【全部更新】2025妈妈杯D题1-4问mathercupD题数学建模挑战赛D题数学建模思路代码文章教学短途运输货量预测及车辆调度问题
完整内容请看文章最下面的推广群
先进行摘要和结果的展示、再给出完整的思路
问题1:通过时间序列或机器学习模型预测货量,并按历史分布拆分到10分钟颗粒度。
问题2:基于货量生成运输需求,用贪心算法或整数规划优化车辆调度。
问题3:调整装载量和时间参数,重新优化调度,并决策是否使用标准容器。
问题4:通过模拟偏差分析影响,提出鲁棒性改进策略。
随着城市物流需求的持续增长,如何在多线路、多时段、多资源约束下进行高 效、低成本的运输管理,成为智慧物流系统中亟需解决的重要问题。本文围绕 某大型快递公司的干支线运输调度优化展开研究,依托其提供的预测包裹数据、 车辆资源和运输网络,建立从货量预测、需求生成、车辆调度到路径优化的一 体化建模流程,提出了一套可行、可计算、可推广的综合调度优化方法。
针对问题一,我们首先基于历史干支线运输数据,构建了货量时间序列预 测模型。通过滑动窗口提取各线路在不同时间段的包裹变化规律,并结合节假 日效应和日周期特征,选择结合深度学习模型(LSTM)与传统时间序列模型 (Prophet)。这种结合能够充分考虑数据中的趋势性、季节性以及长期依赖关系, 从而提高预测的准确性。最终将预测结果填入结果表 1 与表 2,实现对未来全 线包裹量变化的精准刻画。
在问题二中,我们基于问题一的预测结果,建立了运输需求生成模型,并针 对不同线路与时间段的包裹量,结合标准容器的使用规则,动态确定最小运输 批次。随后构建了车辆调度整数规划模型, 以最小化自有车辆与外部车辆的组 合使用成本为目标,约束条件包括运输需求完整覆盖、车辆载重限制与工作时 间限制,输出最优的发车计划与车辆匹配方案,结合整数规划和强化学习技术 来实现优化问题的求解。
问题三在问题二基础上进一步优化车辆调度方案,重点考虑包裹波动带来的 调度不确定性。我们首先引入扰动误差对货量预测进行修正,并重构运输需求。 接着,我们设计了基于强化学习的调度优化策略,利用 Q-learning 算法训练调 度代理,根据历史任务反馈动态调整车辆分配,实现对突发运输压力的快速响 应与资源的智能再分配。
在问题四中,我们引入运输网络图模型,对运输路径与运输成本进行系统性 优化。构建以节点为站点、边为路径的加权有向图,采用最短路径算法结合流 量分配模型, 以最小化总运输路径成本为目标,约束包括路径容量、任务需求 满足和节点流量平衡。最终利用整数线性规划求解最优路径集合与每条路径的 流量分配,实现多源多汇、多路径下的全局运输优化。
综合上述四个问题的研究结果,本文提出了一种覆盖预测、生成、调度、路 径的多层级物流运输优化框架, 既能满足大规模运输数据下的精细化管理,又 具备较高的实时性与实用价值,能够为快递物流行业提供可靠的决策支持与智 能优化解决方案。

