[MySQL数据库] InnoDB存储引擎(三): 内存结构详解
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(97平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(95平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 1. InnoDB存储引擎中内存结构的组成部分有哪些?
- 2. 为什么需要内存结构?
- 3. 缓冲池-Buffer Pool
- 3.1 缓冲池的作用
- 3.2 缓冲池是如何组织数据的?
- 3.2.1 缓冲池的结构是怎样的?
- 3.2.2 缓冲池中页与页之间是如何建立连接的?
- 3.2.3 衍生问题1: 内存中的数据页与磁盘上的数据页是什么关系
- 3.2.4 衍生问题4: Buffer Pool的大小可以设置吗?
- 3.2.5 衍生问题3: chunk的作用是什么?
- 3.2.6 控制块与Page是如何初始化的?
- 3.2.7 可以通过缓冲池来提升性能吗?
- 3.3 缓冲池中的页是如何进行管理的?
- 3.3.1 衍生问题1: 内存中有这么多数据页如何快速找到目标页
- 3.3.2 衍生问题2: 缓冲池中的数据放不下怎么办?
- 3.4 缓冲池采用哪种淘汰策略?是如何实现的?
- 3.4.1 为什么要把页插入到中间而不是直接插入到新子列表的头部?
- 4. 变更缓冲区
- 4.1 变更缓冲区的作用?
- 4.1.1 衍生问题: 为什么是二级索引?
- 4.2 变更缓冲区的主要配置项有哪些?
- 5. 自适应哈希索引
- 5.1 自适应哈希索引的作用
- 5.1.1 衍生问题1: 为什么要建立自适应哈希索引?
- 5.1.2 衍生问题2: 自适应哈希索引保存在哪里?
- 6. 日志缓冲区
- 6.1 日志缓冲区的作用
- 6.1.1 衍生问题1: 日志不通过Log Buffer直接写入磁盘不行吗?
- 6.1.2 衍生问题2: Log Buffer与日志文件是如何配合工作的?
1. InnoDB存储引擎中内存结构的组成部分有哪些?
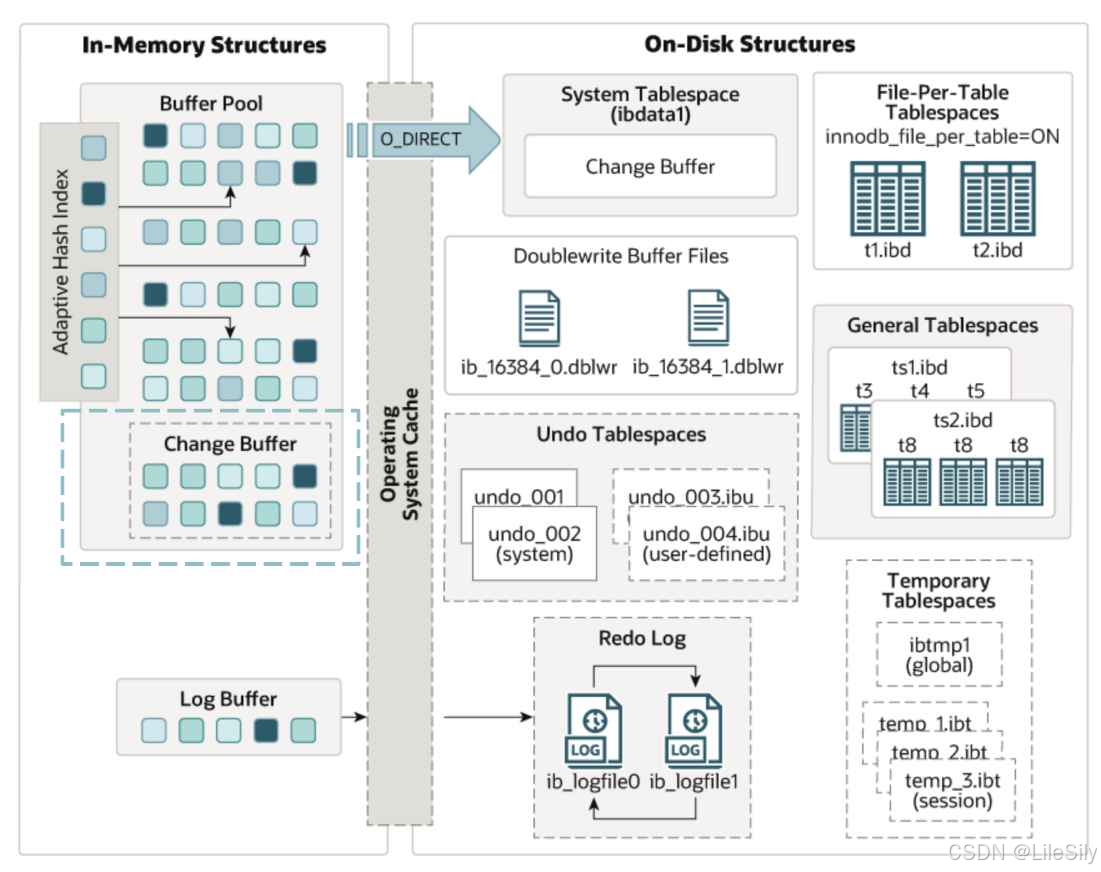
InnoDB存储引起中内存结构主要分为:
- Buffer Pool缓冲池
- Change Buffer变更缓冲区
- adaptive_hash_index自适应哈希索引
- Log Buffer日志缓冲区
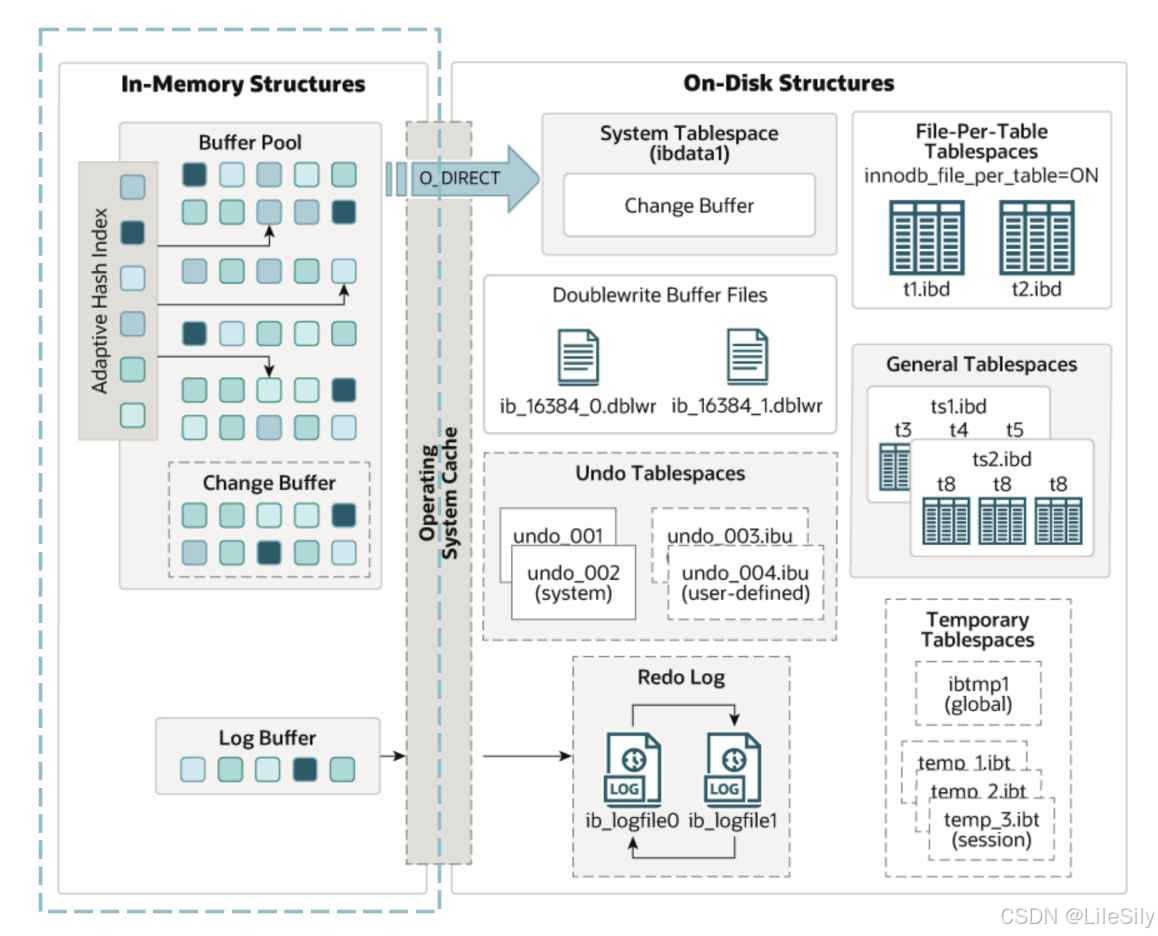
2. 为什么需要内存结构?
这个问题在InnoDB架构章节已经做了一些解释,从MySQL实现的角度来思考这个问题,数据库的作用就是保存数据,用户真实的数据最终都会保存在磁盘上,在查询数据的过程中,如果每次都从磁盘上读取会严重影响效率,为了提高数据的访问效率,InnoDB会把查询到的数据缓存到缓存中,当再查询时,如果目标数据已经存在于内存中,就可以从内存中直接读取,从而大幅提升效率.
也就是说磁盘结构中的文件是用来保存数据实现数据持久化的,内存结构是用来缓存数据提升效率的.
3. 缓冲池-Buffer Pool
3.1 缓冲池的作用
缓冲池在内存结构中的位置如下图所示
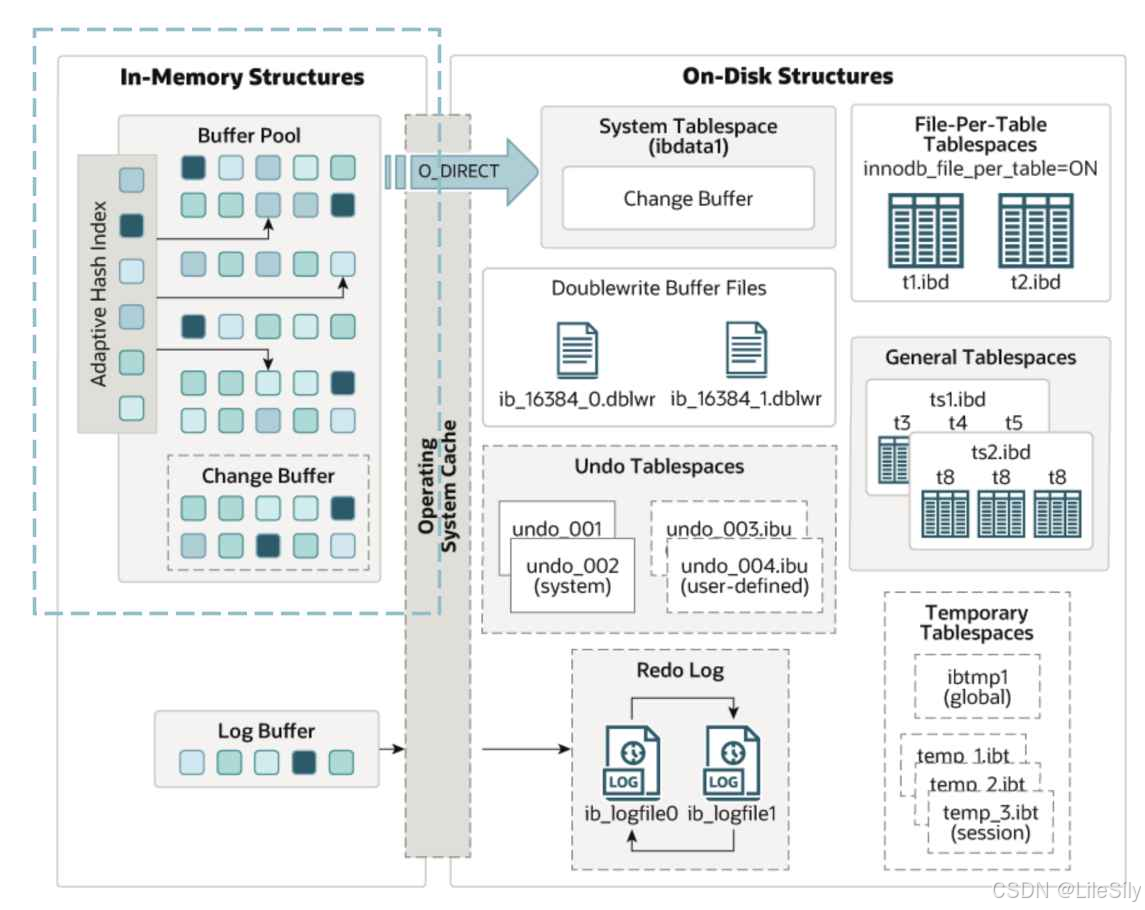
- 缓冲池主要用来缓存被访问的InnoDB表数据页和索引数据页,是主内存中的一篇区域,允许直接从内存中访问频繁使用的数据从而提升效率.在专用数据库服务器上,通常会将多达80%的物理内存分配给缓冲池.
- 其次缓存池中不仅仅缓存了磁盘的数据页,页存储了锁信息,Change Buffer信息,Adaptive Hash index,double write Buffer等信息.
3.2 缓冲池是如何组织数据的?
3.2.1 缓冲池的结构是怎样的?
- 从缓冲池的概念了解到他是主内存中的一片区域,在专用服务器上会将多达80%的物理内存分配给缓冲池,在这么大的内存空间中如何保证效率就是要解决的问题.
- 缓冲池采用与表空间类似的方式对数据进行组织,如下图所示:
