2025.4.20机器学习笔记:文献阅读
2025.4.20周报
- 题目信息
- 摘要
- 创新点
- 网络架构
- 实验
- 生成性能对比
- 预测性能对比
- 结论
- 不足以及展望
题目信息
- 题目: A novel flood forecasting model based on TimeGAN for data-sparse basins
- 期刊: Stochastic Environmental Research and Risk Assessment
- 作者: Chang Chen, Fan Wang, Zhongxiang Wang, Dawei Zhang, Liyun Xiang
- 发表时间: 2025
- 文章链接:https://link.springer.com/article/10.1007/s00477-025-02968-4
摘要
随着城市化加速,城市洪涝防治对高精度洪水预报需求迫切。当前模型分为物理机制驱动与数据驱动两类:传统水文模型依赖精确地理数据且计算复杂;数据驱动模型虽效率高,但神经网络需要大量洪水时序数据,而实际洪灾事件稀少导致样本不足,易引发过拟合问题。针对TimeGAN在洪水场景的应用局限,本文提出新型双注意力数据增强网络TW-TimeGAN。该模型创新融合Transformer架构与Wasserstein距离损失函数,有效解决梯度异常问题,提升长期序列预测稳定性;通过特征-时间双注意力机制与RNN结合,增强了对降雨径流时空特征的提取能力。采用济南黄台桥流域1998-2021年实测数据进行验证,结果表明TW-TimeGAN-BiLSTM模型在纳什效率系数等关键指标上表现最优,预测精度较传统LSTM提升12.3%,有效解决了小样本条件下的模型泛化难题。研究为水文建模提供了兼顾物理机制与数据驱动优势的新方法,显著提高了城市洪水预警的可靠性和时效性。
创新点
作者提出基于双注意力机制的TW - TimeGAN,其嵌入Transformer和Wasserstein距离损失函数,提升长期预测准确性与鲁棒性;且首次将Wasserstein距离与洪水预测结合和在恢复函数中引入特征 - 时间双注意力机制,增强特征提取能力。
网络架构
有关于GAN和TimeGAN的一些概念和前置知识我之前有介绍过,这里就不再赘述了。链接如下:https://blog.csdn.net/Zcymatics/article/details/145981612?spm=1001.2014.3001.5501
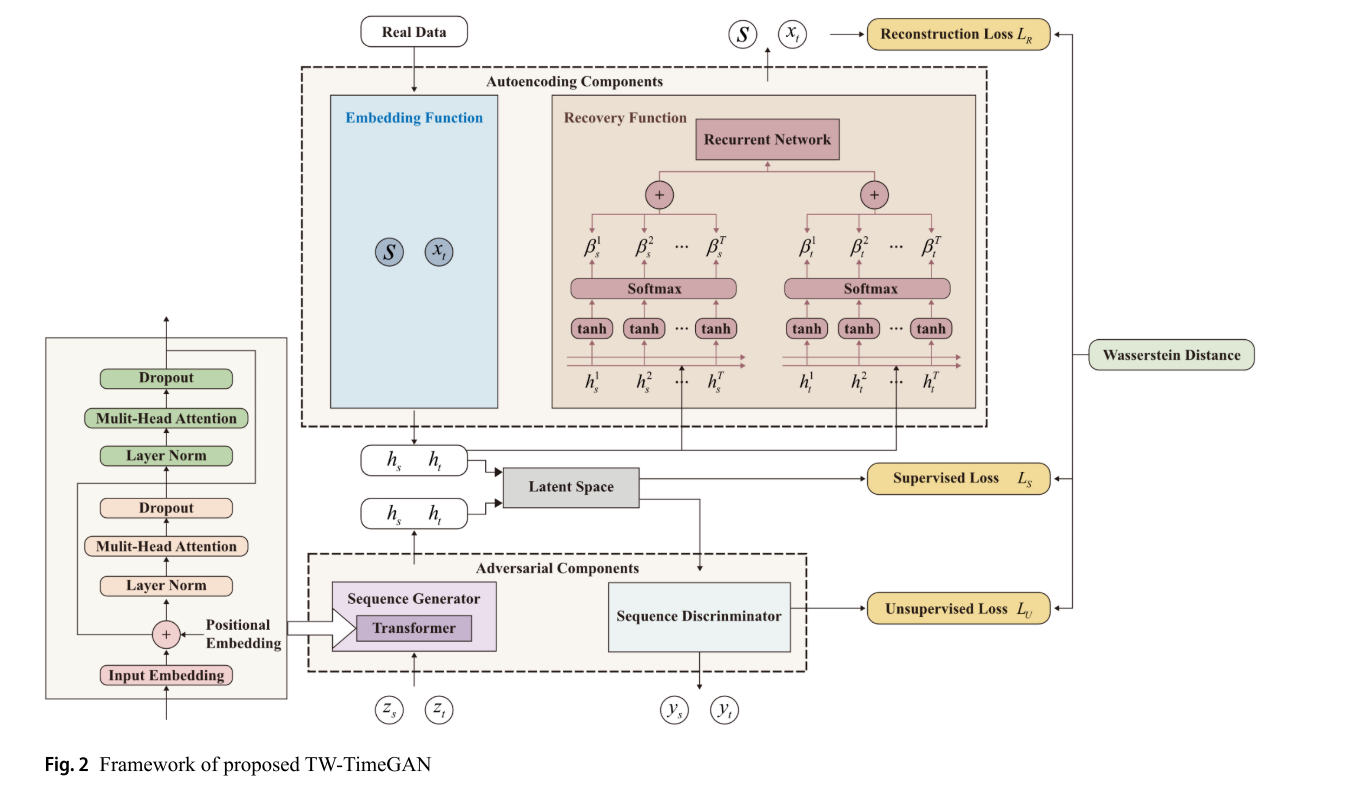
接下来就来详细解释一下本论文构建TW - TimeGAN模型,嵌入Transformer编码器结构,采用Wasserstein距离损失函数,引入特征 - 时间双注意力机制。其网络架构包含的内容如下:
双注意力机制增强了模型对这些特征和关系的提取能力,提高了合成数据的质量。其中包括:
特征注意力:用于关注不同特征(如降雨和径流)之间的关系。
时间注意力:用于关注时间序列中的时间依赖性。
下图中的模型框架的解释:
嵌入函数:
将原始序列映射到潜在空间。输入 为 x(真实洪水序列) 到嵌入函数,通过嵌入函数映射为潜在代码 h t h_t ht
序列生成器
关于Transformer可以看我之前的博客:https://blog.csdn.net/Zcymatics/article/details/142283856?spm=1001.2014.3001.5501与https://blog.csdn.net/Zcymatics/article/details/142406494?spm=1001.2014.3001.5501
通过嵌入Transformer编码器,从随机噪声生成合成序列,过程如下:
- 噪声通过transformer的嵌入层添加位置编码,位置编码确保Transformer能捕捉时间依赖性,公式如下: P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos); P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)。其中pos 是序列中的位置;i 是维度索引;dmodel是模型的嵌入维度;PE 是位置编码向量。
- Transformer编码器通过多头注意力处理,多头注意力允许模型同时关注序列中的多个时间点,捕捉降雨和径流之间的复杂关系。 Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V,其中Q(查询)、K(键)、V(值)是输入序列的线性变换表示;d表示维度。
序列判别器
用于判断序列真假,使用Wasserstein距离优化。接收真实序列x 和合成序列 x ^ \hat{x} x^,计算Wasserstein距离: L W = E x ∼ p x [ D ( x ) ] − E z ∼ p z [ D ( G ( z ) ) ] L_W = \mathbb{E}_{x \sim p_x}[D(x)] - \mathbb{E}_{z \sim p_z}[D(G(z))] LW=Ex∼px[D(x)]−Ez∼pz[D(G(z))]。其中,Wasserstein距离衡量真实分布 𝑝𝑥和生成分布pG(z)之间的差异,判别器 D 估计分布间的距离,生成器 G 最小化此距离。
恢复函数
其用于从潜在空间重建序列,嵌入特征-时间双注意力机制。
时间注意力机制用于提取关键时刻,计算潜在代码的时间特征权重,其中:
