Python爬虫第16节-动态渲染页面抓取之Selenium使用上篇
目录
前言
一、Selenium的简介和学习准备
二、Selenium基本使用
三、声明浏览器对象
四、访问页面
五、查找节点
5.1 单个节点
5.2 多个节点
六、节点交互
七、动作链
八、执行JavaScript
前言
本专栏之前的内容,我们讲了怎么分析和抓取Ajax,这其实是JavaScript动态渲染页面的一种情况。利用requests或者urllib,直接对Ajax进行分析,也能实现数据爬取。
不过,JavaScript动态渲染页面可不只有Ajax这一种。就说中国青年网(网址是[http://news.youth.cn/gn/](http://news.youth.cn/gn/)),它的分页部分是用JavaScript生成的,不是原本的HTML代码,而且里面也没有Ajax请求。再看看ECharts的官方实例(网址是[http://echarts.baidu.com/demo.html](http://echarts.baidu.com/demo.html)),页面上的图形都是通过JavaScript计算后生成的。还有淘宝这类页面,虽然数据是通过Ajax获取的,但是它的Ajax接口有好多加密参数,我们很难直接找出规律,也就没办法光靠分析Ajax来抓取数据。
要解决这些问题,可以用模拟浏览器运行的办法。这样一来,浏览器里显示的页面是什么样,我们抓取到的源码内容就是什么样,也就是达到“所见即所得”,能实现“可见即可爬”。这么做,我们就不用去管网页内部JavaScript用的页面渲染算法,也不用操心网页后台Ajax接口具体的参数设置了。
Python有不少能模拟浏览器运行的库,像Selenium、Splash、PyV8、Ghost等等。接下来,我们主要讲讲Selenium和Splash的使用方法。学会了它们,抓取动态渲染页面就没那么难了。这一节我们开始进入新版Selenium 4的使用学习,旧版的会稍微提到。
一、Selenium的简介和学习准备
Selenium是一个自动化测试工具,借助它可以操控浏览器去执行一些特定的操作,比如点击按钮、下拉页面等。而且,它还能获取到浏览器当前显示页面的源代码,从而实现“可见即可爬”,这对于抓取那些由JavaScript动态渲染的页面来说非常有用。在这一节内容里,我们就一起来感受一下Selenium的强大之处。
这一节我们会以Chrome浏览器为例,详细讲解Selenium的具体使用方法。在正式开始操作之前,大家要通过正确运行pip命令来安装Python的Selenium库。另外,一定要保证已经正确安装了Chrome浏览器,并且也要安装上 ChromeDriver 到 Chrome 同级目录下,并配置好环境变量,ChromeDriver如何安装请自行网上查找教程。下面我们都是在windows上进行实操。
selenium学习文档如下:
(1)入门指南和api使用:
( https://www.selenium.dev/zh-cn/documentation/webdriver/getting_started/ )
(2)官方文档(最权威):
包含了最新的 API 文档和使用指南
- https://www.selenium.dev/documentation/
- https://www.selenium.dev/selenium/docs/api/py/
(3)Python Selenium 包文档:
这是专门针对 Python 的 Selenium 文档,比较容易理解
https://selenium-python.readthedocs.io/
二、Selenium基本使用
当把前期的准备工作都妥善完成后,我们首先来初步认识一下Selenium所拥有的各项功能。下面为大家展示一个具体的示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options# 配置Chrome选项
chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,不显示浏览器窗口
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
# 添加实验性选项,防止浏览器自动关闭
chrome_options.add_experimental_option("detach", True)# 创建Chrome浏览器实例
browser = webdriver.Chrome(options=chrome_options)try:browser.get('https://www.baidu.com')# 使用新的查找元素方法input_element = browser.find_element(By.ID, 'kw')input_element.send_keys('Python')input_element.send_keys(Keys.ENTER)wait = WebDriverWait(browser, 10)wait.until(EC.presence_of_element_located((By.ID, 'content_left')))print(browser.current_url)print(browser.get_cookies())print(browser.page_source)# 保持浏览器打开,直到用户手动关闭print("\n浏览器将保持打开状态。要关闭浏览器,请按回车键...")input() # 等待用户输入
except Exception as e:print(f"发生错误: {e}")
finally:# 如果用户按了回车,则关闭浏览器if input("是否关闭浏览器?(y/n): ").lower() == 'y':browser.quit()else:print("浏览器将保持打开状态。请手动关闭浏览器窗口。")执行完上面的代码以后,会自动弹出一个Chrome浏览器窗口。这个浏览器会先跳转到百度的首页,然后在搜索框里输入“Python”这个关键词,输入完成后就会跳转到相应的搜索结果页面了,具体页面显示的样子就如同下面的图片所示。
