2025-04-18 李沐深度学习3 —— 线性代数
文章目录
- 1 线性代数
- 1.1 标量、向量与矩阵
- 1.2 矩阵概念
- 1.3 按特定轴求和
- 2 实战:线性代数
- 2.1 标量
- 2.2 向量
- 2.3 矩阵
- 2.4 张量
- 2.5 降维
- 2.6 点积
- 2.7 矩阵-向量积
- 2.8 矩阵-矩阵乘法
- 2.9 范数
- 2.10 练习
1 线性代数

1.1 标量、向量与矩阵
标量(Scalar)
- 定义:单个数值(如 a = 3 a=3 a=3),是 0 维张量。
- 运算规则:
- 加减乘除: c = a + b c = a + b c=a+b。
- 绝对值(长度): ∣ a ∣ |a| ∣a∣,满足三角不等式 ∣ a + b ∣ ≤ ∣ a ∣ + ∣ b ∣ |a+b| ≤ |a| + |b| ∣a+b∣≤∣a∣+∣b∣。

向量(Vector)
-
定义:一维数组(如 [ 1 , 2 , 3 ] [1,2,3] [1,2,3]),是 1 维张量。
-
操作:
- 按元素运算: c = a + b c = a + b c=a+b( c i = a i + b i c_i = a_i + b_i ci=ai+bi)。
- 标量乘法: c = α ⋅ b c = α·b c=α⋅b( c i = α ⋅ b i c_i = α·b_i ci=α⋅bi)。
- 向量长度(L2 范数): ∣ ∣ a ∣ ∣ = ( ∑ a i 2 ) ||a|| = \sqrt{(∑a_i²)} ∣∣a∣∣=(∑ai2)。

- 点积(内积): a ⋅ b = ∑ a i ⋅ b i a·b = ∑a_i·b_i a⋅b=∑ai⋅bi,正交时 a ⋅ b = 0 a·b=0 a⋅b=0。

-
几何意义:
- 向量加法:平行四边形法则(如图,蓝 + 黄 = 绿向量)
- 标量乘法:向量缩放(拉伸或压缩)

矩阵(Matrix)
-
定义:二维数组(如 [ [ 1 , 2 ] , [ 3 , 4 ] ] [[1,2],[3,4]] [[1,2],[3,4]]),是 2 维张量。
-
核心运算:
- 按元素运算:同向量(如 C = A + B C = A + B C=A+B)。

-
矩阵乘法: C = A ⋅ B C = A·B C=A⋅B。(行乘列内积)
- 几何意义:空间线性变换(扭曲空间,如旋转/缩放)。
- 示例:若 A A A 将蓝/绿向量映射为新方向,则 A A A 代表该变换。


-
转置: A T A^T AT(行列互换),对称矩阵满足 A = A T A = A^T A=AT。
1.2 矩阵概念
范数(Norm)
-
向量范数:L2 范数(欧氏距离)最常用。
-
矩阵范数:
- Frobenius范数: ∣ ∣ A ∣ ∣ F r o = ( ∑ ∑ A i j 2 ) ||A||_{Fro} = \sqrt{(∑∑A_ij²)} ∣∣A∣∣Fro=(∑∑Aij2)(类似向量 L2 范数)
-
诱导范数:最小化 ∣ ∣ A ⋅ x ∣ ∣ / ∣ ∣ x ∣ ∣ ||A·x|| / ||x|| ∣∣A⋅x∣∣/∣∣x∣∣(用于理论分析)

特殊矩阵
| 类型 | 定义 | 深度学习应用 |
|---|---|---|
| 对称矩阵 | A = A T A = A^T A=AT | 参数优化(如 Hessian 矩阵) |
| 正交矩阵 | U ⋅ U T = I U·U^T = I U⋅UT=I(行/列正交) | 初始化(避免梯度消失/爆炸) |
| 置换矩阵 | 每行/列只有一个 1,其余为 0 | 数据重排(如 ShuffleNet) |


特征分解
- 特征向量/值: A ⋅ v = λ ⋅ v A·v = λ·v A⋅v=λ⋅v( v v v 方向不变,仅缩放 λ λ λ 倍)
- 意义:
- 对称矩阵总能特征分解(PCA 降维基础)
- 非对称矩阵可能无实数特征值(需复数域分析)

1.3 按特定轴求和
张量 shape 属性
- 描述张量在每个维度的长度,例如
shape=[5,4]表示 5 行 4 列的矩阵。 - 轴编号:从 0 开始,
axis=0对应第一个维度(行),axis=1对应第二个维度(列)。
沿轴求和
- 操作定义:沿指定轴对元素求和,结果会消除该轴(除非设置
keepdims=True)。 - 几何意义:
axis=0:将每一列压缩为一个值(纵向压缩)。axis=1:将每一行压缩为一个值(横向压缩)。

2 实战:线性代数
2.1 标量
标量由只有一个元素的张量表示。 下面的代码将实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torchx = torch.tensor(3.0)
y = torch.tensor(2.0)x + y, x * y, x / y, x**y

2.2 向量
向量可以被视为标量值组成的列表。 这些标量值被称为向量的元素(element)或分量(component)。
在数学表示法中,向量通常记为粗体、小写的符号(例如, x \mathbf{x} x、 y \mathbf{y} y 和 z \mathbf{z} z)。
x = torch.arange(4)
x

在数学中,向量 x \mathbf{x} x 可以写为:
x = [ x 1 x 2 ⋮ x n ] \mathbf{x} =\begin{bmatrix}x_{1} \\x_{2} \\ \vdots \\x_{n}\end{bmatrix} x= x1x2⋮xn
其中 x 1 , … , x n x_1,\ldots,x_n x1,…,xn 是向量的元素。在代码中,我们通过张量的索引来访问任一元素。
注意,元素 x i x_i xi 是一个标量,所以我们在引用它时不会加粗。
x[3]

长度、维度和形状
-
长度
向量中元素的个数。
-
形状
是一个元素组,列出了张量沿每个轴的长度(维数)。对于只有一个轴的张量,形状只有一个元素。
-
维度
在不同上下文时往往会有不同的含义,这经常会使人感到困惑。为了清楚起见,我们在此明确一下:
- 向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。
- 张量的维度用来表示张量具有的轴数。
在这个意义上,张量的某个轴的维数就是这个轴的长度。
在数学表示法中,如果我们想说一个向量 x \mathbf{x} x 由 n n n 个实值标量组成,可以将其表示为 x ∈ R n \mathbf{x}\in\mathbb{R}^n x∈Rn。
向量的长度通常称为向量的维度(dimension)。
len(x), x.shape # 长度,形状

