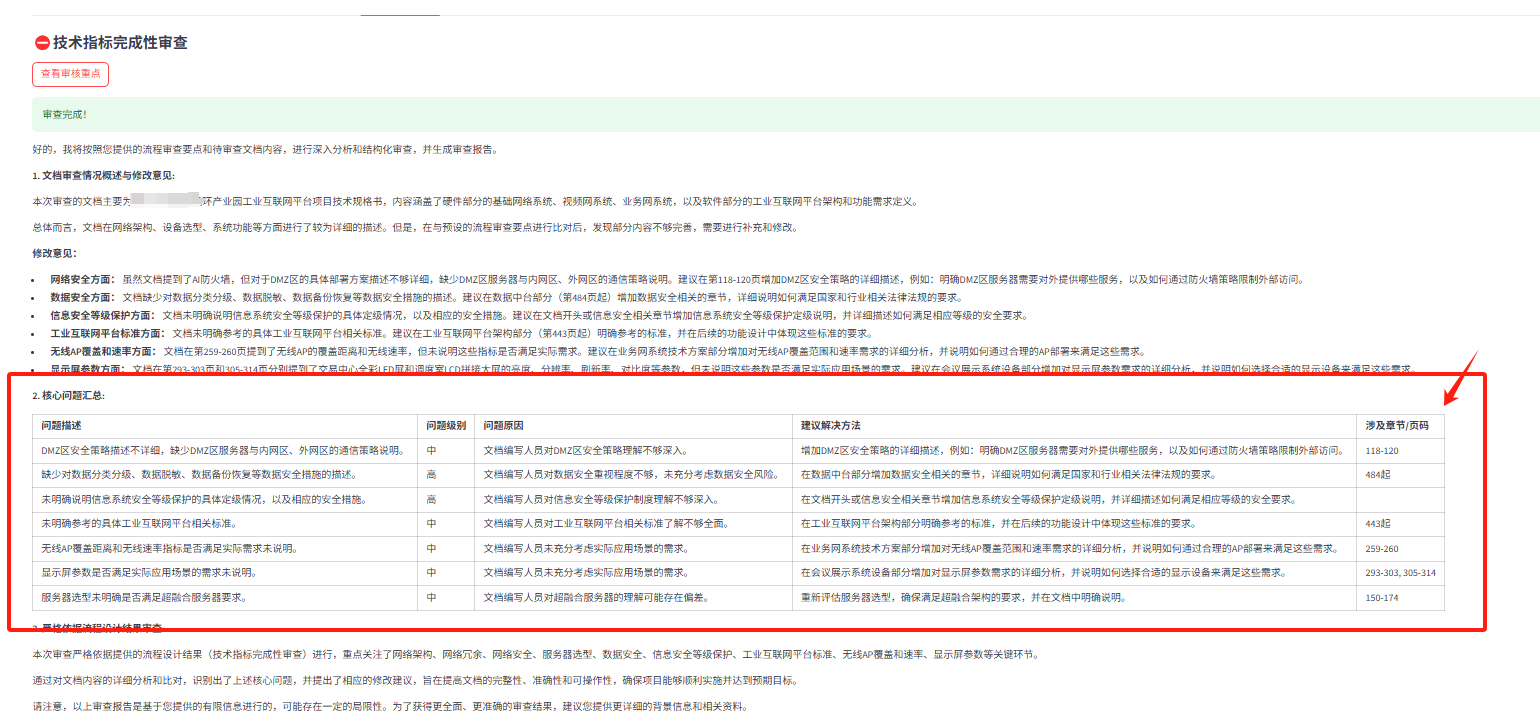
- 流程审查智能体:
- 功能:根据流程设计智能体生成的审查流程,对文档内容进行详细审查 [cite: 47, 48]。识别文档中的业务流程,将审核重点与文档内容关联,设计验证点,并识别核心问题及其原因、级别和建议解决方法。
- 输入:文档内容和流程设计结果 。
- 输出:Markdown 格式的审查报告,包含文档审查概述、带页码的修改意见和核心问题汇总表格。
- 代码
##流程审查智能体:根据流程设计的各个流程,对文档内容进行审查,输出对文档内容审查的流程,结构化输出,包括流程的名称、流程主要审核的重点
def flow_review_agent(docunments,process_design_result):docunments = str(docunments)llm = ChatOpenAI(temperature=0, model= model_use)messages = [("system",f""" # 角色: 流程审查智能体 (Process Review Agent)# 背景信息:您是一位专业的文档审查流程助手,您的核心任务是根据预设的流程审查要点,对接收到的文档内容及其相关的知识检索结果进行深入分析和结构化审查。**流程审查要点:** {process_design_result}**待审查文档内容:** {docunments}# 任务:请严格按照以下步骤分析文档内容,并生成结构化的审查报告:**1. 流程识别与提取:**- 仔细阅读并分析文档内容,识别其中明确描述或隐含的业务流程。- 将识别出的流程步骤清晰地罗列出来。**2. 审核重点关联:**- 针对预设的流程审查要点,将每个要点与文档中识别出的具体流程步骤或相关内容进行精确关联。- 说明每个审查要点在文档的哪个部分(章节、页码)有所体现或应该有所体现。**3. 结构化审查与验证点生成:**- 基于流程审查要点和文档内容关联,为每个审查要点设计具体的验证问题或检查点。- 这些验证点应能够指导后续对文档内容的细致核查。**4. 核心问题识别与评估:**- 运用您对流程审查要点的理解,以及对文档内容的分析,识别文档中违反流程要求、存在缺陷或需要改进的关键问题。- 对每个核心问题进行评估,包括其级别(例如:高、中、低)、可能的原因以及建议的解决方法。# 输出要求:**1. 文档审查情况概述与修改意见:**- 使用Markdown格式总结本次审查的整体情况,包括文档是否清晰描述了相关流程、是否符合预设的审查要点等。- 针对文档中不符合审查要点的地方,提出明确、可操作的修改意见,并给出详细的解释说明其原因和重要性。- 在提供修改意见时,务必指明相关的章节和页码。**2. 核心问题汇总:**- 将识别出的核心问题以Markdown表格的形式清晰地呈现,表格应包含以下列:| 问题描述 | 问题级别 | 问题原因 | 建议解决方法 | 涉及章节/页码 ||---|---|---|---|---|| [具体的问题描述] | [高/中/低] | [导致问题的原因分析] | [可行的解决方案建议] | [相关的章节和页码] |**3. 严格依据流程设计结果审查:**- 在识别核心问题时,务必以提供的流程设计结果为核心依据进行详细审查,确保所有关键环节都得到充分评估。**请开始分析待审查文档内容和相关知识检索结果,并按照上述要求生成审查报告。**"""),("human",f"需要对文档进行详细审查,并输出核心问题。")]result = llm.invoke(messages)result = result.contentreturn result
- 文档总结智能体:
- 功能:整合各个流程审查智能体的结果,生成最终的文档审查总结报告 。报告对问题进行汇总、分类和优先级排序,评估文档的整体合规状态。
- 输入:各个流程的审查结果 。
- 输出:Markdown 格式的总结报告,包含问题汇总、分类、优先级排序、合规状态评估和关键问题表格.
- 代码
def flow_summary_agent(docunments,process_review_result):docunments = str(docunments)llm = ChatOpenAI(temperature=0, model= model_use)messages = [("system",""" # Role: 文档审查总结智能体 (Document Review Summary Agent)# Context:您接收来自流程审查阶段的多个审查结果和原始文档内容。# Task:需要完成以下综合分析:1. **问题汇总** - 整合所有审查流程发现的核心问题2. **问题分类** - 按严重性(关键/重要/建议)分类问题3. **优先级排序** - 根据业务影响排序改进建议4. **合规状态评估** - 生成整体合规状态判断# Output Format Instructions:1. 以markdown格式输出审查总结报告,包含问题汇总、分类、优先级排序和合规状态评估。2. 输出审查总结报告时,请根据流程审查结果,对文档进行详细审查3. 关键问题以markdown的表格形式输出,包含问题描述、问题级别、问题原因、问题解决方法等信息。"""),("human",f"请生成总结报告:{process_review_result}")]result = llm.invoke(messages)result = result.contentreturn result
此外,平台还设计了文件质量检测智能体和多轮对话输出智能体,分别用于文档结构化质量检测和支持用户与平台进行交互,尽管在提供的代码中未详细展示其具体实现。整个智能体设计体现了通过分工协作和信息流转来高效完成复杂文档审查任务的思路。
多智能体协作机制设计及平台实现
