SpringAI+DeepSeek大模型应用开发——2 大模型应用开发架构
目录
2.大模型开发
2.1 模型部署
2.1.1 云服务-开放大模型API
2.1.2 本地部署
搜索模型
运行大模型
2.2 调用大模型
接口说明
提示词角色
编辑
会话记忆问题
2.3 大模型应用开发架构
2.3.1 技术架构
纯Prompt模式
FunctionCalling
RAG检索增强
Fine-tuning
2.3.2 技术选型
2.大模型开发
2.1 模型部署
首先大模型应用开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互;
因此,需要有一个可访问的大模型,通常有三种选择:
2.1.1 云服务-开放大模型API
部署在云服务器上,部署维护简单,部署方案简单,全球访问 ,缺点:数据隐私,网络依赖,长期成本问题
通常发布大模型的官方、大多数的云平台都会提供开放的、公共的大模型服务。以下是一些国内提供大模型服务的云平台
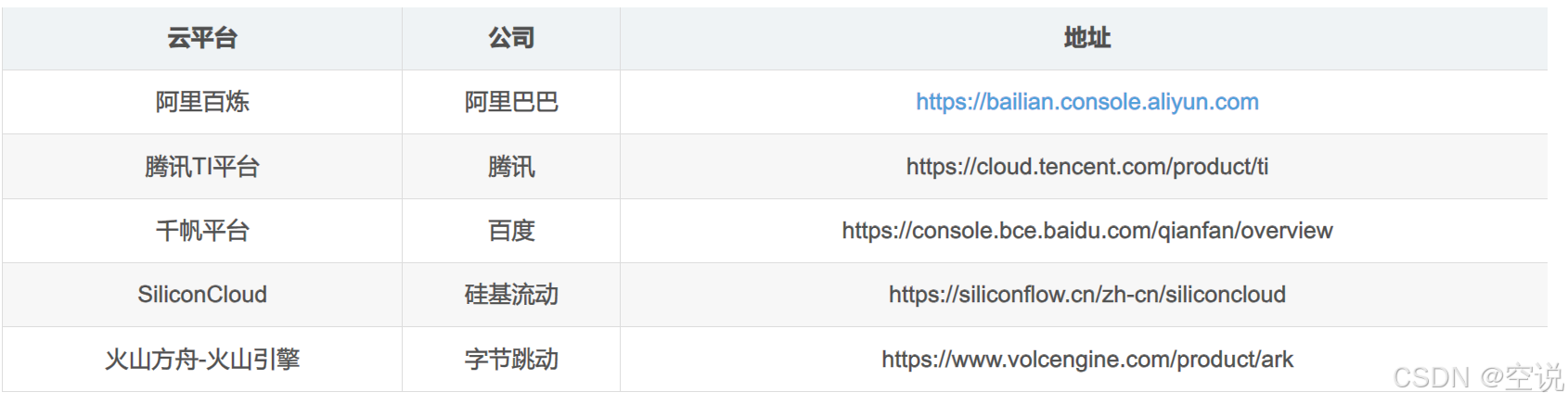
这些开放平台并不是免费,而是按照调用时消耗的token来付费,每百万token通常在几毛~几元钱,而且平台通常都会赠送新用户百万token的免费使用权;
以百炼大模型为例 大模型服务平台百炼_企业级大模型开发平台_百炼AI应用构建-阿里云
注册一个阿里云账号==>然后访问百炼平台,开通服务(首次开通应该会赠送百万token的使用权,包括DeepSeek-R1模型、qwen模型。)
==>申请API_KEY(百炼平台右上角个人中心)==>创建APIKEY==>进入模型广场
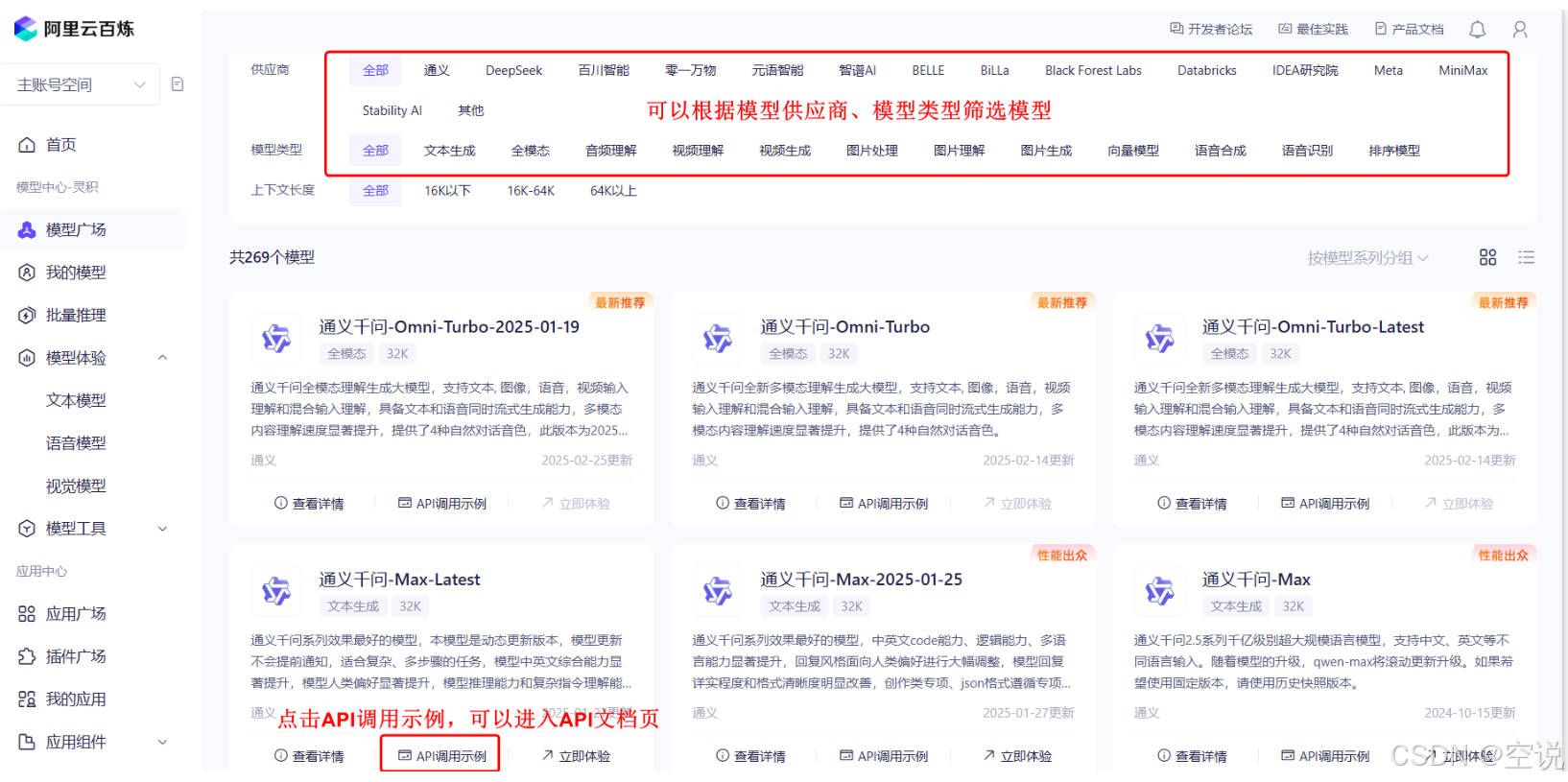
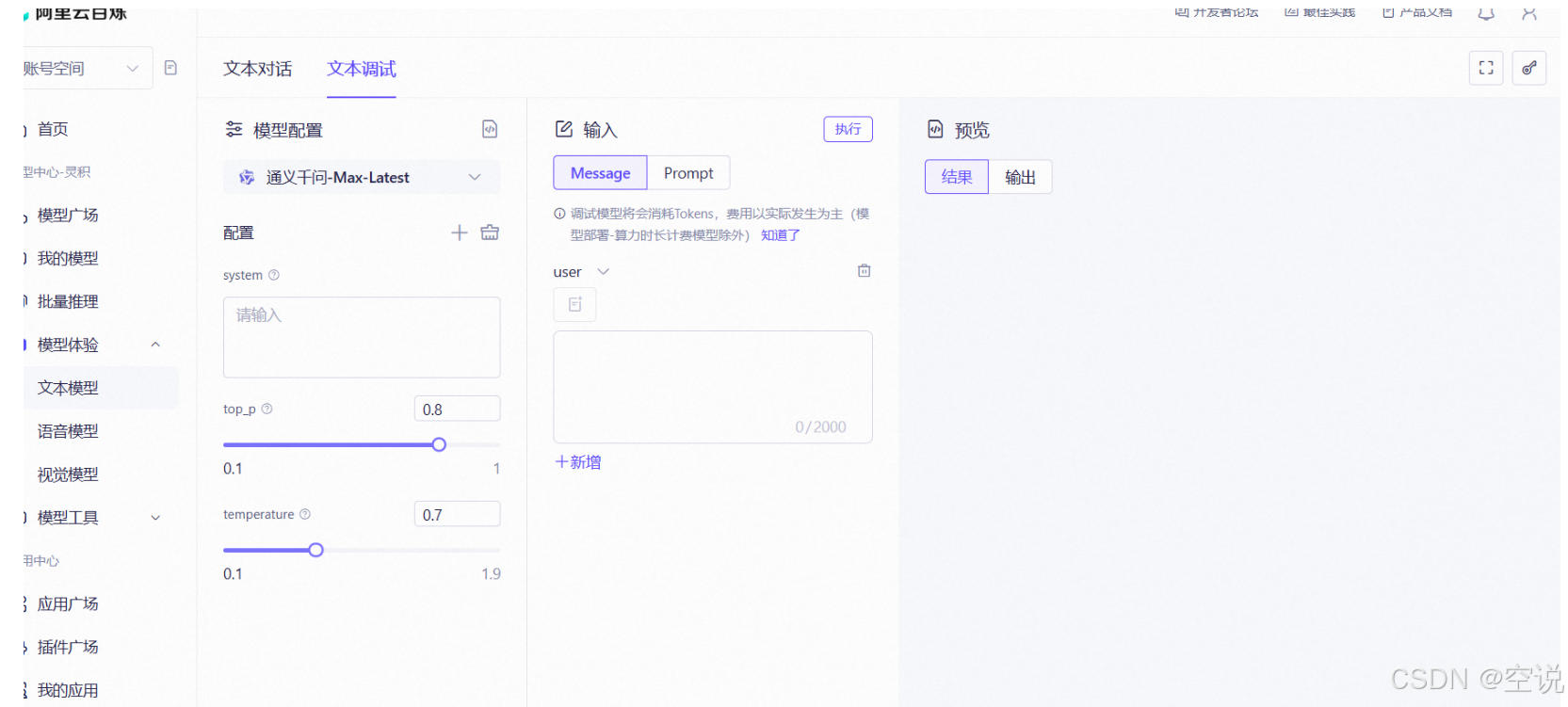
选择一个自己喜欢的模型,然后点击API调用示例,即可进入API文档页===>立即体验==>进入API调用大模型的试验台==>模拟调用大模型接口
2.1.2 本地部署
数据安全,不依赖网络,成本低,缺点:初期成本高,部署麻烦周期长
最简单的方案是使用ollama Download Ollama on macOS,当然这种方式不推荐,阉割版
访问官网下载查看对应模型的本地调用即可
在OllamaSetup.exe所在目录打开cmd命令行,然后输入命令如下:
OllamaSetup.exe /DIR=你要安装的目录位置