2.3 矩阵
我们通常用粗体、大写字母来表示矩阵(例如, X \mathbf{X} X、 Y \mathbf{Y} Y 和 Z \mathbf{Z} Z),在代码中表示为具有两个轴的张量。
数学表示法使用 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 来表示矩阵 A \mathbf{A} A,其由 m m m 行和 n n n 列的实值标量组成。其中每个元素 a i j a_{ij} aij 属于第 i i i 行第 j j j 列:
A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] \mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \\ \end{bmatrix} A= a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn
对于任意 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n, A \mathbf{A} A 的形状是( m , n m,n m,n)或 m × n m \times n m×n。当矩阵具有相同数量的行和列时,其形状将变为正方形,因此被称为方阵(square matrix)。
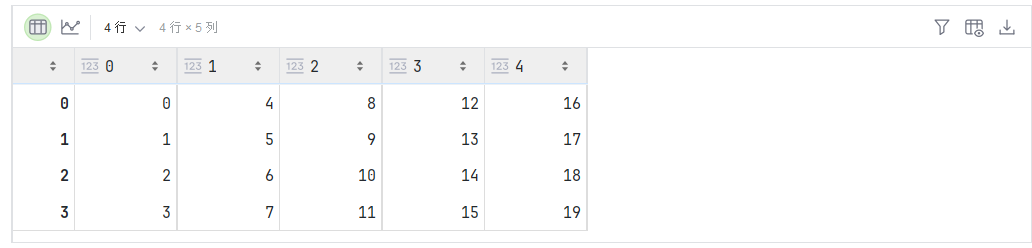
A = torch.arange(20).reshape(5, 4)
A
使用 A.T 访问矩阵 A \mathbf{A} A 的转置:
A.T
2.4 张量
张量就像向量是标量的推广,矩阵是向量的推广一样,我们可以构建具有更多轴的数据结构。
X = paddle.reshape(paddle.arange(24), (2, 3, 4))
X

任何按元素的一元运算都不会改变其操作数的形状。 同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。 例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
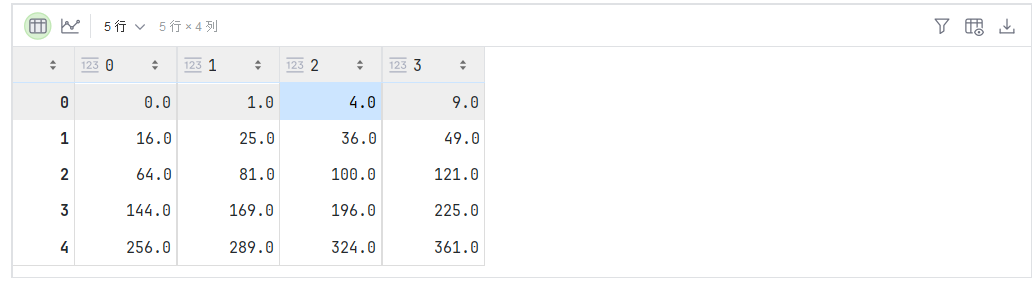
A = paddle.reshape(paddle.arange(20, dtype=paddle.float32), (5, 4))
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B

两个矩阵的按元素乘法称为 Hadamard 积(Hadamard product,数学符号 ⊙ \odot ⊙)。
对于矩阵 B ∈ R m × n \mathbf{B} \in \mathbb{R}^{m \times n} B∈Rm×n,矩阵 A \mathbf{A} A 和 B \mathbf{B} B 的 Hadamard 积为:
A ⊙ B = [ a 11 b 11 a 12 b 12 … a 1 n b 1 n a 21 b 21 a 22 b 22 … a 2 n b 2 n ⋮ ⋮ ⋱ ⋮ a m 1 b m 1 a m 2 b m 2 … a m n b m n ] \mathbf{A} \odot \mathbf{B} = \begin{bmatrix} a_{11} b_{11} & a_{12} b_{12} & \dots & a_{1n} b_{1n} \\ a_{21} b_{21} & a_{22} b_{22} & \dots & a_{2n} b_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} b_{m1} & a_{m2} b_{m2} & \dots & a_{mn} b_{mn} \end{bmatrix} A⊙B= a11b11a21b21⋮am1bm1a12b12a22b22⋮am2bm2……⋱…a1nb1na2nb2n⋮amnbmn
A * B
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a = 2
X = paddle.reshape(paddle.arange(24), (2, 3, 4))
a + X, (a * X).shape

2.5 降维
在代码中调用计算求和的函数:
x = torch.arange(4, dtype=torch.float32)
x, x.sum()

我们可以表示任意形状张量的元素和。例如,矩阵 A \mathbf{A} A 中元素的和可以记为 ∑ i = 1 m ∑ j = 1 n a i j \sum_{i=1}^{m} \sum_{j=1}^{n} a_{ij} ∑i=1m∑j=1naij。
A.shape, A.sum()

默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。我们还可以指定张量沿哪一个轴来通过求和降低维度。
以矩阵为例,为了通过求和所有行的元素来降维(轴 0),可以在调用函数时指定axis=0。
由于输入矩阵沿 0 轴降维以生成输出向量,因此输入轴 0 的维数在输出形状中消失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape

沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # 结果和A.sum()相同

一个与求和相关的量是平均值(mean 或 average)。通过将总和除以元素总数来计算平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel() # 等价