- e t = v a T ⋅ tanh ( W a h t + b a ) e_t = v_a^T \cdot \tanh(W_a h_t + b_a) et=vaT⋅tanh(Waht+ba)。通过非线性变换计算每个时间步的注意力得分。
- α t = softmax ( e t ) = exp ( e t ) ∑ t ′ = 1 T exp ( e t ′ ) \alpha_t = \text{softmax}(e_t) = \frac{\exp(e_t)}{\sum_{t'=1}^T \exp(e_{t'})} αt=softmax(et)=∑t′=1Texp(et′)exp(et)。将得分归一化为权重,表示各时间步的相对重要性。
- c = ∑ t = 1 T α t h t c = \sum_{t=1}^T \alpha_t h_t c=∑t=1Tαtht。根据权重加权隐藏状态,生成时间注意力输出。
其中 ht是时间步的隐藏状态;et是注意力得分;α t是归一化权重;c 是加权后的上下文向量。
损失函数:
三个损失函数协同优化,分别如下:
- 重构损失: L R = E x ∼ p x [ ∥ x − x ^ ∥ 2 2 ] L_R = \mathbb{E}_{x \sim p_x} \left[ \| x - \hat{x} \|_2^2 \right] LR=Ex∼px[∥x−x^∥22]
衡量原始时间序列x与生成的序列 x ^ \hat{x} x^ 之间的均方误差。确保嵌入和恢复函数能保留原始数据的特征。 - 监督损失 : L S = E x ∼ p x [ ∑ t = 1 T ∥ h t − h ^ t ∥ 2 2 ] L_S = \mathbb{E}_{x \sim p_x} \left[ \sum_{t=1}^T \| h_t - \hat{h}_t \|_2^2 \right] LS=Ex∼px[∑t=1T∥ht−h^t∥22]
衡量真实潜在表示 h t h_t ht和生成潜在表示 h ^ t \hat{h}_t h^t的差值,确保生成器捕捉时间动态 - 无监督损失: L U = E x ∼ p x [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] L_U = \mathbb{E}_{x \sim p_x} \left[ \log D(x) \right] + \mathbb{E}_{z \sim p_z} \left[ \log (1 - D(G(z))) \right] LU=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]
传统GAN对抗损失,优化判别器区分真假序列,生成器生成逼真序列G是生成器,D是判别器。
实验
这篇论文围绕基于TimeGAN改进的TW - TimeGAN模型在洪水预测中的应用展开实验,从生成性能和预测性能两方面进行评估,采用t - SNE评估生成性能,DTW定量比较实际和合成时间序列数据的相似度,用RMSE、MAE、NSE等评估预测性能。
其中:
- DTW(动态时间规整),用于衡量时间序列相似性,通过动态规划找到两个序列的最佳对齐路径,计算累积距离。值越小,序列越相似。
DTW ( X , Y ) = min π ∑ ( i , j ) ∈ π d ( x i , y j ) \text{DTW}(X, Y) = \min_{\pi} \sum_{(i,j) \in \pi} d(x_i, y_j) DTW(X,Y)=minπ∑(i,j)∈πd(xi,yj)
X,Y 是两个时间序列;π 是对齐路径;d(xi,yj)是欧氏距离 - NSE衡量预测值与真实值的拟合度,是真实值均值。值接近1表示预测准确,公式如下:
NSE = 1 − ∑ i = 1 N ( y i − y ^ i ) 2 ∑ i = 1 N ( y i − y ˉ ) 2 \text{NSE} = 1 - \frac{\sum_{i=1}^N (y_i - \hat{y}_i)^2}{\sum_{i=1}^N (y_i - \bar{y})^2} NSE=1−∑i=1N(yi−yˉ)2∑i=1N(yi−y^i)2
y ˉ \bar{y} yˉ是真实值的均值;y_i真实值; y ^ i \hat{y}_i y^i预测值
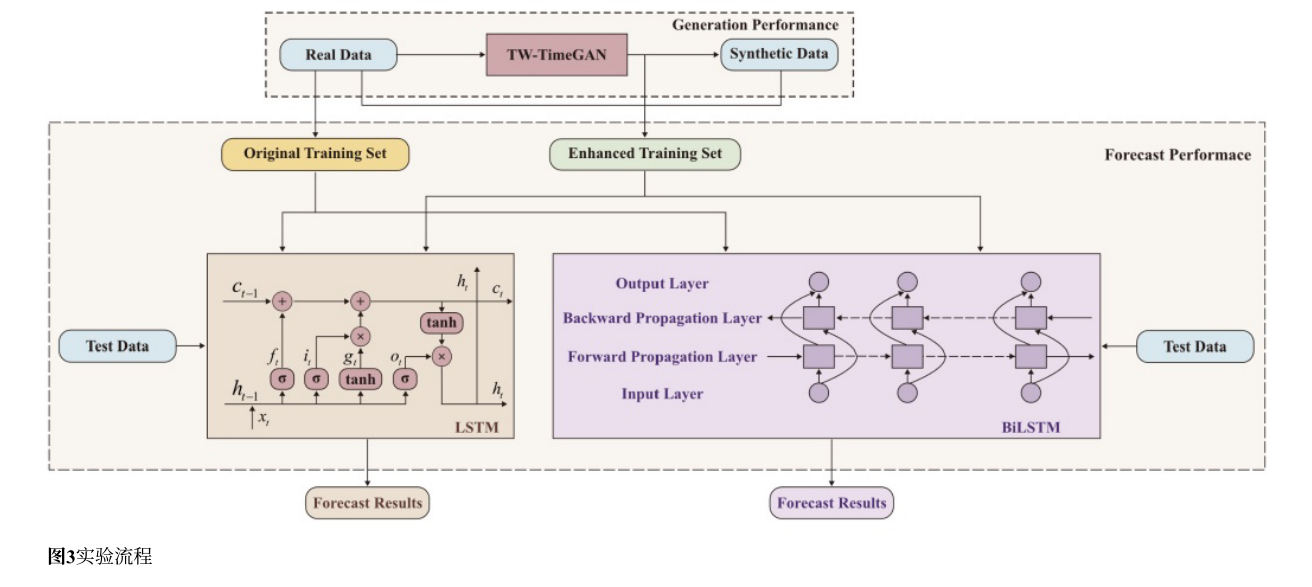
实验流程如下图所示:
作者使用原始TimeGAN和其他改进的生成模型生成真实和合成的洪水序列。这些模型包括不同的改进版本,用于比较生成性能。
将不同方法生成的合成洪水序列的分布与真实序列的分布进行比较,以评估合成样本的真实性;随后,使用上述数据增强方法扩充训练数据,并比较扩充前后洪水预报结果,评估生成数据的有效性;扩充数据包括真实数据和合成数据,比较旨在验证合成数据是否提升了预报性能;通过比较五种模型,证明TW-TimeGAN的综合优势。
实验结果如下:
生成性能对比
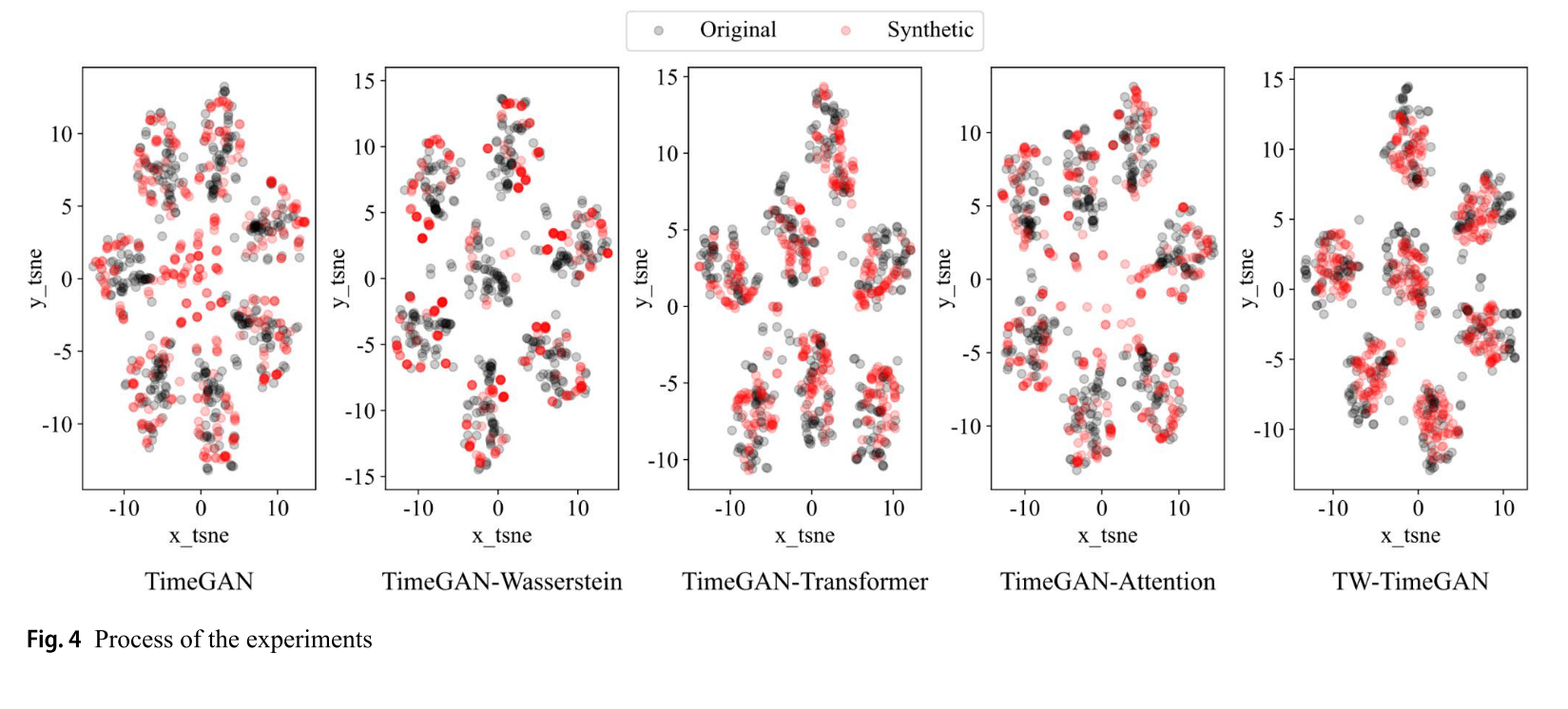
不同模型生成序列的相似度对比:研究使用原始TimeGAN、TimeGAN - Wasserstein、TimeGAN - Transformer、TimeGAN - Attention和TW - TimeGAN五种模型生成合成洪水序列。通过DTW评估,TW - TimeGAN的DTW值最低,表明其生成的合成洪水序列与实际洪水序列相似度最高,数据质量最佳。