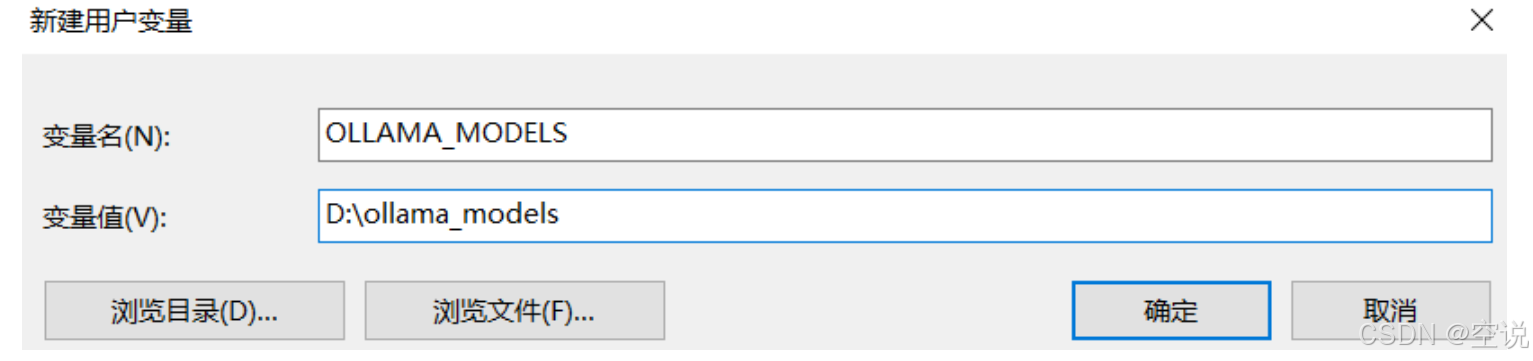
安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。配置完成如图:
搜索模型
-
Ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,可以在其官网上搜索自己需要的模型:Ollama Search;
-
搜索DeepSeek-R1后,进入DeepSeek-R1页面,会发现DeepSeek-R1也有很多版本:
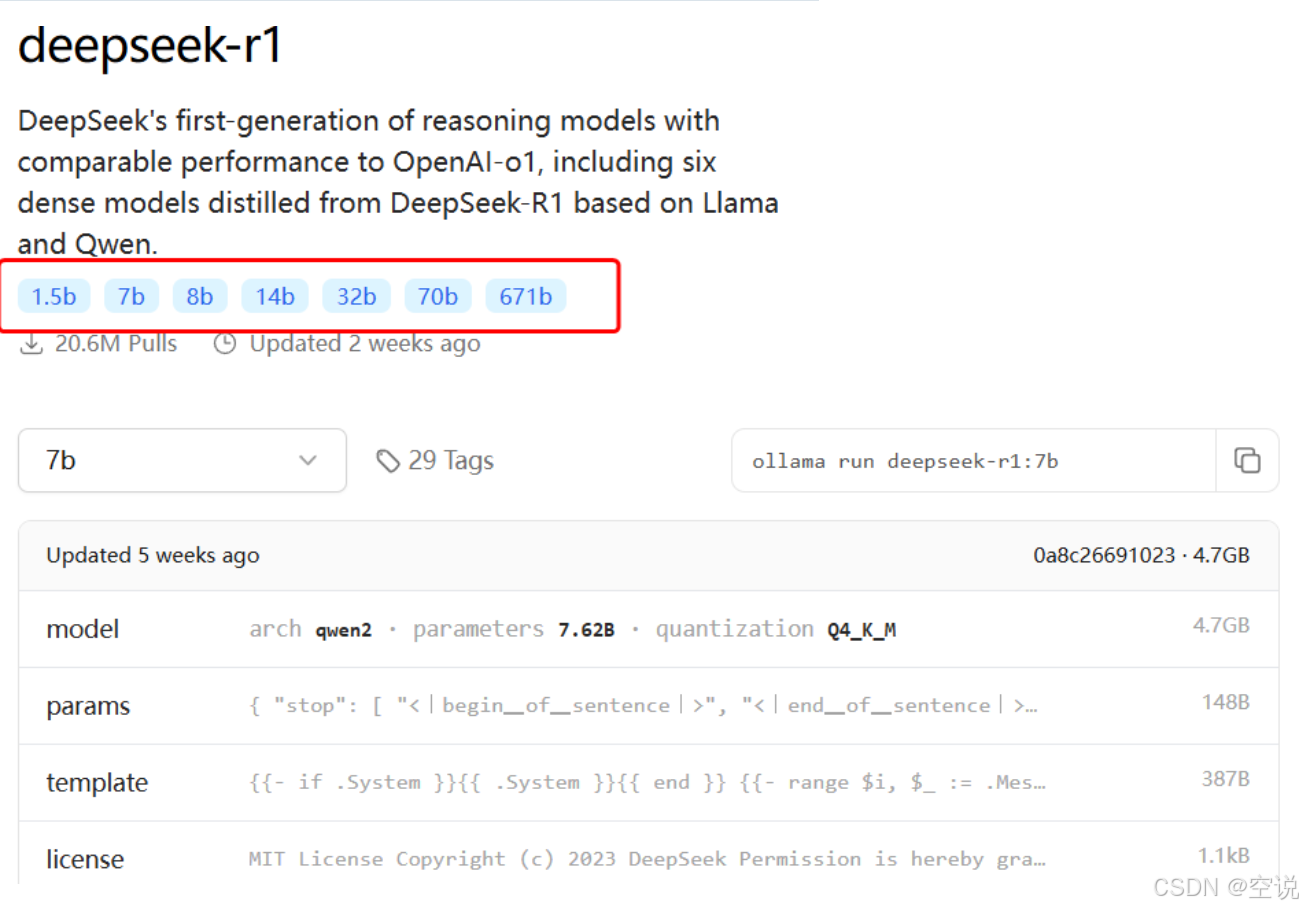
运行大模型
选择自己电脑合适的模型后,Ollama会给出运行模型的命令: 打开cmd运行即可
ollama run deepseek-r1:7b #运行大模型
/bye #退出当前大模型
ollama ps #查看运行的大模型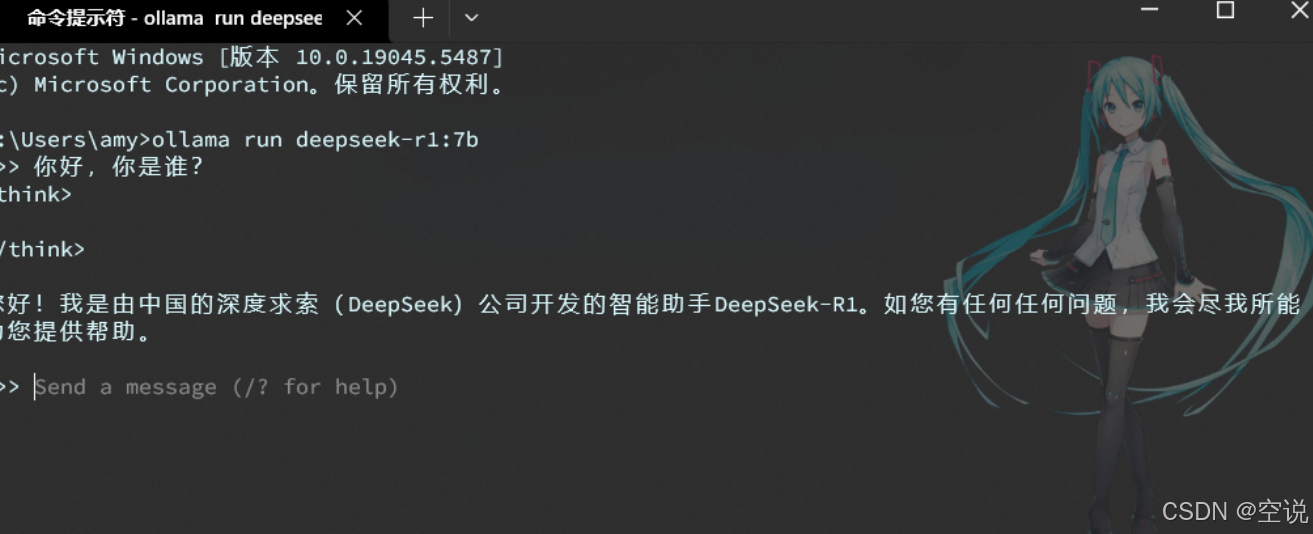 Ollama是一个模型管理工具,有点像Docker,而且命令也很像,常见命令如下:
Ollama是一个模型管理工具,有点像Docker,而且命令也很像,常见命令如下:
ollama serve # Start ollama
ollama create # Create a model from a Modelfile
ollama show # Show information for a model
ollama run # Run a model
ollama stop # Stop a running model
ollama pull # Pull a model from a registry
ollama push # Push a model to a registry
ollama list # List models
ollama ps # List running models
ollama cp # Copy a model
ollama rm # Remove a model
ollama help # Help about any command2.2 调用大模型
调用大模型并不是在浏览器中跟AI聊天,而是通过访问模型对外暴露的API接口,实现与大模型的交互;所以要学习大模型应用开发,就必须掌握模型的API接口规范;