非降维求和
有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A
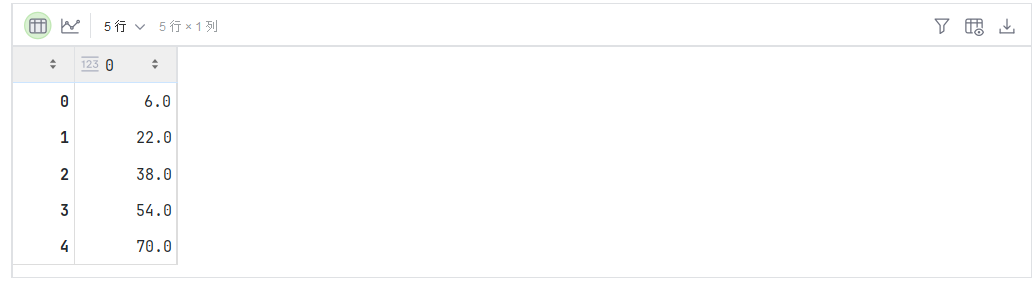
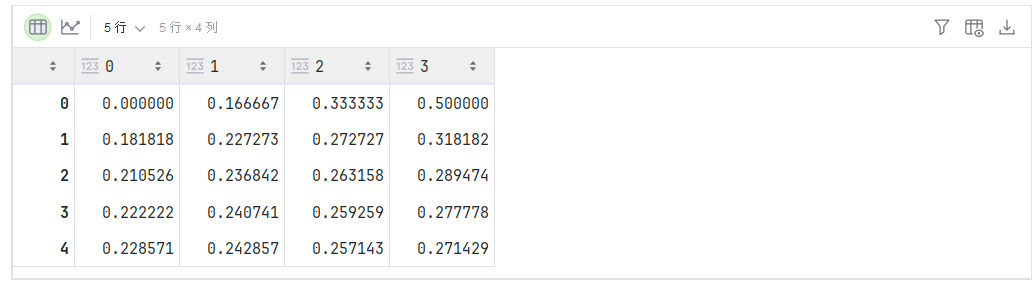
例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。
A / sum_A
如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
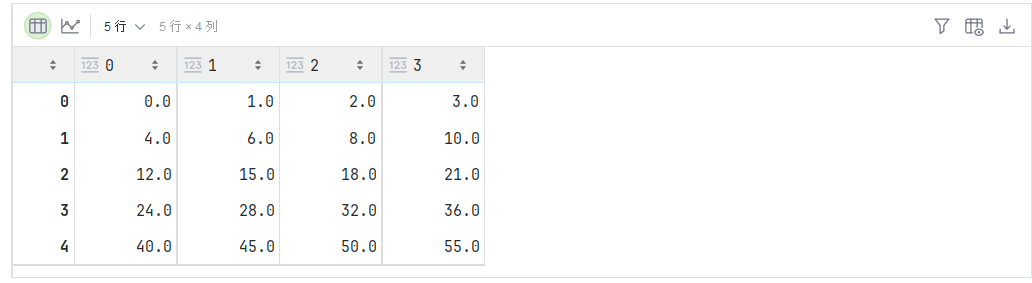
2.6 点积
给定两个向量 x , y ∈ R d \mathbf{x},\mathbf{y}\in\mathbb{R}^d x,y∈Rd,它们的点积(dot product) x ⊤ y \mathbf{x}^\top\mathbf{y} x⊤y(或 ⟨ x , y ⟩ \langle\mathbf{x},\mathbf{y}\rangle ⟨x,y⟩)是相同位置的按元素乘积的和: x ⊤ y = ∑ i = 1 d x i y i \mathbf{x}^\top \mathbf{y} = \sum_{i=1}^{d} x_i y_i x⊤y=∑i=1dxiyi。
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)

也可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)