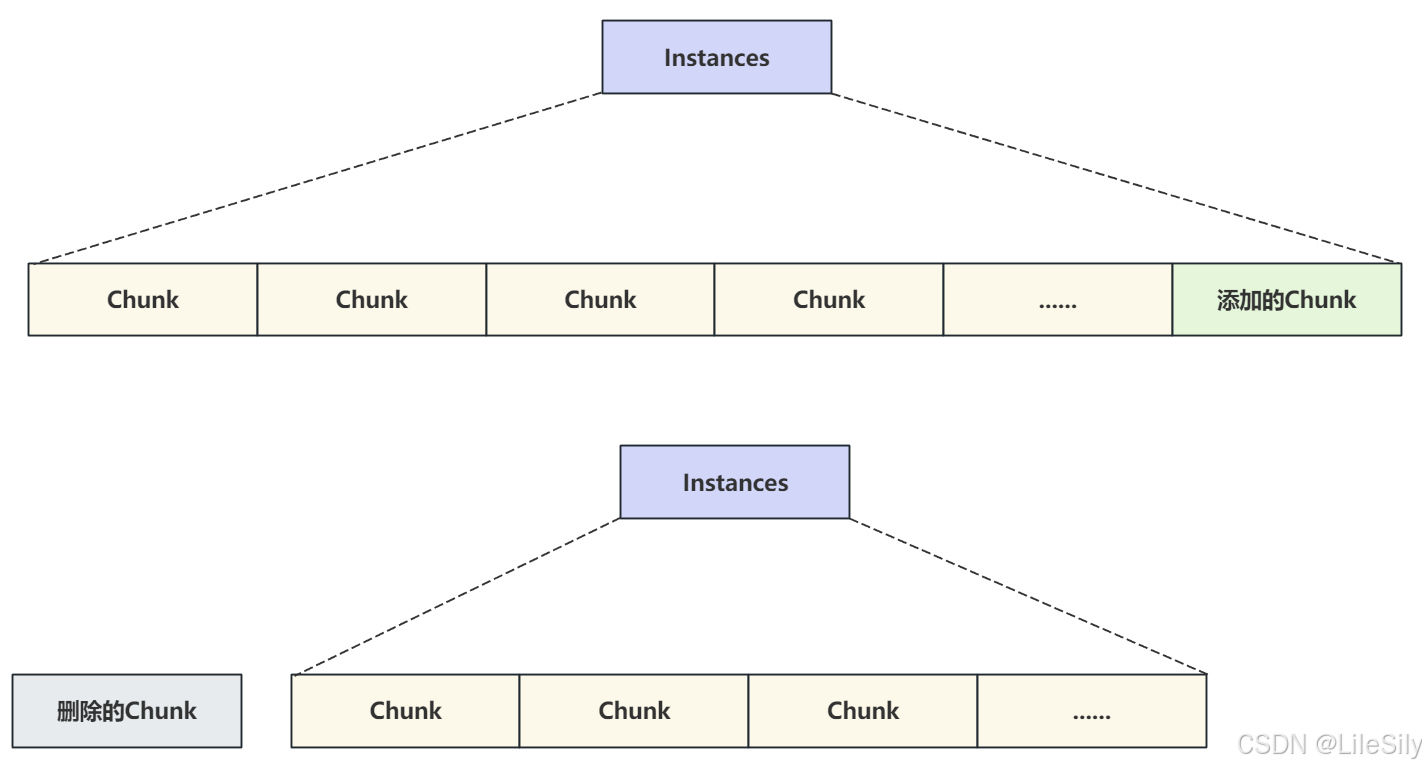
- 缓冲池中包含至少一个Instance实例,Instance是真正的缓冲池的实例对象,内存操作都是在Instances中进行的.
- 每个Instances中包含至少一个chunk块,chunk是在服务器运行状态下动态调用缓冲池进行大小时操作的块大小.
- 每个块中包含和管理若干个从磁盘加载到内存的Page数据页.
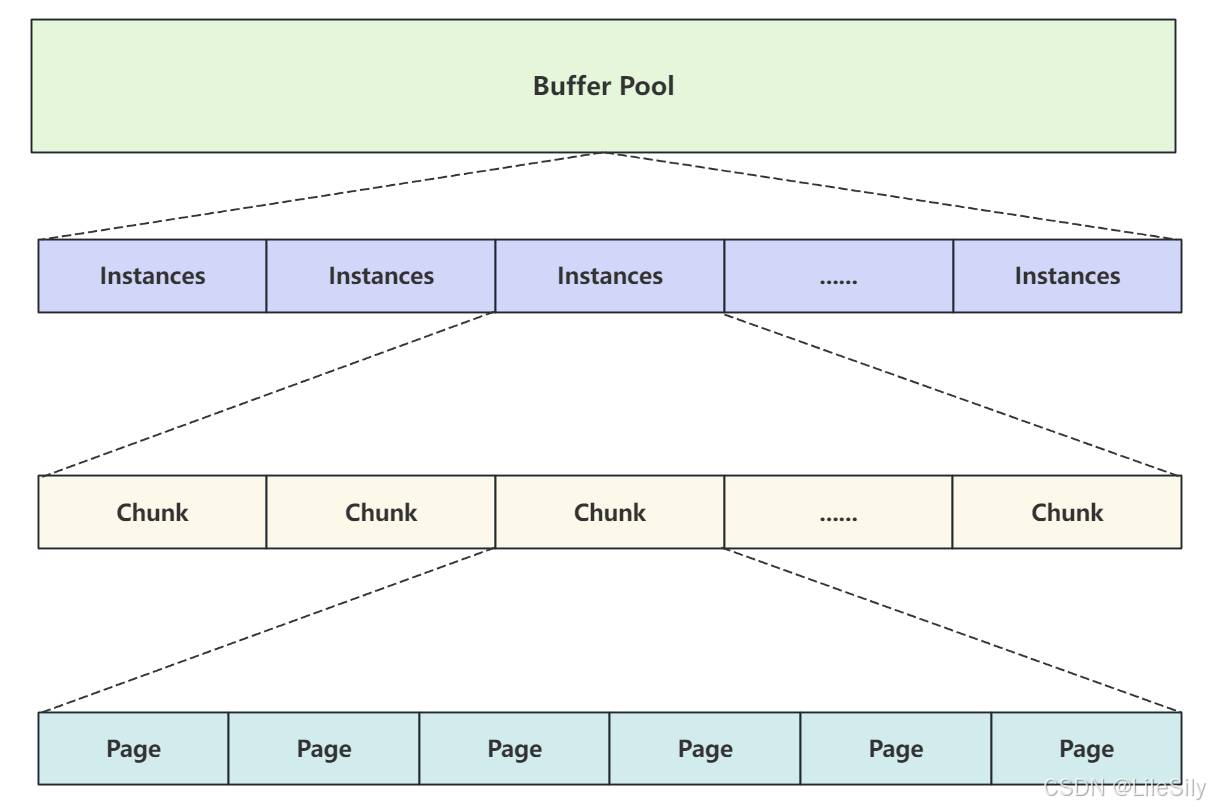
- 可以看出缓冲池通过定义不同的数据结构,但最终管理的是每个数据页,这些数据页是从磁盘加载到内存中的,也就是说磁盘中的数据页加载到内存中之后,对应的就是内存中的数据页,并且页与页之间用链表连接.
- 那么这时候就有一个问题,我们知道磁盘中的每个数据页大小默认是16KB,并且行与行之间通过头信息中的
next_record记录下一行的地址偏移量,在页结构定义中并没有一个字段用来表示内存中下一页的地址,那么在内存中如何为每个页建立连接呢?
3.2.2 缓冲池中页与页之间是如何建立连接的?
- 由于数据页中没有一个字段用来表示下一页的地址,为了每个数据页在内存中实现表连接,InnoDB定义了一个叫"控制块"的数据结构,"控制块"中有三个重要信息分别是:
- 指向数据页的内存地址
- 前一个控制块的内存地址
- 后一个控制块的内存地址
- 之后再用一个双向链表管理每个控制块,如下图所示:
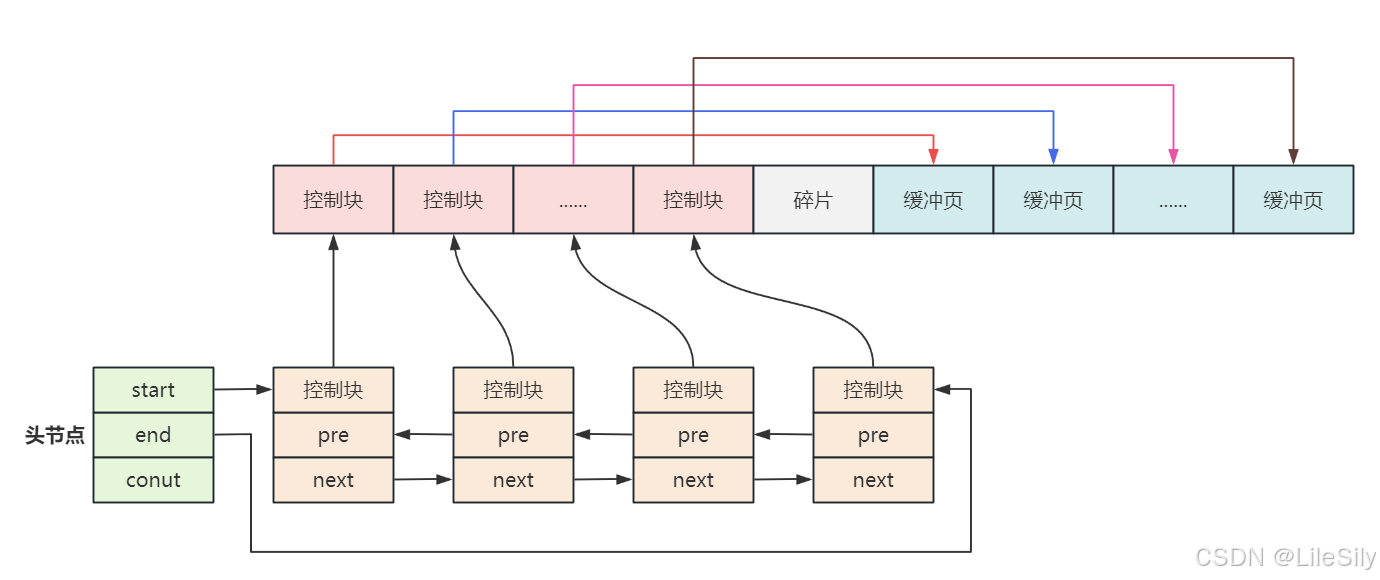
- 为了确定控制块链表的起始位置,专门定义了一个头结点,头结点中包含了三个主要信息,如图所示:
- 第一个控制块的内存地址
- 最后一个控制块的内存地址
- 链表中控制块的数量
- 通过遍历控制块链表就可以遍历内存中的数据页.
- 总结: 缓冲池中主要缓存的是磁盘中的数据页,由于数据页中没有一个字段用来表示内存中下一页的地址,InnoDB定义了"控制块"的数据结构,控制块中有一个指向数据页内存地址的指针,实现"控制块"与数据页的一一对应,并且把每个控制块连接成一个双向链表,用一个单独的头结点记录链表的第一个和最后一个结点,这样通过遍历控制块链表就可以遍历内存中的数据页.
3.2.3 衍生问题1: 内存中的数据页与磁盘上的数据页是什么关系
磁盘上的数据页加载到内存中后,在缓存池中都有一个内存页与他对应,只不过内存中管理的是控制块组成的链表,控制块有一个指针指向了内存中的真实的数据页.
3.2.4 衍生问题4: Buffer Pool的大小可以设置吗?
- 可以通过系统变量innodb_buffer_pool_size进行设置,设置的时候以字节为单位: 默认值为134217728字节,即128MB.
- 这里需要注意的是,InnoDB为"控制块"分配额外的内存空间,也就是控制块不会占用BufferPool的内存空间,所以实际分配的内存总空间比指定的缓冲池大小大10%左右.
- 缓冲池设置的值越大,在多次访问相同表数据时,磁盘的IO就会越少,因为数据都已经缓存在内存中,所以效率也就越高,但是服务器启动时初始化的时间会比较长.
3.2.5 衍生问题3: chunk的作用是什么?
-
chunk是在服务器运行状态下动态调用缓冲池进行大小时操作的块大小,为了避免在调整大小操作期间复制所有缓冲池中的数据页,调整操作以"块"为基本单位执行.
-
比如在服务器运行时想要调整缓冲池的大小可以通过以下的sql语句:
#把缓冲池大小设置为1GB
mysql> SET GLOBAL innodb_buffer_pool_size=1073741824;
- 注意: 启动调整大小操作的时候,在所有活动事务完成后操作才会开始,一旦调整大小操作开始,新的事务必须等到调整大小操作完成之后才可以访问缓冲池.
3.2.6 控制块与Page是如何初始化的?
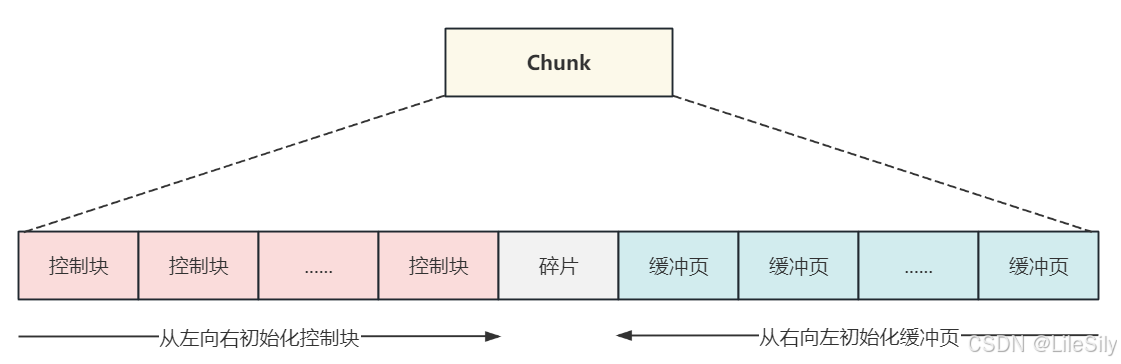
- 前面介绍了Chunk中管理的是具体的数据页,当缓冲池初始化完成时会把每个数据页所占用的内存空间和对应的控制块分配好,只不过是没有从磁盘加载数据时,内存中的数据页是空的而已.