t - SNE可视化对比:原始TimeGAN生成的合成洪水序列有较多离群值,分布与实际序列差异大;TimeGAN - Wasserstein生成的序列分布接近实际序列,但数据点多集中在周边,未能充分捕捉实际洪水序列特征;TimeGAN - Transformer和TimeGAN - Attention覆盖了更多实际洪水序列特征;TW - TimeGAN生成的合成数据与实际数据分布重叠度最高,能有效学习降水和流量特征,生成的合成洪水序列更具多样性。
预测性能对比
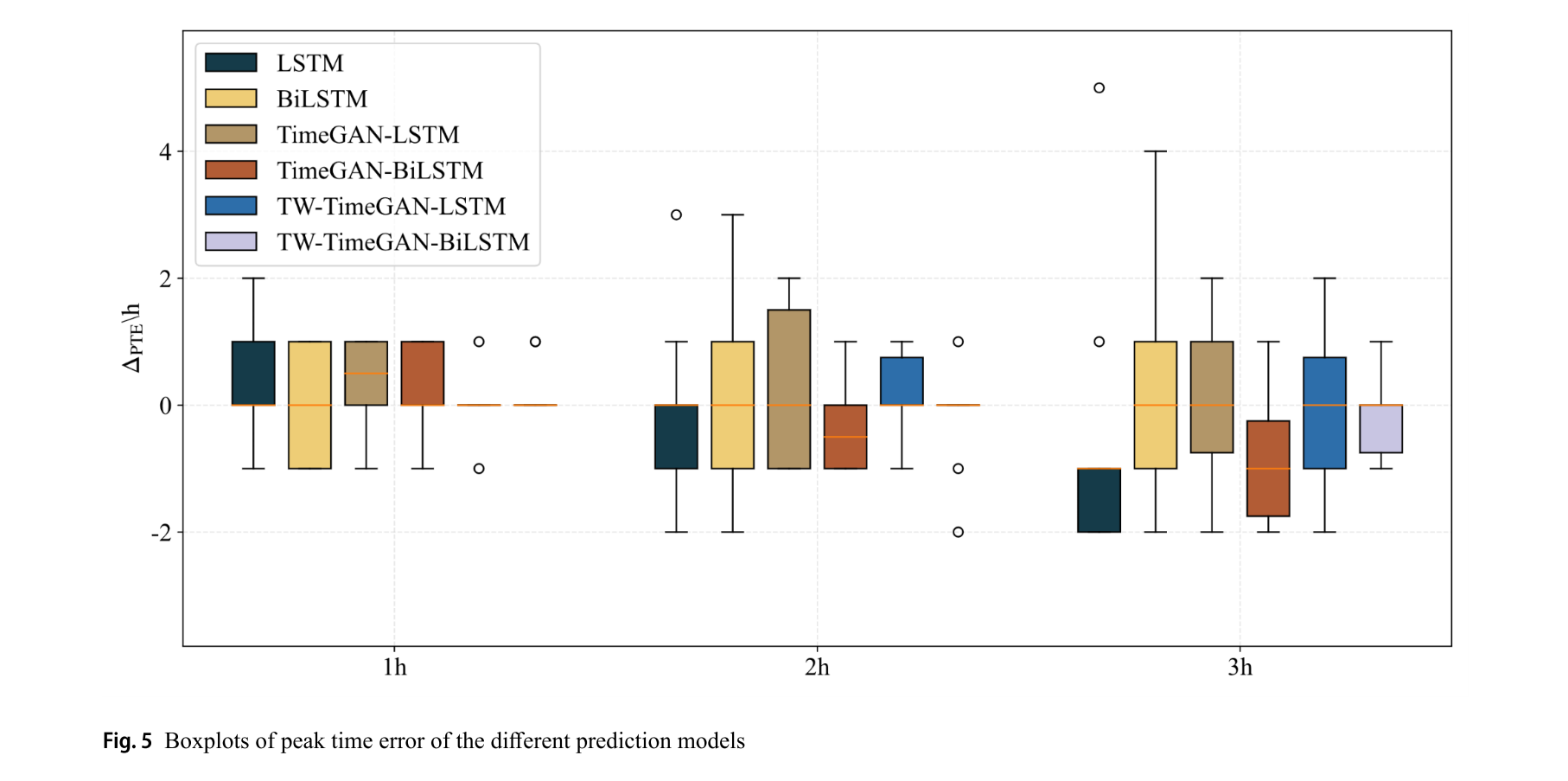
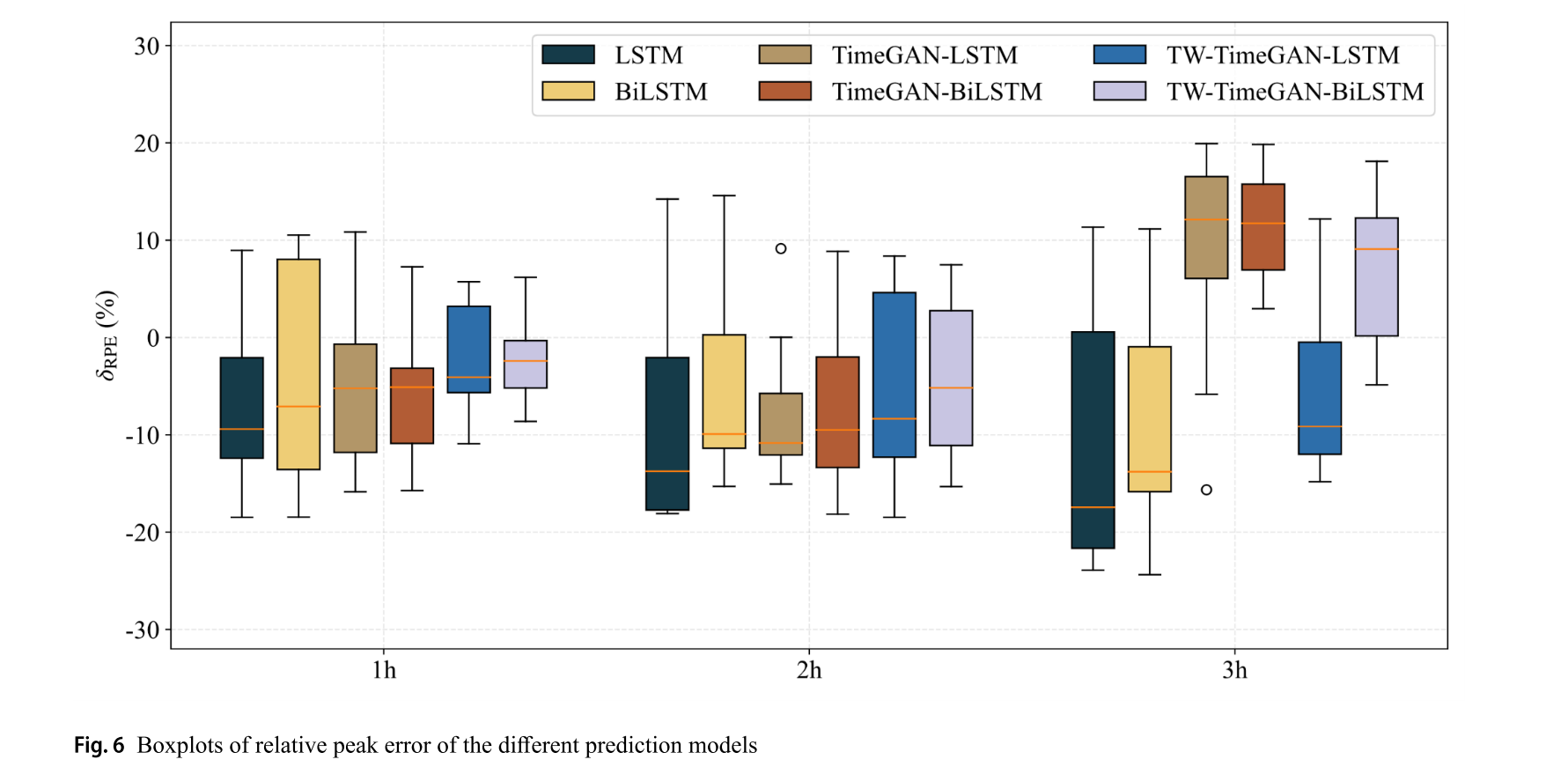
峰值时间误差:原始小样本洪水预测中,LSTM和BiLSTM模型的峰值时间误差随提前时间增加而增大,在T + 3时出现偏差为4H和5H的离群值;引入TimeGAN在T + 1和T + 2时对峰值时间误差影响小;TW - TimeGAN显著降低了峰值时间误差,分布更集中,预测准确性提高。
峰值流量预测:LSTM和BiLSTM模型严重低估峰值流量,且预测准确性随提前时间增加而下降;TimeGAN - LSTM和TimeGAN - BiLSTM模型相对峰值误差较小,但预测结果波动大;TW - TimeGAN使预测结果分布更集中,相对峰值误差最小,虽随预测步长增加误差分布逐渐分散,但仍优于其他模型。
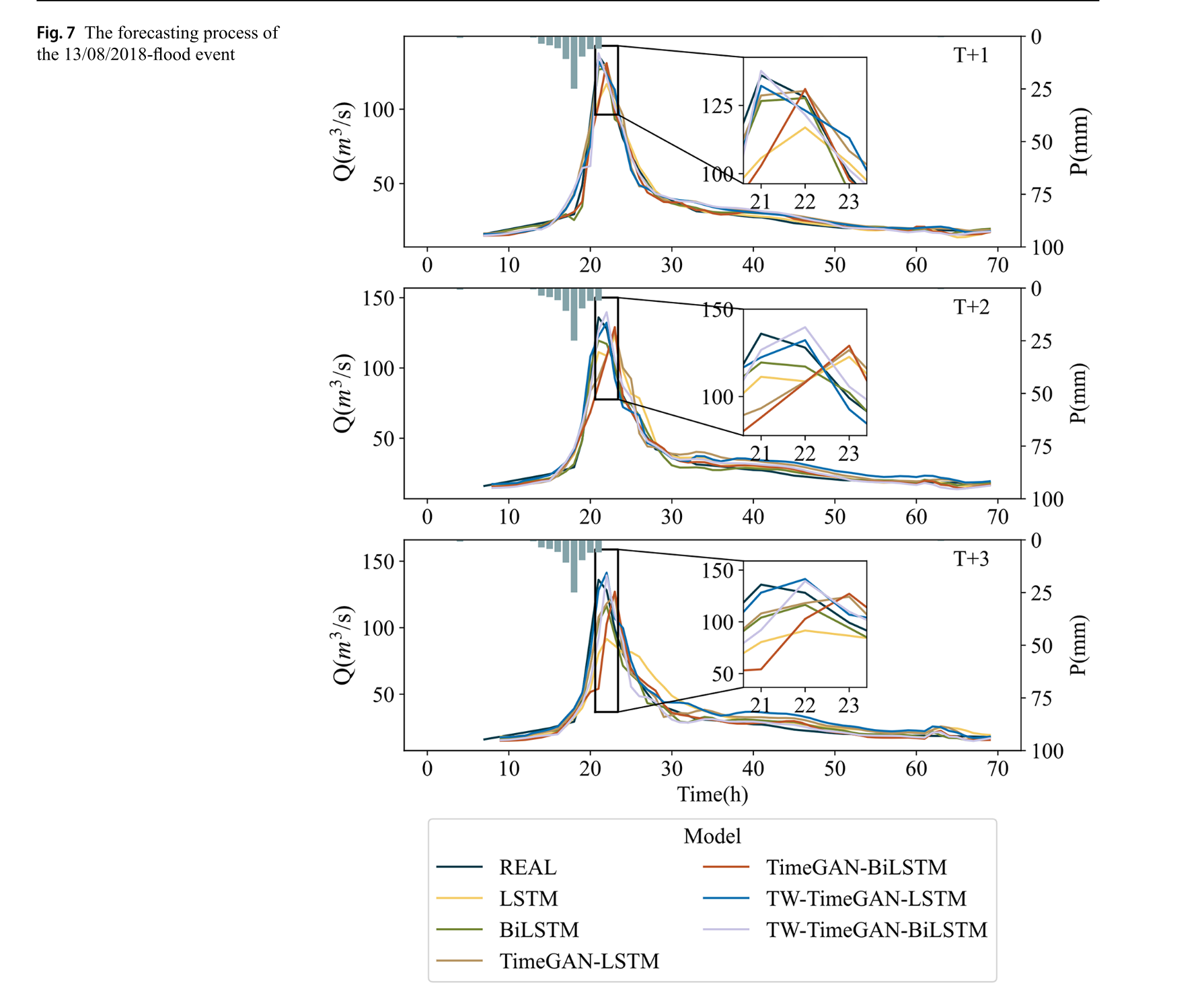
具体洪水事件预测过程分析
2018年8月13日洪水事件:LSTM模型严重低估峰值流量,预测准确性低;BiLSTM模型在T + 1时能估计峰值流量,但随提前时间增加预测能力下降;TimeGAN - LSTM和TimeGAN - BiLSTM模型在峰值流量预测上优于前两者,但在峰值时间误差预测上表现弱;TW - TimeGAN - LSTM和TW - TimeGAN - BiLSTM模型在峰值流量预测上表现出色,能模拟洪水涨落过程,其中TW - TimeGAN - BiLSTM预测结果更准确。
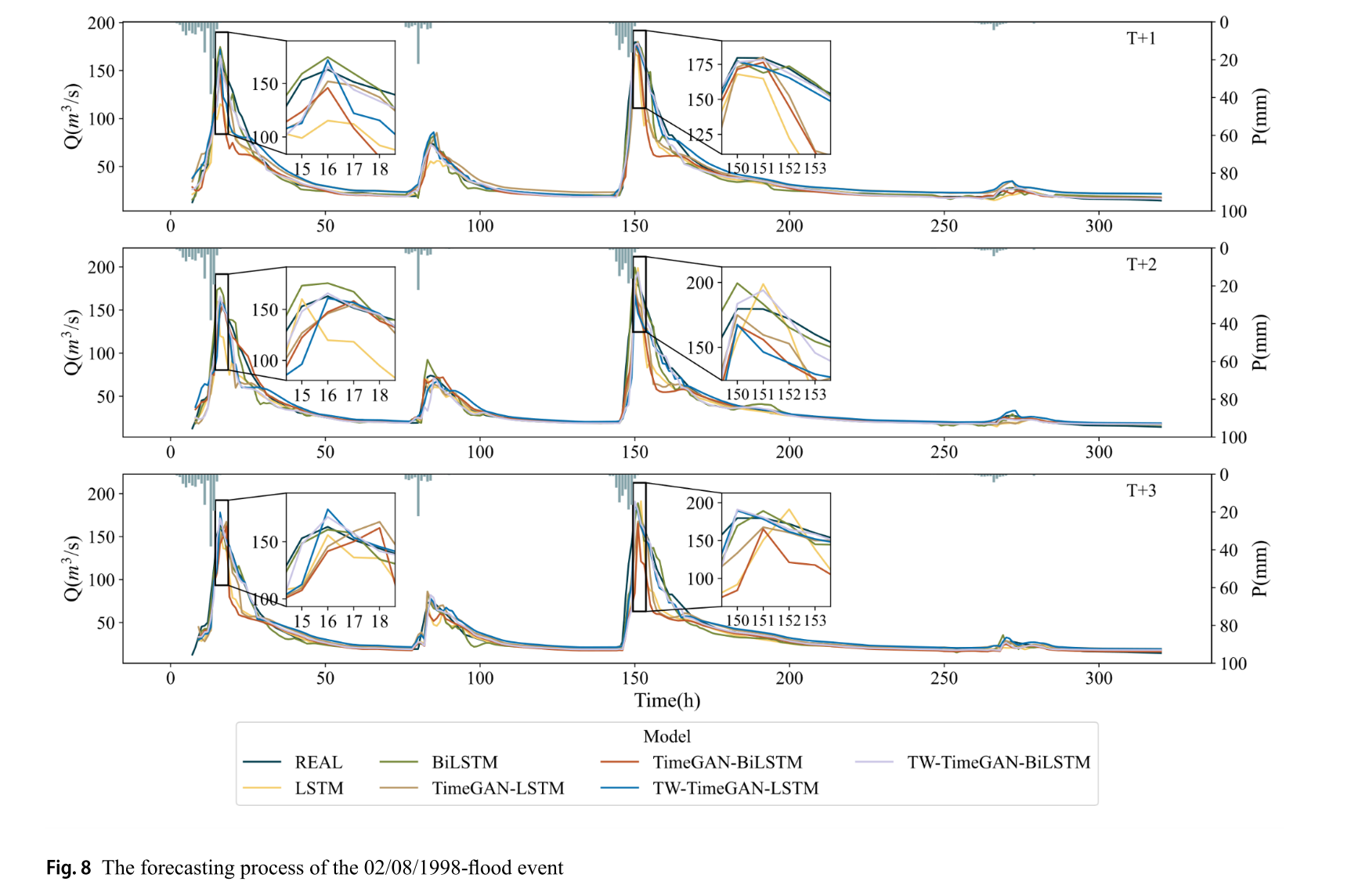
1998年8月2日洪水事件:LSTM模型波动大,预测性能最差;BiLSTM模型高估峰值流量,不利于防洪决策;TimeGAN - LSTM和TimeGAN - BiLSTM模型能较好模拟峰值流量,但严重高估退水过程;TW - TimeGAN - LSTM模型低估洪水上涨过程;TW - TimeGAN - BiLSTM模型在T + 1和T + 2时准确捕捉峰值流量和退水过程,T + 3时虽略微高估峰值流量,但相对误差小,预测结果更准确。
论文代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 超参数设置
batch_size = 64
seq_len = 24 # 时间序列长度(如24小时)
feature_dim = 2 # 特征维度(如降雨和径流)
hidden_dim = 64 # 隐藏层维度
num_heads = 4 # Transformer多头注意力头数
num_layers = 2 # Transformer层数
latent_dim = 32 # 潜在空间维度
lambda_gp = 10 # 梯度惩罚权重
lr = 0.0002 # 学习率
num_epochs = 100 # 训练轮数# 设置随机种子以确保可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 模拟洪水时间序列数据
def generate_synthetic_data(batch_size, seq_len, feature_dim):# 使用正弦波叠加噪声模拟降雨和径流t = np.linspace(0, 2 * np.pi, seq_len)data = np.zeros((batch_size, seq_len, feature_dim))for i in range(batch_size):for j in range(feature_dim):data[i, :, j] = np.sin(t + np.random.randn() * 0.1) + np.random.randn(seq_len) * 0.05return torch.FloatTensor(data).to(device)# Transformer编码器模块
class TransformerEncoder(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(TransformerEncoder, self).__init__()# 输入线性层self.input_linear = nn.Linear(input_dim, hidden_dim)# Transformer编码器层encoder_layer = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=num_heads, dim_feedforward=hidden_dim * 4, dropout=0.1)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 位置编码self.positional_encoding = self.create_positional_encoding(seq_len, hidden_dim)def create_positional_encoding(self, seq_len, d_model):# 实现位置编码position = torch.arange(0, seq_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))pe = torch.zeros(seq_len, d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pe.unsqueeze(0).to(device)def forward(self, x):# x: [batch_size, seq_len, input_dim]x = self.input_linear(x) # 映射到隐藏维度x = x + self.positional_encoding[:, :x.size(1), :] # 添加位置编码x = x.permute(1, 0, 2) # [seq_len, batch_size, hidden_dim]output = self.transformer_encoder(x) # Transformer编码return output.permute(1, 0, 2) # [batch_size, seq_len, hidden_dim]# 特征-时间双注意力机制(用于恢复函数)