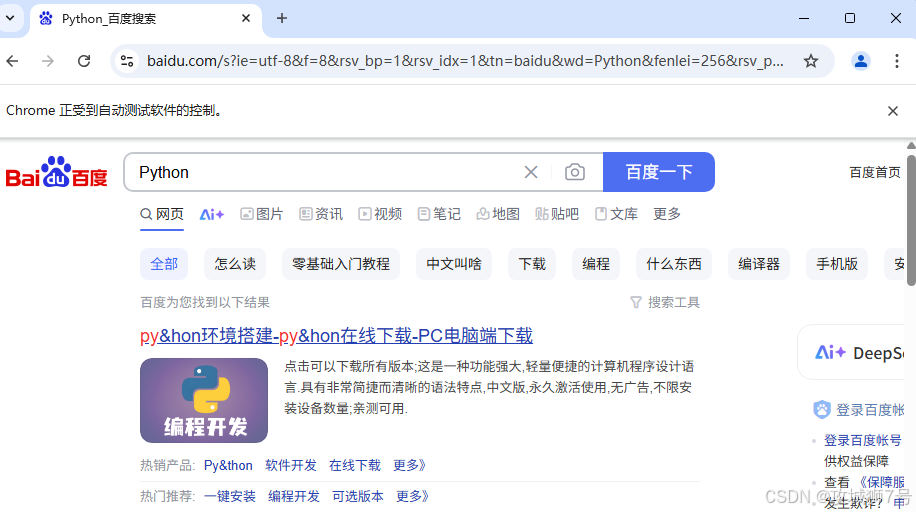
在这个时候,控制台会把我们获取到的当前网页的URL地址、Cookies信息以及网页的源代码都输出显示出来,这些输出的内容可都是浏览器里实实在在存在的真实信息。
从这里就能看出来,要是用Selenium来操控浏览器去加载网页,我们可以直接拿到经过JavaScript渲染之后的网页内容,根本不用去担心网页所使用的加密系统是怎么回事。那接下来呢,我们就再进一步详细地了解一下Selenium具体的使用方法吧。
三、声明浏览器对象
Selenium能够适配多种不同的浏览器。像常见的桌面端浏览器,比如Chrome、Firefox、Edge这些它都支持;在手机端,像Android系统、BlackBerry系统所使用的浏览器也在其支持范围内。另外,还有无界面浏览器PhantomJS,Selenium同样可以支持。要是我们想使用Selenium,可通过下面这些方式来完成初始化操作:
from selenium import webdriverbrowser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()通过上面给出的代码,我们成功地对浏览器对象进行了初始化设置,并把初始化后的浏览器对象赋值给了名为browser的变量。在接下来的操作中,我们只要调用这个browser变量所代表的对象,就能够让它去执行各种各样的动作,从而实现对浏览器实际操作的模拟。
四、访问页面
利用Selenium来访问网页特别简单,只要调用它的get()方法就行,并且把想要访问的网页链接URL当作参数传进去就可以了。就好比说,我们要用get()方法来访问淘宝网页,然后把页面的源代码打印出来,具体的代码如下所示:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()当我们运行上述代码后,Chrome浏览器会自行弹出并开始访问淘宝网站。紧接着,控制台就会把淘宝页面的源代码显示出来。等到这些操作完成后,浏览器也会随之关闭。
仅仅依靠这简短的几行代码,我们就成功地做到了驱动浏览器去访问网页,并且还获取到了网页的源代码,整个过程操作起来真的非常方便快捷。
五、查找节点
Selenium可以操控浏览器完成各种复杂的操作,像填充表单、模拟点击等。要是我们想往某个输入框里输入文字,得先知道这个输入框在网页上的位置。为了解决这个问题,Selenium提供了一堆查找节点的方法,用这些方法,我们就能找到目标节点,之后就能执行相关操作或者提取需要的信息了。
5.1 单个节点
就拿从淘宝页面提取搜索框节点这件事来说吧,我们第一步要做的就是查看淘宝页面的源代码,具体情况就像下面的图片展示的那样。
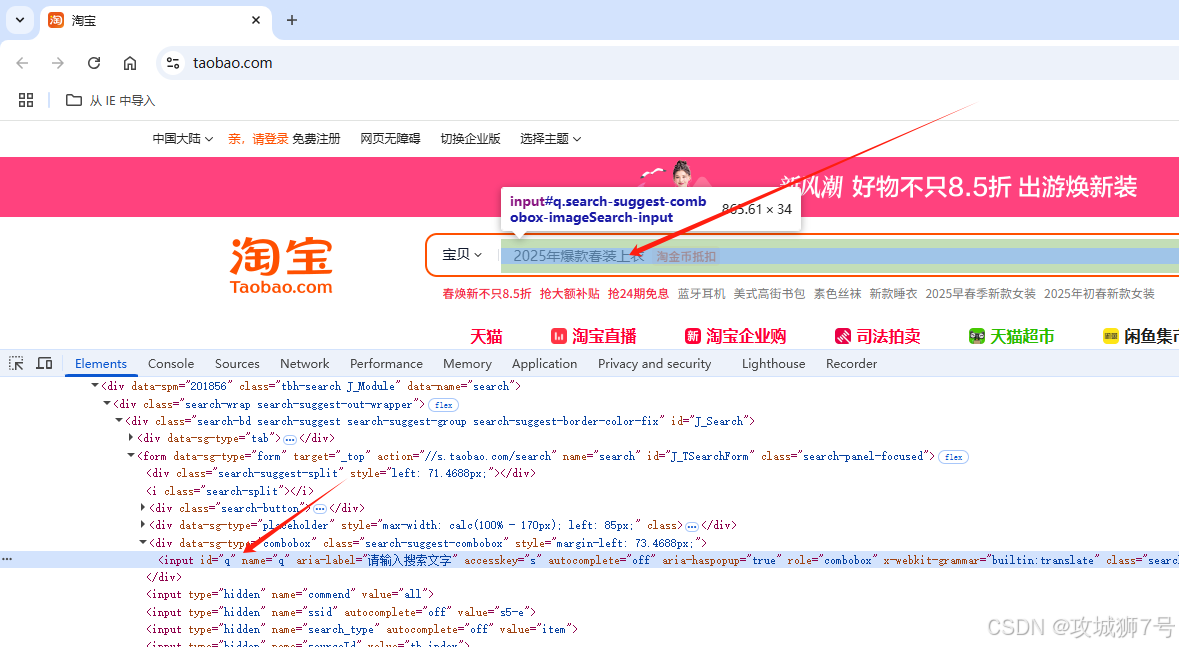
从这张图上我们能够看到,这个搜索框的id和name属性值都是“q”,除此之外,它还有很多其他的属性。根据这些特点,我们有好几种办法可以获取到这个节点。比如说,旧版本利用find_element_by_name()方法,通过输入name的值就能够获取到对应的节点;而find_element_by_id()方法呢,则是按照id的值来获取节点。另外,我们还可以借助XPath、CSS选择器这些方式来确定节点的位置。然而我们要用新版的api-find_element完成,下面我们就通过代码来实际展示一下这些方法是怎么操作的:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options# 配置Chrome选项
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) # 保持浏览器打开browser = webdriver.Chrome(options=chrome_options)
browser.get('https://www.taobao.com')# 旧版本的元素查找方法(已不支持)
# input_first = browser.find_element_by_id('q')
# input_second = browser.find_element_by_css_selector('#q')
# input_third = browser.find_element_by_xpath('//*[@id="q"]')# 使用新版本的元素查找方法
input_first = browser.find_element(By.ID, 'q')
input_second = browser.find_element(By.CSS_SELECTOR, '#q')
input_third = browser.find_element(By.XPATH, '//*[@id="q"]')print(input_first, input_second, input_third)# 不关闭浏览器
# browser.close()在上述的代码里,我们依次运用了依据ID、CSS选择器以及XPath这三种不同的方法去获取输入框的节点。从运行的结果来看,这三种方式所返回的结果是一模一样的。具体的输出内容如下所示:
可以看到,这三个节点均为WebElement类型,且完全相同。
以下是获取单个节点的所有方法列表:
旧版本(Selenium 3及之前) → 新版本(Selenium 4及之后):
1. `find_element_by_id()` → `find_element(By.ID, ...)`
2. `find_element_by_name()` → `find_element(By.NAME, ...)`