def documents_parser_page_():# Initialize session state variablesif 'knowledge_retrieval_result' not in st.session_state:st.session_state.knowledge_retrieval_result = Noneif 'process_design_result' not in st.session_state:st.session_state.process_design_result = Noneif 'documents_parser_review' not in st.session_state:st.session_state.documents_parser_review = []if 'user_question' not in st.session_state:st.session_state.user_question = Noneif 'parsed_data' not in st.session_state:st.session_state.parsed_data = {'summary': None,'toc': None,'documents': None}if 'process_reviews' not in st.session_state:st.session_state.process_reviews = {}if 'stadderd_parsed_data' not in st.session_state:st.session_state.stadderd_parsed_data = {}st.session_state.stadderd_parsed_data['summary'] = Nonest.session_state.stadderd_parsed_data['toc'] = Nonest.session_state.stadderd_parsed_data['documents'] = Nonest.title("📰 Dcocument Key Points Review")#st.markdown("### 上传文件")# File upload sectionuploaded_file_path = file_upload()# Main processing containerwith st.container():if uploaded_file_path:# Parse documents only onceif st.session_state.parsed_data['documents'] is None:file_extension = os.path.splitext(uploaded_file_path)[1].lower()try:if file_extension == ".pdf":st.session_state.parsed_data['documents'] = parse_pdf_with_page_numbers(uploaded_file_path)elif file_extension in [".doc", ".docx"]:st.session_state.parsed_data['documents'] = parse_word_with_page_numbers(uploaded_file_path)except Exception as e:st.error(f"文件解析失败: {str(e)}")return#上传标准文件st.markdown("### ⚖️Standard Document Specifications")uploaded_file = st.file_uploader("Upload a standard file", type=["pdf", "docx", "txt"])st.markdown("### ⌨️Key review points for the document to be audited")user_question = st.text_input(label="Please enter the key review points for the document to be audited", placeholder="Please enter your Key Points for this document")st.session_state.user_question = user_question# Document parsing sectionif st.button("解析文档", key='parse_btn'):with st.spinner("正在解析文档..."):try:st.session_state.parsed_data['summary'] = parse_documents_summary(st.session_state.parsed_data['documents'])st.session_state.parsed_data['toc'] = parse_documents_toc(st.session_state.parsed_data['documents'])#st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(# st.session_state.parsed_data['summary']#)st.success("文档解析完成!")except Exception as e:st.error(f"解析过程中发生错误: {str(e)}")#本模块上传标准文件,并使用knowledge_retrieval_agent模块进行解析,并返回解析结果if uploaded_file is not None:if st.button("解析标准文件", key='parse_staddard_btn'): # Save the uploaded file to a temporary locationtemp_file_path = os.path.join("temp", uploaded_file.name)with open(temp_file_path, "wb") as f:f.write(uploaded_file.getbuffer())st.success(f"File uploaded: {temp_file_path}")# Use theknowledge_retrieval_agent module to parse the uploaded file#读取文件内容stadderd_file_extension = os.path.splitext(temp_file_path)[1].lower()if stadderd_file_extension == ".pdf":st.session_state.stadderd_parsed_data['documents'] = parse_pdf_with_page_numbers(temp_file_path)elif stadderd_file_extension in [".doc", ".docx"]:st.session_state.stadderd_parsed_data['documents'] = parse_word_with_page_numbers(temp_file_path)st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(st.session_state.parsed_data['summary'],st.session_state.stadderd_parsed_data)else:st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(st.session_state.parsed_data['summary'])# Display parsed resultsif st.session_state.parsed_data['summary']:tabs = st.tabs(["文档摘要", "目录信息", "SOP知识检索结果"])with tabs[0]:st.markdown("### 摘要信息")st.write(st.session_state.parsed_data['summary'])with tabs[1]:st.markdown("### 目录信息")st.write(st.session_state.parsed_data['toc'])with tabs[2]:st.markdown("### SOP知识检索结果")st.write(st.session_state.knowledge_retrieval_result)#设置一条分割线# Process design sectionif st.session_state.knowledge_retrieval_result and st.button("文档合规性流程设计", key='process_design_btn'):st.markdown('<hr style="border:1px solid #000000" />', unsafe_allow_html=True)st.markdown("### 🚀Document Review Process Design")with st.spinner("正在设计文档合规性流程..."):try:st.session_state.process_design_result = flow_design_agent(st.session_state.parsed_data['documents'],st.session_state.knowledge_retrieval_result,st.session_state.user_question)st.success("流程设计完成!")except Exception as e:st.error(f"流程设计失败: {str(e)}")# Display process design resultsif st.session_state.process_design_result:st.markdown("### 流程设计结果")processes = st.session_state.process_design_result['data']['processes']# Create dynamic tabstab_titles = ["流程总览"] + [p['process_name'] for p in processes]tabs = st.tabs(tab_titles)with tabs[0]: # Overview tabst.write(st.session_state.process_design_result['data']['processes'])# Process-specific tabsfor idx, process in enumerate(processes, start=1):with tabs[idx]:st.markdown(f"#### {process['process_name']}")if process['process_name'] in st.session_state.process_reviews:st.markdown(st.session_state.process_reviews[process['process_name']])# Use a unique key for each buttonbtn_key = f"review_btn_{idx}"if st.button("查看审核重点", key=btn_key):with st.spinner("正在审查..."):try:review_result = flow_review_agent(st.session_state.parsed_data['documents'],process)st.session_state.process_reviews[process['process_name']] = review_resultst.success("审查完成!")st.markdown(review_result)except Exception as e:st.error(f"审查失败: {str(e)}")# Summary report sectionif st.session_state.process_reviews and st.button("生成审查总结报告", key='summary_btn'):st.markdown('<hr style="border:1px solid #000000" />', unsafe_allow_html=True)st.markdown("### 🚀Document Review Summary Report")with st.spinner("正在生成总结报告..."):try:summary_result = flow_summary_agent(st.session_state.parsed_data['documents'],st.session_state.documents_parser_review)st.markdown("### 最终审查报告")st.markdown(summary_result)except Exception as e:st.error(f"报告生成失败: {str(e)}")
实践成果展示
- 任务:招投标文件审查
1、文件上传及解析
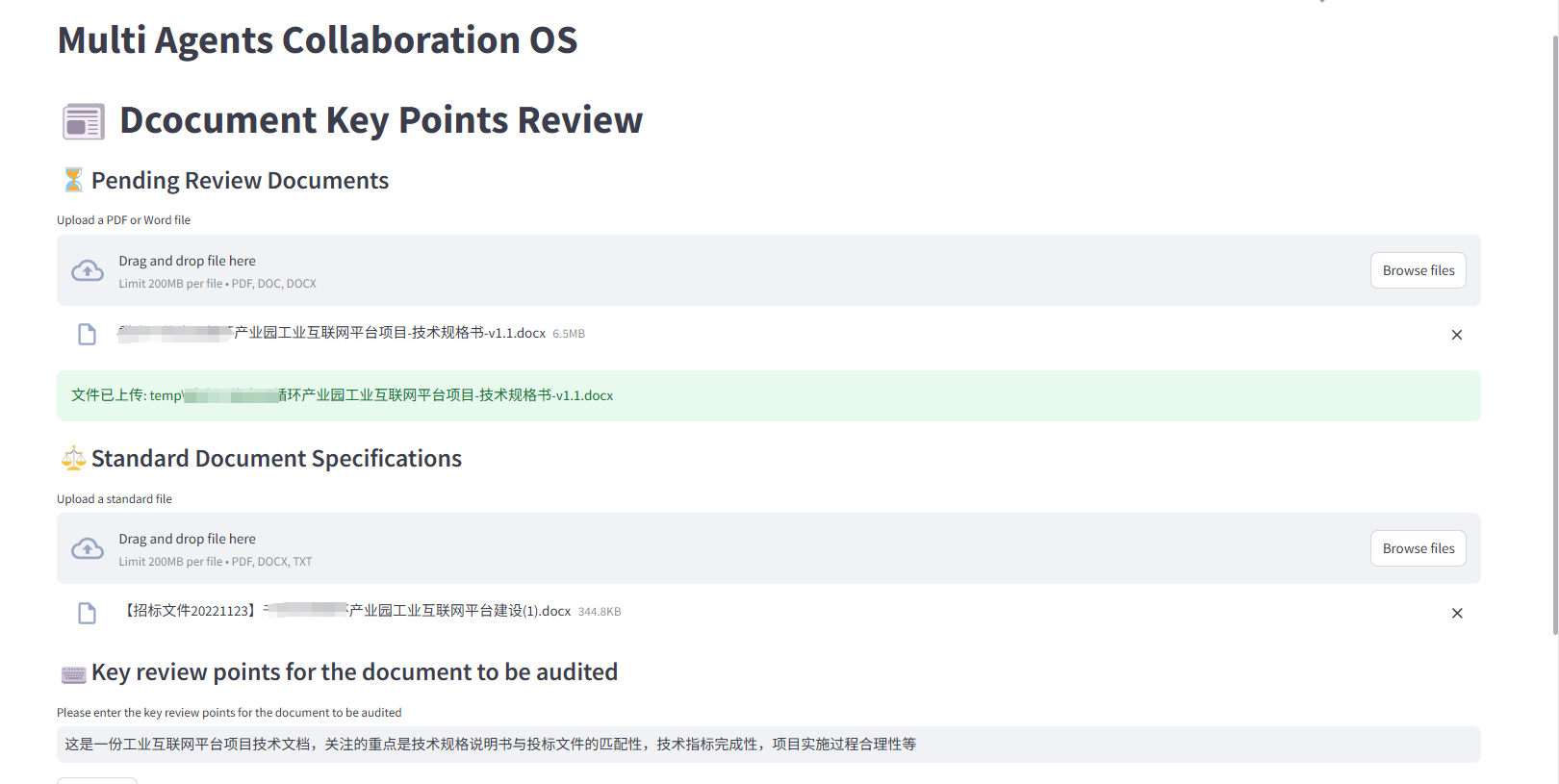
- 2.文档结构化信息解析
- 3.标准规范解析(以该项目的招标文件技术部分为基准)
- 4.文档审查流程设计
**自动生成 8 个审查节点:**文档完整性检查、整体合规性审查、技术规格书与招标文件匹配性审査、技术指标完成性审査、项目实施过程合理性审査、【数据准确性、完整性、一致性和唯一性审查】 、软件功能需求审查
-
5.审查节点建议(示例)
-
6.文档问题审查总结报告

