Linux:线程概念与控制
✨✨所属专栏:Linux✨✨
✨✨作者主页:嶔某✨✨

Linux:线程概念于控制
var code = “d7e241ae-ed4d-475f-aa3d-8d78f873fdca”
概念
在一个程序里的一个执行路线就叫做线程
thread。更准确一点:线程是“一个进程内部的控制序列”一切进程都至少有一个线程
线程在进程内部运行,本质是在进程地址空间运行
在
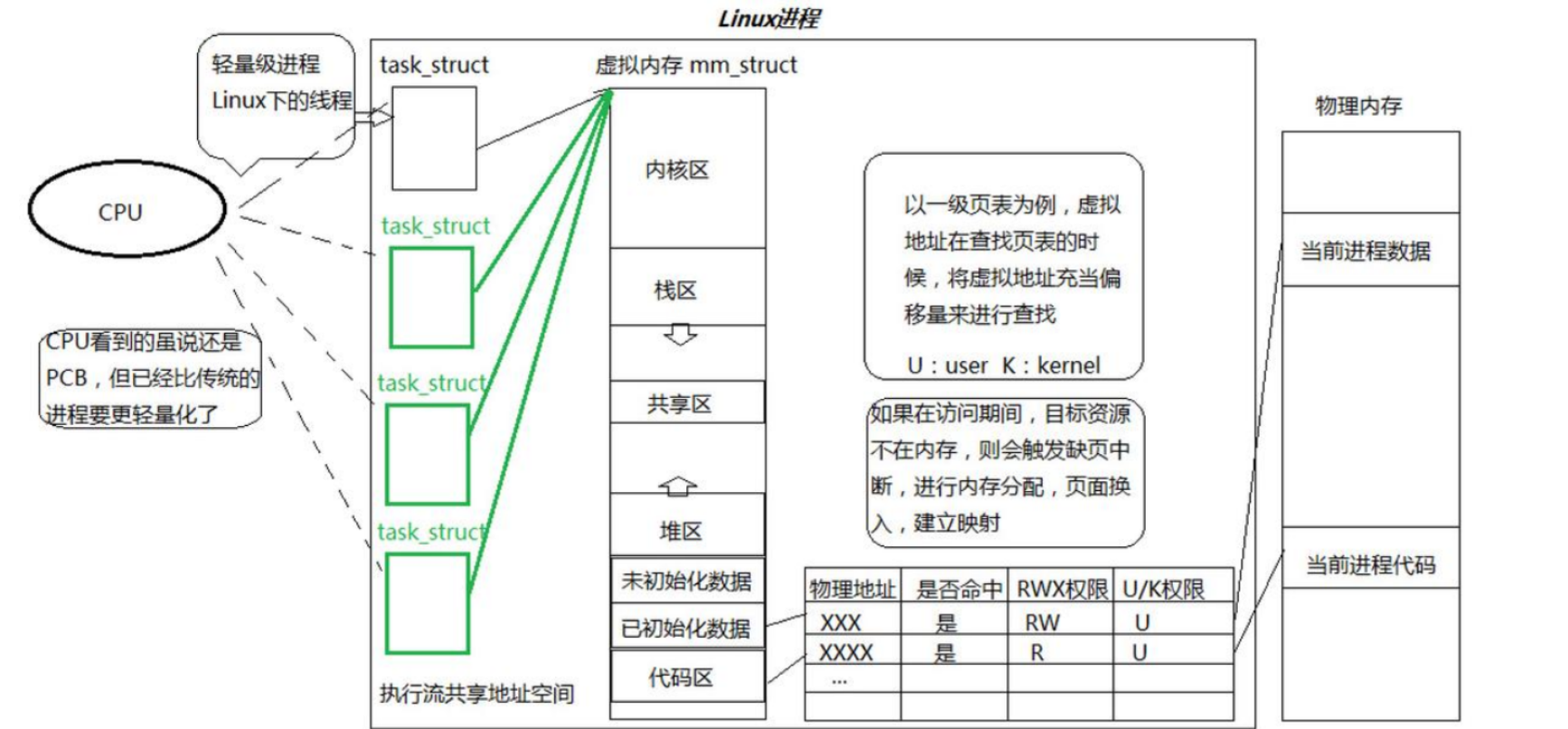
Linux系统中,在CPU眼中,看到的PCB都要比传统的要轻量化透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
分页式储存管理
如果没有虚拟内存和分页机制,每一个用户在物理内存上的空间必须是连续的,如下图
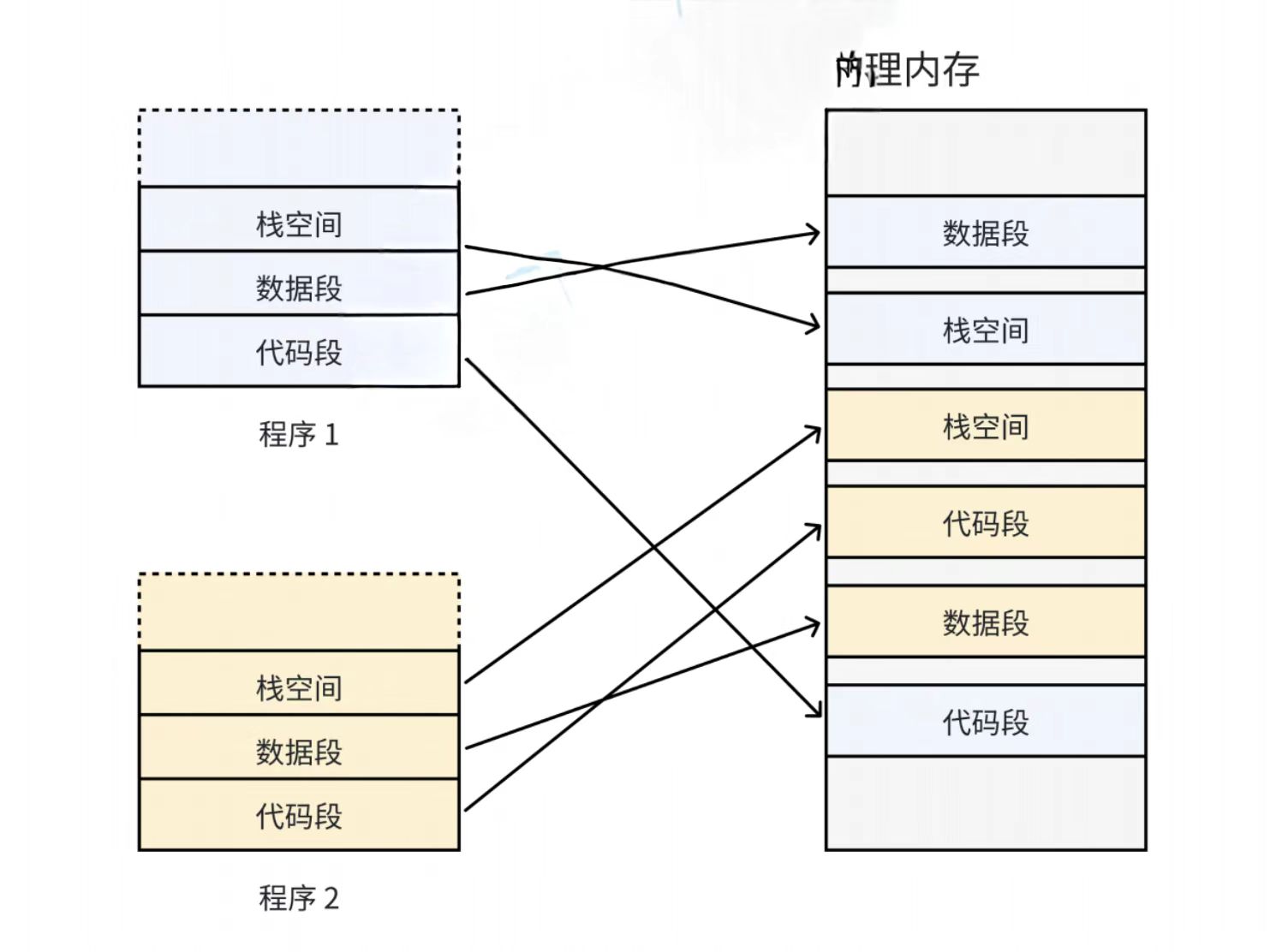
因为每一个程序的代码、数据长度都是不一样的,按照这样的映射方式,物理内存会被分成各种离散的大小不同的块。有些程序会退出,它们占据的物理内存会被回收,一段时间过后,物理内存就变得非常碎片化,不易管理了。
所以我们希望操作系统给用户的空间是连续的,但是物理内存最好不要连续,那么虚拟内存和分页就出现了。
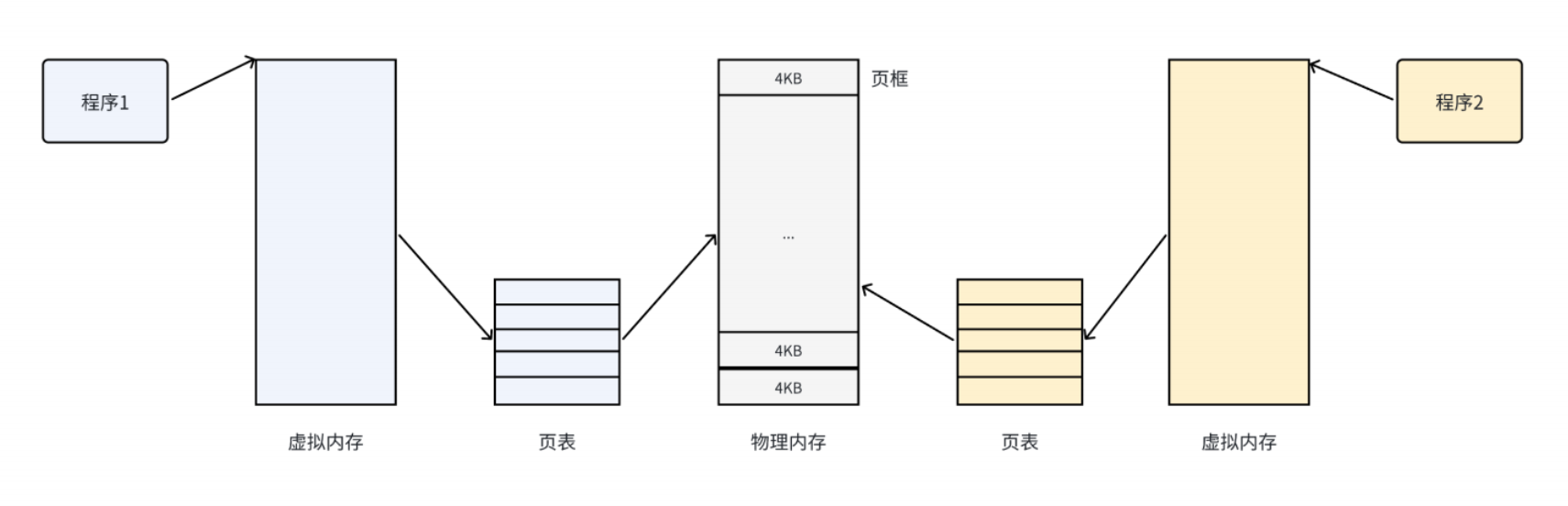
把物理内存按照一个固定的长度页框进行分割,叫做物理页。每一个页框包含一个物理页page。页的大小就是页框的大小。32位机器支持4kb的页,64位机器支持8kb的页。
- 页框是一个储存区域
- 页是一个数据块,可以存放在任何页框中,或者磁盘中
有了这种机制,CPU并非直接访问物理地址,而是通过虚拟地址空间来间接的访问物理内存地址。所谓的虚拟地址空间,是操作系统位每一个在执行的进程分配的一个逻辑地址,32位机器上其范围为0-4GB。
操作系统通过将虚拟地址空间与物理地址间建立映射关系:页表,这张表上记录了每一对页和页框的映射关系,能让CPU间接访问物理内存地址。
其思想就是**将虚拟内存下的逻辑地址空间分为若干的页,将物理内存空间分为若干页框,通过页表将连续的虚拟内存,映射到若干个不连续的物理内存页。**这样就解决了使用连续的物理内存造成的碎片问题。
物理内存管理
假设一个可用的物理内存有4GB的空间。按照一个页框的大小4KB划分,4GB的空间就是4GB/4KB = 1048576个页框。有这么多的物理页,操作系统肯定是要对它们进行管理的,OS要知道哪些页被使用,哪些页在空闲。
Linux内核里面使用了struct page结构描述系统中的每个物理页,为了节省内存(这个结构体本身也是在内核,也是在内存里面的)这里面使用了大量的联合体union
/* include/linux/mm_types.h */
struct page
{/* 原⼦标志,有些情况下会异步更新 */unsigned long flags;union{struct{/* 换出⻚列表,例如由zone->lru_lock保护的active_list */struct list_head lru;/* 如果最低为为0,则指向inode* address_space,或为NULL* 如果⻚映射为匿名内存,最低为置位* ⽽且该指针指向anon_vma对象*/struct address_space *mapping;/* 在映射内的偏移量 */pgoff_t index;/** 由映射私有,不透明数据* 如果设置了PagePrivate,通常⽤于buffer_heads* 如果设置了PageSwapCache,则⽤于swp_entry_t* 如果设置了PG_buddy,则⽤于表⽰伙伴系统中的阶*/unsigned long private;};struct{ /* slab, slob and slub */union{struct list_head slab_list; /* uses lru */struct{ /* Partial pages */struct page *next;
#ifdef CONFIG_64BITint pages; /* Nr of pages left */int pobjects; /* Approximate count */