3. `find_element_by_xpath()` → `find_element(By.XPATH, ...)`
4. `find_element_by_link_text()` → `find_element(By.LINK_TEXT, ...)`
5. `find_element_by_partial_link_text()` → `find_element(By.PARTIAL_LINK_TEXT, ...)`
6. `find_element_by_tag_name()` → `find_element(By.TAG_NAME, ...)`
7. `find_element_by_class_name()` → `find_element(By.CLASS_NAME, ...)`
8. `find_element_by_css_selector()` → `find_element(By.CSS_SELECTOR, ...)`
主要变化:
1. 所有方法统一使用 `find_element()` 函数
2. 使用 `By` 类的常量来指定查找方式
3. 参数分为两部分:查找方式和查找值
另外还要注意:
- 查找单个元素用 `find_element()`
- 查找多个元素用 `find_elements()`(返回列表)
- 所有的 `By` 常量都是大写的
- 新版本的写法更统一,更容易记忆
通用方法find_element(),该方法需要传入两个参数:查找方式By和对应的值。实际上,它是find_element_by_id()等方法的通用版本,例如find_element_by_id(id)与find_element(By.ID, id)的功能完全一致,二者返回的结果也相同。通过代码演示如下:
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()这种查找方式在功能上与上述列举的查找函数相同,但参数设置更为灵活。
5.2 多个节点
要是在网页里,我们要查找的目标就只有一个,那么使用find_element()方法就行。但要是有多个节点都符合我们设定的查找条件,这时再用find_element()方法,就只能获取到这些符合条件的节点里的第一个。如果我们想把所有满足条件的节点都找出来,那就得用find_elements()方法。要注意哦,这个方法的名称里,element后面多了个“s”,使用的时候一定要区分清楚。
打个比方,要是我们想找出淘宝左侧导航栏里的所有条目,你可以参考下面这张图。
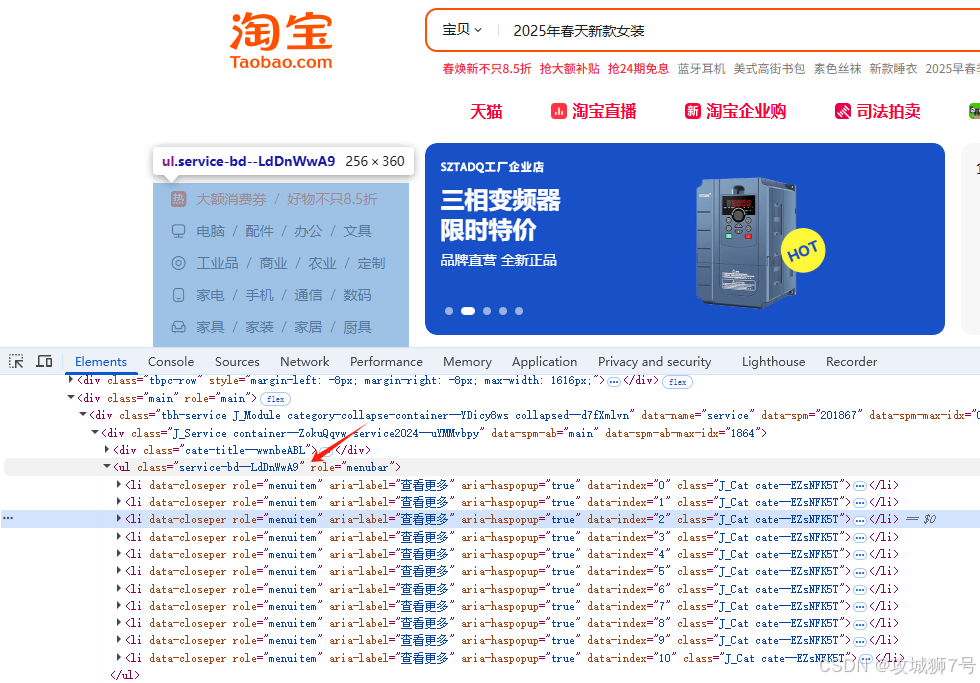
实现代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
# lis = browser.find_elements_by_css_selector('.service-bd li') # 旧版本写法
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd--LdDnWwA9 li') # 新版本写法
print(lis)
browser.close()运行上述代码后,输出结果如下:
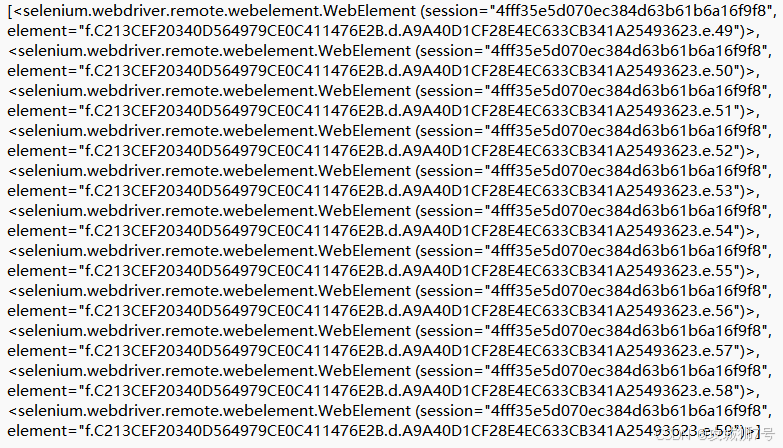
从输出结果能够发现,获取到的内容属于列表类型,并且列表里的每个节点都是WebElement类型。
这就意味着,使用find_element()方法只能获取到符合匹配条件的第一个节点,其结果是WebElement类型;而使用find_elements()方法,返回的结果是列表类型,列表中的每个节点同样是WebElement类型。
下面为你介绍获取多个节点的所有方法:
# 1. ID查找
旧版本: browser.find_elements_by_id('myId')
新版本: browser.find_elements(By.ID, 'myId')# 2. NAME查找
旧版本: browser.find_elements_by_name('myName')
新版本: browser.find_elements(By.NAME, 'myName')# 3. XPATH查找
旧版本: browser.find_elements_by_xpath('//div[@class="myClass"]')
新版本: browser.find_elements(By.XPATH, '//div[@class="myClass"]')# 4. 链接文本查找
旧版本: browser.find_elements_by_link_text('点击这里')
新版本: browser.find_elements(By.LINK_TEXT, '点击这里')# 5. 部分链接文本查找
旧版本: browser.find_elements_by_partial_link_text('点击')
新版本: browser.find_elements(By.PARTIAL_LINK_TEXT, '点击')# 6. 标签名查找
旧版本: browser.find_elements_by_tag_name('div')
新版本: browser.find_elements(By.TAG_NAME, 'div')# 7. 类名查找
旧版本: browser.find_elements_by_class_name('myClass')
新版本: browser.find_elements(By.CLASS_NAME, 'myClass')# 8. CSS选择器查找
旧版本: browser.find_elements_by_css_selector('.myClass > div')
新版本: browser.find_elements(By.CSS_SELECTOR, '.myClass > div')六、节点交互