class DualAttention(nn.Module):def __init__(self, hidden_dim):super(DualAttention, self).__init__()# 特征注意力self.feature_attn = nn.Sequential(nn.Linear(hidden_dim, hidden_dim // 2),nn.Tanh(),nn.Linear(hidden_dim // 2, 1))# 时间注意力self.time_attn = nn.Sequential(nn.Linear(hidden_dim, hidden_dim // 2),nn.Tanh(),nn.Linear(hidden_dim // 2, 1))def forward(self, h):# h: [batch_size, seq_len, hidden_dim]# 特征注意力feature_scores = self.feature_attn(h) # [batch_size, seq_len, 1]feature_weights = torch.softmax(feature_scores, dim=-1)feature_context = h * feature_weights # 加权特征# 时间注意力time_scores = self.time_attn(feature_context) # [batch_size, seq_len, 1]time_weights = torch.softmax(time_scores, dim=1) # [batch_size, seq_len, 1]context = torch.sum(feature_context * time_weights, dim=1) # [batch_size, hidden_dim]return context# 序列生成器
class Generator(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_heads, num_layers):super(Generator, self).__init__()self.transformer = TransformerEncoder(input_dim, hidden_dim, num_heads, num_layers)self.output_linear = nn.Linear(hidden_dim, output_dim)def forward(self, z):# z: [batch_size, seq_len, input_dim]h = self.transformer(z) # Transformer编码output = self.output_linear(h) # 映射到输出维度return output # [batch_size, seq_len, output_dim]# 序列判别器
class Discriminator(nn.Module):def __init__(self, input_dim, hidden_dim):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.LeakyReLU(0.2),nn.Linear(hidden_dim, hidden_dim // 2),nn.LeakyReLU(0.2),nn.Linear(hidden_dim // 2, 1))def forward(self, x):# x: [batch_size, seq_len, input_dim]x = x.view(x.size(0), -1) return self.model(x) # [batch_size, 1]# 嵌入函数
class Embedder(nn.Module):def __init__(self, input_dim, latent_dim):super(Embedder, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, latent_dim),nn.ReLU(),nn.Linear(latent_dim, latent_dim))def forward(self, x):return self.model(x) # [batch_size, seq_len, latent_dim]# 恢复函数(包含双注意力)
class Recovery(nn.Module):def __init__(self, latent_dim, hidden_dim, output_dim):super(Recovery, self).__init__()self.attention = DualAttention(hidden_dim)self.model = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim))def forward(self, h):# h: [batch_size, seq_len, latent_dim]h = self.model(h) # 映射context = self.attention(h) # 双注意力output = self.model(h) # 最终输出return output # [batch_size, seq_len, output_dim]# TW-TimeGAN模型