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist; /* first free object */union{void *s_mem; /* slab: first object */unsigned long counters; /* SLUB */struct{ /* SLUB */unsigned inuse : 16; /* ⽤于SLUB分配器:对象的数⽬ */unsigned objects : 15;unsigned frozen : 1;};};};...};union{/* 内存管理⼦系统中映射的⻚表项计数,⽤于表⽰⻚是否已经映射,还⽤于限制逆向映射搜索*/atomic_t _mapcount;unsigned int page_type;unsigned int active; /* SLAB */int units; /* SLOB */};...
#if defined(WANT_PAGE_VIRTUAL)/* 内核虚拟地址(如果没有映射则为NULL,即⾼端内存) */void *virtual;
#endif /* WANT_PAGE_VIRTUAL */...
}
重要参数
flags:用来存放页的状态。包括是不是脏的,是不是被锁定在内存中等等。flags的每一位单独表示一种状态,所以他至少可以同时表示出32种不同的状态。这些标志定义在<linux/page-flags.h>中。其中⼀些比特位非常重要,如PG_locked⽤于指定页是否锁定,PG_uptodate⽤于表示页的数据已经从块设备读取并且没有出现错误。_mapcount:表示在页表中有多少项指向该页,也就是这一页被引⽤了多少次。当计数值变为-1时,就说明当前内核并没有引⽤这一页,于是在新的分配中就可以使用它。virtual:是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的⾼端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的时候,必须动态地映射这些页。
要注意的是struct page与物理页相关,⽽并非与虚拟页相关。⽽系统中的每个物理页都要分配⼀个这样的结构体,让我们来算算对所有这些页都这么做,到底要消耗掉多少内存。
算struct page占40个字节的内存吧,假定系统的物理页为 4KB ⼤⼩,系统有 4GB 物理内存。那么系统中共有页面 1048576 个(1兆个),所以描述这么多⻚⾯的page结构体消耗的内存只不过40MB ,相对系统 4GB 内存而言,仅是很小的⼀部分罢了。因此,要管理系统中这么多物理⻚⾯,这个代价并不算太大。
要知道的是,页的大小对于内存利⽤和系统开销来说非常重要,页太大,页必然会剩余较⼤不能利⽤的空间(页内碎片)。页太小,虽然可以减小页内碎片的大小,但是页太多,会使得页表太长而占⽤内存,同时系统频繁地进行页转化,加重系统开销。因此,页的大小应该适中,通常为 512B -8KB ,windows系统的页框大小为4KB。
页表
页表中的每一个表项都指向一个物理页的起始地址。在32位机器上要将4GB的空间全部用页表指向的话需要4GB/4KB = 1048576个表项。
页表中的物理地址,和真实的物理页之间是随机映射关系,哪里可用就指向哪里。**最终使用的物理内存是离散的,但是虚拟地址是连续的。**处理器在访问数据、获取指令都是用的虚拟地址,最终都能通过页表找到物理地址。
我们可以算一下,在32位机器上,地址长度为4字节,页表占用的空间为1048576 * 4 = 4MB,映射页表本身就要消耗4MB / 4KB = 1024个物理页。每次新起一个进程,都要将这占用了1024个物理页的页表加载映射到内存,但是根据局部性原理,一个进程在一段时间内只需要访问某几个页就可以正常运行了。所以根本没有必要将所有的物理页都常驻内存。
解决这一问题的方法就是对页表再次分页,即多级页表。
我们将单一的一个页表再次拆分为1024个更小的映射表。1024(每个表中的表项数)* 1024(表的个数)仍然可以覆盖4GB的物理内存空间。
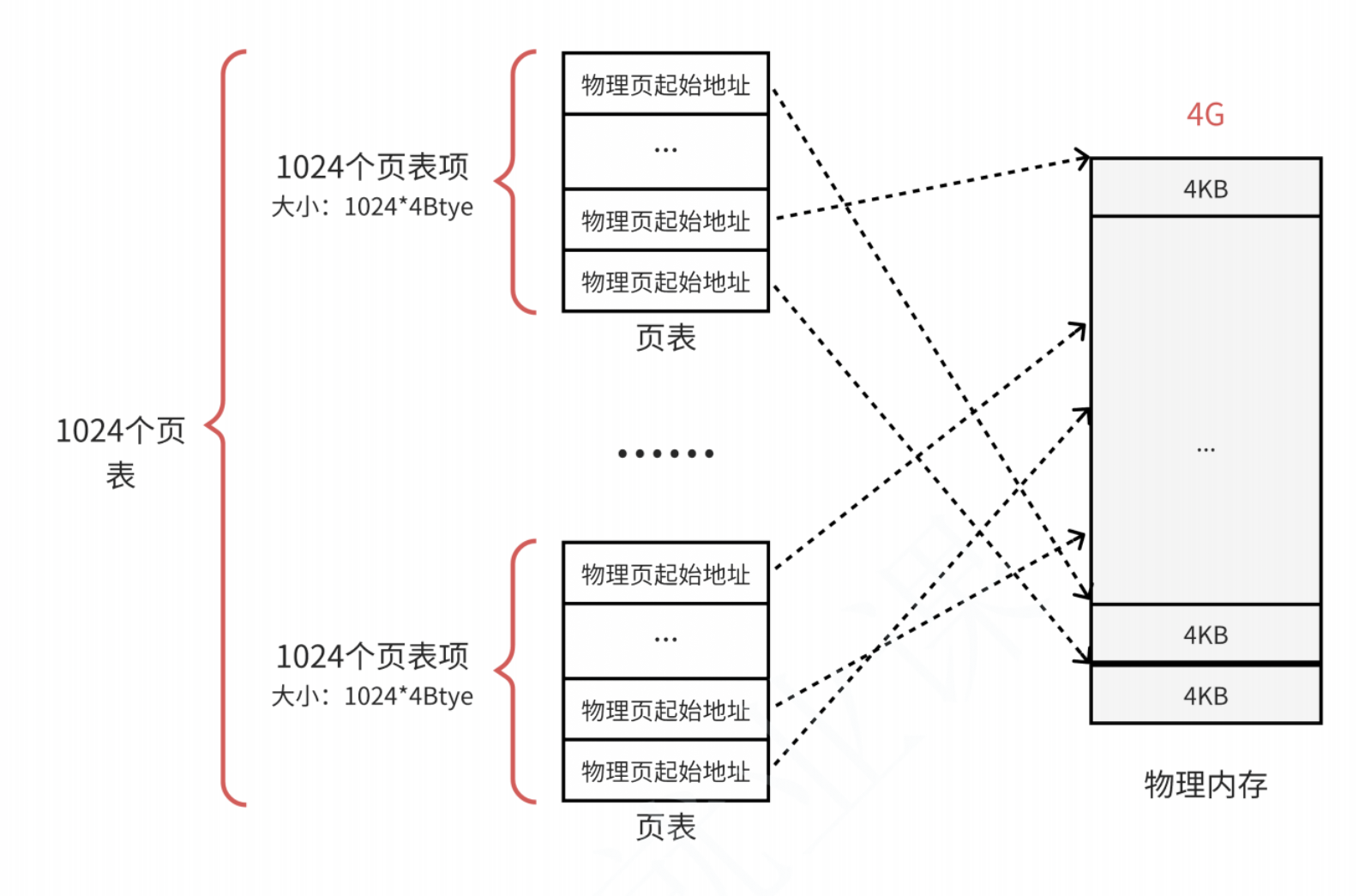