- 当缓冲池初始化的过程中,会为Chunk分配内存空间,此时"控制块"会从Chunk的内存空间中从左向右进行初始化,数据页所占用的内存会从Chunk的内存空间从右向左进行初始化,当所剩的内存空间不够一组"控制块"+数据页所占的空间时,就会产生内存碎片,如果刚好够用则不会出现内存碎片空间.
- 内存初始化完成之后,建立控制块与内存中缓冲池数据页之间的关系,从左开始第一个控制块直系那个第一个缓冲数据页的内存地址.
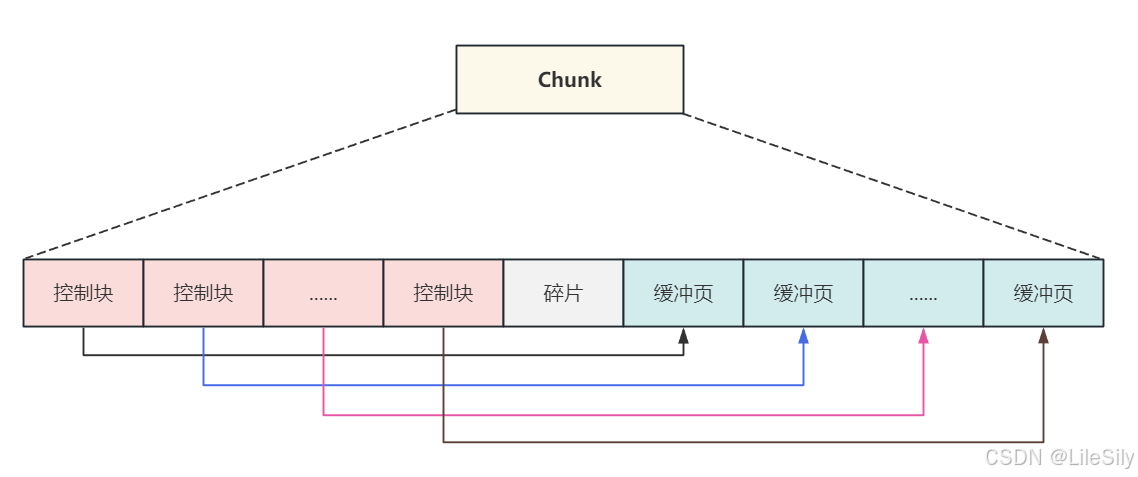
- 当前从磁盘中加载数据页的时候,就可以把数据缓存在内存中的空闲区域中.
3.2.7 可以通过缓冲池来提升性能吗?
当然可以,通过配置一下关于缓冲池的系统变量来提高性能,其中包括:
- 配置缓冲池的大小
- 配置多个缓冲池实例
- 防止缓冲池扫描
- 配置缓冲池预读取
- 配置缓冲池刷新策略
- 保存和恢复缓冲池状态
- 从核心文件中排除缓冲页
- 关于这些配置操作中,我们在后面的专题中介绍.
3.3 缓冲池中的页是如何进行管理的?
- 当缓冲池初始化完成之后,缓冲池中的数据页只是被分配了内存空间,并没有真实的数据,当用户进行数据查- 询时真实的数据从磁盘加载到内存中并分配一个内存中的数据页,这时内存中的数据页的状态从空间变成了有实际的数据,当用户修改数据时,并不是直接修改磁盘中的数据页,而是修改内存中数据页,这时内存中数据页的状态从有实际数据变成了被修改.
- 在缓冲池中采用三个链表维护内存页,这三个链表也对应着内存中页的三种状态,分别是:
- Free未使用的页,也可以称作空闲页.
- Clean已经使用但是未修改的页,也可以称作干净页.
- Dirty已修改的也,也可以称作脏页.
- 对应的三个链表分别是Free List,LRU List和Flush List
- Free List: 只管理Free页
- LRU List: 管理Clean页和Dirty页
- Flush List: 只管理Dirty页.
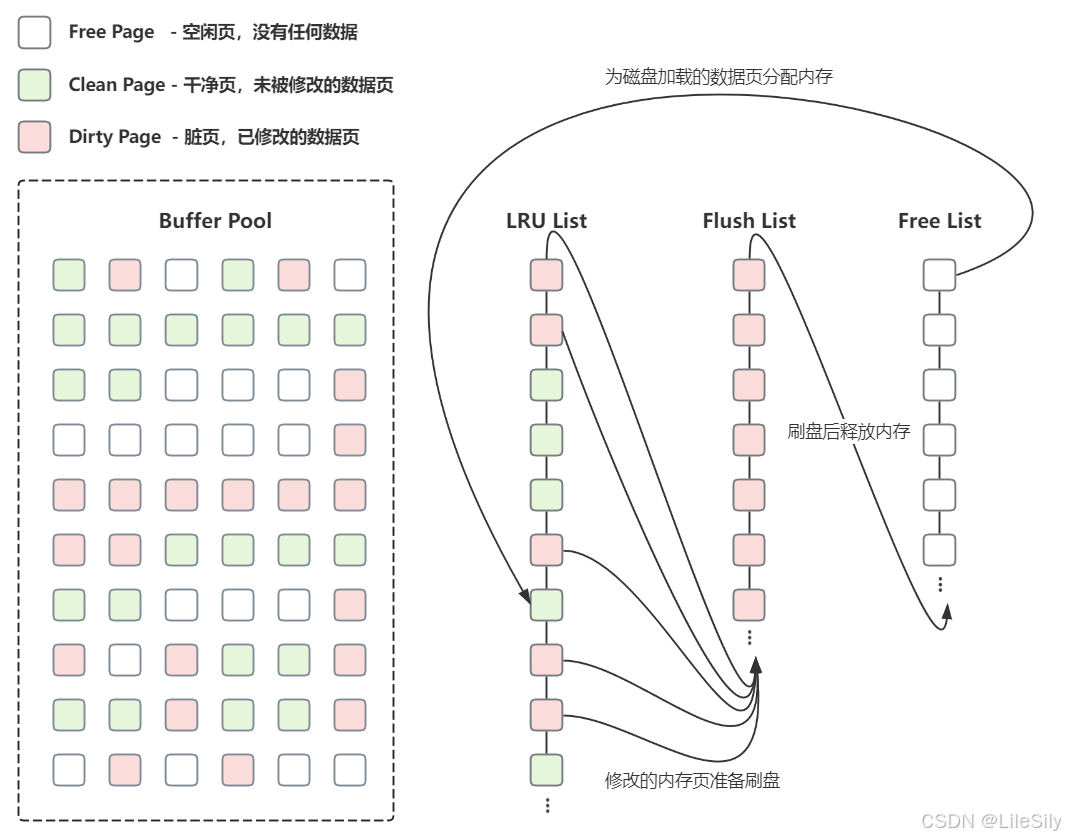
- Free List: 管理着空闲的也就是没有被使用过的内存页,当执行查询操作时,如果对应的也已经在buffer pool中则直接返回数据,如果没有且Free List不为空,则从磁盘中查询对应的数据并保存到Free List的某一页,然后把这个页从Free List中移除并放入LRU List中.
- LRU List: 管理所有从磁盘中读取的数据页,包括未被修改的和已经被修改的数据页,并根据LRU算法对链表中的页节点进行维护与淘汰,当数据库刚启动时LRU List是空的,这时候从内存中申请到的页都在存放在Free List中,当数据中磁盘读取到缓冲池时,首先从Free List中查找是否有空闲的页,如果有则把该页从Free List中删除并加入到LRU List ,如果没有,则根据LRU算法淘汰LRU List末尾的页,并将该内存空间分配给新数据页.
- Flush List: 当LRU List中的页被修改后会被标识为脏页,并把脏页加入到FlushList中,在这种情况之下,数据库通过刷盘机制把Flush List中的脏页刷会磁盘,Flush List是一个专门用来管理脏页的列表.脏页即存在于LRU List中每页存在于Flush List中,LRU List用来管理缓冲池中页的可用性,Flush List用来管理要被刷会磁盘的页,二者互不影响,Flush List中的脏页在执行了刷盘操作后会将空间还给Free List.
- 总结: 每个缓冲池都采用三个链表维护内存页,这三个链表对应着内存中的三种状态,分别是:
- Free未使用的页,也可以叫做空闲页.
- Clean已使用的页,也可以称作干净页.
- Dirty已修改的页,也可以称作脏页.
3.3.1 衍生问题1: 内存中有这么多数据页如何快速找到目标页
- 首先第一种办法就是通过遍历,这种做法显然不能满足性能要求.
- InnoDB采用的PageHash的方式,也就是每当把磁盘中数据页加载到内存时,用数据页的表空间Id和页号座位Key,当前页在内存中的地址作为Value保存起来,每次查询时就可以通过key快速定位到目标页,如果内存中没有目标页,则从磁盘中获取.