2.7 矩阵-向量积
回顾分别矩阵 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 和向量 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn,将矩阵 A \mathbf{A} A 用它的行向量表示:
A = [ a 1 ⊤ a 2 ⊤ ⋮ a m ⊤ ] \mathbf{A}= \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_m \\ \end{bmatrix} A= a1⊤a2⊤⋮am⊤
其中每个 a i ⊤ ∈ R n \mathbf{a}^\top_{i} \in \mathbb{R}^n ai⊤∈Rn 都是行向量,表示矩阵的第 i i i 行。
矩阵向量积 A x \mathbf{A}\mathbf{x} Ax 是一个长度为 m m m 的列向量,其第 i i i 个元素是点积 a i ⊤ x \mathbf{a}^\top_i \mathbf{x} ai⊤x:
A x = [ a 1 ⊤ a 2 ⊤ ⋮ a m ⊤ ] x = [ a 1 ⊤ x a 2 ⊤ x ⋮ a m ⊤ x ] \mathbf{A}\mathbf{x} = \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_m \\ \end{bmatrix}\mathbf{x} = \begin{bmatrix} \mathbf{a}^\top_{1} \mathbf{x} \\ \mathbf{a}^\top_{2} \mathbf{x} \\ \vdots\\ \mathbf{a}^\top_{m} \mathbf{x}\\ \end{bmatrix} Ax= a1⊤a2⊤⋮am⊤ x= a1⊤xa2⊤x⋮am⊤x
我们可以把一个矩阵 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n 乘法看作一个从 R n \mathbb{R}^{n} Rn 到 R m \mathbb{R}^{m} Rm 向量的转换。
通常,使用矩阵-向量积来描述在给定前一层的值时,求解神经网络每一层所需的复杂计算。
A.shape, x.shape, torch.mv(A, x)
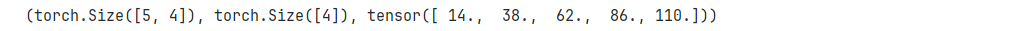
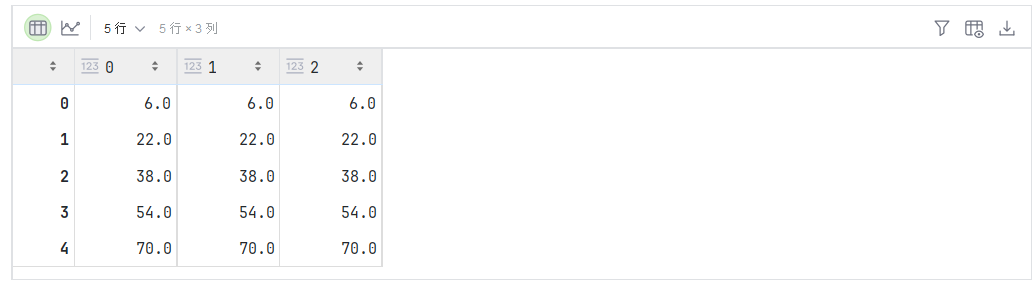
2.8 矩阵-矩阵乘法
假设有两个矩阵 A ∈ R n × k \mathbf{A} \in \mathbb{R}^{n \times k} A∈Rn×k 和 B ∈ R k × m \mathbf{B} \in \mathbb{R}^{k \times m} B∈Rk×m:
A = [ a 11 a 12 ⋯ a 1 k a 21 a 22 ⋯ a 2 k ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n k ] , B = [ b 11 b 12 ⋯ b 1 m b 21 b 22 ⋯ b 2 m ⋮ ⋮ ⋱ ⋮ b k 1 b k 2 ⋯ b k m ] \mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1k} \\ a_{21} & a_{22} & \cdots & a_{2k} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nk} \\ \end{bmatrix},\quad \mathbf{B}=\begin{bmatrix} b_{11} & b_{12} & \cdots & b_{1m} \\ b_{21} & b_{22} & \cdots & b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ b_{k1} & b_{k2} & \cdots & b_{km} \\ \end{bmatrix} A= a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1ka2k⋮ank ,B= b11b21⋮bk1b12b22⋮bk2⋯⋯⋱⋯b1mb2m⋮bkm
用行向量 a i ⊤ ∈ R k \mathbf{a}^\top_{i} \in \mathbb{R}^k ai⊤∈Rk 表示矩阵 A \mathbf{A} A 的第 i i i 行,并让列向量 b j ∈ R k \mathbf{b}_{j} \in \mathbb{R}^k bj∈Rk 作为矩阵 B \mathbf{B} B的第 j j j列。要生成矩阵积 C = A B \mathbf{C} = \mathbf{A}\mathbf{B} C=AB,最简单的方法是考虑 A \mathbf{A} A 的行向量和 B \mathbf{B} B 的列向量:
A = [ a 1 ⊤ a 2 ⊤ ⋮ a n ⊤ ] , B = [ b 1 b 2 ⋯ b m ] \mathbf{A}= \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_n \\ \end{bmatrix}, \quad \mathbf{B}=\begin{bmatrix} \mathbf{b}_{1} & \mathbf{b}_{2} & \cdots & \mathbf{b}_{m} \\ \end{bmatrix} A= a1⊤a2⊤⋮an⊤ ,B=[b1b2⋯bm]
当我们简单地将每个元素 c i j c_{ij} cij 计算为点积 a i ⊤ b j \mathbf{a}^\top_i \mathbf{b}_j ai⊤bj:
C = A B = [ a 1 ⊤ a 2 ⊤ ⋮ a n ⊤ ] [ b 1 b 2 ⋯ b m ] = [ a 1 ⊤ b 1 a 1 ⊤ b 2 ⋯ a 1 ⊤ b m a 2 ⊤ b 1 a 2 ⊤ b 2 ⋯ a 2 ⊤ b m ⋮ ⋮ ⋱ ⋮ a n ⊤ b 1 a n ⊤ b 2 ⋯ a n ⊤ b m ] \mathbf{C} = \mathbf{AB} = \begin{bmatrix} \mathbf{a}^\top_{1} \\ \mathbf{a}^\top_{2} \\ \vdots \\ \mathbf{a}^\top_n \\ \end{bmatrix} \begin{bmatrix} \mathbf{b}_{1} & \mathbf{b}_{2} & \cdots & \mathbf{b}_{m} \\ \end{bmatrix} = \begin{bmatrix} \mathbf{a}^\top_{1} \mathbf{b}_1 & \mathbf{a}^\top_{1}\mathbf{b}_2& \cdots & \mathbf{a}^\top_{1} \mathbf{b}_m \\ \mathbf{a}^\top_{2}\mathbf{b}_1 & \mathbf{a}^\top_{2} \mathbf{b}_2 & \cdots & \mathbf{a}^\top_{2} \mathbf{b}_m \\ \vdots & \vdots & \ddots &\vdots\\ \mathbf{a}^\top_{n} \mathbf{b}_1 & \mathbf{a}^\top_{n}\mathbf{b}_2& \cdots& \mathbf{a}^\top_{n} \mathbf{b}_m \end{bmatrix} C=AB= a1⊤a2⊤⋮an⊤ [b1b2⋯bm]= a1⊤b1a2⊤b1⋮an⊤b1a1⊤b2a2⊤b2⋮an⊤b2⋯⋯⋱⋯a1⊤bma2⊤bm⋮an⊤bm
可以将矩阵-矩阵乘法 A B \mathbf{AB} AB 看作执行 m m m 次矩阵-向量积,并将结果拼接在一起,形成一个 n × m n \times m n×m 矩阵。
在下面的代码中,我们在A和B上执行矩阵乘法。这里的A是一个 5 行 4 列的矩阵,B是一个 4 行 3 列的矩阵。两者相乘后,我们得到了一个 5 行 3 列的矩阵。
B = torch.ones(4, 3)
torch.mm(A, B)
2.9 范数
向量的范数表示一个向量有多大。这里考虑的大小(size)概念不涉及维度,而是分量的大小。在线性代数中,向量范数是将向量映射到标量的函数 f f f。
给定任意向量 x \mathbf{x} x,向量范数要满足一些属性:
-
如果按常数因子 α \alpha α 缩放向量的所有元素,其范数也会按相同常数因子的绝对值缩放:
f ( α x ) = ∣ α ∣ f ( x ) f(\alpha \mathbf{x}) = |\alpha| f(\mathbf{x}) f(αx)=∣α∣f(x) -
满足三角不等式:
f ( x + y ) ≤ f ( x ) + f ( y ) f(\mathbf{x} + \mathbf{y}) \leq f(\mathbf{x}) + f(\mathbf{y}) f(x+y)≤f(x)+f(y) -
范数必须是非负的:
f ( x ) ≥ 0 f(\mathbf{x}) \geq 0 f(x)≥0
因为在大多数情况下,任何东西的最小的大小是 0。 -
要求范数最小为 0,当且仅当向量全由 0 组成:
∀ i , [ x ] i = 0 ⇔ f ( x ) = 0 \forall i, [\mathbf{x}]_i = 0 \Leftrightarrow f(\mathbf{x})=0 ∀i,[x]i=0⇔f(x)=0
范数很像距离的度量。
L 2 L_2 L2 范数
假设 n n n 维向量 x \mathbf{x} x 中的元素是 x 1 , … , x n x_1,\ldots,x_n x1,…,xn,其 L 2 L_2 L2 范数是向量元素平方和的平方根:
∥ x ∥ 2 = ∑ i = 1 n x i 2 , \|\mathbf{x}\|_2 = \sqrt{\sum_{i=1}^n x_i^2}, ∥x∥2=i=1∑nxi2,
其中,在 L 2 L_2 L2 范数中常常省略下标 2 2 2,即 ∥ x ∥ \|\mathbf{x}\| ∥x∥ 等同于 ∥ x ∥ 2 \|\mathbf{x}\|_2 ∥x∥2。
在代码中,我们可以按如下方式计算向量的 L 2 L_2 L2 范数。
u = torch.tensor([3.0, -4.0])
torch.norm(u)