这里的每一个页表就是真正的页表了,一共有1024个页表,一个页表占用4KB,一共也就是4MB。虽然和之前没区别,但是一个应用程序不可能把这些页表全部用完的,这样设计方便用多少,开多少。例如:一个程序的代码段、数据段、栈、一共只需要10MB的空间,那么使用3个页表就够用了。(一个页表能覆盖4MB的物理空间)
页目录结构
那么每一个页框都有一个页表项来指向,这1024个页表也需要被管理起来。管理页表的表称为页目录表,形成了二级页表:
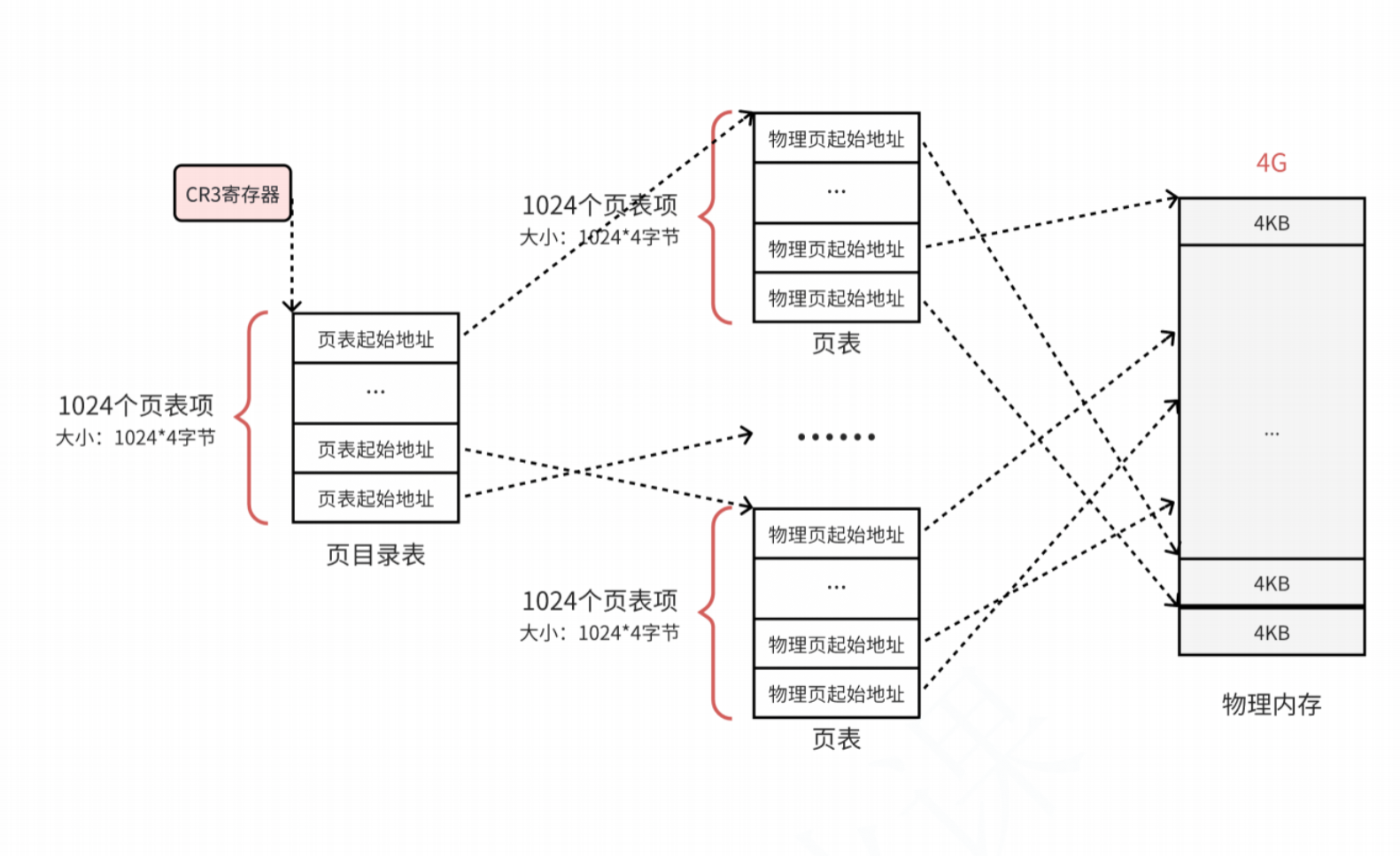
所有页表的物理地址都被页目录表指向
页目录的物理地址被
CR3寄存器指向,此寄存器保存了当前正在执行任务的页目录地址。
所以在程序被加载的时候,不仅要为程序的内容分配物理内存,还需要为保存程序物理地址和虚拟地址映射的页目录和页表分配物理内存。
两级页表的地址转换
下面以一个逻辑地址为例。将逻辑地址0000000000,0000000001,111111111111转化为物理地址的过程:
- 在32为处理器中,采用4KB页大小,则虚拟地址中的低12为为页偏移,剩下的高20位给页表分成两级,每个级占10位。
CR3寄存器读取页目录起始地址,再根据一级页号查页目录表,找到下一级页表在物理内存中存放位置。- 根据二级页号查表,找到最终想要访问的内存块号。
- 结合页内偏移量得到物理地址。
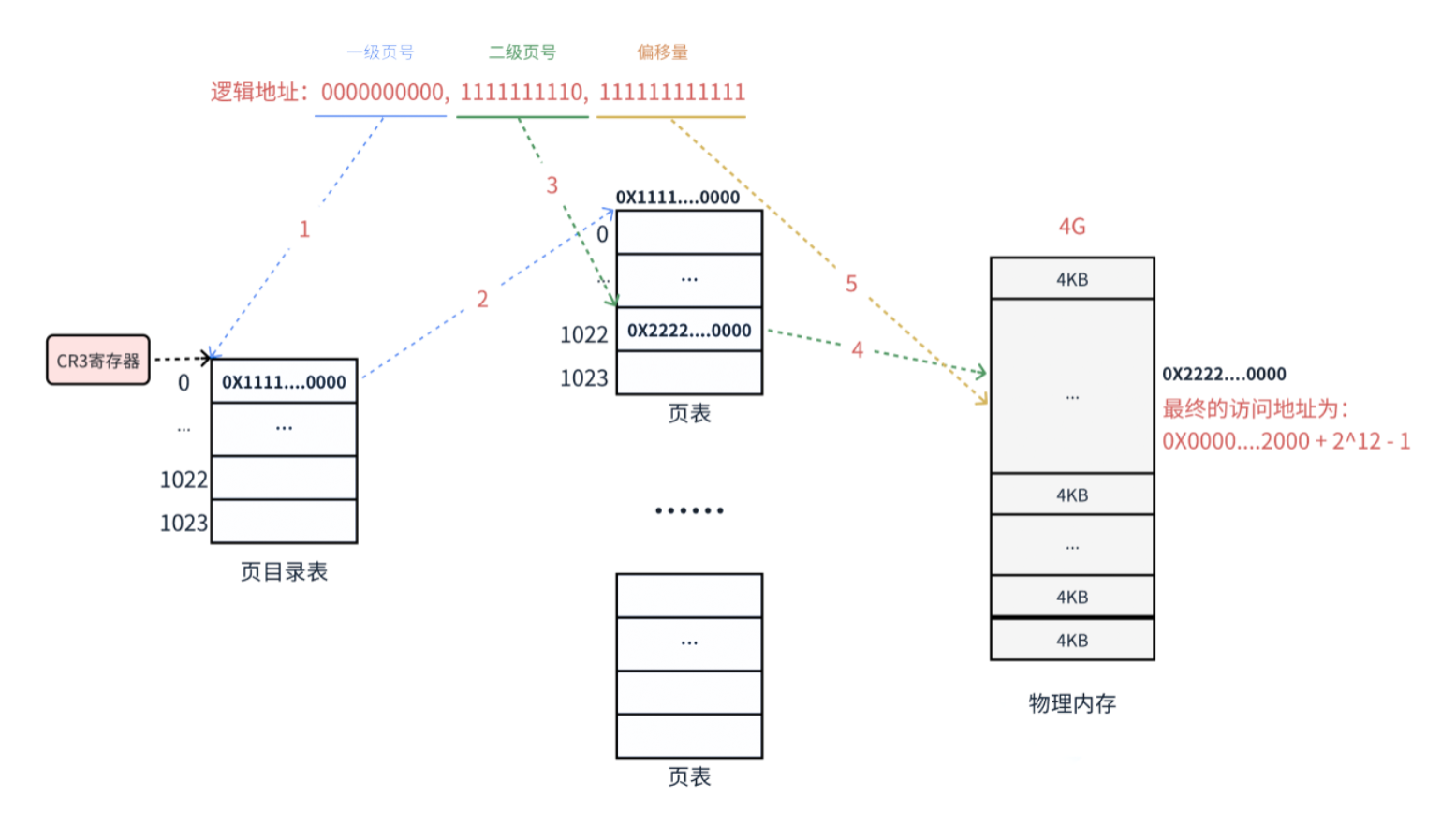
- 一个物理页的地址,一定是对齐4KB的(最后的12位全为0),所以其实只需要记录物理页地址的高20位即可。
- 以上就是
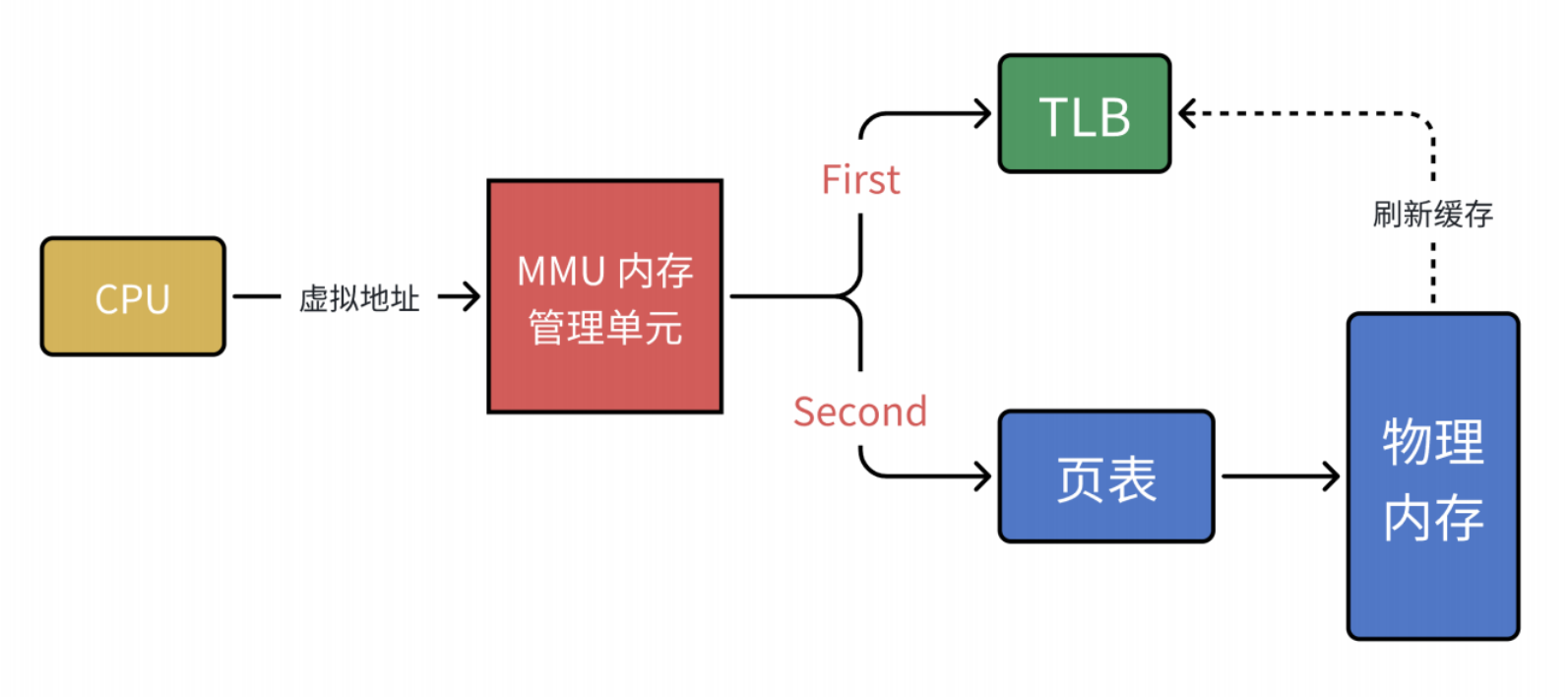
MMU的工作流程,Memory Manage Unit是一种硬件电路,其速度很快,主要工作是做内存管理,地址转换只是其工作之一。
那么这个工作流就没有缺点了吗?当然是有的!MMU进行两次查询确定物理地址,在确认了权限问题后,将这个物理地址发到总线,内存收到后开始读取数据并返回。当页表变为N级时需要经过N次检索+1次读写,查询效率就会变低。
那么有没有提升效率的方法呢?有的,那就是添加一层中间层也就是TLB江湖人称“快表”,其实也就是缓存。当 CPU 给 MMU 传新虚拟地址之后, MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到总线给内存,⻬活。但 TLB 容量比较小,难免发生 Cache Miss ,这时候 MMU 还有保底的⽼武器页表,在页表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录⼀下刷新缓存。
缺页异常
设想,CPU 给 MMU 的虚拟地址,在 TLB 和页表都没有找到对应的物理页,该怎么办呢?其实这就是缺页异常 Page Fault ,它是⼀个由硬件中断触发的可以由软件逻辑纠正的错误。假如目标内存页在物理内存中没有对应的物理页或者存在但⽆对应权限,CPU 就⽆法获取数据,这种情况下CPU就会报告⼀个缺页错误。由于 CPU 没有数据就无法进行计算,CPU罢工了用户进程也就出现了缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler 处理。
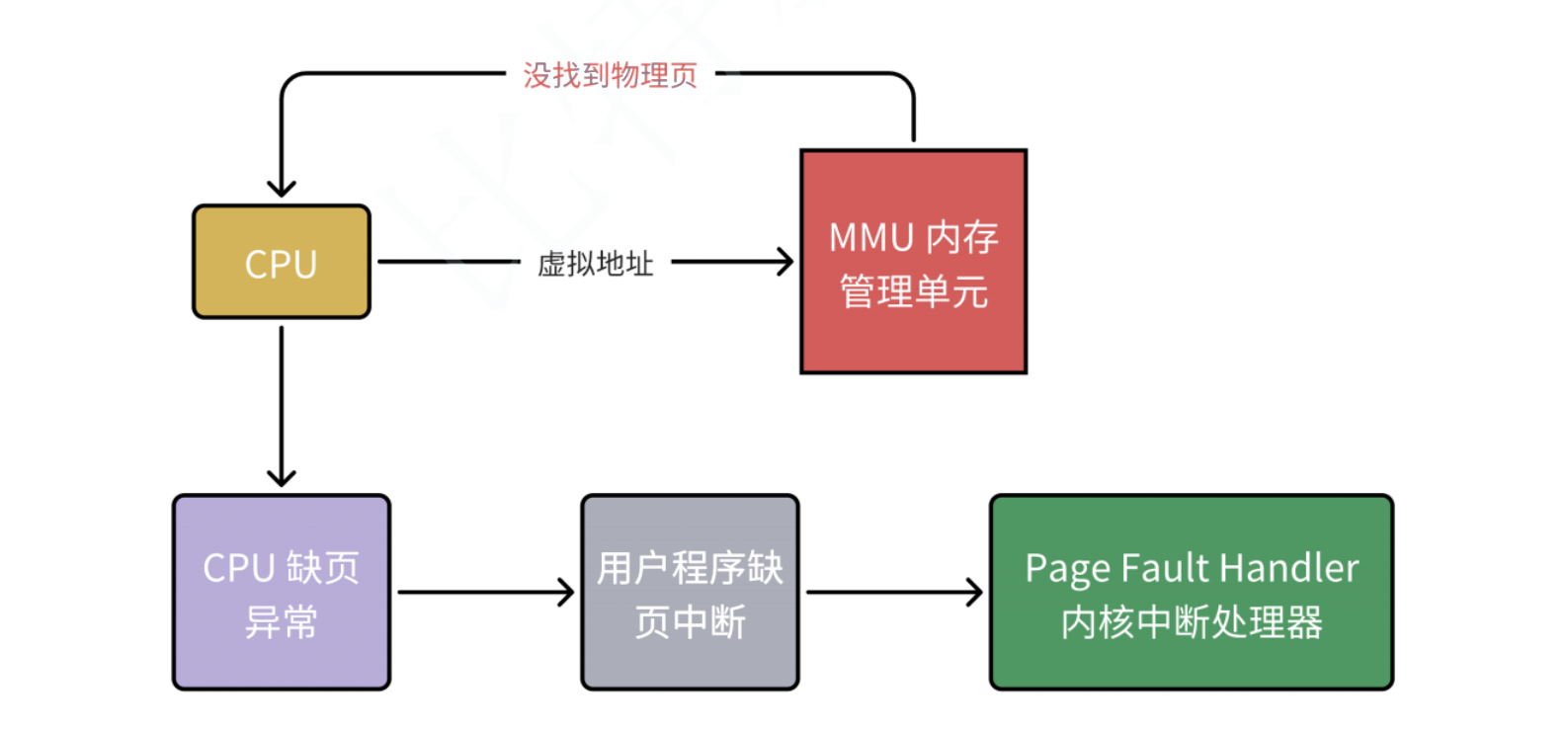
缺页中断会交给PageFaultHandler处理,其根据缺页中断的不同类型进行不同的处理:
Hard Page Fault也被称为Major Page Fault,翻译为硬缺页错误/主要缺页错误,这时物理内存中没有对应的物理页,需要CPU打开磁盘设备读取到物理内存中,再让MMU建立虚拟地址和物理地址的映射。Soft Page Fault也被称为Minor Page Fault,翻译为软缺页错误/次要缺页错误,这时物理内存中是存在对应物理页的,只不过可能是其他进程调入的,发出缺页异常的进程不知道⽽已,此时MMU只需要建立映射即可,无需从磁盘读取写入内存,⼀般出现在多进程共享内存区域。Invalid Page Fault翻译为无效缺页错误,比如进程访问的内存地址越界访问,⼜比如对空指针解引用内核就会报segment fault错误中断进程直接挂掉。