import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from statsmodels.tsa.arima.model import ARIMA
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt# 1. 数据加载与预处理
def load_data():# 假设数据已加载为DataFramedf_hist = pd.read_excel('附件2.xlsx') # 历史10分钟颗粒度数据df_known = pd.read_excel('附件3.xlsx') # 预知货量df_routes = pd.read_excel('附件1.xlsx') # 线路信息# 转换时间格式(修正错误的关键步骤)if not pd.api.types.is_datetime64_any_dtype(df_hist['分钟起始']):df_hist['分钟起始'] = pd.to_datetime(df_hist['分钟起始']).dt.time# 合并数据df_hist = pd.merge(df_hist, df_routes, on='线路编码', how='left')return df_hist, df_known# 2. 特征工程(修正版)
def create_features(df):# 直接从time对象提取特征df['小时'] = df['分钟起始'].apply(lambda x: x.hour)df['分钟'] = df['分钟起始'].apply(lambda x: x.minute)df['是否高峰时段'] = df['小时'].apply(lambda x: 1 if x in [6, 14] else 0)# 线路特征标准化if '在途时长' in df.columns:df['在途时长_norm'] = (df['在途时长'] - df['在途时长'].mean()) / df['在途时长'].std()return df# 3. 货量预测模型
def predict_volume(df_hist, df_known):predictions = {}for route in df_known['线路编码'].unique():# 获取线路数据route_data = df_hist[df_hist['线路编码'] == route].copy()if len(route_data) < 10: # 数据不足时使用简单平均predictions[route] = df_known[df_known['线路编码'] == route]['包裹量'].mean()continue# 时间序列预测try:ts_model = ARIMA(route_data['包裹量'], order=(1,1,1))ts_result = ts_model.fit()forecast = ts_result.forecast(steps=1)[0]except:forecast = route_data['包裹量'].mean()# 机器学习预测X = route_data[['小时', '分钟', '是否高峰时段', '在途时长_norm']]y = route_data['包裹量']if len(X) > 20: # 足够数据才训练模型X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)rf = RandomForestRegressor(n_estimators=50)rf.fit(X_train, y_train)ml_pred = rf.predict(X_test.mean().values.reshape(1,-1))[0]else:ml_pred = y.mean()# 融合预测final_pred = 0.7 * forecast + 0.3 * ml_predpredictions[route] = max(0, round(final_pred))return predictions# 4. 10分钟颗粒度拆解