目前大多数大模型都遵循OpenAI的接口规范,是基于Http协议的接口。因此请求路径、参数、返回值信息都是类似的,可能会有一些小的差别。具体需要查看大模型的官方API文档。
以DeepSeek官方给出的文档为例:
# Please install OpenAI SDK first: `pip3 install openai`from openai import OpenAI# 1.初始化OpenAI客户端,要指定两个参数:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")# 2.发送http请求到大模型,参数比较多
response = client.chat.completions.create(# 2.1.选择要访问的模型model="deepseek-chat",# 2.2.发送给大模型的消息messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "Hello"},],# 2.3.是否以流式返回结果stream=False
)
print(response.choices[0].message.content)接口说明
-
请求方式:通常是POST,因为要传递JSON风格的参数;
-
请求路径:与平台有关
-
DeepSeek官方平台:https://api.deepseek.com;
-
阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1;
-
本地ollama部署的模型:http://localhost:11434;
-
-
安全校验:开放平台都需要提供API_KEY来校验权限,本地Ollama则不需要;
-
请求参数:参数很多,比较常见的有:
-
model:要访问的模型名称;
-
messages:发送给大模型的消息,是一个数组;
-
stream:-
true,代表响应结果流式返回;
-
false,代表响应结果一次性返回,但需要等待;
-
-
temperature:取值范围[0:2),代表大模型生成结果的随机性,越小随机性越低。DeepSeek-R1不支持;
-
-
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
-
role:消息对应的角色;
-
content:消息内容;也被称为提示词(Prompt),也就是发送给大模型的指令。
-
提示词角色
常用的消息的角色有三种:

其中System类型的消息非常重要!影响了后续AI会话的行为模式;
-
比如,当我们询问AI对话产品(文心一言、DeepSeek等)“你是谁” 这个问题的时候,每一个AI的回答都不一样,这是怎么回事呢?
-
这其实是因为AI对话产品并不是直接把用户的提问发送给LLM,通常都会在user提问的前面通过System消息给模型设定好背景
-
所以,当你问问题时,AI就会遵循System的设定来回答了。因此,不同的大模型由于System设定不同,回答的答案也不一样;
## Role
System: 你是邓超
## Example
User: 你是谁
Assisant: 到!gogogo,黑咖啡品味有多浓!我是邓超啊!哈哈,你没看错,就是那个又帅又幽默的邓超!怎么样,是不是被我的魅力惊到了?😎 会话记忆问题
为什么要把历史消息都放入Messages中,形成一个数组呢?
这是因为大模型是没有记忆的,因此在调用API接口与大模型对话时,每一次对话信息都不会保留,但是可以发现AI对话产品却能够记住每一轮对话信息,根据这些信息进一步回答,这是怎么回事呢?
答案就是Messages数组;
只需要每一次发送请求时,都把历史对话中每一轮的User消息、Assistant消息都封装到Messages数组中,一起发送给大模型,这样大模型就会根据这些历史对话信息进一步回答,就像是拥有了记忆一样;
2.3 大模型应用开发架构
2.3.1 技术架构
目前,大模型应用开发的技术架构主要有四种
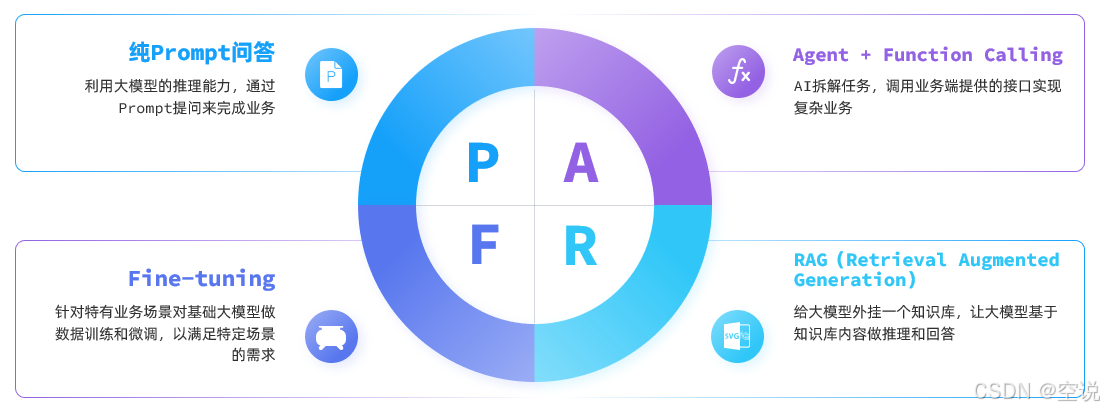
纯Prompt模式
不同的提示词能够让大模型给出差异巨大的答案;
不断雕琢提示词,使大模型能给出最理想的答案,这个过程就叫做提示词工程(Prompt Engineering);
很多简单的AI应用,仅仅靠一段足够好的提示词就能实现了,这就是纯Prompt模式;流程如图:
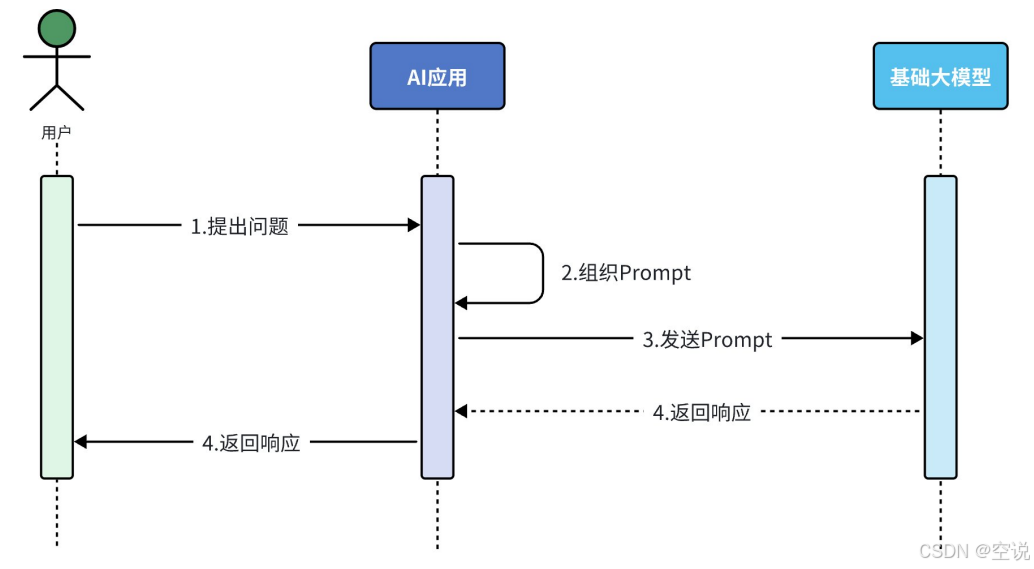
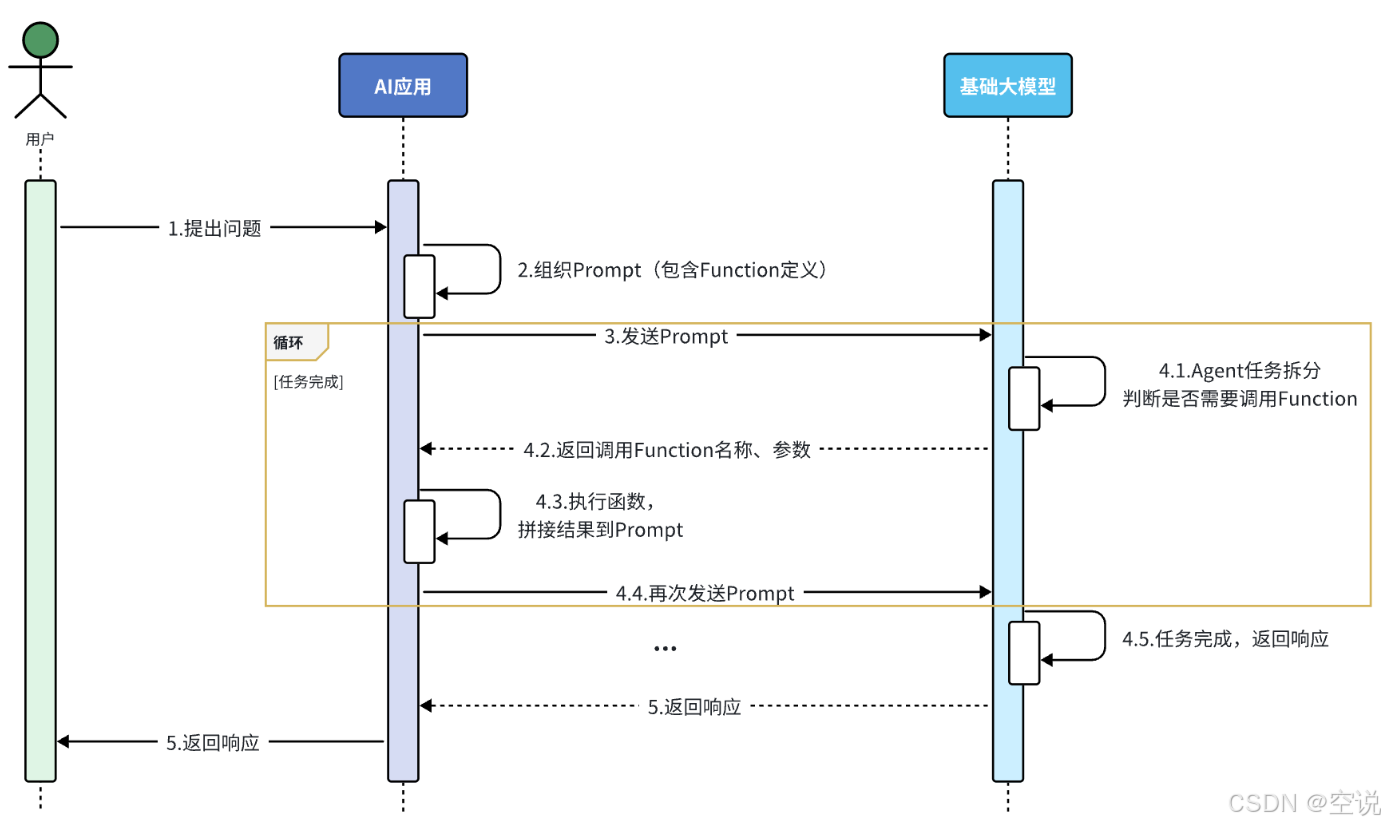
FunctionCalling
大模型虽然可以理解自然语言,更清晰地弄懂用户意图,但是确无法直接操作数据库、执行严格的业务规则。这个时候就可以整合传统应用与大模型的能力了;
-
把传统应用中的部分功能封装成一个个函数(Function);
-
在提示词中描述用户的需求,并且描述清楚每个函数的作用,要求AI理解用户意图,判断什么时候需要调用哪个函数,并且将任务拆解为多个步骤(Agent);
-
当AI执行到某一步,需要调用某个函数时,会返回要调用的函数名称、函数需要的参数信息;
-
传统应用接收到这些数据以后,就可以调用本地函数。再把函数执行结果封装为提示词,再次发送给AI;
-
以此类推,逐步执行,直到达成最终结果。
RAG检索增强
检索增强生成(Retrieval-Augmented Generation,简称RAG)已成为构建智能问答系统的关键技术。
模型从知识角度存在很多限制:
-
时效性差:大模型训练比较耗时,其训练数据都是旧数据,无法实时更新;
-
缺少专业领域知识:大模型训练数据都是采集的通用数据,缺少专业数据;