Linux进程VS线程
线程优点
- 创建⼀个新线程的代价要比创建⼀个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的⼯作要少很多
- 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
- 另外⼀个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,⼀旦去切换上下文,处理器中所有已经缓存的内存地址⼀瞬间都作废了。还有⼀个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲
TLB(快表)会被全部刷新,这将导致内存的访问在⼀段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。 - 线程占⽤的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速
I/O操作结束的同时,程序可执⾏其他的计算任务 - 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应⽤,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程缺点
- 性能损失
⼀个很少被外部事件阻塞的计算密集型线程往往⽆法与其它线程共享同⼀个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可⽤的资源不变。
- 健壮性降低
编写多线程需要更全⾯更深入的考虑,在⼀个多线程程序⾥,因时间分配上的细微偏差或者因共享了不该共享的变量⽽造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
- 缺乏访问控制
进程是访问控制的基本粒度,在⼀个线程中调⽤某些
OS函数会对整个进程造成影响。
- 编程难度提高
编写与调试⼀个多线程程序比单线程程序困难得多
线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执⾏分⽀,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
用途
- 合理的使用多线程,能提高
CPU密集型程序的执行效率 - 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们⼀边写代码⼀边下载开发⼯具,就是多线程运行的⼀种表现)
进程和线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
- 线程共享进程数据,但也拥有⾃⼰的⼀部分数据: 1、线程
ID2、⼀组寄存器 3、栈 4、errno5、信号屏蔽字 6、调度优先级
进程的多个线程共享
同⼀地址空间,因此Text Segment、Data Segment都是共享的,如果定义⼀个函数,在各线程中都可以调⽤,如果定义⼀个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理⽅式(
SIG_IGN、SIG_DFL或者⾃定义的信号处理函数) - 当前工作目录
- 用户
id和组id
进程和线程的关系如下图:
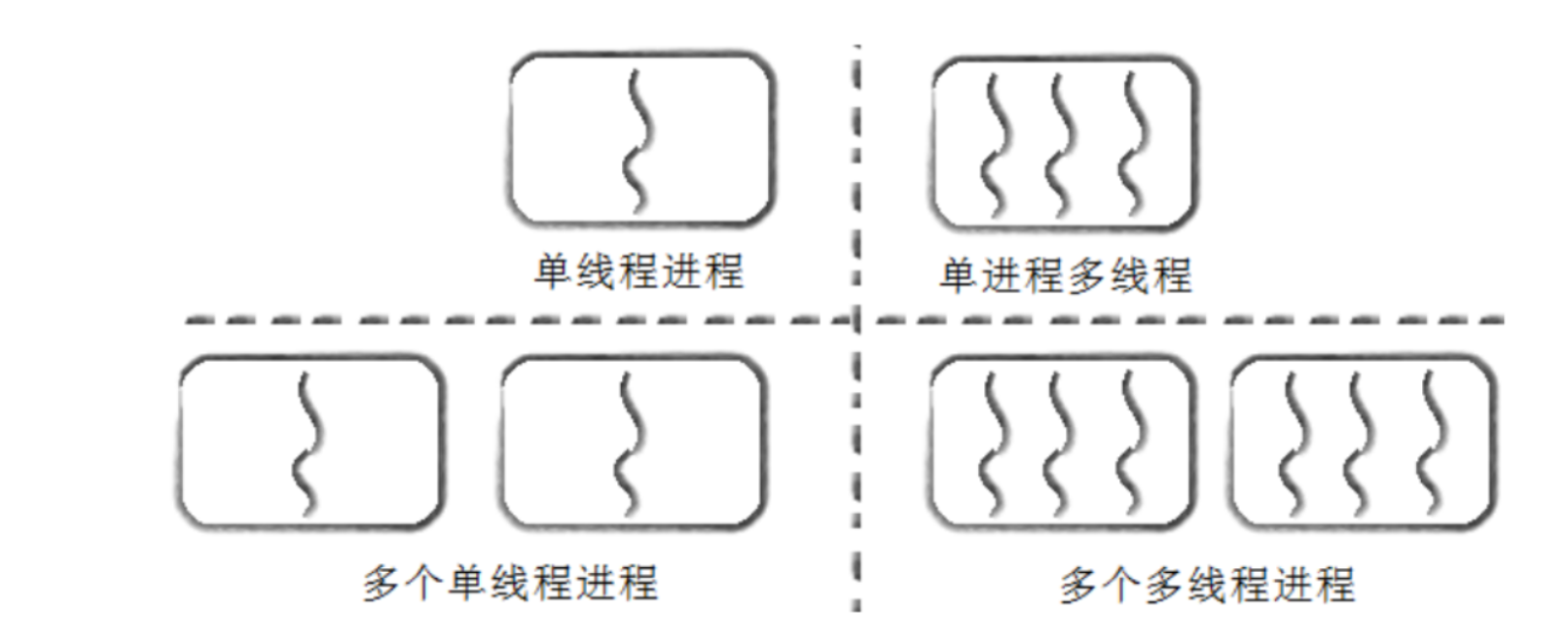
对于之前学习的进程和这个线程是相悖的吗?并不是,进程就可以看作一个有一个线程执行流的进程。
Linux线程控制
POSIX线程库
- 与线程有关的函数构成了⼀个完整的系列,绝大多数函数的名字都是以“
pthread_”打头的 - 要使用这些函数库,要通过引入头文件
<pthread.h> - 链接这些线程函数库时要使用编译器命令的
-lpthread选项
创建线程
功能:创建⼀个新的线程原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);
参数:thread:返回线程IDattr:设置线程的属性,attr为NULL表示使用默认属性start_routine:是个函数地址,线程启动后要执行的函数arg:传给线程启动函数的参数返回值:成功返回0;失败返回错误码