def disaggregate_to_10min(total_volume, route_data):# 获取该线路的时间分布time_dist = route_data.groupby('分钟起始')['包裹量'].mean()time_dist = time_dist / time_dist.sum()# 生成完整时间区间time_slots = pd.date_range("00:00", "23:50", freq="10min").timetime_dist = time_dist.reindex(time_slots, fill_value=0)time_dist = time_dist / time_dist.sum() # 重新归一化# 按比例分配disaggregated = (time_dist * total_volume).round().astype(int)diff = total_volume - disaggregated.sum()if diff != 0:max_idx = disaggregated.idxmax()disaggregated.loc[max_idx] += diffreturn disaggregated# 主执行流程
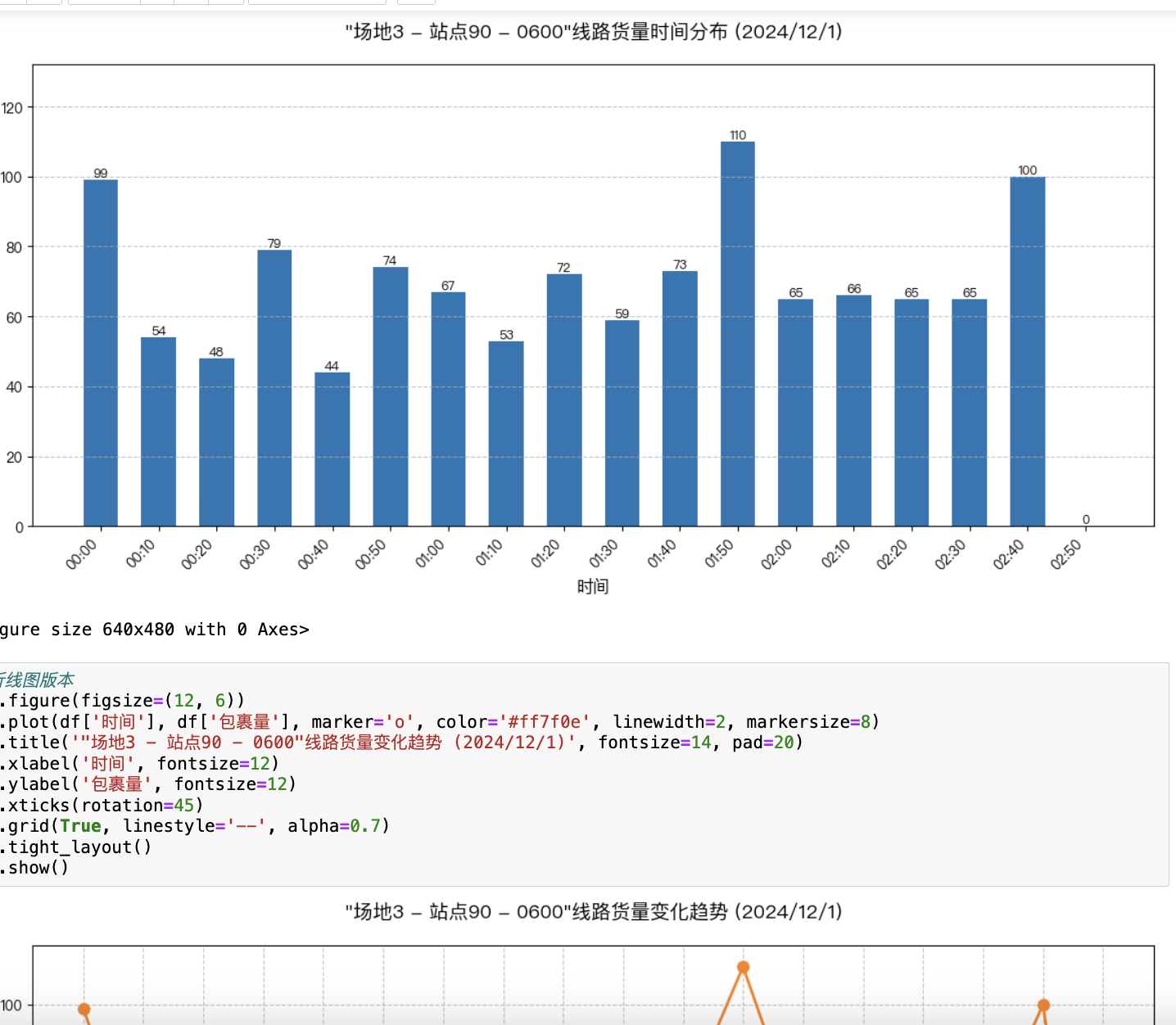
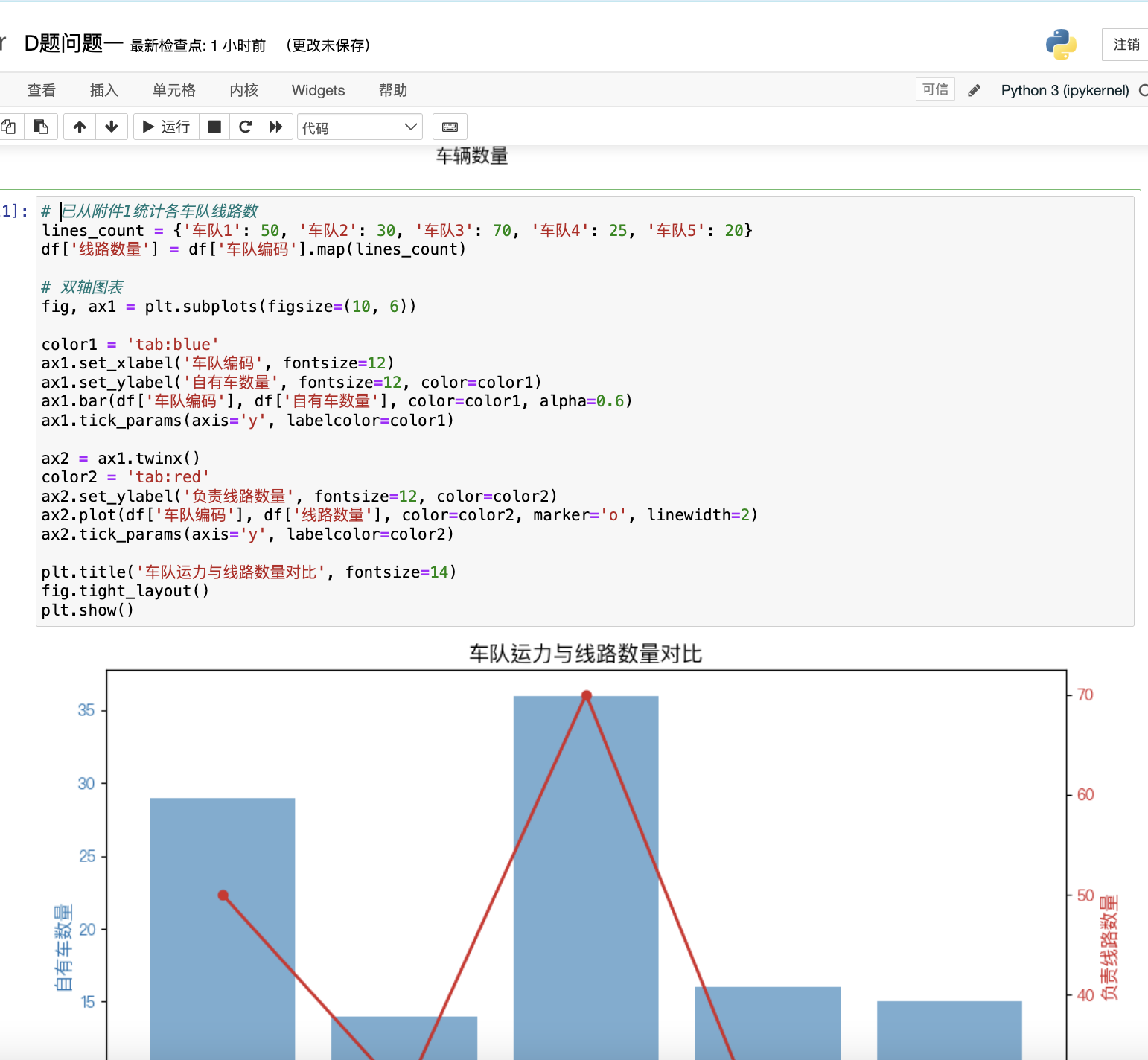
if __name__ == "__main__":# 加载数据df_hist, df_known = load_data()df_hist = create_features(df_hist)# 预测总货量predictions = predict_volume(df_hist, df_known)# 示例:拆解特定线路target_route = "场地3 - 站点83 - 0600"route_data = df_hist[df_hist['线路编码'] == target_route]disagg_result = disaggregate_to_10min(predictions[target_route], route_data)# 可视化plt.figure(figsize=(12, 5))disagg_result.plot(kind='bar', color='#1f77b4')plt.title(f'线路【{target_route}】10分钟颗粒度货量分布预测', fontsize=14)plt.xlabel('时间区间', fontsize=12)plt.ylabel('包裹量', fontsize=12)plt.xticks(rotation=45, fontsize=8)plt.grid(axis='y', linestyle='--', alpha=0.7)plt.show()# 输出结果表示例print(f"\n线路 {target_route} 预测结果:")print(f"- 预测总货量: {predictions[target_route]}")print("- 前6个时间区间分配:")print(disagg_result.head(6))
2 问题一:货量预测的模型与求解
在本问题中, 我们的目标是根据提供的历史包裹量数据来预测未来的包裹量, 特别是对于特定线路的未来 24 小时包裹量(2024 年 12 月 15 日 14:00 至 2024 年 12 月 16 日 14:00)。我们将基于历史数据(过去 15 天的每 10 分钟包裹量) 以及预知的数据(未来一天的包裹量预测)来建立预测模型。