L 1 L_1 L1 范数
L 1 L_1 L1 范数将绝对值函数和按元素求和组合起来。
∥ x ∥ 1 = ∑ i = 1 n ∣ x i ∣ \|\mathbf{x}\|_1 = \sum_{i=1}^n \left|x_i \right| ∥x∥1=i=1∑n∣xi∣
L 1 L_1 L1 范数受异常值的影响较小。
torch.abs(u).sum()

Frobenius 范数(Frobenius norm)
矩阵 X ∈ R m × n \mathbf{X} \in \mathbb{R}^{m \times n} X∈Rm×n 的 Frobenius 范数是矩阵元素平方和的平方根:
∥ X ∥ F = ∑ i = 1 m ∑ j = 1 n x i j 2 \|\mathbf{X}\|_F = \sqrt{\sum_{i=1}^m \sum_{j=1}^n x_{ij}^2} ∥X∥F=i=1∑mj=1∑nxij2
Frobenius 范数满足向量范数的所有性质,它就像是矩阵形向量的 L 2 L_2 L2 范数。
调用以下函数将计算矩阵的 Frobenius 范数。
torch.norm(torch.ones((4, 9)))

2.10 练习
-
证明一个矩阵 A \mathbf{A} A 的转置的转置是 A \mathbf{A} A,即 ( A ⊤ ) ⊤ = A (\mathbf{A}^\top)^\top = \mathbf{A} (A⊤)⊤=A。
A.T.T == A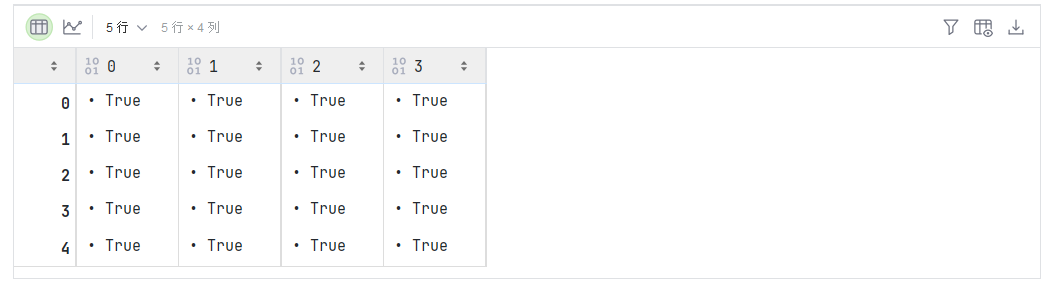
-
给出两个矩阵 A \mathbf{A} A 和 B \mathbf{B} B,证明“它们转置的和”等于“它们和的转置”,即 A ⊤ + B ⊤ = ( A + B ) ⊤ \mathbf{A}^\top + \mathbf{B}^\top = (\mathbf{A} + \mathbf{B})^\top A⊤+B⊤=(A+B)⊤。
A = torch.arange(20).reshape(5, 4)B = torch.arange(20).reshape(5, 4) + 1A.T + B.T, (A + B).T
-
给定任意方阵 A \mathbf{A} A, A + A ⊤ \mathbf{A} + \mathbf{A}^\top A+A⊤总是对称的吗?为什么?
答:是的。由前两问可知, ( A + A T ) T = A T + ( A T ) T = A T + A (\mathbf{A}+\mathbf{A}^T)^T = \mathbf{A}^T+(\mathbf{A}^T)^T=\mathbf{A}^T+\mathbf{A} (A+AT)T=AT+(AT)T=AT+A,且矩阵加法满足交换律。
A + A T = [ a 11 + a 11 a 12 + a 21 ⋯ a 1 n + a n 1 a 21 + a 12 a 22 + a 22 ⋯ a 2 n + a n 2 ⋮ ⋮ ⋱ ⋮ a n 1 + a 1 n a n 2 + a n 2 ⋯ a n k + a n n ] \mathbf{A}+\mathbf{A}^T=\begin{bmatrix} a_{11}+ a_{11} & a_{12}+ a_{21} & \cdots & a_{1n}+ a_{n1} \\ a_{21}+ a_{12} & a_{22}+ a_{22} & \cdots & a_{2n}+ a_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1}+ a_{1n} & a_{n2}+ a_{n2} & \cdots & a_{nk}+ a_{nn} \\ \end{bmatrix} A+AT= a11+a11a21+a12⋮an1+a1na12+a21a22+a22⋮an2+an2⋯⋯⋱⋯a1n+an1a2n+an2⋮ank+ann -
本节中定义了形状 ( 2 , 3 , 4 ) (2,3,4) (2,3,4) 的张量
X。len(X)的输出结果是什么?len(X), X.shape
-
对于任意形状的张量
X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?答:是的,总是对应轴 0 的长度。
X1 = torch.ones(4) X2 = torch.ones(3, 3) X3 = torch.ones(2, 3, 4)len(X1), len(X2), len(X3)
-
运行
A/A.sum(axis=1),看看会发生什么。请分析一下原因?答:发生报错,因为长度 4 和 5 不匹配。