3.3.2 衍生问题2: 缓冲池中的数据放不下怎么办?
InnoDB根据自身的使用场景,使用淘汰策略来淘汰相应的数据页,从而释放出内存空间,以便更新的数据页加载到内存中.
3.4 缓冲池采用哪种淘汰策略?是如何实现的?
- 缓冲池淘汰策略采用变形的最近最少使用的(LRU)算法(在原来的LRU算法的基础上做了修改),以下出现的LRU算法指的是LRU变形算法.
- 缓冲池使用LRU算法管理链表,当有新页面添加到缓冲池时,最近最少使用的页将被淘汰,并将新的页添加到列表的中间,这种中点插入策略将列表视为两个子列表:
- 链表头部,是存放最近访问的**新页(年轻页)**子列表.
- 链表尾部,是存放最近较少访问的旧页的子列表.
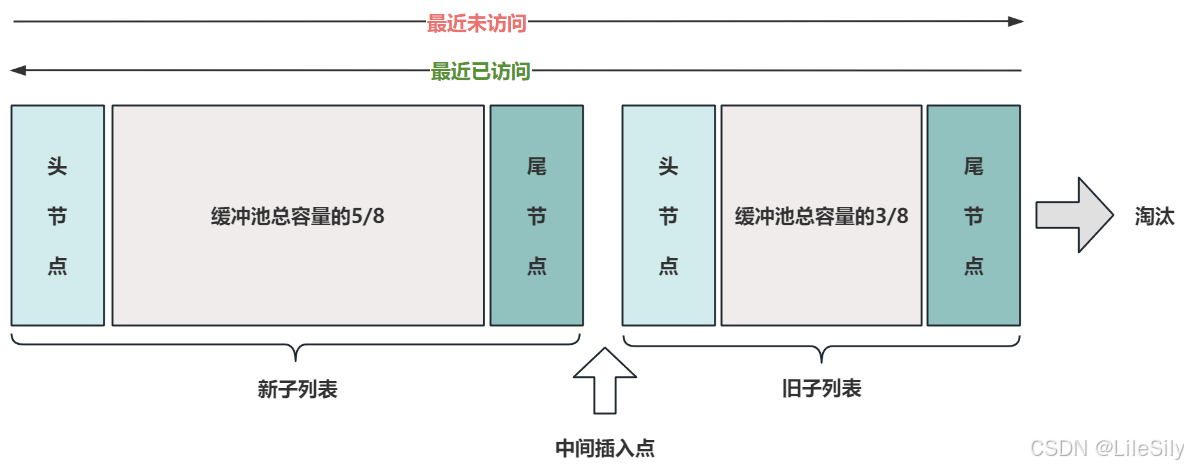
- 经常使用的页保存在新子列表中,较少使用的页保存在旧子列表中,随着时间的推移,旧子列表中的页将会被淘汰.
- 总结: 缓冲池淘汰策略采用变形的最近最少使用(LRU)算法.
3.4.1 为什么要把页插入到中间而不是直接插入到新子列表的头部?
- 因为InnoDB在读取页时,可能会发生"预读",预读的意思是InnoDB根据当前访问的记录自动推断后面可能会访问哪个页,并把他们加载到内存中,从而提高查询的效率,预读的页以并不一定会被真正的读取,从中间插入可以使起尽快被淘汰.
4. 变更缓冲区
变更缓冲区在内存中的位置
4.1 变更缓冲区的作用?
- 变更缓冲区占用BufferPool的一部分空间,具体如图所示:
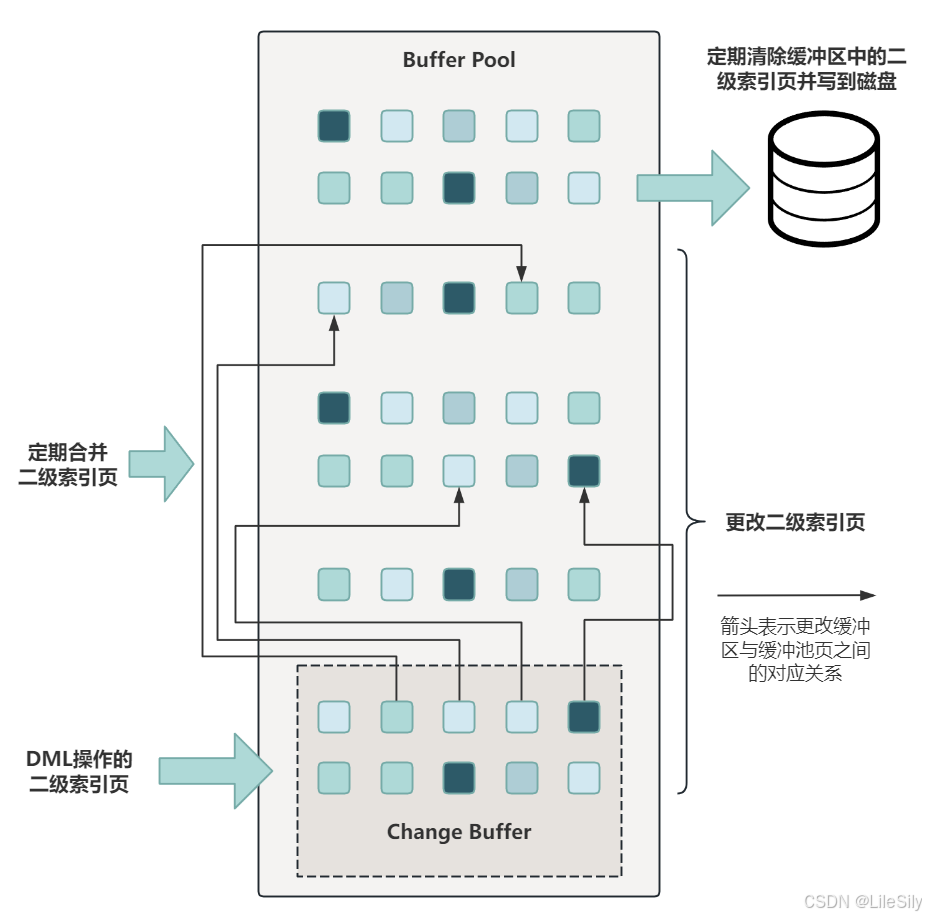
- 变更缓冲区用来对缓存二级索引数据的修改,则是一个数据结构,当使用Insert,update,delete语句修改二级索引对应的数据的时候,如果对应的数据页在缓冲池中则直接更新,如果不在缓冲池中,那么就把修改操作缓存到变更缓冲区,这样就不需要立即从磁盘中读取对应的数据页了,之后的读操作将对应的数据页从磁盘加载到缓冲池中时,变更缓冲区中缓存的修改操作再批量合并到缓冲池,从而达到减少磁盘IO的目的.
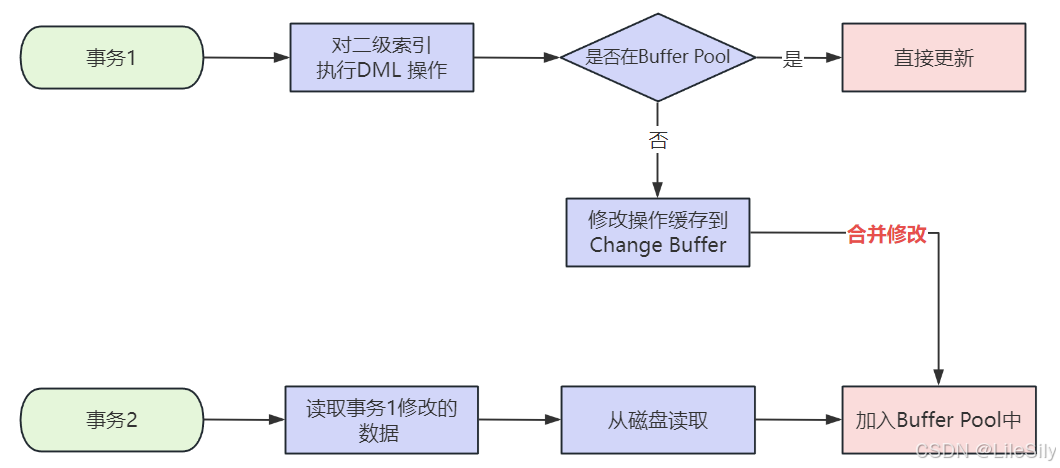
- 总结: 变更缓冲区用来缓存对二级索引数据的修改,当数据页没有被回载到内存中时先把修改缓存起来,等到其他查询操作发生的时候数据页被加载到内存后,直接修改内存中的数据页,从而达到减少磁盘IO的目的.
4.1.1 衍生问题: 为什么是二级索引?
- 关于数据库的索引,我们知道索引分为聚集索引和二级索引.
- 由于聚集索引具有唯一性,我们来分析一下聚集索引为什么不能被放入变更缓存,假设表中有一个主键,现在有两条insert语句,都在插入数据id的值相同,那么在变更缓冲区中就存在两个修改的操作,如果以后要合并到缓冲池,这时就会出现重复的主键值,所以聚集索引的修改不能被加入到变更缓冲区.
- 与聚集索引不同,二级索引通常不是唯一的,并且向二级索引中插入数据时由于数据列不同,所以位置相对随机,同样对于删除和更新操作可能会影响不相邻的二级索引页,如果每次都从磁盘中读取数据就会发生大量的随机IO,以变更缓冲区的方式先将修改缓存起来,当真正去读取数据时再把修改合并到缓冲池中可以提升效率.
4.2 变更缓冲区的主要配置项有哪些?
- 主要的配置项有缓冲类型和更改缓冲区的最大大小.
- 缓冲类型
在修改二级索引数据变更缓冲区可以减少磁盘IO从而提高效率,但是变更缓冲区占用了缓冲池中的一部分空间,从而减少了可用于缓存数据页的内存,如果业务场景读多写少,或是表中的二级索引相对较少,那么可以考虑禁用更改缓冲区从而提高缓冲池的空间.
可以通过选项文件或set global语句对系统变量innodb_change_buffering进行设置,来控制变更缓冲区对于插入,删除操作(索引记录被标记为删除)和清除操作(当索引记录被物理删除时)的开启或禁用:
删除操作: 索引记录被标记为删除
清除操作: 索引记录被物理删除
更新操作: 是插入和删除操作的组合
- all: 默认值,缓存插入,删除标记操作和清除.
- none: 不缓存任何数据
- inserts: 只缓存插入操作