class TWTimeGAN(nn.Module):def __init__(self):super(TWTimeGAN, self).__init__()self.generator = Generator(latent_dim, hidden_dim, latent_dim, num_heads, num_layers)self.discriminator = Discriminator(feature_dim * seq_len, hidden_dim)self.embedder = Embedder(feature_dim, latent_dim)self.recovery = Recovery(latent_dim, hidden_dim, feature_dim)def forward(self, x, z):# 嵌入和恢复h = self.embedder(x) # 真实序列嵌入x_hat = self.recovery(h) # 重构序列# 生成h_hat = self.generator(z) # 生成潜在代码x_tilde = self.recovery(h_hat) # 生成序列# 判别y_real = self.discriminator(x) # 真实序列得分y_fake = self.discriminator(x_tilde) # 生成序列得分return h, x_hat, h_hat, x_tilde, y_real, y_fake# 梯度惩罚计算
def compute_gradient_penalty(D, real_samples, fake_samples):alpha = torch.rand(real_samples.size(0), 1, 1).to(device)alpha = alpha.expand_as(real_samples)interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)d_interpolates = D(interpolates)gradients = torch.autograd.grad(outputs=d_interpolates,inputs=interpolates,grad_outputs=torch.ones_like(d_interpolates),create_graph=True,retain_graph=True)[0]gradients = gradients.view(gradients.size(0), -1)gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()return gradient_penalty# 训练函数
def train_tw_timegan():# 初始化模型model = TWTimeGAN().to(device)optimizer_g = optim.Adam(list(model.generator.parameters()) + list(model.embedder.parameters()) + list(model.recovery.parameters()),lr=lr, betas=(0.5, 0.9))optimizer_d = optim.Adam(model.discriminator.parameters(), lr=lr, betas=(0.5, 0.9))# 训练循环for epoch in range(num_epochs):# 生成批次数据real_data = generate_synthetic_data(batch_size, seq_len, feature_dim)z = torch.randn(batch_size, seq_len, latent_dim).to(device)# 前向传播h, x_hat, h_hat, x_tilde, y_real, y_fake = model(real_data, z)# 计算损失# 重构损失loss_reconstruction = torch.mean((real_data - x_hat) ** 2)# 监督损失loss_supervised = torch.mean((h - h_hat) ** 2)# Wasserstein判别器损失gradient_penalty = compute_gradient_penalty(model.discriminator, real_data, x_tilde)loss_discriminator = -torch.mean(y_real) + torch.mean(y_fake) + lambda_gp * gradient_penalty# Wasserstein生成器损失loss_generator = -torch.mean(y_fake)# 联合生成器损失loss_g_total = loss_generator + 10 * loss_reconstruction + 5 * loss_supervised# 优化optimizer_d.zero_grad()loss_discriminator.backward(retain_graph=True)optimizer_d.step()optimizer_g.zero_grad()loss_g_total.backward()optimizer_g.step()# 打印损失if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch+1}/{num_epochs}] | D Loss: {loss_discriminator.item():.4f} | G Loss: {loss_g_total.item():.4f}")# 运行训练
if __name__ == "__main__":train_tw_timegan()
结论
本文提出增强型数据增强网络TW - TimeGAN用于小样本洪水序列预测。实验表明,该模型能有效学习降水和流量特征,生成高质量合成洪水序列。结合BiLSTM预测模型,其预测结果的平均RMSE和MAE最小,NSE最大,TW - TimeGAN - BiLSTM预测性能最佳,在洪水预测中适用性更强,还能优化水资源管理。
不足以及展望
文章未提及模型在不同气候、地理条件下的泛化能力,也未对模型训练的计算成本和时间进行分析。此外,仅使用了有限的评价指标评估模型性能,可能无法全面反映模型优劣。后续研究可整合卫星观测气象数据、蒸发数据及地面观测站数据,纳入土壤湿度、温度和融雪等特征,增强合成洪水序列的真实性与多样性。还可进一步探索模型在不同流域、气候条件下的适用性,优化模型结构和参数,提高预测精度。同时,分析模型训练的计算成本和时间,提升模型的实用性。
相关文章:

2025.4.20机器学习笔记:文献阅读
2025.4.20周报 题目信息摘要创新点网络架构实验生成性能对比预测性能对比 结论不足以及展望 题目信息 题目: A novel flood forecasting model based on TimeGAN for data-sparse basins期刊: Stochastic Environmental Research and Risk Assessment作…...

Leetcode 3359. 查找最大元素不超过 K 的有序子矩阵【Plus题】
1.题目基本信息 1.1.题目描述 给定一个大小为 m x n 的二维矩阵 grid。同时给定一个 非负整数 k。 返回满足下列条件的 grid 的子矩阵数量: 子矩阵中最大的元素 小于等于 k。 子矩阵的每一行都以 非递增 顺序排序。 矩阵的子矩阵 (x1, y1, x2, y2) 是通过选择…...

Redis面试——事务
一、Redis原子性是什么? (1)单个命令的原子性 原子性是指一组操作,要么全部执行成功,要么全部失败。Redis 中的单个命令是天然原子性的,因为 Redis 的命令执行采用单线程模型,同一时间只会执行…...

【远程管理绿联NAS】家庭云存储无公网IP解决方案:绿联NAS安装内网穿透
文章目录 前言1. 开启ssh服务2. ssh连接3. 安装cpolar内网穿透4. 配置绿联NAS公网地址 前言 大家好,今天要带给大家一个超级酷炫的技能——如何让绿联NAS秒变‘千里眼’,通过简单的几步操作就能轻松实现内网穿透。想象一下,无论你身处何地&a…...