-
考虑一个具有形状 ( 2 , 3 , 4 ) (2,3,4) (2,3,4) 的张量,在轴 0、1、2 上的求和输出是什么形状?
sum_axis_0 = X3.sum(axis=0) sum_axis_1 = X3.sum(axis=1) sum_axis_2 = X3.sum(axis=2)sum_axis_0.shape, sum_axis_1.shape, sum_axis_2.shape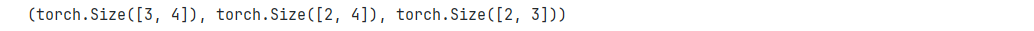
-
为
linalg.norm函数提供 3 个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?# 创建一个 3D 张量(形状:2x3x4) x = torch.arange(24, dtype=torch.float32).reshape(2, 3, 4) print("原始张量:\n", x)# 沿不同轴计算 L2 范数 norm_dim0 = torch.linalg.norm(x, dim=0) # 沿第0轴(2消失) norm_dim1 = torch.linalg.norm(x, dim=1) # 沿第1轴(3消失) norm_dim2 = torch.linalg.norm(x, dim=2) # 沿第2轴(4消失) norm_dims = torch.linalg.norm(x, dim=(1, 2)) # 沿第1和第2轴(3和4消失)print("\n沿 dim=0 的范数(形状 3x4):\n", norm_dim0) print("\n沿 dim=1 的范数(形状 2x4):\n", norm_dim1) print("\n沿 dim=2 的范数(形状 2x3):\n", norm_dim2) print("\n沿 dim=(1,2) 的范数(形状 2):\n", norm_dims)

相关文章:

2025-04-18 李沐深度学习3 —— 线性代数
文章目录 1 线性代数1.1 标量、向量与矩阵1.2 矩阵概念1.3 按特定轴求和 2 实战:线性代数2.1 标量2.2 向量2.3 矩阵2.4 张量2.5 降维2.6 点积2.7 矩阵-向量积2.8 矩阵-矩阵乘法2.9 范数2.10 练习 1 线性代数 1.1 标量、向量与矩阵 标量(Scalarÿ…...
)
2026《数据结构》考研复习笔记三(C++高级教程)
C高级教程 一、文件和流二、异常处理三、命名空间四、模板五、信号处理六、多线程 一、文件和流 iostream 用于标准输入/输出(控制台I/O),处理与终端(键盘输入和屏幕输出)的交互 包含以下全局流对象: cin&…...

python进阶: 深入了解调试利器 Pdb
Python是一种广泛使用的编程语言,以其简洁和可读性著称。在开发和调试过程中,遇到错误和问题是不可避免的。Python为此提供了一个强大的调试工具——Pdb(Python Debugger)。 Pdb是Python标准库中自带的调试器,可以帮助…...
)
前端资源加载失败后重试加载(CSS,JS等引用资源)
前端资源加载失败后的重试 .前端引用资源时出现了资源加载失败(这里针对的是路径引用异常或者url解析错误时) 解决这个问题首先要明确一下几个步骤 1.什么情况或者什么时候重试 2.如何重试 3.重试过程中的边界处理 这里引入里三个测试脚本,分别加载里三个不同的脚…...
)
每日算法【双指针算法】(Day 2-复写零)
双指针算法 1.算法题目(复写零)2.讲解算法原理3.编写代码 1.算法题目(复写零) 注意:不要越界,不能开额外的数组,只能从现有数组上进行操作,没有返回值。 2.讲解算法原理 解法:双指针操作 先根据“异地”操作…...
)
【C++深入系列】:模版详解(上)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 你不需要很厉害才能开始,但你需要开始才能很厉害。 ★★★ 本文前置知识: 类和对象(上) …...

PyCharm Flask 使用 Tailwind CSS v3 配置
安装 Tailwind CSS 步骤 1:初始化项目 在 PyCharm 终端运行:npm init -y安装 Tailwind CSS:npm install -D tailwindcss3 postcss autoprefixer初始化 Tailwind 配置文件:npx tailwindcss init这会生成 tailwind.config.js。 步…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 15:享元模式(Flyweight Pattern)完整讲解与实战应用
🔄 回顾 Day 14:组合模式小结 在 Day 14 中,我们学习了组合模式(Composite Pattern): 适用于构建树状层级结构,使得“单个对象”和“对象集合”统一操作。广泛用于文件系统、UI 控件树、组织结…...

使用Service发布应用程序
使用Service发布应用程序 文章目录 使用Service发布应用程序[toc]一、什么是Service二、通过Endpoints理解Service的工作机制1.什么是Endpoints2.创建Service以验证Endpoints 三、Service的负载均衡机制四、Service的服务发现机制五、定义Service六、Service类型七、无头Servic…...

美家市场2025电视版分享码-美家市场电视直播软件分享码免费获取
美家市场2025电视版作为一款备受欢迎的应用市场,为用户提供了海量的电视直播软件,而分享码则是免费获取这些资源的重要途径。与此同时,乐看家桌面也是一款在智能电视领域极具特色的软件,它能与美家市场搭配使用,为用户…...

动手学深度学习:手语视频在NiN模型中的测试
前言 NiN模型是在LeNet的基础上修改,提出了1x1卷积层和全局平均池化层的概念,减少了全连接所带来的参数量很多的问题。本篇在之前代码的基础上添加了模型保存,loss和acc记录以及记录模型时间等功能,所以模型后面的代码会重新记录…...

医院数据中心智能化数据上报与调数机制设计
针对医院数据中心的智能化数据上报与调数机制设计,需兼顾数据安全性、效率性、合规性及智能化能力。以下为系统性设计方案,分为核心模块、技术架构和关键流程三部分: 一、核心模块设计 1. 数据上报模块 子模块功能描述多源接入层对接HIS/LIS/PACS/EMR等异构系统,支持API/E…...

Ubuntu命令速查
当你在Ubuntu系统中需要快速查询常用命令时,可以使用以下速查表: 列出文件和目录: ls切换目录: cd [目录路径]显示当前工作目录的绝对路径: pwd创建新目录: mkdir [目录名]删除文件或目录: rm […...
)
一次制作参考网杂志的阅读书源的实操经验总结(附书源)
文章目录 一、背景介绍二、书源文件三、详解制作书源(一)打开Web服务(二)参考网结构解释(三)阅读书源 基础(四)阅读书源 发现(五)阅读书源 详细(六…...
)
python抓取HTML页面数据+可视化数据分析(投资者数量趋势)
本文所展示的代码是一个完整的数据采集、处理与可视化工具,主要用于从指定网站下载Excel文件,解析其中的数据,并生成投资者数量的趋势图表。以下是代码的主要功能模块及其作用: 1.网页数据获取 使用fetch_html_page函数从目标网…...