- deletes: 只缓存删除标记操作
- changes: 缓存插入和删除标记操作.
- purges: 缓存发生在后台的物理删除操作.
- 更改缓冲区的最大大小
- 通过
innodb_change_buffer_max_size系统变量可以设置更改缓冲区的最大大小,默认为25,最大为50,表示更改缓冲区占用缓冲池内存总大小的百分比. - 在有大量插入,更新和删除的业务场景中,可以考虑增加
innodb_change_buffer_max_size的值,大部分是读多写少,比如用户报表的金泰数据场景中考虑减少innodb_change_buffer_max_size的值. - 需要注意的是,如果更改缓冲区占用了缓冲池太多的内存空间,会导致缓冲池中的数据页更快的淘汰.
5. 自适应哈希索引
- 自适应哈希索引在内存中的位置
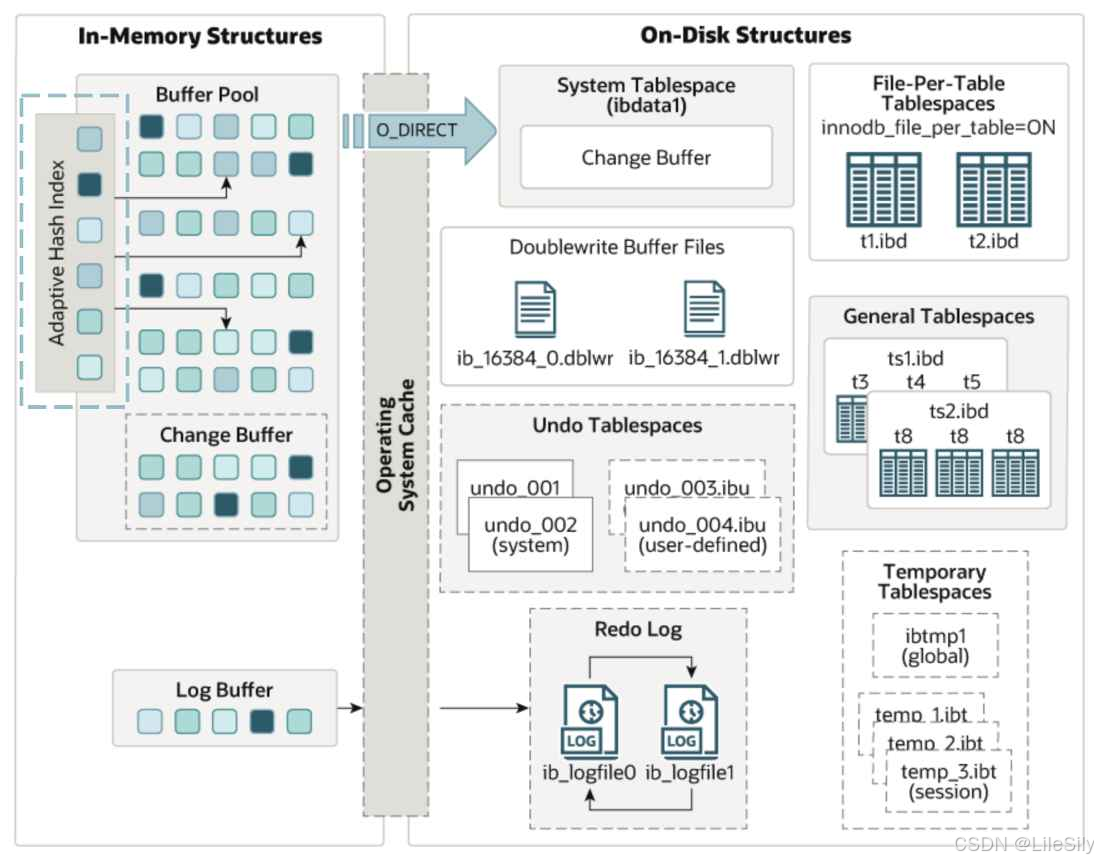
5.1 自适应哈希索引的作用
- 自适应哈希索引可以使用InnoDB存储引擎在不牺牲事务特新和可靠性以及缓冲池空间足够的前提之下提升效率,使用起来更像是内存数据库,哈希索引根据访问的索引也自动构建.
- 根据InnoDB内部的监控机制,如果监控到某些查询通过建立哈希索引可以提高性能,则自动对这个也创建一个哈希索引,这个过程称为自适应,所以叫做自适应哈希索引.
- 如果表完全放在内存中,则哈希索引可以通过直接查找任何元素来加快查询速度.
- 总结: 自适应哈希索引主要的作用是提升查询速率.
5.1.1 衍生问题1: 为什么要建立自适应哈希索引?
- InnoDB存储引擎的数据存储于B+树中,B+树通常只有3-5层,但是从根节点到叶子结点的寻路涉及到多层页面内记录的比较,即使所有路径上的页面都在内存中,也非常消耗CPU资源.
- InnoDB对寻路的开销进行了优化,比如寻路结束之后将cursor缓存起来方便下次使用,尽可能的避免寻路开销.
- 本质上是通过缩短寻路路径从而提升MySQL查询性能的一种方式,在内存级别进一步提升查询效率.
5.1.2 衍生问题2: 自适应哈希索引保存在哪里?
自适应哈希索引会占用缓冲池一部分的内存区域,在缓冲池初始化后被初始化,为了避免自适应哈希索引的锁竞争压力,自适应哈希索引支持分区,可以使用innodb_adaptive_hash_index_parts参数配置分区个数,默认是8.
6. 日志缓冲区
日志缓冲区在内存中的位置
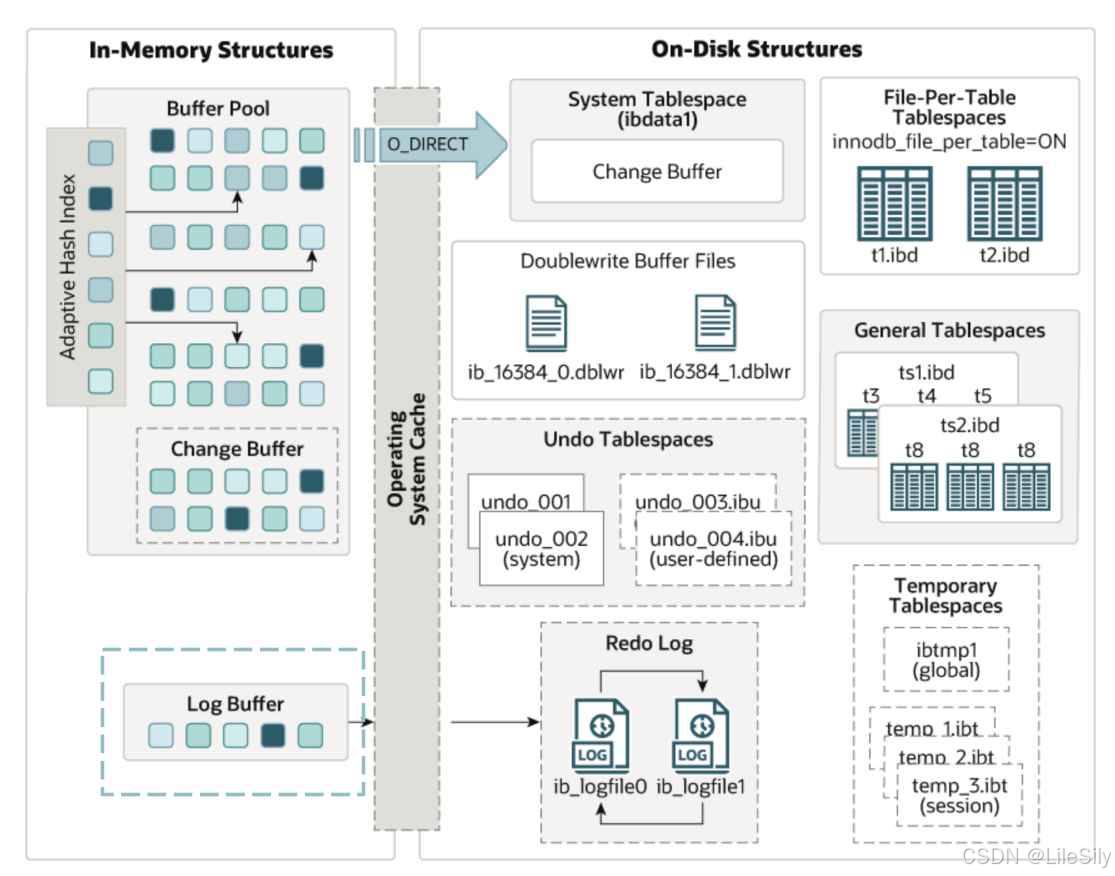
6.1 日志缓冲区的作用
- 日志缓冲区是服务器启动时相操作系统申请的一片连续的内存区域,存储即将要写入的磁盘日志文件的数据.
- 在对数据库进行CRUD操作时,InnoDB会记录对应操作的日志,比如为保证数据完整性实现数据库崩溃恢复的Redo Log,这些日志会首先写入Log Buffer中,从而解决同步写磁盘导致的性能问题,然后根据不同的落盘策略最终写入磁盘.
6.1.1 衍生问题1: 日志不通过Log Buffer直接写入磁盘不行吗?
如果日志不通过LogBuffer直接写入磁盘,那么每次进行CRUD操作都会进行一次磁盘IO,这样会严重影响效率,所以把日志统一写入内存中的LogBuffer,根据刷盘策略统一进行落盘操作,可以实现一次磁盘IO写入多条日志,从而提升效率.
6.1.2 衍生问题2: Log Buffer与日志文件是如何配合工作的?
关于Log Buffer与日志文件之间的交互过程,RedoLog的结构,RedoLog的写入时机,我们在后面介绍.
相关文章:
: 内存结构详解)
[MySQL数据库] InnoDB存储引擎(三): 内存结构详解
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
TDengine 存储引擎剖析:数据文件与索引设计(一)
TDengine 存储引擎简介 在物联网、工业互联网等快速发展的今天,时间序列数据呈爆发式增长。这些数据具有产生频率高、依赖采集时间、测点多信息量大等特点,对数据存储和处理提出了极高要求。TDengine 作为一款高性能、分布式、支持 SQL 的时序数据库&am…...