把最新的数据或者专业文档都拼接到提示词,一起发给大模型,不就可以了?
现在的大模型都是基于Transformer神经网络,Transformer的强项就是所谓的注意力机制。它可以根据上下文来分析文本含义
但是,上下文的大小是有限制的,GPT3刚刚出来的时候,仅支持2000个token的上下文。所以海量知识库数据是无法直接写入提示词的;
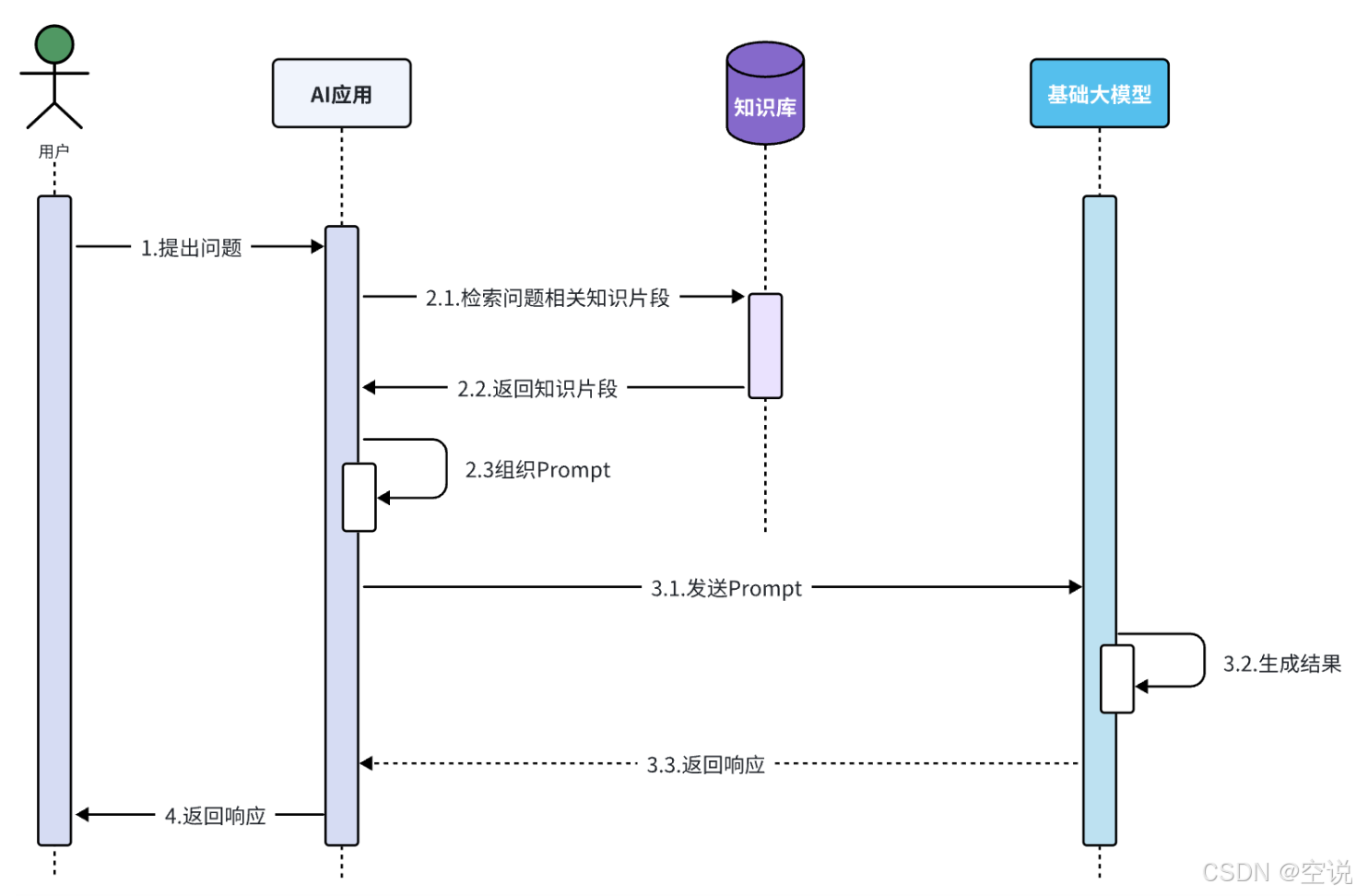
RAG原理
RAG 的核心原理是将检索技术与生成模型相结合,结合外部知识库或私有数据源来检索相关信息来指导和增强生成模型的输出,有效解决了传统大语言模型的知识更新滞后和"幻觉"问题。
其核心工作流程分为三个阶段:
-
接收请求: 首先,系统接收到用户的请求(例如提出一个问题)
-
信息检索(R): 系统从一个大型文档库中检索出与查询最相关的文档片段。这一步的目标是找到那些可能包含答案或相关信息的文档。这里不一定是从向量数据库中检索,但是向量数据库能反应相似度最高的几个文档(比如说法不同,意思相同),而不是精确查找
-
文本拆分:将文本按照某种规则拆分为很多片段;
-
文本嵌入(Embedding):根据文本片段内容,将文本片段归类存储;
-
文本检索:根据用户提问的问题,找出最相关的文本片段;
-
-
生成增强(A): 将检索到的文档片段与原始查询一起输入到大模型(如chatGPT)中,注意使用合适的提示词,比如原始的问题是XXX,检索到的信息是YY,给大模型的输入应该类似于: 请基于YYY回答XXXX。
-
输出生成(G): 大模型LLM 基于输入的查询和检索到的文档片段生成最终的文本答案,并返回给用户
由于每次都是从向量库中找出与用户问题相关的数据,而不是整个知识库,所以上下文就不会超过大模型的限制,同时又保证了大模型回答问题是基于知识库中的内容;
Fine-tuning
模型微调,就是在预训练大模型(比如DeepSeek、Qwen)的基础上,通过企业自己的数据做进一步的训练,使大模型的回答更符合自己企业的业务需求。这个过程通常需要在模型的参数上进行细微的修改,以达到最佳的性能表现;
在进行微调时,通常会保留模型的大部分结构和参数,只对其中的一小部分进行调整。减少了训练时间和计算资源的消耗。
微调的过程包括以下几个关键步骤:
-
选择合适的预训练模型:根据任务的需求,选择一个已经在大量数据上进行过预训练的模型,如Qwen-2.5;
-
准备特定领域的数据集:收集和准备与任务相关的数据集,这些数据将用于微调模型;
-
设置超参数:调整学习率、批次大小、训练轮次等超参数,以确保模型能够有效学习新任务的特征;
-
训练和优化:使用特定任务的数据对模型进行训练,通过前向传播、损失计算、反向传播和权重更新等步骤,不断优化模型的性能;
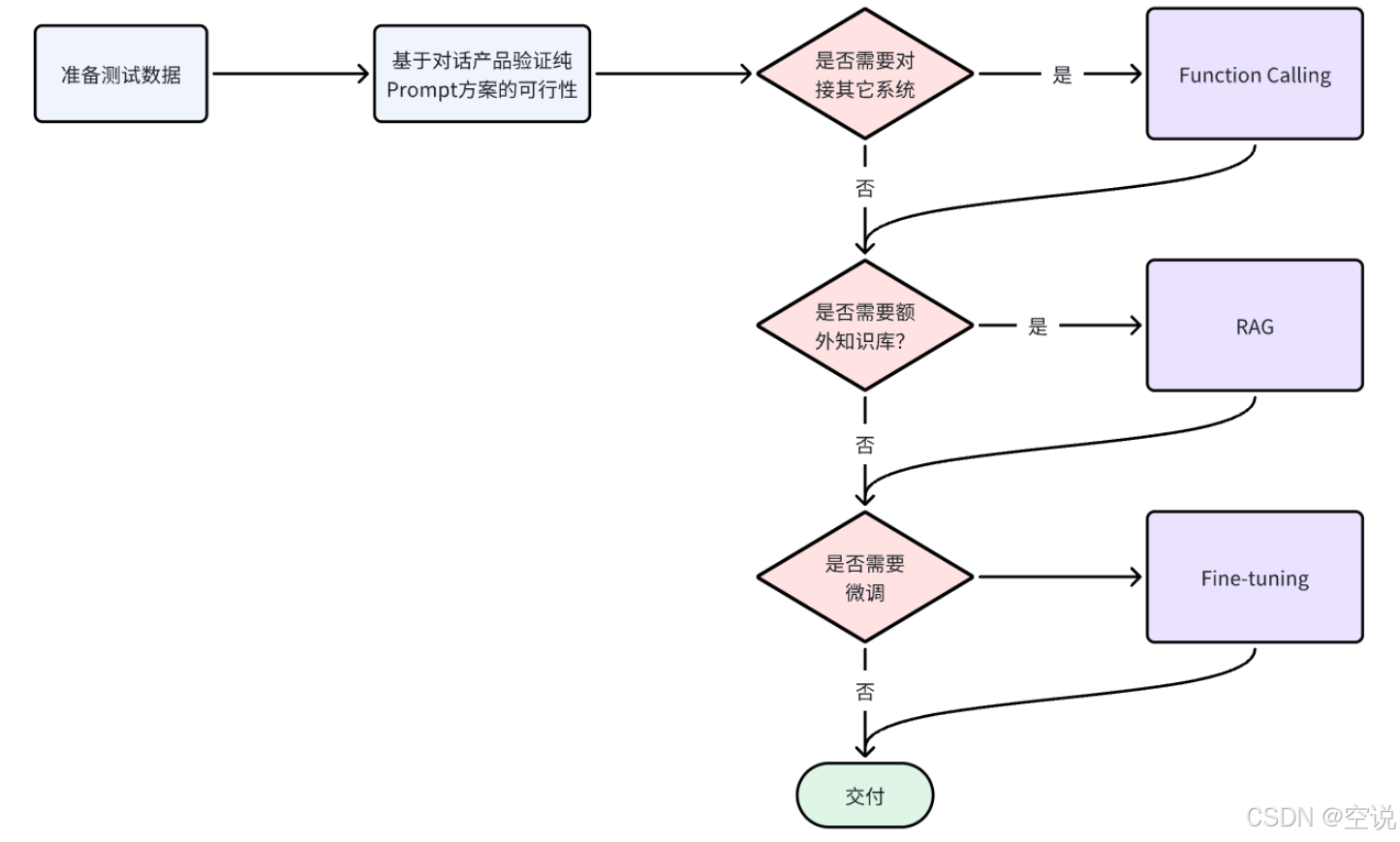
2.3.2 技术选型
-
从开发成本由低到高来看,四种方案的排序:
Prompt < Function Calling < RAG < Fine-tuning -
所以在选择技术时通常也应该遵循"在达成目标效果的前提下,尽量降低开发成本"这一首要原则。然后可以参考以下流程来思考:
相关文章:

SpringAI+DeepSeek大模型应用开发——2 大模型应用开发架构
目录 2.大模型开发 2.1 模型部署 2.1.1 云服务-开放大模型API 2.1.2 本地部署 搜索模型 运行大模型 2.2 调用大模型 接口说明 提示词角色 编辑 会话记忆问题 2.3 大模型应用开发架构 2.3.1 技术架构 纯Prompt模式 FunctionCalling RAG检索增强 Fine-tuning …...

Prometheus thanos架构
Thanos 是一个用于扩展 Prometheus 的高可用性和长期存储的解决方案。它通过整合多个 Prometheus 实例,提供了全局查询、长期存储、以及高可用性的能力。Thanos 的架构主要由以下几个核心组件组成: 1. Sidecar 功能: Sidecar 是与每个 Prom…...

嵌入式软件--stm32 DAY 1
一、STM32概述 1.ARM内核 ARM是一家英国公司。后被日本软银收购。 RISC(精简指令集计算机) 产品:ARM架构处理器,相关外围组件的电路设计方案。 怎么卖 :知识产权授权 只卖方案不卖具体产品 买了如何用 拿到ARM的方案 设计产…...
】解锁家政平台高可用秘籍:负载均衡与架构部署)
【家政平台开发(53)】解锁家政平台高可用秘籍:负载均衡与架构部署
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...