总结
本文详细阐述了基于 Multi-Agent Collaboration OS 的文档合规性及质量检测助手的技术背景、核心流程设计以及智能体实现。通过本次设计与实践,我们验证了多智能体协作在自动化文档审查领域的可行性。
该文档审查助手作为一个通用平台,其核心价值体现在以下几个方面:
- 文件重点解析的设计及实践:平台能够高效地对不同格式的文档进行深度解析,提取关键信息,为后续审查奠定基础。
- 文件审查流程的自动生成:平台能够根据文档内容和相关知识,智能地设计定制化的审查流程,提高了审查的针对性和效率。
- 领域知识工程的引入增强:通过集成领域知识库,平台能够对文档进行更专业的合规性及质量检测。
- 文档问题及修改意见的整合:平台能够清晰地识别文档中存在的问题,精确定位问题位置,并提供具体的修改意见,极大地便利了用户的文档优化工作。
然而,在实践过程中,我们也面临一些核心问题:
- 大型复杂文档超出上下文窗口:对于篇幅巨大、结构复杂的文档,如何有效地进行知识检索和深度分析仍然是一个挑战,容易受到语言模型上下文窗口的限制。
- 实时数据/知识的补充完善审查流程和知识工程:法律法规和行业标准会不断更新,如何确保平台使用的知识库始终保持最新,并能够引入实时数据进行审查(如数据准确性核验),是未来需要持续改进的方向。
针对这些核心问题,我们认为待改进的模块包括:
- 探索使用多层次摘要、滑动窗口等技术,以更好地支持对大型复杂文件的知识检索和处理。
- 进一步完善知识工程体系,引入行业或企业核心 SOP 相关制度,以增强审查流程的设计和执行的专业性和准确性。
- 引入数据实时检索和分析能力,以补充对待查文档中数据、表格、指标等的深度分析和核验。
总而言之,基于 Multi-Agent Collaboration OS 的文档合规性及质量检测助手展现了智能体协作在自动化文档处理领域的巨大潜力,未来的工作将专注于解决现有挑战,进一步提升平台的性能和智能化水平。
相关文章:

Multi Agents Collaboration OS:文档合规性及质量检测助手设计及实践
文档审查及质量检测背景 随着企业运营和知识管理的日益复杂,文档的合规性与质量成为确保信息准确、流程顺畅及风险控制的关键环节。传统上,人工进行文档的合规性和质量检测不仅耗时耗力,且易受主观因素影响,难以保证检测的全面性…...

Vue Teleport 及其在 SSR 中的潜在问题
Vue 3 的 Teleport 特性为开发者提供了更灵活的 DOM 结构控制能力,但在服务端渲染(SSR)场景中,它可能引发一些需要注意的问题。本文将深入探讨 Teleport 的核心机制及其在 SSR 中的使用陷阱。 一、Teleport 核心机制解析 1. 基本…...

Fastapi 日志处理
uvicorn 日志处理总结: 一、日志的结构 日志结构如下: {"version": 1,"disable_existing_loggers": false,"formatters": {},"handlers": {},"loggers": {} }loggers 用于定义日志处理最顶层的标识…...

FME实现矢量建筑面shp拉伸并贴纹理
文章目录 效果2、数据准备3、整理流程图4、操作步骤4.1 打开软件4.2 添加shp数据4.3 添加Extruder转换器4.4 添加AppearanceSetter转换器4.5 添加png纹理数据4.6 添加输出节点4.7 添加Logger节点4.8 执行5、执行结果效果 2、数据准备 (1)建筑面shp (2)纹理 test.png 其中s…...

仿腾讯会议项目实现——设置配置文件
目录 1、初始化配置 2、实现初始化配置的函数 3、修改配置文件内的ip地址 1、初始化配置 Ckernel.h 2、实现初始化配置的函数 3、修改配置文件内的ip地址 首先修改IP 运行出现设置的IP, 找到运行的配置文件,修改成自己当前的ip 将函数运行条件改成非…...

1187. 【动态规划】竞赛总分
题目描述 学生在我们USACO的竞赛中的得分越多我们越高兴。我们试着设计我们的竞赛以便人们能尽可能的多得分。 现在要进行一次竞赛,总时间T固定,有若干类型可选择的题目,每种类型题目可选入的数量不限,每种类型题目有一个si(解答…...