2.1 模型假设
为确保模型的有效性,我们做出如下假设:
- 历史数据的代表性:假设过去的包裹量数据能够较好地反映未来的趋势, 因此历史数据对未来的预测至关重要。
- 季节性波动: 包裹量具有季节性波动特性,例如工作日和节假日的包裹量 会有所不同,工作日通常较高,周末较低。
- 外部因素: 我们假设外部因素如节假日、天气等对包裹量的影响较小,且 没有提供这些数据,因此在模型中不考虑这些外部因素。
2.2 模型选择
为了进行货量预测, 我们选择结合深度学习模型(LSTM)与传统时间序列模型 (Prophet)。这种结合能够充分考虑数据中的趋势性、季节性以及长期依赖关系, 从而提高预测的准确性。
2.2.1 LSTM (长短时记忆网络)模型
LSTM 是一种特殊的循环神经网络(RNN),尤其适用于时间序列预测。 LSTM 能够捕捉时间序列中的长期依赖关系,这对于包裹量预测至关重要。
LSTM 的基本公式如下:
ht = σ(Wh xt + Uhht−1 + bh )
其中:
• ht 是当前时间步的隐藏状态。
• Wh 和 Uh 是权重矩阵, bh 是偏置。
• xt 是当前时间步的输入数据。
• σ 是激活函数(如 tanh 或 sigmoid)。
LSTM 模型能够有效地学习包裹量数据中的时间依赖性, 通过调整其隐层和 输入层之间的权重矩阵来更好地捕捉历史数据的模式。
2.2.2 Prophet 模型
Prophet 是由 Facebook 开发的时间序列预测工具, 能够处理数据中的趋势、季 节性和假期效应。 Prophet 的公式为:
y(t) = g(t) + s(t) + h(t) + ϵt
其中:
• y(t) 是时间 t 的预测值,即包裹量。
• g(t) 是趋势部分,表示长期的增长或下降趋势。
• s(t) 是季节性部分,表示季节性波动。
• h(t) 是假期效应,表示节假日的影响。
• ϵt 是误差项,表示模型的随机误差。
Prophet 模型主要通过调整趋势和季节性部分来做出预测,适用于具有强季 节性波动的时间序列数据,且具有较高的鲁棒性。
2.3 模型建立与求解
为了预测未来 24 小时的包裹量,我们将通过以下步骤来建立和求解模型:
-
数据预处理: 将提供的历史包裹量数据按时间顺序整理,并格式化为适用 于 Prophet 和 LSTM 模型的输入数据(即, 时间列和包裹量列)。对于 LSTM 模型,我们需要将数据转换为时序对,以便训练和验证。
-
Prophet 模型训练:使用历史数据训练 Prophet 模型,提取趋势部分、季 节性部分和假期效应部分。这一阶段的目标是捕捉数据中的长期趋势和周 期性波动。
-
LSTM 模型训练: 将历史包裹量数据输入 LSTM 模型, 以学习时间序列 中的长期依赖性。 LSTM 模型将在此基础上生成未来的预测结果, 重点学 习包裹量的变化趋势。
-
模型结合:将 Prophet 模型的预测结果作为 LSTM 模型的输入之一,结 合两者的优点进行最终的包裹量预测。Prophet 主要用于捕捉季节性和趋 势性,而 LSTM 则补充了长期的时间依赖性,从而提高预测的准确性。
-
预测与优化: 基于训练后的模型, 预测未来 24 小时(2024 年 12 月 15 日 14:00 至 2024 年 12 月 16 日 14:00)的包裹量。将模型的输出与实际结果 进行比较,通过误差评估来优化模型。
2.4 误差评估
为了评估模型的准确性,我们将使用以下误差评估指标:
• 均方误差(MSE):
其中,yi 为真实包裹量, i 为预测包裹量。
• 均方根误差(RMSE):
RMSE 能够直接反映预测误差的大小。
• 平均绝对误差(MAE):
MAE 衡量的是预测误差的平均绝对值。