Selenium可以操控浏览器开展一系列操作,以此模拟浏览器在实际中的行为。一些常见的操作方法有:利用send_keys方法往输入框里输入文字,使用clear方法清空输入框里已有的内容,通过click方法点击页面上的按钮等等。下面给出一个示例来进行说明:
from selenium import webdriver
from selenium.webdriver.common.by import By
import timebrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')# 旧版API
# input = browser.find_element_by_id('q')
# 新版API
input = browser.find_element(By.ID, 'q')input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')# 旧版API
# button = browser.find_element_by_class_name('btn-search')
# 新版API
button = browser.find_element(By.CLASS_NAME, 'btn-search')button.click()
在这段代码里,第一步是让浏览器启动并进入淘宝页面。接着,运用新版 find_element 函数,成功定位到页面上的搜索框节点。随后,借助send_keys()函数,往搜索框里输入了“iPhone”。稍作停顿,等待1秒钟后,使用clear()函数把搜索框里刚输入的内容清空。紧接着,再次调用send_keys()函数,这次输入的是“iPad”。之后,利用新版 find_element 函数,找到了搜索按钮对应的节点,最后通过click()函数执行点击操作,完成了搜索。
利用上述这些步骤,我们实现了与页面中常见节点的交互操作。要是你还想了解更多这类交互操作的方法,可以查阅官方文档中有关交互动作的内容,链接为:(http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement) 。
七、动作链
在之前的例子里,大部分交互操作都是围绕特定节点展开的。就像对输入框进行输入内容和清空内容的操作,对按钮进行点击操作。不过,还有一些操作并不针对特定的某个节点,像鼠标拖曳、按下键盘按键等,这类操作可以借助动作链来达成。
下面以节点拖曳操作为例,也就是把某个节点从一个位置拖到另一个位置,代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import timebrowser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)# 等待iframe加载
time.sleep(2)
browser.switch_to.frame('iframeResult')# 等待元素加载
time.sleep(2)# 新版API
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')# 执行拖拽操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()# 等待alert出现
time.sleep(1)# 处理alert
alert = browser.switch_to.alert
print(alert.text) # 应该输出 "dropped"
alert.accept()# 保持浏览器打开
input("按回车键关闭浏览器...")
在上述代码当中,最开始的操作是打开那个带有拖曳示例的网页。随后,运用switch_to.frame()方法,切换进入到指定的iframe框架里面。紧接着,分别把需要进行拖曳的源节点以及目标节点选取出来,同时声明一个ActionChains对象,并将其赋值给actions这个变量。
而后,调用actions变量所对应的drag_and_drop()方法,以此来设定拖曳的动作,再通过perform()方法来执行这一动作,如此便成功完成了对节点的拖曳操作。在进行拖曳操作之前和之后,页面所呈现出来的效果分别如下面的两张图片所示。
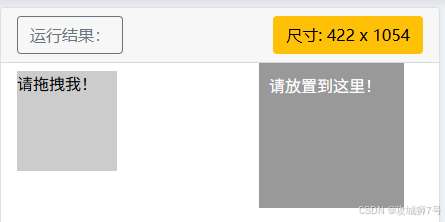
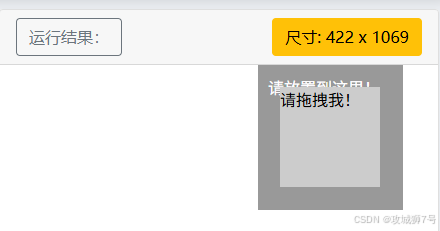
注意:运行的时候可能需要等待一会看效果
要是还想了解更多关于动作链的操作方法,可以查阅官方文档里有关动作链的相关内容,具体的链接是 (http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains)。
八、执行JavaScript
在使用Selenium开展自动化测试工作时,有时会遇到一些Selenium API并未直接支持的操作,像下拉网页进度条这种需求就难以直接借助Selenium API完成。不过,我们可以采用直接模拟运行JavaScript代码的方式来实现这类操作。在这种场景下,能够使用`execute_script()`方法。下面给出示例代码,通过它可以清晰地看到如何运用该方法达成特定的操作目的:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')# 等待用户按回车键
input("按回车键关闭浏览器...")前面已经说过,利用`page_source`属性能够获取网页的源代码,之后可以使用正则表达式、Beautiful Soup、pyquery等解析库来提取我们需要的信息。
不过,因为Selenium已经提供了选择节点的方法,而且这些方法返回的是WebElement类型的对象,所以Selenium肯定也有直接提取节点属性、文本等信息的方法和属性。这样的话,我们就不用再通过解析源代码来获取信息了,操作会变得更加方便快捷。
相关文章:

Python爬虫第16节-动态渲染页面抓取之Selenium使用上篇
目录 前言 一、Selenium的简介和学习准备 二、Selenium基本使用 三、声明浏览器对象 四、访问页面 五、查找节点 5.1 单个节点 5.2 多个节点 六、节点交互 七、动作链 八、执行JavaScript 前言 本专栏之前的内容,我们讲了怎么分析和抓取Ajax,…...

KMP算法动态演示
KMP算法 1.动态演示 https://tsccg-oss.oss-cn-guangzhou.aliyuncs.com/image/KMP%E7%AE%97%E6%B3%95%E5%8A%A8%E6%80%81%E6%BC%94%E7%A4%BA.gif 2.代码实现 Testpublic void test5(){String parent "ABC ABCDAB ABCDABCDABDE";String child "ABCDABD&quo…...
)
linux获取cpu使用率(sy%+us%)
float getCpuUsage() { // C11兼容的元组解包 typedef std::tuple<unsigned long long, unsigned long long, unsigned long long> CpuTuple; auto parseCpuLine [](const std::string& line) -> CpuTuple { std::istringstream iss(line); …...

ESP-IDF教程2 GPIO - 输入、输出和中断
文章目录 1、前提1.1、基础知识1.1.1、GPIO 分类1.1.2、FALSH SPI 模式1.1.3、过滤器1.1.4、外部中断 1.2、数据结构1.2.1、GPIO1.2.2、毛刺过滤器 1.3、硬件原理图 2、示例程序2.1、GPIO 输出 - 点亮 LED 灯2.2、GPIO 输入 - 按键响应2.3、GPIO 外部中断 - 按键响应 3、常用函…...