从零开始学Python游戏编程31-类3
2.6 run()方法 run()方法的作用是在while循环中调用以上方法,运行游戏。代码如图11所示。 图11 run()方法代码 其中,第43行控制while循环的是实例属性running,在图7所示的__init__()方法中定义;第44-46行代码分别调用了processI…...
Transformer 架构 - 解码器 (Transformer Architecture - Decoder)
一、解码器整体结构:多层堆叠设计 Transformer解码器由N个相同结构的解码器层堆叠而成(通常N=6),每层包含三个核心子模块(图1) 1 5 12 : 带掩码的多头自注意力层(Masked Multi-Head Self-Attention)编码器-解码器注意力层(Encoder-Deco…...

解锁健康生活:养生新主张
在生活节奏日益加快的当下,健康养生不再是中老年人的专属话题,越来越多的人开始意识到,它是维持生命活力、抵御疾病的重要保障。 中医养生讲究 “药食同源”,在饮食上,我们可以根据季节变化调整食谱。春天气候多变&…...

__call__ 方法
__call__ 是 Python 中的一个魔法方法,也称为类方法。 它的作用是将类的实例变成可调用对象,类似于像函数一样被调用。 __call__ 使用举例 class MyClass:def __call__(self, x, y):return x yobj MyClass() print(obj(1, 2)) 对比其他类/对象的使用…...

济南通过首个备案生活服务大模型,打造行业新标杆
近日,一则振奋人心的消息在人工智能领域传开:济南本土企业丽阳神州智能科技有限公司自主研发的 “丽阳雨露” 大模型成功通过国家网信办的备案。这一成果不仅是济南企业在科技创新道路上的重大突破,更标志着我国在生活服务领域的人工智能应用…...

UE5有些场景的导航生成失败解决方法
如果导航丢失,就在项目设置下将: 即可解决问题: 看了半个小时的导航生成代码发现,NavDataSet这个数组为空,导致异步构建导航失败。 解决 NavDataSet 空 无法生成如下: 当 NavDataSet 为空的化 如果 bAut…...
生成随机数并显示波形)
STM32使用rand()生成随机数并显示波形
一、随机数生成 1、加入头文件:#include "stdlib.h" 2、定义一个用作生成随机数种子的变量并加入到滴答定时器中不断自增:uint32_t run_times 0; 3、设置种子:srand(run_times);//每次生成随机数前调用一次为佳 4、生成一个随…...

继承的了解与学习
目录 1. 继承的概念及定义 1.1 继承的概念 1.2继承的名称 1.3继承方式 1.4继承类模板 2.基类和派生类之间的转化 3.继承中的作用域 4.派生类的默认成员函数 5.继承与友元 6.继承与静态函数 7.多继承与其菱形继承问题 8.虚继承 9.继承和组合 1. 继承的概念及定义 …...

如何精通C++编程?
如果从学生时代算起的话,我学习和使用C已经差不多快十年了,仍然不敢说自己已经掌握了C的全部特性,但或许能够给出一些有用的建议吧。 我学习C全靠自学,花费了不少的功夫,在这里分享一些学习心得,希望对大家…...
)
【科研绘图系列】R语言绘制多个气泡图组合图(bubble plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图函数画图系统信息介绍 【科研绘图系列】R语言绘制多个气泡图组合图(bubble plot) 加载R包 library(dplyr) library(tidyr) library(ggp…...

利用大模型实现地理领域文档中英文自动化翻译
一、 背景描述 在跨国性企业日常经营过程中,经常会遇到专业性较强的文档翻译的需求,例如法律文书、商务合同、技术文档等;以往遇到此类场景,企业内部往往需要指派专人投入数小时甚至数天来整理和翻译,效率低下&#x…...
)
Oracle 19c部署之手工建库(四)
#Oracle #19c #手工建库 手工创建Oracle数据库(也称为手工建库)是指在已经安装了Oracle数据库软件的基础上,通过手动执行一系列命令和步骤来创建一个新的数据库实例。这种方法与使用Database Configuration Assistant (DBCA)等工具自动创建数…...

Leetcode 2158. 每天绘制新区域的数量【Plus题】
1.题目基本信息 1.1.题目描述 有一幅细长的画,可以用数轴来表示。 给你一个长度为 n 、下标从 0 开始的二维整数数组 paint ,其中 paint[i] [starti, endi] 表示在第 i 天你需要绘制 starti 和 endi 之间的区域。 多次绘制同一区域会导致不均匀&…...

使用最新threejs复刻经典贪吃蛇游戏的3D版,附完整源码
基类Entity 建立基类Entity,实现投影能力、动画入场效果(从小变大的弹性动画)、计算自己在地图格位置的方法。 // 导入gsap动画库(用于创建补间动画) import gsap from gsap// 定义Entity基类 export default class …...
为欧洲用户带来更丰富的结果)
Google优化搜索体验:全新动态摘要功能(Beta)为欧洲用户带来更丰富的结果
Google持续推动搜索体验的创新,最新推出的动态摘要(Dynamic Snippets)功能(Beta版)为欧洲经济区(EEA)的用户和企业带来了全新的交互方式。2025年4月,Google更新了动态摘要的文档&…...