相关文章:

【全部更新】2025妈妈杯D题1-4问mathercupD题数学建模挑战赛D题数学建模思路代码文章教学短途运输货量预测及车辆调度问题
完整内容请看文章最下面的推广群 先进行摘要和结果的展示、再给出完整的思路 问题1:通过时间序列或机器学习模型预测货量,并按历史分布拆分到10分钟颗粒度。 问题2:基于货量生成运输需求,用贪心算法或整数规划优化车辆调度。 问…...

考研408第一章计算机系统概述——1.1-1.2操作系统的基本概念与发展历程
考研408计算机系统概述——操作系统的基本概念与发展历程 一、操作系统的基本概念 1.1 操作系统的定义与功能 1.1.1 定义 操作系统(Operating System, OS)是管理计算机硬件与软件资源的程序集合,为应用程序和用户提供接口与服务。其核心功能包括: 资源管理者:处理机、…...

《从理论到实践:CRC校验的魔法之旅》
循环冗余校验(Cyclic Redundancy Check ,CRC )是一种用于检测数据传输或存储过程中错误的算法。他通过计算数据的校验值(也称为CRC码),并在数据接收端验证校验值是饭否正确,从而检测数据是否在传输过程中被…...
专题整理)
【算法笔记】整除与最大公约数(GCD)专题整理
参考文章链接(已获得作者授权) 一、整除:数学中的"完美分割" 定义 若整数 a a a能整除整数 b b b(记作 a ∣ b a\mid b a∣b),则存在整数 k k k使得 b a ⋅ k ba\cdot k ba⋅k。 通俗理解&…...

JDBC 与 MyBatis 详解:从基础到实践
目录 一、JDBC 介绍 二、使用 JDBC 查询用户信息 三、ResultSet 结果集 四、预编译 SQL - SQL 注入问题 五、预编译 SQL - 性能更高 六、JDBC 增删改操作 插入数据: 更新数据: 删除数据: 七、MyBatis 介绍 八、MyBatis 入门程序 引…...

虚拟机开发环境搭建与内网迁移
以下是关于在虚拟机中搭建开发环境并迁移至内网的详细步骤及注意事项,适用于需要在内网隔离环境中进行开发的场景(如企业安全要求、离线开发等): 一、虚拟机开发环境搭建 1. 选择虚拟机平台 推荐工具: V…...

【HFP】蓝牙HFP协议音频连接核心技术深度解析
目录 一、音频连接建立的总体要求 1.1 发起主体与时机 1.2 前提条件 1.3 同步连接的建立 1.4 通知机制 二、不同主体发起的音频连接建立流程 2.1 连接建立触发矩阵 2.2 AG 发起的音频连接建立 2.3 HF 发起的音频连接建立 三、编解码器连接建立流程 3.1 发起条件 3.…...

PowerBI 表格显示无关联的表数据
假设有两张没有建立关联的数据表: 产品表 库存表 我们将他们放入表格里显示,数据会出问题。 因为 [库存表] 里的数据有除 [产品表] 以外的产品的数据,所以PBI无法从两张表中找到一一对应的数据。 解决方法:(不建立关联关系的情况下) 新建一个度量值&a…...

观察者模式详解与C++实现
1. 模式定义 观察者模式(Observer Pattern)是一种行为型设计模式,定义了对象间的一对多依赖关系。当一个对象(被观察者/主题)状态改变时,所有依赖它的对象(观察者)都会自动收到通知…...