Ubuntu安装MySQL步骤及注意事项
一、安装前准备 1. 系统更新:在安装 MySQL 之前,确保你的 Ubuntu 系统软件包是最新的,这能避免因软件包版本问题导致的安装错误,并获取最新的安全补丁。打开终端,执行以下两条命令: sudo apt update sudo …...

支持mingw g++14.2 的c++23 功能print的vscode tasks.json生成调试
在mingw14.2版本中, print库的功能默认没有开启, 生成可执行文件的tasks.json里要显式加-lstdcexp, 注意放置顺序. tasks.json (支持mingw g14.2 c23的print ) {"version": "2.0.0","tasks": [{"type": "cppbuild","…...

WPF常用技巧汇总
主要用于记录工作中发现的一些问题和常见的解决方法。 此文会持续更新。 >abp new Evan.MyWpfApp -t wpf --old --framework .net8 1. 解决不同屏幕分辨率下的锯齿问题 UseLayoutRounding"True" <Grid UseLayoutRounding"True"><Border Mar…...
)
【文件操作与IO】详细解析文件操作与IO (一)
本篇博客给大家带来的是文件操作的知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快乐顺便进步 一. …...
函数解析)
yaffs_write_new_chunk()函数解析
yaffs_write_new_chunk() 是 YAFFS(Yet Another Flash File System)文件系统中用于将数据写入新物理块(chunk)的关键函数。以下是其详细解析: 函数原型 int yaffs_write_new_chunk(struct yaffs_dev *dev, const u8 *…...

「数据可视化 D3系列」入门第九章:交互式操作详解
交互式操作详解 一、交互式操作的核心概念二、当前柱状图的交互实现三、交互效果的增强建议四、为饼图做准备五、交互式柱状图代码示例小结核心要点 下章预告:将这些交互技术应用于饼图实现 在上一章的柱状图基础上,我们增加了交互功能,让图表…...
:多模态输入与自定义输出)
吃透LangChain(五):多模态输入与自定义输出
多模态数据输入 这里我们演示如何将多模态输入直接传递给模型。我们目前期望所有输入都以与OpenAl 期望的格式相同的格式传递。对于支持多模态输入的其他模型提供者,我们在类中添加了逻辑以转换为预期格式。 在这个例子中,我们将要求模型描述一幅图像。 …...

数据结构基本概念
1 数据结构概述 数据结构是计算机组织(逻辑结构)、存储(物理结构)数据的方式。和具体的计算机编程语言无关,可以使用任何编程语言来实现数据结构 1.1 数据逻辑结构 反映数据元素之间的逻辑关系,逻辑关系…...

flutter app实现分辨率自适应的图片资源加载
在 Flutter 中,为了实现分辨率自适应的图片资源加载,确实需要遵循特定的目录结构和命名规则。这种机制允许 AssetImage 根据设备的 设备像素比(Device Pixel Ratio, DPR) 自动选择最合适的图片资源。以下是详细的说明和实现步骤&a…...

Webpack基础
目录 一、Webpack概念 二、Webpack使用步骤 三、Webpack.config.js配置文件 四、entry 和 output 1. entry 2. output 五、module 1. CSS 2. 图片 3. babel 4. 总结 六、plugins 1.自动生成 html 文件 七、其它 1.webpack-dev-server 开发服务器 2. mode 打包模…...

极狐GitLab 用户 API 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 用户 API 速率限制 (BASIC SELF) 您可以为对 Users API 的请求配置每个用户的速率限制。 要更改速率限制: 1.在…...
)
用 Go 实现一个轻量级并发任务调度器(支持限速)
前言 在日常开发中,我们经常会遇到这样的场景: • 有一堆任务要跑(比如:发请求、处理数据、爬虫等)• 不希望一次性全部跑完,担心打爆服务端或者被封• 想要设置并发数、限速,还能控制任务重试…...
Java/python/JavaScript/C++/C语言/GO六种最佳实现)
华为OD机试真题——最长的顺子(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录全流程解析/备考攻略/经验…...

3.8/Q1,GBD数据库最新文章解读
文章题目:Regional and National Burden of Traumatic Brain Injury and Spinal Cord Injury in North Africa and Middle East Regions, 1990-2021: A Systematic Analysis for The Global Burden of Disease Study 2021 DOI:10.1007/s44197-025-00372-…...

Java面试中问单例模式如何回答
1. 什么是单例模式? 单例模式(Singleton Pattern)是一种设计模式,确保某个类在整个应用中只有一个实例,并且提供全局访问点。它有以下特点: 确保只有一个实例。提供全局访问点。防止多次实例化࿰…...
检索增强生成方案-VDocRAG)
再看开源多模态RAG的视觉文档(OCR-Free)检索增强生成方案-VDocRAG
前期几个工作提到,基于OCR的文档解析RAG的方式进行知识库问答,受限文档结构复杂多样,各个环节的解析泛化能力较差,无法完美的对文档进行解析。因此出现了一些基于多模态大模型的RAG方案。如下: 【RAG&多模态】多模…...