错误检查:
- 传统的⼀些函数是,成功返回0,失败返回-1,并且对全局变量
errno赋值以指示错误 pthreads函数出错时不会设置全局变量errno(⽽⼤部分其他POSIX函数会这样做)。⽽是将错误代码通过返回值返回pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,建议通过返回值来判定,因为读取返回值要比读取线程内的errno变量的开销更小
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <pthread.h>
void *rout(void *arg) {int i;for( ; ; ) {printf("I'am thread 1\n");sleep(1);}
}
int main( void )
{pthread_t tid;int ret;if ( (ret=pthread_create(&tid, NULL, rout, NULL)) != 0 ) {fprintf(stderr, "pthread_create : %s\n", strerror(ret));exit(EXIT_FAILURE);}int i;for(; ; ) {printf("I'am main thread\n");sleep(1);}
}
#include <pthread.h>
// 获取线程ID
pthread_t pthread_self(void);
这个函数返回pthread_t类型的值,指代的是调用pthread_self函数的线程id。这个id是pthread库给每个线程定义的进程内唯一标识,是pthread库维持的。没错,在内核层面根本没有“线程”这个概念,有的只是进程,只是PCB其它的东西都是库给我们封装的。Linux下是根据进程PCB重复利用,搞成了线程,windows下则是另起炉灶,搞出来了一套新的东西。
由于每个进程都有自己独立的内存空间,故这个id的作用域是进程级的而不是系统级(内核不认识)。
其实pthread库中也是通过内核提供的系统调用clone...来创建线程的,而内核会为每个线程创建系统全局唯一的id来唯一标识这个线程。
我们可以使用PS命令查看线程信息:
$ ps -aL | head -1 && ps -aL | grep mythreadPID LWP TTY TIME CMD
2711838 2711838 pts/235 00:00:00 mythread
2711838 2711839 pts/235 00:00:00 mythread-L 选项:打印线程信息
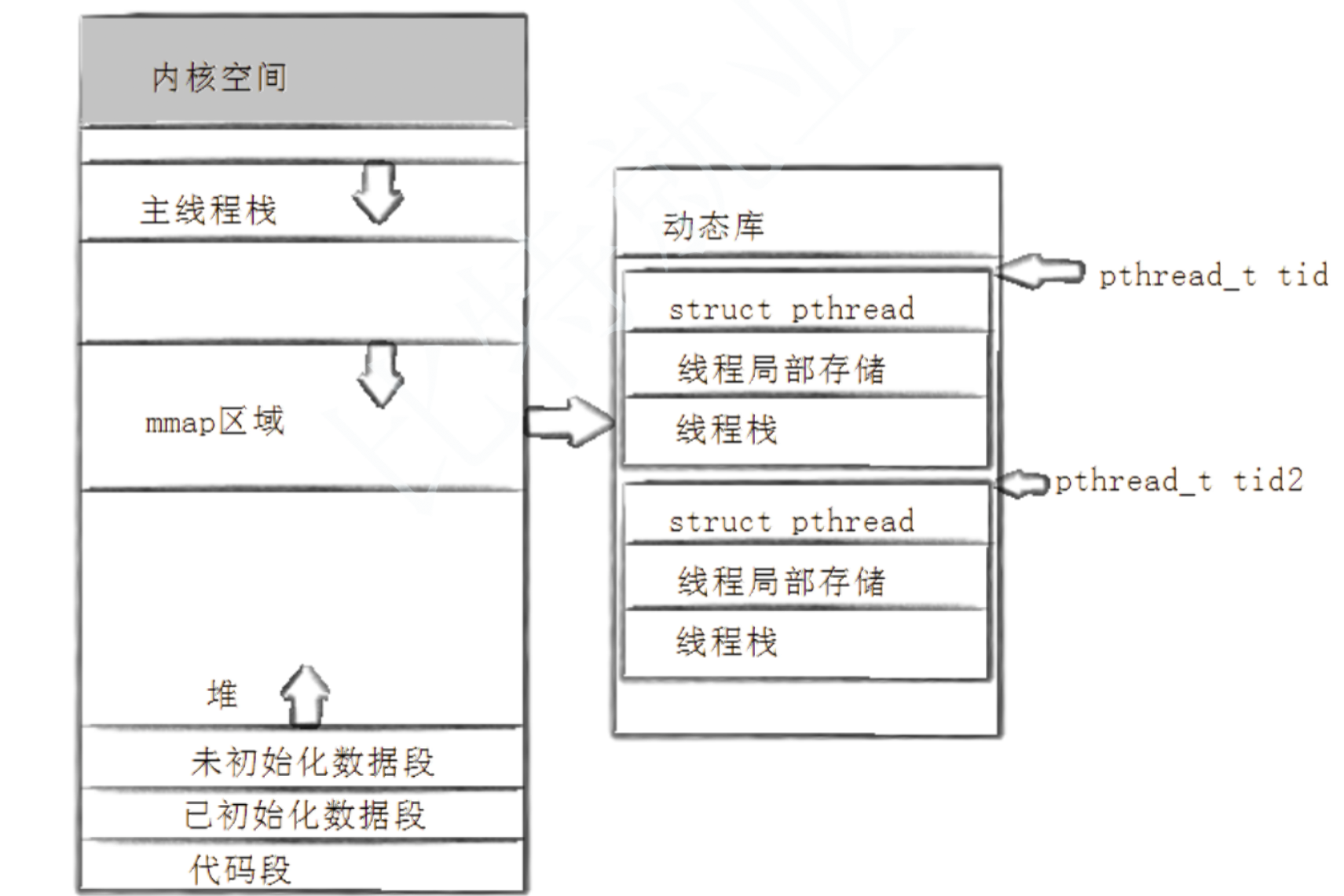
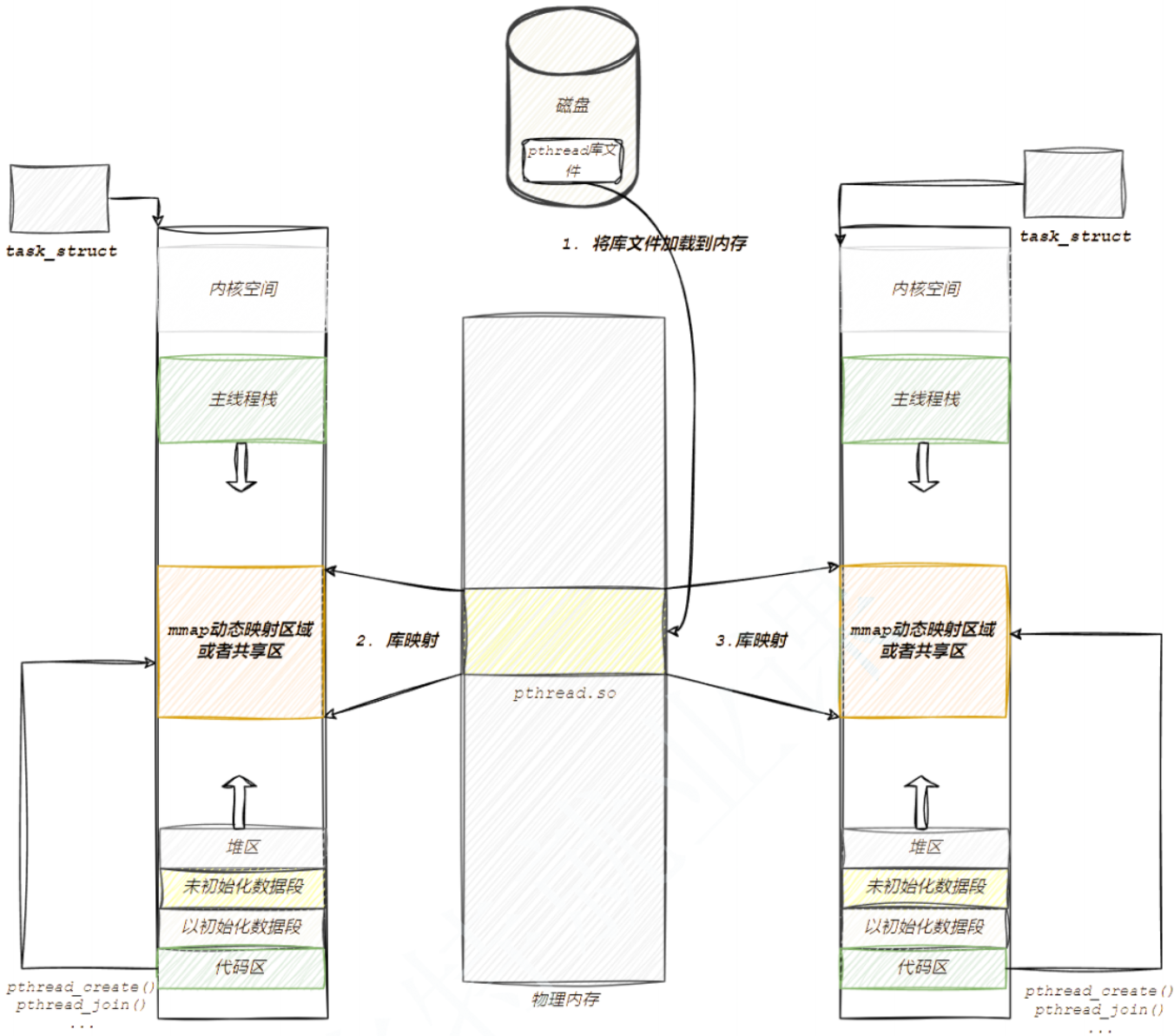
其中LWP就是真正的线程id可以使用gettid()调用,之前使用 pthread_self 得到的这个数实际上是一个地址,在虚拟地址空间上的一个地址,通过这个地址,可以找到关于这个线程的基本信息,包括线程ID,线程栈,寄存器等属性。
在 ps -aL 得到的线程ID,有⼀个线程ID和进程ID相同,这个线程就是主线程,主线程的栈在虚拟地址空间的栈上,而其他线程的栈在是在共享区(堆栈之间),因为pthread系列函数都是pthread库提供给我们的。而pthread库是在共享区的。所以除了主线程之外的其他线程的栈都在共享区。
线程终止
如果需要止终止某个线程而不终止整个进程,可以有三种方法:
- 从线程函数
return。这种方法对主线程不适⽤,从main函数return相当于调用exit。 - 线程可以调用
pthread_exit终止自己。 - ⼀个线程可以调用
pthread_cancel终止同一进程中的另⼀个线程
pthread_exit函数
功能:线程终⽌
原型:void pthread_exit(void *value_ptr);
参数:value_ptr:value_ptr不要指向一个局部变量。
返回值:无返回值,跟进程一样,线程结束的时候无法返回到它的调用者(自身)
注意:pthread_exit函数中的输出型参数指向的内存必须是全局的,或者用malloc在堆上开辟的空间,不能指向在线程函数的栈上分配的空间,因为当其他线程得到这个返回值时,这个线程已经退出,会导致非法访问等内存问题。