用ffmpeg 实现拉取h265的flv视频转存成264的mp4 实现方案
1.需要对ffmpeg进行源码修改 这里使用 https://github.com/numberwolf/FFmpeg-QuQi-H265-FLV-RTMP 这位大神提供的源码 需要 x265_3.2.1.tar.gz last_x264.tar.bz2 fdk-aac-2.0.1.tar.gz FFmpeg-QuQi-H265-FLV-RTMP-master.zip 这些包 升级ubuntu18.04 apt update a…...

《AI赋能职场:大模型高效应用课》第8课 AI辅助职场沟通与协作
【本课目标】 掌握AI辅助邮件、沟通话术的优化技巧。学习利用AI快速生成高效的会议纪要。通过实操演练,提升职场沟通效率与协作能力。 【准备工具】 DeepSeek大模型(deepseek.com)百度文心一言(yiyan.baidu.com) 一…...

PowerBI下载安装教程
1、打开官方下载链接,或者Microsoft store里搜索下载(通过官网下载可以选择安装路径,应用商店直接会安装到默认路径里)。 2、等待下载成功后,直接点击【打开】即可。...

PowerBI如何钻取到明细
PowerBI如何钻取到明细 最近做项目领导提到一需求,在查看账龄的时候,还想查看到它的一个明细情况。 PowerBI如何钻取到明细,以一个案例分享下: 第一步:我们先查看账龄的一个分布情况: 第二步:…...

常见算法题
import java.util.*;class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) { this.val val; }TreeNode(int val, TreeNode left, TreeNode right) {this.val val;this.left left;this.right right;} }public class test_04_16 {//获取二叉…...

C语言超详细结构体知识
1.自定义类型:结构体的介绍 在之前的博客中,我们简单介绍过了关于结构体的基本知识,这里我们稍微复习一下。 结构体(struct)是C语言中一种重要的复合数据类型,它允许将不同类型的数据组合成一个整体。 1.1结构体的定义 结构体使…...

2N60-ASEMI功业控制与自动化专用2N60
编辑:ll 2N60-ASEMI功业控制与自动化专用2N60 型号:2N60 品牌:ASEMI 封装:TO-220F 批号:最新 最大漏源电流:2A 漏源击穿电压:600V RDS(ON)Max:5.00Ω…...

发现“横”字手写有难度,对比两个“横”字
我发现手写体“横”字“好看”程度,难以比得上印刷体: 两个从方正简体启体来的“横”字: 哪个更好看?我是倾向于左边一点。 <div style"transform: rotate(180deg); display: inline-block;"> 左边是我从方正简…...

深入解析 HTML5 Web IndexedDB 数据库:构建高效离线应用的基石
摘要 在现代 Web 应用开发中,离线访问和高效处理大量结构化数据的需求日益增长。HTML5 的 IndexedDB 作为一种强大的客户端 NoSQL 数据库,为开发者提供了可靠的解决方案。本文将全面介绍 IndexedDB 的特性、语法、方法、应用实例、使用场景,以及其优势与劣势,帮助开发者深…...
-第十七天)
17-算法打卡-哈希表-快乐数-leetcode(202)-第十七天
1 题目地址 202. 快乐数 - 力扣(LeetCode)202. 快乐数 - 编写一个算法来判断一个数 n 是不是快乐数。「快乐数」 定义为: * 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。 * 然后重复这个过程直到这个数变为 1…...
与重排(Reflow)的性能优化策略)
决战浏览器渲染:减少重绘(Repaint)与重排(Reflow)的性能优化策略
在现代Web开发中,流畅的用户体验是衡量应用质量的关键指标之一。用户与界面的每一次交互,背后都牵动着浏览器复杂而精密的渲染过程。当这个过程不够高效时,用户就会感受到卡顿、延迟,甚至页面“掉帧”。在众多影响渲染性能的因素中…...

深度解析生成对抗网络:原理、应用与未来趋势
在人工智能的浩瀚星空中,生成对抗网络(Generative Adversarial Networks,GAN)犹如一颗璀璨的明星,自 2014 年由 Ian Goodfellow 等人提出以来,便以其独特而强大的生成能力,在计算机视觉、自然语…...

电能质量治理解决方案:构建高效、安全的电力系统
随着“双碳”目标的推进及新型电力系统的快速发展,大量电力电子设备(如光伏逆变器、充电桩、变频器等)接入电网,导致谐波畸变、无功功率激增、电压波动等问题日益突出。电能质量恶化不仅威胁设备安全,还影响电网稳定运…...