Kotlin整数相除精度损失roundToInt
Kotlin整数相除精度损失roundToInt import kotlin.math.roundToIntfun main() {val a 0.0fval delta 0.1ffor (i in 0..10) {val r a i * deltaprintln("float${r} toInt${r.toInt()} (0.5 toInt)${(r 0.5).toInt()} round${Math.round(r)} roundToInt${r.roundToInt…...

RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之初始化中的u.ConnSendContext----RPC源代码分析
RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之初始化中的u.ConnSendContext 第一部分: 1: kd> kc # 00 RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION 01 RPCRT4!OSF_CASSOCIATION::AllocateCCall 02 RPCRT4!OSF_BINDING_HANDLE::AllocateCCall 03 RPCRT4!OSF…...
)
visual studio 2022更改项目名称,灾难性故障(异常来自HRESULT)
系列文章目录 文章目录 系列文章目录前言一、具体步骤二、遇到的问题 前言 在visual studio 2022中,有时候遇到一个很大的工程,我们只是想改写工程名称,而又不想重建项目,如何实现呢? 比如将 Visual Studio 中的 Qt 工…...

用 Deepseek 写的uniapp油耗计算器
下面是一个基于 Uniapp 的油耗计算器实现,包含 Vue 组件和页面代码。 1. 创建页面文件 在 pages 目录下创建 fuel-calculator 页面: <!-- pages/fuel-calculator/fuel-calculator.vue --> <template><view class"container"…...

【KWDB创作者计划】_KwDB2.2.0深度实践:从存储引擎到物联网场景的多模数据库实战
简介 本文基于KwDB2.2.0最新版本,通过存储引擎原理、跨模计算实战和物联网场景落地三个维度,结合代码示例与实操案例,系统解析KwDB的分布式多模能力。从零搭建物联网数据平台,探索多模数据融合的创新价值,助你掌握新一…...

linux 学习 2.vim学习指南
vim vim是一款功能及其强大的编辑器,我们需要掌握其基本的操作才能数量的使用他 如果你想要功能更加丰富的vim获得代码补全之类的复杂功能,强烈建议你安装一下vimplus,可以参考这里vimplus 官方教程 建议学习的时候直接跟着教程一步步操作…...

深度学习在自动驾驶车辆车道检测中的应用
引言 自动驾驶技术是人工智能领域的一个前沿方向,而车道检测是实现自动驾驶的关键技术之一。通过识别和跟踪车道线,自动驾驶车辆能够保持在车道内行驶,提高行车安全。本文将详细介绍如何使用深度学习技术进行车道检测,并提供一个…...

深度学习-Torch框架-2
八、自动微分 自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。 1. 基础概念 张量 Torch中一切皆…...

FlinkCDC初始化时报错“IllegalArgumentException: Unexpected input: “异常定位与原理分析
本篇是纯技术文章,是排查线上问题的真实记录。这个异常我在网上没搜到相同案例,所以特此记录下,方便后期回顾。 一、背景 利用FlinkCDC3.0动态监听数据库Schema变更的能力开发了一个生产数据库DDL语句变更审计告警的服务,这两天突然发现服务一直报错,经过4个小时的排查,…...
从代码学习深度学习 - Transformer PyTorch 版
文章目录 前言1. 位置编码(Positional Encoding)2. 多头注意力机制(Multi-Head Attention)3. 前馈网络与残差连接(Position-Wise FFN & AddNorm)3.1 基于位置的前馈网络(PositionWiseFFN)3.2 残差连接和层规范化(AddNorm)4. 编码器(Encoder)4.1 编码器块(Enco…...
)
多模态大语言模型arxiv论文略读(二十五)
ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation ➡️ 论文标题:ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation ➡️ 论文作者:Xiaoqi Li, Mingxu Zhang…...

LVS+Keepalived+dns高可用项目架构
一、搭建DNS服务 配置主服务器 1.修改核心配置文件 [rootDNS-master ~]# vim /etc/named.conf options { listen-on port 53 { 192.168.111.107;192.168.111.100; }; directory "/var/named"; }; zone "haha.com" IN { ty…...
实现)
C#日志辅助类(Log4Net)实现
一、Log4Net类库安装 在解决方案中项目上右键单击,选择“管理NuGet程序包”,在浏览窗口的搜索框输入log4net进行搜索,安装搜索出的第一项,如下图。 二、辅助类实现(Log4NetHelper) using log4net.Appender; using log4net.Config; using log4net.Layout; using log4net…...

【FFmpeg从入门到精通】第二章-FFmpeg工具使用基础
1 ffmpeg常用命令 ffmpeg在做音视频编解码时非常方便,所以在很多场景下转码使用的是ffmpeg,通过 ffmpeg --help可以看到 ffmpeg 常见的命令大概分为6个部分,具体如下。 ffmpeg信息查询部分公共操作参数部分文件主要操作参数部分视频操作参数…...

论文阅读:2022 ACL TruthfulQA: Measuring How Models Mimic Human Falsehoods
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 TruthfulQA: Measuring How Models Mimic Human Falsehoods https://arxiv.org/pdf/2109.07958 https://www.doubao.com/chat/3130551217163266 https://github.com/sylin…...
实现的文件管理系统)
基于C++(MFC)实现的文件管理系统
基于 MFC 的文件管理系统 第一章 题目解读与要求分析 1 实习题目 实现一个文件系统。 2 功能要求 界面上显示树形目录结构 a)根节点是“我的电脑” b)“我的电脑”下有几个盘符(C、D、E 等)就有几个子节点,递归…...

selenium 实现模拟登录中的滑块验证功能
用python在做数据采集过程中,经常需要用到模拟登录,经常遇到各种图片、文字甚至短信等验证,如果能通过脚本的方便实现验证,就可以自动帮我更高效地收集数据。Selenium 是一个开源的 Web 自动化测试工具,最初是为网站自…...
)
Oracle 19c部署之数据库软件安装(二)
在完成了Oracle Linux 9的初始化配置之后,我们准备安装Oracle 19c数据库软件。 Oracle数据库支持两种主要的安装方式:图形化安装和静默安装。这两种方法各有优缺点,选择哪种取决于你的具体需求、环境配置以及个人偏好。 图形化安装 图形化安…...

Paramiko 使用教程
目录 简介安装 Paramiko连接到远程服务器执行远程命令文件传输示例 简介 Paramiko 是一个基于 Python 的 SSH 客户端库,它提供了在网络上安全传输文件和执行远程命令的功能。本教程将介绍 Paramiko 的基本用法,包括连接到远程服务器、执行命令、文件传输…...

从EOF到REOF:如何用旋转经验正交函数提升时空数据分析精度?
目录 1. 基本概念与原理2. 应用场景3. 与传统EOF的区别4. 技术实现5. 其他领域中的“REOF”参考资料 REOF 的输入是多个地区在不同时间的气候数据(如温度或降雨量),它的作用是通过旋转计算找出这些数据中最主要的变化规律,输出则是…...

VS-Code创建Vue3项目
1 创建工程文件 创建一个做工程项目的文件夹 如:h5vue 2 cmd 进入文件 h5vue 3 输入如下命令 npm create vuelatest 也可以输入 npm create vitelatest 4 输入项目名称 项目名称:自已输入 回车 可以按键盘 a (全选) 回车: Playwright…...

JESD204B接收器核心实现和系统级关键细节
目录 1.通道偏移 2.弹性缓冲器的实现 3.接受延迟 4.RX端到端延迟 5.计算端到端延迟 6.实现可重复的延迟 1.通道偏移 JESD204B接收器核心已经过验证,其功能具有高达8个字节的通道到通道偏斜。 2.弹性缓冲器的实现 在JESD204B设备中,接收通道对齐弹性缓冲区是在分布式…...
NLP高频面试题(四十七)——探讨Transformer中的注意力机制:MHA、MQA与GQA
MHA、MQA和GQA基本概念与区别 1. 多头注意力(MHA) 多头注意力(Multi-Head Attention,MHA)通过多个独立的注意力头同时处理信息,每个头有各自的键(Key)、查询(Query)和值(Value)。这种机制允许模型并行关注不同的子空间上下文信息,捕捉复杂的交互关系。然而,MHA…...
)
k230学习笔记-疑难点(1)
1.出现boot failed with exit code 19: 需要将k230开发板的btoot0拨到ON 2.出现boot failed with exit code 13: 说明k230开发板的固件烧录已经丢失,需要重新烧录 *** 注意重新烧录时需要将btoot0重新拨到OFF,才会弹出加载固件需要的通用串行总线&…...