pehread_cancel函数
功能:取消⼀个执行中的线程
原型:int pthread_cancel(pthread_t thread);
参数:thread:线程ID
返回值:成功返回0; 失败返回错误码
线程等待
已经退出的线程,其地址空间没有被释放,仍然在进程地址空间内占据位置,新起来的线程也需要空间,所以需要回收退出线程的空间。
功能:等待线程结束
原型:int pthread_join(pthread_t thread, void **value_ptr);
参数:thread:线程IDvalue_ptr:它指向⼀个指针,后者指向线程的返回值
返回值:成功返回0; 失败返回错误码
调用该函数的线程将挂起等待,直到要join的线程终止。被join的线程以不同的方法终止,通过pthread_join得到的终止状态时不同的,总结如下:
- 如果
thread线程通过return返回,value_ptr所指向的单元⾥存放的是thread线程函数的返回值。 - 如果
thread线程被别的线程调⽤pthread_cancel异常终掉,value_ptr所指向的单元⾥存放的是常数PTHREAD_CANCELED。 - 如果
thread线程是自己调用pthread_exit终⽌的,value_ptr所指向的单元存放的是传给pthread_exit的参数。 - 如果对
thread线程的终止状态不感兴趣,可以传NULL给value_ptr参数。
分离线程
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是⼀种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
int pthread_detach(pthread_t thread);
可以是线程组内对其它线程进行分离,亦可以是线程自己分离
pthread_detach(pthread_self());
线程被分离了就不是joinable的了
线程ID及进程地址空间布局
pthread_create函数会产⽣⼀个线程ID,存放在第⼀个参数指向的地址中。该线程ID和前⾯说的线程ID不是⼀回事。前面讲的线程ID(LWP)属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要⼀个数值来唯⼀表示该线程。pthread_create函数第⼀个参数指向⼀个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,属于NPTL线程库的范畴。- 线程库的后续操作,就是根据该线程ID来操作线程的。线程库
NPTL提供了pthread_self函数,可以获得线程⾃⾝的ID:
pthread_t pthread_self(void);
| 特征 | LWP | pthread_self()返回值 |
|---|---|---|
| 作用范围 | 内核空间(系统级调度) | 用户空间(线程库级操作) |
| 唯一性 | 全局唯一(整个系统) | 进程内唯一 |
| 数据类型 | pid_t(通常为整数) | pthread_t(具体实现依赖系统) |
| 获取方式 | syscall(SYS_gettid) 或 gettid() | pthread_self() |
| 用途 | 内核调度、系统调用、信号处理 | 线程库函数参数(如pthread_equal) |
关于pthread_t的类型,取决于具体实现,对于Linux目前实现的NPTL而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
线程封装
最新线程封装具体参考:
25/Udp/chat/thread.hpp · 钦某/Code - 码云 - 开源中国 (gitee.com)
Code/25/Udp/chat/thread.hpp at master · QinMou000/Code (github.com)
没什么好说的,注意detach的顺序就行,造一次轮子就行了。
_t`类型的线程ID,本质就是一个进程地址空间上的一个地址。**
相关文章:

Linux:线程概念与控制
✨✨所属专栏:Linux✨✨ ✨✨作者主页:嶔某✨✨ Linux:线程概念于控制 var code “d7e241ae-ed4d-475f-aa3d-8d78f873fdca” 概念 在一个程序里的一个执行路线就叫做线程thread。更准确一点:线程是“一个进程内部的控制序列” …...

双轮驱动能源革命:能源互联网与分布式能源赋能工厂能效跃迁
在全球能源结构深度转型与“双碳”目标的双重驱动下,工厂作为能源消耗的主力军,正站在节能变革的关键节点。能源互联网与分布式能源技术的融合发展,为工厂节能开辟了全新路径。塔能科技凭借前沿技术与创新实践,深度探索能源协同优…...

网络安全-Burp Suite基础篇
声明 本文主要用做技术分享,所有内容仅供参考。任何使用或者依赖于本文信息所造成的法律后果均与本人无关。请读者自行判断风险,并遵循相关法律法规。 1 Burp Suite功能介绍 1.1 Burp Suite 简介 Burp Suite 是一款极为强大且广受欢迎的集成化 …...

从人工到智能:外呼系统如何重构企业效率新生态
在数字化转型的浪潮中,智能外呼系统正从边缘辅助工具演变为企业效率革命的核心引擎。根据Gartner最新调研数据,部署AI外呼系统的企业客服效率平均提升68%,销售线索转化率增长42%。但在这场技术驱动的变革中,真正决定成败的往往不是…...

折扣电影票api对接详细指南,如何对接?
以下是折扣电影票 API 对接的一般指南: 对接前准备 明确需求:确定对接的目的和所需功能,如电影信息查询、场次查询、座位预订、支付等。明确支持的数据字段和业务流程。选择 API 服务提供商:选择技术成熟、服务稳定、覆盖范围广的…...

初识Redis · 客户端“Hello world“
目录 前言: 环境配置 Hello world 前言: 前文我们已经介绍了Redis的不常见的五种数据类型,并且补充了几个渐进式命令和数据库管理命令等,最后简单认识了一下RESP协议,但是老实说,我们只能算是知道了这个…...

51单片机实验一:点亮led灯
目录 一、实验环境与实验器材 二、实验内容及实验步骤 1.用keil 软件创建工程,C文件编写程序,编译生成hex文件编辑 2.用STC烧写hex文件,点亮第一个LED灯 3.使用法2,点除第一个以外的LED灯 一、实验环境与实验器材 环境&am…...

基于WOA鲸鱼优化的NARMAX模型参数辨识算法MATLAB仿真,对比PSO优化算法
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1 NARMAX模型定义 4.2 鲸鱼优化算法WOA原理 4.3 粒子群优化算法PSO原理 5.完整程序 1.程序功能描述 基于WOA鲸鱼优化的NARMAX模型参数辨识算法MATLAB仿真,对比PSO优化算法。分别通过WOA…...

AWS上构建基于自然语言的数值和符号计算系统
我想要实现一个通过使用C#、Semantic Kernel库、OpenAI GPT 4的API和以下使用C#开源库MathNet实现通过中文自然语言提示词中包含LATEX代码输入到系统,通过以下符号和数值计算和其它符号和数值计算程序输出计算结果和必要步骤的应用,这样的数学计算使用程序直接产生结果,可以…...
等级考试试卷(三级)真题)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(三级)真题
青少年软件编程(Python)等级考试试卷(三级) 分数:100 题数:38 答案解析:https://blog.csdn.net/qq_33897084/article/details/147341388 一、单选题(共25题,共50分) 1. 学校进行体…...

校平机:精密制造的“材料雕刻家“
在液晶面板生产线的无尘车间里,一片薄如蝉翼的玻璃基板正经历纳米级的形态修正;在新能源电池极片生产线上,铜箔以每秒5米的速度穿越精密辊系,完成微米级的平整蜕变。这些现代工业的"毫米级魔术",都离不开一台…...

FPGA HR Bank如何支持ODELAY问题分析
目录 1.ODELAY简单介绍 2.IODELAY 的特性 3.IODELAY 的 资源支持的管脚 4.HR bank如何支持ODELAY固定延迟 1.ODELAY简单介绍 FPGA 中的 IODELAY(Input/Output Delay),这是 Xilinx(现 AMD)FPGA 中一种用于精确控制输入/输出信号时序延迟的硬件资源。以下是关于 IODELAY…...

深入解析C++驱动开发实战:优化高效稳定的驱动应用
深入解析C驱动开发实战:优化高效稳定的驱动应用 在现代计算机系统中,驱动程序(Driver)扮演着至关重要的角色,作为操作系统与硬件设备之间的桥梁,驱动程序负责管理和控制硬件资源,确保系统的稳定…...

高级java每日一道面试题-2025年4月13日-微服务篇[Nacos篇]-Nacos如何处理网络分区情况下的服务可用性问题?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos如何处理网络分区情况下的服务可用性问题? 我回答: 在讨论 Nacos 如何处理网络分区情况下的服务可用性问题时,我们需要深入理解 CAP 理论以及 Nacos 在这方面的设计选择。Nacos 允许用户根据具体的应用…...

07_Docker 资源限制
Docker 容器做资源限制,是为了不让某个容器抢光 CPU、内存等主机资源,保证所有容器都能稳定运行,还能避免宿主机资源被耗尽,让资源利用更高效,也方便管理和满足服务的性能要求。 监控容器资源使用情况 docker stats …...

Flutter Notes | 我用到的一些插件整理
Flutter开发必备插件推荐与iOS上架工具分享 前言 一个项目的开始和结束,总会遇到很多意料之外的东西。大神和菜鸟的区别,个人感觉更多的是大神花费了很多私下时间去了解每个问题的根本是什么,而我这小菜鸟,仅仅网上浪一圈&#…...

WordPress自定义页面与文章:打造独特网站风格的进阶指南
文章目录 引言一、理解WordPress页面与文章的区别二、主题与模板层级:自定义的基础三、自定义页面模板:打造专属页面风格四、自定义文章模板:打造个性化文章呈现五、使用自定义字段和元数据:增强内容灵活性六、利用WordPress钩子&…...

golang channel源码
解析 数据结构 hchan:channel 数据结构 qcount:当前 channel 中存在多少个元素; dataqsize: 当前 channel 能存放的元素容量; buf:channel 中用于存放元素的环形缓冲区; elemsize:channel 元素…...
算法漏洞修复)
麒麟操作系统漏洞修复保姆级教程弱(一)算法漏洞修复
如果你想拥有你从未拥有过的东西,那么你必须去做你从未做过的事情 目录 一、相关问题 二、建议修复方法 修复方案(方案一和方案二是错误示范,干货在方案三) 方案一、首先我想按照第一步,将OpenSSH升级解决这一漏洞…...

汉诺塔专题:P1760 通天之汉诺塔 题解 + Problem D: 汉诺塔 题解
1. P1760 通天之汉诺塔 题解 题目背景 直达通天路小A历险记第四篇 题目描述 在你的帮助下,小 A 成功收集到了宝贵的数据,他终于来到了传说中连接通天路的通天山。但是这距离通天路仍然有一段距离,但是小 A 突然发现他没有地图࿰…...

vscode中markdown一些插件用不了解决方式
我发现我安装了vscode的一些插件,但是没起效果(就是该插件暗淡了),后面得知,是因为没有信任工作空间。 This extension has been disabled because the current workspace is not trusted 这个提示信息表明,…...