生态篇|多总线融合与网关设计
引言 1. 车内多总线概览 2. 主流车载总线技术对比 3. 网关设计原则与架构 4. 协议转换与映射策略 5. 安全与诊断功能集成...
)
热门与冷门并存,25西电—电子工程学院(考研录取情况)
1、电子工程学院各个方向 2、电子工程学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、电子科学与技术25年相较于24年上升20分 2、信息与通信工程、控制科学与工程、新一代电子信息技术(专硕)25年相较于24年下降25分 3、25vs24推…...

HDFS入门】HDFS安全与权限管理解析:从认证到加密的完整指南
目录 引言 1 认证与授权机制 1.1 Kerberos认证集成 1.2 HDFS ACL细粒度控制 2 数据加密保护 2.1 传输层加密(SSL/TLS) 2.2 静态数据加密 3 审计与监控体系 3.1 操作审计流程 3.2 安全监控指标 4 权限模型详解 4.1 用户/组权限模型 4.2 umask配置原理 5 安全最佳实…...

合成数据中的对抗样本生成与应用:让AI模型更强、更稳、更安全
目录 合成数据中的对抗样本生成与应用:让AI模型更强、更稳、更安全 一、什么是对抗样本? 二、为什么要在合成数据中引入对抗样本? 三、对抗样本在图像合成数据中的生成方法 ✅ 方法1:FGSM(Fast Gradient Sign Met…...

考研系列-计算机网络-第二章、物理层
一、通信基础 1.物理层基本概念 2.数据通信基础知识...

uni-app 安卓10以上上传原图解决方案
在Android 10及以上版本中,由于系统对文件访问的限制,使用chooseImage并勾选原图上传后,返回的是图片的外部存储路径,如:file:///storage/emulated/0/DCIM/Camera/。这种外部存储路径,无法直接转换成所需要…...
方法触发两次)
关于element的dialog的取消(关闭弹窗)方法触发两次
在这里插入图片描述 关闭的时候加个修饰符.native close.native...

vue,uniapp解决h5跨域问题
如果有这样的跨域问题,解决办法: ✅ 第一步:在项目根目录下创建 vue.config.js 和 package.json 同级目录。 // vue.config.js module.exports {devServer: {proxy: {/api: {target: https://app.yycjkb.cn, // 你的后端接口地址changeOrig…...

2025-04-18 李沐深度学习3 —— 线性代数
文章目录 1 线性代数1.1 标量、向量与矩阵1.2 矩阵概念1.3 按特定轴求和 2 实战:线性代数2.1 标量2.2 向量2.3 矩阵2.4 张量2.5 降维2.6 点积2.7 矩阵-向量积2.8 矩阵-矩阵乘法2.9 范数2.10 练习 1 线性代数 1.1 标量、向量与矩阵 标量(Scalarÿ…...
)
2026《数据结构》考研复习笔记三(C++高级教程)
C高级教程 一、文件和流二、异常处理三、命名空间四、模板五、信号处理六、多线程 一、文件和流 iostream 用于标准输入/输出(控制台I/O),处理与终端(键盘输入和屏幕输出)的交互 包含以下全局流对象: cin&…...

python进阶: 深入了解调试利器 Pdb
Python是一种广泛使用的编程语言,以其简洁和可读性著称。在开发和调试过程中,遇到错误和问题是不可避免的。Python为此提供了一个强大的调试工具——Pdb(Python Debugger)。 Pdb是Python标准库中自带的调试器,可以帮助…...
)
前端资源加载失败后重试加载(CSS,JS等引用资源)
前端资源加载失败后的重试 .前端引用资源时出现了资源加载失败(这里针对的是路径引用异常或者url解析错误时) 解决这个问题首先要明确一下几个步骤 1.什么情况或者什么时候重试 2.如何重试 3.重试过程中的边界处理 这里引入里三个测试脚本,分别加载里三个不同的脚…...
)
每日算法【双指针算法】(Day 2-复写零)
双指针算法 1.算法题目(复写零)2.讲解算法原理3.编写代码 1.算法题目(复写零) 注意:不要越界,不能开额外的数组,只能从现有数组上进行操作,没有返回值。 2.讲解算法原理 解法:双指针操作 先根据“异地”操作…...
)
【C++深入系列】:模版详解(上)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 你不需要很厉害才能开始,但你需要开始才能很厉害。 ★★★ 本文前置知识: 类和对象(上) …...