JavaScript性能优化实战:让你的Web应用飞起来
JavaScript性能优化实战:让你的Web应用飞起来 在前端开发中,JavaScript性能优化是提升用户体验的关键。一个性能良好的应用不仅能吸引用户,还能提高转化率和用户留存率。今天,我们就来深入探讨JavaScript性能优化的实战技巧&…...

金融数据库转型实战读后感
荣幸收到老友太保科技有限公司数智研究院首席专家林春的签名赠书。 这是国内第一本关于OceanBase数据库实际替换过程总结的的实战书。打个比方可以说是从战场上下来分享战斗经验。读后感受颇深。我在这里讲讲我的感受。 第三章中提到的应用改造如何降本。应用改造是国产化替换…...
)
血脂代谢通路(医学-计算机系统对照方式)
血脂代谢通路(医学-计算机系统对照方式) 整合所有类比,用医学-计算机系统对照的方式完整描述血脂代谢通路,采用分步骤的对照结构: 1. 食物摄入(数据输入层) # 医学术语: 膳食脂肪摄入 → 计算机类比: 原始数据输入 …...

git更新的bug
文章目录 1. 问题2. 分析 1. 问题 拉取了一个项目后遇到了这个问题, nvocation failed Server returned invalid Response. java.lang.RuntimeException: Invocation failed Server returned invalid Response. at git4idea.GitAppUtil.sendXmlRequest(GitAppUtil…...

直流电源基本原理
整流电路 在构建整流电路时,要选择合适参数的二极管 If是二极管能够通过电流的能力,也是最大整流的平均电流。 还要考虑二极管的反向截至电压。 脉动系数电压交流幅值/直流平均电压(越小越好) 三相整流电路优点: …...

Git -> git merge --no-ff 和 git merge的区别
git merge --no-ff <branch> 与 git merge <branch> 的区别 核心区别 git merge <branch>: 默认使用Fast-forward模式(若可行)不创建额外的合并提交记录合并后看不出曾经存在过分支 git merge --no-ff <branch>:强制创建一个…...
含运行文档)
名胜古迹传承与保护系统(springboot+ssm+vue+mysql)含运行文档
名胜古迹传承与保护系统(springbootssmvuemysql)含运行文档 名胜古迹传承与保护系统是一个专注于文化遗产保护和管理的综合性平台。系统提供了一系列功能模块,包括名胜古迹管理、古迹预约管理、古迹故事管理、举报信息管理、保护措施管理、古迹讨论、管理员管理、版…...

windows资源管理器左边导航窗格增加2个项,windows10/11有效
下面文档存为.reg文件, Windows Registry Editor Version 5.00; 根 CLSID —— 名称、图标、固定到导航窗格 [HKEY_CURRENT_USER\Software\Classes\CLSID\{C1A3F2D2-BD2D-4D60-82C5-394F01753A5F}] "手机系统" "System.IsPinnedToNamespaceTree&quo…...

【八股文】基于源码聊聊ConcurrentHashmap的设计
版本演进 jdk 1.7中是分段锁的设计,将哈希表划分为多个segment,每个段独立加锁,锁粒度为段级别。 操作需两次哈希,第一次定位段,第二次定位桶内链表。这种实现方式的缺点就是段数量固定,扩容复杂…...

Mysql--基础知识点--93--两阶段提交
1 两阶段提交 以update语句的具体执行过程为例: 具体更新一条记录 UPDATE t_user SET name ‘xiaolin’ WHERE id 1;的流程如下: 1.执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id 1 这一行记录&#…...

数字化招标采购系统怎么让招采协同更高效?
招标采购领域的数智化转型正在引发行业革命性变革。从传统线下模式到全流程电子化,再到当前数智化阶段的超时空协同,行业的演进路径清晰展现了技术与管理的深度融合。郑州信源信息数智化招采系统作为行业标杆,其创新实践为未来协同工作方式的…...
)
池塘计数(BFS)
题目描述 由于最近的降雨,光头强的田地里的各个地方都积水了,用 NM(1≤N≤100;1≤M≤100)NM(1≤N≤100;1≤M≤100) 的正方形的矩形表示。每个广场都有水 W 或旱地 .。光头强想知道他的田地里形成了多少池塘。池塘是指一组相邻的有…...
)
《Science》观点解读:AI无法创造真正的智能体(AI Agent)
无论是想要学习人工智能当做主业营收,还是像我一样作为开发工程师但依然要运用这个颠覆开发的时代宠儿,都有必要了解、学习一下人工智能。 近期发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,入行门槛低&#x…...

从零开始学A2A四:A2A 协议的安全性与多模态支持
文章目录 A2A 协议的安全性与多模态支持一、A2A 协议安全机制1. 认证机制2. 授权机制3. 数据加密 二、多模态交互支持1. 文本交互2. 音频支持3. 视频与图像处理4. 复合数据格式 三、安全与多模态最佳实践1. 安全性实践2. 多模态实践 四、与 MCP 的对比1. 安全机制对比2. 多模态…...

一种大位宽加减法器的时序优化
平台:vivado2018.3 芯片:xc7a100tfgg484-2 (active) 在FPGA中实现超高位宽加减法器(如256)时,时序收敛常成为瓶颈。由于进位链(Carry Chain)跨越多级逻辑单元,关键路径延迟会随位宽…...
】大语言模型与传统编程的桥梁)
【专业解读:Semantic Kernel(SK)】大语言模型与传统编程的桥梁
目录 Start:什么是Semantic Kernel? 一、Semantic Kernel的本质:AI时代的操作系统内核 1.1 重新定义LLM的应用边界 1.2 技术定位对比 二、SK框架的六大核心组件与技术实现 2.1 内核(Kernel):智能任务调度中心 2…...

InfiniBand与RoCEv2负载均衡机制的技术梳理与优化实践
AI技术的高速迭代正驱动全球算力格局进入全新纪元。据IDC预测,未来五年中国智能算力规模将以超50%的年复合增长率爆发式扩张,数据中心全面迈入“智能算力时代”。然而,海量AI训练、实时推理等高并发场景对底层网络提出了更严苛的挑战——超大…...

Vue与React组件化设计对比
组件化是现代前端开发的核心思想之一,而Vue和React作为两大主流框架,在组件化设计上既有相似之处,也存在显著差异。本文将从语法设计、数据管理、组件通信、性能优化、生态系统等多个方向,结合实例详细对比两者的特点。 一、模板…...

UE中通过AAIController::MoveTo函数巡逻至目标点后没法正常更新巡逻目标点
敌人巡逻的逻辑如下: 敌人在游戏一开始的时候就通过moveto函数先前往首先设定的patroltarget目标,在距离patroltarget距离为patroradius(200unit)之内时就可以通过checkpatroltarget函数更新新的patroltarget目标,随后前往新的pat…...

Python-细节知识点range函数的详解
在 Python 中,range 是一个内置函数,用于生成一个不可变的整数序列,通常用于控制循环次数或生成数值范围。以下是详细说明: 基本语法 range(stop) # 生成 [0, stop) 的整数,步长为1 range(start, stop) …...

git rebase的使用
我的使用 git checkout feature # 本地分支 git pull origin main --rebase # 目标分支 git pull origin feature --rebase git push origin featuregit rebase 是 Git 中用于重写提交历史的强大工具,可将分支的提交移动到新的基点上,使历史更线性。以…...
:)
CMake Error at build/_deps/glog-src/CMakeLists.txt:1 (cmake_minimum_required):
这个错误提示意思是你当前系统上安装的 CMake 版本过低,不满足项目的要求。根据错误信息: CMake Error at build/_deps/glog-src/CMakeLists.txt:1 (cmake_minimum_required): CMake 3.22 or higher is required. You are running version 3.16.3 项目…...