[苍穹外卖 | 项目日记] 第三天
前言 实现了新增菜品接口实现了菜品分页查询接口实现了删除菜品接口实现了根据id查询菜品接口实现了修改菜品接口 今日收获: 今日的这几个接口其实和之前写的对员工的操作是一样的,都是一整套Curd操作,所以今天在技术层面上并没有…...

【Python爬虫基础篇】--2.模块解析
目录 1.urllib库 1.1.request模块 1.1.1、urllib.request.urlopen() 函数 1.1.2.urllib.request.urlretrieve() 函数 1.2. error模块 1.3. parse 模块 2. BeautifulSoup4库 2.1.对象种类 2.2.对象属性 2.2.1.子节点 2.2.2.父节点 2.2.3.兄弟节点 2.2.4.回退和前进 …...

LabVIEW技巧——获取文件版本信息
获取可执行文件(exe)版本信息的几种方法 方法1. LabVIEW自带函数 labview自带了获取文件版本号的VI,但是没有开放到程序框图的函数选板中,在该目录下可以找到:...\LabVIEW 20xx\vi.lib\Platform\fileVersionInfo.llb…...
)
【软件工程】用飞书画各种图(流程图,架构图···)
笔者在做服务外包大赛的时候被文档内容的编写反复折磨,网上的工程图绘画工具要么是展示效果不佳,要么要收大几百的VIP费,最后发现飞书竟然可以直接绘画并插入示意图。 一、为什么选择飞书文档画流程图? 完全免费,无广…...

RFID图书管理系统如何重构数字化仓储管理新生态
引言 在图书馆与出版行业数字化转型进程中,RFID图书管理系统正打破传统人工管理的效率瓶颈,通过与数字化仓储管理系统的深度融合,实现从图书采购、入库到借阅的全链路智能化。本文结合RFID固定资产管理软件的应用逻辑,解析这一技…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...

操作系统-PV
🧠 背景:为什么会有 PV? 类比:内存(生产者) 和 CPU(消费者) 内存 / IO / 磁盘 / 网络下载 → 不断“生产数据” 例如:读取文件、下载视频、从数据库加载信息 CPU → 负…...
)
工厂方法模式详解及c++代码实现(以自动驾驶感知模块中的应用为例)
模式定义 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,通过定义抽象工厂接口将对象创建过程延迟到子类实现,实现对象创建与使用的解耦。该模式特别适合需要动态扩展产品类型的场景。 自动驾驶感知场景分析 自动驾…...

Jsp技术入门指南【五】详细讲解jsp结构页面
Jsp技术入门指南【五】详细讲解jsp结构页面 前言一、JSP页面的结构二、JSP页面的部件1. 指令(核心控制部件)2. 动作(页面交互部件,了解即可)3. 脚本(Java逻辑嵌入部件) 三、JSP指令详解1.1 JSP指…...

游戏APP如何抵御DDoS攻击与黑客勒索?实战防护全攻略
一、游戏行业安全挑战与攻击危害 游戏APP因高实时性、高并发及虚拟资产交易特性,成为DDoS攻击和勒索的重灾区,典型威胁包括: DDoS攻击瘫痪服务: UDP Flood:针对游戏服务器端口(如UDP 7777)发起…...

Mac 选择下载安装工具 x86 还是 arm64 ?
要确定你的 Mac 电脑应该选择下载安装工具的 x86 还是 arm64 版本,关键是判断你的 Mac 使用的是 Intel 处理器(x86 架构)还是 Apple Silicon(如 M1、M2 等,arm64 架构)。具体方法如下: 方法 1&…...

string函数的应用
字符串查找 find 方法 实例 string s "Hello World,C is awesome!";//查找子串 size_t pos1 s.find("World"); //pos16 size_t pos2 s.find("Python"); //pos2string::npos//查找字符 size_tpos3s.find(c); //pos313//从指定位置开始查找 size…...

使用Trae CN分析项目架构
架构分析后的截图 A区是打开的项目、B区是源码区、C区是AI给出当前项目的架构分析结果。 如何用 Trae CN 快速学习 STM32 嵌入式项目架构 在嵌入式开发领域,快速理解现有项目的架构是一项关键技能。Trae CN 作为一款强大的分析工具,能帮助开发者高效剖…...
暴力娱乐篇33)
每日一题(小白)暴力娱乐篇33
由题意可知我们今天要解决的问题是在1~2025中去找合适的数字,这里要找出一些特殊的数字,这些数字要满足以下条件,是三的倍数,是8的倍数,是38的倍数,老板就给要多给一个红包,我们循环然后相应条件…...