CentOS更换yum源
CentOS更换yum源 视频教程: https://www.bilibili.com/video/BV1yWaSepE6z/?spm_id_from333.1007.top_right_bar_window_history.content.click 步骤: 第一步: cd /etc/yum.repos.d第二步:cp CentOS-Base.repo CentOS-Base.repo…...

【Kubernetes基础--持久化存储原理】--查阅笔记5
目录 持久化存储机制PV 详解PV 关键配置参数PV 生命周期的各个阶段 PVC 详解PVC 关键配置参数PV 和 PVC 的生命周期 StorageClass 详解StorageClass 关键配置参数设置默认的 StorageClass 持久化存储机制 k8s 对于有状态的容器应用或对数据需要持久化的应用,不仅需…...

数据库子查询实验全解析
目录 一、验证性实验:夯实基础(一)查询同班学生信息(二)查询成绩相关信息(三)查询课程选课人数(四)相关子查询(五)EXISTS嵌套子查询(六…...

HTML:表格数据展示区
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>人员信息表</title><link rel"styl…...

webgl入门实例-08索引缓冲区的基本概念
WebGL 索引缓冲区 (Index Buffer) 索引缓冲区(也称为元素数组缓冲区)是WebGL中一种优化渲染性能的重要机制,它允许您重用顶点数据来绘制复杂的几何图形。 基本概念 索引缓冲区的工作原理: 您创建一个顶点缓冲区(包含所有顶点数据)然后创建一个索引缓…...