【go】什么是Go语言中的GC,作用是什么?调优,sync.Pool优化,逃逸分析演示
Go 语言中的 GC 简介与调优建议 一、GC 简介 Go 的 GC(Garbage Collection)用于自动管理内存,开发者无需手动释放内存,可以专注于业务逻辑,降低出错概率,提升开发效率。 GC 能够自动发现和回收不再使用的…...

ctfshow-大赛原题-web702
因为该题没有理解到位,导致看wp也一直出错,特此反思一下。 参考yu22x师傅的文章 :CTFSHOW大赛原题篇(web696-web710)_ctfshow 大赛原题-CSDN博客 首先拿到题目: // www.zip 下载源码 我们的思路就是包含一个css文件,…...

基于Redis的4种延时队列实现方式
延时队列是一种特殊的消息队列,它允许消息在指定的时间后被消费。在微服务架构、电商系统和任务调度场景中,延时队列扮演着关键角色。例如,订单超时自动取消、定时提醒、延时支付等都依赖延时队列实现。 Redis作为高性能的内存数据库&#x…...

基于Django实现农业生产可视化系统
基于Django实现农业生产可视化系统 项目截图 登录 注册 首页 农业数据-某一指标表格展示 农业数据-某一指标柱状图展示 农业数据-某一指标饼状图展示 气候数据-平均气温地图展示 气候数据-降水量合并图展示 后台管理 一、系统简介 农业生产可视化系统是一款基于DjangoMVTMyS…...

yocto编译使用共享缓存
注意 服务器端与客户端系统的版本号需为Ubuntu20.04执行用户需要为sudo权限服务器端nfs目录权限必须为nobody:nogroup 服务端配置: 在服务器192.168.60.142上配置 NFS 共享: 1.安装 NFS 服务器: 1 sudo apt-get install nfs-kernel-serve…...
)
uCOS3实时操作系统(系统架构和中断管理)
文章目录 系统架构中断管理ARM中断寄存器相关知识ucos中断机制 系统架构 ucos主要包含三个部分的源码: 1、OS核心源码及其配置文件(ucos源码) 2、LIB库文件源码及其配置文件(库文件,比如字符处理、内存管理࿰…...

web后端语言下篇
#作者:允砸儿 #日期:乙巳青蛇年 三月廿一 笔者今天将web后端语言PHP完结一下,后面还会写一个关于python的番外。 PHP函数 PHP函数它和笔者前面写的js函数有些许类似,都是封装的概念。将实现某一功能的代码块封装到一个结构中…...

Tensorflow释放GPU资源
语言:python 框架:tensorflow 现有问题:用tensorflow进行模型训练,训练完成后用tf.keras.backend.clear_session()命令无法真正实现释放资源的效果。 解决方案:创建多进程,将模型训练作为子进程,…...

vscode、cherry studio接入高德mcp服务
最近mcp协议比较火,好多平台都已经开通了mcp协议,今天来接入下高德的mcp看看效果如何。 话不多说,咱们直接开干。 先来看下支持mcp协议的工具有cusor、cline等等。更新cherrystudio后发现上面也有mcp服务器了。今天咱就来试试添加高德的mcp协…...
)
软考高级-系统架构设计师 论文范文参考(二)
文章目录 论企业应用集成论软件三层结构的设计论软件设计模式的应用论软件维护及软件可维护性论信息系统安全性设计论信息系统的安全性设计(二)论信息系统的架构设计论信息系统架构设计(二) 论企业应用集成 摘要: 2016年9月,我国某省移动通信有限公司决定启动VerisB…...
)
熵权法+TOPSIS+灰色关联度综合算法(Matlab实现)
熵权法TOPSIS灰色关联度综合算法(Matlab实现) 代码获取私信回复:熵权法TOPSIS灰色关联度综合算法(Matlab实现) 摘要: 熵权法TOPSIS灰色关联度综合算法(Matlab实现)代码实现了一种…...

【java 13天进阶Day05】数据结构,List,Set ,TreeSet集合,Collections工具类
常见的数据结构种类 集合是基于数据结构做出来的,不同的集合底层会采用不同的数据结构。不同的数据结构,功能和作用是不一样的。数据结构: 数据结构指的是数据以什么方式组织在一起。不同的数据结构,增删查的性能是不一样的。不同…...

极狐GitLab 议题和史诗创建的速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 议题和史诗创建的速率限制 (BASIC SELF) 速率限制是为了控制新史诗和议题的创建速度。例如,如果您将限制设置为 …...
)
AIGC-几款本地生活服务智能体完整指令直接用(DeepSeek,豆包,千问,Kimi,GPT)
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列AIGC(GPT、DeepSeek、豆包、千问、Kimi)👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资…...

十、数据库day02--SQL语句01
文章目录 一、新建查询1.查询窗口的开启方法2. 单语句运行方法 二、数据库操作1.创建数据库2. 使用数据库3. 修改数据库4. 删除数据库和查看所有数据库5. 重点:数据库备份5.1 应用场景5.2 利用工具备份备份操作还原操作 5.3 扩展:使用命令备份 三、数据表…...