Python爬虫第16节-动态渲染页面抓取之Selenium使用上篇
目录 前言 一、Selenium的简介和学习准备 二、Selenium基本使用 三、声明浏览器对象 四、访问页面 五、查找节点 5.1 单个节点 5.2 多个节点 六、节点交互 七、动作链 八、执行JavaScript 前言 本专栏之前的内容,我们讲了怎么分析和抓取Ajax,…...

KMP算法动态演示
KMP算法 1.动态演示 https://tsccg-oss.oss-cn-guangzhou.aliyuncs.com/image/KMP%E7%AE%97%E6%B3%95%E5%8A%A8%E6%80%81%E6%BC%94%E7%A4%BA.gif 2.代码实现 Testpublic void test5(){String parent "ABC ABCDAB ABCDABCDABDE";String child "ABCDABD&quo…...
)
linux获取cpu使用率(sy%+us%)
float getCpuUsage() { // C11兼容的元组解包 typedef std::tuple<unsigned long long, unsigned long long, unsigned long long> CpuTuple; auto parseCpuLine [](const std::string& line) -> CpuTuple { std::istringstream iss(line); …...

ESP-IDF教程2 GPIO - 输入、输出和中断
文章目录 1、前提1.1、基础知识1.1.1、GPIO 分类1.1.2、FALSH SPI 模式1.1.3、过滤器1.1.4、外部中断 1.2、数据结构1.2.1、GPIO1.2.2、毛刺过滤器 1.3、硬件原理图 2、示例程序2.1、GPIO 输出 - 点亮 LED 灯2.2、GPIO 输入 - 按键响应2.3、GPIO 外部中断 - 按键响应 3、常用函…...

Ubuntu安装MySQL步骤及注意事项
一、安装前准备 1. 系统更新:在安装 MySQL 之前,确保你的 Ubuntu 系统软件包是最新的,这能避免因软件包版本问题导致的安装错误,并获取最新的安全补丁。打开终端,执行以下两条命令: sudo apt update sudo …...

支持mingw g++14.2 的c++23 功能print的vscode tasks.json生成调试
在mingw14.2版本中, print库的功能默认没有开启, 生成可执行文件的tasks.json里要显式加-lstdcexp, 注意放置顺序. tasks.json (支持mingw g14.2 c23的print ) {"version": "2.0.0","tasks": [{"type": "cppbuild","…...

WPF常用技巧汇总
主要用于记录工作中发现的一些问题和常见的解决方法。 此文会持续更新。 >abp new Evan.MyWpfApp -t wpf --old --framework .net8 1. 解决不同屏幕分辨率下的锯齿问题 UseLayoutRounding"True" <Grid UseLayoutRounding"True"><Border Mar…...
)
【文件操作与IO】详细解析文件操作与IO (一)
本篇博客给大家带来的是文件操作的知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快乐顺便进步 一. …...
函数解析)
yaffs_write_new_chunk()函数解析
yaffs_write_new_chunk() 是 YAFFS(Yet Another Flash File System)文件系统中用于将数据写入新物理块(chunk)的关键函数。以下是其详细解析: 函数原型 int yaffs_write_new_chunk(struct yaffs_dev *dev, const u8 *…...

「数据可视化 D3系列」入门第九章:交互式操作详解
交互式操作详解 一、交互式操作的核心概念二、当前柱状图的交互实现三、交互效果的增强建议四、为饼图做准备五、交互式柱状图代码示例小结核心要点 下章预告:将这些交互技术应用于饼图实现 在上一章的柱状图基础上,我们增加了交互功能,让图表…...
:多模态输入与自定义输出)
吃透LangChain(五):多模态输入与自定义输出
多模态数据输入 这里我们演示如何将多模态输入直接传递给模型。我们目前期望所有输入都以与OpenAl 期望的格式相同的格式传递。对于支持多模态输入的其他模型提供者,我们在类中添加了逻辑以转换为预期格式。 在这个例子中,我们将要求模型描述一幅图像。 …...

数据结构基本概念
1 数据结构概述 数据结构是计算机组织(逻辑结构)、存储(物理结构)数据的方式。和具体的计算机编程语言无关,可以使用任何编程语言来实现数据结构 1.1 数据逻辑结构 反映数据元素之间的逻辑关系,逻辑关系…...

flutter app实现分辨率自适应的图片资源加载
在 Flutter 中,为了实现分辨率自适应的图片资源加载,确实需要遵循特定的目录结构和命名规则。这种机制允许 AssetImage 根据设备的 设备像素比(Device Pixel Ratio, DPR) 自动选择最合适的图片资源。以下是详细的说明和实现步骤&a…...

Webpack基础
目录 一、Webpack概念 二、Webpack使用步骤 三、Webpack.config.js配置文件 四、entry 和 output 1. entry 2. output 五、module 1. CSS 2. 图片 3. babel 4. 总结 六、plugins 1.自动生成 html 文件 七、其它 1.webpack-dev-server 开发服务器 2. mode 打包模…...

极狐GitLab 用户 API 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 用户 API 速率限制 (BASIC SELF) 您可以为对 Users API 的请求配置每个用户的速率限制。 要更改速率限制: 1.在…...
)
用 Go 实现一个轻量级并发任务调度器(支持限速)
前言 在日常开发中,我们经常会遇到这样的场景: • 有一堆任务要跑(比如:发请求、处理数据、爬虫等)• 不希望一次性全部跑完,担心打爆服务端或者被封• 想要设置并发数、限速,还能控制任务重试…...
Java/python/JavaScript/C++/C语言/GO六种最佳实现)
华为OD机试真题——最长的顺子(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录全流程解析/备考攻略/经验…...

3.8/Q1,GBD数据库最新文章解读
文章题目:Regional and National Burden of Traumatic Brain Injury and Spinal Cord Injury in North Africa and Middle East Regions, 1990-2021: A Systematic Analysis for The Global Burden of Disease Study 2021 DOI:10.1007/s44197-025-00372-…...

Java面试中问单例模式如何回答
1. 什么是单例模式? 单例模式(Singleton Pattern)是一种设计模式,确保某个类在整个应用中只有一个实例,并且提供全局访问点。它有以下特点: 确保只有一个实例。提供全局访问点。防止多次实例化࿰…...
检索增强生成方案-VDocRAG)
再看开源多模态RAG的视觉文档(OCR-Free)检索增强生成方案-VDocRAG
前期几个工作提到,基于OCR的文档解析RAG的方式进行知识库问答,受限文档结构复杂多样,各个环节的解析泛化能力较差,无法完美的对文档进行解析。因此出现了一些基于多模态大模型的RAG方案。如下: 【RAG&多模态】多模…...

【go】什么是Go语言中的GC,作用是什么?调优,sync.Pool优化,逃逸分析演示
Go 语言中的 GC 简介与调优建议 一、GC 简介 Go 的 GC(Garbage Collection)用于自动管理内存,开发者无需手动释放内存,可以专注于业务逻辑,降低出错概率,提升开发效率。 GC 能够自动发现和回收不再使用的…...

ctfshow-大赛原题-web702
因为该题没有理解到位,导致看wp也一直出错,特此反思一下。 参考yu22x师傅的文章 :CTFSHOW大赛原题篇(web696-web710)_ctfshow 大赛原题-CSDN博客 首先拿到题目: // www.zip 下载源码 我们的思路就是包含一个css文件,…...

基于Redis的4种延时队列实现方式
延时队列是一种特殊的消息队列,它允许消息在指定的时间后被消费。在微服务架构、电商系统和任务调度场景中,延时队列扮演着关键角色。例如,订单超时自动取消、定时提醒、延时支付等都依赖延时队列实现。 Redis作为高性能的内存数据库&#x…...

基于Django实现农业生产可视化系统
基于Django实现农业生产可视化系统 项目截图 登录 注册 首页 农业数据-某一指标表格展示 农业数据-某一指标柱状图展示 农业数据-某一指标饼状图展示 气候数据-平均气温地图展示 气候数据-降水量合并图展示 后台管理 一、系统简介 农业生产可视化系统是一款基于DjangoMVTMyS…...

yocto编译使用共享缓存
注意 服务器端与客户端系统的版本号需为Ubuntu20.04执行用户需要为sudo权限服务器端nfs目录权限必须为nobody:nogroup 服务端配置: 在服务器192.168.60.142上配置 NFS 共享: 1.安装 NFS 服务器: 1 sudo apt-get install nfs-kernel-serve…...
)
uCOS3实时操作系统(系统架构和中断管理)
文章目录 系统架构中断管理ARM中断寄存器相关知识ucos中断机制 系统架构 ucos主要包含三个部分的源码: 1、OS核心源码及其配置文件(ucos源码) 2、LIB库文件源码及其配置文件(库文件,比如字符处理、内存管理࿰…...

web后端语言下篇
#作者:允砸儿 #日期:乙巳青蛇年 三月廿一 笔者今天将web后端语言PHP完结一下,后面还会写一个关于python的番外。 PHP函数 PHP函数它和笔者前面写的js函数有些许类似,都是封装的概念。将实现某一功能的代码块封装到一个结构中…...

Tensorflow释放GPU资源
语言:python 框架:tensorflow 现有问题:用tensorflow进行模型训练,训练完成后用tf.keras.backend.clear_session()命令无法真正实现释放资源的效果。 解决方案:创建多进程,将模型训练作为子进程,…...

vscode、cherry studio接入高德mcp服务
最近mcp协议比较火,好多平台都已经开通了mcp协议,今天来接入下高德的mcp看看效果如何。 话不多说,咱们直接开干。 先来看下支持mcp协议的工具有cusor、cline等等。更新cherrystudio后发现上面也有mcp服务器了。今天咱就来试试添加高德的mcp协…...