大数据应用开发——大数据平台集群部署
目录 前言 目录 基础环境 安装虚拟机 基础环境 VMware Workstation 虚拟机版本 : centos7 主机名 ip 用户名 密码 master192.168.245.100root123456slave1192.168.245.101root123456slave2192.168.245.102root123456 安装虚拟机 安装 名称、路径自己改 我有16核&…...

GPT对话UI--通义千问API
GPT对话UI 项目介绍 一个基于 GPT 的智能对话界面,提供简洁优雅的用户体验。本项目使用纯前端技术栈实现,无需后端服务器即可运行。 功能特点 💬 实时对话:支持与 AI 进行实时对话交互🌓 主题切换:支持…...

智能体数据分析
数据概览: 展示智能体的累计对话次数、累计对话用户数、对话满意度、累计曝光次数。数据分析: 统计对话分析、流量分析、用户分析、行为分析数据指标,帮助开发者完成精准的全面分析。 ps:数据T1更新,当日12点更新前一天…...
)
泛型算法——只读算法(一)
在 C 标准库中,泛型算法的“只读算法”指那些 不会改变它们所操作的容器中的元素,仅用于访问或获取信息的算法,例如查找、计数、遍历等操作。 accumulate std::accumulate()是 C 标准库**numeric**头文件中提供的算法,用于对序列…...
config.txt介绍)
树莓派超全系列教程文档--(29)config.txt介绍
config.txt介绍 什么是 config.txt ?文件格式高级功能include条件过滤 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 什么是 config.txt ? Raspberry Pi 设备使用名为 config.txt 的配置文件,而不是传统 PC …...

第十六届蓝桥杯大赛软件赛省赛 C++ 大学 B 组 部分题解
赛时参加的是Python组,这是赛后写的题解,还有两题暂时还不会,待更新 题目链接题目列表 - 洛谷 | 计算机科学教育新生态 A 移动距离 答案:1576 C 可分解的正整数 Python3 import itertools from functools import cmp_to_ke…...

C++栈与堆内存详解:Visual Studio实战指南
C++栈与堆内存详解:Visual Studio实战指南 IDE环境:Visual Studio 2022 一、内存分区与核心概念 在C++程序中,内存分为**栈(Stack)和堆(Heap)**两大核心区域,两者的管理方式、生命周期和适用场景差异显著。 1. 栈内存(Stack Memory) • 特性: • 自动管理:由编…...

在Ubuntu服务器上部署xinference
一、拉取镜像 docker pull xprobe/xinference:latest二、启动容器(GPU) docker run -d --name xinference -e XINFERENCE_MODEL_SRCmodelscope -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 # 启动一个新的Docker容…...

非洲电商争夺战:中国闪电战遭遇本土游击队的降维打击
2024年5月,南非电商市场爆发史诗级对决——Temu闪电突袭下载量破百万,却在30天内遭遇Takealot的本土化反击致留存率腰斩。这场价值500亿美元市场的攻防战,揭开了非洲电商最残酷的生存法则:低价利刃砍不动本土化铁壁。 一、跨境模式…...

亚瑟阿伦36问
问 36 个问题,你就能爱上一个人,对方也能爱上你。 第一组 聚焦个人背景与价值观 例如“你最感激生命中的什么?”、“如果可以改变成长经历,你会改变什么?” 1、如果可以跟世上任何人共进晚餐,你会选择谁&…...

Ubuntu 20.04.6编译安装COMFAST CF-AX90无线网卡驱动
目录 0 前言 1 CF-AX90无线网卡驱动 1.1 驱动下载 1.2 驱动准备 2 编译安装驱动 2.1 拷贝驱动依赖到系统 2.2 驱动安装编译 3 重启 0 前言 COMFAST CF-AX90或者说AIC8800D80的Linux版本驱动不支持高版本的linux内核,实测目前仅支持最高5.15的内核。Ubuntu2…...
)
函数的极限与连续(强化和真题)
强化错题如下:...

4.15【Q】netsafe
我正在学习网络空间安全,” Cookie:使用防hash技术防御SYN泛洪攻击,减少服务器内存消耗“什么意思?什么是SYN泛洪攻击?什么又是防hash技术防御? ?详细解释,越细节越好 连接成功率 …...
无单臂路由(简单版))
多个路由器互通(静态路由)无单臂路由(简单版)
多个路由器互通(静态路由)无单臂路由(简单版) 开启端口并配ip地址 维护1 Router>en Router#conf t Router(config)#int g0/0 Router(config-if)#no shutdown Router(config-if)#ip address 192.168.10.254 255.255.255.0 Ro…...

opencv HSV的具体描述
色调H: 使用角度度量,取值范围为0\~360,从红色开始按逆时针方向计算,红色为0,绿色为120,蓝色为240。它们的补色是:黄色为60,青色为180,紫色为300。通过改变H的值&#x…...

ubuntu磁盘挂载
1、查看磁盘设备及分区 命令:列出所有块设备(磁盘及分区) lsblk 0表示此块未挂载 2、格式化分区 sudo mkfs.ext4 /dev/sdb 注意sdb换成自己的块名称 3、创建挂载点目录 sudo mkdir -p /mnt/data4、永久挂载 sudo blkid /dev…...