下拉框select标签类型
在我们很多页面里有下拉框的选择,这种元素怎么定位呢?下拉框分为两种类型:我们分别针对这两种元素进行定位和操作 select标签 : 通过select类处理。 非select标签 1、针对下拉框元素,如果是Select标签类型,…...

嵌入式C语言位操作的几种常见用法
作为一名老单片机工程师,我承认,当年刚入行的时候,最怕的就是看那些密密麻麻的寄存器定义,以及那些让人眼花缭乱的位操作。 尤其是遇到那种“明明改了寄存器,硬件就是不听话”的情况,简直想把示波器砸了&am…...

数据库原理及应用mysql版陈业斌实验四
🏝️专栏:Mysql_猫咪-9527的博客-CSDN博客 🌅主页:猫咪-9527-CSDN博客 “欲穷千里目,更上一层楼。会当凌绝顶,一览众山小。” 目录 实验四索引与视图 1.实验数据如下 student 表(学生表&…...

【免登录ORACLE,jdk8安装包下载】jdk-8u441-windows-i586.exe和jdk-8u441-windows-x64.exe有什么区别
jdk-8u441-windows-i586.exe和jdk-8u441-windows-x64.exe主要有以下区别: 我用夸克网盘分享了「jdk」,链接:https://pan.quark.cn/s/c72666843e2b 适用系统架构: jdk-8u441-windows-i586.exe适用于32位的Windows操作系统&#x…...

Oracle日志系统之附加日志
Oracle日志系统之附加日志 在 Oracle 数据库中,附加日志(Supplemental Log)是一种增强日志记录的机制,用于在数据库的 redo log 中记录更多的变更信息,尤其是在进行数据迁移、复制和同步等任务时,能够确保…...

从零到一:管理系统设计新手如何快速上手?
管理系统设计是一项复杂而富有挑战性的任务,它要求设计者具备多方面的知识和技能,包括需求分析、架构设计、数据管理、用户界面设计等。对于初次接触这一领域的新手而言,如何快速上手并成为一名合格的管理系统设计者呢?本文将从管…...

Web 前端包管理工具深度解析:npm、yarn、pnpm 全面对比与实战建议
引言: 在现代web前端开发中,包管理工具的重要性不言而喻,无论是构建项目脚手架,安装ui库,管理依赖版本,还是实现monorepo项目结构,一个高效稳定的包管理工具都会大幅提升开发体验和协作效率 作为一名前端工程师,深入了解这些工具背后的机制与差异,对于提升项目可维护性和团队…...
)
Windows 图形显示驱动开发-WDDM 1.2功能—Windows 8 中的 DirectX 功能改进(六)
一、具有多示例抗别名示例访问权限的 UAV Direct3D 11 允许光栅化到无序访问视图, (UAV) 没有呈现目标视图 (RTV) /DSV 绑定。 即使 UAV 可以具有任意大小,实现也可以使用视区/剪刀矩形的像素尺寸来操作光栅器。 DirectX 11 硬件的示例模式仅为单个示例…...

Jenkins 多分支流水线: 如何创建用于 Jenkins 状态检查的 GitHub 应用
使用 Jenkins 多分支流水线时,您可以将状态检查与 GitHub 拉取请求集成。 以下是状态检查的示例 要实现这些类型的状态检查,您需要创建一个与 Jenkins 主实例集成的 GitHub 应用。 在本博客中,我们将介绍如何创建一个 GitHub 应用ÿ…...

LeeCode912. 排序数组
给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1: 输入:nums [5,2,3,1] 输出:[1,2,3,5]示例 2…...
)
Maven 简介(图文)
Maven 简介 Maven 是一个Java 项目管理和构建的工具。可以定义项目结构、项目依赖,并使用统一的方式进行自动化构建,是Java 项目不可缺少的工具。 Maven 的作用 提供标准化的项目结构:以前不同的开发工具创建的项目结构是不一样的…...

深入规划 Elasticsearch 索引:策略与实践
一、Elasticsearch 索引概述 (一)索引基本概念 Elasticsearch 是一个分布式、高性能的全文搜索引擎,其核心概念之一便是索引。索引本质上是一个存储文档的逻辑容器,它使得数据能够在高效的检索机制下被查询到。当我们对文档进行…...

基于X86/RK/全志+FPGA+AI工业一体机在电力接地系统中的应用方案
随着电力技术的发展和需求增加,智能电网建设受到全球关注。电力五防系统建设是确保我国电力安全的核心任务,接地管理系统是其中的关键部分,对电力系统的安全、稳定和高效运行至关重要。工业一体机,凭借其卓越的性能、稳定性和环境…...

论文阅读:2024 arxiv AI Safety in Generative AI Large Language Models: A Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Safety in Generative AI Large Language Models: A Survey https://arxiv.org/pdf/2407.18369 https://www.doubao.com/chat/3262156521106434 速览 研究动机&#x…...

JVM对象创建全过程
JVM对象创建全过程深度解析 1. 对象创建的整体流程 JVM创建对象的过程可以分为7个关键步骤,从类检查到内存分配,再到对象初始化: 类加载检查 → 内存分配 → 内存空间初始化 → 对象头设置 → 构造函数执行 → 栈帧引用建立 → 对象使用2.…...

ubuntu 22.04 使用ssh-keygen创建ssh互信账户
现有两台ubuntu 22.04服务器,ip分别为192.168.66.88和192.168.88.66。需要将两台服务器创建新用户并将新用户做互信。 创建账户 adduser user1 # 如果此用户不想使用密码,直接一直回车就行,创建的用户是没法使用用户密码进行登陆的 su - …...
)
蓝牙开发那些事儿12——(记一颗BLE芯片BringUp折腾过程)
1.背景 蓝牙这个系列已经很久很久没有更新了,感慨良多。 现在写这篇文章主要是BringUp一颗蓝牙芯片的过程中遇到了一些奇怪的问题,想了一些办法,一一克服了,看看对其他做蓝牙的同学有没有启发。 同时也安利一个叫做HACKRF的设备…...