AI写程序:用 AI 实现一个递归批量转化 GBK/GB2312 转 UTF-8 工具:轻松解决文本编码转换难题
用 AI 实现一个递归批量转化 GBK/GB2312 转 UTF-8 工具 在处理历史文件或与不同系统交互时,我们经常会遇到 GBK 或 GB2312 编码的文本文件。虽然现在 UTF-8 是主流,但手动转换这些旧编码文件既繁琐又容易出错。为了解决这个问题,我开发了一个…...
的详细解析)
首席人工智能官(Chief Artificial Intelligence Officer,CAIO)的详细解析
以下是**首席人工智能官(Chief Artificial Intelligence Officer,CAIO)**的详细解析: 1. 职责与核心职能 制定AI战略 制定公司AI技术的长期战略,明确AI在业务中的应用场景和优先级,推动AI与核心业务的深度…...

uview1.0 tabs组件放到u-popup中在微信小程序中滑块样式错乱
解决思路 重新计算布局信息:在弹窗显示后重新调用 init 方法来计算组件的布局信息。使用 nextTick:保证在视图更新之后再进行布局信息的计算。 <u-tabs ref"tabsRef" ></u-tabs> makeClick(){this.makeShowtruethis.$nextTick…...

私人笔记:动手学大模型应用开发llm-universe项目环境创建
项目代码:datawhalechina/llm-universe: 本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/ 项目书:动手学大模型应用开发 一、初始化项目 uv init llm-universe-te…...
,源码可白嫖!)
基于Django框架的图书索引智能排序系统设计与实现(源码+lw+部署文档+讲解),源码可白嫖!
摘要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,图书管理系统当然不能排除在外。图书索引智能排序系统是在实际应用和软件工程的开发原理之上,运用Python语言以及Django框架进…...

网络类型学习
网络类型的分类依据-----基于二层(数据链路层)使用的协议不同而导致数据包的封装方式不同,工作方式也不同。 OSPF协议根据链路层协议类型将网络分为四种类型:广播型网络(BMA)、非广播多路访问(…...

ubuntu24.04离线安装deb格式的mysql-community-8.4.4
1,下载解压 参考: https://blog.csdn.net/2202_76101487/article/details/145967039 下载: wget https://cdn.mysql.com//Downloads/MySQL-8.4/mysql-server_8.4.4-1ubuntu24.04_amd64.deb-bundle.tar 建议个目录mysql8然后把安装包移过去&…...

电控---printf重定向输出
在嵌入式系统开发中,printf 重定向输出是将标准输出(stdout)从默认设备(如主机终端)重新映射到嵌入式设备的特定硬件接口(如串口、LCD、USB等)的过程。 一、核心原理:标准IO库的底层…...

uniapp使用createSelectorQuery,boundingClientRect获取宽度和高度不准确的可用的解决方案
场景展示: uniapp使用createSelectorQuery,boundingClientRect获取宽度和高度不准确的可用的解决方案,正常来说,使用下面的代码是可以正确获得宽高的,但是里面含有图片,在图片没有加载完的情况下,我们可以…...

DSO:牛津大学推出的物理一致性3D模型优化框架
在数字内容创作和制造领域,将2D图像转换为高质量、物理上稳定的3D模型一直是一个挑战。传统的3D建模方法往往需要大量的手动调整以确保生成的物体不仅美观而且符合物理定律,能够在现实世界中稳定存在。牛津大学近期推出了一款名为DSO(Direct Sparse Odometry)的项目,它不仅…...

Delphi Ini文件对UTF8支持不爽的极简替代方案
如题,没太多废话,直接复制走即可。 unit uConfig;interfaceuses classes, Sysutils;typeTConfig class privateFFileName: String;FConfig:TStringList; protectedpublicconstructor Create(ConfigFile:String);destructor Destroy;property FileName…...

Windows平台使用Docker部署Neo4j
✅ Docker 安装 Neo4j 前提条件:安装docker 打开docker desktop docker run \--name neo4j \-p7474:7474 -p7687:7687 \-d \-e NEO4J_AUTHneo4j/password123 \neo4j:5默认用户名是 neo4j,密码是你设置的,比如上面是 password123 ✅用 Pyt…...

FreeRTOS二值信号量详解与实战教程
FreeRTOS二值信号量详解与实战教程 📚 作者推荐:想系统学习FreeRTOS嵌入式开发?请访问我的FreeRTOS开源学习库,内含从入门到精通的完整教程和实例代码! 1. 二值信号量核心概念解析 二值信号量(Binary Semaphore)是Fre…...

数据结构与算法[零基础]---6.算法概况
六、算法概述 (一)算法的概述 任何解决问题的过程都是由一定的步骤组成的,把解决问题的方法和有限的步骤称作算法 (二)算法的基本特征 1.有穷性 算法必须在执行有限个操作之后终止,且每一步都可在有限时间内完成。 2.确定性 算…...
)
STL简介(了解)
1.什么是STL STL(standard template libaray)是标准模板库,它是C标准库的一部分。C标准库中还有一些其它东西,比如之前用的IO流。它主要是数据结构和算法的库。 2.STL的版本 C3.0出来后就有了模板,此时大家已经深受没有数据结构算法库的痛苦…...

使用 Oh My Posh 自定义 PowerShell 提示符
使用 Oh My Posh 自定义 PowerShell 提示符 由于ai生图,ai视频这方面mac太差了,买N卡,转windows了,这里也记录一下 PowerShell 配置Oh My Posh 先上效果图 一、下载 PowerShell7 默认的 PowerShell5 太差了,下载地…...

4月17号
//1.编码 String str "ai你哟"; byte[] bytes1 str.getBytes(); System.out.println(Arrays.toString(bytes1)); byte[] bytes2 str.getBytes(charsetName: "GBK"); System.out.println(Arrays.toString(bytes2));//2.解码 String str2 new String(byt…...

react-native搭建开发环境过程记录
主要参考:官网的教程 https://reactnative.cn/docs/environment-setup 环境介绍:macos ios npm - 已装node18 - 已装,通过nvm进行版本控制Homebrew- 已装yarn - 已装ruby - macos系统自带的2.2版本。watchman - 正常安装Xcode - 正常安装和…...
技术。)
自然语言处理(NLP)技术。
自然语言处理(NLP)技术可以应用于多个领域,以下是一些示例: 情感分析:NLP可以用来分析文本中包含的情感,帮助企业了解用户对他们产品或服务的感受。例如,社交媒体平台可以利用情感分析技术来监测…...

Ubuntu 安装WPS Office
文章目录 Ubuntu 安装WPS Office下载安装文件安装WPS问题1.下载缺失字体文件2.安装缺失字体 Ubuntu 安装WPS Office 下载安装文件 需要到 WPS官网 下载最新软件,比如wps-office_12.1.0.17900_amd64.deb 安装WPS 执行命令进行安装 sudo dpkg -i wps-office_12.1…...

【WPF】 自定义控件的自定义属性
文章目录 前言一、自定义控件部分二、在页面中使用总结 前言 在一个页面,重复用到同一个自定义控件时,该如何对控件分别进行数据绑定呢?这时候可以赋予控件一个自定义的属性,来完成此操作。 一、自定义控件部分 为自定以控件设置…...