Visual Studio C++引入第三方库
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 本文主要整理visual studio C导入第三方库的注意事项与操作 bilibili配套视频:【visual studio C导入第三方库-哔哩哔哩】 https://b23.tv/vphfXnv 运行库选项 右键项目 -> 属性 -> C/C ->代码生成->…...

2025中国移动云智算大会回顾:云智变革,AI+跃迁
4月10日,2025中国移动云智算大会在苏州举办。会上,中国移动开启“由云向智”新范式,以“智”为核心开辟算网新生态,彰显其在AI新时代的战略远见与技术引领力。 “云智算”将如何通过算网基础设施与人工智能核心技术的深度融合&am…...

海珠区公示人工智能大模型应用示范区第二批资金奖励企业名单,助力产业蓬勃发展
2025 年 4 月 15 日,广州琶洲人工智能与数字经济试验区管理委员会在广州市海珠区人民政府门户网站发布重要通知,对人工智能大模型应用示范区政策兑现工作(第二批)(大模型专题)资金奖励企业名单予以公示。这…...

golang处理时间的包time一次性全面了解
本文旨在对官方time包有个全面学习了解。不钻抠细节,但又有全面了解,重点介绍常用的内容,一些低频的可能这辈子可能都用不上。主打一个花最少时间办最大事。 Duration对象: 两个time实例经过的时间,以长度为int64的纳秒来计数。 常见的durati…...

文件的加密与解密学习笔记
一些可能想知道的: cryptography库:密码学工具包 Fernet 是crytography 里的一个模块,用于对称加密 with open() as file #为了保证无论是否出错都能正确地关闭文件,与try...finally...相同 open() #用于读文件(默认…...

《TCP/IP网络编程》学习笔记 | Chapter 24:制作 HTTP 服务器端
《TCP/IP网络编程》学习笔记 | Chapter 24:制作 HTTP 服务器端 《TCP/IP网络编程》学习笔记 | Chapter 24:制作 HTTP 服务器端HTTP 概要理解 Web 服务器端无状态的 Stateless 协议请求消息(Request Message)的结构响应消息&#x…...
)
Apache POI(笔记)
介绍: 坐标: 写入Excel表格: 读取Excel表格:...

Table类型的表单
形如下面的图片 1 label与prop属性 const columns[{label: "文件名",prop: "fileName",scopedSlots: "fileName",},{ label: "删除时间",prop: "recoveryTime",width: "200",},{ label: "大小",prop:…...

Spring 中的验证、数据绑定和类型转换
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

【技术派后端篇】canal实现MySQL/Redis缓存一致性
1 前言 在探讨如何利用canal实现MySQL/Redis缓存一致性之前,强烈建议大家先阅读以下几篇相关文章,因为本文是基于这些文章的基础上展开的: 《深度剖析 MySQL 与 Redis 缓存一致性:理论、方案与实战》 :该文详细阐述了…...

华清远见STM32F103智能小车重磅上线!循迹避障红外遥控WiFi远程控制,0基础小白从入门到单片机软硬件项目实战!
STM32F103智能云控小车是由华清远见倾力打造的一款多功能智能小车,专为高校教学、学生毕业设计、创新竞赛、单片机入门学习及项目实践量身定制。这款小车集红外遥控、远程物联网控制、智能巡线、高精度避障和交互式显示屏五大核心功能于一体,融合了物联网…...

李飞飞团队新作WorldScore:“世界生成”能力迎来统一评测,3D/4D/视频模型同台PK
从古老神话中对世界起源的幻想,到如今科学家们在实验室里对虚拟世界的构建,人类探索世界生成奥秘的脚步从未停歇。如今,随着人工智能和计算机图形学的深度融合,我们已站在一个全新的起点,能够以前所未有的精度和效率去…...

seaborn库详解
Seaborn 是一个基于 Python 的统计数据可视化库,它建立在 matplotlib 之上,旨在提供更高级、更美观、更具统计意义的可视化功能。 CONTENT 1. 单变量分布可视化功能代码 2. 双变量联合分布可视化功能代码 3. 分类数据柱状图可视化功能代码 4. 箱线图可视…...
(附脚本))
UNACMS PHP对象注入漏洞复现(CVE-2025-32101)(附脚本)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前言…...
)
应用篇02-镜头标定(上)
本节主要介绍相机的标定方法,包括其内、外参数的求解,以及如何使用HALCON标定助手实现标定。 计算机视觉——相机标定(Camera Calibration)_摄像机标定-CSDN博客 1. 原理 本节介绍与相机标定相关的理论知识,不一定全,可以参考相…...

游戏引擎学习第230天
回顾并为今天的内容定下基调 今天是我们进行“排序”工作的第二天。昨天我们在渲染器中实现了排序功能。这其实是从一开始就知道必须做的事情,只是一直没有合适的时机。而昨天终于迎来了这个时机,不知道为什么,可能就是突然有了冲动和想法&a…...

3.串口通信之SPI
—>1.串口通信之UART见这篇<— —>2.串口通信之IIC见这篇<— 1.SPI特点 SPI(Serial Peripheral Interface)即串行外设接口,有4条总线,分别是SCLK(SPI Clock),MISO(Master Input Slave Output),MOSI(Mast…...

无人机姿态稳定与动态控制模块概述!
一、设计难点 1. 动态算力需求与硬件能力的不匹配** 无人机边缘计算设备通常受限于体积和重量,导致其计算单元(如CPU、GPU)的算力有限,难以应对突发的高负载任务(如实时图像处理、AI推理)。 挑战&am…...

【shell】终端文本的颜色和样式打印
在Shell脚本中,\033[XXm 是 ANSI转义序列,用于控制终端文本的颜色和样式。以下是完整的颜色和样式代码列表: 1. 基本格式 echo -e "\033[CODEm你的文本\033[0m"\033[:转义序列开始(\e[ 或 \x1b[ 等效&#…...

模型加载常见问题
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge 问题代码: model AutoModelForVision2Seq.from_pretrained( "/data-nvme/yang/Qwen2.5-VL-32B-Instruct", trust_remote_codeTrue, torch_dtypetorc…...

HCIA-Access V2.5_16_3_数据业务维护
查询ONT上的业务配置 查询ONU上的业务配置 查询OLT上网业务 查询上网业务流量 查询上网业务相关MAC地址 删除故障ONT 删除故障ONU...

Java设计开发商城抢票功能
在开发一个商城抢购功能时,需要考虑几个关键方面,包括并发控制、数据一致性、用户体验以及系统的可扩展性。下面我将通过一个简单的步骤指南来介绍如何设计这样一个功能。 1. 需求分析 首先,明确抢购功能的需求: 限制购买数量。…...

【APM】Build an environment for Traces, Metrics and Logs of App by OpenTelemetry
系列文章目录 此系列文章介绍如何搭建Observability(可观测性)环境(Opentelemetry-Collector、Tempo、Prometheus、Loki和Grafana),以及应用。 【APM】Observability Solution 【APM】Build an environment for Traces, Metrics and Logs …...
自动驾驶热点技术的成熟之处就是能判断道路修复修路,能自动利用类似“人眼”的摄像头进行驾驶!值得学习!)
全自动驾驶(FSD,Full Self-Driving)自动驾驶热点技术的成熟之处就是能判断道路修复修路,能自动利用类似“人眼”的摄像头进行驾驶!值得学习!
全自动驾驶(FSD,Full Self-Driving)软件是自动驾驶领域中的热点技术,其核心目标是实现车辆在各种复杂交通环境下的安全、稳定、高效自动驾驶。FSD软件的技术核心涉及多个方面的交叉技术,下面将详细分析说明其主要核心技…...

需要处理哪些响应数据?
在调用淘宝商品搜索 API 时,响应数据通常是一个 JSON 对象,包含了搜索结果的详细信息。以下是需要处理的主要响应数据字段及其说明: 响应数据结构 示例 JSON 数据 JSON {"code": "0","errorMessage": &quo…...

【NLP 63、大模型应用 —— Agent】
人与人最大的差距就是勇气和执行力,也是唯一的差距 —— 25.4.16 一、Agent 相关工作 二、Agent 特点 核心特征: 1.专有场景(针对某个垂直领域) 2.保留记忆(以一个特定顺序做一些特定任务,记忆当前任务的前…...
)
Windows 图形显示驱动开发-WDDM 1.2功能—Windows 8 中的 DirectX 功能改进(三)
一、与目标无关的光栅化 (TIR) 独立于目标的光栅化 (TIR) 为涉及结构化图形的高质量抗锯齿的 Direct2D 使用方案提供高性能抗锯齿路径。 TIR 使 Direct2D 能够将光栅化步骤从 CPU 移动到 GPU,同时保留 Direct2D 抗锯齿语义和质量。 使用此功能,软件层可…...