从零构建 Vue3 登录页:结合 Vant 组件与 Axios 实现完整登录功能
在 Web 开发的世界里,登录页是用户与应用交互的第一道门槛,它的体验好坏直接影响着用户对整个应用的印象。本文将详细记录如何使用 Vue3、Vant 组件库和 Axios 构建一个兼具美观与实用的登录页面,并实现完整的登录逻辑与数据验证,…...
——MCAL架构及其模块详解)
AutoSAR从概念到实践系列之MCAL篇(一)——MCAL架构及其模块详解
欢迎大家学习我的《AutoSAR从概念到实践系列之MCAL篇》系列课程,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢各位的支持! 老规矩,…...
])
多线程编程的简单案例——单例模式[多线程编程篇(3)]
目录 前言 1.wati() 和 notify() wait() 和 notify() 的产生原因 如何使用wait()和notify()? 案例一:单例模式 饿汉式写法: 懒汉式写法 对于它的优化 再次优化 结尾 前言 如何简单的去使用jconsloe 查看线程 (多线程编程篇1)_eclipse查看线程-CSDN博客 浅谈Thread类…...

万物互联时代,AWS IoT Core如何构建企业级物联网中枢平台?
在智能制造、智慧城市、车联网等场景爆发的今天,全球物联网设备数量已突破150亿台。企业如何高效管理海量设备并挖掘数据价值?AWS IoT Core作为亚马逊云科技推出的全托管物联网平台,正在为数千家企业提供设备连接、数据采集、实时分析的一站式…...

论文阅读:2023 arxiv Safe RLHF: Safe Reinforcement Learning from Human Feedback
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 Safe RLHF: Safe Reinforcement Learning from Human Feedback https://arxiv.org/pdf/2310.12773 https://github.com/PKU-Alignment/safe-rlhf 速览 研究动机ÿ…...

链表相关算法题
小细节 初始化问题 我们这样子new一个ListNode 它里面的默认值是0,所以我们不能这样 如果我们为空,我们要返回null 节点结束条件判断(多创建节点问题) 参考示例3217 解析: 我的答案是多了一个无用节点 这是因为我每…...

招商信诺原点安全:一体化数据安全管理解决方案荣获“鑫智奖”!
近日,“鑫智奖 2025第七届金融数据智能优秀解决方案评选”榜单发布,原点安全申报的《招商信诺:数据安全一体化管理解决方案》荣获「信息安全创新优秀解决方案」。 “鑫智奖第七届金融数据智能优秀解决方案评选”活动由金科创新社主办&#x…...
)
实战篇|多总线网关搭建与量产验证(5000 字深度指南)
引言 1. 环境准备与硬件选型 1.1 项目需求分析 1.2 SoC 与开发板选型 1.3 物理接口与 PCB 设计 1.4 电源与供电保护 2. 软件架构与协议栈移植 2.1 分层架构详解 2.2 协议栈移植步骤 2.3 高可用驱动设计 2.4 映射逻辑与 API 定义 3. 开发流程与实践 3.1 敏捷迭代与里程碑 3.2 核…...

Jenkins 简易使用记录
一、Jenkins 核心功能与适用场景 核心功能: 持续集成(CI):自动构建代码、运行单元测试。持续交付(CD):自动化部署到测试/生产环境。任务调度:定时执行任务(如备份、清理&…...

第十四节:实战场景-何实现全局状态管理?
React.createElement调用示例 Babel插件对JSX的转换逻辑 React 全局状态管理实战与 JSX 转换原理深度解析 一、React 全局状态管理实现方案 1. Context API useReducer 方案(轻量级首选) // 创建全局 Context 对象 const GlobalContext createConte…...

启动vite项目报Unexpected “\x88“ in JSON
启动vite项目报Unexpected “\x88” in JSON 通常是文件被防火墙加密需要寻找运维解决 重启重装npm install...

Jenkins 多分支管道
如果您正在寻找一个基于拉取请求或分支的自动化 Jenkins 持续集成和交付 (CI/CD) 流水线,本指南将帮助您全面了解如何使用 Jenkins 多分支流水线实现它。 Jenkins 的多分支流水线是设计 CI/CD 工作流的最佳方式之一,因为它完全基于 git(源代…...

PHP腾讯云人脸核身获取NONCE ticket
参考腾讯云官方文档: 人脸核身 获取 NONCE ticket_腾讯云 前提条件,已经成功获取了access token。 获取参考文档: PHP腾讯云人脸核身获取Access Token-CSDN博客 public function getTxFaceNonceTicket($uid) {$access_token file_get_c…...
概述——从AWS开始)
云计算(Cloud Computing)概述——从AWS开始
李升伟 编译 无需正式介绍亚马逊网络服务(Amazon Web Services,简称AWS)。作为行业领先的云服务提供商,AWS为全球开发者提供了超过170项随时可用的服务。 例如,Adobe能够独立于IT团队开发和更新软件。通过AWS的服务&…...

51单片机实验五:A/D和D/A转换
一、实验环境与实验器材 环境:Keli,STC-ISP烧写软件,Proteus. 器材:TX-1C单片机(STC89C52RC)、电脑。 二、 实验内容及实验步骤 1.A/D转换 概念:模数转换是将连续的模拟信号转换为离散的数字信…...

重构未来智能:Anthropic 解码Agent设计哲学三重奏
第一章 智能体进化论:从工具到自主体的认知跃迁 1.1 LLM应用范式演进图谱 阶段技术形态应用特征代表场景初级阶段单功能模型硬编码规则执行文本摘要/分类进阶阶段工作流编排多模型协同调度跨语言翻译流水线高级阶段自主智能体动态决策交互编程调试/客服对话 1.1.…...

MCP协议在纳米材料领域的深度应用:从跨尺度协同到智能研发范式重构
MCP协议在纳米材料领域的深度应用:从跨尺度协同到智能研发范式重构 文章目录 MCP协议在纳米材料领域的深度应用:从跨尺度协同到智能研发范式重构一、MCP协议的技术演进与纳米材料研究的适配性分析1.1 MCP协议的核心架构升级1.2 纳米材料研发的核心挑战与…...

.NET Core 服务实现监控可观测性最佳实践
.NET Core 概述 .Net Core 是一个开源的、跨平台的高性能框架,由微软开发并维护,现由 .NET Foundation 提供支持。它用于构建现代化、可扩展的云端和本地应用程序,支持开发 Web 应用、微服务、API、物联网应用以及移动后端服务,是…...