Unity URP Moblie AR示例工程,真机打包出来,没阴影
效果: unity ar示例演示 现象: 真机打包测试私活没有阴影 Unity版本:2022.3.4f1c1 分析原因: Prefab :ARFeatheredPlane中也有材质,一个用于环境遮挡,一个用于阴影接受。 按理说有啊。 urp …...
_word三个减号回车的横线怎么删除-CSDN博客)
如何删除word中的长横线(由三个减号---自动生成/由三个等号===自动生成/由三个###自动生成)_word三个减号回车的横线怎么删除-CSDN博客
方法1、选中前后行ctrlX剪切掉 方法2:如果文件中没有表格就非常简单,直接CtrlA全选整个文档,然后在表格边框里面选择“无框线”OK,如果有表格的话,就从横线的下行开始向上随意选取一部分,同样在表格边框中选…...

函数返回const引用,使用const修饰变量接收
函数返回const引用,使用const修饰变量接收 1、背景 想获取红绿灯时长数组并添加新的值。有个函数是返回红绿灯时长数组的。函数返回类型为const引用,我使用无修饰的变量接收。但是感觉有些问题,并且之前看到const变量变成非const还需要使用…...

在激烈竞争下B端HMI设计怎样打造独特用户体验?
在当今数字化高度发展的时代,B 端市场竞争愈发激烈。对于 B 端 HMI(人机界面)设计而言,打造独特的用户体验已成为在竞争中脱颖而出的关键因素。B 端用户在复杂的工作场景中,对 HMI 设计有着独特的需求和期望࿰…...
综论与跨学科应用)
数理逻辑(Mathematical Logic)综论与跨学科应用
李升伟 整理 数理逻辑(Mathematical Logic)是现代逻辑学与数学交叉的核心学科,以严格的数学方法研究逻辑推理的形式与规律。其发展深刻影响了数学基础、计算机科学、语言哲学等领域。以下从多个维度综论数理逻辑: 1. 核心分支 命…...

4.17---实现商铺和缓存与数据库双写一致以及宕机处理
实现商铺和缓存与数据库双写一致(以及强双写一致策略) redis点评项目采用的是延时双删策略 双删: 我们更新完数据库之后删除缓存,这样即使有线程并发进来查询,会发现缓存中没有数据,从而会去mysql中查找…...

qt与html通信
**Cef视图(CefView)**是指在使用Chromium Embedded Framework(CEF)时,嵌入到应用程序中的浏览器视图。CEF是一个开源项目,它基于Google的Chromium浏览器,允许开发者将Web浏览器功能嵌入到自己的…...

【从零实现高并发内存池】thread cache、central cache 和 page cache 回收策略详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

算法5-16 对二进制字符串解码
输入样例: 5 a 4 b 3 c 2 w 1 z 1 100001110101101101100111输出样例: baaacabwbzc ac代码: #include<iostream> #include<queue> #include<map> using namespace std; const int N10010; int idx; int a[N][2]; char b…...
: 内存结构详解)
[MySQL数据库] InnoDB存储引擎(三): 内存结构详解
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
TDengine 存储引擎剖析:数据文件与索引设计(一)
TDengine 存储引擎简介 在物联网、工业互联网等快速发展的今天,时间序列数据呈爆发式增长。这些数据具有产生频率高、依赖采集时间、测点多信息量大等特点,对数据存储和处理提出了极高要求。TDengine 作为一款高性能、分布式、支持 SQL 的时序数据库&am…...

CentOS更换yum源
CentOS更换yum源 视频教程: https://www.bilibili.com/video/BV1yWaSepE6z/?spm_id_from333.1007.top_right_bar_window_history.content.click 步骤: 第一步: cd /etc/yum.repos.d第二步:cp CentOS-Base.repo CentOS-Base.repo…...

【Kubernetes基础--持久化存储原理】--查阅笔记5
目录 持久化存储机制PV 详解PV 关键配置参数PV 生命周期的各个阶段 PVC 详解PVC 关键配置参数PV 和 PVC 的生命周期 StorageClass 详解StorageClass 关键配置参数设置默认的 StorageClass 持久化存储机制 k8s 对于有状态的容器应用或对数据需要持久化的应用,不仅需…...

数据库子查询实验全解析
目录 一、验证性实验:夯实基础(一)查询同班学生信息(二)查询成绩相关信息(三)查询课程选课人数(四)相关子查询(五)EXISTS嵌套子查询(六…...

HTML:表格数据展示区
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>人员信息表</title><link rel"styl…...

webgl入门实例-08索引缓冲区的基本概念
WebGL 索引缓冲区 (Index Buffer) 索引缓冲区(也称为元素数组缓冲区)是WebGL中一种优化渲染性能的重要机制,它允许您重用顶点数据来绘制复杂的几何图形。 基本概念 索引缓冲区的工作原理: 您创建一个顶点缓冲区(包含所有顶点数据)然后创建一个索引缓…...

大数据应用开发——大数据平台集群部署
目录 前言 目录 基础环境 安装虚拟机 基础环境 VMware Workstation 虚拟机版本 : centos7 主机名 ip 用户名 密码 master192.168.245.100root123456slave1192.168.245.101root123456slave2192.168.245.102root123456 安装虚拟机 安装 名称、路径自己改 我有16核&…...

GPT对话UI--通义千问API
GPT对话UI 项目介绍 一个基于 GPT 的智能对话界面,提供简洁优雅的用户体验。本项目使用纯前端技术栈实现,无需后端服务器即可运行。 功能特点 💬 实时对话:支持与 AI 进行实时对话交互🌓 主题切换:支持…...

智能体数据分析
数据概览: 展示智能体的累计对话次数、累计对话用户数、对话满意度、累计曝光次数。数据分析: 统计对话分析、流量分析、用户分析、行为分析数据指标,帮助开发者完成精准的全面分析。 ps:数据T1更新,当日12点更新前一天…...
)
泛型算法——只读算法(一)
在 C 标准库中,泛型算法的“只读算法”指那些 不会改变它们所操作的容器中的元素,仅用于访问或获取信息的算法,例如查找、计数、遍历等操作。 accumulate std::accumulate()是 C 标准库**numeric**头文件中提供的算法,用于对序列…...
config.txt介绍)
树莓派超全系列教程文档--(29)config.txt介绍
config.txt介绍 什么是 config.txt ?文件格式高级功能include条件过滤 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 什么是 config.txt ? Raspberry Pi 设备使用名为 config.txt 的配置文件,而不是传统 PC …...

第十六届蓝桥杯大赛软件赛省赛 C++ 大学 B 组 部分题解
赛时参加的是Python组,这是赛后写的题解,还有两题暂时还不会,待更新 题目链接题目列表 - 洛谷 | 计算机科学教育新生态 A 移动距离 答案:1576 C 可分解的正整数 Python3 import itertools from functools import cmp_to_ke…...

C++栈与堆内存详解:Visual Studio实战指南
C++栈与堆内存详解:Visual Studio实战指南 IDE环境:Visual Studio 2022 一、内存分区与核心概念 在C++程序中,内存分为**栈(Stack)和堆(Heap)**两大核心区域,两者的管理方式、生命周期和适用场景差异显著。 1. 栈内存(Stack Memory) • 特性: • 自动管理:由编…...

在Ubuntu服务器上部署xinference
一、拉取镜像 docker pull xprobe/xinference:latest二、启动容器(GPU) docker run -d --name xinference -e XINFERENCE_MODEL_SRCmodelscope -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 # 启动一个新的Docker容…...

非洲电商争夺战:中国闪电战遭遇本土游击队的降维打击
2024年5月,南非电商市场爆发史诗级对决——Temu闪电突袭下载量破百万,却在30天内遭遇Takealot的本土化反击致留存率腰斩。这场价值500亿美元市场的攻防战,揭开了非洲电商最残酷的生存法则:低价利刃砍不动本土化铁壁。 一、跨境模式…...