MyBatis框架
前言: MyBatis框架相比JDBC来说大大提升了我们写代码的效率,但是对初学者来说框架还是有点难以理解,所以本篇博客会十分详细的讲解MyBatis框架 目录 一.MyBatis概述 1.什么是映射? 2.什么是XML? 二.MyBatis框架搭建 1.创建一张表和表对…...

基于SpringBoot的新闻小程序开发与设计
概述 在信息爆炸的时代,高效获取新闻资讯成为现代人的刚需。幽络源平台今日分享一款基于SpringBoot框架开发的微信小程序新闻资讯系统,该系统采用前后端分离架构,实现了新闻分类管理、个性化推荐、用户收藏等功能,为新闻传播提供…...

IE之路专题12.BGP专题
BGP协议有哪些特点 BGP时边界网关协议(EGP),是一种用在自治系统之间传递路由信息的路由协议; 提供了丰富的路由属性以及强大的路由过滤和路由策略,实现灵活选路和路由控制; 策略方式更改属性或根据更新信息中属性实现过滤和策略 BGP是工作在传输层TCP之上的,使用TCP的端口号…...
)
文件包含(详解)
文件包含漏洞是一种常见的Web安全漏洞,其核心在于应用程序未对用户控制的文件路径或文件名进行严格过滤,导致攻击者能够包含并执行任意文件(包括本地或远程恶意文件)。 1. 文件包含原理 动态文件包含机制 开发者使用动态包含函数…...

智慧养老照护实训室:推动养老服务数字化转型实践
在人口老龄化加速与数字化浪潮席卷的当下,传统养老服务模式在效率、精准度及个性化服务上的局限日益明显。智慧养老成为行业转型的必然方向,但专业人才短缺与技术应用落地困难制约着发展。智慧养老照护实训室通过整合虚拟仿真等前沿技术,构建…...

NOIP2015提高组.信息传递
目录 题目算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量思路 T a r j a n Tarjan Tarjan算法求解代码 题目 517. 信息传递 算法标签: 并查集, T a r j a n Tarjan Tarjan算法, s c c scc scc强连通分量 思路 使用强连通分量算法求环上点…...

Wireshark 搜索组合速查表
文章目录 Wirshark使用记录基本语法规则搜索条件符号速查表捕获过滤器组合指令速查表筛选过滤器组合命令速查表Wireshark Frame 协议字段解析 Wirshark使用记录 官网地址:https://www.wireshark.org/ 基本语法规则 字段描述示例说明type用于指定数据包的类型&…...

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

我的gittee仓库
日常代码: 日常代码提交https://gitee.com/xinxin-pingping/daily-code 有需要的宝子们可自行读取。...

RT-Thread开发文档合集
瑞萨VisionBoard开发实践指南 RT-Thread 文档中心 RT-Thread-【RA8D1-Vision Board】 RA8D1 Vision Board上的USB实践RT-Thread问答社区 - RT-Thread 【开发板】环境篇:05烧录工具介绍_哔哩哔哩_bilibili 【RA8D1-Vision Board】基于OpenMV 实现图像分类_哔哩哔哩_…...

SPWM-H桥逆变器工作原理
SPWM-H桥逆变器(Sinusoidal Pulse Width Modulation H-Bridge Inverter)是一种基于正弦脉宽调制(SPWM)技术的电力电子装置,用于将直流(DC)转换为交流(AC)。它广泛应用于光…...
)
【数据结构_10】二叉树(2)
一、根据树的遍历结果还原树 紧接着(1),我们继续来讨论:如果给了树的遍历结果,我们能否把这个树给还原出来呢? 如果只给一种遍历结果,那么我们无法对树进行还原。 只有给了我们先序中序&…...
---(jdk安装和环境变量配置))
day1-小白学习JAVA(mac版)---(jdk安装和环境变量配置)
JDK安装和环境变量配置 我的电脑系统一、下载JDK1、oracle官网下载适合的JDK安装包,选择Mac OS对应的版本。 二、安装三、配置环境变量1、终端输入/usr/libexec/java_home -V查询所在的路径,复制备用2、输入ls -a3、检查文件目录中是否有.bash_profile文…...

Muduo网络库实现 [十六] - HttpServer模块
设计思路 本模块就是设计一个HttpServer模块,提供便携的搭建http协议的服务器的方法。那么这个模块需要如何设计呢? 这还需要从Http请求说起。 首先从http请求的请求行开始分析,请求行里面有个方法。分为静态资源请求和功能性请求的。 静态…...

工业触摸显示器助力智慧工业实验室发展
工业触摸显示器作为智慧工业实验室的核心人机交互设备,凭借其卓越的性能和灵活性,为实验室的智能化、自动化发展提供了强有力的支持。以下从多个方面阐述工业触摸显示器如何助力智慧工业实验室的发展: 一、提升操作便捷性与效率 直观操作&a…...