PyCharm Flask 使用 Tailwind CSS v3 配置
安装 Tailwind CSS 步骤 1:初始化项目 在 PyCharm 终端运行:npm init -y安装 Tailwind CSS:npm install -D tailwindcss3 postcss autoprefixer初始化 Tailwind 配置文件:npx tailwindcss init这会生成 tailwind.config.js。 步…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 15:享元模式(Flyweight Pattern)完整讲解与实战应用
🔄 回顾 Day 14:组合模式小结 在 Day 14 中,我们学习了组合模式(Composite Pattern): 适用于构建树状层级结构,使得“单个对象”和“对象集合”统一操作。广泛用于文件系统、UI 控件树、组织结…...

使用Service发布应用程序
使用Service发布应用程序 文章目录 使用Service发布应用程序[toc]一、什么是Service二、通过Endpoints理解Service的工作机制1.什么是Endpoints2.创建Service以验证Endpoints 三、Service的负载均衡机制四、Service的服务发现机制五、定义Service六、Service类型七、无头Servic…...

美家市场2025电视版分享码-美家市场电视直播软件分享码免费获取
美家市场2025电视版作为一款备受欢迎的应用市场,为用户提供了海量的电视直播软件,而分享码则是免费获取这些资源的重要途径。与此同时,乐看家桌面也是一款在智能电视领域极具特色的软件,它能与美家市场搭配使用,为用户…...

动手学深度学习:手语视频在NiN模型中的测试
前言 NiN模型是在LeNet的基础上修改,提出了1x1卷积层和全局平均池化层的概念,减少了全连接所带来的参数量很多的问题。本篇在之前代码的基础上添加了模型保存,loss和acc记录以及记录模型时间等功能,所以模型后面的代码会重新记录…...

医院数据中心智能化数据上报与调数机制设计
针对医院数据中心的智能化数据上报与调数机制设计,需兼顾数据安全性、效率性、合规性及智能化能力。以下为系统性设计方案,分为核心模块、技术架构和关键流程三部分: 一、核心模块设计 1. 数据上报模块 子模块功能描述多源接入层对接HIS/LIS/PACS/EMR等异构系统,支持API/E…...

Ubuntu命令速查
当你在Ubuntu系统中需要快速查询常用命令时,可以使用以下速查表: 列出文件和目录: ls切换目录: cd [目录路径]显示当前工作目录的绝对路径: pwd创建新目录: mkdir [目录名]删除文件或目录: rm […...
)
一次制作参考网杂志的阅读书源的实操经验总结(附书源)
文章目录 一、背景介绍二、书源文件三、详解制作书源(一)打开Web服务(二)参考网结构解释(三)阅读书源 基础(四)阅读书源 发现(五)阅读书源 详细(六…...
)
python抓取HTML页面数据+可视化数据分析(投资者数量趋势)
本文所展示的代码是一个完整的数据采集、处理与可视化工具,主要用于从指定网站下载Excel文件,解析其中的数据,并生成投资者数量的趋势图表。以下是代码的主要功能模块及其作用: 1.网页数据获取 使用fetch_html_page函数从目标网…...

下拉框select标签类型
在我们很多页面里有下拉框的选择,这种元素怎么定位呢?下拉框分为两种类型:我们分别针对这两种元素进行定位和操作 select标签 : 通过select类处理。 非select标签 1、针对下拉框元素,如果是Select标签类型,…...

嵌入式C语言位操作的几种常见用法
作为一名老单片机工程师,我承认,当年刚入行的时候,最怕的就是看那些密密麻麻的寄存器定义,以及那些让人眼花缭乱的位操作。 尤其是遇到那种“明明改了寄存器,硬件就是不听话”的情况,简直想把示波器砸了&am…...

数据库原理及应用mysql版陈业斌实验四
🏝️专栏:Mysql_猫咪-9527的博客-CSDN博客 🌅主页:猫咪-9527-CSDN博客 “欲穷千里目,更上一层楼。会当凌绝顶,一览众山小。” 目录 实验四索引与视图 1.实验数据如下 student 表(学生表&…...

【免登录ORACLE,jdk8安装包下载】jdk-8u441-windows-i586.exe和jdk-8u441-windows-x64.exe有什么区别
jdk-8u441-windows-i586.exe和jdk-8u441-windows-x64.exe主要有以下区别: 我用夸克网盘分享了「jdk」,链接:https://pan.quark.cn/s/c72666843e2b 适用系统架构: jdk-8u441-windows-i586.exe适用于32位的Windows操作系统&#x…...

Oracle日志系统之附加日志
Oracle日志系统之附加日志 在 Oracle 数据库中,附加日志(Supplemental Log)是一种增强日志记录的机制,用于在数据库的 redo log 中记录更多的变更信息,尤其是在进行数据迁移、复制和同步等任务时,能够确保…...