2025年MathorCup数学应用挑战赛D题问题一求解与整体思路分析
D题 短途运输货量预测及车辆调度 问题背景 问题分析:四个问题需要建立数学模型解决就业状态分析与预测,旨在通过数学建模对宜昌地区的就业数据进行深入分析,并基于此预测就业状态。提供的数据涵盖了被调查者的个人信息、就业信息、失业信息…...

关于三防漆清除剂
成分及原理 主要成分:通常包含有机溶剂,如丙酮、甲苯、二甲苯等,以及一些表面活性剂、缓蚀剂等添加剂。工作原理:有机溶剂能够溶解三防漆中的树脂等成分,使其失去粘性和附着性,从而可以被轻易地擦拭或冲洗…...

2025年MathorCup数学应用挑战赛【选题分析】
【25MathorCup选题分析】 🙋♀🙋♂数模加油站初步分析评估了此次竞赛题目: ✅A题:该题新颖性强,属于“算子学习深度学习几何建模”的交叉问题,涉及PINN、FNO、KAN等算子神经网络模型构建,任…...

在windows上交叉编译opencv供RK3588使用
环境 NDK r27、RK3588 安卓板子、Android 12 步骤操作要点1. NDK 下载选择 r27 版本,解压到无空格路径(如 C:/ndk)2. 环境变量配置添加 ANDROID_NDK_ROOT 和工具链路径到系统 PATH3. CMake 参数调整指定 ANDROID_NATIVE_API_LEVEL31、ANDRO…...

零基础玩转AI数学建模:从理论到实战
前言 数学建模作为连接数学理论与现实世界的桥梁,在科学研究、工程实践和商业决策等领域发挥着越来越重要的作用。随着人工智能技术的迅猛发展,以ChatGPT为代表的大语言模型为数学建模领域带来了革命性的变革。本书旨在帮助读者掌握这一变革带来的新机遇…...

IDEA 2025.1更新-AI助手试用和第三方模型集成方案
今天刚把 IntelliJ IDEA 更新到了 2025.1 版本,主要是想看看这次 AI Assistant 有什么新东西。之前看到消息说功能有更新,而且似乎可以免费试用,就动手试了试,顺便把过程和一些发现记录下来,给可能需要的朋友一个参考。…...

static关键字
思维导图: 在 Java 中,static 是一个非常重要的关键字,它可以用来修饰类的成员,包括变量、方法、代码块以及内部类。下面为你详细介绍 static 关键字的各种用法和特点。 一.修饰内部类 静态内部类:当 static 修饰内部类…...

gl-matrix 库简介
gl-matrix 库简介 gl-matrix 是一个高性能的 JavaScript 矩阵和向量库,专门为 WebGL 和其他 3D 图形应用设计。它提供了处理 2D、3D 和 4D 向量以及矩阵运算的高效方法。 主要特性 高性能:经过高度优化,执行速度快轻量级:体积小…...

Spring Boot 核心注解全解:@SpringBootApplication背后的三剑客
大家好呀!👋 今天我们要聊一个超级重要的Spring Boot话题 - 那个神奇的主类注解SpringBootApplication!很多小伙伴可能每天都在用Spring Boot开发项目,但你真的了解这个注解背后的秘密吗?🤔 别担心&#x…...

Android 音频架构全解析:从 AudioTrack 到 AudioFlinger
在开发音视频相关应用时,我们常会接触到 MediaPlayer、SoundPool、AudioTrack、OpenSL ES、AAudio、Oboe 等名词,它们都与 Android 的音频播放息息相关。然而,真正理解它们之间的关系以及背后运行机制,才能写出高性能、低延迟的音…...

【教程】无视硬件限制强制升级Windows 11
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 1、下载升级工具:https://github.com/builtbybel/Flyby11/releases 2、解压后打开软件: 3、拖入win11.iso或者自动下载…...

ICPR-2025 | 让机器人在未知环境中 “听懂” 指令精准导航!VLTNet:基于视觉语言推理的零样本目标导航
作者:Congcong Wen, Yisiyuan Huang, Hao Huang ,Yanjia Huang, Shuaihang Yuan, YuHao, HuiLin and Yi Fang 单位:纽约大学阿布扎比分校具身人工智能与机器人实验室,纽约大学阿布扎比分校人工智能与机器人中心,纽约大学坦登工程…...

替代升级VMware | 云轴科技ZStack构建山西证券一云多芯云平台
通过云轴科技ZStack Cloud云平台,山西证券打造了敏捷部署、简单运维的云平台,不仅兼容x86、海光、鲲鹏三种异构服务器实现一云多芯,还通过云平台虚拟化纳管模块纳管原有VMware虚拟化资源,并对接第三方集中式存储,在保护…...

Houdini python code:参数指定文件路径
创建null节点并命名为control并增加filedir参数 创建python节点 node hou.pwd() geo node.geometry()node hou.node(/obj/output_tetgen/control) filedir node.parm(filedir).eval() print("filedir:",filedir)得到输出...

ChatGPT-o3辅助学术写作的关键词和引言效果如何?
目录 关键词 引言 论文引言(≈300 字) 大家好这里是AIWritePaper官方账号,官网👉AIWritePaper~ 关键词 摘要是文章的精华,通常在200-250词左右。要包括研究的目的、方法、结果和结论。让AI工具作为某领域内资深的研…...